
Assets

Deploying the Llama 3.1 405b Model Using NVIDIA NIM

Fri, 11 Oct 2024 12:35:47 -0000
|Read Time: 0 minutes
This blog is one in a series of three that shows how Dell Technologies and our partner AI ecosystem can help you to provision the most powerful open-source model available easily. In this series of blogs, we share information about the ease of deploying the Llama 3.1 405b model in the Dell PowerEdge XE9680 server using NVIDIA NIM microservices, Dell Enterprise Hub using Text Generation Inference (TGI), or vLLM for LLMs. We hope this series equips you with the knowledge and tools needed for a successful deployment.
This blog describes the NVIDIA NIM for LLMs option.
Overview
On July 23, 2024, Meta announced the most capable open-source LLM model, Llama 3.1 405b. This model is so powerful that it competes with the best-in-class commercial models, exceeding or matching the performance in several benchmarks. However, with great power comes considerable requirements.
Dell Technologies has been working with many partners to create an ecosystem to help customers succeed on their AI journey. For the Llama 3.1 405b model, we worked directly with Meta and published the Running Llama 3.1 405B models on Dell PowerEdge XE9680 blog. The blog explains how to run model inference on a Dell PowerEdge XE9680 server with torchrun from PyTorch, which is the base process provided by Meta with the Llama 3.1 405b model.
Deployment with NVIDIA NIM
We recently published a guide about how to run NVIDIA NIM using Docker in the Introduction to NVIDIA Inference Microservices, aka NIM blog. The following steps guide the deployment of the Llama 3.1 405b model.
NVIDIA provides documentation about how to deploy NVIDIA NIM for LLM at https://docs.nvidia.com/nim/large-language-models/latest/deploy-helm.html. However, before starting the deployment, note that NVIDIA prepared four different versions of the model that are called NIM Profiles. The NIM Profiles enable you to select the version of the model to deploy, based on your hardware availability and business requirements.
Inside the NIM container that is available for download from the NVIDIA NGC at nvcr.io/nim/meta/llama-3.1-405b-instruct:1.2.0, run the following command to list the profiles:
nim@my-nim-0:/$ list-model-profiles SYSTEM INFO - Free GPUs: - [2330:10de] (0) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (1) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (2) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (3) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (4) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (5) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (6) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] - [2330:10de] (7) NVIDIA H100 80GB HBM3 (H100 80GB) [current utilization: 0%] MODEL PROFILES - Compatible with system and runnable: - 8860fe7519bece6fdcb642b907e07954a0b896dbb1b77e1248a873d8a1287971 (tensorrt_llm-h100-fp8-tp8-throughput) - With LoRA support: - Incompatible with system: - b80e254301eff63d87b9aa13953485090e3154ca03d75ec8eff19b224918c2b5 (tensorrt_llm-h100-fp8-tp8-latency) - f8bf5df73b131c5a64c65a0671dab6cf987836eb58eb69f2a877c4a459fd2e34 (tensorrt_llm-a100-fp16-tp8-latency) - b02b0fe7ec18cb1af9a80b46650cf6e3195b2efa4c07a521e9a90053c4292407 (tensorrt_llm-h100-fp16-tp8-latency)
Looking closer at this profile information, we see:
- 8860fe7519bece6fdcb642b907e07954a0b896dbb1b77e1248a873d8a1287971—Sequence of characters that is used to select the version of the model that will be loaded into the GPU memory.
- tensorrt_llm—Backend used by Triton to load the model. For the Llama 3.1 405b model, we have only TRT-LLM, but for other models, vLLM is also available.
- h100—Model of the supported GPU.
- fp8—Float point of the model, which can be FP8 or FP16 for the Llama 3.1 405b model.
- tp8—Number of Tensor Parallelism used to deploy the model. This value represents the number of GPUs that must be available on your system to deploy it, in this case, eight GPUs per node.
- throughput—If the model is optimized for throughput or latency, this information indicates the number of nodes or Pipeline Parallelism (PP). For the throughput model, you can use a single PowerEdge XE9680 server with eight NVIDIA H100 GPUs. For the latency model, you use two PowerEdge XE9680 servers with PP2.
With this profile information in mind, you can select the model to use depending on the necessity and infrastructure available.
NVIDIA NIM prerequisites
To run the following procedure, the infrastructure must be deployed with Kubernetes, NVIDIA GPU Operator, one or two PowerEdge XE9680 servers with eight NVIDIA H100 or A100 GPUs, and follows the Support Matrix.
The Dell AI Factory easily deploys this model. The following figure shows the infrastructure used for the deployment:
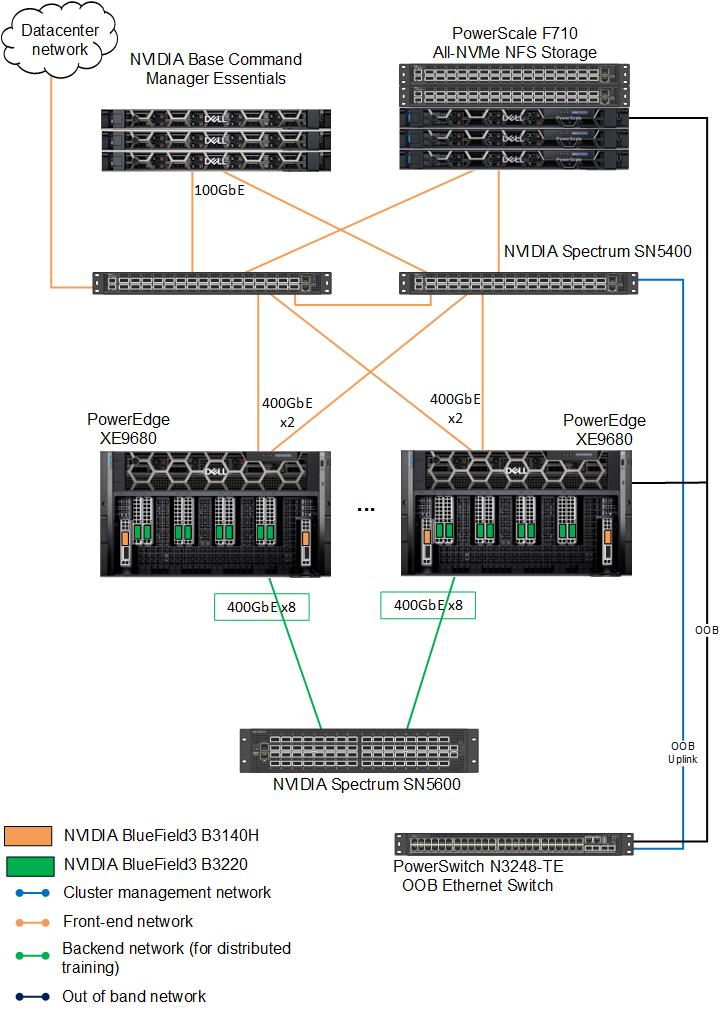
Figure 1: Dell AI Factory connection diagram
Downloading the Helm chart for NIM
To download the Helm chart for NIM:
- Set up the NGC API Key. See the Introduction to NVIDIA Inference Microservices, aka NIM blog for details.
- Download the Helm chart, which will enable installation on a Kubernetes cluster:
fbronzati@login01:/mnt/f710/NIM$ helm fetch https://helm.ngc.nvidia.com/nim/charts/nim-llm-1.1.2.tgz --username='$oauthtoken' --password=<replace_by_your_NGC_API_KEY> fbronzati@login01:/mnt/f710/NIM$ ll total 184 drwxrwxr-x 2 fbronzati fbronzati 35 Aug 29 11:30 ./ drwxrwxrwx 33 nobody nogroup 1018 Aug 29 11:25 ../ -rw-r--r-- 1 fbronzati fbronzati 27959 Aug 29 11:30 nim-llm-1.1.2.tgz
Creating the Kubernetes namespace and secret
To avoid any conflict, deploy the pod on a new namespace:
- Create the namespace:
fbronzati@login01:/mnt/f710/NIM$ kubectl create namespace nim namespace/nim created
- Create the secret for downloading the container and models from NVIDIA NGC:
fbronzati@login01:/mnt/f710/NIM$ kubectl create secret docker-registry ngc-secret --docker-server="nvcr.io" --docker-username='$oauthtoken' --docker-password=<replace_by_your_NGC_API_KEY> -n nim secret/ngc-secret created fbronzati@login01:/mnt/f710/NIM$ kubectl create secret generic ngc-api --from-literal=NGC_API_KEY=<replace_by_your_NGC_API_KEY> -n nim secret/ngc-api created
- Run the following command to verify that the secrets were properly created inside the NIM namespace:
fbronzati@login01:/mnt/f710/NIM$ kubectl get secrets -n nim NAME TYPE DATA AGE ngc-api Opaque 1 18s ngc-secret kubernetes.io/dockerconfigjson 1 50s
Installing LWS
We recommend LeaderWorkerSet (LWS) deployments as the method for deploying multimode models with NVIDIA NIM. To enable LWS deployments, see the installation instructions in the LWS documentation. The Helm chart defaults to LWS for multinode deployments.
With LWS deployments, Leader and Worker pods coordinate to run your multinode models.
LWS deployments support manual scaling and auto scaling, in which the entire set of pods are treated as a single replica. However, there are some limitations to scaling when using LWS deployments. If scaling manually (autoscaling is not enabled), you cannot scale above the initial number of replicas set in the Helm chart.
The following example command deploys and verifies that the pod was properly deployed and is running:
fbronzati@login01:/mnt/f710/NIM$ kubectl apply --server-side -f https://github.com/kubernetes-sigs/lws/releases/download/v0.3.0/manifests.yaml namespace/lws-system serverside-applied customresourcedefinition.apiextensions.k8s.io/leaderworkersets.leaderworkerset.x-k8s.io serverside-applied serviceaccount/lws-controller-manager serverside-applied role.rbac.authorization.k8s.io/lws-leader-election-role serverside-applied clusterrole.rbac.authorization.k8s.io/lws-manager-role serverside-applied clusterrole.rbac.authorization.k8s.io/lws-metrics-reader serverside-applied clusterrole.rbac.authorization.k8s.io/lws-proxy-role serverside-applied rolebinding.rbac.authorization.k8s.io/lws-leader-election-rolebinding serverside-applied clusterrolebinding.rbac.authorization.k8s.io/lws-manager-rolebinding serverside-applied clusterrolebinding.rbac.authorization.k8s.io/lws-proxy-rolebinding serverside-applied secret/lws-webhook-server-cert serverside-applied service/lws-controller-manager-metrics-service serverside-applied service/lws-webhook-service serverside-applied deployment.apps/lws-controller-manager serverside-applied mutatingwebhookconfiguration.admissionregistration.k8s.io/lws-mutating-webhook-configuration serverside-applied validatingwebhookconfiguration.admissionregistration.k8s.io/lws-validating-webhook-configuration serverside-applied
The following command shows if LWS was properly installed and is running on the cluster:
fbronzati@login01:/mnt/f710/NIM$ kubectl get pods --all-namespaces | grep lws lws-system lws-controller-manager-5c4ff67cbd-n4glc 2/2 Running 0 48s
Customizing the deployment file
Create a custom-values.yaml file and add the following content to the file, customizing as needed for your deployment:
image: # Adjust to the actual location of the image and version you want repository: nvcr.io/nim/meta/llama-3.1-405b-instruct tag: 1.2.0 imagePullSecrets: - name: ngc-secret env: - name: NIM_MODEL_PROFILE #value: "8860fe7519bece6fdcb642b907e07954a0b896dbb1b77e1248a873d8a1287971" #Llama3.1 405b(tensorrt_llm-h100-fp8-tp8-throughput) #value: "b80e254301eff63d87b9aa13953485090e3154ca03d75ec8eff19b224918c2b5" #Llama 3.1 405b(tensorrt_llm-h100-fp8-tp8-latency) pp2 value: "b02b0fe7ec18cb1af9a80b46650cf6e3195b2efa4c07a521e9a90053c4292407" #Llama3.1 405b(tensorrt_llm-h100-fp16-tp8-latency) pp2 nodeSelector: # likely best to set this to `nvidia.com/gpu.present: "true"` depending on cluster setup nvidia.com/gpu.product: NVIDIA-H100-80GB-HBM3 model: name: meta/llama-3_1-405b-instruct ngcAPISecret: ngc-api # NVIDIA recommends using an NFS-style read-write-many storage class. # All nodes will need to mount the storage. In this example, we assume a storage class exists name "nfs". nfs: enabled: true server: f710.f710 path: /ifs/data/Projects/NIM/models readOnly: false # This should match `multiNode.gpusPerNode` resources: limits: nvidia.com/gpu: 8 multiNode: enabled: true workers: 2 gpusPerNode: 8 # Downloading the model will take quite a long time. Give it as much time as ends up being needed. startupProbe: failureThreshold: 1500
We already added the three NVIDIA H100 profiles on the configuration file. You can comment or uncomment the wanted model in the NIM_MODEL_PROFILE section.
Installing the Helm chart
To deploy the model, run the following command to download and start the Kubernetes pod inside the NIM namespace:
fbronzati@login01:/mnt/f710/NIM$ helm install my-nim nim-llm-1.1.2.tgz -f custom-values.yaml -n nim NAME: my-nim LAST DEPLOYED: Wed Sep 11 08:59:26 2024 NAMESPACE: nim STATUS: deployed REVISION: 1 NOTES: Thank you for installing nim-llm. ************************************************** | It may take some time for pods to become ready | | while model files download | ************************************************** Your NIM version is: 1.2.0
The pod will have one or two containers depending on the profile and number of workers. The following example shows the pod running the model over two containers:
fbronzati@login01:/mnt/f710/NIM$ kubectl get pods -n nim -o widefNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESfmy-nim-0 1/1 Running 0 14m *.*.*.* helios26 <none> <none> my-nim-0-1 1/1 Running 0 14m *.*.*.* helios24 <none> <none>
Sending requests
The Helm chart also deploys a Kubernetes service to interact with the model sending a request. The following command provides the IP address and port that is created to access the model:
fbronzati@login01:/mnt/f710/NIM$ kubectl get services -n nim NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-nim ClusterIP None <none> <none> 110s my-nim-nim-llm ClusterIP *.*.*.* <none> 8000/TCP 110s
NVIDIA NIM uses OpenAI API, therefore, there are many ways to interact with the model. See https://docs.api.nvidia.com/nim/reference/meta-llama-3_1-405b-infer for information to understand the best ways to send requests with Python, Node, and Shell. The following example is a simple shell script to test if the model was deployed correctly:
fbronzati@login01:/mnt/f710/NIM$ curl -X 'POST' \
'http://*.*.*.*:8000/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama-3.1-405b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64
}' The response is similar to the following example:
{"id":"cmpl-5df0e556fcbf48738159707b65055d83","object":"text_completion","created":1726096116,"model":"meta/llama-3.1-405b-instruct","choices":[{"index":0,"text":", in a small village nestled in the rolling hills of Tuscany, there was a young apprentice named Dario . Dario was an aspiring sommelier, eager to learn the art of pairing wines with the region’s famous dishes. His mentor, the wise and kind-hearted Giovanni, noticed Dario’s passion and","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":5,"total_tokens":69,"completion_tokens":64}}Conclusion
Deploying the Llama 3.1 405b model can be challenging due to its size and hardware requirements. However, with NVIDIA NIM on Dell PowerEdge servers, most of the complexity is removed and the task becomes achievable, providing flexibility and scalability for a wide range of applications. The collaboration between Dell Technologies and NVIDIA showcases a high degree of synergy, offering a pathway to use cutting-edge AI capabilities in a production environment. This blog serves as a valuable resource for understanding the deployment intricacies and selecting the optimal approach based on hardware and performance requirements.
Dell AI Factory further simplifies this process by providing preconfigured environments and deployment templates, making it easier for enterprises to adopt the Llama 3.1 405b model without compromising performance or resource efficiency.

Deploying the Llama 3.1 405b Model Using Dell Enterprise Hub
Thu, 10 Oct 2024 19:42:19 -0000
|Read Time: 0 minutes
This blog is one in a series of three that shows how Dell Technologies and our partner AI ecosystem can help you to provision the most powerful open-source model available easily. In this series of blogs, we share information about the ease of deploying the Llama 3.1 405b model on the Dell PowerEdge XE9680 server by using NVIDIA NIM, Dell Enterprise Hub using Text Generation Inference (TGI), or vLLM for Large Language Models (LLMs). We hope this series equips you with the knowledge and tools needed for a successful deployment.
This blog describes the Dell Enterprise Hub for LLMs option.
Overview
In this blog, we describe how to deploy the Llama 3.1 405b model on a Dell PowerEdge XE9680 server using the Dell Enterprise Hub portal developed in partnership with Hugging Face.
We also published the steps to run models using Kubernetes and the Dell Enterprise Hub with Hugging Face in the Scale your Model Deployments with the Dell Enterprise Hub blog, in which we used the Llama 3.1 70b model. We recommend reading this blog for more details about the Text Generation Inference (TGI) implementation and the infrastructure used. TGI is a toolkit for deploying and serving LLMs that enables high-performance text generation for the most popular open-source LLMs.
Dell Enterprise Hub
The Dell Enterprise Hub (https://dell.huggingface.co/) revolutionizes access to and use of optimized models on cutting-edge Dell hardware. It offers a curated collection of models that have been thoroughly tested and validated on Dell systems.
The Dell Enterprise Hub has curated examples for deploying the models with Docker and Kubernetes. In this blog, we show how easy it is to start inferencing with the Llama 3.1 405b model.
The Scale your Model Deployments with the Dell Enterprise Hub blog describes how to access the portal and retrieve the examples, therefore we do not include this information. For more information, see the blog.
Deploying with Docker
To deploy the model with Docker:
- Go to https://dell.huggingface.co/authenticated/models/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8/deploy/docker to access the portal.
- Run the following command to deploy the Llama 3.1 405b model:
docker run \ -it \ --gpus 8 \ --shm-size 1g \ -p 80:80 \ -e NUM_SHARD=8 \ -e MAX_BATCH_PREFILL_TOKENS=16182 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
The following example shows a deployment and the output of the command:
fbronzati@node005:~$ docker run \
-it \
--gpus 8 \
--shm-size 1g \
-p 80:80 \
-e NUM_SHARD=8 \
-e MAX_BATCH_PREFILL_TOKENS=16182 \
-e MAX_INPUT_TOKENS=8000 \
-e MAX_TOTAL_TOKENS=8192 \
registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
Unable to find image 'registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8:latest' locally
latest: Pulling from enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
43f89b94cd7d: Pull complete
45f7ea5367fe: Pull complete
.
.
.
.
e4fdac914fb9: Pull complete
Digest: sha256:c6819ff57444f51abb2a2a5aabb12b103b346bfb056738a613f3fcc0eecbd322
Status: Downloaded newer image for registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8:latest
2024-09-14T01:06:21.279409Z INFO text_generation_launcher: Args {
model_id: "/model",
revision: None,
validation_workers: 2,
sharded: None,
num_shard: Some(
8,
),
quantize: None,
speculate: None,
dtype: None,
trust_remote_code: false,
max_concurrent_requests: 128,
max_best_of: 2,
max_stop_sequences: 4,
max_top_n_tokens: 5,
max_input_tokens: Some(
8000,
),
max_input_length: None,
max_total_tokens: Some(
8192,
),
waiting_served_ratio: 0.3,
max_batch_prefill_tokens: Some(
16182,
),
max_batch_total_tokens: None,
max_waiting_tokens: 20,
max_batch_size: None,
cuda_graphs: None,
hostname: "1adda5a941d3",
port: 80,
shard_uds_path: "/tmp/text-generation-server",
master_addr: "localhost",
master_port: 29500,
huggingface_hub_cache: Some(
"/data",
),
weights_cache_override: None,
disable_custom_kernels: false,
cuda_memory_fraction: 1.0,
rope_scaling: None,
rope_factor: None,
json_output: false,
otlp_endpoint: None,
otlp_service_name: "text-generation-inference.router",
cors_allow_origin: [],
watermark_gamma: None,
watermark_delta: None,
ngrok: false,
ngrok_authtoken: None,
ngrok_edge: None,
tokenizer_config_path: None,
disable_grammar_support: false,
env: false,
max_client_batch_size: 4,
lora_adapters: None,
disable_usage_stats: false,
disable_crash_reports: false,
}
2024-09-14T01:06:21.280278Z INFO text_generation_launcher: Using default cuda graphs [1, 2, 4, 8, 16, 32]
2024-09-14T01:06:21.280285Z INFO text_generation_launcher: Sharding model on 8 processes
2024-09-14T01:06:21.280417Z INFO download: text_generation_launcher: Starting check and download process for /model
2024-09-14T01:06:25.598785Z INFO text_generation_launcher: Files are already present on the host. Skipping download.
2024-09-14T01:06:26.485957Z INFO download: text_generation_launcher: Successfully downloaded weights for /model
2024-09-14T01:06:26.486723Z INFO shard-manager: text_generation_launcher: Starting shard rank=1
2024-09-14T01:06:26.486744Z INFO shard-manager: text_generation_launcher: Starting shard rank=2
.
.
.
.
2024-09-14T01:09:41.599375Z WARN tokenizers::tokenizer::serialization: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/tokenizers-0.19.1/src/tokenizer/serialization.rs:159: Warning: Token '<|reserved_special_token_247|>' was expected to have ID '128255' but was given ID 'None'
2024-09-14T01:09:41.601329Z INFO text_generation_router: router/src/main.rs:357: Using config Some(Llama)
2024-09-14T01:09:41.601337Z WARN text_generation_router: router/src/main.rs:366: no pipeline tag found for model /model
2024-09-14T01:09:41.601339Z WARN text_generation_router: router/src/main.rs:384: Invalid hostname, defaulting to 0.0.0.0
2024-09-14T01:09:42.024203Z INFO text_generation_router::server: router/src/server.rs:1572: Warming up model
2024-09-14T01:09:48.458410Z INFO text_generation_launcher: Cuda Graphs are enabled for sizes [32, 16, 8, 4, 2, 1]
2024-09-14T01:09:51.114877Z INFO text_generation_router::server: router/src/server.rs:1599: Using scheduler V3
2024-09-14T01:09:51.114907Z INFO text_generation_router::server: router/src/server.rs:1651: Setting max batch total tokens to 55824
2024-09-14T01:09:51.221691Z INFO text_generation_router::server: router/src/server.rs:1889: ConnectedConfirming the deployment
To confirm that the model is working, send a curl command. Ensure that you use the localhost if you submit the request from the node or the IP address of the host if you are testing from other system.
fbronzati@login01:/mnt/f710/vllm$ curl -X 'POST' 'http://localhost:80/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"prompt": "Once upon a time",
"max_tokens": 64
}' The following example is a response from the model:
{"object":"text_completion","id":"","created":1726319779,"model":"/model","system_fingerprint":"2.2.0-sha-db7e043","choices":[{"index":0,"text":" in the not so distant past, “EarthFirst” – a search word in the Datastream terminal in the university’s Reference Library brought up a thumbnail entry for Earth First!\nAccording to the International Association of Scholarly Publishers Second Nature Project, published in The Open Library the Earth First! movement held an impressive set of un","logprobs":null,"finish_reason":"length"}],"usage":{"prompt_tokens":5,"completion_tokens":64,"total_tokens":69}}Because the container being used supports the OpenAI API, you can use Python or other languages to interact with the model.
Deploying with Kubernetes
For deploying the model with Kubernetes, go to https://dell.huggingface.co/authenticated/models/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8/deploy/kubernetes?gpus=8&replicas=1&sku=xe9680-nvidia-h100 to access the Dell Enterprise Hub.
Creating the deployment file
To create the deployment file, copy the example available at https://dell.huggingface.co/authenticated/models/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8/deploy/kubernetes?gpus=8&replicas=1&sku=xe9680-nvidia-h100 and save it to a YAML file. For our example, we saved the file as deploy-hf-llama3.1-405B-8xH100-9680.yaml.
The following example is a copy of the content from the Dell Enterprise Hub. We recommend that you always consult the Dell Enterprise Hub for the latest updates.
apiVersion: apps/v1 kind: Deployment metadata: name: tgi-deployment spec: replicas: 1 selector: matchLabels: app: tgi-server template: metadata: labels: app: tgi-server hf.co/model: meta-llama--Meta-Llama-3.1-405B-Instruct-FP8 hf.co/task: text-generation spec: containers: - name: tgi-container image: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8 resources: limits: nvidia.com/gpu: 8 env: - name: NUM_SHARD value: "8" - name: MAX_BATCH_PREFILL_TOKENS value: "16182" - name: MAX_INPUT_TOKENS value: "8000" - name: MAX_TOTAL_TOKENS value: "8192" volumeMounts: - mountPath: /dev/shm name: dshm volumes: - name: dshm emptyDir: medium: Memory sizeLimit: 1Gi nodeSelector: nvidia.com/gpu.product: NVIDIA-H100-80GB-HBM3 --- apiVersion: v1 kind: Service metadata: name: tgi-service spec: type: LoadBalancer ports: - protocol: TCP port: 80 targetPort: 80 selector: app: tgi-server --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: tgi-ingress annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: ingressClassName: nginx-ingress rules: - http: paths: - path: / pathType: Prefix backend: service: name: tgi-service port: number: 80
Creating the Kubernetes namespace and secrets
After creating the deployment file, create a namespace. For our example, we used deh for simple identification on the pods:
fbronzati@login01:/mnt/f710/DEH$ kubectl create namespace deh namespace/deh created
Deploying the deh pod
To deploy the pod and the services that are required to access the model, run the following command:fbronzati@login01:/mnt/f710/DEH$ kubectl apply -f deploy-hf-llama3.1-405B-8xH100-9680.yaml -n dehdeployment.apps/tgi-deployment created service/tgi-service created ingress.networking.k8s.io/tgi-ingress created
For a first-time deployment, the process of downloading the image takes some time because the container is approximately 507 GB and the model is built in to the container image.- To monitor the deployment of the pod and services, run the following commands:
fbronzati@helios25:~$ kubectl get pods -n deh -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES tgi-deployment-69fd54c8dd-9fzgn 0/1 ContainerCreating 0 4h49m <none> helios25 <none> <none> fbronzati@helios25:~$ kubectl get services -n deh -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR tgi-service LoadBalancer *.*.*.* <pending> 80:30523/TCP 4h49m app=tgi-server
- To verify any errors or if the container image is being downloaded, run the kubectl describe command:
fbronzati@login01:/mnt/f710/DEH$ kubectl describe pod tgi-deployment-69fd54c8dd-9fzgn -n deh
Name: tgi-deployment-69fd54c8dd-9fzgn
Namespace: deh
Priority: 0
Service Account: default
Node: helios25/*.*.*.*
Start Time: Fri, 13 Sep 2024 07:19:38 -0500
Labels: app=tgi-server
hf.co/model=meta-llama--Meta-Llama-3.1-8B-Instruct
hf.co/task=text-generation
pod-template-hash=69fd54c8dd
Annotations: cni.projectcalico.org/containerID: c68dc175a1e11bb85435c6b8aaf193c106959087af26f496d7d71cba1b43b779
cni.projectcalico.org/podIP: *.*.*.*/32
cni.projectcalico.org/podIPs: *.*.*.*/32
k8s.v1.cni.cncf.io/network-status:
[{
"name": "k8s-pod-network",
"ips": [
"*.*.*.*"
],
"default": true,
"dns": {}
}]
k8s.v1.cni.cncf.io/networks-status:
[{
"name": "k8s-pod-network",
"ips": [
"*.*.*.*"
],
"default": true,
"dns": {}
}]
Status: Running
IP: *.*.*.*
IPs:
IP: *.*.*.*
Controlled By: ReplicaSet/tgi-deployment-69fd54c8dd
Containers:
tgi-container:
Container ID: containerd://813dc0f197e53d51cfd1a2e9df531cacdfeec0ad205ca517f6c536de509f6182
Image: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8
Image ID: registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8@sha256:c6819ff57444f51abb2a2a5aabb12b103b346bfb056738a613f3fcc0eecbd322
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 13 Sep 2024 17:30:38 -0500
Ready: True
Restart Count: 0
Limits:
nvidia.com/gpu: 8
Requests:
nvidia.com/gpu: 8
Environment:
NUM_SHARD: 8
PORT: 80
MAX_BATCH_PREFILL_TOKENS: 16182
MAX_INPUT_TOKENS: 8000
MAX_TOTAL_TOKENS: 8192
Mounts:
/dev/shm from dshm (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-zxwnf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
dshm:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium: Memory
SizeLimit: <unset>
kube-api-access-zxwnf:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: nvidia.com/gpu.product=NVIDIA-H100-80GB-HBM3
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 52m kubelet Successfully pulled image "registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3.1-405b-instruct-fp8" in 10h10m58.973s (10h10m58.973s including waiting)
Normal Created 52m kubelet Created container tgi-container
Normal Started 52m kubelet Started container tgi-containerModel Initialization
The model is integrated in the container in the Dell Enterprise Hub. When the container image is downloaded and the container is running, the model is loaded on the GPUs and is ready for use in a few minutes.
To monitor the logs of the pod to verify if the loading process worked or if verification is required, run the following command:
fbronzati@helios25:~$ kubectl logs tgi-deployment-69fd54c8dd-9fzgn -n deh
2024-09-13T22:30:38.886576Z INFO text_generation_launcher: Args {
model_id: "/model",
revision: None,
validation_workers: 2,
sharded: None,
num_shard: Some(
8,
),
quantize: None,
speculate: None,
dtype: None,
trust_remote_code: false,
max_concurrent_requests: 128,
max_best_of: 2,
max_stop_sequences: 4,
max_top_n_tokens: 5,
max_input_tokens: Some(
8000,
),
max_input_length: None,
max_total_tokens: Some(
8192,
),
waiting_served_ratio: 0.3,
max_batch_prefill_tokens: Some(
16182,
),
max_batch_total_tokens: None,
max_waiting_tokens: 20,
max_batch_size: None,
cuda_graphs: None,
hostname: "tgi-deployment-69fd54c8dd-9fzgn",
port: 80,
shard_uds_path: "/tmp/text-generation-server",
master_addr: "localhost",
master_port: 29500,
huggingface_hub_cache: Some(
"/data",
),
weights_cache_override: None,
disable_custom_kernels: false,
cuda_memory_fraction: 1.0,
rope_scaling: None,
rope_factor: None,
json_output: false,
otlp_endpoint: None,
otlp_service_name: "text-generation-inference.router",
cors_allow_origin: [],
watermark_gamma: None,
watermark_delta: None,
ngrok: false,
ngrok_authtoken: None,
ngrok_edge: None,
tokenizer_config_path: None,
disable_grammar_support: false,
env: false,
max_client_batch_size: 4,
lora_adapters: None,
disable_usage_stats: false,
disable_crash_reports: false,
}
2024-09-13T22:30:38.886713Z INFO text_generation_launcher: Using default cuda graphs [1, 2, 4, 8, 16, 32]
2024-09-13T22:30:38.886717Z INFO text_generation_launcher: Sharding model on 8 processes
2024-09-13T22:30:38.886793Z INFO download: text_generation_launcher: Starting check and download process for /model
2024-09-13T22:30:45.130039Z INFO text_generation_launcher: Files are already present on the host. Skipping download.
2024-09-13T22:30:45.991211Z INFO download: text_generation_launcher: Successfully downloaded weights for /model
2024-09-13T22:30:45.991407Z INFO shard-manager: text_generation_launcher: Starting shard rank=0
2024-09-13T22:30:45.991421Z INFO shard-manager: text_generation_launcher: Starting shard rank=1
.
.
.
.
2024-09-13T22:33:22.394579Z INFO shard-manager: text_generation_launcher: Shard ready in 156.399351673s rank=7
2024-09-13T22:33:22.394877Z INFO shard-manager: text_generation_launcher: Shard ready in 156.4004131s rank=5
2024-09-13T22:33:22.490441Z INFO text_generation_launcher: Starting Webserver
2024-09-13T22:33:22.875150Z WARN tokenizers::tokenizer::serialization: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/tokenizers-0.19.1/src/tokenizer/serialization.rs:159: Warning: Token '<|begin_of_text|>' was expected to have ID '128000' but was given ID 'None'
.
.
.
.
2024-09-13T22:33:22.875571Z WARN tokenizers::tokenizer::serialization: /usr/local/cargo/registry/src/index.crates.io-6f17d22bba15001f/tokenizers-0.19.1/src/tokenizer/serialization.rs:159: Warning: Token '<|reserved_special_token_247|>' was expected to have ID '128255' but was given ID 'None'
2024-09-13T22:33:22.877378Z INFO text_generation_router: router/src/main.rs:357: Using config Some(Llama)
2024-09-13T22:33:22.877385Z WARN text_generation_router: router/src/main.rs:366: no pipeline tag found for model /model
2024-09-13T22:33:22.877388Z WARN text_generation_router: router/src/main.rs:384: Invalid hostname, defaulting to 0.0.0.0
2024-09-13T22:33:23.514440Z INFO text_generation_router::server: router/src/server.rs:1572: Warming up model
2024-09-13T22:33:28.860027Z INFO text_generation_launcher: Cuda Graphs are enabled for sizes [32, 16, 8, 4, 2, 1]
2024-09-13T22:33:30.914329Z INFO text_generation_router::server: router/src/server.rs:1599: Using scheduler V3
2024-09-13T22:33:30.914341Z INFO text_generation_router::server: router/src/server.rs:1651: Setting max batch total tokens to 54016
2024-09-13T22:33:30.976105Z INFO text_generation_router::server: router/src/server.rs:1889: ConnectedVerifying the model’s use of GPU memory
You can verify GPU use by using the nvidia-smi utility. However, with the Dell AI Factory, you can also monitor GPU use with Base Command Manager. The following figure shows that 590 GB of the memory is being used for the PowerEdge XE9680 server with eight NVIDIA H100 GPUs with 80 GB, for a total of 640 GB:
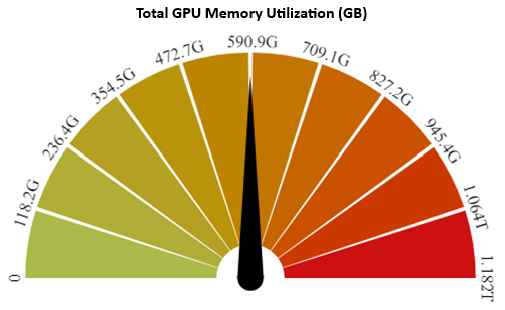
Figure 1: Total GPU memory use
There is an option to identify the memory use of each GPU. The following figure shows that all GPUs are being evenly used with approximately 73 GB of memory:
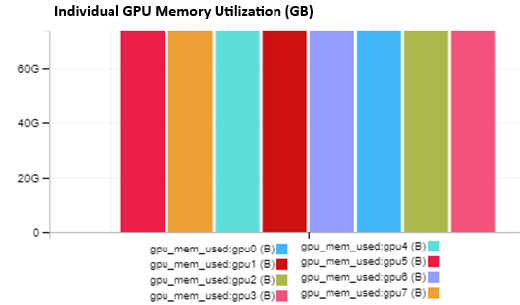
Figure 2: Individual GPU memory use
Confirming the model
When the model is loaded on the GPUs, send a curl command to confirm that is working as planned:
fbronzati@login01:/mnt/f710/DEH$ curl -X 'POST' 'http://*.*.*.*:80/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"prompt": "Once upon a time",
"max_tokens": 64
}'The following example is a response from the model:
{"object":"text_completion","id":"","created":1726269695,"model":"/model","system_fingerprint":"2.2.0-sha-db7e043","choices":[{"index":0,"text":", in a small village nestled in the rolling hills of the countryside, there lived a young girl named Emily. Emily was a curious and adventurous child, with a mop of curly brown hair and a smile that could light up the darkest of rooms. She loved to explore the world around her, and spent most of her days","logprobs":null,"finish_reason":"length"}],"usage":{"prompt_tokens":5,"completion_tokens":64,"total_tokens":69}}Because the container that is being used deploys the OpenAI API, you can use Python or other languages to interact with the model.
Conclusion
Using the Dell Enterprise Hub using TGI platform is an exceptional and easy option to deploy the Llama 3.1 405b model. The Dell partnership with Hugging Face prepares, optimizes, and tests the containers so that you can focus on the development of the application. It will solve your business problems and alleviates worry about the complexities of optimizing and building your deployment environment.
The Llama 3.1 405b model is a powerful open-source tool that offers various deployment options that can often lead to dilemmas in the deployment process. This blog series aims to clarify what to expect by providing practical examples, including code snippets and outputs, to enhance your understanding. For additional deployment assistance, we developed the Dell AI Factory, which embodies Dell’s strategy for embracing and implementing AI. It ensures successful and consistent deployments at any scale and in any location.
Ultimately, the Llama 3.1 405b model deploys seamlessly on a single Dell PowerEdge XE9680 server, making it an excellent choice for organizations looking to leverage AI technology effectively.

Deploying the Llama 3.1 405b Model Using vLLM
Thu, 10 Oct 2024 19:42:18 -0000
|Read Time: 0 minutes
This blog is one in a series of three that shows how Dell Technologies and our partner AI ecosystem can help you to provision the most powerful open-source model available easily. In this series of blogs, we share information about the ease of deploying the Llama 3.1 405b model in the Dell PowerEdge XE9680 server by using NVIDIA NIM, Dell Enterprise Hub using Text Generation Inference (TGI), or vLLM for LLMs. We hope this series equips you with the knowledge and tools needed for a successful deployment.
This blog describes the vLLM for LLMs option.
Overview
In another blog in the series, we show how to deploy the Llama 3.1 405b model using NVIDIA NIM in a single and multimode deployment, also known as distributed inference.
By following the process described in the NVIDIA NIM blog, this blog demonstrates how easily you can deploy Llama 3.1 405b in a Dell PowerEdge XE9680 server using vLLM with Docker or with Kubernetes.
Deployment with vLLM
The vLLM library is designed for high-throughput and memory-efficient inference and serving of large language models (LLMs). The vLLM community is a vibrant and active membership that is centered around the development and use of the vLLM library.
In the following sections, we show two simple ways to deploy vLLM with the Llama 3.1 405b model.
Docker deployment
The easiest deployment is to run Llama 3.1 405b with vLLM. The basic requirements include a Dell PowerEdge XE9680 server running Linux, Docker, NVIDIA GPU Driver, and the NVIDIA Container Toolkit. This blog does not include installation information; see https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html for more information.
To deploy the container and download the model, run the following command. The following example shows the output when the command is completed and the model is deployed:
fbronzati@node005:~$ docker run --runtime nvidia --gpus all -v /aipsf710-21/vllm:/root/.cache/huggingface --env "HUGGING_FACE_HUB_TOKEN=<replace_with_your_HuggingFcae_key" -p 8000:8000 --ipc=host vllm/vllm-openai:latest --model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 --tensor-parallel-size 8 --max_model_len 10000 INFO 09-11 13:44:28 api_server.py:459] vLLM API server version 0.6.0 INFO 09-11 13:44:28 api_server.py:460] args: Namespace(host=None, port=8000, uvicorn_log_level='info', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_auto_tool_choice=False, tool_call_parser=None, model='meta-llama/Meta-Llama-3.1-405B-Instruct-FP8', tokenizer=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, download_dir=None, load_format='auto', dtype='auto', kv_cache_dtype='auto', quantization_param_path=None, max_model_len=10000, guided_decoding_backend='outlines', distributed_executor_backend=None, worker_use_ray=False, pipeline_parallel_size=1, tensor_parallel_size=8, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=16, enable_prefix_caching=False, disable_sliding_window=False, use_v2_block_manager=False, num_lookahead_slots=0, seed=0, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_seqs=256, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, enforce_eager=False, max_context_len_to_capture=None, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, enable_lora=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, override_neuron_config=None, engine_use_ray=False, disable_log_requests=False, max_log_len=None) INFO 09-11 13:44:31 api_server.py:160] Multiprocessing frontend to use ipc:///tmp/4761d363-8d98-4215-a0ae-1d63b684f5c1 for RPC Path. INFO 09-11 13:44:31 api_server.py:176] Started engine process with PID 78 INFO 09-11 13:44:36 config.py:890] Defaulting to use mp for distributed inference INFO 09-11 13:44:36 llm_engine.py:213] Initializing an LLM engine (v0.6.0) with config: model='meta-llama/Meta-Llama-3.1-405B-Instruct-FP8', speculative_config=None, tokenizer='meta-llama/Meta-Llama-3.1-405B-Instruct-FP8', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, rope_scaling=None, rope_theta=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=10000, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=8, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=fbgemm_fp8, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=meta-llama/Meta-Llama-3.1-405B-Instruct-FP8, use_v2_block_manager=False, num_scheduler_steps=1, enable_prefix_caching=False, use_async_output_proc=True) WARNING 09-11 13:44:37 multiproc_gpu_executor.py:56] Reducing Torch parallelism from 112 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed. INFO 09-11 13:44:37 custom_cache_manager.py:17] Setting Triton cache manager to: vllm.triton_utils.custom_cache_manager:CustomCacheManager (VllmWorkerProcess pid=209) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=215) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=211) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=213) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=214) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=210) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=212) INFO 09-11 13:44:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=210) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=210) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=212) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=209) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=212) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=214) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=215) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=209) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=215) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=214) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=213) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=213) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=211) INFO 09-11 13:44:40 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=211) INFO 09-11 13:44:40 pynccl.py:63] vLLM is using nccl==2.20.5 INFO 09-11 13:44:48 custom_all_reduce_utils.py:204] generating GPU P2P access cache in /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=214) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=212) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=211) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=210) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=213) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=209) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=215) INFO 09-11 13:45:08 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json INFO 09-11 13:45:08 shm_broadcast.py:235] vLLM message queue communication handle: Handle(connect_ip='127.0.0.1', local_reader_ranks=[1, 2, 3, 4, 5, 6, 7], buffer=<vllm.distributed.device_communicators.shm_broadcast.ShmRingBuffer object at 0x7fff44678250>, local_subscribe_port=45245, remote_subscribe_port=None) INFO 09-11 13:45:08 model_runner.py:915] Starting to load model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8... (VllmWorkerProcess pid=210) INFO 09-11 13:45:08 model_runner.py:915] Starting to load model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8... (VllmWorkerProcess pid=212) INFO 09-11 13:45:08 model_runner.py:915] Starting to load model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8... . . . . (VllmWorkerProcess pid=212) INFO 09-11 13:45:11 weight_utils.py:236] Using model weights format ['*.safetensors'] (VllmWorkerProcess pid=210) INFO 09-11 13:45:11 weight_utils.py:236] Using model weights format ['*.safetensors'] Loading safetensors checkpoint shards: 0% Completed | 0/109 [00:00<?, ?it/s] Loading safetensors checkpoint shards: 1% Completed | 1/109 [00:02<04:05, 2.28s/it] Loading safetensors checkpoint shards: 2% Completed | 2/109 [00:05<05:20, 3.00s/it] Loading safetensors checkpoint shards: 3% Completed | 3/109 [00:09<05:47, 3.28s/it] Loading safetensors checkpoint shards: 4% Completed | 4/109 [00:12<05:49, 3.32s/it] Loading safetensors checkpoint shards: 5% Completed | 5/109 [00:17<06:33, 3.78s/it] . . . Loading safetensors checkpoint shards: 97% Completed | 106/109 [06:28<00:11, 3.67s/it] Loading safetensors checkpoint shards: 98% Completed | 107/109 [06:32<00:07, 3.59s/it] Loading safetensors checkpoint shards: 99% Completed | 108/109 [06:36<00:03, 3.86s/it] Loading safetensors checkpoint shards: 100% Completed | 109/109 [06:39<00:00, 3.69s/it] Loading safetensors checkpoint shards: 100% Completed | 109/109 [06:39<00:00, 3.67s/it] INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=213) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=212) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=214) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=210) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=215) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=211) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=209) INFO 09-11 13:51:55 model_runner.py:926] Loading model weights took 56.7677 GB INFO 09-11 13:52:04 distributed_gpu_executor.py:57] # GPU blocks: 3152, # CPU blocks: 4161 (VllmWorkerProcess pid=213) INFO 09-11 13:52:08 model_runner.py:1217] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. (VllmWorkerProcess pid=213) INFO 09-11 13:52:08 model_runner.py:1221] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. . . . . INFO 09-11 13:52:09 model_runner.py:1217] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. INFO 09-11 13:52:09 model_runner.py:1221] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. (VllmWorkerProcess pid=214) INFO 09-11 13:52:09 model_runner.py:1217] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. (VllmWorkerProcess pid=214) INFO 09-11 13:52:09 model_runner.py:1221] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. (VllmWorkerProcess pid=215) INFO 09-11 13:52:25 custom_all_reduce.py:223] Registering 8855 cuda graph addresses . . . . .. (VllmWorkerProcess pid=209) INFO 09-11 13:52:26 model_runner.py:1335] Graph capturing finished in 17 secs. (VllmWorkerProcess pid=214) INFO 09-11 13:52:26 model_runner.py:1335] Graph capturing finished in 17 secs. INFO 09-11 13:52:26 model_runner.py:1335] Graph capturing finished in 17 secs. INFO 09-11 13:52:27 api_server.py:224] vLLM to use /tmp/tmpje3c_sb0 as PROMETHEUS_MULTIPROC_DIR WARNING 09-11 13:52:27 serving_embedding.py:190] embedding_mode is False. Embedding API will not work. INFO 09-11 13:52:27 launcher.py:20] Available routes are: INFO 09-11 13:52:27 launcher.py:28] Route: /openapi.json, Methods: HEAD, GET INFO 09-11 13:52:27 launcher.py:28] Route: /docs, Methods: HEAD, GET INFO 09-11 13:52:27 launcher.py:28] Route: /docs/oauth2-redirect, Methods: HEAD, GET INFO 09-11 13:52:27 launcher.py:28] Route: /redoc, Methods: HEAD, GET INFO 09-11 13:52:27 launcher.py:28] Route: /health, Methods: GET INFO 09-11 13:52:27 launcher.py:28] Route: /tokenize, Methods: POST INFO 09-11 13:52:27 launcher.py:28] Route: /detokenize, Methods: POST INFO 09-11 13:52:27 launcher.py:28] Route: /v1/models, Methods: GET INFO 09-11 13:52:27 launcher.py:28] Route: /version, Methods: GET INFO 09-11 13:52:27 launcher.py:28] Route: /v1/chat/completions, Methods: POST INFO 09-11 13:52:27 launcher.py:28] Route: /v1/completions, Methods: POST INFO 09-11 13:52:27 launcher.py:28] Route: /v1/embeddings, Methods: POST INFO 09-11 13:52:27 launcher.py:33] Launching Uvicorn with --limit_concurrency 32765. To avoid this limit at the expense of performance run with --disable-frontend-multiprocessing INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) INFO 09-11 13:52:37 metrics.py:351] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%. INFO 09-11 13:52:47 metrics.py:351] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
Confirming the model
To confirm that the model is working, send a curl command. Ensure that you use the localhost if you submit the request from the node or the IP address of the host if you are testing from another system.
fbronzati@node005:~$ curl -X 'POST' 'http://localhost:8000/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"prompt": "Once upon a time",
"max_tokens": 64
}'The following example is a response from the model:
{"id":"cmpl-9f94c78172db488db84eac5f1fb5165e","object":"text_completion","created":1726232453,"model":"meta-llama/Meta-Llama-3.1-405B-Instruct-FP8","choices":[{"index":0,"text":" there was a man who devoted his entire life to mastering the art of dancing. He trained tirelessly and meticulously in every style he could find, from waltzing to hip-hop. He quickly became a master of each craft, impressing everyone around him with his incredible raw talent and dedication. People everywhere sought after this Renaissance","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":69,"completion_tokens":64}}Because the container that is being used deploys the OpenAI API, you can use Python or other languages to interact with the model.
Kubernetes deployment
Similarly to the NVIDIA NIM deployment, this blog does not describe the installation of the Kubernetes cluster and additional software such as NVIDIA GPU operator. These components are essential. There are many resources on the Internet that describe how to deploy the components. Also, Dell Technologies can provide you with a working environment with the Dell AI Factory solution, which will facilitate your vLLM deployment.
Creating the deployment file
The following example shows how to create a deployment YAML file, which can be expanded with liveness and readiness probes. This blog does not describe these advanced configurations.
- Use your preferred text editor to create a deploy-vllm-llama3.1-405B-8xH100-9680.yaml file.
fbronzati@login01:/mnt/f710/vllm$ vi deploy-vllm-llama3.1-405B-8xH100-9680.yaml
We used vi, however, vim and GNU nano are also good options. - Paste and edit the following content as required for your environment:
apiVersion: apps/v1 kind: Deployment metadata: name: vllm-deployment spec: replicas: 1 selector: matchLabels: app: vllm-server template: metadata: labels: app: vllm-server spec: containers: - name: vllm-container image: "vllm/vllm-openai:v0.6.0" imagePullPolicy: IfNotPresent resources: limits: nvidia.com/gpu: 8 args: - "--model=meta-llama/Meta-Llama-3.1-405B-Instruct-FP8" - "--tensor-parallel-size=8" - "--max_model_len=10000" env: - name: HUGGING_FACE_HUB_TOKEN value: "replace_with_your_HuggingFace_key" volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /root/.cache/huggingface name: model-cache imagePullSecrets: - name: regcred volumes: - name: dshm emptyDir: medium: Memory sizeLimit: 32Gi - name: model-cache nfs: server: f710.f710 path: /ifs/data/Projects/vllm nodeSelector: nvidia.com/gpu.product: NVIDIA-H100-80GB-HBM3 --- apiVersion: v1 kind: Service metadata: name: vllm-service spec: type: LoadBalancer ports: - protocol: TCP port: 8000 targetPort: 8000 selector: app: vllm-server --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: vllm-ingress annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: ingressClassName: nginx-ingress rules: - http: paths: - path: / pathType: Prefix backend: service: name: vllm-service port: number: 8000
Some important considerations include:
- The Llama 3.1 405b model is approximately 700 GB. It is impractical to download the model every time that you switch to a different host. Therefore, we recommend having an external NFS such as the PowerScale F710. This configuration is shown on the volumes section of the file.
- You must accept the Hugging Face and Meta contract and use your HF key to be able to download the model. Otherwise, an error message is displayed when deploying the pod.
- We recommend that you create a new namespace for deploying the pod.
- Because the vLLM image is hosted in the Docker registry, you might need to create a secret. Otherwise, the download might be limited.
Creating the Kubernetes namespace and secrets
After creating the deployment file, create a namespace. For our example, we used vllm for simple identification on the pods.
fbronzati@login01:/mnt/f710/vllm$ kubectl create namespace vllm namespace/vllm created
Create the Docker secret to avoid limiting the number of downloads on the Docker repository:
fbronzati@login01:/mnt/f710/vllm$ kubectl create secret docker-registry regcred --docker-username=<replace_with_your_docker_user> --docker-password=<replace _with_your_docker_key> -n vllm
Deploying the vllm pod
To deploy the pod and the services that are required to access the model:
- Run the following command:
fbronzati@login01:/mnt/f710/vllm$ kubectl apply -f deploy-vllm-llama3.1-405B-8xH100-9680.yaml -n vllmdeployment.apps/vllm-deployment created service/vllm-service created ingress.networking.k8s.io/vllm-ingress created
For a first-time deployment, the process of downloading the image and the model takes some time because the model is approximately 683 GB.
fbronzati@login01:/mnt/f710/vllm$ du -sh hub/* 683G hub/models--meta-llama--Meta-Llama-3.1-405B-Instruct-FP8
- To monitor the deployment of the pod and services, run the following commands
fbronzati@login01:/mnt/f710/vllm$ kubectl get pods -n vllm -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES vllm-deployment-cd6c8564c-kh6tb 1/1 Running 0 58s 10.194.214.55 helios25 <none> <none> fbronzati@login01:/mnt/f710/vllm$ kubectl get services -n vllm -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR vllm-service LoadBalancer *.*.*.* <pending> 8000:30757/TCP 83s app=vllm-server
- To verify any errors or if the container image is being downloaded, run the kubectl describe command:
fbronzati@login01:/mnt/f710/vllm$ kubectl describe pod vllm-deployment-cd6c8564c-kh6tb -n vllm
Name: vllm-deployment-cd6c8564c-kh6tb
Namespace: vllm
Priority: 0
Service Account: default
Node: helios25/*.*.*.*
Start Time: Thu, 12 Sep 2024 09:05:22 -0500
Labels: app=vllm-server
pod-template-hash=cd6c8564c
Annotations: cni.projectcalico.org/containerID: 56bbadf0bf9193c47e481263e2a52770595c5c16f6bbee3e63177953a755c52c
cni.projectcalico.org/podIP: 10.194.214.55/32
cni.projectcalico.org/podIPs: 10.194.214.55/32
k8s.v1.cni.cncf.io/network-status:
[{
"name": "k8s-pod-network",
"ips": [
"10.194.214.55"
],
"default": true,
"dns": {}
}]
k8s.v1.cni.cncf.io/networks-status:
[{
"name": "k8s-pod-network",
"ips": [
"10.194.214.55"
],
"default": true,
"dns": {}
}]
Status: Running
IP: *.*.*.*
IPs:
IP: *.*.*.*
Controlled By: ReplicaSet/vllm-deployment-cd6c8564c
Containers:
vllm-container:
Container ID: containerd://92d98154a4faebfb5fe67ffc5aaa0404f1a6e3c37698a8eb94173543fd2b182c
Image: vllm/vllm-openai:v0.6.0
Image ID: docker.io/vllm/vllm-openai@sha256:072427aa6f95c74782a9bc3fe1d1fcd1e1aa3fe47b317584ea2181c549ad2de8
Port: <none>
Host Port: <none>
Args:
--model=meta-llama/Meta-Llama-3.1-405B-Instruct-FP8
--tensor-parallel-size=8
--max_model_len=10000
State: Running
Started: Thu, 12 Sep 2024 09:05:24 -0500
Ready: True
Restart Count: 0
Limits:
nvidia.com/gpu: 8
Requests:
nvidia.com/gpu: 8
Environment:
HUGGING_FACE_HUB_TOKEN: █████████████████████████████
Mounts:
/dev/shm from dshm (rw)
/root/.cache/huggingface from model-cache (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-kd9zq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
dshm:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium: Memory
SizeLimit: 32Gi
model-cache:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: f710.f710
Path: /ifs/data/Projects/vllm
ReadOnly: false
kube-api-access-kd9zq:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: nvidia.com/gpu.product=NVIDIA-H100-80GB-HBM3
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events: <none> Model Initialization
After downloading the container image and creating the pod/service, the model is downloaded and loaded to the GPUs. This process might take a long time. We recommend that you monitor the logs of the pod to follow the process. The following example shows sample output that enables you to verify if the behavior is the same in your environment:
fbronzati@login01:/mnt/f710/vllm$ kubectl logs vllm-deployment-cd6c8564c-kh6tb -n vllm -f INFO 09-12 07:05:28 api_server.py:459] vLLM API server version 0.6.0 INFO 09-12 07:05:28 api_server.py:460] args: Namespace(host=None, port=8000, uvicorn_log_level='info', allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], api_key=None, lora_modules=None, prompt_adapters=None, chat_template=None, response_role='assistant', ssl_keyfile=None, ssl_certfile=None, ssl_ca_certs=None, ssl_cert_reqs=0, root_path=None, middleware=[], return_tokens_as_token_ids=False, disable_frontend_multiprocessing=False, enable_auto_tool_choice=False, tool_call_parser=None, model='meta-llama/Meta-Llama-3.1-405B-Instruct-FP8', tokenizer=None, skip_tokenizer_init=False, revision=None, code_revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=False, download_dir=None, load_format='auto', dtype='auto', kv_cache_dtype='auto', quantization_param_path=None, max_model_len=10000, guided_decoding_backend='outlines', distributed_executor_backend=None, worker_use_ray=False, pipeline_parallel_size=1, tensor_parallel_size=8, max_parallel_loading_workers=None, ray_workers_use_nsight=False, block_size=16, enable_prefix_caching=False, disable_sliding_window=False, use_v2_block_manager=False, num_lookahead_slots=0, seed=0, swap_space=4, cpu_offload_gb=0, gpu_memory_utilization=0.9, num_gpu_blocks_override=None, max_num_batched_tokens=None, max_num_seqs=256, max_logprobs=20, disable_log_stats=False, quantization=None, rope_scaling=None, rope_theta=None, enforce_eager=False, max_context_len_to_capture=None, max_seq_len_to_capture=8192, disable_custom_all_reduce=False, tokenizer_pool_size=0, tokenizer_pool_type='ray', tokenizer_pool_extra_config=None, limit_mm_per_prompt=None, enable_lora=False, max_loras=1, max_lora_rank=16, lora_extra_vocab_size=256, lora_dtype='auto', long_lora_scaling_factors=None, max_cpu_loras=None, fully_sharded_loras=False, enable_prompt_adapter=False, max_prompt_adapters=1, max_prompt_adapter_token=0, device='auto', num_scheduler_steps=1, scheduler_delay_factor=0.0, enable_chunked_prefill=None, speculative_model=None, speculative_model_quantization=None, num_speculative_tokens=None, speculative_draft_tensor_parallel_size=None, speculative_max_model_len=None, speculative_disable_by_batch_size=None, ngram_prompt_lookup_max=None, ngram_prompt_lookup_min=None, spec_decoding_acceptance_method='rejection_sampler', typical_acceptance_sampler_posterior_threshold=None, typical_acceptance_sampler_posterior_alpha=None, disable_logprobs_during_spec_decoding=None, model_loader_extra_config=None, ignore_patterns=[], preemption_mode=None, served_model_name=None, qlora_adapter_name_or_path=None, otlp_traces_endpoint=None, collect_detailed_traces=None, disable_async_output_proc=False, override_neuron_config=None, engine_use_ray=False, disable_log_requests=False, max_log_len=None) INFO 09-12 07:05:33 api_server.py:160] Multiprocessing frontend to use ipc:///tmp/29c1a11c-a17a-4fa1-8768-a001a3385714 for RPC Path. INFO 09-12 07:05:33 api_server.py:176] Started engine process with PID 78 INFO 09-12 07:05:37 config.py:890] Defaulting to use mp for distributed inference INFO 09-12 07:05:37 llm_engine.py:213] Initializing an LLM engine (v0.6.0) with config: model='meta-llama/Meta-Llama-3.1-405B-Instruct-FP8', speculative_config=None, tokenizer='meta-llama/Meta-Llama-3.1-405B-Instruct-FP8', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, rope_scaling=None, rope_theta=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=10000, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=8, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=fbgemm_fp8, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), observability_config=ObservabilityConfig(otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=0, served_model_name=meta-llama/Meta-Llama-3.1-405B-Instruct-FP8, use_v2_block_manager=False, num_scheduler_steps=1, enable_prefix_caching=False, use_async_output_proc=True) WARNING 09-12 07:05:37 multiproc_gpu_executor.py:56] Reducing Torch parallelism from 112 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed. INFO 09-12 07:05:37 custom_cache_manager.py:17] Setting Triton cache manager to: vllm.triton_utils.custom_cache_manager:CustomCacheManager (VllmWorkerProcess pid=210) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=213) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=212) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=211) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=209) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=214) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=215) INFO 09-12 07:05:38 multiproc_worker_utils.py:215] Worker ready; awaiting tasks (VllmWorkerProcess pid=211) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=209) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=215) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=211) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=209) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=210) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=215) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=213) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=214) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=210) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=212) INFO 09-12 07:05:48 utils.py:977] Found nccl from library libnccl.so.2 (VllmWorkerProcess pid=213) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=214) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 (VllmWorkerProcess pid=212) INFO 09-12 07:05:48 pynccl.py:63] vLLM is using nccl==2.20.5 INFO 09-12 07:05:55 custom_all_reduce_utils.py:204] generating GPU P2P access cache in /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json INFO 09-12 07:06:38 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=213) INFO 09-12 07:06:38 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json (VllmWorkerProcess pid=214) INFO 09-12 07:06:38 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json . . . . (VllmWorkerProcess pid=209) INFO 09-12 07:06:38 custom_all_reduce_utils.py:242] reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1,2,3,4,5,6,7.json INFO 09-12 07:06:38 shm_broadcast.py:235] vLLM message queue communication handle: Handle(connect_ip='127.0.0.1', local_reader_ranks=[1, 2, 3, 4, 5, 6, 7], buffer=<vllm.distributed.device_communicators.shm_broadcast.ShmRingBuffer object at 0x7fff438fd6f0>, local_subscribe_port=33971, remote_subscribe_port=None) INFO 09-12 07:06:38 model_runner.py:915] Starting to load model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8... (VllmWorkerProcess pid=210) INFO 09-12 07:06:38 model_runner.py:915] Starting to load model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8... (VllmWorkerProcess pid=212) INFO 09-12 07:06:38 model_runner.py:915] Starting to load model meta-llama/Meta-Llama-3.1-405B-Instruct-FP8... . . . . (VllmWorkerProcess pid=209) INFO 09-12 07:06:40 weight_utils.py:236] Using model weights format ['*.safetensors'] (VllmWorkerProcess pid=210) INFO 09-12 07:06:40 weight_utils.py:236] Using model weights format ['*.safetensors'] Loading safetensors checkpoint shards: 0% Completed | 0/109 [00:00<?, ?it/s] Loading safetensors checkpoint shards: 1% Completed | 1/109 [00:03<07:09, 3.97s/it] Loading safetensors checkpoint shards: 2% Completed | 2/109 [00:07<06:20, 3.56s/it] Loading safetensors checkpoint shards: 3% Completed | 3/109 [00:10<06:03, 3.42s/it] . . . . . Loading safetensors checkpoint shards: 96% Completed | 105/109 [06:23<00:12, 3.22s/it] Loading safetensors checkpoint shards: 97% Completed | 106/109 [06:27<00:10, 3.51s/it] Loading safetensors checkpoint shards: 98% Completed | 107/109 [06:31<00:06, 3.44s/it] Loading safetensors checkpoint shards: 99% Completed | 108/109 [06:35<00:03, 3.75s/it] Loading safetensors checkpoint shards: 100% Completed | 109/109 [06:38<00:00, 3.59s/it] Loading safetensors checkpoint shards: 100% Completed | 109/109 [06:38<00:00, 3.66s/it] INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=209) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=211) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=212) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=215) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=214) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=210) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB (VllmWorkerProcess pid=213) INFO 09-12 07:13:19 model_runner.py:926] Loading model weights took 56.7677 GB INFO 09-12 07:13:26 distributed_gpu_executor.py:57] # GPU blocks: 2937, # CPU blocks: 4161 (VllmWorkerProcess pid=209) INFO 09-12 07:13:30 model_runner.py:1217] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. (VllmWorkerProcess pid=209) INFO 09-12 07:13:30 model_runner.py:1221] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. . . . . . INFO 09-12 07:13:30 model_runner.py:1217] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. INFO 09-12 07:13:30 model_runner.py:1221] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. (VllmWorkerProcess pid=212) INFO 09-12 07:13:30 model_runner.py:1217] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. (VllmWorkerProcess pid=212) INFO 09-12 07:13:30 model_runner.py:1221] CUDA graphs can take additional 1~3 GiB memory per GPU. If you are running out of memory, consider decreasing `gpu_memory_utilization` or enforcing eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage. (VllmWorkerProcess pid=215) INFO 09-12 07:13:46 custom_all_reduce.py:223] Registering 8855 cuda graph addresses (VllmWorkerProcess pid=211) INFO 09-12 07:13:46 custom_all_reduce.py:223] Registering 8855 cuda graph addresses (VllmWorkerProcess pid=213) INFO 09-12 07:13:46 custom_all_reduce.py:223] Registering 8855 cuda graph addresses . . . . . (VllmWorkerProcess pid=211) INFO 09-12 07:13:46 model_runner.py:1335] Graph capturing finished in 16 secs. (VllmWorkerProcess pid=209) INFO 09-12 07:13:46 model_runner.py:1335] Graph capturing finished in 17 secs. INFO 09-12 07:13:46 model_runner.py:1335] Graph capturing finished in 16 secs. INFO 09-12 07:13:47 api_server.py:224] vLLM to use /tmp/tmpzt8ci2e8 as PROMETHEUS_MULTIPROC_DIR WARNING 09-12 07:13:47 serving_embedding.py:190] embedding_mode is False. Embedding API will not work. INFO 09-12 07:13:47 launcher.py:20] Available routes are: INFO 09-12 07:13:47 launcher.py:28] Route: /openapi.json, Methods: GET, HEAD INFO 09-12 07:13:47 launcher.py:28] Route: /docs, Methods: GET, HEAD INFO 09-12 07:13:47 launcher.py:28] Route: /docs/oauth2-redirect, Methods: GET, HEAD INFO 09-12 07:13:47 launcher.py:28] Route: /redoc, Methods: GET, HEAD INFO 09-12 07:13:47 launcher.py:28] Route: /health, Methods: GET INFO 09-12 07:13:47 launcher.py:28] Route: /tokenize, Methods: POST INFO 09-12 07:13:47 launcher.py:28] Route: /detokenize, Methods: POST INFO 09-12 07:13:47 launcher.py:28] Route: /v1/models, Methods: GET INFO 09-12 07:13:47 launcher.py:28] Route: /version, Methods: GET INFO 09-12 07:13:47 launcher.py:28] Route: /v1/chat/completions, Methods: POST INFO 09-12 07:13:47 launcher.py:28] Route: /v1/completions, Methods: POST INFO 09-12 07:13:47 launcher.py:28] Route: /v1/embeddings, Methods: POST INFO 09-12 07:13:47 launcher.py:33] Launching Uvicorn with --limit_concurrency 32765. To avoid this limit at the expense of performance run with --disable-frontend-multiprocessing INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) INFO 09-12 07:13:57 metrics.py:351] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%. INFO 09-12 07:14:07 metrics.py:351] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
Verifying the model’s use of GPU memory
With access to the host or the container, you can verify GPU use by using the nvidia-smi utility. The following example shows how the GPUs are displayed on the container after the model is loaded:
fbronzati@login01:/mnt/f710/vllm$ kubectl exec -it vllm-deployment-cd6c8564c-kh6tb -n vllm -- bash root@vllm-deployment-cd6c8564c-kh6tb:/vllm-workspace# nvidia-smi Thu Sep 12 11:31:04 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.90.07 Driver Version: 550.90.07 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA H100 80GB HBM3 On | 00000000:19:00.0 Off | 0 | | N/A 40C P0 117W / 700W | 72156MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA H100 80GB HBM3 On | 00000000:3B:00.0 Off | 0 | | N/A 36C P0 114W / 700W | 69976MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 2 NVIDIA H100 80GB HBM3 On | 00000000:4C:00.0 Off | 0 | | N/A 34C P0 115W / 700W | 69976MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 3 NVIDIA H100 80GB HBM3 On | 00000000:5D:00.0 Off | 0 | | N/A 38C P0 112W / 700W | 69976MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 4 NVIDIA H100 80GB HBM3 On | 00000000:9B:00.0 Off | 0 | | N/A 41C P0 119W / 700W | 69976MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 5 NVIDIA H100 80GB HBM3 On | 00000000:BB:00.0 Off | 0 | | N/A 36C P0 111W / 700W | 69976MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 6 NVIDIA H100 80GB HBM3 On | 00000000:CB:00.0 Off | 0 | | N/A 38C P0 117W / 700W | 69976MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ | 7 NVIDIA H100 80GB HBM3 On | 00000000:DB:00.0 Off | 0 | | N/A 34C P0 117W / 700W | 69496MiB / 81559MiB | 0% Default | | | | Disabled | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| +-----------------------------------------------------------------------------------------+
Confirming the model
To confirm that the model is working, send a curl command:
fbronzati@login01:/mnt/f710/vllm$ curl -X 'POST' 'http://*.*.*.*:8000/v1/completions' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"prompt": "Once upon a time",
"max_tokens": 64
}'The following example is a response from the model:
{"id":"cmpl-cc26bb0694e34a26940becc791b2eacf","object":"text_completion","created":1726166028,"model":"meta-llama/Meta-Llama-3.1-405B-Instruct-FP8","choices":[{"index":0,"text":", there was a little girl name Sophie. She was eight years old and lived in a big, noisy city with her parents. Sophie's room was filled with belonging to a grown-up until just a little while ago her mother items. The room was cramped and cluttered, but Sophie loved it because it was hers.\n","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":69,"completion_tokens":64}}Because the container being ussed deploys the OpenAI API, you can use Python or other languages to interact with the model.
Conclusion
The Llama 3.1 405b model is a highly capable open-source model that offers multiple deployment options.
By using vLLM, we increase flexibility by being able to use Docker with a single command line. Installation of the requirements is easier because a Kubernetes cluster or a license is not required for deployment.
While this flexibility is beneficial, it can also introduce complexity when determining the most suitable deployment approach for specific requirements. Enterprises usually require high availability and support that can be more difficult to achieve with open-source tools and a simple Docker deployment.
To address this complexity, Dell Technologies has developed the Dell AI Factory—a comprehensive framework that provides detailed studies, code snippets, and execution outputs to facilitate the deployment process. This resource enables organizations to replicate deployments, gain insights, and evaluate different strategies, helping them select the optimal deployment method based on their unique infrastructure and business needs.

Accelerating AI for Indic Languages with Dell PowerEdge
Tue, 17 Sep 2024 18:24:18 -0000
|Read Time: 0 minutes
In the ever-evolving realm of artificial intelligence, the ability to support multilingual language models has become increasingly essential, especially in a linguistically diverse country like India. This guide explores how Dell PowerEdge servers, paired with NVIDIA H100 GPUs, provide a robust platform for AI workloads. By leveraging Docker for containerization and NVIDIA Triton for efficient inference, these technologies are ideal for running large-scale AI models, such as those developed for Indic language processing.
Introduction: Powering AI with Dell and Nvidia for Indic Languages
Dell PowerEdge servers, which are designed for AI and high performance computing , have proven their capability in deploying sophisticated models that support multiple languages. In one such experiment, a multilingual text generation model—Sarvam-2B from Sarvam AI—was used as a case study. This model, which is designed to generate text in various Indic languages, provided a great example of the potential of Dell's infrastructure when working with large language models.
While Sarvam-2B’s capabilities were tested in this setup, it is one of many AI models that can benefit from Dell’s powerful computational infrastructure. The synergy between Dell PowerEdge servers and NVIDIA H100 GPUs ensures high performance and efficiency, particularly when dealing with large datasets and multilingual outputs. The forthcoming version of this model will expand its capabilities further, having been trained on an extraordinary 4 trillion tokens, evenly divided between English and Indic languages, thereby enhancing its overall performance and utility.
It is important to note that the sarvam-2b-v0.5 model is a pre-trained text-completion model. It is not instruction fine-tuned or aligned, meaning it cannot answer questions or follow instructions. Its primary functionality is limited to generating text completions based on the input that it receives. The model was tested for its ability to handle multilingual text generation on a Dell PowerEdge R760 platform with NVIDIA H100 GPUs. This test confirmed its efficiency in generating text across various Indic languages, showcasing its versatility and effectiveness in real-world applications.
Configuring the Dell PowerEdge Server
Components | Version |
Kernel Version | 5.14.0-162.6.1.el9_1 |
Release Date | Fri Sep 30 07:36:03 EDT 2022 |
Architecture | x86_64 (64-bit) |
Operating System | Linux (RedHat Enterprise Linux) |
Docker version | 27.1.1, build 6312585 |
CUDA Version | 12.4 CUDA version: 6.1 |
Server | Dell™ PowerEdge™ R760 |
GPU | 2x NVIDIA H100 PCIe |
Inference Server | NVIDIA Triton 23.09 (backend by vLLM) |
Model | sarvamai/sarvam-2b-v0.5 |
Supporting AI Innovation in India with Dell Infrastructure
India's growing demand for AI-driven applications necessitates an infrastructure that can handle complex, multilingual models. Dell PowerEdge AI-enabled servers, equipped with NVIDIA H100 GPUs, are ideally suited for these tasks.
In our tests, the system efficiently handled AI models like Sarvam-2B, but the same infrastructure can be used for a wide range of AI models beyond this example. This setup offers flexibility and performance, allowing organizations to build, deploy, and scale AI models that cater to India's diverse linguistic landscape. Whether it's for research, industry, or social applications, Dell’s infrastructure provides the backbone for the next wave of AI innovation.
Empowering India's AI Growth with Global Excellence
AI-Ready Infrastructure: Dell's PowerEdge servers with NVIDIA GPUs provide Indian organizations with the tools to deploy advanced AI models, capable of handling large-scale workloads, while also supporting global AI initiatives.
Localized AI Solutions for India: Dell focuses on AI models tailored for India's diverse needs, ensuring global competitiveness while addressing the country’s unique challenges.
Scalable and Efficient AI: Dell's infrastructure enables Indian organizations to build adaptable, resource-efficient AI models that drive innovation across industries.
Data Sovereignty and Security: Dell upholds India’s data privacy regulations, promoting secure and sovereign AI development, reinforcing its leadership in global AI innovation.
Assessing Indic Language Support with Dell PowerEdge: A Case Study with Sarvam AI’s Multilingual Model
Preparing for Deployment - Key Aspects of Sarvam AI’s Tokenizer and Vocabulary
Before deploying the Sarvam AI model, it's essential to understand the following key aspects of its tokenizer and vocabulary setup:
- Tailored Tokenizer: Sarvam AI employs a custom tokenizer designed for Indic languages, adept at handling diverse scripts and complex linguistic structures.
- Advanced Techniques: Moving beyond traditional Byte Pair Encoding (BPE), the model uses specialized methods such as SentencePiece, which better accommodates the rich morphology of Indic languages.
- Effective Vocabulary: The model features a meticulously constructed vocabulary that ensures accurate text representation by converting and decoding tokens with precision.
- High Precision: The tokenizer and vocabulary are fine-tuned to provide accurate and contextually relevant text generation across multiple Indic languages.
Deploying the Sarwam AI Model
- Set up the Docker container.
To ensure a consistent and isolated environment, a Docker container running the NVIDIA Triton Inference Server was used. The following command configures the container with GPU support and necessary system settings:
- Download and configure the model.
Within the Docker container, the Sarvam-2B model, optimized for Indic language text generation, was downloaded. The transformers library from Hugging Face facilitated this process:

This ensures that the model and tokenizer are correctly installed and available for local use within the Docker container.
- Generate text in multiple Indic languages.
With the model and tokenizer ready, a Python script was created to generate text in various Indic languages. The script loads the model and tokenizer, and produces text based on predefined input texts: With the model and tokenizer ready, a Python script was created to generate text in various Indic languages. The script loads the model and tokenizer and produces text based on predefined input texts:

Observations and Results
The Sarvam-2B model effectively generated meaningful and contextually appropriate text in all tested Indic languages. Sample outputs include:

Conclusion
Integrating Docker containers with Sarvam AI's Sarvam-2B model, and using NVIDIA H100 GPUs within Dell PowerEdge R760 servers, creates a robust framework for multilingual text generation tasks. This configuration ensures high performance and scalability, making it an excellent solution for enterprises and applications requiring advanced language processing capabilities across multiple Indic languages. The setup not only supports efficient model deployment but also leverages state-of-the-art hardware for optimal results.

vLLM Meets Kubernetes-Deploying Llama-3 Models using KServe on Dell PowerEdge XE9680 with AMD MI300X
Fri, 17 May 2024 19:18:34 -0000
|Read Time: 0 minutes
Introduction
Dell's PowerEdge XE9680 server infrastructure, coupled with the capabilities of Kubernetes and KServe, offers a comprehensive platform for seamlessly deploying and managing sophisticated large language models such as Meta AI's Llama-3, addressing the evolving needs of AI-driven businesses.
Our previous blog post explored leveraging advanced Llama-3 models (meta-llama/Meta-Llama-3-8B-Instruct and meta-llama/Meta-Llama-3-70B-Instruct) for inference tasks, where Dell Technologies highlighted the container-based deployment, endpoint API methods, and OpenAI-style inferencing. This subsequent blog delves deeper into the inference process but with a focus on Kubernetes (k8s) and KServe integration.
This method seamlessly integrates with the Hugging Face ecosystem and the vLLM framework, all operational on the robust Dell™ PowerEdge™ XE9680 server, empowered by the high-performance AMD Instinct™ MI300X accelerators.
System configurations and prerequisites
- Operating System: Ubuntu 22.04.3 LTS
- Kernel: Linux 5.15.0-105-generic
- Architecture: x86-64
- ROCm™ version: 6.1
- Server: Dell™ PowerEdge™ XE9680
- GPU: 8x AMD Instinct™ MI300X Accelerators
- vLLM version: 0.4.1.2
- Llama-3: meta-llama/Meta-Llama-3-8B-Instruct, meta-llama/Meta-Llama-3-70B-Instruct
- Kubernetes: 1.26.12
- KServe: V0.11.2
To install vLLM, see our previous blog for instructions on setting up the cluster environment needed for inference.
Deploying Kubernetes and KServe on XE9680
Overview
To set up Kubernetes on a bare metal XE9680 cluster, Dell Technologies used Kubespray, an open-source tool that streamlines Kubernetes deployments. Dell Technologies followed the quick start section of its documentation, which provides clear step-by-step instructions for installation and configuration.
Next, Dell Technologies installed KServe, a highly scalable and standards-based model inference platform on Kubernetes.
KServe provides the following features:
- It acts as a universal inference protocol for a range of machine learning frameworks, ensuring compatibility across different platforms.
- It supports serverless inference workloads with autoscaling capabilities, including GPU scaling down to zero when not in use.
- It uses ModelMesh to achieve high scalability, optimized resource utilization, and intelligent request routing.
- It provides a simple yet modular solution for production-level ML serving, encompassing prediction, preprocessing and postprocessing, monitoring, and explainability features.
- It facilitates advanced deployment strategies such as canary rollouts, experimental testing, model ensembles, and transformers for more complex use cases.

Setting up KServe: Quickstart and Serverless installation
To test inference with KServe, start with the KServe Quickstart guide for a simple setup. If you need a production-ready environment, refer to the Administration Guide. Dell Technologies opted for Serverless installation to meet our scalability and resource flexibility requirements.
Serverless installation:
As part of KServe (v0.11.2) installation, Dell Technologies had to install the following dependencies first:
- Istio (V1.17.0)
- Certificate manager (v1.13.0)
- Knative Serving (v1.11.0)
- DNS Configuration
Each dependency is described below.
Istio (V1.17.0)
Purpose: Manages traffic and security.
Why needed: Ensures efficient routing, secure service communication, and observability for microservices.
- Download the istio tar file - https://github.com/istio/istio/releases/download/1.17.0/istio-1.17.0-linux-amd64.tar.gz
- Extract the tar file and change directory (cd) to the extracted folder.
- Install with the istioctl command - bin/istioctl install --set profile=default -y
See the Istio guide for details.
Certificate manager (v1.13.0)
Purpose: Automates TLS certificate management.
Why needed: Provides encrypted and secure communication between services, crucial for protecting data.
- kubectl apply -f: https://github.com/cert-manager/cert-manager/releases/download/v1.13.0/cert-manager.yaml
Knative Serving (v1.11.0)
Purpose: Enables serverless deployment and scaling.
Why needed: Automatically scales KServe model serving pods based on demand, ensuring efficient resource use.
- kubectl apply -f: https://github.com/knative/serving/releases/download/knative-v1.11.0/serving-crds.yaml
- kubectl apply -f: https://github.com/knative/serving/releases/download/knative-v1.11.0/serving-core.yaml
- kubectl apply -f:https://github.com/knative/net-istio/releases/download/knative-v1.11.0/net-istio.yaml
DNS Configuration
Purpose: Facilitates service domain.
Why needed: Ensures that services can communicate using human-readable names, which is crucial for reliable request routing.
kubectl patch configmap/config-domain \
--namespace knative-serving \
--type merge \
--patch '{"data":{"example.com":""}}'For more details, please see the Knative Serving install guide.
Installation steps for KServe
- kubectl apply -f: https://github.com/kserve/kserve/releases/download/v0.11.2/kserve.yaml
- kubectl apply -f: https://github.com/kserve/kserve/releases/download/v0.11.2/kserve-runtimes.yaml
The deployment requires ClusterStorageContainer. Provide the http_proxy and https_proxy values if the cluster is behind a proxy, and nodes do not have direct Internet access.
KServe is also included with the Kubeflow deployment. If you must deploy Kubeflow, refer to the Kubeflow git page for installation steps. Dell Technologies used a single command installation approach to install Kubeflow with Kustomize.
Llama 3 model execution with Kubernetes
Initiate the execution of the Llama 3 model within Kubernetes by deploying it using the established configurations as given above and then follow the instructions below.
Create the manifest file
This YAML snippet employs the serving.kserve.io/v1beta1 API version, ensuring compatibility and adherence to the standards within the KServe environment. Within this setup, a KServe Inference Service named llama-3-70b is established using a container housing the vLLM model.
The configuration includes precise allocations for MI300X GPUs and environmental settings. It intricately orchestrates the deployment process by specifying resource limits for CPUs, memory, and GPUs, along with settings for proxies and authentication tokens.
In the YAML example file below, arguments are passed to the container's command. This container expects:
- --port: The port on which the service will listen (8080)
- --model: The model to be loaded, specified as meta-llama/Meta-Llama-3-70B-Instruct / meta-llama/Meta-Llama-3-8B
Alternatively, separate YAML files can be created to run both models independently.
For the end-point inferencing, choose any of the three methods (with a container image (offline inferencing, endpoint API, and the OpenAI approach) mentioned in the previous blog.

Apply the manifest file
The next step performs the kubectl apply command to deploy the vLLM configuration defined in the YAML file onto the Kubernetes cluster. This command triggers Kubernetes to interpret the YAML specifications and initiate the creation of the Inference Service, named llama-3-70b. This process ensures that the vLLM model container is set up with the designated resources and environment configurations.

The initial READY status will be either unknown or null. After the model is ready, it changes to True. For an instant overview of Inference Services across all namespaces, check the kubectl get isvc -A command. It provides essential details like readiness status, URLs, and revision information, enabling quick insights into deployment status and history.

For each deployed inference service, one pod gets created. Here we can see that two pods are running; each hosting a distinct Llama-3 model (8b and 70b) on two different GPUs on an XE9680 server.

To get the detailed information about the specified pod's configuration, status, and events use the kubectl describe pod command, which aids in troubleshooting and monitoring within Kubernetes.

After the pod is up and running, users can perform inference through the designated endpoints. Perform the curl request to verify whether the model is successfully served at the specific local host.

Users can also follow the ingress IP and ports method for inferencing.
Conclusion
Integrating Llama 3 with the Dell PowerEdge XE9680 and leveraging the powerful AMD MI300X highlights the adaptability and efficiency of Kubernetes infrastructure. vLLM enhances both deployment speed and prediction accuracy, demonstrating KServe's advanced AI technology and expertise in optimizing Kubernetes for AI workloads.

Run Llama 3 on Dell PowerEdge XE9680 and AMD MI300x with vLLM
Thu, 09 May 2024 18:49:19 -0000
|Read Time: 0 minutes
In the rapidly evolving AI landscape, Meta AI Llama 3 stands out as a leading large language model (LLM), driving advancements across a variety of applications, from chatbots to text generation. Dell PowerEdge servers offer an ideal platform for deploying this sophisticated LLM, catering to the growing needs of AI-centric enterprises with their robust performance and scalability.
This blog demonstrates how to infer with the state-of-the-art Llama 3 model (meta-llama/Meta-Llama-3-8B-Instruct and meta-llama/Meta-Llama-3-70B-Instruct) using different methods. These methods include a container image (offline inferencing), endpoint API, and the OpenAI approach—using Hugging Face with vLLM.

Figure 1. Model Architecture of deploying Llama 3 model on PowerEdge XE9680 with AMD MI300x
Deploy Llama 3
Step 1: Configure Dell PowerEdge XE9680 Server
Use the following system configuration settings:
- Operating System: Ubuntu 22.04.3 LTS
- Kernel: Linux 5.15.0-105-generic
- Architecture: x86-64
- nerdctl: 1.5.0
- ROCm™ version: 6.1
- Server: Dell™ PowerEdge™ XE9680
- GPU: 8x AMD Instinct™ MI300X Accelerators
- vLLM version: 0.3.2+rocm603
- Llama 3 model: meta-llama/Meta-Llama-3-8B-Instruct, meta-llama/Meta-Llama-3-70B-Instruct
Step 2: Build vLLM from container
vLLM is a high-performance, memory-efficient serving engine for large language models (LLMs). It leverages PagedAttention and continuous batching techniques to rapidly process LLM requests.
1. Install the AMD ROCm™ driver, libraries, and tools. Use the following instructions from AMD for your Linux based platform. To ensure these installations are successful, check the GPU info using rocm-smi.

2. To quickly start with vLLM, we suggest using the ROCm Docker container, as installing and building vLLM from source can be complex; however, for our study, we built it from source to access the latest version.
- Git clone fo vLLM 0.3.2 version.
git clone -b v0.3.2 https://github.com/vllm-project/vllm.git
- To use nerdctl requires that BuildKit is enabled. Use the following instructions to set up nerdctl build with BuildKit.
cd vllm sudo nerdctl build -f Dockerfile -t vllm-rocm:latest . (This execution will take approximate 2-3 hours) nerdctl images | grep vllm
- Run it and replace <path/to/model> with the appropriate path if you have a folder of LLMs you would like to mount and access in the container.
nerdctl run -it --network=host --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --device /dev/kfd --device /dev/dri/card0 --device /dev/dri/card1 --device /dev/dri/renderD128 -v <path/to/model>:/app/model vllm-rocm:latest
Step 3: Run Llama 3 using vLLM with three approaches
vLLM provides various deployment methods for running your Llama-3 model - run it offline, with a container image, via an endpoint API, or using the OpenAI approach.
Using the Dell XE9680 server with AMD Mi300 GPUs, let's explore each option in detail to determine which aligns best with your infrastructure and workflow requirements.
Container Image
- Use pre-built container images to install vLLM quickly and with minimal effort.
- Supports consistent deployment across diverse environments, both on-premises and cloud-based.
Endpoint API
- Access vLLM's functionality through a RESTful API, enabling easy integration with other systems.
- Encourages a modular design and smooth communication with external applications for added flexibility.
OpenAI
- Run vLLM using a framework like OpenAI, this option is perfect for those who are familiar with OpenAI's architecture.
- Ideal for users seeking a seamless transition from existing OpenAI workflows to vLLM.
Now, let's dive into the step-by-step process for implementing each of these approaches.
Approach 1: Llama 3 with container image (offline inferencing)
To start the offline inferencing we first need to export the environment variables. To use the Llama-3 model, you must set the HUGGING_FACE_HUB_TOKEN environment variable for authentication, this requires signing up for a Hugging Face account to obtain an access token.
root@16118303efa7:/app# export HUGGING_FACE_HUB_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Use the existing script provided by vLLM , and edit the model needed for your offline inferencing , in our case it would be “meta-llama/Meta-Llama-3-8B-Instruct and meta-llama/Meta-Llama-3-70B-Instruct”. Make sure you have the valid permissions to access the model from HUGGING FACE.
root@16118303efa7:/app# vi vllm/examples/offline_inference.py
Next, the Python script (offline_inference.py) is executed to run the inference process. This script is designed to work with vLLM, an optimized inference engine for large language models.
root@16118303efa7:/app# python vllm/examples/offline_inference.py
The script then, initializes the Llama 3 model by logging key setup information like tokenizer, model configurations, device setup, and weight-loading format and proceeds to download and load the model weights and components (such as tokenizer configurations) for offline inference with detailed logs showing which files are downloaded at what speed.
Finally, the script executes the Llama 3 model with example prompts, displaying text-based responses to demonstrate coherent outputs, confirming the model's offline inference capabilities.
Prompt: 'Hello, my name is', Generated text: ' Helen and I am a second-year student at the University of Central Florida. I' Prompt: 'The president of the United States is', Generated text: " a powerful figure, with the ability to shape the country's laws, policies," Prompt: 'The capital of France is', Generated text: ' a city that is steeped in history, art, and culture. From the' Prompt: 'The future of AI is', Generated text: ' here, and it’s already changing the way we live, work, and interact'
Approach 2: Llama 3 inferencing via api server
This example maintains a consistent server environment and includes vLLM through API server that allows you to run the vLLM backend and interact with it via HTTP endpoints. This provides flexible access to language models for generating text or processing requests.
root@16118303efa7:/app# python -m vllm.entrypoints.api_server --model meta-llama/Meta-Llama-3-8B-Instruct
First, execute the following command to enable the api_server inference endpoint inside the container. User can modify model argument parameter as per their requirement from the supported model list. If you require the 70B model, ensure that it runs on a dedicated GPU, as the VRAM won't be sufficient if other processes are also running.
INFO 01-17 20:25:37 llm_engine.py:222] # GPU blocks: 2642, # CPU blocks: 327 INFO: Started server process [10] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
The following example provides the expected output. Once the above command is executed, vLLM gets enabled through port 8000. Now, you can use the endpoint to communicate with the model.
curl http://localhost:8000/generate -d '{ "prompt": "Dell is", "use_beam_search": true, "n": 5, "temperature": 0 }'
The following example provides the expected output.
{"text":["Dell is one of the world's largest technology companies, providing a wide range of products and","Dell is one of the most well-known and respected technology companies in the world, with a","Dell is a well-known brand in the tech industry, and their laptops are popular among consumers","Dell is one of the most well-known and respected technology companies in the world. With a","Dell is one of the most well-known and respected technology companies in the world, and their"]}Approach 3: Llama 3 inferencing via openai compatible server
This approach maintains a consistent server environment with vLLM deployed as a server that implements the OpenAI API protocol. This allows vLLM to be used as a drop-in replacement for applications using OpenAI API. By default, it starts the server at http://localhost:8000 . You can specify the address with --host and --port arguments. The server currently hosts one model at a time and implements list models, create chat completion, and create completion endpoints. The following actions provide an example for a Llama 3 model.
To activate the openai_compatible inference endpoint within the container, use the following command. If you require the 70B model, ensure it runs on a dedicated GPU, as the VRAM won't be sufficient if other processes are also running.
python -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-8B-Instruct python -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-70B-Instruct
To install OpenAI, run the following command with root privileges from the host entity.
pip install openai
Run the following command to invoke the python file, and then edit the model and openapi base url.
root@compute1:~# cat openai_vllm.py from openai import OpenAI openai_api_key = "EMPTY" openai_api_base = "http://localhost:8000/v1" client = OpenAI( api_key=openai_api_key, base_url=openai_api_base, ) stream = client.chat.completions.create( model="meta-llama/Meta-Llama-3-8B-Instruct", messages=[{"role": "user", "content": "Explain the differences betweem Navy Diver and EOD rate card"}], max_tokens=4000, stream=True, ) for chunk in stream: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="")
Run the following command to execute.
root@compute1:~# python3 openai_vllm.py
The following example provides the expected output.
Navy Diver (ND) and Explosive Ordnance Disposal (EOD) are both specialized ratings in the United States Navy, but they have distinct roles and responsibilities. **Navy Diver (ND) Rating:** Navy Divers are trained to conduct a variety of underwater operations, including: 1. Salvage and recovery of underwater equipment and vessels 2. Construction and maintenance of underwater structures 3. Clearance of underwater obstacles and hazards 4. Recovery of aircraft and other underwater vehicles 5. Scientific and research diving Navy Divers typically work in a variety of environments, including freshwater and saltwater, and may be deployed on board ships, submarines, or ashore. Their primary responsibilities include: * Conducting dives to depths of up to 300 feet (91 meters) in a variety of environments * Operating specialized diving equipment, such as rebreathers and rebreather systems * Performing underwater repairs and maintenance on equipment and vessels * Conducting underwater construction and salvage operations **Explosive Ordnance Disposal (EOD) Rating:**
Conclusion
The inclusion of Llama 3 with Dell PowerEdge XE9680, taps into the powerful capabilities of AMD's MI300 and XE960, underscores swift data processing, and provides a flexible infrastructure. By leveraging vLLM, it enhances model deployment and inference efficiency, reinforcing Meta's focus on advanced open-source AI technology and demonstrating Dell's strength in delivering high-performance solutions for a broad range of applications.
Stay tuned for future blogs posted on the Dell Technologies Info Hub for AI for more information on vLLM with different models and their performance metrics on Poweredge XE9680.

HPC Application Performance on Dell PowerEdge C6620 with INTEL 8480+ SPR
Thu, 09 Nov 2023 15:46:41 -0000
|Read Time: 0 minutes
Overview
With a robust HPC and AI Innovation Lab at the helm, Dell continues to ensure that PowerEdge servers are cutting-edge pioneers in the ever-evolving world of HPC. The latest stride in this journey comes in the form of the Intel Sapphire Rapids processor, a powerhouse of computational prowess. When combined with the cutting-edge infrastructure of the Dell PowerEdge 16th generation servers, a new era of performance and efficiency dawns upon the HPC landscape. This blog post provides comprehensive benchmark assessments spanning various verticals within high-performance computing.
It is Dell Technologies’ goal to help accelerate time to value for customers, as well as leverage benchmark performance and scaling studies to help plan out their environments. By using Dell’s solutions, customers spend less time testing different combinations of CPU, memory, and interconnect, or choosing the CPU with the sweet spot for performance. Additionally, customers do not have to spend time deciding which BIOS features to tweak for best performance and scaling. Dell wants to accelerate the set-up, deployment, and tuning of HPC clusters to enable customers real value while running their applications and solving complex problems (such as weather modeling).
Testbed Configuration
This study conducted benchmarking on high-performance computing applications using Dell PowerEdge 16th generation servers featuring Intel Sapphire Rapids processors.
Benchmark Hardware and Software Configuration
Table 1. Test bed system configuration used for this benchmark study
Platform | Dell PowerEdge C6620 |
Processor | Intel Sapphire Rapids 8480+ |
Cores/Socket | 56 (112 total) |
Base Frequency | 2.0 GHz |
Max Turbo Frequency | 3.80 GHz |
TDP | 350 W |
L3 Cache | 105 MB |
Memory | 512 GB | DDR5 4800 MT/s |
Interconnect | NVIDIA Mellanox ConnectX-7 NDR 200 |
Operating System | Red Hat Enterprise Linux 8.6 |
Linux Kernel | 4.18.0-372.32.1 |
BIOS | 1.0.1 |
OFED | 5.6.2.0.9 |
System Profile | Performance Optimized |
Compiler | Intel OneAPI 2023.0.0 | Compiler 2023.0.0 |
MPI | Intel MPI 2021.8.0 |
Turbo Boost | ON |
Interconnect | Mellanox NDR 200 |
Application | Vertical Domain | Benchmark Datasets |
OpenFOAM | Manufacturing - Computational Fluid Dynamics (CFD) | Motorbike 50 M 34 M and 20 M cell mesh |
Weather Research and Forecasting (WRF) | Weather and Environment | |
Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) | Molecular Dynamics | Rhodo, EAM, Stilliger Weber, tersoff, HECBIOSIM, and Airebo |
GROMACS | Life Sciences – Molecular Dynamics | HECBioSim Benchmarks – 3M Atoms, Water, and Prace LignoCellulose |
CP2K | Life Sciences | H2O-DFT-LS-NREP- 4, 6 H2O-64-RI-MP 2 |
Performance Scalability for HPC Application Domain
Vertical – Manufacturing | Application - OPENFOAM
OpenFOAM is an open-source computational fluid dynamics (CFD) software package renowned for its versatility in simulating fluid flows, turbulence, and heat transfer. It offers a robust framework for engineers and scientists to model complex fluid dynamics problems and conduct simulations with customizable features. This study worked on OpenFOAM version 9, which have been compiled with Intel ONE API 2023.0.0 and Intel MPI 2021.8.0 compilers. For successful compilation and optimization with the Intel compilers, additional flags such as '-O3 -xSAPPHIRERAPIDS -m64 -fPIC' have been added.
The tutorial case under the simpleFoam solver category, motorbike, were used for evaluating the performance of the OpenFOAM package on intel 8480+ processors. Three different types of grids were generated such as 20 M, 34 M, and 50 M cells using the blockMesh and snappyHexMesh utilities of OpenFOAM. Each run was conducted with full cores (112 cores per node) and from a single node to sixteen nodes, while scalability tests were done for all three sets of grids. The steady state simpleFoam solver execution time was noted as performance numbers.
The figure below shows the application performance for all the datasets:
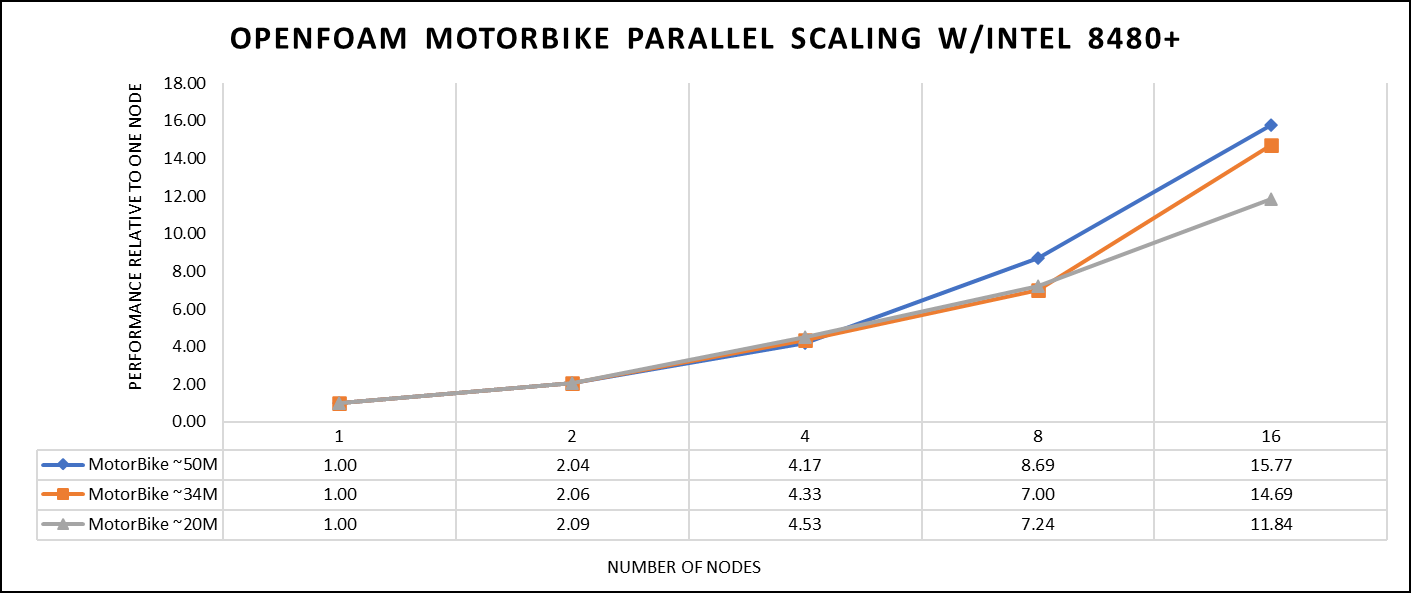
Figure 1. The scaling performance of the OpenFOAM Motorbike dataset using the Intel 8480+ processor, with a focus on performance compared to a single node.
The results are non-dimensionalized with single node result, with the scalability depicted in Figure 1. The Intel-compiled binaries of OpenFOAM shows linear scaling from a single node to sixteen nodes on 8480+ processors for higher dataset (50 M). For other datasets with 20 M and 34 M cells, the linear scaling was shown up to eight nodes and from eight nodes to sixteen nodes the scalability was reduced.
Achieving satisfactory results with smaller datasets can be accomplished using fewer processors and nodes. Nonetheless, augmenting the node count; therefore, the processor count, in relation to the solver's computation time, leads to increased inter-processor communication, later extending the overall runtime. Consequently, higher node counts prove more beneficial when handling larger datasets within OpenFOAM simulations.
Vertical – Weather and Environment | Application - WRF
The Weather Research and Forecasting model (WRF) is at the forefront of meteorological and atmospheric research, with its latest version being a testament to advancements in high-performance computing (HPC). WRF enables scientists and meteorologists to simulate and forecast complex weather patterns with unparalleled precision. This study involved working on WRF version 4.5, which have been compiled with Intel ONEAPI 2023.0.0 and Intel MPI 2021.8.0 compilers. For successful compilation and optimization with the Intel compilers, additional flags such as ' -O3 qopt-zmm-usage=high –xSAPPHIRERAPIDS -fpic’ were used.
The dataset used in this study is CONUS v4.4, meaning the model's grid, parameters, and input data are set up to focus on weather conditions within the continental United States. This configuration is particularly useful for researchers, meteorologists, and government agencies who need high-resolution weather forecasts and simulations tailored to this specific geographic area. The configuration details, such as grid resolution, atmospheric physics schemes, and input data sources, can vary depending on the specific version of WRF and the goals of the modeling project. This study predominantly adhered to the default input configuration, making minimal alterations or adjustments to the source code or input file. Each run was conducted with full cores (112 cores per node). The scalability tests were done from a single node to sixteen nodes, and the performance metric in “sec” was noted.
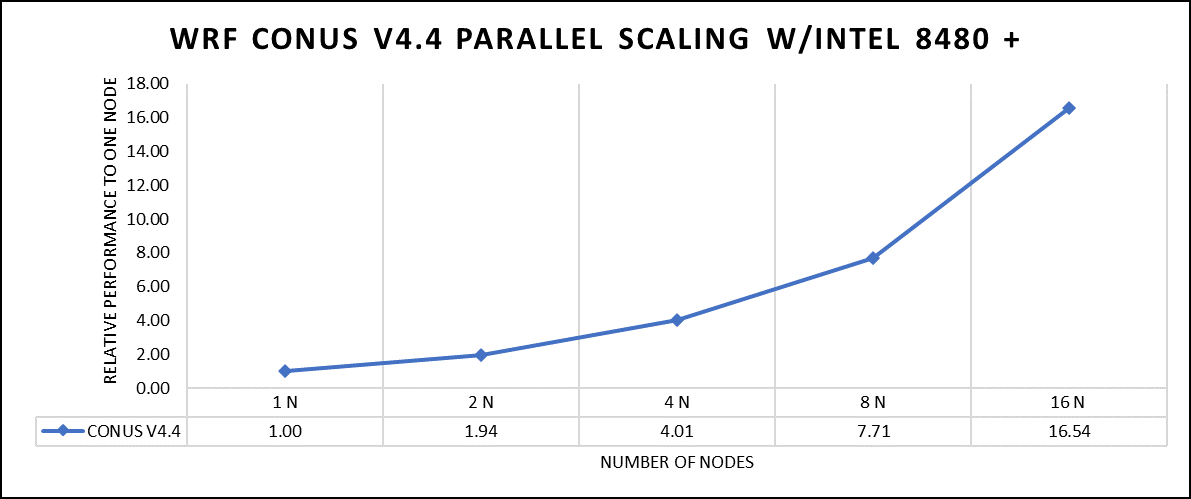
Figure 2. The scaling performance of the WRF CONUS dataset using the Intel 8480+ processor, with a focus on performance compared to a single node.
The INTEL compiled binaries of WRF show linear scaling from a single node to sixteen nodes on 8480+ processors for the new CONUS v4.4. For the best performance with WRF, the impact of the tile size, process, and threads per process should be carefully considered. Given that the memory and DRAM bandwidth constrain the application, the team opted for the latest DDR5 4800 MT/s DRAM for test evaluations. Additionally, it is crucial to consider the BIOS settings, particularly SubNUMA configurations, as these settings can significantly influence the performance of memory-bound applications, potentially leading to improvements ranging from one to five percent.
For more detailed BIOS tuning recommendations, see the previous blog post on optimizing BIOS settings for optimal performance.
Vertical – Molecular Dynamics | Application – LAMMPS
LAMMPS, which stands for Large-scale Atomic/Molecular Massively Parallel Simulator, is a powerful tool for HPC. It is specifically designed to harness the immense computational capabilities of HPC clusters and supercomputers. LAMMPS allows researchers and scientists to conduct large-scale molecular dynamics simulations with remarkable efficiency and scalability. This study worked on LAMMPS, the 15 June 2023 version, which have been compiled with Intel ONEAPI 2023.0.0 and Intel MPI 2021.8.0 compilers. For successful compilation and optimization with the Intel compilers, additional flags such as “ -O3 qopt-zmm-usage=high –xSAPPHIRERAPIDS -fpic,” were used.
The team opted for the default INTEL package, which offers optimized atom pair styles for vector instructions on Intel processors. The team also tried running some benchmarks which are not supported with the INTEL package to check the performance and scaling. The performance metric for this benchmark is nanoseconds per day where higher is considered better.
There are two factors that were considered when compiling data for comparison: the number of nodes and the core count. Below are the results of performance improvement observed on processor 8480+ with 112 cores:
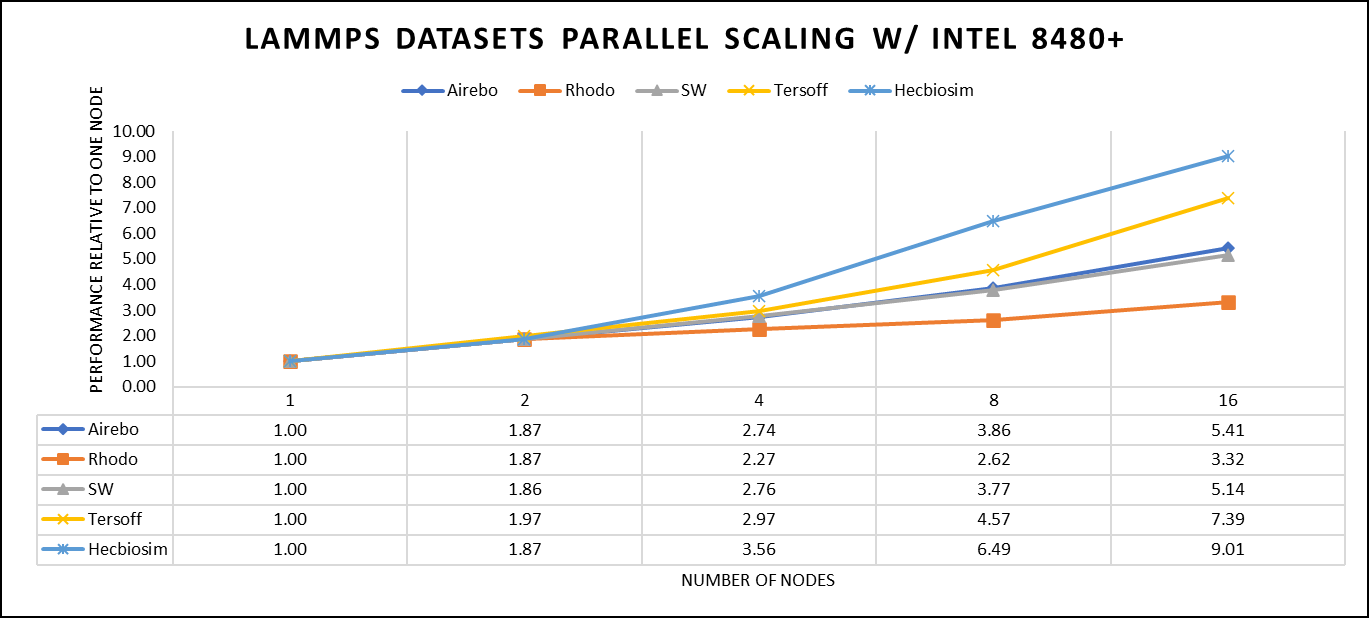
Figure 3. The scaling performance of the LAMMPS datasets using the Intel 8480+ processor, with a focus on performance compared to a single node.
Figure 3 shows the scaling of different LAMMPS datasets. Noticeable enhancement in scalability is evident with the increment in atom size and step size. The examination involved two datasets, EAM and Hecbiosim, each containing over 3 million atoms. The results indicated better scalability when compared to the other datasets analyzed.
Vertical – Molecular Dynamics | Application - GROMACS
GROMACS, a high-performance molecular dynamics software, is a vital tool for HPC environments. Tailored for HPC clusters and supercomputers, GROMACS specializes in simulating the intricate movements and interactions of atoms and molecules. Researchers in diverse fields, including biochemistry and biophysics, rely on its efficiency and scalability to explore complex molecular processes. GROMACS is used for its ability to harness the immense computational power of HPC, allowing scientists to conduct intricate simulations that reveal critical insights into atomicatomic-level behaviours, from biomolecules to chemical reactions and materials. This study worked on GROMACS 2023.1 version, which has been compiled with Intel ONEAPI 2023.0.0 and Intel MPI 2021.8.0 compilers. For successful compilation and optimization with the Intel compilers, additional flags such as “ -O3 qopt-zmm-usage=high –xSAPPHIRERAPIDS -fpic,” were used.
The team curated a range of datasets for the benchmarking assessments. First, the team included "water GMX_50 1536" and "water GMX_50 3072," which represent simulations involving water molecules. These simulations are pivotal for gaining insights into solvation, diffusion, and the water's behavior in diverse conditions. Next, the team incorporated "HECBIOSIM 14 K" and "HECBIOSIM 30 K" datasets, which were specifically chosen for their ability to investigate intricate systems and larger biomolecular structures. Lastly, the team included the "PRACE Lignocellulose" dataset, which aligns with the benchmarking objectives, particularly in the context of lignocellulose research. These datasets collectively offer a diverse array of scenarios for the benchmarking assessments.
The performance assessment was based on the measurement of nanoseconds per day (ns/day) for each dataset, providing valuable insights into the computational efficiency. Additionally, the team paid careful attention to optimizing the mdrun tuning parameters (i.e, ntomp, dlb tunepme nsteps, etc )in every test run to ensure accurate and reliable results. The team examined the scalability by conducting tests spanning from a single node to sixteen nodes.
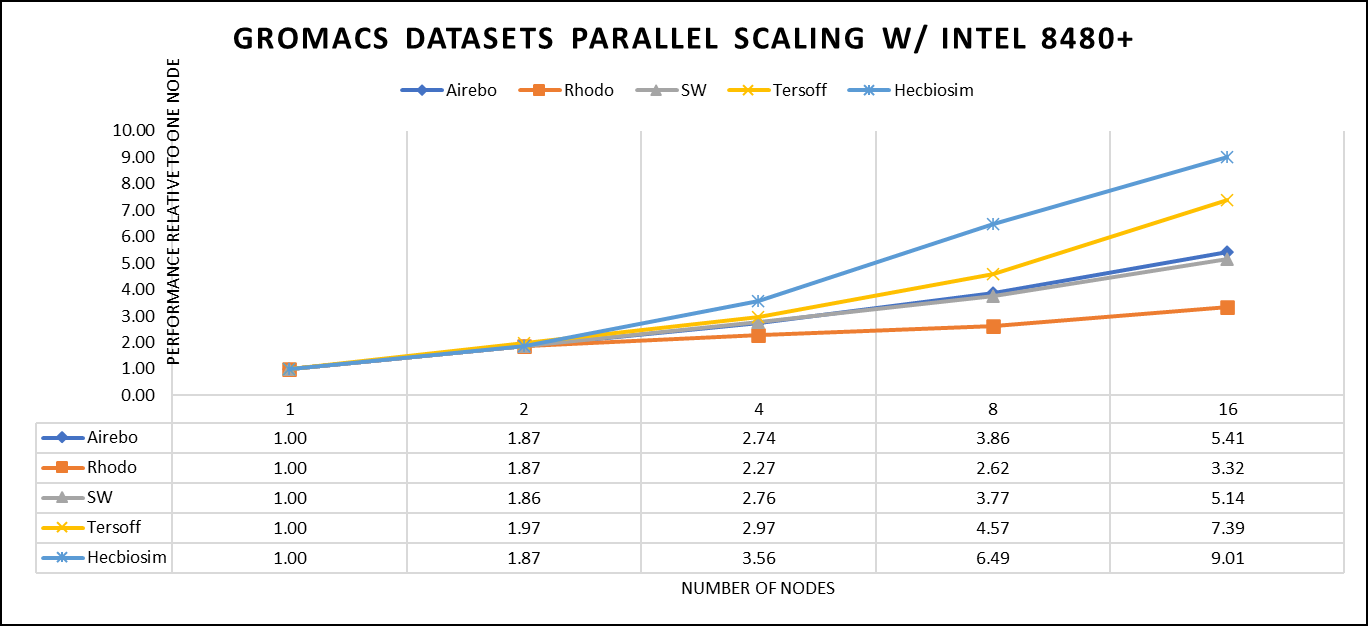
Figure 4. The scaling performance of the GROMACS datasets using the Intel 8480+ processor, with a focus on performance compared to a single node.
For ease of comparison across the various datasets, the relative performance has been included into a single graph. However, each dataset behaves individually when performance is considered, as each uses different molecular topology input files (tpr), and configuration files.
The team achieved the expected linear performance scalability for GROMACS of up to eight nodes All cores in each server were used while running these benchmarks. The performance increases are close to linear across all the dataset types; however, there is a drop in the larger number of nodes due to the smaller dataset size and the simulation iterations.
Vertical – Molecular Dynamics | Application – CP2K
CP2K is a versatile computational software package that covers a wide range of quantum chemistry and solid-state physics simulations, including molecular dynamics. It is not strictly limited to molecular dynamics but is instead a comprehensive tool for various computational chemistry and materials science tasks. While CP2K is widely used for molecular dynamics simulations, it can also perform tasks like electronic structure calculations, ab initio molecular dynamics, hybrid quantum mechanics/molecular mechanics (QM/MM) simulations, and more.
This study worked on the CP2K 2023.1 version, which has been compiled with Intel ONEAPI 2023.0.0 and Intel MPI 2021.8.0 compilers. For successful compilation and optimization with the Intel compilers, additional flags such as “ -O3 qopt-zmm-usage=high –xSAPPHIRERAPIDS -fpic,” were used.
Focusing on high-performance computing (HPC), the team used specific datasets optimized for computational efficiency. The first dataset, "H2O-DFT-LS-NREP-4,6," was configured for HPC simulations and calculations, emphasizing the modeling of water (H2O) using Density Functional Theory (DFT). The appended "NREP-4,6" parameter settings were fine-tuned to ensure efficient HPC performance. The second dataset, "H2O-64-RI-MP2," was exclusively crafted for HPC applications and revolved around the examination of a system consisting of 64 water molecules (H2O). By employing the Resolution of Identity (RI) method with the Møller–Plesset perturbation theory of second order (MP2), this dataset demonstrated the significant computational capabilities of HPC for conducting advanced electronic structure calculations within a high-molecule-count environment. The team examined the scalability by conducting tests spanning from a single node to sixteen nodes.
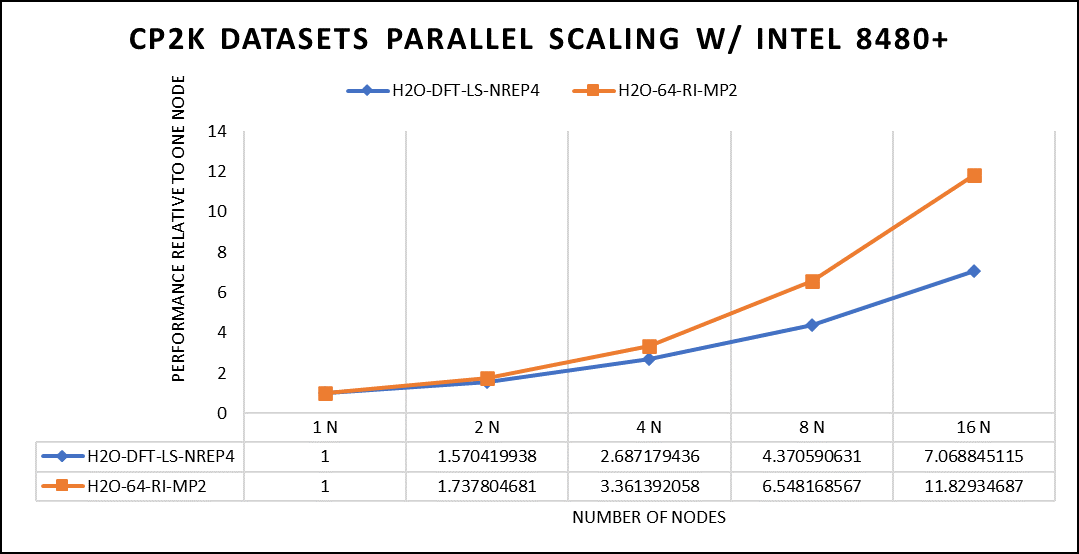
Figure 5. The scaling performance of the CP2K datasets using the Intel 8480+ processor, with a focus on performance compared to a single node.
The datasets represent a single-point energy calculation employing linear-scaling Density Functional Theory (DFT). The system consists of 6144 atoms confined within a 39 Å^3 simulation box, which translates to 2048 water molecules. To adjust the computational workload, you can modify the NREP parameter within the input file.
Performing with NREP6 necessitates more than 512 GB of memory on a single node. Failing to meet this requirement will result in a segmentation fault error. These benchmarking efforts encompass configurations involving up to 16 computational nodes. Optimal performance is achieved when using NREP4 and NREP6 in Hybrid mode, which combines Message Passing Interface (MPI) and Open Multi-Processing (OpenMP). This configuration exhibits the best scaling performance, particularly on four to eight nodes. However, it is worth noting that scaling beyond eight nodes does not exhibit a strictly linear performance improvement. Figure 5 depicts the outcomes when using Pure MPI, using 112 cores with a single thread per core.
Conclusion
With equivalent core counts, the prior generation of Intel Xeon processors can match the performance of the Sapphire Rapids counterpart. However, achieving this level of performance necessitates doubling the number of nodes. Therefore, a single 350W node equipped with the 8480+ processor can deliver comparable performance when compared to using two 500W nodes with the 8358 processor. In addition to optimizing the BIOS settings as outlined in our INTEL-focused blog, the team advises disabling Hyper-threading specifically for the benchmarks discussed in this article. However, for different types of workloads, the team recommends conducting thorough testing and enabling Hyper-threading if it proves beneficial. Furthermore, for this performance study, the team highly recommends using the Mellanox NDR 200 interconnect.

HPC Application Performance on Dell PowerEdge R6625 with AMD EPYC- GENOA
Wed, 08 Nov 2023 21:09:35 -0000
|Read Time: 0 minutes
The AMD EPYC 9354 Processor, when integrated into the Dell R6625 server, offers a formidable solution for high-performance computing (HPC) applications. Genoa, which is built on the Zen 4 architecture, delivers exceptional processing power and efficiency, making it a compelling choice for demanding HPC workloads. When paired with the PowerEdge R6625's robust infrastructure and scalability features, this CPU enhances server performance, enabling efficient and reliable execution of HPC applications. These features make it an ideal choice for HPC application studies and research.
At Dell Technologies, it’s our goal to help accelerate time to value for our customers. Dell wants to help customers leverage our benchmark performance and scaling studies to help plan out their environments. By utilizing our expertise, customers don’t have to spend time testing different combinations of CPU, memory and interconnect or choosing the CPU with the sweet spot for performance. This also saves time, as customers don’t have to spend time deciding which BIOS features to tweak for best performance and scaling. Dell wants to accelerate the set-up, deployment, and tuning of HPC clusters to enable customers to get the real value- running their applications and solving complex problems like manufacturing better products for their customers.
Testbed configuration
Benchmarking for high-performance computing applications was carried out using Dell PowerEdge 16G servers equipped with AMD EPYC 9354 32-Core Processor.
Table 1. Test bed system configuration used for this benchmark study
Platform | Dell PowerEdge R6625 |
Processor | AMD EPYC 9354 32-Core Processor |
Cores/Socket | 32 (64 total) |
Base Frequency | 3.25 GHz |
Max Turbo Frequency | 3.75 GHz |
TDP | 280 W |
L3 Cache | 256 MB |
Memory | 768 GB | DDR5 4800 MT/s |
Interconnect | NVIDIA Mellanox ConnectX-7 NDR 200 |
Operating System | RHEL 8.6 |
Linux Kernel | 4.18.0-372.32.1 |
BIOS | 1.0.1 |
OFED | 5.6.2.0.9 |
System Profile | Performance Optimized |
Compiler | AOCC 4.0.0 |
MPI | OpenMPI 4.1.4 |
Turbo Boost | ON |
Interconnect | Mellanox NDR 200 |
Application | Vertical Domain | Benchmark Datasets |
OpenFOAM | Manufacturing - Computational Fluid Dynamics (CFD) | Motorbike 50M 34M and 20M cell mesh |
Weather Research and Forecasting (WRF) | Weather and Environment |
|
Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) | Molecular Dynamics | Rhodo, EAM, Stilliger Weber, tersoff, HECBIOSIM, and Airebo |
GROMACS | Life Sciences – Molecular Dynamics | HECBioSim Benchmarks – 3M Atoms , Water and Prace LignoCellulose |
CP2K | Life Sciences | H2O-DFT-LS-NREP- 4,6 H2O-64-RI-MP 2 |
Performance Scalability for HPC Application Domain
Vertical – Manufacturing | Application - OPENFOAM
OpenFOAM is an open-source computational fluid dynamics (CFD) software package renowned for its versatility in simulating fluid flows, turbulence, and heat transfer. It offers a robust framework for engineers and scientists to model complex fluid dynamics problems and conduct simulations with customizable features. In this study, worked on OpenFOAM version 9, which have been compiled with gcc 11.2.0 with OPENMPI 4.1.5. For successful compilation and optimization on the AMD EPYC processors, additional flags such as ' -O3 -znver4' have been added.
The tutorial case under the simpleFoam solver category, motorBike, has been used to evaluate the performance of OpenFOAM package on AMD EPYC 9354 processors. Three different types of grids were generated such as 20M, 34M, and 50M cells using the blockMesh and snappyHexMesh utilities of OpenFOAM. Each run was conducted with full cores (64 cores per node) and from single node to sixteen nodes, The scalability tests were done for all the three sets of grids. The steady state simpleFoam solver execution time was noted down as performance numbers. The figure below shows the application performance for all the datasets.
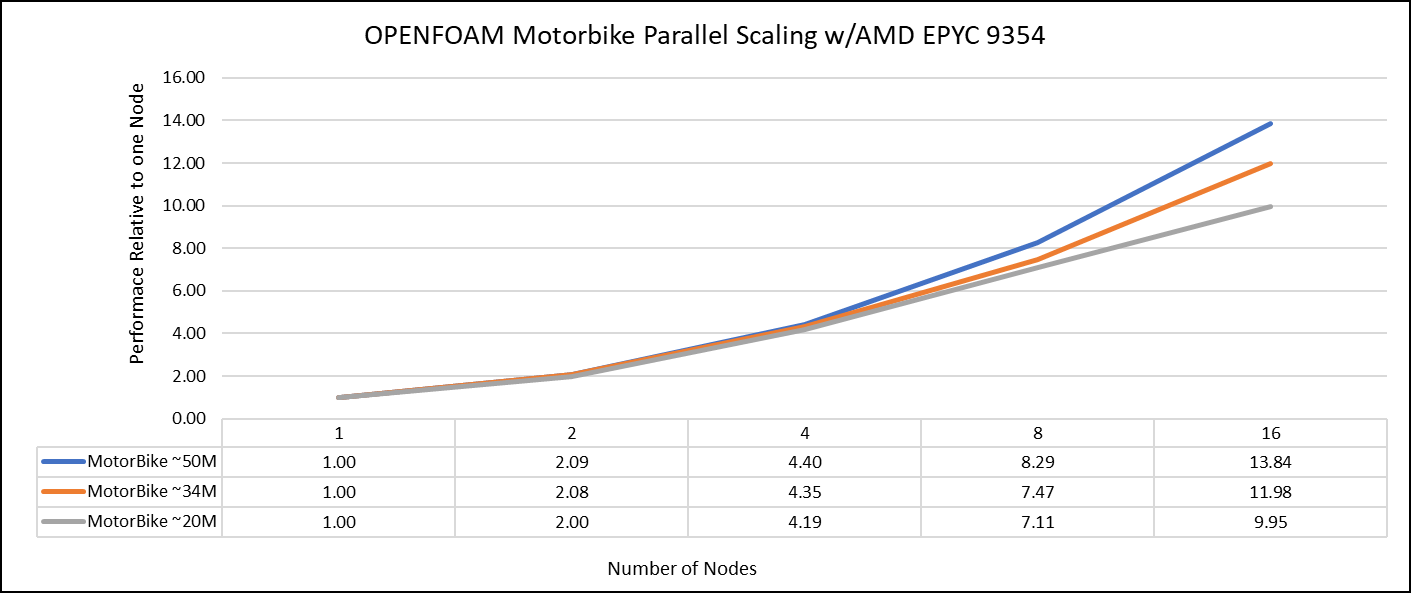
Figure 1: The scaling performance of the OpenFOAM Motorbike dataset using the AMD EPYC Processor, with a focus on performance compared to a single node.
The results are non-dimensionalized with single node result. The scalability is depicted in Figure 1. The OpenFOAM application shows linear scaling from a single node to eight nodes on 9354 processors for higher dataset (50M). For other smaller datasets with 20M and 34M cells, the linear scaling was shown up to four nodes and slightly scaling reduced on eight nodes. For all the datasets (20M, 34M and 50M) on sixteen nodes the scalability was reduced.
Achieving satisfactory results with smaller datasets can be accomplished using fewer processors and nodes, because smaller datasets do not require a higher number of processors. Nonetheless, augmenting the node count, and therefore, the processor count, in relation to the solver's computation time leads to increased interprocessor communication, subsequently extending the overall runtime. Consequently, higher node counts are more beneficial when handling larger datasets within OpenFOAM simulations.
Vertical – Weather and Environment | Application - WRF
The Weather Research and Forecasting model (WRF) is at the forefront of meteorological and atmospheric research, with its latest version being a testament to advancements in high-performance computing (HPC). WRF enables scientists and meteorologists to simulate and forecast complex weather patterns with unparalleled precision. In this study, we have worked on WRF version 4.5, which have been compiled with AOCC 4.0.0 with OPENMPI 4.1.4. For successful compilation and optimization with the AMD EPYC compilers, additional flags such as ' -O3 -znver4' have been added.
The dataset used in our study is CONUS v4.4. This means that the model's grid, parameters, and input data are set up to focus on weather conditions within the continental United States. This configuration is particularly useful for researchers, meteorologists, and government agencies who need high-resolution weather forecasts and simulations tailored to this specific geographic area. The configuration details, such as grid resolution, atmospheric physics schemes, and input data sources, can vary depending on the specific version of WRF and the goals of the modeling project. In this study, we have predominantly adhered to the default input configuration, making minimal alterations or adjustments to the source code or input file. Each run was conducted with full cores (64 cores per node) and from single node to sixteen nodes. The scalability tests were conducted and the performance metric in “sec” was noted.
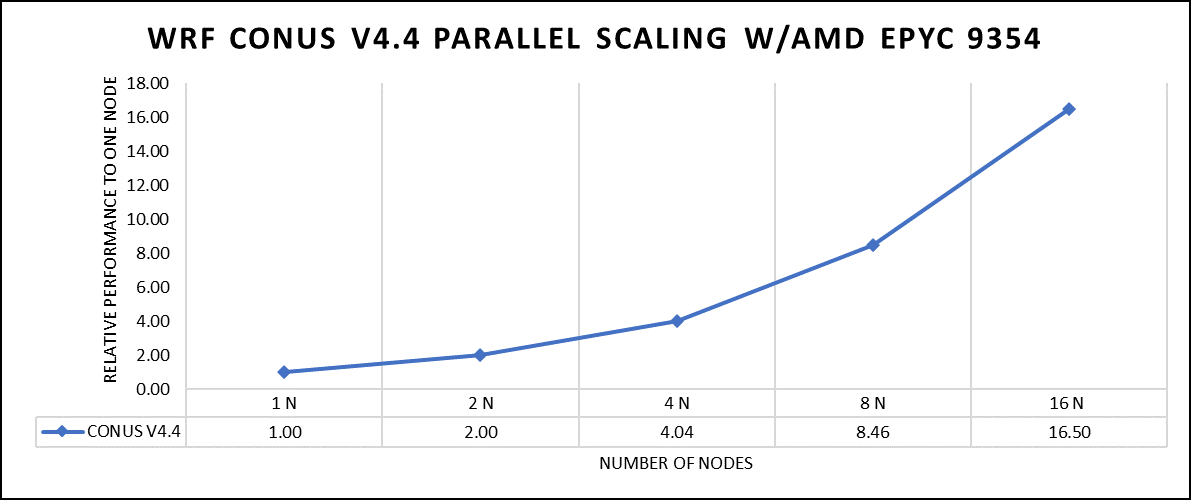
Figure 2: The scaling performance of the WRF CONUS dataset using the AMD EPYC 9354 processor, with a focus on performance compared to a single node.
The AOCC compiled binaries of WRF show linear scaling from a single node to sixteen nodes on 9354 processors for the new CONUS v4.4. For the best performance with WRF, the impact of the tile size, process, and threads per process should be carefully considered. Given that the application is constrained by memory and DRAM bandwidth, we have opted for the latest DDR5 4800 MT/s DRAM for our test evaluations. It is also crucial to consider the BIOS settings, particularly SubNUMA configurations, as these settings can significantly influence the performance of memory-bound applications, potentially leading to improvements ranging from one to five percent. For more detailed BIOS tuning recommendations, please see our previous blog post on optimizing BIOS settings for optimal performance.
Vertical – Molecular Dynamics | Application - LAMMPS
Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) is a powerful tool for HPC. It is specifically designed to harness the immense computational capabilities of HPC clusters and supercomputers. LAMMPS allows researchers and scientists to conduct large-scale molecular dynamics simulations with remarkable efficiency and scalability. In this study, we have worked on LAMMPS, 15 June 2023 version, which have been compiled with AOCC 4.0.0 with OPENMPI 4.1.4. For successful compilation and optimization with the AMD EPYC compilers, additional flags such as ' -O3 -znver4' have been added.
We opted for the non-default package, which offers optimized atom pair styles. We have also tried running some benchmarks which are not supported with default package to check the performance and scaling. Our performance metric for this benchmark is nanoseconds per day, where higher nanoseconds per day is considered a better result .
There are two factors that were considered when compiling data for comparison, the number of nodes and the core count. Figure 3 shows results of performance improvement observed on processor 9354 with 64 cores.
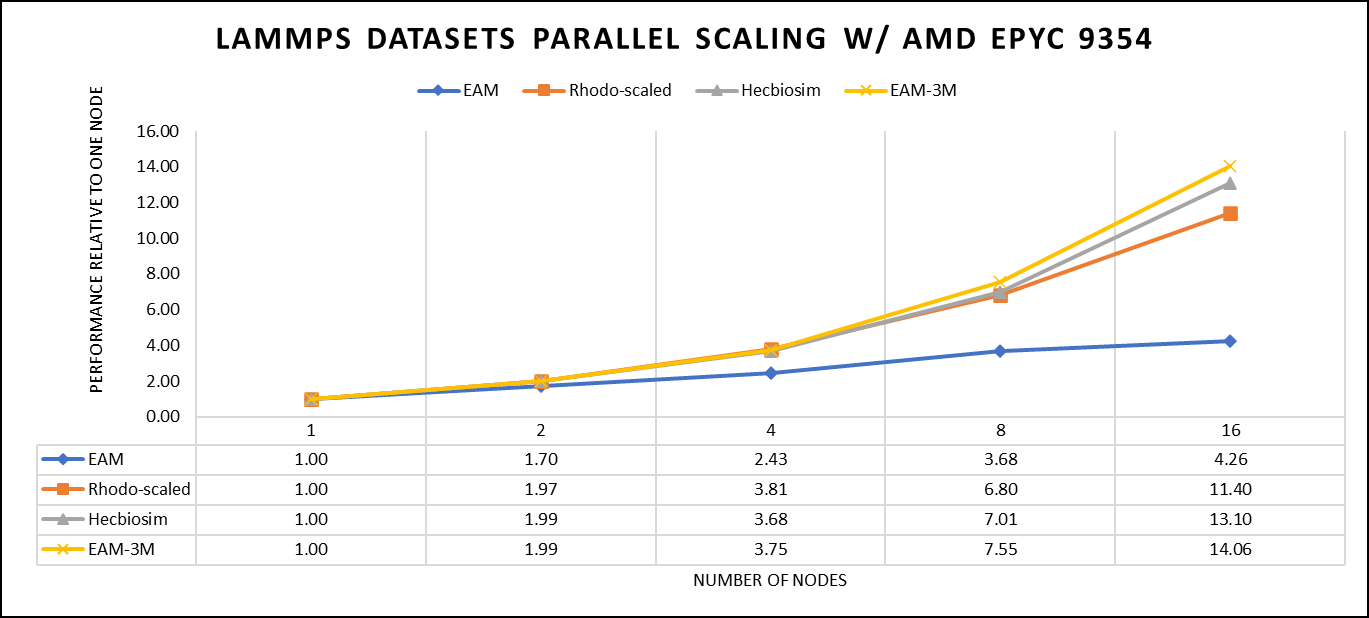
Figure 3: The scaling performance of the LAMMPS datasets using the AMD EPYC 9354 processor, with a focus on performance compared to a single node.
Figure 3 shows the scaling of different LAMMPS datasets. We see a significant improvement in scaling as we increased the atom size and step size. We have tested two datasets EAM and Hecbiosim with more than 3 million atoms and observed a better scalability as compared to other datasets.
Vertical – Molecular Dynamics | Application - GROMACS
GROMACS, a high-performance molecular dynamics software, is a vital tool for HPC environments. Tailored for HPC clusters and supercomputers, GROMACS specializes in simulating the intricate movements and interactions of atoms and molecules. Researchers in diverse fields, including biochemistry and biophysics, rely on its efficiency and scalability to explore complex molecular processes. GROMACS is used for its ability to harness the immense computational power of HPC, allowing scientists to conduct intricate simulations that unveil critical insights into atomic-level behaviors, from biomolecules to chemical reactions and materials. In this study, we have worked on GROMACS 2023.1 version, which have been compiled with AOCC 4.0.0 with OPENMPI 4.1.4. For successful compilation and optimization with the AMD EPYC compilers, additional flags such as ' -O3 -znver4' have been added.
We've curated a range of datasets for our benchmarking assessments. First, we included "water GMX_50 1536" and "water GMX_50 3072," which represent simulations involving water molecules. These simulations are pivotal for gaining insights into solvation, diffusion, and water's behaviour in diverse conditions. Next, we incorporated "HECBIOSIM 14K" and "HECBIOSIM 30K" datasets, which were specifically chosen for their ability to investigate intricate systems and larger biomolecular structures. Lastly, we included the "PRACE Lignocellulose" dataset, which aligns with our benchmarking objectives, particularly in the context of lignocellulose research. These datasets collectively offer a diverse array of scenarios for our benchmarking assessments.
Our performance assessment was based on the measurement of nanoseconds per day (ns/day) for each dataset, providing valuable insights into the computational efficiency. Additionally, we paid careful attention to optimizing the mdrun tuning parameters (i.e, ntomp, dlb tunepme nsteps etc )in every test run to ensure accurate and reliable results. We examined the scalability by conducting tests spanning from a single node to a total of sixteen nodes.
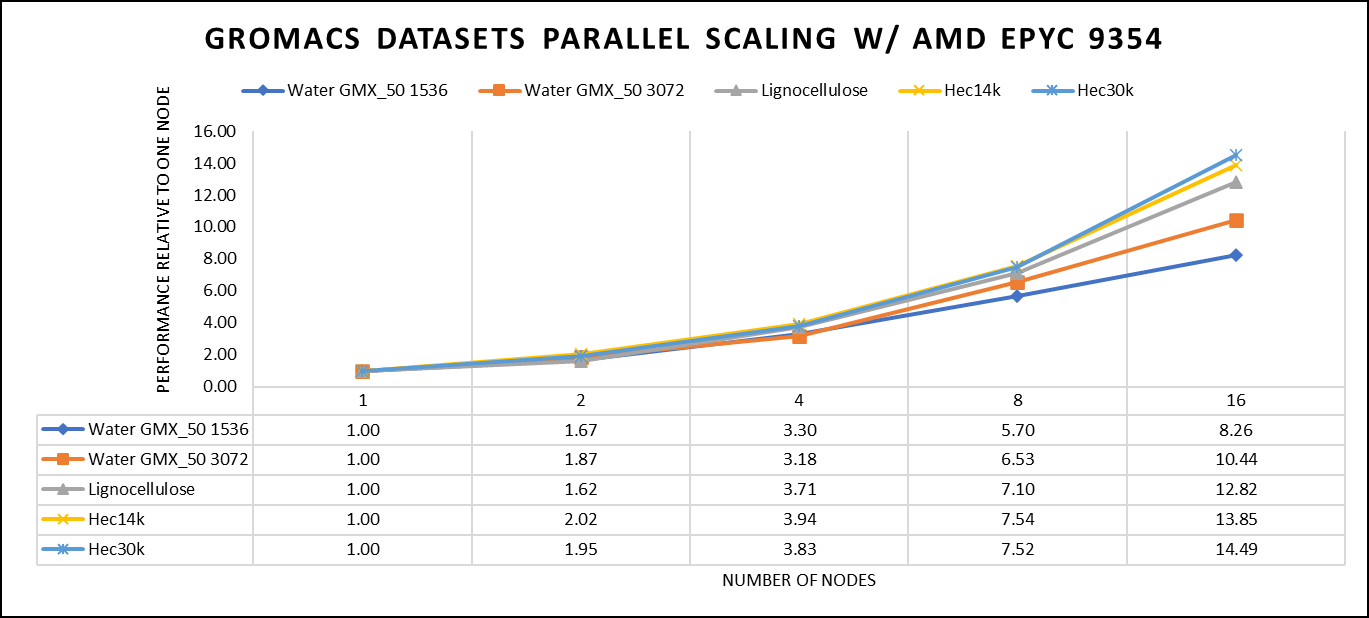
Figure 4: The scaling performance of the GROMACS datasets using the AMD EPYC 9354 processor, with a focus on performance compared to a single node.
For ease of comparison across the various datasets, the relative performance has been included into a single graph. However, it is worth noting that each dataset behaves individually when performance is considered, as each uses different molecular topology input files (tpr), and configuration files.
We were able to achieve the expected performance scalability for GROMACS of up to eight nodes for larger datasets. All cores in each server were used while running these benchmarks. The performance increases are close to linear across all the dataset types, however there is drop in larger number of nodes due to the smaller dataset size and the simulation iterations.
Vertical – Molecular Dynamics | Application – CP2K
CP2K is a versatile computational software package that covers a wide range of quantum chemistry and solid-state physics simulations, including molecular dynamics. It's not strictly limited to molecular dynamics but is instead a comprehensive tool for various computational chemistry and materials science tasks. While CP2K is widely used for molecular dynamics simulations, it can also perform tasks like electronic structure calculations, ab initio molecular dynamics, hybrid quantum mechanics/molecular mechanics (QM/MM) simulations, and more. In this study, we have worked on CP2K 2023.1 version, which have been compiled with AOCC 4.0.0 with OPENMPI 4.1.4. For successful compilation and optimization with the AMD EPYC compilers, additional flags such as ' -O3 -znver4' have been added.
In our study focusing on high-performance computing (HPC), we utilized specific datasets optimized for computational efficiency. The first dataset, "H2O-DFT-LS-NREP-4,6," was configured for HPC simulations and calculations, emphasizing the modeling of water (H2O) using Density Functional Theory (DFT). The appended "NREP-4,6" parameter settings were fine-tuned to ensure efficient HPC performance. The second dataset, "H2O-64-RI-MP2," was exclusively crafted for HPC applications and revolved around the examination of a system comprising 64 water molecules (H2O). By employing the Resolution of Identity (RI) method in conjunction with the Møller–Plesset perturbation theory of second order (MP2), this dataset demonstrated the significant computational capabilities of HPC for conducting advanced electronic structure calculations within a high-molecule-count environment. We examined the scalability by conducting tests spanning from a single node to a total of sixteen nodes.
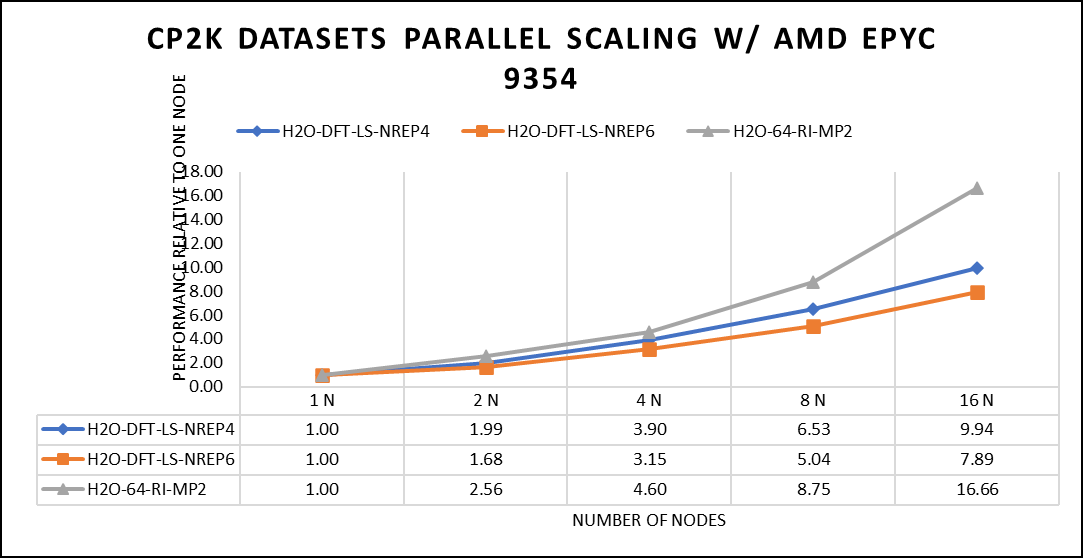
Figure 5: The scaling performance of the CP2K datasets using the AMD EPYC 9354 processor, with a focus on performance compared to a single node.
The datasets represent a single-point energy calculation employing linear-scaling Density Functional Theory (DFT). The system comprises 6144 atoms confined within a 39 Å^3 simulation box, which translates to a total of 2048 water molecules. To adjust the computational workload, you can modify the NREP parameter within the input file.
Our benchmarking efforts encompass configurations involving up to 16 computational nodes .Optimal performance is achieved when using NREP4 and NREP6 in Hybrid mode, which combines MPI (Message Passing Interface) and OpenMP (Open Multi-Processing). This configuration exhibits the best scaling performance, particularly on 4 to 8 nodes. However, it's worth noting that scaling beyond 8 nodes does not exhibit a strictly linear performance improvement. Above figure 5 depict outcomes when using Pure MPI, utilizing 64 cores with a single thread per core.
Conclusion
When considering CPUs with equivalent core counts, the earlier AMD EPYC processors can deliver performance levels like their Genoa counterparts. However, achieving this performance parity may require doubling the number of nodes. To further enhance performance using AMD EPYC processors, we suggest optimizing the BIOS settings as outlined in our previous blog post and specifically disabling Hyper-threading for the benchmarks discussed in this article. various workloads, we recommend conducting comprehensive testing and, if beneficial, enabling Hyper-threading. Additionally, for this performance study, we highly endorse the utilization of the Mellanox NDR 200 interconnect for optimal results.

16G PowerEdge Platform BIOS Characterization for HPC with Intel Sapphire Rapids
Fri, 30 Jun 2023 13:44:52 -0000
|Read Time: 0 minutes
Dell added over a dozen next-generation systems to the extensive portfolio of Dell PowerEdge 16G servers. These new systems are to accelerate performance and reliability for powerful computing across core data centers, large-scale public clouds, and edge locations.
The new PowerEdge servers feature rack, tower, and multi-node form factors, supporting the new 4th-gen Intel Xeon Scalable processors (formerly codenamed Sapphire Rapids). Sapphire Rapids still supports the AVX 512 SIMD instructions, which allow for 32 DP FLOP/cycle. The upgraded Ultra Path Interconnect (UPI) Link speed of 16 GT/s is expected to improve data movement between the sockets. In addition to core count and frequency, Sapphire Rapids-based Dell PowerEdge servers support DDR5 – 4800 MT/s RDIMMS with eight memory channels per processor, which is expected to improve the performance of memory bandwidth-bound applications.
This blog provides synthetic benchmark results and recommended BIOS settings for the Sapphire Rapids-based Dell PowerEdge Server processors. This document contains guidelines that allow the customer to optimize their application for best energy efficiency and provides memory configuration and BIOS setting recommendations for the best out-of-the-box performance and scalability on the 4th Generation of Intel® Xeon® Scalable processor families.
Test bed hardware and software details
Table 1 and Table 2 show the test bed hardware details and synthetic application details. There were 15 BIOS options explored through application performance testing. These options can be set and unset via the Remote Access Control Admin (RACADM) command in Linux or directly when the machines are in the BIOS mode.
Use the following command to set the “HPC Profile” to get the best synthetic benchmark results.
racadm set bios.sysprofilesettings.WorkloadProfile HpcProfile && sudo racadm jobqueue create BIOS.Setup.1-1 -r pwrcycle -s TIME_NOW -e TIME_NA
Once the system is up, use the below command to verify if the setting is enabled.
racadm bios.sysprofilesettings.WorkloadProfile
It should show workload profile set as HPCProfile. Please note that any changes made in BIOS settings on top of the “HPCProfile” will set this parameter to “Not Configured”, while keeping the other settings of “HPCProfile” intact.
Table 1. System details
Component | Dell PowerEdge R660 server (Air cooled) | Dell PowerEdge R760 server (Air cooled) | Dell PowerEdge C-Series (C6620) server (Direct Liquid Cooled) |
SKU | 8452Y | 6430 | 8480+ |
Cores/Socket | 36 | 32 | 56 |
Base Frequency | 2 | 1.9 | 2 |
TDP | 300 | 270 | 350 |
L3Cache | 69.12 MB | 61.44 MB | 10.75 MB |
Operating System | RHEL 8.6 | RHEL 8.6 | RHEL 8.6 |
Memory | 1024 - 64 x 16 | 1024 - 64 x 16 | 512 -32 x 16 |
BIOS | 1.0.1 | 1.0.1 | 1.0.1 |
CPLD | 1.0.1 | 1.0.1 | 1.0.1 |
Interconnect | NDR 400 | NDR 400 | NDR 400 |
Compiler | OneAPI 2023 | OneAPI 2023 | OneAPI 2023 |
Table 2. Synthetic benchmark applications details
Application Name | Version |
High-Performance Linpack (HPL) | Pre-built binary MP_LINPACK INTEL - 2.3 |
STREAM | |
High Performance Conjugate Gradient (HPCG) | Pre-built binary from INTEL oneAPI 2.3 |
Ohio State University (OSU) |
In the present study, synthetic applications such as HPL, STREAM, and HPCG are done on a single node; since the OSU benchmark is a benchmark study on MPI operations, it requires a minimum of two nodes.
Synthetic application performance details
As shown in Table 2, four synthetic applications are tested on the test bed hardware (Table 1). They are HPL, STREAM, HPCG, and OSU. The details of performance of each application are given below:
High Performance Linpack (HPL)
HPL helps measure the floating-point computation efficiency of a system [1]. The details of the synthetic benchmarks can be found in the previous blog on Intel Ice Lake processors.
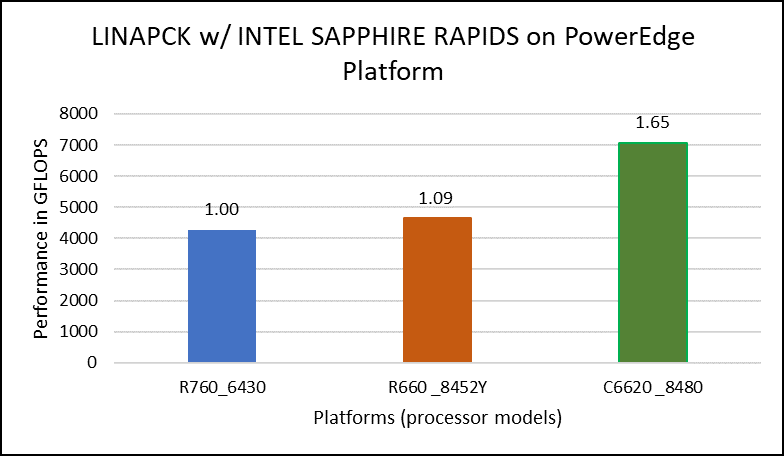
Figure 1. Performance values of HPL application for different processor models
The N and NB sizes used for the HPL benchmark are 348484 and 384, respectively, for the Intel Sapphire Rapids 6430, 8452Y processors, and 246144 and 384, respectively, for the 8480 processor. The difference in N sizes is due to the difference in available memory. Systems with Intel 6430 and 8452Y processors are equipped with 1024 GB of memory; the 8480 processor system has 512 GB. The performance numbers are captured with different BIOS settings, as discussed above, and the delta difference between each result is within 1-2%. The results with the HPC workload BIOS profile are shown in Figure 1. the 8452Y processor performs 1.09 times better than the Intel Sapphire Rapids 6430 processor and the 8480 processor performs 1.65 times better.
STREAM
The STREAM benchmark helps for measuring sustainable memory bandwidth of a processor. In general for STREAM benchmark, each array for STREAM must have at least four times the total size of all last-level caches utilized in the run or 1 million elements, whichever is larger. The STREAM array sizes used for the current study are 4×107 and 12×107 with full core utilization. The STREAM benchmark was also tested with 15 BIOS combinations, and the results depicted in Figure 2 are for the HPC workload profile bios test case. The STREAM TRIAD results are captured here in GB/sec. Results show improvement in performance compared to the Intel 3rd Generation Xeon Scalable processors, such as the 8380 and 6338. Also, if comparing 6430, 8452Y and 8480 processors, the STREAM results with 8452Y and 8480 Intel 4th Generation Xeon Scalable processors are, respectively, 1.12 and 1.24 times better than the Intel 6430 processor.
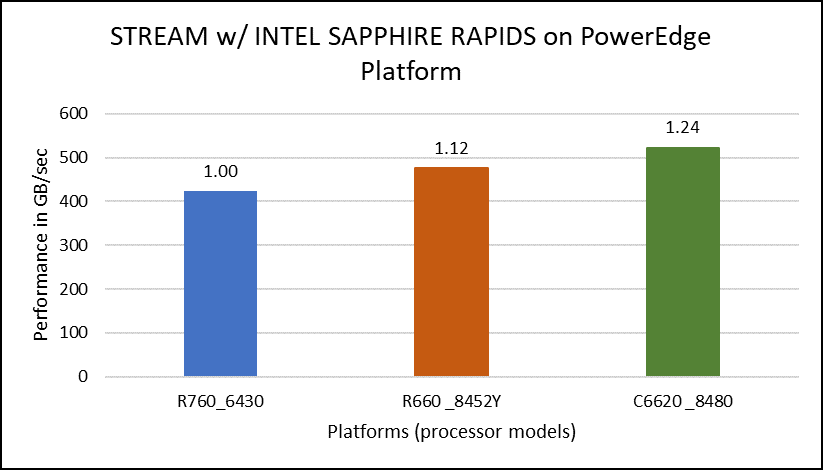
Figure 2. Performance values of STREAM application for different processor models
HPCG
The HPCG benchmark aims to simulate the data access patterns of applications such as sparse matrix calculations, assessing the impact of memory subsystem and internal connectivity constraints on the computing performance of High-Performance Computers, or supercomputers. The different problem sizes used in the study are 192, 256, 176, 168, and so on. Additionally, in this benchmark study, the variation in performance within different BIOS options was within 1–2 percent. Figure 3 shows the HPCG performance results for Intel Sapphire Rapids processors 6430, 8452Y and 8480. In comparison with the Intel 6430 processor, the 8452Y shows 1.02 times and the 8480 shows 1.12 times better performance.
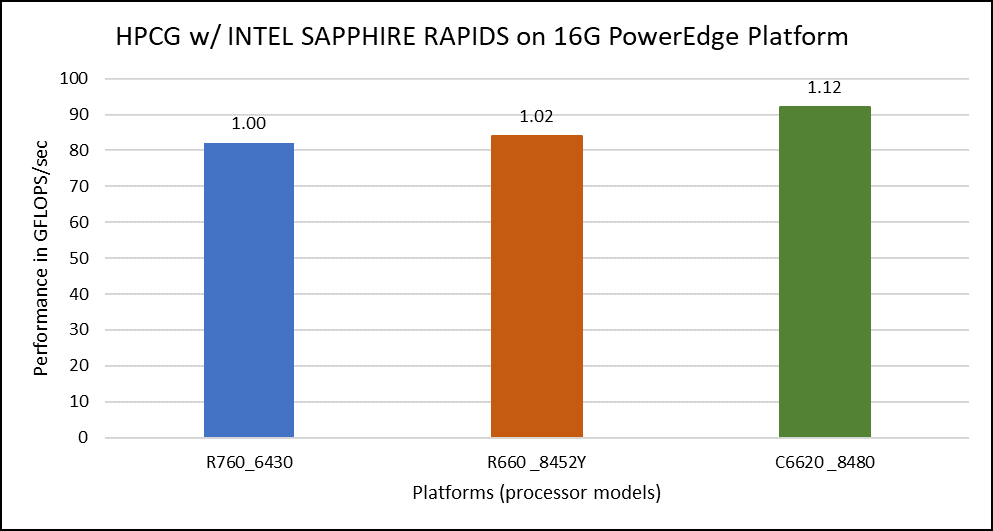
Figure 3. Performance values of HPCG application for different processor models
OSU Micro Benchmarks
OSU Micro Benchmarks are used for measuring the performance of MPI implementations, so we used two nodes connected to NDR200. OSU benchmark determines uni-directional and bi-directional bandwidth and message rate and latency between the nodes. The OSU benchmark was run on all three Intel processors (6430, 8452Y, and 8480) with single core per node; however, we have shown one of the system/processors (Intel 8480 processor) results in the blog starting from Figures 4-7.
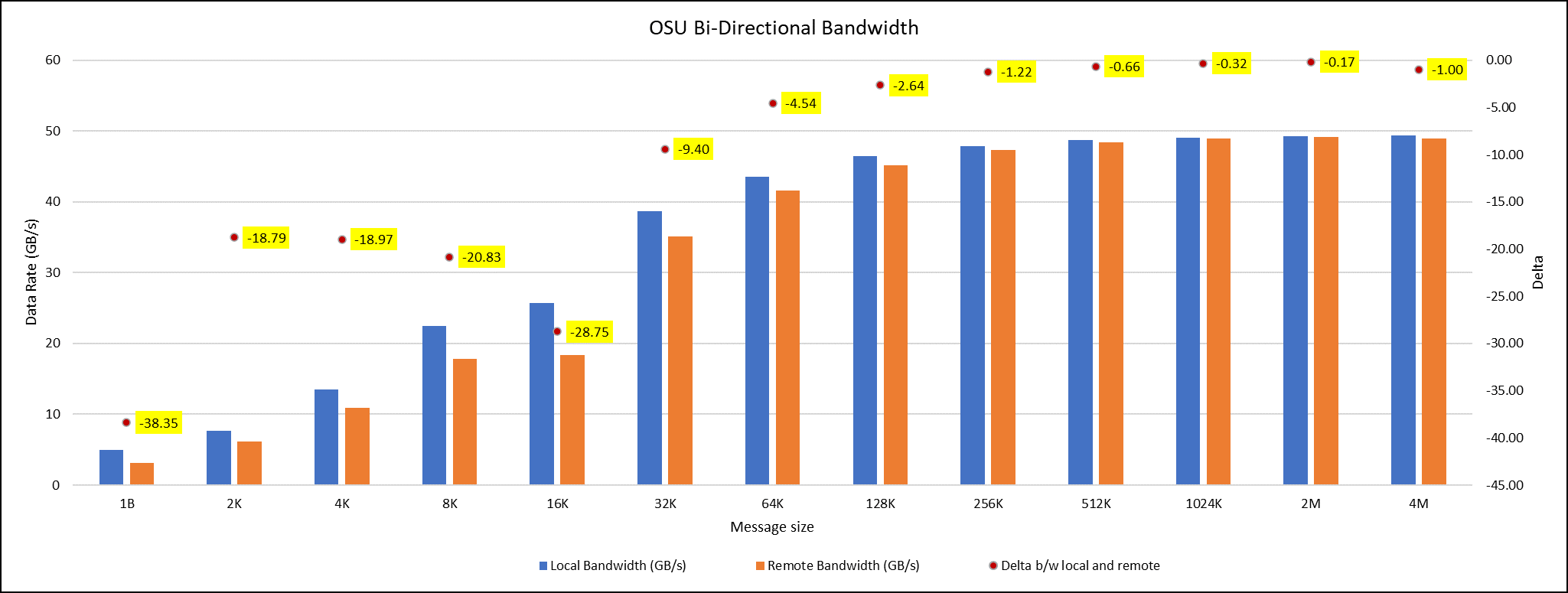
Figure 4. OSU Bi-Directional bandwidth chart for C6620_8480 intel processor
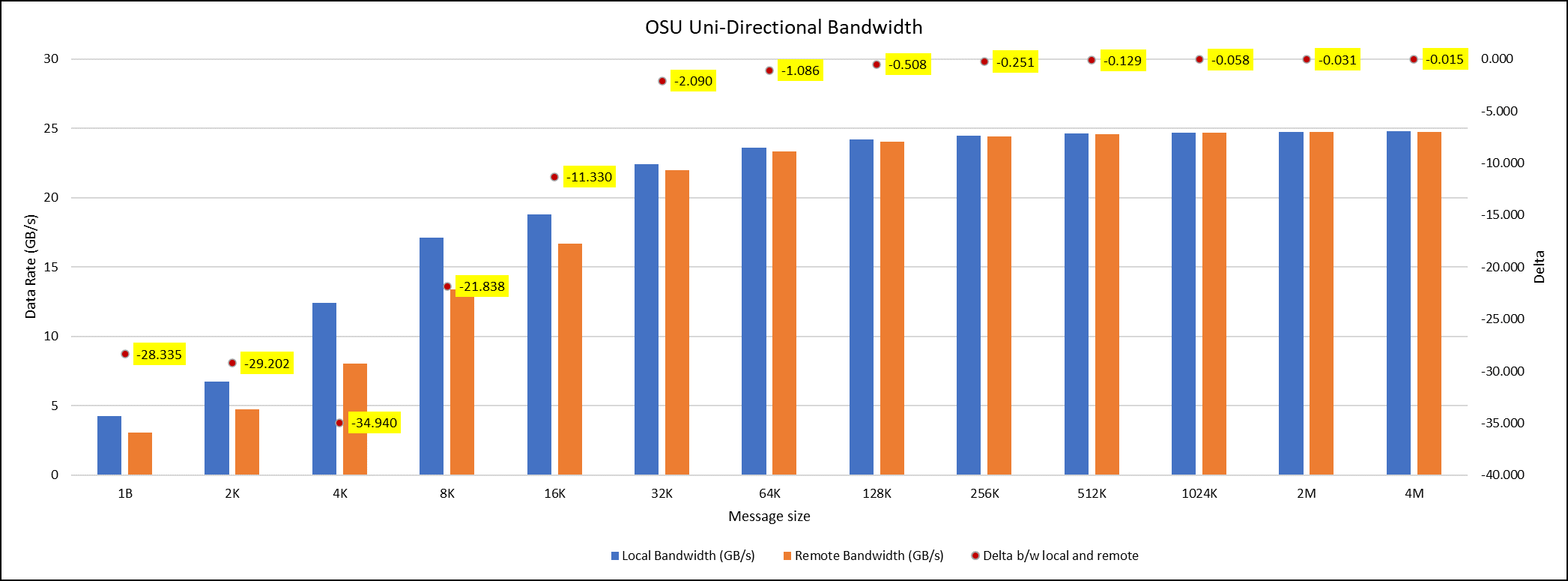
Figure 5. OSU Uni-Directional bandwidth chart for C6620_8480 intel processor
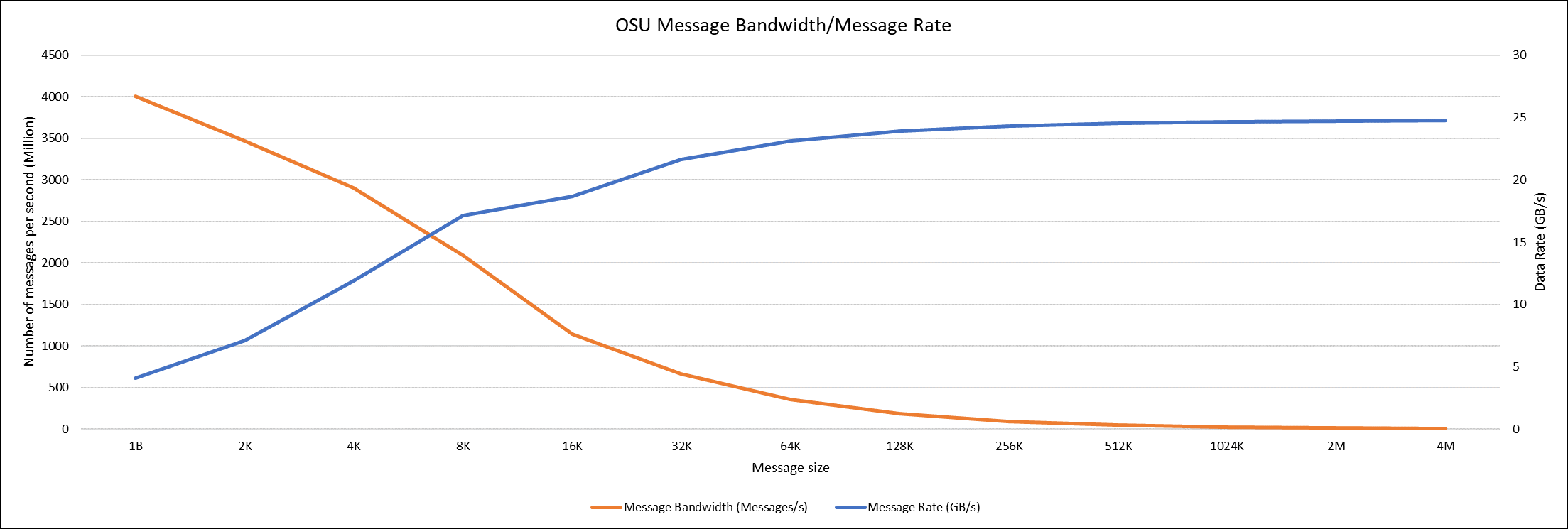
Figure 6. OSU Message bandwidth/Message rate chart for C6620_8480 intel processor
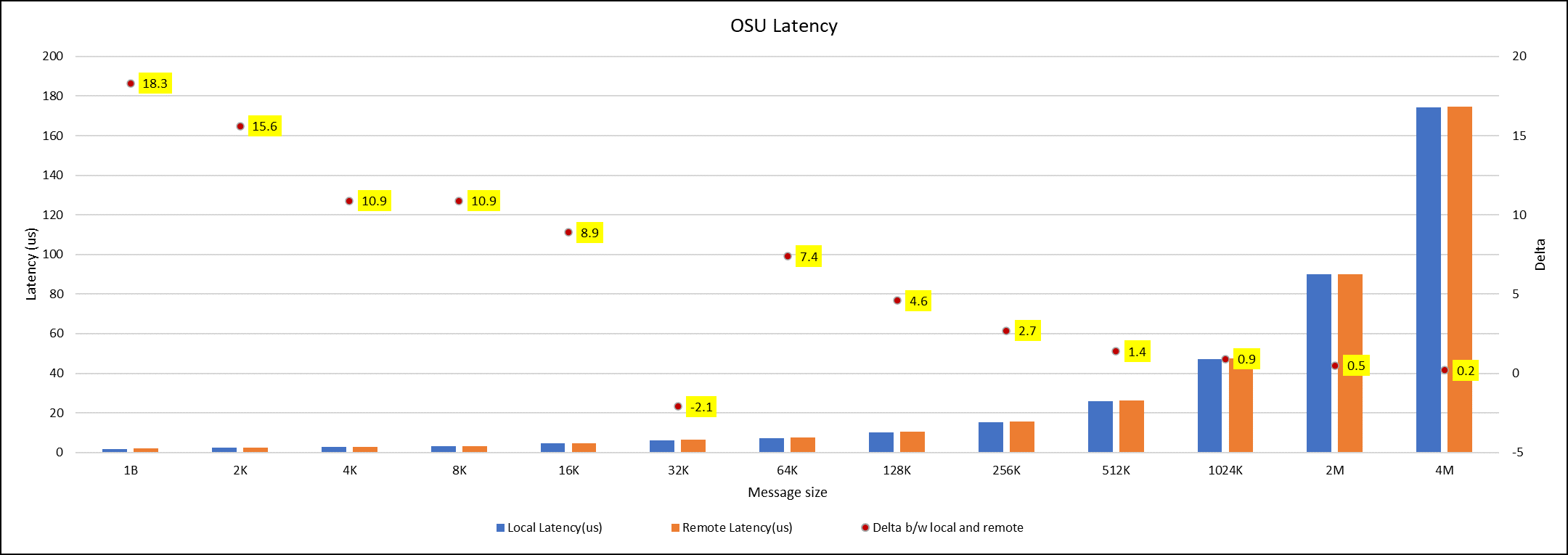
Figure 7. OSU Latency chart for C6620_8480 intel processor
All fifteen BIOS combinations were tested; the OSU benchmark also shows similar performance with a difference within a 1-2% delta.
Conclusion
The performance comparison between various Intel Sapphire Rapids processors (6430, 8452Y and 8480) is done with the help of synthetic benchmark applications such as HPL, STREAM, HPCG and OSU. Nearly 15 BIOS configurations are set on the system, and performance values with different benchmarks were captured to identify the best BIOS configuration to set. From the results, it was found that the difference in performance with any benchmarks for all the BIOS configurations applied is below 3 percent delta.
Therefore, the HPC workload profile provides better benchmark results with all the Intel Sapphire Rapids processors. Among the three Intel processors compared, the 8480 had the highest application performance value, while the 8452Y is in second place. The maximum difference in performance between processors was found for the HPL benchmark, and it was the 8480 Intel Sapphire Rapids processor, which offers 1.65 times better results than the Intel 6430 processor.
Watch out for future application benchmark results on this blog! Visit our page for previous blogs.

GROMACS — with Ice Lake on Dell EMC PowerEdge Servers
Fri, 02 Dec 2022 05:33:27 -0000
|Read Time: 0 minutes
3rd Generation Intel Xeon® Scalable processors (architecture code named Ice Lake) is Intel’s successor to Cascade Lake. New features include up to 40 cores per processor, eight memory channels with support for 3200 MT/s memory speed and PCIe Gen4.
The HPC and AI Innovation Lab at Dell EMC had access to a few systems and this blog presents the results of our initial benchmarking study on a popular open-source molecular dynamics application – GROningen MAchine for Chemical Simulations (GROMACS).
Molecular dynamics (MD) simulations are a popular technique for studying the atomistic behavior of any molecular system. It performs the analysis of the trajectories of atoms and molecules where the dynamics of the system progresses over time.
At HPC and AI Innovation Lab, we have conducted research on the SARS-COV-2 study where applications like GROMACS helped researchers identify molecules that bind to the spike protein of the virus and block it from infecting human cells. Other use cases of MD simulation in medicinal biology is iterative drug design through prediction of protein-ligand docking (in this case usually modelling a drug to target protein interaction).
Overview of GROMACS
GROMACS is a versatile package to perform MD simulations, such as simulate the Newtonian equations of motion for systems with hundreds to millions of particles. GROMACS can be run on CPUs and GPUs in single-node and multi-node (cluster) configurations. It is a free, open-source software released under the GNU General Public License (GPL). Check out this page for more details on GROMACS.
Hardware and software configurations
Table 1: Hardware and Software testbed details
Component | Dell EMC PowerEdge R750 server | Dell EMC PowerEdge R750 server | Dell EMC PowerEdge C6520 server | Dell EMC PowerEdge C6520 server | Dell EMC PowerEdge C6420 server | Dell EMC PowerEdge C6420 server |
SKU | Xeon 8380 | Xeon 8358 | Xeon 8352Y | Xeon 6330 | Xeon 8280 | Xeon 6252 |
Cores/Socket | 40 | 32 | 32 | 28 | 28 | 24 |
Base Frequency | 2.30 GHz | 2.60 GHz | 2.20 GHz | 2.00 GHz | 2.70 GHz | 2.10 – GHz |
TDP | 270 W | 250 W | 205 W | 205 W | 205 W | 150 W |
L3Cache | 60M | 48M | 48M | 42M | 38.5M | 37.75M |
Operating System | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | |||||
Memory | 16 GB x 16 (2Rx8) 3200 MT/s | 16 GB x 12 (2Rx8) 2933 MT/s | ||||
BIOS/CPLD | 1.1.2/1.0.1 | |||||
Interconnect | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR100 | ||||
Compiler | Intel parallel studio 2020 (update 4) | |||||
GROMACS | 2021.1 | |||||
Datasets used for performance analysis
Table 2: Description of datasets used for performance analysis
Datasets/Download Link | Description | Electrostatics | Atoms | System Size |
Movement of Water This example is to simulate- the motion process of many water molecules in each space and temperature.
| Particle Mesh Ewald (PME)
| 1536K | small | |
3072K | Large | |||
This example is to simulate- 1.4M atom system - A Pair of hEGFR Dimers of 1IVO and 1IVO 3M atom system – A Pair of hEGFR tetramers of 1IVO and 1IVO
| Particle Mesh Ewald (PME)
| 1.5M | Small | |
3M | Large | |||
Prace – Lignocellulose | This example is to simulate the lignocellulose – the tpr was obtained from PRACE website
| Reaction Field (rf)
| 3M | Large |
Compilation Details
We compiled GROMACS from source (version-2021.1) using the Intel 2020 Update 5 Compiler to take advantage of AVX2 and AVX512 optimizations, and the Intel MKL FFT library. The new version of GROMACS has a significant performance gain due to the improvements in its parallelization algorithms. The GROMACS build system and the gmx mdrun tool have built-in and configurable intelligence that detects your hardware and make effective use of it.
Objective of Benchmarking
Our objective is to quantify the performance of GROMACS using different test cases, like performance evaluation on different Ice Lake processors as listed in Table 1, then we compare the 2nd and 3rd Gen Xeon Scalable (Cascade Lake vs Ice Lake), and finally we compare multi-node scalability with hyper threading enabled and disabled.
To evaluate the datasets results with an appropriate metric, we added associated high-level compiler flags, electrostatic field load balancing (like PME, etc), tested with multiple ranks, separate PME ranks, varying different nstlist values, and created a paradigm for our application (GROMACS).
The typical time scales of the simulated system are in the order of micro-seconds (µs) or nanoseconds (ns). We measure the performance for the dataset’s simulation as nanoseconds per day (ns/day).
Performance Analyses on Single Node
Figure 1(a): Single node performance of Water 1536K and Water 3072K on Ice Lake processor model
 Figure 1(b): Single node performance of Lignocellulose 3M on Ice Lake processor model
Figure 1(b): Single node performance of Lignocellulose 3M on Ice Lake processor model
 Figure 1(c): Single node performance of HecBioSim 1.4M and HecBioSim 3M on Ice Lake processor model
Figure 1(c): Single node performance of HecBioSim 1.4M and HecBioSim 3M on Ice Lake processor model
Figure 1 (a), (b) and (c) shows are the single node performance analyses for three datasets mentioned in Table 2 with the four processor models available for evaluation of GROMACS.
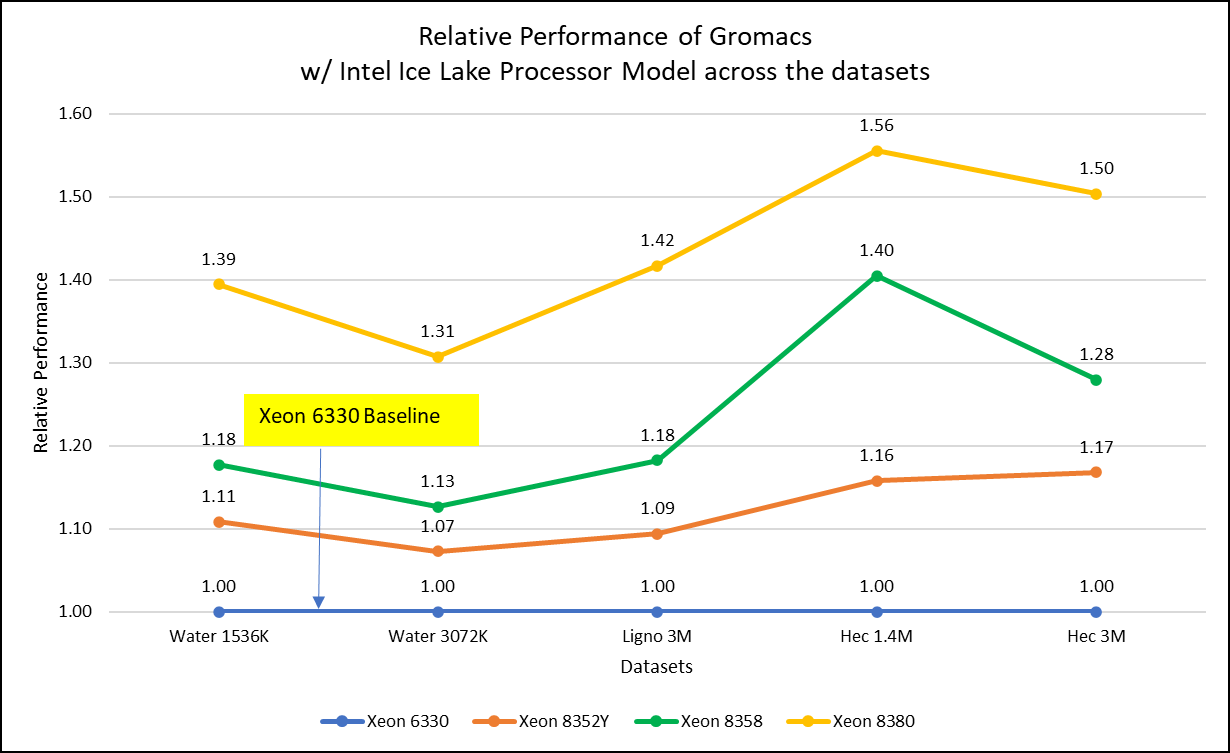
Figure 2: Relative Performance of GROMACS across the datasets with Intel Ice Lake Processor Model
For ease of comparison across the various datasets, the relative performance of the processor model has been included into a single graph. However, it is worth noting that each dataset behaves individually when performance is considered, as each uses different molecular topology input files (tpr), and configuration files.
Individual dataset performance is mentioned in Figures 1(a), 1(b), and 1(c) respectively.
Figure 2 shows increase in the core count in the processor model increases the performance, based on the dataset used. In here, we observe that smaller (water 1536K and HecBioSim 1400K) has more advantage 5 to 6 percent performance gain in counterpart to the larger datasets (water 3072, HecBioSim 3M, and Ligno 3M).
Next, by comparing the relative numbers to the baseline processor Xeon 6330(28C) with Xeon 8380(40C), we found a 30 to 50 percent performance gain according to the datasets with increases in cores, from 28 to 40. A fraction of gain is by frequency of the processor model.
Performance Analyses on Cascade Lake vs Ice Lake
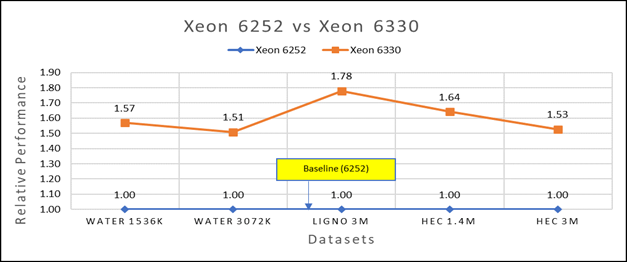
Figure 3(a): Performance of GROMACS on Cascade Lake (Xeon 6252) vs Ice Lake (Xeon 6330)
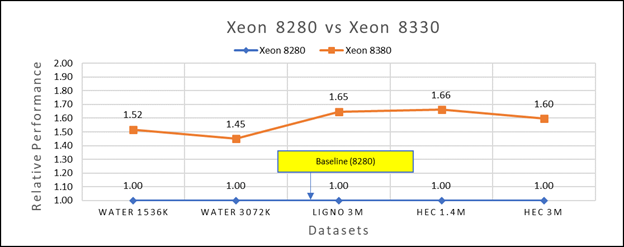
Figure 3(b): Performance of GROMACS on Cascade Lake (Xeon 8280) vs Ice Lake (Xeon 8380)
We accounted for the fact that the memory is rightly fit according to the datasets. To begin, we compared each processor with previous generation processors. For performance benchmark comparisons, we selected Cascade Lake closest to their Ice Lake counterparts in terms of hardware features such as cache size, TDP values, and Processor Base/Turbo Frequency, and marked the maximum value attained for Ns/day by each of the datasets mentioned in Table 2.
Figure 3a shows Ice Lake 6330 is up to 50 to 75 percent faster than the 6252. The Xeon 6330 has 16 percent more cores and 9 percent faster memory bandwidth. Figure 3b shows that Ice Lake 8380 is up to 50-65 percent faster than the Xeon 8280 on single node tests, this is in line with the 42 percent more cores and 9 percent faster memory bandwidth.
This result is due to a higher processor speed, wherein more data can be accessed by each core. Also, datasets are more memory intensive and some percentage is added on due frequency improvement Overall, the Ice Lake processor results demonstrated a substantial performance improvement for GROMACS over Cascade Lake processors.
Performance Analysis on Multi-Node
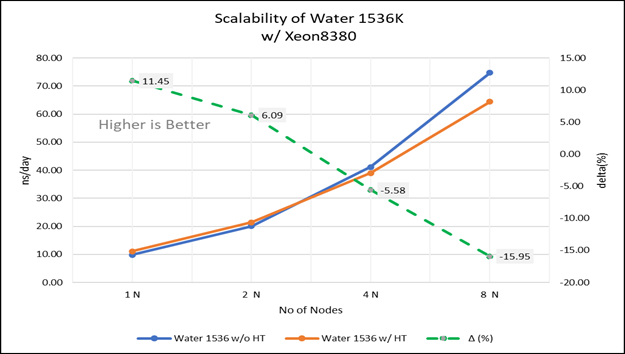 Figure 4(a): Scalability of water 1536K with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/ Xeon 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
Figure 4(a): Scalability of water 1536K with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/ Xeon 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
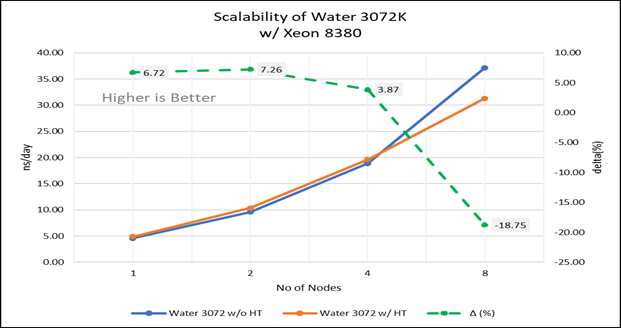 Figure 4(b): Scalability of water 3072K with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/INTEL 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
Figure 4(b): Scalability of water 3072K with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/INTEL 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
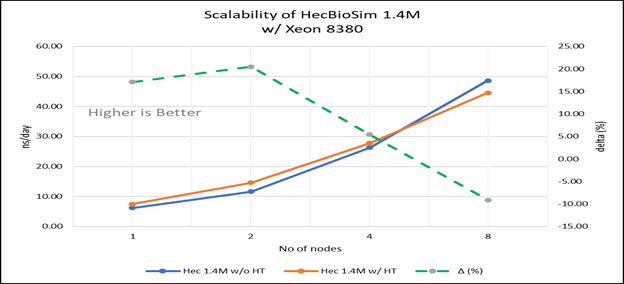 Figure 4(c): Scalability of HecBioSim 1.4M with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/ Xeon 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
Figure 4(c): Scalability of HecBioSim 1.4M with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/ Xeon 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
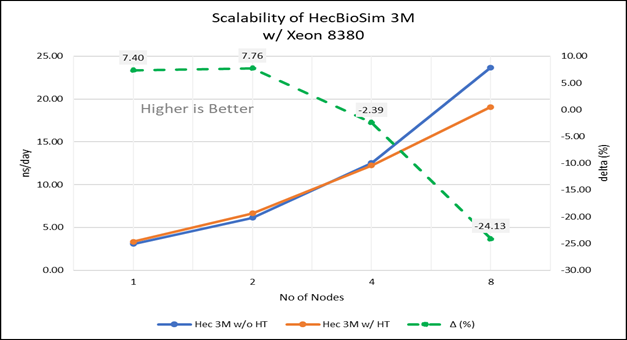 Figure 4(d): Scalability of HecBioSim 3M with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/ Xeon 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
Figure 4(d): Scalability of HecBioSim 3M with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/ Xeon 8380; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
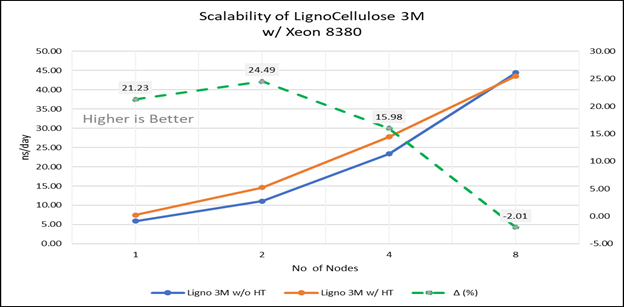 Figure 4(e): Scalability of Lignocellulose 3M with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/INTEL 8380 ; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
Figure 4(e): Scalability of Lignocellulose 3M with hyper threading disabled(80C) vs hyperthreading enabled (160C) w/INTEL 8380 ; the dotted line represent the delta between hyperthreading enabled vs hyperthreading disabled
For multi-node tests, the test bed was configured with an NVIDIA Mellanox HDR interconnect running at 200 Gbps and each server having the Ice Lake processor. We were able to achieve the expected linear performance scalability for GROMACS of up to eight nodes with hyper threading disabled and approximately 7.25X with hyper threading enabled for eight nodes, across the datasets. All cores in each server were used while running these benchmarks. The performance increases are close to linear across all the dataset types as the core count increases.
Conclusion
The Ice Lake processor-based Dell EMC Power Edge servers, with notable hardware feature upgrades over Cascade Lake, show up to 50 to 60 percent performance gain for all the datasets used for benchmarking GROMACS. Hyper threading should be disabled for the benchmarks addressed in this blog for getting better scalability above eight nodes. For small datasets mentioned in this blog benefits 5 to 6 percent in comparison to the larger ones with increase in the core count.
Watch our blog site for updates!

HPC Application Performance on Dell PowerEdge R7525 Servers with the AMD Instinct™ MI210 GPU
Mon, 12 Sep 2022 12:11:52 -0000
|Read Time: 0 minutes
PowerEdge support and performance
The PowerEdge R7525 server can support three AMD Instinct™ MI210 GPUs; it is ideal for HPC Workloads. Furthermore, using the PowerEdge R7525 server to power AMD Instinct MI210 GPUs (built with the 2nd Gen AMD CDNA™ architecture) offers improvements on FP64 operations along with the robust capabilities of the AMD ROCm™ 5 open software ecosystem. Overall, the PowerEdge R7525 server with the AMD Instinct MI210 GPU delivers expectational double precision performance and leading total cost of ownership.

Figure 1: Front view of the PowerEdge R7525 server
We performed and observed multiple benchmarks with AMD Instinct MI210 GPUs populated in a PowerEdge R7525 server. This blog shows the performance of LINPACK and the OpenMM customizable molecular simulation libraries with the AMD Instinct MI210 GPU and compares the performance characteristics to the previous generation AMD Instinct MI100 GPU.
The following table provides the configuration details of the PowerEdge R7525 system under test (SUT):
Table 1. SUT hardware and software configurations
Component | Description |
Processor | AMD EPYC 7713 64-Core Processor |
Memory | 512 GB |
Local disk | 1.8T SSD |
Operating system | Ubuntu 20.04.3 LTS |
GPU | 3xMI210/MI100 |
Driver version | 5.13.20.22.10 |
ROCm version | ROCm-5.1.3 |
Processor Settings > Logical Processors | Disabled |
System profiles | Performance |
NUMA node per socket | 4 |
HPL | rochpl_rocm-5.1-60_ubuntu-20.04 |
OpenMM | 7.7.0_49 |
The following table contains the specifications of AMD Instinct MI210 and MI100 GPUs:
Table 2: AMD Instinct MI100 and MI210 PCIe GPU specifications
GPU architecture | AMD Instinct MI210 | AMD Instinct MI100 |
Peak Engine Clock (MHz) | 1700 | 1502 |
Stream processors | 6656 | 7680 |
Peak FP64 (TFlops) | 22.63 | 11.5 |
Peak FP64 Tensor DGEMM (TFlops) | 45.25 | 11.5 |
Peak FP32 (TFlops) | 22.63 | 23.1 |
Peak FP32 Tensor SGEMM (TFlops) | 45.25 | 46.1 |
Memory size (GB) | 64 | 32 |
Memory Type | HBM2e | HBM2 |
Peak Memory Bandwidth (GB/s) | 1638 | 1228 |
Memory ECC support | Yes | Yes |
TDP (Watt) | 300 | 300 |
High-Performance LINPACK (HPL)
HPL measures the floating-point computing power of a system by solving a uniformly random system of linear equations in double precision (FP64) arithmetic, as shown in the following figure. The HPL binary used to collect results was compiled with ROCm 5.1.3.
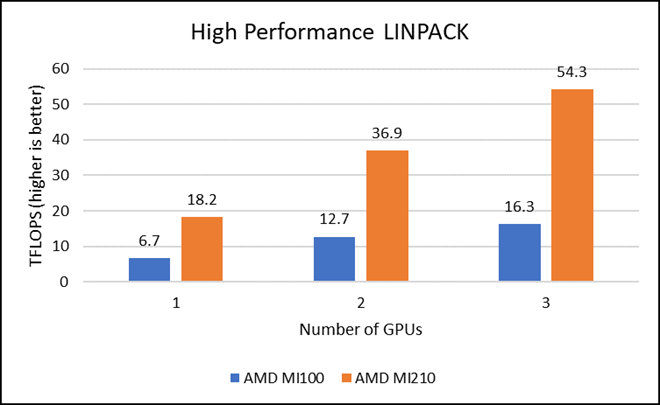
Figure 2: LINPACK performance with AMD Instinct MI100 and MI210 GPUs
The following figure shows the power consumption during a single HPL run:
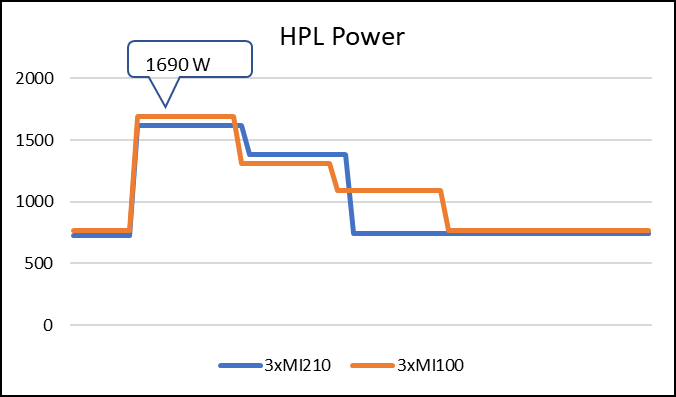
Figure 3: LINPACK power consumption with AMD Instinct MI100 and MI210 GPUs
We observed a significant improvement in the AMD Instinct MI210 HPL performance over the AMD Instinct MI100 GPU. The numbers on a single GPU test of MI210 are 18.2 TFLOPS which is approximately 2.7 times higher than MI100 number (6.75 TFLOPS). This improvement is due to the AMD CDNA2 architecture on the AMD Instinct MI210 GPU, which has been optimized for FP64 matrix and vector workloads. Also, the MI210 GPU has larger memory, so the problem size (N) used here is large in comparison to the AMD Instinct MI100 GPU.
As shown in Figure 2, the AMD Instinct MI210 has shown almost linear scalability in the HPL values on single node multi-GPU runs. The AMD Instinct MI210 GPU reports better scalability compared to its last generation AMD Instinct MI100 GPUs. Both GPUs have the same TDP, with the AMD Instinct MI210 GPU delivering three times better performance. The performance per watt value of a PowerEdge R7525 system is three times more. Figure 3 shows the power consumption characteristics in one HPL run cycle.
OpenMM
OpenMM is a high-performance toolkit for molecular simulation. It can be used as a library or as an application. It includes extensive language bindings for Python, C, C++, and even Fortran. The code is open source and actively maintained on GitHub and licensed under MIT and LGPL.
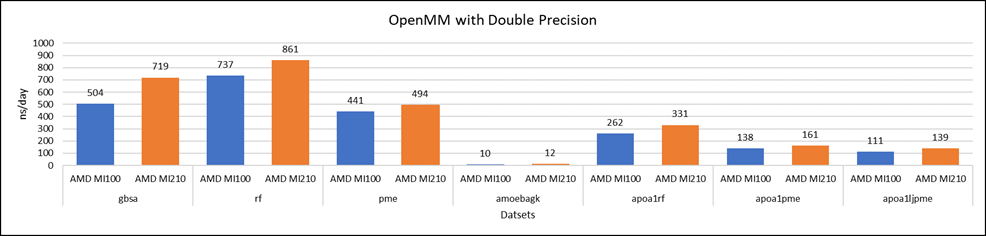
Figure 4: OpenMM double-precision performance with AMD Instinct MI100 and MI210 GPUs
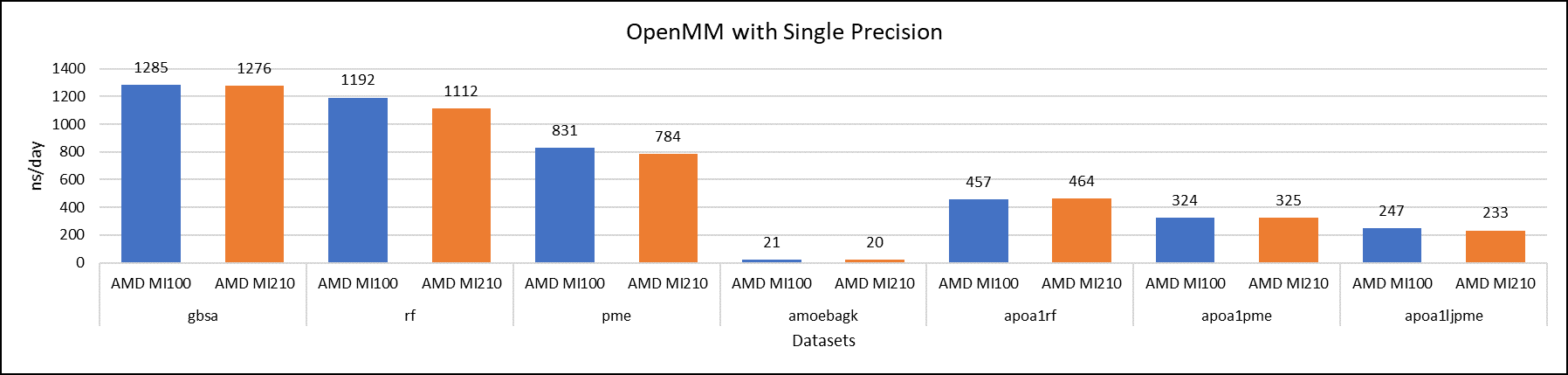
Figure 5: OpenMM single-precision performance with AMD Instinct MI100 and MI210 GPUs
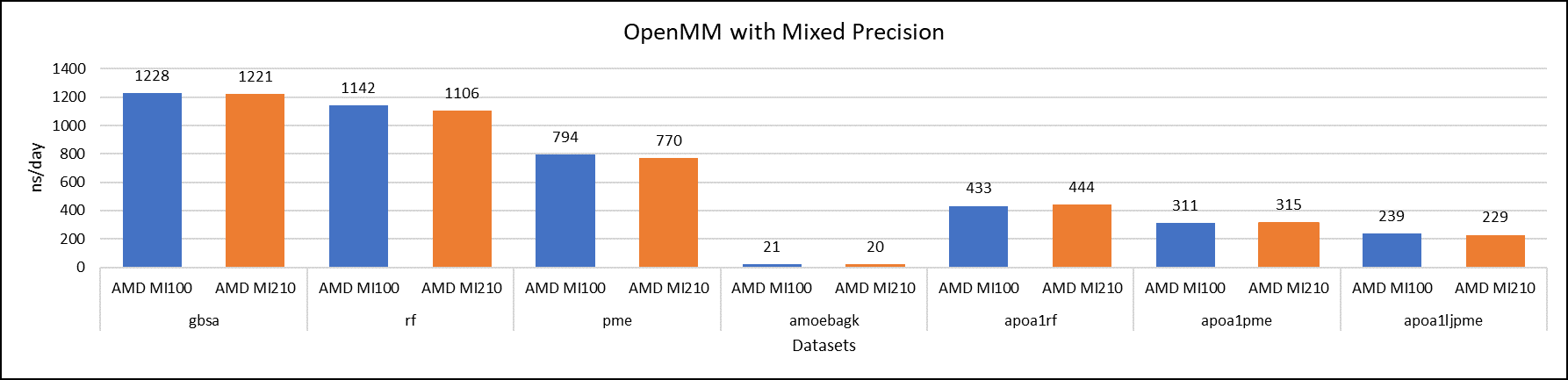
Figure 6: OpenMM mixed-precision performance with AMD Instinct MI100 and MI210 GPUs
We tested OpenMM with seven datasets to validate double, single, and mixed precision. We observed exceptional double precision performance with OpenMM on the AMD Instinct MI210 GPU compared to the AMD Instinct MI100 GPU. This improvement is due to the AMD CDNA2 architecture on the AMD Instinct MI210 GPU, which has been optimized for FP64 matrix and vector workloads.
Conclusion
The AMD Instinct MI210 GPU shows an impressive performance improvement in FP64 workloads. These workloads benefit as AMD has doubled the width of their ALUs to a full 64-bits wide. This change allows the FP64 operations to now run at full speed in the new 2nd Gen AMD CDNA architecture. The applications and workloads that are designed to run on FP64 operations are expected to take full advantage of the hardware.

LAMMPS — with Ice Lake on Dell EMC PowerEdge Servers
Mon, 30 Aug 2021 21:09:22 -0000
|Read Time: 0 minutes
3rd Generation Intel Xeon® Scalable processors (architecture code named Ice Lake) is Intel’s successor to Cascade Lake. New features include up to 40 cores per processor, eight memory channels with support for 3200 MT/s memory speed and PCIe Gen4. The HPC and AI Innovation Lab at Dell EMC had access to a few systems and this blog presents the results of our initial benchmarking study.
LAMMPS Overview
Large-scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) is an open source, well parallelized collection of packages for molecular dynamics (MD) research. LAMMPS has a nice collection of “atom styles”, force fields, and many contributed packages. LAMMPS can run on a single processor or on the largest parallel super-computers. It also has packages that provide force calculations accelerated on GPU’s. It can do simulations with billions of atoms!
LAMMPS can be run on a single processor or in parallel using some form of message passing, such as Message Passing Interface (MPI). The most current source code for LAMMPS is written in C++. For more information about LAMMPS, see the following link: https://www.lammps.org/.
Objective
In this study we measure the performance of LAMMPS on different Ice Lake processor models as listed in Table 1 with a comparison to the previous generation Cascade Lake systems. Single node as well as the multi-node scalability tests were conducted.
Compilation Details
The LAMMPS version used for testing release was lammps-2July-2021, using the Intel 2020 update 5 compiler to take advantage of AVX2 and AVX512 optimizations, and the Intel MKL FFT library. We used the default INTEL package, which comes along the LAMMPS package providing some well optimized atom pair styles in LAMMPS for the vector instructions on Intel processors. The datasets used for our study are described in Table 2, along with detailed configuration of atom sizes and run steps. The unit of performance is timesteps per second, and higher is better.
Hardware and software configurations
Table 1: Hardware and Software test bed details
Component | Dell EMC PowerEdge R750 server | Dell EMC PowerEdge R750 server | Dell EMC PowerEdge C6520 server | Dell EMC PowerEdge C6520 server | Dell EMC PowerEdge C6420 server | Dell EMC PowerEdge C6420 server |
CPU model | Xeon 8380 | Xeon 8358 | Xeon 8352Y | Xeon 6330 | Xeon 8280 | Xeon 6248R |
Cores/Socket | 40 | 32 | 32 | 28 | 28 | 24 |
Base Frequency | 2.30 GHz | 2.60 GHz | 2.20 GHz | 2.00 GHz | 2.70 GHz | 3.00 GHz |
TDP | 270 W | 250 W | 205 W | 205 W | 205 W | 205 W |
Operating System | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | |||||
Memory |
16 GB x 16 (2Rx8) 3200 MT/s
| 16 GB x 12 (2Rx8) 2933 MT/s | ||||
BIOS/CPLD | 1.1.2/1.0.1 | |||||
Interconnect | NVIDIA Mellanox HDR
| NVIDIA Mellanox HDR100 | ||||
Compiler | Intel parallel studio 2020 (update 4) | |||||
LAMMPS | 2july2021 | |||||
Datasets used for performance analysis
Table 2: Description of datasets used for performance analysis
Datasets | Description | Units | Atomic Style | Atom Size | Step Size |
Lennard Jones | Atomic fluid (LJ Benchmark) | lj | atomic | 512000 | 7900 |
Rhodo | Protein (Rhodopsin Benchmark) | real | full | 512000 | 520 |
Liquid crystal | Liquid Crystal w/ Gay-Berne potential | lj | ellipsoid | 524288 | 840 |
Eam | Copper benchmark with Embedded Atom Method | metal | atomic | 512000 | 3100 |
Stilliger Weber | Silicon benchmark with Stillinger-Weber | metal | atomic | 512000 | 6200 |
Tersoff | Silicon benchmark with Tersoff | metal | atomic | 512000 | 2420 |
Water | Coarse-grain water benchmark using Stillinger-Weber | real | atomic | 512000 | 2600 |
Polyethylene | Polyethylene benchmark with AIREBO | metal | atomic | 522240 | 550 |
Figure 1: Image view of datasets from OVITO (scientific data visualization and analysis software for molecular and other particle-based simulation model). Images are listed in order 1a-1h, subfigure 1a- 1h represents a small portion of simulation domain for Atomic Fluid (Lennard Jones), rhodo(protein), liquid crystal(lc), copper(eam), stilliger webner(sw), Terasoff, water, polyethylene datasets respectively.
Table 1 and Figure 1 shows the image view of datasets used for the single and multi-node analysis. For visualization of all datasets was done using OVITO, scientific data visualization and analysis software for molecular and other particle-based simulation model. For single node performance study, all the datasets shown in Table 2 were used, and for multi-node study Atomic fluid was considered for benchmarking.
Performance Analyses on Single Node
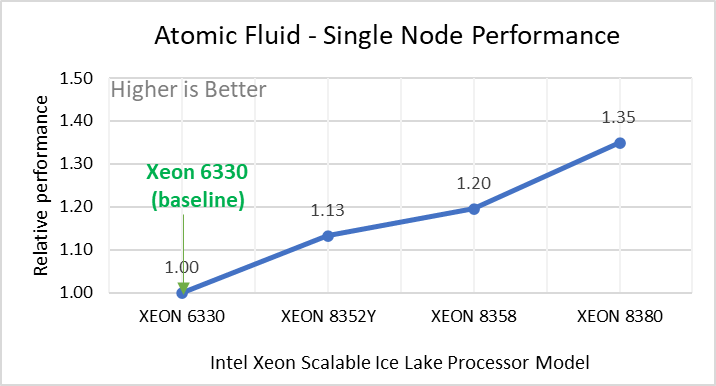
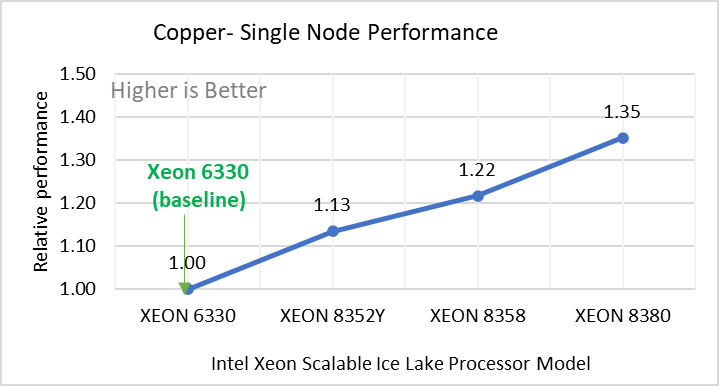
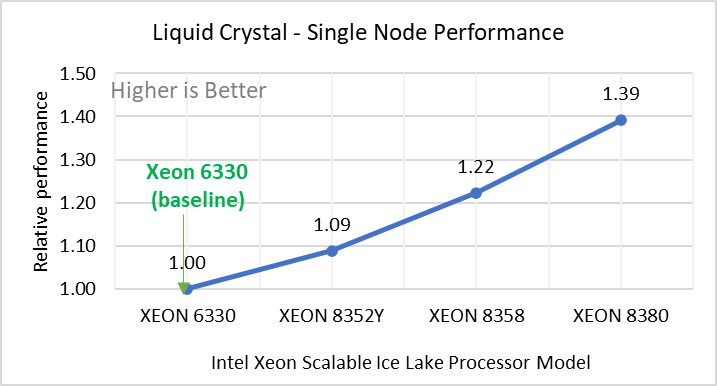
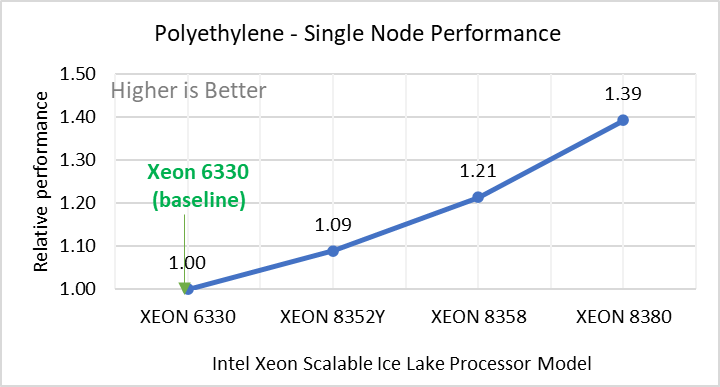
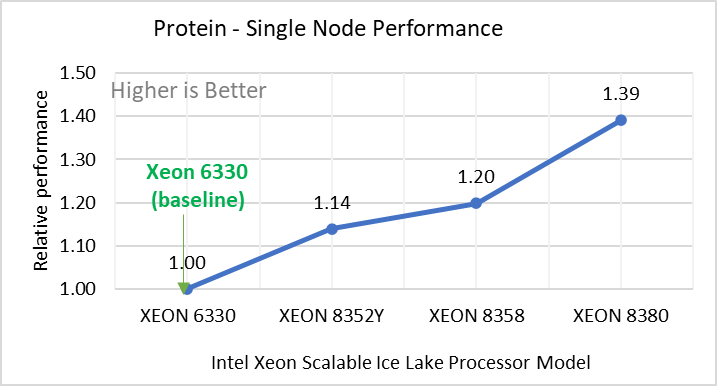
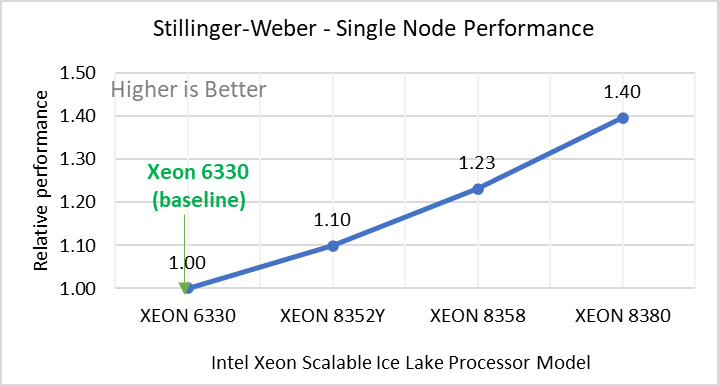
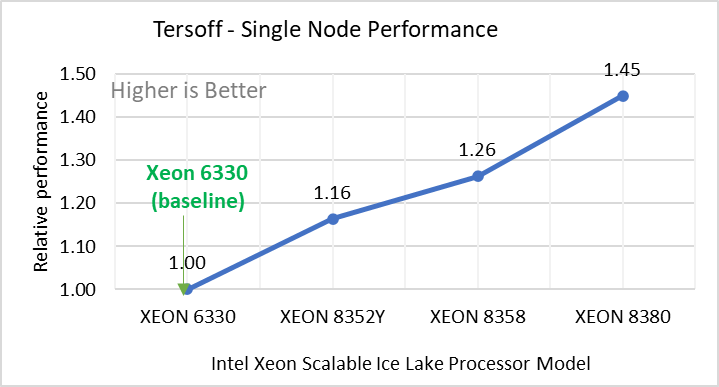
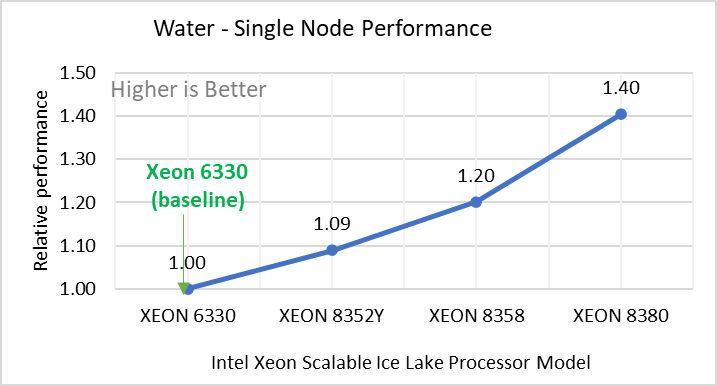
Figure 2: Single Node Performance of LAMMPS across the datasets with Intel Ice Lake processor model. Each graph in Figure 2 is an individual subfigure, labeled (a-h) in the order shown. Each subfigure (2a- 2h) represents single node performance comparison across the Xeon processors with Xeon 6330 as baseline for Atomic Fluid (Lennard Jones), rhodo(protein), liquid crystal(lc), copper(eam), stilliger webner(sw), Terasoff, water, polyethylene datasets respectively.
Figure 2 shows the single node performance for the eight datasets (sub figure 2a-h) listed in Table 2 with the four Ice Lake processor model available for evaluation of LAMMPS.
For ease of comparison across the processor model, the relative performance of the datasets has been included into a different graph. However, it is worth noting that each dataset behaves individually when performance is considered, as each uses different molecular potentials and have different number of atoms. Figure 2 shows that increases in the core count in the processor model increases the performance, across the dataset used. Next, by comparing the relative numbers to the baseline processor Xeon 6330(28C) with Xeon 8380(40C), we measured a 30 to 45 percent performance gain with these datasets. A fraction of these boosts was due to frequency of the processor model.
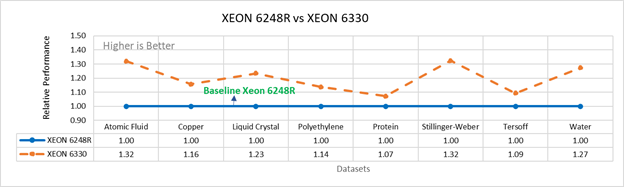
Figure 3a: Performance of LAMMPS on Cascade Lake (Xeon 6248R) in comparison to Ice Lake (Xeon 6330)
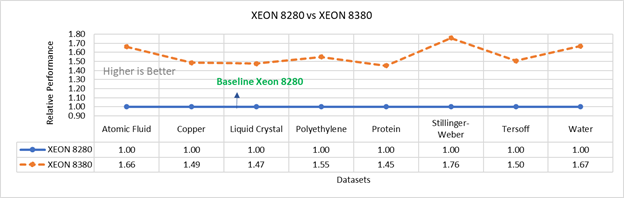
Figure 3b: Performance of LAMMPS on Cascade Lake (Xeon 8280) in comparison to Ice Lake (Xeon 8380)
Figure 3 compares the performance of the mid-bin Cascade Lake 6248R (24core) to the Ice Lake 6330 (28 core), and the top end Cascade Lake 8280 (28 core) to the Ice Lake 8380 (40 core) From the figure 3a, Ice Lake 6330 is up to 30 percent faster than the 6248R. The Xeon 6330 has 16 percent more cores, and 9 percent faster memory bandwidth. Figure 3b shows Ice Lake 8380 is up to 75 percent faster than the Xeon 8280 on single node tests, this is in line with the 42 percent additional cores and 9 percent faster memory bandwidth. These results are due to a higher processor speed wherein more data can be accessed by each core.
Performance Analysis on Multi-Node
To analyze the scalability test with strong and weak scaling, we used the Atom Fluid (LJ) dataset from the Intel package. The job run time was 7900 steps with 512000 atoms in the simulation system.
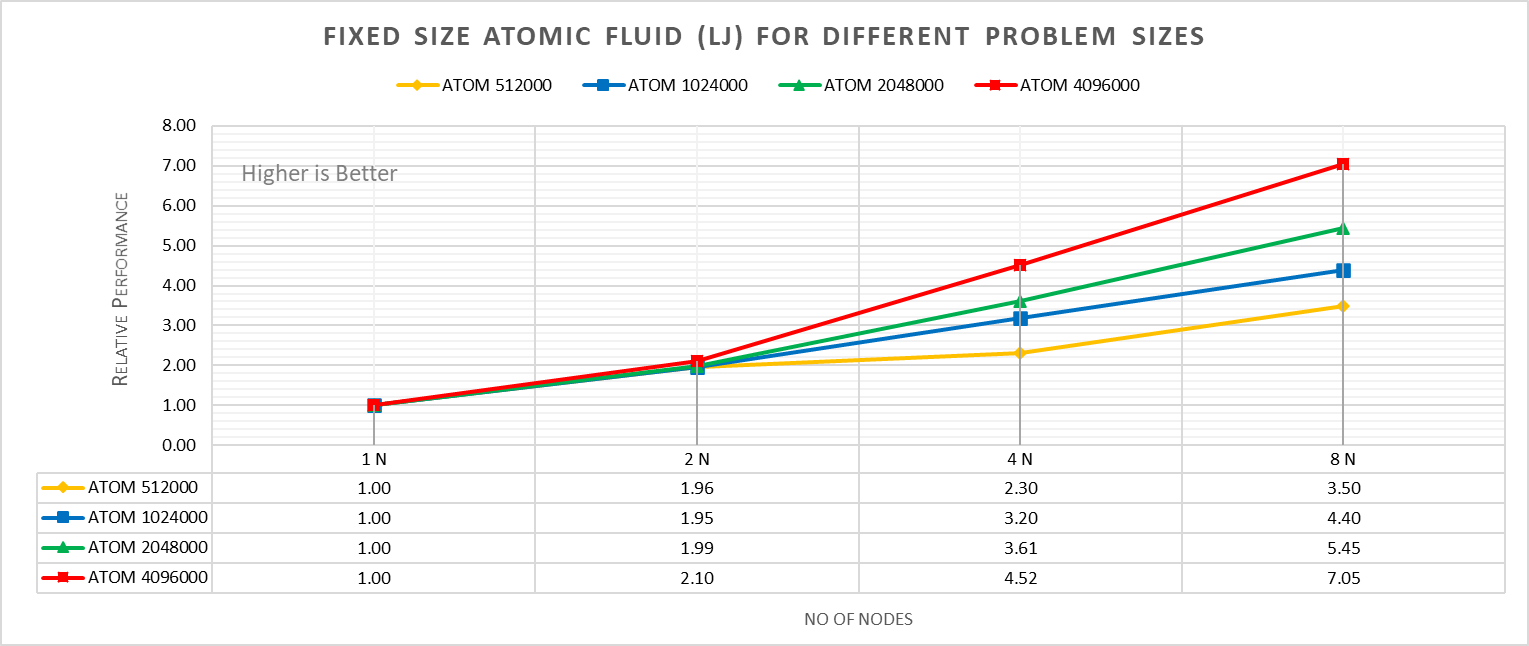
Figure 4a: Fixed size Atomic fluid (LJ) for different problem size (strong scaling) w/ Xeon 8380
With strong scaling, we referred to the fixed problem size and increasing the parallel processes (Amdahl’s law). Whereas in weak scaling, we varied the atom size from 512000 atoms to 4096000 atoms in the simulation environment with an increase in the parallel processes (Gustafson-Barsis law). The test bed included DellEMC Poweredge R750 servers each with dual Ice Lake Xeon 8380 processors an NVIDIA Networking HDR interconnect running at 200 Gbps.Figure 4a plots the fixed-size relative performance for four different problem sizes, viz, 512000,1024000,2048000, and 4096000 atoms, on different number of nodes.
The relative performance is normalized by single node performance. Hence, the single node performance for each curve is 1.00 (unity). Relative Performance for fixed size Atomic fluid was calculated by the following equation:
Relative Performance = loop time of ‘N’ node / loop time for single node
Loop time is the total wall-clock time for the simulation to run. It can be observed that relative performance increases with increase in problem size. This is because for smaller problems system spend more time in inter-nodal communications. Time spent in communication at 8 nodes is 61.91%, 59.74%,48.42%,45.04% for 512000,1024000,2048000,4096000 atom size respectively.
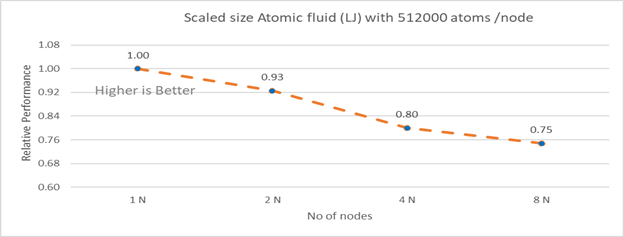
Figure 4b: Scaled size Atomic fluid (LJ) with 512000 atoms per node (weak scaling) w/ Xeon 8380
Figure 4b plots the scaled-size efficiency for runs with 512000 atoms per node. Thus, a scaled-size 2 node run is for 1024000 atoms; 8 node runs is for 4096000 atoms. Relative Performance for Scaled size Atomic fluid was calculated by the following equation:
Relative Performance= loop time for ‘n’ node/ (loop time for single node * number of nodes)
Weak scaling efficiency decreases with increase in no of nodes in the investigated range. This is due to the fact for larger number of nodes the time spend in MPI communication is larger. Time spent in communication with scaled size atom for 1N, 2N, 4N and 8 N are 27.17%, 32.42 %, 40.87%, 45.04 % respectively.
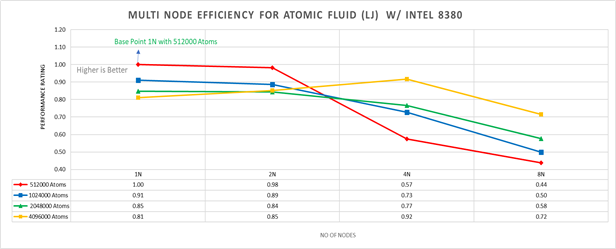
Figure 5: Multi-node efficiency for Atomic Fluid (LJ) w/ I 8380
Figure 5 plots the multi-node efficiency for Atomic Fluid with Xeon 8380. The relative performance is normalized by single node with 512000 atoms performance. Hence, the single node performance for 512000 atoms is 1.00 (unity). This point is taken as baseline for other comparison.
Performance Rating = (loop time * number of atoms)/ (loop time for 512000 atoms on 1 node * number of nodes * 512000)
We observed that for smaller systems, such as those with fewer atoms, the efficiency of strong scaling decreases as the system spends more time in MPI communication; whereas in larger systems with many atoms, the efficiency of strong scaling increases as the time spent in pair-wise force calculation becomes dominant. For weak scaling, as the no of nodes increases the efficiency of weak scaling decreases.
Conclusion
The Ice Lake processor-based Dell EMC Power Edge servers, with its hardware feature upgrades over Cascade Lake, demonstrate up to 50 to70 percent performance gain for all the datasets used for benchmarking LAMMPS. Watch our blog site for updates!

MD Simulation of GROMACS with AMD EPYC 7003 Series Processors on Dell EMC PowerEdge Servers
Thu, 19 Aug 2021 20:06:53 -0000
|Read Time: 0 minutes
AMD has recently announced and launched its third generation 7003 series EPYC processors family (code named Milan). These processors build upon the proceeding generation 7002 series (Rome) processors and improve L3 cache architecture along with an increased memory bandwidth for workloads such as High Performance Computing (HPC).
The Dell EMC HPC and AI Innovation Lab has been evaluating these new processors with Dell EMC’s latest 15G PowerEdge servers and will report our initial findings for the molecular dynamics (MD) application GROMACs in this blog.
Given the enormous health impact of the ongoing COVID-19 pandemic, researchers and scientists are working closely with the HPC and AI Innovation Lab to obtain the appropriate computing resources to improve the performance of molecular dynamics simulations. Of these resources, GROMACS is an extensively used application for MD simulations. It has been evaluated with the standard datasets by combining the latest AMD EPYC Milan processor (based on Zen 3 cores) with Dell EMC PowerEdge servers to get most out of the MD simulations.
In a previous blog, Molecular Dynamic Simulation with GROMACS on AMD EPYC- ROME, we published benchmark data for a GROMACS application study on a single node and multinode with AMD EPYC ROME based Dell EMC servers.
The results featured in this blog come from the test bed described in the following table. We performed a single-node and multi-node application study on Milan processors, using the latest AMD stack shown in Table 1, with GROMACS 2020.4 to understand the performance improvement over the older generation processor (Rome).
Table 1: Testbed hardware and software details
Server | Dell EMC PowerEdge 2-socket servers (with AMD Milan processors) | Dell EMC PowerEdge 2-socket servers (with AMD Rome processors) |
Processor Cores/socket Frequency (Base-Boost ) Default TDP Processor bus speed | 7763 (Milan) 64 2.45 GHz – 3.5 GHz 280 W 256 MB 16 GT/s | 7H12 (Rome) 64 2.6 GHz – 3.3 GHz 280 W 256 MB 16 GT/s |
Processor Cores/socket Frequency Default TDP Processor bus speed | 7713 (Milan) 64 2.0 GHz – 3.675 GHz 225 W 256 MB 16 GT/s | 7702 (Rome) 64 2.0 GHz – 3.35 GHz 200 W 256 MB 16 GT/s |
Processor Cores/socket Frequency Default TDP Processor bus speed | 7543 (Milan) 32 2.8 GHz – 3.7 GHz 225 W 256 MB 16 GT/s | 7542 (Rome) 32 2.9 GHz – 3.4 GHz 225 W 128 MB 16 GT/s |
Operating system | Red Hat Enterprise Linux 8.3 (4.18.0-240.el8.x86_64) | Red Hat Enterprise Linux 7.8 |
Memory | DDR4 256 G (16 GB x 16) 3200 MT/s | |
BIOS/CPLD | 2.0.2 / 1.1.12 |
|
Interconnect | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR 100 |
Table 2: Benchmark datasets used for GROMACS performance evaluation
Datasets | Details |
1536 K and 3072 K | |
1400 K and 3000 K | |
Prace – Lignocellulose | 3M |
The following information describes the performance evaluation for the processor stack listed in the Table 1.
Rome processors compared to Milan processors (GROMACS)
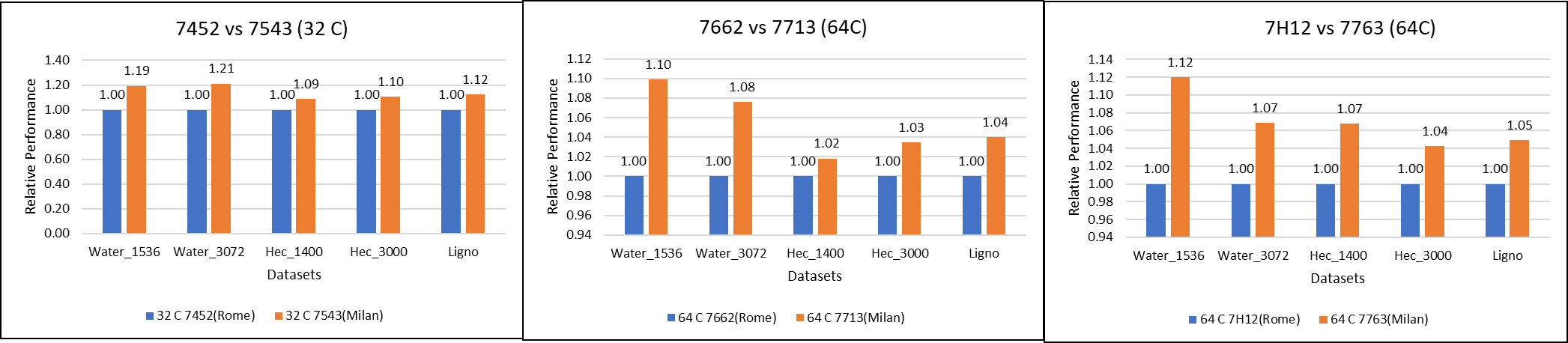 Figure 1: GROMACS performance comparison with AMD Rome processors
Figure 1: GROMACS performance comparison with AMD Rome processors
For performance benchmark comparisons, we selected Rome processors that are closest to their Milan counterparts in terms of hardware features such as cache size, TDP values, and Processor Base/Turbo Frequency, and marked the maximum value attained for Ns/day by each of the datasets mentioned in Table 2.
Figure 1 shows a 32C Milan processor has higher performance improvements (19 percent for water 1536, 21 percent for water 3072, and 10 to approximately 12 percent with HECBIO sim and lingo cellulose datasets) compared to a 32C Rome processor. This result is due to a higher processor speed and improved L3 cache, wherein more data can be accessed by each core.
Next, with the higher end processor we see only 10 percent gain with respect to the water dataset, as they are more memory intensive. Some percentage is added on due to improvement of frequency for the remaining datasets. Overall, the Milan processor results demonstrated a substantial performance improvement for GROMACS over Rome processors.
Milan processors comparison (32C processors compared to 64C processors)
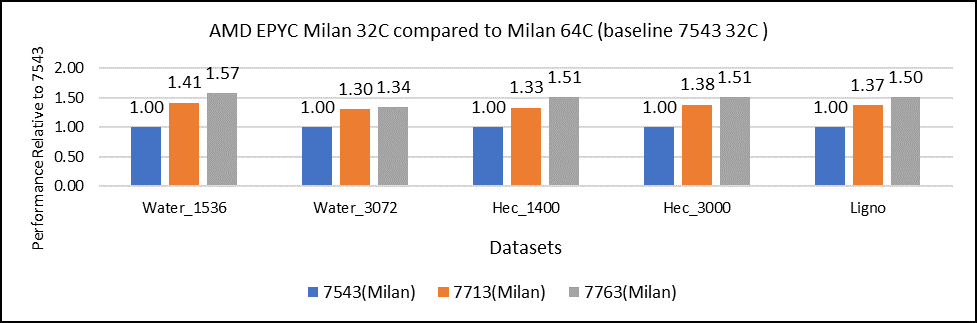
Figure 2: GROMACS performance with Milan processors
Figure 2 shows performance relative to the performance obtained on the 7543 processor. For instance, the performance of water 1536 is improved from the 32C processor to the 64 core (64C) processor from 41 percent (7713 processor) to 57 percent (7763 processor). The performance improvement is due to the increasing core counts and higher CPU core frequency performance improvement. We observed that GROMACS is frequency sensitive, but not to a great extent. Greater gains may be seen when running GROMACS across multiple ensembles runs or running dataset with higher number of atoms.
We recommend that you compare the price-to-performance ratio before choosing the processor based on the datasets with higher CPU core frequency, as the processors with a higher number of lower-frequency cores may provide better total performance.
Multi-node study with 7713 64C processors
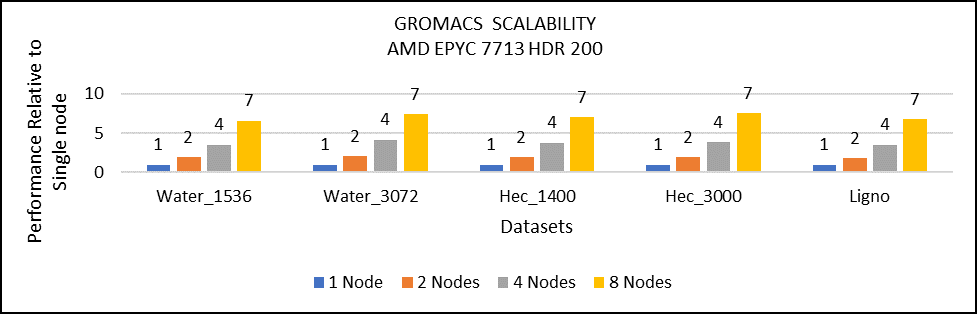
Figure 3: Multi-node study with 7713 64c SKUs
For multi-node tests, the test bed was configured with an NVIDIA Mellanox HDR interconnect running at 200 Gbps and each server included an AMD EPYC 7713 processor. We achieved the expected linear performance scalability for GROMACS of up to four nodes and across each of the datasets. All cores in each server were used while running the benchmarks. The performance increases are close to linear across all the dataset types as core count increases.
Conclusion
For the various datasets we evaluated, GROMACS exhibited strong scaling and was compute intensive. We recommend a processor with high core count for smaller datasets (water 1536, hec 1400); larger datasets (water 3072, ligno,HEC 3000) would benefit from memory per core. Configuring the best BIOS options is important to get the best performance out of the system.
For more information and updates, follow this blog site.

New Frontiers—Dell EMC PowerEdge R750xa Server with NVIDIA A100 GPUs
Tue, 01 Jun 2021 20:18:04 -0000
|Read Time: 0 minutes
Dell Technologies has released the new PowerEdge R750xa server, a GPU workload-based platform that is designed to support artificial intelligence, machine learning, and high-performance computing solutions. The dual socket/2U platform supports 3rd Gen Intel Xeon processors (code named Ice Lake). It supports up to 40 cores per processor, has eight memory channels per CPU, and up to 32 DDR4 DIMMs at 3200 MT/s DIMM speed. This server can accommodate up to four double-width PCIe GPUs that are located in the front left and the front right of the server.
Compared with the previous generation PowerEdge C4140 and PowerEdge R740 GPU platform options, the new PowerEdge R750xa server supports larger storage capacity, provides more flexible GPU offerings, and improves the thermal requirement

Figure 1 PowerEdge R750xa server
The NVIDIA A100 GPUs are built on the NVIDIA Ampere architecture to enable double precision workloads. This blog evaluates the new PowerEdge R750xa server and compares its performance with the previous generation PowerEdge C4140 server.
The following table shows the specifications for the NVIDIA GPU that is discussed in this blog and compares the performance improvement from the previous generation.
Table 1 NVIDIA GPU specifications
PCIe | Improvement | ||
GPU name | A100 | V100 |
|
GPU architecture | Ampere | Volta | - |
GPU memory | 40 GB | 32 GB | 60% |
GPU memory bandwidth | 1555 GB/s | 900 GB/s | 73% |
Peak FP64 | 9.7 TFLOPS | 7 TFLOPS | 39% |
Peak FP64 Tensor Core | 19.5 TFLOPS | N/A | - |
Peak FP32 | 19.5 TFLOPS | 14 TFLOPS | 39% |
Peak FP32 Tensor Core | 156 TFLOPS 312 TFLOPS* | N/A | - |
Peak Mixed Precision FP16 ops/ FP32 Accumulate | 312 TFLOPS 624 TFLOPS* | 125 TFLOPS | 5x |
GPU base clock | 765 MHz | 1230 MHz | - |
Peak INT8 | 624 TOPS 1,248 TOPS* | N/A | - |
GPU Boost clock | 1410 MHz | 1380 MHz | 2.1% |
NVLink speed | 600 GB/s | N/A | - |
Maximum power consumption | 250 W | 250 W | No change |
Test bed and applications
This blog quantifies the performance improvement of the GPUs with the new PowerEdge GPU platform.
Using a single node PowerEdge R750xa server in the Dell HPC & AI Innovation Lab, we derived all results presented in this blog from this test bed. This section describes the test bed and the applications that were evaluated as part of the study. The following table provides test environment details:
Table 2 Server configuration
Component | Test Bed 1 | Test Bed 2 |
Server | Dell PowerEdge R750xa
| Dell PowerEdge C4140 configuration M |
Processor | Intel Xeon 8380 | Intel Xeon 6248 |
Memory | 32 x 16 GB @ 3200MT/s | 16 x 16 GB @ 2933MT/s |
Operating system | Red Hat Enterprise Linux 8.3 | Red Hat Enterprise Linux 8.3 |
GPU | 4 x NVIDIA A100-PCIe-40 GB GPU | 4 x NVIDIA V100-PCIe-32 GB GPU |
The following table provides information about the applications and benchmarks used:
Table 3 Benchmark and application details
Application | Domain | Version | Benchmark dataset |
High-Performance Linpack | Floating point compute-intensive system benchmark | xhpl_cuda-11.0-dyn_mkl-static_ompi-4.0.4_gcc4.8.5_7-23-20 | Problem size is more than 95% of GPU memory |
HPCG | Sparse matrix calculations | xhpcg-3.1_cuda_11_ompi-3.1 | 512 * 512 * 288
|
GROMACS | Molecular dynamics application | 2020 | Ligno Cellulose Water 1536 Water 3072 |
LAMMPS | Molecular dynamics application | 29 October 2020 release | Lennard Jones |
LAMMPS
Large-Scale Atomic/Molecular Massively Parallel simulator (LAMMPS) is distributed by Sandia National Labs and the US Department of Energy. LAMMPS is open-source code that has different accelerated models for performance on CPUs and GPUs. For our test, we compiled the binary using the KOKKOS package, which runs efficiently on GPUs.
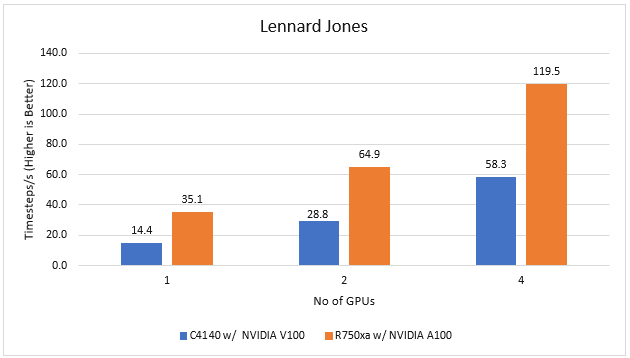
Figure 2 LAMMPS Performance on PowerEdge R750xa and PowerEdge C4140 servers
With the newer generation GPUs, this application improves 2.4 times compared to single GPU performance. The overall performance from a single server improved twice with the PowerEdge R750xa server and NVIDIA A100 GPUs.
GROMACS
GROMACS is a free and open-source parallel molecular dynamics package designed for simulations of biochemical molecules such as proteins, lipids, and nucleic acids. It is used by a wide variety of researchers, particularly for biomolecular and chemistry simulations. GROMACS supports all the usual algorithms expected from modern molecular dynamics implementation. It is open-source software with the latest versions available under the GNU Lesser General Public License (LGPL).
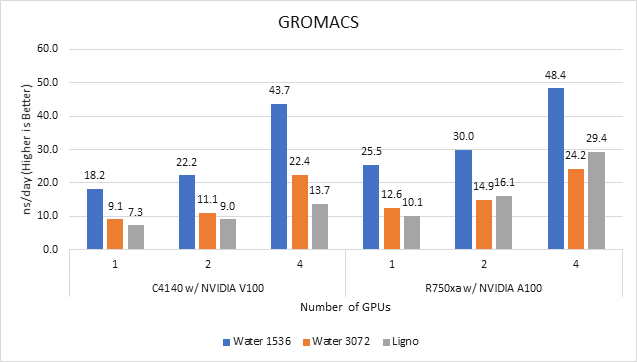
Figure 3 GROMACS performance on PowerEdge C4140 and r750xa servers
With the newer generation GPUs, this application improved approximately 1.5 times across the dataset compared to single GPU performance. The overall performance from a single server improved 1.5 times with a PowerEdge R750xa server and NVIDIA A100 GPUs.
High-Performance Linpack
High-Performance Linpack (HPL) needs no introduction in the HPC arena. It is a widely used standard benchmark tests in the industry.
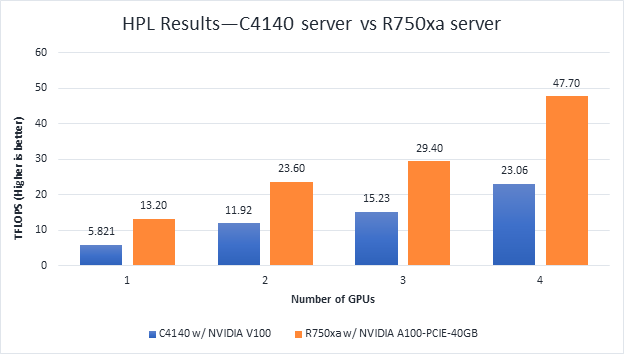
Figure 4 HPL Performance on the PowerEdge R750xa server with A100 GPU and PowerEdge C4140 server with V100 GPU
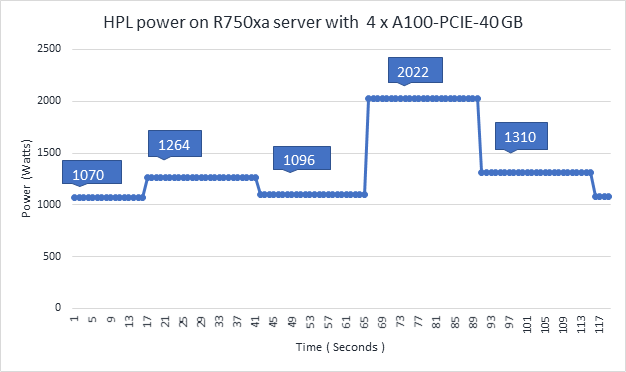
Figure 5 Power use of the HPL running on NVIDIA GPUs
From Figure 4 and Figure 5, the following results were observed:
- Performance—For GPU count, the NVIDIA A100 GPU demonstrates twice the performance of the NVIDIA V100 GPU. Higher memory size, double precision FLOPS, and a newer architecture contribute to the improvement for the NVIDIA A100 GPU.
- Scalability—The PowerEdge R750xa server with four NVIDIA A100-PCIe-40 GB GPUs delivers 3.6 times higher HPL performance compared to one NVIDIA A100-PCIE-40 GB GPU. The NVIDIA A100 GPUs scale well inside the PowerEdge R750xa server for the HPL benchmark.
- Higher Rpeak—The HPL code on NVIDIA A100 GPUs uses the new double-precision Tensor cores. The theoretical peak for each GPU is 19.5 TFlops, as opposed to 9.7 TFlops.
- Power—Figure 5 shows power consumption of a complete HPL run with the PowerEdge R750xa server using four A100-PCIe GPUs. This result was measured with iDRAC commands, and the peak power consumption was observed as 2022 Watts. Based on our previous observations, we know that the PowerEdge C4140 server consumes approximately 1800 W of power.
HPCG
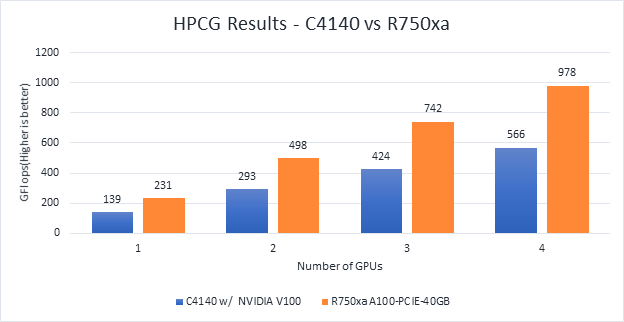
Figure 6 Scaling GPU performance data for HPCG Benchmark
As discussed in other blogs, high performance conjugate gradient (HPCG) is another standard benchmark to test data access patterns of sparse matrix calculations. From the graph, we see that the HPCG benchmark scales well with this benchmark resulting in 1.6 times performance improvement over the previous generation PowerEdge C4140 server with an NVIDIA V100 GPU.
The 72 percent improvement in memory bandwidth of the NVIDIA A100 GPU over the NVIDIA V100 GPU contributes to the performance improvement.
Conclusion
In this blog, we introduced the latest generation PowerEdge R750xa platform and discussed the performance improvement over the previous generation PowerEdge C4140 server. The PowerEdge R750xa server is a good option for customers looking for an Intel Xeon scalable CPU-based platform powered with NVIDIA GPUs.
With the newer generation PowerEdge R750xa server and NVIDIA A100 GPUs, the applications discussed in this blog show significant performance improvement.
Next steps
In future blogs, we plan to evaluate NVLINK bridge support, which is another important feature of the PowerEdge R750xa server and NVIDIA A100 GPUs.

Intel Ice Lake - BIOS Characterization for HPC
Tue, 25 May 2021 13:10:03 -0000
|Read Time: 0 minutes
Intel recently announced the 3rd Generation Intel Xeon Scalable processors (code-named “Ice Lake”), which are based on a new 10 nm manufacturing process. This blog provides the new Ice Lake processor synthetic benchmark results and the recommended BIOS settings on Dell EMC PowerEdge servers.
Ice Lake processors offer a higher core count of up to 40 cores with a single Ice Lake 8380 processor. The Ice Lake processors have larger L3, L2, and L1 data cache than Intel’s second-generation Cascade Lake processors. These features are expected to improve performance of CPU-bound software applications. Table 1 shows the L1, L2, and L3 cache size on the 8380 processor model.
Ice Lake still supports the AVX 512 SIMD instructions, which allow for 32 DP FLOP/cycle. The upgraded Ultra Path Interconnect (UPI) Link speed of 11.2GT/s is expected to improve data movement between the sockets. In addition to core count and frequency, Ice Lake-based Dell EMC PowerEdge servers support DDR4 - 3200 MT/s DIMMS with eight memory channels per processor, which is expected to improve the performance of memory bandwidth-bound applications. Ice Lake processors now support DIMMs with 6 TB per socket.
Instructions such as Vector CLMUL, VPMADD52, Vector AES, and GFNI Extensions have been optimized to improve use of vector registers. The performance of software applications in the cryptography domain is also expected to benefit. The Ice Lake processor also includes improvements to Intel Speed Select Technology (Intel SST). With Intel SST, a few cores from the total available cores can be operated at a higher base frequency, turbo frequency, or power. This blog does not address this feature.
Table 1: hwloc-ls and numactl -H command output on an Intel 8380 processor model-based server with Round Robin core enumeration (MadtCoreEnumeration) and SubNumaCuster(Sub-NUMA Cluster) set to 2-Way
hwloc-ls | numactl -H |
Machine (247GB total) Package L#0 + L3 L#0 (60MB) Group0 L#0 NUMANode L#0 (P#0 61GB) L2 L#0 (1280KB) + L1d L#0 (48KB) + L1i L#0 (32KB) + Core L#0 + PU L#0 (P#0) L2 L#1 (1280KB) + L1d L#1 (48KB) + L1i L#1 (32KB) + Core L#1 + PU L#1 (P#4) L2 L#2 (1280KB) + L1d L#2 (48KB) + L1i L#2 (32KB) + Core L#2 + PU L#2 (P#8) L2 L#3 (1280KB) + L1d L#3 (48KB) + L1i L#3 (32KB) + Core L#3 + PU L#3 (P#12) L2 L#4 (1280KB) + L1d L#4 (48KB) + L1i L#4 (32KB) + Core L#4 + PU L#4 (P#16) L2 L#5 (1280KB) + L1d L#5 (48KB) + L1i L#5 (32KB) + Core L#5 + PU L#5 (P#20) L2 L#6 (1280KB) + L1d L#6 (48KB) + L1i L#6 (32KB) + Core L#6 + PU L#6 (P#24) L2 L#7 (1280KB) + L1d L#7 (48KB) + L1i L#7 (32KB) + Core L#7 + PU L#7 (P#28) L2 L#8 (1280KB) + L1d L#8 (48KB) + L1i L#8 (32KB) + Core L#8 + PU L#8 (P#32) L2 L#9 (1280KB) + L1d L#9 (48KB) + L1i L#9 (32KB) + Core L#9 + PU L#9 (P#36) L2 L#10 (1280KB) + L1d L#10 (48KB) + L1i L#10 (32KB) + Core L#10 + PU L#10 (P#40) L2 L#11 (1280KB) + L1d L#11 (48KB) + L1i L#11 (32KB) + Core L#11 + PU L#11 (P#44) L2 L#12 (1280KB) + L1d L#12 (48KB) + L1i L#12 (32KB) + Core L#12 + PU L#12 (P#48) L2 L#13 (1280KB) + L1d L#13 (48KB) + L1i L#13 (32KB) + Core L#13 + PU L#13 (P#52) L2 L#14 (1280KB) + L1d L#14 (48KB) + L1i L#14 (32KB) + Core L#14 + PU L#14 (P#56) L2 L#15 (1280KB) + L1d L#15 (48KB) + L1i L#15 (32KB) + Core L#15 + PU L#15 (P#60) L2 L#16 (1280KB) + L1d L#16 (48KB) + L1i L#16 (32KB) + Core L#16 + PU L#16 (P#64) L2 L#17 (1280KB) + L1d L#17 (48KB) + L1i L#17 (32KB) + Core L#17 + PU L#17 (P#68) L2 L#18 (1280KB) + L1d L#18 (48KB) + L1i L#18 (32KB) + Core L#18 + PU L#18 (P#72) L2 L#19 (1280KB) + L1d L#19 (48KB) + L1i L#19 (32KB) + Core L#19 + PU L#19 (P#76) HostBridge. <snip> . .
| |
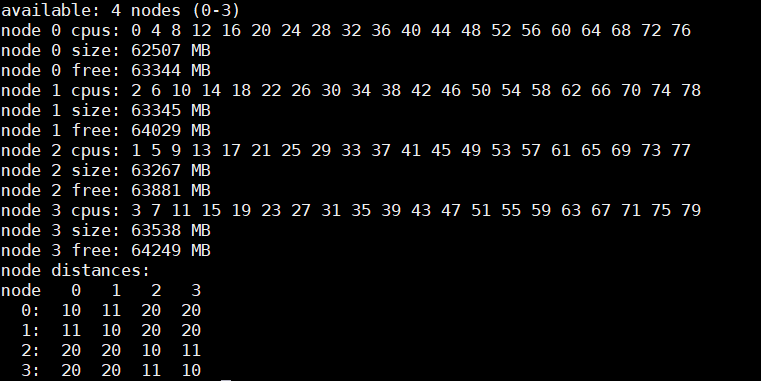
BIOS options tested on Ice Lake processors
Table 2 provides the server details used for the performance tests. The following BIOS options were explored in the performance testing:
- BIOS.ProcSettings.SubNumaCluster—Breaks up the LLC into disjoint clusters based on address range, with each cluster bound to a subset of the memory controllers in the system. It improves average latency to the LLC. Sub-NUMA Cluster (SNC) is disabled if NVDIMM-N is installed in the system.
- BIOS.ProcSettings.DeadLineLlcAlloc—If enabled, fills in dead lines in LLC opportunistically.
- BIOS.ProcSettings.LlcPrefetch—Enables and disables LLC Prefetch on all threads.
- BIOS.ProcSettings.XptPrefetch—If enabled, enables the MS2IDI to take a read request that is being sent to the LLC and speculatively issue a copy of that read request to the memory controller.
- BIOS.ProcSettings.UpiPrefetch—Starts the memory read early on the DDR bus. The UPI Rx path spawns a MemSpecRd to iMC directly.
- BIOS.ProcSettings.DcuIpPrefetcher (Data Cache Unit IP Prefetcher)—Affects performance, depending on the application running on the server. This setting is recommended for High Performance Computing applications.
- BIOS.ProcSettings.DcuStreamerPrefetcher (Data Cache Unit Streamer Prefetcher)—Affects performance, depending on the application running on the server. This setting is recommended for High Performance Computing applications.
- BIOS.ProcSettings.ProcAdjCacheLine—When set to Enabled, optimizes the system for applications that require high utilization of sequential memory access. Disable this option for applications that require high utilization of random memory access.
- BIOS.SysProfileSettings.SysProfile—Sets the System Profile to Performance Per Watt (DAPC), Performance Per Watt (OS), Performance, Workstation Performance, or Custom mode. When set to a mode other than Custom, the BIOS sets each option accordingly. When set to Custom, you can change setting of each option.
- BIOS.ProcSettings.LogicalProc—Reports the logical processors. Each processor core supports up to two logical processors. When set to Enabled, the BIOS reports all logical processors. When set to Disabled, the BIOS only reports one logical processor per core. Generally, a higher processor count results in increased performance for most multithreaded workloads. The recommendation is to keep this option enabled. However, there are some floating point and scientific workloads, including HPC workloads, where disabling this feature might result in higher performance.
You can set the DeadLineLlcAlloc, LlcPrefetch, XptPrefetch, UpiPrefetch, DcuIpPrefetcher, DcuStreamerPrefetcher, ProcAdjCacheLine, and LogicalProc BIOS options to either Enabled or Disabled. You can set the SubNumaCluster to 2-Way and Disabled. The SysProfile setting can have five possible values: PerformanceOptimized, PerfPerWattOptimizedDapc, PerfPerWattOptimizedOs, PerfWorkStationOptimized and Custom.
Table 2: Test bed hardware and software details
Component | Dell EMC PowerEdge R750 server | Dell EMC PowerEdge C6520 server | Dell EMC PowerEdge C6420 server | Dell EMC PowerEdge C6420 server |
OPN | 8380 | 6338 | 8280 | 6252 |
Cores/Socket | 40 | 32 | 28 | 24 |
Frequency (Base-Boost) | 2.30 – 3.40 GHz | 2.0 – 3.20 GHz | 2.70 – 4.0 GHz | 2.10 – 3.70 GHz |
TDP | 270 W | 205 W | 205 W | 150 W |
L3Cache | 60M | 48M | 38.5M | 37.75M |
Operating System | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | Red Hat Enterprise Linux 8.3 4.18.0-240.el8.x86_64 | Red Hat Enterprise Linux 8.3 4.18.0-240.el8.x86_64 |
Memory | 16 GB x 16 (2Rx8) 3200 MT/s | 16 GB x 16 (2Rx8) 3200 MT/s | 16 GB x 12 (2Rx8) 2933 MT/s | 16 GB x 12 (2Rx8) 2933 MT/s |
BIOS/CPLD | 1.1.2/1.0.1 | |||
Interconnect | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR | NVIDIA Mellanox HDR100 | NVIDIA Mellanox HDR100 |
Compiler | Intel parallel studio 2020 (update 4) | |||
Benchmark software |
| |||
The system profile BIOS meta option helps to set a group of BIOS options (such as C1E, C States, and so on), each of which control performance and power management settings to a particular value. It is also possible to set these groups of BIOS options individually to a different value using the Custom system profile.
Application performance results
Table 2 lists details about the software used for benchmarking the server. We used the precompiled HPL and HPCG binary files, which are part of Intel Parallel Studio 2020 update 4 software bundle, for our tests. We compiled the WRF application with AVX2 support. WRF and HPCG issue many nonfloating point packed micro-operations (approximately 73 percent to 90 percent of the total packed micro-operations). They are memory-bound (and DRAM-bandwidth bound) workloads. HPL issues packed double precision micro-operations and is a compute-bound workload.
After setting Sub-NUMA Cluster (BIOS.ProcSettings.SubNumaCluster) to 2-Way, Logical Processors (BIOS.ProcSettings.LogicalProc) to Disabled, and other settings (DeadLineLlcAlloc, LlcPrefetch, XptPrefetch, UpiPrefetch, DcuIpPrefetcher, DcuStreamerPrefetcher, ProcAdjCacheLine) to Enabled, we measured the impact of System Profile (BIOS.SysProfileSettings.SysProfile) BIOS parameters on application performance.
Figure 1 through Figure 4 show application performance. In each figure, the numbers over the bars represent the relative change in the application performance with respect to the application performance obtained on the Intel 6338 Ice Lake processor with the System Profile set to Performance Optimized (PO).
Note: In the figures, PO=PerformanceOptimized, PPWOD=PerfPerWattOptimizedDapc, PPWOO=PerfPerWattOptimizedOs, and PWSO=PerfWorkStationOptimized.
HPL Benchmark
Figure 1: Relative difference in the performance of HPL by processor and Sysprofile setting
HPCG Benchmark
Figure 2: Relative difference in the performance of HPCG by processor and Sysprofile setting
STREAM Benchmark
Figure 3: Relative difference in the performance of STREAM by processor and Sysprofile setting
WRF Benchmark
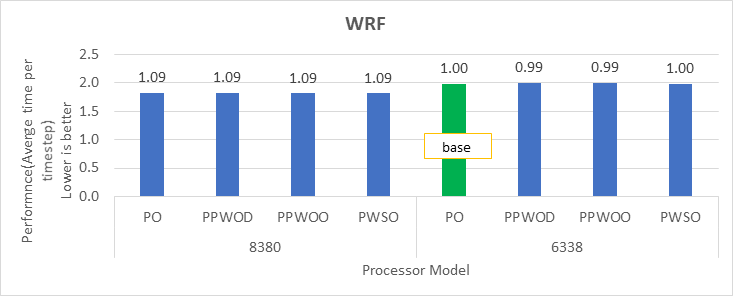
Figure 4: Relative difference in the performance of WRF by processor and Sysprofile setting
We obtained the performance for the applications in Figure 2 through Figure 4 by fully subscribing to all available cores. Depending on the processor model, we achieved 78 percent to 80 percent efficiency with HPL and STREAM benchmarks using the Performance Optimized profile.
Intel has extended the TDP of the Ice Lake processors with the top-end Intel 8380 processor at 270 W TDP. The following figure shows the power use on the systems with the applications listed in Table 2.Note: In this figure, PO=PerformanceOptimized, PPWOD=PerfPerWattOptimizedDapc, PPWOO=PerfPerWattOptimizedOs and PWSO=PerfWorkStationOptimized

Figure 5: Power use by platform and processor type. Average Idle power usage on the PowerEdge C6520 server (Intel 6338 processor) with approximately 335 W and the PowerEdge R750 server (intel 8380 processor) with approximately 470 W using the Performance Optimized System Profile.
When SNC is set to 2-Way, the system exposes four NUMA nodes. We tested the NUMA bandwidth, remote socket bandwidth, and local socket bandwidth using the STREAM TRIAD benchmark. In Figure 6, the CPU NUMA node is represented as c and the memory node is represented as m. As an example for NUMA bandwidth, the c0m0 (blue bars) test type represents the STREAM TRIAD test carried out between NUMA node 0 and memory node 0. Figure 6 shows the best bandwidth numbers obtained on varying the number of threads per test type.
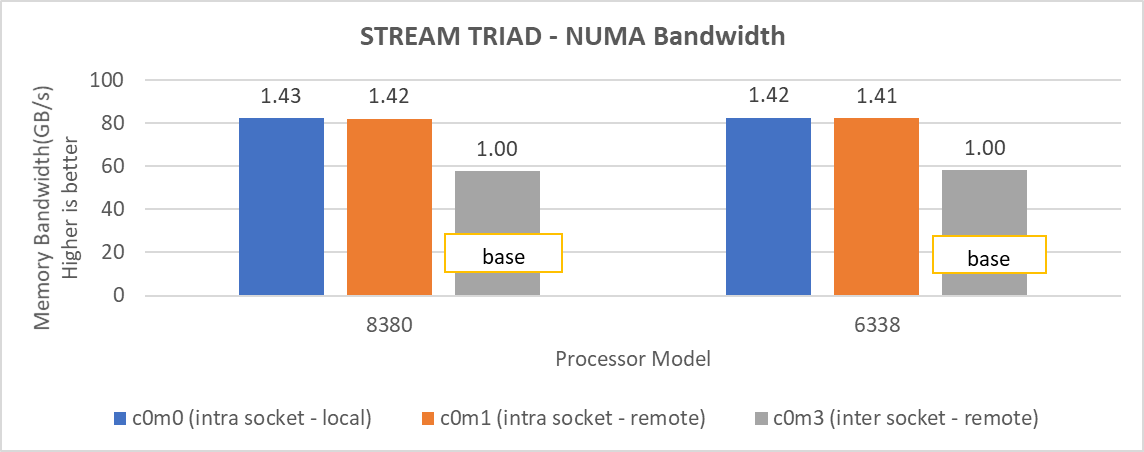
Figure 6: Local and remote NUMA memory bandwidth.
Remote socket bandwidth numbers were measured between CPU node 0, 1 and memory node 2, 3. Local bandwidths were measured between CPU node 0, 1, and 0, 1. The following figure shows the performance numbers.
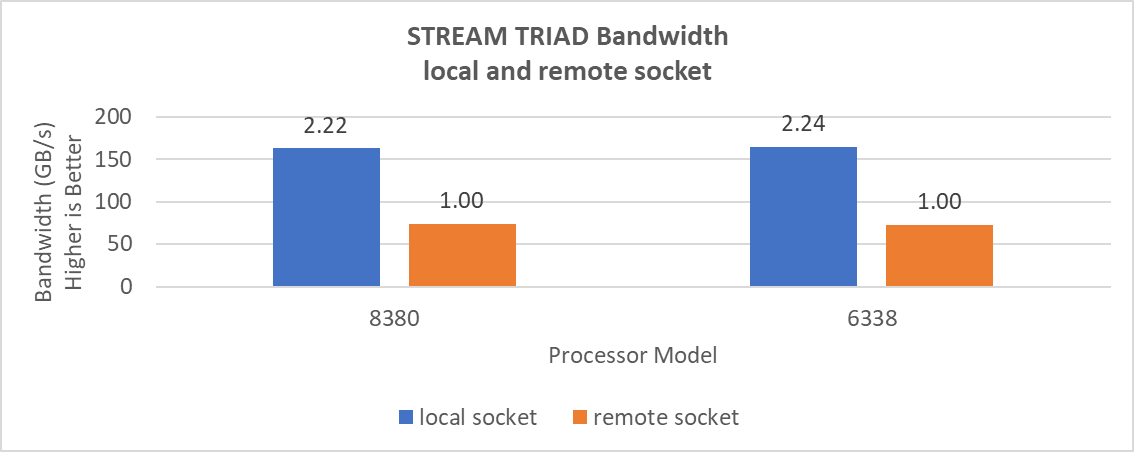
Figure 7: Local and remote processor bandwidth.
Impact of BIOS options on application performance
We tested the impact of the DeadLineLlcAlloc, LlcPrefetch, XptPrefetch, UpiPrefetch, DcuIpPrefetcher, DcuStreamerPrefetcher and ProcAdjCacheLine with the Performance Optimized (PO) system profile. These BIOS options do not have significant impact on the performance of applications addressed in this blog, therefore we recommend that these options be set as Enabled.
Figure 8 and Figure 9 show the impact of the Sub-NUMA Cluster (SNC) BIOS option on the application performance. In each figure, the numbers over the bars represent the relative change in the application performance with respect to the application performance obtained on the Intel 6338 Ice Lake processor with SNC feature set to Disabled.
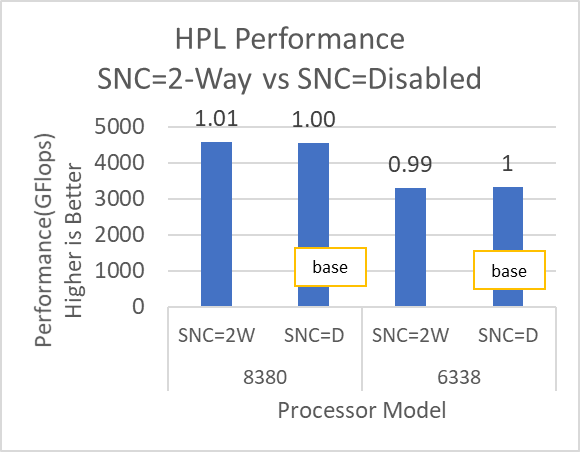
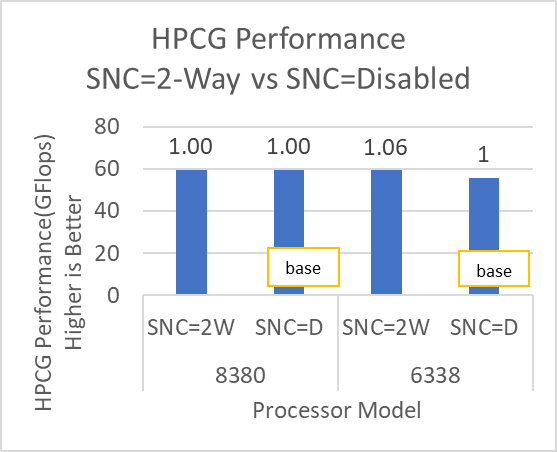
Figure 8: HPL and HPCG performance variation by processor model with Sub-NUMA Cluster set to Disabled (SNC=D) and 2-Way (SNC=2W)
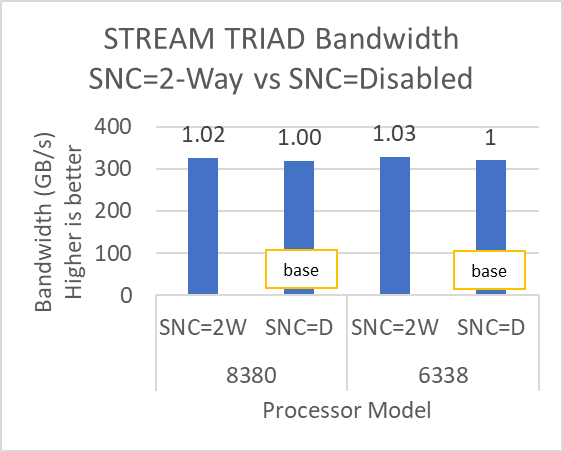
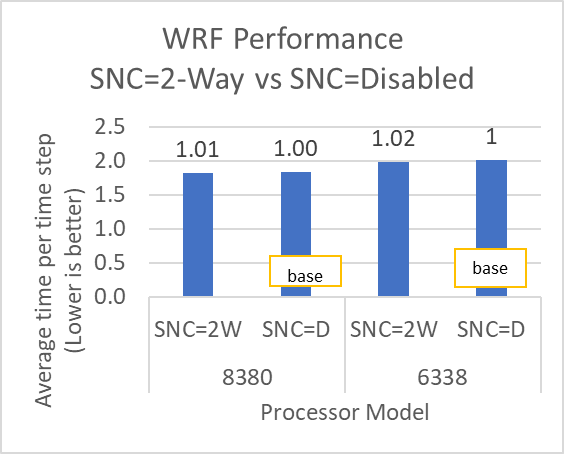
Figure 9: STREAM and WRF performance variation by processor model with Sub-NUMA Cluster set to Disabled (SNC=D) and 2-Way (SNC=2W)
The SubNumaCluster option can impact the applications that are Memory Bandwidth-bound (for example, STREAM, HPCG, and WRF). The SubNumaCluster option is recommended to be set to 2-Way as it can optimize the workloads addressed in this blog by a range of one percent to six percent, depending on the processor model and application.
InfiniBand bandwidth and message rate
The Ice Lake-based processors now support PCIe Gen 4, which allows the NVIDIA MELLANOX HDR adapter cards to be used with Dell EMC PowerEdge servers. Figure 10, Figure 11, and Figure 12 show the Message Rate, Unidirectional, and Bi-directional InfiniBand bandwidth test results of the OSU Benchmarks suite. The network adapter card was connected to the second socket (NUMA node 2), therefore, the local bandwidth tests were carried out with processes bound to NUMA node 2. The remote bandwidth tests were carried out with processes bound to NUMA node 0. In Figure 10 and Figure 11, the numbers in red over the orange bars represent the percentage difference between local and remote bandwidth performance numbers.
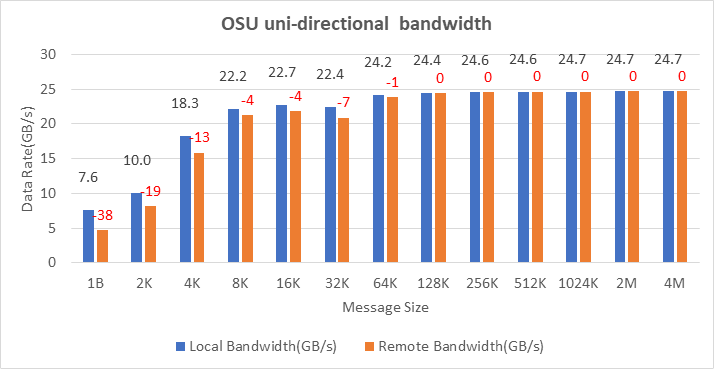 Figure 10: OSU Benchmark unidirectional bandwidth test on two servers with Intel 8380 processors and NVIDIA Mellanox HDR InfiniBand
Figure 10: OSU Benchmark unidirectional bandwidth test on two servers with Intel 8380 processors and NVIDIA Mellanox HDR InfiniBand
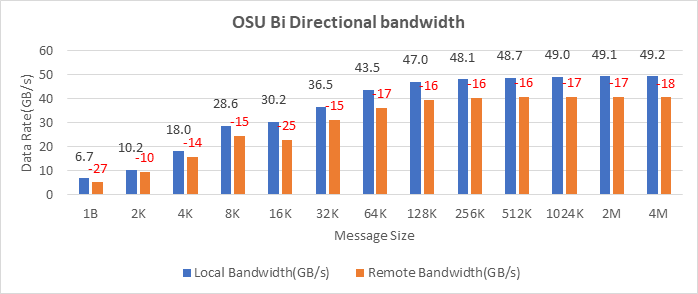 Figure 11: OSU Benchmark bi-directional bandwidth test on two servers with Intel 8380 processors and NVIDIA Mellanox HDR InfiniBand
Figure 11: OSU Benchmark bi-directional bandwidth test on two servers with Intel 8380 processors and NVIDIA Mellanox HDR InfiniBand
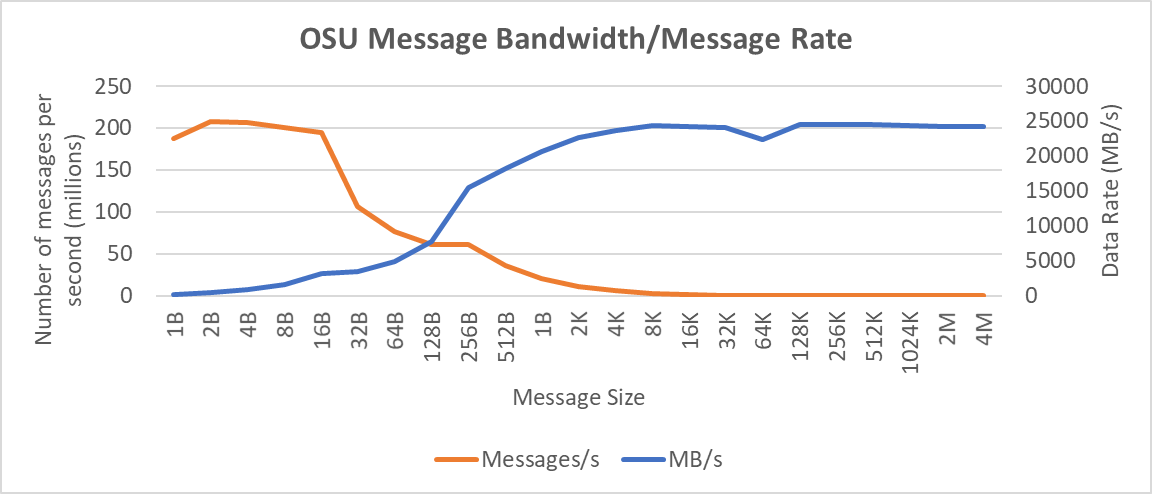
Figure 12: Interconnect bandwidth and message rate performance obtained between two servers having Intel 8380 processors with OSU Benchmark
On two nodes connected using the NVIDIA Mellanox ConnectX-6 HDR InfiniBand adapter cards, we achieved approximately 25 GB/s unidirectional bandwidth and a message rate of approximately 200 million messages/second—almost double the performance numbers obtained on the NVIDIA Mellanox HDR100 card.
Comparison with Cascade Lake processors
Based on the compute resources availability in our Dell EMC HPC & AI Innovation Lab, we selected the Cascade Lake processor-based servers and benchmarked them with software listed in Table 1. Figure 13 through Figure 16 show performance results from the Intel Ice Lake and Cascade Lake processors. The numbers over the bars represent the relative change in the application performance with respect to the application performance obtained on the Intel 6252 Cascade Lake processor.
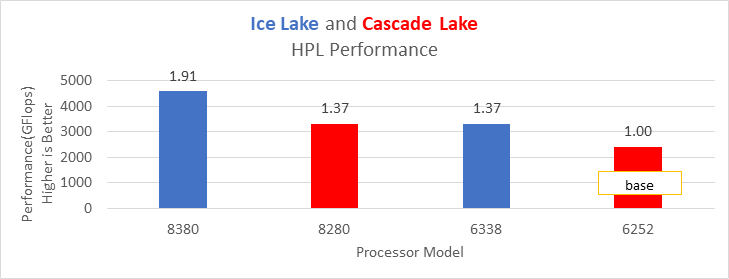 Figure 13: HPL performance on processors listed in Table 2
Figure 13: HPL performance on processors listed in Table 2
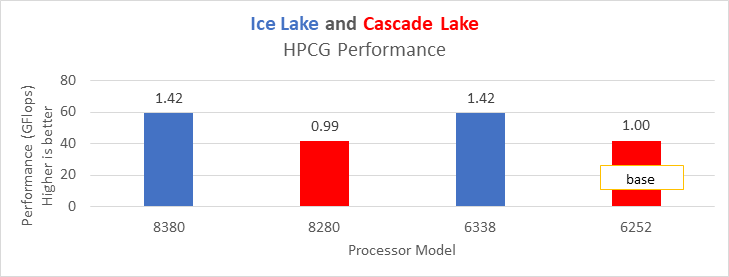 Figure 14: HPCG performance on processors listed in Table 2
Figure 14: HPCG performance on processors listed in Table 2
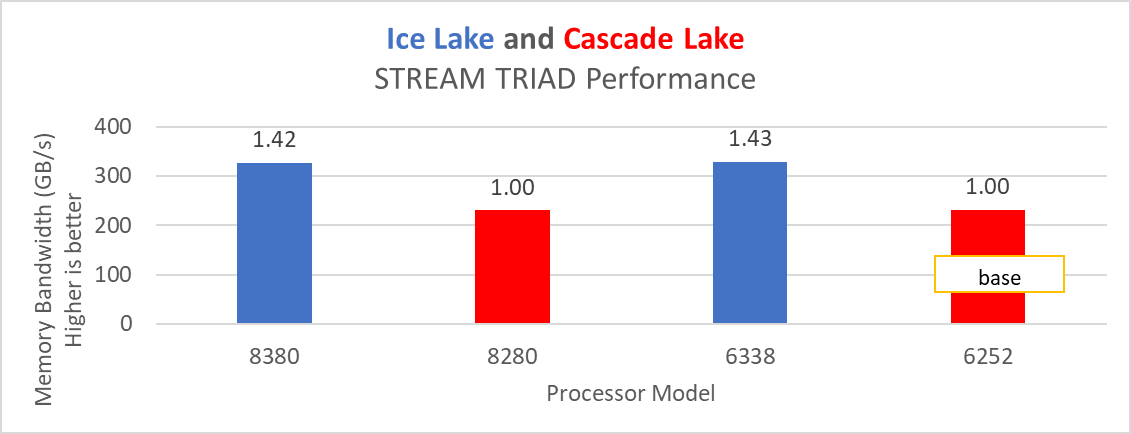 Figure 15: STREAM TRIAD test performance on Processors listed in Table 2
Figure 15: STREAM TRIAD test performance on Processors listed in Table 2
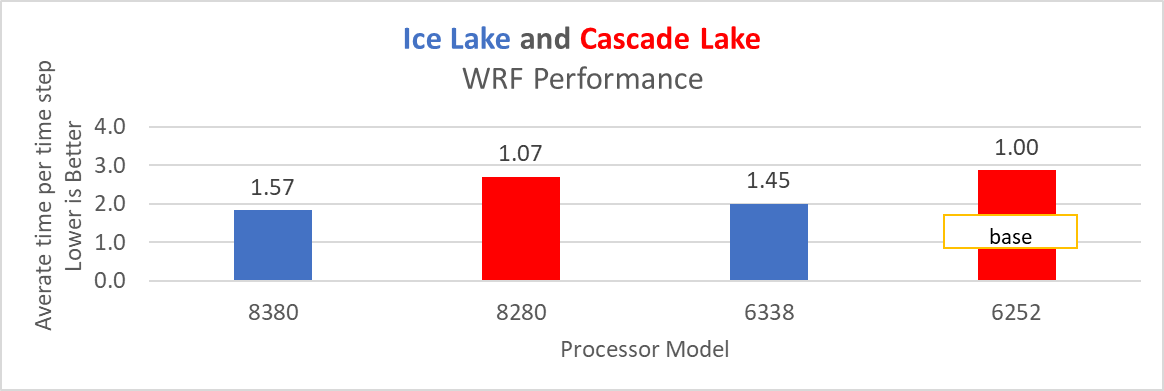 Figure 16: WRF performance on Processors listed in Table 2
Figure 16: WRF performance on Processors listed in Table 2
Ice Lake delivers approximately 38 percent better performance than Cascade Lake with HPL on the top-end processor model. The memory bandwidth-bound benchmarks such as STREAM and HPCG (see Figure 13 and Figure 14) delivered 42 percent to 43 percent performance improvement over the top-end Cascade Lake processors addressed in this blog.
The average real-time power usage of the Dell EMC PowerEdge platforms (listed in Table 1) was measured with the synthetic benchmarks listed in this blog. Figure 17 compares the power usage data from the Cascade Lake and Ice Lake platforms. The number over the bar represents the relative change of power with respect to the base (Intel 6252 processor in the idle state) power measured.
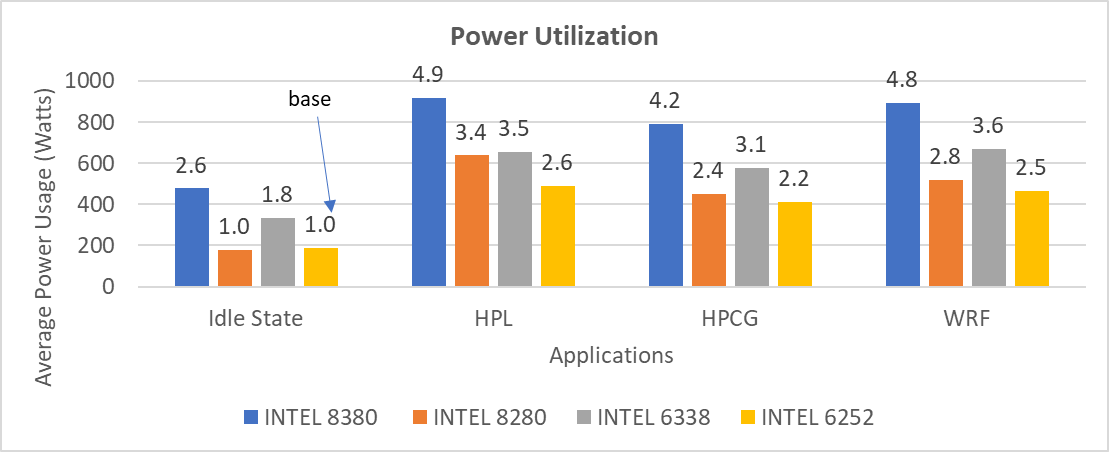
Figure 17: Average power usage during benchmark runs on Dell EMC PowerEdge servers (see details in Table 1)
Considering the data with the Performance Optimized profile with the respective power measurement, the applications (depending on the processor model) were unable to deliver better performance per watt on the Ice Lake platform when compared to the Cascade Lake platform.
Summary and future work
The Ice Lake processor-based Dell EMC Power Edge servers, with notable hardware feature upgrades over Cascade Lake, show up to 47 percent performance gain for all the HPC benchmarks addressed in this blog. Hyper-threading should be Disabled for the benchmarks addressed in this blog; for other workloads the option should be tested and enabled as appropriate. Watch this space for subsequent blogs that describe application performance studies on our new Ice Lake processor-based cluster.

Accelerating HPC Workloads with NVIDIA A100 NVLink on Dell PowerEdge XE8545
Tue, 13 Apr 2021 14:25:31 -0000
|Read Time: 0 minutes
NVIDIA A100 GPU
Three years after launching the Tesla V100 GPU, NVIDIA recently announced its latest data center GPU A100, built on the Ampere architecture. The A100 is available in two form factors, PCIe and SXM4, allowing GPU-to-GPU communication over PCIe or NVLink. The NVLink version is also known as the A100 SXM4 GPU and is available on the HGX A100 server board.
As you’d expect, the Innovation Lab tested the performance of the A100 GPU in a new platform. The new PowerEdge XE8545 4U server from Dell Technologies supports these GPUs with the NVLink SXM4 form factor and dual-socket AMD 3rd generation EPYC CPUs (codename Milan). This platform supports PCIe Gen 4 speed, up to 10 local drives, and up to 16 DIMM slots running at 3200 MT/s. Milan CPUs are available with up to 64 physical cores per CPU.
The PCIe version of the A100 can be housed in the PowerEdge R7525, which also supports AMD EPYC CPUs, up to 24 drives, and up to 16 DIMM slots running at 3200MT/s. This blog compares the performance of the A100-PCIe system to the A100-SXM4 system.

Figure 1: PowerEdge XE8545 Server
A previous blog discussed the performance of the NVIDIA A100-PCIe GPU compared to its predecessor NVIDIA Tesla V100-PCIe GPU in the PowerEdge R7525 platform.
The following table shows the specifications of the NVIDIA A100 and V100 GPUs.
Table 1: NVIDIA A100 and V100 GPUs with PCIe and SXM4 form factors
Form factor | PCIe | SXM (NVIDIA NVLink) | ||
Type of NVIDIA | A100 | V100 | A100 | V100 |
GPU architecture | Ampere | Volta | Ampere | Volta |
GPU memory | 40 GB | 32 GB | 40 GB | 32 GB |
GPU memory bandwidth | 1555 GB/s | 900 GB/s | 1555 GB/s | 900 GB/s |
Peak FP64 | 9.7 TFLOPS | 7 TFLOPS | 9.7 TFLOPS | 7.8 TFLOPS |
Peak FP64 Tensor Core | 19.5 TFLOPS | N/A | 19.5 TFLOPS | N/A |
GPU base clock | 765 MHz | 1230 MHz | 1095 MHz | 1290 MHz |
GPU boost clock | 1410 MHz | 1380 MHz | 1410 MHz | 1530 MHz |
NVLink speed | 600 GB/s | N/A | 600 GB/s | 300 GB/s |
Max power consumption | 250 W | 250 W | 400 W | 300 W |
From Table 1, we see that the A100 offers 42 percent improved memory bandwidth and 20 to 30 percent higher double precision FLOPS when compared to the Tesla V100 GPU. While the A100-PCIe GPU consumes the same amount of power as the V100-PCIe GPU, the NVLink version of the A100 GPU consumes 25 percent more power than the V100 GPU.
How are the GPUs connected in the PowerEdge servers?
An understanding of the server architecture is helpful in determining the behavior of any application. The PowerEdge XE8545 server is an accelerator optimized server with four A100-SMX4 GPUs connected with third generation NVLink, as shown in the following figure.
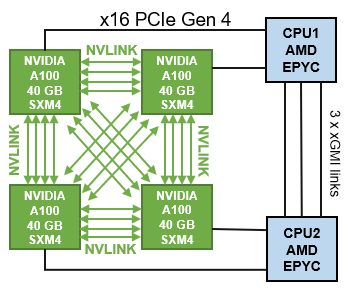
Figure 2: PowerEdge XE8545 CPU-GPU connectivity
In the A100 GPU, each NVLink lane supports a data rate of 50x 4 Gbit/s in each direction. The total number of NVLink lanes increases from six lanes in the V100 GPU to 12 lanes in the A100 GPU, now yielding 600 GB/s total. Workloads that can take advantage of the higher GPU-to-GPU communication bandwidth can be benefit from the NVLink links in PowerEdge XE8545 Server.
As shown in the following figure, the PowerEdge R7525 server can accommodate up to three PCIe-based GPUs; however the configuration chosen for this evaluation used two A100-PCIe GPUs. With this option, the GPU-to-GPU communication must flow through the AMD Infinity Fabric inter-CPU links.
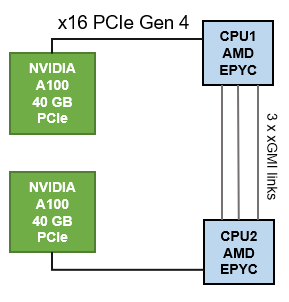
Figure 3: PowerEdge R7525 CPU-GPU connectivity
Testbed details
The following table shows the tested configuration details:
Table 2: Test bed configuration details
Server | PowerEdge XE8545 | PowerEdge R7525 |
Processor | Dual AMD EPYC 7713, 64C, 2.8 GHz | |
Memory | 512 GB (16 x 32 GB @ 3200 MT/s) | 1024 GB (16 x 64 GB @ 3200 MT/s) |
Height of system | 4U | 2U |
GPUs | 4 x NVIDIA A100 SXM4 40 GB | 2 x NVIDIA A100 PCIe 40 GB |
Operating system Kernel | Red Hat Enterprise Linux release 8.3 (Ootpa) 4.18.0-240.el8.x86_64 | |
BIOS settings | Sysprofile=PerfOptimized LogicalProcessor=Disabled NumaNodesPerSocket=4 | |
CUDA Driver CUDA Toolkit | 450.51.05 11.1 | |
GCC | 9.2.0 | |
MPI | OpenMPI - 4.0 | |
The following table lists the version of HPC application that was used for the benchmark evaluation:
Table 3: HPC Applications used for the evaluation
Benchmark | Details |
HPL | xhpl_cuda-11.0-dyn_mkl-static_ompi-4.0.4_gcc4.8.5_7-23-20 |
HPCG | xhpcg-3.1_cuda_11_ompi-3.1 |
GROMACS | v2021 |
NAMD | Git-2021-03-02_Source |
LAMMPS | 29Oct2020 release |
Benchmark evaluation
High Performance Linpack
High Performance Linpack (HPL) is a standard HPC system benchmark that is used to measure the computing power of a server or cluster. It is also used as a reference benchmark by the TOP500 org to rank supercomputers worldwide. HPL for GPU uses double precision floating point operations. There are a few parameters that are significant for the HPL benchmark, as listed below:
- N is the problem size provided as input to the benchmark and determines the size of linear matrix that is solved by HPL. For a GPU system, the highest HPL performance is obtained when the problem size utilizes as much as possible of the GPU memory without exceeding it. For this study, we used HPL compiled with NVIDIA libraries as listed in Table 3.
- NB is the block size which is used for data distribution. For this test configuration, we used an NB of 288.
- PxQ is the matrix size and is equal to the total number of GPUs in the system.
- Rpeak is the theoretical peak of the system.
- Rmax is the maximum measured performance achieved on the system.
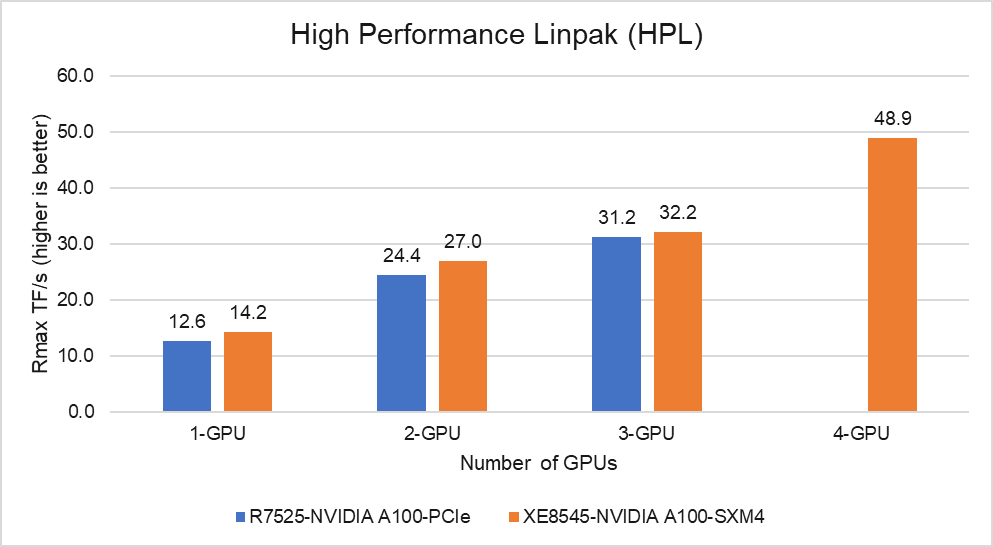
Figure 4: HPL Performance on the PowerEdge R7525 and XE8545 with NVIDIA A100-40 GB
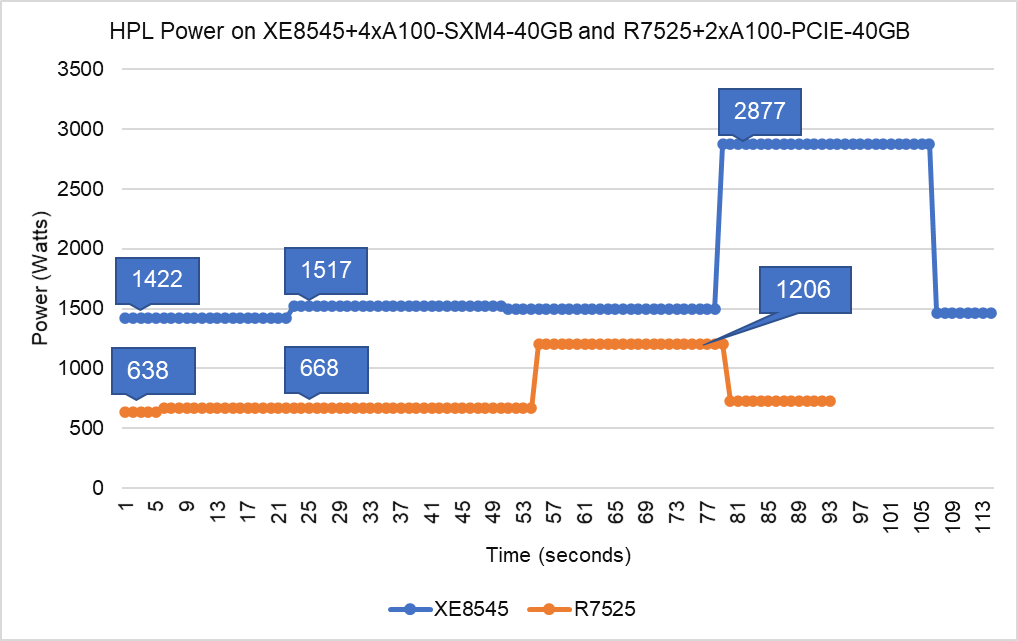
Figure 5: HPL Power Utilization on the PowerEdge XE8545 with four NVIDIA A100 GPUs and R7525 with two NVIDIA A100 GPUs
From Figure 4 and Figure 5, we can make the following observations:
- SXM4 vs PCIe: At 1-GPU, the NVIDIA A100-SXM4 GPU outperforms the A100-PCIe by 11 percent. The higher SMX4 GPU base clock frequency is the predominant factor contributing to the additional performance over the PCIe GPU.
- Scalability: The PowerEdge XE8545 server with four NVIDIA A100-SXM4-40GB GPUs delivers 3.5 times higher HPL performance compared to one NVIDIA A100-SXM4-40GB GPU. On the other hand, two A100-PCIe GPUs is 1.94 times faster than one on the R7525 platform. The A100 GPUs scale well on both platforms for HPL benchmark.
- Higher Rpeak: HPL code on A100 GPUs use the new double-precision Tensor cores. So, the theoretical peak for each card would be 19.5 TFlops, as opposed to 9.7 TFlops.
- Power: Figure 5 shows power consumption of a complete HPL run with PowerEdge XE8545 using 4 x A100-SXM4 GPUs and PowerEdge R7525 using 2 x A100-PCIe GPUs. This was measured with iDRAC commands, and the peak power consumption for XE8545 is 2877 Watts, while peak power consumption for R7525 is 1206 Watts.
High Performance Conjugate Gradient
The TOP500 list has incorporated the High Performance Conjugate Gradient (HPCG) results as an alternate metric to assess system performance.
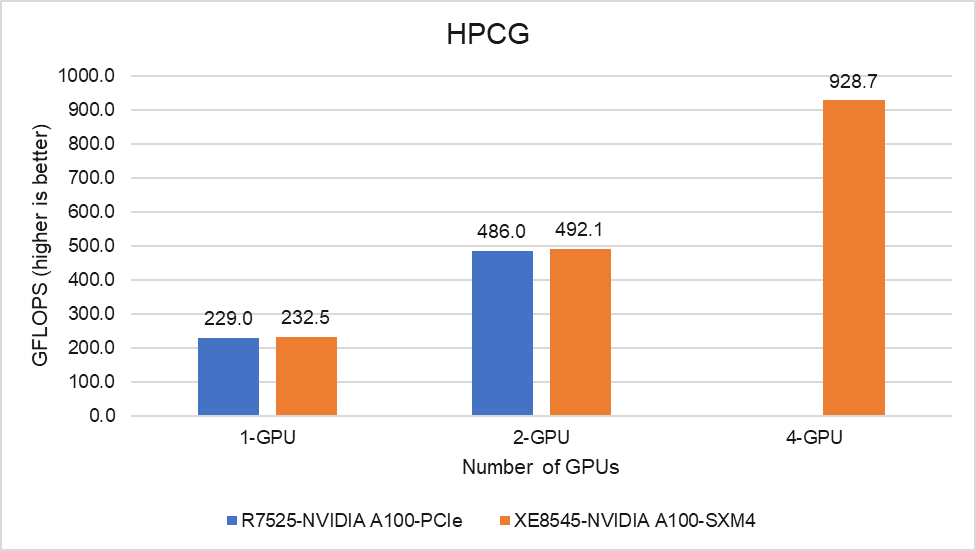
Figure 6: HPCG Performance on the PowerEdge R7525 and PowerEdge XE8545 Servers
Unlike HPL, HPCG performance depends heavily on the memory system and network performance when we go beyond one server. Because both the PCIe and SXM4 form factors of the A100 GPUs have the same memory bandwidth, there is no variation in the performance at a single node and HPCG performance scales well on both servers.
GROMACS
The following figure shows the performance results for GROMACS, a molecular dynamics application, on the PowerEdge R7525 and XE8545 servers. GROMACS 2021.0 was compiled with CUDA compilers and Open-MPI, as shown in Table 3.
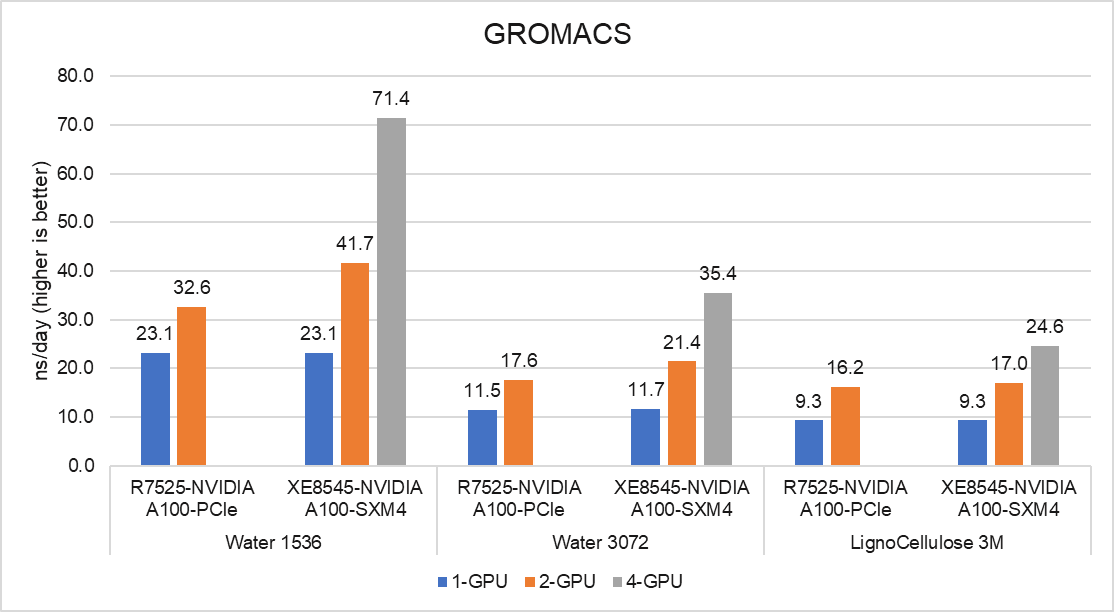
Figure 7: GROMACS performance on the PowerEdge R7545 and PowerEdge XE8545 Server
The GROMACS build included thread MPI (built in with the GROMACS package). Performance results are presented using the ns/day metric. For each test, the performance was optimized by varying the number of MPI ranks and threads, number of PME ranks, and different nstlist values to obtain the best performance result.
With one GPU in test, the performance of the SMX4 XE8545 server is similar to the PCIe R7525. With two GPUs in test, the SMX4 XE8545 performance is up to 28 percent better than the PCIe R7525. As the performance was based on a comparative analysis between NVIDIA PCIe and SXM4 form factors along the server platforms, datasets like Water 1536 and Water 3072 demand more GPU-GPU communication, and SXM4 performs around 28 percent better. On the other hand, for datasets like LignoCellulose 3M, the two GPU R7525 achieves the same per-GPU performance as the XE8545, but with the lower 250 W GPU making it the more efficient solution.
LAMMPS
The following figure shows the performance results for LAMMPS, a molecular dynamics application, on the PowerEdge R7525 and XE8545 servers. The code was compiled with the KOKKOS package to run efficiently on NVIDIA GPUs, and Lennard Jones is the dataset that was tested with Timesteps/s as the metric for comparison.
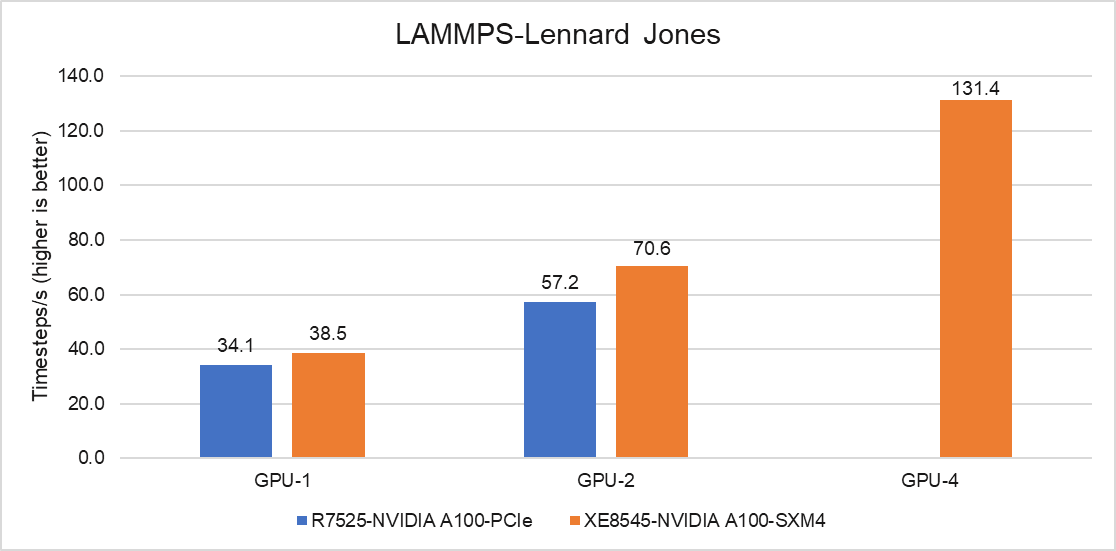
Figure 8: LAMMPS performance on the PowerEdge R7545 and PowerEdge XE8545 Servers
With one GPU in test, the performance of the SMX4 XE8545 server is 13 percent higher than the PCIe R7525, and with two GPUs in test, a 23 percent performance improvement was measured. The PowerEdge XE8545 is at an advantage because the GPUs can communicate with each other over NVLink without the intervention of a CPU. The R7525 server with two GPUs is limited by the GPU-to-GPU communication pattern. Additionally, the other factor contributing for better performance is the higher clock rate of the SXM4 A100 GPU.
Conclusion
In this blog, we discussed the performance of NVIDIA A100 GPUs on the PowerEdge R7525 Server and the PowerEdge XE8545 Server, which is the new addition from Dell Technologies. The A100 GPU has 42 percent more memory bandwidth and higher double precision FLOPs compared to its predecessor, the V100 series GPU. For workloads which demand more GPU-to-GPU communication, the PowerEdge XE8545 server is an ideal choice. For data centers where space and power are limited, the PowerEdge R7525 server may be the right fit. The overall performance of PowerEdge XE8545 Server with four A100-SXM4 GPUs is 1.5 to 2.3 times faster than the PowerEdge R7525 server with two A100-PCIe GPUs.
In the future, we intend to evaluate the A100-80GB GPUs and NVIDIA A40 GPUs that will be available this year. We also plan to focus on a multi-node performance study with these GPUs.
Please contact your Dell sales specialist about the HPC and AI Innovation Lab if you would like to evaluate these GPU servers.

AMD Milan - BIOS Characterization for HPC
Tue, 30 Mar 2021 18:23:11 -0000
|Read Time: 0 minutes
With the release of the AMD EPYC 7003 Series Processors (architecture codenamed "Milan"), Dell EMC PowerEdge servers have now been upgraded to support the new features. This blog outlines the Milan Processor architecture and the recommended BIOS settings to deliver optimal HPC Synthetic benchmark performance. Upcoming blogs will focus on the application performance and characterization of the software applications from various scientific domains such as Weather Science, Molecular Dynamics, and Computational Fluid Dynamics.
AMD Milan with Zen3 cores is the successor of AMD's high-performance second generation server microprocessor (architecture codenamed "Rome"). It supports up to 64 cores at 280w TDP and 8 DDR4 memory channels at speeds up to 3200MT/s.
Architecture
As with AMD Rome, AMD Milan’s 64 core Processor model has 1 I/O die and 8 compute dies (also called CCD or Core Complex Die) – OPN 32 core models may have 4 or 8 compute dies. Milan Processors have upgrades to the Cache (including new prefetchers at both L1 and L2 caches) and Memory Bandwidth which is expected to improve performance of applications requiring higher memory bandwidth.
Unlike Naples and Rome, Milan's arrangement of its CCDs has changed. Each CCD now features up to 8 cores with a unified 32MB L3 cache which could reduce the cache access latency within compute chiplets. Milan Processors can expose each CCD as a NUMA node node by setting the “L3 cache as NUMA Domain” ( from the iDRAC GUI ) or BIOS.ProcSettings.CcxAsNumaDomain (using racadm CLI) option to “Enabled”. Therefore, Milan’s 64 core dual-socket Processors with 8 CCDs per Processor will expose 16 NUMA domains per system in this setting. Here is the logical representation of Core arrangement with NUMA Nodes per socket = 4 and CCD as NUMA = Disabled.
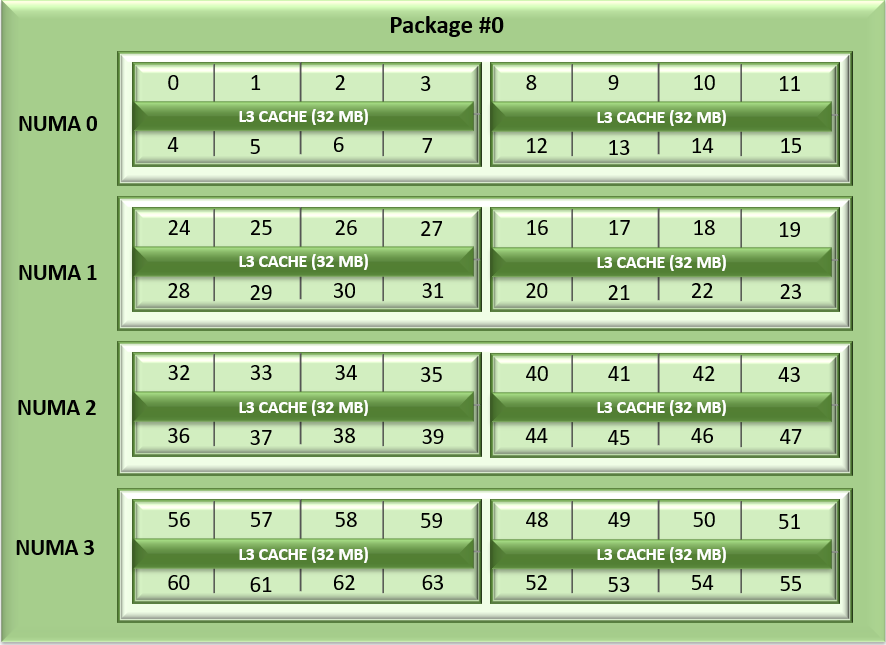
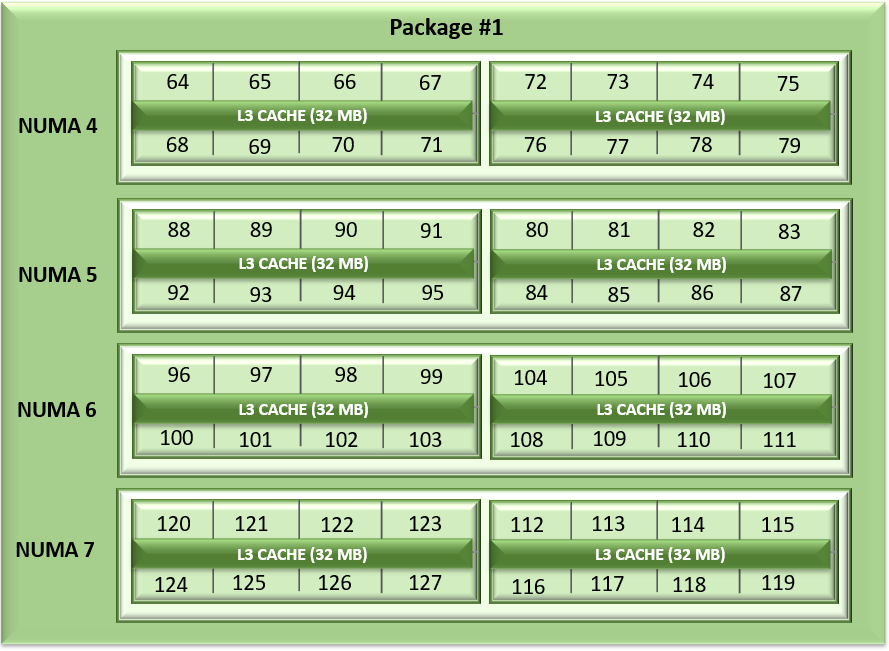
Figure1: Linear core enumeration on a dual-socket system, 64c per socket, NPS4 configuration on an 8 CCD Processor model
As with AMD Rome, AMD Milan Processors support the AVX256 instruction set allowing 16 DP FLOP/cycle.
BIOS Options Available on AMD Milan and Tuning
Processors from both Milan and Rome generations are socket compatible, so the BIOS Options are similar across these Processor generations. Server details are mentioned in Table 1 below.
Table 1: Testbed hardware and software details
Server | Dell EMC PowerEdge 2 socket servers (with AMD Milan Processors) | Dell EMC PowerEdge 2 socket servers (with AMD Rome Processors) |
OPN Cores/Socket Frequency (Base-Boost) TDP | 7763 (Milan) 64 2.45GHz – 3.5GHz 280W 256 MB | 7H12 (Rome) 64 2.6GHz – 3.3 GHz 280W 256 MB |
OPN Cores/Socket Frequency TDP | 7713 (Milan) 64 2.0GHz – 3.7GHz 225W 256 MB | 7702 (Rome) 64 2.0 GHz – 3.35 GHz 200W 256 MB |
OPN Cores/Socket Frequency TDP | 7543 (Milan) 32 2.8GHz – 3.7 GHz 225W 256 MB | 7542 (Rome) 32 2.9GHz – 3.4 GHz 225W 128 MB |
Operating System | RHEL 8.3 (4.18.0-240.el8.x86_64) | RHEL 8.2 (4.18.0-193.el8.x86_64) |
Memory | DDR4 256G (16Gb x 16) 3200 MT/s | |
BIOS / CPLD | 2.0.3 / 1.1.12 | 1.1.7 |
Interconnect | Mellanox HDR 200 (4X HDR) | Mellanox HDR 100 |
The following BIOS options were explored –
- BIOS.SysProfileSettings.SysProfile: This field sets the System Profile to Performance Per Watt (OS), Performance, or Custom mode. When set to a mode other than Custom, BIOS will set each option accordingly. When set to Custom, you can change setting of each option. Under Custom mode when C state is enabled, Monitor/Mwait should also be enabled.
- BIOS.ProcSettings.L1StridePrefetcher: When set to Enabled, the Processor provides additional fetch to the data access for an individual instruction for performance tuning by controlling the L1 stride prefetcher setting.
- BIOS.ProcSettings.L2StreamHwPrefetcher: When set to Enabled, the Processor provides advanced performance tuning by controlling the L2 stream HW prefetcher setting.
- BIOS.ProcSettings.L2UpDownPrefetcher: When set to Enabled, the Processor uses memory access to determine whether to fetch next or previous for all memory accesses for advanced performance tuning by controlling the L2 up/down prefetcher setting.
- BIOS.ProcSettings.CcxAsNumaDomain: This field specifies that each CCD within the Processor will be declared as a NUMA Domain.
- BIOS.MemSettings.MemoryInterleaving: When set to Auto, memory interleaving is supported if a symmetric memory configuration is installed. When set to Disabled, the system supports Non-Uniform Memory Access (NUMA) (asymmetric) memory configurations. Operating Systems that are NUMA-aware understand the distribution of memory in a particular system and can intelligently allocate memory in an optimal manner. Operating Systems that are not NUMA-aware could allocate memory to a Processor that is not local, resulting in a loss of performance. Die and Socket Interleaving should only be enabled for Operating Systems that are not NUMA-aware.
After setting System Profile (BIOS.SysProfileSettings.SysProfile) to PerformanceOptimized, NUMA Nodes Per Socket (NPS) to 4, and Prefetchers (L1Region,L1Stream,L1Stride,L2Stream, L2UpDown) to “Enabled” we measured the impact of CcxAsNumaDomain and MemoryInterleaving BIOS parameters on application performance. We tested the performance of the applications listed in Table 1 with following settings.
Table 2: Combinations of CCX as NUMA domain and Memory Interleaving
CCX as NUMA Domain | Memory Interleaving | |
Setting01 | Disabled | Disabled |
Setting02 | Disabled | Auto |
Setting03 | Enabled | Auto |
Setting04 | Enabled | Disabled |
With Setting01 and Setting02 (CCX as NUMA Domain = Disabled), the system will expose 8 NUMA nodes. With Setting03 and Setting04, there will be 16 NUMA nodes on a dual socket server with 64 core based Milan Processors.
Table 3: hwloc-ls and numactl -H command output on 64c server with setting01/setting02 and (listed in Table 2)
Table 4: hwloc-ls and numactl -H command output on 128 core (2x 64c) server with setting03/setting04 and (listed in Table 2)
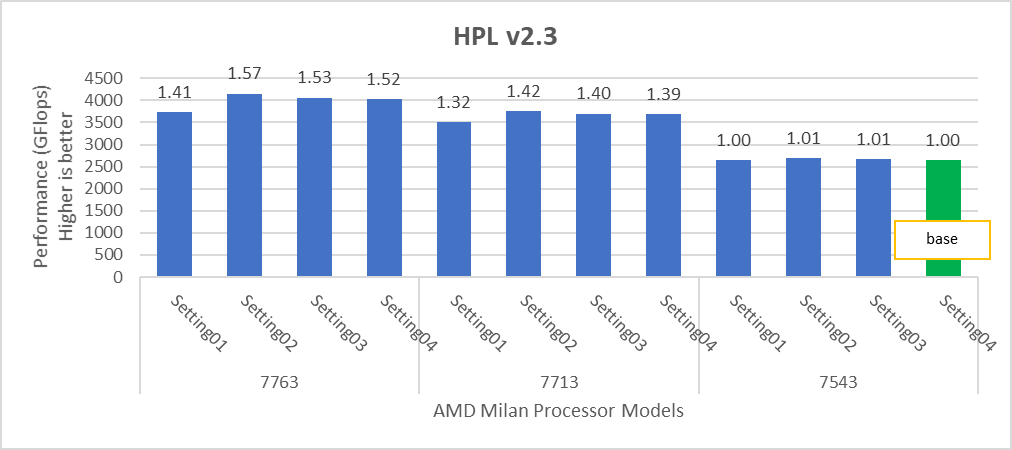
Figure 2: Relative difference in the performance of HPL by processor and BIOS settings mentioned in Table 1 and Table 2.
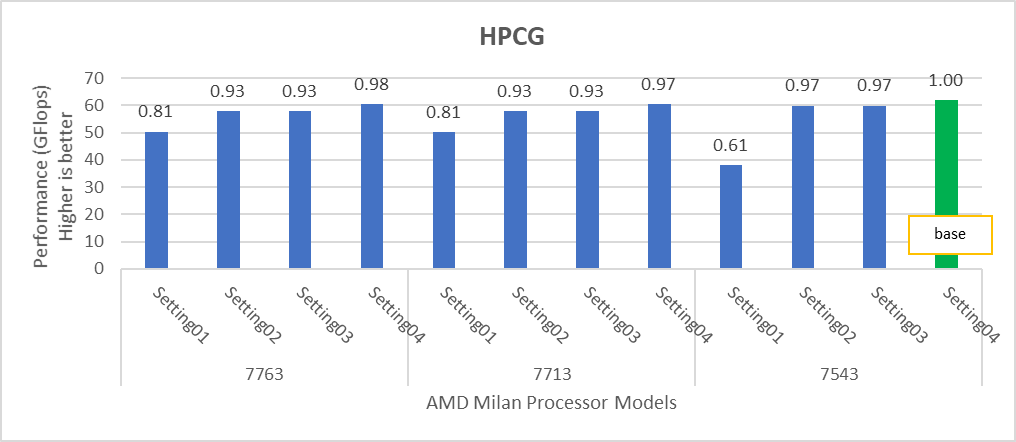
Figure 3: Relative difference in the performance of HPCG by processor and BIOS settings mentioned in Table 1 and Table 2.
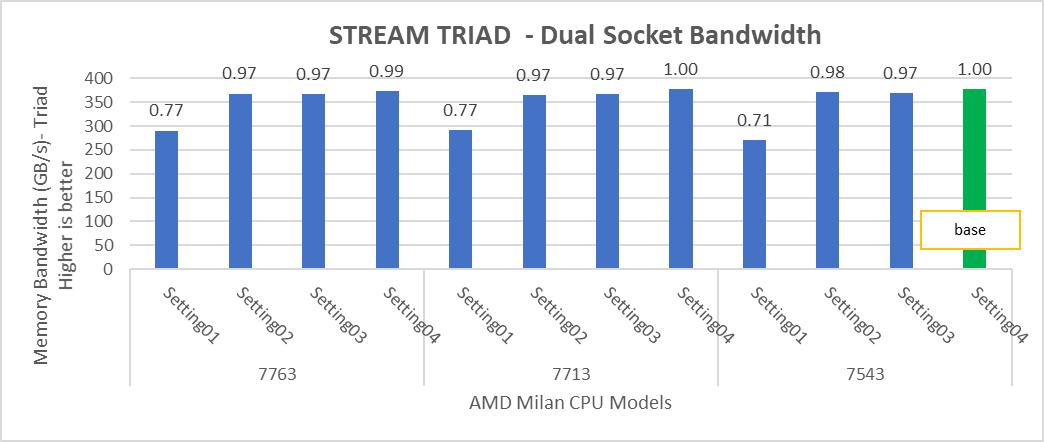
Figure 4: Relative difference in the performance of STREAM by processor and BIOS settings mentioned in Table 1 and Table 2.
HPL delivers the best performance numbers on setting02 with 82-93% efficiency depending on Processor Model, whereas STREAM and HPCG deliver better performance with setting04.
STREAM TRIAD tests generate best performance numbers at ~378 GB/s memory bandwidth across all of the 64 and 32 core Processor Models mentioned in Table 1 with efficiency up to 90%.
In Figure 4, the STREAM TRIAD performance numbers were measured by undersubscribing the server by utilizing only 16 cores on the servers. The comparison of the performance numbers by utilizing all the available cores and 16 cores per system has been shown in Figure 5. The numbers on top of the orange bars shows the relative difference.
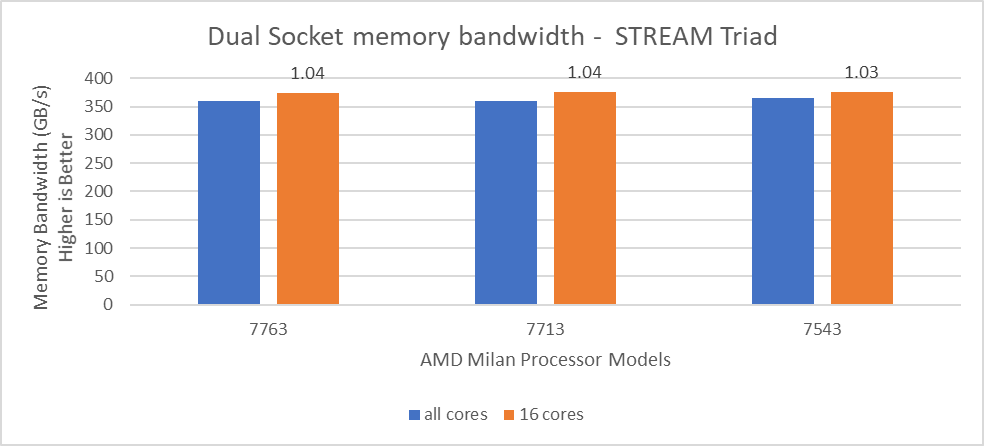
Figure 5: Relative difference in the memory bandwidth.
From Figure 5, we observed that by using 16 cores, the STREAM TRIAD test’s performance numbers were ~3-4% higher than the performance numbers measured by subscribing all available cores.
We carried out NUMA bandwidth tests using setting02 and setting04 mentioned in Table01. With setting02, system exposes a total of 8 NUMA nodes while with setting04, system exposes a total of 16 NUMA nodes with 8 cores per NUMA node In Figure 6 and 7, NUMA node presented as “c” and memory node as “m”. As an example, c0m0 represents NUMA node 0 and memory node 0. The best bandwidth numbers obtained on varying the number of threads
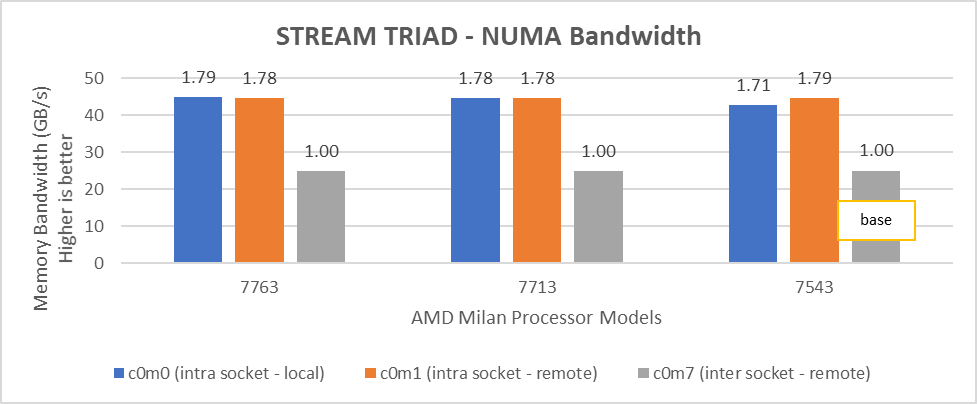
Figure 6: Local and remote NUMA memory bandwidth with CCXasNUMADomain=Disabled
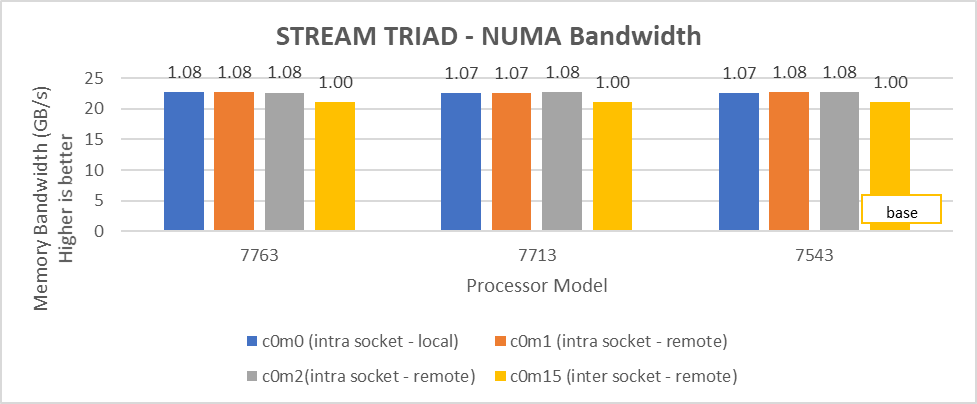
Figure 7: Local and remote NUMA memory bandwidth with CCXasNUMADomain=ENabled
We observed that the optimal intra socket local memory bandwidth numbers were obtained with 2 threads per NUMA node with setting2 on both 64 core and 32 core processor models. In Figure 6 with setting02 (Table 2) the intra socket local memory bandwidth, at 2 threads per NUMA node, can be up to 79% more than inter remote memory bandwidth. With setting02 (Figure 6) we get at least 96% higher intra socket local memory bandwidth per NUMA domain than setting04 (Figure 7).
Impact of new Prefetch options
Milan introduces two new prefetchers for L1 cache and one for L2 Cache with a total of five prefetcher options which can be configured using BIOS. We tested combinations listed in Table 5 by keeping L1 Stream and L2 Stream prefetcher as Enabled.
Table 5: Cache Prefetchers
L1StridePrefetcher | L1RegionPrefetcher | L2UpDownPrefetcher | |
setting01 | Disabled | Enabled | Enabled |
setting02 | Enabled | Disabled | Enabled |
setting03 | Enabled | Enabled | Disabled |
setting04 | Disabled | Disabled | Disabled |
We found that these new prefetchers do not have significant impact on the performance of the synthetic benchmarks covered in this blog.
InfiniBand bandwidth, message rate and scalability
For Multinode tests, the testbed was configured with Mellanox HDR interconnect running at 200 Gbps with each server having the AMD 7713 Processor Model and Preferred IO setting set to Enabled from BIOS.Along with the setting02 (Table 2) and Prefetchers (L1Region,L1Stream,L1Stride,L2Stream, L2UpDown) set to “Enabled” we were able to achieve the expected linear performance scalability for HPL and HPCG Benchmarks.
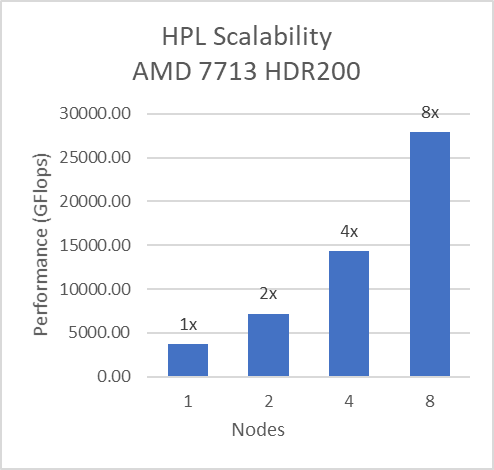
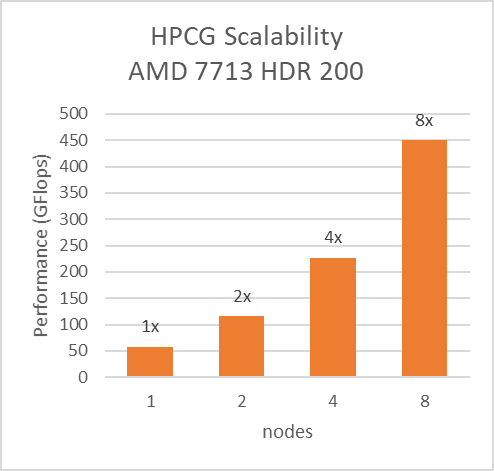
Figure 8: Multinode scalability of HPL and HPCG with setting02 (Table 2) with 7713 Processor model, HDR200 Infiniband
We tested the Message Rate, Unidirectional, and Bidirectional InfiniBand bandwidth using OSU Benchmarks and results are in Figure 9, Figure 10 and Figure 11. Except the Numa Nodes per socket setting, all other BIOS settings for these tests were same as mentioned above. The OSU Bidirectional bandwidth and OSU Unidirectional tests were carried out with Numa Nodes per socket set to 2 and the and Message rate test was carried out with Numa Nodes per socket set to 4. In Figure 9 and Figure10, the numbers on top of the orange bars represent the percentage difference between Local and Remote bandwidth performance numbers.
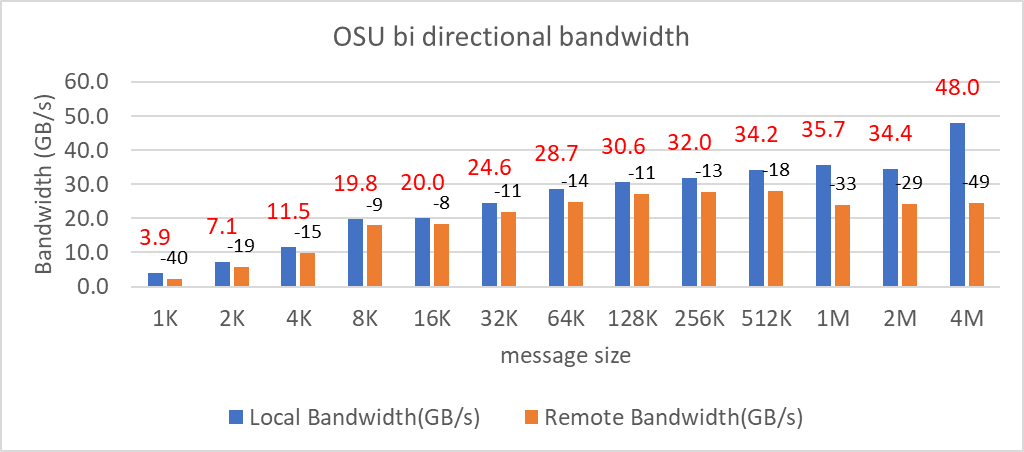
Figure 9: OSU bi-directional bandwidth test on AMD 7713, HDR 200 InfiniBand
 Figure 10: OSU uni-directional bandwidth test on AMD 7713, HDR 200 Infiniband
Figure 10: OSU uni-directional bandwidth test on AMD 7713, HDR 200 Infiniband
For Local Latency and Bandwidth performance numbers, the MPI process was pinned to the NUMA node 1 (closest to the HCA). For Remote Latency and Bandwidth tests, processes were pinned to NUMA node 6.
Figure 11: OSU Message rate and bandwidth performance on 2 and 4 nodes of 7713 Processor model
On 2 nodes using HDR200, we are able to achieve ~24 GB/s unidirectional bandwidth and message rate of 192 Million messages/second – almost double the performance numbers obtained on HDR100.
Comparison with Rome SKUs
In order to draw out performance improvement comparisons, we have selected Rome SKUs closest to their Milan counterparts in terms of hardware features such as Cache Size, TDP values, and Processor Base/Turbo Frequency.
Figure 12: HPL performance comparison with Rome Processor Models
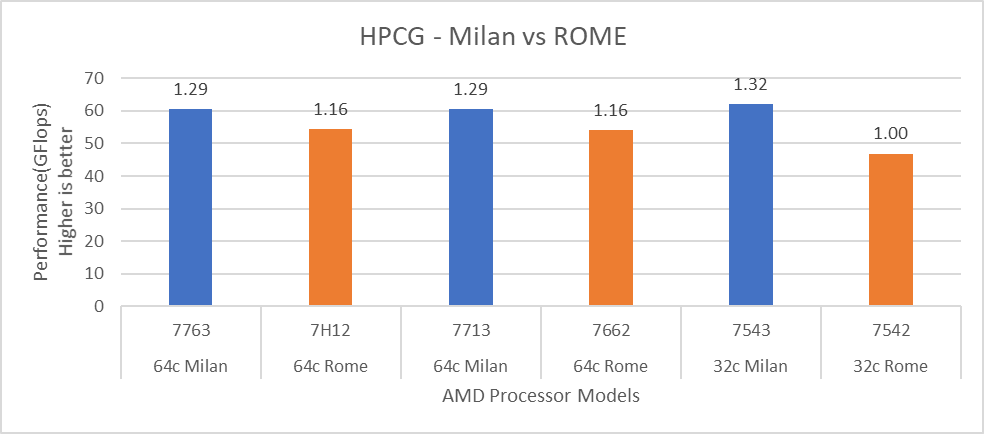
Figure 13: HPCG performance comparison with Rome Processor Models
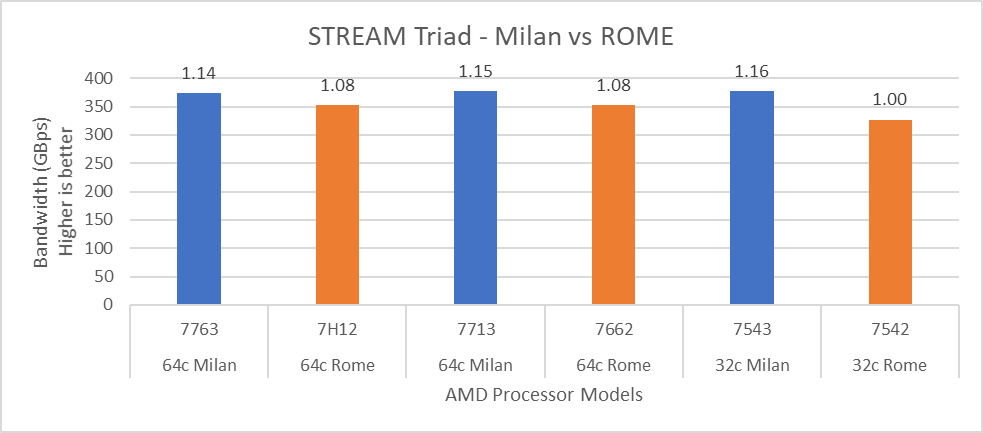
Figure 14: STREAM performance comparison with Rome Processor Models
For HPL (Figure 12) we observed that, on higher end Processor Models, Milan delivers 10% better performance than Rome. As expected, on the Milan platform, memory bandwidth bound applications like STREAM and HPCG (Figure 13 and Figure 14) gain 6-16 % and 13-32% in the performance over Rome Processor Models covered in this blog.
Summary and Future Work
Milan-based servers show expected performance upgrades, especially for the memory bandwidth bound synthetic HPC benchmarks covered in this blog. Configuring the BIOS options is important in order to get the best performance out of the system. The Hyper-Threading should be Disabled for general-purpose HPC systems, and benefits of this feature should be tested and enabled as appropriate for the synthetic benchmarks not covered in this blog.
Check back soon for subsequent blogs that describe application performance studies on our Milan Processor based cluster.

HPC Application Performance on Dell PowerEdge R7525 Servers with NVIDIA A100 GPGPUs
Tue, 24 Nov 2020 17:49:03 -0000
|Read Time: 0 minutes
Overview
The Dell PowerEdge R7525 server powered with 2nd Gen AMD EPYC processors was released as part of the Dell server portfolio. It is a 2U form factor rack-mountable server that is designed for HPC workloads. Dell Technologies recently added support for NVIDIA A100 GPGPUs to the PowerEdge R7525 server, which supports up to three PCIe-based dual-width NVIDIA GPGPUs. This blog describes the single-node performance of selected HPC applications with both one- and two-NVIDIA A100 PCIe GPGPUs.
The NVIDIA Ampere A100 accelerator is one of the most advanced accelerators available in the market, supporting two form factors:
- PCIe version
- Mezzanine SXM4 version
The PowerEdge R7525 server supports only the PCIe version of the NVIDIA A100 accelerator.
The following table compares the NVIDIA A100 GPGPU with the NVIDIA V100S GPGPU:
NVIDIA A100 GPGPU | NVIDIA V100S GPGPU | |||
Form factor | SXM4 | PCIe Gen4 | SXM2 | PCIe Gen3 |
GPU architecture | Ampere | Volta | ||
Memory size | 40 GB | 40 GB | 32 GB | 32 GB |
CUDA cores | 6912 | 5120 | ||
Base clock | 1095 MHz | 765 MHz | 1290 MHz | 1245 MHz |
Boost clock | 1410 MHz | 1530 MHz | 1597 MHz | |
Memory clock | 1215 MHz | 877 MHz | 1107 MHz | |
MIG support | Yes | No | ||
Peak memory bandwidth | Up to 1555 GB/s | Up to 900 GB/s | Up to 1134 GB/s | |
Total board power | 400 W | 250 W | 300 W | 250 W |
The NVIDIA A100 GPGPU brings innovations and features for HPC applications such as the following:
- Multi-Instance GPU (MIG)—The NVIDIA A100 GPGPU can be converted into as many as seven GPU instances, which are fully isolated at the hardware level, each using their own high-bandwidth memory and cores.
- HBM2—The NVIDIA A100 GPGPU comes with 40 GB of high-bandwidth memory (HBM2) and delivers bandwidth up to 1555 GB/s. Memory bandwidth with the NVIDIA A100 GPGPU is 1.7 times higher than with the previous generation of GPUs.
Server configuration
The following table shows the PowerEdge R7525 server configuration that we used for this blog:
Server | PowerEdge R7525 |
Processor | 2nd Gen AMD EPYC 7502, 32C, 2.5Ghz |
Memory | 512 GB (16 x 32 GB @3200MT/s) |
GPGPUs | Either of the following: 2 x NVIDIA A100 PCIe 40 GB 2 x NVIDIA V100S PCIe 32 GB |
Logical processors | Disabled |
Operating system | CentOS Linux release 8.1 (4.18.0-147.el8.x86_64) |
CUDA | 11.0 (Driver version - 450.51.05) |
gcc | 9.2.0 |
MPI | OpenMPI-3.0 |
HPL | hpl_cuda_11.0_ompi-4.0_ampere_volta_8-7-20 |
HPCG | xhpcg-3.1_cuda_11_ompi-3.1 |
GROMACS | v2020.4 |
Benchmark results
The following sections provide our benchmarks results with observations.
High-Performance Linpack benchmark
High Performance Linpack (HPL) is a standard HPC system benchmark. This benchmark measures the compute power of the entire cluster or server. For this study, we used HPL compiled with NVIDIA libraries.
The following figure shows the HPL performance comparison for the PowerEdge R7525 server with either NVIDIA A100 or NVIDIA V100S GPGPUs:
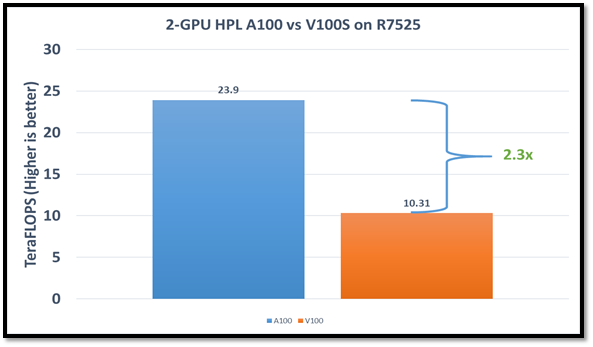
Figure1: HPL performance on the PowerEdge R7525 server with the NVIDIA A100 GPGPU compared to the NVIDIA V100SGPGPU
The problem size (N) is larger for the NVIDIA A100 GPGPU due to the larger capacity of GPU memory. We adjusted the block size (NB) used with the:
- NVIDIA A100 GPGPU to 288
- NVIDIA V100S GPGPU to 384
The AMD EPYC processors provide options for multiple NUMA combinations. We found that the best value of 4 NUMA per socket (NPS=4), with NUMA per socket 1 and 2 lower the performance by 10 percent and 5 percent respectively. In a single PowerEdge R7525 node, the NVIDIA A100 GPGPU delivers 12 TF per card using this configuration without an NVLINK bridge. The PowerEdge R7525 server with two NVIDIA A100 GPGPUs delivers 2.3 times higher HPL performance compared to the NVIDIA V100S GPGPU configuration. This performance improvement is credited to the new double-precision Tensor Cores that accelerate FP64 math.
The following figure shows power consumption of the server while running HPL on the NVIDIA A100 GPGPU in a time series. Power consumption was measured with an iDRAC. The server reached 1038 Watts at peak due to a higher GFLOPS number.
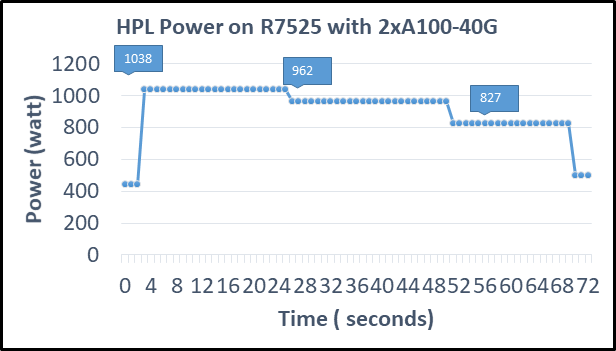
Figure2: Power consumption while running HPL
High Performance Conjugate Gradient benchmark
The High Performance Conjugate Gradient (HPCG) benchmark is based on a conjugate gradient solver, in which the preconditioner is a three-level hierarchical multigrid method using the Gauss-Seidel method.
As shown in the following figure, HPCG performs at a rate 70 percent higher with the NVIDIA A100 GPGPU due to higher memory bandwidth:
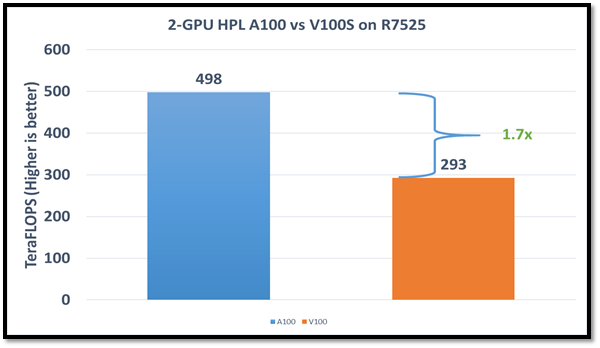
Figure 3: HPCG performance comparison
Due to different memory size, the problem size used to obtain the best performance on the NVIDIA A100 GPGPU was 512 x 512 x 288 and on the NVIDIA V100S GPGPU was 256 x 256 x 256. For this blog, we used NUMA per socket (NPS)=4 and we obtained results without an NVLINK bridge. These results show that applications such as HPCG, which fits into GPU memory, can take full advantage of GPU memory and benefit from the higher memory bandwidth of the NVIDIA A100 GPGPU.
GROMACS
In addition to these two basic HPC benchmarks (HPL and HPCG), we also tested GROMACS, an HPC application. We compiled GROMACS 2020.4 with the CUDA compilers and OPENMPI, as shown in the following table:
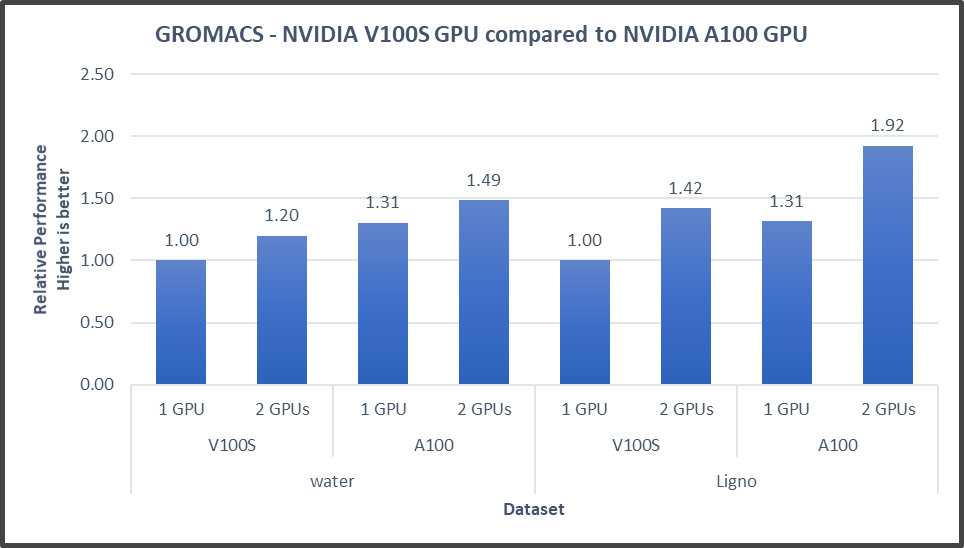
Figure4: GROMACS performance with NVIDIA GPGPUs on the PowerEdge R7525 server
The GROMACS build included thread MPI (built in with the GROMACS package). All performance numbers were captured from the output “ns/day.” We evaluated multiple MPI ranks, separate PME ranks, and different nstlist values to achieve the best performance. In addition, we used settings with the best environment variables for GROMACS at runtime. Choosing the right combination of variables avoided expensive data transfer and led to significantly better performance for these datasets.
GROMACS performance was based on a comparative analysis between NVIDIA V100S and NVIDIA A100 GPGPUs. Excerpts from our single-node multi-GPU analysis for two datasets showed a performance improvement of approximately 30 percent with the NVIDIA A100 GPGPU. This result is due to improved memory bandwidth of the NVIDIA A100 GPGPU. (For information about how the GROMACS code design enables lower memory transfer overhead, see Developer Blog: Creating Faster Molecular Dynamics Simulations with GROMACS 2020.)
Conclusion
The Dell PowerEdge R7525 server equipped with NVIDIA A100 GPGPUs shows exceptional performance improvements over servers equipped with previous versions of NVIDIA GPGPUs for applications such as HPL, HPCG, and GROMACS. These performance improvements for memory-bound applications such as HPCG and GROMACS can take advantage of higher memory bandwidth available with NVIDIA A100 GPGPUs.