




HPC Application Performance on Dell PowerEdge R7525 Servers with NVIDIA A100 GPGPUs
Overview
The Dell PowerEdge R7525 server powered with 2nd Gen AMD EPYC processors was released as part of the Dell server portfolio. It is a 2U form factor rack-mountable server that is designed for HPC workloads. Dell Technologies recently added support for NVIDIA A100 GPGPUs to the PowerEdge R7525 server, which supports up to three PCIe-based dual-width NVIDIA GPGPUs. This blog describes the single-node performance of selected HPC applications with both one- and two-NVIDIA A100 PCIe GPGPUs.
The NVIDIA Ampere A100 accelerator is one of the most advanced accelerators available in the market, supporting two form factors:
- PCIe version
- Mezzanine SXM4 version
The PowerEdge R7525 server supports only the PCIe version of the NVIDIA A100 accelerator.
The following table compares the NVIDIA A100 GPGPU with the NVIDIA V100S GPGPU:
NVIDIA A100 GPGPU | NVIDIA V100S GPGPU | |||
Form factor | SXM4 | PCIe Gen4 | SXM2 | PCIe Gen3 |
GPU architecture | Ampere | Volta | ||
Memory size | 40 GB | 40 GB | 32 GB | 32 GB |
CUDA cores | 6912 | 5120 | ||
Base clock | 1095 MHz | 765 MHz | 1290 MHz | 1245 MHz |
Boost clock | 1410 MHz | 1530 MHz | 1597 MHz | |
Memory clock | 1215 MHz | 877 MHz | 1107 MHz | |
MIG support | Yes | No | ||
Peak memory bandwidth | Up to 1555 GB/s | Up to 900 GB/s | Up to 1134 GB/s | |
Total board power | 400 W | 250 W | 300 W | 250 W |
The NVIDIA A100 GPGPU brings innovations and features for HPC applications such as the following:
- Multi-Instance GPU (MIG)—The NVIDIA A100 GPGPU can be converted into as many as seven GPU instances, which are fully isolated at the hardware level, each using their own high-bandwidth memory and cores.
- HBM2—The NVIDIA A100 GPGPU comes with 40 GB of high-bandwidth memory (HBM2) and delivers bandwidth up to 1555 GB/s. Memory bandwidth with the NVIDIA A100 GPGPU is 1.7 times higher than with the previous generation of GPUs.
Server configuration
The following table shows the PowerEdge R7525 server configuration that we used for this blog:
Server | PowerEdge R7525 |
Processor | 2nd Gen AMD EPYC 7502, 32C, 2.5Ghz |
Memory | 512 GB (16 x 32 GB @3200MT/s) |
GPGPUs | Either of the following: 2 x NVIDIA A100 PCIe 40 GB 2 x NVIDIA V100S PCIe 32 GB |
Logical processors | Disabled |
Operating system | CentOS Linux release 8.1 (4.18.0-147.el8.x86_64) |
CUDA | 11.0 (Driver version - 450.51.05) |
gcc | 9.2.0 |
MPI | OpenMPI-3.0 |
HPL | hpl_cuda_11.0_ompi-4.0_ampere_volta_8-7-20 |
HPCG | xhpcg-3.1_cuda_11_ompi-3.1 |
GROMACS | v2020.4 |
Benchmark results
The following sections provide our benchmarks results with observations.
High-Performance Linpack benchmark
High Performance Linpack (HPL) is a standard HPC system benchmark. This benchmark measures the compute power of the entire cluster or server. For this study, we used HPL compiled with NVIDIA libraries.
The following figure shows the HPL performance comparison for the PowerEdge R7525 server with either NVIDIA A100 or NVIDIA V100S GPGPUs:
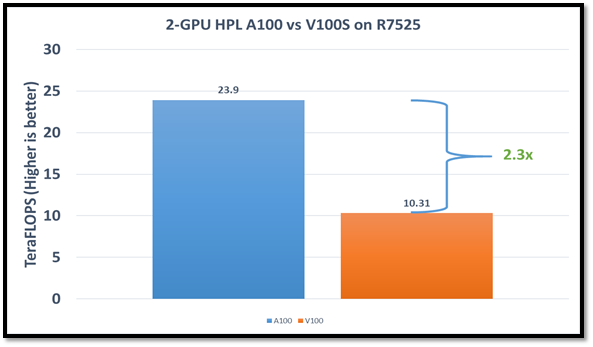
Figure1: HPL performance on the PowerEdge R7525 server with the NVIDIA A100 GPGPU compared to the NVIDIA V100SGPGPU
The problem size (N) is larger for the NVIDIA A100 GPGPU due to the larger capacity of GPU memory. We adjusted the block size (NB) used with the:
- NVIDIA A100 GPGPU to 288
- NVIDIA V100S GPGPU to 384
The AMD EPYC processors provide options for multiple NUMA combinations. We found that the best value of 4 NUMA per socket (NPS=4), with NUMA per socket 1 and 2 lower the performance by 10 percent and 5 percent respectively. In a single PowerEdge R7525 node, the NVIDIA A100 GPGPU delivers 12 TF per card using this configuration without an NVLINK bridge. The PowerEdge R7525 server with two NVIDIA A100 GPGPUs delivers 2.3 times higher HPL performance compared to the NVIDIA V100S GPGPU configuration. This performance improvement is credited to the new double-precision Tensor Cores that accelerate FP64 math.
The following figure shows power consumption of the server while running HPL on the NVIDIA A100 GPGPU in a time series. Power consumption was measured with an iDRAC. The server reached 1038 Watts at peak due to a higher GFLOPS number.
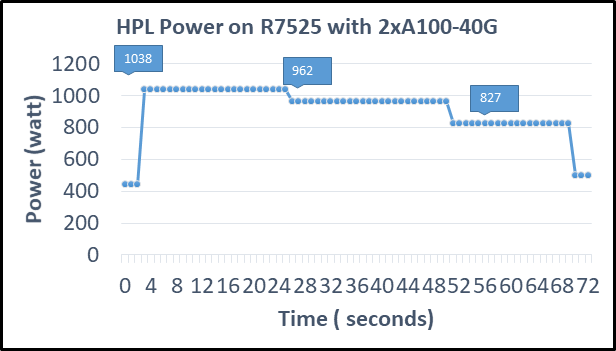
Figure2: Power consumption while running HPL
High Performance Conjugate Gradient benchmark
The High Performance Conjugate Gradient (HPCG) benchmark is based on a conjugate gradient solver, in which the preconditioner is a three-level hierarchical multigrid method using the Gauss-Seidel method.
As shown in the following figure, HPCG performs at a rate 70 percent higher with the NVIDIA A100 GPGPU due to higher memory bandwidth:
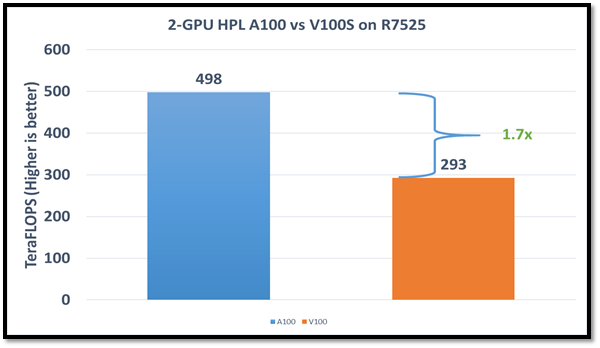
Figure 3: HPCG performance comparison
Due to different memory size, the problem size used to obtain the best performance on the NVIDIA A100 GPGPU was 512 x 512 x 288 and on the NVIDIA V100S GPGPU was 256 x 256 x 256. For this blog, we used NUMA per socket (NPS)=4 and we obtained results without an NVLINK bridge. These results show that applications such as HPCG, which fits into GPU memory, can take full advantage of GPU memory and benefit from the higher memory bandwidth of the NVIDIA A100 GPGPU.
GROMACS
In addition to these two basic HPC benchmarks (HPL and HPCG), we also tested GROMACS, an HPC application. We compiled GROMACS 2020.4 with the CUDA compilers and OPENMPI, as shown in the following table:
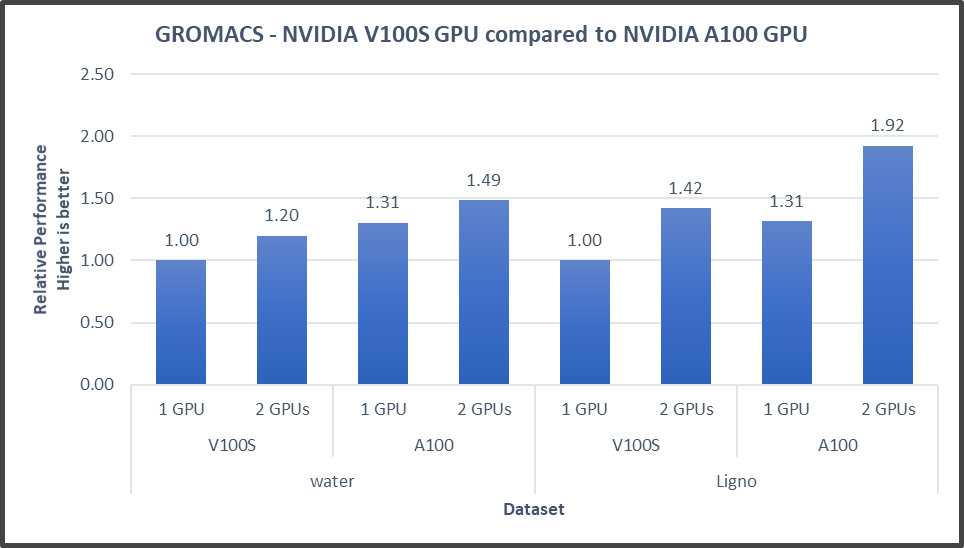
Figure4: GROMACS performance with NVIDIA GPGPUs on the PowerEdge R7525 server
The GROMACS build included thread MPI (built in with the GROMACS package). All performance numbers were captured from the output “ns/day.” We evaluated multiple MPI ranks, separate PME ranks, and different nstlist values to achieve the best performance. In addition, we used settings with the best environment variables for GROMACS at runtime. Choosing the right combination of variables avoided expensive data transfer and led to significantly better performance for these datasets.
GROMACS performance was based on a comparative analysis between NVIDIA V100S and NVIDIA A100 GPGPUs. Excerpts from our single-node multi-GPU analysis for two datasets showed a performance improvement of approximately 30 percent with the NVIDIA A100 GPGPU. This result is due to improved memory bandwidth of the NVIDIA A100 GPGPU. (For information about how the GROMACS code design enables lower memory transfer overhead, see Developer Blog: Creating Faster Molecular Dynamics Simulations with GROMACS 2020.)
Conclusion
The Dell PowerEdge R7525 server equipped with NVIDIA A100 GPGPUs shows exceptional performance improvements over servers equipped with previous versions of NVIDIA GPGPUs for applications such as HPL, HPCG, and GROMACS. These performance improvements for memory-bound applications such as HPCG and GROMACS can take advantage of higher memory bandwidth available with NVIDIA A100 GPGPUs.