




HPC Application Performance on Dell PowerEdge R7525 Servers with the AMD Instinct™ MI210 GPU
PowerEdge support and performance
The PowerEdge R7525 server can support three AMD Instinct™ MI210 GPUs; it is ideal for HPC Workloads. Furthermore, using the PowerEdge R7525 server to power AMD Instinct MI210 GPUs (built with the 2nd Gen AMD CDNA™ architecture) offers improvements on FP64 operations along with the robust capabilities of the AMD ROCm™ 5 open software ecosystem. Overall, the PowerEdge R7525 server with the AMD Instinct MI210 GPU delivers expectational double precision performance and leading total cost of ownership.

Figure 1: Front view of the PowerEdge R7525 server
We performed and observed multiple benchmarks with AMD Instinct MI210 GPUs populated in a PowerEdge R7525 server. This blog shows the performance of LINPACK and the OpenMM customizable molecular simulation libraries with the AMD Instinct MI210 GPU and compares the performance characteristics to the previous generation AMD Instinct MI100 GPU.
The following table provides the configuration details of the PowerEdge R7525 system under test (SUT):
Table 1. SUT hardware and software configurations
Component | Description |
Processor | AMD EPYC 7713 64-Core Processor |
Memory | 512 GB |
Local disk | 1.8T SSD |
Operating system | Ubuntu 20.04.3 LTS |
GPU | 3xMI210/MI100 |
Driver version | 5.13.20.22.10 |
ROCm version | ROCm-5.1.3 |
Processor Settings > Logical Processors | Disabled |
System profiles | Performance |
NUMA node per socket | 4 |
HPL | rochpl_rocm-5.1-60_ubuntu-20.04 |
OpenMM | 7.7.0_49 |
The following table contains the specifications of AMD Instinct MI210 and MI100 GPUs:
Table 2: AMD Instinct MI100 and MI210 PCIe GPU specifications
GPU architecture | AMD Instinct MI210 | AMD Instinct MI100 |
Peak Engine Clock (MHz) | 1700 | 1502 |
Stream processors | 6656 | 7680 |
Peak FP64 (TFlops) | 22.63 | 11.5 |
Peak FP64 Tensor DGEMM (TFlops) | 45.25 | 11.5 |
Peak FP32 (TFlops) | 22.63 | 23.1 |
Peak FP32 Tensor SGEMM (TFlops) | 45.25 | 46.1 |
Memory size (GB) | 64 | 32 |
Memory Type | HBM2e | HBM2 |
Peak Memory Bandwidth (GB/s) | 1638 | 1228 |
Memory ECC support | Yes | Yes |
TDP (Watt) | 300 | 300 |
High-Performance LINPACK (HPL)
HPL measures the floating-point computing power of a system by solving a uniformly random system of linear equations in double precision (FP64) arithmetic, as shown in the following figure. The HPL binary used to collect results was compiled with ROCm 5.1.3.
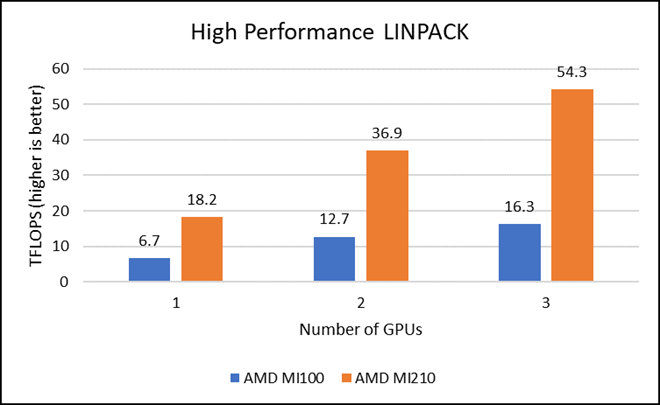
Figure 2: LINPACK performance with AMD Instinct MI100 and MI210 GPUs
The following figure shows the power consumption during a single HPL run:
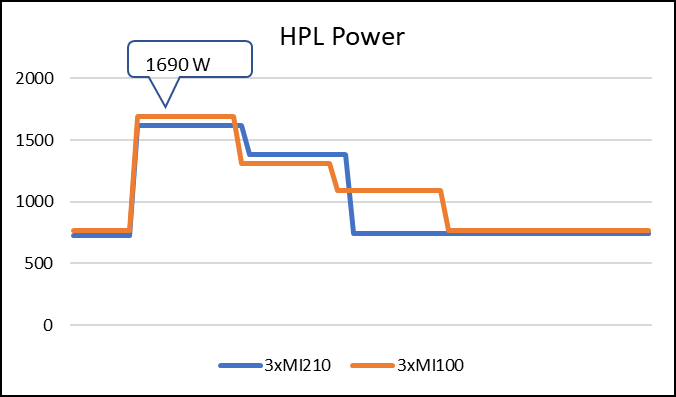
Figure 3: LINPACK power consumption with AMD Instinct MI100 and MI210 GPUs
We observed a significant improvement in the AMD Instinct MI210 HPL performance over the AMD Instinct MI100 GPU. The numbers on a single GPU test of MI210 are 18.2 TFLOPS which is approximately 2.7 times higher than MI100 number (6.75 TFLOPS). This improvement is due to the AMD CDNA2 architecture on the AMD Instinct MI210 GPU, which has been optimized for FP64 matrix and vector workloads. Also, the MI210 GPU has larger memory, so the problem size (N) used here is large in comparison to the AMD Instinct MI100 GPU.
As shown in Figure 2, the AMD Instinct MI210 has shown almost linear scalability in the HPL values on single node multi-GPU runs. The AMD Instinct MI210 GPU reports better scalability compared to its last generation AMD Instinct MI100 GPUs. Both GPUs have the same TDP, with the AMD Instinct MI210 GPU delivering three times better performance. The performance per watt value of a PowerEdge R7525 system is three times more. Figure 3 shows the power consumption characteristics in one HPL run cycle.
OpenMM
OpenMM is a high-performance toolkit for molecular simulation. It can be used as a library or as an application. It includes extensive language bindings for Python, C, C++, and even Fortran. The code is open source and actively maintained on GitHub and licensed under MIT and LGPL.
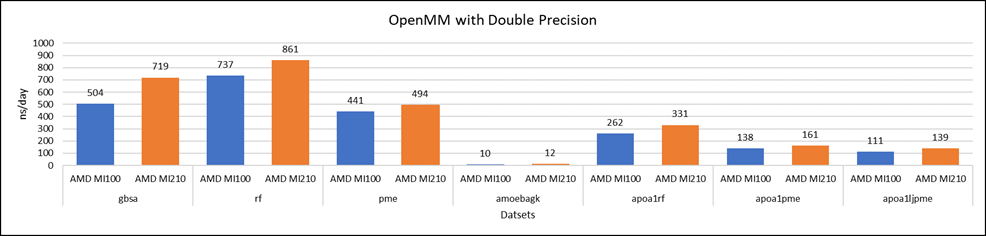
Figure 4: OpenMM double-precision performance with AMD Instinct MI100 and MI210 GPUs
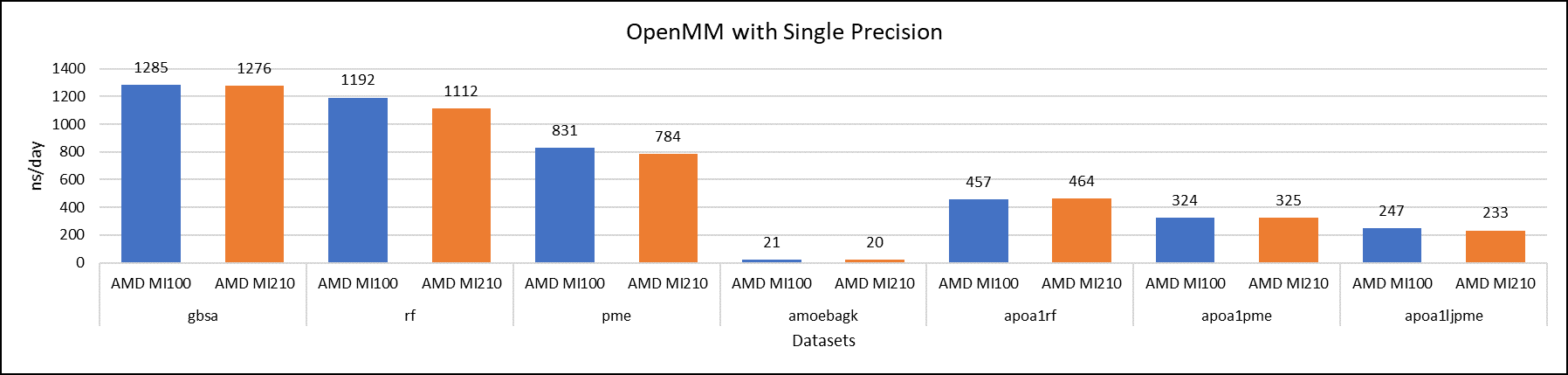
Figure 5: OpenMM single-precision performance with AMD Instinct MI100 and MI210 GPUs
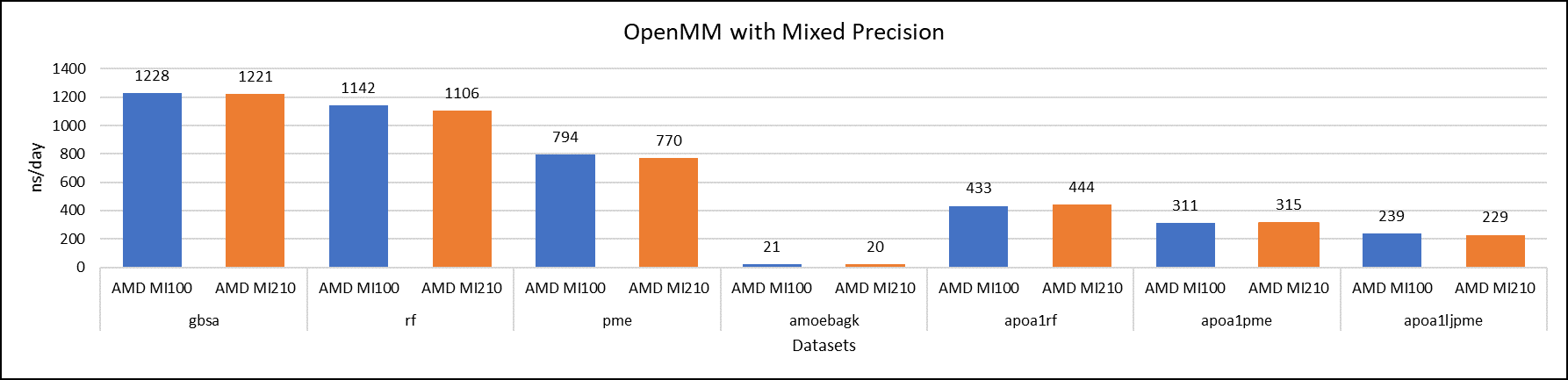
Figure 6: OpenMM mixed-precision performance with AMD Instinct MI100 and MI210 GPUs
We tested OpenMM with seven datasets to validate double, single, and mixed precision. We observed exceptional double precision performance with OpenMM on the AMD Instinct MI210 GPU compared to the AMD Instinct MI100 GPU. This improvement is due to the AMD CDNA2 architecture on the AMD Instinct MI210 GPU, which has been optimized for FP64 matrix and vector workloads.
Conclusion
The AMD Instinct MI210 GPU shows an impressive performance improvement in FP64 workloads. These workloads benefit as AMD has doubled the width of their ALUs to a full 64-bits wide. This change allows the FP64 operations to now run at full speed in the new 2nd Gen AMD CDNA architecture. The applications and workloads that are designed to run on FP64 operations are expected to take full advantage of the hardware.