
Blogs
Short articles related to Microsoft HCI Solutions from Dell Technologies

Preview of Intelligent Automation in Dell APEX Cloud Platform for Microsoft Azure
Wed, 24 Apr 2024 15:35:21 -0000
|Read Time: 0 minutes
UPDATE 11/7/2023: This blog and the embedded YouTube videos were published after Dell APEX Cloud Platform for Microsoft Azure was first announced at Dell Technologies World 2023. It contains early preview content. Please proceed to the following links to see the most up-to-date collateral and YouTube demo videos created after the platform was generally available Sept. 2023. https://www.youtube.com/playlist?list=PL2nlzNk2-VMEkNM7E8m0ia_lLHWlOuT5h |
It was another exhilarating Dell Technologies World (DTW) back in May. It’s always fun connecting with colleagues, customers, and partners in Las Vegas. As always, Vegas managed to surprise me with something I’d never seen before. I finally witnessed the incredible iLuminate team up close and personal at the APEX After Dark party. I tried to describe the phenomenon to a friend who hasn’t experienced one of their performances, but words cannot adequately convey this mesmerizing spectacle of sight and sound! In the end, only one of my photos from the event and a link to one of their recorded shows could make it real for them.

Similarly, words alone can’t do justice to the game changing potential of the new APEX Cloud Platform announced at DTW. That’s why I created a demo video giving customers an early preview[1] of the new management and orchestration capabilities coming to our APEX Cloud Platform Foundation Software. This software integrates intelligent automation into the familiar management tools of each supported cloud ecosystem – Microsoft Azure, Red Hat OpenShift, and VMware vSphere.
In this blog, I want to showcase APEX Cloud Platform for Microsoft Azure and the features and functionality we integrate into Microsoft Windows Admin Center. My colleague and friend, Kenny Lowe, wrote a brilliant analysis of our new solution in his recent blog post, Delving Into the APEX Cloud Platform for Microsoft Azure. He included some screen shots from my demo video, which hasn’t been shared publicly until now. I highly recommend reading his enlightening article, which provides invaluable context before viewing the demos.
Please be aware that the clips below are sections of a lengthier video that shares the story of a fictional retail company named WhyGoBuy. They used APEX Cloud Platform Foundation Software to accelerate their time to value and improve operational efficiency. Because this video was over 15 minutes long, I divided it into bite-sized chunks and included a brief introduction to each administrative task. You can view the full video HERE.
Seeing is believing
Without further ado, let’s dive into the technology!
At initial release of APEX Cloud Platform for Microsoft Azure, Dell Technologies is offering a white-glove deployment experience through Dell ProDeploy Services. Our expert technicians will walk you through your first deployments to help you get comfortable with the process. Soon after announcing general availability, we will empower you to install the platform yourself using the APEX Cloud Platform Foundation Software deployment automation. In this first video, our administrators at WhyGoBuy followed the step-by-step user input configuration method and provided the settings in each step of the deployment wizard.
The next video presents a common Day 2 operations scenario. Some of WhyGoBuy’s Storage Spaces Direct volumes were approaching maximum capacity, and one volume required immediate attention. Luckily, APEX Cloud Platform for Microsoft Azure offered a consistent hybrid management experience. Administrators were promptly made aware of the issue through Azure Monitor, which provided observability for their entire fleet of platforms across data center and edge locations. Then, they navigated to the Windows Admin Center extension for further investigation and remediation of the issue.
Lifecycle management is critical to ensuring the optimal security, performance, and reliability of any infrastructure. With APEX Cloud Platform Foundation Software, Dell helps our customers remain in a continuously validated state – updating the platform from one known good state to the next, inclusive of hardware, operating system, and systems management software. A few months passed since WhyGoBuy deployed their first platform, and the time came to apply a quarterly baseline bundle using the Windows Admin Center extension. The following video captures their experience.
WhyGoBuy was committed to maintaining a robust security posture. They used APEX Cloud Platform Foundation Software intrinsic infrastructure security management features to help them accomplish this. The next video showcases two of these features:
- Infrastructure Lock – Protects against unauthorized or malicious changes to configuration settings by enabling the System Lockdown feature in Dell iDRAC. This also prevents updates to BIOS, firmware, and drivers to guard against cybersecurity attacks.
- Secured-core server – Proactively defends against many of the paths attackers might use to exploit a system by establishing a hardware root-of-trust, protecting firmware, and introducing virtualization-based security.
In this final video, WhyGoBuy set up connectivity to Dell ProSupport to benefit from log collection, phone home, automated case creation, and remote support. They also wanted to send telemetry data to Dell CloudIQ cloud-based software for multi-cluster monitoring. CloudIQ provided proactive monitoring, machine learning, and predictive analytics so they could take quick action and simplify operations of all their on-premises APEX Cloud Platforms.
The future’s so bright
We are excited to bring Dell APEX Cloud Platform for Microsoft Azure to market later this year. I’ve compiled the following list of available resources for further learning.
- Dell APEX Cloud Platform for Microsoft Azure Playlist
- Solution Brief – Deploy mission-critical database and virtual desktop workloads in a Microsoft hybrid cloud environment
- Thomas Maurer Speaks with Kenny Lowe on APEX Cloud Platform for Microsoft Azure
- Building the Future of Azure Stack HCI
- Delving Into the APEX Cloud Platform for Microsoft Azure
After we launch this solution, you’ll be able to find white papers, videos, blogs, and more at the APEX tile at our Info Hub site.
And as always, please reach out to your Dell account team if you would like to have more in-depth discussions about the APEX portfolio. If you don’t currently have a Dell contact, we’re here to help on our corporate website.
Author: Michael Lamia, Engineering Technologist at Dell Technologies
Follow me on Twitter: @Evolving_Techie
LinkedIn: https://www.linkedin.com/in/michaellamia/
Email: michael.lamia@dell.com
[1] Dell APEX Cloud Platform for Microsoft Azure will be generally available later in 2023. Some of the features and functionality depicted in these videos may behave differently at initial release or may not be available until later releases. Dell makes no representation and undertakes no obligations with regard to product planning information, anticipated product characteristics, performance specifications, or anticipated release dates (collectively, “Roadmap Information”). Roadmap Information is provided by Dell as an accommodation to the recipient solely for the purposes of discussion and without intending to be bound thereby.

Accelerate your SQL Server Workloads with Dell Integrated System for Azure Stack HCI
Fri, 28 Jul 2023 16:05:27 -0000
|Read Time: 0 minutes
Microsoft presented SQL Server 2022 last November, during the Microsoft Ignite 2022 event. This was a highly expected release, introducing several key improvements for database operations, availability, security, and performance.
SQL Server 2022 constitutes the most cloud-connected database Microsoft has released to date. Building an Azure Arc-enabled database platform with Azure Arc-enabled SQL Server facilitates extending your data management operations from your own data center to any edge location, public cloud, or hosting facility.
With the simple installation of a new agent into the SQL Server instance, a full set of management, security, and performance options are enabled.
See more details on these new features at this Microsoft learn page.
As of today, one of the most powerful deployment scenarios for SQL Server is a hybrid environment. With Arc-enabled service, we can deploy, manage, and operate from a single point and have the flexibility to place every SQL Server instance where it should be to benefit from the best resource allocation and manageability, and thus provide the best IT experience to meet the business demands.
Thinking about an HCI platform to host the on-premises side of our hybrid approach seems reasonable, as HCI solutions have become predominant in their IT segment, as analysts report.
Dell Integrated System for Azure Stack HCI represents a perfect choice to meet the SQL Server 2022 requirements, providing a fully productized platform that offers, out of the box, intelligently designed configurations to minimize hardware and software customizations often required for this type of environment.
If we want to populate our hybrid solution with a set of tools to ensure repeatable and predictable infrastructure operations, Dell OpenManage Integration with Microsoft Windows Admin Center provides in-depth, cluster-level automation capabilities that enable an efficient and flexible operation of the Azure Stack HCI platform.
For optimal platform sizing, to properly address SQL Server workload demands, we can use a free, online tool such Dell Live Optics. With the information gathered by Live Optics software collectors, we can better understand application performance and capacity requirements. That information can be used by the Dell sales team to influence the selection available to configure the Azure Stack HCI platform in Dell’s Azure Stack HCI Sizer tool. You can find more details on Live Optics here. For specifics on Live Optics and database workloads, check this site.
To evaluate SQL Server performance in this hybrid scenario, we have configured a four-node Dell Integrated System for Microsoft Azure Stack HCI. The underlying infrastructure is based on Dell AX-7525 nodes, each powered by two AMD EPYC processors, 2 TB of RAM and 12 NVMe drives.
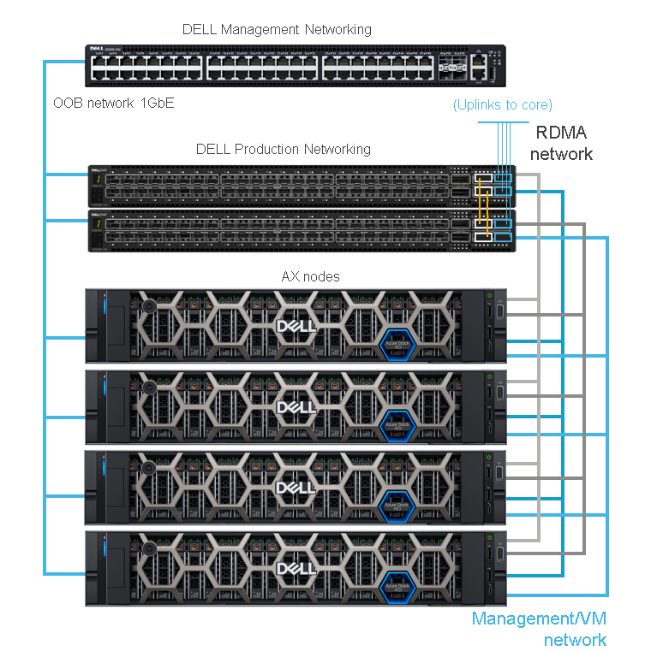
The solution architecture looks like this:
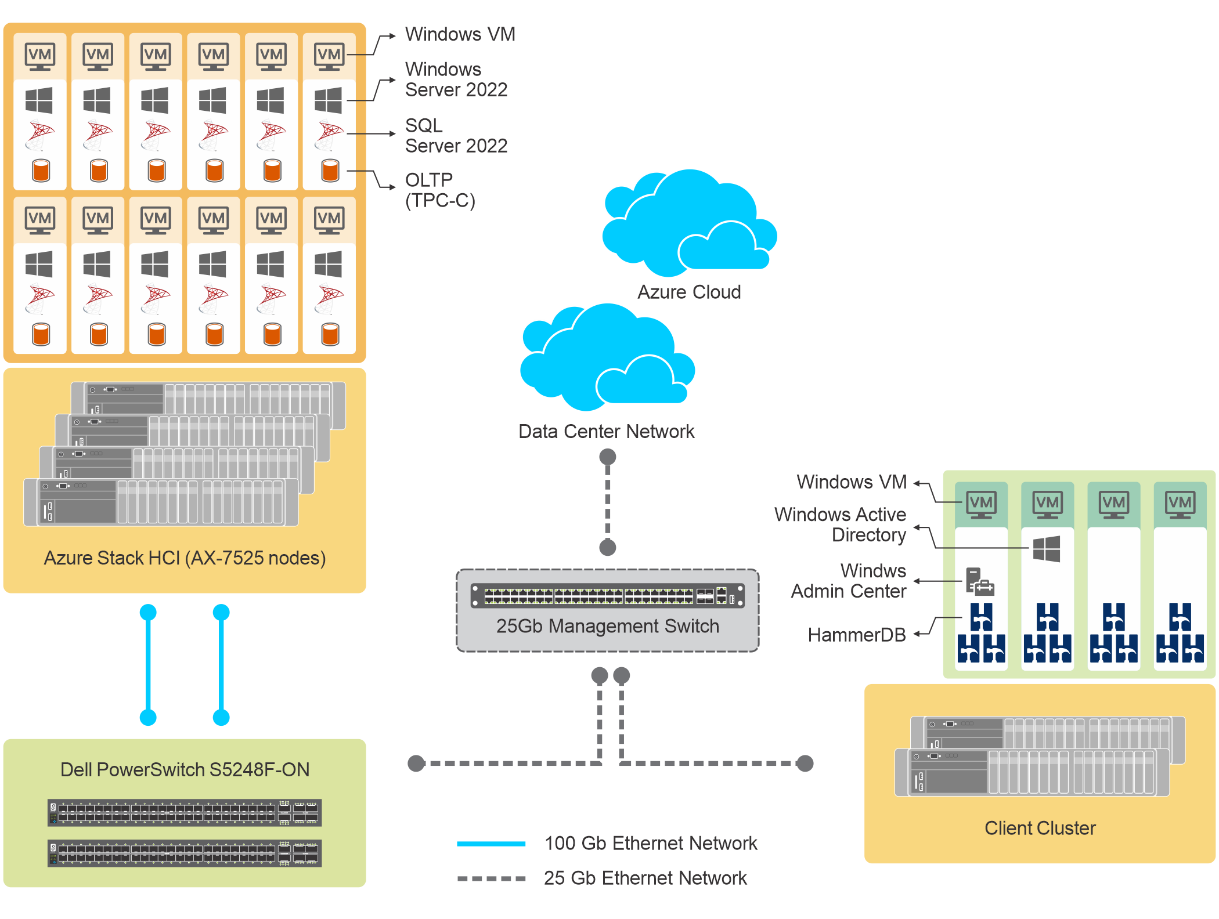
Figure 1. Dell Integrated System for Azure Stack HCI architecture overview
On the storage side of the solution, Microsoft Storage Spaces Direct manages the NVMe drives made available by the four AX-7525 nodes, creating a single pool, accessed through Cluster Shared Volumes (CSVs) in which Virtual Hard Disks (.vhds) were placed.
The following figure shows the volume and controller layout.
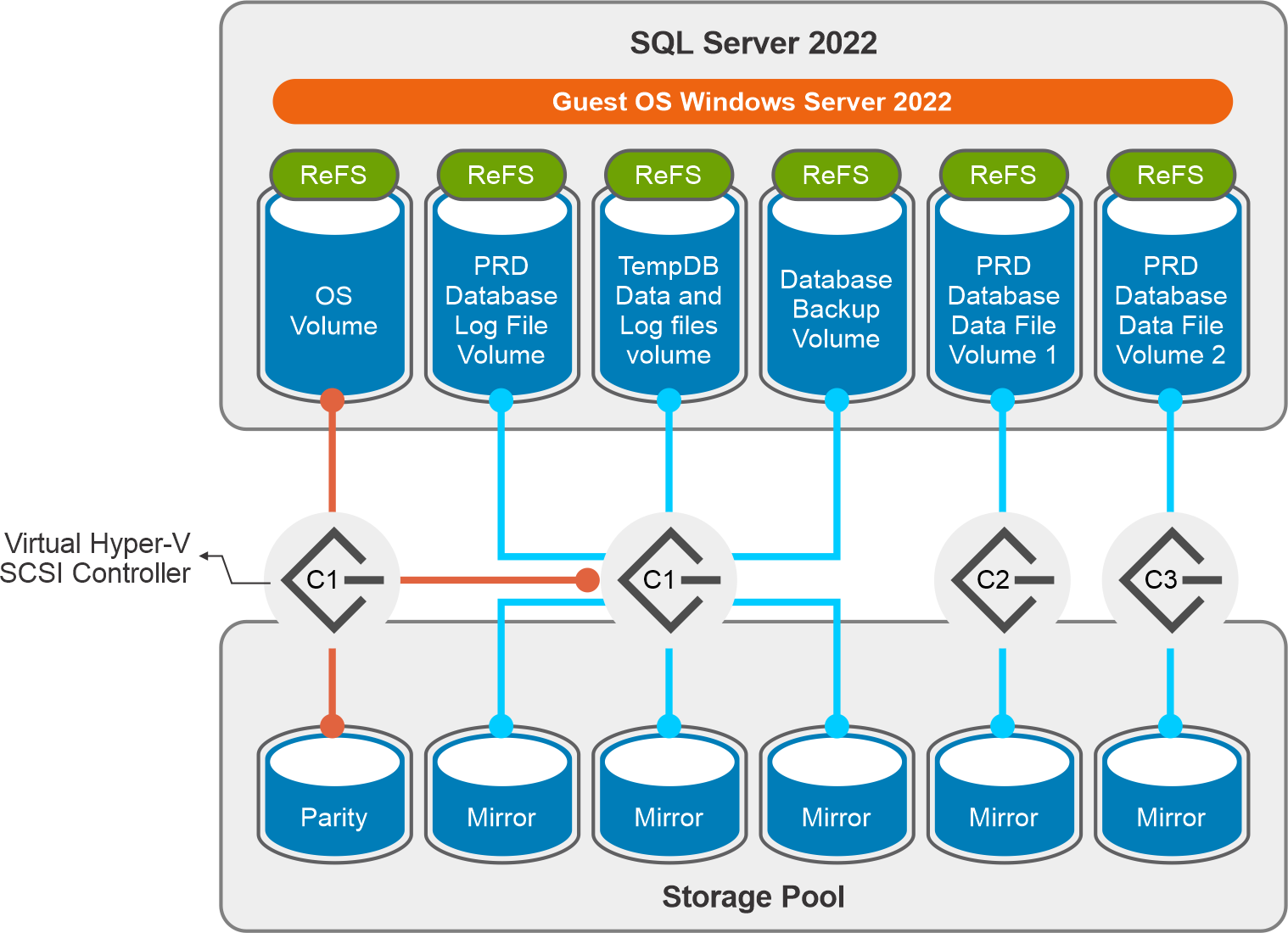
Figure 2. Storage layout
We also need to design and configure the networking component of the test environment. For this SQL Server case, we have chosen to provide top-of-rack connectivity through two Dell S5248F-ON switches, with L2 multipath support using Virtual Link Trunking (VLT) for a highly available configuration. With the addition of NVIDIA Mellanox ConnectX-6 Dx Dual Port 100 GbE adapters, we can provide Remote Direct Memory Access (RDMA) with RDMA over Ethernet capabilities (RoCE) to our storage network. The overarching network architecture looks as follows:
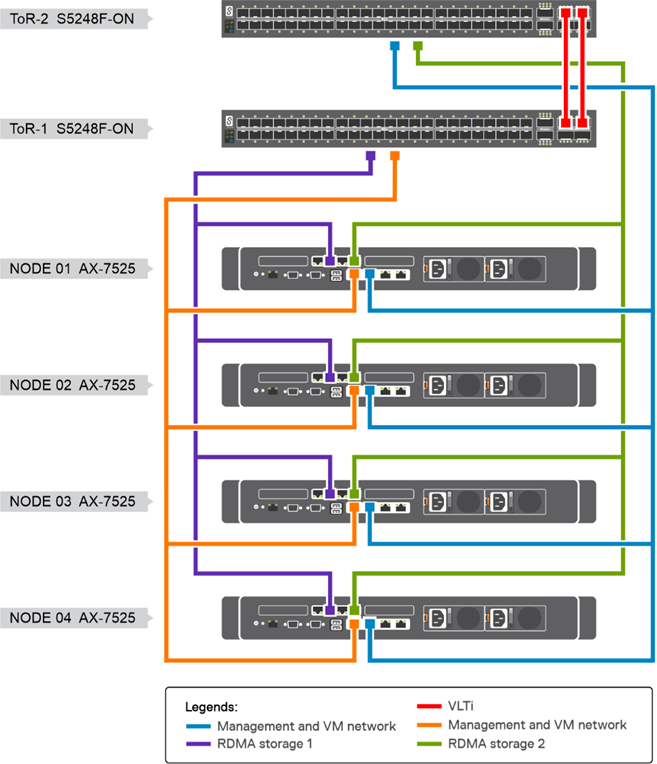
Figure 3. Network architecture
With this infrastructure scenario, we chose a test methodology that started with one SQL Server VM and scaled up to 12 VMs. In each SQL Server VM, we installed and configured HammerDB instances on a cluster of clients running Windows Server 2022. For benchmarking, we chose the TPROC-C, an online transaction processing (OLTP) benchmarking standard derived from TPC-C.
With a dataset of a 4,000 scale factor and a size of 400 GB, we started running the test on one SQL Server VM, then scaling to two, four, eight, and finally, 12 VMs.
We focused the test on two key performance indicators, transactions per minute (TPM) and new orders per minute (NOPM). The main goal was to obtain performance scaling as linear as possible when going from one to twelve VMs, keeping CPU utilization in a safe range, to leave ample performance space to run other workloads. Each of these benchmarking tests was conducted while the TPROC-C transaction load from HammerDB was running concurrently on the respective number of VMs running SQL Server.
The following figure shows a summary of the results obtained:
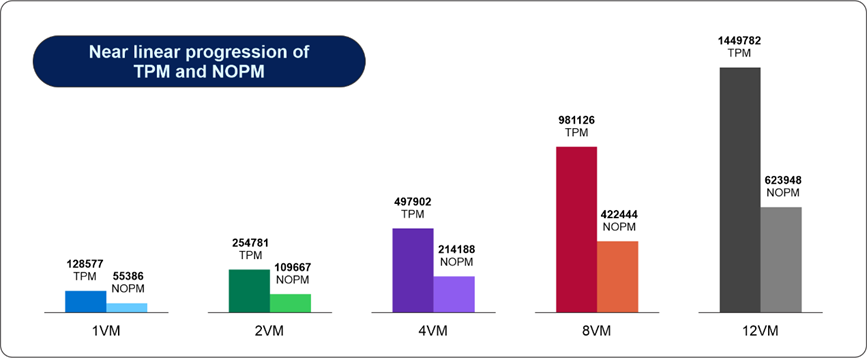
Figure 4. SQL performance summary
As usual, keeping a low latency, increasing IOPS score, was an ad hoc goal to maintaining consistent CPU utilization all along the tests. A summary of the results is shown in the following figure:

Figure 5. Latency, IOPS, and CPU utilization results
In summary, running our SQL Server 2022 workloads on Dell’s Azure Stack HCI, connected to Microsoft Azure through Azure Arc Resource Manager, provides excellent performance with rich management features for on-premises operations through Dell OpenManage Integration for Microsoft Windows Admin Center.
For more technical content on Dell Integrated System for Azure Stack HCI, visit our Info Hub.
Resources
- Dell Integrated Systems for Azure Stack HCI Info Hub
- Microsoft Storage Spaces Direct
- Live Optics main page
- Live Optics Knowledge Base
Author:
Inigo Olcoz, Senior Principal Engineer Technologist at Dell
Twitter: @VirtualOlcoz

2023 Updates for Azure Stack HCI and Hub (Part I)
Wed, 30 Aug 2023 22:05:17 -0000
|Read Time: 0 minutes
The first half of 2023 has been quite prolific for the Dell Azure Stack HCI ecosystem, providing many important incremental updates in the platform. This article summarizes the most relevant changes inside the program.
 Azure Stack HCI
Azure Stack HCI
Dell Integrated System for Microsoft Azure Stack HCI delivers a fully productized, validated, and supported hyperconverged infrastructure solution that enables organizations to modernize their infrastructure for improved application uptime and performance, simplified management and operations, and lower total cost of ownership. The solution integrates the software-defined compute, storage, and networking features of Microsoft Azure Stack HCI with AX nodes from Dell to offer the high-performance, scalable, and secure foundation needed for a software-defined infrastructure.
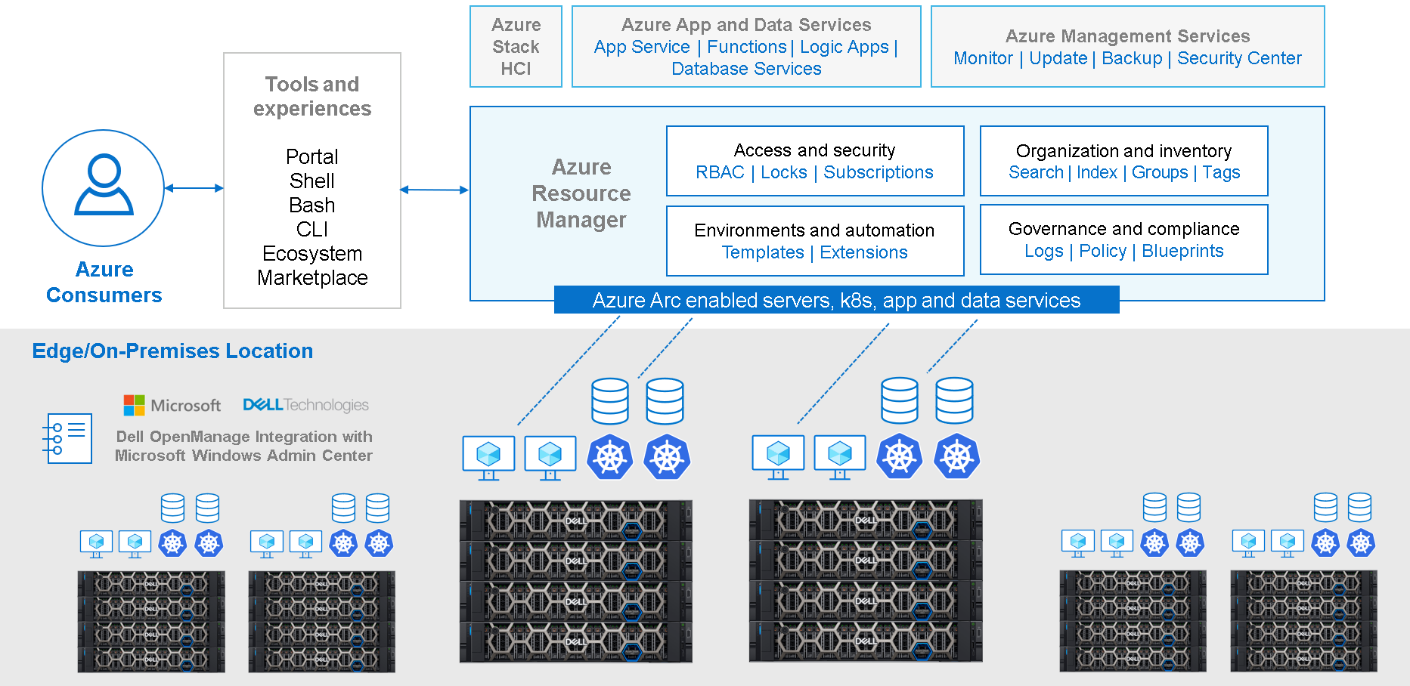
With Azure Arc, we can now unlock new hybrid scenarios for customers by extending Azure services and management to our HCI infrastructure. This allows customers to build, operate, and manage all their resources for traditional, cloud-native, and distributed edge applications in a consistent way across the entire IT estate.
What’s new with Azure Stack HCI?
A lot. There have been so many updates in the Azure Stack HCI front that it is difficult to detail all of them in just a single blog. So, let’s focus on the most important ones.
Azure Stack HCI software and hardware updates
From a software and hardware perspective, the biggest change during the first half of 2023 was the introduction of Azure Stack HCI, version 22H2 (factory install and field support). The most important features in this release are Network ATC, GPU partitioning (GPU-P), and security improvements.
- Network ATC simplifies the virtual network configuration by leveraging intent-based network deployment and incorporating Microsoft best practices by default. It provides the following advantages over manual deployment:
- Reduces network configuration deployment time, complexity, and incorrect input errors
- Uses the latest Microsoft validated network configuration best practices
- Ensures configuration consistency across all nodes in the cluster
- Eliminates configuration drift, with periodic consistency checks every 15 minutes
- GPU-P allows sharing a physical GPU device among several VMs. By leveraging single root I/O virtualization (SR-IOV), GPU-P provides VMs with a dedicated and isolated fractional part of the physical GPU. The obvious advantage of GPU-P is that it enables enterprise-wide utilization of highly valuable and limited GPU resources.
- Azure Stack HCI OS 22H2 security has been improved with more than 200 security settings enabled by default within the OS (“Secured-by-default”), enabling customers to closely meet Center for Internet Security (CIS) benchmark and Defense Information System Agency (DISA) Security Technical Implementation Guide (STIG) requirements for the OS. All these security changes improve the security posture by also disabling legacy protocols and ciphers.
From a hardware perspective, these are the most relevant additions to the AX node family:
- More NIC options:
- Mellanox ConnectX-6 25 GbE
- Intel E810 100 GbE; also adds RoCEv2 support (now iWARP or RoCE)
- More GPU options for GPU-P and Discrete Device Assignment (DDA):
- GPU-P validation for: NVIDIA A40, A16, A2
- DDA options: NVIDIA A30, T4
To better understand GPU-P and DDA, check this blog.
Azure Stack HCI End of Life (EOL) for several components
As the platforms mature, it is inevitable that some of the aging components are discontinued or replaced with newer versions. The most important changes on this front have been:
- EOL for AX-640/AX-740xd nodes: Azure Stack HCI 14G servers, AX-640, and AX-740xd reached their EOL on March 31, 2023, and are therefore no longer available for quoting, or new orders. These servers will be supported for up to seven years, until their End of Service Life (EOSL) date. Azure Stack HCI 15G AX-650/AX-750/AX-6515/AX-7525 platforms will continue to be offered to address customer demands.
- EOL for Windows Server 2019: While Windows Server 2019 will be reaching end of sales/distribution from Dell on June 30, 2023, the product will continue to be in Microsoft Mainstream Support life cycle until January 9, 2024. That means that our customers will be eligible for security and quality updates from Microsoft free of charge until that date. After January 9, 2024, Windows Server will enter a 5-year Extended Support life cycle that will provide our customers with security updates only. Any quality and product fixes will be available from Microsoft for a fee. It is highly recommended that customers migrate their current Windows Server 2019 workloads to Windows Server 2022 to maintain up-to-date support.
Finally, we have introduced a set of short and easily digestible training videos (seven minutes each, on average) to learn everything you need to know about Azure Stack HCI, from the AX platform and Microsoft’s Azure Stack HCI operating system, to the management tools and deploy/support services.
Conclusion
It’s certainly a challenge to synthesize the last six months of incredible innovation into a brief article, but we have highlighted the most important updates: focus on learning all the new Azure Stack HCI 22H2 features and updates, keep current with the hardware updates, and… stay tuned for important announcements by the last quarter of the year: big things are coming in Part 2!!!
Thank you for reading.
Author: Ignacio Borrero, Senior Principal Engineer, Technical Marketing

Live Optics and Azure Stack HCI
Thu, 15 Jun 2023 00:58:28 -0000
|Read Time: 0 minutes
The IT industry has coped with many challenges during the last decades. One of the most impactful ones, probably due to its financial implications, has been the “IT budget reduction”—the need for IT departments to increase efficiency, reduce the cost of their processes and operations, and optimize asset utilization.
This do-more-with-less mantra has a wide range of implications, from cost of acquisition to operational expenses and infrastructure payback period.
Cost of acquisition is not only related to our ability to get the best IT infrastructure price from technology vendors but also to the less obvious fact of optimal workload characterization that leads to the minimum infrastructure assets to service business demand.
Without the proper tools, assessing the specific needs that each infrastructure acquisition process requires is not simple. Obtaining precise workload requirements often involves input from several functional groups, requiring their time and dedication. This is often not possible, so the only choice is to do a high-level estimation of requirements and select a hardware offering that can cover by ample margin the performance requirements.
Those ample margins do not align very well with concepts such as optimal asset utilization and, thus, do not lead to the best choice under a budget reduction paradigm.
But there is free online software, Live Optics, that can be used to collect, visualize, and share data about your IT infrastructure and the workloads they host. Live Optics helps you understand your workloads’ performance by providing in-depth data analysis. It makes the project requirements much clearer, so the sizing decision—based on real data—is more accurate and less estimated.
Azure Stack HCI, as a hyperconverged system, greatly benefits from such sizing considerations. It is often used to host a mix of workloads with different performance profiles. Being able to characterize the CPU, memory, storage, network, or protection requirements is key when infrastructure needs to be defined. This way, the final node configuration for the Azure Stack HCI platform will be able to cope with the workload requirements without oversizing the hardware and software offerings, and we are able to select the type of Azure Stack HCI node that best fits the workload requirements.
Microsoft recommends using an official sizing tool such as Dell’s tool, and Live Optics incorporates all Azure Stack HCI design constraints and best practices, so the tool outcome is optimized to the workload requirements.
Imagine that we had to host in the Azure Stack HCI infrastructure a number of business applications with sets of users. With the performance data gathered by Live Optics, and using the Azure Stack HCI sizing tool, we can select the type of node we need, the amount of memory each node will have, what CPU we will equip, how many drives are needed to cover the I/O demand, and the network architecture.
We can see a sample of the sizing tool input in the following figure:
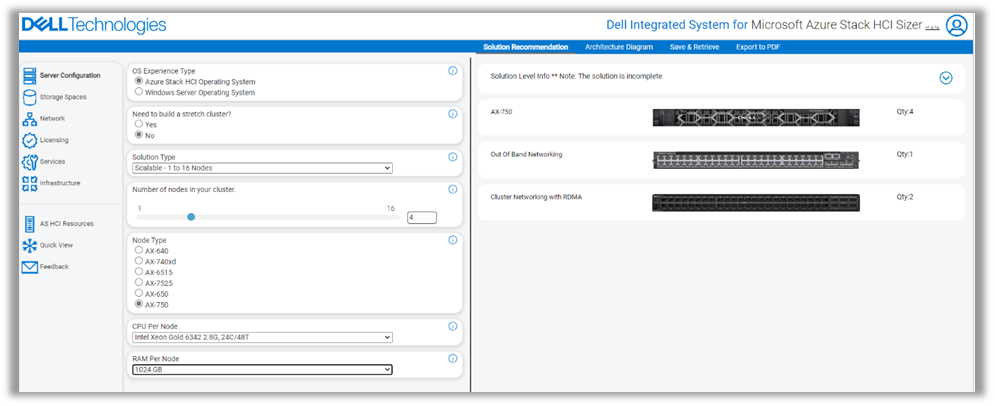
Figure 1. Example from Dell's sizing tool for Azure Stack HCI
In this case, we have chosen to base our Azure Stack HCI infrastructure on four AX-750 nodes, with Intel Gold 6342 CPUs and 1 GB of RAM per node.
Because we have used Live Optics to gather and analyze performance data, we have sized our hardware assets based on real customer usage data such as that shown in the next figure:
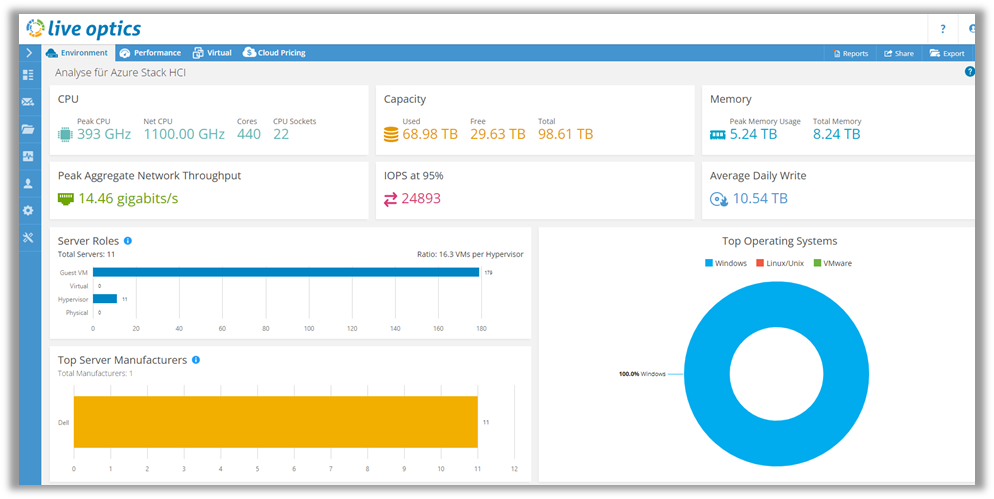
Figure 2. Live Optics performance dashboard
This Live Optics dashboard shows the general requirements of the analyzed environment. Data of aggregated network throughput, IOPS, and memory usage or CPU utilization are displayed and, thus, can be used to size the required hardware.
There are more specific dashboards that show more details on each performance core statistic. For precise storage sizing, we can display read and write I/O behavior in great detail, as we can see in the following figure:
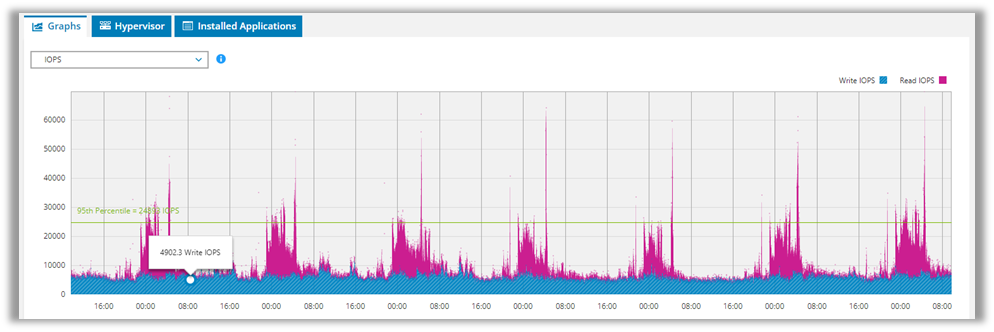
Figure 3. IOPS graphics through a Live Optics read/write I/O dashboard
With a tool such as Live Optics, we can size our Azure Stack HCI infrastructure based on real workload requirements, not assumptions made because information is lacking. This leads to an accurate configuration, usually resulting in a lower price, and warranties that the proposed infrastructure can handle even the peak business workload requirements.
Check the resources shown below to find links to the Live Optics site and collector application, as well as some Dell technical information and sizing tools for Azure Stack HCI.
Resources
- Live Optics app
- Live Optics site
- Info Hub: Microsoft HCI Solutions from Dell Technologies
- Microsoft Azure Stack HCI sizer from Dell Technologies
Author: Inigo Olcoz
Twitter: VirtualOlcoz

Dell and Azure Stack HCI Made Easy: the Video Series
Tue, 25 Apr 2023 17:05:23 -0000
|Read Time: 0 minutes
It is incredible how time flies and it still feels like yesterday since December 10, 2020, when Microsoft initially released Azure Stack HCI. 
Today, Azure Stack HCI is a huge success and, in combination with Azure Arc, the foundation for any real Microsoft hybrid strategy.
But believe it or not, 850+ days later, Azure Stack HCI is still a big unknown for part of the Microsoft community. In our daily customer engagements, we keep on observing that there are knowledge gaps around the Azure Stack HCI program itself and the partner ecosystem that surrounds it.
In these circumstances, we have decided to take action and create a very short and easy-to-follow video series explaining everything you need to know about Azure Stack HCI from a technical perspective.
What you will find
This initial video training library consist of five videos, each averaging seven minutes in length. Here’s a summary of what you will discover in each of the videos:
Video: What Is Inside Azure Stack HCI
Learn the basics and fundamental components of Azure Stack HCI and get to know the Dell Integrated System for Microsoft Azure Stack HCI platform.
Meet the AX node platform and take the Dell Integrated System for Microsoft Azure Stack HCI route to deliver consistent Azure Stack HCI deployments.
Video: Topology and networking
Explore topology and network deployment options for Dell Integrated System for Microsoft Azure Stack HCI. Make good Azure Stack HCI environments even better with the Dell PowerSwitch family.
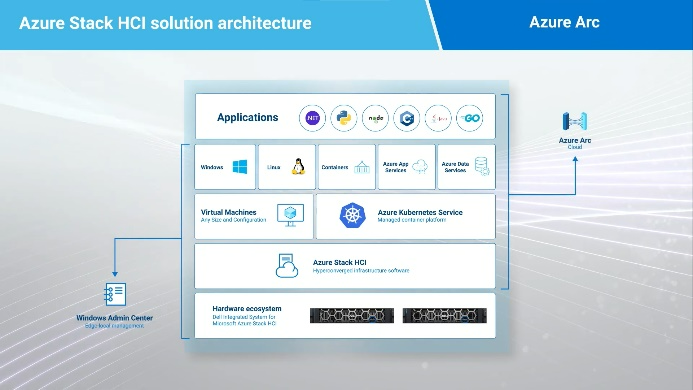
Learn about Azure Stack HCI local management with Windows Admin Center and OpenManage. This is the perfect combination for quick and easy controlled local deployments…and a solid foundation for true hybrid management.
Describes end to end deployment and support for the Dell Integrated System for Microsoft Azure Stack HCI platform with ProDeploy and ProSupport services.
Will there be more?
Absolutely.
We are already working on the next series where we’ll be covering other important topics that are beyond the scope for this initial launch (such as best practices and stretched clusters).
Conclusion
There is no doubt that Azure Stack HCI is a very hot topic. In fact, it is the key foundational element that enables a true Microsoft hybrid strategy by delivering on-premises infrastructure fully integrated with Azure. This video series explains the different elements that make this possible.
All videos in the series are important, none should be skipped… but if there is one not to be missed, please, go for Dell Azure Stack HCI: Local Management. This topic is actually the hook for the next release (Hint -> Hybrid management is the next big thing!).
Thanks for reading and… stay tuned for additional videos on the Info Hub!
Author: Ignacio Borrero, Senior Principal Engineer, Technical Marketing Dell CI & HCI

Test Drive Azure Stack HCI in the Dell Demo Center!
Wed, 24 Apr 2024 15:29:51 -0000
|Read Time: 0 minutes
A picture is worth a thousand words, but the value of a good hands-on lab is immeasurable!
Our newly minted interactive demo and hands-on lab are published in the Dell Technologies Demo Center:
- The interactive demo (ITD-0910) offers an immersive look at all Azure Stack HCI management and governance features in Dell OpenManage Integration with Microsoft Windows Admin Center.
- If you're seeking a deep-dive into the Dell Integrated System for Microsoft Azure Stack HCI initial deployment experience, you may prefer the PowerShell-heavy hands-on lab (HOL-0313-01).
In this blog, we'll begin with a brief introduction to these test drives. Then, we'll share our list of other virtual labs that will prove invaluable on your journey to becoming an Azure Stack HCI champion. Fasten your seatbelt and get ready to take your skills to the next level!
The interactive demo can be accessed directly by all customers and partners. When first navigating to the Demo Center site, remember to click the Sign In drop-down menu in the upper right corner of the page.
At the present time, you will not see the hands-on lab appear in the Demo Center catalog. You will need to contact your Dell Technologies account team to gain access to HOL-0313-01.
Interactive Demo ITD-0910
Taking this demo is like competing in a Formula1 or NASCAR race. It is fast-paced and remains within the secure confines of the track's guardrails. Each module in the demo guides you down a well-defined path that leads to a desired business outcome. Here is a summary of the benefits our OpenManage Integration extension delivers:
- Uses automation to streamline operational efficiency and flexibility
- Provides a consistent hybrid management experience by using a single Dell HCI Configuration Profile policy definition
- Reduces operational expense by intelligently right-sizing infrastructure to match your workload profile
- Ensures stability and security of infrastructure with real-time monitoring and lifecycle management
- Protects your IT estate from costly changes to configuration settings made inadvertently or maliciously
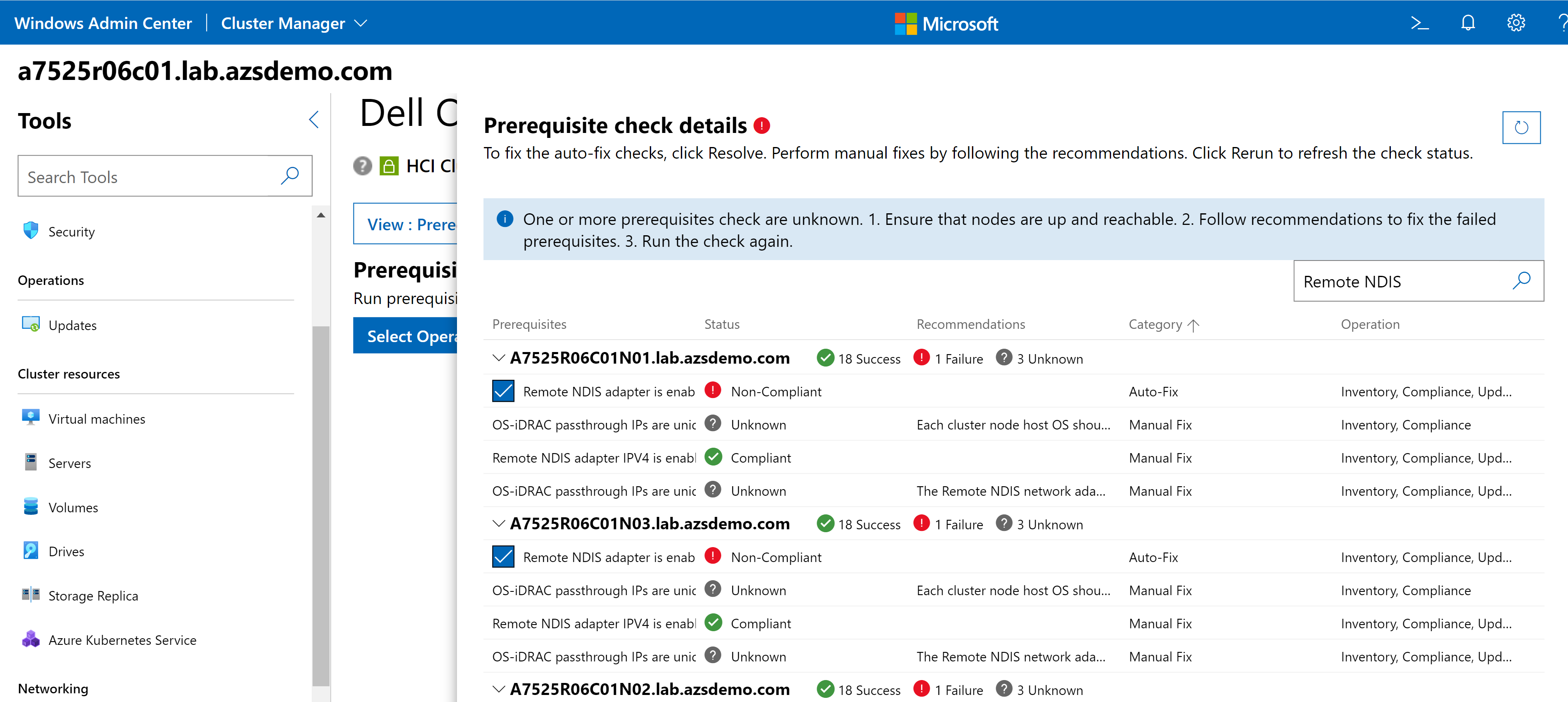
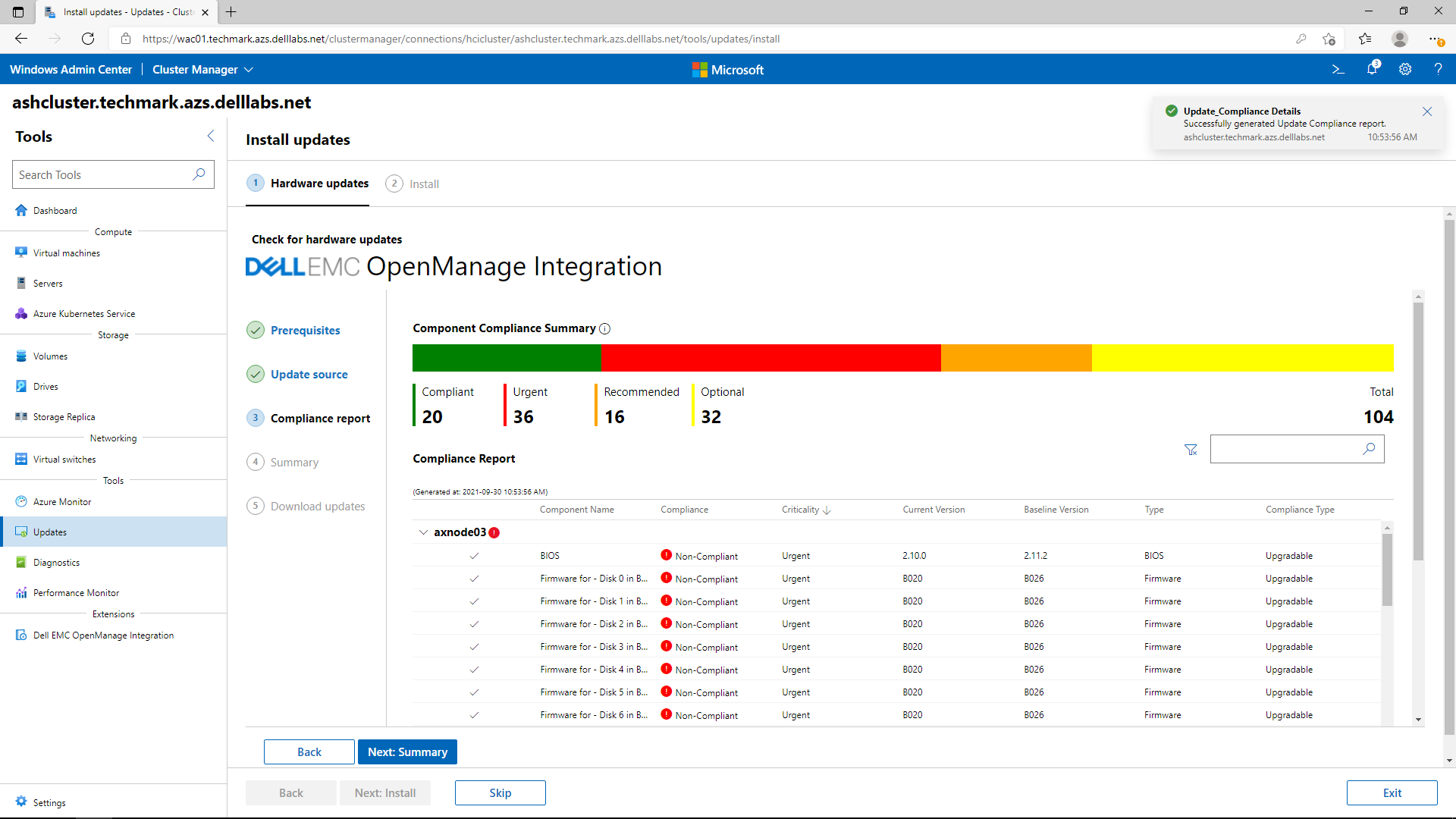
Whenever new features are released for our extension, you'll be able to familiarize yourself with them here first. In the latest release (v3.0), we completely revamped the user interface for improved usability and navigation. We also added server and cluster-level checks to ensure that all prerequisites are met for seamless enablement of management and monitoring operations. The following figure illustrates the results of a prerequisite check. In the interactive demo, you learn more about these failures and how to use the OpenManage Integration extension to fix them.
When we first start driving, we need our parents and teachers to provide turn-by-turn directions. If you're exploring the extension for the first time, you'll want to keep the guides enabled to aid your understanding.
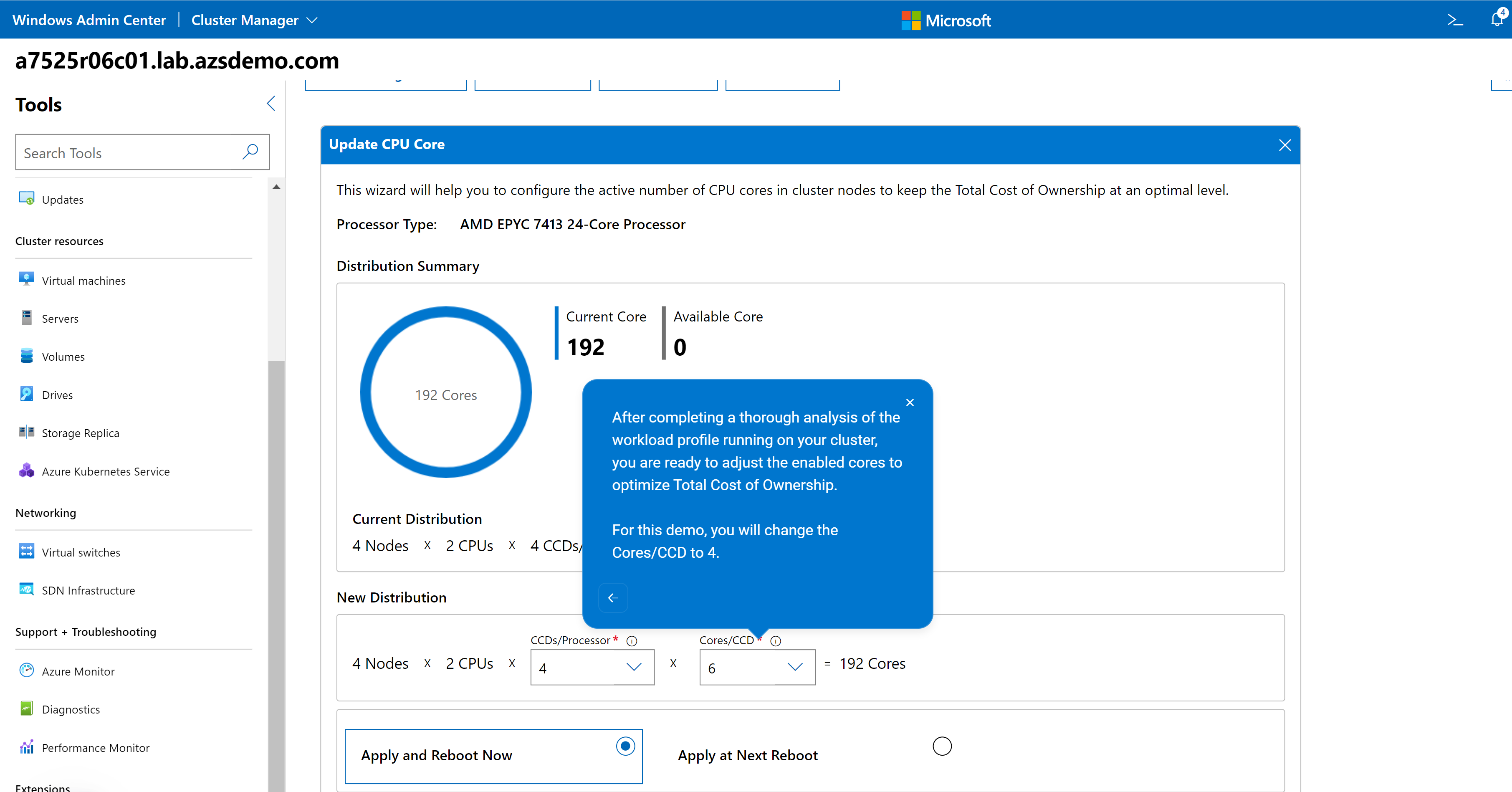
For example, consider the CPU Core Management feature. This feature allows you to right size your Azure Stack HCI cluster by enabling/disabling CPU cores to meet the requirements of your workload profile. It can also help save in subscription costs because Azure Stack HCI hosts are billed by CPU core per month. The guide in the following figure reminds you that a thorough analysis of your workload characteristics is essential prior to reducing the enabled CPU cores on this cluster.
After you've familiarized yourself with the talk track, you can leave your parents and teachers at home and drive through the demos without the detailed explanations. You can navigate using links alone by clicking the X in the upper right-hand corner of any guide. You might choose to proceed down this road to test your knowledge. As a Dell Technologies partner, you might want to create the illusion of performing a demo from a live environment to impress prospective clients.
Hands-on Lab HOL-0313-01
The Microsoft Azure Stack HCI Deployment hands-on lab in the Demo Center will appeal to the more mechanically inclined. It pops open the hood so you can get your hands dirty with all the PowerShell automation in our End-to-End Deployment Guide for Day 1 deployments. It is accompanied by an in-depth student manual to point you in the right direction, but there is a bit more freedom to go off-road compared with the interactive demo. Keep in mind that this is a virtual environment, so certain tasks that require the physical hardware may be limited.
This figure illustrates how you can drag and drop the PowerShell code into the console, so you aren't wasting time typing everything yourself:
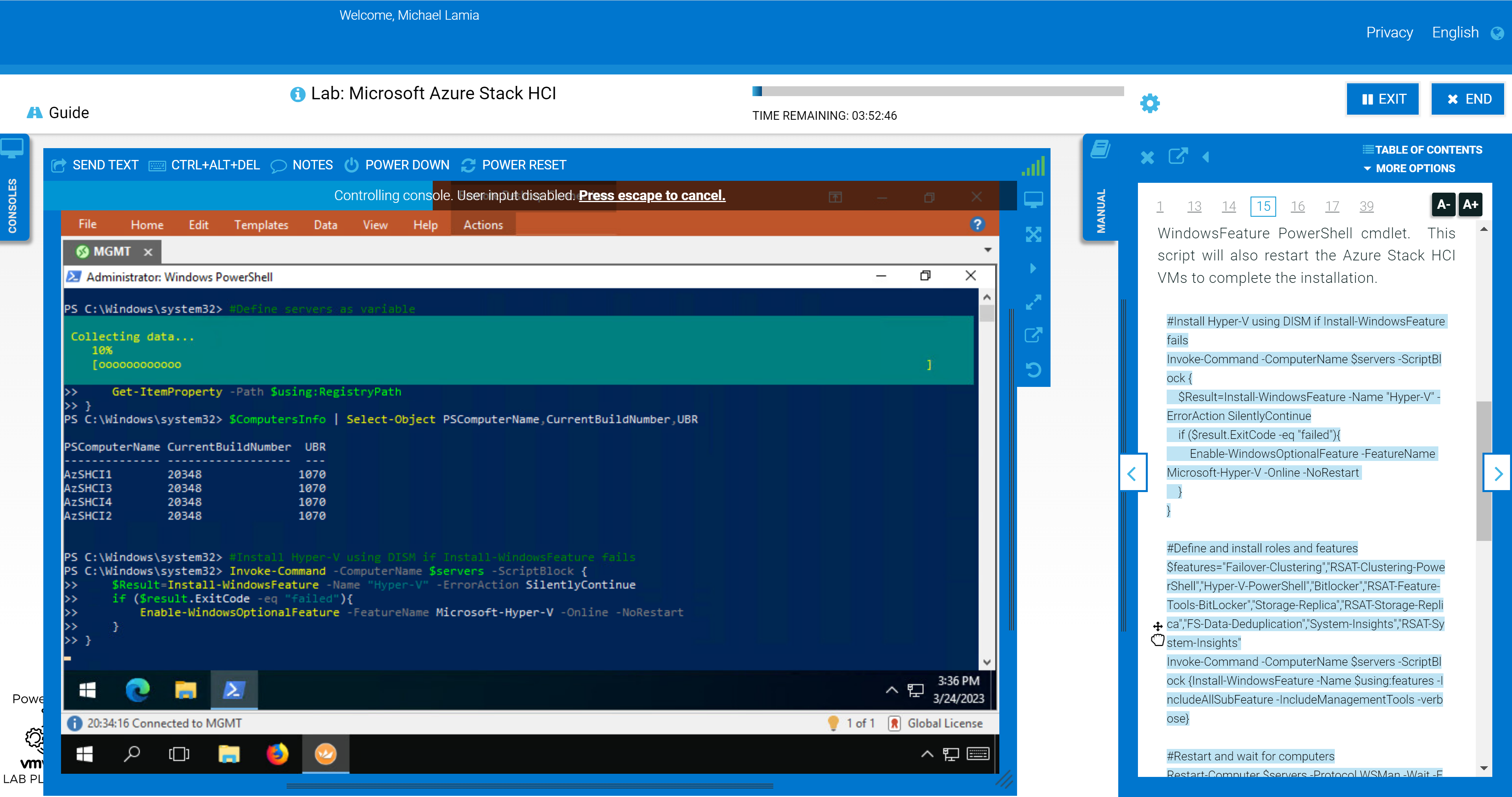
We still show the GUI some love in the later portions of the lab. Failover Cluster Manager and Windows Admin Center make an appearance after you've used PowerShell to configure the hosts, create the cluster, configure a cluster witness, and enable Storage Spaces Direct (S2D). You'll be able to confirm the expected outcome at the command line using the graphical tools.
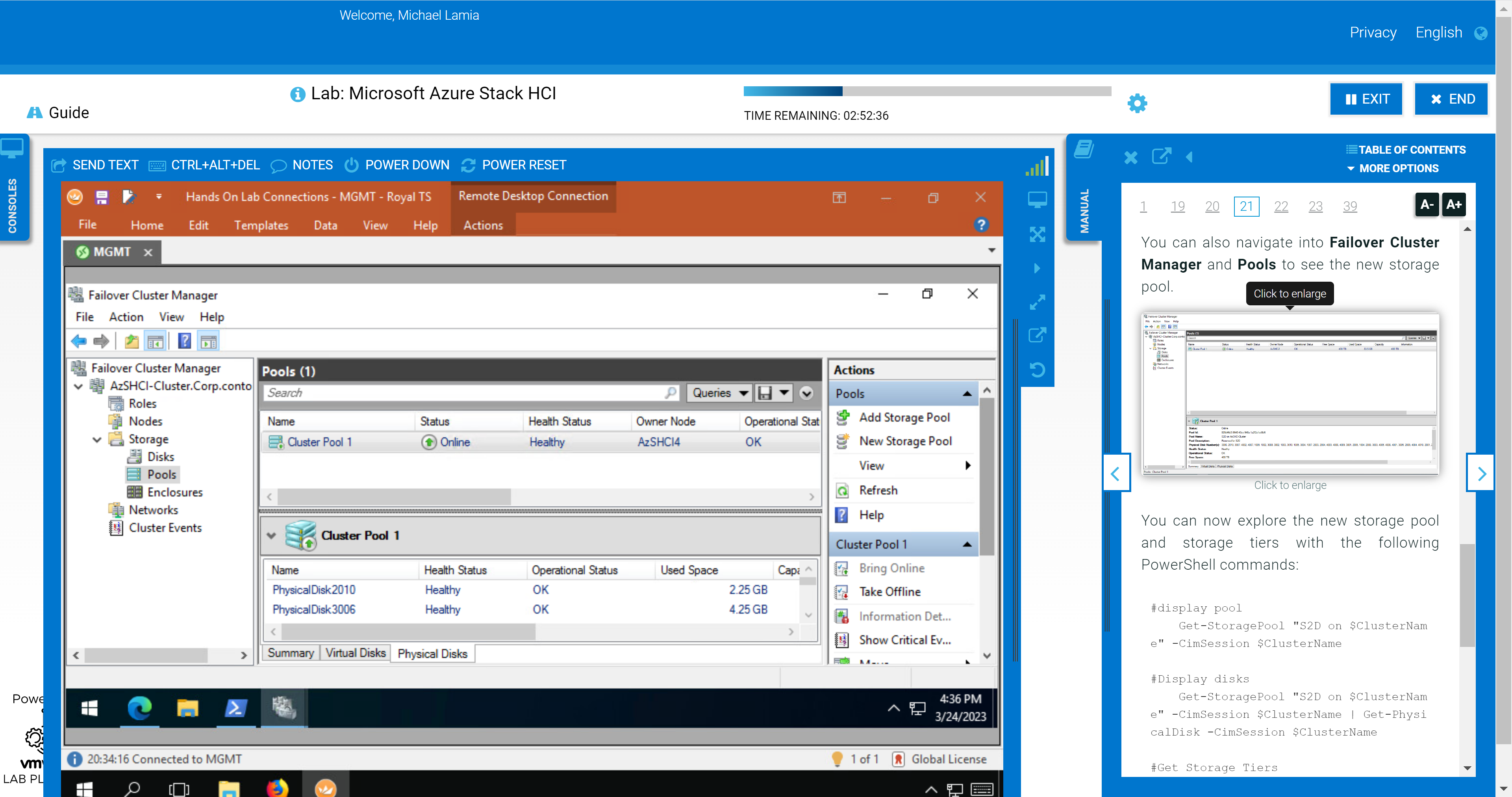
The following figure shows the step where you use Failover Cluster Manager to inspect the newly created storage pool after its created with PowerShell.
You'll also explore some of the management and monitoring capabilities in Windows Admin Center after adding your new cluster as a connection. This section of the HOL stops short of exploring the OpenManage Integration extension, though. We provide a link in the student manual to the interactive demo. If you’re not a fan of the layout of the lab shown in the following figure, you can rearrange the panes to fit your preferences. For example, you can open the manual in a separate window and allow your virtual desktop to consume all your screen real estate.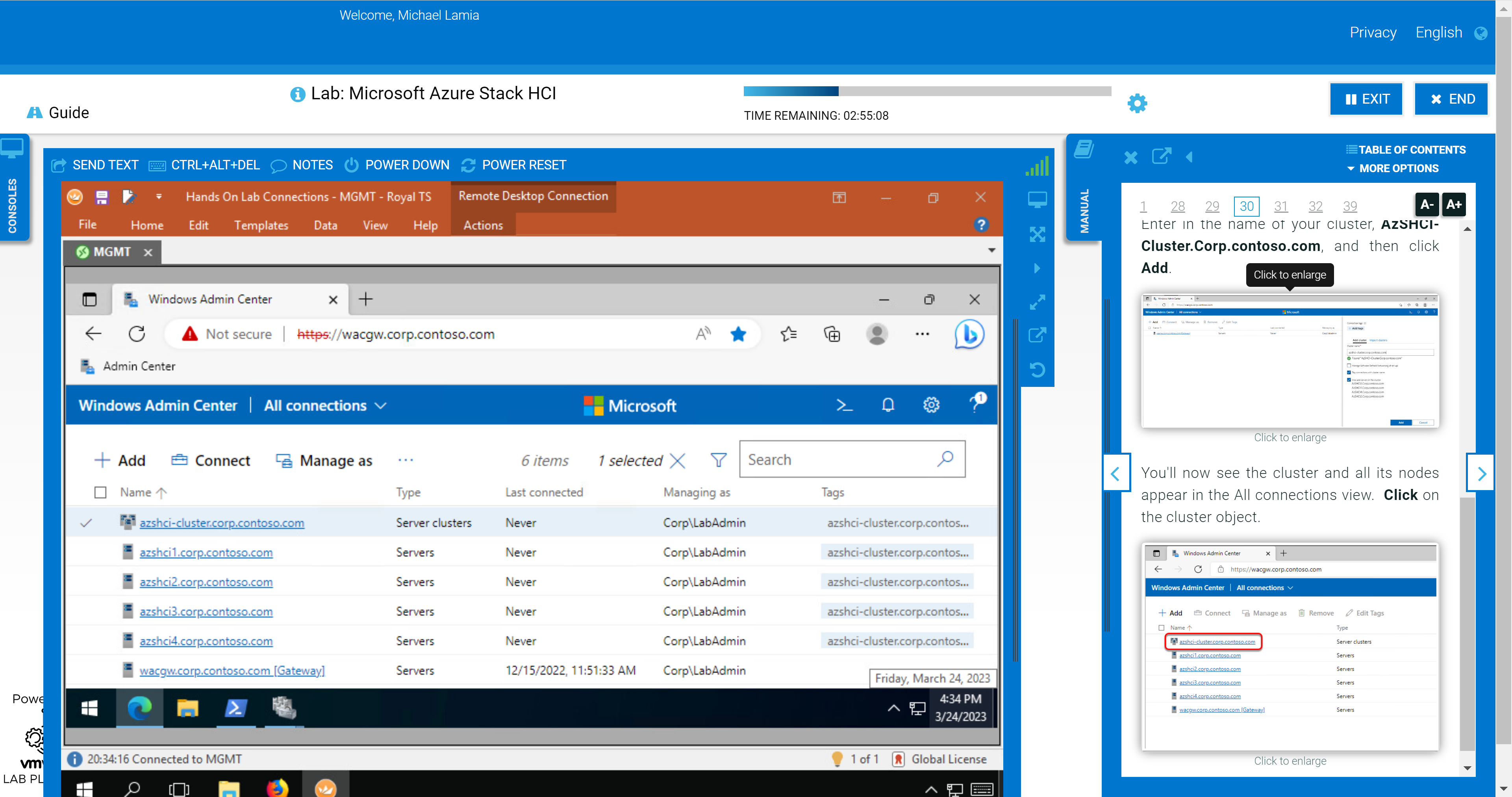
Other Opportunities to Get Hands-On
Maybe the interactive demo and hands-on lab don't meet your needs. Maybe you're looking to kick the tires on Azure Stack HCI without any training wheels. In that case, there are other options available to you. We have compiled a great list of resources that address a variety of use cases:
- MSLab – Using this GitHub project, you can run entire virtual Azure Stack HCI environments directly on your laptop if it meets moderate hardware requirements. There are endless Azure hybrid scenarios available to try (Azure Kubernetes Service hybrid, Azure Virtual Desktop, Azure Arc portfolio, and so on), and new ones are added almost immediately after new features are released.
- Dell GEOS Azure Stack HCI Hands-on Lab Guides – The Dell Global Engineering Outreach Specialists have crafted extensive guides to accompany the MSLab scenarios.
- Dell Technologies & Microsoft | Hybrid Jumpstart – The goal of this jumpstart is to help you grow your knowledge, skills, and experience around several core hybrid cloud solutions from the Dell Technologies and Microsoft hybrid portfolio. This has many highly prescriptive hands-on modules and resembles more of a Pluralsight or Microsoft Learn course.
- Azure Arc Jumpstart – If you want to skip the infrastructure deployment steps and get right into the key features of the Azure Arc portfolio, then this project is for you. All you need is an Azure subscription and a single resource group to get started immediately.
- Dell Technologies Customer Solution Center – Speak with your Dell Technologies account team to schedule a personalized engagement with a Customer Solution Center. Our dedicated subject matter experts can help you with extensive Proofs of Concept with your target workloads.
If you're looking for educational materials on Azure Stack HCI, like white papers, blogs, and videos, visit our Info Hub and main product page.
Be sure to follow me on Twitter @Evolving_Techie and LinkedIn.
Author: Mike Lamia

GPU Acceleration for Dell Azure Stack HCI: Consistent and Performant AI/ML Workloads
Wed, 01 Feb 2023 15:50:35 -0000
|Read Time: 0 minutes
The end of 2022 brought us excellent news: Dell Integrated System for Azure Stack HCI introduced full support for GPU factory install.
As a reminder, Dell Integrated System for Microsoft Azure Stack HCI is a fully integrated HCI system for hybrid cloud environments that delivers a modern, cloud-like operational experience on-premises. It is intelligently and deliberately configured with a wide range of hardware and software component options (AX nodes) to meet the requirements of nearly any use case, from the smallest remote or branch office to the most demanding business workloads.
With the introduction of GPU-capable AX nodes, now we can also support more complex and demanding AI/ML workloads.
New GPU hardware options
Not all AX nodes support GPUs. As you can see in the table below, AX-750, AX-650, and AX-7525 nodes running AS HCI 21H2 or later are the only AX node platforms to support GPU adapters.
Table 1: Intelligently designed AX node portfolio
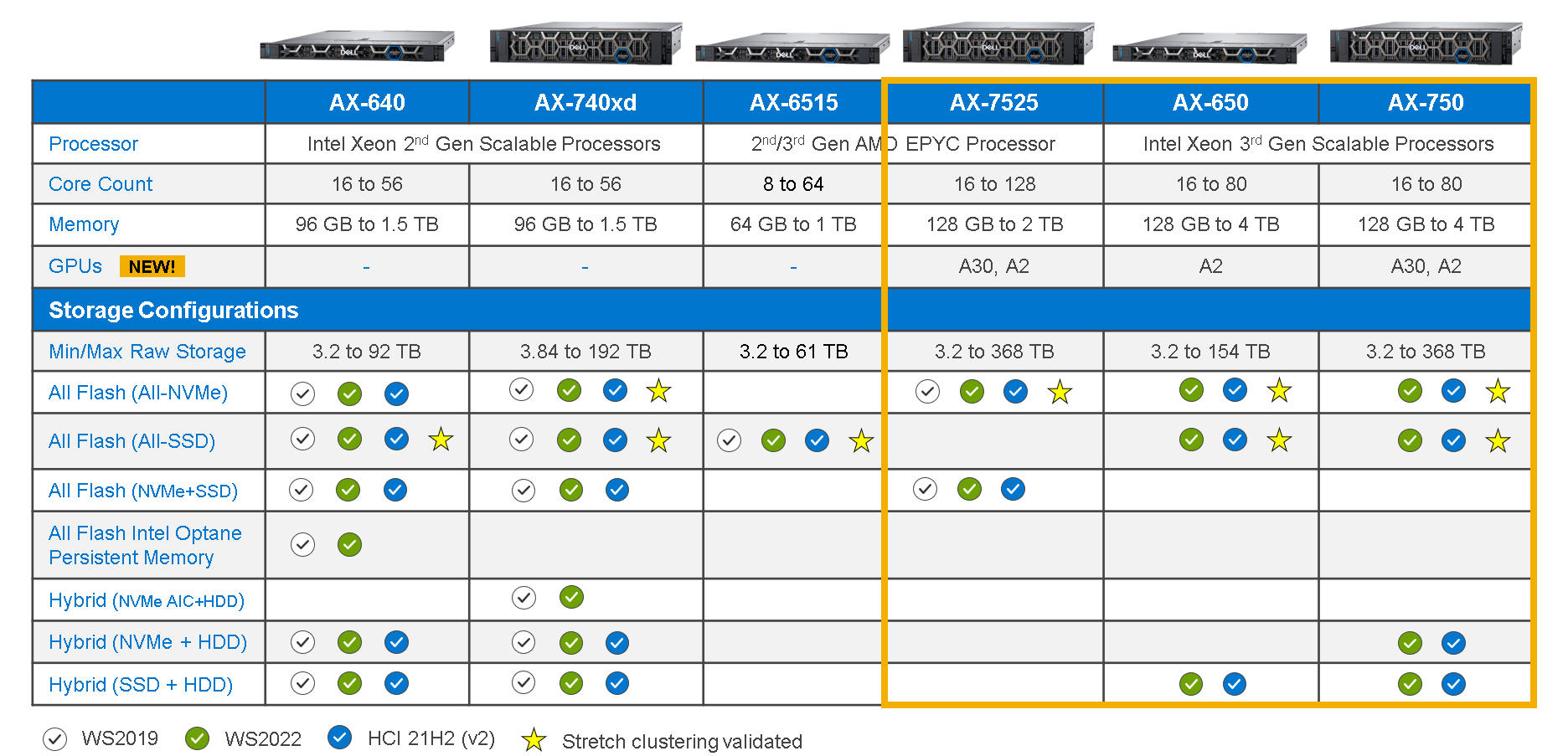
Note: AX-640, AX-740xd, and AX-6515 platforms do not support GPUs.
The next obvious question is what GPU type and number of adapters are supported by each platform.
We have selected the following two NVIDIA adapters to start with:
- NVIDIA Ampere A2, PCIe, 60W, 16GB GDDR6, Passive, Single Wide
- NVIDIA Ampere A30, PCIe, 165W, 24GB HBM2, Passive, Double Wide
The following table details how many GPU adapter cards of each type are allowed in each AX node:
Table 2: AX node support for GPU adapter cards
| AX-750 | AX-650 | AX-7525 | |
|---|---|---|---|
| NVIDIA A2 | Up to 2 | Up to 2 | Up to 3 |
| NVIDIA A30 | Up to 2 | -- | Up to 3 |
| Maximum GPU number (must be same model) | 2 | 2 | 3 |
Use cases
The NVIDIA A2 is the entry-level option for any server to get basic AI capabilities. It delivers versatile inferencing acceleration for deep learning, graphics, and video processing in a low-profile, low-consumption PCIe Gen 4 card.
The A2 is the perfect candidate for light AI capability demanding workloads in the data center. It especially shines in edge environments, due to the excellent balance among form factor, performance, and power consumption, which results in lower costs.
The NVIDIA A30 is a more powerful mainstream option for the data center, typically covering scenarios that require more demanding accelerated AI performance and a broad variety of workloads:
- AI inference at scale
- Deep learning training
- High-performance computing (HPC) applications
- High-performance data analytics
Options for GPU virtualization
There are two GPU virtualization technologies in Azure Stack HCI: Discrete Device Assignment (also known as GPU pass-through) and GPU partitioning.
Discrete Device Assignment (DDA)
DDA support for Dell Integrated System for Azure Stack HCI was introduced with Azure Stack HCI OS 21H2. When leveraging DDA, GPUs are basically dedicated (no sharing), and DDA passes an entire PCIe device into a VM to provide high-performance access to the device while being able to utilize the device native drivers. The following figure shows how DDA directly reassigns the whole GPU from the host to the VM:
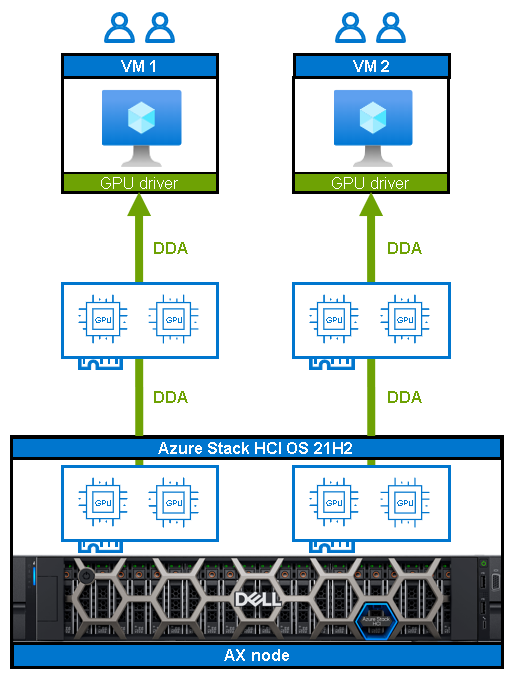
Figure 1: Discrete Device Assignment in action
To learn more about how to use and configure GPUs with clustered VMs with Azure Stack HCI OS 21H2, you can check Microsoft Learn and the Dell Info Hub.
GPU partitioning (GPU-P)
GPU partitioning allows you to share a physical GPU device among several VMs. By leveraging single root I/O virtualization (SR-IOV), GPU-P provides VMs with a dedicated and isolated fractional part of the physical GPU. The following figure explains this more visually:
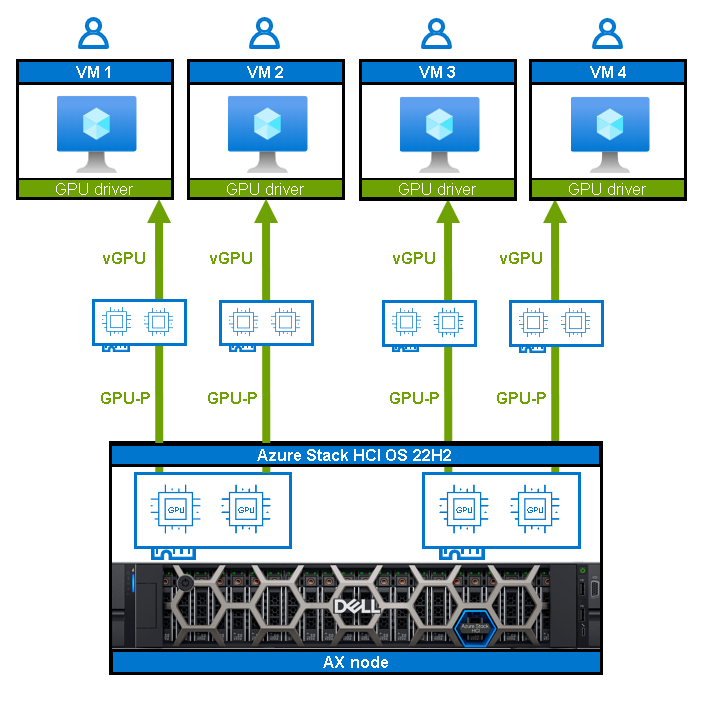
Figure 2: GPU partitioning virtualizing 2 physical GPUs into 4 virtual vGPUs
The obvious advantage of GPU-P is that it enables enterprise-wide utilization of highly valuable and limited GPU resources.
Note these important considerations for using GPU-P:
- Azure Stack HCI OS 22H2 or later is required.
- Host and guest VM drivers for GPU are needed (requires a separate license from NVIDIA).
- Not all GPUs support GPU-P; currently Dell only supports A2 (A16 coming soon).
- We strongly recommend using Windows Admin Center for GPU-P to avoid mistakes.
You’re probably wondering about Azure Virtual Desktop on Azure Stack HCI (still in preview) and GPU-P. We have a Dell Validated Design today and will be refreshing it to include GPU-P during this calendar year.
To learn more about how to use and configure GPU-P with clustered VMs with Azure Stack HCI OS 22H2, you can check Microsoft Learn and the Dell Info Hub (Dell documentation coming soon).
Timeline
As of today, Dell Integrated System for Microsoft Azure Stack HCI only provides support for Azure Stack HCI OS 21H2 and DDA.
Full support for Azure Stack HCI OS 22H2 and GPU-P is around the corner, by the end of the first quarter, 2023.
Conclusion
The wait is finally over, we can now leverage in our Azure Stack HCI environments the required GPU power for AI/ML highly demanding workloads.
Today, DDA provides fully dedicated GPU pass-through utilization, whereas with GPU-P we will very soon have the choice of providing a more granular GPU consumption model.
Thanks for reading, and stay tuned for the ever-expanding list of validated GPUs that will unlock and enhance even more use cases and workloads!
Author: Ignacio Borrero, Senior Principal Engineer, Technical Marketing Dell CI & HCI
@virtualpeli

Single-Node Azure Stack HCI is now available!
Wed, 19 Oct 2022 15:25:20 -0000
|Read Time: 0 minutes
Single-Node Azure Stack HCI is now available!
Earlier this year, Microsoft announced the release of a new flavor for Azure Stack HCI: Azure Stack HCI single node. This is another milestone in Microsoft’s long history of evolution for the Azure Stack family of products.
Back in 2017, Microsoft announced Azure Stack, the platform to extend the cloud to the customers’ data centers. One of the key design principles for this release was to make it easy to create hybrid cloud environments.
In March 2019, a new member of the Azure Stack family was announced: Azure Stack HCI. This incumbent is a main driver for IT modernization, infrastructure consolidation, and true hybridity for Microsoft environments. Azure Stack HCI enables customers to run virtual machines (VMs), cloud native applications, and Azure Services on-premises on top of hyperconverged infrastructure (HCI) integrated systems as an optimal solution in performance and cost. Dell Integrated Systems for Azure Stack HCI delivers a seamless Azure experience, simplifies Azure on-premises, and accelerates innovation.
Figure 1 Dell Technologies vision of Microsoft Azure Stack HCI
While Azure Stack HCI was born as a scalable solution to adapt to most customer IT needs, certain scenarios require other intrinsic characteristics. We think of the “edge” as the IT place where data is acted on near its creation point to generate immediate and essential value. In many cases, these edge locations have severe space and cooling restrictions, with more emphasis on data proximity and operational efficiency than scalability or resiliency. For these scenarios, having a low-cost, highly performing, and easy-to-manage platform is more important than prioritizing scalability and cluster-level high availability.
The edge is becoming the next technology turning point, where organizations are planning to increase their IT spending significantly (IDC EdgeView Survey). Microsoft designed an Azure Stack HCI platform for this scenario. Any IT deployment in which we benefit from the data being collected and processed where it’s produced, away from a core data center, will become eligible for an Azure Stack HCI single-node deployment. Edge can be manufacturing, retail, energy, telco, healthcare, smart connected cities—you name it. If we think about Machine Learning (ML), Artificial Intelligence (AI), or Internet of Things (IoT) scenarios, single-node Azure Stack HCI clusters fit perfectly into these typical edge needs. A single-node cluster provides a cost-sensitive solution that supports the same workloads a multi-node cluster does and behaves in a similar way.
Dell Technologies portfolio for Azure Stack HCI single node is based on the same 15G models also available for multi-node deployments, as shown here:

Figure 2 Dell Technologies Integrated System for Microsoft Azure Stack HCI portfolio
In terms of features, as mentioned before, single-node and multi-node systems behave similarly. The following table shows the main attributes of both. Note that they are nearly identical except for a few distinctions, the most relevant being the lack of stretched-cluster support:
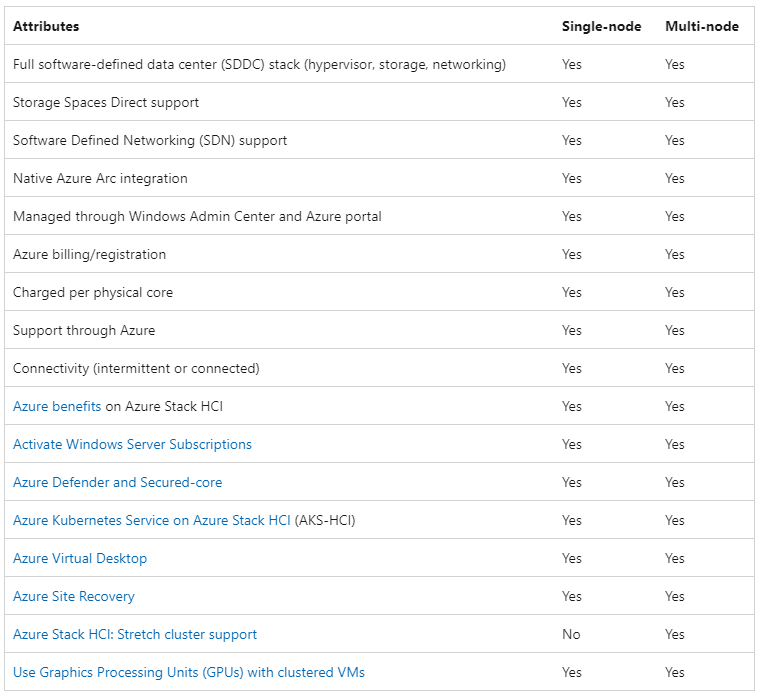
Figure 3 Azure Stack HCI single and multi-node attributes comparison (Source: Microsoft)
There are a few differences worth highlighting:
- Windows Admin Center (WAC) does not support the creation of single-node clusters. Deployment is done through PowerShell and Storage Spaces Direct enablement.
- Stretched clusters are not supported with single-node deployments. Stretched clusters require a minimum of two nodes at each site.
- Storage Bus Cache (SBL), which is commonly used to improve read/write performance on Windows Server/Azure Stack HCI OS, is not supported in single-node clusters.
- There are limitations on WAC cluster management functionality. PowerShell can be used to cover those limitations.
- Single-node clusters support only a single drive type: either NVMe or SSD drives, but not a mix of both.
- For cluster lifecycle management, Open Manage Integration with Microsoft Admin Center (OMIMSWAC) Cluster Aware Updating (CAU) cannot be used. Vendor-provided solutions (drives and firmware) or a PowerShell and Server Configuration tool (SConfig) are valid alternatives.
If your Azure based edge workloads are moving further from the data center, and you understand the design differences listed above for Dell Azure Stack HCI single node, this could be a great fit for your business.
We expect Azure Stack HCI single-node clusters to evolve over time, so check our Info Hub site for the latest updates!
Author: Iñigo Olcoz
Twitter: VirtualOlcoz
References
- IDC EdgeView Survey 2022
- Microsoft: Azure Stack HCI single-node clusters
- Info Hub: Microsoft HCI Solutions
- Info Hub: Dell OpenManage Integration with Microsoft Windows Admin Center v2.0 Technical Walkthrough
- Info Hub: Technology leap ahead: 15G Intel based Dell Integrated System for Microsoft Azure Stack HCI

Dell Hybrid Management: Azure Policies for HCI Compliance and Remediation
Mon, 30 May 2022 17:05:47 -0000
|Read Time: 0 minutes
Dell Hybrid Management: Azure Policies for HCI Compliance and Remediation
Companies that take an “Azure hybrid first” strategy are making a wise and future-proof decision by consolidating the advantages of both worlds—public and private—into a single entity.
Sounds like the perfect plan, but a key consideration for these environments to work together seamlessly is true hybrid configuration consistency.
A major challenge in the past was having the same level of configuration rules concurrently in Azure and on-premises. This required different tools and a lot of costly manual interventions (subject to human error) that resulted, usually, in potential risks caused by configuration drift.
But those days are over.
We are happy to introduce Dell HCI Configuration Profile (HCP) Policies for Azure, a revolutionary and crucial differentiator for Azure hybrid configuration compliance.
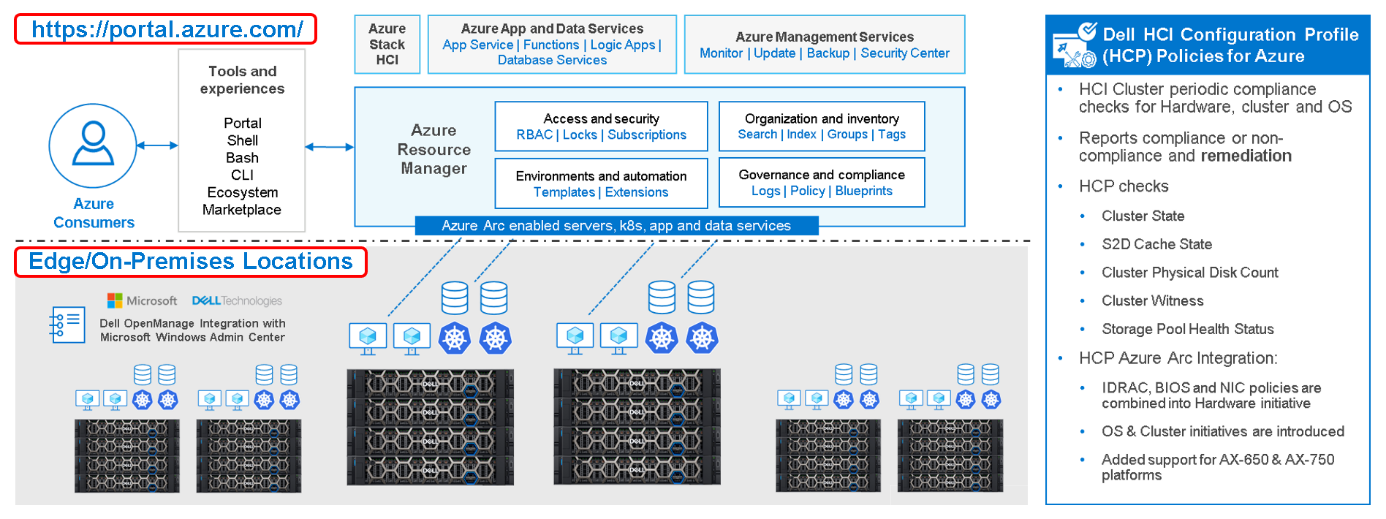
Figure 1: Dell Hybrid Management with Windows Admin Center (local) and Azure/Azure Arc (public)
So, what is it? How does it work? What value does it provide?
Dell HCP Policies for Azure is our latest development for Dell OpenManage Integration with Windows Admin Center (OMIMSWAC). With it, we can now integrate Dell HCP policy definitions into Azure Policy. Dell HCP is the specification that captures the best practices and recommended configurations for Azure Stack HCI and Windows-based HCI solutions from Dell to achieve better resiliency and performance with Dell HCI solutions.
The HCP Policies feature functions at the cluster level and is supported for clusters that are running Azure Stack HCI OS (21H2) and pre-enabled for Windows Server 2022 clusters.
IT admins can manage Azure Stack HCI environments through two different approaches:
- At-scale through the Azure portal using the Azure Arc portfolio of technologies
- Locally on-premises using Windows Admin Center
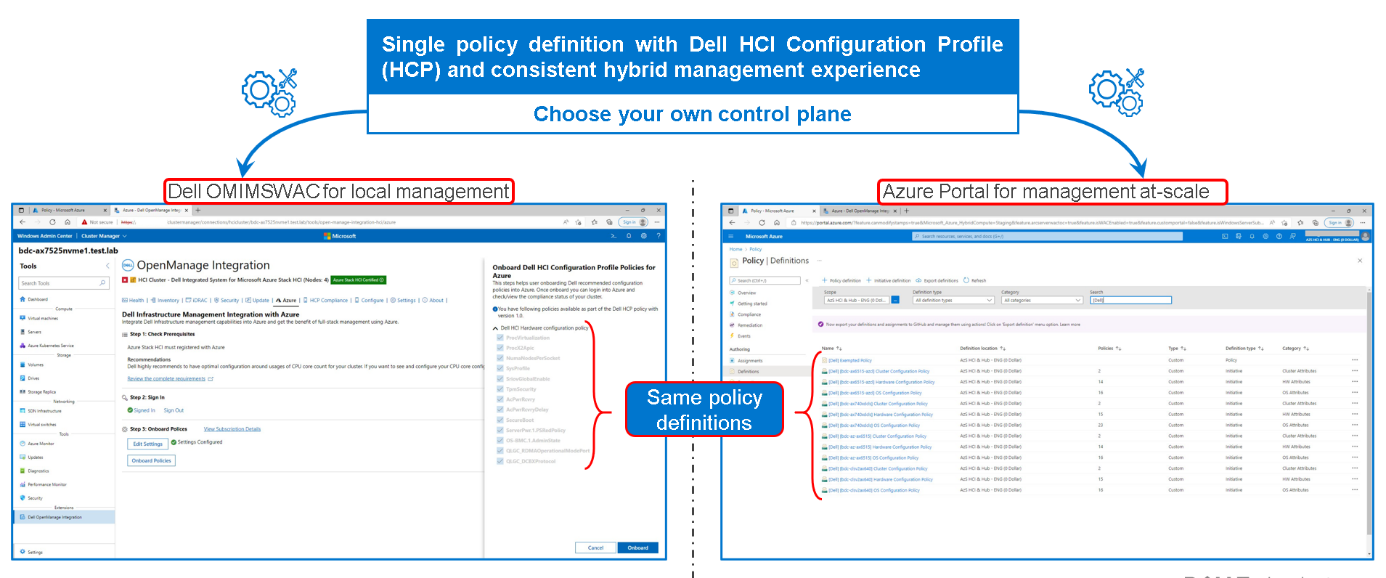
Figure 2: Dell HCP Policies for Azure - onboarding Dell HCI Configuration Profile
By using a single Dell HCP policy definition, both options provide a seamless and consistent management experience.
Running Check Compliance automatically compares the recommended rules packaged together in the Dell HCP policy definitions with the settings on the running integrated system. These rules include configurations that address the hardware, cluster symmetry, cluster operations, and security.

Figure 3: Dell HCP Policies for Azure - HCP policy compliance
Dell HCP Policy Summary provides the compliance status of four policy categories:
- Dell Infrastructure Lock Policy - Indicates enhanced security compliance to protect against unintentional changes to infrastructure
- Dell Hardware Configuration Policy - Indicates compliance with Dell recommended BIOS, iDRAC, firmware, and driver settings that improve cluster resiliency and performance
- Dell Hardware Symmetry Policy - Indicates compliance with integrated-system validated components on the support matrix and best practices recommended by Dell and Microsoft
- Dell OS Configuration Policy - Indicates compliance with Dell recommended operating system and cluster configurations
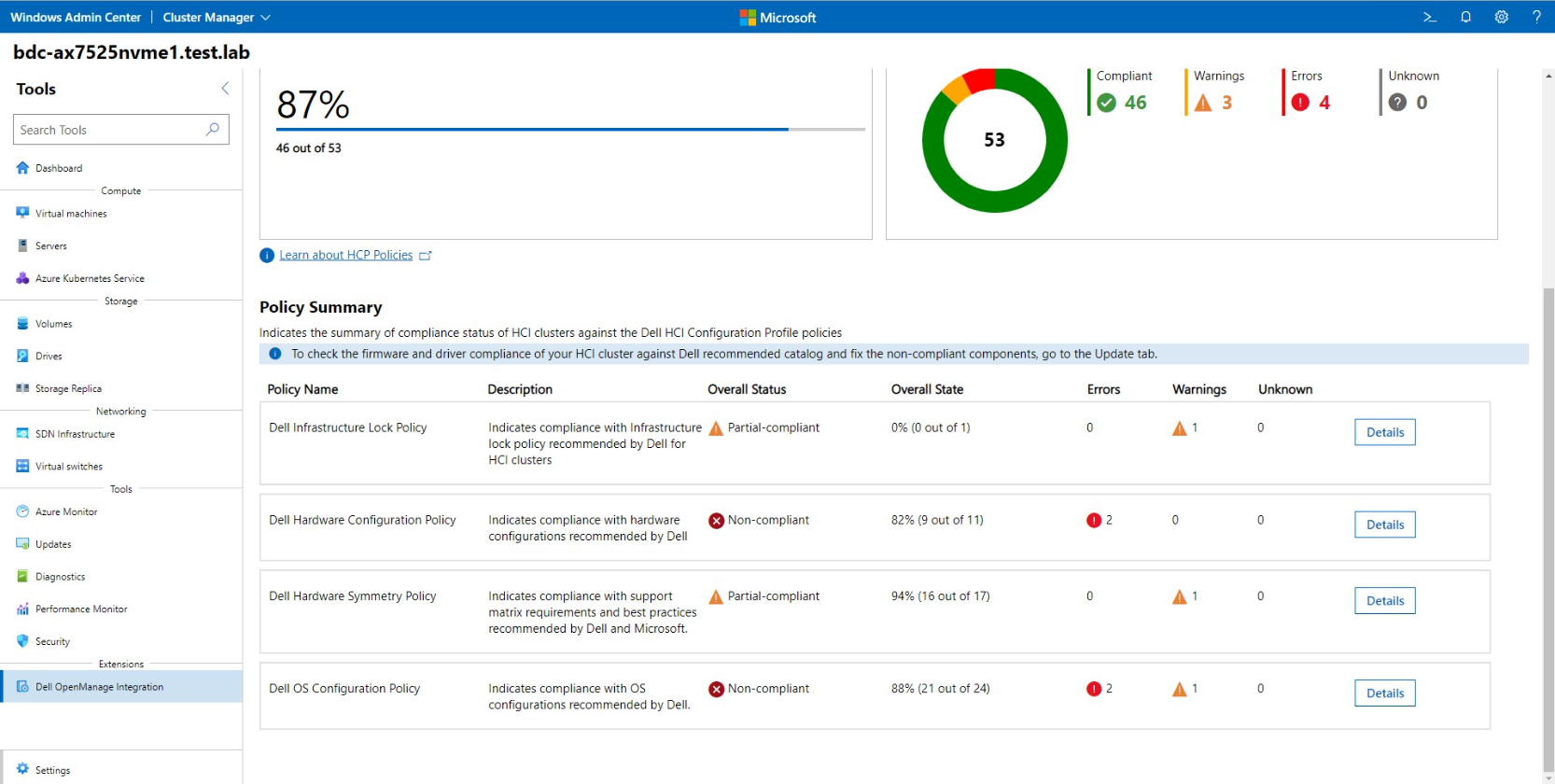
Figure 4: Dell HCP Policies for Azure - HCP Policy Summary
To re-align non-compliant policies with the best practices validated by Dell Engineering, our Dell HCP policy remediation integration with WAC (unique at the moment) helps to fix any non-compliant errors. Simply click “Fix Compliance.”

Figure 5: Dell HCP Policies for Azure - HCP policy remediation
Some fixes may require manual intervention; others can be corrected in a fully automated manner using the Cluster-Aware Updating framework.
Conclusion
The “Azure hybrid first” strategy is real today. You can use Dell HCP Policies for Azure, which provides a single-policy definition with Dell HCI Configuration Profile and a consistent hybrid management experience, whether you use Dell OMIMSWAC for local management or Azure Portal for management at-scale.
With Dell HCP Policies for Azure, policy compliance and remediation are fully covered for Azure and Azure Stack HCI hybrid environments.
You can see Dell HCP Policies for Azure in action at the interactive Dell Demo Center.
Thanks for reading!
Author: Ignacio Borrero, Dell Senior Principal Engineer CI & HCI, Technical Marketing
Twitter: @virtualpeli

Exclusive Preview of Dell Azure Stack HCI Arc Integrated Configuration Compliance
Tue, 01 Mar 2022 20:39:03 -0000
|Read Time: 0 minutes
Who doesn’t enjoy VIP treatment? Exciting opportunities to feel like royalty include winning box seats at a sporting event or getting invited to attend opening night at a new restaurant. I received an unexpected upgrade to business class on a flight a couple years ago and remember texting every celebratory meme I could find to friends and family! These are the moments in life to really savor.

In my line of work as a technical marketing engineer, I relish any situation where VIP stands for Very Important Person rather than Virtual IP address. Private previews of the latest technology often provide both flavors of VIP.
I consider myself fortunate to be among the first to experience cutting-edge solutions with the potential to solve today’s most vexing business challenges. I also get direct access to the best minds in the software and hardware industry. They welcome my feedback, and there’s no better feeling than knowing that I’ve made a meaningful contribution to a product that will benefit the broader community! Now it’s your turn to feel the thrill of gaining early access to long-awaited new software capabilities for Azure Stack HCI.
Your official preview invitation has arrived.
You are cordially invited to participate in an exclusive VIP preview of Azure Stack HCI Configuration and Policy Compliance Visibility from Dell Technologies, integrated with Azure Arc.
The Azure Arc portfolio demonstrates the unique Microsoft approach to delivering hybrid cloud by extending Azure platform services and management capabilities to data center, edge, and multi-cloud environments. Dell Technologies uses the Azure Policy guest configuration feature and Azure Arc-enabled servers to audit software and hardware settings in Dell Integrated System for Microsoft Azure Stack HCI.
Our engineering-validated integrated system is Azure hybrid by design and delivers efficient operations using our Dell OpenManage Integration with Microsoft Windows Admin Center extension and snap-ins.
When we first developed our extension, we delivered deep hardware monitoring, inventory, and troubleshooting capabilities. Over the last few years, we have collected valuable feedback from preview programs to drive further investment and innovation into our extension. Customer experience has helped us shape new features including:
- One-click full stack lifecycle management using Cluster-Aware Updating
- Automated cluster creation and expansion
- Dynamic CPU core management
- Intrinsic infrastructure security management
The Azure Arc integration from Dell Technologies complements Windows Admin Center and our OpenManage extension by applying robust governance services to the integrated system. Our Azure Arc integration creates software and hardware compliance policies for near real-time detection of infrastructure configuration drift at-scale. It protects clusters in the data center or geographically dispersed to ROBO and edge locations from malicious threats and inadvertent changes to operating system, BIOS, iDRAC, and network adapter settings on AX nodes from Dell Technologies. Without this visibility, you leave yourself vulnerable to security breaches, costly downtime, and degraded application performance.
All we need now is your experience and valuable feedback to help us fine-tune this critical capability!
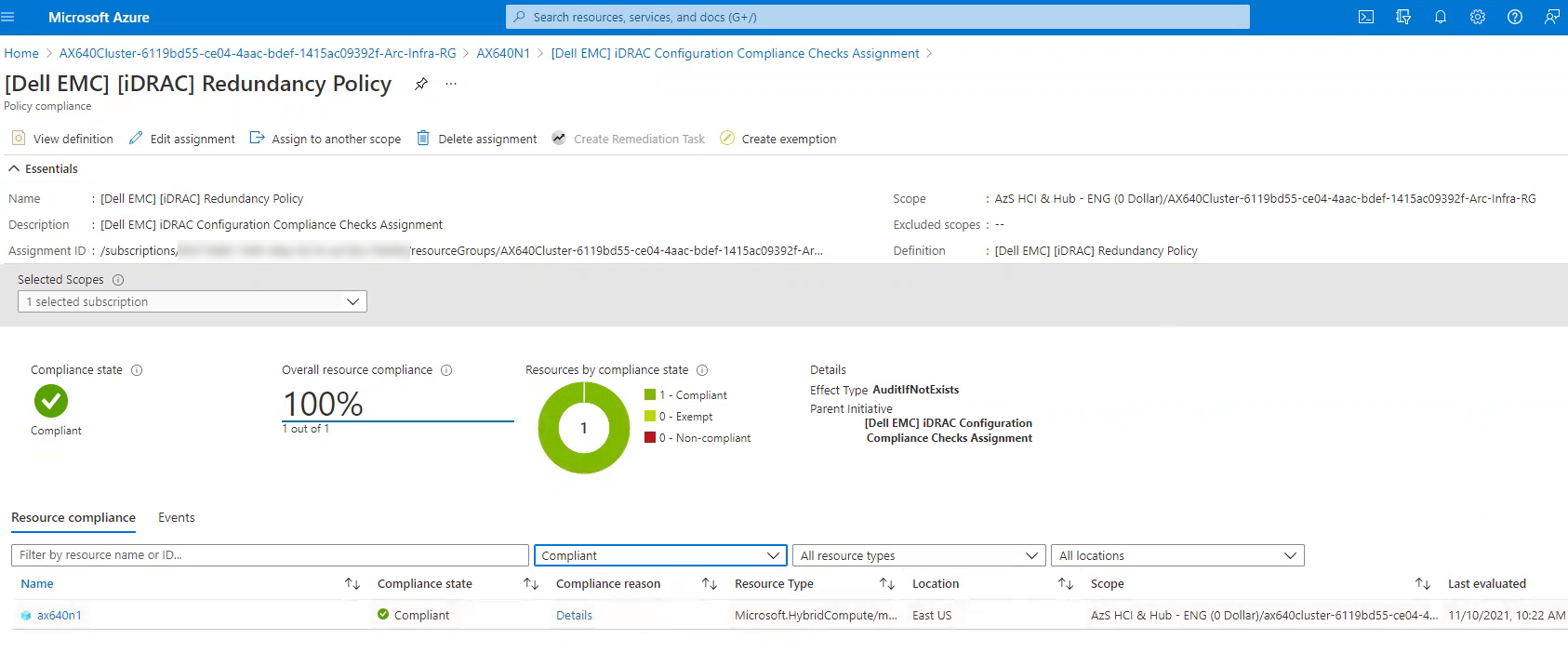
Consider Azure Portal your observation deck.
Intentionally selected AX node attributes and values targeted by our Azure Arc integration are routinely checked for compliance against pre-defined business rules. Then, compliance results are visualized in the Policy blade of the Azure portal as shown in the following screen shots.
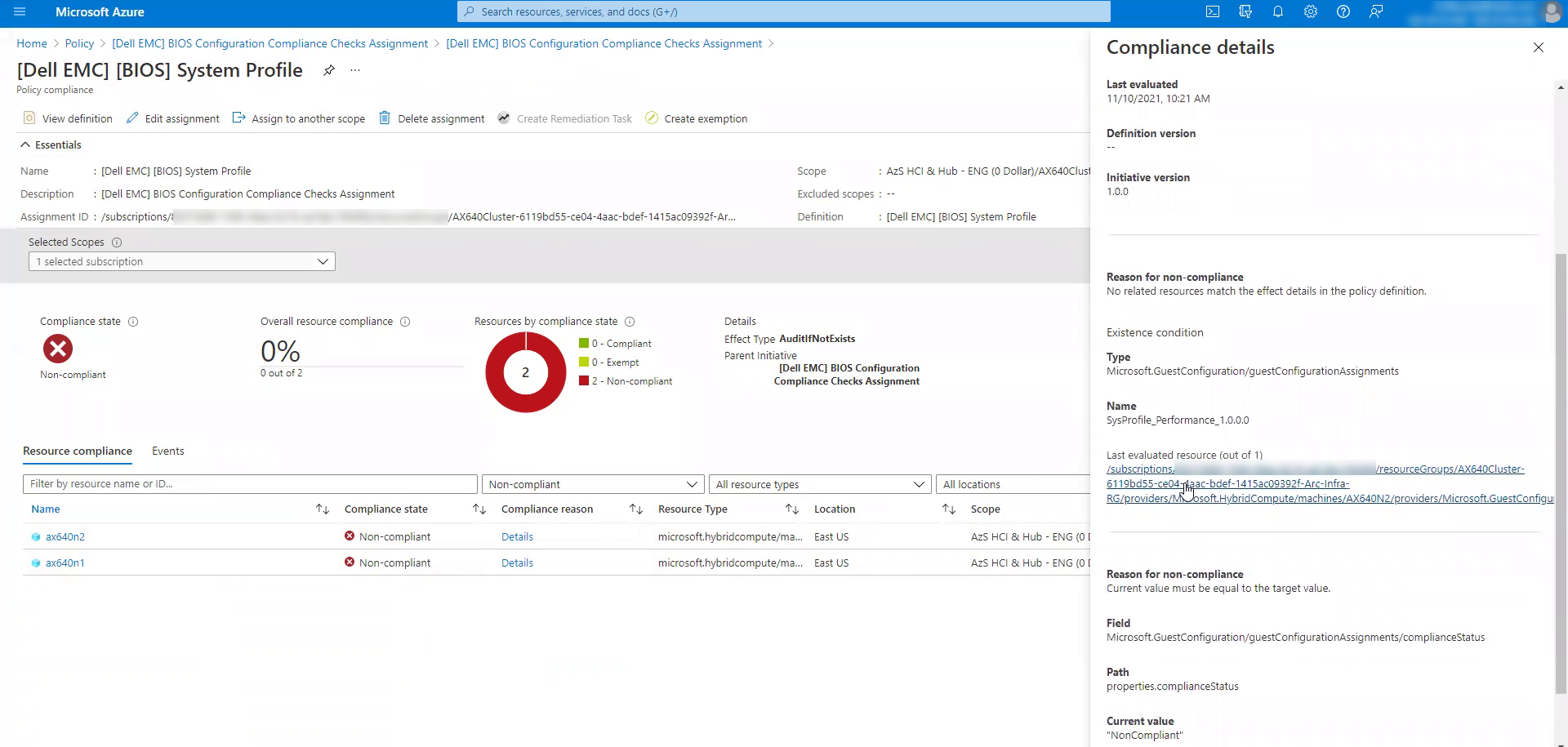
Help prevent costly business setbacks.
This guided preview is checking select OS-level, cluster-level, BIOS, iDRAC, and network adapter attributes that optimize Azure Stack HCI. If an unapproved change to these attribute values goes undetected, the integrated system may experience degradation to performance, availability, and security. The abnormal behavior of the system may not be readily traced back to the modified OS and hardware setting – delaying Mean Time to Repair (MTTR). The longer the incident takes to resolve, the greater the consequences to your business in the form of decreased productivity, lost revenue, or tarnished reputation.
Ready for your sneak peek?
Here are just some of the preview benefits in store:
Playing with the newest toys in your own sandbox and directly with the engineers creating the solution
Helping to make a cutting-edge technology even better with a vendor who is listening and responding to your feedback
Achieving superhero status at your business by automating routine administrative tasks that strengthen infrastructure integrity and improve operational efficiency
Availability is limited for this guided preview. To claim your spot, please contact your account manager right away. They will coordinate with the internal teams at Dell Technologies and schedule further conversations with you. A professional services engagement is required to install the Azure Arc integration during the preview phase. We will work together to prepare the Azure artifacts and run the required scripts. Over time, Dell Technologies intends to expand this compliance visibility to a much larger set of attributes in an extensible, user-friendly framework.
I hope you’re as excited as I am to deliver this configuration and policy compliance visibility using Azure Arc to Dell Integrated System for Microsoft Azure Stack HCI. The technical previews that I’ve been a part of have been some of the most memorable and rewarding experiences of my career. An unexpected upgrade to business class is nice but contributing to the success of a technology that will help my industry peers for years to come? Priceless.
Author: Michael Lamia
Twitter: @Evolving_Techie
LinkedIn: https://www.linkedin.com/in/michaellamia/

Azure Stack HCI automated and consistent protection through Secured-core and Infrastructure lock
Mon, 21 Feb 2022 17:45:58 -0000
|Read Time: 0 minutes
Global damages related to cybercrime were predicted to reach USD 6 trillion in 2021! This staggering number highlights the very real security threat faced not only by big companies, but also for small and medium businesses across all industries.
Cyber attacks are becoming more sophisticated every day and the attack surface is constantly increasing, now even including the firmware and BIOS on servers.

Figure 1: Cybercrime figures for 2021
However, this isn’t all bad news, as there are now two new technologies (and some secret sauce) that we can leverage to proactively defend against unauthorized access and attacks to our Azure Stack HCI environments, namely:
- Secured-core Server
- Infrastructure lock
Let’s briefly discuss each of them.
Secured-core is a set of Microsoft security features that leverage the latest security advances in Intel and AMD hardware. It is based on the following three pillars:
- Hardware root-of-trust: requires TPM 2.0 v3, verifies for validly signed firmware at boot times to prevent tamper attacks
- Firmware protection: uses Dynamic Root of Trust of Measurement (DRTM) technology to isolate the firmware and limit the impact of vulnerabilities
- Virtualization-based security (VBS): in conjunction with hypervisor-based code integrity (HVCI), VBS provides granular isolation of privileged parts of the OS (like the kernel) to prevent attacks and exfiltration of data
Infrastructure lock provides robust protection against unauthorized access to resources and data by preventing unintended changes to both hardware configuration and firmware updates.
When the infrastructure is locked, any attempt to change the system configuration is blocked and an error message is displayed.
Now that we understand what these technologies provide, one might have a few more questions, such as:
- How do I install these technologies?
- Is it easy to deploy and configure?
- Does it require a lot of human manual (and perhaps error prone) interaction?
In short, deploying these technologies is not an easy task unless you have the right set of tools in place.
This is when you’ll need the “secret sauce”— which is the Dell OpenManage Integration with Microsoft Windows Admin Center (OMIMSWAC) on top of our certified Dell Cyber-resilient Architecture, as illustrated in the following figure:
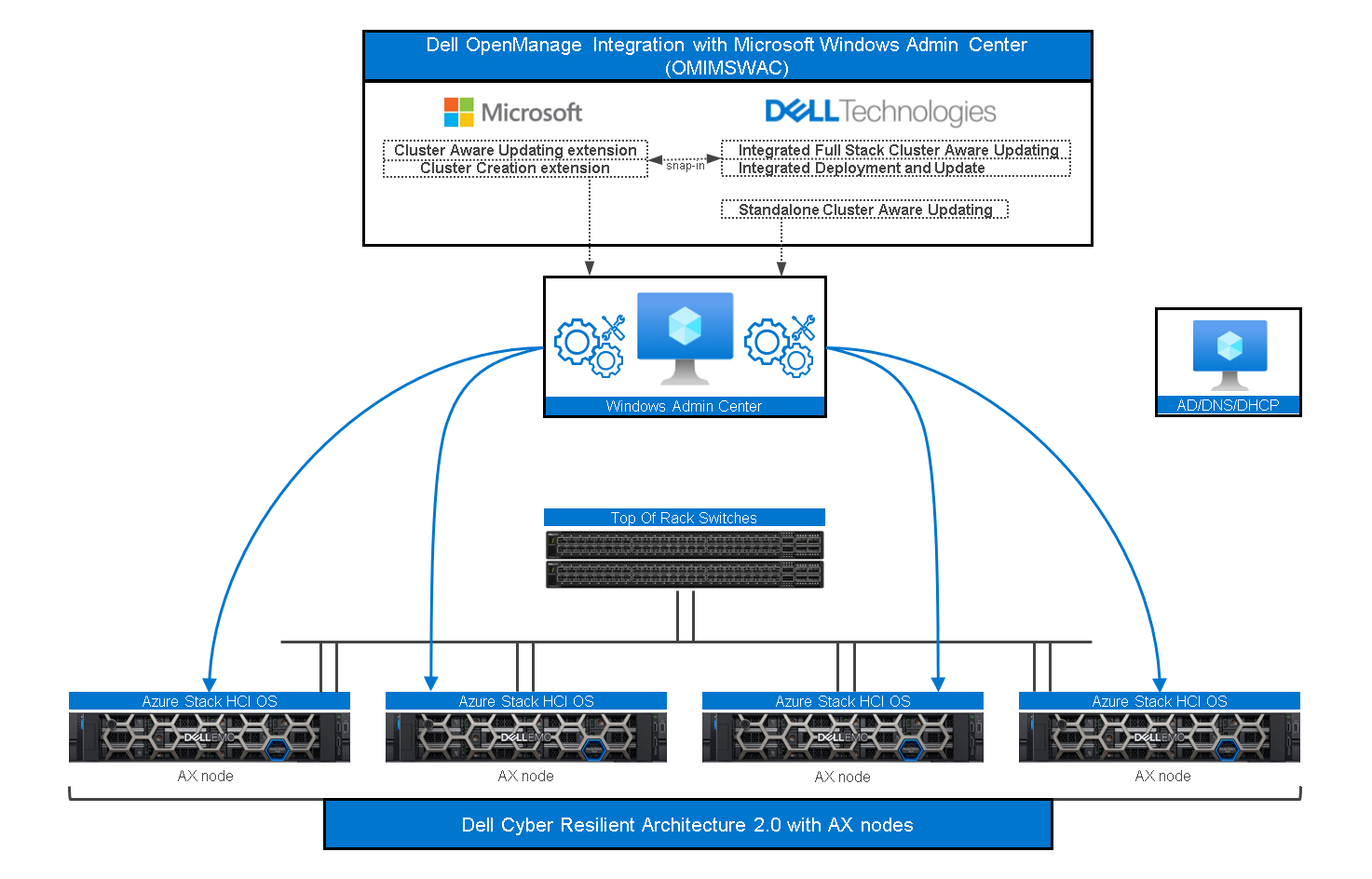
Figure 2: OMIMSWAC and Dell Cyber-resilient Architecture with AX Nodes
As a quick reminder, Windows Admin Center (WAC) is Microsoft’s single pane of glass for all Windows management related tasks.
Dell OMIMSWAC extensions make WAC even better by providing additional controls and management possibilities for certain features, such as Secured-core and Infrastructure lock.
Dell Cyber Resilient Architecture 2.0 safeguards customer’s data and intellectual property with a robust, layered approach.
Since a picture is worth a thousand words, the next section will show you what WAC extensions look like and how easy and intuitive they are to play with.
Dell OMIMSWAC Secured-core
The following figure shows our Secured-core snap-in integration inside the WAC security blade and workflow.
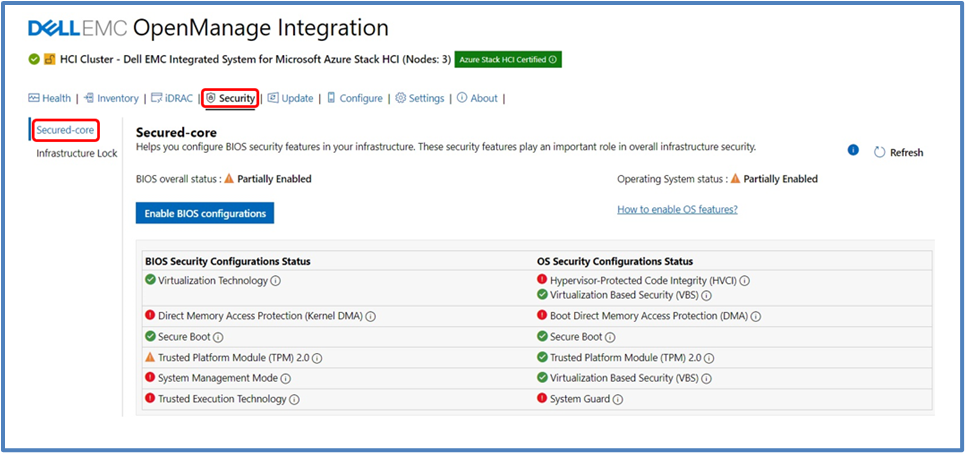
Figure 3: OMIMSWAC Secured-core view
The OS Security Configuration Status and the BIOS Security Configuration Status are displayed. The BIOS Security Configuration Status is where we can set the Secured-core required BIOS settings for the entire cluster.
OS Secured-core settings are visible but cannot be altered using OMIMSWAC (you would directly use WAC for it). You can also view and manage BIOS settings for each node individually.
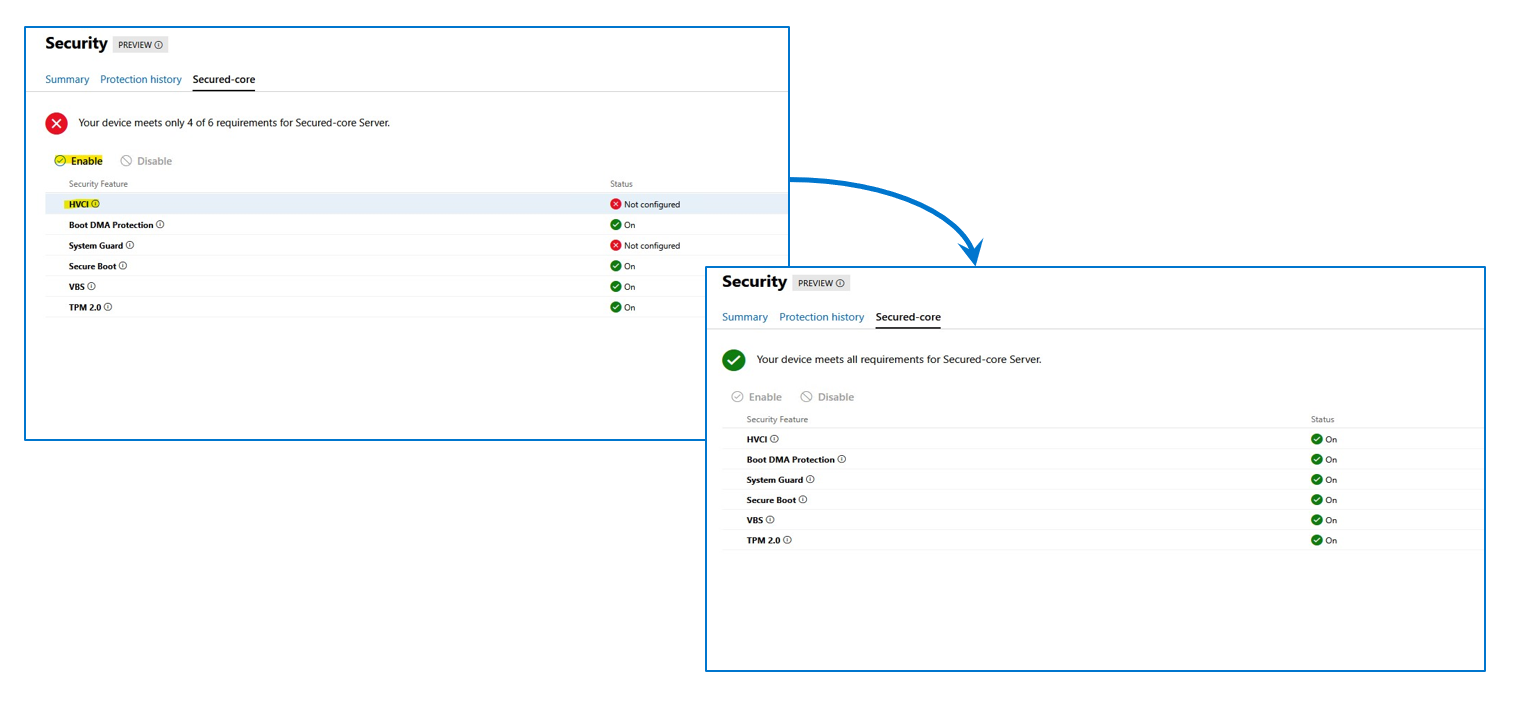
Figure 4: OMIMSWAC Secured-core, node view
Prior to enabling Secured-core, the cluster nodes must be updated to Azure Stack HCI, version 21H2 (or newer). For AMD Servers, the DRTM boot driver (part of the AMD Chipset driver package) must be installed.
Dell OMIMSWAC Infrastructure lock
The following figure illustrates the Infrastructure lock snap-in integration inside the WAC security blade and workflow. Here we can enable or disable Infrastructure lock to prevent unintended changes to both hardware configuration and firmware updates.
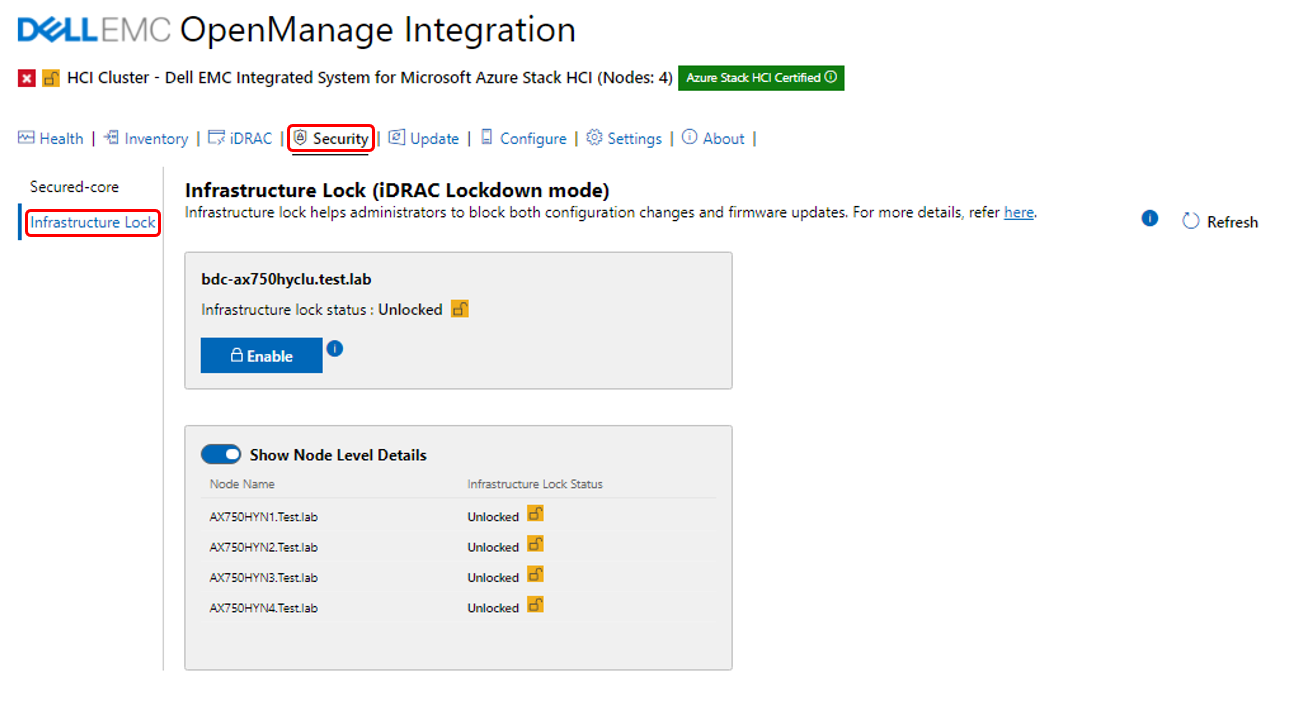
Figure 5: OMIMSWAC Infrastructure lock
Enabling Infrastructure lock also blocks the server or cluster firmware update process using OpenManage Integration extension tool. This means a compliance report will be generated if you are running a Cluster Aware Update (CAU) operation with Infrastructure lock enabled, which will block the cluster updates. If this occurs, you will have the option to temporarily disable Infrastructure lock and have it automatically re-enabled when the CAU is complete.
Conclusion
Dell understands the importance of the new security features introduced by Microsoft and has developed a programmatic approach, through OMIMSWAC and Dell’s Cyber-resilient Architecture, to consistently deliver and control these new features in each node and cluster. These features allow customers to always be secure and compliant on Azure Stack HCI environments.
Stay tuned for more updates (soon) on the compliance front, thank you for reading this far!
Author Information
Ignacio Borrero, Senior Principal Engineer, Technical Marketing
Twitter: @virtualpeli
References
2020 Verizon Data Breach Investigations Report
2019 Accenture Cost of Cybercrime Study
Global Ransomware Damage Costs Predicted To Reach $20 Billion (USD) By 2021
Cybercrime To Cost The World $10.5 Trillion Annually By 2025
The global cost of cybercrime per minute to reach $11.4 million by 2021

Experts Recommend Automation for a Healthier Lifestyle
Wed, 20 Oct 2021 19:59:25 -0000
|Read Time: 0 minutes
Like any good techie, I can get a little obsessed with gadgets that improve my quality of life. Take, for example, my recent discovery of wearable technology that eases the symptoms of motion sickness. For most of my life, I’ve had to take over-the-counter or prescription medicine when boating, flying, and going on road trips. Then, I stumbled across a device that I could wear around my wrist that promised to solve the problem without the side effects. Hesitantly, I bought the device and asked a friend to drive like a maniac around town while I sat in the back seat. It actually worked – no headache, no nausea, and no grogginess from meds! Needless to say, I never leave home without my trusty gizmo to keep motion sickness at bay.

Throughout my career in managing IT infrastructure, stress has affected my quality of life almost as much as motion sickness. There is one responsibility that has always caused more angst than anything else: lifecycle management (LCM). To narrow that down a bit, I’m specifically talking about patching and updating IT systems under my control. I have sometimes been derelict in my duties because of annoying manual steps that distract me from working on the fun, highly visible projects. It’s these manual steps that can cause the dreaded DU/DL (data unavailable or data loss) to rear its ugly head. Can you say insomnia?
Innovative technology to the rescue once again! While creating a demo video last year for our Dell EMC OpenManage Integration with Microsoft Windows Admin Center (OMIMSWAC), I was blown away by how easy we made the BIOS, firmware, and driver updates on clusters. The video did a pretty good job of showing the power of the Cluster-Aware Updating (CAU) feature, but it didn’t go far enough. I needed to quantify its full potential to change an IT profressional’s life by pitting an OMIMSWAC’s automated, CAU approach against a manual, node-based approach. I captured the results of the bake off in Dell EMC HCI Solutions for Microsoft Windows Server: Lifecycle Management Approach Comparison.

Automation Triumphs!
For this white paper to really stand the test of time, I knew I needed to be very clever to compare apples-to-apples. First, I referred to HCI Operations Guide—Managing and Monitoring the Solution Infrastructure Life Cycle, which detailed the hardware updating procedures for both the CAU and node-based approaches. Then, I built a 4-node Dell EMC HCI Solutions for Windows Server 2019 cluster, performed both update scenarios, and recorded the task durations. We all know that automation is king, but I didn’t expect the final tally to be quite this good:
- The automated approach reduced the number of steps in the process by 82%.
- The automated approach required 90% less of my focused attention. In other words, I was able to attend to other duties while the updates were installing.
- If I was in a production environment, the maintenance window approved by the change control board would have been cut in half.
- The automated process left almost no opportunity for human error.
As you can see from the following charts taken from the paper, these numbers only improved as I extrapolated them out to the maximum Windows Server HCI cluster size of 16 nodes.
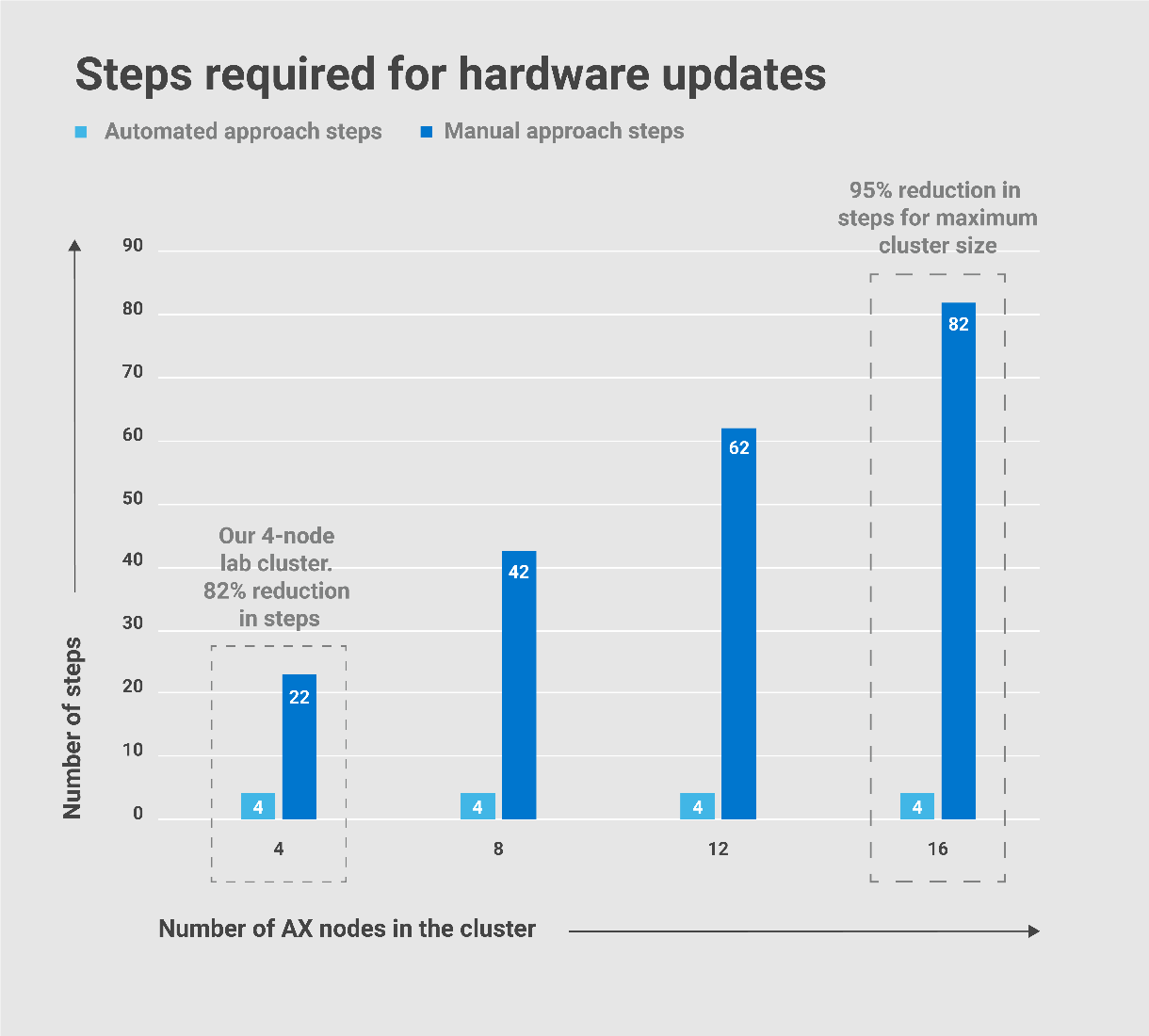
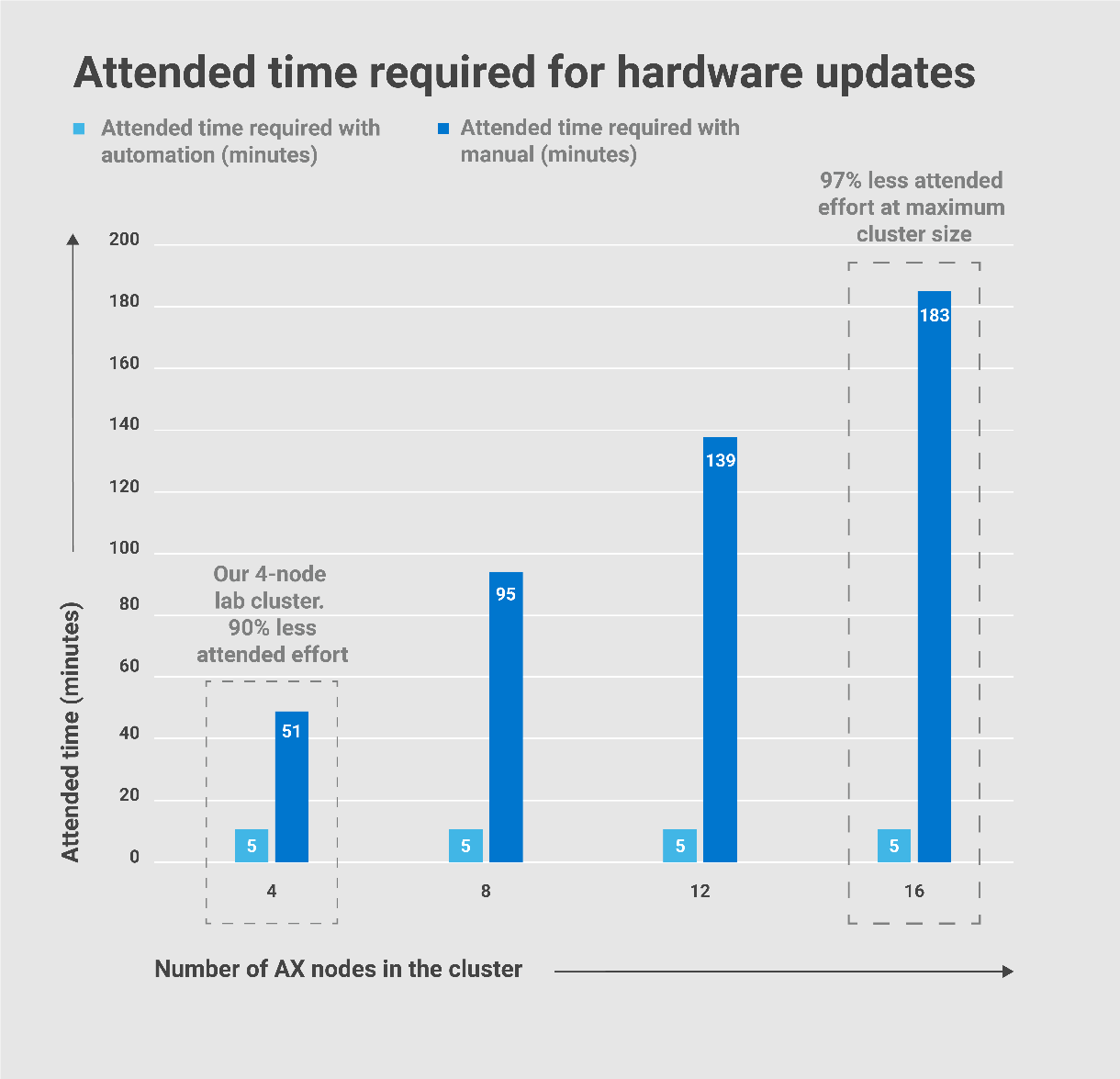
I thought these results were too good to be true, so I checked my steps about 10 times. In fact, I even debated with my Marketing and Product Management counterparts about sharing these claims with the public! I could hear our customers saying, “Oh, yeah, right! These are just marketecture hero numbers.” But in this case, I collected the hard data myself. I am still confident that these results will stand up to any scrutiny. This is reality – not dreamland!
Just when I thought it couldn’t get any better
So why am I blogging about a project I did last year? Just when I thought the testing results in the white paper couldn’t possibly get any better, Dell EMC Integrated System for Microsoft Azure Stack HCI came along. Azure Stack HCI is Microsoft’s purpose-built operating system delivered as an Azure service. The current release when writing this blog was Azure Stack HCI, version 20H2. Our Solution Brief provides a great overview of our all-in-one validated HCI system, which delivers efficient operations, flexible consumption models, and end-to-end enterprise support and services. But what I’m most excited about are two lifecycle management enhancements – 1-click full stack LCM and Kernel Soft Reboot – that will put an end to the old adage, “If it looks too good to be true, it probably is.”
Let’s invite OS updates to the party
OMIMSWAC was at version 1.1 when I did my testing last year. In that version, the CAU feature focused on the hardware – BIOS, firmware, and drivers. In OMIMSWAC v2.0, we developed an exclusive snap-in to Microsoft’s Failover Cluster Tool Extension to create 1-click full stack LCM. Only available for clusters running Azure Stack HCI, a simple workflow in Windows Admin Center automates not only the hardware updates – but also the operating system updates. How do I see this feature lowering my blood pressure?
- Applying the OS and hardware updates can typically require multiple server reboots. With 1-click full stack LCM, reboots are delayed until all updates are installed. A single reboot per node in the cluster results in greater time savings and shorter maintenance windows.
- I won’t have to use multiple tools to patch different aspects of my infrastructure. The more I can consolidate the number of management tools in my environment, the better.
- A simple, guided workflow that tightly integrates the Microsoft extension and OMIMSWAC snap-in ensures that I won’t miss any steps and provides one view to monitor update progress.
- The OMIMSWAC snap-in provides necessary node validation at the beginning of the hardware updates phase of the workflow. These checks verify that my cluster is running validated AX nodes from Dell Technologies and that all the nodes are homogeneous. This gives me peace of mind knowing that my updates will be applied successfully. I can also rest assured that there will be no interruption to the workloads running in my VMs and containers since this feature leverages CAU.
- The hardware updates leverage the Microsoft HCI solution catalog from Dell Technologies. Each BIOS, firmware, and driver in this catalog is validated by our engineering team to optimize the Azure Stack HCI experience.
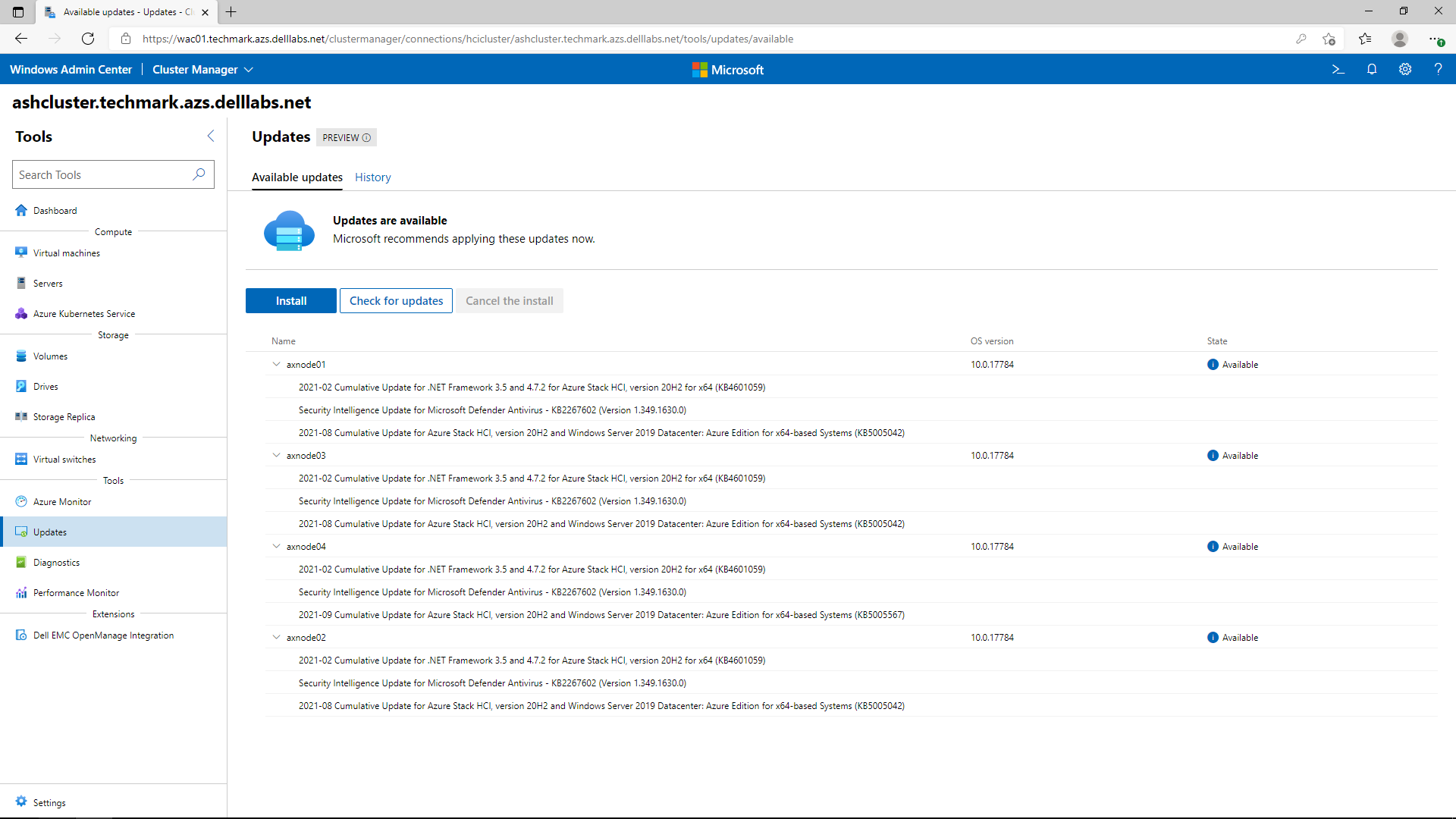
The following screen shots were taken from the full stack CAU workflow. The first step indicates which OS updates are available for the cluster nodes.
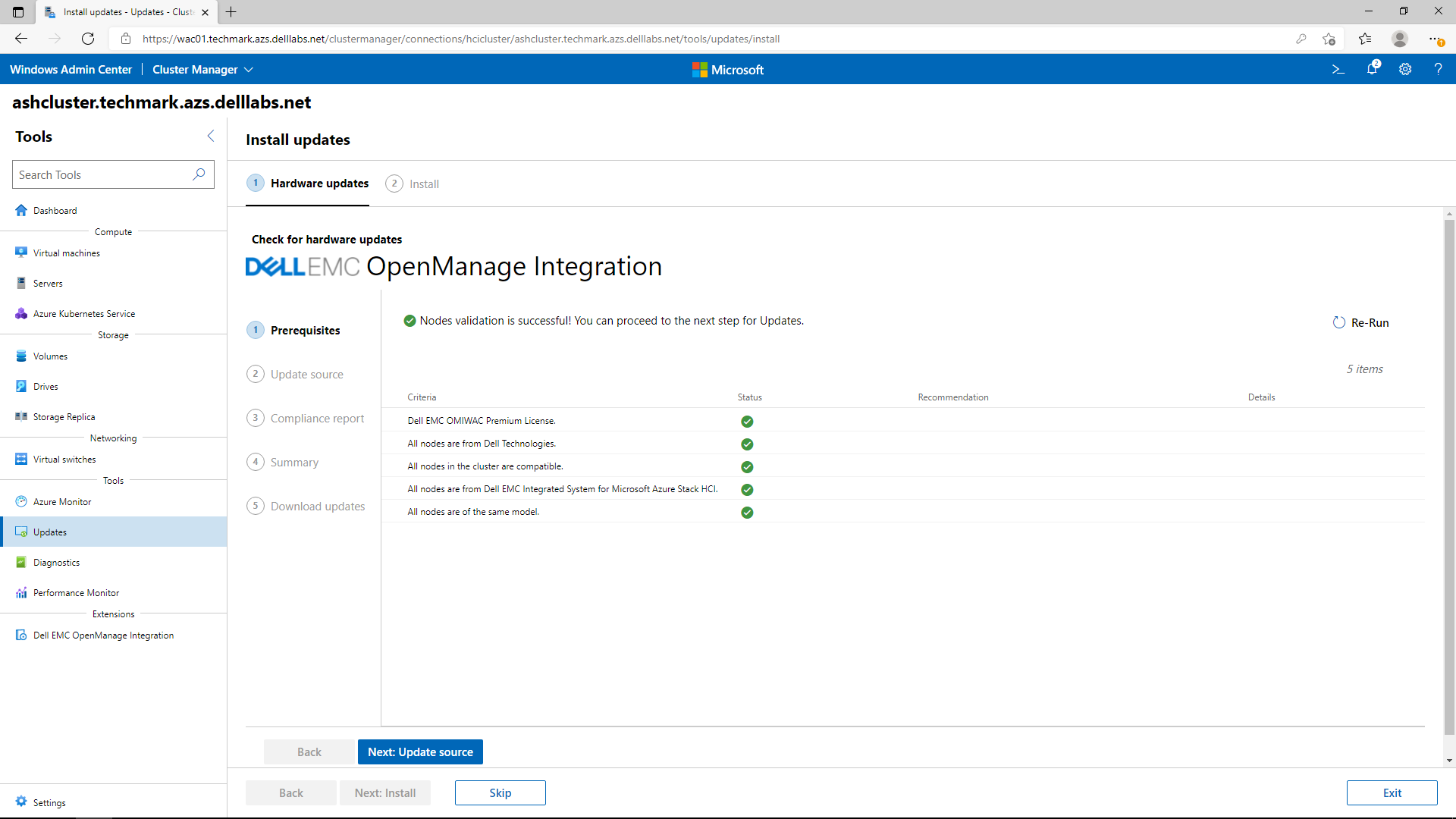
Node validation is performed first before moving forward with hardware updates.
If the Windows Admin Center host is connected to the Internet, the online update source approach obtains all the systems management utilities and the engineering validated solution catalog automatically. If operating in an edge or disconnected environment, the solution catalog can be created with Dell EMC Repository Manager and placed on a file server share accessible from the cluster nodes.
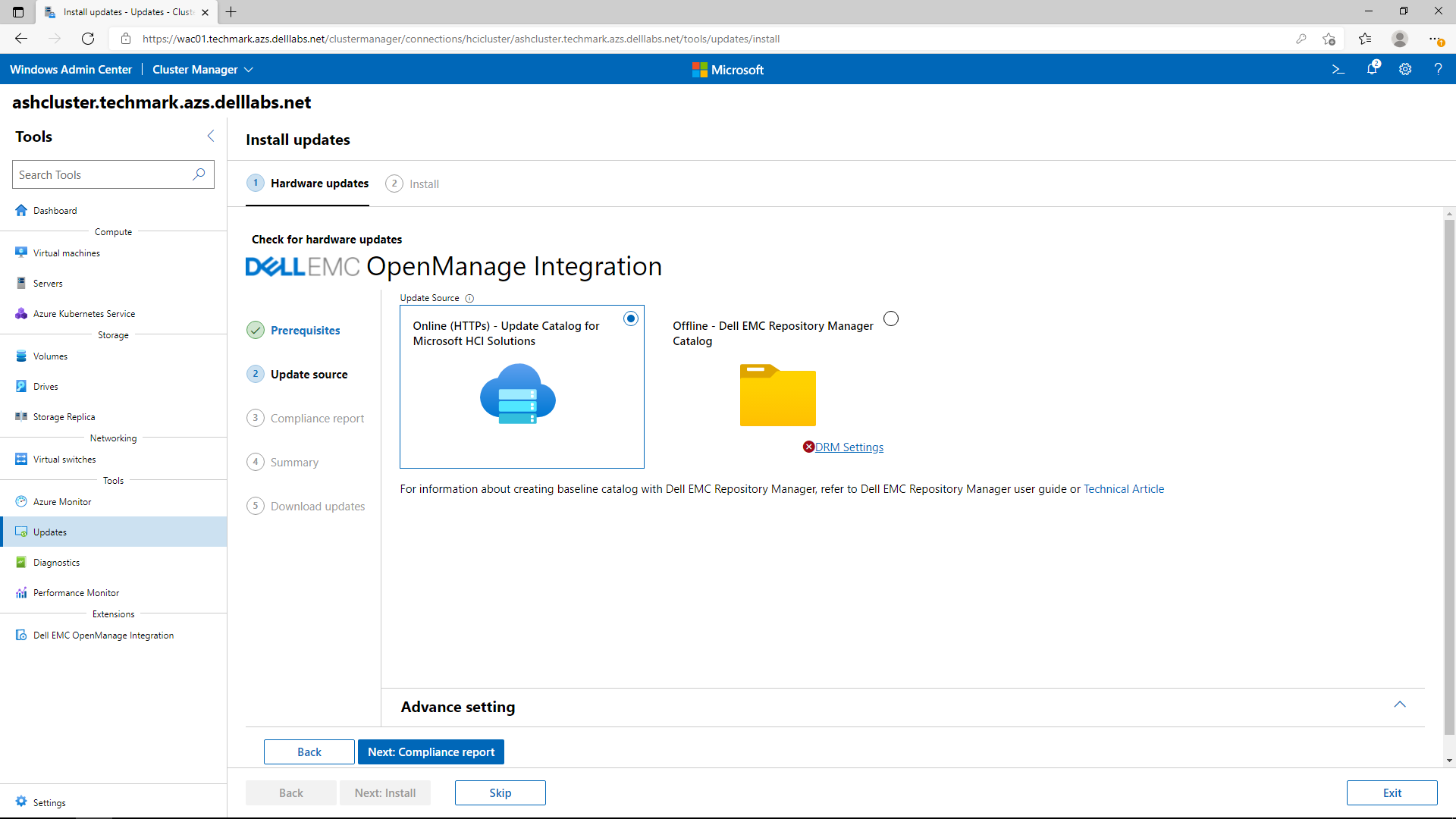
The following image shows a generated compliance report. All non-compliant components are selected by default for updating. After this point, all the OS and non-compliant hardware components will be updated together with only a single reboot per node in the cluster and with no impact to running workloads.
Life is too short to wait for server reboots
Speaking of reboots, Kernel Soft Reboot (KSR) is a new feature coming in Azure Stack HCI, version 21H2 that also has the potential to make my white paper claims even more jaw dropping. KSR will give me the ability to perform a “software-only restart” on my servers – sparing me from watching the paint dry during those long physical server reboots. Initially, the types of updates in scope will be OS quality and security hotfixes since these don’t require BIOS/firmware initialization. Dell Technologies is also working on leveraging KSR for the infrastructure updates in a future release of OMIMSWAC.
KSR will be especially beneficial when using Microsoft’s CAU extension in Windows Admin Center. The overall time savings using KSR multiplies for clusters because faster restarts means less resyncing of data after CAU resumes each cluster node. Each node should reboot with Mach Speed if there are only Azure Stack HCI OS hotfixes and Dell EMC Integrated System infrastructure updates that do not require the full reboot. I will definitely be hounding my Product Managers and Engineering team to deliver KSR for infrastructure updates in our OMIMSWAC extension ASAP.
Bake off rematch
I decided to hold off on doing a new bakeoff until Azure Stack HCI, version 21H2 is released with KSR. I also want to wait until we bring the benefits of KSR to OMIMSWAC for infrastructure updates. The combination of OMIMSWAC 1-click full stack CAU and KSR will continue to make OMIMSWAC unbeatable for seamless lifecycle management. This means better outcomes for our organizations, improved blood pressure and quality of life for IT pros, and more motion-sickness-free adventure vacations. I’m also looking forward to spending more time learning exciting new technologies and less time with routine administrative tasks.
If you’d like to get hands-on with all the different features in OMIMSWAC, check out the Interactive Demo in Dell Technologies Demo Center. Also, check out my other white papers, blogs, and videos in the Dell Technologies Info Hub.

It’s Time to Expect Flexible Disaster Recovery
Thu, 14 Oct 2021 14:52:42 -0000
|Read Time: 0 minutes
Rigid and complex disaster recovery (DR) can be a thing of the past with Dell EMC Integrated System for Microsoft Azure Stack HCI.
When data Is currency, DR is non-negotiable
If your organization is like many others—of any size—it relies increasingly on data to thrive. This is particularly true for businesses that are on track to modernize their infrastructure and application architectures. For those organizations, data and the workloads that process it are truly the lifeblood of the business.
When business relies on data to function, recovery-point objectives (RPOs) and recovery-time objectives (RTOs) must be as low as possible. However, legacy disaster recovery (DR) solutions are complex to design and maintain, and they might require manual intervention during a DR scenario. These solutions can also be costly, especially if you must maintain a dedicated DR site. That’s why a flexible and performant DR solution is a crucial part of infrastructure modernization.
Stretch clustering could be the answer
Today, enterprise organizations are consolidating, refreshing, and modernizing their aging virtualization platforms with hyperconverged infrastructure (HCI). HCI architectures help customers achieve a highly automated and orchestrated cloud-operations experience. The architectures are designed to deliver high levels of performance and scalability with software-defined compute, storage and networking. HCI solutions are also designed to simplify the implementation of high availability and DR for workloads running in virtual machines (VMs) and containers.
What if you could stretch a single HCI cluster across two locations as a DR solution? That would simplify and accelerate DR. Such a solution is now within reach using Microsoft Azure Stack HCI, version 20H2 or later. Azure Stack HCI includes built-in stretch clustering capabilities, which use Storage Replica for volume replication. Stretch clustering allows organizations to split a single HCI cluster across two locations, whether they be rooms, buildings, cities or regions. It provides automatic failover of Microsoft Hyper-V VMs if a site failure occurs.
In general, stretch clustering on Azure Stack HCI is an ideal DR solution for scenarios like these:
- Introducing automatic failover with orchestration for recovery of a web-based application’s front-end server tier after a disaster at a hosting location
- Distributing primary and secondary instances of an infrastructure’s core services, such as Microsoft Active Directory, across two physical locations
- Hosting applications with lower write input/output (I/O) performance characteristics
- Running file-system-based services and other business services that can tolerate being hosted on crash-consistent volumes
- Running database workloads such as Microsoft SQL Server, which often cannot sustain the loss of even a single transaction, where using application-layer recoverability solutions such as SQL Always On availability groups might be more appropriate
Putting the solution to the test
Dell Technologies engineers conducted proof-of-concept (PoC) tests to show how Dell EMC Integrated System for Azure Stack HCI with stretch clustering can handle VM and volume placement. We also wanted to observe the impact of a real running application (Dell EMC OpenManage Enterprise) during failover scenarios. Each of the four nodes (two per site) in our testing environment included two Intel® Xeon® Gold 6230R processors and 384 GB of memory, running Azure Stack HCI, version 20H2.
We tested the following scenarios and observed the outcomes listed. For full details, read the white paper, Adding Flexibility to DR Plans with Stretch Clustering for Azure Stack HCI.
- Unplanned cluster-node failure: All VMs fully restarted on the second node at the same site in about 5 minutes.
- Unplanned site failure: Affected VMs moved and came fully back online in 15–20 minutes.
- Planned site failover: The OpenManage Enterprise application was reachable from the client device within 3 minutes of the live migration to site 2.
- Lifecycle management: Applying the BIOS, firmware and driver updates to the stretched cluster took approximately three hours, and the process had no impact on the Dell EMC OpenManage Enterprise (OME) application.
An accelerated path to simple DR
Dell Technologies offers a broad portfolio of solution configurations designed to meet the requirements of any workload. The solution for DR built on Dell EMC Integrated System for Azure Stack HCI features intelligently designed AX nodes from Dell Technologies configurations. Dell engineers validate every component of these configurations, including firmware and driver versions. Additionally, Dell ProSupport technicians know the entire solution, from hardware to operating system to Microsoft Storage Spaces Direct to networking. They can help keep the cluster operating at peak performance and availability.
To see the full details of our tests and to learn more about the stretch clustering capability in Azure Stack HCI, read the white paper, Adding Flexibility to DR Plans with Stretch Clustering for Azure Stack HCI.

Virtualize Demanding Applications with a Dell EMC Integrated System for Microsoft Azure Stack HCI
Thu, 14 Oct 2021 14:52:42 -0000
|Read Time: 0 minutes
Break through performance barriers
If your organization is on the road to infrastructure modernization, chances are good that your underlying legacy virtualization clusters are being stretched to their limits. This could mean suboptimal performance and resiliency, which can make it difficult to scale clusters and meet service-level agreements (SLAs).
In addition, with overtaxed and aging clusters, you can’t virtualize applications that you would like to because of performance requirements, which can mean a larger data center footprint and higher corresponding power and cooling costs.
If you’re thinking about refreshing and modernizing your legacy virtualization environments, you might want to consider a Dell EMC Integrated System for Microsoft Azure Stack HCI.
Solution overview
This all-in-one validated hyperconverged infrastructure (HCI) solution includes full-stack lifecycle management, native integration into Microsoft Azure, flexible consumption models and solution-level enterprise support and services expertise. Dell EMC Integrated System for Azure Stack HCI is available in a broad range of configurations, and it include engineering-validated AX nodes and networking topologies with Dell EMC PowerSwitch network switches. This design and validation can help ensure that every component—including firmware and driver versions—is optimized for demanding workloads.
Dell Technologies performed synthetic workload testing on one of these systems to see how it performed with highly demanding real-world application profiles. The cluster included four AX-7525 nodes, each populated with two 64-core AMD EPYC™ 7742 processors, 24 NVM Express (NVMe) drives (PCIe Gen4) and 100 gigabit Ethernet (GbE) remote direct memory access (RDMA) networking. Dell Technologies tested workloads under these conditions:
- Healthy cluster running 64 virtual machines (VMs) per node
- Healthy cluster running 32 VMs per node
- Degraded cluster with one node failed
- Degraded cluster with two nodes failed
The configuration delivered outstanding results in all tested scenarios, even when the cluster was in a degraded condition. This means that end users will not notice reduced response times, even if it takes IT longer to return the cluster to its fully operational state. You’ll find all the testing details and results in this white paper.
Reasons to believe
When you modernize your virtualization clusters by deploying Dell EMC Integrated System for Azure Stack HCI, you can:
- Virtualize demanding applications that historically needed to remain on physical servers because of their performance requirements.
- Take advantage of a performant, modernized infrastructure that can support the most demanding business services.
- Save precious real estate in the data center by minimizing the cluster size required to deliver performance SLAs.
- Accelerate online transaction processing (OLTP) workloads and improve end-user response times for database applications.
- Achieve fast times to insight with exceptional online analytical processing (OLAP) performance.
- Deliver high throughput at low latency, which means outstanding performance for applications like Microsoft SQL Server.
- Monitor and manage many aspects of the cluster with Dell EMC OpenManage Integration with Microsoft Windows Admin Center. This tool includes one-click, full-stack lifecycle management with Cluster-Aware Updating, dynamic CPU core management, automated cluster creation and cluster expansion.
To see our full test environment details and results and to learn more about Dell EMC Integrated System for Azure Stack HCI, download the white paper, Crash Through Workload Performance Boundaries with Azure Stack HCI.

Technology leap ahead: 15G Intel based Dell EMC Integrated System for Microsoft Azure Stack HCI
Wed, 22 Sep 2021 18:15:33 -0000
|Read Time: 0 minutes
We are happy to announce the latest members of the family for our Microsoft HCI Solutions from Dell Technologies: the new AX-650 and AX-750 nodes.
If you are already familiar with our existing integrated system offering, you can directly jump to the next section. For those new to the party, keep on reading!
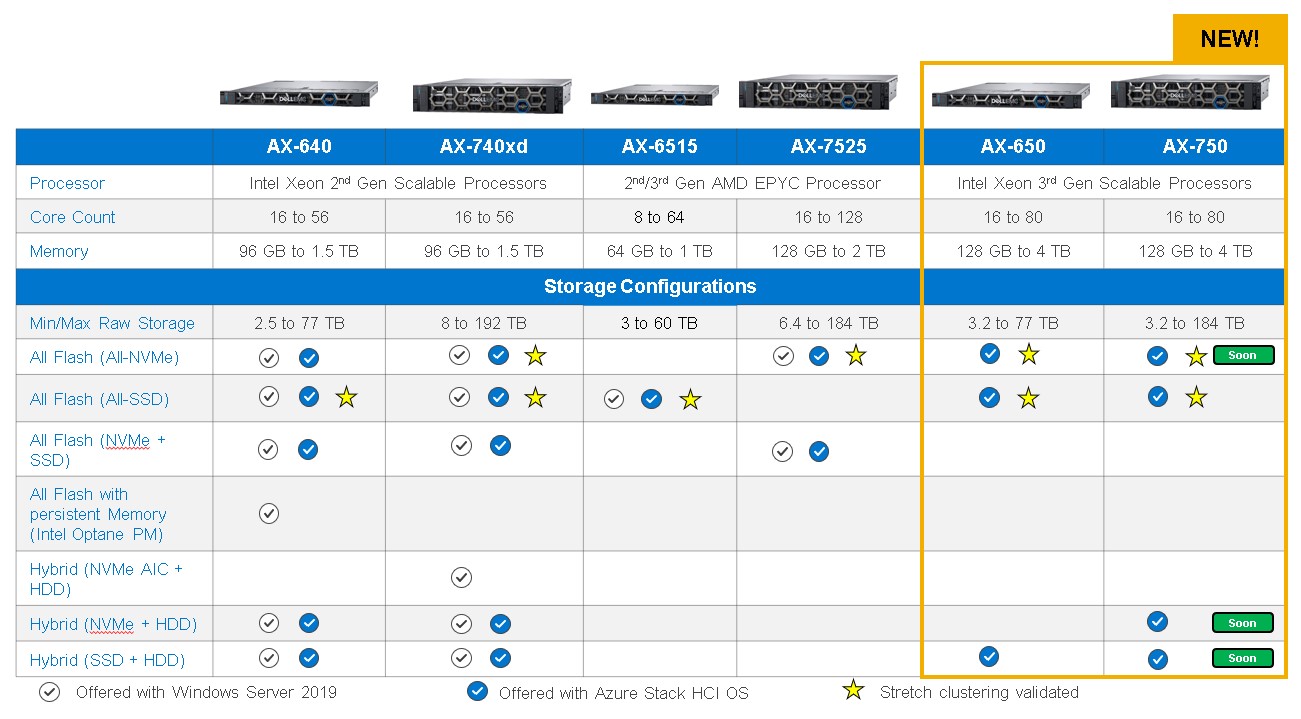
Figure 1: Dell EMC Integrated System for Microsoft Azure Stack HCI portfolio: New AX-650 and AX-750 nodes
As with all other nodes supported by Dell EMC Integrated System for Microsoft Azure Stack HCI, the AX-650 and AX-750 nodes have been intelligently and deliberately configured with a wide range of component options to meet the requirements of nearly any use case – from the smallest remote or branch office to the most demanding database workloads.
The chassis, drive, processor, DIMM module, network adapter, and their associated BIOS, firmware, and driver versions have been carefully selected and tested by the Dell Technologies engineering team to optimize the performance and resiliency of Azure Stack HCI. Our engineering has also validated networking topologies using PowerSwitch network switches.
Arguably the most compelling aspect of our integrated system is our life cycle management capability. The Integrated Deploy and Update snap-in works with the Microsoft cluster creation extension to deliver Dell EMC HCI Configuration Profile. This Configuration Profile ensures a consistent, automated initial cluster creation experience on Day 1. The one-click full stack life cycle management snap-in for the Microsoft Cluster-Aware Updating extension allows administrators to apply updates. This seamlessly orchestrates OS, BIOS, firmware, and driver updates through a common Windows Admin Center workflow.
On top of it, Dell Technologies makes support services simple, flexible, and worry free – from installation and configuration to comprehensive, single source support. Certified deployment engineers ensure accuracy and speed, reduce risk and downtime, and free IT staff to work on those higher value priorities. Our one-stop cluster level support covers the hardware, operating system, hypervisor, and Storage Spaces Direct software, whether you purchased your license from Dell EMC or from Microsoft.
Now that we are at the same page with our integrated system…
What’s new with AX-650 and AX-750? Why are they important for our customers?
AX-650 and AX-750 are based on Intel Xeon Scalable 3rd generation Ice Lake processors that introduce big benefits in three main areas:
- Hardware improvements
- New features
- Management enhancements
Hardware improvements
Customers always demand the highest levels of performance available, and our new 15G platforms, through Intel Ice Lake and its latest 10nm technology, deliver huge performance gains (compared to the previous generation) for:
- Processing: up to a 40 percent CPU performance increase, a 15 percent per core performance boost, and 42 percent more cores
- Memory: 33 percent more memory channels, a 20 percent frequency boost, and a 2.66x increase in memory capacity
- PCIe Gen4 IO acceleration: a doubled throughput increase compared to PCIe Gen3, 33 percent more lanes, an increase in direct attached Gen4 NVMe drives, and support for the latest Gen4 accelerators and GPUs
These impressive figures are a big step forward from a hardware boost perspective, but there are even more important things going on than just brute power and performance.
Our new 15G platforms lay the technology foundation for the latest features that are coming (really) soon with the new version of Microsoft Azure Stack HCI.
New features
Windows Server 2022 and Azure Stack HCI, version 21H2 will bring in (when they are made available) the following two key features:
- Secured-core Server
- GPU support
The fundamental idea of Secured-core Server is to stay ahead of attackers and protect our customers’ infrastructure and data all through hardware, BIOS, firmware, boot, drivers, and the operating system. This idea is based on three pillars:
- Simplified security: easy integration and consumption through Windows Admin Center
- Advanced protection: leveraging hardware root-of-trust, firmware protection, and virtualization-based security (VBS)
- Preventative defense: proactively block the paths attackers use to exploit a system
For more details about Secured-core Server, click here.
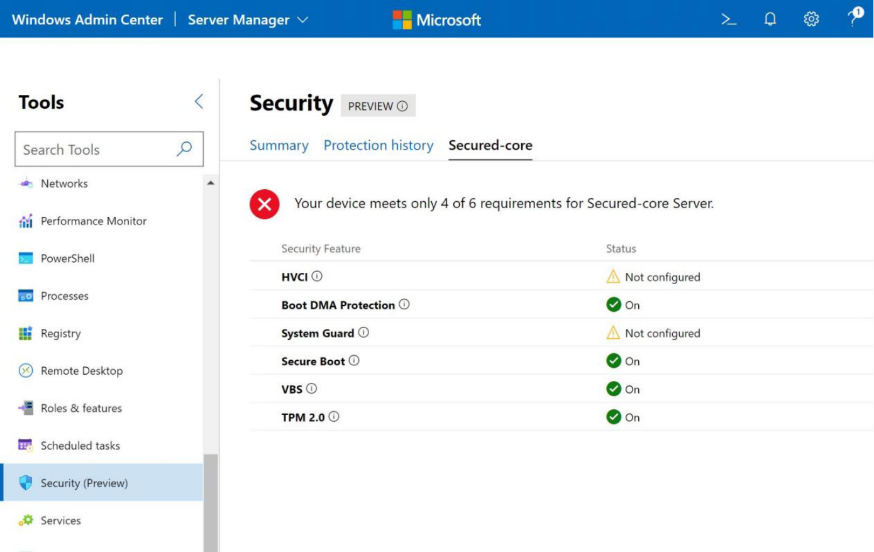
Figure 2: Secured-core Server with Windows Admin Center integration
AX-650, AX-750, and AX-7525 are the first AX nodes to introduce GPU readiness for single-width and double-width GPUs.
With the September 21, 2021 launch, all configurations planned to support GPUs are already enabled in anticipation for the appropriate selection of components (such as GPU risers, power supplies, fans, and heatsinks).
This process permits the GPU(s) to be added later on (when properly validated and certified) as an After Point of Sale (APOS).
The first GPU that will be made available with AX nodes (AX-650, AX-750, and AX-7525) is the NVIDIA T4 card.
To prepare for this GPU, customers should opt for the single-width capable PCI riser.
The following table shows the maximum number of adapters per platform taking into account the GPU form factor:
| AX-750 | AX-650 | AX-7525 | |||
| Single width | Dual width | Single width | Dual width | Single width | Dual width |
All SSD | Up to 31 | Up to 2 | Up to 22 | N/A |
| |
All NVMe | Up to 31 | Up to 2 | Up to 22 | N/A | Up to 33 | Up to 33 |
NVMe+SSD |
| Up to 4 | Up to 3 | |||
1 Max of 3 factory installed with Mellanox NIC adapters. Exploring options for up to 4 SW GPUs
2 Depending on the number of RDMA NICs
3 Only with the x16 NVMe chassis. x24 NVMe chassis does not support any GPUs
Note that no GPUs are available at the September 21, 2021 launch. GPUs will not be validated and factory installable until early 2022.
Management enhancements
Dell EMC OpenManage Integration with Microsoft Windows Admin Center (OMIMSWAC) extension was launched in 2019.
It has included hardware and firmware inventory, real time health monitoring, iDRAC integrated management, troubleshooting tools, and seamless updates of BIOS, firmware, and drivers.
In the 2.0 release in February 2020, we also added single-click full stack life cycle management with Cluster-Aware Updating for the Intel-based Azure Stack HCI platforms. This allowed us to orchestrate OS, BIOS, firmware, and driver updates through a single Admin Center workflow, requiring only a single reboot per node in the cluster and resulting in no interruption to the services running in the VMs.
With the Azure Stack HCI June 2021 release, the OpenManage Integration extension added support for the AX-7525 and AX-6515 AMD based platforms.
Now, with the September 21, 2021 launch, OMIMSWAC 2.1 features a great update for AX nodes, including these important extensions:
- Integrated Deploy & Update
- CPU Core Management
- Cluster Expansion
Integrated Deploy & Update deploys Azure Stack HCI with Dell EMC HCI Configuration Profile for optimal cluster performance. Our integration also adds the ability to apply hardware solution updates like BIOS, firmware, and drivers at the same time as operating system updates as part of cluster creation with a single reboot.
With CPU Core Management, customers can dynamically adjust the CPU core count BIOS settings without leaving the OpenManage Integration extension in Windows Admin Center, helping to maintain the right balance between cost and performance.
Cluster Expansion helps to prepare new cluster nodes before adding them to the cluster, to significantly simplify the cluster expansion process, reduce human error, and save time.
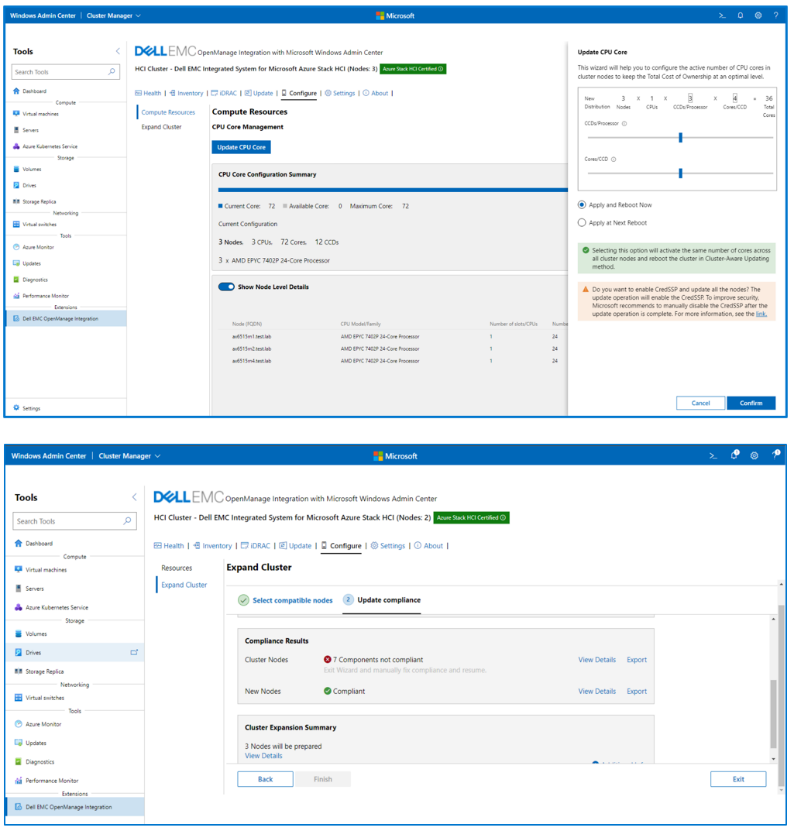
Figure 3: CPU Core Management and Cluster Expansion samples
In conclusion, the AX-650 and AX-750 nodes establish the most performant and easy to operate foundation for Azure Stack HCI today, along with all the new features and goodness that Microsoft is preparing. Stay tuned for more news and updates on this front!
Author Information
Ignacio Borrero, @virtualpeli

Microsoft HCI Solutions from Dell Technologies: Designed for extreme resilient performance
Wed, 16 Jun 2021 13:35:49 -0000
|Read Time: 0 minutes
Dell EMC Integrated System for Microsoft Azure Stack HCI (Azure Stack HCI) is a fully productized HCI solution based on our flexible AX node family as the foundation.
Before I get into some exciting performance test results, let me set the stage. Azure Stack HCI combines the software-defined compute, storage, and networking features of Microsoft Azure Stack HCI OS, with AX nodes from Dell Technologies to deliver the perfect balance for performant, resilient, and cost-effective software-defined infrastructure.
Figure 1 illustrates our broad portfolio of AX node configurations with a wide range of component options to meet the requirements of nearly any use case – from the smallest remote or branch office to the most demanding database workloads.
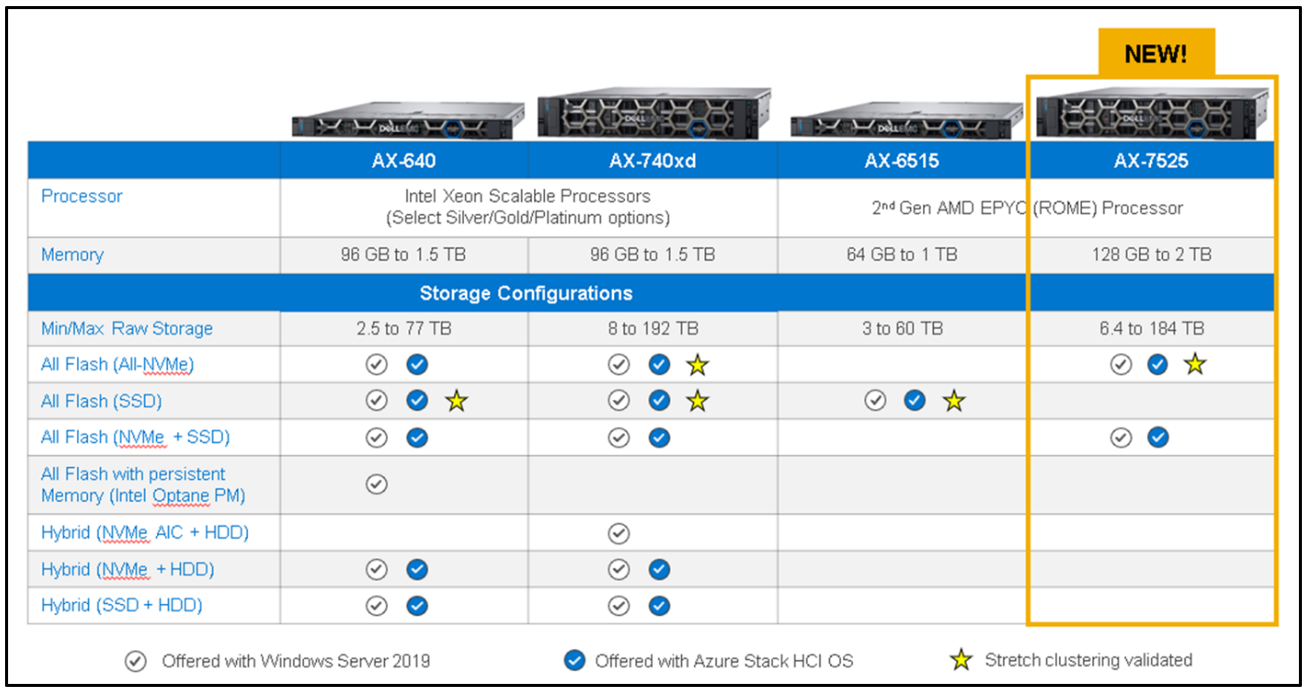
Figure 1: current platforms supporting our Microsoft HCI Solutions from Dell Technologies
Each chassis, drive, processor, DIMM module, network adapter and their associated BIOS, firmware, and driver versions have been carefully selected and tested by the Dell Technologies Engineering team to optimize the performance and resiliency of Microsoft HCI Solutions from Dell Technologies. Our Integrated Systems are designed for 99.9999% hardware availability*.
* Based on Bellcore component reliability modeling for AX-740xd nodes and S5248S-ON switches a) in 2- to 4-node clusters configured with N + 1 redundancy, and b) in 4- to 16-node clusters configured with N + 2 redundancy, March 2021.
Comprehensive management with Dell EMC OpenManage Integration with Windows Admin Center, rapid time to value with Dell EMC ProDeploy options, and solution-level Dell EMC ProSupport complete this modern portfolio.
You'll notice in that table that we have a new addition -- the AX-7525: a dual-socket, AMD-based platform designed for extreme performance and high scalability.
The AX-7525 features direct-attach NVMe drives with no PCIe switch, which provides full Gen4 PCIe potential to each storage device, resulting in massive IOPS and throughput at minimal latency.
To get an idea of how performant and resilient this platform is, our Dell Technologies experts put a 4-node AX-7525 cluster to the test. Each node had the following configuration:
- 24 NVMe drives (PCIe Gen 4)
- Dual-socket AMD EPYC 7742 64-Core Processor (128 cores)
- 1 TB RAM
- 1 Mellanox CX6 100 gigabit Ethernet RDMA NIC
The easy headline would be that this setup consistently delivered nearly 6M IOPs at sub 1ms latency. One could think that we doctored these performance tests to achieve these impressive figures with just a 4-node cluster!
The reality is that we sought to establish the ‘hero numbers’ as a baseline – ensuring that our cluster was configured optimally. However, we didn’t stop there. We wanted to find out how this configuration would perform with real-world IO patterns. This blog won’t get into the fine-grained details of the white paper, but we’ll review the test methodology for those different scenarios and explain the performance results.
Figure 2 shows the 4-node cluster and fully converged network topology that we built for the lab:
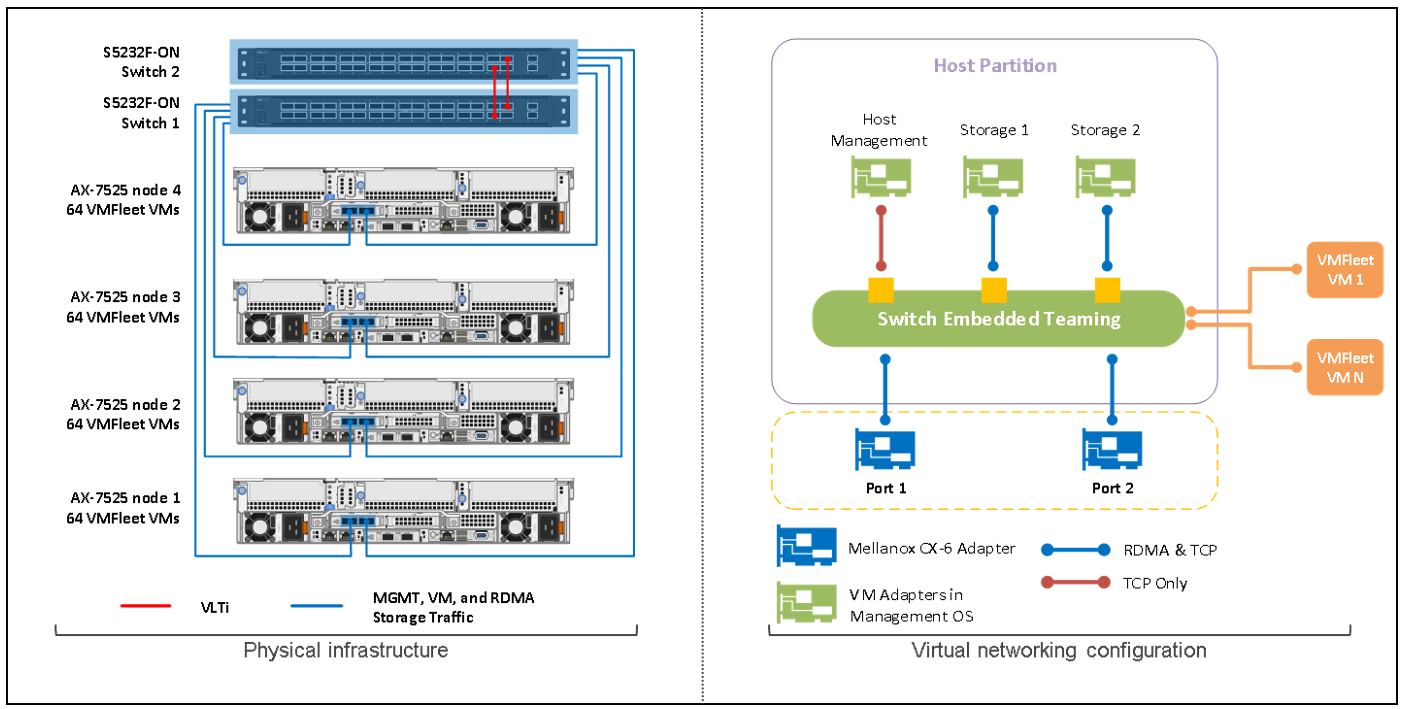
Figure 2: Lab setup
We performed two differentiated sets of tests in this environment:
- Tests with IO profiles aimed at identifying the maximum IOPS and throughput thresholds of the cluster
- Test 1: Using a healthy 4-node cluster
- Tests with IO profiles that are more representative of real-life workloads (online transaction processing (OLTP), online analytical processing (OLAP), and mixed workload types)
- Test 2: Using a healthy 4-node cluster
- Test 3: Using a degraded 4-node cluster, with a single node failure
- Test 4: Using a degraded 4-node cluster, with a two-node failure
To generate real-life workloads, we used VMFleet, which leverages PowerShell scripts to create Hyper-V virtual machines executing DISKSPD to produce the desired IO profiles.
We chose the three-way mirror resiliency type for the volumes we created with VMFleet because of its superior performance versus erasure coding options in Storage Spaces Direct.
Now that we have a clearer idea of the lab setup and the testing methodology, let’s move on to the results for the four tests.
Test 1: IO profile to push the limits on a healthy 4-node cluster with 64 VMs per node
Here are the details of the workload profile and the performance we obtained:
IO profile | Block size | Thread count | Outstanding IO | Write % | IO pattern | Total IOs | Latency |
B4-T2-O32-W0-PR | 4k | 2 | 32 | 0% | 100% random read | 5,727,985 | 1.3 ms (read) |
B4-T2-O16-W100-PR | 4k | 2 | 16 | 100% | 100% random write | 700,256 | 9 ms* (write) |
|
|
|
|
|
| Throughput | |
B512-T1-O8-W0-PSI | 512k | 1 | 8 | 0% | 100% sequential read | 105 GB/s | |
B512-T1-O1-W100-PSI | 512k | 1 | 1 | 100% | 100% sequential write | 8 GB/s | |
* The reason for this slightly higher latency is because we are pushing too many Outstanding IOs and we already plateaued on performance. We noticed that even with 32 VMs, we hit the same IOs, because all we are doing from that point on is adding more load that a) isn’t driving any additional IOs and b) just adds to the latency.
This test sets the bar for the limits and maximum performance we can obtain from this 4-node cluster: almost 6 million read IOs, 700k write IOs, and a bandwidth of 105 GB/s for reads, and 8 GB/s for writes.
Test 2: real-life workload IO profile on a healthy 4-node cluster with 32 VMs per node
The IO profiles for this test encompass a broad range of real-life scenarios:
- OLTP oriented: we tested for a wide spectrum of block sizes, ranging from 4k to 32k, and write IO ratios, varying from 20% to 50%.
- OLAP oriented: the most common OLAP IO profile is large block size and sequential access. Other workloads that follow a similar pattern are file backups and video streaming. We tested 64k to 512k block sizes and 20% to 50% write IO ratios.
The following figure shows the details and results we obtained for all the different tested IO patterns:
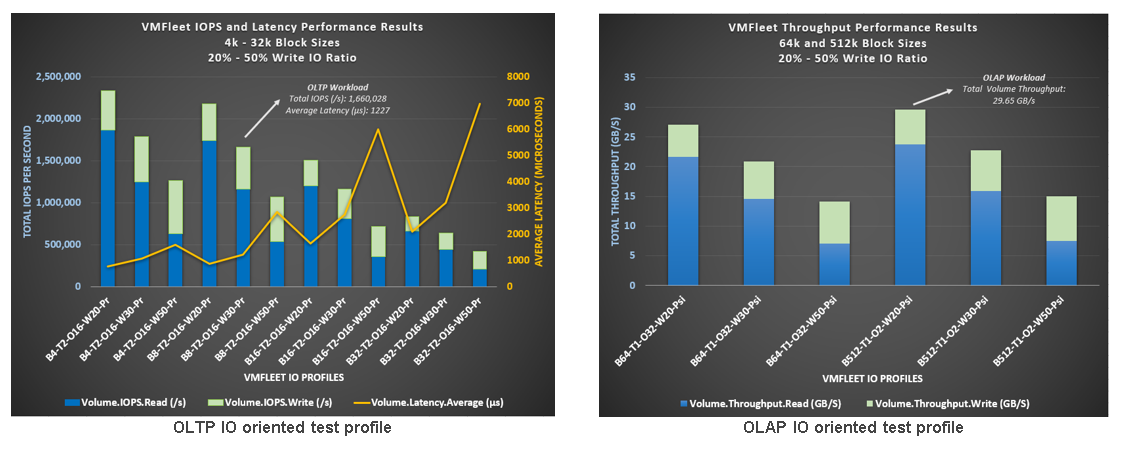
Figure 3: Test 2 results
Super impressive results and important to notice (on the left) the 1.6 million IOPS at 1.2 millisecond average latency for the typical OLTP IO profile of 8 KB block size and 30% random write. Even at 32k block size and 50% write IO ratio, we measured 400,000 IOs at under 7 milliseconds latency.
Also, very remarkable is the extreme throughput we witnessed during all the tests, with special emphasis on the incredible 29.65 GB/s with an IO profile of 512k block size and 20% write ratio.
Tests 3 and 4: push the limits and real-life workload IO profiles on a degraded 4-node cluster
To simulate a one-node failure (Test 3), we shut down node 4, which caused node 2 to take additional ownership of the 32 restarted VMs from node 4, for a total of 64 VMs on node 2.
Similarly, to simulate a two-node failure (Test 4), we shut down nodes 3 and 4, leading to a VM reallocation process from node 3 to node 1, and from node 4 to node 2. Nodes 1 and 2 ended up with 64 VMs each.
The cluster environment continued to produce impressive results even in this degraded state. The table below compares the testing scenarios that used IO profiles aimed at identifying the maximum thresholds.
IO profile | Healthy cluster | One node failure | Two node failure | |||
Total IOs | Latency | Total IOs | Latency | Total IOs | Latency | |
B4-T2-O32-W0-PR | 4,856,796 | 0.38 ms (read) | 4,390,717 | 0.38 ms (read) | 3,842,997 | 0.26 ms (read) |
B4-T2-O16-W100-PR | 753,886 | 3.2 ms (write) | 482,715 | 5.7 ms (write) | 330,176 | 11.4 ms (write) |
| Throughput | Throughput | Throughput | |||
B512-T1-O8-W0-PSI | 91 GB/s | 113 GB/s | 77 GB/s | |||
B512-T1-O1-W100-PSI | 8 GB/s | 6 GB/s | 10 GB/s | |||
Figure 4 illustrates the test results for real-life workload scenarios for the healthy cluster and for the one-node and two-node degraded states.
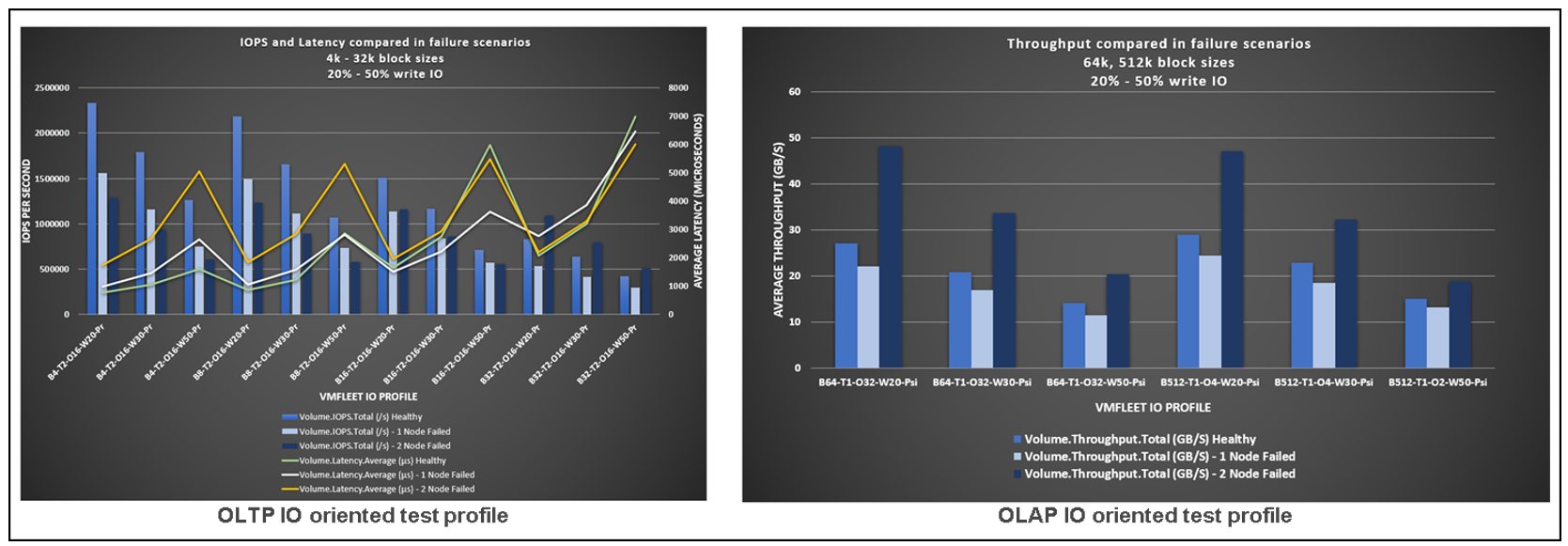
Figure 4: Test 3 and 4 results
Once more, we continued to see outstanding performance results from an IO, latency, and throughput perspective, even with one or two nodes failing.
One important consideration we observed is that for the 4k and 8k block sizes, IOs decrease and latency increases as one would expect, whereas for the 32k and higher block sizes we realized that:
- Latency was less variable across the failure scenarios because write IOs did not need to be committed across as many nodes in the cluster.
- After the two-node failure, there was actually an increase of IOs (20-30%) and throughput (52% average)!
There are two reasons for this:
- The 3-way mirrored volumes became 2-way mirrored volumes on the two surviving nodes. This effect led to 33% fewer backend drive write IOs. The overall drive write latency decreased, driving higher read and write IOs. This only applied when CPU was not the bottleneck.
- Each of the remaining nodes doubled the number of running VMs (from 32 to 64), which directly translated into greater potential for more IOs.
Conclusion
We are happy to share with you these figures about the extreme-resilient performance our integrated systems deliver, during normal operations or in the event of failures.
Dell EMC Integrated System for Microsoft Azure Stack HCI, especially with the AX-7525 platform, is an outstanding solution for customers struggling to support their organization’s increasingly heavy demand for resource intensive workloads and to maintain or improve their corresponding service level agreements (SLAs).

Azure Stack HCI Stretch Clustering: because automatic disaster recovery matters
Wed, 22 Sep 2021 18:17:41 -0000
|Read Time: 0 minutes
If history has taught us anything, it’s that disasters are always around the corner and tend to appear in any shape or form when they’re least expected.
To overcome these circumstances, we need the appropriate tools and technologies that can guarantee resuming operations back to normal in a secure, automatic, and timely manner.
Traditional disaster recovery (DR) processes are often complex and require a significant infrastructure investment. They are also labor intensive and prone to human error.
Since December 2020, the situation has changed. Thanks to the new release of Microsoft Azure Stack HCI, version 20H2, we can leverage the new Azure Stack HCI stretched cluster feature on Dell EMC Integrated System for Microsoft Azure Stack HCI (Azure Stack HCI).
The integrated system is based on our flexible AX nodes family as the foundation, and combines Dell Technologies full stack life cycle management with the Microsoft Azure Stack HCI operating system.
It is important to note that this technology is only available for the integrated system offering under the certified Azure Stack HCI catalog.
Azure Stack HCI stretch clustering provides an easy and automatic solution (no human interaction if desired) that assures transparent failovers of disaster-impacted production workloads to a safe secondary site.
It can also be leveraged to perform planned operations (such as entire site migration, or disaster avoidance) that, until now, required labor intensive and error prone human effort for execution.
Stretch clustering is one type of Storage Replica configuration. It allows customers to split a single cluster between two locations—rooms, buildings, cities, or regions. It provides synchronous or asynchronous replication of Storage Spaces Direct volumes to provide automatic VM failover if a site disaster occurs.
There are two different topologies:
- Active-Passive: All the applications and workloads run on the primary (preferred) site while the infrastructure at the secondary site remains idle until a failover occurs.
- Active-Active: There are active applications in both sites at any given time and replication occurs bidirectionally from either site. This setup tends to be a more efficient use of an organization’s investment in infrastructure because resources in both sites are being used.
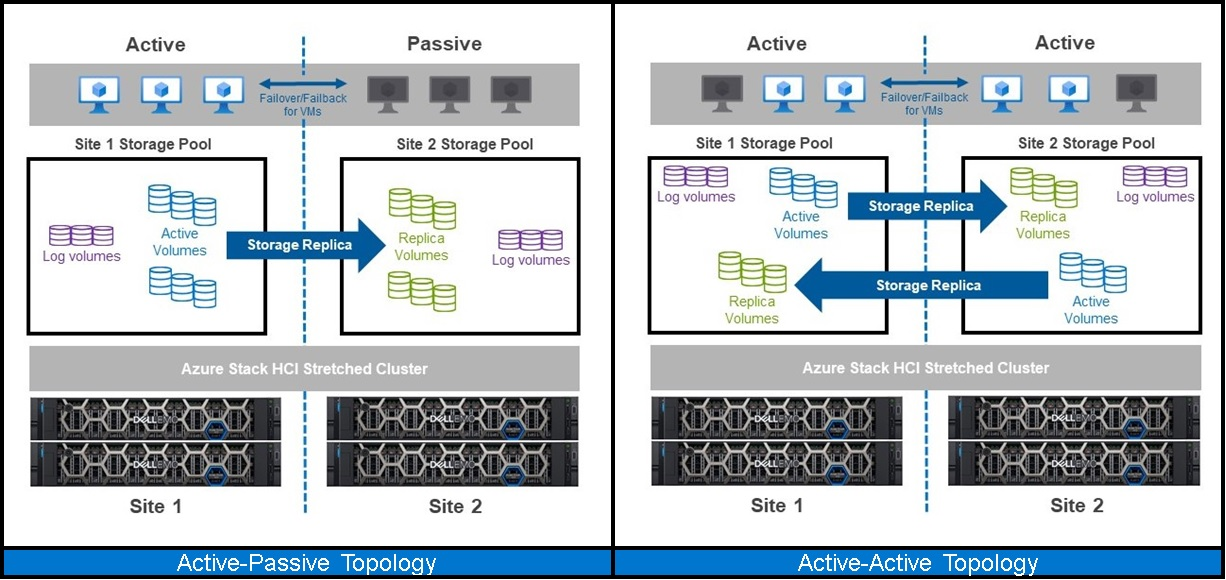
Azure Stack HCI stretch clustering topologies: Active-Passive and Active-Active
To be truly cost-effective, the best data protection strategies incorporate a combination of different technologies (deduplicated backup, archive, data replication, business continuity, and workload mobility) to deliver the right level of data protection for each business application.
The following diagram highlights the fact that just a reduced data set holds the most valuable information. This is the sweet spot for stretch clustering.
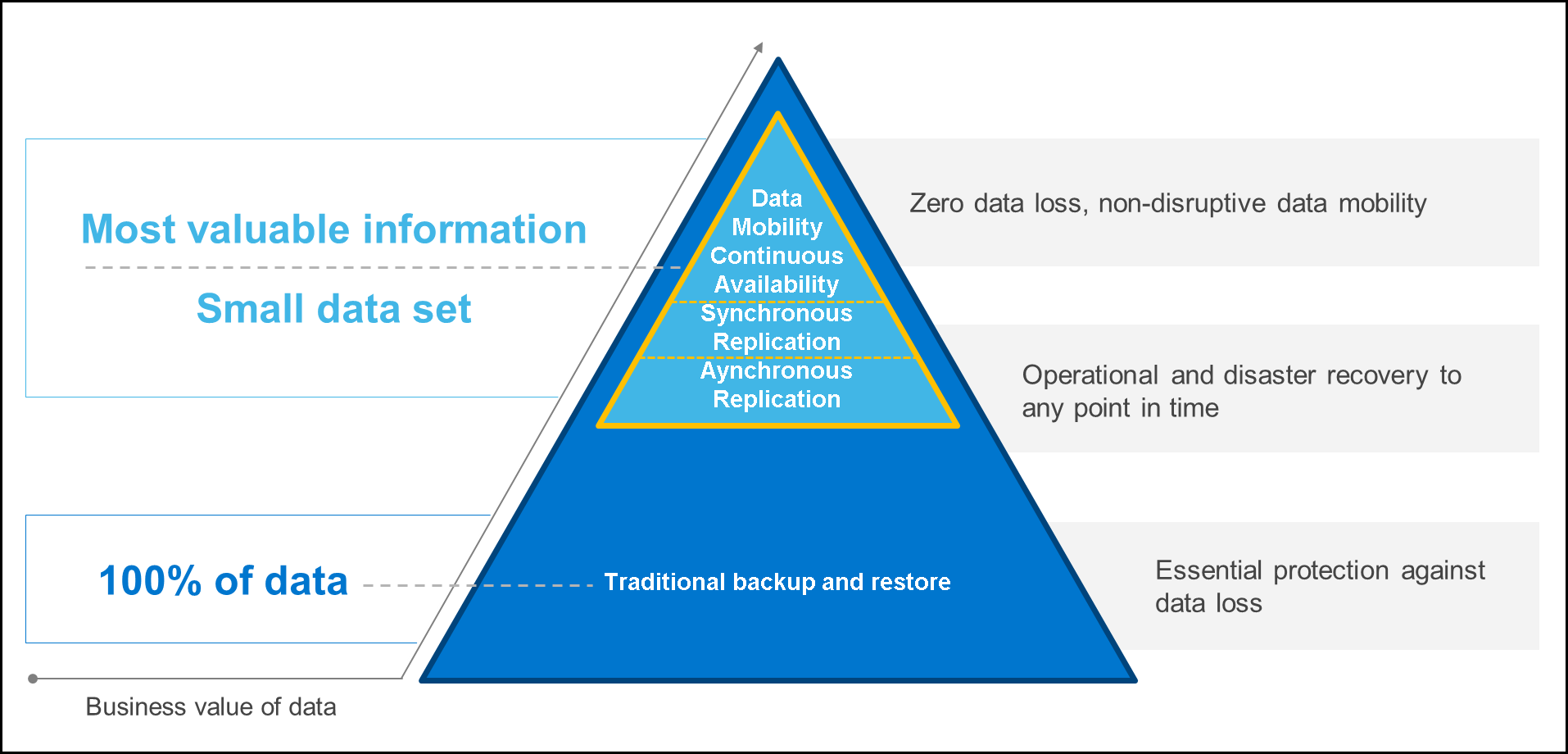
For a real-life experience, our Dell Technologies experts put Azure Stack HCI stretched clustering to the test in the following lab setup:
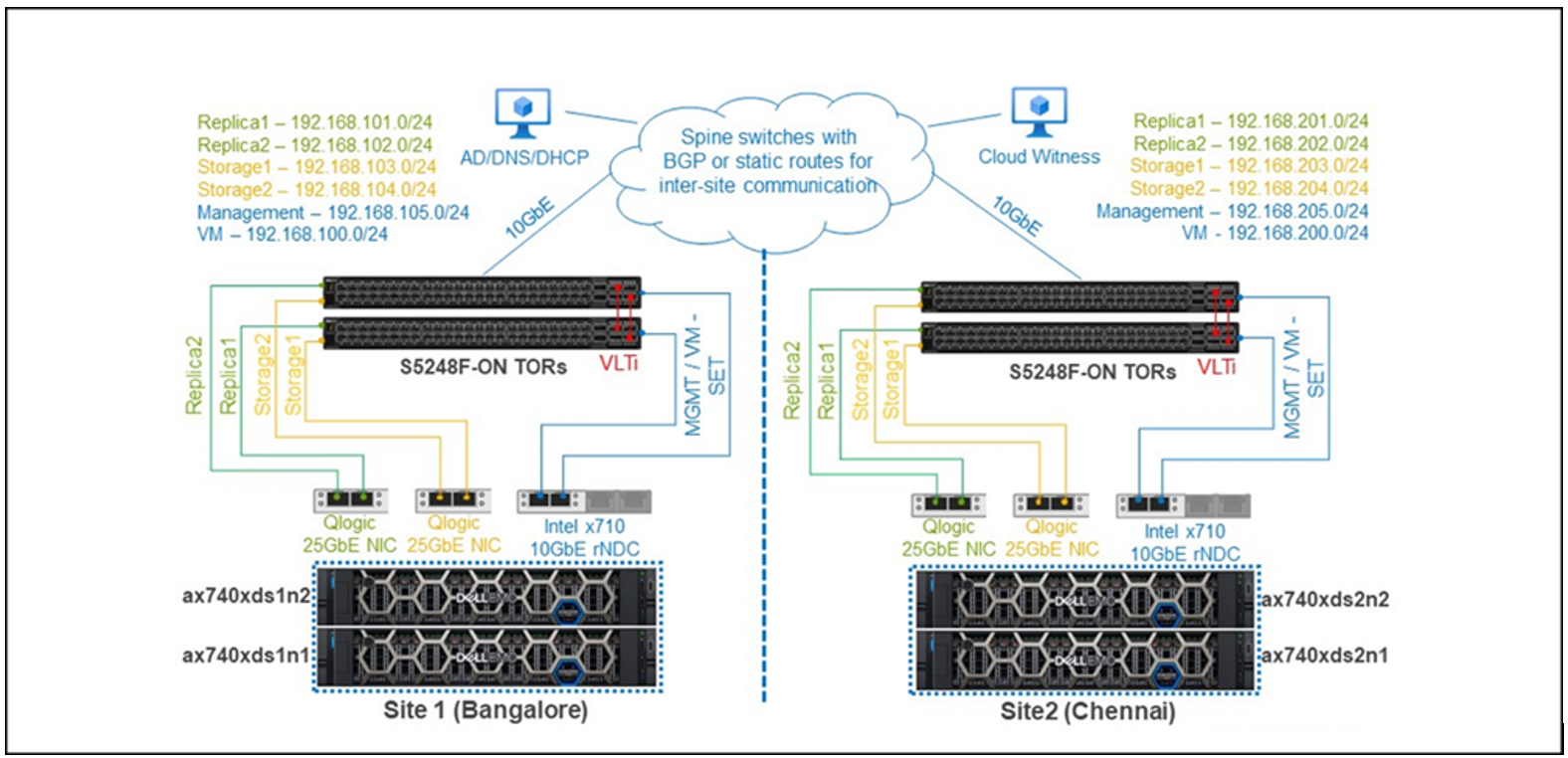
Test lab cluster network topology
Note these key considerations regarding the lab network architecture:
- The Storage Replica, management, and VM networks in each site were unique Layer 3 subnets. In Active Directory, we configured two sites—Bangalore (Site 1) and Chennai (Site 2)—based on these IP subnets so that the correct sites appeared in Failover Cluster Manager on configuration of the stretched cluster. No additional manual configuration of the cluster fault domains was required.
- Average latency between the two sites was less than 5 milliseconds, required for synchronous replication.
- Cluster nodes could reach a file share witness within the 200-millisecond maximum roundtrip latency requirement.
- The subnets in both sites could reach Active Directory, DNS, and DHCP servers.
- Software-defined networking (SDN) on a multisite cluster is not currently supported and was not used for this testing.
For all the details, see this white paper: Adding Flexibility to DR Plans with Stretch Clustering for Azure Stack HCI.
In this blog though, I only want to focus on summarizing the results we obtained in our labs for the following four scenarios:
- Scenario 1: Unplanned node failure
- Scenario 2: Unplanned site failure
- Scenario 3: Planned failover
- Scenario 4: Life cycle management
Scenario | Event | Simulated failure or maintenance event | Stretched Cluster expected response | Stretched Cluster actual response |
1 | Unplanned node failure | Node 1 in Site 1 power-down | Impacted VMs should failover to another local node | In around 5 minutes, all 10 VMs in Node 1 Site 1 fully restarted in Node 2 Site 1.
This is expected behavior since Site 1 has been configured as preferred site; otherwise, the active volume could have been moved to Site 2, and the VMs would have been restarted on a cluster node in Site 2. |
2 | Outage in Site 1 | Simultaneous power-down of Nodes 1 and 2 in site 1 | Impacted VMs should failover to nodes on the secondary site | In 25 minutes, all VMs were restarted, and the included web application was fully responsive.
The volumes owned by the nodes in Site 2 remained online throughout this failure scenario.
The replica volumes remained offline until Site 1 was restored to full health. Once Site 1 was back online, synchronous replication began again from the source volumes in Site 2 to their destination replica partners in Site 1. |
3 | Planned failover | Switch Direction operation on a volume from Windows Admin Center | Selected VMs and workloads should transparently move to secondary site | Within 0 to 3 mins, the application hosted by the affected VMs was reachable without service interruption (time depends on whether IP reassignment is required).
First, the owner node for the volumes changed to Node 2 in Site 2, and owner node for the replica volumes changed to Node 2 in Site 1. No service interruption. At this time, the test VM was running in Site 1, but its virtual disk that resided on the volume was running in Site 2. Performance problems can result because I/O is traversing the replication links across sites. After approximately 10 minutes, a Live Migration of the test VM would occur automatically (if not manually initiated earlier) so that the VM would be on the same node as its virtual disk. |
4 | Lifecycle management | Update all nodes in the cluster by using Single-click Full Stack Cluster Aware Updating (CAU) in Windows Admin Center | Stretched cluster and CAU should work seamlessly together to provide full stack cluster update without service interruption and local only workload mobility for the Live Migrated VMs | The total process of applying the operating system and firmware updates to the stretched cluster took approximately 3 hours, and the process had no application impact.
Each node was drained, and its VMs were live migrated to the other node in the same site. The intersite links between Site 1 and Site 2 were never used during update operations. In addition, the process required only a single reboot per node. This behavior was consistent throughout the update of all the nodes in the stretched cluster. |
To sum up, Azure Stack HCI Stretch Clustering has been shown to work as expected under difficult circumstances. It can easily be leveraged to cover a wide range of data protection scenarios, such as:
- restoring your organization's IT within minutes after an unplanned event
- transparently moving running workloads between sites to avoid incoming disasters or other planned operations
- automatically failing over VMs and workloads of individual failed nodes
This technology may make the difference for businesses to automatically stand up after disaster strikes, a total game changer in the automatic disaster recovery landscape.
Thank you for your time reading this blog and don’t forget to check out the full white paper!!!

Dell EMC OpenManage Integration with Microsoft Windows Admin Center v2.0 Technical Walkthrough
Wed, 16 Jun 2021 13:35:49 -0000
|Read Time: 0 minutes
Introduction
Dell EMC Integrated System for Microsoft Azure Stack HCI is a fully integrated HCI system for hybrid cloud environments that delivers a modern, cloud-like operational experience on-premises from a mature market leader.
The integrated system is based on our flexible AX nodes family as the laying foundation, and combines Dell Technologies full stack life cycle management with the Microsoft Azure Stack HCI operating system.
This blog focuses on one of the most important and critical parts of Azure Stack HCI: the management layer. Check this blog for additional background.
We will show how at Dell Technologies we make the good - Microsoft Windows Admin Center (WAC) - even better, through our OpenManage Integration with Microsoft Windows Admin Center v2.0 (OMIMSWAC).
The following diagram illustrates a typical Dell Technologies Azure Stack HCI setup:
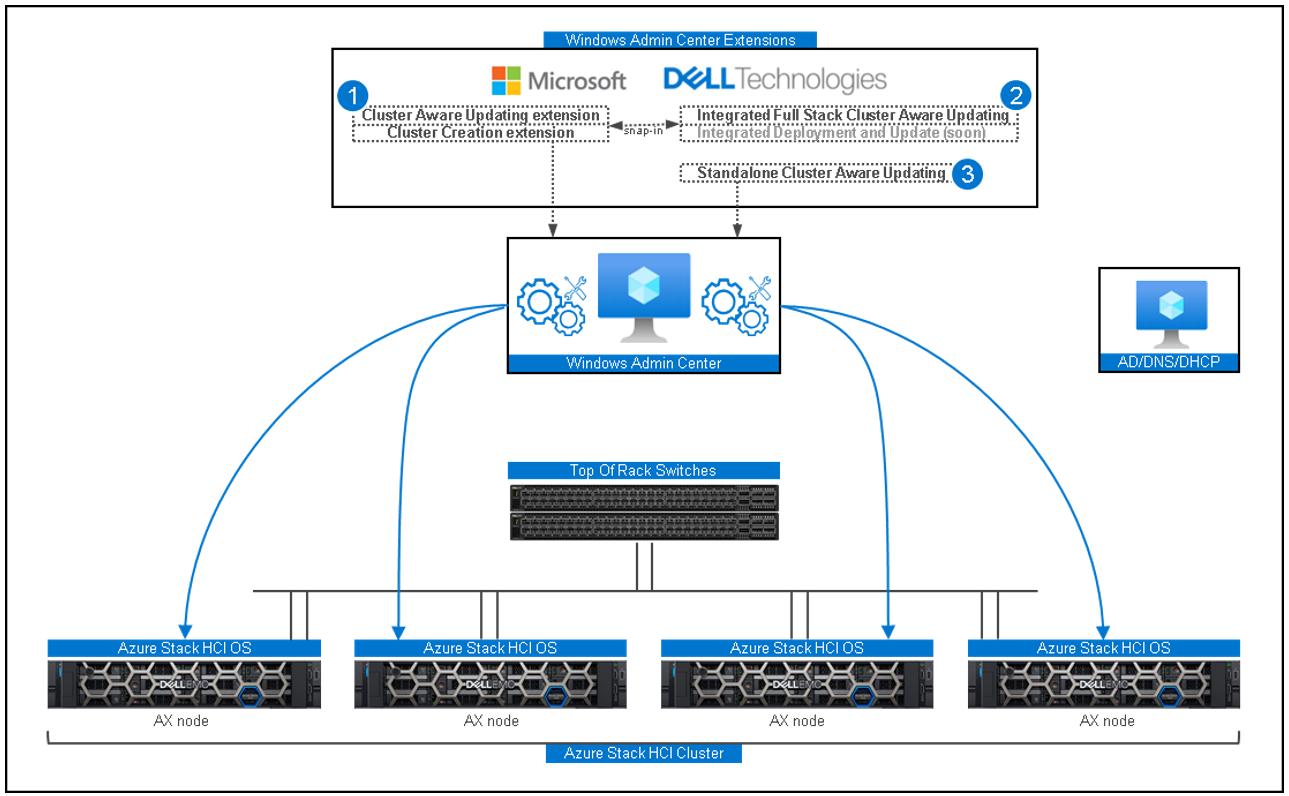
To learn more about Microsoft HCI Solutions from Dell Technologies and get details on each of the different components, check out this video where our Dell Technologies experts examine the solution thoroughly from the bottom up.
Windows Admin Center Extensions from Microsoft
WAC provides the option to leverage easy-to-use workflows to perform many tasks, including automatic deployments (coming soon) and updates.
Dell Technologies has developed specialized snap-ins that integrate OpenManage with WAC to further extend the capabilities of Microsoft’s WAC extensions.
The following table describes the three key elements highlighted in the previous diagram as (1), (2), and (3). We examine each in detail in the next three sections.
| Item | Type | Integrates with | Developed by | Description |
|---|---|---|---|---|
Microsoft Cluster Aware Updating extension Microsoft Failover Cluster Tool Extension 1.250.0.nupkg release* * Min version validated | Extension | WAC | Microsoft | WAC workflow to apply cluster aware OS updates |
Dell EMC Integrated Full Stack Cluster Aware Updating | Integration | Microsoft CAU extension | Dell Technologies | Integration snap-in to main CAU workflow to provide BIOS, firmware and driver updates while performing OS updates |
OMIMSWAC v2.0 Standalone extension | Extension | WAC | Dell Technologies | OpenManage WAC extension for Infrastructure Life cycle management, plus cluster monitoring, inventory and troubleshooting |
Cluster Creation extension Microsoft Cluster Creation Extension 1.529.0.nupkg release* * Min version validated | Extension | WAC | Microsoft | WAC workflow to create Azure Stack HCI Clusters |
Integrated Deployment and Update (coming soon) | Integration | Microsoft IDU extension | Dell Technologies | Integration snap-in to main Cluster Creation workflow to provide BIOS, firmware and driver updates during the cluster creation process |



Windows Admin Center extensions and integrations
You can install Microsoft Cluster Aware Updating extension within WAC by selecting the “Gear” icon on the top right corner, then under “Gateway”, navigate to “Extensions”. Under “Available extensions”, find the desired extension and select “Install”. For details, see the install guide. Please refer to the extensions product documentation for the latest updates.
Microsoft Cluster Aware Updating extension
To get to Microsoft WAC Azure Stack HCI Cluster Aware Updating extension, login to WAC and follow these steps:
- Click on the cluster you want to connect to. This takes us to the cluster Dashboard.
- On the left pane, under “Tools”, select “Update”.
- In the “Updates” window, click on “Check for updates”, which will pop up the “Install updates” window.
- Here we are presented with a three-step process where we select, in order:
- Operating system updates
- Hardware updates
- Proceed with the installation
It is important to note that you can select either to run only one operation at a time by skipping the other or run both in one single process and reboot.
You may select, if available, any Operating system update and click “Next: Hardware updates”. 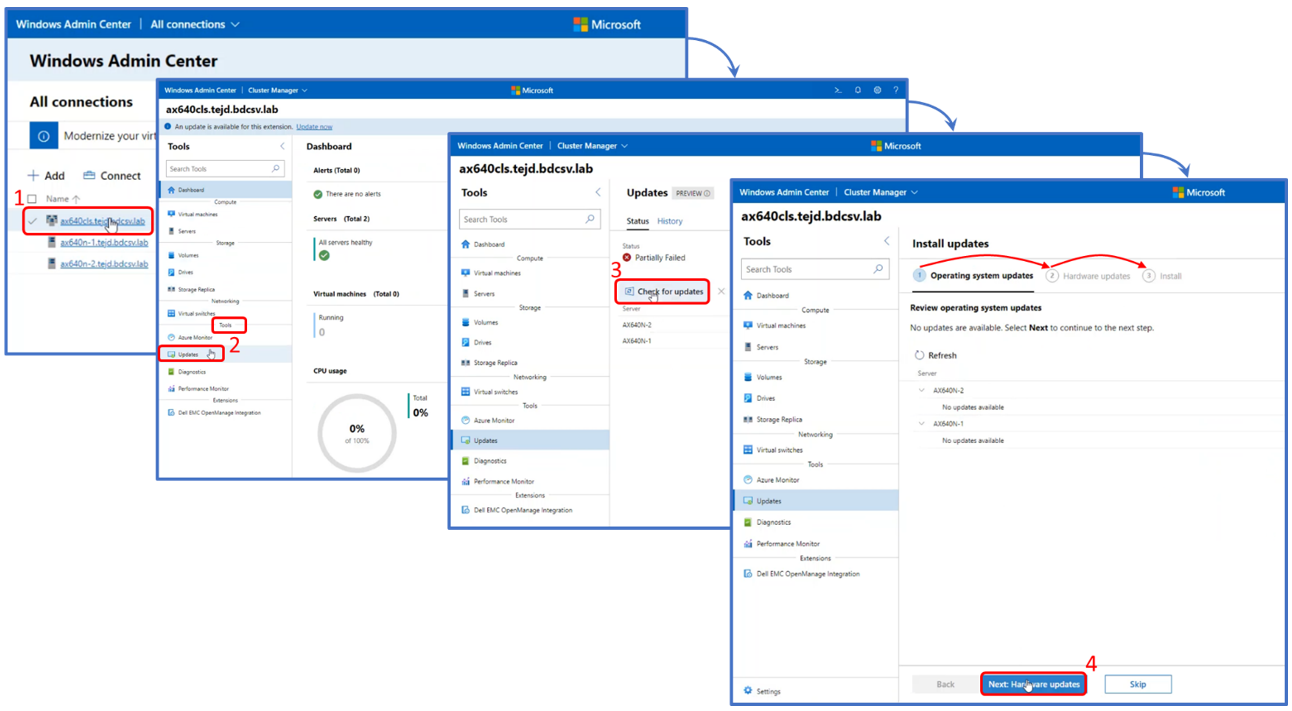
This takes us to the second step of the sequence - Hardware updates - a key phase for the automated end-to-end cluster aware update process.
This is where the Dell Technologies snap-in integrates with Microsoft’s original workflow, allowing us to seamlessly provide automated BIOS, firmware, and driver updates (and OS updates if also selected) to all the nodes in the cluster with a single reboot. Let’s look at this process in detail in the next section.
Dell EMC Integrated Full Stack Cluster Aware Updating
Once you click “Next: Hardware updates” on the original Microsoft’s Azure Stack HCI Cluster Aware Updating workflow, you are taken to Dell EMC Cluster Aware Updating integration.
If the integration is not installed, there is an option to install it from inside the workflow.
Click “Get updates”.
Our snap-in for Cluster Aware Updating (CAU) takes us through the following sequence of five steps.
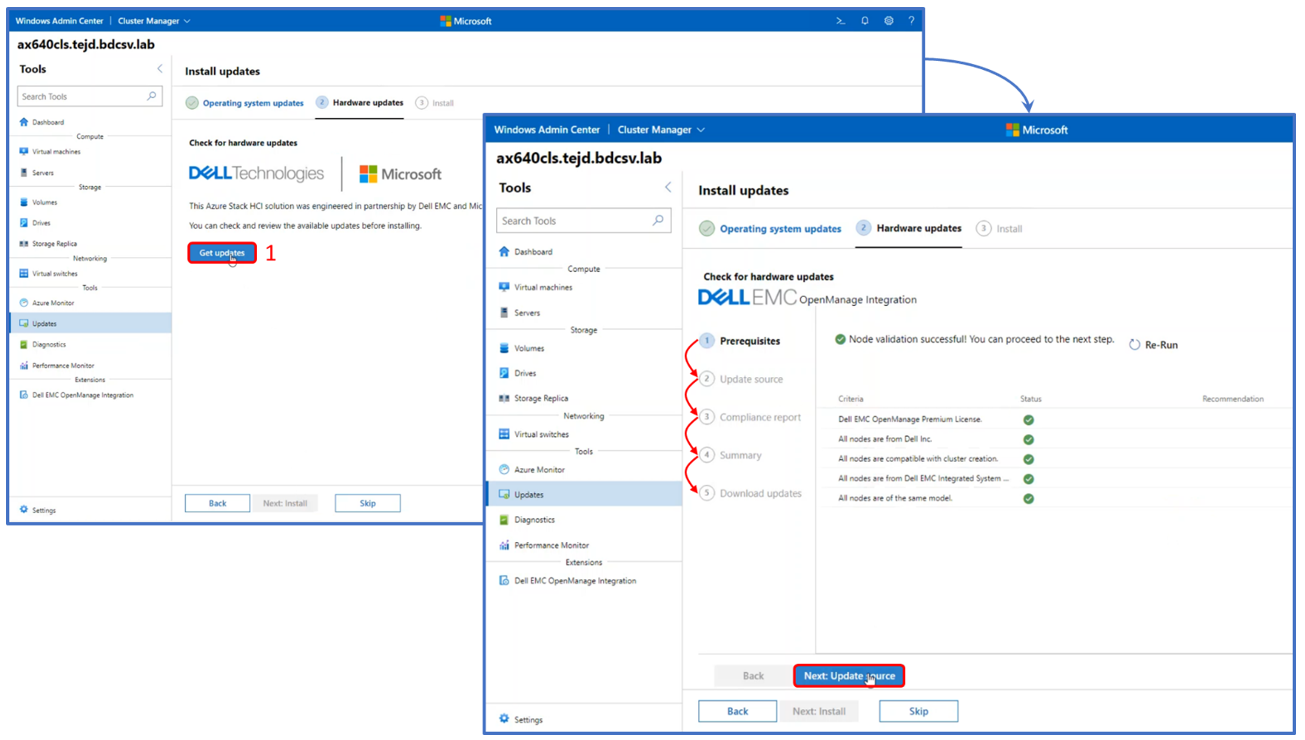
1. Prerequisites (screenshot above)
A validation process occurs, checking that all AX nodes are:
- Supported in the HCL
- Same model
- OpenManage Premium License for MSFT HCI Solutions compliant (included in AX node base solution)
- Compatible with cluster creation
Click “Next: Update source”.
2. Update source
Here we can select the source for our BIOS, firmware, and driver repository, whether online [Update Catalog for Microsoft HCI Solutions] or offline (edge or disconnected) [Dell EMC Repository Manager Catalog]. Dell Technologies has created and keeps these solution catalogs updated.
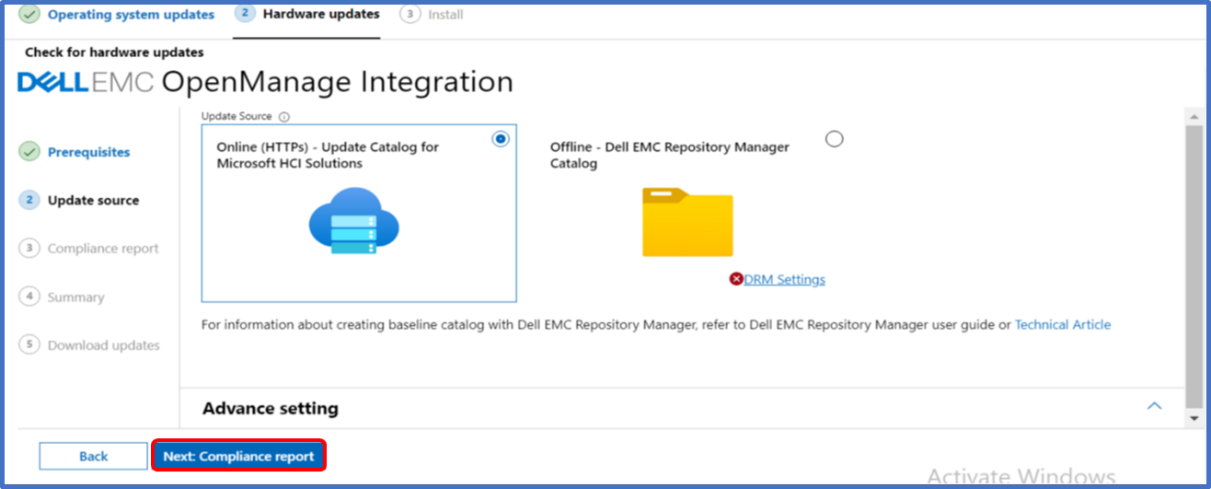
Click “Next: Compliance report”.
3. Compliance report
Now we can check how compliant our nodes are and select for BIOS, firmware, and/or driver remediation. All the recommended components are selected by default.
The compliance operation runs in parallel for all nodes, and the report is shown consolidated across nodes.
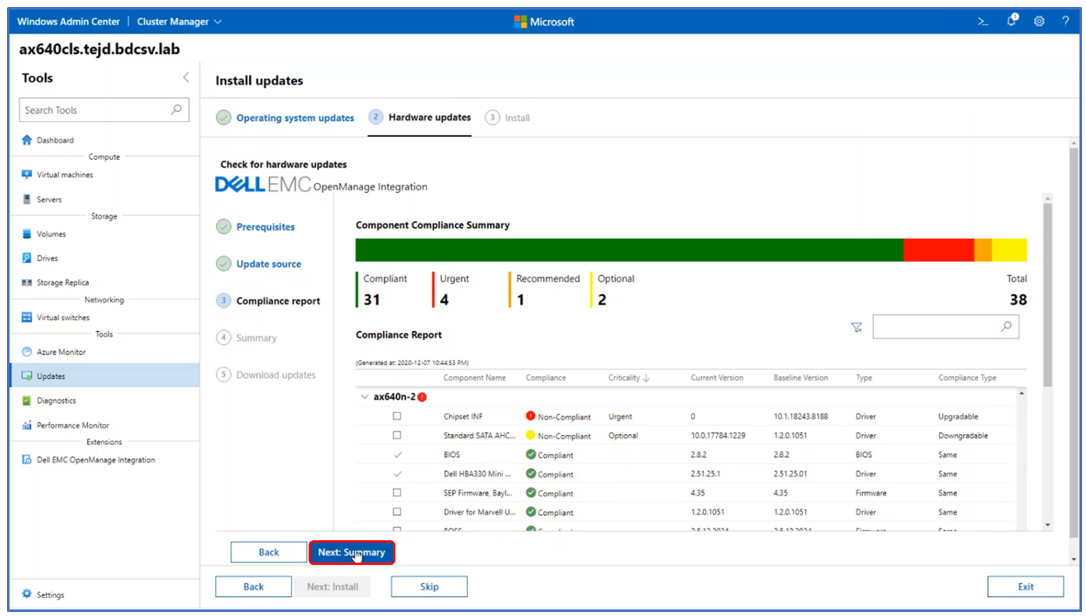
Click “Next: Summary”.
4. Summary
All selections from all nodes are shown in Summary for review before we click “Next: Download updates”.
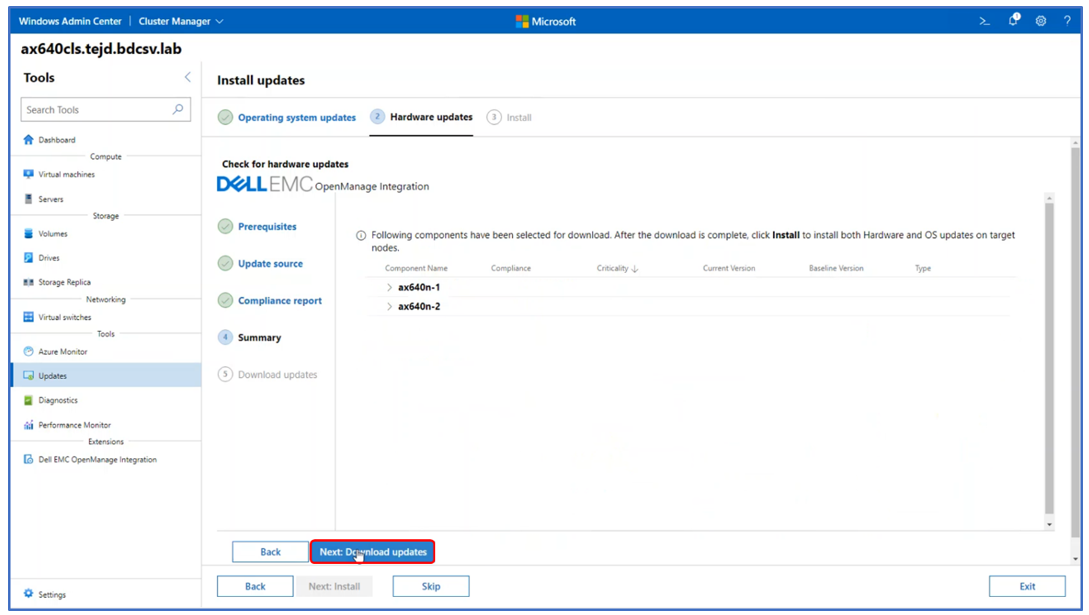
5. Download updates
This window provides the statistics regarding the download process (start time, download status).
When all downloads are completed, we can click “Next: Install”, which takes us back again to Step 3 of the main workflow (“Install”), to begin the installation process of OS and hardware updates (if both were selected) on the target nodes.
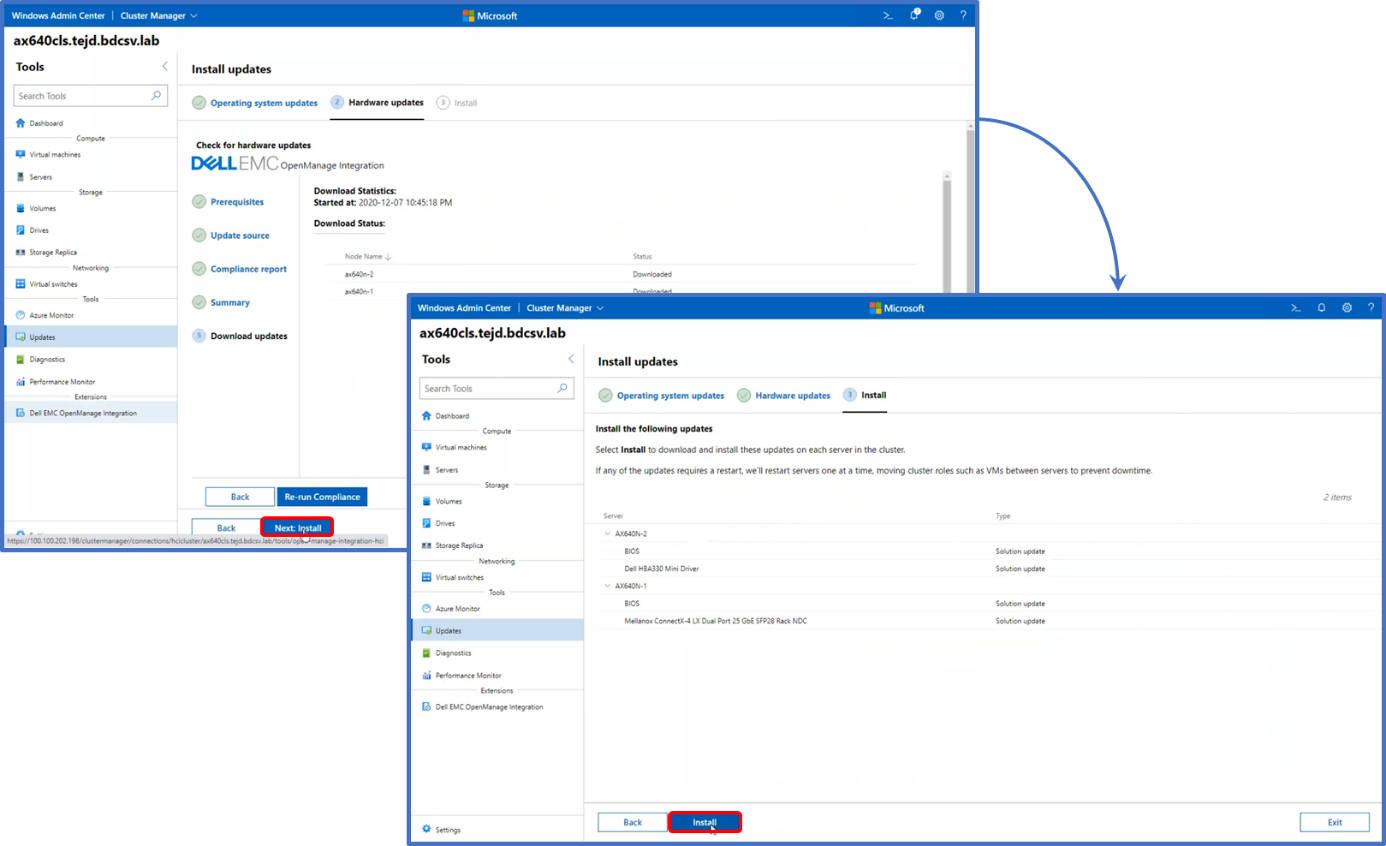
If any of the updates requires a restart, servers will be rebooted one at a time, moving cluster roles such as VMs between servers to prevent downtime and guaranteeing business continuity.
Once the process is finished for all the nodes, we can go back to “Updates” to check for the latest update status and/or Update history for previous updates.
It is important to note that the Cluster Aware Updating extension is supported only for Dell EMC Integrated System for Microsoft Azure Stack HCI.
OMIMSWAC v2.0 Standalone extension
The standalone extension applies to Windows Server HCI and Azure Stack HCI, and continues to provide monitoring, inventory, troubleshooting, and hardware updates with CAU.
New to OMIMSWAC 2.0 is the option to schedule updates during a programmed maintenance window for greater flexibility and control during the update process.
It is important to note that OMIMSWAC Standalone version provides the Cluster Aware Updating feature for the hardware (BIOS, firmware, drivers) in a single reboot, although this process is not integrated with operating system updates. It provides full lifecycle management just for the hardware, not the OS layer.
Another key takeaway is that OMIMSWAC Standalone version fully supports Dell EMC HCI Solutions from Microsoft Windows Server and even certain qualified previous solutions (Dell EMC Storage Spaces Direct Ready Nodes).
Conclusion
Dell Technologies has developed OMIMSWAC to make integrated systems’ lifecycle management a seamless and easy process. It can fully guarantee controlled end-to-end cluster hardware and software update processes during the lifespan of the service.
The Dell EMC OMIMSWAC automated and programmatic approach provides obvious benefits, like mitigating risk caused by human intervention, significantly fewer steps to update clusters, and significantly less focused attention time for IT administrators. In small 4-node cluster deployments, this can mean up to 80% fewer steps and up to 90% less focused attention from an IT operator.
Full details on the benefits of performing these operations automatically through OMIMSWAC versus doing it manually are explained in this white paper.
Thank you for reading this far and stay tuned for more blog updates in this space!

Boost Performance on Dell EMC HCI Solutions for Microsoft Server using Intel Optane Persistent Memory
Wed, 16 Jun 2021 13:35:49 -0000
|Read Time: 0 minutes
Modern IT applications have a broad range of performance requirements. Some of the most demanding applications use Online Transactional Processing (OLTP) database technology. Typical organizations have many mission critical business services reliant on workloads powered by these databases. Examples of such services include online banking in the financial sector and online shopping in the retail sector. If the response time of these systems is slow, customers will likely suffer a poor user experience and may take their business to competitors. Dissatisfied customers may also express their frustration through social media outlets resulting in incalculable damage to a company’s reputation.
The challenge in maintaining an exceptional consumer experience is providing databases with performant infrastructure while also balancing capacity and cost. Traditionally, there have been few cost-effective options that cache database workloads, which would greatly improve end-user response times. Intel Optane persistent memory (Intel Optane PM) offers an innovative path to accelerating database workloads. Intel Optane PM performs almost as well as DRAM, and the data is preserved after a power cycle. We were interested in quantifying these claims in our labs with Dell EMC HCI Solutions for Microsoft Windows Server.
Windows Server HCI running Microsoft Windows Server 2019 provides industry-leading virtual machine performance with Microsoft Hyper-V and Microsoft Storage Spaces Direct technology. The platform supports Non-Volatile Memory Express (NVMe), Intel Optane PM, and Remote Direct Memory Access (RDMA) networking. Windows Server HCI is a fully productized, validated, and supported HCI solution that enables enterprises to modernize their infrastructure for improved application uptime and performance, simplified management and operations, and lower total cost of ownership. AX nodes from Dell EMC, powered by industry-leading PowerEdge server platforms, offer a high-performance, scalable, and secure foundation on which to build a software-defined infrastructure.
In our lab testing, we wanted to observe the impact on performance when Intel Optane PM was added as a caching tier to a Windows Server HCI cluster. We set up two clusters to compare. One cluster was configured as a two-tier storage subsystem with Intel Optane PM in the caching tier and SATA Read-Intensive SSDs in the capacity tier. We inserted 12 x 128 GB Intel Optane PM modules into this cluster for a total of 1.5 TB per node. The other cluster’s storage subsystem was configured as a single-tier of SATA Read-Intensive SSDs. With respect to CPU selection, memory, and Ethernet adapters, the two clusters were configured identically.
Only the Dell EMC AX-640 nodes currently accommodate Intel Optane PM. The clusters were configured as follows:
Cluster Resources | Without Intel Optane PM | With Intel Optane PM |
Number of nodes | 4 | 4 |
CPU | 2 x Intel 6248 CPU @ 2.50 GHz (3.90 GHz with TurboBoost) | 2 x Intel 6248 CPU @ 2.50 GHz (3.90 GHz with TurboBoost) |
Memory | 384 GB RAM | 384 GB RAM |
Disks | 10 x 2.5 in. 1.92 TB Intel S4510 RI SATA SSD | 10 x 2.5 in. 1.92 TB Intel S4510 RI SATA SSD |
NICs | Mellanox ConnectX-5 EX Dual Port 100 GbE | Mellanox ConnectX-5 EX Dual Port 100 GbE |
Persistent memory | None | 12 x 128 GB Intel Optane PM per node |
Volumes were created using three-way mirroring for the best balance between performance and resiliency. Three-way mirroring protects data by enabling the cluster to safely tolerate two hardware failures. For example, data on a volume would be successfully preserved even after the simultaneous loss of an entire node and a drive in another node.
Intel Optane PM has two operating modes – Memory Mode and App Direct Mode. Our tests used App Direct Mode. In App Direct Mode, the operating system uses Intel Optane PM as persistent memory distinct from DRAM. This mode enables extremely high performing storage that is byte-addressable-like, memory coherent, and cache coherent. Cache coherence is important because it ensures that data is a uniformly shared resource across all nodes. In the four-node Windows Server HCI cluster, cache coherence ensured that when data was read or written from one node that the same data was available across all nodes.
VMFleet is a storage load generation tool designed to perform I/O and capture performance metrics for Microsoft failover clusters. For the small block test, we used VMFleet to generate 100 percent reads at a 4K block size. The baseline configuration without Intel Optane PM sustained 2,103,412 IOPS at 1.5-millisecond (ms) average read latency. These baseline performance metrics demonstrated outstanding performance. However, OLTP databases target 1 ms or less latency for reads.

Comparatively, the Intel Optane PM cluster demonstrated 43 percent faster IOPS and decreased latency by 53 percent. Overall, this cluster sustained slightly over 3 million IOPS at .7 ms average latency. Benefits include:
- Significant performance improvement in IOPS means transactional databases and similar workloads will improve in scalability.
- Applications reading from storage will receive data faster, thus improving transactional response times.
- Intel Optane PM coherent cache provides substantial performance benefits without sacrificing availability.
When exploring storage responsiveness, testing large block read and write requests is also important. Data warehouses and decision-support systems are examples of workloads that read larger blocks of data. For this testing, we used 512 KB block sizes and sequential reads as part of the VMFleet testing. This test provided insight into the ability of Intel Optane PM cache to improve storage system throughput.

The cluster populated with Intel Optane PM was 109% faster than the baseline system. Our comparisons of 512 KB sequential reads found total throughput of 11 GB/s for the system without Intel Optane PM and 23 GB/s for the system with Intel Optane PM caching. Benefits include:
- Greater throughput enables faster scans of data for data warehouse systems, decision-support systems, and similar workloads.
- The benefit to the business is faster reporting and analytics.
- Intel Optane PM coherent cache provides substantial throughput benefits without sacrificing availability.
Overall, the VMFleet tests were impressive. Both Windows Server HCI configurations had 40 SSDs across the four nodes for approximately 76 TB of performant storage. To accelerate the entire cluster required 12 Intel Optane PM 128 GB modules per server for a total of 48 modules across the four nodes. Test results show that both OLTP and data-warehouse type workloads would exhibit significant performance improvements.
Testing 100 percent reads of 4K blocks showed:
- 43 percent performance improvement in IOPS.
- 53 percent decrease in average read latency.
- Improved scaling and faster transaction processing. Overall, application performance would be significantly accelerated, improving end-user experience.
Testing 512 KB sequential reads showed:
- 109 percent increased throughput.
- Faster reporting and faster time to analytics and data insights.
The configuration presented in this lab testing scenario will not be appropriate for every application. Any Windows Server HCI solution must be properly scoped and sized to meet or exceed the performance and capacity requirements of its intended workloads. Work with your Dell Technologies account team to ensure that your system is correctly configured for today’s business challenges and ready for expansion in the future. To learn more about Microsoft HCI Solutions from Dell Technologies, visit our Info Hub page.

Value Optimized AX-6515 for ROBO Use Cases
Wed, 16 Jun 2021 13:35:49 -0000
|Read Time: 0 minutes
Introduction
Small offices and remote branch office (ROBO) use cases present special challenges for IT organizations. The issues tend to revolve around how to implement a scalable, resilient, secure, and highly performant platform at an affordable TCO. The infrastructure must be capable enough to efficiently run a highly diversified portfolio of applications and services and yet be simple to deploy, update, and support by a local IT generalist. Dell Technologies and Microsoft help you accelerate business outcomes in these unique ROBO environments with our Dell EMC Solutions for Microsoft Azure Stack HCI.
In this blog post, we share VMFleet results observed in the Dell Technologies labs for our newest AX-6515 two-node configuration – ideal for ROBO environments. Optimized for value, the small but powerful AX-6515 node packs a dense, single-socket 2nd Gen AMD EPYC processor in a 1RU chassis delivering peak performance and excellent TCO. We also included the Dell EMC PowerSwitch S5212F-ON in our testing to provide 25GbE network connectivity for the storage, management, and VM traffic in a small form factor. The Dell EMC Solutions for Azure Stack HCI Deployment Guide was followed to construct the test lab and applies only to infrastructure that is built with validated and certified AX nodes running Microsoft Windows Server 2019 Datacenter from Dell Technologies.
We were quite impressed with the VMFleet results. First, we stressed the cluster’s storage subsystem to its limits using scenarios aimed at identifying maximum IOPS, latency, and throughput. Then, we adjusted the test parameters to be more representative of real-world workloads. The following summary of findings indicated to us that this two-node, AMD-based, all-flash cluster could meet or exceed the performance requirements of workload profiles often found in ROBO environments:
- Achieved over 1 million IOPS at microsecond latency using a 4k block size and 100% random-read IO pattern.
- Achieved over 400,000 IOPS at 4 millisecond latency using a 4k block size and 100% random-write IO pattern.
- Using 512k block sizes, drove 6 GB/s and 12 GB/s throughput for 100% sequential-write and 100% sequential-read IO patterns, respectively.
- Using a range of real-world scenarios, the cluster achieved hundreds of thousands of IOPS at under 7 milliseconds latency and drove between 5 – 12 GB/s of sustained throughput.
Lab Setup
The following diagram illustrates the environment created in the Dell Technologies labs for the VMFleet testing. Ancillary services required for cluster operations such as DNS, Active Directory, and a file server for cluster quorum are not depicted.
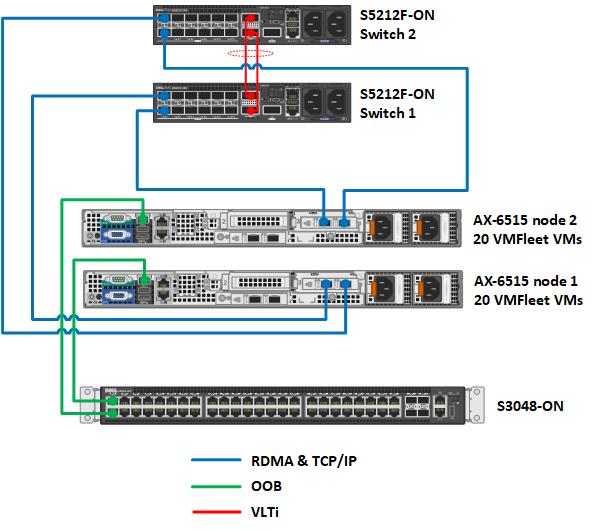
Figure 1 Network topology
Table 1 Cluster configuration
Cluster Design Elements | Description |
Number of cluster nodes | 2 |
Cluster node model | AX-6515 nodes |
Number of network switches for RDMA and TCP/IP traffic | 2 |
Network switch model | Dell EMC PowerSwitch S5212F-ON |
Network topology | Fully-converged network configuration. RDMA and TCP/IP traffic traversing 2 x 25GbE network connections from each host. |
Network switch for OOB management | Dell EMC PowerSwitch S3048-ON |
Resiliency option | Two-way mirror |
Usable storage capacity | Approximately 12 TB |
Table 2 Cluster node resources
Resources per Cluster Node | Description |
CPU | Single-socket AMD EPYC 7702P 64-Core Processor |
Memory | 256 GB DDR4 RAM |
Storage controller for OS | BOSS-S1 adapter card |
Physical drives for OS | 2 x Intel 240 GB M.2 SATA drives configured as RAID 1 |
Storage controller for Storage Spaces Direct (S2D) | HBA330 Mini |
Physical drives | 8 x 1.92 TB Mixed Use KIOXIA SAS SSDs |
Network adapter | Mellanox ConnectX-5 Dual Port 10/25GbE SFP28 Adapter |
Operating System | Windows Server 2019 Datacenter |
The architectures of Azure Stack HCI solutions are highly opinionated and prescriptive. Each design is extensively tested and validated by Dell Technologies Engineering. Here is a summary of the key quality attributes that define these architectures followed by a section devoted to our performance findings.
- Efficiency – Many customers are interested in improving performance and gaining efficiencies by modernizing their aging virtualization platforms with HCI. Using Azure Stack HCI helps avoid a DIY approach to IT infrastructure, which is prone to human error and is more labor intensive.
- Maintainability – Our solution makes it simple to incorporate hybrid capabilities to reduce operational burden using Microsoft Windows Admin Center (WAC). Services in Azure can also be leveraged to avoid additional on-premises investments for management, monitoring, BCDR, security, and more. We have also developed the Dell EMC OpenManage Integration with Microsoft Windows Admin Center to assist with hardware monitoring and to simplify updates with Cluster Aware Updates (CAU).
- Availability – Using a two-way mirror, we always have two copies of our data. This configuration can survive a single drive failure in one node or survive an entire node failure. However, the cluster cannot survive two failures simultaneously on both nodes. In case greater resiliency is desired, volumes can be created using nested resiliency. Nested resiliency is discussed in more detail in the "Optional modifications to the architecture" section later in this blog post.
- Supportability – Support is provided by dedicated Dell Technologies ProSupport Plus and ProSupport for Software technicians who have expertise specifically tailored to Azure Stack HCI solutions.
Testing Results
We leveraged VMFleet to benchmark the storage subsystem of our 2-node cluster. Many Microsoft customers and partners rely on this tool to help them stress test their Azure Stack HCI clusters. VMFleet consists of a set of PowerShell scripts that deploy virtual machines to a Hyper-V cluster and execute Microsoft’s DiskSpd within those VMs to generate IO. The following table presents the range of VMFleet and DiskSpd parameters used during our testing in the Dell Technologies labs.
Table 3 Test parameters
VMFleet and DiskSpd Parameters | Values |
Number of VMs running per node | 20 |
vCPUs per VM | 2 |
Memory per VM | 8 GB |
VHDX size per VM | 40 GB |
VM Operating System | Windows Server 2019 |
0 | |
Block sizes (B) | 4k – 512k |
Thread count (T) | 2 |
Outstanding IOs (O) | 32 |
Write percentages (W) | 0, 20, 50, 100 |
IO patterns (P) | Random, Sequential |
We first selected DiskSpd scenarios aimed at identifying the maximum IOPS, latency, and throughput thresholds of the cluster. By pushing the limits of the storage subsystem, we confirmed that the networking, compute, operating systems, and virtualization layer were configured correctly according to our Deployment Guide and Network Integration and Host Network Configuration Options guide. This also ensured that that no misconfiguration occurred during initial deployment that could skew the real-world storage performance results. Our results are depicted in Table 4.
Table 4 Maximums test results
Scenario | Parameter Values Explained | Performance Metric |
B4-T2-O32-W0-PR | Block size: 4k Thread count: 2 Outstanding IO: 32 IO pattern: 100% random read | IOPS: 1,146,948 Read latency: 245 microseconds CPU utilization: 48% |
B4-T2-O32-W100-PR | Block size: 4k Thread count: 2 Outstanding IO: 32 IO pattern: 100% random write | IOPS: 417,591 Write latency: 4 milliseconds CPU utilization: 25% |
B512-T2-O2-W0-PSI | Block size: 512k Thread count: 2 Outstanding IO: 8 IO pattern: 100% sequential read | Throughput: 12 GB/s |
B512-T2-O2-W100-PSI | Block size: 512k Thread count: 2 Outstanding IO: 8 IO pattern: 100% sequential write | Throughput: 6 GB/s |
We then stressed the storage subsystem using IO patterns more reflective of the types of workloads found in a ROBO use case. These applications are typically characterized by smaller block sizes, random I/O patterns, and a variety of read/write ratios. Examples include general enterprise and small office LOB applications and OLTP workloads. The testing results in Figure 2 below indicate that the cluster has the potential to accelerate OLTP workloads and make enterprise applications highly responsive to end users.
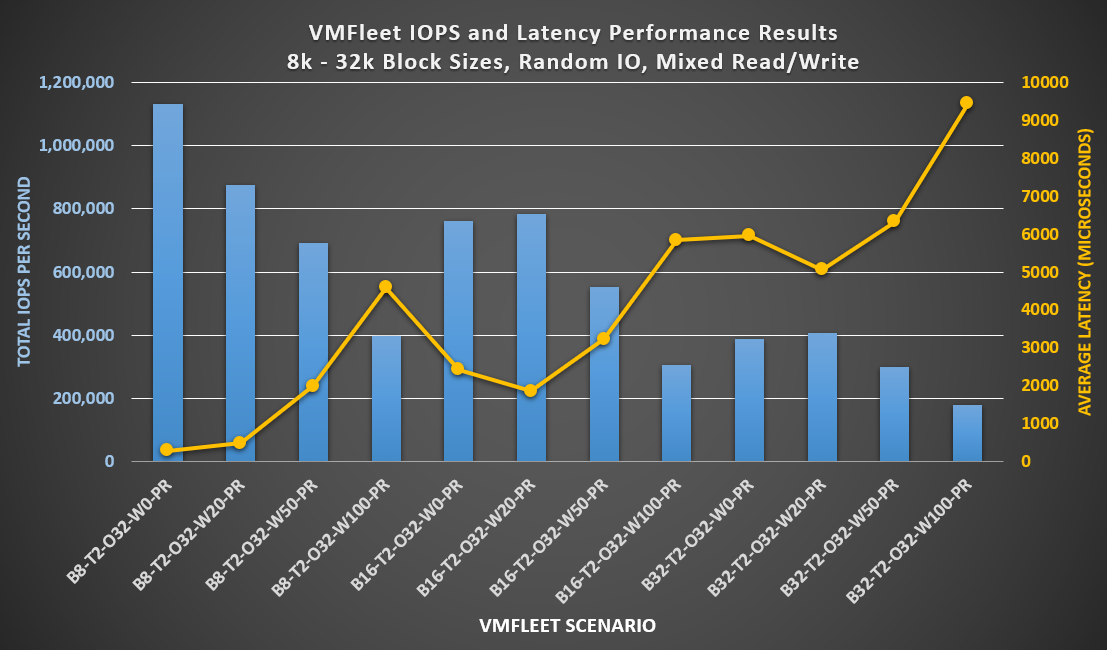
Figure 2 Performance results with smaller block sizes
Other services like backups, streaming video, and large dataset scans have larger block sizes and sequential IO patterns. With these workloads, throughput becomes the key performance indicator to analyze. The results shown in the following graph indicate an impressive sustained throughput that can greatly benefit this category of IT services and applications.
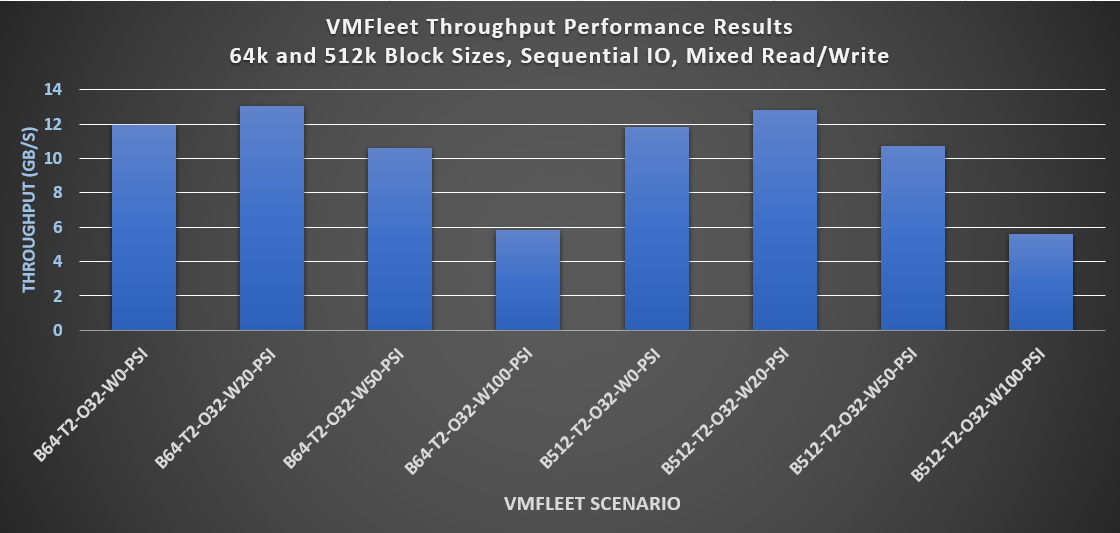
Figure 3 Performance results with larger block sizes
Optional modifications to the architecture
Customers could make modifications to the lab configuration to accommodate different requirements in the ROBO use case. For example, Dell Technologies completely supports a dual-link full mesh topology for Azure Stack HCI. This non-converged storage switchless topology eliminates the need for network switches for storage communications and enables you to use existing infrastructure for management and VM traffic. This approach will result in similar or improved performance metrics versus those mentioned in this blog due to the 2 x 25 GB direct connections between the nodes and the isolation of the storage traffic on these dedicated connections.
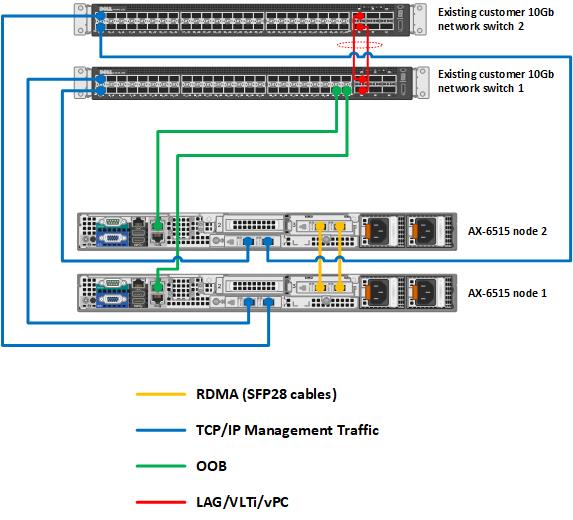
Figure 4 Two-node back-to-back architecture option
There may be situations in ROBO scenarios where there are no IT generalists near the site to address hardware failures. When a drive or entire node fails, it may take days or weeks before someone can service the nodes and return the cluster to full functionality. Consider nested resiliency instead of two-way mirroring to handle multiple failures on a two-node cluster. Inspired by RAID 5 + 1 technology, workloads remain online and accessible even in the following circumstances:
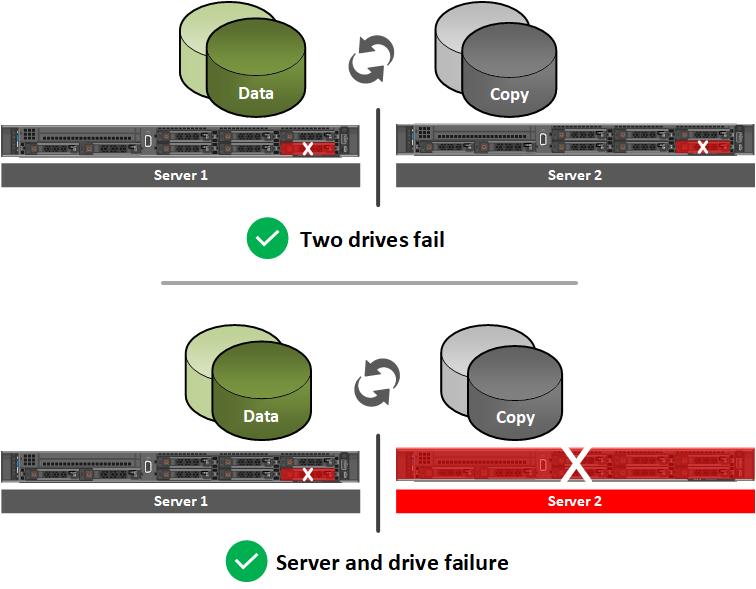
Figure 5 Nested resiliency option
Be aware that there is a capacity efficiency cost when using nested resiliency. Two-way mirroring is 50% efficient, meaning 1 TB of data takes up 2 TB of physical storage capacity. Depending on the type of nested resiliency you choose to configure, capacity efficiency can range between 25% - 40%. Therefore, ensure you have an adequate amount of raw storage capacity if you intend to use this technology. Performance is also going to be affected when using nested resiliency – especially on workloads with a higher percentage of write IO since more copies of the data need to be maintained on the cluster.
If you need greater flexibility in cluster resources, Dell Technologies offers Azure Stack HCI configurations to meet any workload profile and business requirement. The table below shows the different resource options available for each AX node. To find more detailed specifications about these configurations, please review the detailed product specifications on our product page.
Table 5 Azure Stack HCI configuration options
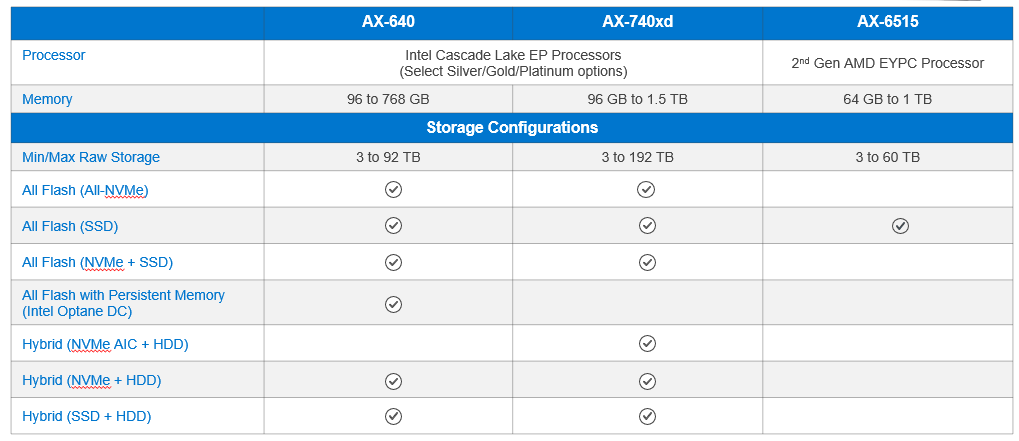
Visit our website for more details on Dell EMC Solutions for Azure Stack HCI.

Dell EMC Solutions for Azure Stack HCI Furthers Customer Value
Wed, 16 Jun 2021 13:35:49 -0000
|Read Time: 0 minutes
As customers address the upgrade cycle of retiring Microsoft Windows Server 2008 into software defined infrastructures using Windows Server 2019, the core tenets of hyperconverged infrastructure (HCI) and hybrid cloud enablement continue to be desired goals. Many customers, however, are unsure how to best leverage their investments in Windows Server to modernize their datacenters to take advantage of software defined infrastructure.
At Dell Technologies, we have leadership positions in converged, hyperconverged, and cloud infrastructures covering several platforms, including being a founding launch partner with Microsoft’s Azure Stack HCI solution. Built over three decades of partnership with Microsoft, we bring the insights and expertise to help our customers with their IT transformation utilizing software defined features of Windows Server 2019, the foundational platform for Azure Stack HCI.
Built on globally available and supported Storage Spaces Direct (S2D) Ready Nodes, Dell EMC offers a wide range of Azure Stack HCI Solutions that provide an excellent value proposition for customers who have standardized on Microsoft Hyper-V and looking to modernize IT infrastructure while utilizing their existing investments and expertise in Windows Server.
As we head to Microsoft’s largest customer event – Microsoft Ignite 2019 – we are delighted to share some new enhancements and offerings to our Azure Stack HCI solution portfolio.
Simplifying Managing Azure Stack HCI via Windows Admin Center (WAC)
With a goal of simplifying Azure Stack HCI management, we have integrated monitoring of S2D Ready Nodes into the Windows Admin Center (WAC) console. The Dell EMC OpenManage Extension for WAC allows our customers to manage Azure Stack HCI clusters from a single pane of glass. The current integration provides health monitoring, hardware inventory, and firmware compliance reporting of S2D Ready Nodes, the core building block of our Azure Stack HCI solution. By using this extension, infrastructure administrators can monitor all their clusters in real time and check if the nodes are compliant to Dell EMC recommended firmware and driver versions. Customers wanting to leverage Azure public cloud to either extend or protect their on-prem applications can do so within the WAC console to utilize services such as Azure Back up, Azure Site Recovery, Azure Monitor, etc.
Here is what Greg Altman, IT Infrastructure Manager at Swiff-Train and one our early customers had to say about our OpenManage integration with WAC:
"The Dell EMC OpenManage Integration with Microsoft Windows Admin Center gives us full visibility to Dell EMC Solutions for Microsoft Azure Stack HCI, enabling us to more easily respond to situations before they become critical. With the new OpenManage integration, we can also manage Microsoft Azure Stack HCI from anywhere, even simultaneously managing our clusters located in different cities."
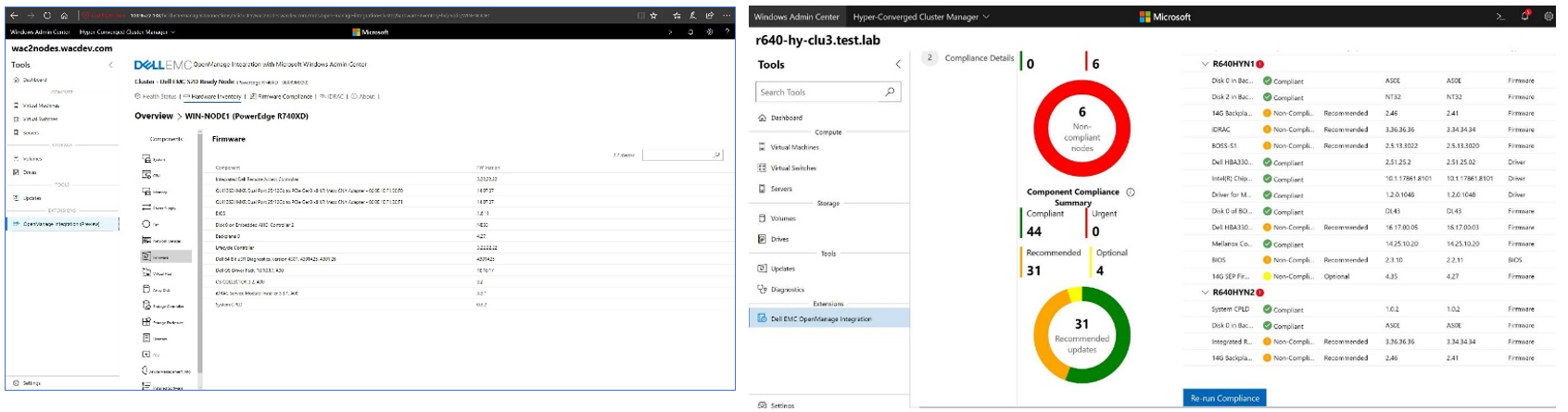
New HCI Node optimized for Edge and ROBO Use Cases
Customers looking at modernizing infrastructure at edge, remote or small office locations now have an option of utilizing the new Dell EMC R440 S2D Ready Node which provides both hybrid and all-flash options. A 2-node Azure Stack HCI cluster provides a great solution for such use cases that need limited hardware infrastructure, yet superior performance and availability and ease of remote management.
The dual socket R440 S2D Ready Node is shallower (depth of 27.26 in) than a typical rack server, comes with up to 8 or 10 2.5” drive configurations providing up to 76.6TB of all-flash capacity in a single 1U node.

The table below summarizes our S2D Ready Node portfolio.
R440 S2D RN | R640 S2D RN | R740xd S2D RN | R740xd2 S2D RN | |
Best For | Edge/ROBO and space (depth) constrained locations | Density optimized node for applications needing balance of high-performance storage and compute | Capacity and performance optimized node for applications needing balance of compute and storage | Capacity optimized node for data intensive applications and use cases such as backup and archive |
Storage Configurations | Hybrid & All-Flash | Hybrid, All-Flash, All-NVMe including Intel Optane DC Persistent Memory | Hybrid, All-Flash, and All-NVMe | Hybrid with SSDs and 3.5” HDDs |
For detailed node specifications, please refer to our website.
Stepping up the Performance Capabilities
With applications and growing data analysis needs increasingly driving the lower latency and higher capacity requirements, it’s imperative the underlying infrastructure does not create performance bottlenecks. The latest refresh of our solution includes several updates to scale infrastructure performance:
- All S2D Ready Nodes now support Intel 2nd Generation Xeon Scalable Processors that provide improved compute performance and security features.
- Support for Intel Optane SSDs and Intel Optane DC memory (on R640 S2D Ready node) enable lower latency storage and persistent memory tier to accelerate application performance. The R640 S2D Ready Node can be configured with 1.5TB of Optane DC persistent memory working in App Direct Mode to a provide a cache tier for the NVMe storage local to the node.
- The new all-NVMe option on R640 S2D Ready Node provides a compact 1U node for applications that are sensitive to both compute and storage performance.
- Faster Networking Options: For applications needing high bandwidth and low latency access to network, the R640 and R740XD S2D Ready Nodes can now be configured with Mellanox CX5 100Gb Ethernet adapters. In addition, we have also qualified the PowerSwitch S5232 100Gb switch to provide a fully validated solution by Dell EMC.
As we drove new hardware enhancements to our Azure Stack HCI portfolio, we also put a configuration to test the performance we can expect from a representative configuration. With just a four node Azure Stack HCI cluster with R640 S2D Ready Nodes configure all NVMe drives and 100Gb Ethernet, we observed:
- 2.95M IOPS with an average read latency of 242μs in a VM Fleet test configured for 4K block size and 100% reads
- 0.8M IOPS with an average write latency of 4121 μs in a VM Fleet test configured for 4K block size and 100% writes
- Up to 63GB/s of 100% sequential read throughput and 9GB/s of 100% sequential write throughput with 512KB block size
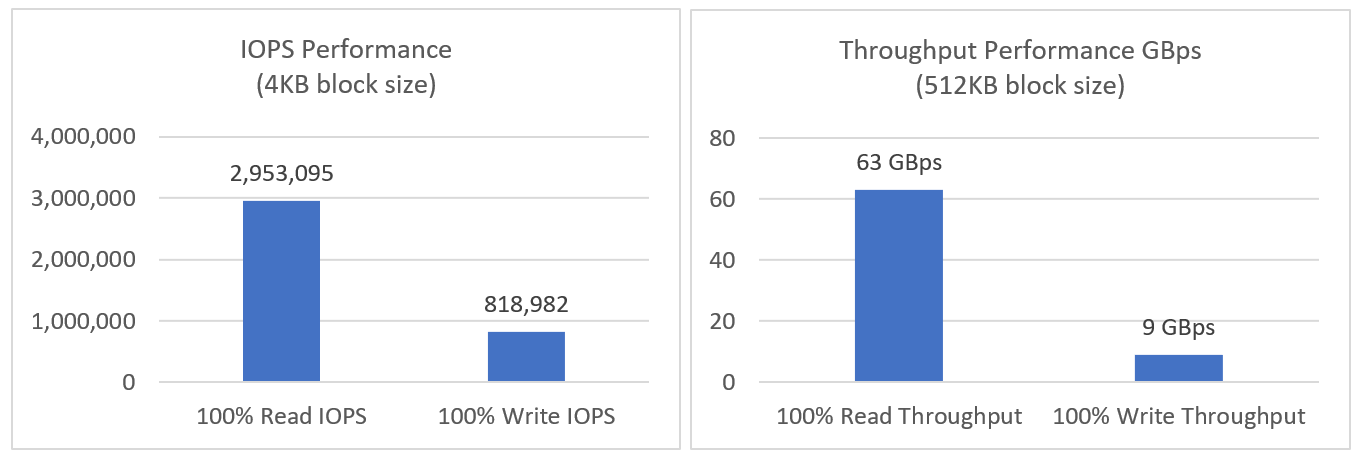
Yes, you got it right. Not only the solution is compact, easy to manage but also provides a tremendous performance capability.
Read our detailed blog for more information on our lab performance test results.
Overall, we are very excited to bring so many new capabilities to our customers. We invite you to come meet us at Microsoft Ignite 2019 at Booth 1547, talk to Dell EMC experts and see live demos. Besides the show floor, Dell EMC experts will also be available at Hyatt Regency Hotel, Level 3, Discovery 43 Suite for detailed conversations. Register here for time with our experts.
Meanwhile, visit our website for more details or if you have any questions, contact our team directly at s2d_readynode@dell.com

Evaluating Performance Capabilities of Dell EMC Solutions for Azure Stack HCI
Wed, 16 Jun 2021 13:35:49 -0000
|Read Time: 0 minutes
Just the facts:
- A Dell EMC Storage Spaces Direct four-node cluster was tested with VM Fleet in a 100 random-read workload and achieved 2,953,095 IOPS with an average read latency of 242 microseconds.
- A Dell EMC Storage Spaces Direct four-node cluster was tested with VM Fleet in a 100 percent random-write workload and achieved 818,982 IOPS at an average write latency of 4 milliseconds.
- A Dell EMC Storage Space Direct four-node cluster was tested with VM Fleet in a 100 percent sequential-read workload and achieved 63 GB/s and with a 100 percent sequential-write workload 9 GB/s
The details:
User experience is everything. In today’s world, fast and intuitive applications are a necessity, and anything less might be labeled slow and not very useful. Once an application is labeled slow, it’s hard to change that impression with end users. Thus, architecting a system for performance is a key consideration in ensuring a good application experience.
In this blog, we explore a Dell EMC Storage Spaces Direct solution that delivered amazing performance in our internal tests. Storage Spaces Direct is part of Azure Stack HCI and enables customers to use industry-standard servers with locally attached drives to create high-performance and high-availability storage. Azure Stack HCI enables the IT organization to run virtual machines with cloud services on-premises. Benefits include:
- The capability to consolidate data center applications with software-defined compute, storage, and networking.
- Using virtual machines to drive greater operational efficiencies while accelerating performance with Storage Spaces Direct. Support for Non-Volatile Memory Express (NVMe) drives enables software-defined storage to reach new levels of performance.
- Improved high availability with clustering and distributed software resiliency.
Database and other storage-intensive applications could benefit from the faster NVMe drives. NVMe is an open logical device specification that has been designed for low latency and internal parallelism of solid-state storage devices. The result is a significant boost in storage performance because data can be accessed faster and with less I/O overhead.
In our labs, we created a Storage Spaces Direct performance cluster consisting of four Dell EMC PowerEdge R640 nodes. Each storage node had two Intel 6248 Cascade Lake processors, ten P4510 Intel NVMe drives, and one Mellanox CX5 dual-port 100 GbE adapter. Networking between the nodes consisted of a Dell EMC S5232 switch that supports up to thirty-two 100 GbE ports. Our goal was to drive simplicity in the configuration while showing performance value.
We used Storage Spaces Direct three-way mirroring because this configuration offers the greatest performance and protection. Protection does have a cost in terms of capacity. The capacity efficiency of a three-way mirror is 33 percent, meaning 3 TB equates to 1 TB of usable storage space. The data protection benefit with three-way mirroring is that the storage cluster can safely tolerate at least two hardware problems—for example, the loss of a drive and server at the same time. The following diagram is a simple representation of the four-node performance configuration of the Storage Spaces Direct cluster.
Figure 1: Storage Spaces Direct Cluster with four PowerEdge R640 nodes

We ran VM Fleet on the storage cluster to test performance, and the results were impressive! Here is the first test configuration:
- Block size: 4 KB
- Thread count: 2
- Outstanding I/O counts: 32
- Write ratio: 0
- Pattern: Random
Thus, this VM Fleet test used 4 KB block sizes, 100 percent reads, and a random-access pattern. This Storage Spaces Direct configuration achieved 2,953,095 IOPS with an average read latency of 242 microseconds. A microsecond is equal to one-millionth of a second. This is the kind of performance that can really accelerate online transaction processing (OLTP) workloads and make enterprise applications highly responsive to the end users.
We also tested a 100 percent random-write workload on the storage cluster. All the VM Fleet configuration settings remained the same, except the write ratio was 100. With 100 percent writes, the storage cluster achieved 818,982 IOPS at an average write latency of 4 milliseconds. We could have been less aggressive in our internal tests and delivered even lower write latency, but the goal was to push the storage cluster in terms of performance. Both these tests were done internally in our Dell EMC labs, and it’s important to note that results will vary.
Figure 2: Summary of internal test findings for 100 percent read and write workloads for IOPS and latency
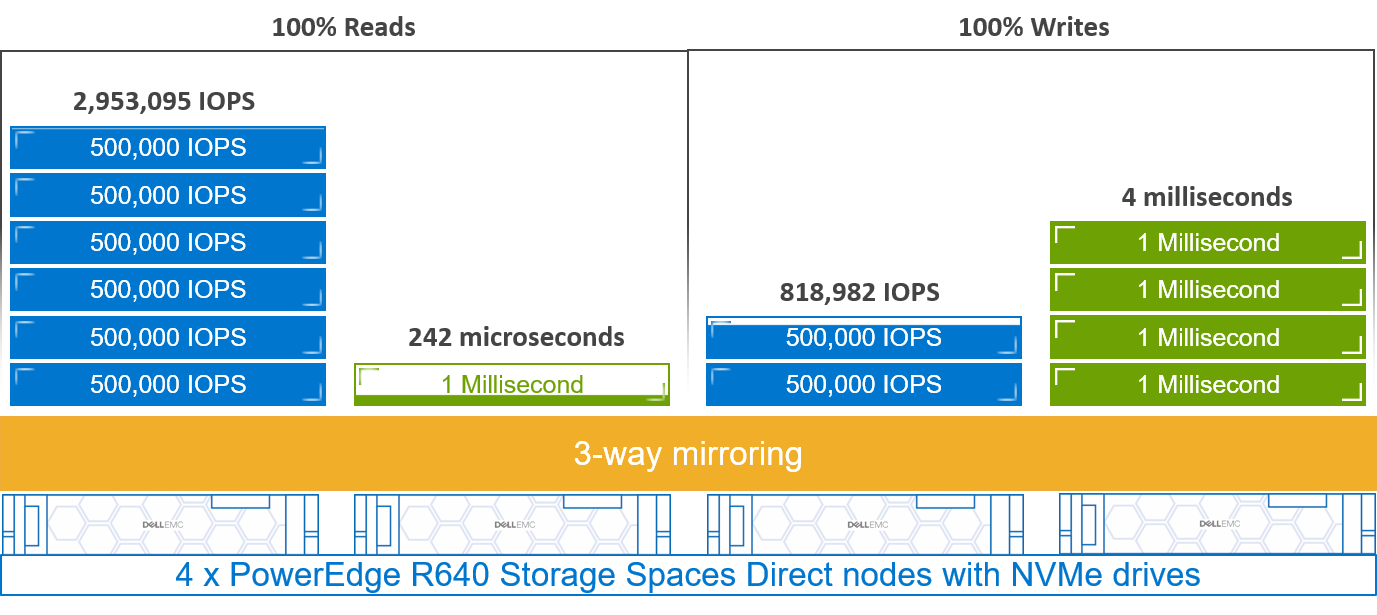
Some applications, such as business intelligence and decision support systems, and some analytical workloads are more dependent on throughput. Throughput is defined by the amount of data that is delivered over a fixed period. The greater the throughput the more data that can be read and the faster the analysis or report. Our labs used the following VM Fleet configuration to test throughput:
- Block size: 512 KB
- Thread count: 2
- Outstanding I/O counts: 2
- Write ratio: 0
- Pattern: Sequential
The throughput test configuration uses larger blocks at 512 KB, 100 percent reads, and a sequential read pattern that is like scanning large datasets. The storage cluster sustained 63 gigabytes per second (GB/s). This throughput could enable faster analytics for the business and provide the capability to make timely decisions.
We also ran the same test with 100 percent writes, which simulates a data load activity such as streaming data from an IoT gateway to an internal database. In this test case, the storage cluster sustained a throughput of 9 GB/s for writes. Both the read and write throughput tests show the strength of this all-NVMe configuration from Dell EMC.
Figure 3: Summary of internal test findings for 100 percent read and write workloads for throughput
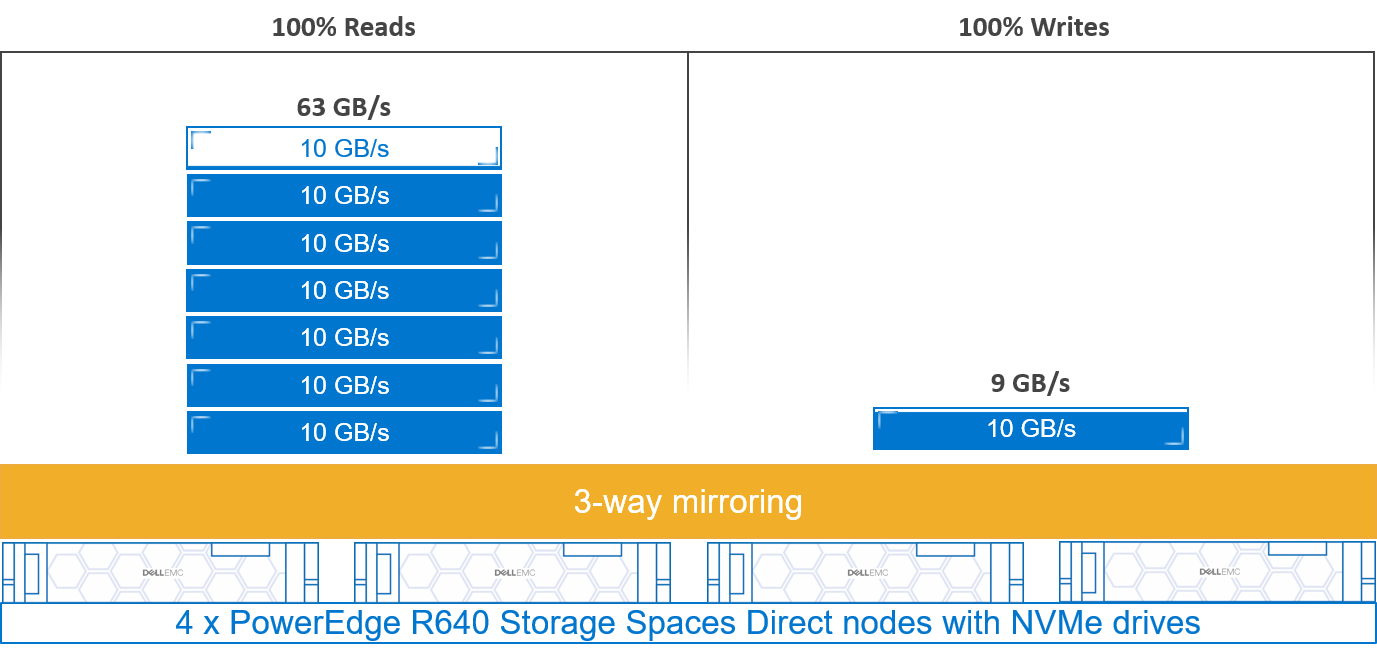
If performance is what you need, then Dell EMC can use NVMe technology to accelerate your applications. But flexibility is another factor that can be equally important. Not every application requires high IOPS and very low latencies. Dell EMC offers an expanded portfolio of Storage Spaces Direct nodes that can meet most any business requirements. A great resource for reviewing the Dell EMC Storage Spaces Direct options is the Azure Stack HCI certification pages. The following table summarizes all the Dell EMC options but doesn’t contain CPU, RAM, and other details that can be found on the certification pages.
PowerEdge R440 | PowerEdge R640 | PowerEdge R740xd | PowerEdge R740xd2 | |
Intel Optane SSD Cache + SDD | ✔ | |||
All-NVMe | ✔ | |||
SDD | ✔ | ✔ | ✔ | |
NVMe + HDD | ✔ | ✔ | ||
NVMe (AIC) + HDD | ✔ | |||
SDD + HDD | ✔ | ✔ | ✔ | ✔ |
Start with a minimal configuration using the R440 Ready Nodes, which can have up to 44 cores, 1 TB of RAM, and 19.2 TB of storage. Or go big with the R740xd2 hybrid with up to 44 cores, 384 GB of RAM, and 240 TB of storage capacity. The range of options provides you with the flexibility to configure a Storage Spaces Direct solution to meet your business needs.
The Dell EMC Ready Nodes have been configured to work with Windows 2019, so they are future-ready. For example, the Ready Nodes integrate with Windows Admin Center, so you can tier storage, implement resiliency, provision VMs and storage, configure networking, and monitor health and performance, all with just a few clicks. With your Windows Server 2019 Datacenter licenses, no separate hypervisor license is needed for VMs. You can create unlimited VMs, achieve high-availability clusters, and secure your tenants or applications with shielded VMs.
Dell EMC Storage Spaces Direct nodes have been designed to make storage in your Azure Stack HCI easy. If you are interested in learning more, see Dell EMC Cloud for Microsoft Azure Stack HCI and contact a Dell EMC expert.