




Azure Stack HCI automated and consistent protection through Secured-core and Infrastructure lock
Global damages related to cybercrime were predicted to reach USD 6 trillion in 2021! This staggering number highlights the very real security threat faced not only by big companies, but also for small and medium businesses across all industries.
Cyber attacks are becoming more sophisticated every day and the attack surface is constantly increasing, now even including the firmware and BIOS on servers.

Figure 1: Cybercrime figures for 2021
However, this isn’t all bad news, as there are now two new technologies (and some secret sauce) that we can leverage to proactively defend against unauthorized access and attacks to our Azure Stack HCI environments, namely:
- Secured-core Server
- Infrastructure lock
Let’s briefly discuss each of them.
Secured-core is a set of Microsoft security features that leverage the latest security advances in Intel and AMD hardware. It is based on the following three pillars:
- Hardware root-of-trust: requires TPM 2.0 v3, verifies for validly signed firmware at boot times to prevent tamper attacks
- Firmware protection: uses Dynamic Root of Trust of Measurement (DRTM) technology to isolate the firmware and limit the impact of vulnerabilities
- Virtualization-based security (VBS): in conjunction with hypervisor-based code integrity (HVCI), VBS provides granular isolation of privileged parts of the OS (like the kernel) to prevent attacks and exfiltration of data
Infrastructure lock provides robust protection against unauthorized access to resources and data by preventing unintended changes to both hardware configuration and firmware updates.
When the infrastructure is locked, any attempt to change the system configuration is blocked and an error message is displayed.
Now that we understand what these technologies provide, one might have a few more questions, such as:
- How do I install these technologies?
- Is it easy to deploy and configure?
- Does it require a lot of human manual (and perhaps error prone) interaction?
In short, deploying these technologies is not an easy task unless you have the right set of tools in place.
This is when you’ll need the “secret sauce”— which is the Dell OpenManage Integration with Microsoft Windows Admin Center (OMIMSWAC) on top of our certified Dell Cyber-resilient Architecture, as illustrated in the following figure:
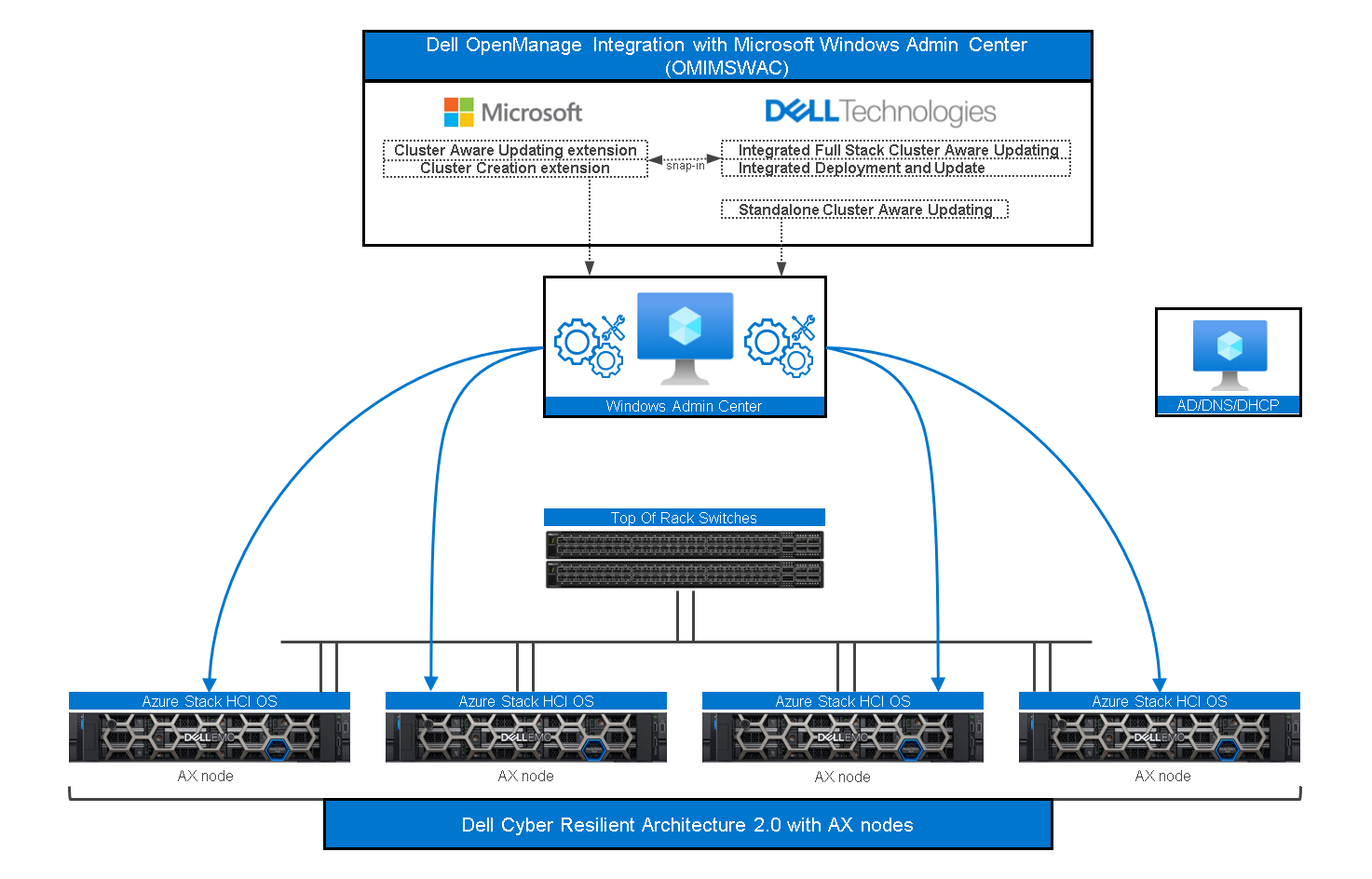
Figure 2: OMIMSWAC and Dell Cyber-resilient Architecture with AX Nodes
As a quick reminder, Windows Admin Center (WAC) is Microsoft’s single pane of glass for all Windows management related tasks.
Dell OMIMSWAC extensions make WAC even better by providing additional controls and management possibilities for certain features, such as Secured-core and Infrastructure lock.
Dell Cyber Resilient Architecture 2.0 safeguards customer’s data and intellectual property with a robust, layered approach.
Since a picture is worth a thousand words, the next section will show you what WAC extensions look like and how easy and intuitive they are to play with.
Dell OMIMSWAC Secured-core
The following figure shows our Secured-core snap-in integration inside the WAC security blade and workflow.
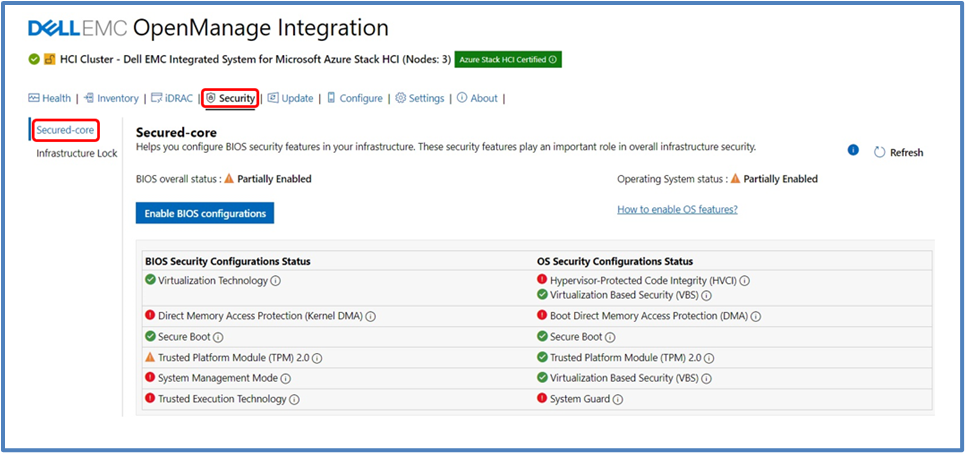
Figure 3: OMIMSWAC Secured-core view
The OS Security Configuration Status and the BIOS Security Configuration Status are displayed. The BIOS Security Configuration Status is where we can set the Secured-core required BIOS settings for the entire cluster.
OS Secured-core settings are visible but cannot be altered using OMIMSWAC (you would directly use WAC for it). You can also view and manage BIOS settings for each node individually.
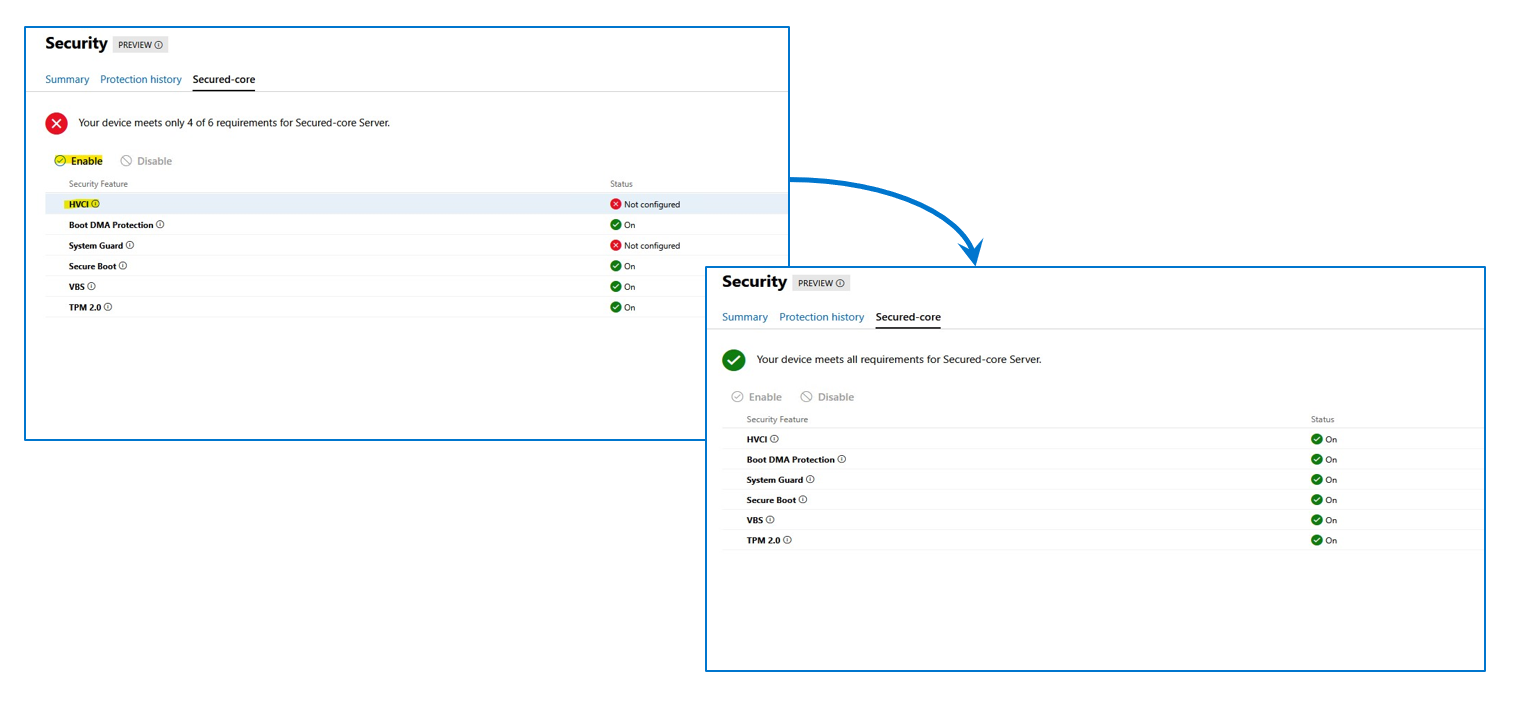
Figure 4: OMIMSWAC Secured-core, node view
Prior to enabling Secured-core, the cluster nodes must be updated to Azure Stack HCI, version 21H2 (or newer). For AMD Servers, the DRTM boot driver (part of the AMD Chipset driver package) must be installed.
Dell OMIMSWAC Infrastructure lock
The following figure illustrates the Infrastructure lock snap-in integration inside the WAC security blade and workflow. Here we can enable or disable Infrastructure lock to prevent unintended changes to both hardware configuration and firmware updates.
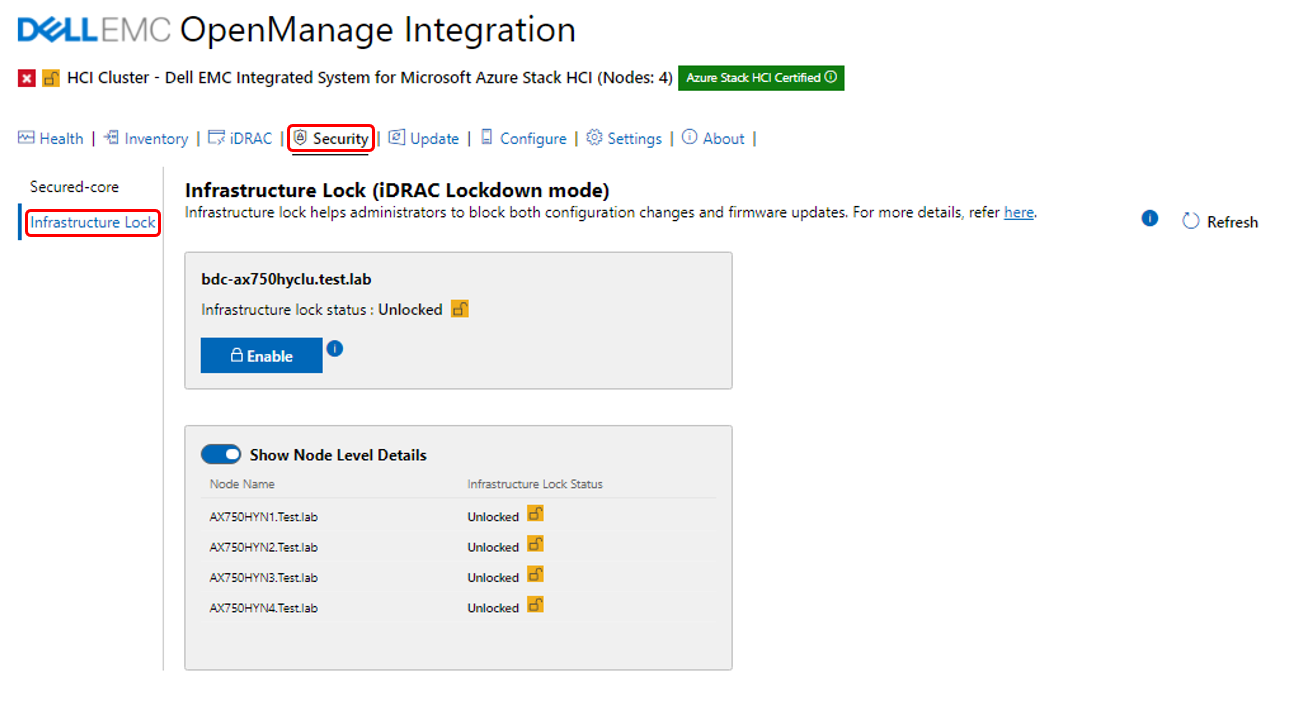
Figure 5: OMIMSWAC Infrastructure lock
Enabling Infrastructure lock also blocks the server or cluster firmware update process using OpenManage Integration extension tool. This means a compliance report will be generated if you are running a Cluster Aware Update (CAU) operation with Infrastructure lock enabled, which will block the cluster updates. If this occurs, you will have the option to temporarily disable Infrastructure lock and have it automatically re-enabled when the CAU is complete.
Conclusion
Dell understands the importance of the new security features introduced by Microsoft and has developed a programmatic approach, through OMIMSWAC and Dell’s Cyber-resilient Architecture, to consistently deliver and control these new features in each node and cluster. These features allow customers to always be secure and compliant on Azure Stack HCI environments.
Stay tuned for more updates (soon) on the compliance front, thank you for reading this far!
Author Information
Ignacio Borrero, Senior Principal Engineer, Technical Marketing
Twitter: @virtualpeli
References
2020 Verizon Data Breach Investigations Report
2019 Accenture Cost of Cybercrime Study
Global Ransomware Damage Costs Predicted To Reach $20 Billion (USD) By 2021
Cybercrime To Cost The World $10.5 Trillion Annually By 2025
The global cost of cybercrime per minute to reach $11.4 million by 2021
Related Blog Posts

Dell Hybrid Management: Azure Policies for HCI Compliance and Remediation
Mon, 30 May 2022 17:05:47 -0000
|Read Time: 0 minutes
Dell Hybrid Management: Azure Policies for HCI Compliance and Remediation
Companies that take an “Azure hybrid first” strategy are making a wise and future-proof decision by consolidating the advantages of both worlds—public and private—into a single entity.
Sounds like the perfect plan, but a key consideration for these environments to work together seamlessly is true hybrid configuration consistency.
A major challenge in the past was having the same level of configuration rules concurrently in Azure and on-premises. This required different tools and a lot of costly manual interventions (subject to human error) that resulted, usually, in potential risks caused by configuration drift.
But those days are over.
We are happy to introduce Dell HCI Configuration Profile (HCP) Policies for Azure, a revolutionary and crucial differentiator for Azure hybrid configuration compliance.
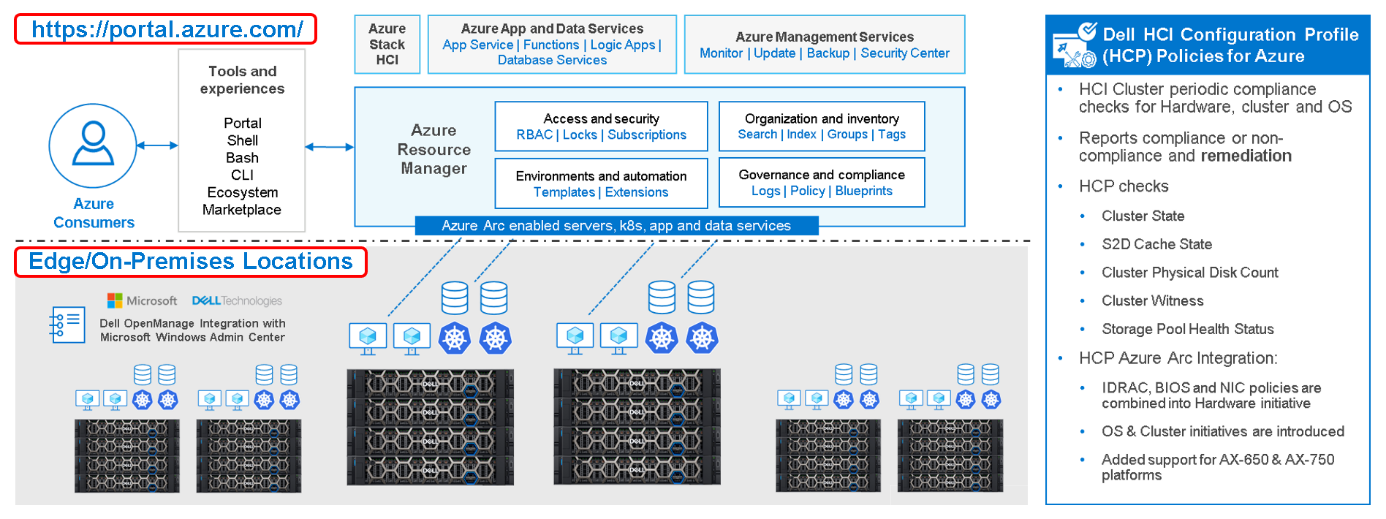
Figure 1: Dell Hybrid Management with Windows Admin Center (local) and Azure/Azure Arc (public)
So, what is it? How does it work? What value does it provide?
Dell HCP Policies for Azure is our latest development for Dell OpenManage Integration with Windows Admin Center (OMIMSWAC). With it, we can now integrate Dell HCP policy definitions into Azure Policy. Dell HCP is the specification that captures the best practices and recommended configurations for Azure Stack HCI and Windows-based HCI solutions from Dell to achieve better resiliency and performance with Dell HCI solutions.
The HCP Policies feature functions at the cluster level and is supported for clusters that are running Azure Stack HCI OS (21H2) and pre-enabled for Windows Server 2022 clusters.
IT admins can manage Azure Stack HCI environments through two different approaches:
- At-scale through the Azure portal using the Azure Arc portfolio of technologies
- Locally on-premises using Windows Admin Center
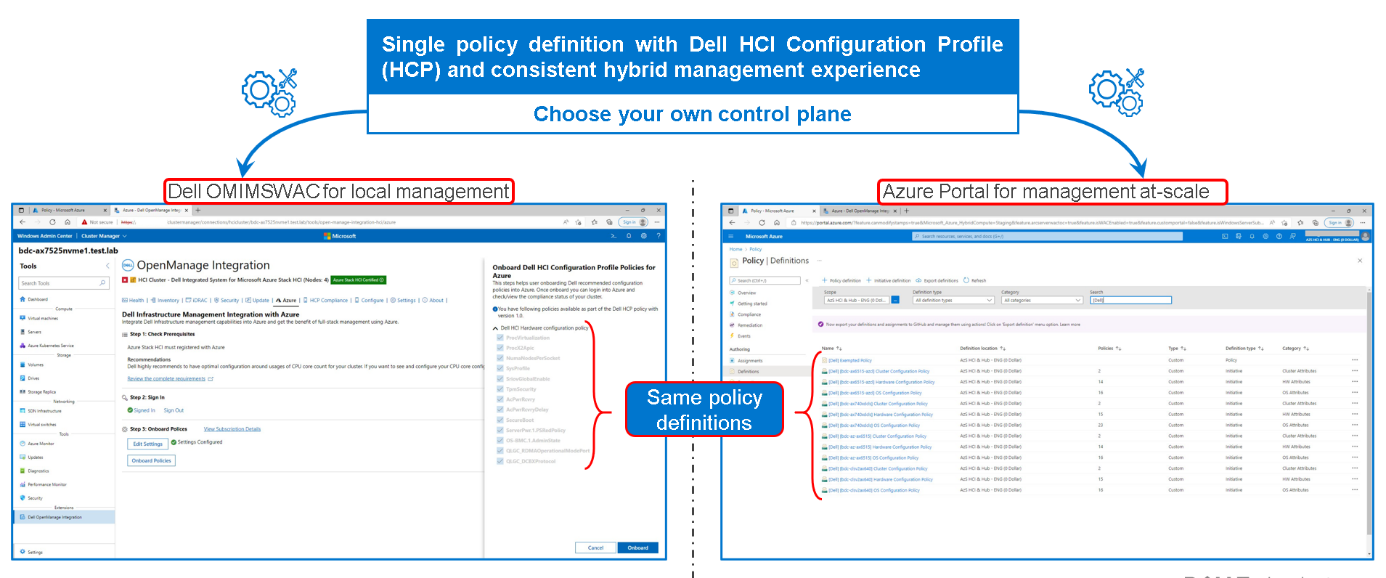
Figure 2: Dell HCP Policies for Azure - onboarding Dell HCI Configuration Profile
By using a single Dell HCP policy definition, both options provide a seamless and consistent management experience.
Running Check Compliance automatically compares the recommended rules packaged together in the Dell HCP policy definitions with the settings on the running integrated system. These rules include configurations that address the hardware, cluster symmetry, cluster operations, and security.

Figure 3: Dell HCP Policies for Azure - HCP policy compliance
Dell HCP Policy Summary provides the compliance status of four policy categories:
- Dell Infrastructure Lock Policy - Indicates enhanced security compliance to protect against unintentional changes to infrastructure
- Dell Hardware Configuration Policy - Indicates compliance with Dell recommended BIOS, iDRAC, firmware, and driver settings that improve cluster resiliency and performance
- Dell Hardware Symmetry Policy - Indicates compliance with integrated-system validated components on the support matrix and best practices recommended by Dell and Microsoft
- Dell OS Configuration Policy - Indicates compliance with Dell recommended operating system and cluster configurations
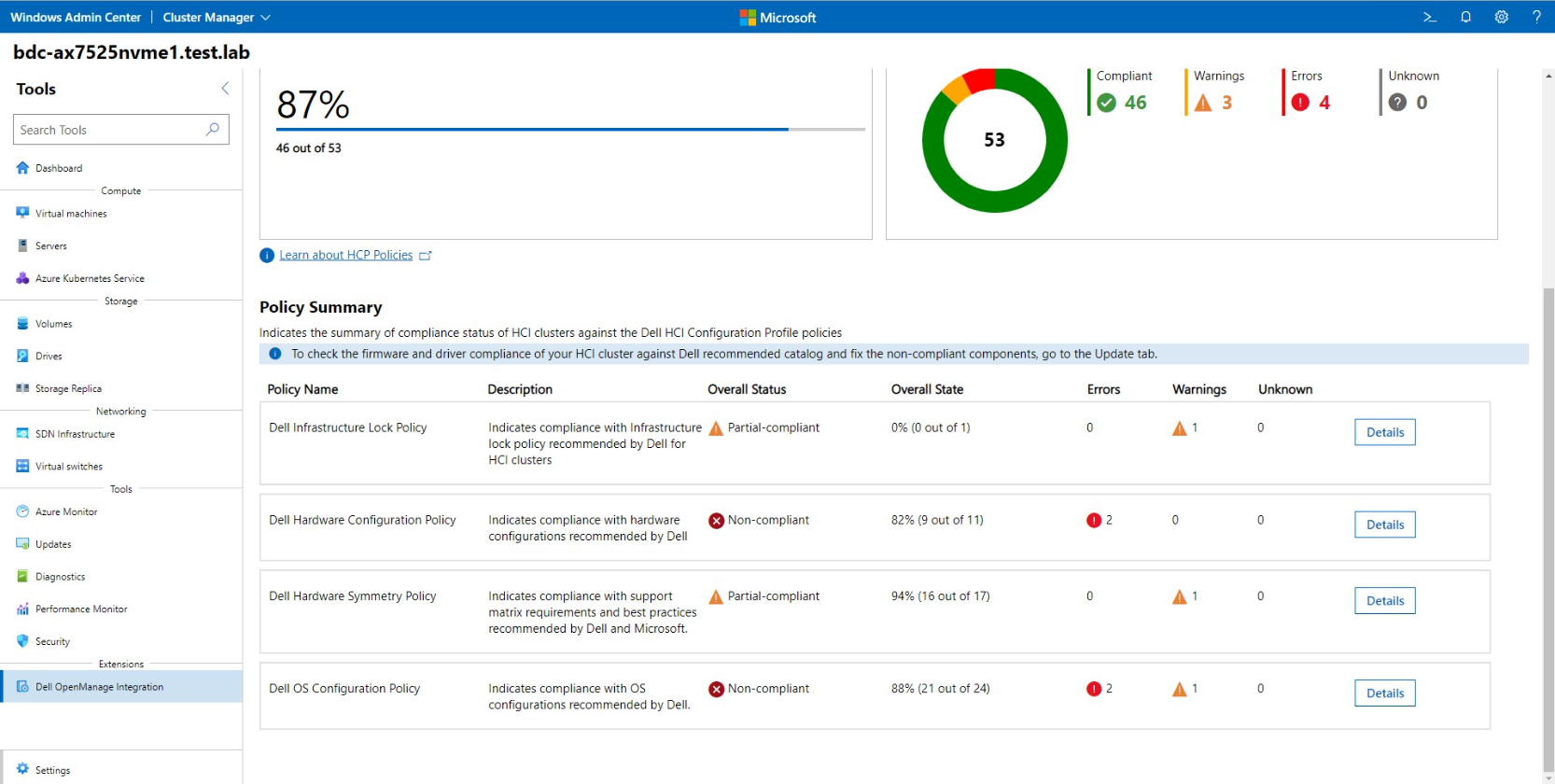
Figure 4: Dell HCP Policies for Azure - HCP Policy Summary
To re-align non-compliant policies with the best practices validated by Dell Engineering, our Dell HCP policy remediation integration with WAC (unique at the moment) helps to fix any non-compliant errors. Simply click “Fix Compliance.”

Figure 5: Dell HCP Policies for Azure - HCP policy remediation
Some fixes may require manual intervention; others can be corrected in a fully automated manner using the Cluster-Aware Updating framework.
Conclusion
The “Azure hybrid first” strategy is real today. You can use Dell HCP Policies for Azure, which provides a single-policy definition with Dell HCI Configuration Profile and a consistent hybrid management experience, whether you use Dell OMIMSWAC for local management or Azure Portal for management at-scale.
With Dell HCP Policies for Azure, policy compliance and remediation are fully covered for Azure and Azure Stack HCI hybrid environments.
You can see Dell HCP Policies for Azure in action at the interactive Dell Demo Center.
Thanks for reading!
Author: Ignacio Borrero, Dell Senior Principal Engineer CI & HCI, Technical Marketing
Twitter: @virtualpeli

Technology leap ahead: 15G Intel based Dell EMC Integrated System for Microsoft Azure Stack HCI
Wed, 22 Sep 2021 18:15:33 -0000
|Read Time: 0 minutes
We are happy to announce the latest members of the family for our Microsoft HCI Solutions from Dell Technologies: the new AX-650 and AX-750 nodes.
If you are already familiar with our existing integrated system offering, you can directly jump to the next section. For those new to the party, keep on reading!
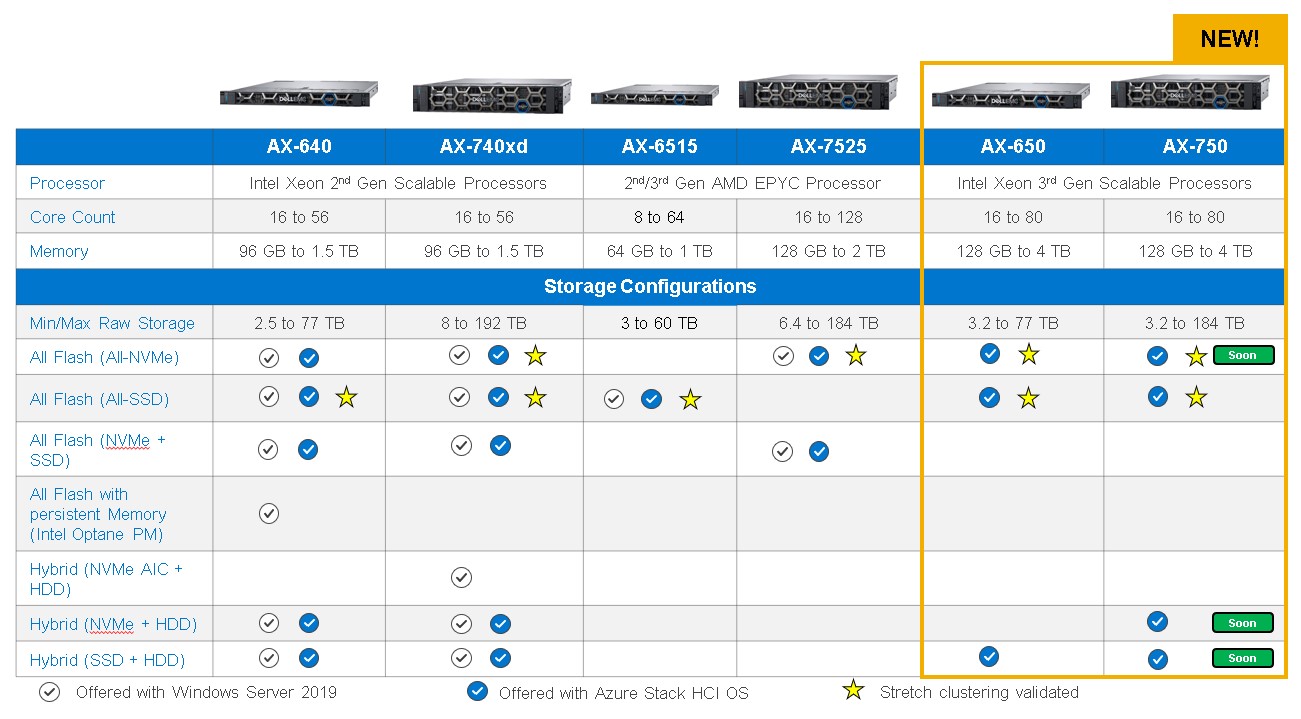
Figure 1: Dell EMC Integrated System for Microsoft Azure Stack HCI portfolio: New AX-650 and AX-750 nodes
As with all other nodes supported by Dell EMC Integrated System for Microsoft Azure Stack HCI, the AX-650 and AX-750 nodes have been intelligently and deliberately configured with a wide range of component options to meet the requirements of nearly any use case – from the smallest remote or branch office to the most demanding database workloads.
The chassis, drive, processor, DIMM module, network adapter, and their associated BIOS, firmware, and driver versions have been carefully selected and tested by the Dell Technologies engineering team to optimize the performance and resiliency of Azure Stack HCI. Our engineering has also validated networking topologies using PowerSwitch network switches.
Arguably the most compelling aspect of our integrated system is our life cycle management capability. The Integrated Deploy and Update snap-in works with the Microsoft cluster creation extension to deliver Dell EMC HCI Configuration Profile. This Configuration Profile ensures a consistent, automated initial cluster creation experience on Day 1. The one-click full stack life cycle management snap-in for the Microsoft Cluster-Aware Updating extension allows administrators to apply updates. This seamlessly orchestrates OS, BIOS, firmware, and driver updates through a common Windows Admin Center workflow.
On top of it, Dell Technologies makes support services simple, flexible, and worry free – from installation and configuration to comprehensive, single source support. Certified deployment engineers ensure accuracy and speed, reduce risk and downtime, and free IT staff to work on those higher value priorities. Our one-stop cluster level support covers the hardware, operating system, hypervisor, and Storage Spaces Direct software, whether you purchased your license from Dell EMC or from Microsoft.
Now that we are at the same page with our integrated system…
What’s new with AX-650 and AX-750? Why are they important for our customers?
AX-650 and AX-750 are based on Intel Xeon Scalable 3rd generation Ice Lake processors that introduce big benefits in three main areas:
- Hardware improvements
- New features
- Management enhancements
Hardware improvements
Customers always demand the highest levels of performance available, and our new 15G platforms, through Intel Ice Lake and its latest 10nm technology, deliver huge performance gains (compared to the previous generation) for:
- Processing: up to a 40 percent CPU performance increase, a 15 percent per core performance boost, and 42 percent more cores
- Memory: 33 percent more memory channels, a 20 percent frequency boost, and a 2.66x increase in memory capacity
- PCIe Gen4 IO acceleration: a doubled throughput increase compared to PCIe Gen3, 33 percent more lanes, an increase in direct attached Gen4 NVMe drives, and support for the latest Gen4 accelerators and GPUs
These impressive figures are a big step forward from a hardware boost perspective, but there are even more important things going on than just brute power and performance.
Our new 15G platforms lay the technology foundation for the latest features that are coming (really) soon with the new version of Microsoft Azure Stack HCI.
New features
Windows Server 2022 and Azure Stack HCI, version 21H2 will bring in (when they are made available) the following two key features:
- Secured-core Server
- GPU support
The fundamental idea of Secured-core Server is to stay ahead of attackers and protect our customers’ infrastructure and data all through hardware, BIOS, firmware, boot, drivers, and the operating system. This idea is based on three pillars:
- Simplified security: easy integration and consumption through Windows Admin Center
- Advanced protection: leveraging hardware root-of-trust, firmware protection, and virtualization-based security (VBS)
- Preventative defense: proactively block the paths attackers use to exploit a system
For more details about Secured-core Server, click here.
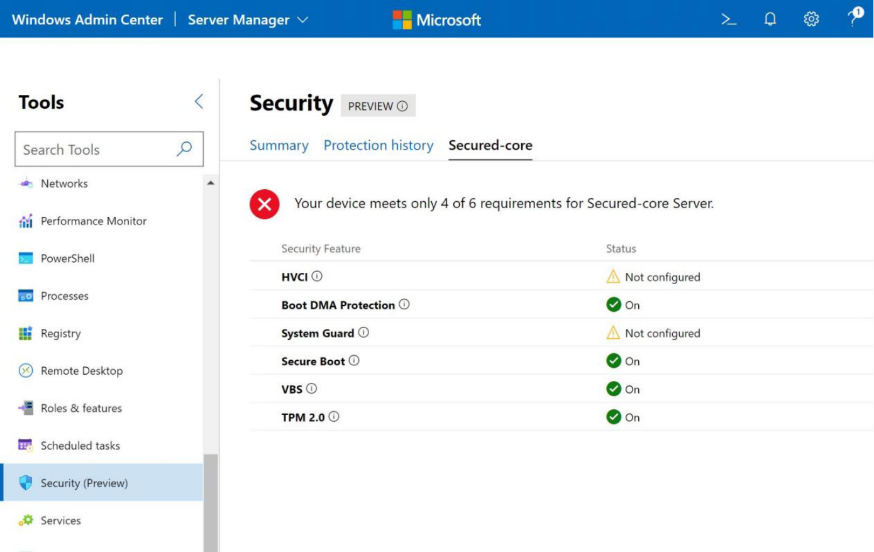
Figure 2: Secured-core Server with Windows Admin Center integration
AX-650, AX-750, and AX-7525 are the first AX nodes to introduce GPU readiness for single-width and double-width GPUs.
With the September 21, 2021 launch, all configurations planned to support GPUs are already enabled in anticipation for the appropriate selection of components (such as GPU risers, power supplies, fans, and heatsinks).
This process permits the GPU(s) to be added later on (when properly validated and certified) as an After Point of Sale (APOS).
The first GPU that will be made available with AX nodes (AX-650, AX-750, and AX-7525) is the NVIDIA T4 card.
To prepare for this GPU, customers should opt for the single-width capable PCI riser.
The following table shows the maximum number of adapters per platform taking into account the GPU form factor:
| AX-750 | AX-650 | AX-7525 | |||
| Single width | Dual width | Single width | Dual width | Single width | Dual width |
All SSD | Up to 31 | Up to 2 | Up to 22 | N/A |
| |
All NVMe | Up to 31 | Up to 2 | Up to 22 | N/A | Up to 33 | Up to 33 |
NVMe+SSD |
| Up to 4 | Up to 3 | |||
1 Max of 3 factory installed with Mellanox NIC adapters. Exploring options for up to 4 SW GPUs
2 Depending on the number of RDMA NICs
3 Only with the x16 NVMe chassis. x24 NVMe chassis does not support any GPUs
Note that no GPUs are available at the September 21, 2021 launch. GPUs will not be validated and factory installable until early 2022.
Management enhancements
Dell EMC OpenManage Integration with Microsoft Windows Admin Center (OMIMSWAC) extension was launched in 2019.
It has included hardware and firmware inventory, real time health monitoring, iDRAC integrated management, troubleshooting tools, and seamless updates of BIOS, firmware, and drivers.
In the 2.0 release in February 2020, we also added single-click full stack life cycle management with Cluster-Aware Updating for the Intel-based Azure Stack HCI platforms. This allowed us to orchestrate OS, BIOS, firmware, and driver updates through a single Admin Center workflow, requiring only a single reboot per node in the cluster and resulting in no interruption to the services running in the VMs.
With the Azure Stack HCI June 2021 release, the OpenManage Integration extension added support for the AX-7525 and AX-6515 AMD based platforms.
Now, with the September 21, 2021 launch, OMIMSWAC 2.1 features a great update for AX nodes, including these important extensions:
- Integrated Deploy & Update
- CPU Core Management
- Cluster Expansion
Integrated Deploy & Update deploys Azure Stack HCI with Dell EMC HCI Configuration Profile for optimal cluster performance. Our integration also adds the ability to apply hardware solution updates like BIOS, firmware, and drivers at the same time as operating system updates as part of cluster creation with a single reboot.
With CPU Core Management, customers can dynamically adjust the CPU core count BIOS settings without leaving the OpenManage Integration extension in Windows Admin Center, helping to maintain the right balance between cost and performance.
Cluster Expansion helps to prepare new cluster nodes before adding them to the cluster, to significantly simplify the cluster expansion process, reduce human error, and save time.
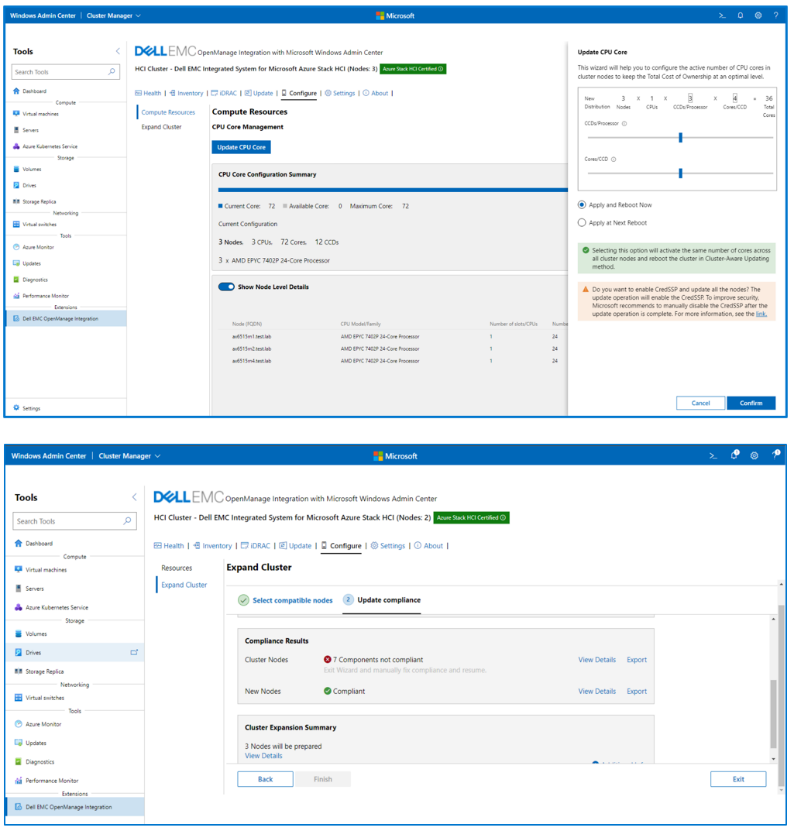
Figure 3: CPU Core Management and Cluster Expansion samples
In conclusion, the AX-650 and AX-750 nodes establish the most performant and easy to operate foundation for Azure Stack HCI today, along with all the new features and goodness that Microsoft is preparing. Stay tuned for more news and updates on this front!
Author Information
Ignacio Borrero, @virtualpeli