




GPU Acceleration for Dell Azure Stack HCI: Consistent and Performant AI/ML Workloads
The end of 2022 brought us excellent news: Dell Integrated System for Azure Stack HCI introduced full support for GPU factory install.
As a reminder, Dell Integrated System for Microsoft Azure Stack HCI is a fully integrated HCI system for hybrid cloud environments that delivers a modern, cloud-like operational experience on-premises. It is intelligently and deliberately configured with a wide range of hardware and software component options (AX nodes) to meet the requirements of nearly any use case, from the smallest remote or branch office to the most demanding business workloads.
With the introduction of GPU-capable AX nodes, now we can also support more complex and demanding AI/ML workloads.
New GPU hardware options
Not all AX nodes support GPUs. As you can see in the table below, AX-750, AX-650, and AX-7525 nodes running AS HCI 21H2 or later are the only AX node platforms to support GPU adapters.
Table 1: Intelligently designed AX node portfolio
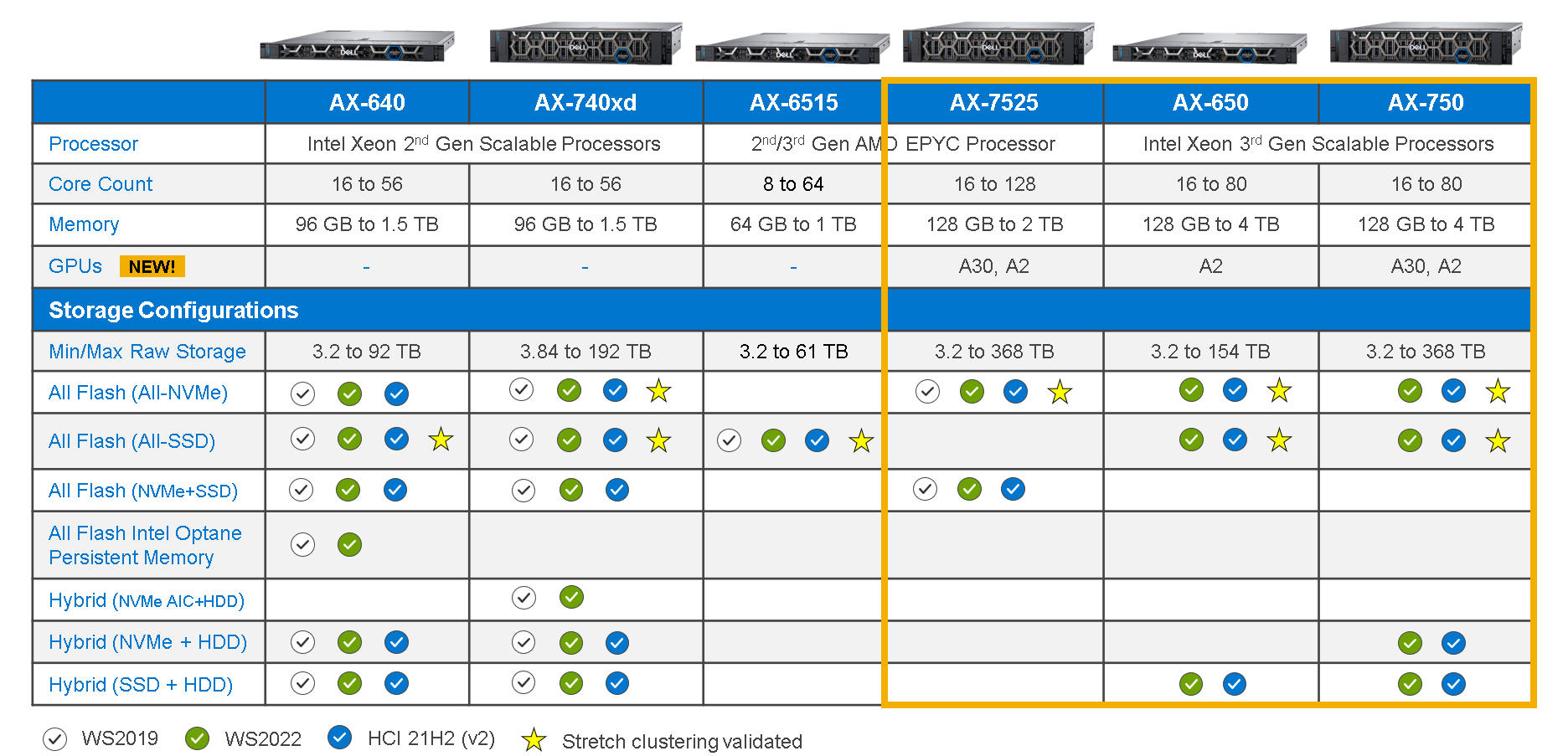
Note: AX-640, AX-740xd, and AX-6515 platforms do not support GPUs.
The next obvious question is what GPU type and number of adapters are supported by each platform.
We have selected the following two NVIDIA adapters to start with:
- NVIDIA Ampere A2, PCIe, 60W, 16GB GDDR6, Passive, Single Wide
- NVIDIA Ampere A30, PCIe, 165W, 24GB HBM2, Passive, Double Wide
The following table details how many GPU adapter cards of each type are allowed in each AX node:
Table 2: AX node support for GPU adapter cards
| AX-750 | AX-650 | AX-7525 | |
|---|---|---|---|
| NVIDIA A2 | Up to 2 | Up to 2 | Up to 3 |
| NVIDIA A30 | Up to 2 | -- | Up to 3 |
| Maximum GPU number (must be same model) | 2 | 2 | 3 |
Use cases
The NVIDIA A2 is the entry-level option for any server to get basic AI capabilities. It delivers versatile inferencing acceleration for deep learning, graphics, and video processing in a low-profile, low-consumption PCIe Gen 4 card.
The A2 is the perfect candidate for light AI capability demanding workloads in the data center. It especially shines in edge environments, due to the excellent balance among form factor, performance, and power consumption, which results in lower costs.
The NVIDIA A30 is a more powerful mainstream option for the data center, typically covering scenarios that require more demanding accelerated AI performance and a broad variety of workloads:
- AI inference at scale
- Deep learning training
- High-performance computing (HPC) applications
- High-performance data analytics
Options for GPU virtualization
There are two GPU virtualization technologies in Azure Stack HCI: Discrete Device Assignment (also known as GPU pass-through) and GPU partitioning.
Discrete Device Assignment (DDA)
DDA support for Dell Integrated System for Azure Stack HCI was introduced with Azure Stack HCI OS 21H2. When leveraging DDA, GPUs are basically dedicated (no sharing), and DDA passes an entire PCIe device into a VM to provide high-performance access to the device while being able to utilize the device native drivers. The following figure shows how DDA directly reassigns the whole GPU from the host to the VM:
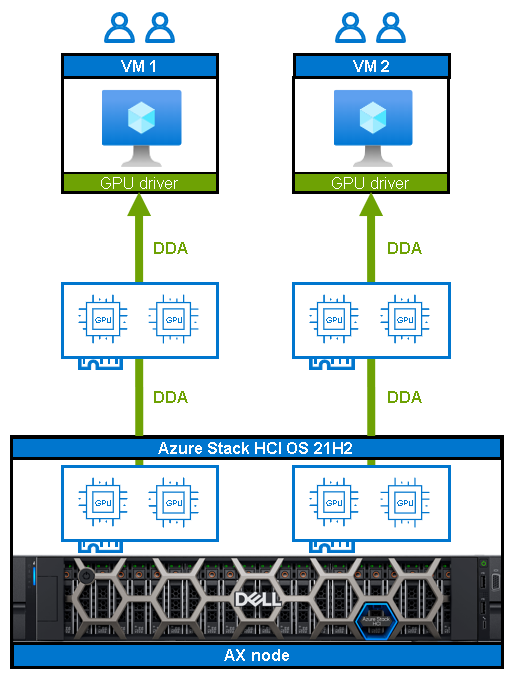
Figure 1: Discrete Device Assignment in action
To learn more about how to use and configure GPUs with clustered VMs with Azure Stack HCI OS 21H2, you can check Microsoft Learn and the Dell Info Hub.
GPU partitioning (GPU-P)
GPU partitioning allows you to share a physical GPU device among several VMs. By leveraging single root I/O virtualization (SR-IOV), GPU-P provides VMs with a dedicated and isolated fractional part of the physical GPU. The following figure explains this more visually:
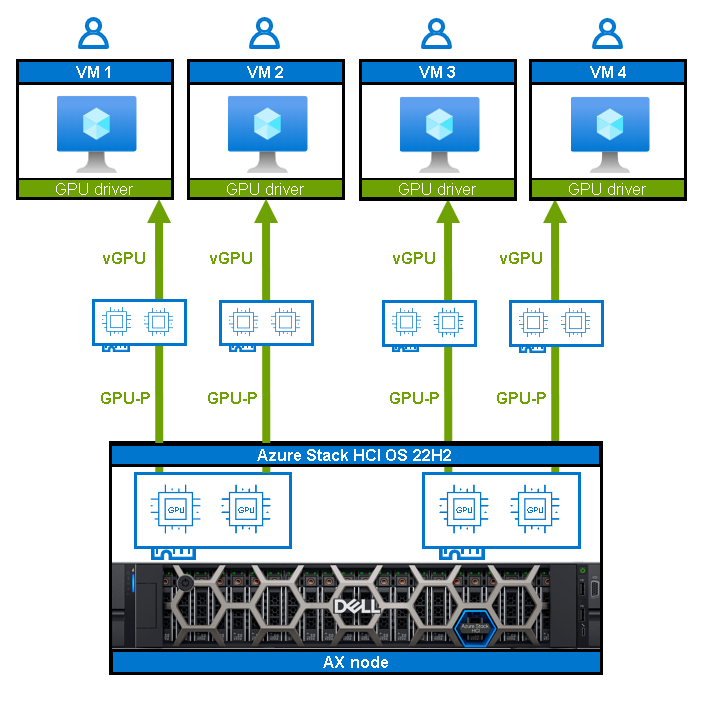
Figure 2: GPU partitioning virtualizing 2 physical GPUs into 4 virtual vGPUs
The obvious advantage of GPU-P is that it enables enterprise-wide utilization of highly valuable and limited GPU resources.
Note these important considerations for using GPU-P:
- Azure Stack HCI OS 22H2 or later is required.
- Host and guest VM drivers for GPU are needed (requires a separate license from NVIDIA).
- Not all GPUs support GPU-P; currently Dell only supports A2 (A16 coming soon).
- We strongly recommend using Windows Admin Center for GPU-P to avoid mistakes.
You’re probably wondering about Azure Virtual Desktop on Azure Stack HCI (still in preview) and GPU-P. We have a Dell Validated Design today and will be refreshing it to include GPU-P during this calendar year.
To learn more about how to use and configure GPU-P with clustered VMs with Azure Stack HCI OS 22H2, you can check Microsoft Learn and the Dell Info Hub (Dell documentation coming soon).
Timeline
As of today, Dell Integrated System for Microsoft Azure Stack HCI only provides support for Azure Stack HCI OS 21H2 and DDA.
Full support for Azure Stack HCI OS 22H2 and GPU-P is around the corner, by the end of the first quarter, 2023.
Conclusion
The wait is finally over, we can now leverage in our Azure Stack HCI environments the required GPU power for AI/ML highly demanding workloads.
Today, DDA provides fully dedicated GPU pass-through utilization, whereas with GPU-P we will very soon have the choice of providing a more granular GPU consumption model.
Thanks for reading, and stay tuned for the ever-expanding list of validated GPUs that will unlock and enhance even more use cases and workloads!
Author: Ignacio Borrero, Senior Principal Engineer, Technical Marketing Dell CI & HCI
@virtualpeli
Related Blog Posts

Can I do that AI thing on Dell PowerFlex?

Thu, 20 Jul 2023 21:08:09 -0000
|Read Time: 0 minutes
The simple answer is Yes, you can do that AI thing with Dell PowerFlex. For those who might have been busy with other things, AI stands for Artificial Intelligence and is based on trained models that allow a computer to “think” in ways machines haven’t been able to do in the past. These trained models (neural networks) are essentially a long set of IF statements (layers) stacked on one another, and each IF has a ‘weight’. Once something has worked through a neural network, the weights provide a probability about the object. So, the AI system can be 95% sure that it’s looking at a bowl of soup or a major sporting event. That, at least, is my overly simplified description of how AI works. The term carries a lot of baggage as it’s been around for more than 70 years, and the definition has changed from time to time. (See The History of Artificial Intelligence.)
Most recently, AI has been made famous by large language models (LLMs) for conversational AI applications like ChatGPT. Though these applications have stoked fears that AI will take over the world and destroy humanity, that has yet to be seen. Computers still can do only what we humans tell them to do, even LLMs, and that means if something goes wrong, we their creators are ultimately to blame. (See ‘Godfather of AI’ leaves Google, warns of tech’s dangers.)
The reality is that most organizations aren’t building world destroying LLMs, they are building systems to ensure that every pizza made in their factory has exactly 12 slices of pepperoni evenly distributed on top of the pizza. Or maybe they are looking at loss prevention, or better traffic light timing, or they just want a better technical support phone menu. All of these are uses for AI and each one is constructed differently (they use different types of neural networks).
We won’t delve into these use cases in this blog because we need to start with the underlying infrastructure that makes all those ideas “AI possibilities.” We are going to start with the infrastructure and what many now consider a basic (by today’s standards) image classifier known as ResNet-50 v1.5. (See ResNet-50: The Basics and a Quick Tutorial.)
That’s also what the PowerFlex Solution Engineering team did in the validated design they recently published. This design details the use of ResNet-50 v1.5 in a VMware vSphere environment using NVIDIA AI Enterprise as part of PowerFlex environment. They started out with the basics of how a virtualized NVIDIA GPU works well in a PowerFlex environment. That’s what we’ll explore in this blog – getting started with AI workloads, and not how you build the next AI supercomputer (though you could do that with PowerFlex as well).
In this validated design, they use the NVIDIA A100 (PCIe) GPU and virtualized it in VMware vSphere as a virtual GPU or vGPU. With the infrastructure in place, they built Linux VMs that will contain the ResNet-50 v1.5 workload and vGPUs. Beyond just working with traditional vGPUs that many may be familiar with, they also worked with NVIDIA’s Multi-Instance GPU (MIG) technology.
NVIDIA’s MIG technology allows administrators to partition a GPU into a maximum of seven GPU instances. Being able to do this provides greater control of GPU resources, ensuring that large and small workloads get the appropriate amount of GPU resources they need without wasting any.
PowerFlex supports a large range of NVIDIA GPUs for workloads, from VDI (Virtual Desktops) to high end virtual compute workloads like AI. You can see this in the following diagram where there are solutions for “space constrained” and “edge” environments, all the way to GPUs used for large inferencing models. In the table below the diagram, you can see which GPUs are supported in each type of PowerFlex node. This provides a tremendous amount of flexibility depending on your workloads.

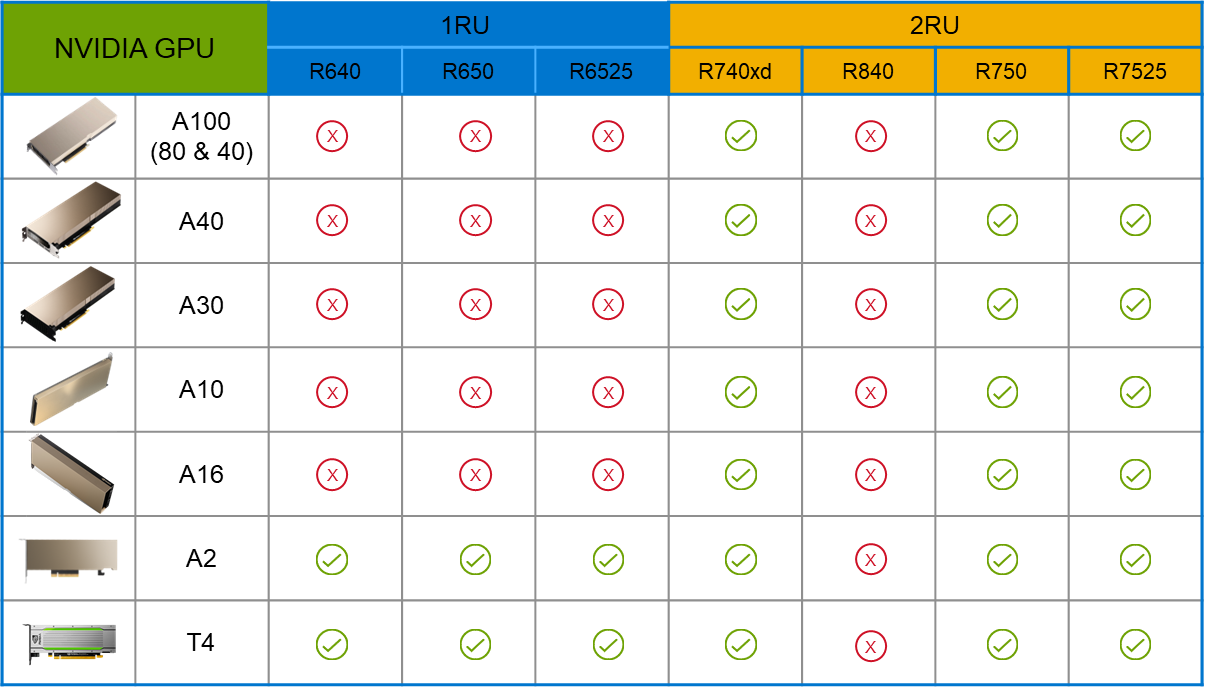
The validated design describes the steps to configure the architecture and provides detailed links to the NVIDIAand VMware documentation for configuring the vGPUs, and the licensing process for NVIDIA AI Enterprise.
These are key steps when building an AI environment. I know from my experience working with various organizations, and from teaching, that many are not used to working with vGPUs in Linux. This is slowly changing in the industry. If you haven’t spent a lot of time working with vGPUs in Linux, be sure to pay attention to the details provided in the guide. It is important and can make a big difference in your performance.
The following diagram shows the validated design’s logical architecture. At the top of the diagram, you can see four Ubuntu 22.04 Linux VMs with the NVIDIA vGPU driver loaded in them. They are running on PowerFlex hosts with VMware ESXi deployed. Each VM contains one NVIDIA A100 GPU configured for MIG operations. This configuration leverages a two-tier architecture where storage is provided by separate PowerFlex software defined storage (SDS) nodes.
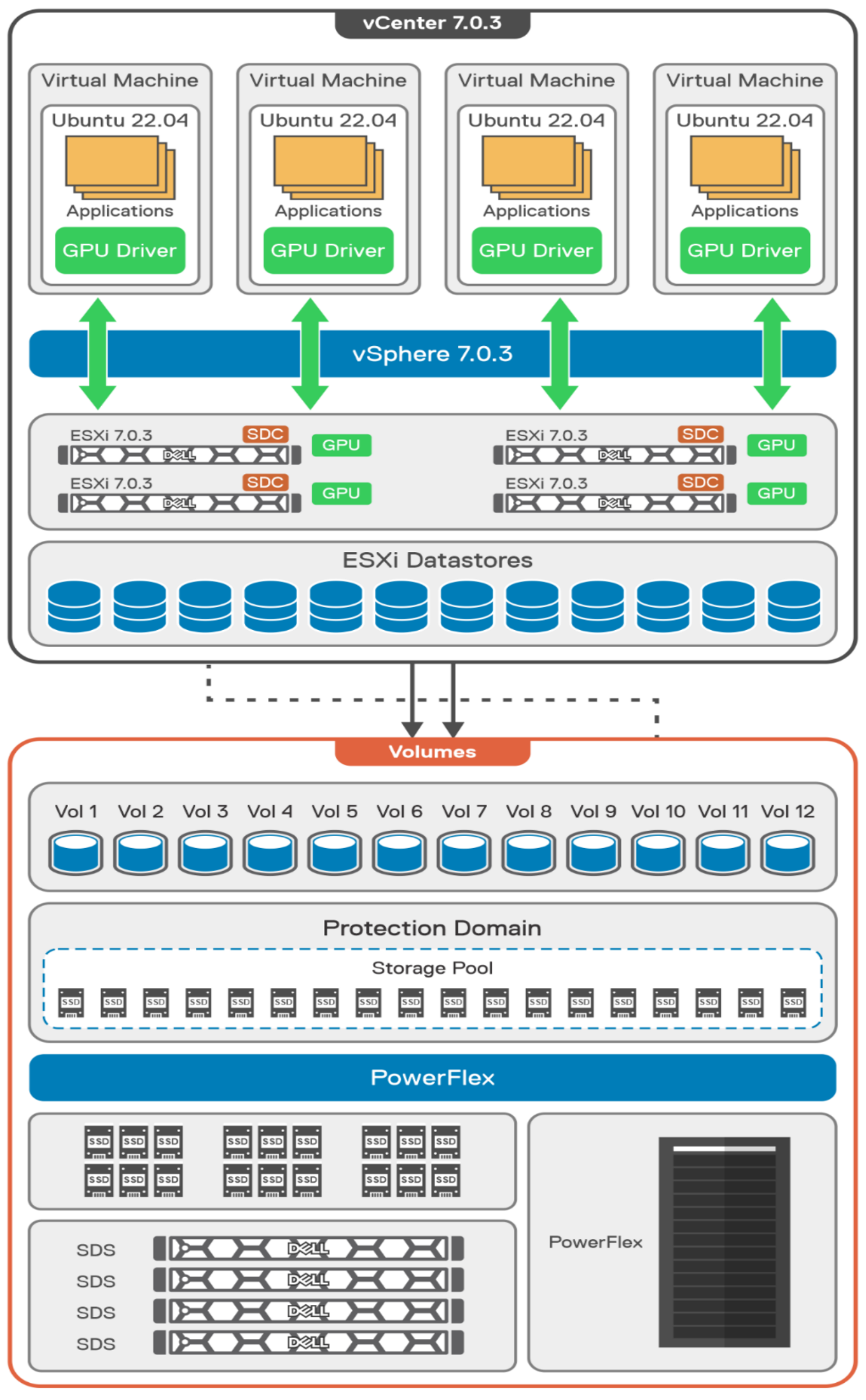
A design like this allows for independent scalability for your workloads. What I mean by this is during the training phase of a model, significant storage may be required for the training data, but once the model clears validation and goes into production, storage requirements may be drastically different. With PowerFlex you have the flexibility to deliver the storage capacity and performance you need at each stage.
This brings us to testing the environment. Again, for this paper, the engineering team validated it using ResNet-50 v1.5 using the ImageNet 1K data set. For this validation they enabled several ResNet-50 v1.5 TensorFlow features. These include Multi-GPU training with Horovod, NVIDIA DALI, and Automatic Mixed Precision (AMP). These help to enable various capabilities in the ResNet-50 v1.5 model that are present in the environment. The paper then describes how to set up and configure ResNet-50 v1.5, the features mentioned above, and details about downloading the ImageNet data.
At this stage they were able to train the ResNet-50 v1.5 deployment. The first iteration of training used the NVIDIA A100-7-40C vGPU profile. They then repeated testing with the A100-4-20C vGPU profile and the A100-3-20C vGPU profile. You might be wondering about the A100-2-10C vGPU profile and the A100-1-5C profile. Although those vGPU profiles are available, they are more suited for inferencing, so they were not tested.
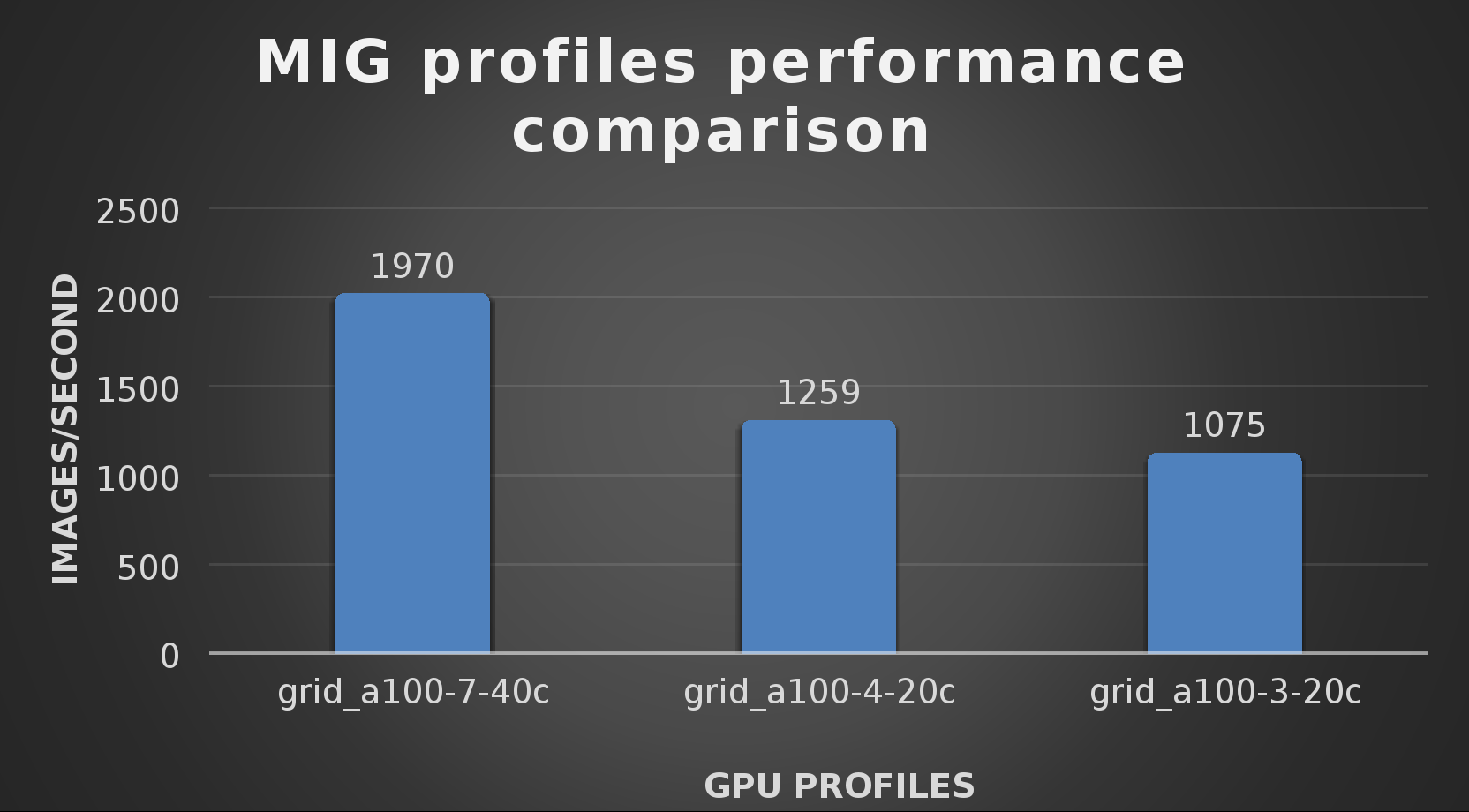
The results from validating the training workloads for each vGPU profile is shown in the following graph. The vGPUs were running near 98% capacity according to nvitop during each test. The CPU utilization was 14% and there was no bottle neck with the storage during the tests.
With the models trained, the guide then looks at how well inference runs on the MIG profiles. The following graph shows inferencing images per second of the various MIG profiles with ResNet-50 v1.5.
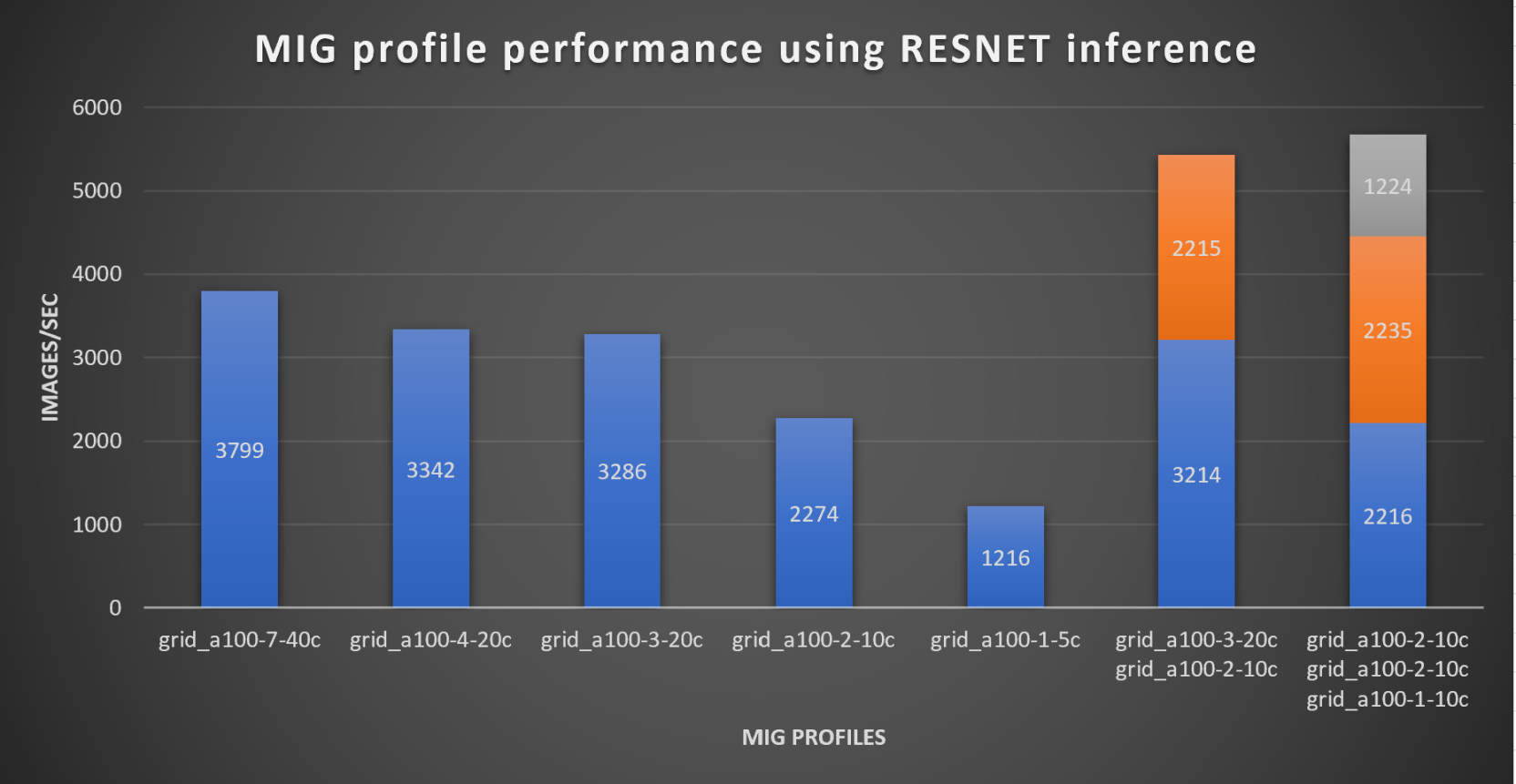
It’s worth noting that the last two columns show the inferencing running across multiple VMs, on the same ESXi host, that are leveraging MIG profiles. This also shows that GPU resources are partitioned with MIG and that resources can be precisely controlled, allowing multiple types of jobs to run on the same GPU without impacting other running jobs.
This opens the opportunity for organizations to align consumption of vGPU resources in virtual environments. Said a different way, it allows IT to provide “show back” of infrastructure usage in the organization. So if a department only needs an inferencing vGPU profile, that’s what they get, no more, no less.
It’s also worth noting that the results from the vGPU utilization were at 88% and CPU utilization was 11% during the inference testing.
These validations show that a Dell PowerFlex environment can support the foundational components of modern-day AI. It also shows the value of NVIDIA’s MIG technology to organizations of all sizes: allowing them to gain operational efficiencies in the data center and enable access to AI.
Which again answers the question of this blog, can I do that AI thing on Dell PowerFlex… Yes you can run that AI thing! If you would like to find out more about how to run your AI thing on PowerFlex, be sure to reach out to your Dell representative.
Resources
- The History of Artificial Intelligence
- ‘Godfather of AI’ leaves Google, warns of tech’s dangers
- ResNet-50: The Basics and a Quick Tutorial
- Dell Validated Design for Virtual GPU with VMware and NVIDIA on PowerFlex
- NVIDIA NGC Catalog ResNet v1.5 for PyTorch
- NVIDIA AI Enterprise
- NVIDIA A100 (PCIe) GPU
- NVIDIA Virtual GPU Software Documentation
- NVIDIA A100-7-40C vGPU profile
- NVIDIA Multi-Instance GPU (MIG)
- NVIDIA Multi-Instance GPU User Guide
- Horovod
- ImageNet
- DALI
- Automatic Mixed Precision (AMP)
- nvitop
Author: Tony Foster
Sr. Principal Technical Marketing Engineer
Twitter: | |
LinkedIn: | |
Personal Blog: | |
Location: | The Land of Oz [-6 GMT] |
Performance of the Dell PowerEdge R750xa Server for MLPerf™ Inference v2.0
Thu, 21 Apr 2022 18:20:33 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. The results provide information about the performance of Dell servers. This blog takes a closer look at the Dell PowerEdge R750xa server and its performance for MLPerf Inference v1.1 and v2.0.
We compare the v1.1 results with the v2.0 results. We show the performance difference between the software stack versions. We also use the PowerEdge R750xa server to demonstrate that the v1.1 results from all systems can be referenced for planning an ML workload on systems that are not available for MLPerf Inference v2.0.
PowerEdge R750xa server
Built with state-of-the-art components, the PowerEdge R750xa server is ideal for artificial intelligence (AI), machine learning (ML), and deep learning (DL) workloads. The PowerEdge R750xa server is the GPU-optimized version of the PowerEdge R750 server. It supports accelerators as 4 x 300 W DW or 6 x 75 W SW. The GPUs are placed in the front of the PowerEdge R750xa server allowing for better airflow management. It has up to eight available PCIe Gen4 slots and supports up to eight NVMe SSDs.
The following figures show the PowerEdge R750xa server (source):

Figure 1: Front view of the PowerEdge R750xa server

Figure 2: Rear view of the PowerEdge R750xa server

Figure 3: Top view of the PowerEdge R750xa server
Configuration comparison
The following table describes the software stack configurations from the two rounds of submission for the closed data center division:
Table 1: MLPerf Inference v1.1 and v2.0 software stacks
NVIDIA component | v1.1 software stack | v2.0 software stack |
TensorRT | 8.0.2 | 8.4.0 |
CUDA | 11.3 | 11.6 |
cuDNN | 8.2.1 | 8.3.2 |
GPU driver | 470.42.01 | 510.39.01 |
DALI | 0.30.0 | 0.31.0 |
Triton | 21.07 | 22.01 |
Although the software has been updated across the two rounds of submission, performance is consistent, if not better, for the v2.0 submission. For MLPerf Inference v2.0, Triton performance results can be extrapolated from MLPerf Inference v1.1 except for the 3D U-Net benchmark, which is due to a v2.0 dataset change.
The following table describes the System Under Test (SUT) configurations from MLPerf Inference v1.1 and v2.0 of data center inference submissions:
Table 2: MLPerf Inference v1.1 and v2.0 system configuration of the PowerEdge R750xa server
Component | v1.1 system configuration | v2.0 system configuration |
Platform | R750xa 4x A100-PCIE-80GB, TensorRT | R750xa 4xA100 TensorRT |
MLPerf system ID | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100_PCIE_80GBx4_TRT |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 1 TB | |
GPU | NVIDIA A100-PCIE-80GB | |
GPU form factor | PCIe | |
GPU count | 4 | |
Software stack | TensorRT 8.0.2 | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.39.01 DALI 0.31.0 |
In the v1.1 round of submission, Dell Technologies submitted four different configurations on the PowerEdge R750xa server. Although the GPU count of four was maintained, Dell Technologies submitted the 40 GB and the 80 GB versions of the NVIDIA A100 GPU. Additionally, Dell Technologies submitted Multi-Instance GPU (MIG) numbers using 28 instances of the one compute instance of the 10gb memory profile on the 80 GB A100 GPU. Furthermore, Dell Technologies submitted power numbers (MaxQ is a performance and power submission) for the 40 GB version of the A100 GPU and submitted with the Triton server on the 80 GB version of the A100 GPU. A discussion about the v1.1 submission by Dell Technologies can be found in this blog.
Performance comparison of the PowerEdge R70xa server for MLPerf Inference v2.0 and v1.1
ResNet 50
ReNet50 is a 50-layer deep convolution neural network that is made up of 48 convolution layers along with a single max pool and average pool layer. This model is used for computer vision applications including image classification, object detection, and object classification. For the ResNet 50 benchmark, the performance numbers from the v2.0 submission match and outperform in the server and offline scenarios respectively when compared to the v1.1 round of submission. As shown in the following figure, the v2.0 submission results are within 0.02 percent in the server scenario and outperform the previous round by 1 percent in the offline scenario:
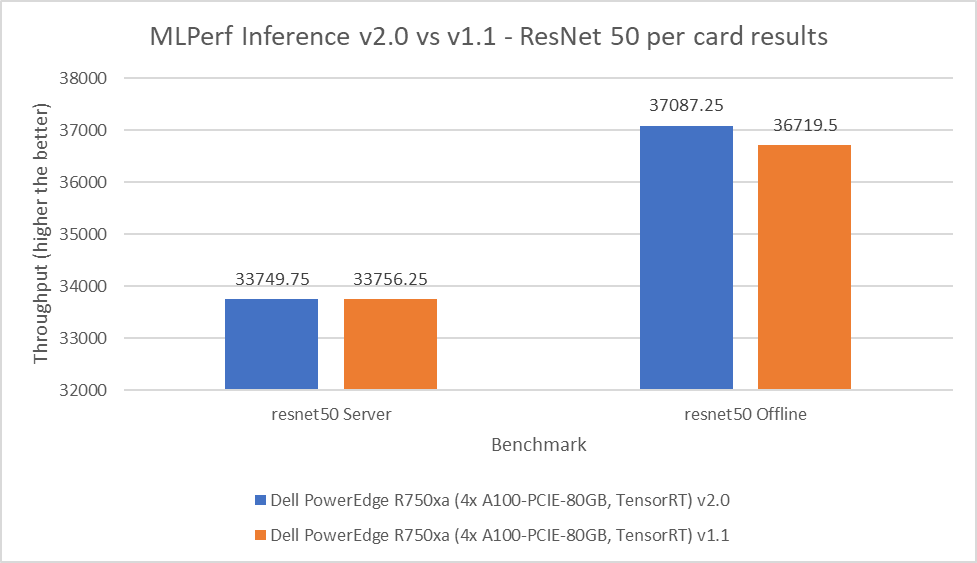
Figure 4: MLPerf Inference v2.0 compared to v1.1 ResNet 50 per card results on the PowerEdge R750xa server
BERT
Bidirectional Encoder Representation from Transformers (BERT) is a state-of-the-art language representational model for Natural Language Processing applications. This benchmark performs the SQuAD question answering task. The BERT benchmark consists of default and high accuracy modes for the offline and server scenarios. In the v2.0 round of submission, the PowerEdge R750xa server matched and slightly outperformed its performance from the previous round. In the default BERT server and offline scenarios, the extracted performance is within 0.06 and 2.33 percent respectively. In the high accuracy BERT server and offline scenarios, the extracted performance is within 0.14 and 1.25 percent respectively.
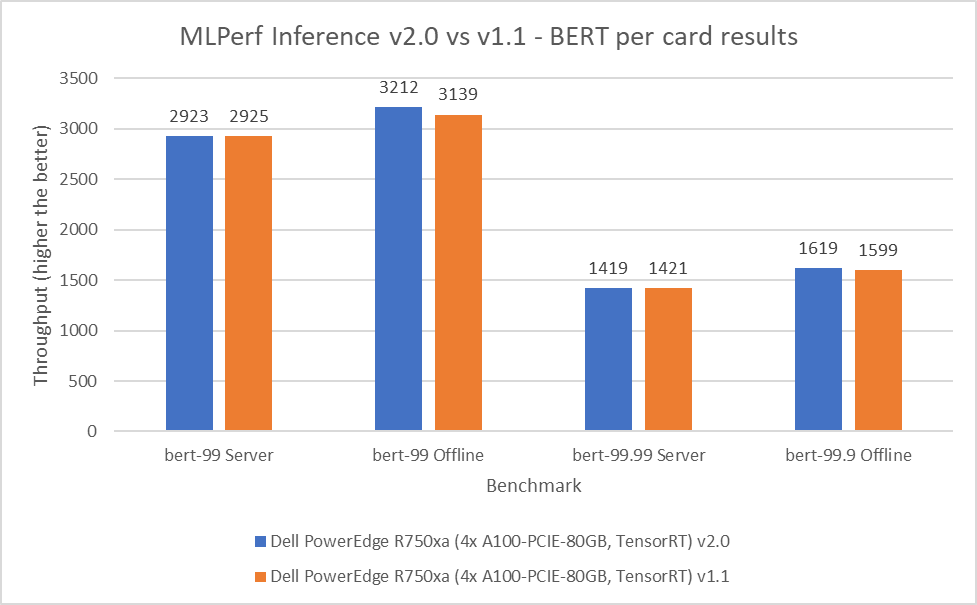
Figure 5: MLPerf Inference v2.0 compared to v1.1 BERT per card results on the PowerEdge R750xa server
SSD-ResNet 34
The SSD-ResNet 34 model falls under the computer vision category. This benchmark performs object detection. For the SSD-ResNet 34 benchmark, the results produced in the v2.0 round of submission are within 0.14 percent for the server scenario and show a 1 percent improvement in the offline scenario.
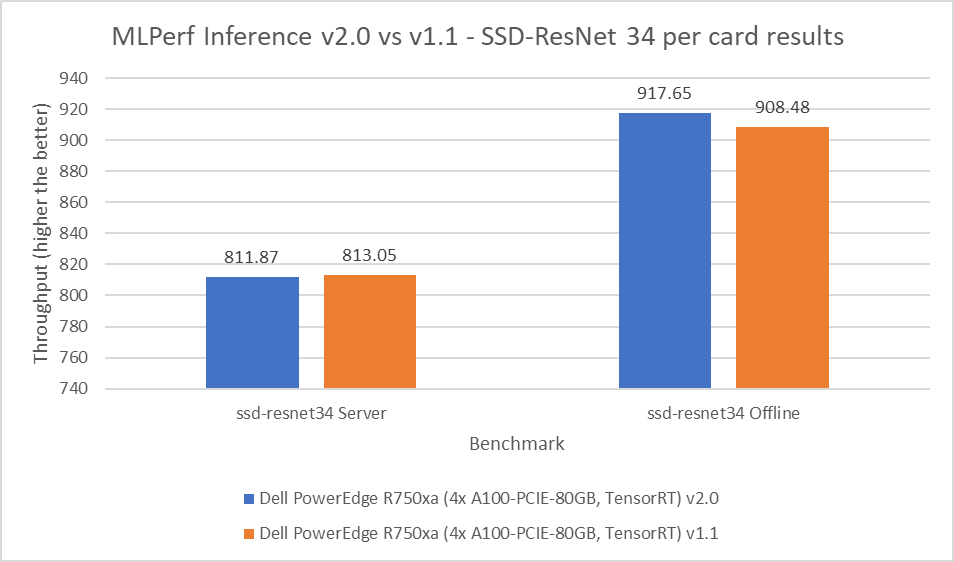
Figure 6: MLPerf Inference v2.0 compared to v1.1 SSD-ResNet 34 per card results on the PowerEdge R750xa server
DLRM
Deep Learning Recommendation Model (DLRM) is an effective benchmark for understanding workload requirements for building recommender systems. This model uses collaborative filtering and predicative analysis-based approaches to process large amounts of data. The DLRM benchmark consists of default and high accuracy modes, both containing the server and offline scenarios. For the server scenario in both the default and high accuracy modes, the v2.0 submissions results are within 0.003 percent. For the offline scenario across both modes, the PowerEdge R750xa server showed a 2.62 percent performance gain.
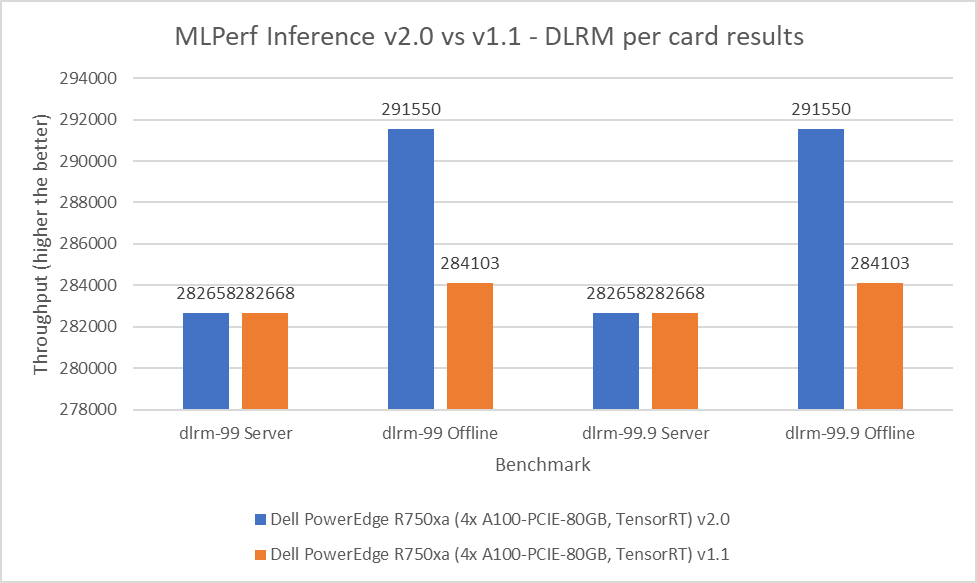
Figure 7: MLPerf Inference v2.0 compared to v1.1 DLRM per card results on the PowerEdge R750xa server
RNNT
The Recurrent Neural Network Transducers (RNNT) model falls under the speech recognition category. This benchmark accepts raw audio samples and produces the corresponding character transcription. For the RNNT benchmark, the PowerEdge R750xa server maintained similar performance behavior within 0.04 percent in the server mode and showing 1.46 percent performance gains in the offline mode.
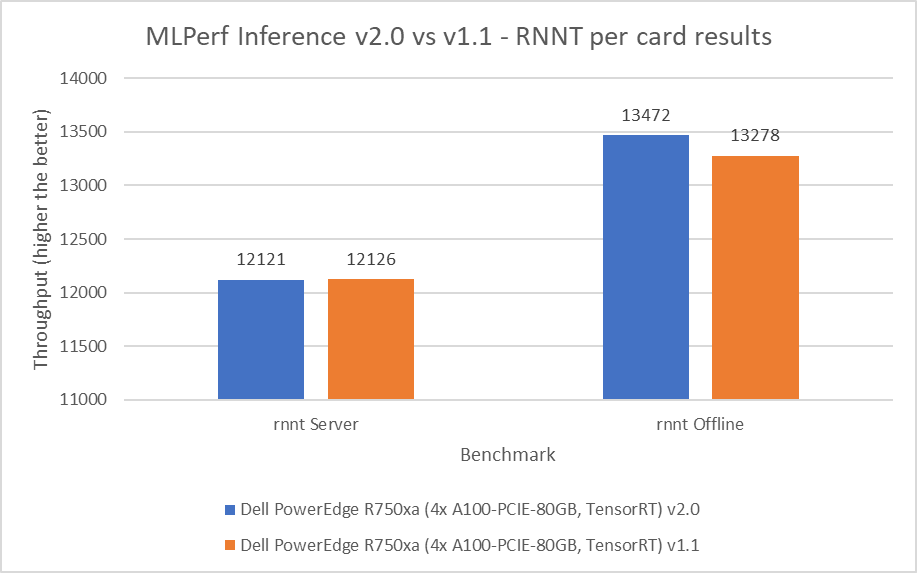
Figure 8: MLPerf Inference v2.0 compared to v1.1 RNNT per card results on the PowerEdge R750xa server
3D U-Net
The 3D U-Net performance numbers have changed in terms of scale and are not comparable in a bar graph because of a change to the dataset. The new dataset for this model is the Kitts 2019 Kidney Tumor Segmentation set. However, the PowerEdge R750xa server yielded Number One results among the PCIe form factor systems that were submitted. This model falls under the computer vision category, but it specifically deals with medical image data.
Results summary
Figure 1 through Figure 8 show the consistent performance of the PowerEdge R750xa server across both rounds of submission.
The following figure shows that in the offline scenarios for the benchmarks there is a small but noticeable performance improvement:
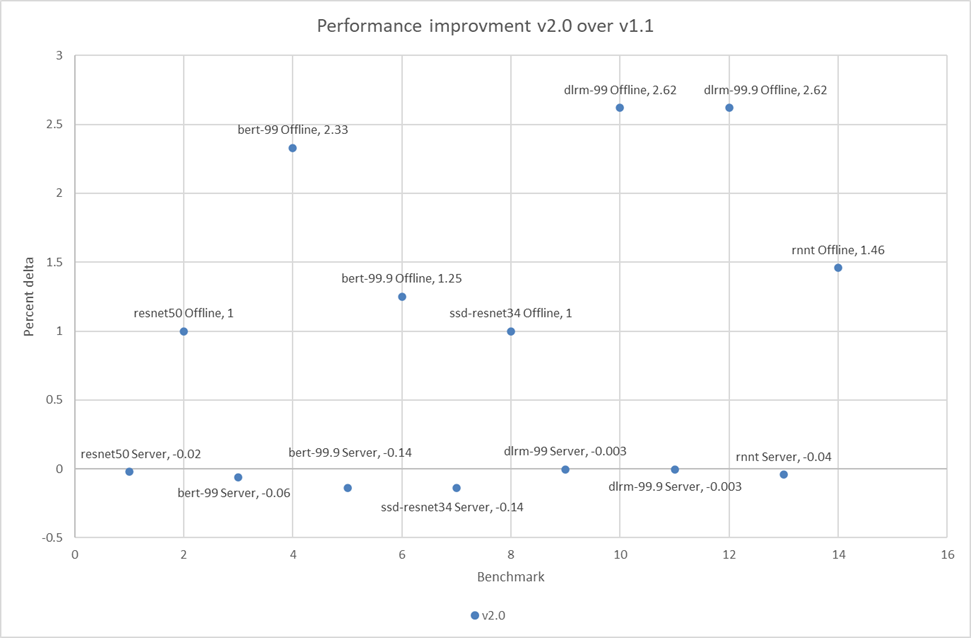
Figure 9: Performance improvement in percentage of the PowerEdge R750xa server across MLPerf Inference v2.0 and v1.1
The small percentage delta in the server scenarios can be a result of noise and are consistent with the previous round of submission.
Conclusion
This blog confirms the consistent performance of the Dell PowerEdge R750xa server across the MLPerf Inference v1.1 and MLPerf Inference v2.0 submissions. Because an identical system from round v1.1 performed at a consistent level for MLPerf Inference v2.0, we see that the software stack upgrades had minimal impact on performance. Therefore, the optimal results from the v1.1 round of submission can be used for making informed decisions about server performance for a specific ML workload. Because Dell Technologies submitted a diverse set of configurations in the v1.1 round of submission, customers can take advantage of many results.