




Microsoft HCI Solutions from Dell Technologies: Designed for extreme resilient performance
Dell EMC Integrated System for Microsoft Azure Stack HCI (Azure Stack HCI) is a fully productized HCI solution based on our flexible AX node family as the foundation.
Before I get into some exciting performance test results, let me set the stage. Azure Stack HCI combines the software-defined compute, storage, and networking features of Microsoft Azure Stack HCI OS, with AX nodes from Dell Technologies to deliver the perfect balance for performant, resilient, and cost-effective software-defined infrastructure.
Figure 1 illustrates our broad portfolio of AX node configurations with a wide range of component options to meet the requirements of nearly any use case – from the smallest remote or branch office to the most demanding database workloads.
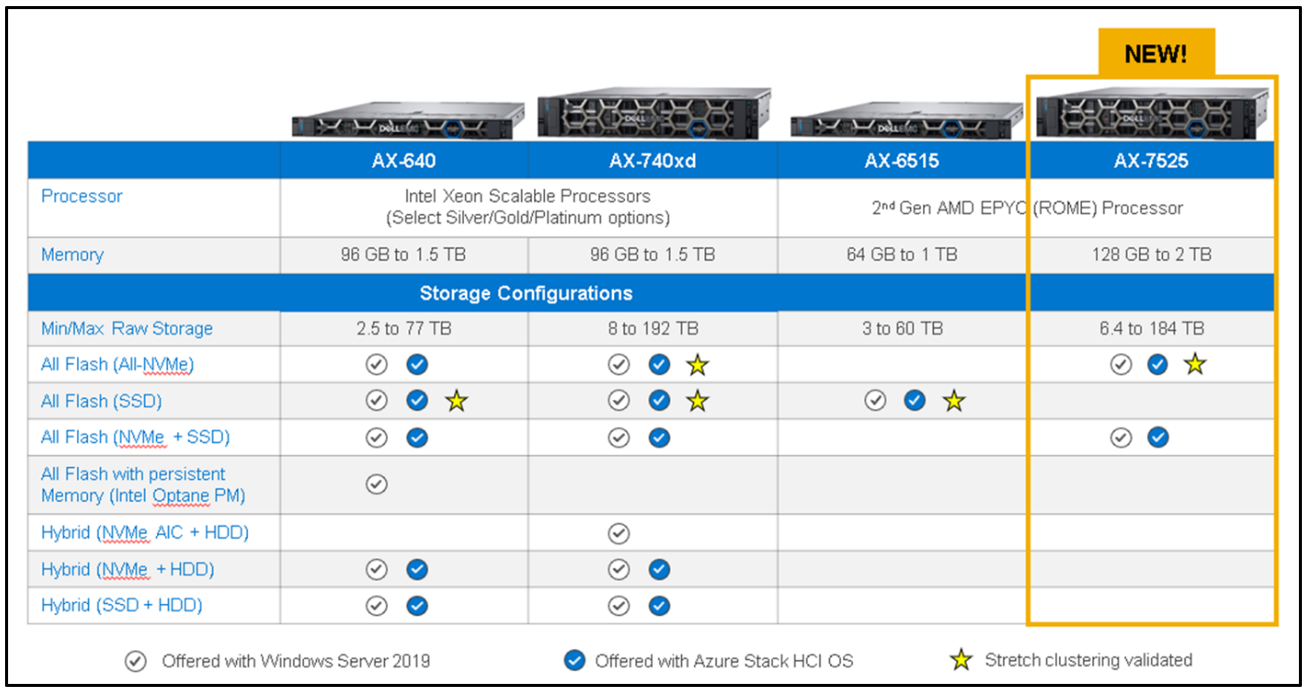
Figure 1: current platforms supporting our Microsoft HCI Solutions from Dell Technologies
Each chassis, drive, processor, DIMM module, network adapter and their associated BIOS, firmware, and driver versions have been carefully selected and tested by the Dell Technologies Engineering team to optimize the performance and resiliency of Microsoft HCI Solutions from Dell Technologies. Our Integrated Systems are designed for 99.9999% hardware availability*.
* Based on Bellcore component reliability modeling for AX-740xd nodes and S5248S-ON switches a) in 2- to 4-node clusters configured with N + 1 redundancy, and b) in 4- to 16-node clusters configured with N + 2 redundancy, March 2021.
Comprehensive management with Dell EMC OpenManage Integration with Windows Admin Center, rapid time to value with Dell EMC ProDeploy options, and solution-level Dell EMC ProSupport complete this modern portfolio.
You'll notice in that table that we have a new addition -- the AX-7525: a dual-socket, AMD-based platform designed for extreme performance and high scalability.
The AX-7525 features direct-attach NVMe drives with no PCIe switch, which provides full Gen4 PCIe potential to each storage device, resulting in massive IOPS and throughput at minimal latency.
To get an idea of how performant and resilient this platform is, our Dell Technologies experts put a 4-node AX-7525 cluster to the test. Each node had the following configuration:
- 24 NVMe drives (PCIe Gen 4)
- Dual-socket AMD EPYC 7742 64-Core Processor (128 cores)
- 1 TB RAM
- 1 Mellanox CX6 100 gigabit Ethernet RDMA NIC
The easy headline would be that this setup consistently delivered nearly 6M IOPs at sub 1ms latency. One could think that we doctored these performance tests to achieve these impressive figures with just a 4-node cluster!
The reality is that we sought to establish the ‘hero numbers’ as a baseline – ensuring that our cluster was configured optimally. However, we didn’t stop there. We wanted to find out how this configuration would perform with real-world IO patterns. This blog won’t get into the fine-grained details of the white paper, but we’ll review the test methodology for those different scenarios and explain the performance results.
Figure 2 shows the 4-node cluster and fully converged network topology that we built for the lab:
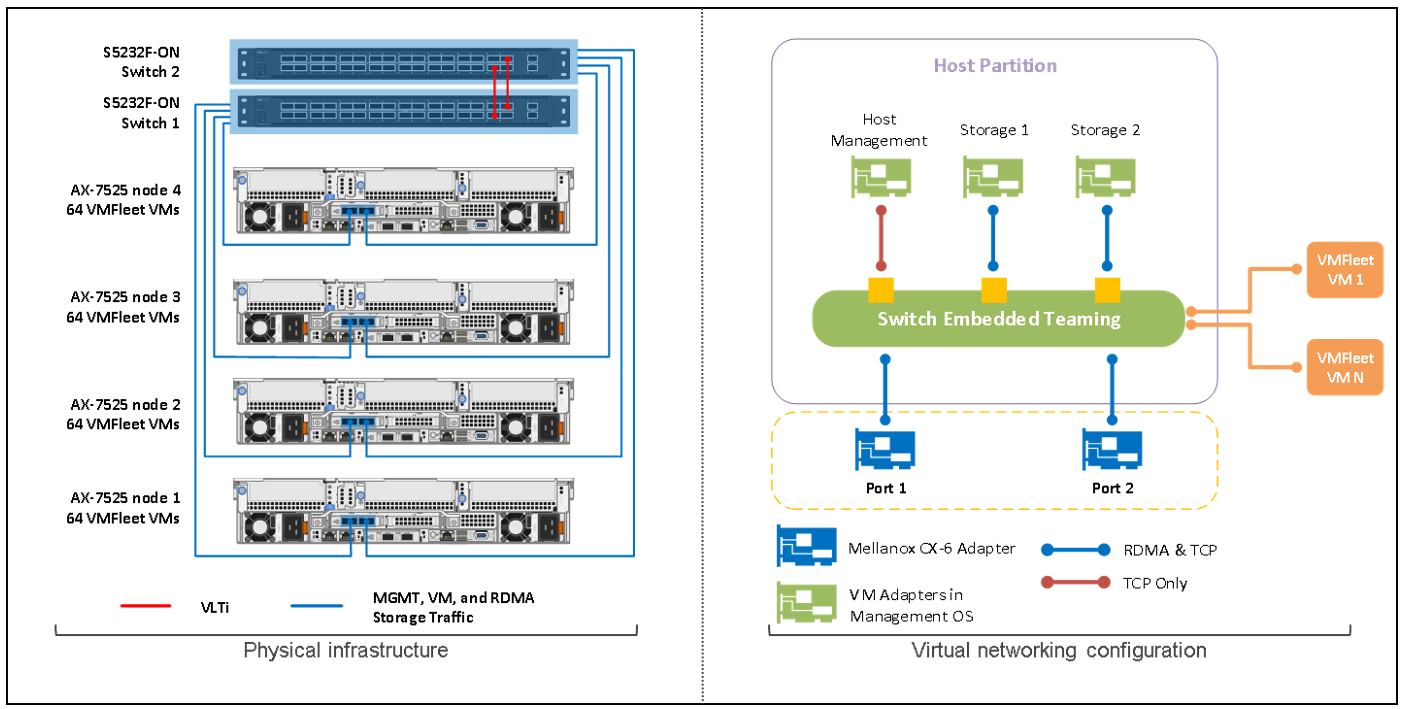
Figure 2: Lab setup
We performed two differentiated sets of tests in this environment:
- Tests with IO profiles aimed at identifying the maximum IOPS and throughput thresholds of the cluster
- Test 1: Using a healthy 4-node cluster
- Tests with IO profiles that are more representative of real-life workloads (online transaction processing (OLTP), online analytical processing (OLAP), and mixed workload types)
- Test 2: Using a healthy 4-node cluster
- Test 3: Using a degraded 4-node cluster, with a single node failure
- Test 4: Using a degraded 4-node cluster, with a two-node failure
To generate real-life workloads, we used VMFleet, which leverages PowerShell scripts to create Hyper-V virtual machines executing DISKSPD to produce the desired IO profiles.
We chose the three-way mirror resiliency type for the volumes we created with VMFleet because of its superior performance versus erasure coding options in Storage Spaces Direct.
Now that we have a clearer idea of the lab setup and the testing methodology, let’s move on to the results for the four tests.
Test 1: IO profile to push the limits on a healthy 4-node cluster with 64 VMs per node
Here are the details of the workload profile and the performance we obtained:
IO profile | Block size | Thread count | Outstanding IO | Write % | IO pattern | Total IOs | Latency |
B4-T2-O32-W0-PR | 4k | 2 | 32 | 0% | 100% random read | 5,727,985 | 1.3 ms (read) |
B4-T2-O16-W100-PR | 4k | 2 | 16 | 100% | 100% random write | 700,256 | 9 ms* (write) |
|
|
|
|
|
| Throughput | |
B512-T1-O8-W0-PSI | 512k | 1 | 8 | 0% | 100% sequential read | 105 GB/s | |
B512-T1-O1-W100-PSI | 512k | 1 | 1 | 100% | 100% sequential write | 8 GB/s | |
* The reason for this slightly higher latency is because we are pushing too many Outstanding IOs and we already plateaued on performance. We noticed that even with 32 VMs, we hit the same IOs, because all we are doing from that point on is adding more load that a) isn’t driving any additional IOs and b) just adds to the latency.
This test sets the bar for the limits and maximum performance we can obtain from this 4-node cluster: almost 6 million read IOs, 700k write IOs, and a bandwidth of 105 GB/s for reads, and 8 GB/s for writes.
Test 2: real-life workload IO profile on a healthy 4-node cluster with 32 VMs per node
The IO profiles for this test encompass a broad range of real-life scenarios:
- OLTP oriented: we tested for a wide spectrum of block sizes, ranging from 4k to 32k, and write IO ratios, varying from 20% to 50%.
- OLAP oriented: the most common OLAP IO profile is large block size and sequential access. Other workloads that follow a similar pattern are file backups and video streaming. We tested 64k to 512k block sizes and 20% to 50% write IO ratios.
The following figure shows the details and results we obtained for all the different tested IO patterns:
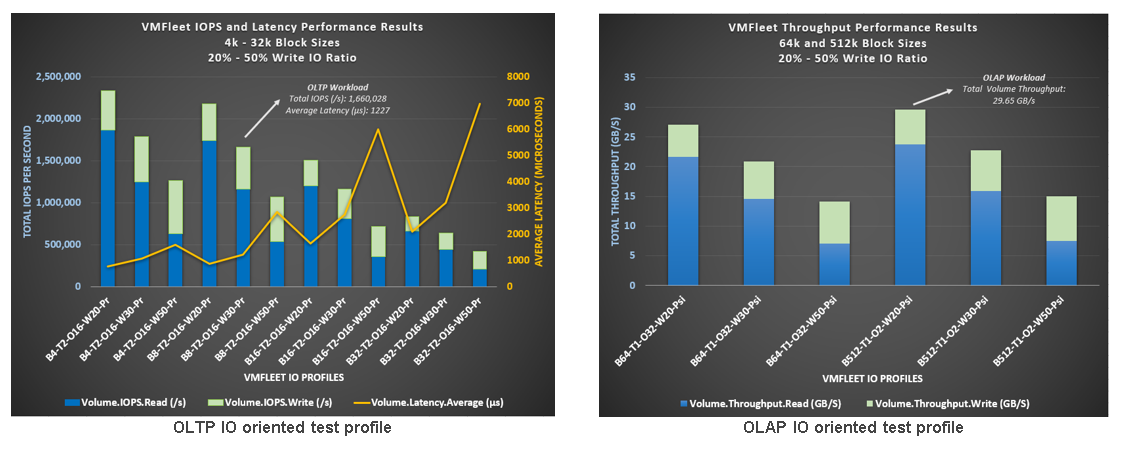
Figure 3: Test 2 results
Super impressive results and important to notice (on the left) the 1.6 million IOPS at 1.2 millisecond average latency for the typical OLTP IO profile of 8 KB block size and 30% random write. Even at 32k block size and 50% write IO ratio, we measured 400,000 IOs at under 7 milliseconds latency.
Also, very remarkable is the extreme throughput we witnessed during all the tests, with special emphasis on the incredible 29.65 GB/s with an IO profile of 512k block size and 20% write ratio.
Tests 3 and 4: push the limits and real-life workload IO profiles on a degraded 4-node cluster
To simulate a one-node failure (Test 3), we shut down node 4, which caused node 2 to take additional ownership of the 32 restarted VMs from node 4, for a total of 64 VMs on node 2.
Similarly, to simulate a two-node failure (Test 4), we shut down nodes 3 and 4, leading to a VM reallocation process from node 3 to node 1, and from node 4 to node 2. Nodes 1 and 2 ended up with 64 VMs each.
The cluster environment continued to produce impressive results even in this degraded state. The table below compares the testing scenarios that used IO profiles aimed at identifying the maximum thresholds.
IO profile | Healthy cluster | One node failure | Two node failure | |||
Total IOs | Latency | Total IOs | Latency | Total IOs | Latency | |
B4-T2-O32-W0-PR | 4,856,796 | 0.38 ms (read) | 4,390,717 | 0.38 ms (read) | 3,842,997 | 0.26 ms (read) |
B4-T2-O16-W100-PR | 753,886 | 3.2 ms (write) | 482,715 | 5.7 ms (write) | 330,176 | 11.4 ms (write) |
| Throughput | Throughput | Throughput | |||
B512-T1-O8-W0-PSI | 91 GB/s | 113 GB/s | 77 GB/s | |||
B512-T1-O1-W100-PSI | 8 GB/s | 6 GB/s | 10 GB/s | |||
Figure 4 illustrates the test results for real-life workload scenarios for the healthy cluster and for the one-node and two-node degraded states.
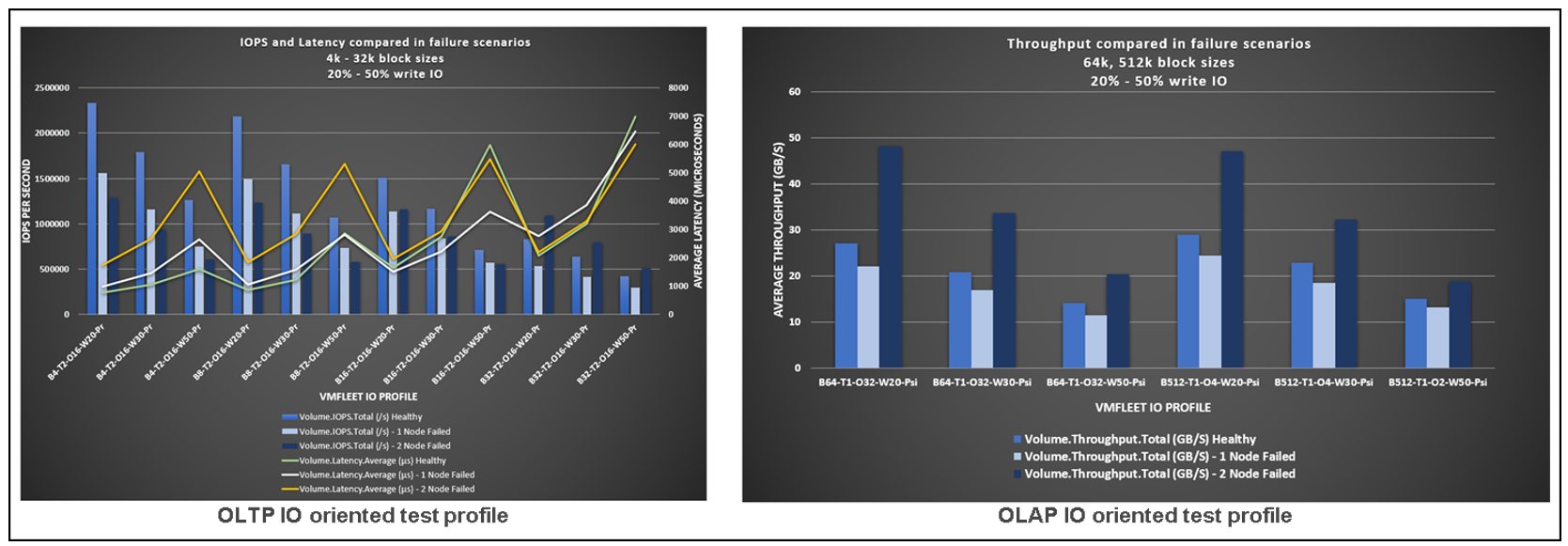
Figure 4: Test 3 and 4 results
Once more, we continued to see outstanding performance results from an IO, latency, and throughput perspective, even with one or two nodes failing.
One important consideration we observed is that for the 4k and 8k block sizes, IOs decrease and latency increases as one would expect, whereas for the 32k and higher block sizes we realized that:
- Latency was less variable across the failure scenarios because write IOs did not need to be committed across as many nodes in the cluster.
- After the two-node failure, there was actually an increase of IOs (20-30%) and throughput (52% average)!
There are two reasons for this:
- The 3-way mirrored volumes became 2-way mirrored volumes on the two surviving nodes. This effect led to 33% fewer backend drive write IOs. The overall drive write latency decreased, driving higher read and write IOs. This only applied when CPU was not the bottleneck.
- Each of the remaining nodes doubled the number of running VMs (from 32 to 64), which directly translated into greater potential for more IOs.
Conclusion
We are happy to share with you these figures about the extreme-resilient performance our integrated systems deliver, during normal operations or in the event of failures.
Dell EMC Integrated System for Microsoft Azure Stack HCI, especially with the AX-7525 platform, is an outstanding solution for customers struggling to support their organization’s increasingly heavy demand for resource intensive workloads and to maintain or improve their corresponding service level agreements (SLAs).
Related Blog Posts

2023 Updates for Azure Stack HCI and Hub (Part I)
Wed, 30 Aug 2023 22:05:17 -0000
|Read Time: 0 minutes
The first half of 2023 has been quite prolific for the Dell Azure Stack HCI ecosystem, providing many important incremental updates in the platform. This article summarizes the most relevant changes inside the program.
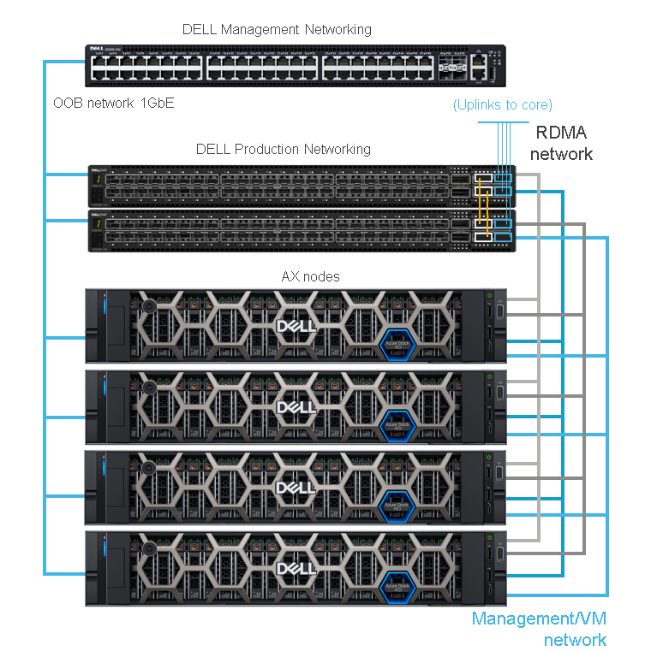 Azure Stack HCI
Azure Stack HCI
Dell Integrated System for Microsoft Azure Stack HCI delivers a fully productized, validated, and supported hyperconverged infrastructure solution that enables organizations to modernize their infrastructure for improved application uptime and performance, simplified management and operations, and lower total cost of ownership. The solution integrates the software-defined compute, storage, and networking features of Microsoft Azure Stack HCI with AX nodes from Dell to offer the high-performance, scalable, and secure foundation needed for a software-defined infrastructure.
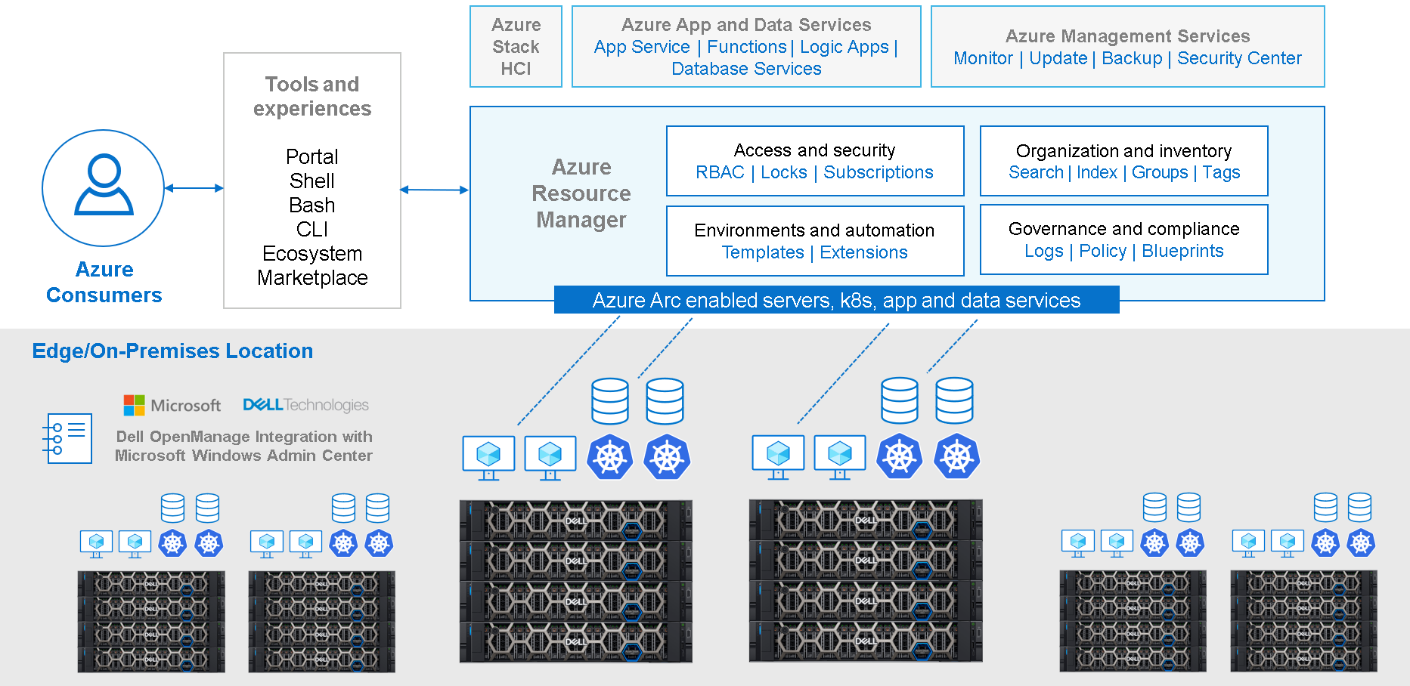
With Azure Arc, we can now unlock new hybrid scenarios for customers by extending Azure services and management to our HCI infrastructure. This allows customers to build, operate, and manage all their resources for traditional, cloud-native, and distributed edge applications in a consistent way across the entire IT estate.
What’s new with Azure Stack HCI?
A lot. There have been so many updates in the Azure Stack HCI front that it is difficult to detail all of them in just a single blog. So, let’s focus on the most important ones.
Azure Stack HCI software and hardware updates
From a software and hardware perspective, the biggest change during the first half of 2023 was the introduction of Azure Stack HCI, version 22H2 (factory install and field support). The most important features in this release are Network ATC, GPU partitioning (GPU-P), and security improvements.
- Network ATC simplifies the virtual network configuration by leveraging intent-based network deployment and incorporating Microsoft best practices by default. It provides the following advantages over manual deployment:
- Reduces network configuration deployment time, complexity, and incorrect input errors
- Uses the latest Microsoft validated network configuration best practices
- Ensures configuration consistency across all nodes in the cluster
- Eliminates configuration drift, with periodic consistency checks every 15 minutes
- GPU-P allows sharing a physical GPU device among several VMs. By leveraging single root I/O virtualization (SR-IOV), GPU-P provides VMs with a dedicated and isolated fractional part of the physical GPU. The obvious advantage of GPU-P is that it enables enterprise-wide utilization of highly valuable and limited GPU resources.
- Azure Stack HCI OS 22H2 security has been improved with more than 200 security settings enabled by default within the OS (“Secured-by-default”), enabling customers to closely meet Center for Internet Security (CIS) benchmark and Defense Information System Agency (DISA) Security Technical Implementation Guide (STIG) requirements for the OS. All these security changes improve the security posture by also disabling legacy protocols and ciphers.
From a hardware perspective, these are the most relevant additions to the AX node family:
- More NIC options:
- Mellanox ConnectX-6 25 GbE
- Intel E810 100 GbE; also adds RoCEv2 support (now iWARP or RoCE)
- More GPU options for GPU-P and Discrete Device Assignment (DDA):
- GPU-P validation for: NVIDIA A40, A16, A2
- DDA options: NVIDIA A30, T4
To better understand GPU-P and DDA, check this blog.
Azure Stack HCI End of Life (EOL) for several components
As the platforms mature, it is inevitable that some of the aging components are discontinued or replaced with newer versions. The most important changes on this front have been:
- EOL for AX-640/AX-740xd nodes: Azure Stack HCI 14G servers, AX-640, and AX-740xd reached their EOL on March 31, 2023, and are therefore no longer available for quoting, or new orders. These servers will be supported for up to seven years, until their End of Service Life (EOSL) date. Azure Stack HCI 15G AX-650/AX-750/AX-6515/AX-7525 platforms will continue to be offered to address customer demands.
- EOL for Windows Server 2019: While Windows Server 2019 will be reaching end of sales/distribution from Dell on June 30, 2023, the product will continue to be in Microsoft Mainstream Support life cycle until January 9, 2024. That means that our customers will be eligible for security and quality updates from Microsoft free of charge until that date. After January 9, 2024, Windows Server will enter a 5-year Extended Support life cycle that will provide our customers with security updates only. Any quality and product fixes will be available from Microsoft for a fee. It is highly recommended that customers migrate their current Windows Server 2019 workloads to Windows Server 2022 to maintain up-to-date support.
Finally, we have introduced a set of short and easily digestible training videos (seven minutes each, on average) to learn everything you need to know about Azure Stack HCI, from the AX platform and Microsoft’s Azure Stack HCI operating system, to the management tools and deploy/support services.
Conclusion
It’s certainly a challenge to synthesize the last six months of incredible innovation into a brief article, but we have highlighted the most important updates: focus on learning all the new Azure Stack HCI 22H2 features and updates, keep current with the hardware updates, and… stay tuned for important announcements by the last quarter of the year: big things are coming in Part 2!!!
Thank you for reading.
Author: Ignacio Borrero, Senior Principal Engineer, Technical Marketing

Dell and Azure Stack HCI Made Easy: the Video Series
Tue, 25 Apr 2023 17:05:23 -0000
|Read Time: 0 minutes
It is incredible how time flies and it still feels like yesterday since December 10, 2020, when Microsoft initially released Azure Stack HCI. 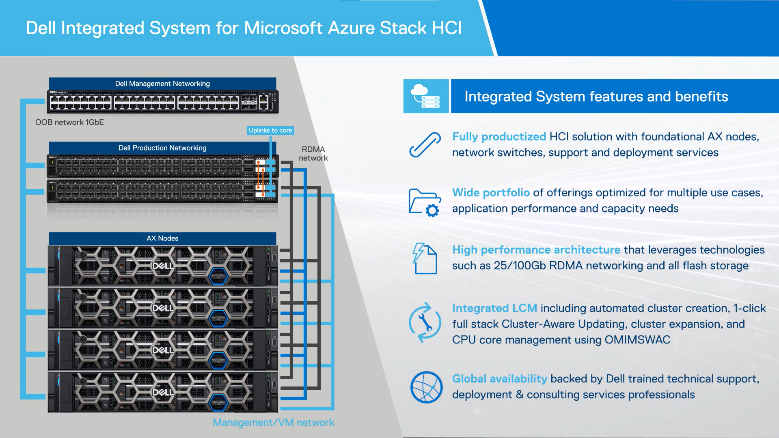
Today, Azure Stack HCI is a huge success and, in combination with Azure Arc, the foundation for any real Microsoft hybrid strategy.
But believe it or not, 850+ days later, Azure Stack HCI is still a big unknown for part of the Microsoft community. In our daily customer engagements, we keep on observing that there are knowledge gaps around the Azure Stack HCI program itself and the partner ecosystem that surrounds it.
In these circumstances, we have decided to take action and create a very short and easy-to-follow video series explaining everything you need to know about Azure Stack HCI from a technical perspective.
What you will find
This initial video training library consist of five videos, each averaging seven minutes in length. Here’s a summary of what you will discover in each of the videos:
Video: What Is Inside Azure Stack HCI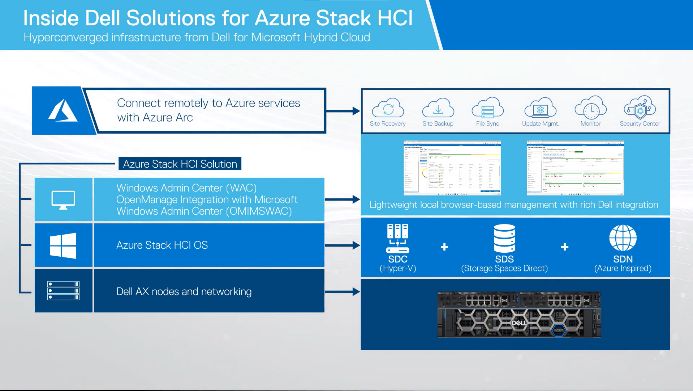
Learn the basics and fundamental components of Azure Stack HCI and get to know the Dell Integrated System for Microsoft Azure Stack HCI platform.
Meet the AX node platform and take the Dell Integrated System for Microsoft Azure Stack HCI route to deliver consistent Azure Stack HCI deployments.
Video: Topology and networking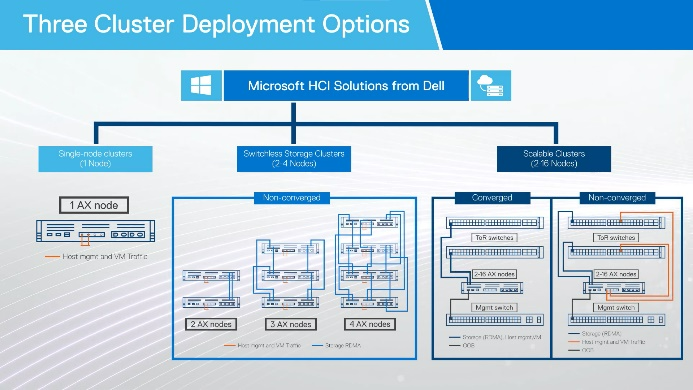
Explore topology and network deployment options for Dell Integrated System for Microsoft Azure Stack HCI. Make good Azure Stack HCI environments even better with the Dell PowerSwitch family.
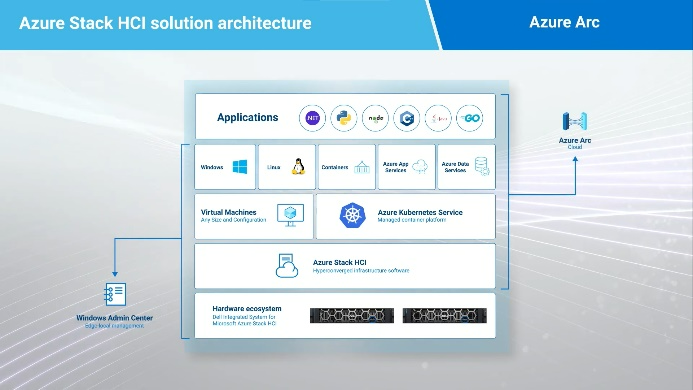
Learn about Azure Stack HCI local management with Windows Admin Center and OpenManage. This is the perfect combination for quick and easy controlled local deployments…and a solid foundation for true hybrid management.
Describes end to end deployment and support for the Dell Integrated System for Microsoft Azure Stack HCI platform with ProDeploy and ProSupport services.
Will there be more?
Absolutely.
We are already working on the next series where we’ll be covering other important topics that are beyond the scope for this initial launch (such as best practices and stretched clusters).
Conclusion
There is no doubt that Azure Stack HCI is a very hot topic. In fact, it is the key foundational element that enables a true Microsoft hybrid strategy by delivering on-premises infrastructure fully integrated with Azure. This video series explains the different elements that make this possible.
All videos in the series are important, none should be skipped… but if there is one not to be missed, please, go for Dell Azure Stack HCI: Local Management. This topic is actually the hook for the next release (Hint -> Hybrid management is the next big thing!).
Thanks for reading and… stay tuned for additional videos on the Info Hub!
Author: Ignacio Borrero, Senior Principal Engineer, Technical Marketing Dell CI & HCI