




Value Optimized AX-6515 for ROBO Use Cases
Introduction
Small offices and remote branch office (ROBO) use cases present special challenges for IT organizations. The issues tend to revolve around how to implement a scalable, resilient, secure, and highly performant platform at an affordable TCO. The infrastructure must be capable enough to efficiently run a highly diversified portfolio of applications and services and yet be simple to deploy, update, and support by a local IT generalist. Dell Technologies and Microsoft help you accelerate business outcomes in these unique ROBO environments with our Dell EMC Solutions for Microsoft Azure Stack HCI.
In this blog post, we share VMFleet results observed in the Dell Technologies labs for our newest AX-6515 two-node configuration – ideal for ROBO environments. Optimized for value, the small but powerful AX-6515 node packs a dense, single-socket 2nd Gen AMD EPYC processor in a 1RU chassis delivering peak performance and excellent TCO. We also included the Dell EMC PowerSwitch S5212F-ON in our testing to provide 25GbE network connectivity for the storage, management, and VM traffic in a small form factor. The Dell EMC Solutions for Azure Stack HCI Deployment Guide was followed to construct the test lab and applies only to infrastructure that is built with validated and certified AX nodes running Microsoft Windows Server 2019 Datacenter from Dell Technologies.
We were quite impressed with the VMFleet results. First, we stressed the cluster’s storage subsystem to its limits using scenarios aimed at identifying maximum IOPS, latency, and throughput. Then, we adjusted the test parameters to be more representative of real-world workloads. The following summary of findings indicated to us that this two-node, AMD-based, all-flash cluster could meet or exceed the performance requirements of workload profiles often found in ROBO environments:
- Achieved over 1 million IOPS at microsecond latency using a 4k block size and 100% random-read IO pattern.
- Achieved over 400,000 IOPS at 4 millisecond latency using a 4k block size and 100% random-write IO pattern.
- Using 512k block sizes, drove 6 GB/s and 12 GB/s throughput for 100% sequential-write and 100% sequential-read IO patterns, respectively.
- Using a range of real-world scenarios, the cluster achieved hundreds of thousands of IOPS at under 7 milliseconds latency and drove between 5 – 12 GB/s of sustained throughput.
Lab Setup
The following diagram illustrates the environment created in the Dell Technologies labs for the VMFleet testing. Ancillary services required for cluster operations such as DNS, Active Directory, and a file server for cluster quorum are not depicted.
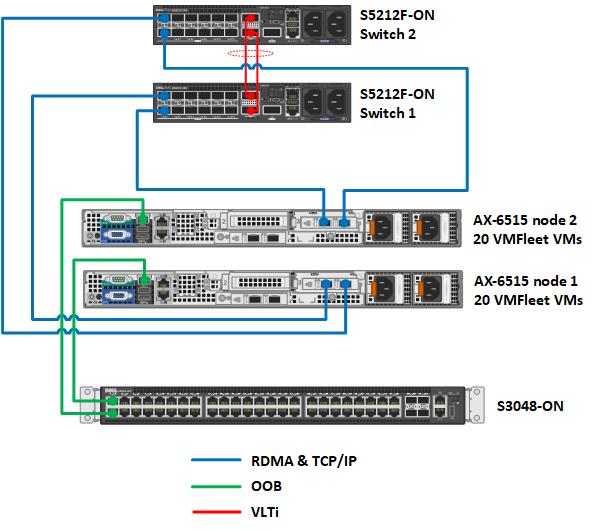
Figure 1 Network topology
Table 1 Cluster configuration
Cluster Design Elements | Description |
Number of cluster nodes | 2 |
Cluster node model | AX-6515 nodes |
Number of network switches for RDMA and TCP/IP traffic | 2 |
Network switch model | Dell EMC PowerSwitch S5212F-ON |
Network topology | Fully-converged network configuration. RDMA and TCP/IP traffic traversing 2 x 25GbE network connections from each host. |
Network switch for OOB management | Dell EMC PowerSwitch S3048-ON |
Resiliency option | Two-way mirror |
Usable storage capacity | Approximately 12 TB |
Table 2 Cluster node resources
Resources per Cluster Node | Description |
CPU | Single-socket AMD EPYC 7702P 64-Core Processor |
Memory | 256 GB DDR4 RAM |
Storage controller for OS | BOSS-S1 adapter card |
Physical drives for OS | 2 x Intel 240 GB M.2 SATA drives configured as RAID 1 |
Storage controller for Storage Spaces Direct (S2D) | HBA330 Mini |
Physical drives | 8 x 1.92 TB Mixed Use KIOXIA SAS SSDs |
Network adapter | Mellanox ConnectX-5 Dual Port 10/25GbE SFP28 Adapter |
Operating System | Windows Server 2019 Datacenter |
The architectures of Azure Stack HCI solutions are highly opinionated and prescriptive. Each design is extensively tested and validated by Dell Technologies Engineering. Here is a summary of the key quality attributes that define these architectures followed by a section devoted to our performance findings.
- Efficiency – Many customers are interested in improving performance and gaining efficiencies by modernizing their aging virtualization platforms with HCI. Using Azure Stack HCI helps avoid a DIY approach to IT infrastructure, which is prone to human error and is more labor intensive.
- Maintainability – Our solution makes it simple to incorporate hybrid capabilities to reduce operational burden using Microsoft Windows Admin Center (WAC). Services in Azure can also be leveraged to avoid additional on-premises investments for management, monitoring, BCDR, security, and more. We have also developed the Dell EMC OpenManage Integration with Microsoft Windows Admin Center to assist with hardware monitoring and to simplify updates with Cluster Aware Updates (CAU).
- Availability – Using a two-way mirror, we always have two copies of our data. This configuration can survive a single drive failure in one node or survive an entire node failure. However, the cluster cannot survive two failures simultaneously on both nodes. In case greater resiliency is desired, volumes can be created using nested resiliency. Nested resiliency is discussed in more detail in the "Optional modifications to the architecture" section later in this blog post.
- Supportability – Support is provided by dedicated Dell Technologies ProSupport Plus and ProSupport for Software technicians who have expertise specifically tailored to Azure Stack HCI solutions.
Testing Results
We leveraged VMFleet to benchmark the storage subsystem of our 2-node cluster. Many Microsoft customers and partners rely on this tool to help them stress test their Azure Stack HCI clusters. VMFleet consists of a set of PowerShell scripts that deploy virtual machines to a Hyper-V cluster and execute Microsoft’s DiskSpd within those VMs to generate IO. The following table presents the range of VMFleet and DiskSpd parameters used during our testing in the Dell Technologies labs.
Table 3 Test parameters
VMFleet and DiskSpd Parameters | Values |
Number of VMs running per node | 20 |
vCPUs per VM | 2 |
Memory per VM | 8 GB |
VHDX size per VM | 40 GB |
VM Operating System | Windows Server 2019 |
0 | |
Block sizes (B) | 4k – 512k |
Thread count (T) | 2 |
Outstanding IOs (O) | 32 |
Write percentages (W) | 0, 20, 50, 100 |
IO patterns (P) | Random, Sequential |
We first selected DiskSpd scenarios aimed at identifying the maximum IOPS, latency, and throughput thresholds of the cluster. By pushing the limits of the storage subsystem, we confirmed that the networking, compute, operating systems, and virtualization layer were configured correctly according to our Deployment Guide and Network Integration and Host Network Configuration Options guide. This also ensured that that no misconfiguration occurred during initial deployment that could skew the real-world storage performance results. Our results are depicted in Table 4.
Table 4 Maximums test results
Scenario | Parameter Values Explained | Performance Metric |
B4-T2-O32-W0-PR | Block size: 4k Thread count: 2 Outstanding IO: 32 IO pattern: 100% random read | IOPS: 1,146,948 Read latency: 245 microseconds CPU utilization: 48% |
B4-T2-O32-W100-PR | Block size: 4k Thread count: 2 Outstanding IO: 32 IO pattern: 100% random write | IOPS: 417,591 Write latency: 4 milliseconds CPU utilization: 25% |
B512-T2-O2-W0-PSI | Block size: 512k Thread count: 2 Outstanding IO: 8 IO pattern: 100% sequential read | Throughput: 12 GB/s |
B512-T2-O2-W100-PSI | Block size: 512k Thread count: 2 Outstanding IO: 8 IO pattern: 100% sequential write | Throughput: 6 GB/s |
We then stressed the storage subsystem using IO patterns more reflective of the types of workloads found in a ROBO use case. These applications are typically characterized by smaller block sizes, random I/O patterns, and a variety of read/write ratios. Examples include general enterprise and small office LOB applications and OLTP workloads. The testing results in Figure 2 below indicate that the cluster has the potential to accelerate OLTP workloads and make enterprise applications highly responsive to end users.
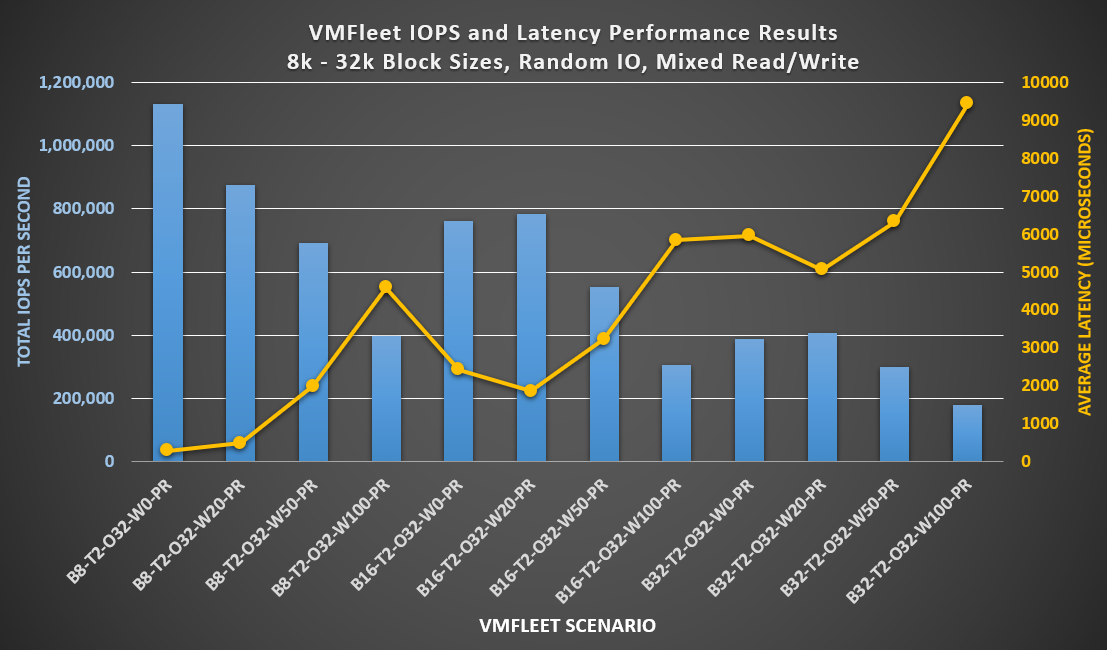
Figure 2 Performance results with smaller block sizes
Other services like backups, streaming video, and large dataset scans have larger block sizes and sequential IO patterns. With these workloads, throughput becomes the key performance indicator to analyze. The results shown in the following graph indicate an impressive sustained throughput that can greatly benefit this category of IT services and applications.
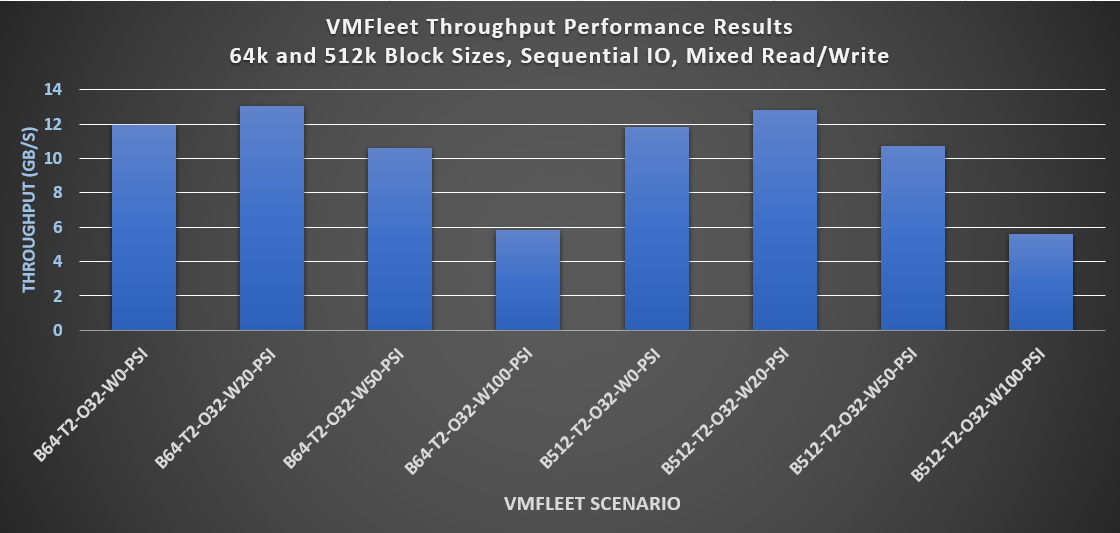
Figure 3 Performance results with larger block sizes
Optional modifications to the architecture
Customers could make modifications to the lab configuration to accommodate different requirements in the ROBO use case. For example, Dell Technologies completely supports a dual-link full mesh topology for Azure Stack HCI. This non-converged storage switchless topology eliminates the need for network switches for storage communications and enables you to use existing infrastructure for management and VM traffic. This approach will result in similar or improved performance metrics versus those mentioned in this blog due to the 2 x 25 GB direct connections between the nodes and the isolation of the storage traffic on these dedicated connections.
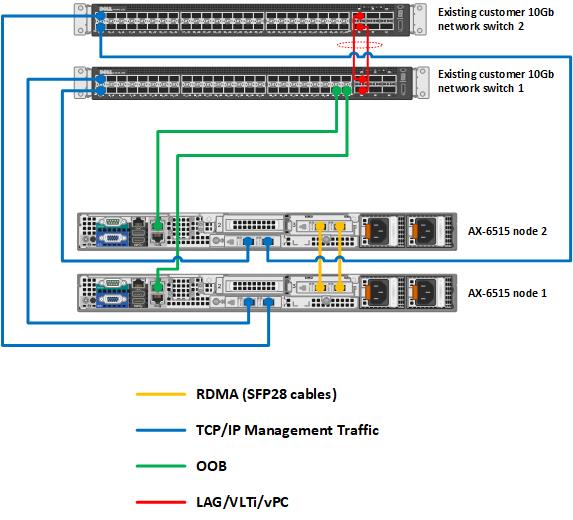
Figure 4 Two-node back-to-back architecture option
There may be situations in ROBO scenarios where there are no IT generalists near the site to address hardware failures. When a drive or entire node fails, it may take days or weeks before someone can service the nodes and return the cluster to full functionality. Consider nested resiliency instead of two-way mirroring to handle multiple failures on a two-node cluster. Inspired by RAID 5 + 1 technology, workloads remain online and accessible even in the following circumstances:
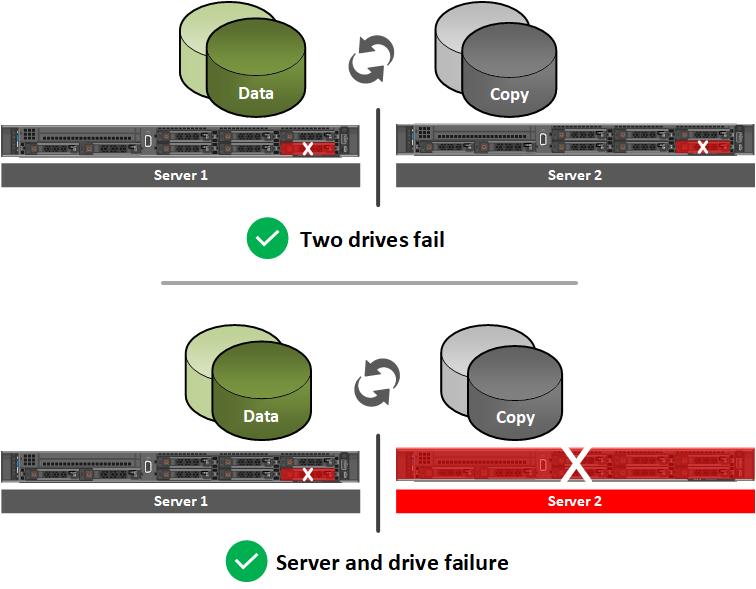
Figure 5 Nested resiliency option
Be aware that there is a capacity efficiency cost when using nested resiliency. Two-way mirroring is 50% efficient, meaning 1 TB of data takes up 2 TB of physical storage capacity. Depending on the type of nested resiliency you choose to configure, capacity efficiency can range between 25% - 40%. Therefore, ensure you have an adequate amount of raw storage capacity if you intend to use this technology. Performance is also going to be affected when using nested resiliency – especially on workloads with a higher percentage of write IO since more copies of the data need to be maintained on the cluster.
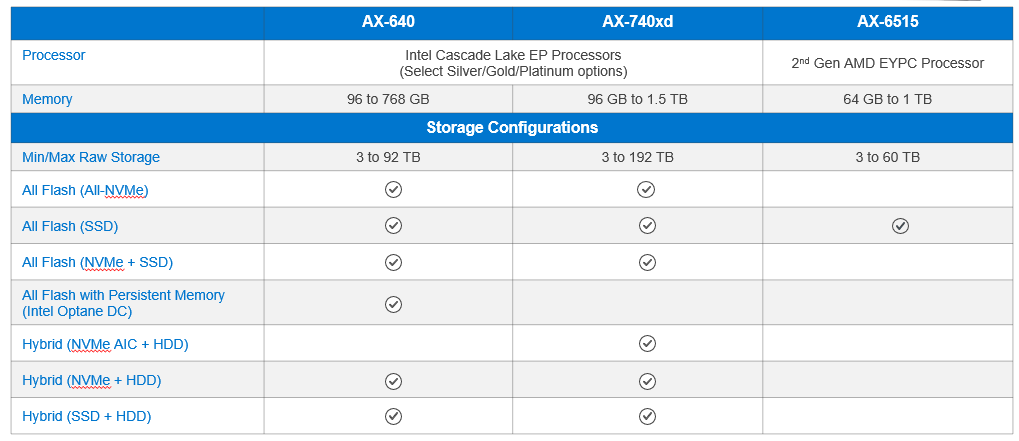
If you need greater flexibility in cluster resources, Dell Technologies offers Azure Stack HCI configurations to meet any workload profile and business requirement. The table below shows the different resource options available for each AX node. To find more detailed specifications about these configurations, please review the detailed product specifications on our product page.
Table 5 Azure Stack HCI configuration options
Visit our website for more details on Dell EMC Solutions for Azure Stack HCI.