

Assets

Oracle Database Solutions on Docker Container and Kubernetes
Sat, 27 Apr 2024 13:07:57 -0000
|Read Time: 0 minutes
The Opportunity
Containers are a lightweight, stand-alone, executable package of software that includes everything that is needed to run an application: code, runtime, system tools, system libraries, and settings. A container isolates software from its environment and ensures that it works uniformly despite any differences between development and staging. Containers share the machine’s operating system kernel and do not require an operating system for each application, driving higher server efficiencies and reducing server and licensing costs.
The traditional build process for database application development is complex, time intensive and difficult to schedule. With containers and the right supporting tools, the traditional build process is transformed into a self-service, on-demand experience that enables developers to rapidly deploy applications. In the remaining sections of this article we describe how to develop the capability to have an Oracle database container running in a matter of minutes.
Oracle has a long commitment to supporting the developer communities working in containerized environments. At the DockerCon US event in April 2017, Oracle announced that its Oracle 12c database software application would be available alongside of other Oracle products on Docker Store, the standard for dev-ops developers. Dev-ops developers have pulled over four billion images from the Docker Store and are increasingly turning to the Docker Store as the canonical source for high-quality curated content. In the present-day database world, customers are invariably switching to the use of containers with Kubernetes management to build and run a wide variety of applications and services in a highly available on-premises hosted environment.
Containerized environments can reliably offer high-performance compute, storage and network capabilities with the necessary configurations. A containerized environment also reduces overhead costs by providing a repeatable process for application deployment across build, test, and production systems. To enable the deployment and management of containerized applications, organizations use Kubernetes technologies to operate at any scale including production. Kubernetes enables powerful collaboration and workflow management capabilities by deploying containers for cloud-native, distributed applications and microservices. It even allows you to repackage legacy applications for increased portability, more efficient deployment, and improved customer and employee engagement.
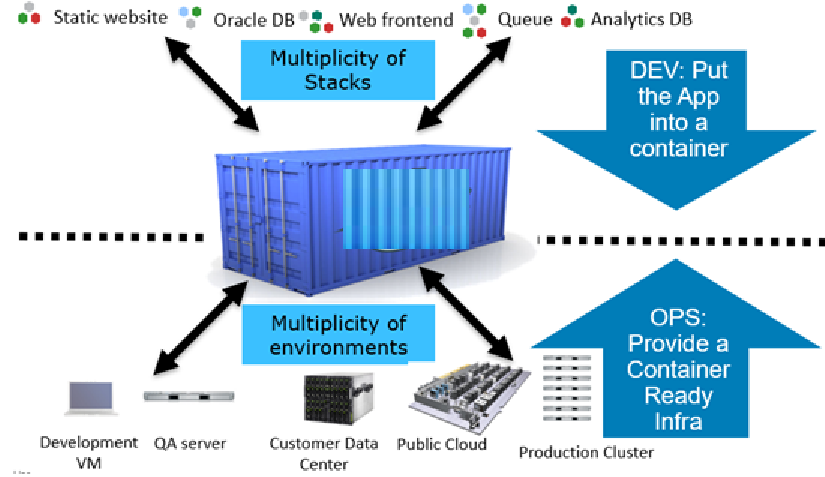
Figure 1: Docker containers for reducing development complexity
The Solution
For many companies, to boost productivity and time to value, container usage starts with the departments that are focused on software development. Their journey typically starts with installing, implementing, and using containers for applications that are based on the microservice architecture as shown in Figure 2. Developers want to be able to build microservices-based container applications without changing code or infrastructure.
This approach enables portability between data centers and obviates the need for changes in traditional applications enabling faster development and deployment cycles. Oracle Docker containers run the microservices while Kubernetes is used for container orchestration. Also, the microservices running within Docker containers can communicate with the Oracle databases by using messaging services.
Figure 2: Architecture for Oracle Database featuring Docker and Kubernetes
Using orchestration and automation for containerized applications, developers can self-provision an Oracle database, thereby increasing flexibility and productivity while saving substantial time in creating a production copy for development and testing environments. This solution enables development teams to quickly provision isolated applications without the traditional complexities.
Our Dell EMC engineers recently tested and validated a solution for Oracle database using Docker containers and Kubernetes. The solution uses Oracle Database in containers, Kubernetes, and the Container Storage Interface (CSI) Driver for Dell EMC PowerFlex OS to show how dev/ops teams can transform their development processes.
Dell EMC engineers demonstrated two use cases for this solution. Both of our use cases feature four Dell EMC PowerEdge R640 servers, which are an integral part of Dell EMC VxFlex Ready Nodes, and a CSI Driver for Dell EMC PowerFlex that were hosted in our DellEMC labs.
Use Case 1
In use case 1, the DellEMC engineers manually provisioned the container-based development and testing environment shown in Figure 3 as follows:
- Install Docker.
- Activate the Docker Enterprise Edition-License.
- Run the Oracle 12c database within the Docker container.
- Build and run the Oracle 19c database in the Docker container.
- Import the sample Oracle schemas that are pulled from GitHub into the Oracle 12c and 19c database.
- Install Oracle SQL Developer and query tables from the container to demonstrate that the connection from Oracle SQL Developer to Oracle database functions.
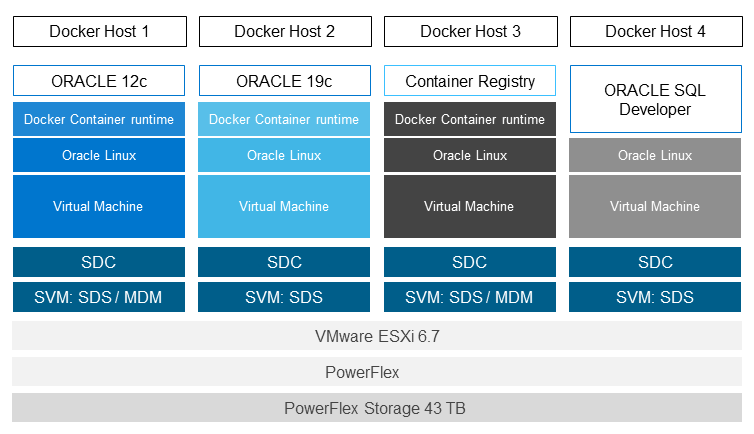
Figure 3: Use Case 1 - Architecture
The key benefit of our first use case was the time that we saved by using Docker containers instead of the traditional manual installation and configuration method of building a typical Oracle database environment. Use Case 1 planning also demonstrated the importance of selecting the Docker registry location and storage provisioning options that are most appropriate for the requirements of a typical development and testing environment.
Use Case 2
Use Case 2 demonstrates the value of CSI plug-in integration with Kubernetes and Dell EMC Power Flex storage to automate storage configuration. Kubernetes orchestration with PowerFlex provides a container deployment strategy with persistent storage. It demonstrates the ease, simplicity, and speed in scaling out a development and testing environment from production Oracle databases. In this use case, a developer provisions the Oracle database in containers on the same infrastructure described in Use Case 1 only this time using Kubernetes with the CSI Driver for Dell EMC PowerFlex. Figure 4 depicts the detailed architecture of Use Case 2.
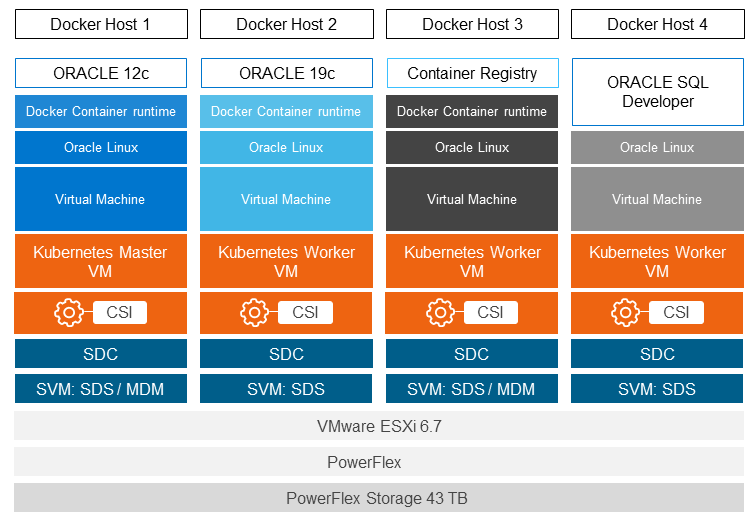
Figure 4. Use Case 2 – Architecture
Use Case 2 demonstrates how Docker, Kubernetes, and the CSI Driver for Dell EMC PowerFlex accelerate the development life cycle for Oracle applications. Kubernetes configured with the CSI Driver for Dell EMC VxFlex OS simplified and automated the provisioning and removal of containers with persistent storage. Engineers used yaml configuration files along with the kubectl command to quickly deploy and delete containers and complete pods. Our solution demonstrates that developers can provision Oracle databases in containers without the complexities that are associated with installing the database and provisioning storage.
Use Case Observations and Benefits
Adding Kubernetes container orchestration is an essential addition for database developers on a containerized development journey. Automation becomes essential with the expansion of containerized application deployments. In this case, it enabled our developers to bypass the complexities that are associated with plain scripting. Instead, our solution uses open source Kubernetes to accomplish the developer’s objectives. The CSI plug-in integrates with Kubernetes and exposes the capabilities of the Dell EMC PowerFlex storage system, enabling the developer to:
- Take a snapshot of the Oracle database, including the sample schema that was pulled from the GitHub site.
- Protect the work of the existing Oracle database, which was changed before taking the snapshot. We can protect any state. Use the CSI plug-in Driver for Dell EMC PowerFlex OS to create a snapshot that is installed in Kubernetes to provide persistent storage.
- Restore an Oracle 19c database to its pre-deletion state using a snapshot, even after removing the containers and the attached storage.
In our second use case, using Kubernetes combined with the CSI Driver for DellEMC PowerFlex OS simplified and automated the provisioning and removal of containers and storage. In this use case, we used yaml files along with the kubectl command to deploy and delete the containers and pods. All these components facilitate the automation of the container hosting the Oracle database on the top of PowerFlex.
Kubernetes, enhanced with the CSI Driver for Dell EMC VxFlex OS, provides the capability to attach and manage Dell EMC VxFlex OS storage system volumes to containerized applications. Our developers worked with a familiar Kubernetes interface to modify a copy of Oracle database schema gathered from the Github repository database and connect it to the Oracle database container. After modifying the database, the developer protected all progress by using the snapshot feature of Dell EMC VxFlex OS storage system and creating a point-in-time copy of the database.
Comparing Use Case 1 to Use Case 2 demonstrated how we can easily shift away from the complexities of scripting and using the command line to implement a self-service model that accelerates container management. The move to a self-service model, which increases developer productivity by removing bottlenecks, becomes increasingly important as the Docker container environment grows.
Summary
The power of containers and automation show how tasks that traditionally required multiple roles—developers and others working with the storage and database administrators - can be simplified. Kubernetes with the CSI plug-in enables developers and others to do more in less time and with fewer complexities. The time savings means that coding projects can be completed faster, benefiting both the developers and the business-side employees and customers. Overall, the key benefit shown in comparing our two use cases was the transformation from a manually managed container environment to an orchestrated system with more capabilities.
Innovation drives transformation. In the case of Docker containers and Kubernetes, the key benefit is a shift to rapid application deployment services. Oracle and many others have embraced containers and provide images of applications, such as for the Oracle 12c database, that can be deployed in days and instantiated in seconds. Installations and other repetitive tasks are replaced with packaged applications that enable the developer to work quickly in the database. The ease of using Docker and Kubernetes, combined with rapid provisioning of persistent storage, transforms development by removing wait time and enabling the developer to move closer to the speed of thought.
The addition of the Kubernetes orchestration system and the CSI Driver for Dell EMC VxFlex OS brings a rich user interface that simplifies provisioning containers and persistent storage. In our testing, we found that Kubernetes plus the CSI Driver for Dell EMC VxFlex OS enabled developers to provision containerized applications with persistent storage. This solution features point-and-click simplicity and frees valuable time so that the storage administrator can focus on business-critical tasks.

Dell Integrated System for Microsoft Azure Stack HCI with Storage Spaces Direct
Fri, 01 Mar 2024 22:18:07 -0000
|Read Time: 0 minutes
Many industry analysts covering the computer vision market are predicting double-digit compound annual growth over the next five years on top of the approximately $60B US yearly expenditures. Organizations investing significantly in greenfield or upgrade projects must evaluate their IT infrastructure designs. Technology options have improved considerably since video management and computer vision with AI systems were introduced. Virtualization technologies like Microsoft Azure Stack have many advantages in efficiency and manageability compared to the traditional approach of dedicating bespoke infrastructure stacks for every application, from video ingest to AI analytics and real-time alerting. This article describes our recent validation of Microsoft Azure Stack Hyperconverged Infrastructure (HCI) for hosting multiple computer vision applications, including video management and two AI-enabled computer vision applications. The full white paper we published based on the work titled Computer Vision on Microsoft Azure Stack HCI is also available for online reading or download.
Microsoft Azure Stack hyperconverged infrastructure (HCI) is an on-premises IT platform integrated with an Azure public cloud management service. Azure Stack (AS) represents a comprehensive solution for organizations looking to leverage the benefits of cloud computing while maintaining control over on-premises infrastructure. This platform is a core component of Microsoft's hybrid cloud strategy, which brings the agility and fast-paced innovation of cloud computing to on-premises environments. ASHCI offerings from Dell Technologies provide flexible, scalable, and secure solutions to customers looking to consolidate virtualized workloads.
The ASHCI platform seamlessly integrates with core Windows Server technologies like Hyper-V for virtualization and Storage Spaces Direct (S2D) for storage. The convergence of management tools for both on-premises and cloud resources with additional options for integration with other Azure services reduces deployment and operation overhead for enterprises pursuing a hybrid cloud strategy.
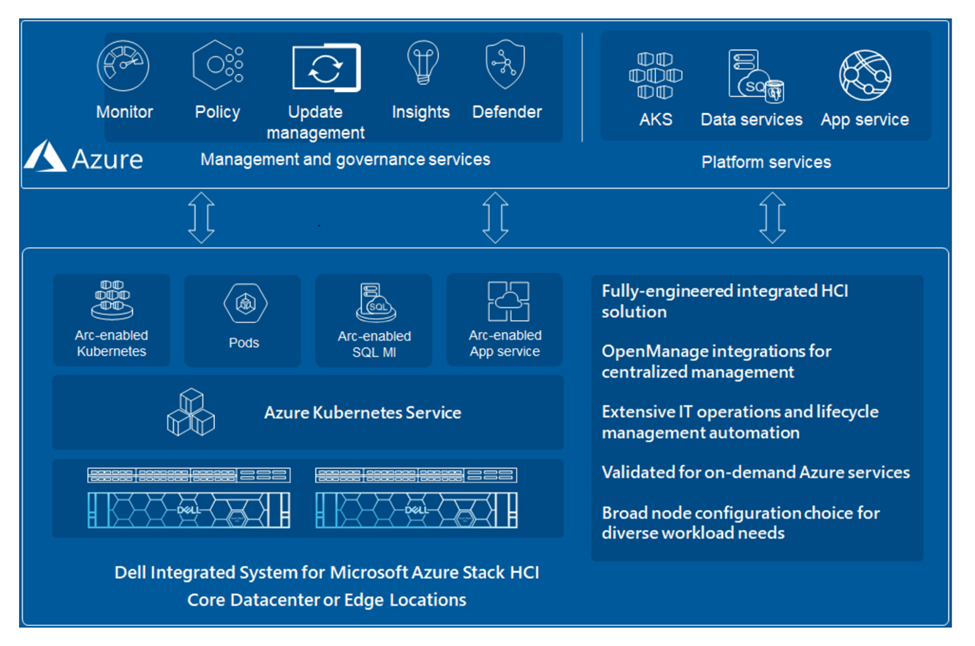 System Architecture Overview
System Architecture Overview
The system architecture we implemented is the Dell Integrated System for Microsoft Azure Stack HCI with Storage Spaces Direct, plus NVIDIA A16 server-class GPUs. The Azure Stack HCI system leverages Microsoft Windows virtual machine virtualization that will be familiar to many IT and OT (operational technology) professionals.
We performed real-time analytics with BriefCam and Ipsotek by integration with the Milestone directory server and video recording services. All three applications were hosted on a 5-node Microsoft Azure Stack HCI cluster.
The three applications chosen for this validation were:
- BriefCam provides an industry-leading application for video analytics for rapid video review and search, real-time alerting, and quantitative video insights.
- Ipsotek specializes in AI-enhanced video analytics software to manage automatically generated alerts in real-time for crowd management, smoke detection, intrusion detection, perimeter protection, number plate recognition, and traffic management.
- The Milestone Systems XProtect platform video management software enables organizations and institutions to create the perfect combination of cameras, sensors, and analytics.
In summary, Azure Stack HCI solutions from Dell Technologies offer a versatile and balanced hybrid cloud approach, allowing organizations to capitalize on the strengths of both on-premises and cloud environments. This flexibility is essential for AI computer vision environments where efficiency, security, compliance, and innovation are keys to sustaining competitive advantage. Our experience working with Microsoft Azure Stack HCI to host enterprise applications for video management and computer vision AI revealed the depth of the platform's innovation and a focus on ease of deployment and management.
For more information:
Computer Vision on Microsoft Azure Stack HCI White Paper
Microsoft Azure Stack HCI
- Dell Integrated System for Microsoft Azure Stack HCI
- Delivering aHybrid Cloud Architecture Through Microsoft-Dell Integrated HCI
- Microsoft Azure Stack HCI documentation
BriefCam Software Website
Ipsotek Ltd Website
Milestone Systems Website
NVIDIA GPU Hardware

The Future of AI Using LiDAR
Tue, 30 Jan 2024 14:48:31 -0000
|Read Time: 0 minutes
Introduction
Light Detection and Ranging (LiDAR) is a method for determining the distance from a sensor to an object or a surface by sending out a laser beam and measuring the time for the reflected light to return to the receiver. We recently designed a solution to understand how using data from multiple LiDAR sensors monitoring a single space can be combined into a three-dimensional (3D) perceptual understanding of how people and objects flow and function within public and private spaces. Our key partner in this research is Seoul Robotics, a leader in LiDAR 3D perception and analytics tools.
Most people are familiar with the use of LiDAR on moving vehicles to detect nearby objects that has become popular in transportation applications. Stationary LiDAR is now becoming more widely adopted for 3D imaging in applications where cameras have been used traditionally.
Multiple sensor LiDAR applications can produce a complete 3D grid map with precise depth and location information for objects in the jointly monitored environment. This technology overcomes several limitations of 2D cameras. Using AI, LiDAR systems can improve the quality of analysis results for data collected during harsh weather conditions like rain, snow, and fog. Furthermore, LiDAR is more robust than optical cameras for conditions where the ambient lighting is low or produces reflections and glare.
Another advantage of LiDAR for computer vision is related to privacy protection. The widespread deployment of high-resolution optical cameras has raised concerns regarding the potential violation of individual privacy and misuse of the data.
LiDAR 3D perception is a promising alternative to traditional camera systems. LiDAR data does not contain biometric data that could be cross-referenced with other sources to identify individuals uniquely. This approach allows operators to track anonymous objects that maintain individuals' privacy. Therefore, it is essential to consider replacing or augmenting such cameras to reduce the overhead of ensuring that data is secure and used appropriately.
Challenges
Worldwide, organizations use AI-enabled computer vision solutions to create safer, more efficient public and private spaces using only optical thermal and infrared cameras. Data scientists have developed many machine learning and deep neural network tools to detect and label objects using data from these different camera types.
As LiDAR becomes vital for the reasons discussed above, organizations are investigating their options for whether LiDAR is best deployed alongside traditional cameras or if there are opportunities to design new systems using LiDAR sensors exclusively. It is rare when existing cameras can be replaced with LiDAR sensors mounted in the exact locations used today.
An example deployment of 2 LiDAR sensors for a medium-sized room is below:
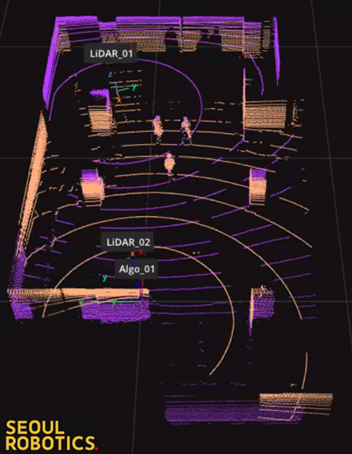
Detecting the position of the stationary objects and people moving through this space (flow and function) with LiDAR requires careful placement of the sensors, calibration of the room's geometry, and data processing algorithms that can extract information from both sensors without distortion or duplications. Collecting and processing LiDAR data for 3D perception requires a different toolset and expertise, but companies like Seoul Robotics can help.
Another aspect of LiDAR systems design that needs to be evaluated is data transfer requirements. In most large environments using camera deployments today (e.g., airport/transportation hubs, etc.), camera data is fed back to a centralized hub for real-time processing.
A typical optical camera in an AI computer vision system would have a resolution and refresh rate of 1080@30FPS. This specification would translate to ~4Mb/s of network traffic per camera. Even with older network technology, thousands of cameras can be deployed and processed.
There is a significant increase in the density of the data produced and processed for LiDAR systems compared to video systems. A currently available 32-channel LiDAR sensor will produce between 25Mb/s and 50Mb/s of data on the network segment between the device and the AI processing node. Newer high-density 128-channel LiDAR sensors consume up to 256Mb/s of network bandwidth, so something will need to change from the current strategy of centralized data processing.
Technical Solution
It is not feasible to design a system that will consume the entire network capacity of a site with LiDAR traffic. In addition, it can also be challenging and expensive to upgrade the site's private network to handle higher speeds. The most efficient solution, therefore, is to design a federated solution for processing LiDAR data closer to the location of the sensors.
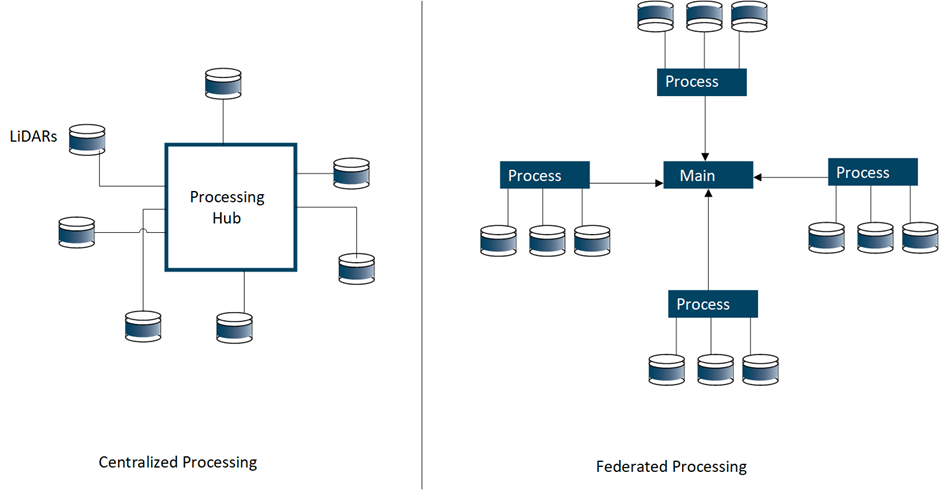
With a switch to the architecture in the right-side panel above, it is possible to process multiple LiDAR sensors closer to where they are mounted at the site and only send any resulting alerts and events back to a central location (primary node) for further processing and triggering corrective actions. This approach avoids the costly transfer of dense LiDAR data across long network segments.
It is important to note that processing LiDAR data with millions of points per second requires significant computational capability. We also validated that leveraging the massive parallel computing power of GPUs like the NVIDIA A2 greatly enhanced the object detection accuracy in the distributed processing nodes. The Dell XR4000 series of rugged Dell servers should be a good option for remote processing in many environments.
Conclusion
LiDAR is becoming increasingly important in designing AI for computer vision solutions due to its ability to handle challenging lighting situations and enhance user privacy. LiDAR differs from video cameras, so planning the deployment carefully is essential.
LiDAR systems can be designed in either a central or federated manner or even a mix of both. The rapidly growing network bandwidth requirements of LiDAR may cause a rethink on how systems for AI-enabled data processes are deployed sooner rather than later.
For more details on CV 3D Flow and Function with LiDAR see Computer Vision 3D Flow and Function AI with LiDAR.

Optimizing Computer Vision Workloads: A Guide to Selecting NVIDIA GPUs
Fri, 27 Oct 2023 15:31:21 -0000
|Read Time: 0 minutes
Introduction
Long gone are the days when facilities managers and security personnel were required to be in a control room with their attention locked onto walls of video monitors. The development of lower-cost and more capable video cameras, more powerful data science computing platforms, and the need to reduce operations overhead have caused the deployment of video management systems (VMS) and computer vision analytics applications to skyrocket in the last ten years in all sectors of the economy. Modern computer vision applications can detect a wide range of events without constant human supervision, including overcrowding, unauthorized access, smoke detection, vehicle operation infractions, and more. Better situational awareness of their environments can help organizations achieve better outcomes for everyone involved.
Table 1 – Outcomes achievable with better situational awareness
Increased operational efficiencies | Leverage all the data that you capture to deliver high-quality services and improve resource allocation. |
Optimized safety and security | Provide a safer, more real-time aware environment. |
Enhanced experience | Provide a more positive, personalized, and engaging experience for both customers and employees. |
Improved sustainability | Measure and lower your environmental impact. |
New revenue opportunities | Unlock more monetization opportunities from your data with more actionable insights. |
The technical challenge
Computer vision analytics uses various techniques and algorithms, including object detection, classification, feature extraction, and more. The computation resources that are required for these tasks depend on the resolution of the source video, frame rates, and the complexity of both the scene and the types of analytics being processed. The diagram below shows a simplified set of steps (pipeline) that is frequently implemented in a computer vision application.
Figure 1: Logical processing pipeline for computer vision
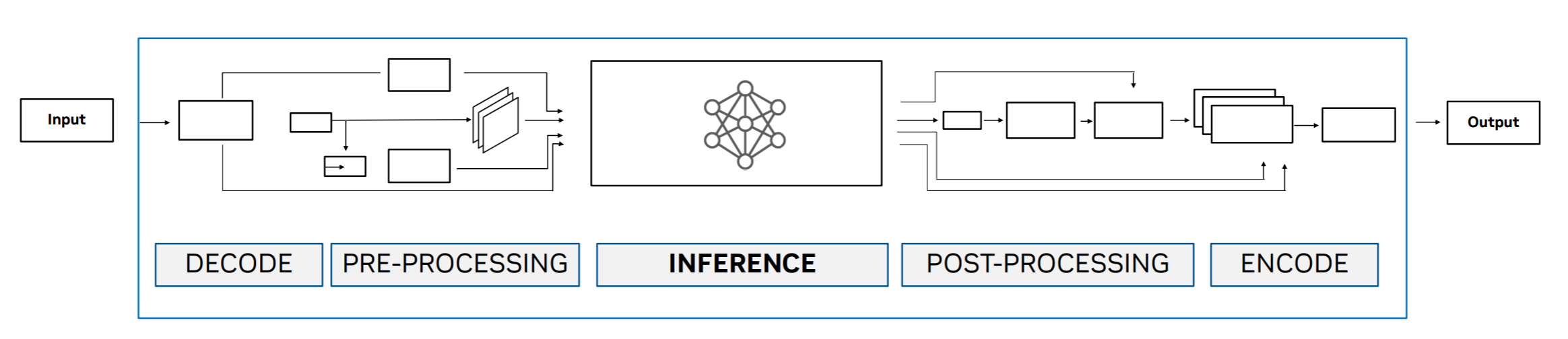
Inference is the step that most people are familiar with. A trained algorithm can distinguish between a passenger automobile and a delivery van, similar to the classic dogs versus cats example often used to explain computer vision. While the other steps are less familiar to the typical user of computer vision applications, they are critical to achieving good results and require dedicated graphics processing units (GPUs). For example, the Decode/Encode steps are tuned to leverage hardware that resides on the GPU to provide optimal performance.
Given the extensive portfolio of NVIDIA GPUs available today, organizations that are getting started with computer vision applications often need help understanding their options. We have tested the performance of computer vision analytics applications with various models of NVIDIA GPUs and collected the results. The remainder of this article provides background on the test results and our choice of model.
Choosing a GPU
The market for GPUs is broadly divided into data center, desktop, and mobility products. The workload that is placed on a GPU when training large image classification and detection models is almost exclusively performed on data center GPUs. Once these models are trained and delivered in a computer vision application, multiple CPU and GPU resource options can be available at run time. Small facilities, such as a small retailer with only a few cameras, can afford to deploy only a desktop computer with a low-power GPU for near real-time video analytics. In contrast, large organizations with hundreds to thousands of cameras need the power of data center-class GPUs.
However, all data center GPUs are not created equal. The table below compares selected characteristics for a sample of NVIDIA data center GPUs. The FP32 floating point calculations per second metric indicates the relative performance that a developer can expect on either model training or the inference stage of the typical pipeline used in a computer vision application, as discussed above.
The capability of the GPU for performing other pipeline elements required for high-performance computer vision tasks, including encoding/decoding, is best reflected by the Media Engines details.
First, consider the Media Engines row entry for the A30 GPU column. There is 1 JPEG decoder and 4 video decoders, but no video encoders. This configuration makes the A30 incompatible with the needs of many market-leading computer vision application vendors' products, even though it is a data center GPU.
Table 2: NVIDA Ampere architecture GPU characteristics
| A2 | A16 | A30 | A40 |
FP32 (Tera Flops) | 4.5 | 4x 4.5 | 10.3 | 37.4 |
Memory (GB) | 16 GDDR6 | 4x 16 GDDR6 | 24 GB HBM2 | 48 GDDR6 with ECC |
Media Engines | 1 video encoder 2 video decoders (includes AV1 decode) | 4 video encoder 8 video decoders (includes AV1 decode) | 1 JPEG decoder 4 video decoders 1 optical flow accelerator | 1 video encoder 2 video decoders (includes AV1 decode) |
Power (Watts) | 40-60 (Configurable) | 250 | 165 | 300 |
Comparing the FP32 TFLOPS between the A30 and A40 shows that the A40 is a more capable GPU for training and pure inference tasks. During our testing, the computer vision applications quickly exhausted the available Media Engines on the A40. Selecting a GPU for computer vision requires matching the available resources needed for computer vision including media engines, available memory, and other computing capabilities that can be different across use cases.
Next, examining the Media Engines description for the A2 GPU column confirms that the product houses 1 video encoder and 2 video decoders. This card will meet the needs of most computer vision applications and is supported for data center use; however, the low number of encoders and decoders, memory, and floating point processing will limit the number of concurrent streams that can be processed. The low power consumption of the A2 increases the flexibility of choice of server for deployment, which is important for edge and near-edge scenarios.
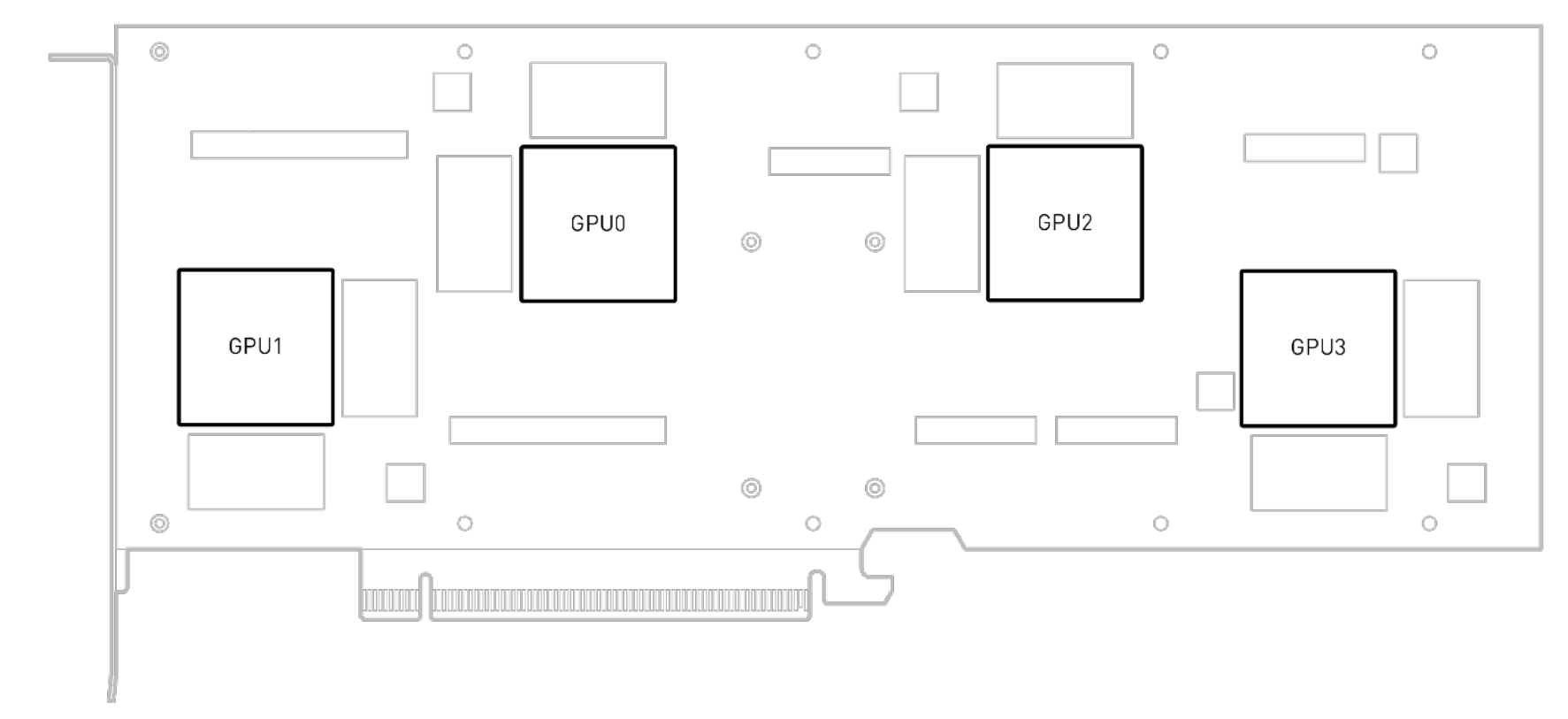
Still focusing on the table above, compare all the characteristics of the A2 GPU column with the A16 GPU. Notice that there are four times the resources on the A16 versus the A2. This can be explained by looking at the diagram below. The A16 was constructed by putting four A2 “engines” on a single PCI card. Each of the boxes labeled GPU0-GPU3 contains all the memory, media engines and other processing capabilities that you would have available to a server that had a standard A2 GPU card installed. Also notice that the A16 requires approximately 4 times the power of an A2.
The table below shows the same metric comparison used in the discussion above for the newest NVIDIA GPU products based on the Ada Lovelace architecture. The L4 GPU offers 2 encoders and 4 decoders for a card that consumes just 72 W. Compared with the 1 encoder and 2 decoder configuration on the A2 at 40 to 60 W, the L4 should be capable of processing many more video streams for less power than two A2 cards. The L40 with 3 encoders and 3 decoders is expected to be the new computer vision application workhorse for organizations with hundreds to thousands of video streams. While the L40S has the same number of Media Engines and memory as the L40, it was designed to be an upgrade/replacement for the A100 Ampere architecture training and/or inference computing leader.
| L4 | L40 | L40S |
FP32 (Tera Flops) | 30.3 | 90.5 | 91.6 |
Memory (GB) | 24 GDDR6 w/ ECC | 48 GDDR6 w/ ECC | 48 GDDR6 w/ ECC |
Media Engines | 2 video encoder 4 video decoders 4 JPEG decoder (includes AV1 decode) | 3 video encoder 3 video decoders
| 3 video encoder 3 video decoders
|
Power (Watts) | 72 | 300 | 350 |
Conclusion
In total seven different NVIDIA GPU cards were discussed that are useful for CV workloads. From the Ampere family of cards we found that the A16 performed well for a wide variety of CV inference workloads. The A16 provides a good balance of video Decoders/Encoders, CUDA cores and memory for computer vision workloads.
For the newer Ada Lovlace family of cards, the L40 looks like a well-balanced card with great throughput potential. We are currently testing out this card in our lab and will provide a future blog on its performance for CV workloads.
References
A2 - https://www.nvidia.com/content/dam/en-zz/solutions/data-center/a2/pdf/a2-datasheet.pdf
A16 - https://images.nvidia.com/content/Solutions/data-center/vgpu-a16-datasheet.pdf
A30 - https://www.nvidia.com/en-us/data-center/products/a30-gpu/
A40 - https://images.nvidia.com/content/Solutions/data-center/a40/nvidia-a40-datasheet.pdf
L4 - https://www.nvidia.com/en-us/data-center/l4/

Who’s watching your IP cameras?
Thu, 20 Jul 2023 18:05:50 -0000
|Read Time: 0 minutes
Introduction
In today’s world, the deployment of security cameras is a common practice. In some public facilities like airports, travelers can be in view of a security camera 100% of the time. The days of security guards watching banks of video panels being fed from hundreds of security cameras are quickly being replaced by computer vision systems powered by artificial intelligence (AI). Today’s advanced analytics can be performed on many camera streams in real-time without a human in the loop. These systems enhance not only personal safety but also provide other benefits, including better passenger experience and enhanced shopping experiences.
Modern IP cameras are complex devices. In addition to recording video streams at increasingly higher resolutions (4k is now common), they can also encode and send those streams over traditional internet protocol IP to downstream systems for additional analytic processing and eventually archiving. Some cameras on the market today have enough onboard computing power and storage to evaluate AI models and perform analytics right on the camera.
The Problem
The development of IP-connected cameras provided great flexibility in deployment by eliminating the need for specialized cables. IP cameras are so easy to plug into existing IT infrastructure that almost anyone can do it. However, since most camera vendors use a modified version of an open-source Linux operating system, IT and security professionals realize there are hundreds or thousands of customized Linux servers mounted on walls and ceilings all over their facilities. Whether you are responsible for <10 cameras at a small retail outlet or >5000 at an airport facility, the question remains “How much exposure do all those cameras pose from cyber-attacks?”
The Research
To understand the potential risk posed by IP cameras, we assembled a lab environment with multiple camera models from different vendors. Some cameras were thought to be up to date with the latest firmware, and some were not.
Working in collaboration with the Secureworks team and their suite of vulnerability and threat management tools, we assessed a strategy for detecting IP camera vulnerabilities Our first choice was to implement their Secureworks Taegis™ VDR vulnerability scanning software to scan our lab IP network to discover any camera vulnerabilities. VDR provides a risk-based approach to managing vulnerabilities driven by automated & intelligent machine learning.
We planned to discover the cameras with older firmware and document their vulnerabilities. Then we would have the engineers upgrade all firmware and software to the latest patches available and rescan to see if all the vulnerabilities were resolved.
Findings
Once the SecureWorks Edge agent was set up in the lab, we could easily add all the IP ranges that might be connected to our cameras. All the cameras on those networks were identified by SecureWorks VDR and automatically added to the VDR AWS cloud-based reporting console.
Discovering Camera Vulnerabilities
The results of the scans were surprising. Almost all discovered cameras had some Critical issues identified by the VDR scanning. In one case, even after a camera was upgraded to the latest firmware available from the vendor, VDR found Critical software and configuration vulnerabilities shown below:
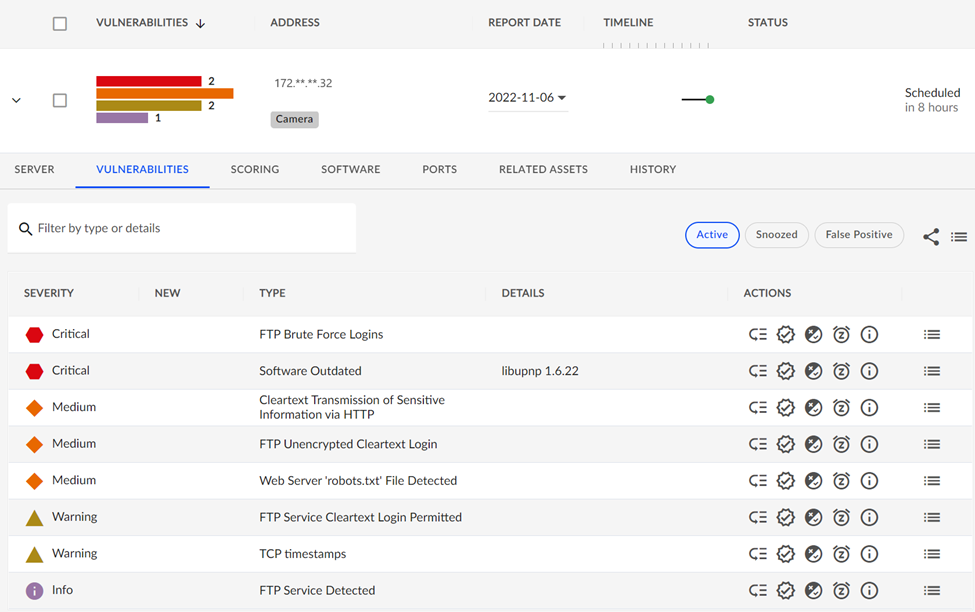
One of the remaining critical issues was the result of an insecure FTP username/password that was not changed from the vendor’s default settings before the camera was put into service. These types of procedural lapses should not happen, but inadvertently they are bound to. The password hardening mistake was easily caught by a VDR scan so that another common cybersecurity risk could be dealt with. This is an example of an issue not related to firmware but a combination of the need for vendors not to ship with a well-known FTP login and the responsibility of users to not forget to harden the login.
Another example of the types of Critical issues you can expect when dealing with IP cameras relates to discovering an outdated library dependency found on the camera. The library is required by the vendor software but was not updated when the latest camera firmware patches were applied.
Camera Administration Consoles
The VDR tool will also detect if a camera is exposing any HTTP sites/services and look for vulnerabilities there. Most IP cameras ship with an embedded HTTP server so administrators can access the cameras' functionality and perform maintenance. Again, considering the number of deployed cameras, this represents a huge number of websites that may be susceptible to hacking. Our testing found some examples of the type of issues that a camera’s web applications can expose:
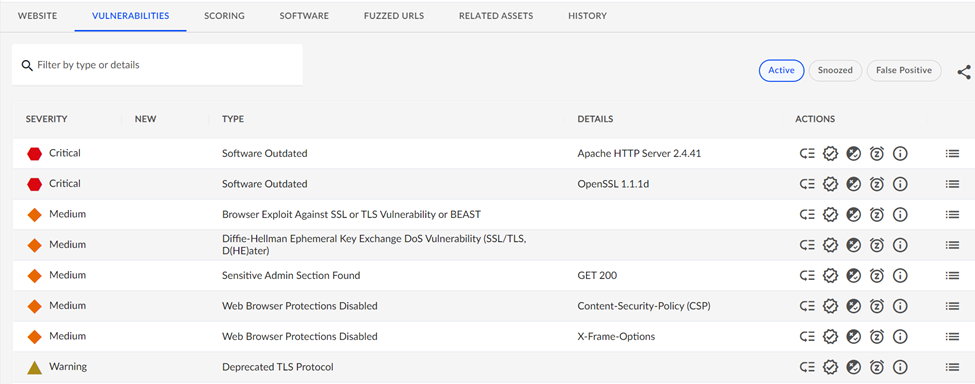
The scan of this device found an older version of Apache webserver software and outdated SSL libraries in use for this cameras website and should be considered a critical vulnerability.
Conclusion
In this article, we have tried to raise awareness of the significant Cyber Security risk that IP cameras pose to organizations, both large and small. Providing effective video recording and analysis capabilities is much more than simply mounting cameras on the wall and walking away. IT and security professionals must ask, “Who’s watching our IP cameras? Each camera should be continuously patched to the latest version of firmware and software - and scanned with a tool like SecureWorks VDR. If vulnerabilities still exist after scanning and patching, it is critical to engage with your camera vendor to remediate the issues that may adversely impact your organization if neglected. Someone will be watching your IP cameras; let’s ensure they don’t conflict with your best interests.
Dell Technologies is at the forefront of delivering enterprise-class computer vision solutions. Our extensive partner network and key industry stakeholders have allowed us to develop an award-winning process that takes customers from ideation to full-scale implementation faster and with less risk. Our outcomes-based process for computer vision delivers:
- Increased operational efficiencies: Leverage all the data you’re capturing to deliver high-quality services and improve resource allocation.
- Optimized safety and security: Provide a safer, more real-time aware environment
- Enhanced experience: Provide a more positive, personalized, and engaging experience for customers and employees.
- Improved sustainability: Measure and lower your environmental impact.
- New revenue opportunities: Unlock more monetization opportunities from your data with more actionable insights
Where to go next...
Dell Technologies Workload Solutions for Computer Vision
Virtualized Computer Vision for Smart Transportation with Genetec
Virtualized Computer Vision for Smart Transportation with Milestone

Removing the barriers to hybrid-cloud flexibility for data analytics
Thu, 20 Jul 2023 17:00:57 -0000
|Read Time: 0 minutes
Introduction
The fundamental tasks of collecting data, storing data, and providing processing power for data analytics is getting more difficult. Increasing data volumes along with the number of remote data sources and the rapidly evolving options for extracting valuable information make forecasting needs challenging and investment risky. IT organizations need the ability to quickly provision resources and incrementally scale both compute and storage on-demand as need develops. The three largest hyper-scale cloud providers all offer a wide range of infrastructure, platform and analytics “as-a-service” but all require vastly different skill sets, security models, and connectivity investments. Organizations interested in having hybrid cloud flexibility for data analytics are forced to choose a single cloud partner or add significant IT complexity by managing multiple options with no common toolset. In this Solutions Insight, we describe how the Robin Cloud-Native Platform (CNP) hosted onsite with Dell EMC PowerEdge servers provide application and infrastructure topology awareness to streamline the provisioning and life cycle management of your data applications with true hybrid cloud flexibility.
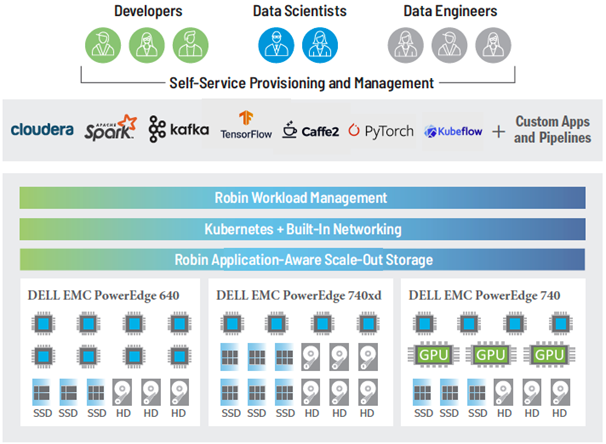 Architecture Diagram
Architecture Diagram
Providing a robust self-service experience
Data analytics professionals want easy access to internally managed provisioning of resources for experimentation and development without complex interactions with IT. Many of these professionals have experience with self-service portals that work for a single cloud service but have not yet had any hybrid cloud flexibility. Robin provides a rich out-of-the-box portal capability that IT can offer to developers, data engineers, and data scientists. Data professionals save valuable development time at each stage of the application lifecycle by leveraging the automation framework of Robin. IT gets a fully functional automation framework for hosting many popular enterprise applications on the Robin Platform. The Robin platform comes out-of-the-box with cluster-aware application bundles including relational databases, big data, NoSQL, and several AI/ML tools.
 Self Service Portal
Self Service Portal
Robin leverages cloud-native technologies such as Kubernetes and Docker to modernize the management of your data analytics infrastructure. The Robin Kubernetes-based architecture gives you complete freedom and offers a consistent self-service capability to provision and move workloads across private and/or public clouds. Native integration between Kubernetes, storage, network, and application management layer enables full automation managing both clusters and applications with all the advantages of a true hybrid cloud experience. Robin has built-in the capability to create managed application snapshots that enable cloning, backup, and migration of applications between on-prem and cloud or between datacenters within an enterprise. Robin fully automates the end-to-end cluster provisioning process for the most challenging platform deployments including Cloudera, Apache Spark, Kafka, TensorFlow, Pytorch, Kubeflow, Scikit-learn, Caffe, Torch, and even custom application configurations.
Organizations that adopt the Robin platform benefit from accelerated deployment and simplified management of complex applications that can be provisioned by end-users through a familiar portal experience and true hybrid cloud flexibility.
Moving from self-service sandboxes to enterprise scale
We described above how the Robin platform benefits both data and IT professionals that want a full-featured self-service data analytics capability with true hybrid cloud operations by layering additional platform awareness and automation to cloud-native technologies such as Kubernetes and Docker. Organizations can start with small deployments, and as applications grow, they can add more resources. Robin can be deployed on the full range of Dell EMC PowerEdge servers with a custom mix of memory, storage, and accelerator options making it easy to scale-out by adding additional servers with the right capabilities to match changing resource demands. The Robin management console provides a single interface to expand existing deployments and/or add new clusters. Consolidation of multiple workloads under Robin management can also improve hardware utilization without compromising SLAs or QoS. The Robin platform provides multi-tenancy with fine-grained Role Based Access Control (RBAC) enabling safe resource sharing on fewer clusters. Applications can be incubated on multi-tenancy, mixed application clusters and then easily migrated to production class clusters hosting one or multiple mission-critical applications using Robin backup and restore capability across clusters and/or clouds.
While open-source Kubernetes has become the de facto platform for deploying on-demand applications, there remains a need for additional investment by organizations that need multi-cluster production deployments and service orchestration that can automate and manage day-0 and day-n lifecycle operations at scale. The Robin Automation Platform combines simplicity, usability, performance, and scale with a modern UI to provide bare metal, cluster, and application-as-a-service for both infrastructure and service orchestration. With Robin Bare Metal-as-a-Service, hundreds of thousands of bare-metal servers can be provisioned with specific BIOS, firmware, OS and other software packages or configurations depending on the needs of the application. With Robin, it is equally easy to manage upgrades, as well as a wide array of PowerEdge server options including firmware, OS, and application software across container platforms.
Automating day-n operations for stateful applications
Several priorities are driving interest in running stateful applications on Kubernetes. These include operational consistency, extending agility of containerization to data, faster collaboration, and the need for simplifying the delivery of data services. Robin solves the storage and network persistency challenges in Kubernetes to enable its use in the provisioning, management, high availability and fault tolerance of mission-critical stateful applications.
Creating a persistent storage volume for a single container is becoming a routine operation. However, when it comes to provisioning storage for complex stateful applications that span multiple pods and services, it requires automation of the cluster resources coordinated with storage management. Managing the changing requirements of stateful applications on a day-to-day basis requires data and storage management services such as snapshotting, backup, and cloning. Traditionally, this capability has resided only on high-end storage systems managed by the IT storage administrator teams. In order to provide true self-service capabilities to data professionals, organizations need simple storage and data management solution for Kubernetes that hides all the above complexities and provides simple commands that are developer-friendly and can easily be incorporated into development and production workflows.
With Robin CNP, analytics and DevOps teams can be self-sufficient while managing complex stateful applications without requiring specific storage expertise. Data management is supported with a Robin managed CSI-compliant block storage access layer with bare-metal performance. Storage management seamlessly integrates with Kubernetes-native administrative tooling such as Kubectl, Helm Charts, and Operators through standard APIs.
Robin CNP simplifies storage operations such as provisioning storage, ensuring data availability, maintaining low latency I/O performance, and detecting and repairing disk and I/O errors. Robin CNP also provides simple commands for data management operations such as backup/recovery, snapshots/rollback, and cloning of entire applications including data, metadata, and application configuration.
Robin CNP offers several improvements on the networking layer over open-source Kubernetes. These improvements are required to run enterprise-scale data and network-centric applications on Kubernetes. With Robin CNP developers/IT can set networking options while deploying applications and clusters in Kubernetes and preserve IP addresses during restarts and application migration. Robin’s flexible networking built on OVS and Calico supports overlay networking. Robin also supports dual-stack (IPV4/IPV6).
Summary
IT organizations adopting the Robin platform benefit from a single approach to application and infrastructure management from experimentation to dev/test to a production environment that can span multiple clouds. Robin excels at managing heterogeneous infrastructure assets with a mix of compute, storage, and workload accelerators that can match the changing needs of fast-moving enterprise-wide demand for resources. Dell Technologies provides a wide range of PowerEdge rack servers with innovative designs to transform IT and maximize performance across the widest range of applications. PowerEdge servers match well with the three main types of infrastructure assets typically needed for a Robin managed implementation:
Compute Intensive | Storage Dense | Accelerator Enabled |
PowerEdge 640 | PowerEdge 740xd | PowerEdge 740 |
The PowerEdge R640 is the ideal dual-socket platform for dense scale-out data center computing. | The PowerEdge R740xd delivers a perfect balance between storage scalability and performance. The 2U two-socket platform is ideal for software defined storage. | The PowerEdge R740 was designed to accelerate application performance leveraging accelerator cards and storage scalability. The 2-socket, 2U platform has the optimum balance of resources to power the most demanding environments. |
Up to two 2nd Generation Intel® Xeon® Scalable processors, up to 28 cores per processor | Up to 24 NVMe drives and a total of 32 x 2.5” or 18 x 3.5” drives in a 2U dual-socket platform. | The scalable business architecture of the R740 can scale up to three 300W or six 150W GPUs, or up to three double-width or four single-width FPGAs |
24 DDR4 DIMM slots, Supports RDIMM /LRDIMM, speeds up to 2933MT/s, 3TB max Up to 12 NVDIMM, 192 GB Max Up to 12 Intel® Optane™ DC persistent memory DCPMM, 6.14TB max, (7.68TB max with DPCMM + LRDIMM) | Front bays: Up to 24 x 2.5” SAS/SATA (HDD/SSD), NVMe SSD max 184.32TB or up to 12 x 3.5” SAS/SATA HDD max 192TB Mid bay: Up to 4 x 2.5”, max 30.72TB SAS/SATA (HDD/SSD), or up to 4 x 3.5” SAS/SATA HDD, max 64TB Rear bays: Up to 4 x 2.5”, max 30.72TB SAS/SATA (HDD/SSD), or up to 2 x 3.5” SAS/SATA HDD max 32TB |
|
Robin is the ideal platform for hosting both stateful and stateless applications with support for both virtual machines and Docker-based applications. It includes a storage layer that provides data services, including snapshots, clones, backup/restore, and replication that enable hybrid cloud and multi-cloud operations for stateful applications that are not possible with pure open-source cloud-native technologies. It also includes a networking layer that supports carrier-grade networking OVS, Calico, VLAN, Overlay networking, Persistent IPs, Multiple NICs, SR-IOV, DPDK, and Dual-stack IPv4/IPv6
With the Robin platform on Dell EMC PowerEdge servers, organizations can:
· Decouple and scale compute and storage independently
· Provision/Decommission compute only clusters within minutes for ephemeral workloads
· All operations can be fully integrated with simple API commands from your development and/or production workflows.
· Migrate data workloads among data centers and public clouds
· Provide self-service capability for developers and data scientists to improve productivity
· Eliminate planning delays, start small and dynamically scale-up/out nodes to meet demand
· Consolidate multiple workloads on shared infrastructure to improve hardware utilization
· Trade resources among application clusters to manage cyclical compute requirements and surges
This results in,
· Reduced Costs
· Delivering faster insights
· Future-proofing the enterprise
For more information
Dell Technologies and Robin Systems welcome your feedback on this article and the information presented herein. Contact the Dell Technologies Solutions team by email.
You can also contact our regional sales teams for more information via email at the following addresses:
North America: analytics.assist@dell.com
LATAM: readysolutions.latam@dell.com
EMEA: EMEA_BigData_Team@dell.com
Thank you for your interest.

Sharing the Love for GPUs in Machine Learning - Part 2
Wed, 17 Mar 2021 17:23:31 -0000
|Read Time: 0 minutes

In Part 1 of “Share the GPU Love” we covered the need for improving the utilization of GPU accelerators and how a relatively simple technology like VMware DirectPath I/O together with some sharing processes could be a starting point. As with most things in technology, some additional technology, and knowledge you can achieve high goals beyond just the basics. In this article, we are going to introduce another technology for managing GPU-as-a-service – NVIDIA GRID 9.0.
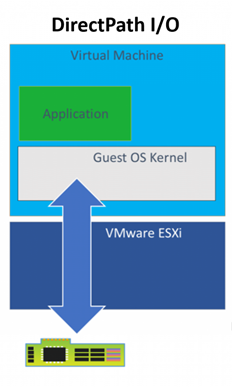
Before we jump to this next technology, let’s review some of the limitations of using DirectPath I/O for virtual machine access to physical PCI functions. The online documentation for VMware DirectPath I/O has a complete list of features that are unavailable for virtual machines configured with DirectPath I/O. Some of the most important ones are:
- Fault tolerance
- High availability
- Snapshots
- Hot adding and removing of virtual devices
The technique of “passing through” host hardware to a virtual machine (VM) is simple but doesn’t leverage many of the virtues of true hardware virtualization. NVIDIA delivers software to virtualize GPUs in the data center for years. The primary use case has been Virtual Desktop Infrastructure (VDI) using vGPUs. The current release - NVIDIA vGPU Software 9 adds the vComputeServer vGPU capability for supporting artificial intelligence, deep learning, and high-performance computing workloads. The rest of this article will cover using vGPU for machine learning in a VMware ESXi environment.
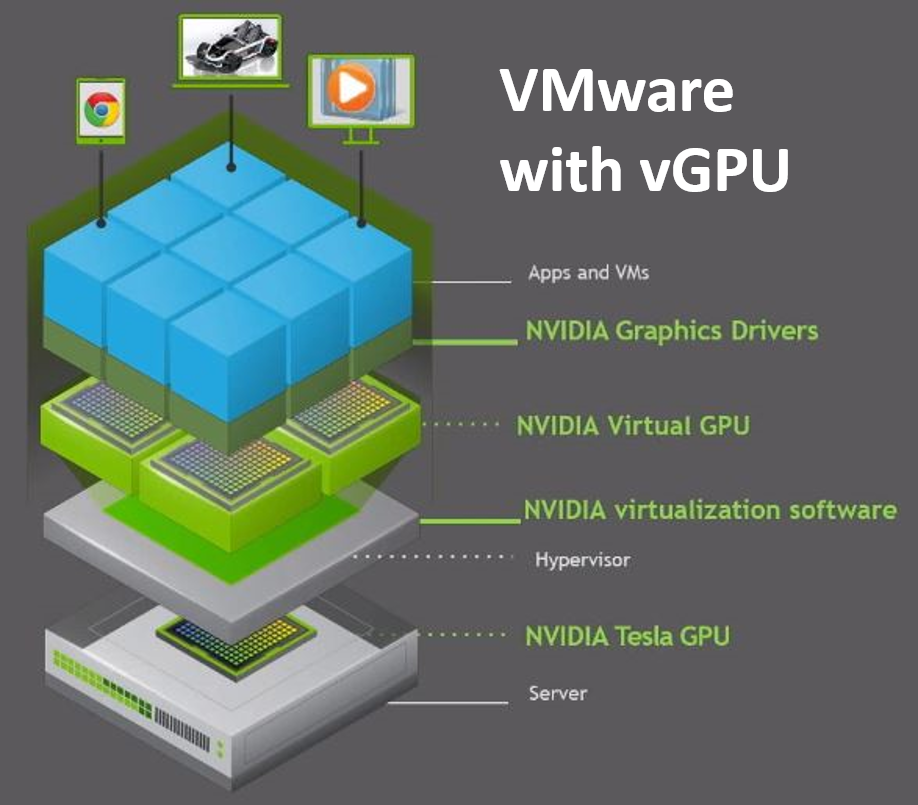
We want to compare the setup and features of this latest NVIDIA software version, so we worked on adding the vComputeServer to our PowerEdge ESXi that we used for the DirectPath I/O research in our first blog in this series. Our NVIDIA Turing architecture T4 GPUs are on the list of supported devices, so we can check that box and our ESXi version is compatible. The NVIDIA vGPU software documentation for VMware vSphere has an exhaustive list of requirements and compatibility notes.
You’ll have to put your host into maintenance mode during installation and then reboot after the install of the VIB completes. When the ESXi host is back online you can use the now-familiar nvidia-smi command with no parameters and see a list of all available GPUs that indicates you are ready to proceed.
We configured two of our T4 GPUs for vGPU use and setup the required licenses. Then we followed the same approach that we used for DirectPath I/O to build out VM templates with everything that is common to all developments and use those to create the developer-specific VMs – one with all Python tools and another with R tools. NVIDIA vGPU software supports only 64-bit guest operating systems. No 32-bit guest operating systems are supported. You should only use a guest OS release that is supported by both for NVIDIA vGPU software and by VMware. NVIDIA will not be able to support guest OS releases that are not supported by your virtualization software.

Now that we have both a DirectPath I/O enabled setup and the NVIDIA vGPU environment let’s compare the user experience. First, starting with vSphere 6.7 U1 release, vMotion with vGPU and suspend and resume with vGPU are supported on suitable GPUs. Always check the NVIDIA Virtual GPU Software Documentation for all the latest details. vSphere 6.7 only supports suspend and resume with vGPU. vMotion with vGPU is not supported in release 6.7. [double check this because vMotion is supported I just can't remember what version and update number it is]
vMotion can be extremely valuable for data scientists doing long-running training jobs that you don’t get with DirectPath I/O and suspend/resume of vGPU enabled VMs creates opportunities to increase the return from your GPU investments by enabling scenarios with data science model training running at night and interactive graphics-intensive applications running during the day utilizing the same pool of GPUs. Organizations with workers spread across time zones may also find that suspend/resume of vGPU enabled VMs to be useful.
There is still a lot of work that we want to do in our lab including capturing some informational videos that will highlight some of the concepts we have been talking about in these last two articles. We are also starting to build out some VMs configured with Docker so we can look at using our vGPUs with NVIDIA GPU Cloud (GCP) deep learning training and inferencing containers. Our goal is to get more folks setting up a sandbox environment using these articles along with the NVIDIA and VMware links we have provided. We want to hear about your experience working with vGPUs and VMware. If you have any questions or comments post them in the feedback section below.
Thanks for reading,
Phil Hummel - On Twitter @GotDisk

Sharing the Love for GPUs in Machine Learning
Wed, 17 Mar 2021 16:53:14 -0000
|Read Time: 0 minutes

Anyone that works with machine learning models trained by optimization methods like stochastic gradient descent (SGD) knows about the power of specialized hardware accelerators for performing a large number of matrix operations that are needed. Wouldn’t it be great if we all had our own accelerator dense supercomputers? Unfortunately, the people that manage budgets aren’t approving that plan, so we need to find a workable mix of technology and, yes, the dreaded concept, process to improve our ability to work with hardware accelerators in shared environments.
We have gotten a lot of questions from a customer trying to increase the utilization rates of machines with specialized accelerators. Good news, there are a lot of big technology companies working on solutions. The rest of the article is going to focus on technology from Dell EMC, NVIDIA, and VMware that is both available today and some that are coming soon. We also sprinkle in some comments about the process that you can consider. Please add your thoughts and questions in the comments section below.
We started this latest round of GPU-as-a-service research with a small amount of kit in the Dell EMC Customer Solutions Center in Austin. We have one Dell EMC PowerEdge R740 with 4 NVIDIA T4 GPUs connected to the system on the PCIe bus. Our research question is “how can a group of data scientists working on different models with different development tools share these four GPUs?” We are going to compare two different technology options:
- VMware Direct Path I/O
- NVIDIA GPU GRID 9.0
Our server has ESXi installed and is configured as a 1 node cluster in vCenter. I’m going to skip the configuration of the host BIOS and ESXi and jump straight to creating VMs. We started off with the Direct Path I/O option. You should review the article “Using GPUs with Virtual Machines on vSphere – Part 2: VMDirectPath I/O” from VMware before trying this at home. It has a lot of details that we won’t repeat here.
There are many approaches available for virtual machine image management that can be set up by the VMware administrators but for this project, we are assuming that our data scientists are building and maintaining the images they use. Our scenario is to show how a group of Python users can have one image and the R users can have another image that both use GPUs when needed. Both groups are using primarily TensorFlow and Keras.
Before installing an OS we changed the firmware setting to EFI in the VM Boot Options menu per the article above. We also used the VM options to assign one physical GPU to the VM using Direct Path I/O before proceeding with any software installs. It is important for there to be a device present during configuration even though the VM may get used later with or without an assigned GPU to facilitate sharing among users and/or teams.
Once the OS was installed and configured with user accounts and updates, we installed the NVIDIA GPU related software and made two clones of that image since both the R and Python environment setups need the same supporting libraries and drivers to use the GPUs when added to the VM through Direct Path I/O. Having the base image with an OS plus NVIDIA libraries saves a lot of time if you want a new type of developer environment.
With this much of the setup done, we can start testing assigning and removing GPU devices among our two VMs. We use VM options to add and remove the devices but only while the VM is powered off. For example, we can assign 2 GPUs to each VM, 4 GPUs to one VM and none to the other or any other combination that doesn’t exceed our 4 available devices. Devices currently assigned to other VMs are not available in the UI for assignment, so it is not physically possible to create conflicts between VMs. We can NVIDIA’s System Management Interface (nvidia-smi) to list the devices available on each VM.
Remember above when we talked about process, here is where we need to revisit that. The only way a setup like this works is if people release GPUs from VMs when they don’t need them. Going a level deeper there will probably be a time when one user or group could take advantage of a GPU but would choose to not take one so other potentially more critical work can have it. This type of resource sharing is not new to research and development. All useful resources are scarce, and a lot of efficiencies can be gained with the right technology, process, and attitude
.Before we talk about installing the developer frameworks and libraries, let’s review the outcome we desire. We have 2 or more groups of developers that could benefit from the use of GPUs at different times in their workflow but not always. They would like to minimize the number of VM images they need and have and would also like fewer versions of code to maintain even when switching between tasks that may or may not have access to GPUs when running. We talked above about switching GPUs between machines but what happens on the software side? Next, we’ll talk about some TensorFlow properties that make this easier.
TensorFlow comes in two main flavors for installation tensorflow and tensorflow-gpu. The first one should probably be called “tensorflow-cpu” for clarity. For this work, we are only installing the GPU enabled version since we are going to want our VMs to be able to use GPU for any operations that TF supports for GPU devices. The reason that I don’t also need the CPU version when my VM has not been assigned any GPUs is that many operations available in the GPU enabled version of TF have both a CPU and a GPU implantation. When an operation is run without a specific device assignment, any available GPU device will be given priority in the placement. When the VM does not have a GPU device available the operation will use the CPU implementation.
There are many examples online for testing if you have a properly configured system with a functioning GPU device. This simple matrix multiplication sample is a good starting point. Once that is working you can move on a full-blown model training with a sample data set like the MNIST character recognition model. Try setting up a sandbox environment using this article and the VMware blog series above. Then get some experience with allocating and deallocating GPUs to VMs and prove that things are working with a small app. If you have any questions or comments post them in the feedback section below.
Thanks for reading.
Phil Hummel - Twitter @GotDisk@GotDisk

IIoT Analytics Design: How important is MOM (message-oriented middleware)?
Tue, 08 Dec 2020 17:45:45 -0000
|Read Time: 0 minutes
Originally published on Aug 6, 2018 1:17:46 PM
Artificial intelligence (AI) is transforming the way businesses compete in today’s marketplace. Whether it’s improving business intelligence, streamlining supply chain or operational efficiencies, or creating new products, services, or capabilities for customers, AI should be a strategic component of any company’s digital transformation.
Deep neural networks have demonstrated astonishing abilities to identify objects, detect fraudulent behaviors, predict trends, recommend products, enable enhanced customer support through chatbots, convert voice to text and translate one language to another, and produce a whole host of other benefits for companies and researchers. They can categorize and summarize images, text, and audio recordings with human-level capability, but to do so they first need to be trained.
Deep learning, the process of training a neural network, can sometimes take days, weeks, or months, and effort and expertise is required to produce a neural network of sufficient quality to trust your business or research decisions on its recommendations. Most successful production systems go through many iterations of training, tuning and testing during development. Distributed deep learning can speed up this process, reducing the total time to tune and test so that your data science team can develop the right model faster, but requires a method to allow aggregation of knowledge between systems.
There are several evolving methods for efficiently implementing distributed deep learning, and the way in which you distribute the training of neural networks depends on your technology environment. Whether your compute environment is container native, high performance computing (HPC), or Hadoop/Spark clusters for Big Data analytics, your time to insight can be accelerated by using distributed deep learning. In this article we are going to explain and compare systems that use a centralized or replicated parameter server approach, a peer-to-peer approach, and finally a hybrid of these two developed specifically for Hadoop distributed big data environments.
Distributed Deep Learning in Container Native Environments
Container native (e.g., Kubernetes, Docker Swarm, OpenShift, etc.) have become the standard for many DevOps environments, where rapid, in-production software updates are the norm and bursts of computation may be shifted to public clouds. Most deep learning frameworks support distributed deep learning for these types of environments using a parameter server-based model that allows multiple processes to look at training data simultaneously, while aggregating knowledge into a single, central model.
The process of performing parameter server-based training starts with specifying the number of workers (processes that will look at training data) and parameter servers (processes that will handle the aggregation of error reduction information, backpropagate those adjustments, and update the workers). Additional parameters servers can act as replicas for improved load balancing.
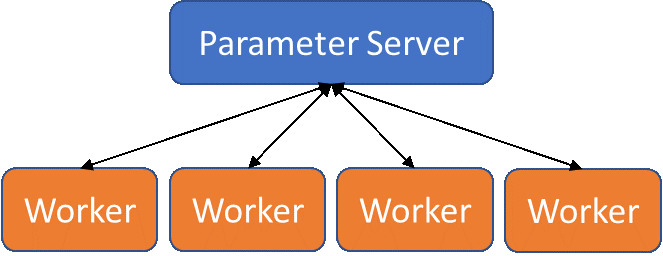 Parameter server model for distributed deep learning
Parameter server model for distributed deep learning
Worker processes are given a mini-batch of training data to test and evaluate, and upon completion of that mini-batch, report the differences (gradients) between produced and expected output back to the parameter server(s). The parameter server(s) will then handle the training of the network and transmitting copies of the updated model back to the workers to use in the next round.
This model is ideal for container native environments, where parameter server processes and worker processes can be naturally separated. Orchestration systems, such as Kubernetes, allow neural network models to be trained in container native environments using multiple hardware resources to improve training time. Additionally, many deep learning frameworks support parameter server-based distributed training, such as TensorFlow, PyTorch, Caffe2, and Cognitive Toolkit.
Distributed Deep Learning in HPC Environments
High performance computing (HPC) environments are generally built to support the execution of multi-node applications that are developed and executed using the single process, multiple data (SPMD) methodology, where data exchange is performed over high-bandwidth, low-latency networks, such as Mellanox InfiniBand and Intel OPA. These multi-node codes take advantage of these networks through the Message Passing Interface (MPI), which abstracts communications into send/receive and collective constructs.
Deep learning can be distributed with MPI using a communication pattern called Ring-AllReduce. In Ring-AllReduce each process is identical, unlike in the parameter-server model where processes are either workers or servers. The Horovod package by Uber (available for TensorFlow, Keras, and PyTorch) and the mpi_collectives contributions from Baidu (available in TensorFlow) use MPI Ring-AllReduce to exchange loss and gradient information between replicas of the neural network being trained. This peer-based approach means that all nodes in the solution are working to train the network, rather than some nodes acting solely as aggregators/distributors (as in the parameter server model). This can potentially lead to faster model convergence.
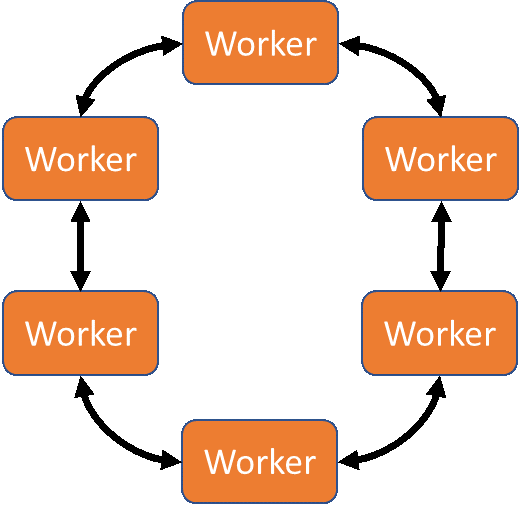 Ring-AllReduce model for distributed deep learning
Ring-AllReduce model for distributed deep learning
The Dell EMC Ready Solutions for AI, Deep Learning with NVIDIA allows users to take advantage of high-bandwidth Mellanox InfiniBand EDR networking, fast Dell EMC Isilon storage, accelerated compute with NVIDIA V100 GPUs, and optimized TensorFlow, Keras, or Pytorch with Horovod frameworks to help produce insights faster.
Distributed Deep Learning in Hadoop/Spark Environments
Hadoop and other Big Data platforms achieve extremely high performance for distributed processing but are not designed to support long running, stateful applications. Several approaches exist for executing distributed training under Apache Spark. Yahoo developed TensorFlowOnSpark, accomplishing the goal with an architecture that leveraged Spark for scheduling Tensorflow operations and RDMA for direct tensor communication between servers.
BigDL is a distributed deep learning library for Apache Spark. Unlike Yahoo’s TensorflowOnSpark, BigDL not only enables distributed training - it is designed from the ground up to work on Big Data systems. To enable efficient distributed training BigDL takes a data-parallel approach to training with synchronous mini-batch SGD (Stochastic Gradient Descent). Training data is partitioned into RDD samples and distributed to each worker. Model training is done in an iterative process that first computes gradients locally on each worker by taking advantage of locally stored partitions of the training data and model to perform in memory transformations. Then an AllReduce function schedules workers with tasks to calculate and update weights. Finally, a broadcast syncs the distributed copies of model with updated weights.
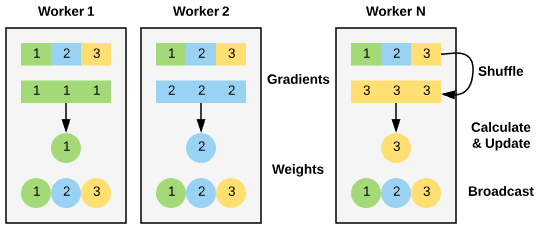 BigDL implementation of AllReduce functionality
BigDL implementation of AllReduce functionality
The Dell EMC Ready Solutions for AI, Machine Learning with Hadoop is configured to allow users to take advantage of the power of distributed deep learning with Intel BigDL and Apache Spark. It supports loading models and weights from other frameworks such as Tensorflow, Caffe and Torch to then be leveraged for training or inferencing. BigDL is a great way for users to quickly begin training neural networks using Apache Spark, widely recognized for how simple it makes data processing.
One more note on Hadoop and Spark environments: The Intel team working on BigDL has built and compiled high-level pipeline APIs, built-in deep learning models, and reference use cases into the Intel Analytics Zoo library. Analytics Zoo is based on BigDL but helps make it even easier to use through these high-level pipeline APIs designed to work with Spark Dataframes and built in models for things like object detection and image classification.
Conclusion
Regardless of whether you preferred server infrastructure is container native, HPC clusters, or Hadoop/Spark-enabled data lakes, distributed deep learning can help your data science team develop neural network models faster. Our Dell EMC Ready Solutions for Artificial Intelligence can work in any of these environments to help jumpstart your business’s AI journey. For more information on the Dell EMC Ready Solutions for Artificial Intelligence, go to dellemc.com/readyforai.
Lucas A. Wilson, Ph.D. is the Chief Data Scientist in Dell EMC's HPC & AI Innovation Lab. (Twitter: @lucasawilson)
Michael Bennett is a Senior Principal Engineer at Dell EMC working on Ready Solutions.

Deep Learning on Spark is Getting Interesting
Mon, 03 Aug 2020 15:53:44 -0000
|Read Time: 0 minutes
The year 2012 will be remembered in history as a break out year for data analytics. Deep learnings meteoric rise to prominence can largely be attributed to the 2012 introduction of convolution neural networks (CNN)for image classification using the ImageNet dataset during the Large-Scale Visual Recognition Challenge (LSVRC) [1]. It was a historic event after a very, very long incubation period for deep learning that started with mathematical theory work in the 1940s, 50s, and 60s. The prior history of neural networks and deep learning development is a fascination and should not be forgotten, but it is not an overstatement to say that 2012 was the breakout year for deep learning.
Coincidentally, 2012 was also a breakout year for in-memory distributed computing. A group of researchers from the University of AMPlab published a paper with an unusual title that changed the world of data analytics. “Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing”. [2] This paper describes how the initial creators developed an efficient, general-purpose and fault-tolerant in-memory data abstraction for sharing data in cluster applications. The effort was motivated by the short-comings of both MapReduce and other distributed-memory programming models for processing iterative algorithms and interactive data mining jobs.
The ongoing development of so many application libraries that all leverage Spark’s RDD abstraction including GraphX for creating graphs and graph-parallel computation, Spark Streaming for scalable fault-tolerant streaming applications and MLlib for scalable machine learning is proof that Spark achieved the original goal of being a general-purpose programming environment. The rest of this article will describe the development and integration of deep learning libraries – a now extremely useful class of iterative algorithms that Spark was designed to address. The importance of the role that deep learning was going to have on data analytics and artificial intelligence was just starting to emerge at the same time Spark was created so the combination of the two developments has been interesting to watch.
MLlib – The original machine learning library for Spark
MLlib development started not long after the AMPlab code was transferred to the Apache Software Foundation in 2013. It is not really a deep learning library however there is an option for developing Multilayer perceptron classifiers [3] based on the feedforward artificial neural network with backpropagation implemented for learning the model. Fully connected neural networks were quickly abandoned after the development of more sophisticated models constructed using convolutional, recursive, and recurrent networks.
 Fully connected shallow and deep networks are making a comeback as alternatives to tree-based models for both regression and classification. There is also a lot of current interest in various forms of autoencoders used to learn latent (hidden) compressed representations of data dimension reduction and self-supervised classification. MLlib, therefore, can be best characterized as a machine learning library with some limited neural network capability.
Fully connected shallow and deep networks are making a comeback as alternatives to tree-based models for both regression and classification. There is also a lot of current interest in various forms of autoencoders used to learn latent (hidden) compressed representations of data dimension reduction and self-supervised classification. MLlib, therefore, can be best characterized as a machine learning library with some limited neural network capability.
BigDL – Intel open sources a full-featured deep learning library for Spark
BigDL is a distributed deep learning library for Apache Spark. BigDL implements distributed, data-parallel training directly on top of the functional compute model using the core Spark features of copy-on-write and coarse-grained operations. The framework has been referenced in applications as diverse as transfer learning-based image classification, object detection and feature extraction, sequence-to-sequence prediction for precipitation nowcasting, neural collaborative filtering for recommendations, and more. Contributors and users include a wide range of industries including Mastercard, World Bank, Cray, Talroo, University of California San Francisco (UCSF), JD, UnionPay, Telefonica, GigaSpaces. [4]
Engineers with Dell EMC and Intel recently completed a white paper demonstrating the use of deep learning development tools from the Intel Analytics Zoo [5] to build an integrated pipeline on Apache Spark ending with a deep neural network model to predict diseases from chest X-rays. [6] Tools and examples in the Analytics Zoo give data scientists the ability to train and deploy BigDL, TensorFlow, and Keras models on Apache Spark clusters. Application developers can also use the resources from the Analytics Zoo to deploy production class intelligent applications through model extractions capable of being served in any Java, Scala, or other Java virtual machine (JVM) language.
The researchers conclude that modern deep learning applications can be developed and deployed at scale on an existing Hadoop and Spark cluster. This approach avoids the need to move data to a different deep learning cluster and eliminates the operational complexities of provisioning and maintaining yet another distributed computing environment. The open-source software that is described in the white paper is available from Github. [7]
H20.ai – Sparkling Water for Spark
H2O is fast, scalable, open-source machine learning, and deep learning for smarter applications. Much like MLlib, the H20 algorithms cover a wide range of useful machine learning techniques but only fully connected MLPs for deep learning. With H2O, enterprises like PayPal, Nielsen Catalina, Cisco, and others can use all their data without sampling to get accurate predictions faster. [8] Dell EMC, Intel, and H2o.ai recently developed a joint reference architecture that outlines both technical considerations and sizing guidance for an on-premises enterprise AI platform. [9]
The engineers show how running H2O.ai software on optimized Dell EMC infrastructure with the latest Intel® Xeon® Scalable processors and NVMe storage, enables organizations to use AI to improve customer experiences, streamline business processes, and decrease waste and fraud. Validated software included the H2O Driverless AI enterprise platform and the H2O and H2O Sparkling Water open-source software platforms. Sparkling Water is designed to be executed as a regular Spark application. It provides a way to initialize H2O services on Spark and access data stored in both Spark and H2O data structures. H20 Sparkling Water algorithms are designed to take advantage of the distributed in-memory computing of existing Spark clusters. Results from H2O can easily be deployed using H2O low-latency pipelines or within Spark for scoring.
H2O Sparkling Water cluster performance was evaluated on three- and five-node clusters. In this mode, H2O launches through Spark workers, and Spark manages the job scheduling and communications between the nodes. Three and five Dell EMC PowerEdge R740xd Servers with Intel Xeon Gold 6248 processors were used to train XGBoost and GBM models using the mortgage data set derived from the Fannie Mae Single-Family Loan Performance data set.
Spark and GPUs
 Many data scientists familiar with Spark for machine learning have been waiting for official support for GPUs. The advantages realized from modern neural network models like the CNN entry in the 2012 LSVRC would not have been fully realized without the work of NVIDIA and others on new acceleration hardware. NVIDIA’s GPU technology like the Volta V100 has morphed into a class of advanced, enterprise-class ML/DL accelerators that reduce training time for all types of neural network configurations including CCN, RNN (recurrent neural networks) and GAN (generative adversarial networks) to mention just a few of the most popular forms. Deep learning researchers see many advantages to building end-to-data model training “pipelines” that take advantage of the generalized distributed computing capability of Spark for everything from data cleaning and shaping through to scale-out training using integration with GPUs.
Many data scientists familiar with Spark for machine learning have been waiting for official support for GPUs. The advantages realized from modern neural network models like the CNN entry in the 2012 LSVRC would not have been fully realized without the work of NVIDIA and others on new acceleration hardware. NVIDIA’s GPU technology like the Volta V100 has morphed into a class of advanced, enterprise-class ML/DL accelerators that reduce training time for all types of neural network configurations including CCN, RNN (recurrent neural networks) and GAN (generative adversarial networks) to mention just a few of the most popular forms. Deep learning researchers see many advantages to building end-to-data model training “pipelines” that take advantage of the generalized distributed computing capability of Spark for everything from data cleaning and shaping through to scale-out training using integration with GPUs.
NVIDIA recently announced that it has been working with Apache Spark’s open source community to bring native GPU acceleration to the next version of the big data processing framework, Spark 3.0 [10] The Apache Spark community is distributing a preview release of Spark 3.0 to encourage wide-scale community testing of the upcoming release. The preview is not a stable release of the expected API specification or functionality. No firm date for the general availability of Spark 3.0 has been released but organizations exploring options for distributed deep learning with GPUs should start evaluating the proposed features and advantages of Spark 3.0.
Cloudera is also giving developers and data science an opportunity to do testing and evaluation with the preview release of Spark 3.0. The current GA version of the Cloudera Runtime includes the Apache Spark 3.0 preview 2 as part of their CDS 3 (Experimental) Powered by Apache Spark release. [11] Full Spark 3.0 preview 2 documentation including many code samples is available from the Apache Spark website [12]
What’s next
It’s been 8 years since the breakout events for deep learning and distributed computing with Spark were announced. We have seen tremendous adoption of both deep learning and Spark for all types of analytics use cases from medical imaging to language processing to manufacturing control and beyond. We are just now poised to see new breakthroughs in the merging of Spark and deep learning, especially with the addition of support for hardware accelerators. IT professionals and data scientists are still too heavily burdened with the hidden technical debt overhead for managing machine learning systems. [13] The integration of accelerated deep learning with the power of the Spark generalized distributed computing platform will give both the IT and data science communities a capable and manageable environment to develop and host end-to-end data analysis pipelines in a common framework.
References
[1] Alom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., ... & Asari, V. K. (2018). The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv preprint arXiv:1803.01164.
[2] Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauly, M., ... & Stoica, I. (2012). Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12) (pp. 15-28).
[3] Apache Spark (June 2020) Multilayer perceptron classifier https://spark.apache.org/docs/latest/ml-classification-regression.html#multilayer-perceptron-classifier
[4] Dai, J. J., Wang, Y., Qiu, X., Ding, D., Zhang, Y., Wang, Y., ... & Wang, J. (2019, November). Bigdl: A distributed deep learning framework for big data. In Proceedings of the ACM Symposium on Cloud Computing (pp. 50-60).
[5] Intel Analytics Zoo (June 2020) https://software.intel.com/content/www/us/en/develop/topics/ai/analytics-zoo.html
[6] Chandrasekaran, Bala (Dell EMC) Yang, Yuhao (Intel) Govindan, Sajan (Intel) Abd, Mehmood (Dell EMC) A. A. R. U. D. (2019). Deep Learning on Apache Spark and Analytics Zoo.
[7] Dell AI Engineering (June 2020) BigDL Image Processing Examples https://github.com/dell-ai-engineering/BigDL-ImageProcessing-Examples
[8] Candel, A., Parmar, V., LeDell, E., and Arora, A. (Apr 2020). Deep Learning with H2O https://www.h2o.ai/wp-content/themes/h2o2016/images/resources/DeepLearningBooklet.pdf
[9] Reference Architectures for H2O.ai (February 2020) https://www.dellemc.com/resources/en-us/asset/white-papers/products/ready-solutions/dell-h20-architectures-pdf.pdf Dell Technologies
[10] Woodie, Alex (May 2020) Spark 3.0 to Get Native GPU Acceleration https://www.datanami.com/2020/05/14/spark-3-0-to-get-native-gpu-acceleration/ datanami
[11] CDS 3 (Experimental) Powered by Apache Spark Overview (June 2020) https://docs.cloudera.com/runtime/7.0.3/cds-3/topics/spark-spark-3-overview.html
[12] Spark Overview (June 2020) https://spark.apache.org/docs/3.0.0-preview2/
[13] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., ... & Dennison, D. (2015). Hidden technical debt in machine learning systems. In Advances in neural information processing systems (pp. 2503-2511).