




The Future of AI Using LiDAR


Introduction
Light Detection and Ranging (LiDAR) is a method for determining the distance from a sensor to an object or a surface by sending out a laser beam and measuring the time for the reflected light to return to the receiver. We recently designed a solution to understand how using data from multiple LiDAR sensors monitoring a single space can be combined into a three-dimensional (3D) perceptual understanding of how people and objects flow and function within public and private spaces. Our key partner in this research is Seoul Robotics, a leader in LiDAR 3D perception and analytics tools.
Most people are familiar with the use of LiDAR on moving vehicles to detect nearby objects that has become popular in transportation applications. Stationary LiDAR is now becoming more widely adopted for 3D imaging in applications where cameras have been used traditionally.
Multiple sensor LiDAR applications can produce a complete 3D grid map with precise depth and location information for objects in the jointly monitored environment. This technology overcomes several limitations of 2D cameras. Using AI, LiDAR systems can improve the quality of analysis results for data collected during harsh weather conditions like rain, snow, and fog. Furthermore, LiDAR is more robust than optical cameras for conditions where the ambient lighting is low or produces reflections and glare.
Another advantage of LiDAR for computer vision is related to privacy protection. The widespread deployment of high-resolution optical cameras has raised concerns regarding the potential violation of individual privacy and misuse of the data.
LiDAR 3D perception is a promising alternative to traditional camera systems. LiDAR data does not contain biometric data that could be cross-referenced with other sources to identify individuals uniquely. This approach allows operators to track anonymous objects that maintain individuals' privacy. Therefore, it is essential to consider replacing or augmenting such cameras to reduce the overhead of ensuring that data is secure and used appropriately.
Challenges
Worldwide, organizations use AI-enabled computer vision solutions to create safer, more efficient public and private spaces using only optical thermal and infrared cameras. Data scientists have developed many machine learning and deep neural network tools to detect and label objects using data from these different camera types.
As LiDAR becomes vital for the reasons discussed above, organizations are investigating their options for whether LiDAR is best deployed alongside traditional cameras or if there are opportunities to design new systems using LiDAR sensors exclusively. It is rare when existing cameras can be replaced with LiDAR sensors mounted in the exact locations used today.
An example deployment of 2 LiDAR sensors for a medium-sized room is below:
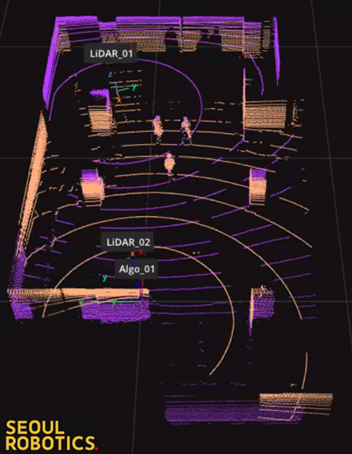
Detecting the position of the stationary objects and people moving through this space (flow and function) with LiDAR requires careful placement of the sensors, calibration of the room's geometry, and data processing algorithms that can extract information from both sensors without distortion or duplications. Collecting and processing LiDAR data for 3D perception requires a different toolset and expertise, but companies like Seoul Robotics can help.
Another aspect of LiDAR systems design that needs to be evaluated is data transfer requirements. In most large environments using camera deployments today (e.g., airport/transportation hubs, etc.), camera data is fed back to a centralized hub for real-time processing.
A typical optical camera in an AI computer vision system would have a resolution and refresh rate of 1080@30FPS. This specification would translate to ~4Mb/s of network traffic per camera. Even with older network technology, thousands of cameras can be deployed and processed.
There is a significant increase in the density of the data produced and processed for LiDAR systems compared to video systems. A currently available 32-channel LiDAR sensor will produce between 25Mb/s and 50Mb/s of data on the network segment between the device and the AI processing node. Newer high-density 128-channel LiDAR sensors consume up to 256Mb/s of network bandwidth, so something will need to change from the current strategy of centralized data processing.
Technical Solution
It is not feasible to design a system that will consume the entire network capacity of a site with LiDAR traffic. In addition, it can also be challenging and expensive to upgrade the site's private network to handle higher speeds. The most efficient solution, therefore, is to design a federated solution for processing LiDAR data closer to the location of the sensors.
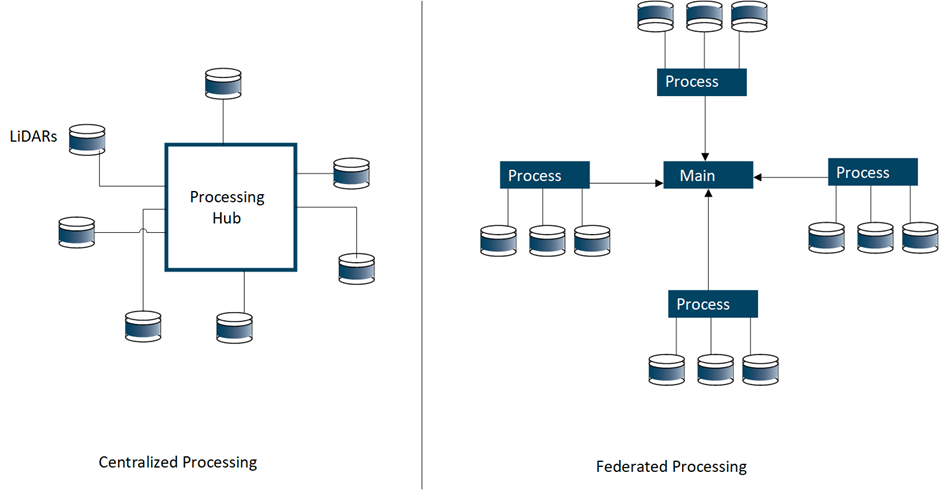
With a switch to the architecture in the right-side panel above, it is possible to process multiple LiDAR sensors closer to where they are mounted at the site and only send any resulting alerts and events back to a central location (primary node) for further processing and triggering corrective actions. This approach avoids the costly transfer of dense LiDAR data across long network segments.
It is important to note that processing LiDAR data with millions of points per second requires significant computational capability. We also validated that leveraging the massive parallel computing power of GPUs like the NVIDIA A2 greatly enhanced the object detection accuracy in the distributed processing nodes. The Dell XR4000 series of rugged Dell servers should be a good option for remote processing in many environments.
Conclusion
LiDAR is becoming increasingly important in designing AI for computer vision solutions due to its ability to handle challenging lighting situations and enhance user privacy. LiDAR differs from video cameras, so planning the deployment carefully is essential.
LiDAR systems can be designed in either a central or federated manner or even a mix of both. The rapidly growing network bandwidth requirements of LiDAR may cause a rethink on how systems for AI-enabled data processes are deployed sooner rather than later.
For more details on CV 3D Flow and Function with LiDAR see Computer Vision 3D Flow and Function AI with LiDAR.