




Dell Integrated System for Microsoft Azure Stack HCI with Storage Spaces Direct

Many industry analysts covering the computer vision market are predicting double-digit compound annual growth over the next five years on top of the approximately $60B US yearly expenditures. Organizations investing significantly in greenfield or upgrade projects must evaluate their IT infrastructure designs. Technology options have improved considerably since video management and computer vision with AI systems were introduced. Virtualization technologies like Microsoft Azure Stack have many advantages in efficiency and manageability compared to the traditional approach of dedicating bespoke infrastructure stacks for every application, from video ingest to AI analytics and real-time alerting. This article describes our recent validation of Microsoft Azure Stack Hyperconverged Infrastructure (HCI) for hosting multiple computer vision applications, including video management and two AI-enabled computer vision applications. The full white paper we published based on the work titled Computer Vision on Microsoft Azure Stack HCI is also available for online reading or download.
Microsoft Azure Stack hyperconverged infrastructure (HCI) is an on-premises IT platform integrated with an Azure public cloud management service. Azure Stack (AS) represents a comprehensive solution for organizations looking to leverage the benefits of cloud computing while maintaining control over on-premises infrastructure. This platform is a core component of Microsoft's hybrid cloud strategy, which brings the agility and fast-paced innovation of cloud computing to on-premises environments. ASHCI offerings from Dell Technologies provide flexible, scalable, and secure solutions to customers looking to consolidate virtualized workloads.
The ASHCI platform seamlessly integrates with core Windows Server technologies like Hyper-V for virtualization and Storage Spaces Direct (S2D) for storage. The convergence of management tools for both on-premises and cloud resources with additional options for integration with other Azure services reduces deployment and operation overhead for enterprises pursuing a hybrid cloud strategy.
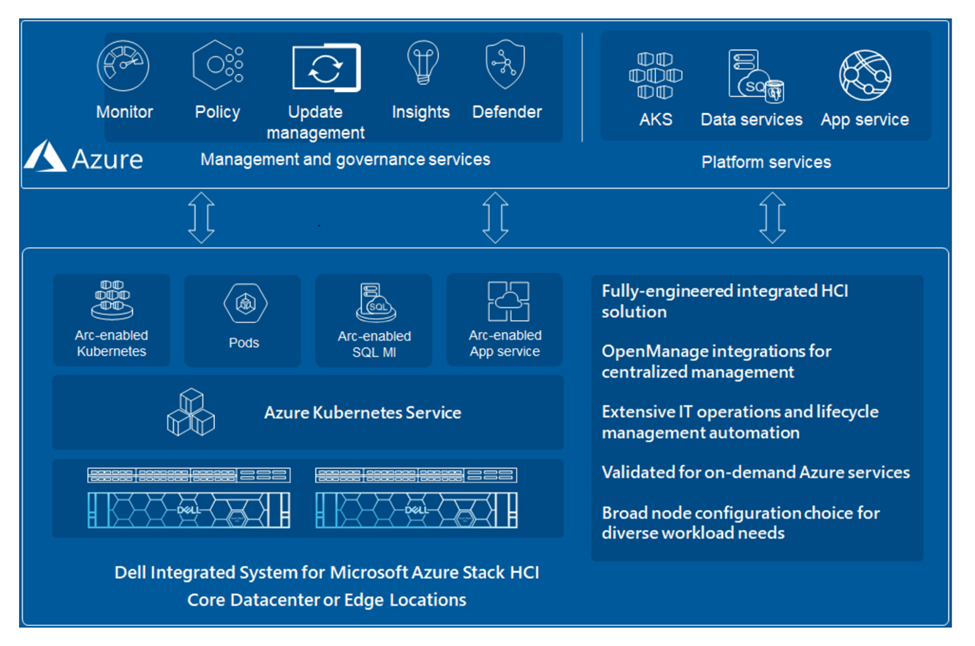 System Architecture Overview
System Architecture Overview
The system architecture we implemented is the Dell Integrated System for Microsoft Azure Stack HCI with Storage Spaces Direct, plus NVIDIA A16 server-class GPUs. The Azure Stack HCI system leverages Microsoft Windows virtual machine virtualization that will be familiar to many IT and OT (operational technology) professionals.
We performed real-time analytics with BriefCam and Ipsotek by integration with the Milestone directory server and video recording services. All three applications were hosted on a 5-node Microsoft Azure Stack HCI cluster.
The three applications chosen for this validation were:
- BriefCam provides an industry-leading application for video analytics for rapid video review and search, real-time alerting, and quantitative video insights.
- Ipsotek specializes in AI-enhanced video analytics software to manage automatically generated alerts in real-time for crowd management, smoke detection, intrusion detection, perimeter protection, number plate recognition, and traffic management.
- The Milestone Systems XProtect platform video management software enables organizations and institutions to create the perfect combination of cameras, sensors, and analytics.
In summary, Azure Stack HCI solutions from Dell Technologies offer a versatile and balanced hybrid cloud approach, allowing organizations to capitalize on the strengths of both on-premises and cloud environments. This flexibility is essential for AI computer vision environments where efficiency, security, compliance, and innovation are keys to sustaining competitive advantage. Our experience working with Microsoft Azure Stack HCI to host enterprise applications for video management and computer vision AI revealed the depth of the platform's innovation and a focus on ease of deployment and management.
For more information:
Computer Vision on Microsoft Azure Stack HCI White Paper
Microsoft Azure Stack HCI
- Dell Integrated System for Microsoft Azure Stack HCI
- Delivering aHybrid Cloud Architecture Through Microsoft-Dell Integrated HCI
- Microsoft Azure Stack HCI documentation