




Deep Learning on Spark is Getting Interesting

The year 2012 will be remembered in history as a break out year for data analytics. Deep learnings meteoric rise to prominence can largely be attributed to the 2012 introduction of convolution neural networks (CNN)for image classification using the ImageNet dataset during the Large-Scale Visual Recognition Challenge (LSVRC) [1]. It was a historic event after a very, very long incubation period for deep learning that started with mathematical theory work in the 1940s, 50s, and 60s. The prior history of neural networks and deep learning development is a fascination and should not be forgotten, but it is not an overstatement to say that 2012 was the breakout year for deep learning.
Coincidentally, 2012 was also a breakout year for in-memory distributed computing. A group of researchers from the University of AMPlab published a paper with an unusual title that changed the world of data analytics. “Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing”. [2] This paper describes how the initial creators developed an efficient, general-purpose and fault-tolerant in-memory data abstraction for sharing data in cluster applications. The effort was motivated by the short-comings of both MapReduce and other distributed-memory programming models for processing iterative algorithms and interactive data mining jobs.
The ongoing development of so many application libraries that all leverage Spark’s RDD abstraction including GraphX for creating graphs and graph-parallel computation, Spark Streaming for scalable fault-tolerant streaming applications and MLlib for scalable machine learning is proof that Spark achieved the original goal of being a general-purpose programming environment. The rest of this article will describe the development and integration of deep learning libraries – a now extremely useful class of iterative algorithms that Spark was designed to address. The importance of the role that deep learning was going to have on data analytics and artificial intelligence was just starting to emerge at the same time Spark was created so the combination of the two developments has been interesting to watch.
MLlib – The original machine learning library for Spark
MLlib development started not long after the AMPlab code was transferred to the Apache Software Foundation in 2013. It is not really a deep learning library however there is an option for developing Multilayer perceptron classifiers [3] based on the feedforward artificial neural network with backpropagation implemented for learning the model. Fully connected neural networks were quickly abandoned after the development of more sophisticated models constructed using convolutional, recursive, and recurrent networks.
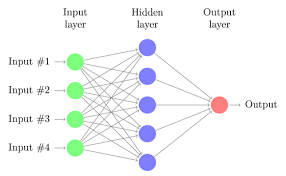 Fully connected shallow and deep networks are making a comeback as alternatives to tree-based models for both regression and classification. There is also a lot of current interest in various forms of autoencoders used to learn latent (hidden) compressed representations of data dimension reduction and self-supervised classification. MLlib, therefore, can be best characterized as a machine learning library with some limited neural network capability.
Fully connected shallow and deep networks are making a comeback as alternatives to tree-based models for both regression and classification. There is also a lot of current interest in various forms of autoencoders used to learn latent (hidden) compressed representations of data dimension reduction and self-supervised classification. MLlib, therefore, can be best characterized as a machine learning library with some limited neural network capability.
BigDL – Intel open sources a full-featured deep learning library for Spark
BigDL is a distributed deep learning library for Apache Spark. BigDL implements distributed, data-parallel training directly on top of the functional compute model using the core Spark features of copy-on-write and coarse-grained operations. The framework has been referenced in applications as diverse as transfer learning-based image classification, object detection and feature extraction, sequence-to-sequence prediction for precipitation nowcasting, neural collaborative filtering for recommendations, and more. Contributors and users include a wide range of industries including Mastercard, World Bank, Cray, Talroo, University of California San Francisco (UCSF), JD, UnionPay, Telefonica, GigaSpaces. [4]
Engineers with Dell EMC and Intel recently completed a white paper demonstrating the use of deep learning development tools from the Intel Analytics Zoo [5] to build an integrated pipeline on Apache Spark ending with a deep neural network model to predict diseases from chest X-rays. [6] Tools and examples in the Analytics Zoo give data scientists the ability to train and deploy BigDL, TensorFlow, and Keras models on Apache Spark clusters. Application developers can also use the resources from the Analytics Zoo to deploy production class intelligent applications through model extractions capable of being served in any Java, Scala, or other Java virtual machine (JVM) language.
The researchers conclude that modern deep learning applications can be developed and deployed at scale on an existing Hadoop and Spark cluster. This approach avoids the need to move data to a different deep learning cluster and eliminates the operational complexities of provisioning and maintaining yet another distributed computing environment. The open-source software that is described in the white paper is available from Github. [7]
H20.ai – Sparkling Water for Spark
H2O is fast, scalable, open-source machine learning, and deep learning for smarter applications. Much like MLlib, the H20 algorithms cover a wide range of useful machine learning techniques but only fully connected MLPs for deep learning. With H2O, enterprises like PayPal, Nielsen Catalina, Cisco, and others can use all their data without sampling to get accurate predictions faster. [8] Dell EMC, Intel, and H2o.ai recently developed a joint reference architecture that outlines both technical considerations and sizing guidance for an on-premises enterprise AI platform. [9]
The engineers show how running H2O.ai software on optimized Dell EMC infrastructure with the latest Intel® Xeon® Scalable processors and NVMe storage, enables organizations to use AI to improve customer experiences, streamline business processes, and decrease waste and fraud. Validated software included the H2O Driverless AI enterprise platform and the H2O and H2O Sparkling Water open-source software platforms. Sparkling Water is designed to be executed as a regular Spark application. It provides a way to initialize H2O services on Spark and access data stored in both Spark and H2O data structures. H20 Sparkling Water algorithms are designed to take advantage of the distributed in-memory computing of existing Spark clusters. Results from H2O can easily be deployed using H2O low-latency pipelines or within Spark for scoring.
H2O Sparkling Water cluster performance was evaluated on three- and five-node clusters. In this mode, H2O launches through Spark workers, and Spark manages the job scheduling and communications between the nodes. Three and five Dell EMC PowerEdge R740xd Servers with Intel Xeon Gold 6248 processors were used to train XGBoost and GBM models using the mortgage data set derived from the Fannie Mae Single-Family Loan Performance data set.
Spark and GPUs
 Many data scientists familiar with Spark for machine learning have been waiting for official support for GPUs. The advantages realized from modern neural network models like the CNN entry in the 2012 LSVRC would not have been fully realized without the work of NVIDIA and others on new acceleration hardware. NVIDIA’s GPU technology like the Volta V100 has morphed into a class of advanced, enterprise-class ML/DL accelerators that reduce training time for all types of neural network configurations including CCN, RNN (recurrent neural networks) and GAN (generative adversarial networks) to mention just a few of the most popular forms. Deep learning researchers see many advantages to building end-to-data model training “pipelines” that take advantage of the generalized distributed computing capability of Spark for everything from data cleaning and shaping through to scale-out training using integration with GPUs.
Many data scientists familiar with Spark for machine learning have been waiting for official support for GPUs. The advantages realized from modern neural network models like the CNN entry in the 2012 LSVRC would not have been fully realized without the work of NVIDIA and others on new acceleration hardware. NVIDIA’s GPU technology like the Volta V100 has morphed into a class of advanced, enterprise-class ML/DL accelerators that reduce training time for all types of neural network configurations including CCN, RNN (recurrent neural networks) and GAN (generative adversarial networks) to mention just a few of the most popular forms. Deep learning researchers see many advantages to building end-to-data model training “pipelines” that take advantage of the generalized distributed computing capability of Spark for everything from data cleaning and shaping through to scale-out training using integration with GPUs.
NVIDIA recently announced that it has been working with Apache Spark’s open source community to bring native GPU acceleration to the next version of the big data processing framework, Spark 3.0 [10] The Apache Spark community is distributing a preview release of Spark 3.0 to encourage wide-scale community testing of the upcoming release. The preview is not a stable release of the expected API specification or functionality. No firm date for the general availability of Spark 3.0 has been released but organizations exploring options for distributed deep learning with GPUs should start evaluating the proposed features and advantages of Spark 3.0.
Cloudera is also giving developers and data science an opportunity to do testing and evaluation with the preview release of Spark 3.0. The current GA version of the Cloudera Runtime includes the Apache Spark 3.0 preview 2 as part of their CDS 3 (Experimental) Powered by Apache Spark release. [11] Full Spark 3.0 preview 2 documentation including many code samples is available from the Apache Spark website [12]
What’s next
It’s been 8 years since the breakout events for deep learning and distributed computing with Spark were announced. We have seen tremendous adoption of both deep learning and Spark for all types of analytics use cases from medical imaging to language processing to manufacturing control and beyond. We are just now poised to see new breakthroughs in the merging of Spark and deep learning, especially with the addition of support for hardware accelerators. IT professionals and data scientists are still too heavily burdened with the hidden technical debt overhead for managing machine learning systems. [13] The integration of accelerated deep learning with the power of the Spark generalized distributed computing platform will give both the IT and data science communities a capable and manageable environment to develop and host end-to-end data analysis pipelines in a common framework.
References
[1] Alom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., ... & Asari, V. K. (2018). The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv preprint arXiv:1803.01164.
[2] Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauly, M., ... & Stoica, I. (2012). Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12) (pp. 15-28).
[3] Apache Spark (June 2020) Multilayer perceptron classifier https://spark.apache.org/docs/latest/ml-classification-regression.html#multilayer-perceptron-classifier
[4] Dai, J. J., Wang, Y., Qiu, X., Ding, D., Zhang, Y., Wang, Y., ... & Wang, J. (2019, November). Bigdl: A distributed deep learning framework for big data. In Proceedings of the ACM Symposium on Cloud Computing (pp. 50-60).
[5] Intel Analytics Zoo (June 2020) https://software.intel.com/content/www/us/en/develop/topics/ai/analytics-zoo.html
[6] Chandrasekaran, Bala (Dell EMC) Yang, Yuhao (Intel) Govindan, Sajan (Intel) Abd, Mehmood (Dell EMC) A. A. R. U. D. (2019). Deep Learning on Apache Spark and Analytics Zoo.
[7] Dell AI Engineering (June 2020) BigDL Image Processing Examples https://github.com/dell-ai-engineering/BigDL-ImageProcessing-Examples
[8] Candel, A., Parmar, V., LeDell, E., and Arora, A. (Apr 2020). Deep Learning with H2O https://www.h2o.ai/wp-content/themes/h2o2016/images/resources/DeepLearningBooklet.pdf
[9] Reference Architectures for H2O.ai (February 2020) https://www.dellemc.com/resources/en-us/asset/white-papers/products/ready-solutions/dell-h20-architectures-pdf.pdf Dell Technologies
[10] Woodie, Alex (May 2020) Spark 3.0 to Get Native GPU Acceleration https://www.datanami.com/2020/05/14/spark-3-0-to-get-native-gpu-acceleration/ datanami
[11] CDS 3 (Experimental) Powered by Apache Spark Overview (June 2020) https://docs.cloudera.com/runtime/7.0.3/cds-3/topics/spark-spark-3-overview.html
[12] Spark Overview (June 2020) https://spark.apache.org/docs/3.0.0-preview2/
[13] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., ... & Dennison, D. (2015). Hidden technical debt in machine learning systems. In Advances in neural information processing systems (pp. 2503-2511).