




Removing the barriers to hybrid-cloud flexibility for data analytics

Introduction
The fundamental tasks of collecting data, storing data, and providing processing power for data analytics is getting more difficult. Increasing data volumes along with the number of remote data sources and the rapidly evolving options for extracting valuable information make forecasting needs challenging and investment risky. IT organizations need the ability to quickly provision resources and incrementally scale both compute and storage on-demand as need develops. The three largest hyper-scale cloud providers all offer a wide range of infrastructure, platform and analytics “as-a-service” but all require vastly different skill sets, security models, and connectivity investments. Organizations interested in having hybrid cloud flexibility for data analytics are forced to choose a single cloud partner or add significant IT complexity by managing multiple options with no common toolset. In this Solutions Insight, we describe how the Robin Cloud-Native Platform (CNP) hosted onsite with Dell EMC PowerEdge servers provide application and infrastructure topology awareness to streamline the provisioning and life cycle management of your data applications with true hybrid cloud flexibility.
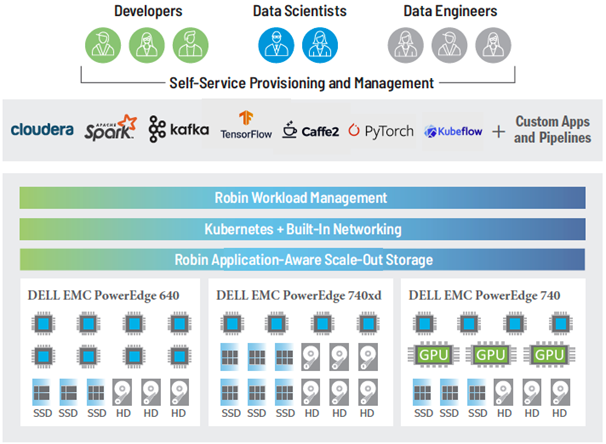 Architecture Diagram
Architecture Diagram
Providing a robust self-service experience
Data analytics professionals want easy access to internally managed provisioning of resources for experimentation and development without complex interactions with IT. Many of these professionals have experience with self-service portals that work for a single cloud service but have not yet had any hybrid cloud flexibility. Robin provides a rich out-of-the-box portal capability that IT can offer to developers, data engineers, and data scientists. Data professionals save valuable development time at each stage of the application lifecycle by leveraging the automation framework of Robin. IT gets a fully functional automation framework for hosting many popular enterprise applications on the Robin Platform. The Robin platform comes out-of-the-box with cluster-aware application bundles including relational databases, big data, NoSQL, and several AI/ML tools.
 Self Service Portal
Self Service Portal
Robin leverages cloud-native technologies such as Kubernetes and Docker to modernize the management of your data analytics infrastructure. The Robin Kubernetes-based architecture gives you complete freedom and offers a consistent self-service capability to provision and move workloads across private and/or public clouds. Native integration between Kubernetes, storage, network, and application management layer enables full automation managing both clusters and applications with all the advantages of a true hybrid cloud experience. Robin has built-in the capability to create managed application snapshots that enable cloning, backup, and migration of applications between on-prem and cloud or between datacenters within an enterprise. Robin fully automates the end-to-end cluster provisioning process for the most challenging platform deployments including Cloudera, Apache Spark, Kafka, TensorFlow, Pytorch, Kubeflow, Scikit-learn, Caffe, Torch, and even custom application configurations.
Organizations that adopt the Robin platform benefit from accelerated deployment and simplified management of complex applications that can be provisioned by end-users through a familiar portal experience and true hybrid cloud flexibility.
Moving from self-service sandboxes to enterprise scale
We described above how the Robin platform benefits both data and IT professionals that want a full-featured self-service data analytics capability with true hybrid cloud operations by layering additional platform awareness and automation to cloud-native technologies such as Kubernetes and Docker. Organizations can start with small deployments, and as applications grow, they can add more resources. Robin can be deployed on the full range of Dell EMC PowerEdge servers with a custom mix of memory, storage, and accelerator options making it easy to scale-out by adding additional servers with the right capabilities to match changing resource demands. The Robin management console provides a single interface to expand existing deployments and/or add new clusters. Consolidation of multiple workloads under Robin management can also improve hardware utilization without compromising SLAs or QoS. The Robin platform provides multi-tenancy with fine-grained Role Based Access Control (RBAC) enabling safe resource sharing on fewer clusters. Applications can be incubated on multi-tenancy, mixed application clusters and then easily migrated to production class clusters hosting one or multiple mission-critical applications using Robin backup and restore capability across clusters and/or clouds.
While open-source Kubernetes has become the de facto platform for deploying on-demand applications, there remains a need for additional investment by organizations that need multi-cluster production deployments and service orchestration that can automate and manage day-0 and day-n lifecycle operations at scale. The Robin Automation Platform combines simplicity, usability, performance, and scale with a modern UI to provide bare metal, cluster, and application-as-a-service for both infrastructure and service orchestration. With Robin Bare Metal-as-a-Service, hundreds of thousands of bare-metal servers can be provisioned with specific BIOS, firmware, OS and other software packages or configurations depending on the needs of the application. With Robin, it is equally easy to manage upgrades, as well as a wide array of PowerEdge server options including firmware, OS, and application software across container platforms.
Automating day-n operations for stateful applications
Several priorities are driving interest in running stateful applications on Kubernetes. These include operational consistency, extending agility of containerization to data, faster collaboration, and the need for simplifying the delivery of data services. Robin solves the storage and network persistency challenges in Kubernetes to enable its use in the provisioning, management, high availability and fault tolerance of mission-critical stateful applications.
Creating a persistent storage volume for a single container is becoming a routine operation. However, when it comes to provisioning storage for complex stateful applications that span multiple pods and services, it requires automation of the cluster resources coordinated with storage management. Managing the changing requirements of stateful applications on a day-to-day basis requires data and storage management services such as snapshotting, backup, and cloning. Traditionally, this capability has resided only on high-end storage systems managed by the IT storage administrator teams. In order to provide true self-service capabilities to data professionals, organizations need simple storage and data management solution for Kubernetes that hides all the above complexities and provides simple commands that are developer-friendly and can easily be incorporated into development and production workflows.
With Robin CNP, analytics and DevOps teams can be self-sufficient while managing complex stateful applications without requiring specific storage expertise. Data management is supported with a Robin managed CSI-compliant block storage access layer with bare-metal performance. Storage management seamlessly integrates with Kubernetes-native administrative tooling such as Kubectl, Helm Charts, and Operators through standard APIs.
Robin CNP simplifies storage operations such as provisioning storage, ensuring data availability, maintaining low latency I/O performance, and detecting and repairing disk and I/O errors. Robin CNP also provides simple commands for data management operations such as backup/recovery, snapshots/rollback, and cloning of entire applications including data, metadata, and application configuration.
Robin CNP offers several improvements on the networking layer over open-source Kubernetes. These improvements are required to run enterprise-scale data and network-centric applications on Kubernetes. With Robin CNP developers/IT can set networking options while deploying applications and clusters in Kubernetes and preserve IP addresses during restarts and application migration. Robin’s flexible networking built on OVS and Calico supports overlay networking. Robin also supports dual-stack (IPV4/IPV6).
Summary
IT organizations adopting the Robin platform benefit from a single approach to application and infrastructure management from experimentation to dev/test to a production environment that can span multiple clouds. Robin excels at managing heterogeneous infrastructure assets with a mix of compute, storage, and workload accelerators that can match the changing needs of fast-moving enterprise-wide demand for resources. Dell Technologies provides a wide range of PowerEdge rack servers with innovative designs to transform IT and maximize performance across the widest range of applications. PowerEdge servers match well with the three main types of infrastructure assets typically needed for a Robin managed implementation:
Compute Intensive | Storage Dense | Accelerator Enabled |
PowerEdge 640 | PowerEdge 740xd | PowerEdge 740 |
The PowerEdge R640 is the ideal dual-socket platform for dense scale-out data center computing. | The PowerEdge R740xd delivers a perfect balance between storage scalability and performance. The 2U two-socket platform is ideal for software defined storage. | The PowerEdge R740 was designed to accelerate application performance leveraging accelerator cards and storage scalability. The 2-socket, 2U platform has the optimum balance of resources to power the most demanding environments. |
Up to two 2nd Generation Intel® Xeon® Scalable processors, up to 28 cores per processor | Up to 24 NVMe drives and a total of 32 x 2.5” or 18 x 3.5” drives in a 2U dual-socket platform. | The scalable business architecture of the R740 can scale up to three 300W or six 150W GPUs, or up to three double-width or four single-width FPGAs |
24 DDR4 DIMM slots, Supports RDIMM /LRDIMM, speeds up to 2933MT/s, 3TB max Up to 12 NVDIMM, 192 GB Max Up to 12 Intel® Optane™ DC persistent memory DCPMM, 6.14TB max, (7.68TB max with DPCMM + LRDIMM) | Front bays: Up to 24 x 2.5” SAS/SATA (HDD/SSD), NVMe SSD max 184.32TB or up to 12 x 3.5” SAS/SATA HDD max 192TB Mid bay: Up to 4 x 2.5”, max 30.72TB SAS/SATA (HDD/SSD), or up to 4 x 3.5” SAS/SATA HDD, max 64TB Rear bays: Up to 4 x 2.5”, max 30.72TB SAS/SATA (HDD/SSD), or up to 2 x 3.5” SAS/SATA HDD max 32TB |
|
Robin is the ideal platform for hosting both stateful and stateless applications with support for both virtual machines and Docker-based applications. It includes a storage layer that provides data services, including snapshots, clones, backup/restore, and replication that enable hybrid cloud and multi-cloud operations for stateful applications that are not possible with pure open-source cloud-native technologies. It also includes a networking layer that supports carrier-grade networking OVS, Calico, VLAN, Overlay networking, Persistent IPs, Multiple NICs, SR-IOV, DPDK, and Dual-stack IPv4/IPv6
With the Robin platform on Dell EMC PowerEdge servers, organizations can:
· Decouple and scale compute and storage independently
· Provision/Decommission compute only clusters within minutes for ephemeral workloads
· All operations can be fully integrated with simple API commands from your development and/or production workflows.
· Migrate data workloads among data centers and public clouds
· Provide self-service capability for developers and data scientists to improve productivity
· Eliminate planning delays, start small and dynamically scale-up/out nodes to meet demand
· Consolidate multiple workloads on shared infrastructure to improve hardware utilization
· Trade resources among application clusters to manage cyclical compute requirements and surges
This results in,
· Reduced Costs
· Delivering faster insights
· Future-proofing the enterprise
For more information
Dell Technologies and Robin Systems welcome your feedback on this article and the information presented herein. Contact the Dell Technologies Solutions team by email.
You can also contact our regional sales teams for more information via email at the following addresses:
North America: analytics.assist@dell.com
LATAM: readysolutions.latam@dell.com
EMEA: EMEA_BigData_Team@dell.com
Thank you for your interest.
Related Blog Posts

Optimizing AI: Meeting Unstructured Storage Demands Efficiently

Thu, 21 Mar 2024 14:46:23 -0000
|Read Time: 0 minutes
The surge in artificial intelligence (AI) and machine learning (ML) technologies has sparked a revolution across industries, pushing the boundaries of what's possible. However, this innovation comes with its own set of challenges, particularly when it comes to storage. The heart of AI's potential lies in its ability to process and learn from vast amounts of data, most of which is unstructured. This has placed unprecedented demands on storage solutions, becoming a critical bottleneck for advancing AI technologies.
Navigating the complex landscape of unstructured data storage is no small feat. Traditional storage systems struggle to keep up with the scale and flexibility required by AI workloads. Enterprises find themselves at a crossroads, seeking solutions that can provide scalable, affordable, and fault-tolerant storage. The quest for such a platform is not just about meeting current needs but also paving the way for the future of AI-driven innovation.
The current state of ML and AI
The evolution of ML and AI technologies has reshaped industries far and wide, setting new expectations for data processing and analysis capabilities. These advancements are directly tied to an organization's capacity to handle vast volumes of unstructured data, a domain where traditional storage solutions are being outpaced.
ML and AI applications demand unprecedented levels of data ingestion and computational power, necessitating scalable and flexible storage solutions. Traditional storage systems—while useful for conventional data storage needs—grapple with scalability issues, particularly when faced with the immense file quantities AI and ML workloads generate.
Although traditional object storage methods are capable of managing data as objects within a pool, they fall short when meeting the agility and accessibility requirements essential for AI and ML processes. These storage models struggle with scalability and facilitating the rapid access and processing of data crucial for deep learning and AI algorithms.
The dire necessity of a new kind of storage solution is evident as the current infrastructure is unable to cope with the silos of unstructured data. These silos make it challenging to access, process, and unify data sources, which in turn cripples the effectiveness of AI and ML projects. Furthermore, the maximum storage capacity of traditional storage, tethering at tens of terabytes, is insufficient for the needs of AI-driven initiatives which often require petabytes of data to train sophisticated models.
As ML and AI continue to advance, the quest for a storage solution that can support the growing demands of these technologies remains pivotal. The industry is in dire need of systems that provide ample storage and ensure the flexibility, reliability, and performance efficiency necessary to propel AI and ML into their next phase of innovation.
Understanding unstructured storage demands for AI
The advent of AI and ML has brought unprecedented advancements across industries, enhancing efficiency, accuracy, and the ability to manage and process large datasets. However, the core of these technologies relies on the capability to store, access, and analyze unstructured data efficiently. Understanding the storage demands essential for AI applications is crucial for businesses looking to harness the full power of AI technology.
High throughput and low latency
For AI and ML applications, time is of the essence. The ability to process data at high speeds with high throughput and access it with minimal delay and low latency are non-negotiable requirements. These applications often involve complex computations performed on vast datasets, necessitating quick access to data to maintain a seamless process. For instance, in real-time AI applications such as voice recognition or instant fraud detection, any delay in data processing can critically impact performance and accuracy. Therefore, storage solutions must be designed to accommodate these needs, delivering data as swiftly as possible to the application layer.
Scalability and flexibility
As AI models evolve and the volume of data increases, the need for scalability in storage solutions becomes paramount. The storage architecture must accommodate growth without compromising on performance or efficiency. This is where the flexibility of the storage solutions comes into play. An ideal storage system for AI would scale in capacity and performance, adapting to the changing demands of AI applications over time. Combining the best of on-premises and cloud storage, hybrid storage solutions offer a viable path to achieving this scalability and flexibility. They enable businesses to leverage the high performance of on-premise solutions and the scalability and cost-efficiency of cloud storage, ensuring the storage infrastructure can grow with the AI application needs.
Data durability and availability
Ensuring the durability and availability of data is critical for AI systems. Data is the backbone of any AI application, and its loss or unavailability can lead to significant setbacks in development and performance. Storage solutions must, therefore, provide robust data protection mechanisms and redundancies to safeguard against data loss. Additionally, high availability is essential to ensure that data is always accessible when needed, particularly for AI applications that require continuous operation. Implementing a storage system with built-in redundancy, failover capabilities, and disaster recovery plans is essential to maintain continuous data availability and integrity.
In the context of AI where data is continually ingested, processed, and analyzed, the demands on storage solutions are unique and challenging. Key considerations include maintaining high throughput and low latency for real-time processing, establishing scalability and flexibility to adapt to growing data volumes, and ensuring data durability and availability to support continuous operation. Addressing these demands is critical for businesses aiming to leverage AI technologies effectively, paving the way for innovation and success in the digital era.
What needs to be stored for AI?
The evolution of AI and its underlying models depends significantly on various types of data and artifacts generated and used throughout its lifecycle. Understanding what needs to be stored is crucial for ensuring the efficiency and effectiveness of AI applications.
Raw data
Raw data forms the foundation of AI training. It's the unmodified, unprocessed information gathered from diverse sources. For AI models, this data can be in the form of text, images, audio, video, or sensor readings. Storing vast amounts of raw data is essential as it provides the primary material for model training and the initial step toward generating actionable insights.
Preprocessed data
Once raw data is collected, it undergoes preprocessing to transform it into a more suitable format for training AI models. This process includes cleaning, normalization, and transformation. As a refined version of raw data, preprocessed data needs to be stored efficiently to streamline further processing steps, saving time and computational resources.
Training datasets
Training datasets are a selection of preprocessed data used to teach AI models how to make predictions or perform tasks. These datasets must be diverse and comprehensive, representing real-world scenarios accurately. Storing these datasets allows AI models to learn and adapt to the complexities of the tasks they are designed to perform.
Validation and test datasets
Validation and test datasets are critical for evaluating an AI model's performance. These datasets are separate from the training data and are used to tune the model's parameters and test its generalizability to new, unseen data. Proper storage of these datasets ensures that models are both accurate and reliable.
Model parameters and weights
An AI model learns to make decisions through its parameters and weights. These elements are fine-tuned during training and crucial for the model's decision-making processes. Storing these parameters and weights allows models to be reused, updated, or refined without retraining from scratch.
Model architecture
The architecture of an AI model defines its structure, including the arrangement of layers and the connections between them. Storing the model architecture is essential for understanding how the model processes data and for replicating or scaling the model in future projects.
Hyperparameters
Hyperparameters are the configuration settings used to optimize model performance. Unlike parameters, hyperparameters are not learned from the data but set prior to the training process. Storing hyperparameter values is necessary for model replication and comparison of model performance across different configurations.
Feature engineering artifacts
Feature engineering involves creating new input features from the existing data to improve model performance. The artifacts from this process, including the newly created features and the logic used to generate them, need to be stored. This ensures consistency and reproducibility in model training and deployment.
Results and metrics
The results and metrics obtained from model training, validation, and testing provide insights into model performance and effectiveness. Storing these results allows for continuous monitoring, comparison, and improvement of AI models over time.
Inference data
Inference data refers to new, unseen data that the model processes to make predictions or decisions after training. Storing inference data is key for analyzing the model's real-world application and performance and making necessary adjustments based on feedback.
Embeddings
Embeddings are dense representations of high-dimensional data in lower-dimensional spaces. They play a crucial role in processing textual data, images, and more. Storing embeddings allows for more efficient computation and retrieval of similar items, enhancing model performance in recommendation systems and natural language processing tasks.
Code and scripts
The code and scripts used to create, train, and deploy AI models are essential for understanding and replicating the entire AI process. Storing this information ensures that models can be retrained, refined, or debugged as necessary.
Documentation and metadata
Documentation and metadata provide context, guidelines, and specifics about the AI model, including its purpose, design decisions, and operating conditions. Proper storage of this information supports ethical AI practices, model interpretability, and compliance with regulatory standards.
Challenges of unstructured data in AI
In the realm of AI, handling unstructured data presents a unique set of challenges that must be navigated carefully to harness its full potential. As AI systems strive to mimic human understanding, they face the intricate task of processing and deriving meaningful insights from data that lacks a predefined format. This section delves into the core challenges associated with unstructured data in AI, primarily focusing on data variety, volume, and velocity.
Data variety
Data variety refers to the myriad types of unstructured data that AI systems are expected to process, ranging from texts and emails to images, videos, and audio files. Each data type possesses its unique characteristics and demands specific preprocessing techniques to be effectively analyzed by AI models.
- Richer Insights but Complicated Processing: While the diverse data types can provide richer insights and enhance model accuracy, they significantly complicate the data preprocessing phase. AI tools must be equipped with sophisticated algorithms to identify, interpret, and normalize various data formats.
- Innovative AI Applications: The advantage of mastering data variety lies in the development of innovative AI applications. By handling unstructured data from different domains, AI can contribute to advancements in natural language processing, computer vision, and beyond.
Data volume
The sheer volume of unstructured data generated daily is staggering. As digital interactions increase, so does the amount of data that AI systems need to analyze.
- Scalability Challenges: The exponential growth in data volume poses scalability challenges for AI systems. Storage solutions must not only accommodate current data needs but also be flexible enough to scale with future demands.
- Efficient Data Processing: AI must leverage parallel processing and cloud storage options to keep up with the volume. Systems designed for high-throughput data analysis enable quicker insights, which are essential for timely decision-making and maintaining relevance in a rapidly evolving digital landscape.
Data velocity
Data velocity refers to the speed at which new data is generated and the pace at which it needs to be processed to remain actionable. In the age of real-time analytics and instant customer feedback, high data velocity is both an opportunity and a challenge for AI.
- Real-Time Processing Needs: AI systems are increasingly required to process information in real-time or near-real-time to provide timely insights. This necessitates robust computational infrastructure and efficient data streaming technologies.
- Constant Adaptation: The dynamic nature of unstructured data, coupled with its high velocity, demands that AI systems constantly adapt and learn from new information. Maintaining accuracy and relevance in fast-moving data environments is critical for effective AI performance.
In addressing these challenges, AI and ML technologies are continually evolving, developing more sophisticated systems capable of handling the complexity of unstructured data. The key to unlocking the value hidden within this data lies in innovative approaches to data management where flexibility, scalability, and speed are paramount.
Strategies to manage unstructured data in AI
The explosion of unstructured data poses unique challenges for AI applications. Organizations must adopt effective data management strategies to harness the full potential of AI technologies. In this section, we delve into key strategies like data classification and tagging and the use of PowerScale clusters to efficiently manage unstructured data in AI.
Data classification and tagging
Data classification and tagging are foundational steps in organizing unstructured data and making it more accessible for AI applications. This process involves identifying the content and context of data and assigning relevant tags or labels, which is crucial for enhancing data discoverability and usability in AI systems.
- Automated tagging tools can significantly reduce the manual effort required to label data, employing AI algorithms to understand the content and context automatically.
- Custom metadata tags allow for the creation of a rich set of file classification information. This not only aids in the classification phase but also simplifies later iterations and workflow automation.
- Effective data classification enhances data security by accurately categorizing sensitive or regulated information, enabling compliance with data protection regulations.
Implementing these strategies for managing unstructured data prepares organizations for the challenges of today's data landscape and positions them to capitalize on the opportunities presented by AI technologies. By prioritizing data classification and leveraging solutions like PowerScale clusters, businesses can build a strong foundation for AI-driven innovation.

Best practices for implementing AI storage solutions
Implementing the right AI storage solutions is crucial for businesses seeking to harness the power of artificial intelligence. With the explosive growth of unstructured data, adhering to best practices that optimize performance, scalability, and cost is imperative. This section delves into key practices to ensure your AI storage infrastructure meets the demands of modern AI workloads.
Assess workload requirements
Before diving into storage solutions, one must thoroughly assess AI workload requirements. Understanding the specific needs of your AI applications—such as the volume of data, the necessity for high throughput/low latency, and the scalability and availability requirements—is fundamental. This step ensures you select the most suitable storage solution that meets your application's needs.
AI workloads are diverse, with each having unique demands on storage infrastructure. For instance, training a machine learning model could require rapid access to vast amounts of data, whereas inference workloads may prioritize low latency. An accurate assessment leads to an optimized infrastructure, ensuring that storage solutions are neither overprovisioned nor underperforming, thereby supporting AI applications efficiently and cost-effectively.
Leverage PowerScale
For managing large volumes and varieties of unstructured data, leveraging PowerScale nodes offers a scalable and efficient solution. PowerScale nodes are designed to handle the complexities of AI and machine learning workloads, offering optimized performance, scalability, and data mobility. These clusters allow organizations to store and process vast amounts of data efficiently for a range of AI use cases due to the following:
- Scalability is a key feature, with PowerScale clusters capable of growing with the organization's data needs. They support massive capacities, allowing businesses to store petabytes of data seamlessly.
- Performance is optimized for the demanding workloads of AI applications with the ability to process large volumes of data at high speeds, reducing the time for data analyses and model training.
- Data mobility within PowerScale clusters on-premise and in the cloud ensures that data can be accessed when and where needed, supporting various AI and machine learning use cases across different environments.
PowerScale clusters allow businesses to start small and grow capacity as needed, ensuring that storage infrastructure can scale alongside AI initiatives without compromising on performance. The ability to handle multiple data types and protocols within a single storage infrastructure simplifies management and reduces operational costs, making PowerScale nodes an ideal choice for dynamic AI environments.
Utilize PowerScale OneFS 9.7.0.0
PowerScale OneFS 9.7.0.0 is the latest version of the Dell PowerScale operating system for scale-out network-attached storage (NAS). OneFS 9.7.0.0 introduces several enhancements in data security, performance, cloud integration, and usability.
OneFS 9.7.0.0 extends and simplifies the PowerScale offering in the public cloud, providing more features across various instance types and regions. Some of the key features in OneFS 9.7.0.0 include:
- Cloud Innovations: Extends cloud capabilities and features, building upon the debut of APEX File Storage for AWS
- Performance Enhancements: Enhancements to overall system performance
- Security Enhancements: Enhancements to data security features
- Usability Improvements: Enhancements to make managing and using PowerScale easier
Employ PowerScale F210 and F710
PowerScale, through its continuous innovation, extends into the AI era by introducing the next generation of PowerEdge-based nodes: the PowerScale F210 and F710. These new all-flash nodes leverage the Dell PowerEdge R660 from the PowerEdge platform, unlocking enhanced performance capabilities.
On the software front, both the F210 and F710 nodes benefit from significant performance improvements in PowerScale OneFS 9.7. These nodes effectively address the most demanding workloads by combining hardware and software innovations. The PowerScale F210 and F710 nodes represent a powerful combination of hardware and software advancements, making them well-suited for a wide range of workloads. For more information on the F210 and F710, see PowerScale All-Flash F210 and F710 | Dell Technologies Info Hub.
Ensure data security and compliance
Given the sensitivity of the data used in AI applications, robust security measures are paramount. Businesses must implement comprehensive security strategies that include encryption, access controls, and adherence to data protection regulations. Safeguarding data protects sensitive information and reinforces customer trust and corporate reputation.
Compliance with data protection laws and regulations is critical to AI storage solutions. As regulations can vary significantly across regions and industries, understanding and adhering to these requirements is essential to avoid significant fines and legal challenges. By prioritizing data security and compliance, organizations can mitigate risks associated with data breaches and non-compliance.
Monitor and optimize
Continuous storage environment monitoring and optimization are essential for maintaining high performance and efficiency. Monitoring tools can provide insights into usage patterns, performance bottlenecks, and potential security threats, enabling proactive management of the storage infrastructure.
Regular optimization efforts can help fine-tune storage performance, ensuring that the infrastructure remains aligned with the evolving needs of AI applications. Optimization might involve adjusting storage policies, reallocating resources, or upgrading hardware to improve efficiency, reduce costs, and ensure that storage solutions continue to effectively meet the demands of AI workloads.
By following these best practices, businesses can build and maintain a storage infrastructure that supports their current AI applications and is poised for future growth and innovation.
Conclusion
Navigating the complexities of unstructured storage demands for AI is no small feat. Yet, by adhering to the outlined best practices, businesses stand to benefit greatly. The foundational steps include assessing workload requirements, selecting the right storage solutions, and implementing robust security measures. Furthermore, integrating PowerScale nodes and a commitment to continuous monitoring and optimization are key to sustaining high performance and efficiency. As the landscape of AI continues to evolve, these practices will not only support current applications but also pave the way for future growth and innovation. In the dynamic world of AI, staying ahead means being prepared, and these strategies offer a roadmap to success.
Frequently asked questions
How big are AI data centers?
Data centers catering to AI, such as those by Amazon and Google, are immense, comparable to the scale of football stadiums.
How does AI process unstructured data?
AI processes unstructured data including images, documents, audio, video, and text by extracting and organizing information. This transformation turns unstructured data into actionable insights, propelling business process automation and supporting AI applications.
How much storage does an AI need?
AI applications, especially those involving extensive data sets, might require significant memory, potentially as much as 1TB or more. Such vast system memory efficiently facilitates the processing and statistical analysis of entire data sets.
Can AI handle unstructured data?
Yes, AI is capable of managing both structured and unstructured data types from a variety of sources. This flexibility allows AI to analyze and draw insights from an expansive range of data, further enhancing its utility across diverse applications.
Author: Aqib Kazi, Senior Principal Engineer, Technical Marketing
Unveiling the Power of the PowerEdge XE9680 Server on the GPT-J Model from MLPerf™ Inference
Tue, 16 Jan 2024 18:30:32 -0000
|Read Time: 0 minutes
Abstract
For the first time, the latest release of the MLPerf™ inference v3.1 benchmark includes the GPT-J model to represent large language model (LLM) performance on different systems. As a key player in the MLPerf consortium since version 0.7, Dell Technologies is back with exciting updates about the recent submission for the GPT-J model in MLPerf Inference v3.1. In this blog, we break down what these new numbers mean and present the improvements that Dell Technologies achieved with the Dell PowerEdge XE9680 server.
MLPerf inference v3.1
MLPerf inference is a standardized test for machine learning (ML) systems, allowing users to compare performance across different types of computer hardware. The test helps determine how well models, such as GPT-J, perform on various machines. Previous blogs provide a detailed MLPerf inference introduction. For in-depth details, see Introduction to MLPerf inference v1.0 Performance with Dell Servers. For step-by-step instructions for running the benchmark, see Running the MLPerf inference v1.0 Benchmark on Dell Systems. Inference version v3.1 is the seventh inference submission in which Dell Technologies has participated. The submission shows the latest system performance for different deep learning (DL) tasks and models.
Dell PowerEdge XE9680 server
The PowerEdge XE9680 server is Dell’s latest two-socket, 6U air-cooled rack server that is designed for training and inference for the most demanding ML and DL large models.

Figure 1. Dell PowerEdge XE9680 server
Key system features include:
- Two 4th Gen Intel Xeon Scalable Processors
- Up to 32 DDR5 DIMM slots
- Eight NVIDIA HGX H100 SXM 80 GB GPUs
- Up to 10 PCIe Gen5 slots to support the latest Gen5 PCIe devices and networking, enabling flexible networking design
- Up to eight U.2 SAS4/SATA SSDs (with fPERC12)/ NVMe drives (PSB direct) or up to 16 E3.S NVMe drives (PSB direct)
- A design to train and inference the most demanding ML and DL large models and run compute-intensive HPC workloads
The following figure shows a single NVIDIA H100 SXM GPU:

Figure 2. NVIDIA H100 SXM GPU
GPT-J model for inference
Language models take tokens as input and predict the probability of the next token or tokens. This method is widely used for essay generation, code development, language translation, summarization, and even understanding genetic sequences. The GPT-J model in MLPerf inference v3.1 has 6 B parameters and performs text summarization tasks on the CNN-DailyMail dataset. The model has 28 transformer layers, and a sequence length of 2048 tokens.
Performance updates
The official MLPerf inference v3.1 results for all Dell systems are published on https://mlcommons.org/benchmarks/inference-datacenter/. The PowerEdge XE9680 system ID is ID 3.1-0069.
After submitting the GPT-J model, we applied the latest firmware updates to the PowerEdge XE9680 server. The following figure shows that performance improved as a result:
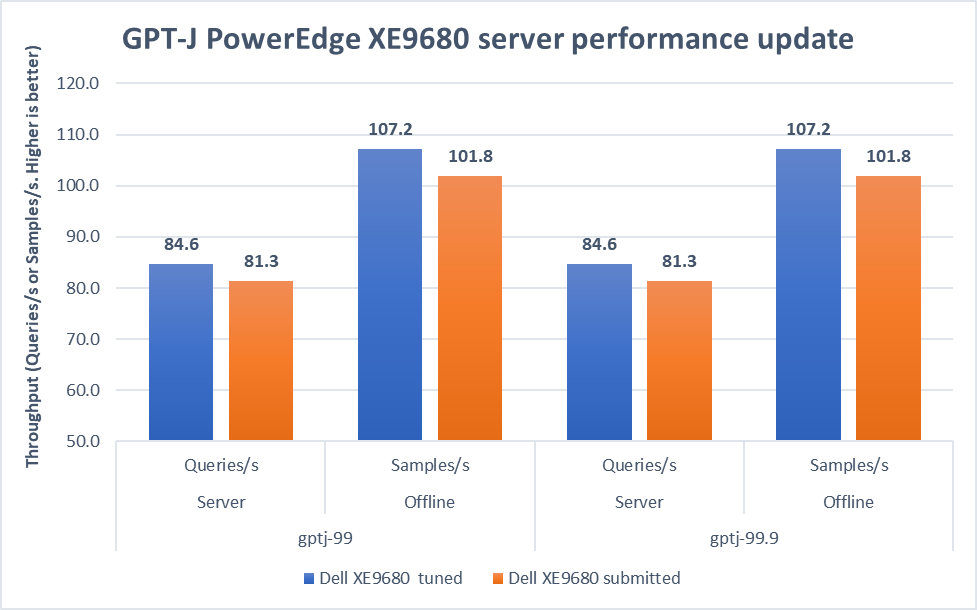
Figure 3. Improvement of the PowerEdge XE9680 server on GPT-J Datacenter 99 and 99.9, Server and Offline scenarios [1]
In both 99 and 99.9 Server scenarios, the performance increased from 81.3 to an impressive 84.6. This 4.1 percent difference showcases the server's capability under randomly fed inquires in the MLPerf-defined latency restriction. In the Offline scenarios, the performance saw a notable 5.3 percent boost from 101.8 to 107.2. These results mean that the server is even more efficient and capable of handling batch-based LLM workloads.
Note: For PowerEdge XE9680 server configuration details, see https://github.com/mlcommons/inference_results_v3.1/blob/main/closed/Dell/systems/XE9680_H100_SXM_80GBx8_TRT.json
Conclusion
This blog focuses on the updates of the GPT-J model in the v3.1 submission, continuing the journey of Dell’s experience with MLPerf inference. We highlighted the improvements made to the PowerEdge XE9680 server, showing Dell's commitment to pushing the limits of ML benchmarks. As technology evolves, Dell Technologies remains a leader, constantly innovating and delivering standout results.
[1] Unverified MLPerf® v3.1 Inference Closed GPT-J. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.