




Sharing the Love for GPUs in Machine Learning - Part 2


In Part 1 of “Share the GPU Love” we covered the need for improving the utilization of GPU accelerators and how a relatively simple technology like VMware DirectPath I/O together with some sharing processes could be a starting point. As with most things in technology, some additional technology, and knowledge you can achieve high goals beyond just the basics. In this article, we are going to introduce another technology for managing GPU-as-a-service – NVIDIA GRID 9.0.
Before we jump to this next technology, let’s review some of the limitations of using DirectPath I/O for virtual machine access to physical PCI functions. The online documentation for VMware DirectPath I/O has a complete list of features that are unavailable for virtual machines configured with DirectPath I/O. Some of the most important ones are:
- Fault tolerance
- High availability
- Snapshots
- Hot adding and removing of virtual devices
The technique of “passing through” host hardware to a virtual machine (VM) is simple but doesn’t leverage many of the virtues of true hardware virtualization. NVIDIA delivers software to virtualize GPUs in the data center for years. The primary use case has been Virtual Desktop Infrastructure (VDI) using vGPUs. The current release - NVIDIA vGPU Software 9 adds the vComputeServer vGPU capability for supporting artificial intelligence, deep learning, and high-performance computing workloads. The rest of this article will cover using vGPU for machine learning in a VMware ESXi environment.
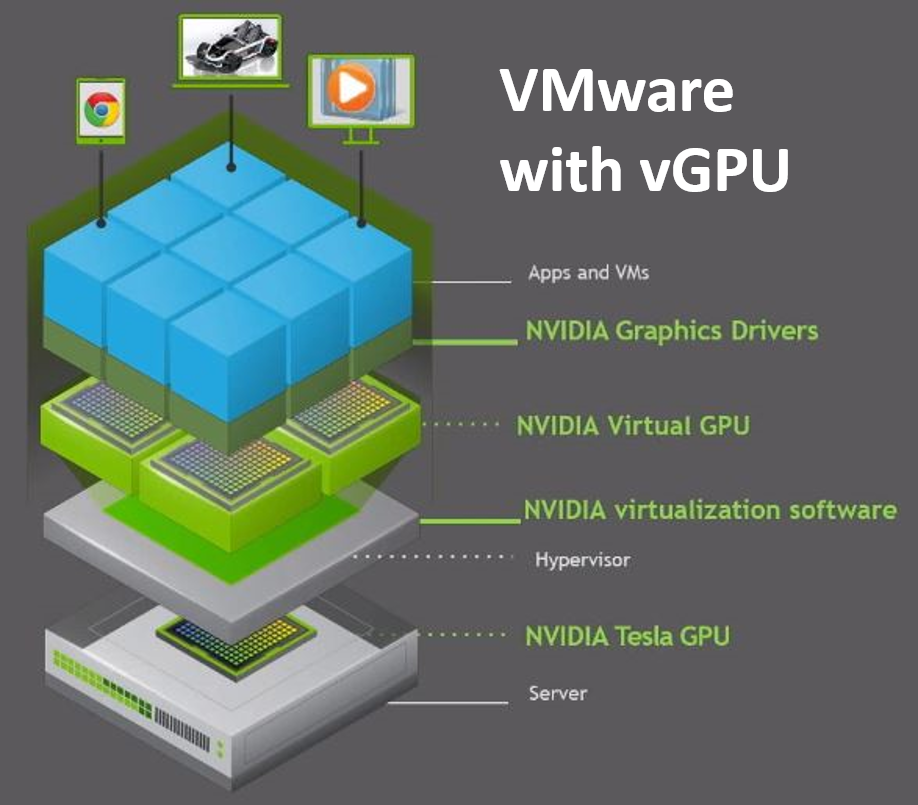
We want to compare the setup and features of this latest NVIDIA software version, so we worked on adding the vComputeServer to our PowerEdge ESXi that we used for the DirectPath I/O research in our first blog in this series. Our NVIDIA Turing architecture T4 GPUs are on the list of supported devices, so we can check that box and our ESXi version is compatible. The NVIDIA vGPU software documentation for VMware vSphere has an exhaustive list of requirements and compatibility notes.
You’ll have to put your host into maintenance mode during installation and then reboot after the install of the VIB completes. When the ESXi host is back online you can use the now-familiar nvidia-smi command with no parameters and see a list of all available GPUs that indicates you are ready to proceed.
We configured two of our T4 GPUs for vGPU use and setup the required licenses. Then we followed the same approach that we used for DirectPath I/O to build out VM templates with everything that is common to all developments and use those to create the developer-specific VMs – one with all Python tools and another with R tools. NVIDIA vGPU software supports only 64-bit guest operating systems. No 32-bit guest operating systems are supported. You should only use a guest OS release that is supported by both for NVIDIA vGPU software and by VMware. NVIDIA will not be able to support guest OS releases that are not supported by your virtualization software.

Now that we have both a DirectPath I/O enabled setup and the NVIDIA vGPU environment let’s compare the user experience. First, starting with vSphere 6.7 U1 release, vMotion with vGPU and suspend and resume with vGPU are supported on suitable GPUs. Always check the NVIDIA Virtual GPU Software Documentation for all the latest details. vSphere 6.7 only supports suspend and resume with vGPU. vMotion with vGPU is not supported in release 6.7. [double check this because vMotion is supported I just can't remember what version and update number it is]
vMotion can be extremely valuable for data scientists doing long-running training jobs that you don’t get with DirectPath I/O and suspend/resume of vGPU enabled VMs creates opportunities to increase the return from your GPU investments by enabling scenarios with data science model training running at night and interactive graphics-intensive applications running during the day utilizing the same pool of GPUs. Organizations with workers spread across time zones may also find that suspend/resume of vGPU enabled VMs to be useful.
There is still a lot of work that we want to do in our lab including capturing some informational videos that will highlight some of the concepts we have been talking about in these last two articles. We are also starting to build out some VMs configured with Docker so we can look at using our vGPUs with NVIDIA GPU Cloud (GCP) deep learning training and inferencing containers. Our goal is to get more folks setting up a sandbox environment using these articles along with the NVIDIA and VMware links we have provided. We want to hear about your experience working with vGPUs and VMware. If you have any questions or comments post them in the feedback section below.
Thanks for reading,
Phil Hummel - On Twitter @GotDisk
Related Blog Posts

Sharing the Love for GPUs in Machine Learning
Wed, 17 Mar 2021 16:53:14 -0000
|Read Time: 0 minutes

Anyone that works with machine learning models trained by optimization methods like stochastic gradient descent (SGD) knows about the power of specialized hardware accelerators for performing a large number of matrix operations that are needed. Wouldn’t it be great if we all had our own accelerator dense supercomputers? Unfortunately, the people that manage budgets aren’t approving that plan, so we need to find a workable mix of technology and, yes, the dreaded concept, process to improve our ability to work with hardware accelerators in shared environments.
We have gotten a lot of questions from a customer trying to increase the utilization rates of machines with specialized accelerators. Good news, there are a lot of big technology companies working on solutions. The rest of the article is going to focus on technology from Dell EMC, NVIDIA, and VMware that is both available today and some that are coming soon. We also sprinkle in some comments about the process that you can consider. Please add your thoughts and questions in the comments section below.
We started this latest round of GPU-as-a-service research with a small amount of kit in the Dell EMC Customer Solutions Center in Austin. We have one Dell EMC PowerEdge R740 with 4 NVIDIA T4 GPUs connected to the system on the PCIe bus. Our research question is “how can a group of data scientists working on different models with different development tools share these four GPUs?” We are going to compare two different technology options:
- VMware Direct Path I/O
- NVIDIA GPU GRID 9.0
Our server has ESXi installed and is configured as a 1 node cluster in vCenter. I’m going to skip the configuration of the host BIOS and ESXi and jump straight to creating VMs. We started off with the Direct Path I/O option. You should review the article “Using GPUs with Virtual Machines on vSphere – Part 2: VMDirectPath I/O” from VMware before trying this at home. It has a lot of details that we won’t repeat here.
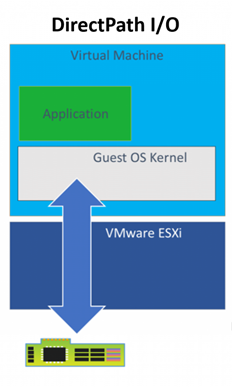
There are many approaches available for virtual machine image management that can be set up by the VMware administrators but for this project, we are assuming that our data scientists are building and maintaining the images they use. Our scenario is to show how a group of Python users can have one image and the R users can have another image that both use GPUs when needed. Both groups are using primarily TensorFlow and Keras.
Before installing an OS we changed the firmware setting to EFI in the VM Boot Options menu per the article above. We also used the VM options to assign one physical GPU to the VM using Direct Path I/O before proceeding with any software installs. It is important for there to be a device present during configuration even though the VM may get used later with or without an assigned GPU to facilitate sharing among users and/or teams.
Once the OS was installed and configured with user accounts and updates, we installed the NVIDIA GPU related software and made two clones of that image since both the R and Python environment setups need the same supporting libraries and drivers to use the GPUs when added to the VM through Direct Path I/O. Having the base image with an OS plus NVIDIA libraries saves a lot of time if you want a new type of developer environment.
With this much of the setup done, we can start testing assigning and removing GPU devices among our two VMs. We use VM options to add and remove the devices but only while the VM is powered off. For example, we can assign 2 GPUs to each VM, 4 GPUs to one VM and none to the other or any other combination that doesn’t exceed our 4 available devices. Devices currently assigned to other VMs are not available in the UI for assignment, so it is not physically possible to create conflicts between VMs. We can NVIDIA’s System Management Interface (nvidia-smi) to list the devices available on each VM.
Remember above when we talked about process, here is where we need to revisit that. The only way a setup like this works is if people release GPUs from VMs when they don’t need them. Going a level deeper there will probably be a time when one user or group could take advantage of a GPU but would choose to not take one so other potentially more critical work can have it. This type of resource sharing is not new to research and development. All useful resources are scarce, and a lot of efficiencies can be gained with the right technology, process, and attitude
.Before we talk about installing the developer frameworks and libraries, let’s review the outcome we desire. We have 2 or more groups of developers that could benefit from the use of GPUs at different times in their workflow but not always. They would like to minimize the number of VM images they need and have and would also like fewer versions of code to maintain even when switching between tasks that may or may not have access to GPUs when running. We talked above about switching GPUs between machines but what happens on the software side? Next, we’ll talk about some TensorFlow properties that make this easier.
TensorFlow comes in two main flavors for installation tensorflow and tensorflow-gpu. The first one should probably be called “tensorflow-cpu” for clarity. For this work, we are only installing the GPU enabled version since we are going to want our VMs to be able to use GPU for any operations that TF supports for GPU devices. The reason that I don’t also need the CPU version when my VM has not been assigned any GPUs is that many operations available in the GPU enabled version of TF have both a CPU and a GPU implantation. When an operation is run without a specific device assignment, any available GPU device will be given priority in the placement. When the VM does not have a GPU device available the operation will use the CPU implementation.
There are many examples online for testing if you have a properly configured system with a functioning GPU device. This simple matrix multiplication sample is a good starting point. Once that is working you can move on a full-blown model training with a sample data set like the MNIST character recognition model. Try setting up a sandbox environment using this article and the VMware blog series above. Then get some experience with allocating and deallocating GPUs to VMs and prove that things are working with a small app. If you have any questions or comments post them in the feedback section below.
Thanks for reading.
Phil Hummel - Twitter @GotDisk@GotDisk

Can I do that AI thing on Dell PowerFlex?

Thu, 20 Jul 2023 21:08:09 -0000
|Read Time: 0 minutes
The simple answer is Yes, you can do that AI thing with Dell PowerFlex. For those who might have been busy with other things, AI stands for Artificial Intelligence and is based on trained models that allow a computer to “think” in ways machines haven’t been able to do in the past. These trained models (neural networks) are essentially a long set of IF statements (layers) stacked on one another, and each IF has a ‘weight’. Once something has worked through a neural network, the weights provide a probability about the object. So, the AI system can be 95% sure that it’s looking at a bowl of soup or a major sporting event. That, at least, is my overly simplified description of how AI works. The term carries a lot of baggage as it’s been around for more than 70 years, and the definition has changed from time to time. (See The History of Artificial Intelligence.)
Most recently, AI has been made famous by large language models (LLMs) for conversational AI applications like ChatGPT. Though these applications have stoked fears that AI will take over the world and destroy humanity, that has yet to be seen. Computers still can do only what we humans tell them to do, even LLMs, and that means if something goes wrong, we their creators are ultimately to blame. (See ‘Godfather of AI’ leaves Google, warns of tech’s dangers.)
The reality is that most organizations aren’t building world destroying LLMs, they are building systems to ensure that every pizza made in their factory has exactly 12 slices of pepperoni evenly distributed on top of the pizza. Or maybe they are looking at loss prevention, or better traffic light timing, or they just want a better technical support phone menu. All of these are uses for AI and each one is constructed differently (they use different types of neural networks).
We won’t delve into these use cases in this blog because we need to start with the underlying infrastructure that makes all those ideas “AI possibilities.” We are going to start with the infrastructure and what many now consider a basic (by today’s standards) image classifier known as ResNet-50 v1.5. (See ResNet-50: The Basics and a Quick Tutorial.)
That’s also what the PowerFlex Solution Engineering team did in the validated design they recently published. This design details the use of ResNet-50 v1.5 in a VMware vSphere environment using NVIDIA AI Enterprise as part of PowerFlex environment. They started out with the basics of how a virtualized NVIDIA GPU works well in a PowerFlex environment. That’s what we’ll explore in this blog – getting started with AI workloads, and not how you build the next AI supercomputer (though you could do that with PowerFlex as well).
In this validated design, they use the NVIDIA A100 (PCIe) GPU and virtualized it in VMware vSphere as a virtual GPU or vGPU. With the infrastructure in place, they built Linux VMs that will contain the ResNet-50 v1.5 workload and vGPUs. Beyond just working with traditional vGPUs that many may be familiar with, they also worked with NVIDIA’s Multi-Instance GPU (MIG) technology.
NVIDIA’s MIG technology allows administrators to partition a GPU into a maximum of seven GPU instances. Being able to do this provides greater control of GPU resources, ensuring that large and small workloads get the appropriate amount of GPU resources they need without wasting any.
PowerFlex supports a large range of NVIDIA GPUs for workloads, from VDI (Virtual Desktops) to high end virtual compute workloads like AI. You can see this in the following diagram where there are solutions for “space constrained” and “edge” environments, all the way to GPUs used for large inferencing models. In the table below the diagram, you can see which GPUs are supported in each type of PowerFlex node. This provides a tremendous amount of flexibility depending on your workloads.

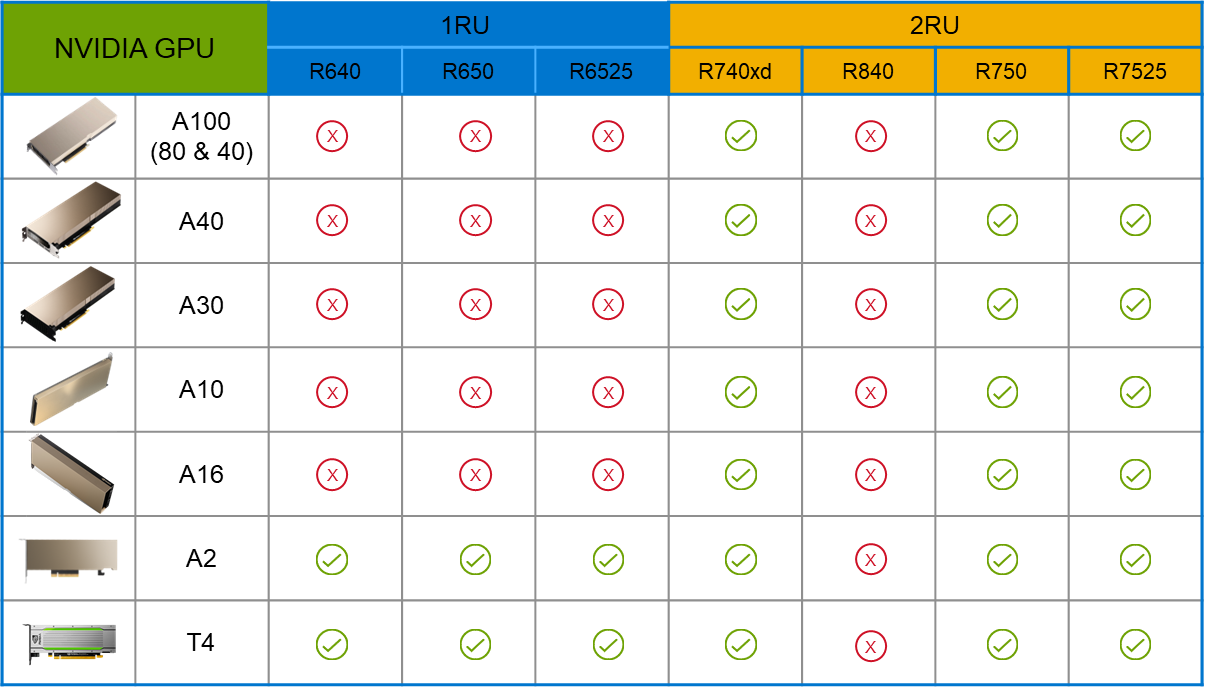
The validated design describes the steps to configure the architecture and provides detailed links to the NVIDIAand VMware documentation for configuring the vGPUs, and the licensing process for NVIDIA AI Enterprise.
These are key steps when building an AI environment. I know from my experience working with various organizations, and from teaching, that many are not used to working with vGPUs in Linux. This is slowly changing in the industry. If you haven’t spent a lot of time working with vGPUs in Linux, be sure to pay attention to the details provided in the guide. It is important and can make a big difference in your performance.
The following diagram shows the validated design’s logical architecture. At the top of the diagram, you can see four Ubuntu 22.04 Linux VMs with the NVIDIA vGPU driver loaded in them. They are running on PowerFlex hosts with VMware ESXi deployed. Each VM contains one NVIDIA A100 GPU configured for MIG operations. This configuration leverages a two-tier architecture where storage is provided by separate PowerFlex software defined storage (SDS) nodes.
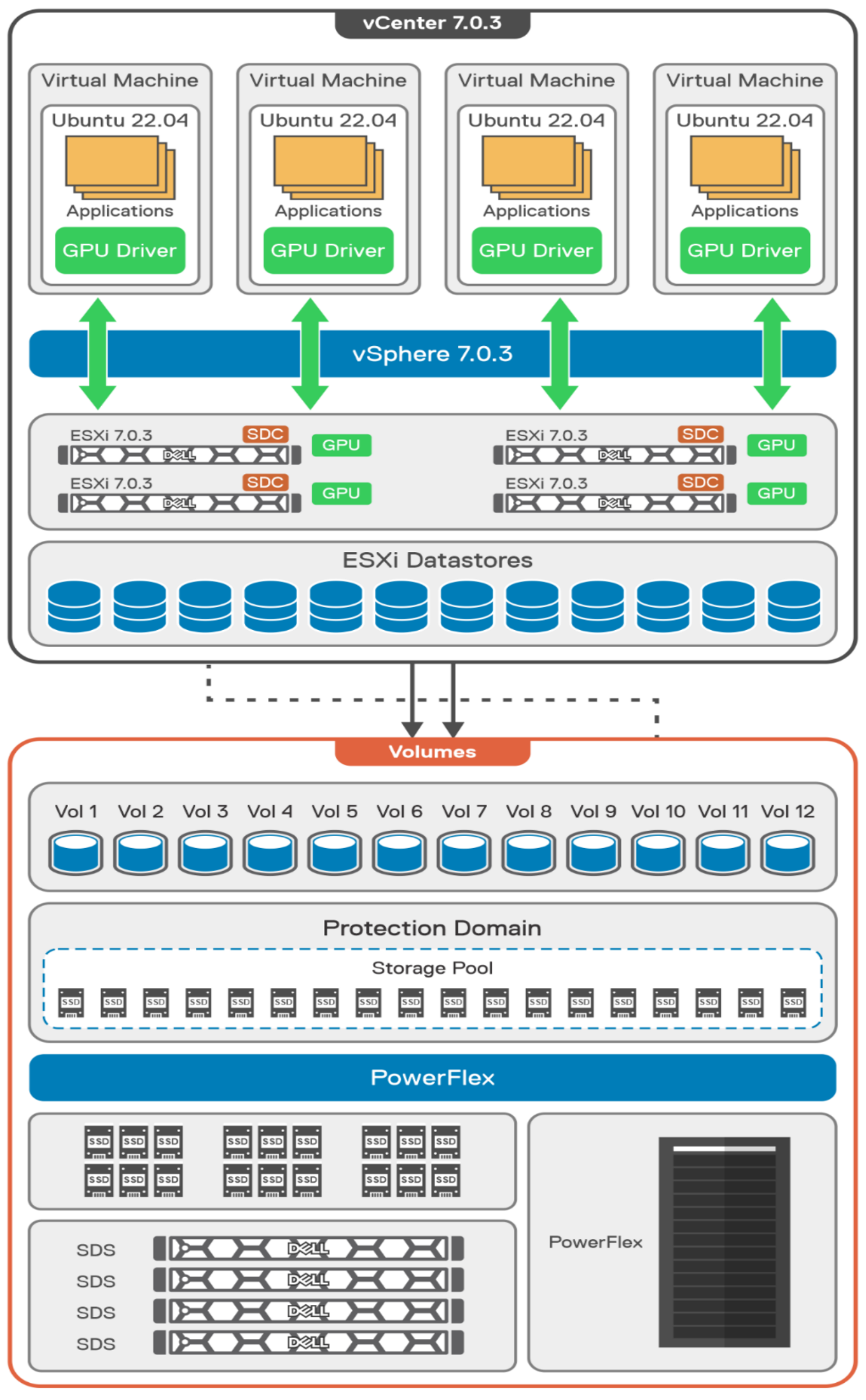
A design like this allows for independent scalability for your workloads. What I mean by this is during the training phase of a model, significant storage may be required for the training data, but once the model clears validation and goes into production, storage requirements may be drastically different. With PowerFlex you have the flexibility to deliver the storage capacity and performance you need at each stage.
This brings us to testing the environment. Again, for this paper, the engineering team validated it using ResNet-50 v1.5 using the ImageNet 1K data set. For this validation they enabled several ResNet-50 v1.5 TensorFlow features. These include Multi-GPU training with Horovod, NVIDIA DALI, and Automatic Mixed Precision (AMP). These help to enable various capabilities in the ResNet-50 v1.5 model that are present in the environment. The paper then describes how to set up and configure ResNet-50 v1.5, the features mentioned above, and details about downloading the ImageNet data.
At this stage they were able to train the ResNet-50 v1.5 deployment. The first iteration of training used the NVIDIA A100-7-40C vGPU profile. They then repeated testing with the A100-4-20C vGPU profile and the A100-3-20C vGPU profile. You might be wondering about the A100-2-10C vGPU profile and the A100-1-5C profile. Although those vGPU profiles are available, they are more suited for inferencing, so they were not tested.
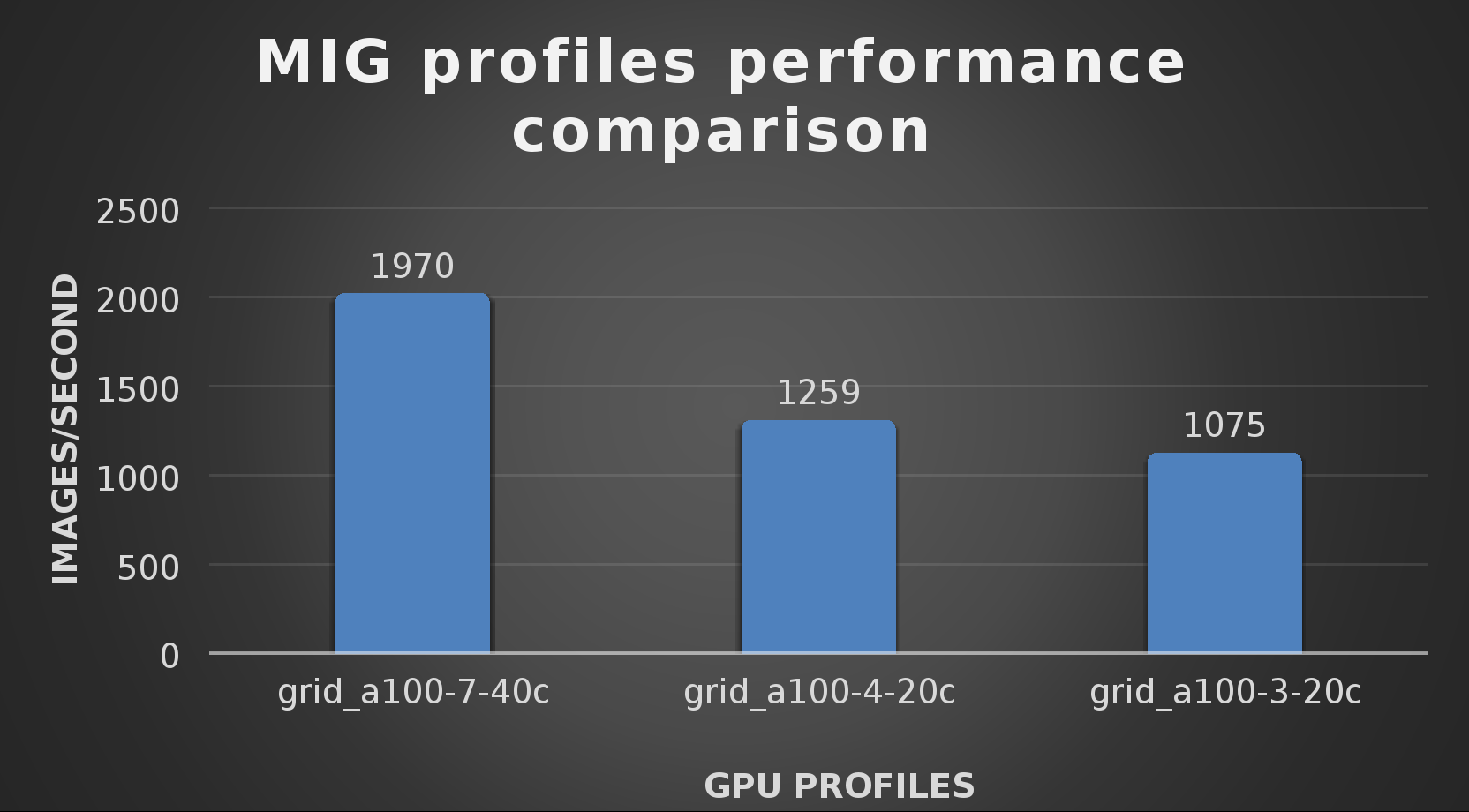
The results from validating the training workloads for each vGPU profile is shown in the following graph. The vGPUs were running near 98% capacity according to nvitop during each test. The CPU utilization was 14% and there was no bottle neck with the storage during the tests.
With the models trained, the guide then looks at how well inference runs on the MIG profiles. The following graph shows inferencing images per second of the various MIG profiles with ResNet-50 v1.5.
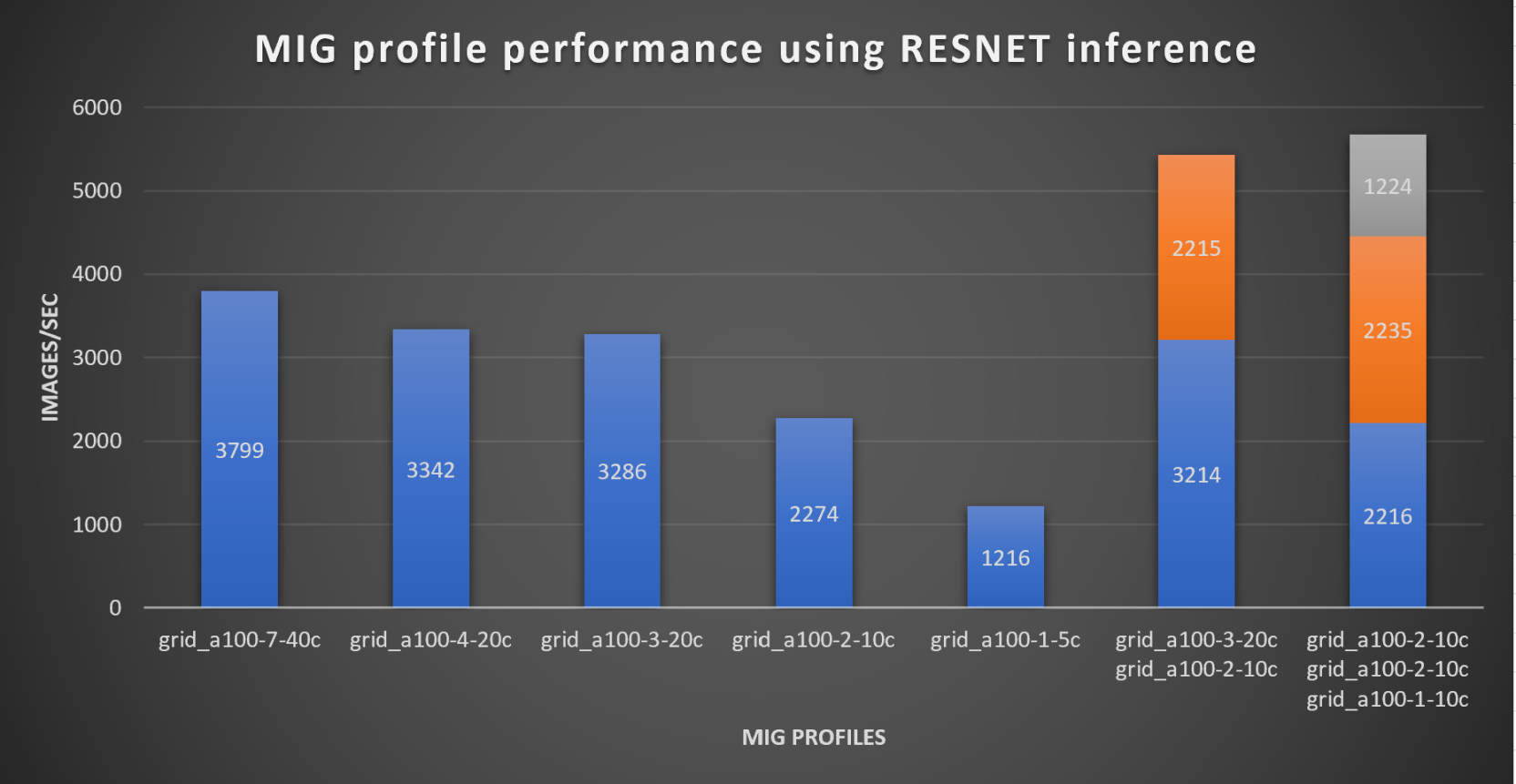
It’s worth noting that the last two columns show the inferencing running across multiple VMs, on the same ESXi host, that are leveraging MIG profiles. This also shows that GPU resources are partitioned with MIG and that resources can be precisely controlled, allowing multiple types of jobs to run on the same GPU without impacting other running jobs.
This opens the opportunity for organizations to align consumption of vGPU resources in virtual environments. Said a different way, it allows IT to provide “show back” of infrastructure usage in the organization. So if a department only needs an inferencing vGPU profile, that’s what they get, no more, no less.
It’s also worth noting that the results from the vGPU utilization were at 88% and CPU utilization was 11% during the inference testing.
These validations show that a Dell PowerFlex environment can support the foundational components of modern-day AI. It also shows the value of NVIDIA’s MIG technology to organizations of all sizes: allowing them to gain operational efficiencies in the data center and enable access to AI.
Which again answers the question of this blog, can I do that AI thing on Dell PowerFlex… Yes you can run that AI thing! If you would like to find out more about how to run your AI thing on PowerFlex, be sure to reach out to your Dell representative.
Resources
- The History of Artificial Intelligence
- ‘Godfather of AI’ leaves Google, warns of tech’s dangers
- ResNet-50: The Basics and a Quick Tutorial
- Dell Validated Design for Virtual GPU with VMware and NVIDIA on PowerFlex
- NVIDIA NGC Catalog ResNet v1.5 for PyTorch
- NVIDIA AI Enterprise
- NVIDIA A100 (PCIe) GPU
- NVIDIA Virtual GPU Software Documentation
- NVIDIA A100-7-40C vGPU profile
- NVIDIA Multi-Instance GPU (MIG)
- NVIDIA Multi-Instance GPU User Guide
- Horovod
- ImageNet
- DALI
- Automatic Mixed Precision (AMP)
- nvitop
Author: Tony Foster
Sr. Principal Technical Marketing Engineer
Twitter: | |
LinkedIn: | |
Personal Blog: | |
Location: | The Land of Oz [-6 GMT] |