




Sharing the Love for GPUs in Machine Learning


Anyone that works with machine learning models trained by optimization methods like stochastic gradient descent (SGD) knows about the power of specialized hardware accelerators for performing a large number of matrix operations that are needed. Wouldn’t it be great if we all had our own accelerator dense supercomputers? Unfortunately, the people that manage budgets aren’t approving that plan, so we need to find a workable mix of technology and, yes, the dreaded concept, process to improve our ability to work with hardware accelerators in shared environments.
We have gotten a lot of questions from a customer trying to increase the utilization rates of machines with specialized accelerators. Good news, there are a lot of big technology companies working on solutions. The rest of the article is going to focus on technology from Dell EMC, NVIDIA, and VMware that is both available today and some that are coming soon. We also sprinkle in some comments about the process that you can consider. Please add your thoughts and questions in the comments section below.
We started this latest round of GPU-as-a-service research with a small amount of kit in the Dell EMC Customer Solutions Center in Austin. We have one Dell EMC PowerEdge R740 with 4 NVIDIA T4 GPUs connected to the system on the PCIe bus. Our research question is “how can a group of data scientists working on different models with different development tools share these four GPUs?” We are going to compare two different technology options:
- VMware Direct Path I/O
- NVIDIA GPU GRID 9.0
Our server has ESXi installed and is configured as a 1 node cluster in vCenter. I’m going to skip the configuration of the host BIOS and ESXi and jump straight to creating VMs. We started off with the Direct Path I/O option. You should review the article “Using GPUs with Virtual Machines on vSphere – Part 2: VMDirectPath I/O” from VMware before trying this at home. It has a lot of details that we won’t repeat here.
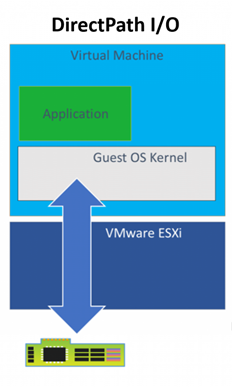
There are many approaches available for virtual machine image management that can be set up by the VMware administrators but for this project, we are assuming that our data scientists are building and maintaining the images they use. Our scenario is to show how a group of Python users can have one image and the R users can have another image that both use GPUs when needed. Both groups are using primarily TensorFlow and Keras.
Before installing an OS we changed the firmware setting to EFI in the VM Boot Options menu per the article above. We also used the VM options to assign one physical GPU to the VM using Direct Path I/O before proceeding with any software installs. It is important for there to be a device present during configuration even though the VM may get used later with or without an assigned GPU to facilitate sharing among users and/or teams.
Once the OS was installed and configured with user accounts and updates, we installed the NVIDIA GPU related software and made two clones of that image since both the R and Python environment setups need the same supporting libraries and drivers to use the GPUs when added to the VM through Direct Path I/O. Having the base image with an OS plus NVIDIA libraries saves a lot of time if you want a new type of developer environment.
With this much of the setup done, we can start testing assigning and removing GPU devices among our two VMs. We use VM options to add and remove the devices but only while the VM is powered off. For example, we can assign 2 GPUs to each VM, 4 GPUs to one VM and none to the other or any other combination that doesn’t exceed our 4 available devices. Devices currently assigned to other VMs are not available in the UI for assignment, so it is not physically possible to create conflicts between VMs. We can NVIDIA’s System Management Interface (nvidia-smi) to list the devices available on each VM.
Remember above when we talked about process, here is where we need to revisit that. The only way a setup like this works is if people release GPUs from VMs when they don’t need them. Going a level deeper there will probably be a time when one user or group could take advantage of a GPU but would choose to not take one so other potentially more critical work can have it. This type of resource sharing is not new to research and development. All useful resources are scarce, and a lot of efficiencies can be gained with the right technology, process, and attitude
.Before we talk about installing the developer frameworks and libraries, let’s review the outcome we desire. We have 2 or more groups of developers that could benefit from the use of GPUs at different times in their workflow but not always. They would like to minimize the number of VM images they need and have and would also like fewer versions of code to maintain even when switching between tasks that may or may not have access to GPUs when running. We talked above about switching GPUs between machines but what happens on the software side? Next, we’ll talk about some TensorFlow properties that make this easier.
TensorFlow comes in two main flavors for installation tensorflow and tensorflow-gpu. The first one should probably be called “tensorflow-cpu” for clarity. For this work, we are only installing the GPU enabled version since we are going to want our VMs to be able to use GPU for any operations that TF supports for GPU devices. The reason that I don’t also need the CPU version when my VM has not been assigned any GPUs is that many operations available in the GPU enabled version of TF have both a CPU and a GPU implantation. When an operation is run without a specific device assignment, any available GPU device will be given priority in the placement. When the VM does not have a GPU device available the operation will use the CPU implementation.
There are many examples online for testing if you have a properly configured system with a functioning GPU device. This simple matrix multiplication sample is a good starting point. Once that is working you can move on a full-blown model training with a sample data set like the MNIST character recognition model. Try setting up a sandbox environment using this article and the VMware blog series above. Then get some experience with allocating and deallocating GPUs to VMs and prove that things are working with a small app. If you have any questions or comments post them in the feedback section below.
Thanks for reading.
Phil Hummel - Twitter @GotDisk@GotDisk