
Assets

It’s Been a Dell EMC VxRail Filled Summer
Fri, 26 Apr 2024 17:21:21 -0000
|Read Time: 0 minutes
Get your VxRail learn on with Tech Field Days and ESG
It has been a busy summer with the launch of our Next Gen VxRail nodes built on 15th Generation PowerEdge servers. This has included working with the fantastic people at ESG and Tech Field Day. Working with these top tier luminaries really forces us to distill our messaging to the key points – no small feat, particularly with so many new releases and enhancements.
 If you are not familiar with Tech Field Days, they are “a series of invite-only technical meetings between delegates invited from around the world and sponsoring enterprise IT companies that share their products and ideas through presentations, demos, roundtables, and more”. The delegates are all hand-picked industry thought leaders – those wicked smart people you are following on Twitter – and they ask tough questions. Earlier this month, Dell Technologies spent two days with them: a day dedicated to storage, and a day for VxRail. You can catch the recordings from both days here: Dell Technologies HCI & Storage: Cutting Edge Infrastructure to Drive Your Business.
If you are not familiar with Tech Field Days, they are “a series of invite-only technical meetings between delegates invited from around the world and sponsoring enterprise IT companies that share their products and ideas through presentations, demos, roundtables, and more”. The delegates are all hand-picked industry thought leaders – those wicked smart people you are following on Twitter – and they ask tough questions. Earlier this month, Dell Technologies spent two days with them: a day dedicated to storage, and a day for VxRail. You can catch the recordings from both days here: Dell Technologies HCI & Storage: Cutting Edge Infrastructure to Drive Your Business.
Of the twelve great jampacked VxRail sessions, if you cannot watch them all, do make time in your day for these three:
- VxRail dynamic nodes – Flexibility for the Future. In short, VxRail without vSAN. Leverage HCI Mesh, or FC SAN storage like PowerStore T or PowerMax, and bring that VxRail LCM goodness to other vSphere clusters in your data center.
- What Does “Seamless Technology Integration” Mean for VxRail? I hate tooting my own horn, but if you want a quick deep dive on where all the storage performance in VxRail is coming from, this is your 22-minute Cliff Notes version.
- Get the Most Out of Your K8s with Tanzu on VxRail This is your crash course about how VxRail can get Tanzu stood up, so you can get Kubernetes at the Speed of Cloud, within your data center.
One more suggestion, if you are new to VxRail, or on the fence about deploying VxRail, tune into this session from Adam Little, Senior Cybersecurity Administrator for New Belgium Brewing, and the reasons they selected VxRail. Even brewing needs high availability, redundancy, and simplicity.
 ESG is an IT analyst, research, validation, and strategy firm whose staff is well known for their technical prowess and frankly are fun to work with. Maybe that is because they are techies at heart who love geeking out over new hardware. I got to work with Tony Palmer as he audited the results of our VxRail on 15th Generation PowerEdge performance testing. Tony went through things with a fine-tooth comb, and asked a lot of great (and tough) probing questions.
ESG is an IT analyst, research, validation, and strategy firm whose staff is well known for their technical prowess and frankly are fun to work with. Maybe that is because they are techies at heart who love geeking out over new hardware. I got to work with Tony Palmer as he audited the results of our VxRail on 15th Generation PowerEdge performance testing. Tony went through things with a fine-tooth comb, and asked a lot of great (and tough) probing questions.
What was most interesting was how he looked at the same data but in a very different way – quickly zeroing in on how much performance VxRail could deliver at sub-millisecond latency, verses peak performance. Tony pointed out “It’s important to note that not too long ago, performance this high with sub-millisecond response times required a significant investment in specialized storage hardware”. Personally, I love this independent validation. It is one thing for our performance team to benchmark VxRail performance, but it is quite another for an analyst firm to audit our results and to be blown out of the water to the degree they were. Read their full Technical Validation of Dell EMC VxRail on 15th Generation PowerEdge Technology: Pushing the Boundaries of Performance and VM Density for Business- and Mission-critical Workloads], and then follow it up with some of their previous work on VxRail.
If performance concerns have been holding you back from putting your toes in the HCI waters, now is a great time to jump in. The 3rd Gen Intel® Xeon® Scalable processors are faster and have more cores, but also bring other hardware architectural changes. From a storage performance perspective, the most impactful of those is PCIe Gen4, with double the bandwidth of PCIe Gen 3 which was introduced in 2012.
From the OLTP16K (70/30) workload in the following figure, we can see that by just upgrading the vSAN cache drive to PCIe Gen 4, an additional 37% of performance can be unleashed. If that is not enough, enabling RDMA for vSAN nets an additional 21% of performance. One more thing, this is with only two diskgroups… check in with me later for when we crank performance up to 11 with four diskgroups, faster cache drives, and a few more changes.
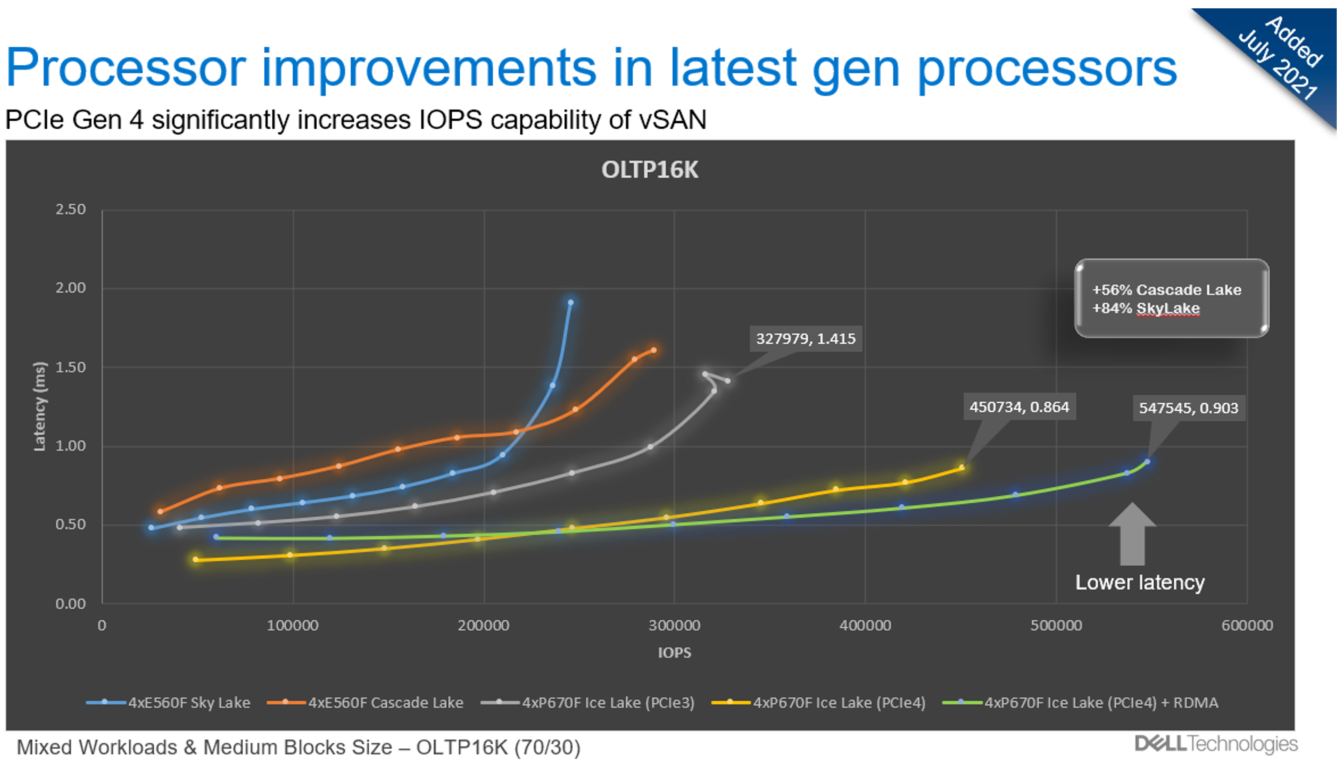
With OLTP4K (70/30) peak IOPS performance clocking in at 155K with 0.853ms latency per node, VxRail can support workloads that demand the most of storage performance. But performance is not always the focus of storage.
If your workloads benefit from SAN data services such as PowerStore’s 4:1 Data Reduction or PowerMax’s SRDF, then now is a great time to learn about the VxRail Advantage and the benefits that VxRail Lifecycle Management provides. Check out Daniel Chiu’s blog post on VxRail dynamic nodes, where the power of the portfolio is delivering the best of both worlds.
Author: David Glynn, Twitter (@d_glynn), LinkedIn

Our fastest and biggest launch ever! - We’ve also made it simpler
Fri, 26 Apr 2024 17:18:33 -0000
|Read Time: 0 minutes
With this hardware launch, we at VxRail are refreshing our mainline platforms. Our “everything” E Series, our performance-focused P Series, and our virtualization-accelerated V Series. You’ve probably already guessed that these nodes are faster and bigger. This is always the case with new hardware in the tech industry, thanks to Moore’s Law of "Cramming more components onto integrated circuits,” but we’ve also made this hardware release simpler. Let’s dig into these changes, what they mean to you, the consumer, and what choices you may need to consider.
Faster. Bigger.
The headline in this could well be the 3rd Generation Intel Xeon Scalable processor (code named Ice Lake) with its increased cores and performance. After all, the CPU is the heart of every computing device from the nebulous public cloud to the smart refrigerator in your kitchen. But there is more to CPUs and servers than cores and clock speeds. The most significant of these, in my opinion, are support for the fourth generation of the PCIe bus. PCIe Gen 3 was introduced on 12th Generation PowerEdge servers in 2012, so the arrival of PCIe Gen 4 with double the bandwidth and 33% more lanes is very much appreciated. The PCIe bus is the highway network that connects everything together, this increase in bandwidth and lanes drives change and enables improvements in many other components.
The most significant impact for VxRail is the performance that it unlocks with PCIe Gen 4 NVMe drives, available on all the new nodes including the V Series. With vSAN’s distributed architecture, all writes go to multiple cache drives on multiple nodes. Anything that improves cache performance, be it high bandwidth, lower latency networking, or faster cache drives, will drive overall application performance and increased densities. For the relatively small price premium of NVMe cache drives over SAS caches drives, VxRail can deliver up to 35% higher IOPS and up to 14% lower latency (OLTP 32K on RAID 1). NVMe cache drives also reduce the performance impact of enabling data service like deduplicate, compression, and encryption at rest. For more information, check out this paper from our performance team last year (did you know that VxRail has its own performance testing team?) where they showed the performance impact of dedupe and compression compared to compression only compared to no data reduction. This data highlights the small performance impact that compression only has on performance and the benefit of NVMe for cache drives.
Staying with storage, the new SAS HBA has double the number of lanes, which doubles the bandwidth available to drives. Don’t assume that this means twice the storage performance – wait for my next post where I’ll delve into those details with ESG. It is a topic worthy of its own post and well worth the wait, I promise! The SAS HBA has been moved to the front of the node right behind the drive bay, this is noteworthy because it frees up a PCIe slot on some configurations. We also freed up a PCIe slot on all configurations with the new Boot Optimized Storage Solution (BOSS) device – more on the new BOSS device below. These changes: deliver a third PCIe slot on the E Series, flexibility on the V Series with support for six GPUs while still offering PCIe slots for networking and FC expansion. Some would argue you can never have enough PCIe slots, but we argued, and sacrificed these gains on the P Series in favor of delivering four additional capacity drive slots, providing 184 TB of raw storage capacity in 2U. Don’t worry, there are still plenty of PCIe slots for additional networking or fibre channel cards – yes, in case you missed it, you can add fibre channel storage to your favorite HCI platform, extending the storage offerings for your various workloads, through the addition of QLogic or Emulex 16/32GB fibre channel cards. These are also PCIe Gen 4 to drive maximum performance.
PCIe Gen 4 is also enabling network cards to drive more throughput. With this new generation of VxRail, we are launching with an onboard quad port 25 GbE networking card, 2.5 times more than what the previous generation launched with. See the Get thee to 25GbE section in my recent post for A trilogy of reasons to see why you need to be looking at 25 GbE NICs today, even if you are not upgrading your network switches just yet. With this release, VxRail is shifting our onboard networking to use the Open Compute Project (OCP) spec 3.0 form factor. For you, the customer, this means greater choice in on-board network cards, with 10 cards from three vendors available at launch, and more to come. If you are not familiar with OCP, check it out. OCP is a large cross company organization that started as an internal project at Facebook, but now has a diverse membership of almost 100 companies working “collaboratively on redesigning hardware technology to efficiently support the growing demands on compute infrastructure.” The quad 25Gbe NIC is only consuming half of the bandwidth that OCP 3.0 can support, so we all have an interesting networking future.
Simpler
This hardware release is not just faster and bigger, we have also made these VxRail nodes simpler. Simplicity, like beauty, is in the eye of the beholder; there isn’t an industry benchmark for it, but I think you’ll agree with me that these changes will make life simpler in the data center. The new BOSS-S2 device is located at the rear of the node and hot-pluggable. In the event of failure of a RAID 1 protected M.2 SATA drive, it can easily and non-disruptively be replaced without powering off and opening the node. We’ve also relocated the power supplies, there is now one on each side of the chassis. This improves air flow, cooling, and enables easier and tidier cabling – we’ve all seen those rats’ nest of cables in the data center. Moving around to the front, we’ve added a Quick Resource Locator (QRL) to the chassis luggage tag, which can be scanned with an Android or iOS app, this will display system and warranty details and also provide links to SolVe procedures and documentation. Sticking with mobile applications, we’ve added OpenManage and Mobile Quick Sync 2 which enables, from the press of the Wireless Activation button, access to iDRAC and all the troubleshooting help it provides – no more dragging a crash cart across the data center.
VxRail is more than the sum of its components, be it through Lifecycle Management, simpler cloud operations, or ongoing product education. The value it delivers is seen daily by our 12.4K customers around the globe. Today we celebrate not just our successes and our new release, but also the successes and achievements of the giants that hoist us up to stand on their shoulders and enable VxRail and our customers to reach for the stars. Join us as we continue our journey and Reimagine HCI.
References

100 GbE Networking – Harness the Performance of vSAN Express Storage Architecture
Wed, 05 Apr 2023 12:48:50 -0000
|Read Time: 0 minutes
For a few years, 25GbE networking has been the mainstay of rack networking, with 100 GbE reserved for uplinks to spine or aggregation switches. 25 GbE provides a significant leap in bandwidth over 10 GbE, and today carries no outstanding price premium over 10 GbE, making it a clear winner for new buildouts. But should we still be continuing with this winning 25 GbE strategy? Is it time to look to a future of 100 GbE networking within the rack? Or is that future now?
This question stems from my last blog post: VxRail with vSAN Express Storage Architecture (ESA) where I called out VMware’s 100 GbE recommended for maximum performance. But just how much more performance can vSAN ESA deliver with 100GbE networking? VxRail is fortunate to have its performance team, who stood up two identical six-node VxRail with vSAN ESA clusters, except for the networking. One was configured with Broadcom 57514 25 GbE networking, and the other with Broadcom 57508 100 GbE networking. For more VxRail white papers, guides, and blog posts visit VxRail Info Hub.
When it comes to benchmark tests, there is a large variety to choose from. Some benchmark tests are ideal for generating headline hero numbers for marketing purposes – think quarter-mile drag racing. Others are good for helping with diagnosing issues. Finally, there are benchmark tests that are reflective of real-world workloads. OLTP32K is a popular one, reflective of online transaction processing with a 70/30 read-write split and a 32k block size, and according to the aggregated results from thousands of Live Optics workload observations across millions of servers.
One more thing before we get to the results of the VxRail Performance Team's testing. The environment configuration. We used a storage policy of erasure coding with a failure tolerance of two and compression enabled.
When VMware announced vSAN with Express Storage Architecture they published a series of blogs all of which I encourage you to read. But as part of our 25 GbE vs 100 GbE testing, we also wanted to verify the astounding claims of RAID-5/6 with the Performance of RAID-1 using the vSAN Express Storage Architecture and vSAN 8 Compression - Express Storage Architecture. In short, forget the normal rules of storage performance, VMware threw that book out of the window. We didn’t throw our copy out of the window, well not at first, but once our results validated their claims… it went out.
Let’s look at the data: Boom!
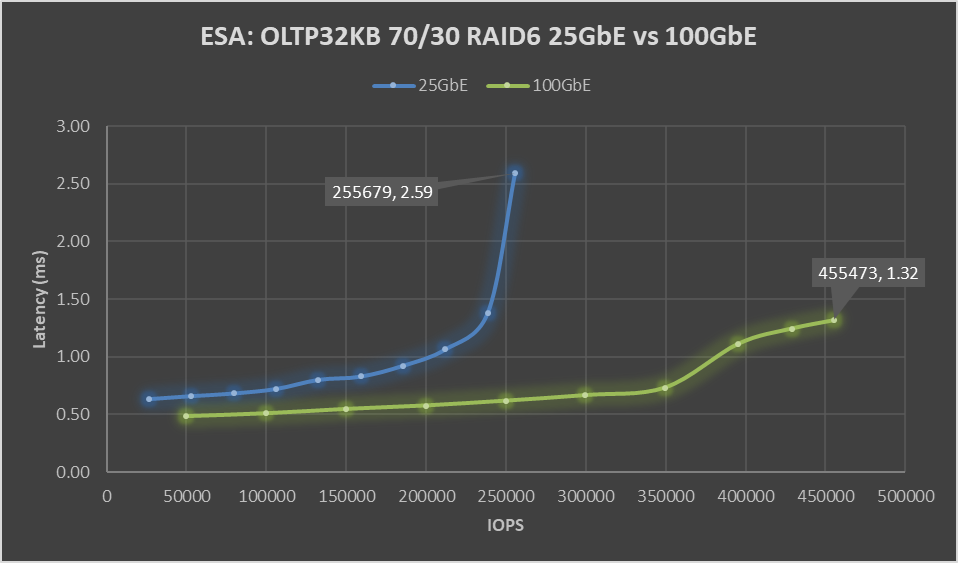
Figure 1. ESA: OLTP32KB 70/30 RAID6 25 GbE vs 100 GbE performance graph
Boom! A 78% increase in peak IOPS with a substantial 49% drop in latency. This is a HUGE increase in performance, and the sole difference is the use of the Broadcom 57508 100 GbE networking. Also, check out that latency ramp-up on the 25 GbE line, it’s just like hitting a wall. While it is almost flat on the 100 GbE line.
But nobody runs constantly at 100%, at least they shouldn’t be. 60 to 70% of absolute max is typically a normal day-to-day comfortable peak workload, leaving some headroom for spikes or node maintenance. At that range, there is an 88% increase in IOPS with a 19 to 21% drop in latency, with a smaller drop in latency attributable to the 25 GbE configuration not hitting a wall. As much as applications like high performance, it is needed to deliver performance with consistent and predictable latency, and if it is low all the better. If we focus on just latency, the 100 GbE networking enabled 350K IOPS to be delivered at 0.73 ms, while the 25 GbE networking can squeak out 106K IOPS at 0.72 ms. That may not be the fairest of comparisons, but it does highlight how much 100GbE networking can benefit latency-sensitive workloads.
Boom, again! This benchmark is not reflective of real-world workloads but is a diagnostic test that stresses the network with its 100% read-and-write workloads. Can this find the bottleneck that 25 GbE hit in the previous benchmark?
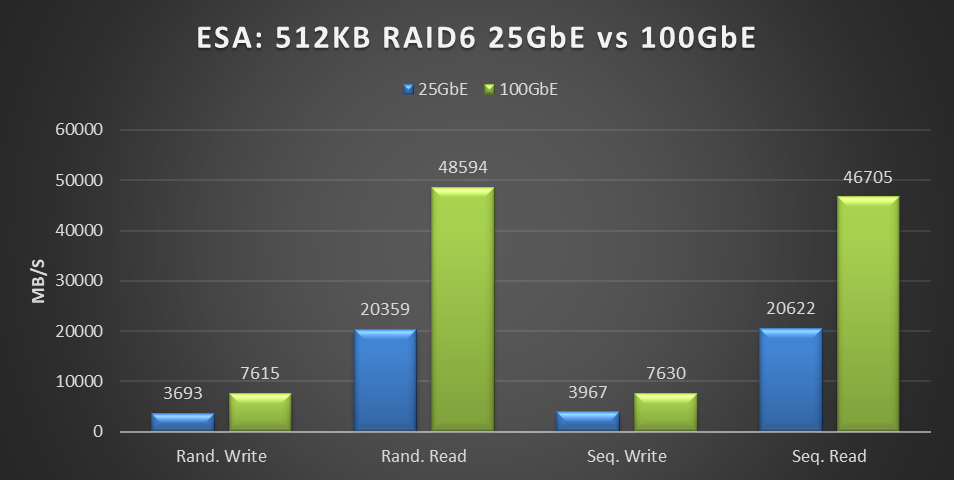
Figure 2. ESA: 512KB RAID6 25 GbE vs 100 GbE performance graph
This testing was performed on a six-node cluster, with each node contributing one-sixth of the throughput shown in this graph. 20359MB/s of random read throughput for the 25 GbE cluster or 3393 MB/s per node. Which is slightly above the theoretical max throughput of 3125 MB/s that 25 GbE can deliver. This is the absolute maximum that 25 GbE can deliver! In the world of HCI, the virtual machine workload is co-resident with the storage. As a result, some of the IO is local to the workload, resulting in higher than theoretical throughput. For comparison, the 100 GbE cluster achieved 48,594 MB/s of random read throughput, or 8,099 MB/s per node out of a theoretical maximum of 12,500 MB/s.
But this is just the first release of the Express Storage Architecture. In the past, VMware has added significant gains to vSAN, as seen in the lab-based performance analysis of Harnessing the Performance of Dell EMC VxRail 7.0.100. We can only speculate on what else they have in store to improve upon this initial release.
What about costs, you ask? Street pricing can vary greatly depending on the region, so it's best to reach out to your Dell account team for local pricing information. Using US list pricing as of March 2023, I got the following:
Component | Dell PN | List price | Per port | 25GbE | 100GbE |
Broadcom 57414 dual 25 Gb | 540-BBUJ | $769 | $385 | $385 |
|
S5248F-ON 48 port 25 GbE | 210-APEX | $59,216 | $1,234 | $1,234 |
|
25 GbE Passive Copper DAC | 470-BBCX | $125 | $125 | $125 |
|
Broadcom 57508 dual 100Gb | 540-BDEF | $2,484 | $1,242 |
| $1,242 |
S5232F-ON 32 port 100 GbE | 210-APHK | $62,475 | $1,952 |
| $1,952 |
100 GbE Passive Copper DAC | 470-ABOX | $360 | $360 |
| $360 |
Total per port |
|
|
| $1,743 | $3,554 |
Overall, the per-port cost of the 100 GbE equipment was 2.04 times that of the 25 GbE equipment. However, this doubling of network cost provides four times the bandwidth, a 78% increase in storage performance, and a 49% reduction in latency.
If your workload is IOPS-bound or latency-sensitive and you had planned to address this issue by adding more VxRail nodes, consider this a wakeup call. Adding dual 100Gb came at a total list cost of $42,648 for the twelve ports used. This cost is significantly less than the list price of a single VxRail node and a fraction of the list cost of adding enough VxRail nodes to achieve the same level of performance increase.
Reach out to your networking team; they would be delighted to help deploy the 100 Gb switches your savings funded. If decision-makers need further encouragement, send them this link to the white paper on this same topic Dell VxRail Performance Analysis (similar content, just more formal), and this link to VMware's vSAN 8 Total Cost of Ownership white paper.
While 25 GbE has its place in the datacenter, when it comes to deploying vSAN Express Storage Architecture, it's clear that we're moving beyond it and onto 100 GbE. The future is now 100 GbE, and we thank Broadcom for joining us on this journey.

VxRail and SmartDPUs—A Transformative Data Center Pairing
Tue, 17 Jan 2023 21:15:58 -0000
|Read Time: 0 minutes
What VMware announced as Project Monterey back in September 2020 has finally come to fruition as the vSphere Distributed Services Engine. While that name may seem like a mouthful, it really does a great job of describing what the product does in just a few words.
vSphere Distributed Services Engine provides a consistent management and services platform to deliver dynamic hardware for the growing world of agile distributed applications. The vSphere Distributed Services Engine will, in the future, be the engine upon which non-hypervisor vSphere services run. Today it begins with NSX, but VMware has set its sights on moving vSAN storage and host management services to the vSphere Distributed Services Engine, thus freeing up x86 resources for virtual machines, containers, and the applications they support.
Powering vSphere Distributed Services Engine is a new type of PCIe card known as a data processing unit (DPU), currently available from NVIDIA and AMD. At Dell, we are calling them SmartDPUs, as these PCIe cards and the software they run are the cornerstone of tomorrow’s disaggregated cloud-native data center.
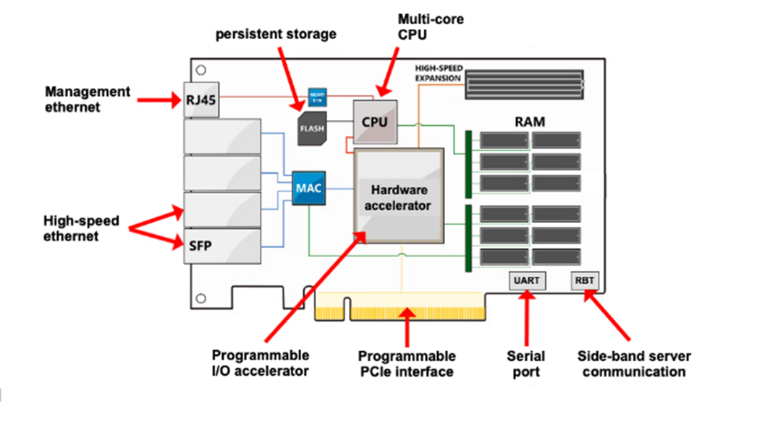 From a hardware perspective, it would be easy to assume that a SmartDPU is just a fancy network card; after all, the most distinguishing external features are the SFP ports. But hiding under the large heatsink is a small powerful server with its own processor, memory, and storage. Most importantly is the programmable hardware I/O accelerator, the core of the SmartDPU that will deliver performance. The PowerEdge server team at Dell has gone a step further. They’ve tightly coupled the SmartDPUs with the existing PowerEdge iDRAC through the serial port and side-band server communication connections, bypassing the RJ45 management port. This allows the iDRAC to not only manage the PowerEdge server, but also to manage the SmartDPUs. As awesome as the hardware is, it needs software for its power to be unleashed.
From a hardware perspective, it would be easy to assume that a SmartDPU is just a fancy network card; after all, the most distinguishing external features are the SFP ports. But hiding under the large heatsink is a small powerful server with its own processor, memory, and storage. Most importantly is the programmable hardware I/O accelerator, the core of the SmartDPU that will deliver performance. The PowerEdge server team at Dell has gone a step further. They’ve tightly coupled the SmartDPUs with the existing PowerEdge iDRAC through the serial port and side-band server communication connections, bypassing the RJ45 management port. This allows the iDRAC to not only manage the PowerEdge server, but also to manage the SmartDPUs. As awesome as the hardware is, it needs software for its power to be unleashed.
This is where vSphere Distributed Services Engine comes into play. In this initial release, VMware is moving NSX and the networking and security services that it provides to the vSphere environment from the main x86 CPU and onto the SmartDPU. This provides several benefits: The most obvious is that this will free up x86 CPU resources for virtual machine and container workloads. Less obvious is the creation of an air gap between the NSX services and ESXi, enabling zero trust security. Does this mean that SmartDPUs are just an NSX offload card? Yes and no. VMware and the industry are taking the first small steps in what will be a leap forward for data center infrastructure and design. Future steps by VMware will expand the vSphere Distributed Services Engine to have storage and host management services running on the SmartDPUs, thus leaving the x86 CPU to run host virtual machines and containers.
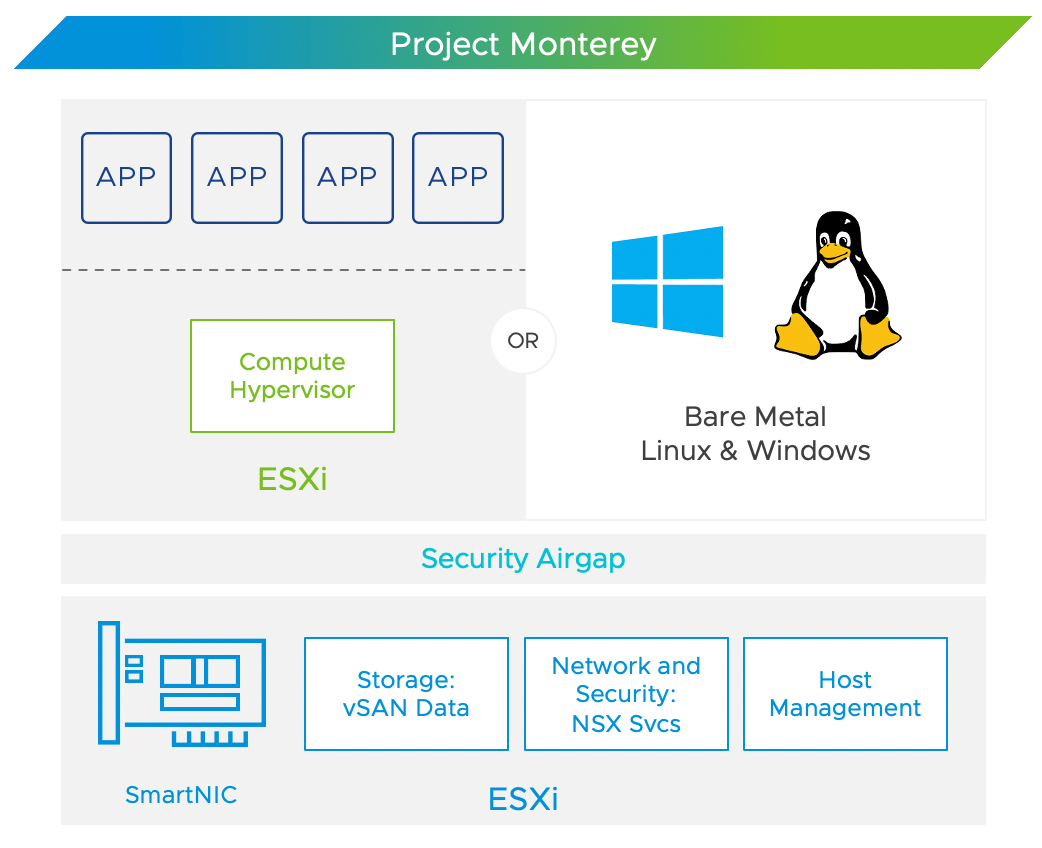
VMware’s journey does not stop there, and these steps may seem blasphemous at first, but VMware will provide bare metal support, enabling Linux or Windows to be deployed on the x86 hardware. VMware acknowledges that not every workload is suited to run on vSphere, but that these workloads would benefit from the security, networking, and storage services provided by the vSphere Distributed Services Engine—transforming the data center, breaking down silo walls, distributing and aggregating any and all workloads.
Where does VxRail fit in all this? In the same place as we always have: Standing on the shoulders of the PowerEdge and VMware giants looking to remove complexity and friction from technology, making it easier and simpler for you to purchase, deploy, manage, update, and most importantly use this transformative technology. Freeing up your cycles to refactor your applications to meet the ever-growing needs of your business. VxRail will be supporting the vSphere Distributed Services Engine with the AMD Pensando and NVIDIA Bluefield-2 SmartDPUs on our core platforms—the E660F, V670F, and P670N. These nodes will be available in configurations for both VxRail with vSAN original storage architecture and VxRail dynamic nodes.
The journey of the modern data center is complex and ever changing, but with VxRail at your side you are in good company.
Author: David Glynn, Sr. Principal Engineer, VxRail Technical Marketing

VxRail with vSAN Express Storage Architecture (ESA)
Mon, 09 Jan 2023 14:40:28 -0000
|Read Time: 0 minutes
vSAN Express Storage Architecture: The New Era. It may well be given the dramatic gains in performance that VMware is claiming (my VxRail with vSAN ESA performance blog will be next month) and the major changes to the capabilities of data services provided in vSAN ESA. It’s important to understand that this is the next step in vSAN’s evolution, not an end. vSAN’s Original Storage Architecture (OSA) has been continuously evolving since it was first released in 2014. vSAN 8.0 Express Storage Architecture is just another small step on that evolutionary journey – well maybe more of a giant leap. A giant leap that VxRail will take along with it.
vSAN OSA was designed at a time when spinning disks were the norm, flash was expensive, double digit multi-core processors were new-ish, and 10Gbit networking was for switch uplinks not servers. Since then, there have been significant changes in the underlying hardware, which vSAN has benefited from and leveraged along the way. Fast forward to today, spinning disk is for archival use, NVMe is relatively cheap, 96 core processors exist, 25Gb networking is the greenfield default with 100Gb networking available for a small premium. Therefore, it is no surprise to see VMware optimizing vSAN to exploit the full potential of the latest hardware, unlocking new capabilities, higher efficiency, and more performance. Does this spell the end of the road for vSAN OSA? Far from it! Both architectures are part of vSAN 8.0, with OSA getting several improvements. The most exciting of which is the Increased Write Buffer Capacity from 600GB to 1.6TB per diskgroup. This will not only increase performance, but equally important also improve performance consistency.
Before you get excited about the performance gains and new capabilities that upgrading to vSAN ESA will unlock on your VxRail cluster, be aware of one important item. vSAN ESA is, for now, greenfield only. This was done to enable vSAN ESA to fully exploit the potential of the latest in server hardware and protocols to deliver new capabilities and performance to meet the ever-evolving demands that business places on today’s IT infrastructure.
Aside from being greenfield only, vSAN ESA has particular hardware requirements. So that you can hit the ground running this New Year with vSAN ESA, we’ve refreshed the VxRail E660N and P670N with configurations that meet or exceed vSAN ESA’s significantly different requirements, enabling you to purchase with confidence:
- Six 3.2TB or 6.4TB mixed-use TLC NVMe devices
- 32 cores
- 512GB RAM
- Two 25Gb NIC ports, with 100Gb recommended for maximum performance. Yes, vSAN ESA will saturate a 25Gb network port. And yes, you could bond multiple 25Gb network ports, but the price delta (including switches and cables) between quad 25Gb and dual 100Gb networking is surprisingly small.
And as you’d expect, VxRail Manager has already been in training and is hitting the ground running alongside you. At deployment, VxRail Manager will recognize this new configuration, deploy the cluster following vSAN ESA best practices and compatibility checks, and perform future updates with Continuously Validated States.
But hardware is only half of the story. What VMware did with vSAN to take advantage of the vastly improved hardware landscape is key. vSAN ESA stands on the shoulders of the work that OSA has done, re-using much of it, but optimizing the data path to utilize today’s hardware. These architectural changes occur in two places: a new log-structured file system, and an optimized log-structured object manager and data structure. Pete Koehler’s blog post An Introduction to the vSAN Express Storage Architecture explains this in a clear and concise manner – and much better than I could. What I found most interesting was that these changes have created a storage paradox of high performing erasure coding with highly valued data services:
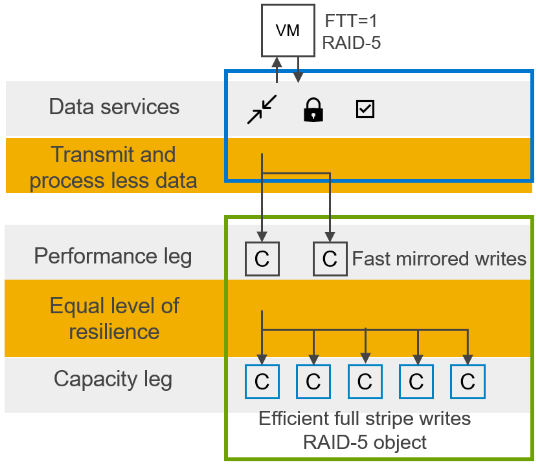
Figure 1. Log structured file system - optimized data handling
- Data services like compression and encryption occur at the highest layer, minimizing process amplification, and lowering processor and network utilization. To put this another way, data services are done once, and the resulting now smaller and encrypted data load is sent over the network to be written on multiple hosts.
- The log-structured file system rapidly ingests data, while organizing it into a full stripe write. The key part here is that full stripe write. Typically, with erasure coding, a partial stripe write is done. This results in a read-modify-write which causes the performance overhead we traditionally associate with RAID5 and RAID6. Thus, full stripe writes enable the space efficiency of RAID5/6 erasure coding with the performance of RAID1 mirroring.
- Snapshots also benefit from the log structured file system, with writes written to new areas of storage and metadata pointers tracking which data belongs to which snapshot. This change enables Scalable, High-Performance Native Snapshots with compatibility for existing 3rd party VDAP backup solutions and vSphere Replication.
Does this mean we get to have our cake and eat it too? This is certainly the case, but check out my next blog where we’ll delve into the brilliant results from the extensive testing by the VxRail Performance team.
Back to the hardware half of the story. Don’t let the cost of mixed-use NVMe drives scare you away from vSAN ESA. The TCO of ESA is actually lower than OSA. There are a few minor things that contribute to this, no SAS controller, and no dedicated cache devices. However, because of ESA’s RAID-5/6 with the Performance of RAID-1, less capacity is needed, delivering significant costs savings. Traditionally, performance and mirroring, required twice the capacity, but ESA RAID6 can deliver comparable performance, with 33% more usable capacity, and better resiliency with a failure to tolerate of two. Even small clusters benefit from ESA with adaptive RAID5, which has a 2+1 data placement scheme for use on clusters with as few as three nodes. As these small clusters grow beyond five nodes, vSAN ESA will adapt that RAID5 2+1 data placement to the more efficient RAID5 4+1 data placement.

Figure 2. Comparing vSAN OSA and ESA on different storage policies against performance and efficiency
Finally, ESA has an ace up its sleeve with the more resource efficient and granular compression with a claimed “up to a 4x improvement over original storage architecture”. ESA’s minimum hardware requirements may seem high, but bear in mind, they are specified to enable ESA to deliver the high performance it is capable of. When running the same workload that you have today on your VxRail with vSAN OSA cluster on a VxRail with vSAN ESA cluster, the resource consumption will be noticeably lower – releasing resources for additional virtual machines and their workloads.
A big shoutout to my technical marketing peers over at VMware for the many great blogs, videos, and other assets they have delivered. I linked to several of them above, but you can find the all of their vSAN ESA material over at core.vmware.com/vsan-esa including a very detailed FAQ, and an updated Foundations of vSAN Architecture video series on YouTube.
vSAN Express Storage Architecture is a giant leap forward for datacenter administrators everywhere and will draw more of them into the world of hyperconverged infrastructure. vSAN ESA on VxRail provides the most effective and secure path for customers to leverage this new technology. The New Era has started, and it is going to be very interesting.
Author: David Glynn, Sr. Principal Engineer, VxRail Technical Marketing
Images courtesy of VMware
For the curious and the planners out there, migrating to vSAN ESA is, as you’d expect, just a vMotion and SvMotion.

New VxRail Node Lets You Start Small with Greater Flexibility in Scaling and Additional Resiliency
Mon, 29 Aug 2022 19:00:25 -0000
|Read Time: 0 minutes
When deploying infrastructure, it is important to know two things: current resource needs and that those resource needs will grow. What we don’t always know is in what way the demands for resources will grow. Resource growth is rarely equal across all resources. Storage demands will grow more rapidly than compute, or vice-versa. At the end of the day, we can only make an educated guess, and time will tell if we guessed right. We can, however, make intelligent choices that increase the flexibility of our growth options and give us the ability to scale resources independently. Enter the single processor Dell VxRail P670F.
The availability of the P670F with only a single processor provides more growth flexibility for our customers who have smaller clusters. By choosing a less compute dense single processor node, the same compute workload will require more nodes. There are two benefits to this:
- More efficient storage: More nodes in the cluster opens the door to using the more capacity efficient erasure coding vSAN storage option. Erasure coding, also known as parity RAID, (such as RAID 5 and RAID 6) has a capacity overhead of 33% compared to the 100% overhead that mirroring requires. Erasure coding can deliver 50% more usable storage capacity while using the same amount of raw capacity. While this increase in storage does come with a write performance penalty, VxRail with vSAN has shown that the gap between erasure coding and mirroring has narrowed significantly, and provides significant storage performance capabilities.
- Reduced cluster overhead: Clusters are designed around N+1, where ‘N’ represents sufficient resources to run the preferred workload, and ‘+1’ are spare and unused resources held in reserve should a failure occur in the nodes that make up the N. As the number of nodes in N increases, the percentage of overall resources that are kept in reserve to provide the +1 for planned and unplanned downtime drops.
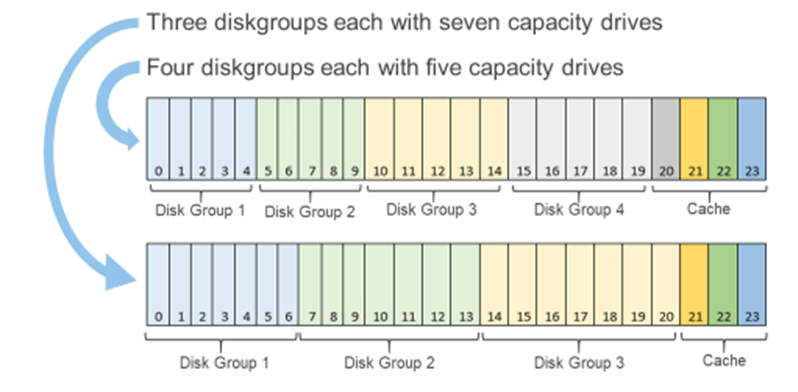
Figure 1: Single processor P670F disk group options
You may be wondering, “How does all of this deliver flexibility in the options for scaling?”
You can scale out the cluster by adding a node. Adding a node is the standard option and can be the right choice if you want to increase both compute and storage resources. However, if you want to grow storage, adding capacity drives will deliver that additional storage capacity. The single processor P670F has disk slots for up to 21 capacity drives with three cache drives, which can be populated one at a time, providing over 160TB of raw storage. (This is also a good time to review virtual machine storage policies: does that application really need mirrored storage?) The single processor P670F does not have a single socket motherboard. Instead, it has the same dual socket motherboard as the existing P670F—very much a platform designed for expanding CPU and memory in the future.
If you are starting small, even really small, as in a 2-node cluster (don’t worry, you can still scale out to 64 nodes), the single processor P670F has even more additional features that may be of interest to you. Our customers frequently deploy 2-node clusters outside of their core data center at the edge or at remote locations that can be difficult to access. In these situations, the additional data resiliency that provided by Nested Fault Domains in vSAN is attractive. To provide this additional resiliency on 2-node clusters requires at least three disk groups in each node, for which the single processor P670F is perfectly suited. For more information, see VMware’s Teodora Hristov blog post about Nested fault domain for 2 Node cluster deployments. She also posts related information and blog posts on Twitter.
It is impressive how a single change in configuration options can add so much more configuration flexibility, enabling you to optimize your VxRail nodes specifically to your use cases and needs. These configuration options impact your systems today and as you scale into the future.
Author Information
Author: David Glynn, Sr. Principal Engineer, VxRail Technical Marketing
Twitter: @d_glynn

Satellite nodes: Because sometimes even a 2-node cluster is too much
Tue, 01 Mar 2022 15:03:31 -0000
|Read Time: 0 minutes
Wait a minute, where's me cluster? Oh no.
You may have noticed a different approach from Dell EMC VxRail in Daniel Chiu’s blog A Taste of VxRail Deployment Flexibility. In short, we are extending the value of VxRail into new adjacencies, into new places, and new use cases. With the release of VxRail dynamic nodes in September, these benefits became a new reality in the landscape of VxRail deployment flexibility:
- Using VxRail for compute clusters with vSAN HCI Mesh
- Using storage arrays with VxRail dynamic nodes in VMware Cloud Foundation on VxRail
- Extending the benefits of VxRail HCI System Software to traditional 3-tier architectures using Dell EMC for primary storage
The newest adjacency in 7.0.320 is the VxRail satellite node, as sometimes even a 2-node cluster may be too much.
A VxRail satellite node is ideal for those workloads where the SLA and compute demands do not justify even the smallest of 2-node clusters – in the past you might have even recycled a desktop to meet these requirements. Think retail and ROBO with their many distributed sites, or 5G with its “shared nothing” architecture. But in today’s IT environment, out of sight cannot mean out of mind. Workloads are everywhere and anywhere. The datacenter and the public cloud are just two of the many locations where workloads exist, and compute is needed. These infrastructure needs are well understood, and in the case of public cloud – out of scope. The challenge for IT is managing and maintaining the growing and varied infrastructure demands of workloads outside of the data center, like the edge, in its many different forms. The demands of the edge vary greatly. But even with infrastructure needs met with a single server, IT is still on the hook for managing and maintaining it.
While satellite nodes are a single node extension of VxRail, they are managed and life cycled by the VxRail Manager from a VxRail with vSAN cluster.  Targeted at existing VxRail customers, these single nodes should not be thought of as lightweights. We’re leveraging the existing VxRail E660, E660F, and V670F with all their varied hardware options, and have added support for the PERC H755 adapter for local RAID protected storage. This provides options as lightweight as a E660 with an eight core Intel Xeon Gen 3 Scalable processor and spinning disks, all the way up to a V670F with dual 40 core Intel Xeon Gen 3 Scalable processors, accelerated by a pair of NVIDIA Ampere A100 80GB Data Center GPUs, and over 150 TB of flash storage. Because edge workloads come in all sizes from small to HUUUUGE!!!
Targeted at existing VxRail customers, these single nodes should not be thought of as lightweights. We’re leveraging the existing VxRail E660, E660F, and V670F with all their varied hardware options, and have added support for the PERC H755 adapter for local RAID protected storage. This provides options as lightweight as a E660 with an eight core Intel Xeon Gen 3 Scalable processor and spinning disks, all the way up to a V670F with dual 40 core Intel Xeon Gen 3 Scalable processors, accelerated by a pair of NVIDIA Ampere A100 80GB Data Center GPUs, and over 150 TB of flash storage. Because edge workloads come in all sizes from small to HUUUUGE!!!
Back when I started in IT, a story about a Missing Novell server discovered after four years sealed behind a wall was making the rounds. While it was later claimed to be false, it was a story that resonated with many season IT professionals and continues to do so today. Regardless as to where a workload is running, the onus is on IT not only to protect that workload, but also to protect the network, all the other workloads on the network, and anything that might connect to that workload. This is done in layers, with firewalls, DMZ, VPN, and so on. But it is also done by keeping hypervisors updated, and BIOS and firmware up to date.
For six years, VxRail HCI System Software has been helping virtualization administrators keep their VxRail with vSAN cluster up to date, regardless as to where they are in the world -- be it at a remote monitoring station, running a grocery store, or in the dark sealed up behind a wall. VxRail satellite nodes and VxRail dynamic nodes extend the VxRail operating model into new adjacencies. We are enabling you our customers to manage and life cycle these ever growing and diverse workloads with the click of a button.
Also, in the release of VxRail 7.0.320 are two notable stand-outs. The first is validation of Dell EMC PowerFlex scale-out SDS as an option for use with VxRail dynamic nodes. The second is increased resilience for vSAN 2-node clusters (also applies to stretched clusters) which are often used at the edge. Both John Nicholson and Teodora Hristov of VMware do a great job of explaining the nuts and bolts of this useful addition. But I want to reiterate that for 2-node deployments, this increased resilience will require that each node have three disk groups.
Don’t let the fact that a workload is too small, or too remote, or not suited to HCI, be the reason for your company to be at risk by running out-of-date firmware and BIOS. There is more flexibility than ever with VxRail, much more, and the value of VxRail’s automation and HCI System Software can now be extended to the granularity of a single node deployment.
Author: David Glynn, Sr. Principal Engineer, VxRail Tech Marketing
Twitter: @d_glynn

I feel the need – the need for speed (and endurance): Intel Optane edition
Wed, 13 Oct 2021 17:37:52 -0000
|Read Time: 0 minutes
It has only been three short months since we launched VxRail on 15th Generation PowerEdge, but we're already expanding the selection of configuration offerings. So far we've added 18 additional processors to power your workloads, including some high frequency and low core count options. This is delightful news for those with applications that are licensed per core, an additional NVIDIA GPU - the A30, a slew of additional drives, and doubled the RAM capacity to 8TB. I've probably missed something, as it can be hard to keep up with the all the innovations taking place within this race car that is VxRail!
In my last blog, I hinted at one of those drive additions, faster cache drives. Today I'm excited to announce that you can now order, and turbo charge your VxRail with the 400GB or 800GB Intel P5800X – Intel’s second generation Optane NVMe drive. Before we delve into some of the performance numbers, let’s discuss what it is about the Optane drives that makes them so special. More specifically, what is it about them that enables them to deliver so much more performance, in addition to significantly higher endurance rates.
 To grossly over-simplify it, and my apologies in advance to the Intel engineers who poured their lives into this, when writing to NAND flash an erase cycle needs to be performed before a write can be made. These erase cycles are time-consuming operations and the main reason why random write IO capabilities on NAND flash is often a fraction of the read capability. Additionally, a garbage collection is running continuously in the background to ensure that there is space available to incoming writes. Optane, on the other hand, does bit-level write in place operations, therefore it doesn’t require an erase cycle, garbage collection, or performance penalty writes. Hence, random write IO capability almost matches the random read IO capability. So just how much better is endurance with this new Optane drive? Endurance can be measured in Drive Writes Per Day (DWPD), which measures how many times the drive's entire size could be overwritten each day of its warranty life. For the 1.6TB NVMe P5600 this is 3 DWPD, or 55 MB per second, every second for five years – just shy of 9PB of writes, not bad. However, the 800GB Optane P5800X will endure 146PB over its five-year warranty life, or almost 1 GB per second (926 MB/s) every second for its five year 100 DWPD warranty life. Not quite indestructible, but that is a lot of writes, so much so you don’t need extra capacity for wear leveling and a smaller capacity drive will suffice.
To grossly over-simplify it, and my apologies in advance to the Intel engineers who poured their lives into this, when writing to NAND flash an erase cycle needs to be performed before a write can be made. These erase cycles are time-consuming operations and the main reason why random write IO capabilities on NAND flash is often a fraction of the read capability. Additionally, a garbage collection is running continuously in the background to ensure that there is space available to incoming writes. Optane, on the other hand, does bit-level write in place operations, therefore it doesn’t require an erase cycle, garbage collection, or performance penalty writes. Hence, random write IO capability almost matches the random read IO capability. So just how much better is endurance with this new Optane drive? Endurance can be measured in Drive Writes Per Day (DWPD), which measures how many times the drive's entire size could be overwritten each day of its warranty life. For the 1.6TB NVMe P5600 this is 3 DWPD, or 55 MB per second, every second for five years – just shy of 9PB of writes, not bad. However, the 800GB Optane P5800X will endure 146PB over its five-year warranty life, or almost 1 GB per second (926 MB/s) every second for its five year 100 DWPD warranty life. Not quite indestructible, but that is a lot of writes, so much so you don’t need extra capacity for wear leveling and a smaller capacity drive will suffice.
You might wonder why you should care about endurance, as Dell EMC will replace the drive under warranty anyway – there are three reasons. When a cache drive fails, its diskgroup is taken offline, so not only have you lost performance and capacity, your environment is taking on the additional burden of a rebuild operation to re-protect your data. Secondly, more and more systems are being deployed outside of the core data center. Replacing a drive in your data center is straightforward, and you might even have spares onsite, but what about outside of your core datacenter? What is your plan for replacing a drive at a remote office, or a thousand miles away? What if that remote location is not an office but an oilrig one hundred miles offshore, or a cruise ship halfway around the world where the cost of getting a replacement drive there is not trivial? In these remote locations, onsite spares are commonplace, but the exceptions are what lead me to the third reason, Murphy's Law. IT and IT staffing might be an afterthought at these remote locations. Getting a failed drive swapped out at a remote location which lacks true IT staffing may not get the priority it deserves, and then there is that ever present risk of user error... “Oh, you meant the other drive?!? Sorry...”
Cache in its many forms plays an important role in the datacenter. Cache enables switches and storage to deliver higher levels of performance. On VxRail, our cache drives fall into two categories, SAS and NVMe, with NVMe delivering up to 35% higher IOPS and 14% lower latency. Among our NVMe cache drive we have two from Intel, the 1.6TB P5600 and the Optane P5800X, in 400GB and 800GB capacities. The links for each will bring you to the drive specification including performance details. But how does the performance at a drive level impact performance at the solution level? Because, at the end of the day that is what your application consumes at the solution level, after cache mirroring, network hops, and the vSAN stack. Intel is a great partner to work with, when we checked with them about publishing solution level performance data comparing the two drives side-by-side, they were all for it.
In my over-simplified explanation above, I described how the write cycle for Optane drives is significantly different as an erase operation and does not need to be done first. So how does that play out in a full solution stack? Figure 1 compares a four node VxRail P670F cluster, running a 100% sequential write 64KB workload. Not a test that reflects any real-world workload, but one that really stresses the vSAN cache layer, highlights the consistent write performance that 3D XPoint technology delivers, and shows how Optane is able to de-stage cache when it fills up without compromising performance.
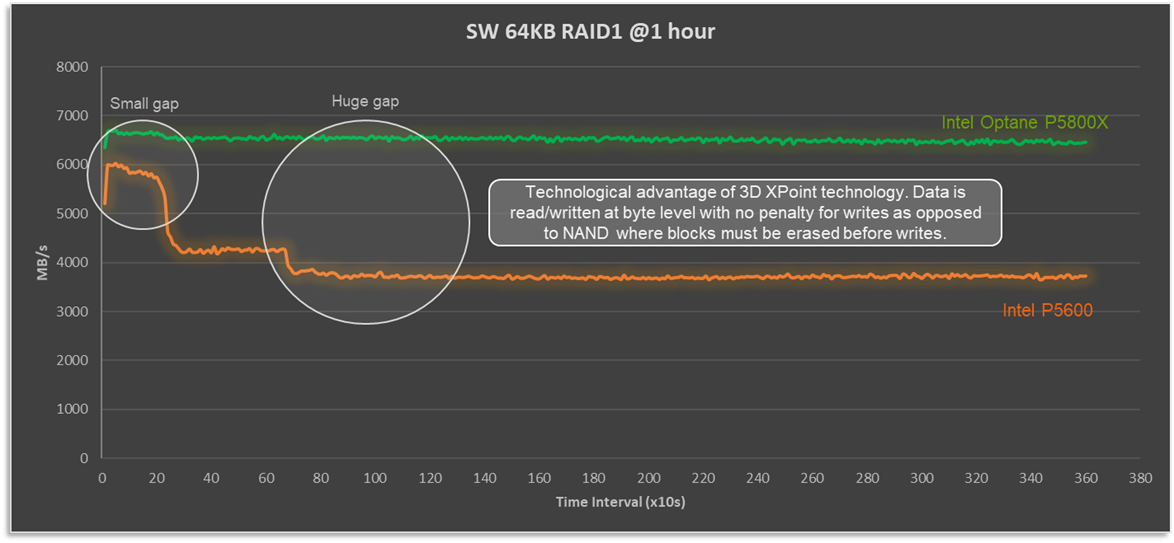
Figure 1: Optane cache drives deliver consistent and predictable write performance
When we look at performance, there are two numbers to keep in mind: IOPS and latency. The target is to have high IOPS with low and predictable latency, at a real-world IO size and read:write ratio. To that end, let’s look at how VxRail performance differs with the P5600 and P5800X under OLTP32K (70R30W) and RDBMS (60R40W) benchmark workload, as shown in Figure 2.
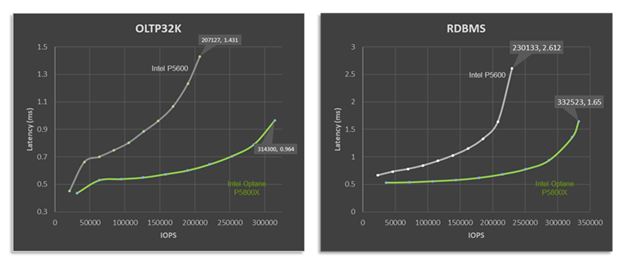
Figure 2: Optane cache drives deliver higher performance and lower latency across a variety of workload types.
It doesn't take an expert to see that with the P5800X this four node VxRail P670F cluster's peak performance is significantly higher than when it is equipped with the P5600 as a cache drive. For RDBMS workloads up to 44% higher IOPS with a 37% reduction in latency. But peak performance isn't everything. Many workloads, particularly databases, place a higher importance on latency requirements. What if our workload, database or otherwise, requires 1ms response times? Maybe this is the Service Level Agreement (SLA) that the infrastructure team has with the application team. In such a situation, based on the data shown, and for a OLTP 70:30 workload with a 32K block size, the VxRail cluster would deliver over twice the performance at the same latency SLA, going from 147,746 to 314,300 IOPS.
In the datacenter, as in life, we are often faced with "Good, fast, or cheap. Choose two." When you compare the price tag of the P5600 and P5800X side by side, the Optane drive has a significant premium for its good and fast. However, keep in mind that you are not buying an individual drive, you are buying a full stack solution of several pieces of hardware and software, where the cost of the premium pales in comparison to the increased endurance and performance. Whether you are looking to turbo charge your VxRail like a racecar, or make it as robust as a tank, Intel Optane SSD drives will get you both.
Author Information
David Glynn, Technical Marketing Engineer, VxRail at Dell Technologies
Twitter: @d_glynn
LinkedIn: David Glynn
Additional Resources
Intel SSD D7P5600 Series 1.6TB 2.5in PCIe 4.0 x4 3D3 TLC Product Specifications
Intel Optane SSD DC P5800X Series 800GB 2.5in PCIe x4 3D XPoint Product Specifications

More GPUs, CPUs and performance - oh my!
Mon, 14 Jun 2021 14:30:46 -0000
|Read Time: 0 minutes
Continuous hardware and software changes deployed with VxRail’s Continuously Validated State
A wonderful aspect of software-defined-anything, particularly when built on world class PowerEdge servers, is speed of innovation. With a software-defined platform like VxRail, new technologies and improvements are continuously added to provide benefits and gains today, and not a year or so in the future. With the release of VxRail 7.0.200, we are at it again! This release brings support for VMware vSphere and vSAN 7.0 Update 2, and for new hardware: 3rd Gen AMD EPYC processors (Milan), and more powerful hardware from NVIDIA with their A100 and A40 GPUs.
VMware, as always, does a great job of detailing the many enhanced or new features in a release. From high level What’s New corporate or personal blog posts, to in-depth videos by Duncan Epping. However, there are a few changes that I want to highlight:
Get thee to 25GbE: A trilogy of reasons - Storage, load-balancing, and pricing.
vSAN is a distributed storage system. To that end, anything that improves the network or networking efficiency improves storage performance and application performance -- but there is more to networking than big, low-latency pipes. RDMA has been a part of vSphere since the 6.5 release; it is only with 7.0 Update 2 that it is leveraged by vSAN. John Nicholson explains the nuts and bolts of vSAN RDMA in this blog post, but only touches on the performance gains. From our performance testing on VxRail, I can share with you the gains we have seen with VxRail: up to 5% reduction in CPU utilization, up to 25% lower latency, and up to 18% higher IOPS, along with increases in read and write throughput. It should be noted that even with medium block IO, vSAN is more than capable of saturating a 10GbE port, RDMA is pushing performance beyond that, and we’ve yet to see what Intel 3rd Generation Xeon processors will bring. The only fly in the ointment for vSAN RDMA is the current small list of approved network cards – no doubt more will be added soon.
vSAN is not the only feature that enjoys large low-latency pipes. Niels Hagoort describes the changes in vSphere 7.0 Update 2 that have made vMotion faster, thus making Balancing Workloads Invisible and the lives of virtualization administrators everywhere a lot better. Aside: Can I say how awesome it is to see VMware continuing to enhance a foundational feature that they first introduced in 2003, a feature that for many was that lightbulb Aha! moment that started their virtualization journey.
One last nudge: pricing. The cost delta between 10GbE and 25GbE network hardware is minimal, so for greenfield deployments the choice is easy; you may not need it today, but workloads and demands continue to grow. For brownfield, where the existing network is not due for replacements, the choice is still easy. 25GbE NICs and switch ports can negotiate to 10GbE making a phased migration, VxRail nodes now and switches in the future, possible. The inverse is also possible: upgrade the network to 25GbE switches while still connecting your existing VxRail 10GbE SFP+ NIC ports.
Is 25GbE in your infrastructure upgrade plans yet? If not, maybe it should be.
A duo of AMD goodness
Last year we released two AMD-based VxRail platforms, the E665/F and the P675F/N, so I’m delighted to see CPU scheduler optimizations for AMD EPYC processors, as described in Aditya Sahu blog post. What is even better is the 29 page performance study Aditya links to, the depth of detail provided on how the ESXi CPU scheduling works, and didn’t work, with AMD EYPC processors is truly educational.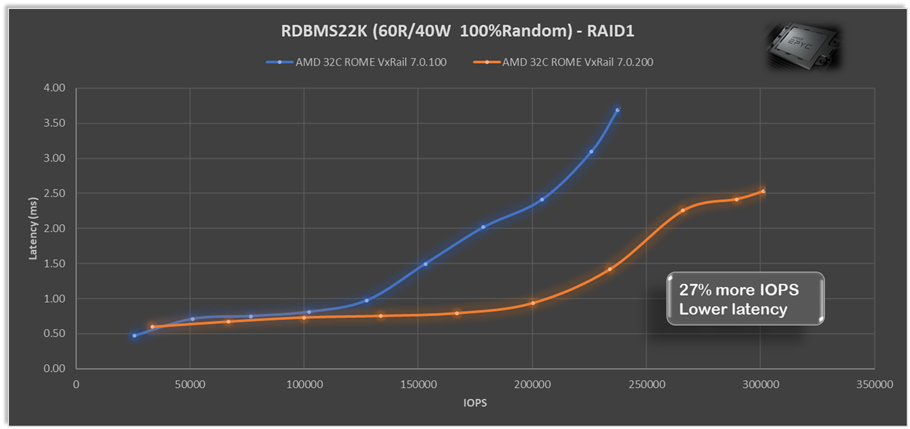 The extensive performance testing VMware continuously runs and the results they share (spoiler: they achieved very significant gains) are also a worthwhile read. In our testing we’ve seen that with just these scheduler optimizations AMD alone VxRail 7.0.200 can provide up to 27% more IOPS and up to 27% lower latency for both RAID1 and RAID5 with relational database (RDBMS22K 60R/40W 100%Random) workloads.
The extensive performance testing VMware continuously runs and the results they share (spoiler: they achieved very significant gains) are also a worthwhile read. In our testing we’ve seen that with just these scheduler optimizations AMD alone VxRail 7.0.200 can provide up to 27% more IOPS and up to 27% lower latency for both RAID1 and RAID5 with relational database (RDBMS22K 60R/40W 100%Random) workloads.
VxRail begins shipping the 3rd generation AMD EYPC processors – also known as
Milan – in VxRail E665 and P675 nodes later this month. These are not a replacement
for the current 2nd Gen EPYC processors we offer, rather the addition of higher
performing 24-core, 32-core, and 64-core choices to the VxRail line up delivering up to 33% more IOPS and 16% lower latency across a range of workloads and block sizes. Check out this VMware blog post for the performance gains they showcase with the VMmark benchmarking tool.
HCI Mesh – only recently introduced, yet already getting better
When VMware released HCI Mesh just last October, it enabled stranded storage on one VxRail cluster to be consumed by another VxRail cluster. With the release of VxRail 7.0.200 this has been expanded to making it more applicable to more customers by enabling any vSphere clusters to also be consumers of that excess storage capacity – these remote clusters do not require a vSAN license and consume the storage in the same manner they would any other datastore. This opens up some interesting multi-cluster use cases, for example:
In solutions where a software application licensing requires each core/socket in the vSphere cluster to be licensed, this licensing cost can easily dwarf other costs. Now this application can be deployed on a small compute-only cluster, while consuming storage from the larger VxRail cluster. Or where the density of storage per socket didn’t make VxRail viable, it can now be achieved with a smaller VxRail cluster, plus a separate compute-only cluster. If only the all the goodness that is VxRail was available in a compute-only cluster – now that would be something dynamic…
A GPU for every workload
GPUs, once the domain of PC gamers, are now a data center staple with their parallel processing capabilities accelerating a variety of workloads. The versatile VxRail V Series has multiple NVIDIA GPUs to choose from and we’ve added two more with the addition of the NVIDIA A40 and A100. The A40 is for sophisticated visual computing workloads – think large complex CAD models, while the A100 is optimized for deep learning inference workloads for high-end data science.
Evolution of hardware in a software-defined world
PowerEdge took a big step forward with their recent release built on 3rd Gen Intel Xeon Scalable processors. Software-defined principles enable VxRail to not only quickly leverage this big step forward, but also to quickly leverage all the small steps in hardware changes throughout a generation. Building on the latest PowerEdge servers we are Reimagine HCI with VxRail with the next generation VxRail E660/F, P670F or V670F. Plus, what’s great about VxRail is that you can seamlessly integrate this latest technology into your existing infrastructure environment. This is an exciting release, but equally exciting are all the incremental changes that VxRail software-defined infrastructure will get along the way with PowerEdge and VMware.
VxRail, flexibility is at its core.
Availability
- VxRail systems with Intel 3rd Generation Xeon processors will be globally available in July 2021.
- VxRail systems with AMD 3rd Generation EPYC processors will be globally available in June 2021.
- VxRail HCI System Software updates will be globally available in July 2021.
- VxRail dynamic nodes will be globally available in August 2021.
- VxRail self-deployment options will begin availability in North America through an early access program in August 2021.
Additional resources
- Blog: Reimagine HCI with VxRail
- Attend our launch webinar to learn more.
- Press release: Dell Technologies Reimagines Dell EMC VxRail to Offer Greater Performance and Storage Flexibility

Deploying SAP HANA at the Rugged Edge
Mon, 14 Dec 2020 18:38:19 -0000
|Read Time: 0 minutes
SAP HANA is one of those demanding workloads that has been steadfastly contained within the clean walls of the core data center. However, this time last year VxRail began to chip away at these walls and brought you SAP HANA certified configurations based on the VxRail all-flash P570F workhorse and powerful quad socket all-NVMe P580N. This year, we are once again in the giving mood and are bringing SAP HANA to the edge. Let us explain.

Dell Technologies defines the edge as “The edge exists wherever the digital world & physical world intersect. It’s where data is securely collected, generated and processed to create new value.” This is a very broad definition that extends the edge from the data center to oil rigs, to mobile response centers for natural disasters. It is a broad claim not only to provide compute and storage in such harsh locations, but also to provide enough of it that meets the strict and demanding needs of SAP HANA, all while not consuming a lot of physical space. After all -- it is the edge where space is at a premium.
Shrinking the amount of rack space needed was the easier of the two challenges, and our 1U E for Everything (or should that be E for Everywhere?) was a perfect fit. The all-flash E560F and all-NVMe E560N, both of which can be enhanced with Intel Optane Persistent Memory, can be thought of as the shorter sibling of our 2U P570F, packing a powerful punch with equivalent processor and memory configurations.
 While the E Series fits the bill for space constrained environments, it still needs data center like conditions. This is not the case for the durable D560F, the tough little champion that joined the VxRail family in June of this year, and which is now the only SAP HANA certified ruggedized platform in the industry. Weighing in at a lightweight 28 lbs. and a short depth of 20 inches, this little fighter will run all day at 45°C with eight hour sprints of up to 55°C, all while enduring shock, vibration, dust, humidity, and EMI, as this little box is MIL-STD 810G and DNV-GL Maritime certified. In other words, if your holiday plans involve a trip to hot sand beaches, a ship cruise through a hurricane, or an alpine climb, and you’re bringing SAP HANA with you (we promise we won’t ask why), then the durable D560F is for you.
While the E Series fits the bill for space constrained environments, it still needs data center like conditions. This is not the case for the durable D560F, the tough little champion that joined the VxRail family in June of this year, and which is now the only SAP HANA certified ruggedized platform in the industry. Weighing in at a lightweight 28 lbs. and a short depth of 20 inches, this little fighter will run all day at 45°C with eight hour sprints of up to 55°C, all while enduring shock, vibration, dust, humidity, and EMI, as this little box is MIL-STD 810G and DNV-GL Maritime certified. In other words, if your holiday plans involve a trip to hot sand beaches, a ship cruise through a hurricane, or an alpine climb, and you’re bringing SAP HANA with you (we promise we won’t ask why), then the durable D560F is for you.
The best presents sometimes come in small packages. So, we won’t belabor this blog with anything more than to announce that these two little gems, the E560 and the D560, are now SAP HANA certified.
Author: David Glynn, Sr. Principal Engineer, VxRail Tech Marketing
References:
360° View: VxRail D Series: The Toughest VxRail Yet
Video: HCI Computing at the Edge
Solution brief: Taking HCI to the Edge: Rugged Efficiency for Federal Teams
Press release: Dell Technologies Brings IT Infrastructure and Cloud Capabilities to Edge Environments
SAP Certification link: Certified and Supported SAP HANA® Hardware Directory

Update to VxRail 7.0.100 and Unleash the Performance Within It
Thu, 05 Nov 2020 23:07:52 -0000
|Read Time: 0 minutes
What could be better than faster storage? How about faster storage, more capacity, and better durability?
Last week at Dell Technologies we released VxRail 7.0.100. This release brings support for the latest versions of VMware vSphere and vSAN 7.0 Update 1. Typically, in an update release we will see a new feature or two, but VMware out did themselves and crammed not only a load of new or significantly enhanced features into this update, but also some game changing performance enhancements. As my peers at VMware already did a fantastic job of explain these features, I won’t even attempt to replicate their work – you can find links to the blogs on features that caught my attention in the reference section below. Rather, I want to draw attention to the performance gains, and ask the question: Could RAID5 with compression only be the new normal?
Don’t worry, I can already hear the cries of “Max performance needs RAID1, RAID5 has IO amplification and parity overhead, data reduction services have drawbacks”, but bear with me a little. Also, I’m not suggesting that RAID5 compression only be used for all workloads, there are some workloads that are definitely unsuitable – streams of compressed video come to mind. Rather I’m merely suggesting that after our customers go through the painless process of updating their cluster to VxRail 7.0.100 from one of our 36 previous releases in over the past two years (yes you can leap straight from 4.5.211 to 7.0.100 in a single update and yes we do handle the converging and decommissioning of the Platform Services Controller), that they check out the reduction in storage IO latency that their existing workload is putting on their VxRail cluster, and investigate what it represents – in short, more storage performance headroom.
As customers buy VxRail clusters to support production workloads, they can’t exactly load it up with a variety of benchmark workload test to see how far they can push it. But at VxRail we are fortune to have our own dedicated performance team, who have enough VxRail nodes to run a mid-sized enterprise, and access to a large library of components so that they can replicate almost any VxRail configuration we sell (and a few we don’t). So, there is data behind my outrageous suggestion, it isn’t just back of the napkin mathematics. Grab a copy of the performance team’s recent findings in their whitepaper: Harnessing the performance of Dell EMC VxRail 7.0.100: A lab based performance analysis of VxRail, and skip to figure 3. There you’ll find some very telling before and after performance latency curves with and without data reduction services for an RDBMS workload. Spoiler: 58% more peak IOPS and almost 40% lower latency, with compression this only drops to a still very significant 45% more peak IOPS with 30% lower latency. (For those of you screaming “but failure domains” check out the blog Space Efficiency Using the New “Compression only” Option where Pete Kohler explains the issue, and how it not longer exists with compression only.) But what about RAID5? Skip up to figure 1 which summarizes the across the board performance gains for IOPS and throughput, impressive, right? Now slide down to figure 2 to compare the throughput, in particular compare RAID 1 on 7.0 with RAID 5 on 7.0 U1 – the read performance is almost identical, while the gap in write performance has narrowed. Write performance on RAID5 will likely always lag RAID1 due to IO amplification, but VMware is clearly looking to narrow that gap as much as possible.
If nothing else the whitepaper should tell you that a simple hassle-free upgrade to VxRail 7.0.100 will unlock additional performance headroom on your vSAN cluster without any additional costs, and that the tradeoffs associated with RAID5 and data reduction services (compression only) are greatly reduced. There are opportunistic space savings to be had from compression only, but they require committing to a cluster wide change to unlock, which is something that should not be taken lightly. However, realizing the guaranteed 33% capacity savings of RAID5, can be unlocked per virtual machine, reverted just as easily, represents a lower risk. I opened asking the question if RAID5 with compression only could be the new normal, and I firmly believe that the data indicates that this is a viable option for many more workloads.
References:
My peers at VMware (John Nicholson, Pete Flecha (these two are the voices and brains behind the vSpeakingPodcast – definitely worth listening to), Teodora Todorova Hristov, Pete Koehler and Cedric Rajendran) have written great and in-depth blogs about these features that caught my attention:
vSAN HCI Mesh – eliminate stranded storage by enabling VMs registered to cluster A access storage from cluster B
Shared Witness for 2-Node Deployments - reduced administration time and infrastructure costs thru one witness for up to sixty-four 2-node clusters
Enhanced vSAN File Services – adds SMB v2.1 and v3 for Windows and Mac clients. Add Kerberos authentication for existing NFS v4.1
Space Efficiency: Compression only option - For demanding workloads that cannot take advantage of deduplication. Compression only has higher throughput, lower latency, and significantly reduced impact on write performance compared to deduplication and compression. Compression only has a reduced failure domain and 7x faster data rebuild rates.
Spare Capacity Management – Slack space guidance of 25% has been replaced with a calculated Operational Reserve the requires less space, and decreases with scale. Additional option to enable Host rebuild reserve, VxRail Sizing Tool reserves this by default when sizing configurations, with the filter Add HA
Enhanced Durability during Maintenance Mode – data being intended for a host in maintenance mode is temporally recorded in a delta file on another host, providing the configured FTT during Maintenance Mode operations

2nd Gen AMD EPYC now available to power your favorite hyperconverged platform ;) VxRail
Mon, 17 Aug 2020 18:31:32 -0000
|Read Time: 0 minutes
Expanding the range of VxRail choices to include 64-cores of 2nd Gen AMD EPYC compute
Last month, Dell EMC expanded our very popular E Series (the E for Everything Series) with the introduction of the E665/F/N, our very first VxRail with an AMD processor, and what a processor it is! The 2nd Gen AMD EPYC processor came to market with a lot of industry-leading capabilities:
- Up to 64-cores in a single processor with 8, 12, 16, 24, 32 or 48 core offerings also available
- Eight memory channels, but not only more channels, they are also faster at 3200MT/s. The 2nd Gen EPYC can also address much more memory per processor
- 7nm transistors. Smaller transistors mean more powerful and more energy efficient processors
- Up to 128 lanes of PCIe Gen 4.0, with 2X the bandwidth of PCIe Gen 3.0.
These industry leading capabilities enable the VxRail E665 series to deliver dual socket performance in a single socket model - and can provide up to 90% greater general-purpose CPU capacity than other VxRail models when configured with single socket processors.
So, what is the sweet spot or ideal use case for the E665? As always, it depends on many things. Unlike the D Series (our D for Durable Series) that we also launched last month, which has clear rugged use cases, the E665 and the rest of the E Series very much live up to their “Everything” name, and perform admirably in a variety of use cases.
While the 2nd Gen EPYC 64-core processors grab the headlines, there are multiple AMD processor options, including the 16 core AMD 7F52 at 3.50GHz with a max boost of 3.9GHz for applications that benefit from raw clock speed, or where application licensing is core based. On the topic of licensing, I would be remiss if I didn’t mention VMware’s update to its per-CPU pricing earlier this year. This results in processors with more then 32-cores requiring a second VMware per-CPU license. This may make a 32-core processor an attractive option from an overall capacity & performance verses hardware & licensing cost perspective.
Speaking of overall costs, the E665 has dual 10Gb RJ45/SFP+ or dual 25Gb SFP28 base networking options, which can be further expanded with PCIe NICs including a dual 100Gb SFP28 option. From a cost perspective, the price delta between 10Gb and 25Gb networking is minimal. This is worth considering particularly for greenfield sites and even for brownfield sites where the networking maybe upgraded in the near future. Last year, we began offering Fibre Channel cards on VxRail, which are also available on the E665. While FC connectivity may sound strange for a hyperconverged infrastructure platform, it does make sense for many of our customers who have existing SAN infrastructure, or some applications (PowerMax for extremely large database requiring SRDF) or storage needs (Isilon for large file repository for medical files) that are more suited to SAN. While we’d prefer these SAN to be a Dell EMC product, as long as it is on the VMware SAN HCL, it can be connected. Providing this option enables customers to get the best both worlds have to offer.
The options don’t stop there. While the majority of VxRail nodes are sold with all-flash configurations, there are customers whose needs are met with hybrid configs, or who are looking towards all-NVMe options. The E665 can be configured with as little as 960GB to maximums of 14TB hybrid, 46TB all-flash, or 32TB all-NVMe of raw storage capacity. Memory options consist of 4, 8, or 16 RDIMMs of 16GB, 32GB or 64GB in size. Maximum memory performance, 3200 MT/s, is achieved with one DIMM per memory channel, adding a second matching DIMM reduces bandwidth slightly to 2933 MT/s.
VxRail and Dell Technologies, very much recognize that the needs of our customers vary greatly. A product with a single set of options cannot meet all our various customers’ different needs. Today, VxRail offers six different series, each with a different focus:
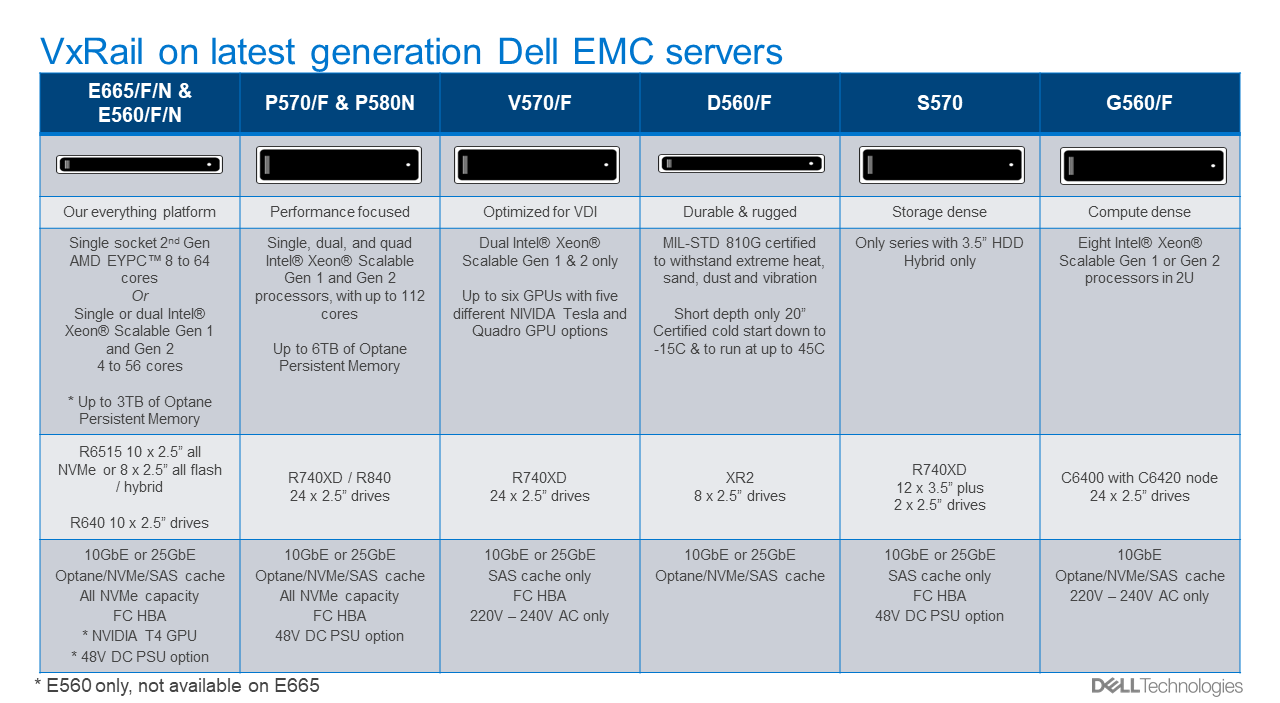
- Everything E Series a power packed 1U of choice
- Performance-focused P Series with dual or quad socket options
- VDI-focused V Series with a choice of five different NIVIDA GPUs
- Durable D Series are MIL-STD 810G certified for extreme heat, sand, dust, and vibration
- Storage-dense S Series with 96TB of hybrid storage capacity
- General purpose and compute dense G Series with 228 cores in a 2U form factor
With the highly flexible configuration choices, there is a VxRail for almost every use case, and if there isn’t, there is more than likely something in the broad Dell Technologies portfolio that is.
Author: David Glynn, Sr. Principal Engineer, VxRail Tech Marketing
Resources:
VxRail Spec Sheet
E665 Product Brief
E665 One Pager
D560 3D product landing page
D Series video
D Series spec sheet
D Series Product Brief

Top benefits to using Intel Optane NVMe for cache drives in VxRail
Mon, 17 Aug 2020 18:31:31 -0000
|Read Time: 0 minutes
Performance, endurance, and all without a price jump!
There is a saying that “A picture paints a thousand words” but let me add that a “graph can make for an awesome picture”.
Last August we at VxRail worked with ESG on a technical validation paper that included, among other things, the recent addition of Intel Optane NVMe drives for the vSAN caching layer. Figure 3 in this paper is a graph showing the results of a throughput benchmark workload (more on benchmarks later). When I do customer briefings and the question of vSAN caching performance comes up, this is my go-to whiteboard sketch because on its own it paints a very clear picture about the benefit of using Optane drives – and also because it is easy to draw.
In the public and private cloud, predictability of performance is important, doubly so for any form of latency. This is where caching comes into play, rather than having to wait on a busy system, we just leave it in the write cache inbox and get an acknowledgment. The inverse is also true. Like many parents I read almost the same bedtime stories to my young kids every night, you can be sure those books remain close to hand on my bedside “read cache” table. This write and read caching greatly helps in providing performance and consistent latency. With vSAN all-flash there no longer any read cache as the flash drives at the capacity layer provide enough random read access performance… just as my collection of bedtime story books has been replaced with a Kindle full of eBooks. Back to the write cache inbox where we’ve been dropping things off – at some point, this write cache needs to be empty, and this is where the Intel Optane NVMe drives shine. Drawing the comparison back to my kids, I no longer drive to a library to drop off books. With a flick of my finger I can return, or in cache terms de-stage, books from my Kindle back to the town library - the capacity drives if you will. This is a lot less disruptive to my day-to-day life, I don’t need to schedule it, I don’t need to stop what I’m doing, and with a bit of practice I’ve been able to do this mid story Let’s look at this in actual IT terms and business benefits.
To really show off how well the Optane drives shine, we want to stress the write cache as much as possible. This is where benchmarking tools and the right knowledge of how to apply them come into play. We had ESG design and run these benchmarking workloads for us. Now let’s be clear, this test is not reflective of a real-world workload but was designed purely to stress the write cache, in particular the de-staging from cache to capacity. The workload that created my go-to whiteboard sketch was the 100% sequential 64KB workload with a 1.2TB working set per node for 75 minutes.
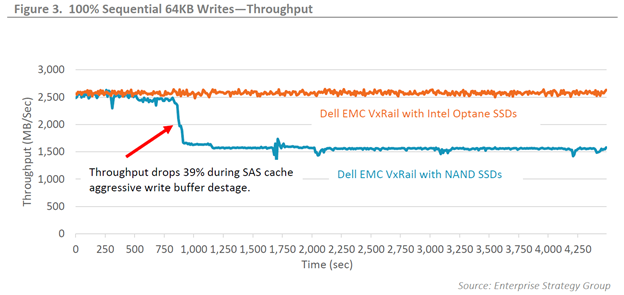
The graph clearly shows the benefit of the Optane drives, they keep on chugging at 2,500MB/sec of throughput the entire time without dropping a beat. What’s not to like about that! This is usually when the techie customer in the room will try to burst my bubble by pointing out the unrealistic workload that is in no way reflective of their environment, or most environments… which is true. A more real-world workload would be a simulated relational database workload with a 22KB block size, mixing random 8K and sequential 128K I/O, with 60% reads and 40% writes, and a 600GB per node working set, which is quite a mouthful and is shown in figure 5. The results there show a steady 8.4-8.8% increase in IOPS across the board and a slower rise in latency resulting in a 10.5% lower response time under 80% load.
Those of you running OLTP workloads will appreciate the graph shown in figure 6 where HammerDB was used to emulate the database activity of a typical online brokerage firm. The Optane cache drives under that workload sustained a remarkable 61% more transactions per minute (TPM) and new orders per minute (NOPM). That can result in significant business improvement for an online brokerage firm who adopts Optane drives versus one who is using NAND SSDs.
When it comes to write cache, performance is not everything, write endurance is also extremely important. The vSAN spec requires that cache drives be SSD Endurance Class C (3,650 TBW) or above, and Intel Optane beats this hands down with an over tenfold margin at 41 PBW (41,984 TBW). The Intel Optane 3D XPoint architecture allows memory cells to be individually addressed in a dense, transistor-less, stackable design. This extremely high write endurance capability has let us spec a smaller sized cache drive, which in turn lets us maintain a similar VxRail node price point, enabling you the customer to get more performance for your dollar.
What’s not to like? Typically, you get to pick any two; faster/better/cheaper. With Intel Optane drives in your VxRail you get all three; more performance and better endurance, at roughly the same cost. Wins all around!
Author: David Glynn, Sr Principal Engineer, VxRail Tech Marketing
Resources: Dell EMC VxRail with Intel Xeon Scalable Processors and Intel Optane SSDs