




VxRail with vSAN Express Storage Architecture (ESA)
vSAN Express Storage Architecture: The New Era. It may well be given the dramatic gains in performance that VMware is claiming (my VxRail with vSAN ESA performance blog will be next month) and the major changes to the capabilities of data services provided in vSAN ESA. It’s important to understand that this is the next step in vSAN’s evolution, not an end. vSAN’s Original Storage Architecture (OSA) has been continuously evolving since it was first released in 2014. vSAN 8.0 Express Storage Architecture is just another small step on that evolutionary journey – well maybe more of a giant leap. A giant leap that VxRail will take along with it.
vSAN OSA was designed at a time when spinning disks were the norm, flash was expensive, double digit multi-core processors were new-ish, and 10Gbit networking was for switch uplinks not servers. Since then, there have been significant changes in the underlying hardware, which vSAN has benefited from and leveraged along the way. Fast forward to today, spinning disk is for archival use, NVMe is relatively cheap, 96 core processors exist, 25Gb networking is the greenfield default with 100Gb networking available for a small premium. Therefore, it is no surprise to see VMware optimizing vSAN to exploit the full potential of the latest hardware, unlocking new capabilities, higher efficiency, and more performance. Does this spell the end of the road for vSAN OSA? Far from it! Both architectures are part of vSAN 8.0, with OSA getting several improvements. The most exciting of which is the Increased Write Buffer Capacity from 600GB to 1.6TB per diskgroup. This will not only increase performance, but equally important also improve performance consistency.
Before you get excited about the performance gains and new capabilities that upgrading to vSAN ESA will unlock on your VxRail cluster, be aware of one important item. vSAN ESA is, for now, greenfield only. This was done to enable vSAN ESA to fully exploit the potential of the latest in server hardware and protocols to deliver new capabilities and performance to meet the ever-evolving demands that business places on today’s IT infrastructure.
Aside from being greenfield only, vSAN ESA has particular hardware requirements. So that you can hit the ground running this New Year with vSAN ESA, we’ve refreshed the VxRail E660N and P670N with configurations that meet or exceed vSAN ESA’s significantly different requirements, enabling you to purchase with confidence:
- Six 3.2TB or 6.4TB mixed-use TLC NVMe devices
- 32 cores
- 512GB RAM
- Two 25Gb NIC ports, with 100Gb recommended for maximum performance. Yes, vSAN ESA will saturate a 25Gb network port. And yes, you could bond multiple 25Gb network ports, but the price delta (including switches and cables) between quad 25Gb and dual 100Gb networking is surprisingly small.
And as you’d expect, VxRail Manager has already been in training and is hitting the ground running alongside you. At deployment, VxRail Manager will recognize this new configuration, deploy the cluster following vSAN ESA best practices and compatibility checks, and perform future updates with Continuously Validated States.
But hardware is only half of the story. What VMware did with vSAN to take advantage of the vastly improved hardware landscape is key. vSAN ESA stands on the shoulders of the work that OSA has done, re-using much of it, but optimizing the data path to utilize today’s hardware. These architectural changes occur in two places: a new log-structured file system, and an optimized log-structured object manager and data structure. Pete Koehler’s blog post An Introduction to the vSAN Express Storage Architecture explains this in a clear and concise manner – and much better than I could. What I found most interesting was that these changes have created a storage paradox of high performing erasure coding with highly valued data services:
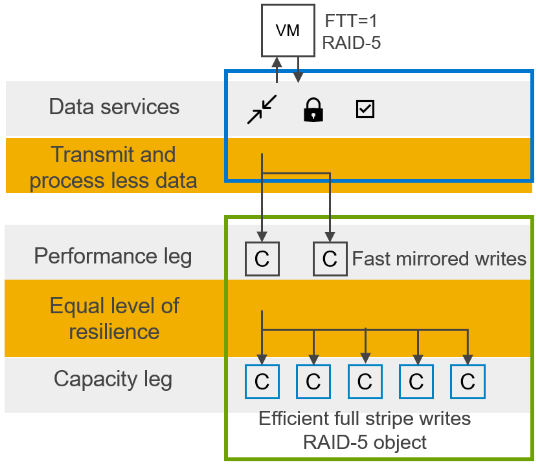
Figure 1. Log structured file system - optimized data handling
- Data services like compression and encryption occur at the highest layer, minimizing process amplification, and lowering processor and network utilization. To put this another way, data services are done once, and the resulting now smaller and encrypted data load is sent over the network to be written on multiple hosts.
- The log-structured file system rapidly ingests data, while organizing it into a full stripe write. The key part here is that full stripe write. Typically, with erasure coding, a partial stripe write is done. This results in a read-modify-write which causes the performance overhead we traditionally associate with RAID5 and RAID6. Thus, full stripe writes enable the space efficiency of RAID5/6 erasure coding with the performance of RAID1 mirroring.
- Snapshots also benefit from the log structured file system, with writes written to new areas of storage and metadata pointers tracking which data belongs to which snapshot. This change enables Scalable, High-Performance Native Snapshots with compatibility for existing 3rd party VDAP backup solutions and vSphere Replication.
Does this mean we get to have our cake and eat it too? This is certainly the case, but check out my next blog where we’ll delve into the brilliant results from the extensive testing by the VxRail Performance team.
Back to the hardware half of the story. Don’t let the cost of mixed-use NVMe drives scare you away from vSAN ESA. The TCO of ESA is actually lower than OSA. There are a few minor things that contribute to this, no SAS controller, and no dedicated cache devices. However, because of ESA’s RAID-5/6 with the Performance of RAID-1, less capacity is needed, delivering significant costs savings. Traditionally, performance and mirroring, required twice the capacity, but ESA RAID6 can deliver comparable performance, with 33% more usable capacity, and better resiliency with a failure to tolerate of two. Even small clusters benefit from ESA with adaptive RAID5, which has a 2+1 data placement scheme for use on clusters with as few as three nodes. As these small clusters grow beyond five nodes, vSAN ESA will adapt that RAID5 2+1 data placement to the more efficient RAID5 4+1 data placement.

Figure 2. Comparing vSAN OSA and ESA on different storage policies against performance and efficiency
Finally, ESA has an ace up its sleeve with the more resource efficient and granular compression with a claimed “up to a 4x improvement over original storage architecture”. ESA’s minimum hardware requirements may seem high, but bear in mind, they are specified to enable ESA to deliver the high performance it is capable of. When running the same workload that you have today on your VxRail with vSAN OSA cluster on a VxRail with vSAN ESA cluster, the resource consumption will be noticeably lower – releasing resources for additional virtual machines and their workloads.
A big shoutout to my technical marketing peers over at VMware for the many great blogs, videos, and other assets they have delivered. I linked to several of them above, but you can find the all of their vSAN ESA material over at core.vmware.com/vsan-esa including a very detailed FAQ, and an updated Foundations of vSAN Architecture video series on YouTube.
vSAN Express Storage Architecture is a giant leap forward for datacenter administrators everywhere and will draw more of them into the world of hyperconverged infrastructure. vSAN ESA on VxRail provides the most effective and secure path for customers to leverage this new technology. The New Era has started, and it is going to be very interesting.
Author: David Glynn, Sr. Principal Engineer, VxRail Technical Marketing
Images courtesy of VMware
For the curious and the planners out there, migrating to vSAN ESA is, as you’d expect, just a vMotion and SvMotion.
Related Blog Posts

100 GbE Networking – Harness the Performance of vSAN Express Storage Architecture
Wed, 05 Apr 2023 12:48:50 -0000
|Read Time: 0 minutes
For a few years, 25GbE networking has been the mainstay of rack networking, with 100 GbE reserved for uplinks to spine or aggregation switches. 25 GbE provides a significant leap in bandwidth over 10 GbE, and today carries no outstanding price premium over 10 GbE, making it a clear winner for new buildouts. But should we still be continuing with this winning 25 GbE strategy? Is it time to look to a future of 100 GbE networking within the rack? Or is that future now?
This question stems from my last blog post: VxRail with vSAN Express Storage Architecture (ESA) where I called out VMware’s 100 GbE recommended for maximum performance. But just how much more performance can vSAN ESA deliver with 100GbE networking? VxRail is fortunate to have its performance team, who stood up two identical six-node VxRail with vSAN ESA clusters, except for the networking. One was configured with Broadcom 57514 25 GbE networking, and the other with Broadcom 57508 100 GbE networking. For more VxRail white papers, guides, and blog posts visit VxRail Info Hub.
When it comes to benchmark tests, there is a large variety to choose from. Some benchmark tests are ideal for generating headline hero numbers for marketing purposes – think quarter-mile drag racing. Others are good for helping with diagnosing issues. Finally, there are benchmark tests that are reflective of real-world workloads. OLTP32K is a popular one, reflective of online transaction processing with a 70/30 read-write split and a 32k block size, and according to the aggregated results from thousands of Live Optics workload observations across millions of servers.
One more thing before we get to the results of the VxRail Performance Team's testing. The environment configuration. We used a storage policy of erasure coding with a failure tolerance of two and compression enabled.
When VMware announced vSAN with Express Storage Architecture they published a series of blogs all of which I encourage you to read. But as part of our 25 GbE vs 100 GbE testing, we also wanted to verify the astounding claims of RAID-5/6 with the Performance of RAID-1 using the vSAN Express Storage Architecture and vSAN 8 Compression - Express Storage Architecture. In short, forget the normal rules of storage performance, VMware threw that book out of the window. We didn’t throw our copy out of the window, well not at first, but once our results validated their claims… it went out.
Let’s look at the data: Boom!
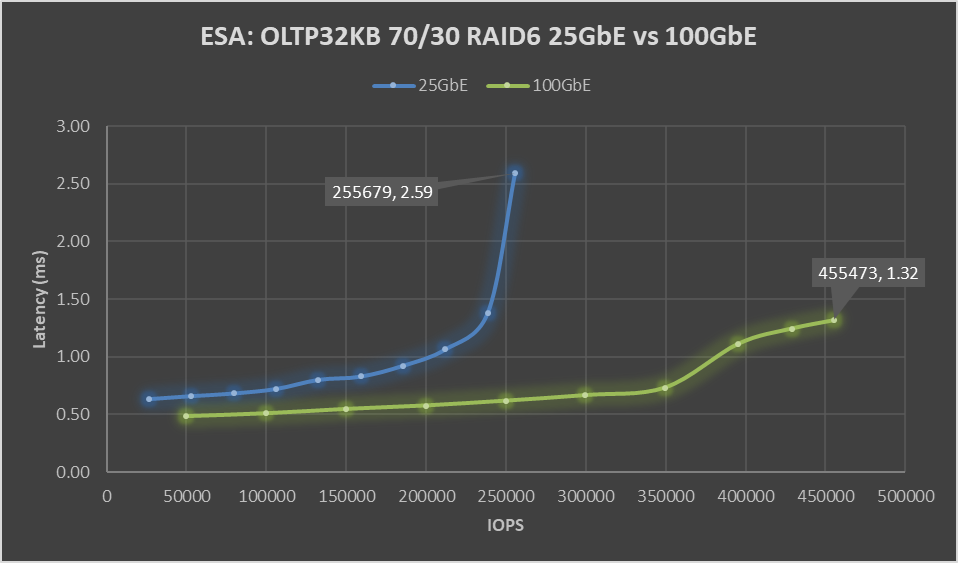
Figure 1. ESA: OLTP32KB 70/30 RAID6 25 GbE vs 100 GbE performance graph
Boom! A 78% increase in peak IOPS with a substantial 49% drop in latency. This is a HUGE increase in performance, and the sole difference is the use of the Broadcom 57508 100 GbE networking. Also, check out that latency ramp-up on the 25 GbE line, it’s just like hitting a wall. While it is almost flat on the 100 GbE line.
But nobody runs constantly at 100%, at least they shouldn’t be. 60 to 70% of absolute max is typically a normal day-to-day comfortable peak workload, leaving some headroom for spikes or node maintenance. At that range, there is an 88% increase in IOPS with a 19 to 21% drop in latency, with a smaller drop in latency attributable to the 25 GbE configuration not hitting a wall. As much as applications like high performance, it is needed to deliver performance with consistent and predictable latency, and if it is low all the better. If we focus on just latency, the 100 GbE networking enabled 350K IOPS to be delivered at 0.73 ms, while the 25 GbE networking can squeak out 106K IOPS at 0.72 ms. That may not be the fairest of comparisons, but it does highlight how much 100GbE networking can benefit latency-sensitive workloads.
Boom, again! This benchmark is not reflective of real-world workloads but is a diagnostic test that stresses the network with its 100% read-and-write workloads. Can this find the bottleneck that 25 GbE hit in the previous benchmark?
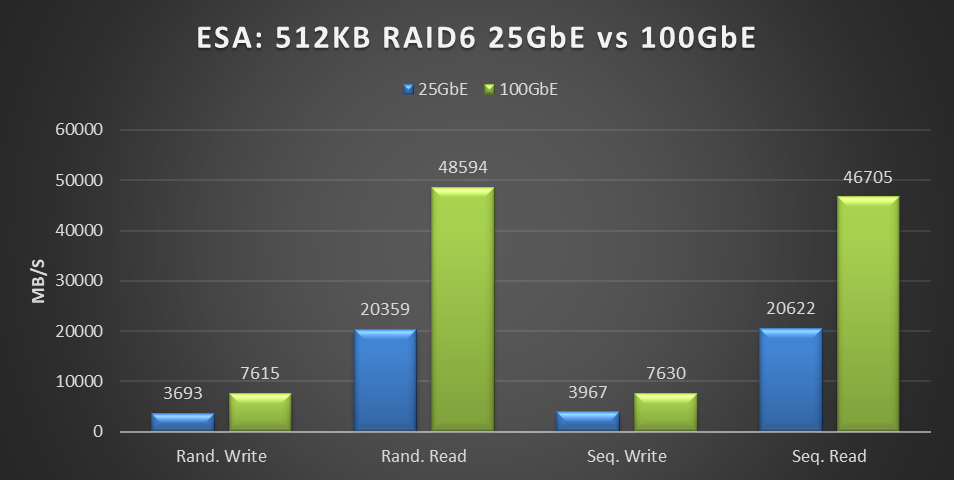
Figure 2. ESA: 512KB RAID6 25 GbE vs 100 GbE performance graph
This testing was performed on a six-node cluster, with each node contributing one-sixth of the throughput shown in this graph. 20359MB/s of random read throughput for the 25 GbE cluster or 3393 MB/s per node. Which is slightly above the theoretical max throughput of 3125 MB/s that 25 GbE can deliver. This is the absolute maximum that 25 GbE can deliver! In the world of HCI, the virtual machine workload is co-resident with the storage. As a result, some of the IO is local to the workload, resulting in higher than theoretical throughput. For comparison, the 100 GbE cluster achieved 48,594 MB/s of random read throughput, or 8,099 MB/s per node out of a theoretical maximum of 12,500 MB/s.
But this is just the first release of the Express Storage Architecture. In the past, VMware has added significant gains to vSAN, as seen in the lab-based performance analysis of Harnessing the Performance of Dell EMC VxRail 7.0.100. We can only speculate on what else they have in store to improve upon this initial release.
What about costs, you ask? Street pricing can vary greatly depending on the region, so it's best to reach out to your Dell account team for local pricing information. Using US list pricing as of March 2023, I got the following:
Component | Dell PN | List price | Per port | 25GbE | 100GbE |
Broadcom 57414 dual 25 Gb | 540-BBUJ | $769 | $385 | $385 |
|
S5248F-ON 48 port 25 GbE | 210-APEX | $59,216 | $1,234 | $1,234 |
|
25 GbE Passive Copper DAC | 470-BBCX | $125 | $125 | $125 |
|
Broadcom 57508 dual 100Gb | 540-BDEF | $2,484 | $1,242 |
| $1,242 |
S5232F-ON 32 port 100 GbE | 210-APHK | $62,475 | $1,952 |
| $1,952 |
100 GbE Passive Copper DAC | 470-ABOX | $360 | $360 |
| $360 |
Total per port |
|
|
| $1,743 | $3,554 |
Overall, the per-port cost of the 100 GbE equipment was 2.04 times that of the 25 GbE equipment. However, this doubling of network cost provides four times the bandwidth, a 78% increase in storage performance, and a 49% reduction in latency.
If your workload is IOPS-bound or latency-sensitive and you had planned to address this issue by adding more VxRail nodes, consider this a wakeup call. Adding dual 100Gb came at a total list cost of $42,648 for the twelve ports used. This cost is significantly less than the list price of a single VxRail node and a fraction of the list cost of adding enough VxRail nodes to achieve the same level of performance increase.
Reach out to your networking team; they would be delighted to help deploy the 100 Gb switches your savings funded. If decision-makers need further encouragement, send them this link to the white paper on this same topic Dell VxRail Performance Analysis (similar content, just more formal), and this link to VMware's vSAN 8 Total Cost of Ownership white paper.
While 25 GbE has its place in the datacenter, when it comes to deploying vSAN Express Storage Architecture, it's clear that we're moving beyond it and onto 100 GbE. The future is now 100 GbE, and we thank Broadcom for joining us on this journey.

New VxRail Node Lets You Start Small with Greater Flexibility in Scaling and Additional Resiliency
Mon, 29 Aug 2022 19:00:25 -0000
|Read Time: 0 minutes
When deploying infrastructure, it is important to know two things: current resource needs and that those resource needs will grow. What we don’t always know is in what way the demands for resources will grow. Resource growth is rarely equal across all resources. Storage demands will grow more rapidly than compute, or vice-versa. At the end of the day, we can only make an educated guess, and time will tell if we guessed right. We can, however, make intelligent choices that increase the flexibility of our growth options and give us the ability to scale resources independently. Enter the single processor Dell VxRail P670F.
The availability of the P670F with only a single processor provides more growth flexibility for our customers who have smaller clusters. By choosing a less compute dense single processor node, the same compute workload will require more nodes. There are two benefits to this:
- More efficient storage: More nodes in the cluster opens the door to using the more capacity efficient erasure coding vSAN storage option. Erasure coding, also known as parity RAID, (such as RAID 5 and RAID 6) has a capacity overhead of 33% compared to the 100% overhead that mirroring requires. Erasure coding can deliver 50% more usable storage capacity while using the same amount of raw capacity. While this increase in storage does come with a write performance penalty, VxRail with vSAN has shown that the gap between erasure coding and mirroring has narrowed significantly, and provides significant storage performance capabilities.
- Reduced cluster overhead: Clusters are designed around N+1, where ‘N’ represents sufficient resources to run the preferred workload, and ‘+1’ are spare and unused resources held in reserve should a failure occur in the nodes that make up the N. As the number of nodes in N increases, the percentage of overall resources that are kept in reserve to provide the +1 for planned and unplanned downtime drops.
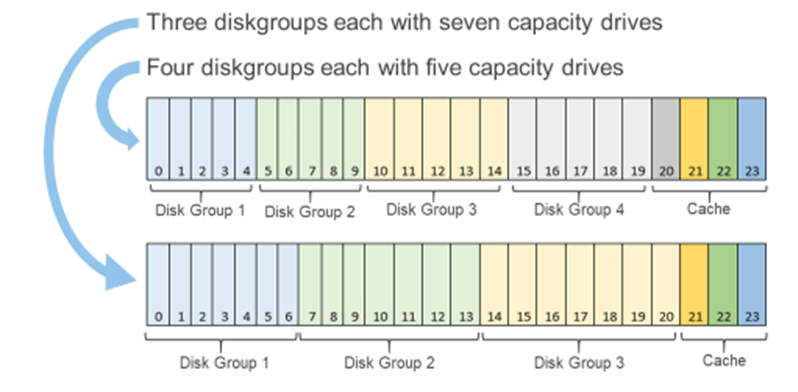
Figure 1: Single processor P670F disk group options
You may be wondering, “How does all of this deliver flexibility in the options for scaling?”
You can scale out the cluster by adding a node. Adding a node is the standard option and can be the right choice if you want to increase both compute and storage resources. However, if you want to grow storage, adding capacity drives will deliver that additional storage capacity. The single processor P670F has disk slots for up to 21 capacity drives with three cache drives, which can be populated one at a time, providing over 160TB of raw storage. (This is also a good time to review virtual machine storage policies: does that application really need mirrored storage?) The single processor P670F does not have a single socket motherboard. Instead, it has the same dual socket motherboard as the existing P670F—very much a platform designed for expanding CPU and memory in the future.
If you are starting small, even really small, as in a 2-node cluster (don’t worry, you can still scale out to 64 nodes), the single processor P670F has even more additional features that may be of interest to you. Our customers frequently deploy 2-node clusters outside of their core data center at the edge or at remote locations that can be difficult to access. In these situations, the additional data resiliency that provided by Nested Fault Domains in vSAN is attractive. To provide this additional resiliency on 2-node clusters requires at least three disk groups in each node, for which the single processor P670F is perfectly suited. For more information, see VMware’s Teodora Hristov blog post about Nested fault domain for 2 Node cluster deployments. She also posts related information and blog posts on Twitter.
It is impressive how a single change in configuration options can add so much more configuration flexibility, enabling you to optimize your VxRail nodes specifically to your use cases and needs. These configuration options impact your systems today and as you scale into the future.
Author Information
Author: David Glynn, Sr. Principal Engineer, VxRail Technical Marketing
Twitter: @d_glynn