
Assets

Big Data as-a-Service(BDaaS) Use Cases on Robin Systems
Wed, 24 Apr 2024 15:27:10 -0000
|Read Time: 0 minutes
Do you have a Big Data mess? Do you have separate infrastructure for the likes of NoSQL databases like Cassandra, MongoDB, Neo4j & Riak? I’ll bet that kafka, spark and elastic search are on separate gear too. Let’s throw in PostgreSQL, MariaDB, MySQL, Greenplum and another db or two. We don’t want to forget machine learning with sckit-learn and DASK nor deep learning with Tensorflow and Pytorch.
What if I told you you could run all of them including test/dev, qa, prod w/ perhaps multiple instances and different versions all on the same multi-tenant, containerized platform?
Enter Robin Systems and their cloud native platform. Some of the features I find useful include:
- Similar to BlueData (HPE) but way better
- Multi-tenant
- Low cost
- Easy to manage
- Containerized via Kubernetes
- Compact and dense
- Disaggregated compute and storage or hybrid
- One platform and set of BOMs for all tenants, multi-tenant
- Can also do Oracle, Hadoop, elastic and more
- Can be delivered direct or via partner
- Infrastructure flexibility (compute-only, storage only, and/or hybrid nodes)
- Infrastructure + application / service / storage level monitoring and visibility via integrated ELK/Grafana/Prometheus (out of the box templates and customizable)
- QoS at the CPU, memory, disk, and network level + storage IOPs guarantees
- App-store enables deployment of new app instances (or entire app pipelines) in minutes
- Support for multiple run-time engines (LXC, Docker, kVM)
- Templates to customize with deep workload knowledge
- Application / storage / service thin cloning
- Native, application-aware backups and snapshots
- Scale up / scale down application / storage / service
- Can use optional VMs
- SAN storage via CSI is possible
As for the use cases some ideas
- Just Oracle dense. 500 dbs on 18 servers. SAN for storage. RAC or not
- MariaDB + Cassandra + MongoDB
- Just Hadoop…all containerized, multiple clusters incl test/prod/qa
- Hadoop + oracle
- Kafka, Hadoop, elastic, Cassandra, Oracle
- ML data pipelines
- DL such as TF w/ GPUs
- Spark
- Any NoSQL database
- RDBMSs such as MySQL, MariaDB, PostgreSQL, Greenplum, Oracle, etc..
- Streaming analytics as with kafka or flink
Contact info for Mike King, Advisory System Engineer for DA / AI / Big Data, Dell Technologies | NA Data Center Workload Solutions
- https://itsavant.wordpress.com
- /https://twitter.com/MikeDataKing
- http://www.linkedin.com/in/mikedataking/
Links
- https://infohub.delltechnologies.com/p/removing-the-barriers-to-hybrid-cloud-flexibility-for-data-analytics/ by Phil Hummel & Raj Naryanan
- https://itsavant.wordpress.com/2021/04/30/big-data-as-a-service-with-robin-systems/
- "Five Reasons to Choose Dell and Robin CNP for AI/ML" by Mike King and Raj Narayanan

An Ace in the Hole for Your Kubernetes Clusters
Mon, 24 Apr 2023 14:12:49 -0000
|Read Time: 0 minutes
Robin Systems SymWorld Cloud, previously known as Cloud Native Platform (CNP), is a killer upstream K8S distribution that you should consider for many of your workloads. I’ve been working with this platform for several years and continue to be impressed with what it can do. Some of the things that I see value in for Symworld Cloud include but are not limited to the following:
- QoS for resources such as CPU, memory and network.
- Templates for workloads that are extensible
- Pre and Post scripting capability that is customizable for each workload
- Automation of all tasks
- Elastic scaling both up and down
- Multi-tenant capabilities
- Easy provisioning
- Simple deployment
- An application store that can house multiple versions of a workload with varied functionality
- Higher resource utilization
- Three types of nodes possible: compute, storage and converged
- Resources may be shared or dedicated as needed
When it comes to workloads there’s an extensive existing catalog. If you need something added it can be added. Workloads that could be deployed include:
- Any NoSQL db including MongoDB, Cassandra, Redis, TigerGraph, Neo4j, Aerospike, Couchbase, RocksDB, etc….
- Select RDBMSs such as PostgreSQL, MySQL, Oracle, SQL Server, Greenplum, Vertica
- Streaming & messaging as with Kafka, Flink, Pulsar, …
- Elastic Search
- Hadoop
- Query engines like Presto, Starburst, Trino
- Spark
With respect to use cases some options might be:
- To glue together your Data Lakehouse. We have a solution that combines spark, deltalake, k8s w/ Robin, PE servers and scalable NAS or object storage. You may find out more about it here & here. The inclusion of Robin allows one to add other workloads which could be kafka and Cassandra w/o having to create separate environments!
- How about Big Data as a Service (BDaaS)? So you have say six different workloads including MySQL, kafka, spark, TigerGraph, Starburst & airflow. Putting all these in the same platform, containerized and scalable on the same set of perhaps eight PE nodes would allow one to save some serious coin.
- Your own slice of heaven including the two to a dozenish apps that matter to you.
- Machine learning and deep learning with some GPU enabled servers.
- Robin Systems has some additional use cases & key info here.
Interested in learning more? We have an upcoming event on May 19th @12N EST that is just what the doctor ordered. I’ll be a panelist for this webinar.
Topic: Solving the Challenges of deployment and management of Complex Data Analytics Pipeline
Register in advance for this webinar:
https://symphony.rakuten.com/dell-webinar-data-analytics-pipeline
After registering, you will receive a confirmation email containing information about joining the webinar
If you just can’t wait till then feel free to reach out to me @ Mike.King2@dell.com to discuss your challenge further.

Cassandra on Dell PowerEdge Servers a Match Made in Heaven
Thu, 09 Feb 2023 20:47:00 -0000
|Read Time: 0 minutes
Cassandra is a popular NoSQL database in a crowded field of perhaps 225+ different NoSQL databases. Backing up a bit there is a taxonomy for NoSQL which has four types:
- Key value as with Redis, Rocksdb & Aerospike
- Wide Column as exemplified by Hbase and Cassandra
- Document contains MongoDB, Couchbase and Marklogic (recently acquired by Progress)
- Graph with TigerGraph, Neo4j, ArangoDB, AllegroGraph, and dozens of others
Cassandra is an excellent replacement for Hbase when migrating away from Hadoop to something like our Data Lakehouse solution here and here. More in a future post on this solution. What does wide column actually mean? It’s simple a key-value pair w/ an amorphous, typically large payload (value). One of the cool things I learned when designing my first Hbase db about nine years back was that the payload can vary from record to record which blew my mind at the time. All I could think of was garbage data, low quality data, no schema, …. What a mess. But for some strange reason folks don’t seem to care much about those items and are more concerned w/ handling growth, scale-out and performance.
Cassandra comes in two versions. The first is community and the second is DataStax edition, DSE. DataStax offers support for both and has excellent services capability after their purchase of Last Pickle. From my experience in my customer base I see about 50% of each. I think DSE is well worth the cost for most customers but then again that’s a choice and the voices against paying for it seem to be stronger.
Cassandra clusters should have a number of nodes evenly divisible by three. I like to start with six myself. As for storage one can probably get by with vSAS RI SSDs. More smaller capacity SSDs will give you more IOPS. 10GbE NICs should suffice but I favor 25GbE these days due to economics, value and future proofing. One can get 150% more throughput for about a 25% uplift. Sorry Cisco but 40GbE is dead and will go the way of the dodo bird. The cores you need can vary but tend to be in the 12-16core per socket range. Most of the time I’m looking for value here. I avoid top end processors due to cost and generally they’re not needed. If I need lots of cores I would look at some of our AMD servers. For this exercise we will consider Intel as it’s way more prevalent. For us at Dell this means and R650 Ice Lake server where we can squeeze a lot in 1U.
The specs for a six node cluster could look like this per node:
- 256GB of RAM with 16 x 16GB DIMMs in a fully balanced config.
- Dual 16c processors w/ a bit faster clock speed. So the 6346 would fit the bill @3.1GHz
- Dual 25GbE NICs
- HBA355E – This assumes no RAID for your db
- If you plan on using RAID for your Cassandra db then select the H755 PERC which has 8GB of cache.
- 6 x 960GB vSAS RI SSDs
- 99% of the time read intensive drives will suffice
- If your retention is one day or less than mixed use would be in order, but I’ve not seen that
- M.2 BOSS 480GB RI SSD pair – fully hot swapable RAID1 pair
- Here’s where your OS and possibly the DSE or Apache Cassandra software would go
For your Cassandra needs contact me @ Mike.King2@dell.com to discuss your challenge further.

Kafka on Dell Power Edge Servers – a Winning Combination
Mon, 06 Feb 2023 19:07:45 -0000
|Read Time: 0 minutes
By far the most popular pub/sub messaging software is kafka. Producers send data and messages to a broker for later use by consumers. Data is published to one or more topics which are queues. Consumers read messages from a topic and mark it as read. Most topics may have multiple consumers. Topics may be partitioned to enable parallel processing by brokers. Once all consumers have read the message it is logically deleted. Replicas create another copy of your data to help prevent data loss.
Regarding your platform choice there are many options including:
- Bare metal servers with DAS
- Virtualized
- HCI
- K8S
Some tips:
- Keep your cluster clean. Don’t use kafka to retain data or replay data past a few days or a week. Once data is consumed let it be deleted.
- Use an odd number of nodes w/ a minimum of three or five depending on your tolerance for failures. Most environments will have many more nodes.
- The storage should be local and SSDs are highly recommended.
- No RAID should be needed if replicas are in effect.
- Use random partitioning
- One replica is likely a minimum viable cfg w/ two replicas or three copies being most common in production.
What might this look like on some PE Servers. For 15G Ice Lake servers the most attractive server would be an R650. It’s a 1U server with 10 drive bays, decent memory and a wide selection of processors. A middle of the road configuration might look something like the following:
- Seven R650 servers
- 256GB of RAM with 16 x 16GB DIMMs in a fully balanced config.
- Dual 16c processors w/ a bit faster clock speed. So the 6346 would fit the bill @3.1GHz
- Dual 25GbE NICs
- HBA355E – This assumes no RAID for your data drives
- If you plan on using RAID for your kafka data then select the H755 PERC which has 8GB of cache.
- 6 x 1.92TB vSAS RI SSDs
- 99% of the time read intensive drives will suffice
- If your retention is one day or less than mixed use would be in order, but I’ve not seen that
- M.2 BOSS 480GB RI SSD pair – fully hot swappable RAID1 pair
- Here’s where your OS and possibly the kafka Confluent software would go
For your kafka needs feel free to contact me @ Mike.King2@dell.com to discuss your challenge further.
Graph DB Use Cases – Put a Tiger in Your Tank
Mon, 06 Feb 2023 18:44:06 -0000
|Read Time: 0 minutes
In the NoSQL Database Taxonomy there are four basic categories:
- Key Value
- Wide Column
- Document
- Graph
Although Graph is arguably the smallest category by several measures it is the richest when it comes to use cases. Here is a sampling of what I’ve seen to date:
- Fraud detection
- Feature store for ML/DL
- C360 – yeah you can do that one in most any db.
- As an overlay to an ERP application allowing the addition of new attributes without changing the underlying data model or code. For select objects the keys (primary & alternate) with select attributes populate the graph. The regular APIs are wrapped to check for new attributes in the graph. If none then the call is passed thru. For new attributes there would be a post processing module that makes sense of it and takes additional actions based on the content.
- One could use this same technique for many homegrown applications.
- As an integrated database for multiple disparate, hetereogenous data store integration. I solutioned this conceptually for a large bank that had data in the likes of Snowflake, Oracle, MySQL, Hadoop and Teradata. The key to success here is not dragging all the data into the graph but merely keys, select attributes
- Recommendation engines
- Configuration management
- Network management
- Transportation problems
- MDM
- Threat detection
- Bad guy databases
- Social networking
- Supply chain
- Telecom
- Call management
- Entity resolution
We’re closely partnered with Tiger Graph and can cover the above use cases and many more.
If you’d like to hear more and work on solutions to your problem please do drop me an email at Mike.King2@Dell.com

You Really Do Need a Database Strategy
Mon, 06 Feb 2023 18:42:50 -0000
|Read Time: 0 minutes
I’m amazed at how many companies I talk to that don’t have a discernable database strategy. Aggregate spending on database technology for software, services, servers, storage, networking & people runs six figures for most medium sized companies and into the tens of millions per annum for large companies. So anyway you slice it it’s a large investment that warrants a strategy.
First let’s consider the different kinds of database technologies out there. There’s relational, time series, geo-spatial, GPU, OLAP, OLTP, HTAP, New SQL, NoSQL including key-value, document, wide-column and graph. All together there’s probably 400ish different choices. Many large companies have 10 – 20 of these different one’s floating around.
How does one get started?
- Firstly, take inventory. This is not as easy as it sounds. People often buy things via their own budgets, use open-source software that may not incur license spend, acquire software packages that have a database in them, clone software and so on.
- Then add up how much is spent on them. Go back three years. This is not to imply that sunk costs matter but what we seek to do with it is understand the trend.
- Categorize all the products starting with what is detailed above.
- Mainstream/Standard, Niche, Emerging, Contained are some categories that may resonate.
- Detail usage
- Determine overlap & redundancy.
- If you have data marts on SQL Server, Greenplum, Netezza and Vertica then you probably have three more databases serving this function then you need.
- You run kafka all over the enterprise but’s it’s running on HCI, baremetal & virtual on Dell, HPE and Lenovo. Simply run it on baremetal with Dell and jettison the rest.
- Inspect acquisitions done over the last five or so years. This is a ripe area.
If you like a free consultation on your particular dilemna please do contact me at Mike.King2@Dell.com

How about SingleStore for your database on 15G Dell PE Servers?
Fri, 02 Dec 2022 04:58:29 -0000
|Read Time: 0 minutes
How about SingleStore for your database on 15G Dell PE Servers?
Singlestore is a distributed relational database that was previously called MemSQL. It is well suited to analytics workloads. There are two data structure constructs available. First is the column store which is on disk. Disk is typically SSDs. Second is a row store that is in memory and essentially a key-value database. Yes you can have both types in the same db and join across the two different table types. Data for the column store is arranged in leaves where the low level detail is stored and aggregators which are summarized data structures. Clients use the aggregators for queries via SQL.
Singlestore uses the MySQL protocol which makes it compatible with anything that can connect to MySQL.
Customers choose this database when they have demanding high performance analytics needs. We have many large financial customers that are very happy with it.
So what does it look like with the latest 15G IceLake servers for Dell.
Although it could run on most any server the leading candidate would be a Dell PowerEdge R650 for db sizes up to 400TBu. Environments that have larger db needs would use a Dell PowerEdge R750.
ROTs
- Aggregators use single 25GbE NIC
- Leaf nodes use a single 10GbE NIC
- Aggregator nodes use about ¼ RAM & ¼ cores as leaf nodes
Other items
- RAID is optional but most customers elect it. The figures below assume RAID10.
- Use an m.2 BOSS card w/ a R1 pair of 480GB RI SSDs for the OS and software. They are now hot swappable.
- As for durability & cost reasons 99.99% of the time read intensive value SAS SSDs will be the right fit.
5TB Env
- 2 aggregators w/ 4 x 480GB RI SSD, 128GB RAM, 2 x 8c, 25GbE NIC
- 4 leaf nodes w/ 4 x 960GB RI SSD, 256GB RAM, 2 x 12c, 10GbE NIC
100TB Env
- 3 aggregators w/ 2 x 960GB RI SSD, 128GB RAM, 2 x 8c, 25GbE NIC
- 7 leaf nodes w/ 8 x 3.84TB RI SSD, 512GB RAM, 2 x 24c, 10GbE NIC
400TB Env
- 4 aggregators w/ 2 x 960GB RI SSD, 128GB RAM, 2 x 8c, 25GbE NIC
- 14 leaf nodes w/ 8 x 7.68TB RI SSD, 1024GB RAM, 2 x 28c, 10GbE NIC
If you need your Singlestore database on Dell PE Servers do let us know.
Yes Virginia, Data Quality Matters to AI & Data Analytics
Thu, 15 Sep 2022 14:22:23 -0000
|Read Time: 0 minutes
How often do we hear a project has failed? Projected benefits were not achieved, ROI is less than expected, predictability results are degrading, and the list goes on.
Data Scientists blame it on not having enough data engineers. Data engineers blame it on poor source data. DBAs blame it on data ingest, streaming, software and such…Scape goats are easy to come by.
Have you ever thought why? Yes there are many reasons but one I run across constantly is data quality. Poor data quality is rampant through the vast majority of enterprises. It remains largely hidden. From what I see most companies say we’re a world class organization with top notch talent and we make lots of money and have happy customers therefore we must have world class data with high data quality. This is a pipe dream. Iif you’re not measuring it it’s almost certainly bad leading to inefficiencies, costly mistakes, bad decisions, high error rates, rework, lost customers and many other maladies.
When I’ve built systems & databases in past lives I’ve looked into data, mostly with a battery of SQL queries and found many a data horror, poor quality, defective items, wrong data and many more.
So if you want to know where you stand you must measure your data quality and have a plan to measure the impact of defects and repair them as justified. I think most folks that start down this path quit as they attempt to boil the ocean and fix all the problems they find. I think the best approach is to rank your data items in terms of importance and then measure perhaps the top 1-3% of them. In that way one can make the most impactful improvements with the least effort.
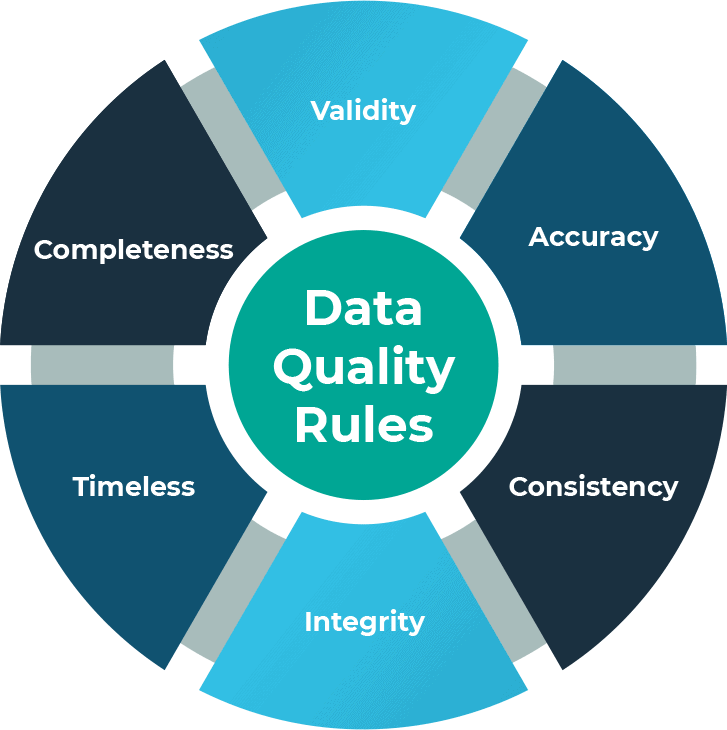
The dimensions of data are varied and can be complex but from a data quality perspective they fall into six or more categories:
- Completeness
- Validity
- Accuracy
- Consistency
- Integrity
- Timeliness
Using a tool is highly recommended. Yes, you probably have to pay for one. I won’t get into all the players here.
So, if you don’t have a data quality program then you should get started today because you do have poor data quality.
In a future post I’ll go into more about data quality measures.
If you like a free consultation on your particular situation please do contact me at Mike.King2@Dell.com

So You'd Like an Easy Button for ML/DL...Look No Further Than Cnvrg.io on Dell
Mon, 08 Aug 2022 17:00:07 -0000
|Read Time: 0 minutes
I consult with various customers on their AI/ML/DL needs while coming up with architectures, designs and solutions that are durable, scalable, flexible, efficient, performant, sensible and cost effective. After having seen perhaps 100 different opportunities I have some observations and yes suggestions on how to do things better.
Firstly, there’s an overwhelming desire for DIY. On the surface the appeal is that it’s easy to download the likes of tensor flow with pip, add some python code to point to four GPUs on four different servers, collect some data, train your model and put it into production. This thinking rarely considers concurrency, multi-tenancy, scheduling, management, sharing and many more. What I can safely state is that this path is the hardest, takes the longest, costs more, creates confusion, fosters low asset utilization and leads to high project rate failures.
Secondly most customers are not concerned with infrastructure, scalability, multi-tenancy, architecture and such at the outset. They are after thoughts and their main focus on building a house is let’s get started and so we can get finished sooner. We don’t need a plan do we?
Thirdly most customers are struggling so when they reach out to talk to their friends down the road they’re all moving slowly, doing it themselves, struggling so it’s ok right?
I think there’s a much better way and it all has to do with the software stack. A cultivated software stack that can manage jobs, configure the environment, share resources, scale-out easily, schedule jobs based on priorities and resource availability, support multi-tenancy, record and share results, etc….is just what the doctor ordered. It can be cheap, efficient, speed up projects and improve the success rate. Enter cnvrg.io, now owned by Intel, and you have a best of breed solution to these items and much more.
Recently I collected some of the reasons why I think cnvrg.io the the cultivated AI stack you need for all your AI/ML/DL projects:
- Allows for reuse of existing assets
- Can mix & match new w/ old
- Any Cloud model
- Multi-cloud
- Hybrid
- OnPrem
- Public cloud
- Fractional GPU capability for all GPUs
- Support multiple container distros
- Improves productivity of:
- Data Scientists
- Data Engineers
- Leads to more efficient asset utilization
- Relatively affordable
- The backing of intel
- Partnered w/ Dell
- Supports multi-tenancy well
- Capability to build pipelines
- Reuse
- Knowledge management and sharing for AI
- Improves AI time to market
- Improves AI project success
- Makes AI easy
- Low code play
- Can construct and link data pipelines
Cnvrg.io is a Dell Technologies partner and we have a variety of solutions and platform options. If you’d like to hear more please do drop me an email at Mike.King2@Dell.com

What's a Data Hoarder to Do?
Tue, 10 May 2022 19:18:45 -0000
|Read Time: 0 minutes
So you're buried in data, your can't afford to expand, your performance is bad and getting worse and your users can't find what they need. Yes it's a tsunami of data that's the root cause of your problems. You ask your Mom for advice and she says "Why don't you watch that TV show called Hoarders?" You watch a few episodes and can relate to the problem but they offer no formidable solutions for our excess data. Then you talk to Mike King over at Dell and he says "That problem has been around since the ENIAC". The bottom line is that almost all systems are designed to store certain kinds of data for a pre-determined amount of time (retention). If you don't have retention rules then you failed as an architect. The solution for data hoarding is much more recent evolving over the last 40 years or so. It was first called data archiving. That term is still used today by some. The concept is really simple one takes the data that is no longer needed and removes it from the system of record. If the data is still needed but just way less frequently then it would be move to a cheaper form of storage. The disciple that evolved around this practice was first called data lifecycle management (DLM) and later information lifecycle management (ILM). ILM considers many more aspects of the archiving process in a more holistic sense including policies, governance, classification, access, compliance, retention, redaction, privacy, recall, query and more. We won't get into all the ILM stuff in this post.
Let's take a concrete example to get started. We have a regional bank called Happy Piggy Bank. They do business in 30 states and have supporting ERP applications like Oracle EBS, databases such as Greenplum & SingleStore for analytics and hadoop for an integrated data warehouse and AI platform. The EBS db has six years of data and a stout 600TB of data. The Greenplum db is around 1PB and stores just 90 days of data. SingleStore is new but they have big plans and it's at 200TB today but will grow to 3PB in a year. The hadoop is the largest of all and has detail transaction and account statements going back 10 years and stores 10PB of raw data. Only the Greenplum db has a formal purge program that was actually written and put in production. Both the hadoop and EBS environments have no purge program. The first order of business is to determine how much data they should or need to retain. This is mostly a business activity. The next step is to determine the access patterns. In order to do data archiving one needs to determine the active portion of the data. In most systems perhaps 99% of the access is constrained to a smaller portion of the retention continuum. Let's consider that EBS db and it's six years of data. We might run some reports and do some analysis and it's highly likely that 90% of the data is less than 6 months old and let's say 99% is less than 1 year old. In this case we should target the 5 oldest years of retention (83% of the data or 498TB of the db) to migrate to a more cost effective platform. In a similar fashion we determine that 60% of the hadoop data is accessed less than 1% of the time so that's a 6PB chunk we can lop off of the hadoop system. So for Happy Piggy Bank we have determined we can remove 6.5PB of data from two of the systems which will yield the following benefits:
- Room for future growth will be created in the source systems
- Performance should improve in these systems
- Overall data storage costs will go down
- The source systems will be easier to manage
- We will likely avoid increased software licensing charges for Oracle and hadoop as compared to doing nothing
So ye ask what might the solution be? Enter Versity a partner of Dell Technologies enabled through our OEM channel. Versity is a full featured archiving solution that enables:
- High performance parallel archive
- Covers a wide variety of applications, databases and such
- Stores data in three successive tiers (local, NAS & object)
- Supports selective recall
The infrastructure includes:
- Versity software
- PE 15G servers such as R750s
- PowerVault locally attached arrays
- PowerScale NAS appliances
- ECS object appliances
A future post will cover more details on what this solution could look like for Happy Piggy Bank.
Versity targets customers that have 5PB of data or more that can be archived.

Live Optics is Your Friend
Tue, 05 Oct 2021 19:01:57 -0000
|Read Time: 0 minutes
It’s a rare day that a free tool exists that can help profile customer workloads to the mutual benefit of all. Live Optics (previously DPack) is a gem in the rough that is truly a win-win proposition for customers and vendors such as Dell. I’ve been using it for years and found that it’s a rare day that I don’t learn something of use.
The tool is similar to SAR on steroids. Data is collected for each host. Hosts can be VMs. Servers can be from any manufacturer. The data collected is on IOPS (size and amount), memory usage, CPU usage and network activity. It can be run in local mode where the data doesn’t go anywhere else or it can be stored in a Dell private cloud. The later is more beneficial as it may be accessed by folks in many roles for various assessments. The data may also be mined to help Dell make better decisions of current and future products based on actual observed user profiles.
I use LiveOptics to profile database workloads like Greenplum and Vertica, Hadoop, NoSQL databases like MongoDB, Cassandra, Marklogic and more.
Upon inspection of the workload the data collected helps facilitate more meaningful discussions with various SMEs and to right size future designs. In one case I found a customer that was using less than half their memory during peak periods…so we suggested new server BOMs with much less memory as they didn’t need what they had.
Can we help you with assessing your workloads of interest on our servers or those of our competitors?
Some links of interest
- https://www.delltechnologies.com/en-us/live-optics/index.htm#pdf-overlay=//www.delltechnologies.com/asset/en-us/solutions/business-solutions/briefs-summaries/cloud-live-optics-data-for-it-decisions-ebrochure.pdf
- https://www.liveoptics.com/
- https://www.starwindsoftware.com/resource-library/understand-your-it-environment-with-dell-live-optics/

Let Robin Systems Cloud Native Be Your Containerized AI-as-a-Service Platform on Dell PE Servers
Fri, 06 Aug 2021 21:31:26 -0000
|Read Time: 0 minutes
Robin Systems has a most excellent platform that is well suited to simultaneously running a mix of workloads in a containerized environment. Containers offer isolation of varied software stacks. Kubernetes is the control plane that deploys the workloads across nodes and allows for scale-out, adaptive processing. Robin adds customizable templates and life cycle management to the mix to create a killer platform.
AI which includes the likes of machine learning for things like scikit-learn with dask, H2o.ai, spark MLlib and PySpark along with deep learning which includes tensor flow, PyTorch, MXNET, keras and Caffe2 are all things that can be run simultaneously in Robin. Nodes are identified by their resources during provisioning for cores, memory, GPUs and storage.
Cultivated data pipelines can be constructed with a mix of components. Consider a use case with ingest from kafka, store to Cassandra and then run spark MLlib to find loans submitted from last week that will be denied. All that can be automated with Robin.
The as-a-service aspect for things like MLops & AutoML can be implemented with a combination of Robin capabilities and other software to deliver a true AI-as-a-Service experience.
Nodes to run these workloads on can support disaggregated compute and storage. Some sample servers might be a combination of Dell PowerEdge C6520s for compute & R750s for storage. The compute servers are very dense and can run four server hosts in 2U offering a full range of Intel Ice Lake processors. For storage nodes the R750s can have onboard NVMe or SSDs (up to 28). For the OS image a hot swappable m.2 BOSS card with self-contained RAID1 can be used for Linux with all 15G servers.

Kinetica Can Give You Accelerated Analytics
Wed, 02 Jun 2021 22:01:28 -0000
|Read Time: 0 minutes
Accelerate Those Analytics With a GPGPU Database
First you might ask what a GPU database actually is. In a nutshell it's typically a relational database that can offload certain operations to a GPU so that queries run faster. There are three players in the space including Kinetica, Sqream and OmniSci. By all measures Kinetica is the leader which is one of the key reasons we've chosen to partner with them through our OEM channel.
The first thing one might ask is what kinds of things can a GPGPU Database do for me. Some ideas for your consideration might be:
- Legacy RDBMS workloads from Oracle, DB2, Teradata, Sybase or SQL Server in an accelerated fashion with lower latency, better performance and greater throughput.
- Conduct location analytics on networks or geolocation data.
- Fraud detection
One of the coolest things I've found to date with Kinetica is that it only runs queries on the GPU where it can be accelerated. Essentially joins, computations and math operations. Queries involving a string search would be run on the CPUs. In this matter collectively the entire workload can be accelerated.
These databases run on servers with direct attach storage capable of running NVidia GPUs. In the Dell 14G product family the most common servers are R740, R740XD and R940XA servers. For 15G the most appealing are R750, R750XA and XE8545 servers. Other models are certainly possible but less common. For purposes of this article we will focus on the R750XA. This brand new server is based on Ice Lake processors and sports two sockets with up to 40 cores per socket for a maximal possible number of cores per server of 80. A pair of top end A100 GPUs can configured with an NVLink bridge to enable interlinks of 600GB/s. Systems can be configured with up to 6TB of memory including the latest 200 series optane modules. Local storage is most common and this server can house up to eight 2.5" drives which can be either NVMe or SSD. I know you're thinking what if my database can't fit on a single server. Luckily the answer is simply to use more servers. Kinetica can shard the db across n nodes.
If you want to learn more about Kinetica on Dell PE servers drop me a line at Mike.King2@Dell.com