




You Really Do Need a Database Strategy
Related Blog Posts

Cassandra on Dell PowerEdge Servers a Match Made in Heaven
Thu, 09 Feb 2023 20:47:00 -0000
|Read Time: 0 minutes
Cassandra is a popular NoSQL database in a crowded field of perhaps 225+ different NoSQL databases. Backing up a bit there is a taxonomy for NoSQL which has four types:
- Key value as with Redis, Rocksdb & Aerospike
- Wide Column as exemplified by Hbase and Cassandra
- Document contains MongoDB, Couchbase and Marklogic (recently acquired by Progress)
- Graph with TigerGraph, Neo4j, ArangoDB, AllegroGraph, and dozens of others
Cassandra is an excellent replacement for Hbase when migrating away from Hadoop to something like our Data Lakehouse solution here and here. More in a future post on this solution. What does wide column actually mean? It’s simple a key-value pair w/ an amorphous, typically large payload (value). One of the cool things I learned when designing my first Hbase db about nine years back was that the payload can vary from record to record which blew my mind at the time. All I could think of was garbage data, low quality data, no schema, …. What a mess. But for some strange reason folks don’t seem to care much about those items and are more concerned w/ handling growth, scale-out and performance.
Cassandra comes in two versions. The first is community and the second is DataStax edition, DSE. DataStax offers support for both and has excellent services capability after their purchase of Last Pickle. From my experience in my customer base I see about 50% of each. I think DSE is well worth the cost for most customers but then again that’s a choice and the voices against paying for it seem to be stronger.
Cassandra clusters should have a number of nodes evenly divisible by three. I like to start with six myself. As for storage one can probably get by with vSAS RI SSDs. More smaller capacity SSDs will give you more IOPS. 10GbE NICs should suffice but I favor 25GbE these days due to economics, value and future proofing. One can get 150% more throughput for about a 25% uplift. Sorry Cisco but 40GbE is dead and will go the way of the dodo bird. The cores you need can vary but tend to be in the 12-16core per socket range. Most of the time I’m looking for value here. I avoid top end processors due to cost and generally they’re not needed. If I need lots of cores I would look at some of our AMD servers. For this exercise we will consider Intel as it’s way more prevalent. For us at Dell this means and R650 Ice Lake server where we can squeeze a lot in 1U.
The specs for a six node cluster could look like this per node:
- 256GB of RAM with 16 x 16GB DIMMs in a fully balanced config.
- Dual 16c processors w/ a bit faster clock speed. So the 6346 would fit the bill @3.1GHz
- Dual 25GbE NICs
- HBA355E – This assumes no RAID for your db
- If you plan on using RAID for your Cassandra db then select the H755 PERC which has 8GB of cache.
- 6 x 960GB vSAS RI SSDs
- 99% of the time read intensive drives will suffice
- If your retention is one day or less than mixed use would be in order, but I’ve not seen that
- M.2 BOSS 480GB RI SSD pair – fully hot swapable RAID1 pair
- Here’s where your OS and possibly the DSE or Apache Cassandra software would go
For your Cassandra needs contact me @ Mike.King2@dell.com to discuss your challenge further.
Graph DB Use Cases – Put a Tiger in Your Tank
Mon, 06 Feb 2023 18:44:06 -0000
|Read Time: 0 minutes
In the NoSQL Database Taxonomy there are four basic categories:
- Key Value
- Wide Column
- Document
- Graph
Although Graph is arguably the smallest category by several measures it is the richest when it comes to use cases. Here is a sampling of what I’ve seen to date:
- Fraud detection
- Feature store for ML/DL
- C360 – yeah you can do that one in most any db.
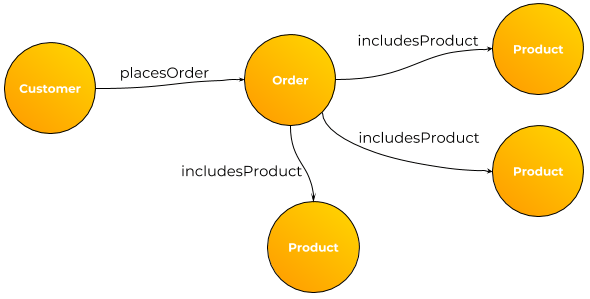
- As an overlay to an ERP application allowing the addition of new attributes without changing the underlying data model or code. For select objects the keys (primary & alternate) with select attributes populate the graph. The regular APIs are wrapped to check for new attributes in the graph. If none then the call is passed thru. For new attributes there would be a post processing module that makes sense of it and takes additional actions based on the content.
- One could use this same technique for many homegrown applications.
- As an integrated database for multiple disparate, hetereogenous data store integration. I solutioned this conceptually for a large bank that had data in the likes of Snowflake, Oracle, MySQL, Hadoop and Teradata. The key to success here is not dragging all the data into the graph but merely keys, select attributes
- Recommendation engines
- Configuration management
- Network management
- Transportation problems
- MDM
- Threat detection
- Bad guy databases
- Social networking
- Supply chain
- Telecom
- Call management
- Entity resolution
We’re closely partnered with Tiger Graph and can cover the above use cases and many more.
If you’d like to hear more and work on solutions to your problem please do drop me an email at Mike.King2@Dell.com