
Blogs
Short articles about data analytics solutions and related technology trends

Navigating the modern data landscape: the need for an all-in-one solution

Mon, 18 Mar 2024 19:56:59 -0000
|Read Time: 0 minutes

Dell Reinforces its TPCx-AI Benchmark Leadership using the 16G PowerEdge R6625 Hardware Platform at SF1000
Wed, 12 Jul 2023 18:52:17 -0000
|Read Time: 0 minutes

Dell and Databricks Announce a Multicloud Analytics and AI Solution
Mon, 22 May 2023 16:58:09 -0000
|Read Time: 0 minutes

Inverse Design Meets Big Data: A Spark-Based Solution for Real-Time Anomaly Detection
Wed, 17 Jan 2024 18:27:32 -0000
|Read Time: 0 minutes

Cassandra on Dell PowerEdge Servers a Match Made in Heaven
Thu, 09 Feb 2023 20:47:00 -0000
|Read Time: 0 minutes

Kafka on Dell Power Edge Servers – a Winning Combination
Mon, 06 Feb 2023 19:07:45 -0000
|Read Time: 0 minutes

An Ace in the Hole for Your Kubernetes Clusters
Mon, 24 Apr 2023 14:12:49 -0000
|Read Time: 0 minutes

Journey into the analytics space with Dell & Starburst
Thu, 02 Feb 2023 14:50:00 -0000
|Read Time: 0 minutes

You Really Do Need a Database Strategy
Mon, 06 Feb 2023 18:42:50 -0000
|Read Time: 0 minutes
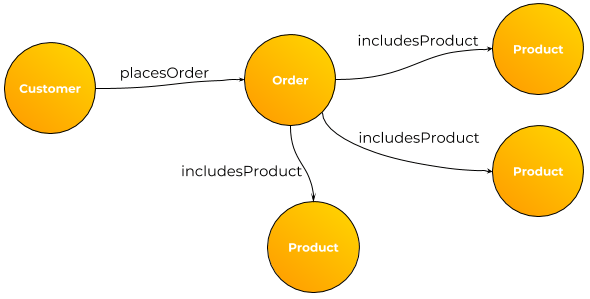
Graph DB Use Cases – Put a Tiger in Your Tank
Mon, 06 Feb 2023 18:44:06 -0000
|Read Time: 0 minutes



How about SingleStore for your database on 15G Dell PE Servers?
Fri, 02 Dec 2022 04:58:29 -0000
|Read Time: 0 minutes

Intelligent Data Pipelining for Splunk with Cribl LogStream
Wed, 18 Aug 2021 09:21:04 -0000
|Read Time: 0 minutes

Distributed Data Analytics Made Easy with Omnia
Thu, 20 Jul 2023 17:03:25 -0000
|Read Time: 0 minutes

Dell EMC PowerEdge R750 Virtualized Workload Performance measurement using VMmark 3.1.1
Tue, 03 Aug 2021 14:21:24 -0000
|Read Time: 0 minutes

Elastic 7.12 Frozen Data and Dell Technologies ECS Enterprise Object Storage
Tue, 22 Jun 2021 12:28:53 -0000
|Read Time: 0 minutes

Kinetica Can Give You Accelerated Analytics
Wed, 02 Jun 2021 22:01:28 -0000
|Read Time: 0 minutes

Big Data as-a-Service(BDaaS) Use Cases on Robin Systems
Wed, 24 Apr 2024 15:27:10 -0000
|Read Time: 0 minutes

TPCx-Big Bench Rocks on Dell EMC PowerEdge R7515 with AMD Milan Processors
Thu, 06 May 2021 11:05:30 -0000
|Read Time: 0 minutes

TPCx-HS Results on Dell EMC Hardware with AMD Milan Processors
Mon, 19 Apr 2021 17:56:26 -0000
|Read Time: 0 minutes

Delivering Innovation with Object-Based Analytics
Thu, 25 Mar 2021 18:17:06 -0000
|Read Time: 0 minutes

AI-based Edge Analytics in the Service Provider Space
Fri, 15 Jan 2021 11:48:37 -0000
|Read Time: 0 minutes

Real-Time Streaming Solutions Beyond Data Ingestion
Thu, 17 Dec 2020 03:05:00 -0000
|Read Time: 0 minutes

MLPerf Inference v0.7 Benchmarks on Power Edge R7515 Servers
Tue, 08 Dec 2020 17:45:45 -0000
|Read Time: 0 minutes

MLPerf Inference v0.7 Benchmarks on PowerEdge R740 Servers
Tue, 08 Dec 2020 17:45:45 -0000
|Read Time: 0 minutes

The Case for Elastic Stack on HCI
Tue, 08 Dec 2020 17:45:45 -0000
|Read Time: 0 minutes
Dell Technologies and Deloitte DataPaaS: Data Platform as a Service
Tue, 08 Dec 2020 17:45:44 -0000
|Read Time: 0 minutes

IIoT Analytics Design: How important is MOM (message-oriented middleware)?

Tue, 08 Dec 2020 17:45:45 -0000
|Read Time: 0 minutes