
Third-party Analysis

Delivering Choice for Enterprise AI: Multi-Node Fine-Tuning on Dell PowerEdge XE9680 with AMD Instinct MI300X
Wed, 15 May 2024 21:26:35 -0000
|Read Time: 0 minutes
In this blog, Scalers AI and Dell have partnered to show you how to use domain-specific data to fine-tune the Llama 3 8B Model with BF16 precision on a distributed system of Dell PowerEdge XE9680 Servers equipped with AMD Instinct MI300X Accelerators.

| Introduction
Large language models (LLMs) have been a significant breakthrough in AI and demonstrated remarkable capabilities in understanding and generating human-like text across a wide range of domains. The first step in approaching an LLM-assisted AI solution is generally pre-training, during which an untrained model learns to anticipate the next token in a given sequence using information acquired from various massive datasets, followed by fine-tuning, which involves adapting the pre-trained model for a domain specific task by updating a task-specific layer on top.
Fine-tuning, however, still requires a lot of time, computation, and RAM. One approach to reducing computation time is distributed fine-tuning, which allows computational resources to be more efficiently utilized by parallelizing the fine-tuning process across multiple GPUs or devices. Scalers AI showcased various industry-leading capabilities of Dell PowerEdge XE9680 Servers paired with AMD Instinct MI300X Accelerators on a distributed fine-tuning task by uncovering these key value drivers:
- Developed a distributed finetuning software stack on the flagship Dell PowerEdge XE9680 Server equipped with eight AMD Instinct MI300X Accelerators.
- Fine-tuned Llama 3 8B with BF16 precision using the PubMedQA medical dataset on two Dell PowerEdge XE9680 Servers each equipped with AMD Instinct MI300X Accelerators.
- Deployed fine-tuned model in an enterprise chatbot scenario & conducted side by side tests with Llama 3 8B.
- Released distributed fine-tuning stack with support for Dell PowerEdge XE9680 Servers equipped with AMD Instinct MI300X Accelerators and NVIDIA H100 Tensor Core GPUs to offer enterprise choice.
| The Software Stack
This solution stack leverages Dell PowerEdge Rack Servers, coupled with Broadcom Ethernet NICs for providing high-speed inter-node communications needed for distributed computing as well as Kubernetes for scaling. Each Dell PowerEdge server contains AI accelerators, specifically AMD Instinct Accelerators to enhance LLM fine-tuning.
The architecture diagram provided below illustrates the configuration of two Dell PowerEdge XE9680 servers with eight AMD Instinct MI300X accelerators each.
Leveraging Dell PowerEdge, Dell PowerSwitch, and high-speed Broadcom Ethernet Network adaptors, the software platform integrates Kubernetes (K3S), Ray, Hugging Face Accelerate, Microsoft DeepSpeed, with other AI libraries and drivers including AMD ROCm™ and PyTorch.
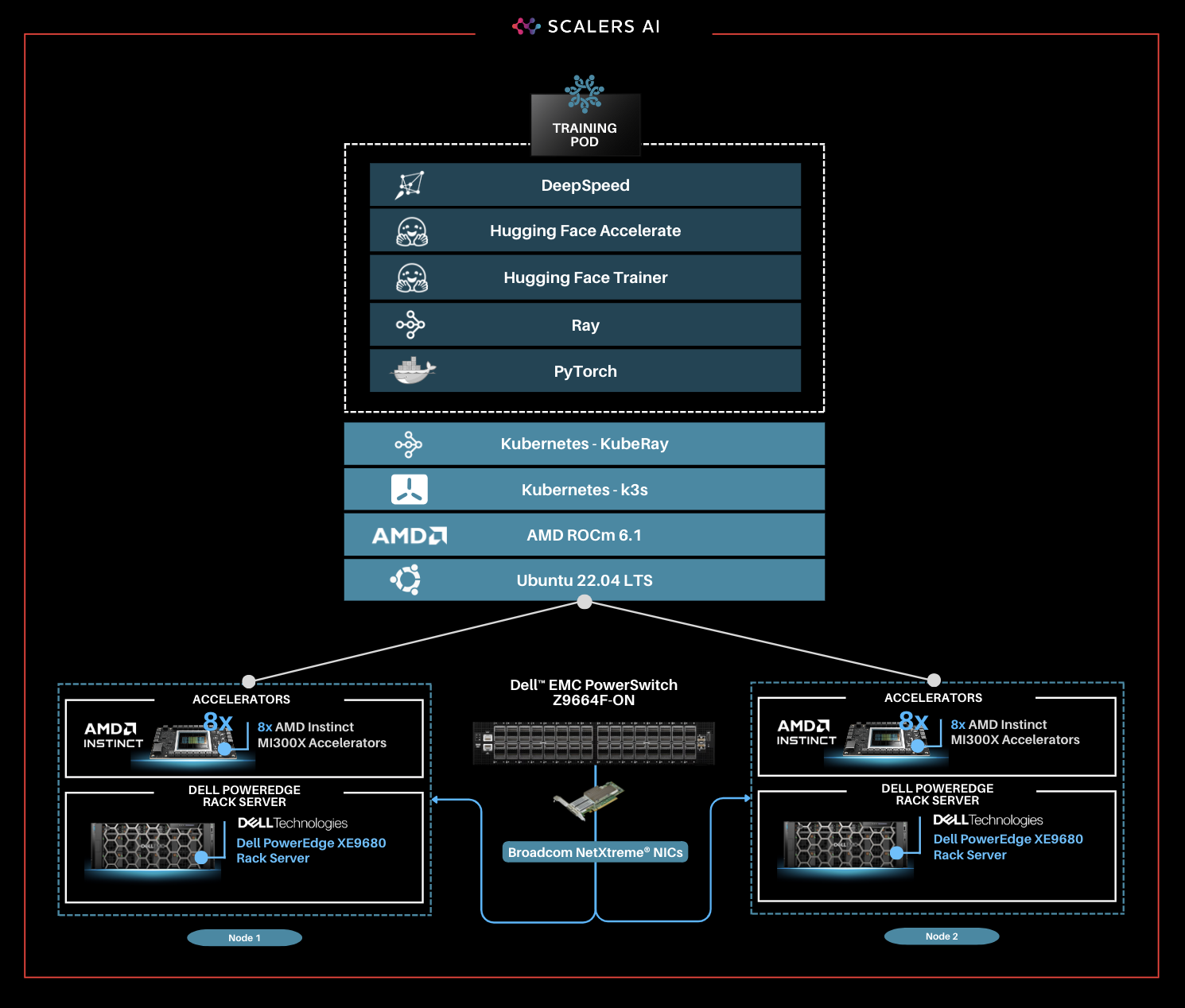
| Step-by-Step Guide
Step 1. Set up the distributed cluster.
Follow the k3s setup and introduce additional parameters for the k3s installation script. This involves configuring flannel, the networking fabric for kubernetes, with a user-selected specified network interface and utilizing the "host-gw" backend for networking. Then, Helm, the package manager for Kubernetes, will be used, and AMD plugins will be incorporated to grant access to AMD Instinct MI300X GPUs for the cluster pods.
Step 2. Install KubeRay and configure Ray Cluster.
The next steps include installing Kuberay, a Kubernetes operator, using Helm. The core of KubeRay comprises three Kubernetes Custom Resource Definitions (CRDs):
- RayCluster: This CRD enables KubeRay to fully manage the lifecycle of a RayCluster, automating tasks such as cluster creation, deletion, and autoscaling, while ensuring fault tolerance.
- RayJob: KubeRay streamlines job submission by automatically creating a RayCluster when needed. Users can configure RayJob to initiate job deletion once the task is completed, enhancing operational efficiency.
- RayService: RayService is made up of two parts: a RayCluster and a Ray Serve deployment graph. RayService offers zero-downtime upgrades for RayCluster and high availability.
helm repo add kuberay https://ray-project.github.io/kuberay-helm/ helm install kuberay-operator kuberay/kuberay-operator --version 1.0.0 |
This RayCluster consists of a head node followed by 1 worker node. In a YAML file, the head node is configured to run Ray with specified parameters, including the dashboard host and the number of GPUs, as shown in the excerpt below. Here, the worker node is under the name "gpu-group”.
... headGroupSpec: rayStartParams: dashboard-host: "0.0.0.0" # setting num-gpus on the rayStartParams enables # head node to be used as a worker node num-gpus: "8" ... |
The Kubernetes service is also defined to expose the Ray dashboard port for the head node. The deployment of the Ray cluster, as defined in a YAML file, will be executed using kubectl.
kubectl apply -f cluster.yml |
Step 3. Fine-tune Llama 3 8B Model with BF16 Precision.
You can either create your own dataset or select one from HuggingFace. The dataset must be available as a single json file with the specified format below.
{"question":"Is pentraxin 3 reduced in bipolar disorder?", "context":"Immunologic abnormalities have been found in bipolar disorder but pentraxin 3, a marker of innate immunity, has not been studied in this population.", "answer":"Individuals with bipolar disorder have low levels of pentraxin 3 which may reflect impaired innate immunity."}
Jobs will be submitted to the Ray Cluster through the Ray Python SDK utilizing the Python script, job.py, provided below.
# job.py
from ray.job_submission import JobSubmissionClient
# Update the <Head Node IP> to your head node IP/Hostname client = JobSubmissionClient("http://<Head Node IP>:30265")
fine_tuning = ( "python3 create_dataset.py \ --dataset_path /train/dataset.json \ --prompt_type 5 \ --test_split 0.2 ;" "python3 train.py \ --num-devices 16 \ # Number of GPUs available --batch-size-per-device 12 \ --model-name meta-llama/Meta-Llama-3-8B-Instruct \ # model name --output-dir /train/ \ --hf-token <HuggingFace Token> " ) submission_id = client.submit_job(entrypoint=fine_tuning,)
print("Use the following command to follow this Job's logs:") print(f"ray job logs '{submission_id}' --address http://<Head Node IP>:30265 --follow") |
This script initializes the JobSubmissionClient with the head node IP address, and sets parameters such as prompt_type, which determines how each question-answer datapoint is formatted when inputted into the model, as well as batch size and number of devices for training. It then submits the job with these set parameter definitions.
The initial phase involves generating a fine-tuning dataset, which will be stored in a specified format. Configurations such as the prompt used and the ratio of training to testing data can be added. During the second phase, we will proceed with fine-tuning the model. For this fine-tuning, configurations such as the number of GPUs to be utilized, batch size for each GPU, the model name as available on HuggingFace, HuggingFace API Token, and the number of epochs to fine-tune can all be specified.
Finally, in the third phase, we can start fine-tuning the model.
python3 job.py |
The fine-tuning jobs can be monitored using Ray CLI and Ray Dashboard.
- Using Ray CLI:
- Retrieve submission ID for the desired job.
- Use the command below to track job logs.
ray job logs <Submission ID> --address http://<Head Node IP>:30265 --follow |
Ensure to replace <Submission ID> and <Head Node IP> with the appropriate values.
- Using Ray Dashboard:
- To check the status of fine-tuning jobs, simply visit the Jobs page on your Ray Dashboard at <Head Node IP>:30265 and select the specific job from the list.
The reference code for this solution can be found here.
| Industry Specific Medical Use Case
Following the fine-tuning process, it is essential to assess the model’s performance on a specific use-case.
This solution uses the PubMedQA medical dataset to fine-tune a Llama 3 8B model on BF16 precision for our evaluation. The process was conducted on a distributed setup, utilizing a batch size of 12 per device, with training performed over 25 epochs. Both the base model and fine-tuned model are deployed in the Scalers AI enterprise chatbot to compare performance. The example below prompts the chatbot with a question from the MedMCQA dataset available on Hugging Face, for which the correct answer is “a.”

As shown on the left, the response generated by the base Llama 3 8B model is unstructured and vague, and returns an incorrect answer. On the other hand, the fine-tuned model returns the correct answer and also generates a thorough and detailed response to the instruction while demonstrating an understanding of the specific subject matter, in this case medical knowledge, relevant to the instruction.
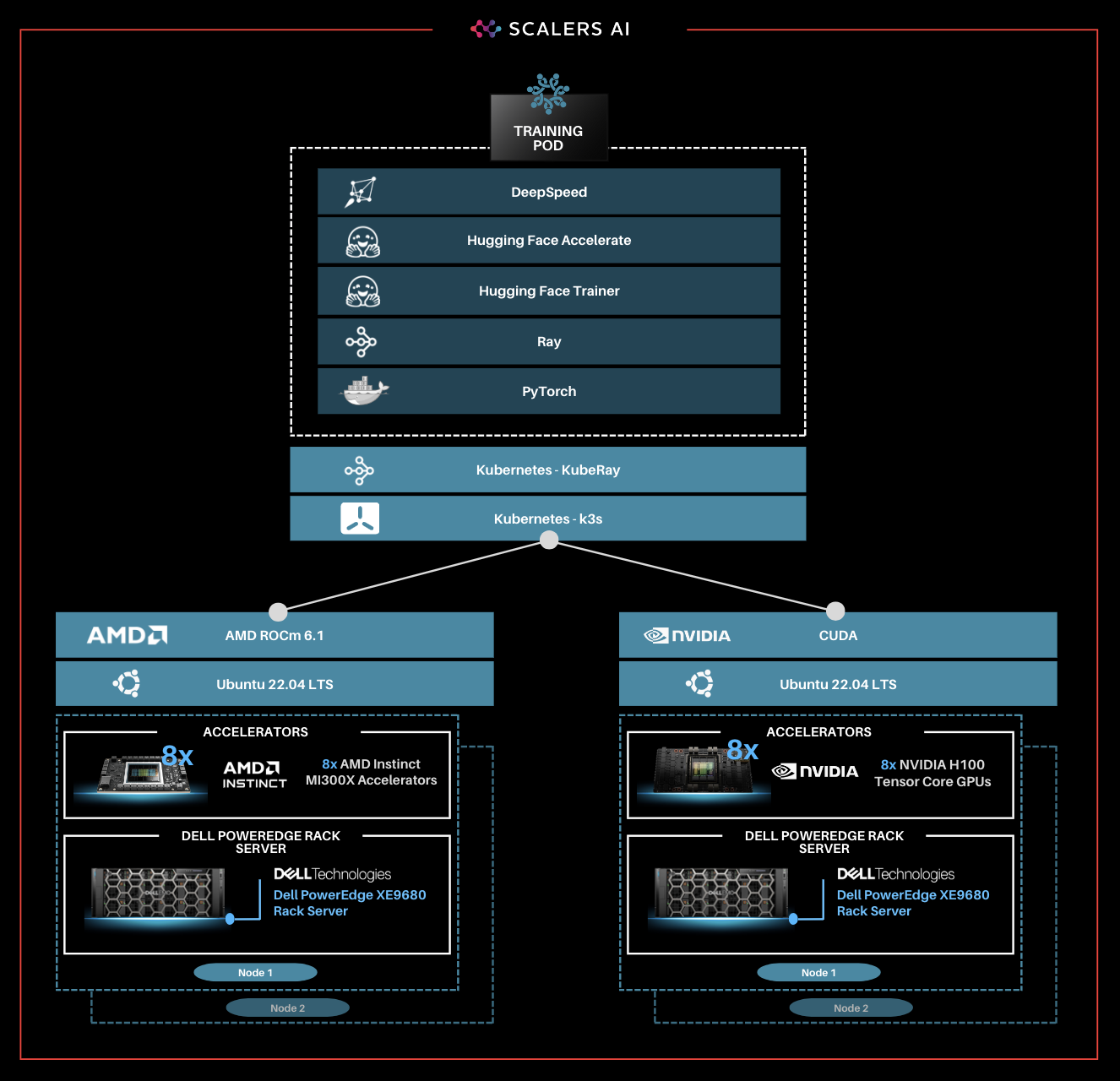
| Enterprise Choice in Industry Leading Accelerators
To deliver enterprise choice, this distributed fine-tuning software stack supports both AMD Instinct MI300X Accelerators as well as NVIDIA H100 Tensor Core GPUs. Below, we show a visualization of the unified software and hardware stacks, running seamlessly with the Dell PowerEdge XE9680 Server.
“Scalers AI is thrilled to offer choice in distributed fine-tuning across both leading AI GPUs in the industry on the flagship PowerEdge XE9680.” -CEO at Scalers AI |
| Summary
Dell PowerEdge XE9680 Server, featuring AMD Instinct MI300X Accelerators, provides enterprises with cutting-edge infrastructure for creating industry-specific AI solutions using their own proprietary data. In this blog, we showcased how enterprises deploying applied AI can take advantage of this unified AI ecosystem by delivering the following critical solutions:
- Developed a distributed finetuning software stack on the flagship Dell PowerEdge XE9680 Server equipped with eight AMD Instinct MI300X Accelerators.
- Fine-tuned Llama 3 8B with BF16 precision using the PubMedQA medical dataset on two Dell PowerEdge XE9680 Servers each equipped with eight AMD Instinct MI300X Accelerators.
- Deployed fine-tuned model in an enterprise chatbot scenario & conducted side by side tests with Llama 3 8B.
- Released distributed fine-tuning stack with support for Dell PowerEdge XE9680 Servers equipped with AMD Instinct MI300X Accelerators and NVIDIA H100 Tensor Core GPUs to offer enterprise choice.
Scalers AI is excited to see continued advancements from Dell and AMD on hardware and software optimizations in the future, including an upcoming RAG (retrieval augmented generation) offering running on the Dell PowerEdge XE9680 Server with AMD Instinct MI300X Accelerators at Dell Tech World ‘24.
| References
AMD products: AMD Library, https://library.amd.com/account/dashboard/
Nvidia images: Nvidia.com
Copyright © 2024 Scalers AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct™, ROCm™, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
***DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.

Silicon Diversity: Deploy GenAI on the PowerEdge XE9680 with AMD Instinct MI300X Accelerators
Wed, 08 May 2024 18:14:35 -0000
|Read Time: 0 minutes
| Entering the Era of Choice in AI: Putting Dell™ PowerEdge™ XE9680 Server with AMD Instinct™ MI300X Accelerators to the Test by Fine-tuning and Deploying Llama 2 70B Chat Model.
In this blog, Scalers AI™ will show you how to fine-tune large language models (LLMs), deploy 70B parameter models, and run a chatbot on the Dell™ PowerEdge™ XE9680 Server equipped with AMD Instinct™ MI300X Accelerators.
With the release of the AMD Instinct MI300X Accelerator, we are now entering an era of choice for leading AI Accelerators that power today’s generative AI solutions. Dell has paired the accelerators with its flagship PowerEdge XE9680 server for high performance AI applications. To put this leadership combination to the test, Scalers AI™ received early access and developed a fine-tuning stack with industry leading open-source components and deployed the Llama 2 70B Chat Model with FP16 precision in an enterprise chatbot scenario. In doing so, Scalers AI™ uncovered three critical value drivers:
- Deployed the Llama 2 70B parameter model on a single AMD Instinct MI300X Accelerator on the Dell PowerEdge XE9680 Server.
- Deployed eight concurrent instances of the model by utilizing all eight available AMD Instinct MI300X Accelerators on the Dell PowerEdge XE9680 Server.
- Fine-tuned the Llama 2 70B parameter model with FP16 precision on one Dell PowerEdge XE9680 Server with eight AMD Instinct MI300X accelerators.

This showcases industry leading total cost of ownership value for enterprises looking to fine-tune state of the art large language models with their own proprietary data, and deploy them on a single Dell PowerEdge XE9680 server equipped with AMD Instinct MI300X Accelerators.
 | “The PowerEdge XE9680 paired with AMD Instinct MI300X Accelerators delivers industry leading capability for fine-tuning and deploying eight concurrent instances of the Llama 2 70B FP16 model on a single server.”
| “The PowerEdge XE9680 paired with AMD Instinct MI300X Accelerators delivers industry leading capability for fine-tuning and deploying eight concurrent instances of the Llama 2 70B FP16 model on a single server.”
- Chetan Gadgil, CTO, Scalers AI
| To recreate, start with Dell PowerEdge XE9680 Server configurations as such.
OS: Ubuntu 22.04.4 LTS
Kernel version: 5.15.0-94-generic
Docker Version: Docker version 25.0.3, build 4debf41
ROCm™ version: 6.0.2
Server: Dell™ PowerEdge™ XE9680
GPU: 8x AMD Instinct™ MI300X Accelerators
| Setup Steps
- Install the AMD ROCm™ driver, libraries, and tools. Follow the detailed installation instructions for your Linux based platform.
To ensure these installations are successful, check the GPU info using rocm-smi.
- Clone the vLLM GitHub repository for 0.3.2 version as below:
git clone -b v0.3.2 https://github.com/vllm-project/vllm.git |
- Build the Docker container from the Dockerfile.rocm file inside the cloned vLLM repository.
cd vllm sudo docker build -f Dockerfile.rocm -t vllm-rocm:latest . |
- Use the command below to start the vLLM ROCm docker container and open the container shell.
sudo docker run -it \ --name vllm \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --shm-size 16G \ --group-add=video \ --workdir=/ \ vllm-rocm:latest bash |
- Request access to Llama 2 70B Chat Model from Llama 2 models from Meta and HuggingFace. Once the request is approved, log in to the Hugging Face CLI and enter your HuggingFace access token when prompted:
huggingface-cli login |
Part 1.0: Let’s start by showcasing how you can run the Llama 2 70B Chat Model on one AMD Instinct MI300X Accelerator on the PowerEdge XE9680 server. Previously we would use two cutting edge GPUs to complete this task. 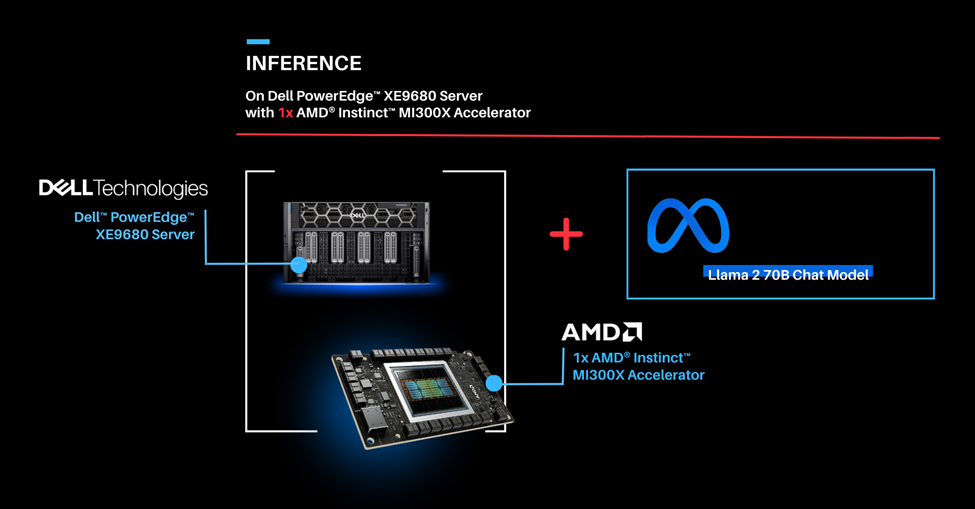
| Deploying Llama 2 70B Chat Model with vLLM 0.3.2 on a single AMD Instinct MI300X Accelerator with Dell PowerEdge XE9680 Server.
| Run vLLM Serving with Llama 2 70B Chat Model.
- Start the vLLM server for Llama 2 70B Chat model with FP16 precision loaded on a single AMD Instinct MI300X Accelerator.
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-70b-chat-hf --dtype float16 --tensor-parallel-size 1 |
- Execute the following curl request to verify if vLLM is successfully serving the model at the chat completion endpoint.
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-70b-chat-hf", "max_tokens":256, "temperature":1.0, "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Describe AMD ROCm in 180 words."} ]
}' |
The response should look as follows.
{"id":"cmpl-42f932f6081e45fa8ce7a7212cb19adb","object":"chat.completion","created":1150766,"model":"meta-llama/Llama-2-70b-chat-hf","choices":[{"index":0,"message":{"role":"assistant","content":" AMD ROCm (Radeon Open Compute MTV) is an open-source software platform developed by AMD for high-performance computing and deep learning applications. It allows developers to tap into the massive parallel processing power of AMD Radeon GPUs, providing faster performance and more efficient use of computational resources. ROCm supports a variety of popular deep learning frameworks, including TensorFlow, PyTorch, and Caffe, and is designed to work seamlessly with AMD's GPU-accelerated hardware. ROCm offers features such as low-level hardware control, GPU Virtualization, and support for multi-GPU configurations, making it an ideal choice for demanding workloads like artificial intelligence, scientific simulations, and data analysis. With ROCm, developers can take full advantage of AMD's GPU capabilities and achieve faster time-to-market and better performance for their applications."},"finish_reason":"stop"}],"usage":{"prompt_tokens":42,"total_tokens":237,"completion_tokens":195}} |
Part 1.1: Now that we have deployed the Llama 2 70B Chat Model on one AMD Instinct MI300X Accelerator on the Dell PowerEdge XE9680 server, let’s create a chatbot.
| Running Gradio Chatbot with Llama 2 70B Chat Model

This Gradio chatbot works by sending the user input query received through the user interface to the Llama 2 70B Chat Model being served using vLLM. The vLLM server is compatible with the OpenAI Chat API hence the request is sent in the OpenAI Chat API compatible format. The model generates the response based on the request which is sent back to the client. This response is displayed on the Gradio chatbot user interface.
| Deploying Gradio Chatbot
- If not already done, follow the instructions in the Setup Steps section to install the AMD ROCm driver, libraries, and tools, clone the vLLM repository, build and start the vLLM ROCm Docker container, and request access to the Llama 2 Models from Meta.
- Install the prerequisites for running the chatbot.
pip3 install -U pip pip3 install openai==1.13.3 gradio==4.20.1 |
- Log in to the Hugging Face CLI and enter your HuggingFace access token when prompted:
huggingface-cli login |
- Start the vLLM server for Llama 2 70B Chat model with data type FP16 on one AMD Instinct MI300X Accelerator.
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Llama-2-70b-chat-hf --dtype float16 |
- Run the gradio_openai_chatbot_webserver.py from the /app/vllm/examples directory within the container with the default configurations.
cd /app/vllm/examples python3 gradio_openai_chatbot_webserver.py --model meta-llama/Llama-2-70b-chat-hf |
The Gradio chatbot will be running on the port 8001 and can be accessed using the URL http://localhost:8001. The query passed to the chatbot is “How does AMD ROCm contribute to enhancing the performance and efficiency of enterprise AI workflows?” The output conversation with the chatbot is shown below:

- To observe the GPU utilization, use the rocm-smi command as shown below.

- Use the command below to access various vLLM serving metrics through the /metrics endpoint.
curl http://127.0.0.1:8000/metrics |
The output should look as follows.
# HELP exceptions_total_counter Total number of requested which generated an exception # TYPE exceptions_total_counter counter # HELP requests_total_counter Total number of requests received # TYPE requests_total_counter counter requests_total_counter{method="POST",path="/v1/chat/completions"} 1 # HELP responses_total_counter Total number of responses sent # TYPE responses_total_counter counter responses_total_counter{method="POST",path="/v1/chat/completions"} 1 # HELP status_codes_counter Total number of response status codes # TYPE status_codes_counter counter status_codes_counter{method="POST",path="/v1/chat/completions",status_code="200"} 1 # HELP vllm:avg_generation_throughput_toks_per_s Average generation throughput in tokens/s. # TYPE vllm:avg_generation_throughput_toks_per_s gauge vllm:avg_generation_throughput_toks_per_s{model_name="meta-llama/Llama-2-70b-chat-hf"} 4.222076684555402 # HELP vllm:avg_prompt_throughput_toks_per_s Average prefill throughput in tokens/s. # TYPE vllm:avg_prompt_throughput_toks_per_s gauge vllm:avg_prompt_throughput_toks_per_s{model_name="meta-llama/Llama-2-70b-chat-hf"} 0.0 ... # HELP vllm:prompt_tokens_total Number of prefill tokens processed. # TYPE vllm:prompt_tokens_total counter vllm:prompt_tokens_total{model_name="meta-llama/Llama-2-70b-chat-hf"} 44 ... vllm:time_per_output_token_seconds_count{model_name="meta-llama/Llama-2-70b-chat-hf"} 136.0 vllm:time_per_output_token_seconds_sum{model_name="meta-llama/Llama-2-70b-chat-hf"} 32.18783768080175 ... vllm:time_to_first_token_seconds_count{model_name="meta-llama/Llama-2-70b-chat-hf"} 1.0 vllm:time_to_first_token_seconds_sum{model_name="meta-llama/Llama-2-70b-chat-hf"} 0.2660619909875095 |
Part 2: Now that we have deployed the Llama 2 70B Chat Model on a single GPU, let’s take full advantage of the Dell PowerEdge XE9680 server and deploy eight concurrent instances of the Llama 2 70B Chat Model with FP16 precision. To handle more simultaneous users and generate higher throughput, the 8x AMD Instinct MI300X Accelerators can be leveraged to deploy 8 vLLM serving deployments in parallel.
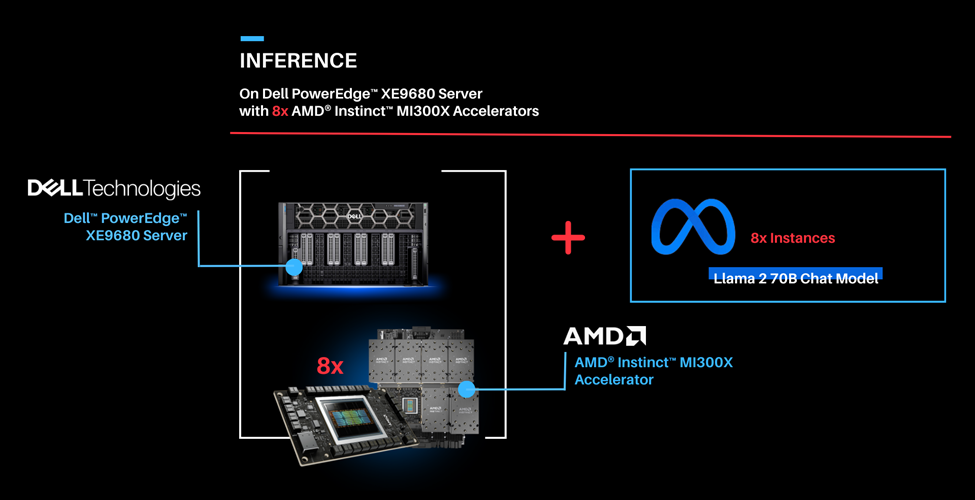
| Serving Llama 2 70B Chat model with FP16 precision using vLLM 0.3.2 on 8x AMD Instinct MI300X Accelerators with the PowerEdge XE9680 Server.
To enable the multi GPU vLLM deployment, we use a Kubernetes based stack. The stack consists of a Kubernetes Deployment with 8 vLLM serving replicas and a Kubernetes Service to expose all vLLM serving replicas through a single endpoint. The Kubernetes Service utilizes a round robin based strategy to distribute the requests across the vLLM serving replicas.
| Prerequisites
- Any Kubernetes distribution on the server.
- AMD GPU device plugins for Kubernetes setup on the installed Kubernetes distribution.
- A Kubernetes secret that grants access to the container registry, facilitating Kubernetes deployment.
| Deploying the multi vLLM serving on 8x AMD Instinct MI300X Accelerators.
- If not already done, follow the instructions in the Setup Steps section to install the AMD ROCm driver, libraries, and tools, clone the vLLM repository, build the vLLM ROCm Docker container, and request access to the Llama 2 Models from Meta. Push the built vllm-rocm:latest image to the container registry of your choice.
- Create a deployment yaml file “multi-vllm.yaml” based on the sample provided below.
# vllm deployment apiVersion: apps/v1 kind: Deployment metadata: name: vllm-serving namespace: default labels: app: vllm-serving spec: selector: matchLabels: app: vllm-serving replicas: 8 template: metadata: labels: app: vllm-serving spec: containers: - name: vllm image: container-registry/vllm-rocm:latest # update the container registry name args: [ "python3", "-m", "vllm.entrypoints.openai.api_server", "--model", "meta-llama/Llama-2-70b-chat-hf" ] env: - name: HUGGING_FACE_HUB_TOKEN value: "" # add your huggingface token with Llama 2 models access resources: requests: cpu: 15 memory: 150G amd.com/gpu: 1 # each replica is allocated 1 GPU limits: cpu: 15 memory: 150G amd.com/gpu: 1 imagePullSecrets: - name: cr-login # kubernetes container registry secret --- # nodeport service with round robin load balancing apiVersion: v1 kind: Service metadata: name: vllm-serving-service namespace: default spec: selector: app: vllm-serving type: NodePort ports: - name: vllm-endpoint port: 8000 targetPort: 8000 nodePort: 30800 # the external port endpoint to access the serving |
- Deploy the multi vLLM serving using the deployment configuration with kubectl. This will deploy eight replicas of vLLM serving using the Llama 2 70B Chat model with FP16 precision.
kubectl apply -f multi-vllm.yaml |
- Execute the following curl request to verify whether the model is being successfully served at the chat completion endpoint at port 30800.
curl http://localhost:30800/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-2-70b-chat-hf", "max_tokens":256, "temperature":1.0, "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Describe AMD ROCm in 180 words."} ]
}' |
The response should look as follows:
{"id":"cmpl-42f932f6081e45fa8ce7dnjmcf769ab","object":"chat.completion","created":1150766,"model":"meta-llama/Llama-2-70b-chat-hf","choices":[{"index":0,"message":{"role":"assistant","content":" AMD ROCm (Radeon Open Compute MTV) is an open-source software platform developed by AMD for high-performance computing and deep learning applications. It allows developers to tap into the massive parallel processing power of AMD Radeon GPUs, providing faster performance and more efficient use of computational resources. ROCm supports a variety of popular deep learning frameworks, including TensorFlow, PyTorch, and Caffe, and is designed to work seamlessly with AMD's GPU-accelerated hardware. ROCm offers features such as low-level hardware control, GPU Virtualization, and support for multi-GPU configurations, making it an ideal choice for demanding workloads like artificial intelligence, scientific simulations, and data analysis. With ROCm, developers can take full advantage of AMD's GPU capabilities and achieve faster time-to-market and better performance for their applications."},"finish_reason":"stop"}],"usage":{"prompt_tokens":42,"total_tokens":237,"completion_tokens":195}} |
- We used load testing tools similar to Apache Bench to simulate concurrent user requests to the serving endpoint. The screenshot below showcases the output of rocm-smi while Apache Bench is running 2048 concurrent requests.

Part 3: Now that we have deployed the Llama 2 70B Chat model on both one GPU and eight concurrent GPUs, let's try fine-tuning Llama 2 70B Chat with Hugging Face Accelerate.
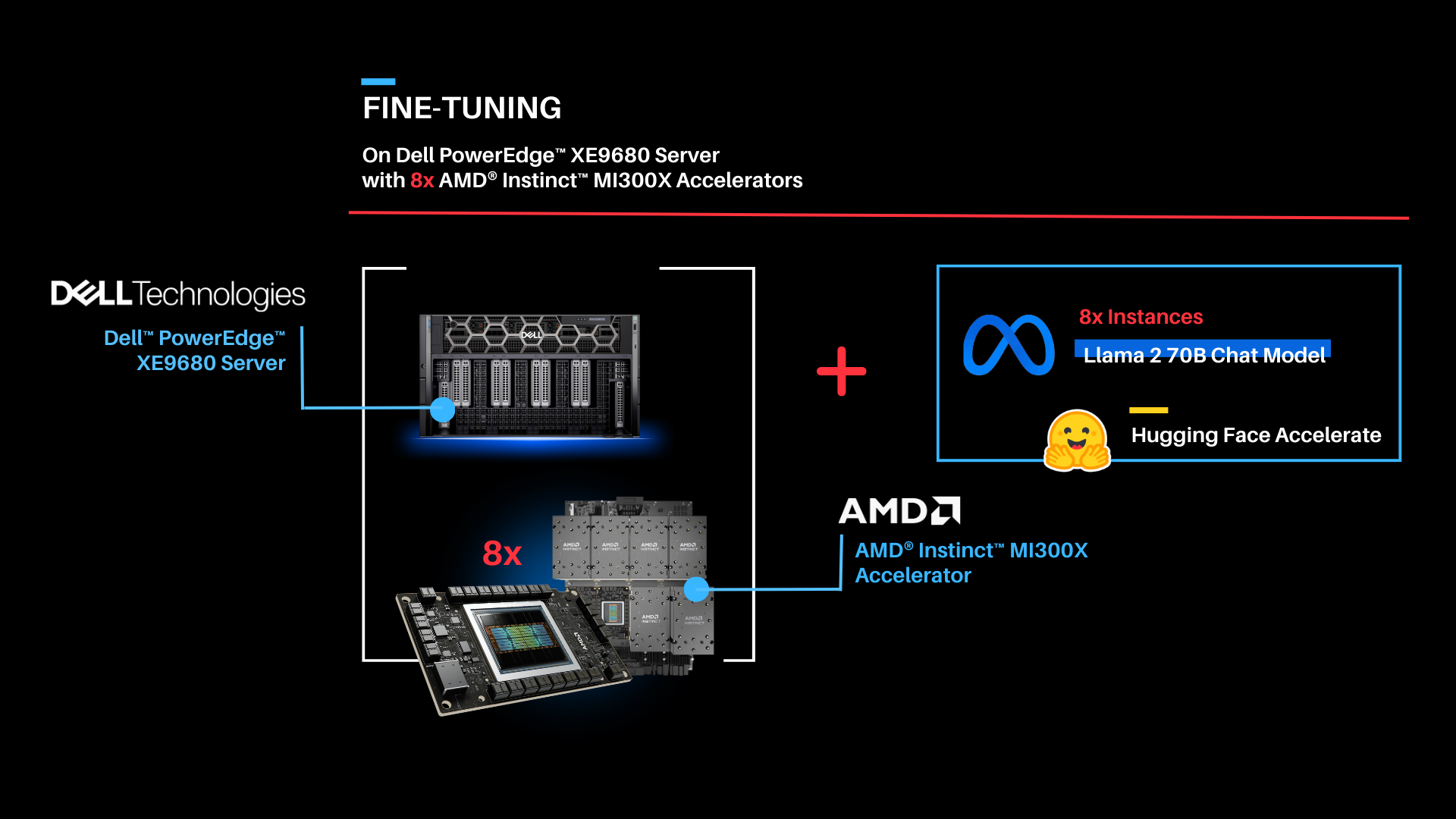
| Fine-tuning
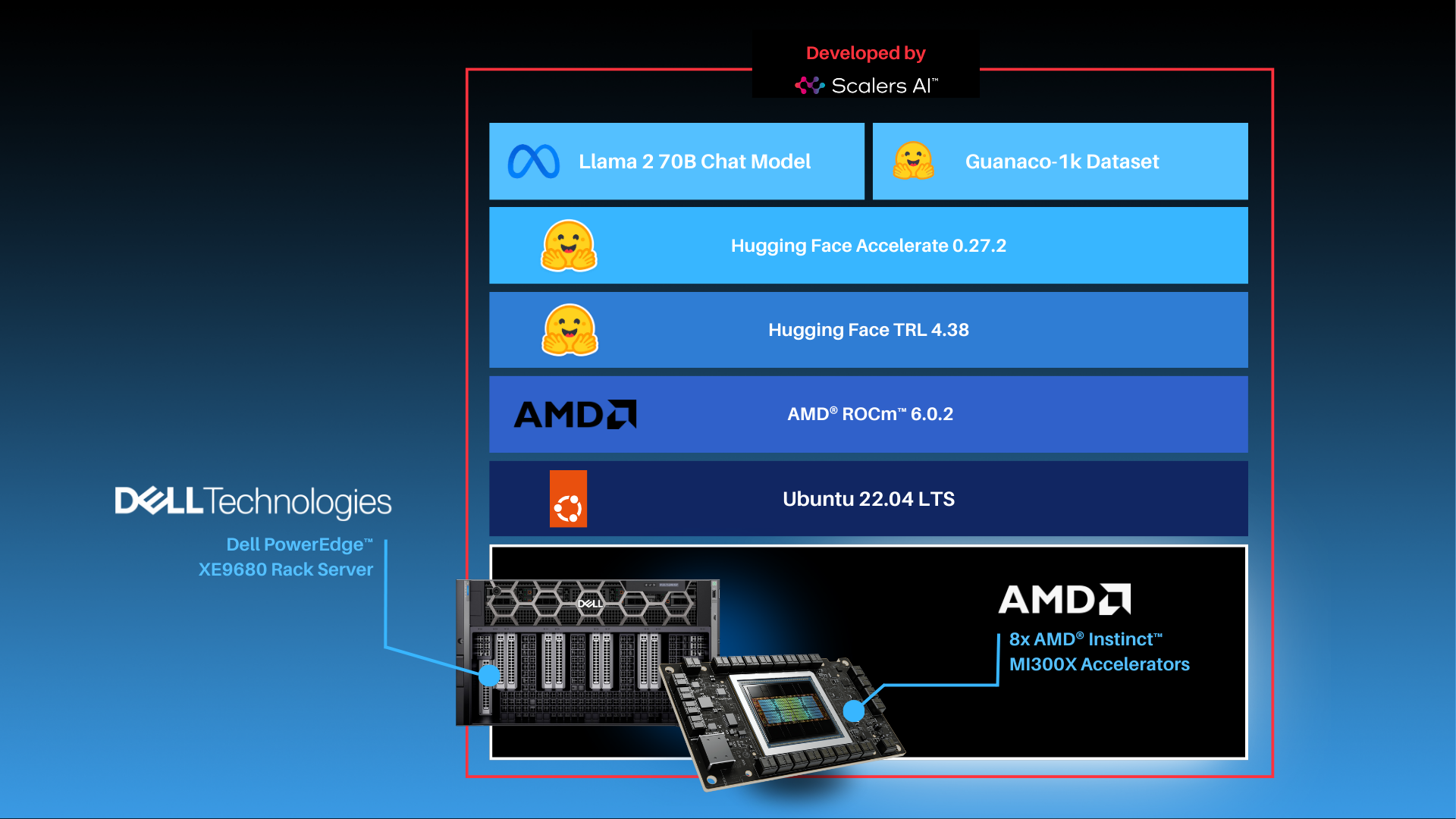
As shown above, the fine-tuning software stack begins with the AMD ROCm PyTorch image serving as the base, offering a tailored PyTorch library for optimal fine-tuning. Leveraging the Hugging Face Transformers library alongside Hugging Face Accelerate, facilitates multi-GPU fine-tuning capabilities. The Llama 2 70B Chat model will be fine-tuned with FP16 precision, utilizing the Guanaco-1k dataset from Hugging Face on eight AMD Instinct MI300X Accelerators.
In this scenario, we will perform full parameter fine-tuning of the Llama 2 70B Chat Model. While you can also implement fine-tuning using optimized techniques such as Low-Rank Adaptation of Large Language Models (LoRA) on accelerators with smaller memory footprints, performance tradeoffs exist on specific complex objectives. These nuances are addressed by full parameter fine-tuning methods, which generally require accelerators that support significant memory requirements.
| Fine-tuning Llama 2 70B Chat on 8x AMD Instinct MI300X Accelerators.
Fine-tune the Llama 2 70B Chat Model with FP16 precision for question and answer tasks by utilizing the mlabonne/guanaco-llama2-1k dataset on the 8X AMD Instinct MI300X Accelerators.
- If not already done, install the AMD ROCm driver, libraries, and tools and request access to the Llama 2 Models from Meta following the instructions in the Setup Steps section.
- Start the fine-tuning docker container with the AMD ROCm PyTorch base image.
The below command opens a shell within the docker container.
sudo docker run -it \ --name fine-tuning \ --network=host \ --device=/dev/kfd \ --device=/dev/dri \ --shm-size 16G \ --group-add=video \ --workdir=/ \ rocm/pytorch:rocm6.0.2_ubuntu22.04_py3.10_pytorch_2.1.2 bash |
- Install the necessary Python prerequisites.
pip3 install -U pip pip3 install transformers==4.38.2 trl==0.7.11 datasets==2.18.0 |
- Log in to Hugging Face CLI and enter your HuggingFace access token when prompted.
huggingface-cli login |
- Import the required Python packages.
from datasets import load_dataset from transformers import ( AutoModelForCausalLM, AutoTokenizer, TrainingArguments, pipeline ) from trl import SFTTrainer |
- Load the Llama 2 70B Chat Model and the mlabonne/guanaco-llama2-1k dataset from Hugging Face.
# load the model and tokenizer base_model_name = "meta-llama/Llama-2-70b-chat-hf"
# tokenizer parameters llama_tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True) llama_tokenizer.pad_token = llama_tokenizer.eos_token llama_tokenizer.padding_side = "right"
# load the based model base_model = AutoModelForCausalLM.from_pretrained( base_model_name, device_map="auto", ) base_model.config.use_cache = False base_model.config.pretraining_tp = 1
# load the dataset from huggingface dataset_name = "mlabonne/guanaco-llama2-1k" training_data = load_dataset(dataset_name, split="train") |
- Define fine-tuning configurations and start fine-tuning for 1 epoch. The fine tuned model will be saved in finetuned_llama2_70b directory.
# fine tuning parameters train_params = TrainingArguments( output_dir="./runs", num_train_epochs=1, # fine tuning for 1 epochs per_device_train_batch_size=8 # setting per GPU batch size )
# define the trainer fine_tuning = SFTTrainer( model=base_model, train_dataset=training_data, dataset_text_field="text", tokenizer=llama_tokenizer, args=train_params, max_seq_length=512 )
# start the fine tuning run fine_tuning.train()
# save the fine tuned model fine_tuning.model.save_pretrained("finetuned_llama2_70b") print("Fine-tuning completed") |
- Use the `rocm-smi` command to observe GPU utilization while fine-tuning.

| Summary

Dell PowerEdge XE9680 Server equipped with AMD Instinct MI300X Accelerators offers enterprises industry leading infrastructure to create custom AI solutions using their proprietary data. In this blog, we showcased how enterprises deploying applied AI can take advantage of this solution in three critical use cases:
- Deploying the entire 70B parameter model on a single AMD Instinct MI300X Accelerator in Dell PowerEdge XE9680 Server
- Deploying eight concurrent instances of the model, each running on one of eight AMD Instinct MI300X accelerators on the Dell PowerEdge XE9680 Server
- Fine-tuning the 70B parameter model with FP16 precision on one PowerEdge XE9680 with all eight AMD Instinct MI300X accelerators
Scalers AI is excited to see continued advancements from Dell, AMD, and Hugging Face on hardware and software optimizations in the future.
| Additional Criteria for IT Decision Makers
| What is fine-tuning, and why is it critical for enterprises?
Fine-tuning enables enterprises to develop custom models with their proprietary data by leveraging the knowledge already encoded in pre-trained models. As a result, fine-tuning requires less labeled data and time for training compared to training a model from scratch, making it a more efficient approach for achieving competitive performance, particularly in the quantity of computational resources used and training time.
| Why is memory footprint critical for LLMs?
Large language models often have enormous numbers of parameters, leading to significant memory requirements. When working with LLMs, it is essential to ensure that the GPU has sufficient memory to store these parameters so that the model can run efficiently. In addition to model parameters, large language models require substantial memory to store input data, intermediate activations, and gradients during training or inference, and insufficient memory can lead to data loss or performance degradation.
| Why is the Dell PowerEdge XE9680 Server with AMD Instinct MI300X Accelerators well-suited for LLMs?
Designed especially for AI tasks, Dell PowerEdge XE9680 Server is a robust data-processing server equipped with eight AMD Instinct MI300X accelerators, making it well-suited for AI-workloads, especially for those involving training, fine-tuning, and conducting inference with LLMs. AMD Instinct MI300X Accelerator is a high-performance AI accelerator intended to operate in groups of eight within AMD’s generative AI platform.
Running inference, specifically with a Large Language Model (LLM), requires approximately 1.2 times the memory occupied by the model on a GPU. In FP16 precision, the model memory requirement can be estimated as 2 bytes per parameter multiplied by the number of model parameters. For example, the Llama 2 70B model with FP16 precision requires a minimum of 168 GB of GPU memory to run inference.
With 192 GB of GPU memory, a single AMD Instinct MI300X Accelerator can host an entire Llama 2 70B parameter model for inference. It is optimized for LLMs and can deliver up to 10.4 Petaflops of performance (BF16/FP16) with 1.5TB of total HBM3 memory for a group of eight accelerators.
Copyright © 2024 Scalers AI, Inc. All Rights Reserved. This project was commissioned by Dell Technologies. Dell and other trademarks are trademarks of Dell Inc. or its subsidiaries. AMD, Instinct™, ROCm™, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other product names are the trademarks of their respective owners.
***DISCLAIMER - Performance varies by hardware and software configurations, including testing conditions, system settings, application complexity, the quantity of data, batch sizes, software versions, libraries used, and other factors. The results of performance testing provided are intended for informational purposes only and should not be considered as a guarantee of actual performance.

Lab Insight: Dell AI PoC for Transportation & Logistics
Wed, 20 Mar 2024 21:23:12 -0000
|Read Time: 0 minutes
Introduction
As part of Dell’s ongoing efforts to help make industry-leading AI workflows available to its clients, this paper outlines a sample AI solution for the transportation and logistics market. The reference solution outlined in this paper specifically targets challenges in the maritime industry by creating an AI powered cargo monitoring PoC built with DellTM hardware.
AI as a technology is currently in a rapid state of advancement. While the area of AI has been around for decades, recent breakthroughs in generative AI and large language models (LLMs) have led to significant interest across almost all industry verticals, including transportation and logistics. Futurum intelligence projects a 24% growth of AI in the transportation industry in 2024 and a 30% growth for logistics.
The advancements in AI now open significant possibilities for new value-adding applications and optimizations, however different industries will require different hardware and software capabilities to overcome industry specific challenges. When considering AI applications for transportation and logistics, a key challenge is operating at the edge. AI-powered applications for transportation will typically be heavily driven by on-board sensor data with locally deployed hardware. This presents a specific challenge, requiring hardware that is compact enough for edge deployments, powerful enough to run AI workloads, and robust enough to endure varying edge conditions.
This paper outlines a PoC for an AI-based transportation and logistics solution that is specifically targeted at maritime use cases. Maritime environments represent some of the most rigorous edge environments, while also presenting an industry with significant opportunity for AI-powered innovation. The PoC outlined in this paper addresses the unique challenges of maritime focused AI solutions with hardware from Dell and BroadcomTM.
The PoC detailed in this paper serves as a reference solution that can be leveraged for additional maritime, transportation, or logistics applications. The overall applicability of AI in these markets is much broader than the single maritime cargo monitoring solution, however, the PoC demonstrates the ability to quickly deploy valuable edge-based solutions for transportation and logistics using readily available edge hardware.
Importance for the Transportation and Logistics Market
Transportation and logistics cover a broad industry with opportunity for AI technology to create a significant impact. While the overarching segment is widespread, including public transportation, cargo shipping, and end-to-end supply chain management, key to any transportation or logistics process is optimization. These processes are dependent on a high number of specific details and variables such as specific routes, number and types of goods transported, compliance regulations, and weather conditions. By optimizing for the many variables that may arise in a logistical process, organizations can be more efficient, save money, and avoid risk.
In order to create these optimal processes, however, the data surrounding the many variables involved needs to be captured. Further, this data needs to be analyzed, understood, and acted on. The large quantity of data required and the speed at which it must be processed in order to make impactful decisions to complex logistical challenges often surpasses what a human can achieve manually.
By leveraging AI technology, impactful decisions to transportation and logistics processes can be achieved quicker and with greater accuracy. Cameras and other sensors can capture relevant data that is then processed and understood by an AI model. AI can quickly process vast amounts of data and lead to optimized logistics conclusions that would otherwise be too timely, costly, or complex for organizations to make.
The potential applications for AI in transportation are vast and can be applied to various means of transportation including shipping, rail, air, and automotive, as well as associated logistical processes such as warehouses and shipping yards. One possible example is AI optimized route planning which could pertain to either transportation of cargo or public transportation and could optimize for several factors including cost, weather conditions, traffic, or environmental impact. Additional applications could include automated fleet management, AI powered predictive vehicle maintenance, and optimized pricing. As AI technology improves, many transportation services may be additionally optimized with the use of autonomous vehicles.
By adopting such AI-powered applications, organizations can implement optimizations that may not otherwise be achievable. While new AI applications show promise of significant value, many organizations may find adopting the technology a challenge due to unfamiliarity with the new and rapidly advancing technology. Deploying complex applications such as AI in transportation environments can pose an additional challenge due to the requirements of operating in edge environments.
The following PoC solution outlines an example of a transportation focused AI application that can offer significant value to maritime shipping by providing AI-powered cargo monitoring using Dell hardware at the edge.
Solution Overview
To demonstrate an AI-powered application focused on transportation and logistics, Scalers AITM, in partnership with Dell, Broadcom, and The Futurum Group implemented a proof-of-concept for a maritime cargo monitoring solution. The solution was designed to capture sensor data from cargo ships as well as image data from on-board cameras. Cargo containers can be monitored for temperature and humidity to ensure optimal conditions are maintained for the shipped cargo. In addition, cameras can be used to monitor workers in the cargo area to ensure worker safety and prevent injury. The captured data is then utilized by an LLM to create an AI generated compliance report at the end of the ship’s voyage.
This proof-of-concept addresses several problems that can be encountered in maritime shipping. Refrigerated cargo, known as reefer, is utilized to ship perishable items and pharmaceuticals that must be kept at specific temperatures. Without proper monitoring to ensure optimal temperatures, reefer may experience swings in temperature, resulting in spoiled products and ultimately financial loss. Predictive forecasting of the power requirements for refrigerated cargo can provide additional cost and environmental savings by providing greater power usage insights.
Similarly, dry cargo can become spoiled or damaged when exposed to excessive moisture. Moisture can be introduced in the form of condensation – known as cargo sweat – due to changes in climate and humidity during the ships journey. By monitoring the temperature and humidity of the cargo, alerts can be raised signaling the possibility of cargo sweat and allowing ventilation adjustments to be made which can prevent moisture related damage.
A third issue addressed by the maritime cargo monitoring PoC is that of worker safety. The possibility of shifting cargo containers can lead to dangerous situations and potential injuries for those working in container storage areas. By using video surveillance of workers in cargo areas, these potential injuries can be avoided.
The PoC provides monitoring of these challenges with an additional visualization dashboard that displays information such as number of cargo containers, forecasted energy consumption, container temperature and humidity, and a video feed of workers. The dashboard additionally raises alerts as issues arise in any of these areas. This information is further compiled in to an end of voyage report for compliance and logging purposes, automatically generated with an LLM.
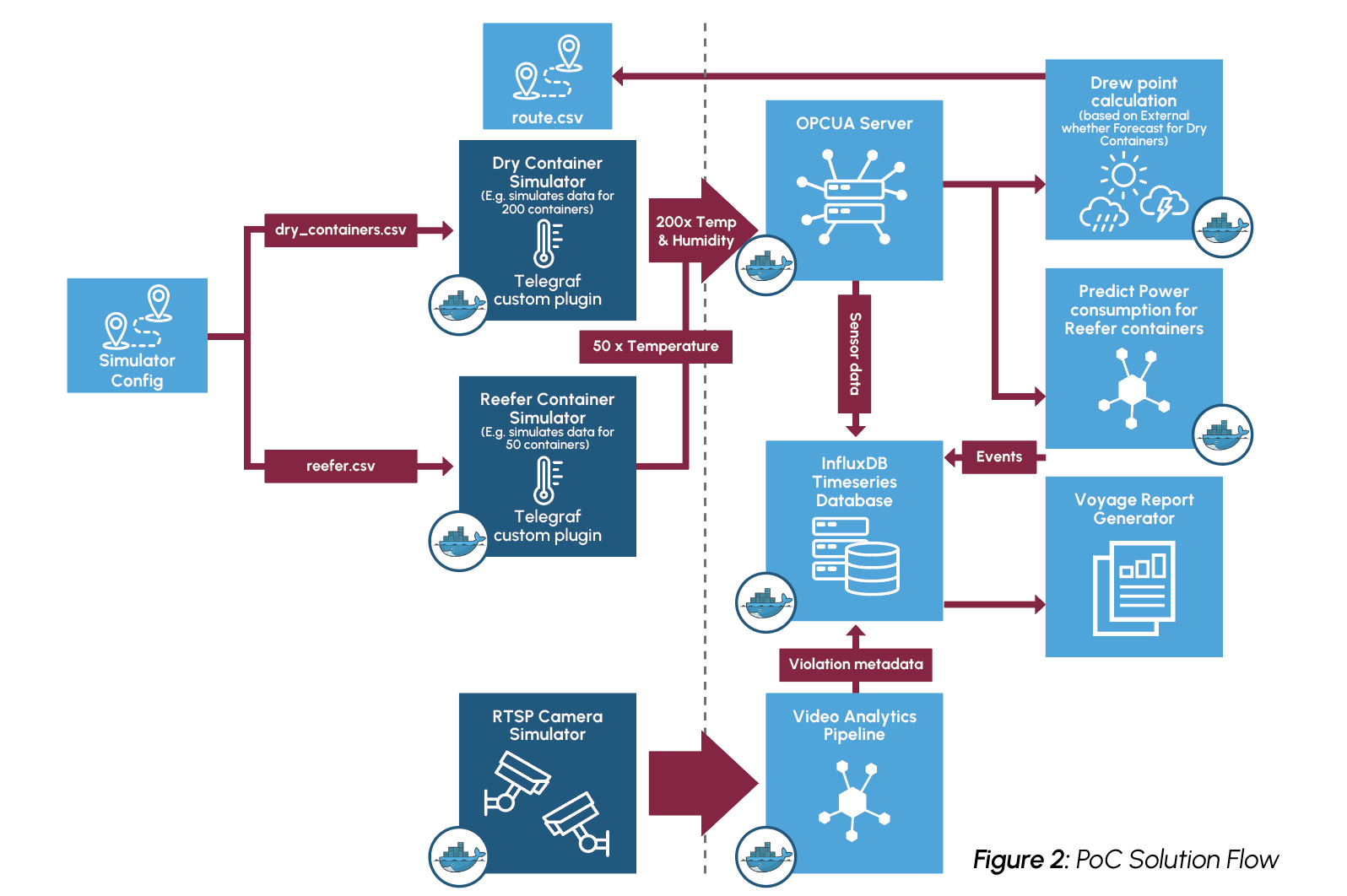
To achieve the PoC solution, simulated sensor data is generated for both reefers and dry containers, approximating the conditions undergone during a real voyage. The sensor data is written to an OPCUA server which then supplies data to a container sweat analytics module and a power consumption predictor. For dry containers, the temperature and humidity data is utilized alongside the forecasted weather of the route to create dew point calculations and monitor potential container sweat. Sensor data recording the temperature of reefer containers is monitored to ensure accurate temperatures are maintained, and a decision tree regressor model is leveraged to predict future power consumption for the next hour.
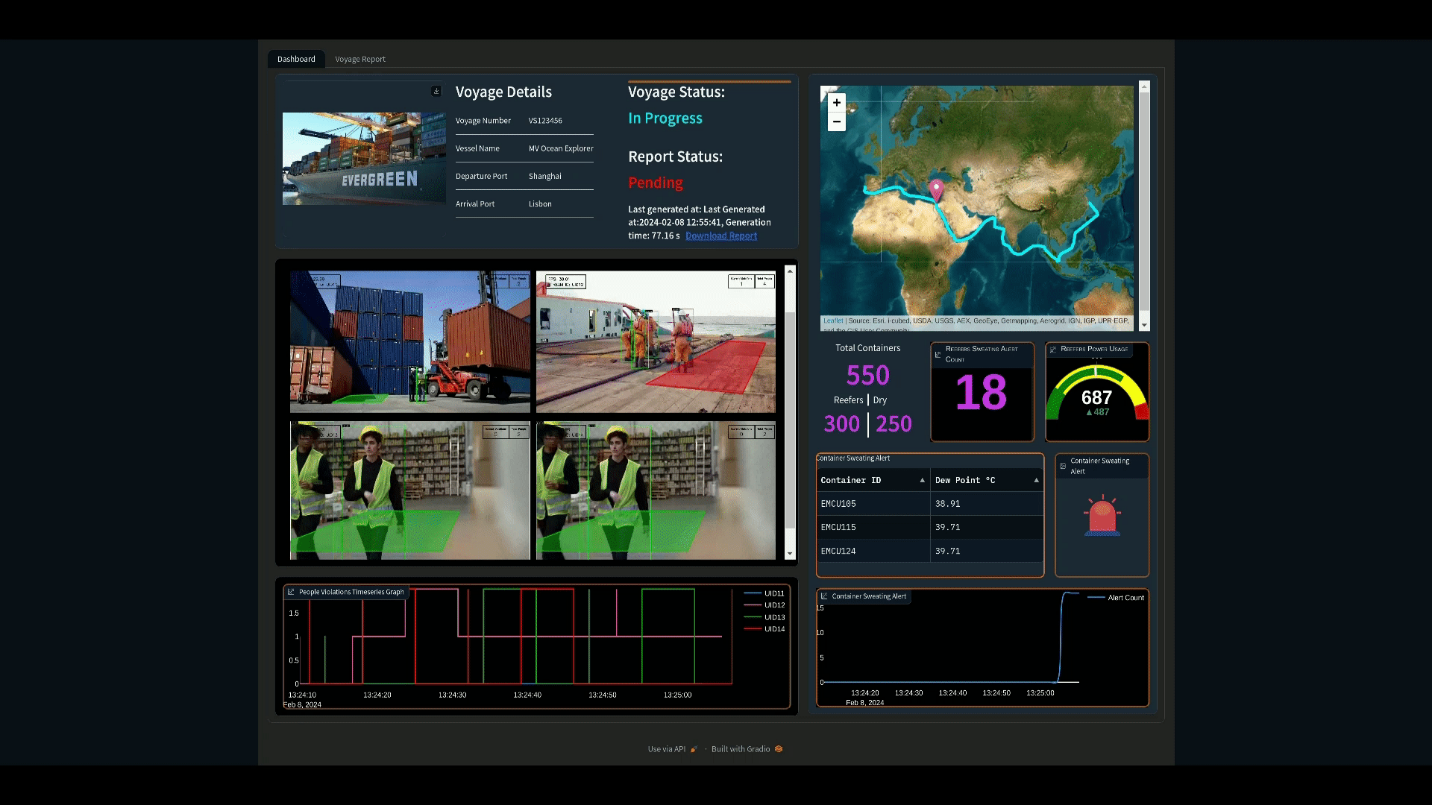
Figure 1: Visualization Dashboard
For monitoring worker safety, RTSP video data is captured into a video analytics pipeline built on NVIDIATM DeepStream. Streaming data is decoded and then inferenced using the YoloV8s model to detect workers entering dangerous, restricted zones. The restricted zones are configured as x,y coordinate pairs stored as JSON objects. Uncompressed video is then published to the visualization service using the Zero Overhead Network Protocol (Zenoh).
Monitoring and alerts for all of these challenges is displayed on a visualization dashboard as can be seen in Figure 1, as well as summarized in an end of voyage compliance report. The resulting compliance report that details the information collected on the voyage is AI generated using the Zephyr 7B model. Testing of the PoC found that the report could be generated in approximately 46 seconds, dramatically accelerating the reporting process compared to a manual approach.
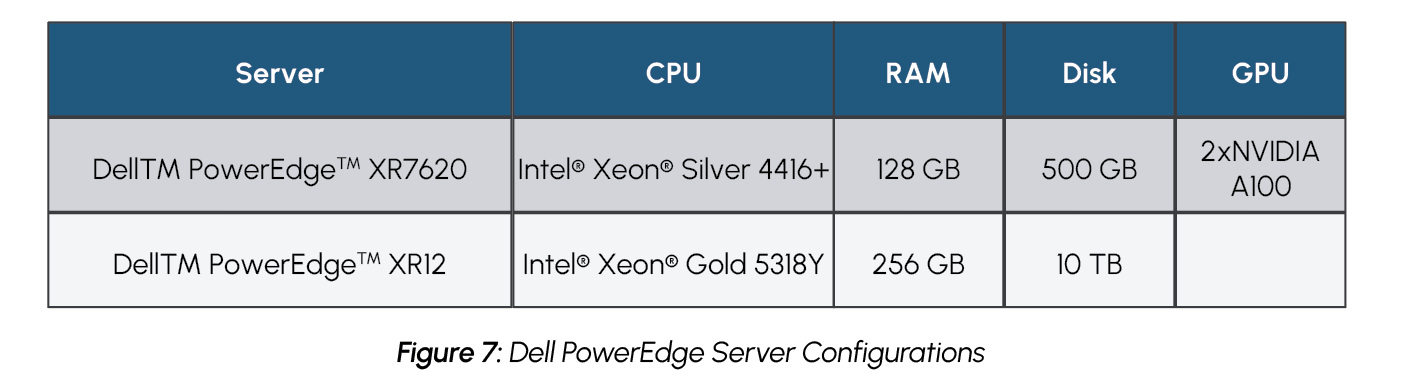
To achieve the PoC solution in-line with the restraints of a typical maritime use case, the solution was deployed using Dell PowerEdge servers designed for the edge. The sensor data calculations and predictions, video pipeline, and AI report generation were achieved on a Dell PowerEdge XR7620 server with dual NVIDIA A100 GPUs. A Dell PowerEdge XR12 server was deployed to host the visualization dashboard. The two servers were connected with high bandwidth Broadcom NICs.
An overview of the solution can be seen in Figure 2
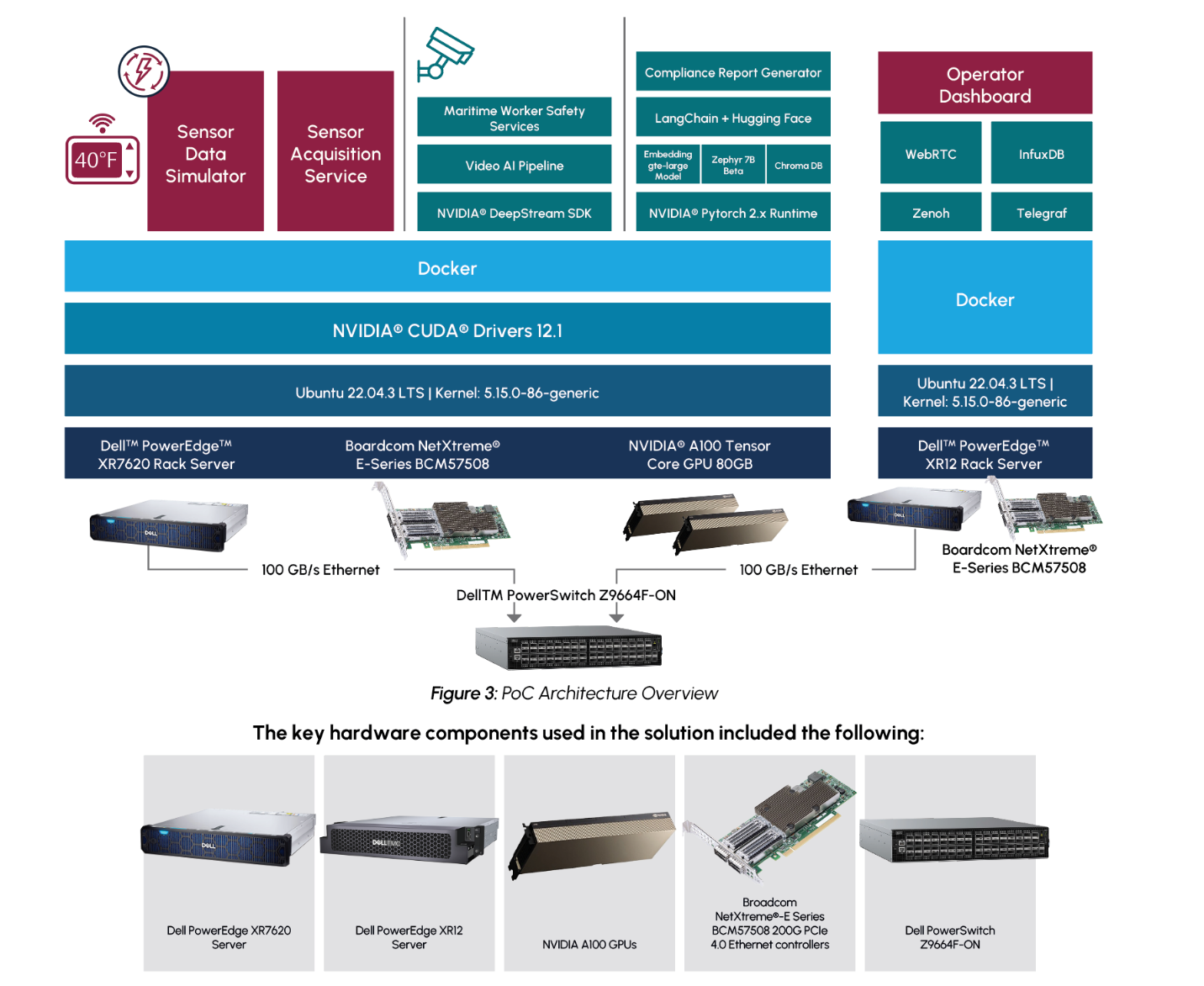
Additional details about the implementation and performance testing of the PoC on GitHub, including:
- Configuration information including diagrams and YAML code
- Instructions for doing the performance tests
- Details of performance results
- Source code
- Samples for test process
https://github.com/dell-examples/generative-ai/tree/main/transportation-maritime
Highlights for AI Practitioners
The cargo monitoring PoC demonstrates a solution that can avoid product loss, enhance compliance and logging, and improve worker safety, all by using AI. The creation of these AI processes was done using readily available AI tools. The process of creating valuable, real-world solutions by utilizing such tools should be noted by AI practitioners.
The end of voyage compliance report is generated using the Zephyr 7B LLM model created by Hugging Face’s H4 team. The Zephyr 7B model, which is a modified version of Mistral 7B, was chosen as it is a publicly available model that is both lightweight and highly accurate. The Zephyr 7B model was created using a process called Distilled Supervised Fine Tuning (DSFT) which allows the model to provide similar performance to much larger models, while utilizing far fewer parameters. Zephyr 7B, which is a 7 Billion parameter model, has demonstrated performance comparable to 70 Billion parameter models. This ability to provide the capabilities of larger models in a smaller, distilled model makes Zephyr 7B an ideal choice for edge-based deployments with limited resources, such as in maritime or other transportation environments.
While Zephyr 7B is a very powerful and accurate LLM model, it was trained on a broad data set and it is intended for general purpose usage, rather than specific tasks such as generating a maritime voyage compliance report. In order to generate a report that is accurate to the maritime industry and the specific voyage, more context must be supplied to the model. This was achieved using a process called Retrieval Augmented Generation (RAG). By utilizing RAG, the Zephyr 7B model is able to incorporate the voyage specific information to generate an accurate report which detailed the recorded container and worker safety alerts. This is notable for AI practitioners as it demonstrates the ability to use a broad, pre-trained LLM model, which is freely available, to achieve an industry specific task.
To provide the voyage specific context to the LLM generated report, time series data of recorded events, such as container sweating, power measurements, and worker safety violations, is queried from InfluxDB at the end of the voyage. This text data is then embedded using the Hugging Face LangChain API with the gte-large embedding model and stored in a ChromaDB vector database. These vector embeddings are then used in the RAG process to provide the Zephyr 7B model with voyage specific context when generating the report.
AI practitioners should also note that AI image detection is utilized to detect workers entering into restricted zones. This image detection capability was built using the YOLOv8s object detection model and NVIDIA DeepStream. YOLOv8s is a state of the art, open source, AI model for object detection built by Ultralytics. The model is used to detect workers within a video frame and detect if they enter into pre-configured restricted zones. NVIDIA DeepStream is a software development toolkit provided by NVIDIA to build and accelerate AI solutions from streaming video data, which is optimized for NVIDIA hardware such asthe A100 GPUs used in this PoC. It is notable that NVIDIA DeepStream can be utilized for free to build powerful video-based AI applications, such as the worker detection component of the maritime cargo monitoring solution. In this case, the YOLOv8s model and the DeepStream toolkit are utilized to build a solution that has the potential to prevent serious workplace injuries.
Key Highlights for AI Practitioners
- Maritime compliance report generated with Zephyr 7B LLM model
- Retrieval Augmented Generation (RAG) approach used to provide Zephyr 7B with voyage specific information
- YOLOv8s and NVIDIA DeepStream used to create powerful AI worker detection solution using video streaming data
Considerations for IT Operations
The maritime cargo monitoring PoC is notable for IT operations as it demonstrates the ability to deploy a powerful AI driven solution at the edge. For many in IT, AI deployments in any setting may be a challenge, due to overall unfamiliarity with AI and its hardware requirements. Deployments at the edge introduce even further complexity.
Hardware deployed at the edge requires additional considerations, including limited space and exposure to harsh conditions, such as extreme temperature changes. For AI applications deployed at the edge, these requirements must be maintained, while simultaneously providing a system powerful enough to handle such a computationally intensive workload.
For the maritime cargo monitoring PoC, Dell PowerEdge XR7620 and PowerEdge XR12 servers were chosen for their ability to meet both the most demanding edge requirements, as well as the most demanding computational requirements. Both servers are ruggedized and are capable of operating in temperatures ranging from -5°C to 55°C, as well as withstanding dusty or otherwise hazardous environments. They additionally offer a compact design that is capable of fitting into tight environments. This provides servers that are ideal for a demanding edge environment, such as in maritime shipping, which may experience large temperature swings and may have limited space for servers. Meanwhile, the Dell PowerEdge XR7620 is also equipped with NVIDIA GPUs, providing it with the compute power necessary to handle AI workloads.

Dell PowerEdge XR7620
NVIDIA A100 GPUs were chosen as they are well suited for various types of AI workflows. The PoC includes both a video classification component and a large language model component, requiring hardware that is well suited for both workloads. While there are other processors that are more specialized specifically for either video processing or language models, the A100 GPU provides flexibility to perform both well on a single platform.
The use of high bandwidth Broadcom NICs is also a notable component of the PoC solution for IT operations to be aware of. The Broadcom NICs are responsible for providing a high bandwidth Ethernet connection between the cargo and worker monitoring applications and the visualization and alerting dashboard. The use of scalable, high bandwidth NICs is crucial to such a solution that requires transmitting large amounts of sensor and video data, which may include time sensitive information.
Detection of issues with either reefer or dry containers may require quick action to protect the cargo, and quick detection of workers in hazardous environments can prevent serious harm or injury. The use of a high bandwidth Ethernet connection ensures that data can be quickly transmitted and received by the visualization dashboard for operators to respond to alerts as they arise.
Key Highlights for IT Operations
- AI solution deployed on rugged Dell PowerEdge XR7620 and PowerEdge XR12 servers to accommodate edge environmentand maintain high computational requirements.
- NVIDIA A100 GPUs provide flexibility to support both video and LLM workloads.
- Broadcom NICs provide high bandwidth connection between monitoring applications and visualization dashboard.
Solution Performance Observations
Key to the performance of the maritime cargo monitoring PoC is its ability to scale to support multiple concurrent video streams for monitoring worker safety. The solution must be able to quickly decode and inference incoming video data to detect workers in restricted areas. The ability for the visualization dashboard to quickly receive this data is additionally critical for actions to be taken on alerts as they are raised. The solution was separated into a distinct inference server, to capture and inference data, and an encode server, to display the visualization service. This architecture allows the solution to scale the services independently as needed for varying requirements of video streams and application logic. The separate services are then connected with high bandwidth Ethernet using Broadcom NetXtreme®-E Series Ethernet controllers. The following performance data demonstrates the ability to scale the solution with an increasing number of data streams. Each test was run for a total of 10 minutes and video streams were scaled evenly across the two NVIDIA A100 GPUs. Additional performance results are available in the appendix.
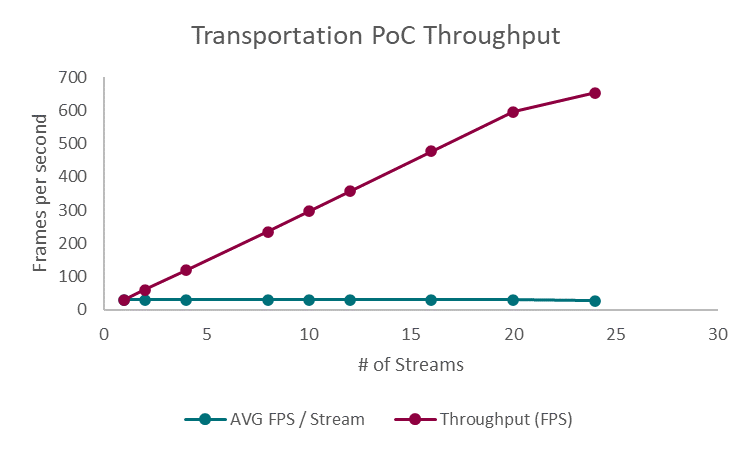
Figure 4: Transportation PoC Throughput
Figure 4 displays the total throughput of frames per second as well as the average throughput as the number of streams increased. The frames per second metric includes video decoding, inference, post-processing, and publishing of an uncompressed stream. The PoC displayed increasing throughput with a maximum of 653.7 frames per second when tested with 24 concurrent streams. Notably, the average frames per second remained steady at approximately 30 frames per second for up to 20 streams, which is considered an industry standard for video processing workloads. When tested with 24 streams, the solution did experience a slight drop, with an average of 27.24 frames per second. Overall, the throughput performance demonstrates the ability of the Dell PowerEdge Server and the NVIDIA A100 GPUs to successfully handle a demanding video-based AI workload with a significant number of concurrent streams.
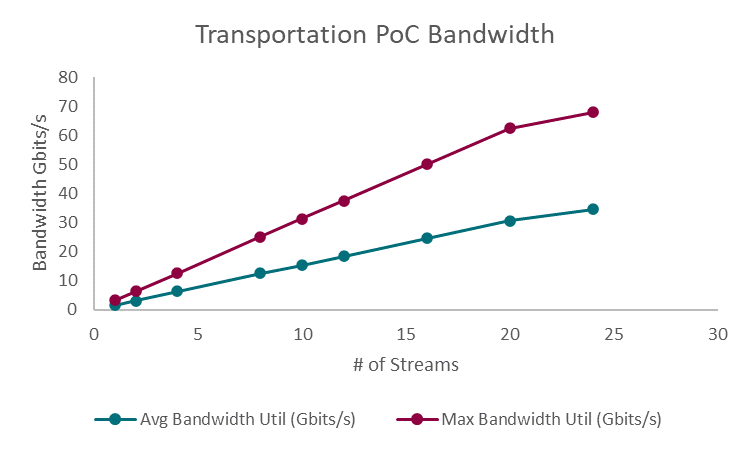
Figure 5: Transportation PoC Bandwidth Utilization
Figure 5 displays the solution’s bandwidth utilization as the number of streams increased from 1 to 24. The results demonstrate the increase in required bandwidth, both at a maximum and on average, as the number of streams increased. The average bandwidth utilization scaled from 1.56 Gb/s with a single video stream, to 34.6 Gb/s when supporting 24 concurrent streams The maximum bandwidth utilization was observed to be 3.13 Gb/s with a single stream, up to 67.9 Gb/s with 24 streams. By utilizing scalable, high bandwidth 100Gb/s Broadcom Ethernet, the solution is able to achieve the increasing bandwidth utilization required when adding additional video streams.
The performance results showcase the PoC as a flexible solution that can be scaled to accommodate varying levels of video requirements while maintaining performance and scaling bandwidth as needed. The solution also provides the foundation for additional AI-powered transportation and logistics applications that may require similar transmission of sensor and video data.
Final Thoughts
The maritime cargo monitoring PoC provides a concrete example of how AI can improve transportation and logistics processes by monitoring container conditions, detecting dangerous working environments, and generating automated compliance reports. While the PoC presented in this paper is limited in scope and executed using simulated sensor datasets, the solution serves as a starting point for expanding such a solution and a reference for developing related AI applications.
The solution additionally demonstrates several notable results. The solution utilizes readily available AI tools including Zephyr 7B, YOLOv8s, and NVIDIA DeepStream to create valuable AI applications that can be deployed to provide tangible value in industry specific environments. The use of RAG in the Zephyr 7B implementation is especially notable, as it provides customization to a general-purpose language model, enabling it to function for a maritime specific use case. The PoC also showcased the ability to deploy an AI solution in demanding edge environments with the use of Dell PowerEdge XR7620 and XR12 servers and to provide high bandwidth when transmitting critical data by using Broadcom NICs.
When tested, the PoC solution demonstrated the ability to scale up to 24 concurrent streams while experience little loss of throughput and successfully supporting increased bandwidth requirements. Testing of the LLM report generation showed that an AI augmented maritime compliance report could be generated in as little as 46 seconds. The testing of the PoC demonstrate both its real-world applicability in solving maritime challenges, as well as its flexibility to scale to individual deployment requirements.
Transportation and logistics are areas that rely heavily upon optimization. With the advancements in AI technology, these markets are well positioned to benefit from AI-driven innovation. AI is capable of processing data and deriving solutions to optimize transportation and logistics processes at a scale and speed that humans are not capable of achieving manually. The opportunity for AI to create innovative solutions in this market is broad and extends well beyond the maritime PoC detailed in this paper. By understanding the approach to creating an AI application and the hardware components used, however, organizations in the transportation and logistics market can apply similar solutions to innovate and optimize their business.
Appendix
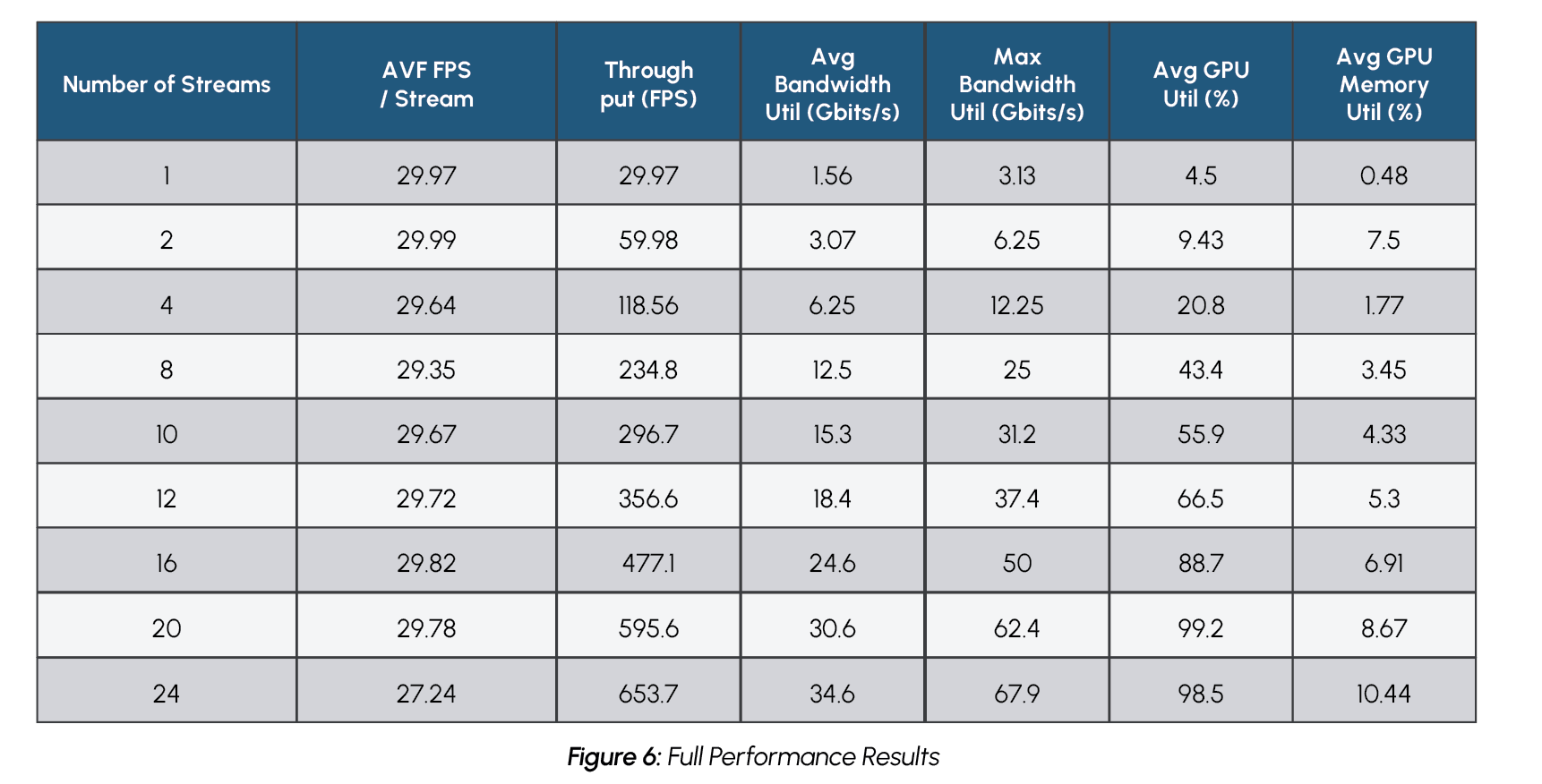
Figure 6 shows full performance testing results for the cargo monitoring PoC.
CONTRIBUTORS
Mitch Lewis
Research Analyst | The Futurum Group
PUBLISHER
Daniel Newman
CEO | The Futurum Group
INQUIRIES
Contact us if you would like to discuss this report and The Futurum Group will respond promptly.
CITATIONS
This paper can be cited by accredited press and analysts, but must be cited in-context, displaying author’s name, author’s title, and “The Futurum Group.” Non-press and non-analysts must receive prior written permission by The Futurum Group for any citations.
LICENSING
This document, including any supporting materials, is owned by The Futurum Group. This publication may not be
reproduced, distributed, or shared in any form without the prior written permission of The Futurum Group.
DISCLOSURES
The Futurum Group provides research, analysis, advising, and consulting to many high-tech companies, including those mentioned in this paper. No employees at the firm hold any equity positions with any companies cited in this document.
ABOUT THE FUTURUM GROUP
The Futurum Group is an independent research, analysis, and advisory firm, focused on digital innovation and market-disrupting technologies and trends. Every day our analysts, researchers, and advisors help business leaders from around the world anticipate tectonic shifts in their industries and leverage disruptive innovation to either gain or maintain a competitive advantage in their markets.
© 2024 The Futurum Group. All rights reserved.

Dell POC for Scalable and Heterogeneous Gen-AI Platform
Fri, 08 Mar 2024 18:35:58 -0000
|Read Time: 0 minutes

Introduction
As part of Dell’s ongoing efforts to help make industry leading AI workflows available to their clients, this paper outlines a scalable AI concept that can utilize heterogeneous hardware components. The featured Proof of Concept (PoC) showcases a Generative AI Large Language Model (LLM) in active production, capable of functioning across diverse hardware systems.
Currently, most AI offerings are highly customized and designed to operate with specific hardware, either a particular vendor's CPUs or a specialized hardware accelerator such as a GPU. Although the operational stacks in use vary across different operational environments, they maintain a core similarity and adapt to each specific hardware requirement.
Today, the conversation around Generative-AI LLMs often revolves around their training and the methods for enhancing their capabilities. However, the true value of AI comes to light when we deploy it in production. This PoC focuses on the application of generative AI models to generate useful results. Here, the term 'inferencing' is used to describe the process of extracting results from an AI application.
As companies transition AI projects from research to production, data privacy and security emerge as crucial considerations. Utilizing corporate IT-managed equipment and AI stacks, firms ensure the necessary safeguards are in place to protect sensitive corporate data. They effectively manage and control their AI applications, including security and data privacy, by deploying AI applications on industry-standard Dell servers within privately managed facilities.
Multiple PoC examples on Dell PowerEdge hardware, offering support for both Intel and AMD CPUs, as well as Nvidia and AMD GPU accelerators. These configurations showcase a broad range of performance options for production inferencing deployments. Following our previous Dell AI Proof of Concept,[1] which examined the use of distributed fine-tuning to personalize an AI application, this PoC can serve as the subsequent step, transforming a trained model into one that is ready for production use.
Designed to be industry-agnostic, this PoC provides an example of how we can create a general-purpose generative AI solution that can utilize a variety of hardware options to meet specific Gen-AI application requirements.
In this Proof of Concept, we investigate the ability to perform scale-out inferencing for production and to utilize a similar inferencing software stack across heterogeneous CPU and GPU systems to accommodate different production requirements. The PoC highlights the following:
- A single CPU based system can support multiple, simultaneous, real-time sessions
- GPU augmented clusters can support hundreds of simultaneous, real-time sessions
- A common AI inferencing software architecture is used across heterogenous hardware
| Futurum Group Comment: The novel aspect of this proof of concept is the ability to operate across different hardware types, including Intel and AMD CPUs along with support for both Nvidia and AMD GPUs. By utilizing a common inferencing framework, organizations are able to choose the most appropriate hardware deployment for each application’s requirements. This unique approach helps reduce the extensive customization required by AI practitioners, while also helping IT operations to standardize on common Dell servers, storage and networking components for their production AI deployments. |
Distributed Inferencing PoC Highlights
The inferencing examples include both single node CPU only systems, multi-node CPU clusters, along with single node and clusters of GPU augmented systems. Across this range of hardware options, the resulting generative AI application provides a broad range of performance, ranging from the ability to support several interactive query and response streams on a CPU, up to the highest performing example supporting thousands of queries utilizing a 3-node cluster with GPU cards to accelerate performance.
The objective of this PoC was to evaluate the scalability of production deployments of Generative-AI LLMs on various hardware configurations. Evaluations included deployment on CPU only, as well as GPU assisted configurations. Additionally, the ability to scale inferencing by distributing the workload across multiple nodes of a cluster were investigated. Various metrics were captured in order to characterize the performance and scaling, including the total throughput rate of various solutions, the latency or delay in obtaining results, along with the utilization rates of key hardware elements.
The examples included between one to three Dell PowerEdge servers with Broadcom NICs, with additional GPU acceleration provided in some cases by either AMD or Nvidia GPUs. Each cluster configuration was connected using Broadcom NICs to a Dell Ethernet switch for distributed inferencing. Each PoC uses one or more PowerEdge servers, with some examples also using GPUs. Dell PowerEdge Servers used included a Dell XE8545, a Dell XE9680 and a Dell R760XA. Each Dell PowerEdge system also included a Broadcom network interface (NIC) for all internode communications connected via a Dell PowerSwitch.
Shown in Figure 1 below is a 3-node example that includes the hardware and general software stack.
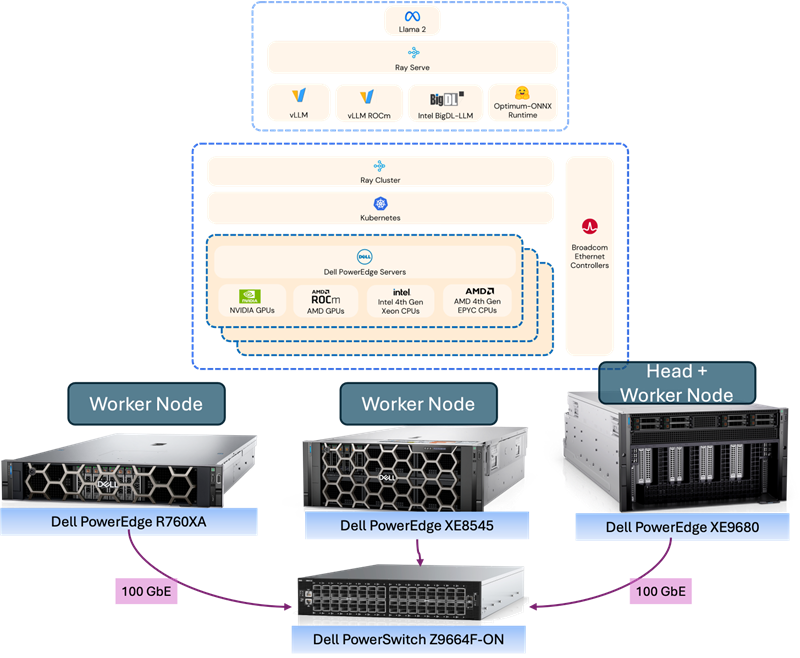
Figure 1: General, Scale-Out AI Inferencing Stack (Source: Scalers.AI)
There are several important aspects of the architecture utilized, enabling organizations to customize and deploy generative AI applications in their choice of colocation or on-premises data center. These include:
- Dell PowerEdge Sixteenth Gen Servers, with 4th generation CPUs and PCIe Gen 5 connectivity
- Broadcom NetXtreme BCM57508 NICs with up to 200 Gb/s per ethernet port
- Dell PowerSwitch Ethernet switches Z line support up to 400 Gb/s connectivity
This PoC demonstrating both heterogeneous and distributed inferencing of LLMs provides multiple advantages compared to typical inferencing solutions:
- Enhanced Scalability: Distributed inferencing enables the use of multiple nodes to scale the solution to the desired performance levels.
- Increased Throughput: By distributing the inferencing processes across multiple nodes, the overall throughput increases.
- Increased Performance: The speed of generated results may be an important consideration, by supporting both CPU and GPU inferencing, the appropriate hardware can be selected.
- Increased Efficiency: Providing a choice of using CPU or GPUs and the number of nodes enables organizations to align the solutions capabilities with their application requirements.
- Increased Reliability: With distributed inferencing, even if one node fails, the others can continue to function, ensuring that the LLM remains operational. This redundancy enhances the reliability of the system
Although each of the capabilities outlined above are related, certain considerations may be more important than others for specific deployments. Perhaps more importantly, this PoC demonstrates the ability to stand up multiple production deployments, using a consistent set of software that can support multiple deployment scenarios, ranging from a single user up to thousands of simultaneous requests. In this PoC, there are multiple hardware solution deployment examples, summarized as follows:
- CPU based inferencing using both AMD and Intel CPUs, scaled from 1 to 2 nodes
- GPU based inferencing using Nvidia and AMD GPUs, scaled from 1 to 3 nodes
For the GPU based configurations, a three node 12-GPU configuration achieved nearly 3,000 words per second in total output generation. For the scale-out configurations, inter-node communications were an important aspect of the solution. Each configuration utilized a Broadcom BCM-57508 Ethernet card enabling high-speed and low latency communications. Broadcom’s 57508 NICs allow data to be loaded directly into accelerators from storage and peers, without incurring extra CPU or memory overhead.
Futurum Group Comment: By using a scale out inferencing solution leveraging industry standard Dell servers, networking and optional GPU accelerators provides a highly adaptable reference that can be deployed as an edge solution where few inferencing sessions are required, up to enterprise deployments supporting hundreds of simultaneous inferencing outputs. |
Evaluating Solution Performance
In order to compare the performance of the different examples, it is important to understand some of the most important aspects of commonly used to measure LLM inferencing. These include the concept of a token, which typically consists of a group of characters, which are groupings of letters, with larger words comprised of multiple tokens. Currently, there is no standard token size utilized across LLM models, although each LLM typically utilizes common token sizes. Each of the PoCs utilize the same LLM and tokenizer, resulting in a common ratio of tokens to words across the examples. Another common metric is that of a request, which is essentially the input provided to the LLM and may also be called a query.
A common method of improving the overall efficiency of the system is to batch requests, or submit multiple requests simultaneously, which improves the total throughput. While batching requests increases total throughput, it comes at the cost of increasing the latency of individual requests. In practice, batch sizes and individual query response delays must be balanced to provide the response throughput and latencies that best meet a particular application’s needs.
Other factors to consider include the size of the base model utilized, typically expressed in billions of parameters, such as Mistral-7B (denoting 7 billion parameters), or in this instance, Llama2-70B, indicating that the base model utilized 70 billion parameters. Model parameter sizes are directly correlated to the necessary hardware requirements to run them.
Performance testing was performed to capture important aspects of each configuration, with the following metrics collected:
- Requests per Second (RPS): A measure of total throughput, or total requests processed per second
- Token Throughput: Designed to gauge the LLMs performance using token processing rate
- Request Latency: Reports the amount of delay (latency) for the complete response, measured in seconds, and for individual tokens, measured in milli-seconds.
- Hardware Metrics: These include CPU, GPU, Network and Memory utilization rates, which can help determine when resources are becoming overloaded, and further splitting or “sharding” of a model across additional resources is necessary.
Note: The full testing details are provided in the Appendix.
Testing evaluated the following aspects and use cases:
- Effects of scaling for interactive use cases, and batch use cases
- Scaling from 1 to 3 nodes, for GPU configurations, using 4, 8, 12 and 16 total GPUs
- Scaling from 1 to 3 nodes for CPU only configurations (using 112, 224 and 448 total CPU cores)
- For GPU configuration, the effect of moderate batch sizes (32) vs. large batching (256)
- Note: for CPU configurations, the batch size was always 1, meaning a single request per instance
We have broadly stated that two different use cases were tested, interactive and batch. An interactive use case may be considered an interactive chat agent, where a user is interacting with the inferencing results and expects to experience good performance. We subsequently define what constitutes “good performance” for an interactive user. An additional use case could be batch processing of large numbers of documents, or other scenarios where a user is not directly interacting with the inferencing application, and hence there is no requirement for “good interactive performance”.
As noted, for GPU configurations, two different batch sizes per instance were used, either 32 or 256. Interactive use of an LLM application may be uses such as chatbots, where small delays (i.e. low latency) is the primary consideration, and total throughput is a secondary consideration. Another use case is that of processing documents for analysis or summarization. In this instance, total throughput is the most important objective and the latency of any one process is inconsequential. For this case, the batch operation would be more appropriate, in order to maximize hardware utilization and total processing throughput.
Interactive Performance
For interactive performance, the rate of text generation should ideally match, or exceed the users reading or comprehension rate. Also, each additional word output should be created with relatively small delays. According to The Futurum Group’s analysis of reading rates, 200 words per minute can be considered a relatively fast rate for comprehending unseen, non-fiction text. Using this as a guideline results in a rate of 3.33 words per second.
- 200 wpm / 60 sec / minute = 3.33 words per second
Moreover, we will utilize a rate of 3.33 wps as the desired minimum generation rate for assessing the ability to meet the needs of a single interactive user. In terms of latency, 1 over 3.33, or 300 milliseconds would be considered an appropriate maximum delay threshold.
Note: For Figures 2 – 5, each utilizes two axes, the primary (left) vertical axis represents the throughput for the bars in words per second. The second (right) vertical axis represents the 95th percentile of latency results for each word generated.
In Figure 2 below, we show the total throughput of 3 different CPU configurations, along with the associated per word latency. As seen, a CPU only example can support over 40 words per second, significantly greater than the 3.33 word per second rate required for good interactive performance, while maintaining a latency of 152 ms., well under 300 ms.
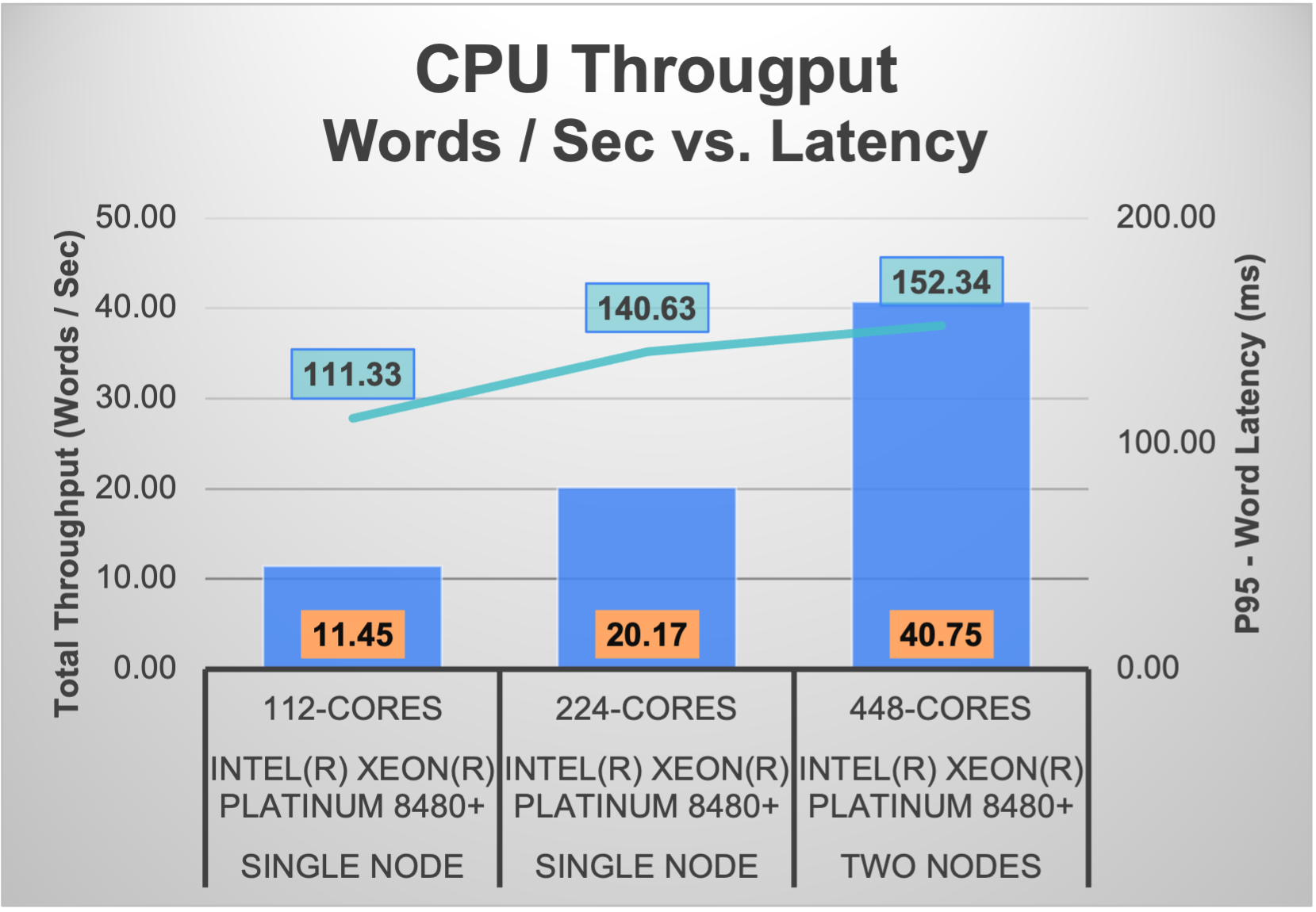
Figure 2: Interactive Inferencing Performance for CPUs (Source: Futurum Group)
Using a rate of 3.33 words / sec., we can see that two system, each with 224 CPU cores can support inferencing of up to 12 simultaneous sessions.
- Calculated as: 40 wps / 3.33 wps / session = 12 simultaneous sessions.
Futurum Group Comment: It is often expected that all generative AI applications require the use of GPUs in order to support real-time deployments. As evidenced by the testing performed, it can be seen that a single system can support multiple, simultaneous sessions, and by adding a second system, performance scales linearly, doubling from 20 words per second up to more than 40 words per second. Moreover, for smaller deployments, a single CPU based system supporting inferencing may be sufficient. |
In Figure 3 below, we show the total throughput of 4 different configurations, along with the associated per word latency. As seen, even at the rate of 1,246 words per second, latency remains at 100 ms., well below our 300 ms. threshold.

Figure 3: Interactive Inferencing Performance for GPUs (Source: Futurum Group)
Again, using 3.33 words / sec., each example can support a large number of interactive sessions:
- 1 node + 4 GPUs: 414 wps / 3.33 wps / session = 124 simultaneous sessions
- 2 nodes + 8 GPUs: 782 wps / 3.33 wps / session = 235 simultaneous sessions
- 2 nodes + 12 GPUs: 1,035 wps / 3.33 wps / session = 311 simultaneous sessions
- 3 nodes + 16 GPUs: 1,246 wps / 3.33 wps / session = 374 simultaneous sessions
Futurum Group Comment: Clearly, the GPU based results significantly exceed those of the CPU based deployment examples. In these examples, we can see that once again, performance scales well, although not quite linearly. Perhaps more importantly, as additional nodes are added, the latency does not increase above 100 ms., which is well below our established desired threshold. Additionally, the inferencing software stack was very similar to the CPU only stack, with the addition of Nvidia libraries in place of Intel CPU libraries. |
Batch Processing Performance
Inferencing of LLMs becomes memory bound as the model size increases. For larger models such as Llama2-70B, memory bandwidth, between either the CPU and main memory, or GPU and GPU memory is the primary bottleneck. By batching requests, multiple processes may be processed by the GPU or CPU without loading new data into memory, thereby improving the overall efficiency significantly.
Having an inference serving system that can operate at large batch sizes is critical for cost efficiency, and for large models like Llama2-70B the best cost/performance occurs at large batch sizes.
In Figure 4 below we show the throughput capabilities of the same hardware configuration used in Figure 3, but this time with a larger batch size of 256.

Figure 4: Batch Inferencing Performance for GPUs (Source: The Futurum Group)
For this example, we would not claim the ability to support interactive sessions. Rather the primary consideration is the total throughput rate, shown in words per second. By increasing the batch size by a factor of 4X (from 32 to 256), the total throughput more than doubles, along with a significant increase in the per word latency, making this deployment appropriate for offline, or non-interactive scenarios.
Futurum Group Comment: Utilizing the exact same inferencing software stack, and hardware deployment, we can show that for batch processing of AI, the PoC example is able to achieve rates up to nearly 3,000 words per second. |
Comparison of Batch vs. Interactive
As described previously, we utilized a total throughput rate of 200 words per minute, or 3.33 words per second, which yields a maximum delay of 300 ms per word as a level that would produce acceptable interactive performance. In Figure 4 below, we compare the throughput and associated latency of the “interactive” configuration to the “batch” configuration.

Figure 5: Comparison of Interactive vs. Batch Inferencing on GPUs (Source: The Futurum Group)
As seen above, while the total throughput, measured in words per second increases by 2.4X, the latency of individual word output slows substantially, by a factor of 6X. It should be noted that in both cases batching was utilized. The batch size of the “interactive” results was set to 32, while the batch size of the “batch” results utilized a setting of 256. The “interactive” label was applied to the lower results, due to the fact that the latency delay of 100 ms. was significantly below the threshold of 300 ms. for typical interactive use. In summary:
- Throughput increase of 2.4X (1,246 to 2,962) for total throughput, measured in words per second
- Per word delays increased 6X (100 ms. to 604 ms.) measured as latency in milli-seconds
These results highlight that total throughput can be improved, albeit at the expense of interactive performance, with individual words requiring over 600 ms (sixth tenths of a second) when the larger batch size of 256 was used. With this setting, the latency significantly exceeded the threshold of what is considered acceptable for interactive use, where a latency of 300 ms would be acceptable.
Highlights for IT Operations
While terms such as tokens per second, and token latency have relevancy to AI practitioners, these are not particularly useful terms for IT professionals or users attempting to interact with generative LLM models. Moreover, we have translated these terms into more meaningful terminology that can help IT operations correctly size the hardware requirements to match expected usage. In particular, for interactive sessions requiring a rate of 200 words per second, and maximum delay of 300 ms. per word, we can then translate a total word per second throughput, into simultaneous streams. By using a rate of 3.33 words per second as the minimum per interactive session, we can determine the number of interactive sessions supported at a certain throughput and latency levels.
Nodes | Total Cores | Words /sec. | Word. Lat. (ms) | # Sessions |
1 | 112 | 11.45 | 111 | 3.4 |
1 | 224 | 20.17 | 140 | 6.1 |
2 | 448 | 40.75 | 152 | 12.2 |
Table 1: Interactive Inferencing Sessions using CPUs (Source: The Futurum Group)
Nodes | Total GPUs | Words /sec. | Word. Lat. (ms) | # Sessions |
1 | 4 | 414 | 76 | 124 |
2 | 8 | 782 | 100 | 235 |
2 | 12 | 1035 | 100 | 310 |
3 | 16 | 1246 | 100 | 374 |
Table 2: Interactive Inferencing Sessions using GPUs (Source: The Futurum Group)
The ability to scale inferencing solutions is important, as outlined previously. Additionally, perhaps the most unique aspect of this PoC is the ability to support operating an AI inferencing stack across both CPU only and GPU enhanced hardware architectures, using an optimized inferencing stacks for each hardware type.
For environments requiring only a few simultaneous inferencing sessions, it is possible to meet these needs with CPU only deployments, even when using a larger LLM model such as Llama2-70B utilized during testing. A current Dell PowerEdge server with a 4th generation processor can support up to 3 simultaneous interactive inferencing sessions per server, with a 3-node CPU cluster able to support up to 12 simultaneous sessions, at a total rate of 40 words per second across all three systems.
Use cases that require higher throughput, or the ability to support a greater number of simultaneous inferencing sessions can utilize a single GPU based PowerEdge server with 4 GPUs, which was found to support up to 124 simultaneous interactive sessions. Scaling beyond this, a 3-node, 16 GPU system was able to support 373 simultaneous inferencing sessions at a rate of 200 words per minute, for a total throughput of 1,245 words per second.
Highlights for AI Practitioners
A key aspect of the PoC is the software stack that helps provide a platform for AI deployments, enabling scale-out infrastructure to significantly increase content creation rates. Importantly, this AI Platform as a Service architecture was built using Dell and Broadcom hardware components, coupled with cloud native components to enable containerized software platform with open licensing to reduce deployment friction and reduce cost.
At a high-level, the inferencing stack is comprised of Ray-Serve, under-pined by vLLM to improve memory utilization during inferencing, including Hugging Face Optimum libraries and ONNX. Additionally, specific libraries were used to further enhance performance, including ROCm for AMD CPUs and GPUs, BigDL for Intel CPUs and CUDA for Nvidia GPUs. Other AI frameworks include the use of PyTorch within each container, along with Kubernetes and KubeRay for distributed cluster management. Shown in Figure 5 is a high-level architecture of the inferencing stack used for all hardware deployments.
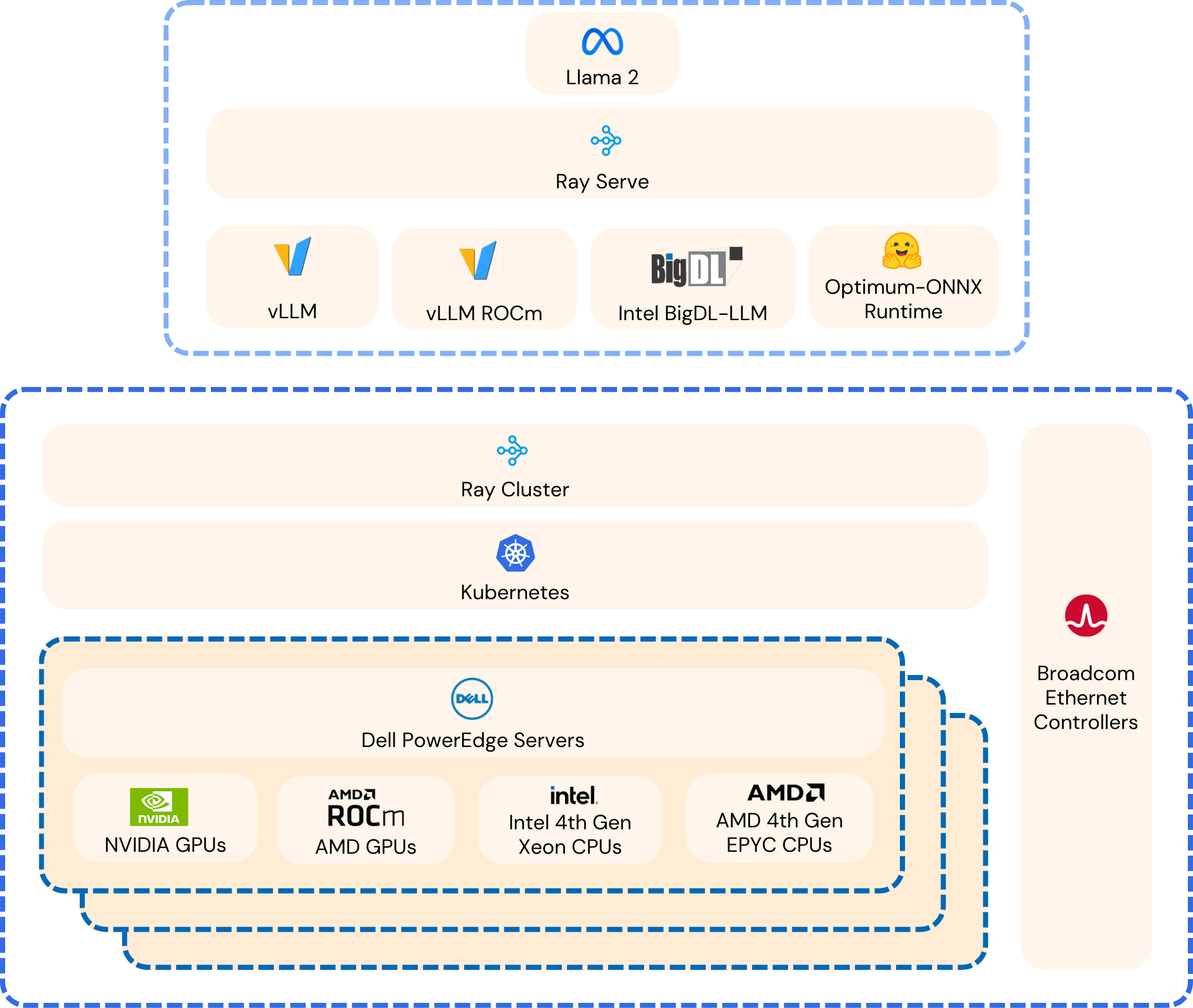
Figure 6: Distributed Inferencing Framework for Heterogeneous Hardware (Source: Scalers.AI)
Variations of the depicted inferencing framework were utilized for the four different hardware types, (AMD CPU, Intel CPU, AMD GPU and Nvidia GPU). The specifics of each of these are provided in the Appendix, in Figures A1-A4.
Note: It is important to recognize that while both Intel and AMD CPUs were verified and tested, only the Intel CPU results are presented here. This is for several reasons, including the fact that comparing CPU performance was not an objective of this PoC. If competing systems performance was provided, the focus would artificially become more about comparing CPU results than showcasing the ability to run across different CPU types. Similarly, while both AMD and Nvidia GPU inferencing was verified, only the Nvidia GPU results are presented, to maintain the focus on the PoC capabilities rather than comparing different GPU vendors performance.
Final Thoughts
As artificial intelligence, and in particular Generative-AI matures, companies are seeking ways to leverage this new technology to provide advantages for their firms, helping to improve efficiency and other measures of user satisfaction. GenAI based Large Language Models are quickly showing their ability to augment some applications focused both on empowering internal users with additional knowledge and insights, and is also becoming increasingly useful for assisting clients, via chatbots or other similar interfaces. However, organizations often have concerns about becoming tied to proprietary, or cloud-based solutions, due to their privacy concerns, lack of transparency or potential vendor lock in.
As part of Dell’s continuing efforts to democratize AI solutions, this proof-of-concept outlines specifically how organizations can build, deploy and operate production use of generative AI models using industry standard Dell servers. In particular, the scale-out PoC detailed in this paper showcases the ability to scale a solution efficiently from supporting a few simultaneous interactive users, up to a deployment supporting hundreds of simultaneous inferencing sessions simultaneously using as few as 3 Dell PowerEdge servers augmented by Nvidia GPUs. In an offline, or batch processing use, the same hardware example can support a throughput of nearly 3,000 words per second when processing multiple documents.
Critically, all the examples leverage a common AI framework, consisting of minimal K3s Kubernetes deployments, along with the Ray framework for distributed processing and vLLM to improve distributed inferencing performance. The outlined PoC utilizes the Hugging Face repository and libraries, along with hardware specific optimizations for each specific deployment of CPU or GPU type. By using a common framework, AI practitioners are better able to focus on enhancing the accuracy of the models and improved training methodologies, rather than trying to debug multiple solution stacks. Likewise, IT operations staff can utilize standard hardware, along with common IT technologies such as Kubernetes running on standard Linux distributions.
References
[1] Futurum Group Labs: Dell and Broadcom Release Scale-Out Training for Large Language Models
Appendix
Due to the fact that LLM inferencing is often memory bound, and due to the manner in which LLMs iteratively generate output, it is possible to optimize performance by batching input. By batching input, more queries are present within the GPU memory card, for the LLM to generate output leveraging the GPU processing. In this way, the primary bottleneck of moving data into and out of GPU memory is reduced per output generated, thereby increasing the throughput, with some increase in latency per request. These optimizations include the use of vLLM, Ray-Serve and Hugging Face Optimizations available through their Optimum inferencing models.
Moreover, continuous batching was utilized, in order to increase throughput with the vLLM library, which helps to manage memory efficiently. Two batch sizes were used with GPU configurations, 32 to provide a lower latency with good throughput, and a larger batch size of 256 to provide the highest throughput for non-interactive use cases where latency was not a concern.
Note: other metrics such as time to first token (TTFT) may be gathered; however, in our testing, the TTFT was not deemed to be a critical element for analysis.
3. Test Scenarios
The Llama 2 70B Chat HF model is loaded with a tensor parallelism of 4 GPUs. A 70B model (Float 32 precision) requires ~260 GB of GPU memory to load the model. Based on the model weight GPU memory requirement and inference requirements, we recommend using 4x80GB GPUs to load a single Llama 2 70B Chat model.
The Llama 2 70B Chat model with bfloat16 precision was used for all test configurations.
AI Inferencing Stack Details
In the figures below, we highlight the various specific stacks utilized for each hardware deployment.

Figure A1: Nvidia GPU inferencing stack (Source: Scalers.AI)

Figure A2: AMD GPU inferencing stack (Source: Scalers.AI)

Figure A3: Intel CPU inferencing stack (Source: Scalers.AI)

Figure A4: AMD CPU inferencing stack (Source: Scalers.AI)
Single Node Inferencing
The below table describes the single node inferencing Kubernetes deployment configuration with 4 GPUs (1 replica).
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | - | - | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Table A1: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Two Node Inferencing
Scenario 1: 8 GPUs, 2 Replicas, shown below.
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head+ Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Table A2: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Scenario 2: 12 GPUs, 3 Replicas
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head+ Worker | NVIDIA A100 SXM 80GB | 8 | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Table A3: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Three Node Inferencing
The below table describes the two node inferencing hardware configuration with 16 GPUs(4 replicas).
Device | Node Type | GPU | GPU Count | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head+ Worker | NVIDIA A100 SXM 80GB | 8 | 160 | 300 GB | 1 TB |
Dell PowerEdge XE8545 | Worker | NVIDIA A100 SXM 80GB | 4 | 160 | 300 GB | 1 TB |
Dell PowerEdge R760xa | Worker | NVIDIA H100 PCIe 80GB | 4 | 160 | 300 GB | 1 TB |
Table A4: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Test Workload Configuration
The workload consists of a set of 1000+ prompts passed randomly for each test [ML1] with different concurrent requests. The concurrent requests are generated by Locust tool.
The inference configuration is as below
- Input token length: 14 to 40.
- Output token length: 256
- Temperature: 1
The tests were run with two different batch sizes per replica - 32 and 256.
Test Metrics
The below are the metrics measured for each tests
Metric | Explanation |
Requests Per Second (RPS) | Evaluate system throughput, measuring requests processed per second. |
Total Token Throughput (tokens/s) | Quantify language model efficiency by assessing token processing rate. |
Request Latency (P50, P95, P99) | Gauge system responsiveness through different latency percentiles. |
Average CPU, Memory, GPU Utilization | Assess system resource usage, including CPU, memory, and GPU. |
Network Bandwidth (Average, Maximum) | Measure efficiency in data transfer with average and maximum network bandwidth. |
Table A5: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Performance Results
Scalability results for batch size of 32 per replica
Inference Nodes | Devices | GPUs | Concurrent Requests | RPS | Tokens/s | P95 Latency(s) | P95 Token Latency(ms) | |
Single Node | Dell PowerEdge XE8545 | 4xNVIDIA A100 SXM 80GB | 32 | 2.7 | 621.4 | 13 | 50.78 | |
Two Nodes | Dell PowerEdge XE9680(4 GPUs) | 8xNVIDIA A100 SXM 80GB | 64 | 4.8 | 1172.63 | 17 | 66.41 | |
Two Nodes | Dell PowerEdge XE9680 | 12xNVIDIA A100 SXM 80GB | 96 | 6.8 | 1551.94 | 17 | 66.4 | |
Three Nodes | Dell PowerEdge XE9680 Dell PowerEdge R760xa | 12xNVIDIA A100 SXM 80GB 4xNVIDIA H100 PCIe 80GB | 128 | 8.3 | 1868.76 | 17 | 66.4 |
Table A6: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Scalability results for batch size of 256 per replica
Inference Nodes | Devices | GPUs | Concurrent Requests | RPS | Throughput | P95 Latency | P95 Token Latency(ms) | |
Single Node | Dell PowerEdge XE8545 | 4xNVIDIA A100 SXM 80GB | 256 | 6.4 | 1475.64 | 45 | 175.78 | |
Two Nodes | Dell PowerEdge XE9680(4 GPUs) | 8xNVIDIA A100 SXM 80GB | 512 | 10.3 | 2542.32 | 61 | 238.28 | |
Two Nodes | Dell PowerEdge XE9680 | 12xNVIDIA A100 SXM 80GB | 768 | 14.5 | 3222.89 | 64 | 250 | |
Three Nodes | Dell PowerEdge XE9680 Dell PowerEdge R760xa | 12xNVIDIA A100 SXM 80GB 4xNVIDIA H100 PCIe 80GB | 1024 | 17.5
| 4443.5 | 103 | 402.34 |
Table A7: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
For more detailed report refer: Dell Distributed Inference Data
Test Methodology for Distributed Inferencing on CPUs
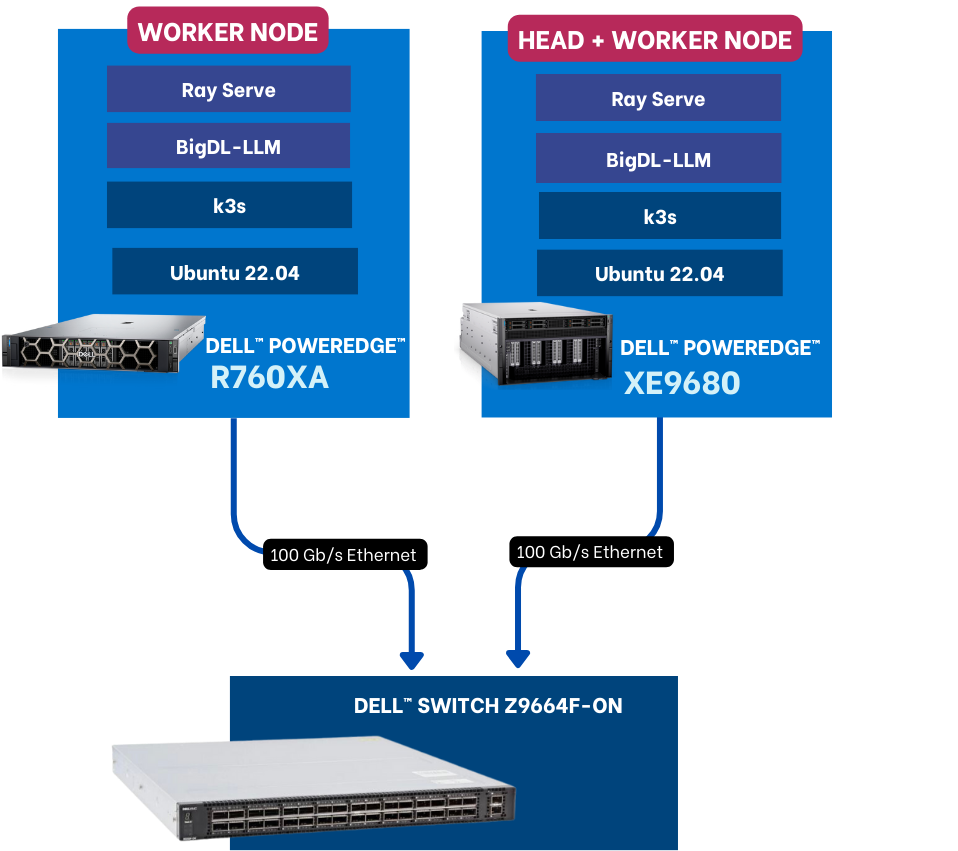
Server | CPU | RAM | Disk |
Dell PowerEdge XE9680 | Intel(R) Xeon(R) Platinum 8480+ | 2 TB | 3 TB |
Dell PowerEdge R760xa | Intel(R) Xeon(R) Platinum 8480+ | 1 TB | 1 TB |
Table A8: Interactive Inferencing Sessions using CPUs (Source: Futurum Group)
Each server is networked to a Dell PowerSwitch Z9664F-ON through Broadcom BCM57508 NICs with 100 Gb/s bandwidth.
3. Test Scenarios
The Llama 2 7B Chat HF model is tested on CPU with int8 precision.
3.1 Single Node Inferencing
Three are two scenarios for single node inferencing
Scenario 1: 112 Cores, 1 Replicas
The below table describes the single node inferencing Kubernetes deployment configuration with 112 CPU Cores of Dell PowerEdge R760xa server (1 replica).
Device | Node Type | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | - | 500 GB | 1 TB |
Dell PowerEdge R760xa | Worker | 112 | 500 GB | 1 TB |
Table A9: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
Scenario 2: 224 Cores, 2 Replicas
The below table describes the single node inferencing Kubernetes deployment configuration with 224 CPU Cores of Dell PowerEdge R760xa server (2 replicas).
Device | Node Type | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | 10 | 500 GB | 1 TB |
Dell PowerEdge R760xa | Worker | 224 | 500 GB | 1 TB |
Table A10: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
3.2 Two Node Scenario
The below table describes the two-node inferencing hardware configuration with both the servers, 448 Cores of CPU (4 replicas).
Device | Node Type | CPU Cores | Memory | Disk |
Dell PowerEdge XE9680 | Head | 224 | 500 GB | 1 TB |
Dell PowerEdge R760xa | Worker | 224 | 500 GB | 1 TB |
Table A11: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
3. Test Workload Configuration
The workload consists of a set of 1000+ prompts passed randomly for each test with different concurrent requests. The concurrent requests are generated by Locust tool.
The inference configuration is as below
- Input token length: 14 to 40.
- Output token length: 256
- Temperature: 1
The tests were run with 1 batch size per replica.
5. Test Metrics
The below are the metrics measured for each tests
Metric | Explanation |
Requests Per Second (RPS) | Evaluate system throughput, measuring requests processed per second. |
Total Token Throughput (tokens/s) | Quantify language model efficiency by assessing token processing rate. |
Request Latency (P50, P95, P99) | Gauge system responsiveness through different latency percentiles. |
Average CPU, Memory | Assess system resource usage, including CPU, memory. |
Network Bandwidth (Average, Maximum) | Measure efficiency in data transfer with average and maximum network bandwidth. |
Table A12: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
4. Performance Reports
Inference Nodes | Devices | CPU Cores | Concurrent Requests | RPS | Throughput | P95 Latency(s) | P95 Token Latency(ms) | |
Single Node | Dell PowerEdge R760xa | Intel Xeon Platinum 8480+ (112 Cores) | 1 | 0.1 | 17.18 | 18 | 70.31 | |
Single Node | Dell PowerEdge R760xa | Intel Xeon Platinum 8480+ (224 Cores) | 2 | 0.1 | 30.26 | 21 | 82.03
| |
Two Nodes | Dell PowerEdge XE9680 | Intel Xeon Platinum 8480+ (448 Cores) | 4 | 0.3 | 61.13
| 23 | 89.84 |
Table A13: Interactive Inferencing Sessions using GPUs (Source: Futurum Group)
About The Futurum Group
The Futurum Group is dedicated to helping IT professionals and vendors create and implement strategies that make the most value of their storage and digital information. The Futurum Group services deliver in-depth, unbiased analysis on storage architectures, infrastructures, and management for IT professionals. Since 1997 The Futurum Group has provided services for thousands of end-users and vendor professionals through product and market evaluations, competitive analysis, and education.
Copyright 2024 The Futurum Group. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or stored in a database or retrieval system for any purpose without the express written consent of The Futurum Group. The information contained in this document is subject to change without notice. The Futurum Group assumes no responsibility for errors or omissions and makes no expressed or implied warranties in this document relating to the use or operation of the products described herein. In no event shall The Futurum Group be liable for any indirect, special, inconsequential, or incidental damages arising out of or associated with any aspect of this publication, even if advised of the possibility of such damages. All trademarks are the property of their respective companies.
This document was developed with funding from Dell Inc. and Broadcom. Although the document may utilize publicly available material from various vendors, including Dell, Broadcom and others, it does not necessarily reflect such vendors' positions on the issues addressed in this document.

Testing LLAMA-2 models on Dell PowerEdge R760xa with 5th Gen Intel Xeon Processors
Tue, 13 Feb 2024 04:08:19 -0000
|Read Time: 0 minutes
This is part three, read part two here: https://infohub.delltechnologies.com/p/expanding-gpu-choice-with-intel-data-center-gpu-max-series/
| NEXT GENERATION OF INTEL® XEON® PROCESSORS
We are excited to showcase our collaboration with Intel® as we explore the capabilities of 5th Gen Intel® Xeon® Processors, now accessible via Dell™ PowerEdge™ R760xa, offering versatile AI solutions that can be deployed onto general purpose servers as an alternative to specialized hardware “accelerator” based implementations. Built upon the advancements of its predecessors, the latest generation of Intel® Xeon® Processors introduces advancements designed to provide customers with enhanced performance and efficiency. 5th Gen Intel® Xeon® Processors are engineered to seamlessly handle demanding AI workloads, including inference and fine-tuning on models containing up to 20 billion parameters, without an immediate need for additional hardware. Furthermore, the compatibility with 4th Gen Intel® Xeon® processors facilitates a smooth upgrade process for existing solutions, minimizing the need for extensive testing and validation.
The integration of 5th Gen Intel® Xeon® Processors with Dell™ PowerEdge™ R760xa, ensures a seamless pairing, providing a wide range of options and scalability in performance.
Dell™ has recently established a strategic partnership with Meta and Hugging Face to facilitate the seamless integration of enterprise-level support for the selection, deployment, and fine-tuning of AI models tailored to industry-specific use cases, leveraging the Llama-2 7B Chat Model from Meta.
In a prior analysis, we integrated Dell™ PowerEdge™ R760xa with 4th Gen Intel® Xeon® Processors and tested the performance of the Llama-2 7B Chat model by measuring both the rate of token generation and the number of concurrent users that can be supported while scaling up to four accelerators. In this demonstration, we explore the advancements offered by 5th Gen Intel® Xeon® Processors paired with Dell™ PowerEdge™ R760xa, while focusing on the same task.
Dell™ PowerEdge™ Servers featuring 5th Gen Intel® Xeon® Processors demonstrated a strong scalability and successfully achieved the targeted end user latency goals.
“Scalers AI™ ran Llama-2 7B Chat with Dell™ PowerEdge™ R760xa Server, powered by 5th Gen Intel® Xeon® Processors, enabling us to meet end user latency requirements for our enterprise AI chatbot.”
 Chetan Gadgil, CTO at Scalers AI
Chetan Gadgil, CTO at Scalers AI
| LLAMA-2 7B CHAT MODEL
For this demonstration, we have chosen to work with Llama-2 7B Chat, an open source large language model from Meta capable of generating text and code in response to given prompts. As a part of the Llama-2 family of large language models, Llama-2 7B Chat is pre-trained on 2 trillion tokens of data from publicly available sources and additionally fine-tuned on public instruction datasets and more than a million human annotations. This particular model is optimized for dialogue use cases, making it ideal for applications such as chatbots or virtual assistants that need to engage in conversational interactions.
| ARCHITECTURES
We initialized our testing environment using Dell™ PowerEdge™ R760xa Rack Server featuring 5th Gen Intel® Xeon® Processors running on Ubuntu 22.04. To ensure maximum efficiency, we used Hugging Face Optimum, an extension of Hugging Face Transformers that provides a set of performance optimization tools to train and run models on the targeted hardware. We specifically selected the Optimum-Intel package, which integrates libraries provided by Intel® to accelerate end-to-end pipelines on Intel® hardware. Hugging Face Optimum Intel is the interface between the Hugging Face Transformers and Diffusers libraries and the different tools and libraries provided by Intel® to accelerate end-to-end pipelines on Intel® architectures.
We also tested 5th Gen Intel® Xeon® Processors with bigdl-llm, a library for running LLMs on Intel® hardware with support for Pytorch and lower precision formats. By using bigdl-llm, we are able to leverage INT4 precision on Llama-2 7B Chat.
The following architectures depict both scenarios:
1) Hugging Face Optimum
2) BigDL-LLM

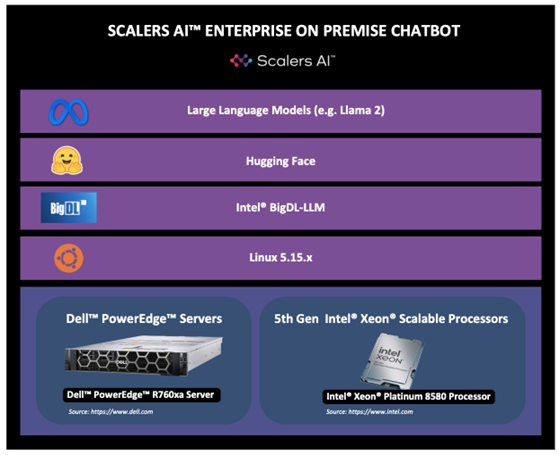
| TEST METHODOLOGY
For each iteration of our performance tests, we prompted Llama-2 with the following command: “Discuss the history and evolution of artificial intelligence in 80 words or less.” We then collected the test response and recorded total inference time in seconds and tokens per second. 25 of these iterations were executed for each inference scenario (Hugging Face Optimum vs BigDL-LLM), out of which the initial five iterations were considered as warm-ups and were discarded for calculating total inference time and tokens per second. Here, the total time collected includes both the encode-decode time using the tokenizer and LLM inference time.
We also scaled the number of processes from one to four to observe how total latency and tokens per second change as the number of concurrent processes is increased. In the hypothetical scenario of an enterprise chatbot, this analysis simulates engaging several different users having separate conversations with the chatbot at the same time, during which the chatbot should still deliver responses to each user in a reasonable amount of time. The total number of tests comes from running each inference scenario with a varying number of processes (1, 2, or 4 processes) and recording the performance (measured in throughput) of different model precision formats.
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH OPTIMUM-INTEL
1. Install the Python dependencies:
openvino==2023.2.0
transformers==4.36.2
optimum-intel==1.12.3
optimum==1.16.1
onnx==1.15.0
2. Request access to Llama-2 model through Hugging Face by following the instructions here:
https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
Use the following command to login to your Hugging Face account:
huggingface-cli login
3. Convert the Llama-2 7B Chat HuggingFace model into Intel® OpenVINO™ IR with INT8 precision format using Optimum-Intel to export it:
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(model_id, export=True, load_in_8bit=True)
model.save_pretrained("llama-2-7b-chat-ov")
tokenizer.save_pretrained("llama-2-7b-chat-ov")
4. Run the code snippet below to generate the text with the Llama-2 7B Chat model:
import time
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_name = "llama-2-7b-chat-ov"
input_text = "Discuss the history and evolution of artificial intelligence"
max_new_tokens = 100
# Initialize and load tokenizer, model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OVModelForCausalLM.from_pretrained(model_name, ov_config= {"INFERENCE_PRECISION_HINT":"f32"}, compile=False)
model.compile()
# Initialize HF pipeline
text_generator = pipeline( "text-generation", model=model, tokenizer=tokenizer, return_tensors=True, )
# Warmup
output = text_generator( input_text, max_new_tokens=max_new_tokens )
# Inference
start_time = time.time()
output = text_generator( input_text, max_new_tokens=max_new_tokens )
_ = tokenizer.decode(output[0]["generated_token_ids"])
end_time = time.time()
# Calculate number of tokens generated
num_tokens = len(output[0]["generated_token_ids"])
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH BIGDL-LLM
1. Install the Python dependencies, our Llama-2 7B Chat model requires:
pip install bigdl-llm[all]==2.4.0
2. Request access to Llama-2 model through Hugging Face by following the instructions here:
https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
Use the following command to login to your Hugging Face account:
huggingface-cli login
3. Run the code snippet below to generate the text with the Llama-2 7B Chat model in INT4 precision:
import torch
import intel_extension_for_pytorch as ipex
import time
import argparse
from bigdl.llm.transformers import AutoModelForCausalLM
from transformers import LlamaTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf",
load_in_4bit=True,
optimize_model=True,
trust_remote_code=True,
use_cache=True)
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", trust_remote_code=True)
with torch.inference_mode():
input_ids = tokenizer.encode("Discuss the history and evolution of artificial intelligence", return_tensors="pt")
# ipex model needs a warmup, then inference time can be accurate
output = model.generate(input_ids,
max_new_tokens=100)
# start inference
start_time = time.time()
output = model.generate(input_ids, max_new_tokens=100)
end_time = time.time()
num_tokens = len(output[0].detach().numpy().flatten())
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| ENTER PROMPT
Discuss the history and evolution of artificial intelligence in 80 words or less.
Output for Llama-2 7B Chat - Using Optimum-Intel:
Artificial intelligence (AI) has a long history dating back to the 1950s when computer scientist Alan Turing proposed the Turing Test to measure machine intelligence. Since then, AI has evolved through various stages, including rule-based systems, machine learning, and deep learning, leading to the development of intelligent systems capable of performing tasks that typically require human intelligence, such as visual recognition, natural language processing, and decision-making.
Output for Llama-2 7B Chat - Using BigDL-LLM:
Artificial intelligence (AI) has a long history dating back to the mid-20th century. The term AI was coined in 1956, and since then, AI has evolved significantly with advancements in computer power, data storage, and machine learning algorithms. Today, AI is being applied to various industries such as healthcare, finance, and transportation, leading to increased efficiency and productivity.
| PERFORMANCE RESULTS & ANALYSIS
Testing Llama-2 7B Chat - Using BigDL-LLM
Figure: Scaling Intel® Xeon® Platinum 8580 Processor for different model precisions while concurrently increasing processes up to four, measured in total throughput represented in tokens per second.
Using the Llama-2 7B Chat model with INT4 precision, we achieved a throughput of ~28 tokens per second with a single process, which increased to ~95 tokens per second when scaling up to four processes.
Testing Llama-2 7B Chat - Using Optimum-Intel
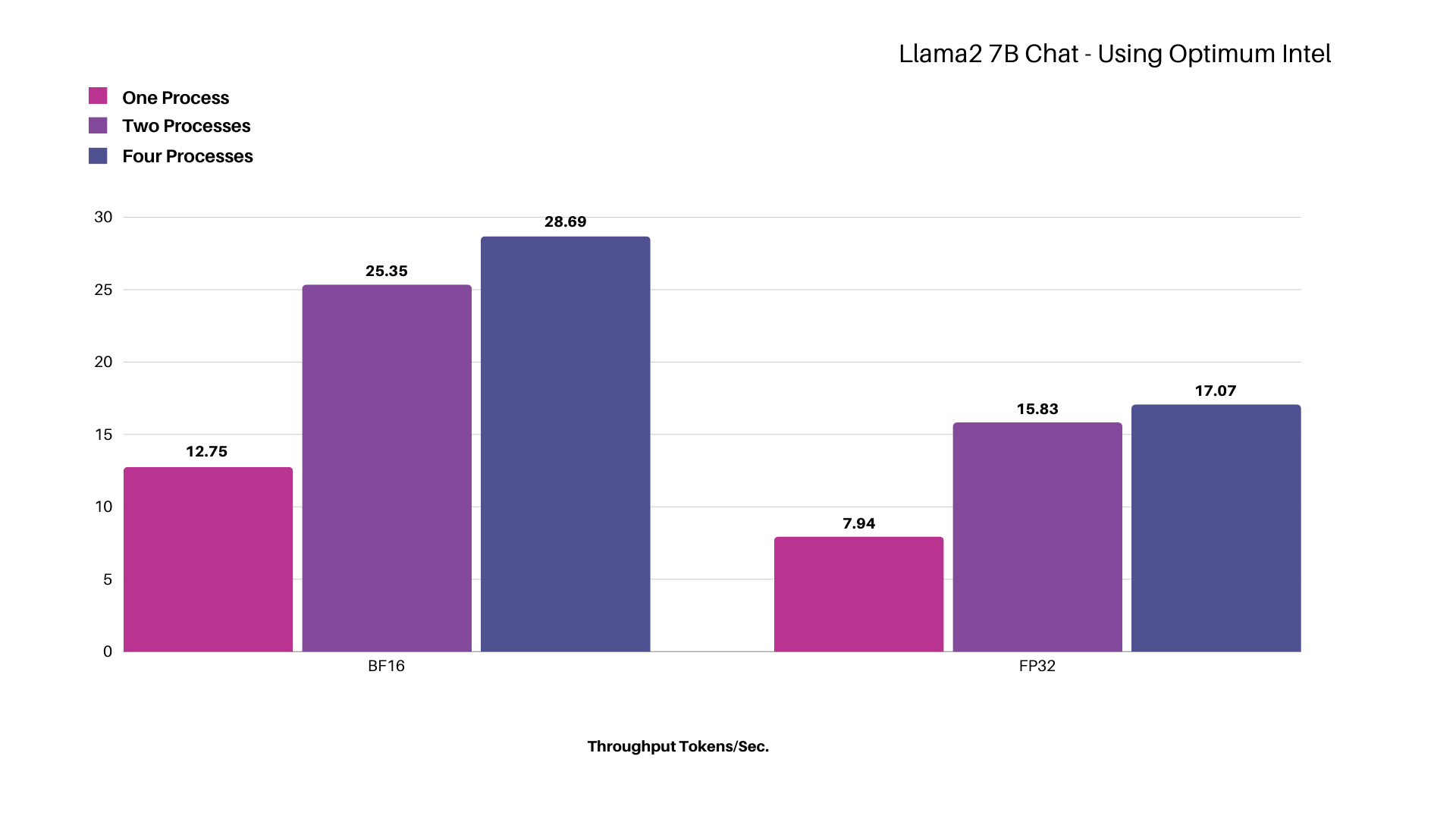
Figure: Scaling Intel® Xeon® Platinum 8580 Processor for different model precisions while concurrently increasing processes up to four, measured in total throughput represented in tokens per second.
Using the Llama-2 7B Chat model with BF16 precision in a single process, we achieved a throughput of ~13 tokens per second, which increased to ~29 tokens per second when scaling up to four processes. The token latency per process remains well below the Scalers AI™ target of 100 milliseconds despite an increase in the number of concurrent processes.
Our results demonstrate that Dell™ PowerEdge™ R760xa Server featuring Intel® Xeon® Platinum 8580 Processor is up to the task of running Llama-2 7B Chat and meeting end user experience responsiveness targets for interactive applications like “chatbots”. For batch processing tasks like report generation where real-time response is not a major requirement, an enterprise will be able to add more workload by scaling the concurrent processes.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| ABOUT SCALERS AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offerings include custom large language models and multimodal platforms supporting voice, video, image, and text. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile, easily available (COTS) hardware that works well across a range of functionality, performance and accuracy requirements.
| Dell™ PowerEdge™ R760xa Server Key Specifications
MACHINE | Dell™ PowerEdge™ R760xa Server |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8580 Processor |
MEMORY | 1024Gi |
| HUGGING FACE OPTIMUM & INTEL® BIGDL-LLM
Learn more:
https://huggingface.co/docs/optimum/intel/index
https://github.com/intel-analytics/BigDL
| References

Fine-Tuning Enterprise LLMs at Scale with Dell™ PowerEdge™ & Broadcom
Tue, 13 Feb 2024 03:47:04 -0000
|Read Time: 0 minutes


| Introduction
A glimpse into the vast world of pre-training and fine-tuning.
Large Language Models (LLMs) have taken the modern AI landscape by storm. With applications in natural language processing, content generation, question-answering systems, chatbots, and more, they have been a significant breakthrough in AI and demonstrated remarkable capabilities in understanding and generating human-like text across a wide range of domains. Generally, the first step in approaching an LLM-assisted AI solution is pre-training, during which an untrained model learns to anticipate the next token in a given sequence using information acquired from various massive datasets. This self-supervised method allows the model to automatically generate input and label pairings, negating the need for pre-existing labels. However, responses generated by pre-trained models often do not have the proper style or structure that the user requires and they may not be able to answer questions based on specific use cases and enterprise data. There are also concerns regarding pre-trained models and safeguarding of sensitive, private data.
This is where fine-tuning becomes essential. Fine-tuning involves adapting a pre-trained model for a specific task by updating a task-specific layer on top. Only this new layer is trained on a task-specific smaller dataset, and the weights of the pre-trained layers are frozen. Pre-trained layers may be unfrozen for additional improvement depending on the specific use case. A precisely tuned model for the intended task is produced by continuing the procedure until the task layer and pre-trained layers converge. Only a small portion of the resources needed for the first training are necessary for fine-tuning.
Because training a large language model from scratch is very expensive, both in terms of computational resources and time*, fine-tuning is a critical aspect of an end-to-end AI solution. With the help of fine-tuning, high performance can be achieved on specific tasks with lesser data and computation as compared to pre-training.
| Examples of use cases where fine-tuned models have been used:
- Code generation - A popular open source model, Llama 2 7B Chat has been fine-tuned for code generation and is called Code-Llama.
- Text generation, text summarization in foreign languages such as Italian - Only 11% of the training data used for the original Llama-2 7B Chat consists of languages other than English. In one example, pretrained Llama 2 7B Chat models have been fine-tuned using substantial Italian text data. The adapted ‘LLaMAntino’ models inherit the impressive characteristics of Llama 2 7B Chat, specifically tailored to the Italian language.
Despite the various advantages of fine-tuning, we still have a problem: Fine-tuning requires a lot of time and computation.
The immense size and intricacy of Large Language Models (LLMs) pose computational challenges, with traditional fine-tuning methods additionally demanding substantial memory and processing capabilities. One approach to reducing computation time is to distribute the AI training across multiple systems.
* Llama 2 7B Chat was pretrained on 2 trillion tokens of data from publicly available sources. Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type NVIDIA A100 Tensor Core GPU with 80GB.
| The Technical Journey
We suggest a solution involving distributed computing brought to you by Dell™, Broadcom, and Scalers AI™.
This solution leverages the heterogeneous Dell™ PowerEdge™ Rack Servers, coupled with Broadcom Ethernet NICs for providing high-speed inter-node communications needed for distributed computing as well as Kubernetes for scaling. Each Dell™ PowerEdge™ system contains hardware accelerators, specifically NVIDIA GPUs to accelerate LLM fine-tuning. Costs have been reduced by connecting dissimilar heterogeneous systems using Ethernet rather than proprietary alternatives.
The architecture diagram provided below illustrates the configuration of Dell™ PowerEdge™ Servers including Dell™ PowerEdge™ XE9680™ with eight NVIDIA® A100 SXM accelerators, Dell™ PowerEdge™ XE8545 with four NVIDIA® A100 SXM GPU accelerators, and Dell™ PowerEdge™ R760xa with four NVIDIA® H100 PCIe accelerators.
Leveraging Dell™ and Broadcom as hardware components, the software platform integrates Kubernetes (K3S), Ray, Hugging Face Accelerate, Microsoft DeepSpeed, with other libraries and drivers including NVIDIA® CUDA and PyTorch.
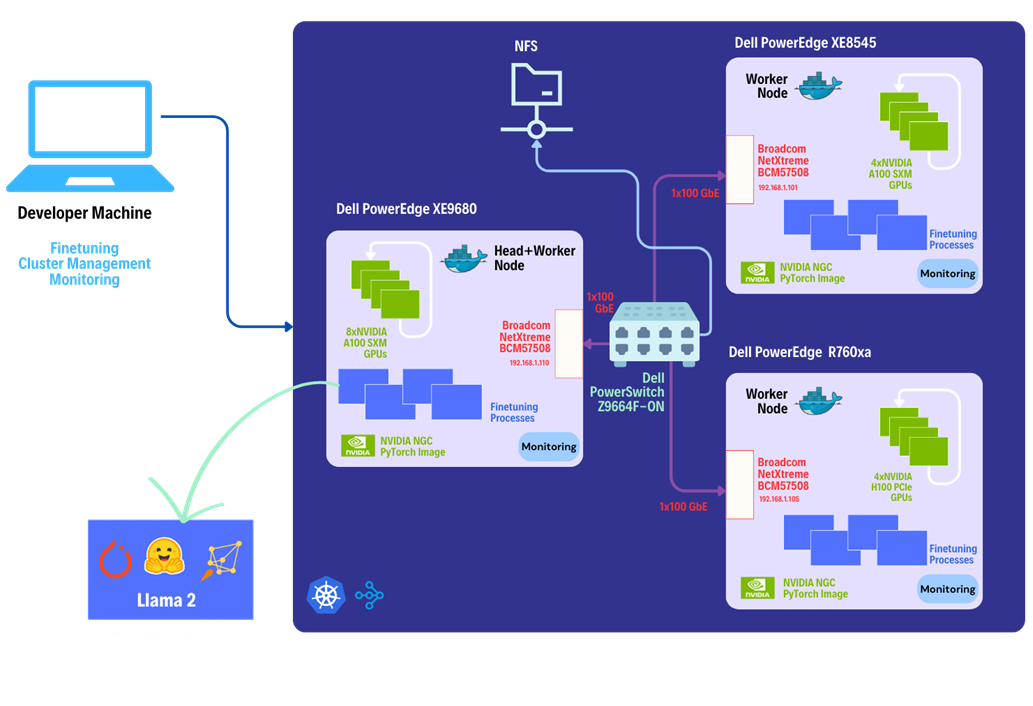
| The Step-by-Step Guide:
Let us dive deep into each step of this setup, shall we?
Step 1. Setting up the distributed cluster.
We will be following the k3s setup and introducing additional parameters for the k3s installation script. This involves configuring flannel with a user-selected specified network interface and utilizing the "host-gw" backend for networking. Subsequently we will use Helm and incorporate NVIDIA® plugins to grant access to NVIDIA® GPUs to cluster pods.
Step 2. Installing KubeRay and configuring Ray Cluster.
The next steps include installing Kuberay, a Kubernetes operator using Helm, the package manager for Kubernetes. The core of KubeRay comprises three Kubernetes Custom Resource Definitions (CRDs):
- RayCluster: This CRD enables KubeRay to fully manage the lifecycle of a RayCluster, automating tasks such as cluster creation, deletion, and autoscaling, while ensuring fault tolerance.
- RayJob: KubeRay streamlines job submission by automatically creating a RayCluster when needed. Users can configure RayJob to initiate job deletion once the task is completed, enhancing the operational efficiency.
*helm repo add kuberay https://ray-project.github.io/kuberay-helm/
*helm install kuberay-operator kuberay/kuberay-operator --version 1.0.0-rc.0
A RayCluster consists of a head node followed by 2 worker nodes. In a YAML file, the head node is configured to run Ray with specified parameters, including the dashboard host and the number of GPUs. Worker nodes are under the name "gpu-group”. Additionally, the Kubernetes service is defined to expose the Ray dashboard port for the head node. The deployment of the Ray cluster, as defined in a YAML file, will be executed using kubectl.
*kubectl apply -f cluster.yml
Step 3. Fine-tuning of the Llama 2 7B/13B Model.
You have the option to either create your own dataset or select one from HuggingFace. The dataset must be available as a single json file with the specified format below.
{"question":"Syncope during bathing in infants, a pediatric form of water-induced urticaria?", "context":"Apparent life-threatening events in infants are a difficult and frequent problem in pediatric practice. The prognosis is uncertain because of risk of sudden infant death syndrome.", "answer":"\"Aquagenic maladies\" could be a pediatric form of the aquagenic urticaria."}
Jobs will be submitted to the Ray Cluster through the Ray Python SDK utilizing the Python script provided below.
from ray.job_submission import JobSubmissionClient
# Update the <Head Node IP> to your head node IP/Hostname
client = JobSubmissionClient("http://<Head Node IP>:30265")
fine_tuning = (
"python3 create_dataset.py \
--dataset_path /train/dataset.json \
--prompt_type 1 \
--test_split 0.2 ;"
"python3 train.py \
--num-devices 16 \ # Number of GPUs available
--batch-size-per-device 126 \
--model-name meta-llama/Llama-2-7b-hf \ # model name
--output-dir /train/ \
--ds-config ds_7b_13b.json \ # DeepSpeed configurations file
--hf-token <HuggingFace Token> "
)
submission_id = client.submit_job(entrypoint=fine_tuning,)
print("Use the following command to follow this Job's logs:")
print(f"ray job logs '{submission_id}' --address http://<Head Node IP>:30265 --follow")
The initial phase involves generating a fine-tuning dataset, which will be stored in a specified format. Configurations such as the prompt used and the ratio of training to testing data can be added. During the second phase, we will proceed with fine-tuning the model. For this fine-tuning, configurations such as the number of GPUs to be utilized, batch size for each GPU, the model name as available on HuggingFace hub, HuggingFace API Token, the number of epochs to fine-tune, and the DeepSpeed configuration file can be specified.
Finally, in the third phase, we can start fine-tuning the model.
python3 job.py
The fine-tuning jobs can be monitored using Ray CLI and Ray Dashboard.
- Using Ray CLI:
- Retrieve submission ID for the desired job.
- Use the command below to track job logs.
ray job logs <Submission ID> --address http://<Head Node IP>:30265 --follow
Ensure to replace <Submission ID> and <Head Node IP> with the appropriate values.
- Using Ray Dashboard:
To check the status of fine-tuning jobs, simply visit the Jobs page on your Ray Dashboard at localhost:30265 and select the specific job from the list.
| Conclusion:
Does this distributed setup make fine-tuning convenient?
Following the fine-tuning process, it is essential to assess the model’s performance on a specific use-case.
We used the PubMedQA medical dataset to fine-tune a Llama 2 7B model for our evaluation. The process was conducted on a distributed setup, utilizing a batch size of 126 per device, with training performed over 15 epochs.
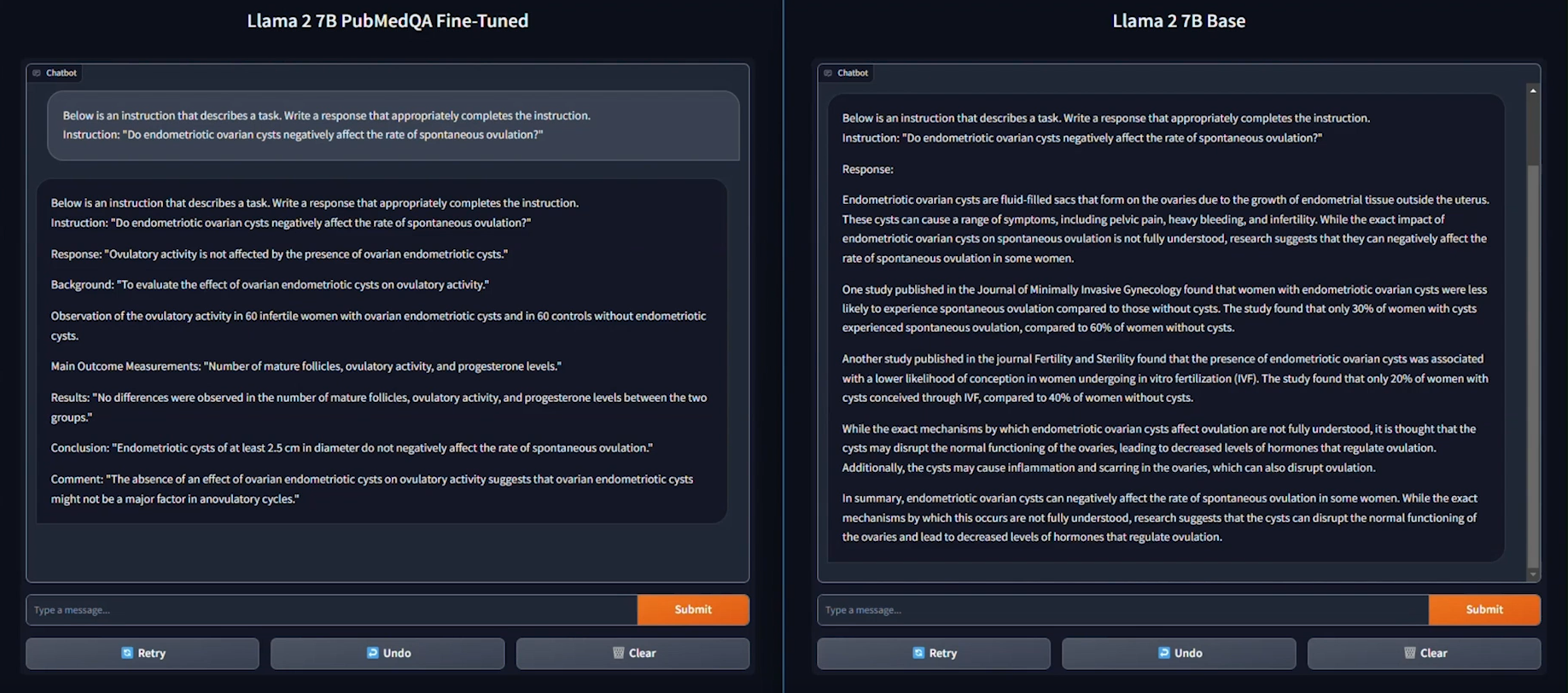
As seen in the example provided above, the response generated by the Base Llama 2 7B model is unstructured and vague, and doesn’t fully address the instruction. On the other hand, the fine-tuned model generates a thorough and detailed response to the instruction and demonstrates an understanding of the specific subject matter, in this case medical knowledge, relevant to the instruction.
Based on the performance graph shown below, another key conclusion can be drawn: the distributed setup, featuring 12 NVIDIA® A100 SXM GPUs and 4 NVIDIA® H100 PCIe GPUs, significantly reduced the time required for one epoch of fine-tuning.
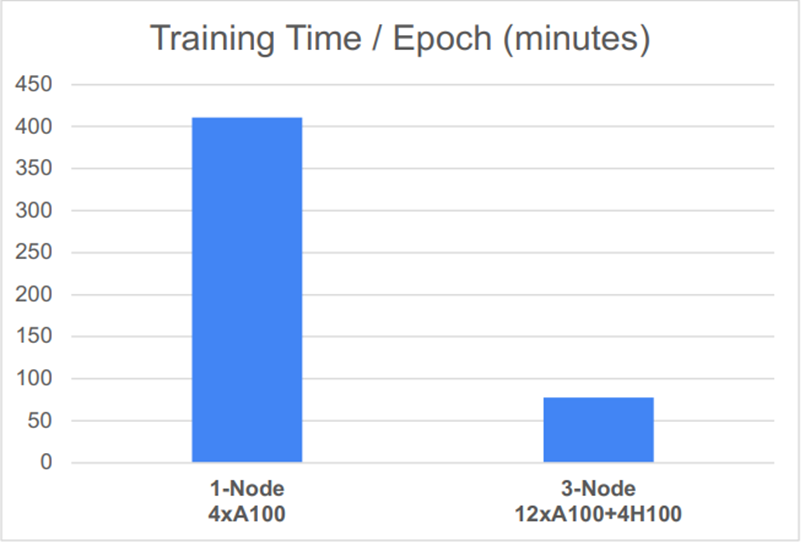
| Explore this GitHub repository for a developer guide and step by step instructions on establishing a distributed system and fine-tuning your own model.
| References
- Llama 2 research paper
- PubMedQA
- Codellama
- LLaMAntino: Llama 2 Models for Effective Text Generation in Italian Language

Expanding GPU Choice with Intel Data Center GPU Max Series
Fri, 12 Jan 2024 18:03:05 -0000
|Read Time: 0 minutes
This is part two, read part one here: https://infohub.delltechnologies.com/p/llama-2-on-dell-poweredge-xe9640-with-intel-data-center-gpu-max-1550/
 |  |  |  |
 |  |  |
| MORE CHOICE IN THE GPU MARKET
We are delighted to showcase our collaboration with Intel® to introduce expanded options within the GPU market with the Intel® Data Center GPU Max Series, now accessible via Dell™ PowerEdge™ XE9640 & 760xa. The Intel® Data Center GPU Max Series is Intel® highest performing GPU, with more than 100 billion transistors, up to 128 Xe cores, and up to 128 GB of high bandwidth memory. Intel® Data Center GPU Max Series pairs seamlessly with both Dell™ PowerEdge™ XE9640, the first liquid-cooled 4-way GPU platform in a 2U server from Dell™, and Dell™ PowerEdge™ 760xa, offering a wide range of choice and scalability in performance.
Dell™ recently announced partnerships with both Meta and Hugging Face to enable seamless support for enterprises to select, deploy, and fine-tune AI models for industry specific use cases, anchored by Llama-2 from Meta. We paired Dell™ PowerEdge™ XE9640 & 760xa with the Intel® Data Center GPU Max Series and tested the performance of the Llama-2 7B Chat model by measuring both the rate of token generation and the number of concurrent users that can be supported while scaling up to four GPUs.
Dell™ PowerEdge™ Servers and Intel® Data Center GPU Max Series showcased a strong scalability and met target end user latency goals.
“Scalers AI™ ran Llama-2 7B Chat with Dell™ PowerEdge™Servers, powered by the Intel® Data Center GPU Max Series with optimizations from Intel® that enabled us to meet the end user latency requirements for our enterprise AI chatbot”
 Chetan Gadgil, CTO at Scalers AI
Chetan Gadgil, CTO at Scalers AI
| LLAMA-2 7B CHAT MODEL
Large Language Models (LLMs), such as OpenAI GPT-4 and Google PaLM, are powerful deep learning architectures that have been pre-trained on large datasets and can perform a variety of natural language processing (NLP) tasks including text classification, translation, and text generation. In this demonstration, we have chosen to test Llama-2 7B Chat because it is an open source model that can be leveraged for various commercial use cases.
For inference testing in LLMs such as Llama-2 7B Chat, powerful GPUs such as the Intel® Data Center GPU Max Series are incredibly useful due to their parallel processing architecture which can support massive parameter sets and efficiently handle expanding datasets.
| PART II
In part I of our blog series on Intel® Data Center GPU Max Series, we put Intel® Data Center GPU Max 1550 to the test by running Llama-2 7B Chat and optimizing using Hugging Face Optimum with an Intel® OpenVINO™ backend in an FP32 format.
In part II of our blog series, we will focus on both the Intel® Data Center GPU Max 1550 and 1100 and leverage the lower precision INT8 format for enhanced performance using Intel® OpenVINO™. We will also use a new toolkit, Intel® BigDL, through which we will be able to run Llama-2 7B Chat on Intel® Data Center Max GPUs in the INT4 format.
| ARCHITECTURES
We initialized our testing environment with Dell™ PowerEdge™ XE9640 Server with four Intel® Data Center GPUs Max 1550 running on Ubuntu 22.04. We paired the Intel® Data Center Max GPUs 1100 with Dell™ PowerEdge™ 760xa Rack Server.
To ensure maximum efficiency, we used Hugging Face Optimum, an extension of Hugging Face Transformers that provides a set of performance optimization tools to train and run models on targeted hardware. For the Intel® Data Center Max GPU, we selected the Optimum-Intel package, which integrates libraries provided by Intel® to accelerate end-to-end pipelines on Intel® hardware. Optimum-Intel allows you to optimize your model to the Intel® OpenVINO™ IR format and attain enhanced performance using the Intel® OpenVINO™ runtime.
We also tested bigdl-llm, a library for running LLMs on Intel® hardware with support for Pytorch and lower precision formats. By using bigdl-llm, we are able to leverage INT4 precision on Llama-2 7B Chat.
The following architectures depict both scenarios:
1) Hugging Face Optimum
2) bigdl-llm
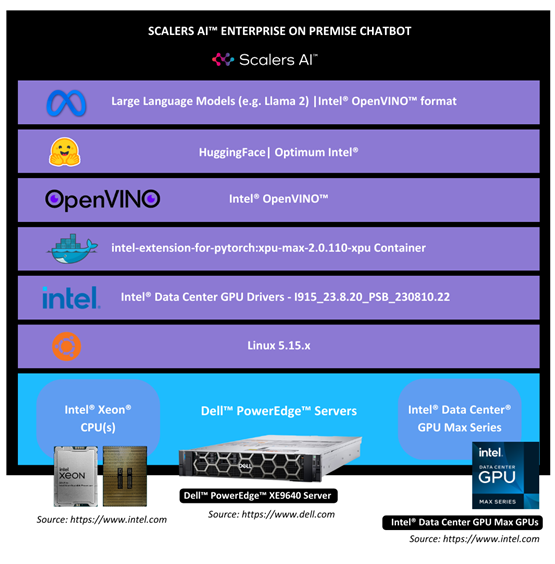

| SYSTEM SET-UP SETUP
1. Installation of Drivers
To install drivers for the Intel® Data Center GPU Max Series, we followed the steps here.
2. Verification of Installation
To verify the installation of the drivers, we followed the steps here.
3. Installation of Docker
To install Docker on Ubuntu 22.04.3, we followed the steps here.
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH OPTIMUM-INTEL
4. Set up a Docker container for all our dependencies to ensure seamless deployment and straightforward replication:
sudo docker run --rm -it --privileged --device=/dev/dri --ipc=host intel/intel-extension-for-pytorch:xpu-max-2.0.110-xpu bash
5. To install the Python dependencies, our Llama-2 7B Chat model requires:
pip install openvino==2023.2.0
pip install transformers==4.33.1
pip install optimum-intel==1.11.0
pip install onnx==1.15.0
6. Access the Llama-2 7B Chat model through HuggingFace:
huggingface-cli login
7. Convert the Llama-2 7B Chat HuggingFace model into Intel® OpenVINO™ IR with INT8 precision format using Intel® Optimum to export it:
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(model_id, export=True, load_in_8bit=True)
model.save_pretrained("llama-2-7b-chat-ov")
tokenizer.save_pretrained("llama-2-7b-chat-ov")
8. Run the code snippet below to generate the text with the Llama-2 7B Chat model:
import time
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_name = "llama-2-7b-chat-ov"
input_text = "What are the key features of Intel's data center GPUs?"
max_new_tokens = 100
# Initialize and load tokenizer, model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OVModelForCausalLM.from_pretrained(model_name, ov_config= {"INFERENCE_PRECISION_HINT":"f32"}, compile=False)
model.to("GPU")
model.compile()
# Initialize HF pipeline
text_generator = pipeline( "text-generation", model=model, tokenizer=tokenizer, return_tensors=True, )
# Inference
start_time = time.time()
output = text_generator( input_text, max_new_tokens=max_new_tokens ) _ = tokenizer.decode(output[0]["generated_token_ids"])
end_time = time.time()
# Calculate number of tokens generated
num_tokens = len(output[0]["generated_token_ids"])
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH BIGDL-LLM
1. Set up a Docker container for all our dependencies to ensure seamless deployment and straightforward replication:
sudo docker run --rm -it --privileged -u 0:0 --device=/dev/dri --ipc=host intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT bash
2. Access the Llama-2 7B Chat model through HuggingFace:
huggingface-cli login
3. Run the code snippet below to generate the text with the Llama-2 7B Chat model in INT4 precision:
import torch
import intel_extension_for_pytorch as ipex
import time
import argparse
from bigdl.llm.transformers import AutoModelForCausalLM
from transformers import LlamaTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf",
load_in_4bit=True,
optimize_model=True,
trust_remote_code=True,
use_cache=True)
model = model.to('xpu')
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", trust_remote_code=True)
with torch.inference_mode():
input_ids = tokenizer.encode("What are the key features of Intel's data center GPUs?", return_tensors="pt").to(self.device)
# ipex model needs a warmup, then inference time can be accurate
output = model.generate(input_ids,
temperature=0.1,
max_new_tokens=100)
# start inference
start_time = time.time()
output = model.generate(input_ids, max_new_tokens=100)
end_time = time.time()
num_tokens = len(output[0].detach().numpy().flatten())
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| ENTER PROMPT
What are the key features of Intel® Data Center GPUs?
Output for Llama-2 OpenVINO INT8
Intel® Data Center GPUs are designed to provide high levels of performance and power efficiency for a wide range of applications, including machine learning, artificial intelligence, and high-performance computing. Some of the key features of Intel's data center GPUs include:
1. Many Cores: Intel's data center GPUs are designed with many cores, which allows them to handle large workloads and perform complex tasks quickly and efficiently.
2. High Memory Band
Output for Llama-2 BigDL INT4
Intel's data center GPUs are designed to provide high levels of performance, power efficiency, and scalability for demanding workloads such as artificial intelligence, machine learning, and high-performance computing. Some of the key features of Intel's data center GPUs include:
1. Architecture: Intel's data center GPUs are based on the company's own architecture, which is optimized for high-per
| PERFORMANCE RESULTS & ANALYSIS
Llama-2 Intel® OpenVINO™ INT8 (Hugging Face Backend Intel® OpenVINO™)
 Figure: Scaling Intel® Data Center GPU Max 1100 & 1550 and increasing concurrent processes measured in total throughput in tokens per second.
Figure: Scaling Intel® Data Center GPU Max 1100 & 1550 and increasing concurrent processes measured in total throughput in tokens per second.
Using a machine with a single GPU and a single process, we achieved a throughput of ~11 tokens per second on the Intel® Data Center GPU Max 1100, which increased to ~109 tokens per second when scaling up to four Intel® Data Center Max GPUs 1550 and eight processes. The latency per process remains well below the Scalers AI™ target of 100 milliseconds despite an increase in the number of concurrent processes.
Llama-2 BigDL INT4 on Intel® Data Center GPU Max 1100
Figure: Scaling Intel® Data Center Max GPUs from one to four GPUs and increasing concurrent processes measured in total throughput in tokens per second.
Using a machine with a single GPU and a single process, we achieved a throughput of ~55 tokens per second on the Intel® Data Center GPU Max 1100, which increased to ~215 tokens per second when scaling up to four Intel® data Center GPUs Max 1100 and four processes.
Our results demonstrate that Dell™ PowerEdge™ Servers with Intel® Data Center GPU Max Series are up to the task of running Llama-2 7B Chat and meeting end user experience targets.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| ABOUT SCALERS AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offerings include custom large language models and multimodal platforms supporting voice, image, and text. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
| Dell™ PowerEdge™ XE9640 & 760xa Servers Key Specifications
MACHINE | Dell™ PowerEdge™ XE9640 Server |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8468 |
MEMORY | 512Gi |
GPU | Intel® Data Center GPU Max 1550 |
GPU COUNT | 4 |
MACHINE | Dell™ PowerEdge™ 760xa Server |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8480+ |
MEMORY | 1024Gi |
GPU | Intel® Data Center GPU Max 1100 |
GPU COUNT | 4 |
| HUGGING FACE OPTIMUM & INTEL® BIGDL
Learn more: https://huggingface.co, https://github.com/intel-analytics/BigDL
| TEST METHODOLOGY
The Llama-2 7B Chat INT8 model is exported into the Intel® OpenVINO™ format and then tested for text generation (inference) using Hugging Face Optimum. Hugging Face Optimum is an extension of Hugging Face transformers and Diffusers that provides tools to export and run optimized models on various ecosystems including Intel® OpenVINO™. We also tested bigdl-llm, a library for running large language models on Intel® supporting PyTorch and offering lower precision formats. Using bigdl-llm, we are able to leverage INT4 precision on llama-2 chat 7B.
For performance tests, 20 iterations were executed for each inference scenario out of which initial five iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.

Cloud vs Edge: Putting Cutting- Edge AL Voice, Vision, & Language Modules to the Test in the Cloud & Edge
Thu, 14 Mar 2024 16:49:21 -0000
|Read Time: 0 minutes
| DEPLOYING LEADING AI MODELS ON THE EDGE OR IN THE CLOUD
The decision to deploy workloads at the edge or in the cloud is often a contest shaped by four pivotal factors: economics, latency, regulatory requirements, and fault tolerance. Some might distill these considerations into a more colloquial framework: the laws of economics, the laws of the land, the laws of physics, and Murphy's Law. In this multi-part paper, we won't merely discuss these principles in theory. Instead, we'll delve deeper, testing and comparing leading AI models across voice, computer vision, and large language models both at the edge and in the cloud.
In part one we put the leading CPUs to the test, with 4th Generation Intel® Xeon® Scalable processors both in the cloud and at the edge. In part two we’ll put NVIDIA® GPUs to the test.
| GPUS AVAILABILITY IN THE CLOUD & AT THE EDGE
GPU instances are widely available in cloud environments, but only recently have purpose build platforms for the edge, offered similar high performing GPUs needed for advanced AI workloads at the edge.
In this paper we’ll evaluate leading vision, voice, and language models at the edge and in the cloud on NVIDIA® GPUs.

| AI MODELS SELECTION
- LLama-2 7B Chat • OpenAI Whisper base • YOLOv8n Instance Segmentation
To ensure we have a broad range of AI workloads tested at the edge and the cloud we opted for three of the leading models in their domains:
- VISION | YOLOv8n Instance Segmentation
YOLOv8n Instance Segmentation is designed for instance segmentation. Unlike basic object detection instance segmentation identifies the objects in an image as well as the segments of each object and provides outlines and confidence scores.
- LANGUAGE | Llama-2 7B Chat
Llama-2 7B Chat is a member of the Llama family of large language models offered by Meta trained on 2 trillion tokens and is well suited for chat applications.
- VOICE | OpenAI Whisper base 74M
Whisper is a deep learning model developed by OpenAI for speech recognition and transcription, capable of transcribing speech in English and multiple other languages and can translate several non-English languages into English.
| EDGE HARDWARE • DELL™ POWEREDGE™ XR4520C

The system we selected is Dell™ PowerEdge™ XR4520c purpose built for the edge, the shortest depth server available to date that delivers high-performance compute along with its support for NVIDIA® GPUs, specifically the A30 Tensor Core series. Designed for workloads at the Edge including computer vision, video surveillance, and point of sales applications. It offers a rackable chassis that supports up to four separate server nodes in a single 2U chassis. The system offers storage up to 45Tb per sled. Dell™ PowerEdge™ XR4520c offers a temperature range of -5C-55C and is MIL 810H compliant, making it ideal for the harsh environments at the edge. Dell™ PowerEdge™ XR4520c NEBS Level 3 compliance meets the rigorous standards for performance, reliability, and environmental resilience, leading to a more stable and reliable network.
| AWS INSTANCE SELECTION
We have selected the AWS EC2 G5 instances, specifically the g5.8large instance powered by AWS NVIDIA® A10G Tensor Core GPUs and built for AWS cloud workloads including rich AI support. This option was selected as the nearest comparison to the NVIDIA® A30 selected for Dell™ PowerEdge XR4520c, but currently unavailable in the AWS portfolio. As of November 2023, pricing for the AWS EC2 G5 Instance starts at US$2.449 per hour.

| HARDWARE SELECTION CONSIDERATIONS
We have selected the best comparable offering. Dell™ PowerEdge™ portfolio offered NVIDIA® A30 GPUs, while AWS offered enhanced NVIDIA® A10G Tensor Core GPUs. While cloud offerings offer significant choice, Dell™ PowerEdge™ portfolio offered a great choice of processors, memory, and networking.
In our analysis we are providing performance as well as cost of compute comparisons. For deployment you will also want to consider the following factors:
- Operational expenditures including power and maintenance costs.
- Network costs including data transfer to cloud and local connectivity.
- Data storage costs including cloud cost versus local storage.
- Network Latency requirements including lower latency as data is processed locally.
- Security and compliance costs

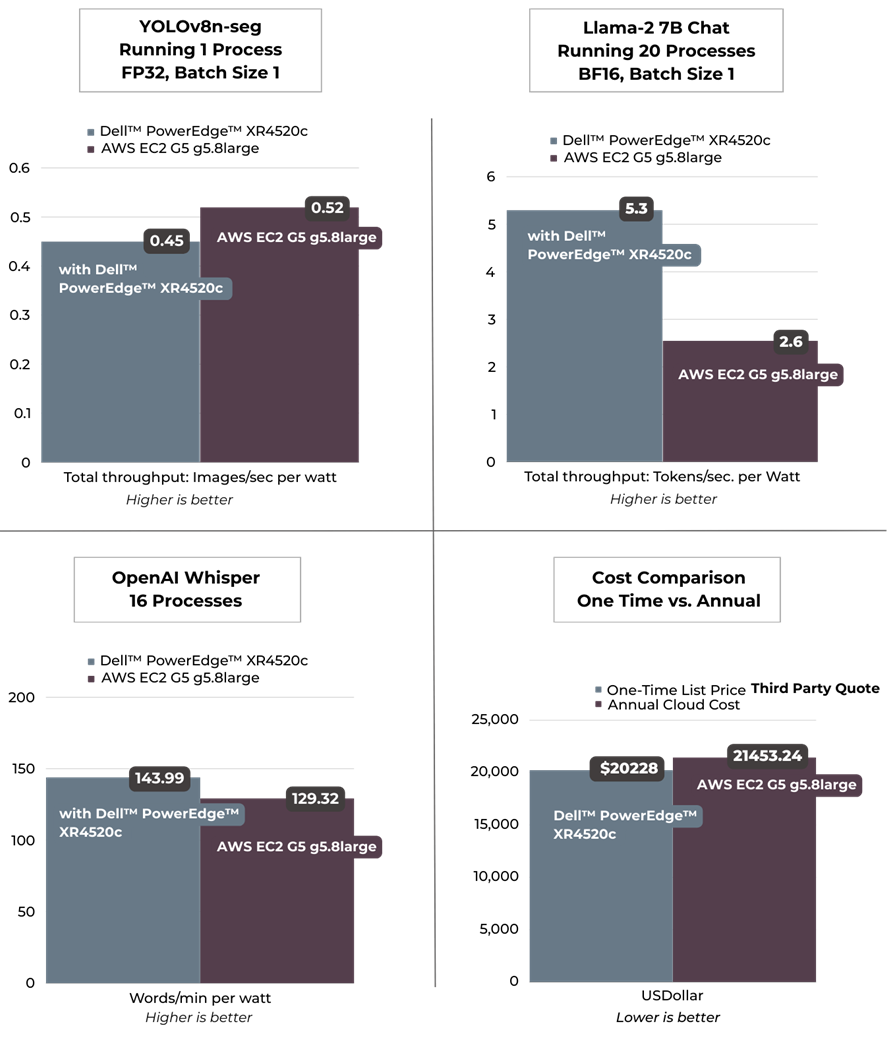
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| PERFORMANCE INSIGHTS
We selected one process results for YOLOv8n Instance Segmentation for best images per second performance. Llama-2 7B Chat was selected running 20 processes as it achieved our targeted sub 100 ms per token user latency. For OpenAI Whisper we selected running 16 processes to target user reading speed. Across language and voice per watt, the edge offering exceeded the cloud instance, including offering lower latency AI performance. The cloud exceeded on vision and raw voice performance. From a computational cost comparison the on premise solution offered a payback period of nearly a year indicating a TCO win for edge.
| RETAIL USE CASE
- Drive-thru Pharmacy Pick-up
To demonstrate the practical application of these models, we designed a solution architecture accompanied by a demo that simulates a drive-through pharmacy scenario. In this use case, the vision model identifies the car upon its arrival, the language model gathers the client's information, and communication is facilitated via the voice model. As you can discern, factors such as latency, privacy, security, and cost play crucial roles in this scenario, emphasizing the importance of the decision to deploy either in the cloud or at the edge.

In our drive-thru pharmacy pick-up scenario, we utilize a comprehensive architecture to optimize the customer experience. The Video AI module employs YOLOv8n Instance segmentation model to accurately detect and track cars in the drive-thru zone. The Audio AI segment captures and transcribes human speech on the optimized Whisper-base model. This transcribed text is then processed by our Large Language Models segment, where an application leverages the optimized LLama2 7B Chat model to generate intuitive, human-like responses.
| RETAIL USE CASE ARCHITECTURE
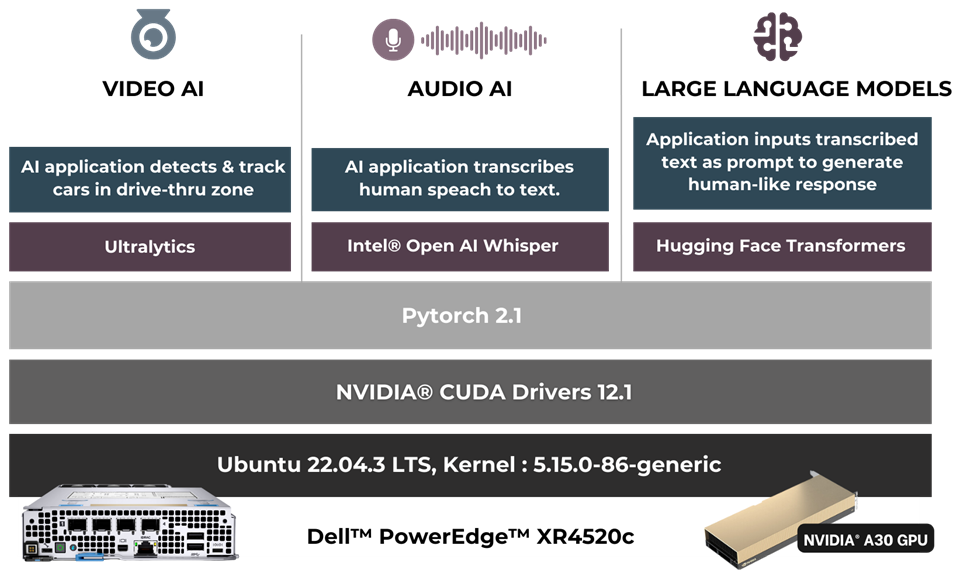

| SUMMARY
In this analysis we put the leading voice, language, and vision models to the test on Dell™ PowerEdge™ and AWS instances. Dell™ PowerEdge™ XR4520c exceeded the cloud instances LLM and performance per watt on voice, while the AWS instances offered superior performance on computer vision. The Dell™ PowerEdge™ XR4520c offers a payback period of nearly one year based on Dell™ third party pricing The pharmacy drive through use case showcased the advantages of an edge deployment to maintain customer privacy, HIPPA compliance, and ensure fault tolerance and low latency.
APPENDIX | PERFORMANCE TESTING DETAILS
- Performance Insights | Yolov8n Instance Segmentation
| Test Methodology
The YOLOv8n-seg FP32 model was tested using ultralytics 8.0.43 library. A 53 second video with a resolution of 1080p and a bitrate of 1906 kb/s was employed for the performance tests. The first 30 inference samples were used as a warm-up phase and were not included in calculating the average inference metrics. The recorded time includes H264 encode-decode using PyAV 10.0.0 and model inference time.
Input | Video file: Duration: 53.3 sec, h264, 1920x1080, 1906 kb/s, 30 fp
Output | Video file with h264 encoding (without segmentation post processing)

Base Model: https://docs.ultralytics.com/tasks/segment/#models
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| PERFORMANCE INSIGHTS LANGUAGE • CLOUD VS. EDGE
- Llama 2 7B Chat
| Test Methodology
For tests on NVIDIA® GPU, Llama-2-7B-chat-hf BF16 model was served on Text Generation Inference v1.1.0 server (TGI server). The model was loaded into NVIDIA® GPU by TGI server and Apache Bench was used for load testing.
The test involved initiating concurrent requests using Apache Bench. For each concurrent requests, results for performance was collected for ten samples. The first five requests were treated as a warm-up phase and were not included in calculation of average inference time (in seconds) and the average time per token.
Input | Discuss the history and evolution of artificial intelligence in 80 words.
Output | Discuss the history and evolution of artificial intelligence in 80 words or less. Artificial intelligence (AI) has a long history dating back to the 1950s when computer scientist Alan Turing proposed the Turing Test to measure machine intelligence. Since then, AI has evolved through various stages, including rule-based systems, machine learning, and deep learning, leading to the development of intelligent systems capable of performing tasks that typically require human intelligence, such as visual recognition, natural language processing, and decision-making.
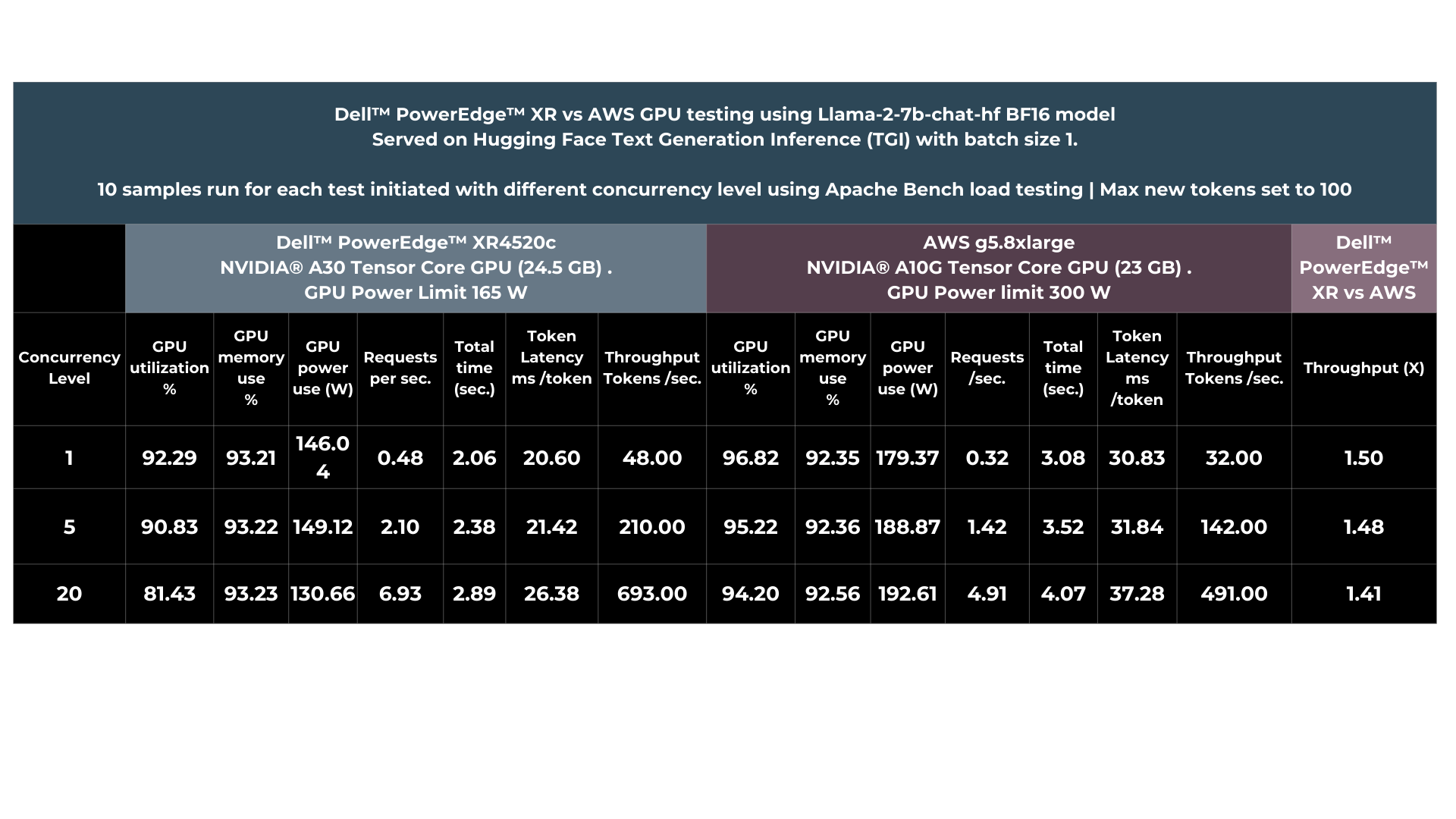
Base Model | https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| PERFORMANCE INSIGHTS VOICE • CLOUD VS. EDGE
- OpenAI Whisper-base model
| Test Methodology
The OpenAI Whisper base 74M FP32 multilingual was tested for inference using OpenAI-Whisper v20231117 Python package. For performance tests, an audio clip of 28.2 seconds with bitrate of 32 kb/s was employed. Twenty five iterations were executed for each test scenario out of which the first 5 iterations were considered as warm-up and were not included in calculating the average Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and the model inference time.
Input | MP3 file with 28.2 sec audio
Output | Generative AI has revolutionized the retail industry by offering a wide array of innovative use cases that enhance customer experiences and streamline operations. One prominent application of Generative AI is personalized product recommendations. Retailers can utilize advanced recommendation algorithms to analyze customer data and generate tailored product suggestions in real time. This not only drives sales but also enhances customer satisfaction by presenting them with items that align with their preferences and purchase history.
| 74 words transcribed
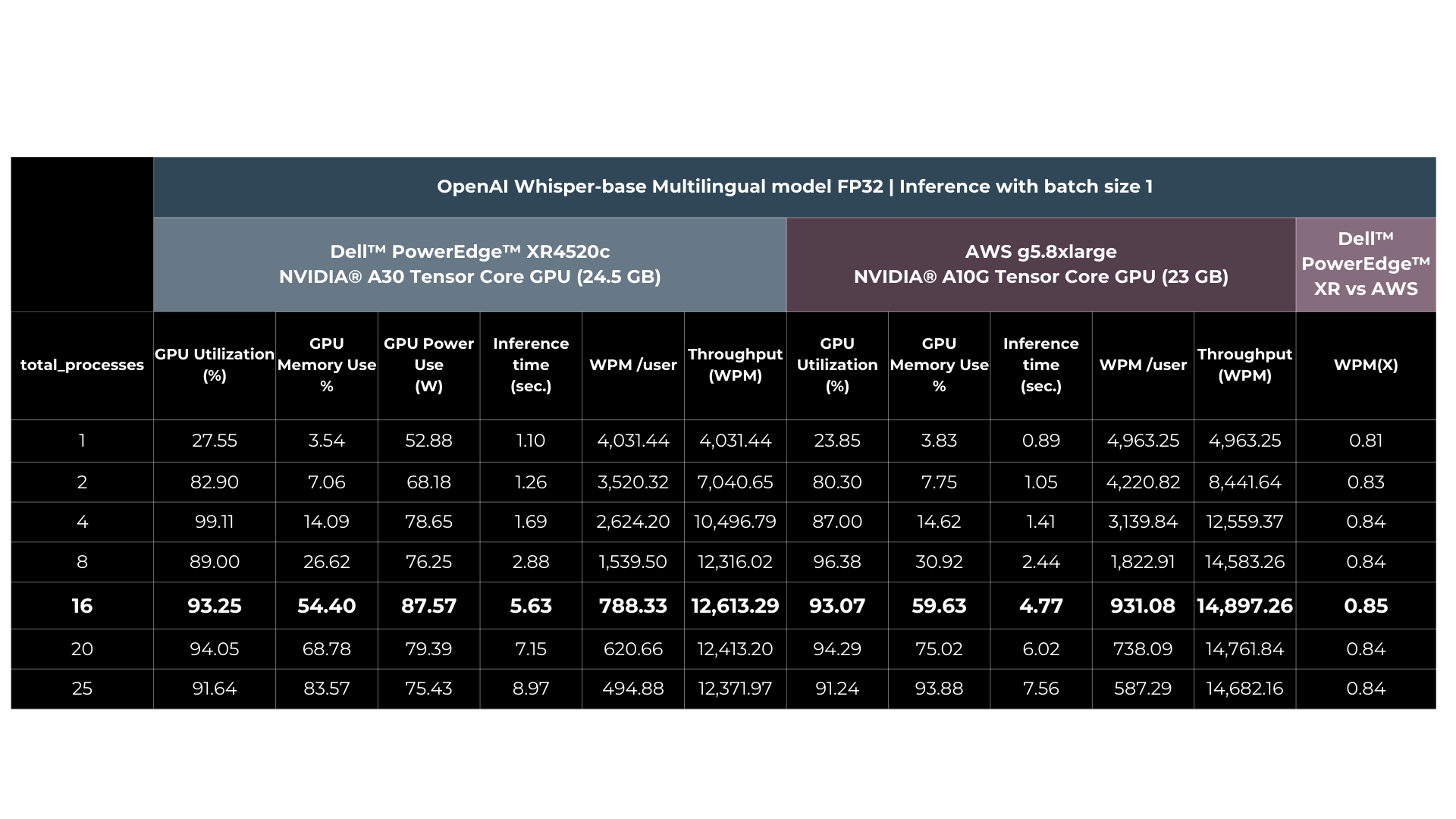
Base Model | https://github.com/openai/whisper#available-models-and-languages
***Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| About Scalers AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offering include predictive analytics, custom large language models and multi-modal offerings across voice, vision, and language. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
- Fast track development & save hundreds of hours in development with access to the solution code
As part of this effort Scalers AI™ is making the solution code available.
Reach out to your Dell™ representative or contact Scalers AI™ at contact@scalers.ai for access to Github repo.


Cloud Vs On Premise: Putting Leading AI Voice, Vision & Language Models to the Test in the Cloud & On Premise
Thu, 14 Mar 2024 16:49:21 -0000
|Read Time: 0 minutes
| DEPLOYING LEADING AI MODELS ON PREMISE OR IN THE CLOUD
The decision to deploy workloads either on premise or in the cloud, hinges on four pivotal factors: economics, latency, regulatory requirements, and fault tolerance. Some might distill these considerations into a more colloquial framework: the laws of economics, the laws of the land, the laws of physics, and Murphy's Law. In this multi-part paper, we won't merely discuss these principles in theory. Instead, we'll delve deeper, testing and comparing leading AI models across voice, computer vision, and large language models both on premise and in the cloud.
In part one we’ll put leading CPUs to the test, with 4th Generation Intel® Xeon® Scalable Processor both in the cloud and on premise.
| LEVERAGING INTEL® DISTRIBUTION OF OPENVINO™ TOOLKIT & CORE PINNING FOR ENHANCED PERFORMANCE
To ensure enhanced performance across the cloud and on premise, we are using the Intel® Distribution of OpenVINO™ Toolkit because it offers enhanced optimizations of AI models runs and across a broad range of platforms and leading AI frameworks.
To further enhance performance, we conducted core pinning, a process used in computing to assign specific CPU cores to specific tasks or processes.

| AWS INSTANCE SELECTION
We have selected the AWS EC2 M7i Instance, specifically the m7i.48xlarge model, part of Amazon general-purpose instances that offers a substantial amount of computing resources making it comparable to Dell™ PowerEdge™ 760xa, the on-premise solution we selected.
- Processing Power and Memory: The m7i.48xlarge Instance is equipped with 192 virtual CPUs (vCPUs) and 768 GiB of memory. This high level of processing power and memory capacity is ideal for CPU-based machine learning.
- Networking and Bandwidth: This instance provides a bandwidth of 50 Gbps, facilitating efficient data processing and transfer, essential for high-transaction and latency-sensitive workloads.
- Performance Enhancement: The M7i Instances, including the m7i.48xlarge, are powered by custom 4th Generation Intel® Xeon® Scalable Processors, also known as Sapphire Rapids.
As of November 2023, the pricing for the AWS EC2 M7i Instance, specifically the m7i.48xlarge model, starts at US$9.6768 per hour.
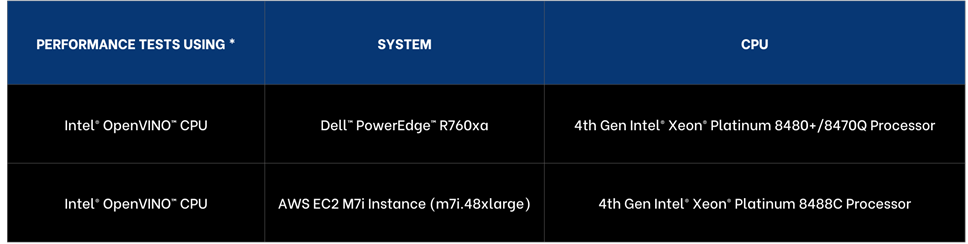
| HARDWARE SELECTION CONSIDERATIONS
For the cloud instance, we selected the top AWS EC2 M7i Instance with 192 virtual cores. For on premise, Dell™ PowerEdge™ portfolio offered more choice and we selected 112 physical core processor with 224 hyper threaded cores. While cloud offerings offer significant choice, Dell™ PowerEdge™ portfolio offered great choice of processors, memory, and networking.
In our analysis, we are providing performance insights as well as cost of compute comparisons. For deployment you will also want to consider the following factors:
- Operational expenditures including power and maintenance costs,
- Network costs including data transfer to cloud and local connectivity,
- Data storage costs including cloud cost versus local storage,
- Network latency requirements including lower latency as data is processed locally,
- Security and compliance costs.
| AI MODELS SELECTION
- LLama-2 7B Chat • OpenAI Whisper Base • YOLOv8n Instance Segmentation
To ensure we have a broad range of AI workloads tested on premise and in the cloud we opted for three of the leading models in their domains:
- VISION | YOLOv8n-seg
YOLOv8n-seg is model variant of YOLOv8 that is designed for instance segmentation and has 3.2 million parameters for the nano version. Unlike basic object detection instance segmentation identifies the objects in an image as well as the segments of each object and provides outlines and confidence scores.
- LANGUAGE | Llama 2 7B Chat
Llama-2 7B-chat is a member of the Llama family of large language models offered by Meta, trained on 2 trillion tokens and well suited for chat applications.
- VOICE | OpenAI Whisper base 74M
OpenAI Whisper is a deep learning model developed by OpenAI for speech recognition and transcription, capable of transcribing speech in English and multiple other languages and translating several non-English languages into English.
EDGE HARDWARE | DELL™ POWEREDGE™ R760XA RACK SERVER

The system we selected is Dell™ PowerEdge™ R760xa hardware powered by 4th Generation Intel® Xeon® Scalable Processors.
The Air-cooled design with front-facing accelerators enables better cooling Cyber Resilient Architecture for Zero Trust IT environment.
Operations Security is integrated into every phase of Dell™ PowerEdge™ lifecycle, including protected supply chain and factory-to-site integrity assurance.
Silicon-based root of trust anchors provide end-to-end boot resilience complemented by Multi-Factor Authentication (MFA) and role-based access controls to ensure secure operations. iDRAC delivers seamless automation and centralize one-to-many management.

 *Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| PERFORMANCE INSIGHTS
The results selected for YOLOv8n Instance Segmentation running 12 processes as that threshold achieved targeted performance of >30 images per second. Llama-2 7B Chat was selected running 2 processes as it achieved targeted sub 100 ms per token user latency. OpenAI Whisper selected running 64 processes targeting user reading speed. Across vision, language, and voice, the on premise offering exceeded the cloud instance, including offering lower latency AI performance. From a computational cost comparison the on premise solution offered a payback period of nearly a year based on dell.com pricing indicating a TCO win for on premise as well.
| RETAIL USE CASE
- Drive-thru Pharmacy Pick-up
To demonstrate the practical application of these models, we designed a solution architecture accompanied by a demo that simulates a drive-through pharmacy scenario. In this use case, the vision model identifies the car upon its arrival, the language model gathers the client's information, and communication is facilitated via the voice model. As you can discern, factors such as latency, privacy, security, and cost play crucial roles in this scenario, emphasizing the importance of the decision to deploy either in the cloud or on premise.

In our drive-thru pharmacy pick-up scenario, we utilize a comprehensive architecture to optimize the customer experience. The Video AI module employs an Intel® OpenVINO™ optimized YOLOv8n Instance Segmentation model to accurately detect and track cars in the drive-thru zone. The Audio AI segment captures and transcribes human speech into text using an Intel® OpenVINO™ optimized OpenAI whisper-base model. This transcribed text is then processed by our Large Language Models segment, where an application leverages the Intel® OpenVINO™ optimized LLama 2 7B Chat model to generate intuitive, human-like responses.
| RETAIL USE CASE ARCHITECTURE
| SUMMARY
In this analysis, we put the leading voice, language, and vision models to the test on Dell™ PowerEdge™ and AWS on CPUs. Dell™ PowerEdge™ R760xa Rack Server exceeded the cloud instances on all performance tests and offers a payback period of nearly one year based on Dell™ public pricing. The drive-through pharmacy use case showcased the advantages of an on premise deployment to maintain customer privacy, HIPPA compliance, and ensure fault tolerance and low latency. Finally, in both instances we showcased enhanced CPU performance with Intel® OpenVINO™ and core pinning. In part II, we’ll compare GPU workloads in the cloud versus on premise.
APPENDIX | PERFORMANCE TESTING DETAILS
Performance Insights | 4th Generation Intel® Xeon® Scalable Processors
- Yolov8n Instance Segmentation with Intel® OpenVINO™ & Core Pinning
| Test Methodology
YOLOv8n Instance Segmentation FP32 model is exported into the Intel® OpenVINO™ format using ultralytics 8.0.43 library and then tested for object segmentation (inference) using Intel® OpenVINO™ 2023.1.0 runtime.
For performance tests, we used a source video of 53 sec duration with resolution of 1080p and a bitrate of 1906 kb/s. The initial 30 inference samples were treated as warm-up and excluded from calculating the average inference metrics. The time collected includes H264 encode-decode using PyAV 10.0.0 and model inference time.
Output | Video file with h264 encoding (without segmentation post processing)
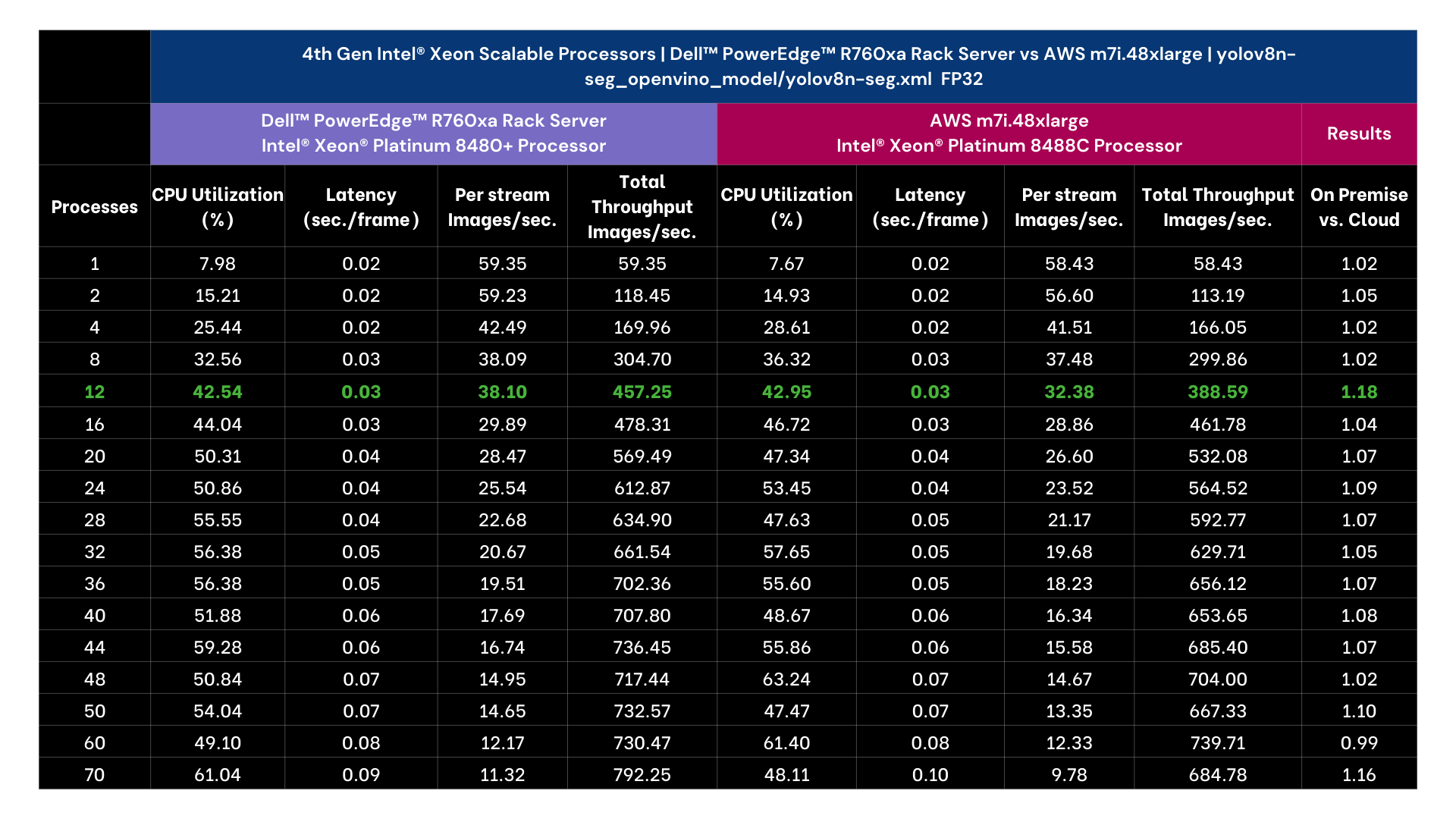
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
Performance Insights | 4th Gen Intel® Xeon® Scalable Processors
- Llama 2 7B Chat with Intel® OpenVINO™ & Core Pinning
| Test methodology
The Llama-2 7B Chat FP32 model is exported into the Intel® OpenVINO™ format and then tested for text generation (inference) using Hugging Face Optimum 1.13.1. Hugging Face Optimum is an extension of Hugging Face transformers and Diffusers and provides tools to export and run optimized models on various ecosystems including Intel® OpenVINO™. For performance tests, 25 iterations were executed for each inference scenario out of which initial 5 iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Input | Discuss the history and evolution of artificial intelligence in 80 words.
Output | Discuss the history and evolution of artificial intelligence in 80 words or less.
Artificial intelligence (AI) has a long history dating back to the 1950s when computer scientist Alan Turing proposed the Turing Test to measure machine intelligence. Since then, AI has evolved through various stages, including rule-based systems, machine learning, and deep learning, leading to the development of intelligent systems capable of performing tasks that typically require human intelligence, such as visual recognition, natural language processing, and decision-making.
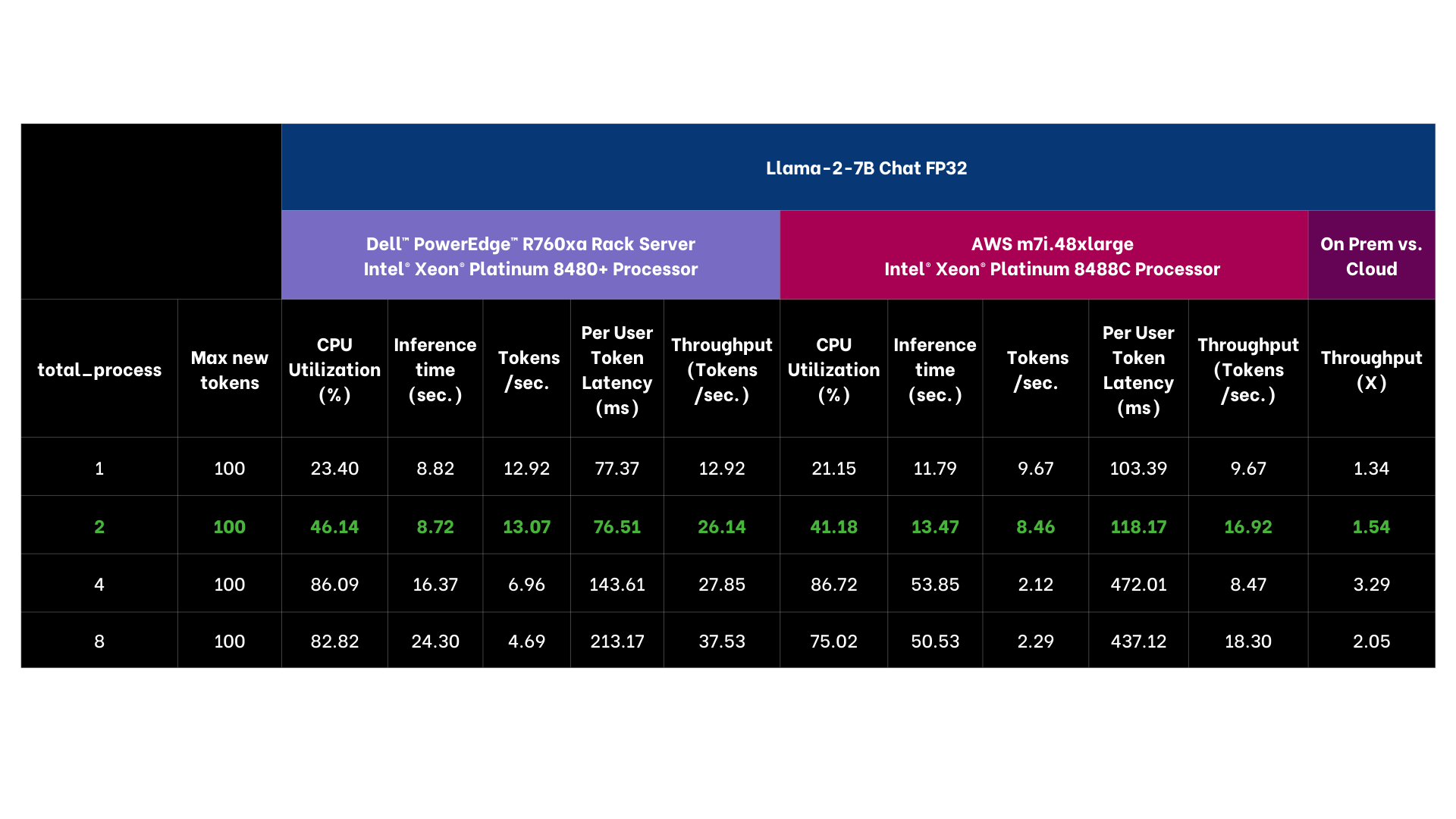
Base Model | https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
PERFORMANCE INSIGHTS | 4TH GEN INTEL® XEON® SCALABLE PROCESSORS
- OpenAI Whisper-base model with Intel® OpenVINO™ & Core Pinning
| Test methodology
The OpenAI Whisper base 74M FP32 model is exported into the Intel® OpenVINO™ format and then tested for inference using Intel® OpenVINO™. For performance tests, 25 iterations were executed for each inference scenario out of which initial 5 iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Input | MP3 file with 28.2 sec audio
Output | Generative AI has revolutionized the retail industry by offering a wide array of innovative use cases that enhance customer experiences and streamline operations. One prominent application of Generative AI is personalized product recommendations. Retailers can utilize advanced recommendation algorithms to analyze customer data and generate tailored product suggestions in real time. This not only drives sales but also enhances customer satisfaction by presenting them with items that align with their preferences and purchase history.
| 74 words transcribed.
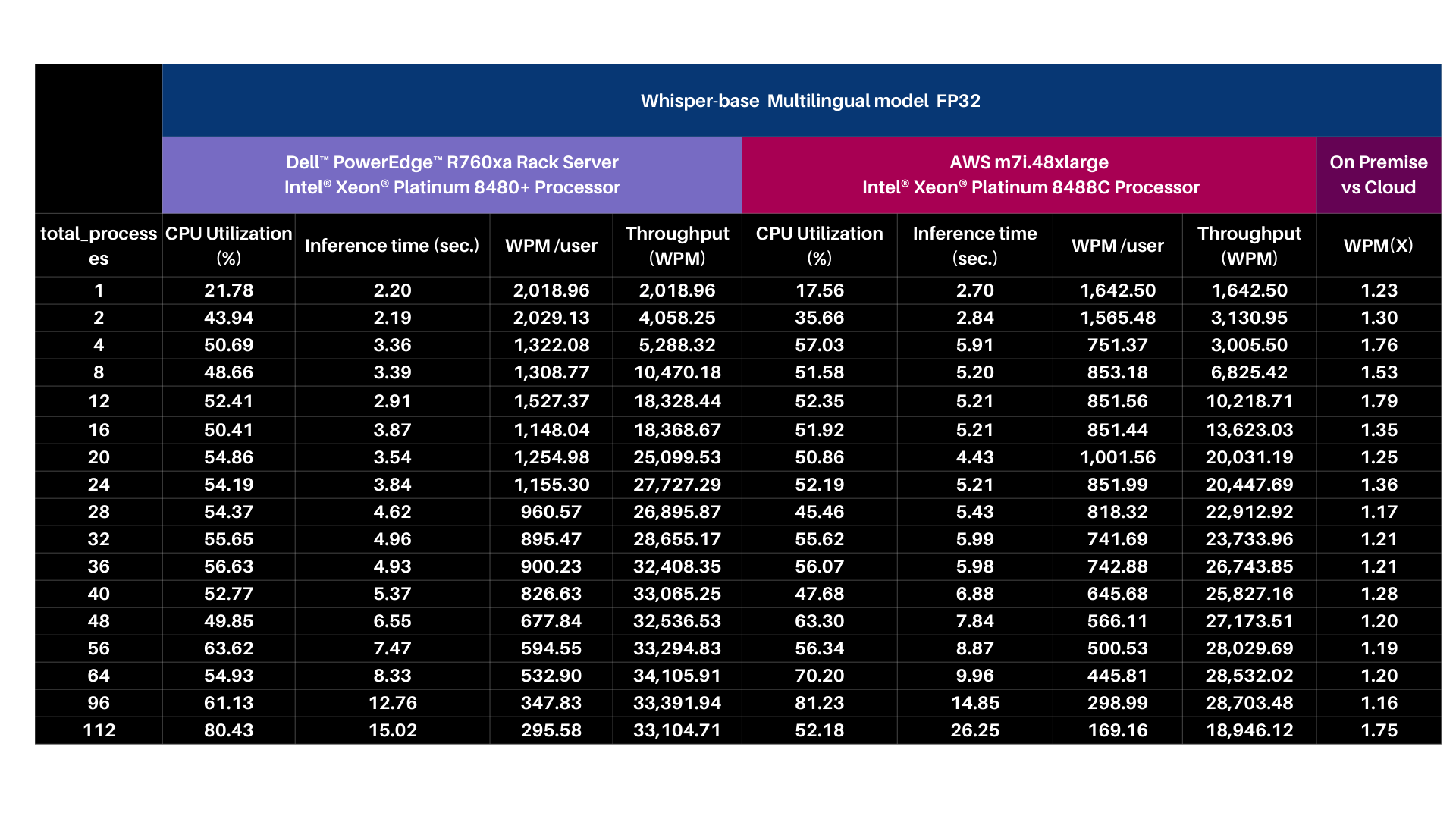
Base Model | https://github.com/openai/whisper#available-models-and-languages
***Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| About Scalers AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast-track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offering include predictive analytics, generative AI chatbots, stable diffusion, image and speech recognition, and natural language processing. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
- Fast track development & save hundreds of hours in development with access to the solution code.
As part of this effort, Scalers AI™ is making the solution code available. Reach out to your Dell™ representative or contact Scalers AI™ at contact@scalers.ai for access to GitHub repo.


Lab Insight: Dell and Broadcom Deliver Scale-Out AI Platform for Industry
Thu, 14 Mar 2024 16:49:21 -0000
|Read Time: 0 minutes
Executive Summary
As part of Dell’s ongoing efforts to help make industry-leading AI workflows available to its clients, this paper outlines a solution example that leverages scale-out hardware and software technologies to deliver a generative AI application.
Over the past decade, the practical applications of artificial intelligence (AI have increased dramatically. The use of
AI-machine learning (ML) has become widespread, and more recently, the use of AI tools capable of comprehending and generating natural language has grown significantly. Within the context of generative AI, large language models (LLMs) have become increasingly practical due to multiple advances in hardware, software, and available tools. This provides companies across a range of industries the ability to deploy customized applications that can help provide significant competitive advantages.
However, there have been issues limiting the broad adoption of LLMs until recently. One of the biggest challenges was the massive investment in time, cost, and hardware required to fully train an LLM. Another ongoing concern is how firms can protect their sensitive, private-data to ensure information is not leaked via access in public clouds.
As part of Dell’s efforts to help firms build flexible AI platforms, Dell together with Broadcom are highlighting a scale-out architecture built on Dell and Broadcom equipment. This architecture can deliver the benefits of AI tools while ensuring data governance and privacy for regulatory, legal or competitive reasons.
By starting with pretrained LLMs and then enhancing or “fine-tuning” the underlying model with additional data, it is
possible to customize a solution for a particular use case. This advancement has helped solve two challenges companies previously faced: how to cost effectively train an LLM and how to utilize private domain information to deliver a relevant solution.
With fine-tuning, graphics processing units (GPUs) are utilized to produce high-quality results within reasonable timeframes. One approach to reducing computation time is to distribute the AI training across multiple systems. While distributed computing has been utilized for decades, often multiple tools are required, along with customization, requiring significant developer expertise.
In this demonstration, Dell and Broadcom worked with Scalers.AI to create a solution that leverages heterogeneous Dell PowerEdge Servers, coupled with Broadcom Ethernet network interface cards (NICs) to provide the high-speed internode communications required with distributed computing. Each PowerEdge system also contained hardware accelerators, specifically NVIDIA GPUs to accelerate LLM training.
Highlights for IT Decision Makers
The distributed training cluster included three Dell PowerEdge Servers, using multi-ported Broadcom NICs and multiple GPUs per system. The cluster was connected using a Dell Ethernet switch, which enabled access to the training data, residing on a Dell PowerScale network attached storage (NAS) system. Several important aspects of the heterogeneous Dell architecture provide an AI platform for fine-tuning and deploying generative AI applications. The key aspects include:
- Dell PowerEdge Sixteenth Gen Servers, with 4th generation CPUs and PCIe Gen 5 connectivity
- Broadcom NetXtreme BCM57508 NICs with up to 200 Gb/s per ethernet port
- Dell PowerScale NAS systems deliver high-speed data to distributed AI workloads
- Dell PowerSwitch Ethernet switches Z line support up to 400 Gb/s connectivity
This solution uses heterogenous PowerEdge Servers spanning multiple generations combined with heterogeneous NVIDIA GPUs using different form factors. The Dell PowerEdge Servers included a Dell XE8545 with four NVIDIA A100 GPU accelerators, a Dell XE9680 with eight Nvidia A100 accelerators, and a Dell R760XA with four NVIDIA H100 accelerators. The PE XE9680 acted as the both a Kubernetes head-node and worker-node. Each Dell PowerEdge system also included a Broadcom NIC for all internode communications and storage access to the Dell PowerScale NAS system
.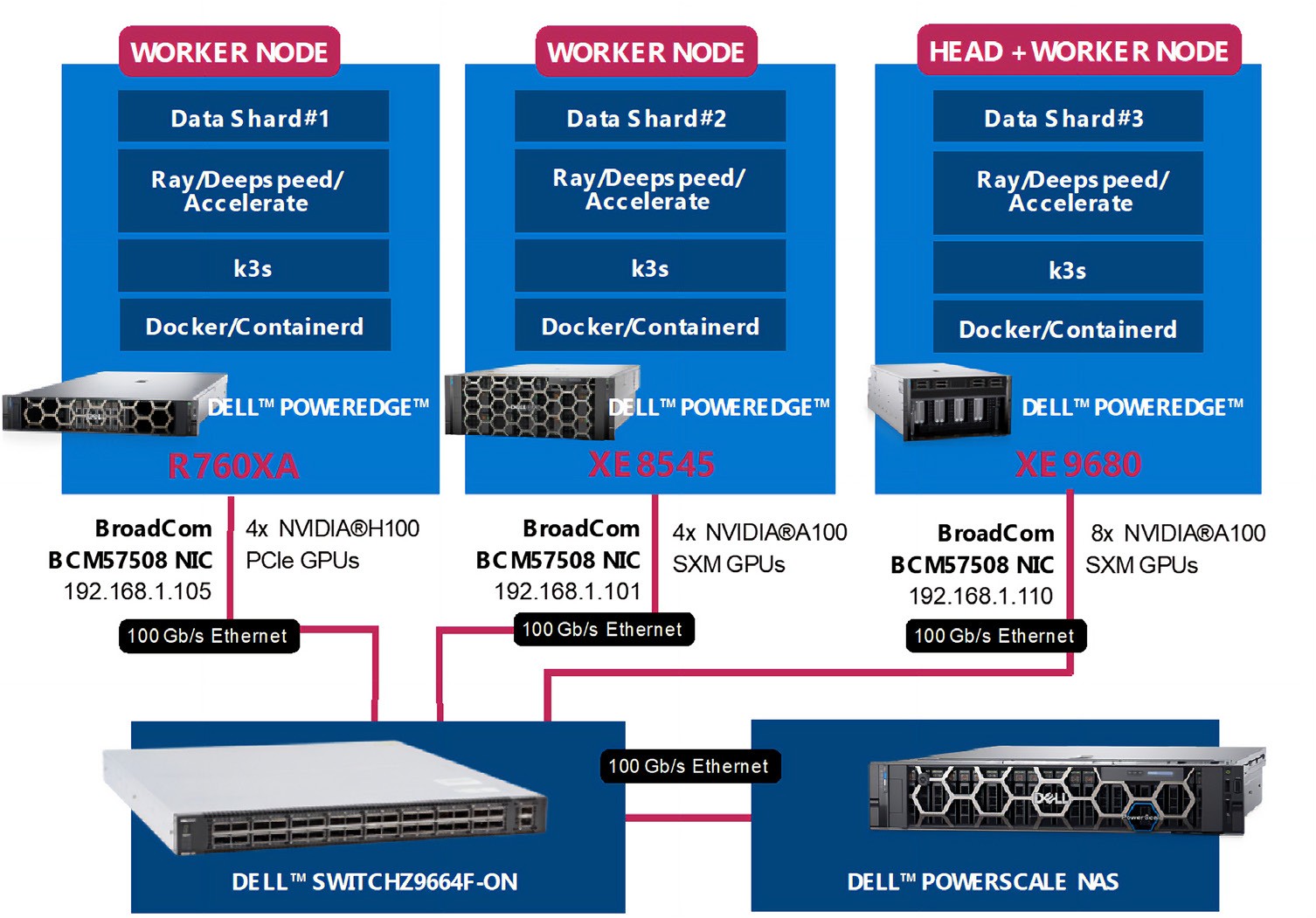
Futurum Group Comment: The hardware architecture utilized showcases the flexibility of using dissimilar, heterogeneous systems to create a scale-out cluster, connected using cost-effective Ethernet rather than proprietary alternatives. Together, Dell and Broadcom along with AI hardware accelerators provide the foundation for successful AI deployments. |
Broadcom BCM57508 Ethernet cards are an important aspect of the solution, solving a common bottleneck with distributed systems, the internode communications, with both bandwidth and latency as key factors. Broadcom’s Peer Direct and GPUDirect remote direct memory access (RDMA) technologies enable data to bypass host CPU and memory for direct transfer from the network into GPUs and other hardware accelerators. Without these technologies, data is driven by the CPU into local memory and then copied into the accelerator’s memory – adding to latency. Broadcom’s 57508 NICs allow data to be loaded directly into accelerators from storage and peers, without incurring extra CPU or memory overhead.
Dell PowerScale NAS for unstructured data used all-flash and RDMA-optimized data access to power the low-latency and high-bandwidth demands of AI workflows. PowerScale supports SMB3, NFSv3/v4 along with S3 object access for the scale-out storage that can meet the needs of AI projects while maintaining data privacy and corporate control over critical data.
Dell PowerSwitch Z-Series core switch line provides connectivity up to 400 Gb/s, with breakout options to support 100 GbE and lower as required. The Z series provides high-density data center Ethernet switching with a choice of network operating systems for fabric orchestration and management.
Highlights for AI Practitioners
A key aspect of the solution is the software stack that helps provide a platform for AI deployments, enabling scale-out infrastructure to significantly reduce training time. Importantly, this AI Platform as a Service architecture was built using Dell and Broadcom hardware components coupled with cloud native components to enable a containerized software platform with open licensing to reduce deployment friction and reduce cost.
- DeepSpeed: deep-learning optimization libraries
- Hugging Face: AI repository and HF-Accelerate library
- PyTorch: Widely utilized AI libraries
- Ray.IO: KubeRay distributed runtime management
- Kubernetes: K3s container native platform Nvidia
- GPUs and Cuda driver for fine-tuning
Futurum Group Comment: The utilized software stack is important for several reasons. First, the support for containerized workloads on Kubernetes is a common industry best practice, along with support for PyTorch, TensorFlow, and CUDA, which are widely utilized AI libraries. Finally, the use of the deep learning accelerators and libraries help automate distributed scale-out fine- tuning. Together this AI Platform plays a critical role in the overall solution’s success. |
The AI platform is based on K3s Kubernetes, Ray.IO KubeRay, Hugging Face Accelerate, Microsoft DeepSpeed, and other libraries and drivers including NVIDIA CUDA, PyTorch, and CNCF tools such as Prometheus and Grafana for data collection and visualization. Another key aspect was the use of the Hugging Face repository, which provided the various Llama 2 models that were trained, including the 7b, 13b, and 70b models containing 7, 13, and 70 billion parameters, respectively.
Additionally, the solution example is being made available through Dell partners on a GitHub repository, which contains the documentation and software tools utilized for this solution. The example provided helps companies quickly deploy a working example from which to begin building their own, customized generative AI solutions.
The distributed AI training setup utilizes the Dell and Broadcom hardware platform outlined previously and is shown in the subsequent steps.
Distributed AI Training Process Overview:
1. Data curation and preparation, including pre-processing as required 2. Load data onto shared NAS storage, ensuring access to each node 3. Deploy the KubeRay framework, leveraging the K3s Flannel virtual network overlayNote: Larger clusters might utilize partitioned networks with multiple NICs to create subnets to reduce inter- node traffic and potential congestion 4. Install and configure the Hugging Face Accelerate distributed graining framework, along with DeepSpeed and other required Python libraries |
Generative AI Training Observations
As described previously, the distributed AI solution was developed utilizing a trained, Llama 2 base model. The solution authors, Scalers.AI, performed fine tuning using each of the three base models from the Hugging Face repository, specifically, 7b, 13b, and 70b to evaluate the fine-tuning time required.

Futurum Group Comment: These results demonstrate the significant improvement benefits of the Dell – Broadcom scale-out cluster. However, specific training times per epoch and total training times are model and data dependent. The performance benefits stated here are shown as examples for the specific hardware, model size, and fine-tuning data used. |
Fine-tuning occurred over five training epochs, using two different hardware configurations. The first utilized a single node and the second configuration used the three-node, scale-out architecture depicted. The training time for the Llama-7b model fell from 120 minutes to just over 46 minutes, which was 2.6 times faster. For the larger Lama-13b model, training time on a single- node was 411 minutes, while the three-node cluster time was 148 minutes, or 2.7 times faster.
Figure 4 shows an overview of the scale-out architecture.

Figure 4: Scale-Out AI Platform Using Dell and Broadcom (Source: Scalers.AI)
A critical aspect of distributed training is that data is split, or “sharded,” with each node processing a subset. After each step, the AI model parameters are synchronized, updating model weights with other nodes. This synchronization is when the most significant network bandwidth utilization occurred, with spikes that approached 100 Gb/s. Distributed training, like many high- performance computing (HPC) workloads, is highly dependent on high bandwidth and low latency for synchronization and communication between systems. Additionally, networking is utilized for accessing the shared NFS training data, which enables easily scaling the solution across multiple nodes without moving or copying data.
To add domain-specific knowledge, an open source “pubmed” data set was used to provide relevant medical understanding and content generation capabilities. This data set was used to enhance the accuracy of medical questions, understanding medical literature, clinician notes, and other related medical use cases. In a real-world deployment, it would be expected that an organization would utilize their own, proprietary, and confidential medical data for fine-tuning.
Another important aspect of the solution, the ability to utilize private data, is a critical part of why companies are choosing to build and manage their own generative AI workflows using systems and data that they manage and control. Specifically,
companies operating in healthcare can maintain compliance with Health Insurance Portability and Accountability Act (HIPAA)/ Health Information Technology for Economic and Clinical Health (HITECH) Act and other regulations around electronic medical record (EMR) and patient records.
Final Thoughts
Recently, the ability to deploy generative AI based applications has been made possible through the rapid advancement of AI research, hardware capabilities combined with open licensing of critical software components. By combining a pre-trained model with proprietary data sets, organizations are able to solve several challenges that were previously solvable by only the very largest corporations. Leveraging base models from an open repository removes the significant burden of training large parameter models and the billions in dollars of resources required.
| Futurum Group Comment: The solution example demonstrated by Dell, Broadcom, and Scalers.AI highlights the possibility of creating a customized, generative AI toolset that can enhance business operations cost effectively and economically. Leveraging heterogenous Dell servers, storage, and switching together with readily available GPUs and Broadcom high-speed ethernet NICs provides a flexible hardware foundation for a scale-out AI platform. |
Additionally, the ability to build and manage both the hardware and software infrastructure helps companies compete effectively while balancing their corporate security concerns and ensuring their data is not compromised or released externally.
The demonstrated AI model leverages key Dell and Broadcom hardware elements along with available GPUs as the foundation for a scalable AI platform. Additionally, the use of key software elements helps enable distributed training optimizations that leverage the underlying hardware to provide an extensible, self-managed AI platform that meets business objectives regardless of industry.
The solution that was demonstrated highlights the ability to distribute AI training across multiple heterogenous systems to reduce training time. This example leverages the value and flexibility of Dell and Broadcom infrastructure as an AI infrastructure platform, combined with open licensed tools to provide a foundation for practical AI development while safeguarding private data.
Important Information About this Lab Insight:
CONTRIBUTORS
Randy Kerns
Senior Strategist and Analysts | The Futurum Group
Russ Fellows
Head of Futurum Labs | The Futurum Group
PUBLISHER
Daniel Newman
CEO | The Futurum Group
INQUIRIES
Contact us if you would like to discuss this report and The Futurum Group will respond promptly.
CITATIONS
This paper can be cited by accredited press and analysts, but must be cited in-context, displaying author’s name, author’s title, and “The Futurum Group.” Non-press and non-analysts must receive prior written permission by The Futurum Group for any citations.
LICENSING
This document, including any supporting materials, is owned by The Futurum Group. This publication may not be
reproduced, distributed, or shared in any form without the prior written permission of The Futurum Group.
DISCLOSURES
The Futurum Group provides research, analysis, advising, and consulting to many high-tech companies, including those mentioned in this paper. No employees at the firm hold any equity positions with any companies cited in this document.
ABOUT THE FUTURUM GROUP
The Futurum Group is an independent research, analysis, and advisory firm, focused on digital innovation and market-disrupting technologies and trends. Every day our analysts, researchers, and advisors help business leaders from around the world anticipate tectonic shifts in their industries and leverage disruptive innovation to either gain or maintain a competitive advantage in their markets.


Llama-2 on Dell PowerEdge XE9640 with Intel Data Center GPU Max 1550
Fri, 12 Jan 2024 18:04:24 -0000
|Read Time: 0 minutes
Part two is now available: https://infohub.delltechnologies.com/p/expanding-gpu-choice-with-intel-data-center-gpu-max-series/
 |  |  |  |
| MORE CHOICE IN THE GPU MARKET
We are delighted to showcase our collaboration with Intel® to introduce expanded options within the GPU market with the Intel® Data Center GPU Max Series, now accessible via Dell™ PowerEdge™ XE9640.
The Intel® Data Center GPU Max Series is Intel® highest performing GPU with more than 100 billion transistors, up to 128 Xe cores, and up to 128 GB of high bandwidth memory. Intel® Data Center GPU Max Series pairs seamlessly with Dell™ PowerEdge™ XE9640, Dell™ first liquid-cooled 4-way GPU platform in a 2u server.
Dell™ recently announced partnerships with both Meta and Hugging Face to enable seamless support for enterprises to select, deploy, and fine-tune AI models for industry specific use cases anchored by Llama 2 7B Chat from Meta.
We put Dell™ PowerEdge™ XE9640 and Intel® Data Center GPU Max Series to the test with the Llama-2 7B Chat model. In doing so, we tested the tokens per second and the number of concurrent users that can be supported while scaling up to four GPUs. Dell™ PowerEdge™ XE9640 and Intel® Data Center GPU Max Series showcased a strong scalability and met target end user latency goals.
“Scalers AI™ ran eight concurrent processes of Llama-2 7B Chat with Dell™ PowerEdge™ XE9640 and Intel® Data Center GPU Max Series for a total throughput of >107 tokens per second, achieving our end user token latency target of 100 milliseconds”
 Chetan Gadgil, CTO at Scalers AI
Chetan Gadgil, CTO at Scalers AI
| LLAMA-2 7B CHAT MODEL
Large Language Models (LLMs) are powerful deep learning architectures that have been pre-trained on large datasets such as OpenAI ChatGPT. We have chosen to test Llama-2 7B Chat because it is an open source model that can be leveraged for commercial use cases, such as coding, functional tasks, and even creative tasks.
For inference testing in Large Language Models such as Llama-2 7B Chat, GPUs are incredibly useful due to their parallel processing architecture which can handle Llama-2's massive parameter sets. To efficiently handle expanding datasets, powerful GPUs such as Intel® Data Center GPU Max 1550 are critical.
| ARCHITECTURE
We started our testing environment with Dell™ PowerEdge™ XE9640 with four Intel® Data Center GPU Max 1550, running on Ubuntu 22.04.
We used Hugging Face Optimum, an extension of Transformers that provides a set of performance optimization tools to train and run models on targeted hardware, ensuring maximum efficiency. For Intel® Data Center GPU Max 1550, we selected the Optimum-Intel package. Optimum-intel integrates libraries provided by Intel® to accelerate end-to-end pipelines on Intel®. With Optimum-intel you can optimize your model to Intel® OpenVINO™ IR format and attain enhanced performance using the Intel® OpenVINO™ runtime.

Dell™ PowerEdge™ XE9640 Intel® Data Center GPU Max 1550
Source: https://www.dell.com/ Source: https://www.intel.com
| SYSTEM SET-UP SETUP
1. Installation of Drivers
To install drivers for the Intel® Data Center GPU Max Series, we followed the steps here.
2. Verification of Installation
To verify the installation of the drivers, we followed the steps here.
3. Installation of Docker
To install Docker on Ubuntu 22.04.3., we followed the steps here.
| RUNNING THE LLAMA-2 7B CHAT MODEL
1. Set up a Docker container for all our dependencies to ensure seamless deployment and straightforward replication:
sudo docker run --rm -it --privileged --device=/dev/dri --ipc=host intel/intel-extension-for-pytorch:xpu-max-2.0.110-xpu bash
2. To install the Python dependencies, our Llama-2 7B Chat model requires:
pip install openvino==2023.2.0
pip install transformers==4.33.1
pip install optimum-intel==1.11.0
pip install onnx==1.15.0
3. Access the Llama-2 7B Chat model through HuggingFace:
huggingface-cli login
4. Convert the Llama-2 7B Chat HuggingFace model into Intel® OpenVINO™ IR format using Intel® Optimum to export it:
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(model_id, export=True) model.save_pretrained("llama-2-7b-chat-ov")
tokenizer.save_pretrained("llama-2-7b-chat-ov")
5. Run the code snippet below to generate the text with the Llama-2 7B Chat model:
import time
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_name = "llama-2-7b-chat-ov"
input_text = "What are the key features of Intel's data center GPUs?"
max_new_tokens = 100
# Initialize and load tokenizer, model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OVModelForCausalLM.from_pretrained(model_name, ov_config= {"INFERENCE_PRECISION_HINT":"f32"}, compile=False)
model.to("GPU")
model.compile()
# Initialize HF pipeline
text_generator = pipeline( "text-generation", model=model, tokenizer=tokenizer, return_tensors=True, )
# Inference
start_time = time.time()
output = text_generator( input_text, max_new_tokens=max_new_tokens ) _ = tokenizer.decode(output[0]["generated_token_ids"])
end_time = time.time()
# Calculate number of tokens generated
num_tokens = len(output[0]["generated_token_ids"])
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| ENTER PROMPT
What are the key features of Intel® Data Center GPUs?
Output
Intel® Data Center GPUs are designed to provide high levels of performance and power efficiency for a wide range of applications including machine learning, artificial intelligence and high performance computing.
Some of the key features of Intel® Data Center GPUs include:
1. High performance Intel® Data Center GPUs are designed to provide high levels of performance for demanding workloads, such as deep learning and scientific simulations.
2. Power efficiency.
| PERFORMANCE RESULTS & ANALYSIS

Figure: Comparing GPU vs CPU Performance
During the evaluation of the GPU configurations performance, we observed that a machine with a single GPU achieved a throughput of ~13 tokens per second across two concurrent processes. With two GPUs, we noted ~13 tokens per second across four concurrent processes for a total throughput of ~54 tokens per second. With four GPUs, we observed a total throughput of ~107 tokens per second supporting eight processes concurrently. The latency per process remains well below Scalers AI™ target of 100 milliseconds, despite an increase in the number of concurrent processes.
As latency represents the time a user must wait before task completion, it is a critical metric for hardware selection on large language models. This evaluation underscores the significant impact of GPU parallelism on both throughput and user response time. The scalability from one GPU to four GPUs reflects a significant enhancement in computational power, enabling more concurrent processes at nearly the same latency.
Our results demonstrate that Dell™ PowerEdge™ XE9640 with four Intel® Data Center GPU Max 1550 is up to the task of running Llama-2 7B Chat and meeting end user experience targets.
Number of GPUS | Throughput (Tokens/second) | Number of processes | Token Latency (ms) |
1 | 26.83 | 2 | 74.55 |
2 | 53.81 | 4 | 74.34 |
3 | 80.35 | 6 | 74.68 |
4 | 107.55 | 8 | 74.38 |
Table: Results after taking different number of GPUs
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| ABOUT SCALERS AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offerings include custom large language models and multimodal platforms supporting voice, image, and text. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
| Dell™ PowerEdge™ XE9640 Key specifications
MACHINE | Dell™ PowerEdge™ XE9640 |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8468 |
MEMORY | 512Gi |
GPU | Intel® Data Center GPU Max 1550 |
GPU COUNT | 4 |
SOFTWARE STACK | Intel® OpenVINO® - 2023.2.0 transformers - 4.33.1 optimum-intel - 1.11.0" xpu-smi - 1.2.22.20231025 |
| HUGGING FACE OPTIMUM
Learn more: https://huggingface.co
| TEST METHODOLOGY
The Llama-2 7B Chat FP32 model is exported into the Intel® OpenVINO™ format and then tested for text generation (inference) using Hugging Face Optimum. Hugging Face Optimum is an extension of Hugging Face transformers and Diffusers that provides tools to export and run optimized models on various ecosystems including Intel® OpenVINO™.
For performance tests, 20 iterations were executed for each inference scenario out of which initial five iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Read part two: https://infohub.delltechnologies.com/p/expanding-gpu-choice-with-intel-data-center-gpu-max-series/

Optimizing Performance Per Watt with Dell PowerEdge XR Servers
Thu, 14 Mar 2024 16:48:00 -0000
|Read Time: 0 minutes

Executive Summary
With power and cooling costs accounting for increasingly large portions of IT budgets, IT departments looking to minimize total cost of ownership (TCO) are making power efficiency a priority when choosing server hardware. This white paper will examine the power efficiency of Dell Edge servers in the multi-node, 2U form factor, a form factor that is one of the most popular in many Edge and Telecom use cases because of the balance it strikes between density and expandability. This white paper will present and analyze power efficiency results for several Dell current-generation PowerEdge XR servers and also illustrate how those results compare on various parameters with a prior-generation Dell Edge server.
The environmental conditions for telecom edge computing are typically vastly different than those at centralized data centers. Telecom edge computing sites might, at best, consist of little more than a telecommunications closet with minimal or no HVAC. Thus, ruggedized, front-access servers are ideal for such deployments. The Dell PowerEdge servers checks all of the boxes.
Dell Technologies commissioned Tolly to evaluate the power efficiency of Dell’s XR8000, XR4000, XR5610, and XR11 servers using the industry standard Standard Performance Evaluation Corporation (SPEC) SPECPower benchmark and compare those to each other. The SPECPower benchmark measures server-side Java (SSJ) throughput and system power consumption. The benchmark calculates SSJ operations per watt of system power consumed. All analysis was based on public data submitted to the SPEC and published on their website.[1]
The Dell PowerEdge XR8000, XR4000, XR5610, and XR11 are all highly-capable edge servers but offer customers different options with respect to form factor, CPU specifications, and power efficiency/cost. The following summary tables provide insights into the value each offers from a different perspective of performance, cost, and energy usage.
The first table, below, summarizes the raw performance results calculated by SPECPower. As one would expect, the newer systems deliver higher performance per watt the older systems. The XR5610[2] and XR11 were measured on 32 cores where the other two systems were measured on 64 cores.
Table 1. SPECPower - Performance/Watt
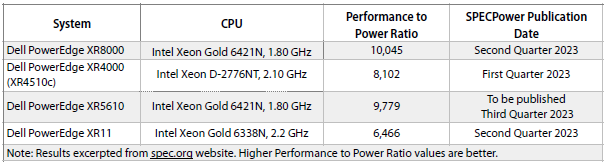 The second table, below, analyzes results on a “per core” basis as the various Dell systems have either 32 or 64 cores. The XR4000 results are 26% higher than the XR11 results, the XR8000 results are 42% higher than the XR11, and the XR5610 results are 62% higher than the XR11 roughly tracking the results shown in the previous table for the entire systems.
The second table, below, analyzes results on a “per core” basis as the various Dell systems have either 32 or 64 cores. The XR4000 results are 26% higher than the XR11 results, the XR8000 results are 42% higher than the XR11, and the XR5610 results are 62% higher than the XR11 roughly tracking the results shown in the previous table for the entire systems.
Table 2. SPECPower - Performance/CPU Core
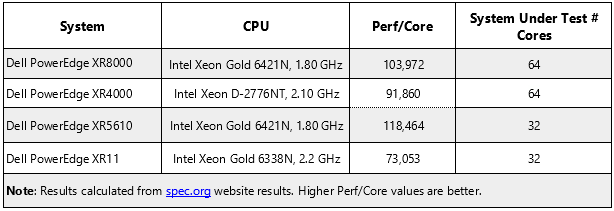
The third table, below, calculates watts consumed per CPU core without reference to performance.The XR4000 and the XR11 results are within 2% of each other. The XR8000 results are13% better than the XR11 and the XR5610 results are 7% better than the XR11. Note that the XR11 is powered by an Intel 3rd Gen Xeon SP CPU while the XR4000 is powered by an Intel Xeon-D CPU.
Table 3. SPECPower - Watts/CPU Core
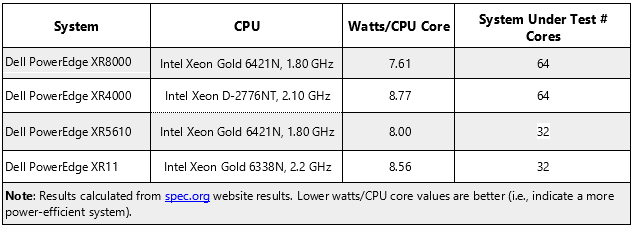
The fourth table, below, factored in the cost of the CPU into the perf/watt equation. Thus, lower cost CPUs will have higher values in this table when the raw performance is the same as higher cost CPUs. The XR4000 results are 120% better than the XR11 results, the XR8000 results are 110% better than the XR11, and the XR5610 results are 104% better than the XR11.
Table 4. SPECPower - Perf/Watts/CPU Cost
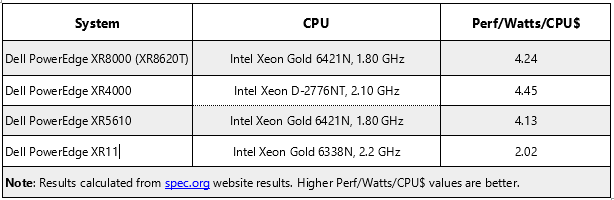
The fifth table, below, provides links to details of each of the CPUs evaluated.
Table 5. Dell PowerEdge Server Systems - Intel CPU Detail Links
System | CPU | Intel Reference Link |
Dell PowerEdge XR8000 (XR8620T) & Dell PowerEdge 5610 | Intel Xeon Gold 6421N, 1.80 GHz | |
Dell PowerEdge XR4000 | Intel Xeon D-2776NT, 2.10 GHz | |
Dell PowerEdge XR11 | Intel Xeon Gold 6338N, 2.2 GHz |
Competitive Positioning
Based on the publicly available data from spec.org/power, we can see high capacity data intensive workload targeted HPE and Supermicro servers. Although these are not direct competitors to Dell PowerEdge XR servers, it is worthwhile to note that the perf/watt/CPU$ for XR8000 is better than both HPE ProLiant DL360 Gen11 (Intel Xeon Platinum 8480+ 2.0 GHz), HPE ProLiant DL380 Gen 1 (Intel Xeon Platinum 8480+ 2.0 GHz), as well as the Supermicro SYS-621C-TN12R (Intel Xeon Platinum 8490H 1.90GHz).
Dell XR servers provide solutions for various edge workloads in a short form factor, edge optimized with power efficiency consideration taken into account.
Air Cooling
Dell created Multi-Vector Cooling (MVC) to maximize the potential of air cooling. It includes control algorithms, thermal and power sensors, component mapped fan zoning and airflow channeling shrouds to balance and intelligently direct airflow across the systems’ components.
New high-performance fans and heatsinks, as well as special airflow-optimized configurations, ensure even high-power CPUs are supported without throttling.
For more information, go to https://www.dell.com/en-us/blog/better-ways-to-cool-your-poweredge-servers, read this “Direct from Development” (DfD) note https://infohub.delltechnologies.com/p/understanding-thermal-design-and-capabilities-for-the-poweredge-xr8000-server, or view a video on the topic at: https://www.youtube.com/watch?v=-rHEXJsX75Y&ab_channel=DellTechnologies.
Telecom Edge Computing
Wireless telecom providers world-wide have at least two things in common: seemingly endless growth, and the rapid migration from specialized, proprietary radio access network (RAN) hardware to scalable, software-based vRAN solutions. Over two dozen system operators and nearly 300 related companies and academic institutions are part of the Open RAN Alliance (O-RAN) working together to bring an open solution to the industry.[3]
The telecom edge, thus, needs ruggedized servers built to resist demanding environmental conditions while delivering significant compute power with cost-efficient use of electric power.
Dell, an acknowledged information technology leader, builds servers that are designed for both the processing requirements and physical deployment requirements of edge servers with a particular focus on telecom applications. In particular, the Dell PowerEdge XR8000 and Dell PowerEdge XR4000 edge servers provides a powerful and flexible selection of configurations focused on the particular needs of the telecom edge.[4]
- Built to withstand extreme heat & dust; operating temperature range from -5 to 55C
- Efficient use of electric power
- Suitable for shock and vibration of factory floors & construction site
- Can be deployed in distributed telecom and other extreme environments
- Short depth (355mm), small form factor
- Ruggedized; tested for NEBS and MIL-STD
- Multi-node capable
PowerEdge XR4000: Scalability and Flexibility with HCI Capabilities
The Dell PowerEdge XR4000 Edge Server is part of Dell’s family of purpose-built, ruggedized servers. The PowerEdge XR4000 is built for environments like telecom edge deployment or factory floors where the servers could be subjected to demanding conditions including high temperatures, dust, shock and vibrations.
The high-performance, multinode XR4000 server was purpose built to address the demands of today’s retail, manufacturing and defense customers. It was designed around a unique chassis and compute sled(s) concept. The actual computer resides in modular 1U or 2U sled form factors. The only shared component between the sleds is power. The server is also designed to support hyperconverged infrastructure (HCI).
The XR4000 is available in two 14" depth “rackable” and “stackable” chassis form factors. The optional nano server sled replaces the need for a virtual witness node. The in-chassis witness node allows for native, two-node vSAN clusters in the stackable server chassis.
The servers are small form factor, short depth units that can be deployed alone or in multi-node configurations.

The XR4000 used for this test was an XR4520c 2U compute sled. See table below for key specifications.
Table 6. Dell PowerEdge XR4520 Compute Sled Key Specifications

PowerEdge XR8000: Flexible, Innovative, Sled-based RAN-Optimized Server
The Dell PowerEdge XR8000 Edge Server is the newest addition Dell’s family of purpose-built, ruggedized servers. The PowerEdge XR4000 is built for environments like telecom edge environments where the servers could be subjected to demanding conditions including high temperatures, dust, shock and vibrations.
The short-depth XR8000 server, which comes in a sledded server architecture (with 1U and 2U single-socket form factors), is optimized for total cost of ownership (TCO) and performance in O-RAN (radio access network) applications. It is RAN optimized with integrated networking and 1/0 PTP/SyncE support. And its front-accessible design radically simplifies sled serviceability in the field.
The XR8000 offers options for multiple sled form factors with up to four nodes per chassis that can work together or independently. The 2U half-width sled configuration accommodates general purpose compute at the edge / far edge, while the 1U half-width sled configuration is ideal for dense compute and network edge-optimized workloads.

Table 7. Dell PowerEdge XR8620 Compute Sled Key Specifications
 The XR8000 delivers extended tolerance to heat and cold with enhanced heatsinks and optimized airflow design. The system supports Sapphire Rapids SP and Edge Enhanced (EE) processors with Intel vRAN Boost, on-chip acceleration and includes both DC and AC power supply options and five total power supply unit (PSU) variants
The XR8000 delivers extended tolerance to heat and cold with enhanced heatsinks and optimized airflow design. The system supports Sapphire Rapids SP and Edge Enhanced (EE) processors with Intel vRAN Boost, on-chip acceleration and includes both DC and AC power supply options and five total power supply unit (PSU) variants
PowerEdge XR5610: All-Purpose, Rugged 1U Edge Server
The Dell PowerEdge XR8000 Edge Server is a new addition Dell’s family of purpose-built, ruggedized servers. As with the PowerEdge XR8000 and PowerEdge XR4000, the PowerEdge XR5610 is built for environments where the servers could be subjected to demanding conditions including high temperatures, dust, shock and vibrations. The XR5610 is the upgraded successor to the XR11 that is also covered in this report.
The PowerEdge XR5610 is a 1U, single-socket server designed for target workloads in networking and communication, enterprise edge, military, and defense. It is well suited for 5G vRAN and ORAN telecom workloads, as well as military and defense deployments and retail AI including video monitoring, IoT device aggregation and PoS analytics. The design specification supports continuous operation in extreme temperatures ranging from -5C to 55C. The design is ruggedized, compliant, and compact.
The server features a filtered smart bezel for dust reduction and the server has undergone MIL810H and NEBS Level 3 testing for handling shocks and vibrations.

Table 8. Dell PowerEdge XR5610 Key Specifications

SPECPower Workload & Results
The Standard Performance Evaluation Corporation (SPEC), according to their website, “is a non-profit corporation formed to establish, maintain and endorse standardized benchmarks and tools to evaluate performance and energy efficiency for the newest generation of computing systems. SPEC develops benchmark suites and also reviews and publishes submitted results from our member organizations and other benchmark licensees.”
SPEC has established benchmarks, to date, in some nine different areas. In addition to power, the focus of this report, the benchmarks include Machine Learning, High Performance Computing, Virtualization, and more.
Server vendors run the benchmark tests in their own labs according to the SPEC benchmark specifications. Vendors may use the results internally and/or they can submit the results to SPEC for review and publication. Once published, the results are freely available and can be used by others in public reports so long as that use complies with the SPEC “Fair Use Policy” for the given benchmark.
SPECPower_ssj2008 Benchmark
As evidenced by its name, the SPECPower benchmark was issued in 2008. The workload, represented in the name by “ssj,” is “Server Side Java (SSJ).“ The benchmark drives the load on the target server while also measuring the power consumption of the server.
While the benchmark allows for different java virtual machines (JVM) to be used in the benchmark, the Oracle JVM is used almost exclusively for the tests. The results document CPU and memory configurations of the systems and reports “submeasurements” of SSL operations at 100% CPU, average watts consumed at 100%, and average watts at idle. The result reported is the overall SSJ operations divided by the watts consumed.
It is important to note that the test is run at 10 different loads from 10% to 100% in increments of 10% load. Only the 100% results are displayed in the SPECPower results table but the SPECPower “result” value is an average of all ten tests.
Raw Results
All results referenced in this report are available to the general public on the SPEC site at: https://www.spec.org/power_ssj2008/results. The information in the following tables is excerpted from the public results. The table, below, contains the submeasurements and the final result for each system discussed in the paper. All other results in this paper are calculated using the the SPECPower raw results below.
Table 9. SPEC SPECPower_ssj2008 Results
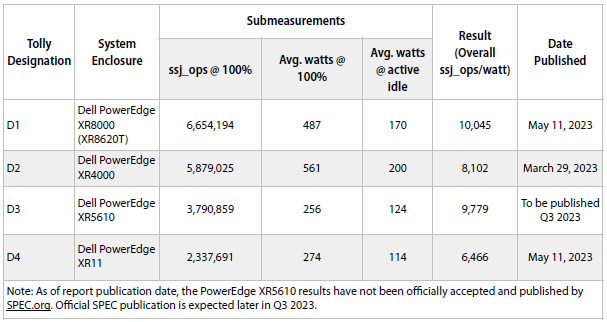
Server Specifications
The table, below, contains the server system specifications as shown on the SPEC results website. All systems were tested using Oracle Corporation’s JVM.
Table 10. Server System Specifications
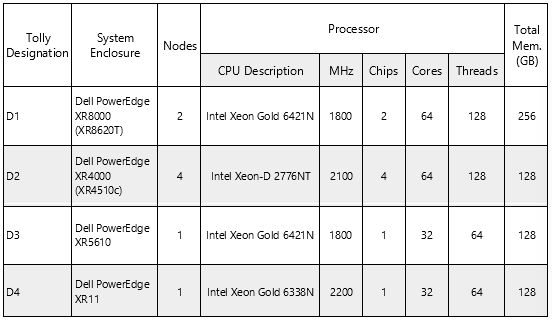
System BIOS Settings
The tests used Dells recommended BIOS settings for power efficiency. The Dell PowerEdge XR8000 and Dell PowerEdge XR4000 systems both used the following BIOS settings.
Table 11. Server System BIOS Settings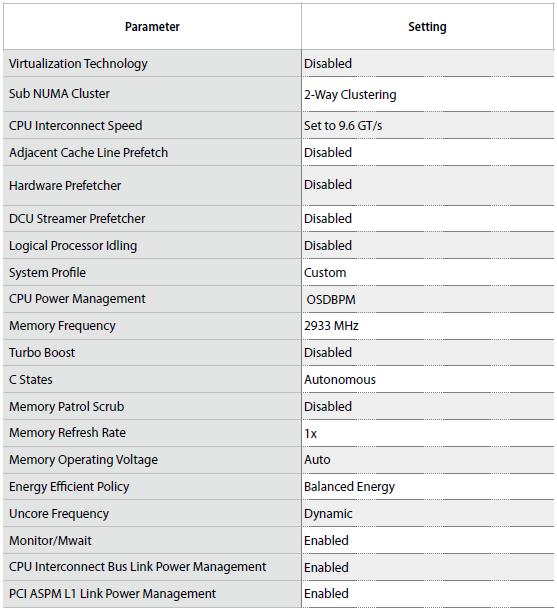
XR Series Price/Power Efficiency Claims
The charts below visualize the tabular results presented in the Executive Summary section earlier in this report.
Performance/Watt (Performance-to-Power-Ratio)
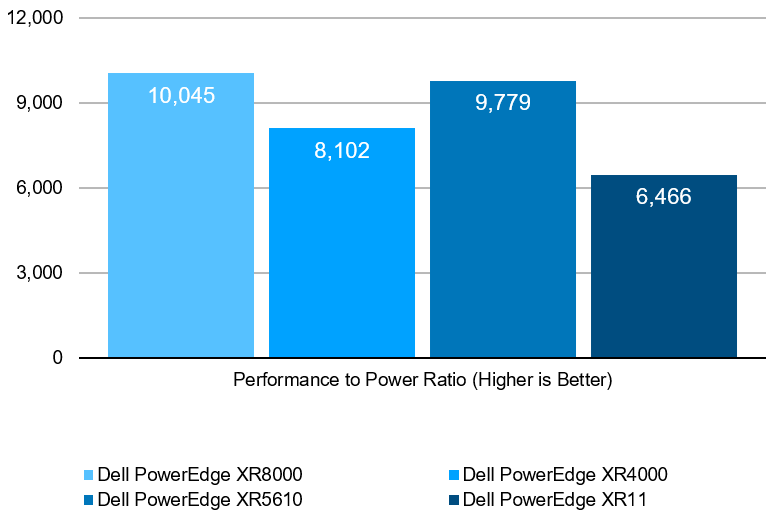
Performance/CPU Core
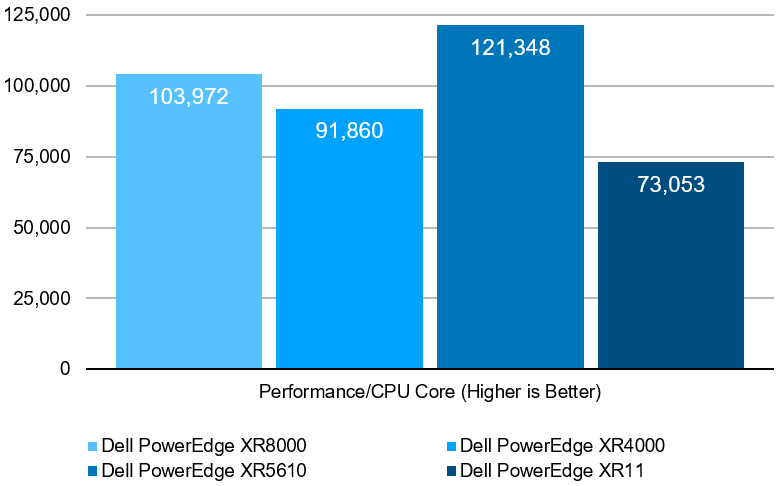
Watt/CPU Core
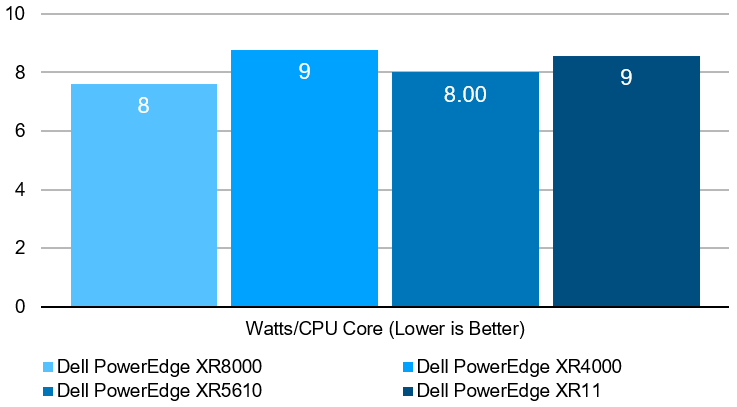
Performance/Watt/CPU Cost
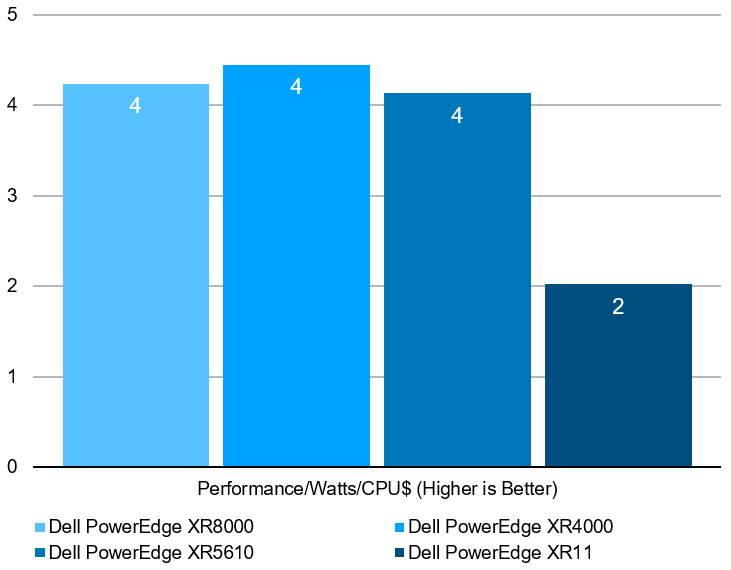
About Tolly
The Tolly Group companies have been delivering world-class IT services for more than 30 years. Tolly is a leading global provider of third-party validation services for vendors of IT products, components and services.
You can reach the company by E-mail at sales@tolly.com, or by telephone at +1 561.391.5610.
Visit Tolly on the Internet at: http://www.tolly.com
Terms of Usage
This document is provided, free-of-charge, to help you understand whether a given product, technology or service merits additional investigation for your particular needs. Any decision to purchase a product must be based on your own assessment of suitability based on your needs. The document should never be used as a substitute for advice from a qualified IT or business professional. This evaluation was focused on illustrating specific features and/or performance of the product(s) and was conducted under controlled, laboratory conditions. Certain tests may have been tailored to reflect performance under ideal conditions; performance may vary under real-world conditions. Users should run tests based on their own real-world scenarios to validate performance for their own networks.
Reasonable efforts were made to ensure the accuracy of the data contained herein but errors and/or oversights can occur. The test/audit documented herein may also rely on various test tools the accuracy of which is beyond our control. Furthermore, the document relies on certain representations by the sponsor that are beyond our control to verify. Among these is that the software/hardware tested is production or production track and is, or will be, available in equivalent or better form to commercial customers. Accordingly, this document is provided "as is", and Tolly Enterprises, LLC (Tolly) gives no warranty, representation or undertaking, whether express or implied, and accepts no legal responsibility, whether direct or indirect, for the accuracy, completeness, usefulness or suitability of any information contained herein. By reviewing this document, you agree that your use of any information contained herein is at your own risk, and you accept all risks and responsibility for losses, damages, costs and other consequences resulting directly or indirectly from any information or material available on it. Tolly is not responsible for, and you agree to hold Tolly and its related affiliates harmless from any loss, harm, injury or damage resulting from or arising out of your use of or reliance on any of the information provided herein.
Tolly makes no claim as to whether any product or company described herein is suitable for investment. You should obtain your own independent professional advice, whether legal, accounting or otherwise, before proceeding with any investment or project related to any information, products or companies described herein. When foreign translations exist, the English document is considered authoritative. To assure accuracy, only use documents downloaded directly from Tolly.com. No part of any document may be reproduced, in whole or in part, without the specific written permission of Tolly. All trademarks used in the document are owned by their respective owners. You agree not to use any trademark in or as the whole or part of your own trademarks in connection with any activities, products or services which are not ours, or in a manner which may be confusing, misleading or deceptive or in a manner that disparages us or our information, projects or developments.
Tolly Report #223124
August 2023
© 2023 TOLLY ENTERPRISES, LLC www.tolly.com
[2] At publication time the XR5610 results were being prepared for submission to SPEC and should appear later in Q3 2023.

Abstract: A Path to Virtualization at the Edge
Thu, 14 Mar 2024 16:47:31 -0000
|Read Time: 0 minutes

Picking the right edge-computing option from the Dell™ PowerEdge™ XR family of servers.
 The Ever-Growing Importance of Edge Computing
The Ever-Growing Importance of Edge Computing
Data at the edge is rich with information. For the most actionable insights, especially with power-hungry workloads like data analytics and AI/ML, modern organizations capture and analyze data when and where it’s generated—even when that location is in an unforgiving environment far from the data center, such as an oil rig in the North Sea.
Prowess Consulting investigated some of the latest-generation edge-computing servers from Dell Technologies to see how they meet the challenge of keeping up with performance needs in the most hostile environments. We looked at inter- and intra-generational differences, compared specs and VMmark® results, and considered potential use cases.
We found that, for organizations looking for the ideal edge server, the Dell™ PowerEdge™ XR7620 server delivers high performance, including excellent virtualization capabilities and VMware vSAN™ performance, whereas PowerEdge XR4000 series servers deliver excellent density and deployment flexibility.
The Unforgiving Edge
Workloads like data analytics and AI/ML, which process data at the edge, drive the need for high performance. And a host of environmental and logistical challenges arise when you move that high performance to the edge. For example, a factory that combines Internet of Things (IoT) and digital twin technologies to automate resource allocation and optimize efficiency through analytics and AI will need servers on the factory floor to generate and capture actionable data. And that means exposure to heat, vibration, dust, and more.
How your organization addresses these considerations of performance and durability inherent to edge computing is key. Regardless of your solution, maximizing performance and safeguarding against harsh environments is critical.
The PowerEdge XR7620 Server: A Generational Update
Figure 1 provides a quick visual reference for the servers discussed in this abstract.
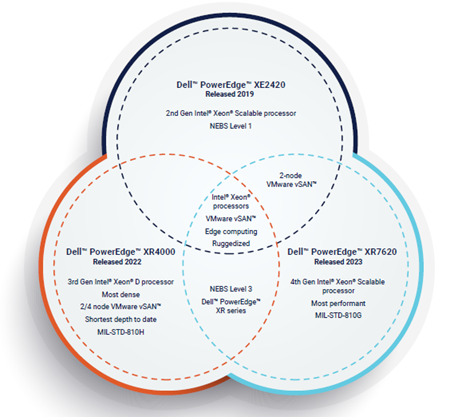
Figure 1. Venn diagram of the Dell™ PowerEdge™ XE2420, XR7620, and XR4000 series servers
PowerEdge XR7620 Server vs. PowerEdge XE2420 Server
Prowess Consulting examined the performance difference between the PowerEdge XR7620 server and its previous generation, the PowerEdge XE2420 server.
The 4th Gen Intel® Xeon® Scalable processors powering the PowerEdge XR7620 server provide several benefits over the 2nd Gen Intel Xeon Scalable processors powering the PowerEdge XE2420 server. These benefits include:
- 1.53x average generation-on-generation performance improvement[1]
- Up to 1.60x higher input/output operations per second (IOPS) and up to 37% latency reduction for large-packet sequential reads using integrated Intel® Data Streaming Accelerator (Intel® DSA) versus the prior generation[2]
- Up to 95% fewer cores and 2x higher level-1 compression throughput using integrated Intel® QuickAssist Technology (Intel® QAT) versus the prior generation[3]
This improved performance between generations can also been seen by comparing VMware vSAN deployments. The PowerEdge XE2420 server and the PowerEdge XR7620 server can both implement two-node vSAN deployments. However, as noted previously, the PowerEdge XR7620 server will be more performant with those deployments. This higher level of performance doesn’t just come from the upgraded processor, either. The 4th Gen Intel Xeon Scalable processors in the PowerEdge XR7620 server are optimized to take full advantage of the new features and software improvements in VMware vSphere® 8, including GPU- and CPU-based acceleration.
VMmark® Examination of PowerEdge XR7620 and PowerEdge XR4000 Series Servers
The PowerEdge XR7620 server is part of the PowerEdge XR family of servers, all of which are built to handle the most extreme environments while still delivering performance and reliability. We wanted to examine the PowerEdge XR7620 server alongside its “younger siblings,” the PowerEdge XR4000 series servers, and investigate the intra-generational differences in the PowerEdge XR family. (While not discussed in this study, the PowerEdge XR8000 series servers provide excellent flexibility and stability, and would be the “elder sibling” in the family.)
The VMmark results show the PowerEdge XR7620 server can achieve more performance across more tiles (fourteen versus four). These results also illustrate what can be achieved at the edge with a full, dual-socket server using the latest-generation processors in a short depth, 2U ruggedized chassis at the edge. While the PowerEdge XR7620 server’s overall performance wins are expected, what’s missing is how performant at the edge the PowerEdge XR4000 series servers are. Given the smaller size and shorter form factor overall, the PowerEdge XR4000 series servers are very performant relative to size, and they are an excellent option when a smaller, denser, more flexible deployment is called for. Moreover, their redundancy allows for more hardware failures, making them resilient and durable.
VMware vSAN is widely deployed as a virtualization software and hyperconverged infrastructure (HCI) solution, so we compared vSAN deployments inter-generationally as well. While both servers take advantage of vSAN, the PowerEdge XR7620 server will offer more overall performance, whereas PowerEdge XR4000 series servers offer the highest density in the smallest form factor.
There is, however, another significant benefit to the upgraded PowerEdge XR7620 server: power savings and sustainability. As shown in our technical research study, the PowerEdge XR7620 server offers double the cores of the PowerEdge XR4510c server tested, for less than double the wattage, resulting in a smaller power draw when the PowerEdge XR7620 is deployed at the edge. The reduced power consumption can also potentially lower total cost of ownership (TCO) and help meet your business’s sustainability goals.
Finding an Edge Within the PowerEdge XR Family
Our research concludes that the Dell PowerEdge XR family of servers is a great option for organizations looking for reliable, high-performing servers in ruggedized, short-depth form factors designed specifically for edge computing. Among the range of PowerEdge XR family servers examined by Prowess Consulting, the PowerEdge XR7620 server represents a solid upgrade from the previous generation, and it is the performance-focused offering in the new PowerEdge XR family of servers. PowerEdge XR4000 series servers are the high-density, performant option when durability and space constraints are primary concerns.
Learn More
For full research results and configuration details, see the technical research report at https://infohub.delltechnologies.com/p/a-path-to-virtualization-at-the-edge.
For more information on the Dell PowerEdge XR7620 server, see “Dell’s PowerEdge XR7620 for Telecom/Edge Compute” and the PowerEdge XR7620 server product page.
For more information on the new offerings in the PowerEdge XR family, see “Dell PowerEdge Gets Edgy with XR8000, XR7620, and XR5610 Servers.
[1] Intel. Performance Index (4th Gen Intel Xeon Scalable Processors, G1). Accessed May 2023. www.intel.com/PerformanceIndex.
[2] Intel. Performance Index (4th Gen Intel Xeon Scalable Processors, N18). Accessed May 2023. www.intel.com/PerformanceIndex.
[3] Intel. Performance Index (4th Gen Intel Xeon Scalable Processors, N16). Accessed May 2023. www.intel.com/PerformanceIndex.

A Path to Virtualization at the Edge
Thu, 14 Mar 2024 16:47:05 -0000
|Read Time: 0 minutes

Get next-generation performance at the edge from the Dell PowerEdge XR family of servers
Executive Summary
Edge sensors and devices generate data on a massive scale. And much of the data is generated in rugged environments. Heavy machinery used in underground mining operations, for example, can be outfitted with smart sensors to monitor gas concentrations, air quality, and temperature. Once this data is captured by a high-performance edge server, an analytics application processes the data to generate real-time insights.
Prowess Consulting investigated options for organizations looking for rugged edge servers with the performance needed for compute-intensive analytics. We started by evaluating the Dell™ PowerEdge™ XR7620 server, a member of Dell Technologies’ PowerEdge XR rugged servers portfolio. We looked at performance, durability, and compliance to military and telecom industry standards.
We then compared the PowerEdge XR7620 server to the PowerEdge XE2420 server, a previous-generation rugged edge server, and observed significant generational performance gains. Finally, we compared the PowerEdge XR7620 server to another member of the PowerEdge XR family, the PowerEdge XR4000 series servers. This helped us summarize key differences between the PowerEdge XR7620 server and the PowerEdge XR4000 series. We found that, for organizations looking for the ideal edge server, the PowerEdge XR7620 server delivers high performance, including excellent virtualization capabilities and VMware vSAN™ performance, whereas the PowerEdge XR4000 series servers deliver excellent density and deployment flexibility.
Life at the Edge
Modern businesses are processing more data at the edge. This brings a unique set of requirements for edge servers: the need for high performance, the ability for a server to fit into tiny spaces, and the ability to tolerate the extremes of remote field deployments whether on a manufacturing floor or in a busy retail environment.
Workloads like data analytics and AI/ML that process data at the edge drive the need for high performance. Decoupled from your data center, servers at the edge combat a host of environmental and logistical challenges. A factory that combines Internet of Things (IoT) and digital twin technologies to automate resource allocation and optimize efficiency through analytics and AI will need servers on the factory floor to generate actionable data. And that means exposure to heat, vibration, dust, and more.
How your organization addresses the dual considerations of performance and durability inherent to edge computing is key. Regardless of your solution, maximizing performance and safeguarding against harsh environments is critical.
The PowerEdge XR7620 Server: Performance and Durability at the Edge
Performance
Research by Prowess Consulting shows that the new PowerEdge XR7620 server, powered by 4th Gen Intel® Xeon® Scalable processors, can meet the challenges of ensuring performance and durability. The PowerEdge XR7620 server is a two-socket server featuring data center–level compute with high performance, high capacity, and reduced latency. Moreover, its rugged form factor ensures performance-protecting durability, from military deployments to the factory floor. The PowerEdge XR7620 server can process and analyze data at the point of capture for maximum impact when away from the data center. Given its high performance, the PowerEdge XR7620 server excels at tasks like virtualization.
The PowerEdge XR7620 server also offers compact GPU- and CPU-optimized variants to further customize performance.
Durability
The PowerEdge XR7620 server—like the entire PowerEdge XR family—is purpose-built to withstand the most extreme environments. It can handle dust, humidity, extreme temperatures, shocks, and more. And it’s both MIL-STD-810G and Network Equipment Building System (NEBS) Level 3, GR-3108 Class 1, tested[1]. This means the PowerEdge XR7620 server is compliant with edge-computing standards for both the telecom industry (NEBS Level 3) and military-related applications (MIL-STD-810G). These are foundational requirements, and we dove deeper into their importance.
NEBS Level 3
“NEBS describes the environment of a typical United States Regional Bell Operating Company (RBOC) central office. NEBS is the most common set of safety, spatial, and environmental design standards applied to telecommunications equipment in the United States. It is not a legal or regulatory requirement, but rather an industry requirement.”[2]
NEBS levels relate primarily to the telecom industry and are rated 1–3. Whereas NEBS Levels 1 and 2 are essentially office-based and targeted toward more controlled environments like data centers, NEBS Level 3 is the standard. It’s what telecom and network providers base their installation requirements on, as this level ensures equipment operability. It also requires the most time, effort, and cost in terms of design and maintenance.
Table 1 illustrates the specific requirements for NEBS Level 3.
Table 1. NEBS Level 3 requirements[3]
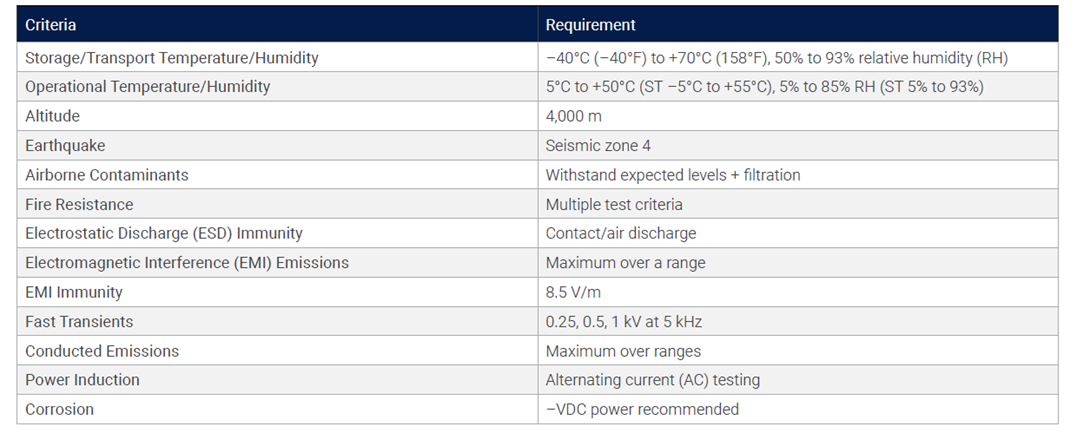
MIL-STD
“This Standard contains materiel acquisition program planning and engineering direction for considering the influences that environmental stresses have on materiel throughout all phases of its service life. It is important to note that this document [the MIL-STD-810G standard] does not impose design or test specifications. Rather, it describes the environmental tailoring process that results in realistic materiel designs and test methods based on materiel system performance requirements.”[4]
A military standard (MIL-STD) is a US defense standard that centers around ensuring standardization and interoperability for the products used by the US Department of Defense (DoD). There are different standards for specific use cases and industries, and the PowerEdge XR7620 server specifically addresses the 810G standard. The 810G standard centers around environmental engineering and testing, and it provides a rigorous framework—rather than universal guidelines—for vetting potential deployments through extensive testing.
Figure 1 shows a decision tree from the 810G standard guidelines that illustrates how rigorous and extensive the requirements for testing are to meet 810G compliance.
Figure 1. A decision tree from the MIL-STD-810G guidelines[5]
The PowerEdge XR7620 Server: A New Generation
Prowess Consulting examined the performance difference between the PowerEdge XR7620 server and the previous-generation PowerEdge XE2420 server. We began by comparing the processors between the generations.
The 4th Gen Intel Xeon Scalable processors that power the PowerEdge XR7620 server provide a number of benefits over the 2nd Gen Intel Xeon Scalable processors that power the PowerEdge XE2420 server. These benefits include:
- 1.53x average generation-on-generation performance improvement[6]
- Up to 1.60x higher input/output operations per second (IOPS) and up to 37% latency reduction for large-packet sequential reads using integrated Intel® Data Streaming Accelerator (Intel® DSA) versus the prior generation[7]
- Up to 95% fewer cores and 2x higher level-1 compression throughput using integrated Intel® QuickAssist Technology (Intel® QAT) versus the prior generation[8]
We then reviewed the top-line specs between the PowerEdge XE2420 server and the PowerEdge XR7620 server, shown in Table 3 in the Methodology section. These specs show a clear and consistent improvement between generations. Further analysis of SPEC® CPU 2017 Integer and Floating Point (FP) rates—both of which measure CPU processing power by integer and floating point rates, respectively—shows the same generational increase, with the PowerEdge XR7620 server and its 4th Gen Intel Xeon Scalable processors the clear winner. These results are shown in Figures 2 and 3.
Figure 2. SPEC® CPU INT Rate for the Dell™ PowerEdge™ XR7620 server (with an Intel® Xeon® Gold 6448Y processor) versus the PowerEdge XE2420 server (with Intel Xeon Gold 6252, Intel Xeon Gold 6252N, and Intel Xeon Gold 6238 processors)[9]
Figure 3. SPEC® CPU FP rate for the Dell™ PowerEdge™ XR7620 server (with an Intel® Xeon® Gold 6448Y processor) versus the PowerEdge XE2420 server (with Intel Xeon Gold 6252, Intel Xeon Gold 6252N, and Intel Xeon Gold 6238 processors)9
This performance improvement between generations can also be seen by comparing VMware vSAN deployments. The PowerEdge XE2420 server and the PowerEdge XR7620 server can both implement two-node vSAN deployments. However, as noted previously, the PowerEdge XR7620 server will be more performant with those deployments. This higher level of performance doesn’t just come from the upgraded processor, either. The 4th Gen Intel Xeon Scalable processors in the PowerEdge XR7620 are optimized to take full advantage of the new features and software improvements in VMware vSphere® 8, including GPU- and CPU-based acceleration.
The PowerEdge XR Family
Before we examine the Dell PowerEdge XR family of servers in more detail, Figure 4 provides a quick visual reference of the servers discussed in this report.
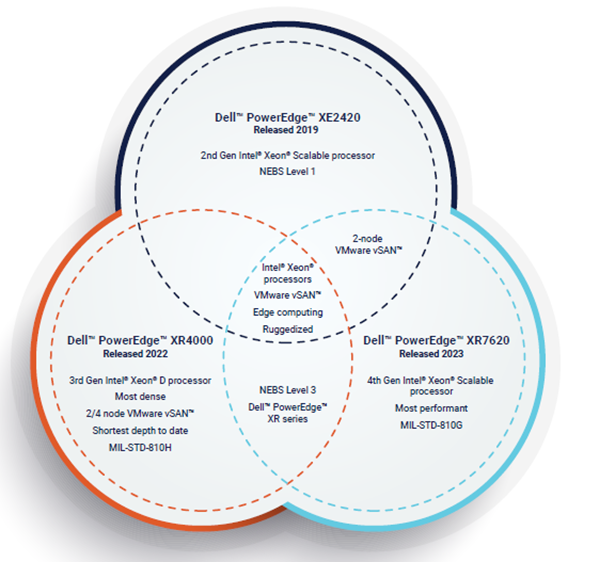
- Venn diagram of the Dell™ PowerEdge™ XE2420, XR7620, and XR4000 series servers
VMmark® Examination of PowerEdge XR7620 and PowerEdge XR4000 Series Servers
The PowerEdge XR7620 server is part of the PowerEdge XR family of servers, all of which are built to handle the most extreme environments while still delivering performance and reliability. We wanted to examine the PowerEdge XR7620 server alongside some of its “younger siblings,” the PowerEdge XR4000 series servers, and investigate the inter-generational differences. (While not discussed in this study, PowerEdge XR8000 series servers provide excellent flexibility and stability, and would be the “elder sibling” in the family.)
To do this, we analyzed VMmark® results for both the PowerEdge XR4510c (representing the PowerEdge XR4000 series) and the PowerEdge XR7620, shown in Table 4 in the Methodology section. VMmark is a tool for hardware vendors and others to measure the performance, scalability, and power consumption of virtualization platforms. VMmark allows for: benchmarking of virtual data center performance and power consumption; comparing performance and power consumption between different virtualization platforms; and examining how changes in hardware, software, or configuration affect performance within the virtualization environment.[10]
The VMmark results show the PowerEdge XR7620 server can achieve more performance across more tiles (fourteen versus four). These results also illustrate what can be achieved with a full, dual-socket server with the latest-generation processors in a short-depth, 2U ruggedized chassis at the edge. Moreover, the 4th Gen Intel Xeon Scalable processors in the PowerEdge XR7620 server also account for the higher performance. While the PowerEdge XR7620 server’s overall performance wins are expected, what’s missing is how performant at the edge PowerEdge XR4000 series servers are. Given the smaller size and shorter form factor overall, the PowerEdge XR4000 series servers are very performant relative to size, and they are an excellent option when a smaller, denser, more flexible deployment is called for. Moreover, their redundancy allows for more hardware failures, making them resilient and durable.

- Optional witness node on the Dell™ PowerEdge™ XR4000 series servers[11]
VMware vSAN is an “enterprise-class storage virtualization software that provides the simplest path to hyperconverged infrastructure (HCI) and multi-cloud.”[12] VMware vSAN is widely deployed, so we also compared vSAN deployments inter-generationally. While the PowerEdge XR7620 server (and PowerEdge XE2420 server, too) can implement two-node vSAN deployments, PowerEdge XR4000 series servers can implement four-node vSAN deployments. Additionally, the PowerEdge XR7620 server can also be deployed in a two-node architecture using a vSAN witness appliance to take advantage of the many benefits of vSAN—especially its performance benefits. While both servers take advantage of vSAN, the PowerEdge XR7620 server will offer more overall performance, whereas PowerEdge XR4000 series servers offer the highest density in the smallest form factor.
There is, however, another significant benefit to the upgraded PowerEdge XR7620 server: power savings and sustainability. As Table 4 in the Methodology section shows, the PowerEdge XR7620 server offers double the cores of the PowerEdge XR4510c server tested for less than double the wattage, resulting in a smaller power draw when the PowerEdge XR7620 is deployed the edge. The PowerEdge XR7620 server reduces power consumption, leading to higher energy efficiency and power availability for the PowerEdge XR7620 server. The reduced power consumption can also potentially lower total cost of ownership (TCO) and help meet your business’s sustainability goals.
Potential PowerEdge XR Family Use Cases
The PowerEdge XR family of servers has use cases in retail, manufacturing, defense, and telecom. We explore two specific use cases in the following sections.
The PowerEdge XR7620 Server: Autonomous Driving
Let’s examine how the PowerEdge XR7620 server—which excels at virtualization—might perform in a real-world setting in the auto industry. As demand increases for technologies such as advanced driver assistance systems (ADAS) and autonomous driving capabilities, the industry needs more efficient development and testing. Virtualization is a key strategy for generating this efficiency, and it’s leading to a change in the way vehicles are designed, developed, manufactured, tested, and maintained.[13]
As software becomes increasingly essential to the average vehicle, updating that software as efficiently as possible becomes a customer pain point and a business requirement. Vast amounts of data are generated when physically testing the update process in the factory or out on the track. You’ll need a high-performance server to capture and process that data as it’s generated for the fastest analytics and most actionable insights possible. Moreover, the 4th Gen Intel Xeon Scalable processors in the PowerEdge XR7620 server are optimized to use the software upgrades in vSphere 8, allowing you to modernize your hardware and software as you replace aging assets, while increasing capacity.
Additionally, this server must be able to withstand the dust and temperature fluctuations of the factory, or the vibrations and humidity of the track, or a host of other adverse conditions. The PowerEdge XR7620 server meets both performance and durability needs, offering the levels of performance required for intense data analytics and the ruggedized form factor required at the edge.
PowerEdge XR4000 Series Servers: Telecom Deployments
Let’s take a proper look at PowerEdge XR4000 series servers now. If the PowerEdge XR7620 server is at home on the factory floor, then the PowerEdge XR4000 series server is at home under the cell tower. While the PowerEdge XR7620 server is built for durability, PowerEdge XR4000 series servers are especially rugged and come in Dell’s smallest form factor for flexibility and customization in the most difficult deployments. They are NEBS Level 3 and MIL-STD-810H tested.[14] Moreover, their four sleds in a single 2U chassis offer excellent scalability and portability when in the field. They have “rackable” and “stackable” configuration options for maximum deployment flexibility, and they support multiple configurations within each option. And PowerEdge XR4000 series servers do so while still offering the high performance needed for analytics and virtualization at the edge.
Finding an Edge Within the PowerEdge XR Family
While the PowerEdge XR family of servers all feature a ruggedized, short-depth form factor, there’s a spectrum of purpose-built options to consider, varying from maximum performance at one end to maximum density and durability at the other.
As our research shows, the PowerEdge XR7620 server is an excellent choice for maximum performance within the PowerEdge family of servers examined. It’s powered by the next-generation Intel Xeon Gold 6448Y processor, giving the PowerEdge XR7620 server excellent virtualization capabilities and vSAN performance. And the PowerEdge XR7620 server does all this in a ruggedized, short-depth form factor that provides the durability required for intense edge computing.
The PowerEdge XR7620 Server: Under the Hood
The performance of the PowerEdge XR7620 server shouldn’t be seen as a simple generational update. It owes some of its performance to the 4th Gen Intel Xeon Scalable processors and the Dell™ PowerEdge RAID Controller 12 (PERC 12).
Intel® Xeon® Gold 6448Y Processor
The Intel Xeon Gold 6448Y processor found in the PowerEdge XR7620 server is based on 4th Gen Intel Xeon Scalable processor architecture, representing a serious upgrade from 2nd and 3rd Gen processors in several ways. With double the cores, a higher max turbo frequency, and a larger cache than the previous model’s processor, the Intel Xeon Gold 6448Y processor is built for performance. Moreover, the processor features Intel DSA, which helps speed up data movement and improve transformation operations to increase performance for storage, networking, and data-intensive workloads.[15]
Dell™ PERC 12
PERC 12, Dell’s latest RAID controller, features the new Broadcom® SAS4116W series chip and offers increased capabilities compared with its predecessor, PERC 11. These capabilities include support for 24 gigabits per second (Gb/s) Serial-Attached SCSI (SAS) drives, increased cache memory speed, and a single front controller that supports both NVM Express® (NVMe®) and SAS. Table 2 shows the generational improvement between PERC 11 and PERC 12.[16]
Table 2. IOPS/bandwidth comparison between the Dell™ PERC 11 and PERC 12 controllers16

PowerEdge XR4000 Series Servers: Inside the Box
At the density end of the spectrum, we have the PowerEdge XR4000 series servers. These are Dell Technologies’ shortest-depth servers to date: modular 2U servers with a sled-based design for maximum flexibility. They come in two new 14”-depth form factors called “rackable” and “stackable,” and they offer rack or wall mounting options.
PowerEdge XR4000 series servers also feature an optional nano-server-sled that can serve as an in-chassis witness node for the vSAN cluster. This replaces the need for a virtual witness node and establishes a native, self-contained, two-node vSAN cluster—even in the 14” x 12” stackable configuration. You can choose between two and four nodes in a chassis while still using vSAN because of the in-chassis witness node. This makes virtual machine (VM) deployments possible where latency or bandwidth constraints previously prevented doing so. PowerEdge XR4000 series servers offer high-performance edge computing in a form factor small enough to fit in a backpack.[17] This form factor and size also lead to high computing density, which is the measurement of the amount of information that can be stored and processed in a given area to determine efficient use of space.
When Rugged Matters as Much as Performance
Our research concludes that the Dell PowerEdge XR family of servers is a great option for organizations looking for reliable, high-performing servers in ruggedized, short-depth form factors designed specifically for edge computing. Among the range of PowerEdge XR family servers examined by Prowess, the PowerEdge XR7620 server represents a solid upgrade from the previous generation, and is the performance-focused offering in the new PowerEdge XR family of servers. PowerEdge XR4000 series servers are the high-density, performant option when durability and space constraints are primary concerns.
Learn More
For more information on the Dell PowerEdge XR7620 server, see “Dell’s PowerEdge XR7620 for Telecom/Edge Compute” and the PowerEdge XR7620 server product page.
For more information on the new offerings in the PowerEdge XR family, see “Dell PowerEdge Gets Edgy with XR8000, XR7620, and XR5610 Servers.”
Methodology
Table 3 shows the configuration details for the comparison between the PowerEdge XE2420 server and the PowerEdge XR7620 server.
Table 3. Dell™ PowerEdge™ XR7620 server versus PowerEdge XE2420 server comparison
Server | ||
Processor | 2nd Gen Intel® Xeon® Scalable processors | 4th Gen Intel® Xeon® Scalable processors |
Cores per Processor | Up to 24 | Up to 32 |
Number of Processors Supported | 2 | 2 |
Memory | 16 x DDR4 RDIMM/LR-DIMM (12 DIMMs are balanced), up to 2,993 megatransfers per second (MT/s) | 16 x DDR5 DIMM slots, supports RDIMM 1 TB max, speeds up to 4,800 MT/s; supports registered error correction code (ECC) DDR5 DIMMs only |
Drive Bays | Up to 4 x 2.5-inch SAS/SATA/NVMe® solid-state drives (SSDs); up to 6 Enterprise and Data Center SSD Form Factor (EDSFF) drives | Front bays: Up to 4 x 2.5-inch SAS/SATA/NVMe® SSDs, 61.44 TB max; up to 8 x E3.S NVMe® direct drives, 51.2 TB max |
Dimensions | 2 x 2.5-inches or 4 x 2.5 with seven possible configurations | Rear-accessed configuration:
Front accessed configuration:
|
Weight | 17.36 kg (38.19 pounds) to 18.93 kg (41.65 pounds), depending on configuration | Max 21.16 kg (46.64 pounds) |
Form Factor | 2U rack | 2U rack |
Table 4 shows the configuration details for the VMmark comparison between the two PowerEdge XR family servers.
Table 4, VMmark® comparison between the Dell™ PowerEdge™ XR7620 server and the PowerEdge XR4510c server
VMmark® 3.1.1 Results | ||
Summary | ||
Category | Dell™ PowerEdge™ XR4510c[23] | Dell™ PowerEdge™ XR7620[24] |
VMmark® 3 Average Watts | 1,085.50 | 1,878.63 |
VMmark® 3 Applications Score | 4.93 | 14.08 |
VMmark® 3 Infrastructure Score | 2.15 | 1.06 |
VMmark® 3 Score | 4.37 | 11.48 |
VMmark® 3 PPKW | 4.0285 at 4 tiles | 6.1093 at 14 tiles |
Configuration | ||
Server | Dell™ PowerEdge™ XR4510c23 | Dell™ PowerEdge™ XR762024 |
Nodes | 4 physical (with local hardware-based witness node) | 2 (with VMware vSAN™ witness appliance) |
Storage | VMware vSAN™ 8.0—all-flash | VMware vSAN™ 8.0—all-flash |
Hypervisor | VMware ESXi™ 8.0 GA, build 20513097 | VMware ESXi™ 8.0b, build 21203435 |
Data Center Management Software | VMware vCenter Server® 8.0 GA, build 20519528 | VMware vCenter Server® 8.0c, build 21457384 |
Number of Servers in System Under Test | 4 | 2 |
Processor | Intel® Xeon® D-2776NT processor | Intel® Xeon® Gold 6448Y processor |
Processor Speed (GHz)/Intel® Turbo Boost Technology Speed (GHz) | 2.10 GHz/3.20 GHz | 2.10 GHz/4.10 GHz |
Total Sockets/Cores/Threads in Test | 4 sockets/64 cores/128 threads | 4 sockets/128 cores/256 threads |
Memory Size (in GB, Number of DIMMs) | 512 GB, 4 | 2,048 GB, 16 |
Memory Type and Speed | 128 GB 4Rx4 DDR4 3,200 MT/s LRDIMM | 128 GB DDR5 4Rx4 4,800 MT/s RDIMMs |
The analysis in this document was done by Prowess Consulting and commissioned by Dell Technologies.
Results have been simulated and are provided for informational purposes only. Any difference in system hardware or software design or configuration may affect actual performance.
Prowess Consulting and the Prowess logo are trademarks of Prowess Consulting, LLC.
Copyright © 2023 Prowess Consulting, LLC. All rights reserved.
Other trademarks are the property of their respective owners.
[1] Dell. “Dell’s PowerEdge XR7620 for Telecom/Edge Compute.” May 2023. https://infohub.delltechnologies.com/p/dell-s-poweredge-xr7620-for-telecom-edge-compute/.
[2] Cisco. “Cisco Firepower 4112, 4115, 4125, and 4145 Hardware Installation Guide.” June 2023. www.cisco.com/c/en/us/td/docs/security/firepower/41x5/hw/guide/install-41x5.html.
[3] Dell. “Computing on the Edge: NEBS Criteria Levels.” November 2022. https://infohub.delltechnologies.com/p/computing-on-the-edge-nebs-criteria-levels/.
[4] MIL-STD-810. “Environmental Engineering Considerations and Laboratory Tests.” May 2022. https://quicksearch.dla.mil/qsDocDetails.aspx?ident_number=35978.
[5] US Department of Defense. “Environmental Engineering Considerations And Laboratory Tests.” Revision G Change 1 (change incorporated). Figure 402-1. Life Cycle Environmental Profile Development Guide. April 2014. https://quicksearch.dla.mil/qsDocDetails.aspx?ident_number=35978 [then select the "Revision G Change 1 (change incorporated)" document].
[6] Intel. Performance Index (4th Gen Intel Xeon Scalable Processors, G1). Accessed May 2023. www.intel.com/PerformanceIndex.
[7] Intel. Performance Index (4th Gen Intel Xeon Scalable Processors, N18). Accessed May 2023. www.intel.com/PerformanceIndex.
[8] Intel. Performance Index (4th Gen Intel Xeon Scalable Processors, N16). Accessed May 2023. www.intel.com/PerformanceIndex.
[9] Data provided by Dell Technologies in May 2023.
[10] VMware. “VMmark.” Accessed June 2023. www.vmware.com/products/vmmark.html.
[11] Dell. "XR4000w Multi-Node Edge Server (Intel)." Accessed July 2023. https://www.dell.com/en-us/shop/ipovw/poweredge-xr4000w.
[12] VMware. “What Is VMware vSAN?” Accessed July 2023. www.vmware.com/products/vsan.html.
[13] Luxoft. “Achieving the benefits of SDVs using virtualization.” May 2023. www.luxoft.com/blog/virtualization-revolutionizing-software-defined-vehicles-development.
[14] Dell. “Dell PowerEdge XR4000 Specification Sheet.” Accessed June 2023. www.dell.com/en-us/dt/oem/servers/rugged-servers.htm#pdf-overlay=//www.delltechnologies.com/asset/en-us/solutions/oem-solutions/technical-support/dell-oem-poweredge-xr4000-spec-sheet.pdf.
[15] Intel. “Intel® Accelerator Engines.” Accessed June 2023. www.intel.com/content/www/us/en/products/docs/accelerator-engines/overview.html.
[16] Dell. “Dell PowerEdge RAID Controller 12.” May 2023. https://infohub.delltechnologies.com/p/dell-poweredge-raid-controller-12/.
[17] Dell. “VMmark on XR4000.” January 2023. https://infohub.delltechnologies.com/p/vmmark-on-xr4000/.
[18] Intel. “Intel Xeon D2776NT Processor.” Accessed June 2023. https://ark.intel.com/content/www/us/en/ark/products/226239/intel-xeon-d2776nt-processor-25m-cache-up-to-3-20-ghz.html.
[19] Dell. “Dell EMC PowerEdge XE2420 Technical Specifications.” Accessed June 2023. https://dl.dell.com/topicspdf/poweredge-xe2420_reference-guide_en-us.pdf.
[20] Dell. “PowerEdge XE2420 Specification Sheet.” Accessed June 2023. https://i.dell.com/sites/csdocuments/Product_Docs/en/PowerEdge-XE2420-Spec-Sheet.pdf.
[21] Intel. “Intel Xeon Gold 6448Y Processor.” Accessed June 2023. https://ark.intel.com/content/www/us/en/ark/products/232384/intel-xeon-gold-6448y-processor-60m-cache-2-10-ghz.html.
[22] Dell. “PowerEdge XR7620 Specification Sheet.” Accessed June 2023. www.delltechnologies.com/asset/en-us/products/servers/technical-support/poweredge-xr7620-spec-sheet.pdf.
[23] VMmark. “VMmark® 3.1.1 Results, November 29, 2022.” www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/vmmark/2022-11-29-Dell-PowerEdge-XR4510c-serverPPKW.pdf.
[24] VMmark. “VMmark® 3.1.1 Results, May 16, 2023.” www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/vmmark/2023-05-16-Dell-PowerEdge-XR7620.pdf.

Dell PowerEdge XR Edge AI Smart City Solutions
Thu, 14 Mar 2024 16:47:06 -0000
|Read Time: 0 minutes
Scalers AI™ tested the latest generation Dell PowerEdge XR 5610 and XR7620 servers for Smart City Solution. Their smart cities solution uses artificial intelligence and computer vision to monitor real-time traffic safety.
Dell™ PowerEdge™ XR5610 system showed better performance compared to Dell™ PowerEdge™XR11system for AI inference and decoding tasks using the TinyYoloV4 model with INT8 precision and the Intel®OpenVINO™ framework. Dell™ PowerEdge™ XR5610 system had a 2.5x improvement in AI inference on images and a 1.77x improvement in AI inference and decoding on video at 1080 P resolution. When running Scalers AI application, which includes AI inference, decoding a video stream, and application services, the Dell™ PowerEdge™ XR5610 system had a 1.9x improvement in performance.
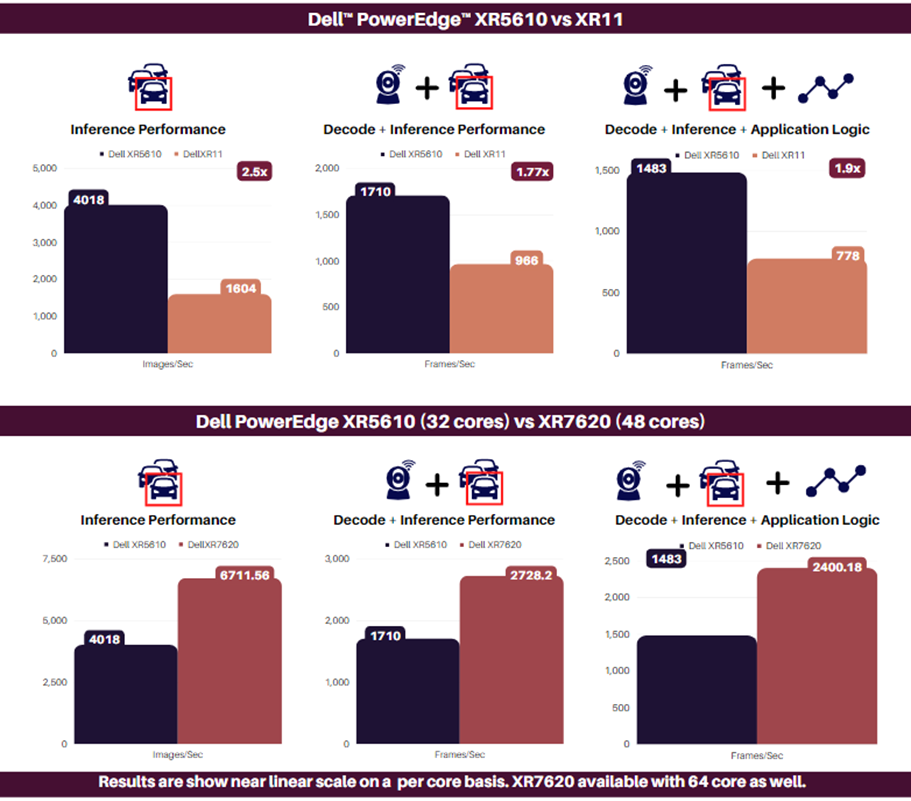
Dell™ PowerEdge™ XR5610 has us covered for real-world deployments in harsh conditions requiring compact form factors that can withstand dust, vibration, extreme temperatures, and humidity. For more compute, Dell™ PowerEdge™ XR7620 offers two 4th Gen Intel® Xeon® Scalable Processors, and we saw near-linear scale in our AI and video decode workloads making Dell™ PowerEdge™ XR ideal for high-performance application deployment in harsh environments.
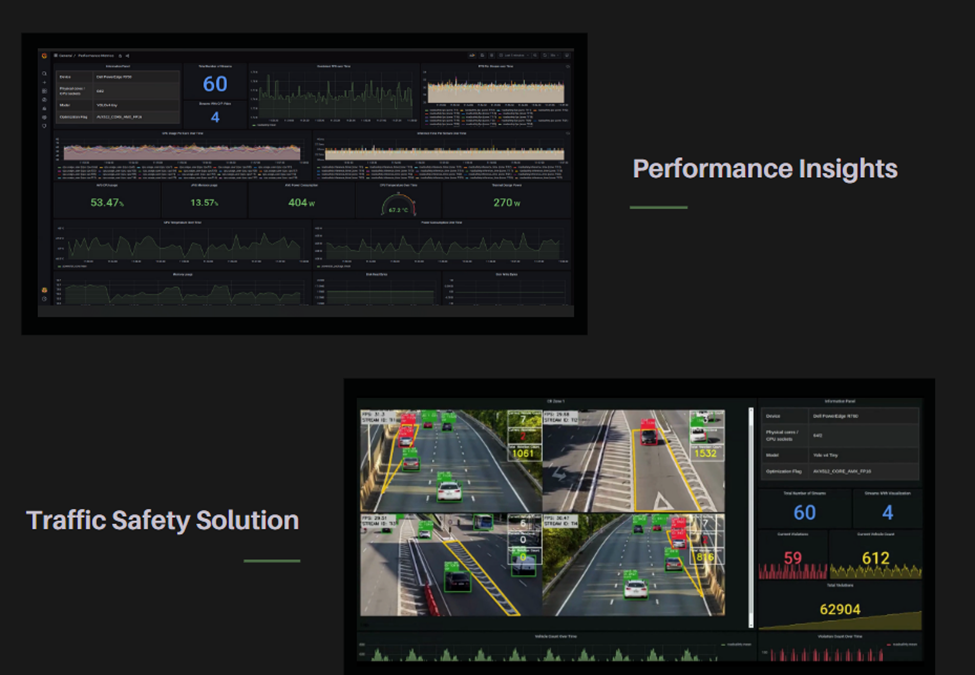
Fast-track development with access to the solution code:
Contact your Dell™ representative or Scalers AI™ at contact@scalers.ai for access. Save hundreds of hours of development with the solution code. As part of this effort, ScalersAI™ is making the solution code available.

Are Rugged Compact Platforms Ready for Edge AI?
Thu, 14 Mar 2024 16:47:06 -0000
|Read Time: 0 minutes
Scalers AI™ tested the Impellers Defect Inspection at the Edge on the Dell PowerEdge XR5610 server. Impellers are rotating components used in various industrial processes, including fluid handling in pumps and fans. Quality inspection of impellers is crucial to ensure their reliable performance and durability.
Dell™ PowerEdge™XR5610 Server supports 50 simultaneous streams running AI defect detection in a single CPU config with Dell™PowerEdge™ XR Portfolio offering scalability to 4CPUs at a near-linear scale. 1.4x Gen on Gen Performance Improvement Using Intel® Deep Learning Boost and Intel® OpenVINO™ Smart Factory Solution | Defect Detection Solution.
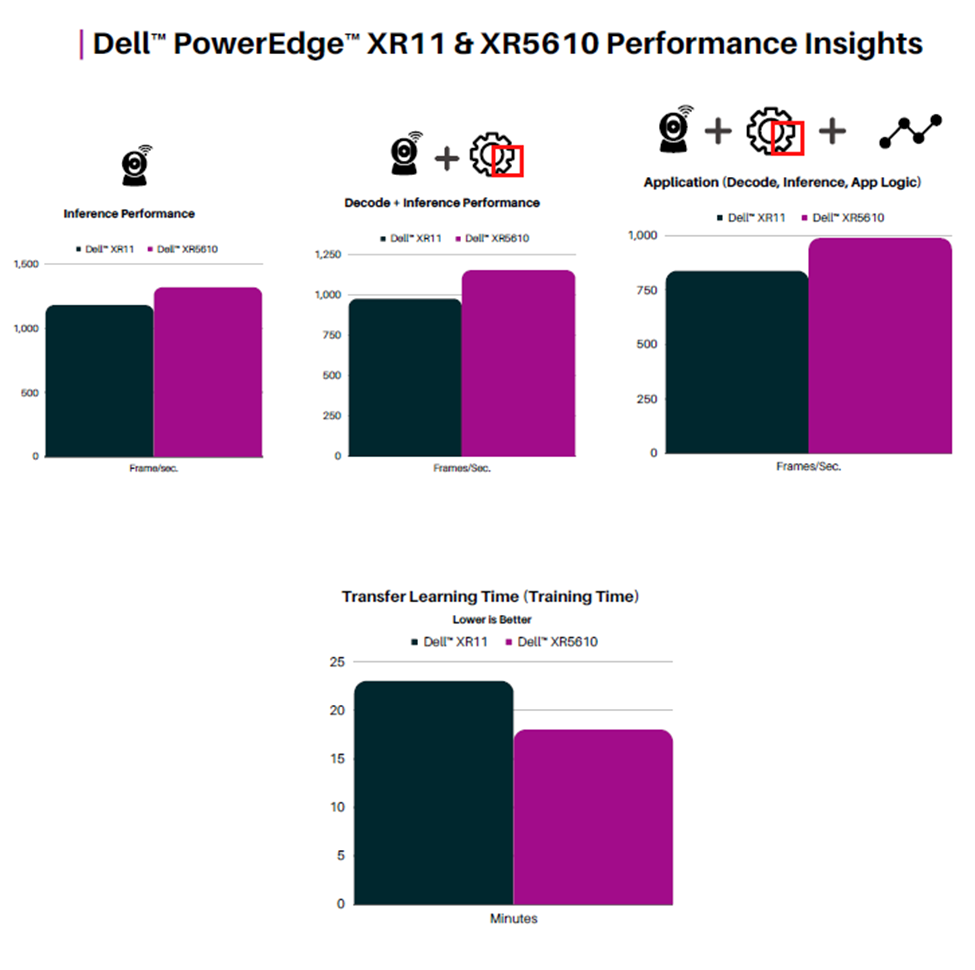
Dell™ PowerEdge™ XR 5610 servers, equipped with fourth Gen Intel® Xeon® scalable processors, are well suited to handle Edge AI applications with both AI inference and training at the Edge. The rugged form factor, extended temp, and scalability to four sockets enable compute to be deployed in the physical world closer to the point of data creation, allowing for near-real-time insights.
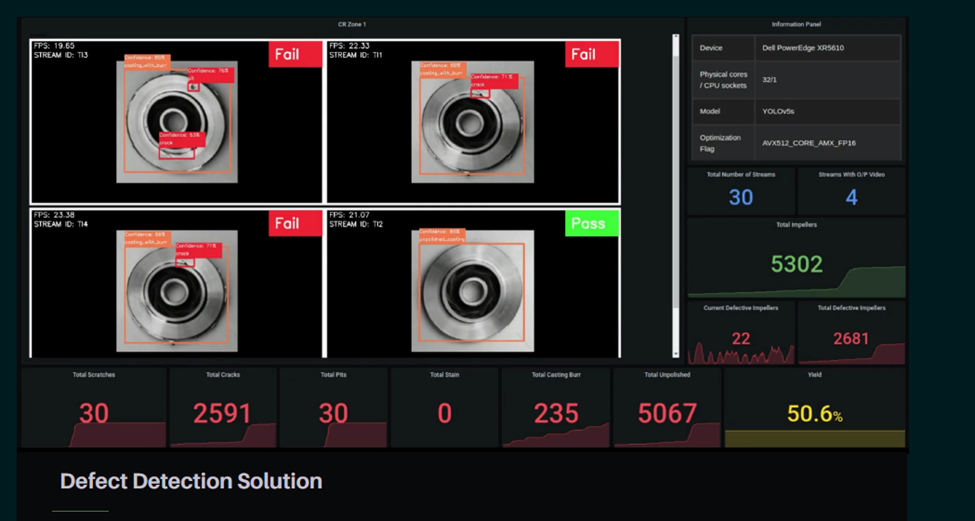
Fast-track development with access to the solution code:
Contact your Dell™ representative or Scalers AI™ at contact@scalers.ai for access. Save hundreds of hours of development with the solution code. As part of this effort, ScalersAI™ is making the solution code available.

Intel Edge Insights for Industrial Software
Thu, 14 Mar 2024 16:47:06 -0000
|Read Time: 0 minutes
Scalers AI™ tested Intel® Edge Insights for Industrial Software package on the latest generation Dell PowerEdge XR 5610 and XR7620 servers for printed circuit board Defect Inspection and Worker Safety use cases.
Dell™ XR5610 Performance Insights with 4th Gen Intel® Xeon® 5 scalable processors using Intel® Deep Learning Boost with Advanced Matrix Extensions results in 1.6x performance from prior generation on Industrial AI workloads.
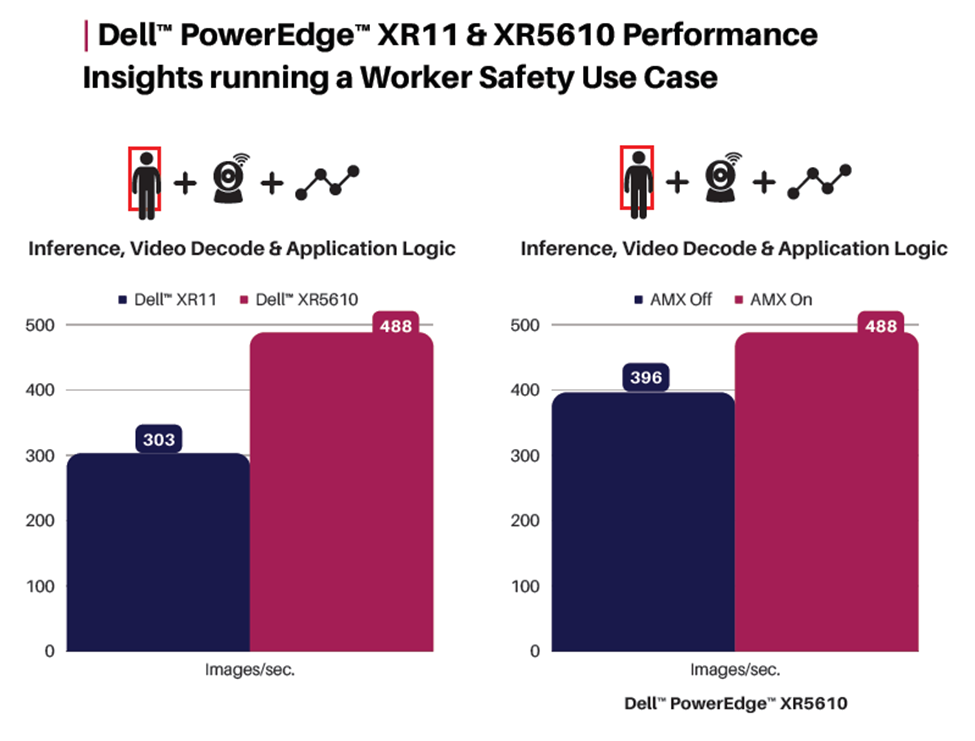
Dell™ XR portfolio includes 2U dual socket Dell™ XR7620 and 2U sled-based XR8000 along with 1U Single Socket Dell™ XR5610, offering flexibility and scalability with highly configurable options for CPU, memory, and I/O needed for Edge and Telecom applications.
Fast-track development with access to the solution code:
Contact your Dell™ representative or Scalers AI™ at contact@scalers.ai for access. Save hundreds of hours of development with the solution code. As part of this effort, ScalersAI™ is making the solution code available.

AI Driven Pop-up Manufacturing Made Possible with PowerEdge XR7620
Thu, 14 Mar 2024 16:47:06 -0000
|Read Time: 0 minutes
| Executive Summary
As traditional manufacturing processes are being gradually replaced by advanced technology, deep learning, 3D printing, and open programmable robotics offer an unprecedented opportunity to accelerate this transformation and deliver high quality, personalized products more affordably.
To demonstrate this opportunity we took on a challenge to showcase AI pop-up manufacturing by 3D printing orthopaedic components, specifically acetabular liners used in hip replacement surgeries and running them through a robotic arm & AI quality inspection and a sorting process, with worker safety embedded within.
This solution was both developed and deployed on Dell™ PowerEdge™ XR7620 purpose built for the edge with NVIDIA® A100 tensor core GPUs, including the custom acetabular liner defect detection model.
The proof of concept resulting in a live demo was completed within a quarter from the AI development, to the mechanical work to create a custom gripper, to the robotic arm assembly programming and AI integration. The live demo was successfully set-up and deployed in a day and ran for three days.
- 1 50% saving in engineering time to reach targeted 1.2 second latency across application with Dell™ PowerEdge™ XR7620
- Three AI models running on Dell™ PowerEdge™ XR7620 to enable Industrial Transformation
We trained our defect defection model for acetabular liners on Dell™ PowerEdge™ XR7620 and deployed it on the same system at the edge. We also ran our worker safety model and segment anything model, all in the compact rugged edge form factor.
- Steen Graham, CEO at Scalers AI™

| Industry Challenge
The American Academy of Orthopedic Surgeons reports more than 300,000 hip replacements are performed annually. Defective hip implants can lead to complications and high-cost revision surgeries. According to the FDA, over 500,000 people in the United States have been injured by defective hip implants. A study published in the Journal of Bone and Joint Surgery found that patients with defective hip implants were 3.5 times more likely to need revision surgery. The same study found that patients with defective hip implants were 2.5 times more likely to experience series complications such as infection, dislocation, and fracture.
Further, the cost of the artificial hip and liner can range into the thousands with the overall surgery range from $20,000 to $45,000 according to the American Academy of Orthopaedic Surgeons, with revision surgery even higher.
| Solution Architecture
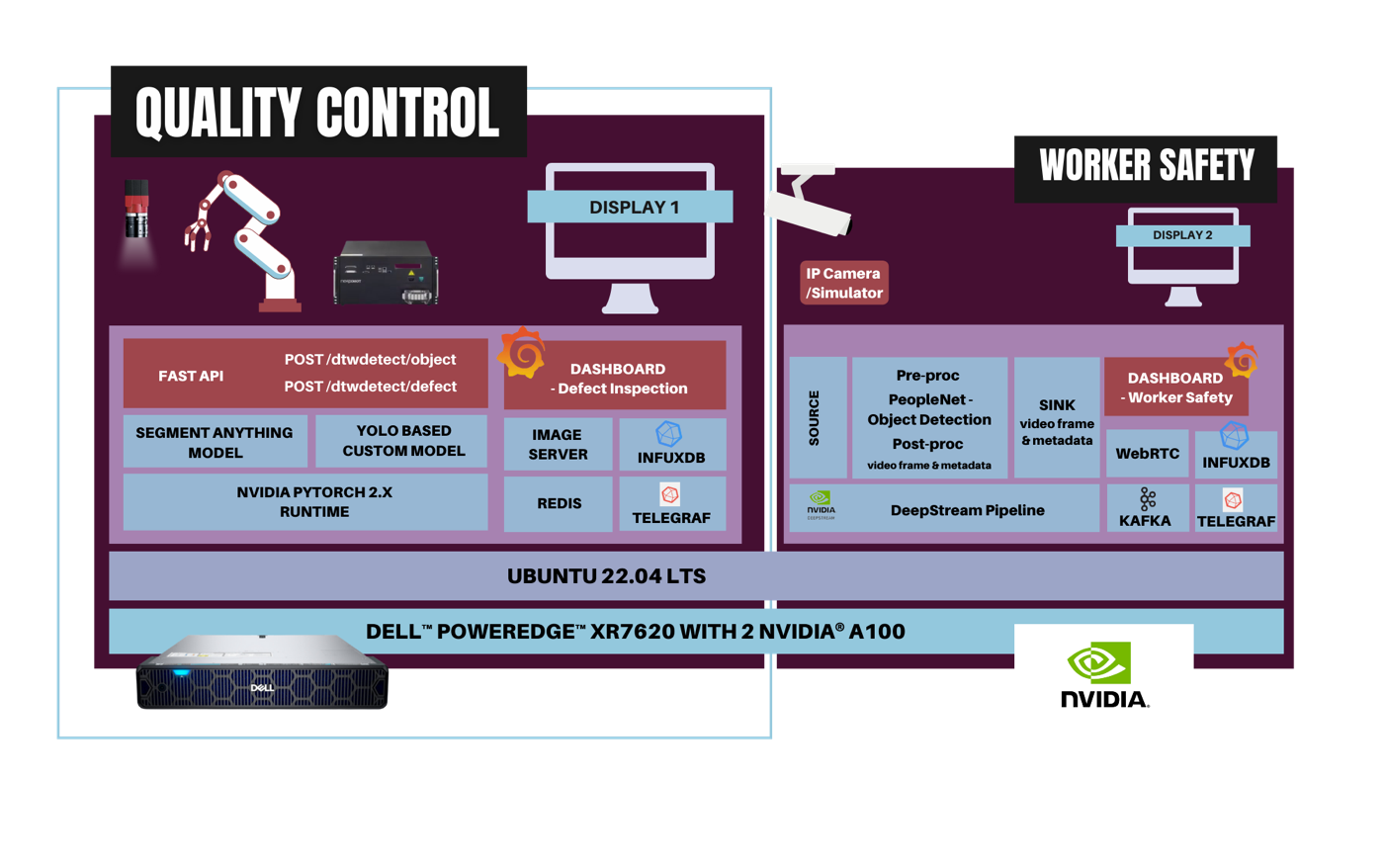
| The Concept
Demonstrate how we can improve production and quality inspection with the latest techniques in deep learning to reduce the likelihood of defective hip implants, while lowering the manufacturing cost. Ultimately, showing how modern techniques in AI, 3D printing, and robotics can improve patient safety and reduce costs.
Note: ~50% time savings estimated based on engineering resources applied in development (~2000 hours) and estimated incremental time required to label, train, custom API development, and post training optimization (~2000 hours).
| Robotics
A 7-axis robotic arm and custom gripper was developed specifically for the demo to pick up acetabular liners within a few months. The robot controller is integrated with the AI APIs to pick up the liners and run defect detection. The robotic arm picks up the liners and rotates them under the camera to enable the defect detection. Then, the robot places the liners in different buckets based on whether they pass or fail the quality inspection.
The NexCOBOT robotic controller and 7-axis robotic arm were integrated with Scalers AI™ APIs and run on Dell™ PowerEdge™ XR7620 server.
| Deep Learning Models
The deep learning model involves three Neural Networks (NNs), including the latest Segment Anything model (SAM) for object detection, and a custom model built specifically to detect defects in acetabular liners, as well as a workers safety model. The custom model showcases the ability to build high-performance models using modest-sized datasets.
| Demo
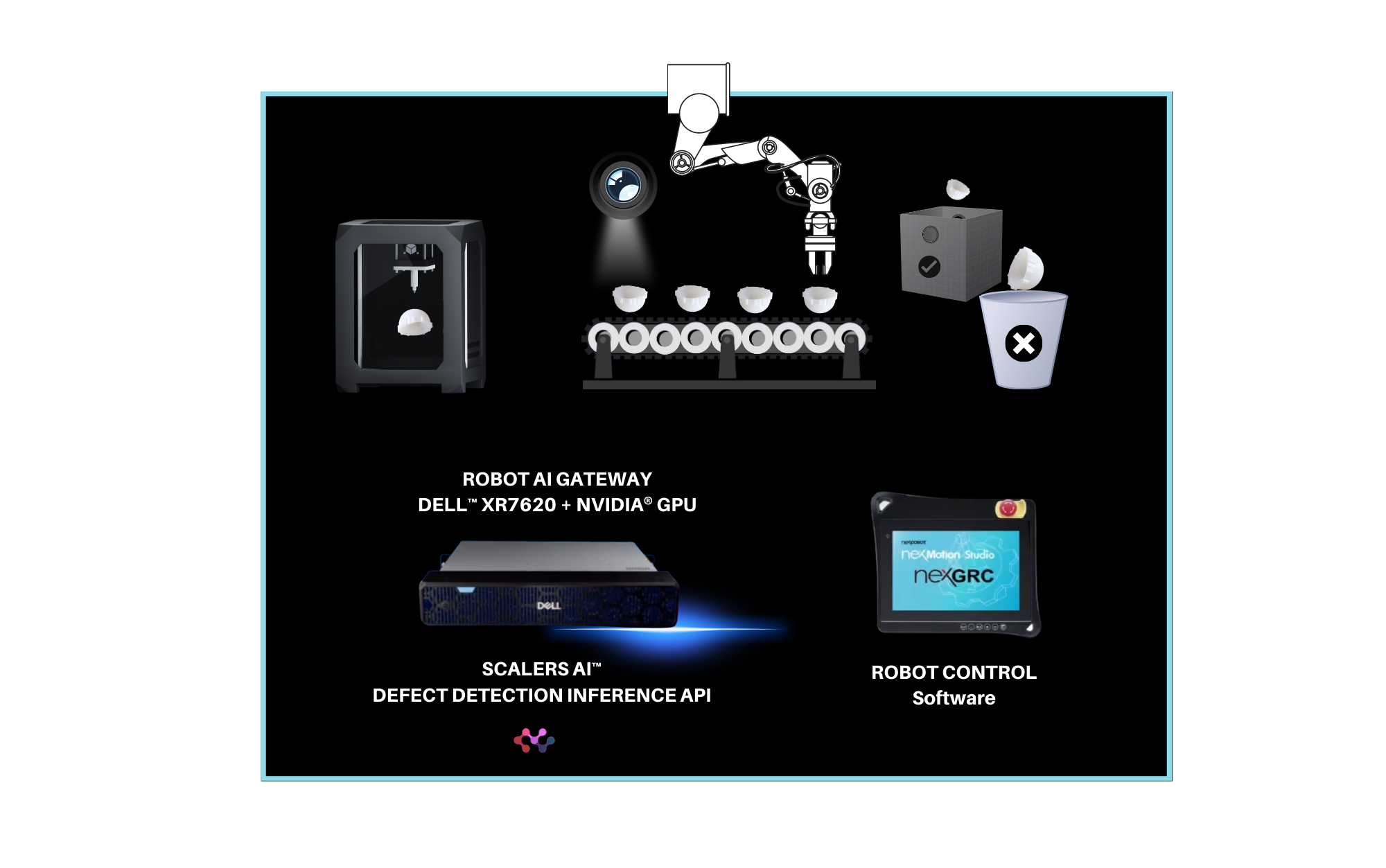
Dashboards | Defect Detection
Quality Inspection Process
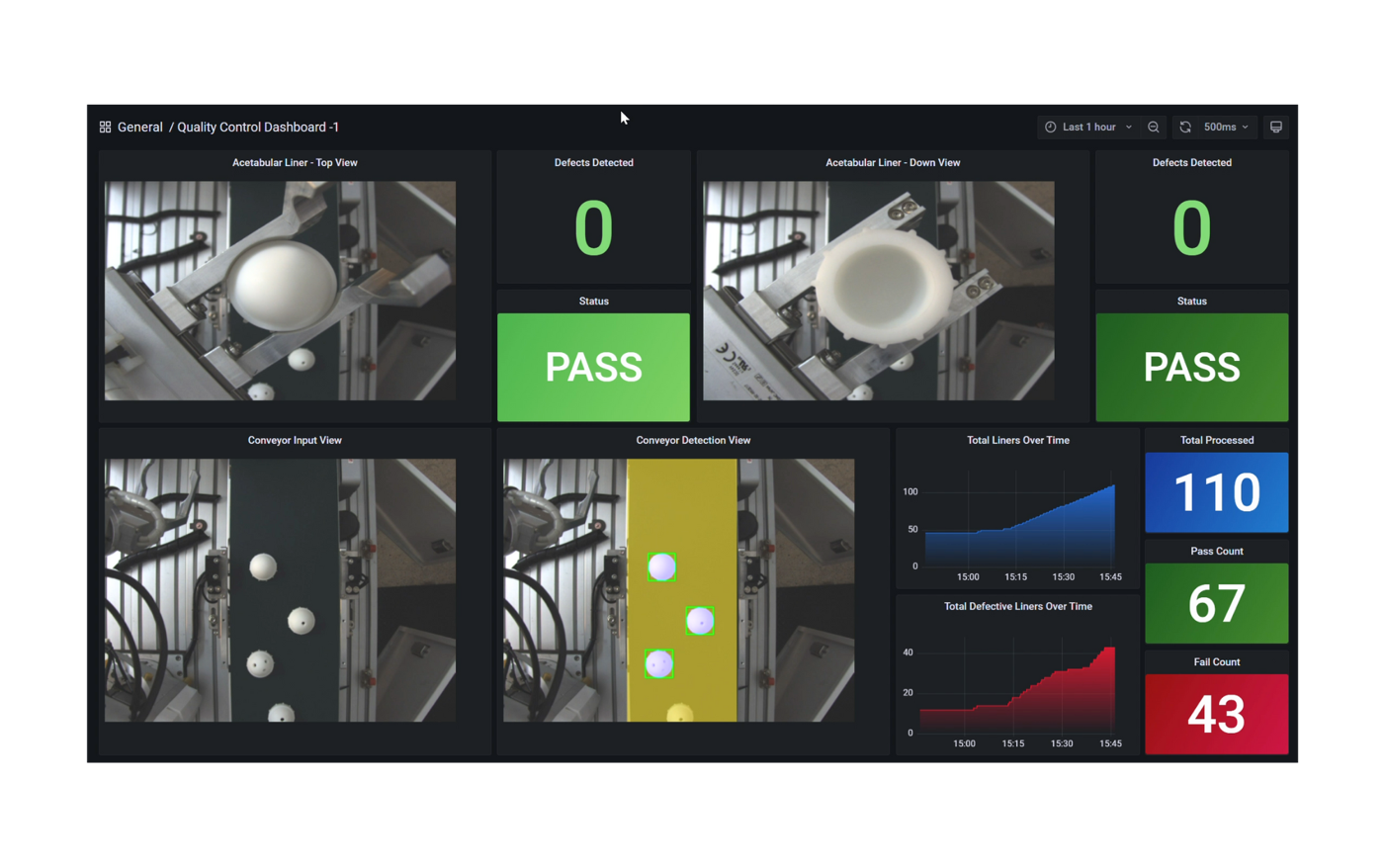
- During the quality control, no defects have been detected on the liner picked up. The robot arm will then place it in the bucket dedicated to non defective hip implants.
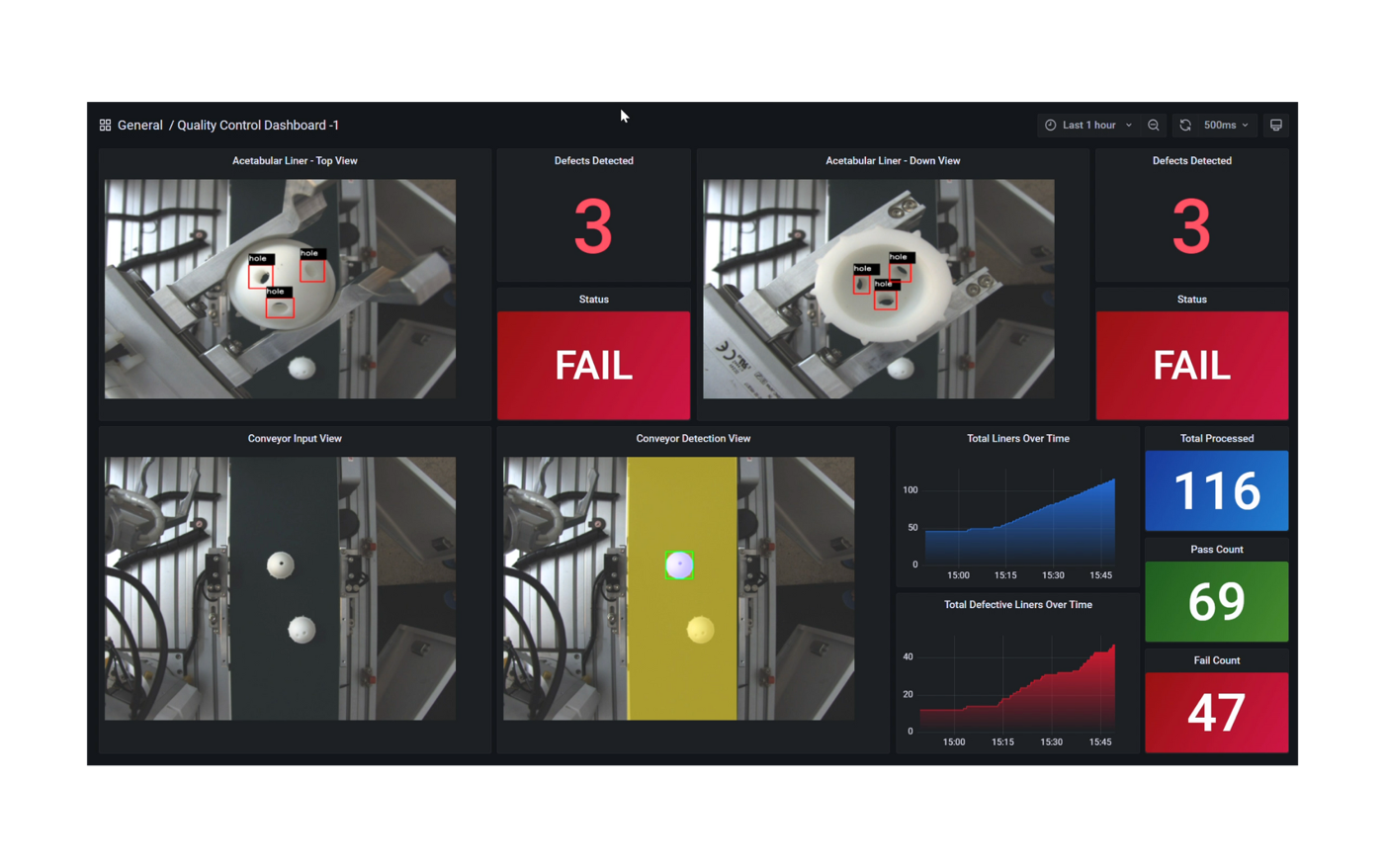
- Three defects have been detected on this acetabular liner. The robot arm will place it in the bucket for hip implants who did not pass the quality inspection.
Dashboards | Worker Safety
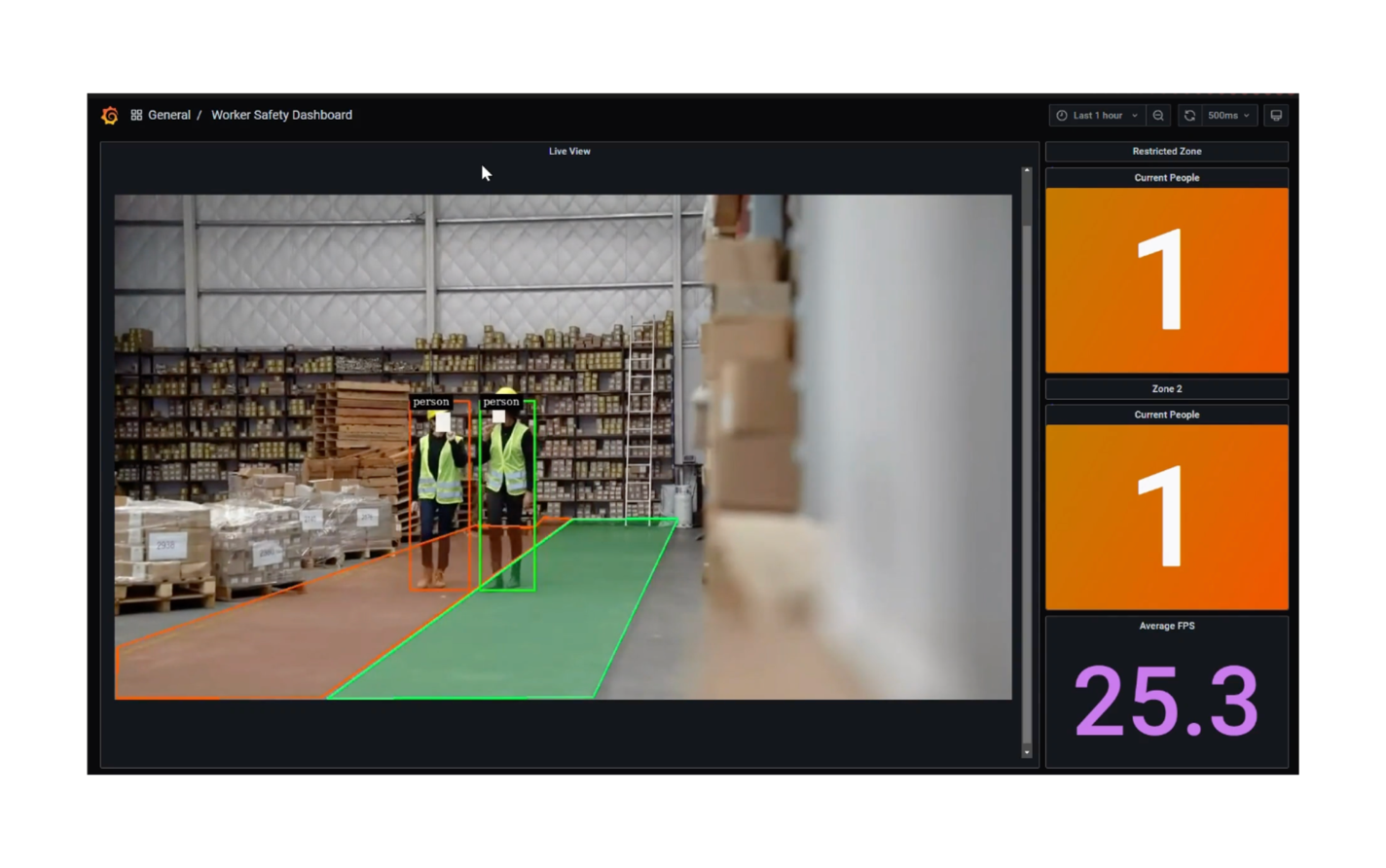
- One worker has been detected in the hazard zone triggering a worker safety notification.
| Integration of Dell™ PowerEdge™ XR7620 Server
Dell™ PowerEdge™ XR7620 server, designed to withstand harsh industrial conditions, houses two Intel® Xeon® Scalable Processors and two NVIDIA® A100 Tensor Core GPUs and KIOXIA SSDs within its 472mm chassis. Its ruggedized design, combined with NVIDIA® A100 GPUs offer powerful parallel processing capabilities, enables real-time analysis of 3D-printed components and rapid defect detection.
| Developed time saving on Dell™ PowerEdge™ XR7620 Server
By selecting the powerful Dell™ PowerEdge™ XR7620 server we are able to make this demonstration possible within a few months. Selecting a CPU or entry level GPU edge platform would have resulted in ~50% increase in development time for additional data labeling, training, custom API development, and post training optimization. This all would be required to reach our minimum latency requirement of sub 1.2 seconds for the object detection and defect detection models.
Note: ~50% time savings estimated based on engineering resources applied in development (~2000 hours) and estimated incremental time required to label, train, custom API development, and post training optimization (~2000 hours).
| Dell Technology™ World 23’
AI Driven Pop-Up Manufaturing Demo

| Conclusion
Our demo has potential implications in revolutionizing orthopedic implant manufacturing. The amalgamation of 3D printing, deep learning, and open programmable robots may provide a flexible, efficient, and affordable manufacturing solution for orthopedic components. The incorporation of Dell™ ruggedized PowerEdge™ XR7620 server and NVIDIA® powerful GPUs ensures reliable and real-time defect detection, proving essential in reducing production delays.
As our proof of concept gains further refinement, we anticipate its adoption in various other manufacturing domains, bringing in a new era of efficiency and precision.
About Scalers AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions for a wide range of industries, including retail, smart cities, manufacturing, and healthcare. The company is dedicated to helping organizations leverage the power of AI for their digital transformation. Scalers AI™ has a team of experienced AI developers and data scientists who are skilled in creating custom AI solutions for a variety of use cases, including predictive analytics, chatbots, image and speech recognition, and natural language processing.
As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads. Additionally, we also need advanced visualization libraries including the ability to render video in modern web application architectures.
| Fast track development with access to the solution code
Save hundreds of hours of development with the solution code. As part of this effort Scalers AI™ is making the solution code available.
Reach out to your Dell™ representative or contact Scalers AI™ at contact@scalers.ai for access.
Resources
- Reach out to your Dell™ representative or contact Scalers AI™ for access to the code!
This project was commissioned by Dell Technologies™ and conducted by Scalers AI, Inc.
Scalers AI™and Scalers AI™ logos are trademarks of Scalers AI, Inc.
Copyright © 2023 Scalers AI, Inc.
All rights reserved.
Other trademarks are the property of their respective owners.
Author:
Steen Graham CEO at Scalers AI™
Chetan Gadgil CTO at Scalers AI™
Delmar Hernandez, Server Technologist at Dell Technologies™
Manya Rastogi, Server Technologist at Dell Technologies™