




Testing LLAMA-2 models on Dell PowerEdge R760xa with 5th Gen Intel Xeon Processors
Tue, 13 Feb 2024 04:08:19 -0000
|Read Time: 0 minutes
This is part three, read part two here: https://infohub.delltechnologies.com/p/expanding-gpu-choice-with-intel-data-center-gpu-max-series/
| NEXT GENERATION OF INTEL® XEON® PROCESSORS
We are excited to showcase our collaboration with Intel® as we explore the capabilities of 5th Gen Intel® Xeon® Processors, now accessible via Dell™ PowerEdge™ R760xa, offering versatile AI solutions that can be deployed onto general purpose servers as an alternative to specialized hardware “accelerator” based implementations. Built upon the advancements of its predecessors, the latest generation of Intel® Xeon® Processors introduces advancements designed to provide customers with enhanced performance and efficiency. 5th Gen Intel® Xeon® Processors are engineered to seamlessly handle demanding AI workloads, including inference and fine-tuning on models containing up to 20 billion parameters, without an immediate need for additional hardware. Furthermore, the compatibility with 4th Gen Intel® Xeon® processors facilitates a smooth upgrade process for existing solutions, minimizing the need for extensive testing and validation.
The integration of 5th Gen Intel® Xeon® Processors with Dell™ PowerEdge™ R760xa, ensures a seamless pairing, providing a wide range of options and scalability in performance.
Dell™ has recently established a strategic partnership with Meta and Hugging Face to facilitate the seamless integration of enterprise-level support for the selection, deployment, and fine-tuning of AI models tailored to industry-specific use cases, leveraging the Llama-2 7B Chat Model from Meta.
In a prior analysis, we integrated Dell™ PowerEdge™ R760xa with 4th Gen Intel® Xeon® Processors and tested the performance of the Llama-2 7B Chat model by measuring both the rate of token generation and the number of concurrent users that can be supported while scaling up to four accelerators. In this demonstration, we explore the advancements offered by 5th Gen Intel® Xeon® Processors paired with Dell™ PowerEdge™ R760xa, while focusing on the same task.
Dell™ PowerEdge™ Servers featuring 5th Gen Intel® Xeon® Processors demonstrated a strong scalability and successfully achieved the targeted end user latency goals.
“Scalers AI™ ran Llama-2 7B Chat with Dell™ PowerEdge™ R760xa Server, powered by 5th Gen Intel® Xeon® Processors, enabling us to meet end user latency requirements for our enterprise AI chatbot.”
 Chetan Gadgil, CTO at Scalers AI
Chetan Gadgil, CTO at Scalers AI
| LLAMA-2 7B CHAT MODEL
For this demonstration, we have chosen to work with Llama-2 7B Chat, an open source large language model from Meta capable of generating text and code in response to given prompts. As a part of the Llama-2 family of large language models, Llama-2 7B Chat is pre-trained on 2 trillion tokens of data from publicly available sources and additionally fine-tuned on public instruction datasets and more than a million human annotations. This particular model is optimized for dialogue use cases, making it ideal for applications such as chatbots or virtual assistants that need to engage in conversational interactions.
| ARCHITECTURES
We initialized our testing environment using Dell™ PowerEdge™ R760xa Rack Server featuring 5th Gen Intel® Xeon® Processors running on Ubuntu 22.04. To ensure maximum efficiency, we used Hugging Face Optimum, an extension of Hugging Face Transformers that provides a set of performance optimization tools to train and run models on the targeted hardware. We specifically selected the Optimum-Intel package, which integrates libraries provided by Intel® to accelerate end-to-end pipelines on Intel® hardware. Hugging Face Optimum Intel is the interface between the Hugging Face Transformers and Diffusers libraries and the different tools and libraries provided by Intel® to accelerate end-to-end pipelines on Intel® architectures.
We also tested 5th Gen Intel® Xeon® Processors with bigdl-llm, a library for running LLMs on Intel® hardware with support for Pytorch and lower precision formats. By using bigdl-llm, we are able to leverage INT4 precision on Llama-2 7B Chat.
The following architectures depict both scenarios:
1) Hugging Face Optimum
2) BigDL-LLM

| TEST METHODOLOGY
For each iteration of our performance tests, we prompted Llama-2 with the following command: “Discuss the history and evolution of artificial intelligence in 80 words or less.” We then collected the test response and recorded total inference time in seconds and tokens per second. 25 of these iterations were executed for each inference scenario (Hugging Face Optimum vs BigDL-LLM), out of which the initial five iterations were considered as warm-ups and were discarded for calculating total inference time and tokens per second. Here, the total time collected includes both the encode-decode time using the tokenizer and LLM inference time.
We also scaled the number of processes from one to four to observe how total latency and tokens per second change as the number of concurrent processes is increased. In the hypothetical scenario of an enterprise chatbot, this analysis simulates engaging several different users having separate conversations with the chatbot at the same time, during which the chatbot should still deliver responses to each user in a reasonable amount of time. The total number of tests comes from running each inference scenario with a varying number of processes (1, 2, or 4 processes) and recording the performance (measured in throughput) of different model precision formats.
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH OPTIMUM-INTEL
1. Install the Python dependencies:
openvino==2023.2.0
transformers==4.36.2
optimum-intel==1.12.3
optimum==1.16.1
onnx==1.15.0
2. Request access to Llama-2 model through Hugging Face by following the instructions here:
https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
Use the following command to login to your Hugging Face account:
huggingface-cli login
3. Convert the Llama-2 7B Chat HuggingFace model into Intel® OpenVINO™ IR with INT8 precision format using Optimum-Intel to export it:
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForCausalLM.from_pretrained(model_id, export=True, load_in_8bit=True)
model.save_pretrained("llama-2-7b-chat-ov")
tokenizer.save_pretrained("llama-2-7b-chat-ov")
4. Run the code snippet below to generate the text with the Llama-2 7B Chat model:
import time
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_name = "llama-2-7b-chat-ov"
input_text = "Discuss the history and evolution of artificial intelligence"
max_new_tokens = 100
# Initialize and load tokenizer, model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OVModelForCausalLM.from_pretrained(model_name, ov_config= {"INFERENCE_PRECISION_HINT":"f32"}, compile=False)
model.compile()
# Initialize HF pipeline
text_generator = pipeline( "text-generation", model=model, tokenizer=tokenizer, return_tensors=True, )
# Warmup
output = text_generator( input_text, max_new_tokens=max_new_tokens )
# Inference
start_time = time.time()
output = text_generator( input_text, max_new_tokens=max_new_tokens )
_ = tokenizer.decode(output[0]["generated_token_ids"])
end_time = time.time()
# Calculate number of tokens generated
num_tokens = len(output[0]["generated_token_ids"])
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| RUNNING THE LLAMA-2 7B CHAT MODEL WITH BIGDL-LLM
1. Install the Python dependencies, our Llama-2 7B Chat model requires:
pip install bigdl-llm[all]==2.4.0
2. Request access to Llama-2 model through Hugging Face by following the instructions here:
https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
Use the following command to login to your Hugging Face account:
huggingface-cli login
3. Run the code snippet below to generate the text with the Llama-2 7B Chat model in INT4 precision:
import torch
import intel_extension_for_pytorch as ipex
import time
import argparse
from bigdl.llm.transformers import AutoModelForCausalLM
from transformers import LlamaTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf",
load_in_4bit=True,
optimize_model=True,
trust_remote_code=True,
use_cache=True)
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", trust_remote_code=True)
with torch.inference_mode():
input_ids = tokenizer.encode("Discuss the history and evolution of artificial intelligence", return_tensors="pt")
# ipex model needs a warmup, then inference time can be accurate
output = model.generate(input_ids,
max_new_tokens=100)
# start inference
start_time = time.time()
output = model.generate(input_ids, max_new_tokens=100)
end_time = time.time()
num_tokens = len(output[0].detach().numpy().flatten())
inference_time = end_time - start_time
token_per_sec = num_tokens / inference_time
print(f"Inference time: {inference_time} sec")
print(f"Token per sec: {token_per_sec}")
| ENTER PROMPT
Discuss the history and evolution of artificial intelligence in 80 words or less.
Output for Llama-2 7B Chat - Using Optimum-Intel:
Artificial intelligence (AI) has a long history dating back to the 1950s when computer scientist Alan Turing proposed the Turing Test to measure machine intelligence. Since then, AI has evolved through various stages, including rule-based systems, machine learning, and deep learning, leading to the development of intelligent systems capable of performing tasks that typically require human intelligence, such as visual recognition, natural language processing, and decision-making.
Output for Llama-2 7B Chat - Using BigDL-LLM:
Artificial intelligence (AI) has a long history dating back to the mid-20th century. The term AI was coined in 1956, and since then, AI has evolved significantly with advancements in computer power, data storage, and machine learning algorithms. Today, AI is being applied to various industries such as healthcare, finance, and transportation, leading to increased efficiency and productivity.
| PERFORMANCE RESULTS & ANALYSIS
Testing Llama-2 7B Chat - Using BigDL-LLM
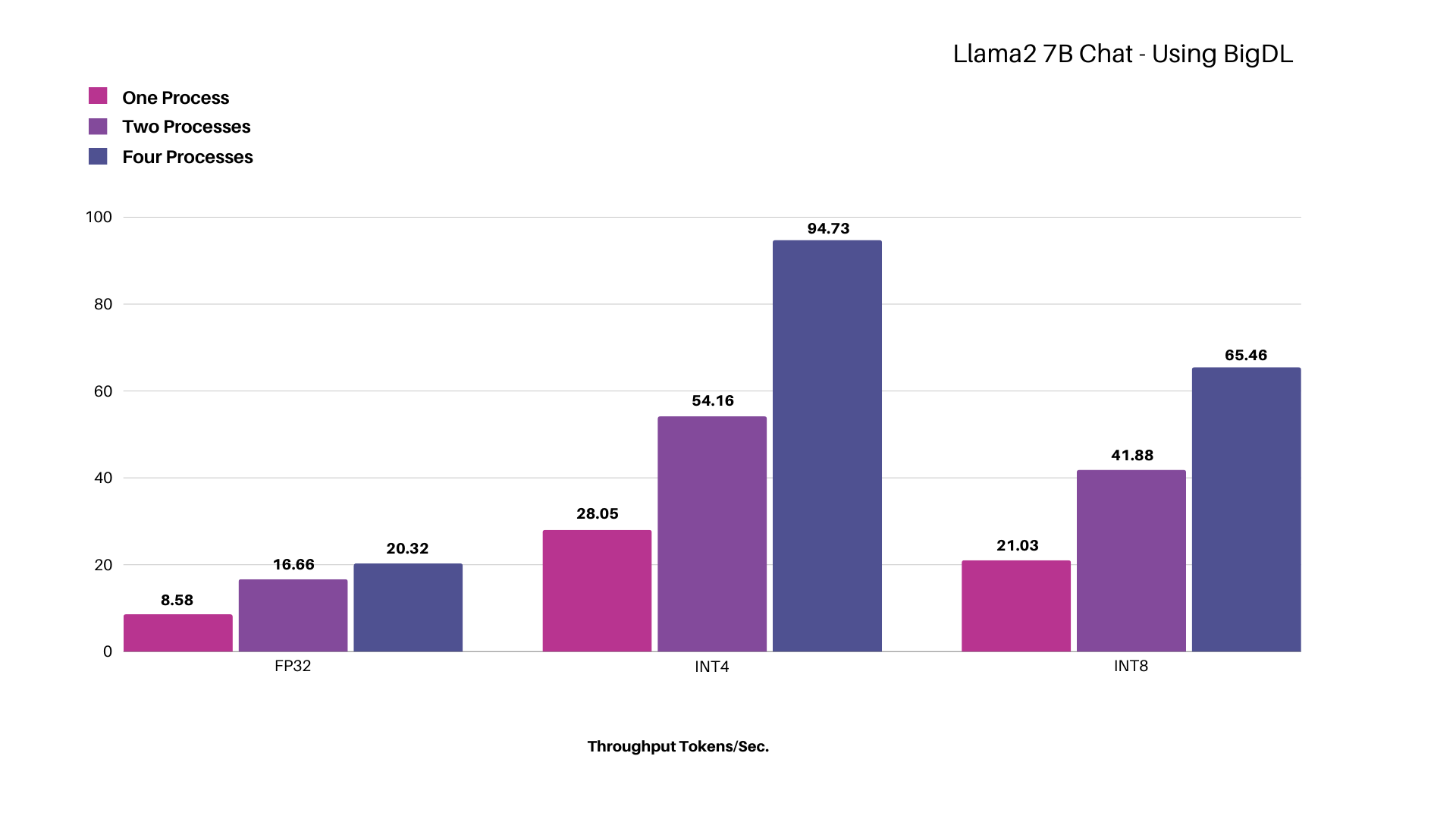
Figure: Scaling Intel® Xeon® Platinum 8580 Processor for different model precisions while concurrently increasing processes up to four, measured in total throughput represented in tokens per second.
Using the Llama-2 7B Chat model with INT4 precision, we achieved a throughput of ~28 tokens per second with a single process, which increased to ~95 tokens per second when scaling up to four processes.
Testing Llama-2 7B Chat - Using Optimum-Intel
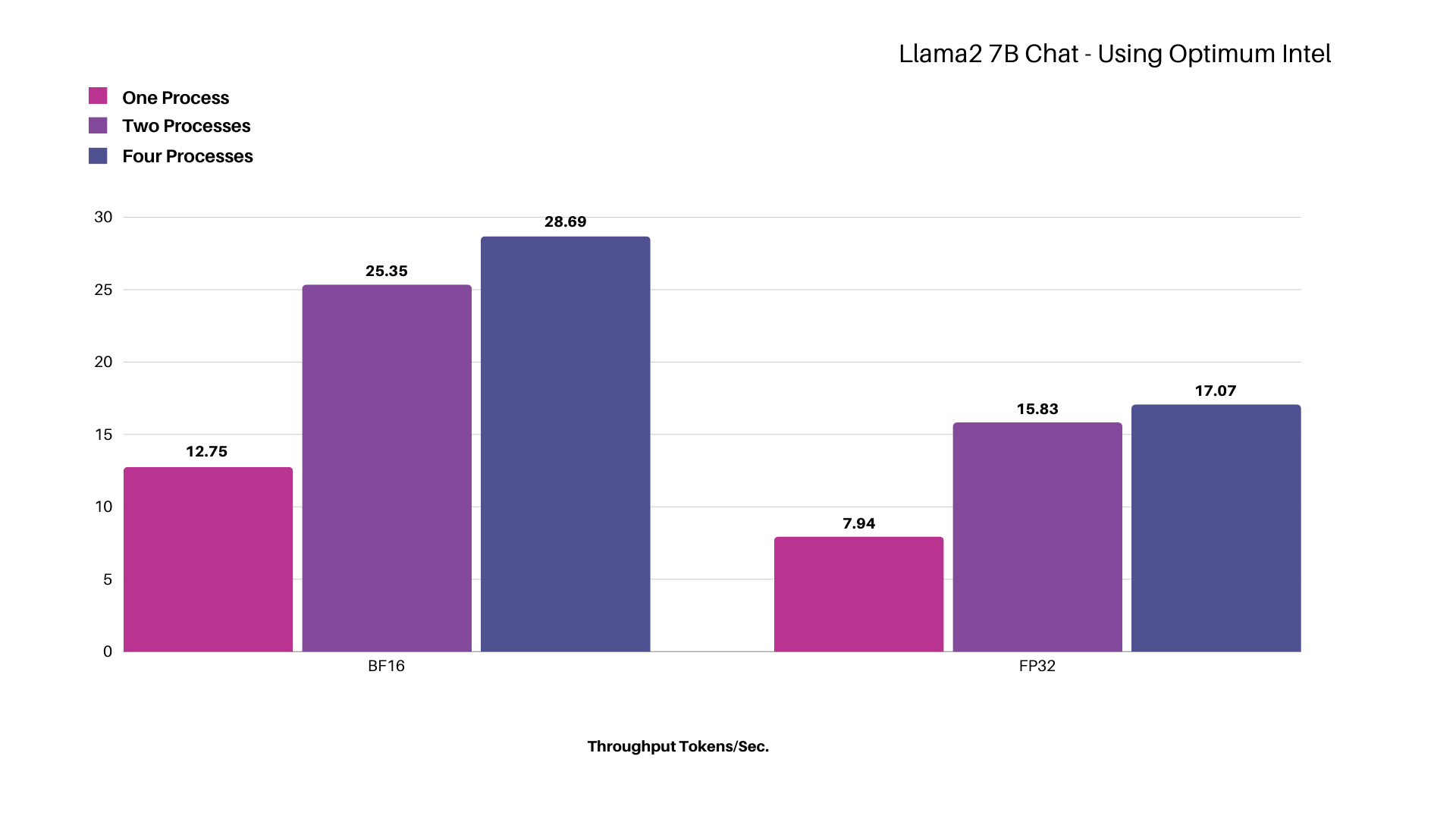
Figure: Scaling Intel® Xeon® Platinum 8580 Processor for different model precisions while concurrently increasing processes up to four, measured in total throughput represented in tokens per second.
Using the Llama-2 7B Chat model with BF16 precision in a single process, we achieved a throughput of ~13 tokens per second, which increased to ~29 tokens per second when scaling up to four processes. The token latency per process remains well below the Scalers AI™ target of 100 milliseconds despite an increase in the number of concurrent processes.
Our results demonstrate that Dell™ PowerEdge™ R760xa Server featuring Intel® Xeon® Platinum 8580 Processor is up to the task of running Llama-2 7B Chat and meeting end user experience responsiveness targets for interactive applications like “chatbots”. For batch processing tasks like report generation where real-time response is not a major requirement, an enterprise will be able to add more workload by scaling the concurrent processes.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| ABOUT SCALERS AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offerings include custom large language models and multimodal platforms supporting voice, video, image, and text. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile, easily available (COTS) hardware that works well across a range of functionality, performance and accuracy requirements.
| Dell™ PowerEdge™ R760xa Server Key Specifications
MACHINE | Dell™ PowerEdge™ R760xa Server |
Operating system | Ubuntu 22.04.3 LTS |
CPU | Intel® Xeon® Platinum 8580 Processor |
MEMORY | 1024Gi |
| HUGGING FACE OPTIMUM & INTEL® BIGDL-LLM
Learn more:
https://huggingface.co/docs/optimum/intel/index
https://github.com/intel-analytics/BigDL
| References