




Fine-Tuning Enterprise LLMs at Scale with Dell™ PowerEdge™ & Broadcom
Tue, 13 Feb 2024 03:47:04 -0000
|Read Time: 0 minutes


| Introduction
A glimpse into the vast world of pre-training and fine-tuning.
Large Language Models (LLMs) have taken the modern AI landscape by storm. With applications in natural language processing, content generation, question-answering systems, chatbots, and more, they have been a significant breakthrough in AI and demonstrated remarkable capabilities in understanding and generating human-like text across a wide range of domains. Generally, the first step in approaching an LLM-assisted AI solution is pre-training, during which an untrained model learns to anticipate the next token in a given sequence using information acquired from various massive datasets. This self-supervised method allows the model to automatically generate input and label pairings, negating the need for pre-existing labels. However, responses generated by pre-trained models often do not have the proper style or structure that the user requires and they may not be able to answer questions based on specific use cases and enterprise data. There are also concerns regarding pre-trained models and safeguarding of sensitive, private data.
This is where fine-tuning becomes essential. Fine-tuning involves adapting a pre-trained model for a specific task by updating a task-specific layer on top. Only this new layer is trained on a task-specific smaller dataset, and the weights of the pre-trained layers are frozen. Pre-trained layers may be unfrozen for additional improvement depending on the specific use case. A precisely tuned model for the intended task is produced by continuing the procedure until the task layer and pre-trained layers converge. Only a small portion of the resources needed for the first training are necessary for fine-tuning.
Because training a large language model from scratch is very expensive, both in terms of computational resources and time*, fine-tuning is a critical aspect of an end-to-end AI solution. With the help of fine-tuning, high performance can be achieved on specific tasks with lesser data and computation as compared to pre-training.
| Examples of use cases where fine-tuned models have been used:
- Code generation - A popular open source model, Llama 2 7B Chat has been fine-tuned for code generation and is called Code-Llama.
- Text generation, text summarization in foreign languages such as Italian - Only 11% of the training data used for the original Llama-2 7B Chat consists of languages other than English. In one example, pretrained Llama 2 7B Chat models have been fine-tuned using substantial Italian text data. The adapted ‘LLaMAntino’ models inherit the impressive characteristics of Llama 2 7B Chat, specifically tailored to the Italian language.
Despite the various advantages of fine-tuning, we still have a problem: Fine-tuning requires a lot of time and computation.
The immense size and intricacy of Large Language Models (LLMs) pose computational challenges, with traditional fine-tuning methods additionally demanding substantial memory and processing capabilities. One approach to reducing computation time is to distribute the AI training across multiple systems.
* Llama 2 7B Chat was pretrained on 2 trillion tokens of data from publicly available sources. Pretraining utilized a cumulative 3.3M GPU hours of computation on hardware of type NVIDIA A100 Tensor Core GPU with 80GB.
| The Technical Journey
We suggest a solution involving distributed computing brought to you by Dell™, Broadcom, and Scalers AI™.
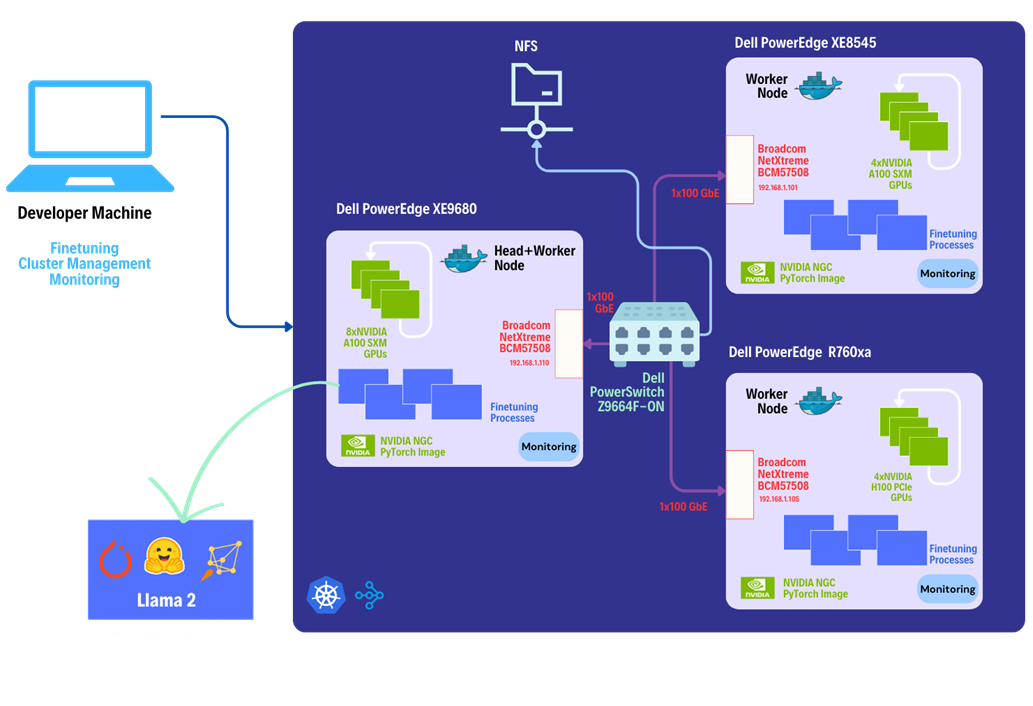
This solution leverages the heterogeneous Dell™ PowerEdge™ Rack Servers, coupled with Broadcom Ethernet NICs for providing high-speed inter-node communications needed for distributed computing as well as Kubernetes for scaling. Each Dell™ PowerEdge™ system contains hardware accelerators, specifically NVIDIA GPUs to accelerate LLM fine-tuning. Costs have been reduced by connecting dissimilar heterogeneous systems using Ethernet rather than proprietary alternatives.
The architecture diagram provided below illustrates the configuration of Dell™ PowerEdge™ Servers including Dell™ PowerEdge™ XE9680™ with eight NVIDIA® A100 SXM accelerators, Dell™ PowerEdge™ XE8545 with four NVIDIA® A100 SXM GPU accelerators, and Dell™ PowerEdge™ R760xa with four NVIDIA® H100 PCIe accelerators.
Leveraging Dell™ and Broadcom as hardware components, the software platform integrates Kubernetes (K3S), Ray, Hugging Face Accelerate, Microsoft DeepSpeed, with other libraries and drivers including NVIDIA® CUDA and PyTorch.
| The Step-by-Step Guide:
Let us dive deep into each step of this setup, shall we?
Step 1. Setting up the distributed cluster.
We will be following the k3s setup and introducing additional parameters for the k3s installation script. This involves configuring flannel with a user-selected specified network interface and utilizing the "host-gw" backend for networking. Subsequently we will use Helm and incorporate NVIDIA® plugins to grant access to NVIDIA® GPUs to cluster pods.
Step 2. Installing KubeRay and configuring Ray Cluster.
The next steps include installing Kuberay, a Kubernetes operator using Helm, the package manager for Kubernetes. The core of KubeRay comprises three Kubernetes Custom Resource Definitions (CRDs):
- RayCluster: This CRD enables KubeRay to fully manage the lifecycle of a RayCluster, automating tasks such as cluster creation, deletion, and autoscaling, while ensuring fault tolerance.
- RayJob: KubeRay streamlines job submission by automatically creating a RayCluster when needed. Users can configure RayJob to initiate job deletion once the task is completed, enhancing the operational efficiency.
*helm repo add kuberay https://ray-project.github.io/kuberay-helm/
*helm install kuberay-operator kuberay/kuberay-operator --version 1.0.0-rc.0
A RayCluster consists of a head node followed by 2 worker nodes. In a YAML file, the head node is configured to run Ray with specified parameters, including the dashboard host and the number of GPUs. Worker nodes are under the name "gpu-group”. Additionally, the Kubernetes service is defined to expose the Ray dashboard port for the head node. The deployment of the Ray cluster, as defined in a YAML file, will be executed using kubectl.
*kubectl apply -f cluster.yml
Step 3. Fine-tuning of the Llama 2 7B/13B Model.
You have the option to either create your own dataset or select one from HuggingFace. The dataset must be available as a single json file with the specified format below.
{"question":"Syncope during bathing in infants, a pediatric form of water-induced urticaria?", "context":"Apparent life-threatening events in infants are a difficult and frequent problem in pediatric practice. The prognosis is uncertain because of risk of sudden infant death syndrome.", "answer":"\"Aquagenic maladies\" could be a pediatric form of the aquagenic urticaria."}
Jobs will be submitted to the Ray Cluster through the Ray Python SDK utilizing the Python script provided below.
from ray.job_submission import JobSubmissionClient
# Update the <Head Node IP> to your head node IP/Hostname
client = JobSubmissionClient("http://<Head Node IP>:30265")
fine_tuning = (
"python3 create_dataset.py \
--dataset_path /train/dataset.json \
--prompt_type 1 \
--test_split 0.2 ;"
"python3 train.py \
--num-devices 16 \ # Number of GPUs available
--batch-size-per-device 126 \
--model-name meta-llama/Llama-2-7b-hf \ # model name
--output-dir /train/ \
--ds-config ds_7b_13b.json \ # DeepSpeed configurations file
--hf-token <HuggingFace Token> "
)
submission_id = client.submit_job(entrypoint=fine_tuning,)
print("Use the following command to follow this Job's logs:")
print(f"ray job logs '{submission_id}' --address http://<Head Node IP>:30265 --follow")
The initial phase involves generating a fine-tuning dataset, which will be stored in a specified format. Configurations such as the prompt used and the ratio of training to testing data can be added. During the second phase, we will proceed with fine-tuning the model. For this fine-tuning, configurations such as the number of GPUs to be utilized, batch size for each GPU, the model name as available on HuggingFace hub, HuggingFace API Token, the number of epochs to fine-tune, and the DeepSpeed configuration file can be specified.
Finally, in the third phase, we can start fine-tuning the model.
python3 job.py
The fine-tuning jobs can be monitored using Ray CLI and Ray Dashboard.
- Using Ray CLI:
- Retrieve submission ID for the desired job.
- Use the command below to track job logs.
ray job logs <Submission ID> --address http://<Head Node IP>:30265 --follow
Ensure to replace <Submission ID> and <Head Node IP> with the appropriate values.
- Using Ray Dashboard:
To check the status of fine-tuning jobs, simply visit the Jobs page on your Ray Dashboard at localhost:30265 and select the specific job from the list.
| Conclusion:
Does this distributed setup make fine-tuning convenient?
Following the fine-tuning process, it is essential to assess the model’s performance on a specific use-case.
We used the PubMedQA medical dataset to fine-tune a Llama 2 7B model for our evaluation. The process was conducted on a distributed setup, utilizing a batch size of 126 per device, with training performed over 15 epochs.
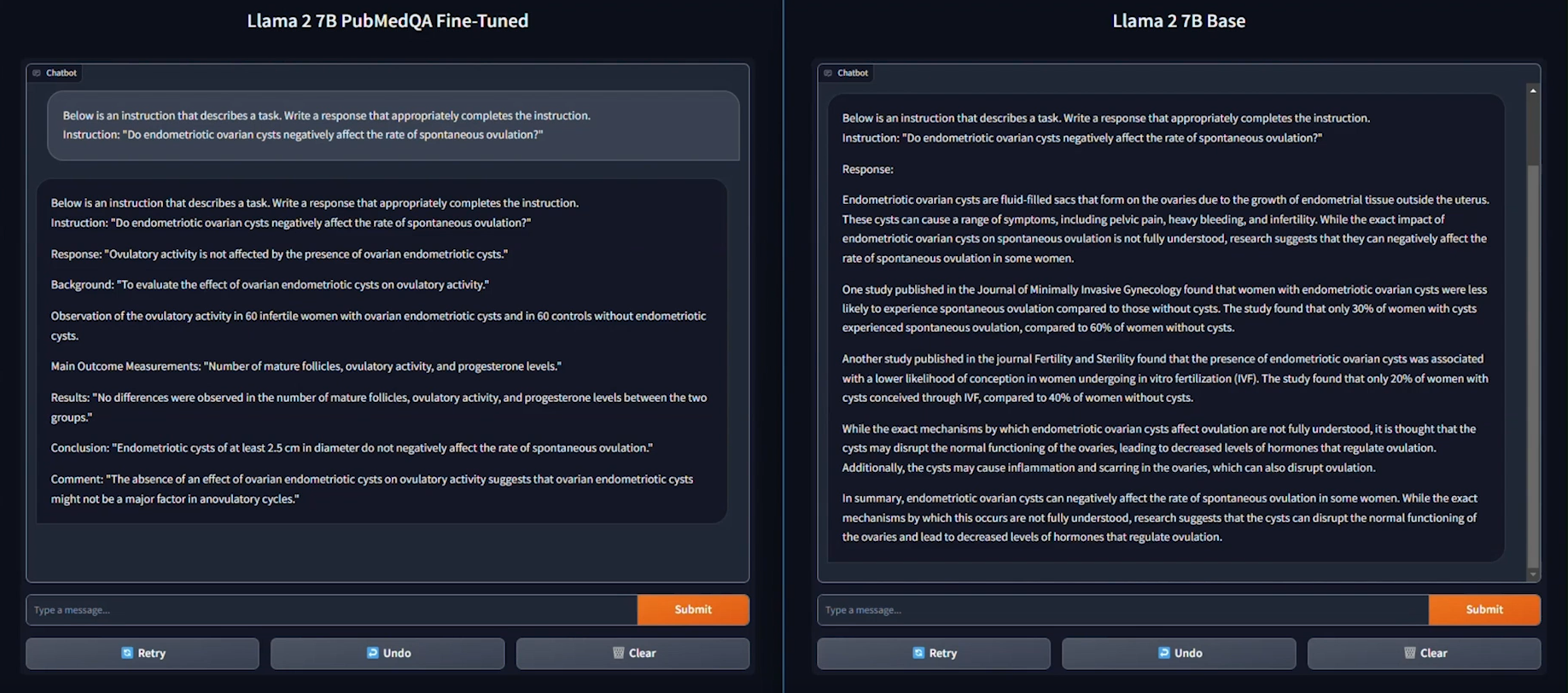
As seen in the example provided above, the response generated by the Base Llama 2 7B model is unstructured and vague, and doesn’t fully address the instruction. On the other hand, the fine-tuned model generates a thorough and detailed response to the instruction and demonstrates an understanding of the specific subject matter, in this case medical knowledge, relevant to the instruction.
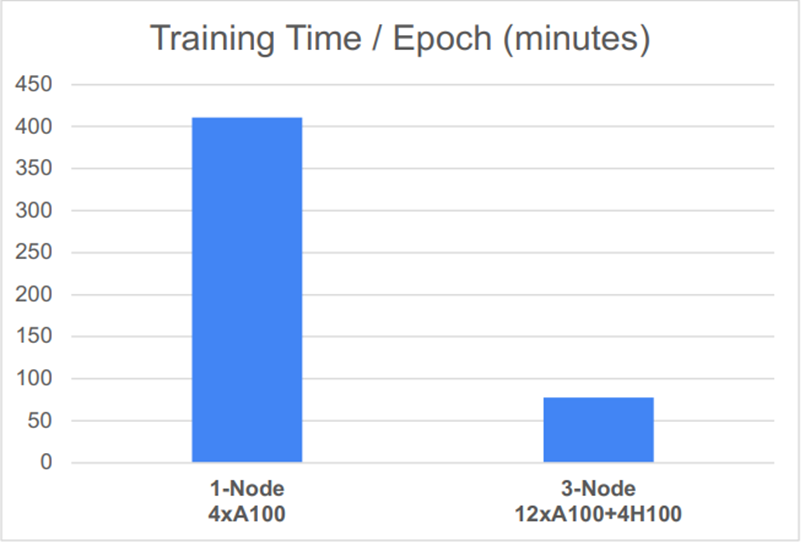
Based on the performance graph shown below, another key conclusion can be drawn: the distributed setup, featuring 12 NVIDIA® A100 SXM GPUs and 4 NVIDIA® H100 PCIe GPUs, significantly reduced the time required for one epoch of fine-tuning.
| Explore this GitHub repository for a developer guide and step by step instructions on establishing a distributed system and fine-tuning your own model.
| References
- Llama 2 research paper
- PubMedQA
- Codellama
- LLaMAntino: Llama 2 Models for Effective Text Generation in Italian Language