
SmartDedupe
SmartDedupe
-
Shadow stores provide the basis for SmartDedupe, which maximizes the storage efficiency of a cluster by decreasing the amount of physical storage required to house an organization’s data. Efficiency is achieved by scanning the on-disk data for identical blocks and then eliminating the duplicates. This means that initial file write or modify performance is not impacted, since no additional computation is required in the write path.
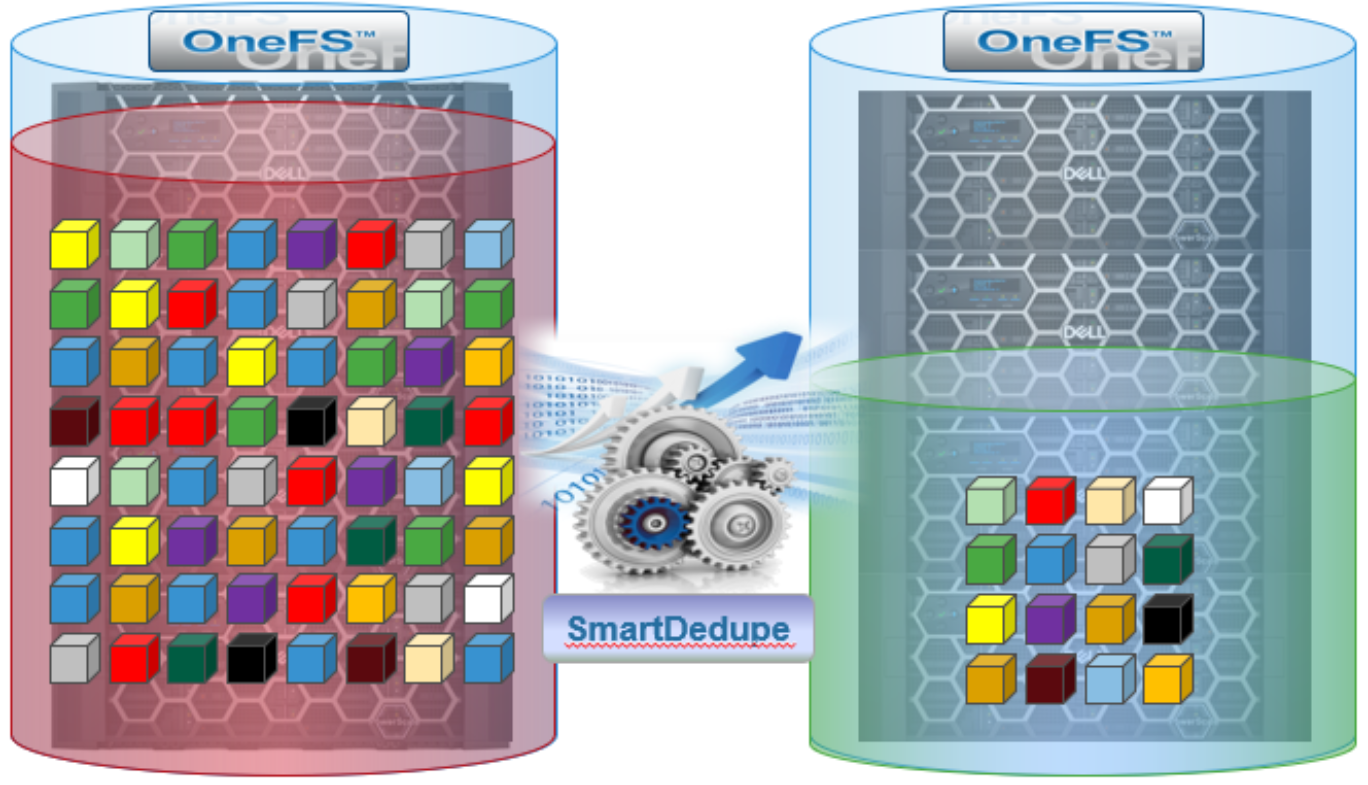
Figure 19. OneFS storage efficiency with SmartDedupe
When SmartDedupe runs for the first time, it scans the dataset and selectively samples data blocks from it, creating the fingerprint index. The index is scanned for duplicates. When a match is found, a byte-by-byte comparison of the blocks is performed to verify that they are identical and to ensure that there are no hash collisions. Then, if the blocks are determined to be identical, duplicate blocks are removed from the actual files and replaced with pointers to the shadow stores.
For more information, see the Dell PowerScale OneFS: Data Reduction and Storage Efficiency white paper.