
Replication
Replication
-
SyncIQ
While snapshots provide an ideal solution for infrequent or smaller-scale data loss occurrences, when it comes to catastrophic failures or natural disasters, a second, geographically separate copy of a dataset is clearly beneficial. Here, a solution is required that is significantly faster and less error-prone than a recovery from tape, yet still protects the data from localized failure.
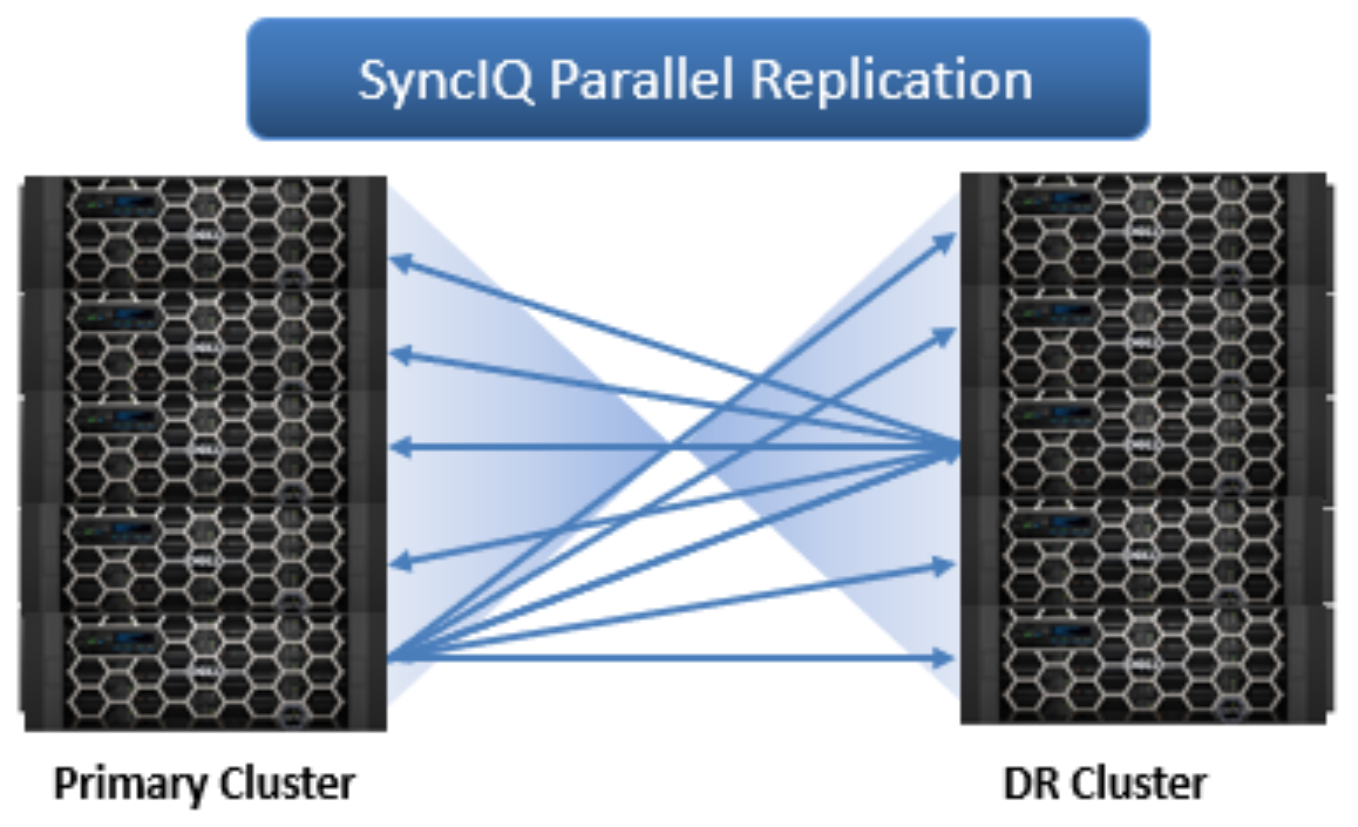
Figure 23. SyncIQ parallel replication across a source and target cluster.
OneFS SyncIQ software delivers high-performance, asynchronous replication of unstructured data to address a broad range of recovery point objectives (RPO) and recovery time objectives (RTO). This enables customers to make an optimal tradeoff between infrastructure cost and potential for data loss if a disaster occurs. SyncIQ does not impose a hard limit on the size of a replicated file system so will scale linearly with an organization’s data growth up into the multiple petabyte ranges.
SyncIQ is easily optimized for either LAN or WAN connectivity and includes policy level bandwidth control and reservation. This allows replication over both short and long distances, while meeting consistent SLAs and providing protection from both site-specific and regional disasters. Also, SyncIQ uses a highly parallel, policy-based replication architecture designed to leverage the performance and efficiency of clustered storage. As such, aggregate throughput scales with capacity and allows a consistent RPO over expanding datasets.
There are two basic implementations of SyncIQ:
- The first uses SyncIQ to replicate to a local target cluster within a data center. The primary use case in this scenario is disk backup and business continuity.
- The second implementation uses SyncIQ to replicate to a remote target cluster, typically in a geographically separate data center across a WAN link. Here, replication is typically used for offsite disaster recovery purposes.
In either case, a secondary cluster synchronized with the primary production cluster can afford a substantially improved RTO and RPO than tape backup and both implementations have their distinct advantages. And SyncIQ performance is easily tuned to optimize either for network bandwidth efficiency across a WAN or for LAN speed synchronization. Synchronization policies may be configured at the file-, directory-, or entire-file-system-level and can either be scheduled to run at regular intervals or run manually.
SyncIQ supports up to one thousand defined policies, of which up to fifty may run concurrently. SyncIQ policies also have a priority setting to allow favored policies to preempt others. In addition to chronological scheduling, replication policies can also be configured to start whenever the source is modified (change based replication). If preferred, a delay period can be added to defer the start of a change-based policy.
SyncIQ encryption, which is available in OneFS 8.2 and later, ensures that the security of replicated data in-flight. X.509 Transport Layer Security (TLS) certificates used by the nodes in the replicating clusters are managed through the SyncIQ certificate store. SyncIQ encryption can be configured either per-policy or globally.
SyncIQ linear restore
Leveraging OneFS SnapshotIQ infrastructure, the Linear Restore functionality of SyncIQ can detect and restore (commit) consistent, point in time, block-level changes between cluster replication sets, with a minimal impact on operations and a granular RPO. This “change set” information is stored in a mirrored database on both source and target clusters and is updated during each incremental replication job, enabling rapid failover and failback RTOs.
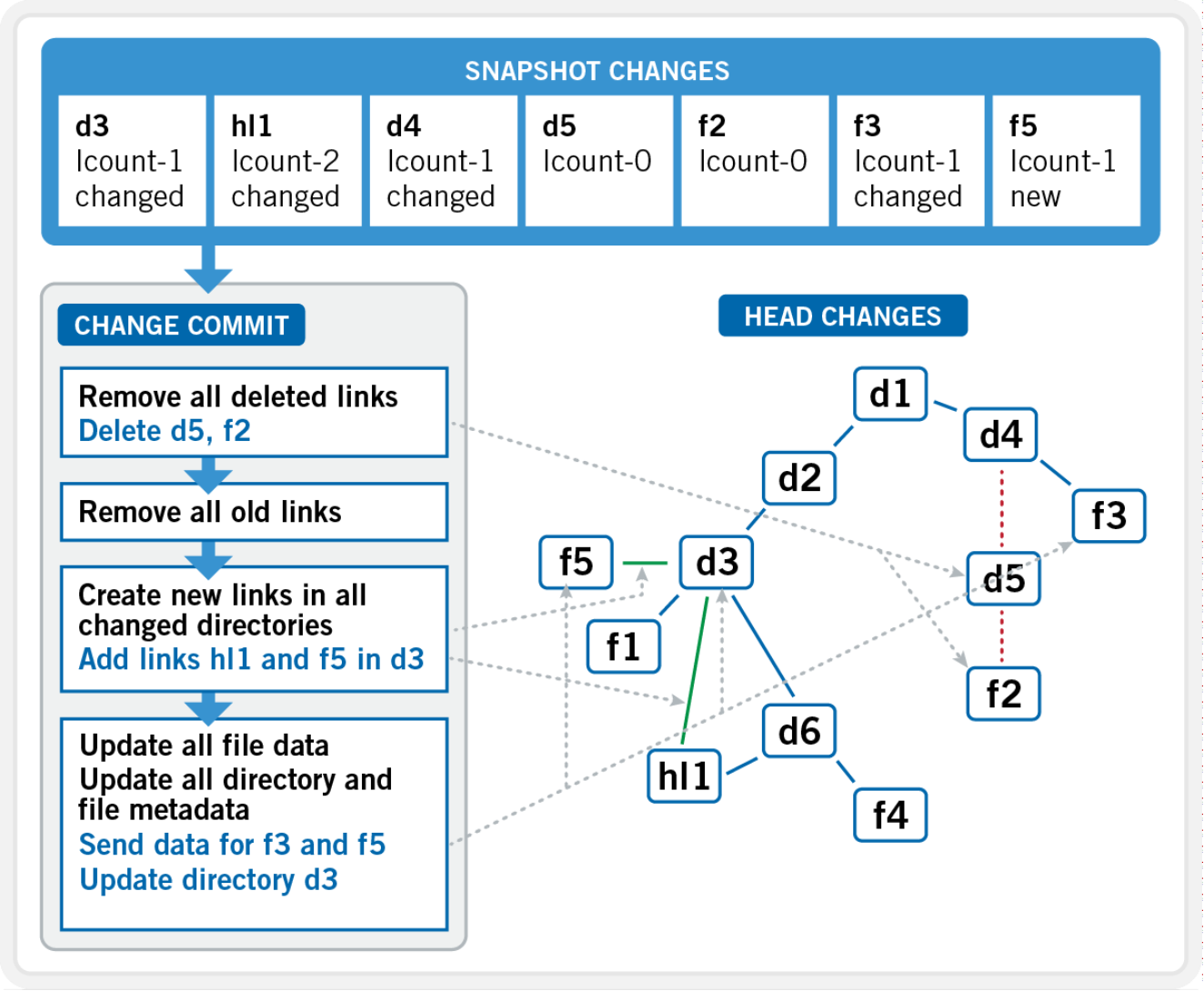
Figure 24. SyncIQ linear restore change commit mechanism
SyncIQ replica protection
All writes outside of the synchronization process itself are disabled on any directory that is a target for a specific SyncIQ job. However, if the association is broken between a target and a source, the target may then return to a writable state. Subsequent resolution of a broken association will force a full resynchronization to occur at the next job run. As such, restricted writes prevent modification, creation, deletion, linking, or movement of any files within the target path of a SyncIQ job. Replicated disaster recovery (DR) data is protected within and by its SyncIQ container or restricted-writer domain, until a conscious decision is made to bring it into a writable state.
SyncIQ failover and failback
If a primary cluster becomes unavailable, SyncIQ enables failover to a mirrored, DR cluster. During such a scenario, the administrator decides to redirect client I/O to the mirror and initiates SyncIQ failover on the DR cluster. Users continue to read and write to the DR cluster while the primary cluster is repaired.
Once the primary cluster becomes available again, the administrator may decide to revert client I/O back to it. To achieve this, the administrator initiates a SyncIQ failback prep process which synchronizes any incremental changes made to the DR cluster back to the primary.
Failback is divided into three distinct phases:
- First, the prep phase readies the primary to receive changes from the DR cluster by setting up a restricted writer domain and then restoring the last known good snapshot.
- Next, upon successful completion of failback prep, a final failback differential sync is performed.
- Lastly, the administrator commits the failback, which restores the primary cluster back to its role as the source and relegates the DR cluster back to a target again.
In addition to the obvious unplanned failover and failback, SyncIQ also supports controlled, proactive cluster failover and failback. This provides two major benefits:
- The ability to validate and test DR procedures and requirements
- The ability to perform planned cluster maintenance
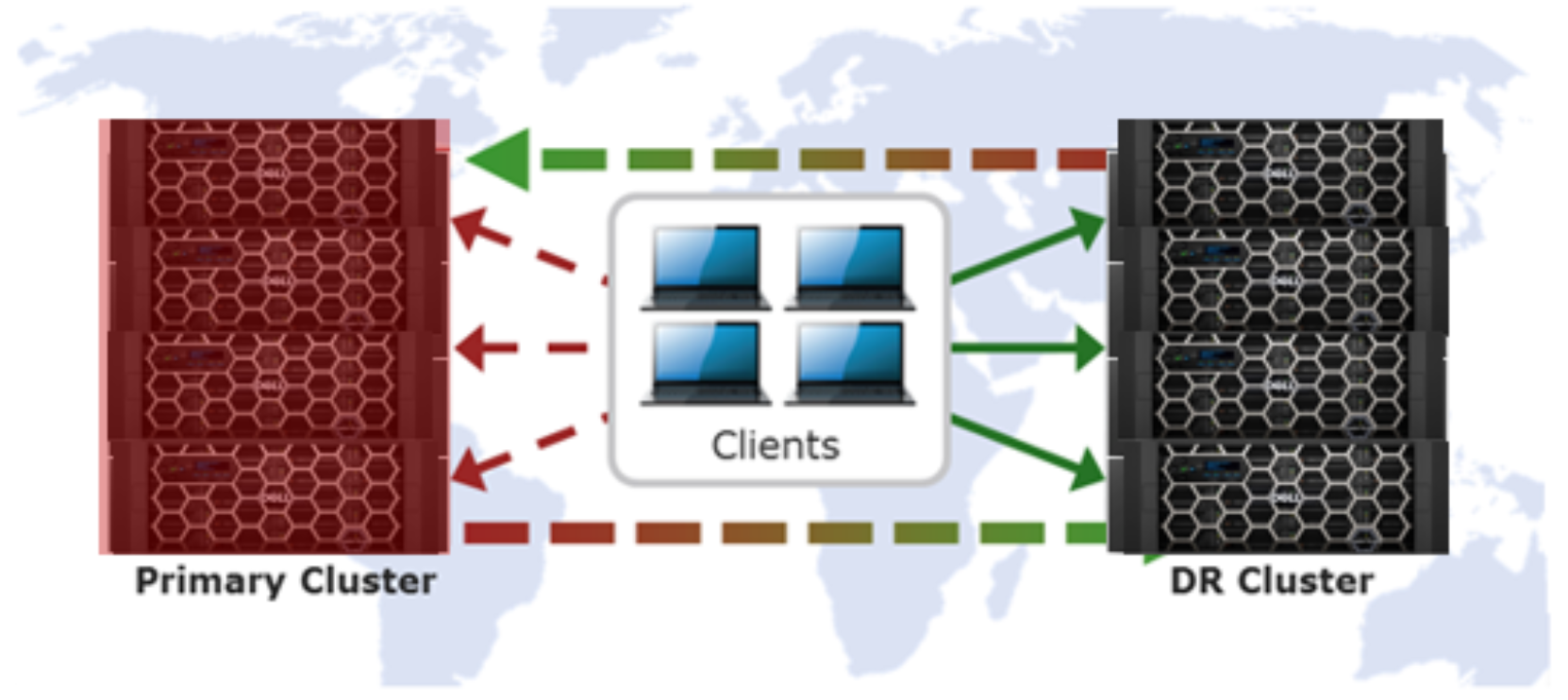
Figure 25. SyncIQ automated data failover and failback
Note: SyncIQ data failover and failback is fully supported for both enterprise and compliance SmartLock WORM datasets.
Continuous replication mode
Complementary to the manual and scheduled replication policies, SyncIQ also offers a continuous mode, or replicate on change, option. When the Whenever the source is modified policy configuration option is selected, SyncIQ will continuously monitor the replication dataset (sync domain) and automatically replicate and changes to the target cluster. Events that trigger replication include file additions, modifications and deletions, directory path, and metadata changes. Also, include and exclude rules can also be applied to the policy, providing a further level of administrative control.
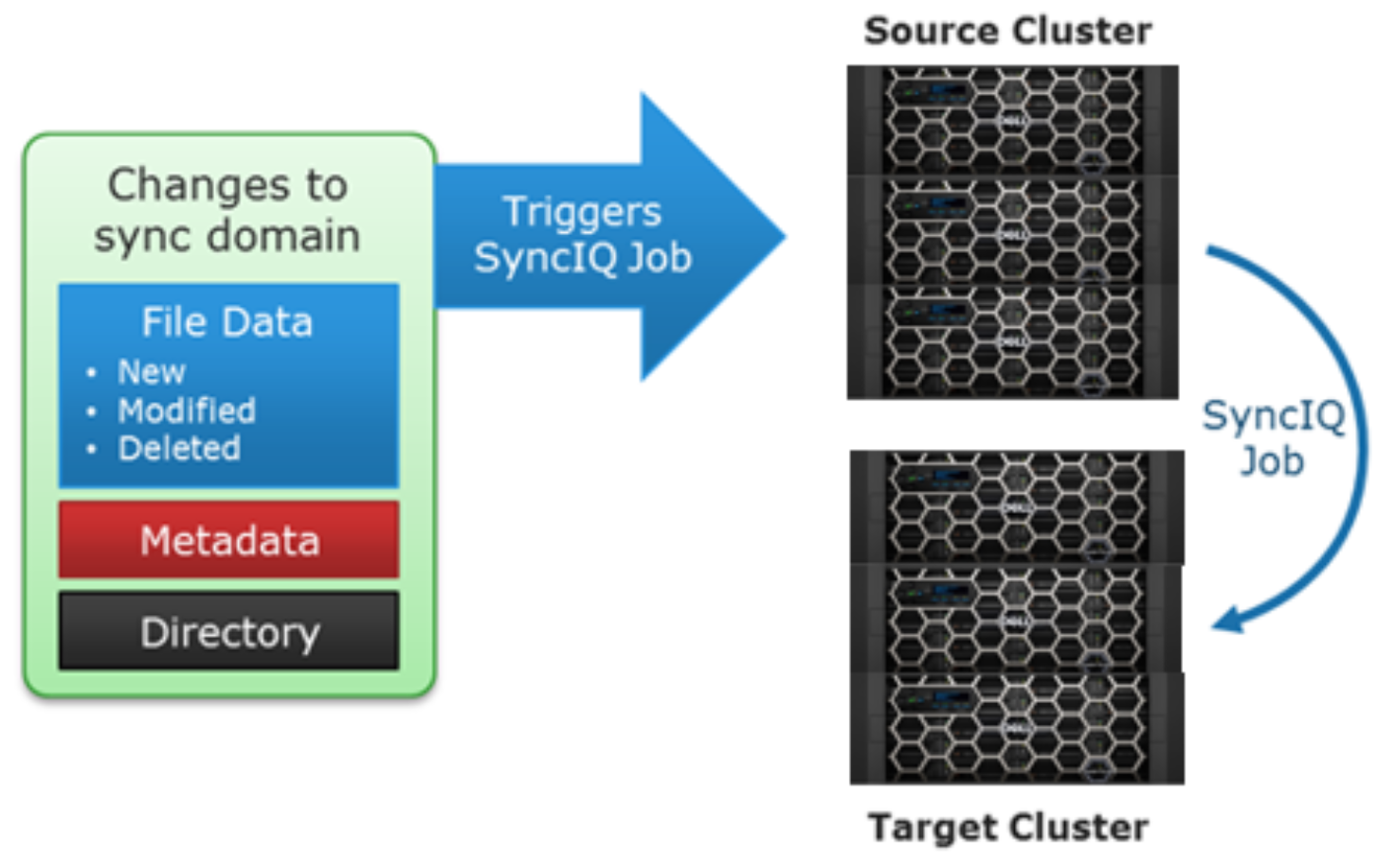
Figure 26. SyncIQ replicate on change mode