




AI Agents Made Easy by Dell Enterprise Hub


From Models to AI Agents: The Future of Intelligent Applications
Our previous blogs explored model selection criteria and model merging for complex applications. Now, let's delve into the next level: AI Agents.
AI Agents: Intelligent Collaboration
AI agents are software programs that learn and act autonomously. They can work alongside other models and tools, forming a powerful team to tackle your application's requirements.
With 2022 being the year of Generative AI and LLMs, and 2023 being the year of RAG, 2024 is poised to be the year of AI Agents. Some might even say they're already here. Unlike LLMs and RAG applications, AI Agents are better built for real-world interaction. They can not only process text but also execute tasks and make decisions, making them ideal for practical applications.
Seamless Flight Information with AI Agents: Imagine a simple yet powerful feature in your airline app:
- Speak Your Request: Tap the microphone icon and ask, "When is my flight tomorrow?".
- AI Agent #1: Understanding Your Voice: This first AI agent specializes in speech recognition, converting your spoken question into text.
- AI Agent #2: Finding Your Flight: The processed text is sent to another AI agent that specializes in querying the airline database, identifying you and retrieving your flight information.
- AI Agent #3: Real-Time Flight Status: The third AI agent, specializing in real-time flight data, checks the departure, boarding, and arrival times for your specific flight.
- AI Agent #1: Speaking the Answer: All the information is gathered and sent back to the first AI agent which converts the text into an audio response personalized for you: "Dear Khushboo, your Delta flight to Las Vegas is on time and departs at 3:00 PM. Would you like me to check you in?"
AI Agents offer a highly versatile architecture where each agent can be independently scaled to meet specific requirements, ensuring optimal performance with minimized costs. Dell Technologies’ diverse platform portfolio provides the ideal environment for running these agents efficiently.
Furthermore, this AI agent architecture allows for seamless A/B testing, guaranteeing reliable service and the implementation of best practices in model deployment for a superior user experience.
Architecture
In this blog, we will share our guide for creating an AI Agent system, connecting multiple models to solve a specific need of an application. We will use the LangChain framework to create a research article search agent utilizing Dell Enterprise Hub. For this guide, we chose the meta-llama/Meta-Llama-3-8b-Instruct model, a smaller yet powerful model refined through Reinforced Learning from Human Feedback (RLHF).
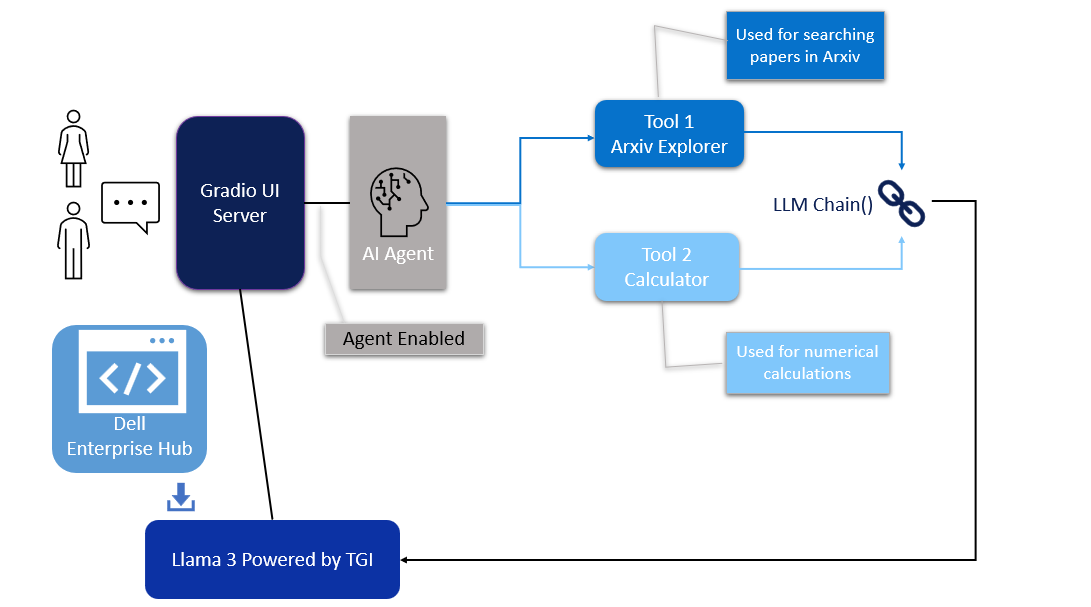
Figure 1. Architecture of the AI Agent
Model deployment
- From Dell Enterprise Hub, select a model from the model dashboard to deploy. In this blog, meta-llama/Meta-Llama-3-8b-Instruct will be used to work with the agents. Select the deployment options that match your environment.
- Now the Docker command to run TGI will be available to be copied. Paste the command in your Linux system. It will look something like the following:
docker run \ -it \ --gpus 1 \ --shm-size 1g \ -p 8080:80 \ -e NUM_SHARD=1 \ -e MAX_BATCH_PREFILL_TOKENS=32768 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-meta-llama-meta-llama-3-8b-instruct
This command will launch a container with the TGI server running the llama3-8b-instruct model on port 8080.
UI interface
The UI server script is the combination of Gradio, LangChain agents, and associated tools. For this example, we have built an agent with arxiv, a tool that helps with searching and summarizing technical papers from arvix.org.
In the following code base, the inference endpoint url values must be changed to your specific server settings. The endpoint_url must point to the TGI server container from Dell Enterprise Hub shown in the model deployment section. You may change gr.Image to an image of your choosing.
The following are the prerequisites to be installed before running the final UI agent code:
pip install gradio,langchain,langchain-community pip install --upgrade --quiet arxiv
Then, run it as:
python3 agent.py
import gradio as gr
from langchain_community.llms import HuggingFaceEndpoint
from langchain.chains import RetrievalQA
from langchain.agents import load_tools
from langchain.agents import initialize_agent
# Create endpoint for llm
llm = HuggingFaceEndpoint(
huggingfacehub_api_token="hf_your_huggingface_access_token",
endpoint_url="http://192.x.x.x:8080",
max_new_tokens=128,
temperature=0.001,
repetition_penalty=1.03
)
# Generating response by the agent
def agent_gen_resp(mes):
tools = load_tools(["arxiv", "llm-math"], llm=llm)
agent = initialize_agent(tools,
llm,
agent="zero-shot-react-description",
verbose=True,
handle_parsing_errors=True)
agent.agent.llm_chain.prompt.template
respond = agent.run(mes)
return respond
# Inferencing using llm or llm+agent
def gen_response(message, history, agent_flag):
if agent_flag == False:
resp = llm(message)
else:
resp = agent_gen_resp(message)
history.append((message, resp))
return "", history
# Flag for agent use
def flag_change(agent_flag):
if agent_flag == False:
return gr.Textbox(visible=False)
else:
return gr.Textbox(visible=True)
# Creating gradio blocks
with gr.Blocks(theme=gr.themes.Soft(), css="footer{display:none !important}") as demo:
with gr.Row():
with gr.Column(scale=0):
gr.Image("dell_tech.png", scale=0, show_download_button=False, show_label=False, container=False)
with gr.Column(scale=4):
gr.Markdown("")
gr.Markdown("# AI Agents made easy by Dell Enterprise Hub")
gr.Markdown("## Using Meta-Llama-3-8B-Instruct")
with gr.Row():
chatbot = gr.Chatbot(scale=3)
prompt = gr.Textbox(container=False)
with gr.Row():
agent_flag = gr.Checkbox(label="Enable ArXiv Agent",scale=4)
clear = gr.ClearButton([prompt, chatbot])
prompt.submit(gen_response, [prompt, chatbot, agent_flag], [prompt, chatbot])
agent_flag.change(flag_change, agent_flag)
# Launching the application
demo.launch(server_name="0.0.0.0", server_port=7860)
Results
We ran an example where we asked the llama3-8b-instruct LLM model to summarize the paper 2401.00304 from arxiv.org. The response from the model is shown in Figure 2. The base model fails to retrieve the correct article.
However, when the model is provided with the arxiv tool from Langchain, the model is able to retrieve the correct article. It then recognizes further instructions to summarize the abstract and produces the results shown in Figure 3. Figure 4 shows the thought processes of an agent, its corresponding actions, and the tools it used to get the results.
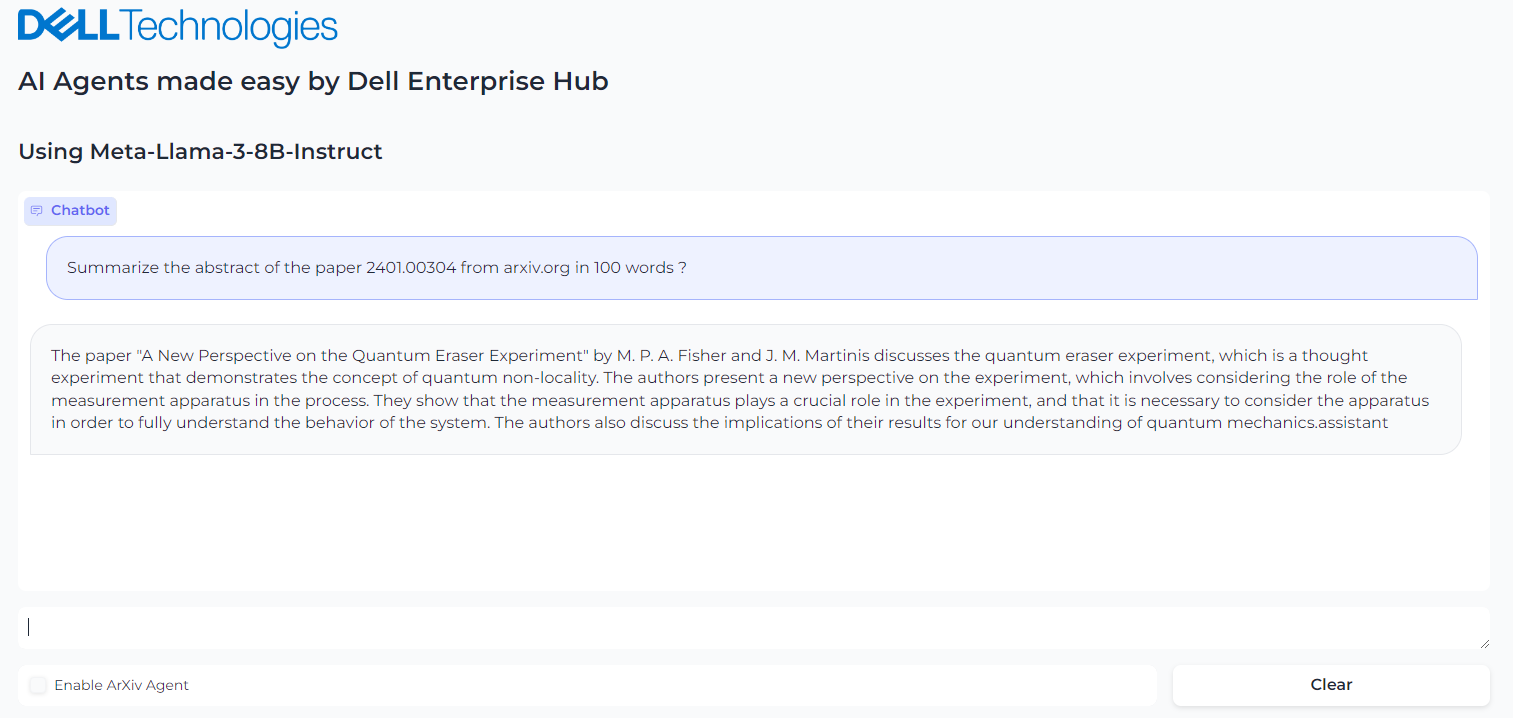
Figure 2. Query the Llama3-8b-istruct to get the summary of the abstract of paper in arxiv.org
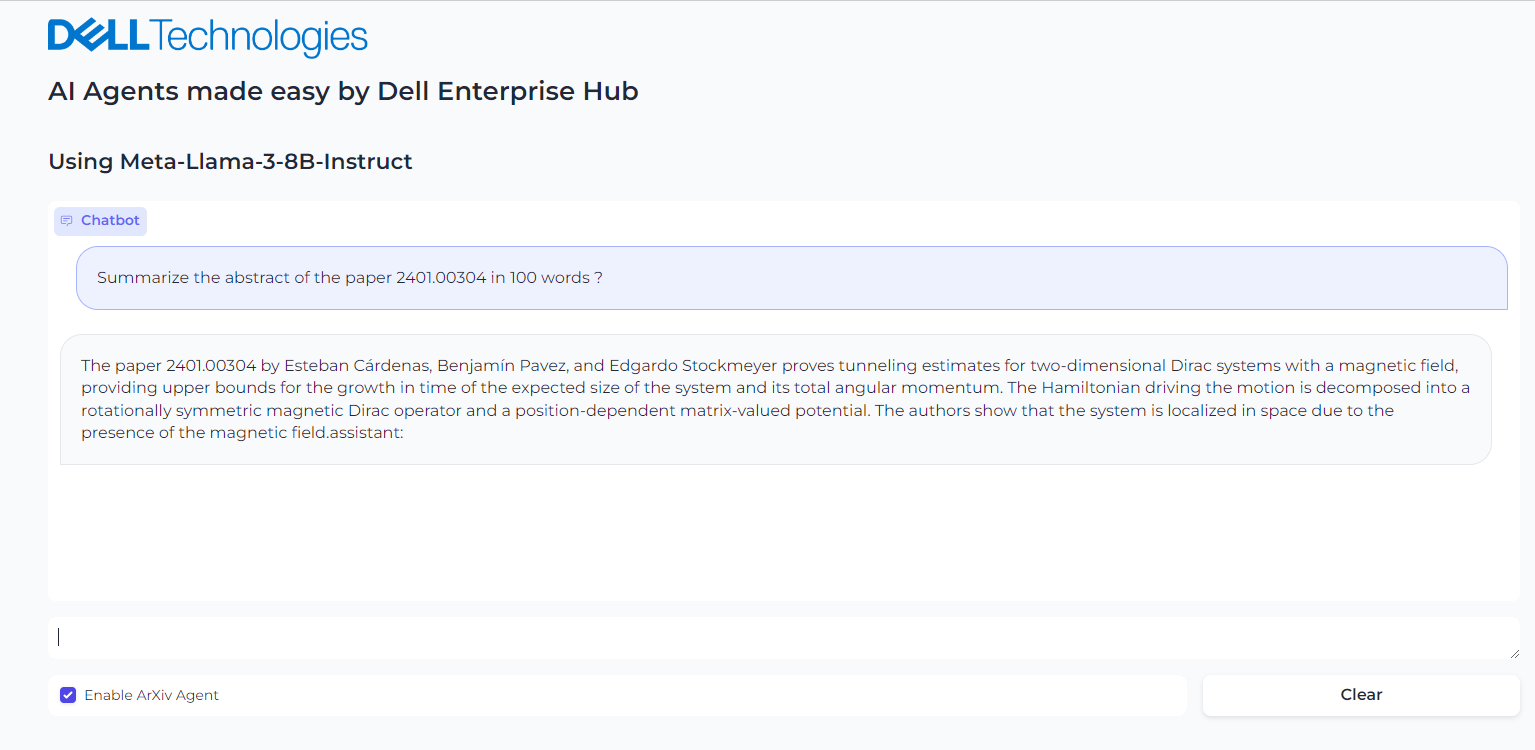
Figure 3. Enabling the Agent and asking it to summarize the paper from arxiv.org
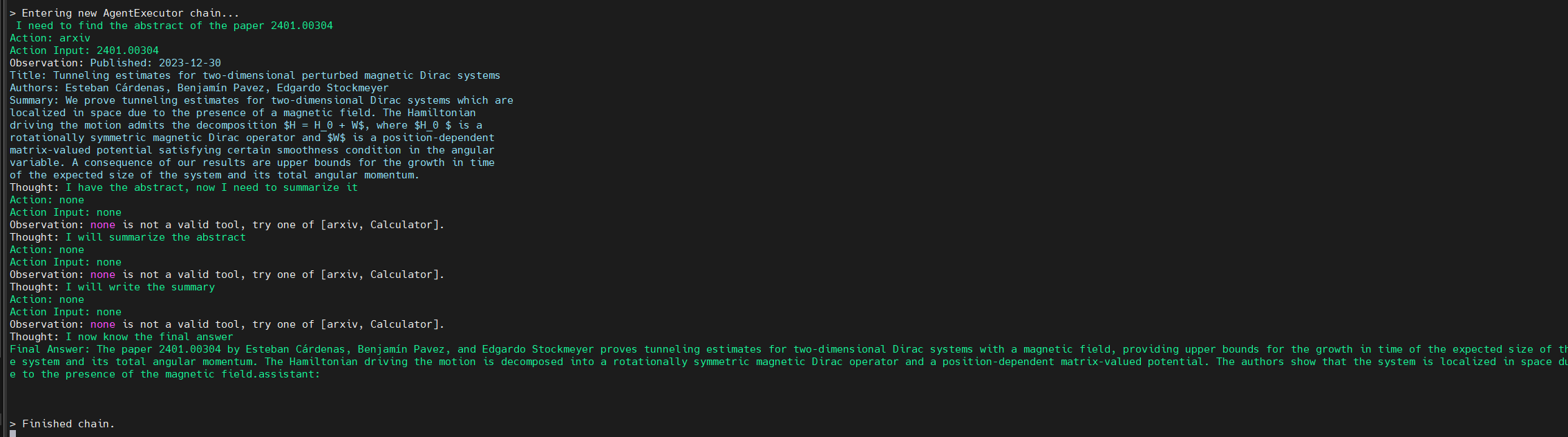
Figure 4. Background process followed by the agent to come to the final answer
Conclusion
With few clicks, you have a live, working AI agent implementation in which the model is seamlessly chained with tools and working to solve a specific application requirement.
Eager for more? Check out the other blogs in this series to get inspired and discover what else you can do with the Dell Enterprise Hub and Hugging Face partnership.
Author: Khushboo Rathi, Engineering Technologist
Bala Rajendran, AI Technologist
To see more from these authors, check out Bala Rajendran and Khushboo Rathi on Info Hub.