




Model Merging Made Easy by Dell Enterprise Hub


Beyond Open-Source LLMs: Tailoring Models for Your Needs
The open-source LLM landscape is booming! But with so many options, choosing the right model can be overwhelming. What if you need a model with both domain-specific knowledge and diverse generation capabilities? Enter model merging, a powerful technique to unlock the full potential of LLMs.
Model merging: Unlocking model versatility
Model merging allows you to combine the strengths of different pre-trained models without additional training. This creates a "multitask" model, excelling in both specific domains and diverse generation tasks and addressing key challenges in AI like:
- Catastrophic Forgetting: This occurs when a model learning new tasks forgets those previously learned. Merging preserves the original model’s capabilities.
- Multitask Learning: Effectively training a model for multiple tasks can be difficult. Merging offers a way to combine pre-trained models with different strengths.
This blog explores the use of the MergeKit Python library to merge pre-trained LLMs like Mistral-7B-v0.1 and Zephyr-7B-alpha. We'll demonstrate how to create a new model that leverages the strengths of both.
Architecture
There are a variety of methods that can be used during model merging, such as Linear, Spherical Linear Interpolation (SLERP), TIES, DARE, Passthrough, and Task Arithmetic. For the purposes of this blog, we will be using the task arithmetic method, which computes the task vector of each model by subtracting it from the base model weights. This method works best with models that were fine-tuned from common ancestors and have a similar model framework. Hence, in this walk-through, we will merge the fine-tuned version of zephyr-7B with its base model—Mistral-7B—to form our new merged model. Alternatively, you could merge your special domain-specific, highly fine-tuned model of Mistral-7B with the base model of Mistral-7B.
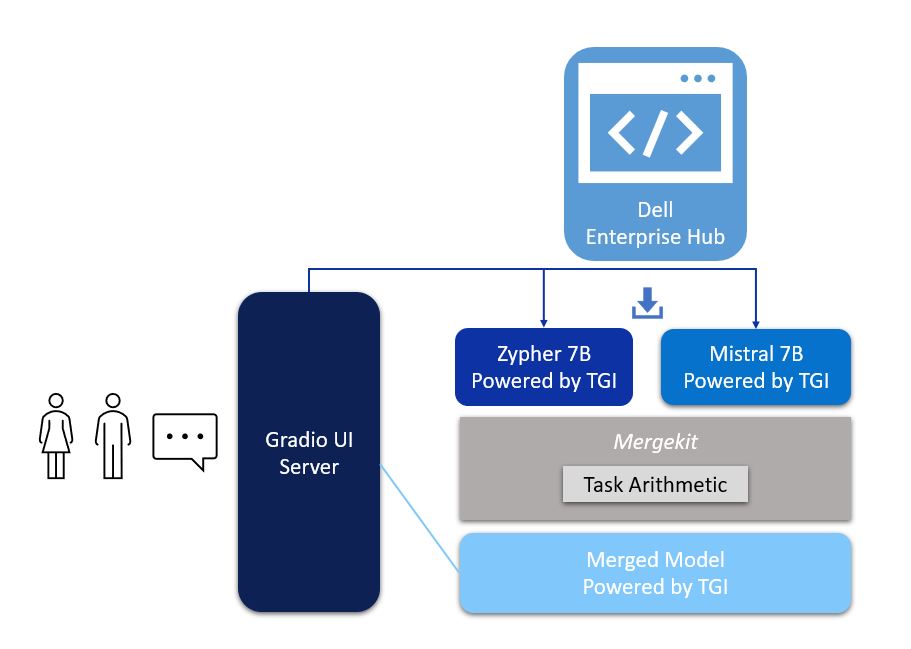
Figure 1. Architecture of model merging deployment, with UI powered by Gradio and Zypher 7B, Mistal 7B and the merged model all powered by TGI from Dell Enterprise Hub
Implementation
The following describes the process for merging two models using mergekit and deploying the merged model to production:
1. Login with your user access token from Hugging Face.
2. From Dell Enterprise Hub, select the models you would like to merge. For the purposes of this blog, we chose Zephyr-7b-beta and mistralai/Mistral-7B-v0.1
docker run \ -it \ --gpus 1 \ --shm-size 1g \ -p 80:80 \ -v /path/on/local_workspace:/Model_zephyr-7b-beta_weights -e NUM_SHARD=1 \ -e MAX_BATCH_PREFILL_TOKENS=32768 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-huggingfaceh4-zephyr-7b-beta
docker run \ --gpus 2 \ --shm-size 1g \ -v /path/on/local_workspace:/Model_mistralai-mistral-7b-v0.1 \ -v /home/$USER/autotrain:/app/autotrain \ registry.dell.huggingface.co/enterprise-dell-training-mistralai-mistral-7b-v0.1 \ --model /app/model \ --project-name fine-tune \ --data-path /app/data \ --text-column text \ --trainer sft \ --epochs 3 \ --mixed_precision bf16 --batch-size 2 \ --peft \ --quantization int4
3. Once we have the Dell optimized containers, the weights of the models must be stored locally to mount them on our training container. The weights can be found on the /model directory inside the container, as shown here:
#container ID of the image running the model kradmin@jpnode4:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 19c2e634c2ba registry.dell.huggingface.co/enterprise-dell-inference-huggingfaceh4-zephyr-7b-beta "/tgi-entrypoint.sh …" 25 seconds ago Up 25 seconds 0.0.0.0:8888->80/tcp, :::8888->80/tcp compassionate_varahamihira #Capture the container ID to execute the docker kradmin@jpnode4:~$ docker exec -it 19c2e634c2ba bash #copying the weights outside from the container root@19c2e634c2ba:/usr/src# cd /model root@19c2e634c2ba:/model# cp -r /model /Model_zephyr-7b-beta_weights
Now, the weights are stored locally in the folder Model_zephyr-7b-beta_weights outside the container. Follow the same process for the mistral-7b-v0.1 model weights.
4. Retrieve the training container from Dell Enterprise Hub, and mount both of these weights:
docker run \ -it \ --gpus 1 \ --shm-size 1g \ -p 80:80 \ -v /path/to/model_weights/:/Model_zephyr-7b-beta_weights\ -v /path/to/mistral_model_weights/:/Model_mistralai-mistral-7b-v0.1 -e NUM_SHARD=1 \ -e MAX_BATCH_PREFILL_TOKENS=32768 \ -e MAX_INPUT_TOKENS=8000 \ -e MAX_TOTAL_TOKENS=8192 \ registry.dell.huggingface.co/enterprise-dell-inference-byom
5. Inside the training container, we git clone the mergekit toolkit locally and install the required packages:
git clone https://github.com/arcee-ai/mergekit.git cd mergekit pip install -e .
6. Create a config YAML file and configure your merge method and percentage weights for each model. Following is the config file we used for the task arithmetic method. Feel free to experiment with various weights associated with the model to achieve optimal performance for your application:
models: - model: /path/to/your/huggingface_model/zephyr-7b-beta parameters: weight: 0.35 - model: /path/to/your/huggingface_model/Mistral-7B-v0.1 parameters: weight: 0.65 base_model:/path/to/your/huggingface_model/Mistral-7B-v0.1 merge_method: task_arithmetic dtype: bfloat16
- The script mergekit-yaml is the main entry point for mergekit, taking your YAML configuration file and an output path to store the merged model:
mergekit-yaml path/to/your/config.yml ./output-model-directory --allow-crimes --copy-tokenizer --out-shard-size 1B --lazy-unpickle --write-model-card
Results
We have run three container servers—Mistral-7B-v0.1, zephyr-7b-beta, and our new merged model. We have built a simple Gradio UI to compare the results from these three models. Check out our blog on model plug and play for a more in-depth implementation of the Gradio UI.
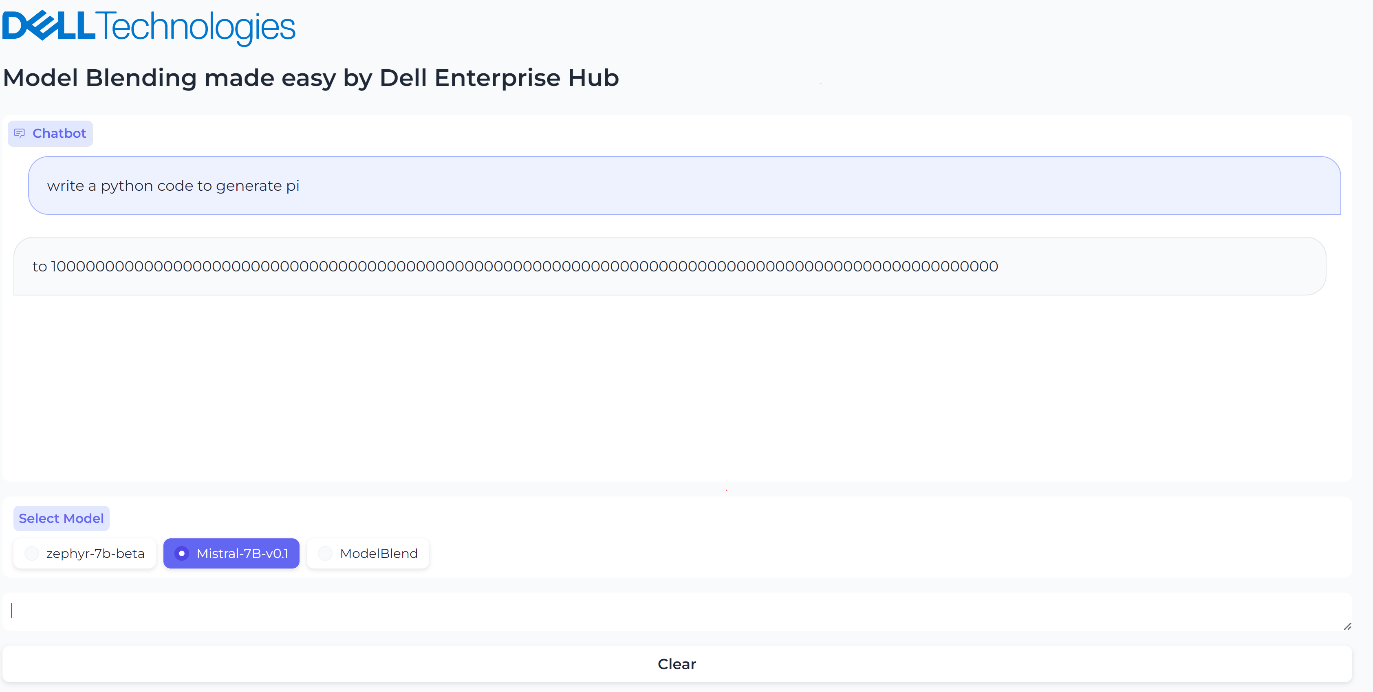
Figure 2. UI when the model Mistal 7B is selected and the inferencing results generated by Mistal 7B model for the prompt, “What is the python code to generate pi?”
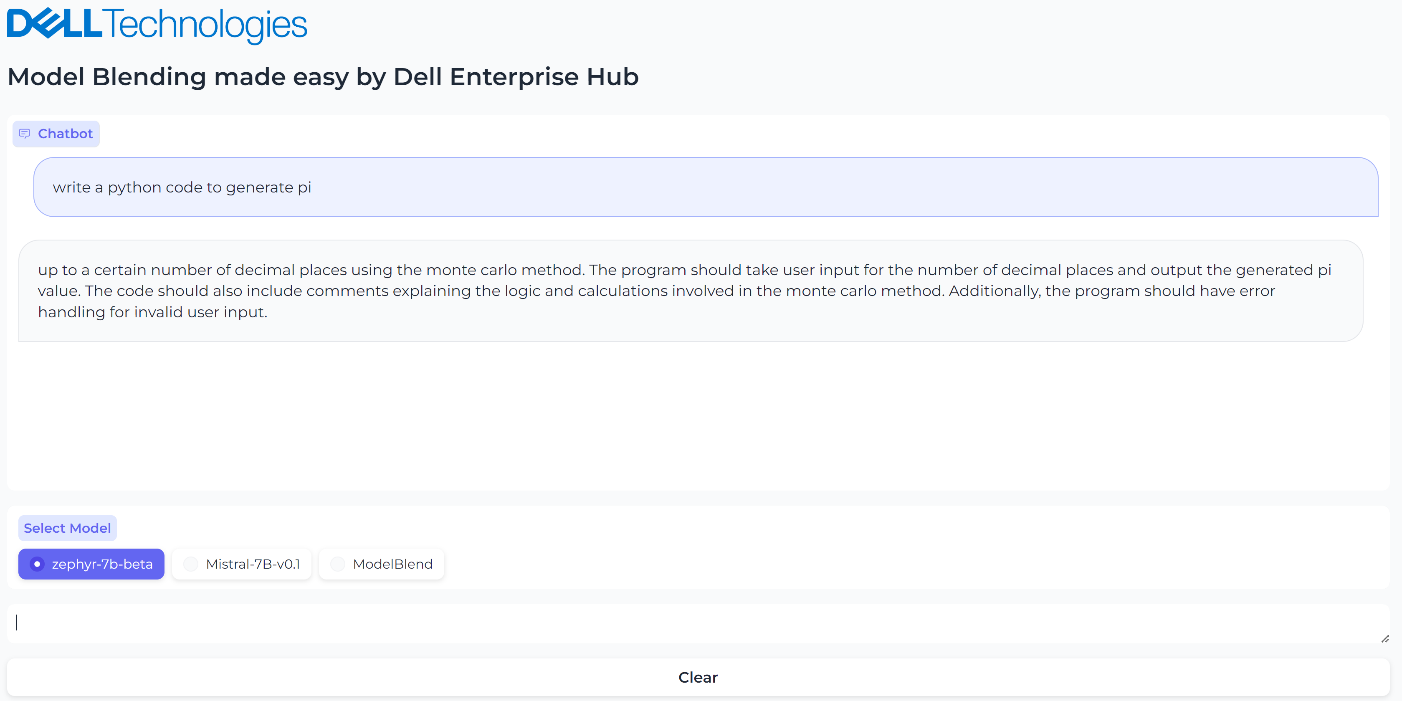
Figure 3. UI when the model Zerphy-7b-beta is selected and the inferencing results generated by Zephyr-7b-beta model for the prompt, “What is the python code to generate pi?”

Figure 4. UI when the merged model is selected, and the inferencing results generated by the merged model
Conclusions
In this small-scale example, both the Mistral-7B-v0.1 and zephyr-7b-beta models failed to generate the correct text for the prompt “What is the python code to generate pi?”, however the blended model generated the text successfully and accurately with no fine-tuning or prompt engineering needed. The core idea of model merging is that the whole is greater than the sum of its parts. Dell Enterprise Hub makes it easy to deploy these blended models at scale.
Eager for more? Check out the other blogs in this series to get inspired and discover what else you can do with the Dell Enterprise Hub and Hugging Face partnership.
Authors: Khushboo Rathi, Engineering Technologist,
Bala Rajendran, AI Technologist
To see more from these authors, check out Bala Rajendran and Khushboo Rathi on Info Hub.