
Archive external data and query
Archive external data and query
-
For structured or semistructured external data, you can perform a simple conversion and processing using Flink SQL and import it into ECS with Iceberg.
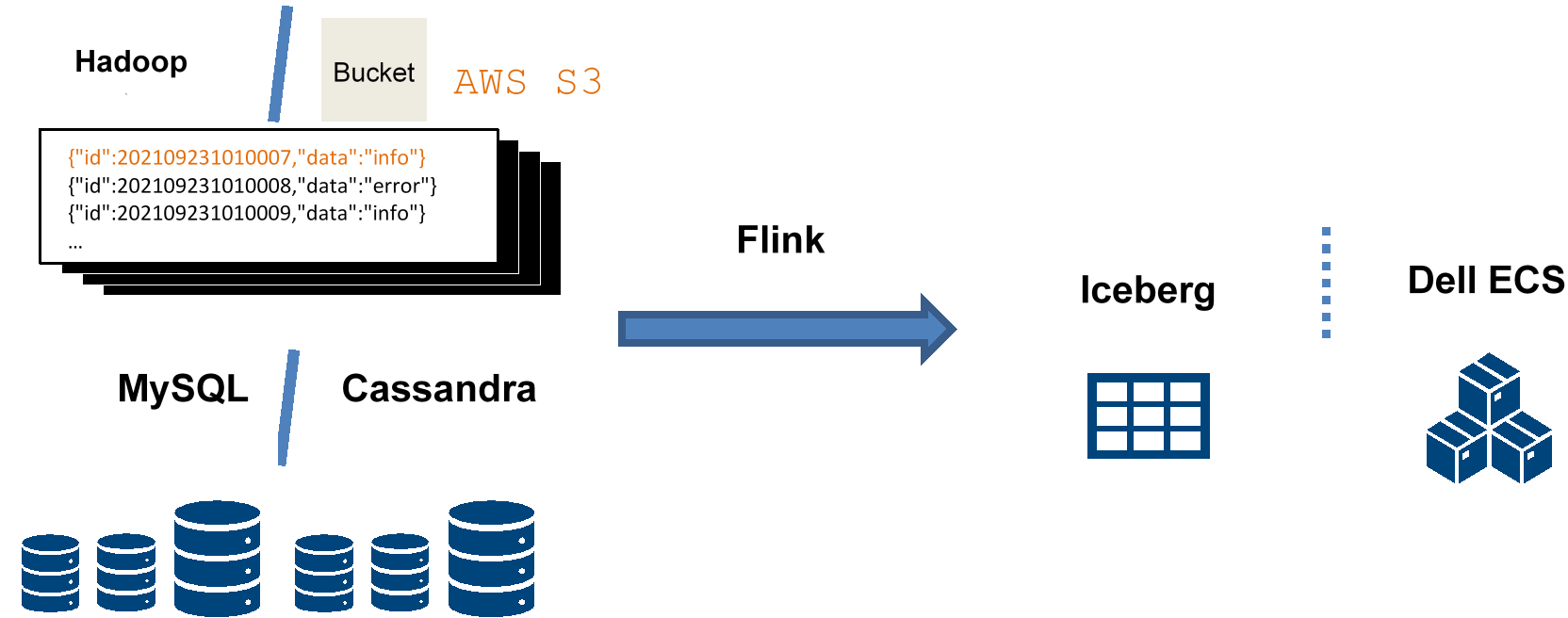
Figure 14. Data archiving
For example, for an external JSON data, you can import it into the Iceberg table using the following SQL:
CREATE TABLE `external`.`sample` (
id BIGINT,
data STRING
) WITH (
'connector' = 'filesystem',
'path' = 'hdfs://namenode:50070/data/sample.jsonl',
'format' = 'json'
);
CREATE TABLE `ecs`.`default`.`sample` (
id BIGINT,
partition_id INT,
data STRING
) PARTITIONED BY (partition_id);
INSERT INTO `ecs`.`default`.`sample`
SELECT
id,
id % 10,
data
FROM `external`.`sample`
In this way, you create a sample table under the default namespace and import JSON data on HDFS into that table. At the same time, users can use SQL to transform, filter, and partition data as necessary.
After importing data, you can query the data using SQL as shown below. This example is a simple demonstration, and you can use more complex logic to fit your business needs.
SET execution.type = batch;
SELECT COUNT(1) FROM `ecs`.`default`.`sample`;