
Overview
Overview
-
A data lake is a method of storing data in a natural format in a system or repository. It helps configure data in various patterns and structures, usually with objects, blocks, or files. The main idea of a data lake is to store all data in the enterprise in a unified way. It stores raw data (an exact copy of the source system data) to target data for various tasks such as reporting, visualization, analysis, and machine learning. Data in the data lake includes structured data (relational database data), semistructured data (CSV, XML, JSON), unstructured data (email, document, PDF), and binary data (image, audio, video).
In essence, a data lake is an enterprise data-architecture method. In a physical implementation, it is the data-storage platform that centralizes the storage of massive, multisource, multitype data in the enterprise. This storage supports the rapid processing and analysis of data. In terms of implementation, Hadoop is the most commonly used technology for deploying data lakes.
The data lake has four main characteristics:
- Store raw data with its diverse sources
- Support multiple computing models
- Ease data management
- Enable access to multiple data sources
- Supporting schema management and authority management
- Provide a flexible storage layer
- The distributed file system such as S3 and HDFS is used and the file format are used to meet the data analysis requirements of corresponding scenarios.
Based on these characteristics, the data lake applies to the following scenarios:
- Data import
- Real-time synchronization
- Real-time reading and writing
In a data lake solution, a user manages data stored in a storage layer, including querying and modifying, through a platform such as Apache Flink or a third-party framework.
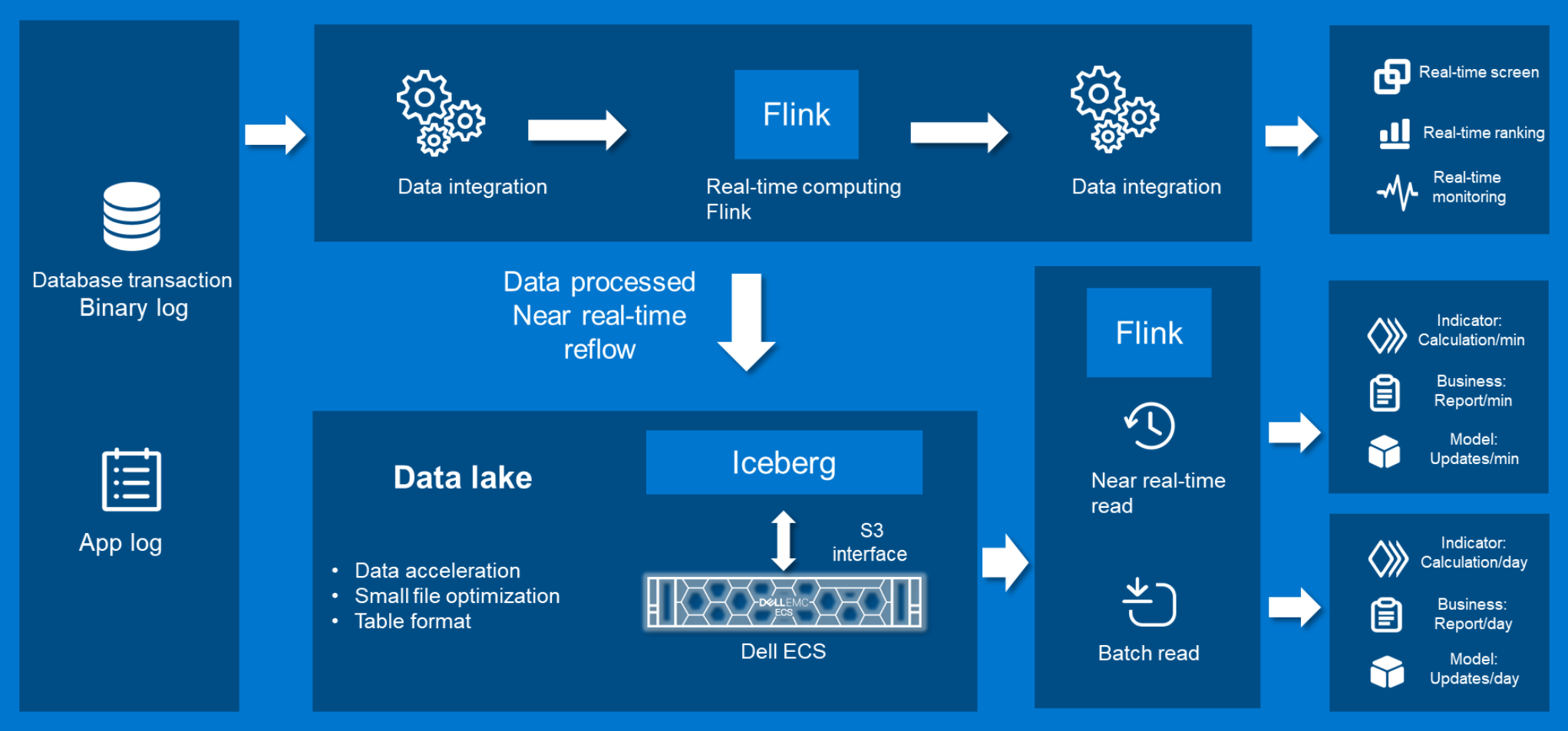
Figure 1. Data lake architecture
Apache Iceberg is an emerging data-definition framework that adapts to multiple computing engines. It is highly scalable, enabling storage tiers to adapt to it. Based on the scalability of Apache Iceberg, we combine it with ECS to provide a powerful data lake solution.