
Access configuration
Access configuration
-
This section provides steps to help you build a data lake solution using Apache Iceberg and ECS. It also gives examples that use the SQL API of Apache Flink to ingress data and access data.
Note: This process assumes that you have a working Apache Flink (version 1.12.4) cluster, an ECS (version 3.6) system, and Apache Iceberg (version 0.12.0) to build the solution.
- Create a user and bucket on ECS.
Apache Iceberg requires the specified user to store the data on the specified bucket. Therefore, it is necessary to create the user and the bucket on ECS in advance.
You can perform these operations in the ECS portal, or create users through management APIs and create the bucket with S3 API to meet the needs of automated deployment.
- Obtain the associated runtime used by the Apache Iceberg runtime and the ECS connection.
You can obtain the corresponding Flink runtime from the Apache Iceberg official website. This runtime is an extension of Apache Flink and does not include Apache Flink itself. You must also get the runtime used by the ECS connection. The relationship between these two Jar files is shown in the following figure:
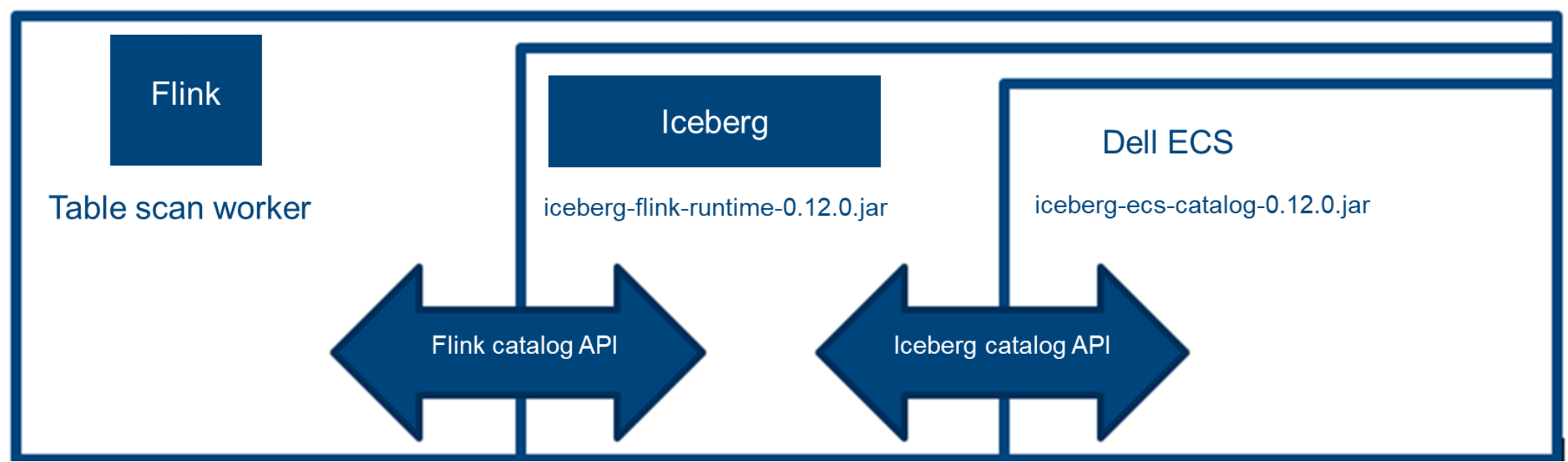
Figure 12. Extended relationship of Flink with Iceberg and ECS
You must import these files into Flink, and depending on the tools used, import the Jar files as follows:
- Replicates the Jar files to all nodes of Flink cluster.
- If sql-client.sh tool is used, configure the Jar path through the -j option: -j iceberg-ecs-catalog -0.12 .0.jar.
- If pyflink is used, the following code is required to import Jar by configuring pipeline.jars.
from pyflink.dataset import ExecutionEnvironment
from pyflink.table import BatchTableEnvironment, DataTypes, EnvironmentSettings, TableConfig
env_settings = EnvironmentSettings.new_instance().in_batch_mode().use_blink_planner().build()
T_env = BatchTableEnvironment.create(Environment_settings = env_settings)
work_space = !pwd
work_space = work_space[0]
jars = ["iceberg-ecs-catalog-0.12.0.jar", "iceberg-flink-runtime-0.12.0.jar"]
Pipeline_jars = ";" .join([f "file://{work_space}/{jar}" for jar in jars])
t_env.get_config().get_configuration().set_string("pipeline.jars", pipeline_jars)
Note: See https://iceberg.apache.org/flink/ for more information.
- Create the catalog in Flink. You can create a catalog named ecs using SQL as follows:
CREATE CATALOG ecs WITH (
'type'='iceberg',
'catalog-impl'='org.apache.iceberg.dell.EcsCatalog',
's3.access.key.id' = '$access_key_id',
's3.secret.access.key' = '$secret_access_key',
's3.endpoint' = '$endpoint',
's3.base.key' = '$iceberg_bucket'
)
The following table shows the key parameters.
Table 2. Key value description
Key
Value
Description
type
iceberg
Uses the Iceberg Flink catalog
catalog-impl
org.apache.iceberg.dell.EcsCatalog
Uses the ECS Iceberg catalog
s3.access.key.id
Username
s3.secret.access.key
User authorization
s3.endpoint
http://x.x.x.x:xxxx
S3 data access endpoint ofECS
s3.base.key
Bucket or bucket/prefix-a
The Flink and Iceberg do not restrict the user from creating multiple catalogs. The data can be split and authorized depending on the actual situation.
As shown in the following figure, you can create a catalog use the entire bucket data, or select a specific namespace as a prefix to provide data access under the namespace.

Figure 13. Catalog example