

Assets

The Evolution of Edge Inferencing with NVIDIA NIM and Dell NativeEdge
Fri, 07 Jun 2024 20:40:35 -0000
|Read Time: 0 minutes
Inferencing at the edge has taken a huge step forward with recent advances in GPU and AI technology. It’s smarter and faster, making it easier for computers to understand pictures and words together. This new way requires less work to train and can recognize many more elements in images than before. It’s like teaching a computer to see and think like a person, but quicker and without much human interaction. With NanoOWL, a special project from NVIDIA, this all happens at lightning speed, even when there is a lot to process. This results in even smarter machines that can do their jobs more effectively, right where they are needed.
This blog discusses the new AI models that enable all of this to work. It focuses on a specific example, and then closes by explaining how to deploy the technology on thousands of devices using NativeEdge.
Before we jump too far, let’s start with a quick recap.
Edge Inferencing at its Infancy – a Recap
In my previous post Inferencing at the Edge, I described the traditional process for edge inferencing. This process involves the following steps, which are also described in the following diagram.
- Create the model.
- Train the model.
- Save the model.
- Apply post-training quantization.
- Convert the model to TensorFlow Lite.
- Compile the TensorFlow Lite model using edge TPU compiler for Edge TPU devices such as Coral Dev board (Google development platform that includes the Edge TPU) to the TPU USB Accelerator (this allows users to add Edge TPU capabilities to existing hardware by simply plugging in the USB device).
- Deploy the model at the edge to make inferences.
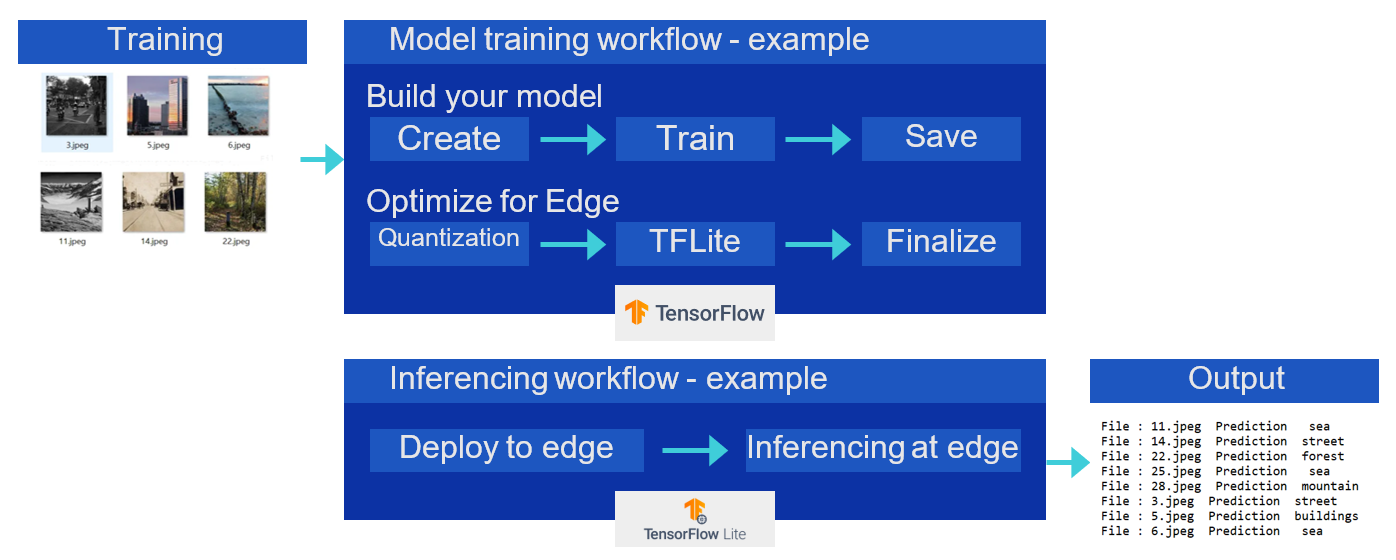 Traditional approach of edge inferencing
Traditional approach of edge inferencing
Challenges with the Initial Approach of Edge Inferencing
There are several key challenges with the traditional Inferencing approach, specifically as it relates to computer vision use cases:
- Labor-intensive data preparation—Traditional vision datasets require substantial human effort to create. This involves manually labeling thousands or even millions of images, which is time-consuming and expensive.
- Limited scope of visual concepts—Often, vision models are trained on datasets with a narrow range of concepts, which limits their ability to understand and classify a wide variety of images.
- Performance under stress—Many models perform poorly on stress tests, which are designed to evaluate how well a model can handle challenging scenarios that it may not have encountered during training.
The Generative AI Upgrade of Edge Inferencing
New AI models like OWL-ViT (Object-Word Learner using Vision Transformers) can find and understand objects in pictures, even those they haven’t been explicitly trained on. Unlike traditional models that rely on limited, labor-intensive datasets, OWL-ViT learns from a much broader range of visual concepts by using large-scale image-text data from the web. In addition, it leverages self-training techniques, where the model uses its own predictions to continually learn and improve its understanding of the object. This approach significantly reduces the need for costly dataset creation. It also combines special tools like Vision Transformers (ViT) to see the picture details and language models to match them into words. OWL-ViT is built on top of another model which was developed by Open-AI, called CLIP (Contrastive Language-Image Pretraining). CLIP specializes in matching pictures with words. OWL-ViT takes CLIP a step further by not just matching, but also finding where objects are located in pictures, using the descriptions in words.
This enables computers to understand and label what’s in an image, just like we describe it in text.
Adding Performance Optimization with NVIDIA NanoOWL Project
NanoOWL is an NVIDIA project that is essentially a performance-enhanced version of the OWL-ViT model that is specifically optimized to work in real-time use cases.
Here’s a simplified breakdown of how NanoOWL operates:
- Optimization—NanoOWL fine-tunes the OWL-ViT model for fast performance on NVIDIA’s computing platforms.
- Tree detection pipeline—It introduces “tree detection”, which allows for layered detection and classification based on text descriptions.
- Real-time processing—The system is designed to work quickly, providing immediate results for object detection and classification tasks.
- Text-based interaction—Users can interact with NanoOWL through text, instructing it to detect and classify objects within images by providing textual prompts.
- Nested detection—The technology can identify and categorize objects at any level of detail, just by analyzing the user’s text.
Building an Edge Inferencing Application using NanoOWL
Most edge inferencing applications have a lot in common. As inputs, they can typically accept text and an image. To process this image-text input, the application should first load the model into memory. Then, the model can be called with an inference function where the image and text are passed in to produce an output.
The general recipe of the reference example can be applied to nearly any generative AI model.
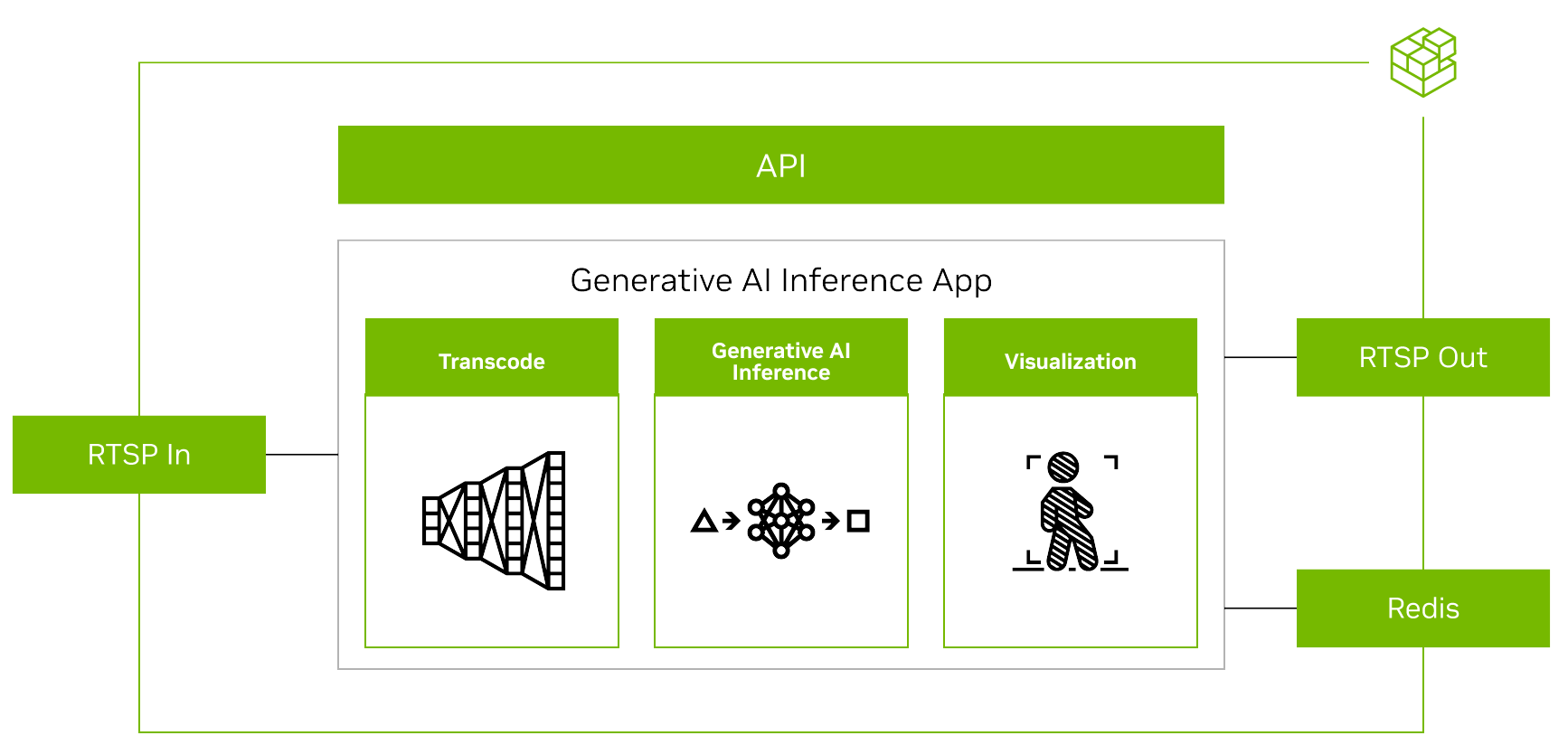 Overview of a GenAI application using Metropolis microservices
Overview of a GenAI application using Metropolis microservices
(Source: Bringing Generative AI to the Edge with NVIDIA Metropolis Microservices for Jetson)
This general process is described in the following steps:
- Stream video—The input and output use the RTSP protocol. RTSP is streamed from Video Storage Toolkit (VST), a video ingestion and management microservice. The output is streamed over RTSP with the overlaid inference output. The output metadata is sent to a Redis stream where other applications can read the data. For more information, see the Video Storage Toolkit with Metropolis Microservices demo videos.
- Introduce an API interface to enable chat interaction—As a generative AI application requires some external interface such as prompts; the application must accept REST API requests.
- Package and deploy the application into containers—The application that was developed in previous steps is containerized to integrate seamlessly with other microservices.
Learning by Example – Writing Text to Image Inferencing Applications using NanoOWL
The following figure shows the architecture of a specific NanoOwl application that can be used as a general recipe to build generative AI–powered applications taken from the NVIDIA guide:
Bringing Generative AI to the Edge.
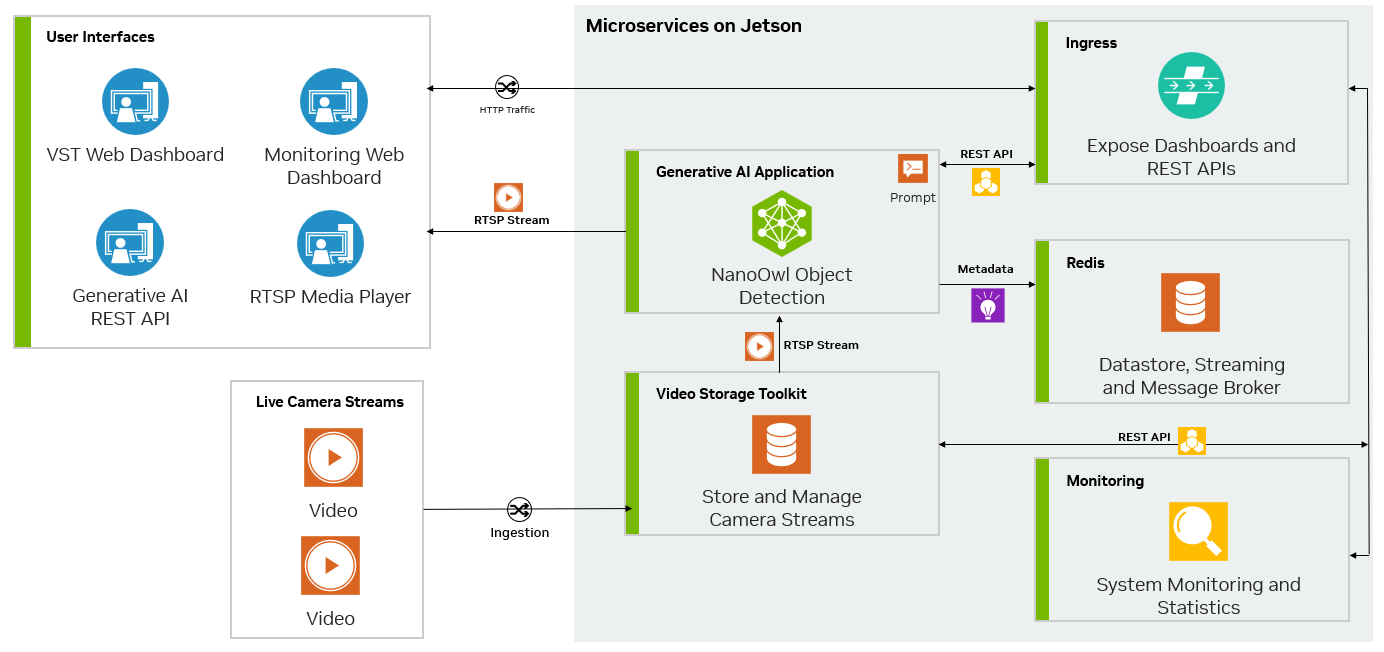 Edge inferencing example architecture using NanoOWL
Edge inferencing example architecture using NanoOWL
(Source: Bringing Generative AI to the Edge with NVIDIA Metropolis Microservices for Jetson)
In this specific example, the application:
- Calls the predict function of the machine learning model to perform inference. This involves processing input data through the model to obtain predictions.
- Integrates RTSP input and output using the jetson-utils library, which is designed for handling video streaming on NVIDIA Jetson devices. This allows for the setup of video streaming services over the network.
- Adds a REST endpoint using Flask, a micro web framework in Python. This endpoint accepts requests to update system settings on-the-fly.
- Adds overlay on the video steam. NVIDIA mmj_utils is a custom utility library used to generate overlays on video streams and interact with a Video Streaming Toolkit (VST) to manage video streams.
- Outputs metadata to a Redis database, which is an in-memory data structure store used as a database, cache, and message broker.
- Containerizes the edge inferencing application.
Deploying and Managing the Edge Inferencing Applications on Thousands of Devices using NativeEdge
In this step, we use NativeEdge as our edge platform. NativeEdge allows us to deploy the edge-inferencing application from the previous step and deploy it on thousands of devices through a single command.
To do so, we integrate the containerized application with a NativeEdge blueprint, together with the necessary NVIDIA runtime services and libraries such as TensorRT, as well as the dependent libraries that are needed such as Flask, Redis, Video Streaming Service, and so on.
The blueprint is now available and all that is left to do is tell NativeEdge to deploy it on one, two, or thousands of endpoints, and then let the NativeEdge Orchestrator do all the deployment work for us.
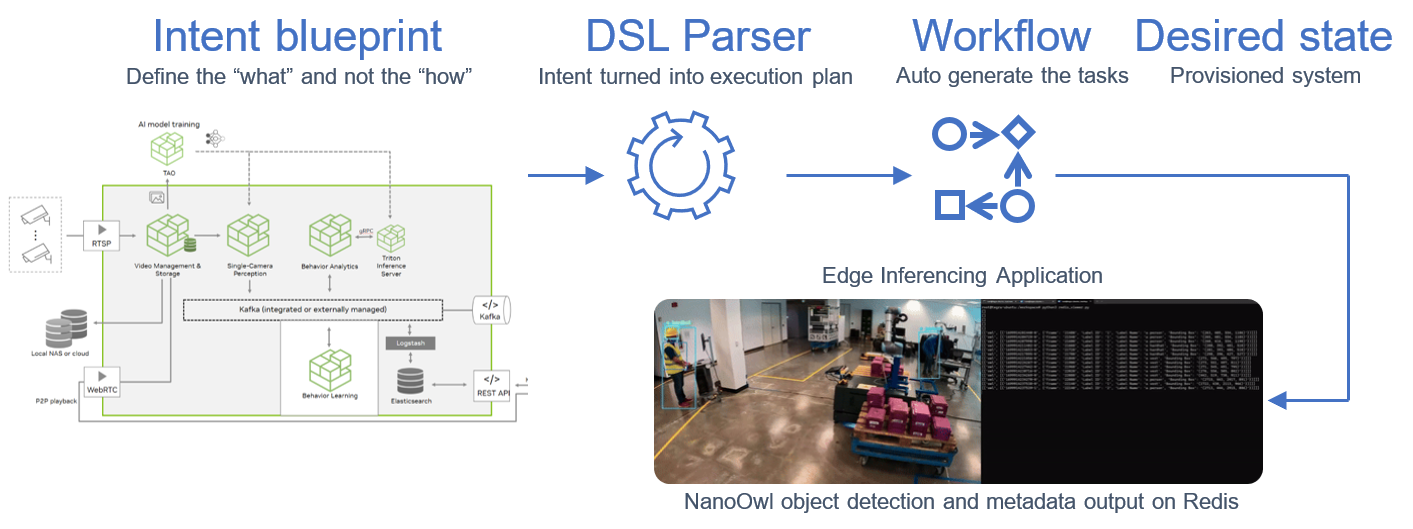 Blueprint automates deployment of inferencing applications across thousands of devices
Blueprint automates deployment of inferencing applications across thousands of devices
Extending our Example to Other Models
This reference example uses NanoOwl. However, you can follow these steps for any model that has a load and inference function callable from Python. For more information about the full implementation, see the reference example on the /NVIDIA-AI-IOT/mmj_genai GitHub project.
Final Notes
The use of the new generative AI models for edge Inferencing in general and compute vision specifically reduces the time to train and build such an application.
NVIDIA provides a useful set of tools and libraries that simplify the development and performance tuning processes on their infrastructure.
NativeEdge reduces the operational complexity involved in deploying and continuously managing those applications across many distributed endpoints.
The entire framework and platform are based on open-source foundations as well as cloud-native and DevOps best practices, which makes the development and management of those applications as simple as any traditional cloud-service.
NativeEdge provides a common platform that can support both traditional and modern edge inferencing applications simultaneously, enabling a smoother transition into this new world.
References:
- Delivering an AI-Powered Computer Vision Application with NVIDIA DeepStream and Dell NativeEdge | Dell Technologies Info Hub
- Inferencing at the Edge
- Bringing Generative AI to the Edge with NVIDIA Metropolis Microservices for Jetson | NVIDIA Technical Blog
- GitHub - NVIDIA-AI-IOT/mmj_genai: A reference example for integrating NanoOwl with Metropolis Microservices for Jetson
- GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
- GitHub - NVIDIA-AI-IOT/nanoowl: A project that optimizes OWL-ViT for real-time inference with NVIDIA TensorRT.
- OWL-ViT (huggingface.co)
- Understanding OpenAI’s CLIP model | by Szymon Palucha | Medium

Harnessing the Power of Machine Vision in Smart Manufacturing - A Dell and Cognex Case Study
Tue, 04 Jun 2024 19:49:17 -0000
|Read Time: 0 minutes
A machine vision solution for smart manufacturing refers to the integration of advanced image processing technology with industrial automation. This technology uses cameras and sensors to capture images, and then analyzes them with software to perform various tasks. Tasks include quality inspection, guidance, identification, and other device measurement within a manufacturing environment. The goal is to improve efficiency, accuracy, and productivity by automating processes that traditionally require human intervention. Machine vision systems are a critical component of Industry 4.0, enabling smarter manufacturing processes through real-time data analysis, predictive maintenance, and enhanced decision-making capabilities. These systems can significantly reduce labor costs, minimize errors, and prevent product recalls by ensuring higher quality control. With the advent of edge AI, machine vision solutions are becoming more sophisticated, capable of processing and analyzing data at the source, which reduces latency and improves data security.
Introduction to the Cognex Vision Application for Smart Manufacturing
Cognex is a global leader in machine vision systems. They offer a suite of powerful tools designed to automate complex inspection tasks, guide assembly robots, and optimize quality control processes. These systems leverage advanced image-processing algorithms and artificial intelligence to interpret visual data in real time, enabling machines to ‘see’ and ‘understand’ their environment.
At the core of Cognex’s machine vision systems is the VisionPro software. VisionPro provides a comprehensive set of vision tools. These tools include pattern matching, image analysis, color recognition, object detection, and more. The software is designed to handle a wide range of applications, from simple barcode reading to complex 3D inspections.
Using Edge-AI and Deep Learning to Handle Complex Failure Detection
Deep learning is a type of artificial intelligence that’s really good at analyzing images for cosmetic inspections, like finding scratches or dents on shiny surfaces. It works well even when the patterns on the surfaces change slightly, which can be hard for traditional image analysis methods to handle. Deep learning uses systems called neural networks, which work like our brains, to tell the difference between normal variations in patterns and actual defects. This is better than older methods that often can’t tell the difference between similar-looking items. Software that uses deep learning, such as Cognex, is now better at making these kinds of detailed inspections than people or older tech.
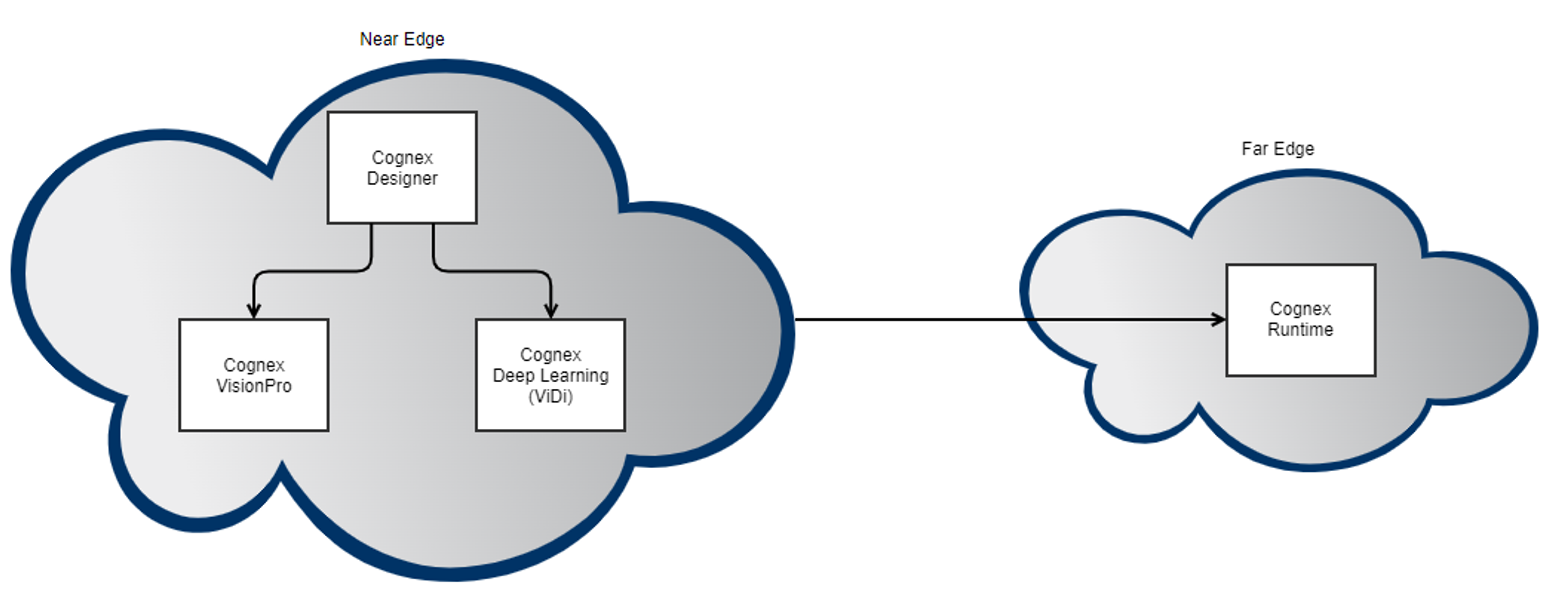 Cognex solution stack in near and far edge
Cognex solution stack in near and far edge
- Far edge platform—The far edge is defined as within the confines of a work cell on the factory floor (Purdue Level 2).
- Near edge platform—The near edge (Purdue Level 3) contains platforms used for ingesting, analyzing, and rendering process data as part of the overall production environment. For the vision system, this is the environment where the deep learning model was developed and trained using the image datasets and ViDi tools.
Introduction to Cognex
Cognex Deep Learning tools solve complex manufacturing applications that are too difficult or time consuming for rule-based machine vision systems, and too fast for reliable, consistent results with human visual inspection.
 Cognex features
Cognex features
The Cognex ViDi deep learning software is used to train a vision-optimized deep neural network (VODNN), based on a labeled image set. The trained network can do the following:
- Locate and identify features in images
- Locate and read characters and strings in images
- Identify, locate, and characterize defects in images
- Classify images
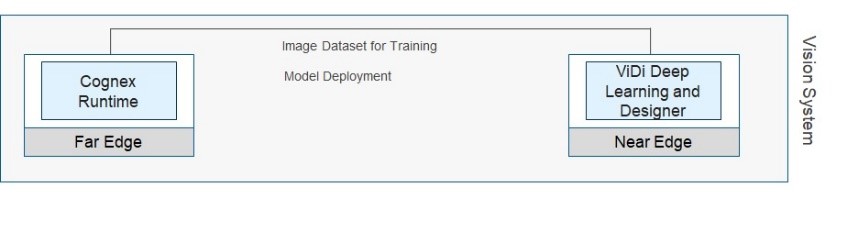 Cognex ViDi deep learning process
Cognex ViDi deep learning process
The operation of the ViDi tools is divided into two phases.
- Training phase—The tools analyze the labeled, training image set, and the network is trained.
- Runtime phase—The tools operate on input images and produce markings based on their training data.
The ViDi user interface (UI) is used for the following:
- Manage images that comprise the training set
- Quickly and accurately label images
- Link multiple ViDi tools into toolchains
- Validate the performance of trained tools
- Export trained networks and toolchains for use at runtime
Use Cases
Several defined use cases were evaluated specifically for the Cognex vision system based on their relevance to AI/ML in the manufacturing process. Those use cases are defined as follows:
- Anomaly and defect detection—Identification of defects, irregularities, and other manufacturing flaws using 2D and 3D vision inspection.
- Pattern detection and classification—Use of object location tools and geometric pattern-matching technology to locate patterns regardless of rotation or scale, as well as the use of classification tools to verify characteristics of completed assemblies.
- Complex text and OCR—Use of font-trainable Optical Character Recognition (OCR) and Verification (OCV) tools with auto-tune capability to read alphanumeric characters, barcodes, and data matrix markings on product surfaces.
Integrating Dell NativeEdge and Cognex to Deliver an End-to-End Solution for Smart Manufacturing
Dell NativeEdge is an edge management platform designed to help businesses simplify and optimize secure edge deployments. Customers can streamline edge operations across thousands of endpoints and locations from the edge to core data centers and multiple clouds.
NativeEdge Orchestrator is a key component of the NativeEdge software platform. It automates edge operations such as application orchestration, fleet management, and lifecycle management, through a TOSCA-based blueprint.
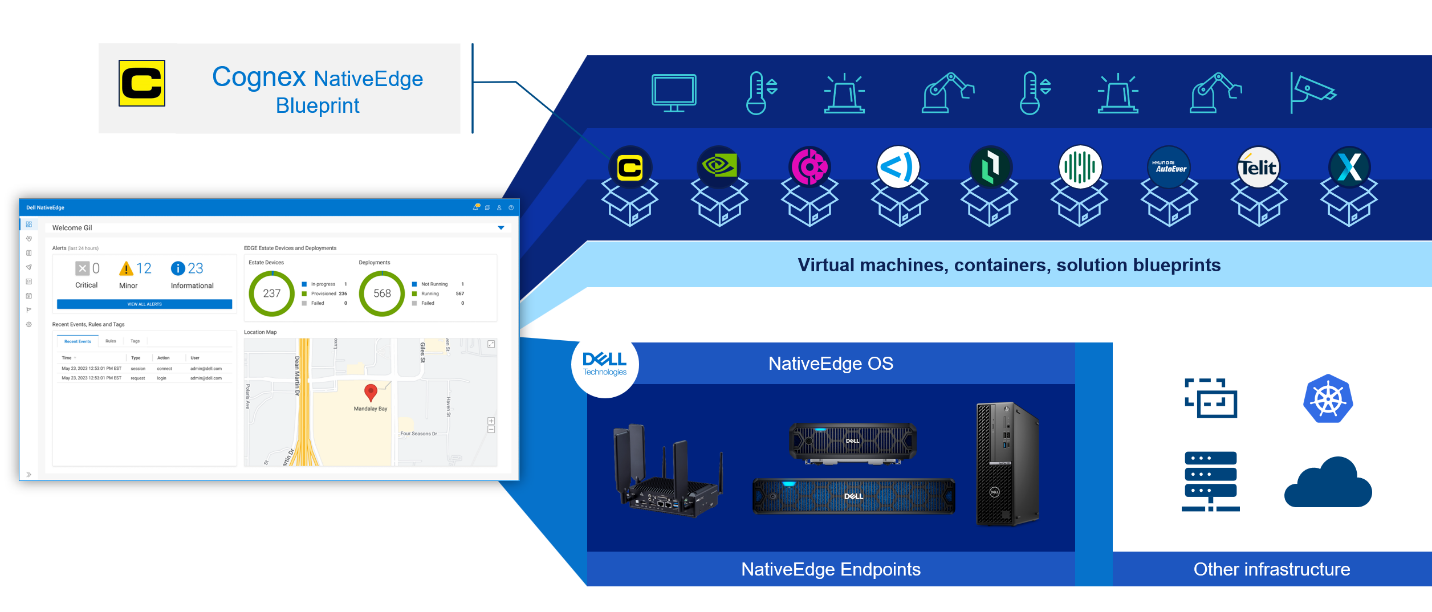 NativeEdge high-level architecture
NativeEdge high-level architecture
The integration of NativeEdge and Cognex is done through a specific solution blueprint that automates the process of provisioning and configuration of the Cognex VisionPro application on a NativeEdge cluster with NativeEdge Endpoints.
How it Works, Step by Step
This example demonstrates how to deploy Cognex VisionPro on a Dell PowerEdge XR4520c server.
1. Log in to NativeEdge Orchestrator and select the target endpoints for your Cognex deployment.
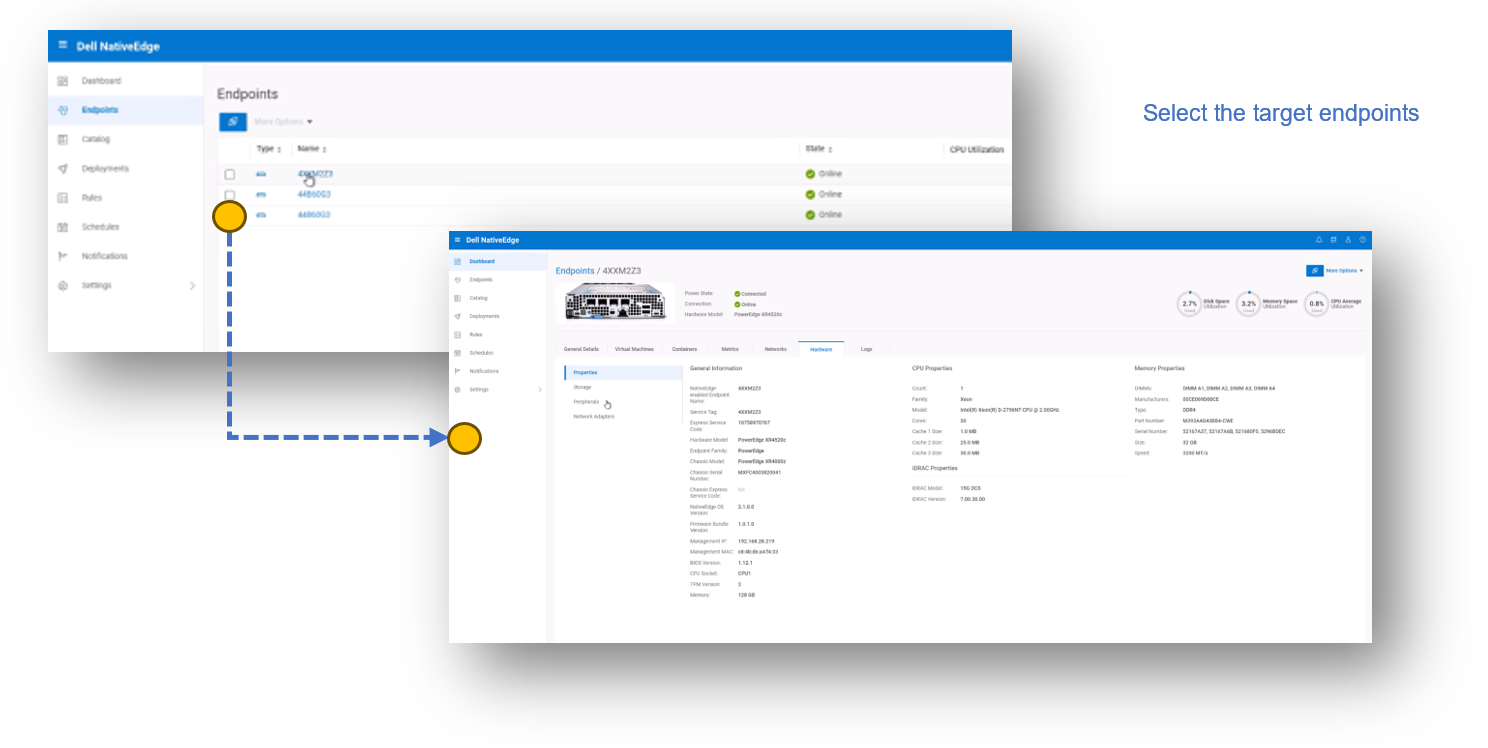
2. Deploy the Cognex solution on the selected endpoints.
- Select the NativeEdge Blueprint for Cognex solution from the NativeEdge Catalog.
- Deploy the solution on the target endpoints.
- Log in to the Cognex virtual machine to confirm installation of the GPU.
- Run the Cognex modeling to identify defects.
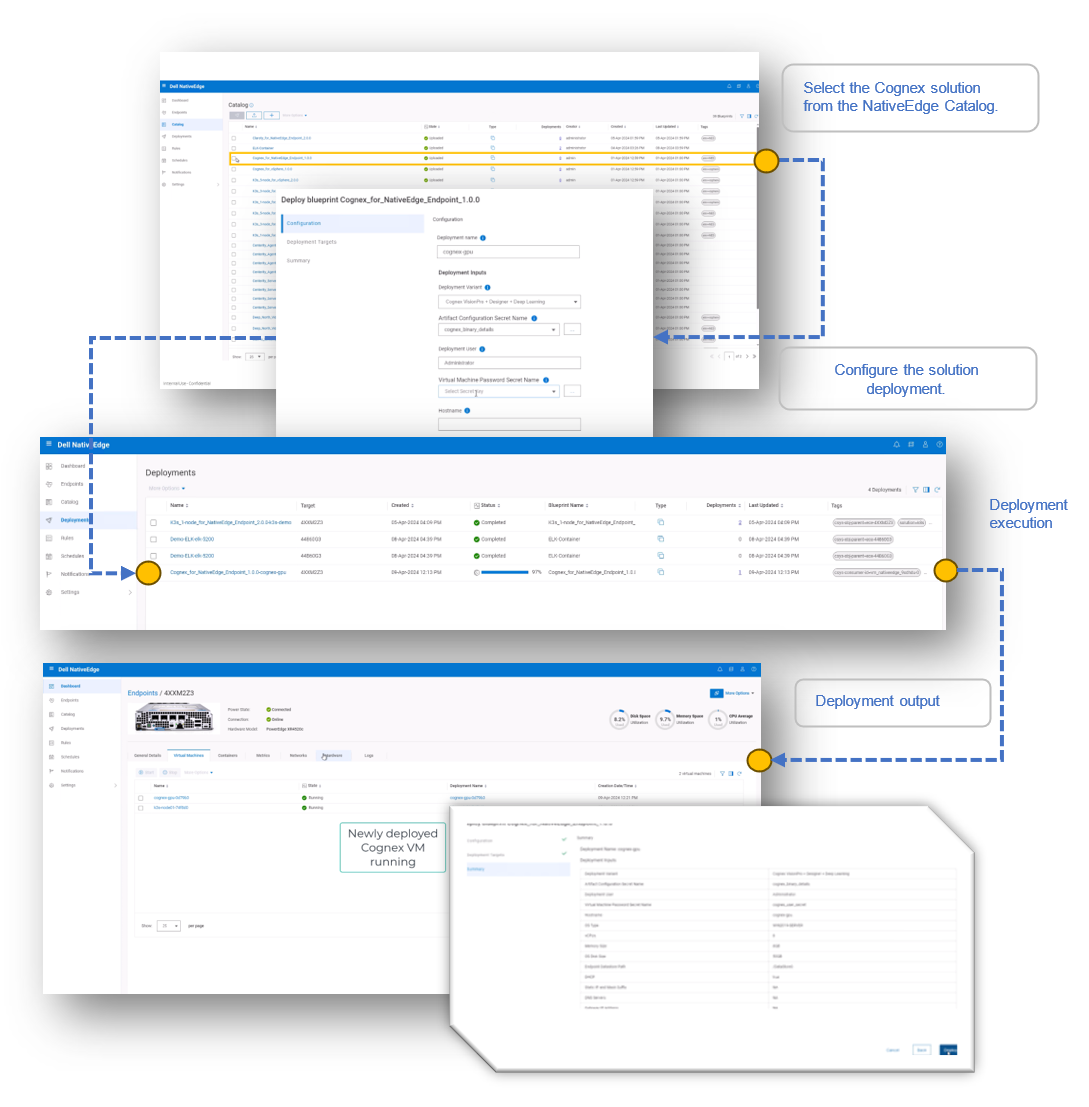
3. Start using Cognex VisionPro to detect defects in the manufacturing facility.
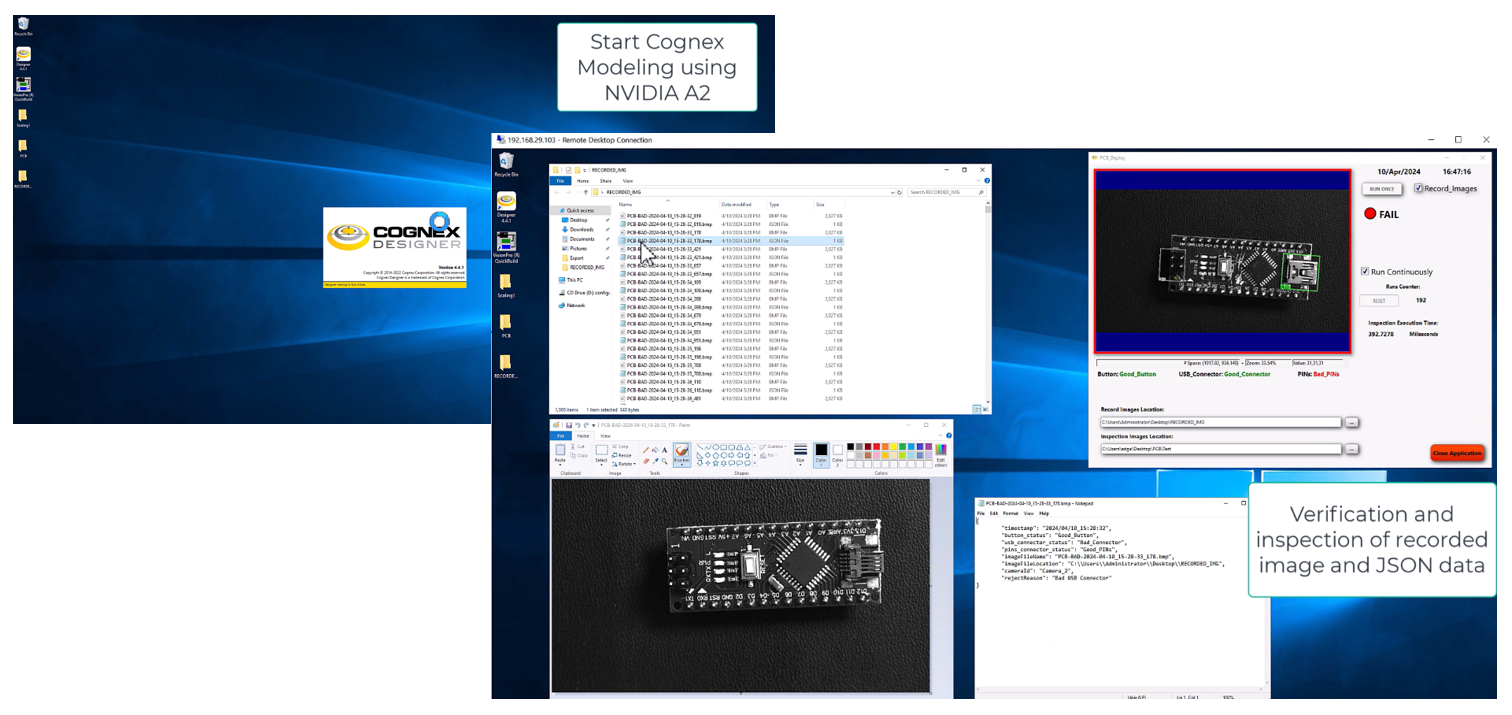
Final Notes
By combining the deployment capabilities of NativeEdge with the vision expertise of Cognex, manufacturers can now enjoy a fully integrated and automated turnkey ISV solution as a Catalog item. This automation reduces operational complexity while providing integration with other manufacturing solutions and IT stacks through a single point of management.
NativeEdge's new blueprint and plugin support enables ISV partners such as Cognex to easily enable their solution on NativeEdge without changing their product, and to benefit from the rich Dell customer ecosystem.
System integrators and partners can leverage the NativeEdge Partner Certification program, which allows them to test and build their own custom blueprint solution.
Additional References
- Dell Validated Design for Manufacturing Edge - Design Guide with Cognex | Dell Technologies Info Hub
- Machine Vision Application for Smart Manufacturing Using Dell and Cognex - Technical Primer (delltechnologies.com)

Delivering an AI-Powered Computer Vision Application with NVIDIA DeepStream and Dell NativeEdge
Mon, 20 May 2024 08:37:34 -0000
|Read Time: 0 minutes
The Dell NativeEdge platform, with its latest 2.0 update, brings to the table an array of features designed to streamline edge operations. From centralized management to zero-touch deployment, it ensures that businesses can deploy and manage their edge solutions with unprecedented ease. The addition of blueprints for key Independent Software Vendors (ISV) and AI applications gives users the ability to get a fully automated end-to-end stack from bare metal to production grade vertical service in retail, manufacturing, energy, and other industries. In essence, it brings the best of both worlds—an open platform that is not bound to any specific ISV or cloud provider while preserving the simplicity of a vertical solution.
This blog describes the specific integration of NativeEdge with NVIDIA DeepStream to enable developers to build AI-powered, high-performance, low-latency video analytics applications and services.
Introduction to NVIDIA DeepStream
NVIDIA DeepStream is a comprehensive streaming analytics toolkit designed to facilitate the development and deployment of AI-powered applications. It is built on the GStreamer framework and is part of NVIDIA’s Metropolis platform. Its main features include: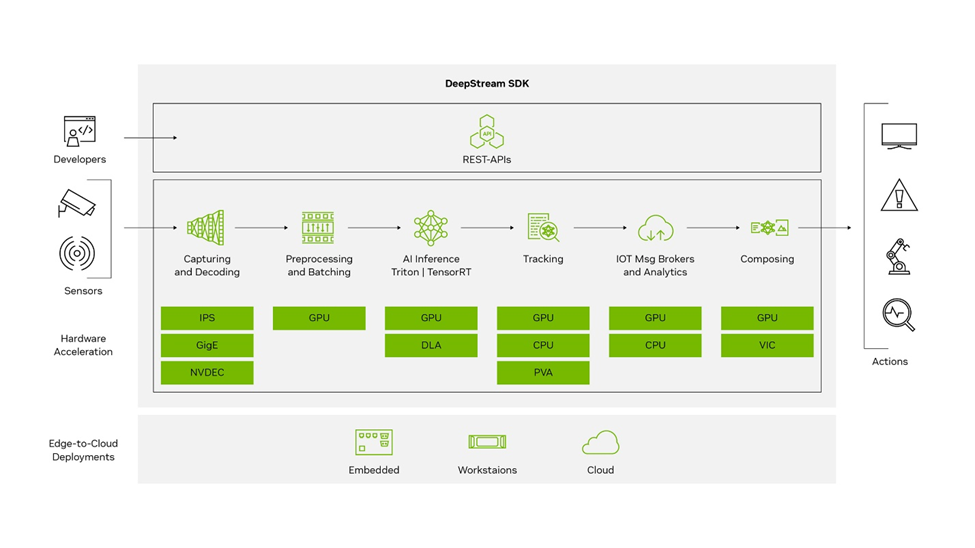 DeepStream SDK
DeepStream SDK
- Input sources—DeepStream accepts streaming data from various sources, including USB/ CSI cameras, video files, or RTSP streams.
- AI and computer vision—It utilizes AI and computer vision to analyze streaming data and extract actionable insights.
- SDK components—The core SDK includes hardware accelerator plugins that leverage accelerators such as VIC, GPU, DLA, NVDEC, and NVENC for compute-intensive operations.
- Edge-to-cloud deployment—Applications can be deployed on embedded edge devices running the Jetson platform or on a larger edge or datacenter GPUs like the T4.
- Security protocols—It offers security features like SASL/ Plain authentication and two way TLS authentication for secure communication between edge and cloud.
- CUDA-X integration—It builds on top of NVIDIA libraries from the CUDA-X stack, including CUDA, TensorRT, and NVIDIA Triton Inference Server, abstracting these libraries in DeepStream plugins.
- Containerization—Its applications can be containerized using NVIDIA Container Runtime, with containers available on NGC or NVIDIA’s GPU cloud registry.
- Programming flexibility—Developers can create applications in C, C++, or Python, and for those preferring a low-code approach, DeepStream offers Graph Composer.
- Real-time analytics—It is optimized for real-time analytics on video, image, and sensor data, providing insights at the edge.
The key benefit of the platform is that it is optimized for NVIDIA’s hardware, providing efficient video decoding and AI inferencing. It can also handle multiple video streams in real time, making it suitable for large-scale applications.
NativeEdge Integration with NVIDIA DeepStream
Deploying an AI application at the edge involves configuring and managing potentially many versions of hardware drivers, applying specific NVIDIA configuration to the containerization platform, and deploying the DeepStream stack with specific AI inferencing models. NativeEdge uses a blueprint model to automate the operational aspect of this integration. This blueprint is delivered as part of the NativeEdge solution catalog. It streamlines the entire deployment process in a way that is consistent with other solutions in the NativeEdge portfolio.
A Deeper Look Into the NativeEdge Blueprint for NVIDIA DeepStream
DeepStream is packaged as a cloud-native container and as such it relies on the availability of a container platform to be available at the edge as a prerequisite. NativeEdge enables two methods to deliver workload at the edge: a packaged virtual machine (VM) which provides full isolation or a bare metal container which maximizes performance. Once the VM or container gets provisioned on the edge, NativeEdge pulls the relevant stack, configures the GPU passthrough, and starts running the target model to enable the inferencing process.
Deployment Configuration
To deploy, the configuration steps allow the user to select the GPU target, deployment mode, and the actual artifacts without having to customize the automation blueprint for each case.
GPU Target
Select the GPU targets for the solution. The target can be A2 to L4 depending on the target footprint and performance. You can find a comparison table which provides guidance on each of the GPU capabilities here.
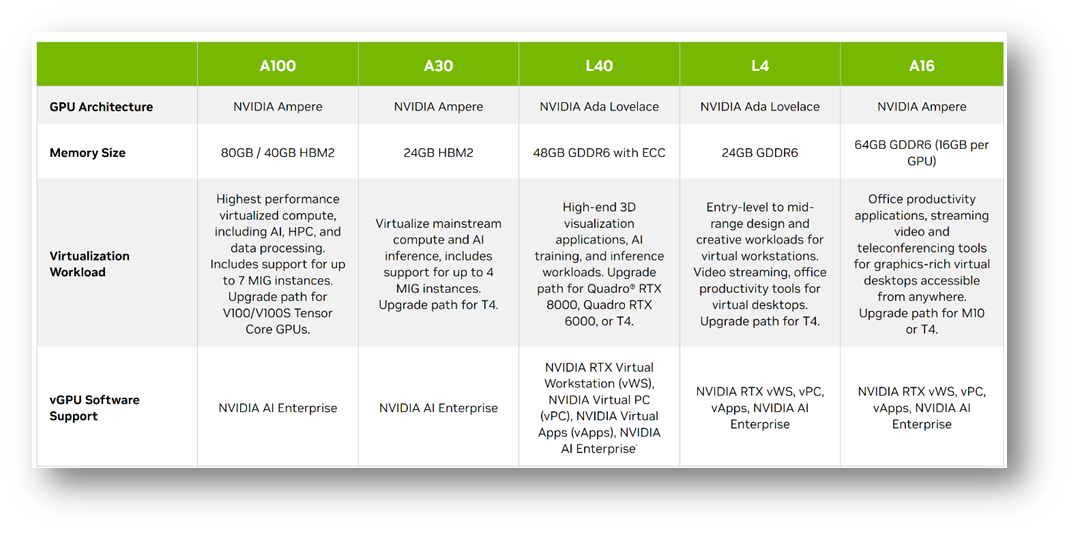 GPU configuration
GPU configuration
Deployment Mode
The deployment mode input specifies how the blueprint should configure the DeepStream container. There are three deployment modes currently supported: demo, custom model, and developer.
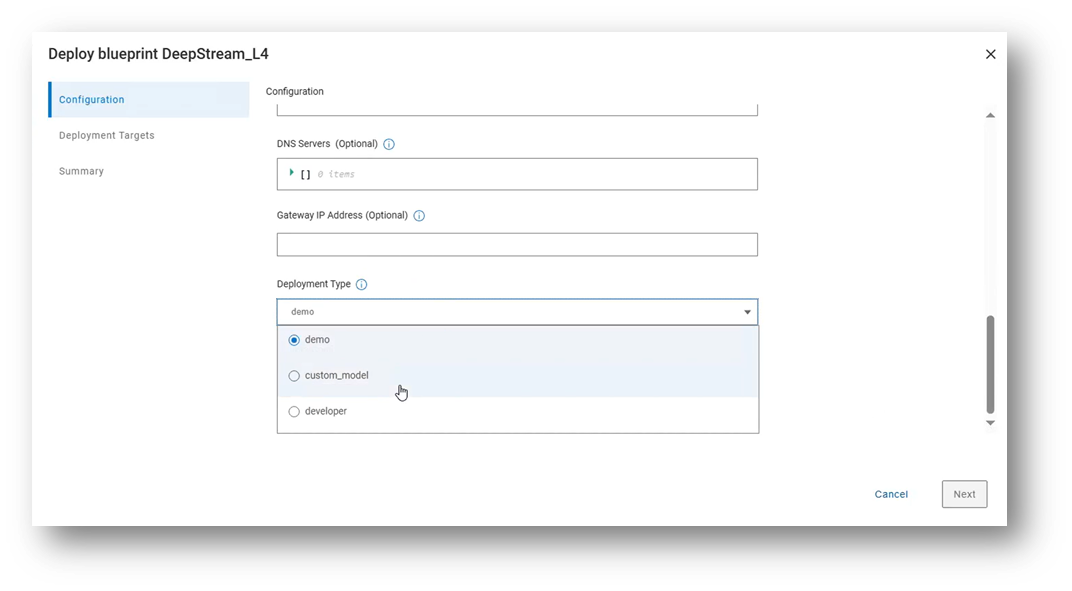 Blueprint deployment modes
Blueprint deployment modes
Demo
This mode deploys the DeepStream container and immediately starts a Triton inferencing pipeline based on an embedded demonstration video file.
Artifacts used in this mode:
- The base DeepStream container
- An archive file containing pre-built Triton inferencing models
Custom Model
This mode deploys the DeepStream container along with a customer’s bespoke pipeline configuration. In addition, the customer has the option to automatically run the pipeline as soon as the DeepStream container is deployed, without any further user intervention.
Artifacts used in this mode:
- The base DeepStream container
- An archive file containing the customer’s pipeline configuration plus any other files or data required
- An archive file containing pre-built Triton inferencing models (optional)
Developer
This mode deploys the DeepStream container and forces it to run in the background, so that a developer can log on to the host and access the container for work such as development or testing.
Artifacts used in this mode:
- The base DeepStream container
- An archive file containing pre-built Triton inferencing models (optional)
Irrespective of which deployment type is chosen, the user also needs to supply a secret artifact, which contains information such as the endpoint of the customer’s artifact repository and the credentials required to download.
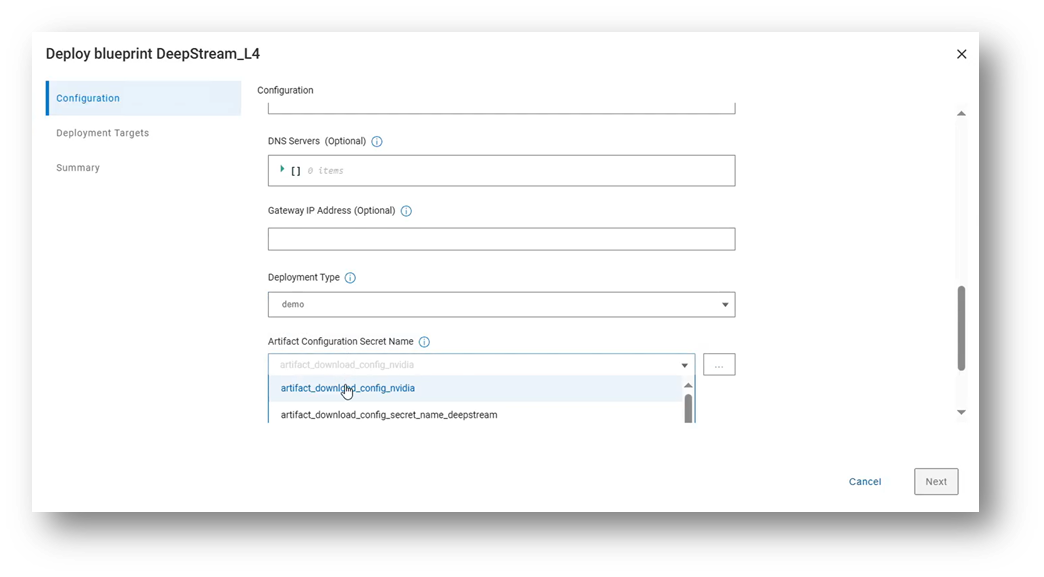 Deployment bundle Configuration
Deployment bundle Configuration
Deploy the DeepStream Solution
To deploy the solution, select the target list of devices and the specific DeepStream solution from the NativeEdge catalog and execute the install workflow.
The install workflow parses the blueprint and auto-generates the execution graph that will automates the entire deployment process based on the provided configuration and environment setup.
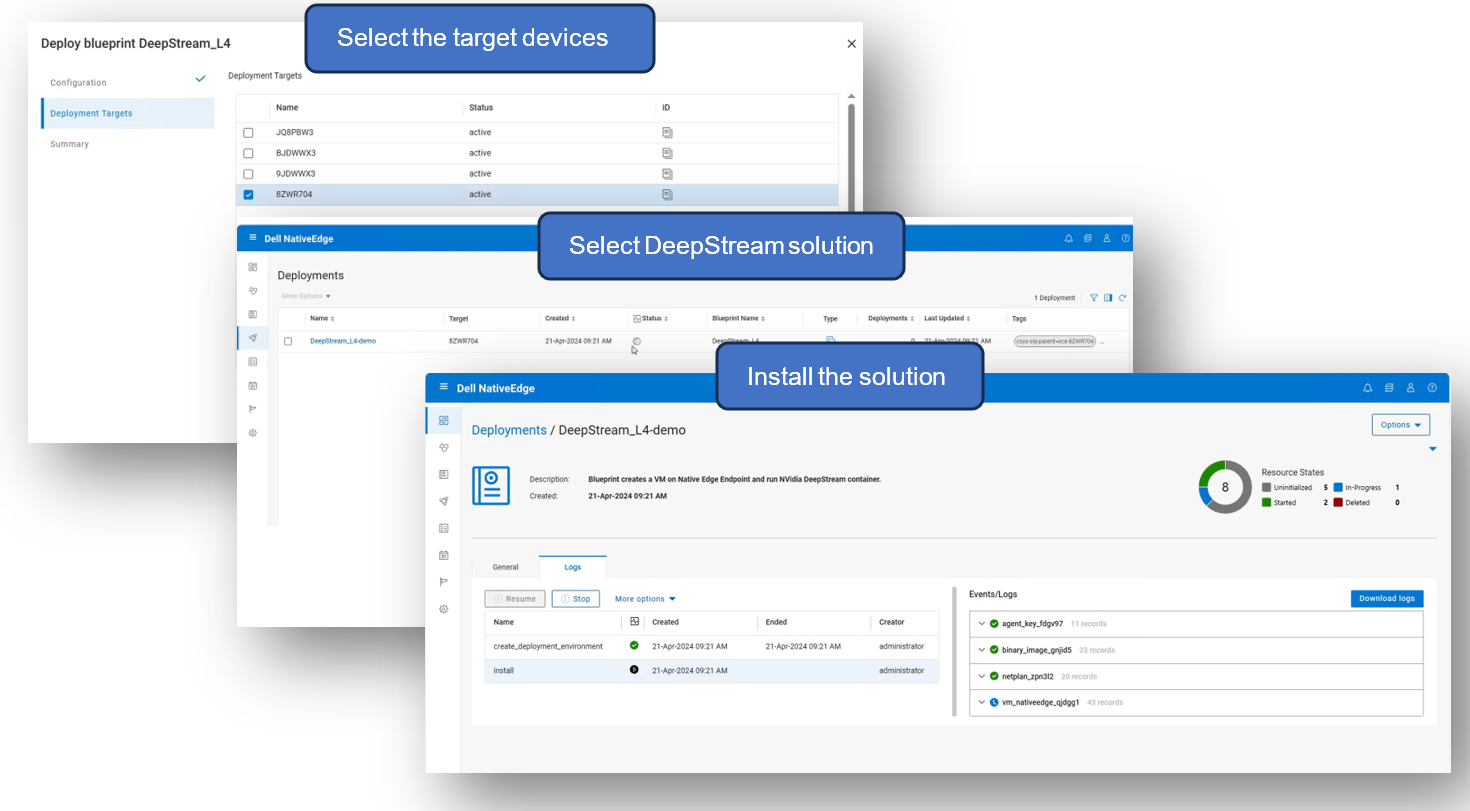 Deploying DeepStream solution in NativeEdge Orchestrator
Deploying DeepStream solution in NativeEdge Orchestrator
The event flow is automated through this process. The process includes everything from setting up the endpoint configuration to the actual deployment of the inferencing model. This enables the full end-to-end automation of the entire stack and thus allows the user to start using the system immediately after it completes the process, without the need for any additional human intervention.
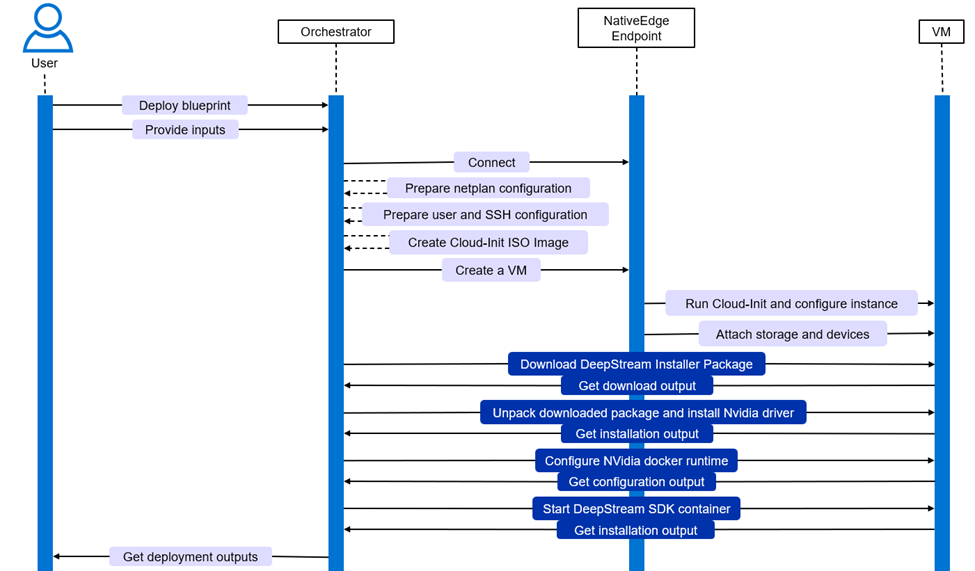 Automation event flow
Automation event flow
Use the DeepStream Solution
Once the installation from the previous step is completed successfully, we can review any relevant outputs (or capabilities) from the blueprint.
For example, if the solution is deployed with the “demo” deployment type, an RTSP feed is automatically created, which can be used by remote clients to view the output of the DeepStream demo application.
This can be seen in the following figure:
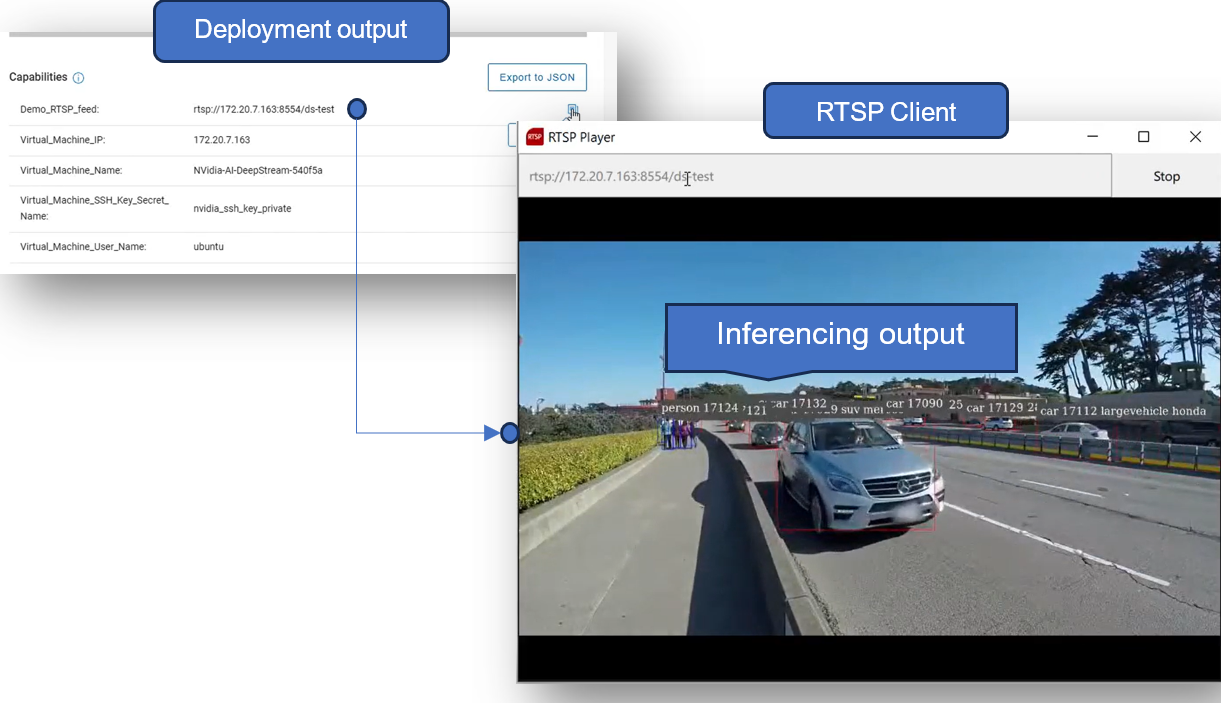 Deployment of the solution and inferencing at the edge
Deployment of the solution and inferencing at the edge
If the “custom model” deployment type is chosen, any output produced from the DeepStream application is configured by the customer themselves. In other words, the custom pipeline could potentially create an RTSP stream, in which case a client could use a similar approach to view the stream. Alternatively, the pipeline could define a video file output instead, configured to output to the persistent storage folder that is configured by NativeEdge.
Conclusion
According to IDC , inferencing at the edge is projected to double the growth rate of training by 2026. This projection is in line with the anticipated expansion of edge computing use cases, as illustrated in the following figure:
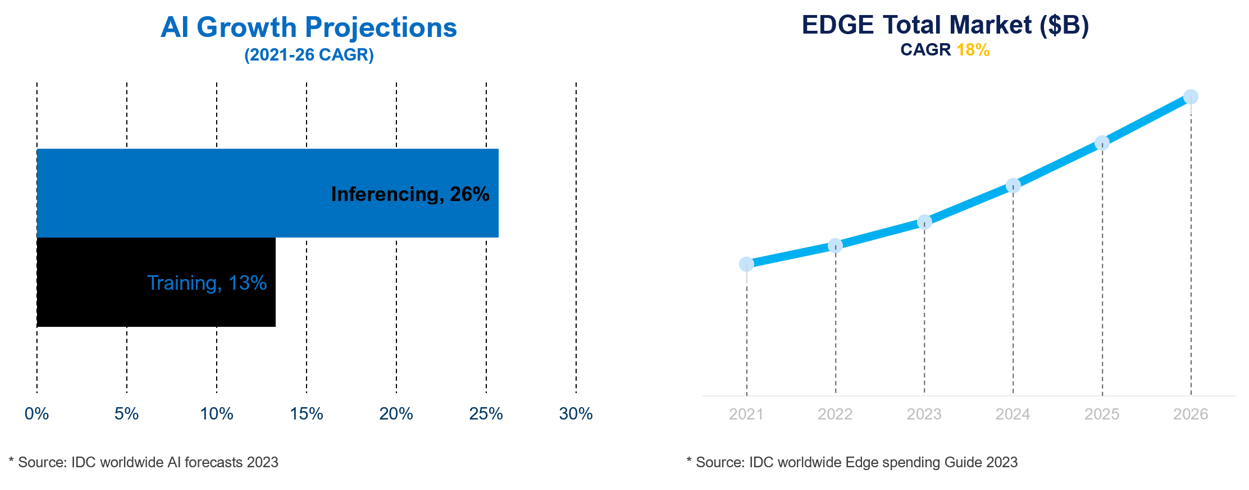 Growth of inferencing opportunities in edge market
Growth of inferencing opportunities in edge market
Dell NativeEdge is the first edge orchestration engine that automates the delivery of NVIDIA AI Enterprise software. In general, and specifically with DeepStream, NativeEdge simplifies the deployment and management of inferencing applications at the edge.
Through this integration, customers have the capability to implement their custom applications, which leverage popular frameworks, on NVIDIA AI accelerators that are compatible with Dell NativeEdge. This is complemented by the ability to incorporate their development infrastructure using the NativeEdge API or CI/CD processes. Additionally, NativeEdge provides support for orchestrating cloud services through Infrastructure as Code (IaC) frameworks like Terraform, Ansible, CloudFormation, or Azure ARM, allowing customers to manage their edge and associated cloud services using the same automation framework.
Integration with ServiceNow enables IT personnel to oversee NativeEdge Endpoints in a manner that is similar to other data center resources, utilizing the ServiceNow CMDB. This integration simplifies edge operations and supports more rapid and flexible release cycles for inferencing services to the edge, thereby helping customers keep pace with the speed of AI developments.
References
- Recent posts for: “DeepStream” | NVIDIA Technical Blog
- Building Intelligent Video Analytics Apps Using NVIDIA DeepStream 5.0 (Updated for GA) | NVIDIA Technical Blog
- Inferencing at the Edge | Dell Technologies Info Hub
- Announcing Dell NativeEdge 2.0: Reimagining Edge Operations | Dell USA
- Managing Video Streams in Runtime with the NVIDIA DeepStream SDK | NVIDIA Technical Blog
- DeepStream SDK | NVIDIA Developer | NVIDIA Developer

Litmus and Dell NativeEdge - A Powerful Duo for Improving Industrial IoT Operations
Wed, 08 May 2024 15:18:51 -0000
|Read Time: 0 minutes
Edge AI plays a significant role in the digital transformation of the industrial Internet of things (IIoT). It improves efficiency, productivity, and decision-making processes in the following areas:
- Predictive maintenance—AI algorithms can analyze data from sensors and other connected devices to predict equipment failures before they happen.
- Anomaly detection—AI can identify abnormal patterns or anomalies in data collected from various sensors.
- Operations optimization—AI algorithms can optimize industrial processes by analyzing data and adjusting parameters in real time.
- Supply chain optimization—AI can optimize supply chain processes by analyzing data from inventory levels, demand forecasting, and logistics.
- Quality control—AI-powered vision systems and machine learning algorithms can be implemented in manufacturing quality control. These systems can identify defects or deviations from quality standards, ensuring that only high-quality products reach the market.
- Energy management—AI can analyze energy consumption patterns and optimize energy usage in industrial settings.
- Continuous improvement—AI facilitates continuous improvement by learning from data over time.
Figure 1. Industrial IoT 4.0
This blog demonstrates the benefits of the edge solutions integration on top of NativeEdge with Litmus, one of the integrated solutions.
Industrial IoT Edge AI with NativeEdge and Litmus
Dell NativeEdge serves as a platform for deploying and managing edge devices and applications at the edge. One notable addition to NativeEdge’s latest version is the ability to deliver an end-to-end solution on top of the platform that includes PTC, Litmus, Telit Cinterion, Centerity, and others. This capability allows users to get a consistent and simple management from bare-metal provisioning to a full-blown solution that is fully automated.

Figure 2. Introducing Edge Solutions on top of NativeEdge
Introduction to Litmus
Litmus is an industrial IoT platform that helps businesses collect, analyze, and manage data from IIoT devices. Dell NativeEdge is a cloud-based and on-premise software solution that helps businesses improve their email security and delivery.
Litmus includes two main parts:
- Litmus Edge Manager
- Litmus Edge
Litmus Edge Manager
Litmus Edge Manager serves as a central management console or interface for configuring, monitoring, and managing the Litmus Edge deployments and Litmus Edge.

Figure 3. Litmus Edge Manager
Litmus Edge
Litmus Edge is an industrial edge computing platform designed for edge inferencing locally in real time. It facilitates edge and IoT device management, supports various industrial protocols, enables analytics and machine learning at the edge, and emphasizes security measures.

Figure 4. Litmus Edge platform
Litmus Edge provides a flexible solution for organizations to optimize data processing, enhance device connectivity, and derive insights directly at the edge of their industrial IoT deployments through a simple no-code user experience.
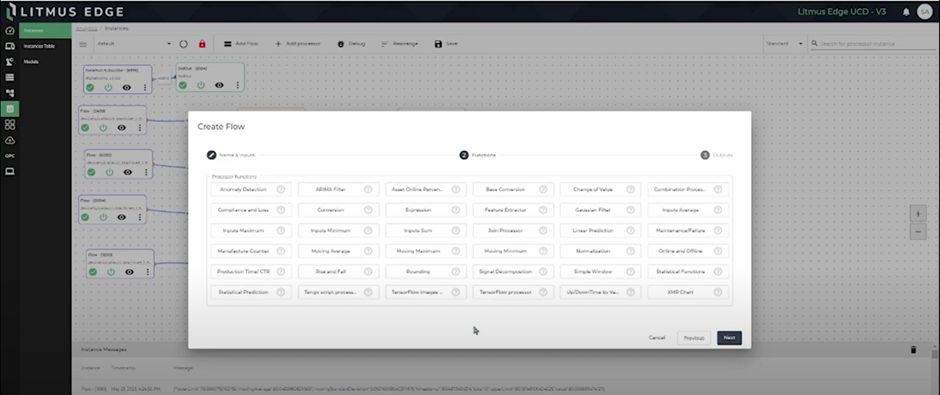
Figure 5. No-Code Editor for Edge Inferencing
Deploying the Litmus Solution on NativeEdge
First, deploy the Litmus Edge. Multiple Litmus Edge instances can be deployed on multiple NativeEdge Endpoints. Each Litmus Edge is connected to sensors like robotic arms and CNCs. The following image shows the blueprint that provisions the Litmus Edge VM from a Litmus Edge image.

The following figure shows the Litmus Edge topology on NativeEdge. We can see the NativeEdge Litmus VM provisioned as well as the binary Litmus image and their dependencies.
We can also see that there is an SDP node, where data is streamed to and persisted.

Figure 6. Litmus Edge blueprint topology
The second blueprint provisions the Litmus Edge Manager VM that can connect to multiple Litmus Edges on multiple NativeEdge Endpoints.

The following figure shows the Litmus Edge Manager topology on NativeEdge. The Litmus Edge Manager can also be provisioned on vSphere. We can see the NativeEdge Litmus Manager VM provisioned as well as the binary Litmus manager image and their dependencies.
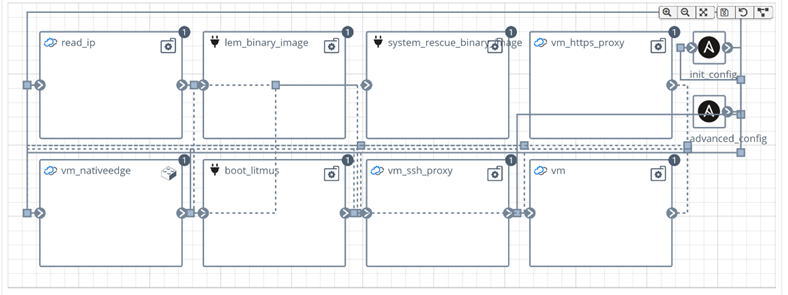
Figure 7. Litmus Edge Manager blueprint topology
Let us look at how a NativeEdge user interacts with Litmus Edge. From the NativeEdge App Catalog, choose the deploy Litmus Edge Manager or Litmus Edge (or both) and go to the deployment inputs customization.
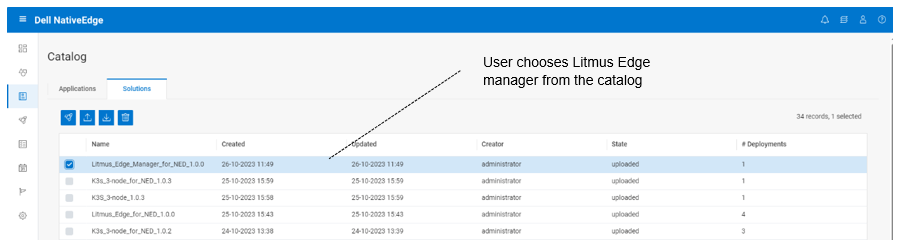
Figure 8. NativeEdge App Catalog
On the deployment inputs, you can customize the IP address and hostname to access the Litmus Edge Manager. This includes the number of vCPUs to allocate for the Litmus Manager VM.
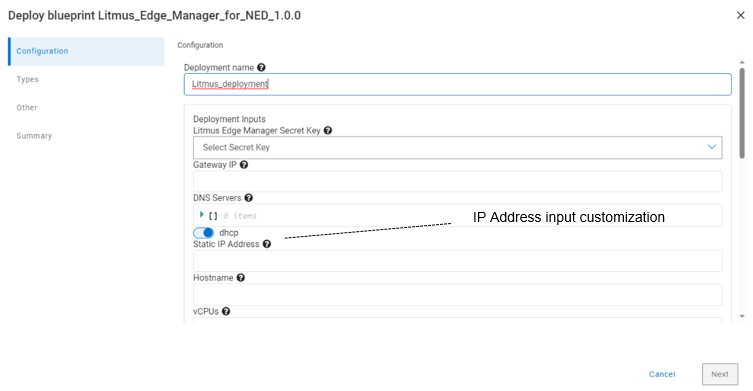
Figure 9. Litmus Edge deployment inputs
After deployment execution, we can see in the following figure that we provisioned multiple Litmus Edges. We can provision a fleet of Litmus Edges that are connected and managed by one Litmus Edge Manager.
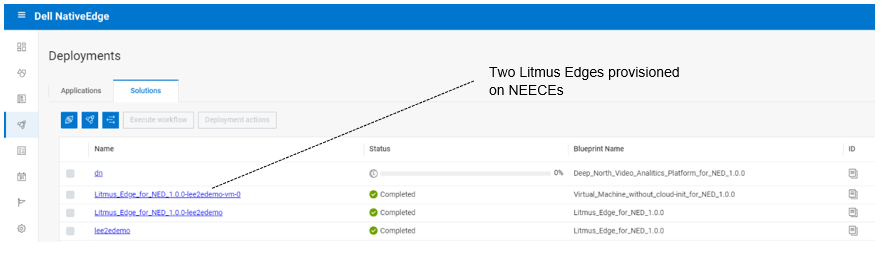
Figure 10. Litmus Edge deployment
Conclusion
Dell NativeEdge provides fully automated, secure device onboarding from bare metal to cloud. As a DevEdgeOps platform, NativeEdge also gives the ability to validate and continuously manage the provisioning and configuration of those device endpoints in a secured manner. This reduces the risk of failure or security breaches due to misconfiguration or human error by detecting those potential vulnerabilities earlier in the pre-deployment development process.
The introduction of NativeEdge Orchestrator enables customers to have consistent and simple management of integrated solutions across their entire fleet of new and existing devices, supporting external services, VxRail, and soon other cloud infrastructures. The separation between the device management and solution is the key to enabling consistent operational management between different solution vendors and cloud infrastructures.
The specific integration between NativeEdge and Litmus provides a full-blown IIoT management platform from bare metal to cloud. It also simplifies the ability to process data at the edge by introducing edge AI inferencing through a simple no-code interface.
The solution framework allows vendors to use Dell NativeEdge as a generic edge infrastructure framework, addressing fundamental aspects of device fleet management. Vendors can then focus on delivering the unique value of their solution, be it predictive maintenance or real-time monitoring, as demonstrated by the Litmus use case.
References
- Litmus Edge | Dell Technologies Validated Design for Manufacturing Edge with Litmus - TechBook | Dell Technologies Info Hub
- Litmus Live Demo
- DevEdgeOps Defined | Dell Technologies Info Hub
- Simplify Edge Operations - Flipbook | Multimedia for the NativeEdge Platform | Dell Technologies Info Hub

Will AI Replace Software Developers?
Thu, 02 May 2024 09:38:01 -0000
|Read Time: 0 minutes
Over the past year, I have been actively involved in generative artificial intelligence (Gen AI) projects aimed at assisting developers in generating high-quality code. Our team has also adopted Copilot as part of our development environment. These tools offer a wide range of capabilities that can significantly reduce development time. From automatically generating commit comments and code descriptions to suggesting the next logical code block, they have become indispensable in our workflow.
According to a recent study by McKinsey, quantify the level of productivity gain in the following areas:

Figure 1. Software engineering: speeding developer work as a coding assistant (McKinsey)
This study shows that “The direct impact of AI on the productivity of software engineering could range from 20 to 45 percent of current annual spending on the function. This value would arise primarily from reducing time spent on certain activities, such as generating initial code drafts, code correction and refactoring, root-cause analysis, and generating new system designs. By accelerating the coding process, Generative AI could push the skill sets and capabilities needed in software engineering toward code and architecture design. One study found that software developers using Microsoft’s GitHub Copilot completed tasks 56 percent faster than those not using the tool. An internal McKinsey empirical study of software engineering teams found those who were trained to use generative AI tools rapidly reduced the time needed to generate and refactor code and engineers also reported a better work experience, citing improvements in happiness, flow, and fulfilment.”
What Makes the Code Assistant (Copilot) the Killer App for Gen AI?
The remarkable progress of AI-based code generation owes its success to the unique characteristics of programming languages. Unlike natural language text, code adheres to a structured syntax with well-defined rules. This structure enables AI models to excel in analyzing and generating code.
Several factors contribute to the swift evolution of AI-driven code generation:
- Structured nature of code–Code follows a strict format, making it amenable to automated analysis. The consistent structure allows AI algorithms to learn patterns and generate syntactically correct code.
- Validation tools–Compilers and other development tools play a crucial role. They validate code for correctness, ensuring that generated code adheres to language specifications. This continuous feedback loop enables AI systems to improve without human intervention.
- Repeatable work identification–AI excels at identifying repetitive tasks. In software development, there are numerous areas where routine work occurs, such as boilerplate code, data transformations, and error handling. AI can efficiently recognize and automate these repetitive patterns.
From Coding Assistant to Fully-Autonomous AI Software Engineer
The Cognition & Development Lab at Washington University in St. Louis investigates how infants and young children think, reason, and learn about the world around them. Their research focuses on the development of early social-cognitive capacities. They are the makers of Devin, the world’s first AI software engineer.
Devin possesses remarkable capabilities in software development in the following areas:
- Complex engineering tasks–With advances in long-term reasoning and planning, Devin can plan and execute complex engineering tasks that involve thousands of decisions. Devin recalls relevant context at every step, learns over time, and even corrects mistakes.
- Coding and debugging–Devin can write code, debug, and address bugs in codebases. It autonomously finds and fixes issues, making it a valuable teammate for developers.
- End-to-end app development–Devin builds and deploys apps from scratch. For example, it can create an interactive website, incrementally adding features requested by the user and deploying the app.
- AI model training and fine-tuning–Devin sets up fine-tuning for large language models, demonstrating its ability to train and improve its own AI models.
- Collaboration and communication–Devin actively collaborates with users. It reports progress in real-time, accepts feedback, and engages in design choices as needed.
- Real-world challenges–Devin tackles real-world GitHub issues found in open-source projects. It can also contribute to mature production repositories and address feature requests. Devin even takes on real jobs on platforms like Upwork, writing and debugging code for computer vision models.
The Devin project is a clear indication of how fast we move from simple coding assistants to more complete engineering capabilities.
Will AI Replace Software Developers?
When I asked this question recently during a Copilot training session that our team took, the answer was “No”, or to be more precise “Not yet”. The common thinking is that it provides a productivity enhancement tool that will save developers from spending time on tedious tasks such as documentation, testing, and so on. This could have been true yesterday, but as seen with project Devin, it already goes beyond simple assistance to full development engineering. We can rely on the experience from past transformations to learn a bit more about where this is all heading.
Learning from Cloud Transformation: Parallels with Gen AI Transformation
The advent of cloud computing, pioneered by AWS approximately 15 years ago, revolutionized the entire IT landscape. It introduced the concept of fully automated, API-driven data centers, significantly reducing the need for traditional system administrators and IT operations personnel. However, beyond the mere shrinking of the IT job market, the following parallel events unfolded:
- Traditional IT jobs shrank significantly–Small to medium-sized companies can now operate their IT infrastructure without dedicated IT operators. The cloud’s self-service capabilities have made routine maintenance and management more accessible.
- Emergence of new job titles: DevOps, SRO, and more–As organizations embrace cloud technologies, new roles emerge. DevOps engineers, site reliability operators (SROs), and other specialized positions became essential for optimizing cloud-based systems.
- The rise of SaaS startups–Cloud computing lowered the barriers of entry for delivering enterprise-grade solutions. Startups capitalized on this by becoming more agile and growing faster than established incumbents.
- Big tech companies’ accelerated growth–Tech giants like Google, Facebook, and Microsoft swiftly adopted cloud infrastructure. The self-service nature of APIs and SaaS offerings allowed them to scale rapidly, resulting in record growth rates.
Impact on Jobs and Budgets
While traditional IT jobs declined, the transformation also yielded positive outcomes:
- Increased efficiency and quality–Companies produced more products of higher quality at a fraction of the cost. The cloud’s scalability and automation played a pivotal role in achieving this.
- Budget shift from traditional IT to cloud–Gartner’s IT spending reports reveal a clear shift in budget allocation. Cloud investments have grown steadily, even amidst the disruption caused by the introduction of cloud infrastructure, see the following figure:
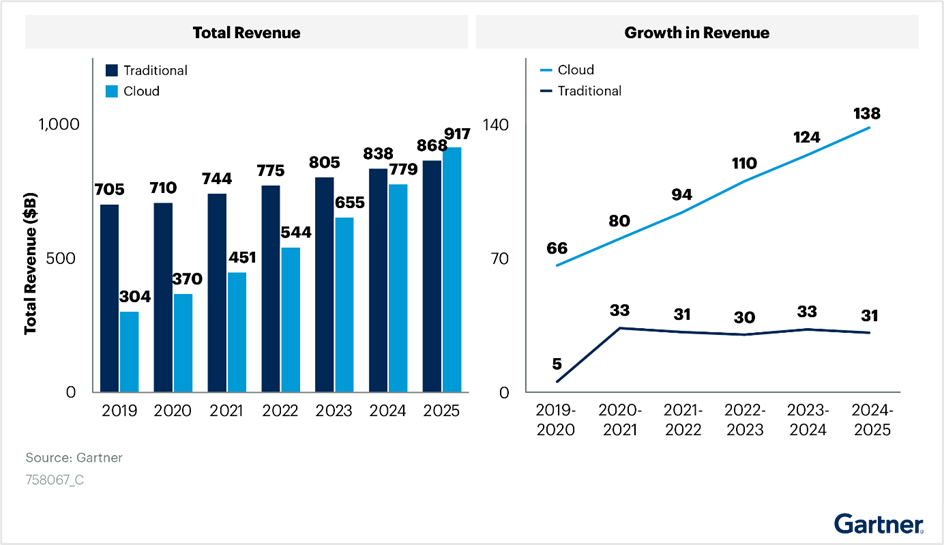
Figure 2. Cloud transformation’s impact on IT budget allocation
Looking Ahead: AI Transformation
As we transition to the era of AI, we can anticipate similar trends:
- Decline in traditional jobs–Just as cloud computing transformed the job landscape, AI adoption may lead to the decline of certain traditional roles.
- Creation of new jobs–Simultaneously, AI will create novel opportunities. Roles related to AI development, machine learning, and data science will flourish.
Short Term Opportunity
Organizations will allocate more resources to AI initiatives. The transition to AI is not merely an evolutionary step; it is a strategic imperative.
According to a research conducted by ISG on behalf of Glean, Generative AI projects consumed an average of 1.5 percent of IT budgets in 2023. These budgets are expected to rise to 2.7 percent in 2024 and further increase to 4.3 percent in 2025. Organizations recognize the potential of AI to enhance operational efficiency and bridge IT talent gaps. Gartner predicts that Generative AI impacts will be more pronounced in 2025. Despite this, worldwide IT spending is projected to grow by 8 percent in 2024. Organizations continue to invest in AI and automation to drive efficiency. The White House budget proposes allocating $75 billion for IT spending at civilian agencies in 2025. This substantial investment aims to deliver simple, seamless, and secure government services through technology.
The impact of AI extends far beyond the confines of the IT job market. It permeates nearly every facet of our professional landscape. As with any significant transformation, AI presents both risks and opportunities. Those who swiftly embrace it are more likely to seize the advantages.
So, what steps can software developers take to capitalize on this opportunity?
Tips for Software Developers in the Age of AI
In the immediate term, developers can enhance their effectiveness when working with AI assistants by acquiring a combination of the following technical skills:
- Learn AI basics–I would recommend starting the learning with AI Terms 101. I also recommend following the leading AI podcasts. I found this useful to keep myself up to date in this space and learn some useful tips and updates from industry experts.
- Use coding assistant tools (Copilot)–Coding assistant tools are definitely the low-hanging fruit and probably the simplest step to get into the AI development world. There is a growing list of tools that are available and can be integrated seamlessly into your existing development IDE. The following provides a useful reference to The Top 11 AI Coding Assistants to Use in 2024.
- Learn machine learning (ML) and deep learning concepts–Understanding the fundamentals of ML and deep learning is crucial. Familiarize yourself with neural networks, training models, and optimization techniques.
- Data science and analytics–Developers should grasp data preprocessing, feature engineering, and model evaluation. Proficiency in tools like Pandas, NumPy, and scikit-learn is beneficial.
- Frameworks and tools–Learn about popular AI frameworks such as TensorFlow, and PyTorch. These tools facilitate model building and deployment.
More skilled developers will need to learn how to create their own “AI engineers” which they will train and fine tune to assist them with user interface (UI), backend, and testing development tasks. They could even run a team of “AI engineers” to write an entire project.
Will AI Reduce the Demand for Software Engineers?
Not necessarily. In the case of cloud transformation, developers with AI expertise will likely be in high demand. Those who will not be able to adapt to this new world are likely to stay behind and face the risk of losing their job.
It would be fair to assume that the scope of work, post-AI transformation, will grow and will not stay stagnant. As an example, we will likely see products adding more “self-driving” capabilities, where they could run more complete tasks without the need for human feedback or enable close to human interaction with the product.
Under this assumption, the scope of new AI projects and products is going to grow, and that growth should balance the declining demand for traditional software engineering jobs.
Conclusion
As a history enthusiast, I often find parallels in the past that can serve as a guide to our future. The industrial era witnessed disruptive technological advancements that reshaped job markets. Some professions became obsolete, while new ones emerged. As a society, we adapted quickly, discovering new growth avenues. However, the emergence of AI presents unique challenges. Unlike previous disruptions, AI simultaneously impacts a wide range of job markets and progresses at an unparalleled pace. The implications are indeed profound.
Recent research by Nexford University on How Will Artificial Intelligence Affect Jobs 2024-2030 reveals some startling predictions. According to a report by the investment bank Goldman Sachs, AI could potentially replace the equivalent of 300 million full-time jobs. It could automate a quarter of the work tasks in the US and Europe, leading to new job creation and a productivity surge. The report also suggests that AI could increase the total annual value of goods and services produced globally by 7 percent. It predicts that two-thirds of jobs in the US and Europe are susceptible to some degree of AI automation, and around a quarter of all jobs could be entirely performed by AI.
The concerns raised by Yuval Noa Harari, a historian and professor at the Department of History of the Hebrew University of Jerusalem, resonate with many. The rapid evolution of AI may indeed lead to significant unemployment.
However, when it comes to software engineers, we can assert with confidence that regardless of how automated our processes become, there will always be a fundamental need for human expertise. These skilled professionals perform critical tasks such as maintenance, updates, improvements, error corrections, and the setup of complex software and hardware systems. These systems often require coordination among multiple specialists for optimal functionality.
In addition to these responsibilities, computer system analysts play a pivotal role. They review system capabilities, manage workflows, schedule improvements, and drive automation. This profession has seen a surge in demand in recent years and is likely to remain in high demand.
In conclusion, AI represents both risk and opportunity. While it automates routine tasks, it also paves the way for innovation. Our response will ultimately determine its impact.
References
- Economic potential of generative AI | McKinsey
- Introducing Devin, the first AI software engineer (cognition-labs.com)
- IT Spending & Budgets: Trends & Forecasts 2024
- Organizations continue to invest in AI and automation to drive efficiency
- This substantial investment aims to deliver simple, seamless, and secure government services through technology
- AI Terms 101: An A to Z AI Terminology Guide for Beginners
- 11 AI Podcasts That Will Shape Your Perspective (geekflare.com)\
- How Will Artificial Intelligence Affect Jobs 2024-2030 | Nexford University
- The Top 11 AI Coding Assistants to Use in 2024 | DataCamp
- Yuval Harari On The Future of Jobs & Technology, Intelligence vs Consciousness, & Future Threats to Humanity - Jacob Morgan (thefutureorganization.com)

Inferencing at the Edge
Wed, 28 Feb 2024 13:03:00 -0000
|Read Time: 0 minutes
Inferencing Defined
Inferencing, in the context of artificial intelligence (AI) and machine learning (ML), refers to the process of classifying or making predictions based on the input information. It involves using existing knowledge or learned knowledge to arrive at new insights or interpretations.
 Figure 1. Inferencing use case – real-time image classification
Figure 1. Inferencing use case – real-time image classification
The Need for Edge Inferencing
Data growth driven by data-intensive applications and ubiquitous sensors to enable real-time insight is growing three times faster than traditional methods that require network access. This drives data processing at the edge to keep up with the pace and reduce cloud cost and latency. S&P Global Market Intelligence estimates that by 2027, 62 percent of enterprises data will be processed at the edge.
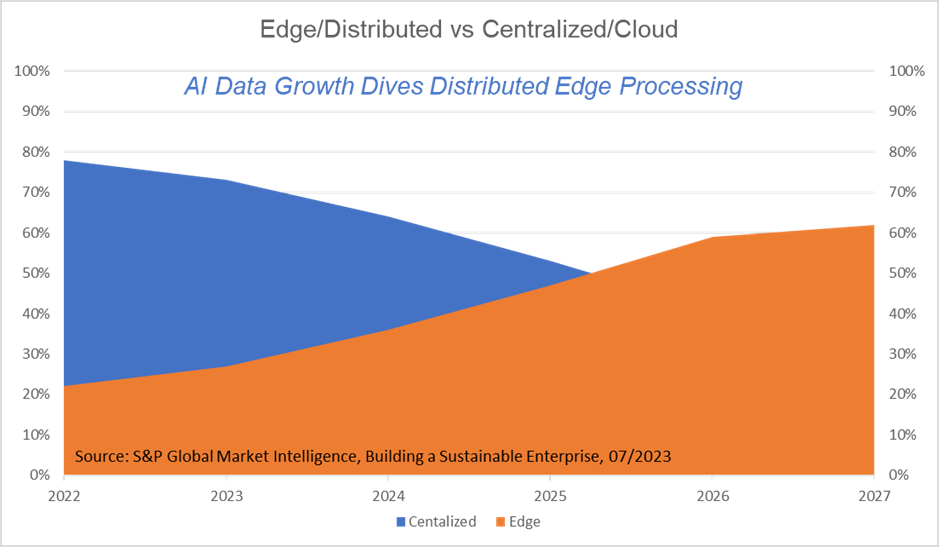 Figure 2. Data growth driven by sensors, apps, and real-time insights driving AI computation to the edge
Figure 2. Data growth driven by sensors, apps, and real-time insights driving AI computation to the edge
How Does Inferencing Work?
Inferencing is a crucial aspect of various AI applications, including natural language processing, computer vision, graph processes, and robotics.
The process of inferencing typically involves the following steps:
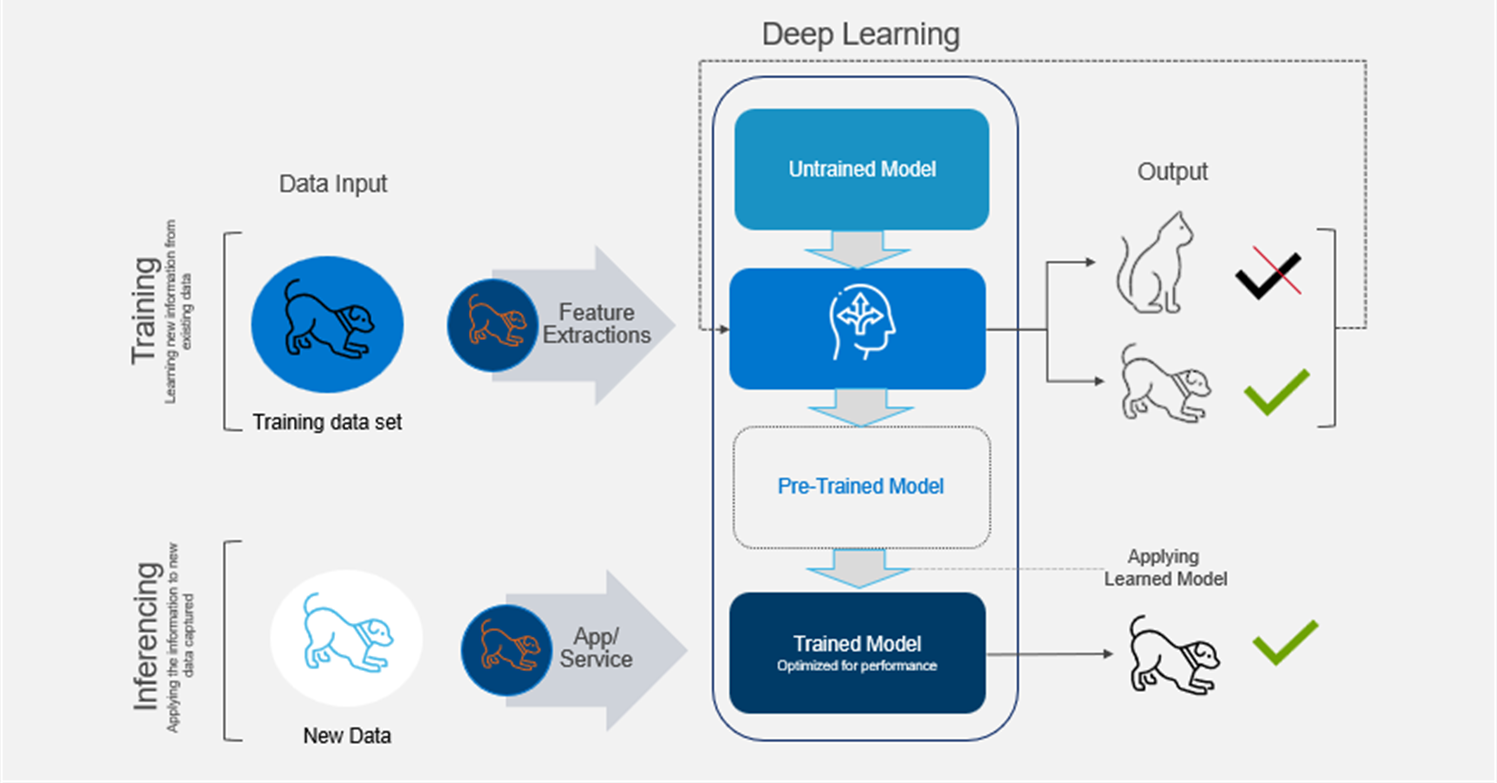 Figure 3. From training to inferencing
Figure 3. From training to inferencing
- Data input—The AI model receives input data, which could be text, images, audio, or any other form of structured or unstructured data.
- Feature extraction—For complex data like images or audio, the AI model may need to extract relevant features from the input data to represent it in a suitable format for processing.
- Pre-trained model—In many cases, AI models are pre-trained on large datasets using techniques like supervised learning or unsupervised learning. During this phase, the model learns patterns and relationships in the data.
- Applying learned knowledge—When new data is presented to the model for inferencing, it applies the knowledge it gained during the training phase to make predictions and classifications or generate responses.
- Output—The model produces an output based on its understanding of the input data.
Edge Inferencing
Inference at the edge is a technique that enables data-gathering from devices to provide actionable intelligence using AI techniques rather than relying solely on cloud-based servers or data centers. It involves installing an edge server with an integrated AI accelerator (or a dedicated AI gateway device) close to the source of data, which results in much faster response time. This technique improves performance by reducing the time from input data to inference insight, and reduces the dependency on network connectivity, ultimately improving the business bottom line. Inference at the edge also improves security as the large dataset does not have to be transferred to the cloud. For more information, see Edge Inferencing is Getting Serious Thanks to New Hardware, What is AI Inference at the Edge?, and Edge Inference Concept Use Case Architecture.
In short, inferencing is the process of an AI model using what it has learned to give us useful answers quickly. This can happen at the edge or on a personal device which maintains privacy and shortens response time.
Challenges
Computational challenges
AI inferencing can be challenging because edge systems may not always have sufficient resources. To be more specific, here are some of the key challenges with edge inferencing:
- Limited computational resources—Edge devices often have less processing power and memory compared to cloud servers. This may limit the complexity and size of AI models that can be deployed at the edge.
- Model optimization—AI models may need to be optimized and compressed to run efficiently on resource-constrained edge devices while maintaining acceptable accuracy.
- Model updates—Updating AI models at the edge can be more challenging than in a centralized cloud environment, as devices might be distributed across various locations and may have varying configurations.
Operational challenges
Handling a deep learning process involves continuous data pipeline management and infrastructure management. This leads to the following question:
- How do I manage the acquisition to the edge platform of the models, how do I stage the model, and how do I update the model?
- Do I have sufficient computational and network resources for the AI inference to execute properly?
- How do I manage the drift and security (privacy protection and adversarial attack) of the model?
- How do I manage the inference pipelines, insight pipelines, and datasets associated with the models?
Edge Inferencing by Example
To illustrate how inferencing works, we use TensorFlow as our deep learning framework.
TensorFlow is an open-source deep learning framework developed by the Google Brain team. It is widely used for building and training ML models, especially those based on neural networks.
The following example illustrates how to create a deep learning model in TensorFlow. The model takes a set of images and classifies them into separate categories, for example, sea, forest, or building.
We can create an optimized version of that TensorFlow Lite model with post-training quantization. The edge inferencing works using TensorFlow-Lite as the underlying framework and Google Edge Tensor Processing Uni (TPU) as the edge device.
This process involves the following steps:
- Create the model.
- Train the model.
- Save the model.
- Apply post-training quantization.
- Convert the model to TensorFlow Lite.
- Compile the TensorFlow Lite model using edge TPU compiler for Edge TPU devices like Coral Dev board (Google development platform that includes the Edge TPU) to TPU USB Accelerator (this allows users to add Edge TPU capabilities to existing hardware by simply plugging in the USB device).
- Deploy the model at the edge to make inferences.
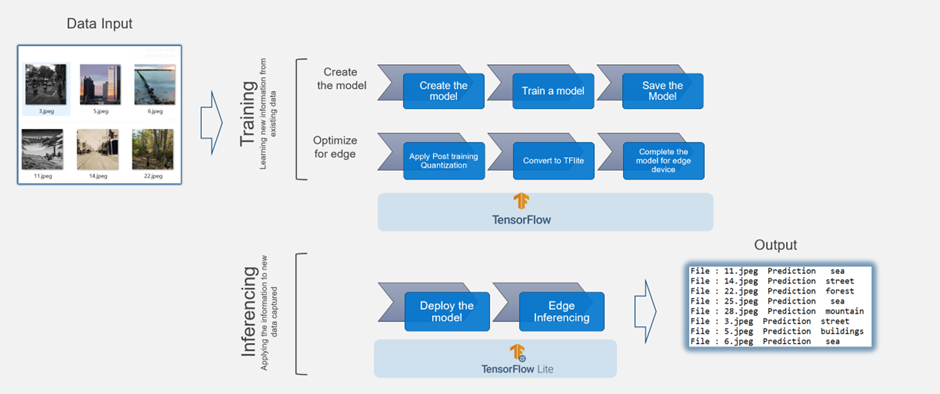 Figure 4. Image inferencing example using TensorFlow and TensorFlow Lite
Figure 4. Image inferencing example using TensorFlow and TensorFlow Lite
You can read the full example in this post: Step by Step Guide to Make Inferences from a Deep Learning at the Edge | by Renu Khandelwal | Towards AI
Conclusion
Inferencing is like a magic show, where AI models surprise us with their clever responses. It's used in many exciting areas like talking to virtual assistants, recognizing objects in pictures, and making smart decisions in various applications.
Edge inferencing allows us to bring the AI processing closer to the source of the data and thus gain the following benefits:
- Reduced latency—By performing inferencing locally on the edge device, the time required to send data to a centralized server and receive a response is significantly reduced. This is especially important in real-time applications where low latency is crucial, such as autonomous vehicles/systems, industrial automation, and augmented reality.
- Bandwidth optimization—Edge inferencing reduces the amount of data that needs to be transmitted to the cloud, which helps optimize bandwidth usage. This is particularly beneficial in scenarios where network connectivity might be limited or costly.
- Privacy and security—For certain applications, such as those involving sensitive data or privacy concerns, performing inferencing at the edge can help keep the data localized and minimize the risk of data breaches or unauthorized access.
- Offline capability—Edge inferencing allows AI models to work even when there is no internet connection available. This is advantageous for applications that need to function in remote or offline environments.
References
What is AI Inference at the Edge? | Insights | Steatite (steatite-embedded.co.uk)

How can Agile Transformation Lead to a One-Team Culture?
Thu, 22 Feb 2024 09:47:46 -0000
|Read Time: 0 minutes
Many blogs cover the Agile process itself; however, this blog is not one of them. Instead, I want to share the lessons learned from working in a highly distributed development team across eleven countries. Our teams ranged from small startups post-acquisition to multiple teams from Dell, and we had an ambitious goal to deliver a complex product in one year! This journey started when Dell’s Project Frontier leaped to the next stage of development and became NativeEdge.
This blog focuses on how Agile transformation enables us to transform into a one-team culture. The journey is ongoing as we get closer to declaring success. The Agile transformation process is a constant iterative process of learning and optimizing along the way, of failing and recovering fast, and above all, of committed leadership and teamwork.
Having said that, I thought that we reached an important milestone, at one year, in this journey that makes it worthwhile sharing.
Why Agile?
Agile methodologies were originally developed in the manufacturing industry with the introduction of Lean methodology by Toyota. Lean is a customer-centric methodology that focuses on delivering value to the customer by optimizing the flow of work and minimizing waste. The evolution of these principles into the software industry is known as Agile development, which focuses on rapid delivery of high-quality software. Scrum is a part of the Agile process framework and is used to rapidly adjust to changes and produce products that meet organizational needs.
Lean Manufacturing Versus Agile Software Delivery
The fact that a software product doesn’t look like a physical device doesn’t make the production and delivery process as different as many tend to think. The increasing prevalence of embedded software in physical products further blurs the line between these two worlds.
Software product delivery follows similar principles to the Lean manufacturing process of any physical product, as shown in the following table:
| Lean manufacturing | Agile software development |
| Supply chain | Features backlog |
| Manufacturing pipeline | CI/CD pipeline |
| Stations | Pods, cells, squads, domains |
| Assembly line | Build process |
| Goods | Product release |
Agile addresses the need of organizations to react quickly to market demands and transform into a digital organization. It encompasses two main principles:
- Project management–Large projects are better broken into smaller increments with minimal dependencies to enable parallel development rather than one large project that is serialized through dependencies. The latter would be a waterfall process where one milestone/dependency missed can cause a reset of the entire program.
- Team structure–The organizational structure should be broken into self-organizing teams that align with the product architecture structure. These teams are often referred to as squads, pods, or cells. Each team needs to have the capability to deliver its specific component in the architecture, as opposed to a tier-based approach where teams are organized based on skills, such as the product management team, UI team, or backend team, and so on.
What Could Lead to an Unsuccessful Agile Transformation?
Many detailed analyses show why Agile transformation fails. However, I would like to suggest a simpler explanation. Despite the similarities between manufacturing and software delivery, as outlined in the previous section, many software companies don’t operate with a manufacturing mindset.
Software companies that operate with a manufacturing mindset are companies where their leadership measures their development efficiency just as they measure other business KPIs, such as sales growth. They understand that their development efficiency directly impacts their business productivity. This is obvious in manufacturing, but for some reason, it has become less obvious in software. When you measure your development efficiency at the top leadership level and even board level, all the rest of the agile transformation issues that are reported in the failure analysis, such as resistance to change, become just symptoms of that root cause. It is, therefore, no surprise that companies like Spotify have been successful in this regard. Spotify has even published a lot of its learning and use cases, as well as open-source projects such as Backstage, which helped them differentiate themselves from other media streaming companies, just as Toyota did when they introduced Lean.
Lessons from a Recent Agile Transformation Journey
Changing a culture is the biggest challenge in any Agile transformation project. As many researchers have noted, Agile transformation requires a big cultural transformation including team structure. Therefore, it is no surprise that this came up as the biggest challenge in the Doing vs being: Practical lessons on building an agile culture article by McKinsey & Company.
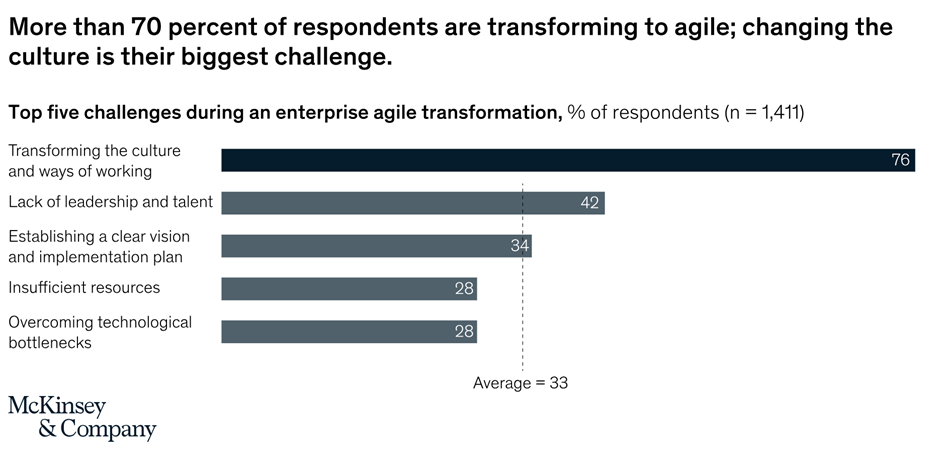
Figure 1. Exhibit 1 from McKinsey & Company article: Doing vs being: Practical lessons on building an Agile culture
Our challenge was probably at the top of the scale in that regard, as our team was built out of a combination of people from all around the world. Our challenge was to create a one-team agile culture that would enable us to deliver a new and complex product in one year.
Getting to this one-team culture is tough, because it works in many ways against human nature, which is often competitive.
One thing that helped us go through this process was the fact that we all felt frustration and pain when things didn’t work. We also had a lot to lose if we failed. At this point, we realized that our only way out of this would be to adopt Agile processes and team structures. The pain that we all felt was a great source of motivation that drove everyone to get out of their comfort zone and be much more open to adopting the changes that were needed to follow a truly Agile culture.
This wasn’t a linear process by any means and involved many iterations and frustrating moments until it became what it is today. For the sake of this blog, I will spare you from that part and focus on the key lessons that we took to implement our specific Agile transformation journey.
Key Lessons for a Successful Agile Transformation
Don’t Re-invent the Wheel
There are many lessons and processes that were already defined on how to implement Agile methodologies. Many of the lessons were built on the success of other companies. So, as a lesson learned, it’s always better to build on a mature baseline and use it as a basis for customization rather than trying to come up with your own method. In our case, we chose to use the Scrum@Scale as our base methodology.
Define Your Custom Agile Process That Is Tailored to Your Organization’s Reality
As one can expect, out-of-the-box methodologies don’t consider your specific organizational reality and challenges. It is therefore very common to customize generic processes to fit your own needs. We chose to write our own guidebook, which summarizes our version of the agile roles and processes. I found that the process of writing our ‘Agile guidebook’ was more important than the book itself. It created a common vocabulary, cleared out differences, and enabled team collaboration, which later led to a stronger buy-in from the entire team.
Test Your Processes Using Real-World Simulation
Defining Agile processes can sometimes feel like an academic exercise. To ensure that we weren’t falling into this trap, we took specific use cases from our daily routine and tested them against the process that we had just defined. We measured how much those processes got clearer or better than the existing ones, and only if we all felt that we had reached a consensus did we make it official.
Restructure the Team Into Self-Organizing Teams
This task is easier said than done. It represents the most challenging aspect, as it necessitates restructuring teams to align with the skills required in each domain. Additionally, we had to ensure that each domain maintained the appropriate capacity, in line with business priorities. Flexibility was crucial, allowing us to adapt teams as priorities shifted.
In this context, it was essential that those involved in defining this structure remained unbiased and earned the trust of the entire team when proposing such changes. As part of our Agile process, we also employed simulations to validate the model’s effectiveness. By minimizing dependencies between teams for each feature development, we transformed the team structure. Initially, features required significant coordination and dependency across teams. However, we evolved to a point where features could be broken down without inter-team dependencies, as illustrated in the following figure:
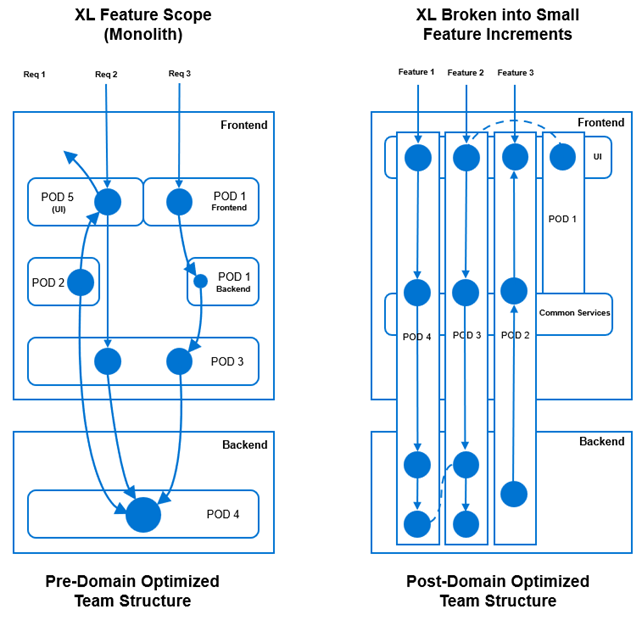
Figure 2. Organizing teams into self-organizing domains teams. Breaking large features into smaller increments (2-4 sprints each) likely fits better into the domain structure than large features
Invest in Improving the Developer Experience (DevX)
Agile processes require an agile development environment. One of the constant challenges that I’ve experienced in this regard is that many organizations fail to put the right investment and leadership attention into this area. If that is the case, you wouldn’t gain the speed and agility that you were hoping to get through the entire Agile transformation. In manufacturing terms, that's like investing in robots to automate the manufacturing pipeline but leaving humans to pass the work between them. A number of these humans could never keep up with the rest of the supply chain. This actually gets worse as the supply (feature development) gets faster. Your development speed is largely determined by how far your development processes are automated. To get to that level of automation, you need to constantly invest in the development platform. The challenge is that in most cases, the ratio between developers and DevOps can sometimes be 20:1, and that turns DevOps quickly into the next bottleneck. Platform engineering can be a solution. In a nutshell, in the shift-left model much of the ongoing responsibility for handling the feature development and testing automation to the development team and puts the main effort of the "DevOps" team to focus mostly on delivering and evolving a self-service development platform that enables the developers to do this work without having to become a DevOps expert themselves.
Keep the ‘Eye on the Ball’ With Clear KPIs
Teams can easily get distracted by daily pressures, causing focus to drift. Keeping discipline on those Agile processes is where a lot of teams fail, as they tend to take shortcuts when the delivery pressure grows. KPIs allow us to keep track of things and ensure that we’re not drifting over time, keeping our ‘eye on the ball’ even when such a distraction happens. There are many KPIs that can measure team effectiveness. The key is to pick the three that are the most important at each stage, such as stability of the release, peer review time, average time to resolve a failure, and test coverage percentage.
Don’t Try It at Home Without a Good Coach
As leaders, we often tend to be impatient and opinionated towards the ‘elephant memory’ of our colleagues. Trying to let the team figure out this sort of transformation all by themselves is a clear recipe for failure. Failure in such a process can make things much worse. On the other hand, having a highly experienced coach with good knowledge of the organization and with the right preparation was a vital facilitator in our case. We needed two iterations to come closer together. The first one was used mostly to get the ‘steam out’, which allowed us to work more effectively on all the rest of these points during the second iteration.
Conclusion
As I close my first year at Dell Technologies and reflect on all the things that I’ve learned, especially for someone who’s been in startups all of his career, I never expected that we could accomplish this level of transformation in less than a year. I hope that the lessons from this journey are useful and hopefully save some of the pain that we had to go through to get there. Obviously, none of this could have been accomplished without the openness and inclusive culture of the entire team in general and leadership specifically within Dell’s NativeEdge team. Thank you!
References
- 8 Reasons Why Agile Projects Fail | Agile Alliance
- Why Many Agile Transformations Fail | Accenture
- Squads, pods, cells? Making sense of Agile teams | TechTarget
- Practical lessons on building an agile culture | McKinsey
The journey to an agile organization | McKinsey - The Toyota Way - Wikipedia
- 11 Agile Metrics For Highly Effective Teams - AGILE KEN
- The Scrum@Scale Guide Online | Scrum@Scale Framework (scrumatscale.com)
- What Is Platform Engineering, and What Does It Do? (gartner.com)
- Talent Assessment & Development Advisors (tada-advisors.com)

Edge AI Integration in Retail: Revolutionizing Operational Efficiency
Mon, 12 Feb 2024 11:43:11 -0000
|Read Time: 0 minutes
Edge AI plays a significant role in the digital transformation of retail warehouses and stores, offering benefits in terms of efficiency, responsiveness, and enhanced customer experience in the following areas:
- Real-time analytics—Edge AI enables real-time analytics for monitoring and optimizing warehouse management systems (WMS). This includes tracking inventory levels, predicting demand, and identifying potential issues in the supply chain. In the store, real-time analytics can be applied to monitor customer behavior, track product popularity, and adjust pricing or promotions dynamically based on the current context using AI algorithms that analyze this data and provide personalized recommendations.
- Inventory management—Edge AI can improve inventory management by implementing real-time tracking systems. This helps in reducing stockouts, preventing overstock situations, and improving the overall supply chain efficiency. On the store shelves, edge devices equipped with AI can monitor product levels, automate reordering processes, and provide insights into shelf stocking and arrangement.
- Optimized supply chain—Edge AI assists in optimizing the supply chain by analyzing data at the source. This includes predicting delivery times, identifying inefficiencies, and dynamically adjusting logistics routes for both warehouses and stores.
- Autonomous systems—Edge AI facilitates the deployment of autonomous systems, such as autonomous robots, conveyor belts, robotic arms, automated guided vehicles (AGVs), and collaborative robotics (cobots). Autonomous systems in the store can include checkout processes, inventory monitoring, and even in-store assistance.
- Predictive maintenance—In both warehouses and stores, Edge AI can enable predictive maintenance of equipment. By analyzing data from sensors on machinery, it can predict when equipment is likely to fail, reducing downtime and maintenance costs.
- Offline capabilities—Edge AI systems can operate offline, ensuring that critical functions can continue even when there is a loss of internet connectivity. This is especially important in retail environments where uninterrupted operations are crucial.
The Operational Complexity Behind the Edge-AI Transformation
The scale and complexity of Edge-AI transformation in retail are influenced by factors such as the number of edge devices, data volume, AI model complexity, real-time processing requirements, integration challenges, security considerations, scalability, and maintenance needs.
The Scalability and Maintenance Challenge
A mid-size retail organization is composed of tens of warehouses and hundreds of stores spread across different locations. In addition to that, it needs to support dozens of external suppliers that also need to become an integral part of the supply chain system. To enable Edge-AI retail, it will need to introduce many new sensors, devices, and systems that will enable it to automate a large part of its daily operation. This will result in hundreds of thousands of devices across the stores and warehouses.
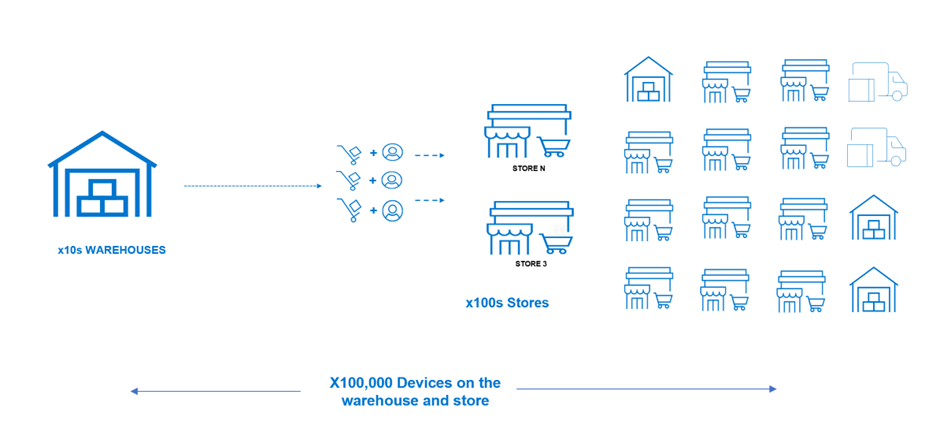
Figure 1. The Edge-AI device scale challenge
The scale of the transformation depends on the number of edge devices deployed in retail environments. These devices could include smart cameras, sensors, RFID readers, and other internet of things (IoT) devices. The ability to scale the Edge-Ai solution as the retail operation grows is an essential factor. Scalability considerations involve not only the number of devices but also the adaptability of the overall architecture to accommodate increased data volume and computational requirements.
Breaking Silos Through Cloud Native and Cloud Transformation
Each device comes with its proprietary stack, making the overall management and maintenance of such a diverse and highly fragmented environment extremely challenging. To address that, Edge-Ai transformation also includes the transformation to a more common cloud-native and cloud-based infrastructure. This level of modernization is quite massive and costly and cannot happen in one go.
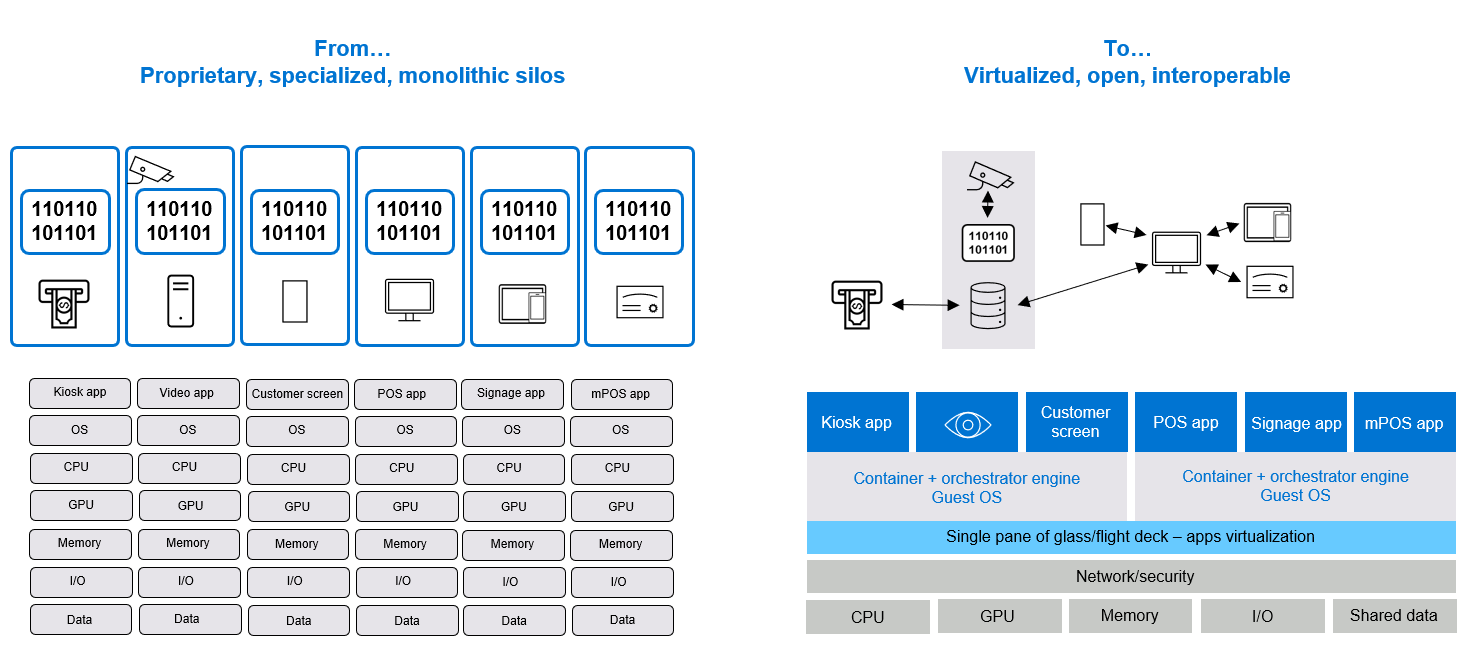
Figure 2. Cloud native and cloud transformation break the device management silos challenges
This brings the need to handle the integration with existing systems (brownfield) to enable smoother transformation. This often involves integration with existing retail systems, such as point-of-sale systems, inventory management software, and customer relationship management tools.
NativeEdge and Centerity Solution to Simplify Retail Edge-AI Transformation
Dell NativeEdge serves as a generic platform for deploying and managing edge devices and applications at the edge of the network. One notable addition in the latest version of NativeEdge is the ability to deliver an end-to-end solution on top of the platform that includes PTC, Litmus, Telit, Centerity, and so on. This capability allows users to get a consistent and simple management from Bare-Metal provisioning to a fully automated full-blown solution.
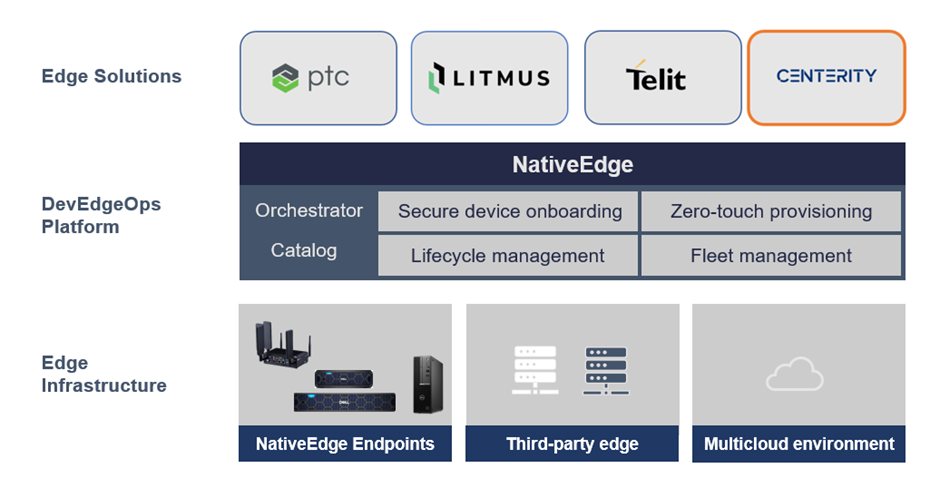
Figure 3. Using NativeEdge and Centerity as part of the open edge solution stack
In this blog, we demonstrate the benefits behind the integration of NativeEdge and Centerity that simplify the retail Edge-AI transformation challenges.
Introduction to Centerity
Centerity CSM² is a purpose-built monitoring, auto-remediation, and asset management platform for enterprise retailers that provides proactive wall-to-wall observability of the in-store technology stack. The key part in the Centrity architecture is the Centerity Manager is responsible for collecting all the data from the edge devices into a common dashboard.
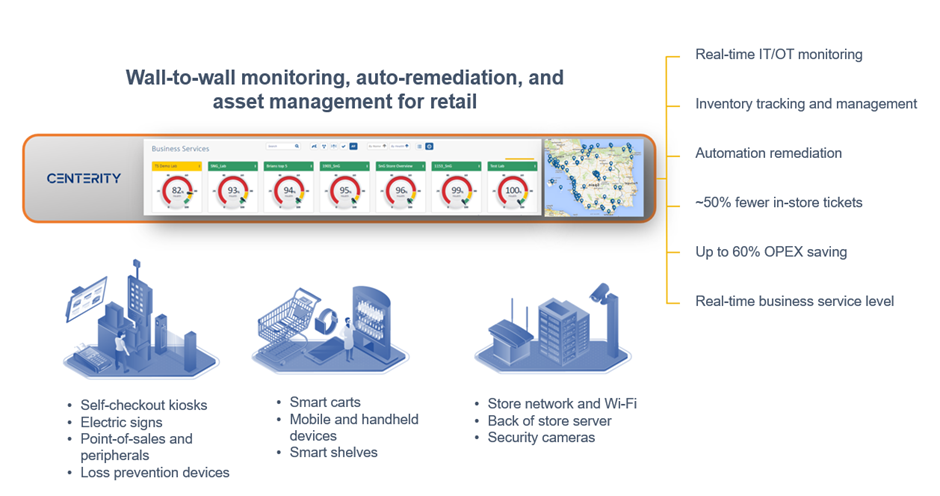
Figure 4. Centerity retail management and monitoring
Using NativeEdge and Centerity to Automate the Entire Retail Operation
The following are the architecture choices made to address the Edge-AI transformation challenges with Dell NativeEdge as the edge platform and Centerity as the asset management and monitoring for both the retail warehouse and store. In this case, we have two sites, one representing a warehouse where we connect to the customer’s existing environment running on VMware infrastructure, and a retail store running in a different location.
Note: The Centrify Proxy (customer site-1 in the following figure) is used to aggregate multiple remote devices through a single network connection.
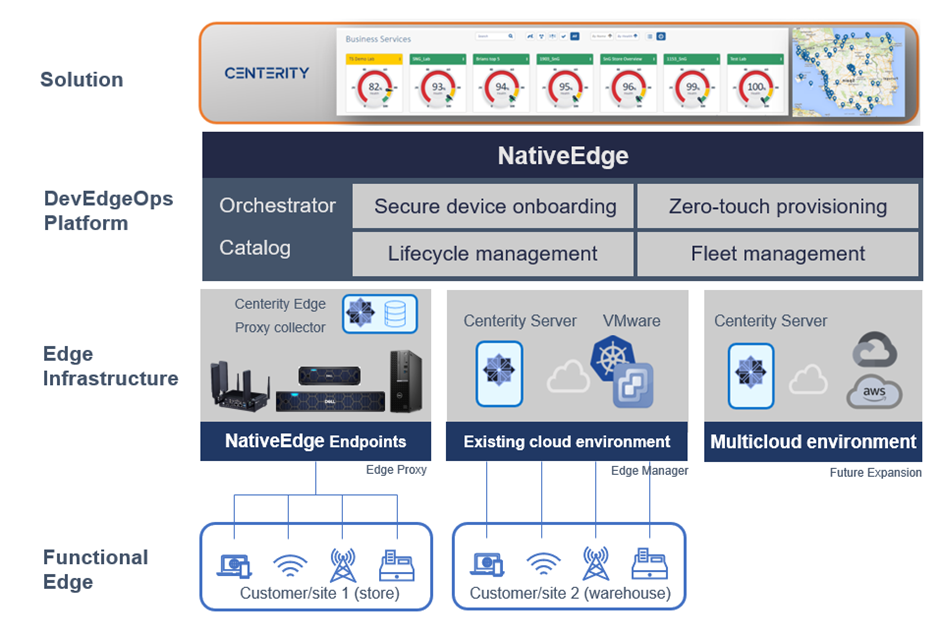
Figure 5. Using NativeEdge and Centerity to fully automate and manage and retail warehouse and store
Since the store is often limited by infrastructure capacity, we will use a gateway to aggregate the data from all the devices. For this purpose, we will use a NativeEdge Endpoint as a gateway and install the Centerity monitoring agent on it. The monitoring agent will act as a proxy that on one hand connects to the individual devices in the store and, on the other hand, sends this information back to the Centerity Manager to aggregate all this information into one control plane. In this case, the warehouse runs on a private cloud based on VMware and represents a central data center. Since we have more capacity on this environment, we will collect the data directly from the device to the manager without the need for a proxy agent. The architecture is also set to enable future expansion to public clouds such as AWS and GCP.
Step 1: Use NativeEdge for zero-touch secure on-boarding of the edge infrastructure
Secure device onboarding—In this step, we will onboard three different edge compute classes (PowerEdge, OptiPlex, and Gateway) to represent a warehouse facility with diverse set of devices. NativeEdge will treat each of these devices as a separate ECE instance and, thus, provide a consistent management layer to all the devices, regardless of their compute class.
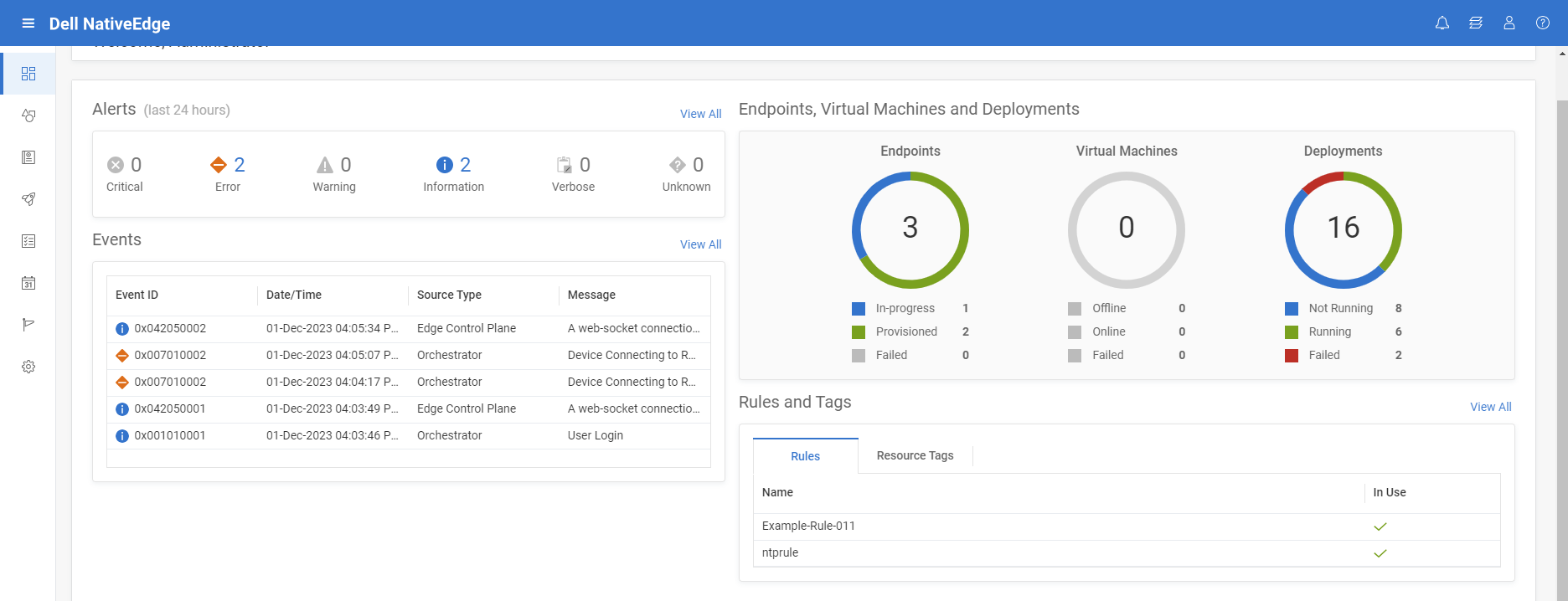
Figure 6. Zero-touch provisioning of edge infrastructure from BareMetal to cloud
Step 2: Deploy Centerity solution on top of NativeEdge infrastructure
This phase is broken down into two parts; The first is provisioning the Centerity Manager which is the main component and then provision the edge proxy on the target store and warehouse.
Step 2.1: Deploy and manage the Centerity Manager on VMware (Site 2)
To do that:
- Choose the on-prem Centerity server catalog item from the NativeEdge solution tab. Full Centerity server installation starts on VMware private cloud (external infra, not NativeEdge Endpoint).
- Use the deployment output to fetch the newly created Centerity server endpoint, credentials, and so on.
Step 2.2: Deploy and manage the Centerity Edge proxy (agent) on NativeEdge Endpoints
To install Centerity Edge proxy collector on each warehouse:
- Choose the Centerity Collector or Edge proxy catalog item.
- Select the target environment and deploy the proxy on all the selected sites. The installation happens in parallel installation on all sites.
- Fill the relevant deployment inputs and install deployment.
- Native Edge starting the fulfillment phase with all operations.
- Install and configure Centos VM per each warehouse, install edge proxy agent/ collector, and connect it to server.
- Execute day-2 operations, such as updating one of the warehouses using security update check, custom workflow.
The following blueprint automates the deployment of the Centerity agent on a NativeEdge Endpoint. It launches a virtual machine (VM) on the remote device which is configured to connect to the Centerity Manager. It also optimizes the VM to support AI workload by enabling GPU passthrough.
Figure 7. Create an AI optimized VM on the target device
NativeEdge can execute the above blueprint simultaneously on all the devices. The following figure shows the result of executing this blueprint on three devices.
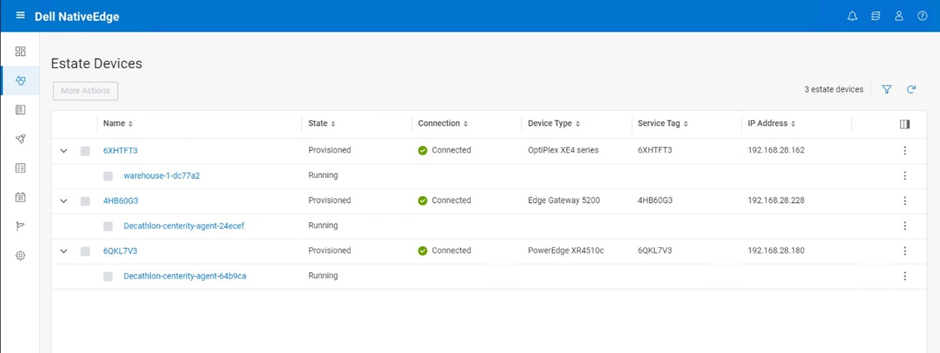
Figure 8. Deploy the Edge Proxy on all the stores in one bulk
Step 3: Connect the retail and logistic devices to Centerity
In this step, we will configure and set up the devices and connect them to the Centerity monitoring service. Note that this step is done directly on the centerity management console and not through NativeEdge console.
In this case, we chose the following endpoints within the logistic center or warehouse.
- Tablet type – Dell Windows11
- Mobile terminal type – Zebra TC52
- API based devices – SES (Digital signage)
- Printer – Bixolon (Log based)
- Agentless based devices – Security camera
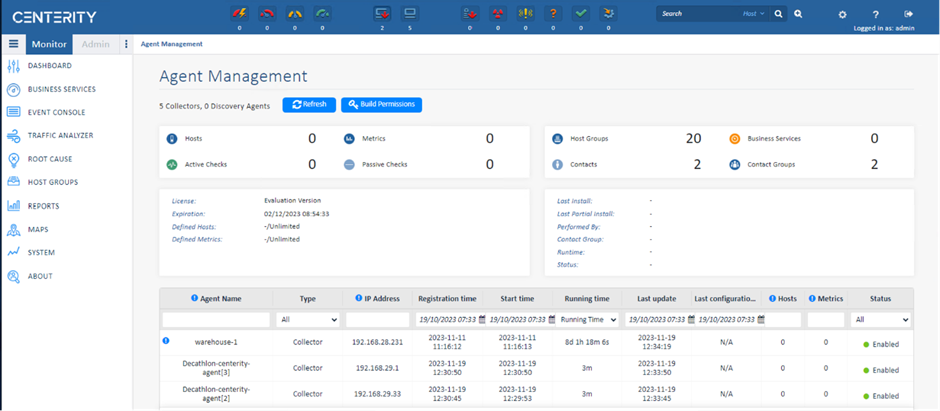
Figure 9. Centerity Management connected to the edge device managed by NativeEdge
Step 4: Managing and monitoring the retail warehouse and store
In this step, we will manage the retail warehouse and store through the monitoring of the devices that we connected to the system in the previous step. This will include the following set of operations:
- Device monitoring
- Inventory tracking (if applicable)
- Failures alerts
- Auto remediation (if applicable)
- Operational and business SLA dashboards
- Reports
- Generating events for proactive operational support
- Updating and keeping up the system software for compliance
- Breaking or fixing the workflow

Figure 10. Monitoring and managing retail devices
Conclusion
Dell NativeEdge provides a fully-automated secure device onboarding from Bare Metal to the cloud. As a DevEdgeOps platform, NativeEdge also provides the ability to validate and continuously manage the provisioning and configuration of those devices in a secure way. This minimizes the risk of failure and security breaches due to misconfiguration or human errorThose potential vulnerabilities can be detected earlier in the pre-deployment development process. The introduction of NativeEdge Orchestrator enables customers to have a consistent and simple management of built-in solutions across their entire fleet of new and existing devices. The separation between the device management and solution is key to enabling consistent operational management between different solution vendors as well as cloud infrastructure. In addition to that, the ability to integrate with the retail existing infrastructure (VMware in this specific example) as well as cloud-native infrastructure simultaneously ensures smoother transformation to a modern Edge-AI-enabled infrastructure.
The specific integration between NativeEdge and Centerity in this specific use case enables customers to deliver a full-blown retail management which integrates with both their legacy and new AI enabled devices. According to recent studies, this level of end-to-end monitoring and automation can reduce the maintenance overhead and potential downtime by 57 percent.
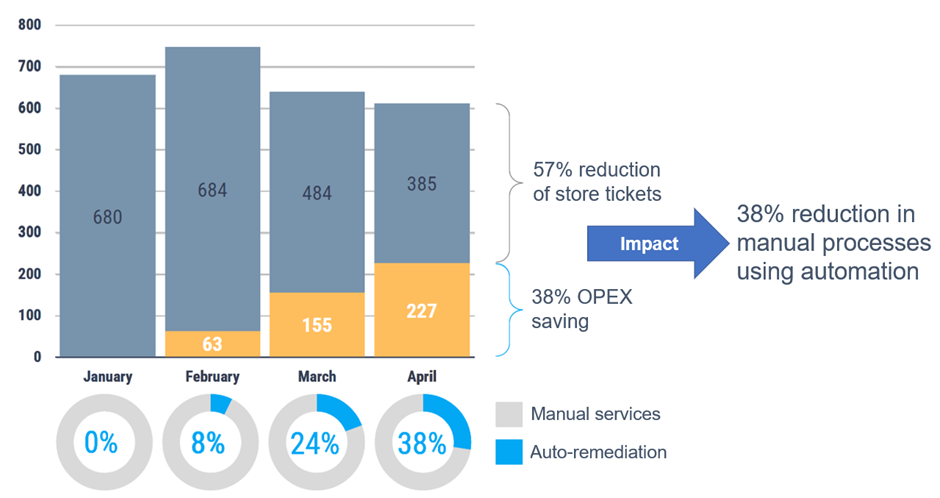
Figure 11. Moving to a fully automated and monitored retail warehouse and store brings a significant TCO saving
It is also worth noting that the open solution framework provided by NativeEdge allows partners such as Centerity to use Dell NativeEdge as a generic edge infrastructure framework, addressing fundamental aspects of device fleet management. Vendors can then focus on delivering the unique value of their solution, be it predictive maintenance or real-time monitoring, as demonstrated by the Centerity use case in this blog.
References

Streaming for Edge Inferencing; Empowering Real-Time AI Applications
Tue, 06 Feb 2024 10:17:30 -0000
|Read Time: 0 minutes
In the era of rapid technological advancements, artificial intelligence (AI) has made its way from research labs to real-world applications. Edge inferencing, in particular, has emerged as a game-changing technology, enabling AI models to make real-time decisions at the edge. To harness the full potential of edge inferencing, streaming technology plays a pivotal role, facilitating the seamless flow of data and predictions. In this blog, we will explore the significance of streaming for edge inferencing and how it empowers real-time AI applications.
The Role of Streaming
Streaming technology is a core component of edge inferencing, as it allows for the continuous and real-time transfer of data between devices and edge servers. Streaming can take various forms, such as video streaming, sensor data streaming, and audio streaming, or depending on the specific application's requirements. This real-time data flow enables AI models to make predictions and decisions on the fly, enhancing the overall user experience and system efficiency.
Typical Use Cases
Streaming for edge inferencing is already transforming various industries. Here are some examples:
- Smart cities—Edge inferencing powered by streaming technology can be used for real-time traffic management, crowd monitoring, and environmental sensing. This enables cities to become more efficient and responsive.
- Healthcare—Wearable devices and IoT sensors can continuously monitor patients, providing early warnings for health issues and facilitating remote diagnosis and treatment.
- Retail—Real-time data analysis at the edge can enhance customer experiences, optimize inventory management, and provide personalized recommendations to shoppers.
- Manufacturing—Predictive maintenance using edge inferencing can help factories avoid costly downtime by identifying equipment issues before they lead to failures.
Dell Streaming Data Platform
The Dell Streaming Data Platform (SDP) is a comprehensive solution for ingesting, storing, and analyzing continuously streaming data in real-time. It provides one single platform to consolidate real-time, batch, and historical analytics for improved storage and operational efficiency.
The following figure shows a high-level overview of the Streaming Data Platform architecture streaming data from the edge to the core.
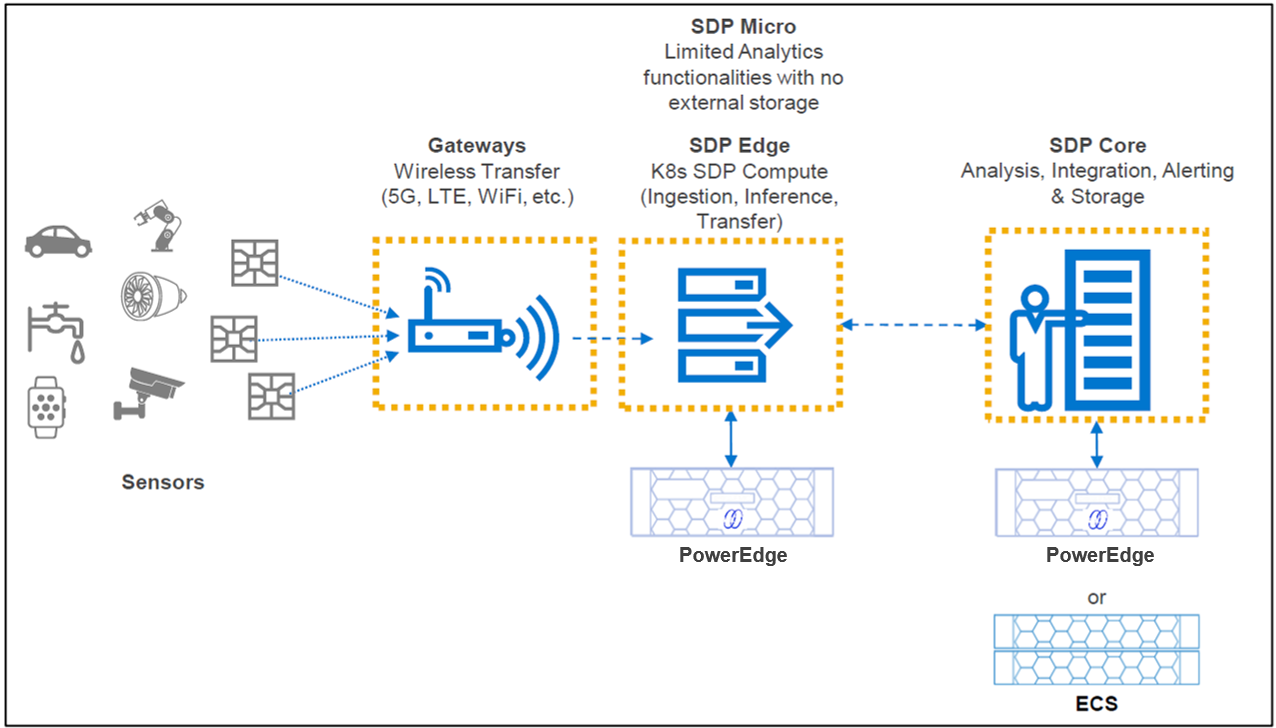
Figure 1. SDP high-level architecture
Using SDP for Edge Video Ingestion Inferencing
The key advantage of SDP, in the context of edge, is the low footprint and the ability to deal with long-term data storage. Because the platform is built on Kubernetes, storing all that data is a matter of adding nodes. Now that you have all that data, using it becomes a practice in innovation. By autotiering storage upon ingestion, SDP allows for unlimited historical data retrieval for analysis alongside real-time streaming data. This enables endless business insights at your fingertips, far into the future.
One key advantage of SDP at edge deployment is its capability of supporting real-time inferencing for edge AI/ML applications as live data is ingested into SDP. Data insights can be obtained without delay while such data is also persistently stored using SDP’s innovative tiered-storage design that provides long-term storage and data protection.
For computer vision use cases, SDP provides plugins for the popular open-source multimedia processing framework GStreamer that enables easy integration with GStreamer video analytics pipelines. See the GStreamer and GStreamer Plugins.
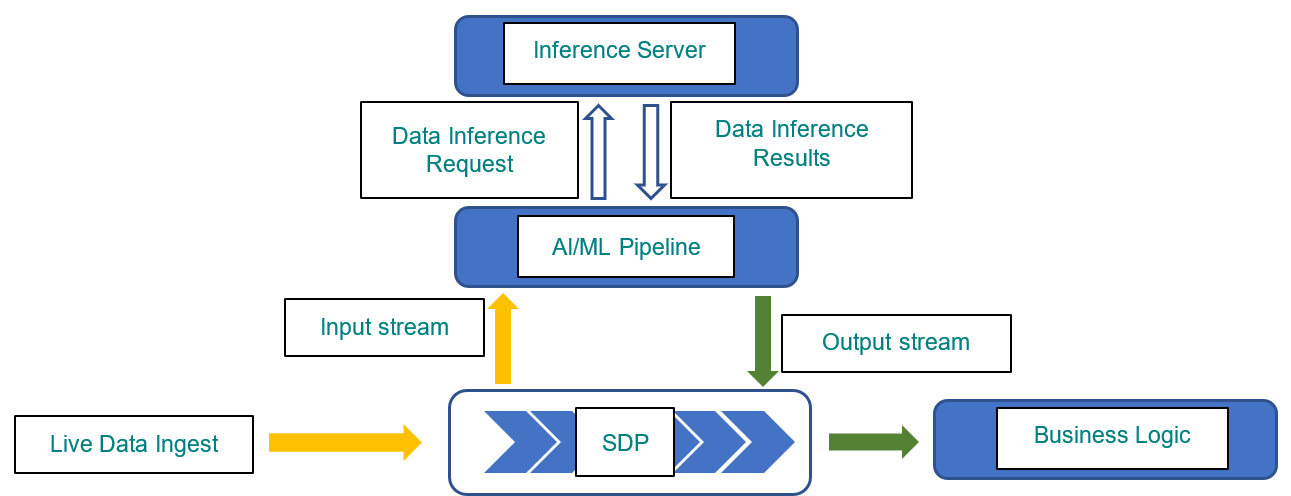
Figure 2. Edge Inferencing with SDP
Optimized for Deep Learning at Edge
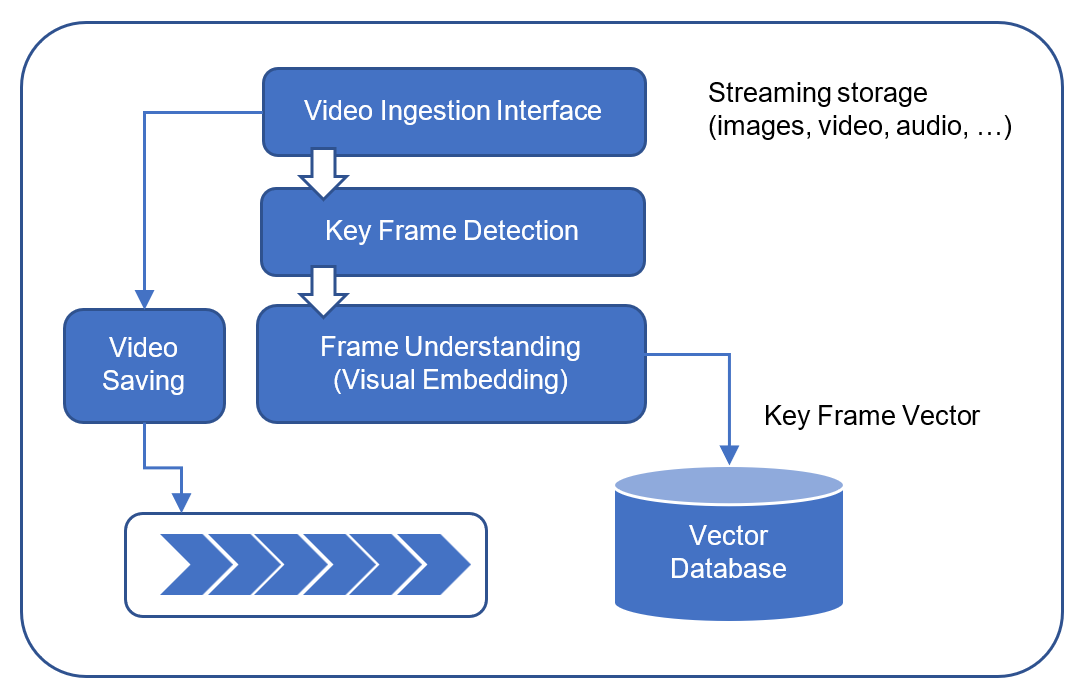
Figure 3. Using SDP for visual embedding of computer vision
SDP was also optimized to process video streaming data and process it at the edge by adding frame detection. Saving video frames combined with an integrated vector database enables to handle video processing at the edge.
SDP is optimized for deep learning by providing semantic embedding of ingested data, especially for unstructured data such as images and videos. As unstructured data is ingested into SDP, they are processed by an embedding pipeline that leverages pretrained models to extract semantic embeddings from raw data and persist such embeddings in a vector database. Such semantic embedding of raw data enables advanced data management capabilities as well as support for GenAI type of applications. For example, these embeddings can provide domain-specific context for GenAI type of query using Retrieval Augmented Generation (RAG).
Optimized for Edge AI
As AI/ML applications are becoming more widely adopted at the edge, SDP is ideally suited to support these applications by enabling real-time inference at the edge. Compared to traditional edge AI applications where data is transported to the cloud or core for inferencing, SDP can provide real-time inference right at the edge when live data is ingested so that inference latency can be greatly reduced.
In addition, SDP embraces rapidly emerging deep learning and GenAI applications by providing advanced data semantic embedding extraction and embedding vector storage, especially for unstructured multimedia data such as audio, image, and video data.
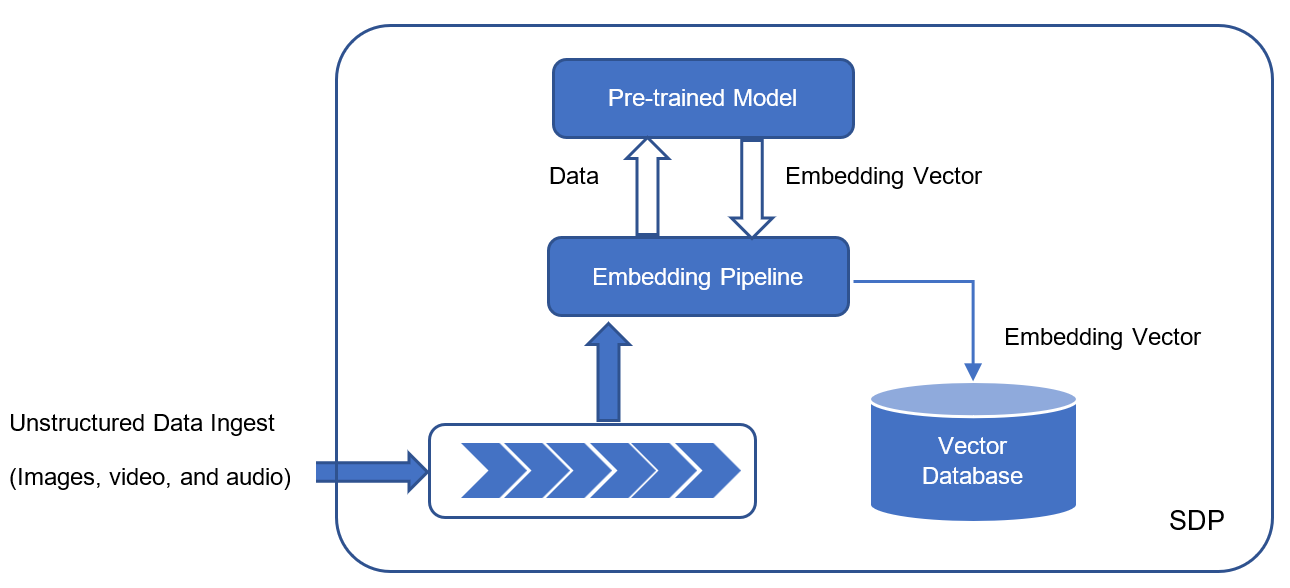
Figure 4. Unstructured data embedding vector generation
Long-Term Storage
SDP is designed with an innovative tiered-storage architecture. Tier-1 provides high performance local storage while tier-2 provides long-term storage. Specifically, tier-1 data storage is provided by replicated Apache Bookkeeper backed by a local storage to guarantee data durability once data is ingested into SDP. Asynchronously, data is flushed into tier-2 long-term storage such as Dell’s PowerScale to provide unlimited data storage and data protection. Alternatively, on NativeEdge, replicated Longhorn storage can also be used as long-term storage for SDP. With long term data storage, analytics applications can consume unbounded data to gain insights over a long period of time.
The following figure illustrates the long-term storage architecture in SDP.
Figure 5. SDP long-term storage
Cloud Native
SDP is fully cloud-native in its design with distributed architecture and autoscaling. SDP can be readily deployed on any Kubernetes environment in the cloud or on-premises. On NativeEdge, SDP is deployed on a K3s cluster by the NativeEdge Orchestrator. In addition, SDP can be easily scaled up and down as the data ingestion rate and application workload vary. This makes SDP flexible and elastic in different NativeEdge deployment scenarios. For example, SDP can leverage Kubernetes and autoscale its stream segment stores to adapt to changing data ingestion rates.
Automating the Deployment of SDP on Dell NativeEdge
Dell NativeEdge is an edge operations software platform that helps customers securely scale their edge operations to power any use case. It streamlines edge operations at scale through centralized management, secure device onboarding, zero-touch deployment, and automated management of infrastructure and applications. With automation, open design, zero-trust security principles, and multicloud connectivity, NativeEdge empowers businesses to attain their wanted outcomes at the edge.
Dell NativeEdge provides several features that make it ideal for deploying SDP on the edge, including:
- Centralized management—Remotely manage your entire edge estate from a central location without requiring local, skilled support.
- Secure device onboarding with zero-touch provisioning—Automate the deployment and configuration of the edge infrastructure managed by NativeEdge, while ensuring a zero-trust chain of custody.
- Zero-trust security enabling technologies—From secure component verification (SCV) to secure operating environment with advanced security control to tamper-resistant edge hardware and software integrity, NativeEdge secures your entire edge ecosystem throughout the lifecycle of devices.
- Lifecycle management—NativeEdge allows complete lifecycle management of your fleet of edge devices as well as applications.
- Multicloud app orchestration—NativeEdge provides templatized application orchestration using blueprints. It also provides the flexibility to choose the ISV application and cloud environments for your edge application workloads.
Deploying SDP as a Cloud Native Service on top of NativeEdge-Enabled Kubernetes Cluster
In a previous blog, we provided insight into how we can turn our Edge devices into a Kubernetes cluster using NativeEdge Orchestrator. This step creates the foundation that allows us to deploy any edge service through a standard Kubernetes Helm package.
Figure 6. Deploying SDP solution on NativeEdge-enabled Kubernetes
The Deployment Process
SDP is built as a cloud native service. The deployment of SDP includes a set of microservices as well as Ansible playbooks to automate the configuration management of those services.
The main blueprint that deploys the SDP app is shown in the following figure. It is a TOSCA node definition of an Application Module type, and it invokes an Ansible playbook to configure and start the deployment process.

Figure 7. Deploying SDP App
For the deployment, SDP is one of the available services we can choose from the NativeEdge Catalog under the Solutions tab. In the following figure, an HA SDP service is deployed on top of a Kubernetes cluster.
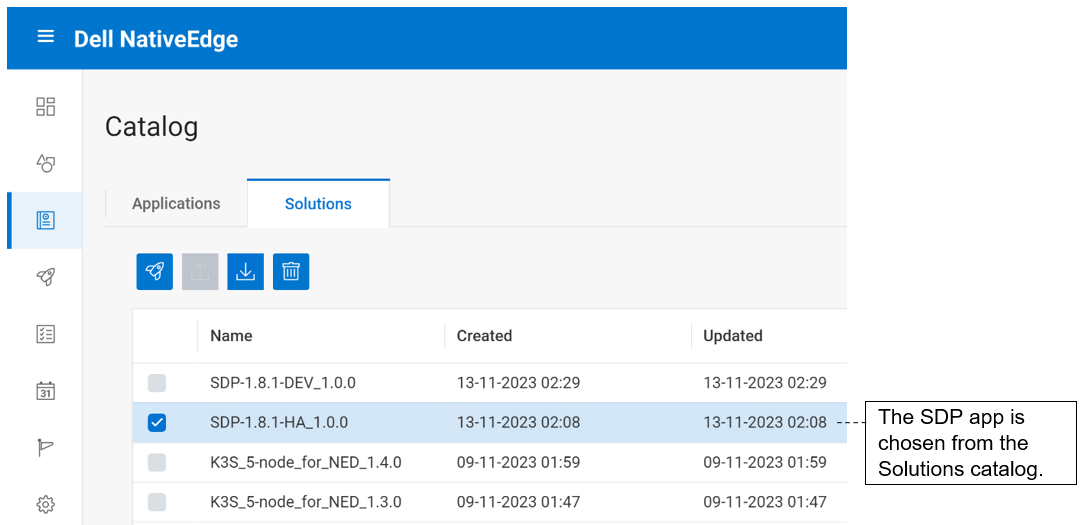
Figure 8. Select the SDP service from the NativeEdge Catalog
In the following figure, as part of the deployment process, we can provide input parameters. In this case, we provide configuration parameters that can vary from one edge location to another. We use the same blueprint definition with different deployment parameters to adjust various edge requirements, like different location requirements, different configurations, and so on.
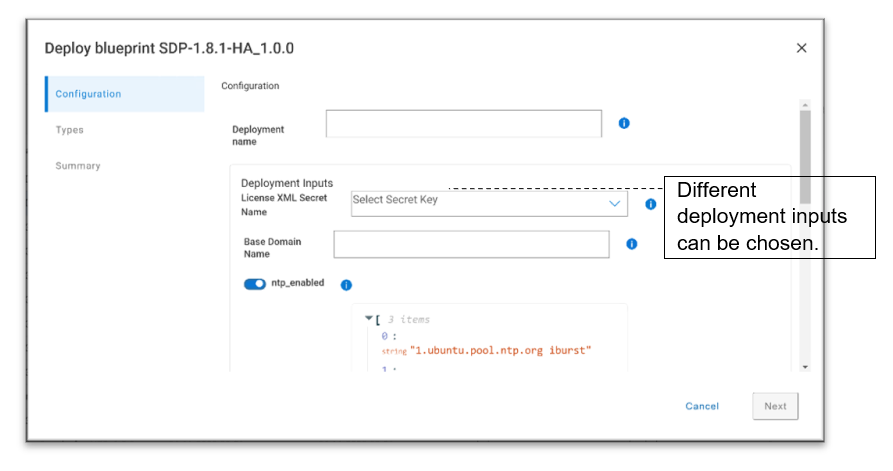
Figure 9. Deploy the SDP blueprint and enter the inputs
SDP service is deployed as can be seen in the following figure.
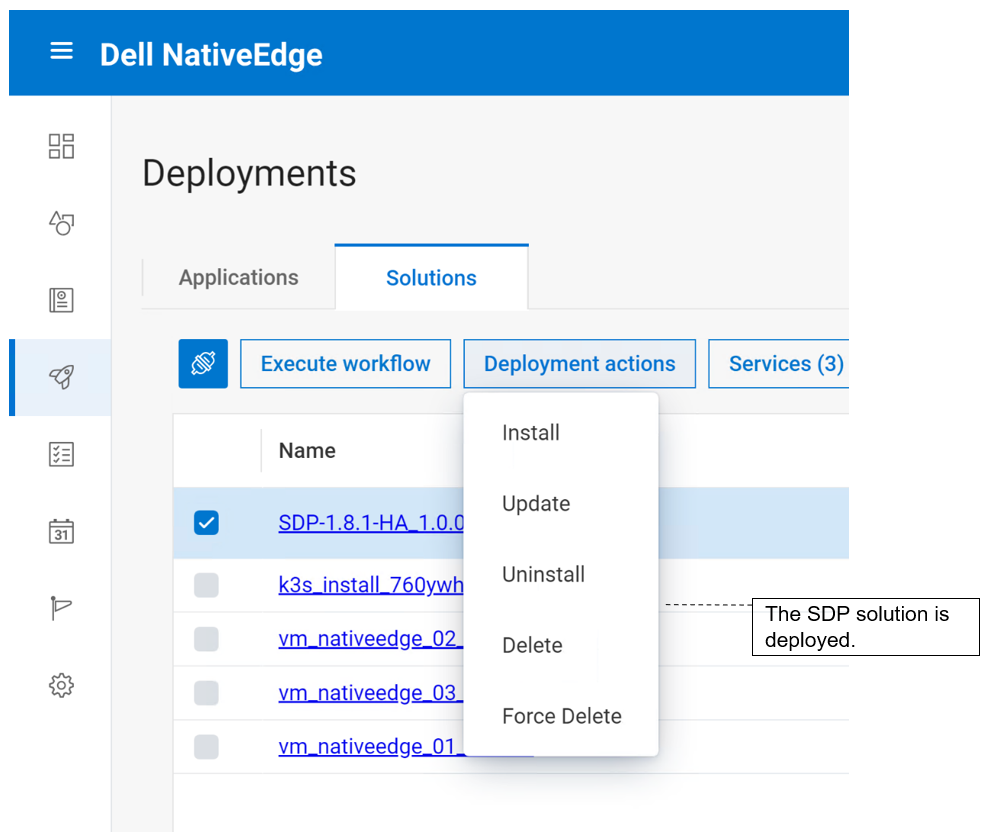
Figure 10. Create an SDP instance by performing the install workflow
Benefits of Streaming Services
Streaming services is a critical part of any edge inferencing solution and comes with the following benefits:
- Reduced latency—Streaming ensures that data is processed when it is generated. This minimal delay is crucial for applications where even a few milliseconds can make a significant difference, such as when autonomous vehicles need to react quickly to changing road conditions.
- Enhanced privacy—By processing data at the edge, streaming minimizes the need to send sensitive information to the cloud for processing. This enhances user privacy and security, which is a critical consideration in applications like healthcare and smart homes.
- Improved scalability—Streaming can efficiently handle large volumes of data generated by edge devices, making it a scalable solution for applications that involve multiple devices or sensors.
- Real-time decision making—Streaming enables AI models to make decisions in real time, which is vital for applications like predictive maintenance in industrial settings or emergency response systems.
- Cost efficiency—By performing inferencing at the edge, streaming reduces the need for continuous cloud processing, which can be costly. This approach optimizes resource utilization and cost savings,
- Adaptability—Streaming is flexible and adaptable, making it suitable for a wide range of applications. Whether it is processing visual data from cameras or analyzing sensor data, streaming can be customized to meet specific needs.
NativeEdge Support for Edge AI-Enabled Streaming Through Integrated SDP Integration
NativeEdge comes with built-in support for SDP which comes with an edge-optimized streaming solution geared specifically to fit edge use cases such as video inferencing.
NativeEdge is a great choice for edge AI-enabled streaming because:
- It is optimized for edge AI data processing
- It has a long-term storage
- It is cloud native
- It has a low footprint
Optimized for NativeEdge
SDP lifecycle management is fully automated on NativeEdge Orchestrator. SDP is available as Solutions in the NativeEdge Catalog. To deploy an instance of SDP on NativeEdge, a customer simply selects SDP from the NativeEdge Catalog under the Solutions tab and triggers the SDP deployment. The SDP blueprint deploys an SDP cluster on NativeEdge Endpoints. Once SDP is deployed, its ongoing day two operations are also managed by NativeEdge Orchestrator, providing a seamless experience for customers.
NativeEdge also comes with a fully optimized stack for handling AI workload through the support integrated accelerators through GPU pass through, SRIOV, and so on.
Support for Custom Streaming Platform
NativeEdge provides an open platform that easily plugs into your custom streaming platform through the support of Kubernetes and Blueprints, which is an integrated part of NativeEdge Orchestrator.
References
For more information, see the following:

From Bare-Metal Edge Devices to a Full-Blown Kubernetes Cluster
Tue, 02 Jan 2024 09:45:00 -0000
|Read Time: 0 minutes
Deploying a Kubernetes cluster on the edge involves setting up a lightweight, efficient Kubernetes (K8s) environment suitable for edge computing scenarios. Edge computing often involves deploying clusters on remote or resource-constrained locations, such as remote data centers, or even on-premise hardware in locations with limited connectivity.
This blog describes the steps for deploying an edge-optimized Kubernetes cluster on Dell NativeEdge.
Step 1: Select an Edge-Optimized Kubernetes Stack
Our Kubernetes stack is comprised of a Kubernetes controller, storage, and a virtual IP (also known as load balancer). We have chosen open-source components as our first choice for obvious reasons.
Standard K8s comes with a relatively high footprint cost which doesn’t fit low-cost functional edge use cases, and this is why MicroK8, K3s, K0, KubeVirt, Virtlet, and Krustlet have emerged as smaller footprint variants of Kubernetes.
We have chosen K3s as our Kubernetes cluster, Longhorn for storage, and Kube-VIP for our cluster networking.
Figure 1. Edge-Optimized Kubernetes Stack
The following sections provide a quick overview of each element in the stack.
Edge-Optimized Kubernetes Cluster
Edge is a constrained environment that is often limited by resource capacity.
K3s is a lightweight, certified Kubernetes distribution designed for lightweight environments, including edge computing scenarios. It's an excellent choice for deploying Kubernetes clusters on the edge due to its reduced resource requirements and simplified installation process.
K3s Key Features:
- Minimal resource usage—K3s is designed to have a small memory and CPU footprint. It can run on devices with as little as 512MB of RAM and is suitable for single-node setups.
- Reduced dependencies—K3s eliminates many of the dependencies that are present in a full Kubernetes cluster, resulting in a smaller installation size and simplified management. It uses SQLite as the default database, for example, instead of etcd.
- Lightweight images—K3s uses lightweight container images, which further reduces its overall size. It includes only the necessary components to run a Kubernetes cluster.
- Single binary—K3s is distributed as a single binary, making it easy to install and manage. This binary includes both the server and agent components of a Kubernetes cluster.
- Highly compressed artifacts—K3s uses highly comp
ressed artifacts, including container images and binary files to reduce disk space usage. - Reduced network overhead—K3s can operate in network-constrained environments, making it suitable for edge computing scenarios.
- Efficient updates—K3s is designed to handle updates efficiently, ensuring that the cluster stays small and doesn't accumulate unnecessary data.
Edge-Optimized Storage
Longhorn is an open-source, cloud-native distributed storage system for Kubernetes. It is designed to provide persistent storage for containerized applications in Kubernetes environments.
Longhorn Key Features:
- Distributed block storage—Longhorn offers distributed block storage that can be used as persistent storage for applications running in Kubernetes pods. It uses a combination of block devices on worker nodes to create distributed storage volumes.
- Data redundancy—Longhorn incorporates data redundancy mechanisms such as replication and snapshots to ensure data integrity and high availability. This means that even if a node or volume fails, data is not lost.
- Kubernetes-native—Longhorn is designed specifically for Kubernetes and integrates seamlessly with it. It is implemented as a custom resource definition (CRD) within Kubernetes, making it a first-class citizen in the Kubernetes ecosystem.
- User-friendly UI—Longhorn provides a user-friendly web-based management interface for users to easily create and manage storage volumes, snapshots, and backups. This simplifies storage management tasks.
- Backup and restore—Longhorn offers a built-in backup and restore feature, enabling users to take snapshots of their data and restore them when needed. This is crucial for disaster recovery and data protection.
- Cross-cluster replication—Longhorn has features for replicating data across different Kubernetes clusters, providing data availability and disaster recovery options.
- Lightweight and resource-efficient—Longhorn is resource-efficient and lightweight, making it suitable for various environments, including edge computing, where resource constraints may exist.
- Open source and community-driven—Longhorn is an open-source project with an active community, which means it receives regular updates and improvements.
- Cloud-native storage solutions—It is well-suited for stateful applications, databases, and other workloads that require persistent storage in Kubernetes, offering a cloud-native approach to storage.
Kube-VIP (Load Balancer)
Kubernetes Virtual IP (Kube-VIP) is an open-source tool for providing high availability and load balancing within Kubernetes clusters. It manages a virtual IP address associated with services, ensuring continuous access to services, load balancing, and resilience to node failures.
Kube-VIP Key Features:
- Virtual IP (VIP)—Kube-VIP manages a virtual IP address, which is associated with a Kubernetes service. This IP address can be used to access the service, and Kube-VIP ensures that the traffic is directed to healthy pods and nodes.
- High availability—Kube-VIP supports high-availability configurations, allowing it to function even when nodes or control plane components fail. It can automatically detect node failures and reroute traffic to healthy nodes.
- Load balancing—Kube-VIP provides load-balancing capabilities for services, distributing incoming traffic among multiple pods for the same service. This helps distribute the load evenly and improve the service's availability.
- Support for various load-balancing algorithms—Kube-VIP supports multiple load-balancing algorithms, such as round-robin, least connections, and more, allowing you to choose the most suitable strategy for your services.
- Integration with Kubernetes—Kube-VIP is designed to work seamlessly with Kubernetes clusters and leverages Kubernetes resources to configure and manage the virtual IP and load balancing.
- Customizable configuration—Kube-VIP provides configuration options to fine-tune its behavior based on specific cluster requirements.
- Support for multiple load-balancer implementations—Kube-VIP can be used with different load-balancer implementations, including Border Gateway Protocol (BGP) and other network load-balancing solutions.
Step 2: Automating the Deployment of Edge Kubernetes on Dell NativeEdge
To automate the deployment of Edge Kubernetes on NativeEdge, we need to automate the deployment of all three components of our edge architecture.
For that purpose, we use the NativeEdge Orchestrator blueprint. The blueprint provides the automation scheme for each component and allows us to compose a solution offering an end-to-end automation of the entire cluster on all its components.
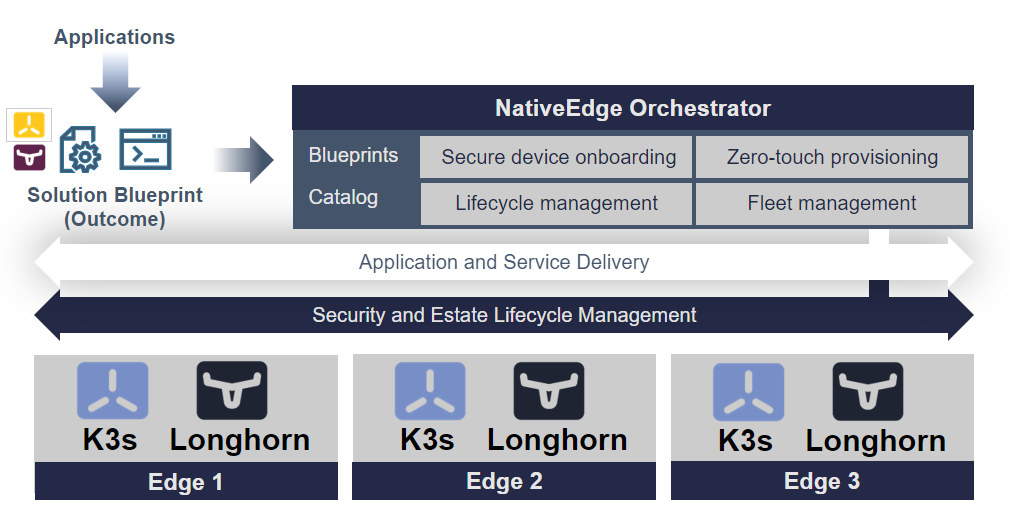
Figure 2. Automating the Kubernetes Cluster Deployment
Step 3: Deployment and Configuration
The following snippets show the blueprint for each of the three components that were previously described. A blueprint is a form of infrastructure as code (IaC) written in YAML format. Each blueprint uses a different automation plugin that fits each unit.
The first snippet shows the provisioning of a virtual IP address (VIP) that serves as the cluster entry point to the outside world. As with any load-balancer, it provides a single VIP address for all three nodes in the cluster. In this case, we chose a fabric plugin (SSH script) to automate the installation and configuration of that VIP service (scripts/install_kvip.sh).

Figure 3. VIP Blueprint Snippet
The second snippet shows the provision of the K3s cluster. It comes in multiple configuration flavors, a single node, and a three or five node HA cluster. We first provision the first node and then, in case of a multi node cluster, provision the rest of the nodes. All of the nodes form a cluster and result in an HA solution.

Figure 4. K3s Blueprint Snippet
The third snippet shows the provision of Longhorn, a cloud-native HA distributed block storage for Kubernetes. It is optional and the user can decide, using inputs, whether to add HA storage to the cluster. Longhorn creates replicas of the data in other nodes' volumes in the cluster, so in the case that a node fails, you still have the other replicas.
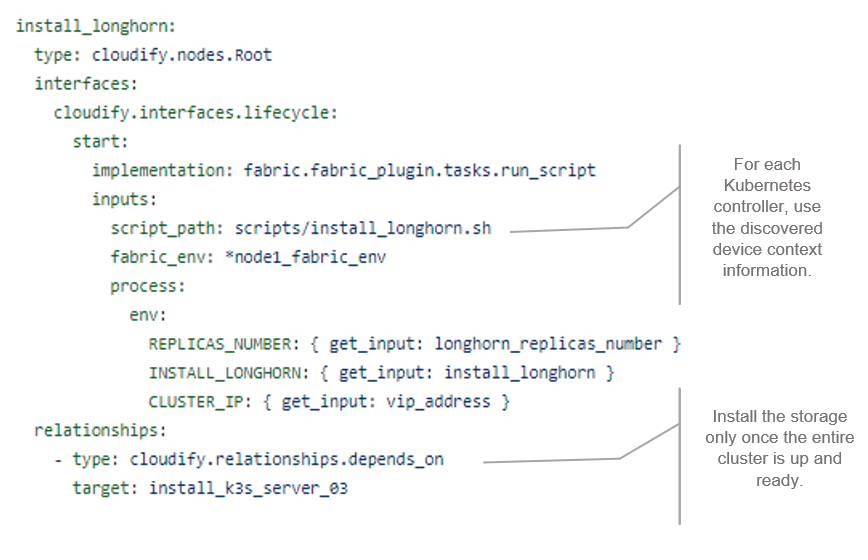
Figure 5. Storage (Longhorn) Helm Chart Blueprint
After you connect all of the components and create the HA Kubernetes cluster, you have a topology of three Kubernetes nodes (in case a of a three-node cluster), plus Kube-VIP as the VIP entry point to the cluster, and a Longhorn storage component, as shown in the following topology diagram.
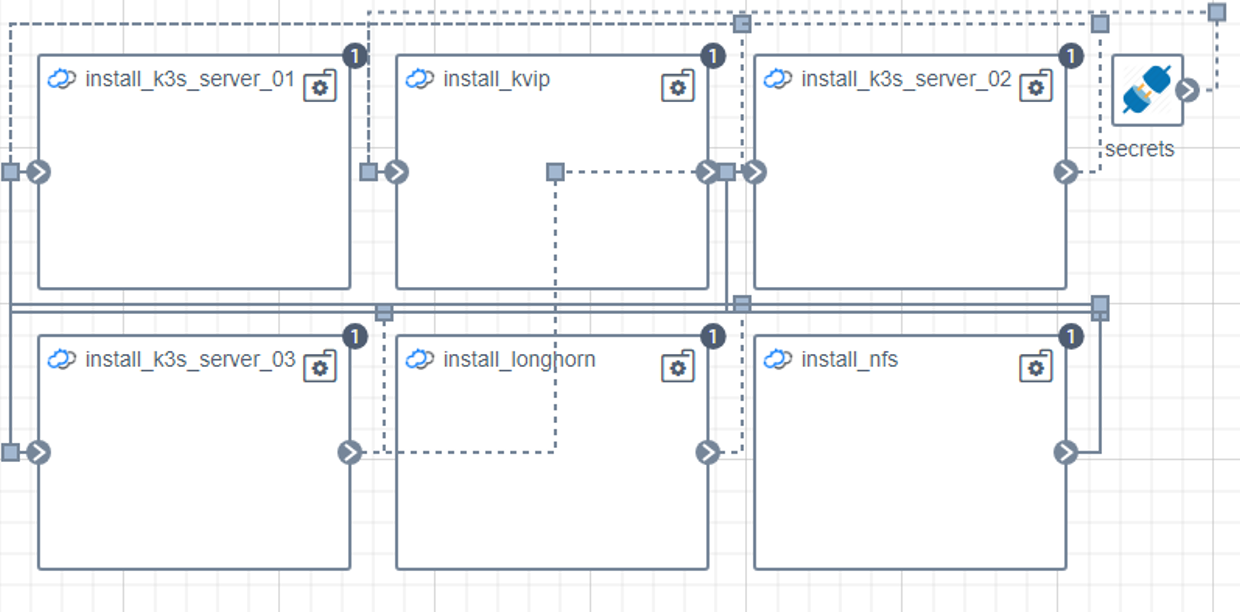
Figure 6. Automation Topology
This process takes a few minutes, and then you have an HA Kubernetes cluster.
Discovery
The discovery phase is responsible for maintaining the list of available edge devices. The result of the discovery is a list of environment entries each containing the relevant device assets management.
This list is used as an input to the deployment phase and lets the user select the designated devices that are used for the cluster.
Figure 7. NativeEdge Discovery
In the previous snippet, we see the available NativeEdge Endpoints that the user can choose from to form a cluster. The user can choose either one or three NativeEdge Endpoints to create an HA cluster. An odd number of endpoints is needed for the cluster leader election algorithm. It is essential to avoid multiple leaders getting elected, a condition known as a split-brain problem. Consensus algorithms use odd number voting to elect the leader. An example of this could be electing the node with majority votes.
Workflow Execution
Workflow execution is the phase where we map the automation plan as described in the blueprint into a chain of tasks. This calls the relevant infrastructure resource API needed to establish our cluster.
The user starts by deploying the K3S blueprint from the application catalog, as shown in the following figure.
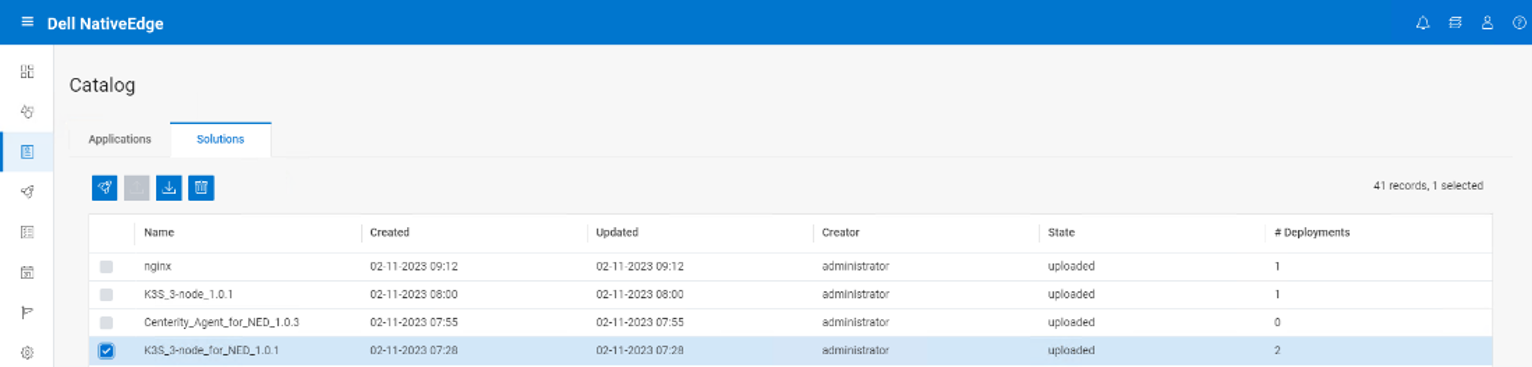
Figure 8. NativeEdge Workflow Execution
In the following figure, we can see the deployment progress bar, at 61 percent complete. It deploys all the necessary cluster resources, the K3S components, the Kube-VIP, and Longhorn.
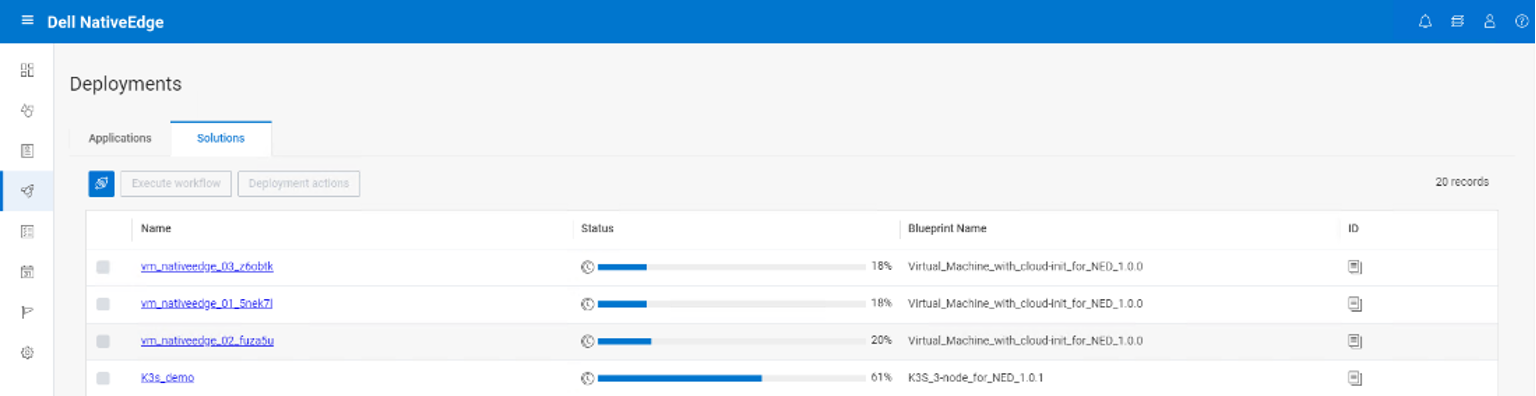
Figure 9. NativeEdge Solution Deployments
Upon deployment completion, NativeEdge shows the Deployment Capabilities and Outputs, as seen in the following figure. This list includes important information such as the K3s cluster endpoint to access the cluster.
The Deployment Capabilities and Outputs display also includes events or logs of the deployment execution, where the user can view various steps of the deployment execution.
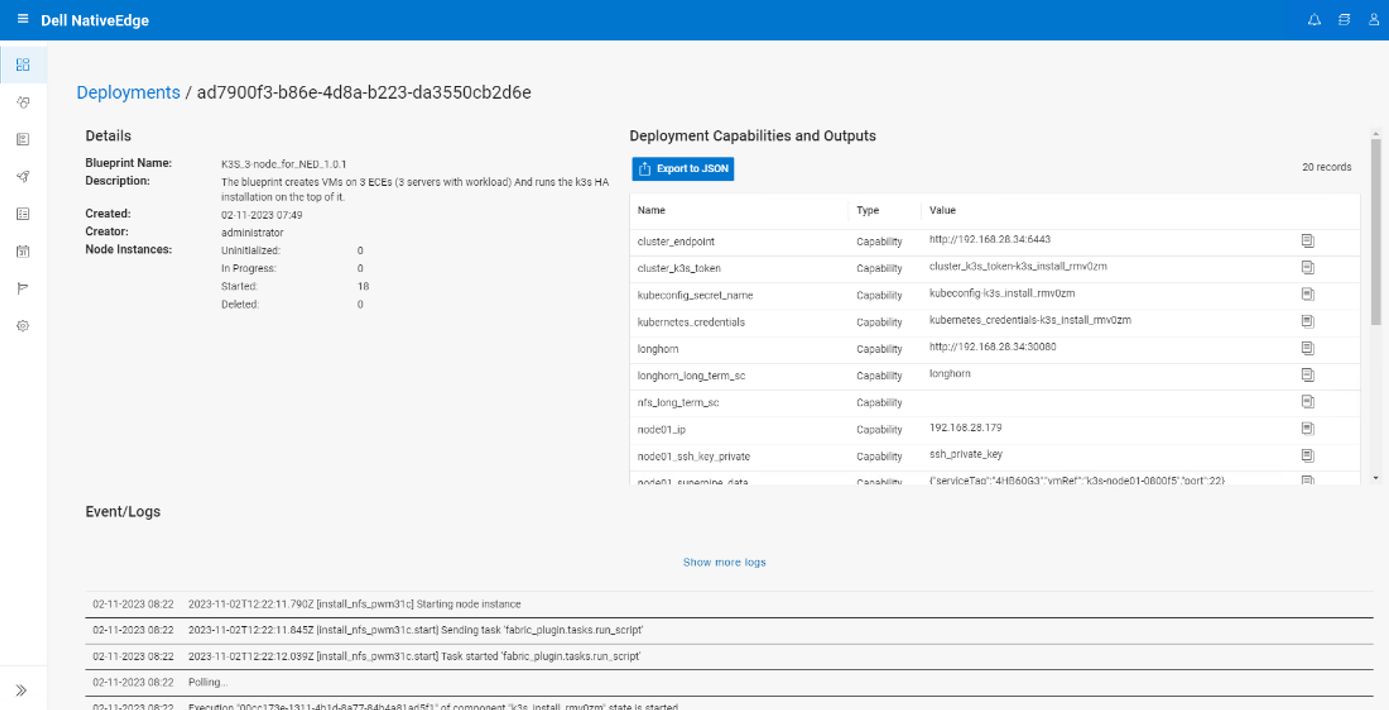
Figure 10. Deployment Details
Final Notes
Edge devices can vary significantly in terms of networking capability, resource level, hardware capabilities, operating systems, and functional role, leading to fragmentation in the edge computing ecosystem.
Edge AI is a catalyst event that leads to even more significant edge device fragmentation. It requires specialized hardware accelerators like GPUs, Neural Processing Units (NPUs), or Tensor Processing Units (TPUs) to efficiently run deep learning models. Different manufacturers produce these accelerators, leading to a variety of hardware platforms and architectures. In addition to that, many organizations, especially in industries such as automotive, healthcare, and industrial IoT, develop custom edge AI solutions tailored to their specific requirements.
Kubernetes Reduces the Edge Fragmentation Complexity
Using Kubernetes at the edge can help reduce device fragmentation complexity through:
- Abstraction—Kubernetes provides an abstraction of hardware differences.
- Containerization—Kubernetes provides a lightweight, portable workload execution framework, and can run consistently across various edge devices, regardless of the underlying operating system or hardware.
- Resource management—Kubernetes provides resource management features that allow you to allocate CPU and memory resources to containers.
- Edge clusters—Kubernetes can be set up to manage clusters of edge devices distributed across different locations, leveraging a fabric or mesh topology architecture.
- Rolling updates and version control—Kubernetes supports rolling updates and version control of containerized applications.
- Avoid vendor lock-in, the right Kubernetes for the job—Evolving extensions or variants of Kubernetes, may be better suited for the edge, including MicroK8, K3s, K0, KubeVirt, Virtlet, and Krustlet.
Having said that, setting up a Kubernetes cluster on edge devices can be a complex task.
NativeEdge provides a built-in blueprint that automates the entire process through a single API call.
It is also important to note that in this specific example, we refer to a specific edge Kubernetes stack. The provided blueprint can be easily extended to fit your specific environment or your choice of Kubernetes stack.

Edge Computing in the Age of AI: An Overview
Wed, 27 Sep 2023 05:19:01 -0000
|Read Time: 0 minutes
Introduction to Edge Computing
Edge computing is a distributed computing paradigm that brings data processing and analysis closer to the source of data generation, rather than relying on centralized cloud or datacenter resources. It aims to address the limitations of traditional cloud computing, such as latency, bandwidth constraints, privacy concerns, and the need for real-time decision-making.
 Figure 1: Innovation and momentum building at the edge. Source: Edge PowerPoint slides, Dell Technologies World 2023
Figure 1: Innovation and momentum building at the edge. Source: Edge PowerPoint slides, Dell Technologies World 2023
Edge Computing Use Cases
Edge computing finds applications across various industries, including manufacturing, transportation, healthcare, retail, agriculture, and digital cities. It empowers real-time monitoring, control, and optimization of processes. This enables efficient data analysis and decision-making at the edge as it complements cloud computing by providing a distributed computing infrastructure.
Here are some common examples:
- Industrial internet of things (IIoT)—Edge computing enables real-time monitoring, control, and optimization of industrial processes. It can be used for predictive maintenance, quality control, energy management, and overall operational efficiency improvements.
- Digital cities—Edge computing supports the development of intelligent and connected urban environments. It can be utilized for traffic management, smart lighting, waste management, public safety, and environmental monitoring.
- Autonomous vehicles—Edge computing plays a vital role in autonomous vehicle technology. By processing sensor data locally, edge computing enables real-time decision-making, reducing reliance on cloud connectivity and ensuring quick response times for safe navigation.
- Healthcare—Edge computing helps in remote patient monitoring, telemedicine, and real-time health data analysis. It enables faster diagnosis, personalized treatment, and improved patient outcomes.
- Retail—Edge computing is used in retail for inventory management, personalized marketing, loss prevention, and in-store analytics. It enables real-time data processing for optimizing supply chains, improving customer experiences, and implementing dynamic pricing strategies.
- Energy management—Edge computing can be employed in smart grids to monitor energy consumption, optimize distribution, and detect anomalies. It enables efficient energy management, load balancing, and integration of renewable energy sources.
- Surveillance and security—Edge computing enhances video surveillance systems by enabling local video analysis, object recognition, and real-time threat detection. It reduces bandwidth requirements and enables faster response times for security incidents.
- Agriculture—Edge computing is utilized in precision farming for monitoring and optimizing crop conditions. It enables the analysis of sensor data related to soil moisture, weather conditions, and crop health, allowing farmers to make informed decisions regarding irrigation, fertilization, and pest control.
These are just a few examples, and the applications of edge computing continue to expand as technology advances. The key idea is to process data closer to its source, reducing latency, improving reliability, and enabling real-time decision-making for time-sensitive applications.
The Challenges with Edge Computing
Edge computing brings numerous benefits, but it also presents a set of challenges that organizations need to address. The following image highlights some common challenges associated with edge computing:
 Figure 2: Common challenges with edge computing. Source: Edge PowerPoint slides, Dell Technologies World 2023
Figure 2: Common challenges with edge computing. Source: Edge PowerPoint slides, Dell Technologies World 2023
Edge Computing Architecture Overview
The following diagram represents a typical edge computing architecture and its associated taxonomy.
 Figure 3: A typical edge architecture
Figure 3: A typical edge architecture
A typical edge computing architecture consists of several components working together to enable data processing and analysis at the edge. Here are the key elements you would find in such an architecture:
- Edge devices—These are the devices deployed at the network edge, such as sensors, IoT devices, gateways, or edge servers. They collect and generate data from various sources and act as the first point of data processing.
- Edge gateway—An edge gateway is a device that acts as an intermediary between edge devices and the rest of the architecture. It aggregates and filters data from multiple devices, performs initial pre-processing, and ensures secure communication with other components.
- Edge computing infrastructure—This includes edge servers or edge nodes deployed at the edge locations. These servers have computational power, storage, and networking capabilities. They are responsible for running edge applications and processing data locally.
- Edge software stack—The edge software stack consists of various software components installed on edge devices and servers. It typically includes operating systems, containerization technologies (such as Docker or Kubernetes), and edge computing frameworks for deploying and managing edge applications.
- Edge analytics and AI—Edge analytics involves running data analysis and machine learning algorithms at the edge. This enables real-time insights and decision-making without relying on a centralized cloud infrastructure. Edge AI refers to the deployment of artificial intelligence algorithms and models at the edge for local inference and decision-making. The next section: Edge Inferencing describes the main use case in this regard.
- Connectivity—Edge computing architectures rely on connectivity technologies to transfer data between edge devices, edge servers, and other components. This can include wired and wireless networks, such as Ethernet, Wi-Fi, cellular networks, or even specialized protocols for IoT devices.
- Cloud or centralized infrastructure—While edge computing emphasizes local processing, there is often a connection to a centralized cloud or data center for certain tasks. This connection allows for remote management, data storage, more resource-intensive processing, or long-term analytics. Those resources are often broken down into two tiers – near and far edge:
- Far edge: Far edge refers to computing infrastructure and resources that are located close to the edge devices or sensors generating the data. It involves placing computational power and storage capabilities in proximity to where the data is produced. Far edge computing enables real-time or low-latency processing of data, reducing the need for transmitting all the data to a centralized cloud or datacenter.
- Near edge: Near edge, sometimes referred to as the "cloud edge" or "remote edge" describes computing infrastructure and resources that are positioned farther away from the edge devices. In the near edge model, data is typically collected and pre-processed at the edge, and then transmitted to a more centralized location, such as a cloud or datacenter for further analysis, storage, or long-term processing.
- Management and orchestration—To effectively manage the edge computing infrastructure, there is a need for centralized management and orchestration tools. These tools handle tasks like provisioning, monitoring, configuration management, software updates, and security management for the edge devices and servers.
It is important to note that while the components and the configurations of edge solution may differ, the overall objective remains the same: to process and analyze data at the edge to achieve real-time insights, reduced latency, improved efficiency, and better overall performance.
Edge Inferencing
Data growth driven by data intensive applications and ubiquitous sensors to enable real time insight is growing three times faster than access network. This drives data processing at the edge to keep up with the pace and reduce cloud cost and latency. IDC estimates that by 2027 62% of enterprises data will be processed at the edge!
Inference at the edge is a technique that enables data-gathering from devices to provide actionable intelligence using AI techniques rather than relying solely on cloud-based servers or data centers. It involves installing an edge server with an integrated AI accelerator (or a dedicated AI gateway device) close to the source of data, which results in much faster response time.1 This technique improves performance by reducing the time from input data to inference insight, and reduces the dependency on network connectivity, ultimately improving the business bottom line.2 Inference at the edge also improves security as the large dataset do not have to be transferred to the cloud.3
 Figure 4: Edge computing in the age of AI: An overview
Figure 4: Edge computing in the age of AI: An overview
Final Notes
Edge computing in the age of AI marks a significant paradigm shift in how data is processed, and insights are generated. By bringing AI to the edge, we can unlock real-time decision-making, improve efficiency, and enable innovations across various industries. While challenges exist, advancements in hardware, software, and security are paving the way for a future where intelligent edge devices are an integral part of our interconnected world.
It is expected that Inferencing market alone will overtake training with highest growth at the edge – necessitating competition in data center, near edge, and far edge.
For more information on how edge-inferencing works, refer to the next post on this regard: Inferencing at the Edge
 Figure 5: Reference slide on edge type definitions
Figure 5: Reference slide on edge type definitions
1 https://steatite-embedded.co.uk/what-is-ai-inference-at-the-edge/
2 https://www.storagereview.com/review/edge-inferencing-is-getting-serious-thanks-to-new-hardware

DevEdgeOps Defined
Mon, 25 Sep 2023 07:30:48 -0000
|Read Time: 0 minutes
What is a DevEdgeOps Platform?
As the demand for edge computing continues to grow, organizations are seeking comprehensive solutions that streamline the development and operational processes in edge environments. This has led to the emergence of DevEdgeOps platforms, with specialized processes and tools. Including frameworks designed to support the unique requirements of developing, deploying, and managing applications in edge computing architectures.
Edge Operations Shift Left
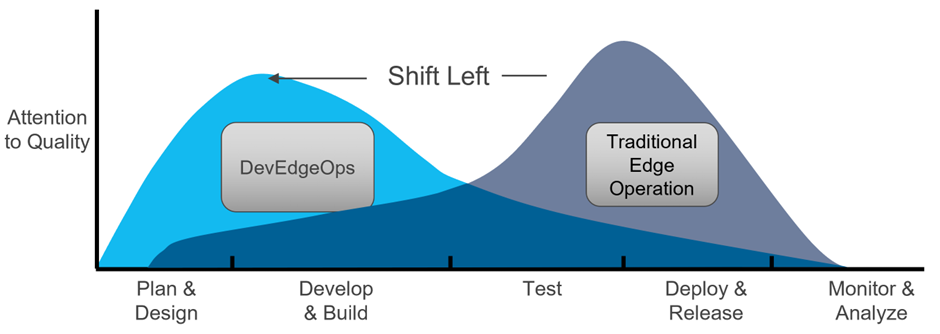 Figure 1: DevEdgeOps platform, as part of the Shift Left movement, focuses on pushing the operational challenges of edge computing to the development stage.
Figure 1: DevEdgeOps platform, as part of the Shift Left movement, focuses on pushing the operational challenges of edge computing to the development stage.
Shift Left refers to the practice of moving activities that were traditionally performed mostly at production stage to an earlier in the development stage. It is often applied in software development and DevOps to integrate testing, security, and other considerations earlier in the development lifecycle. Similarly, in the world of edge computing, we are moving operational tasks to an earlier stage, just like how we did with Shift Left in DevOps. We call this new idea, DevEdgeOps.
A DevEdgeOps platform facilitates collaboration between developers and operations teams, addressing challenges like network connectivity, security, scalability, and edge deployment management.
In this blog post, we introduce edge computing, its use cases, and architecture. We explore DevEdgeOps platforms, discussing their features and impact on edge computing development and operations.
Introduction to Edge Computing
Edge computing is a distributed computing paradigm that brings data processing and analysis closer to the source of data generation, rather than relying on centralized cloud or datacenter resources. It aims to address the limitations of traditional cloud computing, such as latency, bandwidth constraints, privacy concerns, and the need for real-time decision-making.
To learn more about the use cases, unique challenges, typical architecture and taxonomy refer to my previous post: Edge Computing in the Age of AI: An Overview
 Figure 2: Innovation and momentum building at the edge. Source: Edge PowerPoint slides, Dell Technologies World 2023
Figure 2: Innovation and momentum building at the edge. Source: Edge PowerPoint slides, Dell Technologies World 2023
DevEdgeOps
DevEdgeOps is a term that combines elements of development (DevOps) and edge computing. It refers to the practices, methodologies, and tools used for managing and deploying applications in edge computing environments while leveraging the principles of DevOps. In other words, it aims to enable efficient development, deployment, and management of applications in edge computing environments, combining the agility and automation of DevOps with the unique requirements of edge deployments.
DevEdgeOps Platform
A DevEdgeOps platform provides developers and operations teams with a unified environment for managing the entire lifecycle of edge applications, from development and testing to deployment and monitoring. These platforms typically combine essential DevOps practices with features specific to edge computing, allowing organizations to build, deploy, and manage edge applications efficiently.
Key Features of DevEdgeOps Platforms
- Centralized edge application management—DevEdgeOps platforms provide centralized management capabilities for edge applications. They offer dashboards, interfaces, and APIs that allow operations teams to monitor the health, performance, and status of edge deployments in real-time. These platforms may also include features for configuration management, remote troubleshooting, and log analysis, enabling efficient management of distributed edge nodes.
- Integration with edge infrastructure—DevEdgeOps platforms often integrate with edge infrastructure components such as edge gateways, edge servers, or cloud-based edge computing services. This integration simplifies the deployment process by providing seamless connectivity between the development platform and the edge environment, facilitating the deployment and scaling of edge applications.
- Edge-aware development tools—DevEdgeOps platforms offer development tools tailored for edge computing. These tools assist developers in optimizing their applications for edge environments, providing features such as code editors, debuggers, simulators, and testing frameworks specifically designed for edge scenarios.
- CI/CD pipelines for edge deployments—DevEdgeOps platforms enable the automation of continuous integration and deployment processes for edge applications. They provide pre-configured pipelines and templates that consider the unique requirements of edge environments, including packaging applications for different edge devices, managing software updates, and orchestrating deployments to distributed edge nodes.
- Edge simulation and testing capabilities—DevEdgeOps platforms often include simulation and testing features that help developers validate the functionality and performance of edge applications in various scenarios. These features simulate edge-specific conditions such as low-bandwidth networks, intermittent connectivity, and edge device failures, allowing developers to identify and address potential issues proactively.
Final Words
The emergence of new edge use cases that combine cloud-native infrastructure and AI introduces an increased operational complexity and demands more advanced application lifecycle management. Traditional management approaches may no longer be sustainable or efficient in addressing these challenges.
In my previous post, How the Edge Breaks DevOps, I referred to the unique challenges that the edge introduces and the need for a generic platform that will abstract the complexity associated with those. In this blog, I introduced DevEdgeOps platforms that combine essential DevOps practices with features specific to edge computing. I also described the set of features that are expected to be part of this new platform category. By embracing these approaches, organizations can effectively manage operational complexity and fully harness the potential of edge computing and AI.