
Snapshots
Snapshots
-
SnapshotIQ
Next along the high availability and data protection continuum are snapshots. The RTO of a snapshot can be small, and the RPO is also highly flexible with the use of rich policies and schedules. SnapshotIQ software can take read-only, point-in-time copies of any directory or subdirectory within OneFS.
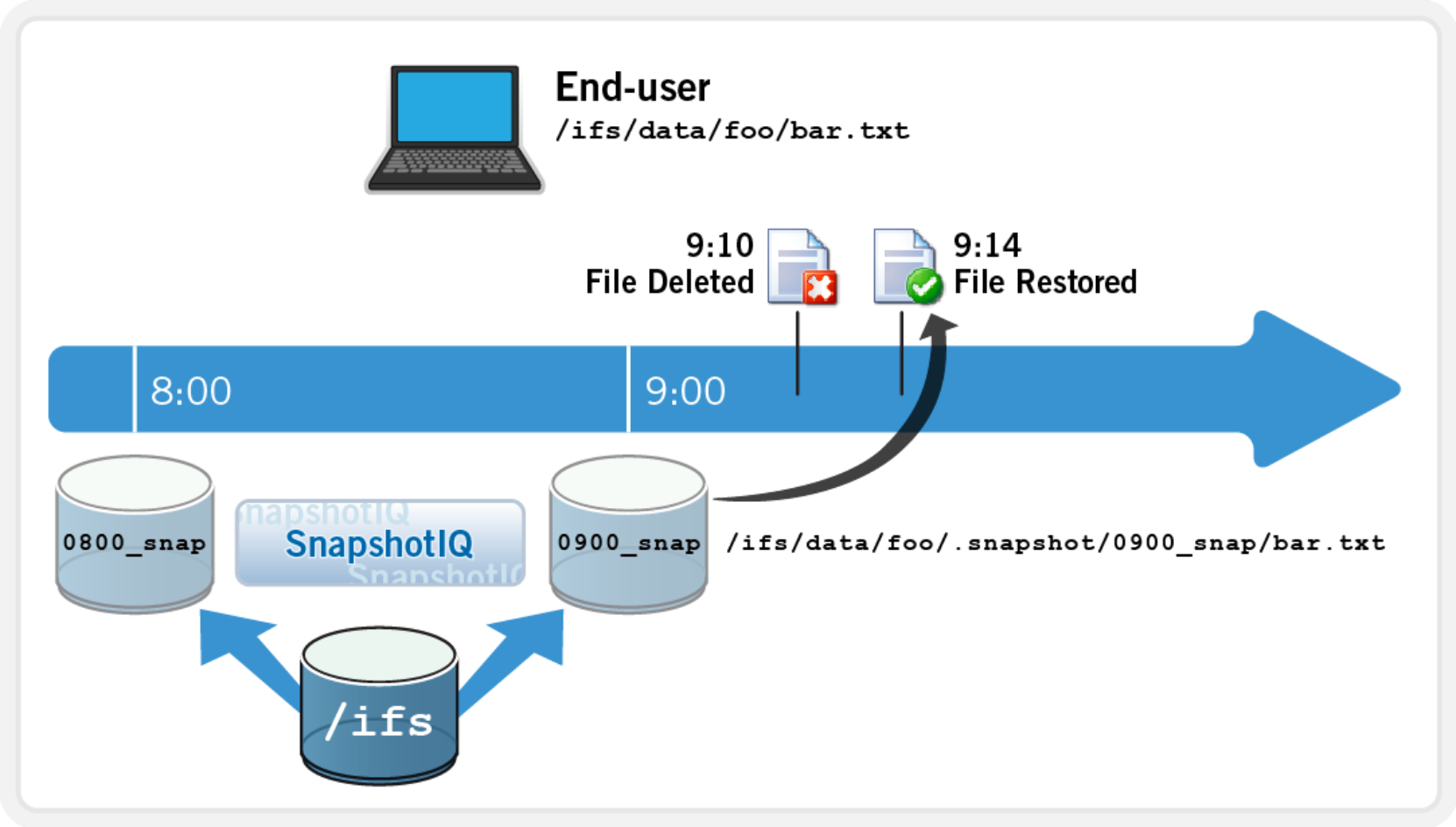
User-driven file recovery with SnapshotIQ
OneFS Snapshots are highly scalable and typically take less than one second to create. They create little performance overhead, regardless of the level of activity of the file system, the size of the file system, or the size of the directory being copied. Also, only the changed blocks of a file are stored when updating the snapshots, thereby ensuring highly efficient snapshot storage utilization. User access to the available snapshots is through a /.snapshot hidden directory under each file system directory.
SnapshotIQ can also create unlimited snapshots on a cluster. This provides a substantial benefit over most other snapshot implementations because the snapshot intervals can be far more granular and so offer improved RPOs.
Snapshot architecture
SnapshotIQ has several fundamental differences as compared to most snapshot implementations. The most significant of these are, first, that OneFS snapshots are per-directory based. This is in contrast to the traditional approach, where snapshots are taken at a file system or volume boundary. Second, since OneFS manages and protects data at the file-level, there is no inherent, block-level indirection layer for snapshots to use. Instead, OneFS takes copies of files, or pieces of files (logical blocks and inodes) in a logical snapshot process.
The process of taking a snapshot in OneFS is relatively instantaneous. However, there is a small amount of snapshot preparation work that has to occur. First, the coalescer is paused and any existing write caches flushed in order for the file system to be quiesced for a short time. Next, a marker is placed at the top-level directory inode for a particular snapshot and a unique snapshot ID is assigned. Once this has occurred, the coalescer resumes and writes continue as normal. Therefore, the moment a snapshot is taken, it essentially consumes zero space until file creates, delete, modifies, and truncates start occurring in the structure underneath the marked top-level directory.
Any changes to a dataset are then recorded in the pertinent snapshot inodes, which contain only referral (“ditto”) records, until any of the logical blocks they reference are altered, or another snapshot is taken. To reconstruct data from a particular snapshot, OneFS iterates though all the more recent versions snapshot tracking files (STFs) until it reaches HEAD (current version). In so doing, it will systematically find all the changes and “paint” the point-in-time view of that dataset.
OneFS uses both Copy on Write (CoW) and Redirect on Write (RoW) strategies for its differential snapshots and uses the most appropriate method for any given situation. Both have advantages and disadvantages, and OneFS dynamically picks the method that will maximize performance and keep overhead to a minimum. Typically, CoW is most prevalent and is primarily used for small changes, inodes, and directories. RoW is adopted for more substantial changes such as deletes and large sequential writes.
OneFS does not require reserved space for snapshots. Snapshots can use as much or little of the available file system space as desirable. A snapshot reserve can be configured if preferred, although this will be an accounting reservation rather than a hard limit. Also, when SmartPools is used, snapshots can be stored on a different disk tier than the one that the original data resides on. For example, the snapshots taken on a performance-aligned tier can be physically housed on a more cost-effective archive tier.
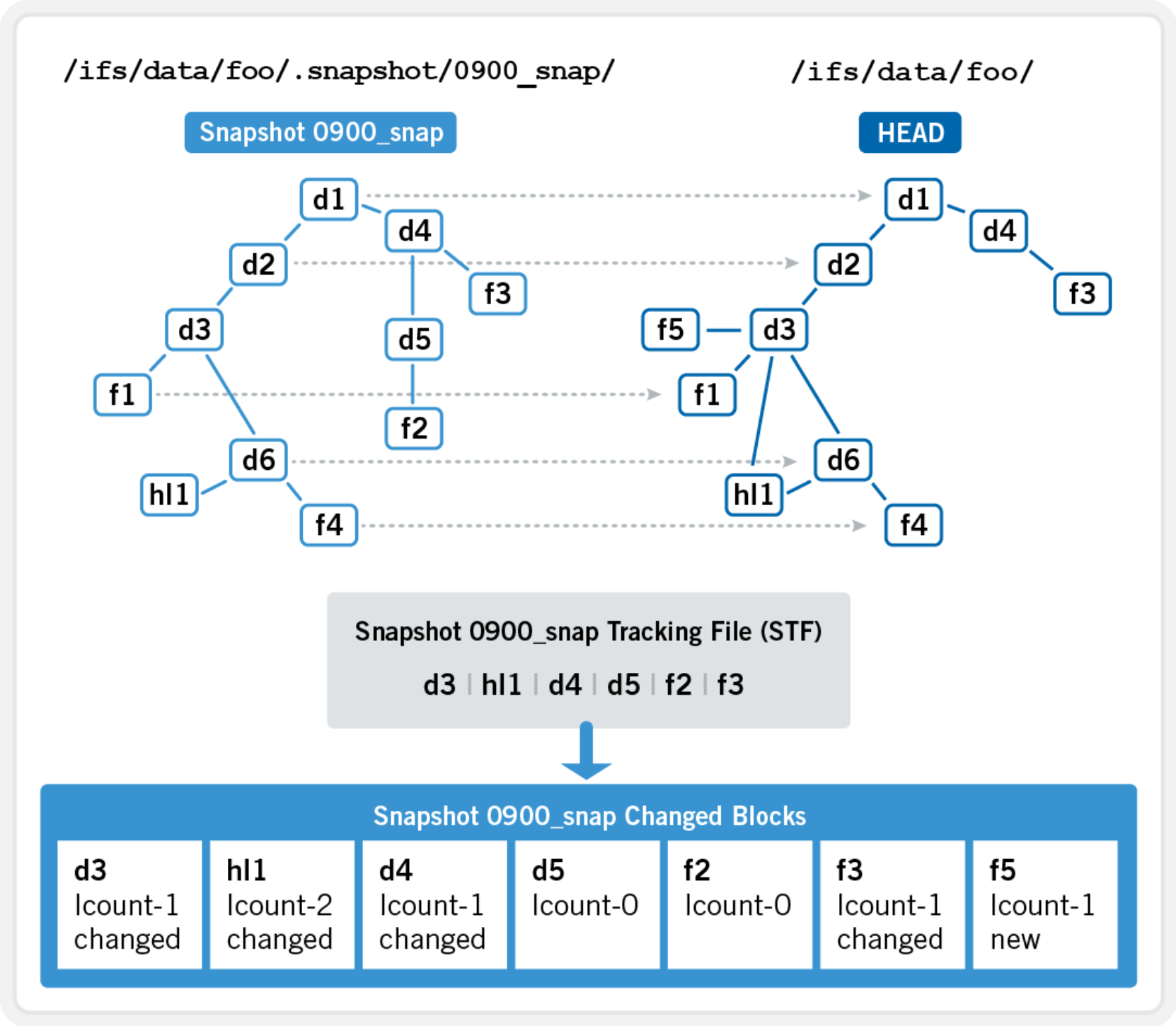
Snapshot change tracking
Snapshot scheduling
Snapshot schedules are configured at a daily, weekly, monthly, or yearly interval, with single or multiple job frequencies per schedule, down to a per-minute granularity. Automatic deletion can be configured per defined schedule at an hourly through yearly range.
Snapshot deletes
When snapshots are manually deleted, OneFS will mark the appropriate snapshot IDs and queue a Job Engine job to affect their removal. The SnapshotDelete job is queued immediately, but the Job Engine typically waits a minute or so to actually start running it. During this interval, the snapshot is marked as delete pending.
A similar procedure occurs with expired snapshots. Here, the snapshot daemon is responsible for checking expiration of snapshots and marking them for deletion. The daemon performs the check every 10 seconds. The job is then queued to delete a snapshot completely, and then it is up to the Job Engine to schedule it. The job might run immediately (after a minute or so) if the Job Engine determines that the job is runnable and there are no other jobs with higher priority running. For SnapshotDelete, the job is only run if the group is in a pristine state (no drives or nodes are down).
The most efficient method for deleting multiple snapshots simultaneously is to process older through newer, and SnapshotIQ will automatically attempt to orchestrate deletes in this manner. A SnapshotDelete Job Engine schedule can also be defined so snapshot deletes only occur during selected times.
In summary, SnapshotIQ affords the following benefits:
- Snapshots are created at the directory-level instead of the volume-level, providing improved granularity.
- There is no requirement for reserved space for snapshots in OneFS. Snapshots can use as much or little of the available file system space as desirable.
- Integration with Windows Volume Snapshot Manager allows Windows clients a method to restore from “Previous Versions.”
- Snapshots are easily managed using flexible policies and schedules.
- Using SmartPools, snapshots can physically reside on a different disk tier than the original data.
- Up to 1,024 snapshots can be created per directory.
- The default snapshot limit is 20,000 per cluster.
Snapshot restore
For simple, efficient snapshot restoration, SnapshotIQ provides SnapRevert functionality. Using the Job Engine for scheduling, a SnapRevert job automates the restoration of an entire snapshot to its top-level directory. This is invaluable for quickly and efficiently reverting to a previous, known-good recovery point, for example, if there is a virus or malware outbreak. Also, individual files, rather than entire snapshots, can also be restored in place using FileRevert functionality. This can help drastically simplify virtual machine management and recovery.
For more information, see the Data Protection with Dell PowerScale Snapshot IQ white paper.
File clones
OneFS File Clones provides a rapid, efficient method for provisioning multiple read/write copies of files. Common blocks are shared between the original file and clone, providing space efficiency and offering similar performance and protection levels across both. This mechanism is ideal for the rapid provisioning and protection of virtual machine files and is integrated with VMware's linked cloning and block and file storage APIs. This uses the OneFS shadow store metadata structure, which can reference physical blocks, references to physical blocks, and nested references to physical blocks.
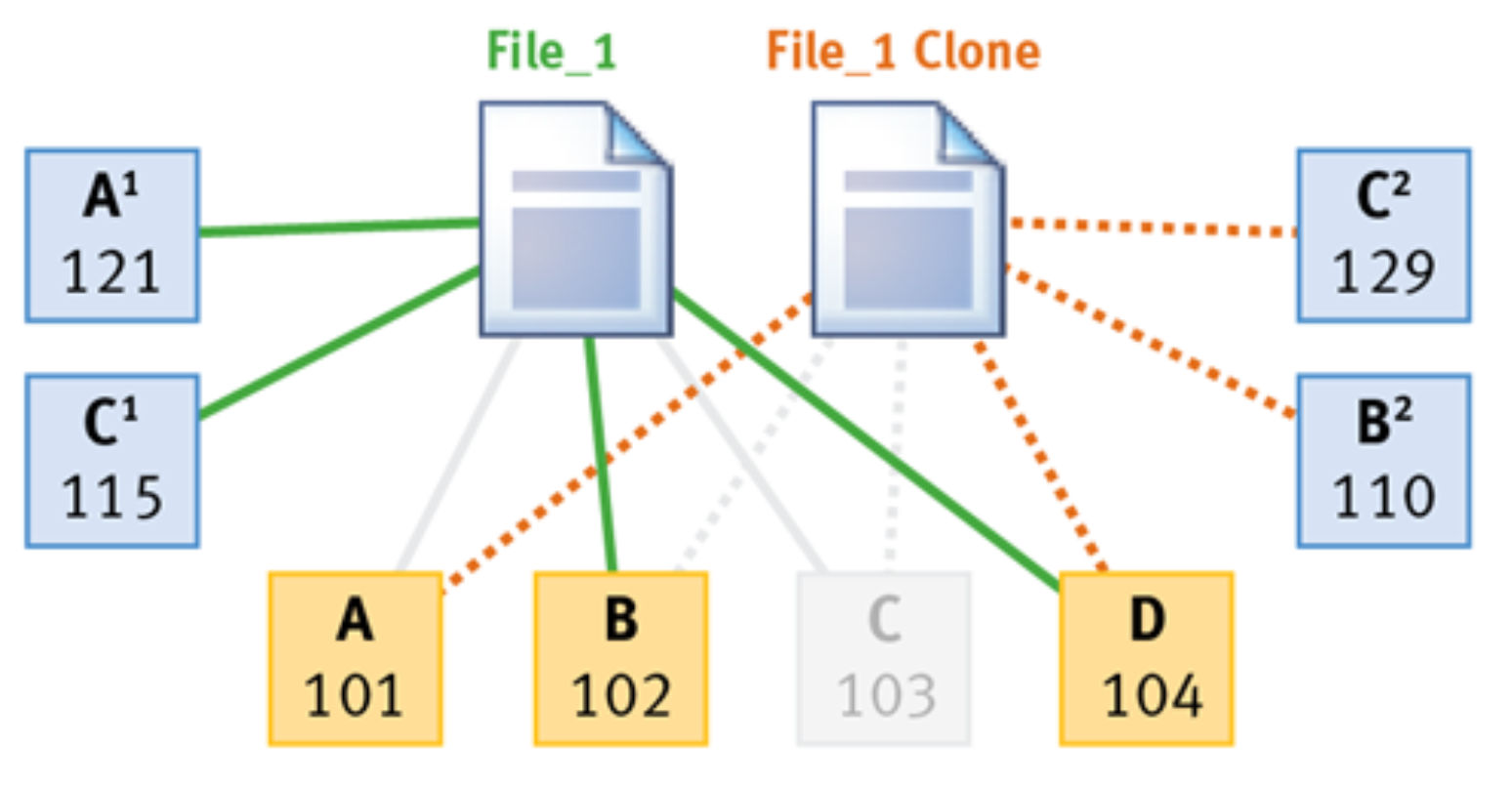
File clones