

Assets

Hybrid Kubernetes Clusters with PowerStore CSI
Fri, 26 Apr 2024 17:47:47 -0000
|Read Time: 0 minutes
In today’s world and in the context of Kubernetes (K8s), hybrid can mean many things. For this blog I am going to use hybrid to mean running both physical and virtual nodes in a K8s cluster. Often, when we think of a K8s cluster of multiple hosts, there is an assumption that they should be the same type and size. While that simplifies the architecture, it may not always be practical or feasible. Let’s look at an example of using both physical and virtual hosts in a K8s cluster.
Necessity is the mother of invention
When you need to get things done, often you will find a way to do it. This happened on a recent project at Dell Technologies where I needed to perform some storage testing with Dell PowerStore on K8s, but I didn’t have enough physical servers in my environment for the control plane and the workload. I knew that I wanted to run my performance workload on my physical servers and knowing that the workload of the control plane would be light, I opted to run them on virtual machines (VMs). The additional twist is that I also wanted additional worker nodes, but I didn’t have enough physical servers for everything. The goal was to run my performance workload on physical servers and allow everything else to run on VMs.
Dell PowerStore CSI to the rescue!
My performance workload that I am running on physical hosts was also using Fibre Channel storage. This adds a bit of a twist for workloads running on virtual machines if I were to present the storage uniformly to all the hosts. However, using the features of Dell PowerStore CSI and Kubernetes, I don’t need to do that. I can simply present Dell PowerStore storage with Fibre Channel to my physical hosts and run my workload there.
The following is a diagram of my infrastructure and key components. There is one physical server running VMware ESXi that hosts several VMs used for K8s nodes, and then three other physical servers that run as physical nodes in the cluster.
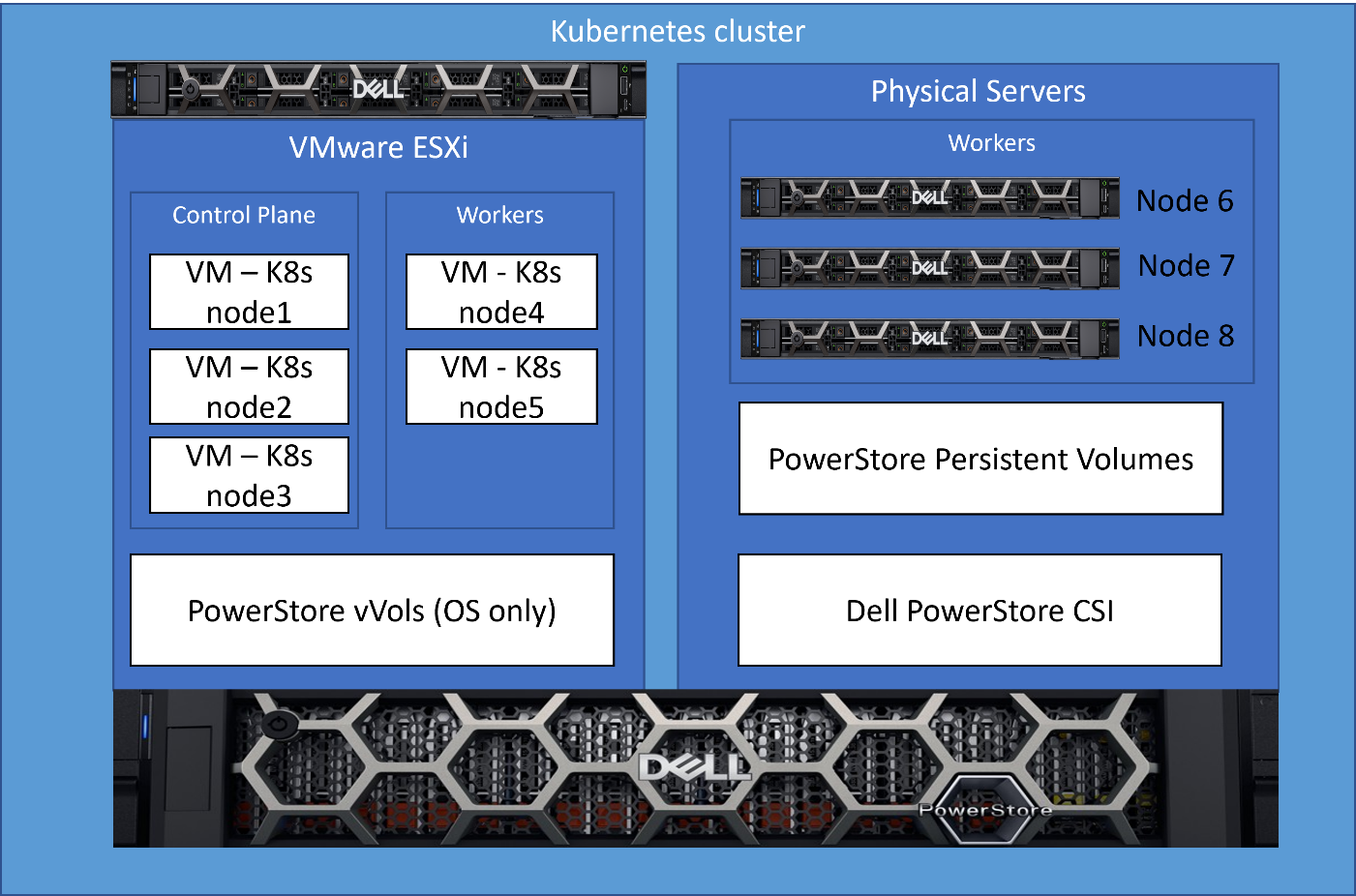
What kind of mess is this?!?
As the reader, you’re probably thinking…what kind of hodge-podge maintenance nightmare is this? I have K8s nodes that aren’t all the same and then some hacked up solution to make it work?!? Well, it’s not a mess at all, allow me to explain how it’s quite simple and elegant.
For those new to K8s, implementing something like this probably seems very complicated and hard to manage. After all, the workload should only run on the physical K8s nodes that are connected though Fiber Channel. Outside of K8s, Dell CSI, and the features they provide, it likely would be a mess of scripting and dependency checking.
An elegant solution!
In this solution I leveraged the labels and scheduling features of K8s with the PowerStore CSI features to implement a simple solution to accomplish this. This implementation is very clean and easy to maintain with no complicated scripts or configuration to maintain.
Step 1 – PowerStore CSI Driver configuration
As part of the PowerStore CSI driver configuration, one of the supported features (node selection) is the ability to select the nodes on which the K8s pods (in this case the CSI driver) will run, by using K8s labels. In the following figure, in the driver configuration, I specify that the PowerStore CSI driver should only run on nodes that contain the label “fc=true”. The label itself can contain any value; the key is that this value must match in a search.
The following is an excerpt from the Dell PowerStore CSI configuration file showing how this is done.
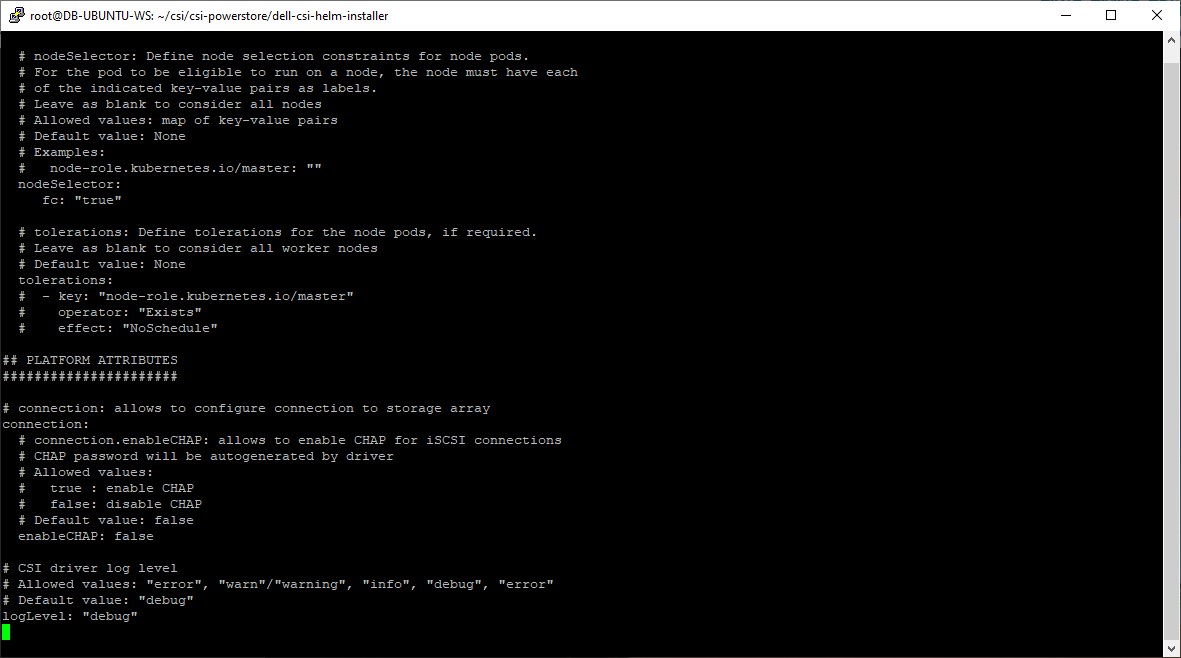
This is a one-time configuration setting that is done during Dell CSI driver deployment.
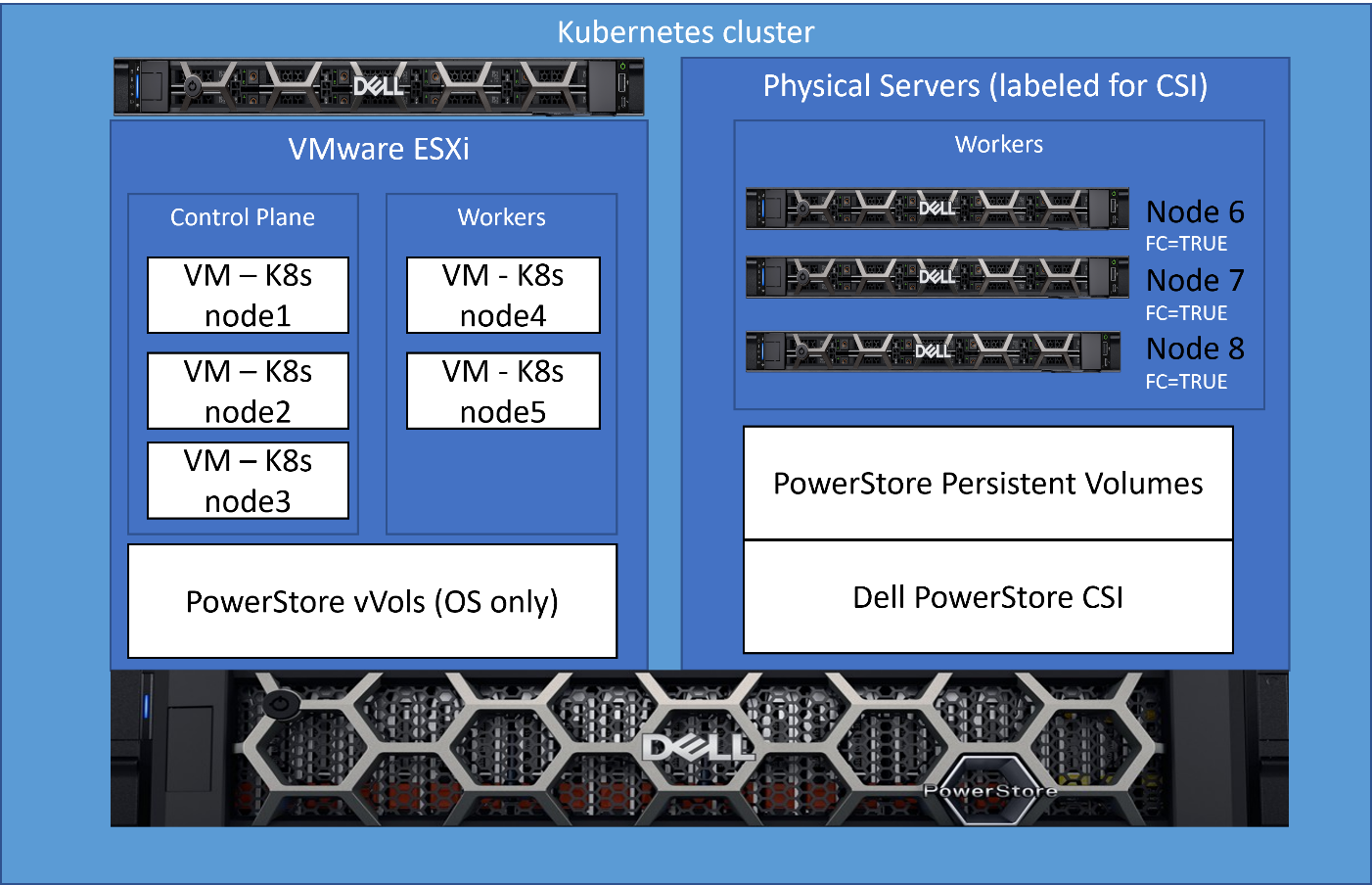
Step 2 – Label the physical nodes
The next step is to apply a label “fc=true” to the nodes that contain a Fibre Channel configuration on which we want the node to run. It’s as simple as running the command “kubectl label nodes <your-node-name> fc=true”. When this label is set, the CSI driver pods will only run on K8s nodes that contain this label value.
This label only needs to be applied when adding new nodes to the cluster or if you were to change the role of this node and remove it from this workload.
Step 3 – Let Kubernetes do its magic
Now, I leverage basic K8s functionality. Kubernetes resource scheduling evaluates the resource requirements for a pod and will only schedule on the nodes that meet those requirements. Storage volumes provided by the Dell PowerStore CSI driver are a dependency for my workload pods, and therefore, my workload will only be scheduled on K8s nodes that can meet this dependency. Because I’ve enabled the node selection constraint for the CSI driver only on physical nodes, they are the only nodes that can fill the PowerStore CSI storage dependency.
The result of this configuration is that the three physical nodes that I labeled are the only ones that will accept my performance workload. It’s a very simple solution that requires no complex scripting or configuration.
Here is that same architecture diagram showing the nodes that were labeled for the workload.
Kubernetes brings lots of exciting new capabilities that can provide elegant solutions to complex challenges. Our latest collaboration with Microsoft utilized this architecture. For complete details, see our latest joint white paper: Dell PowerStore with Azure Arc-enabled Data Services which highlights performance and scale.
Also, for more information about Arc-enabled SQL Managed Instance and PowerStore, see:
- the Microsoft blog post: Performance benchmark of Azure Arc-enabled SQL Managed Instance
- the Microsoft digital events Microsoft Build and Azure Hybrid, Multicloud, and Edge Day
Author: Doug Bernhardt
Sr. Principal Engineering Technologist

Dell Technologies Has the Storage Visibility You’re Looking For!
Fri, 26 Apr 2024 17:42:19 -0000
|Read Time: 0 minutes
It’s no secret that high-performance storage is crucial for demanding database workloads. Database administrators (DBAs) work diligently to monitor and assess all aspects of database performance -- and storage is a top priority. As database workloads grow and change, storage management is critical to meeting SLAs.
How do you manage what you can’t see?
As a former DBA, one of the challenges that I faced when assessing storage performance and troubleshooting storage latency was determining root cause. Root cause analysis requires an end-to-end view to collect all data points and determine where the problem lies. It’s like trying to find a water leak, you must trace the route from beginning to end.
This becomes more complicated when you replace a single disk drive with a drive array or modern storage appliances. The storage is no longer part of the host, so from an operating system (OS) perspective, storage visibility is lost beyond the host. Popular third party monitoring tools don’t solve the problem because they don’t have access to that information either. This is where the finger pointing begins between storage administrators and DBAs because neither has access (or understanding) of the other side.
Stop the finger pointing!
Dell Technologies heard the need to provide end-to-end storage visibility and we have listened. Kubernetes brings a lot of production-grade capabilities and frameworks, and we are working to leverage these wherever possible. One of these is storage visibility, or observability. Now, everyone who works with Kubernetes (K8s) can view end-to-end storage metrics on supported Dell Storage appliances! DBAs, storage administrators, and developers can now view the storage metrics they need, track end-to-end performance, and communicate effectively.
How does it work?
The Dell Container Storage Module (CSM) for Observability is an OpenTelemetry agent that provides volume-level metrics for Dell PowerStore and other Dell storage products. The Dell CSM for Observability module leverages Dell Container Storage Interface (CSI) drivers to communicate with Dell storage. Metrics are then collected from the storage appliance and stored in a Prometheus database for consumption by popular monitoring tools that support a Prometheus data source such as Grafana. Key metrics collected by CSM observability include but are not limited to:
- Storage pool consumption by CSI Driver
- Storage system I/O performance by Kubernetes node
- CSI Driver positioned volume I/O performance
- CSI Driver provisioned volume topology
Let’s take a look
Let’s walk through a quick end-to-end example. A familiar display from SQL Server Management Studio shows the files and folders that comprise our tpcc database:
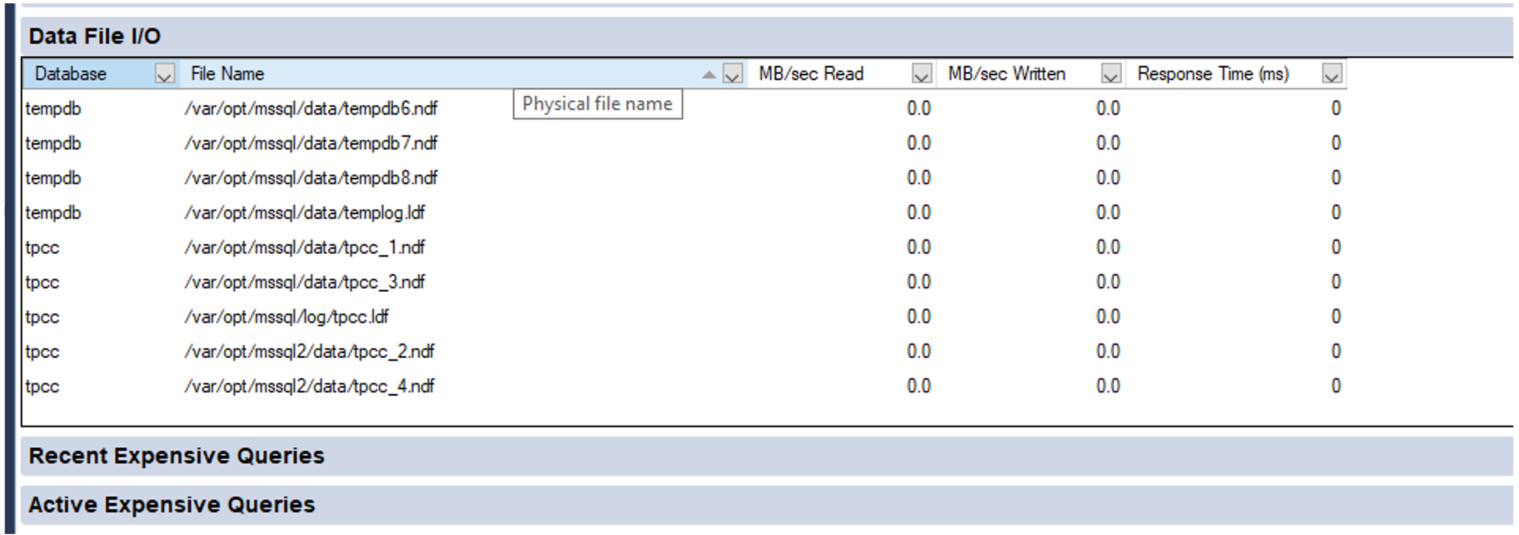
Now we need to translate that into K8s storage terms. Using meaningful naming standards for Persistent Volume Claims will negate a lot of this process, but it’s good to know how it all ties together!
A SQL Server pod will contain one or more Persistent Volume Claims (unless you don’t want to persist data 😊). These represent storage volumes and are presented to the SQL Server instance as a mount point.
The following example shows the deployment definition for our SQL Server pod with one of the mount points and Persistent Volume Claims highlighted. By examining the pod deployment, we can see that the folder/mount point /var/opt/mssql presented to SQL Server is tied to the K8s volume mssqldb and the underlying persistent volume claim mssql-data.
apiVersion: apps/v1 kind: Deployment metadata: name: mssql-deployment spec: replicas: 1 selector: matchLabels: app: mssql template: metadata: labels: app: mssql spec: terminationGracePeriodSeconds: 30 hostname: mssqlinst securityContext: fsGroup: 10001 containers: - name: mssql image: mcr.microsoft.com/mssql/server:2019-latest ports: - containerPort: 1433 resources: limits: cpu: "28" memory: "96Gi" requests: cpu: "14" memory: "48Gi" env: - name: MSSQL_PID value: "Developer" - name: ACCEPT_EULA value: "Y" - name: SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: SA_PASSWORD volumeMounts: - name: mssqldb mountPath: /var/opt/mssql - name: mssqldb2 mountPath: /var/opt/mssql2 - name: mssqllog mountPath: /var/opt/mssqllog volumes: - name: mssqldb persistentVolumeClaim: claimName: mssql-data - name: mssqldb2 persistentVolumeClaim: claimName: mssql-data2 - name: mssqllog persistentVolumeClaim: claimName: mssql-log
Following that example, you can see how the other Persistent Volume Claims, mssql-data2 and mssql-log are used by the SQL Server database files. The following figure shows one of the Grafana dashboards that makes it easy to tie the Persistent Volume Claims for the mssql-data, mssql-data2, and mssql-log used by the SQL Server pod to the Persistent Volume name.
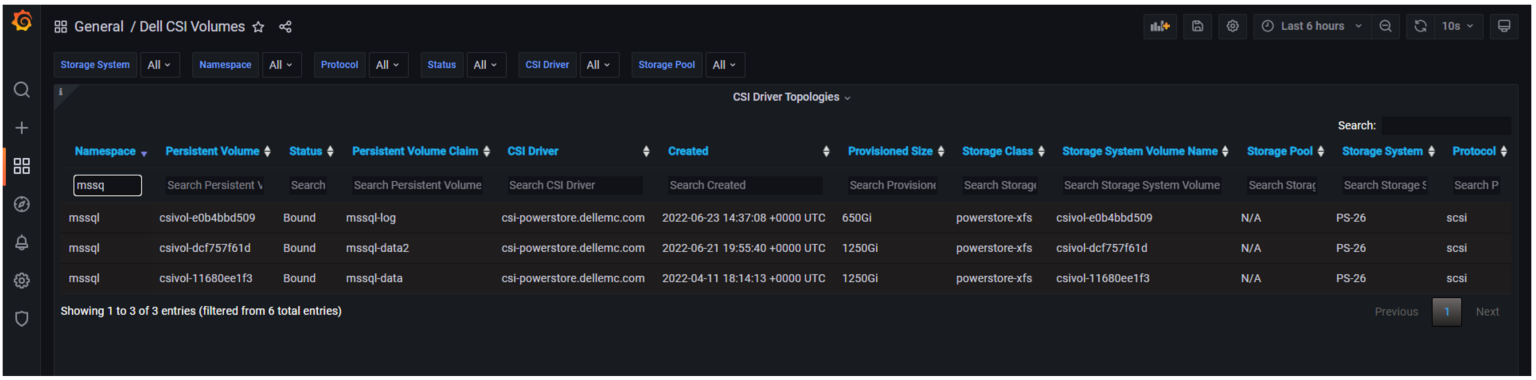
From here, we can use the Persistent Volume name associated with the Persistent Volume Claim to view metrics on the storage appliance, or better yet, in another Grafana dashboard.
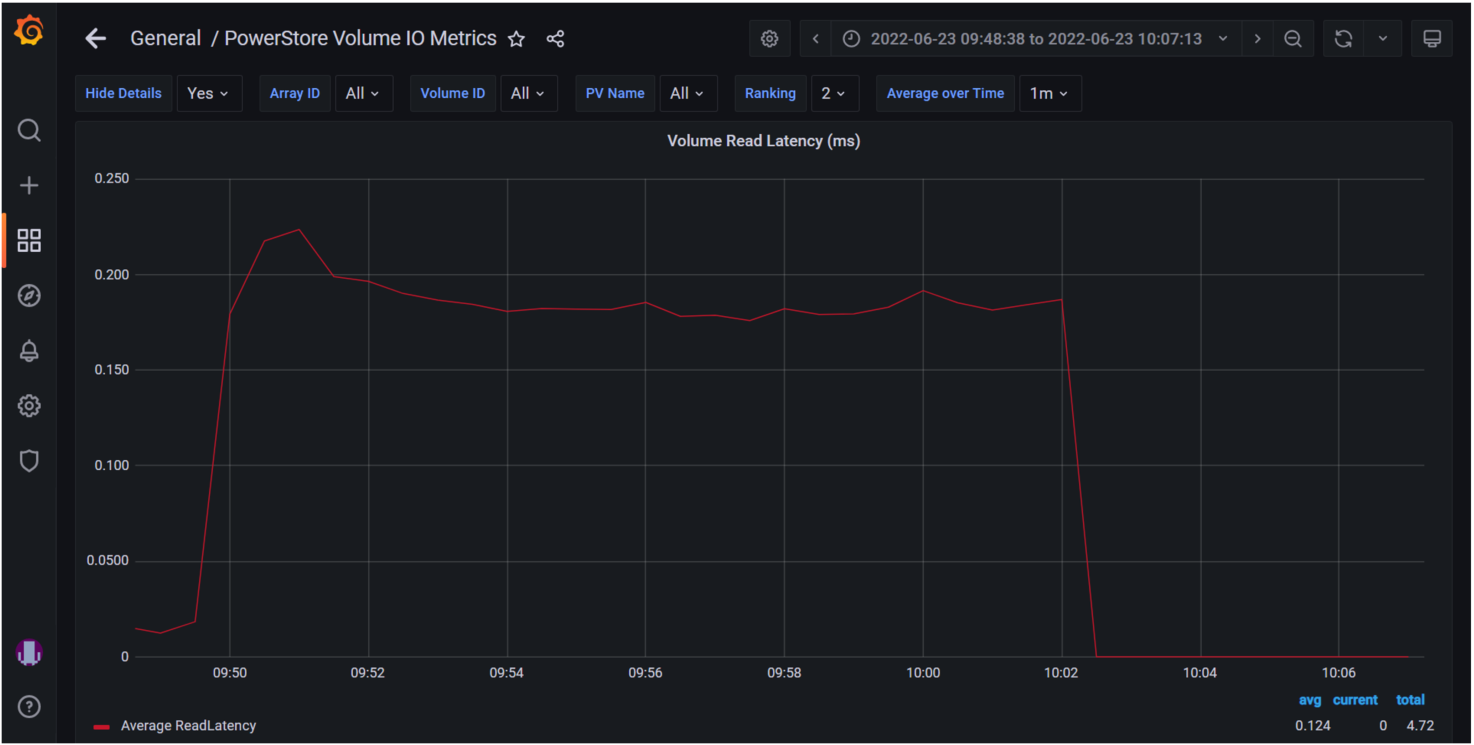
The following example shows the PowerStore Volume I/O Metrics dashboard. The key storage metrics (IOPS, latency, and bandwidth) are displayed as reported by the Dell PowerStore storage appliance.

You can select any of the charts for expanded viewing. The Volume Read Latency chart is selected below.
Rapid Adoption
These Kubernetes frameworks are becoming popular, and adoption is happening rapidly. Microsoft SQL Server Big Data Clusters and their latest offering Azure Arc-enabled SQL Managed Instance both display SQL statistics in Grafana as well. This allows single pane of glass viewing for all your key SQL metrics!

Kubernetes and cloud-native design are here to stay. They bridge the gap between cloud and on-premises deployments and the wealth of capabilities provided by K8s make it impossible to ignore.
Dell Technologies is leading the way with PowerStore capabilities as well as the full Dell portfolio of products. We are working diligently with partners such as Microsoft to prove out new technologies so you can modernize your data estate with confidence!
For more information about Azure Arc-enabled SQL Managed Instance and PowerStore, see:
- Our latest joint white paper: Dell PowerStore with Azure Arc-enabled Data Services which highlights performance and scale.
- The Microsoft blog post: “Performance benchmark of Azure Arc-enabled SQL Managed Instance.”
- The Microsoft digital events Microsoft Build and Azure Hybrid, Multicloud, and Edge Day.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist

PowerStore: The Perfect Choice for Azure Arc-enabled Data Services
Fri, 26 Apr 2024 17:37:36 -0000
|Read Time: 0 minutes
Keeping pace with technology can be tough. Often our customers’ resources are stretched thin, and they want to be confident that the solutions offered by Dell Technologies are up to the task. Dell Technologies performs an astonishing amount of work to prove out our products and give customers confidence that we have done our homework to make customers' experiences the best they can be. Additionally, we work with partners like Microsoft whenever possible to ensure that our integrations are world class as well.
Great partnership
Recently we partnered with Microsoft on one of their newest and most exciting offerings in the Microsoft Data Platform, Azure Arc-enabled SQL Managed Instance. This exciting new product deploys containerized SQL Server in a High Availability (HA) configuration on the infrastructure of your choice. This new offering allows SQL Server instances to be deployed on-premises, yet deployed through and monitored by Azure.
Dell Technologies collaborated with Microsoft to plan and perform lab testing to evaluate the performance and scale of Azure Arc-enabled SQL Managed Instance. Based on that plan, we executed several test scenarios and submitted the test configuration and results to Microsoft for review.
Dell PowerStore: the perfect storage solution
Due to the HA features of Azure Arc-enabled SQL Managed Instance, Kubernetes ReadWriteMany (RWX) storage is recommended as a backup target and a typical implementation of this is a Network File Share (NFS). Typically, this would require two storage devices, one for block (database files) and one for file (database backup), or an NFS server backed by block storage. PowerStore is uniquely suited to meet this storage requirement, offering both block and file storage in the same appliance. PowerStore also offers all-flash performance, containerized architecture, and data services such as data reduction, replication, and encryption for demanding database workloads. Dell PowerStore meets all the feature and performance requirements for Azure Arc-enabled SQL Managed Instance in a single appliance.
Incredible results
In our testing, we deployed SQL Managed Instance by means of the Azure portal onto our on-prem Kubernetes cluster and put it through its paces to assess performance and scale. The configuration that we used was not sized for maximum performance, but an average configuration that is typical of what customers order for a general-purpose workload. The results were incredible!
The slide below, presented by Microsoft at Microsoft Build 2022, summarizes it nicely!

The full Microsoft Build session where this slide was presented can be found here. Other details are covered in a Microsoft Blog Post: “Performance benchmark of Azure Arc-enabled SQL Managed Instance.” Complete details and additional benefits are covered in our co-authored whitepaper, “Dell PowerStore with Azure Arc-enabled Data Services.”
For even more background on the work Dell Technologies is doing with Microsoft to enable hybrid, multicloud, and edge solutions, see this on-demand replay of the Azure Hybrid, Multicloud, and Edge Day digital event.
We learned a lot from this project. Stay tuned for additional blogs about more of the great findings from our latest collaborative effort!
Author: Doug Bernhardt, Sr. Principal Engineering Technologist

Dell PowerStore Enables Kubernetes Stretched Clusters

Wed, 24 Apr 2024 12:50:42 -0000
|Read Time: 0 minutes
Kubernetes (K8s) is one of the hottest platforms for building enterprise applications. Keeping enterprise applications online is a major focus for IT administrators. K8s includes many features to provide high availability (HA) for enterprise applications. Dell PowerStore and its Metro volume feature can make K8s availability even better!
Enhance local availability
K8s applications should be designed to be as ephemeral as possible. However, there are some workloads such as databases that can present a challenge. If these workloads are restarted, it can cause an interruption to applications, impacting service levels.
Deploying K8s on VMware vSphere adds a layer of virtualization that allows a virtual machine, in this case a K8s node, to be migrated live (vMotion) to another host in the cluster. This can keep pods up and running and avoid a restart when host hardware changes are required. However, if those pods have a large storage footprint and multiple storage appliances are involved, storage migrations can be resource and time consuming.
Dell PowerStore Metro Volume provides synchronous data replication between two volumes on two different PowerStore clusters. The volume is an identical, active-active copy on both PowerStore clusters. This allows compute-only virtual machine migrations. Compute-only migrations occur much faster and are much more practical in most cases. Therefore, more workloads can take advantage of vMotion and availability is increased.
PowerStoreOS 3.6 introduces a witness component to the Metro Volume architecture. The functional design of the witness adds more resiliency to Metro Volume deployments and further mitigates the risk of split-brain situations. The witness enables PowerStore OS 3.6 to make intelligent decisions across a wider variety of infrastructure outage scenarios, including unplanned outages.
K8s stretched or geo clusters
Spreading an application cluster across multiple sites is a common design for increasing availability. The compute part is easy to solve because K8s will restart workloads on the remaining nodes, regardless of location. However, if the workload requires persistent storage, the storage needs to exist in the other site.
PowerStore Metro Volume solves this requirement. Metro Volume support for VMware ESXi synchronizes volumes across PowerStore clusters to meet latency and distance requirements. In addition to the enhanced vMotion experience, PowerStore Metro volume provides active-active storage to VMware VMFS datastores that can span two PowerStore clusters. For in-depth information about PowerStore Metro Volume, see the white paper Dell PowerStore: Metro Volume.
Lab testing
We tested Dell PowerStore Metro Volume with a SQL Server workload driven by HammerDB on a stretched K8s cluster running on vSphere with three physical hosts and two PowerStore clusters[1]. The K8s cluster was running Rancher RKE2 1.25.12+rke2r1 with a VMFS datastore on PowerStore Metro volume using the VMware CSI provider for storage access. We performed vMotion compute only migrations and simulated storage network outages as part of the testing.
During the testing, the synchronized active-active copy of the volume was able to assume the IO workload, maintain IO access, and keep SQL Server and the HammerDB workload online. This prevented client disconnects and reconnects, application error messages, and costly recovery time to synchronize and recover data.
After we successfully completed testing on Rancher, we pivoted to another K8s platform: a VMware Tanzu Kubernetes Cluster deployed on VMware vSphere 8 Update 1. We deployed the SQL Server and HammerDB workload and performed a number of other K8s deployments in parallel. Workload test results were consistent. When we took the PowerStore cluster that was running the workload offline, both compute and storage remained available. The result was that the containerized applications were continuously available: not only during the failover, but during the failback as well.
In our Tanzu environment, Metro Volume went beyond data protection alone. It also provided infrastructure protection for objects throughout the Workload Management hierarchy. For example, the vSphere Tanzu supervisor cluster control plane nodes, pods, Tanzu Kubernetes clusters, image registry, and content library can all be assigned a VM storage policy and a corresponding storage class which is backed by PowerStore Metro Volumes. Likewise, NSX Manager and NSX Edge networking components on Metro Volume can also take advantage of this deployment model by remaining highly available during an unplanned outage.
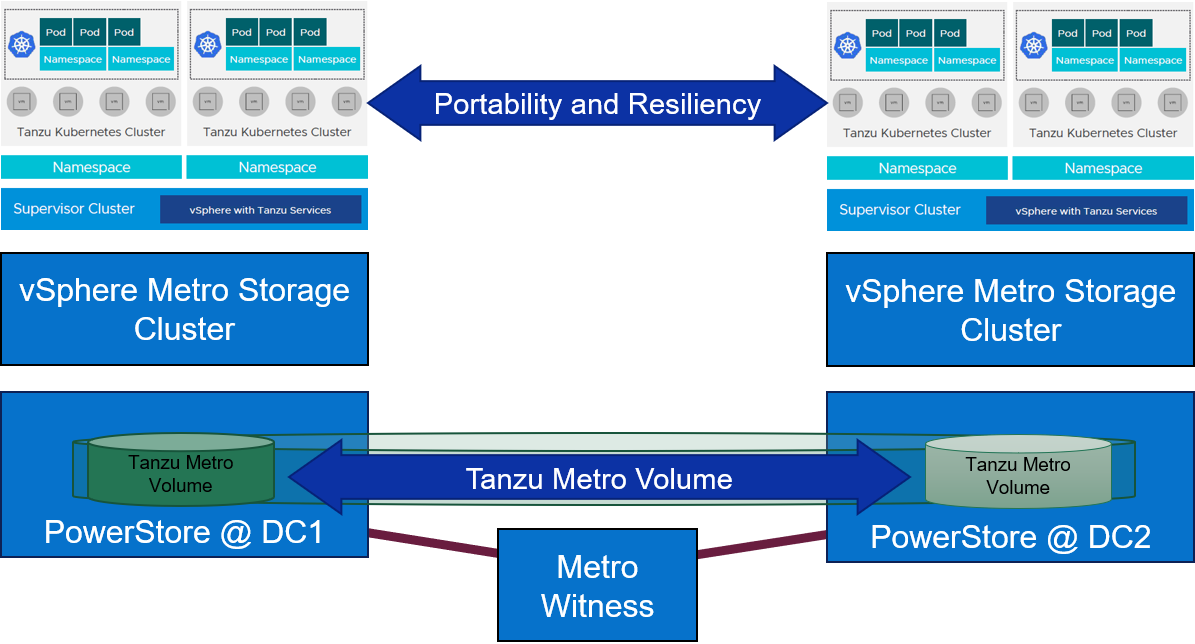
Figure 1. Metro Volume with a witness adds portability and resiliency to Tanzu deployments
For more information about PowerStore Metro Volume, increasing availability on SQL Server, and other new features and capabilities, be sure to check out all the latest information on the Dell PowerStore Info Hub page.
Authors:
Doug Bernhardt, Sr. Principal Engineering Technologist, LinkedIn
Jason Boche, Sr. Principal Engineering Technologist, LinkedIn
[1] Based on Dell internal testing, conducted in September 2023.

When Performance Testing Your Storage, Avoid Zeros!
Tue, 20 Feb 2024 17:37:42 -0000
|Read Time: 0 minutes
Storage benchmarking
Occasionally, Dell Technologies customers will want to run their own storage performance tests to ensure that their storage can meet the demands of their workload. Dell Technologies partners like Microsoft publish guidance on how to use benchmarking tools such as Diskspd to test various workloads. When running these tools on intelligent storage appliances like those offered by Dell Technologies, don’t forget to watch for how your test files are populated!
The first step in using performance benchmark tools is creating one or more test files for use when testing. The benchmark tool will then write and read data to and from these files, taking measurements to assess performance. An important detail that is often overlooked is how the test files are populated with data. If the files are not populated correctly, it can lead to misleading results and inaccurate conclusions.
We’ll use Diskspd as an example, however please note that most tools have the same default behavior. By default, when you run a Diskspd test, you need to specify several parameters, such as a test file location and size, IO block size, read/write ratio, queue depth, and so on.
If we open a test file created with default parameters and examine it with a hexadecimal editor, this is what it looks like:
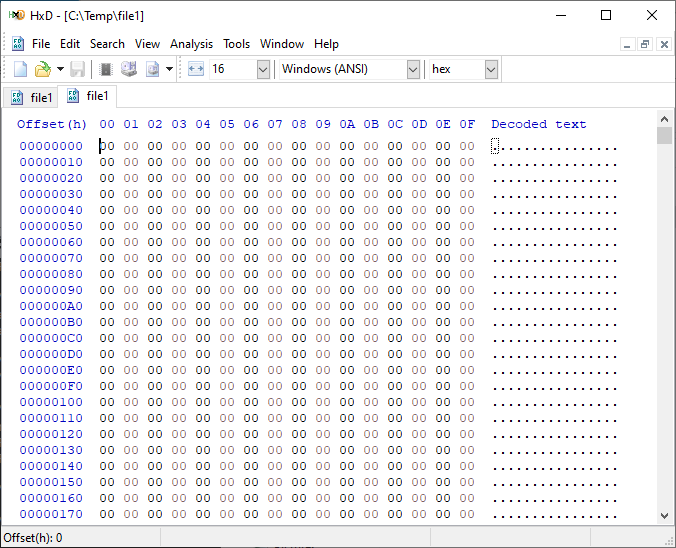
It is filled with nothing, 0x00 throughout the entire file – all “zeros”!
OK, so what is the problem?
When storage benchmarking tools create test files, they all use synthetic data for testing. This is fine when performing IO to a storage device with no “intelligence” built in because it will perform unaltered IO directly to the storage without the data content mattering. In the past, storage devices were simple and would read and write data as commanded, so the data content was irrelevant.
However, intelligent storage appliances such as those offered by Dell Technologies look at data differently. These products are built for efficiency and performance. Compression, deduplication, zero detection, and other optimizations may be used for space savings and performance. Since an empty file would obviously compress and deduplicate well, most of this IO will not access the disks in the same manner that a file of actual data would. It is also possible that other components in the data path would behave differently than normal when repeatedly presented with an identical piece of data.
It is safe to assume that these optimizations likely exist on data being stored in the cloud as well. Many cloud providers use intelligent storage appliances or have developed proprietary software to optimize storage.
The bottom line is that your test is likely inaccurate and may not represent your storage performance under more realistic conditions. While no synthetic test can reproduce a real workload 100%, you should try to make it as realistic as possible.
Mitigations
Some tools can initialize the test files with random data. Diskspd, for example, has parameters that can be added to create a buffer of random data to be used to write to the files or specify a source file of data. Regardless of the method used, you should inspect the test files to make sure that at a minimum, random data is being used. Zero-filled files and repeating patterns should be avoided.
Random data also may not achieve the expected behavior when compression and deduplication capabilities are used. More advanced testing tools such as vdbench can use target compression and deduplication capabilities independently.
Tips
Here are a few more tips when benchmarking storage performance to try to make it as realistic as possible:
- Use datasets of comparable size to real data workloads. Smaller datasets may fit entirely in the cache and skew results.
- Use IO sizes and read/write ratios that match your workload. If you are unsure of what your workload looks like, your Dell Technologies representative can assist you.
- Test with “multiples”. Intelligent storage assumes multiple files, volumes, and hosts. At a minimum, use multiple files and volumes. When testing larger block sizes, you may need to use multiple hosts and multiple host bus adapters to generate enough IO to test the full bandwidth capabilities of the storage.
- Start with a light load and scale up. Begin with one file, one worker thread, and a queue depth of one. In general, modern storage is designed for concurrency. Some amount of concurrency will be required to fully use storage system resources. As you scale up, observe the behavior. Pay attention to the measured latency. At some point as you scale the test, latency will start to increase rapidly.
- Excessive latency indicates a bottleneck. Once latencies are excessive, you have encountered a bottleneck somewhere. “Excessive” is a relative term when it comes to storage latency and is determined by your workload and business needs. Only scale the test to the point where the measured latency is within your acceptable range or above. Further increasing the test load will result in diminishing returns.
- Make sure the entire test environment can drive the wanted performance. The storage network and host configuration must be capable of desired performance levels and configured properly.
- Beware of outdated guidance. There are still articles online that are over a decade old that reference testing methods and best practices that were developed when storage was based on spinning disks. Those assumptions may be inaccurate on the latest storage devices and storage network protocols.
Summary
Storage performance benchmarking can be interesting and provide useful data points. That said, what is most important is how the storage supports actual business workloads and—most importantly—your unique workload. As such, there is no true substitute for testing with your actual workload.
Selecting the proper storage fit for your environment can be challenging, and Dell Technologies has the expertise to help. Leveraging tools like CloudIQ and LiveOptics, Dell Technologies can help you analyze your storage performance, explain storage metrics, and make recommendations to increase storage efficiency.
Author: Doug Bernhardt, Sr. Principal Engineering Technologist | LinkedIn

PowerStore validation with Microsoft Azure Arc-enabled data services updated to 1.25.0
Mon, 12 Feb 2024 20:04:34 -0000
|Read Time: 0 minutes
Microsoft Azure Arc-enabled data services allow you to run Azure data services on-premises, at the edge, or in the cloud. Arc-enabled data services align with Dell Technologies’ vision, by allowing you to run traditional SQL Server workloads on Kubernetes, on your infrastructure of choice. For details about a solution offering that combines PowerStore and Microsoft Azure Arc-enabled data services, see the white paper Dell PowerStore with Azure Arc-enabled Data Services.
Dell Technologies works closely with partners such as Microsoft to ensure the best possible customer experience. We are happy to announce that Dell PowerStore has been revalidated with the latest version of Azure Arc-enabled data services, 1.25.0.
Deploy with confidence
One of the deployment requirements for Azure Arc-enabled data services is that you must deploy on one of the validated solutions. At Dell Technologies, we understand that customers want to deploy solutions that have been fully vetted and tested. Key partners such as Microsoft understand this too, which is why they have created a validation program to ensure that the complete solution will work as intended.
By working through this process with Microsoft, Dell Technologies can confidently say that we have deployed and tested a full end-to-end solution and validated that it passes all tests.
The validation process
Microsoft haspublished tests for their continuous integration/continuous delivery (CI/CD) pipeline that partners and customers to run. For Microsoft to support an Arc-enabled data services solution, it must pass these tests. At a high level, these tests perform the following:
- Connect to an Azure subscription provided by Microsoft.
- Deploy the components for Arc-enabled data services, including SQL Managed Instance, using both direct and indirect connect modes.
- Validate Kubernetes (K8s), hosts, storage, container storage interface (CSI), and networking.
- Run Sonobuoy tests ranging from simple smoke tests to complex high-availability scenarios and chaos tests.
- Upload results to Microsoft for analysis.
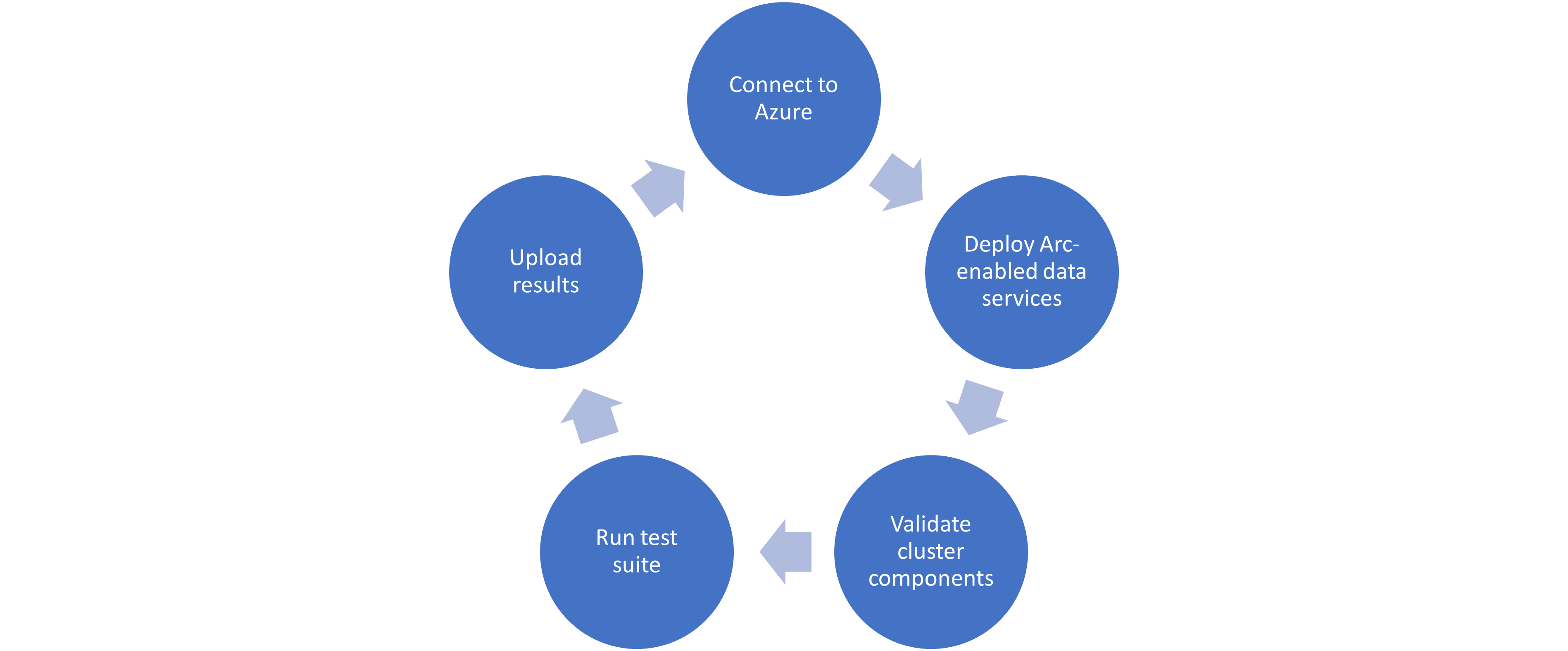
When Microsoft accepts the results, they add the new or updated solution to their list of validated solutions. At that point, the solution is officially supported. This process is repeated as needed as new component versions are introduced. Complete details about the validation testing and links to the GitHub repositories are available here.
More to come
Stay tuned for more additions and updates from Dell Technologies to the list of validated solutions for Azure Arc-enabled data services. Dell Technologies is leading the way on hybrid solutions, proven by our work with partners such as Microsoft on these validation efforts. Reach out to your Dell Technologies representative for more information about these solutions and validations.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist

PowerStore and SQL Server Ledger—Your Data Has Never Been More Secure!
Thu, 10 Aug 2023 17:49:01 -0000
|Read Time: 0 minutes
It’s all about security
Dell and Microsoft are constantly working together to provide the best security, availability, and performance for your valuable data assets. In the latest releases of PowerStoreOS 3.5 and SQL Server 2022, several new capabilities have been introduced that provide zero trust security for data protection.
PowerStore security
PowerStoreOS is packed with security features focused on secure platform, access controls, snapshot, auditing, and certifications. PowerStoreOS 3.5 introduces the following new features:
- STIG (Security Technical Implementation Guides) hardening, which enforces U.S. Department of Defense (DoD) specific rules regarding password complexity, timeout policies, and other practices.
- Multi-factor authentication to shield from hackers and mitigate poor password policies.
- Secure snapshots to prevent snapshots from being modified or deleted before the expiration date, even by an administrator.
- PowerProtect DD integration to create snapshots directly on Dell PowerProtect DD series appliances. The PowerStore Zero Trust video explains these features in more detail.
To enhance database security, Microsoft has introduced a new feature in SQL Server 2022, SQL Ledger. This feature leverages cryptography and blockchain architecture to produce a tamper-proof ledger of all changes made to a database over time. SQL Ledger provides cryptographic proof of data integrity to fulfill auditing requirements and streamline the audit process.
SQL Ledger 101
There are two main storage components to SQL Ledger. First is the database with special configuration that leverages blockchain architecture for increased security. The database resides on standard block or file storage. PowerStore supports both block and file storage, making it ideal for SQL Ledger deployments.
The second is an independently stored ledger digest that includes hash values for auditing and verification. The ledger digest is used as an append-only log to store point-in-time hash values for a ledger database. The ledger digest can then be used to verify the integrity of the main database by comparing a ledger block ID and hash value against the actual block ID and hash value in the database. If there is a mismatch, then some type of corruption or tampering has taken place.
This second component, the ledger digest, requires Write Once Read Many (WORM) storage. PowerStore File-Level Retention (FLR) features can be configured to provide WORM storage for SQL Ledger. Additionally, PowerStore FLR can also be configured to include a data integrity check to detect write-tampering that complies with SEC rule 17a-4(f).
Automatic storage and generation of database digests is only available for Microsoft Azure Storage. For on-premises deployments of SQL Server, Dell Technologies has your back! Let’s look at how this is done with PowerStore.
PowerStore configuration
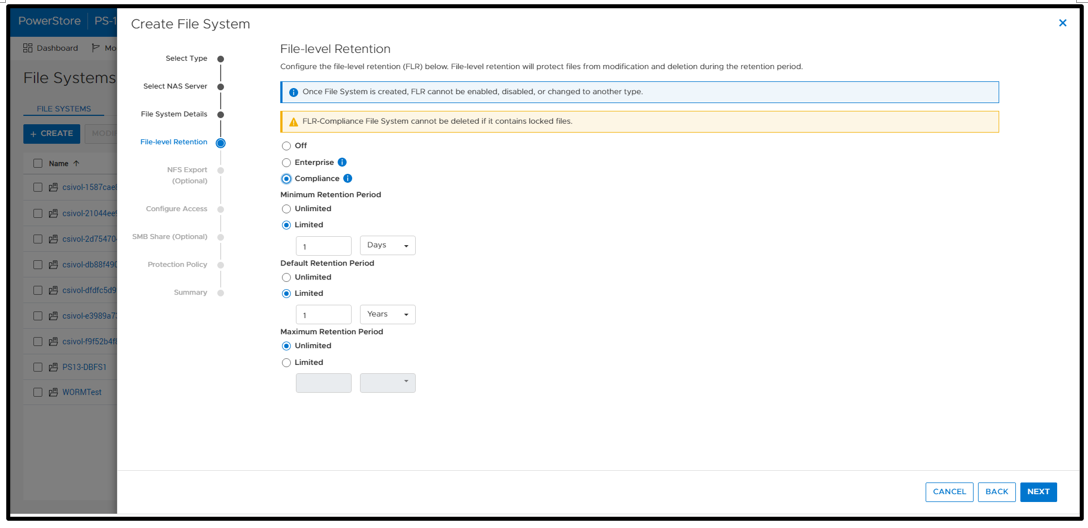
It’s time to deep dive into how to configure this capability with Dell PowerStore and how to implement SQL Ledger. First, we need to configure the basis for WORM storage on PowerStore for the digest portion of SQL Ledger. This is done by creating a file system that is configured for FLR. Due to the write-once feature, this is typically a separate dedicated system. PowerStore supports multiple file systems on the same appliance, so dedicating a separate file system to WORM is not an issue.
WORM functionality is implemented by configuring PowerStore FLR. You have the option of FLR-Enterprise (FLR-E) or FLR-Compliance (FLR-C). FLR-C is the most restrictive.
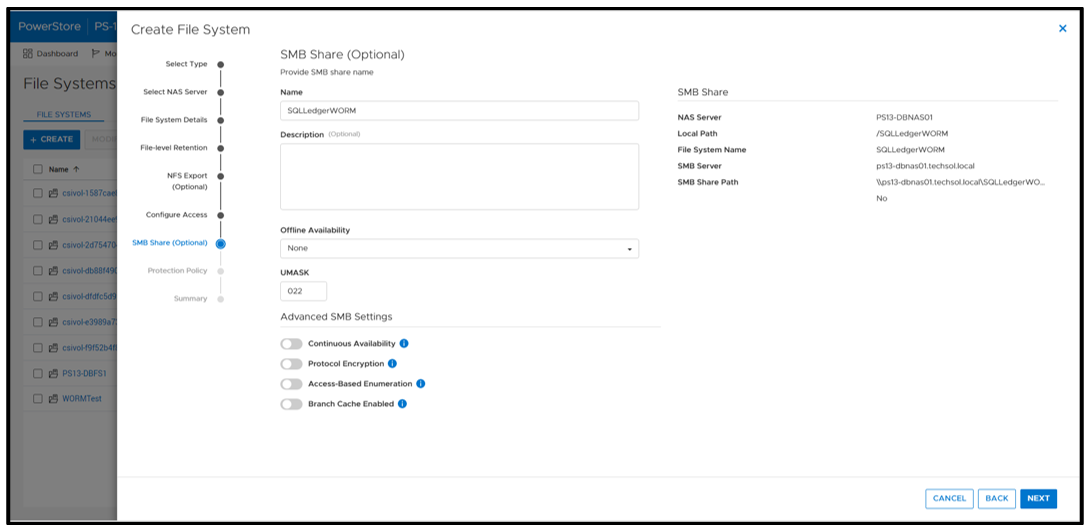
Next, configure an SMB (Server Message Block) Share for SQL Server to access the files. The settings here can be configured as needed; in this example, I am just using the defaults.
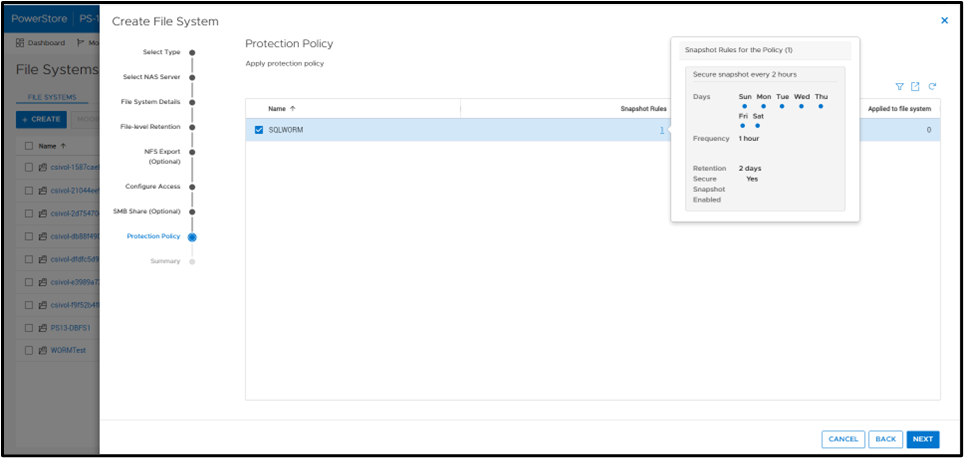
A best practice is to apply a protection policy. In this case, I am selecting a protection policy that has secure snapshot enabled. This will provide additional copies of the data that cannot be deleted prior to the retention period.
SQL Server database ops
Once the file system has been created, you can create a SQL Server database for ledger tables. Only ledger tables can exist in a ledger database. Therefore, it is common to create a separate database.
Database creation
The T-SQL CREATE DATABASE clause WITH LEDGER=ON indicates that it is a ledger database. Using a database name of SQLLedgerDemo, the most basic TSQL syntax would be:
CREATE DATABASE [SQLLedgerDemo] WITH LEDGER = ON
Ledger requires snapshot isolation to be enabled on the database with the following T-SQL command:
ALTER DATABASE SQLLedgerDemo SET ALLOW_SNAPSHOT_ISOLATION ON
Now that the database has been created, you can create either updatable or append-only ledger tables. These are database tables enhanced for SQL Ledger. Creating ledger tables is storage agnostic, so I am going to skip over it for brevity, but full instructions can be found in the Microsoft ledger documentation.
SQL Server ledger digest storage
The next step is to create the tamperproof database digest storage. This is where the verified block address and hash will be stored with a timestamp. The PowerStore file system that we just created will be used to fill this WORM storage device requirement. For it to operate correctly, we want to configure an append-only file. Because Windows does not have the ability to easily set this property, we can signal the PowerStore file system with FLR enabled that a file should be treated as append only.
First, create an empty file. This can be done in Windows File Explorer by right-clicking New and selecting Text Document. Next, right-click the file and select Properties. Select the Read-only attribute, click Apply, and then clear the Read-only attribute, click Apply, and then click OK.
Note: This action must be done on an empty file. It will not work once the file has been written to.
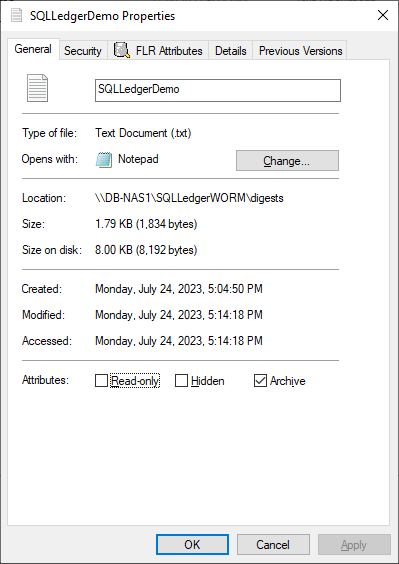
Notice that the dialog has an FLR Attributes tab. This is installed with the Dell FLR Toolkit and provides additional options not available in Windows, such as setting a file retention. Below we can also see that the FLR State of the file is set to Append-Only.
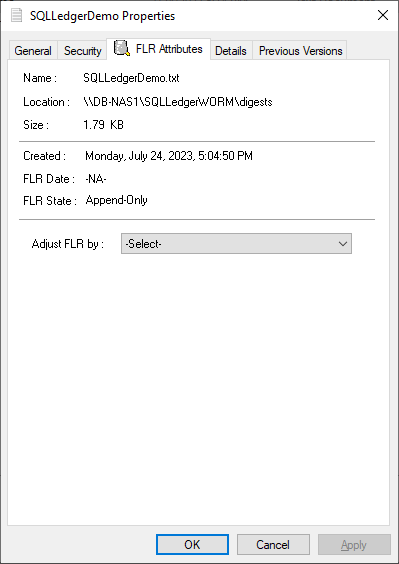
The FLR Toolkit can be downloaded from the Dell Support site. In addition to providing the ability to view the PowerStore FLR state, the FLR toolkit contains an FLR Explorer as well as additional command-line utilities.
The SQLLedgerDemo.txt file is now in the WORM state for SQL ledger digest storage: It is locked for delete and update, and can only be read or appended to.
For those of you running SQL Server on Linux, the process is the same to create the append only file. Create an empty file and then use the chmod command to remove and then reapply write permissions.
Before we get into populating the digest file, let’s understand what is being logged and how it is used. The digest file SQLLedgerDemo.txt will be populated by the output of a SQL Server stored procedure.
SQL Server ledger digest generation
Running the stored procedure sp_generate_database_ledger_digest on a ledger database produces the block ID and hash for our database verification. In this example, the output is:
{"database_name":"SQLLedgerDemo","block_id":0,"hash":"0xB222F775C84DC77BBA98B3C0E4E163484518102A10AE6D6DF216AFEDBD6D02E2","last_transaction_commit_time":"2023-07-24T13:52:20.3166667","digest_time":"2023-07-24T23:17:24.6960600"}This stored procedure is then run at regular intervals to produce a timestamped entry that can be used for validation.
SQL Server ledger digest verification
Using this info, another stored procedure, sp_verify_database_ledger, will recompute the hash for the given block ID to see if they match using the preceding output. You validate the block by passing in a previously generated digest to the stored procedure:
sp_verify_database_ledger N'{"database_name":"SQLLedgerDemo","block_id":0,"hash":"0xB222F775C84DC77BBA98B3C0E4E163484518102A10AE6D6DF216AFEDBD6D02E2","last_transaction_commit_time":"2023-07-24T13:52:20.3166667","digest_time":"2023-07-24T23:17:24.6960600"}'If it returns 0, there is a match; otherwise, you receive the following errors. You can verify this by modifying the hash value and calling sp_verify_database_ledger again, which will produce these errors.
Msg 37368, Level 16, State 1, Procedure sp_verify_database_ledger, Line 1 [Batch Start Line 10] The hash of block 0 in the database ledger does not match the hash provided in the digest for this block. Msg 37392, Level 16, State 1, Procedure sp_verify_database_ledger, Line 1 [Batch Start Line 10] Ledger verification failed.
Automating ledger digest generation and validation
Using these stored procedures, you put an automated process in place to generate a new ledger digest, append it to the file created above, and then verify that there is a match. If there is not a match, then you can go back to the last entry in the digest to determine when the corruption or tampering took place. If you're following the SQL Server Best Practices for PowerStore, you're taking regular snapshots of your database to enable fast point-in-time recovery. Because Dell PowerStore snapshots are secure and immutable, they serve as a fast recovery point, adding an additional layer of protection to critical data.
Because the generation and validation is driven with SQL Server stored procedures, automating the process using your favorite tools is extremely easy. Pieter Vanhove at Microsoft wrote a blog post, Ledger - Automatic digest upload for SQL Server without Azure connectivity, about how to automate the digest generation and verification using SQL Agent. The blog post contains sample scripts to create SQL Server Agent jobs to automate the entire process!
Summary
Your data can never be too secure. PowerStore secure snapshot capabilities add an additional another layer of security to any database. PowerStore FLR capabilities and SQL Server Ledger can be combined to further secure your database data and achieve compliance with the most stringent security requirements. Should the need arise, PowerStore secure, immutable snapshots can be used as a fast recovery point.
Author:
Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/

Time to Rethink your SQL Backup Strategy – Part 2
Wed, 10 May 2023 15:17:38 -0000
|Read Time: 0 minutes
A while back, I wrote a blog about changes to backup/restore functionality in SQL Server 2022: SQL Server 2022 – Time to Rethink your Backup and Recovery Strategy. Now, more exciting features are here in PowerStoreOS 3.5 that provide additional options and enhanced flexibility for protecting, migrating, and recovering SQL Server workloads on PowerStore.
Secure your snapshots
Backup copies provide zero value if they have been compromised when you need them the most. Snapshot removal could happen accidentally or intentionally as part of a malicious attack. PowerStoreOS 3.5 introduces a new feature, secure snapshot, to ensure that snapshots can't be deleted prior to their expiration date. This feature is a simple checkbox on a snapshot or protection policy that protects snapshots until they expire and can't be turned off. This ensures that your critical data will be available when you need it. Secure snapshot can be enabled on new or existing snapshots. Here’s an example of the secure snapshot option on an existing snapshot.
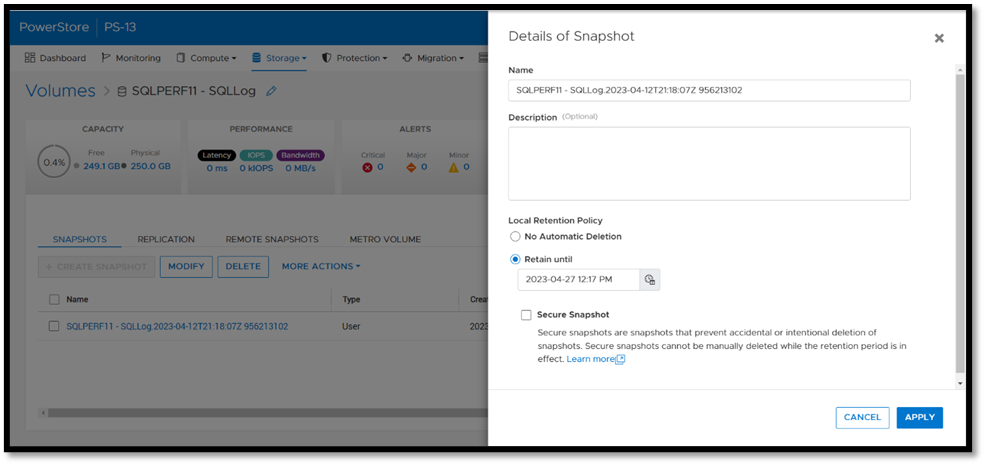
Once this option is selected, a warning is displayed stating that the snapshot can’t be deleted until the retention period expires. To make the snapshot secure, ensure that the Secure Snapshot checkbox is selected and click Apply.
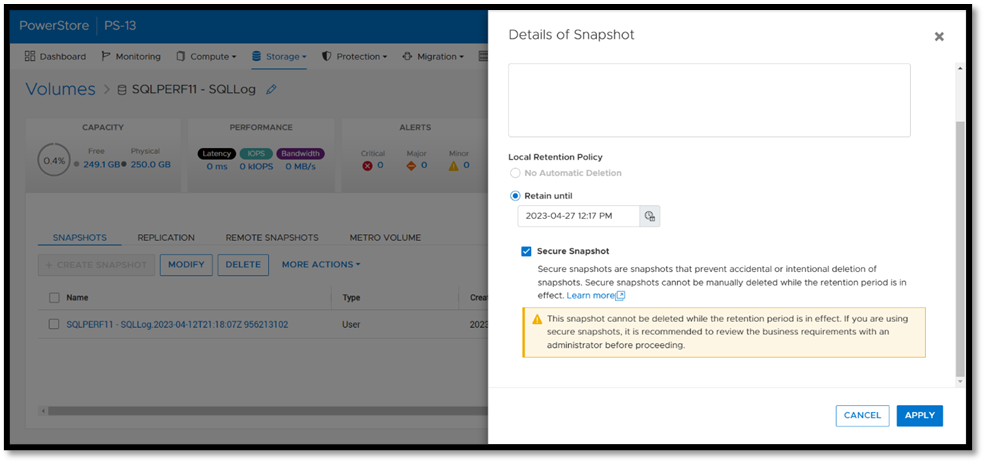
Secure snapshot can be applied to individual snapshots of volumes or volume groups. The secure snapshot option can also be enabled on one or more snapshot rules in a protection policy to ensure that snapshots taken as part of the protection policy have secure snapshot applied.
Since existing snapshots can be marked as secure, this option can be used on snapshots taken outside of PowerStore Manager or even snapshots taken with other utilities such as AppSync. Consider enabling this option on your critical snapshots to ensure that they are available when you need them!
There's no such thing as too many backups!
If you're responsible for managing and protecting SQL Server databases, you quickly learn that it's valuable to have many different backups and in various formats, for various reasons. It could be for disaster recovery, migration, reporting, troubleshooting, resetting dev/test environments, or any combination of these. Perhaps you’re trying to mitigate the risk of failure of a single platform, method, or tool. Each scenario and workflow has different requirements. PowerStoreOS 3.5 introduces direct integration with Dell PowerProtect DD series appliances, including PowerProtect DDVE which is the virtual edition for both on-premises and cloud deployments. This provides an agentless way to take crash consistent, off-array backups directly from PowerStore and send them to PowerProtect DD.
To enable PowerStore remote backup, you need to connect the PowerProtect DD appliance to your PowerStore system as a remote system.
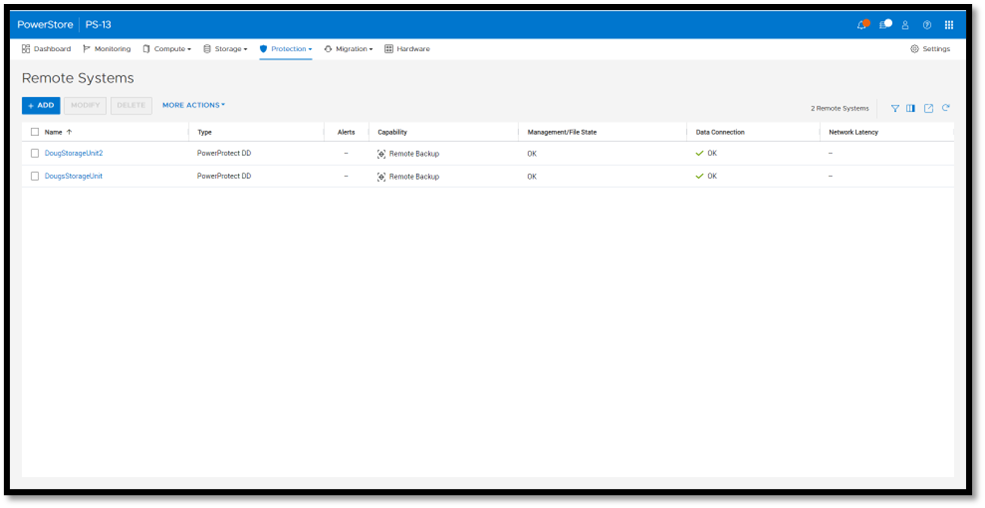
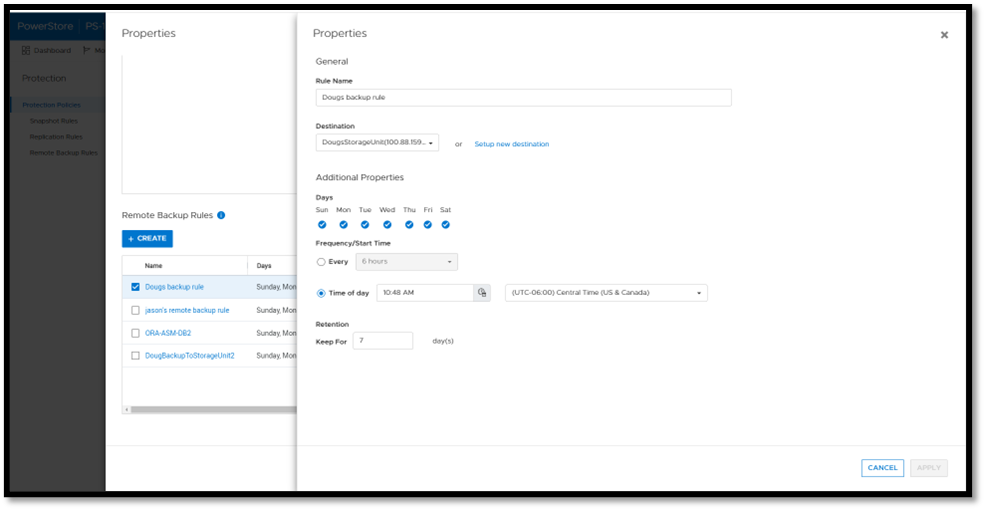
Next, you add a remote backup rule to a new or existing protection policy for the volume or volume group you want to protect, providing the destination, schedule, and retention.
Once a protection policy is created with remote backup rules and assigned to a PowerStore volume or volume group, a backup session will appear.
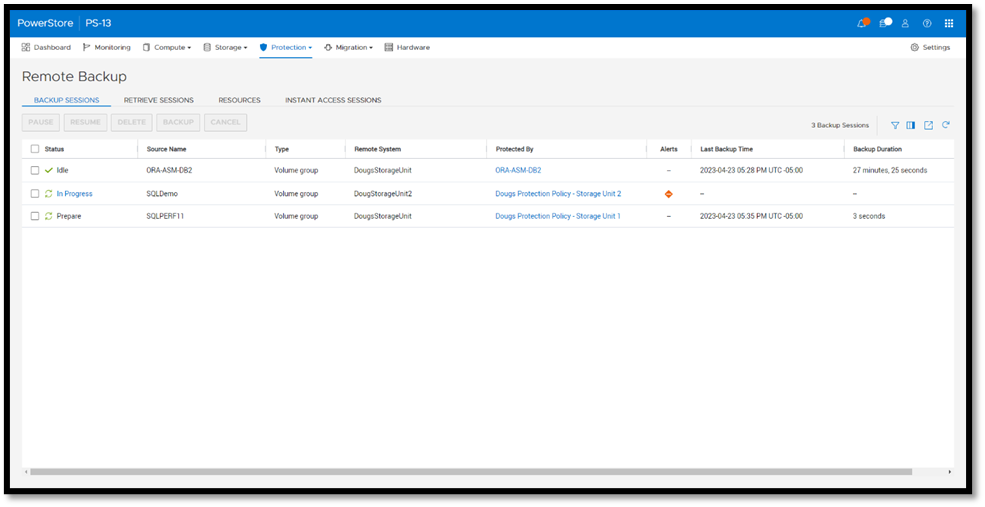
Under Backup Sessions, you can see the status of all the sessions or select one to back up immediately, and click Backup.
Once a remote backup is taken, it will appear under the Volume or Volume Group Protection tab as a remote snapshot.
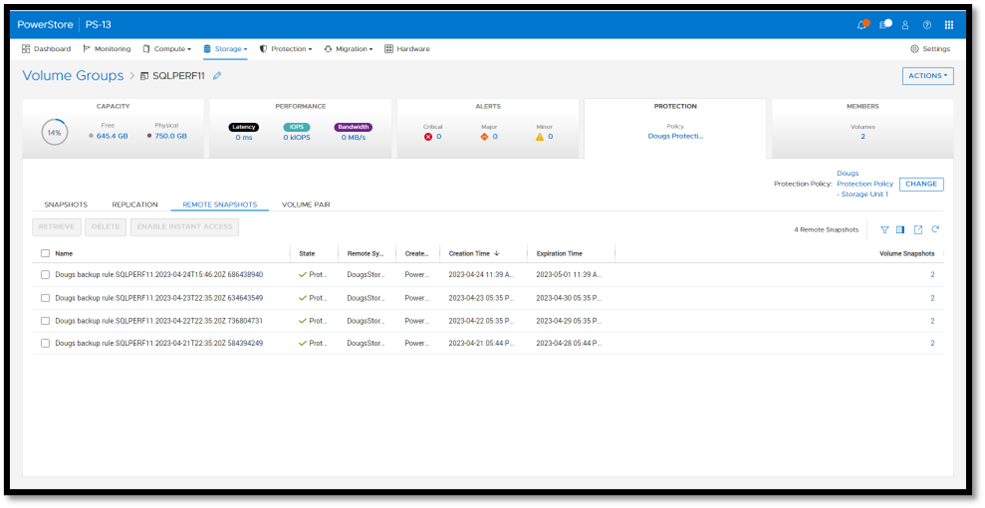
From here, you can retrieve it and work with it as a normal snapshot on PowerStore or enable Instant Access whereby the contents can be accessed by a host directly from PowerProtect DD. You can even retrieve remote snapshots from other PowerStore clusters!
This is yet another powerful tool included with PowerStoreOS 3.5 to enhance data protection and data mobility workflows.
For more information on this feature and other new PowerStore features and capabilities, be sure to check out all the latest information on the Dell PowerStore InfoHub page.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/

PowerStore Revalidated with Microsoft Azure Arc-enabled Data Services
Mon, 27 Feb 2023 22:29:17 -0000
|Read Time: 0 minutes
Microsoft Azure Arc-enabled data services allow you to run Azure data services on-premises, at the edge, or in the cloud. Arc-enabled data services align with Dell Technologies’ vision, by allowing you to run traditional SQL Server workloads or even PostgreSQL on your infrastructure of choice. For details about a solution offering that combines PowerStore and Microsoft Azure Arc-enabled data services, see the white paper Dell PowerStore with Azure Arc-enabled Data Services.
Dell Technologies works closely with partners such as Microsoft to ensure the best possible customer experience. We are happy to announce that Dell PowerStore has been revalidated with the latest version of Azure Arc-enabled data services[1].
Deploy with confidence
One of the deployment requirements for Azure Arc-enabled data services is that you must deploy on one of the validated solutions. At Dell Technologies, we understand that customers want to deploy solutions that have been fully vetted and tested. Key partners such as Microsoft understand this too, which is why they have created a validation program to ensure that the complete solution will work as intended.
By working through this process with Microsoft, Dell Technologies can confidently say that we have deployed and tested a full end-to-end solution with Microsoft and validated that it passes all tests.
The validation process
Microsoft has published tests that are used in their continuous integration/continuous delivery (CI/CD) pipeline for partners and customers to run. For Microsoft to support an Arc-enabled data services solution, it must pass these tests. At a high level, these tests perform the following:
- Connect to an Azure subscription provided by Microsoft
- Deploy the components for Arc-enabled data services, including SQL Managed Instance and PostgreSQL server
- Validate K8s, hosts, storage, networking, and other infrastructure specifics
- Run Sonobuoy tests ranging from simple smoke tests to complex high-availability scenarios and chaos tests
- Upload results
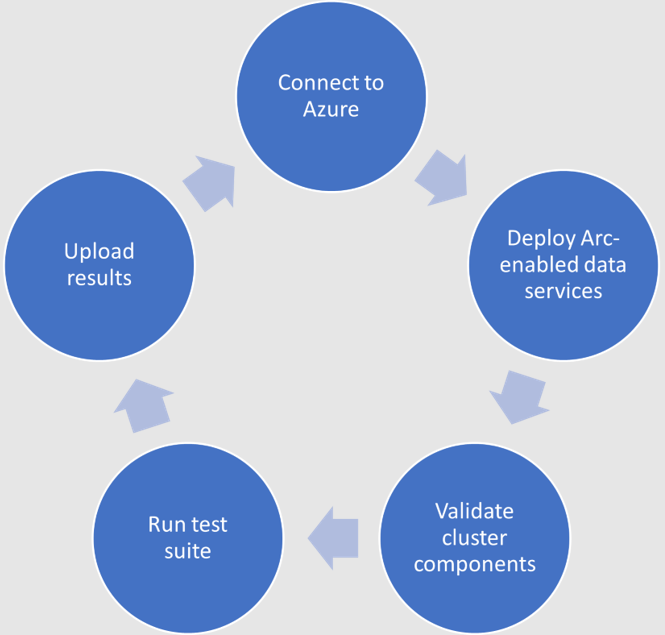
When Microsoft accepts the results, they add the new or updated solution to their list of validated solutions. At that point, the solution is officially supported. This process is repeated as needed as new component versions are introduced. Complete details about the validation testing and links to the GitHub repositories are available here.
More to come
Stay tuned for more additions and updates from Dell Technologies to the list of validated solutions for Azure Arc-enabled data services. Dell Technologies is leading the way on hybrid solutions, proven by our work with partners such as Microsoft on these validation efforts. Reach out to your Dell Technologies representative for more information about these solutions and validations.
Author: Doug Bernhardt, Sr. Principal Engineering Technologist
[1] Dell PowerStore T has been validated with v1.15.0_2023-01-10 of Azure Arc-enabled data services, published 1/13/2023, which is the latest version at the time of publishing.

SQL Server 2022 – Time to Rethink your Backup and Recovery Strategy
Mon, 19 Sep 2022 14:06:43 -0000
|Read Time: 0 minutes
Microsoft SQL Server 2022 is now available in public preview, and it’s jam-packed with great new features. One of the most exciting is the Transact-SQL snapshot backup feature. This is a gem that can transform your backup and recovery strategy and turbocharge your database recoveries!
The power of snapshots
At Dell Technologies we have known the power of storage snapshots for over a decade. Storage snapshots are a fundamental feature in Dell PowerStore and the rest of the Dell storage portfolio. They are a powerful feature that allows point-in-time volume copies to be created and recovered in seconds or less, regardless of size. Since the storage is performing the work, there is no overhead of copying data to another device or location. This metadata operation performed on the storage is not only fast, but it’s space-efficient as well. Instead of storing a full backup copy, only the delta is stored and then coalesced with the base image to form a point-in-time copy.
Starting with SQL Server 2019, SQL Server is also supported on Linux and container platforms such as Kubernetes, in addition to Windows. Kubernetes recognized and embraced the power of storage-based snapshots and provided support a couple of years ago. For managing large datasets in a fast, efficient manner, they are tough to beat.
Lacking full SQL Server support
Unfortunately, prior to SQL Server 2022, there were limitations around how storage-based snapshots could be used for database recovery. Before SQL Server 2022, there was no supported method to apply transaction log backups to these copies without writing custom SQL Server Virtual Device Interface (VDI) code. This limited storage snapshot usage for most customers that use transaction log backups as part of their recovery strategy. Therefore, the most common use cases were repurposing database copies for reporting and test/dev use cases.
In addition, in SQL Server versions earlier than SQL Server 2022, the Volume Shadow Copy Service (VSS) technology used to take these backups is only provided on Windows. Linux and container-based deployments are not supported.
SQL Server 2022 solves the problem!
The Transact-SQL (T-SQL) snapshot backup feature of SQL Server 2022 solves these problems and allows storage snapshots to be a first-class citizen for SQL Server backup and recovery.
There are new options added to T-SQL ALTER DATABASE, BACKUP, and RESTORE commands that allow either a single user database or all user databases to be suspended, allowing the opportunity for storage snapshots to be taken without requiring VSS. Now there is one method that is supported on all SQL Server 2022 platforms.
T-SQL snapshot backups are supported with full recovery scenarios. They can be used as the basis for all common recovery scenarios, such as applying differential and log backups. They can also be used to seed availability groups for fast availability group recovery.
Time to rethink
SQL Server databases can be very large and have stringent recovery time objectives (RTOs) and recovery point objectives (RPOs). PowerStore snapshots can be taken and restored in seconds, where traditional database backup and recovery can take hours. Now that they are fully supported in common recovery scenarios, T-SQL snapshot backup and PowerStore snapshots can be used as a first line of defense in performing database recovery and accelerating the process from hours to seconds. For Dell storage customers, many of the Dell storage products you own support this capability today since there is no VSS provider or storage driver required. Backup and recovery operations can be completely automated using Dell storage command line utilities and REST API integration.
For example, the Dell PowerStore CLI utility (PSTCLI) allows powerful scripting of PowerStore storage operations such as snapshot backup and recovery.
Storage-based snapshots are not meant to replace all traditional database backups. Off-appliance and/or offsite backups are still a best practice for full data protection. However, most backup and restore activities do not require off-appliance or offsite backups, and this is where time and space efficiencies come in. Storage-based snapshots accelerate the majority of backup and recovery scenarios without affecting traditional database backups.
A quick PowerStore example
Backup
The overall workflow for a T-SQL snapshot backup is:
- Issue the T-SQL ALTER DATABASE command to suspend the database:
ALTER DATABASE SnapTest SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON - Perform storage snapshot operations. For PowerStore, this is a single command:
pstcli -d MyPowerStoreMgmtAddress -u UserName -p Password volume_group -name SQLDemo -name SnapTest-Snapshot-2208290922 -description “s:\sql\SnapTest_SQLBackupFull.bkm” - Issue the T-SQL command BACKUP DATABASE command with the METADATA_ONLY option to record the metadata and resume the database:
BACKUP DATABASE SnapTest TO DISK = 's:\sql\SnapTest_SQLBackupFull.bkm' WITH METADATA_ONLY,COPY_ONLY,NOFORMAT,MEDIANAME='Dell PowerStore PS-13',MEDIADESCRIPTION='volume group: SQLDemo',NAME='SnapTest-Snapshot-2208290922',DESCRIPTION=' f85f5a13-d820-4e56-9b9c-a3668d3d7e5e ' ;
Since Microsoft has fully documented the SQL Server backup and restore operations, let’s focus on step 2 above, the PowerStore CLI command. It is important to understand that when taking a PowerStore storage snapshot, the snapshot is being taken at the volume level. Therefore, all volumes that contain data and log files for your database require a consistent point-in-time snapshot. It is a SQL Server Best Practice for PowerStore to place associated SQL Server data and log volumes into a PowerStore volume group. This allows for simplified protection and consistency across all volumes in the volume group. In the PSTCLI command above, a PowerStore snapshot is taken on a volume group containing all the volumes for the database at once.
Also, a couple of tips for making the process a bit easier. The PowerStore snapshot and the backup metadata file need to be used as a set. The proper version is required for each because the metadata file contains information such as SQL Server log sequence numbers (LSNs) that need to match the database files. Therefore, I’m using several fields in the PowerStore and SQL Server snapshot commands to store information on how to tie this information together:
- When the PowerStore snapshot is taken in step 2 above, in the name field I store the database name and the datetime that the snapshot was taken. I store the path to the SQL Server metadata file in the description field.
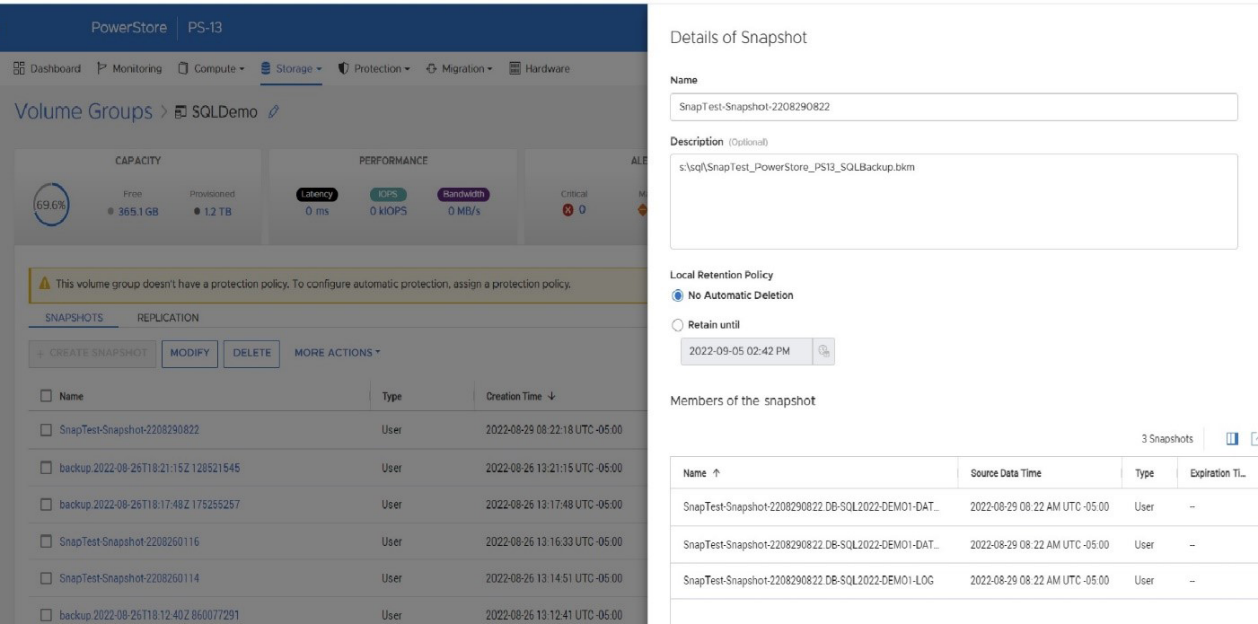
- In step 3, within the BACKUP DATABASE command, I put the PowerStore friendly name in the MEDIANAME field, the PowerStore volume group name in the NAME field, and the PowerStore volume group ID in the DESCRIPTION field. This populates the metadata file with the necessary information to locate the PowerStore snapshot on the PowerStore appliance.
- The T-SQL command RESTORE HEADERONLY will display the information added to the BACKUP DATABASE command as well as the SQL Server name and database name.
Recovery
The overall workflow for a basic recovery is:
- Drop the existing database.
- Offline the database volumes. This can be done through PowerShell, as follows, where X is the drive letter of the volume to take offline:
Set-Disk (Get-Partition -DriveLetter X | Get-Disk | Select number -ExpandProperty number) -isOffline $true - Restore the database snapshot using PowerStore PSTCLI:
- List volume groups.
pstcli -d MyPowerStoreMgmtAddress -u UserName -p Password! volume_group show - Restore the volume group where f85f5a13-d820-4e56-9b9c-a3668d3d7e5e is a volume group ID from above.
pstcli -d MyPowerStoreMgmtAddress -u UserName -p Password! volume_group -name SQLServerVolumeGroup restore -from_snap_id f85f5a13-d820-4e56-9b9c-a3668d3d7e5e
- List volume groups.
- Online the database volumes. The following PowerShell command will online all offline disks:
Get-Disk | Where-Object IsOffline -Eq $True | Select Number | Set-Disk -isOffline $False - Issue the T-SQL RESTORE DATABASE command referencing the backup metadata file, using the NORECOVERY option if applying log backups:
RESTORE DATABASE SnapTest FROM DISK = 's:\sql\SnapTest_PowerStore_PS13_SQLBackup.bkm' WITH FILE=1,METADATA_ONLY,NORECOVERY - If applicable, apply database log backups:
RESTORE LOG SnapTest FROM DISK = 's:\sql\SnapTest20220829031756.trn' WITH RECOVERY
Other items of note
A couple of other items worth discussing are COPY_ONLY and differential backups. You might have noticed above that the BACKUP DATABASE command contains the COPY_ONLY parameter, which means that these backups won’t interfere with another backup and recovery process that you might have in place.
It also means that you can’t apply differential backups to these T-SQL snapshot backups. I’m not sure why one would want to do that; I would just take another T-SQL snapshot backup with PowerStore at the same time, use that for the recovery base, and expedite the process! I’m sure there are valid reasons for wanting to do that, and, if so, you don’t need to use the COPY_ONLY option. Just be aware that you might be affecting other backup and restore operations, so be sure to do your homework first!
Stay tuned
There will be a lot more information and examples coming from Dell Technologies on how to integrate this new T-SQL snapshot backup feature with Linux and Kubernetes on PowerStore as well as on other Dell storage platforms. Also, look for the Dell Technologies sessions at PASS Data Community Summit 2022, where we will have more information on this and other exciting new Microsoft SQL Server 2022 features!
Author: Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/

Azure Arc Data Services on Dell EMC PowerStore
Thu, 04 Nov 2021 19:37:31 -0000
|Read Time: 0 minutes
Azure Data Services is a powerful data platform for building cloud and hybrid data applications. Both Microsoft and Dell Technologies see tremendous benefit in a hybrid computing approach. Therefore, when Microsoft announced Azure Arc and Azure Arc-enabled data services as a way to enable hybrid cloud, this was exciting news!
Enhancing value
Dell Technologies is always looking for ways to bring value to customers by not only developing our own world-class solutions, but also working with key technology partners. The goal is to provide the best experience for critical business applications. As a key Microsoft partner, Dell Technologies looks for opportunities to perform co-engineering and validation whenever possible. We participated in the Azure Arc-enabled Data Services validation process, provided feedback into the program, and worked to validate several Dell EMC products for use with Azure Arc Data Services.
Big announcement
When Microsoft announced general availability of Azure Arc-enabled data services earlier this year, Dell Technologies was there with several supported platforms and solutions from Day 1. The biggest announcement was around Azure Arc-enabled data services with APEX Data Storage Services. However, what you may have missed is that Dell EMC PowerStore is also validated on Azure Arc-enabled data services!
What does this validation mean?
Basically, what this validation means is that Dell Technologies has run a series of tests on the certified solutions to ensure that our solutions provide the required features and integrations. The results of the testing were then reviewed and approved by Microsoft. In the case of PowerStore, both PowerStore X and PowerStore T versions were fully validated. Full details of the validation program are available on GitHub.
Go forth and deploy with confidence knowing that the Dell EMC PowerStore platform is fully validated for Azure Arc!
More information
In addition to PowerStore, Dell Technologies leads the way in certified platforms. Additional details about this validation can be found here.
For more information, you can find lots of great material and detailed examples for Dell EMC PowerStore here: Databases and Data Analytics | Dell Technologies Info Hub
You can find complete information on all Dell EMC storage products on Dell Technologies Info Hub.

Kubernetes Brings Self-service Storage
Tue, 28 Sep 2021 18:49:52 -0000
|Read Time: 0 minutes
There are all sorts of articles and information on various benefits of Kubernetes and container-based applications. When I first started using Kubernetes (K8s) a couple of years ago I noticed that storage, or Persistent Storage as it is known in K8s, has a new and exciting twist to storage management. Using the Container Storage Interface (CSI), storage provisioning is automated, providing real self-service for storage. Once my storage appliance was set up and my Dell EMC CSI driver was deployed, I was entirely managing my storage provisioning from within K8s!
Self-service realized
Earlier in my career as a SQL Server Database Administrator (DBA), I would have to be very planful about my storage requirements, submit a request to the storage team, listen to them moan and groan as if I asked for their first born child, then ultimately provide half of the storage I requested. As my data requirements grew, I would have to repeat this process each time I needed more storage. In their defense, this was several years ago before data reduction and thin provisioning were common.
When running stateful applications and database engines, such as Microsoft SQL Server on K8s, the application owner or database administrator no longer needs to involve the storage administrator when provisioning storage. Volume creation, volume deletion, host mapping, and even volume expansion and snapshots are handled through the CSI driver! All the common functions that you need for day-to-day storage management data are provided by the K8s control plane through common commands.
K8s storage management
When Persistent Storage is required in Kubernetes, using the K8s control plane commands, you create a Persistent Volume Claim (PVC). The PVC contains basic information such as the name, storage type, and the size.
To increase the volume size, you simply modify the size in the PVC definition. Want to manage snapshots? That too can also be done through K8s commands. When it’s time to delete the volume, simply delete the PVC.
Because the CSI storage interface is generic, you don’t need to know the details of the storage appliance. Those details are contained in the CSI driver configuration and a storage class that references it. Therefore, the provisioning commands are the same across different storage appliances.
Rethinking storage provisioning
It’s a whole new approach to managing storage for data hungry applications that not only enables application owners but also challenges how storage management is done and the traditional roles in a classic IT organization. With great power comes great responsibility!
For more information, you can find lots of great material and detailed examples for Dell EMC PowerStore here: Databases and Data Analytics | Dell Technologies Info Hub
You can find complete information on all Dell EMC storage products on Dell Technologies Info Hub.
All Dell EMC CSI drivers and complete documentation can be found on GitHub. Complete information on Kubernetes and CSI is also found on GitHub.
Author: Doug Bernhardt
Twitter: @DougBern
www.linkedin.com/in/doug-bernhardt-data

Dell Technologies partners with Microsoft and Red Hat running SQL Server Big Data Clusters on OpenShift
Wed, 19 Aug 2020 22:32:11 -0000
|Read Time: 0 minutes
Introduced with Microsoft SQL Server 2019, SQL Server Big Data Clusters allow customers to deploy scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes. Complete info on Big Data Clusters can be found in the Microsoft documentation. Many Dell Technologies customers are using Red Hat OpenShift Container Platform as their Kubernetes platform of choice and with this and many other solutions we are leading the way on OpenShift applications.
In Cumulative Update 5 (CU5) of Microsoft SQL Server 2019 Big Data Clusters (BDC), OpenShift 4.3+ is supported as a platform for Big Data Clusters. This has been a highly anticipated launch as customers not only realize the power of BDC and OpenShift but also look for the support of Dell Technologies, Microsoft, and Red Hat to run mission-critical workloads. Dell Technologies has been working with Microsoft and Red Hat to develop architecture guidance and best practices for deploying and running BDC on OpenShift.
For this effort we utilized the Databricks’ TPC-DS Spark SQL kit to populate a dataset and run a workload on the OpenShift 4.3 BDC cluster to test the various architecture components of the solution. The TPC-DS benchmark is a popular database benchmark used to evaluate performance in decision support and Big Data environments.
Based on our testing we were able to achieve linear scale of our workload while fully exercising our OpenShift cluster consisting of 12 Dell EMC R640 PowerEdge Servers and a single Dell EMC Unity 880F storage array.
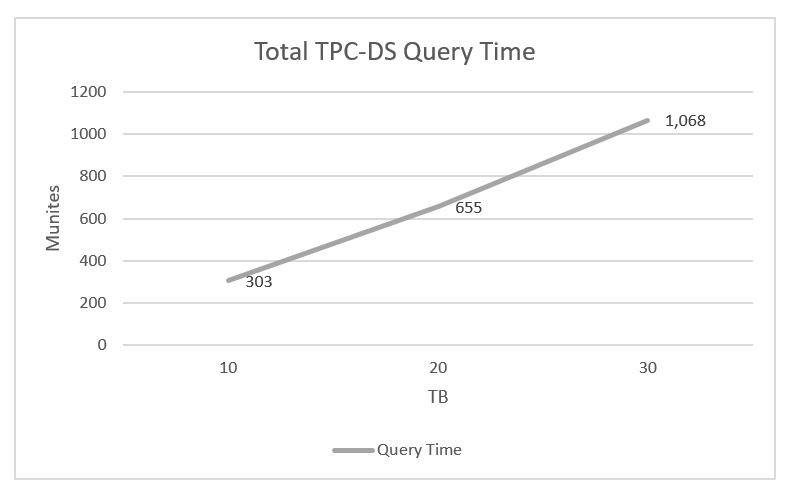
Total time of all queries run for 10,20,and 30TB datasets
As a result of this testing, a fully detailed OpenShift reference architecture and a best practices paper for running Big Data Clusters on Dell EMC Unity storage are under way and will be published soon. More information on Dell Technologies solutions for OpenShift can be found on our OpenShift Info Hub. Additional information on Dell Technologies for SQL Server can be found on our Microsoft SQL webpage.