




Time to Rethink your SQL Backup Strategy – Part 2

A while back, I wrote a blog about changes to backup/restore functionality in SQL Server 2022: SQL Server 2022 – Time to Rethink your Backup and Recovery Strategy. Now, more exciting features are here in PowerStoreOS 3.5 that provide additional options and enhanced flexibility for protecting, migrating, and recovering SQL Server workloads on PowerStore.
Secure your snapshots
Backup copies provide zero value if they have been compromised when you need them the most. Snapshot removal could happen accidentally or intentionally as part of a malicious attack. PowerStoreOS 3.5 introduces a new feature, secure snapshot, to ensure that snapshots can't be deleted prior to their expiration date. This feature is a simple checkbox on a snapshot or protection policy that protects snapshots until they expire and can't be turned off. This ensures that your critical data will be available when you need it. Secure snapshot can be enabled on new or existing snapshots. Here’s an example of the secure snapshot option on an existing snapshot.
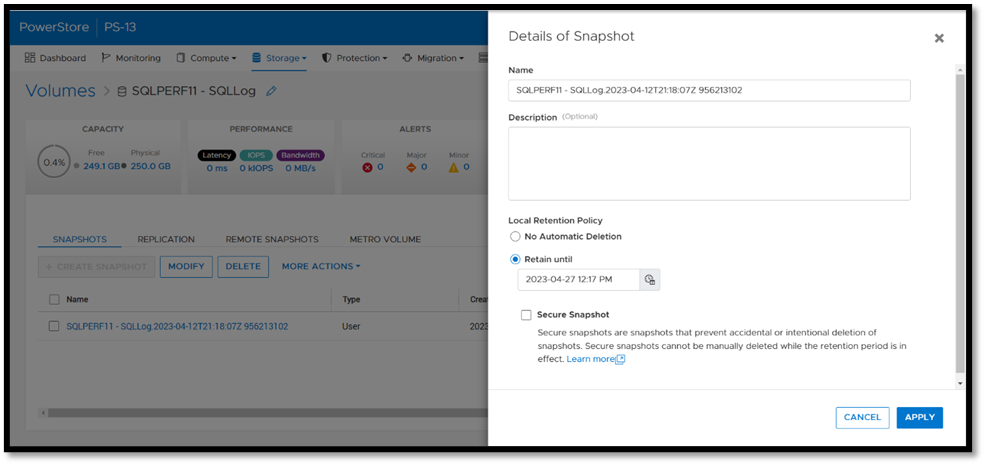
Once this option is selected, a warning is displayed stating that the snapshot can’t be deleted until the retention period expires. To make the snapshot secure, ensure that the Secure Snapshot checkbox is selected and click Apply.
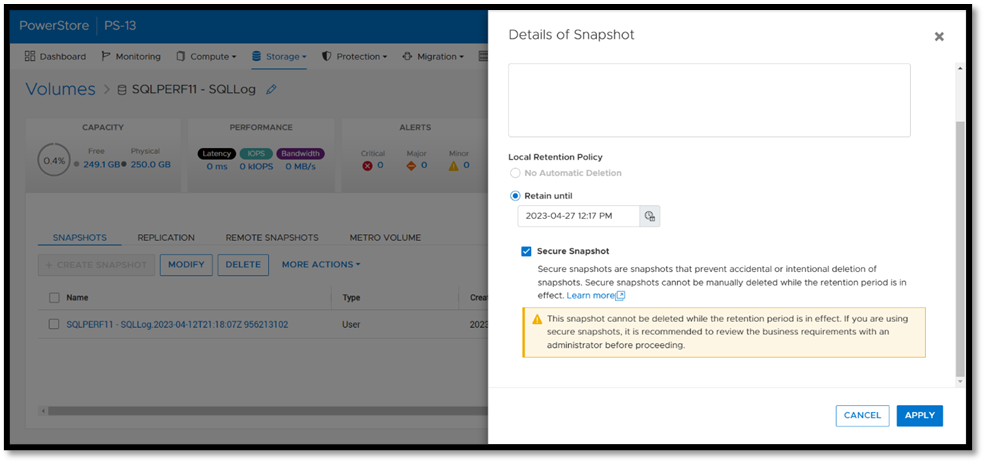
Secure snapshot can be applied to individual snapshots of volumes or volume groups. The secure snapshot option can also be enabled on one or more snapshot rules in a protection policy to ensure that snapshots taken as part of the protection policy have secure snapshot applied.
Since existing snapshots can be marked as secure, this option can be used on snapshots taken outside of PowerStore Manager or even snapshots taken with other utilities such as AppSync. Consider enabling this option on your critical snapshots to ensure that they are available when you need them!
There's no such thing as too many backups!
If you're responsible for managing and protecting SQL Server databases, you quickly learn that it's valuable to have many different backups and in various formats, for various reasons. It could be for disaster recovery, migration, reporting, troubleshooting, resetting dev/test environments, or any combination of these. Perhaps you’re trying to mitigate the risk of failure of a single platform, method, or tool. Each scenario and workflow has different requirements. PowerStoreOS 3.5 introduces direct integration with Dell PowerProtect DD series appliances, including PowerProtect DDVE which is the virtual edition for both on-premises and cloud deployments. This provides an agentless way to take crash consistent, off-array backups directly from PowerStore and send them to PowerProtect DD.
To enable PowerStore remote backup, you need to connect the PowerProtect DD appliance to your PowerStore system as a remote system.
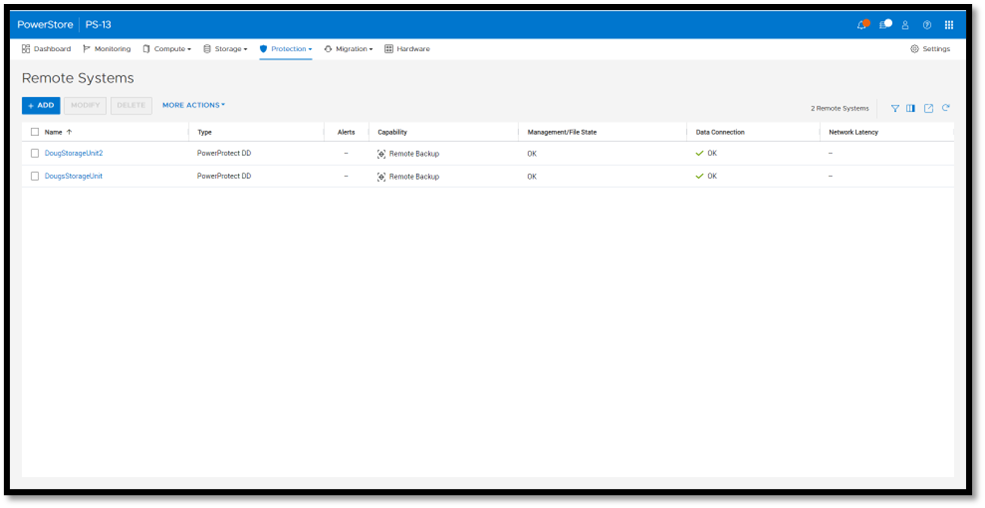
Next, you add a remote backup rule to a new or existing protection policy for the volume or volume group you want to protect, providing the destination, schedule, and retention.
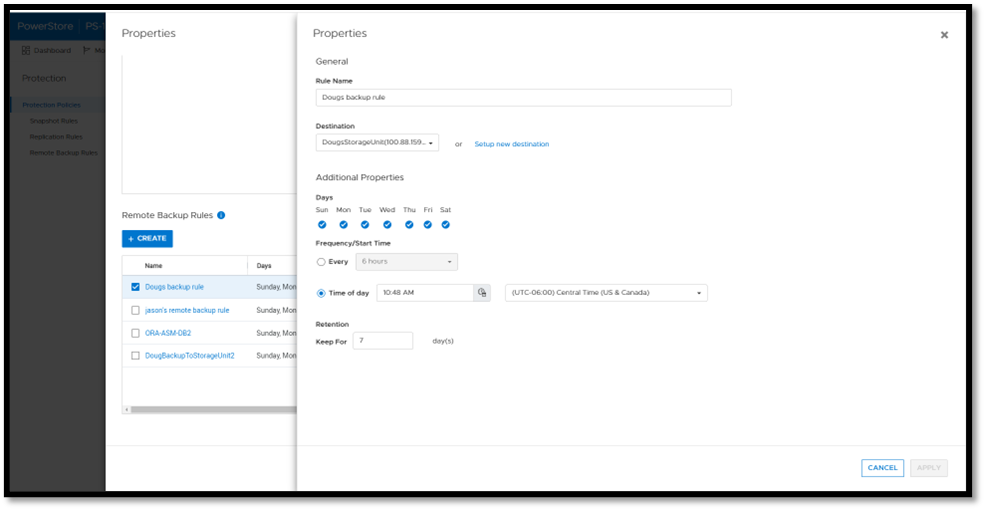
Once a protection policy is created with remote backup rules and assigned to a PowerStore volume or volume group, a backup session will appear.
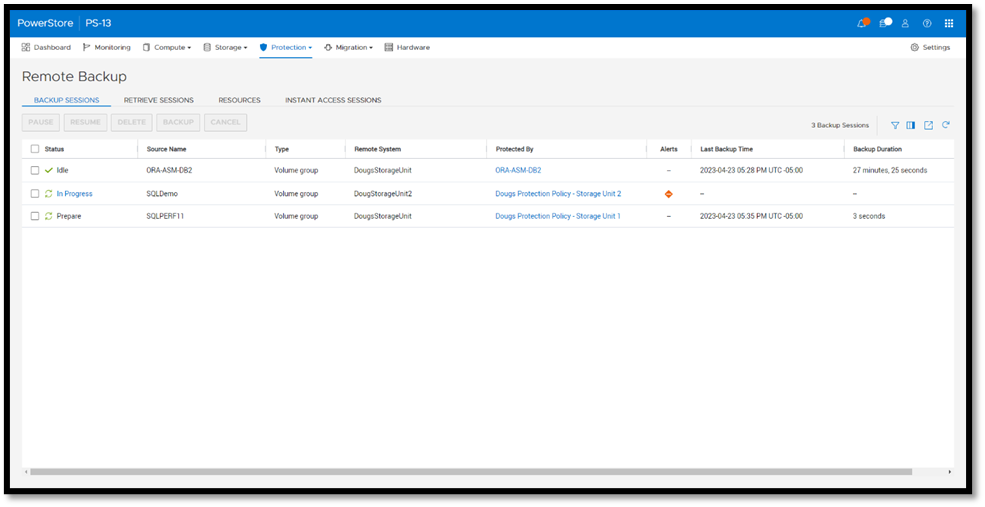
Under Backup Sessions, you can see the status of all the sessions or select one to back up immediately, and click Backup.
Once a remote backup is taken, it will appear under the Volume or Volume Group Protection tab as a remote snapshot.
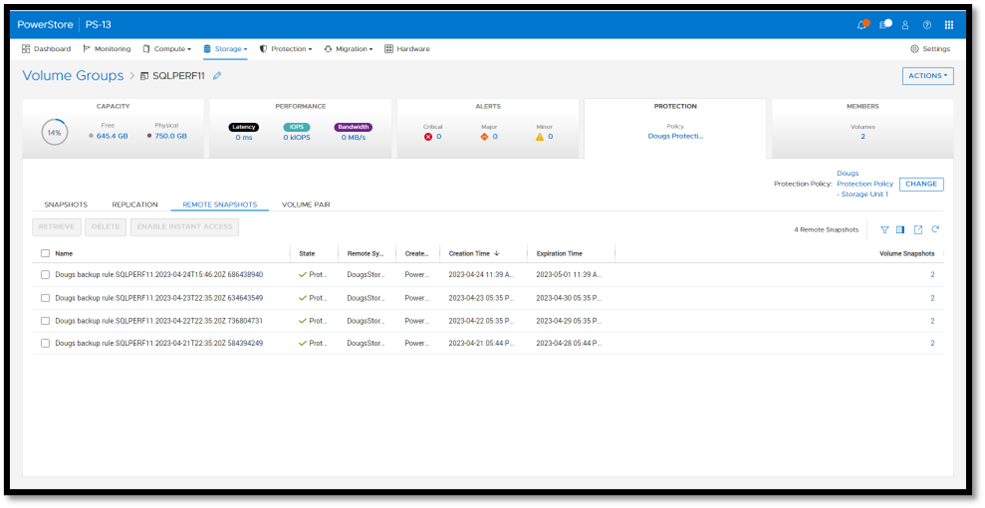
From here, you can retrieve it and work with it as a normal snapshot on PowerStore or enable Instant Access whereby the contents can be accessed by a host directly from PowerProtect DD. You can even retrieve remote snapshots from other PowerStore clusters!
This is yet another powerful tool included with PowerStoreOS 3.5 to enhance data protection and data mobility workflows.
For more information on this feature and other new PowerStore features and capabilities, be sure to check out all the latest information on the Dell PowerStore InfoHub page.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/
Related Blog Posts

SQL Server 2022 – Time to Rethink your Backup and Recovery Strategy
Mon, 19 Sep 2022 14:06:43 -0000
|Read Time: 0 minutes
Microsoft SQL Server 2022 is now available in public preview, and it’s jam-packed with great new features. One of the most exciting is the Transact-SQL snapshot backup feature. This is a gem that can transform your backup and recovery strategy and turbocharge your database recoveries!
The power of snapshots
At Dell Technologies we have known the power of storage snapshots for over a decade. Storage snapshots are a fundamental feature in Dell PowerStore and the rest of the Dell storage portfolio. They are a powerful feature that allows point-in-time volume copies to be created and recovered in seconds or less, regardless of size. Since the storage is performing the work, there is no overhead of copying data to another device or location. This metadata operation performed on the storage is not only fast, but it’s space-efficient as well. Instead of storing a full backup copy, only the delta is stored and then coalesced with the base image to form a point-in-time copy.
Starting with SQL Server 2019, SQL Server is also supported on Linux and container platforms such as Kubernetes, in addition to Windows. Kubernetes recognized and embraced the power of storage-based snapshots and provided support a couple of years ago. For managing large datasets in a fast, efficient manner, they are tough to beat.
Lacking full SQL Server support
Unfortunately, prior to SQL Server 2022, there were limitations around how storage-based snapshots could be used for database recovery. Before SQL Server 2022, there was no supported method to apply transaction log backups to these copies without writing custom SQL Server Virtual Device Interface (VDI) code. This limited storage snapshot usage for most customers that use transaction log backups as part of their recovery strategy. Therefore, the most common use cases were repurposing database copies for reporting and test/dev use cases.
In addition, in SQL Server versions earlier than SQL Server 2022, the Volume Shadow Copy Service (VSS) technology used to take these backups is only provided on Windows. Linux and container-based deployments are not supported.
SQL Server 2022 solves the problem!
The Transact-SQL (T-SQL) snapshot backup feature of SQL Server 2022 solves these problems and allows storage snapshots to be a first-class citizen for SQL Server backup and recovery.
There are new options added to T-SQL ALTER DATABASE, BACKUP, and RESTORE commands that allow either a single user database or all user databases to be suspended, allowing the opportunity for storage snapshots to be taken without requiring VSS. Now there is one method that is supported on all SQL Server 2022 platforms.
T-SQL snapshot backups are supported with full recovery scenarios. They can be used as the basis for all common recovery scenarios, such as applying differential and log backups. They can also be used to seed availability groups for fast availability group recovery.
Time to rethink
SQL Server databases can be very large and have stringent recovery time objectives (RTOs) and recovery point objectives (RPOs). PowerStore snapshots can be taken and restored in seconds, where traditional database backup and recovery can take hours. Now that they are fully supported in common recovery scenarios, T-SQL snapshot backup and PowerStore snapshots can be used as a first line of defense in performing database recovery and accelerating the process from hours to seconds. For Dell storage customers, many of the Dell storage products you own support this capability today since there is no VSS provider or storage driver required. Backup and recovery operations can be completely automated using Dell storage command line utilities and REST API integration.
For example, the Dell PowerStore CLI utility (PSTCLI) allows powerful scripting of PowerStore storage operations such as snapshot backup and recovery.
Storage-based snapshots are not meant to replace all traditional database backups. Off-appliance and/or offsite backups are still a best practice for full data protection. However, most backup and restore activities do not require off-appliance or offsite backups, and this is where time and space efficiencies come in. Storage-based snapshots accelerate the majority of backup and recovery scenarios without affecting traditional database backups.
A quick PowerStore example
Backup
The overall workflow for a T-SQL snapshot backup is:
- Issue the T-SQL ALTER DATABASE command to suspend the database:
ALTER DATABASE SnapTest SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON - Perform storage snapshot operations. For PowerStore, this is a single command:
pstcli -d MyPowerStoreMgmtAddress -u UserName -p Password volume_group -name SQLDemo -name SnapTest-Snapshot-2208290922 -description “s:\sql\SnapTest_SQLBackupFull.bkm” - Issue the T-SQL command BACKUP DATABASE command with the METADATA_ONLY option to record the metadata and resume the database:
BACKUP DATABASE SnapTest TO DISK = 's:\sql\SnapTest_SQLBackupFull.bkm' WITH METADATA_ONLY,COPY_ONLY,NOFORMAT,MEDIANAME='Dell PowerStore PS-13',MEDIADESCRIPTION='volume group: SQLDemo',NAME='SnapTest-Snapshot-2208290922',DESCRIPTION=' f85f5a13-d820-4e56-9b9c-a3668d3d7e5e ' ;
Since Microsoft has fully documented the SQL Server backup and restore operations, let’s focus on step 2 above, the PowerStore CLI command. It is important to understand that when taking a PowerStore storage snapshot, the snapshot is being taken at the volume level. Therefore, all volumes that contain data and log files for your database require a consistent point-in-time snapshot. It is a SQL Server Best Practice for PowerStore to place associated SQL Server data and log volumes into a PowerStore volume group. This allows for simplified protection and consistency across all volumes in the volume group. In the PSTCLI command above, a PowerStore snapshot is taken on a volume group containing all the volumes for the database at once.
Also, a couple of tips for making the process a bit easier. The PowerStore snapshot and the backup metadata file need to be used as a set. The proper version is required for each because the metadata file contains information such as SQL Server log sequence numbers (LSNs) that need to match the database files. Therefore, I’m using several fields in the PowerStore and SQL Server snapshot commands to store information on how to tie this information together:
- When the PowerStore snapshot is taken in step 2 above, in the name field I store the database name and the datetime that the snapshot was taken. I store the path to the SQL Server metadata file in the description field.
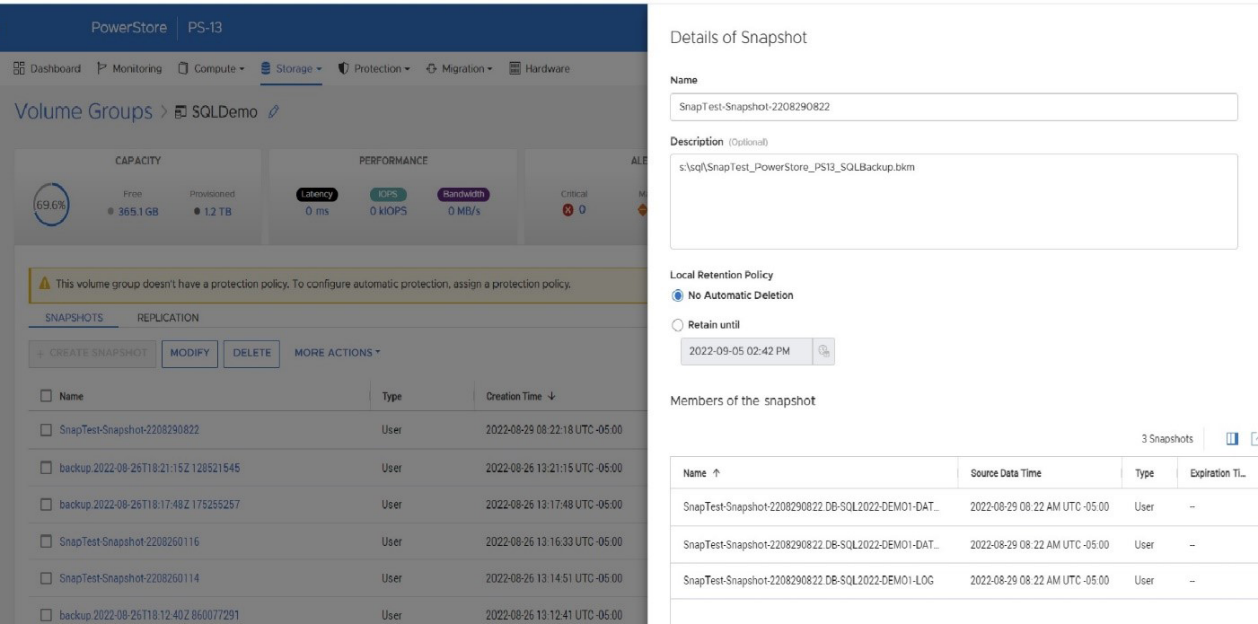
- In step 3, within the BACKUP DATABASE command, I put the PowerStore friendly name in the MEDIANAME field, the PowerStore volume group name in the NAME field, and the PowerStore volume group ID in the DESCRIPTION field. This populates the metadata file with the necessary information to locate the PowerStore snapshot on the PowerStore appliance.
- The T-SQL command RESTORE HEADERONLY will display the information added to the BACKUP DATABASE command as well as the SQL Server name and database name.
Recovery
The overall workflow for a basic recovery is:
- Drop the existing database.
- Offline the database volumes. This can be done through PowerShell, as follows, where X is the drive letter of the volume to take offline:
Set-Disk (Get-Partition -DriveLetter X | Get-Disk | Select number -ExpandProperty number) -isOffline $true - Restore the database snapshot using PowerStore PSTCLI:
- List volume groups.
pstcli -d MyPowerStoreMgmtAddress -u UserName -p Password! volume_group show - Restore the volume group where f85f5a13-d820-4e56-9b9c-a3668d3d7e5e is a volume group ID from above.
pstcli -d MyPowerStoreMgmtAddress -u UserName -p Password! volume_group -name SQLServerVolumeGroup restore -from_snap_id f85f5a13-d820-4e56-9b9c-a3668d3d7e5e
- List volume groups.
- Online the database volumes. The following PowerShell command will online all offline disks:
Get-Disk | Where-Object IsOffline -Eq $True | Select Number | Set-Disk -isOffline $False - Issue the T-SQL RESTORE DATABASE command referencing the backup metadata file, using the NORECOVERY option if applying log backups:
RESTORE DATABASE SnapTest FROM DISK = 's:\sql\SnapTest_PowerStore_PS13_SQLBackup.bkm' WITH FILE=1,METADATA_ONLY,NORECOVERY - If applicable, apply database log backups:
RESTORE LOG SnapTest FROM DISK = 's:\sql\SnapTest20220829031756.trn' WITH RECOVERY
Other items of note
A couple of other items worth discussing are COPY_ONLY and differential backups. You might have noticed above that the BACKUP DATABASE command contains the COPY_ONLY parameter, which means that these backups won’t interfere with another backup and recovery process that you might have in place.
It also means that you can’t apply differential backups to these T-SQL snapshot backups. I’m not sure why one would want to do that; I would just take another T-SQL snapshot backup with PowerStore at the same time, use that for the recovery base, and expedite the process! I’m sure there are valid reasons for wanting to do that, and, if so, you don’t need to use the COPY_ONLY option. Just be aware that you might be affecting other backup and restore operations, so be sure to do your homework first!
Stay tuned
There will be a lot more information and examples coming from Dell Technologies on how to integrate this new T-SQL snapshot backup feature with Linux and Kubernetes on PowerStore as well as on other Dell storage platforms. Also, look for the Dell Technologies sessions at PASS Data Community Summit 2022, where we will have more information on this and other exciting new Microsoft SQL Server 2022 features!
Author: Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/

When Performance Testing Your Storage, Avoid Zeros!
Tue, 20 Feb 2024 17:37:42 -0000
|Read Time: 0 minutes
Storage benchmarking
Occasionally, Dell Technologies customers will want to run their own storage performance tests to ensure that their storage can meet the demands of their workload. Dell Technologies partners like Microsoft publish guidance on how to use benchmarking tools such as Diskspd to test various workloads. When running these tools on intelligent storage appliances like those offered by Dell Technologies, don’t forget to watch for how your test files are populated!
The first step in using performance benchmark tools is creating one or more test files for use when testing. The benchmark tool will then write and read data to and from these files, taking measurements to assess performance. An important detail that is often overlooked is how the test files are populated with data. If the files are not populated correctly, it can lead to misleading results and inaccurate conclusions.
We’ll use Diskspd as an example, however please note that most tools have the same default behavior. By default, when you run a Diskspd test, you need to specify several parameters, such as a test file location and size, IO block size, read/write ratio, queue depth, and so on.
If we open a test file created with default parameters and examine it with a hexadecimal editor, this is what it looks like:
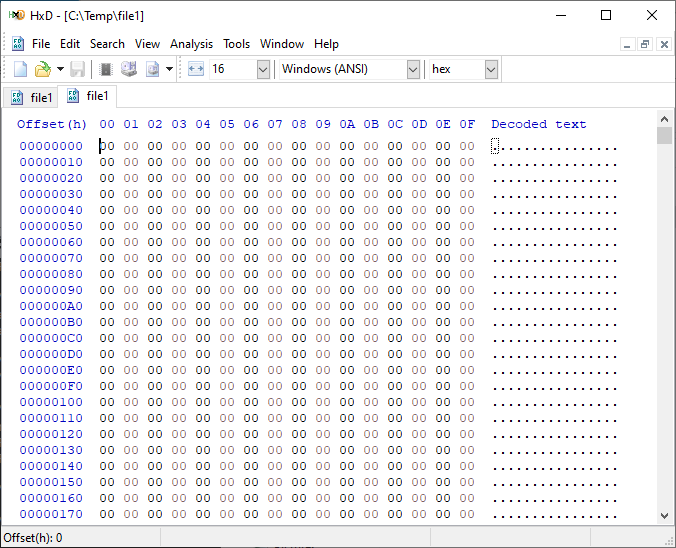
It is filled with nothing, 0x00 throughout the entire file – all “zeros”!
OK, so what is the problem?
When storage benchmarking tools create test files, they all use synthetic data for testing. This is fine when performing IO to a storage device with no “intelligence” built in because it will perform unaltered IO directly to the storage without the data content mattering. In the past, storage devices were simple and would read and write data as commanded, so the data content was irrelevant.
However, intelligent storage appliances such as those offered by Dell Technologies look at data differently. These products are built for efficiency and performance. Compression, deduplication, zero detection, and other optimizations may be used for space savings and performance. Since an empty file would obviously compress and deduplicate well, most of this IO will not access the disks in the same manner that a file of actual data would. It is also possible that other components in the data path would behave differently than normal when repeatedly presented with an identical piece of data.
It is safe to assume that these optimizations likely exist on data being stored in the cloud as well. Many cloud providers use intelligent storage appliances or have developed proprietary software to optimize storage.
The bottom line is that your test is likely inaccurate and may not represent your storage performance under more realistic conditions. While no synthetic test can reproduce a real workload 100%, you should try to make it as realistic as possible.
Mitigations
Some tools can initialize the test files with random data. Diskspd, for example, has parameters that can be added to create a buffer of random data to be used to write to the files or specify a source file of data. Regardless of the method used, you should inspect the test files to make sure that at a minimum, random data is being used. Zero-filled files and repeating patterns should be avoided.
Random data also may not achieve the expected behavior when compression and deduplication capabilities are used. More advanced testing tools such as vdbench can use target compression and deduplication capabilities independently.
Tips
Here are a few more tips when benchmarking storage performance to try to make it as realistic as possible:
- Use datasets of comparable size to real data workloads. Smaller datasets may fit entirely in the cache and skew results.
- Use IO sizes and read/write ratios that match your workload. If you are unsure of what your workload looks like, your Dell Technologies representative can assist you.
- Test with “multiples”. Intelligent storage assumes multiple files, volumes, and hosts. At a minimum, use multiple files and volumes. When testing larger block sizes, you may need to use multiple hosts and multiple host bus adapters to generate enough IO to test the full bandwidth capabilities of the storage.
- Start with a light load and scale up. Begin with one file, one worker thread, and a queue depth of one. In general, modern storage is designed for concurrency. Some amount of concurrency will be required to fully use storage system resources. As you scale up, observe the behavior. Pay attention to the measured latency. At some point as you scale the test, latency will start to increase rapidly.
- Excessive latency indicates a bottleneck. Once latencies are excessive, you have encountered a bottleneck somewhere. “Excessive” is a relative term when it comes to storage latency and is determined by your workload and business needs. Only scale the test to the point where the measured latency is within your acceptable range or above. Further increasing the test load will result in diminishing returns.
- Make sure the entire test environment can drive the wanted performance. The storage network and host configuration must be capable of desired performance levels and configured properly.
- Beware of outdated guidance. There are still articles online that are over a decade old that reference testing methods and best practices that were developed when storage was based on spinning disks. Those assumptions may be inaccurate on the latest storage devices and storage network protocols.
Summary
Storage performance benchmarking can be interesting and provide useful data points. That said, what is most important is how the storage supports actual business workloads and—most importantly—your unique workload. As such, there is no true substitute for testing with your actual workload.
Selecting the proper storage fit for your environment can be challenging, and Dell Technologies has the expertise to help. Leveraging tools like CloudIQ and LiveOptics, Dell Technologies can help you analyze your storage performance, explain storage metrics, and make recommendations to increase storage efficiency.
Author: Doug Bernhardt, Sr. Principal Engineering Technologist | LinkedIn