




PowerStore and SQL Server Ledger—Your Data Has Never Been More Secure!

It’s all about security
Dell and Microsoft are constantly working together to provide the best security, availability, and performance for your valuable data assets. In the latest releases of PowerStoreOS 3.5 and SQL Server 2022, several new capabilities have been introduced that provide zero trust security for data protection.
PowerStore security
PowerStoreOS is packed with security features focused on secure platform, access controls, snapshot, auditing, and certifications. PowerStoreOS 3.5 introduces the following new features:
- STIG (Security Technical Implementation Guides) hardening, which enforces U.S. Department of Defense (DoD) specific rules regarding password complexity, timeout policies, and other practices.
- Multi-factor authentication to shield from hackers and mitigate poor password policies.
- Secure snapshots to prevent snapshots from being modified or deleted before the expiration date, even by an administrator.
- PowerProtect DD integration to create snapshots directly on Dell PowerProtect DD series appliances. The PowerStore Zero Trust video explains these features in more detail.
To enhance database security, Microsoft has introduced a new feature in SQL Server 2022, SQL Ledger. This feature leverages cryptography and blockchain architecture to produce a tamper-proof ledger of all changes made to a database over time. SQL Ledger provides cryptographic proof of data integrity to fulfill auditing requirements and streamline the audit process.
SQL Ledger 101
There are two main storage components to SQL Ledger. First is the database with special configuration that leverages blockchain architecture for increased security. The database resides on standard block or file storage. PowerStore supports both block and file storage, making it ideal for SQL Ledger deployments.
The second is an independently stored ledger digest that includes hash values for auditing and verification. The ledger digest is used as an append-only log to store point-in-time hash values for a ledger database. The ledger digest can then be used to verify the integrity of the main database by comparing a ledger block ID and hash value against the actual block ID and hash value in the database. If there is a mismatch, then some type of corruption or tampering has taken place.
This second component, the ledger digest, requires Write Once Read Many (WORM) storage. PowerStore File-Level Retention (FLR) features can be configured to provide WORM storage for SQL Ledger. Additionally, PowerStore FLR can also be configured to include a data integrity check to detect write-tampering that complies with SEC rule 17a-4(f).
Automatic storage and generation of database digests is only available for Microsoft Azure Storage. For on-premises deployments of SQL Server, Dell Technologies has your back! Let’s look at how this is done with PowerStore.
PowerStore configuration
It’s time to deep dive into how to configure this capability with Dell PowerStore and how to implement SQL Ledger. First, we need to configure the basis for WORM storage on PowerStore for the digest portion of SQL Ledger. This is done by creating a file system that is configured for FLR. Due to the write-once feature, this is typically a separate dedicated system. PowerStore supports multiple file systems on the same appliance, so dedicating a separate file system to WORM is not an issue.
WORM functionality is implemented by configuring PowerStore FLR. You have the option of FLR-Enterprise (FLR-E) or FLR-Compliance (FLR-C). FLR-C is the most restrictive.
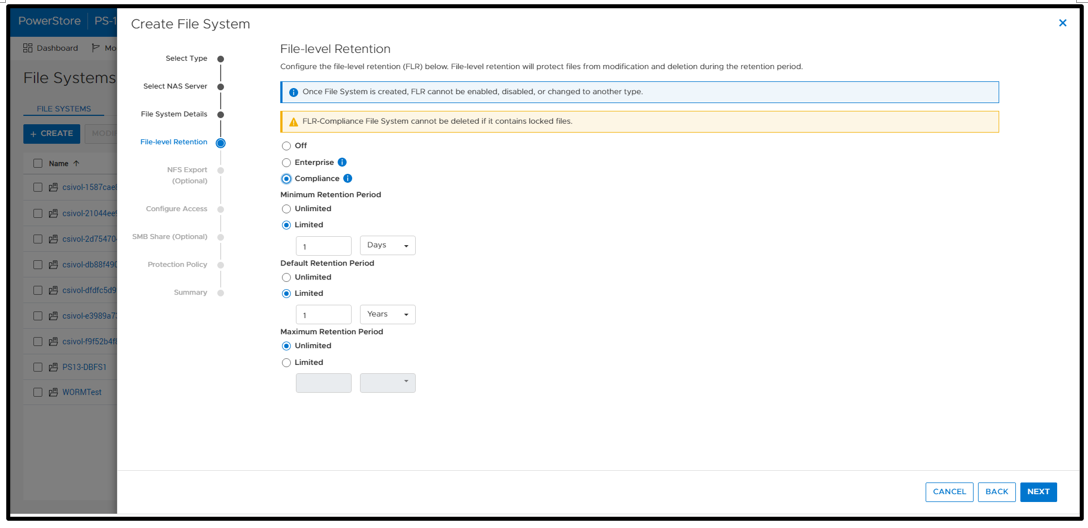
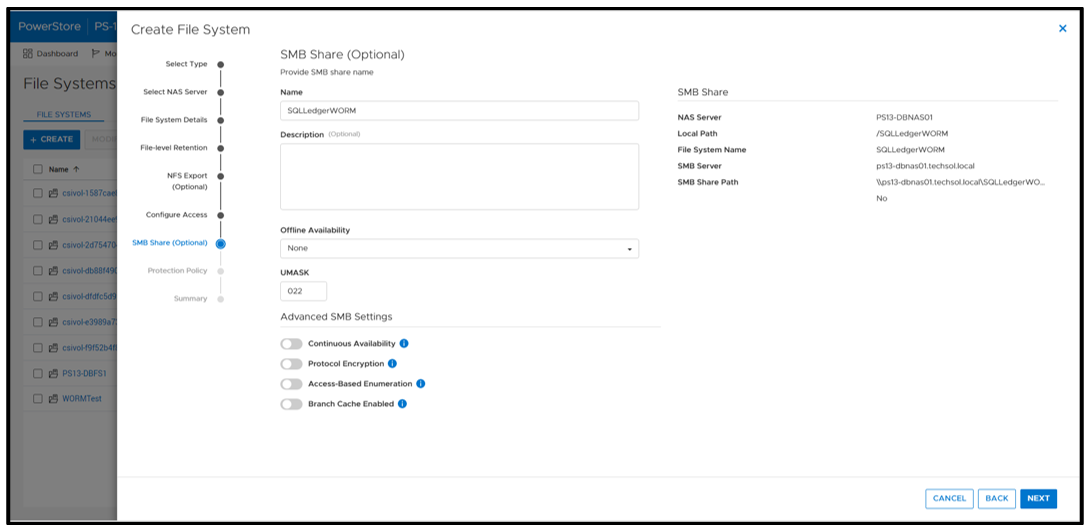
Next, configure an SMB (Server Message Block) Share for SQL Server to access the files. The settings here can be configured as needed; in this example, I am just using the defaults.
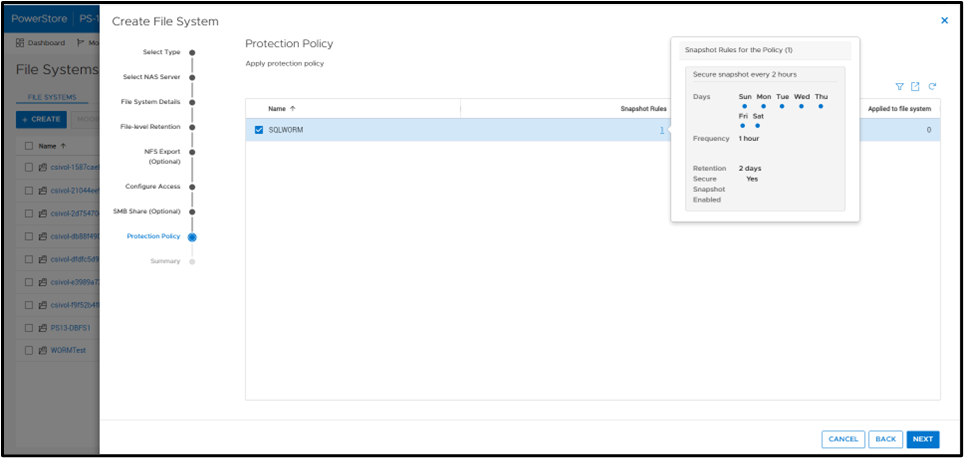
A best practice is to apply a protection policy. In this case, I am selecting a protection policy that has secure snapshot enabled. This will provide additional copies of the data that cannot be deleted prior to the retention period.
SQL Server database ops
Once the file system has been created, you can create a SQL Server database for ledger tables. Only ledger tables can exist in a ledger database. Therefore, it is common to create a separate database.
Database creation
The T-SQL CREATE DATABASE clause WITH LEDGER=ON indicates that it is a ledger database. Using a database name of SQLLedgerDemo, the most basic TSQL syntax would be:
CREATE DATABASE [SQLLedgerDemo] WITH LEDGER = ON
Ledger requires snapshot isolation to be enabled on the database with the following T-SQL command:
ALTER DATABASE SQLLedgerDemo SET ALLOW_SNAPSHOT_ISOLATION ON
Now that the database has been created, you can create either updatable or append-only ledger tables. These are database tables enhanced for SQL Ledger. Creating ledger tables is storage agnostic, so I am going to skip over it for brevity, but full instructions can be found in the Microsoft ledger documentation.
SQL Server ledger digest storage
The next step is to create the tamperproof database digest storage. This is where the verified block address and hash will be stored with a timestamp. The PowerStore file system that we just created will be used to fill this WORM storage device requirement. For it to operate correctly, we want to configure an append-only file. Because Windows does not have the ability to easily set this property, we can signal the PowerStore file system with FLR enabled that a file should be treated as append only.
First, create an empty file. This can be done in Windows File Explorer by right-clicking New and selecting Text Document. Next, right-click the file and select Properties. Select the Read-only attribute, click Apply, and then clear the Read-only attribute, click Apply, and then click OK.
Note: This action must be done on an empty file. It will not work once the file has been written to.
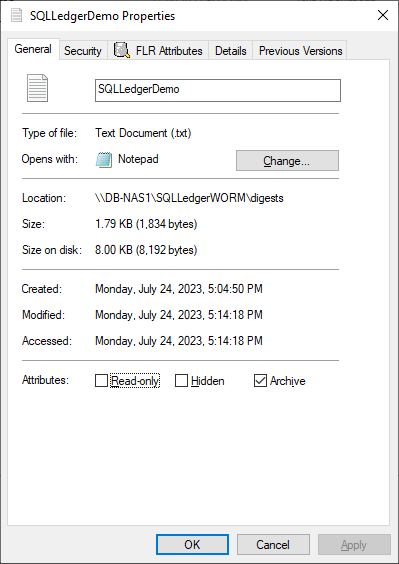
Notice that the dialog has an FLR Attributes tab. This is installed with the Dell FLR Toolkit and provides additional options not available in Windows, such as setting a file retention. Below we can also see that the FLR State of the file is set to Append-Only.
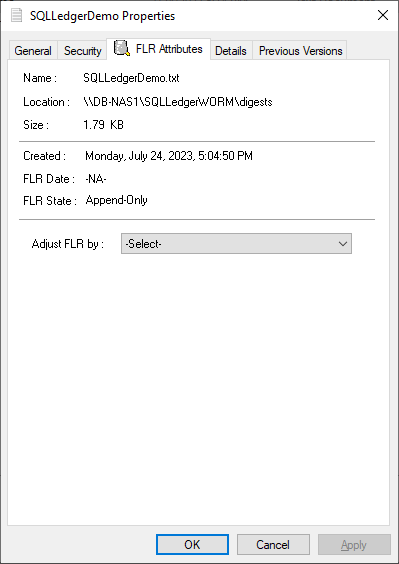
The FLR Toolkit can be downloaded from the Dell Support site. In addition to providing the ability to view the PowerStore FLR state, the FLR toolkit contains an FLR Explorer as well as additional command-line utilities.
The SQLLedgerDemo.txt file is now in the WORM state for SQL ledger digest storage: It is locked for delete and update, and can only be read or appended to.
For those of you running SQL Server on Linux, the process is the same to create the append only file. Create an empty file and then use the chmod command to remove and then reapply write permissions.
Before we get into populating the digest file, let’s understand what is being logged and how it is used. The digest file SQLLedgerDemo.txt will be populated by the output of a SQL Server stored procedure.
SQL Server ledger digest generation
Running the stored procedure sp_generate_database_ledger_digest on a ledger database produces the block ID and hash for our database verification. In this example, the output is:
{"database_name":"SQLLedgerDemo","block_id":0,"hash":"0xB222F775C84DC77BBA98B3C0E4E163484518102A10AE6D6DF216AFEDBD6D02E2","last_transaction_commit_time":"2023-07-24T13:52:20.3166667","digest_time":"2023-07-24T23:17:24.6960600"}This stored procedure is then run at regular intervals to produce a timestamped entry that can be used for validation.
SQL Server ledger digest verification
Using this info, another stored procedure, sp_verify_database_ledger, will recompute the hash for the given block ID to see if they match using the preceding output. You validate the block by passing in a previously generated digest to the stored procedure:
sp_verify_database_ledger N'{"database_name":"SQLLedgerDemo","block_id":0,"hash":"0xB222F775C84DC77BBA98B3C0E4E163484518102A10AE6D6DF216AFEDBD6D02E2","last_transaction_commit_time":"2023-07-24T13:52:20.3166667","digest_time":"2023-07-24T23:17:24.6960600"}'If it returns 0, there is a match; otherwise, you receive the following errors. You can verify this by modifying the hash value and calling sp_verify_database_ledger again, which will produce these errors.
Msg 37368, Level 16, State 1, Procedure sp_verify_database_ledger, Line 1 [Batch Start Line 10] The hash of block 0 in the database ledger does not match the hash provided in the digest for this block. Msg 37392, Level 16, State 1, Procedure sp_verify_database_ledger, Line 1 [Batch Start Line 10] Ledger verification failed.
Automating ledger digest generation and validation
Using these stored procedures, you put an automated process in place to generate a new ledger digest, append it to the file created above, and then verify that there is a match. If there is not a match, then you can go back to the last entry in the digest to determine when the corruption or tampering took place. If you're following the SQL Server Best Practices for PowerStore, you're taking regular snapshots of your database to enable fast point-in-time recovery. Because Dell PowerStore snapshots are secure and immutable, they serve as a fast recovery point, adding an additional layer of protection to critical data.
Because the generation and validation is driven with SQL Server stored procedures, automating the process using your favorite tools is extremely easy. Pieter Vanhove at Microsoft wrote a blog post, Ledger - Automatic digest upload for SQL Server without Azure connectivity, about how to automate the digest generation and verification using SQL Agent. The blog post contains sample scripts to create SQL Server Agent jobs to automate the entire process!
Summary
Your data can never be too secure. PowerStore secure snapshot capabilities add an additional another layer of security to any database. PowerStore FLR capabilities and SQL Server Ledger can be combined to further secure your database data and achieve compliance with the most stringent security requirements. Should the need arise, PowerStore secure, immutable snapshots can be used as a fast recovery point.
Author:
Doug Bernhardt
Sr. Principal Engineering Technologist
https://www.linkedin.com/in/doug-bernhardt-data/
Related Blog Posts

When Performance Testing Your Storage, Avoid Zeros!
Tue, 20 Feb 2024 17:37:42 -0000
|Read Time: 0 minutes
Storage benchmarking
Occasionally, Dell Technologies customers will want to run their own storage performance tests to ensure that their storage can meet the demands of their workload. Dell Technologies partners like Microsoft publish guidance on how to use benchmarking tools such as Diskspd to test various workloads. When running these tools on intelligent storage appliances like those offered by Dell Technologies, don’t forget to watch for how your test files are populated!
The first step in using performance benchmark tools is creating one or more test files for use when testing. The benchmark tool will then write and read data to and from these files, taking measurements to assess performance. An important detail that is often overlooked is how the test files are populated with data. If the files are not populated correctly, it can lead to misleading results and inaccurate conclusions.
We’ll use Diskspd as an example, however please note that most tools have the same default behavior. By default, when you run a Diskspd test, you need to specify several parameters, such as a test file location and size, IO block size, read/write ratio, queue depth, and so on.
If we open a test file created with default parameters and examine it with a hexadecimal editor, this is what it looks like:
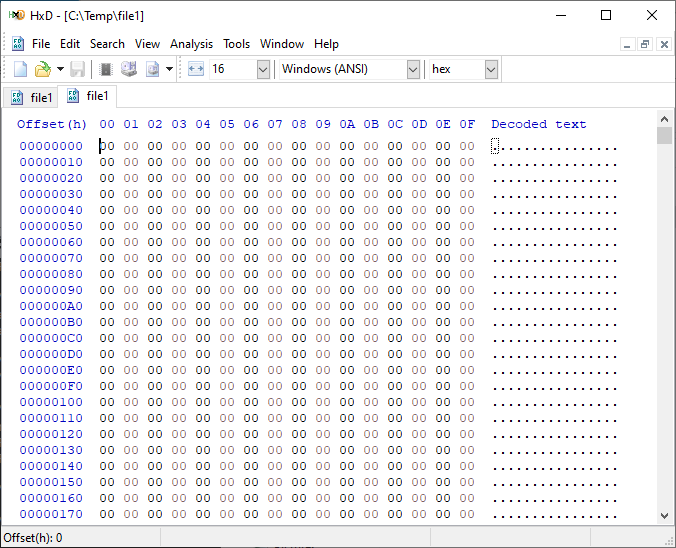
It is filled with nothing, 0x00 throughout the entire file – all “zeros”!
OK, so what is the problem?
When storage benchmarking tools create test files, they all use synthetic data for testing. This is fine when performing IO to a storage device with no “intelligence” built in because it will perform unaltered IO directly to the storage without the data content mattering. In the past, storage devices were simple and would read and write data as commanded, so the data content was irrelevant.
However, intelligent storage appliances such as those offered by Dell Technologies look at data differently. These products are built for efficiency and performance. Compression, deduplication, zero detection, and other optimizations may be used for space savings and performance. Since an empty file would obviously compress and deduplicate well, most of this IO will not access the disks in the same manner that a file of actual data would. It is also possible that other components in the data path would behave differently than normal when repeatedly presented with an identical piece of data.
It is safe to assume that these optimizations likely exist on data being stored in the cloud as well. Many cloud providers use intelligent storage appliances or have developed proprietary software to optimize storage.
The bottom line is that your test is likely inaccurate and may not represent your storage performance under more realistic conditions. While no synthetic test can reproduce a real workload 100%, you should try to make it as realistic as possible.
Mitigations
Some tools can initialize the test files with random data. Diskspd, for example, has parameters that can be added to create a buffer of random data to be used to write to the files or specify a source file of data. Regardless of the method used, you should inspect the test files to make sure that at a minimum, random data is being used. Zero-filled files and repeating patterns should be avoided.
Random data also may not achieve the expected behavior when compression and deduplication capabilities are used. More advanced testing tools such as vdbench can use target compression and deduplication capabilities independently.
Tips
Here are a few more tips when benchmarking storage performance to try to make it as realistic as possible:
- Use datasets of comparable size to real data workloads. Smaller datasets may fit entirely in the cache and skew results.
- Use IO sizes and read/write ratios that match your workload. If you are unsure of what your workload looks like, your Dell Technologies representative can assist you.
- Test with “multiples”. Intelligent storage assumes multiple files, volumes, and hosts. At a minimum, use multiple files and volumes. When testing larger block sizes, you may need to use multiple hosts and multiple host bus adapters to generate enough IO to test the full bandwidth capabilities of the storage.
- Start with a light load and scale up. Begin with one file, one worker thread, and a queue depth of one. In general, modern storage is designed for concurrency. Some amount of concurrency will be required to fully use storage system resources. As you scale up, observe the behavior. Pay attention to the measured latency. At some point as you scale the test, latency will start to increase rapidly.
- Excessive latency indicates a bottleneck. Once latencies are excessive, you have encountered a bottleneck somewhere. “Excessive” is a relative term when it comes to storage latency and is determined by your workload and business needs. Only scale the test to the point where the measured latency is within your acceptable range or above. Further increasing the test load will result in diminishing returns.
- Make sure the entire test environment can drive the wanted performance. The storage network and host configuration must be capable of desired performance levels and configured properly.
- Beware of outdated guidance. There are still articles online that are over a decade old that reference testing methods and best practices that were developed when storage was based on spinning disks. Those assumptions may be inaccurate on the latest storage devices and storage network protocols.
Summary
Storage performance benchmarking can be interesting and provide useful data points. That said, what is most important is how the storage supports actual business workloads and—most importantly—your unique workload. As such, there is no true substitute for testing with your actual workload.
Selecting the proper storage fit for your environment can be challenging, and Dell Technologies has the expertise to help. Leveraging tools like CloudIQ and LiveOptics, Dell Technologies can help you analyze your storage performance, explain storage metrics, and make recommendations to increase storage efficiency.
Author: Doug Bernhardt, Sr. Principal Engineering Technologist | LinkedIn

PowerStore validation with Microsoft Azure Arc-enabled data services updated to 1.25.0
Mon, 12 Feb 2024 20:04:34 -0000
|Read Time: 0 minutes
Microsoft Azure Arc-enabled data services allow you to run Azure data services on-premises, at the edge, or in the cloud. Arc-enabled data services align with Dell Technologies’ vision, by allowing you to run traditional SQL Server workloads on Kubernetes, on your infrastructure of choice. For details about a solution offering that combines PowerStore and Microsoft Azure Arc-enabled data services, see the white paper Dell PowerStore with Azure Arc-enabled Data Services.
Dell Technologies works closely with partners such as Microsoft to ensure the best possible customer experience. We are happy to announce that Dell PowerStore has been revalidated with the latest version of Azure Arc-enabled data services, 1.25.0.
Deploy with confidence
One of the deployment requirements for Azure Arc-enabled data services is that you must deploy on one of the validated solutions. At Dell Technologies, we understand that customers want to deploy solutions that have been fully vetted and tested. Key partners such as Microsoft understand this too, which is why they have created a validation program to ensure that the complete solution will work as intended.
By working through this process with Microsoft, Dell Technologies can confidently say that we have deployed and tested a full end-to-end solution and validated that it passes all tests.
The validation process
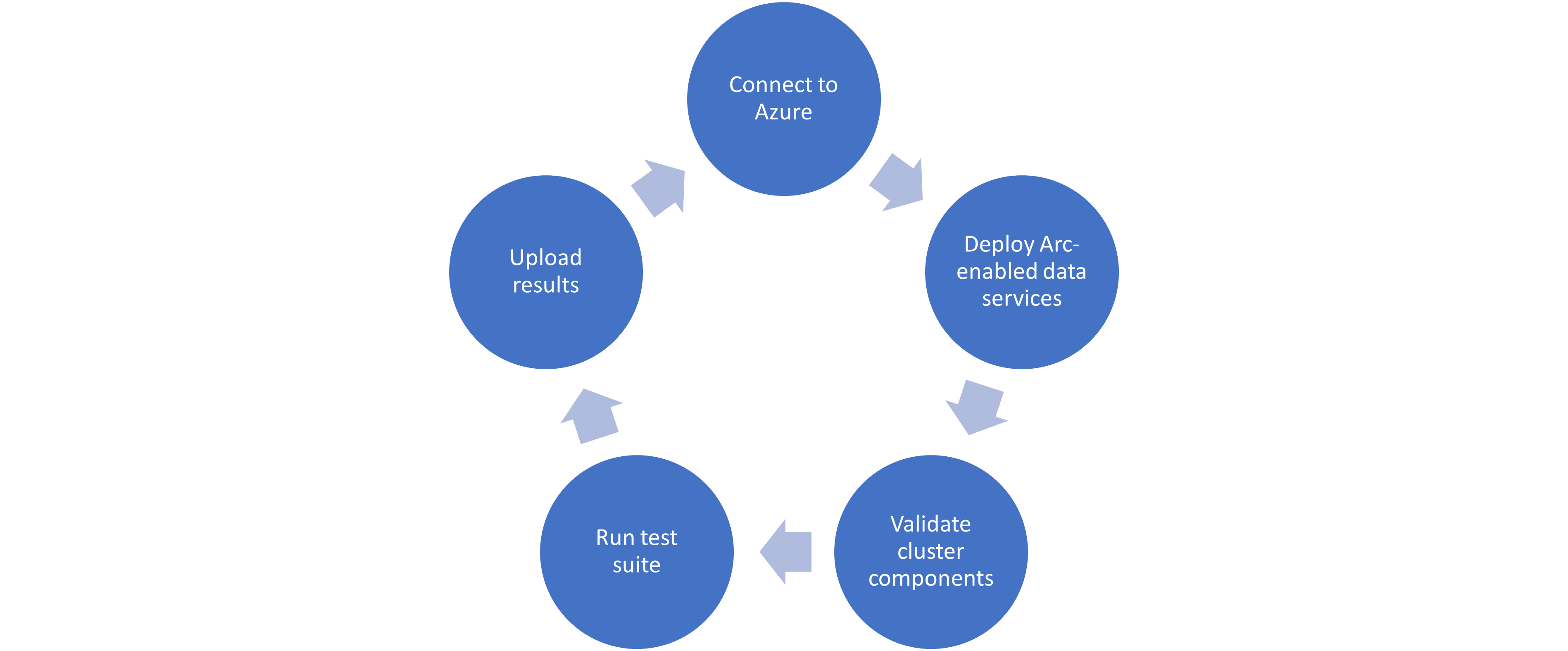
Microsoft haspublished tests for their continuous integration/continuous delivery (CI/CD) pipeline that partners and customers to run. For Microsoft to support an Arc-enabled data services solution, it must pass these tests. At a high level, these tests perform the following:
- Connect to an Azure subscription provided by Microsoft.
- Deploy the components for Arc-enabled data services, including SQL Managed Instance, using both direct and indirect connect modes.
- Validate Kubernetes (K8s), hosts, storage, container storage interface (CSI), and networking.
- Run Sonobuoy tests ranging from simple smoke tests to complex high-availability scenarios and chaos tests.
- Upload results to Microsoft for analysis.
When Microsoft accepts the results, they add the new or updated solution to their list of validated solutions. At that point, the solution is officially supported. This process is repeated as needed as new component versions are introduced. Complete details about the validation testing and links to the GitHub repositories are available here.
More to come
Stay tuned for more additions and updates from Dell Technologies to the list of validated solutions for Azure Arc-enabled data services. Dell Technologies is leading the way on hybrid solutions, proven by our work with partners such as Microsoft on these validation efforts. Reach out to your Dell Technologies representative for more information about these solutions and validations.
Author: Doug Bernhardt
Sr. Principal Engineering Technologist