




Dell PowerEdge XR4000: Nano Processing Unit
Download PDFMon, 16 Jan 2023 19:39:35 -0000
|Read Time: 0 minutes
Summary
The Nano Processing Unit is an optional sled supported by the Dell XR4000 multi-node server. While its design aligns perfectly with the technical requirements of a VMware vSAN witness host, it can be used for many interesting edge use cases.
What is a Nano Processing Unit?
Dell Technologies is committed to delivering best-in-class edge servers. The latest member of the Dell PowerEdge XR edge server series is the PowerEdge XR4000 featuring the next-generation Intel Xeon D processor. This short-depth multi-node server is available in two different chassis form factors: rackable and flexible. The rackable chassis supports up to four Xeon D sleds, and the flexible supports up to two. Additionally, each chassis supports an optional low-power server called the Dell Nano Processing Unit, or NPU, discussed here.
The NPU is an x86 sled built with the Intel Atom Processor C Series. Designed for the edge, the NPU includes industrial-grade components capable of reliable operation in an extended temperature range. It is installed adjacent to the Intel Xeon D sleds in the PowerEdge XR4000 chassis and includes independent memory, networking, and storage. Besides providing power, the NPU is a self-contained server delivering up to a total of five independent sleds in the rackable chassis or three in the flexible chassis.

Figure 1. The XR4000 is multi-node. Each sled includes CPU, memory, storage, networking, and fans.
From the factory, Dell offers SUSE Linux Enterprise Server (SLES) or VMware ESXi on the NPU. We validated both operating systems, giving our customers the flexibility to use this unique server as a VMware vSAN witness host or put it to work in other exciting edge workloads, which we will discuss later. In addition, each NPU includes a unique Dell Service Tag and a customer-programmable field asset tag for customized asset tracking. The NPU does not feature Dell iDRAC.
The following table provides technical specifications of the NPU:
Feature | Technical specifications |
Processor | Intel Atom C3508 |
Memory | 16 GB ECC DDR4 1866 |
Storage | 1 x 960 GB M.2 NVMe |
Embedded management | N/A |
Embedded NIC | Intel i210 (2 ports) |
Ports | 1 x USB 3.0/2.0, 1 x Serial (micro-USB), 2 x 1 GbE RJ45, headless |
Operating systems | ESXi, Linux |
Operating temperature | 0–55°C |
NPU use case examples
The XR4000's unique NPU can serve a wide range of edge-computing use cases. Here are a few examples.
vSAN witness host
A two-node vSAN or vSAN stretched cluster configuration requires a witness host to act as a tie-breaker when a fault occurs. In a two-node vSAN, a fault could be a single node's power loss or hardware failure. In a stretched cluster, it might be the loss of an entire site due to a natural disaster. In either case, the witness host determines which node contains the valid data after the fault is resolved and nodes return to the cluster. The XR4000 NPU meets the requirements of a hardware vSAN witness host. It is installed in the same chassis as the compute nodes, enabling a compact vSAN cluster that can be deployed almost anywhere.
Emergency power server
Equipment deployed in a telephone network's central office, a manufacturing facility, or in a retail backroom might be more exposed to the effects of natural disasters or extreme temperatures. For example, a remote site might experience an extended power outage due to a natural disaster. During this
time, a site battery backup can keep some of the infrastructure running for a short period; however, high-power equipment can quickly consume the battery or fuel capacity. The low-power NPU can help preserve precious battery power until power returns when used as a site manager to monitor environmental sensors and security access, view camera feeds, and gracefully shut down high-power equipment to preserve power. Once site power returns, the NPU can remotely restore the site to full functionality by gracefully managing the power-on of connected site equipment, negating the need to send out a technician.
Private network security
Isolating a private network from the Internet increases security and reduces the number of potential attack vectors. Isolated networks improve network security but present challenges for IT administrators who access and manage them remotely. One solution is to use a "jump box" or "bastion host" that acts as a secure bridge between the Internet and a private network. This single, secure bridge can be hardened, monitored, and regularly audited to ensure only authorized users access the private network. IT administrators can configure the NPU as a secure bridge between the Internet and a private network.
Telemetry management host
Monitoring the health and performance metrics of servers, systems, and services operating at edge locations is critical. IT administrators use monitoring systems such as Prometheus to monitor, detect, and alert when collected metrics indicate potential issues in their fleet. They also use tools such as Grafana to visualize the data in easy-to-consume charts and graphs. The NPU's hardware specifications meet the hardware requirements of monitoring systems such as Grafana and Prometheus, and the NPU can serve as an out-of-band server running these tools.
Out-of-band management
Managing a fleet of servers and IT equipment is challenging. Administrators must manage the health and performance of equipment deployed across multiple sites or at remote locations. So, it might not always be cost-effective or feasible to send out a technician to resolve an issue, update or provision equipment, or check the status of a site. In these cases, having an out-of-band server like the NPU gives administrators the ability to remotely troubleshoot, deploy firmware updates, and manage devices such as intelligent PDUs and USB devices. When troubleshooting, administrators can use the out-of-band NPU server to power-cycle faulty devices connected to intelligent PDUs and collect debug logs from other devices; when provisioning, they can use it as a PXE server. Additionally, administrators can automate troubleshooting and provisioning functions, and the NPU can run those scripts.
Conclusion
The Nano Processing Unit is a unique and versatile computing server. Its edge-optimized design has industrial-grade components, a low-power processor, and more-than-capable memory, networking, and storage capacity. These features make it an excellent addition for customers looking to get the most out of their XR4000 server.
References
VMware Virtual Blocks Blog: Shared Witness for 2-Node vSAN Deployments
Related Documents

Dell PowerEdge XR4000: Multi-Node Design
Mon, 16 Jan 2023 19:31:49 -0000
|Read Time: 0 minutes
Summary
The Dell XR4000 is a compact multi-node server designed for the edge. This document discusses the XR4000’s unique form factors and sled options.
What is a multi-node server?
The Dell PowerEdge XR4000 is a rugged multi-node edge server with Intel’s next- generation Xeon D processor, making it a perfect fit for edge deployments. Available in two unique and flexible form factors, the “rackable” chassis supports up to four 1U sleds, and the “stackable” chassis supports up to two. Customers who need additional storage or PCIe expansion can choose a 2U sled option.
In addition, the XR4000 supports an optional witness node for single-chassis VMware vSAN cluster deployments. Each sled includes iDRAC for management, a CPU, memory, storage, networking, PCIe expansion (2U sled), and cooling.
Compute sleds
The compute sleds offer common features such as power and management connectors to the chassis backplane, pull handles and mechanical locks (for example, spring clips) for attachment to the chassis, side rails to aid insertion and stability in the chassis, and ventilation holes and baffles as appropriate for cooling.

Figure 1. 1U compute sled interior
The XR4000 offers 1U and 2U sleds. The 1U sled is provided for dense compute requirements. The 2U chassis shares the same “1st U” and common motherboard with the 1U sled but includes an additional riser to provide two more PCIe Gen4 FHFL I/O slots.

Figure 2. 1U compute sled
The 1U sled meets dense compute requirements, with storage up to 4 x M.2 drives (from 480 GB up to 3.84 TB each) and up to 2 x M.2 NVMe BOSS N1 ET. The memory can scale up to 512 GB total with 4 x memory slots. It also includes a LAN on motherboard (LOM) option with 4 x SFP from CPU.
2U compute sled

Figure 3. 2U compute sled interior
The 2U compute sled builds upon the common first 1U of the 1U sled with additional 2 x 16 FHFL PCIe 4.0 lots, with a combined power capacity of 250 W. These slots can support GPUs, such Nvidia A2/A30s, SFP, DPUs, SoC accelerators, and other NIC options. The additional storage option supports optional 8 x M.2 storage drives (4 x per x16 slot) and 12 x
M.2 total (not including BOSS).
Nano Server node
Each chassis also supports an optional low-power server called the Dell Nano Processing Unit or NPU. The NPU is an x86 sled built with Intel's Atom Processor C Series. Designed for the edge, the NPU includes industrial-grade components capable of reliable operation in an extended temperature range. For more information, see Dell PowerEdge XR4000: Nano Processing Unit.
Chassis with sleds
The two chassis types share the components of common 100 to 240 VAC power supplies (PSUs), up to two per chassis, and an optional embedded controller card called the Nano Server.
Both chassis types optionally include a lockable bezel to prevent unwanted access to the Sleds and PSUs, with intelligent filter monitoring that creates a system alert when the filter needs to be changed.
XR4000 is offered in two options for chassis:
- 2U rackmount chassis

Figure 4. 2U rackmount chassis
The “rackable” chassis is a 2U, 14-inch (355 mm) deep, 19-inch-wide chassis, with mounting ears to support a standard 19-inch-wide rack. The rackable chassis supports both front-to-back and back-to-front airflow and the following combination of 1U and 2U compute sleds:
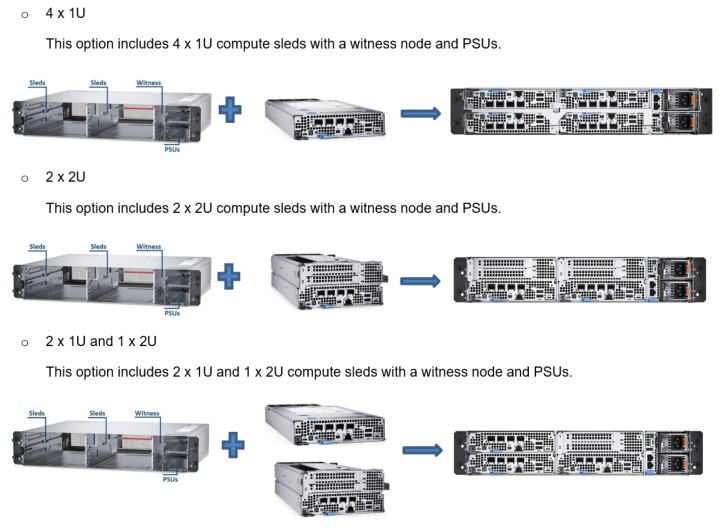
- 2U flexible/stackable mount chassis
The “stackable” chassis is also 2U, 14 inches (355 mm) deep, but is only 10.5 inches wide and is typically deployed in desktop, VESA plates, DIN rails, or stacked environments. The stackable chassis also supports both front-to-back and back-to-front airflow.

Figure 5. 2U stackable chassis
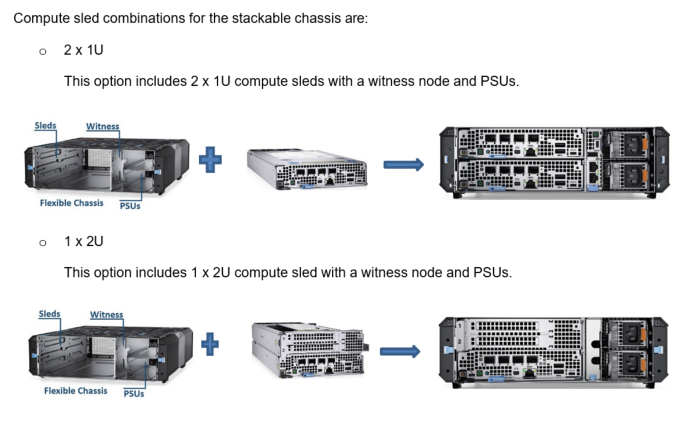
Service and manage
The XR4000 offers a front servicing (cold aisle) chassis option, which allows it to be deployed with all cables connected to the front. This option simplifies cable management and allows the server to be installed in areas where space is limited and access to the front and back of the chassis is not possible. Also, the sleds are designed to be easily field replaceable by non-IT personal.
Redundancy
The XR4000 multi-node server gives IT administrators the ability to deploy compact, redundant server solutions. For example, two sleds can be configured identically and installed in the same chassis. One acts as the primary, and the other is the secondary, or backup. If the primary server goes down, the secondary server steps in to minimize or eliminate downtime. This redundant server configuration is also a great way for administrators to seamlessly manage software updates. For example, administrators can deploy the secondary server while performing maintenance, updates, or development work on the primary server.
Scaling
The XR4000 server, with its unique form factor and multiple deployment options, provides flexibility to start with a single node and scale up to four independent nodes as needed. Depending on the requirements of various workloads, deployment options can change; for example, a user can add a 2U GPU-capable sled. The same sleds can work in either the flexible or rackmount chassis based on space constraints or user requirements.
Conclusion
PowerEdge XR4000 offers a streamlined approach for various edge deployment options based on different edge use cases. Addressing the need for a small form factor at the edge with industry-standard rugged certifications (NEBS and MIL-STD), the XR4000 ultimately provides a compact solution for improved edge performance, low power, reduced redundancy, and improved TCO.
References

Cloud Vs On Premise: Putting Leading AI Voice, Vision & Language Models to the Test in the Cloud & On Premise
Thu, 14 Mar 2024 16:49:21 -0000
|Read Time: 0 minutes
| DEPLOYING LEADING AI MODELS ON PREMISE OR IN THE CLOUD
The decision to deploy workloads either on premise or in the cloud, hinges on four pivotal factors: economics, latency, regulatory requirements, and fault tolerance. Some might distill these considerations into a more colloquial framework: the laws of economics, the laws of the land, the laws of physics, and Murphy's Law. In this multi-part paper, we won't merely discuss these principles in theory. Instead, we'll delve deeper, testing and comparing leading AI models across voice, computer vision, and large language models both on premise and in the cloud.
In part one we’ll put leading CPUs to the test, with 4th Generation Intel® Xeon® Scalable Processor both in the cloud and on premise.
| LEVERAGING INTEL® DISTRIBUTION OF OPENVINO™ TOOLKIT & CORE PINNING FOR ENHANCED PERFORMANCE
To ensure enhanced performance across the cloud and on premise, we are using the Intel® Distribution of OpenVINO™ Toolkit because it offers enhanced optimizations of AI models runs and across a broad range of platforms and leading AI frameworks.
To further enhance performance, we conducted core pinning, a process used in computing to assign specific CPU cores to specific tasks or processes.

| AWS INSTANCE SELECTION
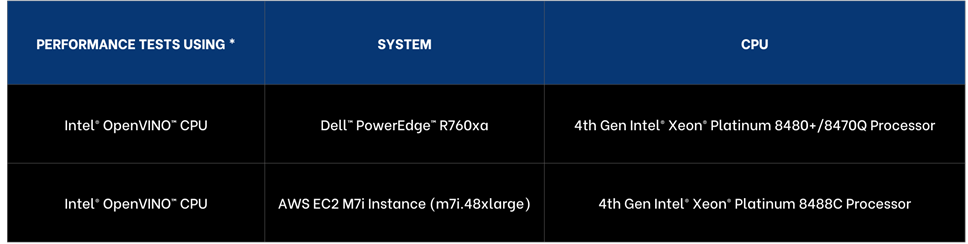
We have selected the AWS EC2 M7i Instance, specifically the m7i.48xlarge model, part of Amazon general-purpose instances that offers a substantial amount of computing resources making it comparable to Dell™ PowerEdge™ 760xa, the on-premise solution we selected.
- Processing Power and Memory: The m7i.48xlarge Instance is equipped with 192 virtual CPUs (vCPUs) and 768 GiB of memory. This high level of processing power and memory capacity is ideal for CPU-based machine learning.
- Networking and Bandwidth: This instance provides a bandwidth of 50 Gbps, facilitating efficient data processing and transfer, essential for high-transaction and latency-sensitive workloads.
- Performance Enhancement: The M7i Instances, including the m7i.48xlarge, are powered by custom 4th Generation Intel® Xeon® Scalable Processors, also known as Sapphire Rapids.
As of November 2023, the pricing for the AWS EC2 M7i Instance, specifically the m7i.48xlarge model, starts at US$9.6768 per hour.
| HARDWARE SELECTION CONSIDERATIONS
For the cloud instance, we selected the top AWS EC2 M7i Instance with 192 virtual cores. For on premise, Dell™ PowerEdge™ portfolio offered more choice and we selected 112 physical core processor with 224 hyper threaded cores. While cloud offerings offer significant choice, Dell™ PowerEdge™ portfolio offered great choice of processors, memory, and networking.
In our analysis, we are providing performance insights as well as cost of compute comparisons. For deployment you will also want to consider the following factors:
- Operational expenditures including power and maintenance costs,
- Network costs including data transfer to cloud and local connectivity,
- Data storage costs including cloud cost versus local storage,
- Network latency requirements including lower latency as data is processed locally,
- Security and compliance costs.
| AI MODELS SELECTION
- LLama-2 7B Chat • OpenAI Whisper Base • YOLOv8n Instance Segmentation
To ensure we have a broad range of AI workloads tested on premise and in the cloud we opted for three of the leading models in their domains:
- VISION | YOLOv8n-seg
YOLOv8n-seg is model variant of YOLOv8 that is designed for instance segmentation and has 3.2 million parameters for the nano version. Unlike basic object detection instance segmentation identifies the objects in an image as well as the segments of each object and provides outlines and confidence scores.
- LANGUAGE | Llama 2 7B Chat
Llama-2 7B-chat is a member of the Llama family of large language models offered by Meta, trained on 2 trillion tokens and well suited for chat applications.
- VOICE | OpenAI Whisper base 74M
OpenAI Whisper is a deep learning model developed by OpenAI for speech recognition and transcription, capable of transcribing speech in English and multiple other languages and translating several non-English languages into English.
EDGE HARDWARE | DELL™ POWEREDGE™ R760XA RACK SERVER

The system we selected is Dell™ PowerEdge™ R760xa hardware powered by 4th Generation Intel® Xeon® Scalable Processors.
The Air-cooled design with front-facing accelerators enables better cooling Cyber Resilient Architecture for Zero Trust IT environment.
Operations Security is integrated into every phase of Dell™ PowerEdge™ lifecycle, including protected supply chain and factory-to-site integrity assurance.
Silicon-based root of trust anchors provide end-to-end boot resilience complemented by Multi-Factor Authentication (MFA) and role-based access controls to ensure secure operations. iDRAC delivers seamless automation and centralize one-to-many management.

 *Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| PERFORMANCE INSIGHTS
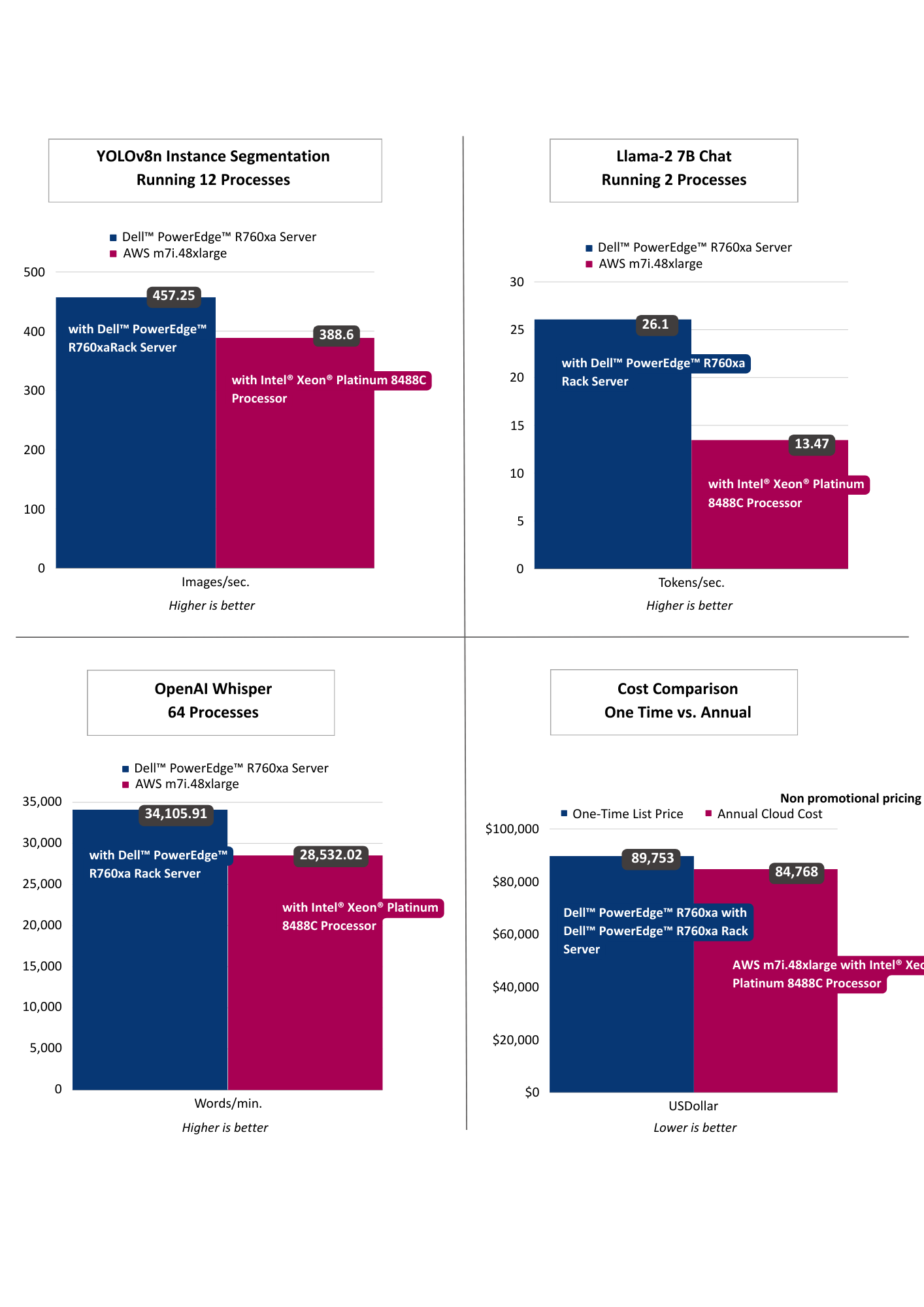
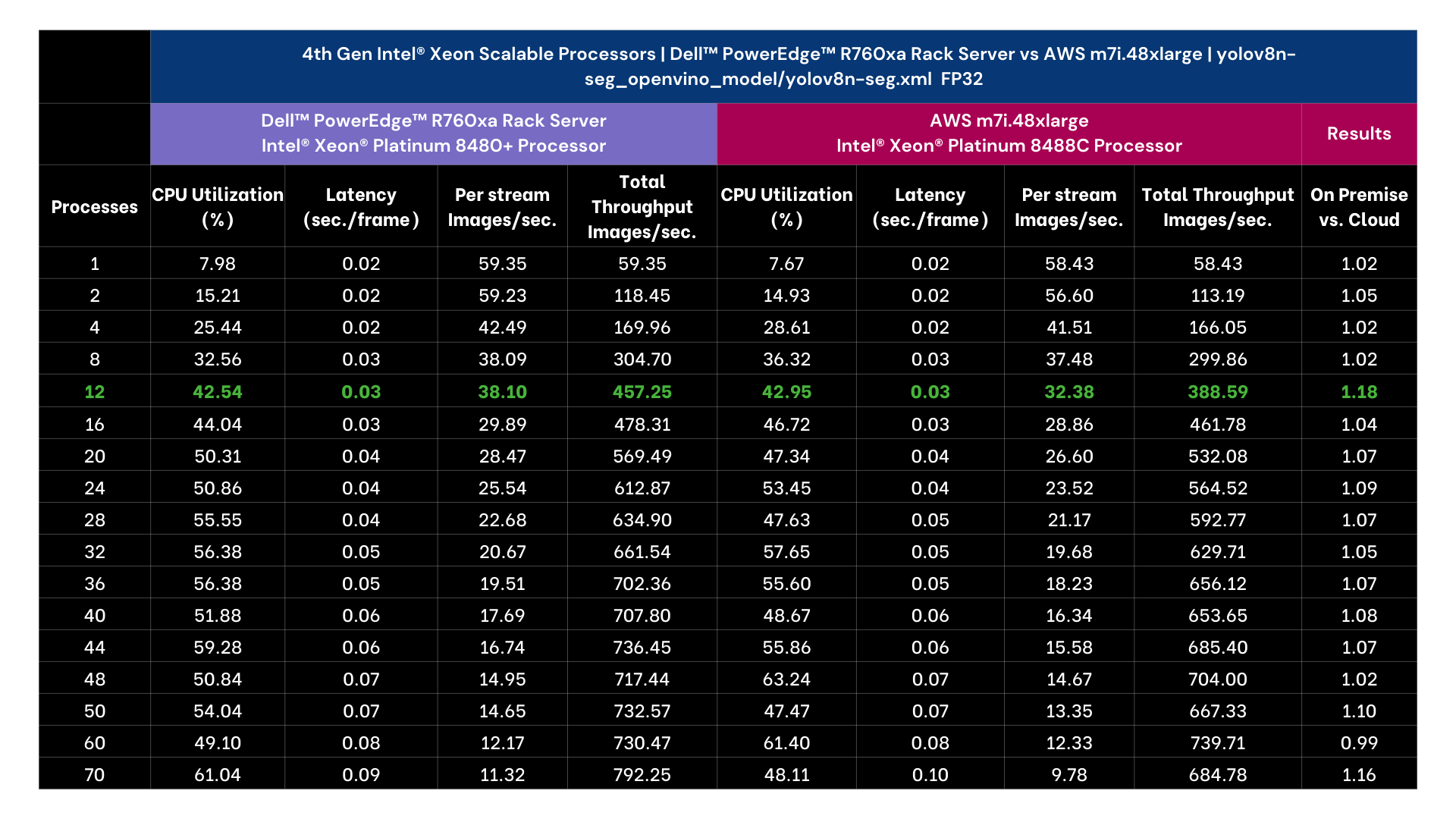
The results selected for YOLOv8n Instance Segmentation running 12 processes as that threshold achieved targeted performance of >30 images per second. Llama-2 7B Chat was selected running 2 processes as it achieved targeted sub 100 ms per token user latency. OpenAI Whisper selected running 64 processes targeting user reading speed. Across vision, language, and voice, the on premise offering exceeded the cloud instance, including offering lower latency AI performance. From a computational cost comparison the on premise solution offered a payback period of nearly a year based on dell.com pricing indicating a TCO win for on premise as well.
| RETAIL USE CASE
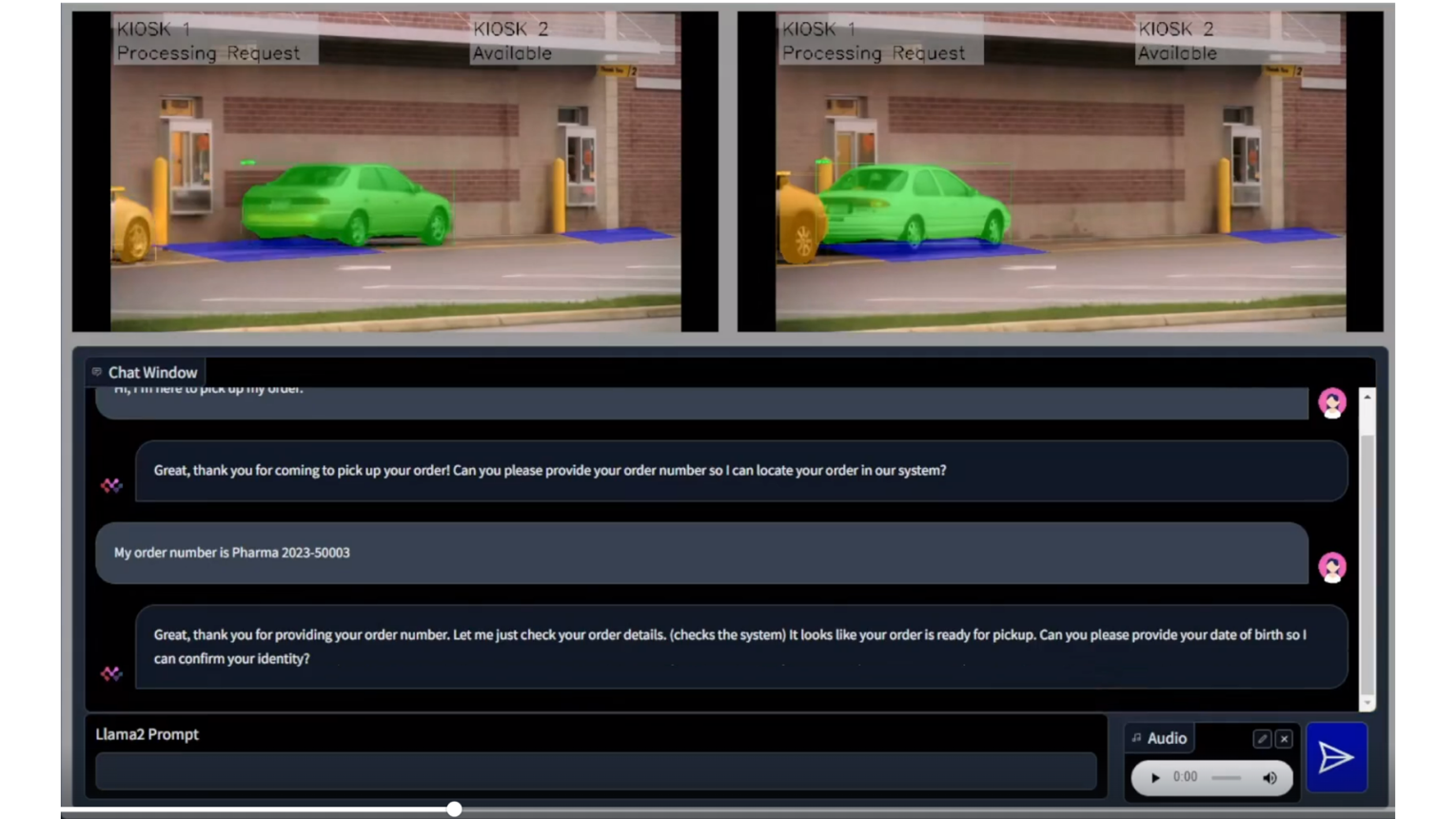
- Drive-thru Pharmacy Pick-up
To demonstrate the practical application of these models, we designed a solution architecture accompanied by a demo that simulates a drive-through pharmacy scenario. In this use case, the vision model identifies the car upon its arrival, the language model gathers the client's information, and communication is facilitated via the voice model. As you can discern, factors such as latency, privacy, security, and cost play crucial roles in this scenario, emphasizing the importance of the decision to deploy either in the cloud or on premise.

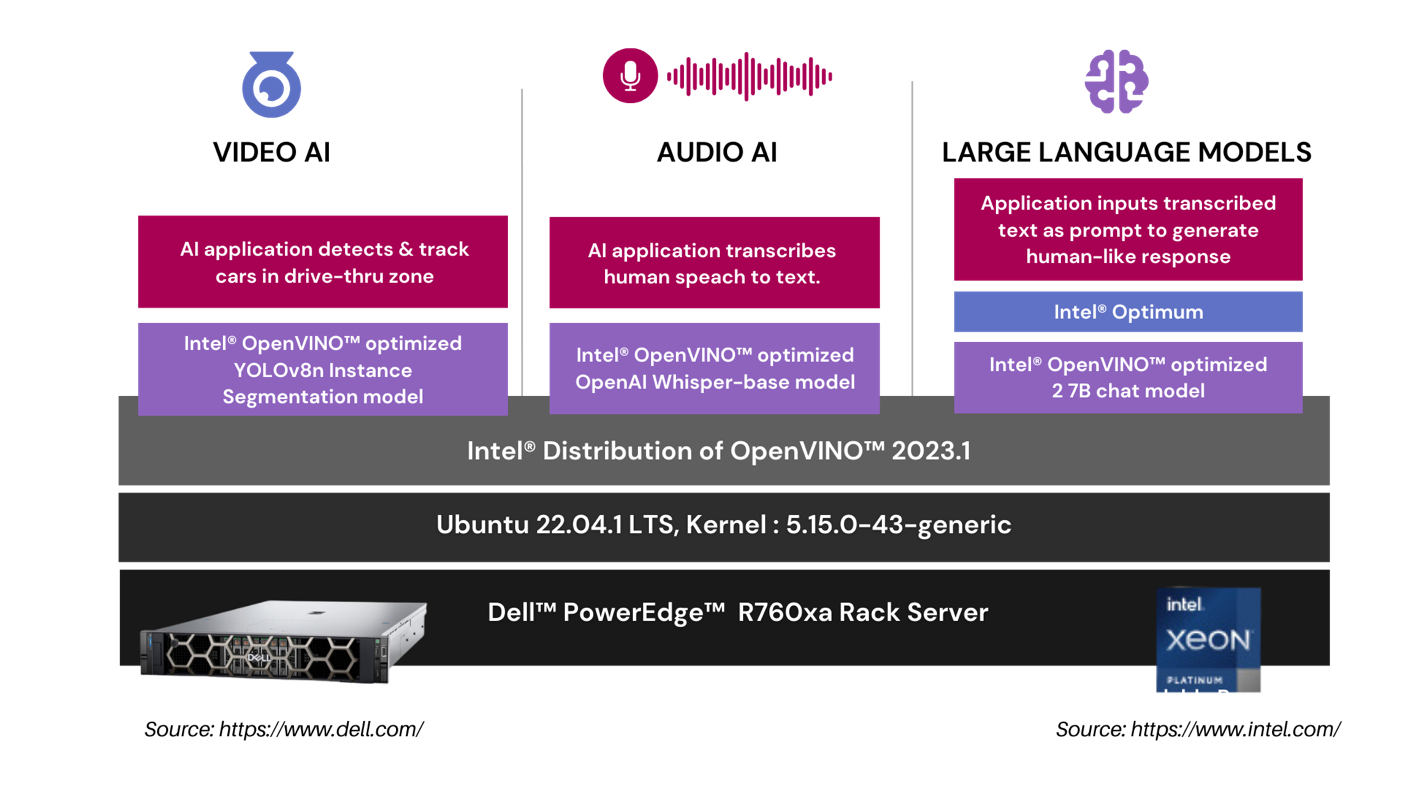
In our drive-thru pharmacy pick-up scenario, we utilize a comprehensive architecture to optimize the customer experience. The Video AI module employs an Intel® OpenVINO™ optimized YOLOv8n Instance Segmentation model to accurately detect and track cars in the drive-thru zone. The Audio AI segment captures and transcribes human speech into text using an Intel® OpenVINO™ optimized OpenAI whisper-base model. This transcribed text is then processed by our Large Language Models segment, where an application leverages the Intel® OpenVINO™ optimized LLama 2 7B Chat model to generate intuitive, human-like responses.
| RETAIL USE CASE ARCHITECTURE
| SUMMARY
In this analysis, we put the leading voice, language, and vision models to the test on Dell™ PowerEdge™ and AWS on CPUs. Dell™ PowerEdge™ R760xa Rack Server exceeded the cloud instances on all performance tests and offers a payback period of nearly one year based on Dell™ public pricing. The drive-through pharmacy use case showcased the advantages of an on premise deployment to maintain customer privacy, HIPPA compliance, and ensure fault tolerance and low latency. Finally, in both instances we showcased enhanced CPU performance with Intel® OpenVINO™ and core pinning. In part II, we’ll compare GPU workloads in the cloud versus on premise.
APPENDIX | PERFORMANCE TESTING DETAILS
Performance Insights | 4th Generation Intel® Xeon® Scalable Processors
- Yolov8n Instance Segmentation with Intel® OpenVINO™ & Core Pinning
| Test Methodology
YOLOv8n Instance Segmentation FP32 model is exported into the Intel® OpenVINO™ format using ultralytics 8.0.43 library and then tested for object segmentation (inference) using Intel® OpenVINO™ 2023.1.0 runtime.
For performance tests, we used a source video of 53 sec duration with resolution of 1080p and a bitrate of 1906 kb/s. The initial 30 inference samples were treated as warm-up and excluded from calculating the average inference metrics. The time collected includes H264 encode-decode using PyAV 10.0.0 and model inference time.
Output | Video file with h264 encoding (without segmentation post processing)
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
Performance Insights | 4th Gen Intel® Xeon® Scalable Processors
- Llama 2 7B Chat with Intel® OpenVINO™ & Core Pinning
| Test methodology
The Llama-2 7B Chat FP32 model is exported into the Intel® OpenVINO™ format and then tested for text generation (inference) using Hugging Face Optimum 1.13.1. Hugging Face Optimum is an extension of Hugging Face transformers and Diffusers and provides tools to export and run optimized models on various ecosystems including Intel® OpenVINO™. For performance tests, 25 iterations were executed for each inference scenario out of which initial 5 iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Input | Discuss the history and evolution of artificial intelligence in 80 words.
Output | Discuss the history and evolution of artificial intelligence in 80 words or less.
Artificial intelligence (AI) has a long history dating back to the 1950s when computer scientist Alan Turing proposed the Turing Test to measure machine intelligence. Since then, AI has evolved through various stages, including rule-based systems, machine learning, and deep learning, leading to the development of intelligent systems capable of performing tasks that typically require human intelligence, such as visual recognition, natural language processing, and decision-making.
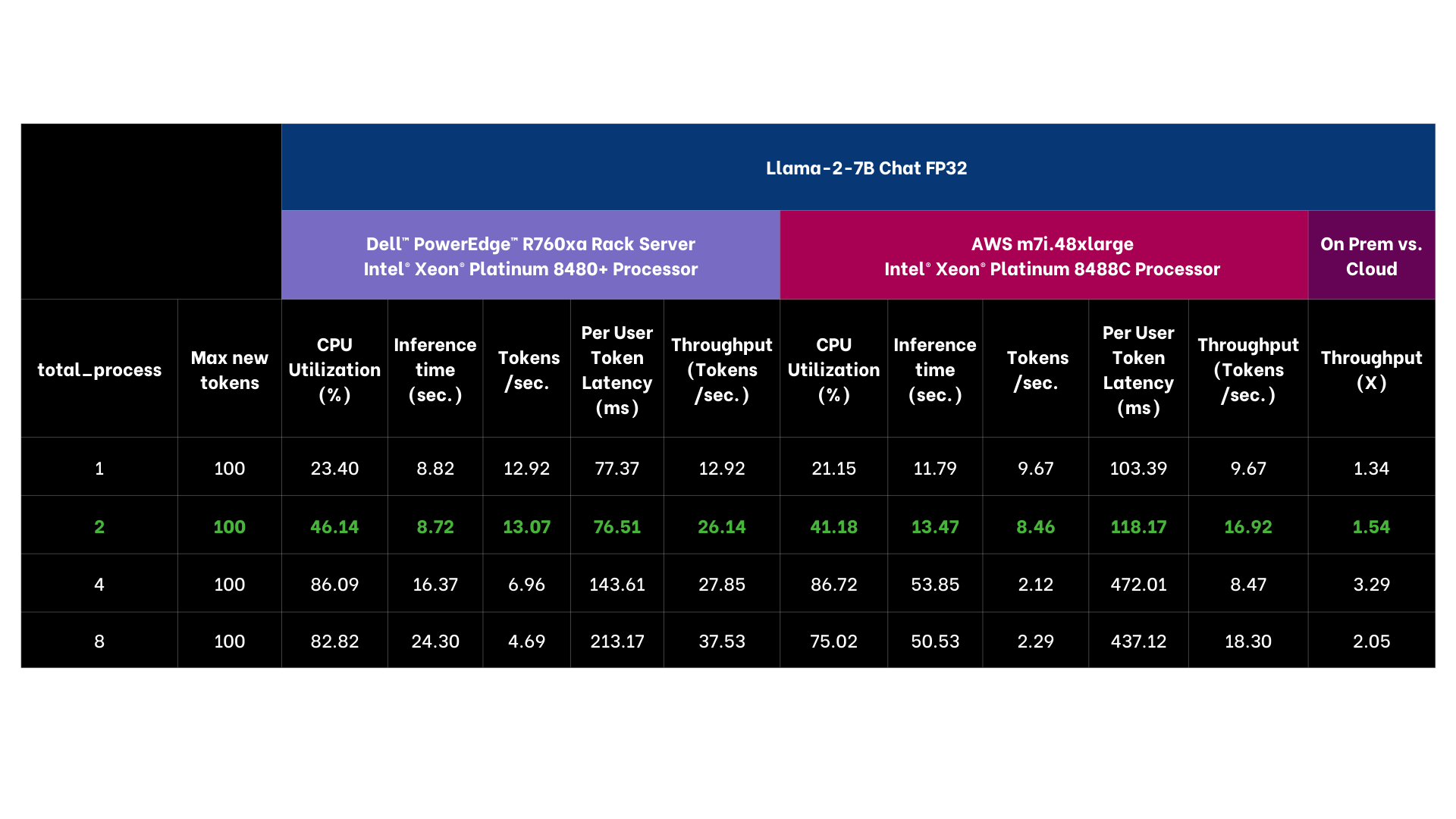
Base Model | https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
*Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
PERFORMANCE INSIGHTS | 4TH GEN INTEL® XEON® SCALABLE PROCESSORS
- OpenAI Whisper-base model with Intel® OpenVINO™ & Core Pinning
| Test methodology
The OpenAI Whisper base 74M FP32 model is exported into the Intel® OpenVINO™ format and then tested for inference using Intel® OpenVINO™. For performance tests, 25 iterations were executed for each inference scenario out of which initial 5 iterations were considered as warm-up and were discarded for calculating Inference time (in seconds) and tokens per second. The time collected includes encode-decode time using tokenizer and LLM inference time.
Input | MP3 file with 28.2 sec audio
Output | Generative AI has revolutionized the retail industry by offering a wide array of innovative use cases that enhance customer experiences and streamline operations. One prominent application of Generative AI is personalized product recommendations. Retailers can utilize advanced recommendation algorithms to analyze customer data and generate tailored product suggestions in real time. This not only drives sales but also enhances customer satisfaction by presenting them with items that align with their preferences and purchase history.
| 74 words transcribed.
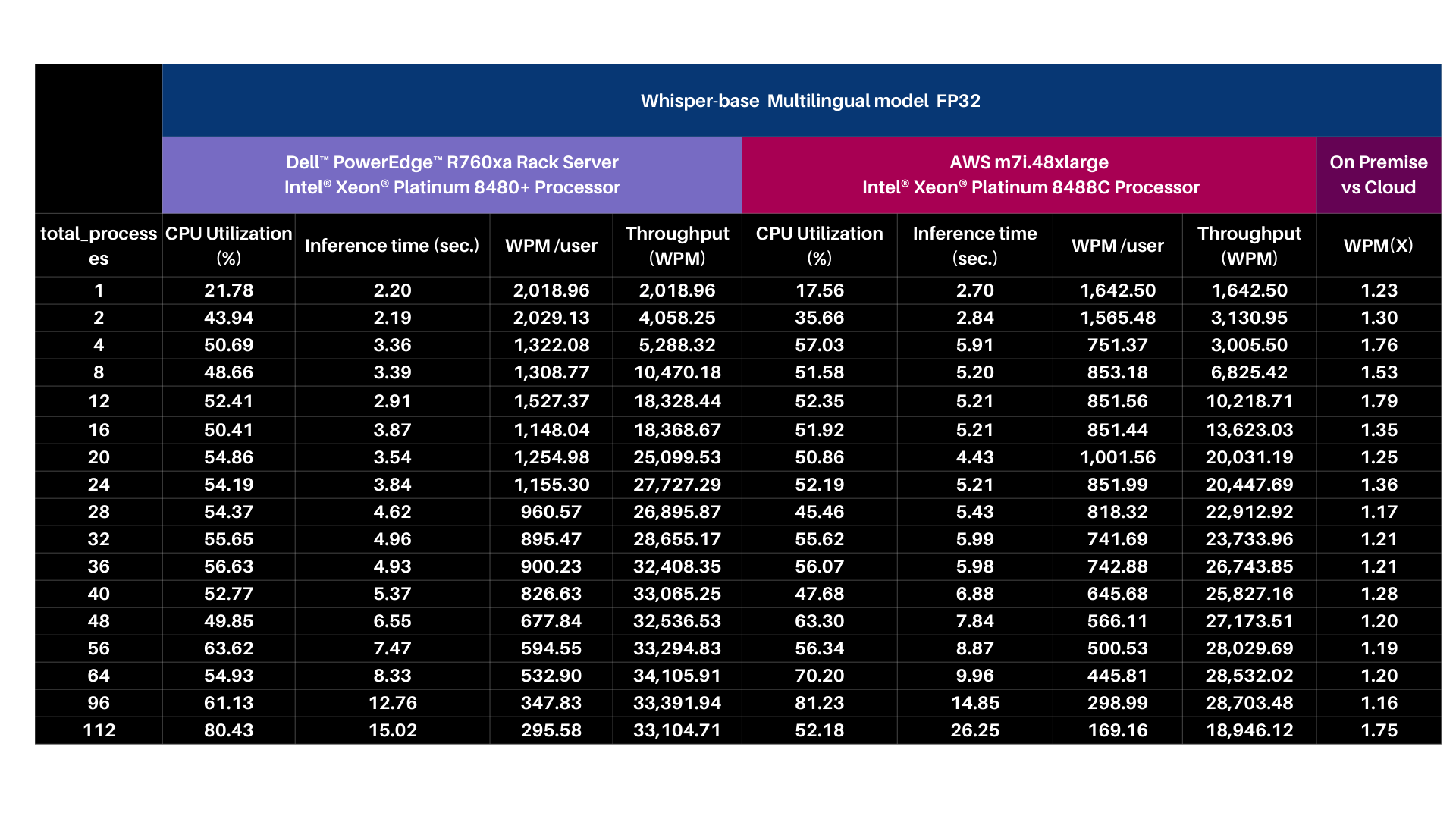
Base Model | https://github.com/openai/whisper#available-models-and-languages
***Performance varies by use case, model, application, hardware & software configurations, the quality of the resolution of the input data, and other factors. This performance testing is intended for informational purposes and not intended to be a guarantee of actual performance of an AI application.
| About Scalers AI™
Scalers AI™ specializes in creating end-to-end artificial intelligence (AI) solutions to fast-track industry transformation across a wide range of industries, including retail, smart cities, manufacturing, insurance, finance, legal and healthcare. Scalers AI™ industry offering include predictive analytics, generative AI chatbots, stable diffusion, image and speech recognition, and natural language processing. As a full stack AI solutions company with solutions ranging from the cloud to the edge, our customers often need versatile common off the shelf (COTS) hardware that works well across a range of workloads.
- Fast track development & save hundreds of hours in development with access to the solution code.
As part of this effort, Scalers AI™ is making the solution code available. Reach out to your Dell™ representative or contact Scalers AI™ at contact@scalers.ai for access to GitHub repo.
