




PowerFlex and CloudLink: A Powerful Data Security Combination
Mon, 17 Aug 2020 21:41:08 -0000
|Read Time: 0 minutes
Security and operational efficiency continue to top IT executives’ datacenter needs lists. Dell Technologies looks at the complete solution to achieve both so customers can focus on their business outcomes.
Dell Technologies’ PowerFlex is a software-defined storage platform designed to significantly reduce operational and infrastructure complexity, empowering organizations to move faster by delivering flexibility, elasticity, and simplicity with predictable performance and resiliency at scale. PowerFlex provides a unified fabric of compute and storage with scale out flexibility for either of these ingredients to match workload requirements with full lifecycle simplification provided by PowerFlex Manager. Dell Technologies’ CloudLink, data encryption and key management solution, supports workload deployments from edge to core to cloud, providing a perfect complement to the PowerFlex family that enables flexible encryption tailored to the modern datacenter’s needs.
With increasing regulatory and compliance requirements, more and more customers now realize how critical encryption is to securing their data centers and need solutions that are built into their platforms. CloudLink, integrated with PowerFlex, provides reliable data encryption and key management in one solution with the flexibility to satisfy most customer's needs.
Built-in, not bolt on
CloudLink’s rich feature set integrates directly into the PowerFlex platform allowing our customers access to CloudLink's encryption and key management functionality, including data at rest and data in motion encryption, full key lifecycle management, and lightweight multi-tenancy support.
- Encryption for PowerFlex
CloudLink provides software-based data encryption and a full set of key management capabilities for PowerFlex, including:
- Policy-based key release to ensure data is only unlocked in a safe environment
- Machine grouping to ensure consistent policy configuration across drives
- Full key lifecycle management to maintain proper encryption key hygiene
- Key Management for Self-Encrypting Drives (SED)
SEDs offer high performant hardware-based Data-at-Rest Encryption ensuring that all data in the deployment is safe from prying eyes. On a PowerFlex platform, CloudLink can manage the keys for each individual drive and store them safely within our encrypted vault where customers can leverage CloudLink's full key lifecycle management feature set. This option, also integrated and deployable with PowerFlex Manager, is ideal for your sensitive data assets that require high-performance.
- Encryption for Machines
Sometimes Data-at-Rest Encryption is not enough, and our customers need to encrypt their virtual machines. CloudLink provides VM encryption by deploying agents on the guest OS. CloudLink's agent encryption gives our customers the ability to move encrypted VMs throughout their environment making tasks such as replication, deployment to production from QA, or out to satellite offices, safer and easier.
CloudLink’s encryption for machines agent can also encrypt data volumes on bare metal servers allowing customers to keep their data safe even when deployed on legacy hardware.
- Key Management over KMIP
When 3rd party encryptors need external key management, they turn to solutions that implement KMIP (Key Management Interoperability Protocol). This open standard defines how encryptors and key managers communicate. CloudLink implements the KMIP protocol both as a client and a server to provide basic key storage and management for encryptors such as VMware’s native encryption features, or to plug-in to a customer’s existing keystore. These capabilities provide the flexibility required for today’s heterogenous environments.
Supporting the modern datacenter
There is a sea change occurring in data centers brought on by the relatively new technology of containers. 451 Research, a global research and advisory firm, released the results of its 2020 Voice of the Enterprise survey, which indicates that as companies consider the move to containerized deployments, security and compliance concerns are top of mind. However, for so many of the new container technology products from which to choose, proper security is not built-in.
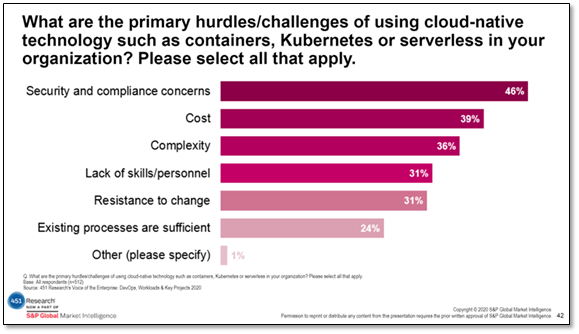
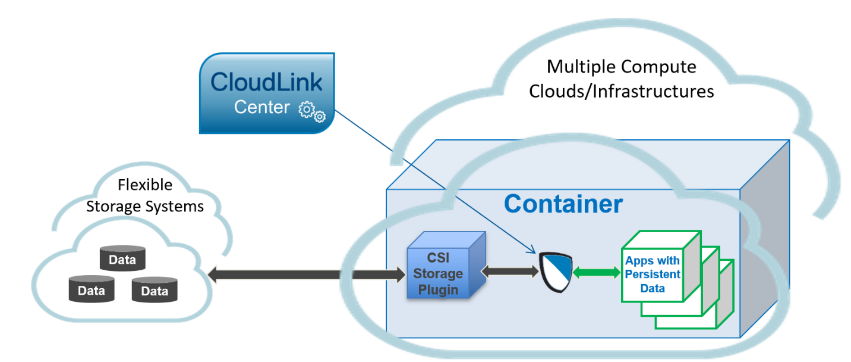
Given the extreme mobility of containers, keeping customers’ data safe as applications move throughout a deployment – especially within the cloud – is a challenge. To address this gap, we introduced file volume encryption for Kubernetes container deployments in our CloudLink 7.0 release, which has been validated with PowerFlex 3.5. Our container encryption functionality is built on the same full lifecycle key management and agent-based encryption architectural model that we currently offer for PowerFlex. We deploy an agent within the container such that it sits directly on the data path. As the data is saved, we intercept it and make sure it is encrypted as it travels to and then comes to rest in the data store.
Data security doesn’t need to mean complex management
Hand in hand with PowerFlex, CloudLink provides data encryption and key management with unmatched flexibility, superior reliability, and simple and efficient operations complete with support from Dell as a complete solution. The PowerFlex Manager is a comprehensive IT operations and lifecycle management tool that drastically simplifies management and ongoing operation. CloudLink is integrated into this tool to make the deployment of the CloudLink agent a natural part the PowerFlex management framework.
Are you interested in PowerFlex and CloudLink? Please visit our websites for PowerFlex or CloudLink or reach out to your Dell Technologies sales representative for help.
Related Blog Posts

OneFS and HTTP Security

Mon, 22 Apr 2024 20:35:30 -0000
|Read Time: 0 minutes
To enable granular HTTP security configuration, OneFS provides an option to disable nonessential HTTP components selectively. This can help reduce the overall attack surface of your infrastructure. Disabling a specific component’s service still allows other essential services on the cluster to continue to run unimpeded. In OneFS 9.4 and later, you can disable the following nonessential HTTP services:
Service | Description |
PowerScaleUI | The OneFS WebUI configuration interface. |
Platform-API-External | External access to the OneFS platform API endpoints. |
Rest Access to Namespace (RAN) | REST-ful access by HTTP to a cluster’s /ifs namespace. |
RemoteService | Remote Support and In-Product Activation. |
SWIFT (deprecated) | Deprecated object access to the cluster using the SWIFT protocol. This has been replaced by the S3 protocol in OneFS. |
You can enable or disable each of these services independently, using the CLI or platform API, if you have a user account with the ISI_PRIV_HTTP RBAC privilege.
You can use the isi http services CLI command set to view and modify the nonessential HTTP services:
# isi http services list ID Enabled ------------------------------ Platform-API-External Yes PowerScaleUI Yes RAN Yes RemoteService Yes SWIFT No ------------------------------ Total: 5
For example, you can easily disable remote HTTP access to the OneFS /ifs namespace as follows:
# isi http services modify RAN --enabled=0
You are about to modify the service RAN. Are you sure? (yes/[no]): yes
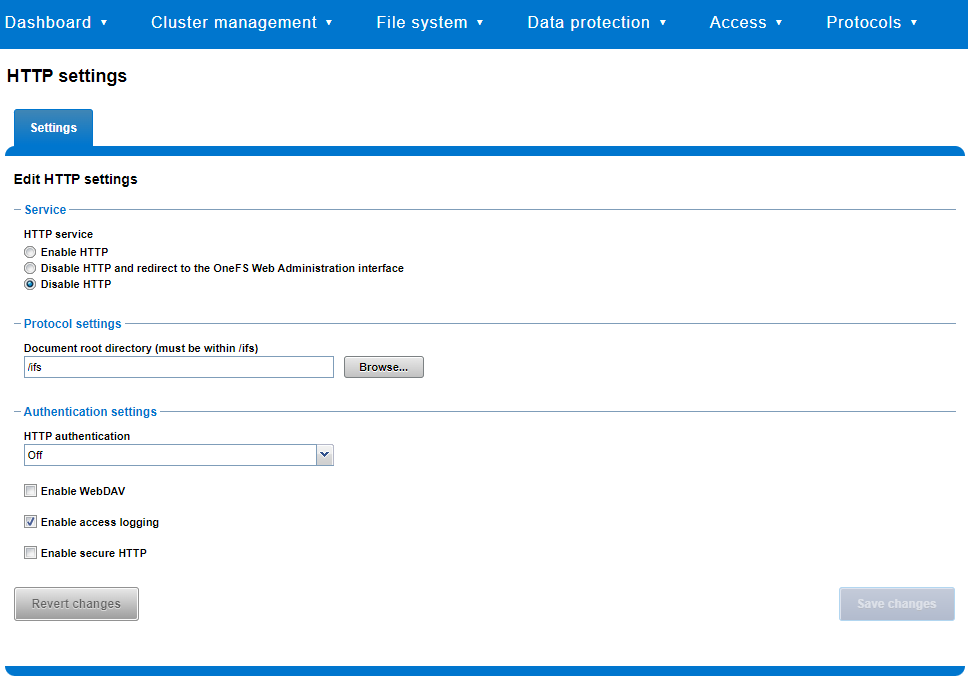
Similarly, you can also use the WebUI to view and edit a subset of the HTTP configuration settings, by navigating to Protocols > HTTP settings:
That said, the implications and impact of disabling each of the services is as follows:
Service | Disabling impacts |
WebUI | The WebUI is completely disabled, and access attempts (default TCP port 8080) are denied with the warning Service Unavailable. Please contact Administrator. If the WebUI is re-enabled, the external platform API service (Platform-API-External) is also started if it is not running. Note that disabling the WebUI does not affect the PlatformAPI service. |
Platform API | External API requests to the cluster are denied, and the WebUI is disabled, because it uses the Platform-API-External service. Note that the Platform-API-Internal service is not impacted if/when the Platform-API-External is disabled, and internal pAPI services continue to function as expected. If the Platform-API-External service is re-enabled, the WebUI will remain inactive until the PowerScaleUI service is also enabled. |
RAN | If RAN is disabled, the WebUI components for File System Explorer and File Browser are also automatically disabled. From the WebUI, attempts to access the OneFS file system explorer (File System > File System Explorer) fail with the warning message Browse is disabled as RAN service is not running. Contact your administrator to enable the service. This same warning also appears when attempting to access any other WebUI components that require directory selection. |
RemoteService | If RemoteService is disabled, the WebUI components for Remote Support and In-Product Activation are disabled. In the WebUI, going to Cluster Management > General Settings and selecting the Remote Support tab displays the message The service required for the feature is disabled. Contact your administrator to enable the service. In the WebUI, going to Cluster Management > Licensing and scrolling to the License Activation section displays the message The service required for the feature is disabled. Contact your administrator to enable the service. |
SWIFT | Deprecated object protocol and disabled by default. |
You can use the CLI command isi http settings view to display the OneFS HTTP configuration:
# isi http settings view Access Control: No Basic Authentication: No WebHDFS Ran HTTPS Port: 8443 Dav: No Enable Access Log: Yes HTTPS: No Integrated Authentication: No Server Root: /ifs Service: disabled Service Timeout: 8m20s Inactive Timeout: 15m Session Max Age: 4H Httpd Controlpath Redirect: No
Similarly, you can manage and change the HTTP configuration using the isi http settings modify CLI command.
For example, to reduce the maximum session age from four to two hours:
# isi http settings view | grep -i age Session Max Age: 4H # isi http settings modify --session-max-age=2H # isi http settings view | grep -i age Session Max Age: 2H
The full set of configuration options for isi http settings includes:
Option | Description |
--access-control <boolean> | Enable Access Control Authentication for the HTTP service. Access Control Authentication requires at least one type of authentication to be enabled. |
--basic-authentication <boolean> | Enable Basic Authentication for the HTTP service. |
--webhdfs-ran-https-port <integer> | Configure Data Services Port for the HTTP service. |
--revert-webhdfs-ran-https-port | Set value to system default for --webhdfs-ran-https-port. |
--dav <boolean> | Comply with Class 1 and 2 of the DAV specification (RFC 2518) for the HTTP service. All DAV clients must go through a single node. DAV compliance is NOT met if you go through SmartConnect, or using 2 or more node IPs. |
--enable-access-log <boolean> | Enable writing to a log when the HTTP server is accessed for the HTTP service. |
--https <boolean> | Enable the HTTPS transport protocol for the HTTP service. |
--https <boolean> | Enable the HTTPS transport protocol for the HTTP service. |
--integrated-authentication <boolean> | Enable Integrated Authentication for the HTTP service. |
--server-root <path> | Document root directory for the HTTP service. Must be within /ifs. |
--service (enabled | disabled | redirect | disabled_basicfile) | Enable/disable the HTTP Service or redirect to WebUI or disabled BasicFileAccess. |
--service-timeout <duration> | The amount of time (in seconds) that the server will wait for certain events before failing a request. A value of 0 indicates that the service timeout value is the Apache default. |
--revert-service-timeout | Set value to system default for --service-timeout. |
--inactive-timeout <duration> | Get the HTTP RequestReadTimeout directive from both the WebUI and the HTTP service. |
--revert-inactive-timeout | Set value to system default for --inactive-timeout. |
--session-max-age <duration> | Get the HTTP SessionMaxAge directive from both WebUI and HTTP service. |
--revert-session-max-age | Set value to system default for --session-max-age. |
--httpd-controlpath-redirect <boolean> | Enable or disable WebUI redirection to the HTTP service. |
Note that while the OneFS S3 service uses HTTP, it is considered a tier-1 protocol, and as such is managed using its own isi s3 CLI command set and corresponding WebUI area. For example, the following CLI command forces the cluster to only accept encrypted HTTPS/SSL traffic on TCP port 9999 (rather than the default TCP port 9021):
# isi s3 settings global modify --https-only 1 –https-port 9921 # isi s3 settings global view HTTP Port: 9020 HTTPS Port: 9999 HTTPS only: Yes S3 Service Enabled: Yes
Additionally, you can entirely disable the S3 service with the following CLI command:
# isi services s3 disable The service 's3' has been disabled.
Or from the WebUI, under Protocols > S3 > Global settings:
Author: Nick Trimbee

PowerScale Security Baseline Checklist

Tue, 16 Apr 2024 22:36:48 -0000
|Read Time: 0 minutes
As a security best practice, a quarterly security review is recommended. Forming an aggressive security posture for a PowerScale cluster is composed of different facets that may not be applicable to every organization. An organization’s industry, clients, business, and IT administrative requirements determine what is applicable. To ensure an aggressive security posture for a PowerScale cluster, use the checklist in the following table as a baseline for security.
This table serves as a security baseline and must be adapted to specific organizational requirements. See the Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub white paper for a comprehensive explanation of the concepts in the table below.
Further, cluster security is not a single event. It is an ongoing process: Monitor this blog for updates. As new updates become available, this post will be updated. Consider implementing an organizational security review on a quarterly basis.
The items listed in the following checklist are not in order of importance or hierarchy but rather form an aggressive security posture as more features are implemented.
Security feature | Configuration | References and notes | Complete (Y/N) | Notes |
Data at Rest Encryption | Implement external key manager with SEDs | Overview | Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub |
|
|
Data in flight encryption | Encrypt protocol communication and data replication | Dell PowerScale: Solution Design and Considerations for SMB Environments (delltechnologies.com)
PowerScale OneFS NFS Design Considerations and Best Practices | Dell Technologies Info Hub
Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations | Dell Technologies Info Hub |
|
|
Role Based Access Control (RBAC) | Assign the lowest possible access required for each role | PowerScale OneFS Authentication, Identity Management, and Authorization | Dell Technologies Info Hub |
|
|
Multifactor authentication |
|
|
| |
Cybersecurity | PowerScale Cyber Protection Suite Reference Architecture | Dell Technologies Info Hub |
|
| |
Monitoring | Monitor cluster activity |
|
|
|
Cluster configuration backup and recovery | Ensure quarterly cluster backups | Backing Up and Restoring PowerScale Cluster Configurations in OneFS 9.7 | Dell Technologies Info Hub |
|
|
Secure Boot | Configure PowerScale Secure Boot | Overview | Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub |
|
|
Auditing | Configure auditing |
|
| |
Custom applications | Create a custom application for cluster monitoring | GitHub - Isilon/isilon_sdk: Official repository for isilon_sdk |
|
|
SED and cluster Universal Key rekey | Set a frequency to automatically rekey the Universal Key for SEDs and the cluster | Cluster services rekey | Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub |
|
|
Perform a quarterly security review | Review all organizational security requirements and current implementation. Check this paper and checklist for updates: |
|
| |
General cluster security best practices | See the best practices section of the Security Configuration Guide for the relevant release, at PowerScale OneFS Info Hubs | Dell US |
|
| |
Login, authentication, and privileges best practices |
|
| ||
SNMP security best practices |
|
| ||
SSH security best practices |
|
| ||
Data-access protocols best practices |
|
| ||
Web interface security best practices |
|
| ||
Anti-virus | PowerScale: AntiVirus Solutions | Dell Technologies Info Hub |
|
| |
Author: Aqib Kazi – Senior Principal Engineering Technologist