

Assets

Dell PowerScale OneFS Introduction for NetApp Admins
Fri, 26 Apr 2024 17:09:51 -0000
|Read Time: 0 minutes
For enterprises to harness the advantages of advanced storage technologies with Dell PowerScale, a transition from an existing platform is necessary. Enterprises are challenged by how the new architecture will fit into the existing infrastructure. This blog post provides an overview of PowerScale architecture, features, and nomenclature for enterprises migrating from NetApp ONTAP.
PowerScale overview
The PowerScale OneFS operating system is based on a distributed architecture, built from the ground up as a clustered system. Each PowerScale node provides compute, memory, networking, and storage. The concepts of controllers, HA, active/standby, and disk shelves are not applicable in a pure scale-out architecture. Thus, when a node is added to a cluster, the cluster performance and capacity increase collectively.
Due to the scale-out distributed architecture with a single namespace, single volume, single file system, and one single pane of management, the system management is far simpler than with traditional NAS platforms. In addition, the data protection is software-based rather than RAID-based, eliminating all the associated complexities, including configuration, maintenance, and additional storage utilization. Administrators do not have to be concerned with RAID groups or load distribution.
NetApp’s ONTAP storage operating system has evolved into a clustered system with controllers. The system includes ONTAP FlexGroups composed of aggregates and FlexVols across nodes.
OneFS is a single volume, which makes cluster management simple. As the cluster grows in capacity, the single volume automatically grows. Administrators are no longer required to migrate data between volumes manually. OneFS repopulates and balances data between all nodes when a new node is added, making the node part of the global namespace. All the nodes in a PowerScale cluster are equal in the hierarchy. Drives share data intranode and internode.
PowerScale is easy to deploy, operate, and manage. Most enterprises require only one full-time employee to manage a PowerScale cluster.
For more information about the PowerScale OneFS architecture, see PowerScale OneFS Technical Overview and Dell PowerScale OneFS Operating System.
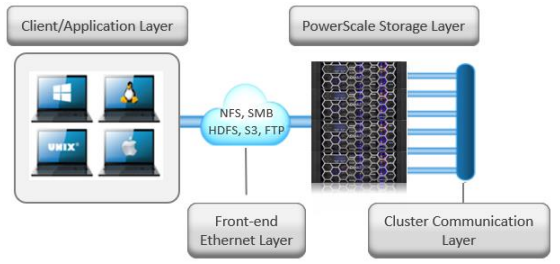
Figure 1. Dell PowerScale scale-out NAS architecture
OneFS and NetApp software features
The single volume and single namespace of PowerScale OneFS also lead to a unique feature set. Because the entire NAS is a single file system, the concepts of FlexVols, shares, qtrees, and FlexGroups do not apply. Each NetApp volume has specific properties associated with limited storage space. Adding more storage space to NetApp ONTAP could be an onerous process depending on the current architecture. Conversely, on a PowerScale cluster, as soon as a node is added, the cluster is rebalanced automatically, leading to minimal administrator management.
NetApp’s continued dependence on volumes creates potential added complexity for storage administrators. From a software perspective, the intricacies that arise from the concept of volumes span across all the features. Configuring software features requires administrators to base decisions on the volume concept, limiting configuration options. The volume concept is further magnified by the impacts on storage utilization.
The fact that OneFS is a single volume means that many features are not volume dependent but, rather, span the entire cluster. SnapshotIQ, NDMP backups, and SmartQuotas do not have limits based on volumes; instead, they are cluster-specific or directory-specific.
As a single-volume NAS designed for file storage, OneFS has the scalable capacity with ease of management combined with features that administrators require. Robust policy-driven features such as SmartConnect, SmartPools, and CloudPools enable maximum utilization of nodes for superior performance and storage efficiency for maximum value. You can use SmartConnect to configure access zones that are mapped to specific node performances. SmartPools can tier cold data to nodes with deep archive storage, and CloudPools can store frozen data in the cloud. Regardless of where the data is residing, it is presented as a single namespace to the end user.
Storage utilization and data protection
Storage utilization is the amount of storage available after the NAS system overhead is deducted. The overhead consists of the space required for data protection and the operating system.
For data protection, OneFS uses software-based Reed-Solomon Error Correction with up to N+4 protection. OneFS offers several custom protection options that cover node and drive failures. The custom protection options vary according to the cluster configuration. OneFS provides data protection against more simultaneous hardware failures and is software-based, providing a significantly higher storage utilization.
The software-based data protection stripes data across nodes in stripe units, and some of the stripe units are Forward Error Correction (FEC) or parity units. The FEC units provide a variable to reformulate the data in the case of a drive or node failure. Data protection is customizable to be for node loss or hybrid protection of node and drive failure.
With software-based data protection, the protection scheme is not per cluster. It has additional granularity that allows for making data protection specific to a file or directory—without creating additional storage volumes or manually migrating data. Instead, OneFS runs a job in the background, moving data as configured.
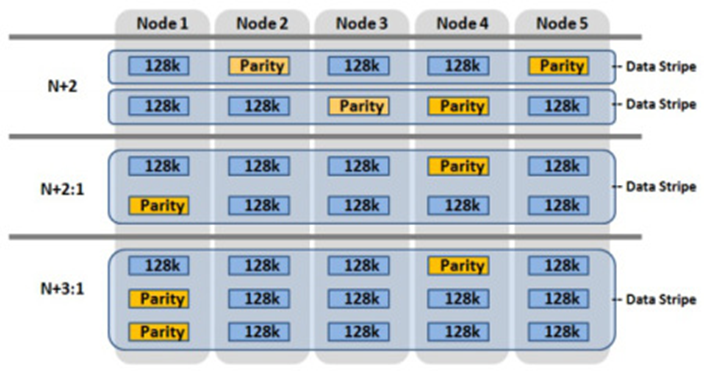
Figure 2. OneFS data protection
OneFS protects data stored on failing nodes, or drives in a cluster through a process called SmartFail. During the process, OneFS places a device into quarantine and, depending on the severity of the issue, places the data on the device into a read-only state. While a device is quarantined, OneFS reprotects the data on the device by distributing the data to other devices.
NetApp’s data protection is all RAID-based, including NetApp RAID-TEC, NetApp RAID-DP, and RAID 4. NetApp only supports a maximum of triple parity, and simultaneous node failures in an HA pair are not supported.
For more information about SmartFail, see the following blog: OneFS Smartfail. For more information about OneFS data protection, see High Availability and Data Protection with Dell PowerScale Scale-Out NAS.
NetApp FlexVols, shares, and Qtrees
NetApp requires administrators to manually create space and explicitly define aggregates and flexible volumes. The concept of FlexVols, shares, and Qtrees are nonexistent in OneFS, as the file system is a single volume and namespace, spanning the entire cluster.
SMB shares and NFS exports are created through the web or command-line interface in OneFS. Both methods allow the user to create either within seconds with security options. SmartQuotas is used to manage storage limits, cluster-wide, across the entire namespace. They include accounting, warning messages, or hard limits of enforcement. The limits can be applied by directory, user, or group.
Conversely, ONTAP quota management is at the volume or FlexGroup level, creating additional administrative overhead because the process is more onerous.
Snapshots
The OneFS snapshot feature is SnapshotIQ, which does not have specified or enforced limits for snapshots per directory or snapshots per cluster. However, the best practice is 1,024 snapshots per directory and 20,000 snapshots per cluster. OneFS also supports writable snapshots. For more information about SnapshotIQ and writable snapshots, see High Availability and Data Protection with Dell PowerScale Scale-Out NAS.
NetApp Snapshot supports 255 snapshots per volume in ONTAP 9.3 and earlier. ONTAP 9.4 and later versions support 1,023 snapshots per volume. By default, NetApp requires a space reservation of 5 percent in the volume when snapshots are used, requiring the space reservation to be monitored and manually increased if space becomes exhausted. Further, the space reservation can also affect volume availability. The space reservation requirement creates additional administration overhead and affects storage efficiency by setting aside space that might or might not be used.
Data replication
Data replication is required for disaster recovery, RPO, or RTO requirements. OneFS provides data replication through SyncIQ and SmartSync.
SyncIQ provides asynchronous data replication, whereas NetApp’s asynchronous replication, which is called SnapMirror, is block-based replication. SyncIQ provides options for ensuring that all data is retained during failover and failback from the disaster recovery cluster. SyncIQ is fully configurable with options for execution times and bandwidth management. A SyncIQ target cluster may be configured as a target for several source clusters.
SyncIQ offers a single-button automated process for failover and failback with Superna Eyeglass DR Edition. For more information about Superna Eyeglass DR Edition, see Superna | DR Edition (supernaeyeglass.com).
SyncIQ allows configurable options for replication down to a specific file, directory, or entire cluster. Conversely, NetApp’s SnapMirror replication starts at the volume at a minimum. The volume concept and dependence on volume requirements continue to add management complexity and overhead for administrators while also wasting storage utilization.
To address the requirements of the modern enterprise, OneFS version 9.4.0.0 introduced SmartSync. This feature replicates file-to-file data between PowerScale clusters. SmartSync cloud copy replicates file-to-object data from PowerScale clusters to Dell ECS and cloud providers. Having multiple target destinations allows administrators to store multiple copies of a dataset across locations, providing further disaster recovery readiness. SmartSync cloud copy replicates file-to-object data from PowerScale clusters to Dell ECS and cloud providers. SmartSync cloud copy also pulls the replicated object data from a cloud provider back to a PowerScale cluster in file. For more information about SyncIQ, see Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations. For more information about SmartSync, see Dell PowerScale SmartSync.
Quotas
OneFS SmartQuotas provides configurable options to monitor and enforce storage limits at the user, group, cluster, directory, or subdirectory level. ONTAP quotas are user-, tree-, volume-, or group-based.
For more information about SmartQuotas, see Storage Quota Management and Provisioning with Dell PowerScale SmartQuotas.
Load balancing and multitenancy
Because OneFS is a distributed architecture across a collection of nodes, client connectivity to these nodes requires load balancing. OneFS SmartConnect provides options for balancing the client connections to the nodes within a cluster. Balancing options are round-robin or based on current load. Also, SmartConnect zones can be configured to have clients connect based on group and performance needs. For example, the Engineering group might require high-performance nodes. A zone can be configured, forcing connections to those nodes.
NetApp ONTAP supports multitenancy with Storage Virtual Machines (SVMs), formerly vServers and Logical Interfaces (LIFs). SVMs isolate storage and network resources across a cluster of controller HA pairs. SVMs require managing protocols, shares, and volumes for successful provisioning. Volumes cannot be nondisruptively moved between SVMs. ONTAP supports load balancing using LIFs, but configuration is manual and must be implemented by the storage administrator. Further, it requires continuous monitoring because it is based on the load on the controller.
OneFS provides multitenancy through SmartConnect and access zones. Management is simple because the file system is one volume and access is provided by hostname and directory, rather than by volume. SmartConnect is policy-driven and does not require continuous monitoring. SmartConnect settings may be changed on demand as the requirements change.
SmartConnect zones allow administrators to provision DNS hostnames specific to IP pools, subnets, and network interfaces. If only a single authentication provider is required, all the SmartConnect zones map to a default access zone. However, if directory access and authentication providers vary, multiple access zones are provisioned, mapping to a directory, authentication provider, and SmartConnect zone. As a result, authenticated users of an access zone only have visibility into their respective directory. Conversely, an administrator with complete file system access can migrate data nondisruptively between directories.
For more information about SmartConnect, see PowerScale: Network Design Considerations.
Compression and deduplication
Both ONTAP and OneFS provide compression. The OneFS deduplication feature is SmartDedupe, which allows deduplication to run at a cluster-wide level, improving overall Data Reduction Rate (DRR) and storage utilization. With ONTAP, the deduplication is enabled at the aggregate level, and it cannot cross over nodes.
For more information about OneFS data reduction, see Dell PowerScale OneFS: Data Reduction and Storage Efficiency. For more information about SmartDedupe, see Next-Generation Storage Efficiency with Dell PowerScale SmartDedupe.
Data tiering
OneFS has integrated features to tier data based on the data’s age or file type. NetApp has similar functionality with FabricPools.
OneFS SmartPools uses robust policies to enable data placement and movement across multiple types of storage. SmartPools can be configured to move data to a set of nodes automatically. For example, if a file has not been accessed in the last 90 days, in can be migrated to a node with deeper storage, allowing admins to define the value of storage based on performance.
OneFS CloudPools migrates data to a cloud provider, with only a stub remaining on the PowerScale cluster, based on similar policies. CloudPools not only tiers data to a cloud provider but also recalls the data back to the cluster as demanded. From a user perspective, all the data is still in a single namespace, irrespective of where it resides.

Figure 3. OneFS SmartPools and CloudPools
ONTAP tiers to S3 object stores using FabricPools.
For more information about SmartPools, see Storage Tiering with Dell PowerScale SmartPools. For more information about CloudPools, see:
- Dell PowerScale: CloudPools and Amazon Web Services
- Dell PowerScale: CloudPools and Amazon Web Services
- Dell PowerScale: CloudPools and Alibaba Cloud
- Dell PowerScale: CloudPools and Google Cloud
- Dell PowerScale: CloudPools and ECS
Monitoring
Dell InsightIQ and Dell CloudIQ provide performance monitoring and reporting capabilities. InsightIQ includes advanced analytics to optimize applications, correlate cluster events, and accurately forecast future storage needs. NetApp provides performance monitoring and reporting with Cloud Insights and Active IQ, which are accessible within BlueXP.
For more information about CloudIQ, see CloudIQ: A Detailed Review. For more information about InsightIQ, see InsightIQ on Dell Support.
Security
Similar to ONTAP, the PowerScale OneFS operating system comes with a comprehensive set of integrated security features. These features include data at rest and data in flight encryption, virus scanning tool, WORM SmartLock compliance, external key manager for data at rest encryption, STIG-hardened security profile, Common Criteria certification, and support for UEFI Secure Boot across PowerScale platforms. Further, OneFS may be configured for a Zero Trust architecture and PCI-DSS.
Superna security
Superna exclusively provides the following security-focused applications for PowerScale OneFS:
- Ransomware Defender: Provides real-time event processing through user behavior analytics. The events are used to detect and stop a ransomware attack before it occurs.
- Easy Auditor: Offers a flat-rate license model and ease-of-use features that simplify auditing and securing PBs of data.
- Performance Auditor: Provides real-time file I/O view of PowerScale nodes to simplify root cause of performance impacts, assessing changes needed to optimize performance and debugging user, network, and application performance.
- Airgap: Deployed in two configurations depending on the scale of clusters and security features:
- Basic Airgap Configuration that deploys the Ransomware Defender agent on one of the primary clusters being protected.
- Enterprise Airgap Configuration that deploys the Ransomware Defender agent on the cyber vault cluster. This solution comes with greater scalability and additional security features.
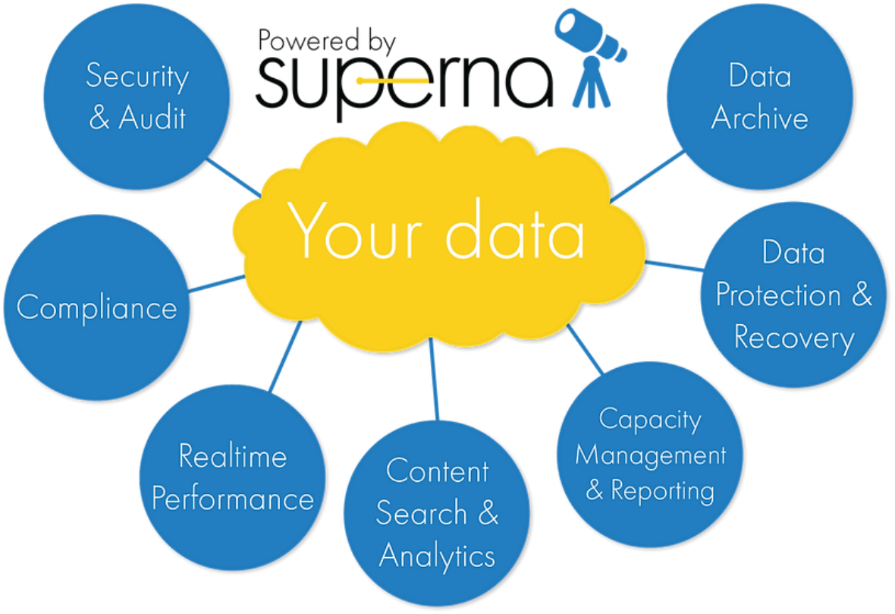
Figure 4. Superna security
NetApp ONTAP security is limited to the integrated features listed above. Additional applications for further security monitoring, like Superna, are not available for ONTAP.
For more information about Superna security, see supernaeyeglass.com. For more information about PowerScale security, see Dell PowerScale OneFS: Security Considerations.
Authentication and access control
NetApp and PowerScale OneFS both support several methods for user authentication and access control. OneFS supports UNIX and Windows permissions for data-level access control. OneFS is designed for a mixed environment that allows the configuration of both Windows Access Control Lists (ACLs) and standard UNIX permissions on the cluster file system. In addition, OneFS provides user and identity mapping, permission mapping, and merging between Windows and UNIX environments.
OneFS supports local and remote authentication providers. Anonymous access is supported for protocols that allow it. Concurrent use of multiple authentication provider types, including Active Directory, LDAP, and NIS, is supported. For example, OneFS is often configured to authenticate Windows clients with Active Directory and to authenticate UNIX clients with LDAP.
Role-based access control
OneFS supports role-based access control (RBAC), allowing administrative tasks to be configured without a root or administrator account. A role is a collection of OneFS privileges that are limited to an area of administration. Custom roles for security, auditing, storage, or backup tasks may be provisioned with RBACs. Privileges are assigned to roles. As users log in to the cluster through the platform API, the OneFS command-line interface, or the OneFS web administration interface, they are granted privileges based on their role membership.
For more information about OneFS authentication and access control, see PowerScale OneFS Authentication, Identity Management, and Authorization.
Learn more about PowerScale OneFS
To learn more about PowerScale OneFS, see the following resources:
- Dell PowerScale Info Hub
- PowerScale OneFS Technical Overview
- Dell PowerScale OneFS Operating System
- OneFS Smartfail blog post
- High Availability and Data Protection with Dell PowerScale Scale-Out NAS
- Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations
- Dell PowerScale: NDMP Technical Overview and Design Considerations
- Storage Quota Management and Provisioning with Dell PowerScale SmartQuotas
- PowerScale: Network Design Considerations
- Dell PowerScale OneFS: Data Reduction and Storage Efficiency
- Next-Generation Storage Efficiency with Dell PowerScale SmartDedupe
- Storage Tiering with Dell PowerScale SmartPools
- Dell PowerScale: CloudPools and Amazon Web Services
- Dell PowerScale: CloudPools and Microsoft Azure
- Dell PowerScale: CloudPools and Alibaba Cloud
- Dell PowerScale: CloudPools and Google Cloud
- Dell PowerScale: CloudPools and ECS
- CloudIQ: A Detailed Review
- InsightIQ (Dell Support page with documentation links)
- Dell PowerScale OneFS: Security Considerations
- PowerScale OneFS Authentication, Identity Management, and Authorization
- Superna website (supernaeyeglass.com)

Address your Security Challenges with Zero Trust Model on Dell PowerScale
Fri, 26 Apr 2024 16:48:47 -0000
|Read Time: 0 minutes
Dell PowerScale, the world’s most secure NAS storage array[1], continues to evolve its already rich security capabilities with the recent introduction of External Key Manager for Data-at-Rest-Encryption, enhancements to the STIG security profile, and support for UEFI Secure Boot across PowerScale platforms.
Our next release of PowerScale OneFS adds new security features that include software-based firewall functionality, multi-factor authentication with support for CAC/PIV, SSO for administrative WebUI, and FIPS-compliant data in flight.
As the PowerScale security feature set continues to advance, meeting the highest level of federal compliance is paramount to support industry and federal security standards. We are excited to announce that our scheduled verification by the Department of Defense Information Network (DISA) for inclusion on the DoD Approved Product List will begin in March 2023. For more information, see the DISA schedule here.
Moreover, OneFS will embrace the move to IPv6-only networks with support for USGv6-r1, a critical network standard applicable to hundreds of federal agencies and to the most security-conscious enterprises, including the DoD. Refreshed Common Criteria certification activities are underway and will provide a highly regarded international and enterprise-focused complement to other standards being supported.
We believe that implementing the zero trust model is the best foundation for building a robust security framework for PowerScale. This model and its principles are discussed below.
Supercharge Dell PowerScale security with the zero trust model
In the age of digital transformation, multiple cloud providers, and remote employees, the confines of the traditional data center are not enough to provide the highest levels of security. In the traditional sense, security was considered placing your devices in an imaginary “bubble.” The thought was that as long as devices were in the protected “bubble,” security was already accounted for through firewalls on the perimeter. However, the age-old concept of an organization’s security depending on the firewall is no longer relevant and is the easiest for a malicious party to attack.

Now that the data center is not confined to an area, the security framework must evolve, transform, and adapt. For example, although firewalls are still critical to network infrastructure, security must surpass just a firewall and security devices.
Why is data security important?
Although this seems like an easy question, it’s essential to understand the value of what is being protected. Traditionally, an organization’s most valuable assets were its infrastructure, including a building and the assets required to produce its goods. However, in the age of Digital Transformation, organizations have realized that the most critical asset is their data.
Why a zero trust model?
Because data is an organization’s most valuable asset, protecting the data is paramount. And how do we protect this data in the modern environment without data center confines? Enter the zero trust model!
Although Forrester Research first defined zero trust architecture in 2010, it has recently received more attention with the ever-changing security environment leading to a focus on cybersecurity. The zero trust architecture is a general model and must be refined for a specific implementation. For example, in September 2019, the National Institute of Standards and Technology (NIST) introduced its concept of Zero Trust Architecture. As a result, the White House has also published an Executive Order on Improving the Nation’s Cybersecurity, including zero trust initiatives.
In a zero trust architecture, all devices must be validated and authenticated. The concept applies to all devices and hosts, ensuring that none are trusted until proven otherwise. In essence, the model adheres to a “never trust, always verify” policy for all devices.
NIST Special Publication 800-207 Zero Trust Architecture states that a zero trust model is architected with the following design tenets:
- All data sources and computing services are considered resources.
- All communication is secured regardless of network location.
- Access to individual enterprise resources is granted on a per session basis.
- Access to resources is determined by dynamic policy—including the observable state of client identity, application/service, and the requesting asset—and may include other behavioral and environmental attributes.
- The enterprise monitors and measures the integrity and security posture of all owned and associated assets.
- All resource authentication and authorization are dynamic and strictly enforced before access is allowed.
- The enterprise collects as much information as possible related to the current state of assets, network infrastructure, and communications and uses it to improve its security posture.

PowerScale OneFS follows the zero trust model
The PowerScale family of scale-out NAS solutions includes all-flash, hybrid, and archive storage nodes that can be deployed across the entire enterprise – from the edge, to core, and the cloud, to handle the most demanding file-based workloads. PowerScale OneFS combines the three layers of storage architecture—file system, volume manager, and data protection—into a scale-out NAS cluster. Dell Technologies follows the NIST Cybersecurity Framework to apply zero trust principles on a PowerScale cluster. The NIST Framework identifies five principles: identify, protect, detect, respond, and recover. Combining the framework from the NIST CSF and the data model provides the basis for the PowerScale zero trust architecture in five key stages, as shown in the following figure.
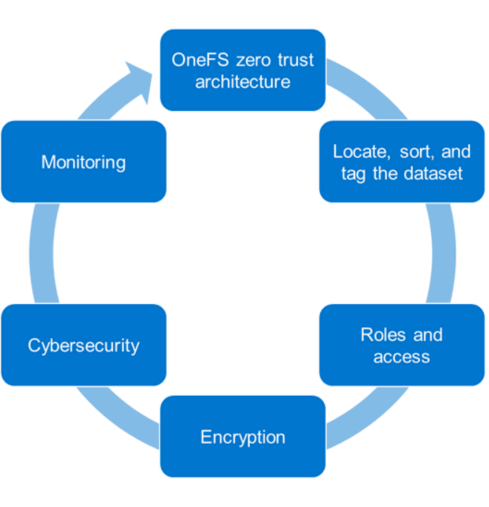
Let’s look at each of these stages and what Dell Technologies tools can be used to implement them.
1. Locate, sort, and tag the dataset
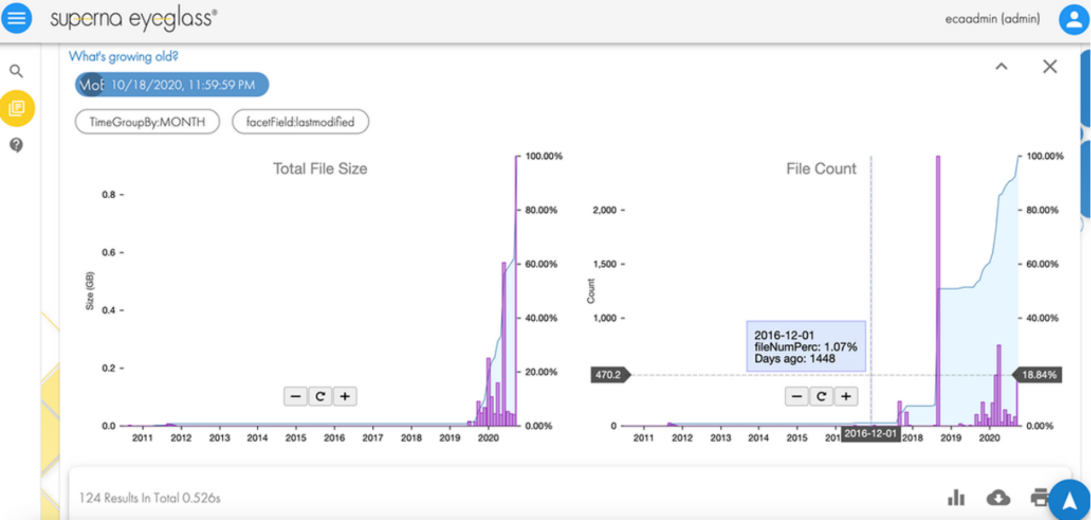
To secure an asset, the first step is to identify the asset. In our case, it is data. To secure a dataset, it must first be located, sorted, and tagged to secure it effectively. This can be an onerous process depending on the number of datasets and their size. We recommend using the Superna Eyeglass Search and Recover feature to understand your unstructured data and to provide insights through a single pane of glass, as shown in the following image. For more information, see the Eyeglass Search and Recover Product Overview.
2. Roles and access
Once we know the data we are securing, the next step is to associate roles to the indexed data. The role-specific administrators and users only have access to a subset of the data necessary for their responsibilities. PowerScale OneFS allows system access to be limited to an administrative role through Role-Based Access Control (RBAC). As a best practice, assign only the minimum required privileges to each administrator as a baseline. In the future, more privileges can be added as needed. For more information, see PowerScale OneFS Authentication, Identity Management, and Authorization.
3. Encryption
For the next step in deploying the zero trust model, use encryption to protect the data from theft and man-in-the-middle attacks.
Data at Rest Encryption
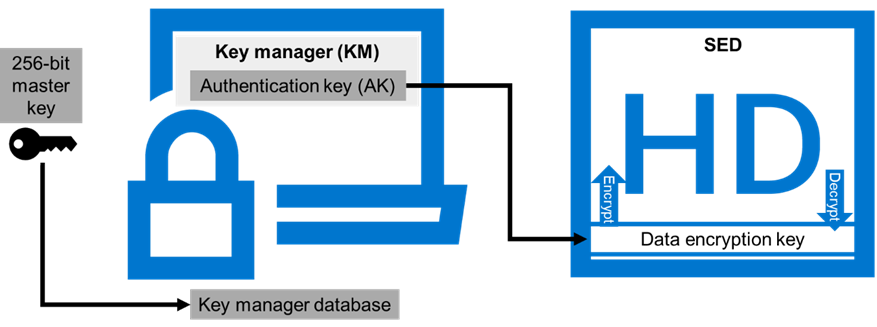
PowerScale OneFS provides Data at Rest Encryption (D@RE) using self-encrypting drives (SEDs), allowing data to be encrypted during writes and decrypted during reads with a 256-bit AES encryption key, referred to as the data encryption key (DEK). Further, OneFS wraps the DEK for each SED in an authentication key (AK). Next, the AKs for each drive are placed in a key manager (KM) that is stored securely in an encrypted database, the key manager database (KMDB). Next, the KMDB is encrypted with a 256-bit master key (MK). Finally, the 256-bit master key is stored external to the PowerScale cluster using a key management interoperability protocol (KMIP)-compliant key manager server, as shown in the following figure. For more information, see PowerScale Data at Rest Encryption.
Data in flight encryption
Data in flight is encrypted using SMB3 and NFS v4.1 protocols. SMB encryption can be used by clients that support SMB3 encryption, including Windows Server 2012, 2012 R2, 2016, Windows 10, and 11. Although SMB supports encryption natively, NFS requires additional Kerberos authentication to encrypt data in flight. OneFS Release 9.3.0.0 supports NFS v4.1, allowing Kerberos support to encrypt traffic between the client and the PowerScale cluster.
Once the protocol access is encrypted, the next step is encrypting data replication. OneFS supports over-the-wire, end-to-end encryption for SyncIQ data replication, protecting and securing in-flight data between clusters. For more information about these features, see the following:
- PowerScale: Solution Design and Considerations for SMB Environments
- PowerScale OneFS NFS Design Considerations and Best Practices
- PowerScale SyncIQ: Architecture, Configuration, and Considerations
4. Cybersecurity
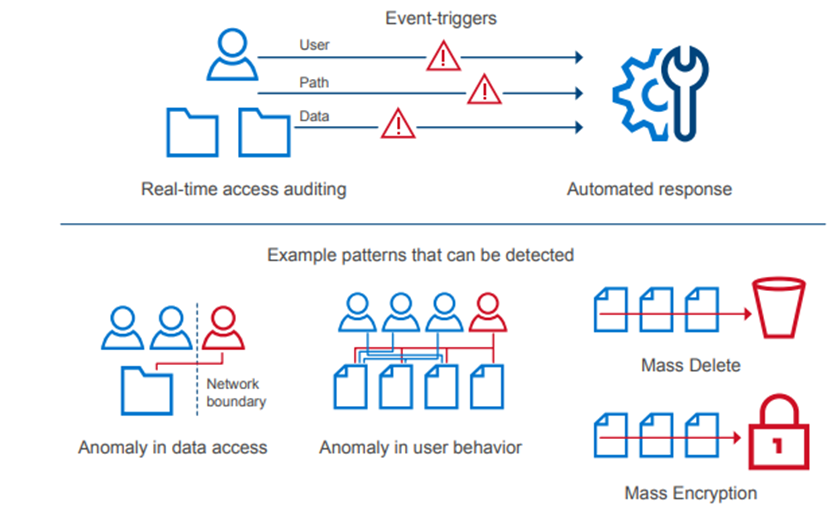
In an environment of ever-increasing cyber threats, cyber protection must be part of any security model. Superna Eyeglass Ransomware Defender for PowerScale provides cyber resiliency. It protects a PowerScale cluster by detecting attack events in real-time and recovering from cyber-attacks. Event triggers create an automated response with real-time access auditing, as shown in the following figure.
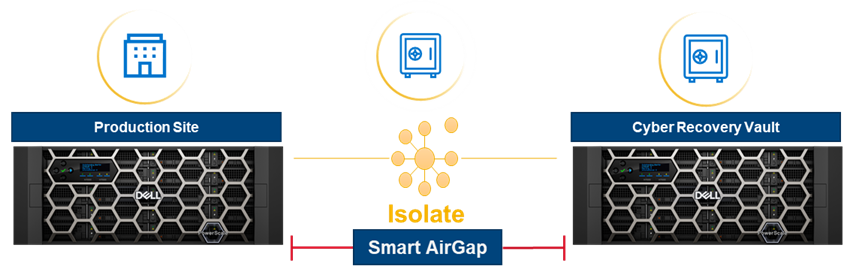
The Enterprise AirGap capability creates an isolated data copy in a cyber vault that is network isolated from the production environment, as shown in the following figure. For more about PowerScale Cyber Protection Solution, check out this comprehensive eBook.
5. Monitoring
Monitoring is a critical component of applying a zero trust model. A PowerScale cluster should constantly be monitored through several tools for insights into cluster performance and tracking anomalies. Monitoring options for a PowerScale cluster include the following:
- Dell CloudIQ for proactive monitoring, machine learning, and predictive analytics.
- Superna Ransomware Defender for protecting a PowerScale cluster by detecting attack events in real-time and recovering from cyber-attacks. It also offers AirGap.
- PowerScale OneFS SDK to create custom applications specific to an organization. Uses the OneFS API to configure, manage, and monitor cluster functionality. The OneFS SDK provides greater visibility into a PowerScale cluster.
Conclusion
This blog introduces implementing the zero trust model on a PowerScale cluster. For additional details and applying a complete zero trust implementation, see the PowerScale Zero Trust Architecture section in the Dell PowerScale OneFS: Security Considerations white paper. You can also explore the other sections in this paper to learn more about all PowerScale security considerations.
Author: Aqib Kazi
[1] Based on Dell analysis comparing cybersecurity software capabilities offered for Dell PowerScale vs competitive products, September 2022.

PowerScale Security Baseline Checklist
Fri, 26 Apr 2024 16:24:29 -0000
|Read Time: 0 minutes
As a security best practice, a quarterly security review is recommended. Forming an aggressive security posture for a PowerScale cluster is composed of different facets that may not be applicable to every organization. An organization’s industry, clients, business, and IT administrative requirements determine what is applicable. To ensure an aggressive security posture for a PowerScale cluster, use the checklist in the following table as a baseline for security.
This table serves as a security baseline and must be adapted to specific organizational requirements. See the Dell PowerScale OneFS: Security Considerations white paper for a comprehensive explanation of the concepts in the table below.
Further, cluster security is not a single event. It is an ongoing process: Monitor this blog for updates. As new updates become available, this post will be updated. Consider implementing an organizational security review on a quarterly basis.
The items listed in the following checklist are not in order of importance or hierarchy but rather form an aggressive security posture as more features are implemented.
Table 1. PowerScale security baseline checklist
Security Feature | Configuration | Links | Complete (Y/N) | Notes |
Data at Rest Encryption | Implement external key manager with SEDs | PowerScale Data at Rest Encryption |
|
|
Data in flight encryption | Encrypt protocol communication and data replication | PowerScale: Solution Design and Considerations for SMB Environments PowerScale OneFS NFS Design Considerations and Best Practices PowerScale SyncIQ: Architecture, Configuration, and Considerations |
|
|
Role-based access control (RBACs) | Assign the lowest possible access required for each role | Dell PowerScale OneFS: Authentication, Identity Management, and Authorization |
|
|
Multi-factor authentication | Dell PowerScale OneFS: Authentication, Identity Management, and Authorization Disabling the WebUI and other non-essential services |
|
| |
Cybersecurity |
|
| ||
Monitoring | Monitor cluster activity | Dell CloudIQ - AIOps for Intelligent IT Infrastructure Insights |
|
|
Secure Boot | Configure PowerScale Secure Boot | See PowerScale Secure Boot section |
|
|
Auditing | Configure auditing | File System Auditing with Dell PowerScale and Dell Common Event Enabler |
|
|
Custom applications | Create a custom application for cluster monitoring |
|
| |
Perform a quarterly security review | Review all organizational security requirements and current implementation. Check this paper and checklist for updates Monitor security advisories for PowerScale: https://www.dell.com/support/security/en-us |
|
| |
General cluster security best practices
| See the Security best practices section in the Security Configuration Guide for the relevant release at OneFS Info Hubs |
|
| |
Login, authentication, and privileges best practices |
|
| ||
SNMP security best practices |
|
| ||
SSH security best practices |
|
| ||
Data-access protocols best practices |
|
| ||
Web interface security best practices |
|
| ||
Anti-Virus |
|
| ||
Author: Aqib Kazi

PowerScale Security Baseline Checklist
Tue, 16 Apr 2024 22:36:48 -0000
|Read Time: 0 minutes
As a security best practice, a quarterly security review is recommended. Forming an aggressive security posture for a PowerScale cluster is composed of different facets that may not be applicable to every organization. An organization’s industry, clients, business, and IT administrative requirements determine what is applicable. To ensure an aggressive security posture for a PowerScale cluster, use the checklist in the following table as a baseline for security.
This table serves as a security baseline and must be adapted to specific organizational requirements. See the Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub white paper for a comprehensive explanation of the concepts in the table below.
Further, cluster security is not a single event. It is an ongoing process: Monitor this blog for updates. As new updates become available, this post will be updated. Consider implementing an organizational security review on a quarterly basis.
The items listed in the following checklist are not in order of importance or hierarchy but rather form an aggressive security posture as more features are implemented.
Security feature | Configuration | References and notes | Complete (Y/N) | Notes |
Data at Rest Encryption | Implement external key manager with SEDs | Overview | Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub |
|
|
Data in flight encryption | Encrypt protocol communication and data replication | Dell PowerScale: Solution Design and Considerations for SMB Environments (delltechnologies.com)
PowerScale OneFS NFS Design Considerations and Best Practices | Dell Technologies Info Hub
Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations | Dell Technologies Info Hub |
|
|
Role Based Access Control (RBAC) | Assign the lowest possible access required for each role | PowerScale OneFS Authentication, Identity Management, and Authorization | Dell Technologies Info Hub |
|
|
Multifactor authentication |
|
|
| |
Cybersecurity | PowerScale Cyber Protection Suite Reference Architecture | Dell Technologies Info Hub |
|
| |
Monitoring | Monitor cluster activity |
|
|
|
Cluster configuration backup and recovery | Ensure quarterly cluster backups | Backing Up and Restoring PowerScale Cluster Configurations in OneFS 9.7 | Dell Technologies Info Hub |
|
|
Secure Boot | Configure PowerScale Secure Boot | Overview | Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub |
|
|
Auditing | Configure auditing |
|
| |
Custom applications | Create a custom application for cluster monitoring | GitHub - Isilon/isilon_sdk: Official repository for isilon_sdk |
|
|
SED and cluster Universal Key rekey | Set a frequency to automatically rekey the Universal Key for SEDs and the cluster | Cluster services rekey | Dell PowerScale OneFS: Security Considerations | Dell Technologies Info Hub |
|
|
Perform a quarterly security review | Review all organizational security requirements and current implementation. Check this paper and checklist for updates: |
|
| |
General cluster security best practices | See the best practices section of the Security Configuration Guide for the relevant release, at PowerScale OneFS Info Hubs | Dell US |
|
| |
Login, authentication, and privileges best practices |
|
| ||
SNMP security best practices |
|
| ||
SSH security best practices |
|
| ||
Data-access protocols best practices |
|
| ||
Web interface security best practices |
|
| ||
Anti-virus | PowerScale: AntiVirus Solutions | Dell Technologies Info Hub |
|
| |
Author: Aqib Kazi – Senior Principal Engineering Technologist

Securing PowerScale OneFS SyncIQ
Tue, 16 Apr 2024 17:55:56 -0000
|Read Time: 0 minutes
In the data replication world, ensuring your PowerScale clusters' security is paramount. SyncIQ, a powerful data replication tool, requires encryption to prevent unauthorized access.
Concerns about unauthorized replication
A cluster might inadvertently become the target of numerous replication policies, potentially overwhelming its resources. There’s also the risk of an administrator mistakenly specifying the wrong cluster as the replication target.
Best practices for security
To secure your PowerScale cluster, Dell recommends enabling SyncIQ encryption as per Dell Security Advisory DSA-2020-039: Dell EMC Isilon OneFS Security Update for a SyncIQ Vulnerability | Dell US. This feature, introduced in OneFS 8.2, prevents man-in-the-middle attacks and addresses other security concerns.
Encryption in new and upgraded clusters
SyncIQ is disabled by default for new clusters running OneFS 9.1. When SyncIQ is enabled, a global encryption flag requires all SyncIQ policies to be encrypted. This flag is also set for clusters upgraded to OneFS 9.1, unless there’s an existing SyncIQ policy without encryption.
Alternative measures
For clusters running versions earlier than OneFS 8.2, configuring a SyncIQ pre-shared key (PSK) offers protection against unauthorized replication policies.
By following these security measures, administrators can ensure that their PowerScale clusters are safeguarded against unauthorized access and maintain the integrity and confidentiality of their data.
SyncIQ encryption: securing data in transit
Securing information as it moves between systems is paramount in the data-driven world. Dell PowerScale OneFS release 8.2 has brought a game-changing feature to the table: end-to-end encryption for SyncIQ data replication. This ensures that data is not only protected while at rest but also as it traverses the network between clusters.
Why encryption matters
Data breaches can be catastrophic, and because data replication involves moving large volumes of sensitive information, encryption acts as a critical shield. With SyncIQ’s encryption, organizations can enforce a global setting that mandates encryption across all SyncIQ policies, to add an extra layer of security.
Test before you implement
It’s crucial to test SyncIQ encryption in a lab environment before deploying it in production. Although encryption introduces minimal overhead, its impact on workflow can vary based on several factors, such as network bandwidth and cluster resources.
Technical underpinnings
SyncIQ encryption is powered by X.509 certificates, TLS version 1.2, and OpenSSL version 1.0.2o6. These certificates are meticulously managed within the cluster’s certificate stores, ensuring a robust and secure data replication process.
Remember, this is just the beginning of a comprehensive guide about SyncIQ encryption. Stay tuned for more insights about configuration steps and best practices for securing your data with Dell PowerScale’s innovative solutions.
Configuration
Configuring SyncIQ encryption requires a supported OneFS release, certificates, and finally, the OneFS configuration. Before enabling SyncIQ encryption in production, test it in a lab environment that mimics the production setup. Measure the impact on transmission overhead by considering network bandwidth, cluster resources, workflow, and policy configuration.
Here’s a high level summary of the configuration steps:
- Ensure compatibility:
- Ensure that the source and target clusters are running OneFS 8.2 or later.
- Upgrade and commit both clusters to OneFS release 8.2 or later.
- Create X.509 certificates:
- Create X.509 certificates for the source and target clusters using publicly available tools.
- The certificate creation process results in the following components:
- Certificate Authority (CA) certificate
- Source certificate and private key
- Target certificate and private key
Note: Some certificate authorities may not generate the public and private key pairs. In that case, manually generate a Certificate Signing Request (CSR) and obtain signed certificates.
3. Transfer certificates to clusters:
- Transfer the certificates to each cluster.
4. Activate each certificate as follows:
- Add the source cluster certificate under Data Protection > SyncIQ > Certificates.
- Add the target server certificate under Data Protection > SyncIQ > Settings.
- Add the Certificate Authority under Access > TLS Certificates and select Import Authority.
5. Enforce encryption:
- Each cluster stores its certificate and its peer’s certificate.
- The source cluster must store the target cluster’s certificate, and vice versa.
- Storing the peer’s certificate creates a list of approved clusters for data replication.
By following these steps, you can secure your data in transit between PowerScale clusters using SyncIQ encryption. Remember to customize the certificates and settings according to your specific environment and requirements.
For more detailed information about configuring SyncIQ encryption, see SyncIQ encryption | Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations | Dell Technologies Info Hub.
SyncIQ pre-shared key
A SyncIQ pre-shared key (PSK) is configured solely on the target cluster to restrict policies from source clusters without the PSK.
Use Cases: This is recommended for environments without SyncIQ encryption, such as clusters pre-OneFS 8.2 or due to other factors.
SmartLock Compliance: Not supported by SmartLock Compliance mode clusters; upgrading and configuring SyncIQ encryption is advised.
Policy Update: After updating source cluster policies with the PSK, no further configuration is needed. Use the isi sync policies view command to verify.
Remember, configuring the PSK will cause all replicating jobs to the target cluster to fail, so ensure that all SyncIQ jobs are complete or canceled before proceeding.
For more detailed information about configuring a SyncIQ pre-shared key, see SyncIQ pre-shared key | Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations | Dell Technologies Info Hub.
Resources
- SyncIQ encryption | Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations | Dell Technologies Info Hub
- SyncIQ pre-shared key | Dell PowerScale SyncIQ: Architecture, Configuration, and Considerations | Dell Technologies Info Hub
Author: Aqib Kazi, Senior Principal Engineering Technologist

Optimizing AI: Meeting Unstructured Storage Demands Efficiently
Thu, 21 Mar 2024 14:46:23 -0000
|Read Time: 0 minutes
The surge in artificial intelligence (AI) and machine learning (ML) technologies has sparked a revolution across industries, pushing the boundaries of what's possible. However, this innovation comes with its own set of challenges, particularly when it comes to storage. The heart of AI's potential lies in its ability to process and learn from vast amounts of data, most of which is unstructured. This has placed unprecedented demands on storage solutions, becoming a critical bottleneck for advancing AI technologies.
Navigating the complex landscape of unstructured data storage is no small feat. Traditional storage systems struggle to keep up with the scale and flexibility required by AI workloads. Enterprises find themselves at a crossroads, seeking solutions that can provide scalable, affordable, and fault-tolerant storage. The quest for such a platform is not just about meeting current needs but also paving the way for the future of AI-driven innovation.
The current state of ML and AI
The evolution of ML and AI technologies has reshaped industries far and wide, setting new expectations for data processing and analysis capabilities. These advancements are directly tied to an organization's capacity to handle vast volumes of unstructured data, a domain where traditional storage solutions are being outpaced.
ML and AI applications demand unprecedented levels of data ingestion and computational power, necessitating scalable and flexible storage solutions. Traditional storage systems—while useful for conventional data storage needs—grapple with scalability issues, particularly when faced with the immense file quantities AI and ML workloads generate.
Although traditional object storage methods are capable of managing data as objects within a pool, they fall short when meeting the agility and accessibility requirements essential for AI and ML processes. These storage models struggle with scalability and facilitating the rapid access and processing of data crucial for deep learning and AI algorithms.
The dire necessity of a new kind of storage solution is evident as the current infrastructure is unable to cope with the silos of unstructured data. These silos make it challenging to access, process, and unify data sources, which in turn cripples the effectiveness of AI and ML projects. Furthermore, the maximum storage capacity of traditional storage, tethering at tens of terabytes, is insufficient for the needs of AI-driven initiatives which often require petabytes of data to train sophisticated models.
As ML and AI continue to advance, the quest for a storage solution that can support the growing demands of these technologies remains pivotal. The industry is in dire need of systems that provide ample storage and ensure the flexibility, reliability, and performance efficiency necessary to propel AI and ML into their next phase of innovation.
Understanding unstructured storage demands for AI
The advent of AI and ML has brought unprecedented advancements across industries, enhancing efficiency, accuracy, and the ability to manage and process large datasets. However, the core of these technologies relies on the capability to store, access, and analyze unstructured data efficiently. Understanding the storage demands essential for AI applications is crucial for businesses looking to harness the full power of AI technology.
High throughput and low latency
For AI and ML applications, time is of the essence. The ability to process data at high speeds with high throughput and access it with minimal delay and low latency are non-negotiable requirements. These applications often involve complex computations performed on vast datasets, necessitating quick access to data to maintain a seamless process. For instance, in real-time AI applications such as voice recognition or instant fraud detection, any delay in data processing can critically impact performance and accuracy. Therefore, storage solutions must be designed to accommodate these needs, delivering data as swiftly as possible to the application layer.
Scalability and flexibility
As AI models evolve and the volume of data increases, the need for scalability in storage solutions becomes paramount. The storage architecture must accommodate growth without compromising on performance or efficiency. This is where the flexibility of the storage solutions comes into play. An ideal storage system for AI would scale in capacity and performance, adapting to the changing demands of AI applications over time. Combining the best of on-premises and cloud storage, hybrid storage solutions offer a viable path to achieving this scalability and flexibility. They enable businesses to leverage the high performance of on-premise solutions and the scalability and cost-efficiency of cloud storage, ensuring the storage infrastructure can grow with the AI application needs.
Data durability and availability
Ensuring the durability and availability of data is critical for AI systems. Data is the backbone of any AI application, and its loss or unavailability can lead to significant setbacks in development and performance. Storage solutions must, therefore, provide robust data protection mechanisms and redundancies to safeguard against data loss. Additionally, high availability is essential to ensure that data is always accessible when needed, particularly for AI applications that require continuous operation. Implementing a storage system with built-in redundancy, failover capabilities, and disaster recovery plans is essential to maintain continuous data availability and integrity.
In the context of AI where data is continually ingested, processed, and analyzed, the demands on storage solutions are unique and challenging. Key considerations include maintaining high throughput and low latency for real-time processing, establishing scalability and flexibility to adapt to growing data volumes, and ensuring data durability and availability to support continuous operation. Addressing these demands is critical for businesses aiming to leverage AI technologies effectively, paving the way for innovation and success in the digital era.
What needs to be stored for AI?
The evolution of AI and its underlying models depends significantly on various types of data and artifacts generated and used throughout its lifecycle. Understanding what needs to be stored is crucial for ensuring the efficiency and effectiveness of AI applications.
Raw data
Raw data forms the foundation of AI training. It's the unmodified, unprocessed information gathered from diverse sources. For AI models, this data can be in the form of text, images, audio, video, or sensor readings. Storing vast amounts of raw data is essential as it provides the primary material for model training and the initial step toward generating actionable insights.
Preprocessed data
Once raw data is collected, it undergoes preprocessing to transform it into a more suitable format for training AI models. This process includes cleaning, normalization, and transformation. As a refined version of raw data, preprocessed data needs to be stored efficiently to streamline further processing steps, saving time and computational resources.
Training datasets
Training datasets are a selection of preprocessed data used to teach AI models how to make predictions or perform tasks. These datasets must be diverse and comprehensive, representing real-world scenarios accurately. Storing these datasets allows AI models to learn and adapt to the complexities of the tasks they are designed to perform.
Validation and test datasets
Validation and test datasets are critical for evaluating an AI model's performance. These datasets are separate from the training data and are used to tune the model's parameters and test its generalizability to new, unseen data. Proper storage of these datasets ensures that models are both accurate and reliable.
Model parameters and weights
An AI model learns to make decisions through its parameters and weights. These elements are fine-tuned during training and crucial for the model's decision-making processes. Storing these parameters and weights allows models to be reused, updated, or refined without retraining from scratch.
Model architecture
The architecture of an AI model defines its structure, including the arrangement of layers and the connections between them. Storing the model architecture is essential for understanding how the model processes data and for replicating or scaling the model in future projects.
Hyperparameters
Hyperparameters are the configuration settings used to optimize model performance. Unlike parameters, hyperparameters are not learned from the data but set prior to the training process. Storing hyperparameter values is necessary for model replication and comparison of model performance across different configurations.
Feature engineering artifacts
Feature engineering involves creating new input features from the existing data to improve model performance. The artifacts from this process, including the newly created features and the logic used to generate them, need to be stored. This ensures consistency and reproducibility in model training and deployment.
Results and metrics
The results and metrics obtained from model training, validation, and testing provide insights into model performance and effectiveness. Storing these results allows for continuous monitoring, comparison, and improvement of AI models over time.
Inference data
Inference data refers to new, unseen data that the model processes to make predictions or decisions after training. Storing inference data is key for analyzing the model's real-world application and performance and making necessary adjustments based on feedback.
Embeddings
Embeddings are dense representations of high-dimensional data in lower-dimensional spaces. They play a crucial role in processing textual data, images, and more. Storing embeddings allows for more efficient computation and retrieval of similar items, enhancing model performance in recommendation systems and natural language processing tasks.
Code and scripts
The code and scripts used to create, train, and deploy AI models are essential for understanding and replicating the entire AI process. Storing this information ensures that models can be retrained, refined, or debugged as necessary.
Documentation and metadata
Documentation and metadata provide context, guidelines, and specifics about the AI model, including its purpose, design decisions, and operating conditions. Proper storage of this information supports ethical AI practices, model interpretability, and compliance with regulatory standards.
Challenges of unstructured data in AI
In the realm of AI, handling unstructured data presents a unique set of challenges that must be navigated carefully to harness its full potential. As AI systems strive to mimic human understanding, they face the intricate task of processing and deriving meaningful insights from data that lacks a predefined format. This section delves into the core challenges associated with unstructured data in AI, primarily focusing on data variety, volume, and velocity.
Data variety
Data variety refers to the myriad types of unstructured data that AI systems are expected to process, ranging from texts and emails to images, videos, and audio files. Each data type possesses its unique characteristics and demands specific preprocessing techniques to be effectively analyzed by AI models.
- Richer Insights but Complicated Processing: While the diverse data types can provide richer insights and enhance model accuracy, they significantly complicate the data preprocessing phase. AI tools must be equipped with sophisticated algorithms to identify, interpret, and normalize various data formats.
- Innovative AI Applications: The advantage of mastering data variety lies in the development of innovative AI applications. By handling unstructured data from different domains, AI can contribute to advancements in natural language processing, computer vision, and beyond.
Data volume
The sheer volume of unstructured data generated daily is staggering. As digital interactions increase, so does the amount of data that AI systems need to analyze.
- Scalability Challenges: The exponential growth in data volume poses scalability challenges for AI systems. Storage solutions must not only accommodate current data needs but also be flexible enough to scale with future demands.
- Efficient Data Processing: AI must leverage parallel processing and cloud storage options to keep up with the volume. Systems designed for high-throughput data analysis enable quicker insights, which are essential for timely decision-making and maintaining relevance in a rapidly evolving digital landscape.
Data velocity
Data velocity refers to the speed at which new data is generated and the pace at which it needs to be processed to remain actionable. In the age of real-time analytics and instant customer feedback, high data velocity is both an opportunity and a challenge for AI.
- Real-Time Processing Needs: AI systems are increasingly required to process information in real-time or near-real-time to provide timely insights. This necessitates robust computational infrastructure and efficient data streaming technologies.
- Constant Adaptation: The dynamic nature of unstructured data, coupled with its high velocity, demands that AI systems constantly adapt and learn from new information. Maintaining accuracy and relevance in fast-moving data environments is critical for effective AI performance.
In addressing these challenges, AI and ML technologies are continually evolving, developing more sophisticated systems capable of handling the complexity of unstructured data. The key to unlocking the value hidden within this data lies in innovative approaches to data management where flexibility, scalability, and speed are paramount.
Strategies to manage unstructured data in AI
The explosion of unstructured data poses unique challenges for AI applications. Organizations must adopt effective data management strategies to harness the full potential of AI technologies. In this section, we delve into key strategies like data classification and tagging and the use of PowerScale clusters to efficiently manage unstructured data in AI.
Data classification and tagging
Data classification and tagging are foundational steps in organizing unstructured data and making it more accessible for AI applications. This process involves identifying the content and context of data and assigning relevant tags or labels, which is crucial for enhancing data discoverability and usability in AI systems.
- Automated tagging tools can significantly reduce the manual effort required to label data, employing AI algorithms to understand the content and context automatically.
- Custom metadata tags allow for the creation of a rich set of file classification information. This not only aids in the classification phase but also simplifies later iterations and workflow automation.
- Effective data classification enhances data security by accurately categorizing sensitive or regulated information, enabling compliance with data protection regulations.
Implementing these strategies for managing unstructured data prepares organizations for the challenges of today's data landscape and positions them to capitalize on the opportunities presented by AI technologies. By prioritizing data classification and leveraging solutions like PowerScale clusters, businesses can build a strong foundation for AI-driven innovation.

Best practices for implementing AI storage solutions
Implementing the right AI storage solutions is crucial for businesses seeking to harness the power of artificial intelligence. With the explosive growth of unstructured data, adhering to best practices that optimize performance, scalability, and cost is imperative. This section delves into key practices to ensure your AI storage infrastructure meets the demands of modern AI workloads.
Assess workload requirements
Before diving into storage solutions, one must thoroughly assess AI workload requirements. Understanding the specific needs of your AI applications—such as the volume of data, the necessity for high throughput/low latency, and the scalability and availability requirements—is fundamental. This step ensures you select the most suitable storage solution that meets your application's needs.
AI workloads are diverse, with each having unique demands on storage infrastructure. For instance, training a machine learning model could require rapid access to vast amounts of data, whereas inference workloads may prioritize low latency. An accurate assessment leads to an optimized infrastructure, ensuring that storage solutions are neither overprovisioned nor underperforming, thereby supporting AI applications efficiently and cost-effectively.
Leverage PowerScale
For managing large volumes and varieties of unstructured data, leveraging PowerScale nodes offers a scalable and efficient solution. PowerScale nodes are designed to handle the complexities of AI and machine learning workloads, offering optimized performance, scalability, and data mobility. These clusters allow organizations to store and process vast amounts of data efficiently for a range of AI use cases due to the following:
- Scalability is a key feature, with PowerScale clusters capable of growing with the organization's data needs. They support massive capacities, allowing businesses to store petabytes of data seamlessly.
- Performance is optimized for the demanding workloads of AI applications with the ability to process large volumes of data at high speeds, reducing the time for data analyses and model training.
- Data mobility within PowerScale clusters on-premise and in the cloud ensures that data can be accessed when and where needed, supporting various AI and machine learning use cases across different environments.
PowerScale clusters allow businesses to start small and grow capacity as needed, ensuring that storage infrastructure can scale alongside AI initiatives without compromising on performance. The ability to handle multiple data types and protocols within a single storage infrastructure simplifies management and reduces operational costs, making PowerScale nodes an ideal choice for dynamic AI environments.
Utilize PowerScale OneFS 9.7.0.0
PowerScale OneFS 9.7.0.0 is the latest version of the Dell PowerScale operating system for scale-out network-attached storage (NAS). OneFS 9.7.0.0 introduces several enhancements in data security, performance, cloud integration, and usability.
OneFS 9.7.0.0 extends and simplifies the PowerScale offering in the public cloud, providing more features across various instance types and regions. Some of the key features in OneFS 9.7.0.0 include:
- Cloud Innovations: Extends cloud capabilities and features, building upon the debut of APEX File Storage for AWS
- Performance Enhancements: Enhancements to overall system performance
- Security Enhancements: Enhancements to data security features
- Usability Improvements: Enhancements to make managing and using PowerScale easier
Employ PowerScale F210 and F710
PowerScale, through its continuous innovation, extends into the AI era by introducing the next generation of PowerEdge-based nodes: the PowerScale F210 and F710. These new all-flash nodes leverage the Dell PowerEdge R660 from the PowerEdge platform, unlocking enhanced performance capabilities.
On the software front, both the F210 and F710 nodes benefit from significant performance improvements in PowerScale OneFS 9.7. These nodes effectively address the most demanding workloads by combining hardware and software innovations. The PowerScale F210 and F710 nodes represent a powerful combination of hardware and software advancements, making them well-suited for a wide range of workloads. For more information on the F210 and F710, see PowerScale All-Flash F210 and F710 | Dell Technologies Info Hub.
Ensure data security and compliance
Given the sensitivity of the data used in AI applications, robust security measures are paramount. Businesses must implement comprehensive security strategies that include encryption, access controls, and adherence to data protection regulations. Safeguarding data protects sensitive information and reinforces customer trust and corporate reputation.
Compliance with data protection laws and regulations is critical to AI storage solutions. As regulations can vary significantly across regions and industries, understanding and adhering to these requirements is essential to avoid significant fines and legal challenges. By prioritizing data security and compliance, organizations can mitigate risks associated with data breaches and non-compliance.
Monitor and optimize
Continuous storage environment monitoring and optimization are essential for maintaining high performance and efficiency. Monitoring tools can provide insights into usage patterns, performance bottlenecks, and potential security threats, enabling proactive management of the storage infrastructure.
Regular optimization efforts can help fine-tune storage performance, ensuring that the infrastructure remains aligned with the evolving needs of AI applications. Optimization might involve adjusting storage policies, reallocating resources, or upgrading hardware to improve efficiency, reduce costs, and ensure that storage solutions continue to effectively meet the demands of AI workloads.
By following these best practices, businesses can build and maintain a storage infrastructure that supports their current AI applications and is poised for future growth and innovation.
Conclusion
Navigating the complexities of unstructured storage demands for AI is no small feat. Yet, by adhering to the outlined best practices, businesses stand to benefit greatly. The foundational steps include assessing workload requirements, selecting the right storage solutions, and implementing robust security measures. Furthermore, integrating PowerScale nodes and a commitment to continuous monitoring and optimization are key to sustaining high performance and efficiency. As the landscape of AI continues to evolve, these practices will not only support current applications but also pave the way for future growth and innovation. In the dynamic world of AI, staying ahead means being prepared, and these strategies offer a roadmap to success.
Frequently asked questions
How big are AI data centers?
Data centers catering to AI, such as those by Amazon and Google, are immense, comparable to the scale of football stadiums.
How does AI process unstructured data?
AI processes unstructured data including images, documents, audio, video, and text by extracting and organizing information. This transformation turns unstructured data into actionable insights, propelling business process automation and supporting AI applications.
How much storage does an AI need?
AI applications, especially those involving extensive data sets, might require significant memory, potentially as much as 1TB or more. Such vast system memory efficiently facilitates the processing and statistical analysis of entire data sets.
Can AI handle unstructured data?
Yes, AI is capable of managing both structured and unstructured data types from a variety of sources. This flexibility allows AI to analyze and draw insights from an expansive range of data, further enhancing its utility across diverse applications.
Author: Aqib Kazi, Senior Principal Engineer, Technical Marketing

Introducing the Next Generation of PowerScale – the AI Ready Data Platform
Tue, 20 Feb 2024 19:07:47 -0000
|Read Time: 0 minutes
Generative AI systems thrive on vast amounts of unstructured data, which are essential for training algorithms to recognize patterns, make predictions, and generate new content. Unstructured data – such as text, images, and audio – does not follow a predefined model, making it more complex and varied than structured data.
Preprocessing unstructured data
Unstructured data does not have a predefined format or schema, including text, images, audio, video, or documents. Preprocessing unstructured data involves cleaning, normalizing, and transforming the data into a structured or semi-structured form that the AI can understand and that can be used for analysis or machine learning.
Preprocessing unstructured data for generative AI is a crucial step that involves preparing the raw data for use in training AI models. The goal is to enhance the quality and structure of the data to improve the performance of generative models.
There are different steps and techniques for preprocessing unstructured data, depending on the type and purpose of the data. Some common steps are:
- Data completion: This step involves filling in missing or incomplete data, either by using average or estimated values or by discarding or ignoring the data points with missing fields.
- Data noise reduction: This step involves removing or reducing irrelevant, redundant, or erroneous data, such as duplicates, spelling errors, hidden objects, or background noise.
- Data transformation: This step involves converting the data into a standard or consistent format, including scaling and normalizing numerical data, encoding categorical data, or extracting features from text, image, audio, or video data.
- Data reduction: This step involves reducing the dimensionality or size of the data, either by selecting a subset of relevant features or data points or by applying techniques such as principal component analysis, clustering, or sampling.
- Data validation: This step involves checking the quality and accuracy of the preprocessed data by using statistical methods, visualization tools, or domain knowledge.
These steps can help enhance the quality, reliability, and interpretability of the data, which can improve the performance and outcomes of the analysis or machine learning models.
PowerScale F210 and F710 platform
PowerScale’s continuous innovation extends into the AI era with the introduction of the next generation of PowerEdge-based nodes, including the PowerScale F210 and F710. The new PowerScale all-flash nodes leverage Dell PowerEdge R660, unlocking the next generation of performance. On the software front, the F210 and F710 take advantage of significant performance improvements in PowerScale OneFS 9.7. Combining the hardware and software innovations, the F210 and F710 tackle the most demanding workloads with ease.
The F210 and F710 offer greater density in a 1U platform, with the F710 supporting 10 NVMe SSDs per node and the F210 offering a 15.36 TB drive option. The Sapphire Rapids CPU provide 19% lower cycles-per-instruction. PCIe Gen 5 doubles throughput when compared to PCIe Gen 4. Additionally, the nodes take advantage of DDR5, offering greater speed and bandwidth.
From a software perspective, PowerScale OneFS 9.7 introduces a significant leap in performance. OneFS 9.7 updates the protocol stack, locking, and direct-write. To learn more about OneFS 9.7, check out this article on PowerScale OneFS 9.7.
The OneFS journal in the all-flash F210 and F710 nodes uses a 32 GB configuration of the Dell Software Defined Persistent Memory (SDPM) technology. Previous platforms used NVDIMM-n for persistent memory, which consumed a DIMM slot.
For more details about the F210 and F710, see our other blog post at Dell.com: https://www.dell.com/en-us/blog/next-gen-workloads-require-next-gen-storage/.
Performance
The introduction of the PowerScale F210 and F710 nodes capitalizes on significant leaps in hardware and software from the previous generations. OneFS 9.7 introduces tremendous performance-oriented updates, including the protocol stack, locking, and direct-write. The PowerEdge-based servers offer a substantial hardware leap from previous generations. The hardware and software advancements combine to offer enormous performance gains, particularly for streaming reads and writes.
PowerScale F210
The PowerScale F210 is a 1U chassis based on the PowerEdge R660. A minimum of three nodes is required to form a cluster, with a maximum of 252 nodes. The F210 is node pool compatible with the F200.

Table 1. F210 specifications
Attribute | PowerScale F210 Specification |
Chassis | 1U Dell PowerEdge R660 |
CPU | Single Socket – Intel Sapphire Rapids 4410Y (2G/12C) |
Memory | Dual Rank DDR5 RDIMMs 128 GB (8 x 16 GB) |
Journal | 1 x 32 GB SDPM |
Front-end networking | 2 x 100 GbE or 25 GbE |
Infrastructure networking | 2 x 100 GbE or 25 GbE |
NVMe SSD drives | 4 |
PowerScale F710
The PowerScale F710 is a 1U chassis based on the PowerEdge R660. A minimum of three nodes is required to form a cluster, with a maximum of 252 nodes.

Table 2. F710 specifications
Attribute | PowerScale F710 Specification |
Chassis | 1U Dell PowerEdge R660 |
CPU | Dual Socket – Intel Sapphire Rapids 6442Y (2.6G/24C) |
Memory | Dual Rank DDR5 RDIMMs 512 GB (16 x 32 GB) |
Journal | 1 x 32 GB SDPM |
Front-end networking | 2 x 100 GbE or 25 GbE |
Infrastructure networking | 2 x 100 GbE |
NVMe SSD drives | 10 |
For more details on the new PowerScale all-flash platforms, see the PowerScale All-Flash F210 and F710 white paper.
Author: Aqib Kazi

Disabling the WebUI and other Non-essential Services
Mon, 25 Jul 2022 13:43:38 -0000
|Read Time: 0 minutes
In today's security environment, organizations must adhere to governance security requirements, including disabling specific HTTP services.
OneFS release 9.4.0.0 has introduced an option to disable non-essential cluster services selectively rather than disabling all HTTP services. Disabling selectively allows administrators to determine which services are necessary. Disabling the services allows other essential services on the cluster to continue to run. You can disable the following non-essential services:
- PowerScaleUI (WebUI)
- Platform-API-External
- Rest Access to Namespace (RAN)
- RemoteService
Each of these services can be disabled independently and has no impact on other HTTP-based data services. The services can be disabled through the CLI or API with the ISI_PRIV_HTTP privilege. To manage the non-essential services from the CLI, use the isi http services list command to list the services. Use the isi http services view and isi http services modify commands to view and modify the services. The impact of disabling each of the services is listed in the following table.
HTTP services impacts
Service | Impacts |
PowerScaleUI | The WebUI is entirely disabled. Attempting to access the WebUI displays Service Unavailable. Please contact Administrator. |
Platform-API-External | Disabling the Platform-API-External service does not impact the Platform-API-Internal service of the cluster. The Platform-API-Internal services continue to function, even if the Platform-API-External service is disabled. However, if the Platform-API-External service is disabled, the WebUI is also disabled at that time, because the WebUI uses the Platform-API-External service. |
RAN (Remote Access to Namespace) | If RAN is disabled, use of the Remote File Browser UI component is restricted in the Remote File Browser and the File System Explorer. |
RemoteService | If RemoteService is disabled, the remote support UI and the InProduct Activation UI components are restricted. |
To disable the WebUI, use the following command:
isi http services modify --service-id=PowerScaleUI --enabled=false
Author: Aqib Kazi

PowerScale Now Supports Secure Boot Across More Platforms
Tue, 21 Jun 2022 19:55:15 -0000
|Read Time: 0 minutes
Dell PowerScale OneFS 9.3.0.0 first introduced support for Secure Boot on the Dell Isilon A2000 platform. Now, OneFS 9.4.0.0 expands that support across the PowerScale A300, A3000, B100, F200, F600, F900, H700, H7000, and P100 platforms.
Secure Boot was introduced as part of the Unified Extensible Firmware Interface (UEFI) Forums of the UEFI 2.3.1 specification. The goal for Secure Boot is to ensure device security in the preboot environment by allowing only authorized EFI binaries to be loaded during the process.
The operating system boot loaders are signed with a digital signature. PowerScale Secure Boot takes the UEFI framework further by including the OneFS kernel and modules. The UEFI infrastructure is responsible for the EFI signature validation and binary loading within UEFI Secure Boot. Also, the FreeBSD veriexec function can perform signature validation for the boot loader and kernel. The PowerScale Secure Boot feature runs during the nodes’ bootup process only, using public-key cryptography to verify the signed code and ensure that only trusted code is loaded on the node.
Supported platforms
PowerScale Secure Boot is available on the following platform:
Platform | NFP version | OneFS release |
Isilon A2000 | 11.4 or later | 9.3.0.0 or later |
PowerScale A300, A3000, B100, F200, F600, F900, H700, H7000, P100 | 11.4 or later | 9.3.0.0 or later |
Considerations
Before configuring the PowerScale Secure Boot feature, consider the following:
- Isilon and PowerScale nodes are not shipped with PowerScale Secure Boot enabled. However, you can enable the feature to meet site requirements.
- A PowerScale cluster composed of PowerScale Secure Boot enabled nodes, and PowerScale Secure Boot disabled nodes, is supported.
- A license is not required for PowerScale Secure Boot because the feature is natively supported.
- At any point, you can enable or disable the PowerScale Secure Boot feature.
- Plan a maintenance window to enable or disable the PowerScale Secure Boot feature, because a node reboot is required during the process to toggle the feature.
- The PowerScale Secure Boot feature does not impact cluster performance, because the feature is only run at bootup.
Configuration
For more information about configuring the PowerScale Secure Boot feature, see the document Dell PowerScale OneFS Secure Boot.
Author: Aqib Kazi

PowerScale OneFS Release 9.3 now supports Secure Boot
Fri, 22 Oct 2021 20:50:20 -0000
|Read Time: 0 minutes
Many organizations are looking for ways to further secure systems and processes in today's complex security environments. The grim reality is that a device is typically most susceptible to loading malicious malware during its boot sequence.
With the introduction of OneFS 9.3, the UEFI Secure Boot feature is now supported on Isilon A2000 nodes. Not only does the release support the UEFI Secure Boot feature, but OneFS goes a step further by adding FreeBSD’s signature validation. Combining UEFI Secure Boot and FreeBSD’s signature validation helps protect the boot process from potential malware attacks.
The Unified Extensible Firmware Interface (UEFI) Forum standardizes and secures the boot sequence across devices with the UEFI specification. UEFI Secure Boot was introduced in UEFI 2.3.1, allowing only authorized EFI binaries to load.
FreeBSD’s veriexec function is used to perform signature validation for the boot loader and kernel. In addition, the PowerScale Secure Boot feature runs during the node’s bootup process only, using public-key cryptography to verify the signed code, to ensure that only trusted code is loaded on the node.
The Secure Boot feature does not impact cluster performance because the feature is only executed at bootup.
Pre-requisites
The OneFS Secure Boot feature is only supported on Isilon A2000 nodes at this time. The cluster must be upgraded and committed to OneFS 9.3. After the release is committed, proceed with upgrading the Node Firmware Package to 11.3 or higher.
Considerations
PowerScale nodes are not shipped with the Secure Boot feature enabled. The feature must be enabled on each node manually in a cluster. Now, a mixed cluster is supported where some nodes have the Secure Boot feature enabled, and others have it disabled.
A license is not required for the PowerScale Secure Boot feature. The Secure Boot feature can be enabled and disabled at any point, but it requires a maintenance window to reboot the node.
Configuration
You can use IPMI or the BIOS to enable the PowerScale Secure Boot feature, but disabling the feature requires using the BIOS.
For more information about the PowerScale Secure Boot feature, and detailed configuration steps, see the Dell EMC PowerScale OneFS Secure Boot white paper.
For more great information about PowerScale, see the PowerScale Info Hub at: https://infohub.delltechnologies.com/t/powerscale-isilon-1/.
Author: Aqib Kazi