




How PowerFlex Transforms Big Data with VMware Greenplum

Quick! The word has just come down. There is a new initiative that requires a massively parallel processing (MPP) database, and you are in charge of implementing it. What are you going to do? Luckily, you know the answer. You also just discovered that the Dell PowerFlex Solutions team has you covered with a solutions guide for VMware Greenplum.
What is in the solutions guide and how will it help with an MPP database? This blog provides the answer. We look at what Greenplum is and how to leverage Dell PowerFlex for both the storage and compute resources in Greenplum.
Infrastructure flexibility: PowerFlex
If you have read my other blogs or are familiar with PowerFlex, you know it has powerful transmorphic properties. For example, PowerFlex nodes sometimes function as both storage and compute, like hyperconverged infrastructure (HCI). At other times, PowerFlex functions as a storage-only (SO) node or a compute-only (CO) node. Even more interesting, these node types can be mixed and matched in the same environment to meet the needs of the organization and the workloads that they run.
This transmorphic property of PowerFlex is helpful in a Greenplum deployment, especially with the configuration described in the solutions guide. Because the deployment is built on open-source PostgreSQL, it is optimized for the needs of an MPP database, like Greenplum. PowerFlex can deliver the compute performance necessary to support massive data IO with its CO nodes. The PowerFlex infrastructure can also support workloads running on CO nodes or nodes that combine compute and storage (hybrid nodes). By leveraging the malleable nature of PowerFlex, no additional silos are needed in the data center, and it may even help remove existing ones.
The architecture used in the solutions guide consists of 12 CO nodes and 10 SO nodes. The CO nodes have VMware ESXi installed on them, with Greenplum instances deployed on top. There are 10 segments and one director deployed for the Greenplum environment. The 12th CO node is used for redundancy.
The storage tier uses the 10 SO nodes to deliver 12 volumes backed by SSDs. This configuration creates a high speed, highly redundant storage system that is needed for Greenplum. Also, two protection domains are used to provide both primary and mirror storage for the Greenplum instances. Greenplum mirrors the volumes between those protection domains, adding an additional level of protection to the environment, as shown in the following figure:
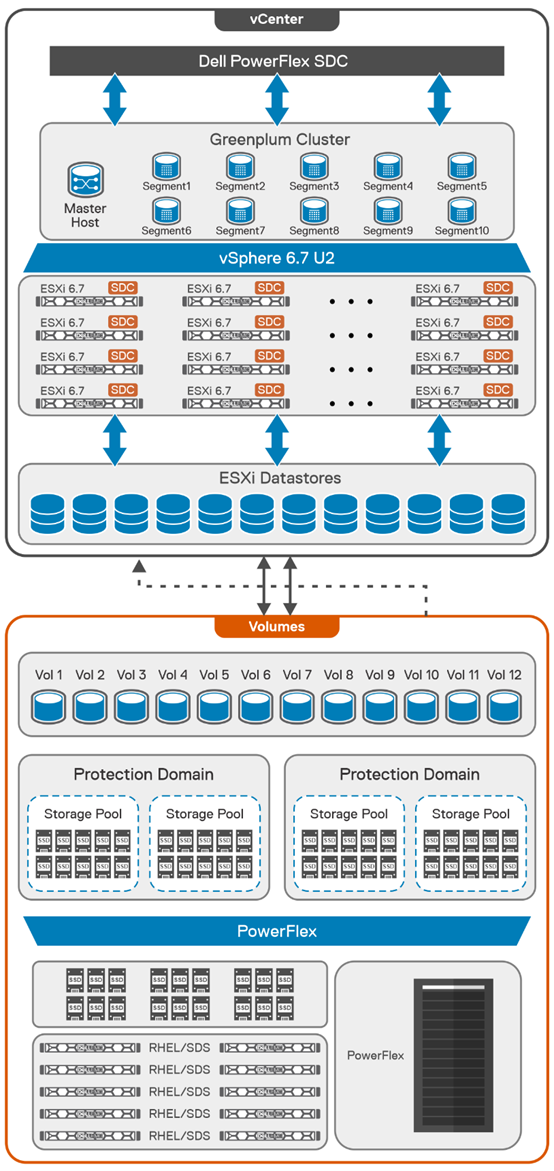
By using this fluid and composable architecture, the components can be scaled independently of one another, allowing for storage to be increased either independently or together with compute. Administrators can use this configuration to optimize usage and deliver appropriate resources as needed without creating silos in the environment.
Testing and validation with Greenplum: we have you covered
The solutions guide not only describes how to build a Greenplum environment, it also addresses testing, which many administrators want to perform before they finish a build. The guide covers performing basic validations with FIO and gpcheckperf. In the simplest terms, these tools ensure that IO, memory, and network performance are acceptable. The FIO tests that were run for the guide showed that the HBA was fully saturated, maximizing both read and write operations. The gpcheckperf testing showed a performance of 14,283.62 MB/sec for write workloads.
Wouldn’t you feel better if a Greenplum environment was tested with a real-world dataset? That is, taking it beyond just the minimum, maximum, and average numbers? The great news is that the architecture was tested that way! Our Dell Digital team has developed an internal test suite running static benchmarked data. This test suite is used at Dell Technologies across new Greenplum environments as the gold standard for new deployments.
In this test design, all the datasets and queries are static. This scenario allows for a consistent measurement of the environment from one run to the next. It also provides a baseline of an environment that can be used over time to see how its performance has changed -- for example, if the environment sped up or slowed down following a software update.
Massive performance with real data
So how did the architecture fare? It did very well! When 182 parallel complex queries were run simultaneously to stress the system, it took just under 12 minutes for the test to run. In that time, the environment had a read bandwidth of 40 GB/s and a write bandwidth of 10 GB/s. These results are using actual production-based queries from the Dell Digital team workload. These results are close to saturating the network bandwidth for the environment, which indicates that there are no storage bottlenecks.
The design covered in this solution guide goes beyond simply verifying that the environment can handle the workload; it also shows how the configuration can maintain performance during ongoing operations.
Maintaining performance with snapshots
One of the key areas that we tested was the impact of snapshots on performance. Snapshots are a frequent operation in data centers and are used to create test copies of data as well as a source for backups. For this reason, consider the impact of snapshots on MPP databases when looking at an environment, not just how fast the database performs when it is first deployed.
In our testing, we used the native snapshot capabilities of PowerFlex to measure the impact that snapshots have on performance. Using PowerFlex snapshots provides significant flexibility in data protection and cloning operations that are commonly performed in data centers.
We found that when the first storage-consistent snapshot of the database volumes was taken, the test took 45 seconds longer to complete than initial tests. This result was because it was the first snapshot of the volumes. Follow-on snapshots during testing resulted in minimal impact to the environment. This minimal impact is significant for MPP databases in which performance is important. (Of course, performance can vary with each deployment.)
We hope that these findings help administrators who are building a Greenplum environment feel more at ease. You not only have a solution guide to refer to as you architect the environment, you can be confident that it was built on best-in-class infrastructure and validated using common testing tools and real-world queries.
The bottom line
Now that you know the assignment is coming to build an MPP database using VMware Greenplum -- are you up to the challenge?
If you are, be sure to read the solution guide. If you need additional guidance on building your Greenplum environment on PowerFlex, be sure to reach out to your Dell representative.
Resources
Authors:
- Tony Foster – Dell Technologies, Twitter: @wonder_nerd
LinkedIn - Sue Mosovich – VMware
Related Blog Posts

Can I do that AI thing on Dell PowerFlex?
Thu, 20 Jul 2023 21:08:09 -0000
|Read Time: 0 minutes
The simple answer is Yes, you can do that AI thing with Dell PowerFlex. For those who might have been busy with other things, AI stands for Artificial Intelligence and is based on trained models that allow a computer to “think” in ways machines haven’t been able to do in the past. These trained models (neural networks) are essentially a long set of IF statements (layers) stacked on one another, and each IF has a ‘weight’. Once something has worked through a neural network, the weights provide a probability about the object. So, the AI system can be 95% sure that it’s looking at a bowl of soup or a major sporting event. That, at least, is my overly simplified description of how AI works. The term carries a lot of baggage as it’s been around for more than 70 years, and the definition has changed from time to time. (See The History of Artificial Intelligence.)
Most recently, AI has been made famous by large language models (LLMs) for conversational AI applications like ChatGPT. Though these applications have stoked fears that AI will take over the world and destroy humanity, that has yet to be seen. Computers still can do only what we humans tell them to do, even LLMs, and that means if something goes wrong, we their creators are ultimately to blame. (See ‘Godfather of AI’ leaves Google, warns of tech’s dangers.)
The reality is that most organizations aren’t building world destroying LLMs, they are building systems to ensure that every pizza made in their factory has exactly 12 slices of pepperoni evenly distributed on top of the pizza. Or maybe they are looking at loss prevention, or better traffic light timing, or they just want a better technical support phone menu. All of these are uses for AI and each one is constructed differently (they use different types of neural networks).
We won’t delve into these use cases in this blog because we need to start with the underlying infrastructure that makes all those ideas “AI possibilities.” We are going to start with the infrastructure and what many now consider a basic (by today’s standards) image classifier known as ResNet-50 v1.5. (See ResNet-50: The Basics and a Quick Tutorial.)
That’s also what the PowerFlex Solution Engineering team did in the validated design they recently published. This design details the use of ResNet-50 v1.5 in a VMware vSphere environment using NVIDIA AI Enterprise as part of PowerFlex environment. They started out with the basics of how a virtualized NVIDIA GPU works well in a PowerFlex environment. That’s what we’ll explore in this blog – getting started with AI workloads, and not how you build the next AI supercomputer (though you could do that with PowerFlex as well).
In this validated design, they use the NVIDIA A100 (PCIe) GPU and virtualized it in VMware vSphere as a virtual GPU or vGPU. With the infrastructure in place, they built Linux VMs that will contain the ResNet-50 v1.5 workload and vGPUs. Beyond just working with traditional vGPUs that many may be familiar with, they also worked with NVIDIA’s Multi-Instance GPU (MIG) technology.
NVIDIA’s MIG technology allows administrators to partition a GPU into a maximum of seven GPU instances. Being able to do this provides greater control of GPU resources, ensuring that large and small workloads get the appropriate amount of GPU resources they need without wasting any.
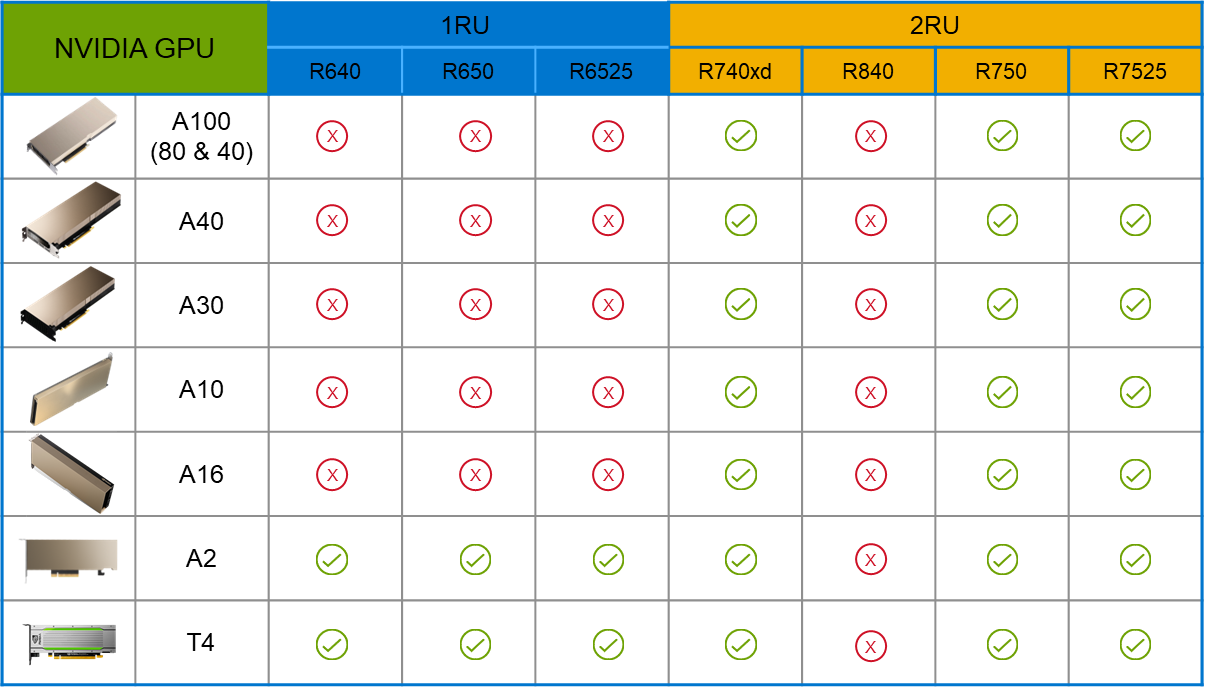
PowerFlex supports a large range of NVIDIA GPUs for workloads, from VDI (Virtual Desktops) to high end virtual compute workloads like AI. You can see this in the following diagram where there are solutions for “space constrained” and “edge” environments, all the way to GPUs used for large inferencing models. In the table below the diagram, you can see which GPUs are supported in each type of PowerFlex node. This provides a tremendous amount of flexibility depending on your workloads.

The validated design describes the steps to configure the architecture and provides detailed links to the NVIDIAand VMware documentation for configuring the vGPUs, and the licensing process for NVIDIA AI Enterprise.
These are key steps when building an AI environment. I know from my experience working with various organizations, and from teaching, that many are not used to working with vGPUs in Linux. This is slowly changing in the industry. If you haven’t spent a lot of time working with vGPUs in Linux, be sure to pay attention to the details provided in the guide. It is important and can make a big difference in your performance.
The following diagram shows the validated design’s logical architecture. At the top of the diagram, you can see four Ubuntu 22.04 Linux VMs with the NVIDIA vGPU driver loaded in them. They are running on PowerFlex hosts with VMware ESXi deployed. Each VM contains one NVIDIA A100 GPU configured for MIG operations. This configuration leverages a two-tier architecture where storage is provided by separate PowerFlex software defined storage (SDS) nodes.
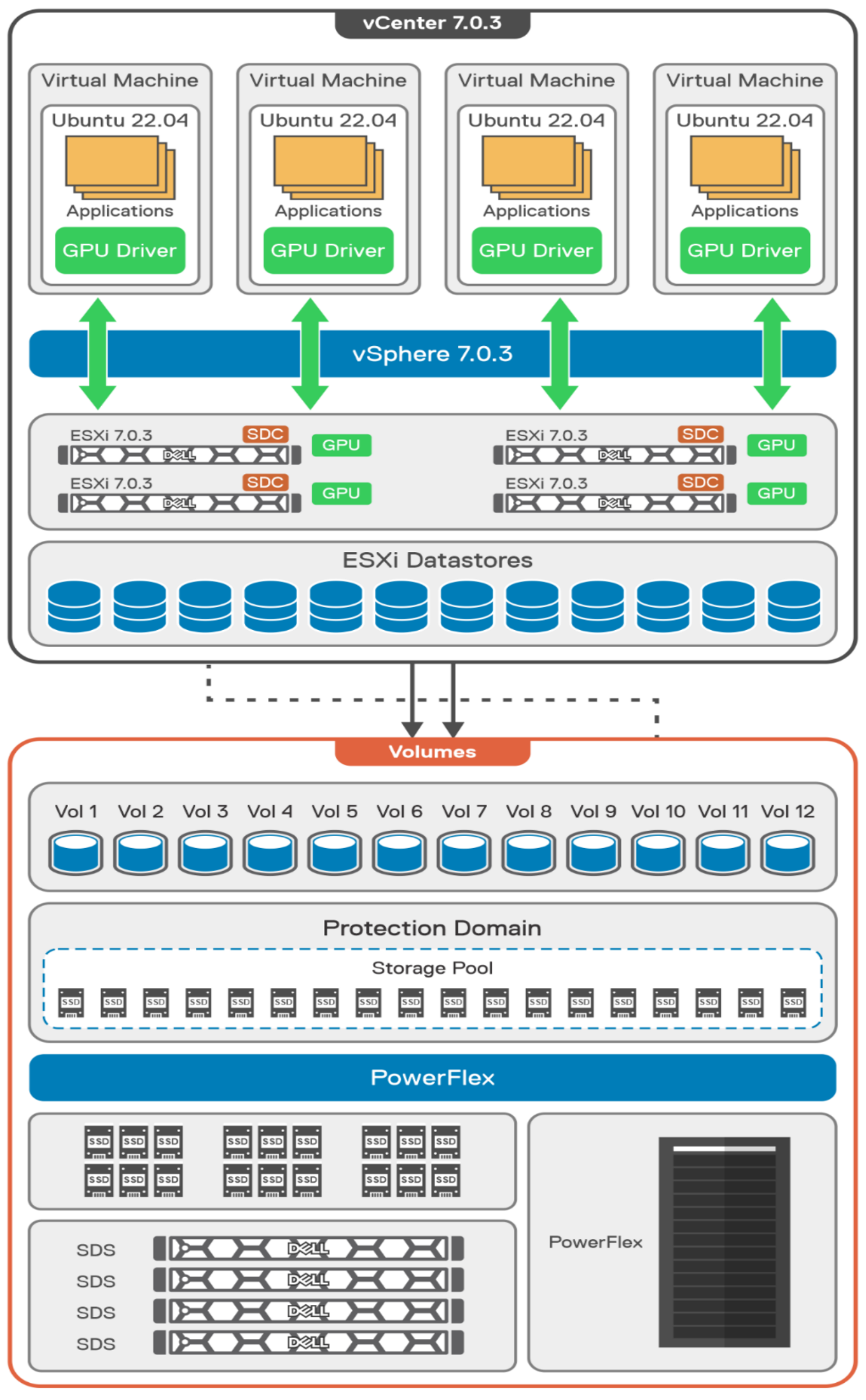
A design like this allows for independent scalability for your workloads. What I mean by this is during the training phase of a model, significant storage may be required for the training data, but once the model clears validation and goes into production, storage requirements may be drastically different. With PowerFlex you have the flexibility to deliver the storage capacity and performance you need at each stage.
This brings us to testing the environment. Again, for this paper, the engineering team validated it using ResNet-50 v1.5 using the ImageNet 1K data set. For this validation they enabled several ResNet-50 v1.5 TensorFlow features. These include Multi-GPU training with Horovod, NVIDIA DALI, and Automatic Mixed Precision (AMP). These help to enable various capabilities in the ResNet-50 v1.5 model that are present in the environment. The paper then describes how to set up and configure ResNet-50 v1.5, the features mentioned above, and details about downloading the ImageNet data.
At this stage they were able to train the ResNet-50 v1.5 deployment. The first iteration of training used the NVIDIA A100-7-40C vGPU profile. They then repeated testing with the A100-4-20C vGPU profile and the A100-3-20C vGPU profile. You might be wondering about the A100-2-10C vGPU profile and the A100-1-5C profile. Although those vGPU profiles are available, they are more suited for inferencing, so they were not tested.
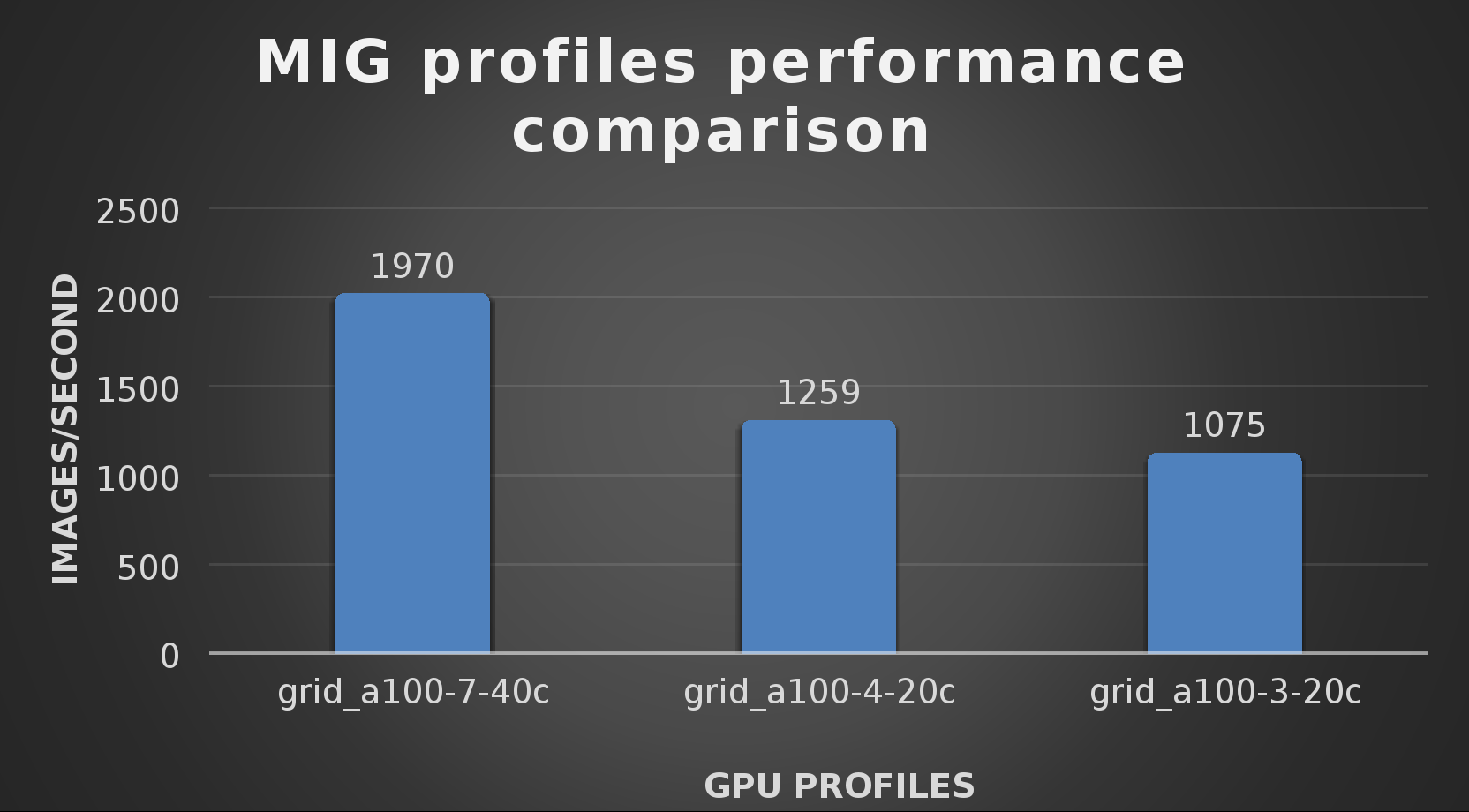
The results from validating the training workloads for each vGPU profile is shown in the following graph. The vGPUs were running near 98% capacity according to nvitop during each test. The CPU utilization was 14% and there was no bottle neck with the storage during the tests.
With the models trained, the guide then looks at how well inference runs on the MIG profiles. The following graph shows inferencing images per second of the various MIG profiles with ResNet-50 v1.5.
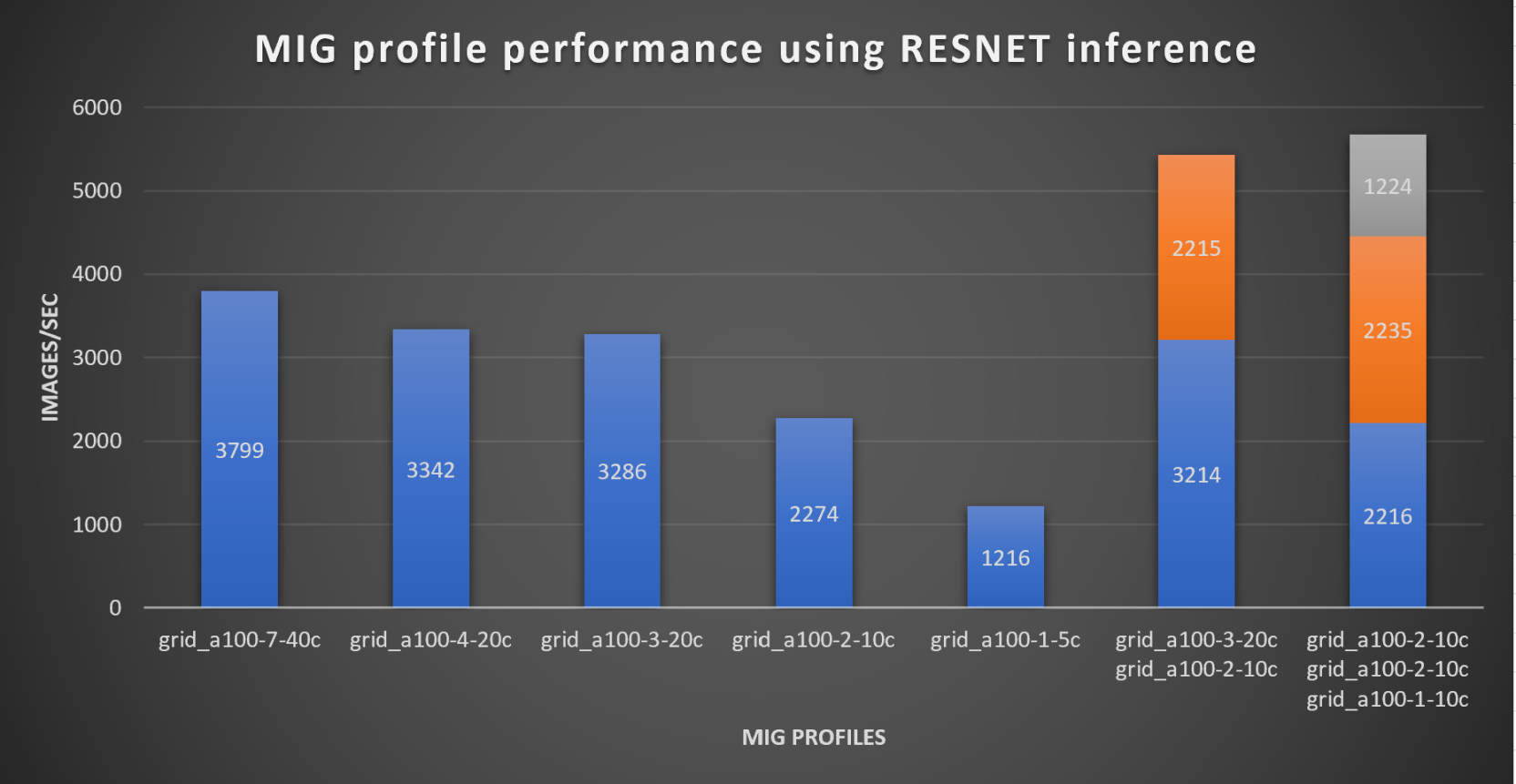
It’s worth noting that the last two columns show the inferencing running across multiple VMs, on the same ESXi host, that are leveraging MIG profiles. This also shows that GPU resources are partitioned with MIG and that resources can be precisely controlled, allowing multiple types of jobs to run on the same GPU without impacting other running jobs.
This opens the opportunity for organizations to align consumption of vGPU resources in virtual environments. Said a different way, it allows IT to provide “show back” of infrastructure usage in the organization. So if a department only needs an inferencing vGPU profile, that’s what they get, no more, no less.
It’s also worth noting that the results from the vGPU utilization were at 88% and CPU utilization was 11% during the inference testing.
These validations show that a Dell PowerFlex environment can support the foundational components of modern-day AI. It also shows the value of NVIDIA’s MIG technology to organizations of all sizes: allowing them to gain operational efficiencies in the data center and enable access to AI.
Which again answers the question of this blog, can I do that AI thing on Dell PowerFlex… Yes you can run that AI thing! If you would like to find out more about how to run your AI thing on PowerFlex, be sure to reach out to your Dell representative.
Resources
- The History of Artificial Intelligence
- ‘Godfather of AI’ leaves Google, warns of tech’s dangers
- ResNet-50: The Basics and a Quick Tutorial
- Dell Validated Design for Virtual GPU with VMware and NVIDIA on PowerFlex
- NVIDIA NGC Catalog ResNet v1.5 for PyTorch
- NVIDIA AI Enterprise
- NVIDIA A100 (PCIe) GPU
- NVIDIA Virtual GPU Software Documentation
- NVIDIA A100-7-40C vGPU profile
- NVIDIA Multi-Instance GPU (MIG)
- NVIDIA Multi-Instance GPU User Guide
- Horovod
- ImageNet
- DALI
- Automatic Mixed Precision (AMP)
- nvitop
Author: Tony Foster
Sr. Principal Technical Marketing Engineer
Twitter: | |
LinkedIn: | |
Personal Blog: | |
Location: | The Land of Oz [-6 GMT] |

Introducing NVMe over TCP (NVMe/TCP) in PowerFlex 4.0
Fri, 26 Aug 2022 18:59:38 -0000
|Read Time: 0 minutes
Anyone who has used or managed PowerFlex knows that an environment is built from three lightweight software components: the MDM, the SDS, and the SDC. To deploy a PowerFlex environment, the typical steps are:
- Deploy an MDM management cluster
- Create a cluster of storage servers by installing and configuring the SDS software component
- Add Protection Domains and Storage Pools
- Install the SDC onto client systems
- Provision volumes and away you go!!*
*No requirement for multipath software, this is all handled by the SDC/SDS
There have been additions to this over the years, such as an SDR component for replication and the configuration of NVDIMM devices to create finegranularity storage pools that provide compression. Also added are PowerFlex rack and appliance environments. This is all automated with PowerFlex Manager. Fundamentally, the process involves the basic steps outlined above.
So, the question is why would we want to change anything from an elegant solution that is so simple?
This is due to where the SDC component ‘lives’ in the operating system or hypervisor hosting the application layer. Referring to the diagram below, it shows that the SDC must be installed in the kernel of the operating system or hypervisor, meaning that the SDC and the kernel must be compatible. Also the SDC component must be installed and maintained, it does not just ‘exist’.
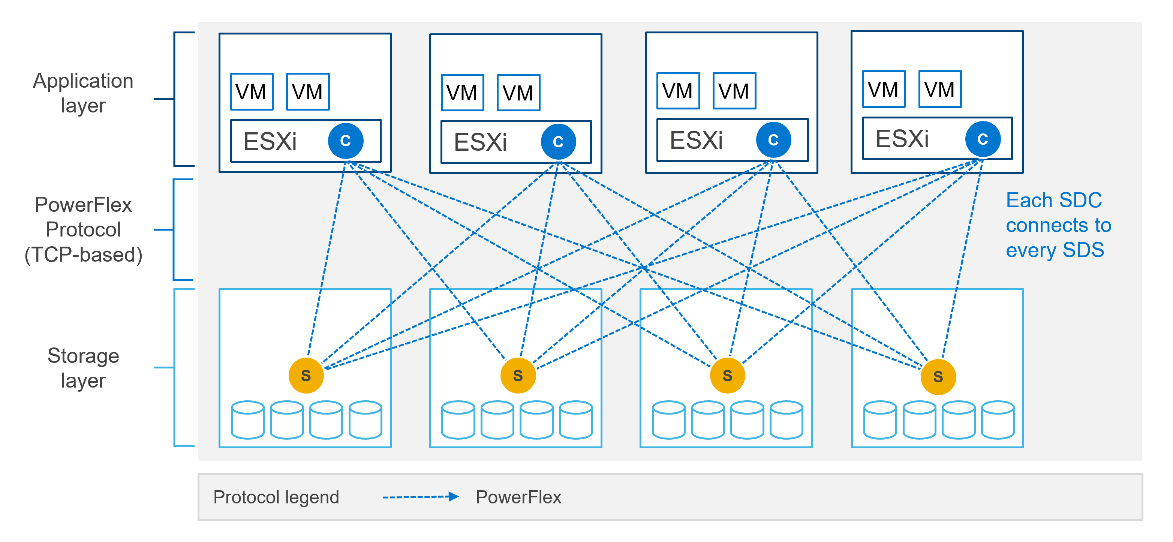
In most cases, this is fine and there are no issues whatsoever. The PowerFlex development team keeps the SDC current with all the major operating system versions and customers are happy to update the SDC within their environment when new versions become available.
There are, however, certain cases where manual deployment and management of the SDC causes significant overhead. There are also some edge use cases where there is no SDC available for specific operating systems. This is why the PowerFlex team has investigated alternatives.
In recent years, the use of Non-Volatile Memory Express (NVMe) has become pervasive within the storage industry. It is seen as the natural replacement to SCSI, due to its simplified command structure and its ability to provide multiple queues to devices, aligning perfectly with modern multi-core processors to provide very high performance.
NVMe appeared initially as a connection directly to disks within a server over a PCIe connection, progressing to being used over a variety of fabric interconnects.
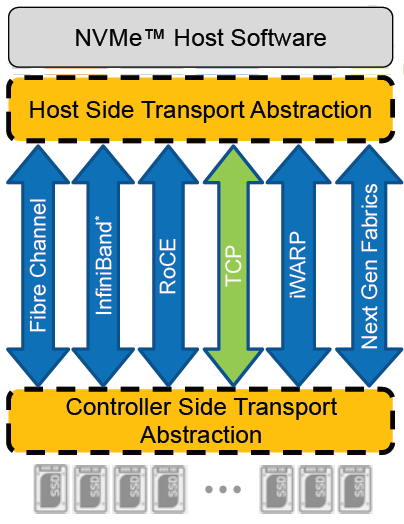
Added to this is the widespread support for NVMe/TCP across numerous operating system and hypervisor vendors. Most include support natively in their kernels.
There have been several announcements by Dell Technologies over the past months highlighting NVMe/TCP as an alternative interconnect to iSCSI across several of the storage platforms within the portfolio. It is therefore a natural progression for PowerFlex to also provide support for NVMe/TCP, particularly because it already uses a TCP-based interconnect.
PowerFlex implements support for NVMe/TCP with the introduction of a new component installed in the storage layer called the SDT.
The SDT is installed at the storage layer. The NVMe initiator in the operating system or hypervisor communicates with the SDT, which then communicates with the SDS. The NVMe initiator is part of the kernel of the operating system or hypervisor.
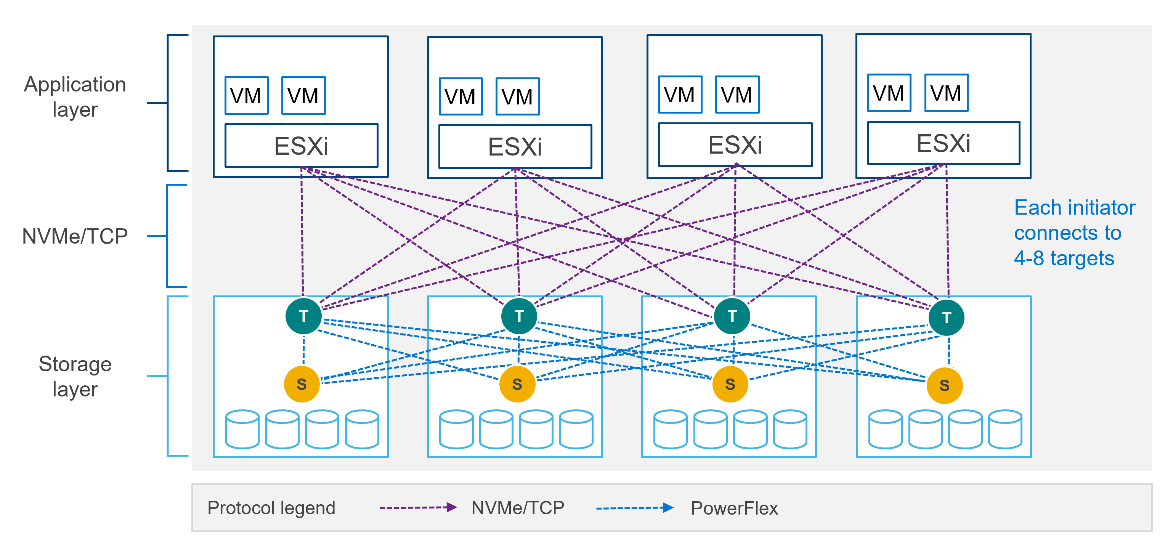
Of course, because PowerFlex is so ‘flexible,’ both connection methods (SDC and NVMe/TCP) are supported at the same time. The only limitation is that a volume can only be presented using one protocol or the other.
For the initial PowerFlex 4.0 release, the VMware ESXi hypervisor is supported. This support starts with ESXi 7.0 U3f. Support for Linux TCP initiators is currently in “tech preview” as the initiators continue to grow and mature, allowing for all failure cases to be accounted for.
NVMe/TCP is a very powerful solution for the workloads that take advantage of it. If you are interested in discovering more about how PowerFlex can enhance your datacenter, reach out to your Dell representative.
Authors:
Kevin M Jones, PowerFlex Engineering Technologist.
Tony Foster, Senior Principal Technical Marketing Engineer.
Twitter: @wonder_nerd
LinkedIn