




GPU-Accelerated AI and ML Capabilities
Dell EMC Integrated System for Microsoft Azure Stack Hub has been extending Microsoft Azure services to customer-owned data centers for over three years. Our platform has enabled organizations to create a hybrid cloud ecosystem that drives application modernization and to address business concerns around data sovereignty and regulatory compliance.
Dell Technologies, in collaboration with Microsoft, is excited to announce upcoming enhancements that will unlock valuable, real-time insights from local data using GPU-accelerated AI and ML capabilities. Actionable information can be derived from large on-premises data sets at the intelligent edge without sacrificing security.
Partnership with NVIDIA
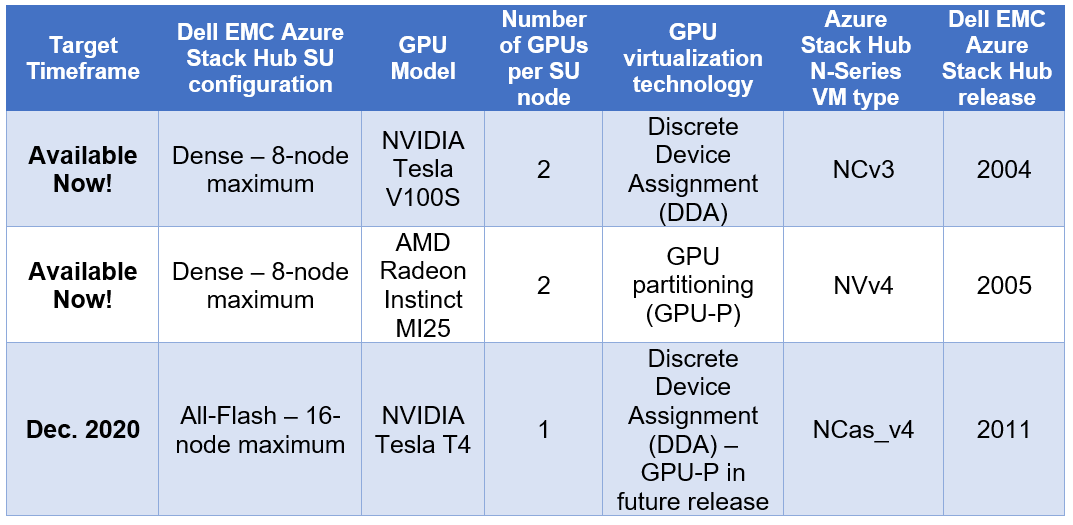
Today, customers can order our Azure Stack Hub dense scale unit configuration with NVIDIA Tesla V100S GPUs for running compute-intensive AI processes like inferencing, training, and visualization from virtual machine or container-based applications. Some customers choose to run Kubernetes clusters on their hardware-accelerated Azure Stack Hub scale units to process and analyze data sent from IoT devices or Azure Stack Edge appliances. Powered by the Dell EMC PowerEdge R840 rack server, these NVIDIA Tesla V100S GPUs use Discrete Device Assignment (DDA), also known as GPU pass-through, to dedicate one or more GPUs to an Azure Stack Hub NCv3 VM.
The following figure illustrates the resources installed in each GPU-equipped Azure Stack Hub dense configuration scale unit node.

This month, our Dell EMC Azure Stack Hub release 2011 will also support the NVIDIA T4 GPU – a single-slot, low-profile adapter powered by NVIDIA Turing Tensor Cores. These GPUs are perfect for accelerating diverse cloud-based workloads, including light machine learning, inference, and visualization. These adapters can be ordered with Dell EMC Azure Stack Hub all-flash scale units powered by Dell EMC PowerEdge R640 rack servers. Like the NVIDIA Tesla V100S, these GPUs use DDA to dedicate one adapter’s powerful capabilities to a single Azure Stack Hub NCas_v4 VM. A future Azure Stack Hub release will also enable GPU partitioning on the NVIDIA T4.
The following figure illustrates the resources installed in each GPU-equipped Azure Stack Hub all-flash configuration scale unit node.

Partnership with AMD
We are also pleased to announce a partnership with AMD to deliver GPU capabilities in our Dell EMC Integrated System for Microsoft Azure Stack Hub. Available today, customers can order our dense scale unit configuration with AMD Radeon Instinct MI25 GPUs aimed at graphics intensive visualization workloads like simulation, CAD applications, and gaming. The MI25 uses GPU partitioning (GPU-P) technology to allow users of an Azure Stack Hub NVv4 VM to consume only a portion of the GPU’s resources based on their workload requirements.
The following table is a summary of our hardware acceleration capabilities.
An engineered approach
Following our stringent engineered approach, Dell Technologies goes far beyond considering GPUs as just additional hardware components in the Dell EMC Integrated System for Microsoft Azure Stack Hub portfolio. We apply our pedigree as leaders in appliance-based solutions to the entire lifecycle of all our scale unit configurations. The dense and all-flash scale unit configurations with integrated GPUs are designed to follow best practices and use cases specifically with Azure-based workloads, rather than workloads running on traditional virtualization platforms. Dell Technologies is also committed to ensuring a simplified experience for initial deployment, patch and update, support, and streamlined operations and monitoring for these new configurations.
Additional considerations
There are a couple of additional details worth mentioning about our new Azure Stack Hub dense and all-flash scale unit configurations with hardware acceleration:
- The use of the GPU-backed N-Series VMs in Azure Stack Hub for compute-intensive AI and ML workloads is still in preview. Dell Technologies is very interested in speaking with customers about their use cases and workloads supported by this configuration. Please contact us at mhc.preview@dell.com to speak with one of our engineering technologists.
- The Dell EMC Integrated System for Microsoft Azure Stack Hub configurations with GPUs can be delivered fully racked and cabled in our Dell EMC rack. Customers can also elect to have the scale unit components re-racked and cabled in their own existing cabinets with the assistance of Dell Technologies Services.
Resources for further study
- At the time of publishing this blog post, only the NCv3 and NVv4 VMs are available in the Azure Stack Hub marketplace. The NCas_v4 currently is not visible in the portal. Please proceed to the Azure Stack Hub User Documentation for more information on these VM sizes.
- Customers may want to explore the Train Machine Learning (ML) model at the edge design pattern in the Azure Hybrid Documentation. This may prove to be a good starting point for putting this technology to work for their organization.
- Customers considering running AI and ML workloads on Dell EMC Integrated System for Microsoft Azure Stack Hub can also greatly benefit from storage-as-a-service with Dell EMC PowerScale. PowerScale can help enable faster training and validation of AI models, improve model accuracy, drive higher GPU utilization, and increase data science productivity. Visit Artificial Intelligence with Dell EMC PowerScale for more information.
Related Blog Posts

Can I do that AI thing on Dell PowerFlex?

Thu, 20 Jul 2023 21:08:09 -0000
|Read Time: 0 minutes
The simple answer is Yes, you can do that AI thing with Dell PowerFlex. For those who might have been busy with other things, AI stands for Artificial Intelligence and is based on trained models that allow a computer to “think” in ways machines haven’t been able to do in the past. These trained models (neural networks) are essentially a long set of IF statements (layers) stacked on one another, and each IF has a ‘weight’. Once something has worked through a neural network, the weights provide a probability about the object. So, the AI system can be 95% sure that it’s looking at a bowl of soup or a major sporting event. That, at least, is my overly simplified description of how AI works. The term carries a lot of baggage as it’s been around for more than 70 years, and the definition has changed from time to time. (See The History of Artificial Intelligence.)
Most recently, AI has been made famous by large language models (LLMs) for conversational AI applications like ChatGPT. Though these applications have stoked fears that AI will take over the world and destroy humanity, that has yet to be seen. Computers still can do only what we humans tell them to do, even LLMs, and that means if something goes wrong, we their creators are ultimately to blame. (See ‘Godfather of AI’ leaves Google, warns of tech’s dangers.)
The reality is that most organizations aren’t building world destroying LLMs, they are building systems to ensure that every pizza made in their factory has exactly 12 slices of pepperoni evenly distributed on top of the pizza. Or maybe they are looking at loss prevention, or better traffic light timing, or they just want a better technical support phone menu. All of these are uses for AI and each one is constructed differently (they use different types of neural networks).
We won’t delve into these use cases in this blog because we need to start with the underlying infrastructure that makes all those ideas “AI possibilities.” We are going to start with the infrastructure and what many now consider a basic (by today’s standards) image classifier known as ResNet-50 v1.5. (See ResNet-50: The Basics and a Quick Tutorial.)
That’s also what the PowerFlex Solution Engineering team did in the validated design they recently published. This design details the use of ResNet-50 v1.5 in a VMware vSphere environment using NVIDIA AI Enterprise as part of PowerFlex environment. They started out with the basics of how a virtualized NVIDIA GPU works well in a PowerFlex environment. That’s what we’ll explore in this blog – getting started with AI workloads, and not how you build the next AI supercomputer (though you could do that with PowerFlex as well).
In this validated design, they use the NVIDIA A100 (PCIe) GPU and virtualized it in VMware vSphere as a virtual GPU or vGPU. With the infrastructure in place, they built Linux VMs that will contain the ResNet-50 v1.5 workload and vGPUs. Beyond just working with traditional vGPUs that many may be familiar with, they also worked with NVIDIA’s Multi-Instance GPU (MIG) technology.
NVIDIA’s MIG technology allows administrators to partition a GPU into a maximum of seven GPU instances. Being able to do this provides greater control of GPU resources, ensuring that large and small workloads get the appropriate amount of GPU resources they need without wasting any.
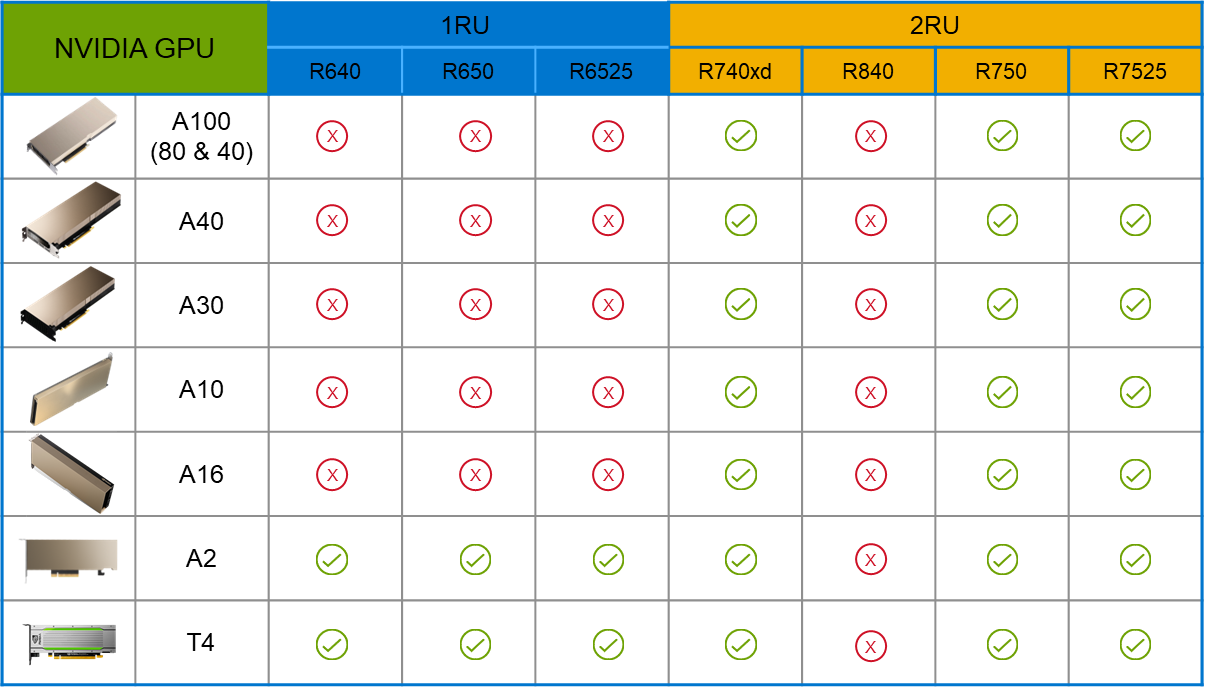
PowerFlex supports a large range of NVIDIA GPUs for workloads, from VDI (Virtual Desktops) to high end virtual compute workloads like AI. You can see this in the following diagram where there are solutions for “space constrained” and “edge” environments, all the way to GPUs used for large inferencing models. In the table below the diagram, you can see which GPUs are supported in each type of PowerFlex node. This provides a tremendous amount of flexibility depending on your workloads.

The validated design describes the steps to configure the architecture and provides detailed links to the NVIDIAand VMware documentation for configuring the vGPUs, and the licensing process for NVIDIA AI Enterprise.
These are key steps when building an AI environment. I know from my experience working with various organizations, and from teaching, that many are not used to working with vGPUs in Linux. This is slowly changing in the industry. If you haven’t spent a lot of time working with vGPUs in Linux, be sure to pay attention to the details provided in the guide. It is important and can make a big difference in your performance.
The following diagram shows the validated design’s logical architecture. At the top of the diagram, you can see four Ubuntu 22.04 Linux VMs with the NVIDIA vGPU driver loaded in them. They are running on PowerFlex hosts with VMware ESXi deployed. Each VM contains one NVIDIA A100 GPU configured for MIG operations. This configuration leverages a two-tier architecture where storage is provided by separate PowerFlex software defined storage (SDS) nodes.
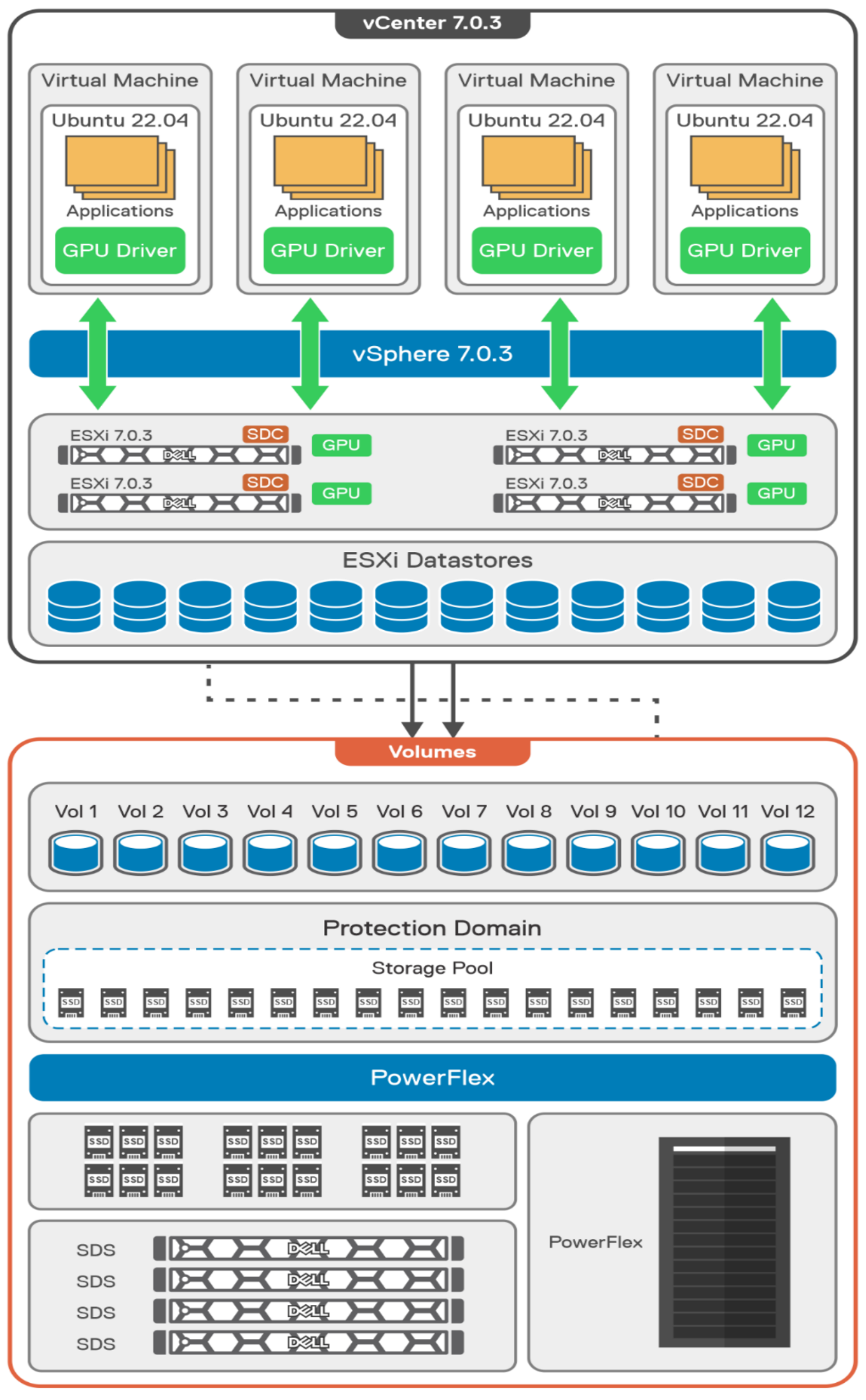
A design like this allows for independent scalability for your workloads. What I mean by this is during the training phase of a model, significant storage may be required for the training data, but once the model clears validation and goes into production, storage requirements may be drastically different. With PowerFlex you have the flexibility to deliver the storage capacity and performance you need at each stage.
This brings us to testing the environment. Again, for this paper, the engineering team validated it using ResNet-50 v1.5 using the ImageNet 1K data set. For this validation they enabled several ResNet-50 v1.5 TensorFlow features. These include Multi-GPU training with Horovod, NVIDIA DALI, and Automatic Mixed Precision (AMP). These help to enable various capabilities in the ResNet-50 v1.5 model that are present in the environment. The paper then describes how to set up and configure ResNet-50 v1.5, the features mentioned above, and details about downloading the ImageNet data.
At this stage they were able to train the ResNet-50 v1.5 deployment. The first iteration of training used the NVIDIA A100-7-40C vGPU profile. They then repeated testing with the A100-4-20C vGPU profile and the A100-3-20C vGPU profile. You might be wondering about the A100-2-10C vGPU profile and the A100-1-5C profile. Although those vGPU profiles are available, they are more suited for inferencing, so they were not tested.
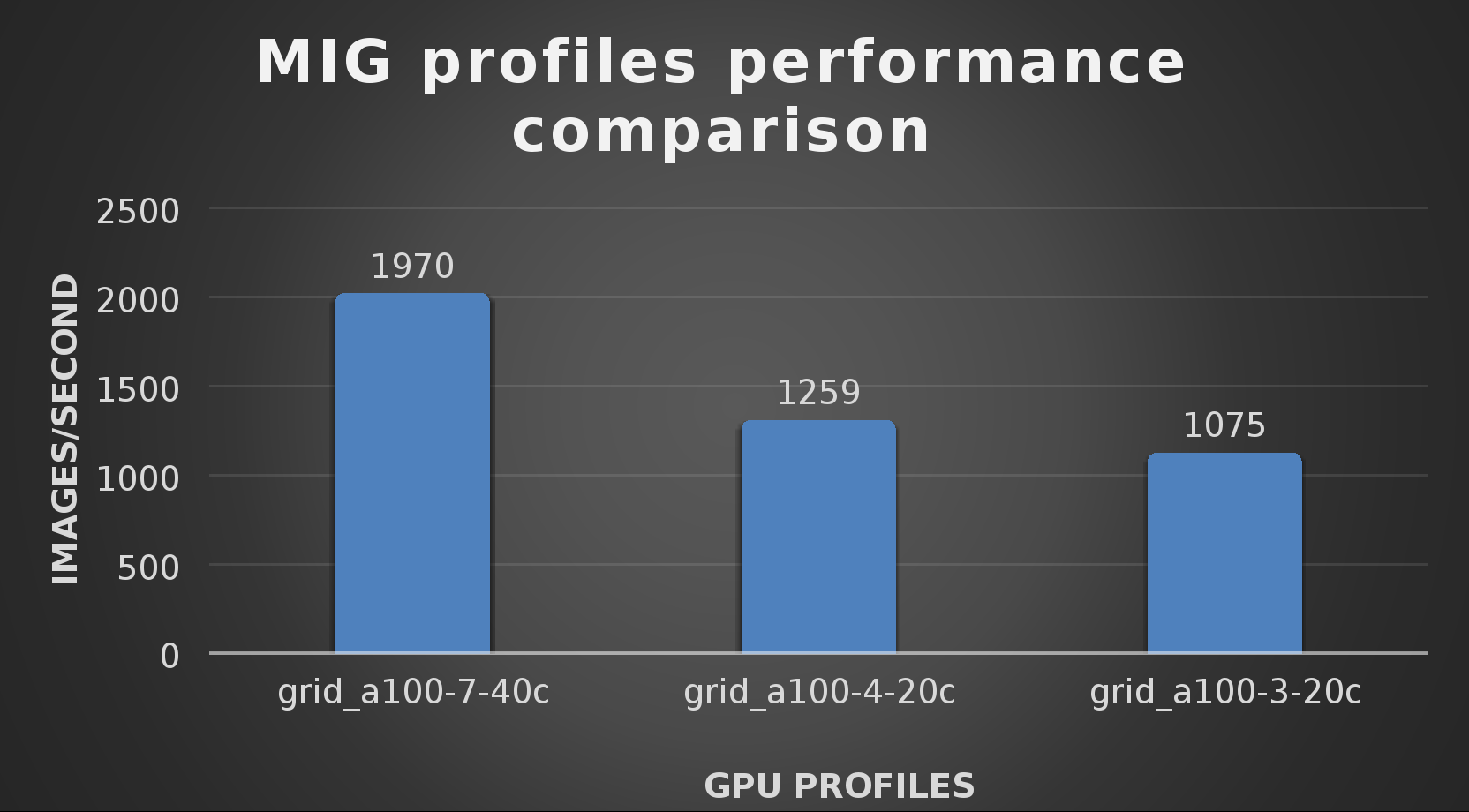
The results from validating the training workloads for each vGPU profile is shown in the following graph. The vGPUs were running near 98% capacity according to nvitop during each test. The CPU utilization was 14% and there was no bottle neck with the storage during the tests.
With the models trained, the guide then looks at how well inference runs on the MIG profiles. The following graph shows inferencing images per second of the various MIG profiles with ResNet-50 v1.5.
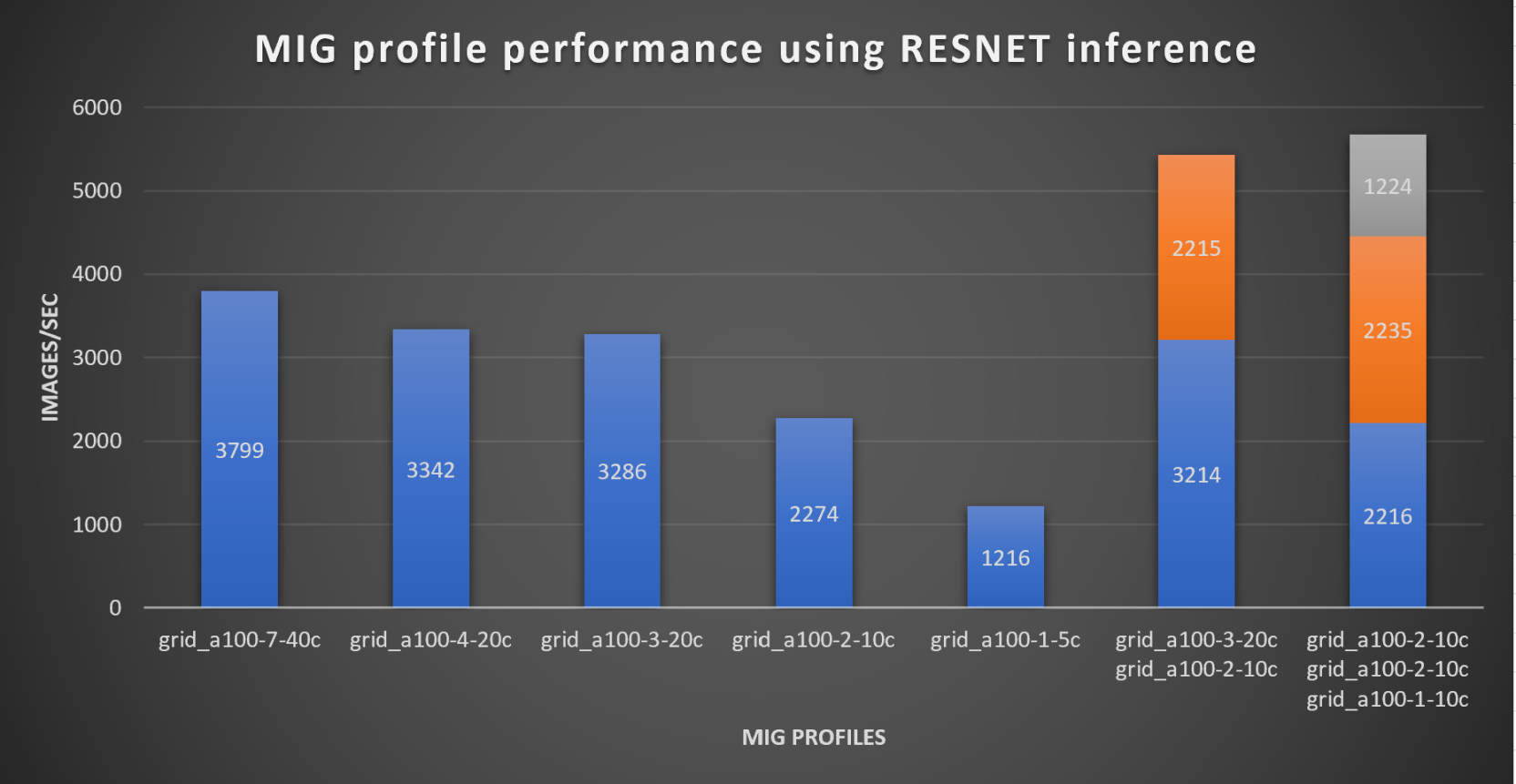
It’s worth noting that the last two columns show the inferencing running across multiple VMs, on the same ESXi host, that are leveraging MIG profiles. This also shows that GPU resources are partitioned with MIG and that resources can be precisely controlled, allowing multiple types of jobs to run on the same GPU without impacting other running jobs.
This opens the opportunity for organizations to align consumption of vGPU resources in virtual environments. Said a different way, it allows IT to provide “show back” of infrastructure usage in the organization. So if a department only needs an inferencing vGPU profile, that’s what they get, no more, no less.
It’s also worth noting that the results from the vGPU utilization were at 88% and CPU utilization was 11% during the inference testing.
These validations show that a Dell PowerFlex environment can support the foundational components of modern-day AI. It also shows the value of NVIDIA’s MIG technology to organizations of all sizes: allowing them to gain operational efficiencies in the data center and enable access to AI.
Which again answers the question of this blog, can I do that AI thing on Dell PowerFlex… Yes you can run that AI thing! If you would like to find out more about how to run your AI thing on PowerFlex, be sure to reach out to your Dell representative.
Resources
- The History of Artificial Intelligence
- ‘Godfather of AI’ leaves Google, warns of tech’s dangers
- ResNet-50: The Basics and a Quick Tutorial
- Dell Validated Design for Virtual GPU with VMware and NVIDIA on PowerFlex
- NVIDIA NGC Catalog ResNet v1.5 for PyTorch
- NVIDIA AI Enterprise
- NVIDIA A100 (PCIe) GPU
- NVIDIA Virtual GPU Software Documentation
- NVIDIA A100-7-40C vGPU profile
- NVIDIA Multi-Instance GPU (MIG)
- NVIDIA Multi-Instance GPU User Guide
- Horovod
- ImageNet
- DALI
- Automatic Mixed Precision (AMP)
- nvitop
Author: Tony Foster
Sr. Principal Technical Marketing Engineer
Twitter: | |
LinkedIn: | |
Personal Blog: | |
Location: | The Land of Oz [-6 GMT] |

New Frontiers—Dell EMC PowerEdge R750xa Server with NVIDIA A100 GPUs
Tue, 01 Jun 2021 20:18:04 -0000
|Read Time: 0 minutes
Dell Technologies has released the new PowerEdge R750xa server, a GPU workload-based platform that is designed to support artificial intelligence, machine learning, and high-performance computing solutions. The dual socket/2U platform supports 3rd Gen Intel Xeon processors (code named Ice Lake). It supports up to 40 cores per processor, has eight memory channels per CPU, and up to 32 DDR4 DIMMs at 3200 MT/s DIMM speed. This server can accommodate up to four double-width PCIe GPUs that are located in the front left and the front right of the server.
Compared with the previous generation PowerEdge C4140 and PowerEdge R740 GPU platform options, the new PowerEdge R750xa server supports larger storage capacity, provides more flexible GPU offerings, and improves the thermal requirement

Figure 1 PowerEdge R750xa server
The NVIDIA A100 GPUs are built on the NVIDIA Ampere architecture to enable double precision workloads. This blog evaluates the new PowerEdge R750xa server and compares its performance with the previous generation PowerEdge C4140 server.
The following table shows the specifications for the NVIDIA GPU that is discussed in this blog and compares the performance improvement from the previous generation.
Table 1 NVIDIA GPU specifications
PCIe | Improvement | ||
GPU name | A100 | V100 |
|
GPU architecture | Ampere | Volta | - |
GPU memory | 40 GB | 32 GB | 60% |
GPU memory bandwidth | 1555 GB/s | 900 GB/s | 73% |
Peak FP64 | 9.7 TFLOPS | 7 TFLOPS | 39% |
Peak FP64 Tensor Core | 19.5 TFLOPS | N/A | - |
Peak FP32 | 19.5 TFLOPS | 14 TFLOPS | 39% |
Peak FP32 Tensor Core | 156 TFLOPS 312 TFLOPS* | N/A | - |
Peak Mixed Precision FP16 ops/ FP32 Accumulate | 312 TFLOPS 624 TFLOPS* | 125 TFLOPS | 5x |
GPU base clock | 765 MHz | 1230 MHz | - |
Peak INT8 | 624 TOPS 1,248 TOPS* | N/A | - |
GPU Boost clock | 1410 MHz | 1380 MHz | 2.1% |
NVLink speed | 600 GB/s | N/A | - |
Maximum power consumption | 250 W | 250 W | No change |
Test bed and applications
This blog quantifies the performance improvement of the GPUs with the new PowerEdge GPU platform.
Using a single node PowerEdge R750xa server in the Dell HPC & AI Innovation Lab, we derived all results presented in this blog from this test bed. This section describes the test bed and the applications that were evaluated as part of the study. The following table provides test environment details:
Table 2 Server configuration
Component | Test Bed 1 | Test Bed 2 |
Server | Dell PowerEdge R750xa
| Dell PowerEdge C4140 configuration M |
Processor | Intel Xeon 8380 | Intel Xeon 6248 |
Memory | 32 x 16 GB @ 3200MT/s | 16 x 16 GB @ 2933MT/s |
Operating system | Red Hat Enterprise Linux 8.3 | Red Hat Enterprise Linux 8.3 |
GPU | 4 x NVIDIA A100-PCIe-40 GB GPU | 4 x NVIDIA V100-PCIe-32 GB GPU |
The following table provides information about the applications and benchmarks used:
Table 3 Benchmark and application details
Application | Domain | Version | Benchmark dataset |
High-Performance Linpack | Floating point compute-intensive system benchmark | xhpl_cuda-11.0-dyn_mkl-static_ompi-4.0.4_gcc4.8.5_7-23-20 | Problem size is more than 95% of GPU memory |
HPCG | Sparse matrix calculations | xhpcg-3.1_cuda_11_ompi-3.1 | 512 * 512 * 288
|
GROMACS | Molecular dynamics application | 2020 | Ligno Cellulose Water 1536 Water 3072 |
LAMMPS | Molecular dynamics application | 29 October 2020 release | Lennard Jones |
LAMMPS
Large-Scale Atomic/Molecular Massively Parallel simulator (LAMMPS) is distributed by Sandia National Labs and the US Department of Energy. LAMMPS is open-source code that has different accelerated models for performance on CPUs and GPUs. For our test, we compiled the binary using the KOKKOS package, which runs efficiently on GPUs.
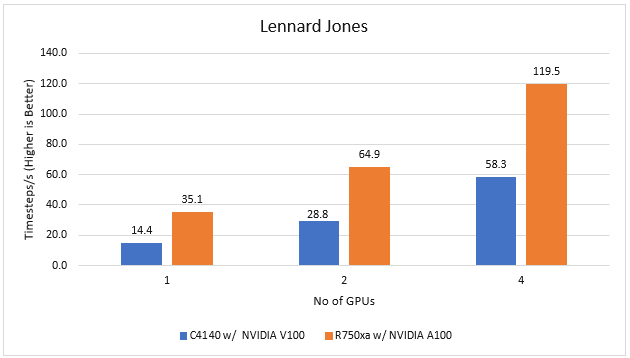
Figure 2 LAMMPS Performance on PowerEdge R750xa and PowerEdge C4140 servers
With the newer generation GPUs, this application improves 2.4 times compared to single GPU performance. The overall performance from a single server improved twice with the PowerEdge R750xa server and NVIDIA A100 GPUs.
GROMACS
GROMACS is a free and open-source parallel molecular dynamics package designed for simulations of biochemical molecules such as proteins, lipids, and nucleic acids. It is used by a wide variety of researchers, particularly for biomolecular and chemistry simulations. GROMACS supports all the usual algorithms expected from modern molecular dynamics implementation. It is open-source software with the latest versions available under the GNU Lesser General Public License (LGPL).
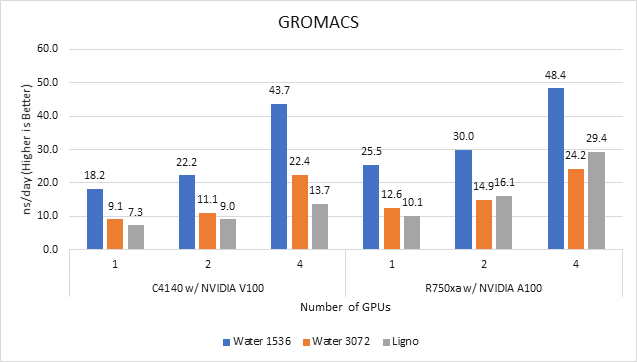
Figure 3 GROMACS performance on PowerEdge C4140 and r750xa servers
With the newer generation GPUs, this application improved approximately 1.5 times across the dataset compared to single GPU performance. The overall performance from a single server improved 1.5 times with a PowerEdge R750xa server and NVIDIA A100 GPUs.
High-Performance Linpack
High-Performance Linpack (HPL) needs no introduction in the HPC arena. It is a widely used standard benchmark tests in the industry.
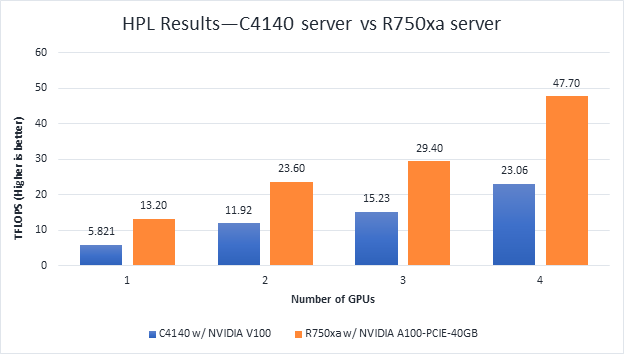
Figure 4 HPL Performance on the PowerEdge R750xa server with A100 GPU and PowerEdge C4140 server with V100 GPU
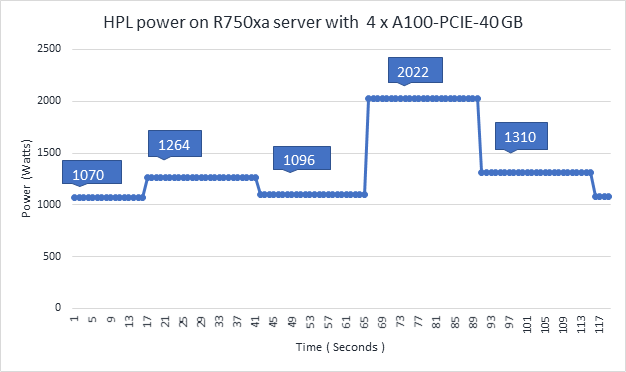
Figure 5 Power use of the HPL running on NVIDIA GPUs
From Figure 4 and Figure 5, the following results were observed:
- Performance—For GPU count, the NVIDIA A100 GPU demonstrates twice the performance of the NVIDIA V100 GPU. Higher memory size, double precision FLOPS, and a newer architecture contribute to the improvement for the NVIDIA A100 GPU.
- Scalability—The PowerEdge R750xa server with four NVIDIA A100-PCIe-40 GB GPUs delivers 3.6 times higher HPL performance compared to one NVIDIA A100-PCIE-40 GB GPU. The NVIDIA A100 GPUs scale well inside the PowerEdge R750xa server for the HPL benchmark.
- Higher Rpeak—The HPL code on NVIDIA A100 GPUs uses the new double-precision Tensor cores. The theoretical peak for each GPU is 19.5 TFlops, as opposed to 9.7 TFlops.
- Power—Figure 5 shows power consumption of a complete HPL run with the PowerEdge R750xa server using four A100-PCIe GPUs. This result was measured with iDRAC commands, and the peak power consumption was observed as 2022 Watts. Based on our previous observations, we know that the PowerEdge C4140 server consumes approximately 1800 W of power.
HPCG
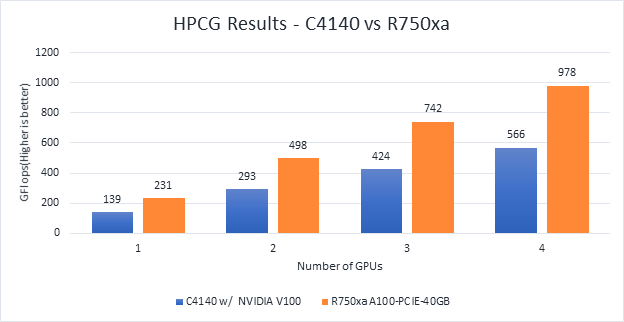
Figure 6 Scaling GPU performance data for HPCG Benchmark
As discussed in other blogs, high performance conjugate gradient (HPCG) is another standard benchmark to test data access patterns of sparse matrix calculations. From the graph, we see that the HPCG benchmark scales well with this benchmark resulting in 1.6 times performance improvement over the previous generation PowerEdge C4140 server with an NVIDIA V100 GPU.
The 72 percent improvement in memory bandwidth of the NVIDIA A100 GPU over the NVIDIA V100 GPU contributes to the performance improvement.
Conclusion
In this blog, we introduced the latest generation PowerEdge R750xa platform and discussed the performance improvement over the previous generation PowerEdge C4140 server. The PowerEdge R750xa server is a good option for customers looking for an Intel Xeon scalable CPU-based platform powered with NVIDIA GPUs.
With the newer generation PowerEdge R750xa server and NVIDIA A100 GPUs, the applications discussed in this blog show significant performance improvement.
Next steps
In future blogs, we plan to evaluate NVLINK bridge support, which is another important feature of the PowerEdge R750xa server and NVIDIA A100 GPUs.