




Exploring the customer experience with lifecycle management for vSAN Ready Nodes and VxRail clusters
Thu, 24 Sep 2020 19:41:49 -0000
|Read Time: 0 minutes
The difference between VMware vSphere LCM (vLCM) and Dell EMC VxRail LCM is still a trending topic that most HCI customers and prospects want more information about. While we compared the two methods at a high level in our previous blog post, let’s dive into the more technical aspects of the LCM operations of VMware vLCM and VxRail LCM. The detailed explanation in this blog post should give you a more complete understanding of your role as an administrator for cluster lifecycle management with vLCM versus VxRail LCM.
Even though vLCM has introduced a vast improvement in automating cluster updates, lifecycle management is more than executing cluster updates. With vLCM, lifecycle management is still very much a customer-driven endeavor. By contrast, VxRail’s overarching goal for LCM is operational simplicity, by leveraging Continuously Validated States to drive cluster LCM for the customer. This is a large part of why VxRail has over 8,600 customers since it was launched in early 2016.
In this blog post, I’ll explain the four major areas of LCM:
- Defining the initial baseline configuration
- Planning for a cluster update
- Executing the cluster update
- Sustaining cluster integrity over the long term
Defining the initial baseline configuration
The baseline configuration is a vital part of establishing a steady state for the life of your cluster. The baseline configuration is the current known good state of your HCI stack. In this configuration, all the component software and firmware versions are compatible with one another. Interoperability testing has validated full stack integrity for application performance and availability while also meeting security standards in place. This is the ‘happy’ state for you and your cluster. Any changes to the configuration use this baseline to know what needs to be rectified to return to the ‘happy’ state.
How is it done with vLCM?
vLCM depends on the hardware vendor to provide a Hardware Management Services virtual machine. Dell provides this support for its Dell EMC PowerEdge servers, including vSAN ReadyNodes. I’ll use this implementation to explain the overall process. Dell EMC vSAN ReadyNodes use the OpenManage Integration for VMware vCenter (OMIVV) plugin to connect to and register with the vCenter Server.
Once the VM is deployed and registered, you need to create a credential-based profile. This profile captures two accounts: one for the out-of-band hardware interface, the iDRAC, and the other for the root credentials for the ESXi host. Future changes to the passwords require updating the profile accordingly.
With the VM connection and profile in place, a Catalog XML file is used by vLCM to define the initial baseline configuration. To create the Catalog XML file, you need to install and configure the Dell Repository Manager (DRM) to build the hardware profile. Once a profile is defined to your specification, it must then be exported and stored on an NFS or CIFS share. The profile is then used to populate the Repository Profile data in the OMIVVV UI. If you are unsure of your configuration, refer to the vSAN Hardware Compatibility List (HCL) for the specific supported firmware versions. Once the hardware profile is created, you can then associate it with the cluster profile. With the cluster profile defined, you can enable drift detection. Any future change to the Catalog XML file is done within the DRM.
It’s important to note that vLCM was introduced in vSphere 7.0. To use vLCM, you must first update or deploy your clusters to run vSphere 7.x.
How is it done with VxRail LCM?
With VxRail, when the cluster arrives at the customer data center, it’s already running in a ‘happy’ state. For VxRail, the ‘happy’ state is called Continuously Validated States. The term is pluralized because VxRail defines all the ‘happy’ states that your cluster will update to over time. This means that your cluster is always running in a ‘happy’ state without you needing to research, define, and test to arrive at Continuously Validated States throughout the life of your cluster. VxRail – well, specifically the VxRail engineering team - does it for you. This has been a central tenet of VxRail since the product first launched with vSphere 6.0. Since then it has helped customers transition to vSphere 6.5, 6.7, and now 7.0.
Once the VxRail cluster initialization is completed, use your Dell EMC Support credentials to configure the VxRail repository setting within vCenter. VxRail Manager plugin to vCenter will automatically connect to the VxRail repository at Dell EMC and pull down the next available update package.
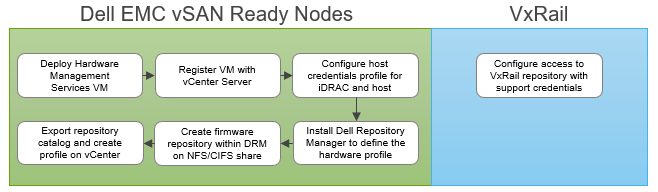
Figure 1 Defining the initial baseline configuration
Planning for a cluster update
Updates are a constant in IT, and VMware is constantly adding new capabilities or product/security fixes that require updating to newer versions of software. Take for example the vSphere 7.0 Update 1 release that VMware and Dell Technologies just announced. Those eye-opening features are available to you when you update to that release. You can check out just how often VMware has historically updated vSphere here: https://kb.vmware.com/s/article/2143832.
As you know, planning for a cluster update is an iterative process with inherent risk associated with it. Failing to plan diligently can cause adverse effects on your cluster, ranging from network outages and node failure to data unavailability or data loss. That said, it’s important to mitigate the risk where you can.
How is it done with vLCM?
With vLCM, the responsibility of planning for a cluster update rests on the customers’ shoulders, including the risk. Understanding the Bill of Materials that makes up your server’s hardware profile is paramount to success. Once all the components are known, and a target version of vSphere ESXi is specified, the supported driver and firmware version needs to be investigated and documented. You must consult the VMware Compatibility Guide to find out which drivers/firmware are supported for each ESXi release.
It is important to note that although vLCM gives you the toolset to apply firmware and driver updates, it does not validate compatibility or support for each combination for you, except for the HBA Driver. This task is firmly in the customer’s domain. It is advisable to validate and test the combination in a separate test environment to ensure that no performance regression or issues are introduced into the production environment. Interoperability testing can be an extensive and expensive undertaking. Customers should create and define robust testing processes to ensure that full interoperability and compatibility is met for all components managed and upgraded by vLCM.
With Dell EMC vSAN Ready Nodes, customers can rest assured that the HCL certification and compatibility validation steps have been performed. However, the customer is still responsible for interoperability testing.
How is it done with VxRail LCM?
VxRail engineering has taken a unique approach to LCM. Rather than leaving the time-consuming LCM planning to already overburdened IT departments, they have drastically reduced the risk by investing over $60 million, more than 25,000 hours of testing for major releases, and more than 100 team members into a comprehensive regression test plan. This plan is completed prior to every VxRail code release. (This is in addition to the testing and validation performed by PowerEdge, on which VxRail nodes are built.)
Dell EMC VxRail engineering performs this testing within 30 days of any new VMware release (even quicker for express patches), so that customers can continually benefit from the latest VMware software innovations and confidently address security vulnerabilities. You may have heard this called “synchronous release”.
The outcome of this effort is a single update bundle that is used to update the entire HCI stack, including the operating system, the hardware’s drivers and firmware, and management components such as VxRail Manager and vCenter. This allows VxRail to define the declarative configuration we mentioned previously (“Continuously Validated States”), allowing us to move easily from one validated state to the next with each update.
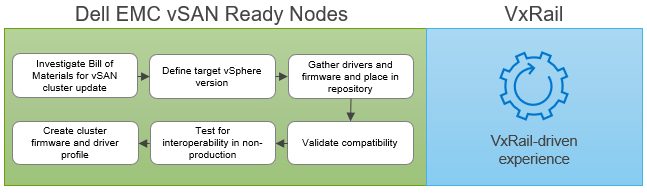
Figure 2 Planning for a cluster update
Executing the cluster update
The biggest improvement with vLCM is its ability to orchestrate and automate a full stack HCI cluster update. This simplifies the update operation and brings enormous time savings. This process is showcased in a recent study performed by Principled Technologies with PowerEdge Servers with vSphere (not including vSAN).
How is it done with vLCM?
The first step is to import the ESXi ISO via the vLCM tab in the vCenter Server UI. Once uploaded, select the relevant cluster, ensure that the cluster profile (created in the initial baseline configuration phase) is associated with the cluster being updated. Now, you can apply the target configuration by editing the ESXi image and, from the OMIVV UI, choose the correct firmware and driver to apply to the hardware profile. Once a compliance scan is complete, you will have the option to remediate all hosts.
If there are multiple homogenous clusters you need to update, it can be as easy as using the same cluster profile to execute the cluster update against. However, if the next cluster has a different hardware configuration, then you would have to perform the above steps over again. Customers with varying hardware and software requirements for their clusters will have to repeat many of these steps, including the planning tasks, to ensure stack integrity.
How it is done with VxRail LCM?
With VxRail and Continuously Validated States, updating from one configuration to another is even simpler. You can access the VxRail Manager directly within the vCenter Server UI to initiate the update. The LCM operation automatically retrieves the update bundle from the VxRail repository, runs a full stack pre-update health check, and performs the cluster update.
With VxRail, performing multi-cluster updates is as simple as performing a single-cluster update. The same LCM cluster update workflow is followed. While different hardware configurations on separate clusters will add more labor for IT staff for vSAN Ready Nodes, this doesn’t apply to VxRail. In fact, in the latest release of our SaaS multi-cluster management capability set, customers can now easily perform cluster updates at scale from our cloud-based management platform, MyVxRail.
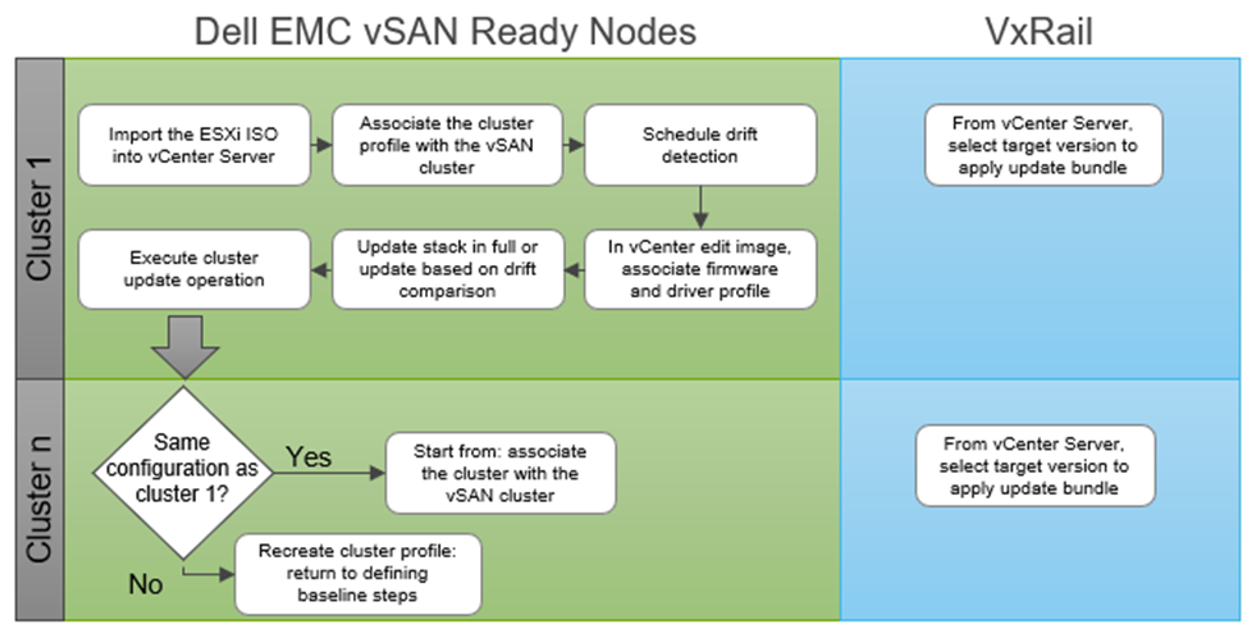
Figure 3 Executing a cluster update
Sustaining cluster integrity over the long term
The long-term integrity of a cluster outlasts the software and hardware in it. As mentioned earlier, because new releases are made available frequently, software has a very short life span. While hardware has more staying power, it won’t outlast some of the applications running on them. New hardware platforms will emerge. New hardware devices will enter the market that will launch new workloads, such as machine learning, graphics rendering, and visualization workflows. You will need the cluster to evolve non-disruptively to deliver the application performance, availability, and diversity your end-users require.
How is it done with vLCM?
In its current form, vLCM will struggle in long-term cluster lifecycle management. In particular, its inability to support heterogeneous nodes (nodes with different hardware configurations) in the same cluster will limit its application diversification and its ability to take advantage of new hardware platforms without impacting end-users.
How it is done with VxRail LCM?
VxRail LCM touts its ability to allow customers to grow non-disruptively and to scale their clusters over time. That includes adding non-identical nodes into the clusters for new applications, adding new hardware devices for new applications or more capacity, or retiring old hardware from the cluster.
Conclusion
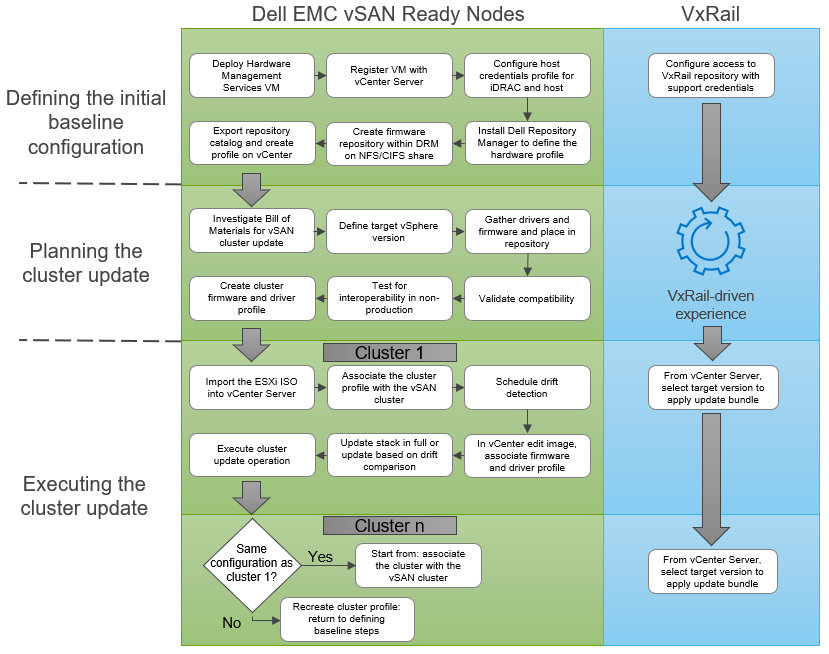
Figure 4 Comparing vSphere LCM and VxRail LCM cluster update operations driven by the customer
The VMware vLCM approach empowers customers who are looking for more configuration flexibility and control. They have the option to select their own hardware components and firmware to build the cluster profile. With this freedom comes the responsibility to define the HCI stack and make investments in equipment and personnel to ensure stack integrity. vLCM supports this customer-driven approach with improvements in cluster update execution for faster outcomes.
Dell EMC VxRail LCM continues to take a more comprehensive approach to optimize operational efficiency from the point of the view of the customer. VxRail customers value its LCM capabilities because it reduces operational time and effort which can be diverted into other areas of need in IT. VxRail takes on the responsibility to drive stack integrity for the lifecycle management of the cluster with Continuously Validated States. And VxRail sustains stack integrity throughout the life of the cluster, allowing you to simply and predictably evolve with technology trends.
Cliff Cahill
VxRail Engineering Technologist
Twitter @cliffcahill
LinkedIn http://linkedin.com/in/cliffcahill
Related Blog Posts

HCI Security Simplified: Protecting Dell VxRail with VMware NSX Security
Fri, 08 Apr 2022 18:14:37 -0000
|Read Time: 0 minutes
The challenge
Cybersecurity and protection against ransomware attacks are among the top priorities for most customers who have successfully implemented or are going through a digital transformation. According to the ESG’s 2022 Technology Spending Intentions Survey:
- 69 percent of respondents shared that their spending on cybersecurity will increase in 2022 (#1).
- 48 percent of respondents believe their IT organizations have a problematic shortage of existing skills in this area (#1).
- 38 percent of respondents believe that strengthening cybersecurity will drive the majority of technology spending in their organization in the next 12 months (#1).
The data clearly shows that this area is one of the top concerns for our customers today. They need solutions that significantly simplify increasing cybersecurity activities due to a perceived skills shortage.
It is worth reiterating the critical role that networking plays within Hyperconverged Infrastructure (HCI). In contrast to legacy three-tier architectures, which typically have a dedicated storage network and storage, HCI architecture is more integrated and simplified. Its design lets you share the same network infrastructure for workload-related traffic and intercluster communication with the software-defined storage. The accessibility of the running workloads (from the external network) depends on the reliability of this network infrastructure, and on setting it up properly. The proper setup also impacts the performance and availability of the storage and, as a result, the whole HCI system. To prevent human error, it is best to employ automated solutions to enforce configuration best practices.
VxRail as an HCI system supports VMware NSX, which provides tremendous value for increasing cybersecurity in the data center, with features like microsegmentation and AI-based behavioral analysis and prevention of threats. Although NSX is fully validated with VxRail as a part of VMware Cloud Foundation (VCF) on VxRail platform, setting it outside of VCF requires strong networking skills. The comprehensive capabilities of this network virtualization platform might be overwhelming for VMware vSphere administrators who are not networking experts. What if you only want to consume the security features? This scenario might present a common challenge, especially for customers who are deploying small VxRail environments with few nodes and do not require full VCF on the VxRail stack.
The great news is that VMware recognized these customer challenges and now offers a simplified method to deploy NSX for security use cases. This method fits the improved operational experience our customers are used to with VxRail. This experience is possible with a new VMware vCenter Plug-in for NSX, which we introduce in this blog.
NSX and security
NSX is a comprehensive virtualization platform that provides advanced networking and security capabilities that are entirely decoupled from the physical infrastructure. Implementing networking and security in software, distributed across the hosts responsible for running virtual workloads, provides significant benefits:
- Flexibility—Total flexibility for positioning workloads in the data center enables optimal use of compute resources (a key aspect of virtualization).
- Optimal consumption of CPU resources —Advanced NSX features only consume CPU from the hosts when they are used. This consumption leads to lower cost and simplified provisioning when compared to running the features on dedicated appliances.
- High performance—NSX features are performed in VMware ESXi kernel space, a unique capability on vSphere.
The networking benefits are evident for large deployments, with NSX running in almost all Fortune 100 companies and many medium scale businesses. In today’s world of widespread viruses, ransomware, and even cyber warfare, the security aspect of NSX built on top of the NSX distributed firewall (DFW) is relevant to vSphere customers, regardless of their size.
The NSX DFW is a software firewall instantiated on the vNICs of the virtual machines in the data center. Thanks to its inline position, it provides maximum filtering granularity because it can inspect the traffic coming in and going out of every virtual machine without requiring redirection of the traffic to a security appliance, as shown in the following figure. It also moves along with the virtual machine during vMotion and maintains its state.
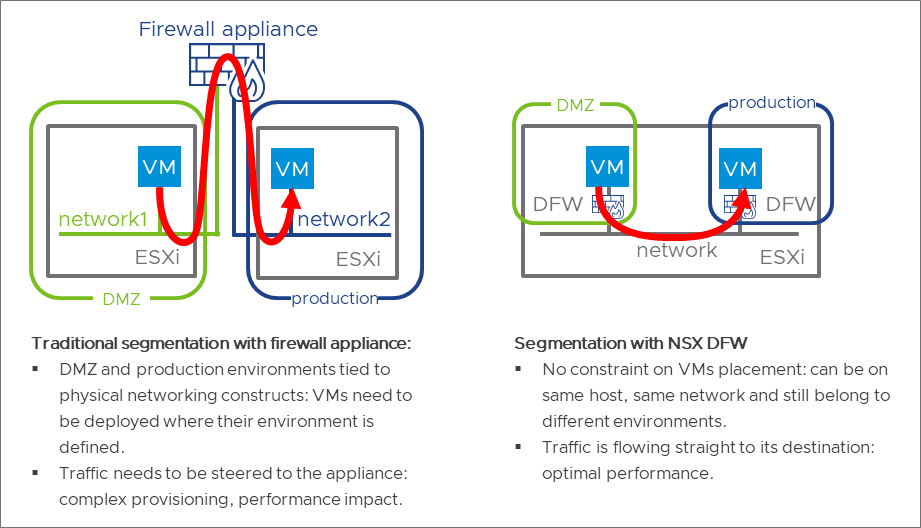
Figure 1: Traditional firewall appliance compared to the NSX DFW
The NSX DFW state-of-the-art capabilities are configured centrally from the NSX Manager and allow implementing security policies independently of the network infrastructure. This method makes it easy to implement microsegmentation and compliance requirements without dedicating racks, servers, or subnets to a specific type of workload. With the NSX DFW, security teams can deploy advanced threat prevention capabilities such as distributed IDS/IPS, network sandboxing, and network traffic analysis/network detection and response (NTA/NDR) to protect against known and zero-day threats.
A dedicated solution for security
Many NSX customers who are satisfied with the networking capability of vSphere run their production environment on a VDS with VLAN-backed dvportgroups. They deploy NSX for its security features only, and do not need its advanced networking components. Until now, those customers had to migrate their virtual machines to NSX-backed dvportgroups to benefit from the NSX DFW. This migration is easy but managing networking from NSX modifies the workflow of all the teams, including those teams that are not concerned by security:

Figure 2: Traditional NSX deployment
Starting with NSX 3.2, you can run NSX security on a regular VDS, without introducing the networking components of NSX. The security team receives all the benefits of NSX DFW, and there is no impact to any other team:

Figure 3: NSX Security with vCenter Plugin
Even better, NSX can now integrate further with vCenter, thanks to a plug-in that allows you to configure NSX from the vCenter UI. This method means that NSX can be consumed as a simple security add-on for a traditional vSphere deployment.
How to deploy and configure NSX Security
Requirements
First, we need to ensure that our VxRail environment meets the following requirements:
- vCenter Server 7.0 U3c (included with VxRail 7.0.320)
- VDS 6.7 or later
- The OVA for NSX-T with the vCenter Plugin version 3.2 or later and an appropriate NSX license
Deploy the NSX Manager and the NSX DFW on ESXi hosts
Running NSX in a vSphere environment consists of deploying a single NSX Manager virtual machine protected by vSphere HA. A shortcut in vCenter enables this step:
Figure 4: Deploy the NSX Manager appliance virtual machine from the NSX tab in vCenter
When the NSX Manager is up and running, it sets up a one-to-one association with vCenter and uploads the plug-in that presents the NSX UI in vCenter, as if NSX security is part of vCenter. The vCenter administrator becomes an effective NSX security administrator.
The next step, performed directly from the vCenter UI, is to enter the NSX license and select the cluster on which to install the NSX DFW binaries:
Figure 5: Select the clusters that will receive the NSX DFW binaries
After the DFW binaries are installed on the ESXi hosts, the NSX security is deployed and operational. You can exit the security configuration wizard (and configure directly from the NSX view in the vCenter UI) or let the wizard run.
Run the security configuration wizard
After installing the NSX binaries on the ESXi hosts, the plug-in runs a wizard that guides you through the configuration of basic security rules according to VMware best practices. The wizard gives the vSphere administrator simple guidance for implementing a baseline configuration that the security team can build on later. There are three different steps in this guided workflow.
First step—Segment the data center in groups
Perform the following steps, as shown in the following figure:
- Create an infrastructure group, identifying the services that the workloads in the data center will access. These services typically include DNS, NTP, DHCP servers, and so on.
- Segment the data center coarsely in environments, such as groups like Development, Production, and DMZ.
- Segment the data center finely by identifying applications running across the different environments.
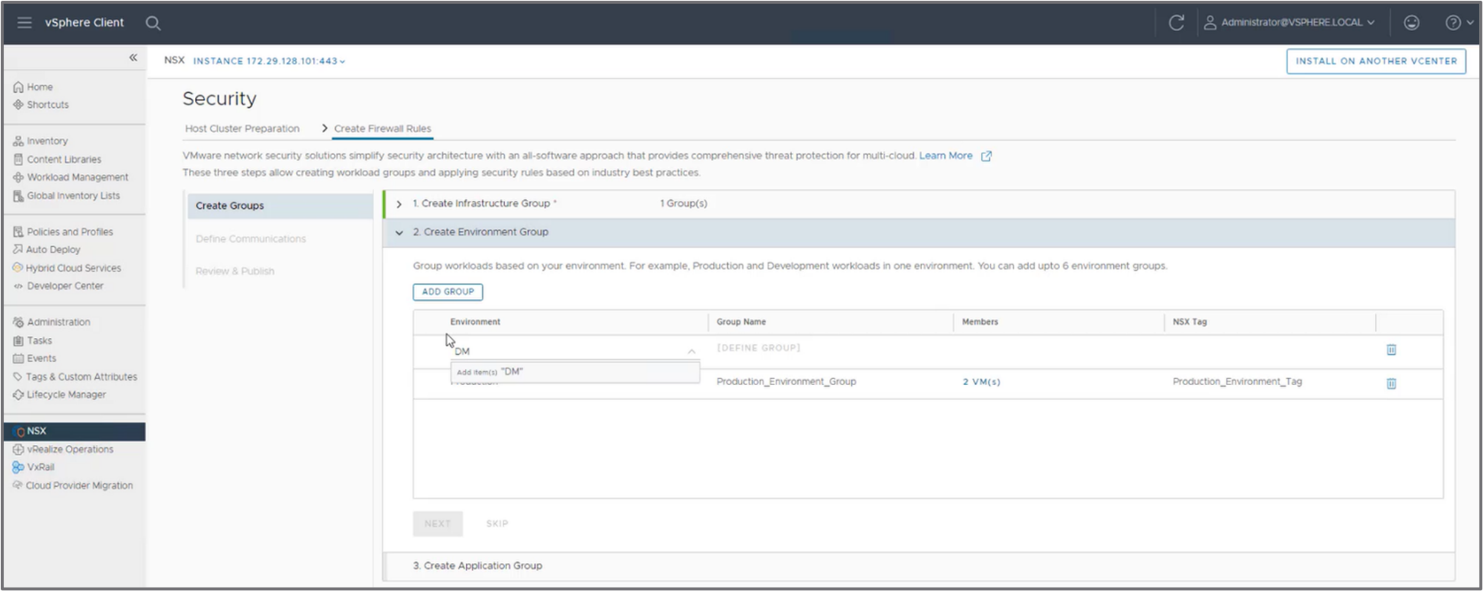
Figure 6: Example of group creation
Second step—Define communication between different groups
Perform the following steps, as shown in the following figure:
- Define which groups can access the infrastructure services
- Define how the different environments communicate with each other
- Define how applications communicate with each other
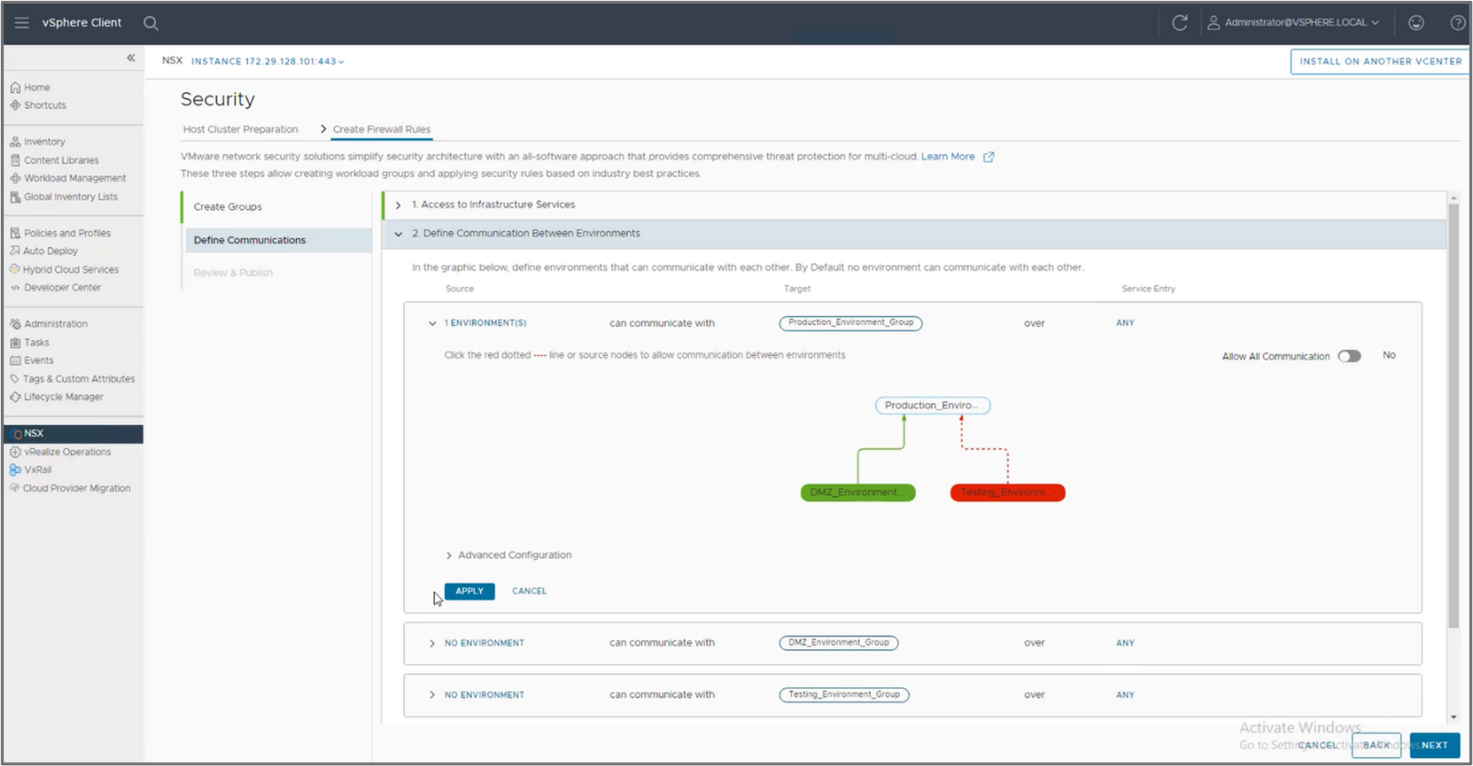
Figure 7: Define the communication between environments using a graphcial represenation
Third step—Review the configuration and publish it to the NSX DFW
After reviewing the configuration, publish the configuration to NSX:
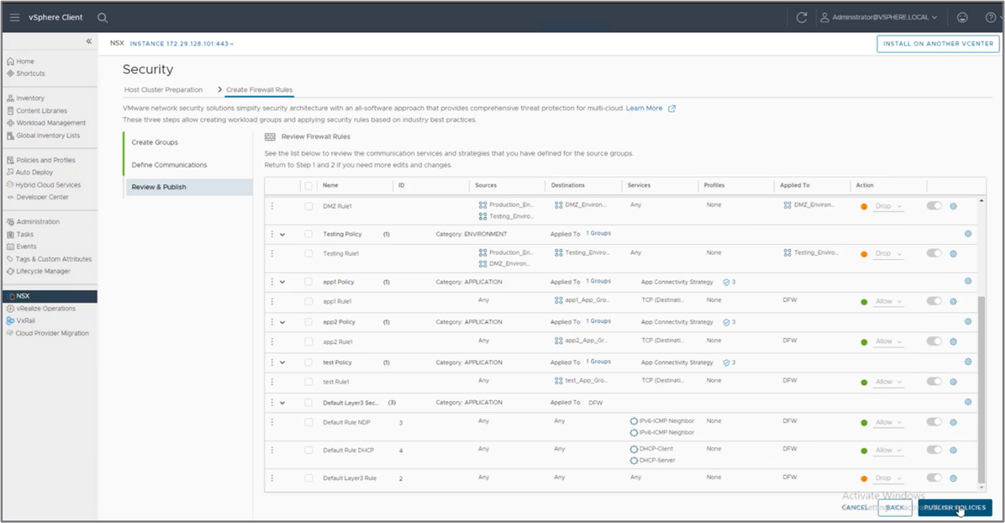
Figure 8: Review DFW rules before exiting the wizard
The full NSX UI is now available in vCenter. Select the NSX tab to access the NSX UI directly.
Final thoughts
The new VMware vCenter Plug-in for NSX drastically simplifies the deployment and adoption of NSX with VxRail for security use cases. In the past, advanced knowledge of the network virtualization platform was required. A vSphere adminstrator can now deploy it easily, using an intuitive configuration wizard available directly from vCenter.
The VMware vCenter Plug-in for NSX provides the kind of simplified and optimized experience that VxRail customers are used to when managing their HCI environment. It also addresses the challenge that customers face today, improving security even with a perceived shortage of skills in this area. Also, it can be configured easily and quickly, making the robust NSX security features more available for smaller HCI deployments.
Additional resources:
VMworld 2021 Session: NET1483 - Deploy and Manage NSX-T via vCenter: A Single Console to Drive VMware SDDC
Planning Guide: Dell EMC VxRail Network Planning Guide – Physical and Logical Network Considerations and Planning
ESG Research Report: 2022 Technology Intentions Survey
Authors:
Francois Tallet, Technical Product Manager, VMware
Karol Boguniewicz, Senior Principal Engineering Technologist, Dell Technologies

Learn More About the Latest Major VxRail Software Release: VxRail 7.0.480
Tue, 24 Oct 2023 15:51:48 -0000
|Read Time: 0 minutes
Happy Autumn, VxRail customers! As the morning air gets chillier and the sun rises later, this blog on our latest software release – VxRail 7.0.480 – paired with your Pumpkin Spice Latte will give you the boost you need to kick start your day. It may not be as tasty as freshly made cider donuts, but this software release has significant additions to the VxRail lifecycle management experience that can surely excite everyone.
VxRail 7.0.480 provides support for VMware ESXi 7.0 Update U3o and VMware vCenter 7.0 Update U3o. All existing platforms that support VxRail 7.0, except ones based on Dell PowerEdge 13th Generation platforms, can upgrade to VxRail 7.0.480. This includes the VxRail systems based on PowerEdge 16th Generation platforms that were released in August.
Read on for a deep dive into the VxRail Lifecycle Management (LCM) features and enhancements in this latest VxRail release. For a more comprehensive rundown of the features and enhancements in VxRail 7.0.480, see the release notes.
Improving update planning activities for unconnected clusters or clusters with limited connectivity
VxRail 7.0.450, released earlier this year, provided significant improvements to update planning activities in a major effort to streamline administrative work and increase cluster update success rates. Enhancements to the cluster pre-update health check and the introduction of the update advisor report were designed to drive even more simplicity to your update planning activities. By having VxRail Manager automatically run the update advisor report, inclusive of the pre-update health check, every 24 hours against the latest information, you will always have an up-to-date report to determine your cluster’s readiness to upgrade to the latest VxRail software version.
If you are not familiar with the LCM capabilities added in VxRail 7.0.450, you can review this blog for more information.
VxRail 7.0.450 offered a seamless path for clusters that are connected to the Dell cloud to take advantage of these new capabilities. Internet-connected clusters can automatically download LCM pre-checks and the installer metadata files, which provide the manifest information about the latest VxRail software version, from the Dell cloud. The ability to periodically scan the Dell cloud for the latest files ensures the update advisor report is always up to date to support your decision-making.
While unconnected clusters could use these features, the user experience in VxRail 7.0.450 made it more cumbersome for users to upload the latest LCM pre-checks and installer metadata files. VxRail 7.0.480 aims to improve the user experience for those who have clusters deployed in dark or remote sites that have limited network connectivity.
Starting in VxRail 7.0.480, users of unconnected clusters will have an easier experience uploading the latest LCM pre-checks file onto VxRail Manager. The VxRail Manager UI has been enhanced, so you no longer have to upload via CLI.
Knowing that some clusters are deployed in areas where network bandwidth is at a premium, the VxRail Manager UI has also been updated so that you only need to upload the installer metadata file to generate the update advisor report. In VxRail 7.0.450, users had to upload the full LCM bundle for the update advisor report. The difference in the payload size of greater than 10GB for a full LCM bundle versus a 50KB installer metadata file is a tremendous improvement for bandwidth-constrained clusters, eliminating a barrier to relying on the update advisor report as a standard cluster management practice. With VxRail 7.0.480, whether you have connected or unconnected clusters, these update planning features are easy to use and will help increase your cluster update success rates.
To accommodate these improvements, the Local Updates tab has been modified to support these new capabilities. There are now two sub-tabs underneath the Local Updates tab:
- The Update sub-tab represents the existing cluster update workflow where you would upload the full LCM bundle to generate the update advisor report and initiate the cluster update operation.
- The Plan and Update sub-tab is the recommended path which incorporates the enhancements in VxRail 7.0.480. Here you can upload the latest LCM pre-checks file and the installer metadata file that you found and downloaded from the Dell Support website. Uploading the LCM pre-checks file is optional to create a new report because there may not always be an updated file to apply. However, you do need to upload an installer metadata file to generate a new report from here. Once uploaded, VxRail Manager will generate an update advisor report against that installer metadata file every 24 hours.
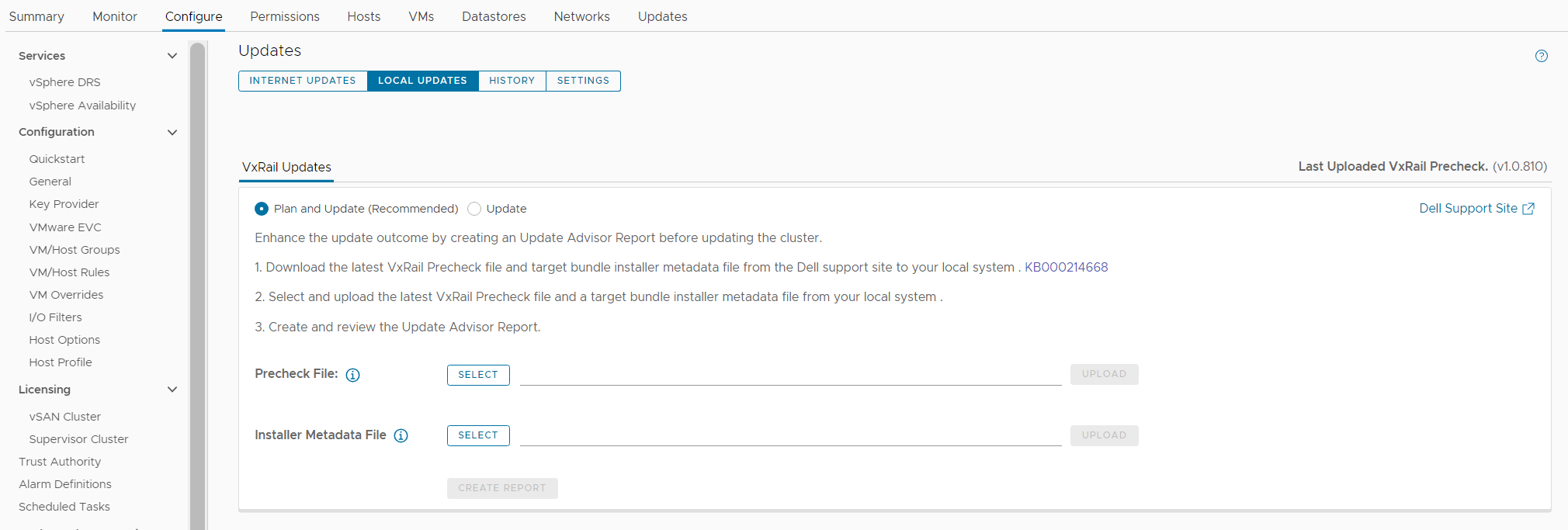
Figure 1. New look to the Local Updates tab
Easier record-keeping for compliance drift and update advisor reports
VxRail 7.0.480 adds new functionality to make the compliance drift reports exportable to outside the VxRail Manager UI while also introducing a history tab to access past update advisor reports.
Some of you use the contents of the compliance drift report to build out a larger infrastructure status report for information sharing across your organizations. Making the report exportable would simplify that report building process. When exporting the report, there is an option to group the information by host if you prefer.
Note that the compliance check functionality has moved from the Compliance tab under the Updates page to a separate page, which you can navigate to by selecting Compliance from under the VxRail section.
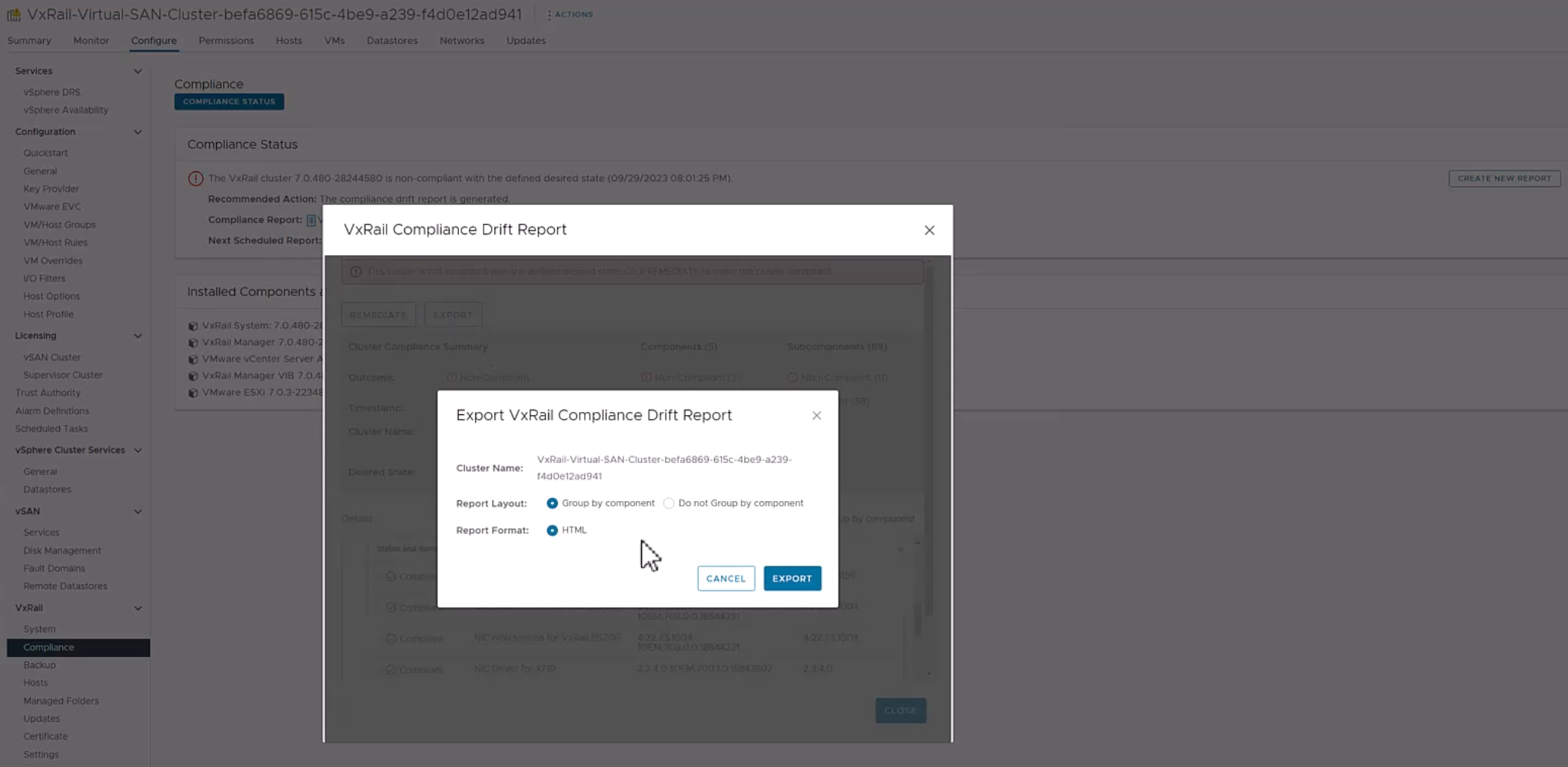
Figure 2. Exporting the compliance drift report
The exit of the Compliance tab comes with the introduction of the History tab on the Updates page in VxRail 7.0.480. Because VxRail Manager automatically generates a new update advisor report every 24 hours and you have the option to generate one on-demand, the update advisor report is often overwritten. To avoid the need to constantly export them as a form of record-keeping, the new History tab stores the last 30 update advisor reports. The reports are listed in a table format where you can see which target version the report was run against and when it was run. To view the full report, you can click on the icon on the left-hand column.
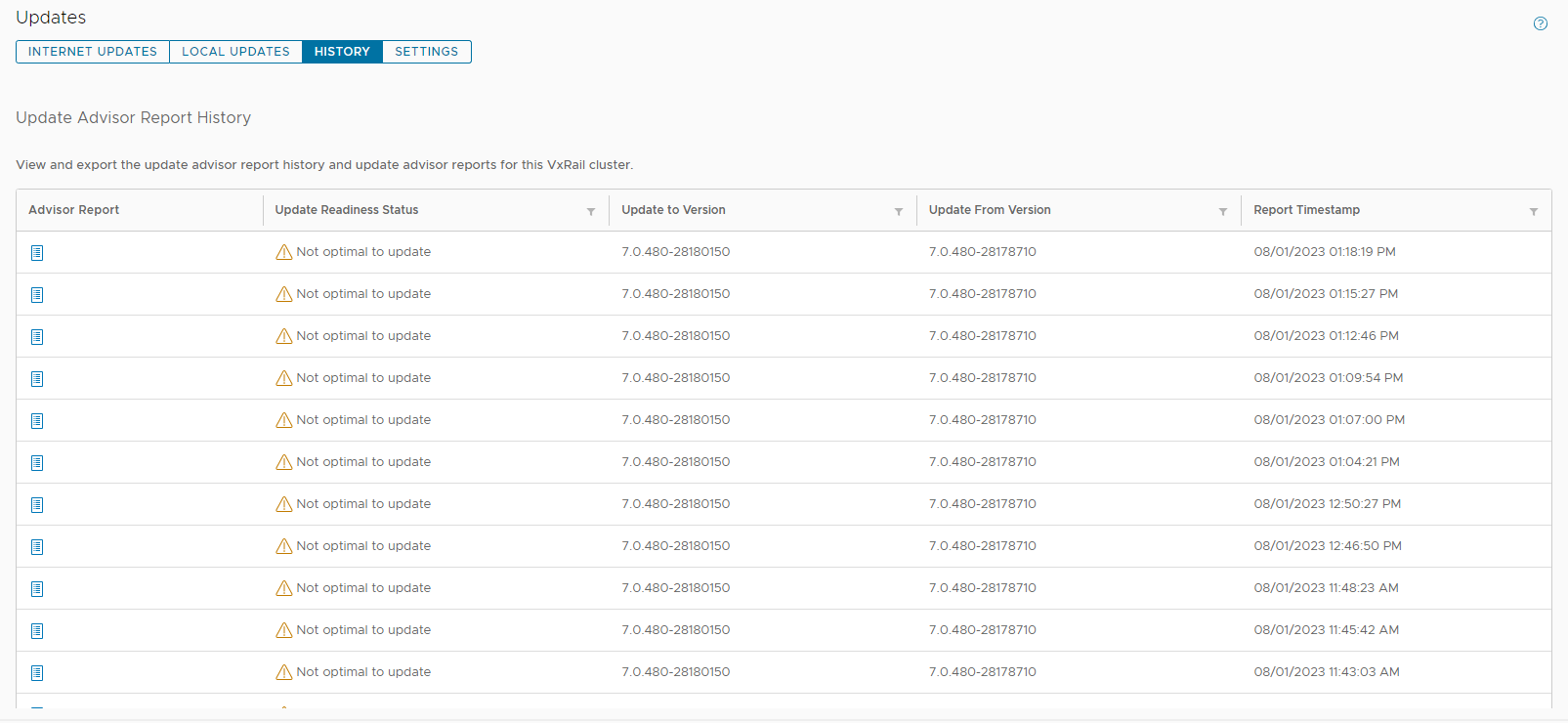
Figure 3. New History tab to store the last 30 update advisor reports
Addressing cluster update challenges for larger-sized clusters
For some of you that have larger-sized clusters, cluster updates pose challenges that may prevent you from upgrading more frequently. For example, the length of the maintenance window required to complete a full cluster update may not fit within your normal business operations such that any cluster update activity will impact service availability. As a result, cluster updates are kept to a minimum and nodes inevitably are not rebooted for long periods of time. While the cluster pre-update health check is an effective tool to determine cluster readiness for an upgrade, some issues may be lurking that a node reboot can uncover. That’s why some of you script your own node reboot sequence that acts as a test run for a cluster upgrade. The script reboots each node one at a time to ensure service levels of your workloads are maintained. If any nodes fail to reboot, you can investigate those nodes.
VxRail 7.0.480 introduces the node reboot sequence on VxRail Manager UI so that you do not have to manage your scripts anymore. The new feature includes cluster-level and node-level prechecks to ensure it is safe to perform this activity. If nodes fail to reboot, there is an option for you to retry the reboot or skip it. Making this activity easy may also encourage more customers to do this additional pre-check before upgrading their clusters.
 Figure 4. Selecting nodes in a cluster to reboot in sequential order
Figure 4. Selecting nodes in a cluster to reboot in sequential order
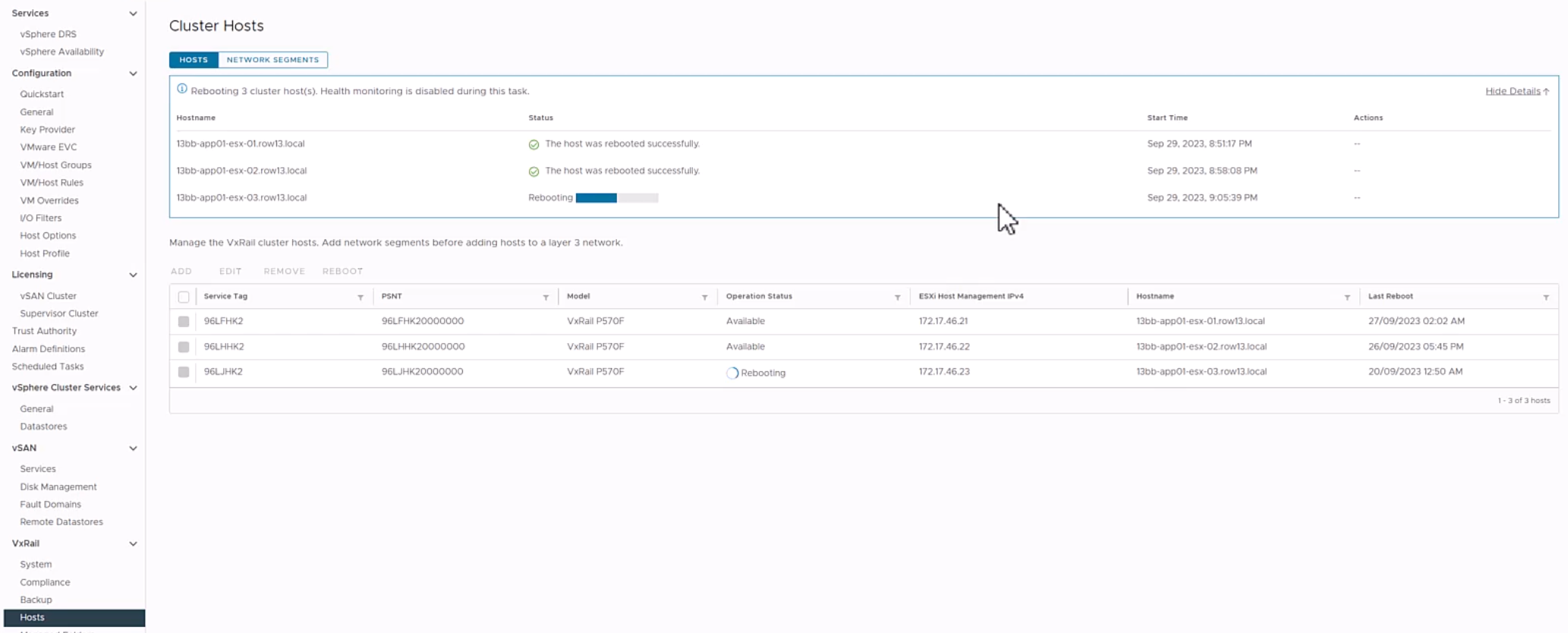
Figure 5. Monitoring the node reboot sequence on the dashboard
VxRail 7.0.480 also provides the capability to split your cluster update into multiple parts. Doing so allows you to separate your cluster upgrade into smaller maintenance windows and work around your business operation needs. Though this capability could reduce the impact of a cluster upgrade to your organization, VMware does recommend that you complete the full upgrade within one week given that there are some Day 2 operations that are disabled while the cluster is partially upgraded. VxRail enables this capability only through VxRail API. When a cluster is in a partially upgraded state, features in the Updates tab are disabled and a banner appears alerting you of the cluster state. Cluster expansion and node removal operations are also unavailable in this scenario.
Conclusion
The new lifecycle management capabilities added to VxRail 7.0.480 are part of the continual evolution of the VxRail LCM experience. They also represent how we value your feedback on how to improve the product and our dedication to making your suggestions come to fruition. The LCM capabilities added to this software release will drive more effective cluster update planning, which will result in higher rates of cluster update success that will drive more efficiencies in your IT operations. Though this blog focuses on the improvements in lifecycle management, please refer to the release notes for VxRail 7.0.480 for a complete list of features and enhancements added to this release. For more information about VxRail in general, visit the Dell Technologies website.
Author: Daniel Chiu