




SUSECON23 – That’s a Wrap!
Fri, 14 Jul 2023 15:25:36 -0000
|Read Time: 0 minutes
SUSECON23 – That’s a Wrap!
Last week, I had the pleasure of being able to attend SUSECON23, which was held in Munich and was the first “in-person” conference that SUSE had run post pandemic. I was lucky enough to be invited to speak at one of the break-out sessions, alongside Gerson Guevara, who works in the Technical Alliances Team at SUSE. It is always a pleasure to meet up with interesting people that you can learn things from, and Gerson was a case in point! Without doubt, he is a great person and it was an honor to co-present the session with him.
Together, we jointly presented a session on “Joint Initiatives & Solutions Between SUSE and Dell PowerFlex” to a packed room. We discussed the joint Dell PowerFlex and SUSE Rancher solutions that we have available today. We also gave a tantalising glimpse of what the future might hold, by discussing the early results from a proof of concept that our Engineering teams have been working on together for a few months.
 Figure 1: Co-Presenting the joint Dell PowerFlex and SUSE session at SUSECON23, Munich, June 2023
Figure 1: Co-Presenting the joint Dell PowerFlex and SUSE session at SUSECON23, Munich, June 2023
What I find very interesting is that a lot of our joint customers remain blissfully unaware of the amount of collaborative work that the Dell PowerFlex and SUSE teams have done together over the years, so I thought it best to give a quick overview on what is already out there and available today.
SUSE and Dell Technologies already have a deep partnership, one that has been built over a 20+ year period. Our joint solutions can be found in sensors and in machines, they exist in the cloud, on-premises and at the edge, all of them built with a strong open source backbone. As such, Dell and SUSE are addressing the operational and security challenges of managing multiple Kubernetes clusters, whilst also providing DevOps teams with integrated tools for running containerized workloads. What many people outside Dell might not be aware of is that a number of SUSE products & tool sets are used by Dell developers when creating the next-generation of Dell products and solutions.
When one looks at the wide range of Kubernetes Management platforms that are available, SUSE are certainly amongst the leaders in that market today. SUSE completed its acquisition of Rancher Labs back in December 2020; by doing so, SUSE was able to bring together multiple technologies to help organizations. SUSE Rancher is a free, 100% open-source Kubernetes management platform that simplifies cluster installation and operations, whether they are on-premises, in the cloud, or at the edge, giving DevOps teams the freedom to build and run containerized applications anywhere. Rancher also supports all the major public cloud distributions, including EKS, AKS, GKE and K3s at Edge. It provides simple, consistent cluster operations, including provisioning, version management, visibility and diagnostics, monitoring and alerting, and centralized audit. Rancher itself is free and has a community support model, so for customers that absolutely need an enterprise-level of support, they can opt for Rancher Prime, which is the model that includes full enterprise support and access to SUSE’s trusted private container registries.
Current Joint Dell PowerFlex-SUSE Rancher Solutions
Back to my earlier point about the collaboration that exists between the SUSE and Dell PowerFlex Solutions Teams. We have been working together on joint solutions for several years now and we are constantly updating our white papers to ensure that remain up to date. To simplify things we have consolidated several white papers into one, so that it not only describes how to deploy SUSE Rancher clusters with PowerFlex, but also how to then protect those systems using Dell PowerProtect Data Manager. The white paper is available on the Dell Info Hub and you can download it from here. It describes how to deploy Rancher in virtual environments, running on top of VMware ESXi, as well as deploying Rancher running on bare-metal nodes. Let me quickly run you through the various solutions that are detailed in the white paper:
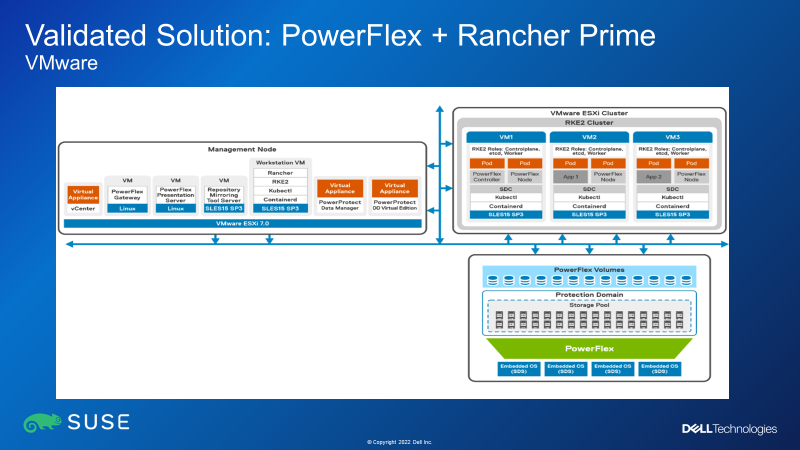 Figure 2: Dell PowerFlex + Rancher Prime on top of VMware ESXi
Figure 2: Dell PowerFlex + Rancher Prime on top of VMware ESXi
As can be seen from Figure 2 above, the RKE2 cluster is running in a two-layer PowerFlex deployment architecture – that is to say, the PowerFlex storage resides on separate nodes than the compute nodes. This separation of storage and compute means that this architecture lends itself really well to Kubernetes environments where there still tends to be a massive disparity between the number of compute nodes needed versus the amount of persistent storage needed. PowerFlex can provide a consolidated software-defined storage infrastructure – think of scenarios where there are lots of clusters, running a mixture of both Kubernetes and VMware workloads, and where you want a shared storage platform to simplify storage operations across all workstreams.
Figure 2 also shows that the RKE2 clusters are deployed on top of VMware ESXi, to obtain the benefits of running each of the RKE2 nodes as VMs.
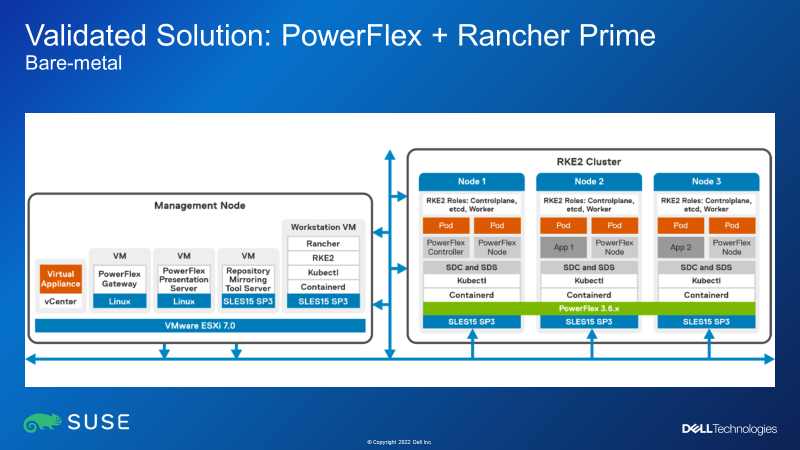 Figure 3: Dell PowerFlex + Rancher Prime on bare-metal compute nodes
Figure 3: Dell PowerFlex + Rancher Prime on bare-metal compute nodes
The white paper also discusses deployment of Rancher clusters running on bare-metal HCI nodes – that is to say, deploying the Rancher Cluster onto nodes that have SSDs in them. The paper talks through an option where first SUSE SLES15 SP is installed, and then PowerFlex is installed to use the SSDs in the nodes to create a storage cluster. Then finally, the RKE2 cluster gets deployed, using the PowerFlex storage as the storage class for persistent volume claims. It is worth noting that “HCI-on-Bare-metal” PowerFlex deployments are usually done using PowerFlex custom nodes or outside of PowerFlex Manager control, as we currently do not have a PowerFlex Manager template that deploys either SLES15 SP3 or RKE2.
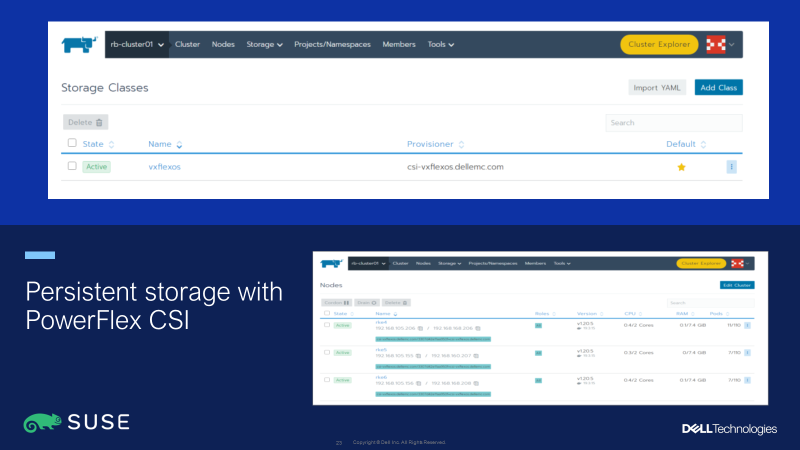 Figure 4: Persistent storage for SUSE Rancher clusters with PowerFlex CSI driver
Figure 4: Persistent storage for SUSE Rancher clusters with PowerFlex CSI driver
Kubernetes clusters that want to access persistent storage resources need to use API calls via the CSI driver for the storage platform being used. With SUSE Rancher, it is easy to deploy the PowerFlex CSI driver, as this is available to be installed via a single-click from the SUSE Rancher Marketplace. Alternatively, the latest CSI driver is also available directly from the Dell CSM Github at: https://dell.github.io/csm-docs/docs/csidriver/
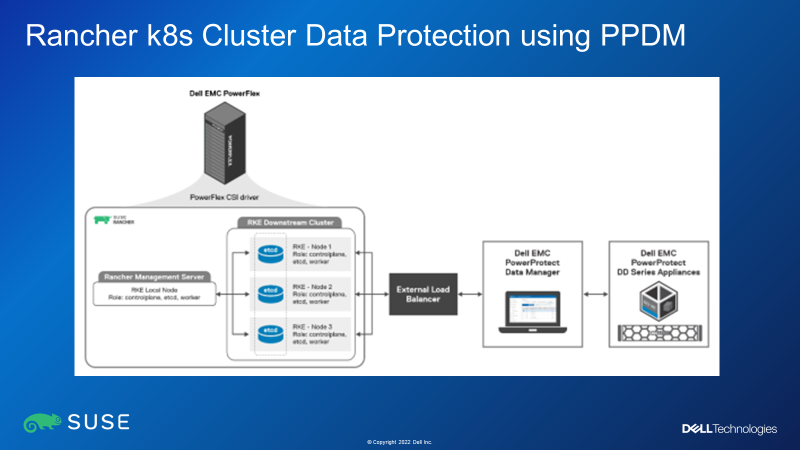 Figure 5: Rancher Cluster Data Protection Using Dell PowerProtect Data Manager
Figure 5: Rancher Cluster Data Protection Using Dell PowerProtect Data Manager
Finally, the white paper also discusses how to integrate SUSE Rancher-managed Kubernetes clusters with Dell PowerProtect Data Manager (PPDM) for data protection in one of two ways: by directly connecting to an RKE2 downstream single node with control plane and etcd roles, or through a load balancer, when there are multiple RKE2 nodes with control plane and etcd roles in an RKE2 downstream cluster.
Hence you can see that Dell and SUSE have worked incredibly closely to create a number of solutions, which not only give customers a choice in how they deploy their RKE2 clusters with PowerFlex (with or without VMware, using either two-layer or hyperconverged options) but also shows how such solutions can be fully protected and restored using Dell DDPM.
A Glimpse into the Future…?
Back to the breakout session at SUSECON, everyone in the room was excited to discover what the the “hush-hush” news from the Proof-of-Concept was all about! Suffice to say that what we were presenting is not on any product roadmaps, nor has it been committed to by either company. What we were able to show was an 8-minute “summary video” that was created in our joint PoC lab environment. The video explained how we were able to use PowerFlex as a storage class in SUSE Harvester HCI clusters. For those not in the know, SUSE Harvester provides small Kubernetes clusters for ROBO, Near-Edge and Edge use cases. Even though Harvester can make use of the Longhorn storage that resides in the Harvester cluster nodes, we are hearing of use cases where hundreds of Harvester clusters all want to access a single shared-storage platform. Does that ring any bells with my observations above? Anyway, suffice to say, such solutions are still being looked at as potential use cases – in my opinion, it is not one that I would have normally associated with edge use-cases, but having seen what was happening myself at SUSECON23 last week, I am happy to stand corrected and will continue to monitor this space going forward!
For the rest of SUSECON23, I shared my time between attending the various keynote sessions, manning the Dell booth and talking with partners and other conference attendees. There was an amount of interest in what Dell are doing in and around the container space, so it was good to be manning a booth from which we were able to show how our Dell CSM app-mobility module makes it simple to migrate Kubernetes applications between multiple Kubernetes clusters.
This was also the first time that I had attended an ‘in-person’ conference since before the pandemic, so it was genuinely fantastic to meet and be able to talk to people again. Sometimes you do not realize just much you have missed things until you do them again! However, I was also reminded of something that I had not missed when it came to finally saying “Auf Wiedersehen” to Munich and embarking on my journey back to the UK: thanks to the incredible storms that swept Germany last Thursday, we eventually took off from Munich 4 hours late, on what I was reliably informed was the last flight that the German ATC allowed to take off before they closed off German Airspace for the night. But when all is said and done….. here’s to SUSECON24!!
Simon Stevens, Dell PowerFlex Engineering Technologist
Related Blog Posts

Q1 2024 Update for Ansible Integrations with Dell Infrastructure

Tue, 02 Apr 2024 14:45:56 -0000
|Read Time: 0 minutes
In this blog post, I am going to cover the new Ansible functionality for the Dell infrastructure portfolio that we released over the past two quarters. Ansible collections are now on a monthly release cadence, and you can bookmark the changelog pages from their respective GitHub pages to get updates as soon as they are available!
PowerScale Ansible collections 2.3 & 2.4
SyncIQ replication workflow support
SyncIQ is the native remote replication engine of PowerScale. Before seeing what is new in the Ansible tasks for SyncIQ, let’s take a look at the existing modules:
- SyncIQPolicy: Used to query, create, and modify replication policies, as well as to start a replication job.
- SyncIQJobs: Used to query, pause, resume, or cancel a replication job. Note that new synciq jobs are started using the synciqpolicy module.
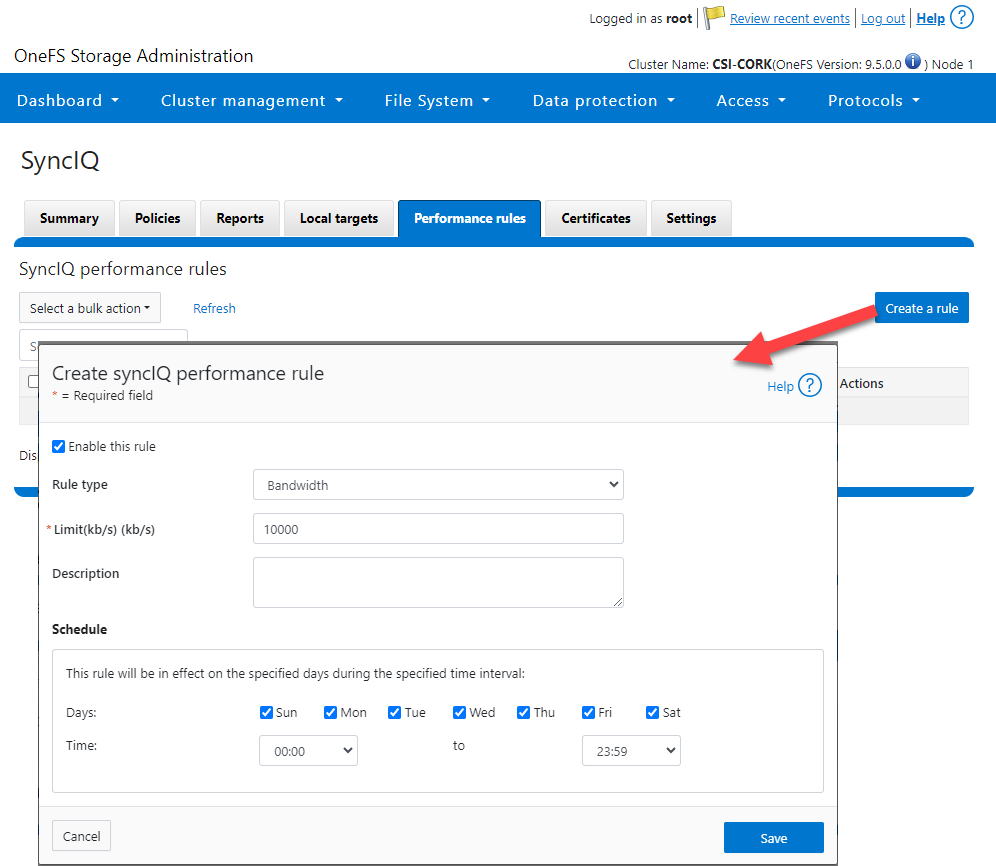
- SyncIQRules: Used to manage the replication performance rules that can be accessed as follows on the OneFS UI:
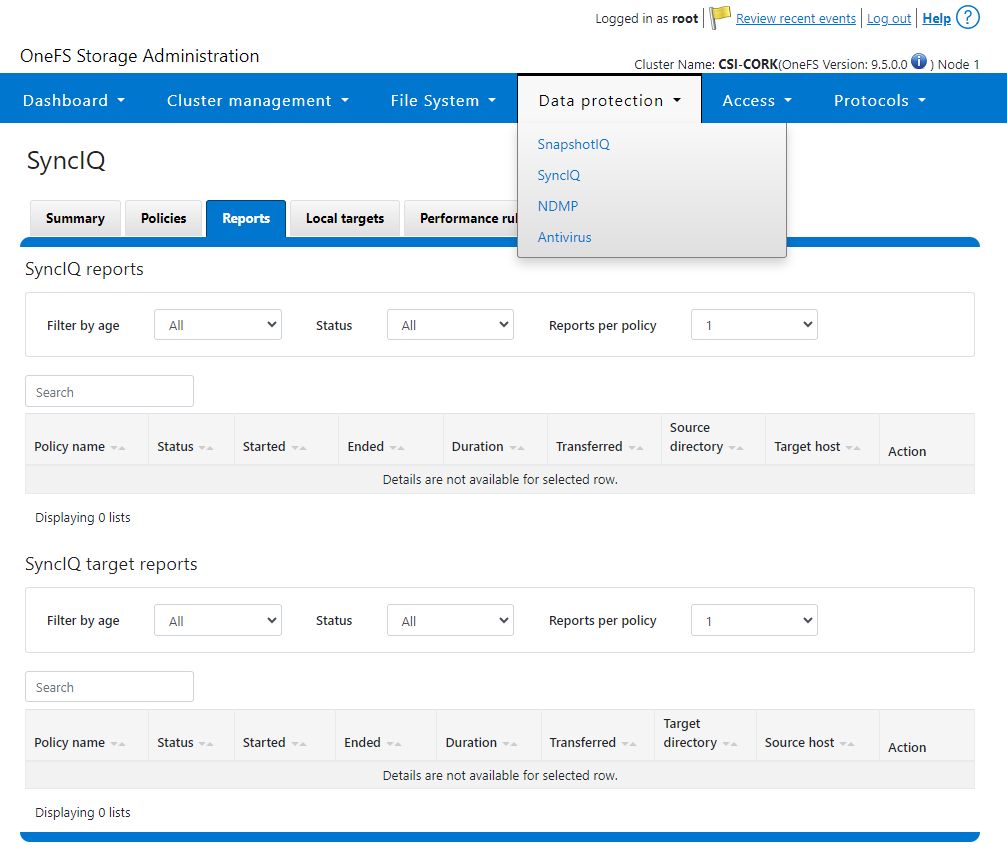
- SyncIQReports and SyncIQTargetReports: Used to manage SyncIQ reports. Following is the corresponding management UI screen where it is done manually:
Following are the new modules introduced to enhance the Ansible automation of SyncIQ workflows:
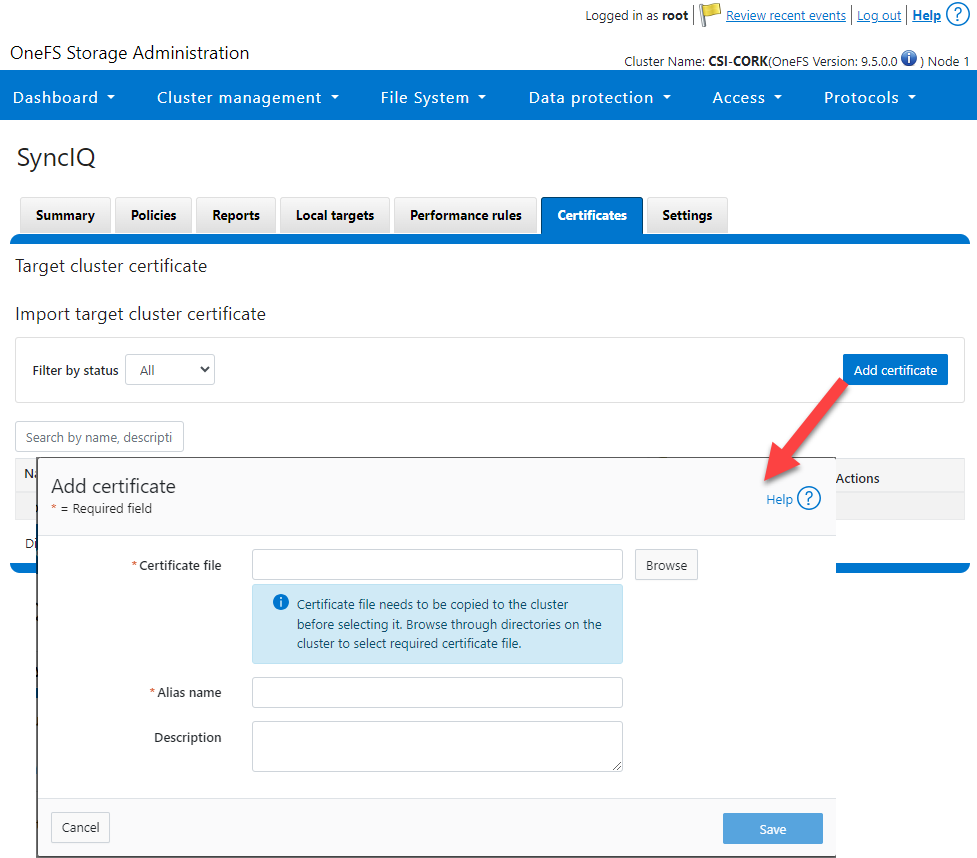
- SyncIQCertificate (v2.3): Used to manage SyncIQ target cluster certificates on PowerScale. Functionality includes getting, importing, modifying, and deleting target cluster certificates. Here is the OneFS UI for these settings:
- SyncIQ_global_settings (v2.3): Used to configure SyncIQ global settings that are part of the include the following:
Table 1. SyncIQ settings
SyncIQ Setting (datatype) | Description |
bandwidth_reservation_reserve_absolute (int) | The absolute bandwidth reservation for SyncIQ |
bandwidth_reservation_reserve_percentage (int) | The percentage-based bandwidth reservation for SyncIQ |
cluster_certificate_id (str) | The ID of the cluster certificate used for SyncIQ |
encryption_cipher_list (str) | The list of encryption ciphers used for SyncIQ |
encryption_required (bool) | Whether encryption is required or not for SyncIQ |
force_interface (bool) | Whether the force interface is enabled or not for SyncIQ |
max_concurrent_jobs (int) | The maximum number of concurrent jobs for SyncIQ |
ocsp_address (str) | The address of the OCSP server used for SyncIQ certificate validation |
ocsp_issuer_certificate_id (str) | The ID of the issuer certificate used for OCSP validation in SyncIQ |
preferred_rpo_alert (bool) | Whether the preferred RPO alert is enabled or not for SyncIQ |
renegotiation_period (int) | The renegotiation period in seconds for SyncIQ |
report_email (str) | The email address to which SyncIQ reports are sent |
report_max_age (int) | The maximum age in days of reports that are retained by SyncIQ |
report_max_count (int) | The maximum number of reports that are retained by SyncIQ |
restrict_target_network (bool) | Whether to restrict the target network in SyncIQ |
rpo_alerts (bool) | Whether RPO alerts are enabled or not in SyncIQ |
service (str) | Specifies whether the SyncIQ service is currently on, off, or paused |
service_history_max_age (int) | The maximum age in days of service history that is retained by SyncIQ |
service_history_max_count (int) | The maximum number of service history records that are retained by SyncIQ |
source_network (str) | The source network used by SyncIQ |
tw_chkpt_interval (int) | The interval between checkpoints in seconds in SyncIQ |
use_workers_per_node (bool) | Whether to use workers per node in SyncIQ or not |
Additions to Info module
The following information fields have been added to the Info module:
- S3 buckets
- SMB global settings
- Detailed network interfaces
- NTP servers
- Email settings
- Cluster identity (also available in the Settings module)
- Cluster owner (also available in the Settings module)
- SNMP settings
- SynciqGlobalSettings
PowerStore Ansible collections 3.1: More NAS configuration
In this release of Ansible collections for PowerStore, new modules have been added to manage the NAS Server protocols like NFS and SMB, as well as to configure a DNS or NIS service running on PowerStore NAS.
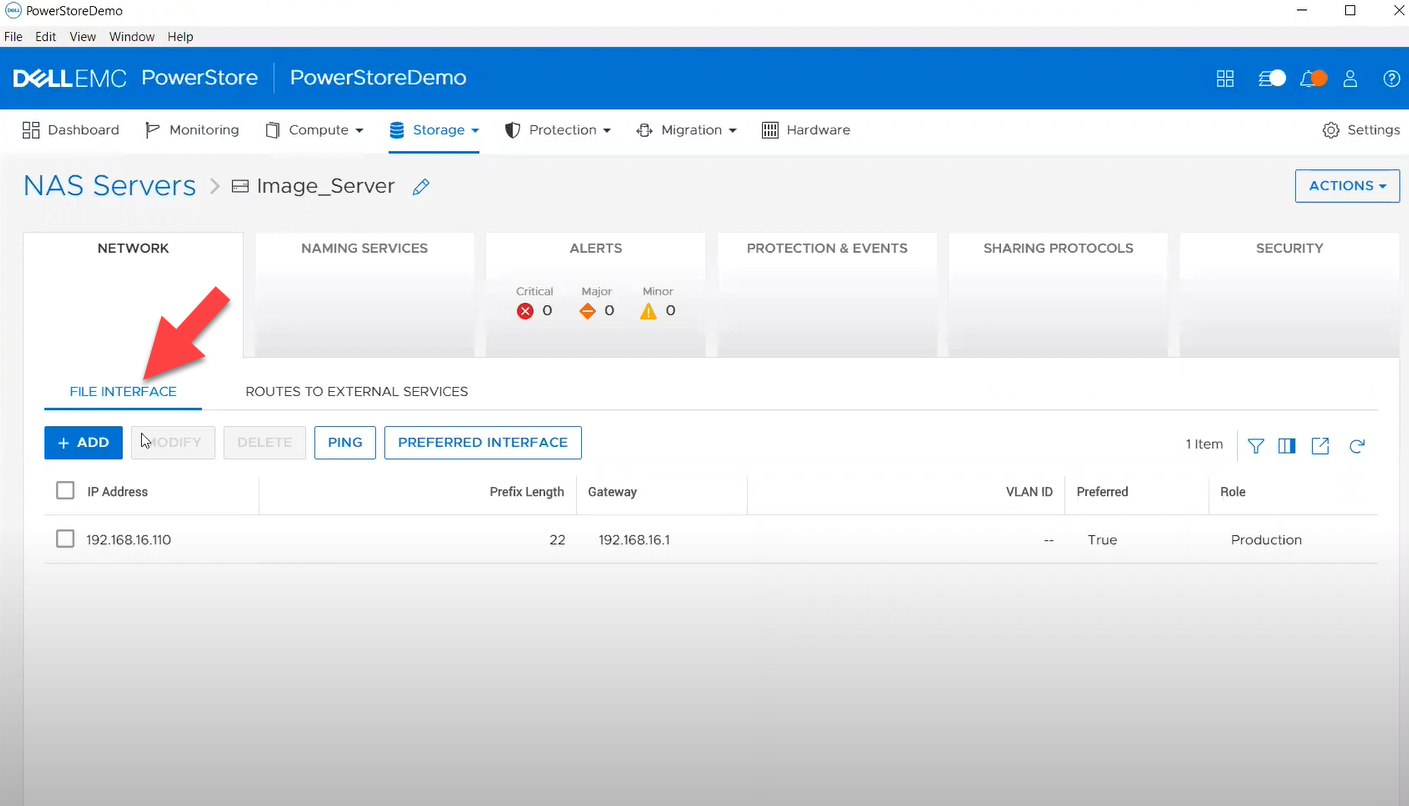
Managing NAS Server interfaces on PowerStore
- file_interface - to enable, query, and modify PowerStore NAS interfaces. Some examples can be found here.
- smb_server - to enable, query, and modify SMB Shares on PowerStore NAS. Some examples can be found here.
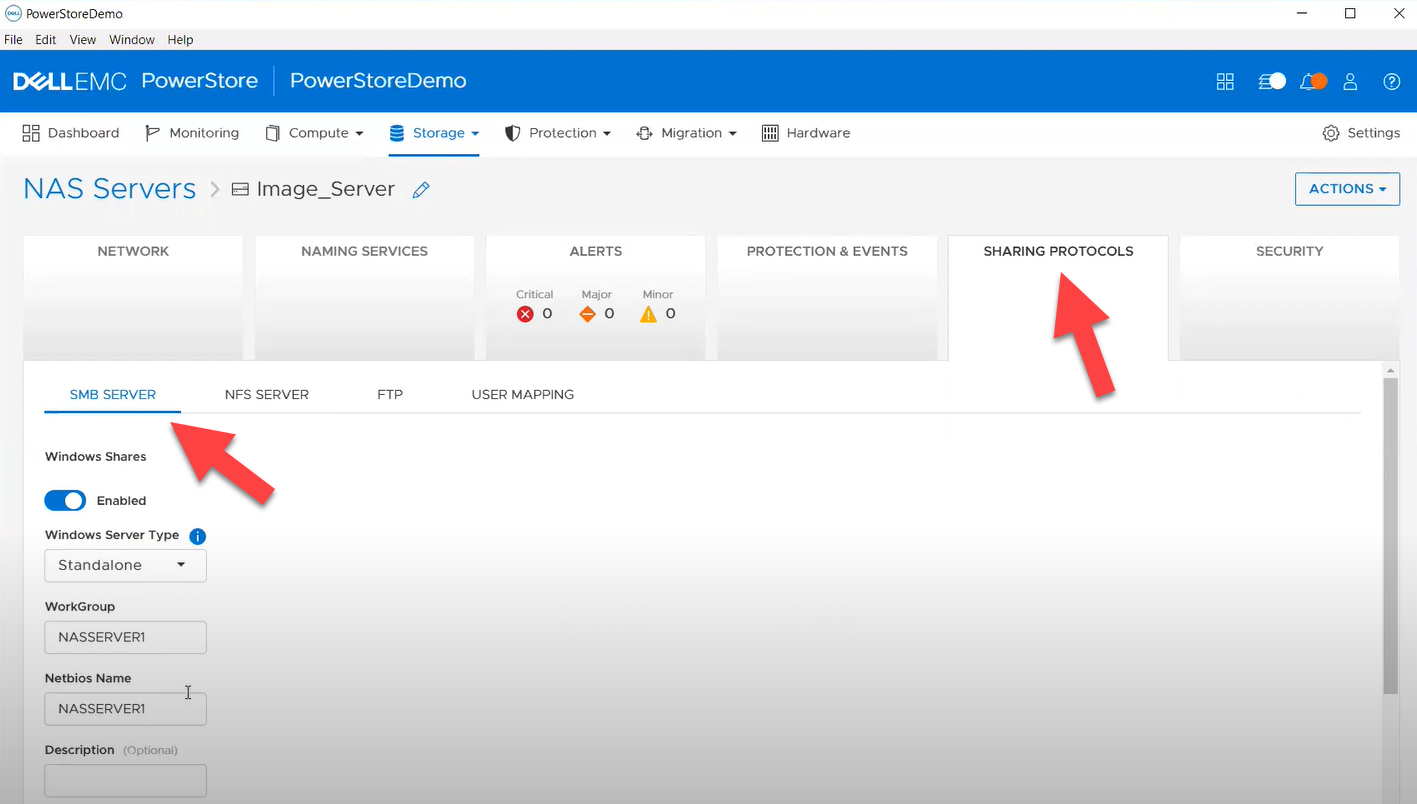
- nfs_server - to enable, query, and modify NFS Server on PowerStore NAS. Some examples can be found here.
Naming services on PowerStore NAS
- file_dns – to enable, query, and modify File DNS on PowerStore NAS. Some examples can be found here.
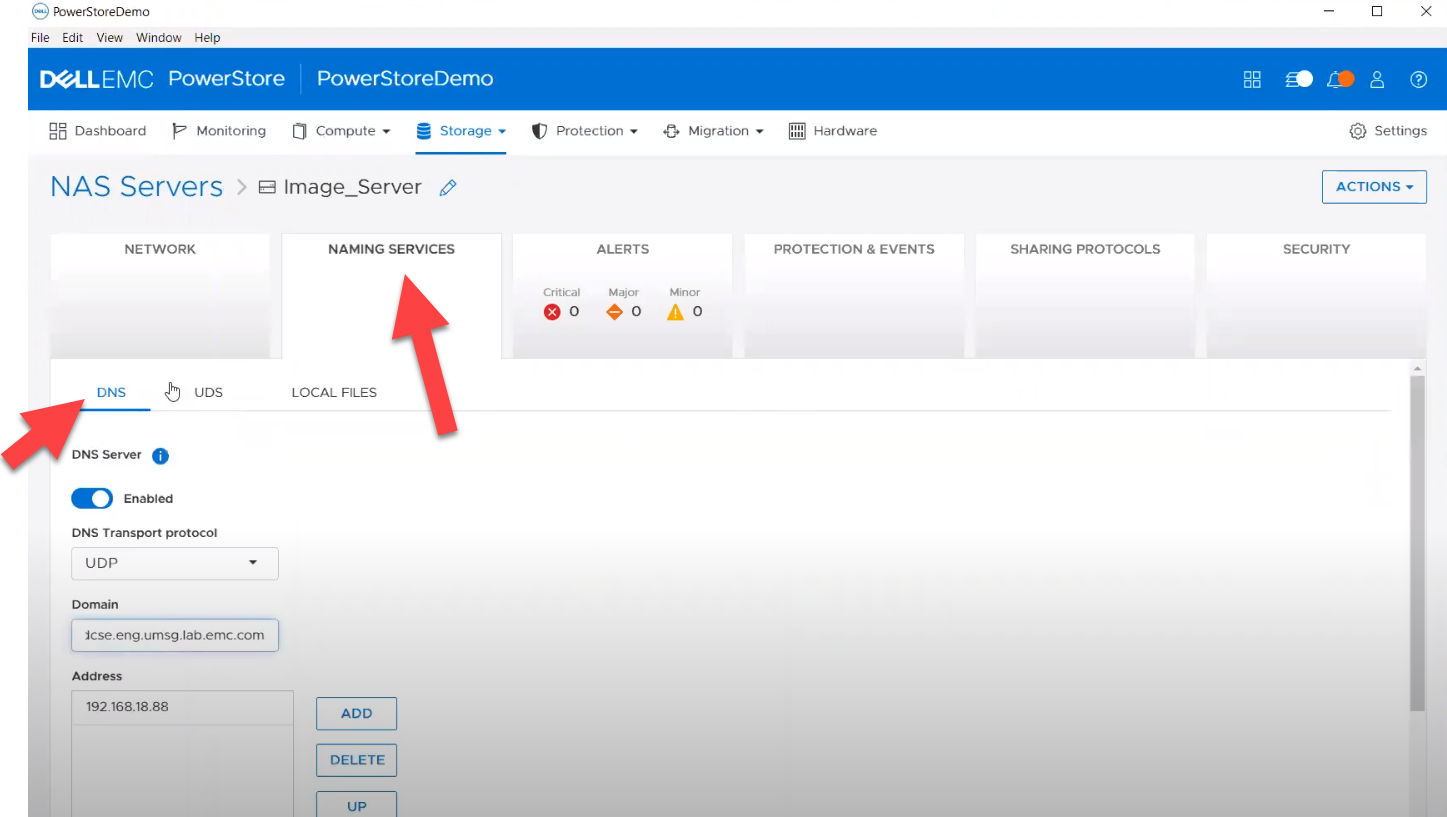
- file_nis - to enable, query, and modify NIS on PowerStore NAS. Some examples can be found here.
- service_config - manage service config for PowerStore
The Info module is enhanced to list file interfaces, DNS Server, NIS Server, SMB Shares, and NFS exports. Also in this release, support has been added for creating multiple NFS exports with same name but different NAS servers.
PowerFlex Ansible collections 2.0.1 and 2.1: More roles
In releases 1.8 and 1.9 of the PowerFlex collections, new roles have been introduced to install and uninstall various software components of PowerFlex to enable day-1 deployment of a PowerFlex cluster. In the latest 2.0.1 and 2.1 releases, more updates have been made to roles, such as:
- Updated config role to support creation and deletion of protection domains, storage pools, and fault sets
- New role to support installation and uninstallation of Active MQ
- Enhanced SDC role to support installation on ESXi, Rocky Linux, and Windows OS
OpenManage Ansible collections: More power to iDRAC
At the risk of repetition, OpenManage Ansible collections have modules and roles for both OpenManage Enterprise as well as iDRAC/Redfish node interfaces. In the last five months, a plethora of a new functionalities (new modules and roles) have become available, especially for the iDRAC modules in the areas of security and user and license management. Following is a summary of the new features:
V9.1
- redfish_storage_volume now supports iDRAC8.
- dellemc_idrac_storage_module is deprecated and replaced with idrac_storage_volume.
v9.0
- Module idrac_diagnostics is added to run and export diagnostics on iDRAC.
- Role idrac_user is added to manage local users of iDRAC.
v8.7
- New module idrac_license to manage iDRAC licenses. With this module you can import, export, and delete licenses on iDRAC.
- idrac_gather_facts role enhanced to add storage controller details in the role output and provide support for secure boot.
v8.6
- Added support for the environment variables, `OME_USERNAME` and `OME_PASSWORD`, as fallback for credentials for all modules of iDRAC, OME, and Redfish.
- Enhanced both idrac_certificates module and role to support the import and export of `CUSTOMCERTIFICATE`, Added support for import operation of `HTTPS` certificate with the SSL key.
v8.5
- redfish_storage_volume module is enhanced to support reboot options and job tracking operation.
v8.4
- New module idrac_network_attributes to configure the port and partition network attributes on the network interface cards.
Conclusion
Ansible is the most extensively used automation platform for IT Operations, and Dell Technologies provides an exhaustive set of modules and roles to easily deploy and manage server and storage infrastructure on-prem as well as on Cloud. With the monthly release cadence for both storage and server modules, you can get access to our latest feature additions even faster. Enjoy coding your Dell infrastructure!
Author: Parasar Kodati, Engineering Technologist, Dell ISG

A Simple Poster at NVIDIA GTC – Running NVIDIA Riva on Red Hat OpenShift with Dell PowerFlex



Fri, 15 Mar 2024 21:45:09 -0000
|Read Time: 0 minutes
A few months back, Dell and NVIDIA released a validated design for running NVIDIA Riva on Red Hat OpenShift with Dell PowerFlex. A simple poster—nothing more, nothing less—yet it can unlock much more for your organization. This design shows the power of NVIDIA Riva and Dell PowerFlex to handle audio processing workloads.
What’s more, it will be showcased as part of the poster gallery at NVIDIA GTC this week in San Jose California. If you are at GTC, we strongly encourage you to join us during the Poster Reception from 4:00 to 6:00 PM. If you are unable to join us, you can view the poster online from the GTC website.
For those familiar with ASR, TTS, and NMT applications, you might be curious as to how we can synthesize these concepts into a simple poster. Read on to learn more.
NVIDIA Riva
For those not familiar with NVIDIA Riva, let’s start there.
NVIDIA Riva is an AI software development kit (SDK) for building conversational AI pipelines, enabling organizations to program AI into their speech and audio systems. It can be used as a smart assistant or even a note taker at your next meeting. Super cool, right?
Taking that up a notch, NVIDIA Riva lets you build fully customizable, real-time conversational AI pipelines, which is a fancy way of saying it allows you to process speech in a bunch of different ways including automatic speech recognition (ASR), text-to-speech (TTS), and neural machine translation (NMT) applications:
- Automatic speech recognition (ASR) – this is essentially dictation. Provide AI with a recording and get a transcript—a near perfect note keeper for your next meeting.
- Text-to-speech (TTS) – a computer reads what you type. In the past, this was often in a monotone voice. It’s been around for more than a couple of decades and has evolved rapidly with more fluid voices and emotion.
- Neural machine translation (NMT) – this is the translation of spoken language in near real-time to a different language. It is a fantastic tool for improving communication, which can go a long way in helping organizations extend business.
Each application is powerful in its own right, so think about what’s possible when we bring ASR, TTS, and NMT together, especially with an AI-backed system. Imagine having a technical support system that could triage support calls, sounded like you were talking to an actual support engineer, and could provide that support in multiple languages. In a word: ground-breaking.
NVIDIA Riva allows organizations to become more efficient in handling speech-based communications. When organizations become more efficient in one area, they can improve in other areas. This is why NVIDIA Riva is part of the NVIDIA AI Enterprise software platform, focusing on streamlining the development and deployment of production AI.
I make it all sound simple, however those creating large language models (LLMs) around multilingual speech and translation software know it’s not so. That’s why NVIDIA developed the Riva SDK.
The operating platform also plays a massive role in what can be done with workloads. Red Hat OpenShift enables AI speech recognition and inference with its robust container orchestration, microservices architecture, and strong security features. This allows workloads to scale to meet the needs of an organization. As the success of a project grows, so too must the project.
Why is Storage Important
You might be wondering how storage fits into all of this. That’s a great question. You’ll need high performance storage for NVIDIA Riva. After all, it’s designed to process and/or generate audio files and being able to do that in near real-time requires a highly performant, enterprise-grade storage system like Dell PowerFlex.
Additionally, AI workloads are becoming mainstream applications in the data center and should be able to run side by side with other mission critical workloads utilizing the same storage. I wrote about this in my Dell PowerFlex – For Business-Critical Workloads and AI blog.
At this point you might be curious how well NVIDIA Riva runs on Dell PowerFlex. That is what a majority of the poster is about.
ASR and TTS Performance
The Dell PowerFlex Solutions Engineering team did extensive testing using the LibriSpeech dev-clean dataset available from Open SLR. With this data set, they performed automatic speech recognition (ASR) testing using NVIDIA Riva. For each test, the stream was increased from 1 to 64, 128, 256, 384, and finally 512, as shown in the following graph.
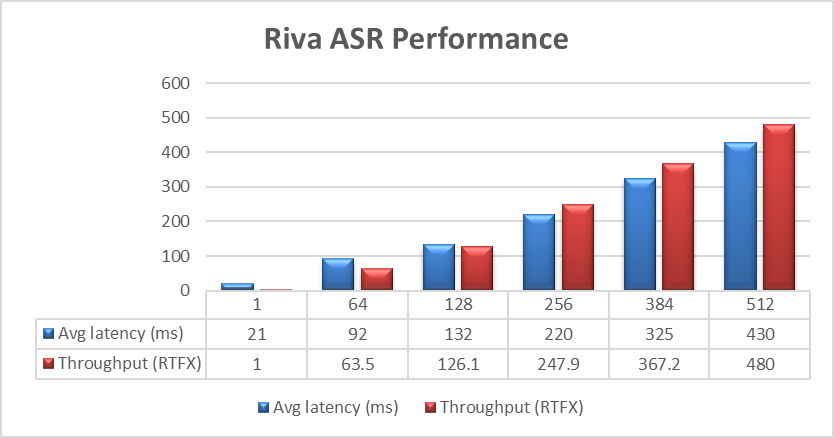 Figure 1. NVIDIA Riva ASR Performance
Figure 1. NVIDIA Riva ASR Performance
The objective of these tests is to have the lowest latency with the highest throughput. Throughput is measured in RTFX, or the duration of audio transcribed divided by computation time. During these tests, the GPU utilization was approximately 48% without any PowerFlex storage bottlenecks. These results are comparable to NVIDIA’s own findings in in the NVIDIA Riva User Guide.
The Dell PowerFlex Solutions Engineering team went beyond just looking at how fast NVIDIA Riva could transcribe text, also exploring the speed at which it could convert text to speech (TTS). They validated this as well. Starting with a single stream, for each run the stream is changed to 4, 6, 8, and 10, as shown in the following graph.
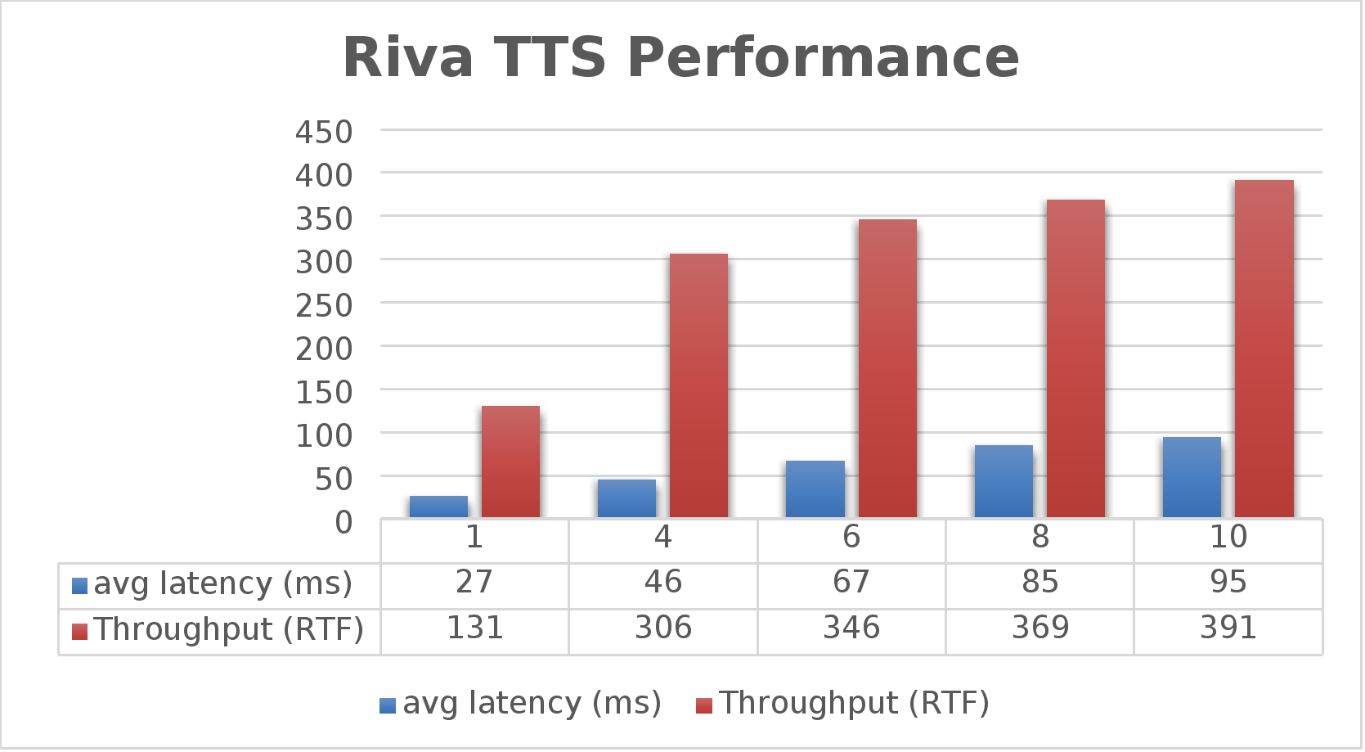 Figure 2. NVIDIA Riva TTS Performance
Figure 2. NVIDIA Riva TTS Performance
Again, the goal is to have a low average latency with a high throughput. The throughput (RTFX) in this case is the duration of audio generated divided by computation time. As we can see, this results in a RTFX throughput of 391 with a latency of 91ms with ten streams. It is also worth noting that during testing, GPU utilization was approximately 82% with no storage bottlenecks.
This is a lot of data to pack into one poster. Luckily, the Dell PowerFlex Solutions Engineering team created a validated architecture that details how all of these results were achieved and how an organization could replicate them if needed.
Now, to put all this into perspective, with PowerFlex you can achieve great results on both spoken language coming into your organization and converting text to speech. Pair this capability with some other generative AI (genAI) tools, like NVIDIA NeMo, and you can create some ingenious systems for your organization.
For example, if an ASR model is paired with a large language model (LLM) for a help desk, users could ask it questions verbally, and—once it found the answers—it could use TTS to provide them with support. Think of what that could mean for organizations.
It's amazing how a simple poster can hold so much information and so many possibilities. If you’re interested in learning more about the research Dell PowerFlex has done with NVIDIA Riva, visit the Poster Reception at NVIDIA GTC on Monday, March 18th from 4:00 to 6:00 PM. If you are unable to join us at the poster reception, the poster will be on display throughout NVIDIA GTC. If you are unable to attend GTC, check out the white paper, and reach out to your Dell representative for more information.
Authors: Tony Foster | Twitter: @wonder_nerd | LinkedIn
Praphul Krottapalli
Kailas Goliwadekar