
Summary
Summary
-
MLCommons™ is an open engineering consortium of corporations, academics, and nonprofit organizations that aims to accelerate machine learning innovation in the areas of benchmarking, datasets, and machine learning best practices. MLCommons hosts MLPerf™ with the objective of producing fair and effective benchmarks. These benchmarks aim to map to real-world use cases that our customers take on more often.
The MLPerf Inference benchmark aims to be a representation of a deep learning workload. It measures the delivered system performance while assuring that the system delivers the required convergence. It measures how fast a system can perform deep learning inference using a trained model in various deployment scenarios.
MLPerf Inference has two different divisions: the closed division and open division. The open division allows using an arbitrary preprocessing or postprocessing model, including retraining. The accuracy constraints are not applicable. The submission must report the latency constraints under which the reported performance was obtained and must indicate the accuracy obtained. The scenario constraints are not applicable.
Our submission to MLPerf Inference benchmarks is for the MLPerf closed division. This submission ensures that comparisons can be made like-for-like among other closed division submitters. These closed divisions require using preprocessing, postprocessing, and a model that is equivalent to the reference or alternative implementation. The closed division allows calibration for quantization but does not allow any retraining.
There are different settings during the inference process of the deployment. These settings enable representative testing of a wide variety of inference platforms and use cases. They are referred to as scenarios. The main differences between these scenarios are based on how the queries are sent and received.
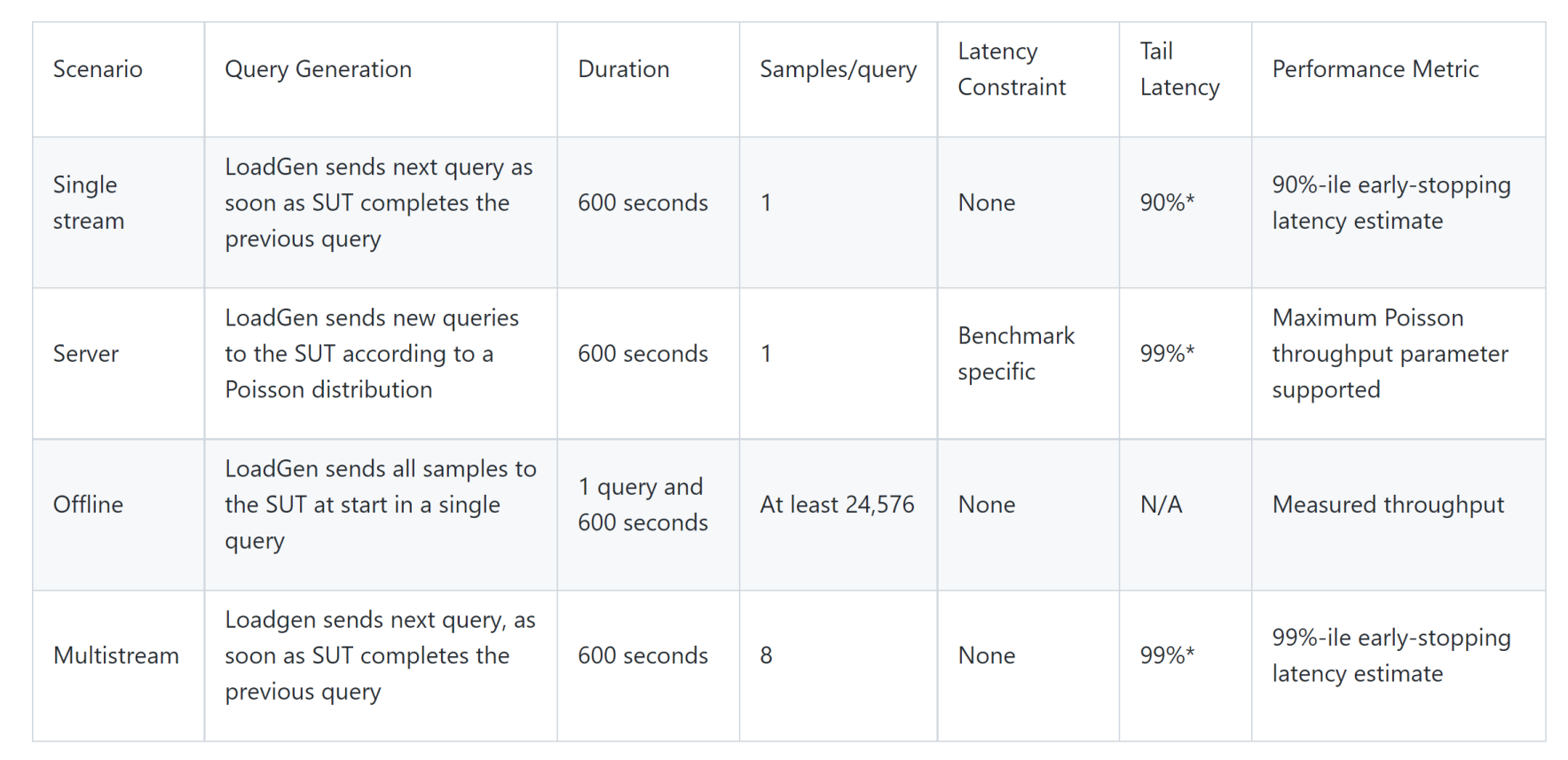
Figure 1. Different scenarios of the inference benchmark and their corresponding measurement metadata
Early stopping sets a threshold that indicates, “If we have processed at least this many queries, we are able to stop processing queries early.”
The load generator, also known as LoadGen, generates queries for all the scenarios, which allows for the system under test (SUT) to consume the queries and run the benchmark.
The following tables provide the benchmarks in the inference process for the closed division. The benchmarks in this white paper are for the closed division. There are two benchmark suites, one for data center systems and one for nondata center systems.
Data center suite
Table 1. Expected quality of the benchmark, dataset, and the latency constraint for the server scenario
Area
Task
Model
Dataset
QSL size
Quality
Server latency constraint
Vision
Image classification
ResNet50-v1.5
ImageNet (224x224)
1024
99% of FP32 (76.46%)
15 ms
Vision
Object detection
RetinaNet
OpenImages (800x800)
64
99% of FP32 (0.3755 mAP)
100 ms
Vision
Medical image segmentation
3D U-Net
KiTS 2019
42
99% of FP32 and 99.9% of FP32 (0.86330 mean DICE score)
N/A
Speech
Speech-to-text
RNN-T
Librispeech dev-clean (samples < 15 seconds)
2513
99% of FP32 (1 -WER, where WER=7.452253714852645%)
1000 ms
Language
Language processing
BERT
SQuAD v1.1 (max_seq_len=384)
10833
99% of FP32 and 99.9% of FP32 (f1_score=90.874%)
130 ms
Commerce
Recommendation
DLRM
1TB Click Logs
204800
99% of FP32 and 99.9% of FP32 (AUC=80.25%)
30 ms
Each data center benchmark requires the following scenarios:
Table 2. Data center benchmark scenarios
Area
Task
Required scenarios
Vision
Image classification
Server, Offline
Vision
Object detection
Server, Offline
Vision
Medical image segmentation
Offline
Speech
Speech-to-text
Server, Offline
Language
Language processing
Server, Offline
Commerce
Recommendation
Server, Offline
Edge (nondata center) suite
Table 3. Edge benchmarks, expected quality, and datasets
Area
Task
Model
Dataset
QSL size
Quality
Vision
Image classification
ResNet50-v1.5
ImageNet (224x224)
1024
99% of FP32 (76.46%)
Vision
Object detection
RetinaNet
OpenImages (800x800)
64
99% of FP32 (0.3755 mAP)
Vision
Medical image segmentation
3D U-Net
KiTS 2019
42
99% of FP32 and 99.9% of FP32 (0.86330 mean DICE score)
Speech
Speech-to-text
RNN-T
Librispeech dev-clean (samples < 15 seconds)
2513
99% of FP32 (1 -WER, where WER=7.452253714852645%)
Language
Language processing
BERT
SQuAD v1.1 (max_seq_len=384)
10833
99% of FP32 (f1_score=90.874%)
Each Edge benchmark requires the following scenarios:
Table 4. Edge benchmark scenarios
Area
Task
Required scenarios
Vision
Image classification
Single Stream, Multistream, Offline
Vision
Object detection
Single Stream, Multistream, Offline
Vision
Medical image segmentation
Single Stream, Offline
Speech
Speech-to-text
Single Stream, Offline
Language
Language processing
Single Stream, Offline
MLPerf Inference uses compliance testing to ensure each submitter is submitting to the benchmark fairly. The compliance testing asserts that the accuracy matches the expected values, the results are not cached, and there is no fine-tuning for a specific seed of the LoadGen.
MLPerf Inference also supports measuring the entire power of the system. There is a specific client/server methodology to assessing the power consumed while running the workload on the SUT.