
Single-server performance
Single-server performance
-
The following figure shows the measured performance of selected Abaqus/Standard benchmarks on a single server with version 2021hf6. The performance for each benchmark is measured using the solver-elapsed time based on the output at the bottom of the .msg file.
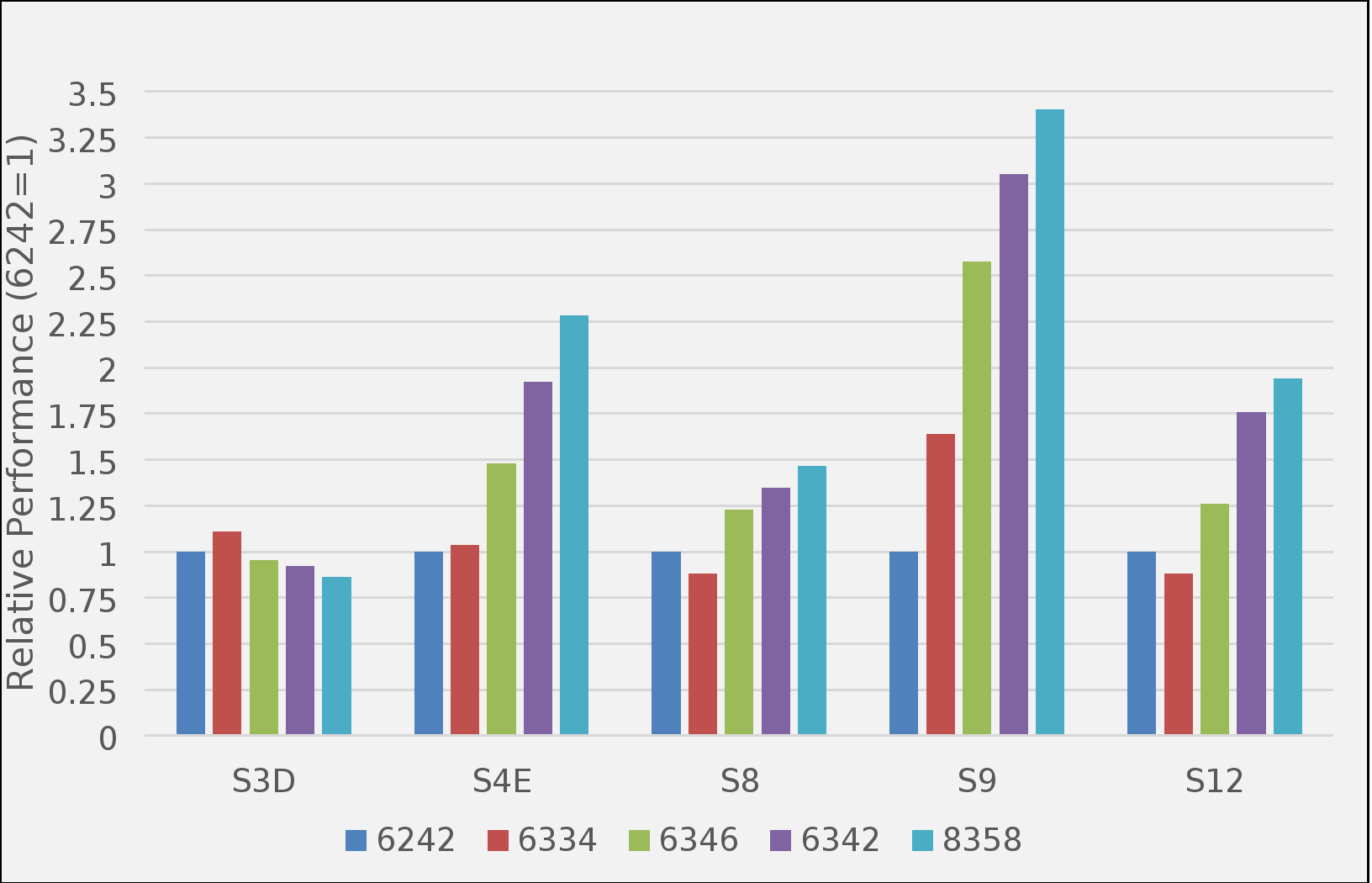
Figure 3. Abaqus/Standard performance
The results are plotted relative to the performance of a single server configured with Intel Xeon Gold 6242 processors. Larger values indicate better overall performance. Except for the “S3D” model, all other models were run with “mp_mode=MPI” and “mp_host_split=8”. The “S3D” benchmark is a modal analysis that operates only in “mp_mode=threads” mode.
These results show the performance advantage available with 3rd Generation Intel Xeon Scalable Processors (code name Ice Lake). These results also show that the Abaqus/Standard benchmarks can use the higher core count processors such as the 32-core Intel Xeon Platinum 8358. The notable exception is the results for the “S3D” case, which is modal analysis. This solver is only thread-based parallel, and as a result, is not able to exploit the larger number of cores available in the Ice Lake-based systems compared to the previous Lake-based systems. For these analyses, the core processors’ clock frequency is critical. The Ice Lake-based processors are typically comparable to their predecessor Cascade Lake processors in this area. For the S4E and S9 benchmarks cases, the 192 GB of memory on the 6242-based server was insufficient to keep the problem all in-core, which contributed to the overall increase in performance for the Ice Lake-based systems equipped with more memory.
The following figure shows the effect of modifying the number of MPI domains for the Abaqus/Standard benchmarks on a single server with Intel’s previous generation dual 24-core Intel Gold 6252 processors with Abaqus 2019:
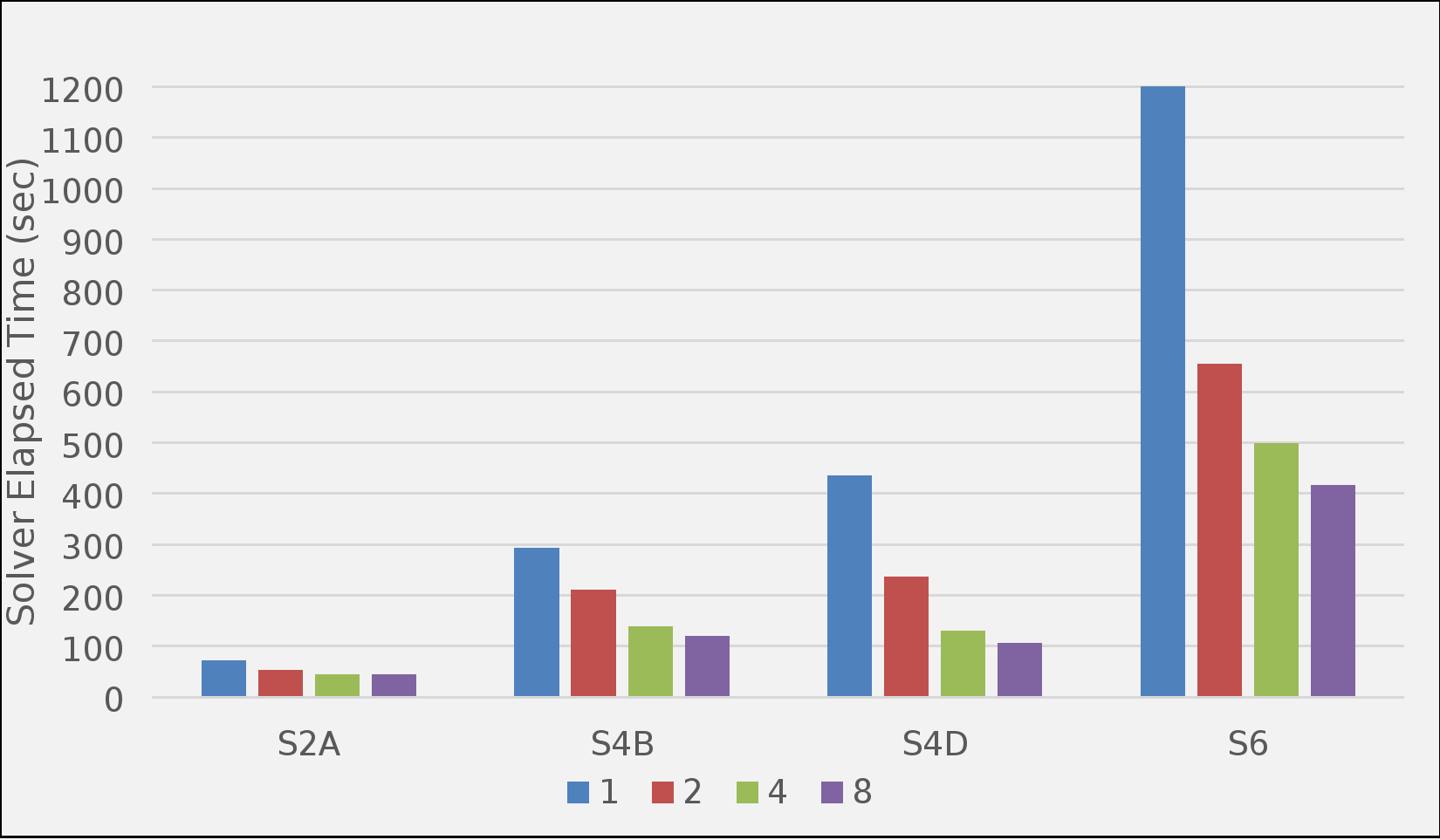
Figure 4. "mp_host_split" performance
For all the models tested, substantial performance gains were made using multiple domains per node. Using eight domains (six threads per domain) delivered the optimal performance. We encourage you to examine this option with your models to determine the optimal value. An even number is preferred because it allows MPI processor binding to be enabled to further improve performance. There might be an increase in the amount of memory required to minimize I/O when more than a single domain is placed on a node. Ensure that you avoid “out-of-core” solutions, causing potentially significant I/O activity and decreasing the overall performance. You can examine the domain memory requirements to minimize I/O in the .dat file to ensure that this issue does not occur.
The following figure shows the measured performance of various Abaqus/Explicit benchmarks on a single server using version 2021hf6. The performance for each benchmark is measured using the solver elapsed time that is obtained from the output at the end of the log file.
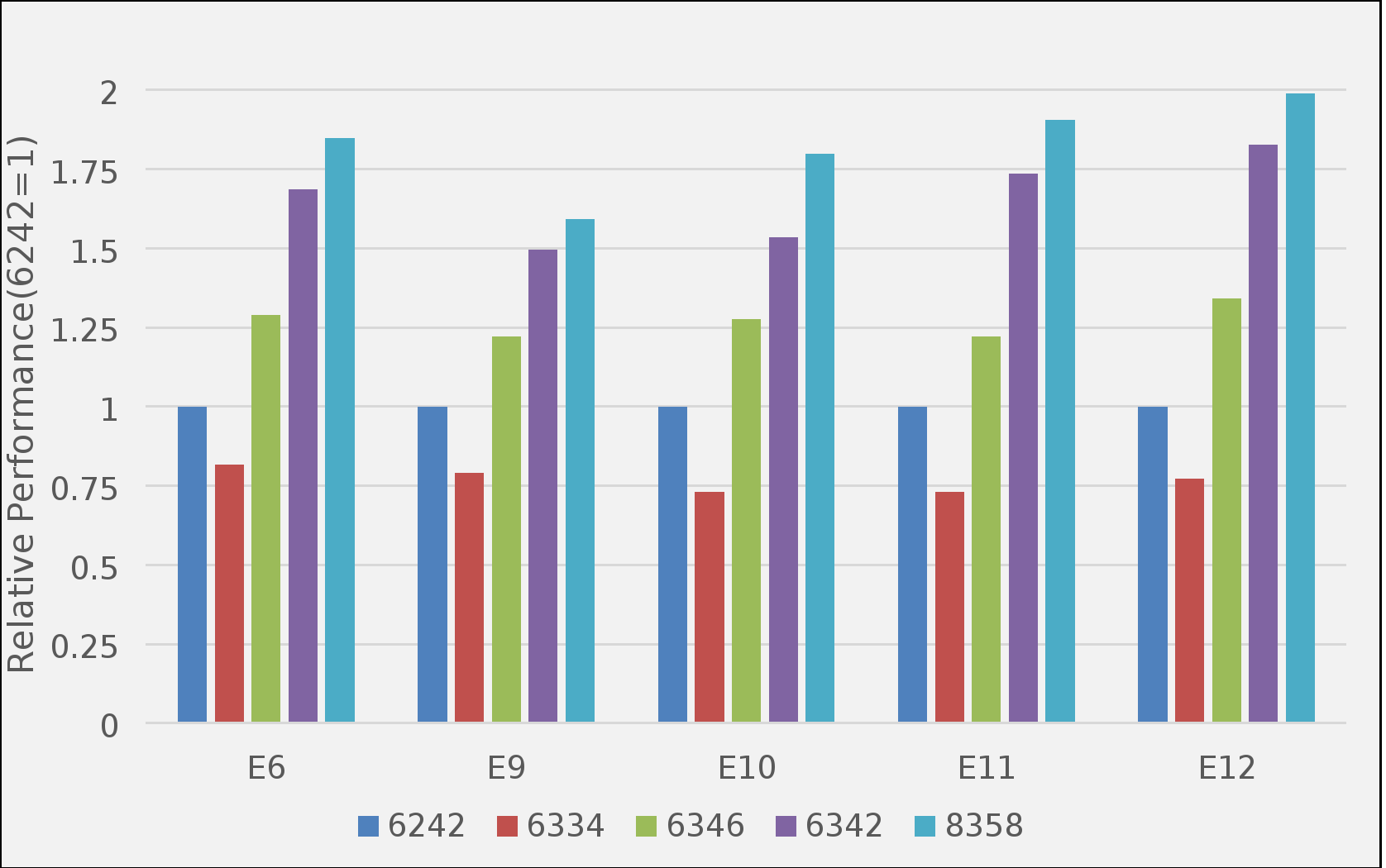
Figure 5. Abaqus/Explicit performance
The results are plotted relative to the performance of a single server configured with Intel Xeon Gold 6242 processors to better indicate generational performance improvements. Larger values indicate better overall performance. These results are similar to the single-server standard benchmarks shown in Figure 3, showing a substantial improvement in the performance for the Ice Lake -based servers over the previous generation Cascade Lake-based servers. For all these benchmarks, there was a strong correlation between the processor performance and the number of processors cores.