
Multiserver scalability
Multiserver scalability
-
The following figure represents the parallel scalability when running Abaqus using up to four nodes configured with Intel Xeon Platinum 8358 processors for various Abaqus/Standard and Abaqus/Explicit benchmarks with version 2021hf6 (described in previous sections). Larger values indicate better overall performance. The performance is presented relative to the performance of a single node 8358-based system.
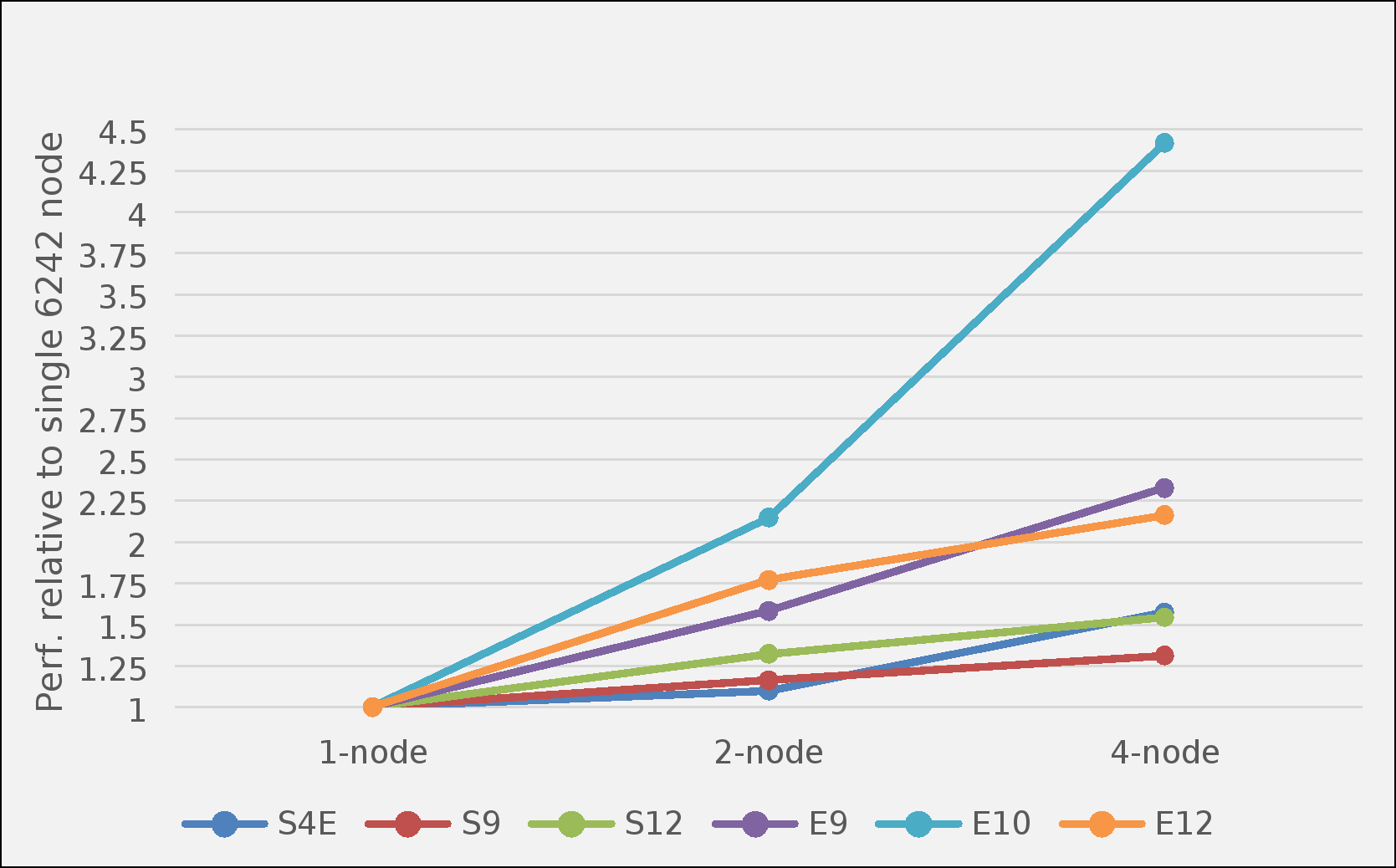
Figure 6. Multiserver parallel performance
The parallel speedup when running jobs across more than a single node is mixed. These datasets are small by current production standards and do not represent typical production-sized simulations. While the parallel speedup tends to correlate to the model size, there are several factors impacting the parallel speedup. Most of the models tested showed a noticeable speedup going from one to two nodes. The notable exception is the E10 case, which displays a superlinear speedup. This behavior is explained by “cache effects,” where the dataset is distributed among a greater number of nodes. There can be a point where the entire problem can fit into cache and the speed of the solver can increase dramatically. Such cache effects are highly problem-specific. In general, there is a tradeoff in distributed memory parallelism where the cache performance typically improves as the problem is distributed to more nodes. However, the communication overhead also increases, counteracting the increased performance from the caching benefit. We encourage you to carry out a few tests with new models to determine the optimum node count for the best job throughput with available resources.