
Dell ECS: Data Lake with Apache Iceberg
Iceberg query table process
Iceberg query table process
-
When you query data from an Iceberg table, you first get the latest version of the table (or use the specified version as required by the user). Then, you get a list of all matching data files from the snapshot. This list of files is then split into tasks that are delegated to the computing platform for execution. Each subtask reads the data file and selects the matching records, finally merging and returning the results of all tasks.
The Manifest file and data file are clipped according to the query criteria. This action ensures that as few data files as possible enter the final retrieval process and improve retrieval efficiency.
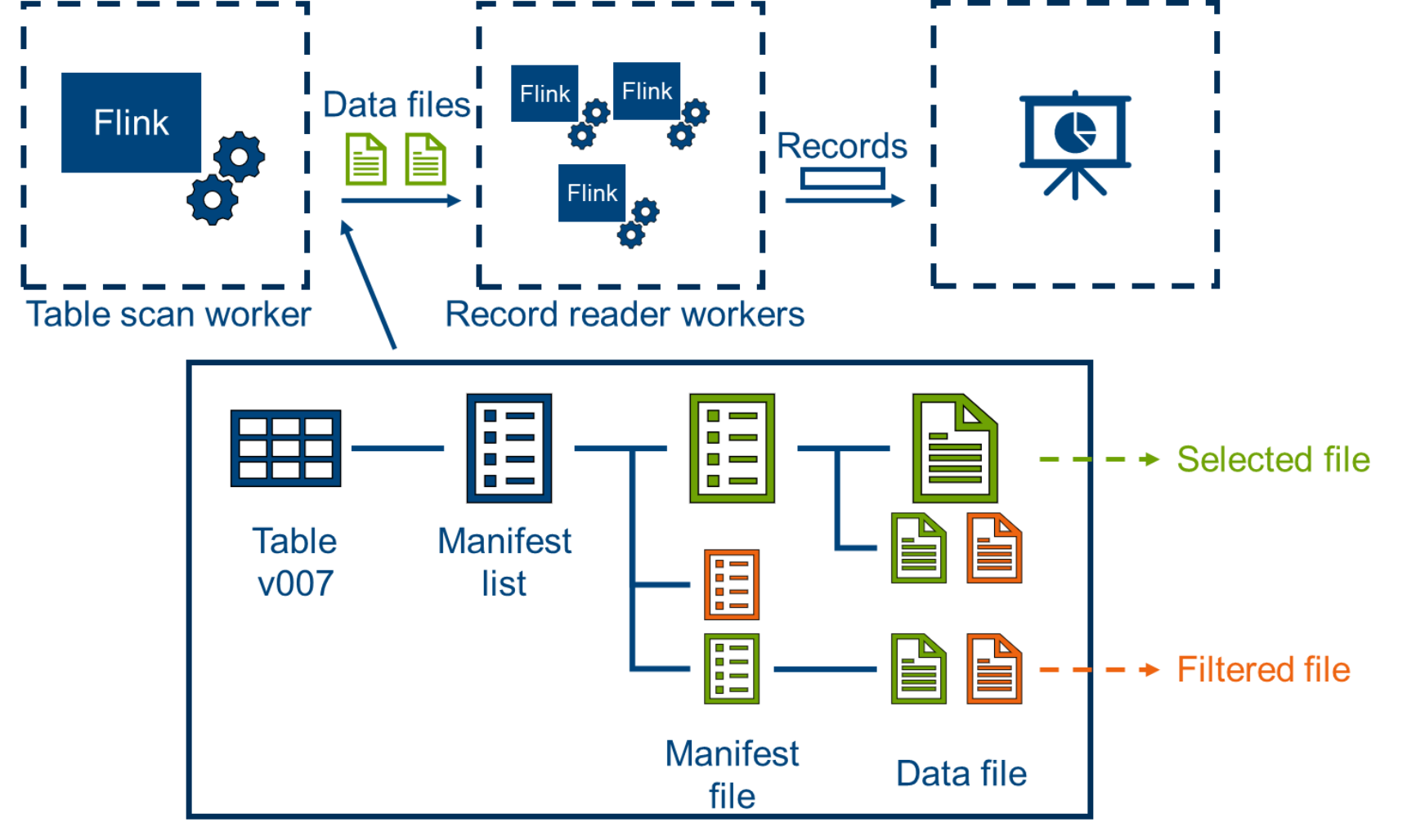
Figure 4. Querying data from the iceberg table