
Dell EMC ECS and HDFS
Dell EMC ECS and HDFS
-
HDFS is a widely used big data component that has a file system abstraction, which makes it easier for developers to use as a storage engine. ECS can be used by big data ecology and can replace HDFS.
In the current situation, some designs of HDFS on append upload and atomic rename still have some challenges for storage. However, storage has natural advantages in cluster scalability, small file storage, multisite deployment, and storage overhead. ECS solves the challenges of additional uploads and atomic rename through its own design and retains the natural advantages of object storage.
Advantages of ECS
Cluster scalability
HDFS uses name node as a metadata-management service, and the metadata of all files is managed by name node. As a result, name node actually becomes a single point of service in an HDFS system that cannot scale out. With increasing data scale, this architecture has disadvantages, often reflected when using a higher configuration to run the name node. The name node should be upgraded to the high-level configuration.
However, the cluster scales out easily in ECS. Since the metadata of the object service is partitioned using methods such as consistent hashing, you can scale capacity according to the size of the data. You can also move the split metadata between different services according to the hash, and implement the interservice failover. These capabilities improve the reliability of the service and avoid having a single point of failure on the system.
Small-file friendly
As mentioned earlier, limited by the architecture of the name node, small files consume a large amount of space for the name node because of their high numbers of metadata. The community uses various methods to optimize small-file storage. However, the basic principle is to combine small files into large files, which has a certain impact on performance and interaction convenience.
ECS uses a distributed-metadata management system, and the advantage of its capacity is reflected. Also, ECS uses various media to store or cache metadata, which accelerates metadata queries under different speeds of storage media, enhancing its performance.
ECS has the capacity and performance advantage for a large number of small files.
Multisite deployment
For the data, multisite deployment is required if multisite backup is required.
HDFS itself does not support multisite deployment. Some commercial software attempts to provide multisite support, but HDFS itself does not natively support this cross-service deployment.
ECS naturally supports multisite deployments where users can configure multiple rules for intersite copying. This allows users to use ECS conveniently to meet their compliance needs.
Low storage overhead
HDFS uses three replicas by default to store data, storage overhead is high for write-once-read-many scenarios. Erasure coding (EC) is already supported in the new version of HDFS, but it is file-based ECs, the overhead increases in small files, and in extreme cases when the file is smaller than the minimum fragment size, the storage overhead even exceeds three copies. At the same time, using of ECs on HDFS presents many limitations, such as the inability to support append upload functionality.
In ECS, ECs are used by default, and erasure coding is performed for data. Such coding can reduce the storage overhead. For 10+2 ECs, the storage overhead is only a factor of 1.2. In this mode, data density is increased and limited storage can be more valuable. For small files, ECS ensures that the same low storage overhead is maintained on small files by merging small files.
Challenge of traditional storage
Additional upload when data file is uploaded
In traditional object storage, the size of the object must be known in advance for uploading data. In the case of additional uploading, the APIs cannot be naturally supported like HDFS.
As shown in the following figure, in a specific implementation, an additional write operation must be cached locally to obtain a complete object, and then it is uploaded as a whole.

Figure 6. Uploading small objects using S3 put object
For larger objects, you must use a multipart upload when uploading the data, as shown in the following figure. With a multipart upload, you can reduce disk and memory overhead without having to cache the entire file locally, while avoiding the latency of caching the entire large file. A multipart upload can support the parallel upload of multiple fragments. By implementing the asynchronous upload mechanism, the parallel upload of multiple append blocks can provide higher performance than the single append upload of HDFS.

Figure 7. Uploading large objects using S3 multipart upload
Although caching locally is required for append uploads, the object stores the additional immutability that is provided to ensure that the data exists in a complete state without partially committed objects. For example, an error was reported during the upload process, some data was not left locally, and all failed data was not actually uploaded.
Atomic renaming at meta-information submission (rename)
When the data is inserted into the Iceberg table, there is a final submission step. This step requires not only writing to the latest version, but also rejecting and rolling back other simultaneous operations.
As shown in the following figure, when multiple tables were submitted in workers, if they get the same table source version at the same time, only one worker can successfully complete the submission at the time of final submission. The other worker must fail and try to submit in the new version again. This behavior requires a mechanism to implement a linear-transaction commit.

Figure 8. Apache Iceberg linear consistency
There are two main genres of design in the official integrated catalog implementation. One genre is a Hadoop-based implementation that uses atomic renaming to ensure a particular version be uniquely committed, as shown in the following figure.

Figure 9. Using atomic rename for concurrent collisions
Another implementation is based on a third-party lock.
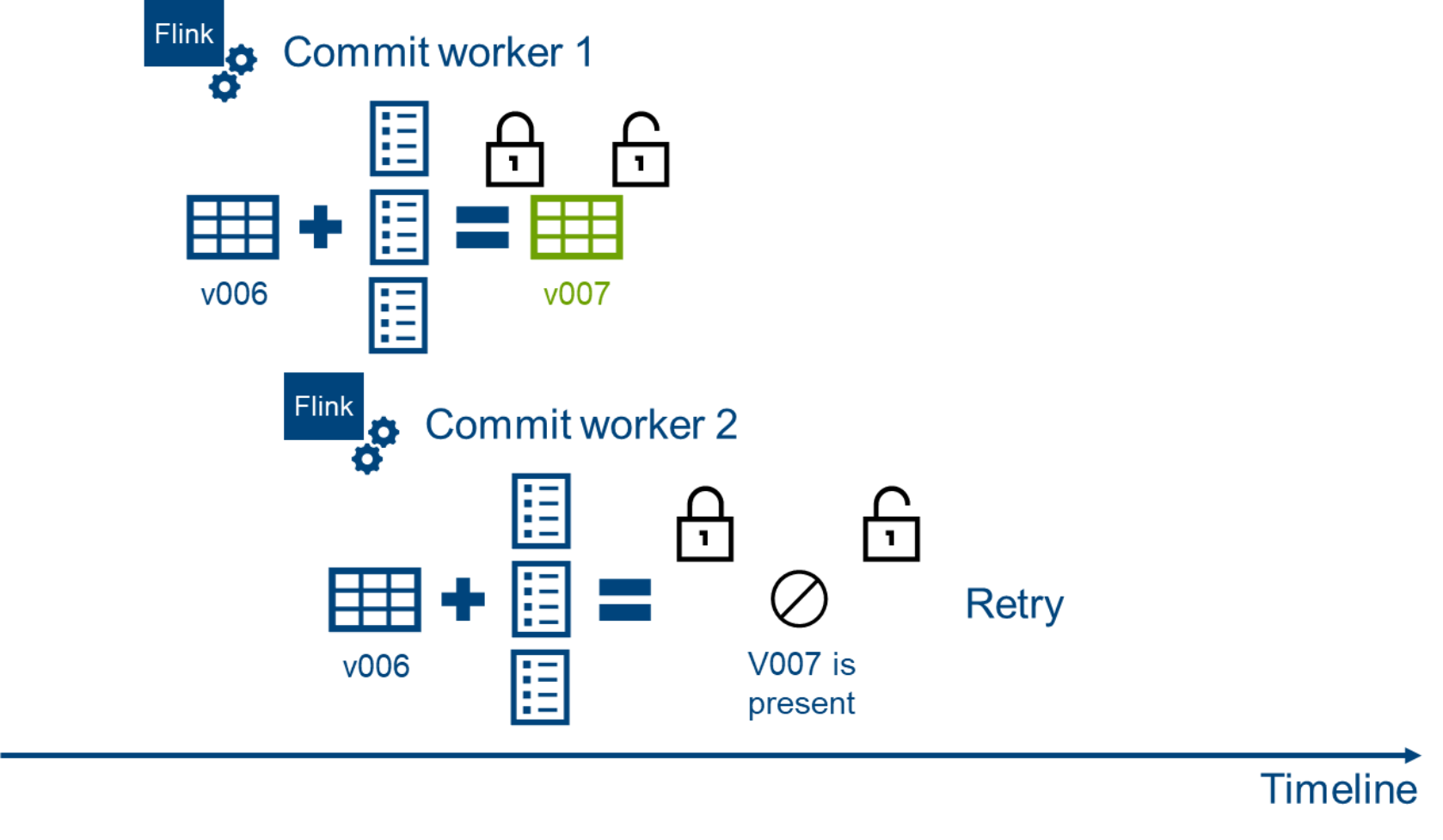
Figure 10. Handling concurrent conflicts using lock mechanism
In object storage, locking mechanisms are used to ensure consistency of submitted data. As shown in the above figure, when the locking mechanism is used, the current table is locked when version v007 is last submitted, and it checks whether there is another version 007. If the version 007 already exists, it is determined that the current submission fails and the data is submitted again.
Solution for ECS
As a commercial implementation of object storage, ECS has solutions for two of the challenges described above, and the ECS catalog is customized for Iceberg.
On one hand, ECS supports the use of append operations. If users do not want to locally write temporary files or consume too much memory to cache data files, they can directly use append operations to submit data, avoiding waste of resources when writing files.
On the other hand, ECS supports the use of if-match to operate on objects to address the challenges of rename, as shown in the following figure. When a version is submitted, the E-tag information of the old version must be carried as the update condition, so that the atomicity operation can be implemented during the update. ECS ensures that the data is updated only when the previous version matches the specified E-tag, and the error is returned synchronously. This behavior allows the commit worker to resubmit with the new version.

Figure 11. ECS uses if-match to handle concurrent conflicts
In that case, you can use ECS to support the full range of Iceberg requirements without relying on other storage or lock scenarios. This ability helps users build data lakes at the lowest possible cost and provides more comprehensive support.