




Unlock the Power of PowerEdge Servers for AI Workloads: Experience Up to 177% Performance Boost!
Download PDFFri, 11 Aug 2023 16:23:55 -0000
|Read Time: 0 minutes
Executive summary
As the digital revolution accelerates, the vision of an AI-powered future becomes increasingly tangible. Envision a world where AI comprehends and caters to our needs before we express them, where data centers pulsate at the heart of innovation, and where every industry is being reshaped by AI's transformative touch. Yet, this burgeoning AI landscape brings an insatiable demand for computational resources. TIRIAS Research estimates that 95% or more of all current AI data processed is through inference processing, which means that understanding and optimizing inference workloads has become paramount. As the adoption of AI grows exponentially, its immense potential lies in the realm of inference processing, where customers reap the benefits of advanced data analysis to unlock valuable insights. Harnessing the power of AI inference, which is faster and less computationally intensive than training, opens the door to diverse applications—from image generation to video processing and beyond.
Unveiling the pivotal role of Intel® Xeon® CPUs, which account for a staggering 70% of the installed inferencing capacity, this paper ventures into a comprehensive exploration, offering simple guidance to fine-tune BIOS on your PowerEdge servers for achieving optimal performance for CPU based AI workloads for their workload. We discuss available server BIOS configurations, AI workloads, and value propositions, explaining which server settings are best suited for specific AI workloads. Drawing upon the results of running 12 diverse workloads across two industry-standard benchmarks and one custom benchmark, our goal is simple: To equip you with the knowledge needed to turbocharge your servers and conquer the AI revolution.
Through extensive testing on Dell PowerEdge servers using industry-standard AI benchmarks, results showed:
 Up to 140% increase in TensorFlow inferencing benchmark performance
Up to 140% increase in TensorFlow inferencing benchmark performance
 Up to 46% increase in OpenVINO inferencing benchmark performance
Up to 46% increase in OpenVINO inferencing benchmark performance
 Up to 177% increase in raw performance for high-CPU-utilization AI workloads
Up to 177% increase in raw performance for high-CPU-utilization AI workloads
 Up to 9% decrease in latency and up to 10% increase in efficiency with no significant increase in power consumption
Up to 9% decrease in latency and up to 10% increase in efficiency with no significant increase in power consumption
The AI performance benchmarks focus on the activity that forms the main stage of the AI life cycle: inference. The benchmarks used here measure the time spent on inference (excluding any preprocessing or post-processing) and then report on the inferences per second (or frames per second or millisecond).
Performance analysis and process
We conducted iterative testing and data analysis on the PowerEdge R760 with 4th Gen Intel Xeon processors to identify optimal BIOS setting recommendations. We studied the impacts of various BIOS settings, power management settings, and different workload profile settings on throughput and latency performance for popular inference AI workloads such as Intel’s OpenVINO, TensorFlow, and customer-specific computer-vision-based workloads.
Dell PowerEdge servers with 4th Gen Intel Xeon processors and Intel delivered!
So what are these AI performance benchmarks?
We used a centralized testing ecosystem where the testing-related tasks, tools, resources, and data were integrated into a unified location, our Dell Labs, to streamline and optimize the testing process. We used various AI computer vision applications useful for person detection, vehicle detection, age and gender recognition, crowd counting, parking spaces detection, suspicious object recognition, and traffic safety analysis, and the following performance benchmarks:
- OpenVINO: A cross-platform deep learning and AI inferencing toolkit, developed by Intel, which has moderate CPU utilization.
- TensorFlow: An open-source deep learning and AI inferencing framework used to benchmark performance and characterized as a high CPU utilization workload.
- Computer-vision-based workload: A customer-specific workload. Scalers AI is a CPU-based smart city solution that uses AI and computer vision to monitor traffic safety in real time and takes advantage of the Intel AMX instructions. The solution identifies potential safety hazards, such as illegal lane changes on freeway on-ramps, reckless driving, and vehicle collisions, by analyzing video footage from cameras positioned at key locations. It is characterized as a high CPU utilization workload.
PowerEdge server BIOS settings
To improve out-of-the-box performance, we used the following server settings to achieve the optimal BIOS configurations for running AI inference workloads:
- Logical Processor: This option controls whether Hyper-Threading (HT) Technology is enabled or disabled for the server processors (see Figure 1 and Figure 2). The default setting is Enabled to potentially increase CPU utilization and overall system performance. However, disabling it may be beneficial for tasks that do not benefit from parallel execution. Disabling HT allows each core to fully dedicate its resources to a single task, often leading to improved performance and reduced resource contention in these cases.
Figure 1. BIOS settings for Logical Processor on Dell server
Figure 2. BIOS settings for Logical Processor on Dell iDRAC
- System Profile: This setting specifies options to change the processor power management settings, memory, and frequency. These five profiles (see Figure 1) can have a significant impact on both power efficiency and performance. The System Profile is set to Performance Per Watt (DAPC) as the default profile, and changes can be made through the BIOS setting on the server or by using iDRAC (See Figure 3 and Figure 4). We focused on the default and Performance options for System Profile because our goal was to optimize performance.
Additionally, we could see improvements in performance (throughput in FPS) and latency (in ms) for no significant increase in power.
- Performance-per-watt (DAPC) is the default profile and represents an excellent mix of performance balanced with power consumption reduction. Dell Active Power Control (DAPC) relies on a BIOS-centric power control mechanism that offers excellent power efficiency advantages with minimal performance impact in most environments and is the CPU Power Management choice for this overall System Profile.
- Performance profile provides potentially increased performance by maximizing processor frequency and disabling certain power-saving features such as C-states. Although not optimal for all environments, this profile is an excellent starting point for performance optimization baseline comparisons.

Figure 3. System BIOS settings—System Profiles Settings server screen
Figure 4. BIOS settings for System Profile and Workload Profile on Dell iDRAC
- Workload Profile: This setting allows the user to specify the targeted workload of a server to optimize performance based on the workload type. It is set to Not Configured as the default profile, and changes can be made through the BIOS setting on the server or by using iDRAC (see Figure 4 and Figure 5).
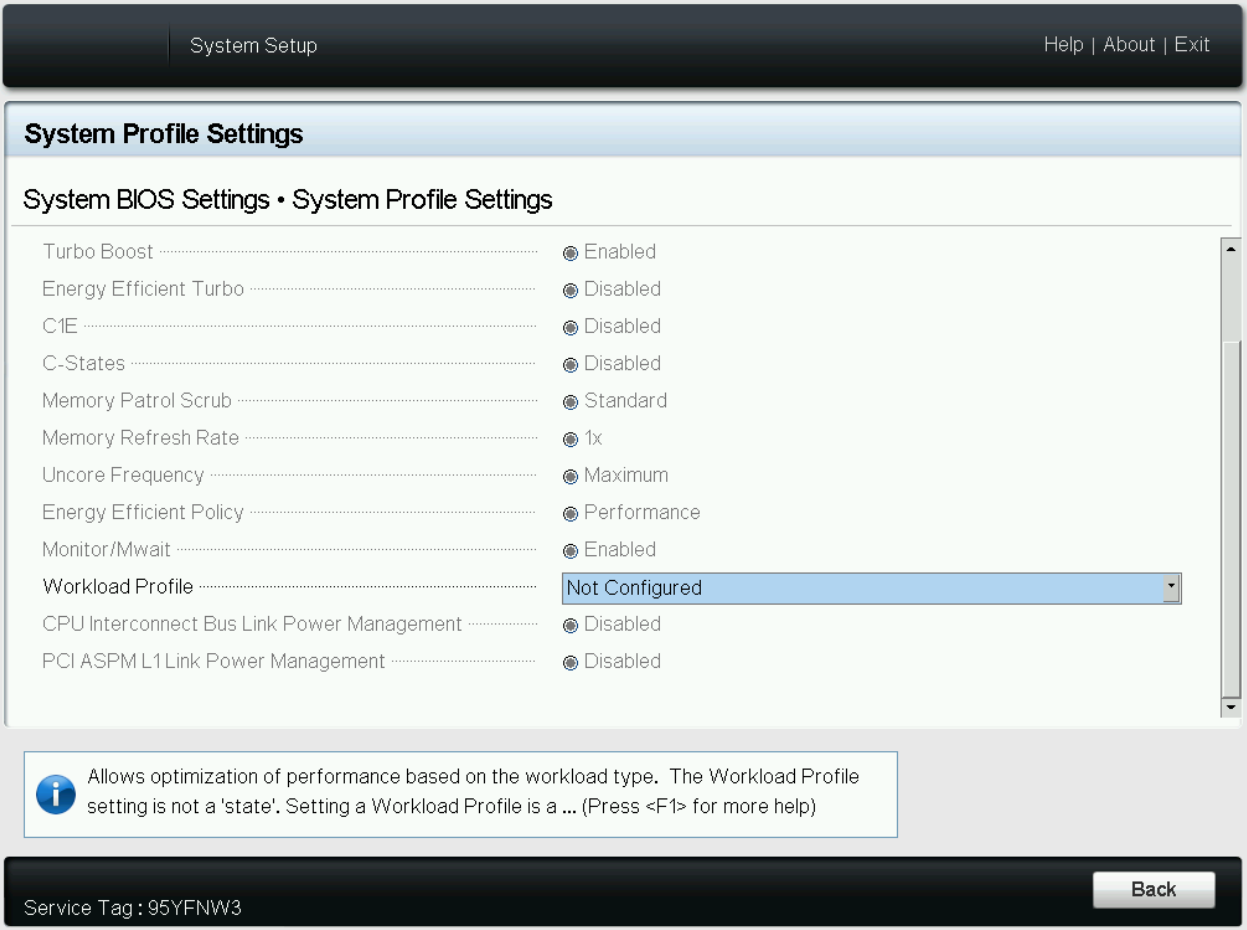
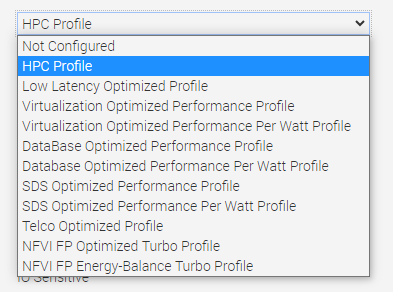 Figure 5. BIOS settings for Workload Profile on Dell iDRAC
Figure 5. BIOS settings for Workload Profile on Dell iDRAC
Now the question is, does the type of workload influence CPU optimization strategies?
When a CPU is used dedicatedly for AI workloads, the computational demands can be quite distinct compared to more general tasks. AI workloads often involve extensive mathematical calculations and data processing, typically in the form of machine learning algorithms or neural networks. These tasks can be highly parallelizable, leveraging multiple cores or even GPUs to accelerate computations. For instance, AI inference tasks involve applying trained models to new data, requiring rapid computations, often in real time. In such cases, specialized BIOS settings, such as disabling hyperthreading for inference tasks or using dedicated AI optimization profiles, can significantly boost performance.
On the other hand, a more typical use case involves a CPU running a mix of AI and other workloads, depending on demand. In such scenarios, the CPU might be tasked with running web servers, database queries, or file system operations alongside AI tasks. For example, a server environment might need to balance AI inference tasks (for real-time data analysis or recommendation systems) with more traditional web hosting or database management tasks. In this case, the optimal configuration might be different, because these other tasks may benefit from features such as hyperthreading to effectively handle multiple concurrent requests. As such, the server's BIOS settings and workload profiles might need to balance AI-optimized settings with configurations designed to enhance general multitasking or specific non-AI tasks.
PowerEdge server BIOS tuning
In the pursuit of identifying optimal BIOS settings for enhancing AI inference performance through a deep dive into BIOS settings and workload profiles, we uncover key strategies for enhancing efficiency across varied scenarios.
Disabling hyperthreading
We determined that disabling the logical processor (hyperthreading) on the BIOS is another simple yet effective means of increasing performance up to 2.8 times for high CPU utilization workloads such as TensorFlow and computer-vision-based workload (Scalers AI), which run AI inferencing object detection use cases.
But why does disabling hyperthreading have such extensive impact on performance?
Disabling hyperthreading proves to be a valuable technique for optimizing AI inference workloads for several reasons. Hyperthreading enables each physical CPU core to run two threads simultaneously, which benefits overall system multitasking. However, AI inference tasks often excel in parallelization, rendering hyperthreading less impactful in this context. With hyperthreading disabled, each core can fully dedicate its resources to a single AI inference task, leading to improved performance and reduced contention for shared resources.
The nature of AI inference workloads involves intensive mathematical computations and frequent memory access. Enabling hyperthreading might result in the two threads on a single core competing for cache and memory resources, introducing potential delays and cache thrashing. In contrast, disabling hyperthreading allows each core to operate independently, enabling AI inference workloads to make more efficient use of the entire cache and memory bandwidth. This enhancement leads to increased overall throughput and reduced latency, significantly boosting the efficiency of AI inference processing.
Moreover, disabling hyperthreading offers advantages in terms of avoiding thread contention and context switching issues. In real-time or near-real-time AI inference scenarios, hyperthreading can introduce additional context switching overhead, causing interruptions and compromising predictability in task execution. When you opt for one thread per core with hyperthreading disabled, AI inference workloads experience minimal context switching and ensure continuous dedicated runtime. As a result, this approach achieves improved performance and delivers more consistent processing times, thereby streamlining the overall AI inference process.
The following charts represent what we learned.
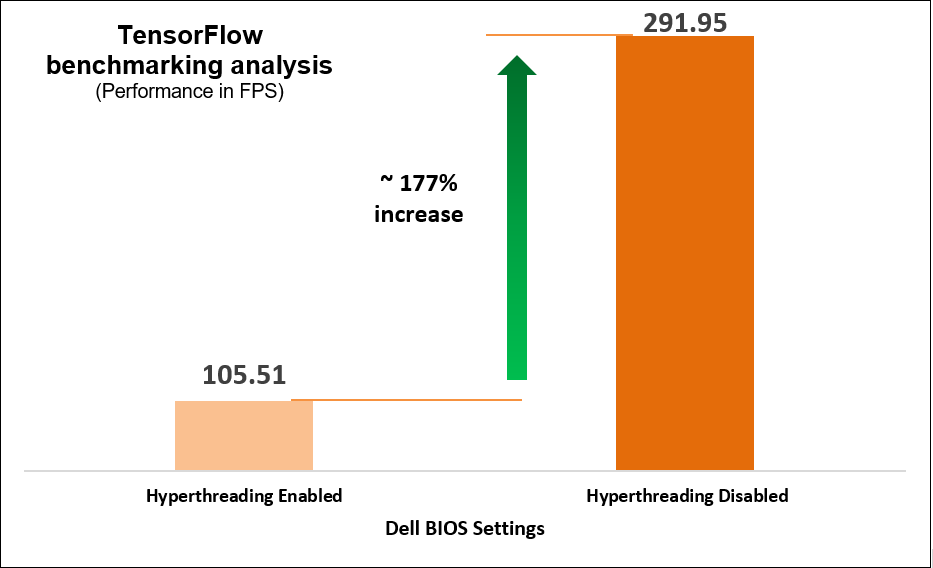
Figure 6. TensorFlow benchmarking results
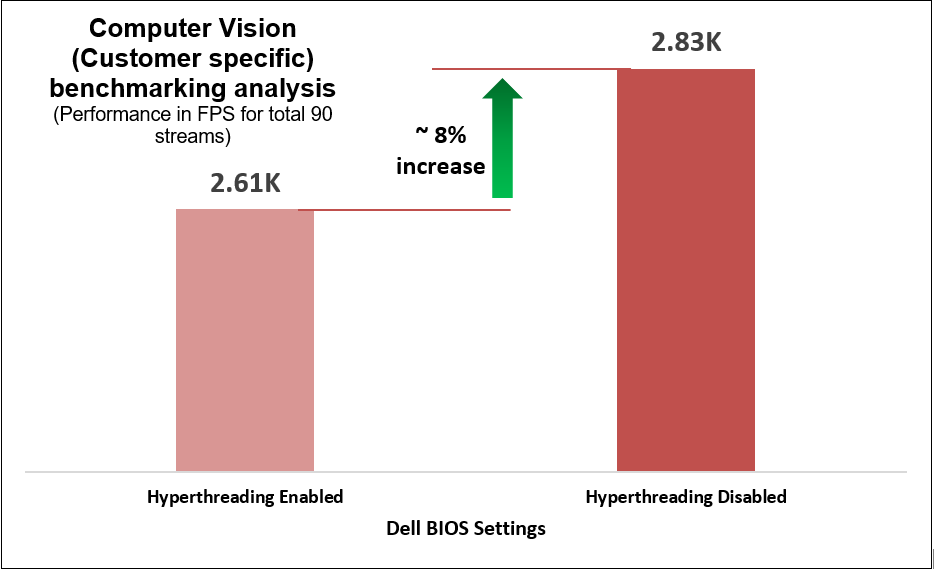
Figure 7. Customer-specific computer-vision-based workload benchmarking results
Identifying optimal System Profile
We began with selecting a baseline System Profile by analyzing the changes in performance and latency for the average power consumed when changing the System Profile from the default Performance per Watt (DAPC) to the Performance setting. The following graphs show the improvements in out-of-the-box performance after we tuned the System Profile.
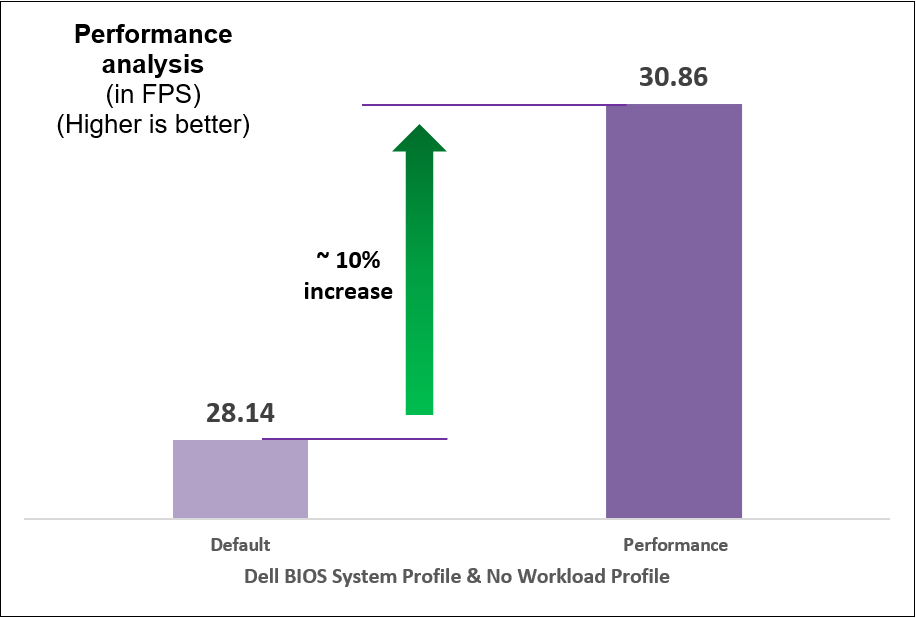
Figure 8. Comparison of default and Performance settings: Performance analysis
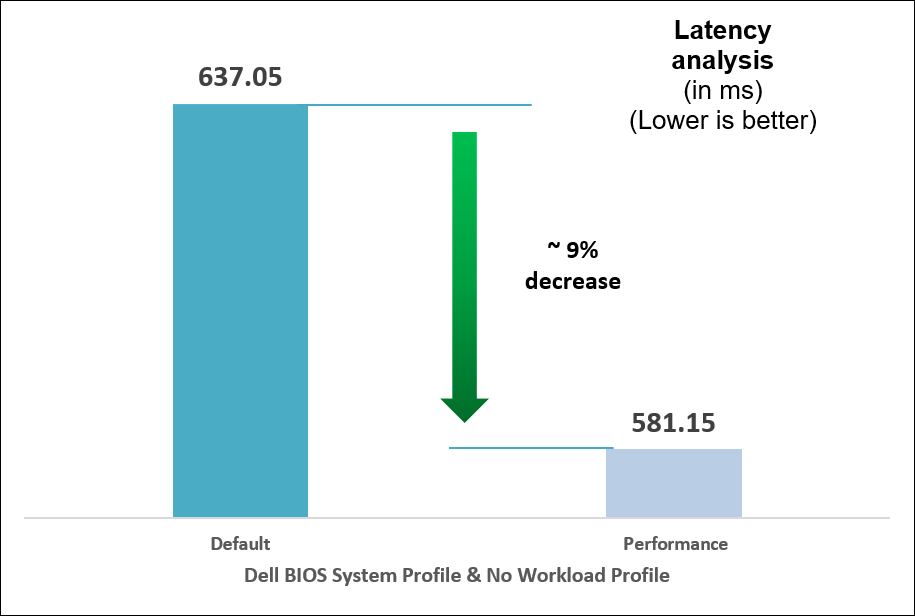
Figure 9. Comparison of default and Performance settings: Latency analysis
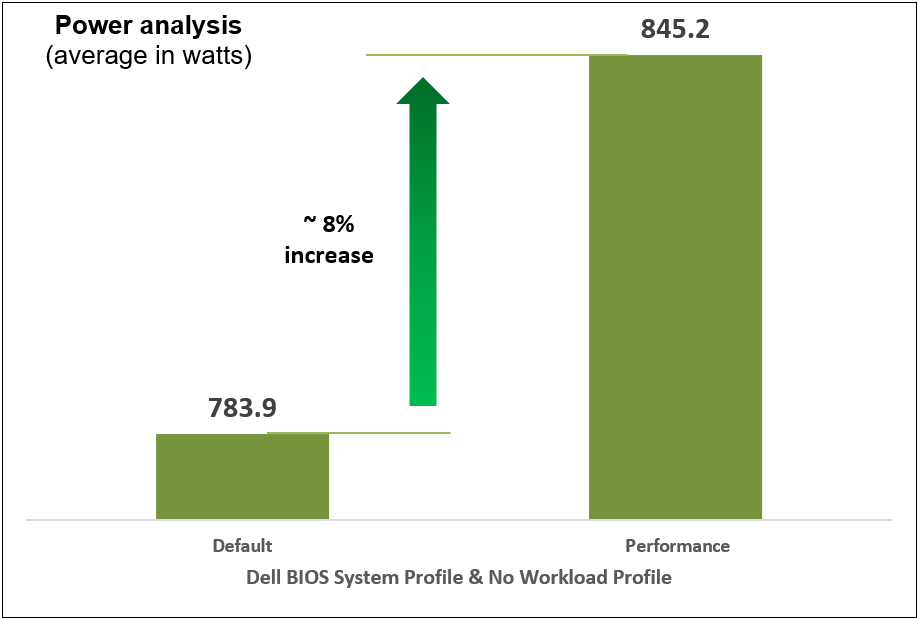
Figure 10. Comparison of default and Performance settings: Power analysis
Identifying optimal workload profile
We performed iterative testing on all current workload profile options on the PowerEdge R760 server for all three performance benchmarks. We found that the optimal, most efficient workload profile to run an AI inference workload is NFVI FP Energy-Balance Turbo Profile, based on improvements in metrics such as performance (throughput in FPS).
Why does this profile perform the best of the existing workload profiles?
The NFVI FP Energy-Balance Turbo Profile (Network Functions Virtualization Infrastructure with Float-Point) is a BIOS setting tailored for NFVI workloads that involve floating-point operations. Building upon the NFVI FP Optimized Turbo Profile, this profile optimizes the system's performance for NFVI tasks that require low-precision math operations, such as AI inference workloads. AI inference tasks often involve performing numerous calculations on large datasets, and some AI models can use lower-precision datatypes to achieve faster processing without sacrificing accuracy.
This profile leverages hardware capabilities to accelerate these low-precision math operations, resulting in improved speed and efficiency for AI inference workloads. With this profile setting, the NFVI platform can take full advantage of specialized instructions and hardware units that are optimized for handling low-precision datatypes, thereby boosting the performance of AI inference tasks. Additionally, the profile's emphasis on energy efficiency is also beneficial for AI inference workloads. Even though AI inference tasks can be computationally intensive, the use of lower-precision math operations consumes less power compared to higher-precision operations. The NFVI FP Energy-Balance Turbo Profile strikes a balance between maximizing performance and optimizing power consumption, making it particularly suitable for achieving energy-efficient NFVI deployments in data centers and cloud environments.
The following table shows the BIOS settings that we tested.
Table 1. BIOS settings for AI benchmarks
Setting | Default | Optimized |
System Profile | Performance Per Watt (DAPC) | Performance |
Workload Profile | No Configured | NFVI FP Energy-Balance Turbo Profile |
The following charts show the results of multiple iterative and exhaustive tests that we ran after tuning the BIOS settings.
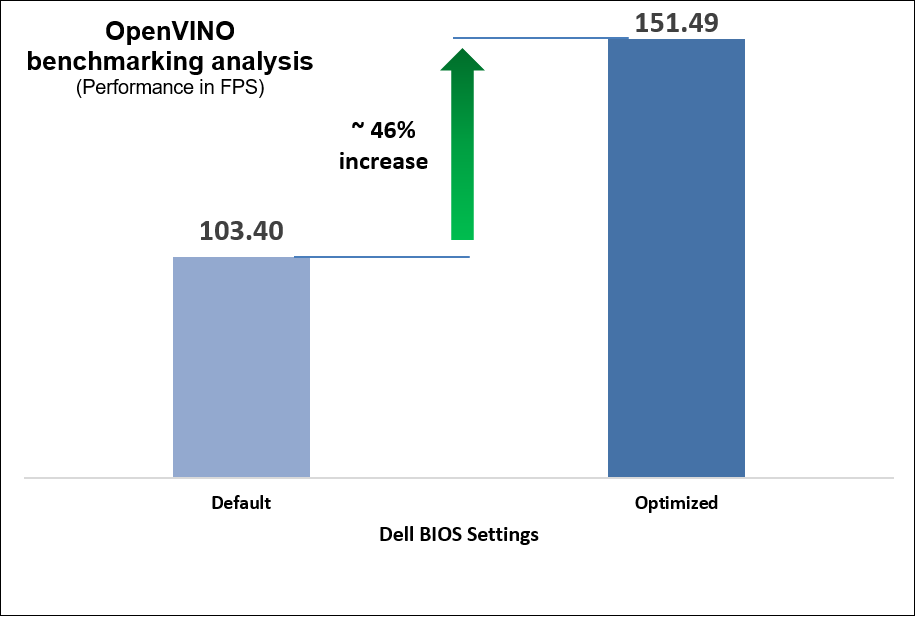
Figure 11. OpenVINO benchmark results
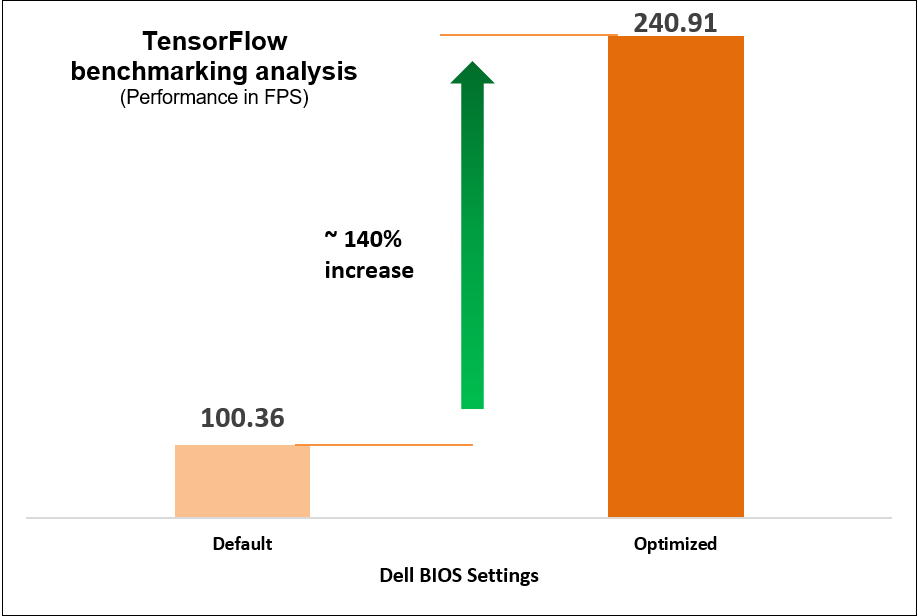
Figure 12. TensorFlow benchmark results
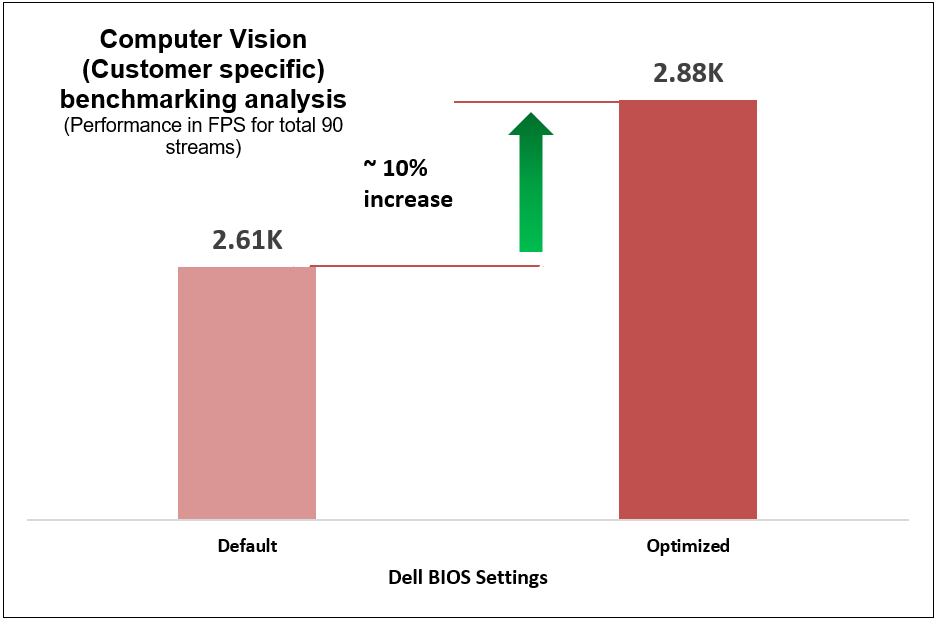
Figure 13. Computer-vision-based (customer-specific) workload benchmark results
These performance improvements reflect a significant impact on AI workload performance resulting from two simple configuration changes on the System Profile and Workload Profile BIOS settings, as compared to out-of-the-box performance.
Performance, latency, and power
We compared power consumption data with performance and latency data when changing the System Profile in the BIOS from the default Performance Per Watt (DAPC) setting to the Performance setting and using a moderate CPU utilization AI inference. Our results reflect that for an increase of up to 8% on average power consumed, the system displayed a 10% increase in performance and 9% decrease in latency with one simple BIOS setting change.
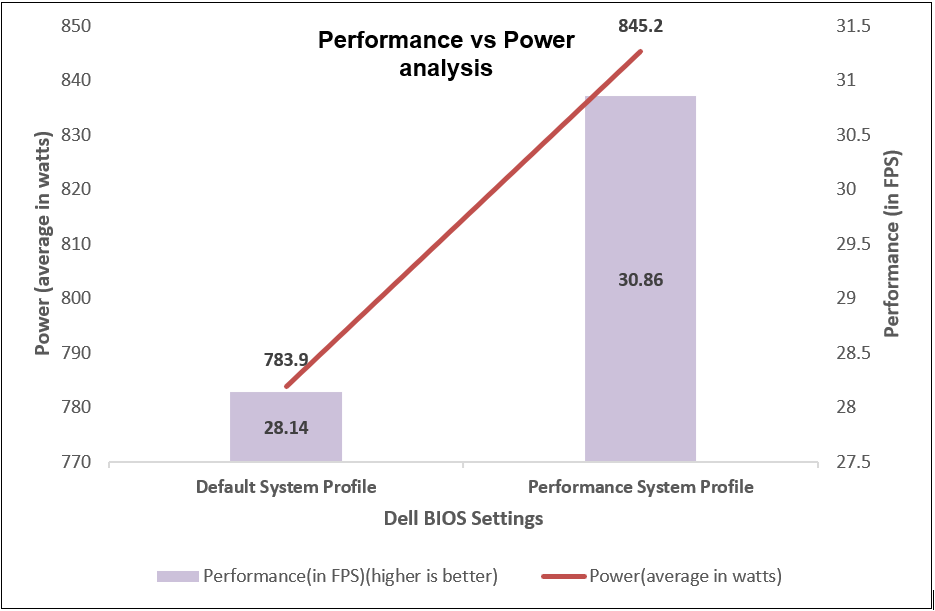
Figure 14. Comparing performance per average power consumed
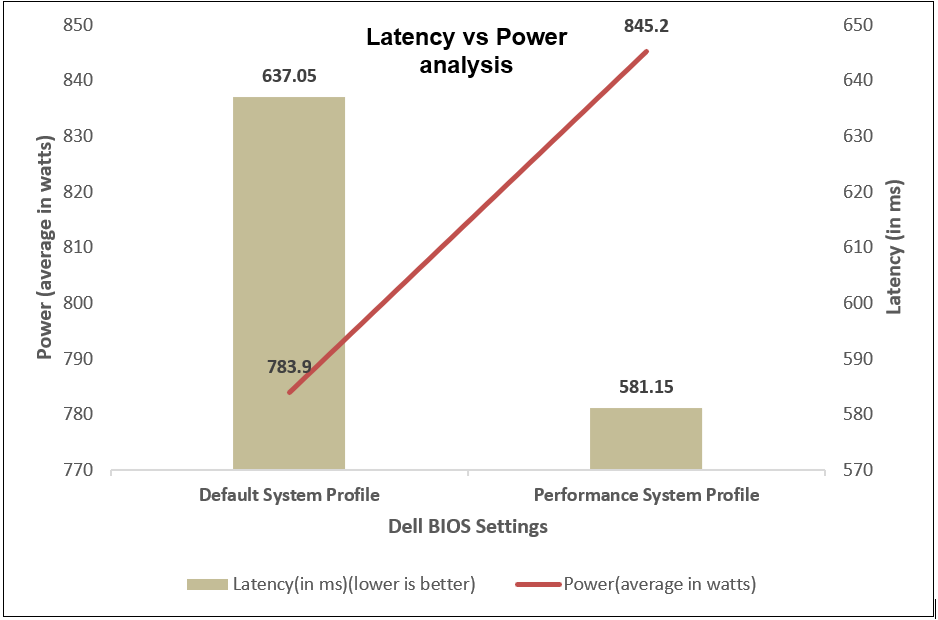
Figure 15. Comparing latency per average power consumed
Comprehensive details of benchmarks
We used the OpenVINO, TensorFlow, and computer-vision-based workload (Scalers AI) benchmarks and their specific use cases that measure the time spent on inference (excluding any preprocessing or post-processing) and then report on the inferences per second (or frames per second or millisecond).
What type of applications do these benchmarks support?
The benchmarks support multiple real-time AI applications such as person detection, vehicle detection, age and gender recognition, crowd counting, suspicious object recognition, parking spaces identification, traffic safety analysis, smart cities, and retail.
Table 2. OpenVINO test cases
Use case | Description |
Face detection | Measures the frames per second (FPS) and time taken (ms) for face detection using FP16 model on CPU |
Person detection
| Evaluates the performance of person detection using FP16 model on CPU in terms of FPS and time taken (ms) |
Vehicle detection | Assesses the CPU performance for vehicle detection using FP16 model, measured in FPS and time taken (ms) |
Person vehicle bike detection | Measures the performance of person vehicle bike detection on CPU using FP16-INT8 model, quantified in FPS and time taken (ms) |
Age and gender recognition | Evaluates the performance of age and gender detection on CPU using FP16 model, measured in FPS and time taken (ms) |
Machine translation | Assesses the CPU performance for machine translation from English using FP16 model, quantified in FPS and time taken |
Table 3. TensorFlow test cases
Use case | Description |
VGG-16 (Visual Geometry Group – 16 layers) | A deep convolutional neural network architecture with 16 layers, known for its uniform structure and use of 3x3 convolutional filters, achieving strong performance in image recognition tasks. This batch includes five different test cases of running the VGG-16 model on TensorFlow using a CPU, with various batch sizes ranging from 16 to 512. The images per second (images/sec) metric is used to measure the performance. |
AlexNet
| A pioneering convolutional neural network with five convolutional layers and three fully connected layers, instrumental in popularizing deep learning and inferencing. This batch includes five test cases of running the AlexNet model on TensorFlow using a CPU, with different batch sizes from 16 to 512. The images per second (images/sec) metric is used to assess the performance. |
GoogLeNet | An innovative CNN architecture using "Inception" modules with multiple filter sizes in parallel, reducing complexity while achieving high accuracy. This batch includes different test cases of running the GoogLeNet model on TensorFlow using a CPU, with varying batch sizes from 16 to 512. The images per second (images/sec) metric is used to evaluate the performance. |
ResNet-50 (Residual Network) | Part of the ResNet family, a deep CNN architecture featuring skip connections to tackle vanishing gradients, enabling training of very deep models. This batch consists of various test cases of running the ResNet-50 model on TensorFlow using a CPU, with different batch sizes ranging from 16 to 512. The images per second (images/sec) metric is used to measure the performance. |
Table 4. Computer-vision-based workload (Scalers AI) test case
Use case | Description |
Scalers AI | YOLOv4 Tiny from the Intel Model Zoo and computation was in int8 format. The tests were run using 90 vstreams in parallel, with a source video resolution of 1080p and a bit rate of 8624 kb/s. |
Conclusion
Using the PowerEdge server, we conducted iterative and exhaustive tests by fine-tuning BIOS settings against industry standard AI inferencing benchmarks to determine optimal BIOS settings that customers can configure with minimum efforts to maximize performance of AI workloads.
Our recommendations are:
 Disable Logical Processor for up to 177% increase in performance for high CPU utilization AI inference workloads.
Disable Logical Processor for up to 177% increase in performance for high CPU utilization AI inference workloads.
 Select Performance as the System Profile BIOS setting to achieve up to 10% increase in performance.
Select Performance as the System Profile BIOS setting to achieve up to 10% increase in performance.
 Select the NFVI FP Energy-Balance Turbo Profile BIOS setting to achieve up to 140 percent increase in performance for high CPU utilization workloads and 46% increase for moderate CPU utilization workload.
Select the NFVI FP Energy-Balance Turbo Profile BIOS setting to achieve up to 140 percent increase in performance for high CPU utilization workloads and 46% increase for moderate CPU utilization workload.
References
- Dell PowerEdge R760 with 4th Gen Intel Xeon Scalable Processors in AI
- Optimize Inference with Intel CPU Technology
Legal disclosures
Based on July 2023 Dell labs testing subjecting the PowerEdge R760 2x Intel Xeon Platinum 8452Y configuration with a 1.2.1 BIOS testing to AI inference benchmarks – OpenVINO and TensorFlow via the Phoronix Test Suite. Actual results will vary.
Related Documents

PowerEdge T560 Delivers Significant Performance Boost and Scalability

Thu, 24 Aug 2023 18:12:49 -0000
|Read Time: 0 minutes
Summary
Dell PowerEdge T560, with 4th Generation Intel® Xeon® Scalable Processors, boosts performance by up to 114% compared to the prior-gen T550 with 3rd Generation Intel® Xeon® Scalable Processors[1]. This document presents gen-over-gen CPU benchmarks for three common T560 CPU configurations, and highlights key features that enable enterprises to host a diverse set of workloads.
Advanced technology with accelerators
From retail, hospitality, and restaurants, to small healthcare, businesses continue to rely on tower servers to enable their day-to-day operations. IDC forecasts $2 billion in worldwide tower server spending for 2024.[2]
The Dell PowerEdge T560 exceeds these business needs while fitting where other servers cannot – under desks, in closets, tucked in any available space. It drives key enterprise workloads, including traditional business applications, virtualization, and data analytics. For customers looking to capture the advantages of AI, the T560 is also tuned to power medium duty AI or ML tailored inferencing algorithms that drive more timely and accurate business insights. In fact, the T560 has 20% more GPU capacity compared to prior-gen T550.
The table below details the gen-over-gen feature improvements that support the T560’s faster, more powerful, and balanced performance:
Table 1. PowerEdge T550 vs T560 key features
| Prior-Gen PowerEdge T550 | PowerEdge T560 |
CPU | 3rd Generation Intel Xeon Scalable Processors | 4th Generation Intel Xeon Scalable Processors |
GPU | Up to 2 DW or 5 SW GPUs | Up to 2 DW or 6 SW GPU |
Storage | Up to 8x3.5” Hot Plug SAS/SATA HDDs 120TB Storage Capacity | Up to 12x3.5” Hot Plug SAS/SATA HDDs 180TB Storage Capacity |
Memory | Up to 3200 MT/s DIMM Speed | Up to 4800 MT/S DIMM Speed |
PCIe Slots | PCIe Gen4 slots | PCIe Gen5 slots |
Performance data
We captured three benchmarks -- SPEC CPU, High-Performance Linpack (HPL), and STREAM -- to compare performance across three T550 3rd Generation Intel Xeon processors and two T560 4th Generation Intel Xeon processors. We report SPEC CPU’s fprate base metric which measures throughput in terms of work per unit of time. HPL is measured in Gflops, or floating-point operations per second, which assesses overall computational power. STREAM captures memory bandwidth in MB/s.
The tests were performed in the Dell Solutions Performance Analysis (SPA) Lab in March 2023. The following gen-over-gen comparisons represent common Intel CPU configurations for T550 and T560 customers, respectively:
Table 2. Selected CPUs for T550 vs T560 performance comparison
T550 CPU Config |
T560 CPU Config |
4309Y, 8 Cores, 2 Processors tested [16 Cores] | 4410Y, 12 Cores, 1 Processor tested |
4310, 12 Cores, 1 Processor tested | 4410Y, 12 Cores, 1 Processor tested |
4314, 16 Cores, 1 Processor tested | 5416S, 16 Cores, 1 Processor tested |
All tested T560 CPU configurations across both the SPEC CPU and HPL Benchmark demonstrate a greater than 47% performance uplift, gen over gen. Most notably, just one Intel Xeon 4410Y (12 core) processor in the T560 performed 114% better than two prior-gen 4309Y processors (16 cores total) in the T550. For these same processors, the HPL benchmark saw a performance uplift of 78%, and STREAM saw an uplift of up to 57%.
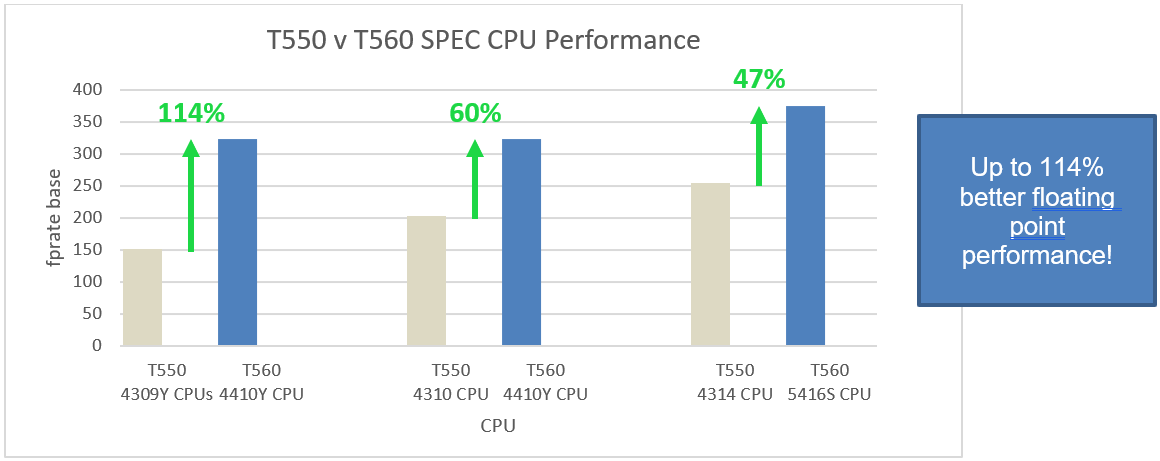
Figure 1. Three CPU comparisons demonstrating gen-over-gen performance uplift for SPEC CPU benchmark
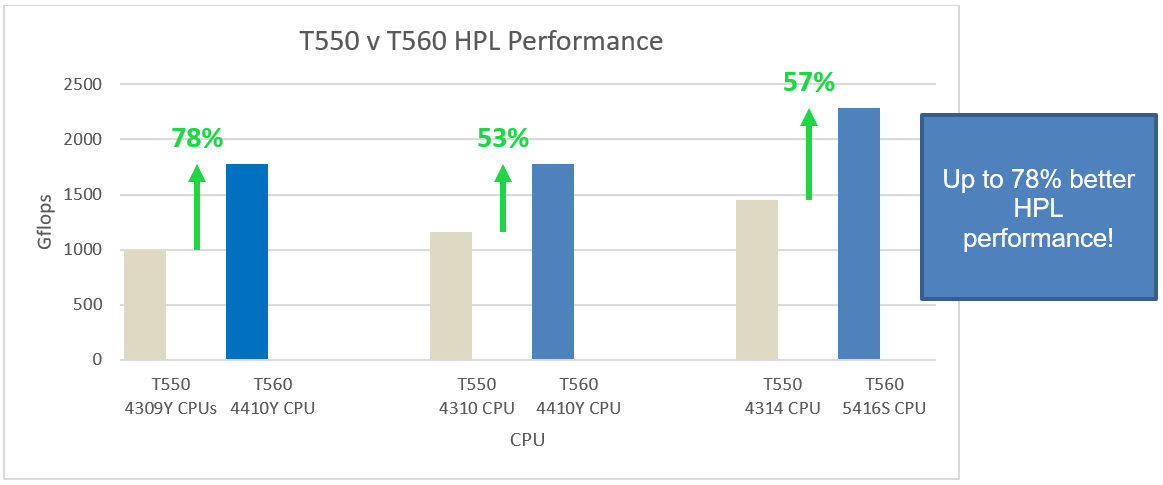
Figure 2. Three CPU comparisons demonstrating gen-over-gen performance uplift for HPL benchmark
Conclusion
For customers looking to upgrade their tower server, the Dell PowerEdge T560 captures up to 114% better performance over the prior-gen. Combined with its increased GPU capacity and 1.5x faster memory, the T560 gives enterprises the freedom to expand and explore AI/ML workloads while still powering its core business operations.
References
[1] March 2023, Dell Solutions Performance Analysis (SPA) lab test comparing 4309Y and 4410Y CPU on www.spec.org

Boost Existing Server Performance by 12%
Thu, 08 Jun 2023 23:15:15 -0000
|Read Time: 0 minutes
Intel® Speed Select Technology (Intel® SST) Performance Profiles can offer enhanced performance, reduced power, and flexibility
Executive Summary
In data center environments, workload performance and efficiency on a per-node basis is key to business operations. Extracting the maximum performance for a given workload on each server is essential.
What if there was a way to do more with what you already have?
This Direct from Development tech note describes how we lab-tested and explored the real-world benefits of Intel® Speed Select Technology Performance Profiles (Intel® SST-PP) on 4th Generation Intel® Xeon® Scalable processors running on Dell PowerEdge servers. Intel SST-PP has been available on Intel Xeon CPUs since 3rd Generation Xeon products came to market in 2021. On Dell PowerEdge servers with supported CPUs, SST-PP allows the enablement of Performance Profiles (Also called Operation Points), which reduces the number of active cores while increasing the frequency of cores still active.
As a result, you can match the CPU to your specific workload and so allocate performance as needed, meaning that you are reducing complexity in your data center and lowering cost.
The following chart shows the SST-PP available for the Intel Xeon Gold 5418Y Processor we tested, with Performance Profile 0 being the default mode:
Xeon Gold 5418Y | Core count | Frequency | Thermal design power (TDP) |
SST-PP 0 | 24 cores | 2.0 GHz | 185 W |
SST-PP 1 | 16 cores | 2.3 GHz | 165 W |
SST-PP 2 | 12 Cores | 2.7 GHz | 165 W |
Test Results
Different workloads respond differently to available resources or changes in configuration. In the arena of CPU configurations, some workloads demonstrate a greater affinity for higher frequency while others respond to an increase in the number of available CPU cores. In this instance, the tested SQL database workload performed optimally using SST-PP 1. This Performance Profile increases each core’s frequency by 300 MHz while reducing the number of available cores by eight.
The following chart illustrates a performance gain greater than 12 percent, which was attained by simply switching to a different SST-PP in the system BIOS.
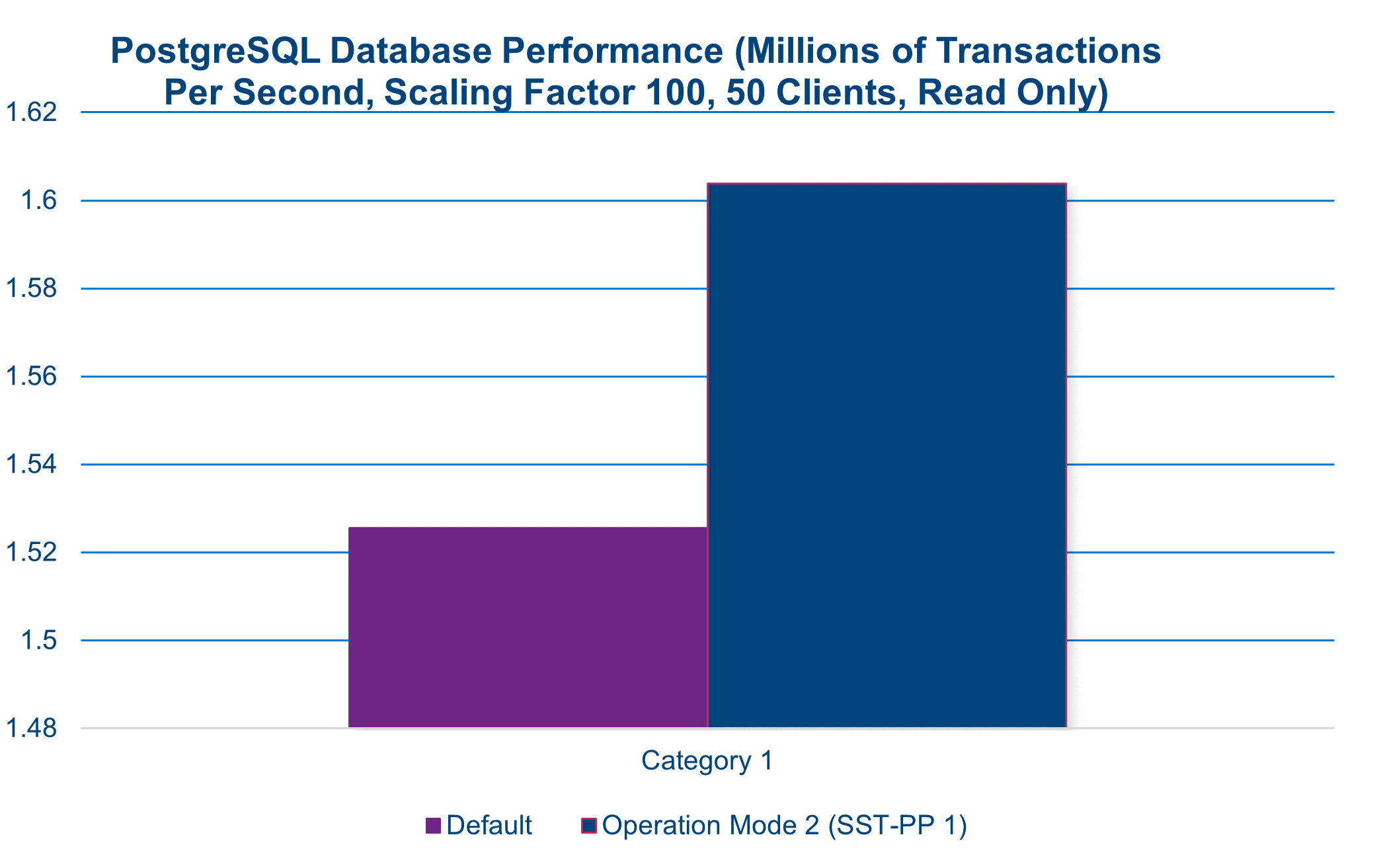
A performance increase is often associated with a commensurate increase in power draw. However, in this instance when leveraging SST-PP, this is not the case. During this benchmark test, we see a nearly 5 percent reduction in total system power while enjoying an increase in performance of approximately 12 percent.
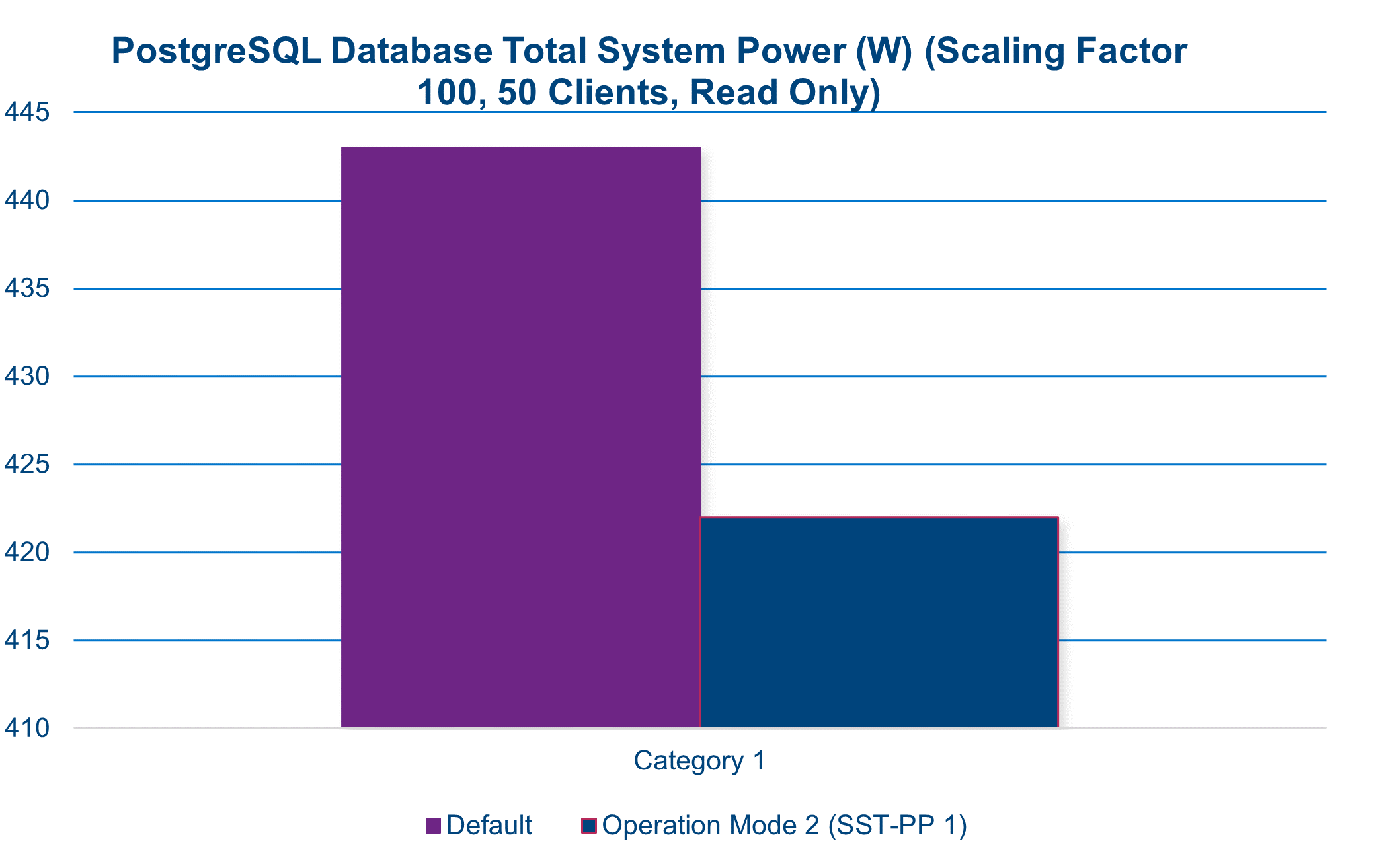

12% performance increase in SQL database workload(1)

Increase of 18% in performance per watt in SQL database workload (2)

Conclusion
Intel SST-PP can enable increased performance and create per-node flexibility in workload specialization, allowing for a dynamic array of servers that can be allocated optimally for any task.
SST-PP technology is available on all servers in Dell’s mainstream server portfolio. It is also available in CSP and Edge focused servers when they are paired with processors featuring SST-PP. Listed here are Xeon 4th Gen processors featuring SST-PP technology. For more information, see the Intel Arc Product Specifications website.
Xeon 4th Gen processors with SST-PP
Intel® Xeon® Gold 6454S Processor | Intel® Xeon® Gold 6448Y Processor |
Intel® Xeon® Platinum 8460Y+ Processor | Intel® Xeon® Gold 6444Y Processor |
Intel® Xeon® Platinum 8468V Processor | Intel® Xeon® Gold 6458Q Processor |
Intel® Xeon® Platinum 8461V Processor | Intel® Xeon® Silver 4410T Processor |
Intel® Xeon® Platinum 8458P Processor | Intel® Xeon® Gold 6416H Processor |
Intel® Xeon® Platinum 8471N Processor | Intel® Xeon® Gold 6418H Processor |
Intel® Xeon® Platinum 8470N Processor | Intel® Xeon® Gold 6448H Processor |
Intel® Xeon® Platinum 8450H Processor | Intel® Xeon® Gold 5418N Processor |
Intel® Xeon® Platinum 8452Y Processor | Intel® Xeon® Gold 5411N Processor |
Intel® Xeon® Silver 4410Y Processor | Intel® Xeon® Gold 6428N Processor |
Intel® Xeon® Gold 6426Y Processor | Intel® Xeon® Gold 6421N Processor |
Intel® Xeon® Gold 5418Y Processor | Intel® Xeon® Gold 5416S Processor |
Intel® Xeon® Gold 6442Y Processor | Intel® Xeon® Gold 6438N Processor |
Intel® Xeon® Gold 6438Y+ Processor | Intel® Xeon® Gold 6438M Processor |
Intel® Xeon® Platinum 8462Y+ Processor |
Legal Disclosures
- Based on March 2023 Dell labs testing subjecting the PowerEdge HS5610 to Openbenchmarking.org PostgreSQL pgbench v1.130 benchmark. Actual results will vary.
- Based on March 2023 Dell labs testing subjecting the PowerEdge HS5610 to Openbenchmarking.org PostgreSQL pgbench v1.130 benchmark. Power collection performed with IPMItool. Actual results will vary.