




Running LLMs on Dell PowerEdge Servers with Intel® 4th Generation Xeon® CPUs


Introduction
Large-language Models (LLMs) have gained great industrial and academic interests in recent years. Different LLMs have been adopted in various applications, such as content generation, text summarization, sentiment analysis, and healthcare. The list goes on.
When we think about LLMs and what methodologies we can use for inferencing and fine-tuning, the question always comes up as to which compute device we should use. For inferencing, we wanted to explore what the performance metrics are when running on an Intel 4th Generation CPU, and what are some of the variables we should explore?
This blog focuses on LLM inference results on Dell PowerEdge Servers with the 4th Generation Intel® Xeon® Scalable Processors. Specifically, we demonstrated their performance and power while running the stable diffusion and Llama2 chat models on R760 and HS5610 servers. We also explored the performance and power impacts with different quantization bits and CPU/socket numbers through experiments and will present the inference results of stable diffusion and Llama2 models obtained on a Dell PowerEdge R760 and HS5610 with the 4th Generation Intel® Xeon® Scalable Processors.
We selected the aforementioned Dell platforms because we wanted to explore how our CSP-focused platforms like HS5610 perform when it comes to inferencing and whether they can meet the requirements for LLM models. These new Intel® Xeon® processors use an Intel AMX® matrix multiplication engine in each core to boost overall inferencing performance. By combining with the quantization techniques, we further improved the inference performance with the CPU-only system. Moreover, we also show how the CPU core and socket numbers affect the performance results.
Background
Transformer is regarded as the 4th fundamental model after Multilayer Perceptron (MLP), Recurrent Neural Networks (RNN), and Convolutional Neural Networks (CNN). Known for its parallelization and scalability, transformer has greatly boosted the performance and capability of LLMs since it was introduced in 2017 [1].
Today, LLMs have been rapidly adopted in various applications like content generation, text summarization, sentiment analysis, code generation, healthcare, and so on, as shown in Figure 1 [2]. This trend is continuing. More open-source LLMs are popping up almost on a monthly basis. Moreover, the transformer-based techniques are being used alongside with other methods, greatly improving the accuracy and performance of the original tasks. For example, the stable diffusion model uses the LLM at the input as the neural language understanding engine. Combined with the diffusion model, it has greatly improved the quality and throughput of the text-to-image generation task [3]. Note that for simplicity in this blog, we use the term “LLMs” to represent both those transformer-based models shown in Figure 1 and the derivative models like stable diffusion models.
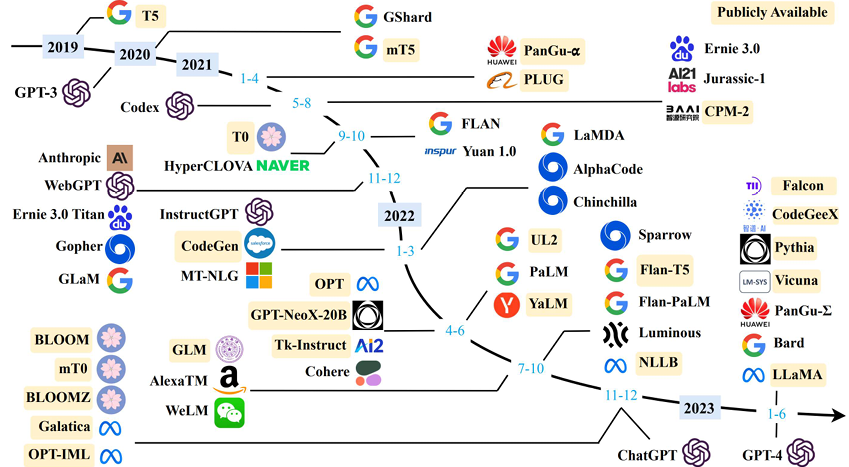
Figure 1. LLM Timeline [2] Image credit: Wayne Xin Zhao, et.al, “A Survey of Large Language Models”]
While training and fine-tuning those LLMs is normally time- and cost-consuming, deploying the LLMs at the edge has its own challenges. Considering both performance and power, deploying the LLMs can be, in a sense, more cost-sensitive given the volumes of the systems required to cover various applications. GPUs are widely used to deploy LLMs. In this blog, we demonstrate the feasibility of deploying those LLMs with Intel 4th generation Intel® Xeon® CPUs with Dell PowerEdge servers and illustrate that good performance can be achieved with a proper hardware configuration – like CPU core numbers and quantization method for popular LLMs.
Test Setup
The hardware platforms we used for the experiments are PowerEdge R760 and HS5610, which are the latest mainstream and cloud-optimized servers respectively from Dell product portfolio. Figure 2 shows the rack-level interface for the HS5610 server. As a cloud-optimized solution, the HS5610 server has been designed with CSP features that allow the same benefits with full PowerEdge features and management like the mainstream server R760, as well as open management (OpenBMC), cold aisle service, channel firmware, and services. Both servers have two sockets with an Intel 4th generation Xeon CPU on each socket. R760 features a 56-core CPU – Intel® Xeon® Platinum 8480+ (TDP: 350W) in each socket, and HS5610 has a 32-core CPU – Intel® Xeon® Gold 6430 (TDP: 250W) in each socket. Tables 1-4 show the details of the server configurations and CPU specifications. During tests, we use the numactl command to set the numbers of the sockets or CPU cores to execute the LLM inference tasks.
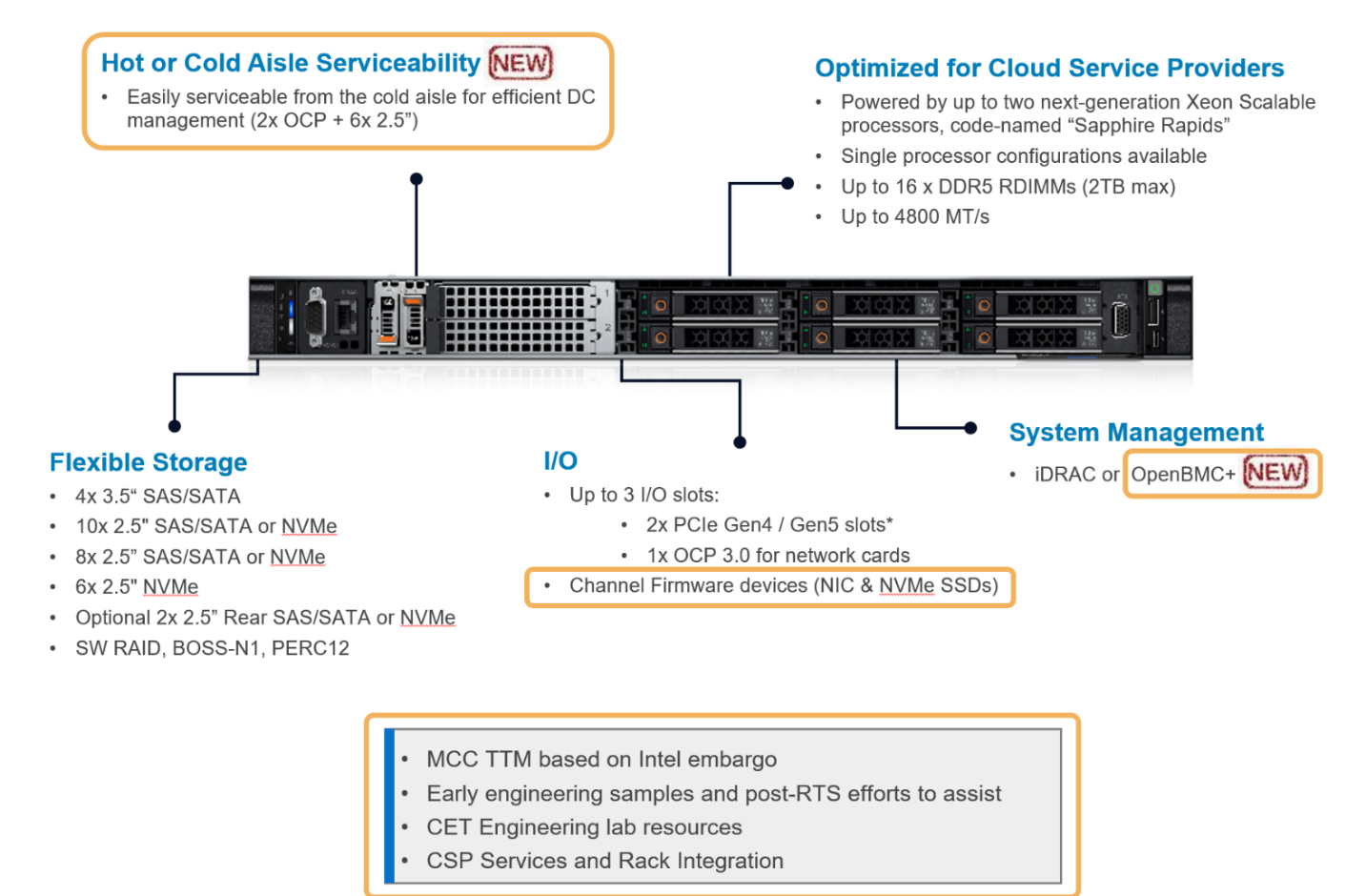
Figure 2. PowerEdge HS5610 [4]
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 56 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 1. R760 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 56 |
# of Threads | 112 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 108 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 2. 4th Generation 56-core Intel® Xeon® Scalable Processor Technical Specifications
System Name | PowerEdge HS5610 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 3. HS5610 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Gold 6430 |
Status | Launched |
# of CPU Cores | 32 |
# of Threads | 64 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 64 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 4. 4th Generation 32-core Intel® Xeon® Scalable Processor Technical Specifications
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5. Optimizations have been done for the PyTorch framework and Transformers library to unleash the Xeon CPU machine learning capabilities. Moreover, a low-level tool -- Intel® Neural Compressor -- has been used for high-accuracy quantization.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW | OneDNN™ Deep Learning, ONNX, Intel® Extension for PyTorch (IPEX), Intel® Extension for Transformers (ITREX), Intel® Neural Compressor |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 5. Software stack and system configuration
The models under testing are stable diffusion model version 1.4 (~1 billion parameters) and Llama2-chat-HF models with 7 billion, 13 billion, and 70 billion parameters. We purposely choose those models because they are open-sourced, representative, and cover a wide parameter range. Different quantization bits are tested to characterize the corresponding performance and power consumption.
All the experiments are based on batch-size equal to 1. Performance is characterized by latency or throughput. To reduce the measurement errors, the inference is executed 10 times to get the averaged value. A warm-up process is executed by loading the parameter and running a sample test before running the defined inference.
Results
We show some typical results in this section alongside brief discussions for each result. The conclusions are summarized in the next section.
HS5610 Results
Latency vs Quantization vs Cores – Stable Diffusion Model:
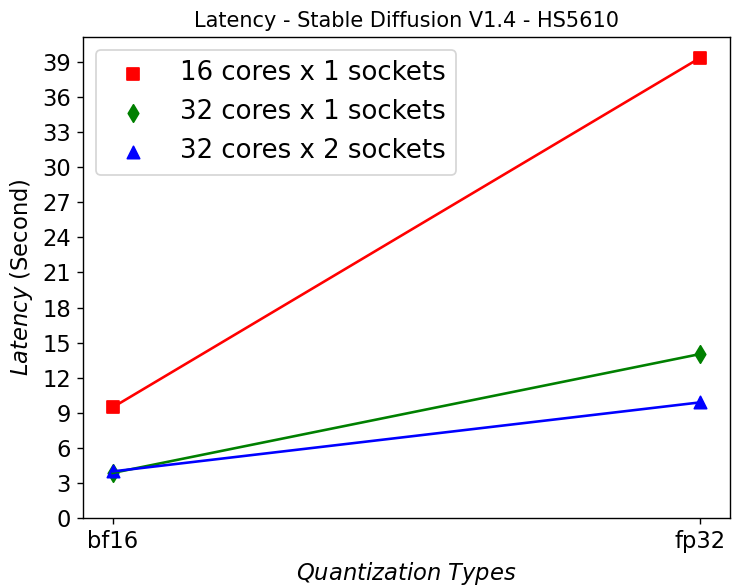
Figure 3. Latency in HS5610 server running Stable Diffusion
Figure 3 shows that HS5610 can generate a new image in approximately 3 seconds when running at bf16 Stable Diffusion V1.4 model. Quantizing to 16 bits greatly reduces the latency compared to using fp32 model. Scaling up the core numbers from 16 to 32 cores greatly reduces the latency, however scaling up across the sockets does not help. This is mainly due to the NUMA remote memory bottleneck.
Power Consumption – Stable Diffusion Model:
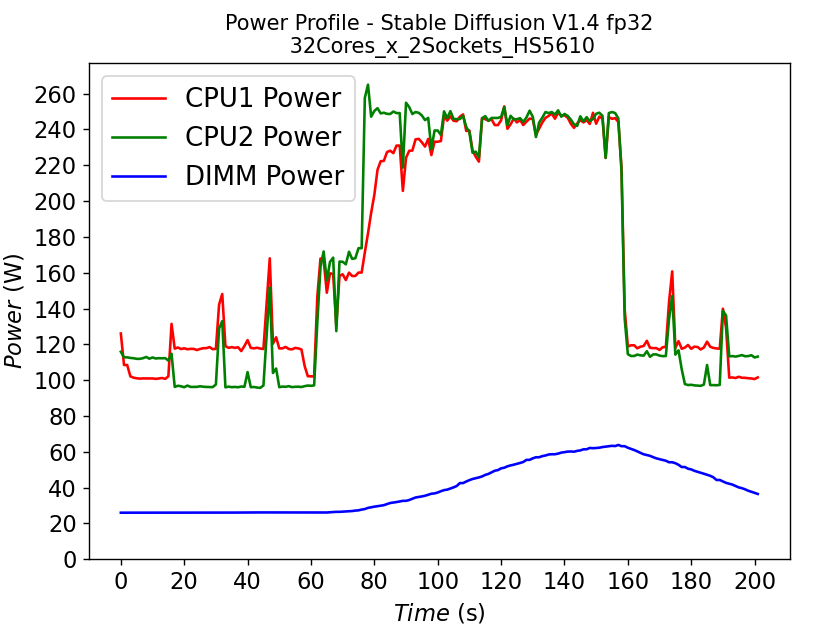 (a)
(a) 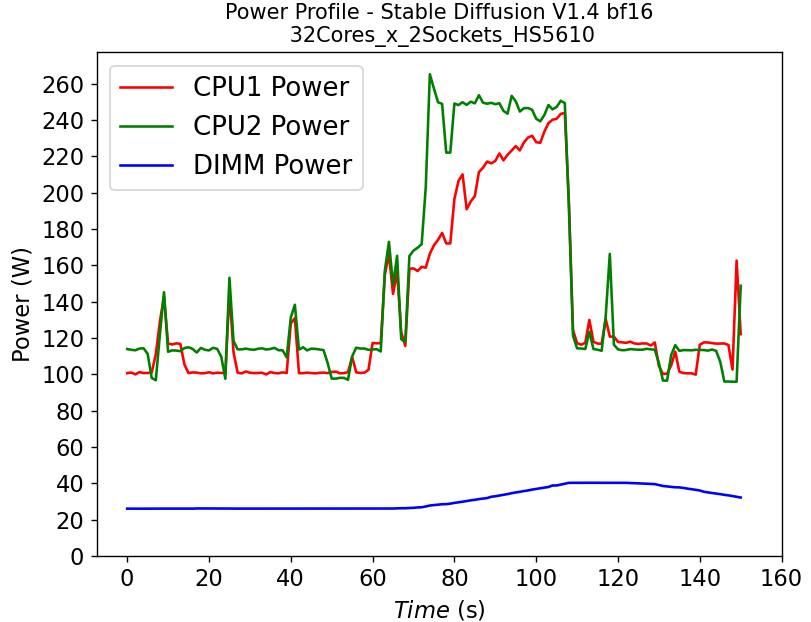 (b)
(b)
Figure 4. Power consumption of CPU and DIMM in HS5610 server running stable diffusion: (a) fp32 model (b) bf16 model
Figure 4 shows the power profile comparison of HS5610 when running the stable diffusion model with (a) fp32 weights and (b) bf16 weights. To finish the same tasks (warm up and inferencing), the bf16 model takes significantly less time (shorter power profile duration) compared to fp32 scenario. The plot also shows that much larger DIMM power is required to run fp32 compared to bf16. Executing the task pushes the CPU working close to the TDP limit, with the exception of the CPU1 in Figure 4b, indicating that further improvement is possible to further reduce the latency for the bf16 model.
Throughput vs Quantization vs Cores – Llama2 Chat Models:
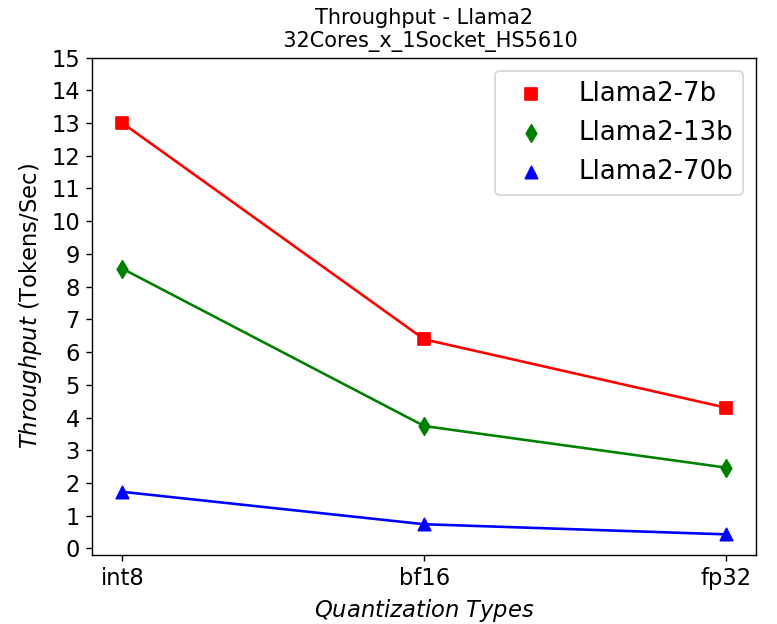 (a)
(a)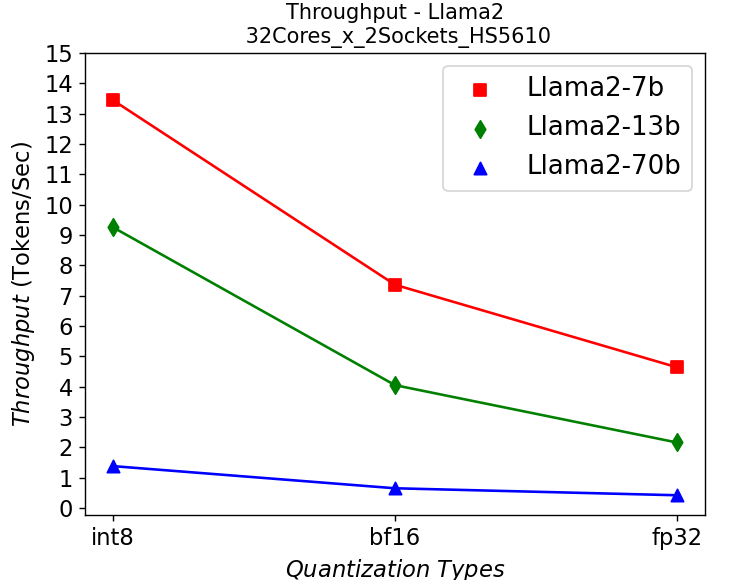 (b)
(b)
Figure 5. Throughput in HS5610 server running Llama2: (a) 1-socket (b) 2-socket
Figure 5 shows the throughput numbers when running Llama2 chat models with different parameter sizes and quantization bits in HS5610 server. Figure 5a shows the single socket scenario and 5b shows the dual-socket scenario. Smaller models with lower quantization bits give higher throughputs which is to be expected. Like the stable diffusion model, quantization greatly improves the throughput. However, scaling up with more CPU cores across the socket has negligible results in boosting the performance.
R760 Results
Throughput vs Quantization vs Cores – Llama2 Chat Models:
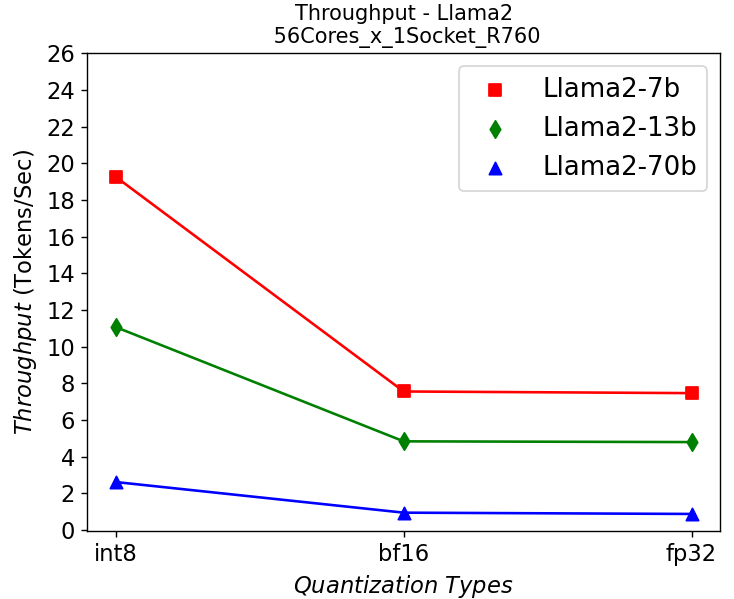 (a)
(a)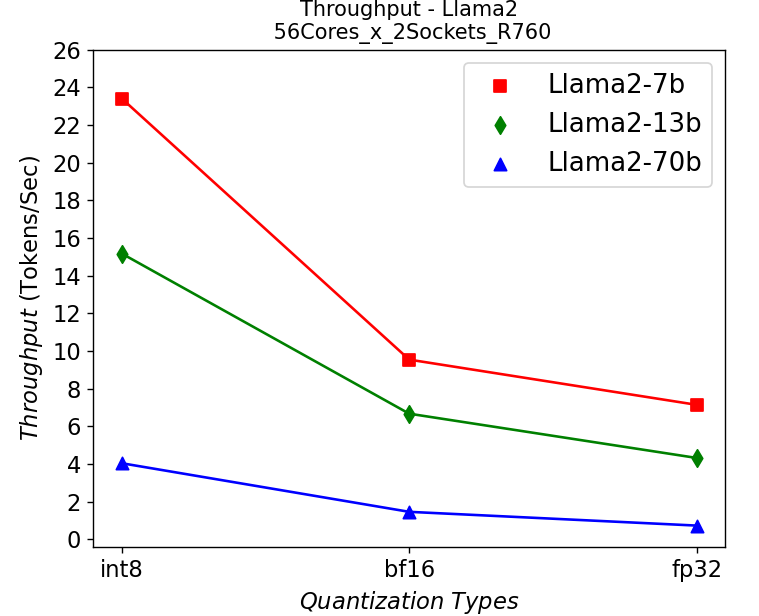 (b)
(b)
Figure 6. Throughput in R760 server running Llama2: (a) 1-socket (b) 2-socket
Figure 6 shows the throughput numbers when running Llama2 chat models with different parameter sizes and quantization bits in R760 server. We get similar observations as the results shown in HS5610 server. A smaller model gives a higher throughput, and quantization greatly improves the throughput. One difference is that we get a 10-30% performance improvement depending on models when scaling up across sockets, showing a benefit from larger core numbers. The performance across the models is good enough for most real-time chatbot applications.
Performance Per Watt – Llama2 Chat Models:
 (a)
(a)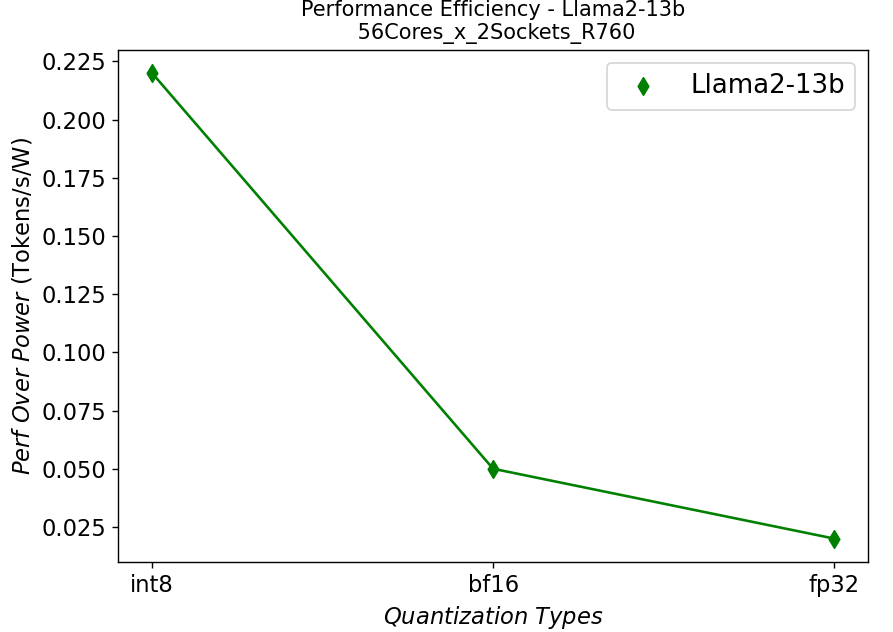 (b)
(b)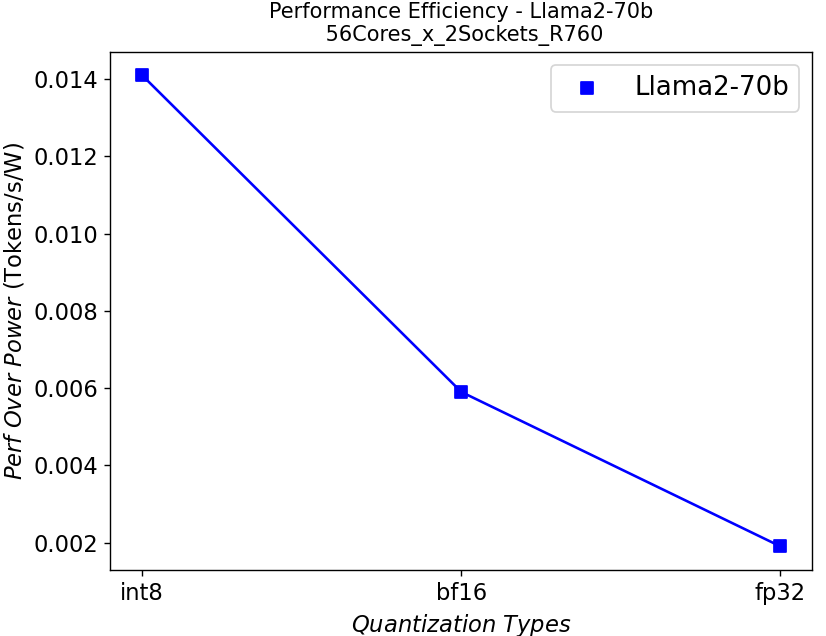 (c)
(c)
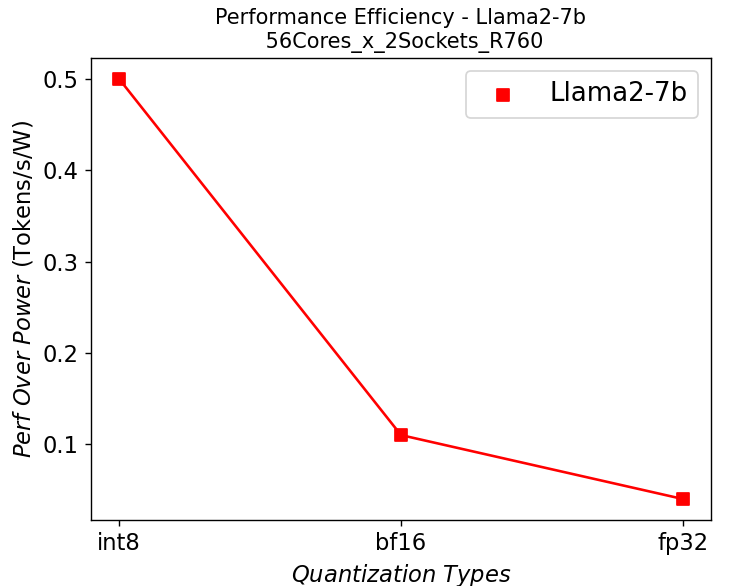
Figure 7. Performance per watt in R760 server running Llama2: (a) 7b (b)13b (c) 70b
We further plot the performance per watt curve which is strongly related to the total cost of ownership (TCO) of the system in Figure 7. From the plots, the quantization can greatly help with the performance efficiency, especially for the models with large parameters.
Conclusion
- We have shown that the Intel 4th generation Intel® Xeon® CPUs on Dell PowerEdge mainstream and HS class platforms can easily meet performance requirements when it comes to Inferencing with Llama2 models.
- We also demonstrate the benefits of quantization or using lower precision for inferencing quantitively, which can give a better TCO in terms of performance per watt and memory footprint as well as enable better user experience by improving the throughput.
- These studies also show that we need to right-size the infrastructure based on the application and model size.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. W. Zhao et. al, “A Survey of Large Language Models”, https://doi.org/10.48550/arXiv.2303.18223
[3]. R. Rombach et. al, “High-Resolution Image Synthesis with Latent Diffusion Models”, https://arxiv.org/abs/2112.10752
[4]. https://www.dell.com/en-us/shop/ipovw/poweredge-hs5610
Authors: Tao Zhang (tao.zhang9@dell.com); Bhavesh Patel (bhavesh_a_patel@dell.com)
Related Blog Posts

MLPerf™ Inference 3.1 on Dell PowerEdge Server with Intel® 4th Generation Xeon® CPU
Thu, 11 Jan 2024 19:43:07 -0000
|Read Time: 0 minutes
Introduction
MLCommons™ has released the v3.1 results for its machine learning inference benchmark suite, MLPerf™. This blog focuses on the impressive datacenter inference results obtained across different use cases by using the new 4th Generation Intel Xeon Scalable Processors on a Dell PowerEdge R760 server. This submission covers the benchmark results for all 7 use cases defined in MLPerf™, which are Natural Language Processing (BERT), Image Classification (ResNet50), Object Detection (RetinaNet), Speech-to-Text (RNN-T), Medical Imaging (3D-Unet), Recommendation Systems (DLRMv2), and Summarization (GPT-J).
These new Intel® Xeon® processors use an Intel AMX® matrix multiplication engine in each core to boost overall inferencing performance. With a focus on ease of use, Dell Technologies delivers exceptional CPU performance results out of the box with an optimized BIOS profile that fully unleashes the power of Intel’s OneDNN software – software which is fully integrated with both PyTorch and TensorFlow frameworks. The server configurations and the CPU specifications in the benchmark experiments are shown in Tables 1 and 2 respectively.
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 56 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 1. Dell PowerEdge R760 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 56 |
# of Threads | 112 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 105 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 2. 4th Generation Intel® Xeon® Scalable Processor Technical Specifications
MLPerf™ Inference v3.1 - Datacenter
The MLPerf™ inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios. There are two benchmark suites – one for Datacenter systems and one for Edge. Table 3 lists the 7 mature models with each targeting a different task in the official release v3.1 for Datacenter systems category that were run on this PowerEdge R760. Compared to the v3.0 release, v3.1 added the updated version of the recommendation model – DLRMv2 – and introduced the first Large-Language Model (LLM) – GPT-J.
Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
Vision | Image classification | ResNet50-v1.5 | ImageNet (224x224) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection | RetinaNet | OpenImages (800x800) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical imaging | 3D-Unet | KITS 2019 (602x512x512) | 16 | 99.9% of FP32 (0.86330 mean DICE score) | N/A |
Speech | Speech-to-text | RNN-T | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT-large | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Language | Summarization | GPT-J-99 | CNN Dailymail (v3.0.0, max_seq_len=2048) | 13368 | 99% of FP32 (f1_score=80.25% rouge1=42.9865, rouge2=20.1235, rougeL=29.9881). | 20 s |
Commerce | Recommendation | DLRMv2 | Criteo 4TB Multi-hot | 204800 | 99% of FP32 (AUC=80.25%) | 60 ms |
Table 3. Datacenter Suite Benchmarks. Source: MLCommons™
Scenarios
The models are deployed in a variety of critical inference applications or use cases known as “scenarios” where each scenario requires different metrics, demonstrating production environment performance in practice. Following is the description of each scenario. Table 4 shows the scenarios required for each Datacenter benchmark included in this submission v3.1.
Offline scenario: represents applications that process the input in batches of data available immediately and do not have latency constraints for the metric performance measured in samples per second.
Server scenario: represents deployment of online applications with random input queries. The metric performance is measured in queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation. This complexity is reflected in the throughput-degradation results compared to the offline scenario.
Each Datacenter benchmark requires the following scenarios:
Area | Task | Required Scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection | Server, Offline |
Vision | Medical imaging | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Language | Summarization | Server, Offline |
Commerce | Recommendation | Server, Offline |
Table 4. Datacenter Suite Benchmark Scenarios. Source: MLCommons™
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW for MLPerf™ | MLPerf™ Intel OneDNN integrated with PyTorch |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 5. System Configuration
What is Intel AMX (Advanced Matrix Extensions)?
Intel AMX is a built-in accelerator that enables 4th Gen Intel Xeon Scalable processors to optimize deep learning (DL) training and inferencing workloads. With the high-speed matrix multiplications enabled by Intel AMX, 4th Gen Intel Xeon Scalable processors can quickly pivot between optimizing general computing and AI workloads.
Imagine an automobile that could excel at city driving and then quickly shift to deliver Formula 1 racing performance. 4th Gen Intel Xeon Scalable processors deliver this level of flexibility. Developers can code AI functionality to take advantage of the Intel AMX instruction set as well as code non-AI functionality to use the processor instruction set architecture (ISA).
Intel has integrated the Intel® oneAPI Deep Neural Network Library (oneDNN) – its oneAPI DL engine – into popular open-source tools for AI applications, including TensorFlow, PyTorch, PaddlePaddle, and ONNX.
AMX architecture
Intel AMX architecture consists of two components, as shown in Figure 1:
- Tiles consist of eight two-dimensional registers, each 1 kilobyte in size. They store large chunks of data.
- Tile Matrix Multiplication (TMUL) is an accelerator engine attached to the tiles that performs matrix-multiply computations for AI.
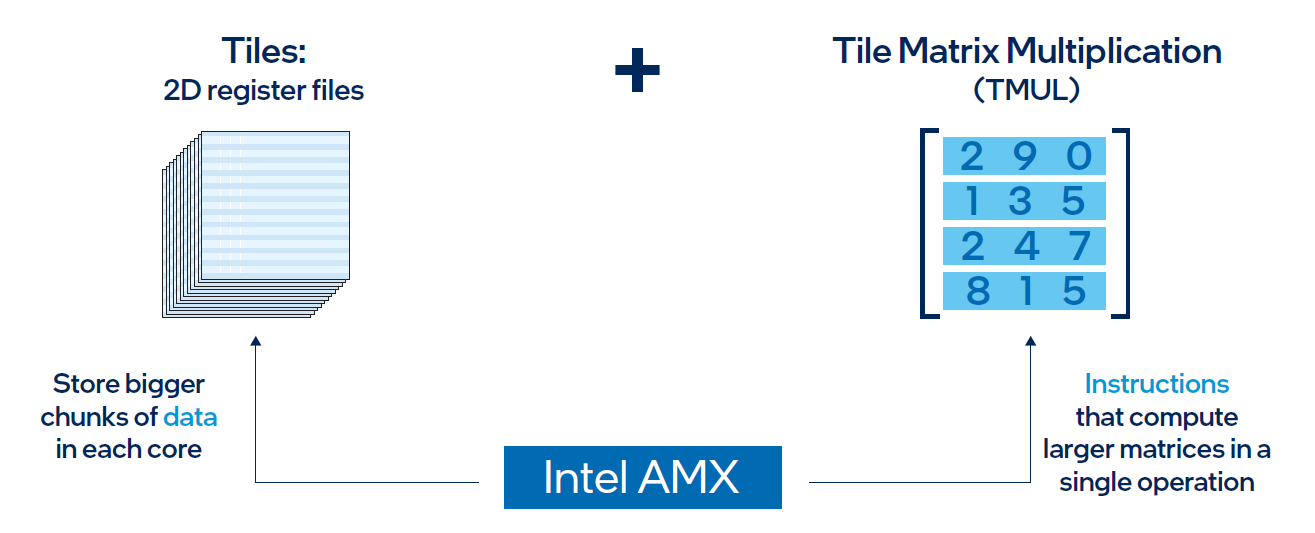
Figure 1. Intel AMX architecture consists of 2D register files (tiles) and TMUL
Results
Both MLPerf™ v3.0 and MLPerf™ v3.1 benchmark results are based on the latest Dell R760 server utilizing 4th Generation Intel® Xeon® Scalable Processors.
For the ResNet50 Image Classification, RetinaNet Object Detection, BERT Large Language, and RNN-T Speech Models – which are identical models with same datasets for both MLPerf™ v3.0 and MLPerf™ v3.1 – we re-run those for the latest submission. The results show negligible differences between two submissions.
We added three new benchmark results for MLPerf™ v3.1 submission compared to MLPerf™ v3.0 submission. Those are 3D-Unet Medical Imaging, DLRMv2 Recommendation, and GPT-J Summarization models. Given that there is no previous result for comparison, we simply show the current result on the R760.
Comparing Performance from MLPerfTM v3.1 to MLPerfTM v3.0
ResNet50 server & offline scenarios:
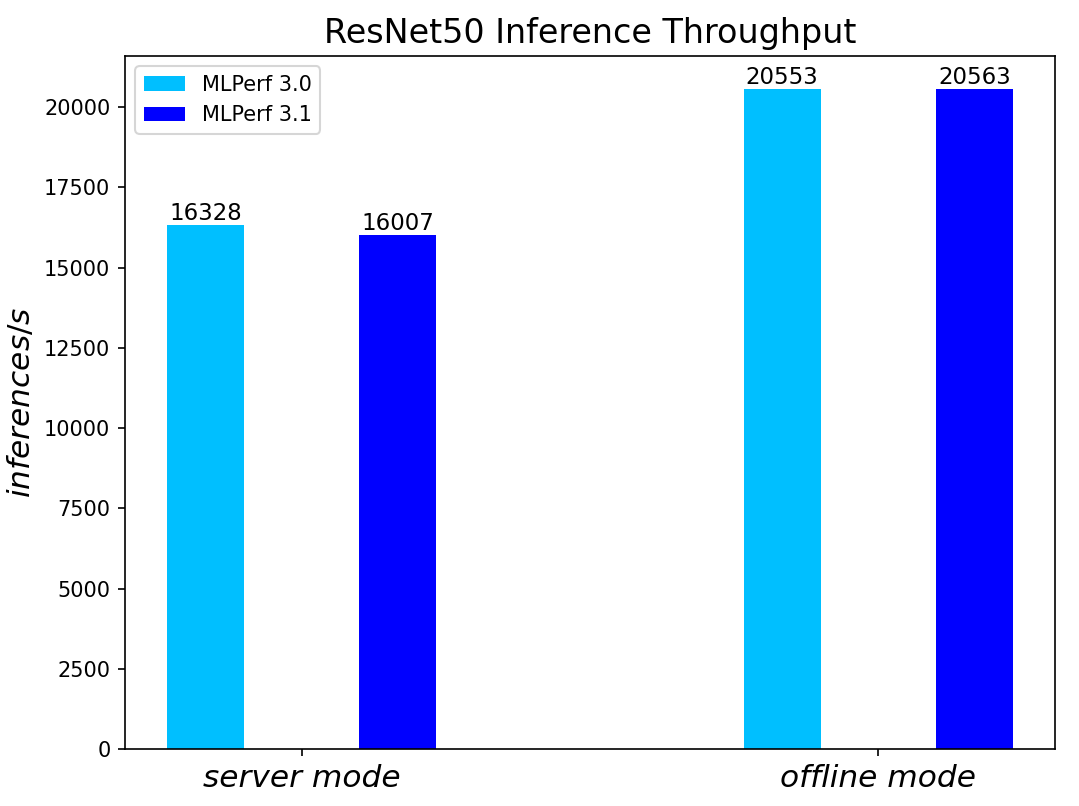
Figure 2. ResNet50 inference throughput in server and offline scenarios
BERT Large Language Model server & offline scenarios:
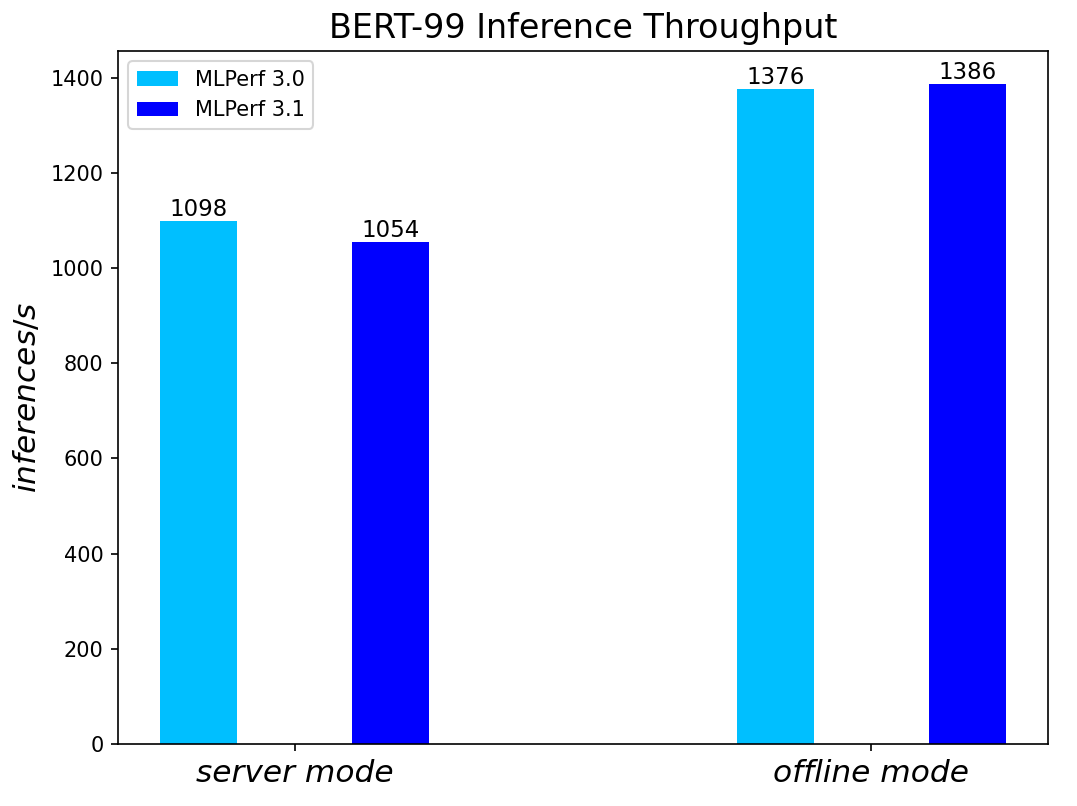
Figure 3. BERT Inference results for server and offline scenarios
RetinaNet Object Detection Model server & offline scenarios:
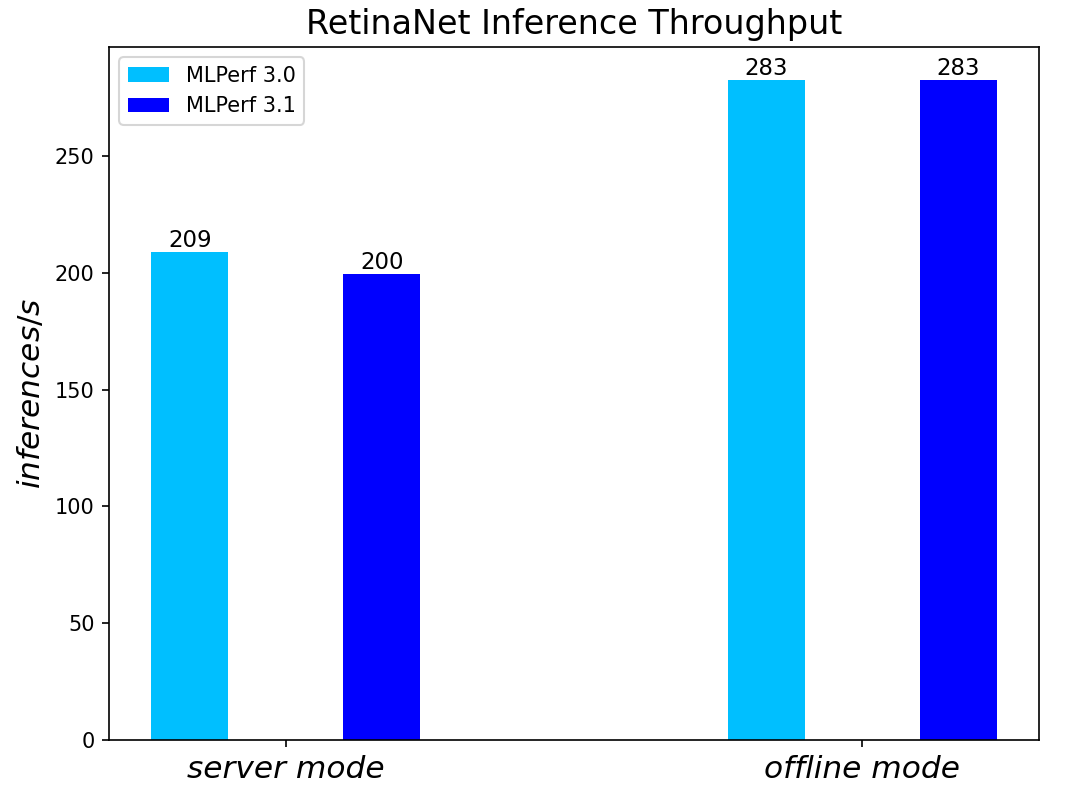
Figure 4. RetinaNet Object Detection Model Inference results for server and offline scenarios
RNN-T Text to Speech Model server & offline scenarios:
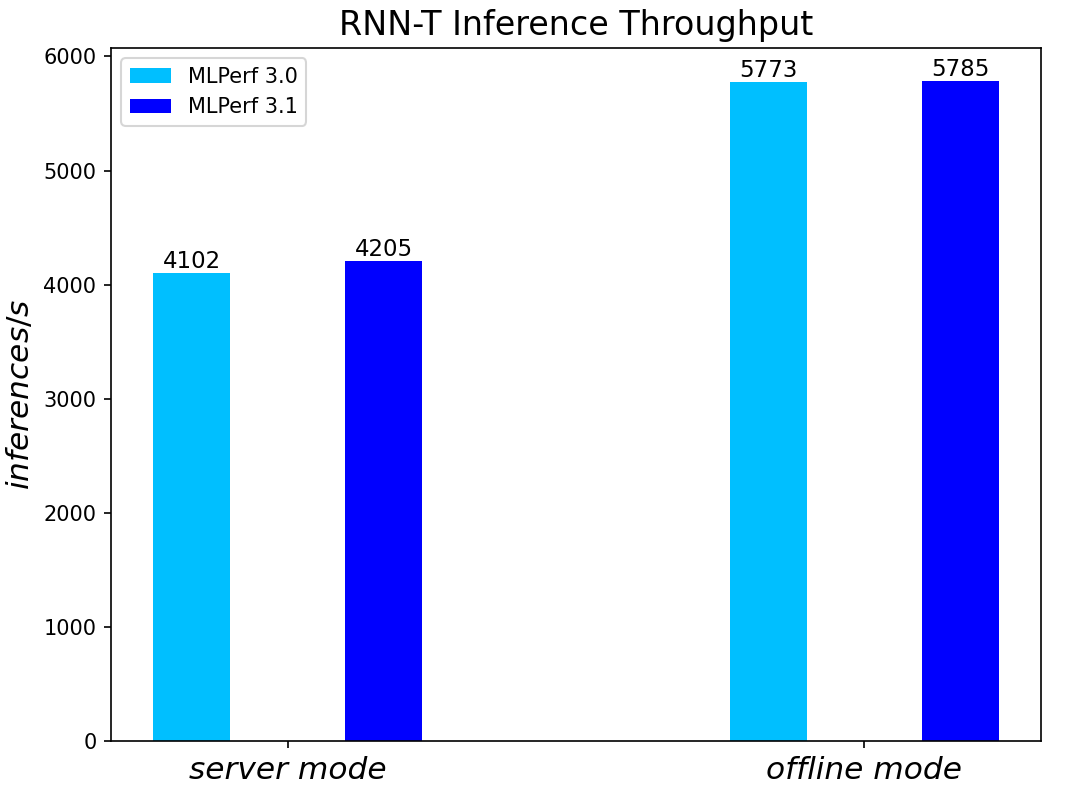
Figure 5. RNN-T Text to Speech Model Inference results for server and offline scenarios
3D-Unet Medical Imaging Model offline scenarios:
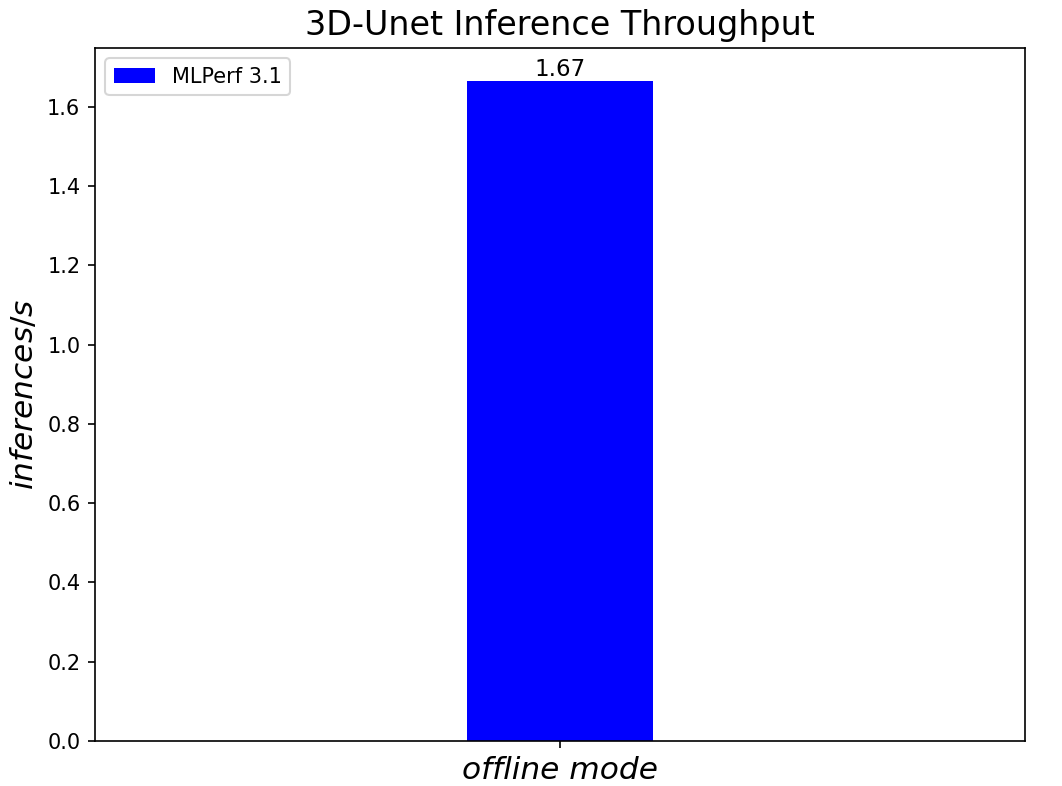
Figure 6. 3D-Unet Medical Imaging Model Inferencing results for server and offline scenarios
DLRMv2-99 Recommendation Model server & offline scenarios:
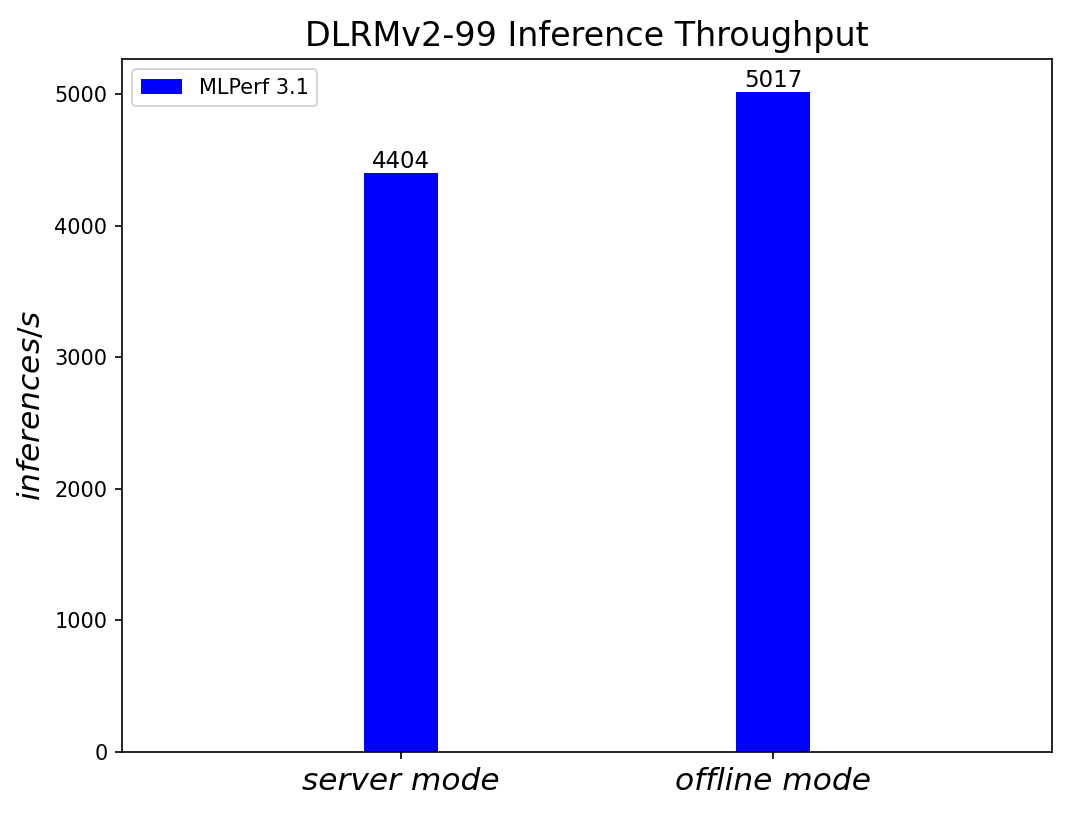
Figure 7. DLRMv2-99 Recommendation Model Inference results for server and offline scenarios (submitted in the open category)
GPT-J-99 Summarization Model server & offline scenarios:
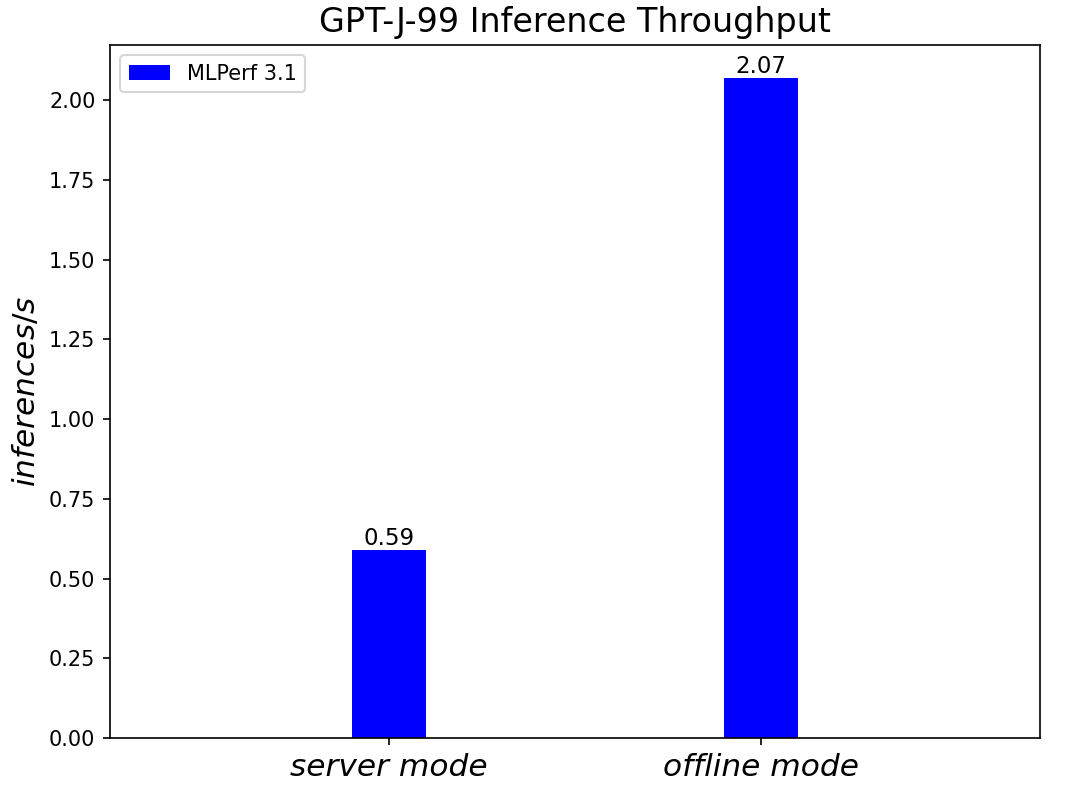
Figure 8. GPT-J-99 Summarization Model Inference results for server and offline scenarios
Conclusion
- The PowerEdge R760 server with 4th Generation Intel® Xeon® Scalable Processors produces strong data center inference performance, confirmed by the official version 3.1 MLPerfTM benchmarking results from MLCommonsTM.
- The high performance and versatility are demonstrated across natural language processing, image classification, object detection, medical imaging, speech-to-text inference, recommendation, and summarization systems.
- The R760 with 4th Generation Intel® Xeon® Scalable Processors show good performance in supporting generative AI models like GPT-J.
- The R760 supports different deep learning inference scenarios in the MLPerfTM benchmark scenarios as well as other complex workloads such as database and advanced analytics. It is an ideal solution for data center modernization to drive operational efficiency, lead higher productivity, and minimize total cost of ownership (TCO).
References
MLCommonsTM MLPerfTM v3.1 Inference Benchmark Submission IDs
ID | Submitter | System |
3.1-0059 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
3.1-0060 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
3.1-4184 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
Authors: Tao Zhang (tao.zhang9@dell.com); Brandt Springman (brandt.springman@dell.com); Bhavesh Patel (bhavesh_a_patel@dell.com); Louie Tsai (louie.tsai@intel.com); Yuning Qiu (yuning.qiu@intel.com); Ramesh Chukka (ramesh.n.chukka@intel.com)

Running Meta Llama 3 Models on Dell PowerEdge XE9680
Thu, 02 May 2024 17:54:12 -0000
|Read Time: 0 minutes
Introduction
Recently, Meta has open-sourced its Meta Llama 3 text-to-text models with 8B and 70B sizes, which are the highest scoring LLMs that have been open-sourced so far in their size ranges, in terms of quality of responses[1]. In this blog, we will run those models on the Dell PowerEdge XE9680 server to show their performance and improvement by comparing them to the Llama 2 models.
Open-sourcing the Large Language Models (LLMs) enables easy access to this state-of-the-art technology and has accelerated innovations in the field and adoption for different applications. As shown in Table 1, this round of Llama 3 release includes the following five models in total, including two pre-trained models with sizes of 8B and 70B and their instruction-tuned versions, plus a safeguard version for the 8B model[2].
Table 1: Released Llama 3 Models
Model size (Parameters) | Model names | Context | Training tokens | Vocabulary length |
8B |
| 8K |
15T |
128K |
70B |
|
Llama 3 is trained on 15T tokens which is 7.5X the number of tokens on which Llama 2 was trained. Training with large, high-quality datasets and refined post-training processes improved Llama 3 model’s capabilities, such as reasoning, code generation, and instruction following. Evaluated across main accuracy benchmarks, the Llama 3 model not only exceeds its precedent, but also leads over other main open-source models by significant margins. The Llama 3 70B instruct model shows close or even better results compared to the commercial closed-source models such as Gemini Pro[1].
The model architecture of Llama 3 8B is similar to that of Llama 2 7B with one significant difference. Besides a larger parameter size, the Llama 3 8B model uses the group query attention (GQA) mechanism instead of the multi-head attention (MHA) mechanism used in the Llama 2 7B model. Unlike MHA which has the same number of Q (query), K (key), and V (value) matrixes, GQA reduces the number of K and V matrixes required by sharing the same KV matrixes across grouped Q matrixes. This reduces the memory required and improves computing efficiency during the inferencing process[3]. In addition, the Llama 3 models improved the max context window length to 8192 compared to 4096 for the Llama 2 models. Llama 3 uses a new tokenizer called tik token that expands the vocabulary size to 128K when compared to 32K used in Llama 2. The new tokenization scheme offers improved token efficiency, yielding up to 15% fewer tokens compared to Llama 2 based on Meta’s benchmark[1].
This blog focuses on the inference performance tests of the Llama 3 models running on the Dell PowerEdge XE9680 server, especially, the comparison with Llama 2 models, to show the improvements in the new generation of models.
Test setup
The server we used to benchmark the performance is the PowerEdge XE9680 with 8x H100 GPUs[4]. The detailed server configurations are shown in Table 2.
Table 2: XE9680 server configuration
System Name | PowerEdge XE9680 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Process Name | Intel® Xeon® Platinum 8470 |
Host Processors per Node | 2 |
Host Processor Core Count | 52 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity and Type | 2TB, 32x 64 GB DIMM, 4800 MT/s DDR5 |
Host Storage Capacity | 1.8 TB, NVME |
GPU Number and Name | 8x H100 |
GPU Memory Capacity and Type | 80GB, HBM3 |
GPU High-speed Interface | PCIe Gen5 / NVLink Gen4 |
The XE9680 is the ideal server, optimized for AI workloads with its 8x NVSwitch interconnected H100 GPUs. The high-speed NVLink interconnect allows deployment of large models like Llama 3 70B that need to span multiple GPUs for best performance and memory capacity requirements. With its 10 PCIe slots, the XE9680 also provides a flexible PCIe architecture that enables a variety of AI fabric options.
For these tests, we deployed the Llama 3 models Meta-Llama-3-8B and Meta-Llama-3-70B, and the Llama 2 models Llama-2-7b-hf and Llama-2-70b-hf. These models are available for download from Hugging Face after permission approved by Meta. For a fair comparison between Llama 2 and Llama 3 models, we ran the models with native precision (float16 for Llama 2 models and bfloat16 for Llama 3 models) instead of any quantized precision.
Given that it has the same basic model architecture as Llama 2, Llama 3 can easily be integrated into any available software eco-system that currently supports the Llama 2 model. For the experiments in this blog, we chose NVIDIA TensorRT-LLM latest release (version 0.9.0) as the inference framework. NVIDIA CUDA version was 12.4; the driver version was 550.54.15. The operating system for the experiments was Rocky Linux 9.1.
Knowing that the Llama 3 improved accuracy significantly, we first concentrated on the inferencing speed tests. More specifically, we tested the Time-to-First-Token (TTFT) and throughput over different batch sizes for both Llama 2 and Llama 3 models, as shown in the Results section. To make the comparison between two generations of models easy, and to mimic a summarization task, we kept the input token length and output token length at 2048 and 128 respectively for most of the experiments. We also measured throughput of the Llama 3 with the long input token length (8192), as one of the most significant improvements. Because H100 GPUs support the fp8 data format for the models with negligible accuracy loss, we measured the throughput under long input token length for the Llama 3 model at fp8 precision.
Results
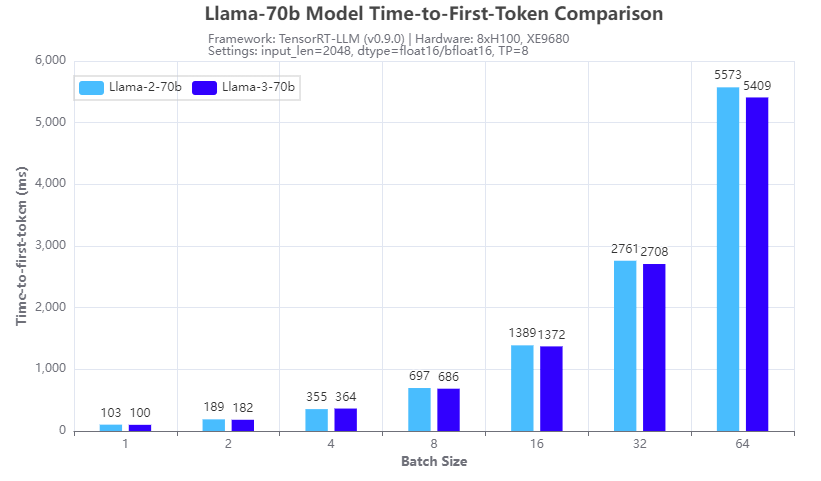
Figure 1. Inference speed comparison: Llama-3-70b vs Llama-2-70b: Time-to-First-Token
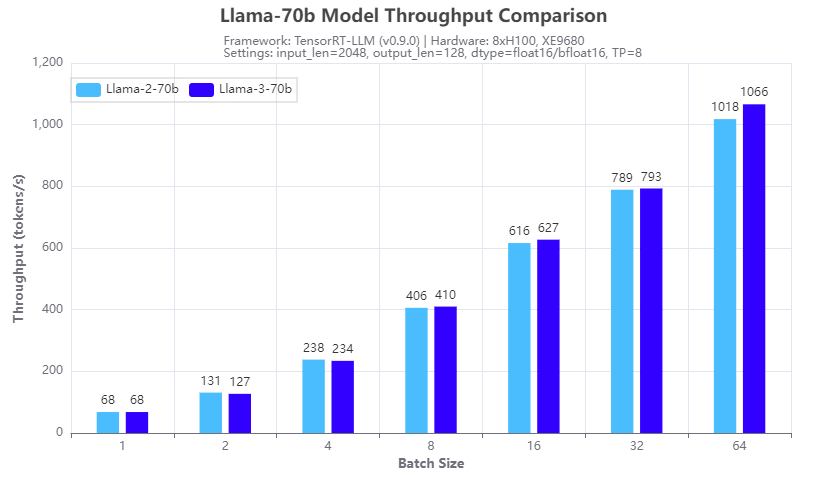
Figure 2: Inference speed comparison: Llama-3-70b vs Llama-2-70b: Throughput
Figures 1 and 2 show the inference speed comparison with the 70b Llama 2 (Llama-2-70b) and Llama 3 (Llama-3-70b) models running across eight H100 GPUs in a tensor parallel (TP=8) fashion on an XE9680 server. From the test results, we can see that for both TTFT (Figure 1) and throughput (Figure 2), the Llama 3 70B model has a similar inference speed to the Llama 2 70b model. This is expected given the same size and architecture of the two models. So, by deploying Llama 3 instead of Llama 2 on an XE9680, organizations can immediately see a big boost in accuracy and quality of responses, using the same software infrastructure, without any impact to latency or throughput of the responses.
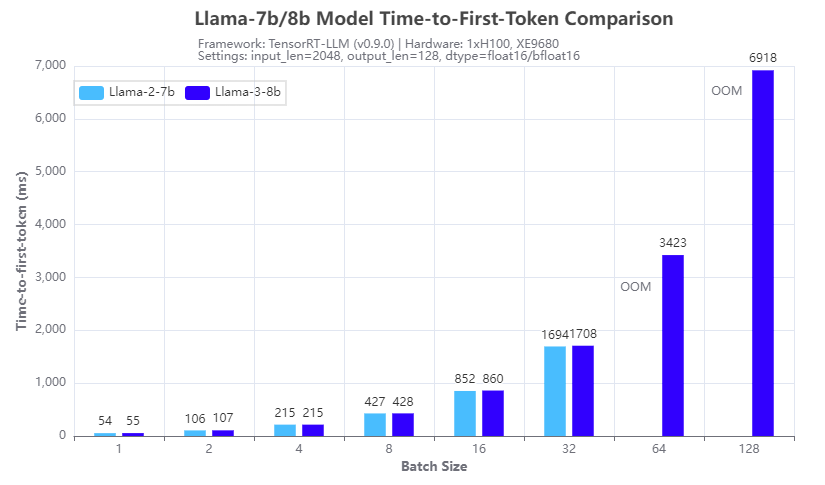
Figure 3. Inference speed comparison: Llama-3-8b vs Llama-2-7b: Time-to-First-Token
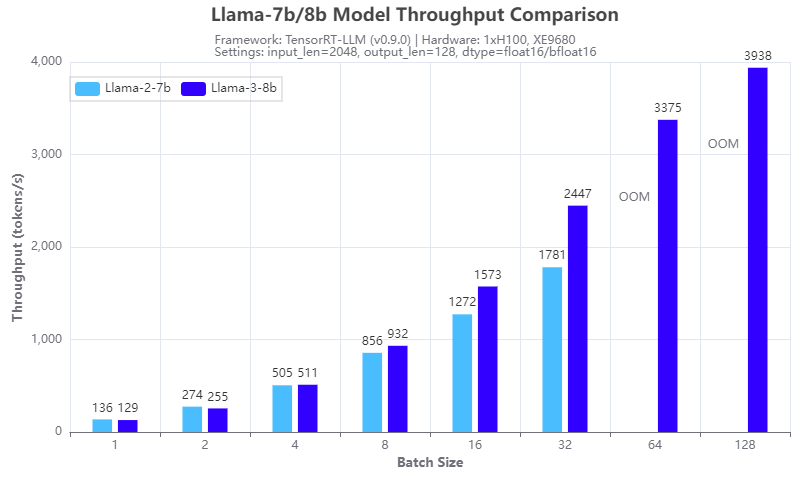
Figure 4: Inference speed comparison: Llama-3-8b vs Llama-2-7b: Throughput
Figures 3 and 4 show the inference speed comparison with the 7b Llama 2 (Llama-2-7b) and 8b Llama 3 (Llama-3-8b) models running on a single H100 GPU on an XE9680 server. From the results, we can see the benefits of using the group query attention (GQA) in the Llama 3 8B architecture, in terms of reducing the GPU memory footprint in the prefill stage and speeding up the calculation in the decoding stage of the LLM inferencing. Figure 3 shows that Llama 3 8B has a similar response time in generating the first token even though it is a 15% larger model compared to Llama-2-7b. Figure 4 shows that Llama-3-8b has higher throughput than Llama-2-7b when the batch size is 4 or larger. The benefits of GQA grow as the batch size increases. We can see from the experiments that:
- the Llama-2-7b cannot run at a batch size of 64 or larger with the 16-bit precision and given input/output token length, because of the OOM (out of memory) error
- the Llama-3-8b can run at a batch size of 128, which gives more than 2x throughput with the same hardware configuration
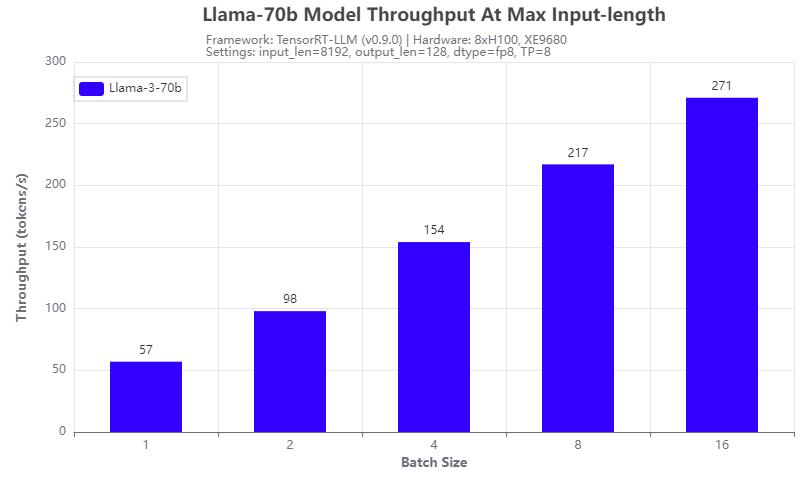
Figure 5: Llama-3-70b throughput under 8192 input token length
Another improvement of the Llama 3 model: it supports a max input token length of 8192, which is 2x of that of a Llama 2 model. We tested it with the Llama-3-70b model running on 8 H100 GPUs of the XE9680 server. The results are shown in Figure 5. The throughput is linearly proportional to the batch size tested and can achieve 271 tokens/s at a batch size of 16, indicating that more aggressive quantization techniques can further improve the throughput.
Conclusion
In this blog, we investigated the Llama 3 models that were released recently, by comparing their inferencing speed with that of the Llama 2 models by running on a Dell PowerEdge XE9680 server. With the numbers collected through experiments, we showed that not only is the Llama 3 model series a big leap in terms of the quality of responses, it also has great inferencing advantages in terms of high throughput with a large achievable batch size, and long input token length. This makes Llama 3 models great candidates for those long context and offline processing applications.
Authors: Tao Zhang, Khushboo Rathi, and Onur Celebioglu
[1] Meta AI, “Introducing Meta Llama 3: The most capable openly available LLM to date”, https://ai.meta.com/blog/meta-llama-3/.
[3] J. Ainslie et. al, “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, https://arxiv.org/abs/2305.13245