
Blogs
Short articles about artificial intelligence solutions and related technology trends

Converting Hugging Face Large Language Models to TensorRT-LLM

Tue, 23 Apr 2024 21:27:56 -0000
|Read Time: 0 minutes
Introduction
Before getting into this blog proper, I want to take a minute to thank Fabricio Bronzati for his technical help on this topic.
Over the last couple of years, Hugging Face has become the de-facto standard platform to store anything to do with generative AI. From models to datasets to agents, it is all found on Hugging Face.
While NVIDIA graphic cards have been a popular choice to power AI workloads, NVIDIA has spent significant investment in building their software stack to help customers decrease the time to market for their generative AI-back applications. This is where the NVIDIA AI Enterprise software stack comes into play. 2 big components of the NVIDIA AI Enterprise stack are the NeMo framework and the Triton Inference server.
NeMo makes it really easy to spin up an LLM and start interacting with it. The perceived downside of NeMo is that it only supports a small number of LLMs, because it requires the LLM to be in a specific format. For folks looking to run LLMs that are not supported by NeMo, NVIDIA provides a set of scripts and containers to convert the LLMs from the Hugging Face format to the TensorRT, which is the underlying framework for NeMo and the Triton Inference server. According to NVIDIA's website, found here, TensorRT-LLM is an open-source library that accelerates and optimizes inference performance of the latest large language models (LLMs) on the NVIDIA AI platform.
The challenge with TensorRT-LLM is that one can't take a model from Hugging Face and run it directly on TensorRT-LLM. Such a model will need to go through a conversion stage and then it can leverage all the goodness of TensorRT-LLM.
When it comes to optimizing large language models, TensorRT-LLM is the key. It ensures that models not only deliver high performance but also maintain efficiency in various applications.
The library includes optimized kernels, pre- and post-processing steps, and multi-GPU/multi-node communication primitives. These features are specifically designed to enhance performance on NVIDIA GPUs.
The purpose of this blog is to show the steps needed to take a model on Hugging Face and convert it to TensorRT-LLM. Once a model has been converted, it can then be used by the Triton Inference server. TensorRT-LLM doesn't support all models on Hugging Face, so before attempting the conversion, I would check the ever-growing list of supported models on the TensorRT-LLM github page.
Pre-requisites
Before diving into the conversion, let's briefly talk about pre-requisites. There are a lot of steps in the conversion leverage docker, so you need: docker-compose and docker-buildx. You will also be cloning repositories, so you need git . One component of git that is required and is not always installed by default is the support for Large File Storage. So, you need to make sure that git-lfs is installed, because we will need to clone fairly large files (in the multi-GB size) from git, and using git-lfs is the most efficient way of doing it.
Building the TensorRT LLM library
At the time of writing this blog, NVIDIA hasn't yet released a pre-built container with the TensorRT LLM library, so unfortunately, it means that it is incumbent on whomever wants to use it to do so. So, let me show you how to do it.
First thing I need to do is clone the TensorRT LLM library repository:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git clone https://github.com/NVIDIA/TensorRT-LLM.gitCloning into 'TensorRT-LLM'...remote: Enumerating objects: 7888, done.remote: Counting objects: 100% (1696/1696), done.remote: Compressing objects: 100% (626/626), done.remote: Total 7888 (delta 1145), reused 1413 (delta 1061), pack-reused 6192Receiving objects: 100% (7888/7888), 81.67 MiB | 19.02 MiB/s, done.Resolving deltas: 100% (5368/5368), done.Updating files: 100% (1661/1661), done.
Then I need to initialize all the submodules contained in the repository:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ git submodule update --init --recursiveSubmodule '3rdparty/NVTX' (https://github.com/NVIDIA/NVTX.git) registered for path '3rdparty/NVTX'Submodule '3rdparty/cutlass' (https://github.com/NVIDIA/cutlass.git) registered for path '3rdparty/cutlass'Submodule '3rdparty/cxxopts' (https://github.com/jarro2783/cxxopts) registered for path '3rdparty/cxxopts'Submodule '3rdparty/json' (https://github.com/nlohmann/json.git) registered for path '3rdparty/json'Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/NVTX'...Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/cutlass'...Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/cxxopts'...Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/3rdparty/json'...Submodule path '3rdparty/NVTX': checked out 'a1ceb0677f67371ed29a2b1c022794f077db5fe7'Submodule path '3rdparty/cutlass': checked out '39c6a83f231d6db2bc6b9c251e7add77d68cbfb4'Submodule path '3rdparty/cxxopts': checked out 'eb787304d67ec22f7c3a184ee8b4c481d04357fd'Submodule path '3rdparty/json': checked out 'bc889afb4c5bf1c0d8ee29ef35eaaf4c8bef8a5d'
and then I need to initialize git lfs and pull the objects stored in git lfs:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ git lfs installUpdated git hooks.Git LFS initialized.fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ git lfs pull
At this point, I am now ready to build the docker container that will contain the TensorRT LLM library:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ make -C docker release_buildmake: Entering directory '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker'Building docker image: tensorrt_llm/release:latestDOCKER_BUILDKIT=1 docker build --pull \ --progress auto \ --build-arg BASE_IMAGE=nvcr.io/nvidia/pytorch \ --build-arg BASE_TAG=23.12-py3 \ --build-arg BUILD_WHEEL_ARGS="--clean --trt_root /usr/local/tensorrt --python_bindings --benchmarks" \ --build-arg TORCH_INSTALL_TYPE="skip" \ --build-arg TRT_LLM_VER="0.8.0.dev20240123" \ --build-arg GIT_COMMIT="b57221b764bc579cbb2490154916a871f620e2c4" \ --target release \ --file Dockerfile.multi \ --tag tensorrt_llm/release:latest \
[+] Building 2533.0s (41/41) FINISHED docker:default => [internal] load build definition from Dockerfile.multi 0.0s => => transferring dockerfile: 3.24kB 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 359B 0.0s => [internal] load metadata for nvcr.io/nvidia/pytorch:23.12-py3 1.0s => [auth] nvidia/pytorch:pull,push token for nvcr.io 0.0s => [internal] load build context 44.1s => => transferring context: 579.18MB 44.1s => CACHED [base 1/1] FROM nvcr.io/nvidia/pytorch:23.12-py3@sha256:da3d1b690b9dca1fbf9beb3506120a63479e0cf1dc69c9256055125460eb44f7 0.0s => [devel 1/14] COPY docker/common/install_base.sh install_base.sh 1.1s => [devel 2/14] RUN bash ./install_base.sh && rm install_base.sh 13.7s => [devel 3/14] COPY docker/common/install_cmake.sh install_cmake.sh 0.0s => [devel 4/14] RUN bash ./install_cmake.sh && rm install_cmake.sh 23.0s => [devel 5/14] COPY docker/common/install_ccache.sh install_ccache.sh 0.0s => [devel 6/14] RUN bash ./install_ccache.sh && rm install_ccache.sh 0.5s => [devel 7/14] COPY docker/common/install_tensorrt.sh install_tensorrt.sh 0.0s => [devel 8/14] RUN bash ./install_tensorrt.sh --TRT_VER=${TRT_VER} --CUDA_VER=${CUDA_VER} --CUDNN_VER=${CUDNN_VER} --NCCL_VER=${NCCL_VER} --CUBLAS_VER=${CUBLAS_VER} && 448.3s => [devel 9/14] COPY docker/common/install_polygraphy.sh install_polygraphy.sh 0.0s => [devel 10/14] RUN bash ./install_polygraphy.sh && rm install_polygraphy.sh 3.3s => [devel 11/14] COPY docker/common/install_mpi4py.sh install_mpi4py.sh 0.0s => [devel 12/14] RUN bash ./install_mpi4py.sh && rm install_mpi4py.sh 42.2s => [devel 13/14] COPY docker/common/install_pytorch.sh install_pytorch.sh 0.0s => [devel 14/14] RUN bash ./install_pytorch.sh skip && rm install_pytorch.sh 0.4s => [wheel 1/9] WORKDIR /src/tensorrt_llm 0.0s => [release 1/11] WORKDIR /app/tensorrt_llm 0.0s => [wheel 2/9] COPY benchmarks benchmarks 0.0s => [wheel 3/9] COPY cpp cpp 1.2s => [wheel 4/9] COPY benchmarks benchmarks 0.0s => [wheel 5/9] COPY scripts scripts 0.0s => [wheel 6/9] COPY tensorrt_llm tensorrt_llm 0.0s => [wheel 7/9] COPY 3rdparty 3rdparty 0.8s => [wheel 8/9] COPY setup.py requirements.txt requirements-dev.txt ./ 0.1s => [wheel 9/9] RUN python3 scripts/build_wheel.py --clean --trt_root /usr/local/tensorrt --python_bindings --benchmarks 1858.0s => [release 2/11] COPY --from=wheel /src/tensorrt_llm/build/tensorrt_llm*.whl . 0.2s => [release 3/11] RUN pip install tensorrt_llm*.whl --extra-index-url https://pypi.nvidia.com && rm tensorrt_llm*.whl 43.7s => [release 4/11] COPY README.md ./ 0.0s => [release 5/11] COPY docs docs 0.0s => [release 6/11] COPY cpp/include include 0.0s => [release 7/11] COPY --from=wheel /src/tensorrt_llm/cpp/build/tensorrt_llm/libtensorrt_llm.so /src/tensorrt_llm/cpp/build/tensorrt_llm/libtensorrt_llm_static.a lib/ 0.1s => [release 8/11] RUN ln -sv $(TRT_LLM_NO_LIB_INIT=1 python3 -c "import tensorrt_llm.plugin as tlp; print(tlp.plugin_lib_path())") lib/ && cp -Pv lib/libnvinfer_plugin_tensorrt_llm.so li 1.8s => [release 9/11] COPY --from=wheel /src/tensorrt_llm/cpp/build/benchmarks/bertBenchmark /src/tensorrt_llm/cpp/build/benchmarks/gptManagerBenchmark /src/tensorrt_llm/cpp/build 0.1s => [release 10/11] COPY examples examples 0.1s => [release 11/11] RUN chmod -R a+w examples 0.5s => exporting to image 40.1s => => exporting layers 40.1s => => writing image sha256:a6a65ab955b6fcf240ee19e6601244d9b1b88fd594002586933b9fd9d598c025 0.0s => => naming to docker.io/tensorrt_llm/release:latest 0.0smake: Leaving directory '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker'
The time it will take to build the container is highly dependent on the resources available on the server you are running the command on. In my case, this was on a PowerEdge XE9680, which is the fastest server in the Dell PowerEdge portfolio.
Downloading model weights
Next, I need to download the weights for the model I am going to be converting to TensorRT. Even though I am doing this in this sequence, this step could have been done prior to cloning the TensorRT LLM repo.
Model weights can be downloaded in 2 different manners:
- Outside of the TensorRT container
- Inside the TensorRT container
The benefit of downloading them outside of the TensorRT container is that they can be reused for multiple conversions, whereas, if they are downloaded inside the container, they can only be used for that single conversion. In my case, I will download them outside of the container as I feel it will be the approach used by most people. This is how to do it:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ cd ..fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git lfs installGit LFS initialized.fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git clone https://huggingface.co/meta-llama/Llama-2-70b-chat-hfCloning into ‘Llama-2-70b-chat-hf’...Username for ‘https://huggingface.co’: ******Password for ‘https://bronzafa@huggingface.co’:remote: Enumerating objects: 93, done.remote: Counting objects: 100% (6/6), done.remote: Compressing objects: 100% (6/6), done.remote: Total 93 (delta 1), reused 0 (delta 0), pack-reused 87Unpacking objects: 100% (93/93), 509.43 KiB | 260.00 KiB/s, done.Updating files: 100% (44/44), done.Username for ‘https://huggingface.co’: ******Password for ‘https://bronzafa@huggingface.co’:
Filtering content: 18% (6/32), 6.30 GiB | 2.38 MiB/s
Filtering content: 100% (32/32), 32.96 GiB | 9.20 MiB/s, done.
Depending on your setup, you might see some error messages about files not being copied properly. Those can be safely ignored. One thing worth noting about downloading the weights is that you need to make sure you have lots of local storage as cloning this particular model will need over 500GB. The amount of storage will obviously depend on the size of the model and the model chosen, but definitely something to keep in mind.
Starting the TensorRT container
Now, I am ready to start the TensorRT container. This can be done with the following command:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ make -C docker release_run LOCAL_USER=1make: Entering directory ‘/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker’docker build –progress –pull --progress auto –build-arg BASE_IMAGE_WITH_TAG=tensorrt_llm/release:latest –build-arg USER_ID=1003 –build-arg USER_NAME=fbronzati –build-arg GROUP_ID=1001 –build-arg GROUP_NAME=ais –file Dockerfile.user –tag tensorrt_llm/release:latest-fbronzati ..[+] Building 0.5s (6/6) FINISHED docker:default => [internal] load build definition from Dockerfile.user 0.0s => => transferring dockerfile: 531B 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 359B 0.0s => [internal] load metadata for docker.io/tensorrt_llm/release:latest 0.0s => [1/2] FROM docker.io/tensorrt_llm/release:latest 0.1s => [2/2] RUN (getent group 1001 || groupadd –gid 1001 ais) && (getent passwd 1003 || useradd –gid 1001 –uid 1003 –create-home –no-log-init –shell /bin/bash fbronzati) 0.3s => exporting to image 0.0s => => exporting layers 0.0s => => writing image sha256:1149632051753e37204a6342c1859a8a8d9068a163074ca361e55bc52f563cac 0.0s => => naming to docker.io/tensorrt_llm/release:latest-fbronzati 0.0sdocker run –rm -it –ipc=host –ulimit memlock=-1 –ulimit stack=67108864 \ --gpus=all \ --volume /aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM:/code/tensorrt_llm \ --env “CCACHE_DIR=/code/tensorrt_llm/cpp/.ccache” \ --env “CCACHE_BASEDIR=/code/tensorrt_llm” \ --workdir /app/tensorrt_llm \ --hostname node002-release \ --name tensorrt_llm-release-fbronzati \ --tmpfs /tmp:exec \ tensorrt_llm/release:latest-fbronzati
=============== PyTorch ===============
NVIDIA Release 23.12 (build 76438008)PyTorch Version 2.2.0a0+81ea7a4
Container image Copyright © 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyrig©(c) 2014-2023 Facebook Inc.Copy©ht (c) 2011-2014 Idiap Research Institute (Ronan Collobert)C©right (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu©opyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuo©)Copyright (c) 2011-2013 NYU (Clement F©bet)Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jas©Weston)Copyright (c) 2006 Idiap Research Institute ©my Bengio)Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, J©ny Mariethoz)Copyright (c) 2015 Google Inc.Copyright (c) 2015 Yangqing JiaCopyright (c) 2013-2016 The Caffe contributorsAll rights reserved.
Variou©iles include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.By pulling and using the container, you accept the terms and conditions of this license:https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
fbronzati@node002-release:/app/tensorrt_llm$
One of the arguments of the command, the LOCAL_USER=1 is required to ensure proper ownership of the files that will be created later. Without that argument, all the newly created files will belong to root thus potentially causing challenges later on.
As you can see in the last line of the previous code block, the shell prompt has changed. Before running the command, it was fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ and after running the command, it is fbronzati@node002-release:/app/tensorrt_llm$ . That is because, once the command completes, you will be inside the TensorRT container, and everything I will need to do for the conversion going forward will be done from inside that container. This is the reason why we build it in the first place as it allows us to customize the container based on the LLM being converted.
Converting the LLM
Now that I have started the TensorRT container and that I am inside of it, I am ready to convert the LLM from the Huggingface format to the Triton Inference server format.
The conversion process will need to download tokens from Huggingface, so I need to make sure that I am logged into Hugginface. I can do that by running this:
fbronzati@node002-release:/app/tensorrt_llm$ huggingface-cli login --token ******Token will not been saved to git credential helper. Pass `add_to_git_credential=True` if you want to set the git credential as well.Token is valid (permission: read).Your token has been saved to /home/fbronzati/.cache/huggingface/tokenLogin successful
Instead of the ******, you will need to enter your Huggingface API token. You can find it by log in to Hugginface and then go to Settings and then Access Tokens. If your login is successful, you will see the message at the bottom Login successful.
I am now ready to start the process to generate the new TensorRT engines. This process takes the weights we have downloaded earlier and generates the corresponding TensorRT engines. The number of engines created will depend on the number of GPUs available. In my case, I will create 4 TensorRT engines as I have 4 GPUs. One non-obvious advantage of the conversion process is that you can change the number of engines you want for your model. For instance, the initial version of the Llama-2-70b-chat-hf model required 8 GPUs, but through the conversion process, I changed that from 8 to 4.
How long the conversion process takes will totally depend on the hardware that you have, but, generally speaking it will take a while. Here is the command to do it :
fbronzati@node002-release:/app/tensorrt_llm$ python3 examples/llama/build.py \
--model_dir /code/tensorrt_llm/Llama-2-70b-chat-hf/ \
--dtype float16 \
--use_gpt_attention_plugin float16 \
--use_gemm_plugin float16 \
--remove_input_padding \
--use_inflight_batching \
--paged_kv_cache \
--output_dir /code/tensorrt_llm/examples/llama/out \
--world_size 4 \
--tp_size 4 \
--max_batch_size 64fatal: not a git repository (or any of the parent directories): .git[TensorRT-LLM] TensorRT-LLM version: 0.8.0.dev20240123[01/31/2024-13:45:14] [TRT-LLM] [W] remove_input_padding is enabled, while max_num_tokens is not set, setting to max_batch_size*max_input_len.It may not be optimal to set max_num_tokens=max_batch_size*max_input_len when remove_input_padding is enabled, because the number of packed input tokens are very likely to be smaller, we strongly recommend to set max_num_tokens according to your workloads.[01/31/2024-13:45:14] [TRT-LLM] [I] Serially build TensorRT engines.[01/31/2024-13:45:14] [TRT] [I] [MemUsageChange] Init CUDA: CPU +15, GPU +0, now: CPU 141, GPU 529 (MiB)[01/31/2024-13:45:20] [TRT] [I] [MemUsageChange] Init builder kernel library: CPU +4395, GPU +1160, now: CPU 4672, GPU 1689 (MiB)[01/31/2024-13:45:20] [TRT-LLM] [W] Invalid timing cache, using freshly created one[01/31/2024-13:45:20] [TRT-LLM] [I] [MemUsage] Rank 0 Engine build starts - Allocated Memory: Host 4.8372 (GiB) Device 1.6502 (GiB)[01/31/2024-13:45:21] [TRT-LLM] [I] Loading HF LLaMA ... from /code/tensorrt_llm/Llama-2-70b-chat-hf/Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15/15 [00:00<00:00, 16.67it/s][01/31/2024-13:45:22] [TRT-LLM] [I] Loading weights from HF LLaMA...[01/31/2024-13:45:34] [TRT-LLM] [I] Weights loaded. Total time: 00:00:12[01/31/2024-13:45:34] [TRT-LLM] [I] HF LLaMA loaded. Total time: 00:00:13[01/31/2024-13:45:35] [TRT-LLM] [I] [MemUsage] Rank 0 model weight loaded. - Allocated Memory: Host 103.0895 (GiB) Device 1.6502 (GiB)[01/31/2024-13:45:35] [TRT-LLM] [I] Optimized Generation MHA kernels (XQA) Enabled[01/31/2024-13:45:35] [TRT-LLM] [I] Remove Padding Enabled[01/31/2024-13:45:35] [TRT-LLM] [I] Paged KV Cache Enabled[01/31/2024-13:45:35] [TRT] [W] IElementWiseLayer with inputs LLaMAForCausalLM/vocab_embedding/GATHER_0_output_0 and LLaMAForCausalLM/layers/0/input_layernorm/SHUFFLE_0_output_0: first input has type Half but second input has type Float.[01/31/2024-13:45:35] [TRT] [W] IElementWiseLayer with inputs LLaMAForCausalLM/layers/0/input_layernorm/REDUCE_AVG_0_output_0 and LLaMAForCausalLM/layers/0/input_layernorm/SHUFFLE_1_output_0: first input has type Half but second input has type Float.....[01/31/2024-13:52:56] [TRT] [I] Engine generation completed in 57.4541 seconds.[01/31/2024-13:52:56] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 1000 MiB, GPU 33268 MiB[01/31/2024-13:52:56] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +33268, now: CPU 0, GPU 33268 (MiB)[01/31/2024-13:53:12] [TRT] [I] [MemUsageStats] Peak memory usage during Engine building and serialization: CPU: 141685 MiB[01/31/2024-13:53:12] [TRT-LLM] [I] Total time of building llama_float16_tp4_rank3.engine: 00:01:13[01/31/2024-13:53:13] [TRT] [I] Loaded engine size: 33276 MiB[01/31/2024-13:53:17] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +64, now: CPU 38537, GPU 35111 (MiB)[01/31/2024-13:53:17] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +1, GPU +64, now: CPU 38538, GPU 35175 (MiB)[01/31/2024-13:53:17] [TRT] [W] TensorRT was linked against cuDNN 8.9.6 but loaded cuDNN 8.9.4[01/31/2024-13:53:17] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +33267, now: CPU 0, GPU 33267 (MiB)[01/31/2024-13:53:17] [TRT-LLM] [I] Activation memory size: 34464.50 MiB[01/31/2024-13:53:17] [TRT-LLM] [I] Weights memory size: 33276.37 MiB[01/31/2024-13:53:17] [TRT-LLM] [I] Max KV Cache memory size: 12800.00 MiB[01/31/2024-13:53:17] [TRT-LLM] [I] Estimated max memory usage on runtime: 80540.87 MiB[01/31/2024-13:53:17] [TRT-LLM] [I] Serializing engine to /code/tensorrt_llm/examples/llama/out/llama_float16_tp4_rank3.engine...[01/31/2024-13:53:48] [TRT-LLM] [I] Engine serialized. Total time: 00:00:31[01/31/2024-13:53:49] [TRT-LLM] [I] [MemUsage] Rank 3 Engine serialized - Allocated Memory: Host 7.1568 (GiB) Device 1.6736 (GiB)[01/31/2024-13:53:49] [TRT-LLM] [I] Rank 3 Engine build time: 00:02:05 - 125.77239561080933 (sec)[01/31/2024-13:53:49] [TRT] [I] Serialized 59 bytes of code generator cache.[01/31/2024-13:53:49] [TRT] [I] Serialized 242287 bytes of compilation cache.[01/31/2024-13:53:49] [TRT] [I] Serialized 14 timing cache entries[01/31/2024-13:53:49] [TRT-LLM] [I] Timing cache serialized to /code/tensorrt_llm/examples/llama/out/model.cache[01/31/2024-13:53:51] [TRT-LLM] [I] Total time of building all 4 engines: 00:08:36
I have removed redundant output lines, so you can expect your output to be much longer than this. In my command, I have set the output directory to
/code/tensorrt_llm/examples/llama/out, so let's check the content of that directory:
fbronzati@node002-release:/app/tensorrt_llm$ ll /code/tensorrt_llm/examples/llama/out/total 156185008drwxr-xr-x 2 fbronzati ais 250 Jan 31 13:53 ./drwxrwxrwx 3 fbronzati ais 268 Jan 31 13:45 ../-rw-r--r-- 1 fbronzati ais 2188 Jan 31 13:46 config.json-rw-r--r-- 1 fbronzati ais 34892798724 Jan 31 13:47 llama_float16_tp4_rank0.engine-rw-r--r-- 1 fbronzati ais 34892792516 Jan 31 13:49 llama_float16_tp4_rank1.engine-rw-r--r-- 1 fbronzati ais 34892788332 Jan 31 13:51 llama_float16_tp4_rank2.engine-rw-r--r-- 1 fbronzati ais 34892800860 Jan 31 13:53 llama_float16_tp4_rank3.engine-rw-r--r-- 1 fbronzati ais 243969 Jan 31 13:53 model.cache
Sure enough, here are my 4 engine files. What can I do with those though? Those can be leveraged by the NVIDIA Triton Inference server to run inference. Let's take a look at how I can do that.
Now that I have finished the conversion, I can exit the TensorRT container:
fbronzati@node002-release:/app/tensorrt_llm$ exitexitmake: Leaving directory '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM/docker'
Deploying engine files to Triton Inference Server
Because NVIDIA is not offering a version of the Triton Inference Server container with the LLM as a parameter to the container, I will need to build it from scratch so it can leverage the engine files built through the conversion. The process is pretty similar to what I have done with the TensorRT container. From a high level, here is the process:
- Clone the Triton Inference Server backend repository
- Copy the engine files to the cloned repository
- Update some of the configuration parameters for the templates
- Build the Triton Inference Server container
Let's clone the Triton Inference Server backend repository:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/TensorRT-LLM$ cd ..fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ git clone https://github.com/triton-inference-server/tensorrtllm_backend.gitCloning into 'tensorrtllm_backend'...remote: Enumerating objects: 870, done.remote: Counting objects: 100% (348/348), done.remote: Compressing objects: 100% (165/165), done.remote: Total 870 (delta 229), reused 242 (delta 170), pack-reused 522Receiving objects: 100% (870/870), 387.70 KiB | 973.00 KiB/s, done.Resolving deltas: 100% (439/439), done.
Let's initialize all the 3rd party modules and the support for Large File Storage for git:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0$ cd tensorrtllm_backend/fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ git submodule update --init --recursiveSubmodule 'tensorrt_llm' (https://github.com/NVIDIA/TensorRT-LLM.git) registered for path 'tensorrt_llm'Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm'...Submodule path 'tensorrt_llm': checked out 'b57221b764bc579cbb2490154916a871f620e2c4'Submodule '3rdparty/NVTX' (https://github.com/NVIDIA/NVTX.git) registered for path 'tensorrt_llm/3rdparty/NVTX'Submodule '3rdparty/cutlass' (https://github.com/NVIDIA/cutlass.git) registered for path 'tensorrt_llm/3rdparty/cutlass'Submodule '3rdparty/cxxopts' (https://github.com/jarro2783/cxxopts) registered for path 'tensorrt_llm/3rdparty/cxxopts'Submodule '3rdparty/json' (https://github.com/nlohmann/json.git) registered for path 'tensorrt_llm/3rdparty/json'Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/NVTX'...Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/cutlass'...Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/cxxopts'...Cloning into '/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend/tensorrt_llm/3rdparty/json'...Submodule path 'tensorrt_llm/3rdparty/NVTX': checked out 'a1ceb0677f67371ed29a2b1c022794f077db5fe7'Submodule path 'tensorrt_llm/3rdparty/cutlass': checked out '39c6a83f231d6db2bc6b9c251e7add77d68cbfb4'Submodule path 'tensorrt_llm/3rdparty/cxxopts': checked out 'eb787304d67ec22f7c3a184ee8b4c481d04357fd'Submodule path 'tensorrt_llm/3rdparty/json': checked out 'bc889afb4c5bf1c0d8ee29ef35eaaf4c8bef8a5d'
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ git lfs installUpdated git hooks.Git LFS initialized.
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ git lfs pull
I am now ready to copy the engine files to the cloned repository:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ cp ../TensorRT-LLM/examples/llama/out/* all_models/inflight_batcher_llm/tensorrt_llm/1/
The next step can be done either by manually modifying the config.pbtxt files under various directories or by using the fill_template.py script to write the modifications for us. I am going to use the fill_template.py script, but that is my preference. Let me update those parameters:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ export HF_LLAMA_MODEL=meta-llama/Llama-2-70b-chat-hf
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ cp all_models/inflight_batcher_llm/ llama_ifb -r
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/preprocessing/config.pbtxt tokenizer_dir:${HF_LLAMA_MODEL},tokenizer_type:llama,triton_max_batch_size:64,preprocessing_instance_count:1
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/postprocessing/config.pbtxt tokenizer_dir:${HF_LLAMA_MODEL},tokenizer_type:llama,triton_max_batch_size:64,postprocessing_instance_count:1
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/tensorrt_llm_bls/config.pbtxt triton_max_batch_size:64,decoupled_mode:False,bls_instance_count:1,accumulate_tokens:False
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/ensemble/config.pbtxt triton_max_batch_size:64
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ python3 tools/fill_template.py -i llama_ifb/tensorrt_llm/config.pbtxt triton_max_batch_size:64,decoupled_mode:False,max_beam_width:1,engine_dir:/llama_ifb/tensorrt_llm/1/,max_tokens_in_paged_kv_cache:2560,max_attention_window_size:2560,kv_cache_free_gpu_mem_fraction:0.5,exclude_input_in_output:True,enable_kv_cache_reuse:False,batching_strategy:inflight_batching,max_queue_delay_microseconds:600
I am now ready to build the Triton Inference Server docker container with my newly converted LLM (this step won't be required after the 24.02 launch):
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ DOCKER_BUILDKIT=1 docker build -t triton_trt_llm -f dockerfile/Dockerfile.trt_llm_backend .[+] Building 2572.9s (33/33) FINISHED docker:default => [internal] load build definition from Dockerfile.trt_llm_backend 0.0s => => transferring dockerfile: 2.45kB 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load metadata for nvcr.io/nvidia/tritonserver:23.12-py3 0.7s => [internal] load build context 47.6s => => transferring context: 580.29MB 47.6s => [base 1/6] FROM nvcr.io/nvidia/tritonserver:23.12-py3@sha256:363924e9f3b39154bf2075586145b5d15b20f6d695bd7e8de4448c3299064af0 0.0s => CACHED [base 2/6] RUN apt-get update && apt-get install -y --no-install-recommends rapidjson-dev python-is-python3 ccache git-lfs 0.0s => [base 3/6] COPY requirements.txt /tmp/ 2.0s => [base 4/6] RUN pip3 install -r /tmp/requirements.txt --extra-index-url https://pypi.ngc.nvidia.com 28.1s => [base 5/6] RUN apt-get remove --purge -y tensorrt* 1.6s => [base 6/6] RUN pip uninstall -y tensorrt 0.9s => [dev 1/10] COPY tensorrt_llm/docker/common/install_tensorrt.sh /tmp/ 0.0s => [dev 2/10] RUN bash /tmp/install_tensorrt.sh && rm /tmp/install_tensorrt.sh 228.0s => [dev 3/10] COPY tensorrt_llm/docker/common/install_polygraphy.sh /tmp/ 0.0s => [dev 4/10] RUN bash /tmp/install_polygraphy.sh && rm /tmp/install_polygraphy.sh 2.5s => [dev 5/10] COPY tensorrt_llm/docker/common/install_cmake.sh /tmp/ 0.0s => [dev 6/10] RUN bash /tmp/install_cmake.sh && rm /tmp/install_cmake.sh 3.0s => [dev 7/10] COPY tensorrt_llm/docker/common/install_mpi4py.sh /tmp/ 0.0s => [dev 8/10] RUN bash /tmp/install_mpi4py.sh && rm /tmp/install_mpi4py.sh 38.7s => [dev 9/10] COPY tensorrt_llm/docker/common/install_pytorch.sh install_pytorch.sh 0.0s => [dev 10/10] RUN bash ./install_pytorch.sh pypi && rm install_pytorch.sh 96.6s => [trt_llm_builder 1/4] WORKDIR /app 0.0s => [trt_llm_builder 2/4] COPY scripts scripts 0.0s => [trt_llm_builder 3/4] COPY tensorrt_llm tensorrt_llm 3.0s => [trt_llm_builder 4/4] RUN cd tensorrt_llm && python3 scripts/build_wheel.py --trt_root="/usr/local/tensorrt" -i -c && cd .. 1959.1s => [trt_llm_backend_builder 1/3] WORKDIR /app/ 0.0s => [trt_llm_backend_builder 2/3] COPY inflight_batcher_llm inflight_batcher_llm 0.0s => [trt_llm_backend_builder 3/3] RUN cd inflight_batcher_llm && bash scripts/build.sh && cd .. 68.3s => [final 1/5] WORKDIR /app/ 0.0s => [final 2/5] COPY --from=trt_llm_builder /app/tensorrt_llm/build /app/tensorrt_llm/build 0.1s => [final 3/5] RUN cd /app/tensorrt_llm/build && pip3 install *.whl 22.8s => [final 4/5] RUN mkdir /opt/tritonserver/backends/tensorrtllm 0.4s => [final 5/5] COPY --from=trt_llm_backend_builder /app/inflight_batcher_llm/build/libtriton_tensorrtllm.so /opt/tritonserver/backends/tensorrtllm 0.0s => exporting to image 69.3s => => exporting layers 69.3s => => writing image sha256:03f4164551998d04aefa2817ea4ba9f53737874fc3604e284faa8f75bc99180c 0.0s => => naming to docker.io/library/triton_trt_llm
If I check my docker images, I can see that I now have a new image for the Triton Inference server (this step won't be required either after the 24.02 launch as there won't be a need to build a custom Triton Inference Server container anymore):
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEtriton_trt_llm latest 03f416455199 2 hours ago 53.1GB
I can now start the newly created docker container:
fbronzati@node002:/aipsf600/project-helix/TensonRT-LLM/v0.8.0/tensorrtllm_backend$ docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $(pwd)/llama_ifb:/llama_ifb -v $(pwd)/scripts:/opt/scripts triton_trt_llm:latest bash
=============================== Triton Inference Server ===============================
NVIDIA Release 23.12 (build 77457706)Triton Server Version 2.41.0
Copyright (c) 2018-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.By pulling and using the container, you accept the terms and conditions of this license:https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
root@node002:/app#
After the launch of version 24.02, the name of the container, which is triton_trt_llm here, will change, so you will need to keep an eye out for the new name. I will update this blog with the changes post-launch.
Once the container is started, I will be again at a shell prompt inside the container. I need to log in to Hugginface again:
root@node002:/app# huggingface-cli login --token ******Token will not been saved to git credential helper. Pass `add_to_git_credential=True` if you want to set the git credential as well.Token is valid (permission: read).Your token has been saved to /root/.cache/huggingface/tokenLogin successful
And I can now run the Triton Inference server:
root@node002:/app# python /opt/scripts/launch_triton_server.py --model_repo /llama_ifb/ --world_size 4root@node002:/app# I0131 16:54:40.234909 135 pinned_memory_manager.cc:241] Pinned memory pool is created at '0x7ffd8c000000' with size 268435456I0131 16:54:40.243088 133 pinned_memory_manager.cc:241] Pinned memory pool is created at '0x7ffd8c000000' with size 268435456I0131 16:54:40.252026 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 0 with size 67108864I0131 16:54:40.252033 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 1 with size 67108864I0131 16:54:40.252035 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 2 with size 67108864I0131 16:54:40.252037 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 3 with size 67108864I0131 16:54:40.252040 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 4 with size 67108864I0131 16:54:40.252042 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 5 with size 67108864I0131 16:54:40.252044 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 6 with size 67108864I0131 16:54:40.252046 133 cuda_memory_manager.cc:107] CUDA memory pool is created on device 7 with size 67108864.....I0131 16:57:04.101557 132 server.cc:676]+------------------+---------+--------+| Model | Version | Status |+------------------+---------+--------+| ensemble | 1 | READY || postprocessing | 1 | READY || preprocessing | 1 | READY || tensorrt_llm | 1 | READY || tensorrt_llm_bls | 1 | READY |+------------------+---------+--------+
I0131 16:57:04.691252 132 metrics.cc:817] Collecting metrics for GPU 0: NVIDIA H100 80GB HBM3I0131 16:57:04.691303 132 metrics.cc:817] Collecting metrics for GPU 1: NVIDIA H100 80GB HBM3I0131 16:57:04.691315 132 metrics.cc:817] Collecting metrics for GPU 2: NVIDIA H100 80GB HBM3I0131 16:57:04.691325 132 metrics.cc:817] Collecting metrics for GPU 3: NVIDIA H100 80GB HBM3I0131 16:57:04.691335 132 metrics.cc:817] Collecting metrics for GPU 4: NVIDIA H100 80GB HBM3I0131 16:57:04.691342 132 metrics.cc:817] Collecting metrics for GPU 5: NVIDIA H100 80GB HBM3I0131 16:57:04.691350 132 metrics.cc:817] Collecting metrics for GPU 6: NVIDIA H100 80GB HBM3I0131 16:57:04.691358 132 metrics.cc:817] Collecting metrics for GPU 7: NVIDIA H100 80GB HBM3I0131 16:57:04.728148 132 metrics.cc:710] Collecting CPU metricsI0131 16:57:04.728434 132 tritonserver.cc:2483]+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Option | Value |+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+| server_id | triton || server_version | 2.41.0 || server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_ || | tensor_data parameters statistics trace logging || model_repository_path[0] | /llama_ifb/ || model_control_mode | MODE_NONE || strict_model_config | 1 || rate_limit | OFF || pinned_memory_pool_byte_size | 268435456 || cuda_memory_pool_byte_size{0} | 67108864 || cuda_memory_pool_byte_size{1} | 67108864 || cuda_memory_pool_byte_size{2} | 67108864 || cuda_memory_pool_byte_size{3} | 67108864 || cuda_memory_pool_byte_size{4} | 67108864 || cuda_memory_pool_byte_size{5} | 67108864 || cuda_memory_pool_byte_size{6} | 67108864 || cuda_memory_pool_byte_size{7} | 67108864 || min_supported_compute_capability | 6.0 || strict_readiness | 1 || exit_timeout | 30 || cache_enabled | 0 |+----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0131 16:57:04.738042 132 grpc_server.cc:2495] Started GRPCInferenceService at 0.0.0.0:8001I0131 16:57:04.738303 132 http_server.cc:4619] Started HTTPService at 0.0.0.0:8000I0131 16:57:04.779541 132 http_server.cc:282] Started Metrics Service at 0.0.0.0:8002
Again, I have removed some of the output lines to keep things within a reasonable size. Once the start sequence has completed, I can see that the Triton Inference server is listening on port 8000, so let's test it, right?
Let's ask the LLama 2 model running within the Triton Inference Server what the capital of Texas in the US is:
root@node002:/app# curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": " <s>[INST] <<SYS>> You are a helpful assistant <</SYS>> What is the capital of Texas?[/INST]","parameters": {"max_tokens": 100,"bad_words":[""],"stop_words":[""],"temperature":0.2,"top_p":0.7}}'
Because I am running the curl command directly from inside the container running the Triton Inference server, I am using localhost as the endpoint. If you are running the curl command from outside of the container, then localhost will need to be replace by the proper hostname. This is the response I got:
{"context_logits":0.0,"cum_log_probs":0.0,"generation_logits":0.0,"model_name":"ensemble","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],"sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":" Sure, I'd be happy to help! The capital of Texas is Austin."}
Yay! It works and I got the right answer from the LLM.
Conclusion
If you have reached this point in the blog, thank you for staying with me. Taking a large language model from Huggingface (that is in one of the supported models) and running it in the NVIDIA Triton Inference server allows customers to leverage the automation and simplicity built into the NVIDIA Triton Inference server. All while retaining the flexibility to choose the large language model that best meets their needs. It is almost like have your cake and eat it to.
Until next time, thank you for reading.

MLPerf™ Inference 4.0 on Dell PowerEdge Server with Intel® 5th Generation Xeon® CPU



Mon, 22 Apr 2024 05:40:38 -0000
|Read Time: 0 minutes
Introduction
In this blog, we present the MLPerf™ v4.0 Data Center Inference results obtained on a Dell PowerEdge R760 with the latest 5th Generation Intel® Xeon® Scalable Processors (a CPU only system).
These new Intel® Xeon® processors use an Intel® AMX matrix multiplication engine in each core to boost overall inferencing performance. With a focus on ease of use, Dell Technologies delivers exceptional CPU performance results out of the box with an optimized BIOS profile that fully unleashes the power of Intel’s OneDNN software – a software which is fully integrated with both PyTorch and TensorFlow frameworks. The server configurations and the CPU specifications in the benchmark experiments are shown in Tables 1 and 2, respectively.
Table 1. Dell PowerEdge R760 Server Configuration
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 5th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 64 |
Host Processor Frequency | 1.9 GHz, 3.9 GHz Turbo Boost |
Host Memory Capacity | 2 TB, 16 x 128 GB 5600 MT/s |
Host Storage Capacity | 7.68TB, NVME |
Table 2. 5th Generation Intel® Xeon® Scalable Processor Technical Specifications
Product Collection | 5th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8592+ |
Status | Launched |
# of CPU Cores | 64 |
# of Threads | 128 |
Base Frequency | 1.9 GHz |
Max Turbo Speed | 3.9 GHz |
Cache L3 | 320 MB |
Memory Type | DDR5 5600 MT/s |
ECC Memory Supported | Yes |
MLPerf™ Inference v4.0 - Datacenter
The MLPerf™ inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios. There are two benchmark suites, one for Datacenter systems and one for Edge. Figure 1 shows the 7 models with each targeting at different task in the official release v4.0 for Datacenter systems category that were run on this PowerEdge R760 and submitted in the closed category. The dataset and quality target are defined for each model for benchmarking, as listed in Table 3.
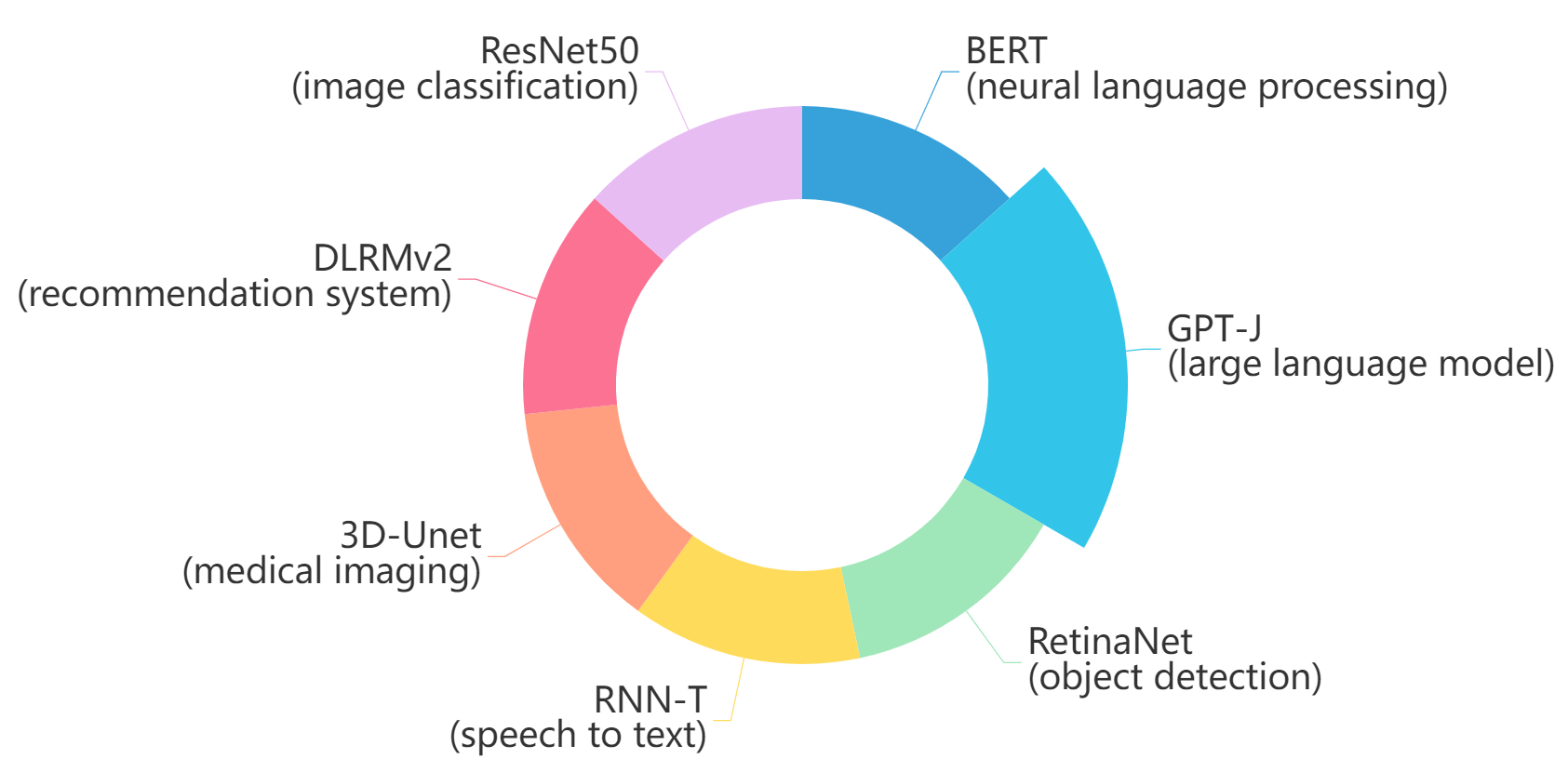
Figure 1. Benchmarked models for MLPerf™ datacenter inference v4.0
Table 3. Datacenter Suite Benchmarks. Source: MLCommons™
Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
Vision | Image classification | ResNet50-v1.5 | ImageNet (224x224) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection | RetinaNet | OpenImages (800x800) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical imaging | 3D-Unet | KITS 2019 (602x512x512) | 16 | 99.9% of FP32 (0.86330 mean DICE score) | N/A |
Speech | Speech-to-text | RNN-T | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT-large | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Language | Summarization | GPT-J | CNN Dailymail (v3.0.0, max_seq_len=2048) | 13368 | 99% of FP32 (f1_score=80.25% rouge1=42.9865, rouge2=20.1235, rougeL=29.9881). | 20 s |
Commerce | Recommendation | DLRMv2 | Criteo 4TB multi-hot | 204800 | 99% of FP32 (AUC=80.25%) | 60 ms |
Scenarios
The models are deployed in a variety of critical inference applications or use cases known as “scenarios” where each scenario requires different metrics, demonstrating production environment performance in practice. Following is the description of each scenario. Table 4 shows the scenarios required for each Datacenter benchmark included in this submission v4.0.
Offline scenario: represents applications that process the input in batches of data available immediately and do not have latency constraints for the metric performance measured in samples per second.
Server scenario: represents deployment of online applications with random input queries. The metric performance is measured in queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation. This complexity is reflected in the throughput-degradation results compared to the offline scenario.
Each Datacenter benchmark requires the following scenarios:
Table 4. Datacenter Suite Benchmark Scenarios. Source: MLCommons™
Area | Task | Required Scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection | Server, Offline |
Vision | Medical imaging | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Language | Summarization | Server, Offline |
Commerce | Recommendation | Server, Offline |
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5.
Table 5. System Configuration
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Kernel | 6.7.4-1.el8.elrepo.x86_64 |
Intel® Optimized Inference SW for MLPerf™ | MLPerf™ Intel® OneDNN integrated with Intel® Extension for PyTorch (IPEX) |
ECC memory mode | ON |
Host memory configuration | 2TB, 16 x 128 GB, 1 DIMM per channel, well balanced |
Turbo mode | ON |
CPU frequency governor | Performance |
What is Intel® AMX (Advanced Matrix Extensions)?
Intel® AMX is a built-in accelerator that enables 5th Gen Intel® Xeon® Scalable processors to optimize deep learning (DL) training and inferencing workloads. With the high-speed matrix multiplications enabled by Intel® AMX, 5th Gen Intel® Xeon® Scalable processors can quickly pivot between optimizing general computing and AI workloads.
Imagine an automobile that could excel at city driving and then quickly shift to deliver Formula 1 racing performance. 5th Gen Intel® Xeon® Scalable processors deliver this level of flexibility. Developers can code AI functionality to take advantage of the Intel® AMX instruction set as well as code non-AI functionality to use the processor instruction set architecture (ISA). Intel® has integrated the oneAPI Deep Neural Network Library (oneDNN) – its oneAPI DL engine – into popular open-source tools for AI applications, including TensorFlow, PyTorch, PaddlePaddle, and ONNX.
AMX architecture
Intel® AMX architecture consists of two components, as shown in Figure 1:
- Tiles consist of eight two-dimensional registers, each 1 kilobyte in size. They store large chunks of data.
- Tile Matrix Multiplication (TMUL) is an accelerator engine attached to the tiles that performs matrix-multiply computations for AI.
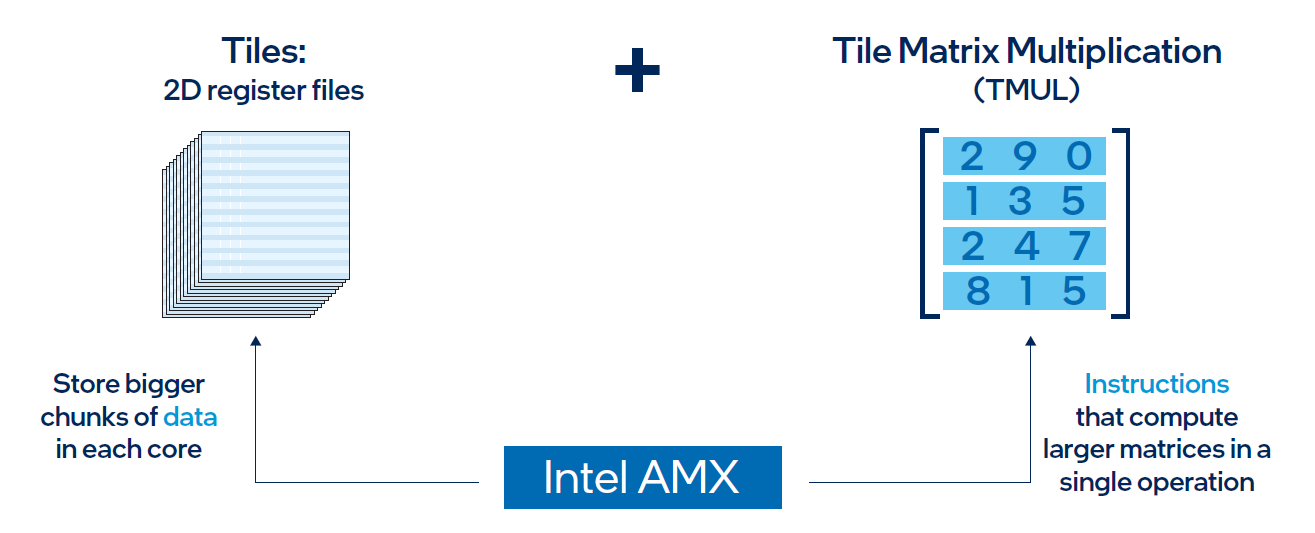
Figure 2. Intel® AMX architecture consists of 2D register files (tiles) and TMUL
Results
Both MLPerf™ v3.1 and MLPerf™ v4.0 benchmark results are based on the Dell R760 server but with different generations of Xeon® CPUs (4th Generation Intel® Xeon® CPUs for MLPerf™ v3.1 versus 5th Generation Intel® Xeon® CPUs for MLPerf™ v4.0) and optimized software stacks. In this section, we show the performance in the comparing mode so the improvement from the last submission can be easily observed.
Comparing Performance from MLPerfTM v4.0 to MLPerfTM v3.1
ResNet50 server & offline scenarios:
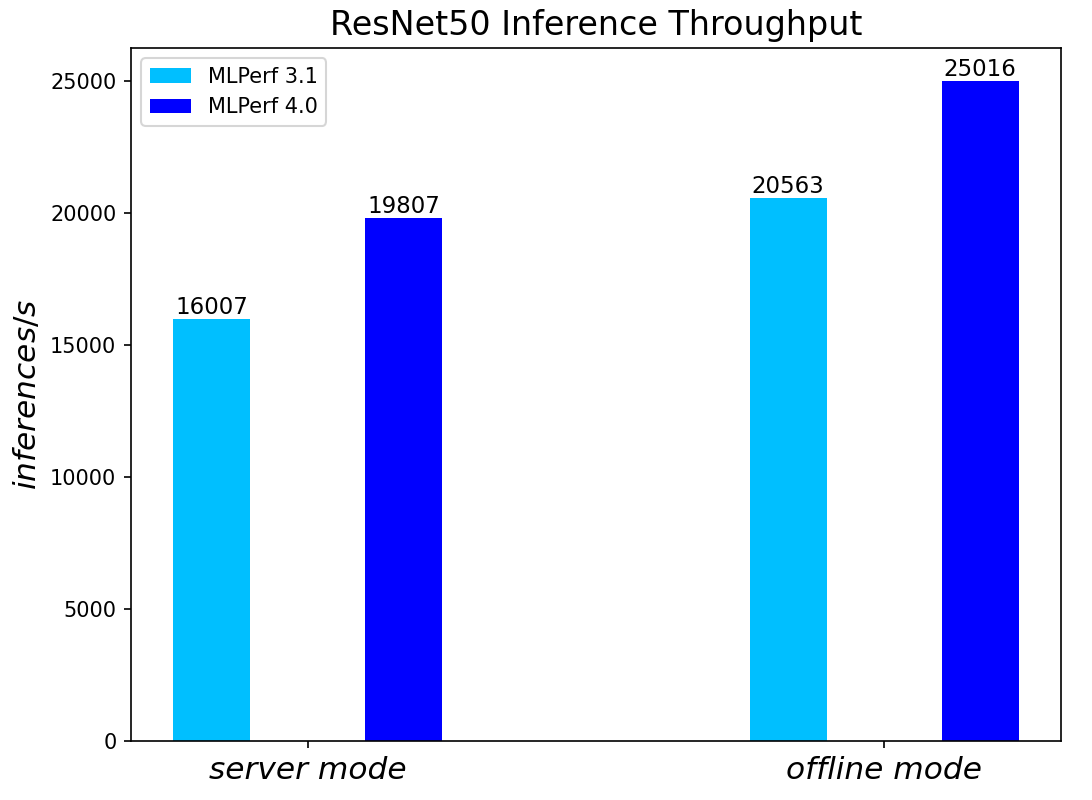
Figure 3. ResNet50 inference throughput in server and offline scenarios
BERT Large Language Model server & offline scenarios:
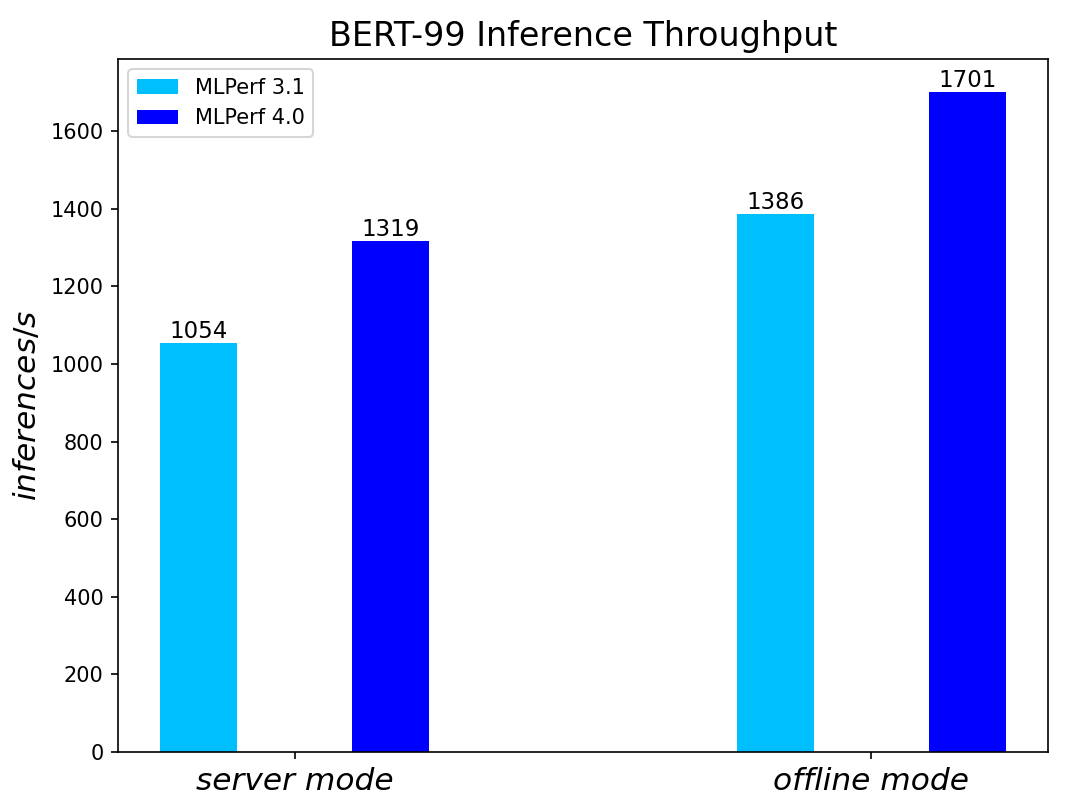
Figure 4. BERT Inference results for server and offline scenarios
RetinaNet Object Detection Model server & offline scenarios:
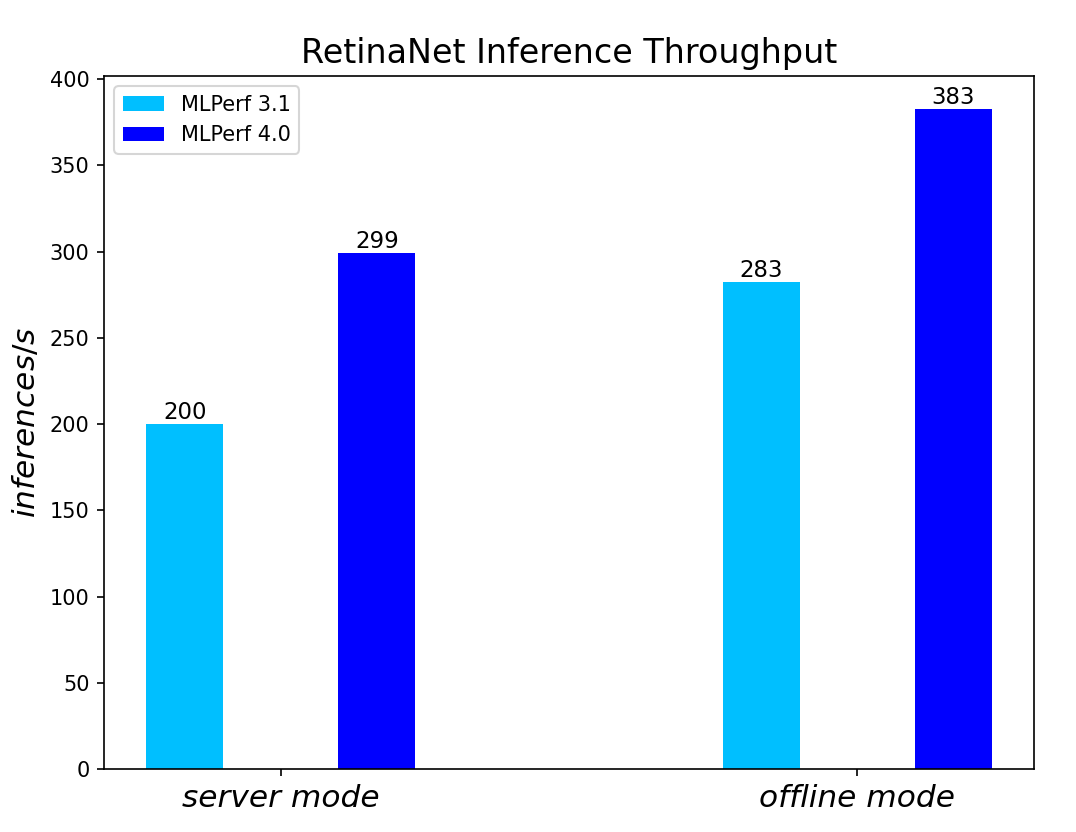
Figure 5. RetinaNet Object Detection Model Inference results for server and offline scenarios
RNN-T Text to Speech Model server & offline scenarios:
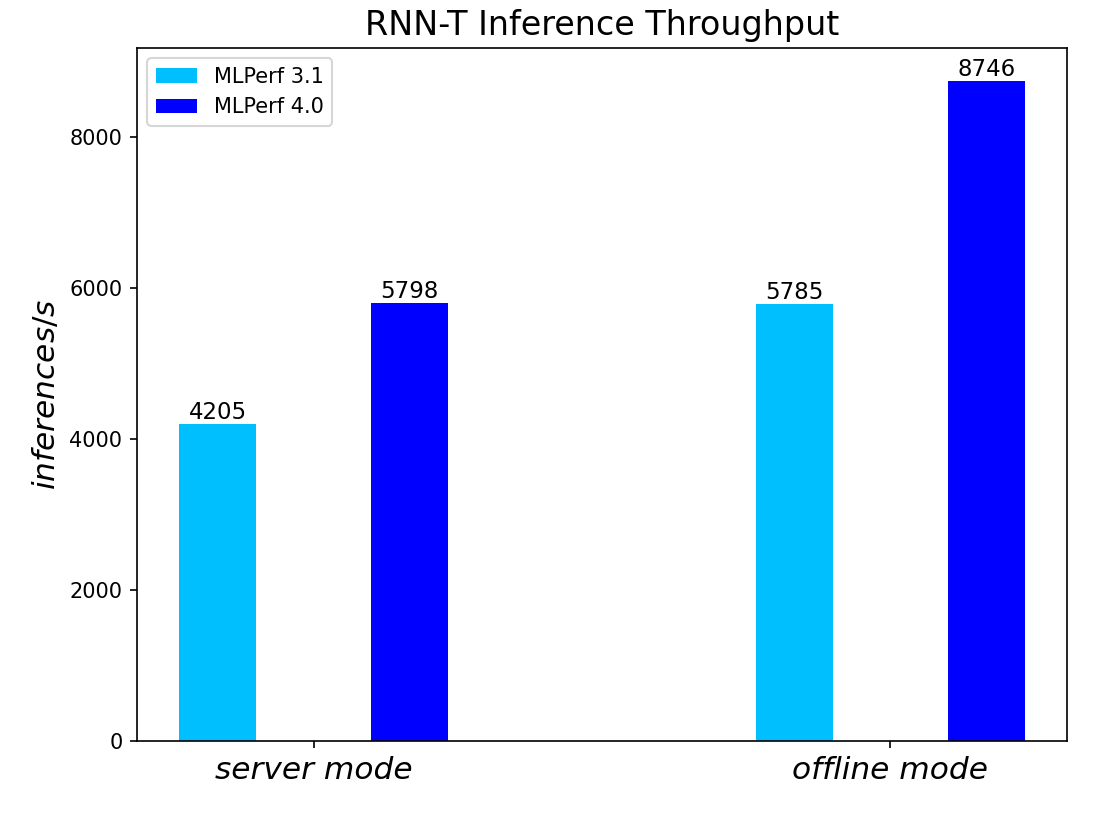
Figure 6. RNN-T Text to Speech Model Inference results for server and offline scenarios
3D-Unet Medical Imaging Model offline scenarios:
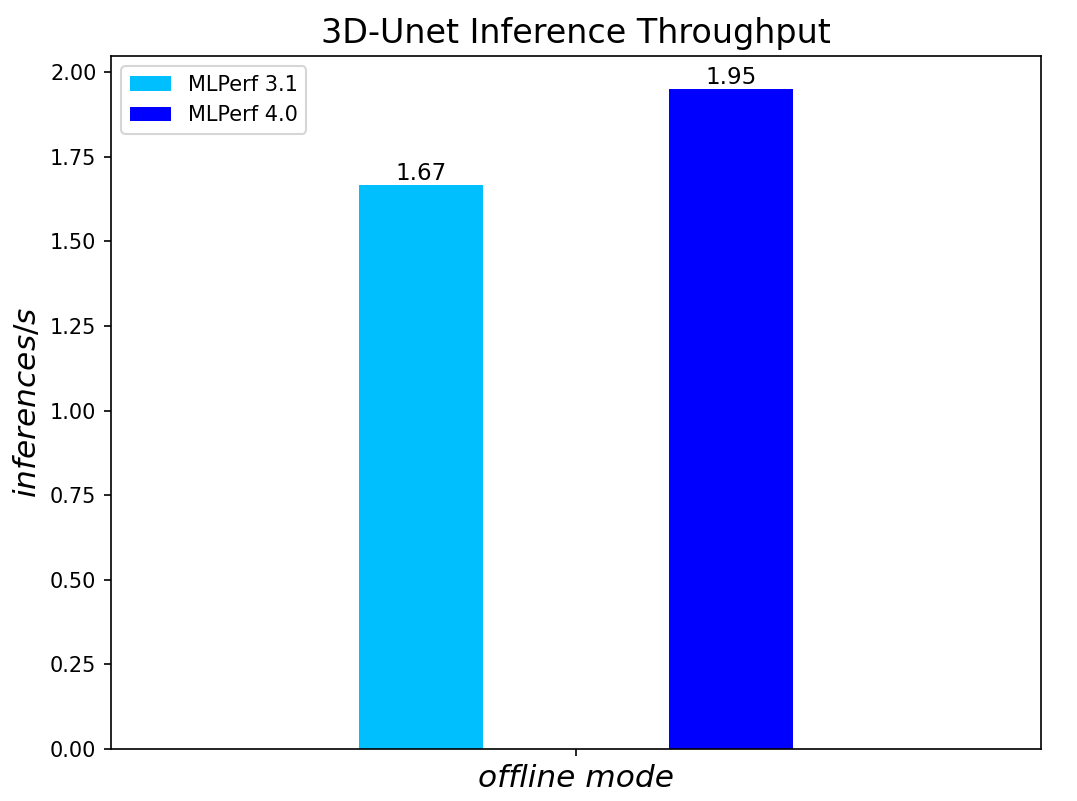
Figure 7. 3D-Unet Medical Imaging Model Inferencing results for server and offline scenarios
DLRMv2-99 Recommendation Model server & offline scenarios:
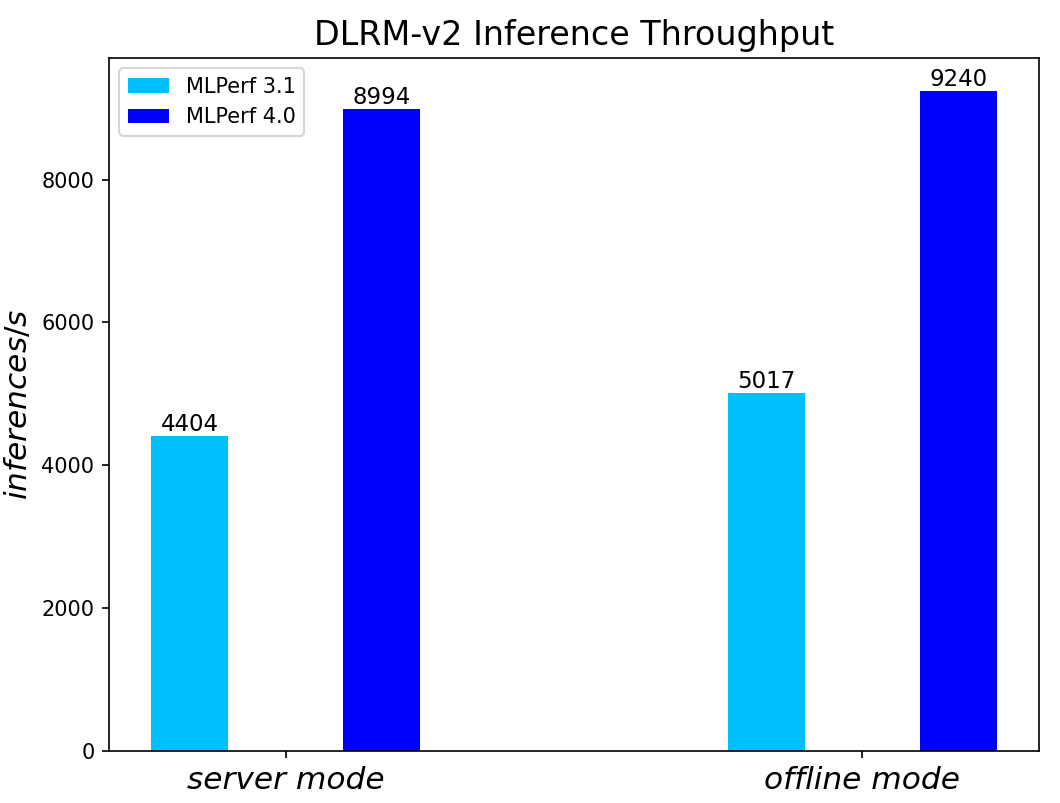
Figure 8. DLRMv2-99 Recommendation Model Inference results for server and offline scenarios
GPT-J-99 Summarization Model server & offline scenarios:
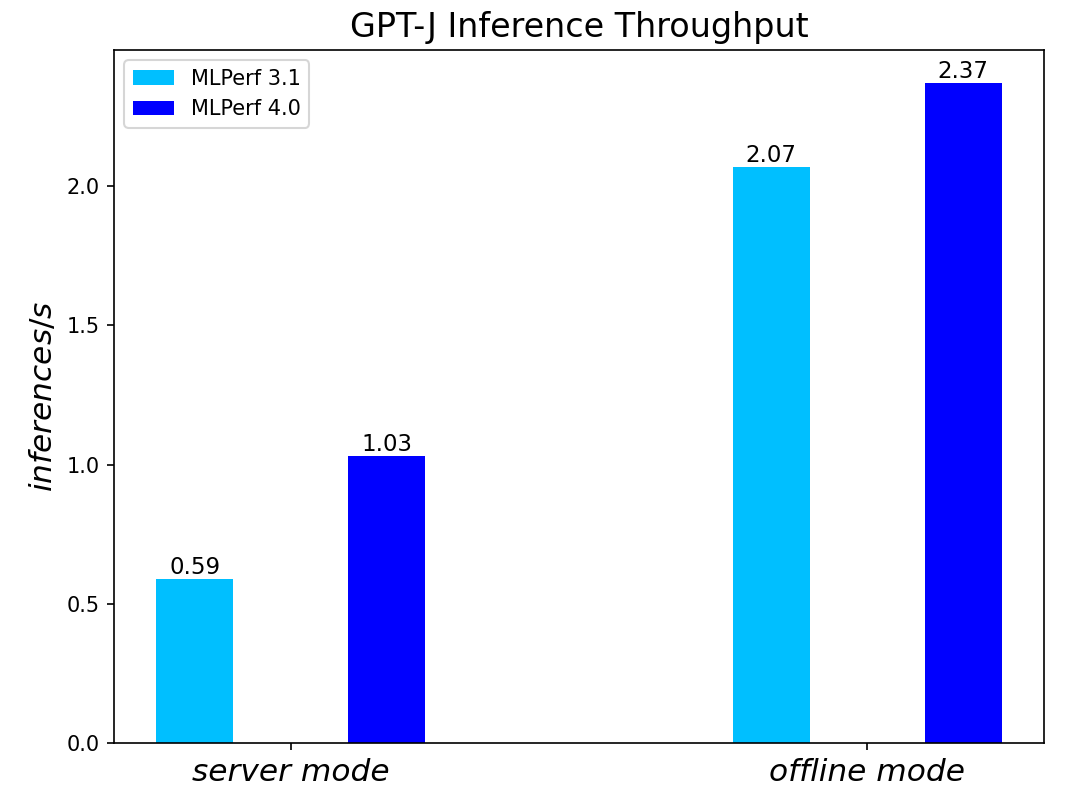
Figure 9. GPT-J-99 Summarization Model Inference results for server and offline scenarios
Conclusion
- The PowerEdge R760 server with 5th Generation Intel® Xeon® Scalable Processors produces strong data center inference performance, confirmed by the official version 4.0 MLPerfTM benchmarking results from MLCommonsTM.
- The high performance and versatility are demonstrated across natural language processing, image classification, object detection, medical imaging, speech-to-text inference, recommendation, and summarization systems.
- Compared to its prior version 3.0 and 3.1 submissions enabled by 4th Generation Intel® Xeon® Scalable Processors, the R760 with 5th Generation Intel® Xeon® Scalable Processors show significant performance improvement across different models, including the generative AI models like GPT-J.
- The R760 supports different deep learning inference scenarios in the MLPerfTM benchmark scenarios as well as other complex workloads such as database and advanced analytics. It is an ideal solution for data center modernization to drive operational efficiency, lead to higher productivity, and minimize total cost of ownership (TCO).
References
MLCommonsTM MLPerfTM v4.0 Inference Benchmark Submission IDs
ID | Submitter | System |
4.0-0026 | Dell | Dell PowerEdge Server R760 (2x Intel® Xeon® Platinum 8592+) |
MLPerf™ Inference v4.0 Performance on Dell PowerEdge R760xa and R7615 Servers with NVIDIA L40S GPUs
Fri, 05 Apr 2024 17:41:56 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf™ Inference v4.0 benchmark suite. This blog highlights Dell Technologies’ closed division submission made for the Dell PowerEdge R760xa, Dell PowerEdge R7615, and Dell PowerEdge R750xa servers with NVIDIA L40S and NVIDIA A100 GPUs.
Introduction
This blog provides relevant conclusions about the performance improvements that are achieved on the PowerEdge R760xa and R7615 servers with the NVIDIA L40S GPU compared to the PowerEdge R750xa server with the NVIDIA A100 GPU. In the following comparisons, we held the GPU constant across the PowerEdge R760xa and PowerEdge R7615 servers to show the excellent performance of the NVIDIA L40S GPU. Additionally, we also compared the PowerEdge R750xa server with the NVIDIA A100 GPU to its successor the PowerEdge R760xa server with the NVIDIA L40S GPU.
System Under Test configuration
The following table shows the System Under Test (SUT) configuration for the PowerEdge servers.
Table 1: SUT configuration of the Dell PowerEdge R750xa, R760xa, and R7615 servers for MLPerf Inference v4.0
Server | PowerEdge R750xa | PowerEdge R760xa | PowerEdge R7615 |
MLPerf Version | V4.0
| ||
GPU | NVIDIA A100 PCIe 80 GB | NVIDIA L40S
| |
Number of GPUs | 4 | 2 | |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | R760xa_L40Sx4_TRT | R7615_L40Sx2_TRT
|
CPU | 2 x Intel Xeon Gold 6338 CPU @ 2.00GHz | 2 x Intel Xeon Platinum 8470Q | 1 x AMD EPYC 9354 32-Core Processor |
Memory | 512 GB | ||
Software Stack | TensorRT 9.3.0 CUDA 12.2 cuDNN 8.9.2 Driver 535.54.03 / 535.104.12 DALI 1.28.0 | ||
The following table lists the technical specifications of the NVIDIA L40S and NVIDIA A100 GPUs.
Table 2: Technical specifications of the NVIDIA A100 and NVIDIA L40S GPUs
Model | NVIDIA A100 | NVIDIA L40S | ||
Form factor | SXM4 | PCIe Gen4 | PCIe Gen4 | |
GPU architecture | Ampere | Ada Lovelace | ||
CUDA cores | 6912 | 18176 | ||
Memory size | 80 GB | 48 GB | ||
Memory type | HBM2e | HBM2e | ||
Base clock | 1275 MHz | 1065 MHz | 1110 MHz | |
Boost clock | 1410 MHz | 2520 MHz | ||
Memory clock | 1593 MHz | 1512 MHz | 2250 MHz | |
MIG support | Yes | No | ||
Peak memory bandwidth | 2039 GB/s | 1935 GB/s | 864 GB/s | |
Total board power | 500 W | 300 W | 350 W | |
Dell PowerEdge R760xa server
The PowerEdge R760xa server shines as an Artificial Intelligence (AI) workload server with its cutting-edge inferencing capabilities. This server represents the pinnacle of performance in the AI inferencing space with its processing prowess enabled by Intel Xeon Platinum processors and NVIDIA L40S GPUs. Coupled with NVIDIA TensorRT and CUDA 12.2, the PowerEdge R760xa server is positioned perfectly for any AI workload including, but not limited to, Large Language Models, computer vision, Natural Language Processing, robotics, and edge computing. Whether you are processing image recognition tasks, natural language understanding, or deep learning models, the PowerEdge R760xa server provides the computational muscle for reliable, precise, and fast results.

Figure 1: Front view of the Dell PowerEdge R760xa server

Figure 2: Top view of the Dell PowerEdge R760xa server
Dell PowerEdge R7615 server
The PowerEdge R7615 server stands out as an excellent choice for AI, machine learning (ML), and deep learning (DL) workloads due to its robust performance capabilities and optimized architecture. With its powerful processing capabilities including up to three NVIDIA L40S GPUs supported by TensorRT, this server can handle complex neural network inference and training tasks with ease. Powered by a single AMD EPYC processor, this server performs well for any demanding AI workloads.

Figure 3: Front view of the Dell PowerEdge R7615 server

Figure 4: Top view of the Dell PowerEdge R7615 server
Dell PowerEdge R750xa server
The PowerEdge R750xa server is a perfect blend of technological prowess and innovation. This server is equipped with Intel Xeon Gold processors and the latest NVIDIA GPUs. The PowerEdge R760xa server is designed for the most demanding AI, ML, and DL workloads as it is compatible with the latest NVIDIA TensorRT engine and CUDA version. With up to nine PCIe Gen4 slots and availability in a 1U or 2U configuration, the PowerEdge R750xa server is an excellent option for any demanding workload.

Figure 5: Front view of the Dell PowerEdge R750xa server

Figure 6: Top view of the Dell PowerEdge R750xa server
Performance results
Classical Deep Learning models performance
The following figure presents the results as a ratio of normalized numbers over the Dell PowerEdge R750xa server with four NVIDIA A100 GPUs. This result provides an easy-to-read comparison of three systems and several benchmarks.
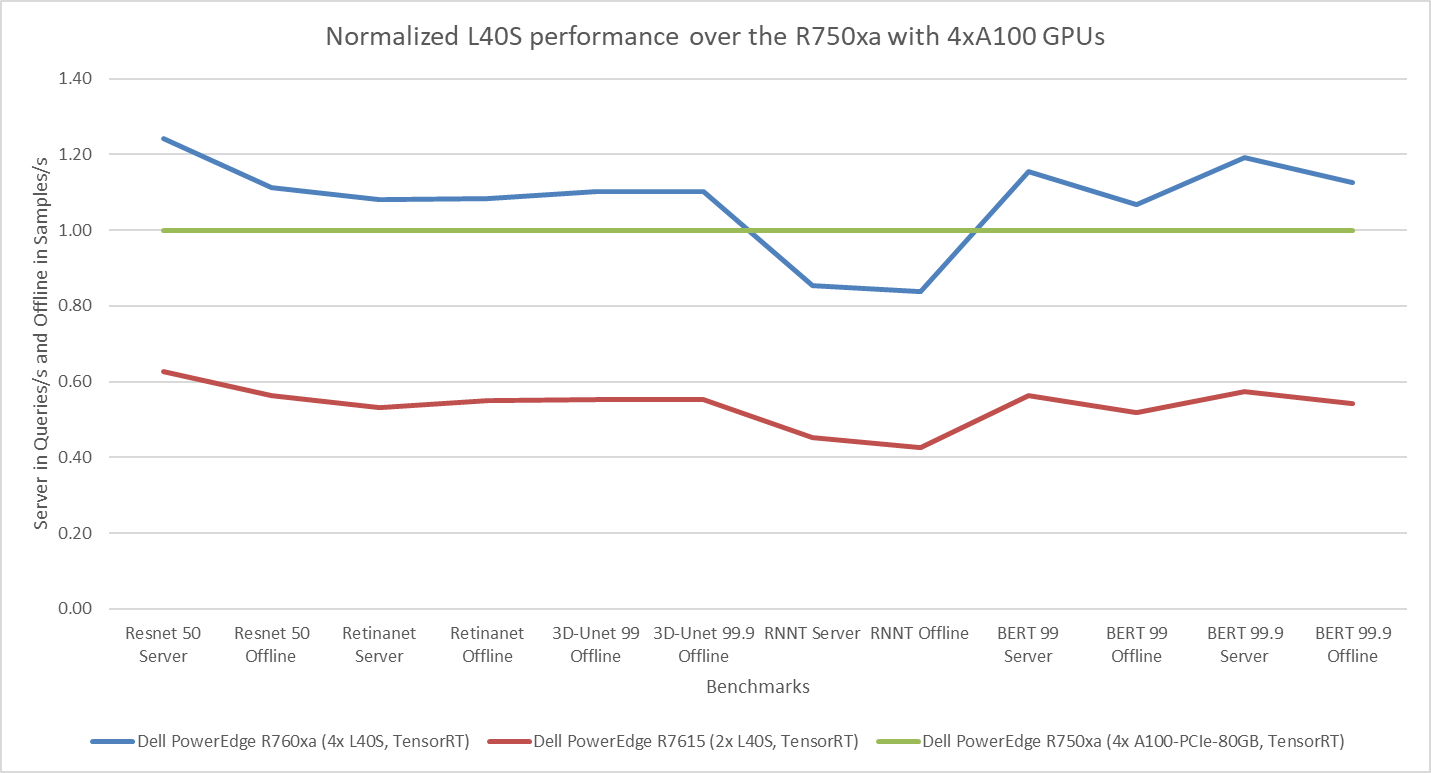
Figure 7: Normalized NVIDIA L40S GPU performance over the PowerEdge R750xa server with four A100 GPUs
The green trendline represents the performance of the Dell PowerEdge R750xa server with four NVIDIA A100 GPUs. With a score of 1.00 for each benchmark value, the results have been divided by themselves to serve as the baseline in green for this comparison. The blue trendline represents the performance of the PowerEdge R760xa server with four NVIDIA L40S GPUs that has been normalized by dividing each benchmark result by the corresponding score achieved by the PowerEdge R750xa server. In most cases, the performance achieved on the PowerEdge R760xa server outshines the results of the PowerEdge R750xa server with NVIDIA A100 GPUs, proving the expected improvements from the NVIDIA L40S GPU. The red trendline has also been normalized over the PowerEdge R750xa server and represents the performance of the PowerEdge R7615 server with two NVIDIA L40S GPUs. It is interesting that the red line almost mimics the blue line. This result suggests that the PowerEdge R7615 server, despite having half the compute resources, still performs comparably well in most cases, showing its efficiency.
Generative AI performance
The latest submission saw the introduction of the new Stable Diffusion XL benchmark. In the context of generative AI, stable diffusion is a text to image model that generates coherent image samples. This result is achieved gradually by refining and spreading out information throughout the generation process. Consider the example of dropping food coloring into a large bucket of water. Initially, only a small, concentrated portion of the water turns color, but gradually the coloring is evenly distributed in the bucket.
The following table shows the excellent performance of the PowerEdge R760xa server with the powerful NVIDIA L40S GPU for the GPT-J and Stable Diffusion XL benchmarks. The PowerEdge R760xa takes the top spot in GPT-J and Stable Diffusion XL when compared to other NVIDIA L40S results.
Table 3: Benchmark results for the PowerEdge R760xa server with the NVIDIA L40S GPU
Benchmark | Dell PowerEdge R760xa L40S result (Server in Queries/s and Offline in Samples/s) | Dell’s % gain to the next best non-Dell results (%) |
Stable Diffusion XL Server | 0.65 | 5.24 |
Stable Diffusion XL Offline | 0.67 | 2.28 |
GPT-J 99 Server | 12.75 | 4.33 |
GPT-J 99 Offline | 12.61 | 1.88 |
GPT-J 99.9 Server | 12.75 | 4.33 |
GPT-J 99.9 Offline | 12.61 | 1.88 |
Conclusion
The MLPerf Inference submissions elicit insightful like-to-like comparisons. This blog highlights the impressive performance of the NVIDIA L40S GPU in the Dell PowerEdge R760xa and PowerEdge R7615 servers. Both servers performed well when compared to the performance of the Dell PowerEdge R750xa server with the NVIDIA A100 GPU. The outstanding performance improvements in the NVIDIA L40S GPU coupled with the Dell PowerEdge server position Dell customers to succeed in AI workloads. With the advent of the GPT-J and Stable diffusion XL Models, the Dell PowerEdge server is well positioned to handle Generative AI workloads.
Dell PowerEdge Servers Unleash Another Round of Excellent Results with MLPerf™ v4.0 Inference
Wed, 27 Mar 2024 15:12:53 -0000
|Read Time: 0 minutes
Today marks the unveiling of MLPerf v4.0 Inference results, which have emerged as an industry benchmark for AI systems. These benchmarks are responsible for assessing the system-level performance consisting of state-of-the-art hardware and software stacks. The benchmarking suite contains image classification, object detection, natural language processing, speech recognition, recommenders, medical image segmentation, LLM 6B and LLM 70B question answering, and text to image benchmarks that aim to replicate different deployment scenarios such as the data center and edge.
Dell Technologies is a founding member of MLCommons™ and has been actively making submissions since the inception of the Inference and Training benchmarks. See our MLPerf™ Inference v2.1 with NVIDIA GPU-Based Benchmarks on Dell PowerEdge Servers white paper that introduces the MLCommons Inference benchmark.
Our performance results are outstanding, serving as a clear indicator of our resolve to deliver outstanding system performance. These improvements enable higher system performance when it is most needed, for example, for demanding generative AI (GenAI) workloads.
What is new with Inference 4.0?
Inference 4.0 and Dell’s submission include the following:
- Newly introduced Llama 2 question answering and text to image stable diffusion benchmarks, and submission across different Dell PowerEdge XE platforms.
- Improved GPT-J (225 percent improvement) and DLRM-DCNv2 (100 percent improvement) performance. Improved throughput performance of the GPTJ and DLRM-DCNv2 workload means faster natural language processing tasks like summarization and faster relevant recommendations that allow a boost to revenue respectively.
- First-time submission of server results with the recently released PowerEdge R7615 and PowerEdge XR8620t servers with NVIDIA accelerators.
- Besides accelerator-based results, Intel-based CPU-only results.
- Results for PowerEdge servers with Qualcomm accelerators.
- Power results showing high performance/watt scores for the submissions.
- Virtualized results on Dell servers with Broadcom.
Overview of results
Dell Technologies delivered 187 data center, 28 data center power, 42 edge, and 24 edge power results. Some of the more impressive results were generated by our:
- Dell PowerEdge XE9680, XE9640, XE8640, and servers with NVIDIA H100 Tensor Core GPUs
- Dell PowerEdge R7515, R750xa, and R760xa servers with NVIDIA L40S and A100 Tensor Core GPUs
- Dell PowerEdge XR7620 and XR8620t servers with NVIDIA L4 Tensor Core GPUs
- Dell PowerEdge R760 server with Intel Emerald Rapids CPUs
- Dell PowerEdge R760 with Qualcomm QAIC100 Ultra accelerators
NVIDIA-based results include the following GPUs:
- Eight-way NVIDIA H100 GPU (SXM)
- Four-way NVIDIA H100 GPU (SXM)
- Four-way NVIDIA A100 GPU (PCIe)
- Four-way NVIDIA L40S GPU (PCIe)
- NVIDIA L4 GPU
These accelerators were benchmarked on different servers such as PowerEdge XE9680, XE8640, XE9640, R760xa, XR7620, and XR8620t servers across data center and edge suites.
Dell contributed to about 1/4th of the closed data center and edge submissions. The large number of result choices offers end users an opportunity to make data-driven purchase decisions and set performance and data center design expectations.
Interesting Dell data points
The most interesting data points include:
- Performance results across different benchmarks are excellent and show that Dell servers meet the increasing need to serve different workload types.
- Among 20 submitters, Dell Technologies was one of the few companies that covered all benchmarks in the closed division for data center suites.
- The PowerEdge XE8640 and PowerEdge XE9640 servers compared to other four-way systems procured winning titles across all the benchmarks including the newly launched stable diffusion and Llama 2 benchmark.
- The PowerEdge XE9680 server compared to other eight-way systems procured several winning titles for benchmarks such as ResNet Server, 3D-Unet, BERT-99, and BERT-99.9 Server.
- The PowerEdge XE9680 server delivers the highest performance/watt compared to other submitters with 8-way NVIDIA H100 GPUs for ResNet Server, GPTJ Server, and Llama 2 Offline
- The Dell XR8620t server for edge benchmarks with NVIDIA L4 GPUs outperformed other submissions.
- The PowerEdge R750xa server with NVIDIA A100 PCIe GPUs outperformed other submissions on the ResNet, RetinaNet, 3D-Unet, RNN-T, BERT 99.9, and BERT 99 benchmarks.
- The PowerEdge R760xa server with NVIDIA L40S GPUs outperformed other submissions on the ResNet Server, RetinaNet Server, RetinaNet Offline, 3D-UNet 99, RNN-T, BERT-99, BERT-99.9, DLRM-v2-99, DLRM-v2-99.9, GPTJ-99, GPTJ-99.9, Stable Diffusion XL Server, and Stable Diffusion XL Offline benchmarks.
Highlights
The following figure shows the different Offline and Server performance scenarios in the data center suite. These results provide an overview; follow-up blogs will provide more details about the results.
The following figure shows that these servers delivered excellent performance for all models in the benchmark such as ResNet, RetinaNet, 3D-UNet, RNN-T, BERT, DLRM-v2, GPT-J, Stable Diffusion XL, and Llama 2. Note that different benchmarks operate on varied scales. They have all been showcased in an exponentially scaled y-axis in the following figure:
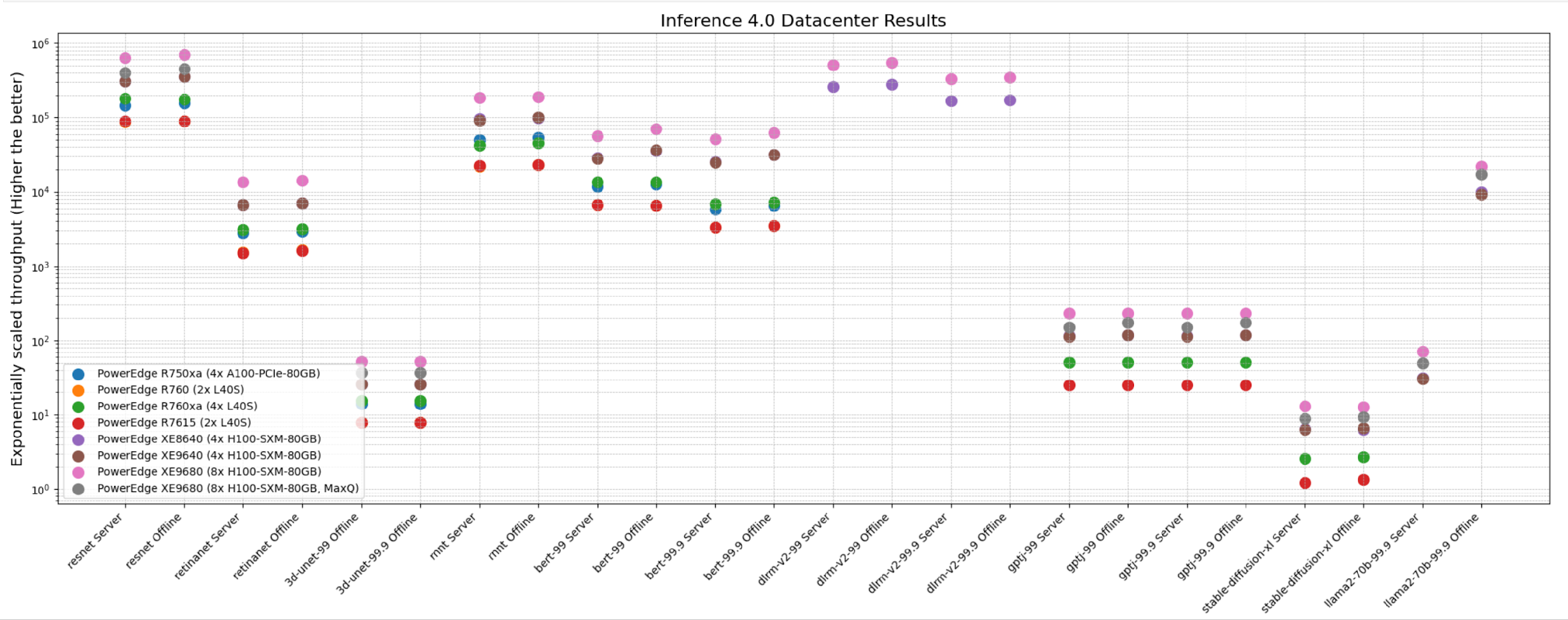
Figure 1: System throughput for submitted systems for the data center suite.
The following figure shows single-stream and multistream scenario results for the edge for ResNet, RetinaNet, 3D-Unet, RNN-T, BERT 99, GPTJ, and Stable Diffusion XL benchmarks. The lower the latency, the better the results and for Offline scenario, higher the better.
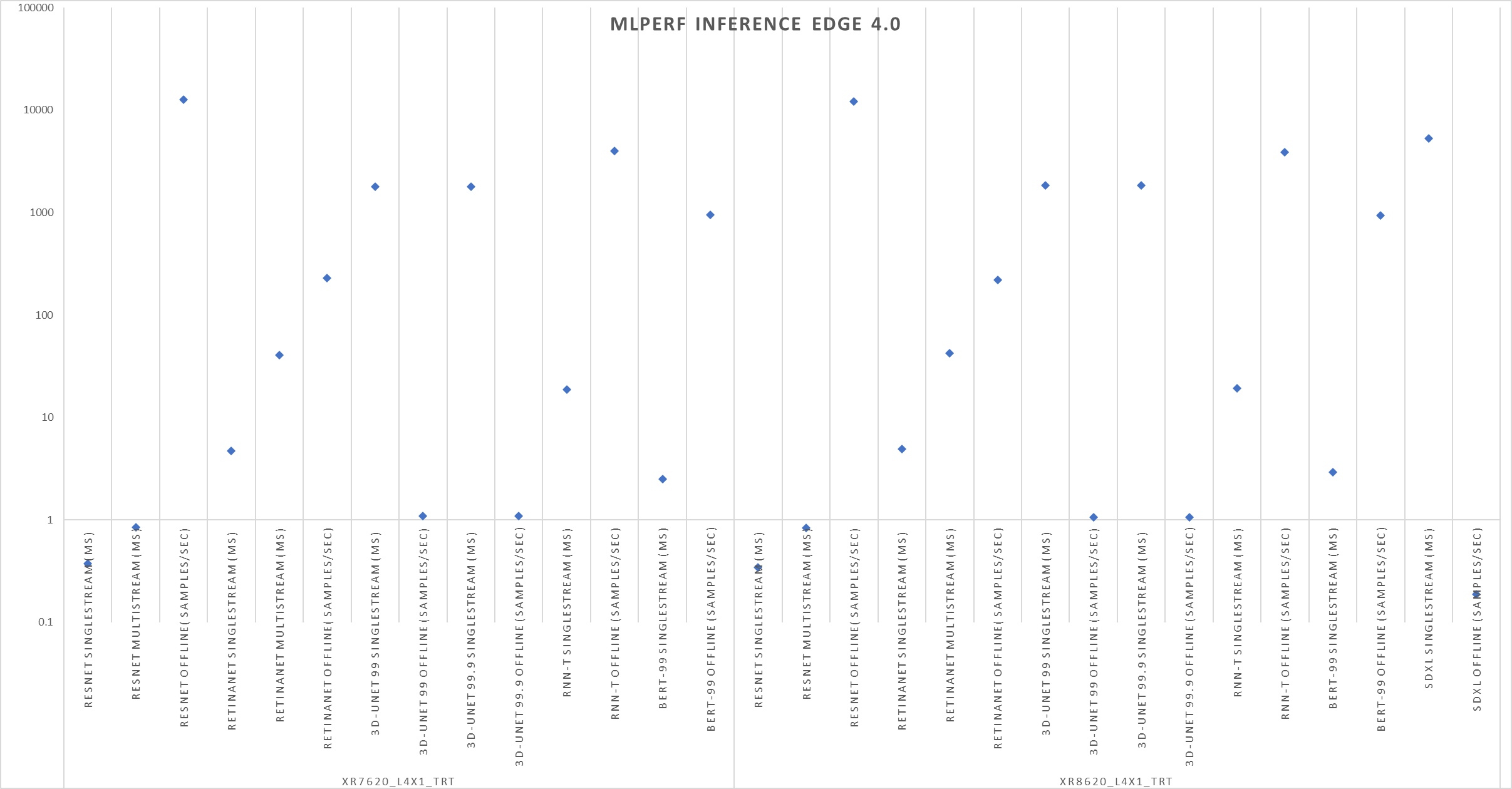
Figure 2: Edge results with PowerEdge XR7620 and XR8620t servers overview
Conclusion
The preceding results were officially submitted to MLCommons. They are MLPerf-compliant results for the Inference v4.0 benchmark across various benchmarks and suites for all the tasks in the benchmark such as image classification, object detection, natural language processing, speech recognition, recommenders, medical image segmentation, LLM 6B and LLM 70B question answering, and text to image. These results prove that Dell PowerEdge XE9680, XE8640, XE9640, and R760xa servers are capable of delivering high performance for inference workloads. Dell Technologies secured several #1 titles that make Dell PowerEdge servers an excellent choice for data center and edge inference deployments. End users can benefit from the plethora of submissions that help make server performance and sizing decisions, which ultimately deliver enterprises’ AI transformation and shows Dell’s commitment to deliver higher performance.
MLCommons Results
https://mlcommons.org/en/inference-datacenter-40/
https://mlcommons.org/en/inference-edge-40/
The preceding graphs are MLCommons results for MLPerf IDs from 4.0-0025 to 4.0-0035 on the closed datacenter, 4.0-0036 to 4.0-0038 on the closed edge, 4.0-0033 in the closed datacenter power, and 4.0-0037 in closed edge power.

Get started building RAG pipelines in your enterprise with Dell Technologies and NVIDIA (Part 1)
Wed, 24 Apr 2024 17:21:42 -0000
|Read Time: 0 minutes

In our previous blog, we showcased running Llama 2 on XE9680 using NVIDIA's LLM Playground (part of the NeMo framework). It is an innovative platform for experimenting with and deploying large language models (LLMs) for various enterprise applications.
The reality is that running straight inference with foundational models in an enterprise context simply does not happen and presents several challenges, such as a lack of domain-specific knowledge, the potential for outdated or incomplete information, and the risk of generating inaccurate or misleading responses.
Retrieval-Augmented Generation (RAG) represents a pivotal innovation within the generative AI space.
RAG combines generative AI foundational models with advanced information retrieval techniques to create interactive systems that are both responsive and deeply informative. Because of their flexibility, RAG can be designed in many different ways. In a blog recently published, David O'Dell showed how RAG can be built from scratch.
This blog also serves as a follow-on companion to the Technical White Paper NVIDIA RAG On Dell available here, which highlights the solution built on Dell Data Center Hardware, K8s, Dell CSI PowerScale for Kubernetes, and NVIDIA AI Enterprise suite. Check out the Technical White Paper to learn more about the solution architectural and logical approach employed.
In this blog, we will show how this new NVIDIA approach provides a more automated way of deploying RAG, which can be leveraged by customers looking at a more standardized approach.
We will take you through the step-by-step instructions for getting up and running with NVIDIA's LLM Playground software so you can experiment with your own RAG pipelines. In future blog posts (once we are familiar with the LLM playground basics), we will start to dig a bit deeper into RAG pipelines so you can achieve further customization and potential implementations of RAG pipelines using NVIDIA's software components.
But first, let's cover the basics.
Building Your Own RAG Pipeline (Getting Started)
A typical RAG pipeline consists of several phases. The process of document ingestion occurs offline, and when an online query comes in, the retrieval of relevant documents and the generation of a response occurs.
At a high level, the architecture of a RAG system can be distilled down to two pipelines:
- A recurring pipeline of document preprocessing, ingestion, and embedding generation
- An inference pipeline with a user query and response generation
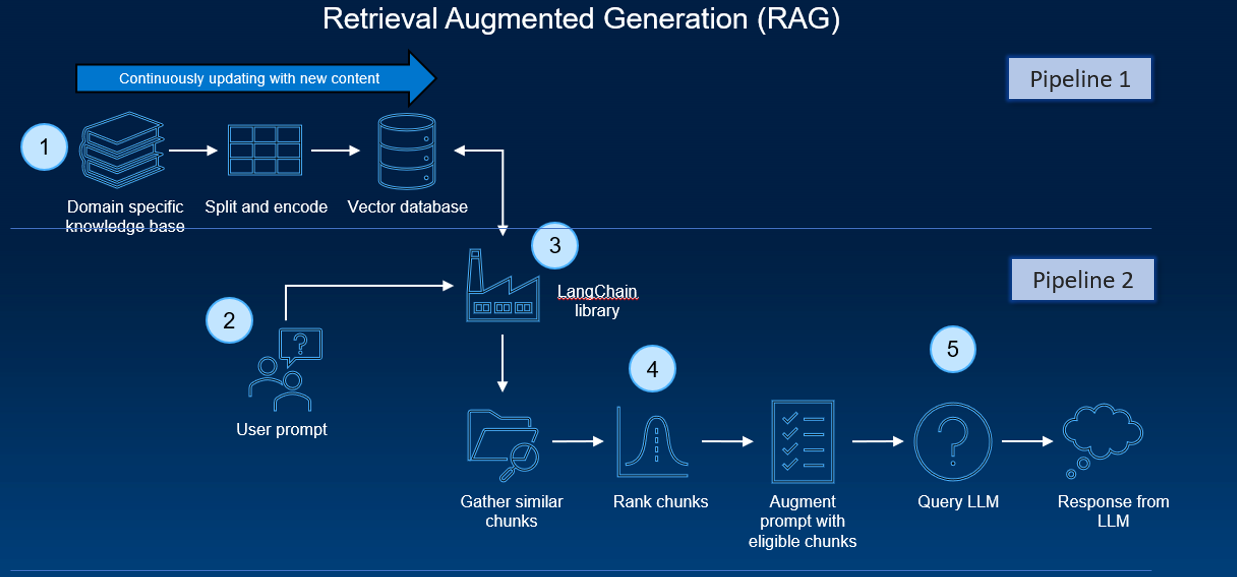
Several software components and tools are typically employed. These components work together to enable the efficient processing and handling of the data, and the actual execution of inferencing tasks.
These software components, in combination with the hardware setup (like GPUs and virtual machines/containers), create an infrastructure for running AI inferencing tasks within a typical RAG pipeline. These tools’ integration allows for processing custom datasets (like PDFs) and generating sophisticated, human-like responses by an AI model.
As previously stated, David O’Dell has provided an extremely useful guide to get a RAG pipeline up and running. One of the key components is the pipeline function.
The pipeline function in Hugging Face’s Transformers library is a high-level API designed to simplify the process of using pre-trained models for various NLP tasks, and it abstracts the complexities of model loading, data pre-processing (like tokenization), inference, and post-processing. The pipeline directly interfaces with the model to perform inference but is more focused on ease-of-use and accessibility rather than scaling and optimizing resource usage. It is as a high-level API that abstracts away much of the complexity involved in setting up and using various transformer-based models.
It’s ideal for quickly implementing NLP tasks, prototyping, and applications where ease of use and simplicity are key.
But is it easy to implement?
Setting up and maintaining RAG pipelines requires considerable technical expertise in AI, machine learning, and system administration. While some components (such as the ‘pipeline function’) have been designed for ease of use, typically, they are not designed to scale.
So, we need robust software that can scale and is easier to use.
NVIDIA's solutions are designed for high performance and scalability which is essential for handling large-scale AI workloads and real-time interactions.
NVIDIA provides extensive documentation, sample Jupyter notebooks, and a sample chatbot web application, which are invaluable for understanding and implementing the RAG pipeline.
The system is optimized for NVIDIA GPUs, ensuring efficient use of some of the most powerful available hardware.
NVIDA’s Approach to Simplify — Building a RAG System with NVIDIA’s Tools:
NVIDIA’s approach is to streamline the RAG pipeline and make it much easier to get up and running.
By offering a suite of optimized tools and pre-built components, NVIDIA has developed an AI workflow for retrieval-augmented generation that includes a sample chatbot and the elements users need to create their own applications with this new method. It simplifies the once daunting task of creating sophisticated AI chatbots, ensuring scalability and high performance.
Getting Started with NVIDIA’s LLM playground
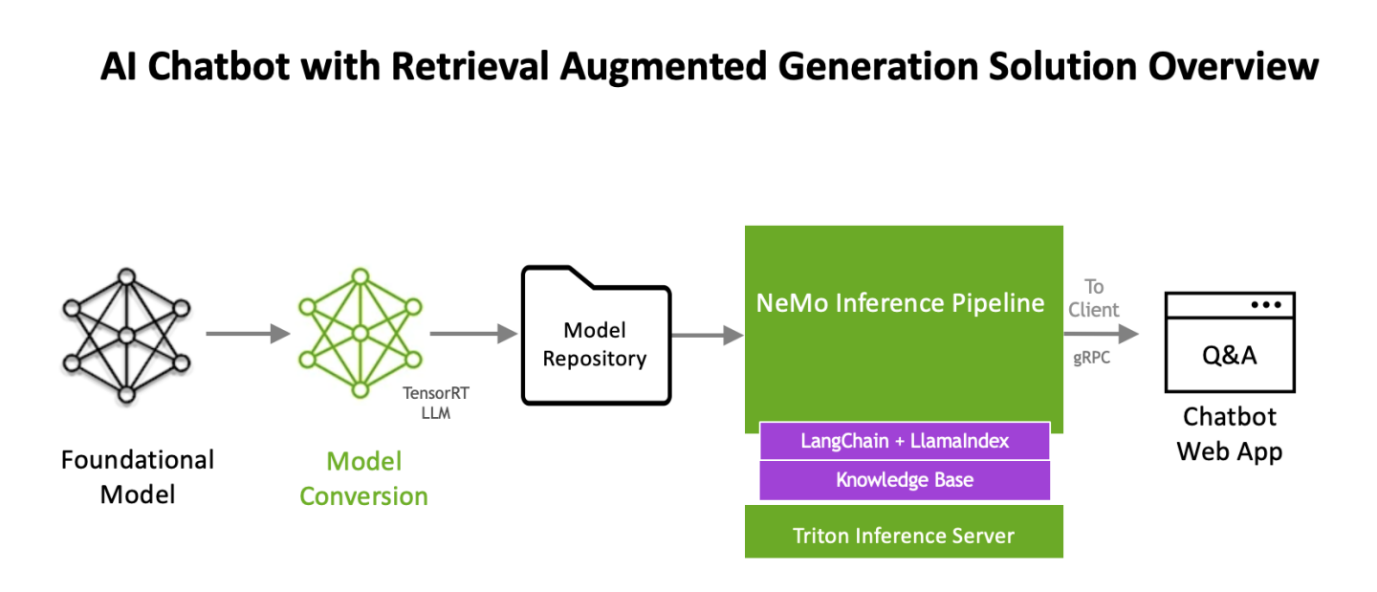
The workflow uses NVIDIA NeMo, a framework for developing and customizing generative AI models, as well as software like NVIDIA Triton Inference Server and NVIDIA TensorRT-LLM for running generative AI models in production.
The software components are all part of NVIDIA AI Enterprise, a software platform that accelerates the development and deployment of production-ready AI with the security, support, and stability businesses need.
Nvidia has published a retrieval augmented generation workflow as an app example at
https://resources.nvidia.com/en-us-generative-ai-chatbot-workflow/knowledge-base-chatbot-technical-brief
Also it maintains a git page with updated information on how to deploy it in Linux Docker, Kubernetes and windows at
https://github.com/NVIDIA/GenerativeAIExamples
Next, we will walk through (at a high level) the procedure to use the NVIDIA AI Enterprise Suite RAG pipeline implementation below.
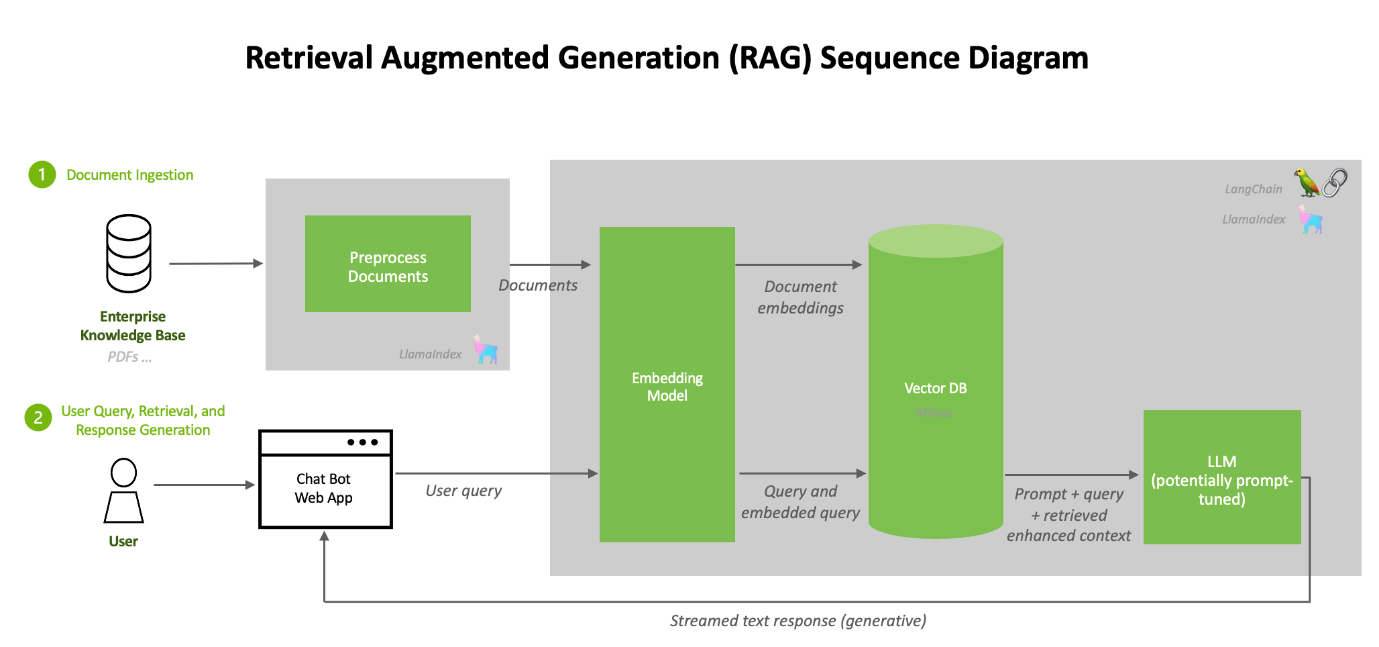
This procedure is based on the documentation on link https://github.com/NVIDIA/GenerativeAIExamples/tree/v0.2.0/RetrievalAugmentedGeneration
Deployment
The NVIDIA developer guide provides detailed instructions for building a Retrieval Augmented Generation (RAG) chatbot using the Llama2 model on TRT-LLM. It includes prerequisites like NVIDIA GPU, Docker, NVIDIA Container Toolkit, an NGC Account, and Llama2 model weights. The guide covers components like Triton Model Server, Vector DB, API Server, and Jupyter notebooks for development.
Key steps involve setting up these components, uploading documents, and generating answers. The process is designed for enterprise chatbots, emphasizing customization and leveraging NVIDIA’s AI technologies. For complete details and instructions, please refer to the official guide.
Key Software components and Architectural workflow (for getting up and running with LLM playground)
1. Llama2: Llama2 offers advanced language processing capabilities, essential for sophisticated AI chatbot interactions. It will be converted into TensorRT-LLM format.
Remember, we cancannot take a model from HuggingFace and run it directly on TensorRT-LLM. Such a model will need to go through a conversion stage before it can leverage all the goodness of TensorRT-LLM. We recently published a detailed blog on how to do this manually here. However, (fear not) as part of the LLM playground docker compose process, all we need to do is point one of our environment variables to the llama model. It will automatically do the conversion process for us! (steps are outlined in the implementation section of the blog)
2. NVIDIA TensorRT-LLM: When it comes to optimizing large language models, TensorRT-LLM is the key. It ensures that models deliver high performance and maintain efficiency in various applications.
- The library includes optimized kernels, pre- and post-processing steps, and multi-GPU/multi-node communication primitives. These features are specifically designed to enhance performance on NVIDIA GPUs.
 It utilizes tensor parallelism for efficient inference across multiple GPUs and servers, without the need for developer intervention or model changes.
It utilizes tensor parallelism for efficient inference across multiple GPUs and servers, without the need for developer intervention or model changes.
We will be updating our Generative AI in the Enterprise – Inferencing – Design Guide to reflect the new sizing requirements based on TensorRT-LLM
3. LLM-inference-server: NVIDIA Triton Inference Server (container): Deployment of AI models is streamlined with the Triton Inference Server. It supports scalable and flexible model serving, which is essential for handling complex AI workloads. The Triton inference server is responsible for hosting the Llama2 TensorRT-LLM model
Now that we have our optimized foundational model, we need to build up the rest of the RAG workflow.
- Chain-server: langChain and LlamaIndex (container): Required for the RAG pipeline to function. A tool for chaining LLM components together. LangChain is used to connect the various elements like the PDF loader and vector database, facilitating embeddings, which are crucial for the RAG process.
4. Milvus (container): As an AI-focused vector database, Milvus stands out for managing the vast amounts of data required in AI applications. Milvus is an open-source vector database capable of NVIDIA GPU accelerated vector searches.
5. e5-large-v2 (container): Embeddings model designed for text embeddings. When content from the knowledge base is passed to the embedding model (e5-large-v2), it converts the content to vectors (referred to as “embeddings”). These embeddings are stored in the Milvus vector database.
The embedding model like “e5-large-v2” is used twice in a typical RAG (Retrieval-Augmented Generation) workflow, but for slightly different purposes at each step. Here is how it works:
Using the same embedding model for both documents and user queries ensures that the comparisons and similarity calculations are consistent and meaningful, leading to more relevant retrieval results.
We will talk about how “provide context to the language model for response generation” is created in the prompt workflow section, but first, let’s look at how the two embedding workflows work.
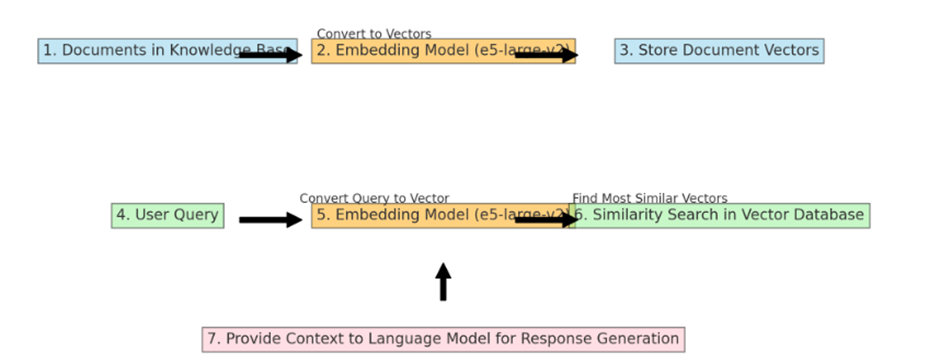
Converting and Storing Document Vectors: First, an embedding model processes the entire collection of documents in the knowledge base. Each document is converted into a vector. These vectors are essentially numerical representations of the documents, capturing their semantic content in a format that computers can efficiently process. Once these vectors are created, they are stored in the Milvus vector database. This is a one-time process, usually done when the knowledge base is initially set up or when it’s updated with new information.
Processing User Queries: The same embedding model is also used to process user queries. When a user submits a query, the embedding model converts this query into a vector, much like it did for the documents. The key is that the query and the documents are converted into vectors in the same vector space, allowing for meaningful comparisons.
Performing Similarity Search: Once the user’s query is converted into a vector, this query vector is used to perform a similarity search in the vector database (which contains the vectors of the documents). The system looks for document vectors most similar to the query vector. Similarity in this context usually means that the vectors are close to each other in the vector space, implying that the content of the documents is semantically related to the user’s query.
Providing Enhanced Context for Response Generation: The documents (or portions of them) corresponding to the most similar vectors are retrieved and provided to the language model as context. This context, along with the user’s original query, helps the language model generate a more informed and accurate response.
6. Container network nvidia-LLM: To allow for communication between containers.
7. Web Front End (LLM-playground container) The web frontend provides a UI on top of the APIs. The LLM-playground container provides a sample chatbot web application. Requests to the chat system are wrapped in FastAPI calls to the Triton Inference Server
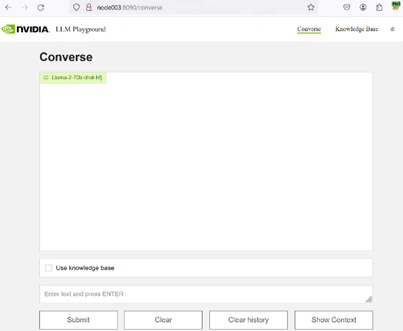
Prompt Workflow
Construction of an Augmented Prompt: The next step is constructing a prompt for the foundational Large Language Model (LLM). This prompt typically includes:
- The User’s Original Query: Clearly stating the query or problem.
- Retrieved Context: The relevant information retrieved from the knowledge base. This context is crucial as it provides the LLM with specific information that it might not have been trained on or that might be too recent or detailed for its training data.
- Formatting and Structuring: The prompt must be formatted and structured in a way that makes it clear to the LLM what information is from the query and what information is context from the retrieval. This can involve special tokens or separators.
Length and Complexity Considerations: The augmented prompt can become very large, especially if the retrieved context is extensive. There is a trade-off to be managed here:
Too Little Context: May not provide enough information for the LLM to generate a well-informed response.
Too Much Context: This can overwhelm the LLM or exceed its token limit, leading to truncated inputs or diluted attention across the prompt.
Feeding the Prompt to the LLM: Once the prompt is constructed, it is fed to the foundational LLM. The LLM then processes this prompt, considering both the user’s original query and the context provided.
Response Generation: The LLM generates a response based on the augmented prompt. This response is expected to be more accurate, informative, and contextually relevant than what the LLM could have produced based solely on the original query, thanks to the additional context provided by the retrieval process.
Post-Processing: In some systems, there might be an additional step of post-processing the response, such as refining, shortening, or formatting it to suit the user’s needs better.
Examples augmented prompt: This format helps the language model understand the specific question being asked and the context in which to answer it, leading to a more accurate and relevant response.
[Query]: "What are the latest developments in the treatment of Alzheimer's disease as of 2024?"
[Context - Memoriax Study]: "A groundbreaking study published in 2023 demonstrated the efficacy of a new drug, Memoriax, in slowing the progression of Alzheimer's disease. The drug targets amyloid plaques in the brain."
[Context - FDA Approval]: "The FDA approved a new Alzheimer's treatment in late 2023, involving medication and targeted brain stimulation therapy."
[Context - Lifestyle Research]: "A 2024 study emphasized the role of diet, exercise, and cognitive training in delaying Alzheimer's symptoms."
Please provide an overview of these developments and their implications for Alzheimer's treatment.
XE9680 Implementation
The following components will need to be installed.
- At least one NVIDIA GPU A100 with Llama 2 7B since it requires approximately 38GB of GPU memory, our implementation was developed using using 8x H100 for Llama2 70B on an XE9680
- Our XE9680 server is running Ubuntu 22.04
- NVIDIA driver version 535 or newer.
- Docker, Docker-Compose and Docker-Buildx
Step 1 – Logging in the NVIDIA GPU Cloud
For logging docker on NGC, you need to create a user and an access key. Please refer to the instructions and run the following command:
Docker login nvcr.io
Step 2 – Download Llama2 Chat Model Weights
Llama 2 Chat Model Weights need to be downloaded from Meta or HuggingFace. We downloaded the files on our deployment and stored them on our Dell PowerScale F600. Our servers can access this share with 100Gb Eth connections, allowing us to span multiple experiments simultaneously on different servers. The following is how the folder with Llama 70b model weights will look after download:
fbronzati@node003:~$ ll /aipsf600/project-helix/models/Llama-2-70b-chat-hf/ -h
total 295G
drwxrwxrwx 3 fbronzati ais 2.0K Jan 23 07:20 ./
drwxrwxrwx 9 nobody nogroup 221 Jan 23 07:20 ../
-rw-r—r—1 fbronzati ais 614 Dec 4 12:25 config.json
-rw-r—r—1 fbronzati ais 188 Dec 4 12:25 generation_config.json
drwxr-xr-x 9 fbronzati ais 288 Dec 4 14:04 .git/
-rw-r—r—1 fbronzati ais 1.6K Dec 4 12:25 .gitattributes
-rw-r—r—1 fbronzati ais 6.9K Dec 4 12:25 LICENSE.txt
-rw-r—r—1 fbronzati ais 9.2G Dec 4 12:40 model-00001-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:09 model-00002-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:30 model-00003-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:21 model-00004-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:14 model-00005-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:12 model-00006-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:55 model-00007-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:24 model-00008-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:00 model-00009-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:11 model-00010-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:22 model-00011-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:17 model-00012-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:02 model-00013-of-00015.safetensors
-rw-r—r—1 fbronzati ais 8.9G Dec 4 13:22 model-00014-of-00015.safetensors
-rw-r—r—1 fbronzati ais 501M Dec 4 13:17 model-00015-of-00015.safetensors
-rw-r—r—1 fbronzati ais 7.1K Dec 4 12:25 MODEL_CARD.md
-rw-r—r—1 fbronzati ais 66K Dec 4 12:25 model.safetensors.index.json
-rw-r—r—1 fbronzati ais 9.2G Dec 4 12:52 pytorch_model-00001-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 12:25 pytorch_model-00002-of-00015.bin
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:46 pytorch_model-00003-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:07 pytorch_model-00004-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 12:49 pytorch_model-00005-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 12:58 pytorch_model-00006-of-00015.bin
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:34 pytorch_model-00007-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:15 pytorch_model-00008-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:05 pytorch_model-00009-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:08 pytorch_model-00010-of-00015.bin
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:28 pytorch_model-00011-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:18 pytorch_model-00012-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:04 pytorch_model-00013-of-00015.bin
-rw-r—r—1 fbronzati ais 8.9G Dec 4 13:20 pytorch_model-00014-of-00015.bin
-rw-r—r—1 fbronzati ais 501M Dec 4 13:20 pytorch_model-00015-of-00015.bin
-rw-r—r—1 fbronzati ais 66K Dec 4 12:25 pytorch_model.bin.index.json
-rw-r—r—1 fbronzati ais 9.8K Dec 4 12:25 README.md
-rw-r—r—1 fbronzati ais 1.2M Dec 4 13:20 Responsible-Use-Guide.pdf
-rw-r—r—1 fbronzati ais 414 Dec 4 12:25 special_tokens_map.json
-rw-r—r—1 fbronzati ais 1.6K Dec 4 12:25 tokenizer_config.json
-rw-r—r—1 fbronzati ais 1.8M Dec 4 12:25 tokenizer.json
-rw-r—r—1 fbronzati ais 489K Dec 4 13:20 tokenizer.model
-rw-r--r-- 1 fbronzati ais 4.7K Dec 4 12:25 USE_POLICY.md
Step 3 – Clone GitHub content
We need to create a new working directory and clone the git repo using the following command:
fbronzati@node003:/aipsf600/project-helix/rag$ git clone https://github.com/NVIDIA/GenerativeAIExamples.git
fbronzati@node003:/aipsf600/project-helix/rag$ cd GenerativeAIExamples
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ git checkout tags/v0.2.0
Step 4 – Set Environment Variables
To deploy the workflow, we use Docker Compose, which allows you to define and manage multi-container applications in a single YAML file. This simplifies the complex task of orchestrating and coordinating various services, making it easier to manage and replicate your application environment.
To adapt the deployment, you need to edit the file compose.env with the information about your environment, information like the folder that you downloaded the model, the name of the model, which GPUs to use, so on, are all included on the file, you will need to use your preferred text editor, following we used vi with the command:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ vi deploy/compose/compose.env
Dell XE9680 variables
Below, we provide the variable used to deploy the workflow on the Dell PowerEdge XE9680.
"export MODEL_DIRECTORY="/aipsf600/project-helix/models/Llama-2-70b-chat-hf/" This is where we point to the model we downloaded from hugging face – the model will be automatically converted into tensorR-TLLM format for us as the containers are deployed using helper scripts
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ cat deploy/compose/compose.env
# full path to the local copy of the model weights
# NOTE: This should be an absolute path and not relative path
export MODEL_DIRECTORY="/aipsf600/project-helix/models/Llama-2-70b-chat-hf/"
# Fill this out if you dont have a GPU. Leave this empty if you have a local GPU
#export AI_PLAYGROUND_API_KEY=""
# flag to enable activation aware quantization for the LLM
# export QUANTIZATION="int4_awq"
# the architecture of the model. eg: llama
export MODEL_ARCHITECTURE="llama"
# the name of the model being used - only for displaying on frontend
export MODEL_NAME="Llama-2-70b-chat-hf"
# [OPTIONAL] the maximum number of input tokens
export MODEL_MAX_INPUT_LENGTH=3000
# [OPTIONAL] the maximum number of output tokens
export MODEL_MAX_OUTPUT_LENGTH=512
# [OPTIONAL] the number of GPUs to make available to the inference server
export INFERENCE_GPU_COUNT="all"
# [OPTIONAL] the base directory inside which all persistent volumes will be created
# export DOCKER_VOLUME_DIRECTORY="."
# [OPTIONAL] the config file for chain server w.r.t. pwd
export APP_CONFIG_FILE=/dev/null
Step 5 – Build and start the containers
As the git repository has large files, we use the git lfs pull command to download the files from the repository:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ source deploy/compose/compose.env; docker-compose -f deploy/compose/docker-compose.yaml build
Following, we run the following command to build docker container images:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ source deploy/compose/compose.env; docker-compose -f deploy/compose/docker-compose.yaml build
And finally, with a similar command, we deploy the containers:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ source deploy/compose/compose.env; docker-compose -f deploy/compose/docker-compose.yaml up -d
WARNING: The AI_PLAYGROUND_API_KEY variable is not set. Defaulting to a blank string.
Creating network "nvidia-LLM" with the default driver
Creating milvus-etcd ... done
Creating milvus-minio ... done
Creating LLM-inference-server ... done
Creating milvus-standalone ... done
Creating evaluation ... done
Creating notebook-server ... done
Creating chain-server ... done
Creating LLM-playground ... done
The deployment will take a few minutes to finish, especially depending on the size of the LLM you are using. In our case, it took about 9 minutes to launch since we used the 70B model:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ae34eac40476 LLM-playground:latest "python3 -m frontend…" 9 minutes ago Up 9 minutes 0.0.0.0:8090->8090/tcp, :::8090->8090/tcp LLM-playground
a9b4996e0113 chain-server:latest "uvicorn RetrievalAu…" 9 minutes ago Up 9 minutes 6006/tcp, 8888/tcp, 0.0.0.0:8082->8082/tcp, :::8082->8082/tcp chain-server
7b617f11d122 evalulation:latest "jupyter lab --allow…" 9 minutes ago Up 9 minutes 0.0.0.0:8889->8889/tcp, :::8889->8889/tcp evaluation
8f0e434b6193 notebook-server:latest "jupyter lab --allow…" 9 minutes ago Up 9 minutes 0.0.0.0:8888->8888/tcp, :::8888->8888/tcp notebook-server
23bddea51c61 milvusdb/milvus:v2.3.1-gpu "/tini -- milvus run…" 9 minutes ago Up 9 minutes (healthy) 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp, 0.0.0.0:19530->19530/tcp, :::19530->19530/tcp milvus-standalone
f1b244f93246 LLM-inference-server:latest "/usr/bin/python3 -m…" 9 minutes ago Up 9 minutes (healthy) 0.0.0.0:8000-8002->8000-8002/tcp, :::8000-8002->8000-8002/tcp LLM-inference-server
89aaa3381cf8 minio/minio:RELEASE.2023-03-20T20-16-18Z "/usr/bin/docker-ent…" 9 minutes ago Up 9 minutes (healthy) 0.0.0.0:9000-9001->9000-9001/tcp, :::9000-9001->9000-9001/tcp milvus-minio
ecec9d808fdc quay.io/coreos/etcd:v3.5.5 "etcd -advertise-cli…" 9 minutes ago Up 9 minutes (healthy) 2379-2380/tcp
Access the LLM playground
The LLM-playground container provides A sample chatbot web application is provided in the workflow. Requests to the chat system are wrapped in FastAPI calls to the LLM-inference-server container running the Triton inference server with Llama 70B loaded.
Open the web application at http://host-ip:8090.
Let's try it out!
Again, we have taken the time to demo Llama2 running on NVIDIA LLM playground on an XE9680 with 8x H100 GPUs. LLM playground is backed by NVIDIA's Triton Inference server (which hosts the llama model).
We hope we have shown you that NVIDIA's LLM Playground, part of the NeMo framework, is an innovative platform for experimenting with and deploying large language models (LLMs) for various enterprise applications. While offering:
- Customization of Pre-Trained LLMs: It allows customization of pre-trained large language models using p-tuning techniques for domain-specific use cases or tasks.
- Experiments with a RAG pipeline

Dell Validated Design Guides for Inferencing and for Model Customization – March ’24 Updates
Fri, 15 Mar 2024 20:16:59 -0000
|Read Time: 0 minutes
Continuous Innovation with Dell Validated Designs for Generative AI with NVIDIA
Since Dell Technologies and NVIDIA introduced what was then known as Project Helix less than a year ago, so much has changed. The rate of growth and adoption of generative AI has been faster than probably any technology in human history.
From the onset, Dell and NVIDIA set out to deliver a modular and scalable architecture that supports all aspects of the generative AI life cycle in a secure, on-premises environment. This architecture is anchored by high-performance Dell server, storage, and networking hardware and by NVIDIA acceleration and networking hardware and AI software.
Since that introduction, the Dell Validated Designs for Generative AI have flourished, and have been continuously updated to add more server, storage, and GPU options, to serve a range of customers from those just getting started to high-end production operations.
A modular, scalable architecture optimized for AI
This journey was launched with the release of the Generative AI in the Enterprise white paper.
This design guide laid the foundation for a series of comprehensive resources aimed at integrating AI into on-premises enterprise settings, focusing on scalable and modular production infrastructure in collaboration with NVIDIA.
Dell, known for its expertise not only in high-performance infrastructure but also in curating full-stack validated designs, collaborated with NVIDIA to engineer holistic generative AI solutions that blend advanced hardware and software technologies. The dynamic nature of AI presents a challenge in keeping pace with rapid advancements, where today's cutting-edge models might become obsolete quickly. Dell distinguishes itself by offering essential insights and recommendations for specific applications, easing the journey through the fast-evolving AI landscape.
The cornerstone of the joint architecture is modularity, offering a flexible design that caters to a multitude of use cases, sectors, and computational requirements. A truly modular AI infrastructure is designed to be adaptable and future-proof, with components that can be mixed and matched based on specific project requirements and which can span from model training, to model customization including various fine-tuning methodologies, to inferencing where we put the models to work.
The following figure shows a high-level view of the overall architecture, including the primary hardware components and the software stack:
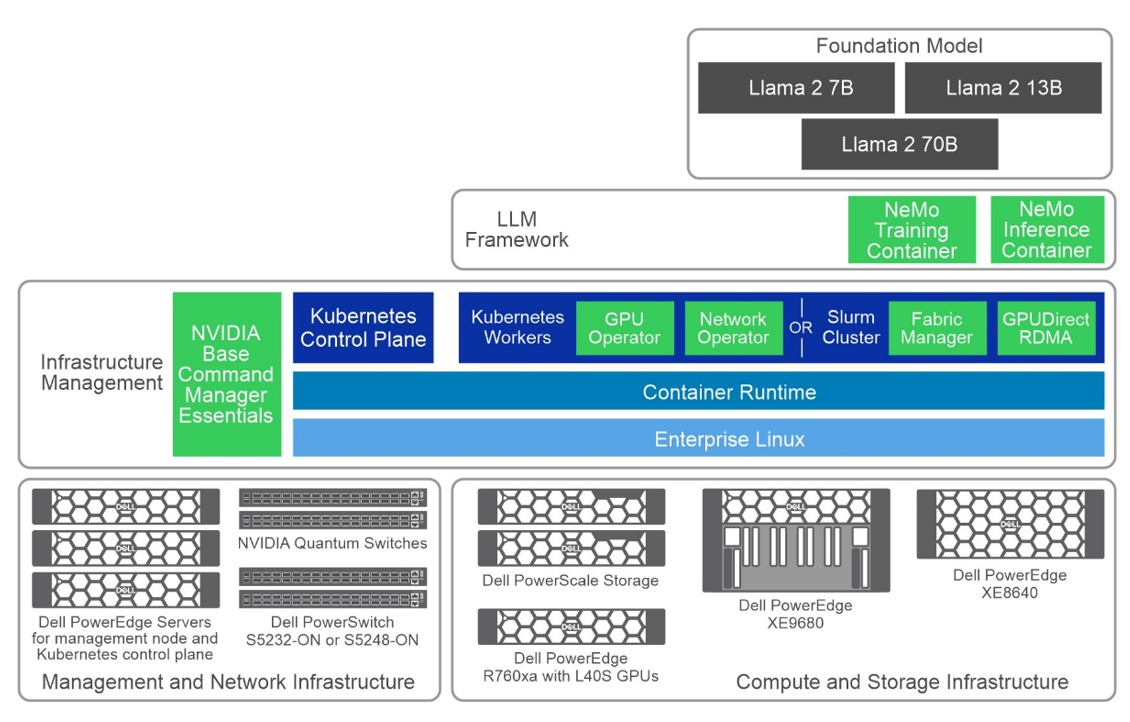
Figure 1: Common high-level architecture
Generative AI Inferencing
Following the introductory white paper, the first validated design guide released was for Generative AI Inferencing, in July 2023, anchored by the innovative concepts introduced earlier.
The complexity of assembling an AI infrastructure, often involving an intricate mix of open-source and proprietary components, can be formidable. Dell Technologies addresses this complexity by providing fully validated solutions where every element is meticulously tested, ensuring functionality and optimization for deployment. This validation gives users the confidence to proceed, knowing their AI infrastructure rests on a robust and well-founded base.
Key Takeaways
- In October 2023, the guide received its first update, broadening its scope with added validation and configuration details for Dell PowerEdge XE8640 and XE9680 servers. This update also introduced support for NVIDIA Base Command Manager Essentials and NVIDIA AI Enterprise 4.0, marking a significant enhancement to the guide's breadth and depth.
- The guide's evolution continues into March 2024 with its third iteration, which includes support for the PowerEdge R760xa servers equipped with NVIDIA L40S GPUs.
- The design now supports several options for NVIDIA GPU acceleration components across the multiple Dell server options. In this design, we showcase three Dell PowerEdge servers with several GPU options tailored for generative AI purposes:
- PowerEdge R760xa server, supporting up to four NVIDIA H100 GPUs or four NVIDIA L40S GPUs
- PowerEdge XE8640 server, supporting up to four NVIDIA H100 GPUs
- PowerEdge XE9680 server, supporting up to eight NVIDIA H100 GPUs
The choice of server and GPU combination is often a balance of performance, cost, and availability considerations, depending on the size and complexity of the workload.
- This latest edition also saw the removal of NVIDIA FasterTransformer, replaced by TensorRT-LLM, reflecting Dell’s commitment to keeping the guide abreast of the latest and most efficient technologies. When it comes to optimizing large language models, TensorRT-LLM is the key. It ensures that models not only deliver high performance but also maintain efficiency in various applications.
The library includes optimized kernels, pre- and postprocessing steps, and multi-GPU/multi-node communication primitives. These features are specifically designed to enhance performance on NVIDIA GPUs.
It uses tensor parallelism for efficient inference across multiple GPUs and servers, without the need for developer intervention or model changes.
- Additionally, this update includes revisions to the models used for validation, ensuring users have access to the most current and relevant information for their AI deployments. The Dell Validated Design guide covers Llama 2 and now Mistral as the foundation models for inferencing with this infrastructure design with Triton Inference Server:
- Llama 2 7B, 13B, and 70B
- Mistral
- Falcon 180B
- Finally (and most importantly) performance test results and sizing considerations showcase the effectiveness of this updated architecture in handling large language models (LLMs) for various inference tasks. Key takeaways include:
- Optimized Latency and Throughput—The design achieved impressive latency metrics, crucial for real-time applications like chatbots, and high tokens per second, indicating efficient processing for offline tasks.
- Model Parallelism Impact—The performance of LLMs varied with adjustments in tensor and pipeline parallelism, highlighting the importance of optimal parallelism settings for maximizing inference efficiency.
- Scalability with Different GPU Configurations—Tests across various NVIDIA GPUs, including L40S and H100 models, demonstrated the design’s scalability and its ability to cater to diverse computational needs.
- Comprehensive Model Support—The guide includes performance data for multiple models (as we already discussed) across different configurations, showcasing the design’s versatility in handling various LLMs.
- Sizing Guidelines—Based on performance metrics, updated sizing examples are available to help users determine the appropriate infrastructure based on their specific inference requirements (these guidelines very welcome)
All this highlights Dell’s commitments and capability to deliver high-performance, scalable, and efficient generative AI inferencing solutions tailored to enterprise needs.
Generative AI Model Customization
The validated design guide for Generative AI Model Customization was first released in October 2023, anchored by the PowerEdge XE9680 server. This guide detailed numerous model customization methods, including the specifics of prompt engineering, supervised fine-tuning, and parameter-efficient fine-tuning.
The updates to the Dell Validated Design Guide from October 2023 to March 2024 included the initial release, the addition of validated scenarios for multi-node SFT and Kubernetes in November 2023, updated performance test results, and new support for PowerEdge R760xa servers, PowerEdge XE8640 servers, and PowerScale F710 all-flash storage as of March 2024.
Key Takeaways
- The validation aimed to test the reliability, performance, scalability, and interoperability of a system using model customization in the NeMo framework, specifically focusing on incorporating domain-specific knowledge into Large Language Models (LLMs).
- The process involved testing foundational models of sizes 7B, 13B, and 70B from the Llama 2 series. Various model customization techniques were employed, including:
- Prompt engineering
- Supervised Fine-Tuning (SFT)
- P-Tuning, and
- Low-Rank Adaptation of Large Language Models (LoRA)
- The design now supports several options for NVIDIA GPU acceleration components across the multiple Dell server options. In this design, we showcase three Dell PowerEdge servers with several GPU options tailored for generative AI purposes:
- PowerEdge R760xa server, supporting up to four NVIDIA H100 GPUs or four NVIDIA L40S GPUs. While the L40S is cost-effective for small to medium workloads, the H100 is typically used for larger-scale tasks, including SFT.
- PowerEdge XE8640 server, supporting up to four NVIDIA H100 GPUs.
- PowerEdge XE9680 server, supporting up to eight NVIDIA H100 GPUs.
As always, the choice of server and GPU combination depends on the size and complexity of the workload.
- The validation used both Slurm and Kubernetes clusters for computational resources and involved two datasets: the Dolly dataset from Databricks, covering various behavioral categories, and the Alpaca dataset from OpenAI, consisting of 52,000 instruction-following records. Training was conducted for a minimum of 50 steps, with the goal being to validate the system's capabilities rather than achieving model convergence, to provide insights relevant to potential customer needs.
The validation results along with our analysis can be found in the Performance Characterization section of the design guide.
What’s Next?
Looking ahead, you can expect even more innovation at a rapid pace with expansions to the Dell’s leading-edge generative AI product and solutions portfolio.
For more information, see the following resources:
- Dell Generative AI Solutions
- Dell Technical Info Hub for AI
- Generative AI in the Enterprise white paper
- Generative AI Inferencing in the Enterprise Inferencing design guide
- Generative AI in the Enterprise Model Customization design guide
- Dell Professional Services for Generative AI
~~~~~~~~~~~~~~~~~~~~~

Dell Technologies and NVIDIA ─Unleashing the Power of Generative AI Through Collaboration
Fri, 15 Mar 2024 12:13:22 -0000
|Read Time: 0 minutes
A new report from McKinsey reveals the staggering potential of generative AI, estimating its annual impact to be between $2.6 trillion and $4.4 trillion across 63 analyzed use cases. This impact not only underscores the immense economic significance of generative AI but also heralds a new era of possibility and prosperity for businesses and societies worldwide.
In the realm of artificial intelligence (AI), discussions often center on advanced hardware and software capabilities. However, the true journey towards AI adoption in enterprises and telecom companies begins with a strategic shift towards thinking about business transformation and gaining a profound understanding of the intrinsic value residing in their data assets. This focus helps enterprises move towards extracting maximum value from existing data repositories and platforms.
A winning strategy based on collaboration
Dell Technologies has collaborated with NVIDIA to pair NVIDIA’s expertise with full-stack accelerated computing for generative AI with Dell infrastructure and services, specifically for AI adoption in enterprises and telecom companies. The combined technologies provide “a one-stop shop” for organizations looking to harness the power of generative AI by providing the tools, expertise, services, and industry-specific solutions to empower businesses on their generative AI journeys.
Dell Technologies is also working with NVIDIA to develop targeted solutions for specific enterprise verticals, including healthcare, manufacturing, and telecommunications to maximize the impact of generative AI in these areas.
The comprehensive AI-validated solutions encompass not only the essential hardware and software required for AI implementation but also a wide array of professional services. These services range from advisory AI and consulting to implementation services and managed services for generative AI. We accompany our customers along their transformation journeys, ensuring end-to-end support – from strategy formulation to deployment and scaling.
A joint initiative between Dell Technologies and NVIDIA, Project Helix offers industry-leading, best-in-class solutions for various generative AI use cases, helping accelerate adoption across industries. The comprehensive, AI-validated solution is based on AI-optimized Dell PowerEdge servers with the latest NVIDIA GPUs to support all phases of generative AI, from training to fine-tuning to inferencing. Scalable Dell Unstructured Data Solutions (UDS) storage like PowerScale and ECS enables rapid data storage for numerous object types and prepares the data for AI model processing. High-performance networking enables low-latency data gravity operations across the organization.
Using Dell’s proven ProConsult Advisory methodology, we facilitate structured interviews and workshops to assist customers in aligning on their generative AI strategic vision, establishing guiding principles, assessing their current (AS-IS) state, and developing future (TO-BE) road maps for achieving wanted outcomes.
Dell and NVIDIA end-to-end validated stack for AI
On top of this accelerated computing platform, NVIDIA offers NVIDIA AI Enterprise software. This end-to-end, cloud-native software platform delivers production-grade AI, which includes the NVIDIA NeMo framework and models for large language model development and deployment.
This solution empowers a wide range of multivendor use cases, including, but not limited to, natural language generation, chatbots, and digital assistants. The use case list for generative AI applications extends to personalized marketing, improved network management, predictive maintenance, enhanced security, resource optimization, new service development, and more.
AI─a paradigm shift for business excellence
Demystifying AI adoption involves moving the narrative away from hardware-centric paradigms towards a holistic focus on business transformation and data value. By recognizing the centrality of data and embracing a strategic approach to AI adoption, enterprises and telecom companies can unlock new avenues of growth and competitiveness. Dell’s collaboration with NVIDIA delivers a unique package of AI solutions to help customers move from the strategy phase to implementing and scaling their AI operations, accelerating the time to innovation.
It is not merely about embracing AI; it is about embracing a mindset of continuous evolution and innovation in the pursuit of organizational excellence.
“To harness the full benefits of generative AI, businesses must first understand their data and goals. Dell’s Validated Designs, integrated with NVIDIA technology, help telecommunications customers more easily move from proof of concept to full-scale deployment of their generative AI-powered data center solutions.” – Chris Penrose, Global Head of Business Development for Telco, NVIDIA
"Our collaboration with NVIDIA is a game-changer for Dell's Telco customers who are at the forefront of AI innovation. By leveraging NVIDIA's cutting-edge GPUs, software, and frameworks, we are empowering our customers to accelerate their Generative AI, Machine Learning, and Deep Learning initiatives across OSS, BSS, Core, and RAN. This partnership enables us to deliver the most advanced AI infrastructure and solutions, helping our Telco customers stay ahead in this rapidly evolving landscape." – Manish Singh, Vice President, Engineering Technology, Dell Technologies

CPU to the Rescue: LLMs for Everyone

Wed, 24 Apr 2024 13:25:19 -0000
|Read Time: 0 minutes
Optimizing Large Language Models
The past year has shown remarkable advances in large language models (LLMs) and what they can achieve. What started as tools for text generation have grown into multimodal models that can translate languages, hold conversations, generate music and images, and more. That said, training and running inference servers of these massive, multi-billion parameter models require immense computational resources and lots of high-end GPUs.
The surge in popularity of LLMs has fueled intense interest in porting these frameworks to mainstream CPUs. Open-source projects like llama.cpp and the Intel® Extension for Transformers aim to prune and optimize models for efficient execution on CPU architectures. These efforts encompass plain C/C++ implementations, hardware-specific optimizations for AVX, AVX2, and AVX512 instruction sets, and mixed precision model representations. Quantization and compression techniques are exploited to shrink models from 16-bit down to 8-bit or even 2-bit sizes. The goal is to obtain smaller, leaner models tailored for inferencing on widely available CPUs from the data center to your laptop.
While GPUs may still be preferred for training, CPUs in data centers and on devices can be used for efficient deployment to inference with these optimized models. CPUs can leverage recent advancements in architecture and provide broader access to large language model capabilities. The past year's advances in model optimization and CPU inferencing show promise in bringing natural language technologies powered by large models to more users.
Hardware
To evaluate these new CPU inferencing tools, we leveraged Dell Omnia cluster provisioning software to deploy Rocky Linux on a Dell PowerEdge C6620 server. Omnia allows rapid deployment of several operating system choices across a cluster of PowerEdge servers featuring Intel® Xeon® processors. By using Omnia for automated OS installation and configuration, we could quickly stand up a test cluster to experiment with the inference capabilities of the CPU-optimized models on our Intel® hardware.
Table 1. Dell PowerEdge C6620 specifications
Hardware | Details |
Server | Dell PowerEdge C6620 |
Processor Model | Intel® Xeon® Gold 6414U (Sapphire Rapids) |
Processors per Node | 2 |
Processor Core Count | 32 |
Processor Frequency | 2GHz |
Host Memory | 256 GB, 8 x 32GB |
Table 2. Involved software specifications
Software | Details |
Omnia | |
Rocky Linux 8.8 | |
Intel® Extensions for Transformers | |
Llama 2 with Intel® Neural Speed
Intel® has open sourced several tools under permissive licenses on GitHub to facilitate development with the Intel® Extensions for Transformers. One key offering is Neural Speed, which aims to enable efficient inferencing of large language models on Intel® hardware. Neural Speed leverages Intel® Neural Compressor, a toolkit for deep learning model optimization, to apply low-bit quantization and sparsity techniques that compress and accelerate the performance of leading LLMs. This allows Neural Speed to deliver state-of-the-art efficient inferencing for major language models. Neural Speed provides an inference stack that can maximize the performance of the latest Transformer-based language models on Intel® platforms ranging from edge to cloud. By open sourcing these technologies with permissive licensing, Intel® enables developers to easily adopt and innovate with optimized LLM inferencing across Intel® hardware.
To get started, clone the Intel® Neural Speed repo and install packages:
git clone https://github.com/intel/neural-speed.git pip install -r requirements.txt pip install .
Neural Speed can support 3 different model types:
- GGUF models generated by llama.cpp
- GGUF models from HuggingFace
- Pytorch models from HuggingFace – quantized by Neural Speed
We began our experiments by working directly with Meta's Llama-2-7B-chat model in Pytorch from Hugging Face. This 7 billion parameter conversational model served as an ideal test case for evaluating end-to-end model conversion, quantization, and inferencing using the Neural Speed toolkit. To streamline testing, Neural Speed provides handy scripts to handle the full pipeline, beginning with taking the original Pytorch model and porting it to a GGUF model, then applying quantization policies to compress the model down to lower precisions like int8 or int4, and finally running inference to assess the performance. In this case, we did not compress the model and retained 32-bit values.
The following command will run a one-click conversion, quantization, and inference:
python scripts/run.py \ /home/models/ Llama-2-7b-chat-hf \ --weight_dtype f32 \ -p "always answer with Haiku. What is the greatest thing about sailing?
Sailing's greatest joy, Freedom on the ocean blue, Serenity found.
Conclusion
In our testing, the converted and quantized Llama-2 model provided not only accurate responses but also excellent response latency, which we will dig deeper into with future blogs. While we demonstrated this workflow on Meta's 7 billion parameter Llama-2 conversational AI, the same process can be applied to port and optimize many other leading large language models to run efficiently on CPUs. Other suitable candidates include chat-centric LLMs like NeuralChat, GPT-J, GPT-NEOX, Dolly-v2, and MPT, as well as general purpose models like Falcon, BLOOM, Mistral, OPT, and Hugging Face's DistilGPT2. Code-focused models like CodeLlama, MagicCoder, and StarCoder could also potentially benefit. Additionally, Chinese models including Baichuan, Baichuan2, and Qwen are prime targets for improved deployment on Intel® CPUs.
The key advantage of this CPU inferencing approach is harnessing all available CPU cores for cost-effective parallel inferencing. By converting and quantizing models to run natively on Intel® CPUs, we can take full advantage of ubiquitous Intel®-powered machines ranging from laptops to servers. For platforms lacking high-end GPUs, optimizing models to leverage existing CPU resources is a compelling way to deliver responsive AI experiences.
Author: John Lockman III, Distinguished Engineer | https://www.linkedin.com/in/johnlockman/

Dell and Northwestern Medicine Collaborate on Next Generation Healthcare Multimodal LLMs
Thu, 15 Feb 2024 15:56:13 -0000
|Read Time: 0 minutes
Generative multimodal large language models, or mLLMs, have shown remarkable new capabilities across a variety of domains, ranging from still images to video to waveforms to language and more. However, the impact of healthcare-targeted mLLM applications remains untried, due in large part to the increased risks and heightened regulation encountered in the patient care setting. A collaboration between Dell Technologies and Northwestern Medicine aims to pave the way for the development and integration of next-generation healthcare-oriented mLLMs into hospital workflows via a strategic partnership anchored in technical and practical expertise at the intersection of healthcare and technology.
One practical application of mLLMs is highlighted in a recent open-source publication from the Research and Development team at Northwestern Medicine which describes the development and evaluation of an mLLM for the interpretation of chest x-rays. These interpretations were judged by emergency physicians to be as accurate and relevant in the emergency setting as interpretations by on-site radiologists, even surpassing teleradiologist interpretations. Clinical implementation of such a model could broaden access to care while aiding physician decision-making. This peer-reviewed study – the first to clinically evaluate a generative mLLM for chest x-ray interpretation – is just one example of the numerous opportunities for meaningful impact by healthcare-tailored mLLMs.
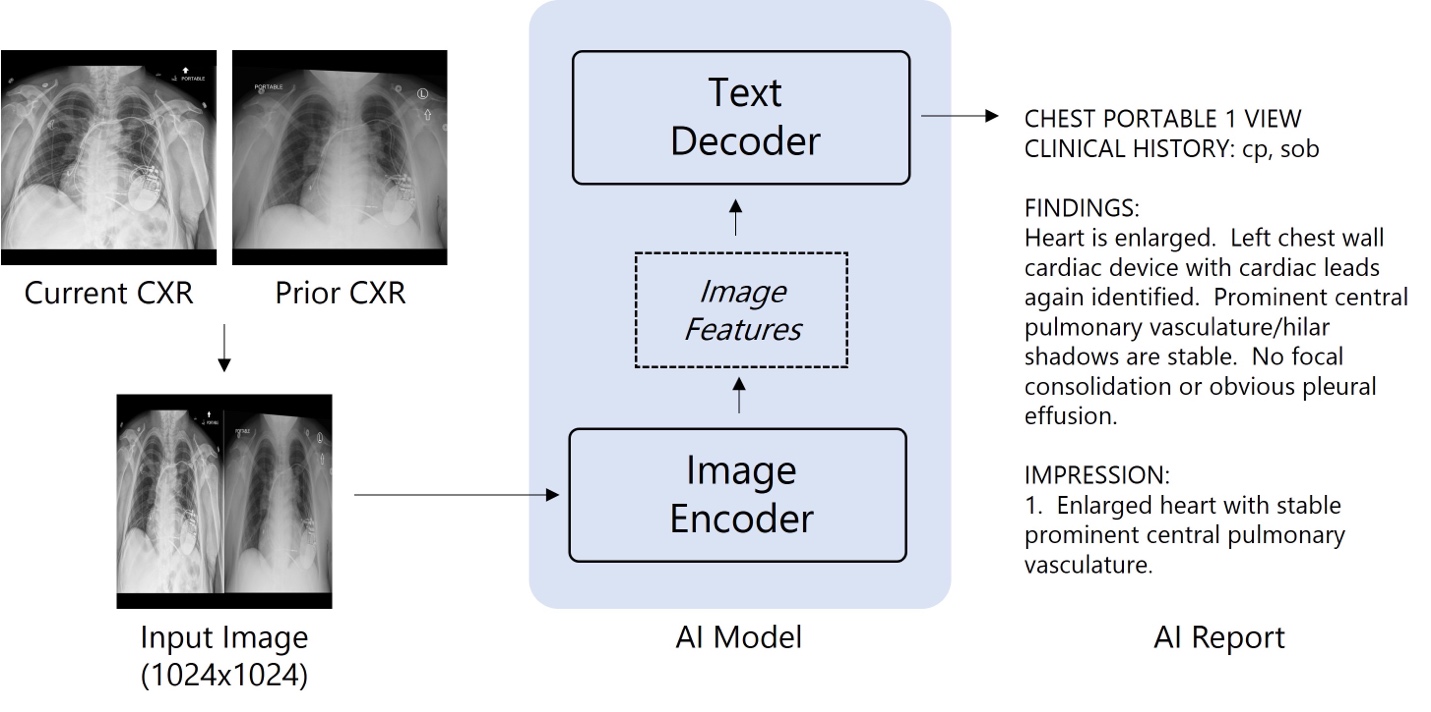 Figure 1. Model architecture for chest x-ray interpretation
Figure 1. Model architecture for chest x-ray interpretation
As illustrated in Figure 1, the model is a vision encoder-decoder model, using pretrained ViT-base and RoBERTa-base as the image encoder and text decoder respectively. In total, over 1 million images and radiology reports were used to train this model using one node with 8 GPUs over three weeks. Expanding the scope of such models, such as to other image modalities like computed tomography and magnetic resonance imaging, requires much greater hardware capabilities to efficiently train at scale.
Notably, this model was trained using only 8 graphics processing units (GPUs) in three weeks. As the broader body of LLM research has shown, there is great promise in scaling up such methods, incorporating more data and larger models to create more powerful solutions. Hospital systems generate vast amounts of data spanning numerous modalities, such as numeric lab values, clinical images and videos, waveforms, and free text clinical notes. A key goal of the collaboration between Dell Technologies and Northwestern Medicine is to expand on this work and scale the capabilities of healthcare systems to use their own data to solve clinical problems and blend cutting edge data-centric platforms with clinical expertise, all targeted toward improving the patient and practitioner experience.
HIPAA Compliant HPC
To bring this vision to fruition, it is necessary to build out capable healthcare-tailored high-performance computing (HPC) clusters in which multiple nodes with varying levels of compute, memory, and storage resources are made available to users to run tasks in parallel and at scale. This enables centralized management of resources with the flexibility to provision resources to jobs ranging from single-node experiments to massively distributed model training. The typical HPC cluster structure is illustrated in Figure 2. Users can connect to a login node via virtual private network (VPN) or secure shell (SSH). These nodes provide access to requested compute resources within the internal HPC cluster network as well as job scheduling software, such as slurm, to coordinate job submission and distribution. Computing nodes are interconnected with varying levels of provisioned access available, ranging from one GPU on a multi-GPU node to dozens of multi-GPU nodes. A shared parallel filesystem is used to access the data storage.
 Figure 2. Typical HPC cluster setup
Figure 2. Typical HPC cluster setup
However, a special consideration within ecosystems handling hospital data is protected health information, or PHI. The Health Insurance Portability and Accountability Act, or HIPAA, mandates a basic level of security to ensure that PHI is adequately protected, ensuring patient privacy around sensitive health data. Thus, HIPAA-compliant healthcare HPC must account for heightened security and segregation of PHI. But what exactly does it mean to be HIPAA compliant? The following will describe some key components necessary to ensure HIPAA compliance and protection of sensitive patient data throughout all aspects of hospital-based collaborations. Though HIPAA compliance may seem challenging, we break down these requirements into two key facets: the data silo and data stewardship, as shown in Figure 3.
 Figure 3. The key facets needed to ensure HIPAA compliance in datacenters housing healthcare data
Figure 3. The key facets needed to ensure HIPAA compliance in datacenters housing healthcare data
Firstly, the data silo must ensure that access is provisioned in a secure and controllable fashion. Data must be encrypted in accordance with the Advanced Encryption Standard (AES), such as by AES-256 which utilizes a 256-bit key. Adequate firewalls, a private IP address, and access via remote VPN are further required to ensure that PHI remains accessible only to authorized parties and in a secure fashion. Finally, physical access controls ensure credentialed access and surveillance within the datacenter itself.
Secondly, data stewardship practices must be in place to ensure that practices remain up to date and aligned with institutional goals. A business associate agreement (BAA) describes the responsibilities of each party with regards to protection of PHI in a legally binding fashion and is necessary if business associate operations require PHI access. Security protocols, along with a disaster recovery plan, should be outlined to ensure protection of PHI in all scenarios. Finally, regular security and risk analyses should be performed to maintain compliance with applicable standards and identify areas of improvement.
While many datacenters have implemented measures to ensure compliance with regulations like HIPAA, the greatest challenge remains providing on-demand separation between general workloads and HIPAA-compliant workloads within the same infrastructure. To address this issue, Dell Technologies is working in collaboration with Northwestern Medicine on a new approach that utilizes flexible, controlled provisioning to enable on-demand HIPAA compliance within existing HPC clusters, as shown in Figure 4. This HPC setup, once deployed, would automatically provide network separation and the reconfiguration of compute and data storage resources, ensuring they are isolated from the general allocation.
This newly HIPAA-compliant portion of the cluster can be accessed only by credentialed users via VPN using dedicated login nodes which provide separate job scheduling and filesystem access, enabling access to AI-ready compute resources without disrupting general workloads. When no longer needed, automatic cluster reconfiguration occurs, returning resources to the general allocation until new HIPAA-compliant workloads are needed.
 Figure 4. Next-generation HIPAA-compliant HPC cluster, which builds on the typical setup presented in Figure 1
Figure 4. Next-generation HIPAA-compliant HPC cluster, which builds on the typical setup presented in Figure 1
Our expertise in compute infrastructure for artificial intelligence (AI) initiatives extends to developing datacenters and datacenter infrastructure with the proper security and controls in place that a health system can leverage as part of their efforts in achieving HIPAA compliance.
This integrated model of HIPAA-compliant compute for healthcare is aimed at democratizing the benefits of the artificial intelligence revolution, enabling healthcare institutions to employ these new technologies and provide better, more efficient care for all.
Resources
Generative Artificial Intelligence for Chest Radiograph Interpretation in the Emergency Department: https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2810195
Author:
Jonathan Huang, MD/PhD Candidate, Research & Development, Northwestern Medicine
Matthew Wittbrodt, Solutions Architect, Research & Development, Northwestern Medicine
Alex Heller, Director, Research & Development, Northwestern Medicine
Mozziyar Etemadi, Clinical Director, Advanced Technologies, Northwestern Medicine
Bhavesh Patel, Sr. Distinguished Engineer, Dell Technologies
Bala Chandrasekaran, Technical Staff, Dell Technologies
Frank Han, Senior Principal Engineer, Dell Technologies
Steven Barrow, Enterprise Account Executive

Unlocking the Power of Large Language Models and Generative AI: A Dell and Run:ai Joint Solution
Tue, 30 Jan 2024 19:47:13 -0000
|Read Time: 0 minutes
In the fast-paced landscape of AI, the last year has undeniably been marked as the era of Large Language Models (LLMs), especially in the Generative AI (GenAI) field. Models like GPT-4 and Falcon have captured our imagination, showcasing the remarkable potential of these LLMs. However, beneath their transformative capabilities lie a substantial challenge: the insatiable hunger for computational resources.
The demand for compute: fueling innovation with computational power
GenAI applications span from media industry to software development, driving innovation across industries. OpenAI's release of GPT-3 was a turning point, demonstrating the capabilities of language models and their potential to revolutionize every sector. On one hand, startups and tech giants have introduced closed-source models, offering APIs for their usage, exemplified by OpenAI and GPT-4. On the other hand, an active open-source community has emerged, releasing powerful models such as Falcon and Llama 2. These models, both closed- and open-source, have spurred a wave of interest, with companies racing to use their potential.
While the promise of LLMs is enormous, they come with a significant challenge—access to high-performance GPUs. Enterprises aiming to deploy these models in their private data centers or cloud environments must contend with the need for substantial GPU power. Security concerns further drive the preference for in-house deployments, making GPU accessibility critical.
The infrastructure required to support LLMs often includes high-end GPUs connected through fast interconnects and storage solutions. These resources are not just expensive and scarce but are also in high demand, leading to bottlenecks in machine learning (ML) development and deployment. Orchestrating these resources efficiently and providing data science and ML teams with easy and scalable access becomes a Herculean task.
Challenges with GPU allocation
In this landscape, GPUs are the backbone of the computational power that fuels these massive language models. Due to the limited availability of on-premises and cloud resources, the open-source community has taken steps to address this challenge. Libraries like bits and bytes (by Tim Dettmers) and ggml (by Georgi Gerganov) have emerged, using various optimization techniques such as quantization to fine-tune and deploy these models on local devices.
However, the challenges are not limited to model development and deployment. These LLMs demand substantial GPU capacity to maintain low latency during inference and high throughput during fine-tuning. In the real world, the need for capacity means having an infrastructure that dynamically allocates GPU resources to handle LLM fine-tuning and inference operations, all while ensuring efficiency and minimal wasted capacity.
As an example, consider loading LLama-7B using half precision (float16). Such a model requires approximately 12GB of GPU memory─a figure that can be even lower with the use of lower precision. In instances where high-end GPUs, like the NVIDIA A100 GPU with 40 GB (or 80 GB) of memory, are dedicated solely to a single model, severe resource waste results, especially when done at scale. The wasted resource does not only translate to financial inefficiencies but also reduced productivity in data science teams, and an increased carbon footprint due to the excessive underutilization of running resources over extended periods.
Some LLMs are so large that they must be distributed across multiple GPUs or multiple GPU servers. Consider Falcon-180B using full precision. Such a model requires approximately 720 GB and the use of more than 16 NVIDIA A100 GPUs with 40 GB each. Fine tuning such models and running them in production requires tremendous computing power and significant scheduling and orchestration challenges. Such workloads require not only a high-end compute infrastructure but also a high-end performant software stack that can distribute these workloads efficiently without bottlenecks.
Apart from training jobs, serving these models also requires efficient autoscaling on hardware. When there is high demand, these applications must be able to scale up to hundreds of replicas rapidly, while in low demand situations, they can be scaled down to zero to save costs.
Optimizing the management of LLMs for all these specific needs necessitates a granular view of GPU use and performance as well as high-level scheduling view of compute-intensive workloads. For instance, it is a waste if a single model like LLama-7B (12 GB) is run on an NVIDIA A100 (40GB) with almost 60 percent spare capacity instead of using this remaining capacity for an inference workload.
Concurrency and scalability are essential, both when dealing with many relatively small, on-premises models, each fine-tuned and tailored to specific use cases as well as when dealing with huge performant models needing careful orchestration. These unique challenges require a resource orchestration tool like Run:ai to work seamlessly on top of Dell hardware. Such a solution empowers organizations to make the most of their GPU infrastructure, ensuring that every ounce of computational power is used efficiently. By addressing these challenges and optimizing GPU resources, organizations can harness the full potential of LLMs and GenAI, propelling innovation across various industries.
Dell Technologies and Run:ai: joint solution
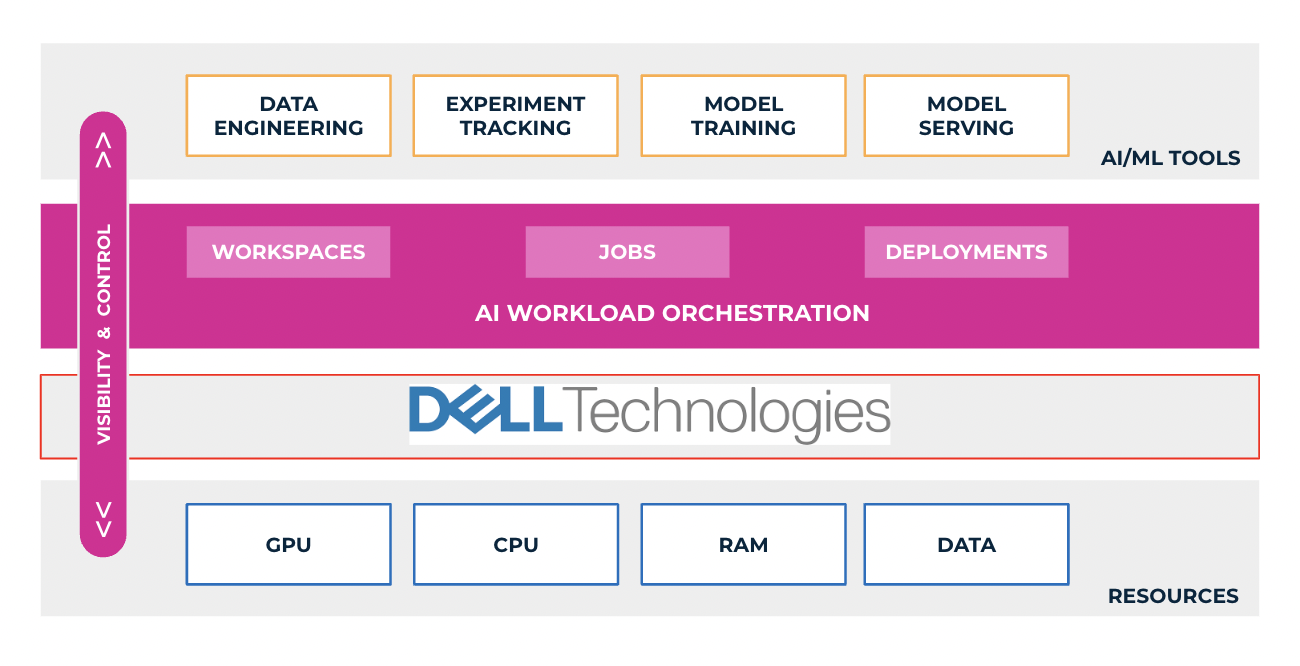
To address these bottlenecks, which hinder the rapid adoption of GenAI in organizations, Run:ai, a compute orchestration solution, teams up with Dell Technology.
The Dell Generative AI Solutions portfolio, a comprehensive suite of Dell products and services (Dell PowerEdge XE9680, PowerEdge 760XA, and PowerEdge XE8640 servers) in collaboration with NVIDIA, enables customers to build GenAI models on-premises quickly and securely, accelerate improved outcomes, and drive new levels of intelligence. Dell Validated Designs for Generative AI now support both model tuning and inferencing, allowing users to deploy GenAI models quickly with pretested and proven Dell infrastructure, software, and services to power transformative business outcomes with GenAI. The Validated designs integrate end-to-end AI solutions including all the critical components (server, networking, storage, and software) for AI systems, while Run:ai introduces two key technological components that unlock the true potential of these AI models: GPU optimization and a sophisticated scheduling system for training and inference workloads. Extending the Dell GenAI approaches with Run:ai orchestration enables customers to optimize GenAI and AI operations to build and train AI models and run inferencing with greater speed and efficiency.
AI-optimized compute: maximizing GPU utilization
Dell Technologies offers a range of acceleration-optimized PowerEdge servers, purpose-built for high-performance workloads like AI and demanding use-cases in generative AI, as part of the extensive server portfolio that supports various NVIDIA GPUs. Dell PowerEdge servers advance accelerated compute to drive enhanced AI workload outcomes with greater insights, inferencing, training, and visualization. However, one of the primary challenges in training and deploying LLMs is GPU use. Together with Dell PowerEdge servers, Run:ai's GPU optimization layer enables features like fractionalizing GPUs and GPU oversubscription. These features ensure that multiple workloads (training and inference), even small models, can efficiently run on the same GPU. By making better use of existing GPU resources, costs are reduced, and bottlenecks are mitigated.
Advanced scheduling: efficient workload management
Run:ai's advanced scheduling system integrates seamlessly into Kubernetes environments on top of PowerEdge servers. It is designed to tackle the complexities that arise when multiple teams and users share a GPU cluster and when running large multi-GPU or multi-node workloads. The scheduler optimizes resource allocation, ensuring efficient utilization of GPUs among various workloads, including training, fine-tuning, and inference.
Autoscaling and GPU optimization for inference workloads
Run:ai's autoscaling functionality enables dynamic adjustments to the number of replicas, allowing for efficient scaling based on demand. In times of increased workload, Run:ai optimally uses the available GPU, scaling up the replicas to meet performance requirements. Conversely, during periods of low demand, the number of replicas can be scaled down to zero, minimizing resource use and leading to cost savings. While there might be a brief cold start delay with the first request, this approach provides a flexible and effective solution to adapt to changing inference demands while optimizing costs.
Beyond autoscaling, deploying models for inference using Run:ai is a straightforward process. Internal users can effortlessly deploy their models and access them through managed URLs or user-friendly web interfaces like Gradio and Streamlit. This streamlined deployment process facilitates sharing and presentation of deployed LLMs, fostering collaboration and delivering a seamless experience for stakeholders.
AI networking
To achieve high throughput in multi-node training and low latency when hosting a model on multiple machines, most GenAI models require robust and highly performant networking capabilities on hardware, which is where Dell's networking capabilities and offerings come into play. The network interconnects the compute nodes among each other to facilitate communications during distributed training and inferencing. The Dell PowerSwitch Z-series are high-performance, open, and scalable data center switches ideal for generative AI, as well as NVIDIA Quantum InfiniBand switches for faster connectivity.
Fast access to your data
Data is a crucial component for each part of the development and deployment steps. Dell PowerScale storage supports the most demanding AI workloads with all-flash NVMe file storage solutions that deliver massive performance and efficiency in a compact form factor. PowerScale is an industry-leading storage platform purpose-built to handle massive amounts of unstructured data, ideal for supporting datatypes required for generative AI.
Streamlined LLM tools
To simplify the experience for researchers and ML engineers, Run:ai offers a suite of tools and frameworks. They remove the complexities of GPU infrastructure with interfaces like command-line interfaces, user interfaces, and APIs on top of Dell hardware. With these tools, training, fine-tuning, and deploying models become straightforward processes, enhancing productivity, and reducing time-to-market. As a data scientist, you can take pretrained models from the Huggingface model hub and start working on them with your favorite IDE and experiment with management tools in minutes, a testament to the efficiency and ease of the Dell and Run:ai solution.
Benefits of the Dell and Run:ai solution for customers
Now that we have explored the challenges posed by LLMs and the joint solution of Dell Technologies and Run:ai to these bottlenecks, let's dive into the benefits that this partnership between Dell Technologies and Run:ai and offers to customers:
1. Accelerated time-to-market
The combination of Run:ai's GPU optimization and scheduling solutions, along with Dell's robust infrastructure, significantly accelerates the time-to-market for AI initiatives. By streamlining the deployment and management of LLMs, organizations can quickly capitalize on their AI investments.
2. Enhanced productivity
Data science and ML engineering teams, often unfamiliar with the complexities of AI infrastructure, can now focus on what they do best: building and fine-tuning models. Run:ai's tools simplify the process, reducing the learning curve and improving productivity.
3. Cost efficiency
Optimizing GPU use not only provides performance but also provides cost-effectiveness. By running multiple workloads on the same GPU, organizations can achieve better cost efficiency, get the most out of their infrastructure, thus making AI initiatives more financially viable.
4. Increased scalability and GPU availability
Run:ai's advanced scheduling system ensures that workloads are efficiently managed, even during peak demand. This scalability is crucial for organizations that need to serve language models in real time to a growing user base. In addition, the scheduling component ensures fair and optimized allocation of GPU resources between multiple users, teams, and tasks, preventing resource bottlenecks and contention and increasing availability of GPUs to allow more users, teams, and AI services to get access and use available GPU resources effectively.
5. Innovation unleashed
The solution empowers enterprise teams to innovate and experiment with LLMs and GenAI without being hindered by infrastructure complexities. Researchers and ML engineers can easily fine-tune and deploy models using abstraction tools, fostering innovation and exploration in AI projects.
Summary
The joint solution offered by Dell Technologies and Run:ai addresses the critical challenges faced by organizations ramping up with GenAI for their business needs and working with LLMs. By enhancing GPU accessibility, optimizing scheduling, streamlining workflows, and saving costs, this solution empowers businesses to fully harness the potential of LLMs in GenAI applications while simplifying the challenges. With AI initiatives becoming increasingly vital in today's world, this partnership offers businesses new ways to automate and simplify their GenAI strategy and drive more business innovation.
For information about how to get started with Dell Technologies and Run:ai on your GenAI journey, see these resources:
- Dell AI Solutions
- GPU Optimization with Run:ai Atlas technical whitepaper
- Accelerate AI by Optimizing Compute Resources
- Run:ai
Authors: Justin King, Ekin Karabulut
Contributor: James Yung
Unveiling the Power of the PowerEdge XE9680 Server on the GPT-J Model from MLPerf™ Inference
Tue, 16 Jan 2024 18:30:32 -0000
|Read Time: 0 minutes
Abstract
For the first time, the latest release of the MLPerf™ inference v3.1 benchmark includes the GPT-J model to represent large language model (LLM) performance on different systems. As a key player in the MLPerf consortium since version 0.7, Dell Technologies is back with exciting updates about the recent submission for the GPT-J model in MLPerf Inference v3.1. In this blog, we break down what these new numbers mean and present the improvements that Dell Technologies achieved with the Dell PowerEdge XE9680 server.
MLPerf inference v3.1
MLPerf inference is a standardized test for machine learning (ML) systems, allowing users to compare performance across different types of computer hardware. The test helps determine how well models, such as GPT-J, perform on various machines. Previous blogs provide a detailed MLPerf inference introduction. For in-depth details, see Introduction to MLPerf inference v1.0 Performance with Dell Servers. For step-by-step instructions for running the benchmark, see Running the MLPerf inference v1.0 Benchmark on Dell Systems. Inference version v3.1 is the seventh inference submission in which Dell Technologies has participated. The submission shows the latest system performance for different deep learning (DL) tasks and models.
Dell PowerEdge XE9680 server
The PowerEdge XE9680 server is Dell’s latest two-socket, 6U air-cooled rack server that is designed for training and inference for the most demanding ML and DL large models.

Figure 1. Dell PowerEdge XE9680 server
Key system features include:
- Two 4th Gen Intel Xeon Scalable Processors
- Up to 32 DDR5 DIMM slots
- Eight NVIDIA HGX H100 SXM 80 GB GPUs
- Up to 10 PCIe Gen5 slots to support the latest Gen5 PCIe devices and networking, enabling flexible networking design
- Up to eight U.2 SAS4/SATA SSDs (with fPERC12)/ NVMe drives (PSB direct) or up to 16 E3.S NVMe drives (PSB direct)
- A design to train and inference the most demanding ML and DL large models and run compute-intensive HPC workloads
The following figure shows a single NVIDIA H100 SXM GPU:

Figure 2. NVIDIA H100 SXM GPU
GPT-J model for inference
Language models take tokens as input and predict the probability of the next token or tokens. This method is widely used for essay generation, code development, language translation, summarization, and even understanding genetic sequences. The GPT-J model in MLPerf inference v3.1 has 6 B parameters and performs text summarization tasks on the CNN-DailyMail dataset. The model has 28 transformer layers, and a sequence length of 2048 tokens.
Performance updates
The official MLPerf inference v3.1 results for all Dell systems are published on https://mlcommons.org/benchmarks/inference-datacenter/. The PowerEdge XE9680 system ID is ID 3.1-0069.
After submitting the GPT-J model, we applied the latest firmware updates to the PowerEdge XE9680 server. The following figure shows that performance improved as a result:
Figure 3. Improvement of the PowerEdge XE9680 server on GPT-J Datacenter 99 and 99.9, Server and Offline scenarios [1]
In both 99 and 99.9 Server scenarios, the performance increased from 81.3 to an impressive 84.6. This 4.1 percent difference showcases the server's capability under randomly fed inquires in the MLPerf-defined latency restriction. In the Offline scenarios, the performance saw a notable 5.3 percent boost from 101.8 to 107.2. These results mean that the server is even more efficient and capable of handling batch-based LLM workloads.
Note: For PowerEdge XE9680 server configuration details, see https://github.com/mlcommons/inference_results_v3.1/blob/main/closed/Dell/systems/XE9680_H100_SXM_80GBx8_TRT.json
Conclusion
This blog focuses on the updates of the GPT-J model in the v3.1 submission, continuing the journey of Dell’s experience with MLPerf inference. We highlighted the improvements made to the PowerEdge XE9680 server, showing Dell's commitment to pushing the limits of ML benchmarks. As technology evolves, Dell Technologies remains a leader, constantly innovating and delivering standout results.
[1] Unverified MLPerf® v3.1 Inference Closed GPT-J. Result not verified by MLCommons Association.
The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.

Deploying Llama 7B Model with Advanced Quantization Techniques on Dell Server
Tue, 16 Jan 2024 20:05:01 -0000
|Read Time: 0 minutes
Introduction
Large-language Models (LLMs) have gained great industrial and academic interest in recent years. Different LLMs have been adopted in various applications, such as: content generation, text summarization, sentiment analysis, and healthcare. The LLM evolution diagram in Figure 1 shows the popular pre-trained models since 2017 when the transformer architecture was first introduced [1]. It is not hard to find the trend of larger and more open-source models following the timeline. Open-source models boosted the popularity of LLMs by eliminating the huge training cost associated with the large scale of the infrastructure and long training time required. Another portion of the cost of LLM applications comes from the deployment where an efficient inference platform is required.
This blog focuses on how to deploy LLMs efficiently on Dell platform with different quantization techniques. We first benchmarked the model accuracy under different quantization techniques. Then we demonstrated their performance and memory requirements of running LLMs under different quantization techniques through experiments. Specifically, we chose the open-source model Llama-2-7b-chat-hf for its popularity [2]. The server is chosen to be Dell main-stream server R760xa with NVIDIA L40 GPUs [3] [4]. The deployment framework in the experiments is TensorRT-LLM, which enables different quantization techniques including advanced 4bit quantization as demonstrated in the blog [5].
Figure 1 :LLM evolution
Background
LLM inferencing processes tend to be slow and power hungry, because of the characteristics of LLMs being large in weight size and having auto-regression. How to make the inferencing process more efficient under limited hardware resources is among the most critical problems for LLM deployment. Quantization is an important technique widely used to push for more efficient LLM deployment. It can relieve the large hardware resource requirements by reducing the memory footprint and computation energy, as well as improve the performance with faster memory access time compared to the deployment with the original un-quantized model. For example, in [6], the performance in terms of throughput by tokens per second (tokens/s) for Llama-2-7b model is improved by more than 2x by quantizing from floating point 16-bit format to integer 8-bit. Recent research made more aggressive quantization techniques like 4-bit possible and available in some deployment frameworks like TensorRT-LLM. However, quantization is not free, and it normally comes with accuracy loss. Besides the cost, reliable performance with acceptable accuracy for specific applications is what users would care about. Two key topics covered in this blog are accuracy and performance. We first benchmark the accuracy of the original model and quantized models over different tasks. Then we deployed those models into Dell server and measured their performance. We further measured the GPU memory usage for each scenario.
Test Setup
The model under investigation is Llama-2-7b-chat-hf [2]. This is a finetuned LLMs with human-feedback and optimized for dialogue use cases based on the 7-billion parameter Llama-2 pre-trained model. We load the fp16 model as the baseline from the huggingface by setting torch_dtype to float16.
We investigated two advanced 4-bit quantization techniques to compare with the baseline fp16 model. One is activation-aware weight quantization (AWQ) and the other is GPTQ [7] [8]. TensorRT-LLM integrates the toolkit that allows quantization and deployment for these advanced 4-bit quantized models.
For accuracy evaluation across models with different quantization techniques, we choose the Massive Multitask Language Understanding (MMLU) datasets. The benchmark covers 57 different subjects and ranges across different difficulty levels for both world knowledge and problem-solving ability tests [9]. The granularity and breadth of the subjects in MMLU dataset allow us to evaluate the model accuracy across different applications. To summarize the results more easily, the 57 subjects in the MMLU dataset can be further grouped into 21 categories or even 4 main categories as STEM, humanities, social sciences, and others (business, health, misc.) [10].
Performance is evaluated in terms of tokens/s across different batch sizes on Dell R760xa server with one L40 plugged in the PCIe slots. The R760xa server configuration and high-level specification of L40 are shown in Table 1 and 2 [3] [4]. To make the comparison easier, we fix the input sequence length and output sequence length to be 512 and 200 respectively.
System Name | PowerEdge R760xa |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Process Name | Intel® Xeon® Gold 6430 |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity and Type | 512GB, 16 x 32GB DIMM, 4800 MT/s DDR5 |
Host Storage Capacity | 1.8 TB, NVME |
Table 1: R760xa server configuration
GPU Architecture | L40 NVIDIA Ada Lovelace Architecture |
GPU Memory Bandwidth | 48 GB GDDR6 with ECC |
Max Power Consumption | 300W |
Form Factor | 4.4" (H) x 10.5" (L) Dual Slot |
Thermal | Passive |
Table 2: L40 High-level specification
The inference framework that includes different quantization tools is NVIDIA TensorRT-LLM initial release version 0.5. The operating system for the experiments is Ubuntu 22.04 LTS.
Results
We first show the model accuracy results based on the MMLU dataset tests in Figure 2 and Figure 3, and throughput performance results when running those models on PowerEdge R760xa in Figure 4. Lastly, we show the actual peak memory usage for different scenarios. Brief discussions are given for each result. The conclusions are summarized in the next section.
Accuracy
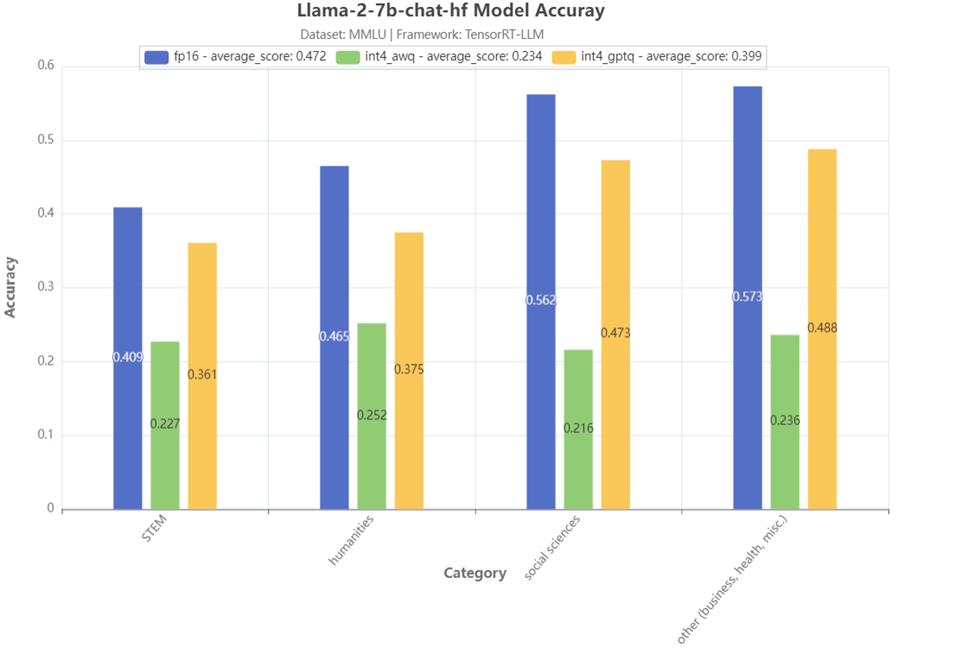
Figure 2:MMLU 4-category accuracy test result
Figure 2 shows the accuracy test results of 4 main MMLU categories for the Llama-2-7b-chat-hf model. Compared to the baseline fp16 model, we can see that the model with 4-bit AWQ has a significant accuracy drop. On the other hand, the model with 4-bit GPTQ has a much smaller accuracy drop, especially for the STEM category, the accuracy drop is smaller than 5%.
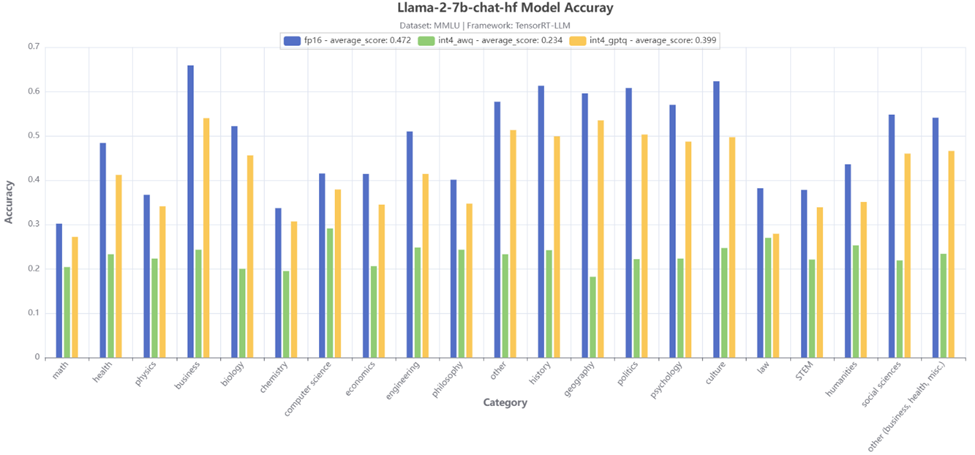
Figure 3:MMLU 21-category accuracy test result
Figure 3 further shows the accuracy test results of 21 MMLU sub-categories for the Llama-2-7b-chat-hf model. Similar conclusions can be made that the 4-bit GPTQ quantization gives much better accuracy, except for the law category, the two quantization techniques achieve a close accuracy.
Performance
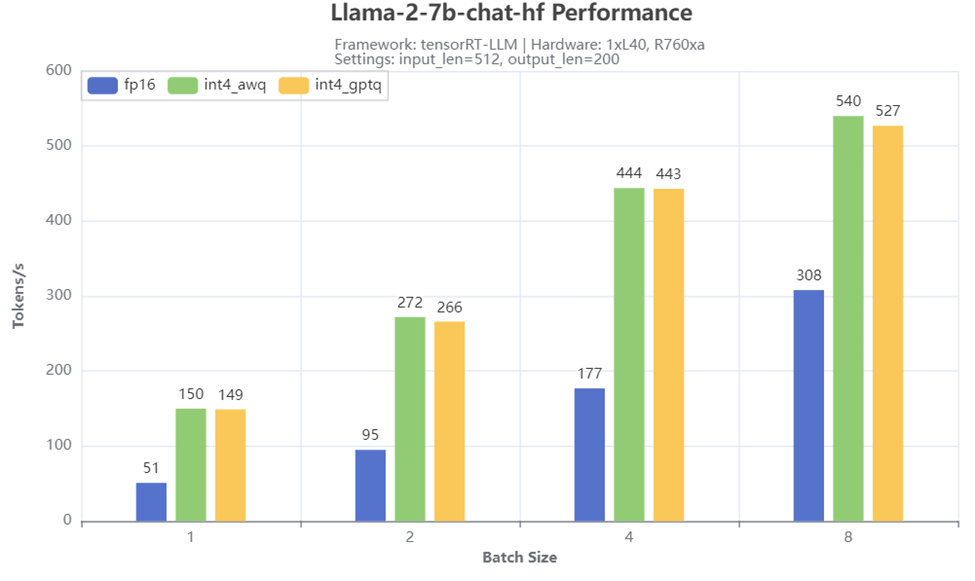
Figure 4: Throughput test result
Figure 4 shows the throughput numbers when running Llama-2-7b-chat-hf with different batch size and quantization methods on R760xa server. We observe significant throughput boost with the 4-bit quantization, especially when the batch size is small. For example, a 3x tokens/s is achieved when the batch size is 1 when comparing the scenarios with 4-bit AWQ or GPTQ quantization to the 16-bit baseline scenario. Both AWQ and GPTQ quantization give similar performance across different batch sizes.
GPU Memory Usage
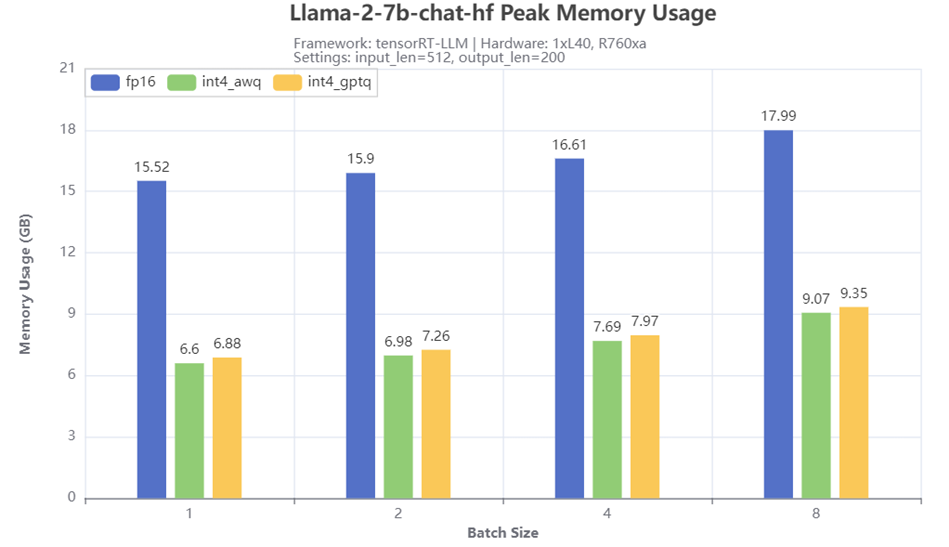
Figure 5: Peak GPU memory usage
Figure 5 shows the peak GPU memory usage when running Llama-2-7b-chat-hf with different batch size and quantization methods on R760xa server. From the results, 4-bit quantization techniques greatly reduced the memory required for running the model. Compared to the memory size required for the baseline fp16 model, the quantized models with AWQ or GPTQ only requires half or even less of the memory, depending on the batch size. A slightly larger peak memory usage is also observed for GPTQ quantized model compared to the AWQ quantized model.
Conclusion
- We have shown the impacts for accuracy, performance, and GPU memory usage by applying advanced 4-bit quantization techniques on Dell PowerEdge server when running Llama 7B model.
- We have demonstrated the great benefits of these 4-bit quantization techniques in terms of improving throughput and saving GPU memory.
- We have quantitively compared the quantized models with the baseline model in terms of accuracy among various subjects based on the MMLU dataset.
- Tests showed that with an acceptable accuracy loss, 4-bit GPTQ is an attractive quantization method for the LLM deployment where the hardware resource is limited. On the other hand, large accuracy drops across many MMLU subjects have been observed for the 4-bit AWQ. This indicates the model should be limited to the applications tied to some specific subjects. Otherwise, other techniques like re-training or fine-turning techniques may be required to improve accuracy.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
[4]. https://www.nvidia.com/en-us/data-center/l40/
[5]. https://github.com/NVIDIA/TensorRT-LLM
[7]. J. Lin et. al, “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration”, https://arxiv.org/abs/2306.00978
[8]. E. Frantar et. al, “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers”, https://arxiv.org/abs/2210.17323
[9]. D. Hendrycks et. all, “Measuring Massive Multitask Language Understanding”, https://arxiv.org/abs/2009.03300
[10]. https://github.com/hendrycks/test/blob/master/categories.py

Investigating the Memory Access Bottlenecks of Running LLMs
Thu, 18 Jan 2024 20:20:03 -0000
|Read Time: 0 minutes
Introduction
Memory access and computing are the two main functions in any computer system. In past decades, the computing capability of a processor has greatly benefited from Moore’s Law which brings smaller and faster transistors into the silicon die almost every year. On the other hand, system memory is regressing. The trend of shrinking fabrication technology for a system is making memory access much slower. This imbalance causes the computer system performance to be bottle-necked by the memory access; this is referred to as the “memory wall” issue. The issue gets worse for large language model (LLM) applications, because they require more memory and computing. Therefore, more memory access is required to be able to execute those larger models.
In this blog, we will investigate the impacts of memory access bottlenecks to the LLM inference results. For the experiments, we chose the Llama2 chat models running on a Dell PowerEdge HS5610 server with the 4th Generation Intel® Xeon® Scalable Processors. For quantitative analysis, we will be using the Intel profile tool – Intel® VTune™ Profiler to capture the memory access information while running the workload. After identifying the location of the memory access bottlenecks, we propose the possible techniques and configurations to mitigate the issues in the conclusion session.
Background
The Natural Language Processing (NLP) has greatly benefited from the transformer architecture since it was introduced in 2017 [1]. The trajectory of the NLP models has been moved to transformer-based architectures given its parallelization and scalability features over the traditional Recurrent Neural Networks (RNN) architectures. Research shows a scaling law of the transformer-based language models, in which the accuracy is strongly related to the model size, dataset size and the amount of compute [2]. This inspired the interest in using Large Language Models (LLMs) for high accuracy and complicated tasks. Figure 1 shows the evolution of the LLMs since the transformer architecture was invented. We can see the parameters of the LLMs have increased dramatically in the last 5 years. This trend is continuing. As shown in the figure, most of the LLMs today come with more than 7 billion parameters. Some models like GPT4 and PaLM2 have trillion-level parameters to support multi-mode features.
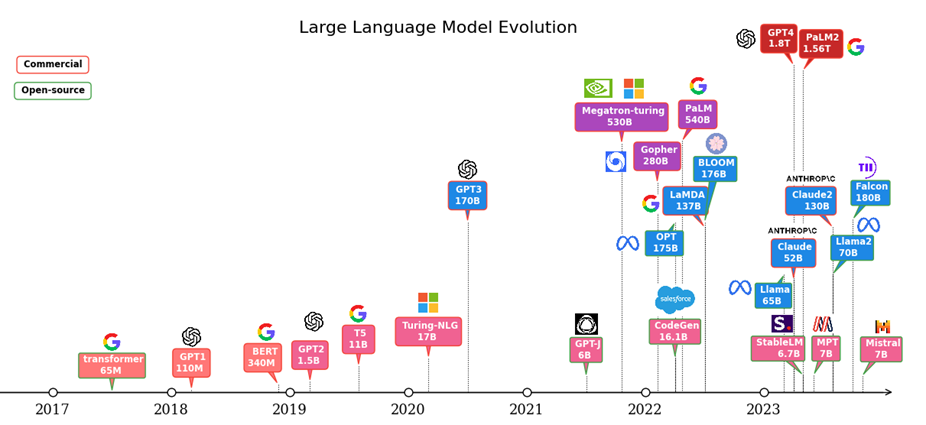
Figure 1: LLM evolution
What comes with the large models are the challenges on the hardware systems for training and inferencing those models. On the one hand, the computation required is tremendous as it is proportional to the model size. On the other hand, memory access is expensive. This mainly comes from the off-chip communication and complicated cache architectures required to support the large model parameters and computation.
Test Setup
The hardware platform we used for this study is HS5610 which is the latest 16G cloud-optimized server from Dell product portfolio. Figure 2 gives an overview of HS5610. It has been designed with CSP features that allow the same benefits with full PowerEdge features & management like mainstream Dell servers, as well as open management (OpenBMC), cold aisle service, channel firmware, and services. The server has two sockets with an Intel 4th generation 32-core Intel® Xeon® CPU on each socket. The TDP power for each CPU is 250W. Table 1 and Table 2 show the details of the server configurations and CPU specifications.
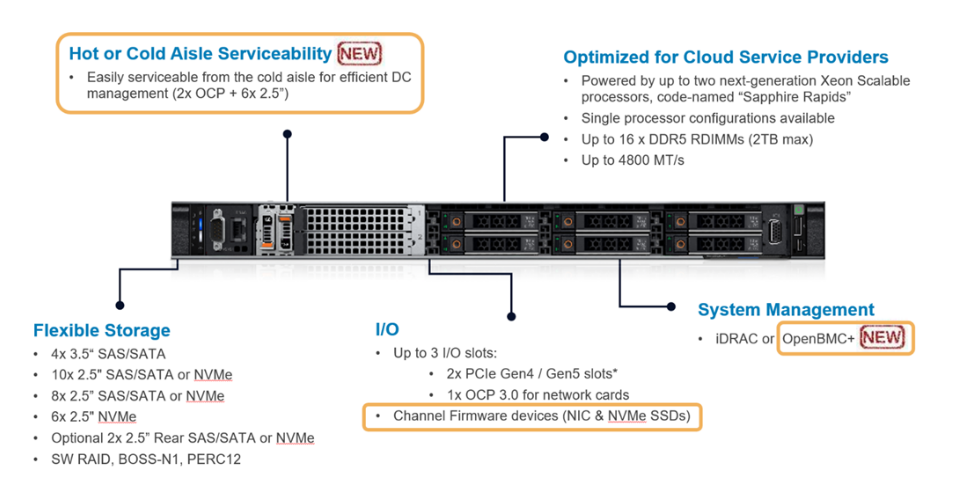
Figure 2: PowerEdge HS5610 [3]
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 32 |
# of Threads | 64 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 64 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 1: HS5610 Server Configurations
System Name | PowerEdge HS5610 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 2: 4th Generation 32-core Intel® Xeon® Scalable Processor Technical Specifications
Software Stack and System Configuration
The software stack and system configuration used for this submission is summarized in Table 3. Optimizations have been done for the PyTorch framework and Transformers library to unleash the Xeon CPU AI instruction capabilities. Also, a low-level tool - Intel® Neural Compressor has been used for high-accuracy quantization.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW | OneDNN™ Deep Learning, ONNX, Intel® Extension for PyTorch (IPEX), Intel® Extension for Transformers (ITREX), Intel® Neural Compressor |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 3: Software stack and system configuration
The model under tests is Llama2-chat-hf models with 13 billion parameters (Llama2-13b-chat-hf). The model is based on the pre-trained 13 billion Llama2 model and fine-tuned with human feedback for chatbot applications. The Llama2 model has light (7b), medium (13b) and heavy (70b) size versions.
The profile tool used in the experiments is Intel® VTune™. It is a powerful low-level performance analysis tool for x86 CPUs that supports algorithms, micro-architecture, parallelism, and IO related analysis etc. For the experiments, we use the memory access analysis under micro-architecture category. Note Intel® VTune™ consumes significant hardware resources which impacts the performance results if we run the tool along with the workload. So, we use it as a profile/debug tool to investigate the bottleneck. The performance numbers we demonstrate here are running without Intel® VTune™ on.
The experiments are targeted to cover the following:
- Single-socket performance vs dual-socket performance to demonstrate the NUMA memory access impact.
- Performance under different CPU-core numbers within a single socket to demonstrate the local memory access impact.
- Performance with different quantization to demonstrate the quantization impact.
- Intel® VTune™ memory access results.
Because Intel® VTune™ has minimum capture durations and max capture size requirements, we focus on capturing the results for the medium-size model (Llama2-13b-chat-hf). This prevents short/long inference time therefore avoiding an underload or overload issue. All the experiments are based on the batch size equals to 1. Performance is characterized by latency or throughput. To reduce the measurement errors, the inference is executed 10 times to get the averaged value. A warm-up process by loading the parameter and running a sample test is executed before running the defined inference.
Results
For this section, we showcase the performance results in terms of throughput for single-socket and dual socket scenarios under different quantization types followed by the Intel® VTune™ capturing results.
Single-socket Results Under Different Quantization Types:
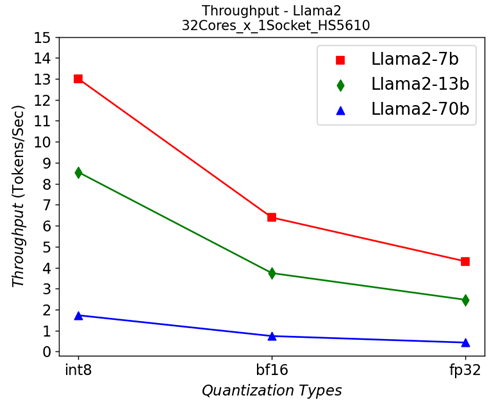
Figure 3: Single-socket throughput in HS5610 server running Llama2 models under different quantization types
Figure 3 shows the throughputs of running different Llama2 chat models with different quantization types on a single socket. The “numactl” command is used to confine the workload within one single 32-core CPU. From the results, we can see that quantization greatly helps to improve the performance across different models.
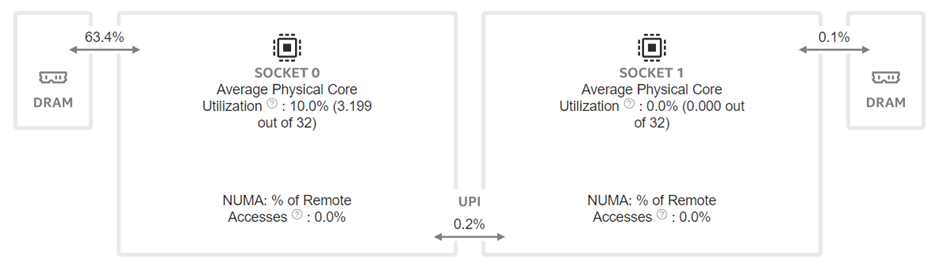 | 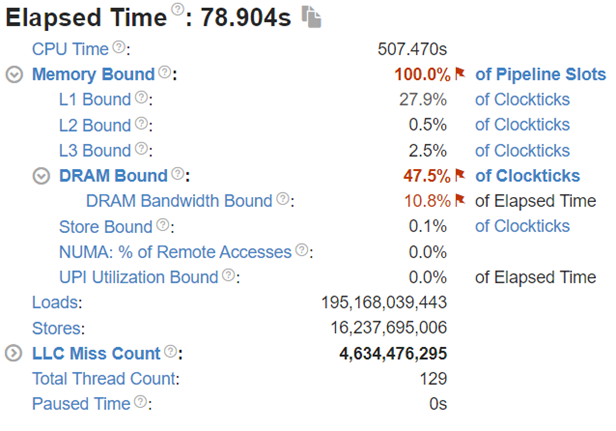 |
(a) | (b) |
Figure 4:Intel® VTune™ memory analysis results for single-socket fp32 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
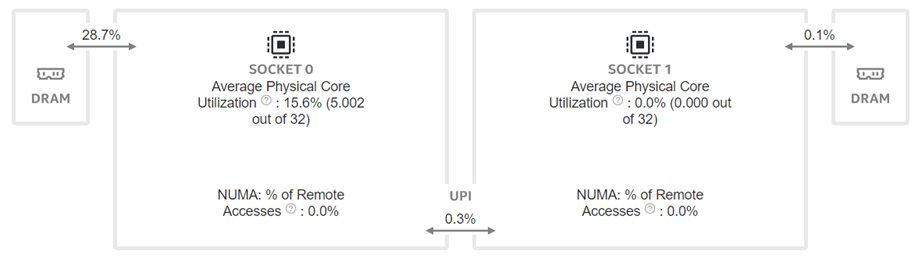 | 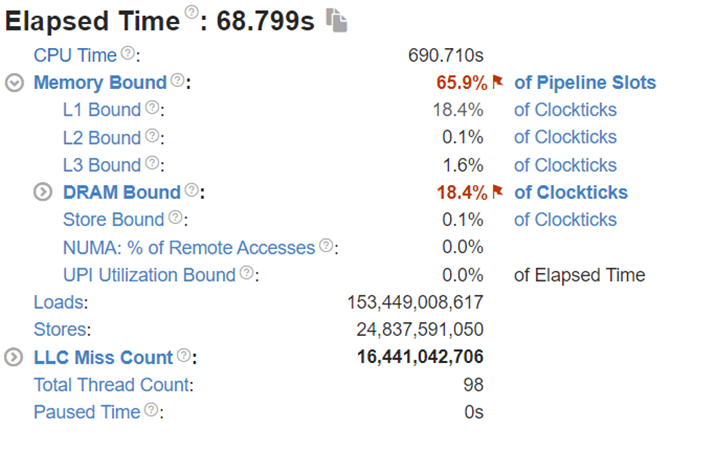 |
(a) | (b) |
Figure 5: Intel® VTune™ memory analysis results for single-socket bf16 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
To better understand what would happen at the lower level, we will take the Llama2 13 billion model as an example. We will use Intel® VTune™ to capture the bandwidth and utilization diagram and the elapsed time analysis for the fp32 data type (shown in Figure 4) and use bf16 data type (shown in Figure 5). We can see that by reducing the representing bits, the bandwidth required for the CPU and DRAM communication is reduced. In this scenario, the DRAM utilization drops from 63.4% for fp32 (shown in Figure 4 (a)) to 28.7% (shown in Figure 4 (b)). The also indicates that the weight data can arrive quicker to the CPU chip. Now we can benefit from the quicker memory communication. The CPU utilization also increases from 10% for fp32 (shown in Figure 4 (a)) to 15.6% for bf16 (shown in Figure 4 (b)). Both faster memory access and better CPU utilization translate to better performance with a more than 50% (from 2.47 tokens/s for fp32 to 3.74 tokens/s) throughput boost as shown in Figure 3. Diving deeper with the elapsed time analysis shown in Figure 4 (b), and Figure 5 (b), L1 cache is one of the performance bottleneck locations on the chip. Quantization reduces the possibility that the task gets stalled.
Dual-socket Results Under Different Quantization Types:
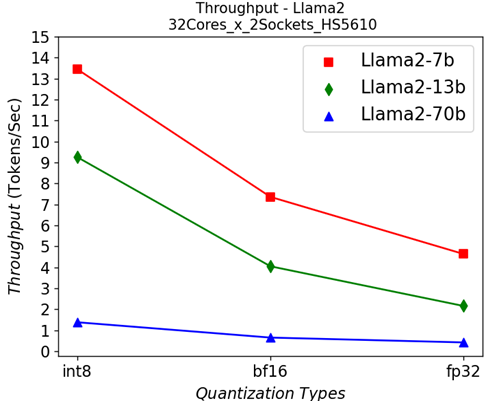
Figure 6: Dual-socket throughput in HS5610 server running Llama2 models under different quantization types
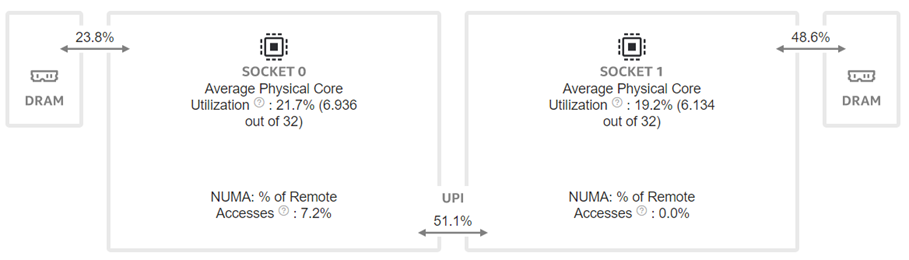 | 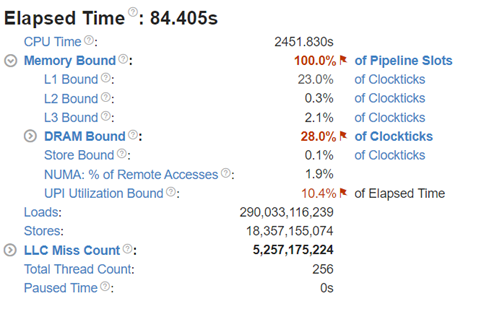 |
(a) | (b) |
Figure 7: Intel® VTune™ memory analysis results for dual-socket fp32 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
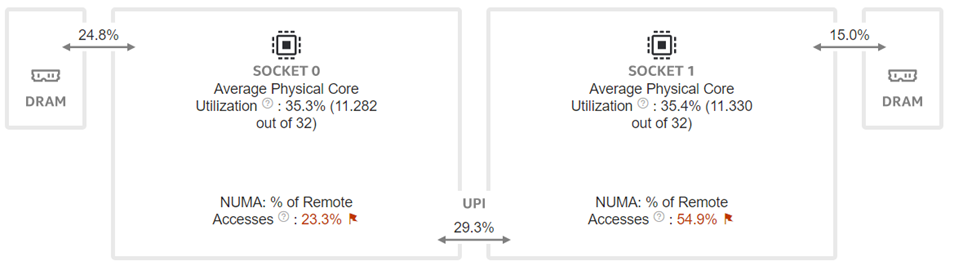 | 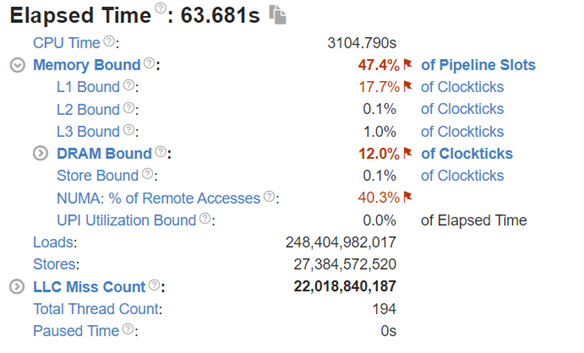 |
(a) | (b) |
Figure 8: Intel® VTune™ memory analysis results for dual-socket bf16 results:
(a). bandwidth and utilization diagram (b). elapsed time analysis
Now moving to the dual-socket scenarios shown in Figure 6-8, we have similar observations regarding the impacts of the quantization: Quantization increases CPU utilization and reduces the L1 cache bottleneck, therefore boosting the throughputs across different Llama2 models.
Comparing the performance between the single-socket (shown in Figure 3) and dual-socket (shown in Figure 6) scenarios indicates negligible performance improvement. As seen in Figure 7 and 8, even though we get better CPU utilizations, the communication between two sockets (the UPI or the NUMA memory access), becomes the main bottleneck that offsets the benefits of having more computing cores.
Conclusion
Based on the experiment results for different Llama2 models under various configurations, we have the conclusions as the following:
- Quantization improves the performance across the models with different weights by reducing the L1 cache bottleneck and increasing the CPU utilization. It also indicates that we can optimize the TCO by reducing the memory requirements (in terms of the capacity and speed) if we were able to quantize the model properly.
- Crossing-socket communication from either UPI or NUMA memory access is a significant bottleneck that may affect performance. Optimizations include the reducing of the inter-socket communication. For example better partitioning of the model is critical. Alternatively, this also indicates that executing one workload on a single dedicated CPU with enough cores is desirable for cost and performance considerations.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. J. Kaplan et. al, “Scaling Laws for Neural Language Models”, https://arxiv.org/abs/2001.08361
[3]. https://www.dell.com/en-us/shop/ipovw/poweredge-hs5610
Dell Technologies Shines in MLPerf™ Stable Diffusion Results
Tue, 12 Dec 2023 14:51:21 -0000
|Read Time: 0 minutes
Abstract
The recent release of MLPerf Training v3.1 results includes the newly launched Stable Diffusion benchmark. At the time of publication, Dell Technologies leads the OEM market in this performance benchmark for training a Generative AI foundation model, especially for the Stable Diffusion model. With the Dell PowerEdge XE9680 server submission, Dell Technologies is differentiated as the only vendor with a Stable Diffusion score for an eight-way system. The time to converge by using eight NVIDIA H100 Tensor Core GPUs is 46.7 minutes.
Overview
Generative AI workload deployment is growing at an unprecedented rate. Key reasons include increased productivity and the increasing convergence of multimodal input. Creating content has become easier and is becoming more plausible across various industries. Generative AI has enabled many enterprise use cases, and it continues to expand by exploring more frontiers. This growth can be attributed to higher resolution text to image, text-to-video generations, and other modality generations. For these impressive AI tasks, the need for compute is even more expansive. Some of the more popular generative AI workloads include chatbot, video generation, music generation, 3D assets generation, and so on.
Stable Diffusion is a deep learning text-to-image model that accepts input text and generates a corresponding image. The output is credible and appears to be realistic. Occasionally, it can be hard to tell if the image is computer generated. Consideration of this workload is important because of the rapid expansion of use cases such as eCommerce, marketing, graphics design, simulation, video generation, applied fashion, web design, and so on.
Because these workloads demand intensive compute to train, the measurement of system performance during their use is essential. As an AI systems benchmark, MLPerf has emerged as a standard way to compare different submitters that include OEMs, accelerator vendors, and others in a like-to-like way.
MLPerf recently introduced the Stable Diffusion benchmark for v3.1 MLPerf Training. It measures the time to converge a Stable Diffusion workload to reach the expected quality targets. The benchmark uses the Stable Diffusion v2 model trained on the LAION-400M-filtered dataset. The original LAION 400M dataset has 400 million image and text pairs. A subset of those images (approximately 6.5 million) is used for training in the benchmark. The validation dataset is a subset of 30 K COCO 2014 images. Expected quality targets are FID <= 90 and CLIP>=0.15.
The following figure shows a latent diffusion model[1]:
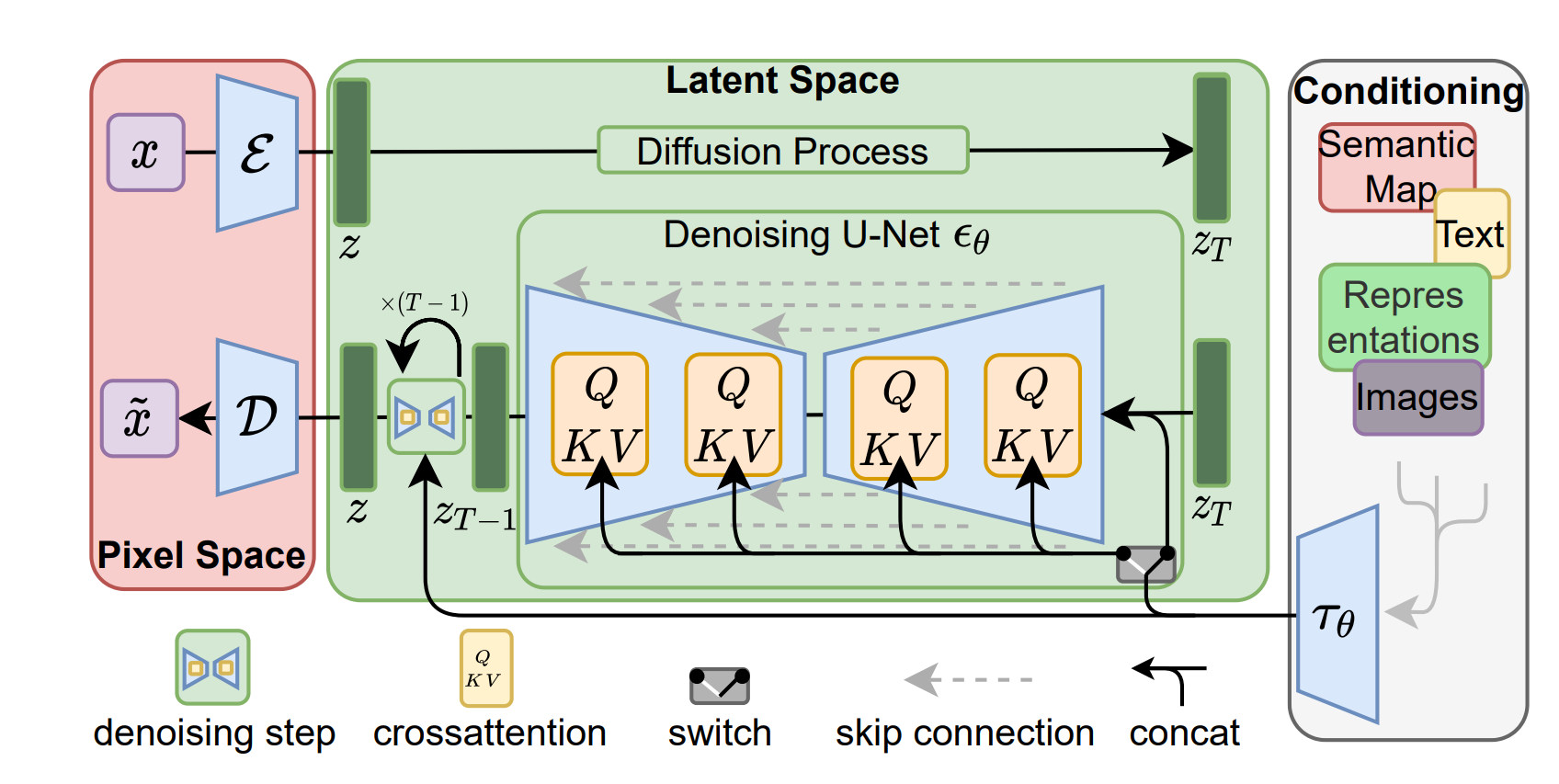
Figure 1: Latent diffusion model
[1] Source: https://arxiv.org/pdf/2112.10752.pdf
Stable Diffusion v2 is a latent diffusion model that combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. MLPerf Stable Diffusion focuses on the U-Net denoising network, which has approximately 865 M parameters. There are some deviations from the v2 model. However, these adjustments are minor and encourage more submitters to make submissions with compute constraints.
The submission uses the NVIDIA NeMo framework, included with NVIDIA AI Enterprise, for secure, supported, and stable production AI. It is a framework to build, customize, and deploy generative AI models. It includes training and inferencing frameworks, guard railing toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost effective, and a fast way to adopt generative AI.
Performance of the Dell PowerEdge XE9680 server and other NVIDIA-based GPUs on Stable Diffusion
The following figure shows the performance of NVIDIA H100 Tensor Core GPU-based systems on the Stable Diffusion benchmark. It includes submissions from Dell Technologies and NVIDIA that use different numbers of NVIDIA H100 GPUs. The results shown vary from eight GPUs (Dell submission) to 1024 GPUs (NVIDIA submission). The following figure shows the expected performance of this workload and demonstrates that strong scaling is achievable with less scaling loss.
Figure 2: MLPerf Training Stable Diffusion scaling results on NVIDIA H100 GPUs from Dell Technologies and NVIDIA
End users can use state-of-the-art compute to derive faster time to value.
Conclusion
The key takeaways include:
- The latest released MLPerf Training v3.1 measures Generative AI workloads like Stable Diffusion.
- Dell Technologies is the only OEM vendor to have made an MLPerf-compliant Stable Diffusion submission.
- The Dell PowerEdge XE9680 server is an excellent choice to derive value from Image Generation AI workloads for marketing, art, gaming, and so on. The benchmark results are outstanding for Stable Diffusion v2.
MLCommons Results
https://mlcommons.org/benchmarks/training/
The preceding graphs are MLCommons results for MLPerf IDs 3.1-2019, 3.1-2050, 3.1-2055, and 3.1-2060.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.

Scaling Hardware and Computation for Practical Deep Learning Applications in Healthcare
Fri, 01 Dec 2023 15:26:29 -0000
|Read Time: 0 minutes
Medical practice requires analysis of large volumes of data spanning multiple modalities. While these can be as simple as numeric lab results, at the other extreme are high-complexity data such as magnetic resonance imaging or decades-worth of text-based clinical documentation which may be present in medical records. Oftentimes, small details buried within piles of clinical information are critical to obtaining a complete clinical picture. Many deep learning methods developed in recent years have focused on very short “sequence lengths” – the term used to describe the number of words or pixels that a model can ingest – of images and text compared to those encountered in clinical practice. How do we scale such tools to model this breadth of clinical data appropriately and efficiently?
In the following blog, we discuss ways to tackle the compute requirements of developing transformer-based deep learning tools for healthcare data from the hardware, data processing, and modeling perspectives. To do so, we present a practical application of Flash Attention using a series of experiments performing an analysis of the publicly available Kaggle RSNA Screening Mammography Breast Cancer Detection challenge, which contains 54,706 images of 11,913 patients. Breast cancer affects 1 in 8 women and is the second leading cause of cancer death. As such, screening mammography is one of the most performed imaging-based medical screening procedures, which offers a clinically relevant and data-centric case study to consider.
Data Primer
To detect breast cancer early when treatments are most effective, high-resolution x-ray images are taken of breast tissue to identify areas of abnormality which require further examination by biopsy or more detailed imaging. Typically, two views are acquired:
- Craniocaudal (CC) – taken from the head-to-toe perspective
- Mediolateral oblique (MLO) – taken at an angle
The dataset contains DICOM-formatted images which must be pre-processed in a standard fashion prior to model training. We detail the data preparation pipeline in figure 1. The CC and MLO views of each study are identified, flipped horizontally if necessary, cropped, and combined to form the model input image. We wrap the standard PyTorch Dataset class to load images and preprocess them for training. Figure 1. Data pre-processing pipeline for DICOM-formatted image
Figure 1. Data pre-processing pipeline for DICOM-formatted image
A more in-depth look at the system for data pre-processing is as follows:
- For each breast with a corresponding cancer label, the CC and MLO views are extracted, and the image data are normalized. Right-sided images are horizontally flipped so that the tissue is to the left side of the image, as shown.
- Images are cropped to the region of interest (ROI), excluding areas of black or non-tissue artifacts.
- Images are resized, maintaining aspect ratio, and tiled to a square of the output size of interest, with the CC view occupying the left half of the output and the MLO view occupying the right.
An important consideration is whether to perform this processing within the dataloader while training or to save a pre-processed version of the dataset. The former approach allows for iteration on different processing strategies without modifying the dataset itself, providing greater ease of experimentation. However, this level of processing during training may limit the rate at which data can be fed to the graphics processing unit (GPU) for training, resulting in time and monetary inefficiencies. In contrast, the latter approach requires that multiple versions of the dataset be saved locally, which is potentially prohibitive when working with large dataset sizes and storage space and/or network limitations. For the purpose of this blog post, to benchmark GPU hardware and training optimizations, we use the second method, saving data on local solid state drives connected via NVMe to ensure GPU saturation despite processor differences. In general, before implementing the training optimizations described below, it is important to first ensure that dataloading does not bottleneck the overall training process.
Scaling Up
Naturally, increasing the capability and amount of compute available for model training yields direct benefits. To demonstrate the influence of hardware on run time, we present a simple 20-epoch training experiment using the same dataset on three different servers, shown in figure 2:
- Dell XE8545 with 4x NVIDIA A100-SXM4 40GB GPUs and an AMD EPYC 7763 with 64 cores
- Dell R750xa with 4x NVIDIA A100 80GB GPUs and an Intel Xeon Gold 5320 processor with 26 cores
- Dell XE9680 server with 8 NVIDIA HGX A100 80GB SXM4 GPUs and an Intel Xeon Platinum 8470 processor with 52 cores
Input data into the model shown in figure 2 were 512x512 with a patch size of 16. Batch size was 24 per GPU on the 40GB and 64 on the 80GB servers.
Parameters remain the same for each run, except that batch size has been increased to maximally utilize GPU memory on the R750xa and XE9680 compared with the XE8545. Gradient accumulation is performed to maintain a constant global batch size per model weight update for each run. We see a clear improvement in runtime as the hardware is scaled up, demonstrating how increased compute capability directly yields time savings which enables researchers to efficiently iterate on experiments and train effective models.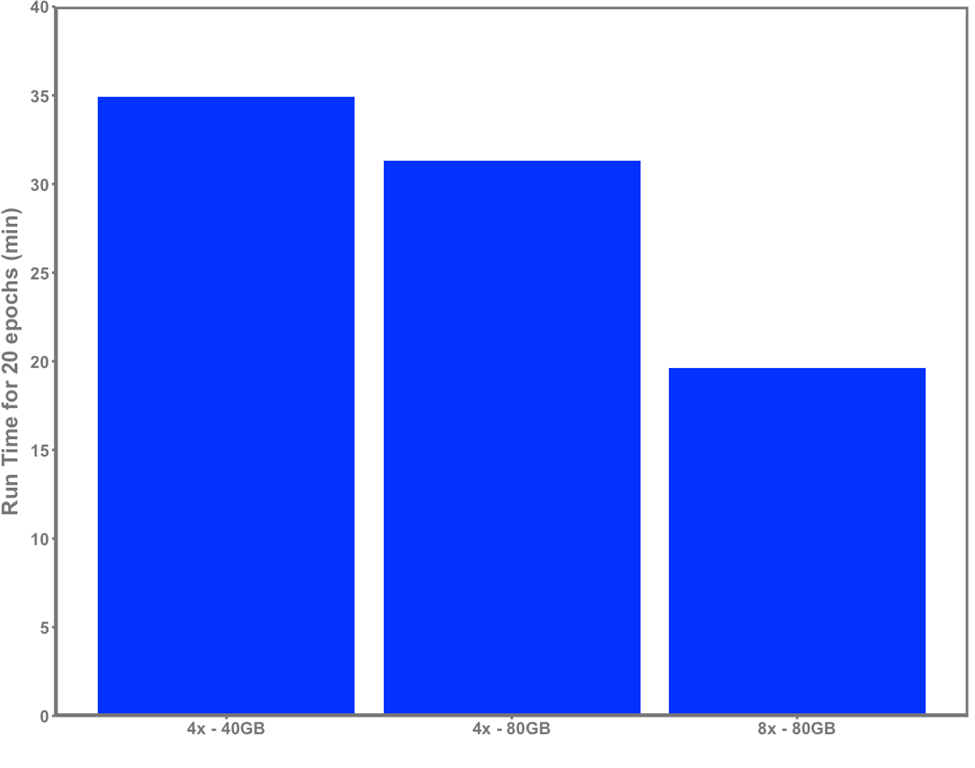 Figure 2. ViT-base training time across 20 epochs with 4xA100 40GB, 4xA100 80GB, and 8xA100 80GB servers
Figure 2. ViT-base training time across 20 epochs with 4xA100 40GB, 4xA100 80GB, and 8xA100 80GB servers
In conjunction with hardware, sequence lengths of data should be carefully considered given the application of interest. The selected tokenization scheme directly impacts sequence length of input data, such as the patch size selected as input to a vision transformer. For example, a patch size of 16 on a 1024x1024 image will result in a sequence length of 4,096 (Height*Width/Patch Size2) while a patch size of 8 will result in a sequence length of 16,384. While GPUs increasingly feature more memory, they present an upper bound on the sequence length that can practicably be considered. Smaller patch sizes – and thus, longer sequences – will result in slower throughput via smaller batch sizes and a greater number of computations, as shown in figure 3. However, larger images sizes coupled with smaller patch sizes are particularly relevant in analysis of mammography and other applications in which fine-resolution features are of interest.
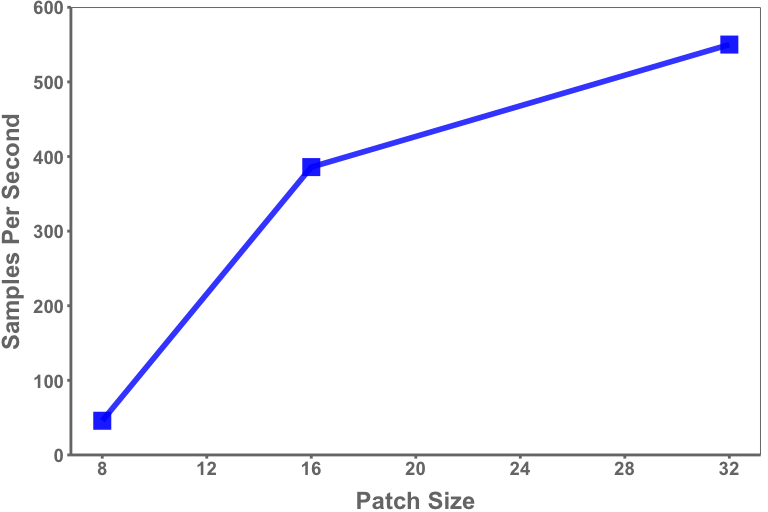 Figure 3. Average training samples per second (per GPU) for mammograms through a vision transformer by patch size
Figure 3. Average training samples per second (per GPU) for mammograms through a vision transformer by patch size
The data illustrated in figure 3 are taken from a run of twenty epochs using an image size of 512x512 and tested on an 8xA100 (80 GB) server.
Flash Attention – Experiments
Recently, Dao et al. have published on Flash Attention (https://arxiv.org/abs/2205.14135), a technique aimed at more efficiently accomplishing the computations involved within transformers via minimizing GPU high-bandwidth memory and the on-chip SRAM. Their reported findings are impressive, yielding 2-3x speedups during an attention forward and backwards pass while also having 3-20x smaller memory requirements.
Using a Dell XE9680 server with 8 NVIDIA HGX A100 80GB SXM4 GPUs and an Intel Xeon Platinum 8470 processor with 52 cores, we provide a practical demonstration of potential applications for Flash Attention and vision transformers in healthcare. Specifically, we performed experiments to demonstrate how sequence length (determined by patch size and image size) and Flash Attention impact training time. To limit confounding variables, all images were pre-sized on disk and directly loaded into the vision transformer without any permutations. For the vision transformer, the ViT-Base from Huggingface was used. For Flash Attention, the Encoder from the x_transformers library was used, shown being implemented in the following code.
All tests were carried out with the Huggingface trainer using an effective batch size of 128 per GPU, “brain" floating-point 16 data, and across twenty epochs at patch sizes of 8, 16, and 32 with image sizes of 384, 512, 1024, and 2048.
from x_transformers import ViTransformerWrapper, Encoder
class FlashViT(nn.Module):
def __init__(self,
encoder = ViTransformerWrapper(
image_size = args.img_size,
patch_size = args.patch_size,
num_classes = 2,
channels=3,
attn_layers = Encoder(
dim = 768,
depth = 12,
heads = 12,
attn_flash=True
)
),
super().__init__()
self.encoder = encoder
def forward(self,
pixel_values:torch.tensor,
labels:torch.tensor):
"""
pixel_values: [batch,channel,ht,wt] of pixel values
labels: labels for each image
"""
logits = self.encoder(pixel_values)
return {'loss':F.cross_entropy(logits,labels),'logits':logits}
model = FlashViT()
Figure 4 demonstrates the pronounced benefit of using Flash Attention within a vision transformer with respect to model throughput. With the exception of the two smallest image sizes and largest patch size (and thus shortest sequence length), Flash Attention resulted in a marked speed increase across all other perturbations. The speed-up range across patch sizes was:
- Patch size of 8: 3.0 - 4.2x
- Patch size of 16: 2.8 – 4.0x
- Patch size of 32: 0 - 2.3x
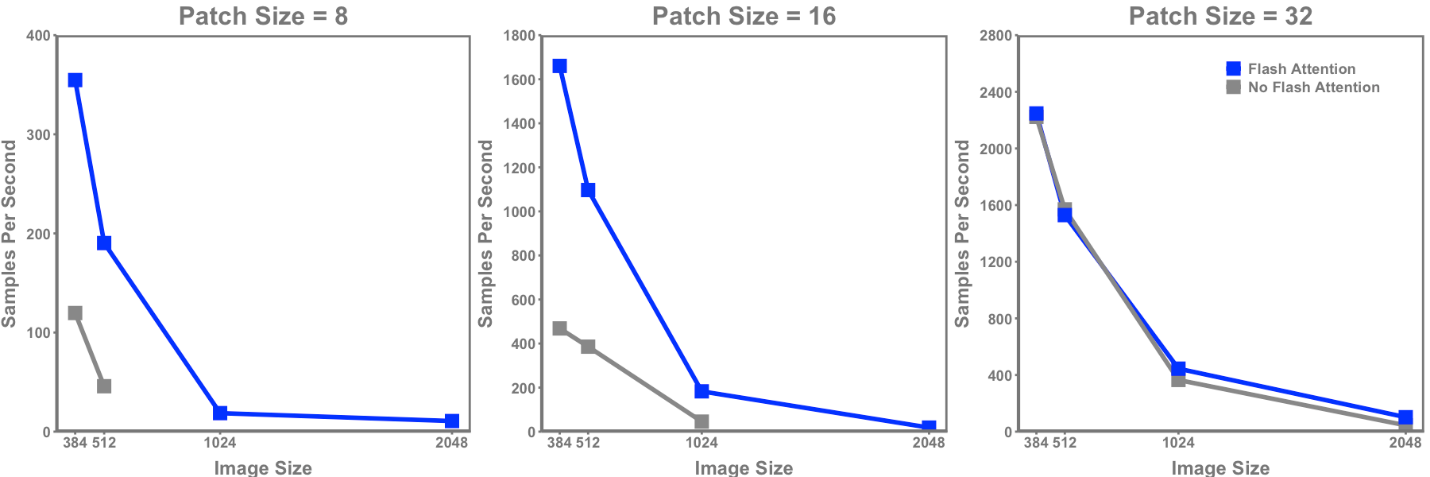 Figure 4. Samples per second throughput for a ViT-base vision transformer with and without Flash Attention across varying image sizes and patch sizes
Figure 4. Samples per second throughput for a ViT-base vision transformer with and without Flash Attention across varying image sizes and patch sizes
Another benefit demonstrated in these experiments is the additional image and patch size combinations achievable only with Flash Attention due to the reduced GPU memory requirement. Non-Flash Attention models could only be used on image sizes of 2,048 if a patch size of 32 was used (sequence length of 4,096), whereas Flash Attention was capable of running on patch sizes of 8 and 16. Even at shorter sequence lengths (576 - 384x384 image, patch size of 16), there was 2.3x less memory used for Flash Attention. Use of Flash Attention will also be critical when considering larger transformer models, with ViT-Huge having more than 7x the parameters than ViT-Base. In conjunction with hardware-enabling distributed training at scale such as the Dell XE9680, these optimizations will enable new findings at unprecedented scales.
Takeaways
We have described methods by which the benefits of transformer-based models can be scaled to the longer sequences which medical data often require. Notably, we demonstrate the benefits of implementing Flash Attention to a vision encoder. Flash Attention presents marked benefit from a modeling perspective, from shorter runtimes (and thus lower cost) to better image encoding (longer sequence lengths). Moreover, we show that these benefits scale substantially along with sequence length, making them indispensable for practitioners aiming to model the full complexity of hospital data. As machine learning continues to grow in healthcare, tight collaborations between hospitals and technology manufactures are thus essential to allow for greater compute resources to input higher-quality data into machine learning models.
Resources
- Dell XE9680 Technical Guide: https://www.delltechnologies.com/asset/en-ca/products/servers/technical-support/poweredge-xe9680-technical-guide.pdf
- Dell R750xa Technical Guide: https://i.dell.com/sites/csdocuments/Product_Docs/en/poweredge-r750xa-technical-guide.pdf
- Dell XE8545 Technical Guide: https://i.dell.com/sites/csdocuments/product_docs/en/poweredge-xe8545-technical-guide.pdf
Authors:
Jonathan Huang, MD/PhD Candidate, Research & Development, Northwestern Medicine
Matthew Wittbrodt, Solutions Architect, Research & Development, Northwestern Medicine
Alex Heller, Director, Research & Development, Northwestern Medicine
Mozziyar Etemadi, Clinical Director, Advanced Technologies, Northwestern Medicine
Bhavesh Patel, Sr. Distinguished Engineer, Dell Technologies
Bala Chandrasekaran, Technical Staff, Dell Technologies
Frank Han, Senior Principal Engineer, Dell Technologies
Dell PowerEdge Servers Achieve Stellar Scores with MLPerf™ Training v3.1
Wed, 08 Nov 2023 17:43:48 -0000
|Read Time: 0 minutes
Abstract
MLPerf is an industry-standard AI performance benchmark. For more information about the MLPerf benchmarks, see Benchmark Work | Benchmarks MLCommons.
Today marks the release of a new set of results for MLPerf Training v3.1. The Dell PowerEdge XE9680, XE8640, and XE9640 servers in the submission demonstrated excellent performance. The tasks included image classification, medical image segmentation, lightweight and heavy-weight object detection, speech recognition, language modeling, recommendation, and text to image. MLPerf Training v3.1 results provide a baseline for end users to set performance expectations.
What is new with MLPerf Training 3.1 and the Dell Technologies submissions?
The following are new for this submission:
- For the benchmarking suite, a new benchmark was added: stable diffusion with the Laion400 dataset.
- Dell Technologies submitted the newly introduced Liquid Assisted Air Cooled (LAAC) PowerEdge XE9640 system, which is a part of the latest generation Dell PowerEdge servers.
Overview of results
Dell Technologies submitted 30 results. These results were submitted using five different systems. We submitted results for the PowerEdge XE9680, XE8640, and XE9640 servers. We also submitted multinode results for the PowerEdge XE9680 and XE8640 servers. The PowerEdge XE9680 server was powered by eight NVIDIA H100 Tensor Core GPUs, while the PowerEdge XE8640 and XE9640 servers were powered by four NVIDIA H100 Tensor Core GPUs each.
Datapoints of interest
Interesting datapoints include:
- Our new stable diffusion results with the PowerEdge XE9680 server have been submitted for the first time and are exclusive. Dell Technologies, NVIDIA, and Habana Labs are the only submitters to have made an official submission. This submission is important because of the explosion of Generative AI workloads. The submission uses the NVIDIA NeMo framework, included in NVIDIA AI Enterprise for secure, supported, and stable production AI.
- Dell PowerEdge XE8640 and XE9640 servers secured several top performer titles (#1 titles) among other systems equipped with four NVIDIA H100 GPUs. The tasks included language modeling, recommendation, heavy-weight object detection, speech to text, and medical image segmentation.
- A number of multinode results were submitted for the previous round, which can be compared with this round. PowerEdge XE9680 multinode results were submitted. Additionally, this round was the first time multinode results with the newer generation PowerEdge XE8640 servers were submitted. The results show near linear scaling. Furthermore, Dell Technologies is the only submitter in addition to NVIDIA, Habana Labs, and Intel making multinode, on-premises result submissions.
- The results for the PowerEdge XE9640 server with liquid assisted air cooling (LAAC) are similar to the PowerEdge XE8640 air-cooled server.
The following figure shows all the convergence times for Dell systems and corresponding workloads in the benchmark. Because different benchmarks are included in the same graph, the y axis is expressed logarithmically. Overall, these numbers show an excellent time to converge for the workload in question.
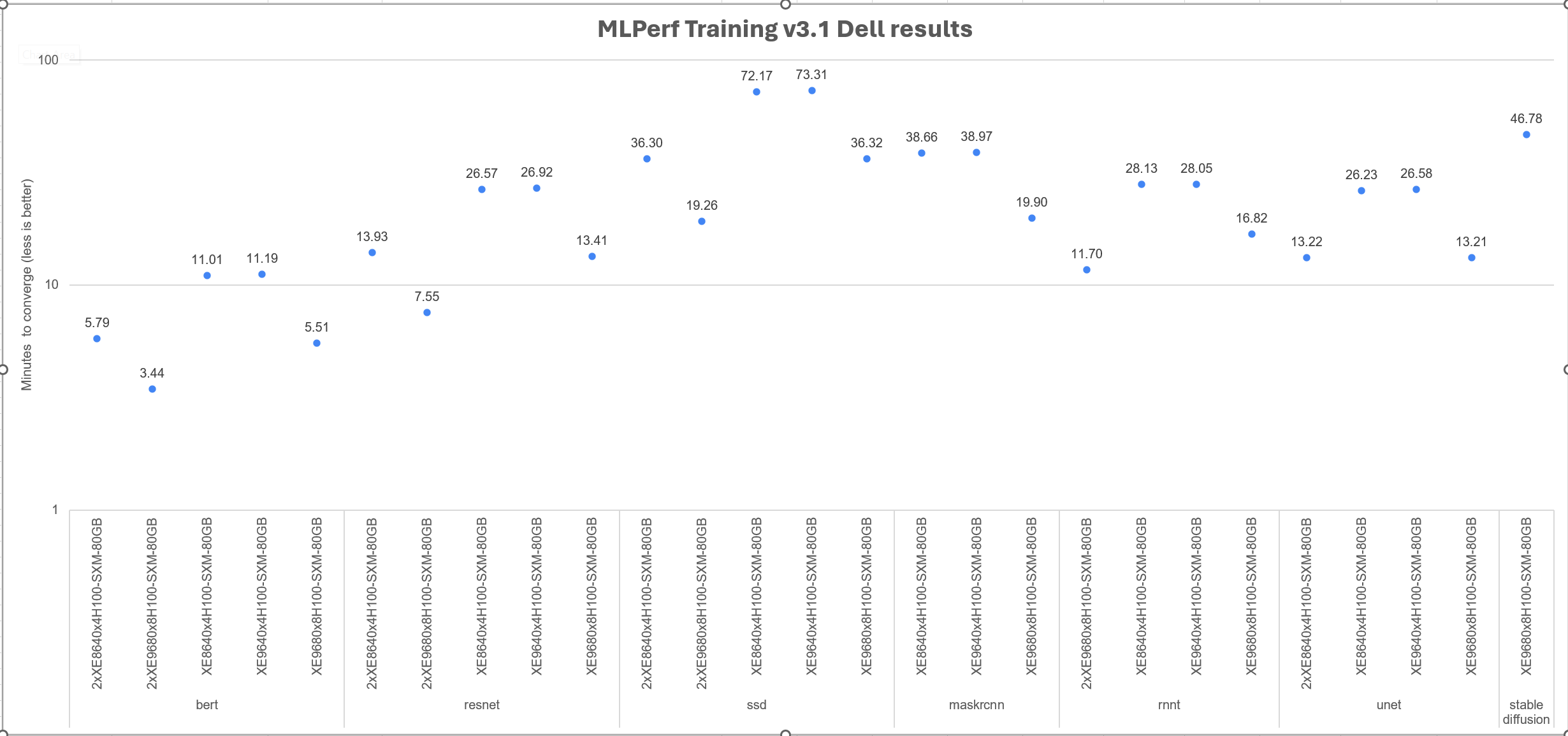
Figure 1. Logarithmic y axis: Overview of Dell MLPerf Training v3.1 results
Conclusion
We submitted compliant results for the MLCommons Training v3.1 benchmark. These results are based on the latest generation of Dell PowerEdge XE9680, XE8640, and XE9640 servers, powered by NVIDIA H100 Tensor Core GPUs. All results are stellar. They demonstrate that multinode scaling is linear and that more servers can help to solve the same problem faster. Different results allow end users to make decisions about expected performance before deploying their compute-intensive training workloads. The workloads in the submission include image classification, medical image segmentation, lightweight and heavy-weight object detection, speech recognition, language modeling, recommendation, and text to image. Enterprises can enable and maximize their AI transformation with Dell Technologies efficiently with Dell solutions.
MLCommons Results
https://mlcommons.org/benchmarks/training/
The preceding graphs are MLCommons results for MLPerf IDs from 3.1-2005 to 3.1-2009.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.

MLPerf™ Inference 3.1 on Dell PowerEdge Server with Intel® 4th Generation Xeon® CPU
Thu, 11 Jan 2024 19:43:07 -0000
|Read Time: 0 minutes
Introduction
MLCommons™ has released the v3.1 results for its machine learning inference benchmark suite, MLPerf™. This blog focuses on the impressive datacenter inference results obtained across different use cases by using the new 4th Generation Intel Xeon Scalable Processors on a Dell PowerEdge R760 server. This submission covers the benchmark results for all 7 use cases defined in MLPerf™, which are Natural Language Processing (BERT), Image Classification (ResNet50), Object Detection (RetinaNet), Speech-to-Text (RNN-T), Medical Imaging (3D-Unet), Recommendation Systems (DLRMv2), and Summarization (GPT-J).
These new Intel® Xeon® processors use an Intel AMX® matrix multiplication engine in each core to boost overall inferencing performance. With a focus on ease of use, Dell Technologies delivers exceptional CPU performance results out of the box with an optimized BIOS profile that fully unleashes the power of Intel’s OneDNN software – software which is fully integrated with both PyTorch and TensorFlow frameworks. The server configurations and the CPU specifications in the benchmark experiments are shown in Tables 1 and 2 respectively.
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 56 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 1. Dell PowerEdge R760 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 56 |
# of Threads | 112 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 105 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 2. 4th Generation Intel® Xeon® Scalable Processor Technical Specifications
MLPerf™ Inference v3.1 - Datacenter
The MLPerf™ inference benchmark measures how fast a system can perform ML inference using a trained model with new data in a variety of deployment scenarios. There are two benchmark suites – one for Datacenter systems and one for Edge. Table 3 lists the 7 mature models with each targeting a different task in the official release v3.1 for Datacenter systems category that were run on this PowerEdge R760. Compared to the v3.0 release, v3.1 added the updated version of the recommendation model – DLRMv2 – and introduced the first Large-Language Model (LLM) – GPT-J.
Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
Vision | Image classification | ResNet50-v1.5 | ImageNet (224x224) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection | RetinaNet | OpenImages (800x800) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical imaging | 3D-Unet | KITS 2019 (602x512x512) | 16 | 99.9% of FP32 (0.86330 mean DICE score) | N/A |
Speech | Speech-to-text | RNN-T | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT-large | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Language | Summarization | GPT-J-99 | CNN Dailymail (v3.0.0, max_seq_len=2048) | 13368 | 99% of FP32 (f1_score=80.25% rouge1=42.9865, rouge2=20.1235, rougeL=29.9881). | 20 s |
Commerce | Recommendation | DLRMv2 | Criteo 4TB Multi-hot | 204800 | 99% of FP32 (AUC=80.25%) | 60 ms |
Table 3. Datacenter Suite Benchmarks. Source: MLCommons™
Scenarios
The models are deployed in a variety of critical inference applications or use cases known as “scenarios” where each scenario requires different metrics, demonstrating production environment performance in practice. Following is the description of each scenario. Table 4 shows the scenarios required for each Datacenter benchmark included in this submission v3.1.
Offline scenario: represents applications that process the input in batches of data available immediately and do not have latency constraints for the metric performance measured in samples per second.
Server scenario: represents deployment of online applications with random input queries. The metric performance is measured in queries per second (QPS) subject to latency bound. The server scenario is more complicated in terms of latency constraints and input queries generation. This complexity is reflected in the throughput-degradation results compared to the offline scenario.
Each Datacenter benchmark requires the following scenarios:
Area | Task | Required Scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection | Server, Offline |
Vision | Medical imaging | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Language | Summarization | Server, Offline |
Commerce | Recommendation | Server, Offline |
Table 4. Datacenter Suite Benchmark Scenarios. Source: MLCommons™
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW for MLPerf™ | MLPerf™ Intel OneDNN integrated with PyTorch |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 5. System Configuration
What is Intel AMX (Advanced Matrix Extensions)?
Intel AMX is a built-in accelerator that enables 4th Gen Intel Xeon Scalable processors to optimize deep learning (DL) training and inferencing workloads. With the high-speed matrix multiplications enabled by Intel AMX, 4th Gen Intel Xeon Scalable processors can quickly pivot between optimizing general computing and AI workloads.
Imagine an automobile that could excel at city driving and then quickly shift to deliver Formula 1 racing performance. 4th Gen Intel Xeon Scalable processors deliver this level of flexibility. Developers can code AI functionality to take advantage of the Intel AMX instruction set as well as code non-AI functionality to use the processor instruction set architecture (ISA).
Intel has integrated the Intel® oneAPI Deep Neural Network Library (oneDNN) – its oneAPI DL engine – into popular open-source tools for AI applications, including TensorFlow, PyTorch, PaddlePaddle, and ONNX.
AMX architecture
Intel AMX architecture consists of two components, as shown in Figure 1:
- Tiles consist of eight two-dimensional registers, each 1 kilobyte in size. They store large chunks of data.
- Tile Matrix Multiplication (TMUL) is an accelerator engine attached to the tiles that performs matrix-multiply computations for AI.
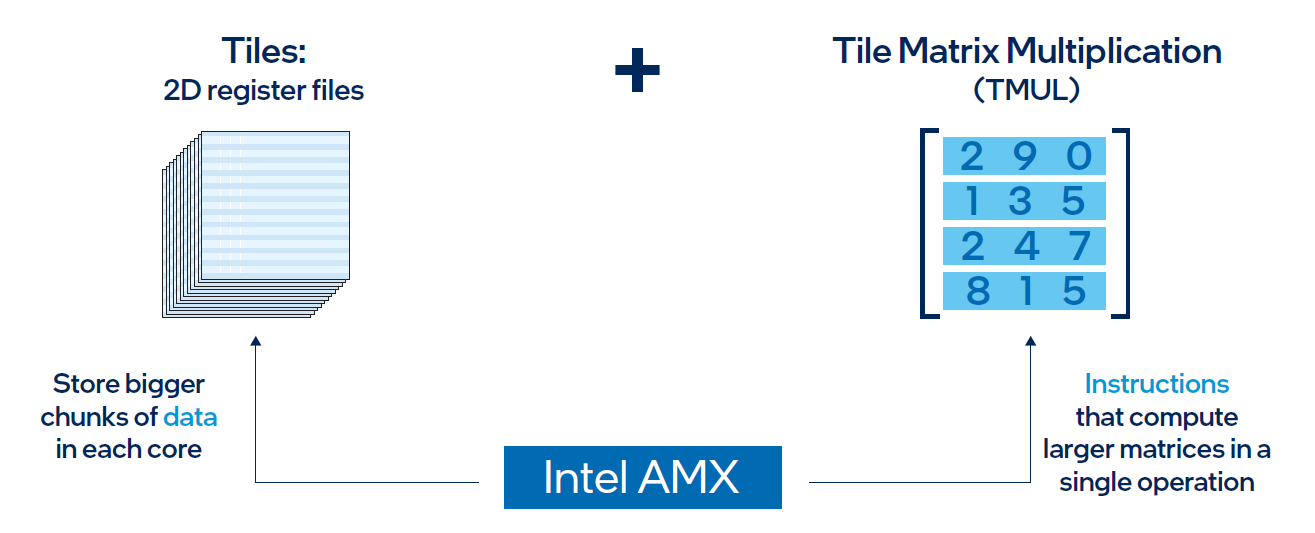
Figure 1. Intel AMX architecture consists of 2D register files (tiles) and TMUL
Results
Both MLPerf™ v3.0 and MLPerf™ v3.1 benchmark results are based on the latest Dell R760 server utilizing 4th Generation Intel® Xeon® Scalable Processors.
For the ResNet50 Image Classification, RetinaNet Object Detection, BERT Large Language, and RNN-T Speech Models – which are identical models with same datasets for both MLPerf™ v3.0 and MLPerf™ v3.1 – we re-run those for the latest submission. The results show negligible differences between two submissions.
We added three new benchmark results for MLPerf™ v3.1 submission compared to MLPerf™ v3.0 submission. Those are 3D-Unet Medical Imaging, DLRMv2 Recommendation, and GPT-J Summarization models. Given that there is no previous result for comparison, we simply show the current result on the R760.
Comparing Performance from MLPerfTM v3.1 to MLPerfTM v3.0
ResNet50 server & offline scenarios:
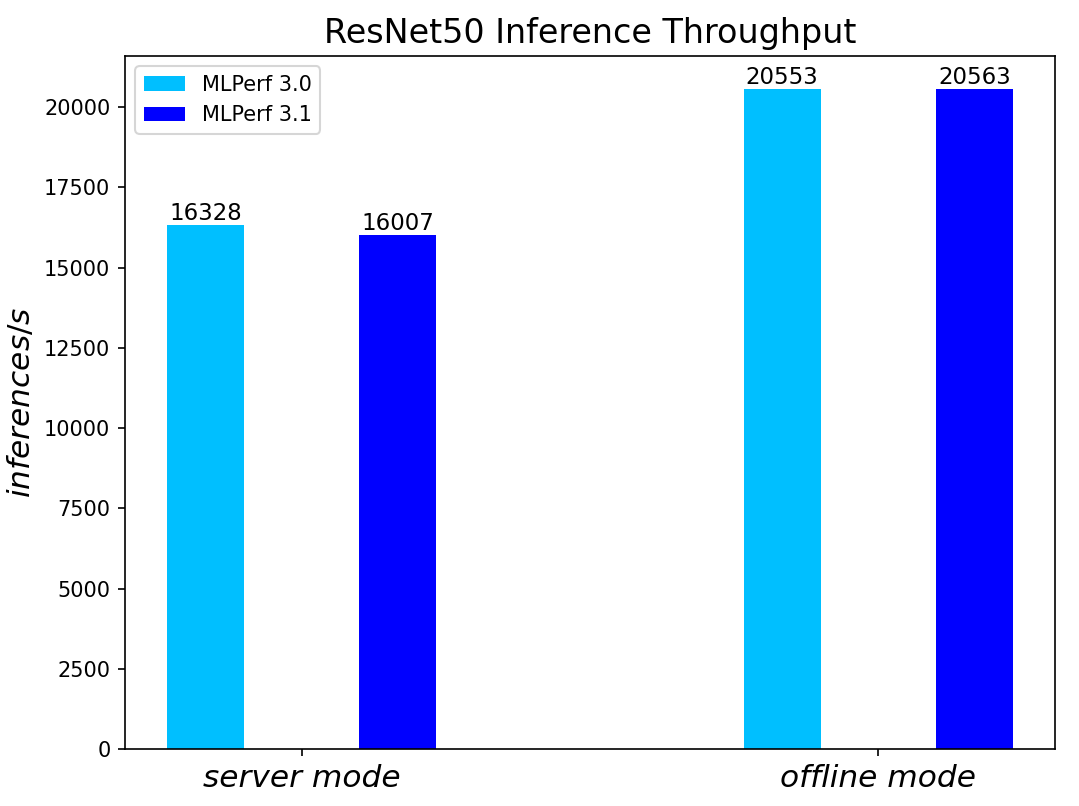
Figure 2. ResNet50 inference throughput in server and offline scenarios
BERT Large Language Model server & offline scenarios:
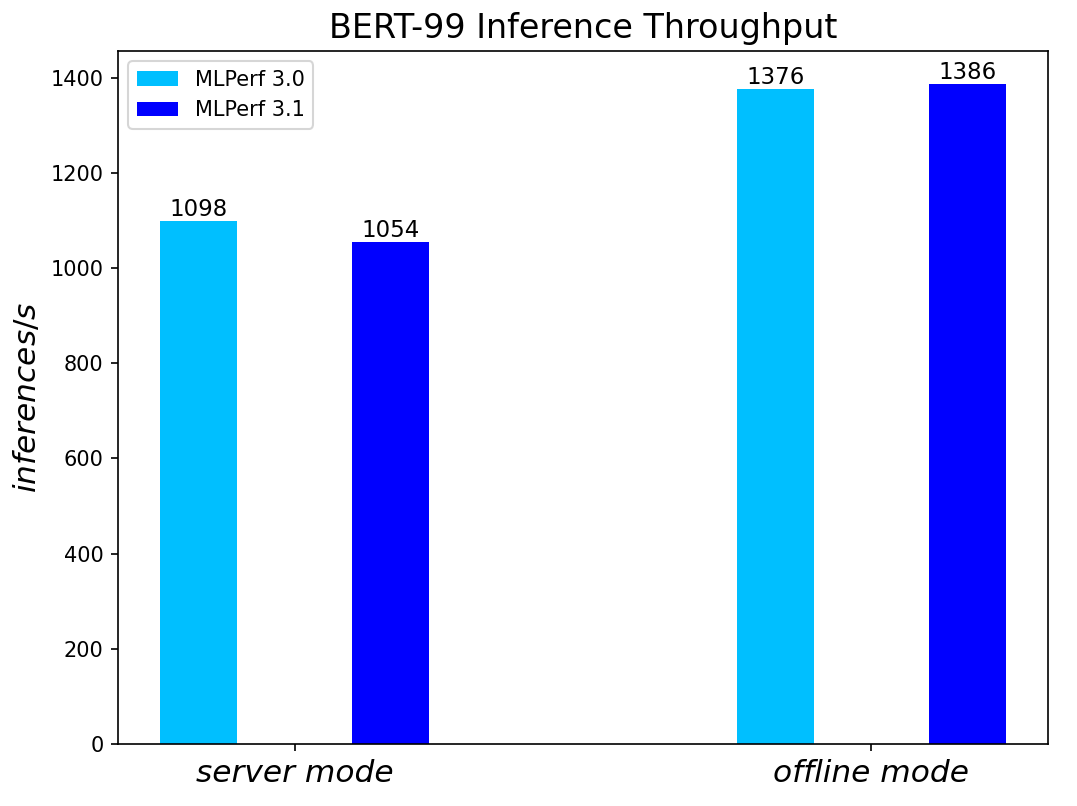
Figure 3. BERT Inference results for server and offline scenarios
RetinaNet Object Detection Model server & offline scenarios:
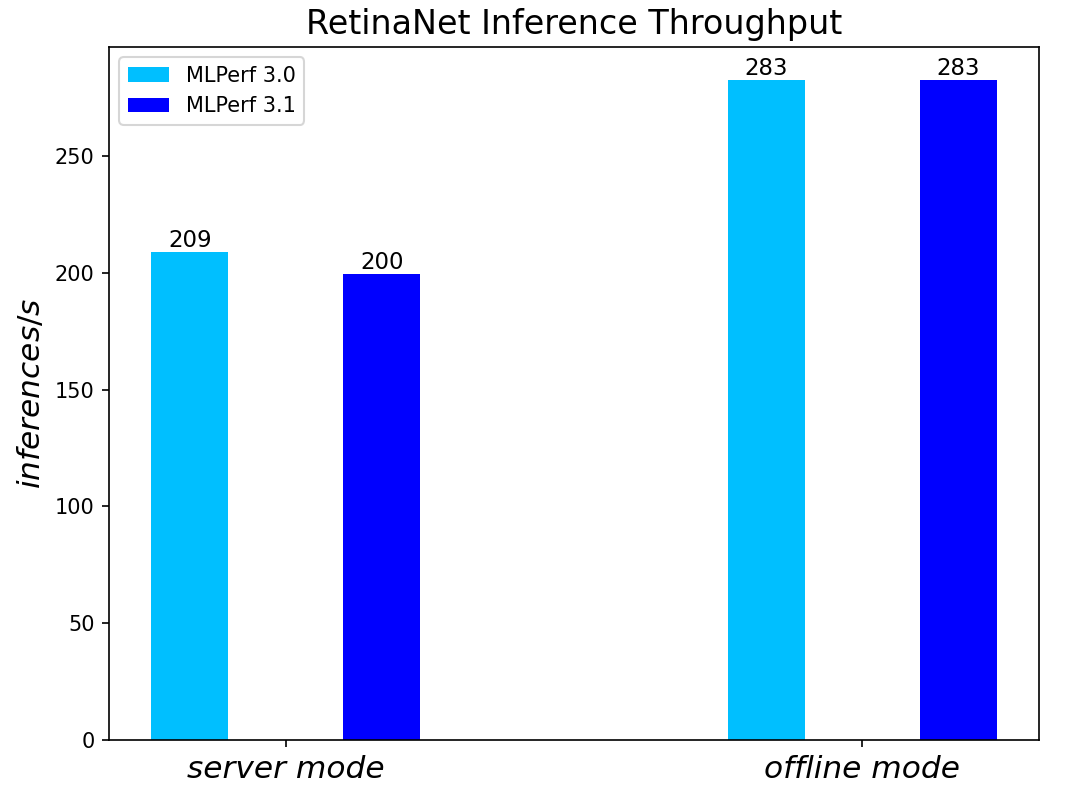
Figure 4. RetinaNet Object Detection Model Inference results for server and offline scenarios
RNN-T Text to Speech Model server & offline scenarios:
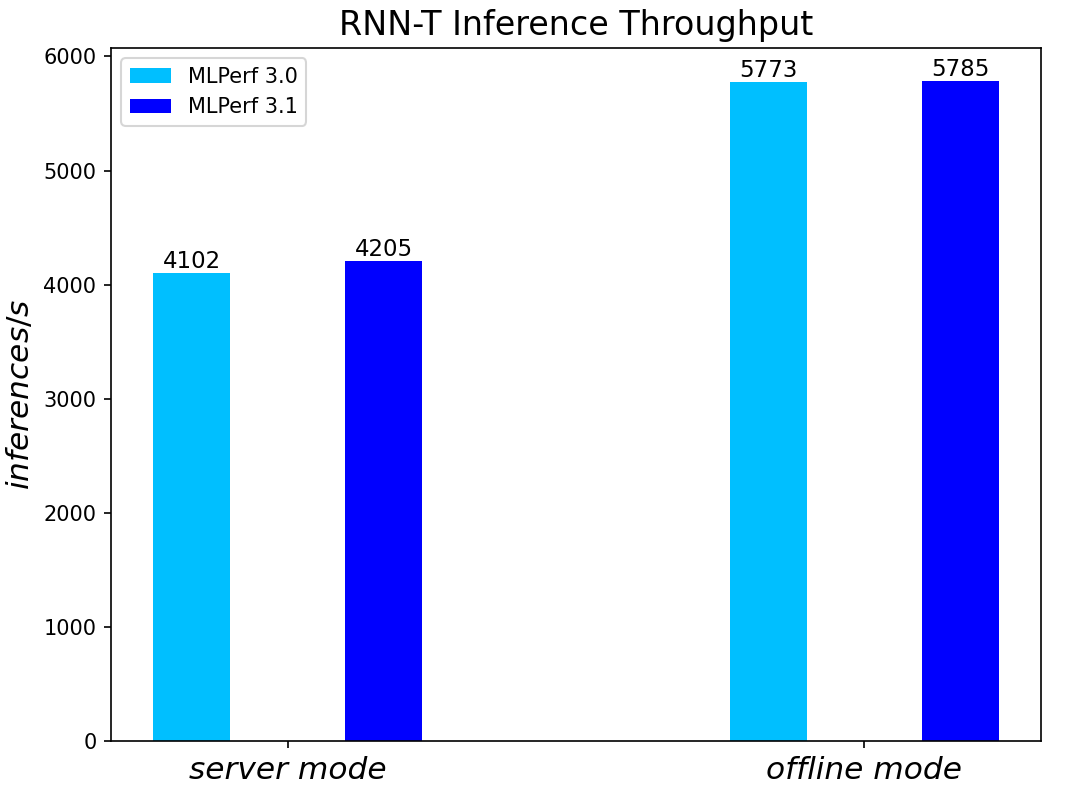
Figure 5. RNN-T Text to Speech Model Inference results for server and offline scenarios
3D-Unet Medical Imaging Model offline scenarios:
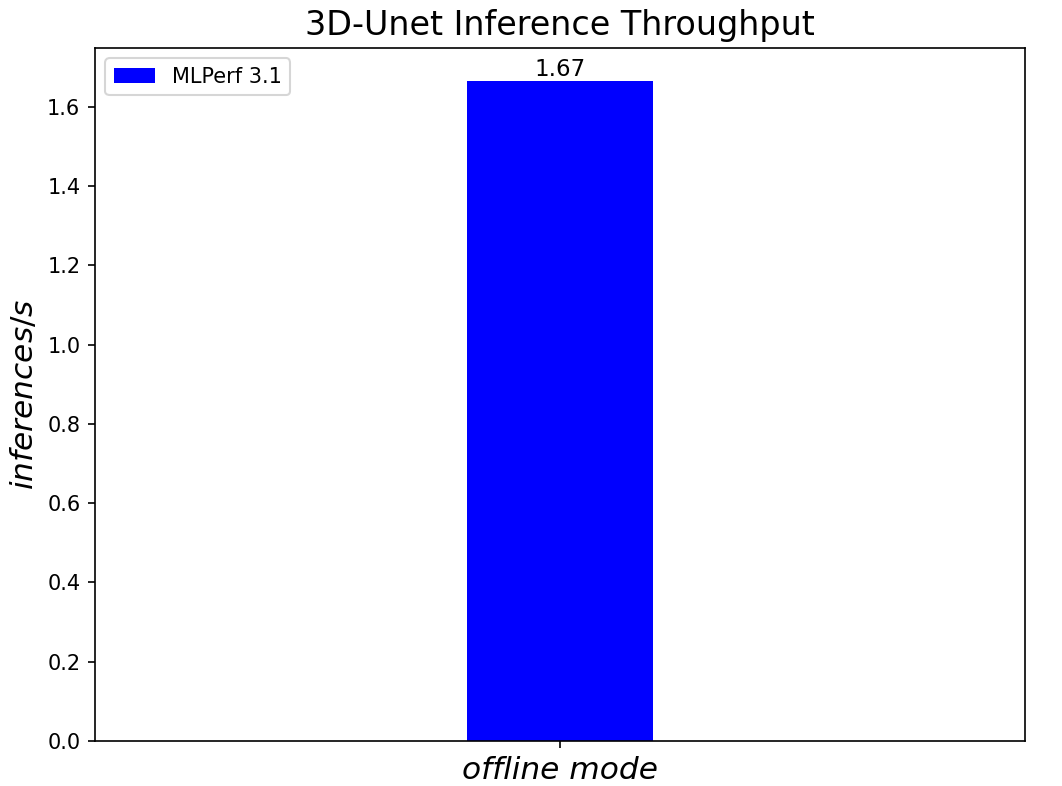
Figure 6. 3D-Unet Medical Imaging Model Inferencing results for server and offline scenarios
DLRMv2-99 Recommendation Model server & offline scenarios:
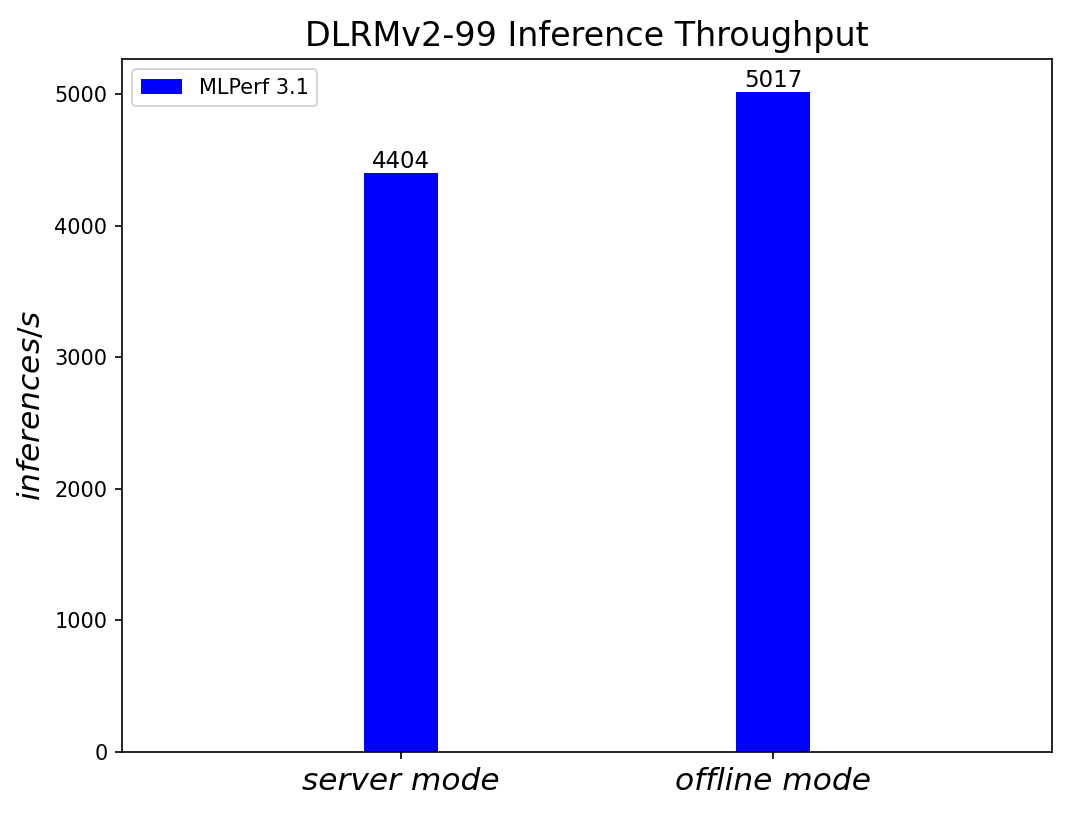
Figure 7. DLRMv2-99 Recommendation Model Inference results for server and offline scenarios (submitted in the open category)
GPT-J-99 Summarization Model server & offline scenarios:
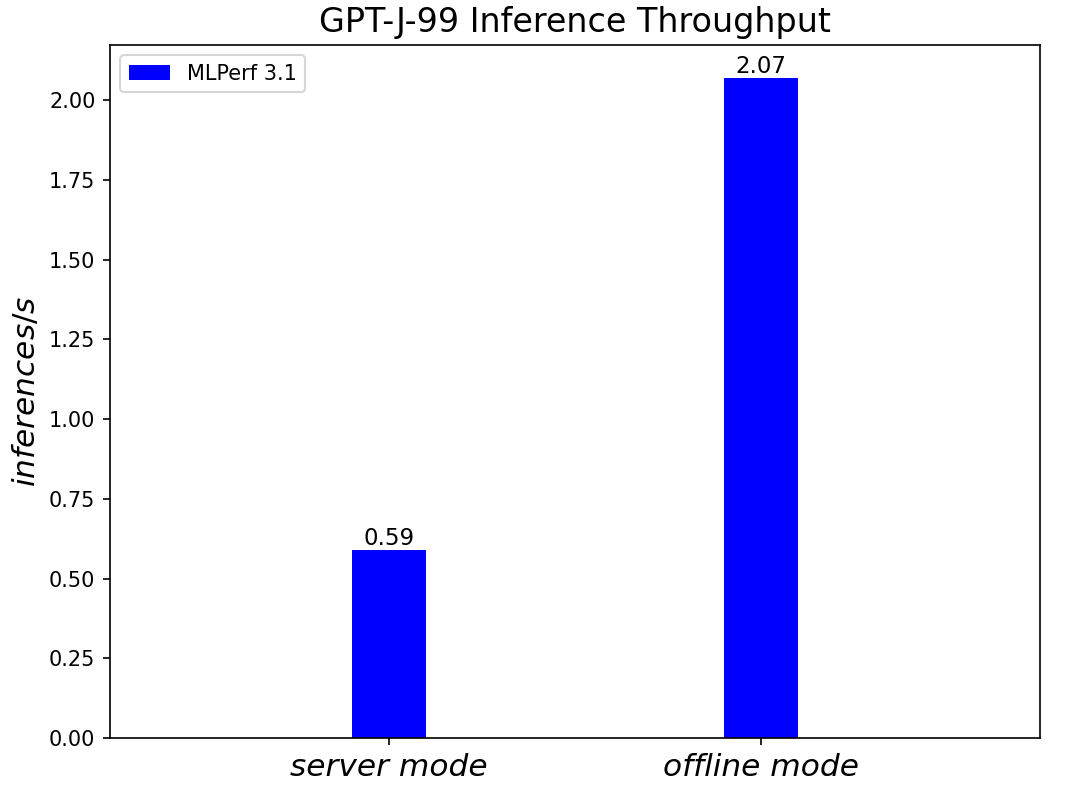
Figure 8. GPT-J-99 Summarization Model Inference results for server and offline scenarios
Conclusion
- The PowerEdge R760 server with 4th Generation Intel® Xeon® Scalable Processors produces strong data center inference performance, confirmed by the official version 3.1 MLPerfTM benchmarking results from MLCommonsTM.
- The high performance and versatility are demonstrated across natural language processing, image classification, object detection, medical imaging, speech-to-text inference, recommendation, and summarization systems.
- The R760 with 4th Generation Intel® Xeon® Scalable Processors show good performance in supporting generative AI models like GPT-J.
- The R760 supports different deep learning inference scenarios in the MLPerfTM benchmark scenarios as well as other complex workloads such as database and advanced analytics. It is an ideal solution for data center modernization to drive operational efficiency, lead higher productivity, and minimize total cost of ownership (TCO).
References
MLCommonsTM MLPerfTM v3.1 Inference Benchmark Submission IDs
ID | Submitter | System |
3.1-0059 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
3.1-0060 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
3.1-4184 | Dell | Dell PowerEdge Server R760 (1x Intel Xeon Platinum 8480+) |
Authors: Tao Zhang (tao.zhang9@dell.com); Brandt Springman (brandt.springman@dell.com); Bhavesh Patel (bhavesh_a_patel@dell.com); Louie Tsai (louie.tsai@intel.com); Yuning Qiu (yuning.qiu@intel.com); Ramesh Chukka (ramesh.n.chukka@intel.com)

Running LLMs on Dell PowerEdge Servers with Intel® 4th Generation Xeon® CPUs
Thu, 11 Jan 2024 19:38:53 -0000
|Read Time: 0 minutes
Introduction
Large-language Models (LLMs) have gained great industrial and academic interests in recent years. Different LLMs have been adopted in various applications, such as content generation, text summarization, sentiment analysis, and healthcare. The list goes on.
When we think about LLMs and what methodologies we can use for inferencing and fine-tuning, the question always comes up as to which compute device we should use. For inferencing, we wanted to explore what the performance metrics are when running on an Intel 4th Generation CPU, and what are some of the variables we should explore?
This blog focuses on LLM inference results on Dell PowerEdge Servers with the 4th Generation Intel® Xeon® Scalable Processors. Specifically, we demonstrated their performance and power while running the stable diffusion and Llama2 chat models on R760 and HS5610 servers. We also explored the performance and power impacts with different quantization bits and CPU/socket numbers through experiments and will present the inference results of stable diffusion and Llama2 models obtained on a Dell PowerEdge R760 and HS5610 with the 4th Generation Intel® Xeon® Scalable Processors.
We selected the aforementioned Dell platforms because we wanted to explore how our CSP-focused platforms like HS5610 perform when it comes to inferencing and whether they can meet the requirements for LLM models. These new Intel® Xeon® processors use an Intel AMX® matrix multiplication engine in each core to boost overall inferencing performance. By combining with the quantization techniques, we further improved the inference performance with the CPU-only system. Moreover, we also show how the CPU core and socket numbers affect the performance results.
Background
Transformer is regarded as the 4th fundamental model after Multilayer Perceptron (MLP), Recurrent Neural Networks (RNN), and Convolutional Neural Networks (CNN). Known for its parallelization and scalability, transformer has greatly boosted the performance and capability of LLMs since it was introduced in 2017 [1].
Today, LLMs have been rapidly adopted in various applications like content generation, text summarization, sentiment analysis, code generation, healthcare, and so on, as shown in Figure 1 [2]. This trend is continuing. More open-source LLMs are popping up almost on a monthly basis. Moreover, the transformer-based techniques are being used alongside with other methods, greatly improving the accuracy and performance of the original tasks. For example, the stable diffusion model uses the LLM at the input as the neural language understanding engine. Combined with the diffusion model, it has greatly improved the quality and throughput of the text-to-image generation task [3]. Note that for simplicity in this blog, we use the term “LLMs” to represent both those transformer-based models shown in Figure 1 and the derivative models like stable diffusion models.
Figure 1. LLM Timeline [2] Image credit: Wayne Xin Zhao, et.al, “A Survey of Large Language Models”]
While training and fine-tuning those LLMs is normally time- and cost-consuming, deploying the LLMs at the edge has its own challenges. Considering both performance and power, deploying the LLMs can be, in a sense, more cost-sensitive given the volumes of the systems required to cover various applications. GPUs are widely used to deploy LLMs. In this blog, we demonstrate the feasibility of deploying those LLMs with Intel 4th generation Intel® Xeon® CPUs with Dell PowerEdge servers and illustrate that good performance can be achieved with a proper hardware configuration – like CPU core numbers and quantization method for popular LLMs.
Test Setup
The hardware platforms we used for the experiments are PowerEdge R760 and HS5610, which are the latest mainstream and cloud-optimized servers respectively from Dell product portfolio. Figure 2 shows the rack-level interface for the HS5610 server. As a cloud-optimized solution, the HS5610 server has been designed with CSP features that allow the same benefits with full PowerEdge features and management like the mainstream server R760, as well as open management (OpenBMC), cold aisle service, channel firmware, and services. Both servers have two sockets with an Intel 4th generation Xeon CPU on each socket. R760 features a 56-core CPU – Intel® Xeon® Platinum 8480+ (TDP: 350W) in each socket, and HS5610 has a 32-core CPU – Intel® Xeon® Gold 6430 (TDP: 250W) in each socket. Tables 1-4 show the details of the server configurations and CPU specifications. During tests, we use the numactl command to set the numbers of the sockets or CPU cores to execute the LLM inference tasks.
Figure 2. PowerEdge HS5610 [4]
System Name | PowerEdge R760 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 56 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 1. R760 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Platinum 8480+ |
Status | Launched |
# of CPU Cores | 56 |
# of Threads | 112 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 108 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 2. 4th Generation 56-core Intel® Xeon® Scalable Processor Technical Specifications
System Name | PowerEdge HS5610 |
Status | Available |
System Type | Data Center |
Number of Nodes | 1 |
Host Processor Model | 4th Generation Intel® Xeon® Scalable Processors |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.0 GHz, 3.8 GHz Turbo Boost |
Host Memory Capacity | 1TB, 16 x 64GB DIMM 4800 MHz |
Host Storage Capacity | 4.8 TB, NVME |
Table 3. HS5610 Server Configuration
Product Collection | 4th Generation Intel® Xeon® Scalable Processors |
Processor Name | Gold 6430 |
Status | Launched |
# of CPU Cores | 32 |
# of Threads | 64 |
Base Frequency | 2.0 GHz |
Max Turbo Speed | 3.8 GHz |
Cache L3 | 64 MB |
Memory Type | DDR5 4800 MT/s |
ECC Memory Supported | Yes |
Table 4. 4th Generation 32-core Intel® Xeon® Scalable Processor Technical Specifications
Software stack and system configuration
The software stack and system configuration used for this submission is summarized in Table 5. Optimizations have been done for the PyTorch framework and Transformers library to unleash the Xeon CPU machine learning capabilities. Moreover, a low-level tool -- Intel® Neural Compressor -- has been used for high-accuracy quantization.
OS | CentOS Stream 8 (GNU/Linux x86_64) |
Intel® Optimized Inference SW | OneDNN™ Deep Learning, ONNX, Intel® Extension for PyTorch (IPEX), Intel® Extension for Transformers (ITREX), Intel® Neural Compressor |
ECC memory mode | ON |
Host memory configuration | 1TiB |
Turbo mode | ON |
CPU frequency governor | Performance |
Table 5. Software stack and system configuration
The models under testing are stable diffusion model version 1.4 (~1 billion parameters) and Llama2-chat-HF models with 7 billion, 13 billion, and 70 billion parameters. We purposely choose those models because they are open-sourced, representative, and cover a wide parameter range. Different quantization bits are tested to characterize the corresponding performance and power consumption.
All the experiments are based on batch-size equal to 1. Performance is characterized by latency or throughput. To reduce the measurement errors, the inference is executed 10 times to get the averaged value. A warm-up process is executed by loading the parameter and running a sample test before running the defined inference.
Results
We show some typical results in this section alongside brief discussions for each result. The conclusions are summarized in the next section.
HS5610 Results
Latency vs Quantization vs Cores – Stable Diffusion Model:
Figure 3. Latency in HS5610 server running Stable Diffusion
Figure 3 shows that HS5610 can generate a new image in approximately 3 seconds when running at bf16 Stable Diffusion V1.4 model. Quantizing to 16 bits greatly reduces the latency compared to using fp32 model. Scaling up the core numbers from 16 to 32 cores greatly reduces the latency, however scaling up across the sockets does not help. This is mainly due to the NUMA remote memory bottleneck.
Power Consumption – Stable Diffusion Model:
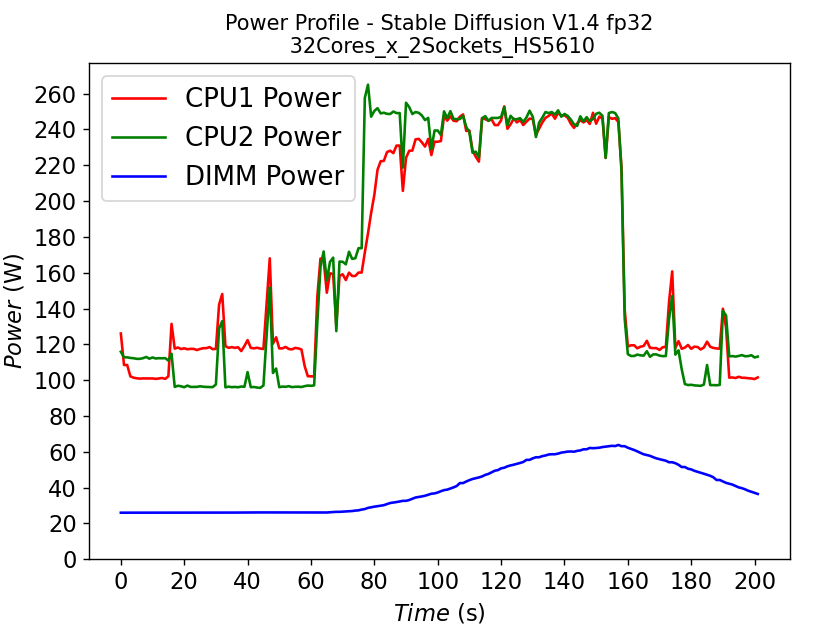 (a)
(a) 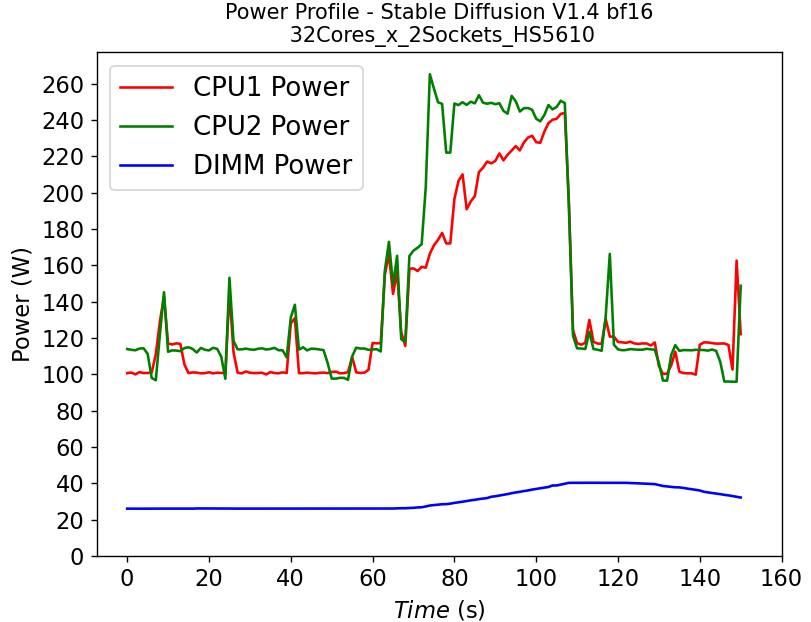 (b)
(b)
Figure 4. Power consumption of CPU and DIMM in HS5610 server running stable diffusion: (a) fp32 model (b) bf16 model
Figure 4 shows the power profile comparison of HS5610 when running the stable diffusion model with (a) fp32 weights and (b) bf16 weights. To finish the same tasks (warm up and inferencing), the bf16 model takes significantly less time (shorter power profile duration) compared to fp32 scenario. The plot also shows that much larger DIMM power is required to run fp32 compared to bf16. Executing the task pushes the CPU working close to the TDP limit, with the exception of the CPU1 in Figure 4b, indicating that further improvement is possible to further reduce the latency for the bf16 model.
Throughput vs Quantization vs Cores – Llama2 Chat Models:
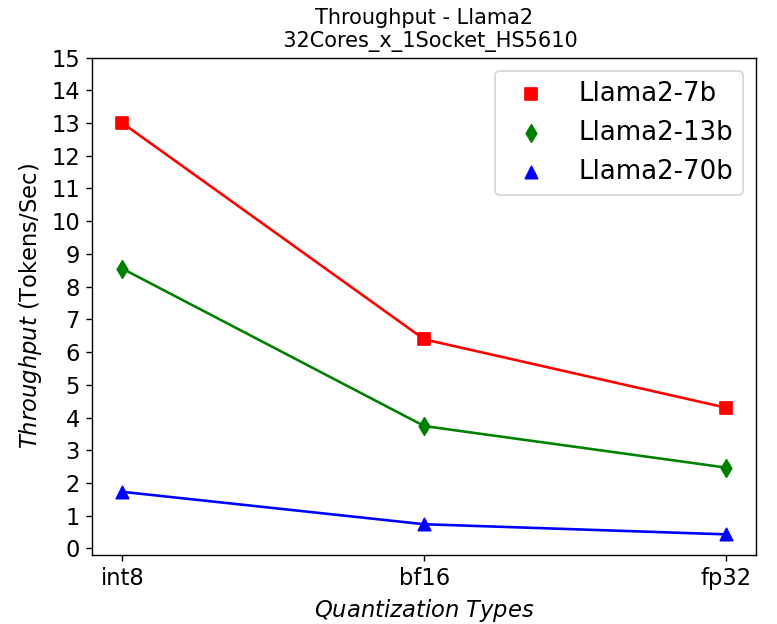 (a)
(a)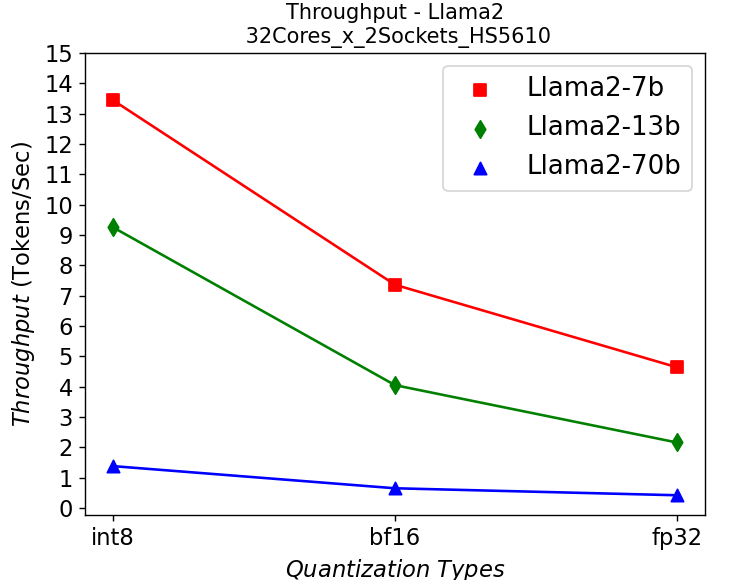 (b)
(b)
Figure 5. Throughput in HS5610 server running Llama2: (a) 1-socket (b) 2-socket
Figure 5 shows the throughput numbers when running Llama2 chat models with different parameter sizes and quantization bits in HS5610 server. Figure 5a shows the single socket scenario and 5b shows the dual-socket scenario. Smaller models with lower quantization bits give higher throughputs which is to be expected. Like the stable diffusion model, quantization greatly improves the throughput. However, scaling up with more CPU cores across the socket has negligible results in boosting the performance.
R760 Results
Throughput vs Quantization vs Cores – Llama2 Chat Models:
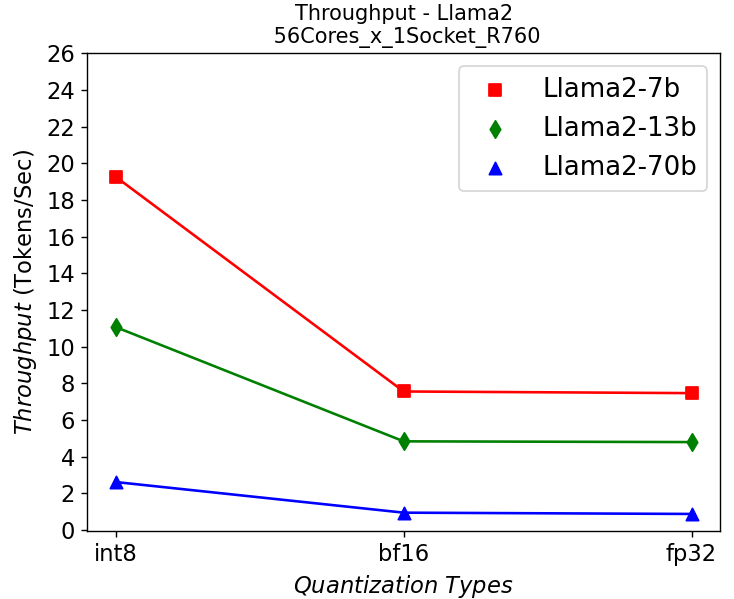 (a)
(a)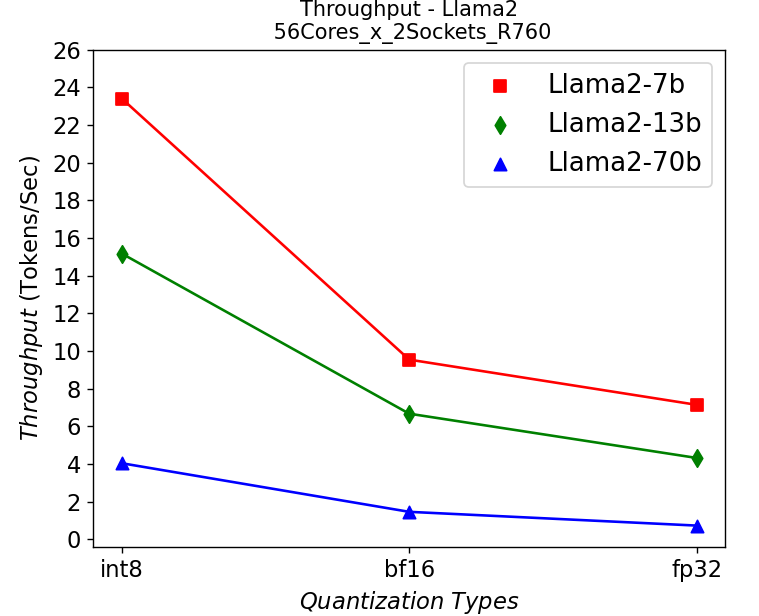 (b)
(b)
Figure 6. Throughput in R760 server running Llama2: (a) 1-socket (b) 2-socket
Figure 6 shows the throughput numbers when running Llama2 chat models with different parameter sizes and quantization bits in R760 server. We get similar observations as the results shown in HS5610 server. A smaller model gives a higher throughput, and quantization greatly improves the throughput. One difference is that we get a 10-30% performance improvement depending on models when scaling up across sockets, showing a benefit from larger core numbers. The performance across the models is good enough for most real-time chatbot applications.
Performance Per Watt – Llama2 Chat Models:
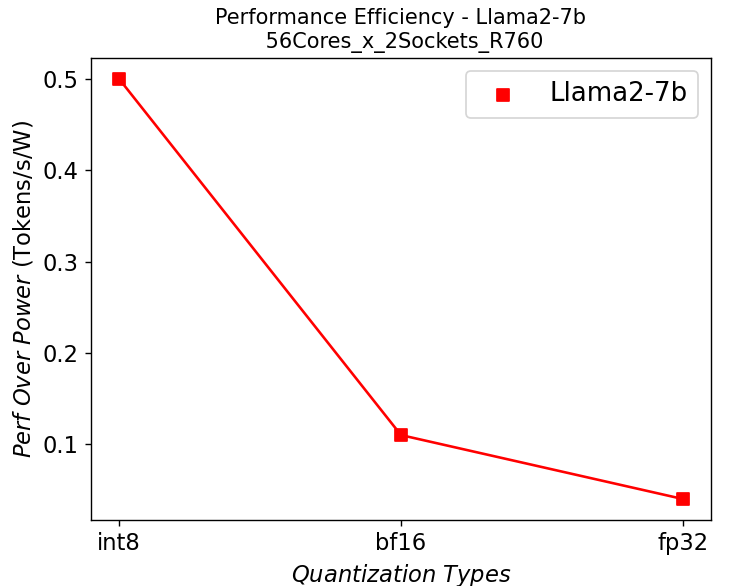 (a)
(a)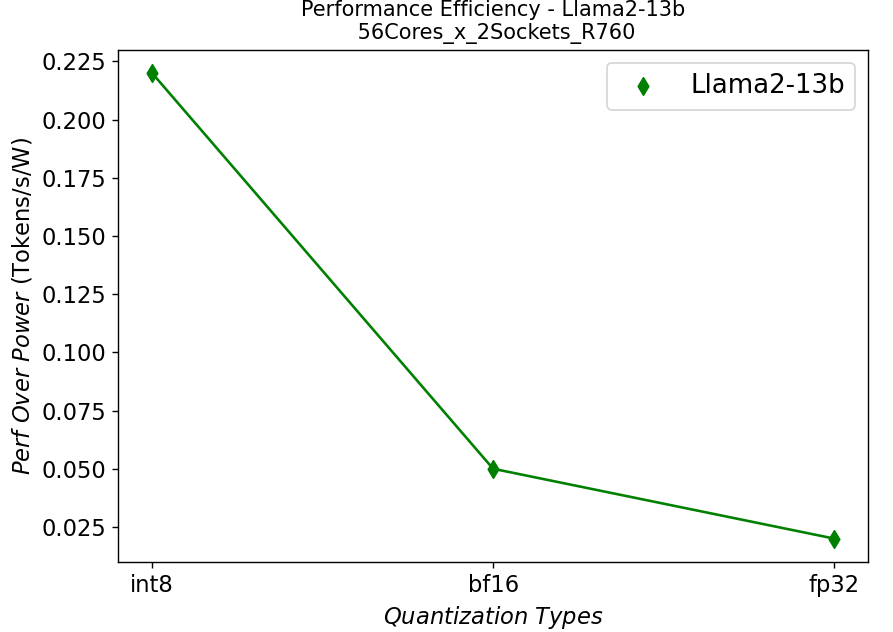 (b)
(b)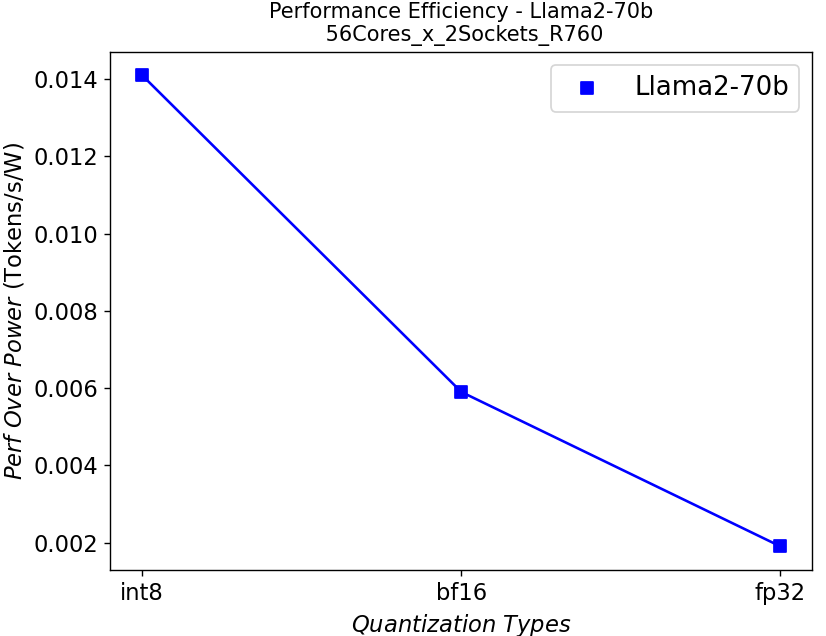 (c)
(c)
Figure 7. Performance per watt in R760 server running Llama2: (a) 7b (b)13b (c) 70b
We further plot the performance per watt curve which is strongly related to the total cost of ownership (TCO) of the system in Figure 7. From the plots, the quantization can greatly help with the performance efficiency, especially for the models with large parameters.
Conclusion
- We have shown that the Intel 4th generation Intel® Xeon® CPUs on Dell PowerEdge mainstream and HS class platforms can easily meet performance requirements when it comes to Inferencing with Llama2 models.
- We also demonstrate the benefits of quantization or using lower precision for inferencing quantitively, which can give a better TCO in terms of performance per watt and memory footprint as well as enable better user experience by improving the throughput.
- These studies also show that we need to right-size the infrastructure based on the application and model size.
References
[1]. A. Vaswani et. al, “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
[2]. W. Zhao et. al, “A Survey of Large Language Models”, https://doi.org/10.48550/arXiv.2303.18223
[3]. R. Rombach et. al, “High-Resolution Image Synthesis with Latent Diffusion Models”, https://arxiv.org/abs/2112.10752
[4]. https://www.dell.com/en-us/shop/ipovw/poweredge-hs5610
Authors: Tao Zhang (tao.zhang9@dell.com); Bhavesh Patel (bhavesh_a_patel@dell.com)

Llama 2: Efficient Fine-tuning Using Low-Rank Adaptation (LoRA) on Single GPU
Wed, 24 Apr 2024 14:23:28 -0000
|Read Time: 0 minutes
Introduction
With the growth in the parameter size and performance of large-language models (LLM), many users are increasingly interested in adapting them to their own use case with their own private dataset. These users can either search the market for an Enterprise-level application which is trained on large corpus of public datasets and might not be applicable to their internal use case or look into using the open-source pre-trained models and then fine-tuning them on their own proprietary data. Ensuring efficient resource utilization and cost-effectiveness are crucial when choosing a strategy for fine-tuning a large-language model, and the latter approach offers a more cost-effective and scalable solution given that it’s trained with known data and able to control the outcome of the model.
This blog investigates how Low-Rank Adaptation (LoRA) – a parameter effective fine-tuning technique – can be used to fine-tune Llama 2 7B model on single GPU. We were able to successfully fine-tune the Llama 2 7B model on a single Nvidia’s A100 40GB GPU and will provide a deep dive on how to configure the software environment to run the fine-tuning flow on Dell PowerEdge R760xa featuring NVIDIA A100 GPUs.
This work is in continuation to our previous work, where we performed an inferencing experiment on Llama2 7B and shared results on GPU performance during the process.
Memory bottleneck
When finetuning any LLM, it is important to understand the infrastructure needed to load and fine-tune the model. When we consider standard fine-tuning, where all the parameters are considered, it requires significant computational power to manage optimizer states and gradient checkpointing. The optimizer states and gradients usually result in a memory footprint which is approximately five times larger than the model itself. If we consider loading the model in fp16 (2 bytes per parameter), we will need around 84 GB of GPU memory, as shown in figure 1, which is not possible on a single A100-40 GB card. Hence, to overcome this memory capacity limitation on a single A100 GPU, we can use a parameter-efficient fine-tuning (PEFT) technique. We will be using one such technique known as Low-Rank Adaptation (LoRA) for this experiment.
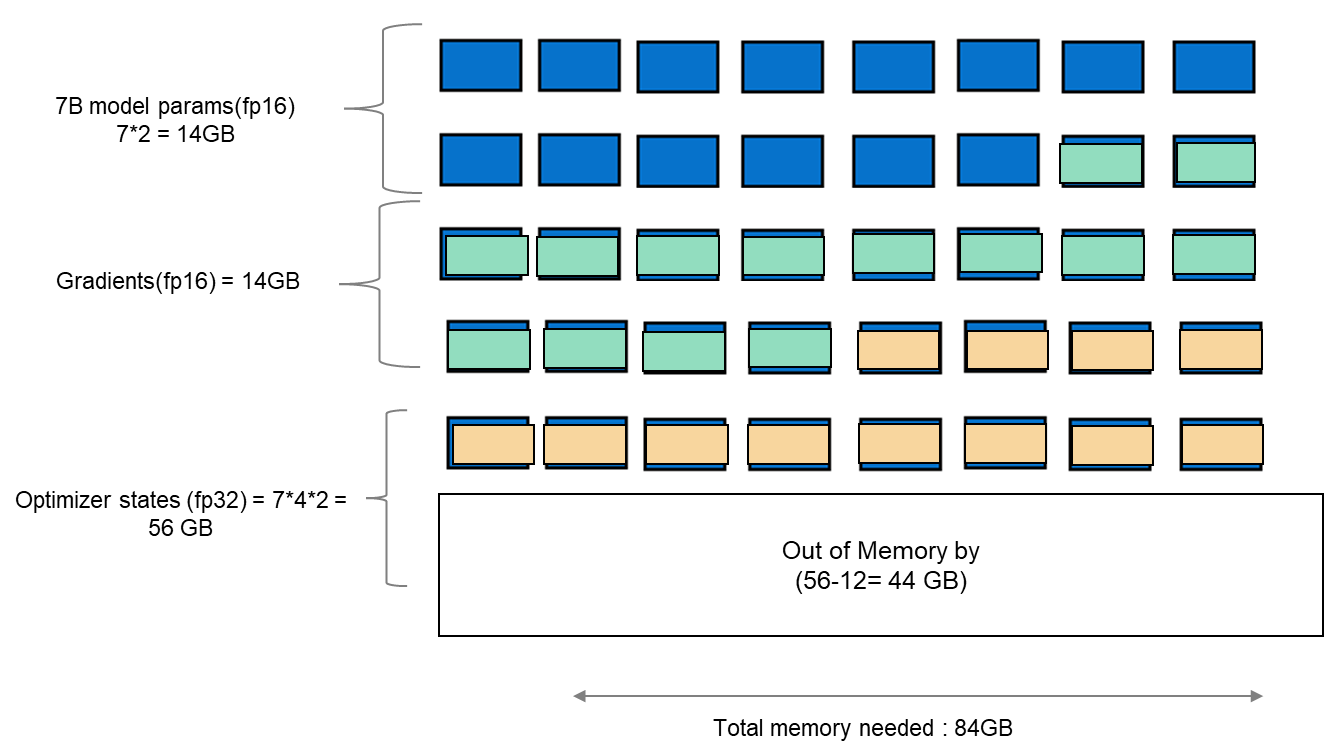
Figure 1. Schematic showing memory footprint of standard fine-tuning with Llama 27B model.
Fine-tuning method
LoRA is an efficient fine-tuning method where instead of finetuning all the weights that constitute the weight matrix of the pre-trained LLM, it optimizes rank decomposition matrices of the dense layers to change during adaptation. These matrices constitute the LoRA adapter. This fine-tuned adapter is then merged with the pre-trained model and used for inferencing. The number of parameters is determined by the rank and shape of the original weights. In practice, trainable parameters vary as low as 0.1% to 1% of all the parameters. As the number of parameters needing fine-tuning decreases, the size of gradients and optimizer states attached to them decrease accordingly. Thus, the overall size of the loaded model reduces. For example, the Llama 2 7B model parameters could be loaded in int8 (1 byte), with 1 GB trainable parameters loaded in fp16 (2 bytes). Hence, the size of the gradient (fp16), optimizer states (fp32), and activations (fp32) aggregates to approximately 7-9 GB. This brings the total size of the loaded model to be fine-tuned to 15-17 GB, as illustrated in figure 2.
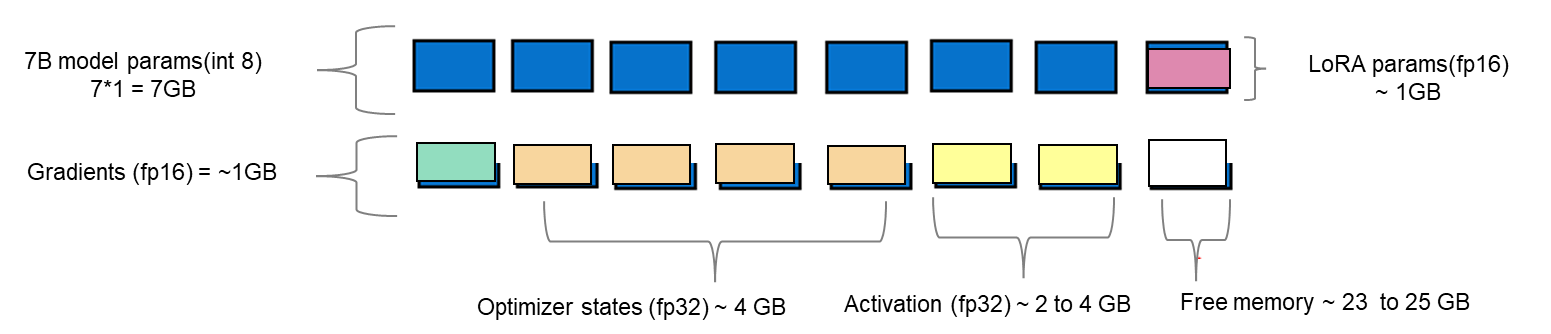
Figure 2. Schematic showing an example of memory footprint of LoRA fine tuning with Llama 2 7B model.
Experimental setup
A model characterization gives readers valuable insight into GPU memory utilization, training loss, and computational efficiency measured during fine-tuning by varying the batch size and observing out-of-memory (OOM) occurrence for a given dataset. In table 1, we show resource profiling when fine-tuning Llama 2 7B-chat model using LoRA technique on PowerEdge R760xa with 1*A100-40 GB on Open- source SAMsum dataset. To measure tera floating-point operations (TFLOPs) on the GPU, the DeepSpeed Flops Profiler was used. Table 1 gives the detail on the system used for this experiment.
Table 1. Actual memory footprint of Llama 27B model using LoRA technique in our experiment.
Trainable params (LoRA) | 0.0042 B (0.06% of 7B model) |
7B model params(int8) | 7 GB |
Lora adapter (fp16) | 0.0084 GB |
Gradients (fp32) | 0.0168 GB |
Optimizer States(fp32) | 0.0168 GB |
Activation | 2.96 GB |
Total memory for batch size 1 | 10 GB = 9.31 GiB |
System configuration
In this section, we list the hardware and software system configuration of the R760xa PowerEdge server used in this experiment for the fine-tuning work of Llama-2 7B model. 
Figure 3. R760XA Specs
Table 2. Hardware and software configuration of the system
Component | Details |
Hardware | |
Compute server for inferencing | PowerEdge R760xa |
GPUs | Nvidia A100-40GB PCIe CEM GPU |
Host Processor Model Name | Intel(R) Xeon(R) Gold 6454S (Sapphire Rapids) |
Host Processors per Node | 2 |
Host Processor Core Count | 32 |
Host Processor Frequency | 2.2 GHz |
Host Memory Capacity | 512 GB, 16 x 32GB 4800 MT/s DIMMs |
Host Storage Type | SSD |
Host Storage Capacity | 900 GB |
Software | |
Operating system | Ubuntu 22.04.1 |
Profiler | |
Framework | PyTorch |
Package Management | Anaconda |
Dataset
The SAMsum dataset – size 2.94 MB – consists of approximately 16,000 rows (Train, Test, and Validation) of English dialogues and their summary. This data was used to fine-tune the Llama 2 7B model. We preprocess this data in the format of a prompt to be fed to the model for fine-tuning. In the JSON format, prompts and responses were used to train the model. During this process, PyTorch batches the data (about 10 to 11 rows per batch) and concatenates them. Thus, a total of 1,555 batches are created by preprocessing the training split of the dataset. These batches are then passed to the model in chunks for fine-tuning.
Fine-tuning steps
- Download the Llama 2 model
- The model is available either from Meta’s git repository or Hugging Face, however to access the model, you will need to submit the required registration form for Meta AI license agreement
- The details can be found in our previous work here
- Convert the model from the Meta’s git repo to a Hugging face model type in order to use the PEFT libraries used in the LoRA technique
- Use the following commands to convert the model
## Install HuggingFace Transformers from source pip freeze | grep transformers ## verify it is version 4.31.0 or higher
git clone git@github.com:huggingface/transformers.git
cd transformers
pip install protobuf
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
- Use the following commands to convert the model
- Build a conda environment and then git clone the example fine-tuning recipes from Meta’s git repository to get started
- We have modified the code base to include Deepspeed flops profiler and nvitop to profile the GPU
- Load the dataset using the dataloader library of hugging face and, if need be, perform preprocessing
- Input the config file entries with respect to PEFT methods, model name, output directory, save model location, etc
- The following is the example code snippet
train_config: model_name: str="path_of_base_hugging_face_llama_model" run_validation: bool=True batch_size_training: int=7 num_epochs: int=1 val_batch_size: int=1 dataset = "dataset_name" peft_method: str = "lora" output_dir: str = "path_to_save_fine_tuning_model" save_model: bool = True |
6. Run the following command to perform fine tuning on a single GPU
python3 llama_finetuning.py --use_peft --peft_method lora --quantization --model_name location_of_hugging_face_model |
Figure 4 shows fine tuning with LoRA technique on 1*A100 (40GiB) with Batch size = 7 on SAMsum dataset, which took 83 mins to complete.

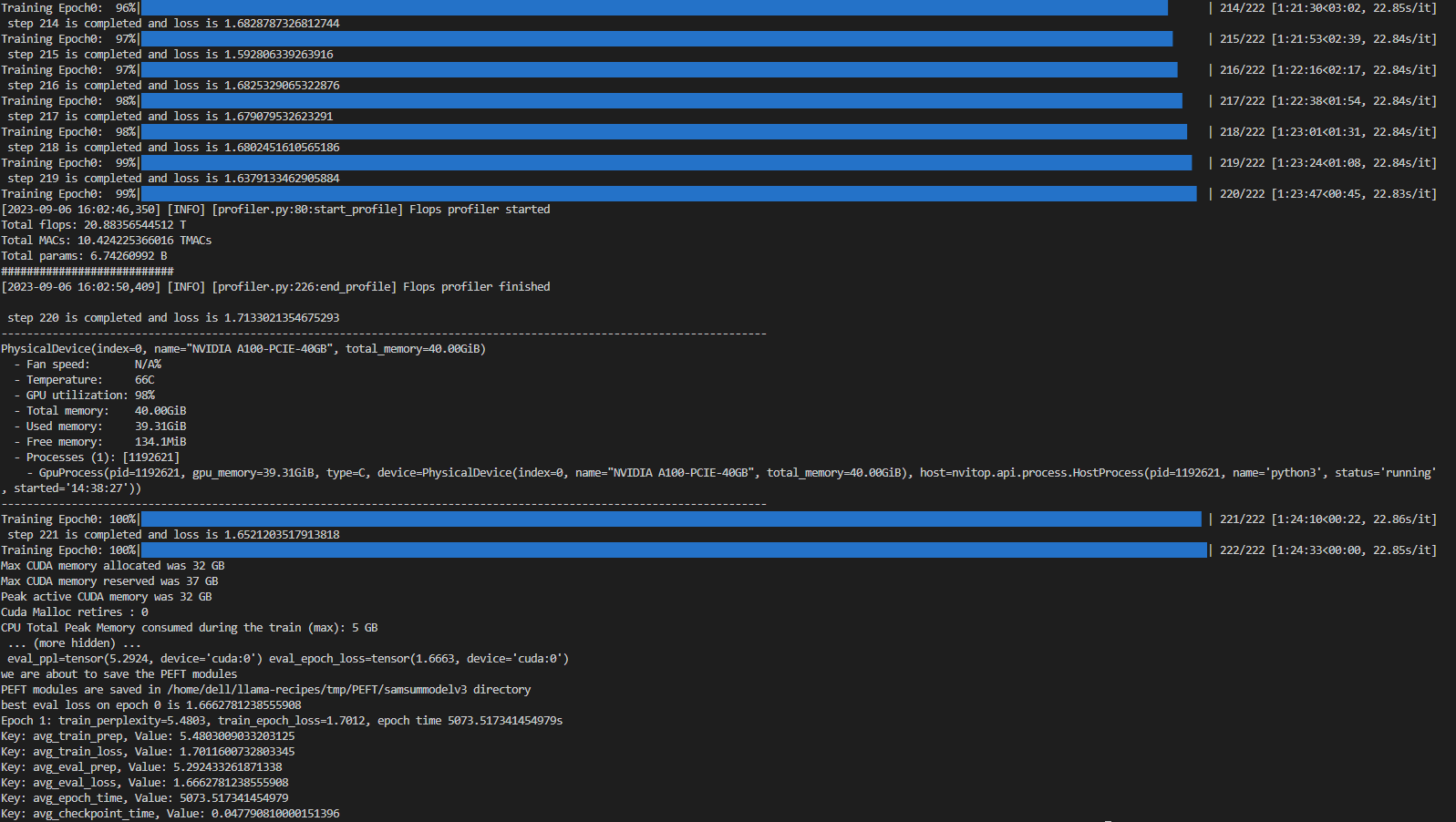
Figure 4. Example screenshot of fine-tuning with LoRA on SAMsum dataset
Experiment results
The fine-tuning experiments were run at batch sizes 4 and 7. For these two scenarios, we calculated training losses, GPU utilization, and GPU throughput. We found that at batch size 8, we encountered an out-of-memory (OOM) error for the given dataset on 1*A100 with 40 GB.
When a dialogue was sent to the base 7B model, the summarization results are not proper as shown in figure 5. After fine-tuning the base model on the SAMsum dataset, the same dialogue prompts a proper summarized result as shown in figure 6. The difference in results shows that fine-tuning succeeded.
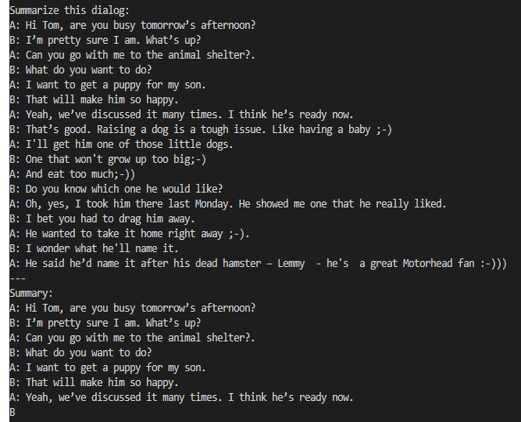
Figure 5. Summarization results from the base model.
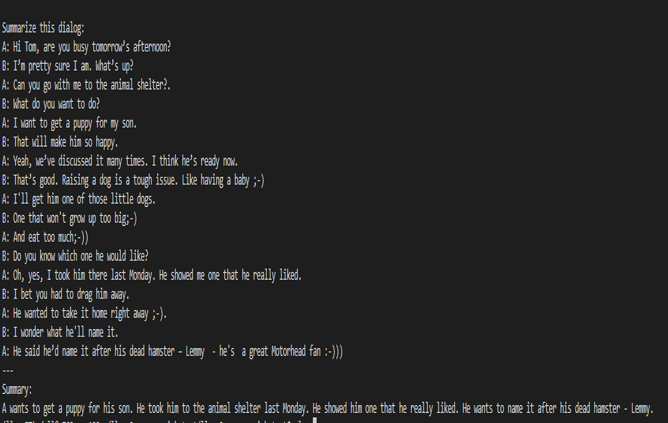
Figure 6. Summarization results from the fine-tuned model.
Figures 7 and 8 show the training losses at batch size 4 and 7 respectively. We found that even after increasing the batch size by approximately 2x times, the model training performance did not degrade.
Figure 7. Training loss with batch size = 4, a total of 388 training steps in 1 epoch.
Figure 8. Training loss with batch size = 7, a total of 222 training steps in 1 epoch.
The GPU memory utilization was captured with LoRA technique in Table 3. At batch size 1, used memory was 9.31 GB. At batch size of 4, used memory was 26.21 GB. At batch size 7, memory used was 39.31 GB. Going further, we see an OOM at batch size 8 for 40 GB GPU card. The memory usage remains constant throughout fine-tuning, as shown in Figure 9, and is dependent on the batch size. We calculated the reserved memory per batch to be 4.302 GB on 1*A100.
Table 3. The GPU memory utilization is captured by varying the max. batch size parameter.
Max. Batch Size | Steps in 1 Epoch | Total Memory (GiB) | Used Memory (GiB) | Free Memory (GiB) |
1 | 1,555 | 40.00 | 9.31 | 30.69 |
4 | 388 | 40.00 | 26.21 | 13.79 |
7 | 222 | 40.00 | 39.31 | 0.69 |
8 | Out of Memory Error | |||
Figure 9. GPU memory utilization for batch size 4 (which remains constant for fine-tuning)
The GPU TFLOP was determined using DeepSpeed Profiler, and we found that FLOPs vary linearly with the number of batches sent in each step, indicating that FLOPs per token is the constant.
Figure 10. Training GPU TFlops for batch sizes 4 and 7 while fine-tuning the model.
The GPU multiple-accumulate operations (MACs), which are common operations performed in deep learning models, are also determined. We found that MACs also follow a linear dependency on the batch size and hence constant per token.
Figure 11. GPU MACs for batch sizes 4 and 7 while the fine-tuning the model.
The time taken for fine-tuning, which is also known as epoch time, is given in table 4. It shows that the training time does not vary much, which strengthens our argument that the FLOPs per token is constant. Hence, the total training time is independent of the batch size.
Table 4. Data showing the time taken by the fine-tuning process.
Max. Batch Size | Steps in 1 Epoch | Epoch time (secs) |
4 | 388 | 5,003 |
7 | 222 | 5,073 |
Conclusion and Recommendation
- We show that using a PEFT technique like LoRA can help reduce the memory requirement for fine-tuning a large-language model on a proprietary dataset. In our case, we use a Dell PowerEdge R760xa featuring the NVIDIA A100-40GB GPU to fine-tune a Llama 2 7B model.
- We recommend using a lower batch size to minimize automatic memory allocation, which could be utilized in the case of a larger dataset. We have shown that a lower batch size affects neither the training time nor training performance.
- The memory capacity required to fine-tune the Llama 2 7B model was reduced from 84GB to a level that easily fits on the 1*A100 40 GB card by using the LoRA technique.
Resources
- Llama 2: Inferencing on a Single GPU
- LoRA: Low-Rank Adaptation of Large Language Models
- Hugging Face Samsum Dataset
Author: Khushboo Rathi khushboo_rathi@dell.com | www.linkedin.com/in/khushboorathi
Co-author: Bhavesh Patel bhavesh_a_patel@dell.com | www.linkedin.com/in/BPat

Using Retrieval Augmented Generation (RAG) on a Custom PDF Dataset with Dell Technologies
Fri, 20 Oct 2023 17:18:40 -0000
|Read Time: 0 minutes
The Generative AI transformation
Artificial Intelligence is transforming the entire landscape of IT and our digital lives. We’ve witnessed several major disruptions that have changed the course of technology over the past few decades. The birth of the internet, virtual reality, 3D printing, containerization, and more have contributed to major shifts in efficiency as well as the democratization of the tools required to create in those spaces.
Generative AI (GenAI) is now a major disruptor, forcing us all to rethink what efficiency leaps can, should, and should not be made with this new technology.
On its current trajectory, the larger AI industry has the potential to change entire economies. AI isn’t tremendously new. Within the past decade, the bottlenecks that once held back progress have been removed by massive gains in GPU technology, abundant data availability, and vast oceans of distributed storage.
Nowadays, we must differentiate between traditional AI – used to perform specific tasks and make predictions based on patterns – and GenAI – used to create new data that resembles human-like content.
With GenAI large-language models (LLM) leading the pack of the latest AI innovations, let’s pause for just a moment and ask ourselves, “Why is it suddenly so popular?”, “How does it work?”, and, more importantly, “How can I make it work better?” There’s no better way to answer these questions than by diving into the code that makes GenAI such a hot item.
Our mission today with GenAI
If I were to ask you a random question, chances are you could answer it in a sophisticated, accurate, and grammatically correct way – a “human-like” way. If I asked you about cars, chances are the topic of tires might come up since cars and tires have a strong relationship. Your response probably wouldn’t contain anything about zebras since zebras and cars are not strongly related. What if I asked you about a skyscraper? The word, “building” is strongly related to skyscrapers, but why not the words, “moon” or “bird” - they’re in the sky too, right?

To achieve a response that pleases us, we want an accurate answer presented to us in a human-like manner. Those two concepts – “accuracy” and “human-like” – are the common threads woven throughout the code for all generative AI development.
A traditional AI response of “yes” or “no” can maintain high accuracy, but is that what I want to give to my users or my customers? A dry, robotic, binary response? Absolutely not. I want a human-like response that provides context and additional help. I want the response to solve my problem either directly through automated actions or indirectly by enabling me to help myself. If we can’t get all of this, then why bother building any of it?
Having a human-like response is of tremendous value and something the market desires. So how do we humanize a computer created response? It takes brains.

Human brains are massive pattern-matching machines that rely on millions of physical neural connections. AI essentially mirrors those physical connections in the form of numerical relationship strings called vectors. Accuracy comes from thousands of interlocking relationships of general knowledge about individual things. Each “thing” you feed an AI model, whether it’s a pixel or a word, is digitized and labeled as a vector that has unique value and location, either on an image or in a sentence.
Once we digitize our content into a form the computer can digest, we can start to analyze it for patterns of relationships and eventually build a model that is good at providing accurate, human-like responses based on the relationships it was given.
Defining the problem
There are dozens of major LLMs to choose from and thousands of homebrewed variants. Each model supports unique features and use cases, so choosing the right one is vital. Let’s first define our problem and then determine model selection.
Our example company would like to improve their overall customer experience when chatting with support. Besides improving the response time and providing a better self-help pathway, they would like to integrate their legacy and future knowledge base articles into a help desk chatbot that can respond to questions with new information obtained from their pdf dataset. In this example, we’ll use a collection of white papers and infographics from Dell Infohub.
Training a model from scratch vs. fine-tuning vs. RAG
If your industry is highly specialized and has a considerably unique vocabulary - such as legal, medical, or scientific – or your business requires a high level of privacy where intermingling publicly and privately sourced data is forbidden, training a model from scratch might be the route to take.
In most cases, using an existing open-source model and then fine-tuning it to enable a new task is preferred since it requires much less compute and saves a lot of time. With the right balance of compute, storage, and software, fine-tuning an existing model can be extremely effective.
If your response model is good and performs the task you want but could use some specific learning based on content from a custom document dataset – a knowledge base for example - then Retrieval Augmented Generation (RAG) would be a great candidate for this type of workload.
Why use Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) is used in LLM applications to retrieve relevant knowledge base-style content, augment the user prompt with this domain-specific content, then feed both the prompt and content into the LLM to generate a more complete, useful response.
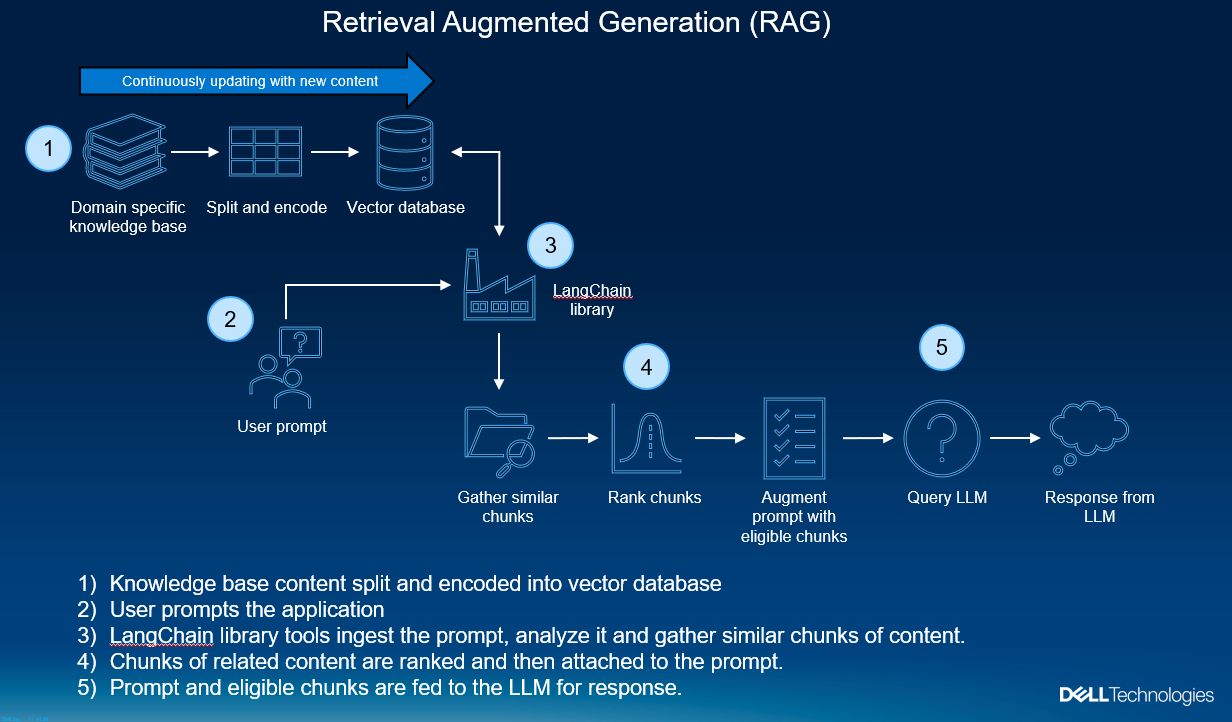
Figure 1. Understanding how RAG works
So how does RAG work? Imagine yourself at a restaurant, asking the waiter a question about wine pairings. In this analogy, you are the user who is inputting a question prompt, and the waiter is our LLM model. The waiter certainly has basic pairing suggestions – “Red wine pairs well with beef” – but this response speaks nothing to centuries of pairing history, recent wine trends, or this restaurant’s decades of culture. This very dry response also doesn’t account for the restaurant’s current inventory. We wouldn’t want the waiter to suggest a wine that isn’t currently stocked.
With a RAG process, the waiter takes the question, retrieves relevant historical and up-to-date information specific to the restaurant (including inventory), and gathers it all together for the customer. That being said, it’s not enough to just retrieve information. Our customer needs the finer touch of a well-informed suggestion rather than being inundated with a bunch of articles or snippets about wine pairings. That’s where the LLM shines.
LLMs are excellent at taking large, disparate chunks of content, organizing them, and providing a human-like response. The original question, along with all those wine and food snippets about pairing, are fed into the LLM whereby a more complete, useful response is given, all without having to relearn the basics. That is to say, our waiter didn’t have to become a sommelier to give this response. No retraining was required. The RAG process doesn’t require time-consuming training runs. The LLM is trained prior to engaging in the process. We simply made new domain-specific knowledge easier for the LLM to digest.
Peeking under the hood
This is all done by taking domain-specific knowledge bases (in this case pdf files), splitting them up intelligently, then encoding the textual content of these chunks into long numerical vectors.
Vectors representing the original text go into a vector database that can be queried extremely quickly. Vector databases come in a variety of types and use cases. In this example, we’re using ChromaDB, a “pure” vector database that is designed to store and retrieve vectors from unstructured data, such as text, images, and files. This is perfect for our use case where we are taking random text from unknown documents in a variety of formats and converting them to vectors that are used to build relationships between the prompt and chunks of content.
In some ways, we can consider the vector database to be a form of long-term memory. As we continue to add new content to it and keep it maintained, our LLM can refer to the contents as the database expands with new information.
Using the original question, the vector database is queried to find which chunks are most related to the original question. The results are ranked for similarity whereby only the most relevant content is eligible to be fed into the LLM for response generation.
Choosing our LLM
We’ll be using the Meta Llama2 model since it can be quantized and run locally on prem, comes in a variety of sizes, performs as well or better than ChatGPT, and is also available for free for commercial use. Llama2 also has a moderately large context window that allows users to introduce text in the form of sentences or entire documents and then generate responses from the new information.
Using Llama2 or other open-source LLMs on prem allows full control over both your domain-specific content and any content that goes into the model, such as prompts or other proprietary information. On prem models are also not executable objects on their own since they lack the ability to send your private data back to the original authors.
Compute and Storage Environment
Our physical environment is on VMware vSphere as the hypervisor in a Dell APEX Private Cloud cluster with VxRail PowerEdge nodes, each with 3 Nvidia T4 GPUs. Storage is on the local vSAN. Our notebook server is running inside a Pytorch virtual environment on an Ubuntu 22.04 virtual machine with Miniconda. This can also be run on bare metal PowerEdge with any OS you choose as long as you can run Jupyter notebooks and have access to GPUs.
GenAI coding first steps
When running any sort of training or fine-tuning, you’ll need access to models, datasets, and monitoring so that you can compare the performance of the chosen task. Luckily, there are free open-source versions of everything you need. Simply set up an account on the following sites and create an API access token to pull the leading models and datasets into your notebooks.
- Hugging Face – incredibly valuable and widely used open-source python libraries, datasets, models, notebook examples, and community support
- Weights and Biases – free SaaS-based monitoring dashboard for model performance analysis
- Github – open-source libraries, tools, and notebook examples
Along with those sites, at some point you will inevitably experiment with or use incarnations of the Meta (Facebook) Llama model. You’ll need to fill out this simple permission form.
- Llama model permission form: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Setting up RAG on the Llama2 model with a custom PDF dataset
First, let’s log in to Huggingface so that we can access libraries, models, and datasets.
## code to auto login to hugging face, avoid the login prompt !pip install -U huggingface-hub # get your account token from https://huggingface.co/settings/tokens token = ‘<insert your token here>’ from huggingface_hub import login login(token=token, add_to_git_credential=True)
With each notebook you run, you’ll end up installing, upgrading, and downgrading all sorts of libraries. The versions shown may very well change over time with added or deprecated features. If you run into version compatibility issues, try upgrading or downgrading the affected library.
!pip install torch !pip install transformers !pip install langchain !pip install chromadb !pip install pypdf !pip install xformers !pip install sentence_transformers !pip install InstructorEmbedding !pip install pdf2image !pip install pycryptodome !pip install auto-gptq
From our newly installed packages, let’s import some of the libraries we’ll need. Most of these will be related to LangChain, an amazing tool for chaining LLM components together as previously seen in figure 1. As you can see from the library titles, LangChain can connect our pdf loader and vector database and facilitate embeddings.
import torch from auto_gptq import AutoGPTQForCausalLM from langchain import HuggingFacePipeline, PromptTemplate from langchain.chains import RetrievalQA from langchain.document_loaders import PyPDFDirectoryLoader from langchain.embeddings import HuggingFaceInstructEmbeddings from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores import Chroma from pdf2image import convert_from_path from transformers import AutoTokenizer, TextStreamer, pipeline DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
Let’s check our Nvidia GPU environment for availability, processes, and CUDA version. Here, we see 3 x T4 GPUs. The driver supports CUDA version up to 12.2 with around 16Gb per device, and no other running processes. Everything looks good to start our run.
!nvidia-smi +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 Tesla T4 Off | 00000000:0B:00.0 Off | Off | | N/A 46C P8 10W / 70W | 5MiB / 16384MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 1 Tesla T4 Off | 00000000:14:00.0 Off | Off | | N/A 30C P8 10W / 70W | 5MiB / 16384MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 2 Tesla T4 Off | 00000000:1D:00.0 Off | Off | | N/A 32C P8 9W / 70W | 5MiB / 16384MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | No running processes found | +---------------------------------------------------------------------------------------+
Let’s check to make sure we can reach some of the pdfs in our repo by placing a pdf file page thumbnail image into an array and calling it for a preview.
pdf_images = convert_from_path("pdfs-dell-infohub/apex-navigator-for-multicloud-storage-solution-overview.pdf", dpi=100)
pdf_images[0]
Let’s call the pdf directory loader from LangChain to get an idea of how many pages we are dealing with.
loader = PyPDFDirectoryLoader("pdfs-dell-infohub")
docs = loader.load()
len(docs)
791Next, let’s split the pages into chunks of useful data. The downloaded hkunlp/instructor-large model helps us split this intelligently rather than via a brute force algorithm. We use the embeddings from this model to recognize our new content. Here we see that we’ve split this into over 1700 chunks.
embeddings = HuggingFaceInstructEmbeddings(
model_name="hkunlp/instructor-large", model_kwargs={"device": DEVICE}
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=64)
texts = text_splitter.split_documents(docs)
len(texts)
1731Next, we prepare our LLM to receive both the prompt and the relevant chunks from our LangChain retrieval process. We’ll be using a variant of the Llama2 13 billion parameter model that provides memory optimized (quantized) revisions for us to download.
model_name_or_path = "TheBloke/Llama-2-13B-chat-GPTQ" model_basename = "model" tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True) model = AutoGPTQForCausalLM.from_quantized( model_name_or_path, revision="gptq-4bit-128g-actorder_True", model_basename=model_basename, use_safetensors=True, trust_remote_code=True, inject_fused_attention=False, device=DEVICE, quantize_config=None, )
Since this is a chatbot, we need to interact with our model directly. We do this by installing Huggingface’s pipeline module that facilitates access to your model and creates a raw chat interactive session directly from your notebook code cells.
text_pipeline = pipeline( "text-generation", model=model, tokenizer=tokenizer, max_new_tokens=1024, temperature=0, top_p=0.95, repetition_penalty=1.15, streamer=streamer, )
Our prompt is vital in this entire effort. We need to tell the LLM how to behave with responses. This system prompt, based on the default prompt for the Llama2 model, will provide enough instruction to get us human-like results once our content and question are fed into it.
SYSTEM_PROMPT = "Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer."
template = generate_prompt(
"""
{context}
Question: {question}
""",
system_prompt=SYSTEM_PROMPT,
)Finally, our chain can be built. LangChain links the retriever and our LLM together, then stuffs the document chunks into the prompt and passes it along as a normal query to the LLM while also asking for the source document chunks.
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectordb.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True,
chain_type_kwargs={"prompt": prompt},
)Let’s ask it a question that could only be found in the new documents. In this example, we’ve chosen a very specific question the Llama2 model was never trained on: “Does APEX block storage support multi availability zones?” The response given is “yes”. Even though the answer is positive, the model goes into a lot more detail on what it did find, giving us a very useful, human-like response.
We can also prove the source of truth by using the return_source_documents feature of LangChain and returning that in the next cell. This way, there is no question of whether the response was part of a hallucination.
result = qa_chain("Does apex block storage support multi availability zones?")Based on the information provided in the text, the answer is yes. APEX Block Storage supports multi-availability zones (AZs). The text states that "data is distributed across three or more availability zones" using fault sets, providing resilience without replication or unnecessary copies of the data. print(result["source_documents"][0].page_content) of data or needing to use replication across AZs. Leveraging the native fault sets feature, data is distributed across three or more availability zones to offer additional protection against AZ failure. Well Suited for Challenging Workloads APEX Block Storage provides proven enterprise data services, such as thin provisioning, snapshots, replication , volume migration, and backup/restore to S3, which are needed to run mission -critical workloads confidently on the public cloud . With it s extre me performance and scalability, APEX Block Storage is well suited to support very large databases, analytics workloads, and multiple container (Kubernetes) development and production deployments. And with the enterprise -class services and resilien ce provided in the cloud , APEX Block Storage for AWS and Microsoft Azure is the ideal solution to run your most challenging workloads in the public cloud wi th confidence that you can meet your SLAs. More Information ---------------------------------------------------
Let’s ask an even more specific question: “Provide a curl example of code to authenticate my PowerFlex.”
The LLM delivers a very pleasant response that is well-formatted, polite, and useful.
result = qa_chain("provide a curl example of code to authenticate my powerflex")
Based on the provided context, here is an example of how to authenticate with PowerFlex using curl:
```bash
curl --location --request POST 'https://<PFXM>/rest/auth/login' \
--header 'Content-Type: application/json' \
--data-raw '{"username": "<username>", "password": "<password>"}'
```
This example uses the `POST` method to send a login request to the PowerFlex Manager, specifying the username and password in the request body. The `--header` option sets the `Content-Type` header to `application/json`, and the `--data-raw` option sends the login credentials in JSON format.
Note that you will need to replace `<PFXM>` with the actual hostname or IP address of your PowerFlex Manager, and `<username>` and `<password>` with your PowerFlex username and password, respectively.
Bringing AI to your data
We’ve shown how the mission of GenAI is to provide accurate, human-like responses and that RAG is a low-impact method to augment those responses with your own custom content. We went through some of the tools that help facilitate this process, such as LangChain, vector databases, and the LLM model itself.
To really make these models shine, you need to apply your own data, which means having data sovereignty as well as secure access to your data. You simply can’t afford to have private data leak, potentially being captured and uncontrollably exposed globally.

Your unique data has immense value. Dell is here to help bring AI to your data and achieve the best possible results with preconfigured or custom solutions catered to your business needs regardless of trajectory, whether it’s using RAG, fine-tuning, or training from scratch.
With Dell Validated Design for Generative AI with Nvidia, customers can optimize the deployment speed of a modular, secure, and scalable AI platform. Dell PowerEdge servers deliver high performance and extreme reliability and can be purchased in a variety of ways, including bare metal, preconfigured with popular cloud stacks like our APEX Cloud Platforms, and as a subscription through Dell APEX. Simplify your structured or unstructured data expansion for GenAI with PowerFlex, PowerScale or ObjectScale, deployed on prem or as a subscription in the major cloud providers. Dell doesn’t just stop at the data center. With Dell Precision AI workstations in the workplace, data scientists can speed innovation on the most intensive workloads.
If you have any questions or need expert assistance, Dell Professional Services can help craft an enterprise GenAI strategy for high value uses cases and the roadmap to achieve them.
Dell enables you to maintain data sovereignty and control while simplifying GenAI processes, providing the outcomes you demand with the flexible financing options you deserve.
Resources
- Code example for this notebook and others at: https://github.com/dell-examples
- Dell Technologies Infohub: https://infohub.delltechnologies.com/
- Original inspiration repo: https://github.com/curiousily/Get-Things-Done-with-Prompt-Engineering-and-LangChain
Author: David O’Dell, Technical Marketing Engineer, AI and Solutions
Promising MLPerf™ Inference 3.1 Performance of Dell PowerEdge XE8640 and XE9640 Servers with NVIDIA H100 GPUs
Wed, 04 Oct 2023 20:54:55 -0000
|Read Time: 0 minutes
Abstract
The recent release of MLPerf Inference v3.1 showcased the latest performance results from Dell's new PowerEdge XE8640 and PowerEdge XE9640 servers, and another submission from the PowerEdge R760xa server. The data underscores the outstanding performance of PowerEdge servers. These benchmarks illustrate the surging demand for compute power, with PowerEdge servers consistently emerging on top across various models, claiming numerous top titles. This blog examines the expected performance for image classification, object detection, question answering, speech recognition, medical image segmentation and summarization, focusing specifically on the capabilities of the PCIe and SXM form factor NVIDIA H100 Tensor Core GPUs in the new generation PowerEdge systems.
Overview of top title results
The PowerEdge XE8640 and XE9640 servers won several #1 titles.
For instance, the PowerEdge XE8640 server emerged as a winner in all benchmarks in the data center suite such as image classification, object detection, question answering, speech recognition, medical image segmentation, and summarization relative to other systems having four NVIDIA H100 SXM GPUs. The PowerEdge XE9640 server received #1 titles for all benchmarks previously mentioned relative to other liquid-cooled systems having four NVIDIA H100 SXM GPUs.
Comparison from the previous rounds of submission
The following figure shows the improvement customers can derive by using the new generation PowerEdge XE8640 and XE9640 servers from our previous generation PowerEdge XE8545 server.
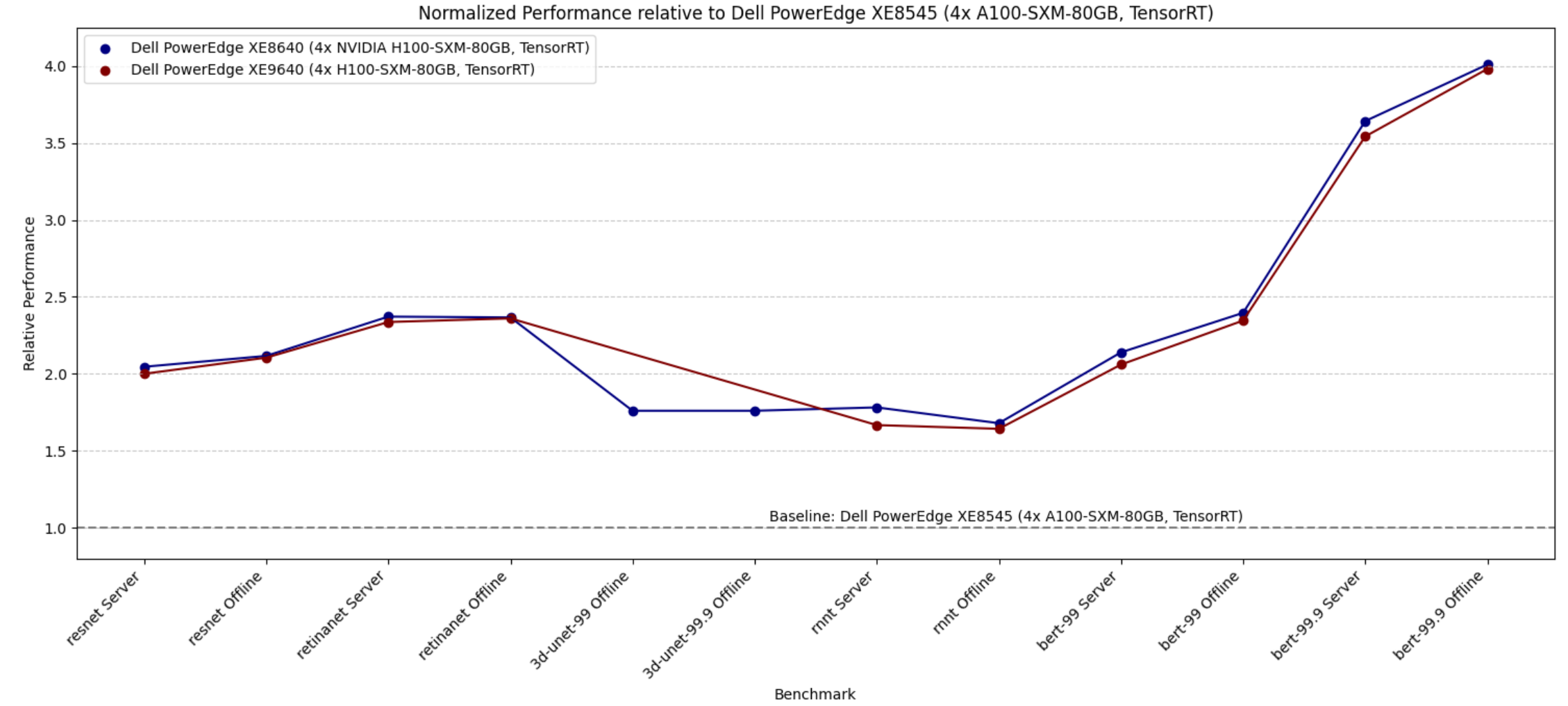
Figure 1. Relative performance of PowerEdge XE8640 and PowerEdge XE9640 servers using the PowerEdge XE8545 server as a baseline reference (for the Y axis, the higher the better)
The graph shows that the relative performance improvement from the PowerEdge XE8545 server with four NVIDIA A100 SXM Tensor Core GPUs as a baseline (from MLPerf Inference v3.0) and the new generation severs such as the PowerEdge XE8640 and PowerEdge XE9640 servers using NVIDIA H100 Tensor Core GPUs. The improvement in performance is substantial, as evident from the graph. End users can derive a two- to four-times improvement in performance for different tasks in MLPerf Inference benchmarks. We see relatively higher performance with BERT benchmarks because of the NVIDIA H100 GPU’s FP8 support.
Comparing air-cooled and liquid-cooled servers
The following figure shows the raw performance of PowerEdge XE8640 and XE9640 servers; this graph and the following graph provide relative scores. The graph includes all the benchmarks in the Inference closed data center suite that we submitted. Note that different benchmarks have different scales. All the benchmarks are presented in one graph, therefore, the y-axis is expressed logarithmically.
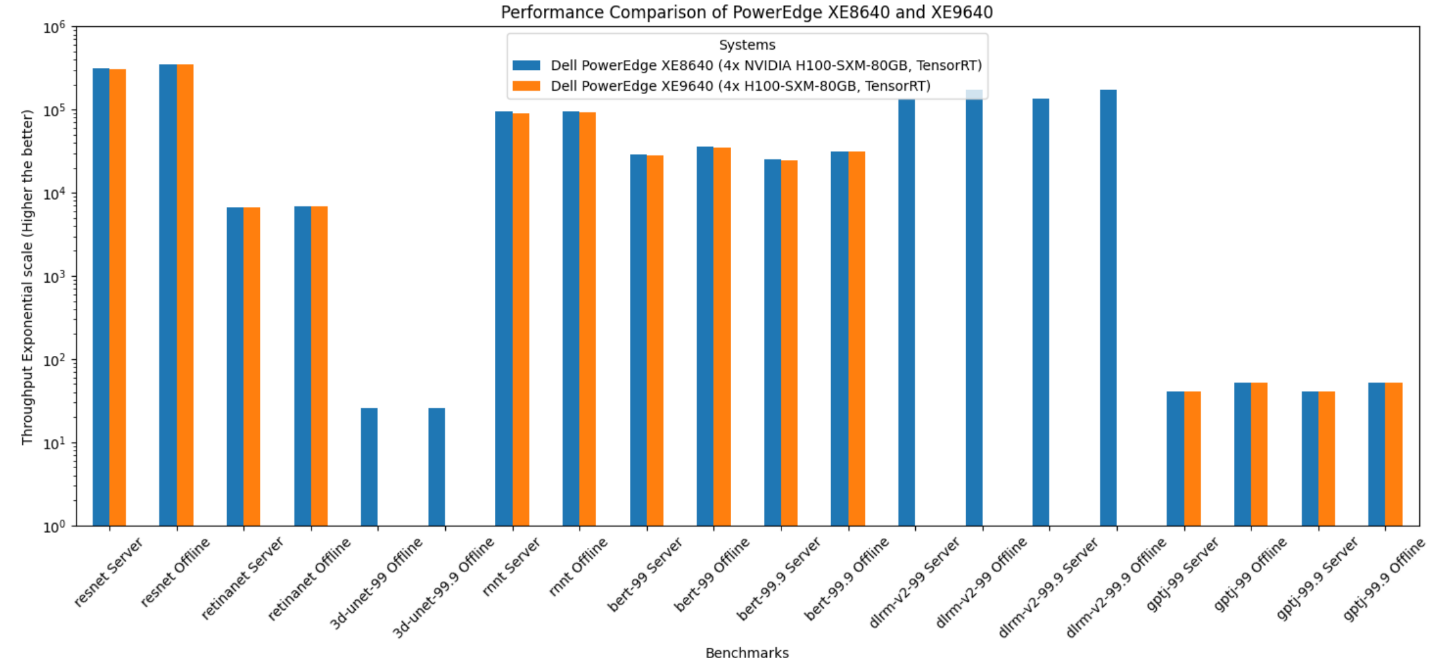
Figure 2. Performance of PowerEdge XE8640 and PowerEdge XE9640 servers
PowerEdge XE8640 and XE9640 servers are both great choices for inference workloads with four NVIDIA H100 SXM Tensor Core GPUs. The PowerEdge XE9640 server is a liquid-cooled server and the PowerEdge XE8640 server is an air-cooled server. The following figure shows the difference in performance between these systems; they both performed optimally. Both systems have similar effective throughput and render excellent performance as the CPU and GPU configurations are the same.
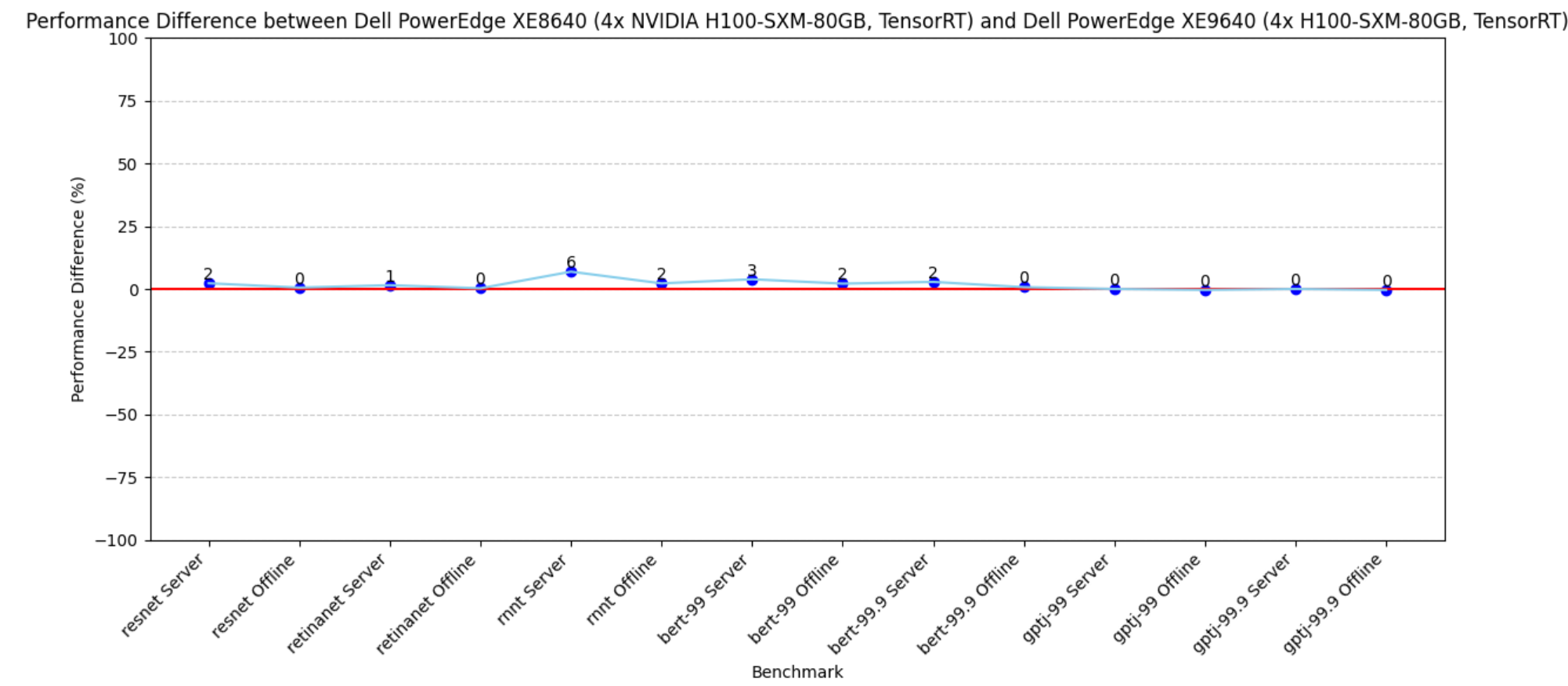
Figure 3. Performance difference between PowerEdge XE9640 and XE8640 servers using the PowerEdge XE9640 server as a baseline
Impact of SXM over PCIe form factors
The following figure shows the performance of the PowerEdge R760xa server with NVIDIA H100 PCIe GPUs as the baseline and shows the performance improvement of PowerEdge XE9640 and PowerEdge XE8640 servers with NVIDIA H100 Tensor Core SXM GPUs. The graph demonstrates that the PowerEdge XE8640 server with NVIDIA H100 SXM GPUs performs approximately 1.25 to 1.7 times better than the PowerEdge R760xa server with NVIDIA H100 PCIe GPUs.
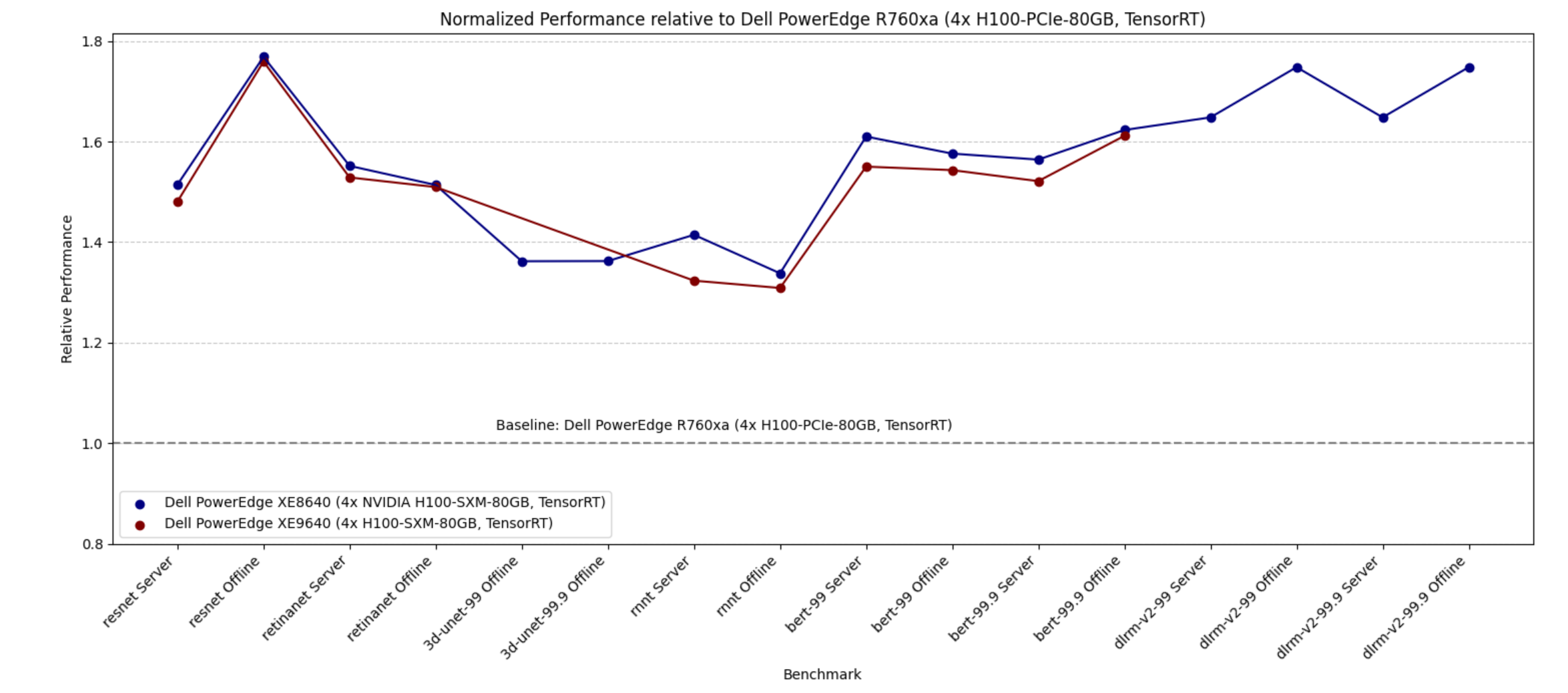
Figure 4. Performance difference between PowerEdge XE9640 and XE8640 servers with 4x H100 SXM and PowerEdge R760xa server with 4x H100 PCIe as a baseline
Because the NVIDIA H100 SXM GPUs have higher Thermal Design Power (TDP), if high performance is imperative, then using NVIDIA SXM GPUs is a great choice.
Comparing efficiency of new and previous generation servers
The following figure shows the performance of the previous generation PowerEdge XE8545 server with NVIDIA A100 SXM GPUs compared to the new generation servers such as the PowerEdge R760xa server with the NVIDIA H100 PCIE form factor and the PowerEdge XE8640 and XE9640 servers with the NVIDIA H100 SXM form factor. We see that all the new generation servers rendered higher performance. Furthermore, our new generation PowerEdge R760xa server with four NVIDIA H100 PCIe GPUs is more power efficient than our previous generation PowerEdge XE8545 server with four NVIDIA A100 SXM GPUs. This result is because NVIDIA A100 SXM GPUs have higher TDP relative to the NVIDIA H100 PCIe GPU.
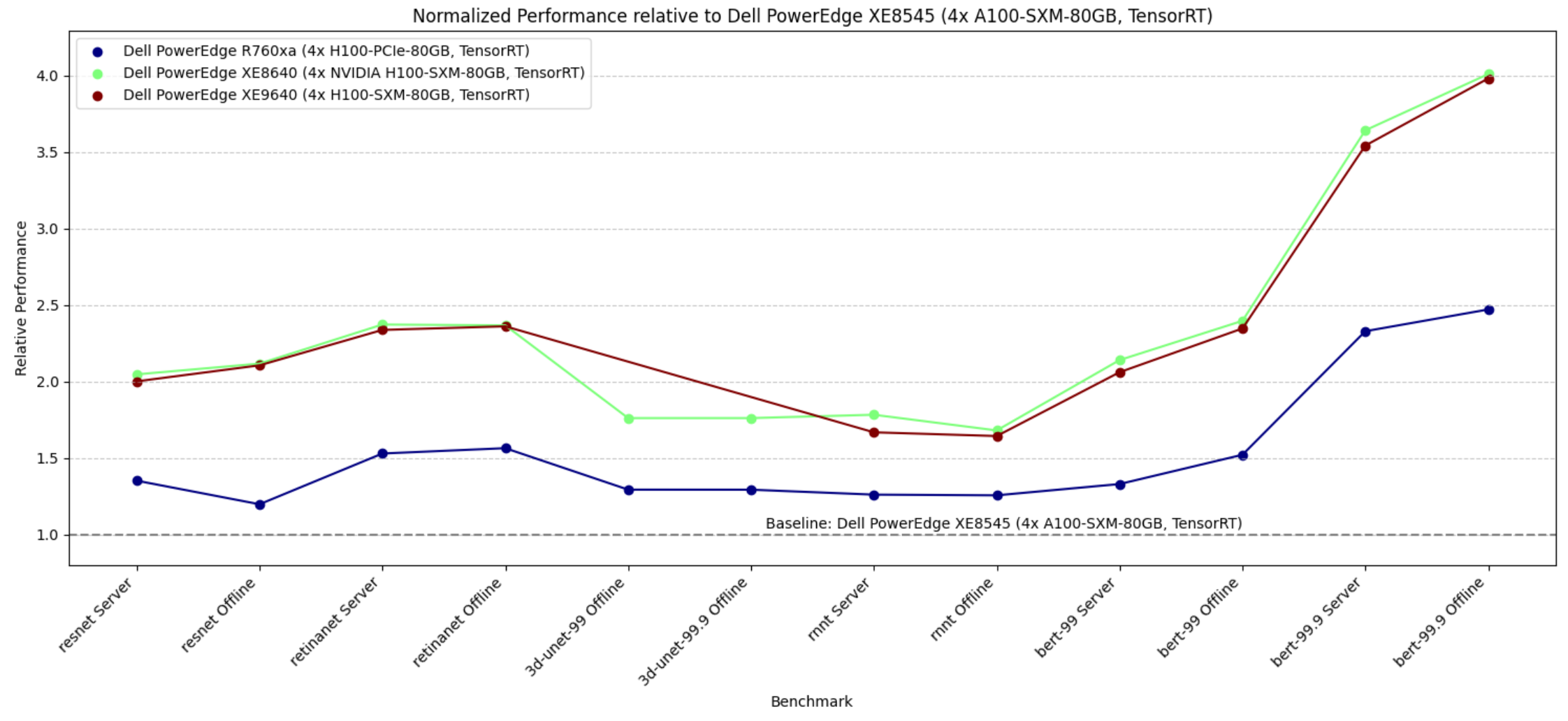
Figure 5. Relative performance of PowerEdge R760xa, PowerEdge XE9640, and PowerEdge XE8640 servers using the PowerEdge XE8545 server as a baseline
Hardware overview
The following sections describe the system components. The appendix lists the system configurations in the benchmark.
Dell PowerEdge XE8640 server
The PowerEdge XE8640 server is an air-cooled 4U server that accelerates traditional AI training and inferencing, modeling, simulation, and other high-performance computing (HPC) applications with optimized compute, turning data and automating insights into outcomes with a four-way GPU platform. Its powerful architecture and the power of two 4th Generation Intel Xeon processors with a high core count of up to 56 cores and the latest on-chip innovations to boost AI and machine learning operations.
The following figure shows the PowerEdge XE8640 server:

Figure 6. Dell PowerEdge XE8640 server
Dell PowerEdge XE9640 server
The PowerEdge XE9640 server is a purpose-built direct liquid-cooled (DLC) 2U server for AI and HPC workloads. NVIDIA NVLink and Intel Xelink technologies in the PowerEdge XE9640 server allow seamless communication between the GPUs, pooling their memory and cores to tackle memory-coherent workloads such as large language models (LLM) efficiently.
The following figure shows the PowerEdge XE9640 server:

Figure 7. Dell PowerEdge XE8640
NVIDIA H100 Tensor core GPU
The NVIDIA H100 GPU is an integral part of the NVIDIA data center platform. Built for AI, HPC, and data analytics, the platform accelerates over 3,000 applications, and is available everywhere from the data center to the edge, delivering both dramatic performance gains and cost-saving opportunities. The NVIDIA H100 Tensor Core GPU delivers unprecedented performance, scalability,
and security for every workload. With NVIDIA® NVLink® Switch System, up to 256
NVIDIA H100 GPUs can be connected to accelerate exascale workloads, while the dedicated
Transformer Engine supports trillion-parameter language models. The NVIDIA H100 GPU uses
breakthrough innovations in the NVIDIA Hopper™ architecture to deliver industry-leading conversational AI, speeding up large language models by 30 times over the previous generation.
The following figure shows the NVIDIA H100 PCIe accelerator:

Figure 8. NVIDIA H100 PCIe accelerator
The following figure shows the NVIDIA H100 SXM accelerator:

Figure 9. NVIDIA H100 SXM accelerator
Conclusion
The key takeaways include:
- Both the Dell PowerEdge XE8640 and Dell PowerEdge XE9640 servers are an excellent choice for inference. The performance of the air-cooled PowerEdge XE8640 server is almost identical to the liquid-cooled PowerEdge XE9640 server. While the PowerEdge XE9640 server is a 2U server, it requires additional cooling unit attachments. It is a good choice if there are space and temperature constraints, otherwise the PowerEdge XE8640 server is a great choice.
- PowerEdge XE8640 and PowerEdge 9640 servers have received several top titles. They are clear leaders in inference compute.
- New generation PowerEdge XE8640 and PowerEdge XE9640 servers with NVIDIA H100 GPUs have delivered 2- to 4-times improvement relative to the previous generation PowerEdge XE8545 server with NVIDIA A100 GPUs. Upgrading from the PowerEdge XE8545 sever would render higher performance.
- The PowerEdge XE9640 and PowerEdge XE8640 servers with four NVIDIA H100 SXM form-factor GPUs are significantly more effective than the PowerEdge R760xa server with four NVIDIA H100 PCIe GPUs by a factor of 1.25 to 1.7 times.
Our submission results to MLPerf Inference since its inception have continuously demonstrated significant performance improvements. We have submitted to different tasks to provide customers with a wide spectrum of possible results to review. This round marked a new and the first submission to MLPerf with PowerEdge XE8640 and XE9640 servers. Customers can rely on these high compute machines for their fast/low latency inference needs. If constrained by TDP or other factors, the PowerEdge R760xa server with the PCIe form factor is an excellent choice on which to run inference workloads.
Appendix
The following table lists the system configuration details for the servers described in this blog:
Table 1. System configurations
| Dell PowerEdge XE 8640 (4x NVIDIA H100-SXM-80GB, TensorRT) | Dell PowerEdge XE 9640 (4x H100-SXM-80GB, TensorRT) | Dell PowerEdge R760xa (4x H100-PCIe-80GB, TensorRT) | Dell PowerEdge XE 8545 (4x A100-SXM-80GB, TensorRT) |
MLPerf submission ID | 3.1-0066 | 3.1-0067 | 3.1-0064 | 3.0-0011 |
MLPerf system ID | XE8640_H100_SXM_80GBx4_TRT | XE9640_H100_SXM_80GBx4_TRT | R760xa_H100_PCIe_80GBx4_TRT | XE8545_A100_SXM4_80GBx4_TRT |
Operating system | Rocky Linux 9.1 | Ubuntu 22.04 | Ubuntu 20.04.4 | Ubuntu 22.04 |
CPU | Intel Xeon Platinum 8480 | Intel Xeon Platinum 8480+ | Intel Xeon Platinum 8480+ | AMD EPYC 7763 |
Memory | 1 TB | 1 TB | 2 TB | 2 TB |
GPU | NVIDIA H100 SXM 80 GB | NVIDIA H100 PCIE 80 GB | NVIDIA A100 SXM 80 GB CTS | |
GPU count | 4 | |||
Software stack | TensorRT 9.0.0 CUDA 12.2 | TensorRT 8.6.0 CUDA 12.2 | ||
MLCommons results
MLPerf system IDs:
- ID 3.0-0011
- ID 3.1-0064
- ID 3.1-0066
- ID 3.1-0067
Note: We reran the RetinaNet Offline benchmark for the PowerEdge R760xa server and the DLRMv2 benchmark for the PowerEdge XE8640 server to reflect the correct performance that the servers can render. Only these two results are not official due to MLCommons rules.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Comparing the NVIDIA H100 and A100 GPUs in Dell PowerEdge R760xa and R750xa Servers
Wed, 04 Oct 2023 16:47:00 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf™ Inference v3.1 benchmark suite. This blog highlights Dell Technologies’ closed division submission made for the Dell PowerEdge R760xa and Dell PowerEdge R750xa servers with NVIDIA H100 and NVIDIA A100 GPUs.
Introduction
This blog provides comparisons that draw relevant conclusions about the performance improvements that are achieved on the Dell PowerEdge R760xa server with the NVIDIA H100 GPU compared to their respective predecessors, the Dell PowerEdge R750xa server with the NVIDIA A100 GPU. In the Dell PowerEdge R760xa server section of this blog, we compare the performance of the PowerEdge R760xa server to the PowerEdge R750xa server while keeping the NVIDIA H100 GPU constant to demonstrate the improvement of the new generation of PowerEdge servers. Also, we compared the performance of the PowerEdge R760xa server with the NVIDIA H100 GPU to the PowerEdge R750xa server with the NVIDIA A100 GPU to showcase the server plus the GPU generation-to-generation improvements. In the Dell PowerEdge R750xa server section of this blog, we kept the server constant and compared the performance of the NVIDIA H100 GPU to the NVIDIA A100 GPU. For an additional angle, we held the PowerEdge R750xa server and the NVIDIA A100 GPU constant to showcase the performance improvements delivered by software stack updates.
System Under Test (SUT) configuration
Table 1: SUT configuration of the Dell PowerEdge R760xa and Dell PowerEdge R750xa servers for MLPerf Inference v3.1 and v3.0
| Platform | R750xa | R750xa | R760xa |
| MLPerf Version | V3.0 | V3.1 | V3.1 |
| GPU | NVIDIA A100 PCIe 80 GB | NVIDIA A100 PCIe 80 GB NVIDIA H100 PCIe 80 GB | NVIDIA H100 PCIe 80 GB |
| GPU Count | 4 | ||
| MLPerf System ID | R750xa_A100_PCIE_80GBx4_TRT | R750xa_A100_PCIe_80GBx4_TRT R750xa_H100_PCIe_80GBx4_TRT | R760xa_H100_PCIe_80GBx4_TRT |
| CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | Intel Xeon Platinum 8480+ | |
| Memory | 512 GB | 512 GB 1 TB | 2 TB |
| Software Stack | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | TensorRT 9.0.0 CUDA 12.2 cuDNN 8.9.2 Driver 535.86.10 DALI 1.28.0 | |
The following table shows the technical specifications of the NVIDIA H100 and NVIDIA A100 GPUs:
Table 2: Technical specification comparison of the NVIDIA H100 and NVIDIA A100 GPUs
GPU | NVIDIA A100 | NVIDIA H100 | ||||||
Form factor | SXM4 | PCIe Gen4 | SXM4 | PCIe Gen4 | PCIe Gen5 | NVL PCIe Gen5 | SXM5 | |
GPU architecture | Ampere | Hopper | ||||||
CUDA cores | 6912 | 14592 | 2x 16895 | 16895 | ||||
Memory size | 40 GB | 80 GB | 80 GB | 2x 94 GB (188 GB) | 80 GB | 94 GB | ||
Memory type | HBM2e | HBM2 | HBM2e | HBM2e | HBM3 | HBM2e | ||
Base clock | 1095 MHz | 765 MHz | 1275 MHz | 1065 MHz | 1095 MHz | 1080 MHz | 1590 MHz | 1605 MHz |
Boost clock | 1410 MHz | 1755 MHz | 1785 MHz | 1980 MHz | ||||
Memory clock | 1215 MHz | 1593 MHz | 1512 MHz | 1593 MHz | 2619 MHz | 1593 MHz | ||
MIG support | Yes | Yes/2nd Gen | ||||||
Peak memory bandwidth | 1555 GB/s | 2039 GB/s
| 1935 GB/s | 2039 GB/s | 3938 GB/s | 3352 GB/s | 2359 GB/s | |
Total board power | 400 W | 250 W | 400 W | 300 W | 310/350 W | 400 W | 700 W | |
Dell PowerEdge R760xa server
The PowerEdge R760xa server shines as an Artificial Intelligence (AI) workload server with its cutting-edge inferencing capabilities. This server represents the pinnacle of performance in the AI inferencing space with its processing prowess enabled by Intel Xeon Platinum processors and NVIDIA H100 PCIe 80 GB GPUs. Coupled with NVIDIA TensorRT and CUDA 12.2, the PowerEdge R760xa server is positioned perfectly for any AI workload including but not limited to Large Language Models, computer vision, Natural Language Processing, robotics, and edge computing. Whether you are processing image recognition tasks, natural language understanding, or deep learning models, the PowerEdge R760xa server provides the computational muscle for reliable, precise, and fast results.

Figure 1: Front view of the Dell PowerEdge R760xa server
 |
|
Figure 2: Top view of the Dell PowerEdge R760xa server
The results in the following figures are represented as percentage differences while maintaining a single SUT as the baseline. To determine the percentage difference between the two results, we subtracted the performance value achieved on the first server from the performance value achieved on the second server. We divided the difference by the performance achieved on the second server and multiplied it by 100 to get a percentage. By applying this formula, we obtain the performance delta between the second and first server. This result provides an easy-to-read comparison across two systems and several benchmarks.
The following figure shows the percent difference between the PowerEdge R760xa and PowerEdge R750xa servers while maintaining the NVIDIA H100 GPU constant. Both results were collected from the latest official MLPerf Inference v.3.1 submission with the identical software stack. Across all the benchmarks, the PowerEdge R760xa server comprehensively outperformed its predecessor. The PowerEdge R760xa server shined in the Natural Language Processing task with a noticeable 15 percent improvement. On average, it performed approximately 6 percent better for all workloads.
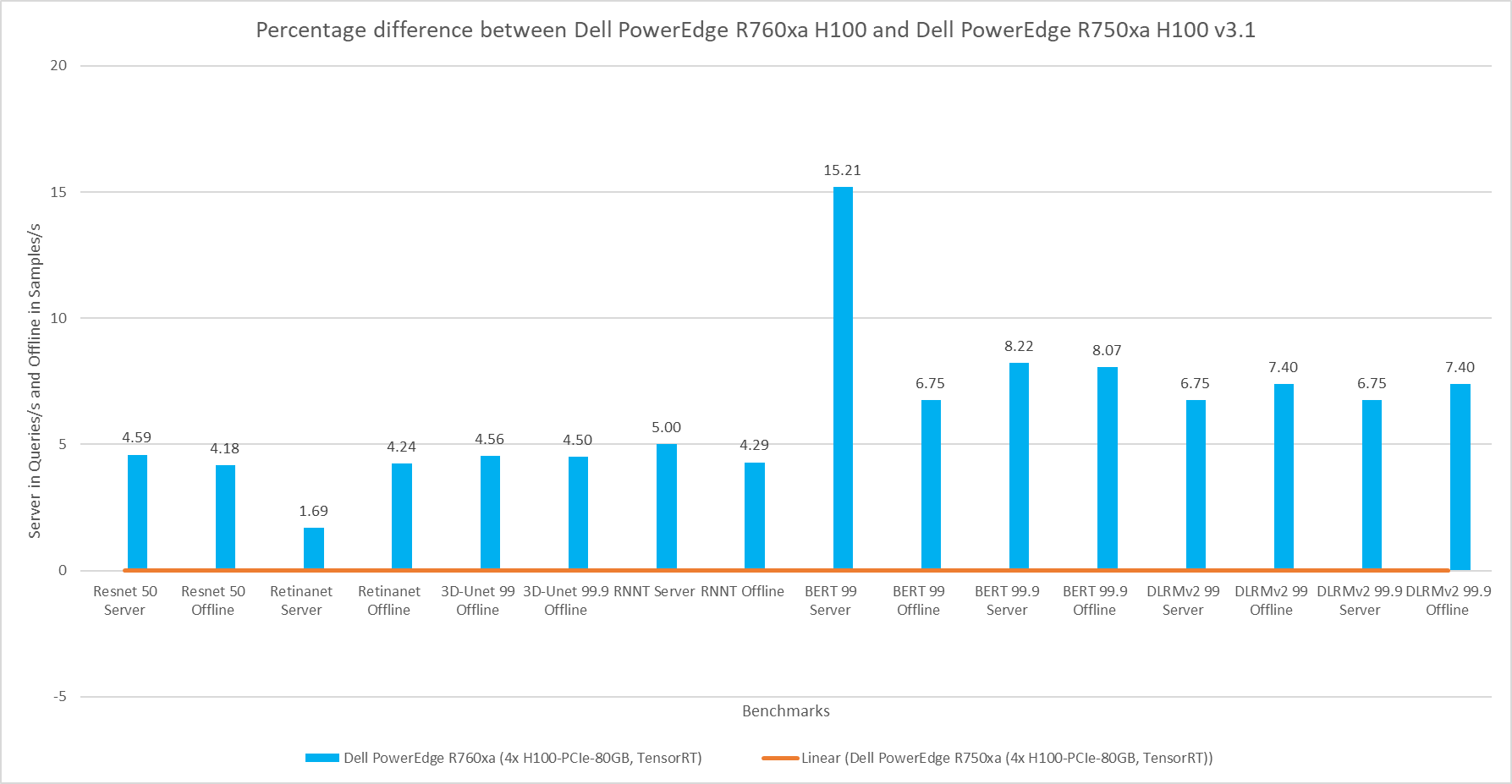
Figure 3: Percentage difference between the Dell PowerEdge R760xa server with the NVIDIA H100 GPU and the Dell PowerEdge R750xa server with the NVIDIA H100 GPU for the v3.1 submission
The following figure shows a comparison of the PowerEdge R760xa server with the NVIDIA H100 GPU to the PowerEdge R750xa server with the NVIDIA A100 GPU. This comparison is expected to yield the highest delta in performance due to the hardware upgrades of both the server and GPU. Both submissions were made to the MLPerf Inference v3.1 round in which the software stack was kept the same. The PowerEdge R760xa server paired with the NVIDIA H100 GPU thoroughly outperformed its predecessor in all workloads. In the high accuracy category of the Natural Language Processing workload, the PowerEdge R760xa server boasts an impressive 178 percent and 197 percent performance improvement in the Server and Offline modes respectively. On average, the newer configuration showcased a noteworthy 71 percent improvement across all the benchmarks.
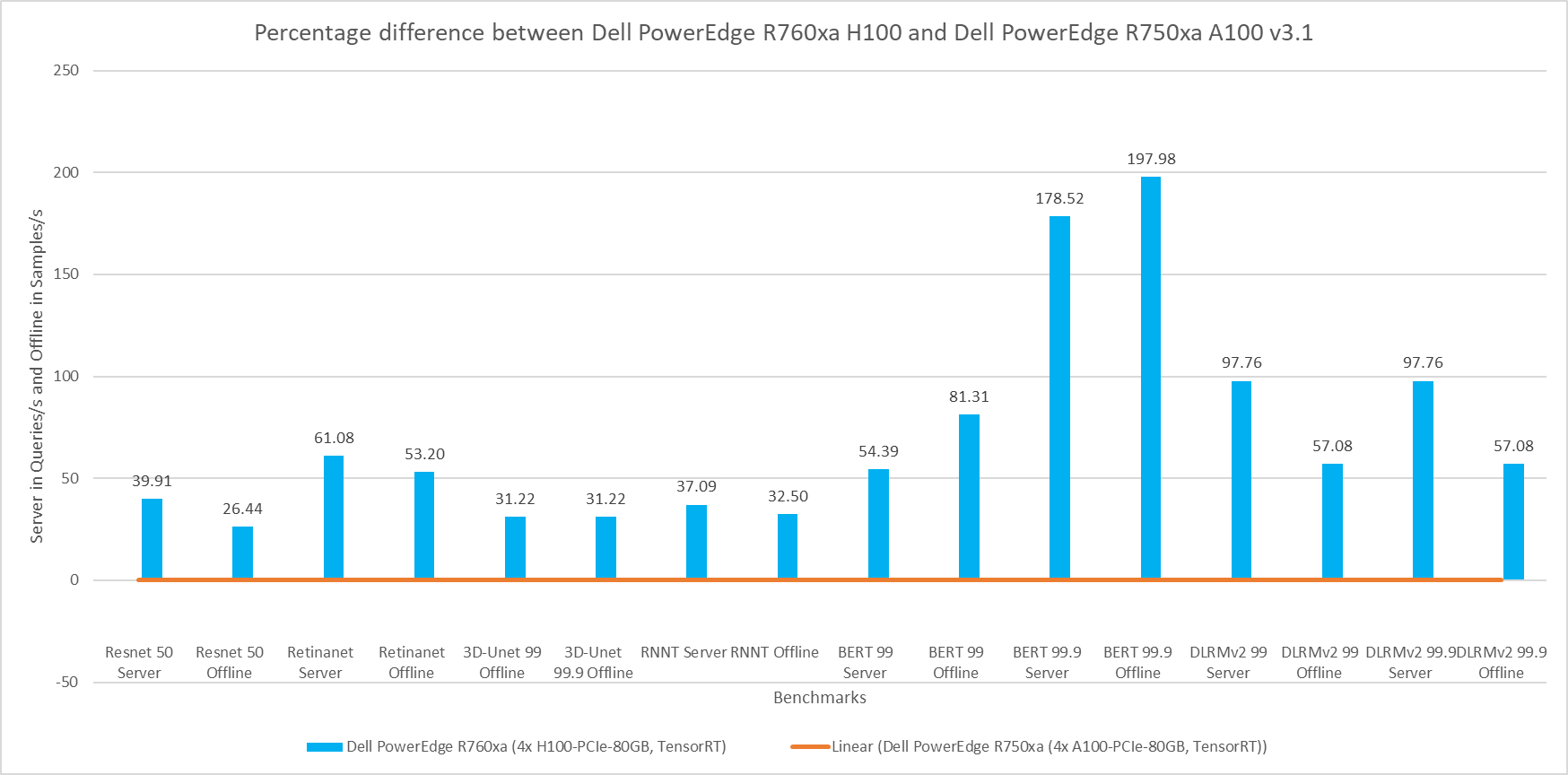
Figure 4: Percentage difference between the Dell PowerEdge R760xa server with the NVIDIA H100 GPU and the Dell PowerEdge R750xa server with the NVIDIA A100 GPU for v3.1
Dell PowerEdge R750xa server
The PowerEdge R750xa server is a perfect blend of technological prowess and innovation. This server is equipped with Intel Xeon Gold processors as well as with the latest NVIDIA GPUs. The PowerEdge R760xa server has been designed for the most demanding AI/ML/DL workloads as it is compatible with the latest NVIDIA TensorRT engine and CUDA version. With up to nine PCIe Gen4 slots and availability in a 1U or 2U configuration, the PowerEdge R750xa server is an excellent option for any demanding workload.

Figure 5: Front view of the Dell PowerEdge R750xa server

Figure 6: Rear view of the Dell PowerEdge R750xa server
For the following comparison, the Dell PowerEdge R750xa server is held constant but the GPU is updated from the NVIDIA A100 GPU to the NVIDIA H100 GPU. This comparison is useful if you are interested in keeping the server that you already have but are upgrading the GPU. As expected, the server with the NVIDIA H100 GPU shows significant performance improvements across all the workloads. Similar to the previous comparison, the high accuracy Natural Language Processing task on the NVIDIA H100 GPU shows promising performance improvements. In the high accuracy Server scenario for BERT, the NVIDIA H100 GPU showed a 156 percent improvement and in the Offline scenario a 174 percent improvement. On average, the PowerEdge R750xa server paired with the NVIDIA H100 GPU performed approximately 60 percent better than its GPU predecessor.
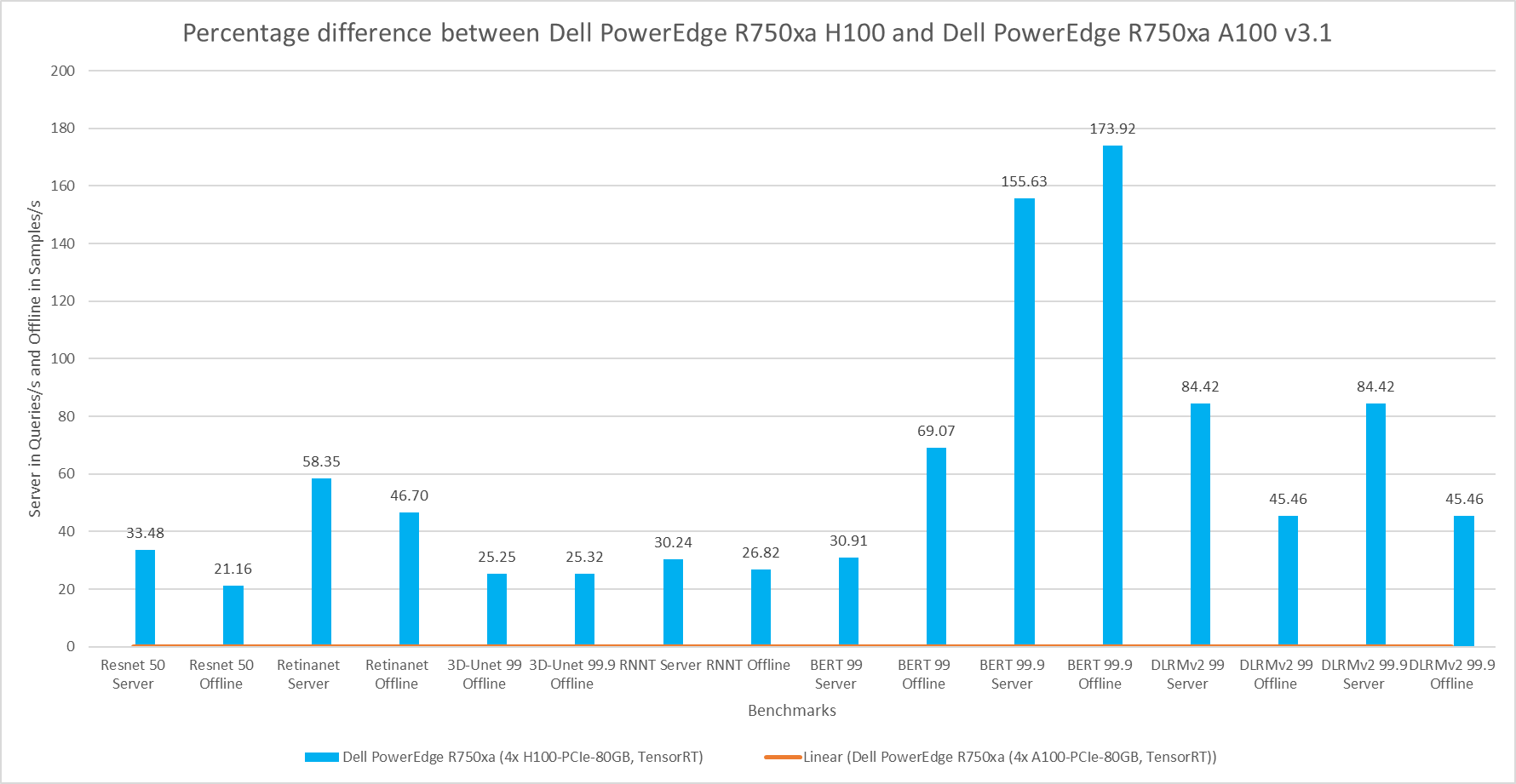
Figure 7: Percentage difference between the Dell PowerEdge R750xa H100 and Dell PowerEdge R750xa A100 for MLPerf Inference v3.1
The comparison shown in the following figure is an interesting comparison across two rounds of submissions. The hardware for the SUT is identical with the Dell PowerEdge R750xa server paired with the NVIDIA A100 GPU. The performance delta from this graph can be attributed to the changes in the software stack. For the vision tasks, RetinaNet and 3D-UNet, the NVIDIA H100 GPU showed a considerable improvement in performance. For the BERT Server scenario, the performance is approximately the same. However, for the BERT Offline scenario in both the default and high accuracy modes, there was a slight regression in performance. This result can be attributed to regressions in the BERT model.
Figure 8: Percentage difference between the Dell PowerEdge R750xa server with the NVIDIA A100 GPU v3.1 submission and the Dell PowerEdge R750xa server with the NVIDIA A100 GPU v3.0 submission
Conclusion
The MLPerf Inference submissions always elicit insightful comparisons. This blog highlighted these comparisons between the MLPerf Inference v3.1 and v3.0 rounds of submission:
- A generation-to-generation comparison of the Dell PowerEdge R760xa server and the Dell PowerEdge R750xa server while keeping the GPU constant on average boasts an impressive 6.22 percent performance improvement.
- An upgrade of the server as well as the GPU from the Dell PowerEdge R750xa server paired with the NVIDIA A100 GPU to the Dell PowerEdge R760xa server paired with the NVIDIA H100 GPU shows a noteworthy boost in performance. You can expect about an average of 71 percent increase in performance across benchmarks by upgrading both the server and the GPU.
- While maintaining the Dell PowerEdge R750xa server and upgrading the GPU from the NVIDIA A100 GPU to the NVIDIA H100 GPU, you can expect an approximate 60 percent increase in performance across benchmarks.
- While maintaining the same SUT across rounds with the Dell PowerEdge R750xa server and the NVIDIA A100 GPU, you can expect on average an 11.36 percent increase in improvement for RetinaNet, 3D-UNet, and RNNT tasks, thanks to software improvements. However, there are minor regressions in performance in the BERT benchmark.
Across the first three comparisons, a pattern of improvement in the Natural Language Processing task was noticeable. With the advent of new Large Language Models, the Dell PowerEdge server is positioned well to handle Generative AI workloads. For the last comparison, we kept the Dell PowerEdge R750xa server and NVIDIA A100 GPU consistent but looked at the performance across different rounds of submission.
MLCommons™ results
Note: We ran the RetinaNet Offline results for the Dell PowerEdge R760xa and Dell PowerEdge R750xa servers with the NVIDIA H100 GPU again after the submission with a larger GPU batch size. These results significantly improved the performance and are a true representation of Dell servers as we saw a 78 percent and 114 percent increase in performance on the PowerEdge R760xa server and PowerEdge R750xa servers respectively. For the Dell PowerEdge R760xa server with four NVIDIA H100 GPUs, the RetinaNet Offline results improved from 2069.79 to 4550.67. The RetinaNet Offline results for the system ID 3.1-0063 and 3.1-0065 submissions are not official due to MLCommons rules because they were rerun after the submission and not officially submitted before the deadline.
MLPerf Inference v3.1 and v3.0 system IDs:
- 3.1-0058, 3.1-0061 Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT)
- 3.1-0062 Dell PowerEdge R750xa (4x H100-PCIe-80GB, TensorRT)
- 3.1-0064 Dell PowerEdge R760xa (4x H100-PCIe-80GB, TensorRT)
- 3.0-0008 Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT)
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.

Code Llama – How Meta Can an Open Source Coding Assistant Get?

Tue, 26 Sep 2023 14:10:49 -0000
|Read Time: 0 minutes
Introduction
The past few years have been an exciting adventure in the field of AI, as increasingly sophisticated AI models continue to be developed to analyze and comprehend vast amounts of data. From predicting protein structures to charting the neural anatomy of a fruit fly to creating optimized math operations that accelerate supercomputers, AI has achieved impressive feats across varied disciplines. Large language models (LLMs) are no exception. Although producing human-like language garners attention, large language models were also created for code generation. By training on massive code datasets, these systems can write code by forecasting the next token in a sequence.
Companies like Google, Microsoft, OpenAI, and Anthropic are developing commercial LLMs for coding such as Codex, GitHub Copilot, and Claude. In contrast to closed systems, Meta has opened up its AI coding tool Code Llama, an AI coding assistant that aims to boost software developer productivity. It is released under a permissive license for both commercial and research use. Code Llama is an LLM capable of generating code and natural language descriptions of code from both code snippets and user-engineered prompts to automate repetitive coding tasks and enhance developer workflows. The open-source release allows the wider tech community to build upon Meta’s foundational model in natural language processing and code intelligence. For more information about the release, see Meta’s blog Introducing Code Llama, an AI Tool for Coding.
Code Llama is a promising new AI assistant for programmers. It can autocomplete code, search through codebases, summarize code, translate between languages, and even fix issues. This impressive range of functions makes Code Llama seem almost magical—like a programmer's dream come true! With coding assistants like Code Llama building applications could become far easier. Instead of writing every line of code, we may one day be able to describe what we want the program to do in a natural language prompt and the model can generate the necessary code for us. This workflow of the future could allow programmers to focus on the high-level logic and architecture of applications, without getting bogged down in implementation details.
Getting up and running with Code Llama was straightforward and fast. Meta released a 7 B, 13 B, and 34 B version of the model including instruction models that were trained with fill-in-the-middle (FIM) capability. This allows the models to insert into existing code, perform code completion, and accept natural language prompts. Using a Dell PowerEdge R740XD equipped with a single Nvidia A100 40GB GPU experimented with the smaller 7 billion parameter model, CodeLlama-Instruct-7 B. We used our Rattler Cluster in the HPC AI Innovation Lab to take advantage of PowerEdge XE8545 servers each equipped with four Nvidia A100 40 GB GPUs for the larger 34 billion parameter model (CodeLlama-Instruct-34 B). The examples provided by Meta were running a few minutes after downloading the model files and we began experimenting with natural language prompts to generate code. By engineering the prompts in a strategic manner, we aimed to produce the scaffolding for a web service wrapping the Code Llama model with an API that could be accessed over the web.
Accept user input from command line
The examples provided in example_instructions.py must be edited manually to add wanted user prompts. To make Code Llama a bit easier to use, we copied example_instructions.py into test_instructions.py and added the ability to send in a prompt from the command line.
The full file with changes:
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
from typing import Optional
import fire
from llama import Llama
def main(
ckpt_dir: str,
tokenizer_path: str,
content:str,
temperature: float = 0.2,
top_p: float = 0.95,
max_seq_len: int = 512,
max_batch_size: int = 8,
max_gen_len: Optional[int] = None,
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
instructions = [
[
{
"role": "user",
"content": content,
}
]
]
results = generator.chat_completion(
instructions, # type: ignore
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for instruction, result in zip(instructions, results):
for msg in instruction:
print(f"{msg['role'].capitalize()}: {msg['content']}\n")
print(
f"> {result['generation']['role'].capitalize()}: {result['generation']['content']}"
)
print("\n==================================\n")
if __name__ == "__main__":
fire.Fire(main)
It is possible to run the standard torchrun command with a --content option to pass in the prompt. Rather than evaluating the model on complex tasks, we started with simple coding challenges. To test the model, we designed a few experiments involving straightforward coding prompts posing basic programming problems. The manual process of directly prompting the model allows us to evaluate the strengths and weaknesses in generating code with this model.
Our first prompt: “Show an example of recursion in Python”
Command:
torchrun test_instructions.py \ --nproc_per_node 1 \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \ --max_seq_len 512 \ --max_batch_size 1 \ --content "Show an example of recursion in Python"
Output:
> Assistant: Sure! Here's an example of recursion in Python: ``` def factorial(n): if n == 0: return 1 else: return n * factorial(n-1) ``` In this example, the `factorial` function takes an integer `n` as input and returns its factorial. The function calls itself with the argument `n-1` until the base case is reached, where `n` is equal to 0. The base case returns 1, and the recursive calls return the factorial of `n-1`. The final result is the product of `n` and the factorial of `n-1`. Here's an example of how the function would work for different values of `n`: * `factorial(5)` would call `factorial(4)`, which would call `factorial(3)`, which would call `factorial(2)`, which would call `factorial(1)`, which would return 1. The final result would be 5! = 120. * `factorial(0)` would return 1. * `factorial(-1)` would raise a `ValueError` because negative numbers are not allowed. Recursion can be a powerful tool for solving problems that have a recursive structure, but it can also be difficult to understand and debug. It's important to use recursion judiciously and to make sure that it's the best approach for the problem you're trying to solve. ==================================
The model not only generates example code, but it also explains how the code works through examples. By providing both code snippets and clarifying descriptions, the model enables a deeper understanding of the functionality. Users can both see concrete implementations and learn the rationale behind them. Now that we have made it easier to provide a prompt to the model, let’s build an API endpoint by prompting Code Llama to build its own server.
Create An API endpoint for Code Llama
RESTful APIs are a popular way to build backend services that can be consumed by various applications over a network with tools such as curl. However, instead of manually coding this, we asked Code Llama to write the code for its own REST server.
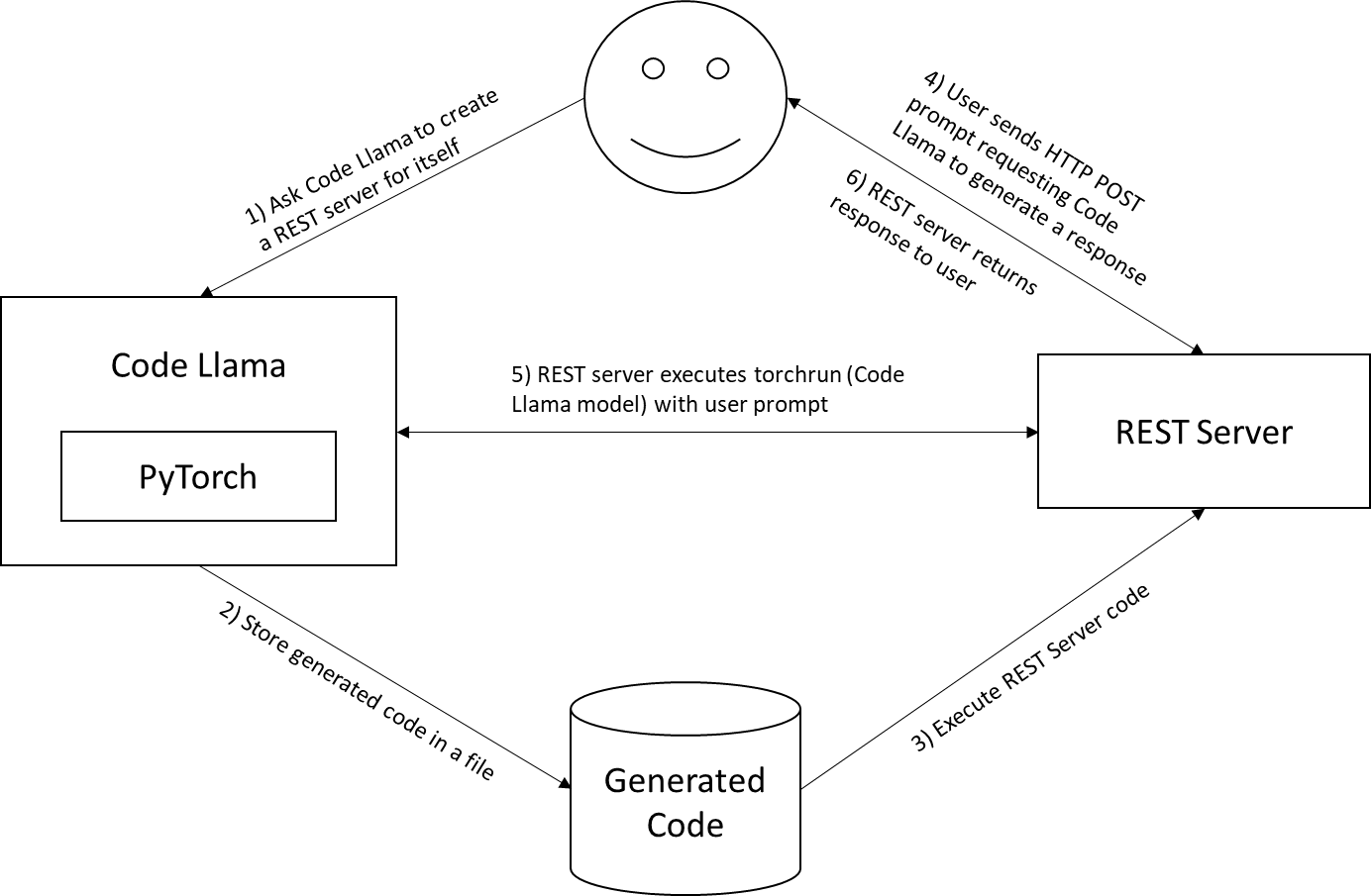
Our process for using Code Llama to produce a web service of itself:
- Step 1: Ask Code Llama to create a REST server for itself
- Step 2: Store the generated code in a file
- Step 3: Run the REST app on same GPU enabled server
- Step 4: Send prompts using HTTP POST requests to Code Llama service on the local host
- Step 5: REST server runs torchrun command with user prompt
- Step 6: REST server returns response to user
We needed to add some context to the prompt for Code Llama to generate the correct code, as the engineered prompt is a bit more complex and includes how to call torchrun with the correct parameters:
torchrun \ --nproc_per_node 1 \ test_instructions.py \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model\ --max_seq_len 512 \ --max_batch_size 1 \ --content "Create a REST server in Python with a POST /codellama URL, expect a JSON payload with a 'content' field, use a subprocess.run(['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content], stdout=subprocess.PIPE) and return stdout from subprocess.run"
All torchrun command line options, except for --content, are defined by Code Llama itself. Let’s break down what our engineered prompt is requesting:
- “Create a REST server in Python” – No framework was defined; Code Llama chose Flask
- “with a POST /codellama URL” – Expect to receive HTTP POSTS to the /codellama URL
- “expect a JSON payload with a ‘content’ field” – Expect a ‘content’ key in the POST JSON. This holds the user prompt.
- “use a subprocess.run(…)” – This is where we tell Code Llama how to call itself
- “return stdout from subprocess.run” – Return any text that Code Llama produces over HTTP
The resulting output:
> Assistant: Here is an example of how you can create a REST server in Python with a POST /codellama URL that expects a JSON payload with a 'content' field, and uses a subprocess.run command to run the torchrun command with the specified arguments:
```
import json
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route('/codellama', methods=['POST'])
def codellama():
if request.method == 'POST':
data = request.get_json()
content = data['content']
args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content]
result = subprocess.run(args, stdout=subprocess.PIPE)
return result.stdout
else:
return 'Invalid request'
if __name__ == '__main__':
app.run(debug=True)
```
This code defines a Flask application with a single route, '/codellama', that handles POST requests. The route expects a JSON payload with a 'content' field, and uses the subprocess.run command to run the torchrun command with the specified arguments. The result of the
==================================We clipped the Code Llama generated code and pasted it into server.py:
import json
import subprocess
from flask import Flask, request
app = Flask(__name__)
@app.route('/codellama', methods=['POST'])
def codellama():
if request.method == 'POST':
data = request.get_json()
content = data['content']
args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', content]
result = subprocess.run(args, stdout=subprocess.PIPE)
return result.stdout
else:
return 'Invalid request'
if __name__ == '__main__':
app.run(debug=True)After running the code:
python server.py
… the REST-like server will be running and waiting for commands.
Using curl, we can send commands over the network to Code Llama now:
curl -X POST -H "Content-Type: application/json" -d '{"content": " Show an example of recursion in Python"}' http://localhost:5000/codellama… and will receive a result like:
> Assistant: Sure! Here's an example of recursion in Python: ``` def factorial(n): if n == 0: return 1 else: return n * factorial(n-1) ``` In this example, the `factorial` function takes an integer `n` as input and returns its factorial. The function calls itself with the argument `n-1` until the base case is reached, where `n` is equal to 0. The base case returns 1, and the recursive calls return the factorial of `n-1`. The final result is the product of `n` and the factorial of `n-1`. Here's an example of how the function would work for different values of `n`: * `factorial(5)` would call `factorial(4)`, which would call `factorial(3)`, which would call `factorial(2)`, which would call `factorial(1)`, which would return 1. The final result would be 5! = 120. * `factorial(0)` would return 1. * `factorial(-1)` would raise a `ValueError` because negative numbers are not allowed Recursion can be a powerful tool for solving problems that have a recursive structure, but it can also be difficult to understand and debug. It's important to use recursion judiciously and to make sure that it's the best approach for the problem you're trying to solve. ==================================
Conclusion
The capabilities of AI and LLMs continue to rapidly evolve. What we find most compelling about an open source model like Code Llama is the potential for customization and data privacy. Unlike closed, proprietary models, companies can run Code Llama on their own servers and fine-tune it using internal code examples and data. This allows enforcement of coding styles and best practices while keeping code and data private. Rather than relying on external sources and APIs, teams can query a customized expert trained on their unique data in their own data center. Whatever your use cases, we found standing up an instance of Code Llama using Dell servers accelerated with Nvidia GPUs a simple and powerful solution that enables an exciting innovation for development teams and enterprises alike.
AI coding assistants such as Code Llama have the potential to transform software development in the future. By automating routine coding tasks, these tools could save developers significant time that can be better spent on higher-level system design and logic. With the ability to check for errors and inconsistencies, AI coders may also contribute to improved code quality and reduced technical debt. However, our experiments reaffirm that generative AI is still prone to limitations like producing low-quality or non-functional code. Now that we have a local API endpoint for Code Llama, we plan to conduct more thorough testing to further evaluate its capabilities and limitations. We encourage developers to try out Code Llama themselves using the resources we provided here. Getting experience with this open-sourced model is a great way to start exploring the possibilities of AI for code generation while contributing to its ongoing improvement.

NVIDIA Metropolis and DeepStream SDK: The Fast Lane to Vision AI Solutions
Mon, 16 Oct 2023 14:41:07 -0000
|Read Time: 0 minutes
What does it take to create an AI vision pipeline using modern tools on a Dell platform?
This blog describes how to implement object detection from a webcam video stream. The steps include:
- Install DeepStream software with a Docker container
- Process webcam Real Time Streaming Protocol (RTSP) output
- Detect objects (person, car, sign, bicycle) in each frame in near real time
- Draw bounding boxes with identifiers around the objects
- Stream the output using RTSP
NVIDIA Metropolis is an application framework with a set of developer tools that reside in a partner ecosystem. It features GPU-accelerated SDKs and tools to build, deploy, and scale AI-enabled video analytics and Internet of Things (IoT) applications optimally.
This blog focusses on NVIDIA DeepStream, which is one of the SDKs of the NVIDIA Metropolis stack. NVIDIA DeepStream SDK is a complete streaming analytics toolkit for AI-based multi-sensor processing, video, audio, and image understanding. Developers can use DeepStream SDK to create stream processing pipelines that incorporate neural networks and other complex processing tasks such as tracking, video encoding and decoding, IOT message brokers, and video rendering. DeepStream includes an open source Gstreamer project.
Metropolis-based components and solutions enable AI solutions that apply to a broad range of industries like manufacturing, retail, healthcare, and smart cities in the edge ecosystem.
The following figure shows the NVIDIA Metropolis framework:
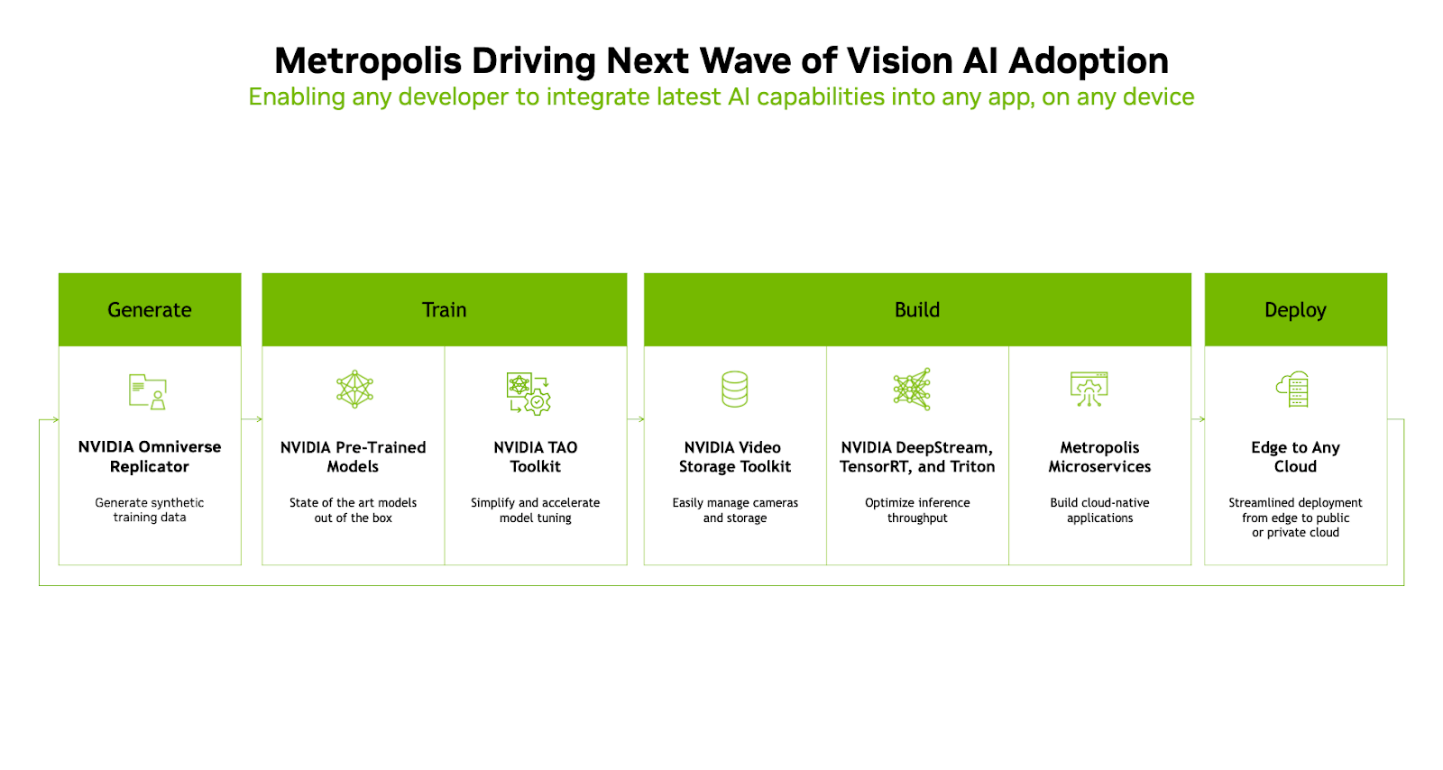
The NVIDIA Metropolis framework consists of the following stages:
Generate─The stage in which images, video streams, and data originate. The data can be real-time data or synthetic data generated by using Synthetic Data Generation (SDG) tools. NVIDIA tools like NVIDIA Omniverse Replicator fit into this stage of the pipeline.
Train─The stage that uses the data from the Generate stage to feed into pretrained models and enables accelerated model tuning. Models developed from standard AI frameworks like TensorFlow and PyTorch are used in this stage and integrate into the Metropolis framework workflow. The NVIDIA Train, Adapt, and Optimize (TAO) toolkit is a low-code AI model development SDK that helps tune the pretrained models.
Build─The stage of the pipeline in which the core functionality of the Vision AI pipeline is performed. The Build stage of the pipeline includes the NVIDIA video storage toolkit, DeepStream, TensorRT, Triton, and Metropolis Microservices. The libraries and functions in these SDK components provide capabilities such as video codec, streaming analytics, inference optimization, runtime libraries, and inference services.
Deploy─The stage that deploys containerized AI solutions into the production environment at the edge or cloud. The deployment of containerized AI solutions uses industry-standard container orchestration technologies such as Kubernetes and Docker.
Test setup
The test setup includes the following hardware:
- Dell PowerEdge R740xd server with an NVIDIA A100 GPU
- Dell PowerEdge R750 server with an NVIDIA A16 GPU
- A 1080p webcam capable of streaming RTSP output and supporting H.264
- Client or laptop with VLC Media Player for viewing results
Note: Two servers are not required. We ran the demo on both servers to test different configurations. This hardware was available in the lab; we recommend the latest hardware for the best performance.
The test setup includes the following software:
- Ubuntu 20.04 server
- NVIDIA CUDA Toolkit and drivers
- Docker runtime
The following figure shows an example configuration:
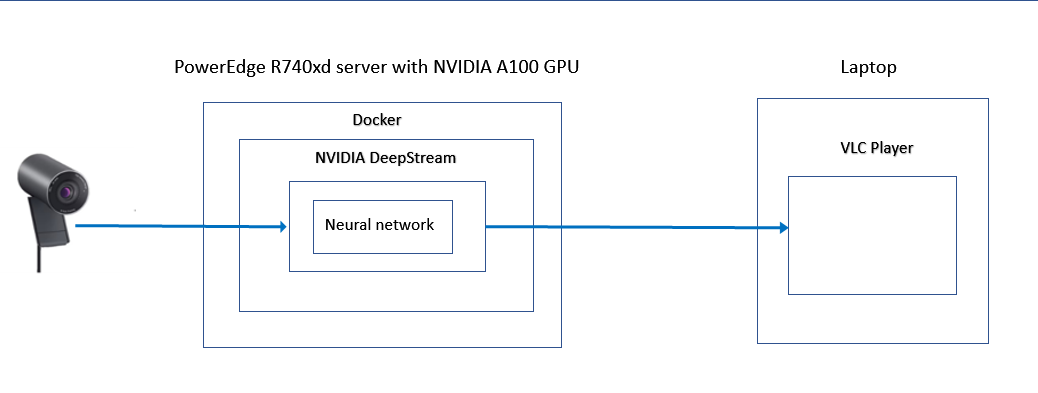
Install NVIDIA CUDA
Enabling the CUDA toolkit on top of the base Ubuntu Linux operating system provides the necessary drivers and tools required to access the NVIDIA GPUs.
The requirements for the CUDA toolkit installation include:
- A CUDA-capable GPU on the platform running the base Linux operating system
- A supported version of the GCC compiler and toolchain on the Linux operating system
- The CUDA Toolkit
- Install the GCC compiler and other developer tool chains and libraries:
ssudo apt-get update ssudo apt-get install build-essential
- Verify that the installation is successful:
gcc --version
- Install the NVIDIA GPU CUDA toolkit and NVIDIA Container Toolkit:
sudo sh NVIDIA-Linux-x86_64-515.76.run
Note: For the PowerEdge system with an NVIDIA A16 GPU, the latest version of CUDA toolkit 12.2 did not function properly. After the installation, the nvidia-smi tool was unable to identify the GPU and activate the driver. Therefore, we chose an earlier version of the runfile (local installer) to install the CUDA toolkit package. We used CUDA Version 11.7 with driver version 515.76. The file used is NVIDIA-Linux-x86_64-515.76.run. - After installing the CUDA toolkit, see the nvidia-smi output for details about the GPU on the system:
nvidia-smi
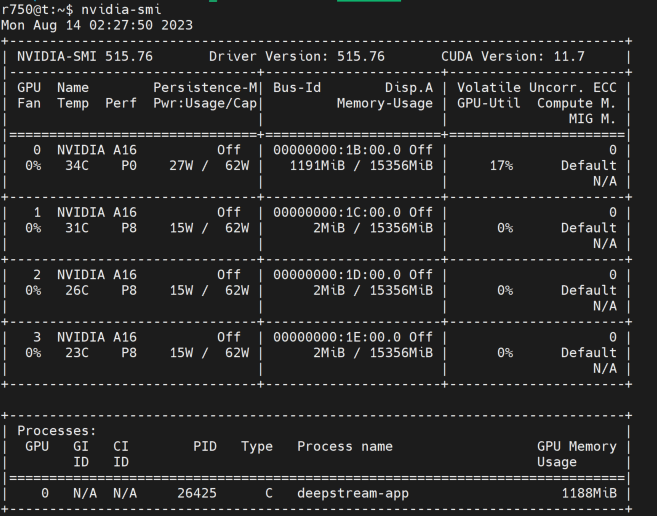
Install Docker Runtime
The following steps describe how to enable a Docker container runtime on top of the base operating system and enabling access to the GPUs from the container environment. With the release of Docker 19.03 and later, nvidia-docker2 packages are no longer required to access the NVIDIA GPUs from the Docker container environment as they are natively supported in Docker runtime.
Perform these steps in Ubuntu 20.04:
- Update the apt package index and allow Advanced Packaging Tool (APT) to use a repository over HTTPS:
sudo apt-get update ssudo apt-get install ca-certificates curl gnupg
- Add Docker's official GPG key:
sudo install -m 0755 -d /etc/apt/keyrings curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg sudo chmod a+r /etc/apt/keyrings/docker.gpg
- Set up the repository:
sudo echo\ "deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \ "$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
- Update the apt package index:
sudo apt-get update
- Install the latest version of the Docker engine:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
- Verify that Docker is installed:
sudo docker run hello-world
After the Docker engine is installed, install the NVIDIA Container Toolkit and enable the NVIDIA runtime to Docker runtime. This step makes the GPUs detectable to the Docker containers.
- Set up the package repository and the GPG key:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
After installing the repository sources, perform the following steps:
- Update the repository list:
sudo apt-get update
- Install the NVIDIA Container Toolkit:
sudo apt-get install -y nvidia-container-toolkit
- Configure the Docker daemon to recognize the NVIDIA Container Runtime:
sudo nvidia-ctk runtime configure --runtime=docker
- Set the default runtime and then restart the Docker daemon to complete the installation:
sudo systemctl restart docker
- Verify that the GPUs are visible from inside a container:
sudo docker run –rm –runtime=nvidia –gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
The following figure shows the NVIDIA SMI output: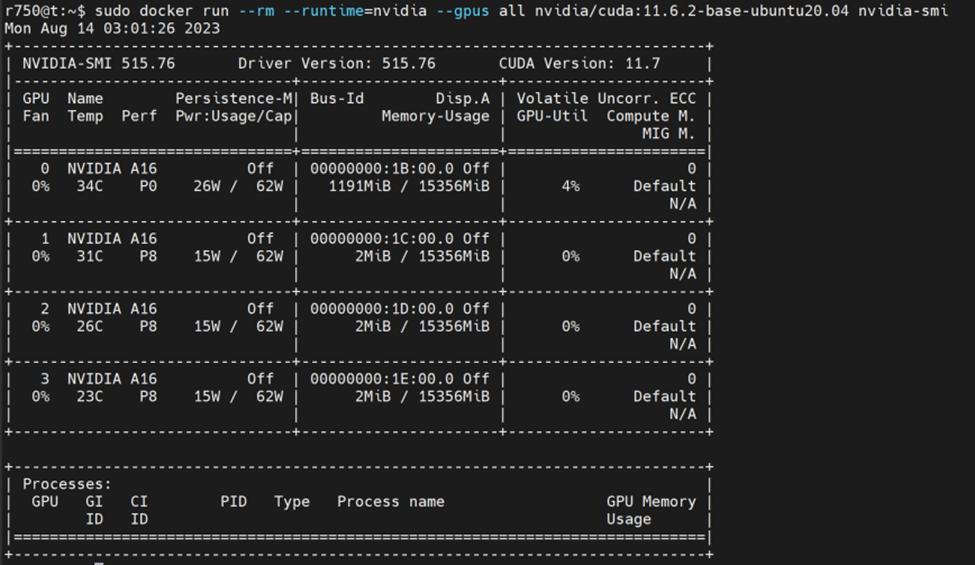
Run the DeepStream Docker Container
To run the DeepStream Docker Container, perform the following steps:
- Obtain the DeepStream docker container:
sudo docker pull nvcr.io/nvidia/deepstream:6.2-devel
At the time of this blog, the latest version is v6.2. Because the container is large, we recommend that you pull it down first before using it. It takes a few minutes to fully download all the container layers. - When the container is fully downloaded, run:
sudo docker run --gpus all -it --rm -p 8554:8554 nvcr.io/nvidia/deepstream:6.2-devel
This command instructs Docker to use any GPU it detects, run interactively, delete itself at termination, and open port 8554 for the RTSP output stream.
When the command runs, the following output indicates that the Docker container is accessible and in interactive mode:root@9cfa2cfeb11b:/opt/nvidia/deepstream/deepstream-6.2#
Configure DeepStream inside a Docker Container
In the Docker container, make configuration changes so that the demo runs properly.
- Install the required dependencies:
/opt/nvidia/deepstream/deepstream/user_additional_install.sh
The resulting output is long. The following example shows the beginning of the output of a successful installation:Get:1 file:/var/nv-tensorrt-local-repo-ubuntu2004-8.5.2-cuda-11.8 InRelease [1575 B] Get:1 file:/var/nv-tensorrt-local-repo-ubuntu2004-8.5.2-cuda-11.8 InRelease [1575 B] Hit:2 http://archive.ubuntu.com/ubuntu focal InRelease
The following example shows the end of the output of a successful installation:Setting up libavfilter7:amd64 (7:4.2.7-0ubuntu0.1) ... Setting up libavresample-dev:amd64 (7:4.2.7-0ubuntu0.1) ... Processing triggers for libc-bin (2.31-0ubuntu9.9) ...
When we did not perform this step and tried to run the demo, we received the following error message, which is a common error reported on message boards:(gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:29.078: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/libgstchromaprint.so': libavcodec.so.58: cannot open shared object file: No such file or directory (gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:29.110: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/libgstmpeg2dec.so': libmpeg2.so.0: cannot open shared object file: No such file or directory (gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:29.111: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/libgstmpeg2enc.so': libmpeg2encpp-2.1.so.0: cannot open shared object file: No such file or directory (gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:29.112: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/libgstmpg123.so': libmpg123.so.0: cannot open shared object file: No such file or directory (gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:29.117: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/libgstopenmpt.so': libmpg123.so.0: cannot open shared object file: No such file or directory (gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:31.675: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/deepstream/libnvdsgst_inferserver.so': libtritonserver.so: cannot open shared object file: No such file or directory (gst-plugin-scanner:12): GStreamer-WARNING **: 18:35:31.699: Failed to load plugin '/usr/lib/x86_64-linux-gnu/gstreamer-1.0/deepstream/libnvdsgst_udp.so': librivermax.so.0: cannot open shared object file: No such file or directory ** ERROR: <create_udpsink_bin:644>: Failed to create 'sink_sub_bin_encoder1' ** ERROR: <create_udpsink_bin:719>: create_udpsink_bin failed ** ERROR: <create_sink_bin:828>: create_sink_bin failed ** ERROR: <create_processing_instance:884>: create_processing_instance failed ** ERROR: <create_pipeline:1485>: create_pipeline failed ** ERROR: <main:697>: Failed to create pipeline Quitting App run failed
- Change directories and edit the configuration file:
cd samples vim configs/deepstream-app/source30_1080p_dec_infer-resnet_tiled_display_int8.txt
- Find the following entries:
[tiled-display] enable=1
- Change enable=1 to enable=0.
A nontiled display makes it easier to compare the before and after webcam video streams. - Find the following entries:
[source0] enable=1 #Type - 1=CameraV4L2 2=URI 3=MultiURI 4=RTSP type=3 uri=file://../../streams/sample_1080p_h264.mp4
- Change:
• type=3 to type=4
• uri to uri=rtsp://192.168.10.210:554/s0
Note: This URI is to the webcam that is streaming output. - Find the following entries:|
[source1] enable=1
- Change enable=1 to enable=0.
- Find the following entries:
[sink0] enable=1
- Change enable=1 to enable=0.
- Find the following entries:
[sink2] enable=0 #Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming type=4 #1=h264 2=h265 codec=1 #encoder type 0=Hardware 1=Software enc-type=0 - Change:
• enable=0 to enable=1
•enc-type=0 to enc-type=1
Note: The enc-type=1 entry changes the configuration to use software encoders instead of the hardware. We changed the entry because our demo system has an NVIDIA A100 GPU that has no hardware encoders. Ideally, keep this entry as enc-type=0 if hardware encoders are available. With the NVIDIA A16 GPU, we used enc-type=0 entry. The Video Encode and Decode GPU Support Matrix at https://developer.nvidia.com/video-encode-and-decode-gpu-support-matrix-new shows the GPU hardware and encoder support.
If you do not change the enc-type=1 entry (software encoder), the following error message might be displayed:ERROR from sink_sub_bin_encoder1: Could not get/set settings from/on resource. Debug info: gstv4l2object.c(3511): gst_v4l2_object_set_format_full (): /GstPipeline:pipeline/GstBin:processing_bin_0/GstBin:sink_bin/GstBin:sink_sub_bin1/nvv4l2h264enc:sink_sub_bin_encoder1: Device is in streaming mode - Save the file and exit the editor.
Running the Demo
To run the demo:
- In the container, start DeepStream to run with the new configuration. This command must be on one line.
deepstream-app -c configs/deepstream-app/source30_1080p_dec_infer-resnet_tiled_display_int8.txt
- Find the following text in the warning messages that are displayed:
*** DeepStream: Launched RTSP Streaming at rtsp://localhost:8554/ds-test ***
Even though the message indicates that DeepStream is bound to localhost, it is accessible remotely due to the Docker port command that was used earlier.
After more text and warning messages are displayed, the following output indicates that the software has started and is processing video input from the webcam:Runtime commands: h: Print this help q: Quit p: Pause r: Resume **PERF: FPS 0 (Avg) **PERF: 0.00 (0.00) ** INFO: <bus_callback:239>: Pipeline ready ** ERROR: <cb_newpad3:510>: Failed to link depay loader to rtsp src ** INFO: <bus_callback:225>: Pipeline running **PERF: 30.89 (30.89) **PERF: 30.00 (30.43) **PERF: 30.00 (30.28)
Viewing the Demo
To view the demo:
- On a laptop, start the media player. We use VLC media player.
- Click Media, and then in the dropdown list, select Open Network Stream… , as shown in the following figure:
- Enter the IP address of the Linux system on which the container is running.
Note: The IP address in the following figure is an example. Use the appropriate IP address of your deployment. - Click Play.
In a few seconds, the webcam streams video that identifies objects with bounding boxes applied in near real time. This demo detects people, cars, signs, and bicycles.
The following figure is an example that shows the video output of recognized objects:

Note: The model is not trained to detect animals and correctly detects people and cars.
Summary
In this blog, we reviewed the Metropolis DeepStream hardware configuration test setup, the software installation steps, and how to use DeepStream to create a common vision AI pipeline with a Dell server. We included detailed instructions so that you can gain a deeper understanding of the configuration and ease of use.
We hope you enjoyed following our DeepStream journey.
Check back regularly for upcoming AI blogs. From Dell data center servers to rugged edge devices, Dell Technologies provides optimized solutions for running your AI workloads.

MLPerf™ Inference v3.1 Edge Workloads Powered by Dell PowerEdge Servers
Tue, 19 Sep 2023 12:07:00 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v3.1 benchmark suite. This blog examines the results on the Dell PowerEdge XR4520c, PowerEdge XR7620, and PowerEdge XR5610 servers with the NVIDIA L4 GPU.
MLPerf Inference background
The MLPerf Inference benchmarking suite is a comprehensive framework designed to fairly evaluate the performance of a wide range of machine learning inference tasks on various hardware and software configurations. The MLCommonsTM community aims to provide a standardized set of deep learning workloads with which to work and as fair measuring and auditing methodologies. The MLPerf Inference submission results serve as valuable information for researchers, customers, and partners to make informed decisions about inference capabilities on various edge and data center systems.
The MLPerf Inference edge suite includes three scenarios:
- Single-stream—This scenario’s performance metric is 90 percent latency. A common use case is the Siri voice assistant on iOS products on which Siri’s engine waits until the query has been asked and then returns results.
- Multi-stream—This scenario has a higher performance metric with a 99 percent latency. An example use case is self-driving cars. Self-driving cars use multiple cameras and lidar inputs to real-time driving decisions that have a direct impact on what happens on the road.
- Offline—This scenario is measured by throughput. An example of Offline processing on the edge is a phone sharing an album suggestion that is based on a recent set of photos and videos from a particular event.
Edge computing
In traditional cloud computing at the data center, data from phones, tablets, sensors, and machines are sent to physically distant data centers to be processed. The location of where the data has been gathered and where it is processed are separate. The concept of edge computing shifts this methodology by processing data on the device itself or on local compute resources that are available nearby. The available compute resources nearby are known as the “devices on the edge.” Edge computing is prevalent in several industries such as self-driving cars, retail analytics, truck fleet management, smart grid energy distribution, healthcare, and manufacturing.
Edge computing complements traditional cloud computing by reducing processing speed in terms of lowering latency, improving efficiency, enhancing security, and enabling higher reliability. By processing data on the edge, the load on central data centers is eased as is the time to receive a response for any type of inference queries. With the offloading of computation in data centers, network congestion for cloud users becomes less of a concern. Also, because sensitive data is processed at the edge and is not exposed to threats across a wider network, the risk of sensitive data being compromised is less. Furthermore, if connectivity to the cloud is disrupted and is intermittent, edge computing can enable systems to continue functioning. With several devices on the edge acting as computational minidata centers, the problem of a single point of failure is mitigated and additional scalability becomes easily achievable.
Dell PowerEdge system and GPU overview
Dell PowerEdge XR4520c server
For projects that need a robust and adaptable server to handle demanding AI workloads on the edge, the PowerEdge XR4520c server is an excellent option. Dell Technologies designed the PowerEdge XR4520c server with reliability to withstand challenging edge environments. The PowerEdge XR4520c server delivers the power and compute required for real-time analytics on the edge with Intel Xeon Scalable processors. The edge-optimized design decisions include a rugged exterior and an extended temperature range to operate in remote locations and industrial environments. Also, the compact form factor and space-efficient design enable deployment on the edge. Like all Dell PowerEdge products, this server comes with world class Dell support and Dell’s (Integrated Dell Remote Access Controller (iDRAC) for remote management. For additional information about the technical specifications of the PowerEdge XR4520c server, see to the specification sheet.

Figure 1: Front view of the Dell PowerEdge XR4520c server

Figure 2: Top view of the Dell PowerEdge XR4520c server
Dell PowerEdge XR7620 server
The PowerEdge XR7620 server is top-of-the-line for deep learning in the edge. Powered with the latest Intel Xeon Scalable processors, the reduced training time and additional number of inferences is remarkable on the PowerEdge XR7620 server. Dell Technologies has designed this as a half-width server for rugged environments with a dust and particle filter and extended temperature range from –5C to 55C (23 F to 131 F). Furthermore, Dell’s comprehensive security and data protection features include data encryption and zero-trust logic for the protection of sensitive data. For additional information about the technical specifications of the PowerEdge XR7620 server, see the specification sheet.

Figure 3: Front view of the Dell PowerEdge XR7620 server

Figure 4: Rear view of the Dell PowerEdge XR7620 server
Dell PowerEdge XR5610 server
The Dell PowerEdge XR5610 server is an excellent option for AI workloads on the edge. This all-pupose, rugged single-socket server is a versatile edge server that has been built for telecom, defense, retail and other demanding edge environments. As shown in the following figures, the short chassis can fit in space-constrained environments and is also a formidable option when considering power efficiency. This server is driven by Intel Xeon Scalable processors and is boosted with NVIDIA GPUs as well as high-speed NVIDIA NVLink interconnects. For additional information about the technical specifications of the PowerEdge XR5610 server, see the specification sheet.

Figure 5: Front view of the Dell PowerEdge XR5610 server

Figure 6: Top view of the Dell PowerEdge XR5610 server
NVIDIA L4 GPU
The NVIDIA L4 GPU is an excellent strategic option for the edge as it consumes less energy and space but delivers exceptional performance. The NVIDIA L4 GPU is based on the Ada Lovelace architecture and delivers extraordinary performance for video, AI, graphics, and virtualization. The NVIDIA L4 GPU comes with NVIDIA’s cutting-edge AI software stack including CUDA, cuDNN, and support for several deep learning frameworks like Tensorflow and PyTorch.
Systems Under Test
The following table lists the Systems Under Test (SUT) that are described in this blog.
Table 1: MLPerf Inference v3.1 system configuration of the Dell PowerEdge XR7620 and the PowerEdge XR4520c servers
Platform | Dell PowerEdge XR7620 (1x L4, TensorRT) | Dell PowerEdge XR4520c (1x L4, TensorRT) |
MLPerf system ID | XR7620_L4x1_TRT | XR4520c_L4x1_TRT |
Operating system | CentOS 8 | Ubuntu 22.04 |
CPU | Dual Intel Xeon Gold 6448Y CPU @ 2.10 GHz | Single Intel Xeon D-2776NT CPU @ 2.10 |
Memory | 256 GB | 128 GB |
GPU | NVIDIA L4 | |
GPU count | 1 | |
Software stack | TensorRT 9.0.0 CUDA 12.2 cuDNN 8.8.0 Driver 535.54.03 DALI 1.28.0 | TensorRT 9.0.0 CUDA 12.2 cuDNN 8.9.2 Driver 525.105.17 DALI 1.28.0
|
Performance from Inference v3.1
The following figure compares the Dell PowerEdge XR4520c and PowerEdge XR7620 servers across the ResNet50, RetinaNet, RNNT and BERT 99 Single-stream, Multi-stream, and Offline benchmarks. Across all the benchmarks in this comparison, we can state that the performance in the image classification, object detection, speech to text and language processing workloads packaged with NVIDIA L4 GPUs for both servers provide exceptional performance.
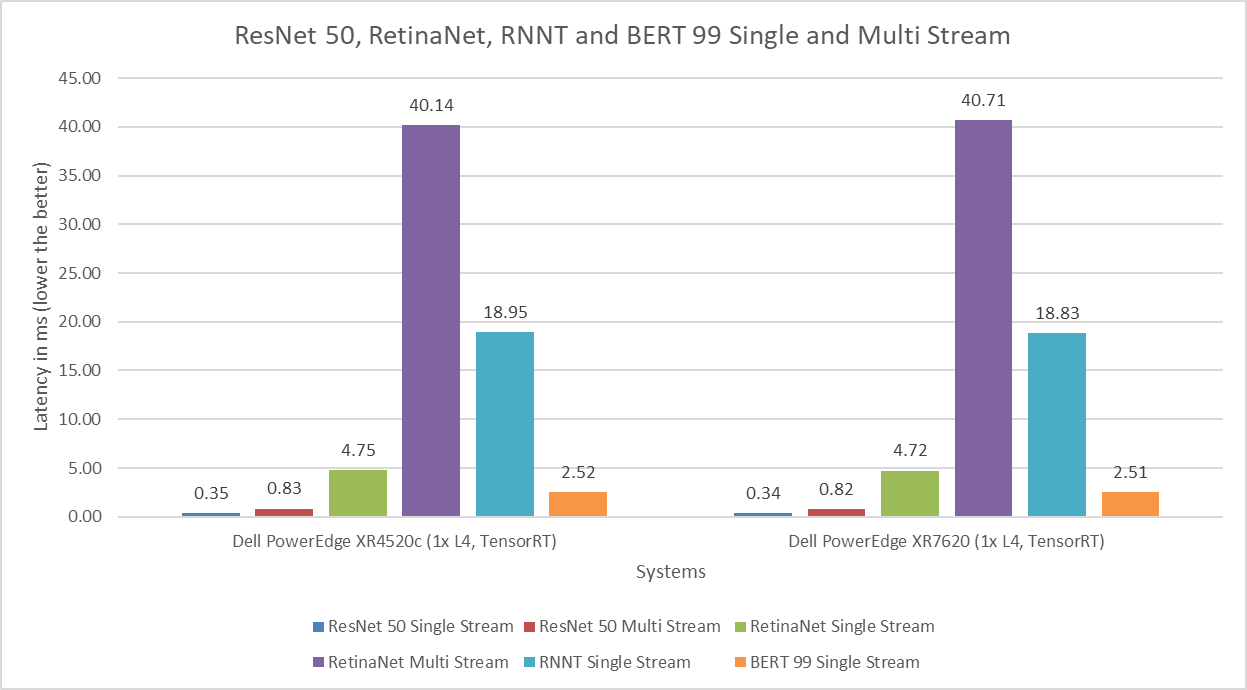
Figure 7: Dell PowerEdge XR4520c and PowerEdge XR7620 servers across the ResNet50, RetinaNet, RNNT, and BERT 99 Single and Multi-stream benchmarks
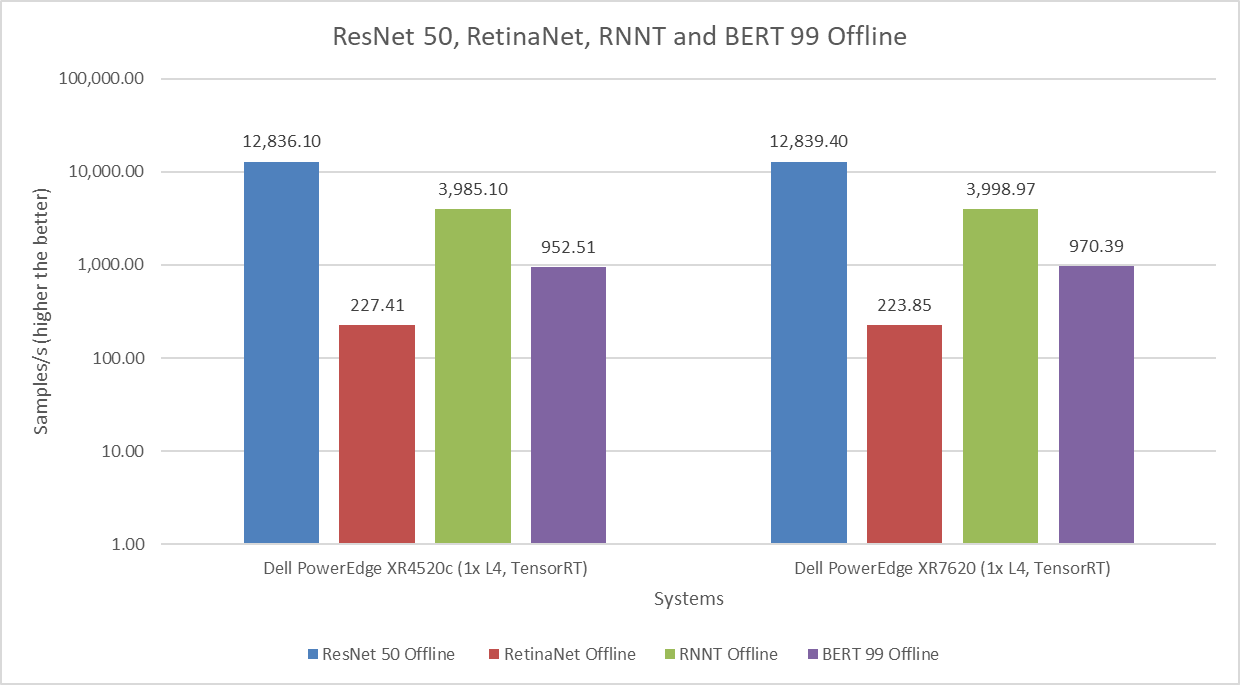
Figure 8: Dell PowerEdge XR4520c and PowerEdge XR7620 servers across the ResNet50, RetinaNet, RNNT, and BERT 99 Offline benchmarks
Like ResNet50 and RetinaNet, the 3D-Unet benchmark falls under the vision area but focuses on the medical image segmentation task. The following figures show identical performance of the two servers in both the default and high accuracy modes in the Single-stream and Offline scenarios.
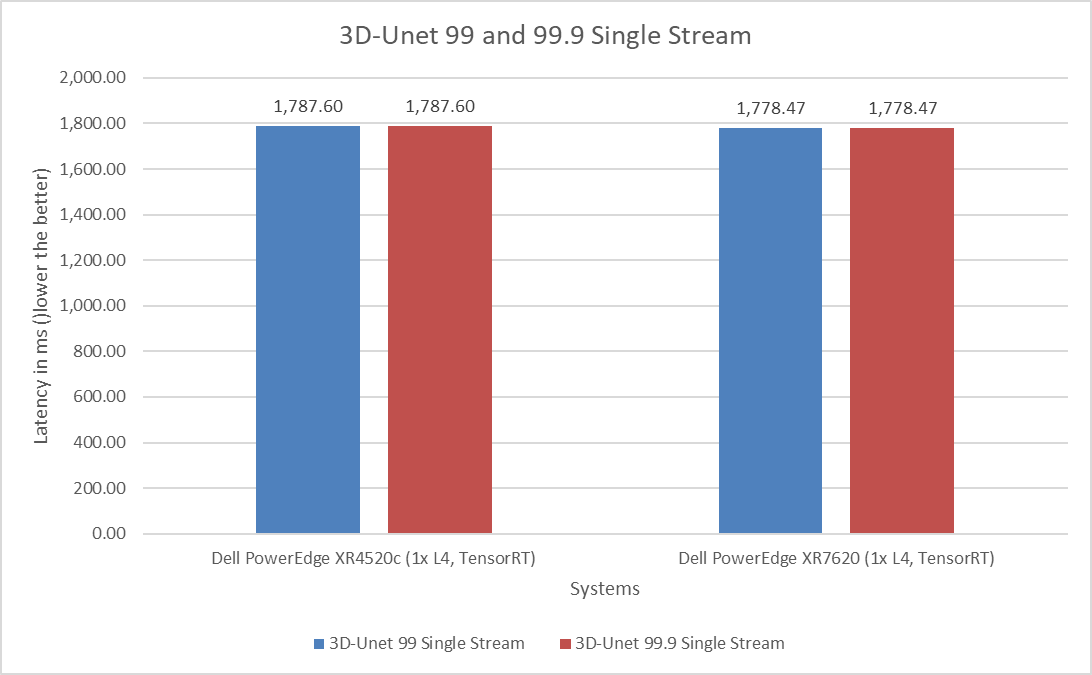
Figure 9: Dell PowerEdge XR4520c and PowerEdge XR7620 servers across 3D-Unet Single-stream
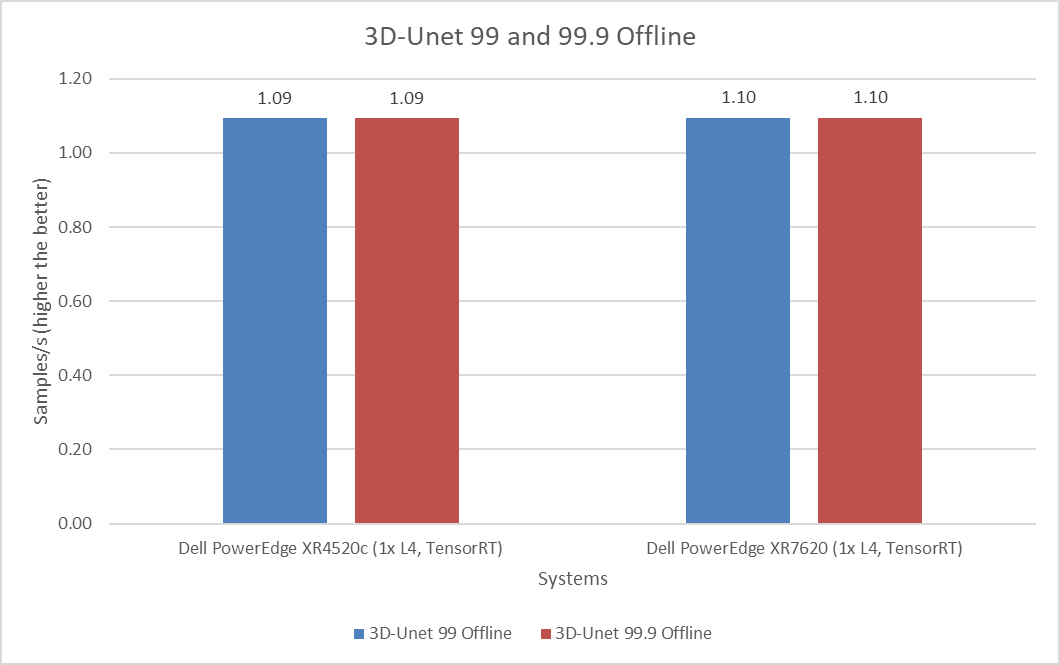
Figure 10: Dell PowerEdge XR4520c and PowerEdge XR7620 server across 3D-Unet Offline
Dell PowerEdge XR5610 power submission
In the MLPerf Inference v3.0 round of submissions, Dell Technologies made a power submission under the preview category for the Dell PowerEdge XR5610 server with the NVIDIA L4 GPU. For the v3.1 round of submissions, Dell Technologies made another power submission for the same server in the closed edge category. As shown in the following table, the detailed configurations of both the systems across the rounds of submissions show that the hardware remained consistent, but that the software stack was updated. In terms of system performance per watt, the PowerEdge XR 5610 server claims the top spot in image classification, object detection, speech-to-text, language processing, and medical image segmentation workloads.
Table 2: MLPerf Inference v3.0 and v3.1 system configuration of the Dell PowerEdge XR5610 server
Platform | Dell PowerEdge XR5610 (1x L4, MaxQ, TensorRT) v3.0 | Dell PowerEdge XR5610 (1x L4, MaxQ, TensorRT) v3.1 |
MLPerf system ID | XR5610_L4x1_TRT_MaxQ | XR5610_L4x1_TRT_MaxQ |
Operating system | CentOS 8.2 | |
CPU | Intel(R) Xeon(R) Gold 5423N CPU @ 2.10 GHz | |
Memory | 256 GB | |
GPU | NVIDIA L4 | |
GPU count | 1 | |
Software stack | TensorRT 8.6.0 CUDA 12.0 cuDNN 8.8.0 Driver 515.65.01 DALI 1.17.0 | TensorRT 9.0.0 CUDA 12.2 cuDNN 8.9.2 Driver 525.105.17 DALI 1.28.0
|
The power submission includes extra power results in each submission. For each submitted benchmark, there is a power metric that is paired with it. The metric for the Single-stream and Multi-stream performance results is Latency in milliseconds and the corresponding power consumption is noted in millijoules (mj). The Offline performance numbers are recorded in samples per second(samples/s), and the corresponding power readings are delivered in watts. The following table shows a breakdown for the calculations for queries per millijoules and samples/s per watt have been calculated.
Table 3: Breakdown of reading a power submission
Scenario | Performance metric | Power metric | Performance per unit of energy |
Single Stream | Latency (ms) | Millijoules (mj) | 1 query/mj -> queries/mj |
Multi Stream | Latency (ms) | Millijoules (mj) | 8 queries/mj -> queries/mj |
Offline | Samples/s | Watts | Samples/s / Watts -> performance per Watt |
The following figure shows the improvements in the performance per energy used on the Dell PowerEdge XR5610 server across the v3.1 and v3.0 rounds of submission. Across all the benchmarks, the server extracted double the performance per energy. For the RNNT Single-stream benchmark, the servers showed a brilliant performance jump of close to five times greater. The performance improvements came from hardware and software optimizations. Also, BIOS firmware upgrades also contributed significantly.
Figure 11: Dell PowerEdge XR5610 with NVIDIA L4 GPU power submission for v3.1 compared to v3.0
The following figure shows the Single-stream and Multi-stream latency results from the Dell PowerEdge XR5610 server:
Figure 12: Dell PowerEdge XR5610 NVIDIA L4 GPU L4 v3.1 server
Conclusion
Both the Dell PowerEdge XR4520c and Dell PowerEdge XR7620 servers continue to showcase excellent performance in the edge suite for MLPerf Inference. The Dell PowerEdge XR5610 server showed a consistent doubling in performance per energy across all benchmarks confirming itself as a power efficient server option. Built for the edge, the Dell PowerEdge XR portfolio proves to be an outstanding option with consistent performance in the MLPerf Inference v3.1 submission. As the need for edge computing continues to grow, the MLPerf Inference edge suite shows that Dell PowerEdge servers continue to be an excellent option for any Artificial Intelligence workload.
MLCommons results
https://mlcommons.org/en/inference-edge-31/
MLPerf Inference v3.1 system IDs:
- 3.1-0072 - Dell PowerEdge XR4520c (1x L4, TensorRT)
- 3.1-0073 - Dell PowerEdge XR5610 (1x L4, MaxQ, TensorRT)
- 3.1-0074 - Dell PowerEdge XR7620 (1x L4, TensorRT)
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Dell PowerEdge Servers deliver excellent performance with MLCommons™ Inference 3.1
Mon, 11 Sep 2023 13:18:00 -0000
|Read Time: 0 minutes
Today, MLCommons released the latest version (v3.1) of MLPerf Inference results. Dell Technologies has made submissions to the inference benchmark since its version 0.5 launch in 2019. We continue to demonstrate outstanding results across different models in the benchmark such as image classification, object detection, natural language processing, speech recognition, recommender system and medical image segmentation, and LLM summarization. See our MLPerf™ Inference v2.1 with NVIDIA GPU-Based Benchmarks on Dell PowerEdge Servers white paper that introduces the MLCommons Inference benchmark. Generative AI (GenAI) has taken deep learning computing needs by storm and there is an ever-increasing need to enable high-performance innovative inferencing approaches. This blog provides an overview of the performance summaries that Dell PowerEdge servers enable end users to deliver on their AI Inference transformation.
What is new with Inference 3.1?
Inference 3.1 and Dell’s submission include the following:
- The inference benchmark has added two exciting new benchmarks:
- LLM-based models, such as GPT-J
- DLRM-V2 with multi-hot encodings using the DLRM-DCNv2 architecture
- Dell’s submission has been expanded to include the new PowerEdge XE8640 and PowerEdge XE9640 servers accelerated by NVIDIA GPUs.
- Dell’s submission includes results of PowerEdge servers with Qualcomm accelerators.
- Besides accelerator-based results, Dell’s submission includes Intel-based CPU-only results.
Overview of results
Dell Technologies submitted 230 results across 20 different configurations. The most impressive results were generated by PowerEdge XE9680, XE9640, XE8640, R760xa, and servers with the new NVIDIA H100 PCIe and SXM Tensor Core GPUs, PowerEdge XR7620 and XR5610 servers with the NVIDIA L4 Tensor Core GPUs, and the PowerEdge R760xa server with the NVIDIA L40 GPU.
Overall, NVIDIA-based results include the following accelerators:
- (New) Four-way NVIDIA H100 Tensor Core GPU (SXM)
- (New) Four-way NVIDIA L40 GPU
- Eight-way NVIDIA H100 Tensor Core GPU (SXM)
- Four-way NVIDIA A100 Tensor Core GPU (PCIe)
- NVIDIA L4 Tensor Core GPU
These accelerators were benchmarked on different servers such as PowerEdge XE9680, XE8640, XE9640, R760xa, XR7620, XR5610, and R750xa servers across data center and edge suites.
The large number of result choices offers end users an opportunity to make system purchase decisions and set performance and design expectations.
Interesting Dell Datapoints
The most interesting datapoints include:
- The performance numbers on newly released Dell PowerEdge servers are outstanding.
- Among 21 submitters, Dell Technologies was one of the few companies that covered all benchmarks in all closed divisions for data center, edge, and edge power suites.
- The PowerEdge XE9680 system with eight NVIDIA H100 SXM GPUs procures the highest performance titles with ResNet Server, RetinaNet Server, RNNT Server and Offline, BERT 99 Server, BERT 99.9 Offline, DLRM-DCNv2 99, and DLRM-DNCv2 99.9 Offline benchmarks.
- The PowerEdge XE8640 system with four NVIDIA H100 SXM GPUs procures the highest performance titles with all the data center suite benchmarks.
- The PowerEdge XE9640 system with four NVIDIA H100 SXM GPUs procures the highest performance titles for all systems among other liquid cooled systems for all data center suite benchmarks.
- The PowerEdge XR5610 system with an NVIDIA L4 Tensor Core GPU offers approximately two- to three-times higher performance/watt compared to the last round and procures the highest power efficiency titles with Resnet RetinaNet 3d-unet 99, 3D U-Net 99.9 and Bert-99.
Highlights
The following figure shows the different system performance for offline and server scenarios in the data center. These results provide an overview; future blogs will provide more details about the results.
The figure shows that these servers delivered excellent performance for all models in the benchmark such as ResNet, RetinaNet, 3D-U-Net, RNN-T, BERT, DLRM-v2, and GPT-J. It is important to recognize that different benchmarks operate on varied scales. They have all been showcased in the following figures to offer a comprehensive overview.
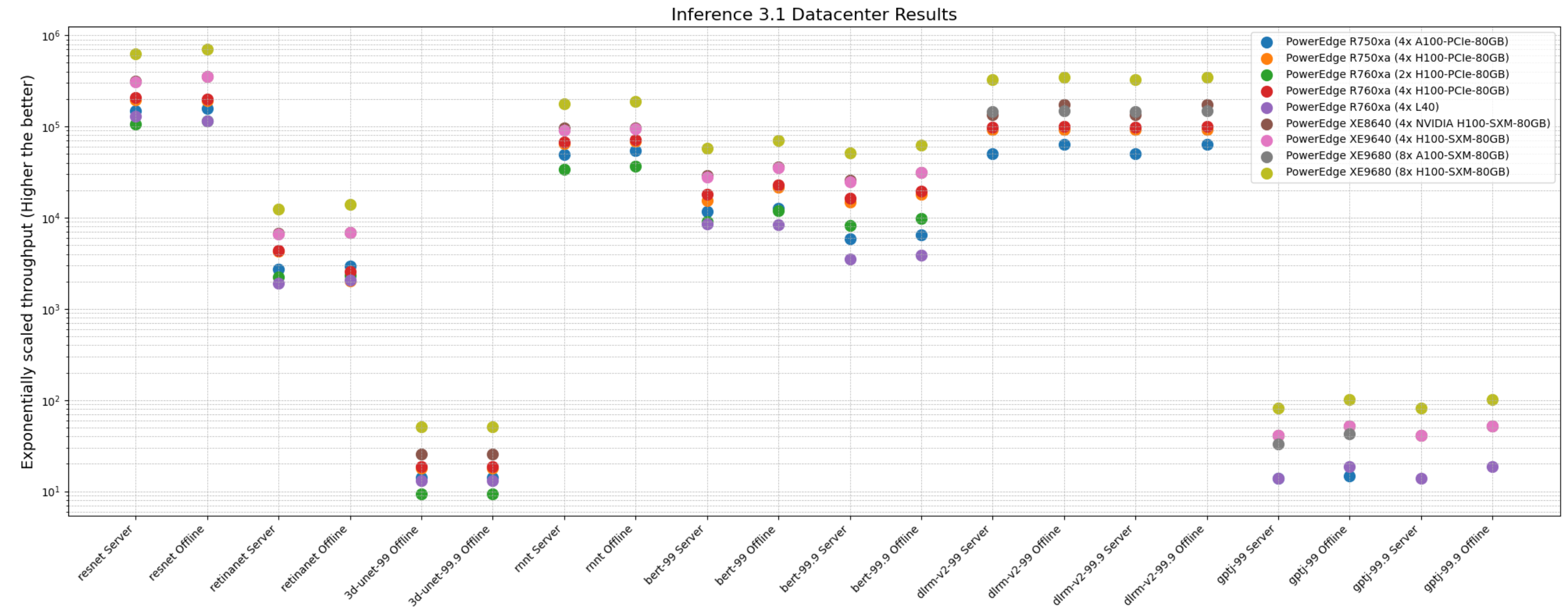
Figure 1: System throughput for submitted systems for the data center suite
The following figure shows single-stream and MultiStream scenario results for the edge for ResNet, RetinaNet, 3D-Unet, RNN-T, and BERT 99 and GPTJ benchmarks. The lower the latency, the better the results.
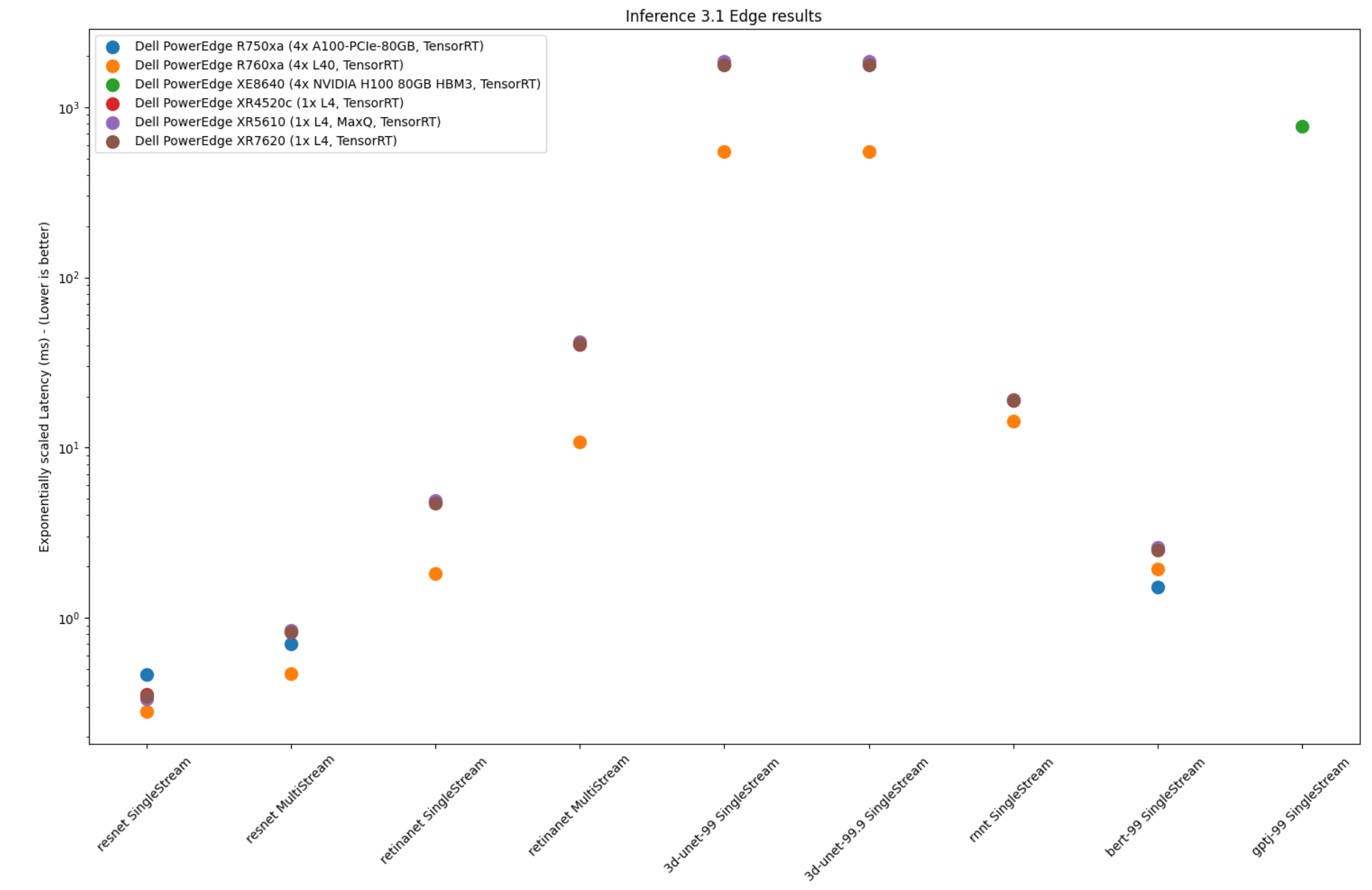
Figure 2: Latency of edge systems
Conclusion
We have provided MLCommons-compliant submissions to the Inference 3.1 benchmark across various benchmarks and suites for all tasks in the benchmark such as image classification, object detection, natural language processing, speech recognition, recommender systems and medical image segmentation, and LLM summarization. These results indicate that with the newer generation of Dell PowerEdge servers such as the PowerEdge XE9680, XE8640, XE9640, and R760xa servers and newer GPUs from NVIDIA, end users can benefit from higher performance from their data center and edge inference deployments. We have also secured numerous Number 1 titles that make Dell PowerEdge servers an excellent choice for inference data center and edge deployments. End users can refer to different results across various servers to make performance and sizing decisions. With these results, Dell Technologies can help fuel enterprises’ AI transformation, including Generative AI adoption and expansion effectively.
Future Steps
More blogs that provide an in-depth comparison of the performance of specific models with different accelerators are on their way soon. For any questions or requests, contact your local Dell representative.
MLCommons Results
https://mlcommons.org/en/inference-datacenter-31/
https://mlcommons.org/en/inference-edge-31/
The graphs above are MLCommons results MLPerf IDs from 3.1-0058 to 3.1-0069 on the closed datacenter, 3.1-0058 to 3.1-0075 on the closed edge, and 3.1-0073 on closed edge power.
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.

Making the Case for Software Development with AI
Tue, 12 Sep 2023 00:50:39 -0000
|Read Time: 0 minutes
There are an astounding number of use cases for artificial intelligence (AI), across nearly every industry and spanning outcomes that range from productivity to security to user experience and more. Many of these use cases are discussed in a Dell white paper on Generative AI in the Enterprise, a collaboration with NVIDIA that enables high performance, scalable, and modular architectures for generative AI solutions.
Some of the most impactful use cases to date are in the field of software development. Here, AI can be used for tasks such as automating code development, detecting issues, correcting erroneous code, and assisting coders. AI can provide suggestions and automated code completion.
One remarkable solution at the forefront of this AI-driven transformation is Codeium Enterprise, a high-quality, enterprise-grade, and exceptionally performant AI-powered code acceleration toolkit. A unique aspect of Codeium Enterprise is that it can be deployed entirely on-premises using Dell hardware. This solution offers enterprises a competitive advantage through faster development in their software teams, with minimal setup and maintenance requirements.
Codeium Enterprise Essentials
Codeium Enterprise is designed to address the key challenges faced by businesses aiming to enhance worker productivity in software development. It leverages industry-leading generative AI capabilities but is accessible to developers without requiring pre-existing AI expertise.
Codeium can be used with existing codebases or for generating new code and offers several essential capabilities including:
- Personalized Coding Assistance: Codeium Enterprise is a personalized AI-powered assistant tailored to enterprise software development teams.
- Industry-Leading Generative AI: It leverages industry-leading generative AI capabilities to enhance developer productivity across the entire software development life cycle.
- Ease of Use: Codeium Enterprise is accessible to developers without requiring pre-existing AI expertise. It can be used with existing codebases or for generating new code.
Codeium Enterprise builds upon the base Codeium Individual product, used by hundreds of thousands of developers. Codeium Individual provides features like autocomplete, chat, and search to assist developers throughout the software development process. The toolkit seamlessly integrates into more than 40 Integrated Development Environments (IDEs) for over 70 programming languages.
Codeium Enterprise on Dell Infrastructure
Collaborating with Dell Technologies, Codeium offers powerful yet affordable hardware configurations that are satisfactory for running Codeium Enterprise on-premises. This approach ensures that both intellectual property and data remain secure within the enterprise's environment.
Dell Technologies can power Codeium Enterprise with PowerEdge servers of various GPU configurations, depending on your development teams’ sizes. Larger development teams can use multiple servers since Codeium is a horizontally scalable system and supports multinode deployments.
Dell Experience
During the initial deployment to software developers within Dell, the results were overwhelmingly positive. After two brief weeks of use following the initial rollout, developers were polled and reported the following feedback:
- 78% of developers reported creating the first revision of code more quickly.
- 89% reported decreased context switching and improved flow state (“being in the zone”).
- 92% reported improved productivity overall.
- 100% wanted to continue using the toolset.
Did we say that the results were overwhelmingly positive?
Conclusion
In a rapidly evolving technological landscape, generative AI holds the potential to revolutionize software development. Codeium Enterprise, running on Dell infrastructure, provides a comprehensive solution designed to meet the requirements of enterprises. It can enhance developer productivity, ensure data and IP security, adhere to licensing compliance, offers transparency through analytics, and minimizes costs. Codeium Enterprise is a great choice for enterprises seeking to leverage generative AI for productivity while maintaining control and security in their software development.
Incorporating Codeium Enterprise into your software development processes is not just a competitive advantage; it is a strategic move towards staying at the forefront of innovation in the software industry.
For more information, view the joint Solution Brief or contact the Codeium team.

Do AI Models and Systems Have to Come in All Shapes and Sizes? If so, Why?

Wed, 24 Apr 2024 13:21:25 -0000
|Read Time: 0 minutes
I was recently in a meeting with some corporate strategists. They were noting that the AI market was too fragmented post ChatGPT and they needed help defining AI. The strategists said that there was too much confusion in the market, and we needed to help our customers understand and simplify this new field of technology. This led to an excellent discussion about general vs. generative AI, their different use cases and infrastructure needs, and why they need to be looked at separately. Then to reinforce that this is top of mind for many, it was not two hours later I was talking to a colleague and almost the same question came up: why the need for different approaches to different types of AI workloads? Why are there no “silver bullets” for AI?
“Traditional” vs. LLM AI
There is a division in AI models. The market has settled on the terms ‘General’ vs. ‘Generative’ for these models. These two types of models can be defined by their size as measured in parameters. Parameters can be defined as the weights given to different probabilities of a given output. The models we used in past years have ranged in parameter size from tens of millions (ResNet) to at most 100s of millions (BERT). These models remain effective and make up the majority of models deployed in production.
The new wave of models, publicly highlighted by OpenAI’s GPT-3 and ChatGPT, show a huge shift. ChatGPT clocks in at five billion to 20 billion parameters; GPT-3 is 175 billion parameters. GPT-4 is even more colossal, somewhere in the range of 1.5 to 170 trillion parameters, depending on the version. This is at the core of why we must treat various AI systems differently in what we want to do with them, their infrastructure requirements, and in how we deploy them. To determine the final size and performance requirements for an AI model, you should factor in the token count as well. Tokens in the context of LLMs are the units of text that models use for input and output. Token count can vary from a few hundred for an LLM inference job to 100s of billions for LLM training.
Why the jump?
So, what happened? Why did we suddenly jump up in model size by 2+ orders of magnitude? Determinism. Previously AI scientists were trying to solve very specific questions.
Let’s look at the example of an ADAS or self-driving car system. There is an image recognition model deployed in a car and it is looking for specific things, such as stop signs. The deployed model will determine when it sees a stop sign and follows a defined and limited set of rules for how to react. While smart in its ability to recognize stop signs in a variety of conditions (faded, snow covered, bent, and so on), it has a set pattern of behavior. The input and output of the model always match (stop sign = stop.)
With LLM or generative systems they must deal with both the problem of understanding the question (prompt) and then generating the most appropriate response. This is why Chat GPT can give you different answers to the same input: it reruns the entire process and even the smallest changes to the particulars of the input or the model itself will cause different outcomes. The outcomes of ChatGPT are not predetermined. This necessitates a much higher level of complexity and that has led to the explosive growth of model size. This size explosion has also led to another oddity: nothing is a set size. Most generative models are sized in a range as different versions and will be optimized for specific focus areas.
So, what do we do?
As AI practitioners we must recognize when to use different forms of AI models and systems. We must continue to monitor for additional changes in the AI model landscape. We must endeavor to find ways to optimize models and use only the parts we need because this will lead to significant reductions in the size of models and the ease, speed, and cost effectiveness of AI system deployments. If your AI project team or company would like to discuss this, reach out to your Dell Technologies contact to start a conversation on how Dell Technologies can help grow your AI at any scale.
Author: Justin Potuznik
Engineering Technologist – High Performance Computing & Artificial Intelligence
Dell Technologies | ISG Chief Technology & Innovation Office
Dell PowerEdge Servers demonstrate excellent performance in MLPerf™ Training 3.0 benchmark
Tue, 27 Jun 2023 19:49:45 -0000
|Read Time: 0 minutes
MLPerf Training v3.0 has just been released and Dell Technologies results are shining brighter than ever. Our submission includes benchmarking test results from new generation servers that were recently launched, such as Dell PowerEdge XE9680, XE8640, and R760xa servers, and our previous generation of servers, such as the PowerEdge XE8545 and R750xa servers. Our submission included various use cases in the MLPerf training benchmark such as image classification, medical image segmentation, lightweight and heavy weight object detection, speech recognition, NLP, and recommendation. We encourage you to read our previous whitepaper about MLPerf Training v2.0, which introduces the MLPerf training benchmark. These benchmarks serve as a reference for the kind of performance customers can expect.
Dell Technologies also announced Project Helix, which introduced a solution that customers can use to run their generative AI workloads.
What’s new with MLPerf Training 3.0 with Dell submissions?
New features for this submission include:
- Significantly improved performance gains.
- Results that include NVIDIA H100 Tensor Core GPUs. Our results included submission to the newly introduced DLRMv2 benchmark, which has multihot encodings.
- First-time training submission using new generation Dell PowerEdge servers.
- First and only multinode results using Cornelis Omnipath interconnect fabric.
- More multinode results using different interconnect fabrics.
Overview of results
Dell Technologies submitted a total of 91 results, the highest number of results compared to other submitters, which constitute over one-third of all the closed division results. These results were submitted using 27 different systems. The most outstanding results were from Dell PowerEdge XE9680, XE8640, and R760xa servers with the new NVIDIA H100 PCIe and NVIDIA H100 SXM form factor-based accelerators. The results included multinodes. Other accelerators included NVIDIA A100 PCIE and SXM form factors.
Interesting data points include the following:
- Among other servers with four GPUs having the NVIDIA H100 PCIe accelerator, the Dell PowerEdge R760xa server has the lowest time to converge in MaskRCNN, ResNet, and UNet-3D benchmarks. Similarly, for the four NVIDIA H100 SXM accelerators, the PowerEdge XE8640 server had the lowest time to converge with BERT, DLRMv2, ResNet, and UNet-3D benchmarks.
- The Dell PowerEdge R760xa server features PCIe Gen 5, which allows for faster multi-GPU training. Our submissions included PowerEdge R750xa and R760xa servers with the same accelerators to show the performance gains customers can expect.
- MLPerf Training 3.0 was the first time that Dell Technologies made an eight-way NVIDIA SXM form factor accelerator submission for training workloads. The Dell PowerEdge XE9680 server with eight NVIDIA HGX H100 SXM GPUs had the lowest time to converge on the ResNet-50 benchmark among eight-GPU configurations, and has closely performed among other NVIDIA HGX systems on other benchmarks.
- Multinode results demonstrate near linear scaling, which shows that customers can gain faster time to value with all the workloads. These multinode submissions include different interconnects such as InfiniBand and Cornelis Omnipath, which allows for customers to make tradeoffs.
- Results for different Dell PowerEdge servers that render different accelerator TDP were submitted. These results are useful for scenarios in which the data center is power-constrained. These results help with FLOPS per watt decisions.
- Intel and AMD-based server submissions enable customers to see how CPUs can influence the training process.
- Our results included not only various systems, but also exceeded performance gains compared to the last round due to the newer generation of hardware acceleration from the newer server and accelerator.
Fig 1: Dell systems used for ResNet, MaskRCNN, and BERT benchmarks
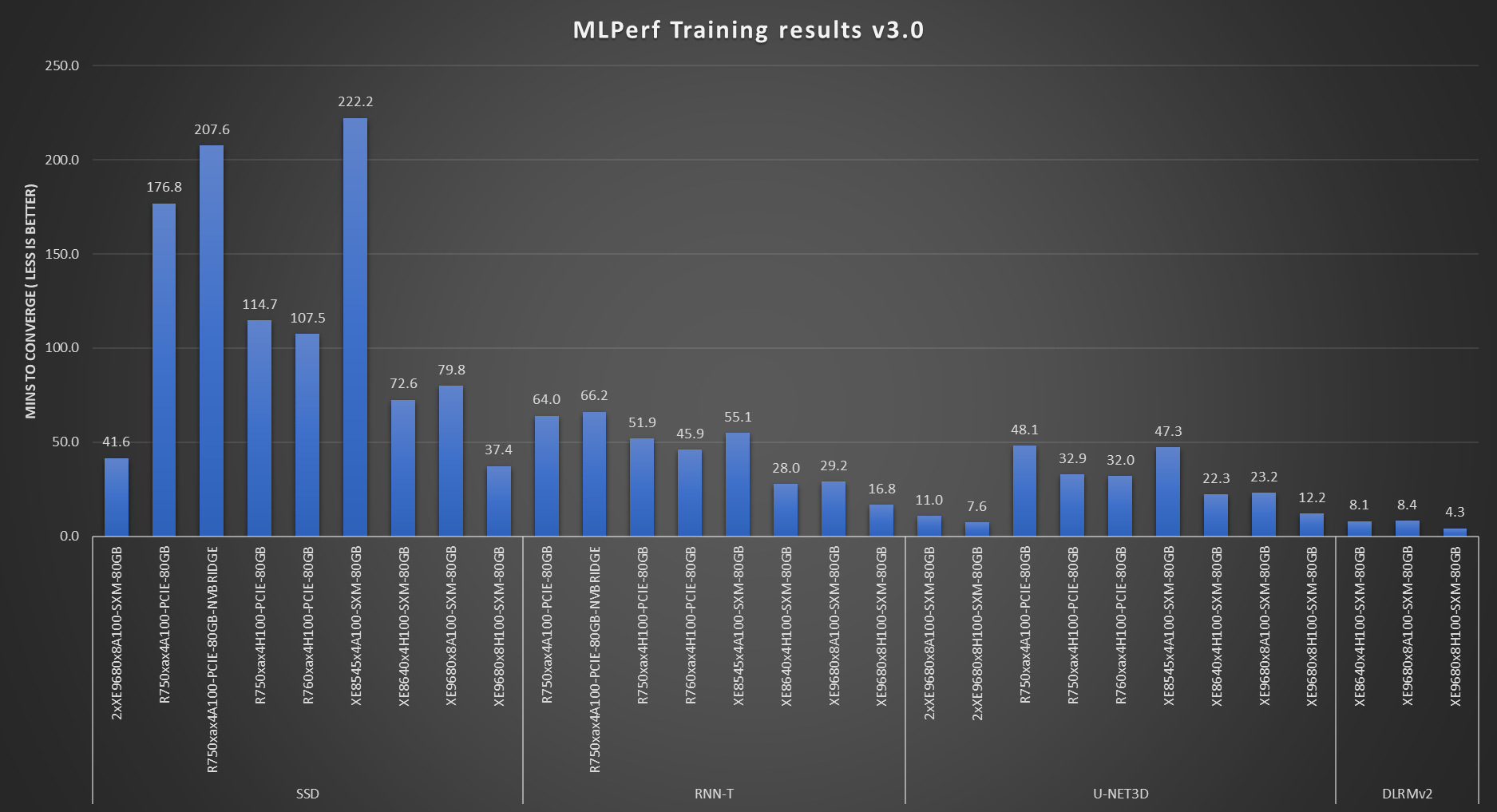
Fig 2: Dell systems used for SSD, RNN-T, UNnet-3D, and DLRM benchmarks
Figure 1 and Figure 2 list the systems and corresponding NVIDIA GPUs that were used in tests. We see that various systems with different NVIDIA GPUs were used for different use cases such as ResNet-50, MaskRCNN, BERT, SSD, RNN-T, UNet-3D, and DLRMv2. All the systems performed optimally and delivered low time to converge. These results also include multinode results.
The single server with the lowest time to converge is the Dell PowerEdge XE9680 server, which delivers incredible time to value for training and inference workloads. These systems scale well and enable the current demand for very high compute. Large AI workloads, including sizable generative AI training (LLMs), can be trained on multiple PowerEdge XE9680 servers.
The following figure shows the improvement in performance from the previous submission. It shows the best Dell single-system training submission results compared to the previous round of submissions.
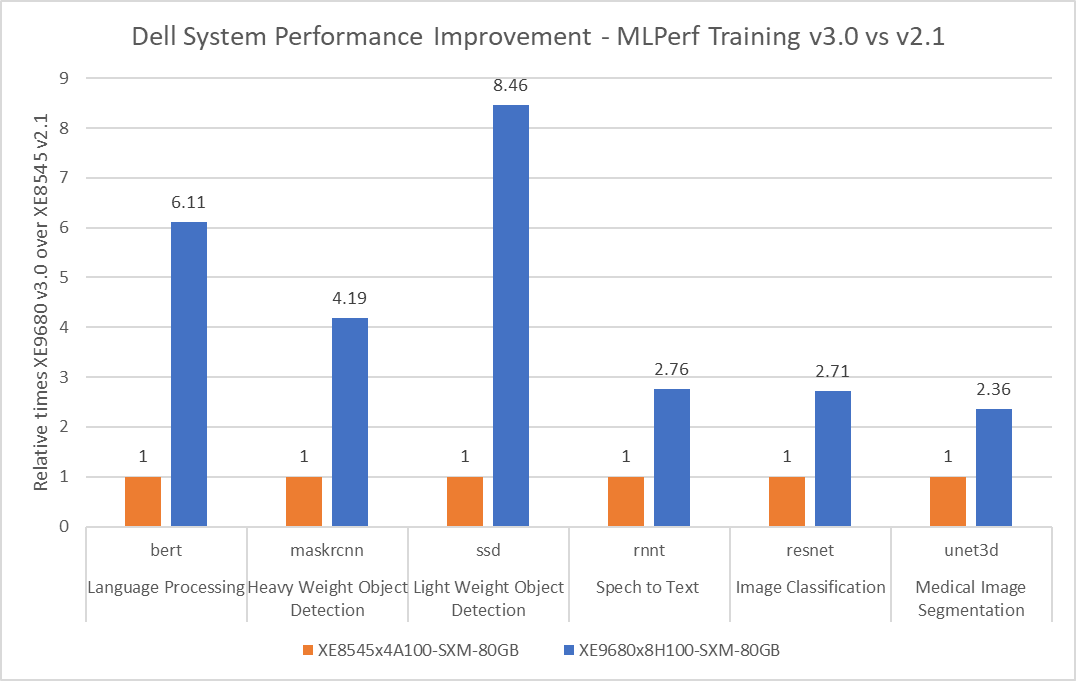
Fig 3: Performance improvement factor using a Dell PowerEdge XE9680 server with the previous generation Dell PowerEdge XE8545 server as a baseline across different benchmark
The figure shows the performance gains customers can expect if they upgrade to the latest generation of servers. Note that the latest generation server, the Dell PowerEdge XE9680 server, has eight NVIDIA H100 SXM GPUs; the previous generation Dell PowerEdge XE8545 server has four NVIDIA A100 SXM GPUs.
The most improvement at 846 percent was observed with the SSD benchmark, followed by the BERT benchmark at 611 percent. Other benchmarks yielded a greater than 230 percent improvement. These results are significant. The two-times improvement in time to train means more time for other workloads in the data center, yielding faster time to value for the business. With this acceleration, customers can expect faster prototyping, model training, and expedite their MLOps pipeline.
Conclusion
We have submitted compliant results for the MLCommons Training 3.0 benchmark. These results are numerous, using different servers powered by NVIDIA GPUs. Results show multinode scaling is linear, where more servers can help to solve the problem faster. Having various results helps customers choose the best server for their data center setting to deploy training workloads. Newer generation servers such as Dell PowerEdge XE9680, XE8640, and R760xa servers all deliver high performance while breaking MLCommons records across different use cases such as image classification, medical image segmentation, lightweight and heavy weight object detection, speech recognition, NLP, and recommendation. Furthermore, Project Helix offers customers an effective way to derive value from generative AI. Enterprises can enable their AI transformation with Dell Technologies efficiently to enable faster time to value to uniquely fit their needs.
MLCommons Results
https://mlcommons.org/en/training-normal-30/
The graphs above are MLCommons results MLPerf IDs from 3.0-2027 to 3.0-2053
The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Choosing a PowerEdge Server and NVIDIA GPUs for AI Inference at the Edge
Fri, 05 May 2023 16:38:19 -0000
|Read Time: 0 minutes
Dell Technologies submitted several benchmark results for the latest MLCommonsTM Inference v3.0 benchmark suite. An objective was to provide information to help customers choose a favorable server and GPU combination for their workload. This blog reviews the Edge benchmark results and provides information about how to determine the best server and GPU configuration for different types of ML applications.
Results overview
For computer vision workloads, which are widely used in security systems, industrial applications, and even in self-driven cars, ResNet and RetinaNet results were submitted. ResNet is an image classification task and RetinaNet is an object detection task. The following figures show that for intensive processing, the NVIDIA A30 GPU, which is a double-wide card, provides the best performance with almost two times more images per second than the NVIDIA L4 GPU. However, the NVIDIA L4 GPU is a single-wide card that requires only 43 percent of the energy consumption of the NVIDIA A30 GPU, considering nominal Thermal Design Power (TDP) of each GPU. This low-energy consumption provides a great advantage for applications that need lower power consumption or in environments that are more challenging to cool. The NVIDIA L4 GPU is the replacement for the best-selling NVIDIA T4 GPU, and provides twice the performance with the same form factor. Therefore, we see that this card is the best option for most Edge AI workloads.
Conversely, the NVIDIA A2 GPU exhibits the most economical price (compared to the NVIDIA A30 GPU's price), power consumption (TDP), and performance levels among all available options in the market. Therefore, if the application is compatible with this GPU, it has the potential to deliver the lowest total cost of ownership (TCO).
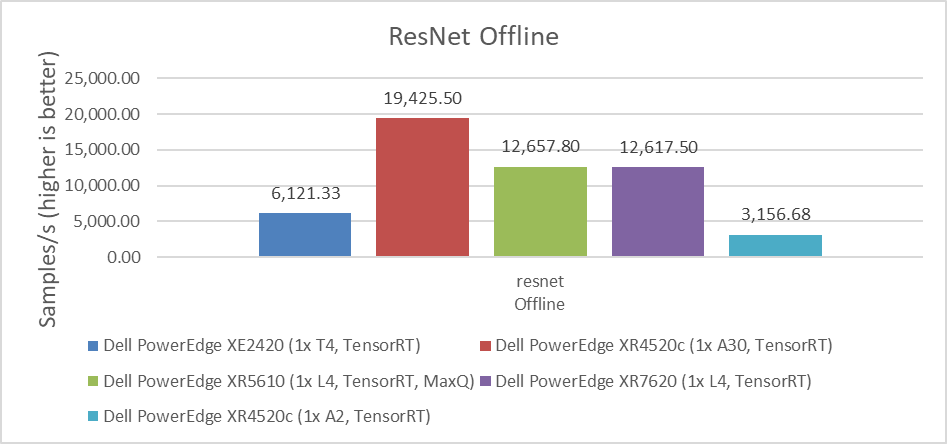
Figure 1: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the ResNet Offline benchmark
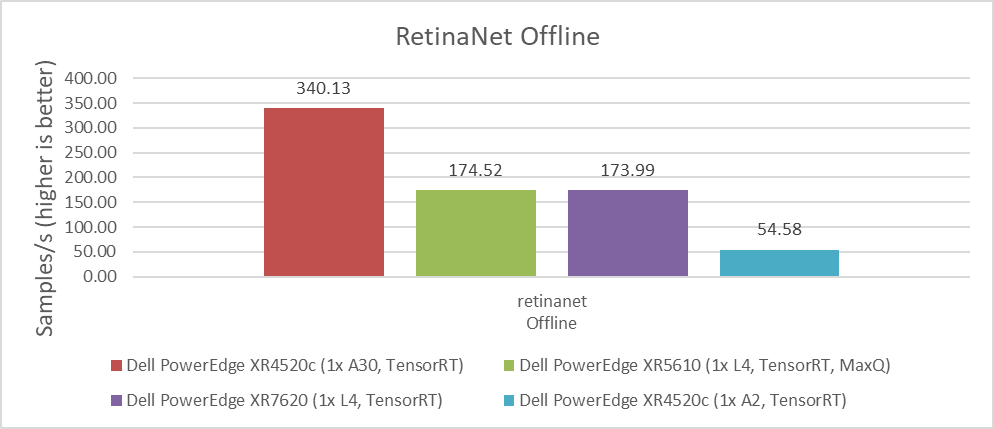
Figure 2: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the RetinaNet Offline benchmark
The 3D-UNet benchmark is the other computer vision image-related benchmark. It uses medical images for volumetric segmentation. We saw the same results for default accuracy and high accuracy. Moreover, the NVIDIA A30 GPU delivered significantly better performance over the NVIDIA L4 GPU. However, the same comparison between energy consumption, space, and cooling capacity discussed previously applies when considering which GPU to use for each application and use case.
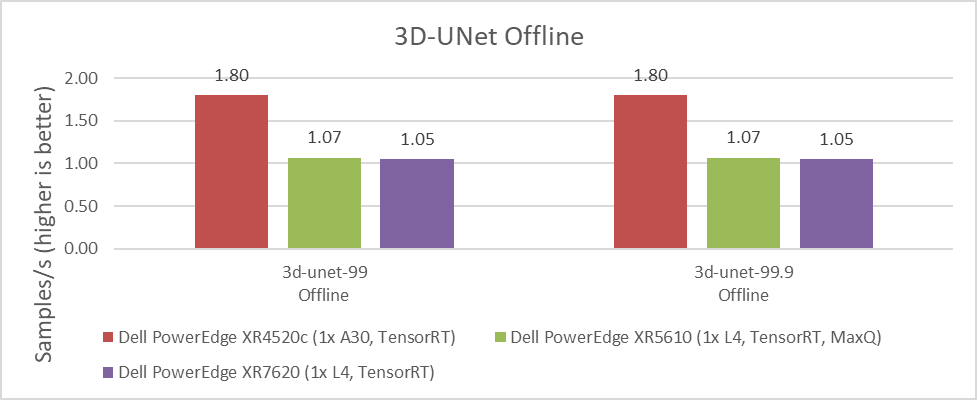
Figure 3: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the 3D-UNet Offline benchmark
Another important benchmark is for BERT, which is a Natural Language Processing model that performs tasks such as question answering and text summarization. We observed similar performance differences between the NVIDIA A30, L4, T4, and A2 GPUs. The higher the value, the better.
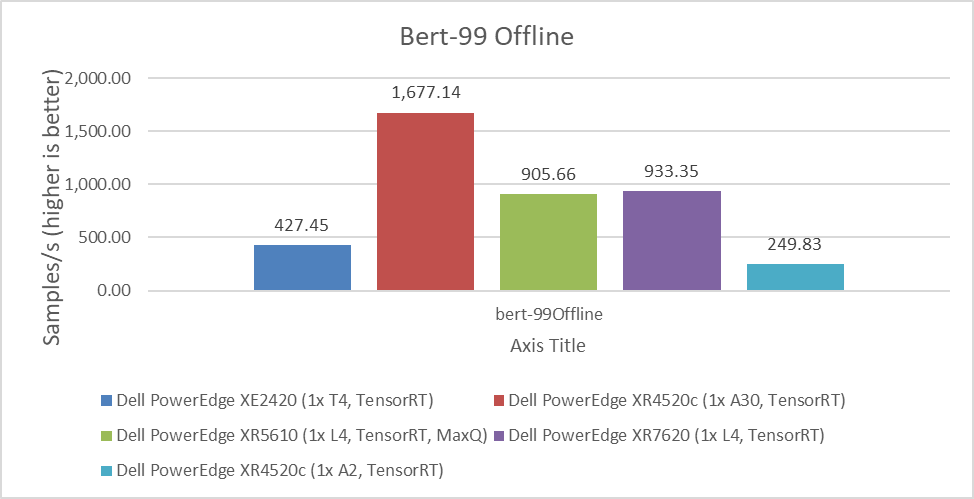
Figure 4: Performance comparison of NVIDIA A30, L4, T4, and A2 GPUs for the BERT Offline benchmark
MLPerf benchmarks also include latency results, which are the time that systems take to process requests. For some use cases, this processing time can be more critical than the number of requests that can be processed per second. For example, if it takes several seconds to respond to a conversational algorithm or an object detection query that needs a real-time response, this time can be particularly impactful on the experience of the user or application.
As shown in the following figures, the NVIDIA A30 and NVIDIA L4 GPUs have similar latency results. Depending on the workload, the results can vary due to which GPU provides the lowest latency. For customers planning to replace the NVIDIA T4 GPU or seeking a better response time for their applications, the NVIDIA L4 GPU is an excellent option. The NVIDIA A2 GPU can also be used for applications that require low latency because it performed better than the NVIDIA T4 GPU in single stream workloads. The lower the value, the better.
Figure 4: Latency comparison of NVIDIA A30, L4, T4, and A2 GPUs for the ResNet single-stream and multistream benchmark
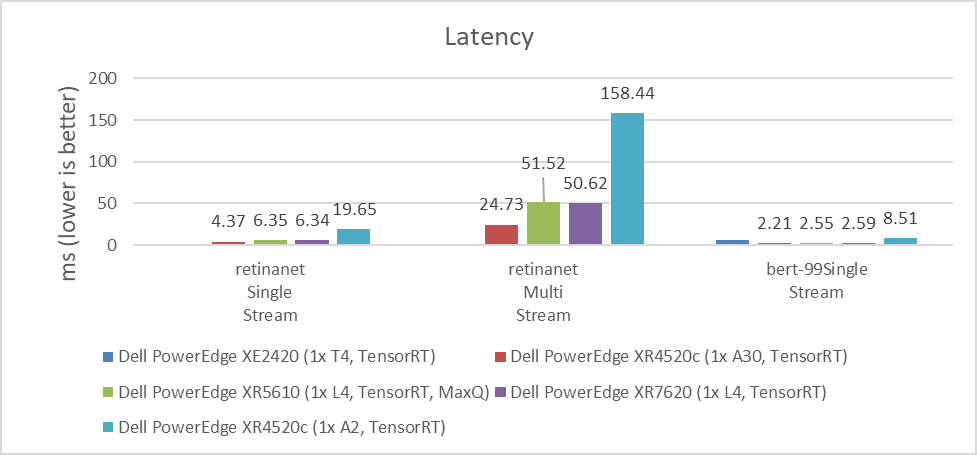
Figure 5: Latency comparison of NVIDIA A30, L4, T4, and A2 GPUs for the RetinaNet single-stream and multistream benchmark and the BERT single-stream benchmark
Dell Technologies submitted to various benchmarks to help understand which configuration is the most environmentally friendly as the data center’s carbon footprint is a concern today. This concern is relevant because some edge locations have power and cooling limitations. Therefore, it is important to understand performance compared to power consumption.
The following figure affirms that the NVIDIA L4 GPU has equal or better performance per watt compared to the NVIDIA A2 GPU, even with higher power consumption. For Throughput and Perf/watt values, higher is better; for Power(watt) values, lower is better.
Figure 6: NVIDIA L4 and A2 GPU power consumption comparison
Conclusion
With measured workload benchmarks on MLPerf Inference 3.0, we can conclude that all NVIDIA GPUs tested for Edge workloads have characteristics that address several use cases. Customers must evaluate size, performance, latency, power consumption, and price. When choosing which GPU to use and depending on the requirements of the application, one of the evaluated GPUs will provide a better result for the final use case.
Another important conclusion is that the NVIDIA L4 GPU can be considered as an exceptional upgrade for customers and applications running on NVIDIA T4 GPUs. The migration to this new GPU can help consolidate the amount of equipment, reduce the power consumption, and reduce the TCO; one NVIDIA L4 GPU can provide twice the performance of the NVIDIA T4 GPU for some workloads.
Dell Technologies demonstrates on this benchmark the broad Dell portfolio that provides the infrastructure for any type of customer requirement.
The following blogs provide analyses of other MLPerfTM benchmark results:
- Dell Servers Excel in MLPerf™ Inference 3.0 Performance
- Dell Technologies’ NVIDIA H100 SXM GPU submission to MLPerf™ Inference 3.0
- Empowering Enterprises with Generative AI: How Does MLPerf™ Help Support
- Comparison of Top Accelerators from Dell Technologies’ MLPerf™
References
For more information about Dell Power Edge servers, go to the following links:
- Dell’s PowerEdge XR7620 for Telecom/Edge Compute
- Dell’s PowerEdge XR5610 for Telecom/Edge Compute
- PowerEdge XR4520c Compute Sled specification sheet
- PowerEdge XE2420 Spec Sheet
For more information about NVIDIA GPUs, go to the following links:
MLCommonsTM Inference v3.0 results presented in this document are based on following system IDs:
| ID | Submitter | Availability | System |
|---|---|---|---|
2.1-0005 | Dell Technologies | Available | Dell PowerEdge XE2420 (1x T4, TensorRT) |
2.1-0017 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A2, TensorRT) |
2.1-0018 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A30, TensorRT) |
2.1-0019 | Dell Technologies | Available | Dell PowerEdge XR4520c (1x A2, MaxQ, TensorRT) |
2.1-0125 | Dell Technologies | Preview | Dell PowerEdge XR5610 (1x L4, TensorRT, MaxQ) |
2.1-0126 | Dell Technologies | Preview | Dell PowerEdge XR7620 (1x L4, TensorRT) |
Table 1: MLPerfTM system IDs
Comparison of Top Accelerators from Dell Technologies’ MLPerf™ Inference v3.0 Submission
Fri, 21 Apr 2023 21:43:39 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to MLPerfTM Inference v3.0 in the closed division. This blog highlights the NVIDIA H100 PCIe GPU and compares the results to the NVIDIA A100 PCIe GPU with the PCIe form factor held constant.
Introduction
MLPerf Inference v3.0 submission falls under the benchmarking pillar of the MLCommonsTM consortium with the objective to make fair comparisons across server configurations. Submissions that are made to the closed division warrant an equitable comparison of the systems.
This blog highlights the closed division submissions Dell Technologies made with the NVIDIA A100 GPU using the PCIe (peripheral component interconnect express) form factor. The PCIe form factor is an interfacing standard for connecting various high-speed components in hardware such as a computer or a server. Servers include a certain number of PCIe slots in which to insert GPUs or other additional cards. Note that there are different physical configurations for the slots to indicate the number of lanes for data to travel to and from the PCIe card. The NVIDIA H100 GPU is truly the latest and greatest GPU with NVIDIA AI Enterprise included; it is a dual-slot air cooled PCIe generation 5.0 GPU. This GPU runs at a memory bandwidth speed of over 2,000 megabits per second and up to seven Multi-Instance GPUs at 10 gigabytes each. The NVIDIA A100 80 GB GPU is a dual-slot PCIe generation 4.0 GPU that runs at a memory bandwidth speed of over 2,000 megabits per second.
NVIDIA H100 PCIe GPU and NVIDIA A100 PCIe GPU comparison
In addition to making a submission with the NVIDIA A100 GPU, Dell Technologies made a submission with the NVIDIA H100 GPU. To make a fair comparison, the systems were identical and the PCIe form factor was held constant.
Platform | Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT) | Dell PowerEdge R750xa (4x H100-PCIe-80GB, TensorRT) |
Round | V3.0 | |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | R750xa_H100_PCIe_80GBx4_TRT |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 1 TB | 1 TB |
GPU | NVIDIA A100-PCIe-80GB | NVIDIA H100-PCIe-80GB |
GPU form factor | PCIe | |
GPU memory configuration | HBM2e | |
GPU count | 4 | |
Software stack | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.60.13 DALI 1.17.0 |
Table 1: Software stack of submissions made on NVIDIA A100 PCIe and NVIDIA H100 PCIe GPUs for MLPerf Inference v3.0 on the Dell PowerEdge R750xa server
In the following figure, the per card numbers are normalized over the NVIDIA A100 GPU results to show a readable comparison of the GPUs on the same system. Across object detection, medical image segmentation, and speech to text and natural language processing, the latest NVIDIA H100 GPU outperforms its predecessor in all categories. Note the outstanding performance of the Dell PowerEdge R750xa server with NVIDIA H100 GPUs with the BERT benchmark in the high accuracy mode. With the advancements in generative artificial intelligence, the Dell PowerEdge R750xa server is a versatile, reliable, and high performing platform.
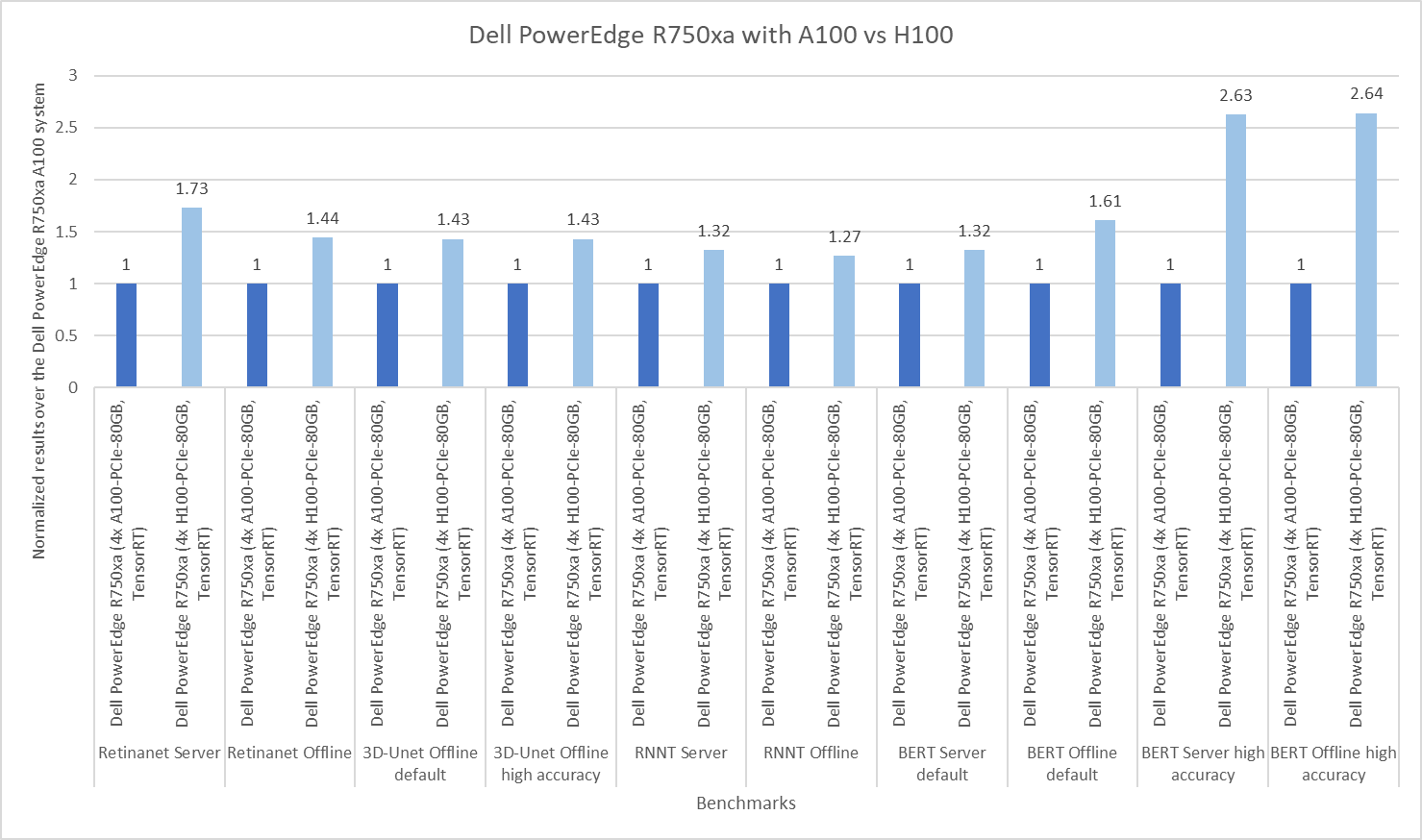
Figure 1: Normalized per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs on the Dell PowerEdge R750xa server
The following figures show absolute numbers for a comparison of the NVIDIA H100 and NVIDIA A100 GPUs.

Figure 2: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for RetinaNet on the PowerEdge R750xa server
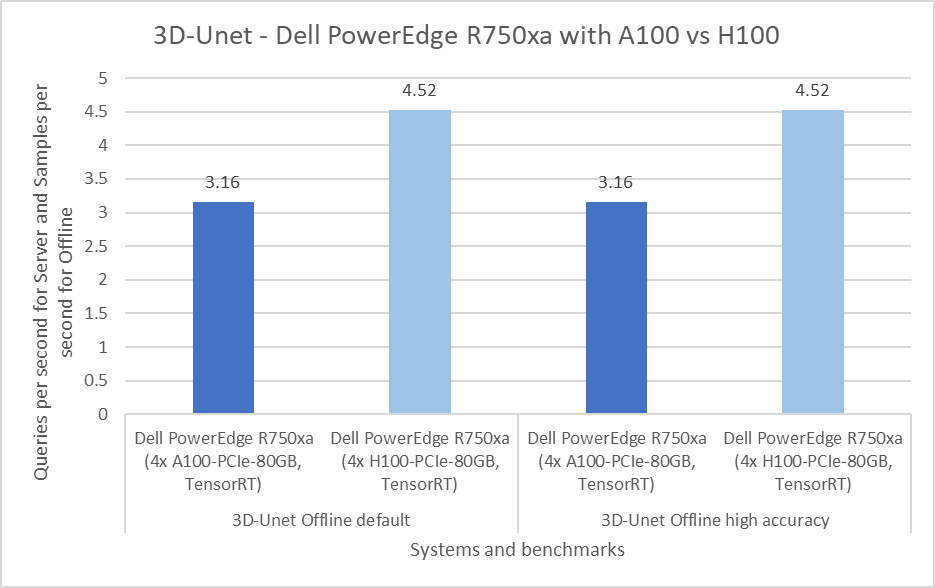
Figure 3: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for 3D-Unet on the PowerEdge R750xa server

Figure 4: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for RNNT on the PowerEdge R750xa server
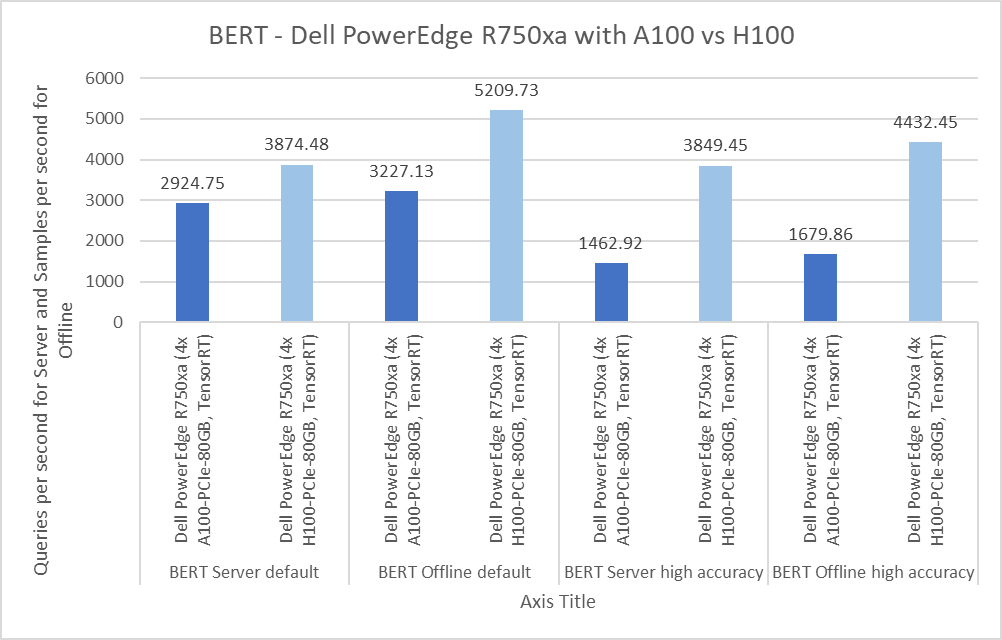
Figure 5: Per GPU comparison of NVIDIA A100 and NVIDIA H100 GPUs for BERT on the PowerEdge R750xa server
These results can be found on the MLCommons website.
Submissions made with the NVIDIA A100 PCIe GPU
In this round of submissions, Dell Technologies submitted results on the PowerEdge R750xa server packaged with four NVIDIA A100 80 GB PCIe GPUs. In previous rounds, the PowerEdge R750xa server showed outstanding performance across all the benchmarks. For a deeper dive of a previous round's submission, check out our blog from MLPerf Inference v2.0. From the previous round of MLPerf Inference v2.1 submissions, Dell Technologies submitted results on an identical system. However, across the two rounds of submissions, the main difference is the upgrades in the software stack, as described in the following table:
Platform | Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT) | Dell PowerEdge R750xa (4x A100-PCIe-80GB, TensorRT) |
Round | V3.0 | V2.1 |
MLPerf System ID | R750xa_A100_PCIe_80GBx4_TRT | |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 512 GB | |
GPU | NVIDIA A100-PCIe-80GB | |
GPU form factor | PCIe | |
GPU memory configuration | HBM2e | |
GPU count | 4 | |
Software stack | TensorRT 8.6 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | TensorRT 8.4.2 CUDA 11.6 cuDNN 8.4.1 Driver 510.39.01 DALI 0.31.0 |
Table 2: Software stack for submissions made on the NVIDIA A100 PCIe GPU in MLPerf Inference v3.0 and v2.1
Comparison of PowerEdge R750xa NVIDIA A100 results from Inference v3.0 and v2.1
Object detection
The RetinaNet benchmark falls under the object detection category and uses the OpenImages dataset. The results from Inference v3.0 show a less than 0.05 percent difference in the Server scenario and a 21.53 percent difference in the Offline scenario. A potential reason for this result might be NVIDIA’s optimizations, as outlined in their technical blog.

Figure 6: RetinaNet Server and Offline results on the PowerEdge R750xa server from Inference v3.0 and Inference v2.1
Medical image segmentation
The 3D-Unet benchmark performs the KiTS 2019 kidney tumor segmentation task. Across the two rounds of submission, the PowerEdge R750xa server performed consistently well with a 0.3 percent difference in both the default and high accuracy modes.
Figure 7: 3D-UNet Offline results on the PowerEdge R750xa server from Inference v3.0 and v2.1
Speech to text
The Recurrent Neural Network Transducers (RNNT) model falls under the speech recognition category. This benchmark accepts raw audio samples and produces the corresponding character transcription. In the Server scenario, the results are within a 2.25 percent difference and 0.41 percent difference in the Offline scenario.

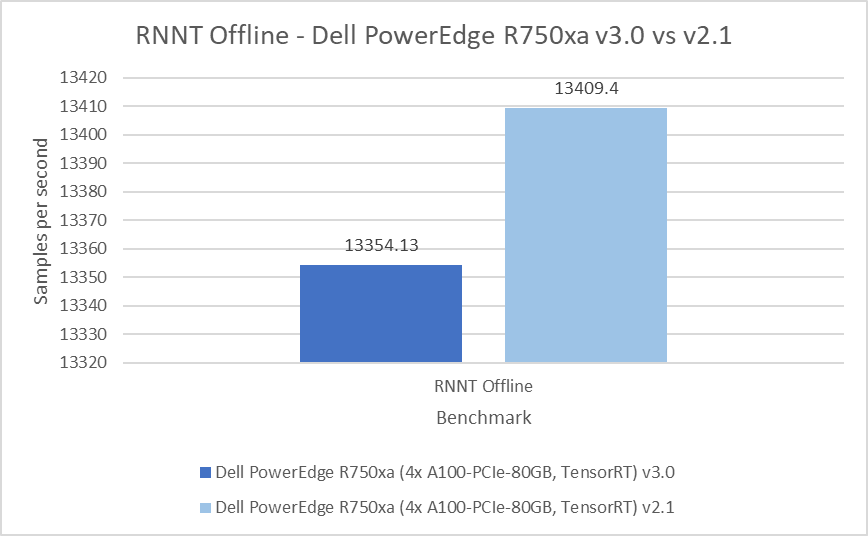
Figure 8: RNNT Server and Offline results on the Dell PowerEdge R750xa server from Inference v3.0 and v2.1
Natural language processing
Bidirectional Encoder Representation from Transformers (BERT) is a state-of-the-art language representational model for Natural Language Processing applications. This benchmark performs the SQuAD question answering task. The BERT benchmark consists of default and high accuracy modes for the Offline and Server scenarios. For the Server scenarios, the default mode results are within a 1.69 percent range and 3.12 percent range for the high accuracy mode. For the Offline scenarios, a similar behavior is noticeable in which the default mode results are within a 0.86 percent range and 3.65 percent range in the high accuracy mode.

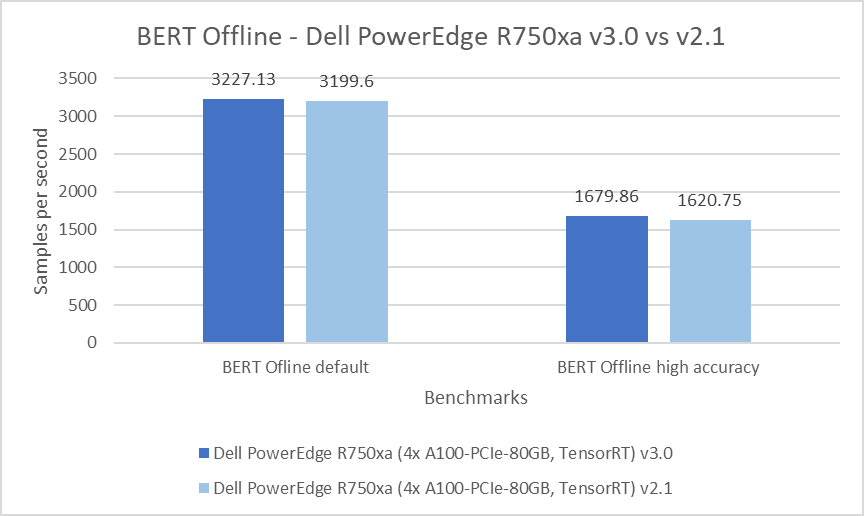
Figure 9: BERT Server and Offline results on the PowerEdge R750xa server from Inference v3.0 and v2.1
Conclusion
Across the various rounds of submissions to the MLPerf Inference benchmark suite, the PowerEdge R750xa server has been a consistent top performer for any machine learning tasks ranging from object detection, medical image segmentation, speech to text and natural language processing. The PowerEdge R750xa server continues to be an excellent server choice for machine learning inference workloads. Customers can take advantage of the diverse results submitted on the Dell PowerEdge R750xa server with the NVIDIA H100 GPU to make an informed decision for their specific solution needs.

Empowering Enterprises with Generative AI: How Does MLPerf™ Help Support Requirements?
Fri, 14 Apr 2023 17:05:26 -0000
|Read Time: 0 minutes
Generative AI has developed into a critical workload in the deep learning ecosystem. In the generative AI world, 2023 has been a year of explosive growth as generative AI continues to make huge progress by improving the quality and ease of access to these ecosystems. With the advent of ChatGPT, Stable Diffusion, and so on, which have gained significant popularity, we can consider generative AI to be one of the pivotal use cases that mainstreams AI to the world. We expect to see generative AI push new frontiers and enable an explosion of productivity. This blog provides an overview of generative AI and its relevance to the MLCommonsTM AI system benchmark to which we submit on a frequent basis.
Introduction to Generative AI
Generative AI is a phenomenon by which AI systems (consisting of hardware and software) can produce plausible renders of images, audio, video, text, code, 3D renders, and so on when given an instruction prompt. The prompt can be text, voice, or other forms. Some popular examples include ChatGPT, Stable Diffusion image generator, and Text to speech engines.
These AI systems can enable a significant productivity boost by generating and modifying existing pieces of content that effectively improve the user’s workflow.
What can these AI Systems do?

Generative AI is capable of generating and optimizing:
- Chat and Text─This modality is useful for customer support, for generating blogs, ad copies, design guides, and technical reports, reading and taking action, answering questions, summarizing large documents, producing code that can run directly, inspiring developers to write improved code, and so on.
- Video generations:
- Talking head videos─These videos can be useful for content producers, tutorial guides, and so on in which personas are able to communicate with voice, lip syncing, and emotions, these are helpful for customer support and other interactive services.
- NERF (neural radiance fields) – Given a few angles from pictures, it can produce an entire scene of smooth footage that looks to be real. NERF can be useful in providing more perspective for a scene and enable more interesting viewpoints.
- High-resolution images─These creative images can be used for multiple purposes including B-rolls, explanation of ideas and simulated concepts, special effects, graphic vectors, infographics, backdrops, scenes and so on.
- High-fidelity audio─These audio samples can be voices, music, and so on. Voices can deliver emotions, be of high quality like voiceovers, and deliver speech for advertisements. Audio samples can also be songs for karaoke, songs with beats, customer support and so on.
- 3D Generations─These renders are useful for producing a new world with just imagination. They are powerful for VFX, VR, and other immersive experiences. These 3D generations can be used for creating digital clones of the real world, games, commercials, movies, and so on.
This blog does not highlight many other use cases. With more innovation and research, there will be a Cambrian explosion of more use cases that are fueled by generative AI. These models can also produce personalized content for the end user as opposed to serving generic material.
What kind of compute is needed to train these AI systems?
Training generative AI systems is a compute-intensive task. Typically, text generation, chatbots, and instruction followers have billions of parameters and use thousands of GPU hours. This task presents a large problem needing different mechanisms of parallelization, training update optimizations, including full stack (hardware and software) optimization, and so on.
For instance, the GPT3 model has 175 B parameters and the Megatron model has approximately 530 B parameters. Training and Inference procedures for these systems are significantly different than the traditional deep learning models that do not have as many parameters. For instance, large language models (LLMs) require large inference setups including multinode inference, scaling training to a trillion parameter models needing different mechanisms including dynamic sparsity, optimizing communication costs, self-tuning, and so on.
In essence, the compute needs for generative AI are ever growing in unique ways. While training generative AI models remains crucial for compute needs, the subsequent necessity for compute could be arriving from fine tuning and inferencing needs.
Why adapt now?
Generative AI has been in development for many years now; Transformers, Wavenet, GANs, Autoencoders with decoders, and so on have been around for quite some time. There has been much innovation in these areas, which continues to be mixed and matched to meet productive outcomes. For instance, the growth of multimodal models (models that take different kinds of inputs) facilitate a more collaborative workflow. Multimodal models form the cornerstone for enabling near human intelligence for a specific task. Although there is small chance of reaching human-level performance overall, these multimodal models can produce plausible results. Consumers of these systems can take the outputs, modify them and use them in their workflow. These systems render output quickly compared to a manual effort and provide more layers of creativity.
These plausible renders, ease of access, and open-source development have been an incredible fuel for popularizing generative AI systems. The next step is pushing these systems to perform better, whether by improving quality of service or improving throughput. Improving quality of service and throughput is an already established problem. To improve convergence and throughput, many benchmarks have been attempting to optimize AI systems.
Relationship to MLCommons
The MLCommons Training benchmark has been instrumental in enabling significant improvements for convergence of the training time of systems by taking a holistic view of the hardware and software. The MLCommons Inference benchmark has been conducive for optimizing the inference of AI systems.
Furthermore, MLCommons has generative AI benchmarks in their road map. For instance, LLM is part of MLCommons v3.0 training; Stable Diffusion is scheduled to be included as part of MLCommons v3.1 training.
The need to continuously improve systems is essential, more so now for generative AI use cases. We can see that the MLCommons community has made significant improvements in performance every year. These optimizations from vendors, benchmarks, and the deep learning community continue to serve this generative AI effort. All these efforts make adoption of generative AI more attractive now.
Paradigms
Some fundamental models that are used for generative AI workloads in MLPerf benchmarks include:
Figure 1: Transformer architecture
- Transformer─This model uses an attention mechanism to model areas of interest in a specific context. This method allows building relationships that signify how one element relates to others.
Figure 2: U-Net architecture
- 3d-UNet─This model uses convolution and pooling blocks to set up a contractive and expanding path that creates a bottleneck. The image is reconstructed from this bottleneck. The bottleneck captures the compression of data; only important information is used to reconstruct the image.
How is generative AI relevant to MLPerf Training and Inference?
MLPerf Training uses the BERT language model. Many text-based generative AI workloads are LLMs. While BERT is not as large as GPT3 (about 1/500th the size of GPT3 based on a number of parameters (340 M compared to 175 B)) it has fundamental blocks that GPT3 uses.
For instance, BERT uses multiple Attention Heads, Layernorms SoftMax, and so on, which GPT3 also uses. While parameters, layer count, and model size are larger for GPT3, BERT uses fundamentally similar procedures that are essential for training.
Conversely, Stable Diffusion uses UNet layers. This method is useful for constructing images of high quality. It takes encoded text and uses the UNet bottleneck to effectively enable a denoising procedure. 3D-UNet is a part of the MLPerf benchmark, which is optimized.
The preceding examples show that optimizations used in MLPerf are transferable, and we can use current MLPerf models to be a relative proxy to the generative AI workloads.
Furthermore, MLPerf includes LLMs and Stable Diffusion on the road map for the upcoming training submission versions. We can expect optimized versions of these implementations to be made available to the public.
The links in the references show optimizations made by NVIDIA for the benchmarks. Customers can take the already optimized references and use them for their generative AI use cases.
We recognize the importance of AI workloads including generative AI. Therefore, we submit to MLCommons benchmarks that provide like-to-like comparisons with different OEMs and vendors. Scale is an important aspect of generative AI workloads. We have introduced the new PowerEdge XE9680 server that produces stellar performance at scale. The following figure shows the performance improvement from MLPerf Inference v2.1 to MLPerf Inference v3.0.
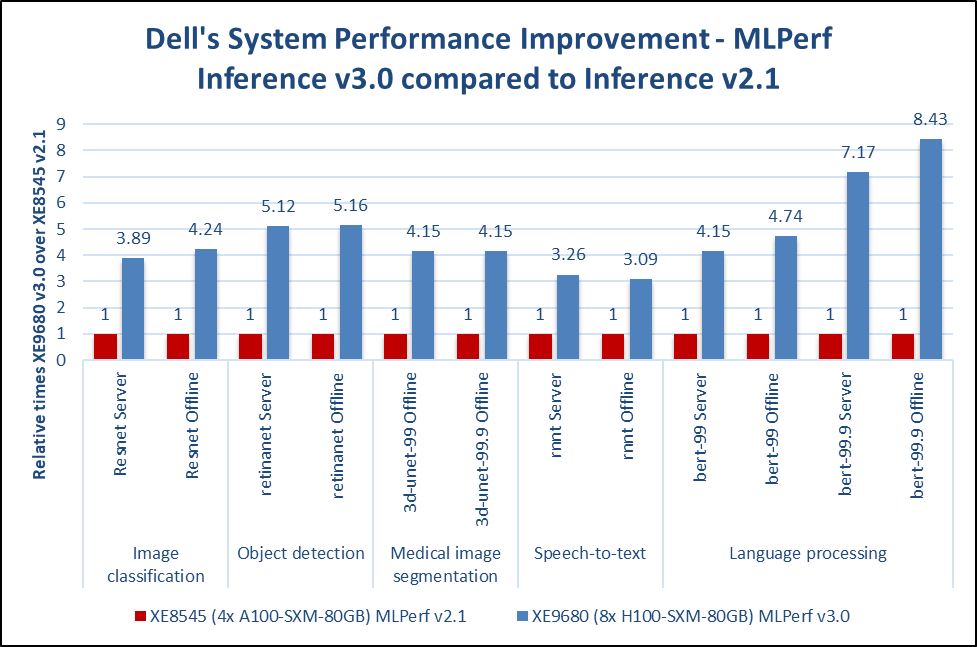
* MLPerf ID 2.1-0014 and MLPerf ID 3.0-0013
Figure 3: MLPerf Inference 3.0 vs Inference 2.1 performance improvement from XE9680 server having 8xH100 GPUs compared to XE8545 having 4xA100 GPUs
PowerEdge XE9680 and XE8545 systems are an excellent choice for generative AI workloads. Customers can expect faster time to value and these systems scale very well, as attributed by the MLPerf training results.
Conclusion
While generative AI has produced enormous excitement, there are many challenges such as biased outputs, incorrect answers, hallucinations, instability, and so on that require monitoring and policing. Generative AI systems still cannot make autonomous decisions tied to other algorithms for mission-critical applications.
The latest MLPerf Inference 3.0 results show up to three times to eight times improvements for all categories. These improvements show Dell Technologies’ commitment to continuously enable improvement in performance. We understand generative AI is an important class of AI workload; Dell hardware supports these workloads. By upgrading to the latest servers, such as the PowerEdge XE9680 servers, customers can derive a faster time to value. Dell Technologies can help customers adapt and deploy generative AI workloads.
To summarize, compute, quality of service (plausible outputs), open-source development, and ease of access are major drivers for mass adoption of generative AI. Organizations can leverage these drivers to produce outputs for their workflow. Enabling these systems with humans in the loop are good first steps to boosting productivity. Dell Technologies has been making MLPerf submissions to show how our servers can deliver excellent performance. The optimizations made for MLPerf are transferable to generative AI workloads.
References
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/1505.04597
https://developer.nvidia.com/blog/leading-mlperf-training-2-1-with-full-stack-optimizations-for-ai/
https://developer.nvidia.com/blog/boosting-mlperf-training-performance-with-full-stack-optimization/
Dell Technologies’ NVIDIA H100 SXM GPU submission to MLPerf™ Inference 3.0
Tue, 23 May 2023 17:10:45 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to MLPerf Inference v3.0 in the closed division. This blog highlights Dell Technologies’ closed division submission made with the NVIDIA H100 Tensor Core GPU using the SXM-based HGX system.
Introduction
MLPerf Inference v3.0 submission falls under the benchmarking pillar of the MLCommonsTM consortium with the objective to make fair comparisons across server configurations. Submissions that are made to the closed division warrant an equitable comparison of the systems.
This blog highlights the closed division submissions that Dell Technologies made with the NVIDIA H100 GPU using an HGX 100 system. The HGX system uses a high-bandwidth socket solution designed to work in parallel with NVIDIA NVSwitch interconnect technology.
Aside from NVIDIA, Dell Technologies was the only company to publish results for the NVIDIA H100 SXM GPU card. The NVIDIA H100 GPU results shine in this MLPerf Inference round. This GPU has between 300 percent to 800 percent increases in performance compared to the NVIDIA A100 Tensor Core GPUs. It achieved top results when considering performance per system and performance per GPU.
Submissions made with the NVIDIA H100 GPU
In this round, Dell Technologies used the Dell PowerEdge XE9680 and Dell PowerEdge XE8545 servers to make submissions for the NVIDIA H100 SXM card. Because the PowerEdge XE9680 server is an eight-way GPU server, it allows customers to experience outstanding acceleration for artificial intelligence (AI), machine learning (ML), and deep learning (DL) training and inference.
Platform | PowerEdge XE9680 (8x H100-SXM-80GB, TensorRT) | PowerEdge XE8545 (4x A100-SXM-80GB, TensorRT) | PowerEdge XE9680 (8x A100-SXM-80GB, TensorRT) |
MLPerf System ID | XE9680_H100_SXM_80GBx8_TRT | XE8545_A100_SXM4_80GBx4_TRT | XE9680_A100_SXM4_80GBx8_TRT |
Operating system | Ubuntu 22.04 | ||
CPU | Intel Xeon Platinum 8470 | AMD EPYC 7763 | Intel Xeon Platinum 8470 |
Memory | 2 TB | 4 TB | |
GPU | NVIDIA H100-SXM-80GB | NVIDIA A100-SXM-80GB CTS | NVIDIA A100-SXM-80GB CTS |
GPU form factor | SXM | ||
GPU memory configuration | HBM3 | HBM2e | |
GPU count | 8 | 4 | 8 |
Software stack | TensorRT 8.6.0 CUDA 12.0 cuDNN 8.8.0 Driver 525.85.12 DALI 1.17.0 | ||
Table 1: Software stack of submissions made on NVIDIA H100 and NVIDIA A100 SXM GPUs in MLPerf Inference v3.0
PowerEdge XE9680 Rack Server
With the PowerEdge XE9680 server, customers can take on demanding artificial intelligence, machine learning, and deep learning workloads, including generative AI. This high-performance application server enables rapid development, training, and deployment of large machine learning models. The PowerEdge XE9680 server was made for artificial intelligence, machine learning, deep learning, and other demanding workloads. The PowerEdge XE9680 server is loaded with features for any possible artificial intelligence, machine learning, and deep learning workload as it supports eight NVIDIA HGX H100 80GB 700W SXM5 GPUs or eight NVIDIA HGX A100 80GB 500W SXM4 GPUs, fully interconnected with NVIDIA NVLink technology. For more details, see the specification sheet for the PowerEdge XE9680 server.

Figure 2: Front side view of the PowerEdge XE9680 Rack Server

Figure 3: Front view of the PowerEdge XE9680 Rack Server

Figure 4: Rear side view of the PowerEdge XE9680 Rack Server

Figure 5: Rear view of the PowerEdge XE9680 Rack Server

Figure 6: Top view of the PowerEdge XE9680 Rack Server
Comparison of the NVIDIA H100 SXM GPU with the NVIDIA A100 SXM GPU
Looking at the best entire system results for this round of submission (v3.0) and the previous round of submission (v2.1), the performance gains achieved by the PowerEdge XE9680 server with eight NVIDIA H100 GPUs are outstanding. In comparison, the NVIDIA H100 GPU server outperforms its predecessor, the NVIDIA A100 GPU server, by a large margin in all the tested workloads, as shown in the following figure. Note that the best results in the previous round of submission were generated by the PowerEdge XE8545 server with four NVIDIA A100 GPUs.
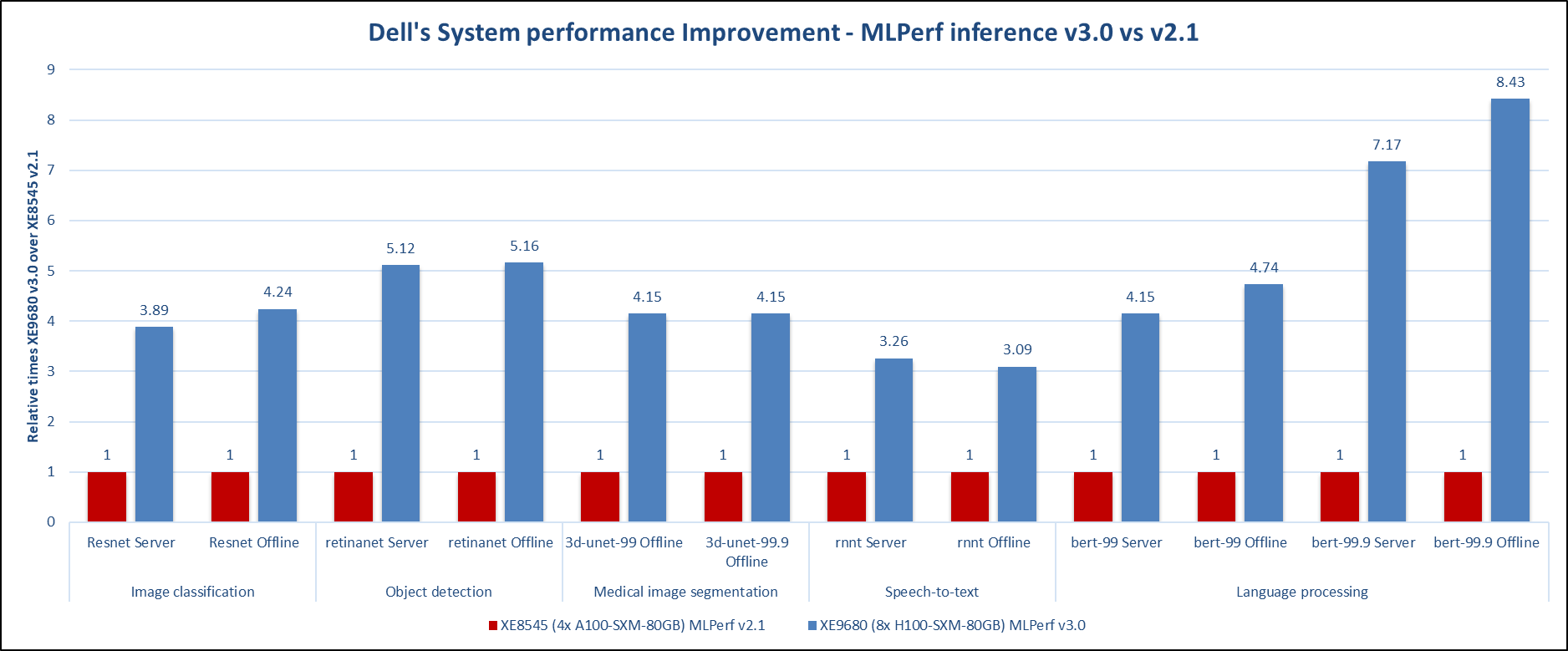
*MLPerf ID 2.1-004 and MLPerf ID 3.0.-0013
Figure 7: Dell’s system performance improvement – MLPerf Inference v3.0 compared to MLPerf Inference v2.1
In the Computer Vision domain for image classification and object detection, the submission for this round showed a four- and five-times performance improvement across the two rounds of submissions respectively. For the medical image segmentation task, the 3D-Unet benchmark, the PowerEdge XE9680 server with NVIDIA H100 GPUs produced up to four times the performance gains. For the RNNT benchmark, which is in the speech-to-text domain, the PowerEdge XE9680 submission for v3.0 showed a three-times performance improvement when compared to the PowerEdge XE8545 submission for v2.1. In the natural language processing benchmark, BERT, we observed impressive gains in both default and high accuracy modes. For the default mode, a four-times performance boost can be seen, and an eight-times performance boost can be claimed for the high accuracy mode. With the recent popularity rise in Large Language Models (LLMs), these results make for an exciting submission.
Conclusion
The NVIDIA H100 GPU is a game changer with its eye-catching performance increases when compared to the NVIDIA A100 GPU. The PowerEdge XE9680 server performed exceptionally well for this round in all machine learning tasks ranging from image classification, object detection, medical image segmentation, speech to text, and language processing. Aside from NVIDIA, Dell Technologies was the only MLPerf submitter for NVIDIA H100 SXM GPU results. Given the high-quality submissions made by Dell Technologies for this round with the PowerEdge XE9680 server, the future in the deep learning space is exciting, especially when we realize the impact this server with NVIDIA H100 GPUs may have for generative AI workloads.

Is GPU integration critical for Predictive Analytics?
Wed, 05 Apr 2023 18:22:40 -0000
|Read Time: 0 minutes
GPUs are getting widespread attention in the Predictive Analytics (PredAn) space. This is due to their ability to perform parallel computation on large volumes of data. GPUs leverage complex models that are tightly integrated to the simulation required to do control synthesis for real-time response in Industry 4.0 (I4) solutions. Consider the predictive maintenance use-case, where telemetry from servers in the datacenter are captured for failure analysis in the analytics cluster and control sequences generated to avoid downtime. Clearly, to be on track, the machine needs to project current data into the future and simulate fault partitions in the monitorable list to negotiate a fix, all in a tight time-window. However, prediction and simulation are inherently slow, particularly when this needs to be done on many fault partitions over multiple servers.
We argue that two things can help:
- Linearizing prediction with Koopman filters
- Leveraging generative models for control synthesis in the simulation space
We use Koopman filter to project data into a skinnier latent basis space for Dimension Reduction (DR) and embed this transformation inside an autoencoder. A probe to convert eigen-vector sections to an Eigen Value Sequence (EVS) that correlates to survival probabilities can then be transformed to Time2Failure (T2F) estimates. This failure detection can then be tagged with a reference to a pre-calibrated auto-fix script derived using Anomaly Fingerprinting (AF) while simulating the projected fault partition. Generative models (GAN) allow performance and footprint optimization, resulting in faster inferencing. In that sense, this improves inferencing throughput. We train generative models for Data, DR, T2F and AF and use them for fast inferencing. Figure 1(a) shows the inferencing flow, 1(b) shows Koopman linearization, and 1(c) shows the underlying GAN footprint.
Figure 1. Inferencing flow, Koopman linearization, and the underlying GAN footprint
In figure 1(a), T2F estimates for all faults on all servers are triaged by the scheduler using DRL in the inferencing phase. In figure 1(b), each fault-group, eigen-vector dimension is searched in the autoencoder frame by resizing the encoder depth for failure clarity in EVS. In figure 1(b), G2 is derived from G1, and G1 from G0 for each fault group. Generative model synthesis enables the mapping of complex computation to high-performance low-footprint analogues that can be leveraged at inference time.
The GPU Argument
A GPU is typically used for both training and inferencing. In the predictive maintenance testbed, we stream live telemetry from iDRACs to the analytics cluster built using Splunk services like streaming, indexing, search, tiering and data-science tools on Robin.io k8s platform. The cluster has access to Nvidia GPU resources for both training and inferencing. The plot in figure 2(a) shows that the use of asynchronous access to Multi-Instance GPU (MIG) inferencing provides performance gain over blocking alternative, measured using wall-clock estimates. The GPU scheduler manages asynchronous T2F workloads better, and blocking calls would require timeout reconfiguration in production. The plot in figure 2(b) shows that inferencing performance of generative models improved by 15% (for 12+ episodes) when selective optimization (DRL-on-CPU and T2F-Calculation-on-GPU) was opted. The direction of this trend makes sense because DRL-in-GPU requires frequent memory-to-memory transfers and so is an ideal candidate for CPU pinning, whereas T2F estimates are dense but relatively less frequent computations that do well when mapped to GPU with MIG enabled. As the gap between the plots widens, this indicates that the CPU only computation cannot keep up with data pile-up, so input sections need to be shortened. The plot in figure 2(c) shows that fewer batches (assuming fixed dataset size) shortened epochs needed to achieve the desired training accuracy in GAN. However, larger batch size requires more GPU memory implying MIG disablement for improved throughput and energy consumption. Based on this data, we argue that dedicating a GPU for training (single kernel) as opposed to switching kernels (between training and inferencing) improves throughput. This tells us that the training GPU (without MIG enablement) and the inferencing GPU (with MIG enablement) should be kept separate in I4 for optimal utilization and performance. Based on current configuration choices, this points to dual Nvidia A30 GPU preference as opposed to a single Nvidia A100 GPU attached to the Power Edge server worker node. The plot in figure 2(d) shows that single layer generative models improve inferencing performance and scales more predictively. The expectation is that multilayering would do better. The plot indicates performance improvement as the section size increases, although more work is needed to understand the impact of multilayering.
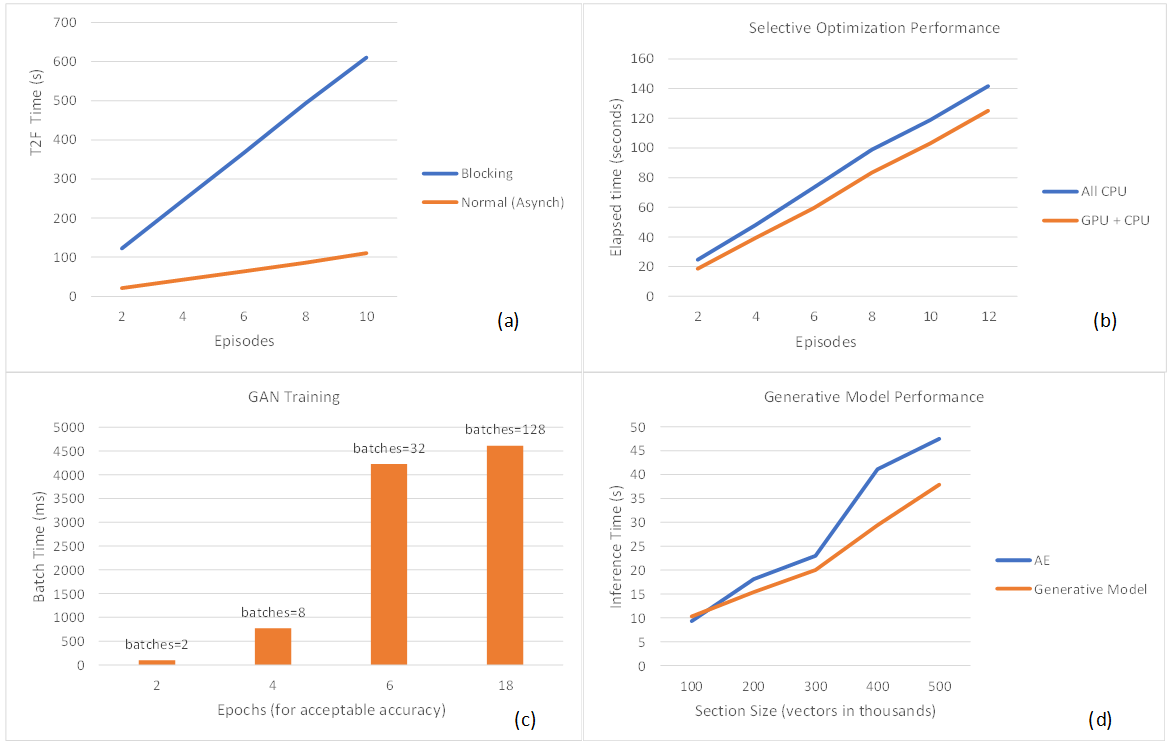
Figure 2. (a) Asynchronous calls for MIG inferencing provide performance gain over blocking calls. (b) Selective optimization provides better inferencing performance. (c) Larger training batch size (fewer batches) shortens the epochs needed to achieve acceptable accuracy. (d) Generative models improve inferencing performance.
In conclusion, predictive analytics is essential for maintenance in the era of digital transformation. We present a solution that scales with Dell server telemetry specification. It is widely accepted that for iterative error correction, linear feedback control systems perform better than their non-linear counterparts. We shaped predictions to behave linearly. By using generative models, one can achieve faster inferencing. We proposed a new way to couple generative models with Digital Twins (DT) simulation models for scheduling shaped by DRL. Our experiments indicate that GPU in analytics cluster accelerates response performance in I4 feedback loops (e.g., MIG enablement at inferencing, leveraging generative models to fast-track control synthesis).
References
- Brunton, S. L.; Budišić, M; Kaiser, E; Kutz, N. Modern Koopman Theory for Dynamical Systems. arXiv 2102.12086 2021.
- Brophy, E; Wang, Z; She, Q; Ward, T. Generative Adversarial Networks in Time Series: A Systematic Literature Survey. ACM Computing Surveys 2023, 55(10), Article 199.
- Matsuo, Y; LeCun, Y; Sahani, M; Precup, D; Silver, D; Sugiyama; M; Uchibe, E; Morimoto, J. Deep learning, reinforcement learning, and world models. Neural Networks Elsevier Press 2022, 152(2022), pp 267-275.
- Gara, S et al. Telemetry Streaming with iDRAC9. Dell White Paper May 2021.
Dell Servers Excel in MLPerf™ Inference 3.0 Performance
Fri, 07 Apr 2023 10:42:23 -0000
|Read Time: 0 minutes
MLCommons has released the latest version (version 3.0) of MLPerf Inference results. Dell Technologies has been an MLCommons member and has been making submissions since the inception of the MLPerf Inference benchmark. Our latest results exhibit stellar performance from our servers and continue to shine in all areas of the benchmark including image classification, object detection, natural language processing, speech recognition, recommender system, and medical image segmentation. We encourage you to see our previous whitepaper about Inference v2.1, which introduces the MLCommons inference benchmark. AI and the most recent awareness of Generative AI, with application examples such as ChatGPT, have led to an increase in understanding about the performance objectives needed to enable customers with faster time-to-model and results. The latest results reflect the continued innovation that Dell Technologies brings to help customers achieve those performance objectives and speed up their initiatives to assess and support workloads including Generative AI in their enterprise.
What’s new with Inference 3.0?
New features for Inference 3.0 include:
- The inference benchmark rules did not make any significant changes. However, our submission has been expanded with the new generation of Dell PowerEdge servers:
- Our submission includes the new PowerEdge XE9680, XR7620, and XR5610 servers.
- Our results address new accelerators from our partners such as NVIDIA and Qualcomm.
- We submitted virtualized results with VMware running on NVIDIA AI Enterprise software and NVIDIA accelerators.
- Besides accelerator-based numbers, we submitted Intel-based CPU-only results.
Overview of results
Dell Technologies submitted 255 results across 27 different systems. The most outstanding results were generated from PowerEdge R750xa and XE9680 servers with the new H100 PCIe and SXM accelerators, respectively, as well as PowerEdge XR5610 and XR7620 servers with the L4 cards. Our overall NVIDIA-based results include the following accelerators:
- (New) Eight-way NVIDIA H100 Tensor Core GPU (SXM)
- (New) Four-way NVIDIA H100 Tensor Core GPU (PCIe)
- (New) Eight-way NVIDIA A100 Tensor Core GPU (SXM)
- Four-way NVIDIA A100 Tensor Core GPU (PCIe)
- NVIDIA A30 Tensor Core GPU
- (New) NVIDIA L4 Tensor Core GPU
- NVIDIA A2 GPU
- NVIDIA T4 GPU
We ran these accelerators on different PowerEdge XE9680, R750xa, R7525, XE8545, XR7620, XR5610 and other server configurations.
This variety of results across different servers, accelerators, and deep learning use cases allows customers to use them as datapoints to make purchasing decisions and set performance expectations.
Interesting Dell datapoints
The most interesting datapoints include:
- Among 21 submitters, Dell Technologies was one of the few companies that submitted results for all closed scenarios including data center, data center power, Edge, and Edge power.
- The PowerEdge XE9680 server procures the highest performance titles with RetinaNet Server and Offline, RNN-T Server, and BERT 99 Server benchmarks. It procures number 2 performance with Resnet Server and Offline, 3D-UNet Offline and 3D-UNet Offline 99.9, BERT 99 Offline, BERT 99.9 Server, and RNN-T Offline benchmarks.
- The PowerEdge XR5610 server procured highest system performance per watt with the NVIDIA L4 accelerator on the ResNet Single Stream, Resnet Multi Stream, RetinaNet Single Stream, RetinaNet Offline, RetinaNet Multi Stream, 3D-UNet 99, 3D-UNet 99.9 Offline, RNN-T Offline, Single Stream, BERT 99 Offline, BERT-99 Single Stream benchmarks.
- Our results included not only various systems, but also exceeded performance gains compared to the last round because of the newer generation of hardware acceleration from the newer server and accelerator.
- The Bert 99.9 benchmark was implemented with FP8 the first time. Because of the accuracy requirement, in the past, the Bert 99.9 benchmark was implemented with FP16 while all other models ran under INT8.
In the following figure, the BERT 99.9 v3.0 Offline scenario renders 843 percent more improvement compared to Inference v2.1. This result is due to the new PowerEdge XE9680 server, which is an eight–way NVIDIA H100 SXM system, compared to the previous PowerEdge XE8545 four-way NVIDIA A100 SXM. Also, the NVIDIA H100 GPU features a Transformer Engine with FP8 precision that speeds up results dramatically.
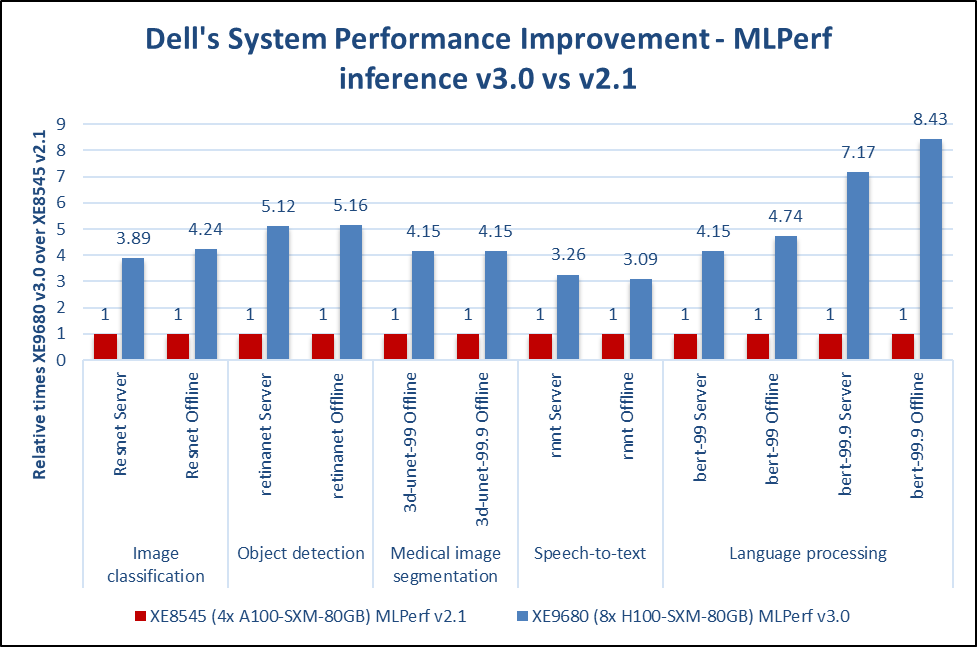
* MLPerf ID 2.1-0014 and MLPerf ID 3.0-0013
Figure 1: Performance gains from Inference v2.1 to Inference v3.0 due to the new system
Results at a glance
The following figure shows the system performance for Offline and Server scenarios. These results provide an overview as upcoming blogs will provide details about these results. High accuracy versions of the benchmark are included for DLRM and 3D-UNet as high accuracy version results are identical to the default version. For the BERT benchmark, both default and high accuracy versions are included as they are different.
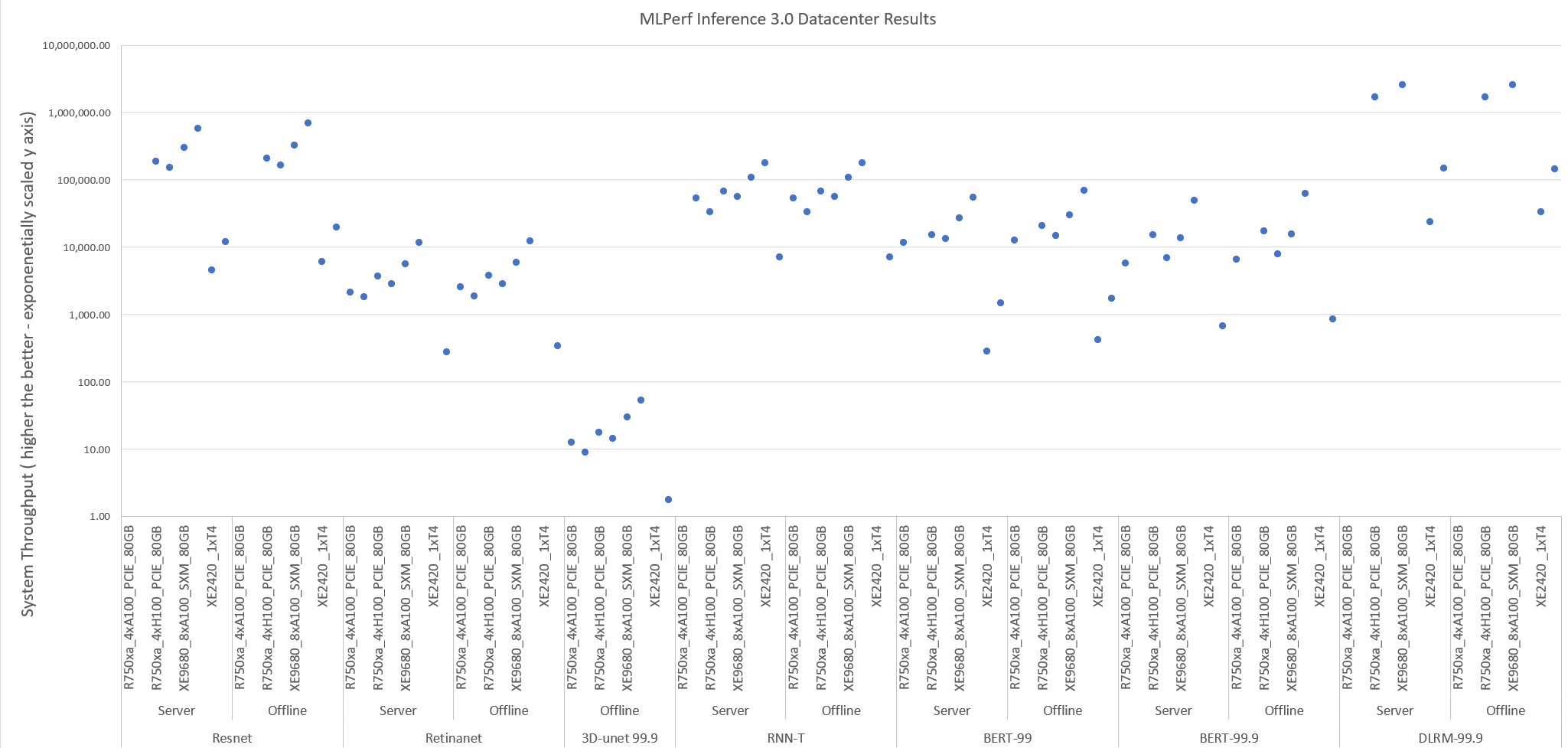
Figure 2: System throughput for data center suite-submitted systems
The following figure shows the Single Stream and Multi Stream scenario latency for the ResNet, RetinaNet, 3D-UNet, RNN-T, and BERT-99 benchmarks. The lower the latency, the better the results.
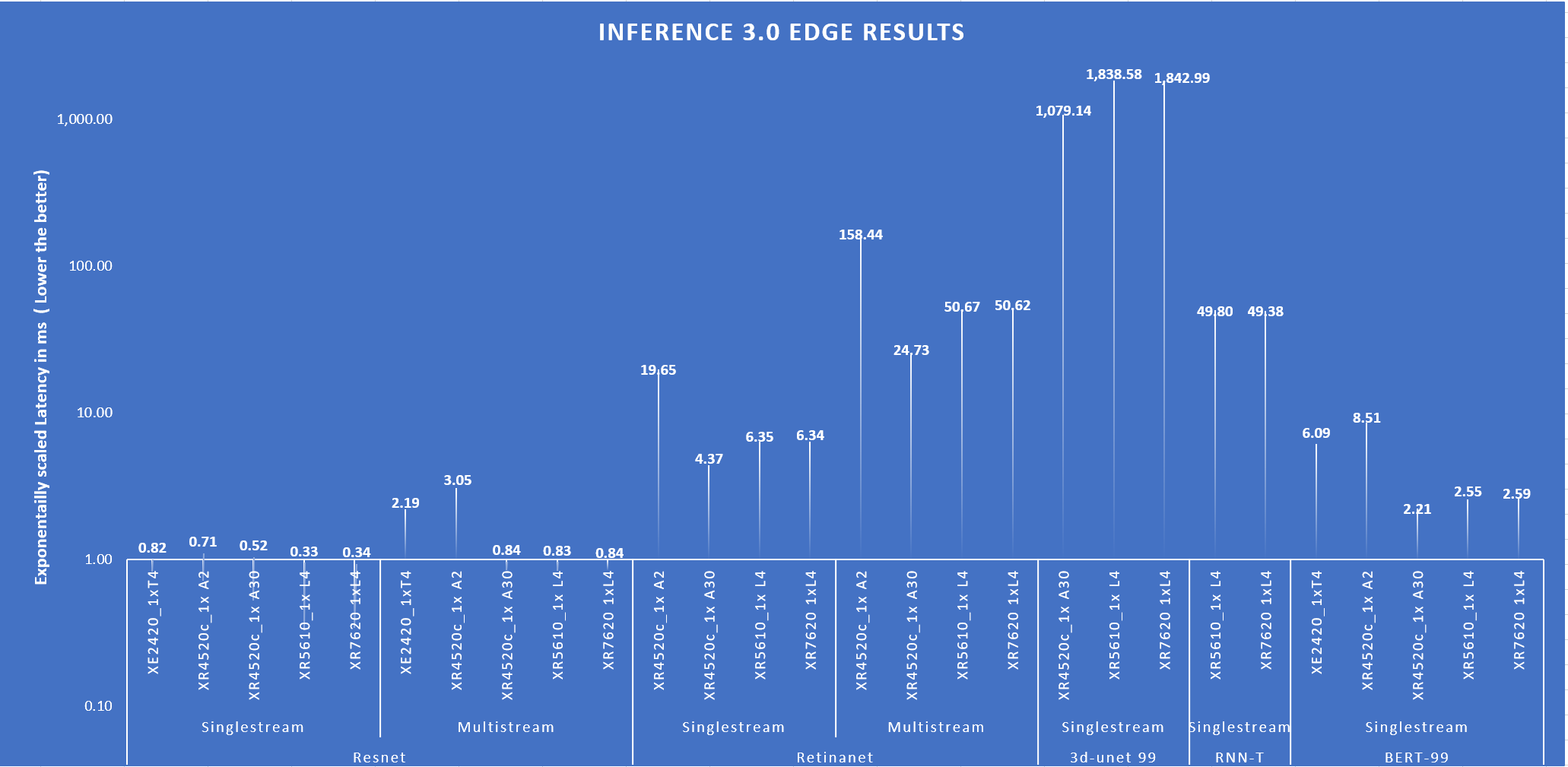
Fig 3: Latency of the systems for different benchmark
Edge benchmark results include Single Stream, Multi Stream, and Offline scenarios. The following figure shows the offline scenario performance.
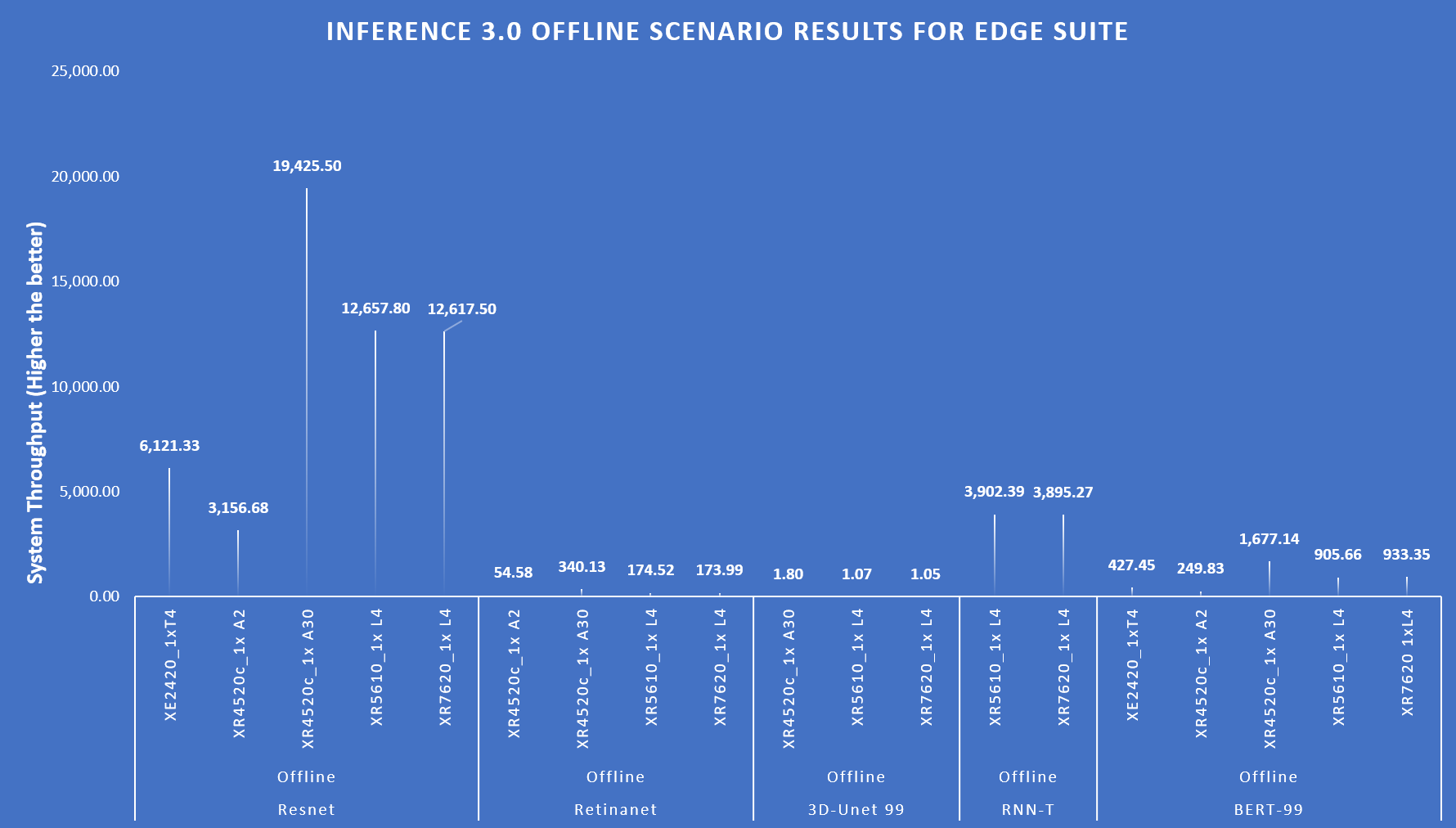
Figure 4: Offline Scenario system throughput for Edge suite
The preceding figures show that PowerEdge servers delivered excellent performance across various benchmarks and scenarios.
Conclusion
We have provided MLCommons-compliant submissions to the Inference 3.0 benchmark across various benchmarks and suites. These results indicate that with the newer generations of servers, such as the PowerEdge XE9680 server, and newer accelerators, such as the NVIDIA H100 GPU, customers can derive higher performance from their data center and edge deployments. Upgrading to newer hardware can yield between 304 and 843 percent improvement across all the benchmarks such as image classification, object detection, natural language processing, speech recognition, recommender systems, and medical image segmentation involved in the MLPerf inference benchmark. From our submissions for new servers such as the PowerEdge XR5610 and XR7620 servers with the NVIDIA L4 GPU, we see exceptional results. These results show that the new PowerEdge servers are an excellent edge platform choice. Furthermore, our variety of submissions to the benchmark can serve as a baseline to enable different performance expectations and cater to purchasing decisions. With these results, Dell Technologies can help fuel enterprises’ AI transformation, including Generative AI adoption, and deployment precisely and efficiently.
MLCommons Results

Accelerate Your Journey to AI Success with MLOps and AutoML
Tue, 07 Feb 2023 22:05:15 -0000
|Read Time: 0 minutes
Artifical Intelligence (AI) and Machine Learning (ML) helps organizations make intelligent data driven business decisions and are critical components to help businesses thrive in a digitally transforming world. While the total annual corporate AI investment has increased substantially since 2019, many organizations are still experiencing barriers to successfully adopt AI. Organizations move along the AI and analytics maturity curve at different rates. Automation methodologies such as Machine Learning Operations (MLOps) and Automatic Machine Learning (AutoML) can serve as the backbone for tools and processes that allow organizations to experiment and deploy models with the speed and scale of a highly efficient, AI-first enterprise. MLOps and AutoML are associated with distinct and important components of AI/ML work streams. This blog introduces how software platfoms like cnvrg.io and H2O Driverless AI make it easy for organizations to adopt these automation methodologies into their AI environment.
This blog is intended to serve as a reference for Dell’s position on MLOps solutions that help organizations scale their AI and ML practices. MLOps and AutoML provide a powerful combination that brings business value out of AI projects quicker and in a secure and scalable way. Dell Validated Designs provides the Reference Architecture that combines the software and Dell hardware to bring these solutions to life.
Importance of automation methodologies
Deploying models to a production environment is an important component to getting the most business value from an AI/ML project. While there are numerous tasks to get a project into production, from Exploratory Data Analysis to model training and tuning, successfully deployed models require additional sets of tasks and procedures, such as runtime model management, model observability and retraining, and inferencing reliability and cost optimization. The lifeycle of a AI/ML project involves disciplines of data engineering, data science, DevOps engineering and roles with differing skillsets across these teams. With all the steps listed above for just a single AI/ML project, it’s not difficult to see the challenges organizations have when faced with wanting to rapidly grow the number of projects across different business units within the organization. Organizations that prioritize ROI, consistency, reusability, traceability, reliability and automation in their AI/ML projects through sets of procedures and tools described in this paper are set up to scale in AI and meet the demand of AI for its business.
Components of an AI/ML project
A typical AI/ML project has many distinct tasks which can flow in a cascading, yet circular manner. This means that while tasks may have dependencies on completion of previous tasks, the continuous learning nature of ML projects create an iterative feedback loop throughout the project.
The following list describes steps that a typical AI/ML project will run through.
- Objective Specification
- Exploratory Data Analysis (EDA)
- Model Training
- Model Implementation
- Model Optimization and Cross Validation
- Testing
- Model Deployment
- Inference
Figure 1. Distinct Tasks in an AI/ML Project
Each task serves an important role in the project and can be grouped at a high level by defining the problem statement, the data and modeling work, and productionizing the final model for inference. Because these groups of tasks have different objectives, there are different automation methodologies that have been developed to streamline and scale projects. The concept of Automated Machine Learning (AutoML) was developed to make the data and modeling work as efficient as possible. AutoML is a set of proven and optimized solutions in data modeling. The practice of ModelOps was developed to deploy models faster and more scalable. While AutoML and ModelOps automate specific tasks within a project, the practice of MLOps serves as an umbrella automation methodology that contains guiding principles for all AI/ML projects.
MLOpsThe key to navigating the challenges of inconsistent data, labor constraints, model complexity, and model deployment to operate efficiently and maximize the business value of AI is through the adoption of MLOps. MLOps, at a high level, is the practice of applying software engineering principles of Continuous Improvement and Continuous Delivery (CI/CD) to Machine Learning projects. It is a set of practices that provide the framework for consistencty and reusability that leads to quicker model deployments and scalability.
MLOps tools are the software based applications that help organizations put the MLOps principles into practice in an automated fashion.
The complexities stemming from ever-changing business environments that affect underlying data, inference needs, etc mean that MLOps in AI/ML projects need to have quicker iteratons than typical DevOps software projects.
AutoML
At the heart of a AI/ML project is the quest for business insights, and the tasks that lead to these insights can be done at a scalable and efficient manner with AutoML. AutoML is the process of automating exploratory data analysis (EDA), algorithm selection, training and optimizations of models.
AutoML tools are low-code or no-code platforms that begin with the ingestion of data. Summary statistics, data visualizations, outlier detection, feature interaction, and other tasks associated with EDA are then automatically completed. For model training, AutoML tools can detect what type of algorthms are appopriate for the data and business question and proceed to test each model. AutoML also itierates over hundreds of versions of the models by tweaking the parameters to find the optimal settings. After cross-validation and further testing of the model, a model package is created which includes the data transformations and scoring pipelines for easy deployment into a production environment.
ModelOps
Oncea trained model is ready for deployment in a production environment, a whole new set of tasks and processes begin. ModelOps is the set of practices and processes that support fast and scalable deployment of models to production. Model performance degrades over time for reasons such as underlying trends in the data changing or introduction of new data, so models need to be monitored closely and be updated to keep peak business value throughout its lifecycle.
Model monitoring and management are key components of ModelOps, but there are many other aspects to consider as part of a ModelOps strategy. Managing infrastructure for proper resource allocation (e.g how and when to include accelerators), automatic model re-training in near real time, and integrating with advanced network sevurity solutions, versioning, and migration are other elements that must be considered when thinking about scaling an AI environment.
Dell solution for automation methodologies
Dell offers solutions that bring together the infrastructure and software partnerships to capitalize on the benefits of AutoML, MLOps and ModelOps. Through jointly engineered and tested solutions with Dell Validated Designs, organizations can provide their AI/ML teams with predictable and configurable ML environments and with their operational AI goals.
Dell has partnered with cnvrg.io and H2O to provide the software platforms to pair with the compute, storage, and networking infrastructure from Dell to complete the AI/ML solutions.
MLOps – cnvrg.io
cnvrg.io is a machine learning platform built by data scientists that makes implementation of MLOps and the process of taking models from experimentation to deployment efficient and scalable. cnvrg.io provides the platform to manage all aspects of the ML life cycle, from data pipelines, to experimentation, to model deployment. It is a Kubernetes-based application that allows users to work in any compute environment, whether it be in the cloud or on-premises and have access to any programming language.
The management layer of cnvrg.io is powered by a control plane that leverages Kubernetes to manage the containers and pods that are needed to orchestrate the tasks of a project. Users can view the state and health and resource statistics of the environment and each task using the cnvrg.io dashboard.
cnvrg.io makes it easy to access the algorithms and data components, whether they are pre-trained models or models built from scratch, with Git interaction through the AI Library. Data pre-processing logic or any customized models can be stored and implemented for tasks across any project by using the drag-and-drop interface for end-to-end management called cnvrg.io Pipelines.
The orchestration and scheduling features use Kubernetes-based meta-scheduler, which makes jobs portable across environments and can scale resources up or down on demand. Cnvrg.io facilitates job scheduling across clusters in the cloud and on-premises to navigate through resource contention and bottlenecks. The ability to intelligently deploy and manage compute resources, from CPU, GPU, and other specialized AI accelerators to the tasks where they can be best used is important to achieving operational goals in AI.
cnvrg.io solution architecture
The cnvrg.io software can be installed directly on your data center, or it can be accessed through the cnvrg.io Metacloud offering. Both versions allow users to configure the organization’s own infrastructure into compute templates. For installations into an on-premises data center, cnvrg.io can be deployed on various Kubernetes infrastructures, including bare metal, but the Dell Validated Design for AI uses VMware and NVIDIA to provide a powerful combination of composability and performance.
Dell’s PowerEdge servers that can be equipped with NVIDIA GPUs provide the compute resources required to run any algorithm in machine learning packages like scikit learn to deep learning algorithms in frameworks like TensorFlow and PyTorch. For storage, Dell’s PowerScale appliance with all-flash, scale out NAS storage deliver the concurrency performance to support data heavy neural networks. VMware vSphere with Tanzu allows for the Tanzu Kubernetes clusters, which are managed by Tanzu Mission Control. The servers running VMware vSAN provide a storage repository for the VM and pods. PowerSwitch network switches with a 25 GbE-based design or 100 GbE-based design allow for neural network training jobs than can run on a single node. Finally, the NVIDIA AI Enterprise comes with the software support for GPUs such as fractionalizing GPU resources with the MIG capability.
Dell provides recommendations for sizing of the different worker node configurations, such as the number of CPUs/GPUs and amount of memory, that users can deploy for the various types of algorithms different AI/ML projects may use.
Figure 2. Dell/cnvrg.io Solution Architecture
For more information, see the Design Guide—Optimize Machine Learning Through MLOps with Dell Technologies cnvrg.io.
AutoML – H2O.ai Driverless AI
Dell has partnered with H2O and its flagship product, Driverless AI, to give organizations a comprehensive AutoML platform to empower both data scientists and non-technical folks to unlock insights efficiently and effectively. Driverless AI has several features that help optimize the model development portion of an AI/ML workflow, from data ingestion to model selection, as organizations look to gain faster and higher quality insights to business stakeholders. It is a true no-code solution with a drag and drop type interface that opens the door for citizen data scientists.
Starting with data ingestion, Driverless AI can connect to datasets in various formats and file systems, no matter where the data resides, from on-premises to a clould provider. Once ingested, Driverless AI runs EDA, provides data visualization, outlier detection, and summary statistics on your data. The tool also automatically suggests data transformations based on the shape of your data and performs a comprehensive feature engineering process that search for high-value predictors against the target variable. A summary of the auto-created features is displayed in an easy to digest dashboard.
For model development, Driverless AI automatically trains multiple in-built models, with numerous iterations for hyper parameter tuning. The tool applies a genetic algorithm that creates an ensemble, ‘survival of the fittest’ final model. The user also has the ability to set the priority on factors of accuracy, time, and interpretability. If the user wishes to arrive at a model that needs to be presented to a less technical busines audience, for example, the tool will focus on algorithms that have more explainable features rather than black box type models that may achieve better accuracy with a longer training time. While the Driverless AI tool may be run as a no-code solution, the bring your own recipe feature empowers more seasoned data scientists to bring custom data transformations and algorithms into the tools as part of the experimenting process.
The final output of Driverless AI, after a champion model is crowned, will include a scoring pipeline file that makes it easy to deploy to a production environment for inference. The scoring pipeline can be saved in Python or a MOJO and includes components like data transformations, scripts, runtime, etc.
Driverless AI solution architecture
The H2O Driverless AI platform can be deployed either in Kubernetes as pods or as a stand-alone container. The Dell Validated Design of Driverless AI highlights the flexibility VMware vSphere with Tanzu for the Kubernetes layer works with H2O’s Enterprise Steam to provide resource control and monitoring, access control, and security out of the box.
Dell PowerEdge servers, with optional NVIDIA GPUs, and the NVIDIA AI Enterprise make building containers easy for different sets of users. For use cases that are heavy on EDA or employ traditional machine learning algorithms, Driverless AI containers with CPUs only may be appropriate, while containers with GPUs are best suited for training deep learning models usually associated with natural language processing and computer vision. Dell PowerScale storage and Dell PowerSwitch network adapters provide concurrency at scale to train the data intensive algorithms found within Driverless AI.
Dell provides sizing deployments recommendations specific to an organization’s requirements and capabilities. For organizations starting their AI journey, a deployment with 5 Driverless AI instances, 40 CPU cores, 3.2 TB of memory, and 5 TB storage is recommended for workloads and projects that perform classic machine learning or statistical modeling. For a mainstream deployment with more users and heavier workloads that would benefit from GPU acceleration, 10 Driverless AI instances with 100 CPU cores and 5 NVIDIA A100 GPUs, 8 TB of memory, and 10 TB of storage is recommended. Finally, for high performance deployments for organizations that want to deploy AI models at scale, 20 Driverless AI instances, 200 CPU cores and 10 A100 GPUs, 16 TB of memory, and 20 TB of storage provides the infrastructure for a full-service AI environment.
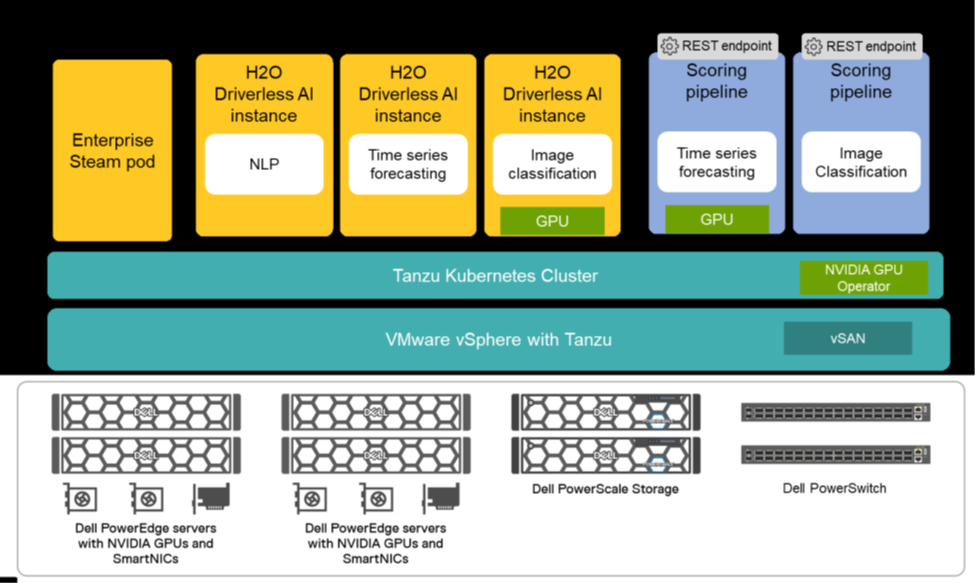
Figure 3. Dell/H2O Driverless AI Solution Architecture
For more information, see Automate Machine Learning with H2O Driverless AI.
Dell is your partner in your AI Journey
AI is constantly evolving, and many organizations do not have the AI expertise to keep up with designing, developing, deploying, and managing solution stacks at the competitive pace. Dell Technologies is your trusted partner and offers solutions that empower your organization in its AI journey. For over the past decade, Dell has been a proven leader in the advanced computing space that includes industry leading products, solutions, and expertise. We have a specialized team of AI, High Performance Computing (HPC), and Data Analytics experts dedicated to helping you keep pace on your AI journey.
AI Professional Services
Regardless of your AI needs, you can rest assured that your deployments will be backed up by Dell’s world class technology services. Our expert consulting services for AI help you plan, implement, and optimize AI solutions, while more than 35,000 services experts can meet you where you are on your AI journey.
- Consulting Services
- Deployment Services
- Support Services
- Payment Solutions
- Managed Services
- Residency Services
Customer Solution Center
The Customer Solution Center is a team of experienced professionals equipped to provide expert advice, recommendations, and demonstrations of the cutting-edge technologies and platforms essential for successful AI implementation. Our staff maintains a thorough understanding of the diverse needs and challenges of our customers and offers valuable insights garnered from extensive engagement with a broad range of clients. By leveraging our extensive knowledge and expertise, you gain a competitive advantage in your pursuit of AI solutions.
AI and HPC Innovation Lab
The AI and HPC Innovation Lab is a premier infrastructure, equipped with a highly skilled team of computer scientists, engineers, and Ph.D. level experts. This team actively engages with customers and members of the AI and HPC community, fostering partnerships and collaborations to drive innovation. With early access to cutting-edge technologies, the Lab is equipped to integrate and optimize clusters, benchmark applications, establish best practices, and publish insightful white papers. By working directly with Dell's subject matter experts, customers can expect tailored solutions for their specific AI and HPC requirements.
Conclusion
MLOps and AutoML play a critical role in fostering the successful integration of AI/ML into organizations. MLOps provides a standardized framework for ensuring consistency, reusability, and scalability in AI/ML initiatives, while AutoML streamlines the data and modeling process. This synergistic approach enables organizations to make data-driven decisions and derive maximum business value from their AI/ML endeavors. Dell Validated Designs offer a blueprint for implementing MLOps, thereby bringing these concepts to fruition. The dynamic nature of AI/ML projects necessitates rapid iterations and automation to tackle challenges such as data inconsistency and resource limitations. MLOps and AutoML serve as crucial enablers in driving digital transformation and establishing an AI-centric enterprise.

Interpreting TPCx-AI Benchmark Results
Wed, 01 Feb 2023 14:29:11 -0000
|Read Time: 0 minutes
TPCx-AI Benchmark
Overview
TPCx-AI Benchmark abstracts the diversity of operations in a retail data center scenario. Selecting a retail business model assists the reader relate intuitively to the components of the benchmark, without tracking that industry segment tightly. Such tracking would minimize the relevance of the benchmark. The TPCx-AI benchmark can be used to characterize any industry that must transform operational and external data into business intelligence.
This paper introduces the TPCx-AI benchmark and uses a published TPCx-AI result to describe how the primary metrics are determined and how they should be read.
Benchmark model
TPCx-AI data science pipeline
The TPCx-AI benchmark imitates the activity of retail businesses and data centers with:
- Customer information
- Department stores
- Sales
- Financial data
- Product catalog and reviews
- Emails
- Data center logs
- Facial images
- Audio conversations
It models the challenges of end-to-end artificial intelligence systems and pipelines where the power of machine learning and deep learning is used to:
- Detect anomalies (fraud and failures)
- Drive AI-based logistics optimizations to reduce costs through real-time forecasts (classification, clustering, forecasting, and prediction)
- Use deep learning AI techniques for customer service management and personalized marketing (facial recognition and speech recognition)
It consists of ten different use cases that help any retail business data center address and manage any business analysis environment.
The TPCx-AI kit uses a Parallel Data Generator Framework (PDGF) to generate the test dataset. To mimic the datasets of different company sizes the user can specify scale factor (SF), a configuration parameter. It sets the target input dataset size in GB. For example, SF=100 equals 100 GB. Once generated, all the data is processed for subsequent stages of postprocessing within the data science pipeline.
Use cases
The TPCx-AI Benchmark models the following use cases:

Figure 1: TPCx-AI benchmark use case pipeline flow
Table 1: TPCx-AI benchmark use cases
ID | Use case | M/DL | Area | Algorithm |
UC01 | Customer Segmentation | ML | Analytics | K-Means |
UC02 | Conversation Transcription | DL | NLP | Recurrent Neural Network |
UC03 | Sales Forecasting | ML | Analytics | ARIMA |
UC04 | Spam Detection | ML | Analytics | Naïve Bayes |
UC05 | Price Prediction | DL | NLP | RNN |
UC06 | Hardware Failure Detection | ML | Analytics | Support Vector Machines |
UC07 | Product Rating | ML | Recommendation | Alternating Least Squares |
UC08 | Trip Type Classification | ML | Analytics | XGBoost |
UC09 | Facial Recognition | DL | Analytics | Logistic Regression |
UC10 | Fraud Detection | ML | Analytics | Logistic Regression |
Benchmark run
The TPCx-AI Benchmark run consists of seven separate tests run sequentially. The tests are listed below:
- Data Generation using PDGF
- Load Test – Loads data into persistent storage (HDFS or other file systems)
- Power Training Test – Generates and trains models
- Power Serving Test I – Uses the trained model in Training Phase to conduct the serving phase (Inference) for each use case
- Power Serving Test II – There are two serving tests that run sequentially. The test with the greater geometric mean (geomean) of serving times is used in the overall score.
- Scoring Test – Model validation stage. Accuracy of the model is determined using defined accuracy metrics and criteria
- Throughput Test – Runs two or more concurrent serving streams
The elapsed time for each test is reported.
Note: There are seven benchmark phases that span an end-to-end data science pipeline as shown in Figure 1. For a compliant performance run, the data generation phase is run but not scored and consists of the subsequent six separate tests, load test through throughput test, run sequentially.
Primary metrics
For every result, the TPC requires the publication of three primary metrics:
- Performance
- Price-Performance
- Availability Date
Performance metric
It is possible that not all scenarios in TPCx-AI will be applicable to all users. To account for this situation, while defining the performance metric for TPCx-AI, no single scenario dominates the performance metric. The primary performance metric is the throughput expressed in terms of AI use cases per minute (AIUCpm) @ SF is defined in the figure below.
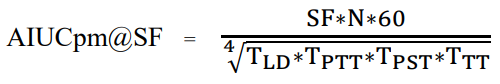
Figure 2: Definition of the TPCx-AI benchmark metric
Where:
TLD = Load time
TPTT = Geomean of training times
TPST1 = Geomean of Serving times
TPST2 = Geomean of serving times
TPST = Max (TPST1, TPST2)
TTT = Total elapsed time/ (#streams * number of use cases)
N = Number of use cases
Note: The elapsed time for the scoring test is not considered for the calculation of the performance metric. Instead, the results of the scoring test are used to determine whether the Performance test was successful.
The scoring test result for each user case should meet or better the reference result set provided in the kit as shown in the figure below.
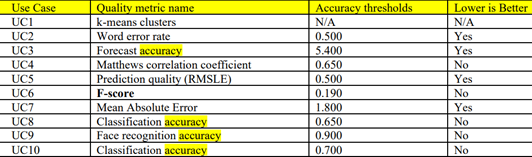
Figure 3: Benchmark run accuracy metrics
Calculating the Performance metric
To illustrate how the performance metric is calculated, let us consider the results published for SF=10 at:
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122110802
A portion of the TPCx-AI result highlights, showing the elapsed time for the six sequential tests constituting the benchmark run is shown in the figure below.
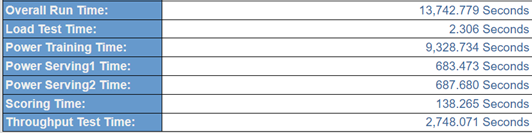
Figure 4: Elapsed time for the benchmark test phases
The result highlights only provide the training times and the serving times. To calculate the final performance metric, we need to use the geometric mean of the training times and serving times. To arrive at the geomean of the training times and the testing times, the time taken for each use case is needed. That time is provided in the Full Disclosure Report (FDR) that is part of the benchmark results. The link to the FDR of the SF=10 results that we are considering are at:
https://www.tpc.org/results/fdr/tpcxai/dell~tpcxai~10~dell_poweredge_r7615~fdr~2022-11-09~v01.pdf
The use case times and accuracy table from the FDR are shown in the figure below.
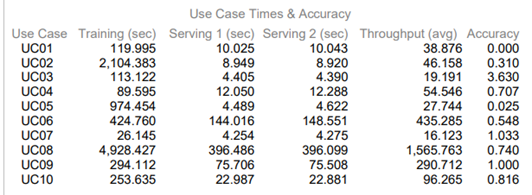
Figure 5: Use case times and accuracy
Note: The accuracy metrics are defined in Table 7a of the TPCx-AI User Guide.
Using the data in Figure 4 and Figure 5:
TLD = Load time =2.306 seconds
TPTT = Geomean of training time =316.799337
(119.995*2104.383*113.122*89.595*974.454*424.76*26.14*4928.427*29.112*253.63)1/10
TPST1 = Geomean of Serving times =19.751 seconds
(10.025*8.949*4.405*12.05*4.489*144.016*4.254*396.486*75.706*22.987)1/10
TPST2 = Geomean of serving times = 19.893 seconds
(10.043*8.92*4.39*12.288*4.622*148.551*4.275*396.099*75.508*22.881)1/0
TPST = Max (TPST1, TPST2)= 19.893 seconds
TTT = Total elapsed time/ (#streams * # of use cases) =2748.071/ (100*10)= 2.748 seconds
N = Number of use cases =10
Note: The geometric mean is arrived at by multiplying the time taken for each of the use cases and finding the 10th root of the product.
Plugging the values in the formula for calculating the AIUCpm@SF given in Figure 2, we get:
AIUCpm@SF= 10*10*60/ (2.306*316.799*19.893*2.748)1/4
= 6000/ (39935.591)1/4
= 6000/14.1365=424.433
The actual AIUCpm@SF10=425.31
Calculating the Price-Performance metric
The Price-Performance metric is defined in the figure below.
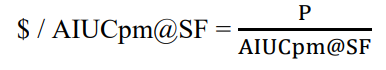
Figure 6: Price-Performance metric definition
Where:
- P = is the price of the hardware and software components in the System Under Test (SUT)
- AIUCpm@SF is the reported primary performance metric
Note: A one-year pricing model must be used to calculate the price and the price-performance result of the TPCx-AI Benchmark.
AIUCpm@SF10 = 425.31
Price of the configuration =$ 48412
$/AIUCpm@SF10 = 113.83 USD per AIUCpm@SF10
Availability date
All components used in this result will be orderable and available for shipping by February 22, 2023.
Performance results
Dell has published six world record-setting results based on the TPCx-AI Benchmark standard of the TPC. Links to the publications are provided below.
SF1000
Dell PowerEdge R650/Intel Xeon Gold (Ice Lake) 6348/CDP 7.1.7—11 nodes
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122120101
SF300
Dell PowerEdge R6625/AMD EPYC Genoa 9354/CDP 7.1.7—four nodes
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122110805
SF100
Dell PowerEdge R6625/AMD EPYC Genoa 9354/CDP 7.1.7—four nodes
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122110804
SF30
Dell PowerEdge R6625/AMD EPYC Genoa 9174F/Anaconda3—one node
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122110803
SF10
Dell PowerEdge R7615/AMD EPYC Genoa 9374F/Anaconda3—one node
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122110802
SF3
Dell PowerEdge R7615/AMD EPYC Genoa 9374F/Anaconda3—one node
https://www.tpc.org/tpcx-ai/results/tpcxai_result_detail5.asp?id=122110801
With these results, Dell Technologies holds the following world records on the TPCx-AI Benchmark Standard:
- #1 Performance and Price-Performance on SF1000
- #1 Performance and Price-Performance on SF300
- #1 Performance and Price-Performance on SF100
- #1 Performance and Price-Performance on SF30
- #1 Performance on SF10
- #1 Performance Price-Performance on SF3
Conclusion
Summary
This blog describes the TPCx-AI benchmark and how the performance result of the TPCx-AI Benchmark can be interpreted. It also describes how Dell Technologies maintains leadership in the TPCx-AI landscape.

Dell Servers Excel in MLPerf™ Training v2.1
Wed, 16 Nov 2022 10:07:33 -0000
|Read Time: 0 minutes
Dell Technologies has completed the successful submission of MLPerf Training, which marks the seventh round of submission to MLCommons™. This blog provides an overview and highlights the performance of the Dell PowerEdge R750xa, XE8545, and DSS8440 servers that were used for the submission.
What’s new in MLPerf Training v2.1?
This round of submission does not include new benchmarks or changes in the existing benchmarks. A change is introduced in the submission compliance checker.
This round adds one-sided normalization to the checker to reduce variance in the number of steps to converge. This change means that if a result converges faster than the RCP mean within a certain range, the checker normalizes the results to the RCP mean. This normalization was not available in earlier rounds of submission.
What’s new in MLPerf Training v2.1 with Dell submissions?
For Dell submission for MLPerf Training v2.1, we included:
- Improved performance with BERT and Mask R-CNN models
- Minigo submission results on Dell PowerEdge R750xa server with A100 PCIe GPUs
Overall Dell Submissions
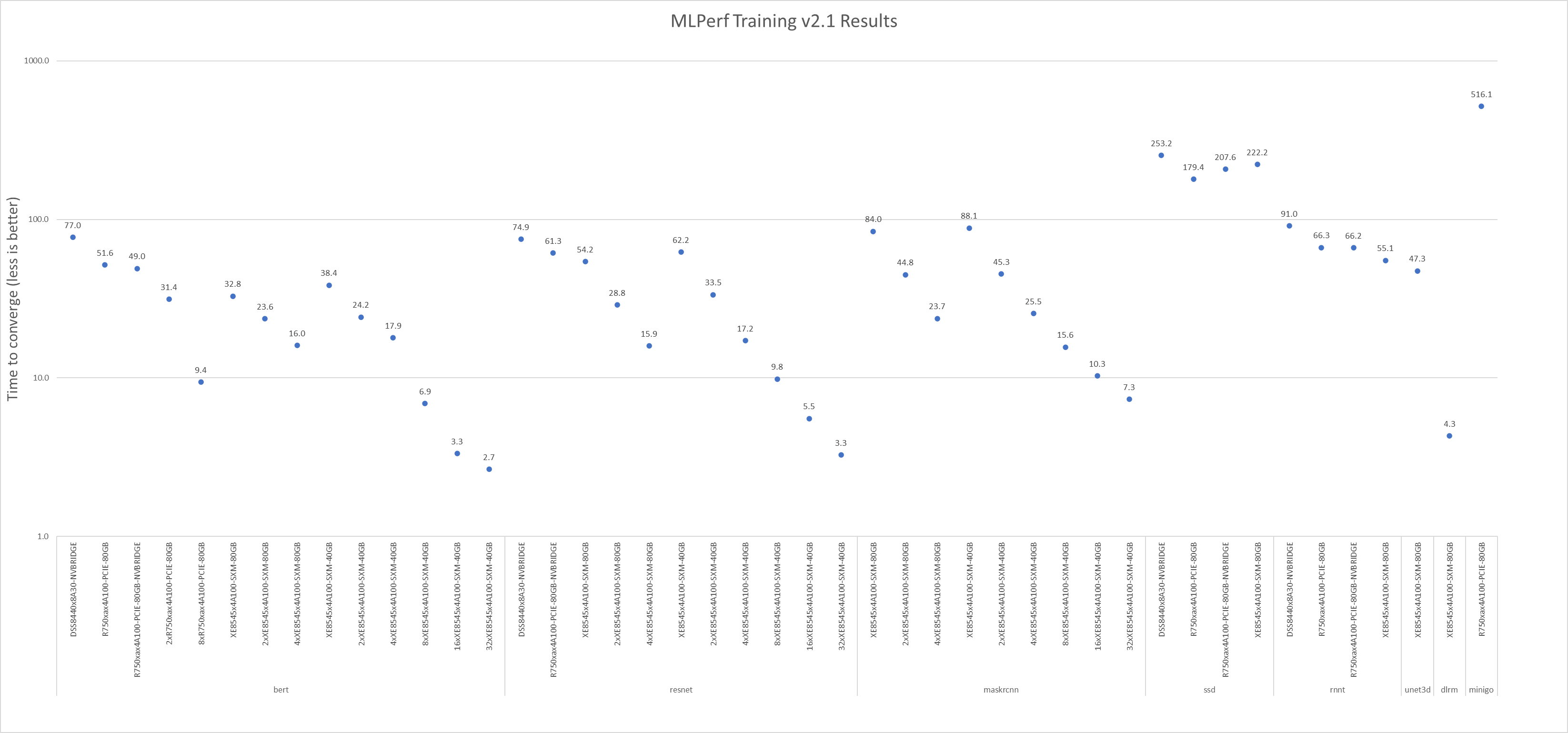
Figure 1. Overall submissions for all Dell PowerEdge servers in MLPerf Training v2.1
Figure 1 shows our submission in which the workloads span across image classification, lightweight and heavy object detection, speech recognition, natural language processing, recommender systems, medical image segmentation, and reinforcement learning. There were different NVIDIA GPUs including the A100, with PCIe and SXM4 form factors having 40 GB and 80 GB VRAM and A30.
The Minigo on the PowerEdge R750xa server is a first-time submission, and it takes around 516 minutes to run to target quality. That submission has 4x A100 PCIe 80 GB GPUs.
Our results have increased in count from 41 to 45. This increased number of submissions helps customers see the performance of the systems using different PowerEdge servers, GPUs, and CPUs. With more results, customers can expect to see the influence of using different hardware settings that can play a vital role in time to convergence.
We have several procured winning titles that demonstrate the higher performance of our systems in relation to other submitters, starting with the highest number of results across all the submitters. Some other titles include the top position in the time to converge for BERT, ResNet, and Mask R-CNN with our PowerEdge XE8545 server powered by NVIDIA A100-40GB GPUs.
Improvement in Performance for BERT and Mask R-CNN
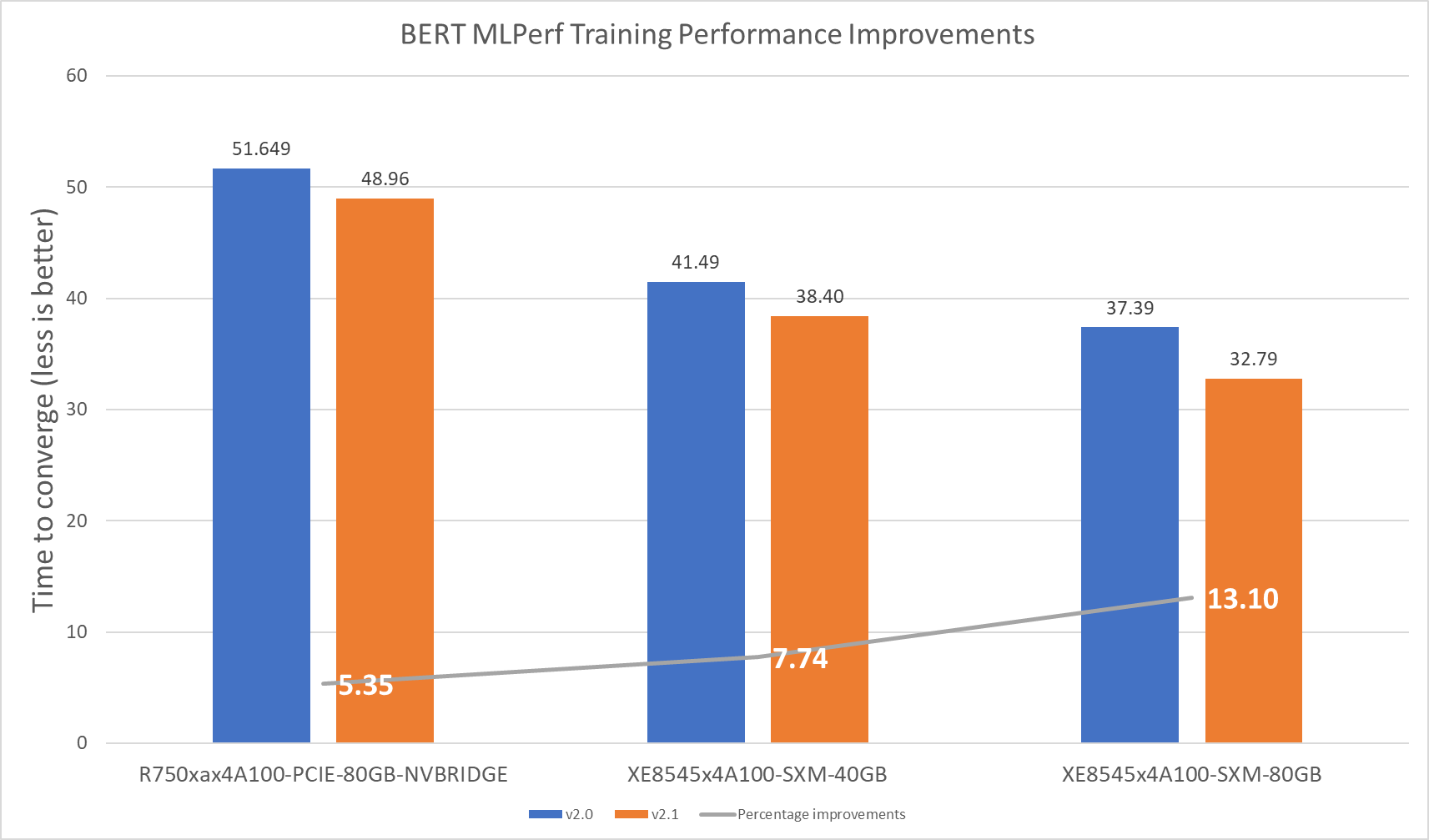 Figure 2. Performance gains from MLPerf v2.0 to MLPerf v2.1 running BERT
Figure 2. Performance gains from MLPerf v2.0 to MLPerf v2.1 running BERT
Figure 2 shows the improvements seen with the PowerEdge R750xa and PowerEdge XE8545 servers with A100 GPUs from MLPerf training v2.0 to MLPerf training v2.1 running BERT language model workload. The PowerEdge XE8545 server with A100-80GB has the fastest time to convergence and the highest improvement at 13.1 percent, whereas the PowerEdge XE8545 server with A100-40GB has 7.74 percent followed by the PowerEdge R750xa server with A100-PCIe at 5.35 percent.
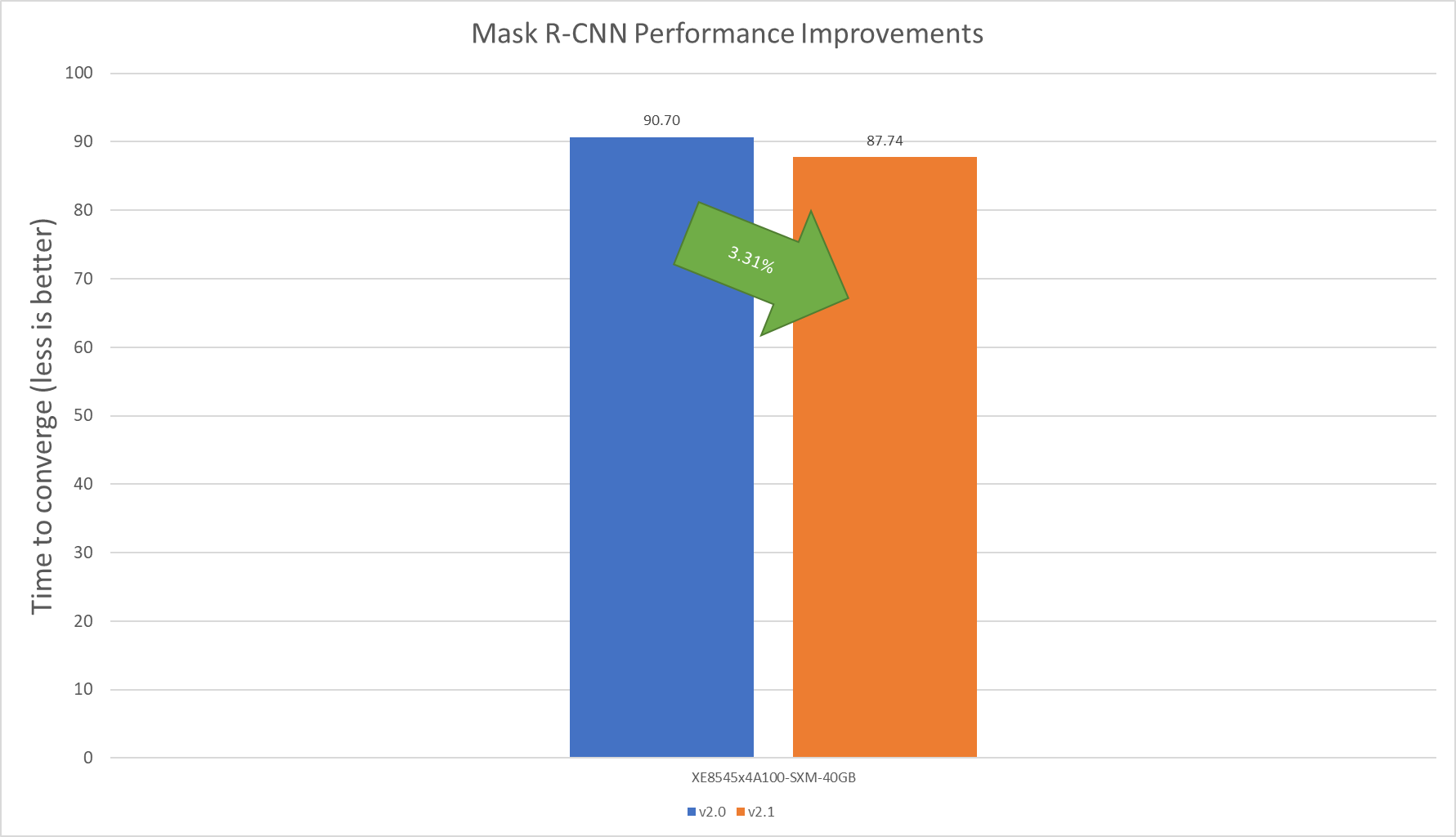
Figure 3. Performance gains from MLPerf v2.0 to MLPerf v2.1 running Mask R-CNN
Figure 3 shows the improvements seen with the PowerEdge XE8545 server with A100 GPUs. There is a 3.31 percent improvement in time to convergence with MLPerf v2.1.
For both BERT and Mask R-CNN, the improvements are software-based. These results show that software-only improvements can reduce convergence time. Customers can benefit from similar improvements without any changes in their hardware environment.
The following sections compare the performance differences between SXM and PCIe form factor GPUs.
Performance Difference Between PCIe and SXM4 Form Factor with A100 GPUs
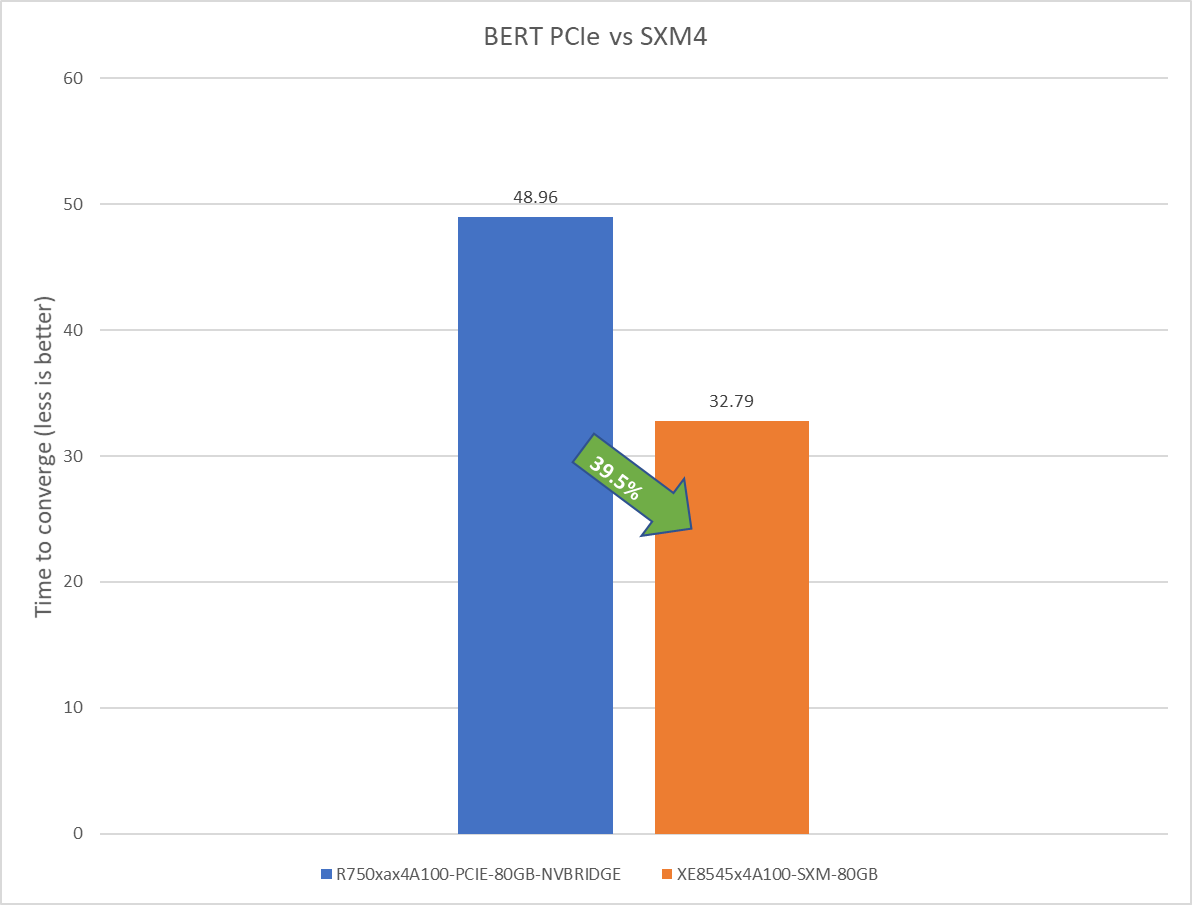
Figure 4. SXM4 form factor compared to PCIe for the BERT
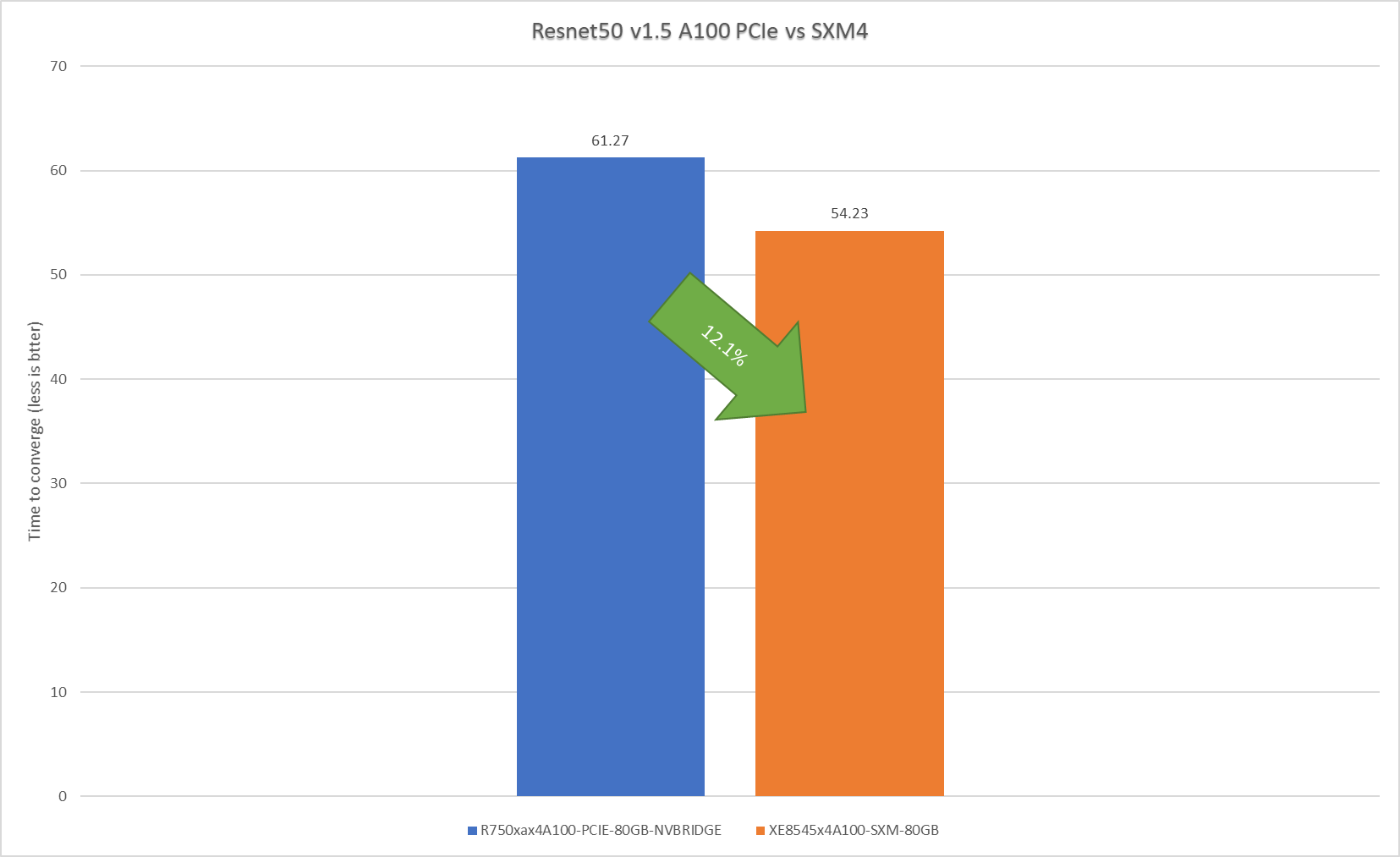
Figure 5. SXM4 form factor compared to PCIe for Resnet50 v1.5
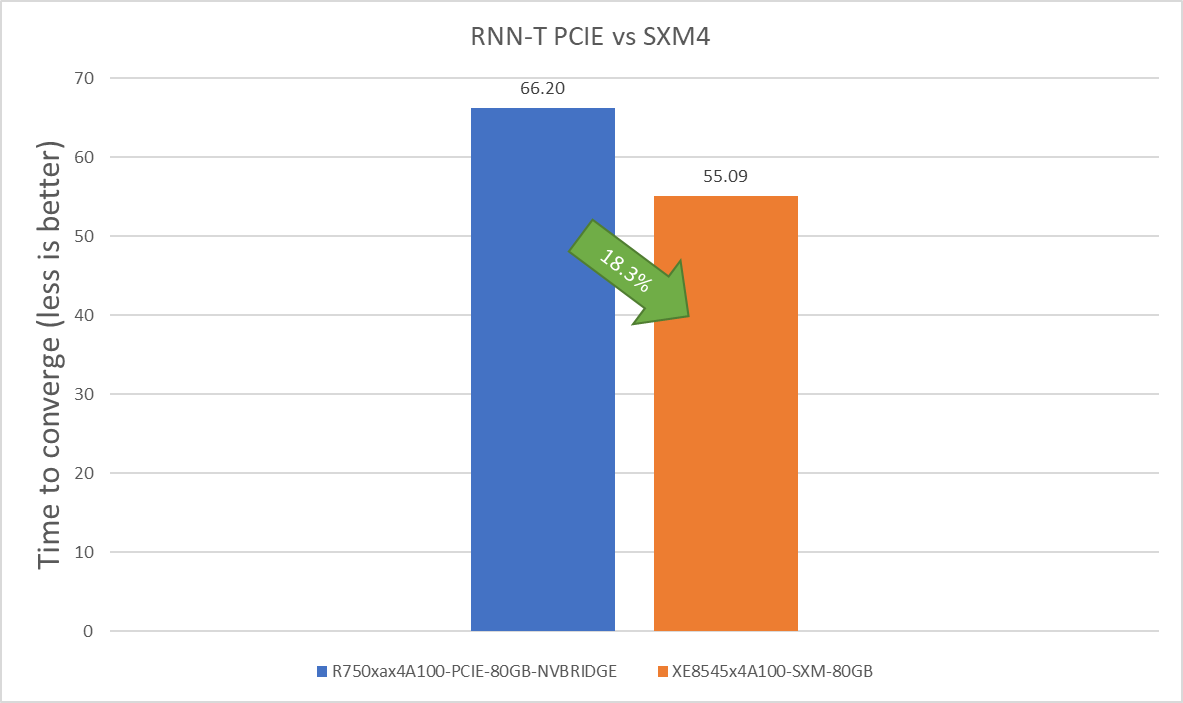
Figure 6. SXM4 form factor compared to PCIe for the RNN-T
Table 1:
System | BERT | Resnet50 | RNN-T |
R750xax4A100-PCIe-80GB | 48.95 | 61.27 | 66.19 |
XE8545x4A100-SXM-80GB | 32.79 | 54.23 | 55.08 |
Percentage difference | 39.54% | 12.19% | 18.32% |
Figures 4, 5, and 6 and Table 1 show that SXM form factor is faster than the PCIe form factor for BERT, Resnet50 v1.5, and RNN-T workloads.
The SXM form factor typically consumes more power and is faster than PCIe. For the above workloads, the minimum percentage improvement in convergence that customers can expect is in double digits, ranging from approximately 12 percent to 40 percent, depending on the workload.
Multinode Results Comparison
Multinode performance assessment is more important than ever. With the advent of large models and different parallelism techniques, customers have an ever-increasing need to find results faster. Therefore, we have submitted several multinode results to assess scaling performance.
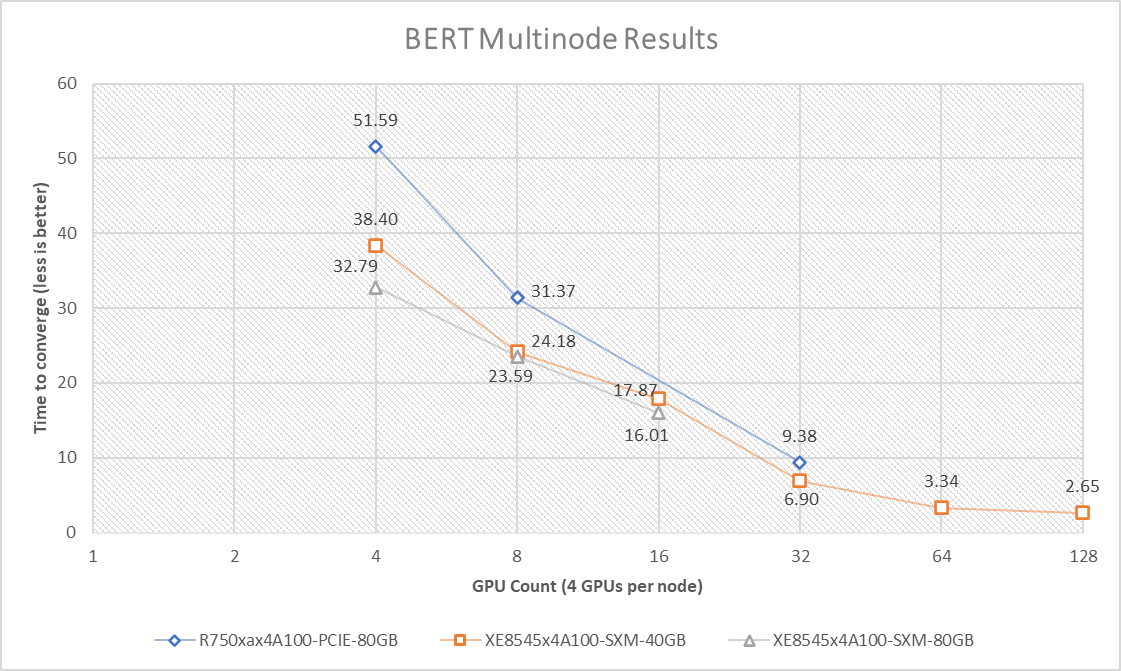 Figure 7. BERT multinode results with PowerEdge R750xa and XE8545 servers
Figure 7. BERT multinode results with PowerEdge R750xa and XE8545 servers
Figure 7 indicates multinode results from three different systems with the following configurations:
- R750xa with 4 A100-PCIe-80GB GPUs
- XE8545 with 4 A100-SXM-40GB GPUs
- XE8545 with 4 A100-SXM-80GB GPUs
Every node of the above system has four GPUs each. When the graph shows eight GPUs, it means that the performance results are derived from two nodes. Similarly, for 16 GPUs the results are derived from four nodes, and so on.
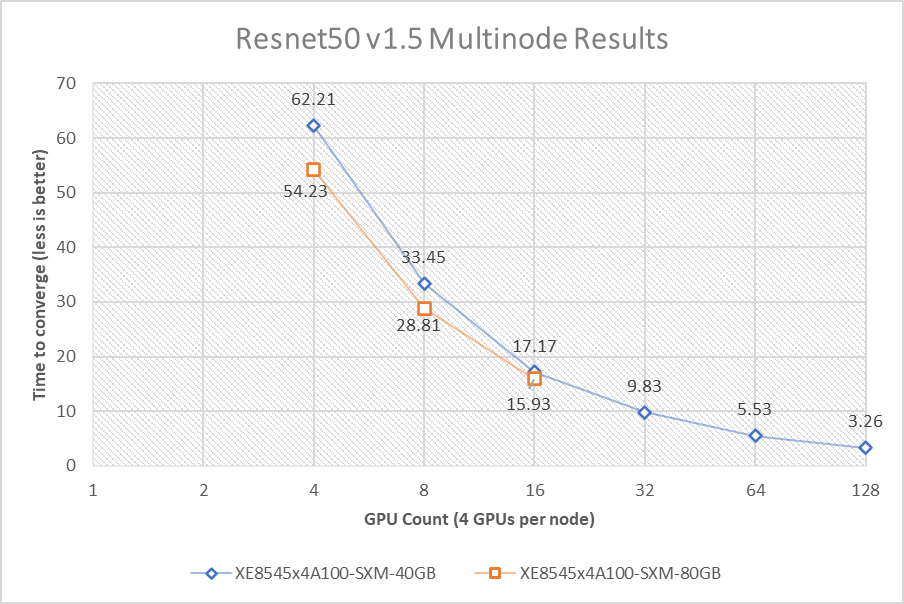
Figure 8. Resnet50 multinode results with R750xa and XE8545 servers
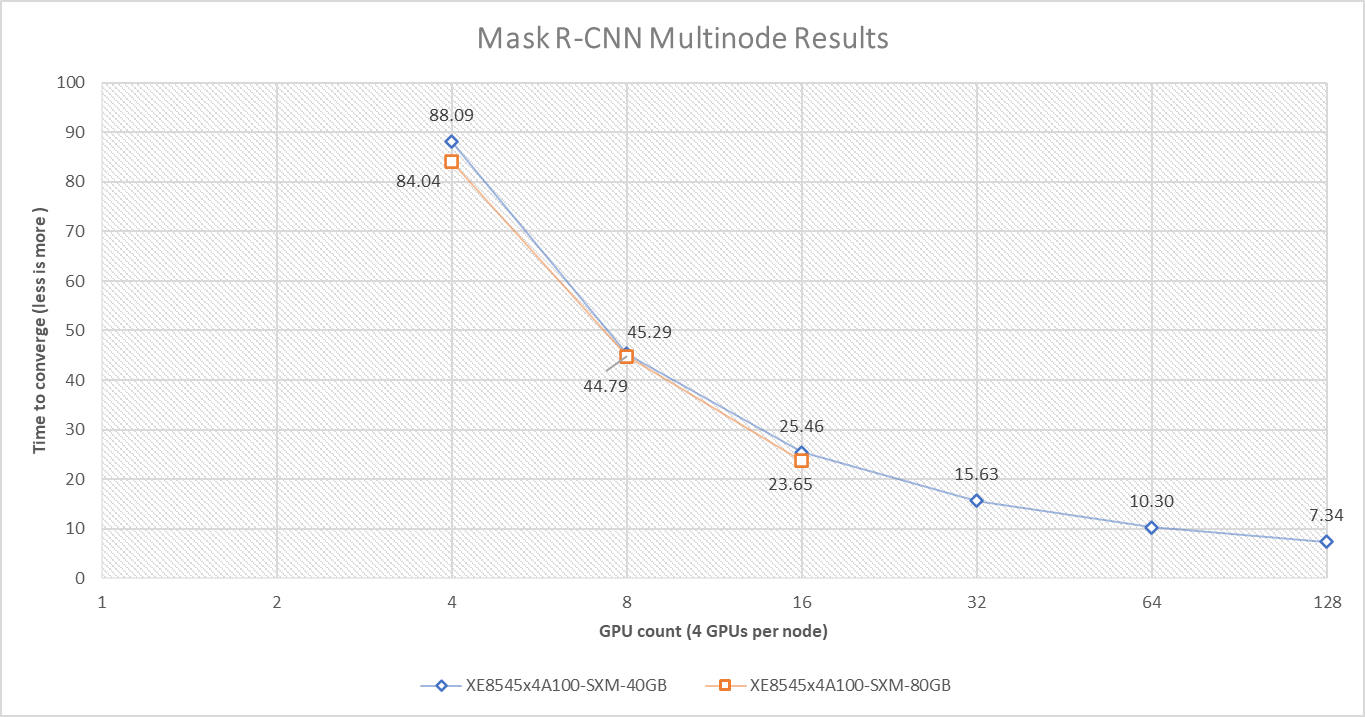
Figure 9. Mask R-CNN multinode results with R750xa and XE8545 servers
As shown in Figures 7, 8, and 9, the multinode scaling results of the BERT, Resnet50, and Mask R-CNN are linear or nearly linear scaled. This shows that Dell servers offer outstanding performance with single-node and multinode scaling.
Conclusion
The findings described in this blog show that:
- Dell servers can run all types of workloads in the MLPerf Training submission.
- Software-only enhancements reduce time to solution for our customers, as shown in our MLPerf Training v2.1 submission, and customers can expect to see improvements in their environments.
- Dell PowerEdge XE8545 and PowerEdge R750xa servers with NVIDIA A100 with PCIe and SXM4 form factors are both great selections for all deep learning models.
- PCIe-based PowerEdge R750xa servers can deliver reinforcement learning workloads in addition to other classes of workloads, such as image classification, lightweight and heavy object detection, speech recognition, natural language processing, and medical image segmentation.
- The single-node results of our submission indicate that Dell servers deliver outstanding performance and that multinode run scales well and helps to reduce time to solution across a distinct set of workload types, making Dell servers apt for single-node and multinode deep learning training workloads.
- The single-node results of our submission indicate that Dell servers deliver outstanding performance and that multinode results show a well-scaled performance that helps to reduce time to solution across a distinct set of workload types. This makes Dell servers apt for both small training workloads on single nodes and large deep learning training workloads on multinodes.
Appendix
System Under Test
MLPerf system configurations for PowerEdge XE8545 systems
Operating system | CPU | Memory | GPU | GPU form factor | GPU count | Networking | Software stack |
XE8545x4A100-SXM-40GB 2xXE8545x4A100-SXM-40GB 4xXE8545x4A100-SXM-40GB 8xXE8545x4A100-SXM-40GB 16xXE8545x4A100-SXM-40GB 32xXE8545x4A100-SXM-40GB | 2x ConnectX-6 IB HDR 200Gb/Sec
|
| |||||
Red Hat Enterprise Linux | AMD EPYC 7713 | 1 TB | NVIDIA A100-SXM-40GB | SXM4 | 4, 8, 16, 32, 64, 128 |
| CUDA 11.6 Driver 510.47.03 cuBLAS 11.9.2.110 cuDNN 8.4.0.27 TensorRT 8.0.3 DALI 1.5.0 NCCL 2.12.10 Open MPI 4.1.1rc1 MOFED 5.4-1.0.3.0 |
XE8545x4A100-SXM-80GB |
|
| |||||
Ubuntu 20.04.4 | AMD EPYC 7763 | 1 TB | NVIDIA A100-SXM-80GB | SXM4 | 4 |
| CUDA 11.6 Driver 510.47.03 cuBLAS 11.9.2.110 cuDNN 8.4.0.27 TensorRT 8.0.3 DALI 1.5.0 NCCL 2.12.10 Open MPI 4.1.1rc1 MOFED 5.4-1.0.3.0 |
2xXE8545x4A100-SXM-80GB 4xXE8545x4A100-SXM-80GB |
|
| |||||
Red Hat Enterprise Linux | AMD EPYC 7713 | 1 TB | NVIDIA A100-SXM-80GB | SXM4 | 4, 8 |
| CUDA 11.6 Driver 510.47.03 cuBLAS 11.9.2.110 cuDNN 8.4.0.27 TensorRT 8.0.3 DALI 1.5.0 NCCL 2.12.10 Open MPI 4.1.1rc1 MOFED 5.4-1.0.3.0 |
MLPerf system configurations for Dell PowerEdge R750xa servers
| 2xR750xa_A100 | 8xR750xa_A100 |
MLPerf System ID | 2xR750xax4A100-PCIE-80GB | 8xR750xax4A100-PCIE-80GB |
Operating system | CentOS 8.2.2004 | |
CPU | Intel Xeon Gold 6338 | |
Memory | 512 GB | |
GPU | NVIDIA A100-PCIE-80GB | |
GPU form factor | PCIe | |
GPU count | 4,32 | |
Networking | 1x ConnectX-5 IB EDR 100Gb/Sec | |
Software stack | CUDA 11.6 Driver 470.42.01 cuBLAS 11.9.2.110 cuDNN 8.4.0.27 TensorRT 8.0.3 DALI 1.5.0 NCCL 2.12.10 Open MPI 4.1.1rc1 MOFED 5.4-1.0.3.0 | CUDA 11.6 Driver 470.42.01 cuBLAS 11.9.2.110 cuDNN 8.4.0.27 TensorRT 8.0.3 DALI 1.5.0 NCCL 2.12.10 Open MPI 4.1.1rc1 MOFED 5.4-1.0.3.0 |
MLPerf system configurations Dell DSS 8440 servers
| DSS 8440 |
MLPerf System ID | DSS8440x8A30-NVBRIDGE |
Operating system | CentOS 8.2.2004 |
CPU | Intel Xeon Gold 6248R |
Memory | 768 GB |
GPU | NVIDIA A30 |
GPU form factor | PCIe |
GPU count | 8 |
Networking | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software stack | CUDA 11.6 Driver 510.47.03 cuBLAS 11.9.2.110 cuDNN 8.4.0.27 TensorRT 8.0.3 DALI 1.5.0 NCCL 2.12.10 Open MPI 4.1.1rc1 MOFED 5.4-1.0.3.0 |
Yes Virginia, Data Quality Matters to AI & Data Analytics
Thu, 15 Sep 2022 14:22:23 -0000
|Read Time: 0 minutes
How often do we hear a project has failed? Projected benefits were not achieved, ROI is less than expected, predictability results are degrading, and the list goes on.
Data Scientists blame it on not having enough data engineers. Data engineers blame it on poor source data. DBAs blame it on data ingest, streaming, software and such…Scape goats are easy to come by.
Have you ever thought why? Yes there are many reasons but one I run across constantly is data quality. Poor data quality is rampant through the vast majority of enterprises. It remains largely hidden. From what I see most companies say we’re a world class organization with top notch talent and we make lots of money and have happy customers therefore we must have world class data with high data quality. This is a pipe dream. Iif you’re not measuring it it’s almost certainly bad leading to inefficiencies, costly mistakes, bad decisions, high error rates, rework, lost customers and many other maladies.
When I’ve built systems & databases in past lives I’ve looked into data, mostly with a battery of SQL queries and found many a data horror, poor quality, defective items, wrong data and many more.
So if you want to know where you stand you must measure your data quality and have a plan to measure the impact of defects and repair them as justified. I think most folks that start down this path quit as they attempt to boil the ocean and fix all the problems they find. I think the best approach is to rank your data items in terms of importance and then measure perhaps the top 1-3% of them. In that way one can make the most impactful improvements with the least effort.
The dimensions of data are varied and can be complex but from a data quality perspective they fall into six or more categories:
- Completeness
- Validity
- Accuracy
- Consistency
- Integrity
- Timeliness
Using a tool is highly recommended. Yes, you probably have to pay for one. I won’t get into all the players here.
So, if you don’t have a data quality program then you should get started today because you do have poor data quality.
In a future post I’ll go into more about data quality measures.
If you like a free consultation on your particular situation please do contact me at Mike.King2@Dell.com
The First MLPerf Inference v2.1 Performance Result on AMD EPYC™ CPU-Based PowerEdge Servers
Thu, 08 Sep 2022 17:00:38 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies, AMD, and Deci AI recently submitted results to MLPerf Inference v2.1 in the open division. This blog showcases our first successful three-way submission and describes how the software and hardware of each party was best used to achieve optimal performance for the MLPerf BERT-Large model.
Introduction
MLCommons™ is a consortium of companies whose mission is to accelerate machine learning innovation to benefit everyone. The organization focuses on benchmarking to enable the display of fair performance measurements and makes datasets open and available, since models in the benchmarks are only as good as the data. It also shares best practices to initiate standardization of sharing and communication among machine learning stakeholders.
The MLPerf Inference v2.1 submission falls under the benchmarking road map for MLCommons. Submissions made to the closed division warrant an equitable comparison of hardware platforms and software frameworks. The submissions must use the same model and optimizer as the reference implementation. Additionally, no retraining is permitted in the closed division. On the other hand, the open division promotes faster models and optimizers as it allows benchmark implementations that use a different model for the same task. Any machine learning approach is permitted if it meets the target quality. Results submitted to the open division showcase exciting technologies that are being developed.
This blog highlights an offline submission made in the open division BERT 99.9 category for the natural language processing (NLP) task. The goal of the submission was to maximize throughput while keeping the accuracy within a 0.1 percent margin of error from the baseline accuracy, which is 90.874 F1 (Stanford Question Answering Dataset (SQuAD)).
Dell PowerEdge R7525 Server Powered with AMD EPYC™ processors
Since MLPerf benchmarking results are a showcase of the joint performance of both the software and underlying hardware, Deci AI’s optimized BERT-Large model, known as DeciBERT-Large, was run using ONNXRT on the Dell PowerEdge R7525 rack server populated with two 64-core AMD EPYC 7773X processors.
The PowerEdge R7525 rack server is a highly scalable and adaptable two-socket 2U rack server that delivers powerful performance and flexible configurations. It is ideal for traditional and emerging workloads and applications that include flash software-defined storage (SDS), virtual desktop infrastructure (VDI), and data analytics (DA) workloads. As this blog’s MLPerf submission shows, the PowerEdge R7525 rack server is also well suited for AI workloads such as deep learning inference.
The PowerEdge R7525 server is an excellent server choice for several reasons. Some of the high-level specifications to meet performance demands include up to 24 directly connected NVMe drives that support all flash AF8 vSAN Ready Nodes. The 4 TB of memory and two AMD EPYC processors enable optimal performance. Also, the PowerEdge R7525 server has maximized IOPS, storage, and memory configurations enabled by up to eight PCIe Gen4 slots. Furthermore, AMD Instinct™ MI100 and MI200 series accelerators and other double-width GPUs can provide additional levels of acceleration.
AMD EPYC processors with AMD 3D V-Cache™ Technology were launched in March 2022. This innovative new lineup of server-class AMD EPYC processors was positioned for accelerating technical computing workloads, including computational fluid dynamics (CFD), electronic design automation (EDA), and finite element analysis (FEA).
With this joint MLPerf submission, a first for AMD EPYC processors with AMD 3D V-Cache Technology, AMD demonstrates the applicability of the new AMD EPYC processors and their extra L3 cache for deep learning inference workloads.
Deci AI DeciBERT-Large Model Comparisons and Metrics
Deci AI used their proprietary AutoNAC™ (Automated Neural Architecture Construction) Engine to generate an optimized BERT-Large model, called DeciBERT-Large, tuned specifically for the underlying PowerEdge R7525 server and two 64-core AMD EPYC 7773X processors. The Deci AI algorithm reduces the reference BERT-Large model size by nearly three times, from 340 million parameters in the standard BERT-Large model down to 115 million parameters, while achieving compelling performance and accuracy.
From a memory capacity perspective, the parameter count reduction also contributes to similarly significant space savings with the DeciBERT-Large model. The ONNX DeciBERT-Large model size is 378 MB in FP32 and 95 MB in INT8 compared to 1.4 GB of the reference BERT-Large model implementation from MLCommons.
By pairing the optimized, smaller DeciBERT-Large model with the extended L3 cache capacity of the AMD EPYC processors with 3D V-Cache, more of the model can be stored in the cache at a time. This method of leveraging the additional L3 cache enables near compute and lower latency memory accesses compared to DRAM.
The following tables highlight the data points collected by Deci AI on the PowerEdge R7525 server with two AMD EPYC 7773X processors. The application of the Deci AI AutoNAC algorithm to generate the DeciBERT-Large model highlights a 6.33 times improvement in FP32 performance and a 6.64 times improvement in INT8 performance, while achieving an INT8 F1 score of 91.08, which is higher than the F1 score of 90.07 of the reference BERT-Large implementation in INT8.
Table 1: BERT-Large comparisons – FP32
F1 accuracy on SQuAD (FP32) | Parameter count | Model size | Throughput (QPS) ONNX runtime FP32 | |
BERT-Large | 90.87 | 340 million | 1.4 GB | 12 |
DeciBERT-Large | 91.08 | 115 million | 378 MB or 0.378 GB | 76 |
Deci Gains | 0.21 better F1 accuracy | 66.2% improvement | 73% size reduction | 6.33 times throughput improvement |
Table 2: BERT-Large comparisons – INT8
F1 accuracy on SQuAD (INT8) | Parameter count | Model size | Throughput (QPS) ONNX runtime INT8 | |
BERT-Large | 90.07 | 340 million | 1.4 GB
| 18 |
DeciBERT-Large | 91.08 | 115 million | 95 MB or 0.095 GB | 116 |
Deci Gains | 1.01 better F1 accuracy | 66.2% improvement | 93.2% size reduction | 6.44 times throughput improvement |
The following figure shows that Deci AI’s implementations of the BERT-Large models compiled with ONNXRT are critical in enabling competitive performance in both FP32 and INT8 precisions:
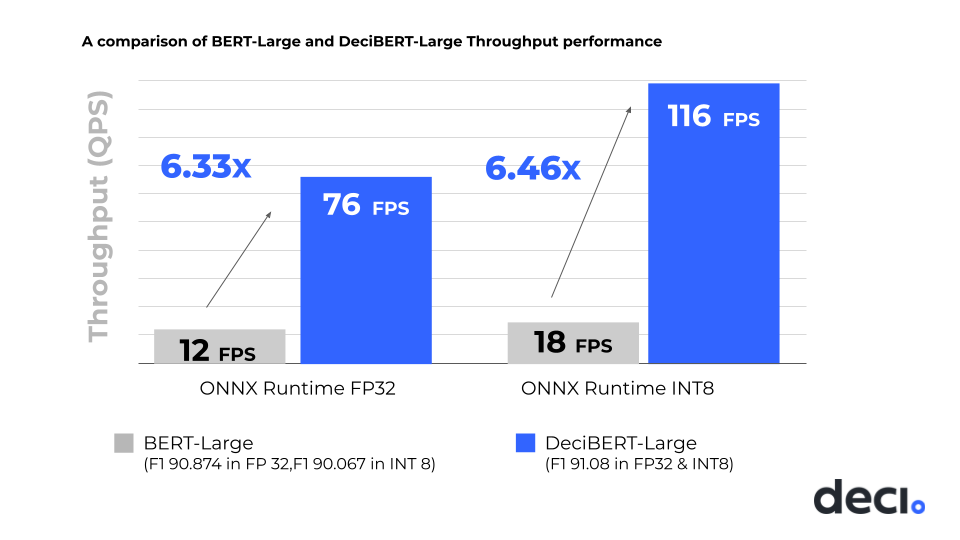
Figure 1: Performance comparison between the reference BERT-Large model implementation and Deci AI’s optimized DeciBERT-Large model
FP32 is commonly used for running deep learning models as it is the default floating datatype in programming languages. It consists of 32 bits of ones and zeros, of which the first bit is the sign bit, representing whether the value is positive. The next eight bits are the exponent of the number, and the last 23 bits are the fraction or mantissa of the number. FP32, or floating point 32, uses nine bits for range and 23 bits for accuracy. The dynamic range of FP32, or the quantity of representable numbers using this datatype, reaches nearly four billion values.
INT8 has become a popular datatype for deep learning inference. Since INT8 has fewer bits and a smaller dynamic range (256 values compared to the four billion values representable by FP32), INT8 compute requirements are considerably reduced compared to FP32. Typically, latencies are lower and throughputs are higher when using INT8 models compared to FP32 models. However, the increased throughput and lower latency tends to come at the cost of accuracy degradation.
Most MLPerf BERT-Large submissions in the 99.9 percent accuracy category use 32-bit or 16-bit quantization because 8-bit quantization is lossy and typically reduces model accuracy below the 99.9 percent threshold. For example, while applying INT8 quantization to the baseline BERT-Large model is an option that accelerates throughput from 12 FPS to 18 FPS, it no longer meets the MLPerf 99.9 percent accuracy constraints.
Deci AI AutoNac Engine and Optimization
The Deci AI AutoNAC engine guarantees that the model designed meets the accuracy requirements set by MLPerf and pursues the most performant variation of the specific model within those constraints, allowing INT8 quantization to be leveraged for the submission.
The Deci AI AutoNAC engine begins by generating a dynamic search space that accounts for parameters such as the baseline accuracy, inference performance targets, underlying hardware, compilers, and quantization, among others. A fast and accurate multiconstraints search algorithm is initiated and creates a new model architecture that delivers the highest performance given the defined constraints.
From a computation time perspective, the AutoNAC search process is approximately three times longer than standard training, depending on the task. For example, training the DeciBert model to perform the SQuAD NLP task requires approximately 60 GPU hours. The search for this DeciBERT model required approximately 180 GPU hours, and the computation involved was parallelized. Therefore, the computation of AutoNAC is commercially affordable for almost any organization.
In summary, Deci AI generated a model using AutoNAC that was specifically designed to deliver optimal performance within the MLPerf constraints when running on a Dell server with AMD EPYC processors with 3D V-Cache.
The following figure shows the AutoNAC optimization process:
Figure 2: Deci AI’s AutoNac process
Conclusion
The Deci AI AutoNAC engine generates optimized deep learning inference models that meet customer accuracy and dataset requirements while maximizing performance. The increased performance, combined with the significant reduction in parameter count and memory size, positions Deci AI optimized models as highly efficient for a range of applications. The DeciBERT-Large model is an optimized version of the state-of-the-art BERT-Large model for NLP applications. Applying that to real-world scenarios, call centers are examples of customers that can take advantage of deep learning insights in the areas of sentiment analysis, live transcription and translation, and question answering. The DeciBERT-Large model, as developed for MLPerf v2.1 by Deci AI, can be easily tuned for a call center’s own dataset and application, and deployed in production today to improve performance, shorten time to insights, and enable the deployment of smaller optimized models with reduced compute requirements, which becomes particularly beneficial in power or cost constrained environments.

So You'd Like an Easy Button for ML/DL...Look No Further Than Cnvrg.io on Dell
Mon, 08 Aug 2022 17:00:07 -0000
|Read Time: 0 minutes
I consult with various customers on their AI/ML/DL needs while coming up with architectures, designs and solutions that are durable, scalable, flexible, efficient, performant, sensible and cost effective. After having seen perhaps 100 different opportunities I have some observations and yes suggestions on how to do things better.
Firstly, there’s an overwhelming desire for DIY. On the surface the appeal is that it’s easy to download the likes of tensor flow with pip, add some python code to point to four GPUs on four different servers, collect some data, train your model and put it into production. This thinking rarely considers concurrency, multi-tenancy, scheduling, management, sharing and many more. What I can safely state is that this path is the hardest, takes the longest, costs more, creates confusion, fosters low asset utilization and leads to high project rate failures.
Secondly most customers are not concerned with infrastructure, scalability, multi-tenancy, architecture and such at the outset. They are after thoughts and their main focus on building a house is let’s get started and so we can get finished sooner. We don’t need a plan do we?
Thirdly most customers are struggling so when they reach out to talk to their friends down the road they’re all moving slowly, doing it themselves, struggling so it’s ok right?
I think there’s a much better way and it all has to do with the software stack. A cultivated software stack that can manage jobs, configure the environment, share resources, scale-out easily, schedule jobs based on priorities and resource availability, support multi-tenancy, record and share results, etc….is just what the doctor ordered. It can be cheap, efficient, speed up projects and improve the success rate. Enter cnvrg.io, now owned by Intel, and you have a best of breed solution to these items and much more.
Recently I collected some of the reasons why I think cnvrg.io the the cultivated AI stack you need for all your AI/ML/DL projects:
- Allows for reuse of existing assets
- Can mix & match new w/ old
- Any Cloud model
- Multi-cloud
- Hybrid
- OnPrem
- Public cloud
- Fractional GPU capability for all GPUs
- Support multiple container distros
- Improves productivity of:
- Data Scientists
- Data Engineers
- Leads to more efficient asset utilization
- Relatively affordable
- The backing of intel
- Partnered w/ Dell
- Supports multi-tenancy well
- Capability to build pipelines
- Reuse
- Knowledge management and sharing for AI
- Improves AI time to market
- Improves AI project success
- Makes AI easy
- Low code play
- Can construct and link data pipelines
Cnvrg.io is a Dell Technologies partner and we have a variety of solutions and platform options. If you’d like to hear more please do drop me an email at Mike.King2@Dell.com

Porting the CUDA p2pbandwidthLatencyTest to the HIP environment on Dell PowerEdge Servers with the AMD GPU
Wed, 13 Jul 2022 14:59:25 -0000
|Read Time: 0 minutes
Introduction
When writing code in CUDA, it is natural to ask if that code can be extended to other GPUs. This extension can allow the “write once, run anywhere” programming paradigm to materialize. While this programming paradigm is a lofty goal, we are in a position to achieve the benefits of porting code from CUDA (for NVIDIA GPUs) to HIP (for AMD GPUs) with little effort. This interoperability provides added value because developers do not have to rewrite code starting at the beginning. It not only saves time, but also saves system administrator efforts to run workloads on a data center depending on hardware resource availability.
This blog provides a brief overview of the AMD ROCm™ platform. It describes a use case that ports the peer-to-peer GPU bandwidth latency test (p2pbandwidthlatencytest) from CUDA to Heterogeneous-Computing Interface for Portability (HIP) to run on an AMD GPU.
Introduction to ROCm and HIP
ROCm is an open-source software platform for GPU-accelerated computing from AMD. It supports running of HPC and AI workloads across different vendors. The following figures show the core ROCm components and capabilities:
Figure 1: The ROCm libraries stack

Figure 2: The ROCm stack
ROCm is a full package of all that is needed to run different HPC and AI workloads. It includes a collection of drivers, APIs, and other GPU tools that support AMD Instinct™ GPUs as well as other accelerators. To meet the objective of running workloads on other accelerators, HIP was introduced.
HIP is AMD’s GPU programming paradigm for designing kernels on GPU hardware. It is a C++ runtime API and a programming language that serves applications on different platforms.
One of the key features of HIP is the ability to convert CUDA code to HIP, which allows running CUDA applications on AMD GPUs. When the code is ported to HIP, it is possible to run HIP code on NVIDIA GPUs by using the CUDA platform-supported compilers (HIP is C++ code and it provides headers that support translation between HIP runtime APIs to CUDA runtime APIs). HIPify refers to the tools that translate CUDA source code into HIP C++.
Introduction to the CUDA p2pbandwidthLatencyTest
The p2pbwLatencyTest determines the data transfer speed between GPUs by computing latency and bandwidth. This test is useful to quantify the communication speed between GPUs and to ensure that these GPUs can communicate.
For example, during training of large-scale data and model parallel deep learning models, it is imperative to ensure that GPUs can communicate after a deadlock or other issues while building and debugging a model. There are other use cases for this test such as BIOS configuration performance improvements, driver update performance implications, and so on.
Porting the p2pbandwidthLatencyTest
The following steps port the p2pbandwidthLatencyTest from CUDA to HIP:
- Ensure that ROCm and HIP are installed in your machine. Follow the installation instructions in the ROCm Installation Guide at:
https://rocmdocs.amd.com/en/latest/Installation_Guide/Installation_new.html#rocm-installation-guide-v4-5
Note: The latest version of ROCm is v5.2.0. This blog describes a scenario running with ROCm v4.5. You can run ROCm v5.x, however, it is recommended that you see the ROCm Installation Guide v5.1.3 at:
https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.1.3/page/Overview_of_ROCm_Installation_Methods.html. - Verify your installation by running the commands described in:
https://rocmdocs.amd.com/en/latest/Installation_Guide/Installation_new.html#verifying-rocm-installation - Optionally, ensure that HIP is installed as described at:
https://github.com/ROCm-Developer-Tools/HIP/blob/master/INSTALL.md#verify-your-installation
We recommend this step to ensure that the expected outputs are produced. - Install CUDA on your local machine to be able to convert CUDA source code to HIP.
To align version dependencies that need CUDA and LLVM +CLANG, see:
https://github.com/ROCm-Developer-Tools/HIPIFY#dependencies - Verify that your installation is successful by testing a sample source conversion and compilation. See the instructions at:
https://github.com/ROCm-Developer-Tools/HIP/tree/master/samples/0_Intro/square#squaremd
Clone this repo to perform the validation test. If you can run the following square.cpp program, the installation is successful:
Congratulations! You can now run the conversion process for the p2pbwLatencyTest. - If you use the Bright Cluster Manager, load the CUDA module as follows:
module load cuda11.1/toolkit/11.1.0
Converting the p2pbwLatencyTest from CUDA to HIP
After you download the p2pbandwidthLatencyTest, convert the test from CUDA to HIP.
There are two approaches to convert CUDA to HIP:
- hipify-perl—A Perl script that uses regular expressions to convert CUDA to HIP replacements. It is useful when direct replacements can solve the porting problem. It is a naïve converter that does not check for valid CUDA code. A disadvantage of the script is that it cannot transform some constructs. For more information, see https://github.com/ROCm-Developer-Tools/HIPIFY#-hipify-perl.
- hipify-clang—A tool that translates CUDA source code into an abstract syntax tree, which is traversed by transformation matchers. After performing all the transformations, HIP output is produced. For more information, see https://github.com/ROCm-Developer-Tools/HIPIFY#-hipify-clang.
For more information about HIPify, see the HIPify Reference Guide at https://docs.amd.com/bundle/HIPify-Reference-Guide-v5.1/page/HIPify.html.
To convert the p2pbwLatencyTest from CUDA to HIP:
- Clone the CUDA sample repository and run the conversion:
git clone https://github.com/NVIDIA/cuda-samples.git cd cuda-samples/Samples/5_Domain_Specific/p2pBandwidthLatencyTest hipify-perl p2pBandwidthLatencyTest.cu > hip_converted.cpp hipcc hip_converted.cpp -o p2pamd.ou
The following example shows the program output:
Figure 3: Output of the CUDAP2PBandWidthLatency test run on AMD GPUs
The output must include all the GPUs. In this use case, there are three GPUs: 0, 1, 2. - Use the rocminfo command to identify GPUs in the server and then you can use the rocm-smi command to identify the three GPUs in the server, as shown in the following figure:
Figure 4: Output of the rocm-smi command showing all three GPUs in the server
Conclusion
HIPify is a time-saving tool for converting CUDA code to run on AMD Instinct accelerators. Because there are consistent improvements from the AMD software team, there are regular releases in the software stack . The HIPify path is an automated way to support conversion from CUDA to a generalized framework. After your code is ported to HIP, this conversion allows for running code on different accelerators from different vendors. This feature helps to enable further developments from a common platform.
This blog showed how to convert a sample use case from CUDA to HIP using the hipify-perl tool.
Run system information
Table 1: System details
Component | Description |
Operating system | CentOS Linux 8 (Core) |
ROCm version | 4.5 |
CUDA version | 11.1 |
Server | Dell PowerEdge R7525 |
CPU | 2 x AMD EPYC 7543 32-Core Processor |
Accelerator | AMD Instinct MI210 |
References
- https://github.com/ROCm-Developer-Tools
- https://github.com/ROCm-Developer-Tools/HIPIFY
- https://github.com/NVIDIA/cuda-samples
- https://github.com/ROCm-Developer-Tools/HIP/
- https://docs.amd.com/
- https://rocmdocs.amd.com/en/latest/Programming_Guides/HIP-porting-guide.html
- https://docs.amd.com/bundle/HIP_API_Guide/page/modules.html
- https://www.amd.com/en/graphics/servers-solutions-rocm
- https://www.amd.com/system/files/documents/the-amd-rocm-5-open-platform-for-hpc-and-ml-workloads.pdf

MLPerf™ v1.1 Inference on Virtualized and Multi-Instance GPUs
Mon, 16 May 2022 18:49:23 -0000
|Read Time: 0 minutes
Introduction
Graphics Processing Units (GPUs) provide exceptional acceleration to power modern Artificial Intelligence (AI) and Deep Learning (DL) workloads. GPU resource allocation and isolation are some of the key components that data scientists working in a shared environment use to run their DL experiments effectively. The need for this allocation and isolation becomes apparent when a single user uses only a small percentage of the GPU, resulting in underutilized resources. Due to the complexity of the design and architecture, maximizing the use of GPU resources in shared environments has been a challenge. The introduction of Multi-Instance GPU (MIG) capabilities in the NVIDIA Ampere GPU architecture provides a way to partition NVIDIA A100 GPUs and allow complete isolation between GPU instances. The Dell Validated Design showcases the benefits of virtualization for AI workloads and MIG performance analysis. This design uses the most recent version of VMware vSphere along with the NVIDIA AI Enterprise suite on Dell PowerEdge servers and VxRail Hyperconverged Infrastructure (HCI). Also, the architecture incorporates Dell PowerScale storage that supplies the required analytical performance and parallelism at scale to feed the most data-hungry AI algorithms reliably.
In this blog, we examine some key concepts, setup, and MLPerf Inference v1.1 performance characterization for VMs hosted on Dell PowerEdge R750xa servers configured with MIG profiles on NVIDIA A100 80 GB GPUs. We compare the inference results for the ResNet50 and Bidirectional Encoder Representations from Transformers (BERT) models.
Key Concepts
Key concepts include:
- Multi-Instance GPU (MIG)—MIG capability is an innovative technology released with the NVIDIA A100 GPU that enables partitioning of the A100 GPU up to seven instances or independent MIG devices. Each MIG device operates in parallel and is equipped with its own memory, cache, and streaming multiprocessors.
In the following figure, each block shows a possible MIG device configuration in a single A100 80 GB GPU:
Figure 1- MIG device configuration - A100 80 GB GPU
The figure illustrates the physical location of GPU instances after they have been instantiated on the GPU. Because GPU instances are generated and destroyed at various locations, fragmentation might occur. The physical location of one GPU instance influences whether more GPU instances can be formed next to it.
Supported profiles for the A100 80GB GPU include:
- 1g.10gb
- 2g.20gb
- 3g.40gb
- 4g.40gb
- 7g.80gb
In Figure 1, a valid combination is constructed by beginning with an instance profile on the left and progressing to the right, ensuring that no two profiles overlap vertically. For detailed information about NVIDIA MIG profiles, see the NVIDIA Multi-Instance GPU User Guide.
- MLPERF—MLCommons™ is a consortium of leading researchers in AI from academia, research labs, and industry. Its mission is to "develop fair and useful benchmarks" that provide unbiased evaluations of training and inference performance for hardware, software, and services—all under controlled conditions. The foundation for MLCommons began with the MLPerf benchmark in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. To stay current with industry trends, MLPerf is always evolving, conducting new tests, and adding new workloads that represent the state of the art in AI.
Setup for MLPerf Inference
A system under test consists of an ESXi host that can be operated from vSphere.
System details
The following table provides the system details.
Table 1: System details
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe (PCI Express) 80 GB |
Network adapter | Mellanox ConnectX-6 Dual Port 100 GbE |
Storage | Dell PowerScale |
ESXi version | 7.0.3 |
BIOS version | 1.1.3 |
GPU driver version | 470.82.01 |
CUDA version | 11.4 |
System configuration for MLPerf Inference
The configuration for MLPerf Inference on a virtualized environment requires the following steps:
- Boot the host with ESXi (see Installing ESXi on the management hosts), install the NVIDIA bootbank driver, enable MIG, and restart the host.
- Create a virtual machine (VM) on the ESXi host with EFI boot mode (see Using GPUs with Virtual Machines on vSphere – Part 2: VMDirectPath I/O) and add the following advanced configuration settings:
pciPassthru.use64bitMMIO: TRUE pciPassthru.allowP2P: TRUE pciPassthru.64bitMMIOSizeGB: 64
- Change the VM settings and add a new PCIe device with a MIG profile (see Using GPUs with Virtual Machines on vSphere – Part 3: Installing the NVIDIA Virtual GPU Technology).
- Boot the Linux-based operating system and run the following steps in the VM.
- Install Docker, CMake (see Installing CMake), the build-essentials package, and CURL
- Download and install the NVIDIA MIG driver (grid driver).
- Install the nvidia-docker repository (see NVIDIA Container Toolkit Installation Guide) for running nvidia-containers.
- Configure the nvidia-grid service to use the vGPU setting on the VM (see Using GPUs with Virtual Machines on vSphere – Part 3: Installing the NVIDIA Virtual GPU Technology) and update the licenses.
- Run the following command to verify that the setup is successful:
nvidia-smi
Note: Each VM consists of 32 vCPUs and 64 GB memory.
MLPerf Inference configuration for MIG
When the system has been configured, configure MLPerf v1.1 on the MIG VMs. To run the MLPerf Inference benchmarks on a MIG-enabled system under test, do the following:
- Add MIG details in the inference configuration file:
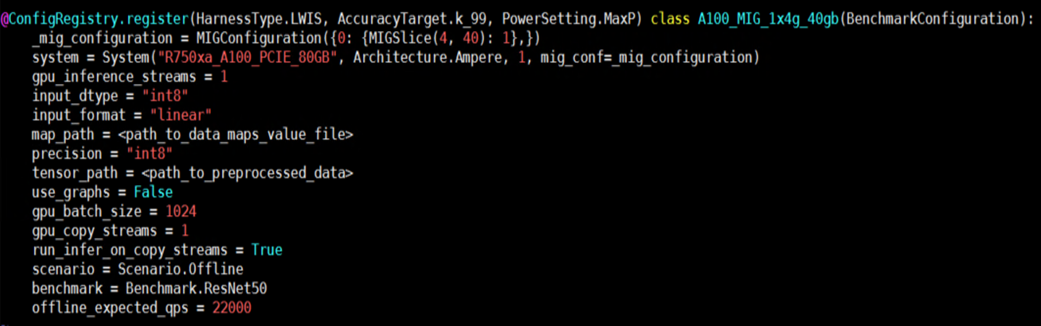 Figure 2- Example configuration for running inferences using MIG enabled VMs
Figure 2- Example configuration for running inferences using MIG enabled VMs - Add valid MIG specifications to the system variable in the system_list.py file.
 Figure 3- Example system entry with MIG profiles
Figure 3- Example system entry with MIG profiles
These steps complete the system setup, which is followed by building the image, generating engines, and running the benchmark. For detailed instructions, see our previous blog about running MLPerf v1.1 on bare metal systems.
MLPerf v1.1 Benchmarking
Benchmarking scenarios
We assessed inference latency and throughput for ResNet50 and BERT models using MLPerf Inference v1.1. The scenarios in the following table identify the number of VMs and corresponding MIG profiles used in performance tests. The total number of tests for each scenario is 57. The results are averaged based on three runs.
Note: We used MLPerf Inference v1.1 for benchmarking but the results shown in this blog are not part of the official MLPerf submissions.
Table 2: Scenarios configuration
Scenario | MIG profiles | Total VMs |
1 | MIG nvidia-7-80c | 1 |
2 | MIG nvidia-4-40c | 1 |
3 | MIG nvidia-3-40c | 1 |
4 | MIG nvidia-2-20c | 1 |
5 | MIG nvidia-1-10c | 1 |
6 | MIG nvidia-4-40c + nvidia-2-20c + nvidia-1-10c | 3 |
7 | MIG nvidia-2-20c + nvidia-2-20c + nvidia-2-20c + nvidia-1-10c | 4 |
8 | MIG nvidia-1-10c* 7 | 7 |
ResNet50
ResNet50 (see Deep Residual Learning for Image Recognition) is a widely used deep convolutional neural network for various computer vision applications. This neural network can address the disappearing gradients problem by allowing gradients to traverse the network's layers using the concept of skip connections. The following figure shows an example configuration for ResNet50 inference:
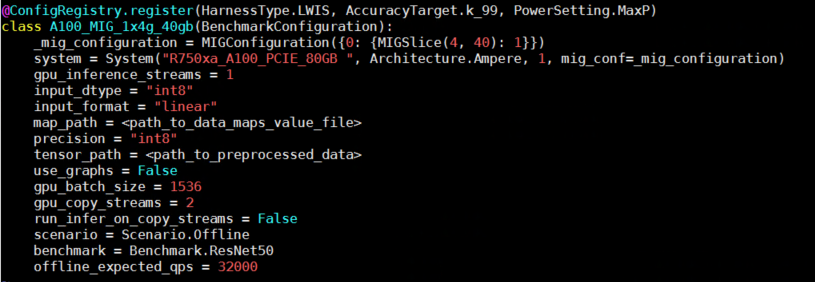
Figure 4- Configuration for running inference using Resnet50 model
The following figure shows ResNet50 inference performance based on the scenarios in Table 2: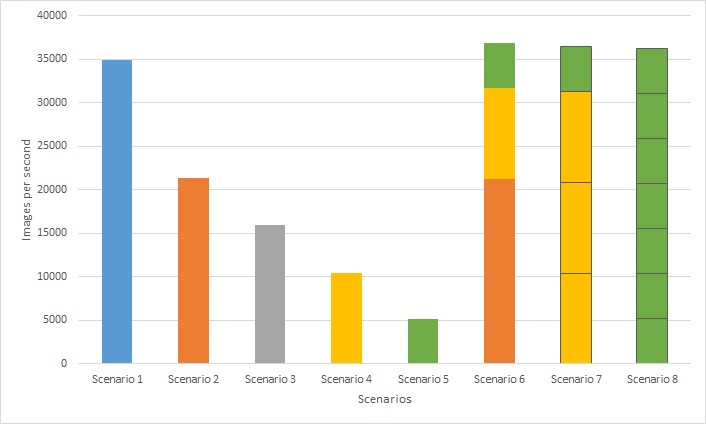
Figure 5- ResNet50 Performance throughput of MLPerf Inference v1.1 across various VMs with MIG profiles
Multiple data scientists can use all the available GPU resources while running their individual workloads on separate instances, improving overall system throughput. This result is clearly seen on Scenarios 6 through 8, which contain multiple instances, compared to Scenario 1 which consists of a single instance with the largest MIG profile for A100 80 GB. Scenario 6 achieves the highest overall system throughput (5.77 percent improvement) compared to Scenario 1. Also, Scenario 8 shows seven VMs equipped with individual GPU instances that can be built for up to seven data scientists who can fine-tune their ResNet50 base models.
BERT
BERT (see BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) is a state-of-the-art language representational model. BERT is essentially a stack of Transformer encoders. It is suitable for neural machine translation, question answering, sentiment analysis, and text summarization, all of which require a working knowledge of the target language.
BERT is trained in two stages:
- Pretrain—During which the model acquires language and context understanding
- Fine-tuning—During which the model acquires task-specific knowledge such as querying and response.
The following figure shows an example configuration for BERT inference:
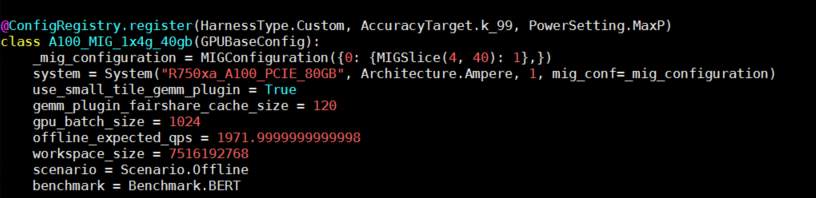
Figure 6- Configuration for running inference using BERT model
The following figure shows BERT inference performance based on scenarios in Table 2:
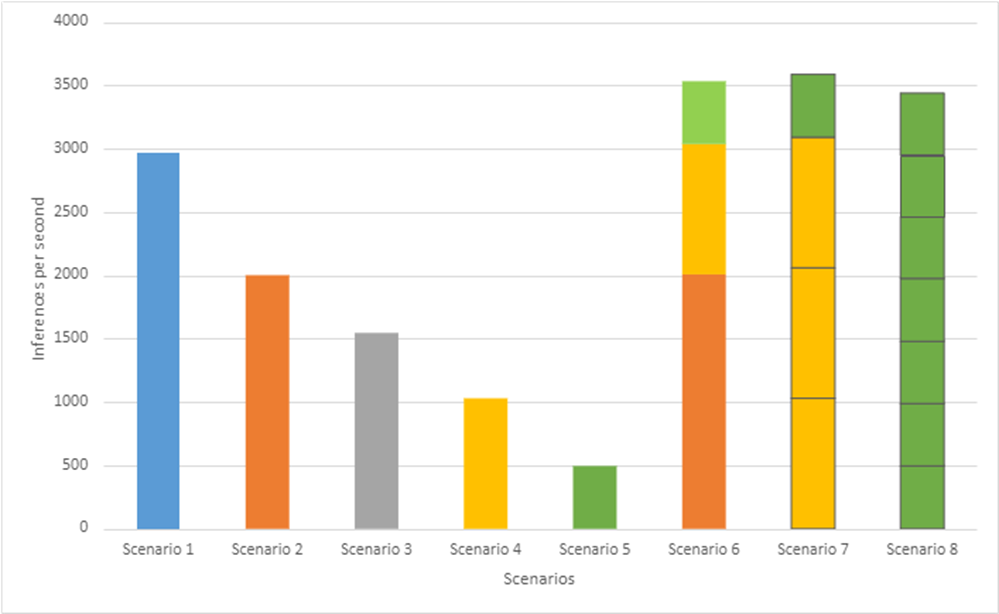 Figure 7- BERT Performance throughput of MLPerf Inference v1.1 across various VMs with MIG profiles
Figure 7- BERT Performance throughput of MLPerf Inference v1.1 across various VMs with MIG profiles
Like Resnet50 Inference performance, we clearly see that Scenarios 6 through 8, which contain multiple instances, perform better compared to Scenario 1. Particularly, Scenario 7 achieves the highest overall system throughput (21 percent improvement) compared to Scenario 1 while achieving 99.9 percent accuracy target. Also, Scenario 8 shows seven VMs equipped with individual GPU instances that can be built for up to seven data scientists who want to fine-tune their BERT base models.
Conclusion
In this blog, we describe how to install and configure MLPerf Inference v1.1 on Dell PowerEdge 750xa servers using a VMware-virtualized infrastructure and NVIDIA A100 GPUs. Furthermore, we examine the performance of single- and multi-MIG profiles running on the A100 GPU. If your ML workload is primarily inferencing-focused and response time is not an issue, enabling MIG on the A100 GPU can ensure complete GPU use with maximum throughput. Developers can use VMs with an independent GPU compute allocated to them. Also, in cases where the largest MIG profiles are used, performance is comparable to bare metal systems. Inference results from ResNet50 and BERT models demonstrate that overall system performance using either the whole GPU or multiple VMs with MIG instances hosted on an R750xa system with VMware ESXi and NVIDIA A100 GPUs performed well and produced valid results for MLPerf Inference v1.1. In both the cases, the average throughput and latency are equal. This result confirms that MIG provides predictable latency and throughput independent of other processes operating on the MIG instances on the GPU.
There is a MIG limitation for GPU profiling on the VMs. Due to the shared nature of the hardware performance across all MIG devices, only one GPU profiling session can run on a VM; parallel GPU profiling sessions on a single VM are not possible.

Accelerating Distributed Training in a Multinode Virtualized Environment
Fri, 13 May 2022 13:57:13 -0000
|Read Time: 0 minutes
Introduction
In the age of deep learning (DL), with complex models, it is vital to have a system that allows faster distributed training. Depending on the application, some DL models require more frequent retraining and fine-tuning of the hyperparameters to be deployed in the production environment. It is important to understand the best practices to improve multinode distributed training performance.
Networking is critical in a distributed training setup as there are numerous gradients exchanged between the nodes. The complexity increases as we increase the number of nodes. In the past, we have seen the benefits of using:
- Direct Memory Access (DMA), which enables a device to access host memory without the intervention of CPUs
- Remote Direct Memory Access (RDMA), which enables access to memory on a remote machine without interrupting the CPU processes on that system
This blog examines performance when direct communication is established between the GPUs in multinode training experiments run on Dell PowerEdge servers with NVIDIA GPUs and VMware vSphere.
GPUDirect RDMA
Introduced as part of Kepler class GPUs and CUDA 5.0, GPUDirect RDMA enables a direct communication path between NVIDIA GPUs and third-party devices such as network interfaces. By establishing direct communication between the GPUs, we can eliminate the critical bottleneck where data needs to be moved into the host system memory before it can be sent over the network, as shown in the following figure:
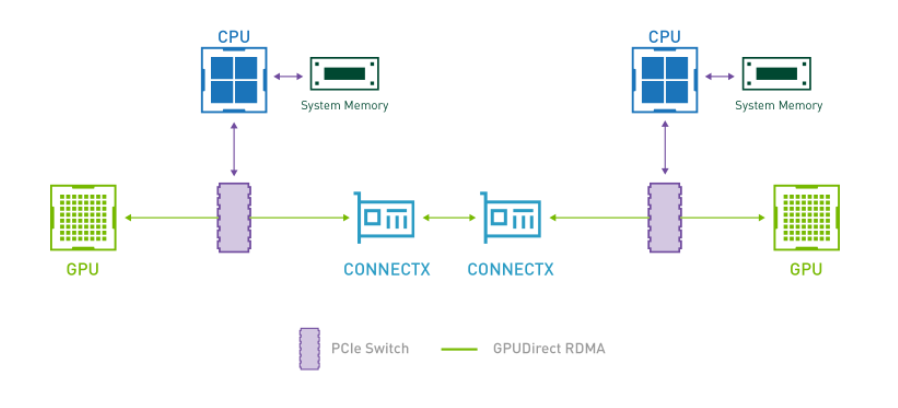
Figure 1: Direct Communication – GPUDirect RDMA
For more information, see:
System details
The following table provides the system details:
Table 1: System details
Component | Details |
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe |
Network adapters | Mellanox ConnectX-6 Dual port 100 GbE and 25 GbE |
Storage | Dell PowerScale |
ESXi version | 7.0.3 |
BIOS version | 1.1.3 |
GPU driver version | 470.82.01 |
CUDA Version | 11.4 |
Setup
The setup for multinode training in a virtualized environment is outlined in our previous blog.
At a high level, after Address Translation Services (ATS) is enabled on VMware ESXi, the VMs, and ConnectX-6 NIC:
- Enable mapping between logical and physical ports.
- Create a Docker container with Mellanox OFED drivers, Open MPI Library, and NVIDIA-optimized TensorFlow.
- Set up a keyless SSH login between VMs
Performance evaluation
For evaluation, we use tf_cnn_benchmarks using the ResNet50 model and synthetic data with a local batch size of 1024. Each VM is configured with 32 vCPUs, 64 GB of memory, and one NVIDIA A100 PCIE 80 GB GPU. The experiments are performed by using a data parallelism approach in a distributed training setup, scaling up to four nodes. The results are based on averaging three experiment runs. Single-node experiments are only for comparison as there is no internode communication.
Note: Use the ibdev2netdev utility to display the installed Mellanox ConnectX-6 card along with the mapping of ports. In the following figures, ON and OFF indicate if the mapping is enabled between logical and physical ports.
The following figure shows performance when scaling up to four nodes using Mellanox ConnectX-6 Dual Port 100 GbE. It is clear that the throughput increases significantly when the mapping is enabled (ON), providing direct communication between NVIDIA GPUs. The two-node experiments show an improvement in throughput of 18.7 percent while the four node experiments improve throughput by 26.7 percent.
Figure 2: 100 GbE network performance
The following figure shows the scaling performance comparison between Mellanox ConnectX-6 Dual Port 100 GbE and Mellanox ConnectX-6 Dual Port 25 GbE while performing distributed training of the ResNet50 model. Using 100 GbE, two-node experiment results show an improved throughput of six percent while four-node experiments show an improved performance of 11.6 percent compared to 25 GbE.
Figure 3: 25 GbE compared to 100 GbE network performance
Conclusion
In this blog, we considered GPUDirect RDMA and a few required steps to setup multinode experiments in the virtualized environment. The results showed that scaling to a larger number of nodes boosts throughput significantly when establishing direct communication between GPUs in a distributed training setup. The blog also showcased the performance comparison between Mellanox ConnectX-6 Dual Port 100 GbE and 25 GbE network adapters used for distributed training of a ResNet50 model.
MLPerf™ Inference v2.0 Edge Workloads Powered by Dell PowerEdge Servers
Fri, 06 May 2022 19:54:11 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. This blog examines the results of two specialty edge servers: the Dell PowerEdge XE2420 server with the NVIDIA T4 Tensor Core GPU and the Dell PowerEdge XR12 server with the NVIDIA A2 Tensor Core GPU.
Introduction
It is 6:00 am on a Saturday morning. You drag yourself out of bed, splash water on your face, brush your hair, and head to your dimly lit kitchen for a bite to eat before your morning run. Today, you have decided to explore a new part of the neighborhood because your dog’s nose needs new bushes to sniff. As you wait for your bagel to toast, you ask your voice assistant “what’s the weather like?” Within a couple of seconds, you know that you need to grab an extra layer because there is a slight chance of rain. Edge computing has saved your morning run.
Although this use case is covered in the MLPerf Mobile benchmarks, the data discussed in this blog is from the MLPerf Inference benchmark that has been run on Dell servers.
Edge computing is computing that takes place at the “edge of networks.” Edge of networks refers to where devices such as phones, tablets, laptops, smart speakers, and even industrial robots can access the rest of the network. In this case, smart speakers can perform speech-to-text recognition to offload processing that ordinarily must be accomplished in the cloud. This offloading not only improves response time but also decreases the amount of sensitive data that is sent and stored in the cloud. The scope for edge computing expands far beyond voice assistants with use cases including autonomous vehicles, 5G mobile computing, smart cities, security, and more.
The Dell PowerEdge XE2420 and PowerEdge XR 12 servers are designed for edge computing workloads. The design criteria is based on real life scenarios such as extreme heat, dust, and vibration from factory floors, for example. However, despite these servers not being physically located in a data center, server reliability and performance are not compromised.
PowerEdge XE2420 server
The PowerEdge XE2420 server is a specialty edge server that delivers high performance in harsh environments. This server is designed for demanding edge applications such as streaming analytics, manufacturing logistics, 5G cell processing, and other AI applications. It is a short-depth, dense, dual-socket, 2U server that can handle great environmental stress on its electrical and physical components. Also, this server is ideal for low-latency and large-storage edge applications because it supports 16x DDR4 RDIMM/LR-DIMM (12 DIMMs are balanced) up to 2993 MT/s. Importantly, this server can support the following GPU/Flash PCI card configurations:
- Up to 2 x PCIe x16, up to 300 W passive FHFL cards (for example, NVIDIA V100/s or NVIDIA RTX6000)
- Up to 4 x PCIe x8; 75 W passive (for example, NVIDIA T4 GPU)
- Up to 2 x FE1 storage expansion cards (up to 20 x M.2 drives on each)
The following figures show the PowerEdge XE2420 server (source):

Figure 1: Front view of the PowerEdge XE2420 server

Figure 2: Rear view of the PowerEdge XE2420 server
PowerEdge XR12 server
The PowerEdge XR12 server is part of a line of rugged servers that deliver high performance and reliability in extreme conditions. This server is a marine-compliant, single-socket 2U server that offers boosted services for the edge. It includes one CPU that has up to 36 x86 cores, support for accelerators, DDR4, PCIe 4.0, persistent memory and up to six drives. Also, the PowerEdge XR12 server offers 3rd Generation Intel Xeon Scalable Processors.
The following figures show the PowerEdge XR12 server (source):

Figure 3: Front view of the PowerEdge XR12 server

Figure 4: Rear view of the PowerEdge XR12 server
Performance discussion
The following figure shows the comparison of the ResNet 50 Offline performance of various server and GPU configurations, including:
- PowerEdge XE8545 server with the 80 GB A100 Multi-Instance GPU (MIG) with seven instances of the one compute instance of the 10gb memory profile
- PowerEdge XR12 server with the A2 GPU
- PowerEdge XE2420 server with the T4 and A30 GPU
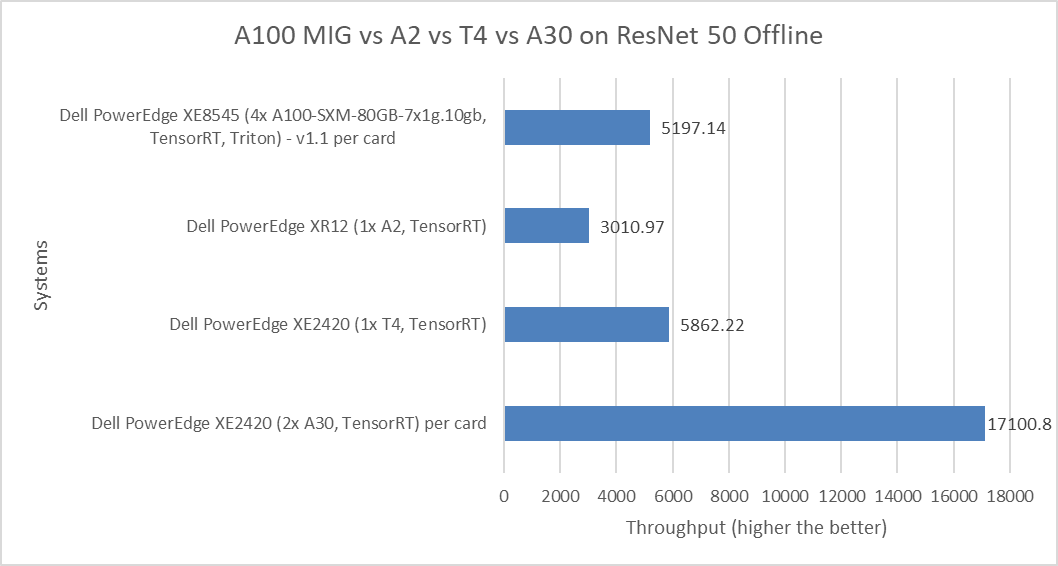
Figure 5: MLPerf Inference ResNet 50 Offline performance
ResNet 50 falls under the computer vision category of applications because it includes image classification, object detection, and object classification detection workloads.
The MIG numbers are per card and have been divided by 28 because of the four physical GPU cards in the systems multiplied by second instances of the MIG profile. The non-MIG numbers are also per card.
For the ResNet 50 benchmark, the PowerEdge XE2420 server with the T4 GPU showed more than double the performance of the PowerEdge XR12 server with the A2 GPU. The PowerEdge XE8545 server with the A100 MIG showed competitive performance when compared to the PowerEdge XE2420 server with the T4 GPU. The performance delta of 12.8 percent favors the PowerEdge XE2420 system. However, the PowerEdge XE2420 server with A30 GPU card takes the top spot in this comparison as it shows almost triple the performance over the PowerEdge XE2420 server with the T4 GPU.
The following figure shows a comparison of the SSD-ResNet 34 Offline performance of the PowerEdge XE8545 server with the A100 MIG and the PowerEdge XE2420 server with the A30 GPU.
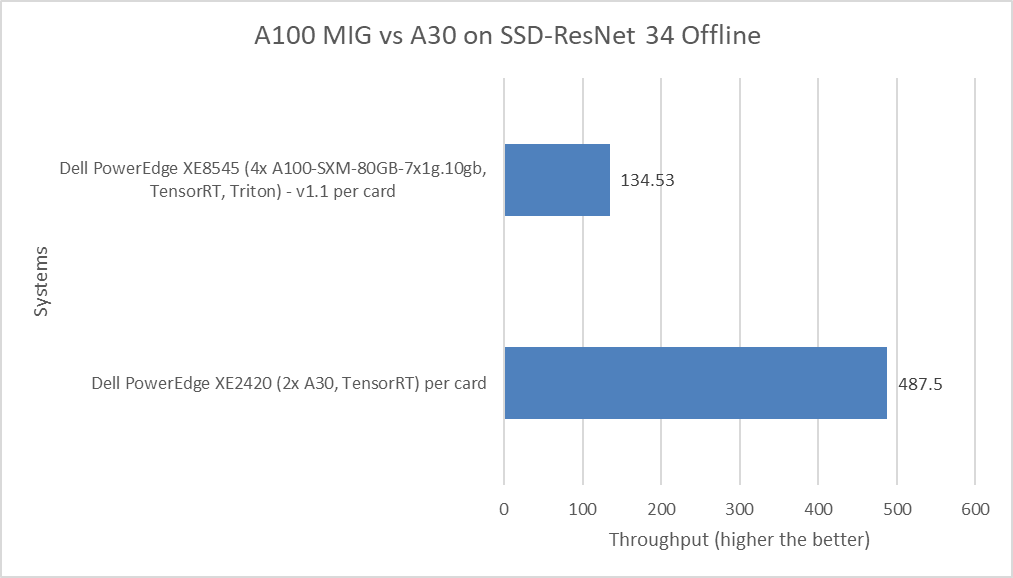
Figure 6: MLPerf Inference SSD-ResNet 34 Offline performance
The SSD-ResNet 34 model falls under the computer vision category because it performs object detection. The PowerEdge XE2420 server with the A30 GPU card performed more than three times better than the PowerEdge XE8545 server with the A100 MIG.
The following figure shows a comparison of the Recurrent Neural Network Transducers (RNNT) Offline performance of the PowerEdge XR12 server with the A2 GPU and the PowerEdge XE2420 server with the T4 GPU:
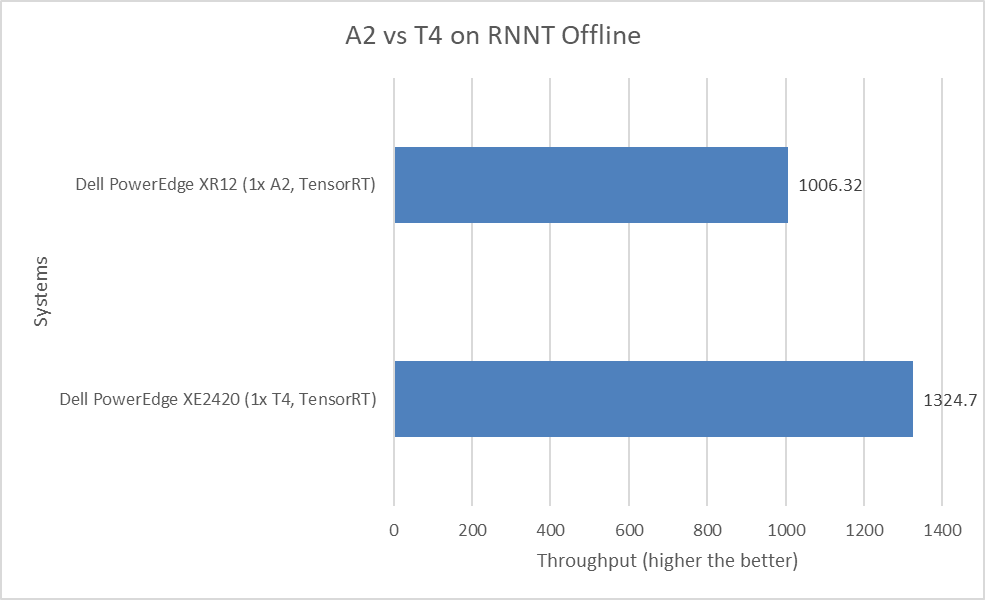
Figure 7: MLPerf Inference RNNT Offline performance
The RNNT model falls under the speech recognition category, which can be used for applications such as automatic closed captioning in YouTube videos and voice commands on smartphones. However, for speech recognition workloads, the PowerEdge XE2420 server with the T4 GPU and the PowerEdge XR12 server with the A2 GPU are closer in terms of performance. There is only a 32 percent performance delta.
The following figure shows a comparison of the BERT Offline performance of default and high accuracy runs of the PowerEdge XR12 server with the A2 GPU and the PowerEdge XE2420 server with the A30 GPU:
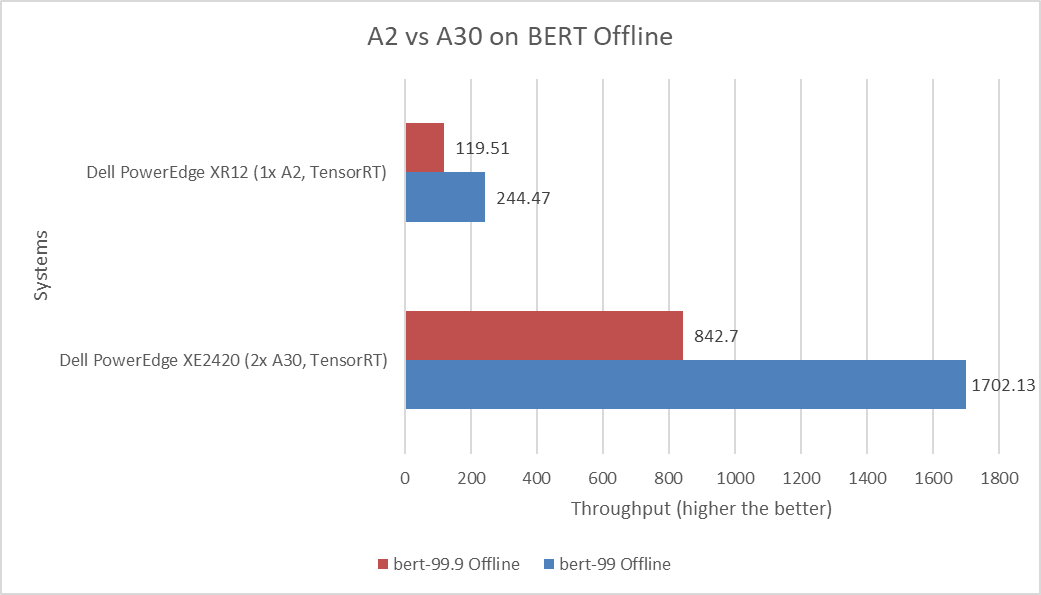
Figure 8: MLPerf Inference BERT Offline performance
BERT is a state-of-the-art, language-representational model for Natural Language Processing applications such as sentiment analysis. Although the PowerEdge XE2420 server with the A30 GPU shows significant performance gains, the PowerEdge XR12 server with the A2 GPU exceeds when considering achieved performance based on the money spent.
The following figure shows a comparison of the Deep Learning Recommendation Model (DLRM) Offline performance for the PowerEdge XE2420 server with the T4 GPU and the PowerEdge XR12 server with the A2 GPU:
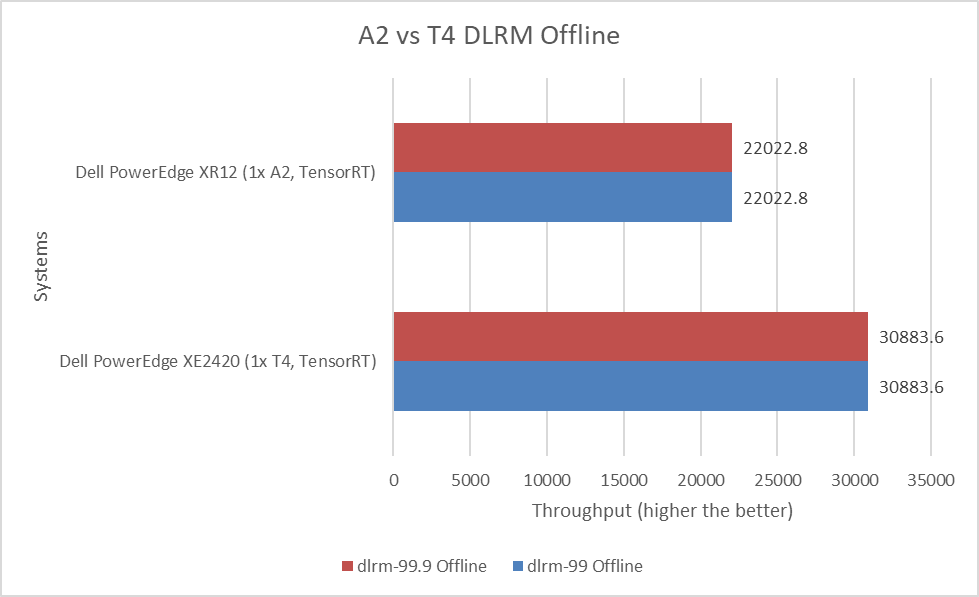
Figure 9: MLPerf Inference DLRM Offline performance
DLRM uses collaborative filtering and predicative analysis-based approaches to make recommendations, based on the dataset provided. Recommender systems are extremely important in search, online shopping, and online social networks. The performance of the PowerEdge XE2420 T4 in the offline mode was 40 percent better than the PowerEdge XR12 server with the A2 GPU.
Despite the higher performance from the PowerEdge XE2420 server with the T4 GPU, the PowerEdge XR12 server with the A2 GPU is an excellent option for edge-related workloads. The A2 GPU is designed for high performance at the edge and consumes less power than the T4 GPU for similar workloads. Also, the A2 GPU is the more cost-effective option.
Power Discussion
It is important to budget power consumption for the critical load in a data center. The critical load includes components such as servers, routers, storage devices, and security devices. For the MLPerf Inference v2.0 submission, Dell Technologies submitted power numbers for the PowerEdge XR12 server with the A2 GPU. Figures 8 through 11 showcase the performance and power results achieved on the PowerEdge XR12 system. The blue bars are the performance results, and the green bars are the system power results. For all power submissions with the A2 GPU, Dell Technologies took the Number One claim for performance per watt for the ResNet 50, RNNT, BERT, and DLRM benchmarks.
Figure 10: MLPerf Inference v2.0 ResNet 50 power results on the Dell PowerEdge XR12 server
Figure 11: MLPerf Inference v2.0 RNNT power results on the Dell PowerEdge XR12 server
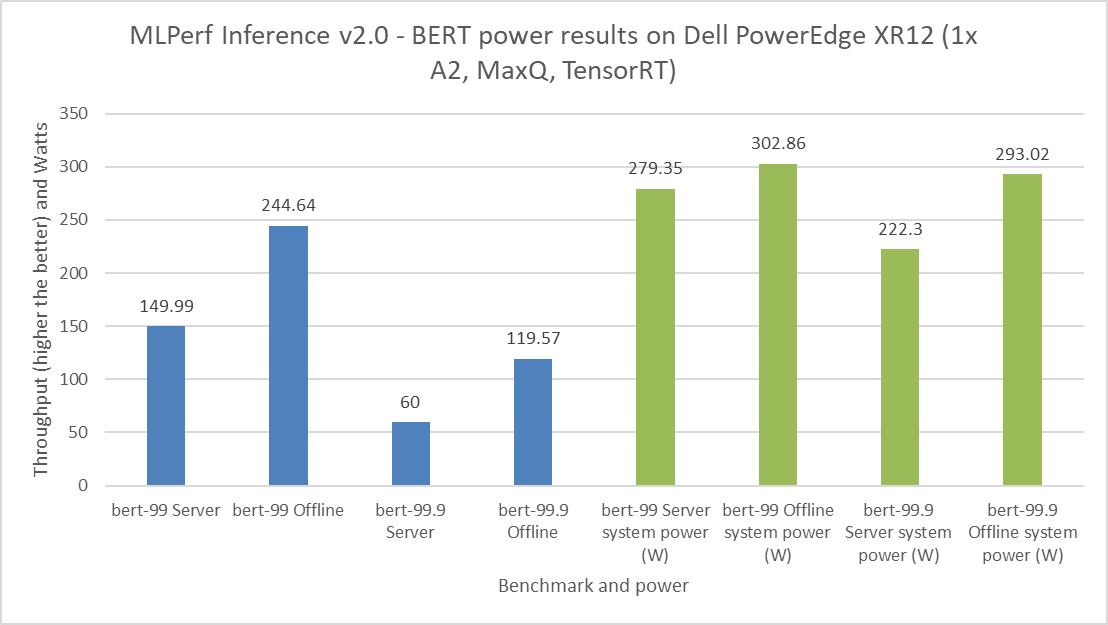
Figure 12: MLPerf Inference v2.0 BERT power results on the Dell PowerEdge XR12 server
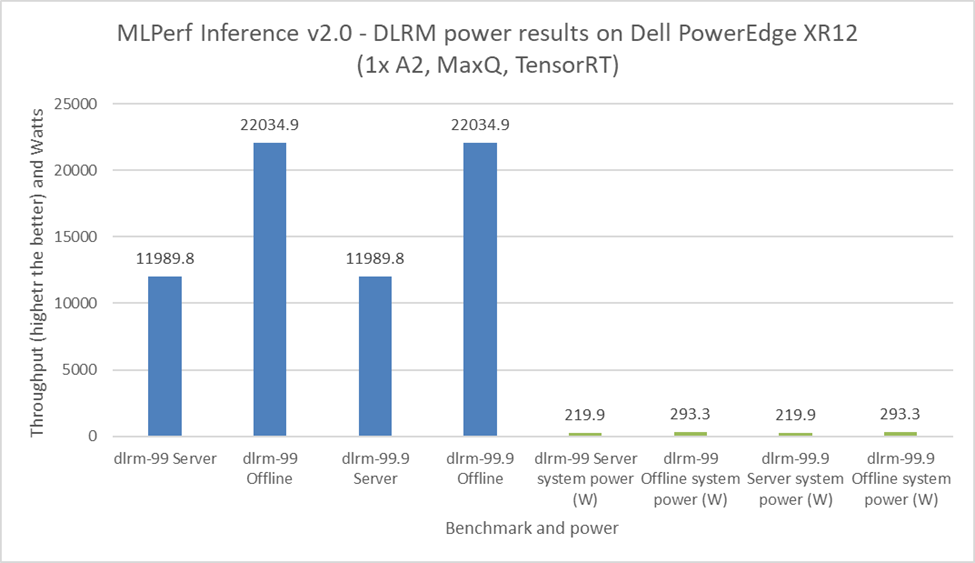 Figure 13: MLPerf Inference v2.0 DLRM power results on the Dell PowerEdge XR12 server
Figure 13: MLPerf Inference v2.0 DLRM power results on the Dell PowerEdge XR12 server
Note: During our submission to MLPerf Inference v2.0 including power numbers, the PowerEdge XR12 server was not tuned for optimal performance per watt score. These results reflect the performance-optimized power consumption numbers of the server.
Conclusion
This blog takes a closer look at Dell Technologies’ MLPerf Inference v2.0 edge-related submissions. Readers can compare performance results between the Dell PowerEdge XE2420 server with the T4 GPU and the Dell PowerEdge XR12 server with the A2 GPU with other systems with different accelerators. This comparison helps readers make informed decisions about ML workloads on the edge. Performance, power consumption, and cost are the important factors to consider when planning any ML workload. Both the PowerEdge XR12 and XE2420 servers are excellent choices for Deep Learning workloads on the edge.
Appendix
SUT configuration
The following table describes the System Under Test (SUT) configurations from MLPerf Inference v2.0 submissions:
Table 1: MLPerf Inference v2.0 system configuration of the PowerEdge XE2420 and XR12 servers
Platform | PowerEdge XE2420 1x T4, TensorRT | PowerEdge XR12 1x A2, TensorRT | PowerEdge XR12 1x A2, MaxQ, TensorRT | PowerEdge XE2420 2x A30, TensorRT |
MLPerf system ID | XE2420_T4x1_edge_TRT | XR12_edge_A2x1_TRT | XR12_A2x1_TRT_MaxQ | XE2420_A30x2_TRT |
Operating system | CentOS 8.2.2004 | Ubuntu 20.04.4 | ||
CPU | Intel Xeon Gold 6238 CPU @ 2.10 GHz | Intel Xeon Gold 6312U CPU @ 2.40 GHz | Intel Xeon Gold 6252N CPU @ 2.30 GHz | |
Memory | 256 GB | 1 TB | ||
GPU | NVIDIA T4 | NVIDIA A2 | NVIDIA A30 | |
GPU form factor | PCIe | |||
GPU count | 1 | 2 | ||
Software stack | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.47.03 DALI 0.31.0 | |||
Table 2: MLPerf Inference v1.1 system configuration of the PowerEdge XE8545 server
Platform | PowerEdge XE8545 4x A100-SXM-80GB-7x1g.10gb, TensorRT, Triton |
MLPerf system ID | XE8545_A100-SXM-80GB-MIG_28x1g.10gb_TRT_Triton |
Operating system | Ubuntu 20.04.2 |
CPU | AMD EPYC 7763 |
Memory | 1 TB |
GPU | NVIDIA A100-SXM-80GB (7x1g.10gb MIG) |
GPU form factor | SXM |
GPU count | 4 |
Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.57.02 DALI 0.31.0 |
Performance of the Dell PowerEdge R750xa Server for MLPerf™ Inference v2.0
Thu, 21 Apr 2022 18:20:33 -0000
|Read Time: 0 minutes
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. The results provide information about the performance of Dell servers. This blog takes a closer look at the Dell PowerEdge R750xa server and its performance for MLPerf Inference v1.1 and v2.0.
We compare the v1.1 results with the v2.0 results. We show the performance difference between the software stack versions. We also use the PowerEdge R750xa server to demonstrate that the v1.1 results from all systems can be referenced for planning an ML workload on systems that are not available for MLPerf Inference v2.0.
PowerEdge R750xa server
Built with state-of-the-art components, the PowerEdge R750xa server is ideal for artificial intelligence (AI), machine learning (ML), and deep learning (DL) workloads. The PowerEdge R750xa server is the GPU-optimized version of the PowerEdge R750 server. It supports accelerators as 4 x 300 W DW or 6 x 75 W SW. The GPUs are placed in the front of the PowerEdge R750xa server allowing for better airflow management. It has up to eight available PCIe Gen4 slots and supports up to eight NVMe SSDs.
The following figures show the PowerEdge R750xa server (source):

Figure 1: Front view of the PowerEdge R750xa server

Figure 2: Rear view of the PowerEdge R750xa server

Figure 3: Top view of the PowerEdge R750xa server
Configuration comparison
The following table describes the software stack configurations from the two rounds of submission for the closed data center division:
Table 1: MLPerf Inference v1.1 and v2.0 software stacks
NVIDIA component | v1.1 software stack | v2.0 software stack |
TensorRT | 8.0.2 | 8.4.0 |
CUDA | 11.3 | 11.6 |
cuDNN | 8.2.1 | 8.3.2 |
GPU driver | 470.42.01 | 510.39.01 |
DALI | 0.30.0 | 0.31.0 |
Triton | 21.07 | 22.01 |
Although the software has been updated across the two rounds of submission, performance is consistent, if not better, for the v2.0 submission. For MLPerf Inference v2.0, Triton performance results can be extrapolated from MLPerf Inference v1.1 except for the 3D U-Net benchmark, which is due to a v2.0 dataset change.
The following table describes the System Under Test (SUT) configurations from MLPerf Inference v1.1 and v2.0 of data center inference submissions:
Table 2: MLPerf Inference v1.1 and v2.0 system configuration of the PowerEdge R750xa server
Component | v1.1 system configuration | v2.0 system configuration |
Platform | R750xa 4x A100-PCIE-80GB, TensorRT | R750xa 4xA100 TensorRT |
MLPerf system ID | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100_PCIE_80GBx4_TRT |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6338 CPU @ 2.00 GHz | |
Memory | 1 TB | |
GPU | NVIDIA A100-PCIE-80GB | |
GPU form factor | PCIe | |
GPU count | 4 | |
Software stack | TensorRT 8.0.2 | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.39.01 DALI 0.31.0 |
In the v1.1 round of submission, Dell Technologies submitted four different configurations on the PowerEdge R750xa server. Although the GPU count of four was maintained, Dell Technologies submitted the 40 GB and the 80 GB versions of the NVIDIA A100 GPU. Additionally, Dell Technologies submitted Multi-Instance GPU (MIG) numbers using 28 instances of the one compute instance of the 10gb memory profile on the 80 GB A100 GPU. Furthermore, Dell Technologies submitted power numbers (MaxQ is a performance and power submission) for the 40 GB version of the A100 GPU and submitted with the Triton server on the 80 GB version of the A100 GPU. A discussion about the v1.1 submission by Dell Technologies can be found in this blog.
Performance comparison of the PowerEdge R70xa server for MLPerf Inference v2.0 and v1.1
ResNet 50
ReNet50 is a 50-layer deep convolution neural network that is made up of 48 convolution layers along with a single max pool and average pool layer. This model is used for computer vision applications including image classification, object detection, and object classification. For the ResNet 50 benchmark, the performance numbers from the v2.0 submission match and outperform in the server and offline scenarios respectively when compared to the v1.1 round of submission. As shown in the following figure, the v2.0 submission results are within 0.02 percent in the server scenario and outperform the previous round by 1 percent in the offline scenario:
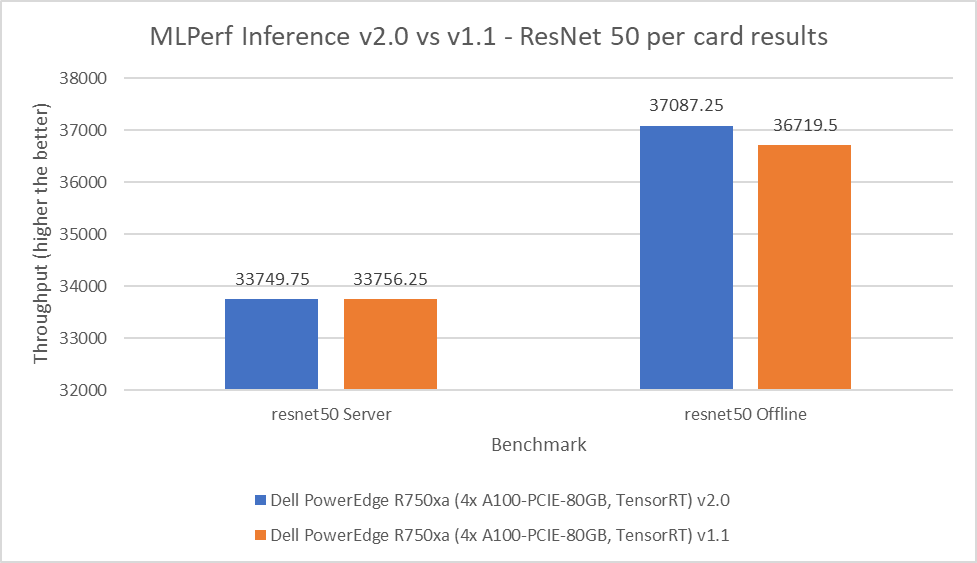
Figure 4: MLPerf Inference v2.0 compared to v1.1 ResNet 50 per card results on the PowerEdge R750xa server
BERT
Bidirectional Encoder Representation from Transformers (BERT) is a state-of-the-art language representational model for Natural Language Processing applications. This benchmark performs the SQuAD question answering task. The BERT benchmark consists of default and high accuracy modes for the offline and server scenarios. In the v2.0 round of submission, the PowerEdge R750xa server matched and slightly outperformed its performance from the previous round. In the default BERT server and offline scenarios, the extracted performance is within 0.06 and 2.33 percent respectively. In the high accuracy BERT server and offline scenarios, the extracted performance is within 0.14 and 1.25 percent respectively.
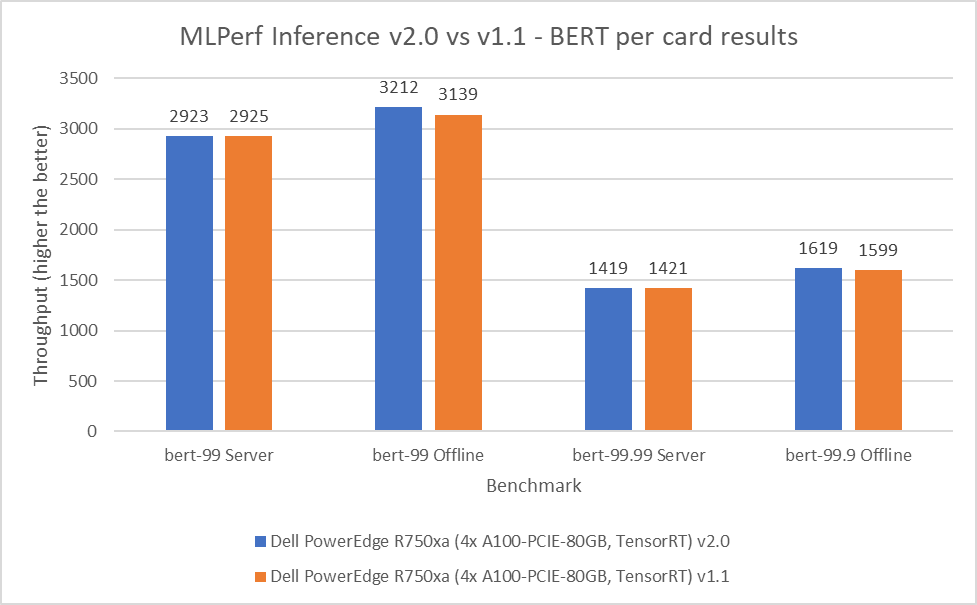
Figure 5: MLPerf Inference v2.0 compared to v1.1 BERT per card results on the PowerEdge R750xa server
SSD-ResNet 34
The SSD-ResNet 34 model falls under the computer vision category. This benchmark performs object detection. For the SSD-ResNet 34 benchmark, the results produced in the v2.0 round of submission are within 0.14 percent for the server scenario and show a 1 percent improvement in the offline scenario.
Figure 6: MLPerf Inference v2.0 compared to v1.1 SSD-ResNet 34 per card results on the PowerEdge R750xa server
DLRM
Deep Learning Recommendation Model (DLRM) is an effective benchmark for understanding workload requirements for building recommender systems. This model uses collaborative filtering and predicative analysis-based approaches to process large amounts of data. The DLRM benchmark consists of default and high accuracy modes, both containing the server and offline scenarios. For the server scenario in both the default and high accuracy modes, the v2.0 submissions results are within 0.003 percent. For the offline scenario across both modes, the PowerEdge R750xa server showed a 2.62 percent performance gain.
Figure 7: MLPerf Inference v2.0 compared to v1.1 DLRM per card results on the PowerEdge R750xa server
RNNT
The Recurrent Neural Network Transducers (RNNT) model falls under the speech recognition category. This benchmark accepts raw audio samples and produces the corresponding character transcription. For the RNNT benchmark, the PowerEdge R750xa server maintained similar performance behavior within 0.04 percent in the server mode and showing 1.46 percent performance gains in the offline mode.
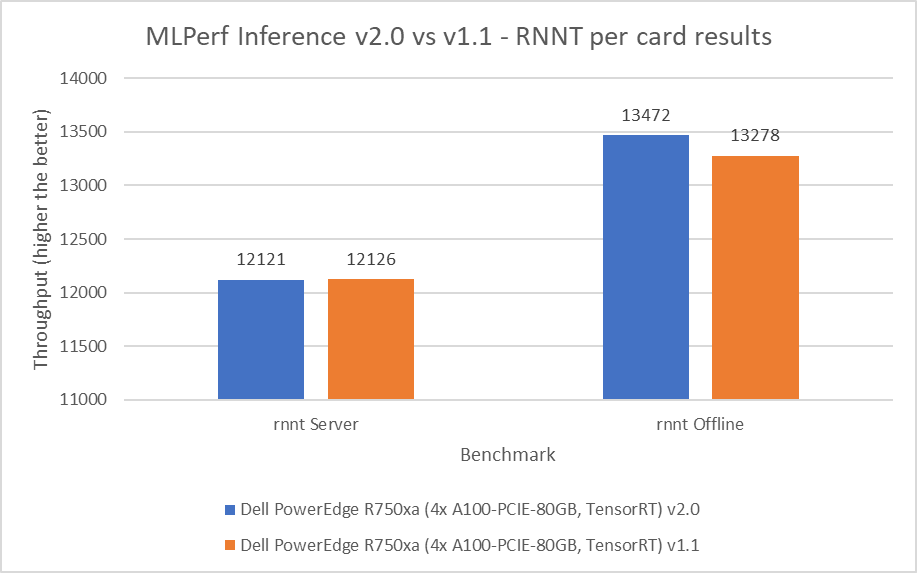
Figure 8: MLPerf Inference v2.0 compared to v1.1 RNNT per card results on the PowerEdge R750xa server
3D U-Net
The 3D U-Net performance numbers have changed in terms of scale and are not comparable in a bar graph because of a change to the dataset. The new dataset for this model is the Kitts 2019 Kidney Tumor Segmentation set. However, the PowerEdge R750xa server yielded Number One results among the PCIe form factor systems that were submitted. This model falls under the computer vision category, but it specifically deals with medical image data.
Results summary
Figure 1 through Figure 8 show the consistent performance of the PowerEdge R750xa server across both rounds of submission.
The following figure shows that in the offline scenarios for the benchmarks there is a small but noticeable performance improvement:
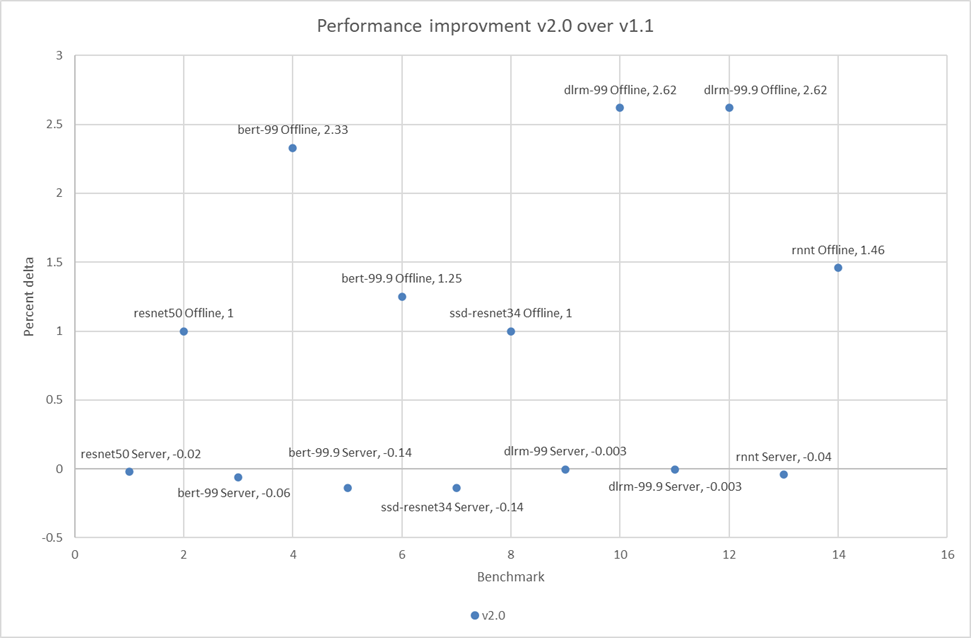
Figure 9: Performance improvement in percentage of the PowerEdge R750xa server across MLPerf Inference v2.0 and v1.1
The small percentage delta in the server scenarios can be a result of noise and are consistent with the previous round of submission.
Conclusion
This blog confirms the consistent performance of the Dell PowerEdge R750xa server across the MLPerf Inference v1.1 and MLPerf Inference v2.0 submissions. Because an identical system from round v1.1 performed at a consistent level for MLPerf Inference v2.0, we see that the software stack upgrades had minimal impact on performance. Therefore, the optimal results from the v1.1 round of submission can be used for making informed decisions about server performance for a specific ML workload. Because Dell Technologies submitted a diverse set of configurations in the v1.1 round of submission, customers can take advantage of many results.
Overview of MLPerf™ Inference v2.0 Results on Dell Servers
Fri, 09 Sep 2022 15:15:36 -0000
|Read Time: 0 minutes
Dell Technologies has been an active participant in the MLCommons™ Inference benchmark submission since day one. We have completed five rounds of inference submission.
This blog provides an overview of the latest results of MLPerf Inference v2.0 closed data center, closed data center power, closed edge, and closed edge power categories on Dell servers from our HPC & AI Innovation Lab. It shows optimal inference and power (performance per watt) performance for Dell GPU-based servers (DSS 8440, PowerEdge R750xa, PowerEdge XE2420, PowerEdge XE8545, and PowerEdge XR12). The previous blog about MLPerf Inference v1.1 performance results can be found here.
What is new?
- There were 3,800 performance results for this round compared to 1,800 performance results for v1.1. Additionally, 885 systems in v2.0 compared to 424 systems in v1.1 shows that there were more than twice the systems submitted for this round.
- For the 3D U-Net benchmark, the dataset now used is the KiTs 2019 Kidney Tumor Segmentation set.
- Early stopping was introduced in this round to replace a deterministic minimum query count with a function that dynamically determines when further runs are not required to identify additional performance gain.
Results at a glance
Dell Technologies submitted 167 results to the various categories. The Dell team made 86 submissions to the closed data center category, 28 submissions to the closed data center power category, and 53 submissions to the closed edge category. For the closed data center category, the Dell team submitted the second most results. In fact, Dell Technologies submitted results from 17 different system configurations with the NVIDIA TensorRT and NVIDIA Triton inference engines. Among these 17 configurations, the PowerEdge XE2420 server with T4 and A30 GPUs and the PowerEdge XR12 server with the A2 GPU were two new systems that have not been submitted before. Additionally, Dell Technologies submitted to the reintroduced Multiterm scenario. Only Dell Technologies submitted results for different host operating systems.
Noteworthy results
Noteworthy results include:
- The PowerEdge XE8545 and R750xa servers yield Number One results for performance per accelerator with NVIDIA A100 GPUs. The use cases for this top classification include Image Classification, Object Detection, Speech-to-text, Medical Imaging, Natural Language Processing, and Recommendation.
- The DSS 8440 server yields Number Two results for system performance for multiple benchmarks including Speech-to-text, Object Detection, Natural Language Processing, and Medical Image Segmentati on uses cases among all submissions.
- The PowerEdge R750xa server yields Number One results for the highest system performance for multiple benchmarks including Image Classification, Object Detection, Speech-to-text, Natural Language Processing, and Recommendation use cases among all the PCIe-based GPU servers.
- The PowerEdge XE8545 server yields Number One results for the lowest multistrand latency with NVIDIA Multi-Instance GPU (MIG) in the edge category for the Image Classification and Object Detection use cases.
- The PowerEdge XE2420 server yields Number One results for the highest T4 GPU inference results for the Image Classification, Speech-to-text, and Recommendation use cases.
- The PowerEdge XR12 server yields Number One results for the highest performance per watt with NVIDIA A2 GPU results in power for the Image Classification, Object Detection, Speech-to-text, Natural Language Processing, and Recommendation use cases.
MLPerf Inference v2.0 benchmark results
The following graphs highlight the performance metrics for the Server and Offline scenarios across the various benchmarks from MLCommons. Dell Technologies presents results as an method for our customers to identify options to suit their deep learning application demands. Additionally, this performance data serves as a reference point to enable sizing of deep learning clusters. Dell Technologies strives to submit as many results as possible to offer answers to ensure that customer questions are resolved.
For the Server scenario, the performance metric is queries per second (QPS). For the Offline scenario, the performance metric is Offline samples per second. In general, the metrics represent throughput, and a higher throughput indicates a better result. In the following graphs, the Y axis is an exponentially scaled axis representing throughput and the X axis represents the systems under test (SUTs) and their corresponding models. The SUTs are described in the appendix.
Figure 1 through Figure 6 show the per card performance of the various SUTs on the ResNet 50, BERT, SSD, 3dUnet, RNNT, and DLRM modes respectively in the Server and Offline scenarios:
Figure 1: MLPerf Inference v2.0 ResNet 50 per card results
Figure 2: MLPerf Inference v2.0 BERT default and high accuracy per card results
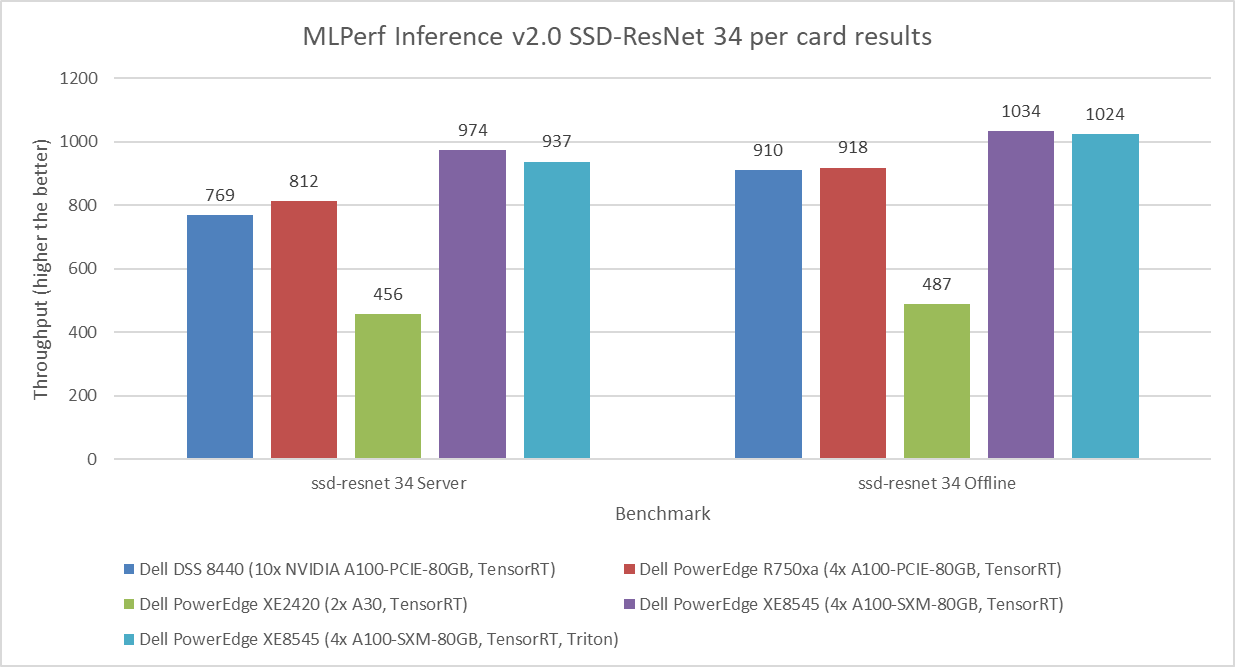
Figure 3: MLPerf Inference v2.0 SSD-ResNet 34 per card results
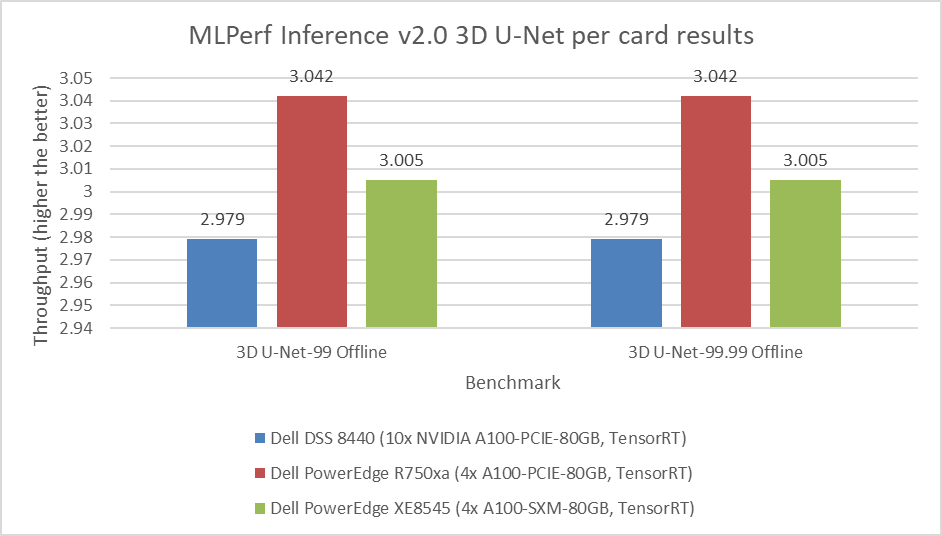
Figure 4: MLPerf Inference v2.0 3D U-Net per card results
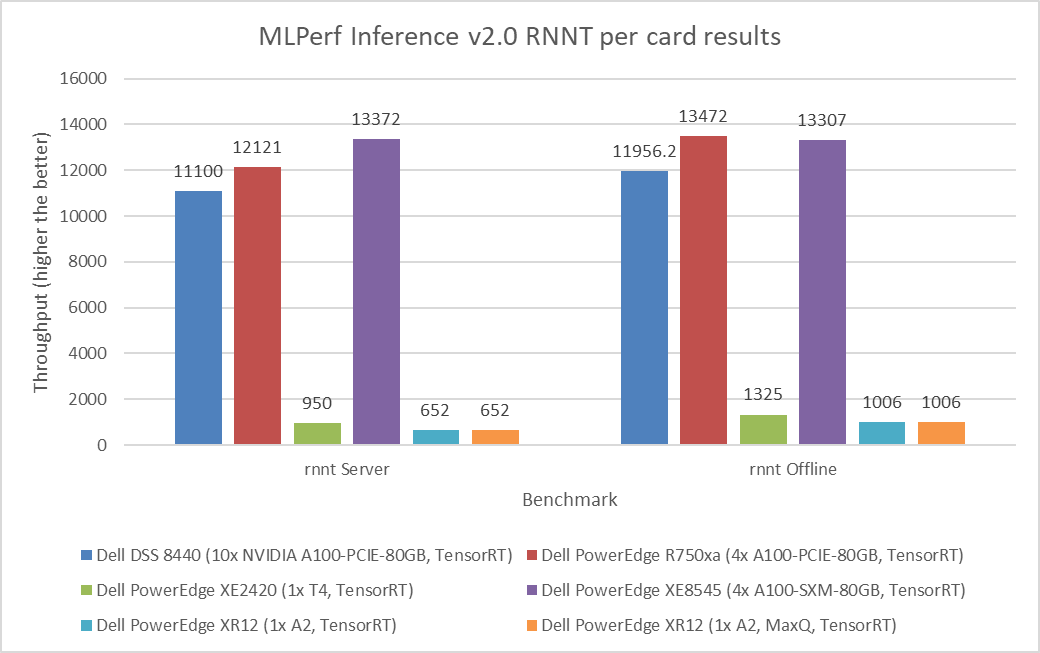
Figure 5: MLPerf Inference v2.0 RNNT per card results
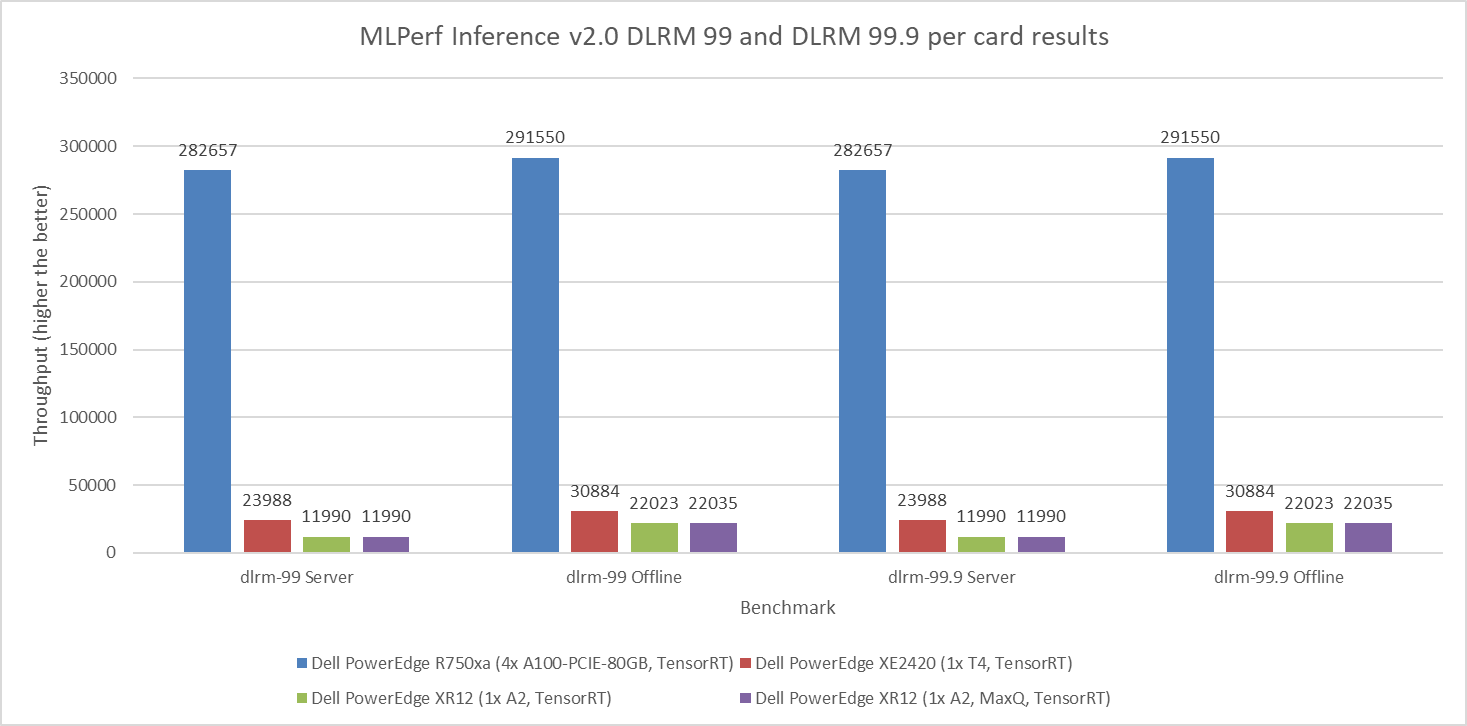
Figure 6: MLPerf Inference v2.0 DLRM default and high accuracy per card results
Observations
The results in this blog have been officially submitted to and accepted by the MLCommons organization. These results have passed compliance tests, been peer reviewed, and adhered to the constraints enforced by MLCommons. Customers and partners can reproduce our results by following steps to run MLPerf Inference v2.0 in its GitHub repository.
Submissions from Dell Technologies included approximately 140 performance results and 28 performance and power results. Across the various workload tasks including Image Classification, Object Detection, Medical Image Segmentation, Speech-to-text, Language Processing, and Recommendation, server performance from Dell Technologies was promising.
Dell servers performed with optimal performance and power results. They were configured with different GPUs such as:
- NVIDIA A30 Tensor Core GPU
- NVIDIA A100 (PCIe and SXM)
- NVIDIA T4 Tensor Core GPU
- NVIDIA A2 Tensor Core GPU, which is newly released
More information about performance for specific configurations that are not discussed in this blog can be found in the v1.1 or v1.0 results.
The submission included results from different inference backends such as NVIDIA TensorRT and NVIDIA Triton. The appendix provides a summary of the full hardware and software stacks.
Conclusion
This blog quantifies the performance of Dell servers in the MLPerf Inference v2.0 round of submission. Readers can use these results to make informed planning and purchasing decisions for their AI workload needs.
Appendix
Software stack
The NVIDIA Triton Inference Server is an open-source inferencing software tool that aids in the deployment and execution of AI models at scale in production. Triton not only works with all major frameworks but also with customizable backends, further enabling developers to focus on their AI development. It is a versatile tool because it supports any inference type and can be deployed on any platform including CPU, GPU, data center, cloud, or edge. Additionally, Triton supports the rapid and reliable deployment of AI models at scale by integrating well with Kubernetes, Kubeflow, Prometheus, and Grafana. Triton supports the HTTP/REST and GRPC protocols that allow remote clients to request inferencing for any model that the server manages.
The NVIDIA TensorRT SDK delivers high-performance deep learning inference that includes an inference optimizer and runtime. It is powered by CUDA and offers a unified solution to deploy on various platforms including edge or data center. TensorRT supports the major frameworks including PyTorch, TensorFlow, ONNX, and MATLAB. It can import models trained in these frameworks by using integrated parsers. For inference, TensorRT performs orders of magnitude faster than its CPU-only counterparts.
NVIDIA MIG can partition GPUs into several instances that extend compute resources among users. MIG enables predictable performance and maximum GPU use by running jobs simultaneously on the different instances with dedicated resources for compute, memory, and memory bandwidth.
SUT configuration
The following table describes the SUT from this round of data center inference submission:
Table 1: MLPerf Inference v2.0 system configurations for DSS 8440 and PowerEdge R750xa servers
Platform | DSS 8440 10xA100 TensorRT | R750xa 4xA100 TensorRT |
MLPerf system ID | DSS8440_A100_PCIE_80GBx10_TRT | R750xa_A100_PCIE_80GBx4_TRT |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6248R CPU @ 3.00 GHz | Intel Xeon Gold 6338 CPU @ 2.00 GHz |
Memory | 768 GB | 1 TB |
GPU | NVIDIA A100 | |
GPU form factor | PCIe | |
GPU count | 10 | 4 |
Software stack | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.39.01 DALI 0.31.0 | |
Table 2: MLPerf Inference v2.0 system configurations for PowerEdge XE2420 servers
Platform | PowerEdge XE2420 1xA30 TensorRT | PowerEdge XE2420 2xA30 TensorRT | PowerEdge XE2420 1xA30 TensorRT MaxQ | PowerEdge XE2420 1xAT4 TensorRT |
MLPerf system ID | XE2420_A30x1_TRT | XE2420_A30x2_TRT | XE2420_A30x1_TRT_MaxQ | XE2420_T4x1_TRT |
Operating system | Ubuntu 20.04.4 | CentOS 8.2.2004 | ||
CPU | Intel Xeon Gold 6252 CPU @ 2.10 GHz | Intel Xeon Gold 6252N CPU @ 2.30 GHz | Intel Xeon Silver 4216 CPU @ 2.10 GHz | Intel Xeon Gold 6238 CPU @ 2.10 GHz |
Memory | 1 TB | 64 GB | 256 GB | |
GPU | NVIDIA A30 | NVIDIA T4 | ||
GPU form factor | PCIe | |||
GPU count | 1 | 2 | 1 | 1 |
Software stack | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.39.01 DALI 0.31.0 | |||
Table 3: MLPerf Inference v2.0 system configurations for PowerEdge XE8545 servers
Platform | PowerEdge XE8545 4xA100 TensorRT | PowerEdge XE8545 4xA100 TensorRT, Triton | PowerEdge XE8545 1xA100 MIG 1x1g.10g TensorRT
|
MLPerf system ID | XE8545_A100_SXM_80GBx4_TRT | XE8545_A100_SXM_80GBx4_TRT_Triton | XE8545_A100_SXM_80GB_1xMIG_TRT |
Operating system | Ubuntu 20.04.3 | ||
CPU | AMD EPYC 7763 | ||
Memory | 1 TB | ||
GPU | NVIDIA A100-SXM-80 GB | NVIDIA A100-SXM-80 GB (1x1g.10gb MIG) | |
GPU form factor | SXM | ||
GPU count | 4 | 1 | |
Software stack | TensorRT 8.4.0 CUDA 11.6 CuDNN 8.3.2 Driver 510.47.03 DALI 0.31.0 | ||
| Triton 22.01 |
| |
Table 4: MLPerf Inference v2.0 system configurations for PowerEdge XR12 servers
Platform | PowerEdge XR12 1xA2 TensorRT | PowerEdge XR12 1xA2 TensorRT MaxQ |
MLPerf system ID | XR12_A2x1_TRT | XR12_A2x1_TRT_MaxQ |
Operating system | CentOS 8.2 | |
CPU | Intel Xeon Gold 6312U CPU @ 2.40 GHz | |
Memory | 256 GB | |
GPU | NVIDIA A2 | |
GPU form factor | PCIe | |
GPU count | 1 | |
Software stack | TensorRT 8.4.0 CUDA 11.6 cuDNN 8.3.2 Driver 510.39.01 DALI 0.31.0 | |

Scaling Deep Learning Workloads in a GPU Accelerated Virtualized Environment
Wed, 12 Jul 2023 15:21:11 -0000
|Read Time: 0 minutes
Introduction
Demand for compute, parallel, and distributed training is ever increasing in the field of deep learning (DL). The introduction of large-scale language models such as Megatron-Turing NLG (530 billion parameters; see References 1 below) highlights the need for newer techniques to handle parallelism in large-scale model training. Impressive results from transformer models in natural language have paved a way for researchers to apply transformer-based models in computer vision. The ViT-Huge (632 million parameters; see References 2 below) model, which uses a pure transformer applied to image patches, achieves amazing results in image classification tasks compared to state-of-the-art convolutional neural networks.
Larger DL models require more training time to achieve convergence. Even smaller models such as EfficientNet (43 million parameters; see References 3 below) and EfficientNetV2 (24 million parameters; see References 3 below) can take several days to train depending on the size of data and the compute used. These results clearly show the need to train models across multiple compute nodes with GPUs to reduce the training time. Data scientists and machine learning engineers can benefit by distributing the training of a DL model across multiple nodes. The Dell Validated Design for AI shows how software-defined infrastructure with virtualized GPUs is highly performant and suitable for AI (Artificial Intelligence) workloads. Different AI workloads require different resources sizing, isolation of resources, use of GPUs, and a better way to scale across multiple nodes to handle the compute-intensive DL workloads.
This blog demonstrates the use and performance across various settings such as multinode and multi-GPU workloads on Dell PowerEdge servers with NVIDIA GPUs and VMware vSphere.
System Details
The following table provides the system details:
Table 1: System details
Component | Details |
Server | Dell PowerEdge R750xa (NVIDIA-Certified System) |
Processor | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz |
GPU | 4 x NVIDIA A100 PCIe |
Network Adapter | Mellanox ConnectX-6 Dual port 100 GbE |
Storage | Dell PowerScale |
ESXi Version | 7.0.3 |
BIOS Version | 1.1.3 |
GPU Driver Version | 470.82.01 |
CUDA Version | 11.4 |
Setup for multinode experiments
To achieve the best performance for distributed training, we need to perform the following high-level steps when the ESXi server and virtual machines (VMs) are created:
- Enable Address Translation Services (ATS) on VMware ESXi and VMs to enable peer to peer (P2P) transfers with high performance.
- Enable ATS on the ConnectX-6 NIC.
- Use the ibdev2netdev utility to display the installed Mellanox ConnectX-6 card and mapping between logical and physical ports, and enable the required ports.
- Create a Docker container with Mellanox OFED drivers, Open MPI Library, and NVIDIA optimized TensorFlow (the DL framework that is used in the following performance tests).
- Set up a keyless SSH login between VMs.
- When configuring multiple GPUs in the VM, connect the GPUs with NVLINK.
Performance evaluation
For the evaluation, we used VMs with 32 CPUs, 64 GB of memory, and GPUs (depending on the experiment). The evaluation of the training performance (throughput) is based on the following scenarios:
- Scenario 1—Single node with multiple VMs and multi-GPU model training
- Scenario 2—Multinode model training (distributed training)
Scenario 1
Imagine the case in which there are multiple data scientists working on building and training different models. It is vital to strictly isolate resources that are shared between the data scientists to run their respective experiments. How effectively can the data scientists use the resources available?
The following figure shows several experiments on a single node with four GPUs and the performance results. For each of these experiments, we run tf_cnn_benchmarks with the ResNet50 model with a batch size of 1024 using synthetic data.
Note: The NVIDIA A100 GPU supports a NVLink bridge connection with a single adjacent NVIDIA A100 GPU. Therefore, the maximum number of GPUs added to a single VM for multi-GPU experiments on a Dell PowerEdge R750xa server is two.
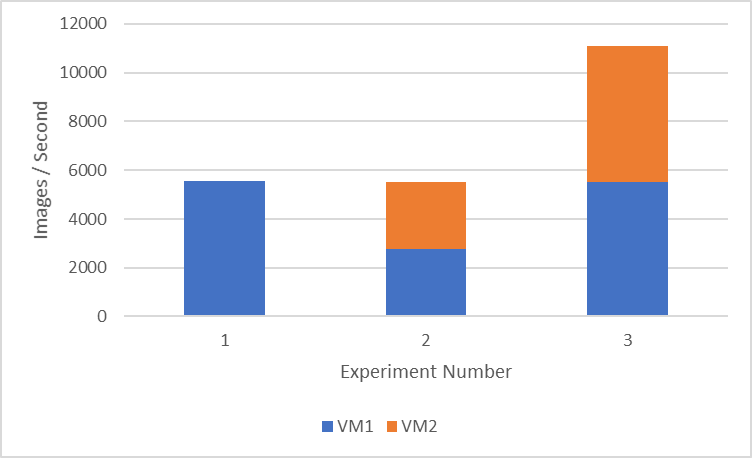
Figure 1: Performance comparison of multi-VMs and multi-GPUs on a single node
Figure 1 shows the throughput (the average on three runs) of three different experiment setups:
- Setup 1 consists of a single VM with two GPUs. This setup might be beneficial to run a machine learning workload, which needs more GPUs for faster training (5500 images/second) but still allows the remaining resources in the available node for other data scientists to use.
- Setup 2 consists of two VMs with one GPU each. We get approximately 2700 images/second on each VM, which can be useful to run multiple hyper-parameter search experiments to fine-tune the model.
- Setup 3 consists of two VMs with two GPUs each. We use all the GPUs available in the node and show the maximum cumulative throughput of approximately 11000 images/second between two VMs.
Scenario 2
Training large DL models requires a large amount of compute. We also need to ensure that the training is completed in an acceptable amount of time. Efficient parallelization of deep neural networks across multiple servers is important to achieve this requirement. There are two main algorithms when we address distributed training, data parallelism, and model parallelism. Data parallelism allows the same model to be replicated in all nodes, and we feed different batches of input data to each node. In model parallelism, we divide the model weights to each node and the same minibatch data is trained across the nodes.
In this scenario, we look at the performance of data parallelism while training the model using multiple nodes. Each node receives different minibatch data. In our experiments, we scale to four nodes with one VM and one GPU each.
To help with scaling models to multiple nodes, we use Horovod (see References 6 below ), which is a distributed DL training framework. Horovod uses the Message Passing Interface (MPI) to effectively communicate between the processes.
MPI concepts include:
- Size indicates the total number of processes. In our case, the size is four processes.
- Rank is the unique ID for each process.
- Local rank indicates the unique process ID in a node. In our case, there is only one GPU in each node.
- The Allreduce operation aggregates data among multiple processes and redistributes them back to the process.
- The Allgather operation is used to gather data from all the processes.
- The Broadcast operation is used to broadcast data from one process identified by root to other processes.
The following table provides the scaling experiment results:
Table 2: Scaling experiments results
Number of nodes | VM Throughput (images/second) |
1 | 2757.21 |
2 | 5391.751667 |
4 | 10675.0925 |
For the scaling experiment results in the table, we run tf_cnn_benchmarks with the ResNet50 model with a batch size of 1024 using synthetic data. This experiment is a weak scaling-based experiment; therefore, the same local batch size of 1024 is used as we scale across nodes.
The following figure shows the plot of speedup analysis of scaling experiment:
Figure 2: Speedup analysis of scaling experiment
The speedup analysis in Figure 2 shows the speedup (times X) when scaling up to four nodes. We can clearly see that it is almost linear scaling as we increase the number of nodes.
The following figure shows how multinode distributed training on VMs compares to running the same experiments on bare metal (BM) servers:
Figure 3: Performance comparison between VMs and BM servers
The four-nodes experiment (one GPU per node) achieves a throughput of 10675 images/second in the VM environment while the similarly configured BM run achieves a throughput of 10818 images/second. One-, two-, and four-node experiments show a percentage difference of less than two percent between BM experiments and VM experiments.
Conclusion
In this blog, we described how to set up the ESXi server and VMs to be able to run multinode experiments. We examined various scenarios in which data scientists can benefit from multi-GPU experiments and their corresponding performance. The multinode scaling experiments showed how the speedup is closer to linear scaling. We also examined how VM-based distributed training compares to BM-server based distributed training. In upcoming blogs, we will look at best practices for multinode vGPU training, and the use and performance of NVIDIA Multi-Instance GPU (MIG) for various deep learning workloads.
References
- Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- EfficientNetV2: Smaller Models and Faster Training
- Virtualizing GPUs for AI with VMware and NVIDIA Based on Dell Infrastructure Design Guide
- https://github.com/horovod/horovod
Contributors
Contributors to this blog: Prem Pradeep Motgi and Sarvani Vemulapalli
Multinode Performance of Dell PowerEdge Servers with MLPerfTM Training v1.1
Mon, 07 Mar 2022 19:51:12 -0000
|Read Time: 0 minutes
The Dell MLPerf v1.1 submission included multinode results. This blog showcases performance across multiple nodes on Dell PowerEdge R750xa and XE8545 servers and demonstrates that the multinode scaling performance was excellent.
The compute requirement for deep learning training is growing at a rapid pace. It is imperative to train models across multiple nodes to attain a faster time-to-solution. Therefore, it is critical to showcase the scaling performance across multiple nodes. To demonstrate to customers the performance that they can expect across multiple nodes, our v1.1 submission includes multinode results. The following figures show multinode results for PowerEdge R750xa and XE8545 systems.
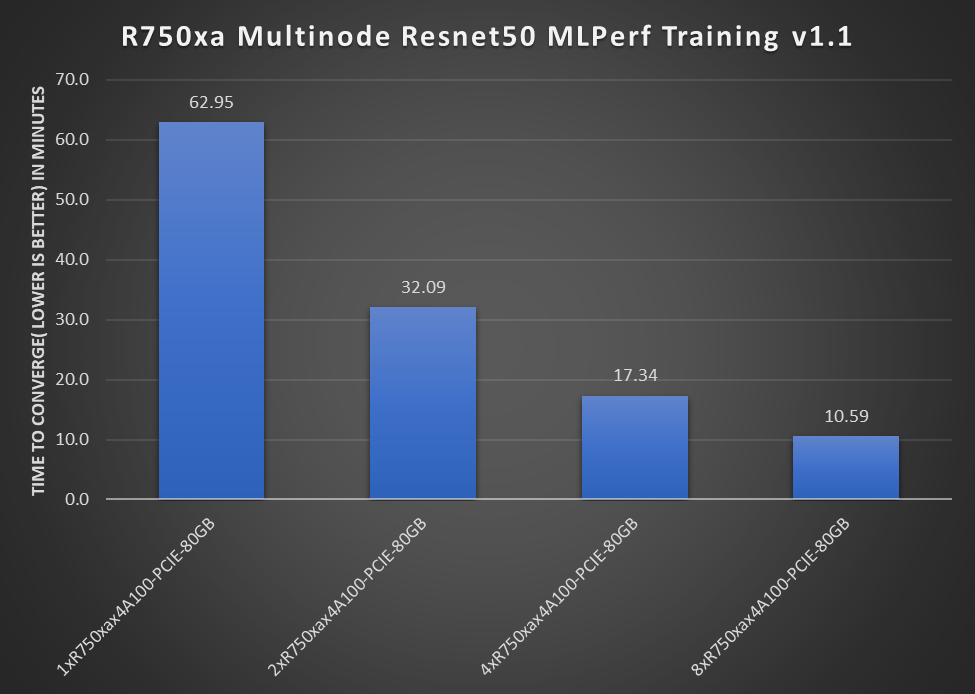
Figure 1: One-, two-, four-, and eight-node results with PowerEdge R750xa Resnet50 MLPerf v1.1 scaling performance
Figure 1 shows the performance of the PowerEdge R750xa server with Resnet50 training. These numbers scale from one node to eight nodes, from four NVIDIA A100-PCIE-80GB GPUs to 32 NVIDIA A100-PCIE-80GB GPUs. We can see that the scaling is almost linear across nodes. MLPerf training requires passing Reference Convergence Points (RCP) for compliance. These RCPs were inhibitors to show linear scaling for the 8x scaling case. The near linear scaling makes a PowerEdge R750xa node an excellent choice for multinode training setup.
The workload was distributed by using singularity on PowerEdge R750xa servers. Singularity is a secure containerization solution that is primarily used in traditional HPC GPU clusters. Our submission includes setup scripts with singularity that help traditional HPC customers run workloads without the need to fully restructure their existing cluster setup. The submission also includes Slurm Docker-based scripts.
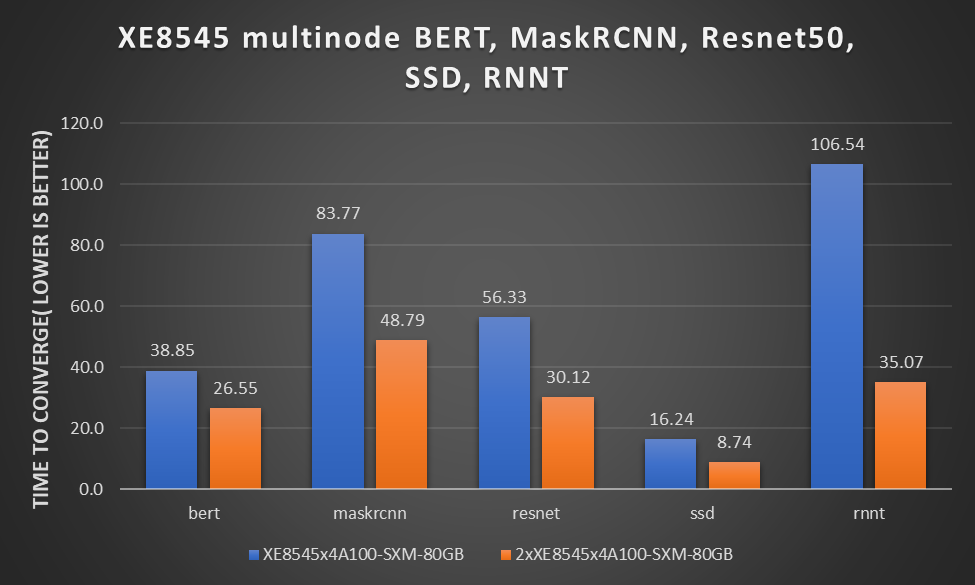
Figure 2: Multinode submission results for PowerEdge XE8545 server with BERT, MaskRCNN, Resnet50, SSD, and RNNT
Figure 2 shows the submitted performance of the PowerEdge XE8545 server with BERT, MaskRCNN, Resnet50, SSD, and RNNT training. These numbers scale from one node to two nodes, from four NVIDIA A100-SXM-80GB GPUs to eight NVIDIA A100-SXM-80GB GPUs. All GPUs operate at 500W TDP for maximum performance. They were distributed using Slurm and Docker on PowerEdge XE8545 servers. The performance is nearly linear.
Note: The RNN-T single node results submitted for the PowerEdge XE8545x4A100-SXM-80GB system used a different set of hyperparameters than for two nodes. After the submission, we ran the RNN-T benchmark again on the PowerEdge XE8545x4A100-SXM-80GB system with the same hyperparameters and found that the new time to converge is approximately 77.37 minutes. Because we only had the resources to update the results for the 2xXE8545x4A100-SXM-80GB system before the submission deadline, the MLCommons results show 105.6 minutes for a single node XE8545x4100-SXM-80GB system.
The following figure shows the adjusted representation of performance for the PowerEdge XE8545x4A100-SXM-80GB system. RNN-T provides an unverified score of 77.31 minutes[1]:
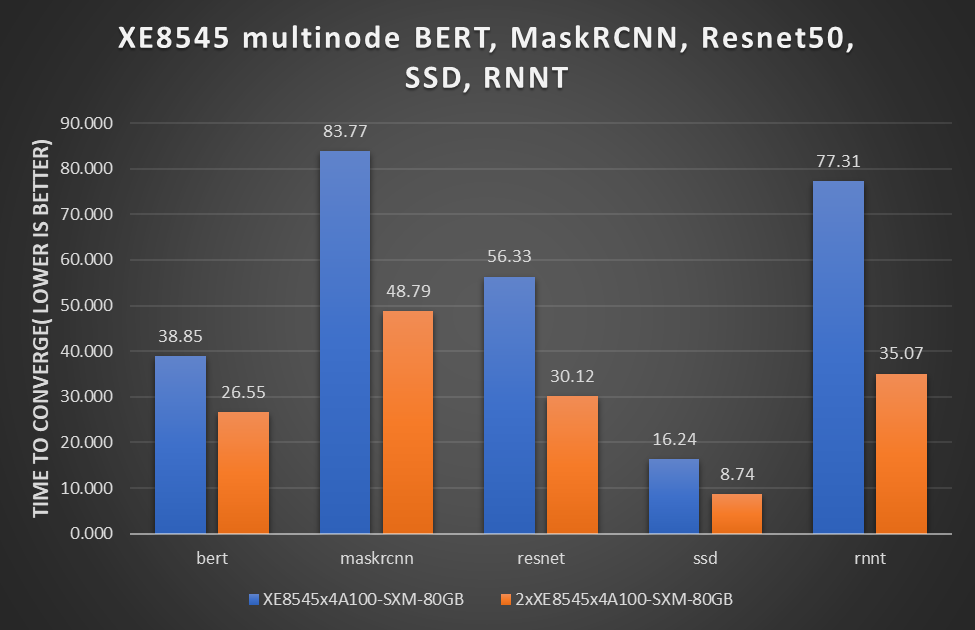
Figure 3: Revised multinode results with PowerEdge XE8545 BERT, MaskRCNN, Resnet50, SSD, and RNNT
Figure 3 shows the linear scaling abilities of the PowerEdge XE8545 server across different workloads such as BERT, MaskRCNN, ResNet, SSD, and RNNT. This linear scaling ability makes the PowerEdge XE8545 server an excellent choice to run large-scale multinode workloads.
Note: This rnnt.zip file includes log files for 10 runs that show that the averaged performance is 77.31 minutes.
Conclusion
- It is critical to measure deep learning performance across multiple nodes to assess the scalability component of training as deep learning workloads are growing rapidly.
- Our MLPerf training v1.1 submission includes multinode results that are linear and perform extremely well.
- Scaling numbers for the PowerEdge XE8545 and PowerEdge R750xa server make them excellent platform choices for enabling large scale deep learning training workloads across different areas and tasks.
[1] MLPerf v1.1 Training RNN-T; Result not verified by the MLCommonsTM Association. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See http://www.mlcommons.org for more information.
Dell EMC Servers Offer Excellent Deep Learning Performance with the MLPerf™ Training v1.1 Benchmark
Wed, 01 Dec 2021 21:31:51 -0000
|Read Time: 0 minutes
Overview
Dell Technologies has submitted results to the MLPerf Training benchmarking suite for the fifth round. This blog provides an overview of our submissions for the latest version, v1.1. Submission results indicate that different Dell EMC servers (Dell EMC DSS8440, PowerEdge R750xa, and PowerEdge XE8545 servers) offer promising performance for deep learning workloads. These workloads are across different problem types such as image classification, medical image segmentation, lightweight object detection, heavyweight object detection, speech recognition, natural language processing, recommendation, and reinforcement learning.
The previous blog about MLPerf v1.0 contains an introduction to MLCommons™ and the benchmarks in the MLPerf training benchmarking suite. We recommend that you read this blog for an overview of the benchmarks. All the benchmarks and rules remain the same as for v1.0.
The following graph with an exponentially scaled y axis indicates time to converge for the servers and benchmarks in question:
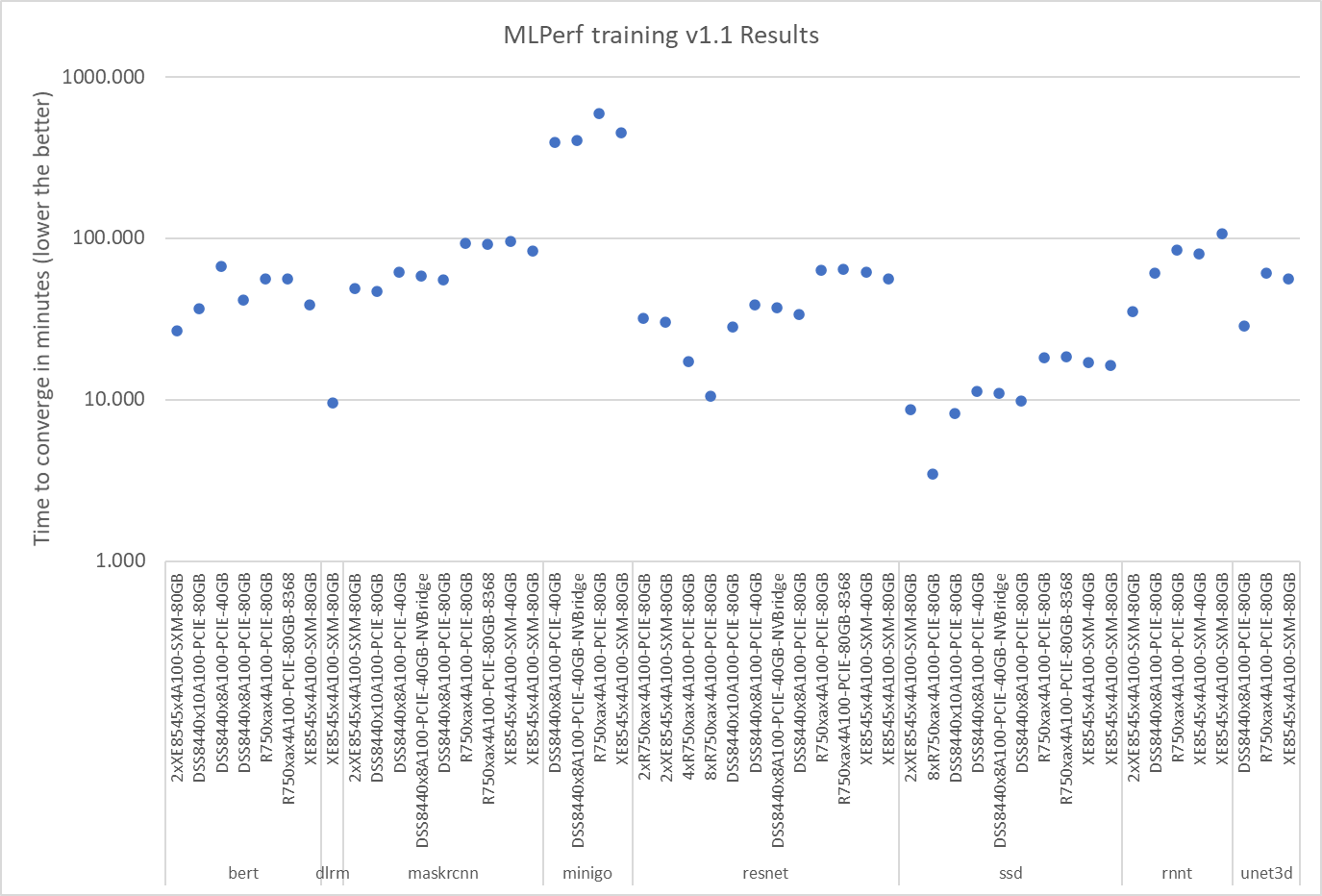
Fig 1: All Dell Technologies submission results for MLPerf Training v1.1
Figure 1 shows that this round of Dell Technologies submissions includes many results. We provided 51 results. These results encompass different Dell Technologies servers including Dell EMC DSS8440, PowerEdge R750xa, and PowerEdge XE8545 servers with various NVIDIA A100 accelerator configurations with different form factors: PCIe, SXM4, and different VRAM variants including 40 GB and 80 GB versions. These variants also include 300 W, 400 W, and 500 W TDP variants.
Note: For the hardware and software specifications of the systems in the graph, see https://github.com/mlcommons/training_results_v1.1/tree/master/Dell/systems.
Different benchmarks were submitted that span areas of image classification, medical image segmentation, lightweight object detection, heavy weight object detection, speech recognition, natural language processing, recommendation, and reinforcement learning. In all these areas, the Dell EMC DSS8440, PowerEdge R750xa, and PowerEdge XE8545 server performance is outstanding.
Highlights
Full coverage
Dell Technologies not only submitted the most results but also comprehensive results from a single system. PowerEdge XE8545 x 4 A100-SXM-80GB server results include submissions across the full spectrum of benchmarked models in the MLPerf training v1.1 suite such as BERT, DLRM, MaskR-CNN, Minigo, ResNet, SSD, RNNT, and 3D U-Net.
Multinode results
The performance scaling of the multinode results is nearly linear or linear and results scale well. This scaling makes the performance of Dell EMC servers in a multinode environment more conducive to faster time to value. Furthermore, among other submitters that include NVIDIA accelerator-based submissions, we are one of three submitters that encompass multinode results.
Improvements from v1.0 to v1.1
Updates for the Dell Technologies v1.1 submission include:
- The v1.1 submission includes results from the PowerEdge R750xa server. The PowerEdge R750xa server offers compelling performance, well suited for artificial intelligence, machine learning, and deep learning training and inferencing workloads.
- Our results include numbers for 10 GPUs with 80 GB A100 variants on the Dell EMC DSS8440 server. The results for 10 GPUs are useful because more GPUs in a server help to train the model faster, if constrained in a single node environment for training.
Fig 2: Performance comparison of BERT between v1.0 and v1.1 across Dell EMC DSS8440 and PowerEdge XE8545 servers
We noticed the performance improvement of v1.1 over v1.0 with the BERT model, especially with the PowerEdge XE8545 server. While many deep learning workloads were similar in performance between v1.0 and v1.1, the many results that we submitted help customers understand the performance difference across versions.
Conclusion
- Our number of submissions was significant (51 submissions). They help customers observe performance with different Dell EMC servers across various configurations. A higher number of results helps customers understand server performance that enables a faster time to solution across different configuration types, benchmarks, and multinode settings.
- Among other submissions that include NVIDIA accelerator-based submissions, we are one of three submitters that encompass multinode results. It is imperative to understand scaling performance across multiple servers as deep learning compute needs continue to increase with different kinds of deep learning models and parallelism techniques.
- PowerEdge XE8545 x 4A100-SXM-80GB server results include all the models in the MLPerf v1.1 benchmark.
- PowerEdge R750xa server results were published for this round; they offer excellent performance.
Next steps
In future blogs, we plan to compare the performance of NVLINK Bridged systems with non-NVLINK Bridged systems.
Dell EMC PowerEdge R750xa Server for Inference on AI Applications
Wed, 01 Dec 2021 13:24:57 -0000
|Read Time: 0 minutes
Introduction to the PowerEdge R750xa server for inference on AI applications
Dell Technologies HPC & AI Innovation Lab has submitted results for the Dell EMC PowerEdge R750xa server to MLPerf™ Inference v1.1, the latest round from MLCommons™, for data center on-premises benchmarks. Based on these results submitted for data center on-premises inference, the PowerEdge R750xa server performs well across many application areas and consistently provides high-performance results for machine-learning inference benchmarks. In this blog, we showcase the PowerEdge R750xa server results as a benchmark for high performance.
The results show that the PowerEdge R750xa server is flexible and can support challenges across many AI applications. Also, the results are reproducible for inference performance in problem areas that are addressed by vision, speech, language, and commerce applications.
PowerEdge R750xa server technical specifications
The PowerEdge R750xa server base configuration provides enterprise solutions for customers in the field of artificial intelligence. It is a 2U, dual-socket server with dual 3rd Gen Intel Xeon Scalable processors with 40 cores and 32 DDR4 RDIMM slots for up to 1 TB of memory at powerful data rates.
With state-of-the-art hardware, the PowerEdge R750xa server is well suited for heavy workloads. It is especially well suited for artificial intelligence, machine learning, and deep learning applications and their heavy computational requirements. Also, the PowerEdge R750xa server is designed for flexibility, capable of adding more processors and PCIe cards, and adequate HDD or SSD/NVMe storage capacity to scale to meet workload needs. With scalability at its foundation, the server can be expanded to manage visualization, streaming, and other types of workloads to address AI processing requirements.
The following figures show the PowerEdge R750xa server:

Figure. 1: Front view of the PowerEdge R750xa server

Figure. 2: Rear view of the PowerEdge R750xa server

Figure. 3: Top view of the PowerEdge R750xa server without the cover
Overview of MLPerf Inference
The MLPerf Inference benchmark is an industry-standard benchmark suite that accepts submission of inference results for a system under test (SUT) to various divisions. Each division is governed by policies that define the conditions for generating the results and the acceptable configurations for the SUTs. This blog provides details about the divisions and policies governing MLPerf Inference Benchmarking. For more information, see the MLCommons Inference Benchmarking website.
The focus of the PowerEdge R750xa server for inference was on the Closed Division Datacenter suite. There are six tasks spanning four areas for which benchmarking results were submitted. Within each task, the closed division defines a set of constraints that the inference benchmark must follow.
Systems submitting inference benchmark results in each of these tasks are required to meet each of the constraints shown in the following table:
Table 1: Benchmark tasks for MLPerf v1.1 Inference
Area | Task | Model | QSL size | Quality | Server latency constraint |
Vision | Image classification | Resnet50-v1.5 | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection (large) | SSD-ResNet34 | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical image segmentation | 3D UNet | 16 | 99% of FP32 and 99.9% of FP32 (0.85300 mean DICE score) | N/A |
Speech | Speech-to-text | RNNT | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Commerce | Recommendation | DLRM | 204800 | 99% of FP32 and 99.9% of FP32 (AUC=80.25%) | 30 ms |
PowerEdge R750xa server performance for inference
We submitted PowerEdge R750xa server benchmarking results for each task listed in the preceding table. For each task, we provided two submissions. The first submission was for the system operating in the Offline scenario, in which the SUT receives all samples in a single query and processes them continuously until completed. In this mode, system latency is not a primary issue. The second submission addressed the system operating in a server scenario, in which the model and data are processed through a network connection and depend on the latency of the SUT.
The PowerEdge R750xa server generated results for each task, in both modes, across three different configurations. The following table lists the three configurations:
Table 2: PowerEdge R750xa server configurations submitted for benchmarking
Configuration | 1 | 2 | 3 |
System | PowerEdge R750xa server | ||
Accelerator | 4x A100-PCIe (80 GB) | ||
CPU | Intel Xeon Gold 6338 | ||
Software stack | CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 | CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 Triton 21.07 | CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 Triton 21.07 Multi-Instance GPU (MIG) |
The table shows that all three configurations are similar, using a 4 x A100-PCIe (80 GB) GPU and the Intel Xeon Gold 6338 CPU. The primary difference is in the software stack. All three configurations use TensorRT. Configuration 2 adds a layer by using the NVIDIA Triton Inference Server as the inference engine. Configuration 3 adds two layers by using the NVIDIA Triton Inference Server and the NVIDIA Multi-Instance GPU (MIG).
The following figures show the results of each of these systems for the Offline and Server scenarios.
The following figure shows the first inference benchmark for image classification inferences with the PowerEdge R750xa server:
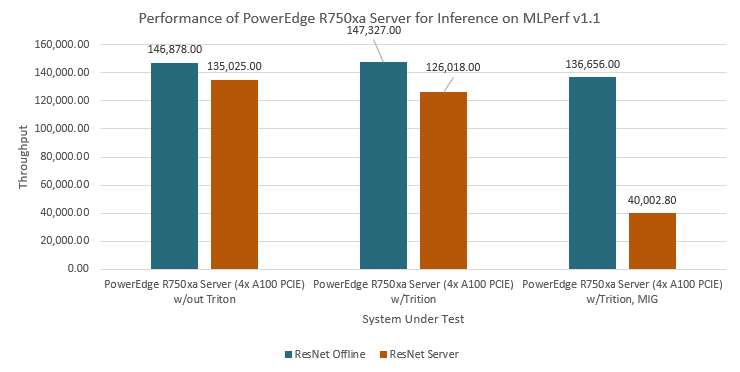
Figure. 1: PowerEdge R750xa server performance on inference for image classification using ResNet
Three different configurations of the PowerEdge R750xa server were benchmarked. Each configuration used ResNet-50 as the base model and we observed performance in both the Offline and Server scenarios. The first configuration with the Triton Inference Server performed slightly faster in the Offline scenario with 147,327 samples per second compared to the other two configurations. The configuration without the Triton Inference Server ran 146,878 samples per second while the configuration with the Triton Inference Server and MIG ran 136,656 samples per second. In the Offline scenario, these results suggest that the Triton Inference Server performs slightly faster, handling batches of samples quicker without regard to latency. These results give the first configuration a performance edge in the Offline scenario. In the Server scenario, the configuration without the Triton Inference Server performed the fastest at 135,025 samples per second. The configuration with the Triton Inference Server ran 126,018 samples per second, while the configuration with the Triton Inference Server and MIG ran 40,003 samples per second. These results show that the configurations including MIG all performed comparably, ranking highly for 4 x A100-PCIe (80 GB) GPU configurations on the image classification task. The results demonstrate that the PowerEdge R750xa server is a high-performance computing platform for image classification, especially when high-performance acceleration is installed on the system.
The following figure shows the second inference benchmark for Natural Language Processing (NLP) inferences with the PowerEdge R750xa server:
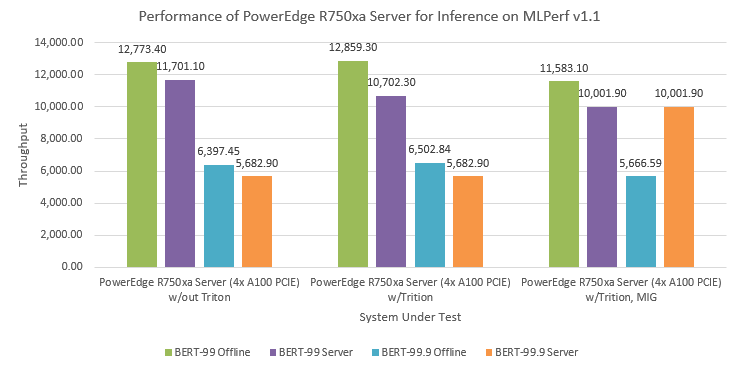
Figure. 2: PowerEdge R750xa server performance on inference for language processing using BERT
The same three configurations of the PowerEdge R750xa server were benchmarked. Each configuration used two versions of BERT as the base model and we observed performance in both the Offline and Server scenarios. The first version of the BERT model (BERT-99) is based on a 99 percent accuracy of inference; the second version (BERT-99.9) is based on a 99.9 percent accuracy of inference. In both cases, the PowerEdge R750xa server ran approximately 50 percent more samples per second with the BERT-99 model compared to the BERT-99.9 model. This result is because using the Bert-99.9 model to achieve 99.9 percent accuracy is based on 16-bit floating point data whereas the BERT-99 model is based on 8-bit integer data. The former requires significantly more computations due to the larger number of bits per sample.
As with the first inference benchmark, the configuration with the Triton Inference Server performed slightly faster in the Offline scenario with 12,859 samples per second compared to the other configurations using the BERT-99 model. It follows that the Triton Inference Server is configured to perform slightly better in the Offline scenario. In the Server scenario, the configuration without the Triton Inference Server performed best at 11,701 samples per second. For the BERT-99.9 model, the configuration without the Triton Inference Server ran 6,397 samples per second in the Offline scenario. Both configurations without MIG performed identically at 5,683 samples per second in the Server scenario for the BERT-99.9 model. This marginal difference can be attributed to run-to-run variability. Therefore, both configurations performed nearly identically.
These results show that all configurations performed comparably with or without the Triton Inference Server. For NLP, all configurations ranked highly for 4 x PCIe GPU configurations. The results suggest that the PowerEdge R750xa server is well suited for handling natural language processing samples in an inference configuration.
The following figure shows the third inference benchmark for light-weight object detection in images with the PowerEdge R750xa server:
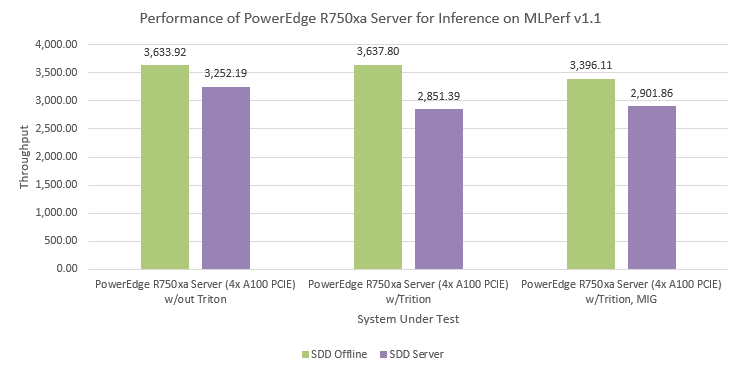
Figure. 3: PowerEdge R750xa server performance on inference for light-weight object detection.
The same three configurations of the PowerEdge R750xa server were benchmarked. Each configuration used SDD-Large as the base model and we observed performance in both the Offline and Server scenarios. The configuration that relied on the Triton Inference Server performed slightly faster in the Offline scenario with 3,638 samples per second. In the Server scenario, the configuration without the Triton Inference Server performed best at 3,252 samples per second, approximately 14 percent faster than the other configurations. Once again, each configuration performed comparably with or without the Triton Inference Server or MIG. For object detection, all configurations ranked highly for 4 x PCIe GPU configurations.
In addition to image classification, NLP, and object detection, the PowerEdge R750xa server was benchmarked for medical image classification, speech-to-text processing, and recommendation systems. The following table shows the best performance of the PowerEdge R750xa server, which relies on 4 x GPU A100 acceleration without the Triton Inference Server or MIG, and its respective performance in both the Offline and Server scenarios for each of the major tasks identified in Table 1.
Table 3: Performance of the PowerEdge R750xa server 4x A100-PCIe (80 GB) on TensorRT
Area | Task | Model | Mode | Samples per second |
Vision | Image classification | Resnet50-v1.5 | Offline | 146,878 |
Vision | Image classification | Resnet50-v1.5 | Server | 135,025 |
Vision | Object detection (large) | SSD-ResNet34 | Offline | 3,634 |
Vision | Object detection (large) | SSD-ResNet34 | Server | 3,252 |
Vision | Medical image segmentation | 3D UNet 99 | Offline | 231 |
Vision | Medical image segmentation | 3D UNet 99.9 | Offline | 231 |
Speech | Speech-to-text | RNNT | Offline | 53,113 |
Speech | Speech-to-text | RNNT | Server | 48,504 |
Language | Language processing | BERT-99 | Offline | 12,773 |
Language | Language processing | BERT-99 | Server | 11,701 |
Language | Language processing | BERT-99.9 | Offline | 6,397 |
Language | Language processing | BERT-99.9 | Server | 5,683 |
Commerce | Recommendation | DLRM-99 | Offline | 1,136,410 |
Commerce | Recommendation | DLRM-99 | Server | 1,136,670 |
Commerce | Recommendation | DLRM-99.9 | Offline | 1,136,410 |
Commerce | Recommendation | DLRM-99.9 | Server | 1,136,670 |
The results show that the system performed well in all tasks, ranking highly for each. These results show that the PowerEdge R750xa server is a solid system with flexibility for handling most AI problems that you might encounter.
Conclusion
In this blog, we quantified the performance of the PowerEdge R750xa server in the MLCommons Inference v1.1 performance benchmarks. Customers can use the submitted results to evaluate the applicability and flexibility of the PowerEdge R750xa server to address their needs and challenges.
The results in this blog show that the PowerEdge R750xa server is a flexible choice for AI inference problems. It has the flexibility to meet the inference requirements across many different scenarios and workload types.
Inference Results Comparison of Dell Technologies Submissions for MLPerf™ v1.0 and MLPerf™ v1.1
Wed, 17 Nov 2021 20:43:29 -0000
|Read Time: 0 minutes
Abstract
The Dell Technologies HPC & AI Innovation Lab recently submitted results to the MLPerf Inference v1.1 benchmark suite. These results provide our customers with transparent information about the performance of Dell EMC servers. This blog highlights the enhancements between the MLPerf™ Inference v1.0 and MLPerf Inference v1.1 submissions from Dell Technologies. These enhancements include improved GPU performance and new software to extract performance. Also, this blog compares server and GPU configurations from the MLPerf Inference v1.0 and v1.1 submissions.
Configuration comparison
The MLPerf Inference submissions focus was on outperforming the expectations outlined by MLPerf. For an introduction to the MLPerf Inference v1.0 performance results, we recommend that you read this blog published by Dell Technologies.
The following table provides the software stack configurations from the two submissions for the closed division benchmarks:
Table 1: MLPerf Inference v1.0 and v1.1 software stacks
| v1.0 | v1.1 |
TensorRT | 7.2.3 | 8.0.2 |
CUDA | 11.1 | 11.3 |
cuDNN | 8.1.1 | 8.2.1 |
GPU driver | 460.32.03 | 470.42.01 |
DALI | 0.30.0 | 0.31.0 |
Triton |
| 21.07 |
The following table shows the Dell EMC servers used for the MLPerf Inference v1.0 and v1.1 submissions:
Table 2: Servers used for the MLPerf Inference v1.0 and v1.1 submissions
| v1.0 | v1.1 |
Server | Accelerator | Accelerator |
DSS 8440 | 10 x A100-PCIe-40GB 10 x A40 | 10 x NVIDIA A100-PCIE-80GB 8 x A30 (TensorRT) 8 x A30 (Triton) |
PowerEdge R7525 | 3 x Quadro RTX 8000 2 x A100-PCIe-40GB 3 x A100-PCIe-40GB | 3 x A100-PCIE-40GB 3 x A30 3 x GRID A100-40C |
PowerEdge R740 | 3 x NVIDIA A100-PCIe-40GB 4 x A100-PCIe-40GB |
|
PowerEdge R750 |
| ICX-6330(2S 28C) ICX-8352M(2S 32C) |
PowerEdge R750xa |
| 4 x A100-PCIE-40GB, MaxQ 4 x A100-PCIE-80GB-MIG-7x1g.10gb 4 x A100-PCIE-80GB (TensorRT) 4 x A100-PCIE-80GB (Triton) |
PowerEdge XE2420 | 4 x T4 | 2 x A10 |
PowerEdge XE8545 | 4 x A100-SXM-40GB 4 x A100-SXM-80GB | 4 x A100-SXM-80GB-7x1g.10gb 4 x A100-SXM-80GB (TensorRT) 4 x A100-SXM-80GB (Triton) |
PowerEdge XR12 |
| 2 x A10 |
Besides the upgrades in the software stack that are detailed in the preceding table and the results from the latest hardware, differences between the MLPerf Inference v1.0 and v1.1 submissions include:
- The Multistream scenario has been deprecated in MLPerf v1.1.
- The total number of submitters increased from 17 to 21.
- There were 1725 total submissions to MLCommons™ in v1.1.
MLPerf Inference v1.0 compared to MLPerf Inference v1.1
We compared the MLPerf v1.0 and v1.1 submissions by looking at results from an identical server and the same GPU configurations used in both rounds of submission. For both submissions, Dell Technologies submitted results for the Dell EMC PowerEdge XE8545 server configured with four A100 SXM 80 GB GPUs. The PowerEdge XE8545 servers used a combination of the latest AMD CPUs and powerful NVIDIA A100 Tensor Core GPUs. The PowerEdge XE8545 Spec Sheet provides additional details about the server.
The following figure shows nearly level performance across the two submissions, which allows for a fair comparison between the submissions. Also, it shows that we need to be aware of the software upgrades listed in Table 1, no matter how minimal.
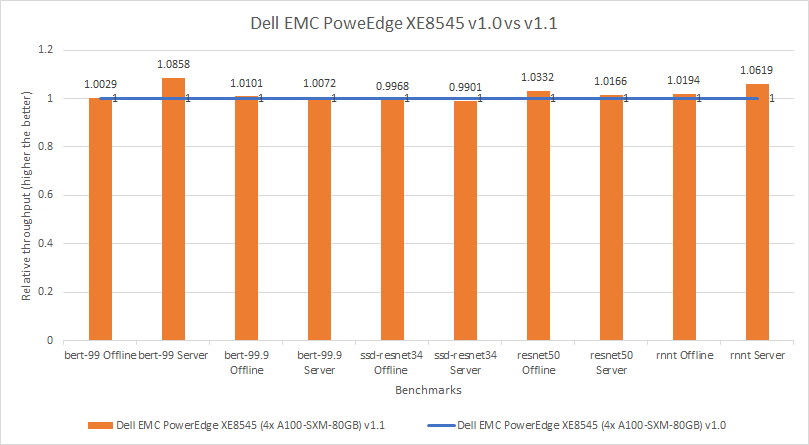
Figure 1: Relative performance comparison of PowerEdge XE8545 4 x A100 SXM 80 GB in MLPerf v1.0 and v1.1
Dell EMC systems improvements for MLPerf Inference v1.1
This section provides detailed comparisons of various GPUs across the MLPerf Inference v1.0 and v1.1 submissions to show an expansion of Dell EMC server and GPU configurations that are available.
A100 40 GB GPU compared with A100 80 GB GPU
Dell EMC DSS 8440 server
The Dell EMC DSS 8440 server delivers high performance at a lower cost compared to our competitors. By offering support for four, eight, or 10 GPUs, this server excels in processing capacity along with a flexible infrastructure. The DSS 8440 server delivers high performance for machine learning workloads. The DSS 8440 Spec Sheet provides more details about the server.
The following figure compares two DSS 8440 servers configured with NVIDIA A100 Tensor Core GPUs. For the v1.0 submission, the DSS 8440 server was configured with the A100 40 GB GPU (shown in blue). For the v1.1 submission, the DSS 8440 server was configured with the A100 80 GB GPU (shown in orange). Across the different models, the performance improvement was between three percent to 20 percent, favoring the system with the A100 80 GB GPU. The more than 10 percent performance improvement can be attributed to the frequency of each card; the A100 80 GB GPU is a 300W card whereas the A100 40 GB GPU is 250W card.
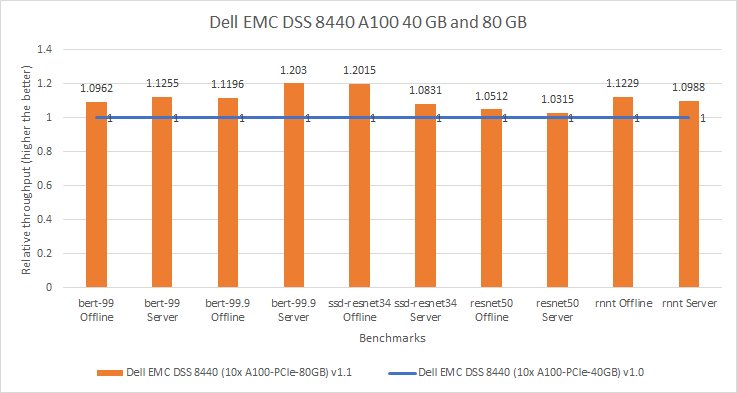
Figure 2: Relative performance comparison of DSS 8440 10 x A100 PCIe 40 GB and 80 GB in MLPerf v1.0 and v1.1
Dell EMC PowerEdge R750xa server
The PowerEdge R750xa server is ideal for Artificial Intelligence (AI)/Machine Learning (ML)/Deep Learning (DL) training and inferencing, high performance computing, and virtualization. See the Dell EMC PowerEdge R750xa Spec Sheet for more information about the server.
For this comparison, the server for both submissions was consistent. For the MLPerf v1.0 submission, the PowerEdge R750xa server was configured with four A100 40 GB GPUs. For the MLPerf v1.1 submission, the PowerEdge R750xa server was configured with four A100 80 GB GPUs. The following figure shows that for the MLPerf v1.1 submission, extra performance was extracted from the system. Across the various models, the MLPerf v1.1 results are seven percent to 22 percent better than the results from the MLPerf v1.0 submission. In the Resnet50 benchmark, the MLPerf v1.1 results are an impressive 15 and 19 percent better in the Offline and Server scenarios respectively.
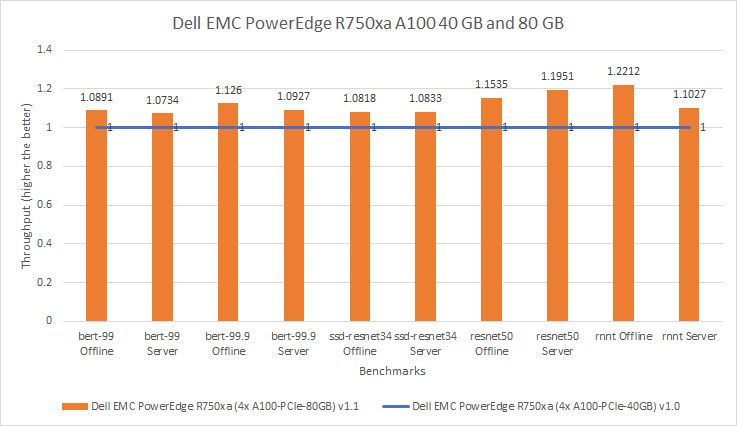
Figure 3: Relative performance of PowerEdge R750xa 4 x A100 40 GB GPU and 80 GB in MLPerf v1.0 and v1.1 respectively
Dell EMC PowerEdge XE8545 server
For the MLPerf v1.0 submission, the PowerEdge XE8545 server was configured with the A100 SXM4 40 GB GPU (shown in blue in figures 4 and 5) and the A100 SXM4 80 GB GPU (shown in orange in figures 4 and 5). For the MLPerf v1.1 submission, the PowerEdge XE 8545 server was configured with the A100 SXM4 80 GB GPU (shown in gray in figures 4 and 5). It was expected that for the MLPerf v1.0 submission, the A100 SXM4 80 GB GPU would outperform the A100 SXM4 40 GB GPU. Across the models in the MLPerf v1.1 submission, the A100 SXM4 80 GB GPU performed between negative one percent (a negative value indicates a performance deficit, noted for SSD ResNet34 in Figure 5) and eight percent better than the identical system in the MLPerf v1.0 submission. Interestingly, for the SSD Resnet-34 benchmark, the A100 GPU in the MLPerf v1.0 submission slightly outperformed the A100 GPU in the MLPerf v1.1 submission.
Figure 4: Performance of PowerEdge XE8545 4 x A100 40 GB and 80 GB in MLPerf v1.0 and 80 GB in MLPerf v1.1 for ResNet50 and RNNT
Figure 5: Performance of PowerEdge XE8545 4 x A100 40 GB and 80 GB in MLPerf v1.0 and 80 GB in MLPerf v1.1 for BERT and SSD ResNet34
NVIDIA A30 GPU compared with NVIDIA A40 GPU
This comparison considers the NVIDIA A40 and NVIDIA A30 Tensor Core GPU. For a fair comparison between the two GPUs, the DSS 8440 server configuration was consistent across the two submissions. For the MLPerf v1.0 submission, the DSS 8440 server was configured with ten A40 GPUs. For the MLPerf v1.1 submission, the server was configured with eight A30 GPUs. For a clear interpretation of the two GPUs, the results in Figure 6 are presented as the per card performance numbers, which means that the throughput results from the A40 GPU have been divided by ten and the results from the A30 GPU have been divided by eight.
The system configured with the A30 GPU performed 15 to 111 percent better than the A40 GPU across the various benchmarks. The A30 GPU is ideal for inference as it is configured with a High Bandwidth Memory (HBM2) and a higher GPU frequency. The A40 GPU is positioned more for Virtual Desktop Infrastructure (VDI) and other workloads.
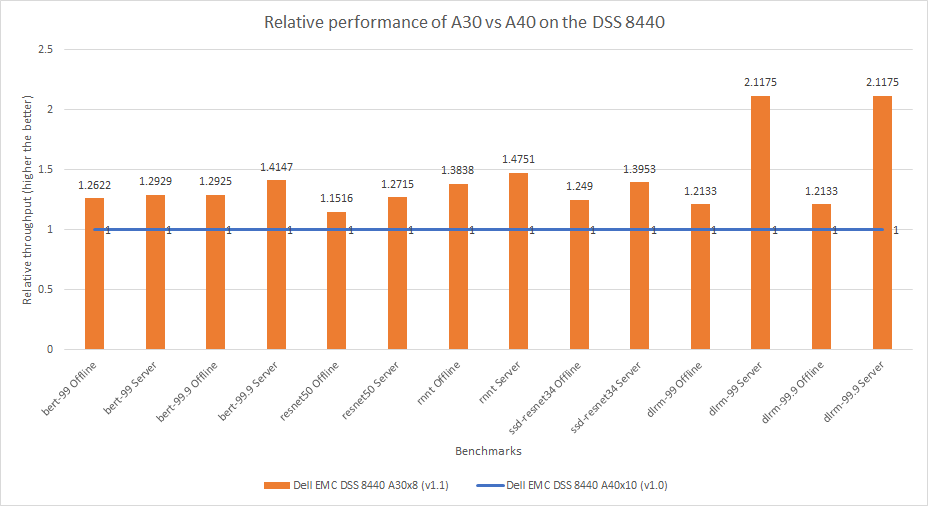
Figure 6: Per card relative performance comparison of the DSS 8440 server with A30 and A40 GPUs in MLPerf v1.0 and v1.1
Comparison of NVIDIA T4, A30, and A10 GPUs
This comparison considers three submissions on three different servers. The numbers are divided to display per card performance.
The Dell EMC PowerEdge XE2420 server is a specialty edge server that supports demanding applications at the edge, retail applications and analytics, manufacturing and logistics applications, and 5G cell processing. See the PowerEdge XE2420 Spec Sheet for more information. Our lab configured the system with four NVIDIA Tesla T4 GPUs that have been optimized for high utilization while also performing in an energy-efficient manner. The results from this system were published in the MLPerf Inference v1.0 Results.
The second server in this comparison is the DSS 8440 server, which was configured with eight NVIDIA A30 GPUs. The final server in this comparison is the PowerEdge XE2420 server, which was configured with two NVIDIA A10 GPUs.
The three cards in this comparison have different form factors; the A10 and A30 GPUs are larger than the T4 GPU. The following figure shows that the A30 GPU performed better than the other two GPUs. Across the various benchmarks, the A30 GPU performed between 204 and 360 percent better than the T4 GPU and between five percent and 57 percent better than the A10 GPU.
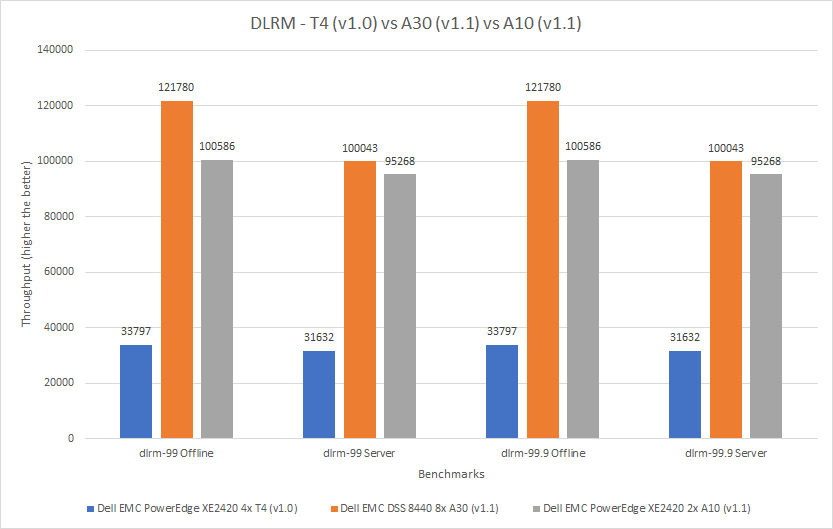
Figure 7: Comparison of T4, A30, and A10 GPUs for DLRM
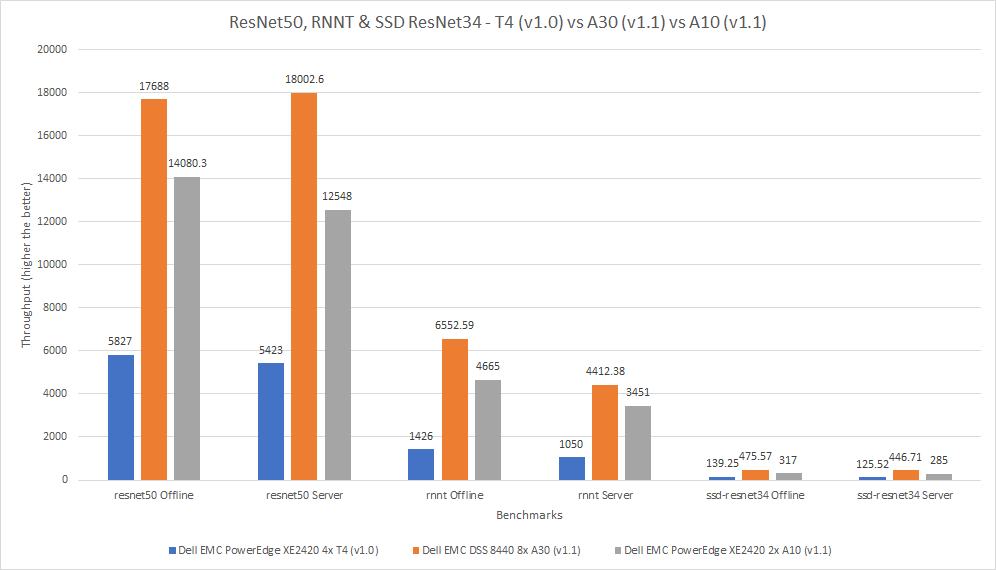
Figure 8: Comparison of T4, A40, and A10 GPUs for ResNet50, RNNT, and SSD ResNet34
Comparison of NVIDIA T4 GPU, A30 Multi-Instance GPU (MIG), and A100 MIG
This comparison also considers three submissions on three different servers. The results from the Resnet50 and SSD Resnet34 benchmarks have been divided to display per card performance.
The PowerEdge XE2420 server was configured with four NVIDIA Tesla T4 GPUs. The results for this system are from the MLPerf v1.0 submission. The PowerEdge R7525 server was configured with three NVIDIA A30 GPUs. MIG was enabled on all these GPUs with a profile of 1g6gb. We did not publish the A30 MIG results on the PowerEdge R7525 server to MLCommons, but the results are compliant.
The PowerEdge R750xa server was configured with four NVIDIA A100 80 GB GPUs, which support Multi-Instance GPU (MIG) and Peripheral Component Interconnect Express (PCIe). MIG is an enhancement for NVIDIA GPUs with the Ampere architecture that allows for seven secure partitions of GPU instances. This architecture is beneficial because it allows for increased parallelism. The results from this system were submitted in the MLPerf Inference v1.1 submission. There are different sizes of MIG slices. The configuration for the A30 and A100 GPUs used the smallest slice possible. For example, the A100 GPU was divided into seven slices and the A30 GPU into four slices.
The following figures show results across the MLPerf v1.0 and v1.1 submissions from Dell Technologies for ResNet50 and SSD ResNet34. Figure 9 shows per physical GPU results. For the ResNet50 Offline benchmark, the A30 GPU performed 232 percent better than the T4 GPU, while the A100 GPU performed 76 percent better than the A30 GPU. In the ResNet 50 Server mode, the A30 GPU outperformed the T4 GPU by 50 percent and the A100 GPU outperformed the A30 GPU by 23 percent. We observed a similar trend across the Offline and Server modes where the A100 GPU outperformed the A30 GPU, which outperformed the T4 GPU.
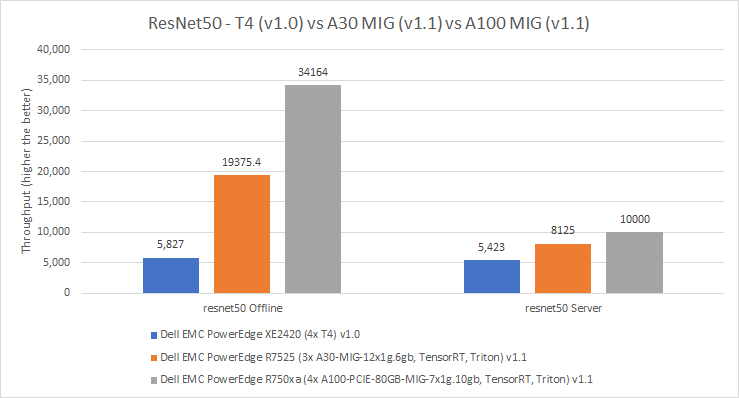
Figure 9: Per card performance of the T4 GPU, A30 MIG, and A100 MIG for ResNet50
In the SSD ResNet34 benchmark, we observed a similar trend where the performance of the A100 GPU was better than the performance of the A30 GPU, which performed better than the T4 GPU. In the Offline mode of the SSD ResNet34 benchmark, the A30 GPU performed 243 percent better than the T4 GPU, and the A100 GPU performed 77 percent better than the A30 GPU. In the Server mode, the A100 GPU outperformed the A30 GPU by 93 percent and the A30 GPU performed 198 percent better than the T4 GPU.
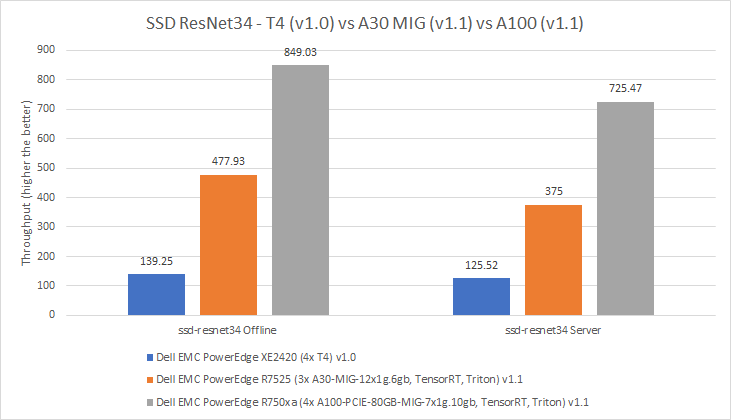
Figure 10: Per card performance of the T4 GPU, A30 MIG, and A100 MIG for SSD ResNet34
Conclusion
This blog has provided a brief introduction to MLPerf Inference benchmarking and a summary of the Dell Technologies submission from MLPerf Inference v1.0. Also, it highlighted the differences in the software stack between the MLPerf v1.0 and v1.1 submissions. This blog quantified results from various server and GPU configurations across the two rounds of MLPerf submissions and displayed noteworthy and relevant performance comparisons.
When comparing the A100 40 GB to the A100 80 GB GPUs on the Dell EMC DSS 8440 server, the latter exhibited an 11 percent increase in performance. On the Dell EMC PowerEdge R750xa server, the A100 PCIe 80 GB GPU performed 12 percent better than the A100 PCIe 40 GB GPU. The Dell EMC PowerEdge XE8545 server confirmed this result for the MLPerf v1.1 submission; the A100 SXM 80 GB GPU performed three percent better than an identical system from the MLPerf v1.0 submission.
The A30 and A40 GPU comparison showed that the former achieved a notable 42 percent performance improvement while maintaining the Dell EMC DSS 8440 server.
The comparison between the T4, A30, and A10 GPUs revealed that the A30 GPU performed significantly better than the T4 GPU and is considered a good upgrade for your ML workloads. The T4 GPU, A30 MIG, and A100 MIG were compared based on results from the ResNet50 and SSD-ResNet34 benchmarks.
Comparison of MLPerf™ Inference v1.1 Results of Dell EMC PowerEdge R7525 Servers with NVIDIA GPUs
Mon, 04 Apr 2022 11:08:17 -0000
|Read Time: 0 minutes
Abstract
This blog showcases the MLPerf Inference v1.1 performance results of Dell EMC PowerEdge R7525 servers configured with NVIDIA A100 40 GB GPUs or with NVIDIA A30 GPUs. We compare the cost of a system with both types of GPUs to help you choose the best configuration for your AI inference workloads.
Introduction
MLPerf Inference v1.1 falls under the benchmarks and metrics category from MLCommons™ and serves as the industry standard for machine learning (ML) inference performance. The MLPerf benchmarking suite measures the performance of ML workloads consistently and fairly. The MLPerf Inference benchmark measures how fast a system can perform ML inference by using a pretrained model in various deployment scenarios. For a comprehensive understanding of MLPerf Inference, see this blog.
Test bed details
The systems under test (SUT) include:
- PowerEdge R7525 server that is configured with three NVIDIA A100 PCIe 40 GB (250 W, 40 GB passive, double wide, full height GPU) GPUs. All references to the PowerEdge R7525 server with A100 GPUs assume that the configuration includes three NVIDIA A100 GPUs.
- PowerEdge R7525 server that is configured with three NVIDIA A30 (165 W, 24 GB passive, double wide, full height GPU with cable) GPUs. All references to the PowerEdge R7525 server with A30 GPUs assume that the configuration includes three NVIDIA A100 GPUs.
The following figure shows the PowerEdge R7525 server:

Both systems run TensorRT, which is a library designed and developed for improved performance in inference on NVIDIA GPUs. For more information about TensorRT, see the NVIDIA documentation.
SUT configuration
The following table shows the MLPerf system configurations for the SUTs:
Table 1: SUT configuration
Platform | PowerEdge R7525 with 3 A100 PCIe 40 GB GPUs | PowerEdge R7525 with 3 A30 GPUs |
MLPerf System ID | R7525_A100-PCIE-40GBx3_TRT | R7525_A30x3_TRT |
Operating system | CentOS 8.2.2004 | |
Memory | 512 GB | 1 TB |
GPU | NVIDIA A100-PCIE-40GB | NVIDIA A30 |
GPU count | 3
| |
Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 GPU Driver 470.42.01 DALI 0.31.0
| |
MLPerf Inference v1.1 results per model
ResNet 50
ResNet50 is a 50-layer deep convolution neural network that is used for many computer vision applications. This neural network can address vanishing gradients using the concept of skip connections by allowing gradients to move through layers in the network. For an introduction to ResNet, see Deep Residual Learning for Image Recognition.
We conducted four tests on this model across the two SUTs: two in the Offline scenario and two in the Server scenario. The following figure shows our ResNet50 results. The performance of the PowerEdge R7525 server with A30 GPUs across both scenarios is approximately 50 percent higher than the PowerEdge R7525 server with A100 GPUs.
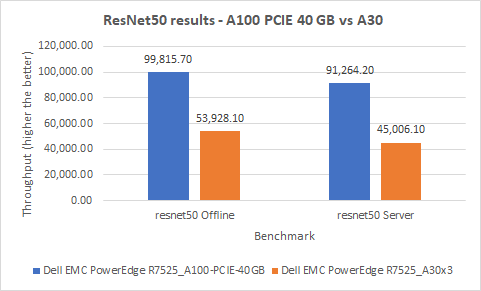
Figure 1: ResNet50 results on a PowerEdge R7525 server with A100 GPUs and a PowerEdge R7525 server with A30 GPUs
BERT
Bidirectional Encoder Representations from Transformers (BERT) is a state-of-the-art language representational model. In essence, BERT is a stack of Transformer encoders. The Transformer architecture is fast because it can process words simultaneously, and the context of words can be learned from both directions simultaneously. BERT can be used for neural machine translation, question answering, sentiment analysis, and text summarization, all of which require language understanding. BERT is trained in two phases: pretrain in which the model understands language and context, and fine-tuning in which BERT learns specific tasks such as questioning and answering. For an in-depth understanding, see BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding from Google AI Language.
For this model, we conducted eight tests across our systems in which we considered the default and high accuracy modes in both the Server and Offline scenarios. In the default mode, the PowerEdge R7525 server with A100 GPUs performed 69 percent better than the PowerEdge R7525 server with A30 GPUs in the Offline scenario and 99 percent better in the Server scenario. The high accuracy mode provided similar results in which the PowerEdge R7525 server with A100 GPUs performed 72 percent better than the PowerEdge R7525 server with A30 GPUs in the Offline scenario and 96 percent better in the Server scenario. In the following figure, bert-99 refers to the default accuracy target, whereas bert-99.9 refers to the high accuracy target.
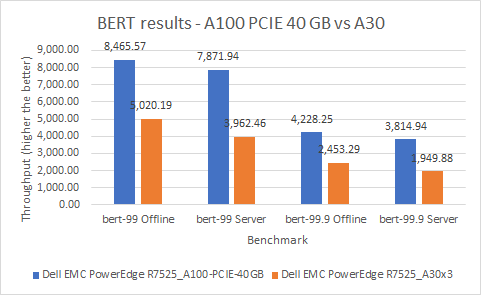
Figure 2: BERT results on a PowerEdge R7525 with A100 GPUs and a PowerEdge R7525 with A30 GPUs
SSD-ResNet34
ResNet34 is an encoder on top of Single Shot Multibox Detector (SSD) that is used to improve performance and reduce training time. As the full form suggests, the SSD is a single stage objection detection model that is known for speed. For an in-depth understanding, see Small Object Detection using Context and Attention.
For this model, we conducted four tests across both of our systems. In the Offline scenario, the PowerEdge R7525 server with A100 GPUs outperformed the PowerEdge R7525 server with A30 GPUs by 74 percent. Similarly, in the Server scenario, the PowerEdge R7525 server with A100 GPUs performed 78 percent better than the PowerEdge R7525 server with A30 GPUs.
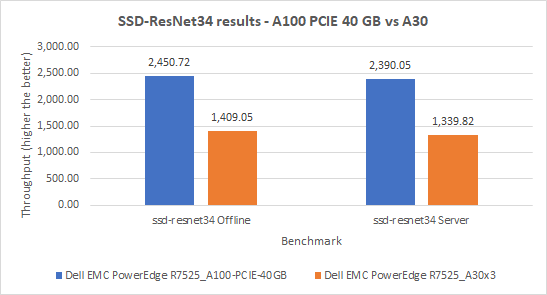
Figure 3: SSD-ResNet34 results on a PowerEdge R7525 server with A100 GPUs and a PowerEdge R7525 server with A30 GPUs
DLRM
DLRM, an open-source Deep Learning Recommendation Model, is available on Facebook’s PyTorch platform. The model is composed of compute-dominated multilayer perceptrons (MLPs) and relies on data parallelism to improve performance. When predicting click percentage for certain items, for example, it is aligned with randomized Las Vegas algorithms in which resources (time and memory) are used freely but the results are always correct. DLRM uses collaborative filtering and predicative analysis-based approaches to process large amounts of data. For more information about DLRM, see Deep Learning Recommendation Model for Personalization and Recommendation Systems.
For this model, we conducted eight tests across both of our systems. For the PowerEdge R7525 server with A100 GPUs, we notice a tight range with a lower and upper bound of 764,569 and 768,806 result samples per second, respectively. Also, the results produced across the default and high accuracy tests are the same for their respective systems. The initial numbers from the PowerEdge R7525 server with A30 GPUs were slightly below expectations. After the submission deadline, our team was able to extract additional performance, particularly in the Server scenario. The numbers for the PowerEdge R7525 server with A30 GPUs shown in the following figure are not the same as the numbers published on the MLCommons website. However, these numbers are valid and pass all the required compliance tests. The PowerEdge R7525 server with A30 GPUs behaved like the PowerEdge R7525 server with A100 GPUs in that the Server scenario results are slightly lower than the Offline results. The tuned numbers provided the best per card performance among all A30 GPU submissions.
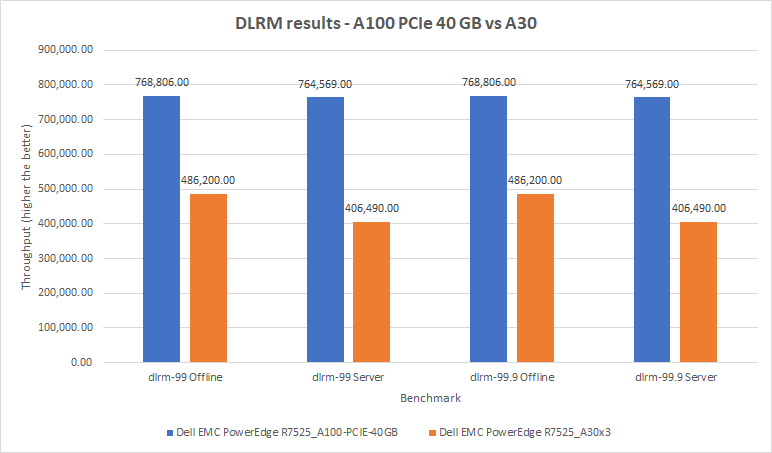
Figure 4: DLRM results on a PowerEdge R7525 server with A100 GPUs and a PowerEdge R7525 server with A30 GPUs
RNNT
Recurrent Neural Network (RNNT) is a type of neural network in which outputs are recycled as inputs for the current step. By using one-hot encoding and memory, RNNT can remember information through time that might be useful in time series prediction. This model uses a squashing function to learn to predict the next potential word or step to take. The result of the squashing function is always between –1 and 1, which allows neural networks to remain nonlinear and thus effective as the same values are passed through the neural network.
For this model, we conducted four tests across both of our systems. In the Offline scenario, the PowerEdge R7525 server with A100 GPUs outperformed the PowerEdge R7525 server with A30 GPUs by 80 percent. In the Server scenario, the PowerEdge R7525 server with A100 GPUs excelled by performing 199 percent better than the PowerEdge R7525 server with A30 GPUs.
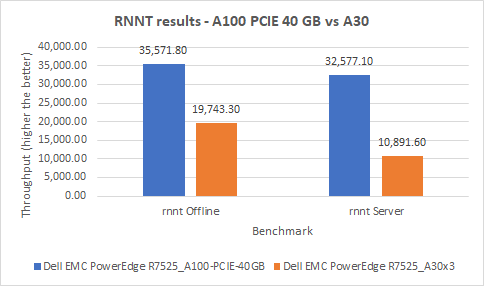
Figure 5: RNNT results on a PowerEdge R7525 server with A100 GPUs and a PowerEdge R7525 server with A30 GPUs
3D U-Net
3D U-Net is an elegant improvement to the sliding window approach of convolution neural networks (CNNs) in which fewer training images can be used and more precise segmentations can be yielded. In brief, an input image goes through a contraction and expansion path (in a U shape architecture with skip connections) and becomes a segmentation map output. This segmentation map provides class labels for what is inside the image. For a deeper understanding of 3D U-Net's architecture, see U-Net: Convolutional Networks for Biomedical.
Across the two systems, we conducted Offline scenario tests for the default and high accuracy modes. The default and high accuracy modes yielded the same results across the two systems. Across the two systems, the PowerEdge R7525 server with A100 GPUs performed 75 percent better than the PowerEdge R7525 server with A30 GPUs.
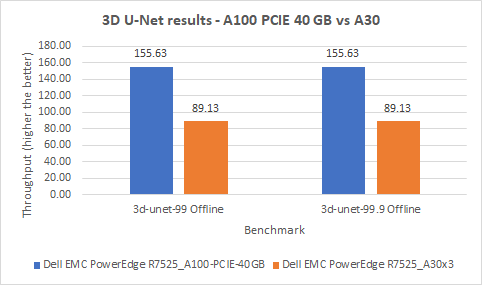
Figure 6: 3D U-Net results on a PowerEdge R7525 server with A100 GPUs and a PowerEdge R7525 server with A30 GPUs
Cost Considerations
When placing an order for the PowerEdge R7525 Rack Server on the Dell Technologies website, customers are guided through the purchasing process with suggestions and requirements for their specific rack server. The PowerEdge R7525 server with three NVIDIA Ampere A100 GPUs is 1.423 times more expensive than the PowerEdge R7525 server with three NVIDIA Ampere A30 GPUs. The price difference between the two configurations is due to the powerful GPU itself. Also, the PowerEdge R7525 server with A100 GPUs requires higher performance fans and a more powerful thermal configuration. Despite the additional options required for the PowerEdge R7525 server with A100 GPUs, understanding the throughput performance (queries per second (QPS) in the Server mode and samples per second in the Offline mode) per dollar provides valuable insight into achievable performance per dollar spent.
The following figure shows the relative performance of the two systems per dollar. If we divide the performance achieved on a system for a particular benchmark by the total cost of the system, we determine the achievable throughput per dollar spent on the system. The higher the throughput per dollar amount indicates that greater performance can be extracted from the system per dollar spent.
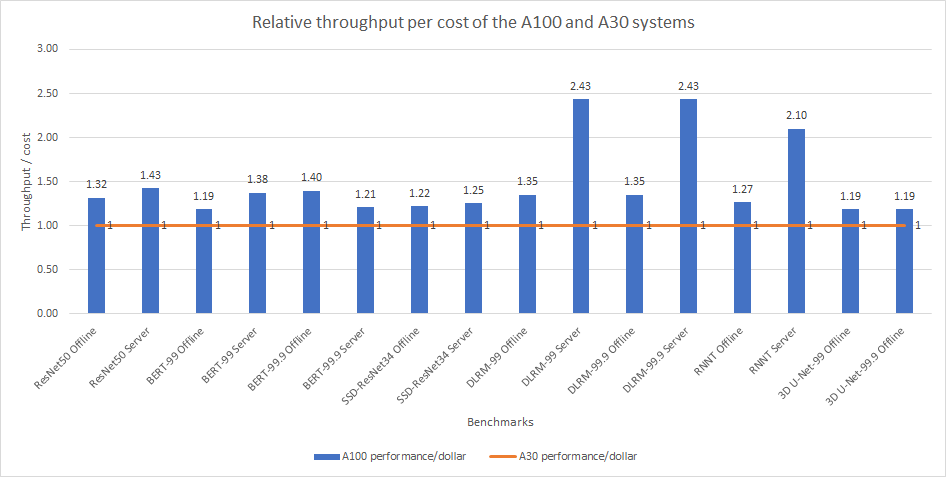
Figure 7: Relative QPS per cost of a PowerEdge R7525 server with A100 GPUs and a PowerEdge R7525 server with A30 GPUs
In the figure, the orange line shows the normalized data of the throughput per cost of the PowerEdge R7525 server with A30 GPUs. The blue bars indicate the relative achievable performance of the PowerEdge R7525 server with A100 GPUs. For most of the benchmarks, we see an acceptable range of performance on both systems. However, the PowerEdge R7525 server with A100 GPUs unconditionally outperformed the PowerEdge R7525 server with A30 GPUs in the DLRM Server default and high accuracy modes as well as in the RNNT Server mode. Both systems perform well per dollar spent.
Note: We compiled the cost data in this section from the PowerEdge R7525 Rack Server page on the Dell Technologies website on September 7, 2021. The data might be subject to change.
Conclusion
The blog provides a detailed comparison of performance between the Dell EMC PowerEdge R7525 server configured with three A100s and the Dell EMC PowerEdge R7525 server configured with three A30 GPUs. If your ML workload focuses on inferencing, the PowerEdge R7525 server configured with A100s might suit your needs well. However, if you are looking for a system that not only performs well, but also is more cost-effective, the PowerEdge R7525 server configured with A30 GPUs will suit those needs. Both systems performed well and are a great investment based on your ML workload requirements.
Next Steps
In future blogs, we plan to describe:
- How to run MLPerf Inference v1.1
- The PowerEdge R750xa server as a platform for inference v1.1
- The DSS8440 server as a platform for inference v1.1
- The PowerEdge R725 server as a platform for inference v1.1
- The PowerEdge XE8545 server as a platform for inference v1.1
- Comparison of inference v1.0 performance with inference v1.1 performance
Introduction to MLPerf™ Inference v1.1 with Dell EMC Servers
Fri, 24 Sep 2021 16:48:39 -0000
|Read Time: 0 minutes
Dell Technologies has participated in MLPerf submission for the past two years. The current submission is our fourth round to the MLPerf inference benchmarking suite.
This blog provides the latest MLPerf Inference v1.1 data center closed results on Dell EMC servers from our HPC & AI Innovation lab. The objective of this blog is to show optimal inference performance and performance/watt for the Dell EMC GPU servers (PowerEdge R750xa, DSS8440, and PowerEdge R7525). A blog about MLPerf Inference v1.0 performance can be found here. This blog also addresses the benchmarks rules, constraints, and submission categories. We recommend that you read it to become familiar with the MLPerf terminologies and rules.
Noteworthy results
Our noteworthy results include:
- The DSS8440 server (10 x A100-PCIE-80GB, TensorRT) yields Number One results across all the submitters for:
- BERT 99 Offline and Server
- BERT 99.9 Offline and Server
- RNN-T Offline and Server
- SSD-Resnet34 Offline and Server
- The R750xa server (4 x A100-PCIE-80GB, TensorRT) yields Number One results per PCIe accelerator for:
- 3D UNet Offline and 3D UNet 99.9 Offline
- Resnet50 Offline and Resnet50 Server
- BERT 99 Offline and BERT 99 Server
- BERT 99.9 Offline and BERT 99.9 Server
- DLRM 99 Offline and DLRM Server
- DLRM 99.9 Offline and DLRM 99.9 Server
- RNN-T Offline and RNN-T Server
- SSD-Resnet34 Offline and SSD-Resnet34 Server
- The R750xa server (4 x A100-PCIE-80GB, MIG) yields Number One results per PCIe accelerator MIG results for:
- Resnet50 Offline and Resnet50 Server
- BERT 99 Offline and BERT 99 Server
- BERT 99.9 Offline and BERT 99.9 Server
- SSD-Resnet34 Offline and SSD-Reset34 Server
- The R750xa server (4 x A100-PCIE-80GB, Triton) yields Number One results per PCIe accelerator Triton results for:
- 3D UNet Offline and 3D UNet 99.9 Offline
- Resnet50 Offline and Resnet50 Server
- BERT 99 Server
- BERT 99.9 Offline and BERT 99.9 Server
- DLRM 99 Offline and DLRM Server
- DLRM 99.9 Offline and DLRM 99.9 Server
To allow the like-to-like comparison of Dell Technologies results, we chose to test under the Datacenter closed division, as shown in this blog. Customers and partners can rely on our results, all of which MLCommonsTM has officially certified. Officially certified results are peer reviewed, have undergone compliance tests, and conform to the constraints enforced by MLCommons. If wanted, customers and partners can also reproduce our results. The blog that explains how to run MLPerf Inference v1.1 can be found here.
What is new?
The difference between MLPerf inference v1.1 and MLPerf inference v1.0 is that the Multistream scenario is deprecated. All other benchmarks and rules remain the same as for MLPerf inference v1.0.
For v1.1 submissions to MLCommons, over 1700 results were submitted. The number of submitters increased from 17 to 21.
Dell Technologies result submissions included new SUT configurations such as NVIDIA A100 Tensor Core 80GB GPU with 300 W TDP, A30, A100-MIG, and power results with NVIDIA-Certified R750xa servers.
MLPerf Inference 1.1 benchmark results
The following graphs include performance metrics for the Offline and Server scenarios. Overall, Dell Technologies results included approximately 200 performance results and 80 performance and power results. These results serve as a reference point to enable sizing deep learning clusters. The higher number of results in our submission helps further fine tune answers to specific questions that customers might have.
For the Offline scenario, the performance metric is Offline samples per second. For the Server scenario, the performance metric is queries per second (QPS). In general, the metrics represent throughput. A higher throughput is a better result. In the following graphs, the Y axis is an exponentially scaled axis representing the throughput and the X axis represents the SUTs and their corresponding models (described in the appendix).
Figures 1, 2, and 3 show the performance of different Dell EMC servers that were benchmarked for the different models. All these servers performed optimally and rendered high throughput. The backends included NVIDIA Triton, NVIDIA TensorRT on Offline and Server scenarios. Some of the results shown in figures 1 and 3 include MIG numbers.
Figure 1: Resnet50, BERT default, and high accuracy results
Figure 2: RNN-T, DLRM default, and high accuracy results
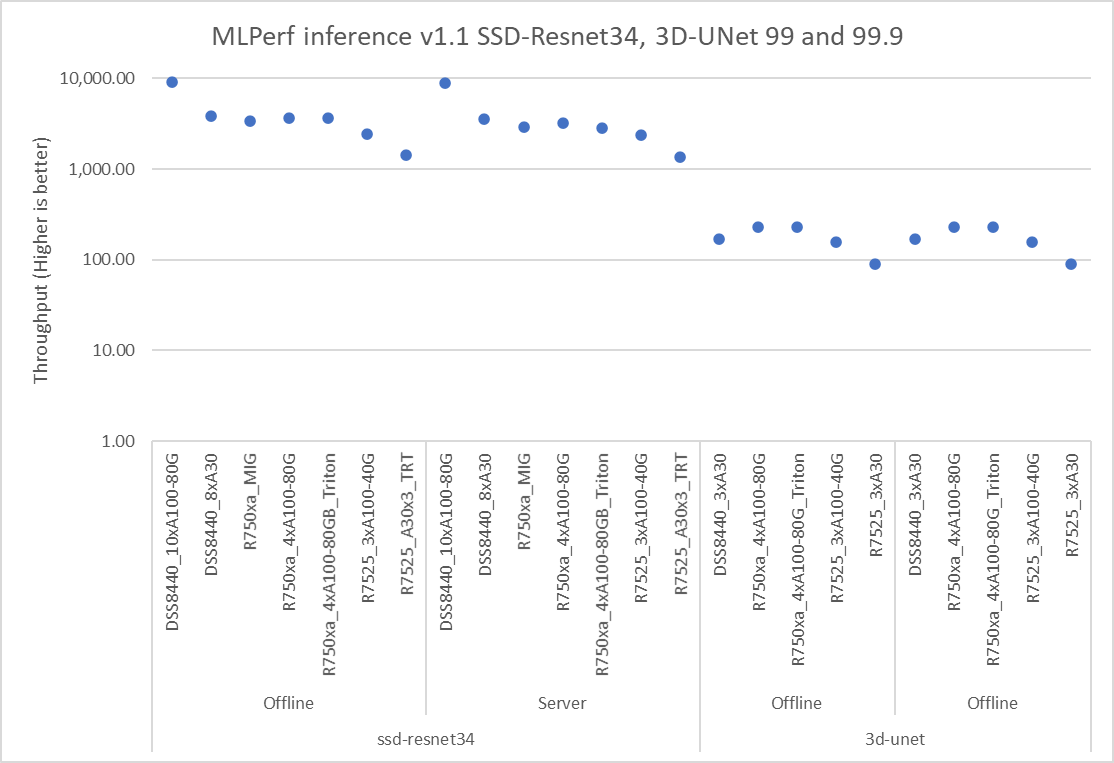
Figure 3: SSD-Resnet34, 3D-UNet default, and high accuracy results
Figure 4 shows the performance of the Dell EMC R750xa server that was benchmarked for the 3D-UNet, BERT 99, BERT 99.9, Resnet and SSD-Resnet34 models. The SUT provided high throughput while maintaining low power consumption. Higher throughputs were achieved with similar power usage for different models. These throughputs established our results in the optimal performance and optimal performance per watt category.
Figure 4: Performance and power submission with inference v1.1 with R750xa and 4 x NVIDIA A100–40G
Observations about results from Dell Technologies
All the preceding results are officially submitted to the MLCommonsTM consortium and verified. Submissions include performance and power-related numbers. Dell Technologies submissions include approximately 200 performance results and 80 performance and power results.
Different types of workload tasks such as image classification, object detection, medical image segmentation, speech to text, language processing, and recommendation were a part of these results, which were promising. These models met the quality-of-service targets as expected by the MLCommons consortium.
With different kinds of GPUs such as the NVIDIA A30 Tensor Core GPU, different NVIDIA A100 variants such as A100 40 GB PCIe and A100 80 GB PCIe, and different CPUs from AMD and Intel, Dell EMC servers performed with optimal performance and power results. Other Dell EMC SUT configuration results for the NVIDIA A40, RTX8000, and T4 GPUs can be found in the v1.0 results, which can be used for comparison with the v1.1 results.
The submission included results from different inference backends such as NVIDIA TensorRT, , and Multi-Instance GPU (MIG). The appendix includes a summary of the NVIDIA software stack.
All our systems are air-cooled. This feature allows data center administrators to perform minimal to no changes to accommodate these systems while delivering high throughput inference performance. Furthermore, Dell EMC servers offer high performance per watt more effectively without adding significant power constraints.
Conclusion
In this blog, we quantified the MLCommons inference v1.1 performance on different Dell EMC servers such as DSS8440 and PowerEdge R750xa and R7525 servers, producing many results. Customers can use these results to address the relative inference performance delivered by these servers. Dell EMC servers are powerful compute machines that deliver high throughput inference capabilities for customers inferencing requirements across different scenarios and workload types.
Next steps
In future blogs, we plan to describe:
- How to run MLPerf Inference v1.1
- The R750xa server as a platform for inference v1.1
- The DSS8440 server as a platform for inference v1.1
- Comparison of inference v1.0 performance with inference v1.1 performance
Appendix
NVIDIA software stack
NVIDIA Triton Inference Server is open-source software that aids the deployment of AI models at scale in production. It is an inferencing solution optimized for both CPUs and GPUs. Triton supports an HTTP/REST and GRPC protocol that allows remote clients to request inferencing for any model that the server manages. It adds support for multiple deep learning frameworks, enables high-performance inference, and is designed to consider IT, DevOps, and MLOps.
NVIDIA TensorRT is an SDK for high-performance, deep learning inference that includes an inference optimizer and runtime. It enables developers to import trained models from all major deep learning frameworks and optimizes them for deployment with the highest throughput and lowest latency, while preserving the accuracy of predictions. TensorRT-optimized applications perform up to 40 times faster on NVIDIA GPUs than CPU-only platforms during inference.
MIG can partition the A100 GPU into as many as seven instances, each fully isolated with their own high-bandwidth memory, cache, and compute cores. Administrators can support every workload, from the smallest to the largest, offering a right-sized GPU with guaranteed quality of service (QoS) for every job, optimizing utilization, and extending the reach of accelerated computing resources to every user.
SUT configurations
We selected servers with different types of NVIDIA GPUs as our SUT to conduct data center inference benchmarks. The following tables list the MLPerf system configurations for these servers.
Note: In the following tables, the main difference in the software stack is the use of NVIDIA Triton Inference Servers.
Table 3: MLPerf system configurations for Dell EMC DSS 8440 servers
| Platform | DSS8440_A100 | DSS8440_A30 | DSS8440_A30 |
| MLPerf System ID | DSS8440_A100-PCIE-80GBx10_TRT | DSS8440_A30x8_TRT | DSS8440_A30x8_TRT_Triton |
| Operating system | CentOS 8.2.2004 | ||
| CPU | Intel Xeon Gold 6248R CPU @ 3.00 GHz | Intel Xeon Gold 6248R | Intel Xeon Gold 6248R |
| Memory | 768 GB | 1 TB | |
| GPU | NVIDIA A100-PCIe-80GB | NVIDIA A30 | |
| GPU form factor | PCIe | ||
| GPU count | 10 | 8 | |
| Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 | ||
| Triton 21.07 | |||
Table 4: MLPerf system configurations for PowerEdge servers
Platform | R750xa_A100 | R750xa_A100 | R750xa_A100 | R7525_A100 | R7525_A30 |
MLPerf System ID | R750xa_A100-PCIE-80GB-MIG_28x1g.10gb_TRT_Triton | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100-PCIE-80GBx4_TRT_Triton | R7525_A100-PCIE-40GBx3_TRT | R7525_A30x3_TRT |
Operating system | CentOS 8.2.2004
| ||||
CPU | Intel Xeon Gold 6338 | AMD EPYC 7502 32-Core Processor | AMD EPYC 7763 | ||
Memory | 1 TB | 512 GB | 1 TB | ||
GPU | NVIDIA A100-PCIE-80GB (7x1g.10gb MIG) | NVIDIA A100-PCIE-80GB
| NVIDIA A100-PCIE-40GB | NVIDIA A30 | |
GPU form factor | PCIe | ||||
GPU count | 4 | 3 | |||
Software stack | TensorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Driver 470.42.01 DALI 0.31.0 | ||||
Triton 21.07 |
| Triton 21.07 |
| ||

Running the MLPerf™ Inference v1.1 Benchmark on Dell EMC Systems
Fri, 24 Sep 2021 16:51:50 -0000
|Read Time: 0 minutes
This blog is a guide for running the MLPerf inference v1.1 benchmark. Information about how to run the MLPerf inference v1.1 benchmark is available online at different locations. This blog provides all the steps in one place.
MLPerf is a benchmarking suite that measures the performance of Machine Learning (ML) workloads. It focuses on the most important aspects of the ML life cycle: training and inference. For more information, see Introduction to MLPerf™ Inference v1.1 Performance with Dell EMC Servers.
This blog focuses on inference setup and describes the steps to run closed data center MLPerf inference v1.1 tests on Dell Technologies servers with NVIDIA GPUs. It enables you to run the tests and reproduce the results that we observed in our HPC & AI Innovation Lab. For details about the hardware and the software stack for different systems in the benchmark, see this list of systems.
The MLPerf inference v1.1 suite contains the following benchmarks:
- Resnet50
- SSD-Resnet34
- BERT
- DLRM
- RNN-T
- 3D U-Net
Note: The BERT, DLRM, and 3D U-Net models have 99 percent (default accuracy) and 99.9 percent (high accuracy) targets.
This blog describes the steps to run all these benchmarks.
1 Getting started
A system under test consists of a defined set of hardware and software resources that will be measured for performance. The hardware resources may include processors, accelerators, memories, disks, and interconnect. The software resources may include an operating system, compilers, libraries, and drivers that significantly influence the running time of a benchmark. In this case, the system on which you clone the MLPerf repository and run the benchmark is known as the system under test (SUT).
For storage, SSD RAID or local NVMe drives are acceptable for running all the subtests without any penalty. Inference does not have strict requirements for fast-parallel storage. However, the BeeGFS or Lustre file system, the PixStor storage solution, and so on help make multiple copies of large datasets.
2 Prerequisites
Prerequisites for running the MLPerf inference v1.1 tests include:
- An x86_64 Dell EMC systems
- Docker installed with the NVIDIA runtime hook
- Ampere-based NVIDIA GPUs (Turing GPUs have legacy support but are no longer maintained for optimizations.)
- NVIDIA driver version 470.xx or later
- As of inference v1.0, ECC turned ON
Set ECC to on,run the following command:sudo nvidia-smi --ecc-config=1
Preparing to run the MLPerf inference v1.1
Before you can run the MLPerf inference v1.1 tests, perform the following tasks to prepare your environment.
3.1 Clone the MLPerf repository
- Clone the repository to your home directory or another acceptable path:
cd - git clone https://github.com/mlperf/inference_results_v1.1
- Go to the closed/DellEMC directory:
cd inference_results_v1.1/closed/DellEMC
- Create a “scratch” directory with at least 3 TB of space in which to store the models, datasets, preprocessed data, and so on:
mkdir scratch
- Export the absolute path for $MLPERF_SCRATCH_PATH with the scratch directory:
export MLPERF_SCRATCH_PATH=/home/user/inference_results_v1.1/closed/DellEMC/scratch
3.2 Set up the configuration file
The closed/DellEMC/configs directory includes an __init__.py file that lists configurations for different Dell EMC servers that were systems in the MLPerf Inference v1.1 benchmark. If necessary, modify the configs/<benchmark>/<Scenario>/__init__.py file to include the system that will run the benchmark.
Note: If your system is already present in the configuration file, there is no need to add another configuration.
In the configs/<benchmark>/<Scenario>/__init__.py file, select a similar configuration and modify it based on the current system, matching the number and type of GPUs in your system.
For this blog, we used a Dell EMC PowerEdge R7525 server with a one-A100 GPU as the example. We chose R7525_A100_PCIE_40GBx1 as the name for this new system. Because the R7525_A100_PCIE_40GBx1 system is not already in the list of systems, we added the R7525_A100-PCIe-40GBx1 configuration.
Because the R7525_A100_PCIE_40GBx3 reference system is the most similar, we modified that configuration and picked Resnet50 Server as the example benchmark.
The following example shows the reference configuration for three GPUs for the Resnet50 Server benchmark in the configs/resnet50/Server/__init__.py file:
@ConfigRegistry.register(HarnessType.LWIS, AccuracyTarget.k_99, PowerSetting.MaxP)
class R7525_A100_PCIE_40GBx3(BenchmarkConfiguration):
system = System("R7525_A100-PCIE-40GB", Architecture.Ampere, 3)
active_sms = 100
input_dtype = "int8"
input_format = "linear"
map_path = "data_maps/<dataset_name>/val_map.txt"
precision = "int8"
tensor_path = "${PREPROCESSED_DATA_DIR}/<dataset_name>/ResNet50/int8_linear"
use_deque_limit = True
deque_timeout_usec = 5742
gpu_batch_size = 205
gpu_copy_streams = 11
gpu_inference_streams = 9
server_target_qps = 91250
use_cuda_thread_per_device = True
use_graphs = True
scenario = Scenario.Server
benchmark = Benchmark.ResNet50
start_from_device=TrueThis example shows the modified configuration for one GPU:
@ConfigRegistry.register(HarnessType.LWIS, AccuracyTarget.k_99, PowerSetting.MaxP)
class R7525_A100_PCIE_40GBx1(BenchmarkConfiguration):
system = System("R7525_A100-PCIE-40GB", Architecture.Ampere, 1)
active_sms = 100
input_dtype = "int8"
input_format = "linear"
map_path = "data_maps/<dataset_name>/val_map.txt"
precision = "int8"
tensor_path = "${PREPROCESSED_DATA_DIR}/<dataset_name>/ResNet50/int8_linear"
use_deque_limit = True
deque_timeout_usec = 5742
gpu_batch_size = 205
gpu_copy_streams = 11
gpu_inference_streams = 9
server_target_qps = 30400
use_cuda_thread_per_device = True
use_graphs = True
scenario = Scenario.Server
benchmark = Benchmark.ResNet50
start_from_device=TrueWe modified the queries per second (QPS) parameter (server_target_qps) to match the number of GPUs. The server_target_qps parameter is linearly scalable, therefore the QPS = number of GPUs x QPS per GPU.
The modified parameter is server_target_qps set to 30400 in accordance with one GPU performance expectation.
3.3 Add the new system
After you add the new system to the __init__.py file as shown in the preceding example, add the new system to the list of available systems. The list of available systems is in the code/common/system_list.py file. This entry informs the benchmark that a new system exists and ensures that the benchmark selects the correct configuration.
Note: If your system is already added, there is no need to add it to the code/common/system_list.py file.
Add the new system to the list of available systems in the code/common/system_list.py file.
At the end of the file, there is a class called KnownSystems. This class defines a list of SystemClass objects that describe supported systems as shown in the following example:
SystemClass(<system ID>, [<list of names reported by nvidia-smi>], [<known PCI IDs of this system>], <architecture>, [list of known supported gpu counts>])
Where:
- For <system ID>, enter the system ID with which you want to identify this system.
- For <list of names reported by nvidia-smi>, run the nvidia-smi -L command and use the name that is returned.
- For <known PCI IDs of this system>, run the following command:
$ CUDA_VISIBLE_ORDER=PCI_BUS_ID nvidia-smi --query-gpu=gpu_name,pci.device_id --format=csv
name, pci.device_id
A100-PCIE-40GB, 0x20F110DE
---This pci.device_id field is in the 0x<PCI ID>10DE format, where 10DE is the NVIDIA PCI vendor ID. Use the four hexadecimal digits between 0x and 10DE as your PCI ID for the system. In this case, it is 20F1.
- For <architecture>, use the architecture Enum, which is at the top of the file. In this case, A100 is Ampere architecture.
- For the <list of known GPU counts>, enter the number of GPUs of the systems you want to support (that is, [1,2,4] if you want to support 1x, 2x, and 4x GPU variants of this system.). Because we already have a 3x variant in the system_list.py file, we simply need to include the number 1 as an additional entry.
Note: Because a configuration is already present for the PowerEdge R7525 server, we added the number 1 for our configuration, as shown in the following example. If your system does not exist in the system_list.py file, add the entire configuration and not just the number.
class KnownSystems: """ Global List of supported systems """ # before the addition of 1 - this config only supports R7525_A100-PCIE-40GB x3 # R7525_A100_PCIE_40GB= SystemClass("R7525_A100-PCIE-40GB", ["A100-PCIE-40GB"], ["20F1"], Architecture.Ampere, [3]) # after the addition – this config now supports R7525_A100-PCIE-40GB x1 and R7525_A100-PCIE-40GB x3 versions. R7525_A100_PCIE_40GB= SystemClass("R7525_A100-PCIE-40GB", ["A100-PCIE-40GB ["20F1"], Architecture.Ampere, [1, 3]) DSS8440_A100_PCIE_80GB = SystemClass("DSS8440_A100-PCIE-80GB", ["A100-PCIE-80GB"], ["20B5"], Architecture.Ampere, [10]) DSS8440_A30 = SystemClass("DSS8440_A30", ["A30"], ["20B7"], Architecture.Ampere, [8], valid_mig_slices=[MIGSlice(1, 6), MIGSlice(2, 12), MIGSlice(4, 24)]) R750xa_A100_PCIE_40GB = SystemClass("R750xa_A100-PCIE-40GB", ["A100-PCIE-40GB"], ["20F1"], Architecture.Ampere, [4]) R750xa_A100_PCIE_80GB = SystemClass("R750xa_A100-PCIE-80GB", ["A100-PCIE-80GB"], ["20B5"], Architecture.Ampere, [4],valid_mig_slices=[MIGSlice(1, 10), MIGSlice(2, 20), MIGSlice(3, 40)]) ----
Note: You must provide different configurations in the configs/resnet50/Server/__init__.py file for the x1 variant and x3 variant. In the preceding example, the R7525_A100-PCIE-40GBx3 configuration is different from the R7525_A100-PCIE-40GBx1 configuration.
3.4 Build the Docker image and required libraries
Build the Docker image and then launch an interactive container. Then, in the interactive container, build the required libraries for inferencing.
- To build the Docker image, run the make prebuild command inside the closed/DellEMC folder:
Command:
make prebuildThe following example shows sample output:
Launching Docker session nvidia-docker run --rm -it -w /work \ -v /home/user/article_inference_v1.1/closed/DellEMC:/work -v /home/user:/mnt//home/user \ --cap-add SYS_ADMIN \ -e NVIDIA_VISIBLE_DEVICES=0 \ --shm-size=32gb \ -v /etc/timezone:/etc/timezone:ro -v /etc/localtime:/etc/localtime:ro \ --security-opt apparmor=unconfined --security-opt seccomp=unconfined \ --name mlperf-inference-user -h mlperf-inference-user --add-host mlperf-inference-user:127.0.0.1 \ --user 1002:1002 --net host --device /dev/fuse \ -v =/home/user/inference_results_v1.0/closed/DellEMC/scratch:/home/user/inference_results_v1.1/closed/DellEMC/scratch \ -e MLPERF_SCRATCH_PATH=/home/user/inference_results_v1.0/closed/DellEMC/scratch \ -e HOST_HOSTNAME=node009 \ mlperf-inference:user
The Docker container is launched with all the necessary packages installed.
- Access the interactive terminal on the container.
- To build the required libraries for inferencing, run the make build command inside the interactive container:
Command
make build
The following example shows sample output:
(mlperf) user@mlperf-inference-user:/work$ make build ……. [ 26%] Linking CXX executable /work/build/bin/harness_default make[4]: Leaving directory '/work/build/harness' make[4]: Leaving directory '/work/build/harness' make[4]: Leaving directory '/work/build/harness' [ 36%] Built target harness_bert [ 50%] Built target harness_default [ 55%] Built target harness_dlrm make[4]: Leaving directory '/work/build/harness' [ 63%] Built target harness_rnnt make[4]: Leaving directory '/work/build/harness' [ 81%] Built target harness_triton make[4]: Leaving directory '/work/build/harness' [100%] Built target harness_triton_mig make[3]: Leaving directory '/work/build/harness' make[2]: Leaving directory '/work/build/harness' Finished building harness. make[1]: Leaving directory '/work' (mlperf) user@mlperf-inference-user:/work
The container in which you can run the benchmarks is built.
3.5 Download and preprocess validation data and models
To run the MLPerf inference v1.1, download datasets and models, and then preprocess them. MLPerf provides scripts that download the trained models. The scripts also download the dataset for benchmarks other than Resnet50, DLRM, and 3D U-Net.
For Resnet50, DLRM, and 3D U-Net, register for an account and then download the datasets manually:
- Resnet50—Download the most common image classification 2012 Validation set and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/<dataset_name>/
(https://github.com/mlcommons/training/tree/master/image_classification). - DLRM—Download the Criteo Terabyte dataset and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/criteo/
- 3D U-Net—Download the BraTS challenge data and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/BraTS/MICCAI_BraTS_2019_Data_Training
Except for the Resnet50, DLRM, and 3D U-Net datasets, run the following commands to download all the models, datasets, and then preprocess them:
$ make download_model # Downloads models and saves to $MLPERF_SCRATCH_PATH/models $ make download_data # Downloads datasets and saves to $MLPERF_SCRATCH_PATH/data $ make preprocess_data # Preprocess data and saves to $MLPERF_SCRATCH_PATH/preprocessed_data
Note: These commands download all the datasets, which might not be required if the objective is to run one specific benchmark. To run a specific benchmark rather than all the benchmarks, see the following sections for information about the specific benchmark.
(mlperf) user@mlperf-inference-user:/work$ tree -d -L 1 . ├── build ├── code ├── compliance ├── configs ├── data_maps ├── docker ├── measurements ├── power ├── results ├── scripts └── systems # different folders are as follows ├── build—Logs, preprocessed data, engines, models, plugins, and so on ├── code—Source code for all the benchmarks ├── compliance—Passed compliance checks ├── configs—Configurations that run different benchmarks for different system setups ├── data_maps—Data maps for different benchmarks ├── docker—Docker files to support building the container ├── measurements—Measurement values for different benchmarks ├── power—files specific to power submission (it’s only needed for power submissions) ├── results—Final result logs ├── scratch—Storage for models, preprocessed data, and the dataset that is symlinked to the preceding build directory ├── scripts—Support scripts └── systems—Hardware and software details of systems in the benchmark
4 Running the benchmarks
After you have performed the preceding tasks to prepare your environment, run any of the benchmarks that are required for your tests.
The Resnet50, SSD-Resnet34, and RNN-T benchmarks have 99 percent (default accuracy) targets.
The BERT, DLRM, and 3D U-Net benchmarks have 99 percent (default accuracy) and 99.9 percent (high accuracy) targets. For information about running these benchmarks, see the Running high accuracy target benchmarks section below.
If you downloaded and preprocessed all the datasets (as shown in the previous section), there is no need to do so again. Skip the download and preprocessing steps in the procedures for the following benchmarks.
NVIDIA TensorRT is the inference engine for the backend. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning applications.
4.1 Run the Resnet50 benchmark
To set up the Resnet50 dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go step 5.
- Download the required validation dataset (https://github.com/mlcommons/training/tree/master/image_classification).
- Extract the images to $MLPERF_SCRATCH_PATH/data/<dataset_name>/
- Run the following commands:
make download_model BENCHMARKS=resnet50 make preprocess_data BENCHMARKS=resnet50 - Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
The following example shows the output for a PerformanceOnly mode and displays a “VALID” result:
======================= Perf harness results: ======================= R7525_A100-PCIe-40GBx1_TRT-default-Server: resnet50: Scheduled samples per second : 30400.32 and Result is : VALID ======================= Accuracy results: ======================= R7525_A100-PCIe-40GBx1_TRT-default-Server: resnet50: No accuracy results in PerformanceOnly mode.
4.2 Run the SSD-Resnet34 benchmark
To set up the SSD-Resnet34 dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=ssd-resnet34 make download_data BENCHMARKS=ssd-resnet34 make preprocess_data BENCHMARKS=ssd-resnet34
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
4.3 Run the RNN-T benchmark
To set up the RNN-T dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=rnnt make download_data BENCHMARKS=rnnt make preprocess_data BENCHMARKS=rnnt
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=rnnt --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
5 Running high accuracy target benchmarks
The BERT, DLRM, and 3D U-Net benchmarks have high accuracy targets.
5.1 Run the BERT benchmark
To set up the BERT dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=bert make download_data BENCHMARKS=bert make preprocess_data BENCHMARKS=bert
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and also for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=bert --scenarios=Offline,Server --config_ver=default,high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=high_accuracy --test_mode=AccuracyOnly"
5.2 Run the DLRM benchmark
To set up the DLRM dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go to step 5.
- Download the Criteo Terabyte dataset.
- Extract the images to $MLPERF_SCRATCH_PATH/data/criteo/ directory.
- Run the following commands:
make download_model BENCHMARKS=dlrm make preprocess_data BENCHMARKS=dlrm
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and also for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=dlrm --scenarios=Offline,Server --config_ver=default, high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=high_accuracy --test_mode=AccuracyOnly"
5.3 Run the 3D U-Net benchmark
Note: This benchmark only has the Offline scenario.
To set up the 3D U-Net dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go to step 5
- Download the BraTS challenge data.
- Extract the images to the $MLPERF_SCRATCH_PATH/data/BraTS/MICCAI_BraTS_2019_Data_Training directory.
- Run the following commands:
make download_model BENCHMARKS=3d-unet make preprocess_data BENCHMARKS=3d-unet
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default,high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly"
6 Limitations and Best Practices for Running MLPerf
Note the following limitations and best practices:
- To build the engine and run the benchmark by using a single command, use the make run RUN_ARGS… shortcut. The shortcut is valid alternative to the make generate_engines … && make run_harness.. commands.
- Include the --fast flag in the RUN_ARGS command to test runs quickly by setting the run time to one minute. For example
make run_harness RUN_ARGS="–-fast --benchmarks=<bmname> --scenarios=<scenario> --config_ver=<cver> --test_mode=PerformanceOnly"
The benchmark runs for one minute instead of the default 10 minutes.
- If the server results are “INVALID”, reduce the server_target_qps for a Server scenario run. If the latency constraints are not met during the run, “INVALID” results are expected.
- If the results are “INVALID” for an Offline scenario run, then increase the offline_expected_qps. “INVALID” runs for the Offline scenario occurs when the system can deliver a significantly higher QPS than what is provided through the offline_expected_qps configuration.
- If the batch size changes, rebuild the engine.
- Only the BERT, DLRM, 3D-U-Net benchmarks support high accuracy targets.
- 3D-U-Net only has the Offline scenario.
- Triton Inference Server runs by passing triton and high_accuracy_triton for default and high_accuracy targets respectively inside the config_ver argument.
- When running a command with RUN_ARGS, be aware of the quotation marks. Errors can occur if you omit the quotation marks.
Conclusion
This blog provided the step-by-step procedures to run and reproduce closed data center MLPerf inference v1.1 results on Dell EMC servers with NVIDIA GPUs.

Deep Learning Performance on MLPerf™ Training v1.0 with Dell EMC DSS 8440 Servers
Mon, 16 Aug 2021 19:23:48 -0000
|Read Time: 0 minutes
Abstract
This blog provides MLPerf™ Training v1.0 data center closed results for Dell EMC DSS 8440 servers running the MLPerf training benchmarks. Our results show optimal training performance for the DSS 8440 configurations on which we chose to run training benchmarks. Also, we can expect higher performance gains by upgrading to the NVIDIA A100 accelerators running the deep learning workload on DSS 8440 servers.
Background
The DSS 8440 server allows up to 10 double-wide GPUs in the PCIe. This configuration makes it an aptly suited server for high compute that is required to run workloads such as deep learning training.
MLPerf Training v1.0 benchmark models address problems such as image classification, medical image segmentation, light weight and heavy weight object detection, speech recognition, natural language processing (NLP), and recommendation and reinforcement learning.
As of June 2021, MLPerf Training has become more mature and has successfully completed v1.0, which is the fourth submission round of MLPerf training. See this blog for new features of the MLPerf Training v1.0 benchmark.
Testbed
The results for the models that are submitted with the DSS 8440 server include:
- 1 x DSS 8440 (x8 A100-PCIE-40GB)—All eight models, which include ResNet50, SSD, MaskRCNN, U-Net3D, BERT, DLRM, Minigo, and RNN-T
- 2 x DSS 8440 (x16 A100-PCIE-40GB)—Two-nodes ResNet50
- 3 x DSS 8440 (x24 A100-PCIe-40GB)—Three-nodes ResNet50
- 1 x DSS 8440 (x8 A100-PCIE-40GB, connected with NVLink Bridges)—BERT
We chose BERT with NVLink Bridge because BERT has plenty of card-to-card communication that allows NVLink Bridge benefits.
The following table shows a single node DSS8440 hardware configuration and software environment:
Table 1: DSS 8440 node specification
Hardware | |
Platform | DSS 8440 |
CPUs per node | 2 x Intel Xeon Gold 6248R CPU @ 3.00 GHz |
Memory per node | 768 GB (24 x 32 GB) |
GPU | 8 x NVIDIA A100-PCIE-40GB (250 W) |
Host storage | 1x 1.5 TB NVMe + 2x 512 GB SSD |
Host network | 1x ConnectX-5 IB EDR 100Gb/Sec |
Software | |
Operating system | CentOS Linux release 8.2.2004 (Core) |
GPU driver | 460.32.03 |
OFED | 5.1-2.5.8.0 |
CUDA | 11.2 |
MXNet | NGC MXNet 21.05 |
PyTorch | NGC PyTorch 21.05 |
TensorFlow | NGC TensorFlow 21.05-tf1 |
cuBLAS | 11.5.1.101 |
NCCL version | 2.9.8 |
cuDNN | 8.2.0.51 |
TensorRT version | 7.2.3.4 |
Open MPI | 4.1.1rc1 |
Singularity | 3.6.4-1.el8 |
MLPerf Training 1.0 benchmark results
Single node performance
The following figure shows the performance of the DSS 8440 server on all training models:
Figure 1: Performance of a single node DSS 8440 with 8 x A100-PCIE-40GB GPUs
The y axis is an exponentially scaled axis. MLPerf training measures the submission by assessing how many minutes it took for a system under test to converge to the target accuracy while meeting all the rules.
Key takeaways include:
- All our results were officially submitted to the MLCommons™ Consortium and are verified.
- The DSS 8440 server was able to run all the models in the MLPerf training v1.0 benchmark across different areas such as vision, language, commerce, and research.
- The DSS8440 server is a good candidate to fit into the high performance per watt category.
- With a thermal design power (TDP) of 250 W, the A100 PCIE 40 GB offers high throughput for all the benchmarks. This throughput, when compared to other GPUs that have a higher TDP, offers almost similar throughputs for many benchmarks (see the results here).
- The DLRM model takes more time to converge because the underlying Merlin HurgeCTR framework implementation is optimized for an SXM4 form factor. Our Dell EMC PowerEdge XE8545 Server supports this form factor.
Overall, by upgrading the accelerator to an NVIDIA A100 PCIE 40 GB, 2.1 to 2.4 times performance improvements can be expected, compared to the previous MLPerf Training v0.7 round that used previous generation NVIDIA V100 PCIe GPUs.
Multinode scaling
Multinode training is critical for large machine learning workloads. It provides a significant amount of compute power, which accelerates the training process linearly. While a single node training certainly converges, multinode training offers higher throughput and converges faster.
Figure 2: Resnet50 multinode scaling on a DSS8440 server with one, two, and three nodes
These results are for multiple (up to three) DSS 8440 servers that are tested with the Resnet50 model.
Note the following about these results:
- Adding more nodes to the same training task helps to reduce the overall turnaround time of training. This reduction helps data scientists to adjust their models rapidly. Some larger models might run days on the fastest single GPU server; multinode training can reduce the time to hours or minutes.
- To be comparable and comply with the RCP rules in MLPerf training v1.0, we keep the global batch sizes the same with two and three nodes. This configuration is considered strong scaling as the workload and the global batch sizes do not increase with the GPU numbers for the multinode scaling setting. Because of RCP constraints, we cannot see linear scaling.
- We see higher throughput numbers with larger batch sizes.
- The ResNet50 model scales well on the DSS 8440 server.
In general, adding more DSS 8440 servers to a large deep learning training problem helps to reduce time spent on those training workloads.
NVLink Bridges
NVLINK Bridges are bridge boards that link a pair of GPUs to help workloads that exchange data frequently between GPUs. Those A100 PCIe GPUs on the DSS 8440 server can support three bridges per each GPU pair. The following figure shows the difference for the BERT model with and without NVLink Bridges:
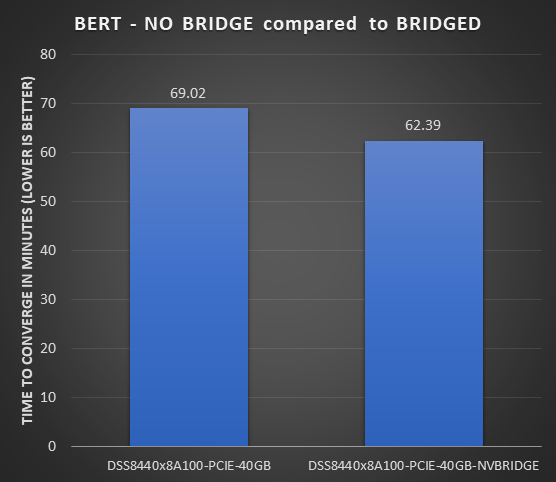
Figure 3: BERT converge-time difference without and with NVLink Bridges on a DSS 8440 server
- An NVLink Bridge offers over 10 percent faster convergence for the BERT model.
- Because the topology of the NVLink Bridge hardware is relatively new, there might be opportunities for this topology to translate into higher performance gains as the supporting software matures.
Conclusion and future work
Dell EMC DSS 8440 servers are an excellent fit for modern deep learning training workloads helping solve different problems spanning image classification, medical image segmentation, light weight and heavy weight object detection, speech recognition, natural language processing (NLP), recommendation and reinforcement learning. These servers offer high throughput and are an excellent scalable medium to run multinode jobs. They offer faster convergence while meeting training constraints. Paring the NVLink Bridge with NVIDIA A100 PCIE accelerators can improve throughput for higher inter-GPU communication models like BERT. Furthermore, data center administrators can expect to improve deep learning training throughput by orders of magnitude by upgrading to NVIDIA A100 accelerators from previous generation accelerators if their data center is already using DSS 8440 servers.
With recent support of the A100-PCIe-80GB GPU on the DSS8440 server, we plan to conduct MLPerf training benchmarks with 10 GPUs in each server, which will allow us to provide a comparison of scale-up and scale-out performance.

Simplifying Machine Learning with Omnia and Polyaxon
Wed, 11 Aug 2021 20:52:33 -0000
|Read Time: 0 minutes
Managing data science projects can be a nightmare
Tracking data science projects can be a nightmare. Making sense of a sea of experiments, models that are all scattered across multiple workstations with no sense of order, different software environments, and other complexities create ever more hurdles to making sense of your data. Then when you add in limited documentation availability plus the intricate interplay of the different technologies being leveraged it's no wonder that reproducing results becomes a tricky task. Fortunately, machine learning (ML) platforms are helping to automate and manage these complexities, leaving data scientists and data science managers to solve the real problem – getting value from the data.
Polyaxon makes developing models easier
Polyaxon is a platform for developing machine learning and deep learning models that can be used on an enterprise scale for all steps of the machine learning and deep learning model development process: building, training, and monitoring. Polyaxon accomplishes this by leveraging a built-in infrastructure, set of tools, trusted algorithms, and industry models, all of which lead to faster innovation. Polyaxon enables data scientists to easily develop and manage experiments and manages the entire workflow with smart containers and advanced scheduling. It is also language and framework agnostic, allowing data scientists to work with popular libraries and frameworks such as R, Python, SAS, Jupyter, RStudio, Tensorflow, and H2O.
Managing multiple data scientists and experiment artifacts
One feature that data scientist managers will find especially useful is Polyaxon’s ease of knowledge distribution. With fast onboarding of new team members and a documented and searchable knowledge base, any new hire can quickly pick up where others left off using each project's artifacts and history. Additionally, Polyaxon includes risk management capabilities and a built-in auto-documentation engine to remove risk and create a searchable knowledge base, avoiding the problem of laptop-centric and scattered scripts-oriented development.
For the executives of an organization, Polyaxon provides improved insights on model development and measuring time to market. By enabling a virtuous experimentation life cycle and giving data-driven feedback, all based on a centralized dashboard, Polyaxon optimizes and the time spent on projects. This means data science teams spend more time producing value, rather than trying to maintain infrastructure and documentation.
Deploying Polyaxon with Omnia
Omnia is an open‑source framework for deploying and managing high-performance clusters for HPC, AI, and data analytics workloads. Omnia not only automates the installation of Slurm and/or Kubernetes for managing your server infrastructure, it also deploys and configures many other packages and services necessary for running diverse workloads on the same converged solution. It also automates the deployment of ML platforms, like Polyaxon. This gives IT infrastructure teams the ability to quickly spin up and offer new capabilities to an organization’s data science and applications teams, giving them more time to do the company’s business.
Automation is key to any data-driven organization
The ability to automate the infrastructure stack, from the server, storage, and network resources up to the data science platforms that help you derive value from their data, is key to the success of modern data-driven organizations. Tools change quickly and frequently, and spending weeks deploying IT solutions for a company’s data science teams is time not spent finding critical value. Omnia simplifies the process of infrastructure deployment, allowing IT groups to get their data science teams up and running in minutes. What could be more transformative than that?
Learn More
Learn more about Polyaxon
Learn more about Omnia

Let Robin Systems Cloud Native Be Your Containerized AI-as-a-Service Platform on Dell PE Servers
Fri, 06 Aug 2021 21:31:26 -0000
|Read Time: 0 minutes
Robin Systems has a most excellent platform that is well suited to simultaneously running a mix of workloads in a containerized environment. Containers offer isolation of varied software stacks. Kubernetes is the control plane that deploys the workloads across nodes and allows for scale-out, adaptive processing. Robin adds customizable templates and life cycle management to the mix to create a killer platform.
AI which includes the likes of machine learning for things like scikit-learn with dask, H2o.ai, spark MLlib and PySpark along with deep learning which includes tensor flow, PyTorch, MXNET, keras and Caffe2 are all things that can be run simultaneously in Robin. Nodes are identified by their resources during provisioning for cores, memory, GPUs and storage.
Cultivated data pipelines can be constructed with a mix of components. Consider a use case with ingest from kafka, store to Cassandra and then run spark MLlib to find loans submitted from last week that will be denied. All that can be automated with Robin.
The as-a-service aspect for things like MLops & AutoML can be implemented with a combination of Robin capabilities and other software to deliver a true AI-as-a-Service experience.
Nodes to run these workloads on can support disaggregated compute and storage. Some sample servers might be a combination of Dell PowerEdge C6520s for compute & R750s for storage. The compute servers are very dense and can run four server hosts in 2U offering a full range of Intel Ice Lake processors. For storage nodes the R750s can have onboard NVMe or SSDs (up to 28). For the OS image a hot swappable m.2 BOSS card with self-contained RAID1 can be used for Linux with all 15G servers.

Dell EMC Servers Excel in MLPerf™ Training v1.0 Benchmarks
Thu, 08 Jul 2021 15:28:25 -0000
|Read Time: 0 minutes
Dell Technologies has submitted MLPerf training v1.0 results. This blog provides an explanation of what is new with MLPerf training v1.0 and a high-level overview of our submissions. Results indicate that Dell EMC DSS8440 and PowerEdge XE8545 servers offer promising performance for Deep Learning training workloads across different areas.
MLCommons™ is a community that contains a consortium of experts in the Machine Learning/Deep Learning industry from different fields within AI technology. It consists of experts from industry, academia, startups, and individual researchers. MLPerf™ Training is the community-led test suite focusing on deep learning training. This test suite aims to measure how fast a system can train deep learning models across eight different problem types:
- Image classification
- Medical image segmentation
- Light-weight object detection
- Heavy-weight object detection
- Speech recognition
- Natural language processing
- Recommendation
- Reinforcement learning
These benchmarks provide a consistent and reproducible way to measure accuracy and convergence on individual accelerators, systems, and cloud setups. As of June 2021, MLPerf™ Training released the latest v1.0 results in the fourth round of submissions of MLPerf Training. The following changes are new with v1.0:
- Addition of two benchmarks:
- RNN-T—RNN-T is a speech recognition model. Speech recognition accepts raw audio samples and produces a corresponding text transcription. It uses the Libri-speech dataset, which is derived from audiobooks. An example of the use of speech recognition is Google Voice Search.
- 3D-UNet—3D-Unet is a model for 3D medical image segmentation. It accepts 3D images that contain tumors; the model divides (or segments) the tumor from the other parts in the image. It uses the KiTs19 dataset. An example of the use of 3D medical image segmentation is for the identification of kidney tumors.
- Introduction of a uniform and more mature process for evaluation and submission:
- Reference Convergence Points (RCP) checker to ensure hyperparameters are assessed consistently and uniformly across different submissions.
- Other checkers such as compliance checker, system desc checker, and package checker to check the accuracy of the submission.
- Result summarizer to provide a submission summary.
- Retirement of two language translation benchmarks from v0.7:
- GNMT
- Transformer
BERT serves as a replacement for language model tasks.
The following figure demonstrates the numbers from the Deep Learning v1.0 benchmarks submitted by Dell Technologies:
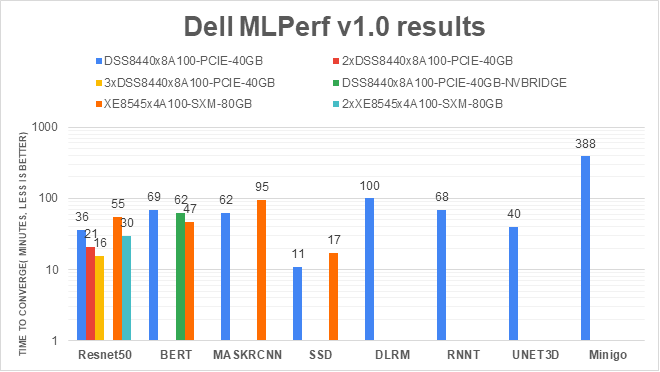
Figure 1: MLPerf v1.0 results from Dell Technologies
Contributions from Dell Technologies
Our submissions focused on Dell EMC DSS 8440 and Dell EMC PowerEdge XE8545 servers. The DSS 8440 server is an Intel-based, PCIe Gen3 4U server that supports up to 10 double-wide PCIe GPUs, focused on Machine Learning/Deep Learning applications such as training. The 4U PowerEdge XE8545 server supports the latest 3rd Gen AMD EPYC processors, PCIe Gen4, and the latest NVIDIA A100 Tensor Core GPUs for cutting edge machine learning workloads. Both of these system configurations are NVIDIA-Certified, which means they have been validated for best performance and optimal scalability. The submission from Dell Technologies also included multinode training entries to showcase scale-out performance.
Multinode training is important. Training is compute intensive, therefore, more compute nodes are used while training models. Because extra compute nodes help to reduce the turnaround time, it is critical to showcase multiple nodes’ performance. Dell Technologies and NVIDIA are the only submitters that submitted multiple nodes on GPUs. The submissions from NVIDIA run on Docker with a customized Slurm environment to optimize performance; we submitted multinode submissions with Singularity on our DSS 8440 servers as well as Docker and Slurm submissions on PowerEdge XE8545 servers. Singularity is a secure containerization solution primarily used in traditional HPC GPU clusters. Setup scripts with singularity help traditional HPC customers run MLPerf™ Training on their cluster without the need to fully restructure their existing cluster setup.
The PowerEdge XE8545 server provides the best performing submission with an air-cooled solution for NVIDIA A100-SXM-80GB 500W GPUs. Typically, 500W GPUs of most vendors' systems are cooled with liquid, due to the challenges presented by the high TDP. However, Dell Technologies invested engineering and design time to solve the thermal challenge and allows customers to avoid the need for costly changes to a standard data center setup.
The DSS 8440 server submissions to MLPerf™ Training v1.0 using the latest generation NVIDIA A100 40 GB-PCIe GPUs show a 2.1 to 2.4 times increase from equivalent MLPerf™ Training v0.7 submissions using NVIDIA V100S PCIe GPUs. Dell Technologies is committed to bringing the latest performance advancements to customers as quickly as possible.
Out of 12 different organizations, Dell Technologies and NVIDIA are the only two organizations that submitted results for all eight models in the MLPerf™ training v1.0 benchmarking suite.
Next steps
As a next step, we will publish more technical blogs to provide deep dives into DSS 8440 server and PowerEdge XE8545 server results.

Supercharge Inference Performance at the Edge using the Dell EMC PowerEdge XE2420 (June 2021 revision)
Mon, 07 Jun 2021 13:42:14 -0000
|Read Time: 0 minutes
Deployment of compute at the Edge enables the real-time insights that inform competitive decision making. Application data is increasingly coming from outside the core data center (“the Edge”) and harnessing all that information requires compute capabilities outside the core data center. It is estimated that 75% of enterprise-generated data will be created and processed outside of a traditional data center or cloud by 2025.[1]
This blog demonstrates the high power-performance potential of the Dell EMC PowerEdge XE2420, an edge-friendly, short-depth server. Utilizing up to four NVIDIA T4 GPUs, the XE2420 can perform AI inference operations faster while efficiently managing power-draw. The XE2420 is capable of classifying images at 23,309 images/second while drawing an average of 794 watts, all while maintaining its equal performance with other conventional rack servers.
XE2420 Features and Capabilities
The Dell EMC PowerEdge XE2420 is a 16” (400mm) deep, high-performance server that is purpose-built for the Edge. The XE2420 has features that provide dense compute, simplified management and robust security for harsh edge environments.

- Built for performance: Powerful 2U, two-socket performance with the flexibility to add up to four accelerators per server and a maximum local storage of 132TB.
- Designed for harsh edge environments: Tested to Network Equipment-Building System (NEBS3) guidelines, with extended operating temperature tolerance of 5˚-45˚C, and an optional filtered bezel to guard against dust. Short depth for edge convenience and lower latency.
- Integrated security and consistent management: Robust, integrated security with cyber-resilient architecture, and the new iDRAC9 with Datacenter management experience. Front accessible and cold-aisle serviceable for easy maintenance.
- Power efficiency: High-end capacity supporting 2x 2000W AC PSUs or 2x 1100W DC PSUs to support demanding configurations, while maintaining efficient operation minimizing power draw
The XE2420 allows for flexibility in the type of GPUs you use in order to accelerate a wide variety of workloads including high-performance computing, deep learning training and inference, machine learning, data analytics, and graphics. It can support up to 2x NVIDIA V100/S PCIe, 2x NVIDIA RTX6000, or up to 4x NVIDIA T4.
Edge Inferencing with the T4 GPU
The NVIDIA T4 is optimized for mainstream computing environments and uniquely suited for Edge inferencing. Packaged in an energy-efficient 70-watt, small PCIe form factor, it features multi-precision Turing Tensor Cores and RT Cores to deliver power efficient inference performance. Combined with accelerated containerized software stacks from NGC, the XE2420 combined with NVIDIA T4s is a powerful solution to deploy AI application at scale on the edge.

Fig 1: NVIDIA T4 Specifications

Fig 2: Dell EMC PowerEdge XE2420 w/ 4x T4 & 2x 2.5” SSDs
Dell EMC PowerEdge XE2420 MLPerf™ Inference v1.0 Tested Configuration
Processors | 2x Intel Xeon Gold 6252 CPU @ 2.10GHz |
Storage
| 1x 2.5" SATA 250GB |
1x 2.5" NVMe 4TB | |
Memory | 12x 32GB 2666MT/s DDR4 DIMM |
GPUs | 4x NVIDIA T4 |
OS | Ubuntu 18.04.4 |
Software
| TensorRT 7.2.3 |
CUDA 11.1 | |
cuDNN 8.1.1 | |
Driver 460.32.03 | |
DALI 0.30.0 | |
Hardware Settings | ECC on |
Inference Use Cases at the Edge
As computing further extends to the Edge, higher performance and lower latency become vastly more important in order to increase throughput, while decreasing response time and power draw. One suite of diverse and useful inference workload benchmarks is the MLPerf™ suite from MLCommons™. MLPerf™ Inference demonstrates performance of a system under a variety of deployment scenarios, aiming to provide a test suite to enable balanced comparisons between competing systems along with reliable, reproducible results.
The MLPerf™ Inference v1.0 suite covers a variety of workloads, including image classification, object detection, natural language processing, speech-to-text, recommendation, and medical image segmentation. Specific datacenter scenarios covered include “offline”, which represents batch processing applications such as mass image classification on existing photos, and “Server”, which represents an application where query arrival is random, and latency is important. An example of server is any consumer-facing website where a consumer is waiting for an answer to a question. For MLPerf™ Inference v1.0, we also submitted using the edge scenario of “SingleStream”, representing an application that delivers single queries in a row, waiting to deliver the next only when the first is finished; latency is important to this scenario. One example of SingleStream is smartphone voice transcription: Each word is rendered as it spoken, and the second word does not render the next until the first is done. Many of these workloads are directly relevant to Telco & Retail customers, as well as other Edge use cases where AI is becoming more prevalent.
MLPerf™ Inference v1.0 now includes power benchmarking. This addition allows for measurement of power draw under active test for any of the benchmarks, which provide accurate and precise power metrics across a range of scenarios, and is accomplished by utilization of the proprietary measurement tool belonging to SPECPower – PTDaemon®. SPECPower is an industry-standard benchmark built to measure power and performance characteristics of single or multi-node compute servers. Dell EMC regularly submits PowerEdge systems to SPECPower to provide customers the data they need to effectively plan server deployment. The inclusion of comparable power benchmarking to MLPerf™ Inference further emphasizes Dell’s commitment to customer needs.
Measuring Inference Performance using MLPerf™
We demonstrate inference performance for the XE2420 + 4x NVIDIA T4 accelerators across the 6 benchmarks of MLPerf™ Inference v1.0 with Power v1.0 in order to showcase the workload versatility of the system. Dell tuned the XE2420 for best performance and measured power under that scenario to showcase the optimized NVIDIA T4 power cooling algorithms. The inference benchmarking was performed on:
- Offline, Server, and SingleStream scenarios at 99% accuracy for ResNet50 (image classification), RNNT (speech-to-text), and SSD-ResNet34 (object detection), including power
- Offline and Server scenarios at 99% and 99.9% for DLRM (recommendation), including power
- Offline and SingleStream scenario at 99% and 99.9% accuracy for 3D-Unet (medical image segmentation)
These results and the corresponding code are available at the MLPerf™ website. We have submitted results to both the Datacenter[2] & the Edge suites[3].
Key Highlights
At Dell, we understand that performance is critical, but customers do not want to compromise quality and reliability to achieve maximum performance. Customers can confidently deploy inference workloads and other software applications with efficient power usage while maintaining high performance, as demonstrated below.
The XE2420 is a compact server that supports 4x 70W NVIDIA T4 GPUs in an efficient manner, reducing overall power consumption without sacrificing performance. This high-density and efficient power-draw lends it increased performance-per-dollar, especially when it comes to a per-GPU performance basis.
Dell is a leader in the new addition of MLPerf™ Inference v1.0 Power measurements. Due to the leading-edge nature of the measurement, limited datasets are available for comparison. Dell also has power measurements for the core datacenter R7525, configured with 3x NVIDIA A100-PCIe-40GB. On a cost per throughput per watt comparison, XE2420 configured with 4x NVIDIA T4s gets better power performance in a smaller footprint and at a lower price, all factors that are important for an edge deployment.
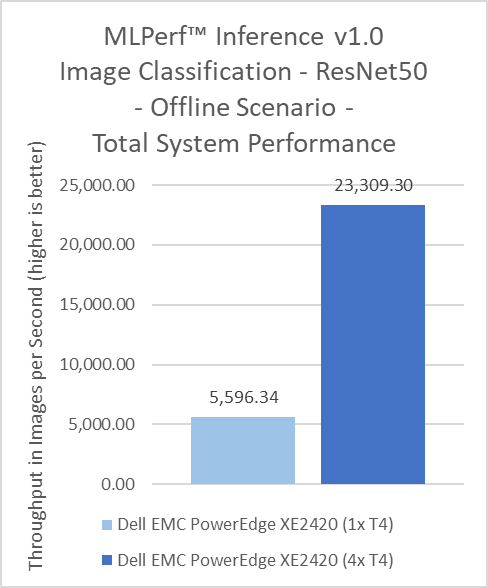
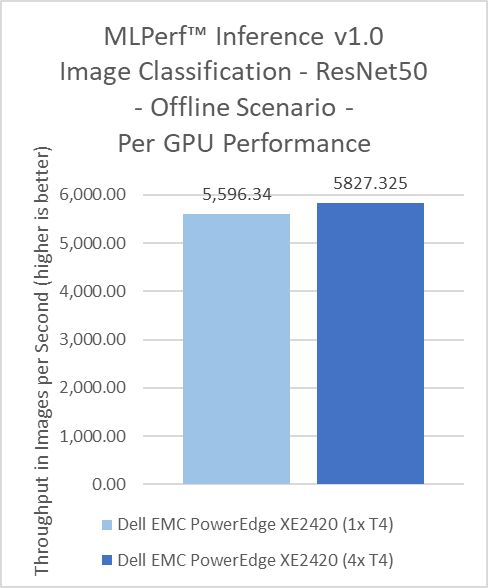
Inference benchmarks tend to scale linearly within a server, as this type of workload does not require GPU P2P communication. However, the quality of the system can affect that scaling. The XE2420 showcases above-average scaling; 4 GPUs provide more than 4x performance increase! This demonstrates that operating capabilities and performance were not sacrificed to support 4 GPUs in a smaller depth and form-factor.
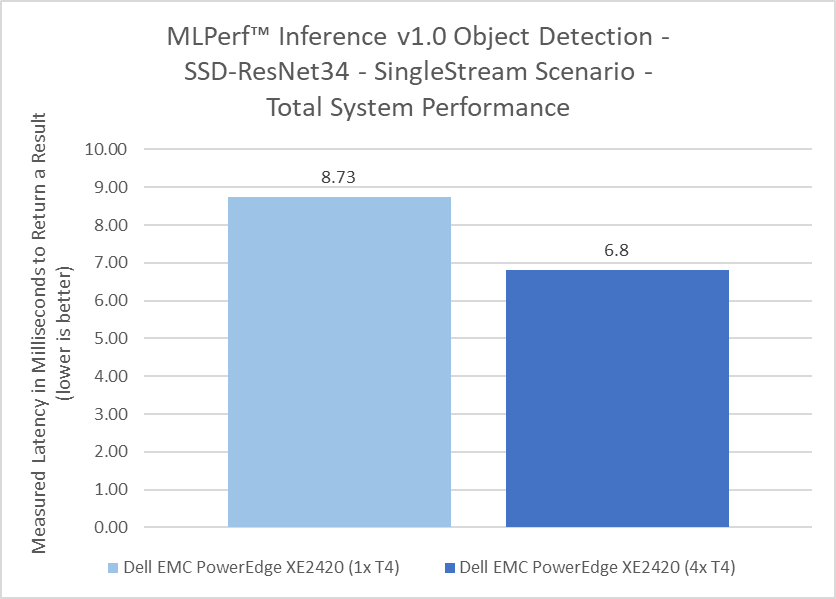
Dell submitted to the Edge benchmark suite of MLPerf™ Inference v1.0 for the third round of MLPerf Inference Testing. The unique scenario in this suite is “SingleStream”, discussed above. With SingleStream, system latency is paramount, as the server cannot move onto the second query until the first is finished. The fewer milliseconds, the faster the system, and the better suited it is for the Edge! System architecture affects latency, so depending on where the GPU is located latency may increase or decrease. This figure can be read as a best and worst case scenario; ie the XE2420 will return results on average in between 6.8 to 8.73 milliseconds, below the range of human-recongnizable delay for the SSD-ResNet34 benchmark. Not every server will meet this bar on every benchmark, and the XE2420 scores below this range on many of the submissions.
Comparisons to MLPerf™ Inference v0.7 XE2420 results will show that v1.0 results are slightly different in terms of total system and per-GPU throughput. This is due to a changed requirement between the two test suites. In v0.7, ECC could be turned off, which is common to improve performance of GDDR6 based GPUs. In v1.0, ECC is turned on. This better reflects most customer environments and use cases, since administrators will typically be alerted to any memory errors that could affect accuracy of results.
Conclusion: Better Performance-per-Dollar and Flexibility at the Edge without sacrificing Performance
MLPerf™ inference benchmark results clearly demonstrate that the XE2420 is truly a high-performance, efficient, half-depth server ideal for edge computing use cases and applications. The capability to support four NVIDIA T4 GPUs in a short-depth, edge-optimized form factor, while keeping them sufficiently cool enables customers to perform AI inference operations at the Edge on par with traditional mainstream 2U rack servers deployed in core data centers. The compact design provides customers new, powerful capabilities at the edge to do more even faster without extra cost or increased power requirements. The XE2420 is capable of true versatility at the edge, demonstrating strong performance not only for mundane workloads but also for a broad range of tested workloads, applicable in a number of Edge industries from Retail to Manufacturing to Autonomous driving. Dell EMC offers a complete portfolio of trusted technology solutions to aggregate, analyze and curate data from the edge to the core to the cloud and XE2420 is a key component of this portfolio to meet your compute needs at the Edge.
XE2420 MLPerf™ Inference v1.0 Full Results
The raw results from the MLPerf™ Inference v1.0 published benchmarks are displayed below, where the performance metric is throughput (items per second) for Offline and Server and latency (length of time to return a result, in milliseconds) for SingleStream. The power metric is Watts for Offline and Server and Energy (Joules) per Stream for SingleStream.
|
| 3d-unet-99 | 3d-unet-99.9 | ||
|
| Offline | SingleStream | Offline | SingleStream |
XE2420_T4x1_TRT | Performance | - | - | - | - |
Power/Energy | - | - | - | - | |
XE2420_T4x4_TRT | Performance | 31.22 (imgs/sec) | 171.73 (ms) | 31.22 (imgs/sec) | 171.73 (ms) |
Power/Energy | - | - | - | - | |
|
| dlrm-99.9 | dlrm-99 | ||
|
| Offline | Server | Offline | Server |
XE2420_T4x1_TRT | Performance | - | - | - | - |
Power/Energy | - | - | - | - | |
XE2420_T4x4_TRT | Performance | 135,149.00 (imgs/sec) | 126,531.00 (imgs/sec) | 135,189.00 (imgs/sec) | 126,531.00 (imgs/sec) |
Power/Energy | 829.09 (W) | 835.52 (W) | 830.13 (W) | 835.91 (W) | |
|
| resnet50 | ||
|
| Offline | Server | SingleStream |
XE2420_T4x1_TRT | Performance | 5,596.34 (imgs/sec) | - | 0.83 (ms) |
Power/Energy | - | - | - | |
XE2420_T4x4_TRT | Performance | 23,309.30 (imgs/sec) | 21,691.30 (imgs/sec) | 0.91 (ms) |
Power/Energy | 794.46 (W) | 792.69 (W) | 0.59 (Joules/Stream) | |
|
| rnnt | ||
|
| Offline | Server | SingleStream |
XE2420_T4x1_TRT | Performance | - | - | - |
Power/Energy | - | - | - | |
XE2420_T4x4_TRT | Performance | 5,704.60 (imgs/sec) | 4,202.02 (imgs/sec) | 71.75 (ms) |
Power/Energy | 856.80 (W) | 862.46 (W) | 31.77 (Joules/Stream) | |
|
| ssd-resnet34 | ||
|
| Offline | Server | SingleStream |
XE2420_T4x1_TRT | Performance | 129.28 (imgs/sec) | - | 8.73 (ms) |
Power/Energy | - | - | - | |
XE2420_T4x4_TRT | Performance | 557.43 (imgs/sec) | 500.96 (imgs/sec) | 6.80 (ms) |
Power/Energy | 792.85 (W) | 790.83 (W) | 4.81 (Joules/Stream) | |
Introduction to MLPerf™ Inference v1.0 Performance with Dell EMC Servers
Wed, 15 Sep 2021 12:09:44 -0000
|Read Time: 0 minutes
This blog provides MLPerf inference v1.0 data center closed results on Dell servers running the MLPerf inference benchmarks. Our results show optimal inference performance for the systems and configurations on which we chose to run inference benchmarks.
The MLPerf benchmarking suite measures the performance of machine learning (ML) workloads. Currently, these benchmarks provide a consistent way to measure accuracy and throughput for the following aspects of the ML life cycle:
- Training—The MLPerf training benchmark suite measures how fast a system can train ML models.
- Inference—The MLPerf inference benchmark measures how fast a system can perform ML inference by using a trained model in various deployment scenarios.
MLPerf is now a part of the MLCommons™ Association. MLCommons is an open engineering consortium that promotes the acceleration of machine learning innovation. Its open collaborative engineering solutions support your machine learning needs. MLCommons provides:
- Benchmarks and metrics
- Datasets and models
- Best practices
MLPerf inference overview
As of March 2021, MLPerf inference has submitted three versions: v0.5, v0.7, and v1.0. The latest version, v1.0, uses the same benchmarks as v0.7 with the following exceptions:
- Power submission—Power submission, which is a wrapper around inference submission, is supported.
- Error connection code (ECC)—The ECC must set to ON.
- 10-minute runtime—The default benchmark run time is 10 minutes.
- Required number of runs for submission and audit tests—The number of runs that are required to submit Server scenario is one.
v1.0 meets v0.7 requirements, therefore v1.0 results are comparable to v0.7 results. Because the MLPerf v1.0 submissions are more restrictive, the v0.7 results do not meet v1.0 requirements.
In the MLPerf inference evaluation framework, the LoadGen load generator sends inference queries to the system under test (SUT). In our case, the SUTs are Dell EMC servers with various GPU configurations. The SUTs uses a backend (for example, TensorRT, TensorFlow, or PyTorch) to perform inferencing and returns the results to LoadGen.
MLPerf has identified four different scenarios that enable representative testing of a wide variety of inference platforms and use cases. The main differences between these scenarios are based on how the queries are sent and received:
- Offline—One query with all samples is sent to the SUT. The SUT can send the results back once or multiple times in any order. The performance metric is samples per second.
- Server—The queries are sent to the SUT following a Poisson distribution (to model real-world random events). One query has one sample. The performance metric is queries per second (QPS) within latency bound.
- Single-stream—One sample per query is sent to the SUT. The next query is not sent until the previous response is received. The performance metric is 90th percentile latency.
- Multi-stream—A query with N samples is sent with a fixed interval. The performance metric is max N when the latency of all queries is within a latency bound.
MLPerf Inference Rules describes detailed inference rules and latency constraints. This blog focuses on Offline and Server scenarios, which are designed for data center environments. Single-stream and Multi-stream scenarios are designed for non-datacenter (edge and IoT) settings.
MLPerf inference results are submitted under either of the following divisions:
- Closed division—The Closed division provides a “like-to-like” comparison of hardware platforms or software frameworks. It requires using the same model and optimizer as the reference implementation.
The Closed division requires using preprocessing, postprocessing, and model that is equivalent to the reference or alternative implementation. It allows calibration for quantization and does not allow retraining. MLPerf provides a reference implementation of each benchmark. The benchmark implementation must use a model that is equivalent, as defined in MLPerf Inference Rules, to the model used in the reference implementation.
- Open division—The Open division promotes faster models and optimizers and allows any ML approach that can reach the target quality. It allows using arbitrary preprocessing or postprocessing and model, including retraining. The benchmark implementation may use a different model to perform the same task.
To allow the like-to-like comparison of Dell Technologies results and enable our customers and partners to repeat our results, we chose to test under the Closed division, as the results in this blog show.
Criteria for MLPerf Inference v1.0 benchmark result submission
For any benchmark, the result submission must meet all the specifications shown in the following table. For example, if we choose the Resnet50 model, then the submission must meet the 76.46 percent target accuracy and the latency must be within 15 ms for the standard image dataset with dimensions of 224 x 224 x 3.
Table 1: Closed division benchmarks for MLPerf inference v1.0 with expectations
Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
Vision | Image classification | Resnet50 – v1.5 | Standard image dataset (224 x 224 x3) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection (large) | SSD-Resnet34 | COCO (1200 x 1200) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical image segmentation | 3D UNet | BraTs 2019 (224 x 224 x 160) | 16 | 99% of FP32 and 99.9% of FP32 (0.85300 mean DICE score) | N/A |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) | 2513
| 99% of FP32 (1 - WER, where WER=7.452253714852645%)
| 1000 ms |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) | 10833
| 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Commerce | Recommendation | DLRM | 1 TB Click Logs | 204800 | 99% of FP32 and 99.9% of FP32 (AUC=80.25%) | 30 ms |
It is not mandatory to submit all the benchmarks. However, if a specific benchmark is submitted, then all the required scenarios for that benchmark must also be submitted.
Each data center benchmark requires the scenarios in the following table:
Table 2: Tasks and corresponding required scenarios for data center benchmark suite in MLPerf inference v1.0.
Area | Task | Required scenario |
Vision | Image classification | Server, Offline |
Vision | Object detection (large) | Server, Offline |
Vision | Medical image segmentation | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Commerce | Recommendation | Server, Offline |
SUT configurations
We selected the following servers with different types of NVIDIA GPUs as our SUT to conduct data center inference benchmarks. The following table lists the MLPerf system configurations:
Table 3: MLPerf system configurations
Platform | Dell EMC DSS8440_A100 | Dell EMC DSS8440_A40 | PowerEdge R750xa | PowerEdge XE8545 |
MLPerf System ID | DSS8440_A100-PCIE-40GBx10_TRT | DSS8440_A40x10_TRT | R750xa_A100-PCIE-40GBx4_TRT | XE8545_7713_A100-SXM4-40GBx4 |
Operating system | CentOS 8.2.2004 | CentOS 8.2.2004 | CentOS 8.2.2004 | CentOS 8.2.2004 |
CPU | 2 x Intel Xeon Gold 6248 CPU @ 2.50 GHz | 2 x Intel Xeon Gold 6248R CPU @ 3.00 GHz | 2 x Intel Xeon Gold 6338 CPU @ 2.00 GHz | 2 x AMD EPYC 7713 |
Memory | 768 GB | 768 GB | 256 GB | 1 TB |
GPU | NVIDIA A100-PCIe-40GB | NVIDIA A40 | NVIDIA A100-PCIE-40GB | NVIDIA A100-SXM4-40GB |
GPU Form Factor | PCIE | PCIE | PCIE | SXM4 |
GPU count | 10 | 10 | 4 | 4 |
Software Stack | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 | TensorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Driver 460.32.03, DALI 0.30.0 |
MLPerf inference 1.0 benchmark results
The following graphs include performance metrics for the Offline and Server scenarios.
For the Offline scenario, the performance metric is Offline samples per second. For the Server scenario, the performance metric is queries per second (QPS). In general, the metrics represent throughput. A higher throughput is a better result.
Resnet50 results
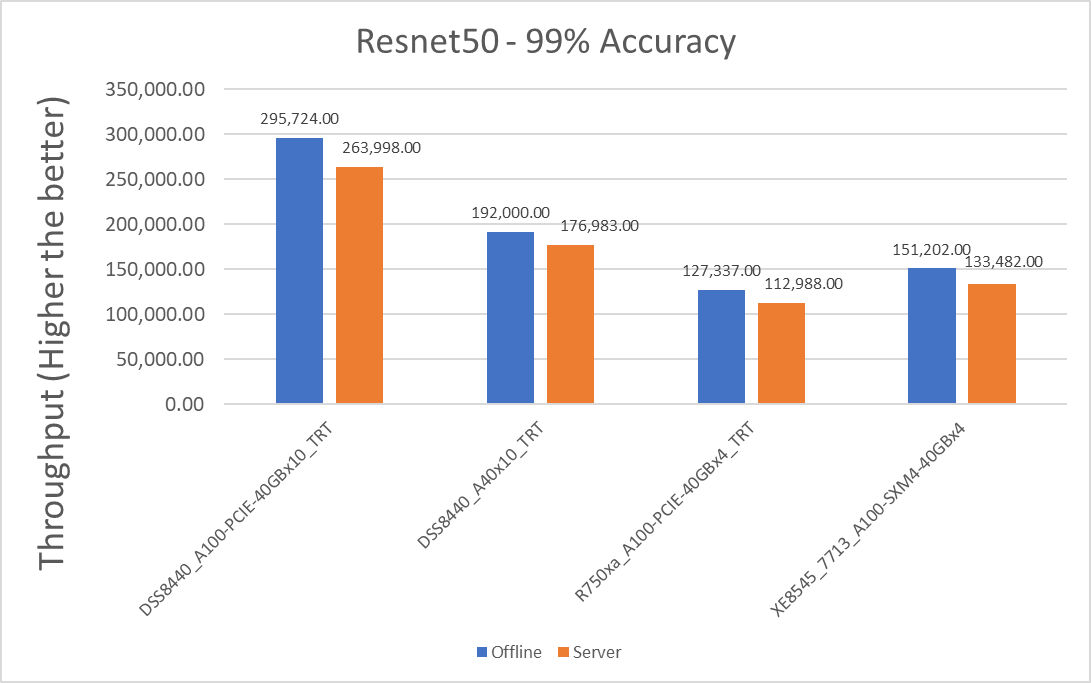
Figure 1: Resnet50 v1.5 Offline and Server scenario with 99 percent accuracy target
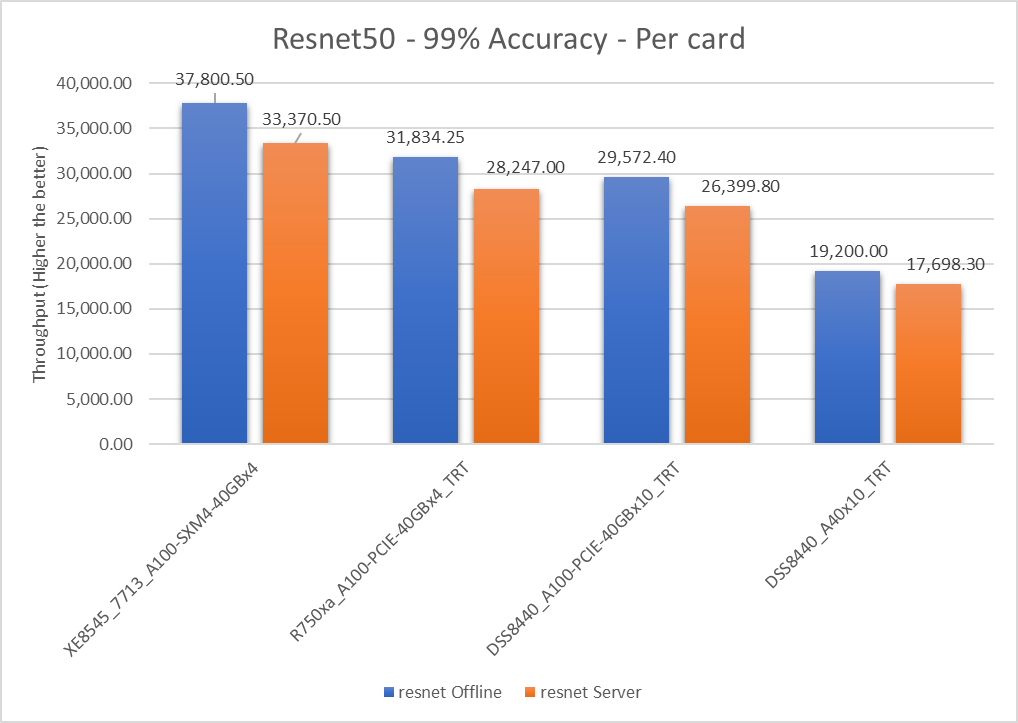
Figure 2: Resnet50 v1.5 Offline and Server scenario with 99 percent accuracy target per card
Table 4: Per card numbers and scenario percentage difference
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 37800.5 | 33370.5 | 12.44 |
R750xa_A100-PCIE-40GBx4_TRT | 31834.25 | 28247 | 11.94 |
DSS8440_A100-PCIE-40GBx10_TRT | 29572.4 | 26399.8 | 11.33 |
DSS8440_A40x10_TRT | 19200 | 17698.3 | 8.139 |
The Offline per card throughput exceeds the Server per card throughput for all the servers in this study.
Table 5: Per card percentage difference from a XE8545_7713_A100-SXM4-40GBx4 system
Dell Server | Offline (in percentage) | Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 17.13 | 16.63 |
DSS8440_A100-PCIE-40GBx10_TRT | 24.42 | 26.39 |
DSS8440_A40x10_TRT | 65.26 | 61.37 |
SSD-Resnet34 results
Figure 3: SSD with Resnet34 Offline and Server scenario with 99 percent accuracy target
Figure 4: SSD-Resnet34, Offline and Server scenario with 99 percent accuracy targets per card
Table 6: Per card numbers and scenario percentage difference on SSD-Resnet34
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 1189.945 | 950.4325 | 22.38 |
R750xa_A100-PCIE-40GBx4_TRT | 839.8275 | 750.3775 | 11.25 |
DSS8440_A100-PCIE-40GBx10_TRT | 761.179 | 826.478 | -8.22 |
DSS8440_A40x10_TRT | 475.978 | 400.236 | 17.28 |
Note: A negative value of percentage difference indicates the Server scenario outperformed the Offline scenario.
Table 7: Per card percentage difference from a XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | Offline (in percentage) | Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 34.4982 | 23.52 |
DSS8440_A100-PCIE-40GBx10_TRT | 43.95067 | 13.95 |
DSS8440_A40x10_TRT | 85.71429 | 81.47 |
BERT Results
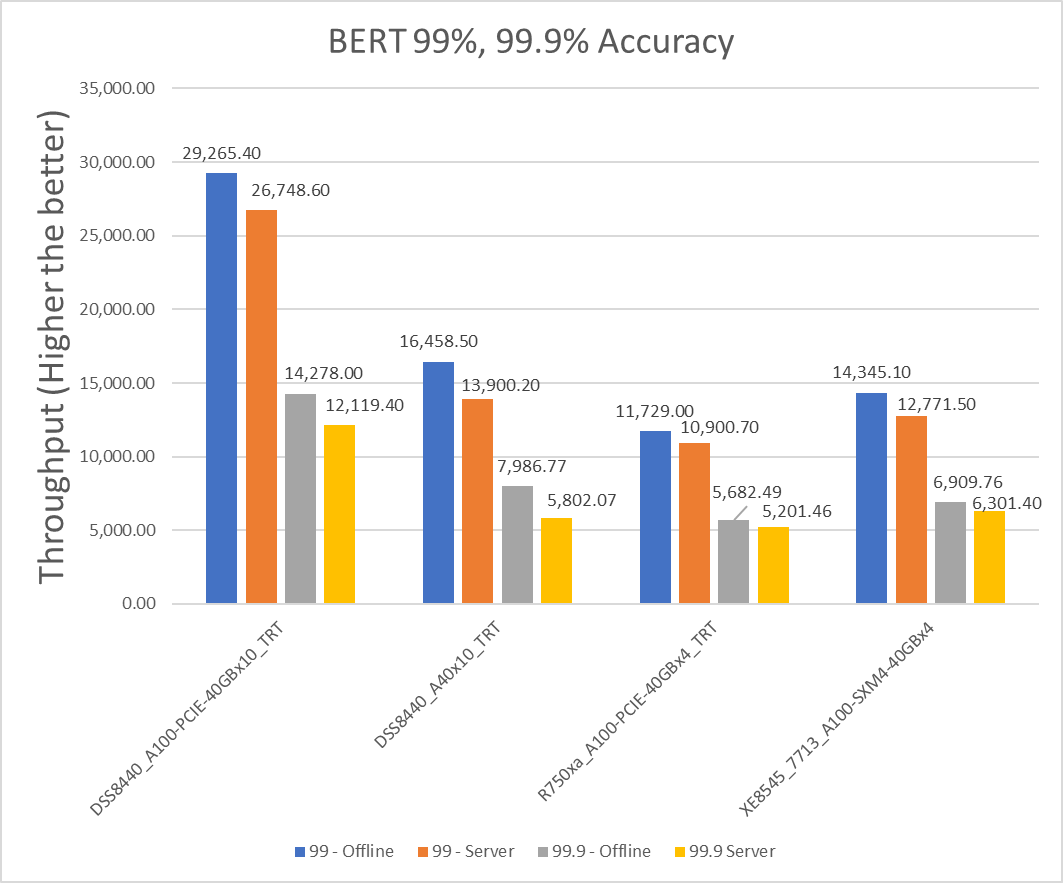
Figure 4: BERT Offline and Server scenario with 99 percent and 99.9 percent accuracy targets
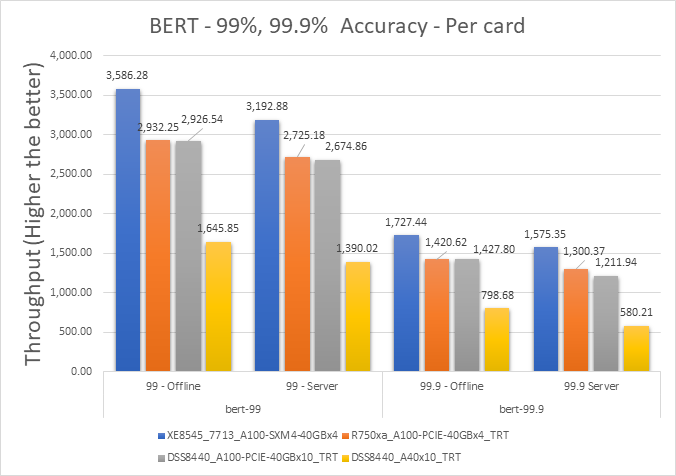
Figure 5: BERT Offline and Server scenario with 99 percent and 99.9 percent accuracy targets per card
Table 8: Per card numbers and scenario percentage difference on BERT with 99 percent accuracy target
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 3586.275 | 3192.875 | 11.60617482 |
R750xa_A100-PCIE-40GBx4_TRT | 2932.25 | 2725.175 | 7.320468234 |
DSS8440_A100-PCIE-40GBx10_TRT | 2926.54 | 2674.86 | 8.986324847 |
DSS8440_A40x10_TRT | 1645.85 | 1390.02 | 16.85381785 |
Table 9: Per card percentage difference from an XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | 99% - Offline (in percentage) | 99% - Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 20.06 | 15.8 |
DSS8440_A100-PCIE-40GBx10_TRT | 20.25 | 17.65 |
DSS8440_A40x10_TRT | 74.17 | 78.67 |
Table 10: Per card numbers and scenario percentage difference on BERT with 99.9 percent accuracy target
Dell Server | 99.9% - Offline throughput | 99.9% Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 1727.44 | 1575.35 | 9.2097893 |
R750xa_A100-PCIE-40GBx4_TRT | 1420.6225 | 1300.365 | 8.8392541 |
DSS8440_A100-PCIE-40GBx10_TRT | 1427.8 | 1211.94 | 16.354641 |
DSS8440_A40x10_TRT | 798.677 | 580.207 | 31.687945 |
Table 11: Per card percentage difference from an XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | 99.9% - Offline (in percentage) | 99.9% - Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 19.49 | 19.12 |
DSS8440_A100-PCIE-40GBx10_TRT | 18.99 | 26.07 |
DSS8440_A40x10_TRT | 73.53 | 92.33 |
RNN-T Results
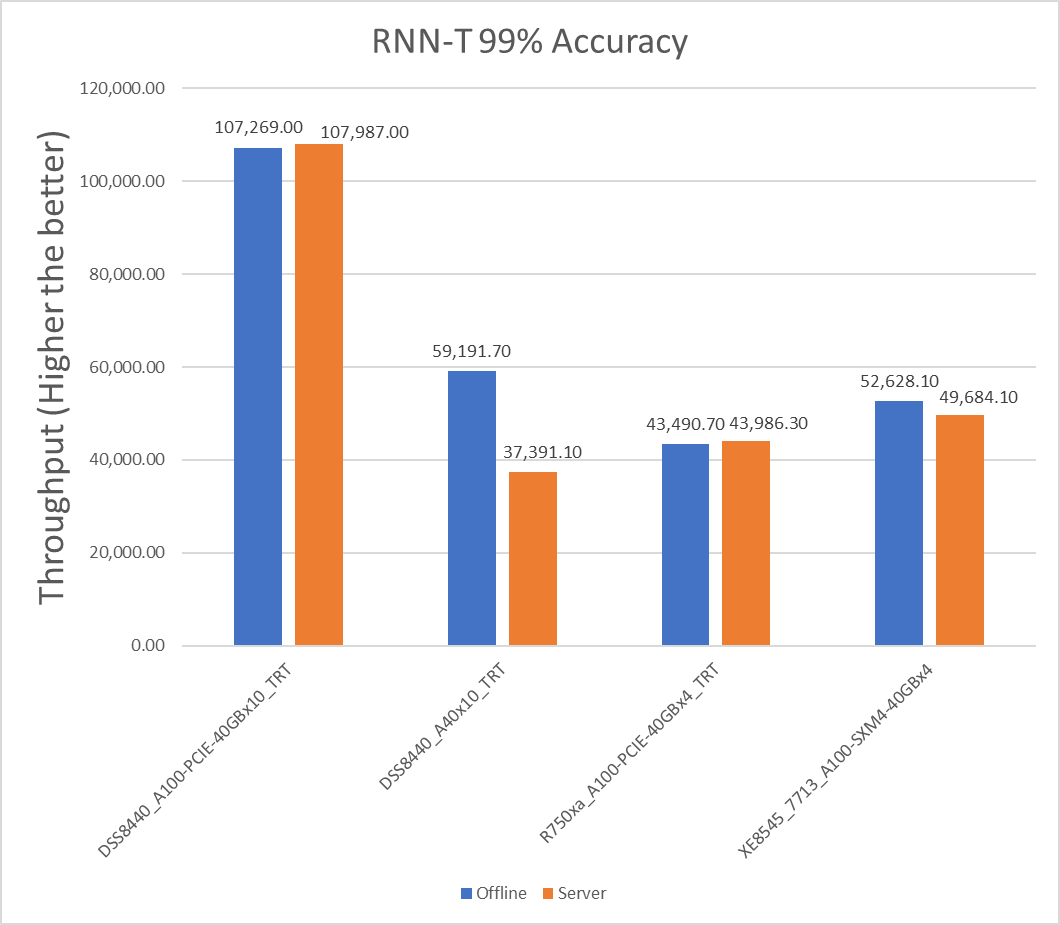
Figure 6: RNN-T Offline and Server scenario with 99 percent accuracy target
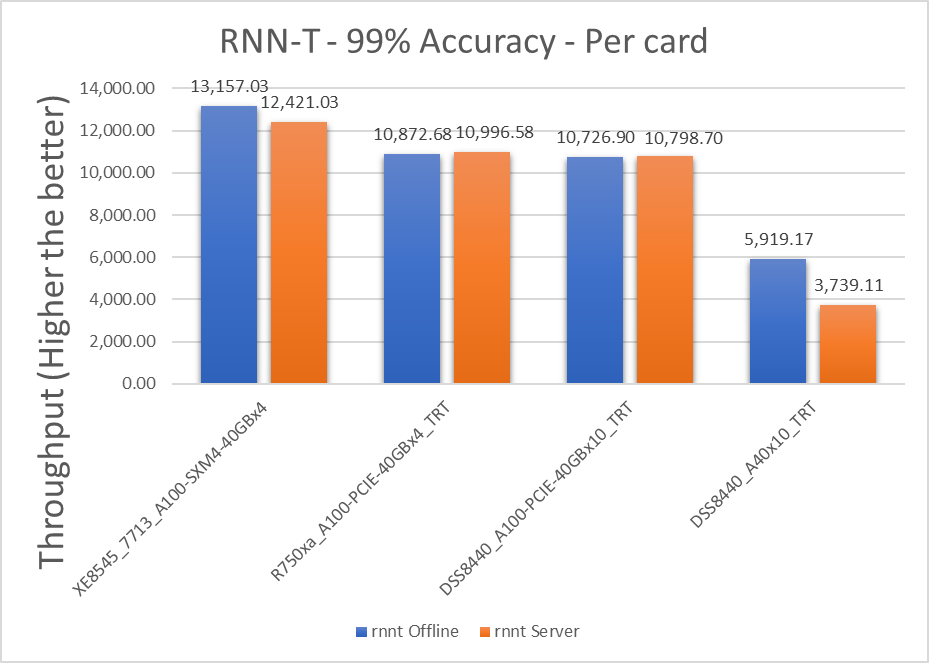
Figure 7: RNN-T Offline and Server scenario with 99 percent accuracy target per card
Table 12: Per card numbers and scenario percentage difference on RNNT with 99 percent accuracy target
Dell Server | Offline throughput | Server throughput | Percentage difference between scenarios |
XE8545_7713_A100-SXM4-40GBx4 | 13157.025 | 12421.025 | 5.754934 |
R750xa_A100-PCIE-40GBx4_TRT | 10872.675 | 10996.575 | -1.1331 |
DSS8440_A100-PCIE-40GBx10_TRT | 10726.9 | 10798.7 | -0.66711 |
DSS8440_A40x10_TRT | 5919.17 | 3739.11 | 45.14386 |
Note: A negative value for the percentage difference indicates that Server scenario performed better than Offline scenario.
Table 13: Per card percentage difference from an XE8545_7713_A100-SXM4-40GBx4 system with an A100 SXM4 card
Dell Server | Offline (in percentage) | Server (in percentage) |
XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
R750xa_A100-PCIE-40GBx4_TRT | 19.01 | 12.16 |
DSS8440_A100-PCIE-40GBx10_TRT | 20.34 | 13.97 |
DSS8440_A40x10_TRT | 75.88 | 107.44 |
3D-UNet Results
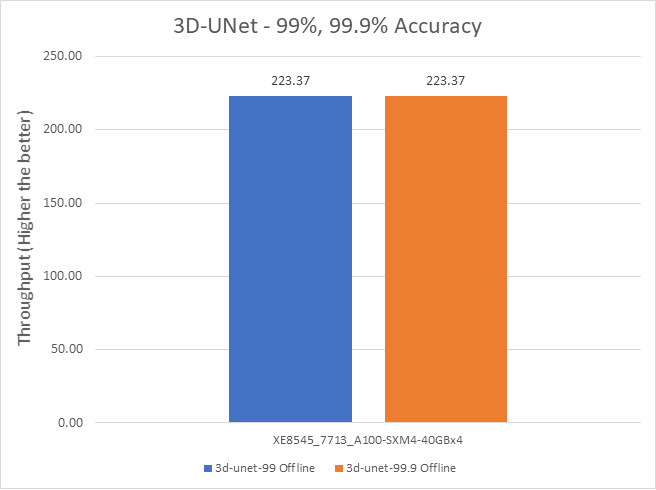
Figure 8: 3D-UNet Offline and Server scenario with 99 percent and 99.9 percent accuracy target
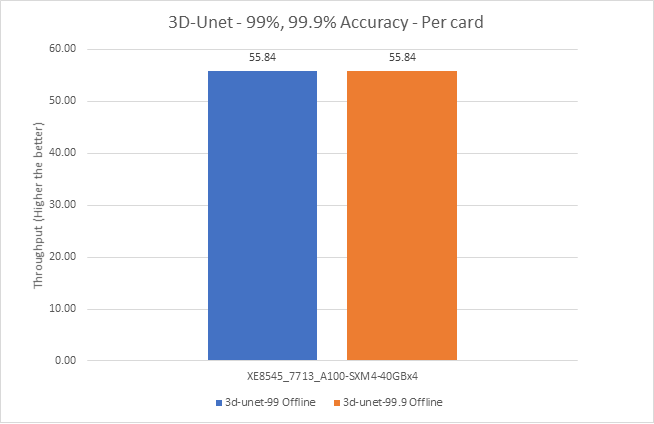
Figure 9: 3D-UNet Offline and Server scenario with 99 percent and 99.9 percent accuracy target
Conclusion
In this blog, we quantified the MLCommons MLPerf inference v1.0 performance on Dell EMC DSS8440, PowerEdge R750xa, and PowerEdge XE8545 servers with A100 PCIE and SXM form factors using benchmarks such as Resnet50, SSD w/ Resnet34, BERT, RNN-T, and 3D-UNet. These benchmarks span tasks from vision to recommendation. Dell EMC servers delivered top inference performance normalized to processor count among commercially available results.
The PowerEdge XE8545 server outperforms the per card numbers of other servers in this study. This result can be attributed to its SXM GPU, which offers higher base and boost clock rate.
The SSD-Resnet34 image segmentation model benefits significantly from an SXM form factor-based GPU. The results show an approximate 34 percent performance difference compared to a PCIE from factor, relative to other models that average approximately 20 percent.
The PowerEdge R750xa server with an A100 GPU performs better in the Server scenario than in the Offline scenario for RNN-T model.
The DSS 8440 server with an A100 GPU performs better in the Server scenario than the Offline scenario for BERT, RNN-T, and SSD-Resnet34 models.
Furthermore, we found that the performance of the DSS8440 server with 10 x A100 PCIE cards exceeded other MLCommons MLPerf inference v1.0 submissions for the RNN-T Server benchmark.
Next Steps
In future blogs, we plan to describe how to:
- Run MLCommons MLPerf inference v1.0
- Understand MLCommons MLPerf inference results on recently released PowerEdge R750xa and PowerEdge XE8545 servers
- Run benchmarks on other servers

Running the MLPerf™ Inference v1.0 Benchmark on Dell EMC Systems
Fri, 24 Sep 2021 15:23:27 -0000
|Read Time: 0 minutes
This blog is a guide for running the MLPerf inference v1.0 benchmark. Information about how to run the MLPerf inference v1.0 benchmark is available online at different locations. This blog provides all the steps in one place.
MLPerf is a benchmarking suite that measures the performance of Machine Learning (ML) workloads. It focuses on the most important aspects of the ML life cycle: training and inference. For more information, see Introduction to MLPerf™ Inference v1.0 Performance with Dell EMC Servers.
This blog focuses on inference setup and describes the steps to run MLPerf inference v1.0 tests on Dell Technologies servers with NVIDIA GPUs. It enables you to run the tests and reproduce the results that we observed in our HPC and AI Innovation Lab. For details about the hardware and the software stack for different systems in the benchmark, see this list of systems.
The MLPerf inference v1.0 suite contains the following models for benchmark:
- Resnet50
- SSD-Resnet34
- BERT
- DLRM
- RNN-T
- 3D U-Net
Note: The BERT, DLRM, and 3D U-Net models have 99% (default accuracy) and 99.9% (high accuracy) targets.
This blog describes steps to run all these benchmarks.
1 Getting started
A system under test consists of a defined set of hardware and software resources that will be measured for performance. The hardware resources may include processors, accelerators, memories, disks, and interconnect. The software resources may include an operating system, compilers, libraries, and drivers that significantly influence the running time of a benchmark. In this case, the system on which you clone the MLPerf repository and run the benchmark is known as the system under test (SUT).
For storage, SSD RAID or local NVMe drives are acceptable for running all the subtests without any penalty. Inference does not have strict requirements for fast-parallel storage. However, the BeeGFS or Lustre file system, the PixStor storage solution, and so on help make multiple copies of large datasets.
2 Prerequisites
Prerequisites for running the MLPerf inference v1.0 tests include:
- An x86_64 system
- Docker installed with the NVIDIA runtime hook
- Ampere-based NVIDIA GPUs (Turing GPUs include legacy support, but are no longer maintained for optimizations)
- NVIDIA Driver Version 455.xx or later
- ECC set to ON
To set ECC to ON, run the following command:sudo nvidia-smi --ecc-config=1
3 Preparing to run the MLPerf inference v1.0
Before you can run the MLPerf inference v1.0 tests, perform the following tasks to prepare your environment.
3.1 Clone the MLPerf repository
- Clone the repository to your home directory or to another acceptable path:
cd - git clone https://github.com/mlcommons/inference_results_v1.0
- Go to the closed/DellEMC directory:
cd inference_results_v1.0/closed/DellEMC - Create a “scratch” directory with a least 3 TB of space in which to store the models, datasets, preprocessed data, and so on:
mkdir scratch - Export the absolute path for $MLPERF_SCRATCH_PATHwith the scratch directory:
export MLPERF_SCRATCH_PATH=/home/user/inference_results_v1.0/closed/DellEMC/scratch
3.2 Set up the configuration file
The closed/DellEMC/configs directory includes a config.json file that lists configurations for different Dell servers that were systems in the MLPerf Inference v1.0 benchmark. If necessary, modify the configs/<benchmark>/<Scenario>/config.json file to include the system that will run the benchmark.
Note: If your system is already present in the configuration file, there is no need to add another configuration.
In the configs/<benchmark>/<Scenario>/config.json file, select a similar configuration and modify it based on the current system, matching the number and type of GPUs in your system.
For this blog, we used a Dell EMC PowerEdge R7525 server with a one-A100 GPU as the example. We chose R7525_A100-PCIe-40GBx1 as the name for this new system. Because the R7525_A100-PCIe-40GBx1 system is not already in the list of systems, we added the R7525_A100-PCIe-40GBx1 configuration.
Because the R7525_A100-PCIe-40GBx2 reference system is the most similar, we modified that configuration and picked Resnet50 Server as the example benchmark.
The following example shows the reference configuration for two GPUs for the Resnet50 Server benchmark in the configs/resnet50/Server/config.json file:
"R7525_A100-PCIe-40GBx2": {
"config_ver": {
},
"deque_timeout_us": 2000,
"gpu_batch_size": 64,
"gpu_copy_streams": 4,
"gpu_inference_streams": 3,
"server_target_qps": 52000,
"use_cuda_thread_per_device": true,
"use_graphs": true
}, This example shows the modified configuration for one GPU:
"R7525_A100-PCIe-40GBx1": {
"config_ver": {
},
"deque_timeout_us": 2000,
"gpu_batch_size": 64,
"gpu_copy_streams": 4,
"gpu_inference_streams": 3,
"server_target_qps": 26000,
"use_cuda_thread_per_device": true,
"use_graphs": true
},We modified the QPS parameter (server_target_qps) to match the number of GPUs. The server_target_qps parameter is linearly scalable, therefore the QPS = number of GPUs x QPS per GPU.
The modified parameter is server_target_qps set to 26000 in accordance with one GPU performance expectation.
3.3 Add the new system to the list of available systems
After you add the new system to the config.json file as shown in the preceding section, add the new system to the list of available systems. The list of available systems is in the code/common/system_list.py file. This entry indicates to the benchmark that a new system exists and ensures that the benchmark selects the correct configuration.
Note: If your system is already added, there is no need to add it to the code/common/system_list.py file.
Add the new system to the list of available systems in the code/common/system_list.py file.
At the end of the file, there is a class called KnownSystems. This class defines a list of SystemClass objects that describe supported systems as shown in the following example:
SystemClass(<system ID>, [<list of names reported by nvidia-smi>], [<known PCI IDs of this system>], <architecture>, [list of known supported gpu counts>])
Where:
- For <system ID>, enter the system ID with which you want to identify this system.
- For <list of names reported by nvidia-smi>, run the nvidia-smi -L command and use the name that is returned.
- For <known PCI IDs of this system>, run the following command:
$ CUDA_VISIBLE_ORDER=PCI_BUS_ID nvidia-smi --query-gpu=gpu_name,pci.device_id --format=csv
name, pci.device_id A100-PCIE-40GB, 0x20F110DE
---The pci.device_id field is in the 0x<PCI ID>10DE format, where 10DE is the NVIDIA PCI vendor ID. Use the four hexadecimal digits between 0x and 10DE as your PCI ID for the system. In this case, it is 20F1.
- For <architecture>, use the architecture Enum, which is at the top of the file. In this case A100 is Ampere architecture.
- For <list of known GPU counts>, enter the number of GPUs of the systems you want to support (that is, [1,2,4] if you want to support 1x, 2x, and 4x GPU variants of this system). Because we already have a 2x variant in the system_list.py file, we simply need to include the number 1 as an additional entry to support our system.
Note: Because a configuration is already present for the PowerEdge R7525 server, we added the number 1 for our configuration, as shown in the following example. If your system does not exist in the system_list.py file, the configuration, add the entire configuration and not just the number.
class KnownSystems: """ Global List of supported systems """ # before the addition of 1 - this config only supports R7525_A100-PCIe-40GB x2 # R7525_A100_PCIE_40GB= SystemClass("R7525_A100-PCIe-40GB", ["A100-PCIe-40GB"], ["20F1"], Architecture.Ampere, [2]) # after the addition – this config now supports R7525_A100-PCIe-40GB x1 and R7525_A100-PCIe-40GB x2 versions. R7525_A100_PCIE_40GB= SystemClass("R7525_A100-PCIe-40GB", ["A100-PCIe-40GB"], ["20F1"], Architecture.Ampere, [1, 2]) DSS8440_A100_PCIE_40GB = SystemClass("DSS8440_A100-PCIE-40GB", ["A100-PCIE-40GB"], ["20F1"], Architecture.Ampere, [10]) DSS8440_A40 = SystemClass("DSS8440_A40", ["A40"], ["2235"], Architecture.Ampere, [10]) R740_A100_PCIe_40GB = SystemClass("R740_A100-PCIe-40GB", ["A100-PCIE-40GB"], ["20F1"], Architecture.Ampere, [3]) R750xa_A100_PCIE_40GB = SystemClass("R750xa_A100-PCIE-40GB", ["A100-PCIE-40GB"], ["20F1"], Architecture.Ampere, [4]) ----
Note: You must provide different configurations in the configs/resnet50/Server/config.json for the x1 variant and x2 variant. In the preceding example, the R7525_A100-PCIe-40GBx2 configuration is different from the R7525_A100-PCIe-40GBx1 configuration.
3.4 Build the Docker image and required libraries
Build the Docker image and then launch an interactive container. Then, in the interactive container, build the required libraries for inferencing.
- To build the Docker image, run the make prebuild command inside the closed/DellEMC folder
Command:
make prebuildThe following example shows sample output:
Launching Docker session nvidia-docker run --rm -it -w /work \ -v /home/user/article_inference_v1.0/closed/DellEMC:/work -v /home/user:/mnt//home/user \ --cap-add SYS_ADMIN \ -e NVIDIA_VISIBLE_DEVICES=0 \ --shm-size=32gb \ -v /etc/timezone:/etc/timezone:ro -v /etc/localtime:/etc/localtime:ro \ --security-opt apparmor=unconfined --security-opt seccomp=unconfined \ --name mlperf-inference-user -h mlperf-inference-user --add-host mlperf-inference-user:127.0.0.1 \ --user 1002:1002 --net host --device /dev/fuse \ -v =/home/user/inference_results_v1.0/closed/DellEMC/scratch:/home/user/inference_results_v1.0/closed/DellEMC/scratch \ -e MLPERF_SCRATCH_PATH=/home/user/inference_results_v1.0/closed/DellEMC/scratch \ -e HOST_HOSTNAME=node009 \ mlperf-inference:user
The Docker container is launched with all the necessary packages installed.
- Access the interactive terminal in the container.
- To build the required libraries for inferencing, run the make build command inside the interactive container.
Command:
make buildThe following example shows sample output:
(mlperf) user@mlperf-inference-user:/work$ make build
The container is built, in which you can run the benchmarks.
…….
[ 26%] Linking CXX executable /work/build/bin/harness_default
make[4]: Leaving directory '/work/build/harness'
make[4]: Leaving directory '/work/build/harness'
make[4]: Leaving directory '/work/build/harness'
[ 36%] Built target harness_bert
[ 50%] Built target harness_default
[ 55%] Built target harness_dlrm
make[4]: Leaving directory '/work/build/harness'
[ 63%] Built target harness_rnnt
make[4]: Leaving directory '/work/build/harness'
[ 81%] Built target harness_triton
make[4]: Leaving directory '/work/build/harness'
[100%] Built target harness_triton_mig
make[3]: Leaving directory '/work/build/harness'
make[2]: Leaving directory '/work/build/harness'
Finished building harness.
make[1]: Leaving directory '/work'
(mlperf) user@mlperf-inference-user:/work
3.5 Download and preprocess validation data and models
To run the MLPerf inference v1.0, download datasets and models, and then preprocess them. MLPerf provides scripts that download the trained models. The scripts also download the dataset for benchmarks other than Resnet50, DLRM, and 3D U-Net.
For Resnet50, DLRM, and 3D U-Net, register for an account and then download the datasets manually:
- DLRM—Download the Criteo Terabyte dataset and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/criteo/
- 3D U-Net—Download the BraTS challenge data and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/BraTS/MICCAI_BraTS_2019_Data_Training
Except for the Resnet50, DLRM, and 3D U-Net datasets, run the following commands to download all the models, datasets, and then preprocess them:
$ make download_model # Downloads models and saves to $MLPERF_SCRATCH_PATH/models $ make download_data # Downloads datasets and saves to $MLPERF_SCRATCH_PATH/data $ make preprocess_data # Preprocess data and saves to $MLPERF_SCRATCH_PATH/preprocessed_data
Note: These commands download all the datasets, which might not be required if the objective is to run one specific benchmark. To run a specific benchmark rather than all the benchmarks, see the following sections for information about the specific benchmark.
(mlperf) user@mlperf-inference-user:/work$ tree -d -L 1 . ├── build ├── code ├── compliance ├── configs ├── data_maps ├── docker ├── measurements ├── power ├── results ├── scripts └── systems # different folders are as follows ├── build—Logs, preprocessed data, engines, models, plugins, and so on ├── code—Source code for all the benchmarks ├── compliance—Passed compliance checks ├── configs—Configurations that run different benchmarks for different system setups ├── data_maps—Data maps for different benchmarks ├── docker—Docker files to support building the container ├── measurements—Measurement values for different benchmarks ├── power—files specific to power submission (it’s only needed for power submissions) ├── results—Final result logs ├── scratch—Storage for models, preprocessed data, and the dataset that is symlinked to the preceding build directory ├── scripts—Support scripts └── systems—Hardware and software details of systems in the benchmark
4.0 Running the benchmarks
After you have performed the preceding tasks to prepare your environment, run any of the benchmarks that are required for your tests.
The Resnet50, SSD-Resnet34, and RNN-T benchmarks have 99% (default accuracy) targets.
The BERT, DLRM, and 3D U-Net benchmarks have 99% (default accuracy) and 99.9% (high accuracy) targets. For information about running these benchmarks, see the Running high accuracy target benchmarks section below.
If you downloaded and preprocessed all the datasets (as shown in the previous section), there is no need to do so again. Skip the download and preprocessing steps in the procedures for the following benchmarks.
NVIDIA TensorRT is the inference engine for the backend. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning applications.
4.1 Run the Resnet50 benchmark
To set up the Resnet50 dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go step 5.
- Download the required validation dataset (https://github.com/mlcommons/training/tree/master/image_classification).
- Extract the images to $MLPERF_SCRATCH_PATH/data/dataset/
- Run the following commands:
make download_model BENCHMARKS=resnet50 make preprocess_data BENCHMARKS=resnet50
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
The following example shows the output for PerformanceOnly mode and displays a “VALID“ result:
======================= Perf harness results: ======================= R7525_A100-PCIe-40GBx1_TRT-default-Server: resnet50: Scheduled samples per second : 25992.97 and Result is : VALID ======================= Accuracy results: ======================= R7525_A100-PCIe-40GBx1_TRT-default-Server: resnet50: No accuracy results in PerformanceOnly mode.
4.2 Run the SSD-Resnet34 benchmark
To set up the SSD-Resnet34 dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=ssd-resnet34 make download_data BENCHMARKS=ssd-resnet34 make preprocess_data BENCHMARKS=ssd-resnet34
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
4.3 Run the RNN-T benchmark
To set up the RNN-T dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=rnnt make download_data BENCHMARKS=rnnt make preprocess_data BENCHMARKS=rnnt
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=rnnt --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
5 Running high accuracy target benchmarks
The BERT, DLRM, and 3D U-Net benchmarks have high accuracy targets.
5.1 Run the BERT benchmark
To set up the BERT dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=bert make download_data BENCHMARKS=bert make preprocess_data BENCHMARKS=bert
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and also for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=bert --scenarios=Offline,Server --config_ver=default,high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=high_accuracy --test_mode=AccuracyOnly"
5.2 Run the DLRM benchmark
To set up the DLRM dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go to step 5.
- Download the Criteo Terabyte dataset.
- Extract the images to $MLPERF_SCRATCH_PATH/data/criteo/ directory.
- Run the following commands:
make download_model BENCHMARKS=dlrm make preprocess_data BENCHMARKS=dlrm
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and also for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=dlrm --scenarios=Offline,Server --config_ver=default, high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=high_accuracy --test_mode=AccuracyOnly"
5.3 Run the 3D U-Net benchmark
Note: This benchmark only has the Offline scenario.
To set up the 3D U-Net dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go to step 5.
- Download the BraTS challenge data.
- Extract the images to the $MLPERF_SCRATCH_PATH/data/BraTS/MICCAI_BraTS_2019_Data_Training directory.
- Run the following commands:
make download_model BENCHMARKS=3d-unet make preprocess_data BENCHMARKS=3d-unet
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default,high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly"
6 Limitations and Best Practices for Running MLPerf
Note the following limitations and best practices:
- To build the engine and run the benchmark by using a single command, use the make run RUN_ARGS… shortcut. The shortcut is a valid alternative to the make generate_engines … && make run_harness.. commands.
- Include the --fast flag with the RUN_ARGS command to test runs quickly by setting the run time to one minute. For example:
make run_harness RUN_ARGS="–-fast --benchmarks=<bmname> --scenarios=<scenario> --config_ver=<cver> --test_mode=PerformanceOnly"The benchmark runs for one minute instead of the default 10 minutes.
- If the server results are “INVALID”, reduce the server_target_qps for a Server scenario run. If the latency constraints are not met during the run, “INVALID” results are expected.
- If the results are “INVALID” for an Offline scenario run, then increase the gpu_offline_expected_qps. “INVALID” runs for Offline scenario occur when the system can deliver a significantly higher QPS than what is provided through the gpu_offline_expected_qps configuration.
- If the batch size changes, rebuild the engine.
- Only the BERT, DLRM, 3D-Unet benchmarks support high accuracy targets.
- 3D-UNet only has Offline scenario.
7 Conclusion
This blog provides step-by-step procedures to run and reproduce MLPerf inference v1.0 results on Dell Technologies servers with NVIDIA GPUs..

Effectiveness of Large Batch Training for Neural Machine Translation with Intel Xeon
Wed, 24 Apr 2024 15:17:12 -0000
|Read Time: 0 minutes
We know that using really large batch sizes during training can cause models to poorly generalize. But how do large batches actually affect the generalization and optimization of neural network models? 2018 was a great year for research on Neural Machine Translation (NMT). We’ve seen an explosion in the number of research papers published in this field, ranging from descriptions of new and interesting architectures to efficient training techniques. Research papers have shown how larger batch sizes and reduced precision can help to improve both the training time and quality.
Figure 1: Numbers of papers published in Arxiv with ‘neural machine translation’ in the title or abstract in the ‘cs’ category.
In our previous blogs, we showed how to effectively scale an NMT system, as well as some of the challenges associated with scaling. In this blog, we will explore the effectiveness of large batch training using Intel® Xeon® Scalable processors. The work discussed in the blog is based on neural network training performed using Zenith supercomputer at Dell EMC’s HPC and AI Innovation Lab.
System Information
CPU Model | Intel® Xeon® Gold 6148 CPU @ 2.40GHz |
Operating System | Red Hat Enterprise Linux Server release 7.4 (Maipo) |
Tensorflow Version | Anaconda TensorFlow 1.12.0 with Intel® MKL |
Horovod Version | 0.15.2 |
MPI | MVAPICH2 2.1 |
Incredible strong scaling efficiency helps to dramatically reduce the time to solution of the model. To best visualize this, consider figure 2. The time to solution drops from around 1 month on a single node to just over 6 hours using 200 nodes. This 121x faster solution would significantly help the productivity of NMT researchers using CPU-based HPC infrastructures. The results observed were based on the models achieving a baseline BLEU score (case-sensitive) of 27.5.
Figure 2: Time to train the model to solution
For the single node case, we have used the largest batch size that could fit in a node's memory, 25,600 tokens per worker. For all other cases, we use a global batch size of 819,200, leading to per-worker batch sizes of 25,600 in the 16-node case, down to only 2,048 in the 200-node case. The number of training iterations is similar for all experiments in the 16-200 node range and is increased by a factor of 16 for the single-node case (to compensate for the larger batch).
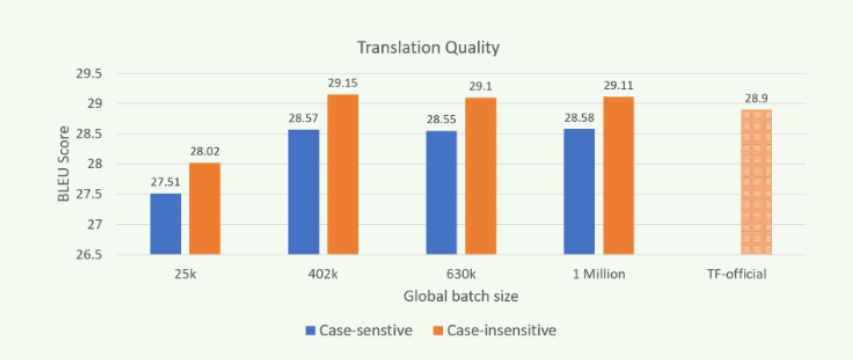
Figure 3: Translation quality (BLEU) when trained with different batch sizes on Zenith.
Scaling out the “transformer” model training using MPI and Horovod improves throughput performance while producing models of similar translation quality as shown in Figure 3. The results were obtained by using newstest2014 as the test set. Models of comparable quality can be trained in a reduced amount of time by scaling computation over many more nodes, and with larger global batch sizes (GBZ). Our experiments on Zenith demonstrate the ability to train models of comparable or higher translation quality (as measured by BLEU score) than the reported best for TensorFlow's official model, even when training with batches of a million or more tokens.
Note: The results shown in figure 3 were obtained by using the settings mentioned in our previous blog and by using Open MPI.
Conclusion
Here in this blog, we showed the generalization of large batch training of NMT model. We also showed how efficiently Intel® Xeon® Scalable processors are able to scale and reduce the time to solution. We hope this would benefit the productivity of the NMT research community using CPU-based HPC infrastructures.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda
LinkedIn: https://www.linkedin.com/in/srinivasvaradharajan
Scaling Neural Machine Translation - Challenges and Solution
Wed, 24 Apr 2024 15:15:31 -0000
|Read Time: 0 minutes
As I mentioned in our previous blog post, the translation quality of neural machine translation (NMT) systems has improved immensely in recent years. However, these models still take considerable time to train, and little work has been focused on improving their time to solution. Distributed training across multiple compute nodes can potentially improve the time to train, but there are various challenges associated with scale-out training of NMT systems.
In this blog, we highlight solutions developed at Dell EMC which address a few common issues encountered when scaling an NMT architecture like the Transformer model in TensorFlow, highlight the performance benefits associated with these solutions. All of the experiments and results obtained used Zenith, DellEMC’s very own Intel® Xeon® Scalable processor-based supercomputer, which is housed in the Dell EMC HPC & AI Innovation Lab in Austin, Texas.
Performance degradation and OOM errors
One of the main roadblocks to scaling NMT models is the memory required to accumulate gradients. When training neural networks, the gradients are vectors – or directional arrays – of numbers that roughly correspond to the difference between the current network weights and a set of weights that provide a better solution. Essentially, the gradients point each weight value in a different, and hopefully, a better direction which leads to better solutions. While convolutional neural networks for image classification use dense gradient vectors which can be easily worked with, the design of the transformer model uses an embedding layer that does not necessarily scale well to multiple servers.
This design causes severe performance degradation and out of memory (OOM) errors because TensorFlow does not accumulate the embedding layer gradients correctly. Gradients from the embedding layer are sparse, whereas the gradients from the projection matrix are dense. TensorFlow then accumulates both of these tensors as sparse objects. This has a dramatic effect on TensorFlow’s gradient accumulation strategy, and subsequently on the total size of the accumulated gradient tensor. This results in large message buffers which scale linearly with the number of processes, thereby causing segmentation faults or out-of-memory errors.
The assumed-sparse tensors make Horovod (the distributed training framework used with TensorFlow) to perform gradient accumulation by MPI_Gather rather than MPI_Reduce. To fix this issue, we can convert all assumed sparse tensors to dense tensors. This is done by adding the flag “sparse_as_dense=True” in Horovod’s DistributedOptimizer method.
opt = hvd.DistributedOptimizer(opt, sparse_as_dense=True)
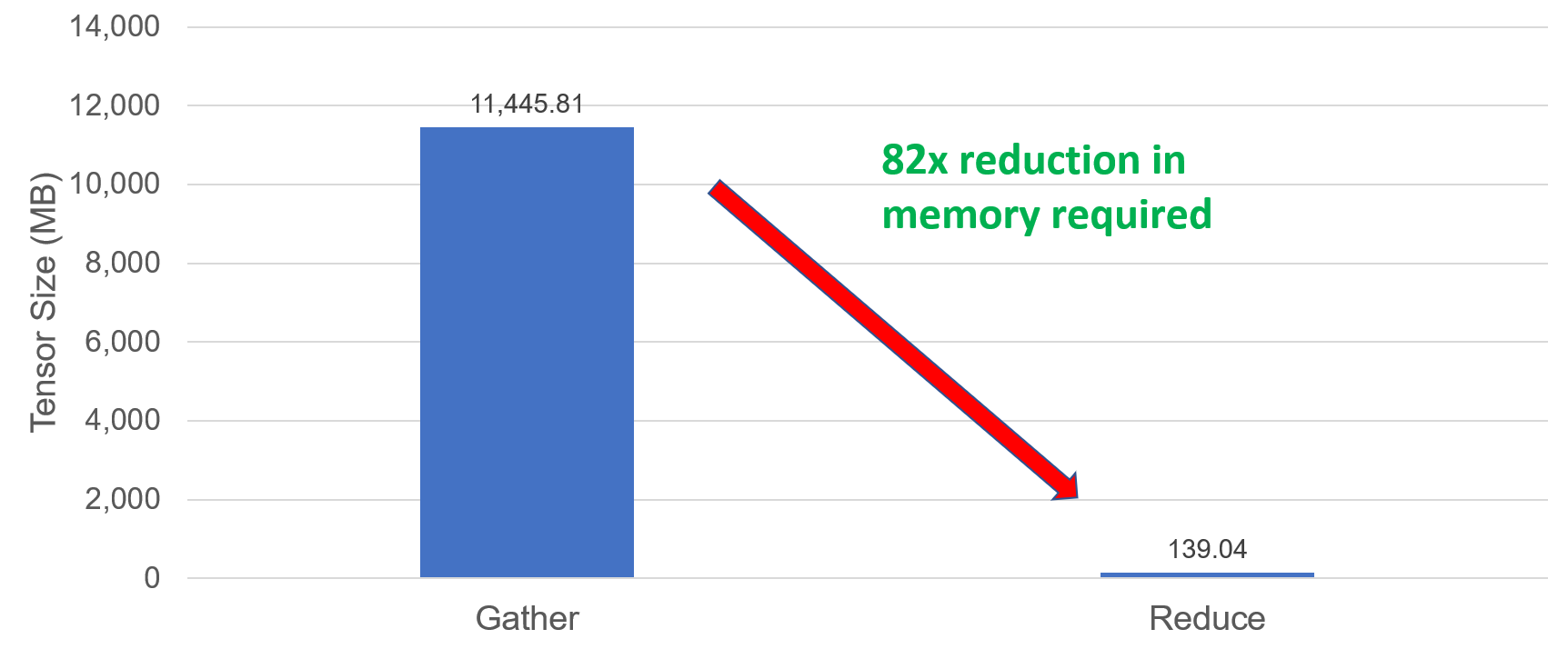
Figure 1: Accumulate size
Figure 1 shows the accumulation size when using 64 nodes (1ppn, batch_size=5000 tokens). There’s an 82x reduction in accumulation size when the assumed sparse tensors are converted to dense. This solution allows to scale and train the model using 100’s of nodes.
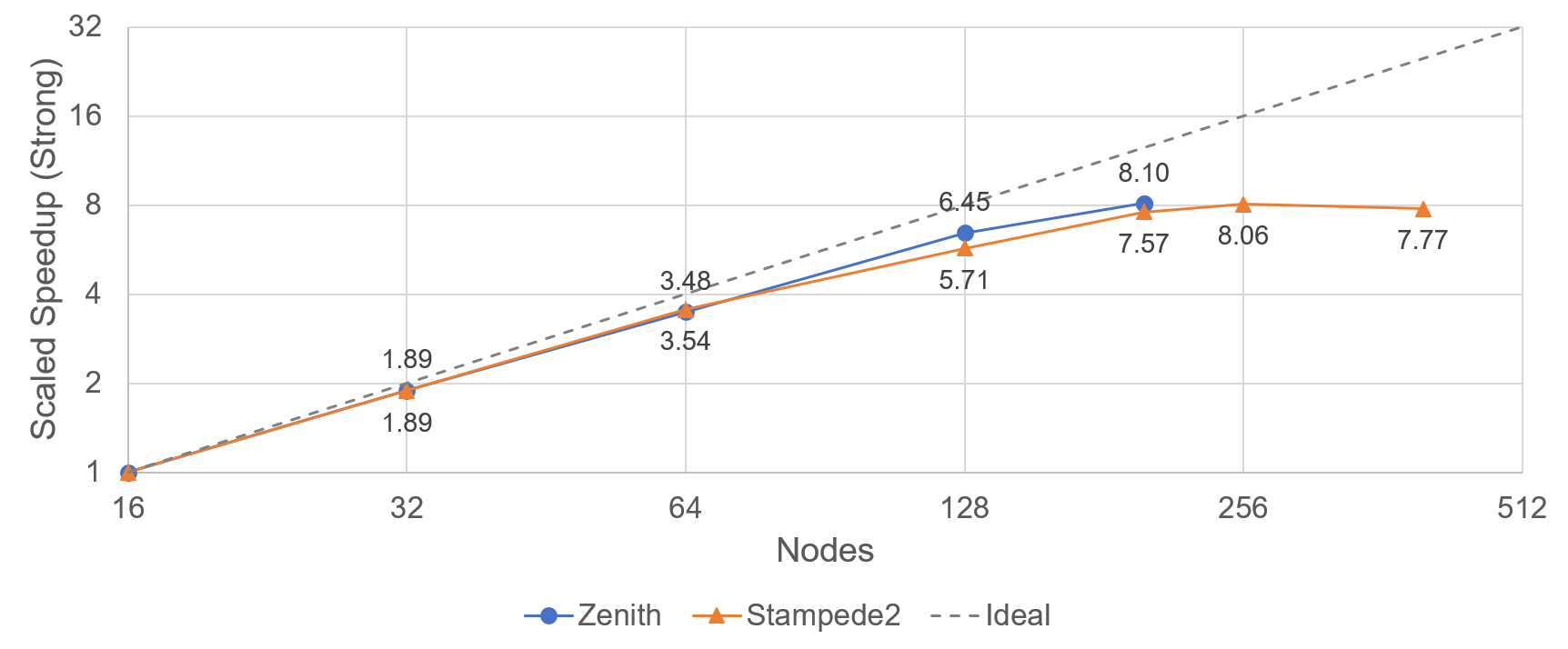
Figure 2: Scaled speedup (strong) performance.
Apart from the weak scaling performance benefit shown in our previous blog, the reduced gradient size also provides a way to perform efficient strong scaling. Figure 2 shows the strong scaling speedup performed on zenith and stampede2 supercomputers using up to 200 nodes on Zenith (Dell EMC) and 256 nodes on Stampede2 (TACC). Efficient strong scaling greatly helps to reduce the time to train the model
Diverged Training
While building a model quickly is important, it is critical the make sure that the resulting model is also accurate. Diverged training, where the produced model becomes less accurate (rather than more accurate) with continued training is a common problem not just for large batch training but in general for any NMT system. Monitoring the loss graph would help to understand the convergence of the deep learning model. Setting the learning rate to an optimal value is crucial for the model’s convergence.
Measures can be taken to prevent diverged training. Experiments suggest that having a very high learning rate at the beginning of the training would cause diverged training. But on the other hand, setting the learning rate too low also would make the model converge slowly. Finding the ideal learning rate for the model is therefore critical.
One solution is to reduce the learning rate (cool down or decay) or increase the learning rate (warm up), or more often a combination of both By allowing the learning rate to increase linearly to the set value for certain number of steps after which it decays based on a chosen function, the resulting model can be more accurate and produced faster. For transformer model, the decay is proportional to the inverse square root of the number of steps.
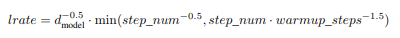
Figure 3: Learning rate decay used in Transformer model
Based on our experiments we found that for large batch sizes (130k, 402k, 630k, 1M tokens), setting the learning rate to 0.001 – 0.005 would prevent diverged training of the big model.
Figure 4: An example loss profile showing diverged training (gbz=130k, lr=0.01)
Figure 5: An example loss profile showing correct training behavior (gbz=130k, lr=0.001)
Figures 4 and 5 show the loss profiles when trained with a global batch size of 130k. Setting the learning rate to a “high” value (0.01) results in diverged training, but when set to 1e-3 (0.001), the model converges better. This results in good translation quality on the final model. Similar results were observed for all other large batch sizes.
Conclusion
In this blog, we highlighted a few common challenges when performing distributed training of the transformer model for neural machine translation (NMT). The solutions developed by Dell EMC in collaboration with Uber, Amazon, Intel, and SURFsara resulted in dramatically improved scaling capabilities and model accuracy. The results are now added part of our research paper accepted at the ISC High Performance 2019 conference. The paper has further details about the modifications to Horovod and improvements in terms of memory usage, scaling efficiency, reduced time to train and translation quality. The work has been incorporated into Horovod so that the research community can explore further scaling potential and produce more efficient NMT models.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda

Scaling Neural Machine Translation with Intel Xeon Scalable Processors
Mon, 12 Dec 2022 18:44:32 -0000
|Read Time: 0 minutes
The field of machine language translation is rapidly shifting from statistical machine learning models to efficient neural network architecture designs which can dramatically improve translation quality. However, training a better performing Neural Machine Translation (NMT) model still takes days to weeks depending on the hardware, size of the training corpus and the model architecture. Improving the time-to-solution for NMT training will be crucial if these approaches are to achieve mainstream adoption.
Intel® Xeon® Scalable processors are the workhorse of the modern datacenter, and over 90% of the Top500 super computers run on Intel. We can apply the supercomputing approach of scaling out to multiple servers to training NMT models in any datacenter. In this article we show some the effectiveness of and highlight important considerations when scaling a NMT model using Intel® Xeon® Scalable processors.
Encoder – decoder architecture
An NMT model reads a sentence in a source language and passes it to an encoder, which builds an intermediate representation. A decoder then processes the intermediate representation to produce a translated sentence in a target language.
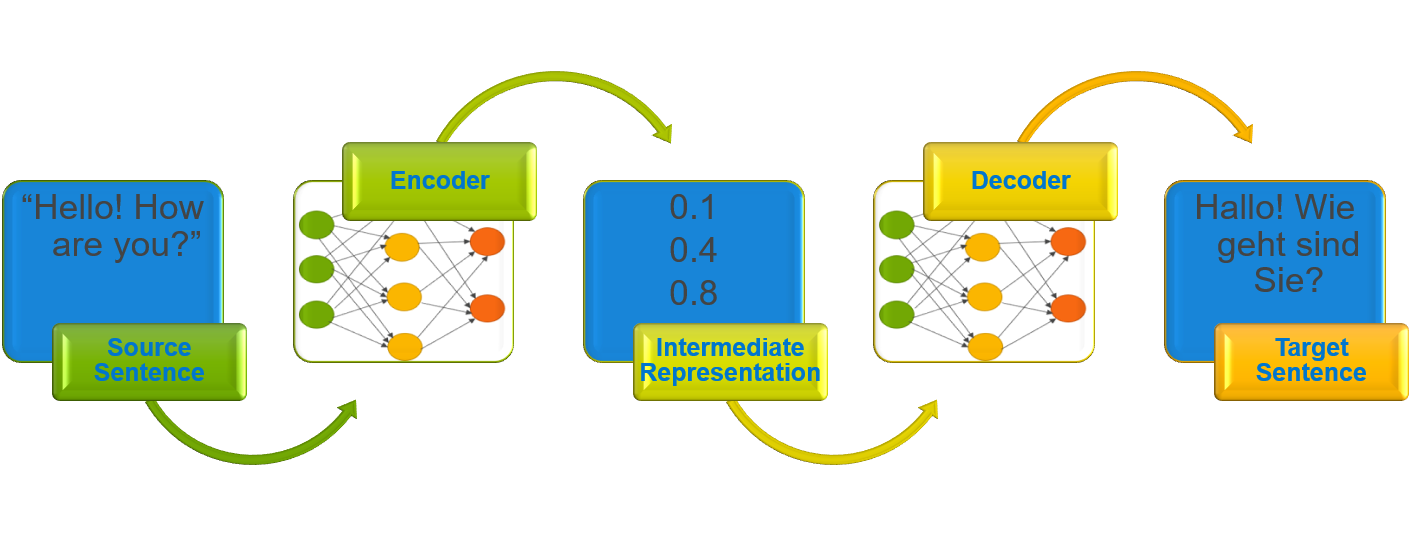
Figure 1: Encoder-decoder architecture
The figure above illustrates the encoder-decoder architecture. The English source sentence, “Hello! How are you?” is read and processed by the architecture to produce a translated German sentence “Hallo! Wie geht sind Sie?”. Traditionally, Recurrent Neural Network (RNN) was used in encoders and decoders, but other neural network architectures such as Convolutional Neural Network (CNN) and attention mechanism-based architectures are also used.
Architecture and environment
The Transformer model is one of the current architectures of interest in the field of NMT, and is built with variants of the attention mechanism which replace the traditional RNN components in the architecture. This architecture was able to produce a model that achieved state of the art results in English-German and English-French translation tasks.
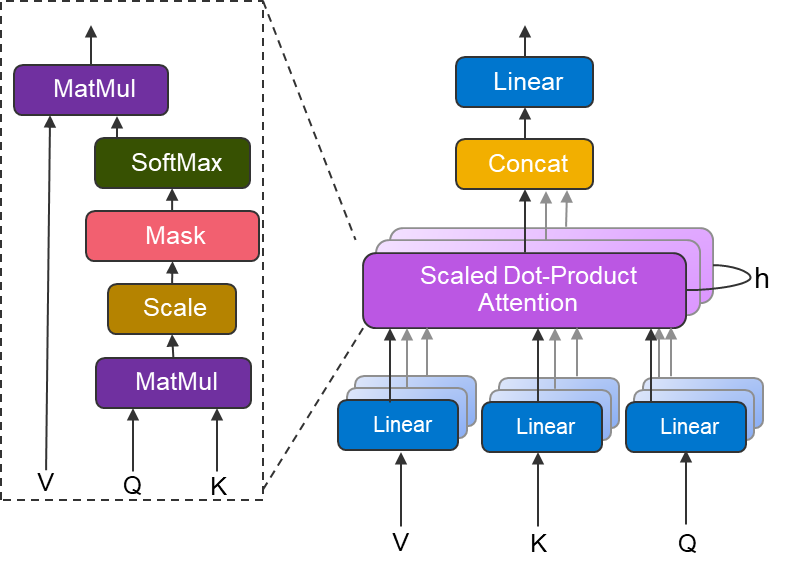
Figure 2: Multi-head attention block
The above figure shows the multi-head attention block used in the transformer architecture. At a high-level, the scaled dot-product attention can be thought as finding the relevant information, in the form of values (V) based on Query (Q) and Keys (K). Multi-head attention can be thought of as several attention layers in parallel, which together can identify distinct aspects of the input.
We use the Tensorflow official model implementation of the transformer architecture, which has been augmented with Uber’s Horovod distributed training framework. The training dataset used is the WMT English-German parallel corpus, which contains 4.5M English-German sentence pairs.
Our tests were performed in house on Zenith super computerin the Dell EMC HPC and AI Innovation lab. Zenith is a Dell EMC PowerEdge C6420-based cluster, consisting of 388 dual socket nodes powered by Intel® Xeon® Scalable Gold 6148 processors and interconnected with an Intel® Omni-path fabric.
System Information
CPU Model | Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz |
Operating System | Red Hat Enterprise Linux Server release 7.4 (Maipo) |
Tensorflow Version | 1.10.1 with Intel® MKL |
Horovod Version | 0.15.0 |
MPI | Open MPI 3.1.2 |
Note: We used a specific Horovod branch to handle sparse gradients. Which is now part of the main branch in their GitHub repository.
Weak scaling, environment variables and TF configurations
When training using CPUs, environment variable settings and TensorFlow runtime configuration values play a vital role in improving the throughput and reducing the time to solution.
Below are the suggested settings based on our empirical tests when running 4 processes per node for the transformer (big) model on 50 zenith nodes.
Environment Variables
export OMP_NUM_THREADS=10 export KMP_BLOCKTIME=0 export KMP_AFFINITY=granularity=fine,verbose,compact,1,0 |
TF Configurations:
intra_op_parallelism_threads=$OMP_NUM_THREADS inter_op_parallelism_threads=1 |
Experimenting with weak scaling options allows finding the optimal number of processes run per node such that the model fits in the memory and performance doesn’t deteriorate. For some reason, TensorFlow creates an extra thread. Hence, to avoid oversubscription it’s better to set the OMP_NUM_THREADS to 9, 19 or 39 when training with 4,2,1 process per node respectively. Although we didn’t see it affecting the throughput performance in our experiments but may affect performance in a very large-scale setup.
Taking advantage of multi-threading can dramatically improve performance. This can be done by setting OMP_NUM_THREADS such that the product of its value and number of MPI ranks per node equals the number of available CPU cores per node. In the case of Zenith, this is 40 cores, as each PowerEdge C6420 node contains 2 20-core Intel® Xeon® Gold 6148 processors.
The KMP_AFFINITY environment variable provides a way to control the interface which binds OpenMP threads to physical processing units, while KMP_BLOCKTIME, sets the time in milliseconds that a thread should wait after completing a parallel execution before sleeping. TF configuration settings, intra_op_parallelism_threads, and inter_op_parallelism_threads are used to adjust the thread pools thereby optimizing the CPU performance.
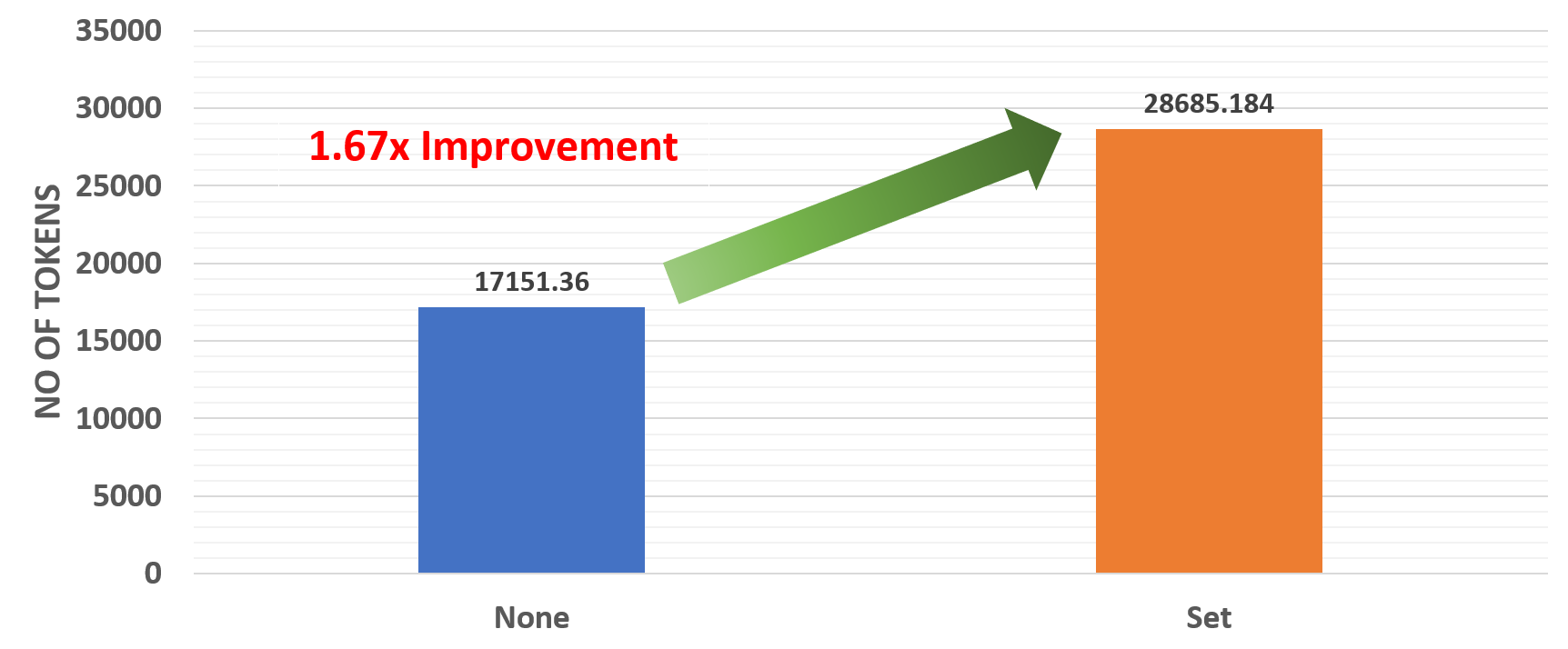
Figure 3: Effect of environment variables
The above results show that there’s a 1.67x improvement when environment variables are set correctly.
Faster distributed training
Training a large neural network architecture can be time-consuming, making it difficult to perform rapid prototyping or hyperparameter tuning. Thanks to distributed training and open source frameworks like Horovod, which allows training a model using multiple workers, the time to train can be substantially reduced. In our previous blog, we showed the effectiveness of training an AI radiologist with distributed deep learning and using Intel® Xeon® Scalable processors. Here, we show how distributed deep learning improves the time to train for machine translation models.
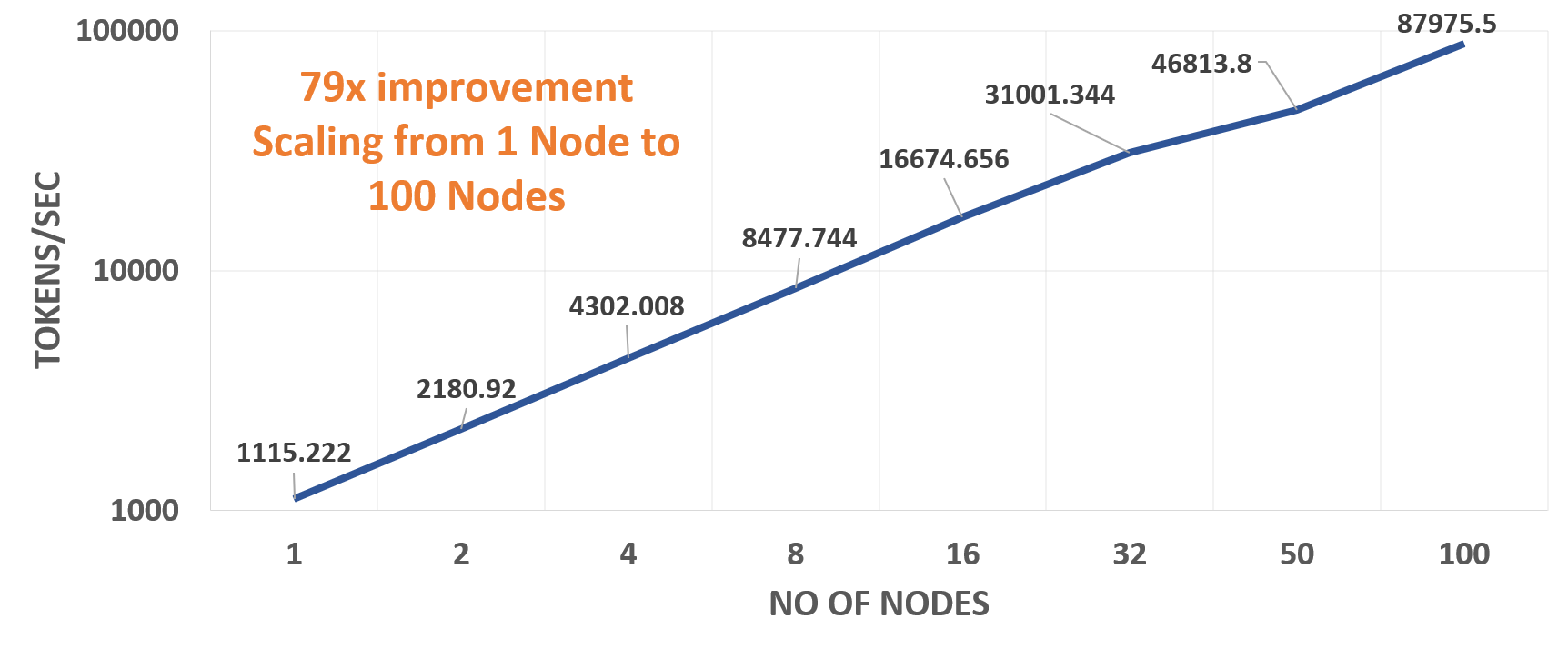
Figure 4: Scaling Performance
The above chart shows the throughput of the transformer (big) model when trained using up to 100 Zenith nodes. Our experiments show linear performance when scaling up the number of nodes. Based on our tests, which include setting the correct environment variables and the optimal number of MPI processes per node, we see a 79x improvement on 100 Zenith nodes with 2 processes per node compared to the throughput on a single node with 4 processes.
Translation Quality
NMT models’ translation quality is measured in terms of BLEU (Bi-Lingual Evaluation Understudy) score. It’s a measure to compute the difference between the human and machine-translated output.
In a previous blog post, we explained some of the challenges of large-batch training of deep learning models. Here, we experimented using a large global batch size of 402k tokens to determine the models’ accuracy on the English to German translation task. Hyperparameters were set to match those used for the transformer (big) model, and the model was trained using 50 Zenith nodes with 4 processes per node. The learning rate grows linearly for 4000 steps to 0.001 and then follows inverse square root decay.
Case-Insensitive BLEU | Case-Sensitive BLEU | |
TensorFlow Official Benchmark Results | 28.9 | - |
Our results | 29.15 | 28.56 |
Note: Case-Sensitive score not reported in the Tensorflow Official Benchmark.
The above table shows our results on the test set (newstest2014) after training the model for around 2.7 days (26000 steps). We can see a clear improvement in the translation quality compared to the results posted on the Tensorflow Official Benchmarks page. This shows that training with large batches does not adversely affect the quality of the resulting translation models, which is an encouraging result for future studies with even larger batch sizes.
Conclusion
In this post, we showed how to effectively train a Neural Machine Translation(NMT) system using Intel® Xeon® Scalable processors using distributed deep learning. We highlighted some of the best practices for setting environment variables and the corresponding scaling performance. Based on our experiments, and following other research work on NMT to understand some of the important aspects of scaling an NMT system, we were able to demonstrate better translation quality and accelerate the training process. With a research interest in the field of neural machine translation continuing to grow, we expect to see more interesting and innovative NMT architectures in the future.
Srinivas Varadharajan - Machine Learning/Deep Learning Developer
Twitter: @sedentary_yoda
LinkedIn: https://www.linkedin.com/in/srinivasvaradharajan

Sharing the Love for GPUs in Machine Learning - Part 2

Wed, 17 Mar 2021 17:23:31 -0000
|Read Time: 0 minutes

In Part 1 of “Share the GPU Love” we covered the need for improving the utilization of GPU accelerators and how a relatively simple technology like VMware DirectPath I/O together with some sharing processes could be a starting point. As with most things in technology, some additional technology, and knowledge you can achieve high goals beyond just the basics. In this article, we are going to introduce another technology for managing GPU-as-a-service – NVIDIA GRID 9.0.
Before we jump to this next technology, let’s review some of the limitations of using DirectPath I/O for virtual machine access to physical PCI functions. The online documentation for VMware DirectPath I/O has a complete list of features that are unavailable for virtual machines configured with DirectPath I/O. Some of the most important ones are:
- Fault tolerance
- High availability
- Snapshots
- Hot adding and removing of virtual devices
The technique of “passing through” host hardware to a virtual machine (VM) is simple but doesn’t leverage many of the virtues of true hardware virtualization. NVIDIA delivers software to virtualize GPUs in the data center for years. The primary use case has been Virtual Desktop Infrastructure (VDI) using vGPUs. The current release - NVIDIA vGPU Software 9 adds the vComputeServer vGPU capability for supporting artificial intelligence, deep learning, and high-performance computing workloads. The rest of this article will cover using vGPU for machine learning in a VMware ESXi environment.
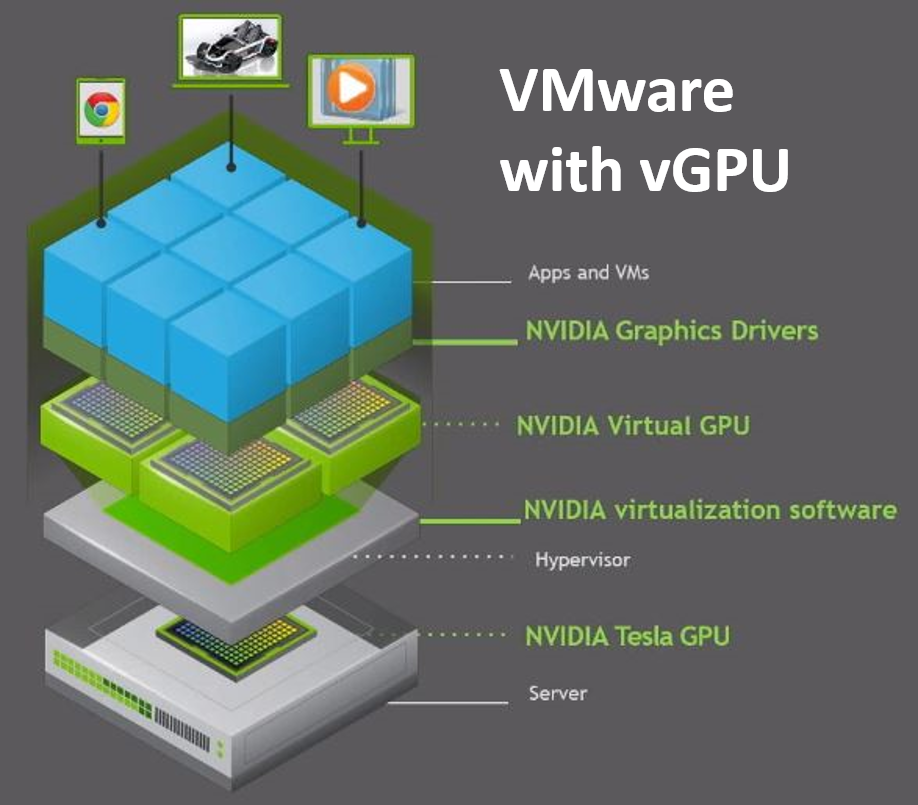
We want to compare the setup and features of this latest NVIDIA software version, so we worked on adding the vComputeServer to our PowerEdge ESXi that we used for the DirectPath I/O research in our first blog in this series. Our NVIDIA Turing architecture T4 GPUs are on the list of supported devices, so we can check that box and our ESXi version is compatible. The NVIDIA vGPU software documentation for VMware vSphere has an exhaustive list of requirements and compatibility notes.
You’ll have to put your host into maintenance mode during installation and then reboot after the install of the VIB completes. When the ESXi host is back online you can use the now-familiar nvidia-smi command with no parameters and see a list of all available GPUs that indicates you are ready to proceed.
We configured two of our T4 GPUs for vGPU use and setup the required licenses. Then we followed the same approach that we used for DirectPath I/O to build out VM templates with everything that is common to all developments and use those to create the developer-specific VMs – one with all Python tools and another with R tools. NVIDIA vGPU software supports only 64-bit guest operating systems. No 32-bit guest operating systems are supported. You should only use a guest OS release that is supported by both for NVIDIA vGPU software and by VMware. NVIDIA will not be able to support guest OS releases that are not supported by your virtualization software.

Now that we have both a DirectPath I/O enabled setup and the NVIDIA vGPU environment let’s compare the user experience. First, starting with vSphere 6.7 U1 release, vMotion with vGPU and suspend and resume with vGPU are supported on suitable GPUs. Always check the NVIDIA Virtual GPU Software Documentation for all the latest details. vSphere 6.7 only supports suspend and resume with vGPU. vMotion with vGPU is not supported in release 6.7. [double check this because vMotion is supported I just can't remember what version and update number it is]
vMotion can be extremely valuable for data scientists doing long-running training jobs that you don’t get with DirectPath I/O and suspend/resume of vGPU enabled VMs creates opportunities to increase the return from your GPU investments by enabling scenarios with data science model training running at night and interactive graphics-intensive applications running during the day utilizing the same pool of GPUs. Organizations with workers spread across time zones may also find that suspend/resume of vGPU enabled VMs to be useful.
There is still a lot of work that we want to do in our lab including capturing some informational videos that will highlight some of the concepts we have been talking about in these last two articles. We are also starting to build out some VMs configured with Docker so we can look at using our vGPUs with NVIDIA GPU Cloud (GCP) deep learning training and inferencing containers. Our goal is to get more folks setting up a sandbox environment using these articles along with the NVIDIA and VMware links we have provided. We want to hear about your experience working with vGPUs and VMware. If you have any questions or comments post them in the feedback section below.
Thanks for reading,
Phil Hummel - On Twitter @GotDisk

Sharing the Love for GPUs in Machine Learning
Wed, 17 Mar 2021 16:53:14 -0000
|Read Time: 0 minutes

Anyone that works with machine learning models trained by optimization methods like stochastic gradient descent (SGD) knows about the power of specialized hardware accelerators for performing a large number of matrix operations that are needed. Wouldn’t it be great if we all had our own accelerator dense supercomputers? Unfortunately, the people that manage budgets aren’t approving that plan, so we need to find a workable mix of technology and, yes, the dreaded concept, process to improve our ability to work with hardware accelerators in shared environments.
We have gotten a lot of questions from a customer trying to increase the utilization rates of machines with specialized accelerators. Good news, there are a lot of big technology companies working on solutions. The rest of the article is going to focus on technology from Dell EMC, NVIDIA, and VMware that is both available today and some that are coming soon. We also sprinkle in some comments about the process that you can consider. Please add your thoughts and questions in the comments section below.
We started this latest round of GPU-as-a-service research with a small amount of kit in the Dell EMC Customer Solutions Center in Austin. We have one Dell EMC PowerEdge R740 with 4 NVIDIA T4 GPUs connected to the system on the PCIe bus. Our research question is “how can a group of data scientists working on different models with different development tools share these four GPUs?” We are going to compare two different technology options:
- VMware Direct Path I/O
- NVIDIA GPU GRID 9.0
Our server has ESXi installed and is configured as a 1 node cluster in vCenter. I’m going to skip the configuration of the host BIOS and ESXi and jump straight to creating VMs. We started off with the Direct Path I/O option. You should review the article “Using GPUs with Virtual Machines on vSphere – Part 2: VMDirectPath I/O” from VMware before trying this at home. It has a lot of details that we won’t repeat here.
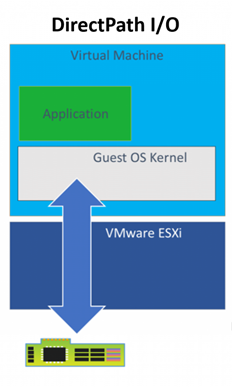
There are many approaches available for virtual machine image management that can be set up by the VMware administrators but for this project, we are assuming that our data scientists are building and maintaining the images they use. Our scenario is to show how a group of Python users can have one image and the R users can have another image that both use GPUs when needed. Both groups are using primarily TensorFlow and Keras.
Before installing an OS we changed the firmware setting to EFI in the VM Boot Options menu per the article above. We also used the VM options to assign one physical GPU to the VM using Direct Path I/O before proceeding with any software installs. It is important for there to be a device present during configuration even though the VM may get used later with or without an assigned GPU to facilitate sharing among users and/or teams.
Once the OS was installed and configured with user accounts and updates, we installed the NVIDIA GPU related software and made two clones of that image since both the R and Python environment setups need the same supporting libraries and drivers to use the GPUs when added to the VM through Direct Path I/O. Having the base image with an OS plus NVIDIA libraries saves a lot of time if you want a new type of developer environment.
With this much of the setup done, we can start testing assigning and removing GPU devices among our two VMs. We use VM options to add and remove the devices but only while the VM is powered off. For example, we can assign 2 GPUs to each VM, 4 GPUs to one VM and none to the other or any other combination that doesn’t exceed our 4 available devices. Devices currently assigned to other VMs are not available in the UI for assignment, so it is not physically possible to create conflicts between VMs. We can NVIDIA’s System Management Interface (nvidia-smi) to list the devices available on each VM.
Remember above when we talked about process, here is where we need to revisit that. The only way a setup like this works is if people release GPUs from VMs when they don’t need them. Going a level deeper there will probably be a time when one user or group could take advantage of a GPU but would choose to not take one so other potentially more critical work can have it. This type of resource sharing is not new to research and development. All useful resources are scarce, and a lot of efficiencies can be gained with the right technology, process, and attitude
.Before we talk about installing the developer frameworks and libraries, let’s review the outcome we desire. We have 2 or more groups of developers that could benefit from the use of GPUs at different times in their workflow but not always. They would like to minimize the number of VM images they need and have and would also like fewer versions of code to maintain even when switching between tasks that may or may not have access to GPUs when running. We talked above about switching GPUs between machines but what happens on the software side? Next, we’ll talk about some TensorFlow properties that make this easier.
TensorFlow comes in two main flavors for installation tensorflow and tensorflow-gpu. The first one should probably be called “tensorflow-cpu” for clarity. For this work, we are only installing the GPU enabled version since we are going to want our VMs to be able to use GPU for any operations that TF supports for GPU devices. The reason that I don’t also need the CPU version when my VM has not been assigned any GPUs is that many operations available in the GPU enabled version of TF have both a CPU and a GPU implantation. When an operation is run without a specific device assignment, any available GPU device will be given priority in the placement. When the VM does not have a GPU device available the operation will use the CPU implementation.
There are many examples online for testing if you have a properly configured system with a functioning GPU device. This simple matrix multiplication sample is a good starting point. Once that is working you can move on a full-blown model training with a sample data set like the MNIST character recognition model. Try setting up a sandbox environment using this article and the VMware blog series above. Then get some experience with allocating and deallocating GPUs to VMs and prove that things are working with a small app. If you have any questions or comments post them in the feedback section below.
Thanks for reading.
Phil Hummel - Twitter @GotDisk@GotDisk

Natural Language Processing
Tue, 02 Mar 2021 16:10:04 -0000
|Read Time: 0 minutes
“Hey Google, do I look good today?”
“You’re more stunning than a new router fresh out of the box.”
“Aww, thank you!”
“You’re welcome.”
Oh, the joys of natural language processing, and one of many short conversations some of us have with our smart home or personal assistance devices.
The AI subfield of Natural Language Processing (NLP) trains computers to understand human language so that computers can communicate using the same language. The interdisciplinary studies of theoretical computer science, principles of linguistics, and artificial intelligence (AI) that are focused on natural human language and human-machine interactions, brought about what we know today as NLP. Linguistics provides the formula for language such as semantics, syntax, vocabulary, grammar and phrases, while computer science and machine/deep learning transform these linguistic formulas into the NLP algorithm itself.
Common examples of NLP in use today include:
- Email spam detection or document classification
- Website chatbots
- Automated voice response systems (IVR/AVR) on support calls
- Support and marketing use cases analyze written text on the Internet, in support tickets, on social media platforms, and more to determine if the content contains positive or negative sentiment about a product or service.
- Real-time translation of a language to another such as in Google Translate.
- Search made simple such as with Google Search
- On-demand spell checking such as in Microsoft Word
- On-demand next word prediction found in messaging applications such as on mobile phones.
- In drug trials where text is scanned to determine overlap in intellectual property during drug development.
- Personal assistance agents such as Siri, Alexa, Cortana, and Google Assistant
In the case of personal assistants as an example, NLP in action looks like the following:
- You ask Siri: ‘What’s the weather today?”
- Siri collects your question in audio format and converts it to text, which is processed for understanding.
- Based on that understanding, a response is created, converted to audio, and then delivered to you.
Algorithmically, NLP starts with understanding the syntax of the text to extract the grammatical sense from the arrangement of words; a much easier task as most language has clearly defined grammatical rules that can be used to train the algorithms. When the syntax is understood, the algorithm works to infer meaning, nuance, and semantics, which is a harder task because language is not a precise science. The same thing can be said in multiple ways and still have the same meaning in and across multiple languages.
Tools and frameworks
Tools and frameworks that support the implementation of NLP applications, like those mentioned earlier, must be able to derive high-quality information from analyzed text through Text Mining. The components of text mining enable NLP to carry out the following operations:
- Noise removal—Extraction of useful data
- Tokenization—Identification and key segmentation of the useful data
- Normalization—Translation of text into equivalent numerical values appropriate for a computer to understand
- Pattern classification—Discovery of relevancy in segmented data pieces and classify them
Common NLP frameworks with the capabilities that are described above are listed below. The intricacies of these frameworks are outside the scope of this blog; go to the following sites to learn more.
Conclusion
We know where NLP came from and some of its applications today, but where is it going and is it ready for wider adoption? What we understand about most existing AI algorithms is that they are suitable for narrow implementations where they carry out a very specific task. Such algorithms are considered to be Artificial Narrow Intelligence, and not Artificial General Intelligence; where the latter implies that they are expert at many things. Most AI is still yet to fully have a grasp on context and what covers time, space, and causality the way humans do. NLP is no exception.
For example, an Internet search returns irrelevant results that do not answer our questions because NLP is excellent at parsing large amounts of data for similarities in content. Then, there is the nuance of spoken language mentioned before and the variance in language rules across languages and even domains. These factors make training for complete accuracy difficult. Some ways to address this might be larger data sets, more infrastructure to train, and perhaps model-based training versus the use of neural networks. However, these come with their own challenges.
At Dell, we have successfully deployed NLP in our tech support center applications, where agents write quick descriptions of a customer’s issues and the application returns predictions for the next best troubleshooting step. 3,000 agents use the tool to service over 10 K customers per day.
We use NLP techniques on input text to generate a format that the AI model can use and have employed K-nearest neighbor (KNN) clustering and logistic regressions for predictions. Microservice APIs are in place to pass information to agents as well. To address the concerns around text as input, we worked with our subject matter experts from the tech support space to identify Dell-specific lingo, which we used to develop a library of synonyms where different entries could mean the same thing. This helped greatly with cleaning up data, providing data to train, and helped us group similar words for context.
For a high turnover role (support agents), we were able to train new agents to be successful sooner by making their onboarding process easier. The support application’s ability to provide the right information quickly lessened the time spent on browsing large irrelevant amounts of information, which can lead to disgruntled customers and frustrated agents. We saw a 10% reduction in the time it took for customers to be serviced. The solution made it possible to feed newly discovered issues to our engineering teams when agents reported or searched for new technical issues with which we were not already familiar. This worked conversely to support agents from engineering as well.
Our research teams at Dell are actively feeding our findings on neural machine translations into the open-source community: one of our current projects is work on AI Voice Synthesis, where NLP works so well you can’t tell that a computer is speaking!
For more information about natural language processing (BERT) MLPerf benchmark ratings for Dell PowerEdge platforms, visit the linked blog posts, then reach out to Dell’s Emerging Tech Team for help with NLP projects in your organization.

Taming the Accelerator Cambrian Explosion with Omnia
Thu, 23 Sep 2021 18:29:00 -0000
|Read Time: 0 minutes
We are in the midst of a compute accelerator renaissance. Myriad new hardware accelerator companies are springing up with novel architectures and execution models for accelerating simulation and artificial intelligence (AI) workloads, each with a purported advantage over the others. Many are still in stealth, some have become public knowledge, others have started selling hardware, and still others have been gobbled up by larger, established players. This frenzied activity in the hardware space, driven by the growth of AI as a way to extract even greater value from new and existing data, has led some to liken it to the “Cambrian Explosion,” when life on Earth diversified at a rate not seen before or since.
If you’re in the business of standing up and maintaining infrastructure for high-performance computing and AI, this type of rapid diversification can be terrifying. How do I deal with all of these new hardware components? How do I manage all of the device drivers? What about all of the device plugins and operators necessary to make them function in my container-orchestrated environment? Data scientists and computational researchers often want the newest technology available, but putting it into production can be next to impossible. It’s enough to keep HPC/AI systems administrators lying awake at night.
At Dell Technologies, we now offer many different accelerator technologies within our PowerEdge server portfolio, from Graphics Processing Units (GPUs) in multiple sizes to Field-Programmable Gate Array (FPGA)-based accelerators. And there are even more to come. We understand that it can be a daunting task to manage all of this different hardware – it’s something we do every day in Dell Technologies’ HPC & AI Innovation Lab. So we’ve developed a mechanism for detecting, identifying, and deploying various accelerator technologies in an automated way, helping us to simplify our own deployment headaches. And we’ve integrated that capability into Omnia, an open-source, community-driven high-performance cluster deployment project started by Dell Technologies and Intel.
Deploy-time accelerator detection and installation
We recognize that tomorrow’s high-performance clusters will not be fully homogenous, consisting of exact copies of the same compute building block replicated tens, hundreds, or thousands of times. Instead clusters are becoming more heterogeneous, consisting of as many as a dozen different server configurations, all tied together under a single (or in some cases – multiple) scheduler or container orchestrator.
This heterogeneity can be a problem for many of today’s cluster deployment tools, which rely on the concept of the “golden image” – a complete image of the server's operating system, hardware drivers, and software stack. The golden image model is extremely useful in many environments, such as homogeneous and diskless deployments. But in the clusters of tomorrow, which will try to capture the amazing potential of this hardware diversity, the golden image model becomes unmanageable.
Instead, Omnia does not rely on the golden image. We think of cluster deployment like 3D-printing – rapidly placing layer after layer of software components and capabilities on top of the hardware until a functional server building block emerges. This allows us, with the use of some intelligent detection and logic, to build bespoke software stacks for each server building block; on demand, at deploy time. From Omnia’s perspective, there’s really no difference between deploying a compute server with no accelerators into a cluster versus deploying a compute server with GPUs or FPGAs into that same cluster. We simply pick different component layers during the process.
What does this mean for cluster deployment?
It means that clusters can now be built from a variety of heterogeneous server building blocks, all managed together as a single entity. Instead of a cluster of CPU servers, another cluster of GPU-accelerated servers, and yet another cluster of FPGA-accelerated servers, research and HPC IT organizations can manage a single resource with all of the different types of technologies that their users demand, all connected by a unified network fabric and sharing a set of unified storage solutions.
And by using Omnia, the process of deploying clusters of heterogeneous building blocks has been dramatically simplified. Regardless of how many types of building blocks an organization wants to use within their next-generation cluster, it can all be deployed using the same approach, and at the same time. There’s no need to build special images for this type of server and that type of server, simply start the Omnia deployment process and Omnia’s intelligent software deployment system will do the rest.
Learn more
Omnia is available to download on GitHub today. You can learn more about the Omnia project in our previous blog post.

Can AI Shape Cellular Network Operations?
Tue, 01 Dec 2020 17:55:41 -0000
|Read Time: 0 minutes
Mobile network operators (MNOs) are in the process of overlaying their conventional macro cellular networks with shorter-range cells such as outdoor pico-cells. This substantially increases network complexity, which makes OPEX planning and management challenging. Artificial intelligence (AI) offers the potential for MNOs to operate their networks in a more cost-efficient manner. Even though AI deployment has its challenges, most agree such deployment will ease emerging network, model, and algorithm complexity.
Advancements in error coding and communication design have resulted in the performance of the point-to-point link being close to the Shannon limit. This has proven to be effective for designing the fourth generation (4G) long-term evolution (LTE)-Advanced air interface, which has multiple parallel point-to-point links. However, 5G air interfaces are more complicated due to their complex network topology and coordination schemes, and vastly diverse end-user applications. Deriving any performance optimum is computationally infeasible. AI, however, can tame the network complexity by providing competitive performances.
Cellular networks have been designed with the goal of approximating end-to-end system behavior using simple modeling approaches that are amenable to clean mathematical analysis. For example, practical systems use digital pre-distortion to linearize the end-to-end model, for which information theory provides a simple closed-form capacity expression. However, with non-linearities in the wireless channel (e.g., mm-Wave) or device components (e.g., power amplifier), it’s difficult to analytically model such behaviors.
In contrast, AI-based detection strategies can easily model such non-linearities. There are examples in cellular networks where the optimal algorithms are well characterized but complex to implement in practice. For example, for a point-to-point multiple-input-multiple-output (MIMO) link operating with an M-ary quadrature amplitude modulation (QAM) constellation and K spatial streams or reconstruction in compressive spectrum sensing, optimum solutions are extremely complex. In practice, most MIMO systems employ linear receivers, e.g., linear minimum mean squared error (MMSE) receivers, which are known to be sub-optimal yet are easy to implement. AI can offer an attractive performance–complexity trade-off. For example, a deep-learning-based MIMO receiver can provide better performance than linear receivers in a variety of scenarios, while retaining low complexity.
Deep learning can be used for devising computationally efficient approaches for physical (PHY) layer communication receivers. Supervised learning can be used for MIMO symbol detection and channel decoding, fetching potentially superior performance; recurrent neural network (RNN)-based detection can be used for MIMO orthogonal frequency division multiplexing (OFDM) systems; convolutional neural network (CNN)-based supervised learning techniques can deliver channel estimation; unsupervised learning approaches can be used for automatic fault detection and root cause analysis leveraging self-organizing maps; deep reinforced learning (DRL) can be used for designing spectrum access, scheduling radio resources, and cell-sectorization. An AI-managed edge or data center can consider diverse network parameters and KPIs for optimizing on-off operation of servers while ensuring uninterrupted services for the clients. Leveraging historical data collected by data center servers, it’s possible to learn emerging service-usage patterns.
Standards bodies like the Third Generation Partnership Project (3GPP) have defined Network Data Analytics Function (NWDAF) specifications for data collection and analytics in automated cellular networks (3GPP TR 23.791 specification). By leaving AI model development to implementation, 3GPP provides adequate flexibility for network vendors to deploy AI-enabled use cases. The inbound interfaces ingest data from various sources such as operation, administration, and maintenance (OAM), network function (NF), application function (AF), and data repositories; the outbound interfaces relay the algorithmic decisions to the NF and AF blocks, respectively.
In addition to 3GPP, MNOs (AT&T, China Mobile, Deutsche Telekom, NTT DOCOMO, and Orange) established the O-RAN Alliance (https://www.o-ran.org/) with the intent to automate network functions and reduce operating expenses. The O-RAN architecture, which is shown in the following figure, includes an AI-enabled RAN intelligent controller (RIC) for both non-real time (non-RT) and near-real time (near-RT), multi-radio access technology protocol stacks.
Figure: O-RAN Architecture (source: O-RAN Alliance)
The non-RT functions include service and policy management, higher-layer procedure optimization, and model training for the near-RT RAN functionality. The near-RT RIC is compatible with legacy radio resource management and enhances challenging operational functions such as seamless handover control, Quality of Service (QoS) management, and connectivity management with AI. The O-RAN alliance has set up two work groups standardizing the A1 interface (between non-RT RIC and near-RT RIC) and E2 interface (between near-RT RIC and digital unit [DU] stack).
Even though AI shows great promise for cellular networks, significant challenges remain:
- From a PHY and MAC layer perspective, training a cellular AI model using over-the-air feedback to update layer weights based on the back-propagation algorithm is expensive in terms of uplink control overhead.
- Separation of information across network protocol layers make it difficult to obtain labeled training data. For example, training an AI model residing within a base-station scheduler might be challenging if it requires access to application layer information.
- It is important for cellular networks to be able to predict the worst-case behavior. This isn’t always easy for non-linear AI building blocks.
- Cellular networks and wireless standards have been designed based on theoretical analysis, channel measurements, and human intuition. This approach allows domain experts to run computer simulations to validate communication system building blocks. AI tools remain black boxes. It is still challenging to develop analytical models to test correctness and explain behaviors in a simple manner.
- If a communication task is performed using an AI model, it is often unclear whether the dataset used for training the model is general enough to capture the distribution of inputs as encountered in reality. For example, if a neural network-based symbol detector is trained under one modulation and coding scheme (MCS), it is unclear how the system would perform for a different MCS level. This is important because if the MCS is changing adaptively due to mobility and channel fading, there has to be a way of predicting system behavior.
- Interoperability is crucial in today’s software defined everything (SDE). Inconsistency among AI-based modules from different vendors can potentially deteriorate overall network performance. For example, some actions (e.g., setting handover threshold) taken by an AI-based module from one vendor could counteract the actions taken by another network module (which may or may not be AI-based) from a second vendor. This could lead to unwanted handover occurrences between the original BS and the neighboring BS, causing increased signaling overhead.
In summary, MNOs agree that:
- Training needs to be distributed as more complex scenarios arise.
- More tools explaining AI decision making are essential.
- More tools are needed to compare AI model output to theoretical performance bounds.
- AI models need to adapt based on surrounding contextual information.
- AI deployment should first focus on wider timescale models until a point is reached when model decision making is indistinguishable from experts.
- Fail-safe wrappers around models should limit impact of cascading errors.
AI can revitalize wireless communications. There are challenges to overcome, but, done right, there is opportunity to deliver massive-scale autonomics in cellular networks that support ultra-reliable low-latency communications, enhanced mobile broadband, and massive machine-to-machine communications.

Quantifying Performance of Dell EMC PowerEdge R7525 Servers with NVIDIA A100 GPUs for Deep Learning Inference
Tue, 17 Nov 2020 21:10:22 -0000
|Read Time: 0 minutes
The Dell EMC PowerEdge R7525 server provides exceptional MLPerf Inference v0.7 Results, which indicate that:
- Dell Technologies holds the #1 spot in performance per GPU with the NVIDIA A100-PCIe GPU on the DLRM-99 Server scenario
- Dell Technologies holds the #1 spot in performance per GPU with the NVIDIA A100-PCIe on the DLRM-99.9 Server scenario
- Dell Technologies holds the #1 spot in performance per GPU with the NVIDIA A100-PCIe on the ResNet-50 Server scenario
Summary
In this blog, we provide the performance numbers of our recently released Dell EMC PowerEdge R7525 server with two NVIDIA A100 GPUs on all the results of the MLPerf Inference v0.7 benchmark. Our results indicate that the PowerEdge R7525 server is an excellent choice for inference workloads. It delivers optimal performance for different tasks that are in the MLPerf Inference v0.7 benchmark. These tasks include image classification, object detection, medical image segmentation, speech to text, language processing, and recommendation.
The PowerEdge R7525 server is a two-socket, 2U rack server that is designed to run workloads using flexible I/O and network configurations. The PowerEdge R7525 server features the 2nd Gen AMD EPYC processor, supports up to 32 DIMMs, has PCI Express (PCIe) Gen 4.0-enabled expansion slots, and provides a choice of network interface technologies to cover networking options.
The following figure shows the front view of the PowerEdge R7525 server:

Figure 1. Dell EMC PowerEdge R7525 server
The PowerEdge R7525 server is designed to handle demanding workloads and for AI applications such as AI training for different kinds of models and inference for different deployment scenarios. The PowerEdge R7525 server supports various accelerators such as NVIDIA T4, NVIDIA V100S, NVIDIA RTX, and NVIDIA A100 GPU s. The following sections compare the performance of NVIDIA A100 GPUs with NVIDIA T4 and NVIDIA RTX GPUs using MLPerf Inference v0.7 as a benchmark.
The following table provides details of the PowerEdge R7525 server configuration and software environment for MLPerf Inference v0.7:
Component | Description |
Processor | AMD EPYC 7502 32-Core Processor |
Memory | 512 GB (32 GB 3200 MT/s * 16) |
Local disk | 2x 1.8 TB SSD (No RAID) |
Operating system | CentOS Linux release 8.1 |
GPU | NVIDIA A100-PCIe-40G, T4-16G, and RTX8000 |
CUDA Driver | 450.51.05 |
CUDA Toolkit | 11.0 |
Other CUDA-related libraries | TensorRT 7.2, CUDA 11.0, cuDNN 8.0.2, cuBLAS 11.2.0, libjemalloc2, cub 1.8.0, tensorrt-laboratory mlperf branch |
Other software stack | Docker 19.03.12, Python 3.6.8, GCC 5.5.0, ONNX 1.3.0, TensorFlow 1.13.1, PyTorch 1.1.0, torchvision 0.3.0, PyCUDA 2019.1, SacreBLEU 1.3.3, simplejson, OpenCV 4.1.1 |
System profiles | Performance |
For more information about how to run the benchmark, see Running the MLPerf Inference v0.7 Benchmark on Dell EMC Systems.
MLPerf Inference v0.7 performance results
The MLPerf inference benchmark measures how fast a system can perform machine learning (ML) inference using a trained model in various deployment scenarios. The following results represent the Offline and Server scenarios of the MLPerf Inference benchmark. For more information about different scenarios, models, datasets, accuracy targets, and latency constraints in MLPerf Inference v0.7, see Deep Learning Performance with MLPerf Inference v0.7 Benchmark.
In the MLPerf inference evaluation framework, the LoadGen load generator sends inference queries to the system under test, in our case, the PowerEdge R7525 server with various GPU configurations. The system under test uses a backend (for example, TensorRT, TensorFlow, or PyTorch) to perform inferencing and sends the results back to LoadGen.
MLPerf has identified four different scenarios that enable representative testing of a wide variety of inference platforms and use cases. In this blog, we discuss the Offline and Server scenario performance. The main differences between these scenarios are based on how the queries are sent and received:
- Offline—One query with all samples is sent to the system under test. The system under test can send the results back once or multiple times in any order. The performance metric is samples per second.
- Server—Queries are sent to the system under test following a Poisson distribution (to model real-world random events). One query has one sample. The performance metric is queries per second (QPS) within latency bound.
Note: Both the performance metrics for Offline and Server scenario represent the throughput of the system.
In all the benchmarks, two NVIDIA A100 GPUs outperform eight NVIDIA T4 GPUs and three NVIDIA RTX800 GPUs for the following models:
- ResNet-50 image classification model
- SSD-ResNet34 object detection model
- RNN-T speech recognition model
- BERT language processing model
- DLRM recommender model
- 3D U-Net medical image segmentation model
The following graphs show PowerEdge R7525 server performance with two NVIDIA A100 GPUs, eight NVIDIA T4 GPUs, and three NVIDIA RTX8000 GPUs with 99% accuracy target benchmarks and 99.9% accuracy targets for applicable benchmarks:
- 99% accuracy (default accuracy) target benchmarks: ResNet-50, SSD-Resnet34, and RNN-T
- 99% and 99.9% accuracy (high accuracy) target benchmarks: DLRM, BERT, and 3D-Unet
99% accuracy target benchmarks
ResNet-50
The following figure shows results for the ResNet-50 model:
Figure 2. ResNet-50 Offline and Server inference performance
From the graph, we can derive the per GPU values. We divide the system throughput (containing all the GPUs) by the number of GPUs to get the Per GPU results as they are linearly scaled.
SSD-Resnet34
The following figure shows the results for the SSD-Resnet34 model:
Figure 3. SSD-Resnet34 Offline and Server inference performance
RNN-T
The following figure shows the results for the RNN-T model:
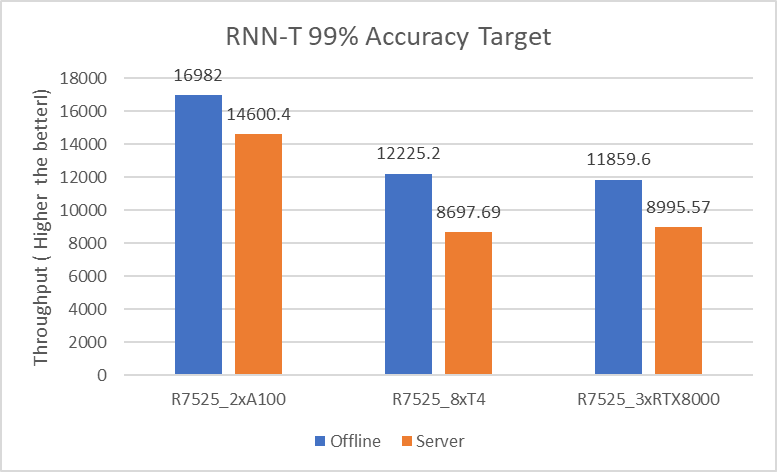
Figure 4. RNN-T Offline and Server inference performance
99.9% accuracy target benchmarks
DLRM
The following figures show the results for the DLRM model with 99% and 99.9% accuracy:
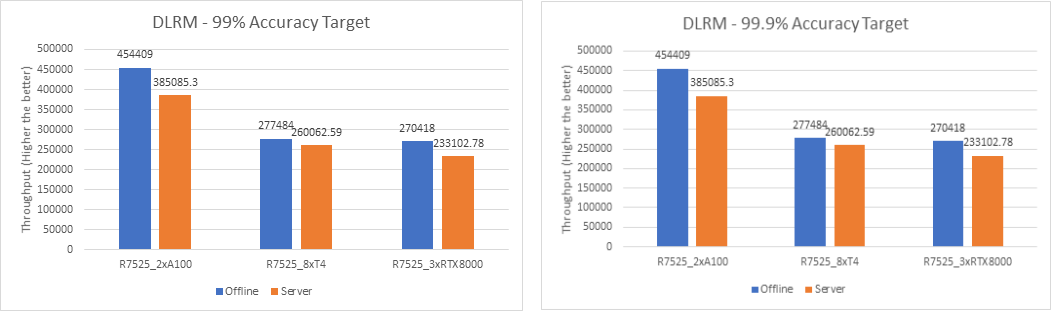
Figure 5. DLRM Offline and Server Scenario inference performance – 99% and 99.9% accuracy
For the DLRM recommender and 3D U-Net medical image segmentation (see Figure 7) models, both 99% and 99.9% accuracy have the same throughput. The 99.9% accuracy benchmark also satisfies the required accuracy constraints with the same throughput as that of 99%.
BERT
The following figures show the results for the BERT model with 99% and 99.9% accuracy:
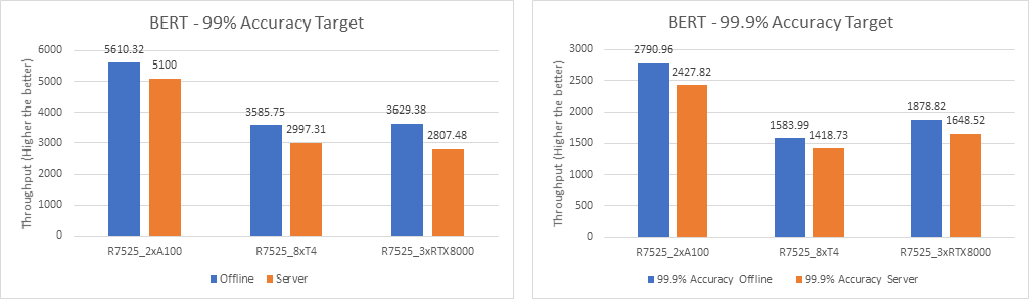
Figure 6. BERT Offline and Server inference performance – 99% and 99.9% accuracy
For the BERT language processing model, two NVIDIA A100 GPUs outperform eight NVIDIA T4 GPUs and three NVIDIA RTX8000 GPUs. However, the performance of three NVIDIA RTX8000 GPUs is a little better than that of eight NVIDIA T4 GPUs.
3D U-Net
For the 3D-Unet medical image segmentation model, only the Offline scenario benchmark is available.
The following figure shows the results for the 3D U-Net model Offline scenario:
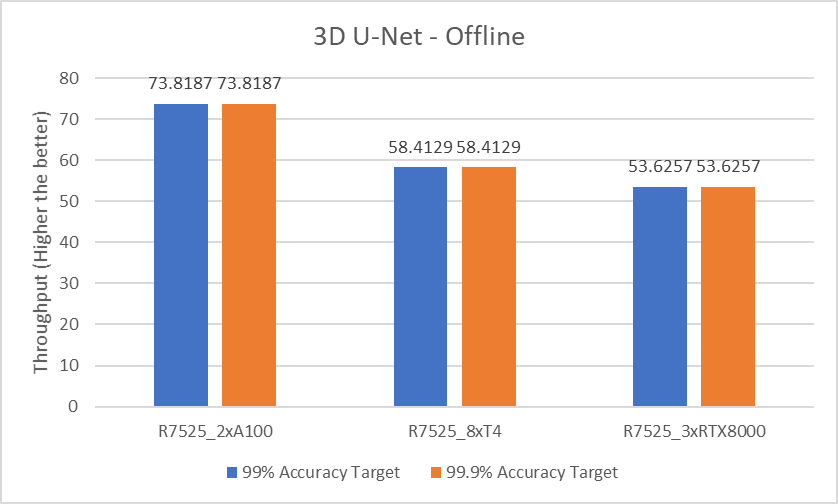
Figure 7. 3D U-Net Offline inference performance
For the 3D-Unet medical image segmentation model, since there is only offline scenario benchmark for 3D-Unet the above graph represents only Offline scenario.
The following table compares the throughput between two NVIDIA A100 GPUs, eight NVIDIA T4 GPUs, and three NVIDIA RTX8000 GPUs with 99% accuracy target benchmarks and 99.9% accuracy targets:
Model | Scenario | Accuracy | 2 x A100 GPUs vs 8 x T4 GPUs | 2 x A100 GPUs vs 3 x RTX8000 GPUs |
ResNet-50 | Offline | 99% | 5.21x | 2.10x |
Server | 4.68x | 1.89x | ||
SSD-Resnet34 | Offline | 6.00x | 2.35x | |
Server | 5.99x | 2.21x | ||
RNN-T | Offline | 5.55x | 2.14x | |
Server | 6.71x | 2.43x | ||
DLRM | Offline | 6.55x | 2.52x | |
Server | 5.92x | 2.47x | ||
Offline | 99.9% | 6.55x | 2.52x | |
Server | 5.92x | 2.47x | ||
BERT | Offline | 99% | 6.26x | 2.31x |
Server | 6.80x | 2.72x | ||
Offline | 99.9% | 7.04x | 2.22x | |
Server | 6.84x | 2.20x | ||
3D U-Net | Offline | 99% | 5.05x | 2.06x |
Server | 99.9% | 5.05x | 2.06x |
Conclusion
With support of NVIDIA A100, NVIDIA T4, or NVIDIA RTX8000 GPUs, Dell EMC PowerEdge R7525 server is an exceptional choice for various workloads that involve deep learning inference. However, the higher throughput that we observed with NVIDIA A100 GPUs translates to performance gains and faster business value for inference applications.
Dell EMC PowerEdge R7525 server with two NVIDIA A100 GPUs delivers optimal performance for various inference workloads, whether it is in a batch inference setting such as Offline scenario or Online inference setting such as Server scenario.
Next steps
In future blogs, we will discuss sizing the system (server and GPU configurations) correctly based on the type of workload (area and task).

Deep Learning Training Performance on Dell EMC PowerEdge R7525 Servers with NVIDIA A100 GPUs
Mon, 21 Jun 2021 20:03:09 -0000
|Read Time: 0 minutes
Overview
The Dell EMC PowerEdge R7525 server, which was recently released, supports NVIDIA A100 Tensor Core GPUs. It is a two-socket, 2U rack-based server that is designed to run complex workloads using highly scalable memory, I/O capacity, and network options. The system is based on the 2nd Gen AMD EPYC processor (up to 64 cores), has up to 32 DIMMs, and has PCI Express (PCIe) 4.0-enabled expansion slots. The server supports SATA, SAS, and NVMe drives and up to three double-wide 300 W or six single-wide 75 W accelerators.
The following figure shows the front view of the server:
Figure 1: Dell EMC PowerEdge R7525 server
This blog focuses on the deep learning training performance of a single PowerEdge R7525 server with two NVIDIA A100-PCIe GPUs. The results of using two NVIDIA V100S GPUs in the same PowerEdge R7525 system are presented as reference data. We also present results from the cuBLAS GEMM test and the ResNet-50 model form the MLPerf Training v0.7 benchmark.
The following table provides the configuration details of the PowerEdge R7525 system under test:
Component | Description |
Processor | AMD EPYC 7502 32-core processor |
Memory | 512 GB (32 GB 3200 MT/s * 16) |
Local disk | 2 x 1.8 TB SSD (No RAID) |
Operating system | RedHat Enterprise Linux Server 8.2 |
GPU | Either of the following:
|
CUDA driver | 450.51.05 |
CUDA toolkit | 11.0 |
Processor Settings > Logical Processors | Disabled |
System profiles | Performance |
CUDA Basic Linear Algebra
The CUDA Basic Linear Algebra (cuBLAS) library is the CUDA version of standard basic linear algebra subroutines, part of CUDA-X. NVIDIA provides the cublasMatmulBench binary, which can be used to test the performance of general matrix multiplication (GEMM) on a single GPU. The results of this test reflect the performance of an ideal application that only runs matrix multiplication in the form of the peak TFLOPS that the GPU can deliver. Although GEMM benchmark results might not represent real-world application performance, it is still a good benchmark to demonstrate the performance capability of different GPUs.
Precision formats such as FP64 and FP32 are important to HPC workloads; precision formats such as INT8 and FP16 are important for deep learning inference. We plan to discuss these observed performances in our upcoming HPC and inference blogs.
Because FP16, FP32, and TF32 precision formats are imperative to deep learning training performance, the blog focuses on these formats.
The following figure shows the results that we observed:
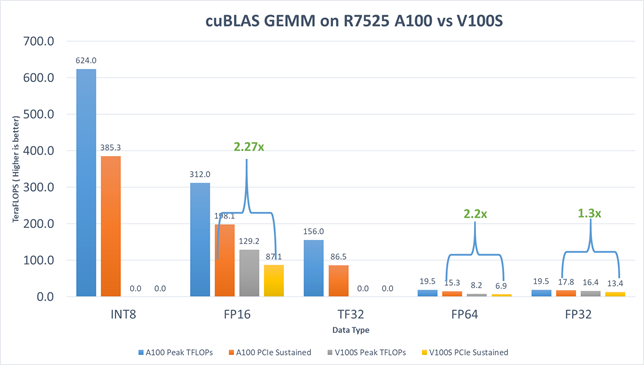
Figure 2: cuBLAS GEMM performance on the PowerEdge R7525 server with NVIDIA V100S-PCIe-32G and NVIDIA A100-PCIe-40G GPUs
The results include:
- For FP16, the HGEMM TFLOPs of the NVIDIA A100 GPU is 2.27 times faster than the NVIDIA V100S GPU.
- For FP32, the SGEMM TFLOPs of the NVIDIA A100 GPU is 1.3 times faster than the NVIDIA V100S GPU.
- For TF32, performance improvement is expected without code changes for deep learning applications on the new NVIDIA A100 GPUs. This expectation is because math operations are run on NVIDIA A100 Tensor Cores GPUs with the new TF32 precision format. Although TF32 reduces the precision by a small margin, it preserves the range of FP32 and strikes an excellent balance between speed and accuracy. Matrix multiplication gained a sizable boost from 13.4 TFLOPS (FP32 on the NVIDIA V100S GPU) to 86.5 TFLOPS (TF32 on the NVIDIA A100 GPU).
MLPerf Training v0.7 ResNet-50
MLPerf is a benchmarking suite that measures the performance of machine learning (ML) workloads. The MLPerf Training benchmark suite measures how fast a system can train ML models.
The following figure shows the performance results of the ResNet-50 under the MLPerf Training v0.7 benchmark:

Figure 3: MLPerf Training v0.7 ResNet-50 performance on the PowerEdge R7525 server with NVIDIA V100S-PCIe-32G and NVIDIA A100-PCIe-40G GPUs
The metric for the ResNet-50 training is the minutes that the system under test spends to train the dataset to achieve 75.9 percent accuracy. Both runs using two NVIDIA A100 GPUs and two NVIDIA V100S GPUs converged at the 40th epoch. The NVIDIA A100 run took 166 minutes to converge, which is 1.8 times faster than the NVIDIA V100S run. Regarding throughput, two NVIDIA A100 GPUs can process 5240 images per second, which is also 1.8 times faster than the two NVIDIA V100S GPUs.
Conclusion
The Dell EMC PowerEdge R7525 server with two NVIDIA A100-PCIe GPUs demonstrates optimal performance for deep learning training workloads. The NVIDIA A100 GPU shows a greater performance improvement over the NVIDIA V100S GPU.
To evaluate deep learning and HPC workload and application performance with the PowerEdge R7525 server powered by NVIDIA GPUs, contact the HPC & AI Innovation Lab.
Next steps
We plan to provide performance studies on:
- Three NVIDIA A100 GPUs in a PowerEdge R7525 server
- Results of other deep learning models in the MLPerf Training v0.7 benchmark
- Training scalability results on multiple PowerEdge R7525 servers

Supercharge Inference Performance at the Edge using the Dell EMC PowerEdge XE2420
Wed, 05 Jul 2023 13:43:30 -0000
|Read Time: 0 minutes
Deployment of compute at the Edge enables the real-time insights that inform competitive decision making. Application data is increasingly coming from outside the core data center (“the Edge”) and harnessing all that information requires compute capabilities outside the core data center. It is estimated that 75% of enterprise-generated data will be created and processed outside of a traditional data center or cloud by 2025.[1]
This blog demonstrates that the Dell EMC PowerEdge XE2420, a high-performance Edge server, performs AI inference operations more efficiently by leveraging its ability to use up to four NVIDIA T4 GPUs in an edge-friendly short-depth server. The XE2420 with NVIDIA T4 GPUs can classify images at 25,141 images/second, an equal performance to other conventional 2U rack servers that is persistent across the range of benchmarks.
XE2420 Features and Capabilities
The Dell EMC PowerEdge XE2420 is a 16” (400mm) deep, high-performance server that is purpose-built for the Edge. The XE2420 has features that provide dense compute, simplified management and robust security for harsh edge environments.

Built for performance: Powerful 2U, two-socket performance with the flexibility to add up to four accelerators per server and a maximum local storage of 132TB.
Designed for harsh edge environments: Tested to Network Equipment-Building System (NEBS) guidelines, with extended operating temperature tolerance of 5˚-45˚C without sacrificing performance, and an optional filtered bezel to guard against dust. Short depth for edge convenience and lower latency.
Integrated security and consistent management: Robust, integrated security with cyber-resilient architecture, and the new iDRAC9 with Datacenter management experience. Front accessible and cold-aisle serviceable for easy maintenance.
The XE2420 allows for flexibility in the type of GPUs you use, in order to accelerate a wide variety of workloads including high-performance computing, deep learning training and inference, machine learning, data analytics, and graphics. It can support up to 2x NVIDIA V100/S PCIe, 2x NVIDIA RTX6000, or up to 4x NVIDIA T4.
Edge Inferencing with the T4 GPU
The NVIDIA T4 is optimized for mainstream computing environments and uniquely suited for Edge inferencing. Packaged in an energy-efficient 70-watt, small PCIe form factor, it features multi-precision Turing Tensor Cores and new RT Cores to deliver power efficient inference performance. Combined with accelerated containerized software stacks from NGC, XE240 and NVIDIA T4 is a powerful solution to deploy AI application at scale on the edge.

Fig 1: NVIDIA T4 Specifications

Fig 2: Dell EMC PowerEdge XE2420 w/ 4x T4 & 2x 2.5” SSDs
Dell EMC PowerEdge XE2420 MLPerf Inference Tested Configuration
Processors | 2x Intel Xeon Gold 6252 CPU @ 2.10GHz |
Storage
| 1x 2.5" SATA 250GB |
1x 2.5" NVMe 4TB | |
Memory | 12x 32GB 2666MT/s DDR4 DIMM |
GPUs | 4x NVIDIA T4 |
OS | Ubuntu 18.04.5 |
Software
| TensorRT 7.2 |
CUDA 11.0 Update 1 | |
cuDNN 8.0.2 | |
DALI 0.25.0 | |
Hardware Settings | ECC off |
Inference Use Cases at the Edge
As computing further extends to the Edge, higher performance and lower latency become vastly more important in order to decrease response time and reduce bandwidth. One suite of diverse and useful inference workload benchmarks is MLPerf. MLPerf Inference demonstrates performance of a system under a variety of deployment scenarios and aims to provide a test suite to enable balanced comparisons between competing systems along with reliable, reproducible results.
The MLPerf Inference v0.7 suite covers a variety of workloads, including image classification, object detection, natural language processing, speech-to-text, recommendation, and medical image segmentation. Specific scenarios covered include “offline”, which represents batch processing applications such as mass image classification on existing photos, and “server”, which represents an application where query arrival is random, and latency is important. An example of server is essentially any consumer-facing website where a consumer is waiting for an answer to a question. Many of these workloads are directly relevant to Telco & Retail customers, as well as other Edge use cases where AI is becoming more prevalent.
Measuring Inference Performance using MLPerf
We demonstrate inference performance for the XE2420 + 4x NVIDIA T4 accelerators across the 6 benchmarks of MLPerf Inference v0.7 in order to showcase the versatility of the system. The inference benchmarking was performed on:
- Offline and Server scenarios at 99% accuracy for ResNet50 (image classification), RNNT (speech-to-text), and SSD-ResNet34 (object detection)
- Offline and Server scenarios at 99% and 99.9% accuracy for BERT (NLP) and DLRM (recommendation)
- Offline scenario at 99% and 99.9% accuracy for 3D-Unet (medical image segmentation)
These results and the corresponding code are available at the MLPerf website.[1]
Key Highlights
The XE2420 is a compact server that supports 4x 70W T4 GPUs in an efficient manner, reducing overall power consumption without sacrificing performance. This high-density and efficient power-draw lends it increased performance-per-dollar, especially when it comes to a per-GPU performance basis.
Additionally, the PowerEdge XE2420 is part of the NVIDIA NGC-Ready and NGC-Ready for Edge validation programs[i]. At Dell, we understand that performance is critical, but customers are not willing to compromise quality and reliability to achieve maximum performance. Customers can confidently deploy inference and other software applications from the NVIDIA NGC catalog knowing that the PowerEdge XE2420 meets the requirements set by NVIDIA to deploy customer workloads on-premises or at the Edge.
In the chart above, per-GPU (aka 1x T4) performance numbers are derived from the total performance of the systems on MLPerf Inference v0.7 & total number of accelerators in a system. The XE2420 + T4 shows equivalent per-card performance to other Dell EMC + T4 offerings across the range of MLPerf tests.
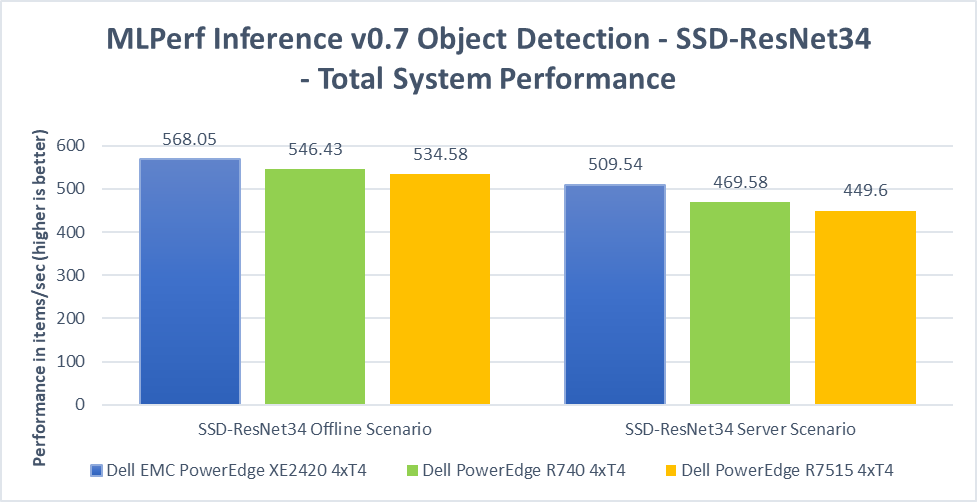
When placed side by side with the Dell EMC PowerEdge R740 (4x T4) and R7515 (4x T4), the XE2420 (4x T4) showed performance on par across all MLPerf submissions. This demonstrates that operating capabilities and performance were not sacrificed to achieve the smaller depth and form-factor.
Conclusion: Better Density and Flexibility at the Edge without sacrificing Performance
MLPerf inference benchmark results clearly demonstrate that the XE2420 is truly a high-performance, half-depth server ideal for edge computing use cases and applications. The capability to pack four NVIDIA T4 GPUs enables it to perform AI inference operations at par with traditional mainstream 2U rack servers that are deployed in core data centers. The compact design provides customers new, powerful capabilities at the edge to do more, faster without extra components. The XE2420 is capable of true versatility at the edge, demonstrating performance not only for common retail workloads but also for the full range of tested workloads. Dell EMC offers a complete portfolio of trusted technology solutions to aggregate, analyze and curate data from the edge to the core to the cloud and XE2420 is a key component of this portfolio to meet your compute needs at the Edge.
XE2420 MLPerf Inference v0.7 Full Results
The raw results from the MLPerf Inference v0.7 published benchmarks are displayed below, where the metric is throughput (items per second).
Benchmark | ResNet50 | RNNT | SSD-ResNet-34 | |||
Scenario | Offline | Server | Offline | Server | Offline | Server |
Result | 25,141 | 21,002 | 6,239 | 4,584 | 568 | 509 |
Benchmark | BERT | DLRM | ||||||
Scenario | Offline | Server | Offline | Server | ||||
Accuracy % | 99 | 99.9 | 99 | 99.9 | 99 | 99.9 | 99 | 99.9 |
Result | 1,796 | 839 | 1,608 | 759 | 140,217 | 140,217 | 126,513 | 126,513 |
Benchmark | 3D-Unet | |
Scenario | Offline | |
Accuracy % | 99 | 99.9 |
Result | 30.32 | 30.32 |

Dell EMC Servers Shine in MLPerf Inference v0.7 Benchmark
Tue, 03 Nov 2020 12:46:25 -0000
|Read Time: 0 minutes
As software applications and systems using Artificial Intelligence (AI) gain mainstream adoption across all industries, inference workloads for ongoing operations are becoming a larger resource consumer in the datacenter. MLPerf is a benchmark suite that is used to evaluate the performance profiles of systems for both training and inference AI tasks. In this blog we take a closer look at the recent results submitted by Dell EMC and how our various servers performed in the datacenter category.
The reason we do this type of work is to help customers understand which server platform makes the most sense for their use case. Dell Technologies wants to make the choice easier and reduce work for our customers, so they don’t waste their precious resources. We want customers to use their time focusing on the use case helping accelerate time to value for the business.
Dell Technologies has a total of 210 submissions for MLPerf Inference v0.7 in the Datacenter category using various server platforms and accelerators. Why so many? It is because many customers have never run AI in their environment, the use cases are endless across industries and expertise limited. Customers have told us they need help identifying the correct server platform based on their workloads.
We’re proud of what we’ve done, but it’s still all about helping customers adopt AI. By sharing our expertise and providing guidance on infrastructure for AI, we help customers become successful and get their use case into production.
MLPerf Benchmarks
 MLPerf was founded in 2018 with a goal of accelerating improvements in ML system performance. Formed as a collaboration of companies and researchers from leading educational institutions, MLPerf leverages open source code, public state-of-the-art Machine Learning (ML) models and publicly available datasets contributed to the ML community. The MLPerf suites include MLPerf Training and MLPerf Inference.
MLPerf was founded in 2018 with a goal of accelerating improvements in ML system performance. Formed as a collaboration of companies and researchers from leading educational institutions, MLPerf leverages open source code, public state-of-the-art Machine Learning (ML) models and publicly available datasets contributed to the ML community. The MLPerf suites include MLPerf Training and MLPerf Inference.
MLPerf Training measures how fast a system can train machine learning models. Training benchmarks have been defined for image classification, lightweight and heavy-weight object detection, language translation, natural language processing, recommendation and reinforcement learning. Each benchmark includes specifications for input datasets, quality targets and reference implementation models. The first round of training submissions was published on the MLPerf website in December 2018 with results submitted by Google, Intel and NVIDIA.
The MLPerf Inference suite measures how quickly a trained neural network can evaluate new data and perform forecasting or classification for a wide range of applications. MLPerf Inference includes image classification, object detection and machine translation with specific models, datasets, quality, server latency and multi-stream latency constraints. MLPerf validated and published results for MLPerf Inference v0.7 on October 21, 2020. In this blog we take a closer look at the for MLPerf Inference v0.7 results submitted by Dell EMC and how the servers performed in the datacenter category.
A summary of the key highlights of the Dell EMC results are shown in Table 1. These are derived from the submitted results in MLPerf datacenter closed category. Ranking and claims are based on Dell analysis of published MLPerf data. Per accelerator is calculated by dividing the primary metric of total performance by the number of accelerators reported.
Rank | Category | Specifics | Use Cases |
#1 | Performance per Accelerator for NVIDIA A100-PCIe | PowerEdge R7525 | Medical Imaging, Image Classification |
#1 | Performance per Accelerator with NVIDIA T4 GPUs | PowerEdge XE2420, PowerEdge R7525, DSS8440 | Medical Imaging, NLP, Image Classification, Speech Recognition, Object Detection, Recommendation |
#1 | Highest inference results with Quadro RTX6000 and RTX8000 | PowerEdge R7525, DSS 8440 | Medical Imaging, NLP, Image Classification, Speech Recognition, Object Detection, Recommendation |
Dell EMC had a total of 210 submissions for MLPerf Inference v0.7 in the Datacenter category using various Dell EMC platforms and accelerators from leading vendors. We achieved impressive results when compared to other submissions in the same class of platforms.
MLPerf Inference Categories and Dell EMC Achievements
A benchmark suite is made up of tasks or models from vision, speech, language and commerce use cases. MLPerf Inference measures how fast a system can perform ML inference by using a load generator against the System Under Test (SUT) where the trained model is deployed.
There are three types of benchmark tests defined in MLPerf inference v0.7, one for datacenter systems, one for edge systems and one for mobile systems. MLPerf then has four different scenarios to enable representative testing of a wide variety of inference platforms and use cases:
- Single stream
- Multiple stream
- Server
- Offline
The single stream and multiple stream scenarios are only used for edge and mobile inference benchmarks. The data center benchmark type targets systems designed for data center deployments and requires evaluation of both the server and offline scenarios. The metrics used in the Datacenter category are inference operations/second. In the server scenario, the MLPerf load generator sends new queries to the SUT according to a Poisson distribution. This is representative of on-line AI applications such as translation, image tagging which have variable arrival patterns based on end-user traffic. Offline represents AI tasks done thru batch processing such as photo categorization where all the data is readily available ahead of time.
Dell EMC published multiple results in the datacenter systems category. Details on the models, dataset and the scenarios submitted for the different datacenter benchmark are shown in Table 2
Area | Task | Model | Dataset | Required Scenarios |
Vision | Image classification | ResNet50-v1.5 | Imagenet (224x224) | Server, Offline |
Object detection (large) | SSD-ResNet34 | COCO (1200x1200) | Server, Offline | |
Medical image segmentation | 3d Unet | BraTS 2019 (224x224x160) | Offline | |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) | Server, Offline |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) | Server, Offline |
Commerce | Recommendation | DLRM | 1TB Click Logs | Server, Offline |
Next we highlight some of the key performance achievements for the broad range of solutions available in the Dell EMC portfolio for inference use cases and deployments.
1. Dell EMC is #1 in total number of datacenter submissions in the closed division including bare metal submissions using different GPUs, Xeon CPUs, Xilinx FPGA and virtualized submission on VMware vSphere
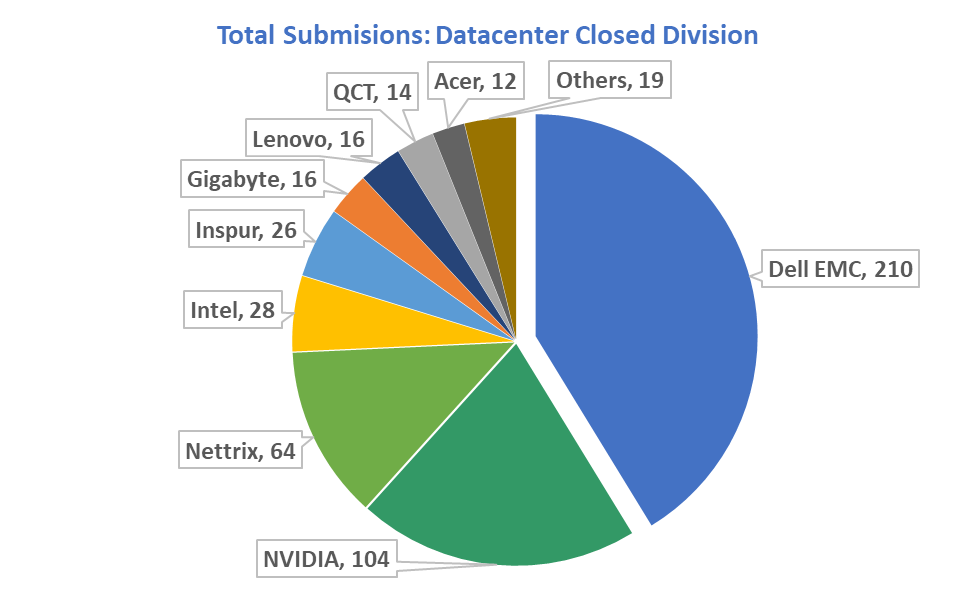
The closed division enables head to head comparisons and consists of server platforms used from the Edge to private or public clouds. The Dell Technologies engineering team submitted 210 out of the total 509 results.
We remain committed to helping customers deploy inference workloads as efficiently as possible, meeting their unique requirements of power, density, budget and performance. The wide range of servers submitted by Dell Technologies’ is a testament to this commitment -
- The only vendor with submissions for a variety of inference solutions – leveraging GPU, FPGA and CPUs for the datacenter/private cloud and Edge
- Unique in the industry by submitting results across a multitude of servers that range from mainstream servers (R740/R7525) to dense GPU-optimized servers supporting up to 16 NVIDIA GPUs (DSS8440).
- Demonstrated that customers that demand real-time inferencing at the telco or retail Edge can deploy up to 4 GPUs in a short depth NEBS-compliant PowerEdge XE2420 server.
- Demonstrated efficient Inference performance using the 2nd Gen Intel Xeon Scalable platform on the PowerEdge R640 and PowerEdge R740 platforms for customers wanting to run inference on Intel CPUs.
- Dell submissions using Xilinx U280 in PowerEdge R740 demonstrated that customers wanting low latency inference can leverage FPGA solutions.
2. Dell EMC is #1 in performance “per Accelerator” with PowerEdge R7525 and A100-PCIe for multiple benchmarks
The Dell EMC PowerEdge R7525 was purpose-built for superior accelerated performance. The MLPerf results validated leading performance across many scenarios including:
Performance Rank “Per Accelerator” | Inference Throughput | Dell EMC System |
#1 ResNet50 (server) | 30,005 | PowerEdge R7525 (3x NVIDIA A100-PCIE) |
#1 3D-Unet-99 (offline) | 39 | PowerEdge R7525 (3x NVIDIA A100-PCIE) |
#1 3D-Unet-99 (offline) | 39 | PowerEdge R7525 (3x NVIDIA A100-PCIE) |
#2 DLRM-99 (server) | 192,543 | PowerEdge R7525 (2x NVIDIA A100-PCIE) |
#2 DLRM-99 (server) | 192,543 | PowerEdge R7525 (2x NVIDIA A100-PCIE) |
3. Dell achieved the highest inference scores with NVIDIA Quadro RTX GPUs using the DSS 8440 and R7525
Dell Technologies engineering understands that since training isn’t the only AI workload, using the right technology for each job is far more cost effective. Dell is the only vendor to submit results using NVIDIA RTX6000 and RTX8000 GPUs that provide up to 48GB HBM memory for large inference models. The DSS 8440 with 10 Quadro RTX achieved
- #2 and #3 highest system performance on RNN-T for Offline scenario.
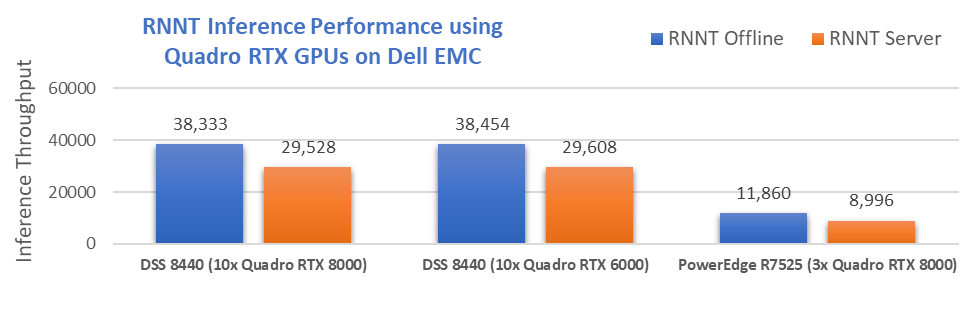
The #1 ranking was delivered using 8x NVIDIA A100 SXM4 that was introduced in May 2020 and is a powerful system for customer to train state of the art deep learning models. Dell Technologies took the #2 and #3 spots with the DSS8440 server equipped with 10x NVIDIA RTX8000 and DSS8440 with 10x NVIDIA RTX6000 providing a better power and cost efficiency for inference workloads compared to other submissions.
4. Dell EMC claims #1 spots for NVIDIA T4 platforms with DSS 8440, XE2420 and PowerEdge R7525
Dell Technologies provides system options for customers to deploy inference workloads that match their unique requirements. Today’s accelerators vary significantly in price, performance and power consumption. For example, the NVIDIA T4 is a low profile, lower power GPU option that is widely deployed for inference due to its superior power efficiency and economic value for that use case.
The MLPerf results corroborate the exemplary inference performance of NVIDIA T4 on Dell EMC Servers. The T4 leads for performance per GPU among the 20 servers used to submit scores using NVIDIA T4 GPUs
- #1 in performance per GPU on 3d-unet-99 and 3d-unet-99.9 Offline scenario
- #1 in performance per GPU on Bert-99 Server and Bert-99.9 Offline scenario
- #1, #2 and #3 in performance with T4 on DLRM-99 & DLRM-99.9 Server scenario
- #1 in performance per GPU on ResNet50 Offline scenario
- #1 in performance per GPU on RNN-T Server and Offline scenario
- #1 in performance per GPU on SSD-large Offline scenario
The best scores achieved for the NVIDIA T4 “Per GPU” rankings above and respective platforms are shown in the table:
Benchmark | Offline Scenario | Server Scenario | ||||
Rank | Throughput | Server | Rank | Throughput | Server | |
3d-unet-99 | #1 | 7.6 | XE2420 | n/a | ||
3d-unet-99.9 | #1 | 7.6 | XE2420 | n/a |
|
|
bert-99 | #3 | 449 | XE2420 | #1 | 402 | XE2420 |
bert-99.9 | #1 | 213 | DSS 8440 | #2 | 190 | XE2420 |
dlrm-99 | #2 | 35,054 | XE2420 | #1 | 32,507 | R7525 |
dlrm-99.9 | #2 | 35,054 | XE2420 | #1 | 32,507 | R7525 |
resnet | #1 | 6,285 | XE2420 | #4 | 5,663 | DSS 8440 |
rnnt | #1 | 1,560 | XE2420 | #1 | 1,146 | XE2420 |
ssd-large | #1 | 142 | XE2420 | #2 | 131 | DSS 8440 |
5. Dell is the only vendor to submit results on virtualized infrastructure with vCPUs and NVIDIA virtual GPUs (vGPU) on VMware vSphere
Customers interested in deploying inference workloads for AI on virtualized infrastructure can leverage Dell servers with VMware software to reap the benefits of virtualization.
To demonstrate efficient virtualized performance on Intel 2nd Generation Intel Xeon Scalable processors, Dell EMC and VMware submitted results using vSphere and OpenVino on the PowerEdge R640.
- Virtualization overhead for a single VM was observed to be minimal and testing showed that using multiple VMs could be deployed on a single server to achieve ~26% better throughput compared to a bare metal environment.
Dell EMC has published guidance on virtualizing GPUs using DirectPath I/O, NVIDIA Virtual Compute Server (vCS) and more. Dell EMC and VMware used NVIDIA vCS virtualization software in vSphere for MLPerf Inference benchmarks on virtualized NVIDIA T4 GPUs
- VMware vSphere using NVIDIA vCS delivers near bare metal performance for MLPerf Inference v0.7 benchmarks. The inference throughput (queries processed per second) increases linearly as the number of vGPUs attached to the VM increases.
Blogs covering these virtualized tests in greater detail are published at VMware’s performance Blog site.
This finishes our coverage of the top 5 highlights out of the 200+ submissions done by Dell EMC in the datacenter division. Next we discuss other aspects of the GPU optimized portfolio that are important for customers – quality and support.
Dell has the highest number of NVIDIA GPU submissions using NVIDIA NGC Ready systems
Dell GPU enabled platforms are part of NVIDIA NGC-Ready and NGC-Ready for Edge validation programs. At Dell, we understand that performance is critical, but customers are not willing to compromise quality and reliability to achieve maximum performance. Customers can confidently deploy inference and other software applications from the NVIDIA NGC catalog knowing that the Dell systems meet all the requirements set by NVIDIA to deploy customer workloads on-premises or at the Edge.
 NVIDIA NGC validated configs that were used for this round of MLPerf submissions are:
NVIDIA NGC validated configs that were used for this round of MLPerf submissions are:
- Dell EMC PowerEdge XE2420 (4x T4)
- Dell EMC DSS 8440 (10x Quadro RTX 8000)
- Dell EMC DSS 8440 (12x T4)
- Dell EMC DSS 8440 (16x T4)
- Dell EMC DSS 8440 (8x Quadro RTX 8000)
- Dell EMC PowerEdge R740 (4x T4)
- Dell EMC PowerEdge R7515 (4x T4)
- Dell EMC PowerEdge R7525 (2x A100-PCIE)
- Dell EMC PowerEdge R7525 (3x Quadro RTX 8000)
Dell EMC portfolio can address customers inference needs from on-premises to the edge
In this blog, we highlighted the results submitted by Dell EMC to demonstrate how our various servers performed in the datacenter category. The Dell EMC server portfolio provides many options for customer wanting to deploy AI inference in their datacenters or on the edge. We also offer a wide range of accelerator options including both multiple GPU and FPGA models for running inference either on bare metal or virtualized infrastructure that can meet specific application and deployment requirements.
Finally, we list the performance for a subset of the server platforms that we see mostly commonly used by customers today for running inference workloads. These rankings highlight that the platform can support a wide range of inference use cases that are showcased in the MLPerf suite.
1. The Dell EMC PowerEdge XE2420 with 4x NVIDIA T4 GPUs: Ranked between #1 and #3 in 14 out of 16 benchmark categories when compared with other T4 Servers
Dell EMC PowerEdge XE2420 (4x T4) Per Accelerator Ranking* | |||
| Offline | Server |
|
3d-unet-99 | #1 | n/a
| |
3d-unet-99.9 | #1 | ||
bert-99 | #3 | #1 | |
bert-99.9 | #2 | #2 | |
dlrm-99 | #1 | #3 | |
dlrm-99.9 | #1 | #3 | |
resnet | #1 |
| |
rnnt | #1 | #1 | |
ssd-large | #1 |
| |

2. Dell EMC PowerEdge R7525 with 8x T4 GPUs: Ranked between #1 and #5 in 11 out of 16 benchmark categories in T4 server submission
Dell EMC PowerEdge R7525 (8x T4) Per Accelerator Ranking* | |||
| Offline | Server |
|
3d-unet-99 | #4 | n/a
| |
3d-unet-99.9 | #4 | ||
bert-99 | #4 |
| |
dlrm-99 | #2 | #1 | |
dlrm-99.9 | #2 | #1 | |
rnnt | #2 | #5 | |
ssd-large | #5 |
| |

3. The Dell EMC PowerEdge R7525 with up to 3xA100-PCIe: ranked between #3 and #10 in 15 out of 16 benchmark categories across all datacenter submissions
Dell EMC PowerEdge R7525 (2|3x A100-PCIe) Per Accelerator | |||
| Offline | Server |
|
3d-unet-99 | #4 | n/a
| |
3d-unet-99.9 | #4 | ||
bert-99 | #8 | #9 | |
bert-99.9 | #7 | #8 | |
dlrm-99 | #6 | #4 | |
dlrm-99.9 | #6 | #4 | |
resnet | #10 | #3 | |
rnnt | #6 | #7 | |
ssd-large | #10 |
| |

4. The Dell EMC DSS 8440 with 16x T4 ranked between #3 and #7 when compared against all submissions using T4
Dell EMC DSS 8440 (16x T4) | |||
| Offline | Server |
|
3d-unet-99 | #4 | n/a
| |
3d-unet-99.9 | #4 | ||
bert-99 | #6 | #4 | |
bert-99.9 | #7 | #5 | |
dlrm-99 | #3 | #3 | |
dlrm-99.9 | #3 | #3 | |
resnet | #6 | #4 | |
rnnt | #5 | #5 | |
ssd-large | #7 | #5 | |

5. The Dell EMC DSS 8440 with 10x RTX6000 ranked between #2 and #6 in 14 out of 16 benchmarks when compared against all submissions
Dell EMC DSS 8440 (10x Quadro RTX6000) | |||
| Offline | Server |
|
3d-unet-99 | #4 | n/a
| |
3d-unet-99.9 | #4 | ||
bert-99 | #4 | #5 | |
bert-99.9 | #4 | #5 | |
dlrm-99 |
|
| |
dlrm-99.9 |
|
| |
resnet | #5 | #6 | |
rnnt | #2 | #5 | |
ssd-large | #5 | #6 | |

6. Dell EMC DSS 8440 with 10x RTX8000 ranked between #2 and #6 when compared against all submissions
Dell EMC DSS 8440 (10x Quadro RTX8000) | |||
| Offline | Server |
|
3d-unet-99 | #5 | n/a
| |
3d-unet-99.9 | #5 | ||
bert-99 | #5 | #4 | |
bert-99.9 | #5 | #4 | |
dlrm-99 | #3 | #3 | |
dlrm-99.9 | #3 | #3 | |
resnet | #6 | #5 | |
rnnt | #3 | #6 | |
ssd-large | #6 | #5 | |

Get more information on MLPerf results at www.mlperf.org and earn more about PowerEdge servers that are optimized for AI / ML / DL at www.DellTechnologies.com/Servers
Acknowledgements: These impressive results were made possible by the work of the following Dell EMC and partner team members - Shubham Billus, Trevor Cockrell, Bagus Hanindhito (Univ. of Texas, Austin), Uday Kurkure (VMWare), Guy Laporte, Anton Lokhmotov (Dividiti), Bhavesh Patel, Vilmara Sanchez, Rakshith Vasudev, Lan Vu (VMware) and Nicholas Wakou. We would also like to thank our partners – NVIDIA, Intel and Xilinx for their help and support in MLPerf v0.7 Inference submissions.

Deep Learning Performance with MLPerf Inference v0.7 Benchmark
Mon, 21 Jun 2021 18:33:56 -0000
|Read Time: 0 minutes
Summary
MLPerf is a benchmarking suite that measures the performance of Machine Learning (ML) workloads. It focuses on the most important aspects of the ML life cycle:
- Training—The MLPerf training benchmark suite measures how fast a system can train ML models.
- Inference—The MLPerf inference benchmark measures how fast a system can perform ML inference by using a trained model in various deployment scenarios.
This blog outlines the MLPerf inference v0.7 data center closed results on Dell EMC PowerEdge R7525 and DSS8440 servers with NVIDIA GPUs running the MLPerf inference benchmarks. Our results show optimal inference performance for the systems and configurations on which we chose to run inference benchmarks.
In the MLPerf inference evaluation framework, the LoadGen load generator sends inference queries to the system under test (SUT). In our case, the SUTs are carefully chosen PowerEdge R7525 and DSS8440 servers with various GPU configurations. The SUT uses a backend (for example, TensorRT, TensorFlow, or PyTorch) to perform inferencing and sends the results back to LoadGen.
MLPerf has identified four different scenarios that enable representative testing of a wide variety of inference platforms and use cases. The main differences between these scenarios are based on how the queries are sent and received:
- Offline—One query with all samples is sent to the SUT. The SUT can send the results back once or multiple times in any order. The performance metric is samples per second.
- Server—The queries are sent to the SUT following a Poisson distribution (to model real-world random events). One query has one sample. The performance metric is queries per second (QPS) within latency bound.
- Single-stream—One sample per query is sent to the SUT. The next query is not sent until the previous response is received. The performance metric is 90th percentile latency.
- Multi-stream—A query with N samples is sent with a fixed interval. The performance metric is max N when the latency of all queries is within a latency bound.
MLPerf Inference Rules describes detailed inference rules and latency constraints. This blog only focuses on Offline and Server scenarios, which are designed for data center environments. Single-stream and Multi-stream scenarios are designed for nondatacenter (edge and IoT) settings.
MLPerf Inference results can be submitted under either of the following divisions:
- Closed division—The Closed division is intended to provide an “apples to apples” comparison of hardware platforms or software frameworks. It requires using the same model and optimizer as the reference implementation.
The Closed division requires using preprocessing, postprocessing, and model that is equivalent to the reference or alternative implementation. It allows calibration for quantization and does not allow any retraining. MLPerf provides a reference implementation of each benchmark. The benchmark implementation must use a model that is equivalent, as defined in MLPerf Inference Rules, to the model used in the reference implementation.
- Open division—The Open division is intended to foster faster models and optimizers and allows any ML approach that can reach the target quality. It allows using arbitrary preprocessing or postprocessing and model, including retraining. The benchmark implementation may use a different model to perform the same task.
To allow the apples-to-apples comparison of Dell EMC results and enable our customers and partners to repeat our results, we chose to conduct testing under the Closed division, as shown in the results in this blog.
Criteria for MLPerf Inference v0.7 benchmark result submission
The following table describes the MLPerf benchmark expectations:
Table 1: Available benchmarks in the Closed division for MLPerf inference v0.7 with their expectations.
Area | Task | Model | Dataset | QSL size | Required quality | Required server latency constraint |
Vision | Image classification | Resnet50-v1.5 | Standard image dataset (224 x 224 x 3) | 1024 | 99% of FP32 (76.46%) | 15 ms |
Vision | Object detection (large) | SSD-ResNet34 | COCO (1200x1200) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
Vision | Medical image segmentation | 3D UNET | BraTS 2019 (224x224x160) | 16 | 99% of FP32 and 99.9% of FP32 (0.85300 mean DICE score) | N/A |
Speech | Speech-to-text | RNNT | Librispeech dev-clean (samples < 15 seconds) | 2513 | 99% of FP32 (1 - WER, where WER=7.452253714852645%) | 1000 ms |
Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Commerce | Recommendation | DLRM | 1 TB Click Logs | 204800 | 99% of FP32 and 99.9% of FP32 (AUC=80.25%) | 30 ms |
For any benchmark, it is essential for the result submission to meet all the specifications in this table. For example, if we choose the Resnet50 model, then the submission must meet the 76.46 percent target accuracy and the latency must be within 15 ms for the standard image dataset with dimensions of 224 x 224 x 3.
Each data center benchmark requires the scenarios in the following table:
Table 2: Tasks and corresponding required scenarios for data center benchmark suite in MLPerf inference v0.7.
Area | Task | Required scenarios |
Vision | Image classification | Server, Offline |
Vision | Object detection (large) | Server, Offline |
Vision | Medical image segmentation | Offline |
Speech | Speech-to-text | Server, Offline |
Language | Language processing | Server, Offline |
Commerce | Recommendation | Server, Offline |
SUT configurations
We selected the following servers with different types of NVIDIA GPUs as our SUT to conduct data center inference benchmarks:
Results
The following provides the results of the MLPerf Inference v0.7 benchmark.
For the Offline scenario, the performance metric is Offline samples per second. For the Server scenario, the performance metric is queries per second (QPS). In general, the metrics represent throughput.
The following graphs include performance metrics for the Offline and Server scenarios. A higher throughput is a better result.
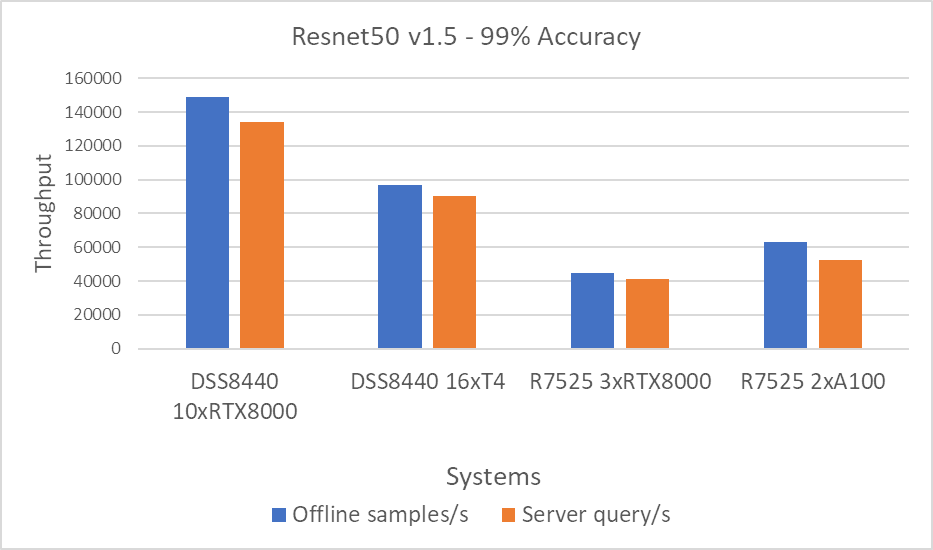
Figure 1: Resnet50 v1.5 Offline and Server scenario with 99 percent accuracy target
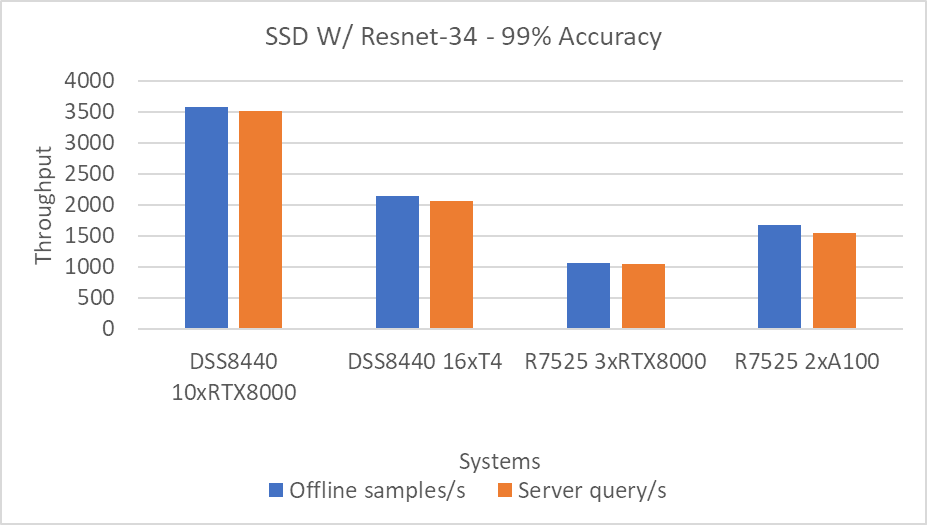
Figure 2: SSD w/ Resnet34 Offline and Server scenario with 99 percent accuracy target
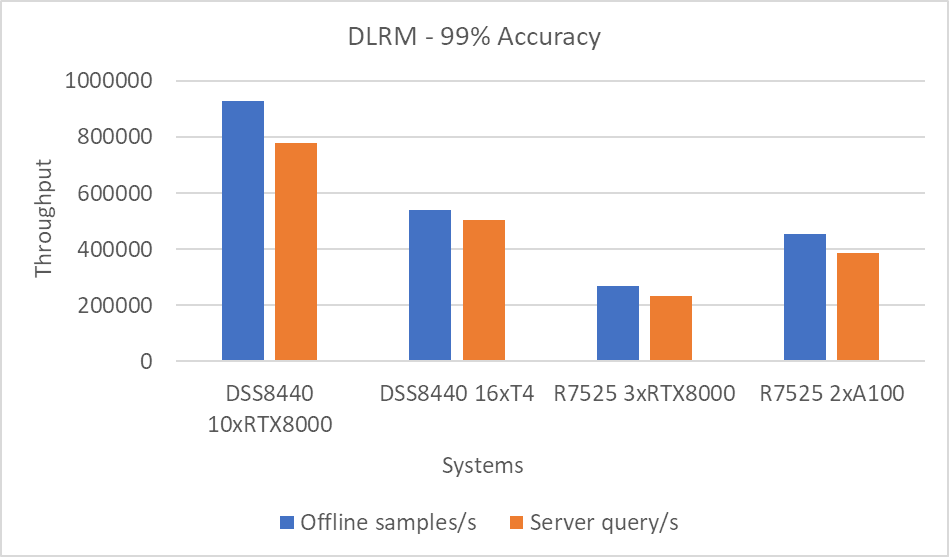
Figure 3: DLRM Offline and Server scenario with 99 percent accuracy target

Figure 4: DLRM Offline and Server scenario with 99.9 percent accuracy target
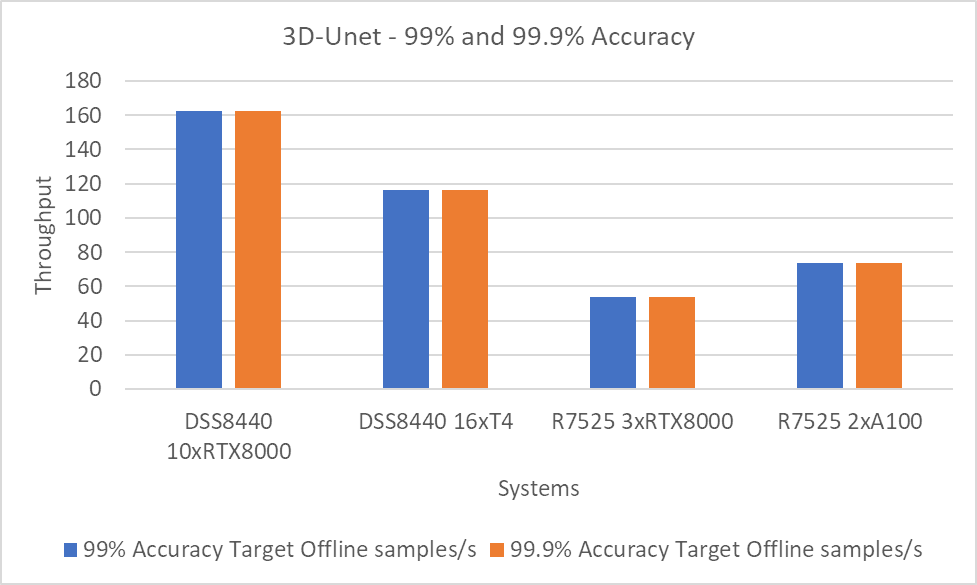
Figure 5: 3D-Unet using the 99 and 99.9 percent accuracy targets.
Note: The 99 and 99.9 percent accuracy targets with DLRM and 3D-Unet show the same performance because the accuracy targets were met early.
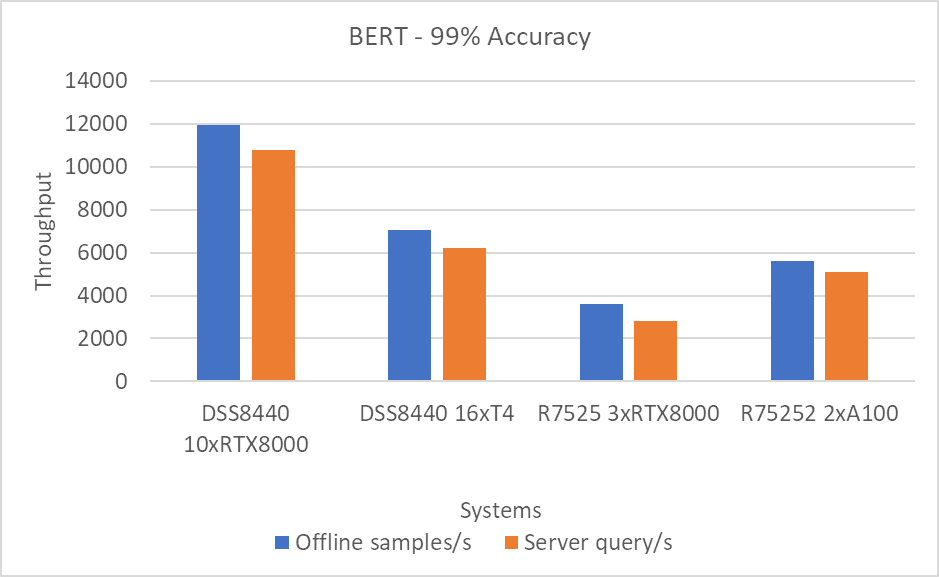
Figure 6: BERT Offline and Server scenario with 99 percent accuracy target
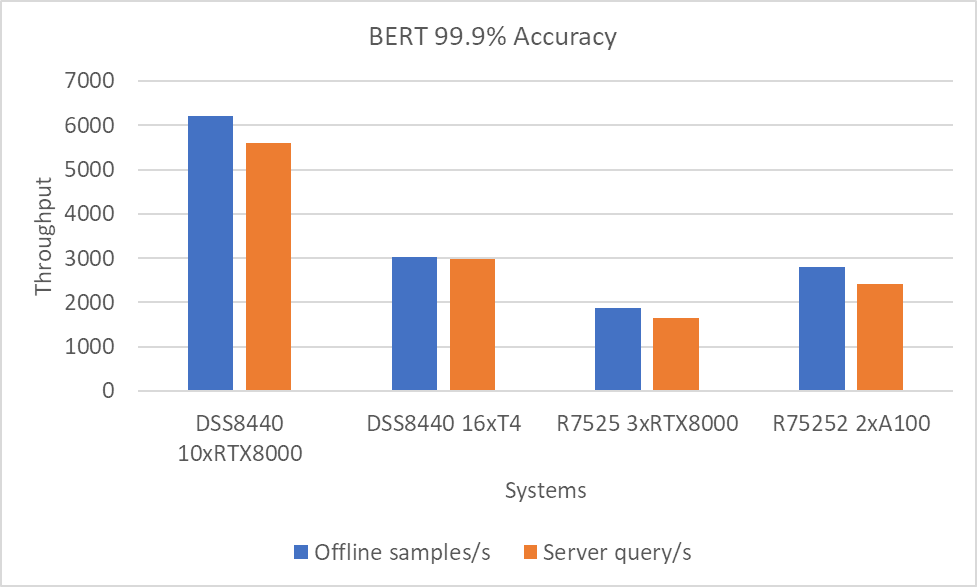
Figure 7: BERT Offline and Server scenario with 99.9 percent accuracy target.
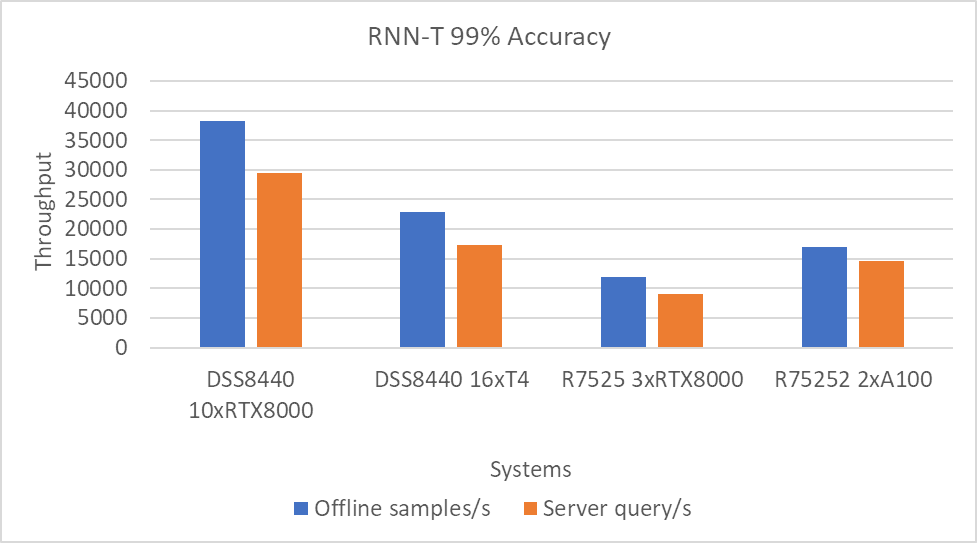
Figure 8: RNN-T Offline and Server scenario with 99 percent accuracy target
Performance per GPU
For an estimate of per GPU performance, we divided the results in the previous section by the number of GPUs on the system. We observed that the performance scales linearly as we increase the number of GPUs. That is, as we add more cards, the performance of the system is multiplied by the number of cards times the performance per card. We will provide this information in a subsequent blog post.
The following figure shows the approximate per GPU performance:
Figure 9: Approximate per card performance for the Resnet50 Offline scenario
The R7525_QuadroRTX8000x3 and DSS8440_QuadroRTX8000x10 systems both use the RTX8000 card. Therefore, performance per card for these two systems is about the same. The A100 cards yield the highest performance; the T4 cards yield the lowest performance.
Conclusion
In this blog, we quantified the MLPerf inference v0.7 performance on Dell EMC DSS8440 and PowerEdge R7525 severs with NVIDIA A100, RTX8000, and T4 GPUs with Resnet50, SSD w/ Resnet34, DLRM, BERT, RNN-T, and 3D-Unet benchmarks. These benchmarks span tasks from vision to recommendation. Dell EMC servers delivered top inference performance normalized to processor count among commercially available results. We found that the A100 GPU delivered the best overall performance and best performance-per-watt while the RTX GPUs delivered the best performance-per-dollar. If constrained in a limited power environment, T4 GPUs deliver the best performance-per-watt.
Next steps
In future blogs, we plan to describe how to:
- Run and performance tune MLPerf inference v0.7
- Size the system (server and GPU configurations) correctly based on the type of workload (area and task)
- Understand per-card, per-watt, and per-dollar metrics to determine your infrastructure needs
- Understand MLPerf training results on recently released R7525 PowerEdge servers with NVIDIA A100 GPUs

Running the MLPerf Inference v0.7 Benchmark on Dell EMC Systems
Mon, 21 Jun 2021 18:22:09 -0000
|Read Time: 0 minutes
MLPerf is a benchmarking suite that measures the performance of Machine Learning (ML) workloads. It focuses on the most important aspects of the ML life cycle:
- Training—The MLPerf training benchmark suite measures how fast a system can train ML models.
- Inference—The MLPerf inference benchmark measures how fast a system can perform ML inference by using a trained model in various deployment scenarios.
The MLPerf inference v0.7 suite contains the following models for benchmark:
- Resnet50
- SSD-Resnet34
- BERT
- DLRM
- RNN-T
- 3D U-Net
Note: The BERT, DLRM, and 3D U-Net models have 99% (default accuracy) and 99.9% (high accuracy) targets.
This blog describes the steps to run MLPerf inference v0.7 tests on Dell Technologies servers with NVIDIA GPUs. It helps you run and reproduce the results that we observed in our HPC and AI Innovation Lab. For more details about the hardware and the software stack for different systems in the benchmark, see this GitHub repository.
Getting started
A system under test consists of a defined set of hardware and software resources that will be measured for performance. The hardware resources may include processors, accelerators, memories, disks, and interconnect. The software resources may include an operating system, compilers, libraries, and drivers that significantly influences the running time of a benchmark. In this case, the system on which you clone the MLPerf repository and run the benchmark is known as the system under test (SUT).
For storage, SSD RAID or local NVMe drives are acceptable for running all the subtests without any penalty. Inference does not have strict requirements for fast-parallel storage. However, the BeeGFS or Lustre file system, the PixStor storage solution, and so on help make multiple copies of large datasets.
Clone the MLPerf repository
Follow these steps:
- Clone the repository to your home directory or another acceptable path:
cd - git clone https://github.com/mlperf/inference_results_v0.7.git
- Go to the closed/DellEMC directory:
cd inference_results_v0.7/closed/DellEMC - Create a “scratch” directory to store the models, datasets, preprocessed data, and so on:
mkdir scratchThis scratch directory requires at least 3 TB of space. - Export the absolute path for MLPERF_SCRATCH_PATH with the scratch directory:
export MLPERF_SCRATCH_PATH=/home/user/inference_results_v0.7/closed/DellEMC/scratch
Set up the configuration file
The closed/DellEMC/configs directory includes a config.json file that lists configurations for different Dell servers that were systems in the MLPerf Inference v0.7 benchmark. If necessary, modify the configs/<benchmark>/<Scenario>/config.json file to include the system that will run the benchmark.
Note: If your system is already present in the configuration file, there is no need to add another configuration.
In the configs/<benchmark>/<Scenario>/config.json file, select a similar configuration and modify it based on the current system, matching the number and type of GPUs in your system.
For this blog, we considered our R7525 server with a one-A100 GPU. We chose R7525_A100x1 as the name for this new system. Because the R7525_A100x1 system is not already in the list of systems, we added the R7525_A100x1 configuration.
Because the R7525_A100x2 reference system is the most similar, we modified that configuration and picked Resnet50 Server as the example benchmark.
The following example shows the reference configuration for two GPUs for the Resnet50 Server benchmark in the configs/<benchmark>/<Scenario>/config.json file:
"R7525_A100x2": { "active_sms": 100, "config_ver": { }, "deque_timeout_us": 2000, "gpu_batch_size": 64, "gpu_copy_streams": 4, "gpu_inference_streams": 3, "input_dtype": "int8", "input_format": "linear", "map_path": "data_maps/dataset/val_map.txt", "precision": "int8", "server_target_qps": 52400, "tensor_path": "${PREPROCESSED_DATA_DIR}/dataset/ResNet50/int8_linear", "use_cuda_thread_per_device": true, "use_deque_limit": true, "use_graphs": true },
This example shows the modified configuration for one GPU:
"R7525_A100x1": { "active_sms": 100, "config_ver": { }, "deque_timeout_us": 2000, "gpu_batch_size": 64, "gpu_copy_streams": 4, "gpu_inference_streams": 3, "input_dtype": "int8", "input_format": "linear", "map_path": "data_maps/dataset/val_map.txt", "precision": "int8", "server_target_qps": 26200, "tensor_path": "${PREPROCESSED_DATA_DIR}/datset/ResNet50/int8_linear", "use_cuda_thread_per_device": true, "use_deque_limit": true, "use_graphs": true },
We modified the QPS parameter (server_target_qps) to match the number of GPUs. The server_target_qps parameter is linearly scalable, therefore the QPS = number of GPUs x QPS per GPU.
We only modified the server_target_qps parameter to get a baseline run first. You can also modify other parameters such as gpu_batch_size, gpu_copy_streams, and so on. We will discuss these other parameters in a future blog that describes performance tuning.
Finally, we added the modified configuration for the new R7525_A100x1 system to the configuration file at configs/resnet50/Server/config.json.
Register the new system
After you add the new system to the config.json file, register the new system in the list of available systems. The list of available systems is in the code/common/system_list.py file.
Note: If your system is already registered, there is no need to add it to the code/common/system_list.py file.
To register the system, add the new system to the list of available systems in the code/common/system_list.py file, as shown in the following:
# (system_id, gpu_name_from_driver, gpu_count) system_list = ([ ("R740_vT4x4", "GRID T4-16Q", 4), ("XE2420_T4x4", "Tesla T4", 4), ("DSS8440_T4x12", "Tesla T4", 12), ("R740_T4x4", "Tesla T4", 4), ("R7515_T4x4", "Tesla T4", 4), ("DSS8440_T4x16", "Tesla T4", 16), ("DSS8440_QuadroRTX8000x8", "Quadro RTX 8000", 8), ("DSS8440_QuadroRTX6000x10", "Quadro RTX 6000", 10), ("DSS8440_QuadroRTX8000x10", "Quadro RTX 8000", 10), ("R7525_A100x2", "A100-PCIE-40GB", 2), ("R7525_A100x3", "A100-PCIE-40GB", 3), ("R7525_QuadroRTX8000x3", "Quadro RTX 8000", 3), ("R7525_A100x1", "A100-PCIE-40GB", 1), ])
In the preceding example, the last line under system_list is the newly added R7525_A100x1 system. It is a tuple of the form (<system name>, <GPU name>, <GPU count>). To find the GPU name from the driver, run the nvidia-smi -L command.
Note: Ensure that you add the system configuration for all the benchmarks that you intend to run and add the system to the system_list.py file. Otherwise, the results might be suboptimal. The benchmark might choose the wrong system configuration or not run at all because it could not find appropriate configuration.
Build the Docker image and required libraries
Build the Docker image and then launch an interactive container. Then, in the interactive container, build the required libraries for inferencing.
- To build the Docker image, run the following command:
make prebuild………
Launching Docker interactive session docker run --gpus=all --rm -ti -w /work -v /home/user/inference_results_v0.7/closed/DellEMC:/work -v /home/user:/mnt// user \ --cap-add SYS_ADMIN -e NVIDIA_MIG_CONFIG_DEVICES="all" \ -v /etc/timezone:/etc/timezone:ro -v /etc/localtime:/etc/localtime:ro \ --security-opt apparmor=unconfined --security-opt seccomp=unconfined \ --name mlperf-inference-user -h mlperf-inference-userv0.7 --add-host mlperf-inference-user:127.0.0.1 \ --user 1004:1004 --net host --device /dev/fuse --cap-add SYS_ADMIN \ -e MLPERF_SCRATCH_PATH=”/home/user/ inference_results_v0.7 /closed/DellEMC/scratch” mlperf-inference:user (mlperf) user@mlperf-inference-user:/work$
The Docker container is launched with all the necessary packages installed. - Access the interactive terminal on the container.
- To build the required libraries for inferencing, run the following command inside the interactive container:
make build(mlperf) user@mlperf-inference-user:/work$ make build ……. [ 92%] Built target harness_triton [ 96%] Linking CXX executable /work/build/bin/harness_default [100%] Linking CXX executable /work/build/bin/harness_rnnt make[4]: Leaving directory '/work/build/harness' [100%] Built target harness_default make[4]: Leaving directory '/work/build/harness' [100%] Built target harness_rnnt make[3]: Leaving directory '/work/build/harness' make[2]: Leaving directory '/work/build/harness' Finished building harness. make[1]: Leaving directory '/work' (mlperf) user@mlperf-inference-user:/work
Download and preprocess validation data and models
To run MLPerf inference v0.7, download datasets and models, and then preprocess them. MLPerf provides scripts that download the trained models. The scripts also download the dataset for benchmarks other than Resnet50, DLRM, and 3D U-Net.
For Resnet50, DLRM, and 3D U-Net, register for an account and then download the datasets manually:
- DLRM—Download the Criteo Terabyte dataset and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/criteo/
- 3D U-Net—Download the BraTS challenge data and extract the downloaded file to $MLPERF_SCRATCH_PATH/data/BraTS/MICCAI_BraTS_2019_Data_Training
Except for the Resnet50, DLRM, and 3D U-Net datasets, run the following commands to download all the models, datasets, and then preprocess them:
$ make download_model # Downloads models and saves to $MLPERF_SCRATCH_PATH/models $ make download_data # Downloads datasets and saves to $MLPERF_SCRATCH_PATH/data $ make preprocess_data # Preprocess data and saves to $MLPERF_SCRATCH_PATH/preprocessed_data
Note: These commands download all the datasets, which might not be required if the objective is to run one specific benchmark. To run a specific benchmark rather than all the benchmarks, see the following sections for information about the specific benchmark.
After building the libraries and preprocessing the data, the folders containing the following are displayed:
(mlperf) user@mlperf-inference-user:/work$ tree -d -L 1.
├── build—Logs, preprocessed data, engines, models, plugins, and so on
├── code—Source code for all the benchmarks
├── compliance—Passed compliance checks
├── configs—Configurations that run different benchmarks for different system setups
├── data_maps—Data maps for different benchmarks
├── docker—Docker files to support building the container
├── measurements—Measurement values for different benchmarks
├── results—Final result logs
├── scratch—Storage for models, preprocessed data, and the dataset that is symlinked to the preceding build directory
├── scripts—Support scripts
└── systems—Hardware and software details of systems in the benchmark
Running the benchmarks
Run any of the benchmarks that are required for your tests.
The Resnet50, SSD-Resnet34, and RNN-T benchmarks have 99% (default accuracy) targets.
The BERT, DLRM, and 3D U-Net benchmarks have 99% (default accuracy) and 99.9% (high accuracy) targets. For information about running these benchmarks, see the Running high accuracy target benchmarks section below.
If you downloaded and preprocessed all the datasets (as shown in the previous section), there is no need to do so again. Skip the download and preprocessing steps in the procedures for the following benchmarks.
NVIDIA TensorRT is the inference engine for the backend. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning applications.
Run the Resnet50 benchmark
To set up the Resnet50 dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go step 5.
- Download the required validation dataset (https://github.com/mlcommons/training/tree/master/image_classification).
- Extract the images to $MLPERF_SCRATCH_PATH/data/dataset/.
- Run the following commands:
make download_model BENCHMARKS=resnet50 make preprocess_data BENCHMARKS=resnet50
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=resnet50 --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
The following output is displayed for a “PerformanceOnly” mode:
The following is a “VALID“ result: ======================= Perf harness results: ======================= R7525_A100x1_TRT-default-Server: resnet50: Scheduled samples per second : 26212.91 and Result is : VALID ======================= Accuracy results: ======================= R7525_A100x1_TRT-default-Server: resnet50: No accuracy results in PerformanceOnly mode.
Run the SSD-Resnet34 benchmark
To set up the SSD-Resnet34 dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=ssd-resnet34 make download_data BENCHMARKS=ssd-resnet34 make preprocess_data BENCHMARKS=ssd-resnet34
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=ssd-resnet34 --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
Run the RNN-T benchmark
To set up the RNN-T dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=rnnt make download_data BENCHMARKS=rnnt make preprocess_data BENCHMARKS=rnnt
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario make generate_engines RUN_ARGS="--benchmarks=rnnt --scenarios=Offline,Server --config_ver=default"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=rnnt --scenarios=Server --config_ver=default --test_mode=AccuracyOnly"
Running high accuracy target benchmarks
The BERT, DLRM, and 3D U-Net benchmarks have high accuracy targets.
Run the BERT benchmark
To set up the BERT dataset and model to run the inference:
- If necessary, download and preprocess the dataset:
make download_model BENCHMARKS=bert make download_data BENCHMARKS=bert make preprocess_data BENCHMARKS=bert
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and also for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=bert --scenarios=Offline,Server --config_ver=default,high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=bert --scenarios=Server --config_ver=high_accuracy --test_mode=AccuracyOnly"
Run the DLRM benchmark
To set up the DLRM dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go to step 5.
- Download the Criteo Terabyte dataset.
- Extract the images to $MLPERF_SCRATCH_PATH/data/criteo/ directory.
- Run the following commands:
make download_model BENCHMARKS=dlrm make preprocess_data BENCHMARKS=dlrm
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and also for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=dlrm --scenarios=Offline,Server --config_ver=default, high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=dlrm --scenarios=Server --config_ver=high_accuracy --test_mode=AccuracyOnly"
Run the 3D U-Net benchmark
Note: This benchmark only has the Offline scenario.
To set up the 3D U-Net dataset and model to run the inference:
- If you already downloaded and preprocessed the datasets, go to step 5
- Download the BraTS challenge data.
- Extract the images to the $MLPERF_SCRATCH_PATH/data/BraTS/MICCAI_BraTS_2019_Data_Training directory.
- Run the following commands:
make download_model BENCHMARKS=3d-unet make preprocess_data BENCHMARKS=3d-unet
- Generate the TensorRT engines:
# generates the TRT engines with the specified config. In this case it generates engine for both Offline and Server scenario and for default and high accuracy targets. make generate_engines RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default,high_accuracy"
- Run the benchmark:
# run the performance benchmark make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly" make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=high_accuracy --test_mode=PerformanceOnly" # run the accuracy benchmark make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=default --test_mode=AccuracyOnly" make run_harness RUN_ARGS="--benchmarks=3d-unet --scenarios=Offline --config_ver=high_accuracy --test_mode=AccuracyOnly"
Limitations and Best Practices
Note the following limitations and best practices:
- To build the engine and run the benchmark by using a single command, use the make run RUN_ARGS… shortcut. The shortcut is valid alternative to the make generate_engines … && make run_harness.. commands.
- If the server results are “INVALID”, reduce the QPS. If the latency constraints are not met during the run, “INVALID” results are expected.
- If you change the batch size, rebuild the engine.
- Only the BERT, DLRM, 3D-Unet benchmarks support high accuracy targets.
- 3D-UNet only has Offline scenario.
Conclusion
This blog provided the step-by-step procedures to run and reproduce MLPerf inference v0.7 results on Dell Technologies servers with NVIDIA GPUs.
Next steps
In future blogs, we will discuss techniques to improvise performance.

Omnia: Open-source deployment of high-performance clusters to run simulation, AI, and data analytics workloads
Mon, 12 Dec 2022 18:31:28 -0000
|Read Time: 0 minutes
High Performance Computing (HPC), in which clusters of machines work together as one supercomputer, is changing the way we live and how we work. These clusters of CPU, memory, accelerators, and other resources help us forecast the weather and understand climate change, understand diseases, design new drugs and therapies, develop safe cars and planes, improve solar panels, and even simulate life and the evolution of the universe itself. The cluster architecture model that makes this compute-intensive research possible is also well suited for high performance data analytics (HPDA) and developing machine learning models. With the Big Data era in full swing and the Artificial Intelligence (AI) gold rush underway, we have seen marketing teams with their own Hadoop clusters attempting to transition to HPDA and finance teams managing their own GPU farms. Everyone has the same goals: to gain new, better insights faster by using HPDA and by developing advanced machine learning models using techniques such as deep learning and reinforcement learning. Today, everyone has a use for their own high-performance computing cluster. It’s the age of the clusters!
Today's AI-driven IT Headache: Siloed Clusters and Cluster Sprawl
Unfortunately, cluster sprawl has taken over our data centers and consumes inordinate amounts of IT resources. Large research organizations and businesses have a cluster for this and a cluster for that. Perhaps each group has a little “sandbox” cluster, or each type of workload has a different cluster. Many of these clusters look remarkably similar, but they each need a dedicated system administrator (or set of administrators), have different authorization credentials, different operating models, and sit in different racks in your data center. What if there was a way to bring them all together?
That’s why Dell Technologies, in partnership with Intel, started the Omnia project.
The Omnia Project
The Omnia project is an open-source initiative with a simple aim: To make consolidated infrastructure easy and painless to deploy using open open source and free use software. By bringing the best open source software tools together with the domain expertise of Dell Technologies' HPC & AI Innovation Lab, HPC & AI Centers of Excellence, and the broader HPC Community, Omnia gives customers decades of accumulated expertise in deploying state-of-the-art systems for HPC, AI, and Data Analytics – all in a set of easily executable Ansible playbooks. In a single day, a stack of servers, networking switches, and storage arrays can be transformed into one consolidated cluster for running all your HPC, AI, and Data Analytics workloads. Omnia project logo
Omnia project logo
Simple by Design
Omnia’s design philosophy is simplicity. We look for the best, most straightforward approach to solving each task.
- Need to run the Slurm workload manager? Omnia assembles Ansible plays which build the right rpm files and deploy them correctly, making sure all the correct dependencies are installed and functional.
- Need to run the Kubernetes container orchestrator? Omnia takes advantage of community supported package repositories for Linux (currently CentOS) and automates all the steps for creating a functional multi-node Kubernetes cluster.
- Need a multi-user, interactive Python/R/Julia development environment? Omnia takes advantage of best-of-breed deployments for Kubernetes through Helm and OperatorHub, provides configuration files for dynamic and persistent storage, points to optimized containers in DockerHub, Nvidia GPU Cloud (NGC), or other container registries for unaccelerated and accelerated workloads, and automatically deploys machine learning platforms like Kubeflow.
Before we go through the process of building something from scratch, we will make sure there isn’t already a community actively maintaining that toolset. We’d rather leverage others' great work than reinvent the wheel.
Inclusive by Nature
Omnia’s contribution philosophy is inclusivity. From code and documentation updates to feature requests and bug reports, every user’s contributions are welcomed with open arms. We provide an open forum for conversations about feature ideas and potential implementation solutions, making use of issue threads on GitHub. And as the project grows and expands, we expect the technical governance committee to grow to include the top contributors and stakeholders from the community.
What's Next?
Omnia is just getting started. Right now, we can easily deploy Slurm and Kubernetes clusters from a stack of pre-provisioned, pre-networked servers, but our aim is higher than that. We are currently adding capabilities for performing bare-metal provisioning and supporting new and varying types of accelerators. In the future, we want to collect information from the iDRAC out-of-band management system on Dell EMC PowerEdge servers, configure Dell EMC PowerSwitch Ethernet switches, and much more.
What does the future hold? While we have plans in the near-term for additional feature integrations, we are looking to partner with the community to define and develop future integrations. Omnia will grow and develop based on community feedback and your contributions. In the end, the Omnia project will not only install and configure the open source software we at Dell Technologies think is important, but the software you – the community – want it to, as well! We can’t think of a better way for our customers to be able to easily setup clusters for HPC, AI, and HPDA workloads, all while leveraging the expertise of the entire Dell Technologies' HPC Community.
Omnia is available today on GitHub at https://github.com/dellhpc/omnia. Join the community now and help guide the design and development of the next generation of open-source consolidated cluster deployment tools!

Bare Metal Compared with Kubernetes
Mon, 17 Aug 2020 23:55:52 -0000
|Read Time: 0 minutes
It has been fascinating to watch the tide of application containerization build from stateless cloud native web applications to every type of data-centric workload. These workloads include high performance computing (HPC), machine learning and deep learning (ML/DL), and now most major SQL and NoSQL databases. As an example, I recently read the following Dell Technologies knowledge base article: Bare Metal vs Kubernetes: Distributed Training with TensorFlow.
Bare metal and bare metal server refer to implementations of applications that are directly on the physical hardware without virtualization, containerization, and cloud hosting. Many times, bare metal is compared to virtualization and containerization is used to contrast performance and manageability features. For example, contrasting an application on bare metal to an application running in a container can provide insights into the potential performance differences between the two implementations.
Figure 1: Comparison of bare metal to containers implementations
Containers encapsulate an application with supporting binaries and libraries to run on one shared operating system. The container’s runtime engine or management applications, such as Kubernetes, manage the container. Because of the shared operating system, a container’s infrastructure is lightweight, providing more reason to understand the differences in terms of performance.
In the case of comparing bare metal with Kubernetes, distributed training with TensorFlow performance was measured in terms of throughput. That is, we measured the number of images per second when training CheXNet. Five tests were run in which each test consecutively added more GPUs across the bare metal and Kubernetes systems. The solid data points in Figure 2 show that the tests were run using 1, 2, 3, 4, and 8 GPUs.
Figure 2: Running CheXNet training on Kubernetes compared to bare metal
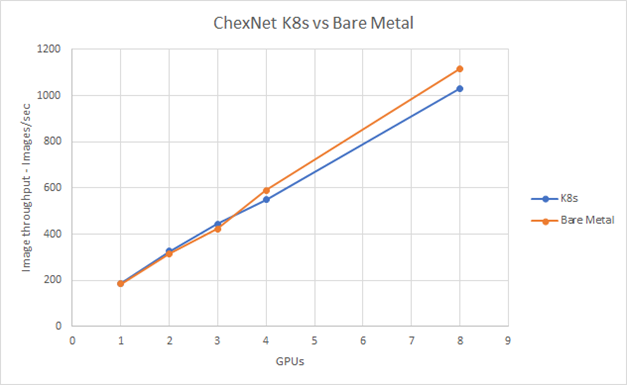
Figure 2 shows that the Kubernetes container configuration was similar in terms of performance to the bare metal configuration through 4 GPUs. The test through 8 GPUs shows an eight percent increase for bare metal compared with Kubernetes. However, the article that I referenced offers factors that might contribute to the delta:
- The bare metal system takes advantage of the full bandwidth and latency of raw InfiniBand while the Kubernetes configuration uses software defined networking using flannel.
- The Kubernetes configuration uses IP over InfiniBand, which can reduce available bandwidth.
Studies like this are useful because they provide performance insight that customers can use. I hope we see more studies that encompass other workloads. For example, a study about Oracle and SQL Server databases in containers compared with running on bare metal would be interesting. The goal would be to understand how a Kubernetes ecosystem can support a broad ecosystem of different workloads.
Hope you like the blog!

Deep Learning on Spark is Getting Interesting
Mon, 03 Aug 2020 15:53:44 -0000
|Read Time: 0 minutes
The year 2012 will be remembered in history as a break out year for data analytics. Deep learnings meteoric rise to prominence can largely be attributed to the 2012 introduction of convolution neural networks (CNN)for image classification using the ImageNet dataset during the Large-Scale Visual Recognition Challenge (LSVRC) [1]. It was a historic event after a very, very long incubation period for deep learning that started with mathematical theory work in the 1940s, 50s, and 60s. The prior history of neural networks and deep learning development is a fascination and should not be forgotten, but it is not an overstatement to say that 2012 was the breakout year for deep learning.
Coincidentally, 2012 was also a breakout year for in-memory distributed computing. A group of researchers from the University of AMPlab published a paper with an unusual title that changed the world of data analytics. “Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing”. [2] This paper describes how the initial creators developed an efficient, general-purpose and fault-tolerant in-memory data abstraction for sharing data in cluster applications. The effort was motivated by the short-comings of both MapReduce and other distributed-memory programming models for processing iterative algorithms and interactive data mining jobs.
The ongoing development of so many application libraries that all leverage Spark’s RDD abstraction including GraphX for creating graphs and graph-parallel computation, Spark Streaming for scalable fault-tolerant streaming applications and MLlib for scalable machine learning is proof that Spark achieved the original goal of being a general-purpose programming environment. The rest of this article will describe the development and integration of deep learning libraries – a now extremely useful class of iterative algorithms that Spark was designed to address. The importance of the role that deep learning was going to have on data analytics and artificial intelligence was just starting to emerge at the same time Spark was created so the combination of the two developments has been interesting to watch.
MLlib – The original machine learning library for Spark
MLlib development started not long after the AMPlab code was transferred to the Apache Software Foundation in 2013. It is not really a deep learning library however there is an option for developing Multilayer perceptron classifiers [3] based on the feedforward artificial neural network with backpropagation implemented for learning the model. Fully connected neural networks were quickly abandoned after the development of more sophisticated models constructed using convolutional, recursive, and recurrent networks.
 Fully connected shallow and deep networks are making a comeback as alternatives to tree-based models for both regression and classification. There is also a lot of current interest in various forms of autoencoders used to learn latent (hidden) compressed representations of data dimension reduction and self-supervised classification. MLlib, therefore, can be best characterized as a machine learning library with some limited neural network capability.
Fully connected shallow and deep networks are making a comeback as alternatives to tree-based models for both regression and classification. There is also a lot of current interest in various forms of autoencoders used to learn latent (hidden) compressed representations of data dimension reduction and self-supervised classification. MLlib, therefore, can be best characterized as a machine learning library with some limited neural network capability.
BigDL – Intel open sources a full-featured deep learning library for Spark
BigDL is a distributed deep learning library for Apache Spark. BigDL implements distributed, data-parallel training directly on top of the functional compute model using the core Spark features of copy-on-write and coarse-grained operations. The framework has been referenced in applications as diverse as transfer learning-based image classification, object detection and feature extraction, sequence-to-sequence prediction for precipitation nowcasting, neural collaborative filtering for recommendations, and more. Contributors and users include a wide range of industries including Mastercard, World Bank, Cray, Talroo, University of California San Francisco (UCSF), JD, UnionPay, Telefonica, GigaSpaces. [4]
Engineers with Dell EMC and Intel recently completed a white paper demonstrating the use of deep learning development tools from the Intel Analytics Zoo [5] to build an integrated pipeline on Apache Spark ending with a deep neural network model to predict diseases from chest X-rays. [6] Tools and examples in the Analytics Zoo give data scientists the ability to train and deploy BigDL, TensorFlow, and Keras models on Apache Spark clusters. Application developers can also use the resources from the Analytics Zoo to deploy production class intelligent applications through model extractions capable of being served in any Java, Scala, or other Java virtual machine (JVM) language.
The researchers conclude that modern deep learning applications can be developed and deployed at scale on an existing Hadoop and Spark cluster. This approach avoids the need to move data to a different deep learning cluster and eliminates the operational complexities of provisioning and maintaining yet another distributed computing environment. The open-source software that is described in the white paper is available from Github. [7]
H20.ai – Sparkling Water for Spark
H2O is fast, scalable, open-source machine learning, and deep learning for smarter applications. Much like MLlib, the H20 algorithms cover a wide range of useful machine learning techniques but only fully connected MLPs for deep learning. With H2O, enterprises like PayPal, Nielsen Catalina, Cisco, and others can use all their data without sampling to get accurate predictions faster. [8] Dell EMC, Intel, and H2o.ai recently developed a joint reference architecture that outlines both technical considerations and sizing guidance for an on-premises enterprise AI platform. [9]
The engineers show how running H2O.ai software on optimized Dell EMC infrastructure with the latest Intel® Xeon® Scalable processors and NVMe storage, enables organizations to use AI to improve customer experiences, streamline business processes, and decrease waste and fraud. Validated software included the H2O Driverless AI enterprise platform and the H2O and H2O Sparkling Water open-source software platforms. Sparkling Water is designed to be executed as a regular Spark application. It provides a way to initialize H2O services on Spark and access data stored in both Spark and H2O data structures. H20 Sparkling Water algorithms are designed to take advantage of the distributed in-memory computing of existing Spark clusters. Results from H2O can easily be deployed using H2O low-latency pipelines or within Spark for scoring.
H2O Sparkling Water cluster performance was evaluated on three- and five-node clusters. In this mode, H2O launches through Spark workers, and Spark manages the job scheduling and communications between the nodes. Three and five Dell EMC PowerEdge R740xd Servers with Intel Xeon Gold 6248 processors were used to train XGBoost and GBM models using the mortgage data set derived from the Fannie Mae Single-Family Loan Performance data set.
Spark and GPUs
 Many data scientists familiar with Spark for machine learning have been waiting for official support for GPUs. The advantages realized from modern neural network models like the CNN entry in the 2012 LSVRC would not have been fully realized without the work of NVIDIA and others on new acceleration hardware. NVIDIA’s GPU technology like the Volta V100 has morphed into a class of advanced, enterprise-class ML/DL accelerators that reduce training time for all types of neural network configurations including CCN, RNN (recurrent neural networks) and GAN (generative adversarial networks) to mention just a few of the most popular forms. Deep learning researchers see many advantages to building end-to-data model training “pipelines” that take advantage of the generalized distributed computing capability of Spark for everything from data cleaning and shaping through to scale-out training using integration with GPUs.
Many data scientists familiar with Spark for machine learning have been waiting for official support for GPUs. The advantages realized from modern neural network models like the CNN entry in the 2012 LSVRC would not have been fully realized without the work of NVIDIA and others on new acceleration hardware. NVIDIA’s GPU technology like the Volta V100 has morphed into a class of advanced, enterprise-class ML/DL accelerators that reduce training time for all types of neural network configurations including CCN, RNN (recurrent neural networks) and GAN (generative adversarial networks) to mention just a few of the most popular forms. Deep learning researchers see many advantages to building end-to-data model training “pipelines” that take advantage of the generalized distributed computing capability of Spark for everything from data cleaning and shaping through to scale-out training using integration with GPUs.
NVIDIA recently announced that it has been working with Apache Spark’s open source community to bring native GPU acceleration to the next version of the big data processing framework, Spark 3.0 [10] The Apache Spark community is distributing a preview release of Spark 3.0 to encourage wide-scale community testing of the upcoming release. The preview is not a stable release of the expected API specification or functionality. No firm date for the general availability of Spark 3.0 has been released but organizations exploring options for distributed deep learning with GPUs should start evaluating the proposed features and advantages of Spark 3.0.
Cloudera is also giving developers and data science an opportunity to do testing and evaluation with the preview release of Spark 3.0. The current GA version of the Cloudera Runtime includes the Apache Spark 3.0 preview 2 as part of their CDS 3 (Experimental) Powered by Apache Spark release. [11] Full Spark 3.0 preview 2 documentation including many code samples is available from the Apache Spark website [12]
What’s next
It’s been 8 years since the breakout events for deep learning and distributed computing with Spark were announced. We have seen tremendous adoption of both deep learning and Spark for all types of analytics use cases from medical imaging to language processing to manufacturing control and beyond. We are just now poised to see new breakthroughs in the merging of Spark and deep learning, especially with the addition of support for hardware accelerators. IT professionals and data scientists are still too heavily burdened with the hidden technical debt overhead for managing machine learning systems. [13] The integration of accelerated deep learning with the power of the Spark generalized distributed computing platform will give both the IT and data science communities a capable and manageable environment to develop and host end-to-end data analysis pipelines in a common framework.
References
[1] Alom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., ... & Asari, V. K. (2018). The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv preprint arXiv:1803.01164.
[2] Zaharia, M., Chowdhury, M., Das, T., Dave, A., Ma, J., McCauly, M., ... & Stoica, I. (2012). Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Presented as part of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12) (pp. 15-28).
[3] Apache Spark (June 2020) Multilayer perceptron classifier https://spark.apache.org/docs/latest/ml-classification-regression.html#multilayer-perceptron-classifier
[4] Dai, J. J., Wang, Y., Qiu, X., Ding, D., Zhang, Y., Wang, Y., ... & Wang, J. (2019, November). Bigdl: A distributed deep learning framework for big data. In Proceedings of the ACM Symposium on Cloud Computing (pp. 50-60).
[5] Intel Analytics Zoo (June 2020) https://software.intel.com/content/www/us/en/develop/topics/ai/analytics-zoo.html
[6] Chandrasekaran, Bala (Dell EMC) Yang, Yuhao (Intel) Govindan, Sajan (Intel) Abd, Mehmood (Dell EMC) A. A. R. U. D. (2019). Deep Learning on Apache Spark and Analytics Zoo.
[7] Dell AI Engineering (June 2020) BigDL Image Processing Examples https://github.com/dell-ai-engineering/BigDL-ImageProcessing-Examples
[8] Candel, A., Parmar, V., LeDell, E., and Arora, A. (Apr 2020). Deep Learning with H2O https://www.h2o.ai/wp-content/themes/h2o2016/images/resources/DeepLearningBooklet.pdf
[9] Reference Architectures for H2O.ai (February 2020) https://www.dellemc.com/resources/en-us/asset/white-papers/products/ready-solutions/dell-h20-architectures-pdf.pdf Dell Technologies
[10] Woodie, Alex (May 2020) Spark 3.0 to Get Native GPU Acceleration https://www.datanami.com/2020/05/14/spark-3-0-to-get-native-gpu-acceleration/ datanami
[11] CDS 3 (Experimental) Powered by Apache Spark Overview (June 2020) https://docs.cloudera.com/runtime/7.0.3/cds-3/topics/spark-spark-3-overview.html
[12] Spark Overview (June 2020) https://spark.apache.org/docs/3.0.0-preview2/
[13] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., ... & Dennison, D. (2015). Hidden technical debt in machine learning systems. In Advances in neural information processing systems (pp. 2503-2511).

Accelerating Insights with Distributed Deep Learning
Fri, 12 Jun 2020 12:22:20 -0000
|Read Time: 0 minutes
Originally published on Aug 6, 2018 1:17:46 PM
Artificial intelligence (AI) is transforming the way businesses compete in today’s marketplace. Whether it’s improving business intelligence, streamlining supply chain or operational efficiencies, or creating new products, services, or capabilities for customers, AI should be a strategic component of any company’s digital transformation.
Deep neural networks have demonstrated astonishing abilities to identify objects, detect fraudulent behaviors, predict trends, recommend products, enable enhanced customer support through chatbots, convert voice to text and translate one language to another, and produce a whole host of other benefits for companies and researchers. They can categorize and summarize images, text, and audio recordings with human-level capability, but to do so they first need to be trained.
Deep learning, the process of training a neural network, can sometimes take days, weeks, or months, and effort and expertise is required to produce a neural network of sufficient quality to trust your business or research decisions on its recommendations. Most successful production systems go through many iterations of training, tuning and testing during development. Distributed deep learning can speed up this process, reducing the total time to tune and test so that your data science team can develop the right model faster, but requires a method to allow aggregation of knowledge between systems.
There are several evolving methods for efficiently implementing distributed deep learning, and the way in which you distribute the training of neural networks depends on your technology environment. Whether your compute environment is container native, high performance computing (HPC), or Hadoop/Spark clusters for Big Data analytics, your time to insight can be accelerated by using distributed deep learning. In this article we are going to explain and compare systems that use a centralized or replicated parameter server approach, a peer-to-peer approach, and finally a hybrid of these two developed specifically for Hadoop distributed big data environments.
Distributed Deep Learning in Container Native Environments
Container native (e.g., Kubernetes, Docker Swarm, OpenShift, etc.) have become the standard for many DevOps environments, where rapid, in-production software updates are the norm and bursts of computation may be shifted to public clouds. Most deep learning frameworks support distributed deep learning for these types of environments using a parameter server-based model that allows multiple processes to look at training data simultaneously, while aggregating knowledge into a single, central model.
The process of performing parameter server-based training starts with specifying the number of workers (processes that will look at training data) and parameter servers (processes that will handle the aggregation of error reduction information, backpropagate those adjustments, and update the workers). Additional parameters servers can act as replicas for improved load balancing.
 Parameter server model for distributed deep learning
Parameter server model for distributed deep learning
Worker processes are given a mini-batch of training data to test and evaluate, and upon completion of that mini-batch, report the differences (gradients) between produced and expected output back to the parameter server(s). The parameter server(s) will then handle the training of the network and transmitting copies of the updated model back to the workers to use in the next round.
This model is ideal for container native environments, where parameter server processes and worker processes can be naturally separated. Orchestration systems, such as Kubernetes, allow neural network models to be trained in container native environments using multiple hardware resources to improve training time. Additionally, many deep learning frameworks support parameter server-based distributed training, such as TensorFlow, PyTorch, Caffe2, and Cognitive Toolkit.
Distributed Deep Learning in HPC Environments
High performance computing (HPC) environments are generally built to support the execution of multi-node applications that are developed and executed using the single process, multiple data (SPMD) methodology, where data exchange is performed over high-bandwidth, low-latency networks, such as Mellanox InfiniBand and Intel OPA. These multi-node codes take advantage of these networks through the Message Passing Interface (MPI), which abstracts communications into send/receive and collective constructs.
Deep learning can be distributed with MPI using a communication pattern called Ring-AllReduce. In Ring-AllReduce each process is identical, unlike in the parameter-server model where processes are either workers or servers. The Horovod package by Uber (available for TensorFlow, Keras, and PyTorch) and the mpi_collectives contributions from Baidu (available in TensorFlow) use MPI Ring-AllReduce to exchange loss and gradient information between replicas of the neural network being trained. This peer-based approach means that all nodes in the solution are working to train the network, rather than some nodes acting solely as aggregators/distributors (as in the parameter server model). This can potentially lead to faster model convergence.
 Ring-AllReduce model for distributed deep learning
Ring-AllReduce model for distributed deep learning
The Dell EMC Ready Solutions for AI, Deep Learning with NVIDIA allows users to take advantage of high-bandwidth Mellanox InfiniBand EDR networking, fast Dell EMC Isilon storage, accelerated compute with NVIDIA V100 GPUs, and optimized TensorFlow, Keras, or Pytorch with Horovod frameworks to help produce insights faster.
Distributed Deep Learning in Hadoop/Spark Environments
Hadoop and other Big Data platforms achieve extremely high performance for distributed processing but are not designed to support long running, stateful applications. Several approaches exist for executing distributed training under Apache Spark. Yahoo developed TensorFlowOnSpark, accomplishing the goal with an architecture that leveraged Spark for scheduling Tensorflow operations and RDMA for direct tensor communication between servers.
BigDL is a distributed deep learning library for Apache Spark. Unlike Yahoo’s TensorflowOnSpark, BigDL not only enables distributed training - it is designed from the ground up to work on Big Data systems. To enable efficient distributed training BigDL takes a data-parallel approach to training with synchronous mini-batch SGD (Stochastic Gradient Descent). Training data is partitioned into RDD samples and distributed to each worker. Model training is done in an iterative process that first computes gradients locally on each worker by taking advantage of locally stored partitions of the training data and model to perform in memory transformations. Then an AllReduce function schedules workers with tasks to calculate and update weights. Finally, a broadcast syncs the distributed copies of model with updated weights.
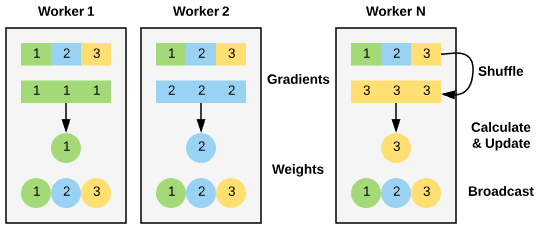 BigDL implementation of AllReduce functionality
BigDL implementation of AllReduce functionality
The Dell EMC Ready Solutions for AI, Machine Learning with Hadoop is configured to allow users to take advantage of the power of distributed deep learning with Intel BigDL and Apache Spark. It supports loading models and weights from other frameworks such as Tensorflow, Caffe and Torch to then be leveraged for training or inferencing. BigDL is a great way for users to quickly begin training neural networks using Apache Spark, widely recognized for how simple it makes data processing.
One more note on Hadoop and Spark environments: The Intel team working on BigDL has built and compiled high-level pipeline APIs, built-in deep learning models, and reference use cases into the Intel Analytics Zoo library. Analytics Zoo is based on BigDL but helps make it even easier to use through these high-level pipeline APIs designed to work with Spark Dataframes and built in models for things like object detection and image classification.
Conclusion
Regardless of whether you preferred server infrastructure is container native, HPC clusters, or Hadoop/Spark-enabled data lakes, distributed deep learning can help your data science team develop neural network models faster. Our Dell EMC Ready Solutions for Artificial Intelligence can work in any of these environments to help jumpstart your business’s AI journey. For more information on the Dell EMC Ready Solutions for Artificial Intelligence, go to dellemc.com/readyforai.
Lucas A. Wilson, Ph.D. is the Chief Data Scientist in Dell EMC's HPC & AI Innovation Lab. (Twitter: @lucasawilson)
Michael Bennett is a Senior Principal Engineer at Dell EMC working on Ready Solutions.

Training an AI Radiologist with Distributed Deep Learning
Wed, 07 Dec 2022 13:25:02 -0000
|Read Time: 0 minutes
Originally published on Aug 16, 2018 11:14:00 AM
The potential of neural networks to transform healthcare is evident. From image classification to dictation and translation, neural networks are achieving or exceeding human capabilities. And they are only getting better at these tasks as the quantity of data increases.
But there’s another way in which neural networks can potentially transform the healthcare industry: Knowledge can be replicated at virtually no cost. Take radiology as an example: To train 100 radiologists, you must teach each individual person the skills necessary to identify diseases in x-ray images of patients’ bodies. To make 100 AI-enabled radiologist assistants, you take the neural network model you trained to read x-ray images and load it into 100 different devices.
The hurdle is training the model. It takes a large amount of cleaned, curated, labeled data to train an image classification model. Once you’ve prepared the training data, it can take days, weeks, or even months to train a neural network. Even once you’ve trained a neural network model, it might not be smart enough to perform the desired task. So, you try again. And again. Eventually, you will train a model that passes the test and can be used out in the world.
 Workflow for developing neural network modelsIn this post, I’m going to talk about how to reduce the time spent in the Train/Test/Tune cycle by speeding up the training portion with distributed deep learning, using a test case we developed in Dell EMC’s HPC & AI Innovation Lab to classify pathologies in chest x-ray images. Through a combination of distributed deep learning, optimizer selection, and neural network topology selection, we were able to not only speed the process of training models from days to minutes, we were also able to improve the classification accuracy significantly.
Workflow for developing neural network modelsIn this post, I’m going to talk about how to reduce the time spent in the Train/Test/Tune cycle by speeding up the training portion with distributed deep learning, using a test case we developed in Dell EMC’s HPC & AI Innovation Lab to classify pathologies in chest x-ray images. Through a combination of distributed deep learning, optimizer selection, and neural network topology selection, we were able to not only speed the process of training models from days to minutes, we were also able to improve the classification accuracy significantly.
Starting Point: Stanford University’s CheXNet
We began by surveying the landscape of AI projects in healthcare, and Andrew Ng’s group at Stanford University provided our starting point. CheXNet was a project to demonstrate a neural network’s ability to accurately classify cases of pneumonia in chest x-ray images.
The dataset that Stanford used was ChestXray14, which was developed and made available by the United States’ National Institutes of Health (NIH). The dataset contains over 120,000 images of frontal chest x-rays, each potentially labeled with one or more of fourteen different thoracic pathologies. The data set is very unbalanced, with more than half of the data set images having no listed pathologies.
Stanford decided to use DenseNet, a neural network topology which had just been announced as the Best Paper at the 2017 Conference on Computer Vision and Pattern Recognition (CVPR), to solve the problem. The DenseNet topology is a deep network of repeating blocks over convolutions linked with residual connections. Blocks end with a batch normalization, followed by some additional convolution and pooling to link the blocks. At the end of the network, a fully connected layer is used to perform the classification.
 An illustration of the DenseNet topology (source: Kaggle)
An illustration of the DenseNet topology (source: Kaggle)
Stanford’s team used a DenseNet topology with the layer weights pretrained on ImageNet and replaced the original ImageNet classification layer with a new fully connected layer of 14 neurons, one for each pathology in the ChestXray14 dataset.
Building CheXNet in Keras
It’s sounds like it would be difficult to setup. Thankfully, Keras (provided with TensorFlow) provides a simple, straightforward way of taking standard neural network topologies and bolting-on new classification layers.
from tensorflow import keras from keras.applications import DenseNet121 orig_net = DenseNet121(include_top=False, weights='imagenet', input_shape=(256,256,3))
In this code snippet, we are importing the original DenseNet neural network (DenseNet121) and removing the classification layer with the include_top=False argument. We also automatically import the pretrained ImageNet weights and set the image size to 256x256, with 3 channels (red, green, blue).
With the original network imported, we can begin to construct the classification layer. If you look at the illustration of DenseNet above, you will notice that the classification layer is preceded by a pooling layer. We can add this pooling layer back to the new network with a single Keras function call, and we can call the resulting topology the neural network's filters, or the part of the neural network which extracts all the key features used for classification.
from keras.layers import GlobalAveragePooling2D filters = GlobalAveragePooling2D()(orig_net.output)
The next task is to define the classification layer. The ChestXray14 dataset has 14 labeled pathologies, so we have one neuron for each label. We also activate each neuron with the sigmoid activation function, and use the output of the feature filter portion of our network as the input to the classifiers.
from keras.layers import Dense classifiers = Dense(14, activation='sigmoid', bias_initializer='ones')(filters)
The choice of sigmoid as an activation function is due to the multi-label nature of the data set. For problems where only one label ever applies to a given image (e.g., dog, cat, sandwich), a softmax activation would be preferable. In the case of ChestXray14, images can show signs of multiple pathologies, and the model should rightfully identify high probabilities for multiple classifications when appropriate.
Finally, we can put the feature filters and the classifiers together to create a single, trainable model.
from keras.models import Model chexnet = Model(inputs=orig_net.inputs, outputs=classifiers)
With the final model configuration in place, the model can then be compiled and trained.
Accelerating the Train/Test/Tune Cycle with Distributed Deep Learning
To produce better models sooner, we need to accelerate the Train/Test/Tune cycle. Because testing and tuning are mostly sequential, training is the best place to look for potential optimization.
How exactly do we speed up the training process? In Accelerating Insights with Distributed Deep Learning, Michael Bennett and I discuss the three ways in which deep learning can be accelerated by distributing work and parallelizing the process:
- Parameter server models such as in Caffe or distributed TensorFlow,
- Ring-AllReduce approaches such as Uber’s Horovod, and
- Hybrid approaches for Hadoop/Spark environments such as Intel BigDL.
Which approach you pick depends on your deep learning framework of choice and the compute environment that you will be using. For the tests described here we performed the training in house on the Zenith supercomputer in the Dell EMC HPC & AI Innovation Lab. The ring-allreduce approach enabled by Uber’s Horovod framework made the most sense for taking advantage of a system tuned for HPC workloads, and which takes advantage of Intel Omni-Path (OPA) networking for fast inter-node communication. The ring-allreduce approach would also be appropriate for solutions such as the Dell EMC Ready Solutions for AI, Deep Learning with NVIDIA.
 The MPI-RingAllreduce approach to distributed deep learning
The MPI-RingAllreduce approach to distributed deep learning
Horovod is an MPI-based framework for performing reduction operations between identical copies of the otherwise sequential training script. Because it is MPI-based, you will need to be sure that an MPI compiler (mpicc) is available in the working environment before installing horovod.
Adding Horovod to a Keras-defined Model
Adding Horovod to any Keras-defined neural network model only requires a few code modifications:
- Initializing the MPI environment,
- Broadcasting initial random weights or checkpoint weights to all workers,
- Wrapping the optimizer function to enable multi-node gradient summation,
- Average metrics among workers, and
- Limiting checkpoint writing to a single worker.
Horovod also provides helper functions and callbacks for optional capabilities that are useful when performing distributed deep learning, such as learning-rate warmup/decay and metric averaging.
Initializing the MPI Environment
Initializing the MPI environment in Horovod only requires calling the init method:
import horovod.keras as hvd hvd.init()
This will ensure that the MPI_Init function is called, setting up the communications structure and assigning ranks to all workers.
Broadcasting Weights
Broadcasting the neuron weights is done using a callback to the Model.fit Keras method. In fact, many of Horovod’s features are implemented as callbacks to Model.fit, so it’s worthwhile to define a callback list object for holding all the callbacks.
callbacks = [ hvd.callbacks.BroadcastGlobalVariablesCallback(0) ]
You’ll notice that the BroadcastGlobalVariablesCallback takes a single argument that’s been set to 0. This is the root worker, which will be responsible for reading checkpoint files or generating new initial weights, broadcasting weights at the beginning of the training run, and writing checkpoint files periodically so that work is not lost if a training job fails or terminates.
Wrapping the Optimizer Function
The optimizer function must be wrapped so that it can aggregate error information from all workers before executing. Horovod’s DistributedOptimizer function can wrap any optimizer which inherits Keras’ base Optimizer class, including SGD, Adam, Adadelta, Adagrad, and others.
import keras.optimizers opt = hvd.DistributedOptimizer(keras.optimizers.Adadelta(lr=1.0))
The distributed optimizer will now use the MPI_Allgather collective to aggregate error information from training batches onto all workers, rather than collecting them only to the root worker. This allows the workers to independently update their models rather than waiting for the root to re-broadcast updated weights before beginning the next training batch.
Averaging Metrics
Between steps error metrics need to be averaged to calculate global loss. Horovod provides another callback function to do this called MetricAverageCallback.
callbacks = [ hvd.callbacks.BroadcastGlobalVariablesCallback(0), hvd.callbacks.MetricAverageCallback() ]
This will ensure that optimizations are performed on the global metrics, not the metrics local to each worker.
Writing Checkpoints from a Single Worker
When using distributed deep learning, it’s important that only one worker write checkpoint files to ensure that multiple workers writing to the same file does not produce a race condition, which could lead to checkpoint corruption.
Checkpoint writing in Keras is enabled by another callback to Model.fit. However, we only want to call this callback from one worker instead of all workers. By convention, we use worker 0 for this task, but technically we could use any worker for this task. The one good thing about worker 0 is that even if you decide to run your distributed deep learning job with only 1 worker, that worker will be worker 0.
callbacks = [ ... ]
if hvd.rank() == 0:
callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch].h5'))Result: A Smarter Model, Faster!
Once a neural network can be trained in a distributed fashion across multiple workers, the Train/Test/Tune cycle can be sped up dramatically.
The figure below shows exactly how dramatically. The three tests shown are the training speed of the Keras DenseNet model on a single Zenith node without distributed deep learning (far left), the Keras DenseNet model with distributed deep learning on 32 Zenith nodes (64 MPI processes, 2 MPI processes per node, center), and a Keras VGG16 version using distributed deep learning on 64 Zenith nodes (128 MPI processes, 2 MPI processes per node, far right). By using 32 nodes instead of a single node, distributed deep learning was able to provide a 47x improvement in training speed, taking the training time for 10 epochs on the ChestXray14 data set from 2 days (50 hours) to less than 2 hours!
 Performance comparisons of Keras models with distributed deep learning using Horovod
Performance comparisons of Keras models with distributed deep learning using Horovod
The VGG variant, trained on 128 Zenith nodes, was able to complete the same number of epochs as was required for the single-node DenseNet version to train in less than an hour, although it required more epochs to train. It also, however, was able to converge to a higher-quality solution. This VGG-based model outperformed the baseline, single-node model in 4 of 14 conditions, and was able to achieve nearly 90% accuracy in classifying emphysema.
 Accuracy comparison of baseline single-node DenseNet model vs VGG variant with Horovod
Accuracy comparison of baseline single-node DenseNet model vs VGG variant with Horovod
Conclusion
In this post we’ve shown you how to accelerate the Train/Test/Tune cycle when developing neural network-based models by speeding up the training phase with distributed deep learning. We walked through the process of transforming a Keras-based model to take advantage of multiple nodes using the Horovod framework, and how these few simple code changes, coupled with some additional compute infrastructure, can reduce the time needed to train a model from days to minutes, allowing more time for the testing and tuning pieces of the cycle. More time for tuning means higher-quality models, which means better outcomes for patients, customers, or whomever will benefit from the deployment of your model.
Lucas A. Wilson, Ph.D. is the Chief Data Scientist in Dell EMC's HPC & AI Innovation Lab. (Twitter: @lucasawilson)

Challenges of Large-batch Training of Deep Learning Models
Fri, 12 Jun 2020 12:22:20 -0000
|Read Time: 0 minutes
Originally published on Aug 27, 2018 1:29:28 PM
The process of training a deep neural network is akin to finding the minimum of a function in a very high-dimensional space. Deep neural networks are usually trained using stochastic gradient descent (or one of its variants). A small batch (usually 16-512), randomly sampled from the training set, is used to approximate the gradients of the loss function (the optimization objective) with respect to the weights. The computed gradient is essentially an average of the gradients for each data-point in the batch. The natural way to parallelize the training across multiple nodes/workers is to increase the batch size and have each node compute the gradients on a different chunk of the batch. Distributed deep learning differs from traditional HPC workloads where scaling out only affects how the computation is distributed but not the outcome.
Challenges of large-batch training
It has been consistently observed that the use of large batches leads to poor generalization performance, meaning that models trained with large batches perform poorly on test data. One of the primary reason for this is that large batches tend to converge to sharp minima of the training function, which tend to generalize less well. Small batches tend to favor flat minima that result in better generalization. The stochasticity afforded by small batches encourages the weights to escape the basins of attraction of sharp minima. Also, models trained with small batches are shown to converge farther away from the starting point. Large batches tend to be attracted to the minimum closest to the starting point and lack the exploratory properties of small batches.
The number of gradient updates per pass of the data is reduced when using large batches. This is sometimes compensated by scaling the learning rate with the batch size. But simply using a higher learning rate can destabilize the training. Another approach is to just train the model longer, but this can lead to overfitting. Thus, there’s much more to distributed training than just scaling out to multiple nodes.
 An illustration showing how sharp minima lead to poor generalization. The sharp minimum of the training function corresponds to a maximum of the testing function which hurts the model's performance on test data
An illustration showing how sharp minima lead to poor generalization. The sharp minimum of the training function corresponds to a maximum of the testing function which hurts the model's performance on test data
How can we make large batches work?
There has been a lot of interesting research recently in making large-batch training more feasible. The training time for ImageNet has now been reduced from weeks to minutes by using batches as large as 32K without sacrificing accuracy. The following methods are known to alleviate some of the problems described above:
- Scaling the learning rate
The learning rate is multiplied by k, when the batch size is multiplied by k. However, this rule does not hold in the first few epochs of the training since the weights are changing rapidly. This can be alleviated by using a warm-up phase. The idea is to start with a small value of the learning rate and gradually ramp up to the linearly scaled value. - Layer-wise adaptive rate scaling
A different learning rate is used for each layer. A global learning rate is chosen and it is scaled for each layer by the ratio of the Euclidean norm of the weights to Euclidean norm of the gradients for that layer. - Using regular SGD with momentum rather than Adam
Adam is known to make convergence faster and more stable. It is usually the default optimizer choice when training deep models. However, Adam seems to settle to less optimal minima, especially when using large batches. Using regular SGD with momentum, although more noisy than Adam, has shown improved generalization. - Topologies also make a difference
In a previous blog post, my colleague Luke showed how using VGG16 instead of DenseNet121 considerably sped up the training for a model that identified thoracic pathologies from chest x-rays while improving area under ROC in multiple categories. Shallow models are usually easier to train, especially when using large batches.
Conclusion
Large-batch distributed training can significantly reduce training time but it comes with its own challenges. Improving generalization when using large batches is an active area of research, and as new methods are developed, the time to train a model will keep going down.
Training Neural Network Models for Financial Services with Intel® Xeon Processors
Fri, 12 Jun 2020 12:22:20 -0000
|Read Time: 0 minutes
Originally published on Nov 5, 2018 9:10:17 AM
Time series is a very important type of data in the financial services industry. Interest rates, stock prices, exchange rates, and option prices are good examples for this type of data. Time series forecasting plays a critical role when financial institutions design investment strategies and make decisions. Traditionally, statistical models such as SMA (simple moving average), SES (simple exponential smoothing), and ARIMA (autoregressive integrated moving average) are widely used to perform time series forecasting tasks.
Neural networks are promising alternatives, as they are more robust for such regression problems due to flexibility in model architectures (e.g., there are many hyperparameters that we can tune, such as number of layers, number of neurons, learning rate, etc.). Recently applications of neural network models in the time series forecasting area have been gaining more and more attention from statistical and data science communities.
In this blog, we will firstly discuss about some basic properties that a machine learning model must have to perform financial service tasks. Then we will design our model based on these requirements and show how to train the model in parallel on HPC cluster with Intel® Xeon processors.
Requirements from Financial Institutions
High-accuracy and low-latency are two import properties that financial service institutions expect from a quality time series forecasting model.
High Accuracy A high level of accuracy in the forecasting model helps companies lower the risk of losing money in investments. Neural networks are believed to be good at capturing the dynamics in time series and hence yield more accurate predictions. There are many hyperparameters in the model so that data scientists and quantitative researchers can tune them to obtain the optimal model. Moreover, data science community believes that ensemble learning tends to improve prediction accuracy significantly. The flexibility of model architecture provides us a good variety of model members for ensemble learning.
Low Latency Operations in financial services are time-sensitive. For example, high frequency trading usually requires models to finish training and prediction within very short time periods. For deep neural network models, low latency can be guaranteed by distributed training with Horovod or distributed TensorFlow. Intel® Xeon multi-core processors, coupled with Intel’s MKL optimized TensorFlow, prove to be a good infrastructure option for such distributed training.
With these requirements in mind, we propose an ensemble learning model as in Figure 1, which is a combination of MLP (Multi-Layer Perceptron), CNN (Convolutional Neural Network) and LSTM (Long Short-Term Memory) models. Because architecture topologies for MLP, CNN and LSTM are quite different, the ensemble model has a good variety in members, which helps reduce risk of overfitting and produces more reliable predictions. The member models are trained at the same time over multiple nodes with Intel® Xeon processors. If more models need to be integrated, we just add more nodes into the system so that the overall training time stays short. With neural network models and HPC power of the Intel® Xeon processors, this system meets the requirements from financial service institutions.
 Training high accuracy ensemble model on HPC cluster with Intel® Xeon processors
Training high accuracy ensemble model on HPC cluster with Intel® Xeon processors
Fast Training with Intel® Xeon Scalable Processors
Our tests used Dell EMC’s Zenith supercomputer which consists of 422 Dell EMC PowerEdge C6420 nodes, each with 2 Intel® Xeon Scalable Gold 6148 processors. Figure 2 shows an example of time-to-train for training MLP, CNN and LSTM models with different numbers of processes. The data set used is the 10-Year Treasury Inflation-Indexed Security data. For this example, running distributed training with 40 processes is the most efficient, primarily due to the data size in this time series is small and the neural network models we used did not have many layers. With this setting, model training can finish within 10 seconds, much faster than training the models with one processor that has only a few cores, which typically takes more than one minute. Regarding accuracy, the ensemble model can predict this interest rate with MAE (mean absolute error) less than 0.0005. Typical values for this interest rate is around 0.01, so the relative error is less than 5%.
 Training time comparison: Each of the models is trained on a single Dell EMC PowerEdge C6420 with 2x Intel Xeon® Scalable 6148 processors
Training time comparison: Each of the models is trained on a single Dell EMC PowerEdge C6420 with 2x Intel Xeon® Scalable 6148 processors
Conclusion
With both high-accuracy and low-latency being very critical for time series forecasting in financial services, neural network models trained in parallel using Intel® Xeon Scalable processors stand out as very promising options for financial institutions. And as financial institutions need to train more complicated models to forecast many time series with high accuracy at the same time, the need for parallel processing will only grow.

Neural Network Inference Using Intel® OpenVINO™
Wed, 07 Dec 2022 13:59:38 -0000
|Read Time: 0 minutes
Originally published on Nov 9, 2018 2:12:18 PM
Deploying trained neural network models for inference on different platforms is a challenging task. The inference environment is usually different than the training environment which is typically a data center or a server farm. The inference platform may be power constrained and limited from a software perspective. The model might be trained using one of the many available deep learning frameworks such as Tensorflow, PyTorch, Keras, Caffe, MXNet, etc. Intel® OpenVINO™ provides tools to convert trained models into a framework agnostic representation, including tools to reduce the memory footprint of the model using quantization and graph optimization. It also provides dedicated inference APIs that are optimized for specific hardware platforms, such as Intel® Programmable Acceleration Cards, and Intel® Movidius™ Vision Processing Units.
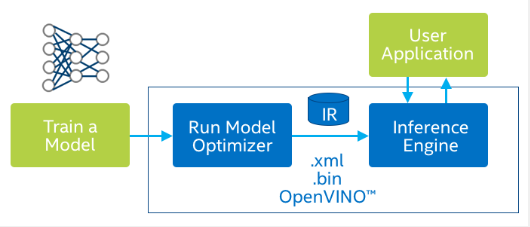
Components
- The Model Optimizer is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts deep learning models for optimal execution on end-point target devices. It is a Python script which takes as input a trained Tensorflow/Caffe model and produces an Intermediate Representation (IR) which consists of a .xml file containing the model definition and a .bin file containing the model weights.
- The Inference Engine is a C++ library with a set of C++ classes to infer input data (images) and get a result. The C++ library provides an API to read the Intermediate Representation, set the input and output formats, and execute the model on devices. Each supported target device has a plugin which is a DLL/shared library. It also has support for heterogenous execution to distribute workload across devices. It supports implementing custom layers on a CPU while executing the rest of the model on a accelerator device.
Workflow
- Using the Model Optimizer, convert a trained model to produce an optimized Intermediate Representation (IR) of the model based on the trained network topology, weights, and bias values.
- Test the model in the Intermediate Representation format using the Inference Engine in the target environment with the validation application or the sample applications.
- Integrate the Inference Engine into your application to deploy the model in the target environment.
Using the Model Optimizer to convert a Keras model to IR
The model optimizer doesn’t natively support Keras model files. However, because Keras uses Tensorflow as its backend, a Keras model can be saved as a Tensorflow checkpoint which can be loaded into the model optimizer. A Keras model can be converted to an IR using the following steps
- Save the Keras model as a Tensorflow checkpoint. Make sure the learning phase is set to 0. Get the name of the output node.
import tensorflow as tf
from keras.applications import Resnet50
from keras import backend as K
from keras.models import Sequential, Model
K.set_learning_phase(0) # Set the learning phase to 0
model = ResNet50(weights='imagenet', input_shape=(256, 256, 3))
config = model.get_config()
weights = model.get_weights()
model = Sequential.from_config(config)
output_node = model.output.name.split(':')[0] # We need this in the next step
graph_file = "resnet50_graph.pb"
ckpt_file = "resnet50.ckpt"
saver = tf.train.Saver(sharded=True)
tf.train.write_graph(sess.graph_def, '', graph_file)
saver.save(sess, ckpt_file) 2. Run the Tensorflow freeze_graph program to generate a frozen graph from the saved checkpoint.
tensorflow/bazel-bin/tensorflow/python/tools/freeze_graph --input_graph=./resnet50_graph.pb --input_checkpoint=./resnet50.ckpt --output_node_names=Softmax --output_graph=resnet_frozen.pb
3. Use the mo.py script and the frozen graph to generate the IR. The model weights can be quantized to FP16.
python mo.py --input_model=resnet50_frozen.pb --output_dir=./ --input_shape=[1,224,224,3] -- data_type=FP16
Inference
The C++ library provides utilities to read an IR, select a plugin depending on the target device, and run the model.
- Read the Intermediate Representation - Using the InferenceEngine::CNNNetReader class, read an Intermediate Representation file into a CNNNetwork class. This class represents the network in host memory.
- Prepare inputs and outputs format - After loading the network, specify input and output precision, and the layout on the network. For these specification, use the CNNNetwork::getInputInfo() and CNNNetwork::getOutputInfo()
- Select Plugin - Select the plugin on which to load your network. Create the plugin with the InferenceEngine::PluginDispatcher load helper class. Pass per device loading configurations specific to this device and register extensions to this device.
- Compile and Load - Use the plugin interface wrapper class InferenceEngine::InferencePlugin to call the LoadNetwork() API to compile and load the network on the device. Pass in the per-target load configuration for this compilation and load operation.
- Set input data - With the network loaded, you have an ExecutableNetwork object. Use this object to create an InferRequest in which you signal the input buffers to use for input and output. Specify a device-allocated memory and copy it into the device memory directly, or tell the device to use your application memory to save a copy.
- Execute- With the input and output memory now defined, choose your execution mode:
- Synchronously - Infer() method. Blocks until inference finishes.
- Asynchronously - StartAsync() method. Check status with the wait() method (0 timeout), wait, or specify a completion callback.
- Get the output - After inference is completed, get the output memory or read the memory you provided earlier. Do this with the InferRequest GetBlob API.
The classification_sample and classification_sample_async programs perform inference using the steps mentioned above. We use these samples in the next section to perform inference on an Intel® FPGA.
Using the Intel® Programmable Acceleration Card with Intel® Arria® 10GX FPGA for inference
The OpenVINO toolkit supports using the PAC as a target device for running low power inference. The pre-processing and post-processing is performed on the host while the execution of the model is performed on the card. The toolkit contains bitstreams for different topologies.
Programming the bitstream
aocl program <device_id> <open_vino_install_directory>/a10_dcp_bitstreams/2-0-1_RC_FP16_ResNet50-101.aocx
The Hetero plugin can be used with CPU as the fallback device for layers that are not supported by the FPGA. The -pc flag prints performance details for each layer
./classification_sample_async -d HETERO:FPGA,CPU -i <path/to/input/image.png> -m <path/to/ir>/resnet50_frozen.xml
Conclusion
Intel® OpenVINO™ toolkit is a great way to quickly integrate trained models into applications and deploy them in different production environments. The complete documentation for the toolkit can be found at https://software.intel.com/en-us/openvino-toolkit/documentation/featured.

Deep Neural Network Inference Performance on Intel FPGAs using Intel OpenVINO
Mon, 03 Aug 2020 15:55:14 -0000
|Read Time: 0 minutes
Originally published on Nov 16, 2018 9:22:39 AM
Inference is the process of running a trained neural network to process new inputs and make predictions. Training is usually performed offline in a data center or a server farm. Inference can be performed in a variety of environments depending on the use case. Intel® FPGAs provide a low power, high throughput solution for running inference. In this blog, we look at using the Intel® Programmable Acceleration Card (PAC) with Intel® Arria® 10GX FPGA for running inference on a Convolutional Neural Network (CNN) model trained for identifying thoracic pathologies.
Advantages of using Intel® FPGAs
System Acceleration: Intel® FPGAs accelerate and aid the compute and connectivity required to collect and process the massive quantities of information around us by controlling the data path. In addition to FPGAs being used as compute offload, they can also directly receive data and process it inline without going through the host system. This frees the processor to manage other system events and enables higher real time system performance.
Power Efficiency: Intel® FPGAs have over 8 TB/s of on-die memory bandwidth. Therefore, solutions tend to keep the data on the device tightly coupled with the next computation. This minimizes the need to access external memory and results in a more efficient circuit implementation in the FPGA where data can be paralleled, pipelined, and processed on every clock cycle. These circuits can be run at significantly lower clock frequencies than traditional general-purpose processors and results in very powerful and efficient solutions.
Future Proofing: In addition to system acceleration and power efficiency, Intel® FPGAs help future proof systems. With such a dynamic technology as machine learning, which is evolving and changing constantly, Intel® FPGAs provide flexibility unavailable in fixed devices. As precisions drop from 32-bit to 8-bit and even binary/ternary networks, an FPGA has the flexibility to support those changes instantly. As next generation architectures and methodologies are developed, FPGAs will be there to implement them.
Model and software
The model is a Resnet-50 CNN trained on the NIH chest x-ray dataset. The dataset contains over 100,000 chest x-rays, each labelled with one or more pathologies. The model was trained on 512 Intel® Xeon® Scalable Gold 6148 processors in 11.25 minutes on the Zenith cluster at DellEMC.
The model is trained using Tensorflow 1.6. We use the Intel® OpenVINO™ R3 toolkit to deploy the model on the FPGA. The Intel® OpenVINO™ toolkit is a collection of software tools to facilitate the deployment of deep learning models. This OpenVINO blog post details the procedure to convert a Tensorflow model to a format that can be run on the FPGA.
Performance
In this section, we look at the power consumption and throughput numbers on the Dell EMC PowerEdge R740 and R640 servers.
Using the Dell EMC PowerEdge R740 with 2x Intel® Xeon® Scalable Gold 6136 (300W) and 4x Intel® PACs
The figures below show the power consumption and throughput numbers for running the model on Intel® PACs, and in combination with Intel® Xeon® Scalable Gold 6136. We observe that the addition of a single Intel® PAC adds only 43W to the system power while providing the ability to inference over 100 chest X-rays per second. The additional power and inference performance scales linearly with the addition of more Intel® PACs. At a system level, wee see a 2.3x improvement in throughput and 116% improvement in efficiency (images per sec per Watt) when using 4x Intel® PACs with 2x Intel® Xeon® Scalable Gold 6136.
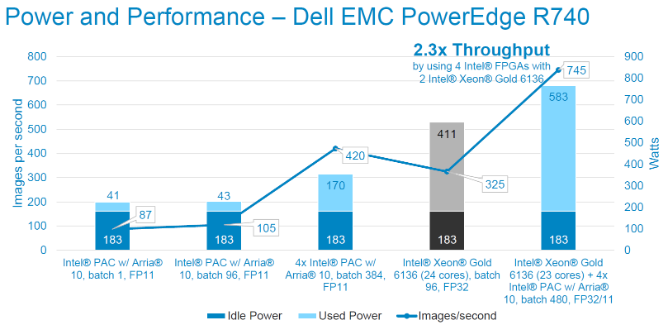 Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
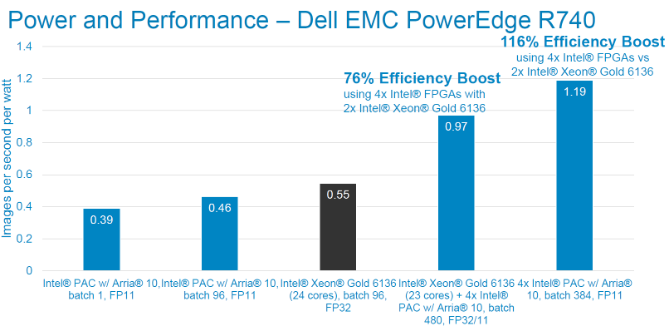 Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadmUsing the Dell EMC PowerEdge R640 with 2x Intel® Xeon® Scalable Gold 5118 (210W) and 2x Intel® PACs
We also used a server with lower idle power. We see a 2.6x improvement in system performance in this case. As before, each Intel® PAC linearly adds performance to the system, adding more than 100 inferences per second for 43W (2.44 images/sec/W).
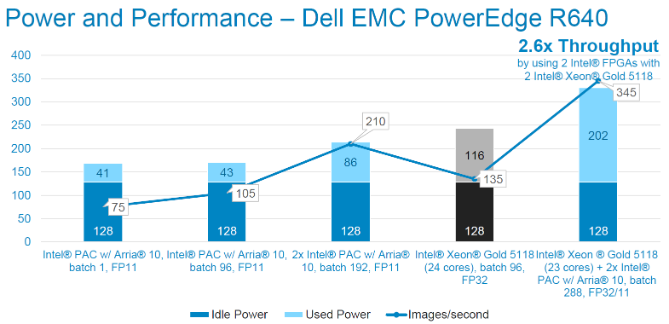 Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Inference performance tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
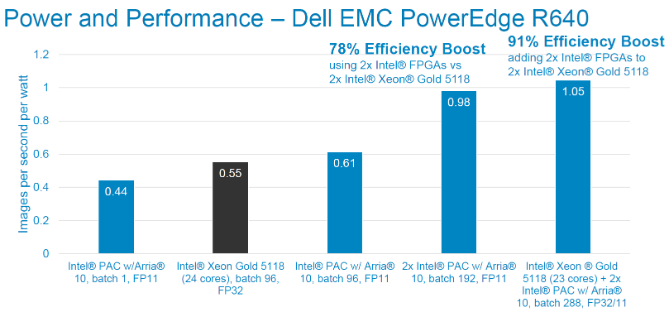 Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Performance per watt tests using ResNet-50 topology. FP11 precision. Image size is 224x224x3. Power measured via racadm
Conclusion
Intel® FPGAs coupled with Intel® OpenVINO™ provide a complete solution for deploying deep learning models in production. FPGAs offer low power and flexibility that make them very suitable as an accelerator device for deep learning workloads.